数据类型
Java虚拟机中,数据类型可以分为两类:基本类型和引用类型。基本类型的变量保存原始值,即:他代表的值就是数值本身;而引用类型的变量保存引用值。“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。
基本类型包括:byte,short,int,long,char,float,double,Boolean,returnAddress
引用类型包括:类类型,接口类型和数组。
堆与栈
堆和栈是程序运行的关键,很有必要把他们的关系说清楚。
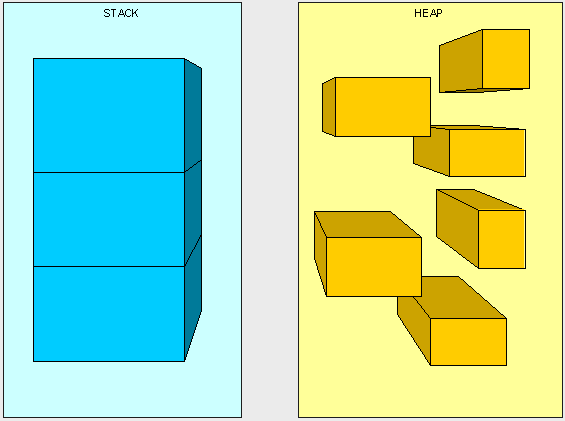
栈是运行时的单位,而堆是存储的单位。
栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
在Java中一个线程就会相应有一个线程栈与之对应,这点很容易理解,因为不同的线程执行逻辑有所不同,因此需要一个独立的线程栈。而堆则是所有线程共享的。栈因为是运行单位,因此里面存储的信息都是跟当前线程(或程序)相关信息的。包括局部变量、程序运行状态、方法返回值等等;而堆只负责存储对象信息。
为什么要把堆和栈区分出来呢?栈中不是也可以存储数据吗?
第一,从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。
第二,堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。
第三,栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。
第四,面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在堆中;而对象的行为(方法),就是运行逻辑,放在栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。不得不承认,面向对象的设计,确实很美。
在Java中,Main函数就是栈的起始点,也是程序的起始点。
程序要运行总是有一个起点的。同C语言一样,java中的Main就是那个起点。无论什么java程序,找到main就找到了程序执行的入口:)
堆中存什么?栈中存什么?
堆中存的是对象。栈中存的是基本数据类型和堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在栈中,一个对象只对应了一个4btye的引用(堆栈分离的好处:))。
为什么不把基本类型放堆中呢?因为其占用的空间一般是1~8个字节——需要空间比较少,而且因为是基本类型,所以不会出现动态增长的情况——长度固定,因此栈中存储就够了,如果把他存在堆中是没有什么意义的(还会浪费空间,后面说明)。可以这么说,基本类型和对象的引用都是存放在栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是栈中的数据一个是堆中的数据。最常见的一个问题就是,Java中参数传递时的问题。
Java中的参数传递时传值呢?还是传引用?
要说明这个问题,先要明确两点:
1、不要试图与C进行类比,Java中没有指针的概念
2、程序运行永远都是在栈中进行的,因而参数传递时,只存在传递基本类型和对象引用的问题。不会直接传对象本身。
明确以上两点后。Java在方法调用传递参数时,因为没有指针,所以它都是进行传值调用(这点可以参考C的传值调用)。因此,很多书里面都说Java是进行传值调用,这点没有问题,而且也简化的C中复杂性。
但是传引用的错觉是如何造成的呢?在运行栈中,基本类型和引用的处理是一样的,都是传值,所以,如果是传引用的方法调用,也同时可以理解为“传引用值”的传值调用,即引用的处理跟基本类型是完全一样的。但是当进入被调用方法时,被传递的这个引用的值,被程序解释(或者查找)到堆中的对象,这个时候才对应到真正的对象。如果此时进行修改,修改的是引用对应的对象,而不是引用本身,即:修改的是堆中的数据。所以这个修改是可以保持的了。
对象,从某种意义上说,是由基本类型组成的。可以把一个对象看作为一棵树,对象的属性如果还是对象,则还是一颗树(即非叶子节点),基本类型则为树的叶子节点。程序参数传递时,被传递的值本身都是不能进行修改的,但是,如果这个值是一个非叶子节点(即一个对象引用),则可以修改这个节点下面的所有内容。
堆和栈中,栈是程序运行最根本的东西。程序运行可以没有堆,但是不能没有栈。而堆是为栈进行数据存储服务,说白了堆就是一块共享的内存。不过,正是因为堆和栈的分离的思想,才使得Java的垃圾回收成为可能。
Java中,栈的大小通过-Xss来设置,当栈中存储数据比较多时,需要适当调大这个值,否则会出现java.lang.StackOverflowError异常。常见的出现这个异常的是无法返回的递归,因为此时栈中保存的信息都是方法返回的记录点。
Java对象的大小
基本数据的类型的大小是固定的,这里就不多说了。对于非基本类型的Java对象,其大小就值得商榷。
在Java中,一个空Object对象的大小是8byte,这个大小只是保存堆中一个没有任何属性的对象的大小。看下面语句:
| Object ob = new Object(); |
这样在程序中完成了一个Java对象的生命,但是它所占的空间为:4byte+8byte。4byte是上面部分所说的Java栈中保存引用的所需要的空间。而那8byte则是Java堆中对象的信息。因为所有的Java非基本类型的对象都需要默认继承Object对象,因此不论什么样的Java对象,其大小都必须是大于8byte。
有了Object对象的大小,我们就可以计算其他对象的大小了。
- Class NewObject {
- int count;
- boolean flag;
- Object ob;
- }
- //其大小为:空对象大小(8byte)+int大小(4byte)+Boolean大小(1byte)+空Object引用的大小(4byte)=17byte。
- 但是因为Java在对对象内存分配时都是以8的整数倍来分,因此大于17byte的最接近8的整数倍的是24,因此此对象的大
- 小为24byte。
|
这里需要注意一下基本类型的包装类型的大小。因为这种包装类型已经成为对象了,因此需要把他们作为对象来看待。包装类型的大小至少是12byte(声明一个空Object至少需要的空间),而且12byte没有包含任何有效信息,同时,因为Java对象大小是8的整数倍,因此一个基本类型包装类的大小至少是16byte。这个内存占用是很恐怖的,它是使用基本类型的N倍(N>2),有些类型的内存占用更是夸张(随便想下就知道了)。因此,可能的话应尽量少使用包装类。在JDK5.0以后,因为加入了自动类型装换,因此,Java虚拟机会在存储方面进行相应的优化。
引用类型
对象引用类型分为强引用、软引用、弱引用和虚引用。
强引用:就是我们一般声明对象是时虚拟机生成的引用,强引用环境下,垃圾回收时需要严格判断当前对象是否被强引用,如果被强引用,则不会被垃圾回收
软引用:软引用一般被做为缓存来使用。与强引用的区别是,软引用在垃圾回收时,虚拟机会根据当前系统的剩余内存来决定是否对软引用进行回收。如果剩余内存比较紧张,则虚拟机会回收软引用所引用的空间;如果剩余内存相对富裕,则不会进行回收。换句话说,虚拟机在发生OutOfMemory时,肯定是没有软引用存在的。
弱引用:弱引用与软引用类似,都是作为缓存来使用。但与软引用不同,弱引用在进行垃圾回收时,是一定会被回收掉的,因此其生命周期只存在于一个垃圾回收周期内。
强引用不用说,我们系统一般在使用时都是用的强引用。而“软引用”和“弱引用”比较少见。他们一般被作为缓存使用,而且一般是在内存大小比较受限的情况下做为缓存。因为如果内存足够大的话,可以直接使用强引用作为缓存即可,同时可控性更高。因而,他们常见的是被使用在桌面应用系统的缓存。
摘要: 我竟然到现在才发现《Fundamental Networking in Java》这本神作,真有点无地自容的感觉。最近几年做的都是所谓的企业级开发,免不了和网络打交道,但在实际工作中,往往会采用框架将底层细节和上层应用隔离开,感觉就像是在一个 Word 模板表单里面填写内容,做出来也没什么成就感。虽然没有不使用框架的理由,但我还真是有点怀念当初直接用套接字做网络编程的日子,既能掌控更多东西,还可以...
阅读全文
数据库是Web大多数应用开发的基础。如果你是用PHP,那么大多数据库用的是MYSQL也是LAMP架构的重要部分。
PHP看起来很简单,一个初学者也可以几个小时内就能开始写函数了。但是建立一个稳定、可靠的数据库确需要时间和经验。下面就是一些这样的经验,不仅仅是MYSQL,其他数据库也一样可以参考。
1、使用MyISAM而不是InnoDB
MySQL有很多的数据库引擎,单一般也就用MyISAM和InnoDB。
MyISAM 是默认使用的。但是除非你是建立一个非常简单的数据库或者只是实验性的,那么到大多数时候这个选择是错误的。MyISAM不支持外键的约束,这是保证数据完整性的精华所在啊。另外,MyISAM会在添加或者更新数据的时候将整个表锁住,这在以后的扩展性能上会有很大的问题。
解决办法很简单:使用InnoDB。
2、使用PHP的mysql方法
PHP从一开始就提供了MySQL的函数库。很多程序都依赖于mysql_connect、mysql_query、mysql_fetch_assoc等等,但是PHP手册中建议:
如果你使用的MySQL版本在4.1.3之后,那么强烈建议使用mysqli扩展。
mysqli,或者说MySQL的高级扩展,有一些优点:
有面向对象的接口
prepared statements(预处理语句,可以有效防止SQL-注入攻击,还能提高性能)
支持多种语句和事务
另外,如果你想支持多数据库那么应该考虑一下PDO。
3、不过滤用户输入
应该是:永远别相信用户的输入。用后端的PHP来校验过滤每一条输入的信息,不要相信Javascript。像下面这样的SQL语句很容易就会被攻击:
- $username = $_POST["name"];
- $password = $_POST["password"];
- $sql = "SELECT userid FROM usertable WHERE username='$username'AND password='$password';"; // run query...
|
这样的代码,如果用户输入”admin’;”那么,就相当于下面这条了:
| SELECT userid FROM usertable WHERE username='admin'; |
这样入侵者就能不输入密码,就通过admin身份登录了。
4、不使用UTF-8
那些英美国家的用户,很少考虑语言的问题,这样就造成很多产品就不能在其他地方通用。还有一些GBK编码的,也会有很多的麻烦。
UTF-8解决了很多国际化的问题。虽然PHP6才能比较完美的解决这个问题,但是也不妨碍你将MySQL的字符集设置为UTF-8。
5、该用SQL的地方使用PHP
如果你刚接触MySQL,有时候解决问题的时候可能会先考虑使用你熟悉的语言来解决。这样就可能造成一些浪费和性能比较差的情况。比如:计算平均值的时候不适用MySQL原生的AVG()方法,而是用PHP将所有值循环一遍然后累加计算平均值。
另外还要注意SQL查询中的PHP循环。通常,在取得所有结果之后再用PHP来循环的效率更高。
一般在处理大量数据的时候使用强有力的数据库方法,更能提高效率。
6、不优化查询
99%的PHP性能问题都是数据库造成的,一条糟糕的SQL语句可能让你的整个程序都非常慢。MySQL的EXPLAIN statement,Query Profiler,many other tools的这些工具可以帮你找出那些调皮的SELECT。
7、使用错误的数据类型
MySQL提供一系列数字、字符串、时间等的数据类型。如果你想存储日期,那么就是用DATE或者DATETIME类型,使用整形或者字符串会让事情更加复杂。
有时候你想用自己定义的数据类型,例如,使用字符串存储序列化的PHP对象。数据库的添加可能很容易,但是这样的话,MySQL就会变得很笨重,而且以后可能导致一些问题。
8、在SELECT查询中使用*
不要使用*在表中返回所有的字段,这会非常的慢。你只需要取出你需要的数据字段。如果你需要取出所有的字段,那么可能你的表需要更改了。
9、索引不足或者过度索引
一般来说,应该索引出现在SELECT语句中WHERE后面所有的字段。
例如,假如我们的用户表有一个数字的ID(主键)和email地址。登录之后,MySQL应该通过email找到相应的ID。通过索引,MySQL可以通过搜索算法很快的定位email。如果没有索引,MySQL就需要检查每一项记录直到找到。
这样的话,你可能想给每一个字段都添加索引,但是这样做的后果就是在你更新或者添加的时候,索引就会重新做一遍,当数据量大的时候,就会有性能问题。所以,只在需要的字段做索引。
10、不备份
也许不常发生,但是数据库损毁,硬盘坏了、服务停止等等,这些都会对数据造成灾难性的破坏。所以你一定要确保自动备份数据或者保存副本。
11、另外:不考虑其他数据库
MySQL可能是PHP用的最多的数据库了,但是也不是唯一的选择。 PostgreSQL和Firebird也是竞争者,他们都开源,而且不被某些公司所控制。微软提供SQL Server Express,Oracle有10g Express,这些企业级的也有免费版。SQLite对于一些小型的或者嵌入式应用来说也是不错的选择。
以前学习面向对象的时候,常听到介绍对象之间的各种关系,常见的有关联,组合与聚合。
关联:
关联是一种最普遍和常见的关系形式。一般是指一个对象可以发消息给另外一个对象。典型的实现情况下指某个对象有一个指针或者引用指向一个实体变量,当通过方法的参数来传递或者创建本地变量来访问这种情况也可以称之为关联。
典型的代码如下:
- class A
- {
- private B itemB;
- }
|
也可能有如下的形式:
- class A
- {
- void test(B b) {...}
- }
|
笼统的情况下,一般两个对象的引用,参数传递等形式产生的关系,我们都可以称之为关联关系。
聚合(aggregation):
聚合表示的是一种has-a的关系,同时,它也是一种整体-部分关系。它的特点在于,它这个部分的生命周期并不由整体来管理。也就是说,当整体这个对象已经不存在的时候,部分的对象还是可能继续存在的。它的uml图表示形式如下:

我们用一个空心的箭头来表示聚合关系。
笼统的说声明周期管理还是比较模糊。我们就以如图的Person和Address类来进一步的解释。假设我们要定义这两个对象,对于每个人来说,他有一个关联的地址。人和地址的关系是has-a的关系。但是,我们不能说这个地址是这个人的一个组成部分。同时,我们建立地址对象和人的对象是可以相对独立存在的。
用代码来表示的话,典型的代码样式如下:
- public class Address
- {
- . . .
- }
- public class Person
- {
- private Address address;
- public Person(Address address)
- {
- this.address = address;
- }
- . . .
- }
|
我们通常通过如下的方式来使用Person对象:
- Address address = new Address();
- Person person = new Person(address);
|
或者:
| Person person = new Person( new Address() ); |
我们可以看到,我们是创建了一个独立的Address对象,然后将这个对象传入了Person的构造函数。当Person对象声明周期结束的时候,Address对象如果还有其他指向它的引用,是可能继续存在的。也就是说,他们的声明周期是相对独立的。
组合(Composition):
当理解了聚合的关系之后,再来看组合的关系就相对来说要好很多。和聚合比起来,组合是一种更加严格的has-a关系。它表示一种严格的组成关系。以汽车和引擎为例子,引擎是汽车的一个组成部分。他们是一种严格的部分组成关系,因此他们的声明周期也应该是一致的。也就是说引擎的声明周期是通过汽车对象来管理。
组合的uml图表示如下:

一般用一个实心的箭头表示组合。
组合代码的典型示例如下:
- public class Engine
- {
- . . .
- }
-
- public class Car
- {
- Engine e = new Engine();
- .......
- }
|
Engine对象是在Car对象里面创建的,所以在Car对象生命周期结束的时候,Engine对象的生命周期也同样结束了。
http://wenku.baidu.com/view/43d702600b1c59eef8c7b4fb.html
http://baike.baidu.com/view/1094245.htm
http://down.51cto.com/data/241953
“青花瓷Java版”为北京师范大学教育学部蔡苏作词原创,覆盖教育技术学院专业选修课《面向对象程序设计》教学大纲中的所有知识点。
视频:http://player.youku.com/player.php/sid/XMjU3Mjk2NzA0/v.swf
歌词:
JDK 和JRE 莫要混淆去
环境变量的配置有时让人迷
初学的人莫贪图上来I D E
先用J D K +文本编辑器
面向对象仨特点一定要牢记
封装继承和多态一个不能离
接口为多重继承
抽象类一定要有实例
O b je c t呀 所有类爹地
package在类中只能有唯一
注释命名时要既规范又明晰
就当为好程序员伏笔
G U I 不是鬼 千万别恐惧
四大布局管理 多练才熟悉
勤能补拙熟能生巧到考试时
你眼带笑意
三整两浮一布尔再加字节符
基本数据Byte数了然于心底
碰到异常一定记得try/catch
要打包发布使用jar命令
线程何时被调用全看调度器
睡眠同步和死锁使用要仔细
网页中Applet
独立程序Application
ApplicationO b je c t呀所有类爹地
package在类中只能有唯一
注释命名时要既规范又明晰就当为好程序员伏笔
(这样程序员才是好样滴)
G U I 不是鬼
千万别恐惧四大布局管理
多练才熟悉
勤能补拙熟能生巧到考试时你眼带笑意
歌词理解:
JDK 和JRE 莫要混淆去
JRE(Java Runtime Environment):即Java运行环境,运行JAVA程序所必须的环境的集合,包含JVM标准实现及Java核心类库。
JDK(Java Development Kit):是整个Java的核心,包括了Java运行环境,Java工具和Java基础的类库。
环境变量的配置有时让人迷
JAVA_HOME、CLASSPATH、PATH
记得加入当前目录“.”
初学的人莫贪图上来IDE
IDE(Integrated Development,集成开发环境)
不错的Java IDE:Eclipse、Netbeans、Jbuilder、 Jcreator
先用JDK +文本编辑器
vim、javac、java
面向对象仨特点一定要牢记,封装继承和多态一个不能离
封装:隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别
继承:对已有类的复用和修改
多态:指一个程序中,同名的不同方法共存的情况
接口为多重继承
抽象类一定要有实例
Object呀,所有类爹地
所有类都是从Object类继承而来的。
package在类中只能有唯一
package 语句必须是文件中除注释以外的第一句程序代码
package 将文件中的类都遮蔽到一定的名字空间下,别的文件导入须用到import关键字
注释命名时要既规范又明晰,就当为好程序员伏笔
GUI 不是鬼,千万别恐惧
四大布局管理 多练才熟悉
勤能补拙熟能生巧到考试时,你眼带笑意
三整两浮一布尔再加字节符
三整:short int long
两浮:float double
一布尔:boolean
字节符:byte char
基本数据Byte数了然于心底
boolean:特殊,表示1 bit的信息,但不明确指定占用内存空间的大小。
char:2 Byte
byte:1 Byte
short:2 Byte
int:4 Byte
long:8 Byte
float:4 Byte
double:8 Byte
碰到异常一定记得try/catch
要打包发布使用jar命令
线程何时被调用全看调度器
睡眠同步和死锁使用要仔细
网页中Applet
独立程序Application
对于系统管理员来说如何管理自己的服务器已经是再简单不过,但是如何管理好服务器却不是一个简单的事情。对于管理员来说重启服务器可不是一件闹着玩的事情。对于Windows服务器管理员来说经常性重启Windows设备已经成为一种生活常态,但在Unix系统中这种办法却难以奏效——在默认情况下重新启动不会带来任何形式的改善。
我打算借此机会跟大家详细聊聊重启的问题。对于每一位服务器管理员来说这都算得上热门话题,但在Unix极客们眼中它则属于一种层次更深的课题——可能因为Windows管理员们往往把重启当成故障排查工作的首要步骤之一,而Unix团队则一般只在束手无策的情况下才进行尝试。
Unix服务器重启的两种情况
实际情况是:服务器重启操作应该极少出现——请注意是极少。在这里我列举内核更新与硬件更换作为例子,因为它们是Unix领域中引发重新启动的两大主要原因。有些人一直在鼓吹什么不重启服务器的话会带来某些严重的安全风险,这简直是一派胡言。如果服务项目与应用程序中确实存在安全风险,那么打上漏洞补丁就能解决问题了,而且补丁往往不要求重启设备。而如果安全风险存在于内核模块中,一般来说只需卸载对应模块、安装补丁,最后重新加载模块。没错,我承认一旦内核中存在安全风险,那么重启操作的确是必要的。但在这种情况之外,大家根本没有切实的理由重新启动Unix服务器。
有些人认为如果不进行重启操作,其它形式的风险往往会接踵而至,例如某些关键性服务项目在开机时没有得到正确启用,而这将导致一系列隐患。当然,这种说法本身是正确的,但只要管理工作执行到位,这其实根本就是种杞人忧天。只有刚刚接掌服务器设备的菜鸟才会忘记正确设置服务项目的启动参数。不过话说回来,如果大家的服务器正处于构建阶段,且其中还不涉及任何生产方面的内容,那么不妨随意进行各类重启测试,这不会带来任何不良影响。而且我认为这正是熟悉重启机制的最好时机。
但还有另一方面需要考虑:那些将重启操作当成故障排查重要步骤之一的家伙是抱着死猪不怕开水烫的心态,打算一次性把问题都暴露出来。就说一套已经出现问题的Unix设备吧,某些还处于运行中的服务项目实际上已经无法再次启动,而这一点在重启之后就会显现出来——也许是由于分段故障或者其它稀奇古怪的原因。
造成Unix服务器重启的原因
如果我们只是简单查看几分钟之后就一拍脑门决定重启设备,那么也许故障的真正原因就彻底湮没在时光中了——也许是某位初级管理员在运行一套自己编写的愚蠢脚本时无意中删除了/boot目录或者/etc、/usr/lib64目录下的部分内容。这正是引发分段故障以及设备不稳定情况的罪魁祸首。然而一旦我们选择直接重启服务器而没有深入挖掘问题,那么显然问题会变得更加严重,接下来不出意外的话大家应该会启动恢复镜像——这就代表需要面对大量恢复工作——而与此同时生产服务器也将陷入停机状态。
以上只是我们在Unix领域中应该尽量避免重启操作的原因之一。与其说这算是种故障排查方法,不如把它看作一类孤注一掷的豪赌——要么发现问题,要么亲手毁掉一切再慢慢重建。总之,没人能利用/var分区重启设备就完全修正错误。(另外请别提什么打开文件句柄这类迂腐的蠢话——我想大家应该理解我的意思)
服务器重启前请做完你该做的工作
在大多数情况下,不进行重启是极其重要的,因为系统中能够帮助我们修复问题的关键性内容在重启前是一定存在的,但在重启后却未必还在。重启之后问题绝对会再次出现,然而一旦解决方案随重启行为而烟消云散,那么故障本身就陷入了无解的死循环中。除非有人决定不进行重启,而是尝试找出问题的根源。遗憾的是,能做了这种明智选择的人实在少之又少。实际情况是:一根小小的故障内存条就能给系统正常运行与设备启动状态带来极大的麻烦。而这个时候,对症下药才是上策,一味重启只会带来额外的损失。
因此,今后大家在面对问题时,如果有某个家伙说什么“嘿,不如先重启一下看看”,不妨直接给他两个大嘴巴。重启当然是方案之一,但在实施重启前请务必确保我们已经采取了一切能够想到的处理措施;毕竟节省下来的都是咱们自己的时间跟精力嘛。
JNDI 是什么
JNDI是 Java 命名与目录接口(Java Naming and Directory Interface),在J2EE规范中是重要的规范之一,不少专家认为,没有透彻理解JNDI的意义和作用,就没有真正掌握J2EE特别是EJB的知识。
那么,JNDI到底起什么作用?
要了解JNDI的作用,我们可以从“如果不用JNDI我们怎样做?用了JNDI后我们又将怎样做?”这个问题来探讨。
没有JNDI的做法:
程序员开发时,知道要开发访问MySQL数据库的应用,于是将一个对 MySQL JDBC 驱动程序类的引用进行了编码,并通过使用适当的 JDBC URL 连接到数据库。
就像以下代码这样:
- Connection conn=null;
- try {
- Class.forName("com.mysql.jdbc.Driver",
- true, Thread.currentThread().getContextClassLoader());
- conn=DriverManager.getConnection("jdbc:mysql://MyDBServer?user=qingfeng&password=mingyue");
- /* 使用conn并进行SQL操作 */
- ......
- conn.close();
- }
- catch(Exception e) {
- e.printStackTrace();
- }
- finally {
- if(conn!=null) {
- try {
- conn.close();
- } catch(SQLException e) {}
- }
- }
|
这是传统的做法,也是以前非Java程序员(如Delphi、VB等)常见的做法。这种做法一般在小规模的开发过程中不会产生问题,只要程序员熟悉Java语言、了解JDBC技术和MySQL,可以很快开发出相应的应用程序。
没有JNDI的做法存在的问题:
1、数据库服务器名称MyDBServer 、用户名和口令都可能需要改变,由此引发JDBC URL需要修改;
2、数据库可能改用别的产品,如改用DB2或者Oracle,引发JDBC驱动程序包和类名需要修改;
3、随着实际使用终端的增加,原配置的连接池参数可能需要调整;
4、......
解决办法:
程序员应该不需要关心“具体的数据库后台是什么?JDBC驱动程序是什么?JDBC URL格式是什么?访问数据库的用户名和口令是什么?”等等这些问题,程序员编写的程序应该没有对 JDBC 驱动程序的引用,没有服务器名称,没有用户名称或口令 —— 甚至没有数据库池或连接管理。而是把这些问题交给J2EE容器来配置和管理,程序员只需要对这些配置和管理进行引用即可。
由此,就有了JNDI。
用了JNDI之后的做法:
首先,在在J2EE容器中配置JNDI参数,定义一个数据源,也就是JDBC引用参数,给这个数据源设置一个名称;然后,在程序中,通过数据源名称引用数据源从而访问后台数据库。
具体操作如下(以JBoss为例):
1、配置数据源
在JBoss的 D:/jboss420GA/docs/examples/jca 文件夹下面,有很多不同数据库引用的数据源定义模板。将其中的 mysql-ds.xml 文件Copy到你使用的服务器下,如 D:/jboss420GA/server/default/deploy。
修改 mysql-ds.xml 文件的内容,使之能通过JDBC正确访问你的MySQL数据库,如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <datasources>
- <local-tx-datasource>
- <jndi-name>MySqlDS</jndi-name>
- <connection-url>jdbc:mysql://localhost:3306/lw</connection-url>
- <driver-class>com.mysql.jdbc.Driver</driver-class>
- <user-name>root</user-name>
- <password>rootpassword</password>
- <exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter</exception-sorter-class-name>
- <metadata>
- <type-mapping>mySQL</type-mapping>
- </metadata>
- </local-tx-datasource>
- </datasources>
|
这里,定义了一个名为MySqlDS的数据源,其参数包括JDBC的URL,驱动类名,用户名及密码等。
2、在程序中引用数据源:
- Connection conn=null;
- try {
- Context ctx=new InitialContext();
- Object datasourceRef=ctx.lookup("java:MySqlDS"); //引用数据源
- DataSource ds=(Datasource)datasourceRef;
- conn=ds.getConnection();
- /* 使用conn进行数据库SQL操作 */
- ......
- c.close();
- }
- catch(Exception e) {
- e.printStackTrace();
- }
- finally {
- if(conn!=null) {
- try {
- conn.close();
- } catch(SQLException e) { }
- }
- }
|
直接使用JDBC或者通过JNDI引用数据源的编程代码量相差无几,但是现在的程序可以不用关心具体JDBC参数了。
在系统部署后,如果数据库的相关参数变更,只需要重新配置 mysql-ds.xml 修改其中的JDBC参数,只要保证数据源的名称不变,那么程序源代码就无需修改。
由此可见,JNDI避免了程序与数据库之间的紧耦合,使应用更加易于配置、易于部署。
JNDI的扩展:JNDI在满足了数据源配置的要求的基础上,还进一步扩充了作用:所有与系统外部的资源的引用,都可以通过JNDI定义和引用。
所以,在J2EE规范中,J2EE 中的资源并不局限于 JDBC 数据源。引用的类型有很多,其中包括资源引用(已经讨论过)、环境实体和 EJB 引用。特别是 EJB 引用,它暴露了 JNDI 在 J2EE 中的另外一项关键角色:查找其他应用程序组件。
EJB 的 JNDI 引用非常类似于 JDBC 资源的引用。在服务趋于转换的环境中,这是一种很有效的方法。可以对应用程序架构中所得到的所有组件进行这类配置管理,从 EJB 组件到 JMS 队列和主题,再到简单配置字符串或其他对象,这可以降低随时间的推移服务变更所产生的维护成本,同时还可以简化部署,减少集成工作。 外部资源”。
具体操作如下(以JBoss为例):
1、配置数据源
在JBoss的 D:/jboss420GA/docs/examples/jca 文件夹下面,有很多不同数据库引用的数据源定义模板。将其中的 mysql-ds.xml 文件Copy到你使用的服务器下,如 D:/jboss420GA/server/default/deploy。
修改 mysql-ds.xml 文件的内容,使之能通过JDBC正确访问你的MySQL数据库,如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <datasources>
- <local-tx-datasource>
- <jndi-name>MySqlDS</jndi-name>
- <connection-url>jdbc:mysql://localhost:3306/lw</connection-url>
- <driver-class>com.mysql.jdbc.Driver</driver-class>
- <user-name>root</user-name>
- <password>rootpassword</password>
- <exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter</exception-sorter-class-name>
- <metadata>
- <type-mapping>mySQL</type-mapping>
- </metadata>
- </local-tx-datasource>
- </datasources>
|
这里,定义了一个名为MySqlDS的数据源,其参数包括JDBC的URL,驱动类名,用户名及密码等。
2、在程序中引用数据源:
- Connection conn=null;
- try {
- Context ctx=new InitialContext();
- Object datasourceRef=ctx.lookup("java:MySqlDS"); //引用数据源
- DataSource ds=(Datasource)datasourceRef;
- conn=ds.getConnection();
- /* 使用conn进行数据库SQL操作 */
- ......
- c.close();
- }
- catch(Exception e) {
- e.printStackTrace();
- }
- finally {
- if(conn!=null) {
- try {
- conn.close();
- } catch(SQLException e) { }
- }
- }
|
直接使用JDBC或者通过JNDI引用数据源的编程代码量相差无几,但是现在的程序可以不用关心具体JDBC参数了。
在系统部署后,如果数据库的相关参数变更,只需要重新配置 mysql-ds.xml 修改其中的JDBC参数,只要保证数据源的名称不变,那么程序源代码就无需修改。
由此可见,JNDI避免了程序与数据库之间的紧耦合,使应用更加易于配置、易于部署。
JNDI的扩展:JNDI在满足了数据源配置的要求的基础上,还进一步扩充了作用:所有与系统外部的资源的引用,都可以通过JNDI定义和引用。
所以,在J2EE规范中,J2EE 中的资源并不局限于 JDBC 数据源。引用的类型有很多,其中包括资源引用(已经讨论过)、环境实体和 EJB 引用。特别是 EJB 引用,它暴露了 JNDI 在 J2EE 中的另外一项关键角色:查找其他应用程序组件。
EJB 的 JNDI 引用非常类似于 JDBC 资源的引用。在服务趋于转换的环境中,这是一种很有效的方法。可以对应用程序架构中所得到的所有组件进行这类配置管理,从 EJB 组件到 JMS 队列和主题,再到简单配置字符串或其他对象,这可以降低随时间的推移服务变更所产生的维护成本,同时还可以简化部署,减少集成工作。 外部资源”。
从我们日常生活中去理解目录服务的概念可以从电话簿说起,电话簿本身就是一个比较典型的目录服务,如果你要找到某个人的电话号码,你需要从电话簿里找到这个人的名称,然后再看其电话号码。

理解了命名服务和目录服务再回过头来看JDNI,它是一个为Java应用程序提供命名服务的应用程序接口,为我们提供了查找和访问各种命名和目录服务的通用统一的接口.通过JNDI统一接口我们可以来访问各种不同类型的服务.如下图所示,我们可以通过JNDI API来访问刚才谈到的DNS。
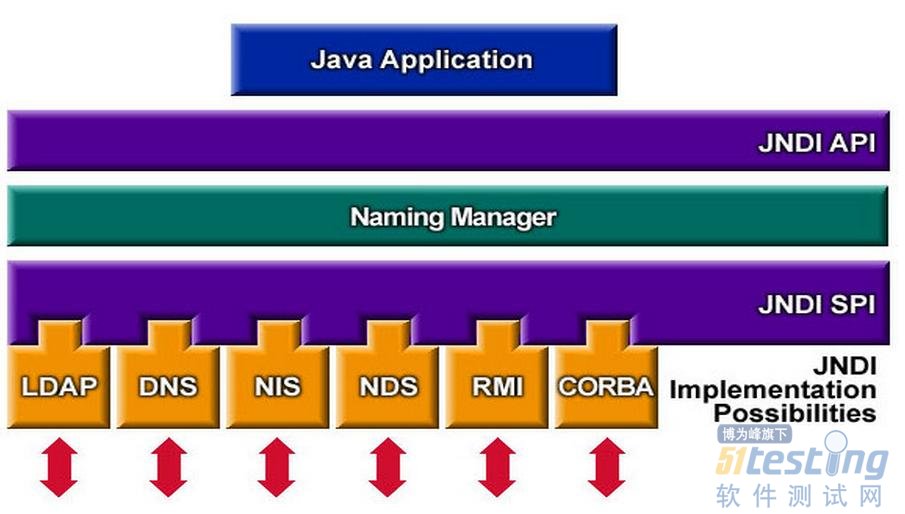
至此已经对JNDI有了一个初步认识,如果想要进一步了解JNDI,并对使用JDNI给我们带来哪些便利之处,我推荐两篇关于JDNI的文章,写的非常的好,两篇文章从“如果不用JNDI我们怎样做?用了JNDI后我们又将怎样做?”这个角度来加深对JNDI的认识。
数据库是存放数据、经常是那些高敏感度数据的宝库,因此它也毫无疑问的是合规检查程序的重点区域。几乎所有的企业合规都会对哪些人、能在什么时间、访问什么数据库作出规定,并且需要一个专职人员来管理这些权限。本文,我们将讨论针对数据库合规的基本数据库安全要求,如PCI DSS和HIPAA,以及为了遵守合规要求用于管理数据库权限和维护的最佳实践。
最常见的五大企业核心数据库环境是:1、微软的SQL Server数据库;2、IBM的DB2数据库;3、MySQL数据库;4、Oracle数据库;5、Postgres数据库。这些数据库在首次实施安装时都能够恰当地配置、加固、保护及锁定。真正的挑战是理解那些实际上需要到位的重要组件。这不只是对数据库本身,还有容纳操作系统和数据库的服务器。
PCI DSS当前对于数据库要求有下述明确的控制措施:
◆ 对访问任意数据库的所有用户进行认证。
◆ 所有用户访问任何数据库时,用户的查询和操作(例如移动、拷贝和删除)只能通过编程性事务(例如存储过程)。
◆ 数据库和应用的配置设置为只限于给DBA(数据库管理员)的直接用户访问或是查询。
◆ 对于数据库应用和相关的应用ID,应用ID只能被应用使用,而不能被单独的用户或是其它进程使用。
就HIPAA法案来说,上述的措施没有作为HIPAA合规要求的内容特别写出来,但是应当看作是用于合规遵从的最佳安全控制组合,并且最终有助于满足HIPAA中安全条款的需要。具体来说,HIPAA的规定条款如下:
◆ 确保所有新建、接收、维护或是传输中的电子个人健康信息(e-PHI)的保密性、完整性和可用性。
◆ 辨识和防范那些对信息的安全性或完整性来说合理的、可预见的威胁。
◆ 防范那些合理的、可预见的、不允许的滥用或是泄漏;并且
◆ 确保他们所有员工的合规性。
此外,除了满足像PCI DSS这样的合规要求外,下述是应该考虑的最佳实践、可用来确保上面列出的所有数据库环境的安全。
就运行数据库的主机的操作系统来说,以下的最佳实践应该到位:
1、系统管理员和其他相关的IT人员应该拥有充分的知识、技能并理解所有关键操作系统的安全要求。
2、当部署操作系统到受管理的服务环境中时,应采用行业领先的配置标准和配套的内部文档。
3、在操作系统上应该只启用那些必需的和安全的服务、协议、守护进程和其它必要的功能。
4、操作系统上所有不需要的功能和不安全的服务及协议应该有效地禁用。