1. 在HP的官方网站上下载LoadRunner9.5 的Linux安装程序[T7177-15009.iso],安装文档[hp_man_LRIG9.50_01_pdf.pdf];
安装程序包括Hp、Ibm、Linux、Solaris系统的支持(LR9.0对应安装文件为[TLRNUX900WC_00.zip])。
2. 安装包的处理:
1. ZIP解压:unzip TLRNUX900WC_00.zip
2. 挂载ISO:mkdir /mnt/LoadRunner ; mount -t iso9660 -o loop T7177-15009.iso /mnt/LoadRunner
3. 开始安装,以LR9.5为例:
/mnt/LoadRunner/Linux/installer.sh
按提示操作,直接Next到完成。
4. 添加用户和环境变量:
useradd -g 0 -s /bin/csh higkoo
cat /opt/HP/HP_LoadGenerator/env.csh > /etc/.login
cat /opt/HP/HP_LoadGenerator/env.csh >~higkoo/.cshrc
touch ~root/.rhosts ~higkoo/.rhosts
5. 检查运行环境(在本机或使用VNC执行):
su - higkoo
cd /opt/HP/HP_LoadGenerator/bin/
./verify_generator
6. 启动服务(用新增的用户higkoo):
cd /opt/HP/HP_LoadGenerator/bin/
./m_daemon_setup start
7. 检查是否启动:
ps aux | grep m_agent_daemon
netstat -naop | grep 54345
8. 注意事项:
开启端口54345或关闭防火墙(service iptables stop)
正确设置后用verify_generator的检测结果是:
| ./verify_generator =================================================== HP Vuser Environment Verification Utility =================================================== Product: HP LoadRunner 9.50 Version: 09.50.0000 Build: 3378 higkoolincn100ce5: verify_generator...OK verify_generator...OK verify_generator...OK Don't forget to make sure that the name of the controller machine is also in .rhosts verify_generator...OK verify_generator...OK verify_generator...OK verify_generator...OK verify_generator...OK verify_generator...OK verify_generator...OK _______________________________________________ Summary: ________ Vuser Host higkoolincn100ce5: OK |
使用Controller连接,在“UNIX Environment Tab”下选择“Don't use RSH ”即可连接Linux负载机。

若使用RSH连接,则负载机必须安装RSH并正确配置,正如检测过程中描述的“Don't forget to make sure that the name of the controller machine”。
补充,Linux下似乎只支持Web/Http协议的脚本。譬如WinSock协议,从名称上都知道只适合Windows:
“Error (-81024): LR_VUG: The 'WinSock' type is not supported on 'LINUX' platforms .”
另外试了Java协议,确实不行,报错如下:
Error (-81024): LR_VUG: The 'General-Java' type is not supported on 'LINUX' platforms .
依赖库:yum -y --disablerepo=\* --enablerepo=AutoInstaller --nogpgcheck --skip-broken localinstall /mnt/CentOS_Final/CentOS/compat-libstdc++-33-3.2.3-61.i386.rpm
否则会报:m_agent_daemon: error while loading shared libraries: libstdc++.so.5: cannot open shared object file: No such file or directory
注意hosts文件的配置,如果机器名和hosts里配置不一致也会导致LoadRunner启动失败,
譬如:Error: Communication error: Failed to get the server host IP by calling the gethostbyname function.。
附上给LoadRunner定制的系统服务脚本(/etc/init.d/loadrunner):
#!/bin/bash # /etc/init.d/loadrunner# Loadrunner负载生成器服务DAEMON=m_daemon_setupARGV="$@"DIR=/opt/HP/HP_LoadGenerator/bin/USER=higkooUBIT="su - $USER -c "
$UBIT "cd $DIR && ./$DAEMON $ARGV" 运行服务:
service loadrunner start
m_agent_daemon ( 1808 ),
1、目的
缺陷记录是软件测试生命周期中最重要的可用产出之一。因此,怎么填写有效的缺陷是非常重要的。一般来说,一条好的缺陷记录至少有以下3个方面的积极作用。
(1)减少测试人员和开发人员的沟通成本。
(2)加快缺陷修复的速度。
(3)增加测试的可信度。
缺陷记录的最终目的是准确地传达测试人员的思想或缺陷的真正所在。只要遵循本规范中的一些简单原则,我们就可以轻松的填好每一条缺陷记录,从而提高工作效率。
2、适用范围
3、填写缺陷规范
3.1 缺陷概要规范
缺陷概要需以简洁的语言表述准确的信息。那么能准确表达意义的缩略语在描述中则具有更高的优先级,一些关键词如“程序崩溃”、“系统无反应”和“文字错误”等,在把缺陷概要作为检索条件的时候,显得非常必要。
3.2 缺陷描述规范
缺陷描述需要遵循以下7个要点:精练、正确、中立、准确、普遍性、可再现和有证据。
3.2.1 精练
缺陷记录的描述需简单明了。不加入与问题无关的叙述,去除不必要的信息。但同时,要涵盖所有必要的信息。
3.2.2 正确
一定要清楚你所记录的缺陷的确存在。在提交前,请先考虑如下5个问题:
(1)我对系统需求是否真正理解?
(2)是否安装和系统相关的软件?我的机器设置有没有问题?
(3)是不是我手动设置的某个地方不合适(被测软件本身的设置)?
(4)是不是我以前测试时遗留的错误数据导致的错误?
(5)会不会是网络状况变化引起的问题?或者其它外在环境因素(如防火墙)引起的错误?
以上这些都对测试的结果有很大的影响,确认这些问题是否存在。
3.2.3 中立
客观地描述每一个缺陷,不要带任何情绪化的语言。在提交一个缺陷记录前首先把它通读一遍,确信你的描述没有伤害到任何人员。
3.2.4 准确
缺陷记录需要准确的描述缺陷发生的位置,产生条件和结果。最好做到让阅读缺陷记录者不需要亲自上机操作就知道问题所在。
例子 | 缺陷描述 |
不准确的描述 | 查询中按项目来源查询发生错误。 |
准确的描述 | 科技项目计划下达中,在查询页面按“项目来源”字段的“资金”查询条件进行查询时,查询结果显示出了属于“资金”和“结转”的项目,应只显示出属于“资金”的项目。 |
3.2.5 普遍性
记录缺陷需要明确的描述出该问题在整个系统中普遍存在的地方。通常,当开发人员修改缺陷的时候,他可能只是修复了你提到的一些特定情况,他并不知道这个问题具有普遍性,尚需更大范围的修复。
3.2.6 可再现 原则上所提交的缺陷都应该能够重现。对很难重现的Bug,你应该记录下什么情况下可以再现它,列出再现Bug的所有步骤,执行次序以及所需要的数据等。
如果你无法再现这个Bug,或者是你怀疑某些条件你还没有想到,你应尽可能的把那些认为可能有用的信息描述清楚。
一个缺陷在你重现它以前,不要假设它是可以重现的,如果你确实无法重现它,在缺陷记录中明确说明也是很重要的。
在考虑对缺陷的重现时我们应该注意以下3点:
(1)怎样才能以最简单的方式把缺陷重现。对于难重现的缺陷,这常常是个漫长而费时的过程。
(2)是否有外在的原因在测试中导致了该缺陷。例如是否和其它软件相冲突的情况。
(3)如果在测试中要输入很多值,尽量在大量的输入中找出导致缺陷的那些特定值,并准确地写出那些导致缺陷的输入。
3.2.7 证据
对于一些数值型的、暂时不能重现的和难以描述的缺陷等,最好提供可以证明它存在的数据、图片和文挡等证据。对记录的缺陷,就应该确信这里的确存 在缺陷并提供所有你能提供的证据,说服别人这里确实存在缺陷。这些证据可能来自于系统数据、现场截图以及需求文挡等。当然这也有利于关闭缺陷和做回归测试 的时候重现该缺陷。
3.3 缺陷属性规范
缺陷属性需要根据不同的软件项目定制不同的属性值。
必须的属性值有:DefectID、Subject、Status、Severity、AssignedTo、Summary、DetectedBy、DetectedonDate、DetectedinVersion和Detectedphase。
3.4 缺陷填写建议
在填写一条缺陷记录的时候,提醒你参考以下2点建议:
(1)在提交一条缺陷前,需检查缺陷库中是否已经存在此缺陷。力求避免重复提交。
(2)对于一些难以理解的、自己还有些模糊的和对缺陷的正确性难以肯定的问题,在记录你的缺陷以前,就需要和有经验的测试人员或开发人员进行讨论。
4、缺陷等级分类与示例
4.1 概述
测试当中发现的缺陷,严重程度划分为三级:High(高)、Medium(中)和Low(低)。在《软件系统测试规程》中已对这三个级别进行了 定义性描述,High等级是指功能不能使用或在使用中出现的问题影响了系统的稳定性、造成数据存储错误或将错误数据带入下一环节、一些重要特性或性能不能 达到指定的要求等。Medium等级是指功能可以使用、在出错后做出一定处理,操作能够继续进行或功能实现有误,但问题的出现应不影响本功能或其他功能的 实质性使用。Low等级是指用户界面显示、对齐、文字错误等。
本文结合实际工作情况,对已发现的大量缺陷数据进行归纳,对缺陷的各个等级进行分类,并在每个分类中列举比较典型的例子。以后测试人员在设定缺 陷严重等级时将据此进行参考,使缺陷严重等级的定位更加规范统一,同时也使测试人员和开发人员对缺陷等级的定位更容易达成一致。本次分类重点关注系统业务 功能在正常操作下可能出现的问题,而有意识地降低了边界值测试发现的缺陷和非正常操作下发现缺陷的等级。
我们主要考虑High等级和Medium等级的情况。因为Low等级的缺陷主要指界面上的显示、对齐、文字错误等,在这里就不再详细列出。
4.2 High等级的分类与示例
(1)关键数据错误。
例:
(a)统计报表中的项目数量和资金统计不正确。
(b)巡视工作任务中,将缺陷记录中的缺陷上报生产,在缺陷登记模块中可看到3条一样的数据。
(c)物资采购数为10,现场和仓库可分别到货10件。
(2)所有功能在正常操作下报错(如500或404等)。
例:
(a)打开计划下达审批页面,系统报500。
(b)点击查询按钮,系统报404。
(3)主要功能在正常操作下没有实现。
例:新增、保存、删除、发送、回退、撤回、导出和查询等操作不成功。
(4)主要功能在正常操作下结果不正确。
例:
(a)检查不通过的项目可以上报成功。
(b)选择全部项目发送,只发走部分。
(c)导出功能,导出的文件格式错乱、内容跟列名不对应,以及内容不正确等。
(d)在多个入库单同时上报时,将入库仓库为观澜仓库的入库单上报给水贝仓库的管理员审批。
(e)在新增两票录入记录时,在新增页面点击一次保存操作就会新增一条记录。
(f)PDA中,缺陷表象的信息错误了,严重等级也没有下下来;设备信息中,有些字段没有下下来。比如“安装日期”、“厂家”、“电压等级”等等。
(5)主要功能存在性能问题。
例:
(a)分发多个项目时,系统响应很慢,如分发30个项目,系统1分钟还没处理完。
(b)单据过帐时,系统出现白屏,显示时间超过10秒。(系统响应时间应符合需求规格说明书的要求,不同系统的响应时间的要求可能不一致。)
(6)系统管理权限错乱,对系统安全造成威胁的。
例:
(a)没有授权用户菜单,但用户登录系统后,能通过该菜单进入相关模块,并对模块的数据进行操作。
(b)未授权的用户可以进行厂家配额。
(c)在角色管理中取消了新增功能位置的权限按钮,在设备台账中变电设施、中心站、设备下还有新增下一级功能位置按钮。
(7)系统业务逻辑关系处理不正确,引起主要功能错误。 例:
(a)项目验收后,已验收状态的项目在待下达库中可被获取继续下达。
(b)生成操作票中,对于已审核通过的操作票,还可以增加操作步骤,应该是不能再编辑操作步骤的。
(c)抢修领料在审批过程中可以上报。
(d)领料退库时,导入的领料单列表中即有现场到货单也有现场领料单,造成同一物资多次退库的现象。
4.3 Medium等级的分类与示例
(1)非主要功能在正常操作下没有实现。
例:
(a)查询页面有某些查询条件查不出相应的数据。
(b)巡视项目定义中,当只有2条巡视内容时,上下移动巡视内容操作不成功。
(c)在单据中物资明细没有超链接。
(2)非主要功能在正常操作下结果不正确。
例:
(a)标题排序不正确。
(b)新增主变压器并修改其技术参数高压额定容量值之后,该设备的上级变电站页面中主变压器总容量的值没有修改。
(3)非主要功能存在性能问题。
例:物资系统中上传附件速度很慢,1M的文件需要30秒以上。
(4)所有功能进行边界值测试,系统报错的。
例:
(a)大文本框输满,保存报500。
(b)资金输入最大值,保存报500。
(c)上传大型文件,系统老处于上传状态。
(d)选中大量项目导出,导出不正确。
(5)模块中的信息显示不正确,起误导用户作用。
例:
(a)资金单位显示不对。
(b)新增推荐单位后,列表中显示的“关联类型”与新增时的输入不一致。
(c)在单据的物资明细列表中将物资明细显示为项目名称。
(d)停电计划查询中的导出字段中,“停电原因”应该是“停电终止原因”。
(6)关键提示不正确,起误导用户作用。
例:
(a)实际操作成功却提示操作失败。
(b)智能操作票系统中,在状态检查时,提示的不合法设备名称不正确。
(c)操作票中,导入操作步骤成功了,但是提示却为不成功。
(7)非主要模块的权限控制不正确。
例:
(a)合同管理的授权给相关人员后,相关人员看不到相应的数据。
(b)领料单在材料员审批时不能填写领料原因。
(8)系统业务逻辑关系处理不正确,引起非主要功错误。
例:项目归档后,在项目申请的已上报页面和申请书的查询页面还能看到该项目。
4.4 Low等级的分类与示例
(1)页面和记录定位。
例:变更申请选中列表中的第2条项目新增变更,新增完返回时系统自动定位到列表中的第一条项目。
(2)用户界面显示、对齐、文字错误等。
例:
(a)页面太小没有将内容显示完整,只要把页面调大即可。
(b)系统将“帐号”显示成“账号”。
(3)报javascript错误,但能操作成功。
(4)用户几乎不太可能进行的操作,导致系统报错。
4.5 填写缺陷时的注意事项
(1)同类型的缺陷只录一条。例如项目审批模块的发送不成功,其他审批模块也有同样的问题,只录一条缺陷就可以,因为都属于工作流的问题。
(2)同一模块的页面显示有几个问题,也只录一条缺陷,并在缺陷的描述里列出各个问题。因为都是同一模块页面显示的问题,放在一起,开发人员可一次将问题改全。
(3)测试中要经常查看同组测试员填写的缺陷,及时了解已存在的缺陷,如有补充可在注释里填写。
(4)查看同组测试员填写的缺陷时,注意其他人对缺陷严重等级的定义,保持同组人员对严重等级定位的一致性。
存储过程的功能非常强大,在某种程度上甚至可以替代业务逻辑层,接下来就一个小例子来说明,用存储过程插入或更新语句。
1、数据库表结构
所用数据库为Sql Server2008。
2、创建存储过程
(1)实现功能:
有相同的数据,直接返回(返回值:0);
有主键相同,但是数据不同的数据,进行更新处理(返回值:2);
没有数据,进行插入数据处理(返回值:1)。
根据不同的情况设置存储过程的返回值,调用存储过程的时候,根据不同的返回值,进行相关的处理。
(2)下面编码只是实现的基本的功能,具体的Sql代码如下:
- Create proc sp_Insert_Student
- @No char(10),
- @Name varchar(20),
- @Sex char(2),
- @Age int,
- @rtn int output
- as
- declare
- @tmpName varchar(20),
- @tmpSex char(2),
- @tmpAge int
-
- if exists(select * from Student where No=@No)
- begin
- select @tmpName=Name,@tmpSex=Sex,@tmpAge=Age from Student where No=@No
- if ((@tmpName=@Name) and (@tmpSex=@Sex) and (@tmpAge=@Age))
- begin
- set @rtn=0 --有相同的数据,直接返回值
- end
- else
- begin
- update Student set Name=@Name,Sex=@Sex,Age=@Age where No=@No
- set @rtn=2 --有主键相同的数据,进行更新处理
- end
- end
- else
- begin
- insert into Student values(@No,@Name,@Sex,@Age)
- set @rtn=1 --没有相同的数据,进行插入处理
- end
|
3、调用存储过程
这里在Sql Server环境中简单的实现了调用,在程序中调用也很方便。
具体的代码如下:
- declare @rtn int
- exec sp_Insert_Student '1101','张三','男',23,@rtn output
- if @rtn=0
- print '已经存在相同的。'
- else if @rtn=1
- print '插入成功。'
- else
- print '更新成功'
|
一个存储过程就实现了3中情况,而且效率很高,使用灵活。希望对大家有所帮助。
在成长学习的过程中,我会不断发一些自己的心得体会,和大家共享。
http://yp.oss.org.cn/software/show_resource.php?resource_id=406
http://www.ltesting.net/ceshi/open/kygncsgj/selenium/2012/0207/204032.html
http://blog.163.com/florazhang800@126/blog/static/210707272008119111818988/
如果你是那种极不情愿写文档的程序员,那么,你并不孤单。然而当你的上司在检查你的
工作时,他才不想看你那一堆一堆的代码,他需要看文档,这时的你需要的是Concordion——一个符合Specification By Example的
自动化测试框架,通过自然语言来描述软件功能,即项目中所有成员都能看懂的而又具备测试功能的html文档。
(一)Concordion的工作原理
简单的说,Concordion测试只是对JUnit的扩展,但是它可以从你写好的测试文档(html)中读取测试数据,通过传统的JUnit来跑测试,并将测试结果输出为具有红绿标记(表示失败或成功)的html文档(基于原测试文档)。

在上图中,Specification即为我们写的html测试文档,与普通的html文档不同的是,我们需要在其中加入一些名为concordion 的标签,浏览器将忽略这些标签,但Concordion用这些标签来执行测试指令,比如调用Fixture中的测试函数等。Fixture为继承自 ConcordionTestCase(最终继承自JUnit测试类)的测试用例,这些测试用例将调用我们自己所开发的功能代码。
(二)Concordion的Hello World
下面就通过一个简单的Hello World例子来演示Concordion。
下载Concordion和其所依赖的包。
首先写一个html测试用例HelloWorld.html:
<html xmlns:concordion=http://www.concordion.org/2007/concordion>
<body>
<p>Should print:</p>
<p concordion:assertEquals="sayHello()">HelloWorld</p>
</body>
</html> |
此html文档可以通过浏览器正常打开,由于浏览器并不知道concordion标签,故将其忽略:
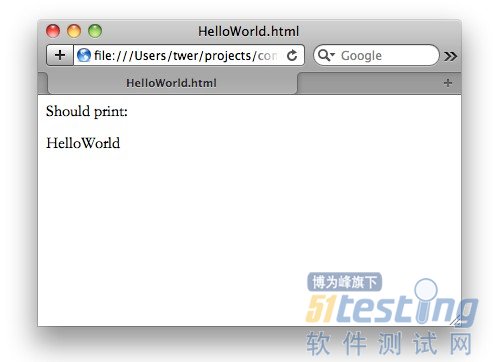
可以看到,以上加入的concordion标签的html测试文档和普通的html文档并无区别,同时我们也看到在concordion标签后有一个 sayHello()函数调用,此函数从什么地方来呢——这就是Concordion的约定,要求在该html文档的同目录下有一个名为 HelloWorldTest.java的测试用例类存在,并且该类有一个测试函数名为sayHello()。约定规则为:如果html文档名为 Foo.html,那么测试用例类应该为FooTest.java。此时Concordion便通过名字匹配去找名为HelloWorldTest类的 sayHello()函数并调用之。
我们还注意到,在concordion标签后有assertEquals,此时Concordion将把helloWorld()函数的输出与之后的“HelloWorld”字符串相比,如果相等,测试成功,否则失败。
接下来实现HelloWorldTest类,在HelloWorld.html同目下创建HelloWorldTest.java文件:
package com.thoughtworks.davenkin.concordion;
import org.concordion.integration.junit3.ConcordionTestCase;
public class HelloWorldTest extends ConcordionTestCase {
public String sayHello()
{
return new HelloWorld().sayHelloWorld();
}
}
在HelloWorldTest.java文件中实例化了一个HelloWorld对象,并调用其sayHelloWorld()方法,于是写一个需要测试的HelloWorld类如下:
| package com.thoughtworks.davenkin.concordion; public class HelloWorld
{
public String sayHelloWorld()
{
return "HelloWorld";
}
} |
最终生成的工程目录结构如下:
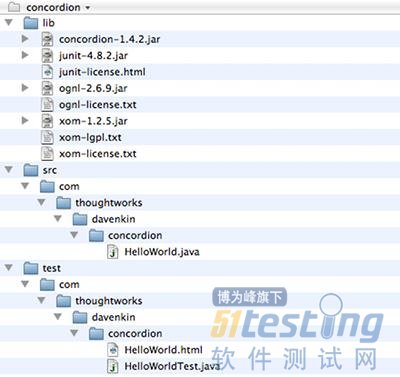
(三)编译并运行测试
打开终端,将目录切换到 concordion(这是笔者为此helloworld创建的工程根目录,请不要与上文提到的concordion混淆)下,编译:
| javac -cp lib/*:src:test test/com/thoughtworks/davenkin/concordion/HelloWorldTest.java |
用JUnit运行测试:
| java -cp lib/*:src:test org.junit.runner.JUnitCore com.thoughtworks.davenkin.concordion.HelloWorldTest |
运行结果如下:
| JUnit version 4.8.2
./var/folders/wM/wMUC8-0FEsq-MMkTzdzYA++++TI/-Tmp-/concordion/com/thoughtworks/davenkin/concordion/HelloWorld.html
Successes: 1, Failures: 0 Time: 0.307 OK (1 test) |
运行成功,并且显示测试输出的html文件的全路径名称(此时应该去掉最前面的那个点"."):
| /var/folders/wM/wMUC8-0FEsq-MMkTzdzYA++++TI/-Tmp-/concordion/com/thoughtworks/davenkin/concordion/HelloWorld.html |
打开该文件:
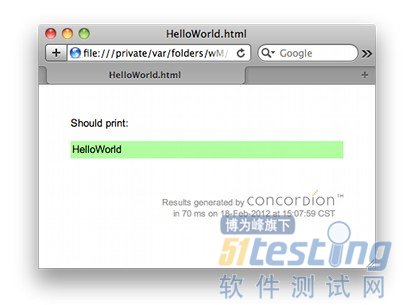
测试运行成功。
http://mirrors.163.com/centos/6.2/isos/i386/
Java查询一次性查询几十万,几百万数据解决办法。
很早的时候写工具用的一个办法,当时是用来把百万数据打包成rar文件。
所以用了个笨办法。 希望高手指导一下,有什么好方法没有啊。
1、先批量查出所有数据,例子中是一万条一批。
2、在查出数据之后把每次的数据按一定规则存入本地文件。
3、获取数据时,通过批次读取,获得大批量数据。
以下是查询数据库。按批次查询
- public static void getMonthDataList() {
- ResultSet rs = null;
- Statement stat = null;
- Connection conn = null;
- List<DataBean> list = new ArrayList<DataBean>();
- try {
- conn = createConnection();
- if(conn!=null){
- SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
- SimpleDateFormat timesdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- String nowDate = sdf.format(new Date());
- Config.lasttimetext = timesdf.format(new Date());
- String lastDate = sdf.format(CreateData.addDaysForDate(new Date(), 30));
- stat = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_UPDATABLE);
- int lastrow = 0;
- int datanum = 0;
- String countsql = "SELECT count(a.id) FROM trip_special_flight a" +
- " where a.dpt_date >= to_date('"+nowDate+"','yyyy-mm-dd') " +
- "and a.dpt_date <= to_date('"+lastDate+"','yyyy-mm-dd') and rownum>"+lastrow+" order by a.get_time desc";
- rs = stat.executeQuery(countsql);
- while (rs.next()) {
- datanum = rs.getInt(1);
- }
- int onerun = 10000;
- int runnum = datanum%onerun==0?(datanum/onerun):(datanum/onerun)+1;
- for(int r =0;r<runnum;r++){
- System.out.println("getMonthDataList--"+datanum+" 开始查询第"+(r+1)+"批数据");
- String sql = "SELECT * FROM (SELECT rownum rn, a.dpt_code, a.arr_code,a.dpt_date,a.airways,a.flight," +
- "a.cabin,a.price FROM trip_special_flight a" +
- " where a.dpt_date >= to_date('"+nowDate+"','yyyy-mm-dd') " +
- "and a.dpt_date <= to_date('"+lastDate+"','yyyy-mm-dd') order by rownum asc) WHERE rn > "+lastrow;
- stat.setMaxRows(onerun);
- stat.setFetchSize(1000);
- rs = stat.executeQuery(sql);
- String text = "";
- int i = 1;
- while (rs.next()) {
- text += rs.getString(2)+"|"+rs.getString(3)+"|"+rs.getDate(4)+"|"+rs.getString(5)+"|"+rs.getString(6)+"|"+rs.getString(7)+"|"+rs.getString(8)+"||";
- if(i%1000==0){
- FileUtil.appendToFile(Config.tempdatafile, text);
- text = "";
- }
- i++;
- }
- if(text.length()>10){
- FileUtil.appendToFile(Config.tempdatafile, text);
- }
- lastrow+=onerun;
- }
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- closeAll(rs, stat, conn);
- }
- }
-----java一次性查询几十万,几百万数据解决办法
存入临时文件之后,再用读取大量数据文件方法。
设置缓存大小BUFFER_SIZE ,Config.tempdatafile是文件地址。
- package com.yjf.util;
- import java.io.File;
- import java.io.RandomAccessFile;
- import java.nio.MappedByteBuffer;
- import java.nio.channels.FileChannel;
-
- public class Test {
- public static void main(String[] args) throws Exception {
- final int BUFFER_SIZE = 0x300000; // 缓冲区为3M
- File f = new File(Config.tempdatafile);
- // 来源博客http://yijianfengvip.blog.163.com/blog/static/175273432201191354043148/
- int len = 0;
- Long start = System.currentTimeMillis();
- for (int z = 8; z >0; z--) {
- MappedByteBuffer inputBuffer = new RandomAccessFile(f, "r")
- .getChannel().map(FileChannel.MapMode.READ_ONLY,
- f.length() * (z-1) / 8, f.length() * 1 / 8);
- byte[] dst = new byte[BUFFER_SIZE];// 每次读出3M的内容
- for (int offset = 0; offset < inputBuffer.capacity(); offset += BUFFER_SIZE) {
- if (inputBuffer.capacity() - offset >= BUFFER_SIZE) {
- for (int i = 0; i < BUFFER_SIZE; i++)
- dst[i] = inputBuffer.get(offset + i);
- } else {
- for (int i = 0; i < inputBuffer.capacity() - offset; i++)
- dst[i] = inputBuffer.get(offset + i);
- }
- int length = (inputBuffer.capacity() % BUFFER_SIZE == 0) ? BUFFER_SIZE
- : inputBuffer.capacity() % BUFFER_SIZE;
- len += new String(dst, 0, length).length();
- System.out.println(new String(dst, 0, length).length()+"-"+(z-1)+"-"+(8-z+1));
- }
- }
- System.out.println(len);
- long end = System.currentTimeMillis();
- System.out.println("读取文件文件花费:" + (end - start) + "毫秒");
- }
-
- }
|
读取大量数据文件方法。
首先,请原谅我用了一个很土,很有争议的标题。小弟才思枯竭,实在想不出来什么文雅的了,抱歉~~
前言
换了东家后,从一个死忠C# Fans摇身一变,客串了一把Java程序员,可能是受老赵的《Why Java Sucks》系列博文影响太大,刚开始那几天有很大的抵触情绪,后来想想,何不乘此机会深入了解一下Java。
扮演Java程序员两个月以来,受到的折磨比较多,由于以前习惯了微软的饭来张口,衣来伸手的策略,咋角色一转变还真有点不适应,什么都得自己动手。虽然Java社区开源项目无数,框架一大把,但可能是选择太多就更迷茫,还是有点不适应。
我想写《Java中有些好的特性》这个系列文章,主要是抱着从一个C#程序员的角度,向Java学习的态度,决没有任何吵架的意思。汲取精华,去其糟粕嘛,呵呵。当然,这个系列是不是写的下去,要看看我是否真的碰到了我觉得Java比C#好的地方,碰到了一个我就会记录一篇~~
静态导入
优点
前言就说到这儿,现在进入今儿这篇文章的正题:静态导入(static import)。
先看下面这段示例代码:
1: public class SayHelloTest{
2: @Test
3: public void should_say_hello_when_given_your_name(){
4: gotoPage("hello");
5:
6: input("name","yuyijq");
7:
8: click("sayButton");
9:
10: assertThat(helloPage.getLabel(),is("hello yuyijq"));
11: }
12: } |
这是一段典型的功能测试代码。对于功能测试来说,关键的就是要模拟用户场景,而不涉及技术细节,用领域的语言来表达出测试。上面的测试用很清晰的步骤表达出了测试的意图,要注意的是这里的gotoPage,input,click以及assertThat方法都不是SayHelloTest类的实例方法,都是定义在别的类甚至是第三方框架中的静态方法。通过Java的静态导入特性,使得现在代码的可读性更高:
| 1: import static com.cnblogs.yuyijq.functionalTest.gotoPage; |
弊端
通过静态导入,我们可以去掉类名的前缀,这样就可以将代码写得更自然,更像是在描述一件事儿。但静态导入也并不是没有缺点。在软件开发中,很多特性适当的使用都很好,但是一旦使用过度就有可能变成坏事,这就是那个名言:不要拿着锤子,就把啥都当钉子。请看下面的代码:
1: map.get(MOST_VIEWED.toString());
2: map.get(LAST_VIEWED.toString());
3: map.get(IS_LAST_ARTICLE.toString());
4: map.get(IS_SHOW_PICTURE.toString());
5: //....下面有类似代码若干行 |
咋一看还以为这些MOST_VIEWED什么的全部是常量,但最后发现这些都是枚举PortalOptions里的项,都是通过静态导入导进来的。但由于没了PortalOptions这个具有说明信息的枚举名作为前缀,丢失了很多信息,造成这段代码不是很容易看懂,不知道map.get出来的到底是什么。代码虽然短了很多,但是如果加上PortalOptions,那么就能很直观的直到我们需要从这个map里获得PortalOptions相关的东东。
在C#里画瓢
好的东西是要学习的,那我们如何在C#里照样画个瓢呢。可惜C#目前还不支持这种静态导入,我也没想到什么好法子能画这个瓢。在C#里不要类名或实例名这个前缀,那除非这个方法是本类的方法,但我们肯定不可能为了使用这样的东东,就给每个类添加这些方法,不过C#里有一个扩展方法特性,我们看看是不是能用扩展方法来画这个瓢:
1: public static class UnitTestExtensions
2: {
3: public static T mock<T>(this object o,Type mockType)
4: {
5: return (T)NMock.Mock(mockType);
6: }
7:
11:
12:
13: } |
由于我们是给object类扩展的方法,所以在所有的类中都可以像是自己的方法一样使用,也就可以写下下面这样的代码了:
1: public class SayHelloControllerTest
2: {
3: [Test]
4: public void should_load_user_when_given_username()
5: {
6: User user = new UserBuilder()
7: .withUserName("yuyijq")
8: .withAge(80)
9: .withSex(male)
10: .build();
11: UserDAO userDAO = mock(typeof(UserDAO));
12: when(userDAO.findByUserName("yuyijq")).thenReturn(user);
13: replay(userDAO);
14: SayHelloController controller = new SayHelloController(userDAO);
15: verify(userDAO);
16: ModelAndView mv = controller.show("yuyijq");
17:
18: assertModelAttribute(mv,"user",user);
19: }
20: } |
不过给object添加扩展方法实在不是一个好主意,污染太大了。目前也没有想出更好的办法,所以就此作罢~~
后语
静态导入就记叙到这里,两个月以来我还是对Java的语法嗤之以鼻,不过对Java社区对开源的采纳程度却是由衷的感叹。
附加说明
我在这里没有任何意思表明Java好于C#,只是我在使用Java过程中发现的一些挺好的地方。这些地方能让我写出我自己觉得更好的代码,而且在我心里C#远超过Java的
地方多得多,这是毋庸置疑的。
Java核心技术卷I里有一个结论我觉得挺有意思的:java中没有引用传递,只有值传递
首先看定义:
值传递,是指方法接收的是调用者提供的值
引用传递,是指方法接收的是调用者提供的变量地址
以前学习C++时把参数传递分为值传递和引用传递,国内的不少java教材愿意把对象的传递理解是引用传递,为什么它们会这么说呢?可以看下面一个例子:
- import java.util.Calendar;
- public class ChangeValue {
- public static void main(String[] args) {
- Calendar oc = Calendar.getInstance();
- System.out.println("origin:"+oc.getTime());
- changeDate(oc);
- System.out.println("after:"+oc.getTime());
- }
-
- static void changeDate(Calendar pd){
- pd.set(1970, 1, 1);
- }
- }
|
某时刻程序输出:
origin:Thu Jan 05 21:15:59 CST 2012
after:Sun Feb 01 21:15:59 CST 1970 |
oc对象的值改变了,很多人就认为java对象传递实际上是引用传递。
过程应该是这样的:
运行changeDate这个函数时,方法得到的是对象引用的拷贝,oc和pd同时引用同一个对象,所以函数运行结束后,pd已经消失了,但是对引用对象的更改却也影响了oc所引用的同一对象,结合对之前的定义理解,这应该是值传递的过程(传递的是对象引用的拷贝)。
以下附上另一个例子,两个对象的交换函数(C++中可以轻易实现):
- public class Swap {
- public static void main(String[] args) {
- ObjectSample o1 = new ObjectSample("hello");
- ObjectSample o2 = new ObjectSample("你好");
- System.out.println("before swap o1:"+o1.getTitle()+" o2:"+o2.getTitle());
- Swap.swapObject(o1, o2);
- System.out.println("after swap o1:"+o1.getTitle()+" o2:"+o2.getTitle());
- }
- static void swapObject(ObjectSample o1, ObjectSample o2){
- ObjectSample temp = new ObjectSample("temp");
- temp = o1;
- o1 = o2;
- o2 = temp;
- }
- }
- class ObjectSample{
- private String title;
-
- ObjectSample(String title){
- this.title = title;
- }
-
- public String getTitle(){
- return title;
- }
- }
|
输出结果:
before swap o1:hello o2:你好
after swap o1:hello o2:你好 |
Java在交换程序中并没有交换两个对象的值,交换的是两个对象的拷贝,不能实现让对象参数引用一个新对象,究其原因还是因为Java是采用了值传递而非引用传递。
还有不少和以前自己接触的观点不一样的地方,当然需要借鉴的吸收并且经过自己的实践来辨别。