Play 框架是一个完整的 Web 应用开发框架,覆盖了 Web 应用开发的各个方面。它借鉴了流行的 Ruby on Rails 和 Grails 等框架,又有自己独有的优势。具体表现在以下几个方面:其一,通过 Play 框架提供的命令行工具,可以快速创建Java Web 应用。其二,它拥有Java 代码动态编译机制,在修改代码之后,不需要重启服务器就可以直接看到修改之后的结果。其三,它还使用 JPA 规范来完成领域对象的持久化,可以很方便的使用不同的关系数据库作为后台存储。其四,它使用 Groovy 作为视图层模板使用的表达式语言。模板之间的继承机制避免了重复的代码。总的来说,Play 框架非常适合快速创建Web 应用开发。本文将为有一定Java Web框架基础的读者,来重点介绍如何使用play框架来编制一个最简单的信息增删改查应用。
一、安装Play框架
安装play框架前,只需要使用JDK 1.5以上的版本即可,将官网上的play框架下载后解压到某个指定目录下,使用的是eclipse开发工具即可。在本文中,将介绍的例子,是一个关于公司、部门、员工之间的CRUD操作,其关系为:一个公司有很多部门,一个部门有很多个员工。
二、开始使用PLAY框架的脚手架功能
PLAY框架为能让用户快速开始搭建play系统的原型。下面是使用play中脚手架功能的步骤:
在命令行方式下,转到play框架的安装目录,本文假设为c:\play下。
假设我们的应用的名称为corporations,则在play中,新建立一个应用只需要用如下命令即可:play new corporations,其中new表示新建应用,new后的名称则为应用的名称。
在输入上面的语句后,会提示输入确认系统的名字,这里输入corporations,按回车确认即可。
我们使用cd corporations目录中,会发现已经有play自带的框架的内容了。我们可以在命令行方式下,执行play run,这时play就会启动自带的jetty服务器,将应用启动起来。
在启动后,可以通过浏览器浏览刚才新建的应用了,方法是http://localhost:9000,就可以看到一个默认的play应用,其中显示的首页中,简单指导了一些简单的配置方法。如下图:
三、配置应用 将框架工程导入eclipse
我们为了要在eclipse中方便我们的编码,所以需要把play刚为我们建立好的框架工程导入到我们的eclipse中去,所以我们按如下步骤去做:
1、使用CTRL-C,先把我们正在运行的应用停止下来。
2、依然在corporations目录下,输入play eclipse,表示要生成能导入eclipse的框架工程。
3、再启动eclipse ,然后使用导入工程的方法,把corporations工程导入。
4、在这个例子中,用的只是HSQL,所以打开conf/application.conf文件,将下面的
db=mem 语句前的注释符号去掉,表示我们将使用hsql。
5、同样,在conf/application.conf文件中,增加如下这行,表示我们将使用play脚手架框架自带的CRUD功能:
| module.crud=${play.path}/modules/crud |
6、在conf/routes文件中,增加如下这行:
注意,在play框架中,routes是路由控制器,这行表示,将所有的CRUD操作都是只有通过 */admin访问的请求,才能实现play自带的CRUD功能。
7、在进行上述修改后,我们再到命令行方式下,运行play eclipse,然后再到ECLIPSE下按F5刷新一下
8、如果此时再使用play run,运行会发现暂时还没有更新,因为我们要进行数据层的配置。
Play 框架是一个完整的 Web 应用开发框架,覆盖了 Web 应用开发的各个方面。它借鉴了流行的 Ruby on Rails 和 Grails 等框架,又有自己独有的优势。具体表现在以下几个方面:其一,通过 Play 框架提供的命令行工具,可以快速创建Java Web 应用。其二,它拥有Java 代码动态编译机制,在修改代码之后,不需要重启服务器就可以直接看到修改之后的结果。其三,它还使用 JPA 规范来完成领域对象的持久化,可以很方便的使用不同的关系数据库作为后台存储。其四,它使用 Groovy 作为视图层模板使用的表达式语言。模板之间的继承机制避免了重复的代码。总的来说,Play 框架非常适合快速创建Web 应用开发。本文将为有一定Java Web框架基础的读者,来重点介绍如何使用play框架来编制一个最简单的信息增删改查应用。
一、安装Play框架
安装play框架前,只需要使用JDK 1.5以上的版本即可,将官网上的play框架下载后解压到某个指定目录下,使用的是eclipse开发工具即可。在本文中,将介绍的例子,是一个关于公司、部门、员工之间的CRUD操作,其关系为:一个公司有很多部门,一个部门有很多个员工。
二、开始使用PLAY框架的脚手架功能
PLAY框架为能让用户快速开始搭建play系统的原型。下面是使用play中脚手架功能的步骤:
在命令行方式下,转到play框架的安装目录,本文假设为c:\play下。
假设我们的应用的名称为corporations,则在play中,新建立一个应用只需要用如下命令即可:play new corporations,其中new表示新建应用,new后的名称则为应用的名称。
在输入上面的语句后,会提示输入确认系统的名字,这里输入corporations,按回车确认即可。
我们使用cd corporations目录中,会发现已经有play自带的框架的内容了。我们可以在命令行方式下,执行play run,这时play就会启动自带的jetty服务器,将应用启动起来。
在启动后,可以通过浏览器浏览刚才新建的应用了,方法是http://localhost:9000,就可以看到一个默认的play应用,其中显示的首页中,简单指导了一些简单的配置方法。如下图:
三、配置应用 将框架工程导入eclipse
我们为了要在eclipse中方便我们的编码,所以需要把play刚为我们建立好的框架工程导入到我们的eclipse中去,所以我们按如下步骤去做:
1、使用CTRL-C,先把我们正在运行的应用停止下来。
2、依然在corporations目录下,输入play eclipse,表示要生成能导入eclipse的框架工程。
3、再启动eclipse ,然后使用导入工程的方法,把corporations工程导入。
4、在这个例子中,用的只是HSQL,所以打开conf/application.conf文件,将下面的
db=mem 语句前的注释符号去掉,表示我们将使用hsql。
5、同样,在conf/application.conf文件中,增加如下这行,表示我们将使用play脚手架框架自带的CRUD功能:
| module.crud=${play.path}/modules/crud |
6、在conf/routes文件中,增加如下这行:
注意,在play框架中,routes是路由控制器,这行表示,将所有的CRUD操作都是只有通过 */admin访问的请求,才能实现play自带的CRUD功能。
7、在进行上述修改后,我们再到命令行方式下,运行play eclipse,然后再到ECLIPSE下按F5刷新一下
8、如果此时再使用play run,运行会发现暂时还没有更新,因为我们要进行数据层的配置。
六、建立部门跟员工之间的连接关系
现在我们在建立了部门类和员工类后,可以开始建立它们之间的关联关系了。由于一个部门中是有多个员工,所以在员工类employee中,写入如下代码,建立两个类之间的关联:
| @ManyToOne public Department department; |
这里依然使用了@ManyToOne的JPA注解去实现多对一的关系。在再次运行程序后,会发现,在增加员工时,会出现下拉菜单选择框,让其选择该员工属于哪一个部门。
七、建立公司实体类和控制类
最后,我们建立公司实体类和控制类。同样,在app/models目录下,建立Company类如下:
| package models; import javax.persistence.Entity; import play.db.jpa.Model; @Entity public class Company extends Model { public String name; public String address; public boolean isPublic; } |
company的控制层类代码如下:
| package controllers; import models.Company; @CRUD.For(Company.class) public class Companies extends CRUD { } |
这里要提醒一点的是,由于company的复数是companies,而play框架原先约定俗成的是在实体类名后直接加字母s,所以这里使用了注解 @CRUD.For(Company.class),以表明该控制类文件Companies是为company实体类服务的。
同样,一个公司里有许多部门,因此在Deparment部门类中,建立如下的多对一关系:
| @ManyToOne public Company company; |
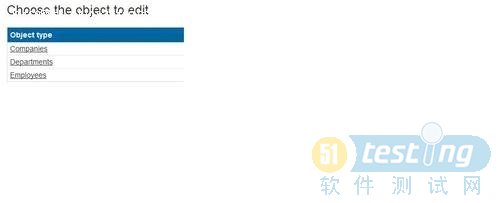
再次运行程序,可以看到,现在三个实体类都建立起来了,可以分别对公司,部门和员工进行CRUD操作,如下图:
八、优化列表
我们在查看每个实体类的列表时,发现在列表中,会把每条记录的id都显示出来,这个在程序中假设不需要看到id字段的话,可以通过修改代码实现,比如在Company类中,增加toString方法即可:
| public String toString() { return name; } |
而在Department和Employee类中,可以采用同样的方法,以不显示它们的id字段。
九、增加校验规则
在输入数据时,校验规则是必不可少的,在play框架中,可以很方便地使用注解来增加校验规则,比如在员工类中,可以要求输入的fullName字段内容不能超过100个字符,而且fullName字段不能为空,则在Employee类中,增加如下代码即可:
| @Required @MaxSize(100) public String fullName; |
下面列出一些常见的校验规则:
@Email 校验email合法性
@InFuture 检验是否将来的日期
@InPast 检验是否是过往的日期
@Match 对正则表达式的判断
@Max 最大值
@Min 最小值
@Range 检验范围
@URL 检验是否URL
十、改变列表的显示格式
在默认情况下,比如查看employee列表,只能看到employee的名称字段,假设要在列表中看到每条记录的每个字段的话,要修改下play的模版,方法如下:
1、停止现在的服务,CTRL-C停止。
2、在命令行下,输入:
play crud:ov --template Employees/list
这将在app/views/Employees目录下新建立一个list.html的页面。
3、重新输入play run,并切换到eclipse中的项目中,按F5更新页面。
4、在eclipse中,打开app/views/Employees/list.html,这个是雇员列表的模版文件。
5、在该页中,找到id=”crudListTable”部分,修改为:
| #{crud.table fields:['fullName', 'dateOfHire', 'salary'] /} |
即显示完整所有字段。
6、重新运行程序,即可看到效果,如下图,可以看到,能看到所有字段值。

十一、改变列表中标题的显示
在默认状态下,列表中显示的字段标题是用实体类中的名称的,假如想把fullName修改位Full Name的话,可以在conf/messages下,增加:
fullName=Full Name
即可,如下图显示:

小结
在本文中,我们学习了如何使用Play框架的脚手架功能,快速搭建CRUD的应用原型。Play框架的配置方法简化了工作代码量。目前Play框架正在不断的完善中,读者可以根据本教程的指引实际操作后,进一步阅读官方文档加以深入学习。