@echo off
: basedata
set ip=10.39.28.234
set user=root
set password=root1234
set databaseName=crm_cloud
set /a backupDays=7
set mysqlBinPath=C:\Program Files (x86)\MySQL\MySQL Server 6.0\bin\
set mysqlBackupPath=C:\mysql_back\
set logs=%mysqlBackupPath%\logs.txt
set day=%date:~7,2%
set month=%date:~4,2%
set /a year=%date:~10,4%
if not exist %mysqlBackupPath% md %mysqlBackupPath%
echo %year%-%month%-%day% >> %logs%
set backupingFilePath=%mysqlBackupPath%\%databaseName%_%year%-%month%-%day%.sql
cd /d %mysqlBinPath%
echo backupdata >> %logs%
set errorlevel=0
echo errorlevel=%errorlevel%
mysqldump -h%ip% -u%user% -p%password% --default-character-set=gbk --opt --extended-insert=false --triggers -R --hex-blob -x %databaseName%>%backupingFilePath%
set /a myerrorlevel=%errorlevel%
echo myerrorlevel=%myerrorlevel%
if %myerrorlevel% leq 0 (
if exist %backupingFilePath% (
echo backupcomplete mysqlBackup_%year%-%month%-%day%.sql
echo backupcomplete mysqlBackup_%year%-%month%-%day%.sql >> %logs%
) else (
echo backupfaile
echo backupfaile >> %logs%
pause
exit
)
) else (
echo backupfail
echo backupfail >> %logs%
if exist %backupingFilePath% (
del %backupingFilePath%
)
pause
exit
)
rem delete backupDays's backup
set /a day=1%day%-100-backupDays
rem
if %day% lss 1 (
set /a daysTemp=day
call :daysOfLastMonth
) else set /a daysTemp=0
set /a day+=daysTemp
rem
if day lss 10 (set day=0%day%)
set /a month=%month%
if %month% lss 10 (set month=0%month%)
set deleteBackupFilePath=%databaseName%%year%%month%%day%.sql
echo mysqlBackup_%year%-%month%-%day%.sql
echo mysqlBackup_%year%-%month%-%day%.sql >> %logs%
if exist %mysqlBackupPath%\%deleteBackupFilePath% (
del %mysqlBackupPath%\%deleteBackupFilePath%
echo delcomplete >> %logs%
) else (
echo the document isn't exist >> %logs%
)
echo -----------------------------------------------------end >> %logs%
:daysOfLastMonth
set /a month=%month%-1
set /a mod1=%year%%%4
set /a mod2=%year%%%100
if %month% lss 1 (
set month=12
set year=%year%-1
set day=31
) else (
if %month% == 2 (
set day=28
if %mod1% == 0 (
set day=29
if mod2 == 0 (
set day=28
)
)
) else (
for %%a in (1 3 5 7 8 10 12) do (
if %month% == %%a (
set day=31
goto :eof
)
)
set day=30
)
)
goto :eof
以上为windows版本
----------------------------------------------------
以下为linux版本第一个
#!/bin/bash
#Write by oneleaf@gmail.com
#数据库服务器地址
DBHOST=localhost
#数据库登录名
USERNAME=root
#数据库密码
PASSWORD=
#需要备份的数据库 或 输入类似 db1 db2 的列表清单
DBNAMES="all"
#备份MYSQL时生成CREATE数据库语句
CREATE_DATABASE="yes"
#备份的目录
BACKUPDIR="/tmp/mysqlbackup"
#发生到邮件的地址
MAILADDR="test@example.com"
#邮件最大附件尺寸2M
MAILMAXATTSIZE="2000000"
#当前备份日期和时间
DATE=`date +%Y-%m-%d_%H_%M`
OPT="--quote-names --opt"
#检查备份路径是否存在,不存在则建立
if [ ! -e "${BACKUPDIR}" ]; then
mkdir -p "${BACKUPDIR}"
fi
#删除备份路径下的所有文件
rm -fv ${BACKUPDIR}/*
#检查是否需要生成CREATE数据库语句
if [ "${CREATE_DATABASE}" = "yes" ]; then
OPT="${OPT} --databases"
else
OPT="${OPT} --no-create-db"
fi
#检查是否是备份所有数据库
if [ "${DBNAMES}" = "all" ]; then
DBNAMES="--all-databases"
fi
BACKUPFILE=${DATE}.sql.gz
cd ${BACKUPDIR}
#备份数据库
`which mysqldump` --user=${USERNAME} --password=${PASSWORD} --host=${DBHOST} ${OPT} ${DBNAMES} |gzip > "${BACKUPFILE}"
#获取备份文件的尺寸
BACKFILESIZE=`du -b ${BACKUPFILE}|sed -e "s/\t.*$//"`
#检查是否需要分割
if [ ${BACKFILESIZE} -ge ${MAILMAXATTSIZE} ]; then
#分割数据库,合并使用 cat ${BACKUPFILE}.* > ${BACKUPFILE}
`which split` -b ${MAILMAXATTSIZE} ${BACKUPFILE} ${BACKUPFILE}.
for BFILE in ${BACKUPFILE}.*
do
echo "Backup Databases: ${DBNAMES}; Use cat ${BACKUPFILE}.* > ${BACKUPFILE}" | mutt ${MAILADDR} -s "MySQL Backup SQL Files for ${HOST} - ${DATE}" -a "${BFILE}"
done
else
echo "Backup Databases: ${DBNAMES}" | mutt ${MAILADDR} -s "MySQL Backup SQL Files for ${HOST} - ${DATE}" -a "${BACKUPFILE}"
fi
--------------------------------------------------------------------------
以下为第二个版本
ubuntu定时备份mysql,首先要写一段shell脚本,用来备份mysql数据库,再通过crontab定时执行备份mysql数据库的shell脚本。
1.备份mysql的shell脚本如下:
?
1
2
3
4
5
6
#!/bin/bash
date_str=$(date +%Y%m%d-%T)
cd /home/steven/backup
mysqldump -h localhost -u root --password=xxxx -R -E -e \
--max_allowed_packet=1048576 --net_buffer_length=16384 databaseName\
| gzip > /home/steven/backup/juziku_$date_str.sql.gz
把上面这个脚本存放位置:/home/steven/mysql_backup.sh (当然,也可以放在其他位置)
再赋于执行的权限,通过下面命令:
sudo chmod +x /home/steven/mysql_backup.sh
完成这步,我们就来执行一下这段脚本,看能不能备份mysql数据库。
在命令行输入
./mysql_backup.sh
就可以看到备份好的数据库文件了
2.完成上面这步,就可以备份mysql数据库了,接下来,我们再通过crontab定时执行这段脚本。
使用crontab -e命令,这个命令的使用比较简单。
在命令行输入中,直接输入 crontab -e
就会打开一个编辑窗口,最后一行会有内容格式的提示:
# m h dom mon dow command
具体意义表示:分钟 小时 日期 月份 星期 命令,在某月(mon)的某天(dom)或者星期几(dow)的几点(h,24小时制)几分(m)执行某个命令(command),*表示任意时间。例如:0 3 * * * /home/steven/mysql_backup.sh就是:每天早上3点,执行mysql_backup.sh脚本。
我们只要在里面添加一行就行了,内容如下:
?
1
2
# 备份mysql数据库 每天早上3点整执行
0 3 * * * /home/steven/mysql_backup.sh
这样,每天早上3点,就会自动备份mysql数据库了。
-=----------------------------------------
第三个版本
我只需要
1、创建保存备份文件的目录:/home/mysql_data
cd /home
mkdir mysql_data
2、创建备份脚本文件:/home/mysql_data/mysql_databak.sh
cd /home
cd mysql_data
touch mysql_databak.sh
vim mysql_databak.sh
输入以下内容:
1
#!/bin/sh
2
/etc/init.d/mysqld stop #执行备份前先停止MySql,防止有数据正在写
入,备份出错
3
date=` date +%Y%m%d ` #获取当前日期
4
DAYS=7 #DAYS=7代表删除7天前的备份,即只保留最近
7天的备份
5
BK_DR=/home/mysql_data #备份文件存放路径
6
DB_DR=/var/lib/mysql/pw85 #数据库路径
7
LINUX_USER=root #系统用户名
8
tar zcvf $BK_DR/mysql_data$date.tar.gz $DB_DR #备份数据
========================================第2页========================================
9
/etc/init.d/mysqld start #备份完成后,启动MySql
10
chown -R $LINUX_USER:$LINUX_USER $BK_DR #更改备份
数据库文件的所有者
11
find $BK_DR -name "mysql_data*" -type f -mtime +$DAYS -exec rm {} \
;
#删除7天前的备份文件(注意:{} \;中间有空格)
12
deldate=` date -d -7day +%Y_%m_%d ` #删除ftp服务器空间7天前的备份
13
ftp -n<open 192.168.1.1 21 #打开ftp服务器。21为ftp端口
14
user admin 123456 #用户名、密码
15
binary #设置二进制传输
16
cd mysqlbak #进入ftp目录(注意:这个目录必须真实存在)
17
lcd /home/mysql_data #列出本地目录
18
prompt
19
mput mysql_data$date.tar.gz mysql_data$date.tar.gz #上传目录中的
文件
20
mdelete mysql_data$deldate.tar.gz mysql_data$deldate.tar.gz #删除
ftp空间7天前的备份
21
close #关闭
22
bye ! #退出
3、修改文件属性,使其可执行
chmod +x /home/mysql_data/mysql_databak.sh
4、修改/etc/crontab #添加计划任务
vi /etc/crontab #在下面添加
5 23 * * * root /home/mysql_data/mysql_databak.sh #表示每天23点05分
执行备份
5、重新启动crond使设置生效
/etc/rc.d/init.d/crond restart
chkconfig crond on #设为开机启动
service crond start #启动
作为一个开发团队的管理者,例如当你是一个团队的项目经理的时候,任务的完成情况通常是你最关心的内容之一,比如说分配的任务是否能够按时间完成,整个项目的进度是否尚在计划之中,团队内的人是不是都在高效地工作,大家有没有什么困难,这些是你经常会关注的问题。在软件开发团队中,任务的分配、跟踪和管理通常是这个团队管理者的一个重要的工作内容。
1、从问题谈起
我曾经碰到过一个项目经理,她管理着一个团队开发一个web应用,团队里开发人员大概10个左右,测试人 员3个,业务分析师1个人。对于任务的管理她是这么做的。通常,她会将需求分析人员分析得到的需求给每个人分一些。然后每个人在领到任务之后会给她承诺一 个大致的时间点。整个项目大致的交付计划用一个excel表管理着,根据客户要求的交付时间点,并且考虑到一些需求之间的集成测试关系,定出了每个需求的 大致交付时间点。只要每个开发人员承诺的时间点和期望的相差不大,她都可以接受,每个开发人员这样就知道自己应该在什么时间点交付什么东西。
一切本该很完美,但是不和谐的问题不断出现。最经常发生的事情就是大家在承诺的时间点快要到的时候不能按时交付,每次她询问进度的时候,会被告知还差一 点就完成了。通常的说法是“底层部分已经做完了,或还差页面部分就可以搞定了”,然而实际情况是又过了相当的时间才真正完成。当然也不是没有按时交付的需 求,但是她发现也许是大家经常加班,已经开始疲倦了,有时候明明很简单的可以提前完成的需求,大家还是到最后一刻才交付给测试。
也有的 开发人员拿到自己的那一批需求之后,会批量工作,把若干个类似的需求的底层逻辑全部实现,然后再实现上层内容。她默认了这种做法,就像这位开发人员说的 “这几个需求都差不多,只要底层做好了,基本上就都差不多完成了”。虽然这部分工作早点和其他人一起集成测试会比较好,但是他这样做也只能推后集成测试的 时间点了。还好承诺给测试团队的交付时间点还在1个月之后,只要1个月之内能够完成这些需求就可以了。
还有一些其他的问题,比如有的新 人经常碰到问题,然而出了问题并不会主动问其他人,而是在胡乱尝试中浪费了时间。组里还有个开发人员非常激进,经常花时间去重构代码,追求完美的架构设 计,进度很让人担忧。组内的开发人员有时候还经常被其他项目的事情打扰,因为有几个人刚刚从上一个项目中调过来,上个项目的有些问题只有他们熟悉和有能力 解决。她就不止一次发现,有一个开发人员经常在修复其他项目的bug。
她会不定时地去询问每个开发人员的开发进度,当需求的计划交付时 间点逼近的时候,这种检查会越来越频繁,开发人员感受到压力,有时候甚至需要加班来完成开发工作。然而尽管她花了很多精力去跟踪和检查每个需求的完成情 况,还是有很多出乎期望的事情在不断发生。尽管她一直相信说,只要开发人员们能够完成任务,采用什么方式她是不干预的,而具体的时间也是由他们自己分配 的。但是她渐渐感觉到,任务越来越不可控,计划通常无法按时完成,每天对大家的检查花了大部分时间,然而却不能揭示出真正的问题。
运转 良好的项目都差不多,而问题项目的问题各有各的不同。尽管每个团队的问题可能不完全相同,但是当我们审视这些项目的运作和管理方式的时候,不难发现一些诸 如多任务并行等共性的问题,这些问题给软件项目带来了各种各样的浪费。当一个团队采用瀑布开发模式的时候,开发阶段全部结束之后测试人员才会介入,开展测 试活动,在一个通常很漫长的开发阶段内,各种开发活动中的浪费、估计的不准确,以及成员自己的拖沓、被打扰、问题阻塞等,都被掩盖住了。只要在最终时间点 前能够全部开发完成,不管是前松后紧,还是加班熬夜,都已经成了项目开发的常态。项目经理只能看到交付的最终时间点,问题不能及时的暴露,而等到问题被暴 露的时候,可以使用的调整手段也非常有限。
这样的一种团队生存状态在外部环境要求短交付周期,需求允许经常变化的情况下显示出了极度地 不适应。市场环境的变化驱动了软件需求的变化,这种变化催生了缩短交付周期的诉求,较短的交付周期使得人们可以不必去预期过于长远的需求,具备根据市场的 变化快速地制定和调整软件需求的能力。而当交付模型由几个月的瀑布模型转变为数周甚至更短的迭代模型的时候,我们在前面谈到的团队中的各种浪费、低效、半 成品堆积等问题,就会急剧地爆发出来。
熟悉敏捷方 法的读者可能都知道,敏捷方法包含一系列实践来帮助团队实现短周期快速交付,更好地响应需求变化。比如说userstory方法,将需求从用户价值的角度 进行组织,避免将需求从功能模块角度划分。小粒度的用户故事可以在一两周的迭代内完成开发和测试(并行开发),从而可以缩短交付周期。问题是,在敏捷团队 内,我们是如何有效管理大量小粒度userstory,同时避免上述项目管理中的问题呢?下面我们结合敏捷开发中的看板工具来看看敏捷团队是如何管理任务的。
2、可视化看板任务管理

看板源于精益生产实践,敏捷将其背后的可视化管理理念借鉴过来,经过一番改造,形成了有自己独特风格的可视化管理工具。曾有人总结过scrum和kanban的使用,而很多时候,我们也将它叫做迭代状态墙。
先看看我们怎么样能用这个状态墙来管理迭代任务。说起来其实是一个很简单的东西。
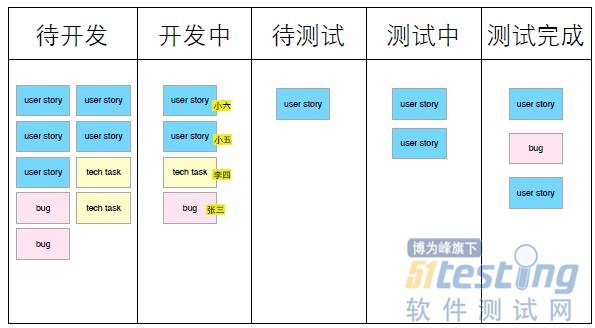
通常一个迭代的状态墙上反映了某一个迭代的计划和任务进展情况。状态墙上按照一个迭代内团队的典型开发活动分成几栏,例如“待开发”、“开发 中”、“待测试”、“测试中”、“测试完成”等。在一个迭代之初,我们会将计划在本迭代完成的故事卡放到“待开发”这一栏中。可视化状态墙的一个好处就是 所有团队成员都可以实时地了解到本迭代的计划和进展情况。开发人员领取任务时,就将他领取的故事卡片从“待开发”移到“开发中”,同时贴上带有自己名字的 小纸条。当他开发完成之后,就将故事卡片移到“待测试”一栏。我们的测试人员看到这一栏里有待测的故事卡时,就取下一张,移动到“测试中”,开始这个用户 故事的测试,测试完成后,就将故事卡移动到“测试完成”一栏。如果测试人员发现了一个bug,那么他可以用红颜色的卡片记下这个bug,然后放到待开发这 一栏中。在状态墙上,除了用户故事、bug之外,还会有一些诸如重构、搭建测试环境这样的不直接产生业务价值的任务,这三类任务用不同颜色的卡片,放到状 态墙上统一管理。
这样一个简单的工具,是如何帮助我们消除浪费、解决项目管理中的问题的?让我们逐条分析一下看看。
2.1 如何减少返工带来的浪费
返工是软件开发过程中的一大严重浪费。比如说开发人员开发完成的任务交给测试人员测试的时候,关键流程不能走通,阻碍了测试进程;交付给客户的 东西被客户说“这不是我想要的东西”;分析人员将还没分析透彻的任务交给开发人员,在最后验收的时候发现开发人员加入了自己的一些“发挥”。这些都会造成 返工。返工意味着没有一次性将事情做对,意味着流程中的上游没有交付高质量的工作,也可能意味着团队成员间的沟通出了问题。
在传统的瀑布流程中,我们往往是期望通过前期细致入微的工作来确保一个阶段的工作被高质量完成之后才移交到下一阶段。后来我们慢慢从失败的经验 中学习到,这种方法在变化的需求环境下实在是太过脆弱,不仅不能如愿保证质量,而且会造成更大的浪费,交付周期也不能满足要求。于是我们引入了迭代式开发 方法,一个需求的分析、开发、测试、验收成了一个小粒度地更连续的过程,在这个小的交付循环中,看板帮助我们以更细节的粒度来管理一个任务每个阶段的工作 质量。
通常我们是这么做的。当我们把一张故事卡从“待开发”移动到“开发中”时,这张卡片必须是已经分析完成的。也就是说,当开发人员准备真正开始开 发这张故事卡之前,我们的需求分析师们必须保证这张卡片所包含的所有内容和细节已经被分析完成,不再有模棱两可的细节,不再留给开发人员过多的自我发挥和 想象空间,而且这些细节必须和客户确认过,而不只是团队自己“设计”的结果。
这一道关看似很寻常,实际上很多项目会在这里出问题。很多时候开发人员开始开发的时候,需求还没有分析完成,很多细节尚须澄清确认,实现上的技 术风险还没有被完全排除。也有的分析师善于给开发人员留有大量自我发挥空间,需求过于言简意赅。开发人员开始开发这样的需求时,要么做不下去,要么按照自 己的理解做下去。做完了之后分析师一看发现不对,和我想的不一样,于是开发人员返工。最糟糕的情形莫过于最后被客户发现说,这不是我当初想要的东西。
由此可见,确保开发人员挪卡的时候,这张待开发的用户故事已经被真正分析完成,是我们准确实现用户需求的第一步。通过规定这一挪卡的前提,同时 辅以用户故事的澄清(由分析师向开发人员澄清)或者反向澄清(由开发人员向分析师讲述自己的理解),可以很大程度上将返工减少到最低。
还有一种浪费发生在测试过程中。测试人员经常会发现,处于“待测试”状态中的一些故事卡,在测试的时候主要的流程都走不通,根本无法进一步展开测试,于是乎不得不将故事卡
打回到开发人员手中。而往往这个时候开发人员已经工作在另一个用户故事上了。要么他停下手中的任务解决测试的问题,要么让测试人员等到这些问题修复过后再测。无论哪种都是不好的选择。
这种问题的一个主要原因是因为开发人员声称他已经“开发完成”,将故事卡从“开发中”挪到“待测试”时,实际上自己并没有对这部分功能进行测 试。或者是因为疏忽,或者是因为懒惰,或者是因为过于自信。通过在这个状态转换阶段引入用户故事初验,让分析师在挪卡之前先到开发人员机器上看看是否该故 事卡包含的功能被实现了,可以很大程度上提升效率,减少浪费。若分析师在初验过程中发现了问题,那么开发人员马上能以最小的成本进行修复,而不用等到之后 测试人员发现时再来修复。而且,分析师初验也提供了一个判断实现是否良好的反馈点,这是我们能够看到一个需求是否被实现并能够真正工作的最早的时间点。
2.2 如何避免多任务并行
多任务之间的频繁切换是一个常见的问题。表现在团队里的成员,特别是开发人员,会在不同的任务间切换。就像前面的故事中提到的,可能这一刻还在 实现某一个需求,而下一刻马上就会被叫走去修复某一个遗留版本的缺陷。又或者该人手头被分配了多个任务,每个任务都在进行中,而没有一个处于完成状态。任 务切换是导致效率降低的一个重要原因,不同任务间的上下文的切换会导致频繁地将任务当前状态在头脑中“压栈”和“出栈”,这些操作会耗费时间。如果完成一 个任务需要一个人一天时间,那么两天内这个人可以完成两个任务,但是如果他在第一天同时开始并行工作在这两个任务上,那么完成这两个任务会需要大于两天的 时间。
大家可能已经注意到了,在前面的看板图中,处于“开发中”的所有任务卡片上都有一个小纸条,上面标记着正在这张卡片上工作的人的名字。如果说有 两个人结对在一个卡片上工作,那么这张卡片上应该有两个名字。这一小小的实践可以帮助我们随时发现团队内某一时刻,是否每个人只工作在一个任务上。
如果这一简单的规则能够严格被遵循,那么当我们看到一个人的名字出现在多张卡片上的时候,我们就知道这个人此刻可能忙着在多个任务之间切换,而每 一个任务都将不会在估计的时间点内完成。如果我们看到有人的名字没有出现在任何卡片上,那么他目前大概处于休息状态。团队内的每个人的名字都应该对应在一 个小纸条上,如果你此刻工作在某个任务上,那么就将自己的名字贴到相应卡片上,如果此刻没有工作在该任务上,就将自己的名字移去。
我们在领取“待开发”状态栏中的卡片时,保证每次每人只领一张卡片,不要多领,完成了这张卡片之后,再回来领下一张。当一张卡片被认领之后,我 们就会对这张卡片进行跟踪,在站会上谈论它的完成情况,谈论实现过程中碰到的问题。当它的进度和估计的可能偏差较大时,我们能够及时而不是在最后一刻察觉 到,提供需要的帮助,确保它能够顺利完成。这样一种方式让我们能够将注意力集中到小粒度的需求(例如用户故事)上,更多地关注这些用户故事的流动速度。而 当每个小的用户故事能够顺畅地流动起来时,整个项目的交付也得到了保障。
当然这一实践并不能自动保证团队内不再出现多任务并发、拖延、或者做和任务无关的其他事情等问题。可能有些人在做一个用户故事的过程中,突然中断去做了一些其他事情,但是
却没有及时在状态墙上更新自己的状态。重要的是团队要有实现交付目标的共同愿景,能够透明地暴露问题,并且善于利用状态墙来发现和改进自身的问题。对于不成熟的团队,这可能需要一个转变的周期。
如果一个团队的职责共享较好,代码被所有人集体拥有,每个人都被鼓励熟悉和工作在代码的不同部分,那么在这样的团队内便不太会出现把一大块任务 事先就明确给某一个人的情况。相反,所有人的工作事先不具体确定,大家会更容易形成某一时刻只领取一张卡片的情况,避免同时工作在多个任务上。实际上,状 态墙的使用也可以帮助团队走向职责共享之路,只需要在大家领取任务的时候有意地给人们分配一些之前没做过的内容,同时安排好有经验的人与其结对工作,一段 时间之后,团队内的人便会逐渐体会到和之前只是专注在一个模块内不同的工作方式。
2.3 如何减少半成品库存,缩短交付周期
一个需求的交付周期(leadtime)是从它被识别到最终交付给用户手中所耗费的时间。交付周期越短,意味着客户从提出想法到能够在软件中实 际使用到这个点子的时间越短。从客户的角度来看,更短的交付周期意味着自己的软件能够对市场变化的更快地响应,因而获得更强的竞争力,同时也意味着能够更 快地验证自己的想法。
任务管理的粒度太大会直接导致交付周期变长。最极端的情况是将属于某一模块的任务在一开始就全部分给负责这个模块的人,所有这个模块相关的修改 都由他来实现。在一个按模块划分职责,每个人只负责自己具体模块的团队里,通常这个模块的负责人会实现这个模块的所有修改。不然,就是将一个可能需要做2 周到一个月的任务分给某个人。或者更好一点的情况是,单个任务本身不大,但是会将相关联的任务成批地分配给某个人。如果你的团队内也是采用大篇的“规格说 明书”等word文档来组织需求的,那么就要小心,这种问题很可能在团队内已经存在。整个团队没有小粒度频繁交付的概念,习惯了大批量长时间地交付方式。 由于批量大,所以估计常常不准,而且时间跨度长,中间也会有更多地干扰因素出现,这些都导致任务不能在开始承诺的时间点交付。开发周期长同样导致测试活动 的滞后,极端地滞后就演变为所有开发工作完成之后才能进行测试,这就是我们熟悉的瀑布模式。最终的影响就是需求的交付周期会很长。
传统团队的一个常见组织方式是按照功能模块划分团队成员,明确分离职责,这也会变相增长交付周期。这样的团队通常倾向于按照功能模块来组织半成 品任务,而不是按照可以交付价值的完成品来组织任务。习惯按照功能模块来组织开发的团队通常会阶段性得“联调”,不同模块的人带着自己的代码合在一起调 试,由于缺乏频繁地集成,这种联调活动的时间经常不可控。团队在大部分时间内通常只拥有一大堆半成品,后续的测试和验收活动没有办法进行,而只能等到团队 在某一刻组装出一个完整的功能后才能测试,因此交付周期也会比较长。
因此,如果我们的需求都是按照软件的功能模块划分,而不是按照面向用户的价值来划分的,那么我们在交付用户价值这一目标上,一开始就走错了路。采用用户故事能够把需求以用户能够理解的价值来组织,这一点是我们缩短交付周期的一个重要基础。
我们的状态墙能够揭示需求的交付周期。让我们来看看这样几个场景。
如果我们的需求是按照软件的功能模块划分的,那么通常单个模块的编码完成往往不可测。例如有的团队喜欢将web应用的上层页面部分和下层数据库 逻辑部分划分到不同的模块组,一个用户的需求也会拦腰切成两截,一部分交给上层团队完成,一部分交给下层团队。单个团队的任务完成都不能开展这个需求的测 试,于是这些任务就会堆积在“待测试”这一栏。
如果我们的需求很大,以至于开发人员要花费很长的时间(超过1周)才能完成开发,那么这个需求会在“开发中”这一栏停留很久。大家可以猜到,当一个人同时进行多个任务时,这些任务也会比它们单个依次被开发时在“开发中”这一栏停留更久的时间。
任何一栏中的任务其实都是半成品,只有完成测试,交付到用户手中的需求才是完成品。状态墙上的每一栏都好比一个存放着各种零件的仓库,每一栏中 的卡片越多,停留的越久,就说明当前半成品的库存越多,是该得到团队的认真关注的时候了。状态墙将每个阶段的半成品数量可视化呈现出来,让虚拟的数量通过 卡片这种物理介质的数量得以呈现。
通过状态墙,我们可以计算出每一个需求的交付周期大概是多久。状态墙上一个用户故事从放到“待开发”这一栏,到它被移动到“完成”这一栏,这一 个时间段是需求的整个交付周期的其中一段,也是很重要的一段。通过优化从“待开发”到“完成”的这一个过程,我们可以缩短需求的交付周期。通过比较需求的 交付周期和客户对交付周期的要求,我们可以量化之间的差距,然后指导我们的改进。
在我们理解了状态墙是如何呈现一个需求的交付周期后,我们就不难理解瀑布方法是如何让交付周期变长的。在瀑布模型中,全部开发完成之后才会进行 测试工作,相当于所有的任务卡片都堆积到“待测试”状态之后,才开始逐一测试。所有开发完成的半成品,都会留存在“待测试”这一仓库中,一直等到所有开发 活动结束的那一刻。
当出现库存堆积的时候,就是我们需要改进的时候。如果“待测试”这一栏有太多的任务卡片,那么就说明我们的测试活动没有跟上。有可能是我们的测 试环境出了问题,或者是我们的测试人员人力不足。如果太多的卡片位于“测试完成”状态,说明我们的发布和最终交付过程出了某些问题。如果“待开发”这一栏 中任务过多,说明我们的计划有可能超出了当前团队的开发能力,或者说反映了开发人员的不足。也有一种情况,那就是“待开发”这一栏空了很久,这可能说明了 另外一个问题,那就是我们的分析师的分析速度匹配不上团队的开发能力。一个良好的团队,必然是各种角色协调配合,并行工作,同时他们之间的任务衔接也能够 比较流畅。
2.4 迭代产能的度量,计划及其他
团队在每个迭代所能完成的工作量,通常被成为迭代的velocity(速度),是衡量团队每迭代产能的一个指标。这个指标能够帮助团队进行制定 迭代计划。根据团队估计任务工作量的方法不同,迭代的velocity的单位也可能不同(例如故事点数)。通常,我们只需要在迭代结束的时候,数一数状态 墙上完成的任务工作量就可以了。
当我们经历了若干个迭代以后,通常团队的迭代速度会趋于稳定,我们在做下一个迭代的计划的时候,会参考以往迭代的数据。如果上个迭代完成了15个点,那么下个迭代我们通常也
会计划15个点左右的工作量,将这些卡片放到“待开发”这一栏中。也就是说,每个迭代结束时,我们都会对状态墙进行更新,将即将到来的迭代的卡片放到墙上,并且将一些处于半成品状态的卡片进行适当的调整。
前面提到,状态墙上可能由三种卡片,除了需求,还可能有bug和技术任务。测试人员每次在迭代中测出一个bug,就会将bug写成卡片,放到 “待开发”这一栏。当bug不多的时候,团队可以在不太影响原有计划的情况消化掉这些bug,确保软件的质量持续地得到保证。如果bug太多,则需要做一 些计划,将bug分散到几个迭代里去消化。然而到这个时候,团队可能更需要及时反省一下为什么会出现这么多bug的原因了。
另一类技术任务也需要和bug以及需求卡片一起被考虑到迭代计划中去。通常技术任务包括诸如搭建持续集成环境、准备测试环境、重构这样的任务。 它们虽然不直接给用户带来价值,但是却是保证软件质量、确保团队效率的重要因素。比如重构类的任务,对于工作在遗留系统上的团队来说可能是需要一直考虑的 事情,为了保障新的需求的顺利实现,可能需要有计划地重构之前的一些遗留代码。
bug和技术任务耗费团队成员的时间资源,但是不直接产生用户价值。如果我们衡量团队每个迭代的总体生产能力,需要在计算迭代速度时考虑这三类 任务。但是如果我们只考察团队每迭代交付的用户价值的量的大小,那么就不应该包含技术任务和bug。当一个团队在迭代中花了过多的时间在技术任务上,或者 修复bug上,那么团队就需要回顾反省一下其中的原因,是否是团队的基础设施太差,或者是团队在开发时过于粗心导致太多的bug,抑或是其他的一些原因。
3、总结
在本文中我们从项目管理中常常出现的一些问题着手,分析了其中的一些原因,然后介绍了如何采用状态墙(看板)来可视化任务管理。在敏捷项目中, 状态墙作为一种有效的迭代任务管理工具,已经被广泛地使用。团队利用状态墙这样一种简单的工具,将迭代开发中的日常工作透明实时地跟踪管理起来,能够帮助 团队及时发现问题,消除浪费,快速地交付用户价值。希望这些文字,能够对渴望尝试敏捷、改善任务管理和日常运作的团队带来一些帮助。
离职信(转)
公司诸君:
自吾之来此,已一年有余。本当披肝,以报知遇,却发现往昔之热情所剩无几。想来与人无涉。问题在己,盖因自己实不具荣辱不惊之修为。既已无心向工,终不能 应景混事,长此以往,百无一利。唯今之计,只有主动剥职,才是正议,如此即可顺遂心意,亦可免于日后复为旗下之祭。
其实去不足惜。辗转数月,倍感煎熬,故去留之事可知已。奈何,晃晃终日不安,去留两相难。且画饼充饥,终不可为,此之内伤,故而吾之所事,上效和尚撞钟, 敷衍了事,得过且过。况汝之于如来,吾之于金蝉子,必之为歧。故与子谋皮吾之损已。故而或弃或留,亦为不悖。
吾等人士,或曾芳心暗许,愿择良主,从一而终。奈何落花有意,流水无情。去意生时,悲从中来,心路历程,犹如爪撕。人生一世,草木一春,草木含情,人岂无义?古人云:“
月明星稀,乌鹊南飞,绕树三匝,无枝可依。”此般情景,感同身受。
虽不舍同事,但天下无不散之宴席。一朝同事,终身为友,人虽已走,望茶勿凉。他日遇吾衣食无计,望赐茶一杯以示无望;倘得日后前程无忧,尚能嘘寒问暖,吾愿足已
前些天在网站上看到一篇名为我们需要专职的QA吗?让我很让震惊!
发这篇文章的目的,并不是对原作者的看法表示如何的批评,且说出自己的想法(自认为很中正的看法),希望各位网友能说出你的看法,也希望我能解释很多开发人员的疑惑。
文章链接:我们需要专职的QA吗?
紫色的文字为引用原文,因为引用文章很长,请见谅
在开始今天的讨论之前,先看几个名词解释(参考):
质量保证(QA):QA(QUALITY ASSURANCE,中文意思是“品质保证”,通过过程的持续改进来提高产品质量,是软件成熟度模型(CMMI/ISO)中的一个角色
QA可以对开发的具体技术不了解,但要对CMMI、ISO900等的流程要清楚
软件配置管理(SCM):配置管理(Configuration Management,CM)是通过技术或行政手段对软件产品及其开发过程和生命周期进行控制、规范的一系列措施。配置管理的目标是记录软件产品的演化过程(其中涉及到基线的概念),确保软件开发者在软件生命周期中各个阶段都能得到精确的产品配置;
配置管理包括六大任务:配置标识、版本管理、变更管理、配置审核、状态报告、发布管理,配置管理的最重要的是版本管理和发布管理;
配置管理往往是配置在质量部统一进行管理,现时还要为测试提供一个测试环境,即我们讲的搭测试环境。
软件测试(Tester):使用人工或者自动手段来运行或测试某个系统的过程(他是一个验证的过程),其目的在于检验它是否满足规定的需求或弄清预期结果与实际结果之间的差别,通俗的说是去验证两个方面:是否做了正确的某事,是否正确的做了某事
QA通过对流程(过程)的持续改进来提升产品的最终质量;软件测试通过技术来保证产品的最终质量;配置管理是对过程产品及软件生命周期进行管理。
所以,到这里我们就可以看到,其实标题中把测试和QA的概念混为一谈,是错误的!
“我们都同意,Dev 要懂测试,QA 要懂开发,只不过分工不同,既然你中有我,我中有你,那就不要分彼此了,一起携手开发测试吧 (另外,我个人觉得不懂开发的测试人员不可能测试得好”)
对于上面的观点我是认同的。
至于园子中转载的文章,我不知道作者是谁,既然是分享,那么我们来看一下作者的故事:
我们暂且沿用作者的QA称谓
“我再说说我最糟糕的 QA 经历吧,这个公司的 QA 部门只做测试,他们的 leader 觉得所有的 test design 和 test 的过程都不需要 Dev 参与,他们是独立于 Dev 之外的部门,他们几乎不关心 Dev 的设计和实现,他们只关心能跑通他们自己设计的 test case。但是去执行 Test Case 的时候,又需要 Dev 的支持,尤其在环境设置,测试工具使用,确认是否是 bug 方面,全都在消耗着 Dev 的资源,最扯的是,他们对任何线上的问题不负责,反正出了问题由 Dev 加班搞定。”
上面的文字包含了很多分享者公司的情况,不知是不是可以猜测如下:
把测试能独立于开发之外(把需求视若无物)进行,这首先是Tester或Leader认知层面上的一个错误(是否作者的理解有误差暂且不论);
或者可能从中看出来,分享者的公司中没有测试总监、测试组长之类的Leader或者他们的资质明显不足以胜任他们的工作,才会出现前面所说的将测试独立于开发和其他部门而存在;
我们或者可以从Dev的抱怨中看到,公司的测试人员资质不够(不懂得基本测试工具的使用,不擅长自我学习、自我突破),过分的依赖本身已有的知识及开发人员的协助;
公司对于需求的管理很粗或者根本没有管理(或者还是测试人员的理解能力太差,无法理解需求的含义,无法分辨需求与实现之前的差异是否可以定义为Bug),如果有明确的需求管理,则不会出现经常无法确认是否Bug的情况;
我们可以从字里行间,感觉分享者的公司好像是为了测试而测试,要知道测试的目的是为了最终的质量,这一点在整个公司上下的目的都是一致的,任何的工作都不能偏离这个目标而存在
我认为:
公司要做好测试工作保证质量,公司从CEO到普通员工有质量意识很重要,只有从意识上认识到质量的重要性,才能真正的做好质量的管理,没质量的意识,其他就都是空中楼阁;
同时优秀的测试总监和测试组长是保证测试工作质量的前提 ,相信强将手下少弱兵;
不要认为任何人都能做好测试,基层测试人员的素质很重要(懂开发的测试人员或Dev最好,还要有专业系统的测试理论,同时最好了解需求或业务),他们最终的测试执行者,是质量保证的第一关和最后一关;
需求管理与需求培训很重要,遇到需求问题,沟通很重要;
质量部不是摆设,测试人员也不是找茬的家伙,大家的目标要一致的---质量
“我有一次私自 review 他们的 test case 的时候,发现很多的 test case 这样写到 – “Expected Result:Make sure every thing is fine” ,WTF,什么叫“Every thing is fine”?!而在 test case design 的时候,没有说明 test environment/configuration 是什么?没有说明 test data 在哪里?Test Case、Test Data、Test Configuration 都没有版本控制,还有很多 Test Case 设计得非常冗余(多个 Test Case 只测试了一个功能),不懂得分析 Function Point 就做 Test Design。另外,我不知道他们为什么那么热衷于设计一堆各式各样的 Negative Test Case,而有很多 Positive 的 Test Case 没有覆盖到。为什么呢,因为他们不知道开发和设计的细节,所以没有办法设计出 Effective 的 Test Case,只能从需求和表面上做黑盒。”
我很能理解这会Dev的感受,测试人员把预期结果写成“Every thing is fine”,谁他都受不了!
上面所说到的测试人员存在两个问题:
①测试用例的基本构成不完成,构成元素过于模糊无法达到准确测试的目的,无法实现测试用例的延续(他人无法看懂你的测试用例)
②测试人员对需求或测试理论理解不够,导致很多的漏洞或重复测试
但是我要告诉你的是“这和测试没有什么关系,这所有的一切都只能说明,你们的测试人员很滥,他们的很滥直接影响到了你对整个测试的理解”;
同时,我要讲的是是否了解需求与是否做黑盒测试没有关系,下面是黑盒测试的概念可以参考一下:
黑盒测试:也称功能测试,它是通过测试来检测每个功能是否都能正常使用。在测试中,把程序看作一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下,在程序接口进行测试,它只检查程序功能是否按照需求规格说明书的规定正常使用,程序是否能适当地接收输入数据而产生正确的输出信息。
所以,如果遇到上面的情况,不应该是说对软件测试失去信心(因为我们需要更好的保证质量),而应该向你的上级反应,我们需要更称职的测试人员!!!
建议去51Testing上看一看有关软件测试方面的信息
“在做性能测试的时候,需要 Dev 手把手的教怎么做性能测试,如何找到系统性能极限,如何测试系统的 latency,如何观察系统的负载(CPU,内存,网络带宽,磁盘和网卡I/O,内存换页……)如何做 Soak Test,如何观察各个线程的资源使用情况,如何通过配置网络交换机来模拟各种网络错误,等等,等等。”
这就是我上面说的,测试人员的本身素质太差,无法实现自我学习,自我提升与自我突破的情形
要知道在工作中要用到的东西并不是我们都会的,在这种情况下,我们就要积极主动的去学习,个人认为在有压力的情况下学习,往往是事半功倍的!
“在项目快要上线前的一周,我又私自查看了一下他们的 Test Result,我看到 5 天的 Soak Test 的内存使用一直往上涨,很明显的内存泄露,这个情况发生在 2 个月前,但是一直都没有报告,我只好和我的程序员每天都加班到凌晨,赶在上线前解决了这个问题。但是,QA 部门的同学们就像没发生什么事似的,依然正常上下班。哎……”
首先要肯定的是测试人员没有测试好,开发人员没有开发好,所以谁也不要说谁做得不好。人非圣贤,离孰能无过焉!
出现问题时,先解决问题,而不是先追究责任,在问题解决之后,我们需要讨论问题产生的原因,如何避免下次再出现这样的情况,同时如果可以追溯到相关的责任人,我们要进行一定的处理,但处理不是重点。
出现一些紧急的情况,加班难免,要能扛得住!
“为什么会这样?我觉得有这么几点原因(和邹欣的观点一样)
1、给了 QA 全部测试的权力,但是没有给相应的责任,
2、QA 没有体会过软件质量出问题后的痛苦(解决线上问题的压力),导致 QA 不会主动思考和改进。
3、QA 对 Dev 的开发过程和技术完全不了解,增加了很多 QA 和 Dev 的沟通。
4、QA 对软件项目的设计和实现要点不了解,导致了很多不有效的测试。”
1、质量部的责任是很重的,一量出现漏测或出现线上事故,质量部是要承担一半或以上的责任的(但具体的也要看公司的情况,如果没有系统的管理,这个很难说)
2、软件出现问题,测试人员是不是要重新测试,甚至有时候要加班加点(至于分享者说的他们测试人员不管什么时候按时下班,这还是归结到测试人员的素质问题,就无关乎能力了)是常有的事;计算机行业是一个快速发展的行业,不思考不主动学习,你很快就会被淘汰,如果你的公司的测试人员还抱着过去的知识、抑制学习、被动思考,那么你可以让他回家抱孩子,热坑头……
3、测试人员不了解软件工程或开发语言的情况常有,但有时候我们也需要精通业务的人来进行测试,这个是很重要的!
4、这个涉及到我前面讲过的对需求的管理与测试人员对需求的理解,以及对基础测试理论的缺失
从以上的几个观点来看,可以看出来文章的作者对测试人员还是很存在一定的理解偏差的,他的问题主要是把他们公司的测试一些人员当成了整个软件测试行业!
如果他可以跳出他们公司,去质量管理规范的公司看一看,或许能有极大的改观,不知道他本身是否认可?
“我越来越觉得软件开发,真的不需要专职的 QA,更不需要只写代码不懂做测试的专职的 Dev”
关于作者的这句话,我不敢完全苟同,我觉得更应该这样说:
“我越来越觉得需要软件测试人员,但不需要不专业的测试人员,更不需要只写代码不懂做测试的专职的 Dev”
我为什么我不说“我们需要专业的测试人员”而不是说“我们需要懂开发的测试人员”?
专业,包括懂需求、懂开发、懂测试理论的人员,也包括懂业务、懂需求、懂测试理论的测试人员,这两者都是我们需要的优秀的测试人员!
“1) 开发人员做测试更有效
开发人员本来就要测试自己写的软件,如果开发人员不懂测试,或是对测试不专业,那么这就不是一个专业的开发人员。
开发人员了解整个软件的设计和开发过程,开发人员是最清楚应该怎么测试的,这包括单元测试,功能测试,性能测试,回归测试,以及 Soak Test 等。
开发人员知道怎么测试是最有效的。开发人员知道所有的 function point,知道 fix 一个 bug 后,哪些测试要做回归和验证,哪些不需要。开发人员的技术能力知道怎么才能更好的做测试。
很多开发人员只喜欢写代码,不喜欢做测试,或是他们说,开发人员应该关注于开发,而不是测试。这个思路相当的错误。开发人员最应该关注的是软件质量,需要证明自己的开发成果的质量。开发人员如果都不知道怎么做测试,这个开发人员就是一个不合格的开发人员。
另外,我始终不明白,为什么不做开发的 QA 会比 Dev 在测试上更专业? 这一点都说不通啊。”
闻道有先后,术业有专攻!
首先我对写下这段文字的Dev表示我的景仰,你能说出这番话说明你还是对软件测试、对软件质量、对Dev本身的测试还是有一定的了解和意识的。
但是,要知道软件测试也是一个系统的过程,和软件开发一样,他有一个长期的过程,开发人员通经系统、完善的培训或者可以成为一个优秀的测试人员,这个不虚假;但是术业有专攻,开发人员专攻的是开发,测试人员专攻的是测试(最最好是彼此都有一些了解)。开发人员要进行的测试是对基础功能的粗略测试,因为他有更重要的开发工作要去完成,做不到详细的完全测试;而测试人员一方面要详细的对基础功能进行测试,还要对很多很多的细支末节进行测试,尤其是平常经常使用的或可能会出现,但一般人很少想到的,在测试中我们称之为场景,测试人员要对各种可能出现的场景进行测试,往往这种测试是很烦琐的。
同时,专业的测试人员和专业的开发人员一样,都是要经常系统、完善的培训才能正式以一名合格的测试人员的身份上岗的,所以说,不能单纯的去怀疑Tester对测试的专业性……
“2)减少沟通,扯皮,和推诿
想想下面的这些情况你是否似曾相识?
QA 做的测试计划,测试案例设计,测试结果,总是需要 Dev 来评审和检查。(不是说测试需要依赖开发,这是本身的一个沟通、交流,是保证质量的一个流程需要,在CMMI\ISO中是有明文的规定的)
QA 在做测试的过程中,总是需要 Dev 对其测试的环境,配置,过程做指导。(这个是为了保证测试的正确性,要是因为配置不正确而导致误报,当如何?)
QA 总是会和 Dev 争吵某个问题是不是 BUG,争吵要不要解决。(是不是缺陷需要相互沟通,需要判断优先级,需要参考需求,需要领导定夺,而不是开发和测试的吵,凡事要有依据)
无论发现什么样的问题,总是 Dev 去解决,QA 从不 fix 问题。(Tester fix Bug?部分的缺陷是可以,如果他有开发的经验,但你会放心么?项目经理能放心么,术业有专攻)
我们总是能听到,线上发生问题的时候,Dev 的抱怨 QA 这样的问题居然没测出来(出现漏测,是双方的责任,不要想到推诿责任,这样的人不仅人品存在问题,连职业道德也值得重新审视)
QA 也总会抱怨 Dev 代码太差,一点也不懂测试,没怎么测就给 hand over 给 QA 了。(所以说开发要懂测试,提高交付质量,避免低级错误,但有偶尔有也是可以理解的,人非圣贤嘛)
QA 总是会 push Dev,这个 bug 再不 fix,你就影响我的进度了。(相互理解、支持)
等等,等等。
如果没有 QA,那么就没有这么多事了,DEV 自己的干出来的问题,自己处理,没什么好扯皮的。
而一方面,QA 说 Dev 不懂测试,另一方面 Dev 说 QA 不懂技术,而我们还要让他们隔离开来,各干各的,这一点都不利于把 Dev 和 QA 的代沟给填平了。要让 Dev 理解 QA,让 QA 理解 Dev,减少公说公有理,婆说婆有理的只站在自己立场上的沟通,只有一个方法,那就是让 Dev 来做测试,让 QA 来做开发。这样一样,大家都是程序员了。”
(扯皮,多么俗的字眼,当然不是说这种情况没有,但这种情况是不应该的,还是那句:相互的沟通、相互的理解、统一的目标很重要)
“3)吃自己的狗食
真的优秀的开发团队都是要吃自己狗食的。这句话的意思是——如果你不能切身体会到自己干的烂事,自己的痛苦,你就不会有想要去改进的动机。没有痛苦,就不会真正地去思考,没有真正的思考,就没有真正的进步。
在我现在的公司,程序员要干几乎有的事,从需求分析,设计,编码,集成,测试,部署,运维,OnCall,从头到尾,因为:
只有了解了测试的难度,你才明白怎么写出可测试的软件,怎么去做测试的自动化和测试系统。
只有自己真正去运维自己的系统,你才知道怎么在程序里写日志,做监控,做统计……
只有自己去使用自己的系统,你才明白用户的反馈,用户的想法,和用户的需求。
所以,真正的工程师是能真正明白软件开发不单单只是 coding,还更要明白整个软件工程。只明白或是只喜欢 coding 的,那只是码农,不能称之为工程师。”
这段的理解,说明文章作者对开发者自测还是有比较深的理解,比较重视的!
一个优秀的程序员,不,应该是工程师,要知道的、要做的还是很多的!
“关于 SDET。全称是 Software Development Engineer on Test。像微软,Google, Amazon 都有这样的职位。但我不知道这样的职位在微软和 Google 的比例是多少,在 Amazon 是非常少的。那么像这样的懂开发的专职测试可以有吗?我的答案是可以有!但是,我在想,如果一个人懂开发,为什么只让其专职做测试呢?这样的程序员分工合理吗?把程序分成两等公民有意义吗?试问有多少懂开发的程序员愿意只做测试开发呢?所以,SDET 在实际的操作中,更多的还是对开发不熟的测试人员。还是哪句话,不懂开发的人是做不好测试的。”
虽然我对上面的“不懂开发是做不好测试的”这句话表示同意,但反过来我是不能同意的,是存在需求(业务)测试工程师,也就是说他们不懂开发,但相当的精通业务、需求
只要是对工作、对最终的目标是合理的,那么怎样的工作都是需要人去完成的,所以不要认为做哪样工作就不怎么的,这个可以做为你奋斗的动力,但不能作为评价一个人的标准
“如果你说 Dev 对测试不专业,不细心,不认真,那么我们同样也无法保证 QA 的专业,细心和认真。在 Dev 上可能出现的问题,在 QA 也也会一样出现。而出了问题 QA 不会来加班解决,还是开发人员自己解决。所以,如果 QA 不用来解决问题,那么,QA 怎么可能真正的细心和认真呢?”
是的,都会出现问题,开发人员开发代码时会出现问题,所以需要测试;测试人员测试会出现问题,所以需要开发人加班加点解决问题;而往往两者都会出现问题
在这个问题上作者陷入了一个死循环中,记住“没有成功个人,只有成功的团队”
“如果你说不要 QA 的话,Dev 人手会不够。你这样想一下,如果把你团队中现有的 QA 全部变成 Dev,然后,大家一起开发,一起测试,亲密无间,沟通方便,你会不会觉得这样会更有效?你有没有发现,在重大问题上,Dev 可以帮上 QA 的忙,但是 QA 帮不上 Dev 的忙。”
首先肯定作者话,如果能从开发中转过来部分专业的测试人员,这样对于项目肯定是有帮助的,但我们仍然需要质量管理体系来管理,通过流程来保证我们的产品/项目质量
从文章作者的言语中可以看到他作为开发人员的优越性,而这种优越性容易造成的结果是:“我不应该来做这个事,我可以做更高级、更有难度的事”
有人说态度决定一切,虽然我不太赞成这句话,但我也明白一个人的能力重要,一个人的心态也很重要
最后,让一个优秀的开发人员做测试确实有些浪费,公司损失不起
“第三方中立,你会说人总是测不好自己写的东西,因为有思维定式。没错,我同意。但是如果是 Dev 交叉测试呢?你可能会说开发人员会有开发人员的思维定式。那这只能说明开发人员还不成熟,他们还不合格。没关系,只要吃自己的狗食,痛苦了,就会负责的。”
思维定式、个人习惯、自我保护意识是三个魔鬼
当然测试人员也有这三个魔鬼,所以测试负责人在安排测试时,一般会交叉测试,具体的涉及到测试策略的问题,就不在这里说了
越多的测试越能保证产品的质量,所以一般都会要求开发人员对自己的程序进行测试,会有代码评审,会有同行评审,其中的原因也就不言而喻
“磨刀不误砍柴功。如果你开发的东西自己在用,那么自己就是自己天然的 QA,如果有别的团队也在用你开发的模块,那么,别的团队也就很自然地在帮你做测试了,而且是最真实的测试。”
说的没有错,是测试,但是不完全的测试,对于质量我们追求的是质量的零缺陷,虽然那不可能实现,而实现的基础是专业、系统、完整的测试
“关于自动化测试。所谓自动化的意思是,这是一个机械的重复劳动,我想让测试人员思考一下,你是否在干这样的事?如果你正在干这样的事,那么,你要思考一下你的价值了。但凡是重复性比较高的机械性的劳动,总有一天都会被机器取代的。”
知道为什么人没有被机器人替代么?
因为人有无穷无尽的思想
“关于线上测试。我们都知道,无论自己内测的怎么样,到了用户那边,总是会有一些测试不到的东西。所以,有些公司会整出个 UAT,用户验收测试。做产品的公司会叫 Beta 测试。无论怎么样,你总是要上生产线做测试的。对于互联网企业来说,生产线上测试有的玩A/B测试,有的玩部分用户测试,比如,新上线的功能只有 10% 的用户可以访问得到,这样不会因为出问题让全部用户受到影响。做这种测试的人必然是开发人员。”
UAT是用户会要求进行的,如果不做接收测试,客户不满意你的项目,后期的款项如何收回?
Beta测试一方面是通过线上的真实情况,检查程序的功能、性能,同时也是对市场的试探、对用户的试探,观察市场、用户对产品的响应,为公司的后期决策做以参考。
写在结尾:
对于你的耐心,Tester Chen很感谢,成文时间仓促,如有不妥,希望留下你宝贵的意见、建议。
这篇
文章是以
MySQL 为背景,很多内容同时适用于其他关系型
数据库,需要有一些索引知识为基础。
优化目标
1、减少 IO 次数
IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当然,也是收效最明显的优化手段。
2、降低 CPU 计算
除了 IO 瓶颈之外,SQL优化中需要考虑的就是 CPU 运算量的优化了。order by, group by,distinct … 都是消耗 CPU 的大户(这些操作基本上都是 CPU 处理内存中的数据比较运算)。当我们的 IO 优化做到一定阶段之后,降低 CPU 计算也就成为了我们 SQL 优化的重要目标
优化方法
1、改变 SQL 执行计划
明确了优化目标之后,我们需要确定达到我们目标的方法。对于 SQL 语句来说,达到上述2个目标的方法其实只有一个,那就是改变 SQL 的执行计划,让他尽量“少走弯路”,尽量通过各种“捷径”来找到我们需要的数据,以达到 “减少 IO 次数” 和 “降低 CPU 计算” 的目标
常见误区
1、count(1)和count(primary_key) 优于 count(*)
很多人为了统计记录条数,就使用 count(1) 和 count(primary_key) 而不是 count(*) ,他们认为这样性能更好,其实这是一个误区。对于有些场景,这样做可能性能会更差,应为数据库对 count(*) 计数操作做了一些特别的优化。
2、count(column) 和 count(*) 是一样的
这个误区甚至在很多的资深工程师或者是 DBA 中都普遍存在,很多人都会认为这是理所当然的。实际上,count(column) 和 count(*) 是一个完全不一样的操作,所代表的意义也完全不一样。
count(column) 是表示结果集中有多少个column字段不为空的记录;
count(*) 是表示整个结果集有多少条记录;
3、select a,b from … 比 select a,b,c from … 可以让数据库访问更少的数据量
这个误区主要存在于大量的开发人员中,主要原因是对数据库的存储原理不是太了解。
实际上,大多数关系型数据库都是按照行(row)的方式存储,而数据存取操作都是以一个固定大小的IO单元(被称作 block 或者 page)为单位,一般为4KB,8KB… 大多数时候,每个IO单元中存储了多行,每行都是存储了该行的所有字段(lob等特殊类型字段除外)。
所以,我们是取一个字段还是多个字段,实际上数据库在表中需要访问的数据量其实是一样的。
当然,也有例外情况,那就是我们的这个查询在索引中就可以完成,也就是说当只取 a,b两个字段的时候,不需要回表,而c这个字段不在使用的索引中,需要回表取得其数据。在这样的情况下,二者的IO量会有较大差异。
4、order by 一定需要排序操作
我们知道索引数据实际上是有序的,如果我们的需要的数据和某个索引的顺序一致,而且我们的查询又通过这个索引来执行,那么数据库一般会省略排序操作,而直接将数据返回,因为数据库知道数据已经满足我们的排序需求了。
实际上,利用索引来优化有排序需求的 SQL,是一个非常重要的优化手段
5、执行计划中有 filesort 就会进行磁盘文件排序
有这个误区其实并不能怪我们,而是因为 MySQL 开发者在用词方面的问题。filesort 是我们在使用 explain 命令查看一条 SQL 的执行计划的时候可能会看到在 “Extra” 一列显示的信息。
实际上,只要一条 SQL 语句需要进行排序操作,都会显示“Using filesort”,这并不表示就会有文件排序操作。
其实,这篇短文,我早就应该写了。因为,
Java存储过程今后在各大
数据库厂商中越来越流行,功能也越来越强大。这里以
Oracle为例,介绍一下java存储过程的具体用法。
一、如何创建java存储过程?
通常有三种方法来创建java存储过程。
1、使用oracle的sql语句来创建:
e.g. 使用create or replace and compile java source named "<name>" as
后边跟上java源程序。要求类的方法必须是public static的,才能用于存储过程。
- SQL> create or replace and compile java source named "javademo1"
- 2 as
- 3 import java.sql.*;
- 4 public class JavaDemo1
- 5 {
- 6 public static void main(String[] argv)
- 7 {
- 8 System.out.println("hello, java demo1");
- 9 }
- 10 }
- 11 /
- Java 已创建。
- SQL> show errors java source "javademo1"
- 没有错误。
- SQL> create or replace procedure javademo1
- 2 as
- 3 language java name 'JavaDemo1.main(java.lang.String[])';
- 4 /
- 过程已创建。
- SQL> set serveroutput on
- SQL> call javademo1();
- 调用完成。
- SQL> call dbms_java.set_output(5000);
- 调用完成。
- SQL> call javademo1();
- hello, java demo1
- 调用完成。
- SQL> call javademo1();
- hello, java demo1
- 调用完成。
|
2、使用外部class文件来装载创建
e.g. 这里既然用到了外部文件,必然要将class文件放到oracle Server的某一目录下边。
- public class OracleJavaProc
- {
- public static void main(String[] argv)
- {
- System.out.println("It's a Java Oracle procedure.");
- }
- }
- SQL> grant create any directory to scott;
- 授权成功。
- SQL> conn scott/tiger@iihero.oracledb
- 已连接。
- SQL> create or replace directory test_dir as 'd:/oracle';
- 目录已创建。
- SQL> create or replace java class using bfile(test_dir, 'OracleJavaProc.CLASS')
- 2 /
- Java 已创建。
- SQL> create or replace procedure testjavaproc as language java name 'OracleJavaProc.main(java.lang.String[])';
- 2 /
- 过程已创建。
- SQL> call testjavaproc();
- 调用完成。
- SQL> execute testjavaproc;
- PL/SQL 过程已成功完成。
- SQL> set serveroutput on size 5000
- SQL> call dbms_java.set_output(5000);
- 调用完成。
- SQL> execute testjavaproc;
- It's a Java Oracle procedure.
3、我推荐的一种方法,直接使用loadjava命令远程装载并创建。
先创建一个类, e.g.
- import java.sql.*;
- import oracle.jdbc.*;
-
- public class OracleJavaProc {
-
- //Add a salgrade to the database.
- public static void addSalGrade(int grade, int losal, int hisal) {
-
- System.out.println("Creating new salgrade for EMPLOYEE...");
-
- try {
- Connection conn =
- DriverManager.getConnection("jdbc:default:connection:");
-
- String sql =
- "INSERT INTO salgrade " +
- "(GRADE,LOSAL,HISAL) " +
- "VALUES(?,?,?)";
- PreparedStatement pstmt = conn.prepareStatement(sql);
- pstmt.setInt(1,grade);
- pstmt.setInt(2,losal);
- pstmt.setInt(3,hisal);
- pstmt.executeUpdate();
- pstmt.close();
- }
- catch(SQLException e) {
- System.err.println("ERROR! Adding Salgrade: "
- + e.getMessage());
- }
- }
- }
|
使用loadjava命令将其装载到服务器端并编译:
- D:eclipse3.1workspacedbtest>loadjava -u scott/tiger@iihero.oracledb -v -resolve Or
- acleJavaProc.java
- arguments: '-u' 'scott/tiger@iihero.oracledb '-v' '-resolve' 'OracleJavaProc.java'
- creating : source OracleJavaProc
- loading : source OracleJavaProc
- resolving: source OracleJavaProc
|
查询一下状态:
- 连接到:
- Oracle9i Enterprise Edition Release 9.2.0.1.0 - Production
- With the Partitioning, OLAP and Oracle Data Mining options
- JServer Release 9.2.0.1.0 - Production
-
- SQL> SELECT object_name, object_type, status FROM user_objects WHERE object_type LIKE 'JAVA%';
-
- OBJECT_NAME
- --------------------------------------------------------------------------------
-
- OBJECT_TYPE STATUS
- ------------------------------------ --------------
- OracleJavaProc
- JAVA CLASS VALID
-
- OracleJavaProc
- JAVA SOURCE VALID
|
测试一下存储过程:
- SQL> create or replace procedure add_salgrade(id number, losal number, hisal num
- ber) as language java name 'OracleJavaProc.addSalGrade(int, int, int)';
- 2 /
-
- 过程已创建。
-
- SQL> set serveroutput on size 2000
- SQL> call dbms_java.set_output(2000);
-
- 调用完成。
-
- SQL> execute add_salgrade(6, 10000, 15000);
- Creating new salgrade for EMPLOYEE...
-
- PL/SQL 过程已成功完成。
-
- SQL> select * from salgrade where grade=6;
-
- GRADE LOSAL HISAL
- ---------- ---------- ----------
- 6 10000 15000
二、如何更新你已经编写的java存储过程?
假如要往类OracleJavaProc里添加一个存储过程方法,如何开发?
正确的步骤应该是先dropjava, 改程序,再loadjava。
e.g.修改OracleJavaProc类内容如下:
- import java.sql.*;
- import oracle.jdbc.*;
-
- public class OracleJavaProc {
-
- // Add a salgrade to the database.
- public static void addSalGrade(int grade, int losal, int hisal) {
-
- System.out.println("Creating new salgrade for EMPLOYEE...");
-
- try {
- Connection conn =
- DriverManager.getConnection("jdbc:default:connection:");
-
- String sql =
- "INSERT INTO salgrade " +
- "(GRADE,LOSAL,HISAL) " +
- "VALUES(?,?,?)";
- PreparedStatement pstmt = conn.prepareStatement(sql);
- pstmt.setInt(1,grade);
- pstmt.setInt(2,losal);
- pstmt.setInt(3,hisal);
- pstmt.executeUpdate();
- pstmt.close();
- }
- catch(SQLException e) {
- System.err.println("ERROR! Adding Salgrade: "
- + e.getMessage());
- }
- }
-
- public static int getHiSal(int grade)
- {
- try {
- Connection conn =
- DriverManager.getConnection("jdbc:default:connection:");
- String sql = "SELECT hisal FROM salgrade WHERE grade = ?";
- PreparedStatement pstmt = conn.prepareStatement(sql);pstmt.setInt(1, grade);
- ResultSet rset = pstmt.executeQuery();
- int res = 0;
- if (rset.next())
- {
- res = rset.getInt(1);
- }
- rset.close();
- return res;
- }
- catch (SQLException e)
- {
- System.err.println("ERROR! Querying Salgrade: "
- + e.getMessage());
- return -1;
- }
- }
-
- }
如何更新呢?
- D:eclipse3.1workspacedbtest>dropjava -u scott -v OracleJavaProc
-
- D:/tiger@iihero.oracledbeclipse3.1workspacedbtest>loadjava -u scott -v -resolve Or
- acleJavaProc/tiger@iihero.oracledb.java
- arguments: '-u' 'scott/tiger@iihero.oracledb' '-v' '-resolve' 'OracleJavaProc.java'
- creating : source OracleJavaProc
- loading : source OracleJavaProc
- resolving: source OracleJavaProc
|
后边的应用示例:
- SQL> create or replace function query_hisal(grade number) return number as langu
- age java name 'OracleJavaProc.getHiSal(int) return int';
- 2 /
-
- 函数已创建。
-
- SQL> set serveroutput on size 2000
- SQL> call dbms_java.set_output(2000);
-
- 调用完成。
- SQL> select query_hisal(5) from dual;
-
- QUERY_HISAL(5)
- --------------
- 9999
|
全文完!
用法个人见解:不要手动drop java source,不要手动drop procedure。
内部类:定义在类的内部的类
为什么需要内部类?
● 典型的情况是,内部类继承自某个类或实现某个接口,内部类的代码操作创建其的外围类的对象。所以你可以认为内部类提供了某种进入其外围类的窗口。
● java中的内部类和接口加在一起,可以实现多继承。
● 可以使某些编码根简洁。
● 隐藏你不想让别人知道的操作。
使用内部类最吸引人的原因是:
每个内部类都能独立地继承自一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。如果没有内部类提供的可以继 承多个具体的或抽象的类的能力,一些设计与编程问题就很难解决。从这个角度看,内部类使得多重继承的解决方案变得完整。接口解决了部分问题,而内部类有效 地实现了“多重继承”。
内部类分为: 成员内部类、静态嵌套类、方法内部类、匿名内部类。
特点:
一、内部类仍然是一个独立的类,在编译之后内部类会被编译成独立的.class文件,但是前面冠以外部类的类命和$符号。
二、内部类可以直接或利用引用访问外部类的属性和方法,包括私有属性和方法(但静态内部类不能访问外部类的非静态成员变量和方法)。内部类所访问的外部属性的值由构造时的外部类对象决定。
三、而外部类要访问内部类的成员,则只能通过引用的方式进行,可问内部类所有成员
四、访问机制:
- System.out.println(this.x);或System.out.println(x);//内部类访问内部类的成员变量或成员方法可用此方法。
- System.out.println(OuterClass.this.x);//内部类访问外部类的同名变量时可用此方法,如果没有同名可用System.out.println(x);
|
五、内部类可以使用任意的范围限定:public/private/protected class InnerClass,且严格按照这几种访问权限来控制内部类能使用的范围。普通类的范围限定只可以是public或者不加。
六、内部类的命名不允许与外部类 重名,内部类可以继承同级的内部类,也可继承其它类(除内部类和外部类)。
七、内部类可以定义为接口,并且可以定义另外一个类来实现它
八、内部类可以定义为抽象类,可以定义另外一个内部类继承它
九、内部类使用static修饰,自动升级为顶级类,外部类不可以用static修饰,用OuterClass.InnerClass inner=new OuterClass.InnerClass();创建实例。内部类还可定义为final.
十、内部类可以再定义内部类(基本不用)
十一、方法内的内部类:
方法内的内部类不能加范围限定(protected public private)
方法内的内部类不能加static修饰符
方法内的内部类只能在方法内构建其实例
方法内的内部类如果访问方法局部变量,则此局部变量必须使用final修饰
1)静态内部类(静态嵌套类)
从技术上讲,静态嵌套类不属于内部类。因为内部类与外部类共享一种特殊关系,更确切地说是对实例的共享关系。而静态嵌套类则没有上述关系。它只是位置在另一个类的内部,因此也被称为顶级嵌套类。
静态的含义是该内部类可以像其他静态成员一样,没有外部类对象时,也能够访问它。静态嵌套类不能访问外部类的成员和方法。
语法
- package com.tarena.day13;
-
- import com.tarena.day13.Foo.Koo;
- /**
- * 静态类内部语法演示
- */
- public class StaticInner {
- public static void main(String[] args) {
- Koo koo = new Koo();
- System.out.println(koo.add());//4
- }
-
- }
- class Foo{
- int a = 1;
- static int b = 3;
- /** 静态内部类,作用域类似于静态变量,属于类的 */
- static class Koo{
- public int add(){
- //a ,不能访问a
- return b+1;
- }
- }
- }
|
2)成员内部类
* 1 成员内部类必须利用外部类实例创建
* 2 成员内部类可以共享外部类的实例变量
- import com.tarena.day13.inn.Goo.Moo;
-
- public class InnerClassDemo {
- public static void main(String[] args) {
- //Moo moo = new Moo(); //编译错误,必须创建Goo的实例
- Goo goo = new Goo();
- Moo moo = goo.new Moo();//利用goo实例创建Moo实例
- Moo moo1 = goo.new Moo();
- //moo和moo1共享同一个goo实例的实例变量
- System.out.println(moo.add());//2
- System.out.println(moo1.add());//2
- Goo goo1 = new Goo();
- goo1.a = 8;
- Moo m1 = goo1.new Moo();
- Moo m2 = goo1.new Moo();
- System.out.println(m1.add());//9
- System.out.println(m2.add());//9
-
- }
- }
- class Goo{
- int a = 1;
- /**成员内部类*/
- class Moo{
- public int add(){
- return a+1;
- }
- }
- }
|
3)局部内部类(方法内部类)
(1)方法内部类只能在定义该内部类的方法内实例化,不可以在此方法外对其实例化。
(2)方法内部类对象不能使用该内部类所在方法的非final局部变量。
因为方法的局部变量位于栈上,只存在于该方法的生命期内。当一个方法结束,其栈结构被删除,局部变量成为历史。但是该方法结束之后,在方法内创 建的内部类对象可能仍然存在于堆中!例如,如果对它的引用被传递到其他某些代码,并存储在一个成员变量内。正因为不能保证局部变量的存活期和方法内部类对 象的一样长,所以内部类对象不能使用它们。用法
- package com.tarena.day13.inn;
-
- import java.util.Comparator;
-
- /**
- * 局部内部类
- */
- public class LocalInnerClassDemo {
- public static void main(String[] args) {
- int a = 5;
- final int b = 5;
- //局部内部类,定义在方法内部,作用域类似于局部变量
- //仅仅在方法内部可见
- //在局部内部类中可以访问方法中的局部final变量
- class Foo{
- public int add(){
- return b;//正确
- //return a;//编译错误
- }
- }
-
- Foo foo = new Foo();
- //临时的自定义比较规则
- class ByLength implements Comparator<String>{
- public int compare(String o1,String o2){
- return o1.length()-o2.length();
- }
- }
- }
-
- }
|
4)匿名内部类
顾名思义,没有名字的内部类。表面上看起来它们似乎有名字,实际那不是它们的名字。
匿名内部类就是没有名字的内部类。什么情况下需要使用匿名内部类?如果满足下面的一些条件,使用匿名内部类是比较合适的:
只用到类的一个实例。
● 类在定义后马上用到。
● 类非常小(SUN推荐是在4行代码以下)
● 给类命名并不会导致你的代码更容易被理解
在使用匿名内部类时,要记住以下几个原则:
● 匿名内部类不能有构造方法。
● 匿名内部类不能定义任何静态成员、方法和类。
● 匿名内部类不能是public,protected,private,static。
● 只能创建匿名内部类的一个实例。
● 一个匿名内部类一定是在new的后面,用其隐含实现一个接口或实现一个类。
● 因匿名内部类为局部内部类,所以局部内部类的所有限制都对其生效。
A、继承式的匿名内部类和接口式的匿名内部类。
- import java.util.Arrays;
- import java.util.Comparator;
-
- /**匿名内部类 语法*/
- public class AnnInnerClass {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- Yoo yoo = new Yoo();//创建Yoo的实例
- Yoo y1 = new Yoo(){};
- //new Yoo(){}创建匿名类实例
- //匿名类new Yoo(){}是继承Yoo类,并且同时创建了对象
- //new Yoo(){}是Yoo的子类型,其中{}是类体(class Body)
- //类体中可以定义任何类内的语法,如:属性,方法,方法重载,方法覆盖,等
- //子类型没有名字,所以叫匿名类!
- Yoo y2 = new Yoo(){
- public String toString(){//方法重写(覆盖)
- return "y2"; //y2是子类的实例
- }
- };
- System.out.println(y2);//"y2",调用了匿名类对象toString()
- //匿名内部类可以继承/实现 于 类,抽象类,接口等
- //按照继承的语法,子类型必须实现所有的抽象方法
-
- //Xoo x = new Xoo(){};//编译错误,没有实现方法
- final int b = 5;
- Xoo xoo = new Xoo(){ //是实现接口,并且创建匿名类实例,不是创建接口对象
- public int add(int a){//实现接口中的抽象方法
- return a+b; //要访问局部变量b,只能访问final变量
- }
- };
- System.out.println(xoo.add(5));//10,调用对象的方法
- //Comparator接口也可以使用匿名类的方式
- Comparator<String> byLength = new Comparator<String>(){
- public int compare(String o1,String o2){
- return o1.length()-o2.length();
-
- }
- };
- String[] names = {"Andy","Tom","Jerry"};
- Arrays.sort(names,byLength);
- System.out.println(Arrays.toString(names));
- //也可以这样写,工作中常用
- Arrays.sort(names,new Comparator<String>(){
- public int compare(String o1,String o2){
- return o1.length()-o2.length();
- }
- });
- }
-
- }
接口式的匿名内部类是实现了一个接口的匿名类。而且只能实现一个接口。
B. 参数式的匿名内部类。
- class Bar{
- void doStuff(Foo f){
- }
- }
- interface Foo{
- void foo();
- }
- class Test{
- static void go(){
- Bar b = new Bar();
- b.doStuff(new Foo(){
- public void foo(){
- System.out.println("foofy");
- }
- });
- }
- }
|
构造内部类对象的方法有:
1、内部类在自己所处的外部类的静态方法内构建对象或在另一个类里构造对象时应用如下形式:
(1)
- OuterClass out = new OuterClass();
- OuterClass.InnerClass in = out.new InnerClass();
|
(2)
| OuterClass.InnerClass in=new OuterClass().new InnerClass(); |
其中OuterClass是外部类,InnerClass是内部类。
2、内部类在它所在的外部类的非静态方法里或定义为外部类的成员变量时,则可用以下方式来构造对象:
| InnerClass in = new InnerClass(); |
3、如果内部类为静态类,则可用如下形式来构造函数:
| OuterClass.InnerClass in = new OuterClass.InnerClass(); |
无需再利用外部类的对象来来构造内部类对象,如果静态内部类需要在静态方法或其它类中构造对象就必须用上面的方式来初始化。
引子
按照原定计划,今天开始研究 JMeter,一天的时间看完了大半的 User Manual,发现原来只要沉住气,学习效率还是蛮高的,而且大堆的英文文档也没有那么可怕。
本来想顺便把文档翻译一下,不过后来想了想,看懂是一回事,全部翻译出来又是另外一回事了,工作量太大,而且这也不是我一开始要研究 JMeter 的本意。不如大家有兴趣一起研究的遇到问题再一起讨论吧。
开源工具通常都是为了某个特定的目的而开发出来的,所以如果想找到一个开源的性能测试工具去与LoadRunner 或者 QALoad 之类去比较,实在有些勉强。但是开源工具也有它自己的优势:小巧、轻便,在自己擅长的领域可以提供优秀的解决方案。所以,我们可以考虑准备一个自己的“开 源测试工具箱”,平时利用空闲时间了解各种工具所适用的环境和目的,知识慢慢积累下来以后,就可以在遇到问题时顺手拈来,轻松化解。
另外,如果8月份和9月份的空闲时间足够多,我想我会写一个系列文章来讲述在实际的开发和测试过程中引入开源性能测试工具的情况。如果有朋友感兴趣,希望大家可以一起研究和讨论。
简介
ab的全称是ApacheBench,是 Apache 附带的一个小工具,专门用于 HTTP Server 的benchmark testing,可以同时模拟多个并发请求。前段时间看到公司的开发人员也在用它作一些测试,看起来也不错,很简单,也很容易使用。
通过下面的一个简单的例子和注释,相信大家可以更容易理解这个工具的使用。
一个简单的例子
在这个例子的一开始,我执行了这样一个命令 ab -n 10 -c 10 http://www.google.com/
这个命令的意思是启动 ab ,模拟10个用户(-n 10)同时访问 www.google.com ,并迭代10次(-c 10)。跟着下面的是 ab 输出的测试报告,红色部分是我添加的注释。
/*在这个例子的一开始,我执行了这样一个命令ab -n 10 -c 10http://www.google.com/。这个命令的意思是启动 ab ,向www.google.com发送10个请求(-n 10) ,并每次发送10个请求(-c 10)——也就是说一次都发过去了。跟着下面的是 ab 输出的测试报告,红色部分是我添加的注释。*/ C:\Program Files\Apache Software Foundation\Apache2.2\bin>ab -n 10 -c 10 http://www.google.com/ This is ApacheBench, Version 2.0.40-dev <$Revision: 1.146 $> apache-2.0 Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Copyright 1997-2005 The Apache Software Foundation, http://www.apache.org/ Benchmarking www.google.com (be patient).....done Server Software: GWS/2.1 Server Hostname: www.google.com Server Port: 80 Document Path: / Document Length: 230 bytes Concurrency Level: 10 /*整个测试持续的时间*/ Time taken for tests: 3.234651 seconds /*完成的请求数量*/ Complete requests: 10 /*失败的请求数量*/ Failed requests: 0 Write errors: 0 Non-2xx responses: 10 Keep-Alive requests: 10 /*整个场景中的网络传输量*/ Total transferred: 6020 bytes /*整个场景中的HTML内容传输量*/ HTML transferred: 2300 bytes /*大家最关心的指标之一,相当于 LR 中的每秒事务数,后面括号中的 mean 表示这是一个平均值*/ Requests per second: 3.09 [#/sec] (mean) /*大家最关心的指标之二,相当于 LR 中的平均事务响应时间,后面括号中的 mean 表示这是一个平均值*/ Time per request: 3234.651 [ms] (mean) /*这个还不知道是什么意思,有知道的朋友请留言,谢谢 ^_^ */ Time per request: 323.465 [ms] (mean, across all concurrent requests) /*平均每秒网络上的流量,可以帮助排除是否存在网络流量过大导致响应时间延长的问题*/ Transfer rate: 1.55 [Kbytes/sec] received /*网络上消耗的时间的分解,各项数据的具体算法还不是很清楚*/ Connection Times (ms) min mean[+/-sd] median max Connect: 20 318 926.1 30 2954 Processing: 40 2160 1462.0 3034 3154 Waiting: 40 2160 1462.0 3034 3154 Total: 60 2479 1276.4 3064 3184 /*下面的内容为整个场景中所有请求的响应情况。在场景中每个请求都有一个响应时间,其中 50% 的用户响应时间小于 3064 毫秒,60 % 的用户响应时间小于 3094 毫秒,最大的响应时间小于 3184 毫秒*/ Percentage of the requests served within a certain time (ms) 50% 3064 66% 3094 75% 3124 80% 3154 90% 3184 95% 3184 98% 3184 99% 3184 100% 3184 (longest request) |
在这个例子的一开始,我执行了这样一个命令 ab -n 10 -c 10http://www.google.com/
这个命令的意思是启动 ab ,模拟10个用户(-n 10)同时访问www.google.com,并迭代10次(-c 10)。跟着下面的是 ab 输出的测试报告,红色部分是我添加的注释。
更多信息 ab 不像 LR 那么强大,但是它足够轻便,如果只是在开发过程中想检查一下某个模块的响应情况,或者做一些场景比较简单的测试,ab 还是一个不错的选择——至少不用花费很多时间去学习 LR 那些复杂的功能,就更别说那 License 的价格了。
下面是 ab 的详细参数解释。
ab [ -A auth-username:password ] [ -c concurrency ] [ -C cookie-name=value ] [ -d ] [ -e csv-file ] [ -g gnuplot-file ] [ -h ] [ -H custom-header ] [ -i ] [ -k ] [ -n requests ] [ -p POST-file ] [ -P proxy-auth-username:password ] [ -q ] [ -s ] [ -S ] [ -t timelimit ] [ -T content-type ] [ -v verbosity] [ -V ] [ -w ] [ -x <table>-attributes ] [ -X proxy[:port] ] [ -y <tr>-attributes ] [ -z <td>-attributes ] [http://]hostname[:port]/path
-A auth-username:password
Supply BASIC Authentication credentials to the server. The username and password are separated by a single : and sent on the wire base64 encoded. The string is sent regardless of whether the server needs it (i.e., has sent an 401 authentication needed).
-c concurrency
Number of multiple requests to perform at a time. Default is one request at a time.
-C cookie-name=value
Add a Cookie: line to the request. The argument is typically in the form of a name=value pair. This field is repeatable.
-d
Do not display the "percentage served within XX [ms] table". (legacy support).
-e csv-file
Write a Comma separated value (CSV) file which contains for each percentage (from 1% to 100%) the time (in milliseconds) it took to serve that percentage of the requests. This is usually more useful than the 'gnuplot' file; as the results are already 'binned'.
-g gnuplot-file
Write all measured values out as a 'gnuplot' or TSV (Tab separate values) file. This file can easily be imported into packages like Gnuplot, IDL, Mathematica, Igor or even Excel. The labels are on the first line of the file.
-h
Display usage information.
-H custom-header
Append extra headers to the request. The argument is typically in the form of a valid header line, containing a colon-separated field-value pair (i.e., "Accept-Encoding: zip/zop;8bit").
-i
Do HEAD requests instead of GET.
-k
Enable the HTTP KeepAlive feature, i.e., perform multiple requests within one HTTP session. Default is no KeepAlive.
-n requests
Number of requests to perform for the benchmarking session. The default is to just perform a single request which usually leads to non-representative benchmarking results.
-p POST-file
File containing data to POST.
-P proxy-auth-username:password
Supply BASIC Authentication credentials to a proxy en-route. The username and password are separated by a single : and sent on the wire base64 encoded. The string is sent regardless of whether the proxy needs it (i.e., has sent an 407 proxy authentication needed).
-q
When processing more than 150 requests, ab outputs a progress count on stderr every 10% or 100 requests or so. The -q flag will suppress these messages.
-s
When compiled in
1
搭建良好的测试环境是执行测试用例的前提,也是完成测试任务顺利完成的保证。测试环境大体可分为硬件环境和软件环境,硬件环境包括测试必须的PC机,服务器,设备,网线,分配器等硬件设备;软件环境包括数据库,操作系统,被测试软件,共存软件等;特殊条件下还要考虑网络环境,比如网络带宽,IP地址设置等。
搭建测试环境前后要注意以下几点:
1> 搭建测试环境前,确定测试目的
即是功能测试,稳定性测试,还是性能测试, 测试目的不同,搭建测试环境时应注意的点也不同。比如要进行功能测试,那么我们就不需要大量的数据,需要覆盖率高,测试数据要求尽量真实,这对硬件环境配 置的好坏要求不是太苛刻,为提高覆盖率,就要配置不同的硬件环境。如要进行性能测试,就需要大量的数据,测试数据应尽可能的达到符合实际的数据分配,这时 可能需要大量的设备来给测试对象施加压力,要提前准备大量设备。
2> 测试环境时尽可能的模拟真实环境
这个要求对测试人员要求很高,因为很多测试人员没有去过用户使用现场,要完全模拟用户使用环境根本不可能。这时我们就应该通过技术支持人员,销售人员了 解,尽可能的模拟用户使用环境,选用合适的操作系统和软件平台,了解符合测试软件运行的最低要求及用户使用的硬件配置,了解用户常用的软件,避免所有配置 所有操作系统下都要进行测试,没有侧重点,浪费时间。这样一方面,可以在测试执行过程中发生软件产品与其他协同工作产 品之间的兼容性,避免软件发布给用户之后才发现的问题;另一方面也可以用来检验产品是不是用户真正需要的。多说情况下,测试环境都是真空环境,完全纯净的 平台,测试时,没有问题,一旦拿到现场,与其它软件并存,硬件配置等原因,问题多多,这个就是搭建测试环境时没有考虑用户的使用环境。
3> 确保无毒环境
我测试过几个项目都是因为搭建的测试环境感染病毒,导致测试软件经常出现莫名的崩溃,运行不起来等现象,导致测试中断。这是杀毒是必要的,但是杀毒的时 间也应掌握好,具体可按照下列步骤:选择PC机-à安装操作系统—>安装杀毒软件杀毒—>安装驱动程序及用户常用软件及浏览器à杀毒à安装测 试软件—>杀毒,安装测试软件后杀毒,要注意如果我们不是使用正版杀毒软件,很可能我们安装的测试软件的一些文件被当做可疑文件或者病毒被清除,导 致测试软件直接不可用。要确保杀毒软件正版,如果不是正版,建议在安装测试软件前,卸载掉杀毒软件。测试过程中,要注意U盘的使用以及测试环境与外网的控 制。每次使用U盘前,要在其它机器上先杀毒;当测试环境与外网联通时,不建议使用共享方式互访测试机。当小范围PC机与外界隔离起来做测试环境时,可以禁 掉可移动存储设备的使用,只允许一台PC使用,这台PC机上安装杀毒软件,进行资料传送时,先拷贝到这台机器上杀毒,然后以共享的方式进行资料的传送。经 过这些措施可以很好的防止病毒感染测试环境,确保无毒环境。
4> 营造独立的测试环境
测试过程中要确保我们的测试环境独立,避免测试环境被占用,影响测试进度及测试结果,比如设备连网后,是不是其他测试组也在共用,这样就可能影响我们的 测试结果。有时开发人员为确定问题会使用我们的测试环境,这样会打乱我们的测试活动,更严重的是影响测试进度。为避免这种情况,测试人员在提交缺陷单时, 提供详细的复现步骤以及尽可能多的信息。让开发人员根据缺陷单,在开发环境中复现和定位问题。
5> 构建可复用的测试环境
当我们刚搭建好测试环境,安装测试软件之前及测试过程中,对操作系统及测试环境进行备份是必要的,这样一来可以为我们下轮测试时直接恢复测试环境,避免 重新搭建测试环境花费时间,二来在当测试环境遭到破坏时,可以恢复测试环境,避免测试数据丢失,重现问题。构建可“复用”的测试环境,往往要用到如 ghost、Drive Image等磁盘备份工具软件;这些工具软件,主要实现对磁盘文件的备份和还原功能;在应用这些工具软件之前,我们首先要做好以下几件十分必要的准备工 作:
A、确保所使用的磁盘备份工具软件本身的质量可靠性,建议使用正版软件;
B、利用有效的正版杀毒软件检测要备份的磁盘,保证测试环境中没有病毒
C、对于在测试过程中备份时,为减少镜像文件的体积,要删除掉Temp文件夹下的所有文件,要删除掉Win386.swp文件或_RESTORE文件夹,这样C盘就不至于过分膨胀,选择采用压缩方式进行镜像文件的创建,可使要备份的数据量大大减小;
D、最后,再进行一次彻底的磁盘碎片整理,将C盘调整到最优状态。
对于刚安装的操作系统,驱动程序等安装完成之后,测试程序安装之前,也要进行备份工作,这样可以防止不同项目交叉进行时,当使用相同操作系统时,直接恢复即可。
完成了这些准备工作,我们就可以用备份工具逐个逐个的来创建各种组合类型的软件测试环 境的磁盘镜像文件了。对已经创建好的各种镜像文件,要将它们设成系统、隐含、只读属性,这样一方面可以防止意外删除、感染病毒;另一方面可以避免在对磁盘 进行碎片整理时,频繁移动镜像文件的位置,从而可节约整理磁盘的时间;同时还要记录好每个镜像文件的适用范围,所备份的文件的信息等内容。
测试环境的搭建和维护处在重要的位置,它的好坏直接影响测试结果的真实性和准确性。维护测试环境需要大量的精力,不是一个人能完成的,需要我们大家积极配合。
成功的软件产品是建立在成功的需求基础之上的,而高质量的需求来源于用户与开发人员之间有效的沟通与合作。当用户有一个问题可以用计算机系统来解决,而开发人员开始帮助用户解决这个问题,沟通就开始了。
需求获取可能是软件开发中 最困难、最关键、最易出错及最需要沟通交流的活动。对需求的获取往往有错误的认识:用户知道需求是什么,我们所要做的就是和他们交谈从他们那里得到需求, 只要问用户系统的目标特征,什么是要完成的,什么样的系统能适合商业需要就可以了,但是实际上需求获取并不是想象的这样简单,这条沟通之路布满了荆棘。首 先需求获取要定义问题范围,系统的边界往往是很难明确的,用户不了解技术实现的细节,这样造成了系统目标的混淆。
其次是对问题的理解,用户对计算机系统的能力和限制缺乏了解,任何一个系统都会有很多的用户或者不同类型的用户,每个用户只知道自己需要的系统,而不知道系统的整体情况,他们不知道系统作为一个整体怎么样工作效 率更好,也不太清楚那些工作可以交给软件完成,他们不清楚需求是什么,或者说如何以一种精确的方式来描述需求,他们需要开发人员的协助和指导,但是用户与 开发人员之间的交流很容易出现障碍,忽略了那些被认为是“很明确的信息。最后是需求的确认,因为需求的不稳定性往往随着时间的推移产生变动,使之难以确 认。为了克服以上的问题,必须有组织的执行需求的获取活动。
需求获取活动建议要完成的11个任务或者说步骤分别是确定需求过程、编写项 目视图和范围文档、用户群分类、选择用户代表、选择用户代表、建立核心队伍、确定使用实例、召开联合会议、分析用户工作流程、确定质量属性、检查问题报告 和需求重用。当然应该根据组织和项目的具体情况进行适当的裁减,比如根据项目和用户情况把需求获取会议改成问卷调查或者座谈等等。
1、编写项目视图和范围文档
系统的需求包括四个不同的层次:业务需求、用户需求和功能需求、非功能性需求。业务需求说明了提供给用户新系统的最初利益,反映了组织机构或用户对系 统、产品高层次的目标要求,它们在项目视图与范围文档中予以说明。用户需求文档描述了用户使用产品必须要完成的任务,这在使用实例文档或方案脚本说明中予 以说明。功能需求定义了开发人员必须实现的软件功能,使得用户能完成他们的任务,从而满足了业务需求。
非功能性需求是用户对系统良好运 作提出的期望,包括了易用性、反应速度、容错性、健壮性等等质量属性。需求获取就是根据系统业务需求去获得系统用户需求,然后通过需求分析得到系统的功能 需求和非功能需求。项目视图和范围文档就是从高层次上描述系统的业务需求,应该包括高层的产品业务目标,评估问题解决方案的商业和技术可行性,所有的使用 实例和功能需求都必须遵从的标准。而范围文档定义了项目产品所包括的所有工作及产生产品所用的过程。项目相关人员对项目的目标和范围能达成共识,整个项目 组都应该把注意力集中在项目目标和范围上。
2、用户群分类
系统用户在很多方面存 在着差异,例如:使用系统的频度和程度、应用领域和计算机系统知识、所使用的系统特性、所进行的业务过程、访问权限、地理上的布局以及个人的素质和喜好等 等。根据这些差异,你可以把这些不同的用户分成不同的用户类。与UML中Usecase的Actor概念一样,用户类不一定都指人,也可以包括其他应用系 统、接口或者硬件,这样做使得与系统边界外的接口也成为系统需求。将用户群分类并归纳各自特点,并详细描述出它们的个性特点及任务状况,将有助于需求的获 取和系统设计。
3、选择用户代表
不可能对所有的用户都进行需求获取,这样做时间 不允许效果也不一定好,所以要识别出能够确定需求和了解业务流程的用户作为每类用户的代表。每类用户至少选择一位能真正代表他们需求的人作为代表并且能够 作出决策,用户代表往往是本类用户中三类人:对项目有决定权的领导、熟悉业务流程的专家、系统最终用户。
每一个用户代表者代表了一个特定的用户类,并在那个用户类和开发者之间充当主要的接口,用户代表从他们所代表的用户类中收集需求信息,同时每个用户代表又负责协调他们所代表的用户在需求表达上的不一致性和不兼容性。
4、建立核心队伍
通常用户和开发人员不自觉的都有一种”我们和他们“的想法,产生一种对立关系,把彼此放在对立面,每一方都定义自己的”边界“,只想自己的利益而忽略对 方的想法。他们通过文档、记录和对话来沟通,而不是作为一个合作的整体去识别和确定需求完成任务。实践证明这样的方法是不正确的,不会给双方带来一点益 处,良好的沟通关系没有建立导致了误解和忽略重要的信息。只有当双方参与者都明白要成功自己需要什么,同时也知道要成功对方需要什么时,才能建立起一种合 作关系。
为了建立合作关系通常采取一种组队的方式来获取需求,建立一个由用户代表和开发人员组成的联合小组作为需求获取的核心队伍。联 合小组将负责识别需求、分析解决方案和协商分歧,小组成员可以采用会议、电子邮件、综合办公系统等方式进行交流,但交流时应注意以下原则:小组会议应该由 中立方来组织和主持,用户和开发人员都要参加;交流预先要确定准备和参与的规则;议题要明确并覆盖所有关键点,但信息来源应该自由;交流目标要明确,并告 知所有的成员。
5、确定使用实例
从用户代表处收集他们将使用系统完成所需任务的 描述,讨论用户与系统间的交互方式和对话要求,这就是使用实例,一个单一的使用实例可能包括完成某项任务的许多逻辑相关任务和交互顺序。使用实例方法给需 求获取带来的好处来自于该方法是用以任务为中心和以用户为中心的观点,比起使用以功能为中心和以开发者为中心的方法,使用实例方法可以使用户更清楚地理解 和认识到新系统允许他们做什么和怎么做。描写使用实例的时候要注意使用简洁直白的表述,尽量使用主动语态,”系统“或者”用户“作为主语,比如”用户提交 用户密码,系统验证用户密码是否正确“,还有一点在描述中不要设计界面细节,比如”用户从下拉框中选择产品类型“。使用实例为以后写用例场景描述中的基本 路径和扩展路径提供了素材。
6、召开联合会议
最常见的需求获取方法是召开会议或者面谈,联合会议是范围广的、简便的讨论会,也是核心队伍成员之间一种很好的沟通方法,该会议通过紧密而集中 的讨论得以将用户代表与开发人员间的合作伙伴关系付诸于实践并能由此拟出需求文档的底稿。联合会议的第一个议题就是系统的必要性和合理性,必须所有成员都 同意系统是必要的而且合理的。接下来就可以讨论使用实例清单,清单可以打印成大纸挂在墙上、写在黑板上或做成演示材料。对每个清单合并去掉重复项,加上补 充内容就可以得到一份总的清单,注意避免采用负面的”太差“”不可行“去否定用户的想法,这些想法都应该保留下来作为被评议的清单项,这样保护了小组成员 开放的思维。最后对清单进行讨论,会议成员必须检查每一个使用实例,在把它们纳入需求之前决定其是否在项目所定义的范围内,形成最终的需求报告。
在进行讨论时,也应该避免受不成熟的细节的影响,在对系统需求取得共识之前,用户能很容易地在一个报表或对话框中列出某些精确设计,如果这些细 节都作为需求记录下来,他们会给随后的设计过程带来不必要的限制,应确保用户参与者将注意力集中在与所讨论的话题适合的抽象层上,重点就是讨论做什么而不 是怎么做。这里有一点很重要就是要让用户理解对于某些功能的讨论并不意味着即将在系统中实现它,更不要做暗示或者承诺什么时候完成需求。在讨论之后,记下 所讨论的条目,并请参与讨论的用户评论并更正,因为只有提供需求的人才能确定是否真正获取需求。当最后拿到了一份详细准确的需求报告书的时候,会议就算成 功完成了。但是要清楚需求过程本身就是一个迭代的过程,在以后的过程活动中不可避免的将要修改和完善这份报告。
7、分析用户工作流程
分析用户工作流程观察用户执行业务任务的过程,通过分析使用实例得到系统的用例图。编制用例图文档将有助于明确系统的使用实例和功能需求,统一 建模语言的使用有助于与用户进一步交流。每个用例的描述应包括:编号,为每个用例分配一个唯一的编号,为需求的追溯提供了方便;参与者,与这个用例交互的 actor;前置条件,开始用例前所必须具备的系统状态;后置条件,用例完成后系统达到的状态;基本路径,用例完成的关键路径,也是用户期望的路径;扩展 点,基本路径的分枝,表示意外情况;字段说明,路径中名称的进一步分解说明,对以后类属性的定义和数据库字段设计起作用;设计约束,实现用例的非功能约 束。写基本路径时应该使用主动语句;句子以actor或者系统作为主语;一句表示一个actor动作,一句表示系统动作,交叉表现交互;不要涉及界面细 节,比如“用户在文本框输入名称,下拉框选择类型”。
| |
| 编号 | UC1 |
| 参与者 | 用户 |
| 前置条件 | 用户访问系统,系统运行正常 |
| 后置条件 | 系统记录用户注册信息 |
| 基本路径 | 1. 用户请求注册。
2. 系统显示注册界面。
3. 用户提交注册信息。
4. 系统验证注册信息是否正确。
5. 系统生成用户名和密码,保存注册信息。
6. 系统显示"注册成功"信息,进入会员页面。 |
| 扩展点 | 4a. 用户提供的信息不正确: 4a1. 系统提示输入正确信息 4a2. 返回3 |
| 补充说明 | 注册信息包括=用户实名+电话+传真+Email+联系地址联系地址=省份+城市+街道+邮编 |
| 设计约束 | 注册反应时间不能超过3秒 |
8、确定质量属性
在功能需求之外再考虑一下非功能的质量特点,以及确定由于特殊的商业应用环境对系统提出的功能或性能上的约束,这会 使你的产品达到并超过客户的期望。对系统如何能很好地执行某些行为或让用户采取某一措施的陈述就是质量属性,这是一种非功能需求。听取那些描述合理特性的 意见:快捷、简易、直觉性、用户友好、健壮性、可靠性、安全性和高效性。你将要和用户一起商讨精确定义他们模糊的和主观言辞的真正含义,并且要将质量属性 分配到每个用例的设计约束中去。
9、检查问题报告
通过检查当前已经运行系统的问题报告来进一步完善需求客户的问题报告及补充需求为新系统或新版本提供了大量丰富的改进及增加特性的想法,负责提供用户支持及帮助的人能为收集需求过程提供极有价值的信息。
10、需求重用
如果客户要求的功能与已有的系统很相似,则可查看需求是否有足够的灵活性以允许重用一些已有的软件组件。业务建模和领域建模式需求重用的最好方法,像分析模式和设计模式一样,需求也有自己的模式。