一般来说,对于做B/S架构的朋友来说,更有机会遇到高并发的数据库访 问情况,因为现在WEB的普及速度就像火箭升空,同时就会因为高访问量带来一系列性能问题,而数据库一直是用户与商人之间交流的重要平台。用户是没有耐心 忍受一个查询需要用上10秒以上的,或者更少些,如果经常出现服务器死机或者是报查询超时,我想那将是失败的项目。做了几年的WEB工作,不才,一直没有 遇到过大访问量或者是海量数据的情况。这里并不是说没有海量数据的项目就不是好项目,要看项目的应用场合。
最近做项目时,偶然得到了这个机会,在我工作过程中,本人发现的单表最大记录数高达9位数。像订单表什么的也有8位数。在查询订单的时候往往不能通过单表查询就能解决,还要和其它相关表进行关联查询。如此关联的表数据不大还好,一旦发生大表关联大表,在查询时就有可能出现慢长的等待。
主旨: 如何避免这种情况的发生呢?既然有了这样的数据,需求还是要实现,这里就我最近针对数据库的优化过程,我分两篇文章来说明下。
第一篇:如何尽量避免大表关联。
第二篇:对大表进行分区。
背景:有两张表:
1:订单表:记录用户订单的详细信息。order,其中有一个会员卡号字段cardNo,订单产生时间。
2:会员表:记录会员相关信息。member,一个会员有一个代理号:proxyID,代理下面有许多的会员卡:cardNo,它们共用一个代理号。
两表通过cardNo来相关联。
需求:查询一个用户或者某些用户某一时间段所有会员卡产生的订单情况。
实现SQL:
select 字段 from order
inner join member on
order.cardNo=member.cardNo
and member.proxyID in('a-01',代理号二)
and 时间 between '20080101' and '20080131'
本人见解:我想一般的朋友看到这样的需求大多会写出这样的查询SQL,如果不喜欢用in或者认为in的性能不好的朋友可用union all 代替。SQL语句可以说简单的不能再简单了,本身并无问题,只是如果两表的数据都在百万以上,而且字段都特别多。此时如果只有索引的帮忙下并不一定能达到 预期的效果。
解决方案一:利用表变量来替换大表关联,表变量的作用域为一个批处理,批处理完了,表变量也会随之失效,比起临时表有它独特的优点:不用手动去删除表变量以释放内存。
可行性:因为需求中的输出字段大多来自订单表,member表只起到数据约束的作用,和查询用户会员卡号的作用,所有可以先把代理的会员卡号先取到表变量中,然后利用带有卡号的表变量和订单表相关联查询。
declare @t table
(cardNo int)
insert @t
select cardNo from member where in('a-01',代理号二)
select 字段 from order
inner join @t on
order.cardNo=@t.cardNoand 时间 between '20080101' and '20080131' |
这里我就不贴性能比较图了,有兴趣的朋友可以自己尝试下。这种方法在查询人员比较多的时候特别有帮助。它要开发员根据实际情况详细比较,结果并不是统一的,不同的环境结果可能不一样。希望大家理解。
解决方案二:利用索引视图来提高大表关联的性能。
可行性:一般在大表关联时,我们的输出列都远小于两表的字段合,像上面的member表只用到了其中的两个字段(cardNo,proxyID)。设想一下,此时的member表如果只有这两个字段情况会不会好些呢?答案不言而喻。
视图这个名词在我以前对它的印象中,从来没有认为视图能优化查询,因为我认为视图对于数据库来说就是一个虚假表,在数据库中并无实际物理位置来存储数 据。对于用户来说无非就是通过不同的视角来观看结果。视图数据的产生都是实时的,即当调用视图时,自动扩展视图,去运行里面相应的select语句。后来 才知道在2000后的版本中视图分一般视图和索引视图,一般视图就是没有创建索引的我印象中的视图。而创建了视图后就称为索引视图。索引视图是物理存在 的,可在视图上首先创建一个唯一的聚集索引,其它字段上也可创建非聚集索引。在不改变基础表的情况下,起到了优化的效果。
CREATE VIEW memberView
WITH SCHEMABINDING
AS
SELECT cardNo,proxyID from member
GO
--以会员卡号创建一个唯一聚集索引
CREATE UNIQUE CLUSTERED INDEX ix_member_cardNo
ON member (cardNo);
GO |
注意:创建索引视图要点:
1: CREATE VIEW memberView后面要跟上WITH SCHEMABINDING
理由:
● 使用 schemaname。objectname 明确识别视图所引用的所有对象,而不管是哪个用户访问该视图。
● 不会以导致视图定义非法或强制 SQL Server 在该视图上重新创建索引的方式,更改视图定义中所引用的对象。
2:视图上的第一个索引必须为 CLUSTERED 和 UNIQUE。
理由:必须为 UNIQUE 以便在维护索引视图期间,轻松地按键值查找视图中的记录,并阻止创建带有重复项目的视图(要求维护特殊的逻辑)。必须为 CLUSTERED,因为只有聚集索引才能在强制唯一性的同时存储行。
3:以下情况可考虑创建索引视图:
● 可预先计算聚合并将其保存在索引中,从而在查询执行时,最小化高成本的计算。
● 可预先联接各个表并保存最终获得的数据集。
● 可保存联接或聚合的组合。
4:基础表的更新会引发索引视力的更新。
5:索引视图的创建同时会带来维护上的开销。
理由:
1)因为索引视图是物理存在的。
2)要额外的维护索引。
实现:SQL:select 字段 from order
inner join memberView on
order.cardNo=member.cardNo
and member.proxyID=in('a-01',代理号二)
and 时间 between '20080101' and '20080131' |
总结:两种解决方案来看,各有所长,一般可以优先考虑使用索引视图来优化大表关联。以上是本人对于如何尽量避免发生大表关联所采取的措施,望大家指教。
根据约定,在使用
java编程的时候应尽可能的使用现有的类库,当然你也可以自己编写一个排序的方法,或者框架,但是有几个人能写得比JDK里的还要好呢?使用现有的类的另一个好处是代码易于阅读和维护,这篇
文章主要讲的是如何使用现有的类库对数组和各种Collection容器进行排序,(文章中的一 部分例子来自《Java Developers Almanac 1.4》)
首先要知道两个类:java.util.Arrays和java.util.Collections(注意和Collection的区 别)Collection是集合框架的顶层接口,而Collections是包含了许多静态方法。我们使用Arrays对数组进行排序,使用 Collections对结合框架容器进行排序,如ArraysList,LinkedList等。
例子中都要加上import java.util.*和其他外壳代码,如类和静态main方法,我会在第一个例子里写出全部代码,接下来会无一例外的省略。
对数组进行排序
比如有一个整型数组:
| int[] intArray = new int[] {4, 1, 3, -23}; |
我们如何进行排序呢?你这个时候是否在想快速排序的算法?看看下面的实现方法:
- import java.util.*;
- public class Sort{
- public static void main(String[] args){
- int[] intArray = new int[] {4, 1, 3, -23};
- Arrays.sort(intArray);
- }
- }
|
这样我们就用Arrays的静态方法sort()对intArray进行了升序排序,现在数组已经变成了{-23,1,3,4}。
如果是字符数组:
| String[] strArray = new String[] {"z", "a", "C"}; |
我们用:
进行排序后的结果是{C,a,z},sort()会根据元素的自然顺序进行升序排序。如果希望对大小写不敏感的话可以这样写:
| Arrays.sort(strArray, String.CASE_INSENSITIVE_ORDER); |
当然我们也可以指定数组的某一段进行排序比如我们要对数组下表0-2的部分(假设数组长度大于3)进行排序,其他部分保持不变,我们可以使用:
| Arrays.sort(strArray,0,2); |
这样,我们只对前三个元素进行了排序,而不会影响到后面的部分。
当然有人会想,我怎样进行降序排序?在众多的sort方法中有一个
| sort(T[] a, Comparator<? super T> c) |
我们使用Comparator获取一个反序的比较器即可,Comparator会在稍后讲解,以前面的intArray[]为例:
| Arrays.sort(intArray,Comparator.reverseOrder()); |
这样,我们得到的结果就是{4,3,1,-23}。如果不想修改原有代码我们也可以使用:
| Collections.reverse(Arrays.asList(intArray)); |
得到该数组的反序。结果同样为4,3,1,-23}。
现在的情况变了,我们的数组里不再是基本数据类型(primtive type)或者String类型的数组,而是对象数组。这个数组的自然顺序是未知的,因此我们需要为该类实现Comparable接口,比如我们有一个Name类:
- class Name implements Comparable<Name>{
- public String firstName,lastName;
- public Name(String firstName,String lastName){
- this.firstName=firstName;
- this.lastName=lastName;
- }
- public int compareTo(Name o) { //实现接口
- int lastCmp=lastName.compareTo(o.lastName);
- return (lastCmp!=0?lastCmp:firstName.compareTo(o.firstName));
- }
- public String toString(){ //便于输出测试
- return firstName+" "+lastName;
- }
- }
这样,当我们对这个对象数组进行排序时,就会先比较lastName,然后比较firstName 然后得出两个对象的先后顺序,就像compareTo(Name o)里实现的那样。不妨用程序试一试:
- import java.util.*;
- public class NameSort {
- public static void main(String[] args) {
- Name nameArray[] = {
- new Name("John", "Lennon"),
- new Name("Karl", "Marx"),
- new Name("Groucho", "Marx"),
- new Name("Oscar", "Grouch")
- };[page]
- Arrays.sort(nameArray);
- for(int i=0;i<nameArray.length;i++){
- System.out.println(nameArray[i].toString());
- }
- }
- }
|
结果正如我们所愿:
- Oscar Grouch
- John Lennon
- Groucho Marx
- Karl Marx
|
对集合框架进行排序
如果已经理解了Arrays.sort()对数组进行排序的话,集合框架的使用也是大同小异。只是将Arrays替换成了Collections,注意Collections是一个类而Collection是一个接口,虽然只差一个"s"但是它们的含义却完全不同。
假如有这样一个链表:
- LinkedList list=new LinkedList();
- list.add(4);
- list.add(34);
- list.add(22);
- list.add(2);
|
我们只需要使用:
就可以将ll里的元素按从小到大的顺序进行排序,结果就成了:
如果LinkedList里面的元素是String,同样会想基本数据类型一样从小到大排序。
如果要实现反序排序也就是从达到小排序:
| Collections.sort(list,Collectons.reverseOrder()); |
如果LinkedList里面的元素是自定义的对象,可以像上面的Name对象一样实现Comparable接口,就可以让Collection.sort()为您排序了。
如果你想按照自己的想法对一个对象进行排序,你可以使用
| sort(List<T> list, Comparator<? super T> c) |
这个方法进行排序,在给出例子之前,先要说明一下Comparator的使用,Comparable接口的格式:
- public interface Comparator<T> {
- int compare(T o1, T o2);
- }
|
其实Comparator里的int compare(T o1,T o2)的写法和Comparable里的compareTo()方法的写法差不多。在上面的Name类中我们的比较是从LastName开始的,这是西方 人的习惯,到了中国,我们想从fristName开始比较,又不想修改原来的代码,这个时候,Comparator就可以派上用场了:
- final Comparator<Name> FIRST_NAME_ORDER=new Comparator<Name>() {
- public int compare(Name n1, Name n2) {
- int firstCmp=n1.firstName.compareTo(n2.firstName);
- return (firstCmp!=0?firstCmp:n1.lastName.compareTo
- (n2.firstName));
- }
- };
|
这样一个我们自定义的Comparator FIRST_NAME_ORDER就写好了。
将上个例子里那个名字数组转化为List:
- List<Name> list=Arrays.asList(nameArray);
- Collections.sort(list,FIRST_NAME_ORDER);
|
这样我们就成功的使用自己定义的比较器设定排序。
不同角色之间的划分往往有助于在角色的冲突中将问题暴露,实现透明,最终改进和保证质量。任何的软件开发团队都离不开两个基本角色:开发与测试。 你可以没有项目经理,可以没有架构师,也可以没有设计师;但是不能没有开发,否则没有人可以帮你实现产品;也不能没有测试,否则没有人可以决定你的产品是 否能够交付。这就好像你往杯子里面倒水必须要用眼睛看着,没有眼睛反馈的信息,你永远不知道何时该停下来,也不知道停在那里;我们不希望水太少,更不希望 水溢出来。眼睛与手的反馈循环就是我们实现倒水这一动作高质量的必要系统,而开发和测试的有效循环就是我们实现高质量软件的必须环节。
但是开发和测试本身的角色的局限性造成了他们往往没有办法有效地形成循环,比如我们经常会听到这样的抱怨:
测试:这个软件需要的环境太复杂,没有办法为每种情况都创建测试环境.
测试:我没有办法保证测试的一致性,因为环境在不停地变化,恢复到原来的状态很麻烦.
开发:你是怎么测出这个Bug的,我怎么没法重现?测试:我忘记步骤了.
其实这些问题都和测试人员本身的定位有关系,测试人员的首要目标是发现软件中的问题,要做到这一点他们往往专注于软件的反应而忽视了造成这种响应的原因,如:硬件软件环境,系统配置情况,操作一致性等等;测试用例失败有几种原因:
功能缺陷BUG;
测试用例本身写的有问题(ST或者ET脚本问题);
测试环境有问题;
而这些正是开发人员修复Bug最需要的内容。但是测试人员不关心,或者没有更多的精力来关心这些内容,造成了非常多的“不可重现”的Bug的出现。
我们可以通过持续集成以及对代码进行版本管理控制来定位变更和导致功能缺陷的原因,同样的,我们也可以对测试环境的变更进行控制和版本管理。之前提到过持续集成要求对一切进行版本管理,其中也包括测试环境。
初看上去,测试环境的管理是一个非常复杂的问题,之前是否遇到过下面一类问题?
“要测一个什么东西,需要什么软件,然后手动安装一遍,结果发现另外一个机器上其实已经有这个软件了。” ——测试环境的复用和共享问题。
“有一个测试用例失败了,可是之前测试的时候一直通过的,开发人员在开发环境下测试也没有问题,测试人员费了九牛二虎之力,借助开发人员的调试帮助,结 果发现是测试环境中的一个配置参数改变了。 此时,另外一个测试人员冒了一句,我之前测试另外一个问题的时候将这个参数改掉了。” ——测试人员花了大量时间确定环境变更,测试环境的变更控制问题。
“有一个机器,你也在里面装个东西,我也在里面装个东西,结果这个机 器的环境越来越乱,桌面上乱起八糟,最后谁也不记得机器里面的一些文件有什么用处了,当初是因为什么原因使用的,又不敢删除,怕其他人有用,可是又不知道 会是谁。” 测试环境的管理和记录问题,好一些的会渐渐使用一些文档进行记录并共享,但是还是经常出现问题,毕竟文档也会过期。
“一个测试MM突然大喊, 谁把我的模板和数据删除啦,给我出来!!! 四周鸦雀无声。我小声的问一句,你上传到svn上了吗,上次不是说过一切都要版本控制吗?” 测试环境和数据的备份和删除,广义上说这个也属于变更。
“我这里需要再安装针对ubuntu和suse操作系统的测试,并且需要32位和64位都有,而且还要设置一大堆配置。可是现有的5台机器都安装满了, 总不能重装来重装去的吧,每次重装都要了我的老命了...” 测试硬件资源的利用,和环境管理的效率问题。自动配置技术和利用虚拟化技术解决,测试环境数据化,配置化,然后才能版本控制和管理。
开发人员:“我在自己机器上测试了没问题啊”, 测试人员:“可我在测试环境下面就是有问题啊。” 统一的测试环境问题。
以上的这些问题,都指向了一个关键点,测试环境的管理,分而细之,又包括几个重要的因素:变更、自动化、数据化、虚拟化、共享。
虚拟化技术
虚拟化技术可以帮助将测试环境数据化,自动化,并借此达到重复利用的目的。虚拟化技术有很多,比较优秀的有VMWare和Virtual Box。比如,很多测试环境是寄生在操作系统中的,我们可以将这些操作系统做成操作系统基线,平时不需要测试时可以不开着,要用的时候再开。这些操作系统基线可以进行版本控制,因为文件比较大,用svn之类的管理可能会遇到一些问题,可以针对性设计一些大文件版本控制软件(比如:结合SVN和FTP的优点)。
配置管理自动化
先后研究了几种配置管理的工具,Chef, CfEngine, puppet,最后用的比较多的是Chef。Chef比较好的一点是提供OpenSouce Chef Server,可以自己搭建服务器,也是这几个里面最先搭成功的,算是比较容易上手吧。就像一个大厨(Chef)使用刀(Knife)实验各种不同的菜单 (Recipes),制成各种食谱(CookBook)一样,一个配置管理工程师就是用它来制作不同的测试环境。
当我们用iPhone玩一个很有名的游戏——坚守阵地(FieldRunners)时,防御的布局非常重要。如果布局不好,如图2-1所示,就玩得很累,看着“生命”一个一个死去,即使采用了一些小的技巧,最后也过不了关。

图2-1 不好的布局决定着失败
而如果换一个思路,进行不同的布局,如图2-2所示,不采用自然的竖直排序,而采用斜线排序,充分利用空间,而且进攻部队前进的速度会大大降低,结果就很不一样,游戏者便能轻松过关。
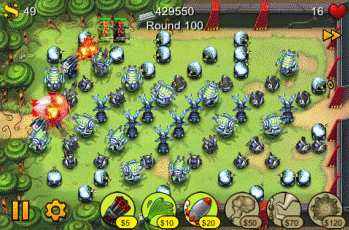
图2-2 良好的布局是成功的一半
这里的布局,是指处理问题的全局规划、整体设计。全局规划如何、整体设计效果如何,自然关系到后面的整个过程,所以总会受到我们重视。
说到架构,我们会想到软件架构,如C/S架构、SOA架构,甚至会想到以架构设计为中心的RUP。软件架构的概念由来已久,软件架构师的头衔容易被大家认可,但“测试架构”的概念还不够清晰,人家会有很多的问题要问:
什么是测试架构?
测试架构对软件测试有什么帮助?
软件公司需要设置“软件测试架构师”职位吗?
软件测试架构师做哪些事情?
当人们知道微软公司、阿里巴巴集团等设有“测试架构师(Test Architect)”职位时,可能会惊奇地问:什么? 测试团队也设立“架构师”头衔吗?人们对开发团队设立架构师已经比较习惯了,因为大家知道,在设计一个软件系统时,需要考虑整个产品架构如何设计
、系统各个组件如何集成在一起、如何相互协调工作,而这些都需要“软件架构师”来完成,但对测试团队为何要设立“架构师”头衔还是不够清楚,主要是因为不了解测试架构从何而来。
在日常测试工作中,如何选择测试工具和如何建立统一的自动化测试框架?这是经常困扰我们的问题。除此之外,我们还会碰到如下的一系列问题:
如何帮助开发人员提高产品设计和代码的可测试性?
如何找到更有效的办法来设计
测试用例?
如何通过一些技术手段来提高测试的覆盖率?
如何完成复杂系统的非功能性(性能、安全性、兼容性、可靠性等)测试任务?
如何通过分析系统测试结果,找出系统存在的问题?
能否对测试技术的发展趋势做出正确判断,从而更有针对性地提高测试团队的技术能力?
举例、暗喻
测试架构从何而来?其实它就是为了解决上述问题而产生的。从基本的观点看,测试架构是由软件系统技术架构和软件测试框架(特别是自动化测试框架)构建的需求而定。这些需求,决定了以下从不同方面所形成的测试架构。
大家都能理解,越早进行测试,就能越早地发现缺陷,对提高产品质量、降低企业成本就越有利,更重要的是越能预防系统 设计时出现严重的缺陷。如果所设计的系统架构存在严重的缺陷,直到系统集成测试时才发现,所造成的返工将是可怕的。这就需要测试人员对设计进行复审、评 审。测试人员应参与系统架构及其组件接口等设计的审查,包括是否全面考虑非功能特性、各个特性的可测试性评估、设计的合理性等。
从软件系统来看,如何验证系统的性能、安全性、可靠性和可伸缩性等,例如网站能否支持扩展到100M的点击率,投票系统是否安全等都需要对系统架构进行分析,建立测试概念模型,从而科学、有效地完成认证。
现在的系统越来越复杂,其设计往往不是一蹴而就的,需要不断地重构和优化,而这些工作是基于以前版本的测试结果(包 括发现的问题)来实施的。测试人员在完成系统测试后,可以通过对测试结果的分析发现问题,如系统性能瓶颈、安全漏洞等,进而可以对系统的性能、可靠性、安 全性等改善提出有价值的建设性意见。
在系统功能测试时,需要对功能进行合理的划分、归类,建立用例模型,设计合理的测试结构。
从测试工作自身来看,需要建立合适的测试管理系统,包括测试用例库的设计、缺陷跟踪机制等。
设计自动化测试框架,包括集成测试环境、测试脚本分层处理、执行结果自动生成报告等。
掌握测试技术发展趋势,研发新的测试方法,并借助测试工具来实现,例如,在安全性测试上如何采用合适的模糊测试方法。
性能测试顾名思义,测试服务(
web服务,
数据库服务,其他网络应用服务,本地服务)的性能如何?如何衡量性能?最表面的无非就是看能支撑多少个用户同时使用该服务。且关注用户使用过程中的用户体验。
Transactions per Second(每秒通过事务数)
“每秒通过事务数/TPS”显示在场景运行的每一秒钟,每个事务通过、失败以及停止的数量,使考查系统性能的一个重要参数。通过它可以确定系统在任何给定时刻的时间事务负载。分析TPS主要是看曲线的性能走向。
将它与平均事务响应时间进行对比,可以分析事务数目对执行时间的影响。
例:当压力加大时,点击率/TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈。
Average Transaciton Response Time(事务平均响应时间)
“事务平均响应时间”显示的是测试场景运行期间的每一秒内事务执行所用的平均时间,通过它可以分析测试场景运行期间应用系统的性能走向。
例:随着测试时间的变化,系统处理事务的速度开始逐渐变慢,这说明应用系统随着投产时间的变化,整体性能将会有下降的趋势。
通常web服务还需要关心如下点:
Hits per Second(每秒点击次数)
“每秒点击次数”,即使运行场景过程中虚拟用户每秒向Web服务器提交的HTTP请求数。
通过它可以评估虚拟用户产生的负载量,如将其和“平均事务响应时间”图比较,可以查看点击次数对事务性能产生的影响。通过对查看“每秒点击次数”,可以判断系统是否稳定。系统点击率下降通常表明服务器的响应速度在变慢,需进一步分析,发现系统瓶颈所在。
性能测试工具一般都会根据实际测试的场景和结果,画出tps,average response time,点击率等曲线图表。 同时还会算出其他一些非常参考意义的数值和图表。
1、当压力加大时,TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈。
解析:tps 曲线为什么会变平坦?因为系统处理事务的线程数往往是固定的一个数值。(一般是由程序设定或者服务器配置决定),假设响应时间是固定的一个值时,那么每秒 中系统能够处理的事务数是固定的数值。不会因为压力的增大,TPS也会一直增大。实际上,响应时间并不是一个固定的值,而是随着压力变大,响应时间往往会 增加。那么,实际上,系统最大的TPS值,往往会比根据基准值估算出来的TPS要小。
2、当压力加大时,点击率曲线变化缓慢或者平坦,很有可能是服务器开始出现瓶颈。
解析:在web服务测试当中,点击率和模拟的用户数是能够反映出服务压力的大小。当压力变大时,事务的响应时间变长,则导致点击率会受到响应时间的影响,不会因为用户增多,而增加。点击率在服务器出现瓶颈时,压力的增加不会增加点击率。
3、事务平均响应时间增长
解析:事务平均响应时间增加,必然是指服务器性能有所下降。服务器压力的加大,是主要原因。
a)压力增大到每秒钟事务的请求数,超过了系统每秒处理事务占用的线程数。这时,一些事务开始排队。排队的事务请求的响应时间必然大于之前的平均响应时间。
能够写出可维护的面向对象JavaScript代码不仅可以节约金钱,还能让你很受欢迎。不信?有可能你自己或者其他什么人有一天会回来重用你 的代码。如果能尽量让这个经历不那么痛苦,就可以节省不少时间。地球人都知道,时间就是金钱。同样的,你也会因为帮某人省去了头疼的过程而获得他的偏爱。 但是,在开始探索如何编写可维护的面向对象JavaScript代码之前,我们先来快速看看什么是面向对象。如果已经了解面向对象的概念了,就可以直接跳 过下一节。
什么是面向对象?
面向对象编程主要通过代码代表现实世界中的实质对 象。要创建对象,首先需要写一个“类”来定义。 类几乎可以代表所有的东西:账户,员工,导航菜单,汽车,植物,广告,饮料,等等。而每次要创建对象的时候,就从类实例化一个对象。换句话说,就是创建类 的实例做为对象。事实上,通常处理一个以上的同类事物时就会使用到对象。另外,只需要简单的函数式程序就可以做的很好。对象实质上是数据的容器。因此在一 个employee对象中,你可能要储存员工号,姓名,入职日期,职称,工资,资历,等等。对象也包括处理数据的函数(也叫做“方法”)。方法被用作媒介 来确保数据的完整性,以及在储存之前对数据进行转换。例如,方法可以接收任意格式的日期然后在储存之前将其转化成标准化格式。最后,类还可以继承其他的 类。继承可以让你在不同类中重复使用相同代码。例如,银行账户和音像店账户都可以继承一个基本的账户类,里面包括个人信息,开户日期,分部信息,等等。然 后每个都可以定义自己的交易或者借款处理等数据结构和方法。
警告:JavaScript面向对象是不一样的
在上一节中,概述了经典的面向对象编程的基本知识。说经典是因为JavaScript并不遵循这些规则。相反地,JavaScript的类是写成函数的样子,而继承则是通过原型实现的。原型继承基本上意味着使用原型属性来实现对象的继承,而不是从类继承类。
———————————————–
【2012-4-25 11:11:35 更新】:根据微博网友@高翌翔 的反馈,前文中有关“JS 面向对象”的内容不够细。现推荐《Javascript 面向对象编程》《再谈javascript面向对象编程》两篇文章。
———————————————–
对象的实例化
以下是JavaScript中对象实例化的例子:
| // 定义Employee类 functionEmployee(num, fname, lname) {
this.getFullName =function() {
returnfname +" "+ lname;
}
};
// 实例化Employee对象
varjohn =newEmployee("4815162342","John","Doe");
alert("The employee's full name is "+ john.getFullName());
|
在这里,有三个重点需要注意:
1、“class”函数名的第一个字母要大写。这表明该函数的目的是被实例化而不是像一般函数一样被调用。
2、在实例化的时候使用了new操作符。如果省略掉new而仅仅调用函数则会产生很多问题。
3、因为getFullName指定给this操作符了,所以是公共可用的,但是fname和lname则不是。由Employee函数产生的闭包给了getFullName到fname和lname的入口,但同时对于其他类仍然是私有的。
原型继承
下面是JavaScript中原型继承的例子:
| // 定义Human类 functionHuman() {
this.setName =function(fname, lname) {
this.fname = fname;
this.lname = lname;
}
this.getFullName =function() {
returnthis.fname +" "+this.lname;
}
}
// 定义Employee类
functionEmployee(num) {
this.getNum =function() {
returnnum;
}
};
//让Employee继承Human类
Employee.prototype =newHuman();
// 实例化Employee对象
varjohn =newEmployee("4815162342");
john.setName("John","Doe");
alert(john.getFullName() +"'s employee number is "+ john.getNum());
|
这一次,创建的Human类包含人类的一切共有属性——我也将fname和lname放进去了,因为不仅仅是员工才有名字,所有人都有名字。然后将Human对象赋值给它的prototype属性。
通过继承实现代码重用
在前面的例子中,原来的Employee类被分解成两个部分。所有的人类通用属性被移到了Human类中,然后让Employee继承 Human。这样的话,Human里面的属性就可以被其他的对象使用,例如Student(学生),Client(顾客),Citizen(公 民),Visitor(游客),等等。现在你可能注意到了,这是分割和重用代码很好的方式。处理Human对象时,只需要继承Human来使用已存在的属 性,而不需要对每种不同的对象都重新一一创建。除此以外,如果要添加一个“中间名字”的属性,只需要加一次,那些继承了 Human 类的就可以立马使用了。反而言之,如果我们只是想要给一个对象加“中间名字”的属性,我们就直接加在那个对象里面,而不需要在Human 类里面加。
1、Public(公有的)和Private(私有的)
接下来的主题,我想谈谈类中的公有和私有变量。根据对象中处理数据的方式不同,数据会被处理为私有的或者公有的。私有属性并不一定意味着其他人无法访问。可能只是某个方法需要用到。
● 只读
有时,你只是想要在创建对象的时候能有一个值。一旦创建,就不想要其他人再改变这个值。为了做到这点,可以创建一个私有变量,在实例化的时候给它赋值。
| function Animal(type) {
var data = [];
data['type'] = type;
this.getType = function () {
return data['type'];
}
}
var fluffy = new Animal('dog');
fluffy.getType(); // 返回 'dog'
|
在这个例子中,Animal类中创建了一个本地数组data。当 Animal对象被实例化时,传递了一个type的值并将该值放置在data数组中。因为它是私有的,所以该值无法被覆盖(Animal函数定义了它的范 围)。一旦对象被实例化了,读取type值的唯一方式是调用getType方法。因为getType是在Animal中定义的,因此凭借Animal产生 的闭包,getType可以进到data中。这样的话,虽可以读到对象的类型却无法改变。
有一点非常重要,就是当对象被继承时,“只读”技术就无法运用。在执行继承后,每个实例化的对象都会共享那些只读变量并覆盖其值。最简单的解决办法是将类中的只读变量转换成公共变量。但是你必须保持它们是私有的,你可以使用Philippe在评论中提到的技术。
● Public(公有)
当然也有些时候你想要任意读写某个属性的值。要实现这一点,需要使用this操作符。
| function Animal() {
this.mood = '';
}
var fluffy = new Animal();
fluffy.mood = 'happy';
fluffy.mood; // 返回 'happy
|
这次Animal类公开了一个叫mood的属性,可以被随意读写。同样地,你还可以将函数指定给公有的属性,例如之前例子中的getType函数。只是要注意不要给getType赋值,不然的话你会毁了它的。
完全私有
最后,可能你发现你需要一个完全私有化的本地变量。这样的话,你可以使用与第一个例子中一样的模式而不需要创建公有方法。
function Animal() {
var secret = "You'll never know!"
}
var fluffy = new Animal();
2、写灵活的API
既然我们已经谈到类的创建,为了保持与产品需求变化同步,我们需要保持代码不过时。如果你已经做过某些项目或者是长期维护过某个产品,那么你就 应该知道需求是变化的。这是一个不争的事实。如果你不是这么想的话,那么你的代码在还没有写之前就将注定荒废。可能你突然就需要将选项卡中的内容弄成动画 形式,或是需要通过Ajax调用来获取数据。尽管准确预测未来是不大可能,但是却完全可以将代码写灵活以备将来不时之需。
● Saner参数列表
在设计参数列表的时候可以让代码有前瞻性。参数列表是让别人实现你代码的主要接触点,如果没有设计好的话,是会很有问题的。你应该避免下面这样的参数列表:
function Person(employeeId, fname, lname, tel, fax, email, email2, dob) {
};
|
这个类十分脆弱。如果在你发布代码后想要添加一个中间名参数,因为顺序问题,你不得不在列表的最后往上加。这让工作变得尴尬。如果你没有为每个参数赋值的话,将会十分困难。例如:
| var ara = new Person(1234, "Ara", "Pehlivanian", "514-555-1234", null, null, null, "1976-05-17"); |
操作参数列表更整洁也更灵活的方式是使用这个模式:
| function Person(employeeId, data) { }; |
有第一个参数因为这是必需的。剩下的就混在对象的里面,这样才可以灵活运用。
var ara = new Person(1234, {
fname: "Ara",
lname: "Pehlivanian",
tel: "514-555-1234",
dob: "1976-05-17"
});
| |
这个模式的漂亮之处在于它即方便阅读又高度灵活。注意到fax, email和email2完全被忽略了。不仅如此,对象是没有特定顺序的,因此哪里方便就在哪里添加一个中间名参数是非常容易的:
var ara = new Person(1234, {
fname: "Ara",
mname: "Chris",
lname: "Pehlivanian",
tel: "514-555-1234",
dob: "1976-05-17"
});
|
类里面的代码不重要,因为里面的值可以通过索引来访问:
function Person(employeeId, data) {
this.fname = data['fname'];
}; |
如果data['fname'] 返回一个值,那么他就被设定好了。否则的话,没被设定好,也没有什么损失。
● 让代码可嵌入 随着时间流逝,产品需求可能对你类的行为有更多的要求。而该行为却与你类的核心功能没有半毛钱关系。也有可能是类的唯一一种实现,好比在一个选 项卡的面板获取另一个选项卡的外部数据时,将这个选项卡面板中的内容变灰。你可能想把这些功能放在类的里面,但是它们不属于那里。选项卡条的责任在于管理 选项卡。动画和获取数据是完全不同的两码事,也必须与选项卡条的代码分开。唯一一个让你的选项卡条不过时而又将那些额外的功能排除在外的方法是,允许将行 为嵌入到代码当中。换句话说,通过创建事件,让它们在你的代码中与关键时刻挂钩,例如onTabChange, afterTabChange, onShowPanel, afterShowPanel等等。那样的话,他们可以轻易地与你的onShowPanel事件挂钩,写一个将面板内容变灰的处理器,这样就皆大欢喜了。 JavaScript库让你可以足够容易地做到这一点,但是你自己写也不那么难。下面是使用YUI 3的一个例子。
| <script type="text/javascript" src="http://yui.yahooapis.com/combo?3.2.0/build/yui/yui-min.js"></script>
<script type="text/javascript">
YUI().use('event', function (Y) {
function TabStrip() {
this.showPanel = function () {
this.fire('onShowPanel');
// 展现面板的代码
this.fire('afterShowPanel');
};
};
// 让TabStrip有能力激发常用事件
Y.augment(TabStrip, Y.EventTarget);
var ts = new TabStrip();
// 给TabStrip的这个实例创建常用时间处理器
ts.on('onShowPanel', function () {
//在展示面板之前要做的事
});
ts.on('onShowPanel', function () {
//在展示面板之前要做的其他事
});
ts.on('afterShowPanel', function () {
//在展示面板之后要做的事
});
ts.showPanel();
});
|
这个例子有一个简单的 TabStrip 类,其中有个showPanel方法。这个方法激发两个事件,onShowPanel和afterShowPanel。这个能力是通过用 Y.EventTarget扩大类来实现的。一旦做成,我们就实例化了一个TabStrip对象,并将一堆处理器都分配给它。这是用来处理实例的唯一行为 而又能避免混乱当前类的常用代码。
总结
如果你打算重用代码,无论是在同一网页,同一网站还是跨项目操作,考虑一下在类里面将其打包和组织起来。面向对象JavaScript很自然地 帮助实现更好的代码组织以及代码重用。除此以外,有点远见的你可以确保代码具有足够的灵活性,可以在你写完代码后持续使用很长时间。编写可重用的不过时 JavaScript代码可以节省你,你的团队还有你公司的时间和金钱。这绝对能让你大受欢迎。
一旦UseStatic 类被装载,所有的static语句被运行。首先,a被设置为3,接着static 块执行(打印一条消息),最后,b被初始化为a*4 或12。然后调用main(),main() 调用meth() ,把值42传递给x。3个println () 语句引用两个static变量a和b,以及局部变量x 。
注意:在一个static 方法中引用任何实例变量都是非法的。
下面是该程序的输出:
Static block initialized.
x = 42
a = 3
b = 12 |
在定义它们的类的外面,static 方法和变量能独立于任何对象而被使用。这样,你只要在类的名字后面加点号运算符即可。例如,如果你希望从类外面调用一个static方法,你可以使用下面通用的格式:
这里,classname 是类的名字,在该类中定义static方法。可以看到,这种格式与通过对象引用变量调用非static方法的格式类似。一个static变量可以以同样的 格式来访问——类名加点号运算符。这就是Java 如何实现全局功能和全局变量的一个控制版本。
下面是一个例子。在main() 中,static方法callme() 和static 变量b在它们的类之外被访问。
- class StaticDemo {
- static int a = 42;
- static int b = 99;
- static void callme() {
-
- System.out.println("a = " + a);
- }
- }
-
- class StaticByName {
-
- public static void main(String args[]) {
- StaticDemo.callme();
- System.out.println("b = " + StaticDemo.b);
- }
- }
|
下面是该程序的输出:
static成员是不能被其所在class创建的实例访问的。
如果不加static修饰的成员是对象成员,也就是归每个对象所有的。
加static修饰的成员是类成员,就是可以由一个类直接调用,为所有对象共有的。
运行结果:
利用静态代码块可以对一些static变量进行赋值,最后再看一眼这些例子,都一个static的main方法,这样JVM在运行main方法的时候可以直接调用而不用创建实例。
4、static和final一块用表示什么
static final用来修饰成员变量和成员方法,可简单理解为“全局常量”!
对于变量,表示一旦给值就不可修改,并且通过类名可以访问。
对于方法,表示不可覆盖,并且可以通过类名直接访问。
有时你希望定义一个类成员,使它的使用完全独立于该类的任何对象。通常情况下,类成员必须通过它的类的对象访问,但是可以创建这样一个成员,它 能够被它自己使用,而不必引用特定的实例。在成员的声明前面加上关键字static(静态的)就能创建这样的成员。如果一个成员被声明为static,它 就能够在它的类的任何对象创建之前被访问,而不必引用任何对象。你可以将方法和变量都声明为static。static 成员的最常见的例子是main() 。因为在程序开始执行时必须调用main() ,所以它被声明为static。
声明为static的变量实质上就是全局变量。当声明一个对象时,并不产生static变量的拷贝,而是该类所有的实例变量共用同一个static变量。声明为static的方法有以下几条限制:
● 它们仅能调用其他的static 方法。
● 它们只能访问static数据。
● 它们不能以任何方式引用this 或super(关键字super 与继承有关,在下一章中描述)。
如果你需要通过计算来初始化你的static变量,你可以声明一个static块,Static 块仅在该类被加载时执行一次。下面的例子显示的类有一个static方法,一些static变量,以及一个static 初始化块:
- // Demonstrate static variables,methods,and blocks.
-
- class UseStatic {
- static int a = 3;
- static int b;
-
- static void meth(int x) {
- System.out.println("x = " + x);
- System.out.println("a = " + a);
- System.out.println("b = " + b);
- }
-
- static {
- System.out.println("Static block initialized.");
- b = a * 4;
- }
-
- public static void main(String args[]) {
- meth(42);
- }
- }
static表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块,但是Java语言中没有全局变量的概念。
被static修饰的成员变量和成员方法独立于该类的任何对象。也就是说,它不依赖类特定的实例,被类的所有实例共享。
只要这个类被加载,Java虚拟机就能根据类名在运行时数据区的方法区内定找到他们。因此,static对象可以在它的任何对象创建之前访问,无需引用任何对象。
用public修饰的static成员变量和成员方法本质是全局变量和全局方法,当声明它类的对象市,不生成static变量的副本,而是类的所有实例共享同一个static变量。
static变量前可以有private修饰,表示这个变量可以在类的静态代码块中,或者类的其他静态成员方法中使用(当然也可以在非静态成员 方法中使用--废话),但是不能在其他类中通过类名来直接引用,这一点很重要。实际上你需要搞明白,private是访问权限限定,static表示不要 实例化就可以使用,这样就容易理解多了。static前面加上其它访问权限关键字的效果也以此类推。
static修饰的成员变量和成员方法习惯上称为静态变量和静态方法,可以直接通过类名来访问,访问语法为:
类名.静态方法名(参数列表...)
类名.静态变量名
用static修饰的代码块表示静态代码块,当Java虚拟机(JVM)加载类时,就会执行该代码块(用处非常大,呵呵)。
1、static变量
按照是否静态的对类成员变量进行分类可分两种:一种是被static修饰的变量,叫静态变量或类变量;另一种是没有被static修饰的变量,叫实例变量。
两者的区别是:
对于静态变量在内存中只有一个拷贝(节省内存),JVM只为静态分配一次内存,在加载类的过程中完成静态变量的内存分配,可用类名直接访问(方便),当然也可以通过对象来访问(但是这是不推荐的)。
对于实例变量,没创建一个实例,就会为实例变量分配一次内存,实例变量可以在内存中有多个拷贝,互不影响(灵活)。
所以一般在需要实现以下两个功能时使用静态变量:
● 在对象之间共享值时
● 方便访问变量时
2、静态方法
静态方法可以直接通过类名调用,任何的实例也都可以调用,
因此静态方法中不能用this和super关键字,不能直接访问所属类的实例变量和实例方法(就是不带static的成员变量和成员成员方法),只能访问所属类的静态成员变量和成员方法。
因为实例成员与特定的对象关联!这个需要去理解,想明白其中的道理,不是记忆!!!
因为static方法独立于任何实例,因此static方法必须被实现,而不能是抽象的abstract。
例如为了方便方法的调用,Java API中的Math类中所有的方法都是静态的,而一般类内部的static方法也是方便其它类对该方法的调用。
静态方法是类内部的一类特殊方法,只有在需要时才将对应的方法声明成静态的,一个类内部的方法一般都是非静态的
3、static代码块
static代码块也叫静态代码块,是在类中独立于类成员的static语句块,可以有多个,位置可以随便放,它不在任何的方法体内,JVM加 载类时会执行这些静态的代码块,如果static代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。例如:
- public class Test5 {
- private static int a;
- private int b;
-
- static{
- Test5.a=3;
- System.out.println(a);
- Test5 t=new Test5();
- t.f();
- t.b=1000;
- System.out.println(t.b);
- }
- static{
- Test5.a=4;
- System.out.println(a);
- }
- public static void main(String[] args) {
- // TODO 自动生成方法存根
- }
- static{
- Test5.a=5;
- System.out.println(a);
- }
- public void f(){
- System.out.println("hhahhahah");
- }
- }
CC(Attributes Components Compatibilities)是
Google测试团 队使用的一种建模方法,用来快速地建立产品的模型,以指导下一步的测试计划和设计。在Google内部,ACC得到较普遍的应用,一些工程师还开发了支持 ACC模型的Web应用,并将其开源。本文将介绍ACC的内容,所引用的Google+的例子摘录自《How Google Tests Software》一书。此外,本文还将使用
启发式测试策略模型(Heuristic
Test Strategy Model,简称HTSM)来分析ACC。
运用ACC建模的第一步是确定产品的Attributes(属性)。按照谷歌的定义,Attributes是产品的形容词(adjectives),是与竞争对手相区别的关键特征。按照敏捷开发的观点,Attributes是产品所交付的核心价值(values)。从HTSM的角度,Attributes位于HTSM->Quality Criteria->Operation Criteria,隶属于面向用户的质量标准。
Google+的Attributes如下:
● Social(社交):鼓励用户去分享信息和他们的状态
● Expressive(表现力):用户可以运用各种功能去表达自我
● Easy(容易):让用户以直观的方式做他们想做的事
● Relevant(相关):只显示用户感兴趣的内容
● Extensible(可扩展):能够与Google的已有功能、第三方网站和应用(Application)集成
● Private(隐私):用户数据不会泄漏
ACC以Attribute开始,是产品竞争的自然选择,也符合Google的开发实践。在Google的项目中,开发人员和测试人员的比例通常是10:1或更高。开发人员会编写大量的自动化测试用 例,对产品实施周密的测试,因此测试人员主要关注用户价值和系统级测试。即便如此,测试人员也没有足够的资源测试所有用户行为。所以,测试人员需要通过确 定Attributes来明确产品的核心价值,从而区分出测试对象的轻重缓急(priorities)。获取Attributes的信息源可以是产品经 理、市场营销人员、技术布道者、商业宣传材料、产品广告等。测试人员也可以使用“卖点漫游”(The Money Tour)来发掘和检验产品的卖点。
第二步是确定产品的Components(部件)。Components是产品的名词(nouns),可以理解为产品的主要模块、组件、子系统。从 HTSM的角度,Components位于HTSM->Product Elements->Structure和HTSM->Product Elements->Function,即同时具备代码结构和产品功能的特征。
Google+的Components如下:
● Profile(个人资料):用户的帐户信息和兴趣爱好
● People(人脉):用户已经连接的好友
● Stream(信息流):由帖子、评论、通知、照片等组成的有序的信息流
● Circles(圈子):将好友分组,如把不同的好友归于“朋友”、“同事”等小组
● Notifications(通知):当用户被帖子提到时,向他显示提示信息
● Hangouts(视频群聊):视频对话的小组
● Posts(帖子):用户和好友所发表的信息
● Comments(评论):对帖子、照片、视频等的评论
● Photos(照片):用户和好友所上传的照片
Components可以看作功能列表(Function List)的顶层元素,是产品核心功能的清单。《How Google Tests Software》建议Components列表要尽可能简单,10个Components很好,20个就太多了。其目的是重点考虑对产品、对用户最重要 的功能与代码,并避免漫长的Components列表所导致的分析瘫痪。
第三步是确定产品的Compatibilities(能力)。 Compatibilities是产品的动词(verbs),描述了一个Component提供了何种能力来实现一个Attribute。在HTSM的角 度,Compatibilities位于HTSM->Product Elements->Function和HTSM->Quality Criteria->Operation Criteria->Compatibility,刻画了产品实现其核心价值的手段。
Google+的Compatibilities矩阵如下:
| Social | Expressive | Easy | Relevant | Extensible | Private |
| Profile | 在好友中分享个人资料和兴趣爱好 | 用户可以在网上表达自我 | 很容易创建、更新、传播信息 |
| 向被批准的、拥有恰当访问权限的应用提供数据 | -
用户可以保密隐私信息 -
只向被批准、拥有恰当访问权限的应用提供信息
|
| People | 用户能够连接他的朋友 | 用户可以定制个人资料,使自己与众不同 | 提供工具让管理好友变得轻松 | 用户可以用相关性规则过滤好友 | 向应用提供好友数据 | 只向被批准、拥有恰当访问权限的应用提供信息 |
| Stream | 向用户提示其好友的更新 |
|
| 用户可以根据兴趣过滤好友更新 | 向应用提供信息流 |
|
| Circles | 将好友分组 | 根据用户的语境创建新圈子 | 鼓励创建和修改圈子 |
| 向应用提供圈子数据 |
|
| Notifications |
|
| 简明地展示通知 |
| 向应用提供通知数据 |
|
| Hangouts | | 加入群聊前,用户可以预览自己的形象 | -
只要一次点击就可以关闭视频和音频输入 -
可将好友加入已有的群聊
|
| -
用户可以在群聊中使用文字交流 -
YouTube视频可以加入群聊 -
在“设置”中可以配置群聊的硬件 -
没有摄像头的用户可以音频交谈
| -
只有被邀请的用户才能加入群聊 -
只有被邀请的用户才能收到群聊通知
|
| Posts |
| 表达用户的想法 |
|
| 向应用提供帖子数据 | 帖子只向被批准的用户公布 |
| Comments |
| 用评论表达用户的想法 |
|
| 向应用提供评论数据 | 评论只向被批准的用户公布 |
| Photos | 用户可以分享他的照片 |
| -
用户能方便地上传照片 -
用户能方便的从其他来源导入照片
|
| 与其他照片服务集成 | 照片只向被批准的用户公布 |
Compatibilities通常是面向用户的(user-oriented),反映了用户视角的产品行为。测试 人员也应该保持Compatibilities矩阵的简洁,他们应该关注对用户而言最有价值、最有吸引力的能力,并在合适的抽象层次(right level of abstraction)记录Compatibilities。最重要的是,Compatibilities应该是可测的(testable),测试人员 能够设计测试来检查产品实现了预期的Compatibilities。
有了Compatibilities矩阵,测试团队就完成初始的测试计划。这就是前Google测试总监James Whittaker所说的10分钟测试计划(The Ten Minutes Test Plan)。其基本思路是专注于核心属性、核心功能和核心能力,而省略一切不必要的细节。之后,测试团队会利用矩阵去指导测试设计,通常矩阵中的一条 Compatibility就是一个测试对象、测试策略或测试情景,而复杂的Compatibility会演化出更多的测试设计。
Google所提供的开源Web应用可以分析项目信息,包括测试用例、代码变更、产品缺陷等,以确定Compatibilities矩阵中的高 风险区域。下图引用自James Whittaker在GTAC 2010的闭幕演讲的幻灯片,是Chrome OS的Compatibilities矩阵的热点图(heap map)。图中绿色表示低风险区域,红色表示高风险区域,粉红色和橙色则表示风险居于前两者之间。测试人员可以根据热点图,更好地确定测试优先级,将有限 的资源运用在最需要的地方。

许多团队的风险分析依赖于测试人员的经验和猜测,Google的ACC工具则通过分析项目元素(测试用例、代码变 更、产品缺陷等)来识别风险。这些被分析的元素位于HTSM->Project Environment,是项目环境的一部分。即便不使用Google的工具,测试人员也可以利用电子表格记录Compatibilities矩阵,并自 行计算各个条目的风险(一些Google的测试人员也是这么做的)。在评估风险时,他可以考虑如下因素:
● 自动化测试用例:该区域有自动化测试用例吗?测试在定期运行吗?测试通过率是多少?测试用例覆盖了哪些方面,没有覆盖哪些方面?
● 手动测试:有人手动测试该区域吗?经过测试,他们对该区域有信心吗?如果满分是10分,他们会打几分?
● 代码变更:该区域近期存在代码变更吗?变更频繁吗?变更是新增功能、代码重构、还是缺陷修复?
● 代码复杂度:代码的规模是多少?代码是否复杂?如果复杂度的满分是10分,该区域的代码能得几分?
● 产品缺陷:该区域的缺陷多吗?有哪些典型缺陷?哪些缺陷已经被修复?哪些缺陷还没有被修复?活跃的缺陷是在快速增加还是稳步下降?
在计算此类风险因素时,测试人员可以采用尽可能简单的度量方法。一方面,简单的方法更容易解释度量值的含义,从而有 助于针对度量值采取相应的行动。另一方面,复杂的方法增大了分析的难度,却往往不能提供更多的收益。通过测试去获得直接的反馈,并定期重新度量风险因素, 是更注重实效的方法。这也符合ACC的风格:快速的前进,持续的迭代。在测试计划时,测试人员只要快速地确定Compatibilities矩阵,而不必 担心遗漏。随着测试的进展,他会对矩阵做出必要的调整,以优化测试的价值。
版权声明:本文出自 liangshi 的51Testing软件测试博客:http://www.51testing.com/?298785
摘要: 【IT168 技术文档】作为一名开发人员,大多情况下都会认真的做好功能测试,但是却常常忽略了软件开发之后的压力测试,尤其是在面向大量用户同时使用的Web应用系统的开发过程,压力测试往往是不够充分的。近期我在一个求职招聘型的网站项目中就对压力测试的重要性体会颇深。 在项目中,我负责开发职位信息的搜索部分,但是由于缺乏压力测试,仓促将搜素部分的功能提交到生产环境,结果当并发量稍稍到达一定程度时,数据...
阅读全文