
数据库漏洞的种类繁多和危害性严重是数据库系统受到攻击的主要原因,通过研究数据库漏洞分类,有助于人们对漏洞的深入理解并加以预防和避免。

美国Verizon就“核心数据是如何丢失的”做过一次全面的市场调查,结果发现,75%的数据丢失情况是由于数据库漏洞造成的,这说明数据库的安全非常重要。
据CVE的数据安全漏洞统计,Oracle、SQL Server、MySQL等主流数据库的漏洞逐年上升,以Oracle为例,当前漏洞总数已经超过了1200多个。
数据库安全漏洞从来源上,大致可以分为四类:缺省安装漏洞、人为使用上的漏洞、数据库设计缺陷、数据库产品的bug。
1、缺省安装漏洞
● 数据库安装后的缺省用户名和密码
在主流数据库中往往存在若干缺省数据库用户,并且缺省密码都是公开的,攻击者完全可以利用这些缺省用户登录数据库。
例如,Oracle中有sys、system、sysman、scott等700多个缺省用户;MySQL本机的root用户可以没有口令;网络上主机名为build的root和用户可以没有口令。
● 数据库安装后的缺省端口号
在主流数据库中缺省端口号是固定的,如Oracle是1521、SQL Server是1433、MySQL是3306等。
● 数据库安装后低安全级别设置
数据库安装后的缺省设置,安全级别一般都较低。
如MySQL中本地用户登录和远程build主机登录不校验用户名密码
如Oracle中不强制修改密码、密码的复杂度设置较低、不限定远程链接范围、通讯为明文等。
● 启用不必要的数据库功能
在数据库的缺省安装中为了便于使用和学习,提供了过量的功能和配置。如Oracle安装后无用的示例库、有威胁的存储过程; MySQL的自定义函数功能。
典型数据库泄密案例:Korea会展中心数据库被入侵
2011年5月,黑客入侵Korea会展中心数据库,在网上爆出其中大量的客户资料数据,并展示数据库操操作过程。
黑客首先通过端口扫描技术,检测出该服务器上开放着1521端口(Oracle数据库的缺省端口),首先探明该主机便是数据库服务器。接着利用扫描程序,检测到缺省系统用户dbsnmp并未被锁定,且保留着数据库安装时的缺省密码。
之后黑客利用权限提升的漏洞,将dbsnmp用户的权限提升至DBA,开始了数据库访问之旅。
2、人为使用漏洞
● 过于宽泛的权限授予
在很多系统维护中,数据库管理员并未细致地按照最小授权原则给予数据库用户授权,而是根据最为方便的原则给予了较为宽泛的授权。
例如,一个普通的数据库维护人员被授予了任意表的创建和删除、访问权限,甚至是给予DBA角色;
例如,一个大学管理员在工作中只需要能够更改学生的联系信息,不过他可能会利用过高的数据库更新权限来更改分数。
● 口令复杂度不高
弱口令:非默认的数据库口令也是不安全的,通过暴力破解,攻击者不断地输入用户名和密码组合,直到找到可以登录的一组。暴力过程可能是靠猜想,也可能是系统地枚举可能的用户名/密码组合。通常,攻击者会使用自动化程序来加快暴力过程的速度。口令破解的工具有很多,并且通过Google搜索或sectools.org等站点就可以轻易地获得,这样就会连接到Cain、Abel或John the Ripper等流行的工具。
密码曝光:一些公众权限的存储过程、表的调用会导致密码曝光。例如,通过执行公众权限的存储过程msdb.dbo.sp_get_sqlagent_properties可以获得SQL Agent密码;通过查询公众权限的表RTblDBMProps可查看DTS密码;Microsoft SQL Server允许本地用户通过数据转换服务(DTS)包属性对话框获得数据库密码。
例如,Oracle 10.1及早期版本,sysman用户的密码明文存储在emoms.properties中,10.2后,虽加密存储,但密钥也存在该文件中,且用DES算法,很容易解密。
因此建议管理员细致地按照最小授权原则给予数据库用户授权;数据库用户口令长度应大于等于10,并且应该包括字母和数字,应该通过一个口令检验函数来实施这一点。
3、数据库设计缺陷
● 明文存储引起的数据泄密
在当前的主流数据库中,数据以明文形式放置在存储设备中,存储设备的丢失将引起数据泄密风险。
数据库数据文件在操作系统中以明文形式存在,非法使用者可以通过网络、操作系统接触到这些文件,从而导致数据泄密风险。
通过UE这样的文本工具即可得到部分明文的信息,通过DUL/MyDUL这样的工具能够完全实现将数据文件格式化导出。
典型数据库泄密案例:7天酒店数据库被盗
会员人数超过1650万,酒店总数逼近600家,在美国纽约证券交易所上市的7天连锁酒店集团无疑是国内经济型连锁酒店集团的龙头企业之一,但更多人所不知道的是,从去年开始,7天酒店在国内黑客圈中成了“明星”。
黑客通过“刷库”直接盗走整个数据库数据。即黑客利用企业网站存在的漏洞入侵数据库服务器,直接将整个数据库文件拷贝,通过DUL/MyDUL这种类似的工具将所有二进制方式存储的数据还原成清晰地格式化数据。
● SYSDBA、DBA等超级用户的存在
在数据库中,以sys和sa为代表的系统管理员,可以访问到任何数据;除了系统管理员,以用户数据分析人员、程序员、开发方维护人员为代表的特权用户,在特殊的时候,也需要访问到敏感数据,从而获得了权限。这些都为数据的泄密留下了极大的隐患。
例如,掌握特权用户口令的维护人员,进入了CRM系统,只需具有对数据库的只读性访问权限,这样,这个用户就可以访问读取数据库内的任何表,包括信用卡信息、个人信息。
● 无法鉴别应用程序的访问是否合法
对于合法的数据库用户,通过合法的业务系统访问数据是正常的行为,但是数据库的一个缺陷在于,无法鉴别应用程序的合法性。
在现实系统维护或开发过程中,应用系统后台使用的合法数据库用户,常由于人为因素或管理不善,用户名及口令很容易泄露给第三方,第三方则可以通过命令行或管理工具直接访问密文数据,批量窃取数据。
典型数据库泄密案例:陕西移动1400万手机用户个人信息泄漏
今年3月以来,周双成利用职务之便,多次侵入陕西移动用户数据库,盗取手机用户个人信息,贩卖给侦探公司。
周双成利用工作之便,能在研发和维护系统过程中获知数据库口令,数据库口令泄漏后,完全可以绕开合法的业务系统,直接使用该用户通过其他程序(自己编写的木马程序)定期访问数据库,进而窃取数据库中的客户隐私信息。
4、数据库产品bug
● 缓冲区溢出
这类漏洞是由于不严谨的编码,使数据库内核中存在对于过长的连接串、函数参数、SQL语句、返回数据不能严谨的处理,造成代码段被覆盖。
通过覆盖的代码段,黑客可以对数据库服务器进行各种操作,最常见的是使数据库崩溃,引起拒绝服务。
例如,SQL Server中利用缓冲区溢出,攻击者可以通过以下函数或存储过程执行任意代码:RAISERROR、FORMATMESSAGE、xp_sprintf、 sp_Mscopyscriptfile、xp_sqlinventory、xp_sqlagent_monitor、sp_OACreate、sp_OAMethod、sp_OAGetProperty、sp_OASetProperty、sp_OADestroy;另外,xp_peekqueue、xp_displayparamstmt、xp___execresultset等40多个函数或扩展存储过程也存在缓冲区溢出。
● 拒绝服务攻击漏洞
数据库中存在多种漏洞,可以导致服务拒绝访问,如命名管道拒绝服务、拒绝登录、RPC请求拒绝服务等。
例如Microsoft SQL 7.0服务允许一个远程攻击者通过不正确格式的TDS数据包引起拒绝服务;本地或远程用户通过向命名管道发送一个长请求引发拒绝服务。
例如MySQL中Data_format()函数在处理用户提交的参数时存在漏洞,畸形的参数数据会导致MySQL服务器崩溃。
● 权限提升漏洞
黑客攻击者可以利用数据库平台软件的漏洞将普通用户的权限转换为管理员权限。漏洞可以在存储过程、内置函数、协议实现甚至是SQL语句中找到。
例如,Oracle中一系列系统对象如PL/SQL包,缺省赋予了Public角色的执行权限,借助这些包执行注入了” grant dba to user”的函数或过程,或直接作为参数执行即可。有PUBLIC执行权限的包共计30多个,例如:ctxsys.driload.validate_stmt()将grant语句作为参数即可完成权限提升。
例如,在SQL Server中,通过Job输出文件覆盖,没有权限的用户可以创建job并通过SQL Server代理的权限提升执行该job。
例如,一个金融机构的软件开发人员可以利用有漏洞的函数来获得数据库管理权限。使用管理权限,恶意的开发人员可以禁用审计机制、开设伪造的账户以及转账。
作为一个刚入门的Liunx爱好者,必须了解的Liunx基础知识有哪些?
1、Linux的文件系统
Unix的文件系统管理是极具特色的。NFS、UFS、TMPFS、VFS、PROC等各类文件系统均承担不同角色。Unix将硬盘、打印机等字符设备和块设备都以文件的方式管理起来,对这些设备的操作就如同访问一个文件。
2、什么是shell
shell是人机交互的字符界面。Unix中提供多种shell供使用者选择,例如RedHat中的bash、tcsh、ksh等,由不同的作者编写完成。在这些shell中,用户都可以输入命令完成系统管理、配置等任务;而在Solaris中,有sh、csh等。
3、Linux用户与用户登录
Linux是一个真正意义上的多用户操作系统,用户要使用该系统,必须输入用户名和密码,经系统验证无误后才可以登录系统使用。
Linux下有两种用户:
1)root用户:超级权限者和系统的拥有者,在Linux系统中有且只有一个root用户,它可以在系统中做任何操作。在系统安装时所设定的密码就是root用户的密码,该密码请牢记,并出于安全考虑,请定期修改。密码的保密性也要得到保证。
2)普通用户:Linux系统可以创建许多普通用户,并为其指定相应的权限,使其有限地使用Linux系统,如安装msyql时需要创建的mysql用户。用户通过本机的Xwindow或Telnet远程登录后,执行exit命令即可退出登录。
4、修改口令
为了更好地保护用户帐号的安全,Linux允许用户在登录之后随时使用passwd命令修改自己的口令。修改口令需要经历三步:
输入原来的口令,如果口令输错,将中止程序,无法修改口令;
输入新的口令;
重新输入一次新的口令,如果两次输入的口令相吻合,则口令修改成功。
5、用户的环境变量
环境变量定义了用户执行命令操作所需要的诸如命令路径、库路径、别名、字符集等等的内容。/etc/profile是缺省所有bash用户的环境变量文件。而用户home目录下的.bash_profile、.bashrc等文件是bash用户自己定义的环境变量文件。例如,ifconfig命令在/sbin目录下,如果不将/sbin路径加入到环境变量PATH中,那么每次执行这个命令,都需要输入/sbin/ifconfig。
不同shell的环境变量定义方式不同。bash采取赋值的方式,再export生效。
执行env命令可以查看当前用户使用的所有环境变量。
6、Linux文件与目录权限
在Linux系统中,每一个文件和目录都有相应的访问许可权限,分为可读、可写和可执行三种,分别以r、w、x表示,其含义为read、write、execute(目录的可执行指的可以进入目录)。每一个文件或目录的访问权限都有三组,每组用三位表示,如: d rwx r-x r--。
第一部分:这里的d代表目录,其它的有:- 代表普通文件,c代表字符设备文件;
第二部分:文件所有者的权限字;
第三部分:与文件所有者同组的用户的权限字;
第四部分:其它用户的权限字。
1)文件/目录权限设置命令:chmod [mode] 文件名
如果要对文件a.txt的权限要设置为rw-rw-r--,则转换成二进制数就是110 110 100,再每三位转换成为一个十进制数得到664,因此我们执行命令:
chmod 664 a.txt
表示a.txt文件属主和同组用户可读可写,其他用户只可读。
2)改变文件/目录的属主命令:chown [选项] 用户名:组名文件/目录名
其中最常用的选项是“R”,加上这个参数,可以将整个目录里的所有子目录和文件的属主都改变成指定用户。
7、Linux的Daemon
Daemon守护进程是指系统启动时需要加载的必要的服务和应用。如xinetd等。主要的守护进程在/etc/xinetd.d目录下,而/etc/init.d是在系统初始化的时候需要加载的进程,如syslogd、sendmail等。
例如,当我们telnet一个Linux主机时,xinetd监听23端口,当发现有连接请求时,xinetd启动telnetd守护进程,处理这个telnet连接。
4、Drive quality upstream
我们都知道bug越是滞后发现,修复的成本越高。据微软统计,如果产品发布以后需要发布一个热修复,它的直接成本是150万美元(间接成本在200万美元),而在发布之前的一个月发现的话,修复成本是5万,设计阶段修复成本是1千,需求阶段修复成本是1百。在需求分析阶段,测试人员主要职责就是验证需求分析的可行性和可靠性。PM和DEV的共性是易于乐观,倾向于把实际情况简单化,所以会作出很多假设。比如用户肯定不会这么使用,用户肯定知道如何用,所有用户的环境肯定都有该配置。但是实际情况下总会有用户不知道如何用,总会有用户会不按“预先设计”的方式使用,总会有用户环境没有该项配置。所以测试人员的主要职责就是找出这些假设并提出疑问并加以验证。
在dev设计阶段,测试人员需要验证设计,同样找出dev的假设然后疑问这些假设是否合理,看看该设计是否处理很多没有预料的但是有可能会发生的情况,比如用户输入特殊字符,非常规操作,非常规流程,机器重启,死机,数据库连接中断,网络中断,内存耗尽等等。除了验证设计是否处理非正常情况外,测试人员的另外一个更为重要的职责是验证设计的可测试性。可测试性是指测试软件容易的程度。软件的可测性对于提高软件的质量至关重要。道理很简单,如果你的软件很难测试,无从下手,测试一个用例需要几个小时甚至几天的话,你的软件质量也就无从保证。提高软件可测试性通常的做法是把软件模块化,松耦合,模块内部运行状态可见,模块内部运行分支可控制。在评审一个设计时通常问的问题是该如何测试该模块,是否容易测试它,能不能单独测试它。如果不可以的话,需要重新考虑设计。因为一个设计的很容易测试的模块和产品可以使得后期的测试代价大大降低。微软大部分复杂系统都会有一个“one-box”版本,该版本是个假的模拟系统但是拥有真正系统的几乎所有功能,它可以运行在任何机器上。系统的绝大部分功能都可以在该模拟系统上快速方便验证。我在培训的时候很多学生问??他们在后期测试的时候遇到许多无法测试或者很难测试的困境,问我该如何解决。在具体了解困难和困境之后,我发现他们的测试策略非常单调,只能把产品部署到有限的测试环境下从用户界面上做端到端的测试。如果想测试某个特定模块或功能需要好几个其它模块配合起来才可以。我就坦率的说如果你的软件是这么架构设计的话而且已经到了这一步,世界上没有人可以解决你现在面临的困难。因为看起来好像你是卡在现在这一步了,但实际上根本问题是在前期,在需求或设计。就像解决河流的水质污染问题,你在下游无论多大的代价也只能稍微改善,解决问题的根本方法是在解决上游的污染源。或者像隔靴挠痒,隔着厚厚的靴子无法挠到关键地方,必须能够把靴子脱掉直接挠。
5、Getting better every day
软件测试的目的一个是找出bug,另外一个是衡量软件的质量。通过测试来了解产品哪些地方薄弱,哪些地方不稳定. 通过监控测试的结果,包括功能测试,性能压力测试,安全测试,本地化测试,容错测试等等来反映当前软件的质量。这也是持续集成的一个重要原因,它一方面短期迭代,另一方面可以在最短的时间内知道软件的质量,同时跟踪软件质量重开始到发布,软件质量的变化曲线。衡量软件质量的通常指标有:测试用例通过率/趋势,bug数量,种类/趋势,代码覆盖率等等。另外测试在开发周期中通常做的其它工作还有:bug root cause analysis,Bug analysis,Testcase failure analysis, test gap analysis,Bug talk,bug share,CCS data analysis等等。这一方面促使产品质量逐渐变好,而且是看得见的好。另外也促使自己放下繁忙的工作静心思考一下,如何更有效率更进一步提高质量。
6、Engineering agility
随着软件即服务和云计算的兴起,它们给开发管理,质量管理,运营管理等提出了很多新的挑战。以前那种保密开发测试2-3年再突然发布的策略无法适应互联网应用服务的要求,而是逐渐演变成快速开发出产品基本原型,然后就发布,根据用户反馈不断加以改进的方式。质量管理方面,基于服务的产品除了关注功能性能,还有其它特别重要的方面,比如scalability, high availability, fault tolerance, disaster recovery, etc.. 这些都是桌面型产品所没有的或不重视的。微软从2010年开始在很多组开始实践如何提高服务型产品的质量,比如Azure, Bing, etc…。其中最为根本的一点就是提高整个团队的敏捷度,团队能够跟的上快速迭代交付的节奏。这需要从产品设计上到测试自动化,工具,基础设施上得以保障。另外一个非常重要的实践就是TiP (test in production) 或 crowd-sourced testing. 我们在前面谈到“drive quality upstream”,也即是提前测试。test in production正好相反是“drive quality downstream”,也即是在产品环境中测试。传统的桌面产品发布之后就不再测试了。服务型产品,产品发布后继续测试。它的基本出发点是:无论投资多少建立测试环境用以模拟产品运行环境,测试环境和真正产品环境总会有不同。无论花费多大的代价做前期测试,都不可能找出所有的bug。所以无论在发布之前花费多大的代价做测试,在产品上线后总会发现新的bug。现在既然发布产品更新非常快和容易,为什么不干脆在真正产品环境中来测试,或者利用真正的用户使用真正的产品来测试(当然用户意识不到)。一旦发现bug,马上修复,马上更新。这不仅减轻了前期测试的投入,而且提高的测试效率。看看我们在测试环境中发现的bug有多少没有被认为是“真正”的bug就明白了。当然要做到test in production, 需要很多具体的流程、技术,工具作为保障。不能影响用户的关键业务,不能让用户发现过于简单的bug。 除了基本的测试自动化基础设施和测试用例外,常用的一些TiP技术有:A/B testing,expose control/slicing model,on/off features,chaos-monkey,measuring/monitoring.
最后一篇将和大家讨论一下测试工程师的技能提高和职业发展,to be continued .....
相关链接:
第一部分:重构
第二部分:设计原则与代码所有权
第三部分:进化型设计
第四部分:灵活性与复杂性
第五部分:测试驱动开发
第六部分:性能与过程调优
第三部分:进化型设计
在连载的第三部分,福勒讨论了计划型设计和进化型设计的区别,揭示了着眼于解决表象问题可以使开发者发现本质问题,并主张好的设计工作不会降低工作效率。
计划型设计和进化型设计
比尔:在你的论文《设计是否已死》(Is Design Dead)一文中,谈到了计划型设计。那么什么是计划型设计?
马丁:我将设计区分为计划型设计和进化型设计。当开发者着手实施一个软件时,他首先需要做设计,然后再按照这个设计进行编 码实现软件,这就是我所说的计划型设计。计划型设计可能借助 UML;或者把整个系统分为若干子系统,定义这些子系统间的接口。在计划型设计中,在设计和代码实现这二者之间存在明确的切换。而这二者又往往由不同的人 来完成。架构师构思设计,开发者编码实现。做好的设计并不是说一点都不能改变,但基本上是固定的。你可能会说,设计做得越好,在编码的时候,就会越少对设 计做出改动。
而在进化型设计中,开发者在编程实践的过程中逐渐完善设计。刚开始的时候并没有设计,而是先实现一些小的功能。随着实现的功能越来越多,设计才逐渐成型。
我在《设计是否已死》一文中想要强调的是,很多人在尝试进化型设计时,往往是在一种无约束无原则的环境里,最终的设计必然很蹩脚。这是人们之所以倾向于计划型设计的原因之一。
但是,在我看来,极限编程实践中,通过持续不断的集成、测试和重构,进化型设计能够做到比计划型设计更有效。计划型设计的弱点就是,要想做出一个好的设计非常难。
比尔:为什么?
马丁:我解释不清楚。这就跟解释不清楚为什么谱一曲交响乐会如此困难一样。世界上能把这些工作做好的人可以说是凤毛麟角。我想,我认为预先设计(upfront design)就属于这类工作。要做好这类工作实在是太难了。
有趣的是,很多进化型设计的倡导者,比如肯特·贝克和沃德·坎宁安,都是非常出色的设计师。但正是他们,最后认识到自己所做的预先设计往 往不够好。他们容易把一些事情过于工程化,在不需要灵活性的地方设计灵活性,而在需要灵活性的地方又未予以考虑。因此,他们最终采用了进化型设计,并通过 运用一套规则,保证了设计效果。其结果是,不但最终的设计更加出色,并且速度也加快了。拿我自己来说,80%左右的时间里,进化型设计会得到不错的结果。 而不客气地说一句,我认为我的设计水平要比一般人高。因此,我认为进化型设计应该可以适用于更广泛的人群。
重构与预先设计
比尔:重构如何改变了预先设计的地位?
马丁:人们之所以采用计划型设计,是因为他们认为改动代码是件很麻烦的事情。因为当你改变代码时,有可能破坏了一些东西并造成许多漏洞。可是,如果你既有单元测试,又有在测试基础上建立起来的有条理的重构技术,那么你就能十分快速有效地改动代码,并且不太会引起什么问题。
比尔:预先设计在重构和其他可行的实践中有什么作用?你现在还会做一些预先设计吗?
马丁:我认为一些地方还是可以用到预先设计的,不过不会很多。一些人——像肯特·贝克和罗恩·杰弗里斯——认为预先设计已 经消亡了。从某种意义上来说,他们是对的,因为你可以借助进化型设计搭建更复杂的系统。但在某些情况下,预先设计可能让你的进度加快一些。比如说,我不赞 同在架设数据库之前就讨论数据库的进化问题。我可能会对数据库的存在有一个初步的判断,然后以此作为起点。当然,我仍会用进化的方式完成大部分设计。
比尔:构造良好的(well-factored)程序和设计良好的(well-designed)程序之间有区别吗?
马丁:它们在本质上并没有什么区别,但侧重点有所不同。设计强调的是构造——将程序划分为若干分割清晰的部分。对我来说,“构造良好的”一词表达了更多对于设计的感觉,也即当你审视或使用这个设计时的感觉。代码中的“坏味道”
比尔:在你的《重构》一书中,关于何时应用重构,你是这样阐述的:“与其去追求一些很模棱两可的编程美学原则(坦率地说,这是我们咨询师们最喜欢做的事情),还不如来点儿更实际的。”
我很好奇,你是怎么看待美学的?我的经历中有很多次都是跟已有的代码打交道。这些代码的设计很烂,因此处理起来非常痛苦。如果这些设计能做得好些,让我不那么痛苦的话,我会非常感激。所以,对我来说,美学至少还是有些意义的,它可以使我的工作轻松些。
马丁:嗯,在讨论何时应用重构时,我的确是这样谈论美学的。从某种意义上说,我在重构准则中所给的那些条条框框也是一种模 棱两可的美学原则。不过,我试着给出更多的说明,而不是仅仅说“当你的代码看上去很丑陋的时候就需要做重构。”比如说,重复的代码是一种“坏味道”,再比如 说,很长的方法是一种“坏味道”,或者很臃肿的类也是一种“坏味道”。
很多“坏味道”是很容易嗅出来的。令人惊奇的是,当你审视你的程序时,往往一些很明显的现象,像是某个方法长达100行,就能引导你改进你的设计。
在重构这个长达100行的方法时,你可能会发现一些诸如责任分配(responsibility allocation)不合理这样的设计问题。像这样的问题,你是不可能光凭扫一眼代码就发现的;但是,一个长达100行的方法,却是一眼就能看出来的。 所以说,很表象的问题能够把你带向更深层的问题。
比尔:我参与过的一个项目竟然有一个长达11页的 while 循环。
马丁:这太不可思议了。
比尔:我们苦干了六个月试图让这个软件稳定运行,可是我们不敢动这个11页的循环。
马丁:这恰恰从另一个侧面说明了这个长达11页的循环是个糟糕的设计。如果你对改动某处代码心存顾虑的话,那它显然是一个蹩脚的设计。
良好的设计与效率
比尔:我想,人们不注重设计的一个原因是由于工作的流动性。那个最初编写11页 while 循环的程序员在我们接手项目的时候已经离开了公司。我认为,程序员因为自己的糟糕设计而自食其果的情况很少发生,因此他们没有足够的动因去注重设计。此 外,即便他们注重,但设计毕竟是一项费力不讨好的工作,好的设计需要时间,而开发中的时间压力往往很大。
马丁:我不同意“好的设计需要更长的时间”这样的说法。
比尔:为什么?
马丁:这是很有意思的一件事。在软件业,我们似乎普遍认为,慢工出细活。但当我回顾我自己的经历时,却发现保持代码的良好构造以及编写测试反而使我的工作加快了。
我想,人们把改进设计所花的时间看作是“失去”的时间,但却没有看到将来对代码的改动会容易得多,往往只需要几分钟的时间,否则可能要花上两三个小时。
人们往往还低估了在调试上所花的时间,低估了他们用来追踪一个“潜伏”很久的漏洞所花的时间。我在写代码的时候可以立即察觉产生的漏洞,这使得我能在它潜伏下来之前就解决它。没有几件事比调试更花时间和更令人沮丧的了。假如我们一开始就能避免产生漏洞,那效率岂不是要提高很多?
为了充分利用LoadRunner的场景控制和分析器,帮助我们更好地控制脚本加载过程,从而展现更直观有效的场景分析图表。本次将重点讨论LoadRunner如何调用Java测试代码,完成压力测试。
通常我们在执行一些Server的压力测试的时候,总会不经意间想要一个Client完成对Server的调用示例,以至于我们可以通过LoadRunner直接录制,对于测试人员来说确实很方便。不过,开发人员如果没有那么多时间去为测试人员服务,那可能就比较悲剧了,只能自己尝试去调用接口来完成压力测试了,这样就需要具备一些代码的功底了。当然如果完成接口代码的调用之后,还要保证LoadRunner能够正确录制,那确实有点麻烦了。很多时候,我们的接口压力可能确实无法通过Client端来展现,那就只能在Server使用纯代码形式完成,要么是多线程,要么是重复调用,但对于测试结果的收集就不那么方便了。所以我们还是要向办法利用一些工具的优势,取之所长,为我们所用,LoadRunner的图表分析就是所有工具里面最优秀的,正好它也支持Java代码、C++等调用接口,这里以Java为例。
通常在一个工程文件下,我们想对其中某一个Java文件进行调用,但这一个Java代码总是与其他的代码进行相互调用,所以我就需要引入很多的Java包或者是一些Jar包,下面就通过本次实践来详细讲述LoadRunner调用Java代码的步骤了,我这里的环境是LoadRunner11,JDK1.6,工程开发是Java+Flex,完成的是一个统一登录接口的测试。具体步骤如下:
1、将Java工程文件打包成jar格式,比如我这里的工程为logindemo,打包jar之后为logindemo.jar
2、将Java工程文件下的lib目录找出来,lib文件中基本都是jar包,这个是工程文件的调用jar包
3、开启LoadRunner新建一个Java Vuser的脚本,先运行哈,看脚本是否正确执行,并保存文件
4、将logindemo.jar和lib下的jar全部导入到LoadRunner的ClassPath下,前提是要保证JDK文件要导入到LR中,在LR中的Vuser——》运行时设置里,如下图所示;
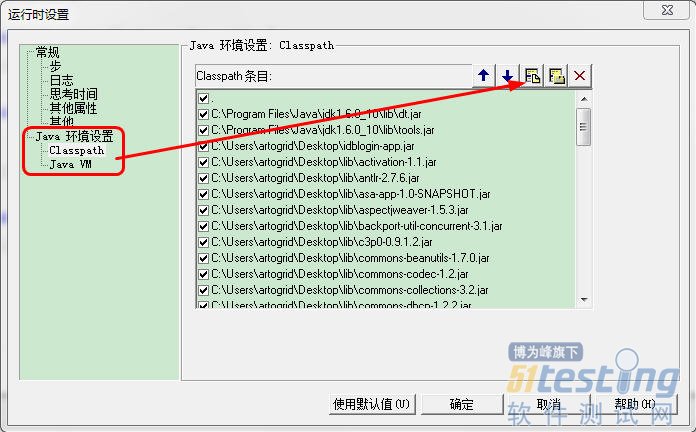
5、完成以上操作之后,这个时候我们就可以在Vuser脚本中引入Java中的调用程序了,本人开始用import方式引入的时候,发现很奇怪,第一次居然是成功的,但后台就一直都报找不到包,暂停了很久,于是用package的方式引入,发现还是真可以,于是接下来就开始运行,发现很好用,而且程序调用也确实是ok的。
注意:这里其实没什么特殊的操作,主要是对于jar包的调用方式上,可能需要注意一下几点:
1、在引入jar包的时候,比如上图上面的引入jar文件夹的方式,就不可行,这个是一个疑点,所以就只能选择将所有的jar包一并导入就ok了。
2、在Vuser中引入Java包文件时,import方式居然是偶尔行偶尔不行,所以选择package方式是绝对可行的。
3、在Vuser引入Java包之后运行时可能会出现一些报错,基本都是jar文件情况,只要找对了LoadRunner的Classpath就基本没问题,还有就是JDK一定要先导入,不然会直接提示进程被终止,不能运行Java文件。
4、LoadRunner对于Java文件的引入方式有多种,这里调用jar包的方式是我们平常应用最多的,也是最方便的。当然还可以将Java编译后的class文件,复制到LoadRunner的安装路径下的classes下,必须将Java class整个包文件夹全部复制才能执行,这种方式可需要花费调用的时间,而且最终要调用的jar包,还是要到Classpath下导入才行。
至于Java业务逻辑的实现,可以在Java中实现,然后Vuser直接调用方法接口,淡然也可以在Vuser中完成。然后就可以到场景中设置虚拟用户数进行场景测试了,然后根据场景测试的结果得出分析图表,跟其他录制之后的测试方式基本相同。
本文主要学习以下几点内容:
以下这些案例,有的带来巨大的经济损失,有的带来很大的人员伤亡,软件错误案例真正的影响到了我们的生活,我们对软件错误不得不加以特别的重视。

说了半天,到底什么是软件缺陷呢?用英文说就是Bug。

为什么会出现软件缺陷呢?是不是软件测试员不合格呢?其实,不是即使用再好的测试员,软件测试员,软件缺陷也是无法避免的,并且软件缺陷的修复费用会随时间的推移,数十倍的增长。

那么,作为软件测试员,究竟要做些什么呢?

怎么样才能成为一名优秀的软件测试员呢?

软件测试和做科学实验一样,经常需要在被测试数据之外,增加设计一组数据作为对比样本,用以判断软件在被测试条件下的实际执行结果是否与预期相符。在很多时候,这个对比样本也就是预期结果。在工作中,经常有测试人员对于如何选取测试对比样本感到比较疑惑,所以我把个人在这方面的经验总结成本文。
在我的测试经验中,测试对比样本主要可以通过如下几种途径来选取:
1、人工分析;
2、被测软件的其他输入;
3、同类软件。
一、人工分析
人工分析:也就是根据相关的需求和设计文档,分析待测程序在被测试条件下的内部处理逻辑,以人工方式进行计算、推导,得到的预期结果。
当然,这里说的人工方式,其实也有可能是测试人员自己编写一个小程序或脚本、甚至是电子表格公式来计算,取决于分析和计算的复杂程度。一般情况下,测试对比样本(预期结果)都可以通过这种方式得到。实际的例子太多了,比如:测试软件有个功能是用来改变某个数据对象的状态的,可以直接通过设计文档知道该功能会影响哪些数据和文件属性等。
优点:应用广泛、几乎适用于所有情况
缺点:在复杂的计算中较为费时费力、只能从正面验证
二、被测软件的其他输入
被测软件的其他输入:被测试软件在与被测条件可类比的输入条件下的执行结果,使被测条件下的实际结果是否正确能一目了然。
增加或减少特定的被测条件,就可以直观地了解到该条件对结果的影响,从而判断实际执行结果是否与该被测条件对结果的预期影响相符。特别需要提醒注意,此方法有一个前提:被测试软件在其他条件下的执行结果可信赖,也就是用以进行类比的测试条件通过了测试。实际的例子,比如搜索功能里的是否区分大小写选项,测试时只需要在不启用该选项时的结果通过测试的情况下,与启用该选项后的结果对比即可。
优点:直观、比手工分析省时省力、可进行负面验证
缺点:依赖于待测软件的已验证功能、难以应付预期结果不是“非此即彼”的测试条件
三、同类软件
同类软件:其他可信赖的同类软件在被测条件或类似条件下的执行结果。
这里的同类软件,可以是被测试软件的已通过测试版本,也可以是使用同一设计标准的同行(竞争对手)软件。实际的例子,如计算两个句子的相似程度。由于该算法比较复杂,用第一种方式虽然是最准确的,但是太费时费力,在实际测试中不具有可行性,所以我们一般是用待测软件的上一个公开发布版本作参考。另外一个选择是其他竞争对手的同类软件,但由于算法上的细节或多或少肯定有区别,这类结果只能作为参考,而不能直接照搬。
优点:直观、比手工分析省时省力
缺点:依赖于被测软件的已测试版本或其他同类软件
CentOS安装mysql
原文地址
http://www.centospub.com/make/mysql.html安装MySQL。[root@sample ~]# yum -y install mysql-server ← 安装MySQL
[root@sample ~]# yum -y install php-mysql ← 安装php-mysql
配置MySQL[root@sample ~]#gedit /etc/my.cnf ← 编辑MySQL的配置文件[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Default to using old password format for compatibility with mysql 3.x
# clients (those using the mysqlclient10 compatibility package).
old_passwords=1 ← 找到这一行,在这一行的下面添加新的规则,让MySQL的默认编码为UTF-8
default-character-set = utf8 ← 添加这一行
然后在配置文件的文尾填加如下语句:
[mysql]
default-character-set = utf8
启动MySQL服务[root@sample ~]# chkconfig mysqld on ← 设置MySQL服务随系统启动自启动
[root@sample ~]# chkconfig --list mysqld ← 确认MySQL自启动
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off ← 如果2--5为on的状态就OK
[root@sample ~]#/etc/rc.d/init.d/mysqld start ← 启动MySQL服务Initializing MySQL database: [ OK ]
Starting MySQL: [ OK ]
MySQL初始环境设定
[1]为MySQL的root用户设置密码
MySQL在刚刚被安装的时候,它的root用户是没有被设置密码的。首先来设置MySQL的root密码。
[root@sample ~]# mysql -u root ← 用root用户登录MySQL服务器Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2 to server version: 4.1.20
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> select user,host,password from mysql.user; ← 查看用户信息
+------+------------------------------+---------------+
| user | host | password |
+------+------------------------------+---------------+
| root | localhost | | ← root密码为空
| root | sample.centospub.com | | ← root密码为空
| | sample.centospub.com | |
| | localhost | |
|root | % |XXX |
| | | |
+------+------------------------------+---------------+
4 rows in set (0.00 sec)
mysql> set password for root@localhost=password('在这里填入root密码'); ← 设置root密码
Query OK, 0 rows affected (0.01 sec)
mysql> set password for root@'sample.centospub.com'=password('在这里填入root密码'); ← 设置root密码
Query OK, 0 rows affected (0.01 sec)
只有设置了这个才可以,才可以通过数据库来安装网址
mysql> set password for root@'xxx'=password('xxx'); ← 设置root密码
Query OK, 0 rows affected (0.01 sec)
mysql> select user,host,password from mysql.user; ← 查看用户信息
+------+--------------------------------+--------------------------+
| user | host | password |
+------+--------------------------------+--------------------------+
| root | localhost | 19b68057189b027f | ← root密码被设置
| root | sample.centospub.com | 19b68057189b027f | ← root密码被设置
| | sample.centospub.com | |
| | localhost | |
+------+--------------------------------+--------------------------+
4 rows in set (0.01 sec)
mysql> exit ← 退出MySQL服务器
Bye
然后,测试一下root密码有没有生效。
[root@sample ~]# mysql -u root ← 通过空密码用root登录ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO) ← 出现此错误信息说明密码设置成功
[root@localhost ~]# mysql -u root -h sample.centospub.com ← 通过空密码用root登录
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO) ← 出现此错误信息说明密码设置成功
[root@sample ~]#mysql -u root -p ← 通过密码用root登录
Enter password: ← 在这里输入密码Welcome to the MySQL monitor. Commands end with ; or \g. ← 确认用密码能够成功登录
Your MySQL connection id is 5 to server version: 4.1.20
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> exit
Bye
[root@sample ~]# mysql -u root -h sample.centospub.com -p ← 通过密码用root登录
Enter password: ← 在这里输入密码
Welcome to the MySQL monitor. Commands end with ; or \g. ← 确认用密码能够成功登录
Your MySQL connection id is 6 to server version: 4.1.20
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> exit ← 退出MySQL服务器
Bye
[2] 删除匿名用户
在MySQL刚刚被安装后,存在用户名、密码为空的用户。这使得数据库服务器有无需密码被登录的可能性。为消除隐患,将匿名用户删除。
[root@sample ~]# mysql -u root -p ← 通过密码用root登录
Enter password: ← 在这里输入密码
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 7 to server version: 4.1.20
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> select user,host from mysql.user; ← 查看用户信息
+------+----------------------------+
| user | host |
+------+----------------------------+
| | localhost |
| root | localhost |
| | sample.centospub.com |
| root | sample.centospub.com |
+------+----------------------------+
4 rows in set (0.02 sec)
mysql> delete from mysql.user where user=''; ← 删除匿名用户
Query OK, 2 rows affected (0.17 sec)
mysql> select user,host from mysql.user; ← 查看用户信息
+------+----------------------------+
| user | host |
+------+----------------------------+
| root | localhost |
| root | sample.centospub.com |
+------+----------------------------+
2 rows in set (0.00 sec)
mysql> exit ← 退出MySQL服务器
Bye
好了,下面都不是必须的了!
测试MySQL
[root@sample ~]# mysql -u root -p ← 通过密码用root登录
Enter password: ← 在这里输入密码
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 9 to server version: 4.1.20
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> grant all privileges on test.* to centospub@localhost identified by '在这里定义密码'; ← 建立对test数据库有完全操作权限的名为centospub的用户
Query OK, 0 rows affected (0.03 sec)
mysql> select user from mysql.user where user='centospub'; ← 确认centospub用户的存在与否
+---------+
| user |
+---------+
| centospub | ← 确认centospub已经被建立
+---------+
1 row in set (0.01 sec)
mysql> exit ← 退出MySQL服务器
Bye
[root@sample ~]# mysql -u centospub -p ← 用新建立的centospub用户登录MySQL服务器
Enter password: ← 在这里输入密码
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10 to server version: 4.1.20
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> create database test; ← 建立名为test的数据库
Query OK, 1 row affected (0.00 sec)
mysql> show databases; ← 查看系统已存在的数据库
+-------------+
| Database |
+-------------+
| test |
+-------------+
1 row in set (0.00 sec)
mysql> use test ← 连接到数据库
Database changed
mysql> create table test(num int, name varchar(50)); ← 在数据库中建立表
Query OK, 0 rows affected (0.03 sec)
mysql> show tables; ← 查看数据库中已存在的表
+-------------------+
| Tables_in_test |
+-------------------+
| test |
+-------------------+
1 row in set (0.01 sec)
mysql> insert into test values(1,'Hello World!'); ← 插入一个值到表中
Query OK, 1 row affected (0.02 sec)
mysql> select * from test; ← 查看数据库中的表的信息
+------+-------------------+
| num | name |
+------+-------------------+
| 1 | Hello World! |
+------+-------------------+
1 row in set (0.00 sec)
mysql> update test set name='Hello Everyone!'; ← 更新表的信息,赋予新的值
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from test; ← 查看数据库中的表的信息
+------+----------------------+
| num | name |
+------+----------------------+
| 1 | Hello Everyone! | ← 确认被更新到新的值
+------+----------------------+
1 row in set (0.01 sec)
mysql> delete from test where num=1; ← 删除表内的值
Query OK, 1 row affected (0.00 sec)
mysql> select * from test; ← 确认删除结果
Empty set (0.01 sec)
mysql> drop table test; ← 删除表
Query OK, 0 rows affected (0.01 sec)
mysql> show tables; ← 查看表信息
Empty set (0.00 sec) ← 确认表已被删除
mysql> drop database test; ← 删除名为test的数据库
Query OK, 0 rows affected (0.01 sec)
mysql> show databases; ← 查看已存在的数据库
Empty set (0.01 sec) ← 确认test数据库已被删除(这里非root用户的关系,看不到名为mysql的数据库)
mysql> exit ← 退出MySQL服务器
Bye
然后,删除测试用过的遗留用户。
[root@sample ~]# mysql -u root -p ← 通过密码用root登录
Enter password: ← 在这里输入密码
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 12 to server version: 4.1.20
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> revoke all privileges on *.* from centospub@localhost; ← 取消centospub用户对数据库的操作权限
Query OK, 0 rows affected (0.00 sec)
mysql> delete from mysql.user where user='centospub' and host='localhost'; ← 删除centospub用户
Query OK, 1 row affected (0.01 sec)
mysql> select user from mysql.user where user='centospub'; ← 查找用户centospub,确认已删除与否
Empty set (0.01 sec) ← 确认centospub用户已不存在
mysql> flush privileges; ← 刷新,使以上操作生效
Query OK, 0 rows affected (0.01 sec)
mysql> exit
Bye
[root@sample ~]# /etc/rc.d/init.d/httpd restart ← 重新启动HTTP服务
Stopping httpd: [ OK ]
Starting httpd: [ OK ]
用sudo时提示"xxx is not in the sudoers file. This incident will be reported.其中XXX是你的用户名,也就是你的用户名没有权限使用sudo,我们只要修改一下/etc/sudoers文件就行了。下面是修改方法:
1)进入超级用户模式。也就是输入"su -",系统会让你输入超级用户密码,输入密码后就进入了超级用户模式。(当然,你也可以直接用root用)
2)添加文件的写权限。也就是输入命令"chmod u+w /etc/sudoers"。
3)编辑/etc/sudoers文件。也就是输入命令"vim /etc/sudoers",输入"i"进入编辑模式,找到这一 行:"root ALL=(ALL) ALL"在起下面添加"xxx ALL=(ALL) ALL"(这里的xxx是你的用户名),然后保存(就是先按一 下Esc键,然后输入":wq")退出。
4)撤销文件的写权限。也就是输入命令"chmod u-w /etc/sudoers"。
1、添加用户,首先用adduser命令添加一个普通用户,命令如下:
#adduser junguoguo//添加一个名为junguoguo的用户
#passwd junguoguo //修改密码
Changing password for user junguoguo.
New UNIX password: //在这里输入新密码
Retype new UNIX password: //再次输入新密码
passwd: all authentication tokens updated successfully.
2、赋予root权限
方法一: 修改 /etc/sudoers 文件,找到下面一行,把前面的注释(#)去掉
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
然后修改用户,使其属于root组(wheel),命令如下:
#usermod -g root junguoguo
修改完毕,现在可以用junguoguo帐号登录,然后用命令 su – ,即可获得root权限进行操作。
方法二: 修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
junguoguo ALL=(ALL) ALL
修改完毕,现在可以用junguoguo帐号登录,然后用命令 su – ,即可获得root权限进行操作。
方法三: 修改 /etc/passwd 文件,找到如下行,把用户ID修改为 0 ,如下所示:
junguoguo:x:500:500:junguoguo:/home/junguoguo:/bin/bash
修改后如下
junguoguo:x:0:500:junguoguo:/home/junguoguo:/bin/bash
保存,用junguoguo账户登录后,直接获取的就是root帐号的权限。
之前写了一篇文章:关于SQL函数效率的一些测试与思考,在当中提到了将数据库中一对多关系转换为一对一关系显示的两种方法:第一种方法是在数据库中写一个函数,第二种方法为在程序中获取表Class与表Student所有数据,然后对比ClassID。
那么除了这两种方法,还有没有更快、更好的方法呢?在这里我再介绍两种方法与大家分享、讨论
闲话不多说,下面进入正文。还是那两张表
Student:

Class:
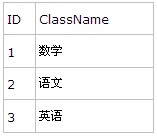
想要获得的数据效果为

第三种方法:使用SQL函数stuff
SQL语句如下
| SELECT C.ID, C.ClassName,stuff((select ',' + S.StuName from dbo.Student S where S.ClassID = C.ID for xml path('')),1,1,'')as stuName FROM Class C |
将第三种方法与第二种方法(在程序中获取表Class与表Student所有数据,然后对比ClassID)对比效率,输出结果如下:
00:00:00.5497196
00:00:00.3517834
效率比1.562665
=============================
00:00:01.0181020
00:00:00.7060913
效率比1.441884
=============================
00:00:01.4912831
00:00:01.0682834
效率比1.395962
=============================
00:00:01.9636678
00:00:01.4199062
效率比1.382956
=============================
00:00:02.4391574
00:00:01.7712431
效率比1.377088
=============================
00:00:02.9111560
00:00:02.1255719
效率比1.369587
=============================
00:00:03.3923697
00:00:02.5069699
效率比1.353175
=============================
00:00:03.8671226
00:00:02.8594541
效率比1.352399
=============================
00:00:04.3314012
00:00:03.2064415
效率比1.350844
=============================
00:00:04.8019142
00:00:03.5546490
效率比1.350883
=============================
第一个时间为第二种方法的执行时间,第二个时间为第三种方法执行时间。每种方法循环了10次以确保数据准确性
关于测试程序代码在之前的文章中有提到,改一下SQL语句就可以使用了
数据结果显示第三种方法要优秀不少。至于为什么第三种方法快,我心里已经有了个大致的想法,不过因为太难表述了,就懒得浪费口水说了,大家记住结论就好了
接下来介绍第四种方法:在SQL中加载程序集,在查询时调用程序集
加载程序集的方法有些难以表述,感兴趣的朋友可以自己去查找相关资料。在此我贴出主要代码:
View Code /// <summary>
/// The variable that holds the intermediate result of the concatenation
/// </summary>
private StringBuilder intermediateResult; /// <summary>
/// Initialize the internal data structures
/// </summary>
public void Init()
{
this.intermediateResult = new StringBuilder();
} /// <summary>
/// Accumulate the next value, not if the value is null
/// </summary>
/// <param name="value"></param>
public void Accumulate(SqlString value)
{
if (value.IsNull)
{
return;
} this.intermediateResult.Append(value.Value).Append(',');
} /// <summary>
/// Merge the partially computed aggregate with this aggregate.
/// </summary>
/// <param name="other"></param>
public void Merge(Concatenate other)
{
this.intermediateResult.Append(other.intermediateResult);
} /// <summary>
/// Called at the end of aggregation, to return the results of the aggregation.
/// </summary>
/// <returns></returns>
public SqlString Terminate()
{
string output = string.Empty;
//delete the trailing comma, if any
if (this.intermediateResult != null
&& this.intermediateResult.Length > 0)
{
output = this.intermediateResult.ToString(0, this.intermediateResult.Length - 1);
} return new SqlString(output);
} public void Read(BinaryReader r)
{
intermediateResult = new StringBuilder(r.ReadString());
} public void Write(BinaryWriter w)
{
w.Write(this.intermediateResult.ToString());
} |
这个方法比第三种方法快得不多,大概只有5%到10%的性能提升,但是这种方法十分优雅,我窃以为这种方法是解决一对多关系转换一对一方法中最好的方法
PS:最近太懒了,都没有来写东西。罪过罪过
再PS:想吐槽一下,最近园子里几个小妹子写的生活上的杂七杂八的东西居然引起了那么多人的追捧,而真正的技术贴却是无人问津,不得不说是一种悲哀
再再PS:欢迎留言讨论,欢迎转载。不足之处望海涵
LoadRunner controller将使用驱动程序mmdrv运行Vuser。用户可以在controller的run-time setting中选择Vuser的运行方式, 是多进程方式or多线程方式。
如果选择以线程方式来运行虚拟用户:
在场景设置时,“是单行脚本,还是多行脚本”会决定系统启动的进程数的多少: 假设并发用户设置为30,如果是单行30个用户,系统只需启动一个进程; 假设并发用户设置为30,如果是多行,30行,每行一个用户,系统就需要启动30个进程;
如果选择以线程程方式来运行虚拟用户:
那么无论脚本在场景组中怎么设置,是单行多用户还是多行少用户方式,系统需要启动的进程数是一定的,就是并发用户的总数;
进程方式和线程方式的优缺点:
如果选择按照进程方式运行,每个用户都将启动一个mmdrv进程,多个mmdrv进程会占用大量内存及其他系统资源,这就限制了可以在任一负载生成器上运行的并发用户数的数量,因为负载机的资源(内存及其他系统资源)是有限的。 如果选择按照线程方式运行,在默认情况下,controller为每50个用户仅启动一个mmdrv进程,而每个用户都按线程方式来运行,这些线程用户将共享父进程的内存段,这就节省了大量内存空间,从而可以在一个负载生成器上运行更多的用户。(如果选择线程方式来运行用户,每个进程中会多出几个线程,例如是53个,多出来的进程可能是用于维护进程之间的运行的) 选择线程方式虽然可以减少启动的mmdrv进程数,减少了内存的占用,但是也容易出现一个问题,例如,同一个测试场景,用线程并发就会出现超时失败或报错,而用进程并发就没错。为什么呢?因为线程的资源是从进程资源中分配出来的,因此同一个进程中的多个线程会有共享的内存空间,假设a线程要用资源就必须等待b线程释放,而b线程也在等待其他资源释放才能继续,这样就会出现这个问题。
系统需要启动的mmdrv进程数与哪些因素有关:
与在controller 的运行时设置中选择的是进程方式or线程方式来运行虚拟用户有关 进程方式:无论是单行or多行脚本,需要启动的进程数就是并发用户数; 线程方式:假设是单行脚本,每50个用户才启动一个进程;多行脚本,有几行(每行<50人)就启动几个进程,而不是每个用户启动一个进程。 如果选择了线程方式,需启动的进程数,进一步还与脚本是单行还是多行有关 单行脚本,多用户,假设少于50,只需启动一个进程,100个用户,只需启动2个进程,依此类推; 多行脚本,即使每行一个用户,也需要启动一个进程,多一行就需要多启动一个进程;不是每个用户启动一个进程,有几行(每行<50人)就需要启动几个进程。 在启动了IP欺骗功能后,所需启动的进程数,还与选择的是按进程还是按线程来分配IP地址有关 按进程分IP:每个ip(负载生成器)就需要多启动一个进程; 按线程分IP:每个ip(负载生成器)不需要多启动一个进程。