
DOM全称”Document Object Model”,字面上叫做”文档对象模型”,它是一款主要用于Web Html中的一种独立语言。Html Dom主要通过定义一套标准的对象通道接口,使得我们能够轻松访问并控制Html对象元素,它是一种用于Html和Xml文档的编程接口。DOM的表现方 法是一种树状结构。
有些时候
QTP只对标准控件支持比较好,而对特殊的控件无法识别。DOM是一种罪底层的对象操作模型,使用它来控制对象不但速度快,而且可以访问很多QTP无法访问的东西。
1. 修改控件自身接口
QTP本身无法修改控件自身接口属性,但通过DOM我们可以访问并修改自身接口属性
2. DOM对象下CurrentStyle对象应用
CurrentStyle是一个可以与Html对象元素style sheets进行交互的接口,它可以获取对象元素的字体名,字体大小,颜色,是否可见等,在验证点时有重要作用。
3. 性能提升
DOM执行速度会比QTP对象库的执行速度快好几倍,这是因为DOM是底层对象接口,而QTP首先要把对象封装,然后在脚本运行时调用对象库的对象,最后与页面上的对象进行比对,如果匹配才可控制
测试对象。而DOM是直接找对象进行控制。
下面的例子是IE对象模型里的DOM应用
1. 启动IE的三种常见方法
在QTP中启动IE:
SystemUtil.Run “iexplore.exe”
2. 使用WSH启动IE:
Set oShell = CreateObject(“wscript.shell”)
3. 使用IE COM对象:
Set oIE = CreateObject("InternetExplorer.Application")
oIE.Visible = True
oIE.Navigate http://www.baidu.com
使用第三种方法还可以获得当前窗口的句柄,并通过QTP来定位浏览器:
ieHwnd = oIE.HWND
Browser(“hwnd:=” & ieHwnd).Close
接下来的这个例子就是使用到DOM去操作页面元素了
Set oIE = CreateObject("InternetExplorer.Application")
oIE.Visible = True
oIE.Navigate "http://www.baidu.com"
'While oIE.Busy
'Wend
oIE.Document.f.wd.value = "sunyu"
我把While oIE.Busy:Wend这两句话注释掉了,运行结果如下:
程序运行出错了,主要是因为我们没有等待页面加载完,就进行了下一步的填值操作,QTP会找不到这个对象。如果你点击Retry再次运行,那么这次会通过,因为页面已经加载完毕了。所以我们在操作Web对象时,要特别注意需要等待页面加载完毕。
注:以上这个错误我们会经常遇到,有时候你只需要关掉QTP再重新打开后就不会再遇到这个错误了。
遍历所有IE对象:
Function EnumIE()
Set EnumIE = CreateObject("Scripting.Dictionary")
Set winShell = CreateObject("
Shell.Application")
Set allWins = winShell.Windows
For each win in allWins
If instr(1,win.FullName,"iexplore.exe",vbTextCompare) Then
EnumIE.Add win.hwnd,win
End If
Next
End Function
我打开一共两个IE窗口,但是第一个IE窗口里有四个子窗口,如下图:
然后调用上面的代码:
Set allIE = EnumIE()
For each oIE in allIE.Items
oIE.quit
Next
结果QTP报错了
这是因为在同一个窗口下的四个子窗口使用的是同一个句柄,所以无法加入到Dictionary对象里去。只要对代码稍加修改就可以了:
Function EnumIE()
Set EnumIE = CreateObject("Scripting.Dictionary")
Set winShell = CreateObject("Shell.Application")
Set allWins = winShell.Windows
For each win in allWins
If instr(1,win.FullName,"iexplore.exe",vbTextCompare) Then
If Not EnumIE.Exists(win.hwnd) Then
EnumIE.Add win.hwnd,win
End If
End If
Next
End Function
调用的时候,我采用了递归调用,只要有子窗口没有关完,就会继续关。这里用do while的话会多执行一次EnumIE这个函数,大家可以考虑换一种循环方式,我就不多说了。
Set allIE = EnumIE()
Do while allIE.Count>0
For each oIE in allIE.Items
oIE.quit
Next
Set allIE = EnumIE()
Loop
当然了QTP有自己的方法会很快关闭所有的IE窗口:
SystemUtil.CloseProcessByName(“iexplore.exe”)
下面介绍下利用DOM操作测试对象的几种常用方法,还是用百度主页做例子,首先将百度主页加进对象库。
IE8里会自带F12开发工具,可以方便你看你需要的DOM属性
Set oDOM = Browser("百度一下,你就知道").Page("百度一下,你就知道").Object
需要注意的是,此处的Object属性目前只支持IE,而对其他的浏览器目前还没有加入支持。
1. 通过getElementById方法获取定位对象,对其进行操作:
oDOM.getElementById("kw").value = "态度决定测试"
oDOM.getElementById("su").click
2. 通过getElementsByName方法获取定位对象,对其进行操作:
方法一:
Set oEdits = oDOM.getElementsByName("wd")
For each oEdit in oEdits
oEdit.value = "态度决定测试"
Next
oDOM.getElementById("su").click
方法二:
Set oEdits = oDOM.getElementsByName("wd")
oEdits(0).value = "态度决定测试"
oDOM.getElementById("su").click
通过方法名里Element后面的复数形式也大概可以知道这个方法返回的是一个集合,所以需要遍历集合里的对象获取这个对象。
3. 通过getElementsByTagName方法获取定位对象,对其进行操作:
Set oEdits = oDOM.getElementsByTagName("INPUT")
For each oEdit in oEdits
If oEdit.type = "text" Then
oEdit.value = "态度决定测试"
End If
Next
oDOM.getElementById("su").click
用这个方法遍历之后通常要加判断,因为一个页面里可能有很多INPUT标签。
4. 利用FORM来获取对象元素,对其进行操作:
oDOM.f.wd.value = "态度决定测试"
oDOM.f.su.click
5. 访问页面里的Script脚本变量
通过DOM可以直接访问到页面中的JS或者VBS中的变量,还是以百度为例,我们用F12进行探测,可以看到k这个变量: k = d.f.wd
oDOM.parentWindow.k.value = "态度决定测试"
oDOM.getElementById("su").click
从代码里可以看出,我们只需要通过parentWindow去访问web页面中的变量即可。
下面我们来说说利用DOM完成QTP无法完成的任务:
还是百度,假设我们需要验证一些属性,此时我们可以使用CurrentStyle来验证。
Set oDOM = Browser("百度一下,你就知道").Page("百度一下,你就知道").Object
Set p = oDOM.f.CurrentStyle
msgbox p.color
我们可以验证表单的颜色。
利用DOM还可以提升我们的脚本性能,举个例子,自己构建一个含有100个文本框的HTML页面,每个文本框的name属性都是由text_开头,之后由1到100递增。首先将Page对象加到对象库里去。
效果图如下:
接下来我们就可以引入保留对象Services的Transaction属性来验证性能是否有提高。
QTP描述性编程:
Services.StartTransaction "test"
For i =1 to 100
Browser("Browser").Page("Page").webEdit("name:=text_"+cstr(i)).Set "hello world"
Next
Services.EndTransaction "test"
运行后结果大概用了11.5秒时间填写完一百个webEdit对象。
DOM操作脚本:
Set oDOM= Browser("Browser").Page("Page").Object
Services.StartTransaction "test"
For i =1 to 100
oDOM.getElementsByName("text_"+cstr(i))(0).value = "hello world"
Next
Services.EndTransaction "test"
结果只用了1.8秒时间,效率惊人。
如果文本框更多的话,那么DOM操作对象的优势将进一步显现出来。这对性能的提升会有巨大的帮助。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
关于
Selenium RC的原理,还是Selenium私房菜系列6比较详细。 虽然我只看懂了组成。
按照上面的步骤,搭建后的工程:
一个简单的Case,不完整,纯粹为了
测试环境是否搭成功。
package com.dhy.selenium.test; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.firefox.FirefoxDriver; import org.openqa.selenium.remote.RemoteWebDriver; import org.openqa.selenium.remote.DesiredCapabilities; public class Case1 { public static void main(String[] args) throws Exception{ // WebDriver driver = new RemoteWebDriver(new URL("http://localhost:4444/wd/hub"), // DesiredCapabilities.firefox()); WebDriver driver = new FirefoxDriver(); driver.get("http://2j.isurveylink.com/s/183/?test_mode=1"); WebElement element = driver.findElement(By.id("start_btn")); element.click(); try { Thread.sleep(3000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println("Page title is : " + driver.getTitle()); driver.quit(); } } |
这里的语法啊、类啊什么的,需要慢慢研究。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
方法一
这个实现其实蛮简单,只不过官网上的手册写得不是很详细。
首先你在入口文件中定义你生成html页面的路径常量HTML_PATH,一般路径都定义在根目录,比较直观。把手册上写得代码copy到你要生成页面的应用项目的配置文件中,只要写静态缓存规则就行。比如你要生成关于我们页面,你的规则可以这样写
'HTML_CACHE_ON' => true, // 开启静态缓存 'HTML_CACHE_TIME' => 60, // 全局静态缓存有效期(秒) 'HTML_FILE_SUFFIX' => '.shtml', // 设置静态缓存文件后缀 'HTML_CACHE_RULES' => array( // 定义静态缓存规则 'About' => array('/About/index.html') |
当你访问关于我们页面的时候,就会生成这个页面的纯html页面,当你这个页面更新数据的时候,隔60秒后,前台页面就会自动重新写入,因为缓存有效期设置的60秒,你也可以设置永久有效,这样的话不会每隔60秒重新写入一次,浪费性能。设置永久有效的话,你更新数据前台是不会更新的,这个时候你只要删除缓存就行了,缓存就是这个生成的页面文件,将其删除。或者你在后台写个一键更新缓存等都可以,这种缓存访问页面速度是非常可观的。而且还能脱离程序运行,不怕程序发生意外报错情况。
方法二
ob_start(); //打开缓冲区 $data = ob_get_contents(); //获取缓冲区的内容 ob_end_clean(); //关闭缓冲 $fp = fopen("/index.html","w"); //将内容写入文件 if(!$fp) { echo "文件无权限"; exit(); } else { fwrite($fp,$data); fclose($fp); echo "生成成功"; } |
这代码写在前台相应的控制器中,会自动生成html页面。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
JIRA 使用神奇的JQL查询数据,很nice啊 !
官网API: https://docs.atlassian.com/jira/REST/latest/#d2e2344
/rest/api/2/search request query parameters parametervaluedescription jql string a JQL query string startAt int the index of the first issue to return (0-based) maxResults int the maximum number of issues to return (defaults to 50). The maximum allowable value is dictated by the JIRA property 'jira.search.views.default.max'. If you specify a value that is higher than this number, your search results will be truncated. validateQuery boolean Default:true whether to validate the JQL query fields string the list of fields to return for each issue. By default, all navigable fields are returned. expand string A comma-separated list of the parameters to expand. |
其中jql 是一个JQL的query string。
测试代码:
string url = baseURL + "/search?jql=assignee=" +username +" and (status=1 or status=2)"; HttpWebRequest req = WebRequest.Create(url) as HttpWebRequest; try { req.ContentType = "application/json"; req.Headers.Add("Authorization", "Basic " + m_authString); using (HttpWebResponse resp = req.GetResponse() as HttpWebResponse) { StreamReader reader = new StreamReader(resp.GetResponseStream()); response = reader.ReadToEnd(); } } catch (Exception e) { response = e.Message; m_errorMsg = e.Message; return false; } |
也可以直接装好以后,用url直接回车访问上述创建的链接,会直接得到数据信息到页面
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
因电脑上装了两个系统,导致我的JIRA服务不能和tomcat同时启动,让我弄了好久都不知道是啥原因,经过请教,总算得出原来是JIRA的Port和Tomcat的Port冲突。在
server.xml中修改即可。<Server port="8006" shutdown="SHUTDOWN">两个改成不一样就好了。装好后,记得要配置环境变量,这个跟配置tomcat是一样的。之后记得破解哦。如果要汉化的话,也有相关操作说明。
破解说明:
1.将atlassian-extras-2.2.2.jar 覆盖至%JIRA_HOME%/atlassian-jira/WEB-INF/lib/atlassian-extras-2.2.2.jar
2.将atlassian-extras-2.2.2.crack 覆盖至先将这个文件复制到%JIRA_HOME%/atlassian-jira/WEB-INF/classes下,然后把文件中的MaintenanceExpiryDate项修改到你想要的日期
重启Jira
JIRA汉化
1、用管理员登录,进入管理页面;
2、进入插件页面
3、进入install标签页
4、点击
5、 在弹出的对话框中选择 中文插件文件(.jar)
6、“中文插件文件.jar”下载地址:
文件名:JIRA-5.0-language-pack-zh_CN.jar
7、系统会自动安装,并转换语言为中文。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我两年多的
测试生涯到头了。我想再这里总结一下点点滴滴。以及我也会说明我为什么选择离开。在中国有着很多很多的
软件测试,很多迫于环境,迫于leader,迫于很多原因,导致只是一个“执行者”。以下只是我个人的一些经历。大家可以借鉴,也可吐槽,大家随意。
首先在测试的时候需要有一些心理暗示,其实未必是暗示,可能是给自己的一些自信。
第一:产品一定是有bug的。
无论你测试什么产品,一定是需要报有这样的心态。为什么?其实就如一句说的“如果自己都不爱自己,那么就不要奢望别人来爱你”。如果连测试潜意识里面都觉得产品是没有bug的那么还能有谁认为产品是有bug的呢?
测试的历史上有两种验证方法,一种是测试是用来验证产品一定是没有bug的,一种是测试是用来验证产品是有bug的。无论哪种你都要有一种原则,要有一种信念。就如人生漫漫长路一样,我们必须坚信自己的梦想,坚信自己是能够成功的。那么才有可能,才有希望。当碰见挫折的时候,当迷茫的时候,才不会真的被打败。
一个新的feature,一个刚刚fix的bug,一个用户反馈,一个不起眼的问题。我们都需要坚信里面有缺陷的。没有任何一个产品,任何一个细节是完美的。
许多公司从上级到下属对于产品的质量根本没有概念,又或者对于质量不重视。在这种情况下,就需要测试产生力量,需要用各种事实依据去告诉公司,告诉大家这样一个产品质量的真想。国外的公司相对好点,国内有很多公司是需要有这种有责任感的测试存在。
第二,任何的bug都是能够repro的
无论你面对一个很小的
功能测试,还是很复杂的场景化的测试,又或者说某个用户很简单明了的描述了一个问题。我们需要坚定不移的告诉自己,只要是一个bug就是有重现步骤的。
微软曾经有测试,一个问题的重现步骤长达50步。虽然可能不是最佳的步骤,但是依然对于解决问题起到了决定性的作用。
自然,在实际中很多情况下的确会碰见一下子找不到重现步骤的方法。找不到方法意味着什么?意味着你可以开bug,dev可以fix这个bug。但是谁都不知道到底有没有真的修复这个问题。还可能因此出现很多regression的bug。所以找到一个bug的repro step可以说是一个测试基本功也是体现价值的地方。
和第一点一样,只有你自己信念中去相信了,那么你才有可能成功。
第三,只相信自己看到的
在很多情况下,dev或者同事会告诉测试“这个功能很小,没有bug的”“简单测一下就好啦”等等的话。我主张还是不要太相信任何一个人。
面对bug,我们需要好好的理清问题的根源逻辑,在进行一个完全的测试之后告诉自己“这个功能基本上不会有很大,或者很block用户的问题”;面对一个讨论,不要听到别人说什么就是什么,任何的决定都没有完全正确的。我们需要自己亲手去验证很多决定和设计,小到你可以google,找出各种证据来证明某些事情。大到你可以进行用户数据搜集,很多企业不会去做。但是如果一个有sense的测试,我相信必须什么事情都亲手去实践去证明!
以上说了这么多,可能很多人觉得,这个还是测试么?ok,我认为真正的一个测试满足以上三点是远远不够的。以下是我认为一个有sense的测试,记住是有sense的测试需要做到的。
为什么我将这两个放在一起呢。两者密不可分。我所在公司是做android产品的。目前中国国内很多企业也是一样的问题,就是只是在乎自己的产品怎么样,并不会很关心你的发展。作为测试,必须有探知精神,必须乐于学习。比如你测试A平台的B产品,如果只是一味的测试,只是一味的报bug。的确你会有进步,做任何一行你都会有进步,行行都能够出状元。但是几年光阴一过去,当别人或者自己问问自己,自己真的知道了多少?可能对于自己公司做的产品很了解之外,一无所知。那么这样对于自身发展又有什么好处呢?
探知,对于任何一个design,任何一个bug,任何一个细节都需要去探知。这样无论你做了多久,无论你是否做多少个项目都会依然有进步。时不时的问问自己,对于这个产品feature真的了解很透彻么?对于产品功能逻辑很清楚么?对于这个产品所在平台了解么?业内是不是主流的tools都清楚了呢?是不是自己已经没有了进步的余地了。这样自己会明了很多。
第二:责任
这点可能很多人会说,测试最基本的不就是责任么?没有责任怎么去做一个测试呢?是的,责任每个人都有,程度是不同的。你作为一个tester,需要保证产品的质量。勿以bug小而不重视,本质上依然是不负责任的表现。
相反的,很多测试对于产品是负责了,对于自己却是不负责任的。因为他们只是一个傀儡,天天被人操控着。做这个做那个,我觉得这种是更加可悲的。
如果你作为一个tester leader,那么你的责任不是去指挥别人做事情,不是去拍老板马屁。而是自己不要忘记进一步的学习,不要忘记对于任何的细节去了解。更不要忘记如果出了什么问题,自己勇于承担这个责任。真正的leader是什么?需要在流程以及技术上面有自己的sense,需要不停的去完善项目流程,从而提高测试team的效率以及项目的效率。
第三:通过各种渠道找到bug repro step
bug会从各个渠道发现。公司内部bug bash的时候,用户反馈的问题,自己找到的问题。老板发现的问题等等。这个时候能否找到repro step就是体现一个测试的价值所在了。
测试往往碰见的问题是这样的。突然发现一个问题,欣喜若狂!但是然后问问自己“我刚刚做了什么”,基本上很多人都不知道。有的时候是有log可以取,但是log只是一个告诉开发如何dev去解决bug的。所以找出重现步骤才是王道。并非要时时刻刻保持警惕,可以有两个做法,一个就是自己在测试的时候留个心眼,养成时不时回忆自己做了哪些操作。一个就是养成一边测试一边记录log的方法,这个方法相对很保险,不过前提是自己需要有完全看得懂log的能力。
另外一类bug是从用户这里报出。用户一般是无知的,根本不会懂你产品的逻辑,可能描述出来的错误和真正的错误根本就是天差地别。这个时候就需要测试去按照经验以及各种方法去判断。判断出用户说的产品的真正的问题在哪里,然后使用各种方法(automation.etc)去模拟bug产生的环境。这样一来,bug在修复的情况下能够在公司内部马上得到confirm。这样无论是对于产品,用户,还是公司都是一种无限大的利益。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
作为一名
测试人员我知道我不可能找到每一个错误。但即便如此,当一个问题从你眼前溜过,跑向生产这一本垒时,我经常会问自己,我怎么就漏过了这个问题呢?有什么是我可以做得更好的?我能做些什么来防止未来这种情况的再次发生?
这些都是很好的问题,但更实际的来说,我们需要认识到一点,错误往往会偷偷溜过而未被我们发现。有一些方法可以帮助我们减少这些未被发现的bug数量,但我明白没有任何办法能够保证产品完全无缺陷。
当我刚开始做测试时我总是对别人在我测试过的产品的部分发现bug非常敏感。我常听到办公室回响着可怕的句子——“谁测试过这个?为什么没有发现这个错误?”那时我还没有足够的经验可以通过合理的方式来争论,为什么不是任何产品在任意给定时间段中都可以找到所有的bug。
虽然在某些方面,这些经历帮助我使我的测试方法更完备。
所以,我列出了一些你可以尝试一下的事情,以限制未被检测到的bug的数量,我有几个故事分享给大家,关于那些像夜晚的忍者那样悄悄溜过而未被我发现的错误。这些故事表明,即使最明显的错误(一旦知道就觉得很明显),可能发生也将发生。
我们怎么会错过呢?
在一个项目中,一个网站,正在一些关键部分,如注册和产品选择进行了重新设计并添加了一些额外的功能,我花了大约两个月进行各种测试活动。在这段时间内熟悉设置的各种变化和改进,我们都知道危险,并试图减少它们,我们找了一些人来进行用户支持测试以帮助测试。不幸的是,这些主要覆盖在验证bug修复或者专门针对测试网站的某些部分。
在产品环境中启动网站的第一分钟,一个问题被确定。这是非常明显的bug,也产生了一些相当大的混乱,它是怎么能够被错过的。这个问题并不是说需要任何除了会拼写之外的特殊的技能才能找到的。在该网站的首页(它通常被称为商店橱窗),客户登陆后看到的你的网站的第一页,在屏幕中间非常大的字体,写着“BRAODBAND“而不是“BROADBAND”。 “这是一个非常明显的错误拼写,但不知何故,每个人都错过了发现它,直到这个网站开始使用,然后由于某种原因,这个错误立即被所有人发现了。
它是活的!
我现在受到了“它还活着”,在1931年的老电影科学怪人中那句台词的启发。当产品处于成熟状态,我用这句话来慢慢的推进我的想法,为了能够看到那些可能被我错过的东西。在这种情况下,问题是那么明显它造成了混乱的奇怪的氛围,而且可能因为修补程序过于简单而无从指责。然而,这很清楚地表明了,即使是最公然明显的错误也很容易被很多人错过。
本应该,早该,早可以。
这些错误不一定在测试过程中由于没有找到他们而被错过,而是因为测试者没有考虑如果X事件发生了,在整个开发周期中将会或者可能会发生什么错误。当在当天晚些时候发现或者当产品在生产过程中发现这些bug时,常常招来了一句“是啊,我就觉得这可能会发生”或“我就知道会发生这个问题。”
这些方案有时被称为边缘情况(极限测试情况下)或边角情况(非常具体的,很少发生的情况下)。后者常常使我感到惊讶,因为它们可能很早就在项目中被定义为边角情况,可是后来发现实际上是一些经常发生的情况。这主要是由于不理解系统以及其相互作用够好才能够使得最初做出这样的判断。
我曾有过此类的经历,测试一个新的需要处理成千上万的客户记录的应用程序。在测试过程中,我问了一个问题:“是否进行过负载测试?”对此的答复是“哦,这不是问题,它可以轻松地处理高达一百万条记录的负载。”然而,当推出了这个改变后,在前几分钟有显著的负载,经过观察其证明之后会导致严重的问题并且对应的代码会被还原。在那段时间,我并没有完全理解所涉及的技术,并假定了开发人员比我知道得更清楚,可能已经考虑过这个潜在的问题。从那天起我才知道,当我有直觉某处可能有问题,我不应该认为别人快速而简单的答案就是真理。我应该从别处寻求可以支持的资料以证实或反驳我的假设。
我的第六感正在提醒!
我把这称为我的“第六感”启发,当我对某些东西有一种感觉,比如我不能完全的理解或我所得到的信息看来可疑的情况下,我不愿意就此忽略它并继续下一步除非我对其有一个合理的认识。在这种情况下,我会让参与该项目的每个人都知道,我对这部分有所顾虑。这通常会有所帮助因为其他人会开始质疑为什么我会有顾虑;无论是由于我缺乏相关知识使得我的假设是错误的,或我的假设是正确的,对我而言都没关系。重要的是,我明白如果我忽视自己的直觉进行测试,我不认为自己能有效地做好
工作。
容易复制。不容易找到。
通常如果测试需要涵盖产品或系统的各个方面,其场景数量会高得难以负担。即使对于看来可以相对简单的进行测试的系统也可以有数以百万计的排列。有些办法可以处理这样的问题,其中之一被称为成对(或组合)的测试,我不会在这里来详述这个方法,但如果你想了解更多,可以看看Michael Bolton所著的对于这个方法的优秀的处理方式。
我对于这一类的问题的经历是个标准的负面答案,当发现一个问题时,这是100%可复制的。由于只要通过5个简单的步骤,就次次都可复制,并最终导致“怎么又没发现这个bug?”的指责。
问题是这样,基于一个复制系统,该系统有多个文件夹,每一个文件都具有三个不同的使用权限,仅读取,读或写以及拒绝。在每个文件夹中,每个文件都可以有相同的三个文件权限。 我现在更有经验并愿意挑战回复其他人提出的意见,如“你为什么没有发现错误?”因此,我设计了一个简单的场景,说明给定变量的数量有限的测试,测试所有排列所需的时间是巨大的。该方案是这样的:
三个文件夹的层次结构
每个文件夹包含四个文件
文件夹和文件都可以有不同的权限
覆盖这个相对简单情况下所有排列的测试次数为14348907。这是3^15(15个实体与3种状态)。很明显,这么大的数字显示了你是无法在可行的时间内测试完所有排列的。当然,你可以创建一个自动化的测试,以更迅速地完成,但这里的问题是,这种情况甚至不是一个现实世界中真正存在的情况。我仅仅是创建了一个简单的练习,以显示要测试这个看似简单的可复制问题是有多么困难。要知道在现实世界中的客户会有几百个文件夹,包含数百或上千个文件的大层次结构。通过交流关于这个简单的场景很快使我能够说明为何测试无法发现每一个漏洞,无论在事后它是多么的明显。
还有什么?
正如已经叙述的这三个真实世界的故事,即使你认为你已经完成了测试而实际你还没有。有许多原因可以停止测试,但其中并没有你已完成了所有测试这一理由。我觉得思考我是否错过了什么是非常宝贵的。有什么是我没有想到的?有什么是我觉得太明显了,就对其忽视或认为是不值得考虑?我一般尽量记录这些问题。有些会得到答案,有些则没有;但是这并不会阻止我思考具有启发性的“还有什么?”。
避免令人尴尬的错误!
命名您的启发式方法,让你可以在未来轻松地回忆起来。
如果你要问如何做,你才可以进行测试,当心——无论是与你的理解还是所给的答案都可能有问题。
创建许多测试的想法。你真的不应该有没有想法的时候。
想想“假设?”
请注意你的情绪。他们会告诉你一些事情
有新的眼光来看待变化,而不要指示它们要测试的内容。
意识到“没有人会这么做”的声明。
与其他测试人员,开发人员,产品经理,市场营销——所有可用的并有意愿的人合作测试!
在测试中,我们需要大量的实用主义。不管我们使用什么样的方法来帮助防止检测失误,bug总会被漏过。使用启发方式可以帮助减少总数。
给启发方式命名或助记符可以帮助您同时记住并利用它们来帮助你早期识别错误和防止明显的错误。命名您的启发方式可以根据自己的个人喜好来完成,因此,如果以上任何一个方法对你有用,请随意命名并利用它们来帮助你找到那些所谓明显的错误。
作者简介
Stephen Blower 已经作为测试员在不同的机构工作了18年。目前,身为Ffrees家庭财务的测试经理,他有令人羡慕的位置,能够从头开始创建一个测试团队。他职位的重要部分是激发测试者,而不仅仅是创建流程。Stephen大力鼓励互动和反馈,并让测试者获得控制权,使他们成为发展具有价值的发展团队的成员。
译者简介:大头,在读日本九州大学修士,计算机专业,主研究方向为文本挖掘,及自然语言处理。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
代码测试的立足点是Code,是基于代码基础之上的,而传统的
功能测试和接口测试是基于应用的,必须对应的测试系统是在运行中的。
代码测试不会特别注重接口测试的可持续性集成。
代码测试的特点是快捷高效准确的完成测试
工作,快速推进产品的迭代。
(1) 代码走读和review
适合场景:逻辑相对简单,有较多的边界值。
方法介绍:直接查看和阅读代码,检验逻辑是否正确。
(2) 代码debug与代码运行中测试
适合场景:数据构造比较困难,特殊的场景覆盖。
方法介绍:1.直接在debug代码过程中查看数据流走向,校验逻辑。
2.在debug过程中直接将变量的值或者对象的值直接改成想要的场景
(3) 私有方法测试
适合场景:需要测试的类的复杂逻辑处理是放在一个特定的方法中,而且该方法中没有使用到其他引用的bean
方法介绍:通过反射的方式调用方法,进行测试。
例子:
假设有一个待测试的类叫MyApp,有一个私有方法叫getSortList, 参数是一个整形List。
/** * Created by yunmu.wgl on 2014/7/16. */ public class MyApp { private List getSortList(List<Integer> srcList){ Collections.sort(srcList); return srcList; } } |
那么测试类的代码如下:
/** * Created by yunmu.wgl on 2014/7/16. */ public class MyAppTest { @Test public void testMyApp() throws NoSuchMethodException, InvocationTargetException, IllegalAccessException { Class clazz = MyApp.class; Method sortList = clazz.getDeclaredMethod("getSortList",List.class); //获取待测试的方法 sortList.setAccessible(true); //私有方法这个是关键 List<Integer> testList = new ArrayList<Integer>();//构造测试数据 testList.add(1); testList.add(3); testList.add(2); MyApp myApp = new MyApp(); // 新建一个待测试类的对象 sortList.invoke(myApp,testList); //执行测试方法 System.out.println(testList.toString()); //校验测试结果 } } |
(4) 快速搭建测试脚本环境
适合场景:待测试的方法以hsf提供接口方法,或者需要测试的类引入了其他bean 配置。
方法介绍:直接在开发工程中添加测试依赖,主要是junit,如果是需要测试hsf接口,则加入hsf的依赖,如果需要使用itest的功能,加入itest依赖。
Junit 的依赖一般开发都会加,主要看下junit的版本,最好是4.5 以上
HSF的测试依赖:以前的hsfunit 和hsf.unit 最好都不要使用了。
<dependency>
<groupId>com.taobao.hsf</groupId>
<artifactId>hsf-standalone</artifactId>
<version>2.0.4-SNAPSHOT</version>
</dependency>
Hsf 接口测试代码示例:
// 启动HSF容器,第一个参数设置taobao-hsf.sar路径,第二个参数设置HSF版本
HSFEasyStarter.start("d:/tmp/", "1.4.9.6");
String springResourcePath = "spring-hsf-uic-consumer.xml";
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext(springResourcePath);
UicReadService uicReadService = (UicReadService) ctx.getBean("uicReadService");
// 等待相关服务的地址推送(等同于sleep几秒,如果不加,会报找不到地址的错误)
ServiceUtil.waitServiceReady(uicReadService);
BaseUserDO user = uicReadService.getBaseUserByUserId(10000L, "detail").getModule();
System.out.println("user[id:10000L] nick:" + user.getNick());
Hsf bean的配置示例:
<beans>
<bean name="uicReadService" class="com.taobao.hsf.app.spring.util.HSFSpringConsumerBean"
init-method="init">
<property name="interfaceName" value="com.taobao.uic.common.service.userinfo.UicReadService" />
<property name="version" value="1.0.0.daily" />
</bean>
</beans>
Itest的依赖:这个版本之前修复了较多的bug。
<dependency>
<groupId>com.taobao.test</groupId>
<artifactId>itest</artifactId>
<version>1.3.2.1-SNAPSHOT</version>
<dependency>
(5) 程序流程图校验
适合场景:业务流程的逻辑较为复杂,分支和异常情况很多
方法介绍:根据代码逻辑画出业务流程图,跟实际的业务逻辑进行对比验证,是否符合预期。
(6) 结对编程
适合场景:代码改动较小,测试和开发配对比较稳定
方法介绍:开发修改完代码后,将修改部分的逻辑重复给测试同学,测试同学review 开发同学讲述的逻辑是否和代码的逻辑一致。
3. 具体操作步骤:
(1) checkout代码,在接手项目和日常后第一件事情是checkout 对应的应用的代码
(2) 了解数据结构与数据存储关系:了解应用的数据对象和数据库的表结构及存储关系。
(3) 了解代码结构, 主要搞清楚代码的调用关系。
(4) 了解业务逻辑和代码的关系:业务逻辑肯定是在代码中实现的,找到被测试的业务逻辑对应的代码,比较常见的是通过url 或者接口名称等。
如果是webx框架的可以根据http请求找到对应的代码,如果是其他框架的也可以通过http请求的域名在配置文件中找到对应的代码。
(5) 阅读相关代码,了解数据流转过程。
(6) Review 代码,验证条件,路径覆盖。
(7) 复杂逻辑可以选用写脚本测试或者私有方法测试,或者画出流程图。
4. 代码测试的常见测试场景举例:
(1) 条件,边界值,Null 测试:
复杂的多条件,多边界值如果要手工测试,会测试用例非常多。而且null值的测试往往构造数据比较困难。
例如如下的代码:
if (mm.getIsRate() == UeModel.IS_RATE_YES) { float r; if (value != null && value.indexOf(‘.’) != -1) { r = currentValue – compareValue; } else { r = compareValue == 0 ? 0 : (currentValue – compareValue) / compareValue; } if (r >= mm.getIncrLowerBound()) { score = mm.getIncrScore(); } else if (r <= mm.getDecrUpperBound()) { score = mm.getDecrScore(); } mr.setIncreaseRate(formatFloat(r)); } else { // 目前停留时间为非比率对比 if (currentValue – compareValue >=mm.getIncrLowerBound()) { score = mm.getIncrScore(); } else if (currentValue – compareValue <= mm.getDecrUpperBound()) { score = mm.getDecrScore(); } } |
(2) 方法测试
某个方法相对比较独立,但是是复杂的逻辑处理
例如下面的代码:
private void filtSameItems(List<SHContentDO> contentList) { Set<Integer> sameIdSet = new TreeSet<Integer>(); Set<Integer> hitIdSet = new HashSet<Integer>(); for (int i = 0; i < contentList.size(); i++) { if (sameIdSet.contains(i) || hitIdSet.contains(i)) { continue; } SHContentDO content = contentList.get(i); List<Integer> equals = new ArrayList<Integer>(); equals.add(i); if ("item".equals(content.getSchema())) { for (int j = i + 1; j < contentList.size(); j++) { SHContentDO other = contentList.get(j); if ("item".equals(other.getSchema()) && content.getReferItems().equals(other.getReferItems())) { equals.add(j); } } } if (equals.size() > 1) { Integer hit = equals.get(0); SHContentDO hitContent = contentList.get(hit); for (int k = 1; k < equals.size(); k++) { SHContentDO other = contentList.get(k); if (hitContent.getFinalScore() == other.getFinalScore()) { long hitTime = hitContent.getGmtCreate().getTime(); long otherTime = other.getGmtCreate().getTime(); if (hitTime > otherTime) { hit = equals.get(k); hitContent = other; } } else { if (hitContent.getFinalScore() < other.getFinalScore()) { hit = equals.get(k); hitContent = other; } } } for (Integer tmp : equals) { if (tmp != hit) { sameIdSet.add(tmp); } } hitIdSet.add(hit); } } Integer[] sameIdArray = new Integer[sameIdSet.size()]; sameIdSet.toArray(sameIdArray); for (int i = sameIdArray.length - 1; i >= 0; i--) { contentList.remove((int) sameIdArray[i]); } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
(1)如何进行SQL注入测试?
首先找到带有参数传递的URL页面,如 搜索页面,登录页面,提交评论页面等等.
注1:对 于未明显标识在URL中传递参数的,可以通过查看HTML源代码中的"FORM"标签来辨别是否还有参数传递.在<FORM> 和</FORM>的标签中间的每一个参数传递都有可能被利用.
<form id="form_search" action="/search/" method="get">
<div>
<input type="text" name="q" id="search_q" value="" />
<input name="search" type="image" src="/media/images/site/search_btn.gif" />
<a href="/search/" class="fl">Gamefinder</a>
</div>
</form>
注 2:当你找不到有输入行为的页面时,可以尝试找一些带有某些参数的特殊的URL,如HTTP://DOMAIN/INDEX.ASP?ID=10
其 次,在URL参数或表单中加入某些特殊的SQL语句或SQL片断,如在登录页面的URL中输入HTTP://DOMAIN /INDEX.ASP?USERNAME='HI' OR 1=1
注1:根据实际情况,SQL注入请求可以使用以下语句:
' or 1=1- -
" or 1=1- -
or 1=1- -
' or 'a'='a
" or "a"="a
') or ('a'='a
注2:为什么是OR, 以及',――是特殊的字符呢?
例子:在登录时进行身份验证时,通常使用如下语句来进行验证:sql=select * from user where username='username' and pwd='password'
如 输入http://duck/index.asp?username=admin' or 1='1&pwd=11,SQL语句会变成以下:sql=select * from user where username='admin' or 1='1' and password='11'
' 与admin前面的'组成了一个查询条件,即username='admin',接下来的语句将按下一个查询条件来执行.
接 下来是OR查询条件,OR是一个逻辑运 算符,在判断多个条件的时候,只要一个成立,则等式就成立,后面的AND就不再时行判断了,也就是 说我们绕过了密码验证,我们只用用户名就可以登录.
如 输入http://duck/index.asp?username=admin'--&pwd=11,SQL语 句会变成以下sql=select * from user where name='admin' --' and pasword='11',
'与admin前面的'组成了一个查 询条件,即username='admin',接下来的语句将按下一个查询条件来执行
接下来是"--"查询条件,“--”是忽略或注释,上 述通过连接符注释掉后面的密码验证(注:对ACCESS数据库无 效).
最后,验证是否能入侵成功或是出错的信息是否包含关于
数据库服务器 的相关信息;如果 能说明存在SQL安 全漏洞.
试想,如果网站存在SQL注入的危险,对于有经验的恶意用户还可能猜出数据库表和表结构,并对数据库表进行增\删\改的操 作,这样造成的后果是非常严重的.
(2)如何预防SQL注入?
转义敏感字符及字符串(SQL的敏感字符包括“exec”,”xp_”,”sp_”,”declare”,”Union”,”cmd”,”+”,”//”,”..”,”;”,”‘”,”--”,”%”,”0x”,”><=!-*/()|”,和”空格”).
屏蔽出错信息:阻止攻击者知道攻击的结果
在服务端正式处理之前提交数据的合法性(合法性检查主要包括三 项:数据类型,数据长度,敏感字符的校验)进行检查等。最根本的解决手段,在确认客 户端的输入合法之前,服务端拒绝进行关键性的处理操作.
从测试人员的角度来讲,在程序开发前(即需求阶段),我们就应该有意识的将安全性检查应用到需求测试中,例如对一个表单需求进行检查时,我们一般检验以下几项安全性问题:
需求中应说明表单中某一FIELD的类型,长度,以及取值范围(主要作用就是禁止输入敏感字符)
需求中应说明如果超出表单规定的类型,长度,以及取值范围的,应用程序应给出不包含任何代码或数据库信息的错误提示.
当然在执行测试的过程中,我们也需求对上述两项内容进行测试.
2.Cross-site scritping(XSS):(跨站点脚本攻击)
(1)如何进行XSS测试?
<!--[if !supportLists]-->首先,找到带有参数传递的URL,如 登录页面,搜索页面,提交评论,发表留言 页面等等。
<!--[if !supportLists]-->其次,在页面参数中输入如下语句(如:Javascrīpt,VB scrīpt, HTML,ActiveX, Flash)来进行测试:
<scrīpt>alert(document.cookie)</scrīpt>
最后,当用户浏览 时便会弹出一个警告框,内容显示的是浏览者当前的cookie串,这就说明该网站存在XSS漏洞。
试想如果我们注入的不是以上这个简单的测试代码,而是一段经常精心设计的恶意脚本,当用户浏览此帖时,cookie信息就可能成功的被 攻击者获取。此时浏览者的帐号就很容易被攻击者掌控了。
(2)如何预防XSS漏洞?
从应用程序的角度来讲,要进行以下几项预防:
对Javascrīpt,VB scrīpt, HTML,ActiveX, Flash等 语句或脚本进行转义.
在 服务端正式处理之前提交数据的合法性(合法性检查主要包括三项:数据类型,数据长度,敏感字符的校验)进行检查等。最根本的解决手段,在确认客户端的输入合法之前,服务端 拒绝进行关键性的处理操作.
从测试人员的角度来讲,要从需求检查和执行测试过程两个阶段来完成XSS检查:
在需求检查过程中对各输入项或输出项进行类型、长度以及取 值范围进行验证,着重验证是否对HTML或脚本代码进行了转义。
执行测试过程中也应对上述项进行检查。
3.CSRF:(跨站点伪造请求)
CSRF尽管听起来像跨站脚本(XSS),但它与XSS非常不同,并且攻击方式几乎相左。
XSS是利用站点内的信任用户,而CSRF则通过伪装来自受信任用户的请求来利用受信任的网站。
XSS也好,CSRF也好,它的目的在于窃取用户的信息,如SESSION 和 COOKIES,
(1)如何进行CSRF测试?
目前主要通过安全性测试工具来进行检查。
(2)如何预防CSRF漏洞?
这个我们在这就不细谈了
4.Email Header Injection(邮件标头注入)
Email Header Injection:如果表单用于发送email,表单中可能包括“subject”输入项(邮件标题),我们要验证subject中应能escape掉“\n”标识。
<!--[if !supportLists]--><!--[endif]-->因为“\n”是新行,如果在subject中输入“hello\ncc:spamvictim@example.com”,可能会形成以下
Subject: hello
cc: spamvictim@example.com
<!--[if !supportLists]--><!--[endif]-->如果允许用户使用这样的subject,那他可能会给利用这个缺陷通过我们的平台给其它用 户发送垃圾邮件。
5.Directory Traversal(目录遍历)
(1)如何进行目录遍历测试?
目录遍历产生的原因是:程序中没有过滤用户输入的“../”和“./”之类的目录跳转符,导致恶意用户可以通过提交目录跳转来遍历服务器上的任意文件。
测试方法:在URL中输入一定数量的“../”和“./”,验证系统是否ESCAPE掉了这些目录跳转符。
(2)如何预防目录遍历?
限制Web应用在服务器上的运行
进 行严格的输入验证,控制用户输入非法路径
6.exposed error messages(错误信息)
(1)如何进行测试?
首 先找到一些错误页面,比如404,或500页面。
验证在调试未开通过的情况下,是否给出了友好的错误提示信息比如“你访问的页面不存 在”等,而并非曝露一些程序代码。
(2)如何预防?
测试人员在进行需求检查时,应该对出错信息 进行详细查,比如是否给出了出错信息,是否给出了正确的出错信息。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
简介
本文主要关注
SQL注入,假设读者已经了解一般的SQL注入技术,在我之前的
文章中有过介绍,即通过输入不同的参数,等待服务器的反应,之后通过不同的前缀和后缀(suffix and prefix )注入到
数据库。本文将更进一步,讨论SQL盲注,如果读者没有任何相关知识储备,建议先去wikipedia学习一下。在继续之前需要提醒一下,如果读者也想要按本文的步骤进行,需要在NOWASP Mutillidae环境搭建好之后先注册一个NOWASP Mutillidae帐号。
SQL注入前言
本文演示从
web界面注入SQL命令的方法,但不会直接连接到数据库,而是想办法使后端数据库处理程序将我们的查询语句当作SQL命令去执行。本文先描述一些注入基础知识,之后讲解盲注的相关内容。
Show Time
这里我以用户名“jonnybravo”和密码“momma”登录,之后进入用户查看页面,位于OWASP 2013 > A1 SQL Injection > Extract data > User Info。要查看用户信息,需要输入用户ID与密码登录,之后就可以看到当前用户的信息了。
如我之前的文章所提到的那样,这个页面包含SQL注入漏洞,所以我会尝试各种注入方法来操纵数据库,需要使用我之前文章提到的后缀(suffix)与前缀(prefix)的混合。这里我使用的注入语句如下:
Username: jonnybravo’ or 1=1; –
该注入语句要做的就是从数据库查询用户jonnybravo,获取数据后立刻终止查询(利用单引号),之后紧接着一条OR语句,由于这是一条“if状态”查询语句,而且这里给出 “or 1=1”,表示该查询永远为真。1=1表示获取数据库中的所有记录,之后的;–表示结束查询,告诉数据库当前语句后面没有其它查询语句了。
图1 正常方式查看用户信息
将payload注入后,服务器泄露了数据库中的所有用户信息。如图2所示:
图2 注入payload导致数据库中所有数据泄露
至此,本文向读者演示了一种基本SQL注入,下面笔者用BackTrack和Samurai 等渗透
测试发行版中自带的SQLmap工具向读者演示。要使用SQLmap,只需要打开终端,输入SQLmap并回车,如下图所示:
如果读者首次使用SQLmap,不需要什么预先操作。如果已经使用过该工具,需要使用—purge-output选项将之前的输出文件删除,如下图所示:

图3 将SQLmap output目录中的原输出文件删除
本文会演示一些比较独特的操作。通常人们使用SQLmap时会直接指定URL,笔者也是用该工具分析请求,但会先用Burp查看请求并将其保存到一个文本文件中,之后再用SQLmap工具调用该文本文件进行扫描。以上就是一些准备工作,下面首先就是先获取一个请求,如下所示:
GET /chintan/index.php?page=user-info.php&username=jonnybravo&password=
momma&user-info-php-submit-button=View+Account+Details HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:27.0) Gecko/20100101 Firefox/27.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://localhost/chintan/index.php?page=user-info.php
Cookie: showhints=0; username=jonnybravo; uid=19; PHPSESSID=f01sonmub2j9aushull1bvh8b5
Connection: keep-alive
将该请求保存到一个文本文件中,之后发送到KALI linux中,用如下命令将该请求头部传给SQLmap:
SQLmap –r ~/root/Desktop/header.txt
命令中-r选项表示要读取一个包含请求的文件,~/root/Desktop/header.txt表示文件的位置。如果读者用VMware,例如在Windows上用虚拟机跑KALI,执行命令时可能产生如下图所示的错误提示:
这里必须在请求头中指定一个IP地址,使KALI linux能与XP正常通信,修改如下图所示:
之后命令就能正常执行了,显示结果如下图所示:
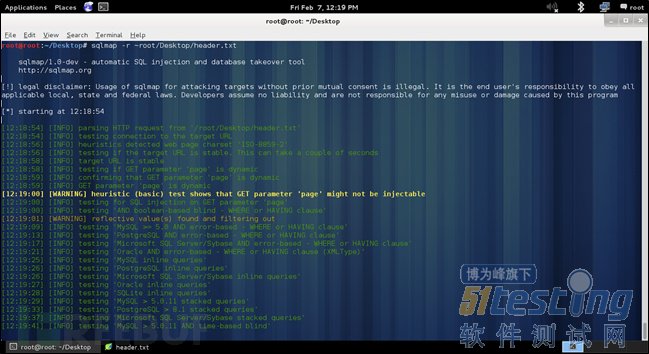
基本上该工具做的就是分析请求并确定请求中的第一个参数,之后对该参数进行各种测试,以确定服务器上运行的数据库类型。对每个请求,SQLmap都会对请求中的第一个参数进行各种测试。
GET /chintan/index.php?page=user-info.php&username=jonnybravo&password=momma&user-
info-php-submit-button=View+Account+Details HTTP/1.1
SQLmap可以检测多种数据库,如MySQL、Oracle SQL、PostgreSQL、Microsoft SQL Server等。
下图是笔者系统中SQLmap正在对指定的请求进行检测时显示的数据库列表:
首先它会确定给定的参数是否可注入。根据本文演示的情况,我们已经设置OWASP mutillidae的安全性为0,因此这里是可注入的,同时SQLmap也检测到后台数据库DBMS可能为MYSQL。
如上图所示,工具识别后台数据库可能为MYSQL,因此提示用户是否跳过其它类型数据库的检测。
“由于本文在演示之前已经知道被检测数据库是MYSQL,因此这里选择跳过对其它类型数据库的检测。”
之后询问用户是否引入(include)测试MYSQL相关的所有payload,这里选择“yes”选项:
测试过一些payloads之后,工具已经识别出GET参数上一个由错误引起的注入问题和一个Boolean类型引起的盲注问题。
之后显示该GET参数username是一个基于MYSQL union(union-based)类型的查询注入点,因此这里跳过其它测试,深入挖掘已经找出的漏洞。
至此,工具已经识别出应该深入挖掘的可能的注入点:
接下来,我把参数username传递给SQLmap工具,以对其进行深入挖掘。通过上文描述的所有注入点和payloads,我们将对username参数使用基于Boolean的SQL盲注技术,通过SQLmap中的–technique选项实现。其中选择如下列表中不同的选项表示选用不同的技术:
B : 基于Boolean的盲注(Boolean based blind)
Q : 内联查询(Inline queries)
T : 基于时间的盲注(time based blind)
U : 基于联合查询(Union query based)
E : 基于错误(error based)
S : 栈查询(stack queries)
本例中也给出了参数名“username”,因此最后构造的命令如下:
SQLmap –r ~root/Desktop/header.txt – -technique B – -p username – -current-user
这里-p选项表示要注入的参数,“–current-user“选项表示强制SQLmap查询并显示登录MYSQL数据库系统的当前用户。命令得到输出如下图所示:
同时也可以看到工具也识别出了操作系统名,DBMS服务器以及程序使用的编程语言。
“”当前我们所做的就是向服务器发送请求并接收来自服务器的响应,类似客户端-服务器端模式的交互。我们没有直接与数据库管理系统DBMS交互,但SQLmap可以仍识别这些后台信息。
同时本次与之前演示的SQL注入是不同的。在前一次演示SQL注入中,我们使用的是前缀与后缀,本文不再使用这种方法。之前我们往输入框中输入内容并等待返回到客户端的响应,这样就可以根据这些信息得到切入点。本文我们往输入框输入永远为真的内容,通过它判断应用程序的响应,当作程序返回给我们的信息。“
结果分析
我们已经给出当前的用户名,位于本机,下面看看它在后台做了什么。前文已经说过,后台是一个if判断语句,它会分析该if查询,检查username为jonnybravo且7333=7333,之后SQLmap用不同的字符串代替7333,新的请求如下:
page=user-info.php?username=’jonnybravo’ AND ‘a’='a’ etc..FALSE
page=user-info.php?username=’jonnybravo’ AND ‘l’='l’ etc..TRUE
page=user-info.php?username=’jonnybravo’ AND ‘s’='s’ etc..TRUE
page=user-info.php?username=’jonnybravo’ AND ‘b’='b’ etc..FALSE
如上所示,第一个和最后一个查询请求结果为假,另两个查询请求结果为真,因为当前的username是root@localhost,包含字母l和s,因此这两次查询在查询字母表时会给出包含这两个字母的用户名。
“这就是用来与web服务器验证的SQL server用户名,这种情况在任何针对客户端的攻击中都不应该出现,但我们让它发生了。”
去掉了–current-user选项,使用另外两个选项-U和–password代替。-U用来指定要查询的用户名,–password表示让SQLmap去获取指定用户名对应的密码,得到最后的命令如下:
SQLmap -r ~root/Desktop/header.txt --technique B -p username -U root@localhost --passwords
命令输出如下图所示:
Self-Critical Evaluation
有时可能没有成功获取到密码,只得到一个NULL输出,那是因为系统管理员可能没有为指定的用户设定认证信息。如果用户是在本机测试,默认情况下用户root@localhost是没有密码的,需要使用者自己为该用户设置密码,可以在MySQL的user数据表中看到用户的列表,通过双击password区域来为其添加密码。或者可以直接用下图所示的命令直接更新指定用户的密码:
这里将密码设置为“sysadmin“,这样SQLmap就可以获取到该密码了,如果不设置的话,得到的就是NULL。
通过以上方法,我们不直接与数据库服务器通信,通过SQL注入得到了管理员的登录认证信息。
总结
本文描述的注入方法就是所谓的SQL盲注,这种方法更繁琐,很多情况下比较难以检测和利用。相信读者已经了解传统SQL注入与SQL盲注的不同。在本文所处的背景下,我们只是输入参数,看其是否以传统方式响应,之后凭运气尝试注入,与之前演示的注入完全是不同的方式。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters