IT项目管理从某个意义上来说,就是风险管理。从理论上讲风险管理可以分为三个部分:风险识别、风险分析和风险解决。 传统的风险管理系统只能帮我们较正规地统计和管理风险,这些系统本身是不能规避或解决任何风险的。在实际操作上,由于可能发生风险的种类很多,处理起来所耗费的人力物力也相当可观。在下列的案例中,我们建议的不是一套昂贵而且全面的风险管理系统,而是一套扼住最关键部位,高效且低成本,适合于千万中小企业的小型解决方案。
一个案例
在2009年某家在北京海淀区的嵌入式产品公司跟我们讨论项目管理时,该公司的王总监跟我们做了以下沟通。他们项目风险种类可以概略分为四类:
(1)需求风险 ——对需求理解不够透彻或需求变更频繁;
(2)人员风险 ——人员生病或离职,一时无法找到替代者;
(3)技术风险 ——某个关键的技术问题无法快速攻克;
(4)管理风险 ——管理人员协调能力和执行力能力不足,计划偏差,流程更改和沟通不良等。
这些风险的发生导致的结果就是项目延期和成本大幅攀升。无法有效处理这些风险的两个最大问题在于:
(1)对风险的反应迟钝 ——常常是太晚发现问题,以至于无法弥补或是弥补成本太大;
(2)对过程难以掌控 ——虽已有既定的流程,但由于人员变动、流程变动、系统出错等问题,很难照着走。
为了让我们更理解,王总监很生动的解释了以上两个问题。对风险反应迟钝的问题,他说,在做项目计划时为求实际,总会多估个20%到40%的时间。如果项目需求清晰,或是团队做过类似项目,就用20%或多些;如果是新项目,或风险因素多便用30%到40%。所以,当某些风险(如,需求变更或人员变动)发生了,一般也未必马上就造成项目延期。可是,如果风险发生量继续增加,或是某一两个风险产生较严重的冲击,在某个时刻就会过了临界点。难的地方就是项目大人员多,就是连项目经理也是见树不见林。
对过程难以掌控的问题,王总监举了个例子。公司的研发制度里规定,为保证需求的准确性,一个需求的变更要经过(1)该项目经理,(2)一位资深程序员,和(3)该产品经理,等三个关键人审核后才可以进行更改。王总监说:需求变更的过程在逻辑上看似简单,但在实际操作时却不断地发生问题。举例来说,内部沟通主要是以邮件通知的方式进行,需求变更的文档寄来寄去,版本很多,而且邮件总是遗失。另有一次更严重,产品经理因为休假,没能及时查邮件。在等了两天后,因怕误了工期,项目经理便越权要求程序员把代码写了。不巧,产品经理对这需求的更改有他强烈的意见。当他看到在没得到他的同意下就把代码写了,火冒三丈,直接在会议中就和项目经理吵了起来。
两个控制风险的原则
虽然风险总是发生,但就如同大多数的公司一样,该公司也不愿意花费太多的精力和时间在这风险管控上,所以在寻求一个低成本又高效的管控方法。王总监和我们在研讨后,使用工具DevSuite基于下列两个原则做了处理。(为避免篇幅太大,以下我们仅把最精彩的点列出来。)
(1)提高项目的可视性
不论是哪一种风险,其最后冲击的基本上就是项目本身,延期是最常见的结果。如果是对可能发生的风险都一一进行管控,成本必然很高,而且还可能有疏漏。使用燃尽图(Burn Down Chart)可能是针对项目延期最有效的解决办法,因为它很大程度地提高了项目的可视性。在实际操作时,我们让团队成员每天对其参与的每一任务都键入下列两项数字:1)该任务花费时间,和2)该任务所剩时间。结果就会生了类似如下的燃尽图。
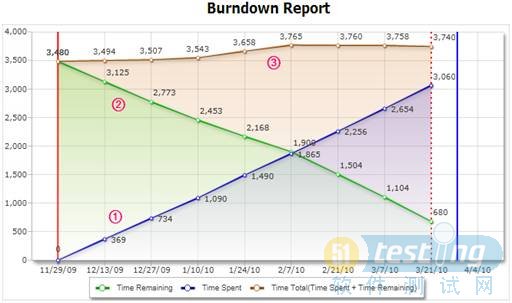
如图所示,起初这项目被估计是要3480小时完成。大致上来说,一般的研发团队因着人员请假、会议和其他突发事情,平均每人每天只能有六小时花在实际项目工作上。现这项目有七个人参与,估算出来大约需要四个月完成。(也就是从2009年11月29日到2010年3月29日,图中红色直立线为起始线,蓝色直立线为终止线。)这图里共有三条曲线。红色号码?/span>表示到现在为止在该项目的总花费时间,红色号码?表示估算的项目剩余时间,红色号码?是到目前为止所花的时间与剩余时间之和的曲线。到了2010年3月21日就得到了上面的这个图。到了这一天,我们发现原本估计的3480总小时数是低估了,更可能的是?所示的3740小时。
以纵轴的性质区分,燃尽图可以分为两大类,即纵轴可以是时间或是事件。以范围区分,燃尽图至少可以分为三类:项目级的、任务级的和需求级的。透过燃尽图,我们可以看到项目进行的情况,项目需求是否按计划进入开发流程,工作是否有延时,或者工作安排的饱和度是否适合。如上图所示,我们可以轻易地看到,照着现在的进度,这项目最可能会延期6到7工作天。当高层看到这图时,就可以在资源上做调动,以避免延期产生的不良后果。
我们刻意使用了这个较理想的图做讲解,为的是让读者更容易理解。它不是个典型的图。在大多情况,使用燃尽图会是比较复杂的,因为它可能包含了需求搜集、编程、单元测试、集成测试和缺陷修复,并且还可能有迭代。所以估算时间会较困难。这个燃尽图的过程是比较稳定的,结果是比较理想的,其原因至少有二:(一)项目里单纯地只有编程、单元测试和缺陷修复任务,全都由程序员搞定;它里头没有需求搜集、集成测试或其他任务。(二)这个项目复杂度低,约一半的编码任务是机械性的,所以估出来的时间较为准确。
(2)固化工作流以管控过程
对于公司里既定的流程,我们在DevSuite里以图形化的工作流将其固化。下图就是以前面王总监提到的需求变更流程设计出来的。
这工作流指明了,在一个变更事件被创建后,它需要经过一个《评审》状态。在评审阶段里,有三个人(A,B和C)要全部同意,才能到达《通过》状态。有任何一人不同意,状态就转到《拒绝》。当一到达《评审》状态,系统马上促发邮件和手机通知,将信息寄给A,B和C。系统可以预先设定这三人有两天的时间评审该变更。假如两天过了,状态仍为《评审》,那就是有人未及时处理该事件。这时候,系统会自动将事件升级,把状态转换为《升级处理》,系统马上促发邮件,将信息寄给研发部王总监。王总监可以斟酌情况,做最妥善的处理。
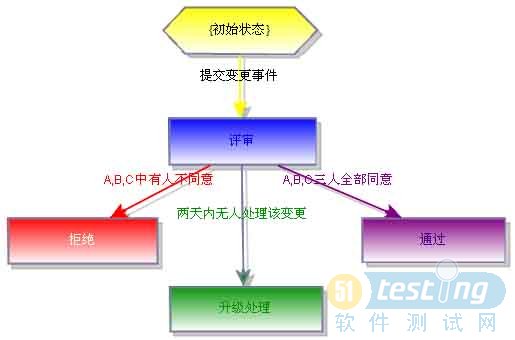
使用固化的工作流至少有四个优点:1)提高通知效率 ?邮件和手机自动通知提高效率,沟通出错的机会减少了;2)避免流程出错 ?DevSuite的工作流将流程完全自动化,每个人在收到邮件或短信通知时,照着工作流中既定的步骤操作就行了,省心又省力; 3)工作流变动时处理很容易 ?当流程或人员变动时,系统配置员可以轻易地花几分钟就做完调整,之后所有团队成员就照着流程走便行了;4)避免摩擦?人是有情绪的,固化的工作流使得操作完全对事不对人,避免了人和人之间不必要的摩擦。
以上提到的软件项目风险实例几乎在每个项目中都出现,而且,它们造成的损失也是严重的。所幸,从实际操作中,我们发现处理它们的成本并不高:1)培训团队成员照工作流中既定的步骤操作,学会填写任务花费时间和任务所剩时间,并理解意图,所花时间不超过1小时,2)系统配置员要了解需求,设计工作流,并设置人员(如例子中的A、B、C和走流程的人)的权限等,所花费时间在1到3天之间,也算合理,3)以往当团队人员或评审流程有变动,管理人员要更改文档并向所有人宣布;现系统配置员只要花几分钟改系统配置,一切就就绪了。
小结
这并不是一个全方位的风险管控系统;相反的,它是个相当简化,只对关键点作处理的系统。虽然只是做在关键点上,但效果却十分明显。就拿需求变更来说,需求变更一直都是项目中让人恨得牙痒痒的瘤。既然需求变更是不可避免,那我们所能做的就是,尽可能减少变更的次数,降低变更造成的冲击。以往大多数人审核需求变更时较为草率,导致同一个功能点变了又变。在一轮又一轮的返工后,程序员和测试人员会产生倦怠感,编码和测试的质量一再下降。使用了DevSuite后,所有的操作都在系统里留下记录,这统计在年终时可以作为考评的参考材料。自然而然地,审核人员就很严谨地审核每一个需求变更。而且,因为系统设置了每人只有两天的时间处理,审核人员处理需求变更时不仅是快,而且较仔细。单单就这个变化,就使得整个团队的气象焕然一新。
在系统实施后半年,我们做了客户回访,我劈头就问王总监,说的那位产品经理还跟项目经理还吵架吗?瞪了我一眼,停了一下,然后皱了皱眉头说:倒是不吵架了。他们俩现在成了好朋友,联合起来一起对付我了。他自己呵呵呵地笑了起来