
Nginx以其消耗资源少,承受并发量大,配置文件简洁等特点,深受广大sa们的喜欢,但是网上传播的nginx 配置并没有对做过多的优化。那么接下来,我就从某大型媒体网站的实际运维nginx优化角度,来给大家讲解一下nginx主要优化的那些方面。
一、编译方面优化
1、首先就要从configure 参数分析,根据网上最常用的configure 参数来说,大都是
| ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_stub_status_module --with-http_ssl_module |
应该说这个参数是通用的,适用于各种环境的需要,比如php环境、纯静态文件环境、代理环境等等。编译nginx程序文件大约有2M大小,跟全面优化的500多K,相差了不少。
下面我们修改一下参数,减少不必要的功能。
纯静态文件环境参数
| ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_stub_status_module --without-http_fastcgi_module --without-http_proxy_module --without-http_upstream_ip_hash_module --without-http_autoindex_module --without-http_ssi_module --without-http_proxy_module --without-mail_pop3_module --without-mail_imap_module --without-mail_smtp_module --without-http_uwsgi_module --without-http_scgi_module --without-http_memcached_module |
去掉了在mail模块fastcgi模块 代理模块 ip_hash模块等,在纯静态文件用不到的模块,现在看看nginx程序文件是不是少了一些。
Php环境的话,只需要去掉--with-http_fastcgi_module 重新编译即可。
代理环境的话,只需要去掉--with_proxy_module重新编译即可。
2、去掉nginx 默认的debug跟踪设置。这一步需要修改nginx 源码。
cd nginx-1.0.x
vim auto/cc/gcc |
第175行
前面加#注释掉改行。
这样的话,编译的参数,就会减少到500多K的标准,这样在大并发量的条件下,性能提升明显。
二、利用google-perftools来优化高并发条件下的nginx
在32位系统下,可以直接安装google-peftools,64位条件下,需要先安装libunwind库。然后再nginx configure 参数增加--with-google_perftools_module 重新编译安装nginx 。
这里以64位环境为准
1)安装libunwind库
wget http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99.tar.gz
tar zxvf libunwind-0.99.tar.gz
cd libunwind-0.99/
CFLAGS=-fPIC ./configure –prefix=/usr
make CFLAGS=-fPIC
make CFLAGS=-fPIC install |
Nginx以其消耗资源少,承受并发量大,配置文件简洁等特点,深受广大sa们的喜欢,但是网上传播的nginx 配置并没有对做过多的优化。那么接下来,我就从某大型媒体网站的实际运维nginx优化角度,来给大家讲解一下nginx主要优化的那些方面。
一、编译方面优化
1、首先就要从configure 参数分析,根据网上最常用的configure 参数来说,大都是
| ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_stub_status_module --with-http_ssl_module |
应该说这个参数是通用的,适用于各种环境的需要,比如php环境、纯静态文件环境、代理环境等等。编译nginx程序文件大约有2M大小,跟全面优化的500多K,相差了不少。
下面我们修改一下参数,减少不必要的功能。
纯静态文件环境参数
| ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_stub_status_module --without-http_fastcgi_module --without-http_proxy_module --without-http_upstream_ip_hash_module --without-http_autoindex_module --without-http_ssi_module --without-http_proxy_module --without-mail_pop3_module --without-mail_imap_module --without-mail_smtp_module --without-http_uwsgi_module --without-http_scgi_module --without-http_memcached_module |
去掉了在mail模块fastcgi模块 代理模块 ip_hash模块等,在纯静态文件用不到的模块,现在看看nginx程序文件是不是少了一些。
Php环境的话,只需要去掉--with-http_fastcgi_module 重新编译即可。
代理环境的话,只需要去掉--with_proxy_module重新编译即可。
2、去掉nginx 默认的debug跟踪设置。这一步需要修改nginx 源码。
cd nginx-1.0.x
vim auto/cc/gcc |
第175行
前面加#注释掉改行。
这样的话,编译的参数,就会减少到500多K的标准,这样在大并发量的条件下,性能提升明显。
二、利用google-perftools来优化高并发条件下的nginx
在32位系统下,可以直接安装google-peftools,64位条件下,需要先安装libunwind库。然后再nginx configure 参数增加--with-google_perftools_module 重新编译安装nginx 。
这里以64位环境为准
1)安装libunwind库
wget http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99.tar.gz
tar zxvf libunwind-0.99.tar.gz
cd libunwind-0.99/
CFLAGS=-fPIC ./configure –prefix=/usr
make CFLAGS=-fPIC
make CFLAGS=-fPIC install |
Java代码编译是由Java源码编译器来完成,流程图如下所示:

Java字节码的执行是由JVM执行引擎来完成,流程图如下所示:
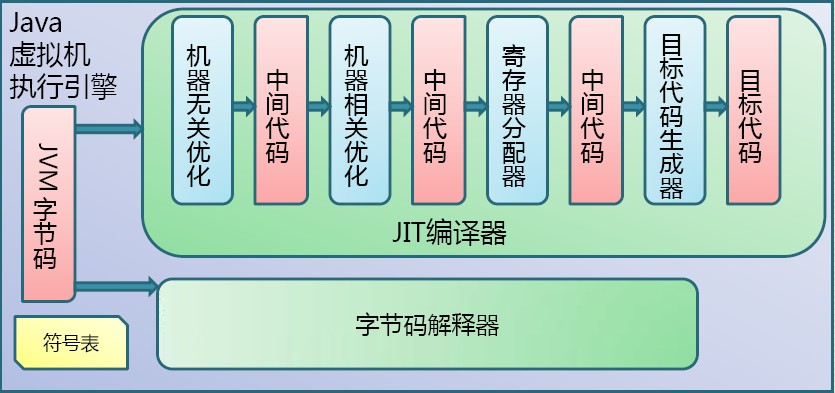
Java代码编译和执行的整个过程包含了以下三个重要的机制:
● Java源码编译机制
● 类加载机制
● 类执行机制
Java源码编译机制
Java 源码编译由以下三个过程组成:
● 分析和输入到符号表
● 注解处理
● 语义分析和生成class文件
流程图如下所示:

最后生成的class文件由以下部分组成:
● 结构信息。包括class文件格式版本号及各部分的数量与大小的信息。
● 元数据。对应于Java源码中声明与常量的信息。包含类/继承的超类/实现的接口的声明信息、域与方法声明信息和常量池。
● 方法信息。对应Java源码中语句和表达式对应的信息。包含字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试符号信息。
类加载机制
JVM的类加载是通过ClassLoader及其子类来完成的,类的层次关系和加载顺序可以由下图来描述:

1)Bootstrap ClassLoader
负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类
2)Extension ClassLoader
负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
3)App ClassLoader
负责记载classpath中指定的jar包及目录中class
4)Custom ClassLoader
属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader
加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
类执行机制
JVM是基于栈的体系结构来执行class字节码的。线程创建后,都会产生程序计数器(PC)和栈(Stack),程序计数器存放下一条要执行的指令在方法内的偏移量,栈中存放一个个栈帧,每个栈帧对应着每个方法的每次调用,而栈帧又是有局部变量区和操作数栈两部分组成,局部变量区用于存放方法中的局部变量和参数,操作数栈中用于存放方法执行过程中产生的中间结果。栈的结构如下图所示:

模型驱动的软件测试技术
一、引言
模型驱动的软件测试(Model-Driven Test)技术是针对软件中的一些常见的软件模型而提出的一种测试技术,如故障模型、安全模型、死锁模型等。模型驱动的软件测试以明确描述系统预期行为的抽象模型为依据,根据模型覆盖测试准则自动生成抽象的测试用例,自动地产生测试脚本,执行测试并自动评价测试结果,从而有效提高测试效率。这一技术正成为当前软件工程学术界研究的一个重要方向。
近年来,基于模型的软件测试技术得到快速的发展,大量的软件测试工具被研制出来从而可以自动地检测软件中的故障,并且在对一些大型商业软件和开源软件的测试中发现了大量的以前测试没有发现的软件故障和安全隐患。
二、模型驱动的软件测试技术的特点
与其他测试技术相比,基于模型的软件测试技术具有如下特点:
(1)故障模型根据被测试应用程序的分析设计模型及其生成测试模型、产生测试用例和进行测试结果评价。
(2)大大提高了测试自动化水平以及测试效率。
(3)部分解决了测试失效辨识问题,往往能发现其他测试技术难以发现的故障,保证了软件质量。
(4)有利于测试用例的重用,并可以应用成熟的理论和技术获得比较完善的分析结果。
三、软件模型分类
软件模型是对软件行为和软件结构的抽象描述。软件模型通常可以分为以下7 类:
(1)故障模型
故障模型主要是会引起错误的常见软件模型, 应该尽量避免, 如内存泄漏故障(MLF) 、使用空指针故障(NPDF) 、数组越界故障(OOBF) 、非法计算类故障(ILCF) 、使用未初始化变量的故障(UVF) 、不完备的构造函数故障(ICF) 以及操作符异常故障(OAF) 等。
(2)安全漏洞模型
安全漏洞模型为他人攻击软件提供可能。而一旦软件被攻击成功,系统就可能发生瘫痪,所造成的危害可能更大。因此,此类漏洞应当尽量避免,如:缓冲区溢出漏洞模型、被感染数据漏洞模型、竞争条件漏洞模型等。
(3)差性能模型
该模型在软件动态运行时效率比较低下,因此建议采用更高效的代码来完成同样的功能。这类模型主要包括调用了不必要的基本类型包装类的构造方法、空字符串的比较、拷贝字符串、未声明为static 的内部类、参数为常数的数学方法、创建不必要的对象以及声明未使用的属性及方法等。
(4)并发故障模型
该模型主要是针对程序员对多线程的编码机制不十分了解,对各种同步的方法、Java 存储器模型和Java 虚拟机的工作机制不是很清楚,而且由于线程启动的任意性和不确定性使用户无法确定所编写的代码具体何时执行而导致对公共区域的错误使用,如死锁等。
(5)不良习惯模型
该模型主要是由于程序员编写代码的不好习惯造成的一些错误。包括文件的空输入、垃圾回收的问题,类、方法和域的命名问题,方法调用,对象序列化,域初始化等。
(6)代码国际化模型
该模型主要是在语言进行国际化的过程中,可能造成本地设置和程序需求不符的情况,造成匹配错误。
(7)易诱骗代码模型
该模型主要指代码中容易引起歧义的、迷惑人的编写方式。比如无意义的比较,永远是真值的判断,条件分支使用相同的代码,声明了却未使用的域等,即那些混淆视听,无法正常判断程序的真正意图的代码。
四、模型驱动的软件测试过程
模型驱动的软件测试方法通过对测试过程的抽象化,分离测试模型和测试执行,从而能够通过正向或逆向手段建立针对WA某方面特征的测试模型,并重用有针对性的测试执行手段。传统黑盒、白盒测试方法与模型驱动的软件测试方法并不矛盾,它们可以被包含到模型驱动的软件测试过程中。
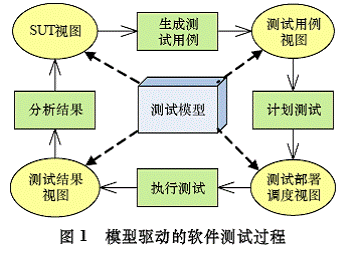
如图1所示,测试模型是模型驱动的软件测试的核心概念,它在测试的不同阶段表现为不同视图。
(1)通过被测系统(SUT)视图得到测试模型;
(2)基于测试模型,自动化或半自动化地得到测试用例集,通过测试用例视图描述;
(3)在测试执行阶段,测试部署和调度视图通过相应模型描述测试的执行环境以及执行过程;
(4)根据部署调度模型自动执行测试用例,生成的结果通过测试结果视图显示,并将某些结果直接反馈给被测系统模型、测试用例模型以及部署调度模型,在各自视图上直观的显示出来,便于分析结果进行回归测试。
五、模型驱动的软件测试工具
模型驱动的软件测试必须有相关工具支持。当前,有代表性的模型驱动的软件测试工具中有:
(1)支持状态机模型的工具。包括:Software Engineering Technology的测试工具toolSET_Certify,运行于RISC6000和SUN平台;IBM的GOTCHA,可以根据用户事先确定的测试充分性准则进行基于软件状态模型的测试例生成;IBM 的TCBean是一个提供测试脚本管理功能的基于状态机的测试引擎。
(2)支持马尔可夫链模型的工具。包括:Cleanroom Software Engineering的CleanTest,支持统计测试,是商用的使用模型及统计测试例生成工具;IBM 的CleanroomCertification Assistant,可以自动化统计验证过程,通过使用概率分布产生测试例,并对测试结果进行分析。
(3)对UML模型提供测试支持的工具。包括:SilverMark公司针对IBM 公司的VisualAge开发的支持测试用例生成和回归测试的TestMetor和UML Designer Connection。
如何进行需求矩阵管理
产品经理需要掌握并管理产品的全部需求,需求是软件项目成败的关键所在,好的需求应具备“内涵一致,外延完整”的特质,这个特质可以保证需求分析无歧义、完整、一致、正确、可行、必要、可检验、可跟踪。
软件需求是多层次的,包括业务需求、用户需求、功能需求和非功能需求。如下图所示:

启动一个新产品时,产品经理需和各方进行充分的沟通,深刻理解客户或者公司高层对系统、产品高层次的目标要求,将业务需求反映在产品的创意阶段、策划阶段的《产品项目策划书》、《产品项目规划方案》中予以说明。
用户需求主要描述了用户能使用系统来做什么,用例、场景描述都是表达用户需求的有效途径。这部分需求通常在用例文档或方案脚本说明中予以说明。
功能需求定义了开发人员必须实现的软件功能,用户能够利用这些功能完成任务,从而满足业务需求。功能需求通常是通过对系统特性的描述表现出来的,它记录在《软件需求规格说明书》(SRS)中。《软件需求规格说明书》完整地描述了软件系统的预期特性,是开发、测试、质量保证、项目管理的重要依据。因设计的产品功能一般都较为复杂,业务规则的描述也需尽可能详尽,所以通常情况下《软件需求规格说明书》并不是一份文档,而是根据功能模块的划分由多个子文件组成。每一篇需求说明文档中均必须包含功能列表和功能详细描述,可依据实际业务情况增加数据字典方面的描述。《软件需求规格说明书》中的功能列表需要和《需求跟踪矩阵》一一对应,包括功能点编号、功能点名称。需要强调一点,需求文档的重点是说明功能所在,无需描述界面中的Icon、色彩、像素等信息,为避免和界面设计稿等展示高保真产品原型的文档发生冲突,需求文档中应尽量全部采用低保真界面,界面类描述交由《交互设计说明书》及界面设计稿、Html文件去说明。
《软件需求规格说明书》中还应包括非功能需求,非功能需求描述了系统展现给用户的行为和执行的操作等,它包括产品必须遵从的标准、规范和约束,操作界面的具体细节要求,性能要求,设计或实现的约束条件及质量属性。通俗地讲,非功能需求是这样一种需求,它不是解决“我想要我的系统实现这种功能”,而是解决“如何使这个系统能在实际环境中运行”。在非功能需求中,针对性能方面一般需要有单点、混合、持续三方面的要求:
1、在单点方面,要求延迟和吞吐量有对应关系,假如我们设计一款BS软件,要求打开登录页面的延迟要求为响应时间3秒、抖动2秒,那么一定要在吞吐量的要求上写上针对这一点的高峰并发人数,比如100人。
2、在混合方面,产品经理依据业务的实际情况,定义混合并发值,并依据单点定义的部分或全部点以百分比的形式分配并发比例,注意混合下的并发值不得高于单点下的并发值。比如定义混合并发值200人,其中20%访问首页,20%登录,20%上传文件,40%浏览页面。
3、在持续方面,通常定义为单点最高并发值二分之一情况下的2*24小时或3*24小时持续测试。比如定义50人并发下持续性测试时间2*24小时。
《需求跟踪矩阵》主要是跟踪及统计功能需求和非功能需求。当需求基线第一次形成时就需要填写这个文档,这篇文档中的功能点名称和编号需和需求文档中对应,不得存在差异,每个功能点都需要定义它的级别(P1、P2、P3,P1为最高级别)。通常,重要程度为P1级的功能点数,不超过50%;或者P1级和P2级的功能点数,不超过80%。需求发生变更时,需填写《需求跟踪矩阵》中的需求变更记录表用以记录新增、修改、删除的功能点,并需在各模块的功能点列表中标记变更状态,通常如有新增功能,则增加在相应模块底部,字体设置为红色,如有删除功能,用蓝色标记。
在《需求跟踪矩阵》的需求变更统计表中,有一组图表可以直观地展现各阶段需求变更工作量、项目整体需求变更率、项目整体功能点变化的情况,如下图所示:

以上主要解释并分析了需求的四个层次,以及如何管理需求跟踪矩阵,希望能对产品经理们有所启发。
最后附上Jan L.A. Van de Snepscheut的一段话,可以细细品味:就理论而言,理论和实践并无差异。但真付诸实行之时,差异即开始显现。
序言:不知道有多少人对开源社区真的很有了解,个人以为在自动化测试中,开源也是一个很好的利器,往往商业性的工具针对普遍人群,而自动化测试是“定制型”的,不一定特别适合,而且自动化测试是预言型的,所以一般而言,可以考虑开源。因为可以快速应用其提高效率,我个人觉得:自动化测试在追求发展过程中,要学会借助各种工具提高效率,而不是仅仅局限于一种。还是那句话,能提高测试效率和工作效率的才是王道,“摘花折草即可伤人也”。
一、自动化测试中的开源软件分类
开源工具因为其零许可费以及开放和自由的理念逐渐得到了大家的认可和广泛的传播,而且由于自动化测试的差异性,其开源软件的灵活性更能在自动化测试中很好的体现,而且随着开源软件和自动化测试的发展,其开源工具在自动化测试中也形成了一股应用的趋势。其实,在工作中,我们都在不断的与自动化测试打着交道。
在自动化测试过程中,我们与之打交道的开源工具,可以分为
1、编程语言与平台,即在自动化测试过程中应用的语言和操作系统
1)Andriod,大家应该都有所了解,其是以Liunx为内核底层来支持不同硬件,并在其上搭建一个类java的运行环境,其大概有几层,包括:linux内核、底层库、JAVA框架(包括其API)、Andriod应用程序。
2)LINUX,大家熟知的开源操作系统。
3)脚本语言:Python、ruby、perl等,这些都是在自动化测试中因为其简便性与动态性多有用到的编程语言。这些语言的维护、开发和发展都是通过开源社区和开源标准组织(例如ISO和Ecma)进行的,所以它们称为开源语言。而java因为受Oracle支配,所以称得上开源不开源,我也不是很清楚…
4)Flex:是在FLASH基础上做的一层封装,提供了组件库,开发人员可以直接编写MXML,即在FLEX中布局用户界面组件的一种XML语言来搭建用户界面。同时,完成负责数据逻辑的ActionScript脚本,最好编程成FLASH文件。所以,有些用户界面是用FLEX开发的。
……
2、开源开发工具
1)Eclipse,这个用过java的一般都很熟悉吧,是一款很好的IDE。其是基于”OSGi”的“即插即用”理念,所有功能以组件形式存在。其理念我觉得非常好,其插件只要遵循其平台的规范,就能集成到其中应用。例如:Pydev是一款python的插件,jython是一款Java与python集成的插件,还有andriod、ant等集成的插件,当然,我觉得可以的话,最好先应用一下独立版,再去在eclipse中应用,这样,可以更好的了解其运作原理。
而且,我觉得这种理念在自动化测试中也可以很好的应用,使得各个工具之间能够在一个平台上作为模块互相通用,而且也能独自使用。其IBM rational开发的jazz平台也是基于一种这么理念的。
2)Ant,这个大家也许不是很熟悉,但是开发过java应用程序或者做个持续集成的也有有所了解,它就是一款构建的工具,即用XML描述任务的形式,自动完成其定义的工作,例如:可以帮助开发人员自动完成编译、单元测试、打包、发布等工作。
3)Maven,Java开源项目的开发管理工具,涵盖了项目构建、文档管理、报告生成等方面,与Ant功能类似,其差别在于ant每一个项目需要独立维护一个XML构建描述文件,而Maven能够帮助快速搭建一个项目框架,而无需从头编写,其是一种“约定胜于配置”的理念,即先抽象出一个原型。这理念也可应用在自动化测试中的,即先提供一个脚本模板,然后根据这个模板,搭建一定的测试流程。
4)版本管理工具,例如:SVN和CVS,其都能够应用脚本控制其代码版本的签入和签出,在其自动化测试中也能有一定应用,方便管理脚本与代码程序。
5)Bugzilla,缺陷管理工具,可以管理和跟踪缺陷,即,可以在自动化测试中应用来管理相应结果或者缺陷跟踪等。
6)Junit,大家都恨熟知的吧,单元测试的一款工具,即事先规定好单元测试模板,开发人员只需去根据被测试代码,搭建其测试代码即可。
7)TestNG,与junit类似。在自动化测试中也能有所应用。
3、编程及测试框架与库
1)在J2EE开发中,大家熟知的SSH,即Spring、Struts、Hibernate。具体的大家可以去查阅相关资料,我想说的是,如果大家深入学习的话,会发现,其开发理念和自动化测试思想很相似,像Struts的MVC思想,与自动化测试的分层理念可以很好的结合。Hibernate的数据库持久层思想也可以用于自动化测试的数据管理应用,总之,了解这些软件设计框架,对于加强自动化测试思想的理解很有帮助。
2)Selenium,大家都很清楚的web自动化测试框架,很多人都说这是一种工具,其实说工具也行,框架也一样,其提供了一种测试web的自动化思想,即采用绕过web中“同源策略”的方法,用JS来控制web的操作。你可以编写脚本应用其API,来控制web的相应控件的操作。一般是集成在你的自动化测试管理框架或者系统平台中的。
3)Robutium,andriod UI测试的一个自动化测试框架,理念类似,只是应用场合不一样。
4)Abbot,测试java UI的一个自动化测试框架,其录制的测试用例是用XML进行描述,其只能用录制的方式生成XML文件,而且其abbot只能去读取XML,所以你可以自己写一个脚本库去生成相应的XML去控制aboot,其在测试java UI方面的稳定性还是不错的。
当然,还有各种各样的编程框架与自动化测试框架,但是随着接触的多了,你会发现其理念都是一样的,所以要学会自己从各个工具中提炼其思想与共性。
4、应用服务器软件
1)web服务器,举一个例子,大家熟知的Tomcat,其中也继承了J2EE中的servlet,其web服务器的作用主要是提供HTTP协议操作,将web客户端提交的页面请求进行处理后,然后动态返回相应的HTML页面即可。
2)数据库,MySQL,开源的关系数据库系统,在一般的中小型项目还是很好用的,数据库设计在自动化测试中,个人认为也很重要,如果将自动化测试设计成一个平台的话,需要涉及大量的测试用例与脚本、测试用户权限的管理等。所以,数据库设计需要在自动化测试平台设计之前,定义好表以及表之间的联系,方便以后拓展使用。
二、如何去保证开源工具的应用
1、在自动化测试开展过程中,首先要对其测试需求以及对自动化测试的开展程度进行分析,包括自动化测试的规模、自动化测试的紧急程度以及实际需要应用程度、自动化测试的成本考虑等因素。
2、之后,就去根据相应的需求,在不同方面采用不同的测试软件或者工具,不需要局限和死专于一种,哪种能提高效率,就尽快采用。
3、总之,在这些软件或者工具的基础上,如果要规模化的话,你需要有一个自己定义好的平台进行规范,各个工具软件框架都可以以模块化的形式存在,当然,我建议最好要慎重考虑其“高内聚、低耦合”的思想。
三、开源工具的应用策略
我大概想了一下,其在自动化测试应用中,这些工具都扮演着不同的角色,对推动这个测试,甚至说软件行业都起到很大作用。
1)常规的开发和测试流程
当然这个自动化测试不会起到主要性的作用,但是能提高一定的效率。
2)持续集成的流程
需要搭配单元测试框架、构建工具、以及持续集成管理工具(例如:cruisecontrol)
3)敏捷开发与测试流程
敏捷开发中我觉得自动化测试是很重要的一个角色,其能够快速保证其发布周期。
4)云端测试流程
现在出来的云端提交测试,需要自动化形式提交以及进行相应的处理,其都是在web上面进行提交与返回的。
总之,“预先善其事,必先利其器”,但是,在众多的自动化测试软件工具和框架中,我们要保持一个清醒的思想,要能够去抓到本质,真正能为我所用,就像武侠小说里面似的,侠客之路,从手中有剑到手中无剑、从有招到无招,从无心到有心。共勉之。
摘要:
你的项目出了严重问题,客户向你公司的领导投诉,你的领导兴师问罪要追究责任!这是测试的错?开发的错?PM的错?还是研发流程的错?中国教育制度的错?社会的错?反正、总之、一定、必须不是我的错!
事件回放:
某项目部署给客户后,重现了一些以前已经解决的问题,而这些问题测试时并没有出现。经检查,发现测试的版本不是部署的版本,不知道为什么老版本部署给客户了。领导要追究责任,于是大家各有说法:
开发人员说:我是按要求打标签的,没有问题。
测试人员说:我是在提交区中取版本来测试的,我没有出错。
实施人员说:我是按照开发给我的版本去部署的,我没有过失。
最后终于有人说:是之前已经离职的某某弄错版本号导致的。
思考:
1、该事件反应了什么问题?将来应该如何改进?
2、这么多问题中,最大的问题是哪个问题?
在继续往下阅读之前,建议你先写写对以上问题的想法,然后再继续阅读。
本事件并没有什么标准的答案,下面分析仅供大家参考,欢迎大家提出自己的想法!
事件的补充说明:
这是发生在我以前公司的真实个案。第一次听说时,我觉得很不可思议,也觉得非常的丢人!
客户当前版本是1.1,我们打算为之安装1.2版本,安装后客户反馈怎么以前已经解决的缺陷又再次出现了?检查后发现,原来我们安装的是1.0版本的程序。相当于大家辛辛苦苦地奋战了数天,最后竟然没有将工作成果给客户,而是将以前的东西给客户了。作为软件公司来说,这是一个超级低级的错误!
经过检查,终于发现了问题的真正原因:开发人员A让实施人员B直接在他的电脑上取安装程序,而不是根据研发流程的要求到配置库中取,而该开发人员A让实施人员B所取的版本,是1.0版本的老程序,而不是最新的1.2。这个原因主要是通过实施人员B得到的,但开发人员A已经离职了,“死无对证”!
似乎整个事件需要负责任的就是这位已经离职的仁兄,而该仁兄已经离职,更加是百口莫辩。我的领导对于这样的结论,苦笑说:呵呵,这样好,推到一个离职的人身上!
问题1:某些人员失职,没执行流程!
开发人员A和实施人员B违反了相关规定,严重失职,应为此负责。而开发人员A已经离职,故应由实施人员B来负担主要责任。这样处理是否合适呢?
问题2:研发流程和公司制度有漏洞,应进一步改善!
研发流程虽然规定了要从配置库中取安装程序,但没有版本确认的步骤,而且安装程序应该由配置人员提供,而不应该由实施人员直接问开发人员要,这是流程中需要改善的。
于是配置管理员提出建议:规定所有的安装程序只能由配置管理员提供,不能通过其他途径!
但项目经理、开发、实施都反对,因为经常需要加班,往往在加班的时候需要提供安装程序,但这个时候配置管理员往往已经下班了,无法向配置管理员要安装程序。如果配置管理员就算没事干都好,愿意一起加班的话,可以这样规定。
于是配置管理员就再无意见了……
另HR提出,此事其实是开发人员A付主要责任的,出现这样的问题原因之一是离职交接没有做好,工作没有检查好。此意见一出,项目组、负责交接A工作的开发、同意A离职的部门经理,几乎全部晕倒了!交接已经做得很不错了,什么问题都要防住,你叫这个交接怎样做?
研发流程和制度确实需要不断完善,但如果老是从细节上规定,是不是有点本末倒置呢?研发工作中的问题总是很多的,不太可能规定所有细节的,而且一旦规定了一些细节,似乎避免了一个问题,但会带来更多的问题。
问题3:喜欢做好好先生、好好小姐!
事件中其实很多人大概知道问题所在的,但就不指出来,不想得罪人,要做“好人”。如果要追求责任,那么最好将错赖在一个不能追究责任的人身上,就是那位可能是很无辜的已经离职的仁兄。或者将错赖在制度和流程上,这招是最绝的,没有人需要负责,这是制度的错、社会的错!
问题4:没有人首先从自己身上找原因,每个人首先想到的是推卸责任!
研发工作中的很多成果,是经过一系列的环节和各人的配合作出来的,任何一个环节有问题,都可能会导致最终成果出问题。那似乎将各环节责任、流程等定义好,就可以很好地追求责任了?
如果某个环节都留下一些隐患,但不至于马上出问题,但经过多个环节累积之后,问题爆发!这时应该哪个环节负责呢?
如果前面某个环节出现一些问题,但下一个环节的人发现了并及时提出来,最终不影响最终成果,这是不是一种很好的效果呢?
如果每个人除了做好本职工作,还主动提醒他人,主动提供一些有利于项目的建议,帮助项目成功,这是不是非常好呢?
软件研发中的问题,往往不是某个环节造成的,而是各种因素作用逐步导致的。项目需要团队一起努力、互相纠正、互相提醒,每个人都应该为项目的最终成功负责!某项目出问题了,是不是应该整个项目组都应该负责呢?是不是大家应该首先从自己身上找原因呢?
哪个问题更加严重?
个人认为问题4是最严重的问题,流程、制度、职责等这些,如果为了解决某一问题而去修改和细化,可能会陷入无休止的类似工作中。这和修复一个bug的道理是一样的,每修复1个bug,可能会带来10个bug。过于从细节上细化流程和制度,我个人是不太赞同的,会陷入某种死循环。
我们喜欢说依法办事,往往用法律来比喻,我们研发过程也需要有法可依。法律规定的一般是不能做什么,但我们流程中规的的往往是必须做什么、应该做什么等,一旦规定应该怎样做,就很容易出问题。研发活动是很复杂的智力活动,不应该在一些细节上套太多的框框条条。
做好团队建设,树立良好的团队观,项目团队应该是“一荣俱荣,一损俱损”的!要打造这样的团队是不容易的,但也不是很难,其实取决于公司领导的管理思想。以目标来驱动,鼓励创新,允许犯错,奖励自我批评,这些都有助于良好的团队建设。但有些领导喜欢工厂化管理,喜欢将工作细化,喜欢根据工作职责来考核,喜欢根据问题多少来考核,这样难以避免这些踢皮球事件了。
这个事件我有什么责任?
说了这么多别人的问题,我是不是应该从自己身上找找原因呢?
我不直接负责该项目工作,是公司的常务副总,公司中的大部分员工都是经过我面试进来的,我一直在尽力打造良好的团队文化,而研发流程大部分是由我制定的,或者是经过我批准的。要兴师问罪的是公司的大领导,不是我,其实如果要问起罪来,可以说公司内部的跟研发相关的所有问题,我都需要负责任!因为这些事基本上都是我管的。
出现踢皮球事件,我觉得很无奈。自己一直以来期望做到的团队“一荣俱荣、一损俱损”,在事到临头的时候,只是一种口号而已,我需要检讨自己的做法和想法。那种美好的团队建设可能只是一种乌托邦,可能难以实现甚至无法实现,但我觉得我还是应该继续为之努力的。
其他的一些想法:
这只是一个小小的案例,但相信很多朋友会经历过类似的情况。推卸责任可能是人的本能反应吧,我也会这样。大家都能主动从自己身上找原因,这可能是一个遥远的梦。
我曾经试过参加一个会,两个高层在PK,老板在一旁看,PK一大通后,最后那项大家都不想干的工作落到了一直没有出声的我的头上,刚才PK的两个人,都一致同意让我来做这项工作!我只能说:很无语……
有些事情我们可能控制不了,但如果咱们能带领一个团队的话,我们应该在能力范围内做一些对团队各人都有益的事情,尽量打造好的团队气氛,挡住影响团队气氛的外部的不利影响。对你的团队成员好,将来得到的回报肯定会远远大于你的付出!
如果还想在测试这条路上继续走下去的话,那么下面这些东西就是我们必须去掌握的,至少你还不想止步于简单的黑盒测试~~其实,一直想去接触Linux下的应用测试,这样能学到东西会很多,而且会非常的受用。之前听小布老师讲,如果你想在IT技术上长期发展下去,那么你就大胆拥抱Linux吧,因为在这里你能学到东西远胜过于你在Windows平台下学到的东西,而其中最经典的一段话就是:如果你一直跟随微软的技术,那么终究会被拖死,因为微软的技术一直在变化,而你却需要不断的去学习他的东西。而Linux不一样,它更多的是让你去理解底层的技术,让你从原理上去理解技术的核心,永远以不变应万变的姿态去面对未来的技术革新。
我想作为一个测试人员,如果你确实还没接触过网络、数据通信方面的技术,那么咱们的路还很长,至少我认为软件测试并非只停留在上层的应用,而测试的最高境界应该是对底层核心技术的测试,通过架构分析、协议数据包分析等等来测试出结果~~~所以我们应该掌握的技术有:TCP/IP、Socket、多线程,这些是必须的。
1、先来看看TCP/IP的体系结构,如下图:

TCP/IP协议实际上就是在物理网上的一组完整的网络协议。其中TCP是提供传输层服务,而IP则是提供网络层服务。下面是各个层的协议说明:
IP: 网间协议(Internet Protocol) 负责主机间数据的路由和网络上数据的存储。同时为ICMP,TCP,UDP提供分组发送服务。用户进程通常不需要涉及这一层。
ARP: 地址解析协议(Address Resolution Protocol)
此协议将网络地址映射到硬件地址。
RARP: 反向地址解析协议(Reverse Address Resolution Protocol)
此协议将硬件地址映射到网络地址
ICMP: 网间报文控制协议(Internet Control Message Protocol)
此协议处理信关和主机的差错和传送控制。
TCP: 传送控制协议(Transmission Control Protocol)
这是一种提供给用户进程的可靠的全双工字节流面向连接的协议。它要为用户进程提供虚电路服务,并为数据可靠传输建立检查。(注:大多数网络用户程序使用TCP)
UDP: 用户数据报协议(User Datagram Protocol)
这是提供给用户进程的无连接协议,用于传送数据而不执行正确性检查。
FTP: 文件传输协议(File Transfer Protocol)
允许用户以文件操作的方式(文件的增、删、改、查、传送等)与另一主机相互通信。
SMTP: 简单邮件传送协议(Simple Mail Transfer Protocol)
SMTP协议为系统之间传送电子邮件。
TELNET:终端协议(Telnet Terminal Procotol)
允许用户以虚终端方式访问远程主机
HTTP: 超文本传输协议(Hypertext Transfer Procotol)
TFTP: 简单文件传输协议(Trivial File Transfer Protocol)
2、TCP/IP协议的核心部分是传输层协议(TCP、UDP),网络层协议(IP)和物理接口层,这三层通常是在操作系统内核中实现。通常用户的服务需要通过应用程序来实现,所以在底层与应用层就是通过套接字来实现,也就是我们通常所说的Socket来建立连接的。具体如下图所示:
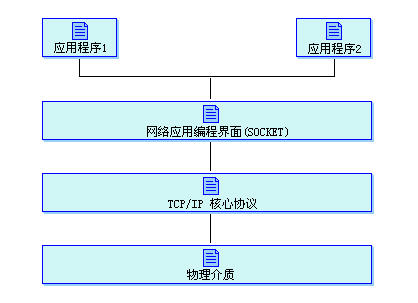
TCP/IP协议核心与应用程序关系如上图所示,所以对照这个图来理解我们的应用层开发,就直观多了,特别是对一些应用进行性能测试时,基于什么协议来通信,分析也会得心应手了。
所以说测试要学的东西还很多,到最后技术也许比开发人员都要牛,最重要的是这些东西能够给你的工作带来实际的帮助。正所谓高手过招比的内功,这些都是内功的修炼,别等到用的时候才发现自己不会,那就迟了。测试的路还很长,埋头学习吧,啥也不说~~
从Java平台的逻辑结构上来看,我们可以从下图来了解JVM:

从上图能清晰看到Java平台包含的各个逻辑模块,也能了解到JDK与JRE的区别
对于JVM自身的物理结构,我们可以从下图鸟瞰一下:

对于JVM的学习,在我看来这么几个部分最重要:
● Java代码编译和执行的整个过程
● JVM内存管理及垃圾回收机制
下面将这两个部分进行详细学习。