把HTML的内容输出到LOG中的方法
1、在脚本要记录HTML的URL前面加入函数:web_create_html_param("MyHtml", "<html>", "");;
2、在脚本要记录HTML的URL后面加入函数:lr_output_message("###the HTML is %s", lr_eval_string(" {MyHtml}"));;
3、在Controller中设置Run-Time Settings,把log设置为Always Send Message;
4、在Controller中设置Run-Time Settings,把Miscellaneous设置为在发生错误时继续运行(在这里不是必须);
5、在Controller中设置Run-Time Settings,把Preferences设置为Enable image and text check;(在这里不是必须);
6、在Controller的日志文件RES中可以查看到每个虚拟用户的LOG;
如何在Controller中添加系统资源检测
今天早上突然想把Windows的性能监视放到LR中,达到方便快捷的目的,下面的是具体的步骤:
1、使用192.168.0.159作为监控的对象,开通Remote Procedure Call和Remote Registry两个服务,Remote Registry一般都是给禁止的,可以改为手动并启动;
2、在159中右击我的电脑,选择管理->共享文件夹->共享 在这里面要有C$这个共享文件夹;
3、在159中使用命令netstat /ano查看445端口是否被打开;
4、输入\\192.168.0.159\c$,再输入用户名和密码,如果能进入c盘,那就说明有控制权了;
5、在Controller的Run中找到Windows Resources,对图点击右键中的Add Measurements,添加计数器;
6、需注意159机上的BlackIce;
7、对Windows Resources Graph的技巧使用,可以冻结窗体,导出HMTL,显示某个计数器等;
对ANALYSIS中不能导出页面细分下的子项的问题的处理方法
1、问题描述:对ANALYSIS的导出WORD功能中只能导出树中的图表,在页面细分中点击不同的节点会有不同的图表,但是却无法把所有节点的图表一起导出;
2、如果想生成Time to First Buffer Breakdown下面Login事务和Loading事务下的图表都导出来,方法就是新建两张Time to First Buffer Breakdown图表,在不同的下面点击图表,并修改名称;
3、在导出列表中选中要导出的图表:Time to First Buffer Breakdown-All && Time to First Buffer Breakdown-Login && Time to First Buffer Breakdown-Loading;
4、总结:虽然这样做有点麻烦,但是比之前点击每个图再导出一个WORD来有用的多,但是LR可以做到在导出列表中以树的形式显示可以导出的图表,不过LR要解决图表没有名称的问题;
在中文版Analysis中显示系统资源图的原因与解决
1、是否可以通过修改ACCESS记录来修改这个BUG?
2、不知道它添加图表的列表是不是通过数据库LOAD的?迄今还没有找到这些记录,只找到资源图表数据;
3、解决办法1:是用VNC截图,但是这样只能看到计数器曲线,没什么意义;
4、解决办法2:在Controller中导出系统资源数据,里面有量化数据,比较真实,不过每个场景都要导出一次就很麻烦,并且不好管理,无法对数据进行帅选和合并,如果打开导出的页面有乱码,那就在编码方式选择"自动选择";
5、解决办法3:使用英文版生成的ANALYSIS,再拿到中文版下面,是可以看到系统资源这个图表的,其实我应该早想到这样的,因为在中文版下无法显示不是Analysis的错,而是Controller的错,Analysis里面是包括ACCESS和其它包含系统资源的记录的,所以在中文版是能显示的;
LoadRunner 参数化详解
LoadRunner,是一种预测系统行为和性能的负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner能够对整个企业架构进行测试。通过使用 LoadRunner,企业能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。 LoadRunner是一种适用于各种体系架构的自动负载测试工具,它能预测系统行为并优化系统性能。
参数化的定义:使用指定的数据源中的值来替换脚本录制生成的语句中的参数。
对Vuser脚本进行参数化的好处:
1、减小脚本的大小
2、提供了使用不同的脚本的值执行脚本的能力
参数化涉及两个任务:
1、用参数替换Vuser脚本的常量值
2、为参数设置属性和数据源
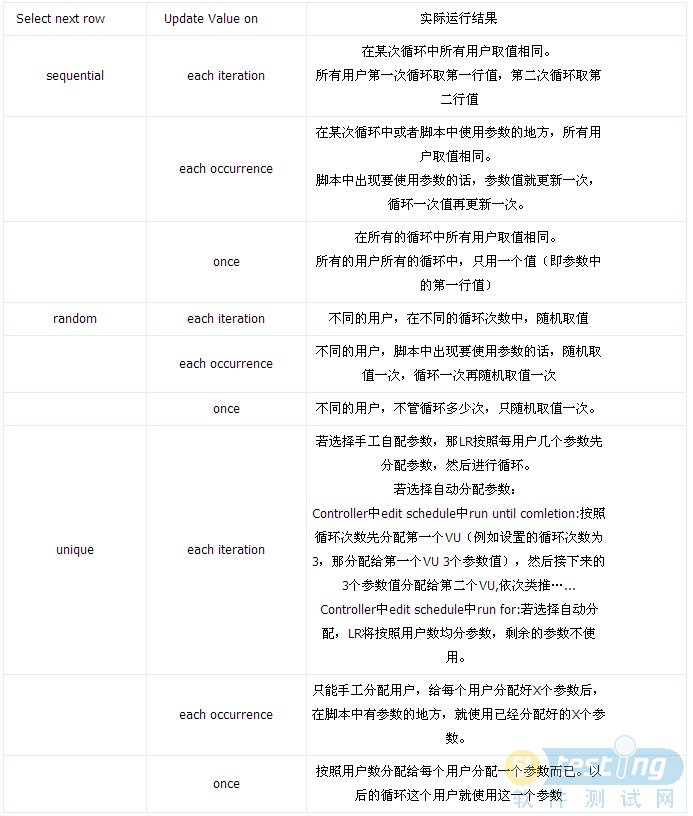
“Select next row”定义的是如何选择下一行数据。该处有三个选项"Sequential","Random","Unique",
Sequential:顺序地向Vuser分配数据。
Random:当测试开始运行时,“随机”方法为每个Vuser分配一个数据表中的随机值。
Unique:为每一个Vuser的参数分配一个唯一的顺序值。在这种情况下必须确保表中的数据对所有的Vuser
和它们的迭代来说是充足的。如果拥有20个Vuser并且要进行5次迭代,则测试者的表格中必须至
少包含100个数值。
“Update value on”定义的是什么时候更新数据值,备选项有每次迭代,每次出现和一次。
表 LoadRunner参数更新方法和数据分配

如果LoadRunner的函数中某个参数不能直接使用LoadRunner参数,那么可以通过lr_eval_string进行转换取到参数的值。
参数表中select next row和update value on的设置
LR的参数的取值,和select next row和update value on的设置都有密不可分的关系。下表给出了select next row和update value on不同的设置,对于LR的参数取值的结果将不同,给出了详细的描述。
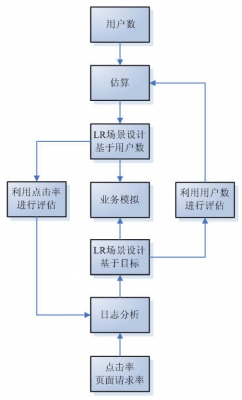
LR场景设计、点击率和用户数的相互联系
1、场景设计、点击率和用户数关系图
2、如何获得需要的测试数据
测试的数据来源于:1)需求;2)系统日志。
从日志中获取数据,可以采用日志分析工具,常用的日志分析工具有Awstat和WebTrends,对于它们的区别是前者是轻量级分析工具,分析速度快,报告简单实用,后者是重量级工具,分析速度慢,报告丰富多样。
估算虚拟用户数,虽然有多种方法,但是这里重点推荐以下两种方法:
方法一,采用Little`s Law方法,它是从服务器端提出的一种计算虚拟用户数的方法。
方法二,采用段念书中提到的公式。
3、用户速率不等于并发用户数
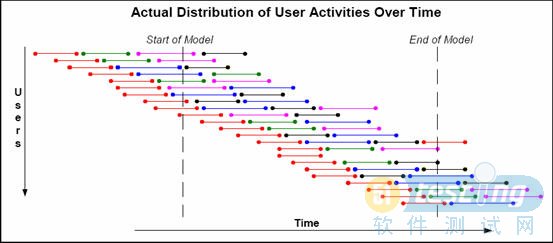
在测试的时候,通常想获取系统的并发用户数、峰值用户数,这些数据都可以从日志中获取,因此在日志中都会关注当日、月、年的用户访问量,我们可以把这些数据平均到每秒访问用户数。此时的平均每秒访问用户数难道就是我们要找的平均并发用户数吗?其实不是的。用户速率不等于并发用户数。如下图,纵坐标代表虚拟用户,横坐标代表时间,每条线段代表用户的一个行为,Start of Model到End of Model代表测试开始和结束过程,持续1个小时。
从服务器角度看,在1个小时内有23个用户访问系统,换个角度理解,每小时有23个用户在访问系统,在Start of Model到End of Model之间任意一时刻都只有10个用户在访问系统。
4、点击率、用户数该从哪里入手
缩小话题范围,这里以用户体验感为测试目标,从而提出进行性能测试的重要性是模拟真实的用户行为,因此提出如何模拟用户行为?通常进行性能测试的时候,采用估算虚拟用户数然后进行相关的压力测试、负载测试。但是这样测试出来的结果正确吗?很显然我们无法断定,因此提出了对测试结果的评估。
从估算虚拟用户数开始,以基于用户数的方式设计场景,进行性能测试,获得测试结果和点击率,将测试得到的点击率和日志中分析的点击率进行比较,来验证测试的效果。
从日志中获取的点击率或者页面请求率开始,以基于目标的方式设计场景,进行性能测试,获得测试结果和用户数,将测试得到用户数和日志中估算的虚拟用户数进行比对,来验证测试效果。
通过上面的方法都可以完成测试且能保证测试结果的准确性,但是点击率和用户数从哪个开始比较好呢?个人观点从点击率可以更好的去模拟真实用户对服务器的压力,而当需求中有明确的并发用户数要求的时候,从用户数开始比较好。
在新浪微博上大家常讨论和抱怨,中国测试所处的环境多么初级和落后。我也常参与讨论,无奈微博140字的限制,表达有限,还导致一些误解。其实下面的内容,我在2011年2月就整理最原始的思路,今天周末正好拿出来与大家分享,听听大家的意见和批判:
我在某软件工程积累很多的大公司从事过一段时间early testing工作的探索,因此有几个月时间经常和公司的产品架构师混在一起工作,全程参与了需求和设计工作。从而积累了很多软件设计,软件开发工程领域的认知,也对软件开发工程的发展历史和规律有了更多了解。(early testing就是没写代码前的测试怎么做?测试人员如何尽可能去发现需求,架构,设计中的缺陷或不足)
原来软件开发也经历了:没有章法单兵作战,凭感觉开发的1.0时代——>接着有了开发流程的2.0时代——>接着又发现流程的每个环节如何做好,还需要一些更具体的指导(方法论)和帮助(技术工具), 于是有了软件开发3.0时代,各种IDE开发工具,各种编程规范,各种编程技巧——>进入九十年代后软件领域有了更多的开发框架(比一般的API库集成度更高)如J2EE,.net,这些框架不是API代码或函数的简单拼凑,而是重用了前辈或领域专家们的设计经验,系统性的构建起来,是对前人设计技术和思想的继承重用,从而既提升了开发效率也提升了质量。唯一坏处多增加了一些学习成本(不光学基本语言,还要学习前人定下了的设计规则)。
一直以来测试行业的难题,如何评审用例,如何评审测试设计?在自动化测试运动结束后,这个问题最终还是被测试经理们提出落到我头上去解决,原来那些评审单个用例文字编写规范的东西早已不被一线测试经理们认可,必须要有所突破否则整个组织的测试用例质量无法提升,绝大部分的测试执行和测试资源都将在地基不牢的地方浪费,质量提升就等同皇帝新装。 当时我另开辟渠道,想了解软件开发如何评审设计的?后来看了一个公司软件开发专家的内部ppt,他在几年前也在解决软件设计如何评审的问题?最终我暂时找到了一个可用答案——设计约束、设计模板、设计回溯 三板斧。 原来现在很流行的J2EE,.net的框架不仅仅是加快开发速度,还提供了设计模板,通过设计约束来保障了基本的设计质量。从而我认为测试设计领域也应该有自己的设计约束和设计模板,测试分析设计人员可以按设计约束和设计模板来填空,测试技术主管或管理主管可以用设计约束和设计模板通过设计回溯的方法评审测试用例。 需要特别强调的是:测试设计模板,不是传统意义上单个用例的结构或文字描述规范的规定。而是测试用例是通过什么严谨系统的大脑处理流程而来的。为此,我从2010年底到2011年初整理开发了《软件可靠性测试分析设计框架》,《压力测试分析设计框架》《长时间测试分析设计框架》来辅助不同项目组改进现有这些领域的专项测试用例,改善了用例不再完全凭个人经验和感觉编写的问题,给测试经理接下来测试用例评审的武器。
最后再总结整理下软件开发的发展趋势:
1.0时代混乱;2.0时代流程化;3、方法和技术;4设计框架。
测试行业的发展和软件开发发展趋势也会一致:
1.0时代无流程 (我入行前) 某公司1998年前
2.0有测试流程 (我刚入行) 某公司1998年-2003年
3.0时代大量测试方法和技术 (我2010年前) 某公司2003至今,特别是08年至今有了大量突飞猛进的突破,正在大面积普及的路上
4.0时代有测试设计框架(设计和经验复用) (我2010年至今,先走一步探索啦)
通过读史明鉴,找到事物发展的规律后,我有信心并相信,中国测试业界相比开发只是晚1个时代,未来10年内中国多数公司的测试也会进步到3.0和4.0时代。某公司走过的历史,也必将是国内才起步后来者们未来走的路以及趋势。
各位tester看到未来的发展方向了吗?
现在,已经有大量的
Android自动化测试架构或工具可供我们使用,其中包括:Activity Instrumentation,MonkeyRunner,Robotium,以及Robolectric。另外LessPainful也提供服务来进行真实设备上的自动化测试。
Android自身提供了对instrumentation测试的基本支持,其中之一就是位于android.test包内的ActivityInstrumentationTestCase2类,它扩展了JUnit的TestCase类来提供Android activities的功能测试。在应用测试中,每一个activity首先会被Instrumentation初始化,然后再加载到Android模拟器或设备的Dalvik虚拟机中来执行。
Android SDK自带一个测试工具MonkeyRunner,它提供的API和执行环境可以运行Python语言编写的测试代码。它提供API来连接设备,安装/卸载应用,运行应用,截屏,比对图片来判断特定命令执行后的屏幕是否包含预期信息,以及运行对应用的测试。MonkeyRunner使用ActivityInstrumentationTestCase2,ProviderTestCase,ServiceTestCase,SingleLaunchActivityTestCase及其他类来定义测试用例,并使用InstrumentationTestRunner类来运行测试。
Robotium是另一种通过InstrumentationTestRunner来完成Android交互式测试的架构,它横跨多个activities,支持功能测试,系统测试和接收测试。Robotium支持Activities、Dialogs、Toasts、Menus、Context Menus甚至Honeycomb,并且它可以同Maven和Ant集成来完成持续集成测试。Robotium被称之为针对Android应用的又一个“Selenium“。
Robolectric另辟蹊径,它并不依赖于Android提供的测试功能,它使用了shadow objects并且运行测试于普通的工作站/服务器JVM,不像模拟器或设备需要dexing(Android dex编译器将类文件编译成Android设备上的Dalvik VM使用的格式),打包,部署和运行的过程,大大减少了测试执行的时间。Pivotal实验室声称使用Robolectric可以在28秒内运行1047个测试。
LessPainful将Android测试又推进了一步,它提供了一个多设备平台自动化测试的服务。用户上传应用(*.apk)和用Cucumber(一种业务相关的DSL)编写的测试文件,选择测试运行需要的设备配置,最后测试将自动执行并生成测试报告。它支持的设备包括Garmin Asus,几款HTC,LG,Samsung Galaxy,Sony Xperia和Motorola Motodefy。
为了了解更多LessPainful提供的服务细节,我们采访了LessPainful公司的CEO Jonas Maturana Larsen。下面就是这次简短的访问:
InfoQ:在不同版本的Android上运行应用程序,存在什么问题?为了保证程序能正常运行,开发者需要在Android的每一个版本上测试他的应用吗?
JML:举个例子,SAXParser在Android 2.2之前有一个bug存在于对ContentHandler.startElement的回调中,它导致应用产生错误的行为。
到目前为止,我们已经在很多方面发现了不同操作系统版本间的差异性。其中一些可能在2.1-update1上导致崩溃,但可以正常运行于2.1-update3和2.2.
InfoQ:不同的设备对Android来说,有没有真正的区别?你能否给我们举个例子,比如Android2.2应用可以运行在HTC但不能运行于Samsung?(或其他各种Android版本和设备制造商的组合)
JML:在LG手机,HorizontalScrollViews有时会导致子视图上的背景图片消失。这个问题存在于我们测试的所有的LG手机,不管Android版本是多少。
如果你不自己处理这类问题,它将导致你的应用在不同设备上不尽相同。例如,Motorola将会用红色边框来高亮一个输入域。在我曾经参与的一个项目中,我们用同样的红色边框来表示输入有误。
还有一些问题,与其说和制造商相关,不如说是和硬件相关:比如,一些手机使用了较小的RAM和高分辨率的摄像头,当你处理手机上的图像时就会将导致崩溃。
InfoQ:这些测试是如何执行的?
JML:测试就如同运行一个ActivityInstrumentationTestCase2,主要使用Robotium来运行。我们对应用所做的唯一修改就是去掉已有的签名,再为它重新生成我们的签名文件。
在测试运行完成后,应用会被卸载,而手机也会被恢复到初始设置。
InfoQ:与MonkeyRunner,Robotium和Robolectric相比,你们所提供的服务有什么优势呢?
JML:LessPainful是一种服务,而并不仅仅是一种架构。我们希望创建一种服务,不但使测试能够进行,并且比起其他任何一种架构,它能够节省我们大量测试时间,还能够帮助我们发现更多的bug。
另外,我们相信使用Cucumber,可以清晰地定义高层次测试描述,同时可以更好地被开发团队以外的人员共享。
以Git领域为例,我们更希望成为像是GitHub那样,而不只是通常的git库。
InfoQ:你们有计划未来要支持更多的设备吗?
JML:是的。我们计划继续增加对更多设备的支持。如果有这样的要求提出,我们就会努力完成它。
目前,我们也在着手于对iOS设备的支持,希望beta版能在今年秋季发布。
InfoQ:什么是LessPainful企业版?
JML:我们将提供一个工具集,它就类似于一个Mac Mini,但我们会非常灵活的满足顾客的需求。LessPainful企业版目前还没有正式推出,所以敬请期待。
在六年半的开发和管理历程中,曾经做过这样的两个项目,都是步履维艰、越做越增添无力感的项目,现在回想起这两个项目,原来有那么多的相似点,而且原来从开始到结束都已经处处透露了危险的信息,只是在初期并未察觉,将危险讯号说出来,让大家能引以为戒。
这两个项目的共同危险点是:
(1)二手项目:都是5、6年前开发完成的项目,新系统的目标是用新平台实现旧平台相同的功能。
(2)开发文档不全:第一个项目之前是C/S结构,使用dephi编写,只有一份代码众多的dephi编写的源代码,涉及到业务逻辑的部分都封装在tuxedo中,数据库不用改造,数据库操作逻辑部分依然调用之前的tuxedo业务。第二个项目使用甲方的呼叫平台编写,该平台功能不够强大,在所有涉及到数据库操作的部分都调用由其开发人员编写的SQL Server存储过程,可以拿到甲方的文档有:数据库说明文档、存储过程源码、呼叫流程(发现已经有一段时间没有同步更新)、简易的需求文档。
(3)需求不明确:第一个项目没有明确的说明文档,为数不多的知道这个项目的人也只能说个五五六六,需要通过他们安装好的C/S系统来了解,甚至要通过源码来了解。第二个项目有简易的需求文档,但年久未更新,而上线的系统却一直在更新,只能提供不够完全的参考。
(4)之前开发人员的流动:第一个项目之前的甲方开发人员都已经走得七七八八,剩下的1、2个知道点情况的人也已经是从前任的前任手里接过来的项目,现在没有正在运行的旧系统。第二个项目虽然情况好点,但知道项目总体情况的人也寥寥无几,但是现网在全国80来个点都有旧系统在运行。
(5)都需要变更平台:第一个项目数据库结构不需要变更,但平台需要变更,由dephi->Java,我们项目组无人学习过dephi。第二个项目之前采用甲方的呼叫开发平台 + SQL Server存储过程,新系统采用我方的呼叫开发平台,该项目甲方还需要变更数据库,从SQL Server变更为Oracle,并且有很长一段时间两套系统要并行,因此不但涉及到要割接数据,还涉及到两边数据库的双向同步。
第一个项目从头到尾都做得苦不堪言:工期紧张(貌似是2个月还是3个月)、项目组成员有几个是新员工、dephi的代码被甲方的开发人员写得晦涩难懂,周旋于一个源文件4000、5000行的dephi代码当中,而且甲方要求甚多,又不能提供良好的支持,项目组成员被摧残得“花容”失色,而且经过日复一日的加班加点让项目组成员流失惨重,经过延期、延期再延期,最后不出所料的以失败收场。
现在如果来总结这个项目,如此多危险信号的项目就不应该签约,这个项目的如此种种,注定了他是一个铁定会失败的项目。甲方开发人员甚多,有若干Java的开发人员,却想交给第三方公司使用 Java来实现,从这里也可以看出这个项目并没有如甲方前期所说的那样是个不难应付的项目。可惜我等开发人员常常没有做不做这个项目的权利,合同已经签在那里了,只能提供做的过程中的参考意见,sigh……
第二个项目相对要好些,虽然暂时还没有交付,但是交付的可能性还是很大的,但是现在已经延期了2、3月左右,在后期很大一部分开发工作都放在割接和同步方面,与甲方的存储过程开发人员(也是甲方对该系统最了解的人员)J君交流时,我们私下认为:“这个项目最大的失误在于当时没采用同样的数据库结构,而导致给割接、同步和项目开发造成不必要的麻烦。” 而这个失误的造成是由于项目前期双方没有人对割接、同步的问题引起重视,而将精力都放在系统的开发方面,当时由上头决定了采用新的数据库结构,前期在我方数据库结构出来之前,甲方都没有提供当前系统的数据库说明文档。
这个项目越到后期做得越步履维艰,为了避免重犯这样的错误,总结如下,希望涉及到割接、同步、新旧系统并行的朋友开发时引以为戒:
(1)如果旧系统数据库设计合理,不要动修改数据库结构的念头,那将是自讨苦吃。因为如果是同样的数据库结构,即使新旧系统采用的是不同的数据库,割接、同步等都可采用数据库方案,即使数据库层面无法实现,也有很多开源的程序能够实现。但如果异库、异构、同步,那将是极其耗费工时,并且麻烦的工作。
(2)如果相对数据库进行优化,可为系统制造第二期计划;
(3)抱着不想看旧系统业务逻辑代码的想法都是过于理想、不现实的。这个项目我是前期的后半段加进来的,之前的核心开发人员对甲方的开发人员说:“我想最坏的情况就是要看你的业务逻辑源码才能实现新系统,这是一份耗时耗力的工作。前期我尽量将你们实际的需求和注意的点都挖掘出来。”前期确实在需求上下了很多功夫,但是真正投入开发后才知道,了解程度远远不够,很多之前的存储过程因为年久未作修改,当时了解时甲方的开发人员都说得有异议。最后在项目后期还是落得去核对甲方的存储过程来确认是否自己的开发过程有细节遗漏。
(4)不要幼稚到将一个已经运行了近6年、一直在增加和修改需求、并且在中国各地都分布运行、甲方若干能力还不错的开发人员维护的系统想象得过于简单。若干的地区个性化需求(有的需求甚至一点都不合理)、长久积累的灵活性功能等等,会让你相信“没那么简单”。
纵观这两个项目,为何做得如此步履维艰?是否做过类似项目的你也有过这样苦不堪言的体会?笔者所做过的其余多个全新系统,好像还没遇到过开发得如此艰难险阻的。希望看到此文的技术同仁们,万一不得已遇到类似的项目,千万不要想得过于简单吧!重视它,是成功的第一步!
在Web测试中,不可避免的会遇到树形节点的识别。如下就是通过IEDevToolBar抓下的一个page的树形结构。
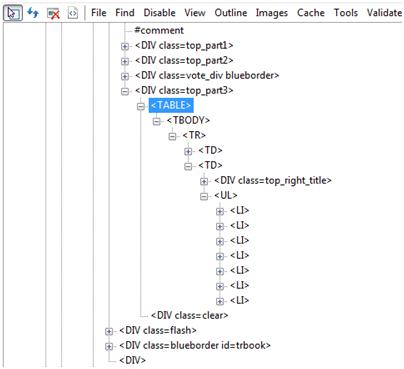
QTP在对树形结构的节点进行识别时,可以采用DOM(Document Object Model文档对象模型)模型,在DOM中,每个网页元素都对应着一个对象。树结构中每一个元素都被称为一个节点。QTP可以通过DOM来访问HTML标签。在QTP中,访问DOM主要通过使用page测试对象的object属性来进一步访问。
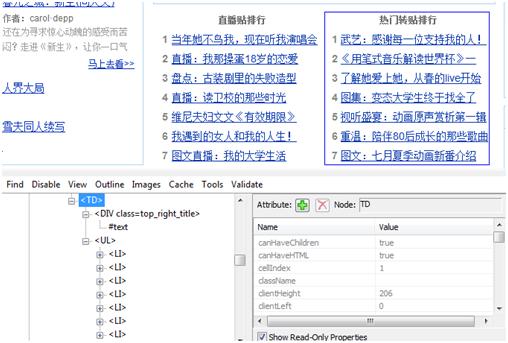
举个简单的例子:在百度贴吧首页,我们需要获得”热门转帖排行”下的标题。
代码如下:
'获得贴吧首页热门转帖排行下的所有标题
Set oBj=Browser("贴吧").Page("贴吧page").WebTable("Table").Object
Set oDIV= oBj.getElementsByTagName("DIV")
num=0
For i=0 to oDIV.length-1
If oDIV(i).innertext="热门转贴排行" then
For j=0 to oDIV(i).NextSibling.ChildNodes.length-1
num=num+1
Datatable.SetCurrentRow(num)
Datatable.Value("innertext")=oDIV(i).NextSibling.ChildNodes(j).innertext '将获得的标题储存到Datatable中
Next
End If
Next
Set oBj=Nothing
Set oDIV=Nothing |
在这段代码中,就是通过访问贴吧页面下的WebTable对象的Object属性来进一步访问HTML标签的。
我们用到了几个方法和属性:
getElementsByTagName()方法:返回带有指定标签名的对象的集合。
NextSibling属性:返回处于同级节点下某个元素之后紧跟的元素。
ChildNodes属性:返回指定节点的子节点的节点列表。
我们借助于IEDevToolBar,可以发现,“热门转帖排行”这一列中,“热门转帖排行”是DIV的innertext,而底下的标题则分别是UL的innertext,因此要访问到UL的节点列表,就需要用到NextSibling属性。
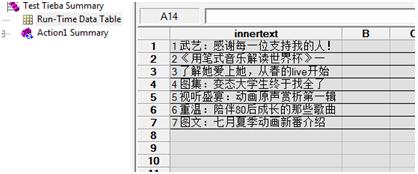
最后程序运行的结果在Report的Run-Time Data Table中:
DOM还有很多方法和属性,之前提到了NextSibling,那么还有PreviouSibling;以及NodeName,NodeType,NodeValue等等。
关于NodeName,NodeType,NodeValue;很多人可能还有很多混淆,这里做些总结:
Nodetype:返回节点的类型,1为元素,2为属性,3为文本,8注释,9文档
Nodename:返回节点的名称,元素返回的是标签名称,属性返回的是属性名称,文本返回的是#text(innertext),文档返回的是#document
Nodevalue:返回当前节点的值,文本节点返回文本值,属性节点返回属性值,标签和文档节点返回null
其他的一些方法和属性待大家自己学习DOM后了解。如果大家熟悉DOM的方法和属性,在利用QTP做Web测试时,将会很有益处。
做软件测试的目的在于找到缺陷和证明缺陷,在这个过程中进行全面覆盖性或反复测试,以图无限地趋近100%,结果可能很好,但工作效率非常低。在WEB安全测试上,如何避免大海捞沙,需要有的放矢,把有价值的信息淘出来。
安全测试的出发点和功能测试不太相同,安全测试的手段就是攻击,攻击,还是攻击。寻找有价值的信息,就是测试的第一招。“淘金”就是其中的一种方式,一般来说由以下信息需要关注。
◆ HTML中的代码注释
◆ HTML中的敏感代码
◆ 服务器或应用程序的错误信息和HTTP响应
代码注释是一块很容易被开发人员忽略掉的信息,因为对于开发人员来说,这些就是他们做后期开发的“工程文档”,再正常不过的东西,甚至很乐意文件中能有更的关键注释。如代码中会出现“标记为1时,表示XXX信息”或“若为空,则交由XX处理”。这类信息只需要通过阅读HTML文件即可发现,并且对于攻击者来说是非常好的指南。
如果攻击者能够根据通过对源代码的处理,获取到数据库信息、用户名、密码等数据时,这个应用是非常危险的。要获取这样的信息,首先需要清楚应用间的数据传递方式。通过GET方式传递的,可以直接在URL中获取到“参数名=参数值”,如果是通过POST传递的,就需要借助抓包工具,比如HttpFox、HttpWatch。当把所有关联页面都浏览完成后,就可以生成一张页面间的映射关系图,同时也可以知道它们之间参数的传递情况。如果应用程序实现了访问级别区分,比如高级别用户享有特权操作,那么就可以从低等级用户开始,逐级淘金。通过映射图阅读源代码,寻找注释中引导信息,就可以获得有价值的信息。除了手工地去寻找,还可以利用正则表达式自动搜寻。
当找到以上信息后,检查页面之间传递的参数,看看哪些参数能够使得应用程序出错,这个时候就能发现一些有用的信息。如连接数据库时出错,脚本无法处理,该出错页面不但会提示错误,还可能把出错点附近的相关代码也显示出来,这些相关代码可能会把数据库名、表对象名及字段名等信息暴露出来。或者强行产生语法错误、营造无法处理的异常场景来破坏应用程序,则会得到服务器对其响应的许多函数调用。因此无论是应用程序还是Web服务器,应该谨慎维护好应对对策略。还有一种常见的漏洞,大家可以到各网站上去自行寻找,即对于用户名和密码输入不正确时触发不同的报错信息。如果使用这样的逻辑进行用户名和密码匹配的判断,当攻击者暴力破解时,他能够很清楚的知道,当前使用的用户名是否是已注册用户(当用户名正确时,提示是密码错误)。
如何进行防范
1、确定HTML中注释是否包含敏感信息;或在日常环境中保留这些注释,而在线上去除这些注释。
2、尽量对于错误信息进行二次处理,尽量让用户看到的错误提示是模糊且有价值的;尽量把相关细节信息保留在服务器的日志文件中,方便开发调试的同时规避安全风险。同时需要定期检查这些日志文件,了解是否有错误信息是未被处理的。
代码示例:
public void test1() { //打开网站 selenium.open("http://xxx.xxx.xxx/yyy"); //通过Xpath 找到页面中的某个DOM对象 selenium.select("xpath=//SELECT[@name='SBBUSYO']", "index=1"); //模拟点击、输入等页面动作 selenium.click("xpath=//input[@type='button']"); //等待页面加载 selenium.waitForPageToLoad("2000"); //断言验证是否正确转向标题为“welcome”的页面 assertEquals(selenium.getTitle(), "Welcome"); } |
代码会启动IE或者firefox执行,这样就将单元测试可以覆盖到了开发的全部环节。我们公司现在使用的LoadRunner是协议级的测试,通过对get\post协议的分析进行测试。
Selenium 是DOM级的测试,通过Xpath 寻找页面标签,验证是否实现了希望的功能。Selenium支持js,和多浏览器,所以还可以用于测试浏览器兼容性。
百度进行web自动化测试的一些相关经验:
1. 通过一些自己写好的框架,加载.xls 文件数据导入测试用例的数据。对于一些需要反复回归测试的测试用例,测试人员只需要用Excel填写测试数据就可以。
2. 测试人员更专注于业务、流程比较复杂的用例,简单的业务可以自动化测试。
3. Web自动化测试并不是为了找到bug,而是作为系统的一个安全网和防护栏,保证代码的变动不会造成基础和核心模块出现问题。
4. Web自动化测试只能应用适合的场景,很多页面还是需要人工测试。以百度目前的经验,大概也只有20-30%的web可以进行自动化测试。所以需要精心挑选和设计测试用例。
5. 测试人员最好也拥有编写代码的能力。
TDD 测试驱动开发
1. 测试驱动开发:写代码前先写测试。
2. 如何切入TDD?:从上到下写代码。即写Web测试>Jsp页面>Action测试>Action实现>service测试>service实现……
3. 通过测试和上层方法进行驱动开发。比如你写Action测试时发现需要跳转首页的方法,就驱动在Action建立toIndex()方法。在Action发现你需要Service ,就建立Service对象,利用IDE的辅助提示功能,快速的进行驱动开发。
4. 随时重构,包括Test的代码。如果感觉代码有bed smell就马上重构。
5. 对于暂时没有实现的或者无法实现的,通过Mock的方式实现。
6. Web测试可以先写空业务场景,暂不实现,因为Web测试需要完整功能开发完毕并进行部署和服务启动,并且耗时也比较长。
7. 测试用例是一种文档,测试方法名称以表达测试目的为第一目标。演示的时候讲师经常起了这样的方法名:Public void testShowMoreDetailWhenFrendListOver5(){} //当好友列表大于5个时显示"show more"
任何一个测试的开始都要制定一个完整的测试计划,现在我们就从web安全测试的测试计划开始
要做一个测试计划首先要明确测试需求。在写测试计划之前必须要明确测试需求,
暗含的要求:例如很少看到这样明确话的文档要求:“入侵这相应手册中不许友拼写错误”但同时有些组织是允许拼写错误存在的。这样暗含的要求我们就要明确,可以通过和主管部门或是用户沟通来明确这样的要求。
不完全的或模糊的要求
比如:“所有的网站都应该安装SP3补丁”这样的要求就是模糊不清的,因为没有指明是操作系统还是网站服务软件,或是某些具体的系统软件。这样的需求就应该有需求提出的人来明确,确定在什么系统上安装sp3补丁。
未指明的要求
如:“必须使用强密码”看起来还向没什么问题,但从测试观点看,设么是强密码呢?是常超过7个字符的,还是应该有大小写的。这样的要求我们就应该根据密码要求标准具体化,比如:要求密码加强必须大于7个字符。
笼统的要求
比如“站点必须是安全的”尽管每个人都会同意这个要求,但展点能够彻底安全的唯一方法就是,断开展点的所有连接,内网的外网的,然后锁在一个加了封条的屋子里。但是这并不是要求的本意。这样的要求应该具体化,制定要求达到的安全程度。
好了要求明确了,下面就说一下就话的结构。呵呵我也是学来的,照别人的说吧,也有我的体会
测试计划的结构
测试计划可以依照工业标准(例如软件文档标准——Std.829)组织,也可以基于内部摸版,甚至可以用创献礼的全新个是编排。但大家一定要注意一点,测试计划重要的不是个是而是创建测试计划的过程一定要获得测试组的认可。但有的测试必须用规格的测试计划格式,行业内部摸版或行业标准,这样的测试如:政府机构、保险承销商等。
测试计划可以长达几百页,也可以简单的只有一张纸,关键测试计划必须实用,也不必要把大量的人力和物理花费在测试计划上,要根据具体情况来确定。
根据IEEE Std.829-1998(软件测试文档标准1998年修订版)来介绍测试计划的内容
1.测试计划标题
就是说没个测试计划和每个测试计划的版本都应该有一个公司内部的独一无二标示,这也是文档控制和版本控制的基本要求,我觉得在正规公司的同仁们都应该明白。
2.介绍
这一部分适度测试的一个总的概括,通过这一部分一该让读者明白此项目的准确目标和测试组如何达到这些目标。根据情况也可以做一些基本概念的解释,比如为什么要做安全测试等等。
3.项目范围
在这一部分中明确项目的测试目标,如果在介绍中已经描述的测试目标的话在这一部分应该详尽的介绍测试目标。同时在这一部分可以列出在测试中不设计的测试项。
4.变动控制过程
这一部分主要是解决再测试中如果有需要变动的测试项应做如何处理,可参考CCB(变动控制委员会)的意见进行适当的变动。