v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VML);} .shape {behavior:url(#default#VML);}
细节优化提升资源利用率
Author: 放翁(文初)
Email: fangweng@taobao.com
Mblog:weibo.com/fangweng
这里通过介绍对于淘宝开放平台基础设置之一的TOPAnalyzer的代码优化,来谈一下对于海量数据处理的Java应用可以共享的一些细节设计(一个系统能够承受的处理量级别往往取决于细节,一个系统能够支持的业务形态往往取决于设计目标)。
先介绍一下整个TOPAnalyzer的背景,目标和初始设计,为后面的演变做一点铺垫。
开放平台从内部开放到正式对外开放,逐步从每天几千万的服务调用量发展到了上亿到现在的15亿,开放的服务也从几十个到了几百个,应用接入从几百个增加到了几十万个。此时,对于原始服务访问数据的分析需求就凸现出来:
<!--[if !supportLists]-->1. <!--[endif]-->应用维度分析(应用的正常业务调用行为和异常调用行为分析)
<!--[if !supportLists]-->2. <!--[endif]-->服务维度分析(服务RT,总量,成功失败率,业务错误及子错误等)
<!--[if !supportLists]-->3. <!--[endif]-->平台维度分析(平台消耗时间,平台授权等业务统计分析,平台错误分析,平台系统健康指标分析等)
<!--[if !supportLists]-->4. <!--[endif]-->业务维度分析(用户,应用,服务之间关系分析,应用归类分析,服务归类分析等)
上面只是一部分,从上面的需求来看需要一个系统能够灵活的运行期配置分析策略,对海量数据作即时分析,将接过用于告警,监控,业务分析。
下图是最原始的设计图,很简单,但还是有些想法在里面:

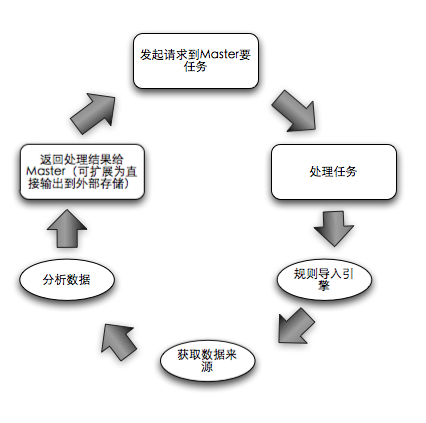
Master:管理任务(分析任务),合并结果(Reduce),输出结果(全量统计,增量片段统计)
Slave:Require Job + Do Job + Return Result,随意加入,退出集群。
Job:(Input + Analysis Rule + Output)的定义。
几个设计点:
<!--[if !supportLists]-->1. <!--[endif]-->后台系统任务分配:无负载分配算法,采用细化任务+工作者按需自取+粗暴简单任务重置策略。
<!--[if !supportLists]-->2. <!--[endif]-->Slave与Master采用单向通信,便于容量扩充和缩减。
<!--[if !supportLists]-->3. <!--[endif]-->Job自描述性,从任务数据来源,分析规则,结果输出都定义在任务中,使得Slave适用与各种分析任务,一个集群分析多种日志,多个集群共享Slave。
<!--[if !supportLists]-->4. <!--[endif]-->数据存储无业务性(意味着存储的时候不定义任何业务含义),分析规则包含业务含义(在执行分析的时候告知不同列是什么含义,怎么统计和计算),优势在于可扩展,劣势在于全量扫描日志(无预先索引定义)。
<!--[if !supportLists]-->5. <!--[endif]-->透明化整个集群运行状况,保证简单粗暴的方式下能够快速定位出节点问题或者任务问题。(虽然没有心跳,但是每个节点的工作都会输出信息,通过外部收集方式快速定位问题,防止集群为了监控耦合不利于扩展)
<!--[if !supportLists]-->6. <!--[endif]-->Master单点采用冷备方式解决。单点不可怕,可怕的是丢失现场和重启或重选Master周期长。因此采用分析数据和任务信息简单周期性外部存储的方式将现场保存与外部(信息尽量少,保证恢复时快速),另一方面采用外部系统通知方式修改Slave集群MasterIP,人工快速切换到冷备。
Master的生活轨迹:
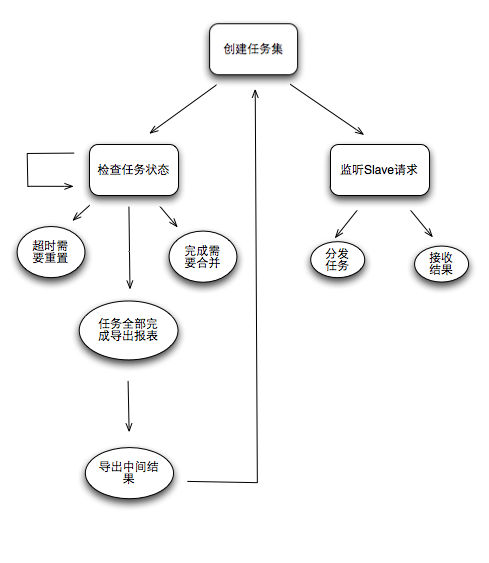
Slave的生活轨迹:
有人会觉得这玩意儿简单,系统就是简单+透明才会高效,往往就是因为系统复杂才会带来更多看似很高深的设计,最终无非是折腾了自己,苦了一线。废话不多说,背景介绍完了,开始讲具体的演变过程。
数据量:2千万 à 1亿 à 8亿 à15亿。报表输出结果:10份配置à30份à60份à100份。统计后的数据量:10k à 10M à 9G。统计周期的要求:1天à5分钟à3分钟à1分半。
从上面这些数据可以知道从网络和磁盘IO,到内存,到CPU都会经历很大的考验,由于Master是纵向扩展的,因此优化Master成为每个数据跳动的必然要求。由于是用Java写的,因此内存对于整体分析的影响更加严重,GC的停顿直接可以使得系统挂掉(因为数据在不断流入内存)。
优化过程:
纵向系统的工作的分担:
从Master的生活轨迹可以看到,它负荷最大的一步就是要去负责Reduce,无论如何都需要交给一个单节点来完成所有的Reduce,但并不表示对于多个Slave的所有的Reduce都需要Master来做。有同学给过建议说让Master再去分配给不同的Slave去做Slave之间的Reduce,但一旦引入Master对Slave的通信和管理,这就回到了复杂的老路。因此这里用最简单的方式,一个机器可以部署多个Slave,一个Slave可以一次获取多个Job,执行完毕后本地合并再汇报给Master。(优势:Master在Job合并所产生的内存消耗可以减轻,因为这是统计,所以合并后数据量一定大幅下降,此时Master合并越少的Job数量,内存消耗越小),因此Slave的生活轨迹变化了一点:
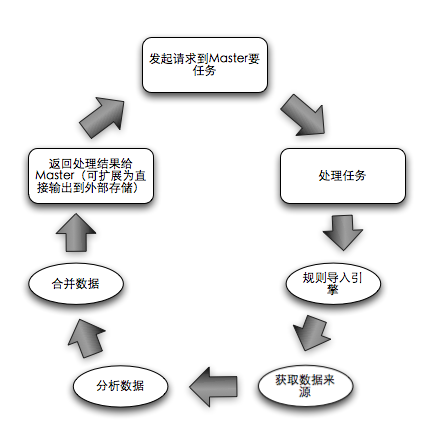
流程中间数据优化:
这里举两个例子来说明对于处理中中间数据优化的意义。
在统计分析中往往会有对分析后的数据做再次处理的需求,例如一个API报表里面会有API访问总量,API访问成功数,同时会要有API的成功率,这个数据最早设计的时候和普通的MapReduce字段一样处理,计算和存储在每一行数据分析的时候都做,但其实这类数据只有在最后输出的时候才有统计和存储价值,因为这些数据都可以通过已有数据计算得到,而中间反复做计算在存储和计算上都是一种浪费,因此对于这种特殊的Lazy处理字段,中间不计算也不存储,在周期输出时做一次分析,降低了计算和存储的压力。
对于MapReduce中的Key存储的压缩。由于很多统计的Key是很多业务数据的组合,例如APPAPIUser的统计报表,它的Key就是三个字段的串联:taobao.user.get—12132342—fangweng,这时候大量的Key会占用内存,而Key的目的就是产生这个业务统计中的唯一标识,因此考虑这些API的名称等等是否可以替换成唯一的短内容就可以减少内存占用。过程中就不多说了,最后在分析器里面实现了两种策略:
<!--[if !supportLists]-->1. <!--[endif]-->不可逆数字摘要采样。
有点类似与短连接转换的方式,对数据做Md5数字摘要,获得16个byte,然后根据压缩配置来采样16个byte部分,用可见字符定义出64进制来标识这些采样,最后形成较短的字符串。
由于Slave是数据分析者,因此用Slave的CPU来换Master的内存,将中间结果用不可逆的短字符串方式表示。弱点:当最后分析出来的数据量越大,采样md5后的数据越少,越容易产生冲突,导致统计不准确。
<!--[if !supportLists]-->2. <!--[endif]-->提供需要压缩的业务数据列表。
业务方提供日志中需要替换的列定义及一组定义内容。简单来说,当日志某一列可以被枚举,那么就意味者这一列可以被简单的替换成短标识。例如配置APIName这列在分析生成key的时候可以被替换,并且提供了500多个api的名称文件载入到内存中,那么每次api在生成key的时候就会被替换掉名称组合在key中,大大缩短key。那为什么要提供这些api的名称呢?首先分析生成key在Slave,是分布式的,如果采用自学习的模式,势必要引入集中式唯一索引生成器,其次还要做好足够的并发控制,另一方面也会由并发控制带来性能损耗。这种模式虽然很原始,但不会影响统计结果的准确性,因此在分析器中被使用,这个列表会随着任务规则每次发送到Slave中,保证所有节点分析结果的一致性。
特殊化处理特殊的流程:
在Master的生活轨迹中可以看出,影响一轮输出时间和内存使用的包括分析合并数据结果,导出报表和导出中间结果。在数据上升到1亿的时候,Slave和Master之间数据通信以及Master的中间结果磁盘化的过程中都采用了压缩的方式来减少数据交互对IO缓冲的影响,但一直考虑是否还可以再压榨一点。首先导出中间结果的时候最初采用简单的Object序列化导出,从内存使用,外部数据大小,输出时间上来说都有不少的消耗,仔细看了一下中间结果是Map<String,Map<String,Obj>>,其实最后一个Obj无非只有两种类型Double和String,既然这样,序列化完全可以简单来作,因此直接很简单的实现了类似Json简化版的序列化,从序列化速度,内存占用减少上,外部磁盘存储都有了极大的提高,外部磁盘存储越小,所消耗的IO和过程中需要的临时内存都会下降,序列化速度加快,那么内存中的数据就会被尽快释放。总体上来说就是特殊化处理了可以特殊化对待的流程,提高了资源利用率。(同时中间结果在前期优化阶段的作用就是为了备份,因此不需要每个周期都做,当时做成可配置的周期值输出)
再接着来谈一下中间结果合并时候对于内存使用的优化。Master会从多个Slave得到多个Map<Key,Map<Key,Value>>,合并过程就是对多个Map将第一级Key相同的数据做整合,例如第一级Key的一个值是API访问总量,那么它对应的Map中就是不同的api名称和总量的统计,而多个Map直接合并就是将一级key(API访问总量)下的Map数据合并起来(同样的api总量相加最后保存一份)。最简单的做法就是多个Map<Key,Map<Key,Value>>递归的来合并,但如果要节省内存和计算可以有两个小改进,首先选择其中一个作为最终的结果集合(避免申请新空间,也避免轮询这个Map的数据),其次每一次递归时候,将合并后的后面的Map中数据移出(减少后续无用的循环对比,同时也节省空间)。看似小改动,但效果很不错。
再谈一下在输出结果时候的内存节省。在输出结果的时候,是基于内存中一份Map<Key,Map<Key,Value>>来构建的。其实将传统的MapReduce的KV结果如何转换成为传统的Report,只需要看看Sql中的Group设计,将多个KV通过Group by key,就可以得到传统意义上的Key,Value,Value,Value。例如:KV可以是<apiName,apiTotalCount>,<apiName,apiResponse>,<apiName,apiFailCount>,如果Group by apiName,那么就可以得到 apiName,apiTotalCount,apiResponse,apiFailCount的报表行结果。这种归总的方式可以类似填字游戏,因为我们结果是KV,所以这个填字游戏默认从列开始填写,遍历所有的KV以后就可以完整的得到一个大的矩阵并按照行输出,但代价是KV没有遍历完成以前,无法输出。因此考虑是否可以按照行来填写,然后每一行填写完毕之后直接输出,节省申请内存。按行填写最大的问题就是如何在对KV中已经处理过的数据打上标识,不要重复处理。(一种方式引入外部存储来标识这个值已经被处理过,因为这些KV不可以类似合并的时候删除,后续还会继续要用,另一种方式就是完全备份一份数据,合并完成后就删除),但本来就是为了节约内存的,引入更多的存储,就和目标有悖了。因此做了一个计算换存储的做法,例如填充时轮训的顺序为:K1V1,K2V2,K3V3,到K2V2遍历的时候,判断是否要处理当前这个数据,就只要判断这个K是否在K1里面出现过,而到K3V3遍历的时候,判断是否要处理,就轮询K1K2是否存在这个K,由于都是Map结构,因此这种查找的消耗很小,由此改为行填写,逐行输出。
最后再谈一下最重头的优化,合并调度及磁盘内存互换的优化
从Master的生活轨迹可以看到,原来的主线程负责检查外部分析数据结果状态,合并数据结果这个循环,考虑到最终合并后数据只有一个主干,因此采用单线程合并模式来运作,见下图:
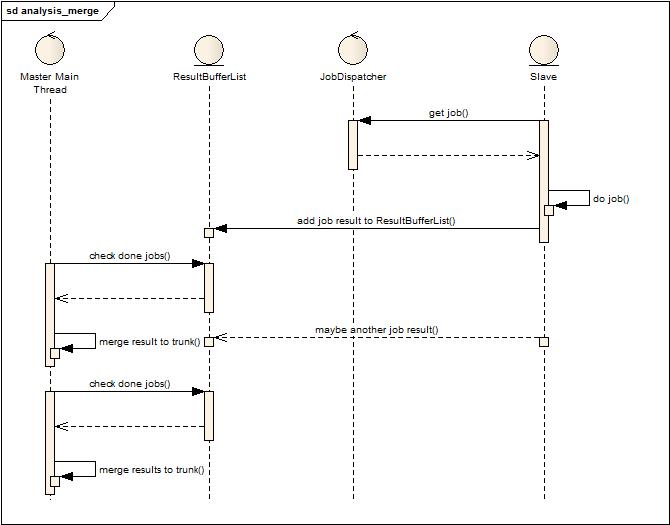
这张图大致描述了一下处理流程,Slave随时都会将分析后的结果挂到结果缓冲队列上,然后主线程负责批量获取结果并且合并。虽然是批量获取,但是为了节省内存,也不能等待太久,因为每一点等待就意味着大量没有合并的数据将会存在与内存中,但合并的太频繁也会导致在合并过程中,新加入的结果会等待很久,导致内存吃紧。或许这个时候会考虑,为什么不直接用多线程来合并,的确,多线程合并并非不可行,但要考虑如何兼顾到主干合并的并发控制,因为多个线程不可能同时都合并到数据主干上,由此引入了下面的设计实现,半并行模式的合并:
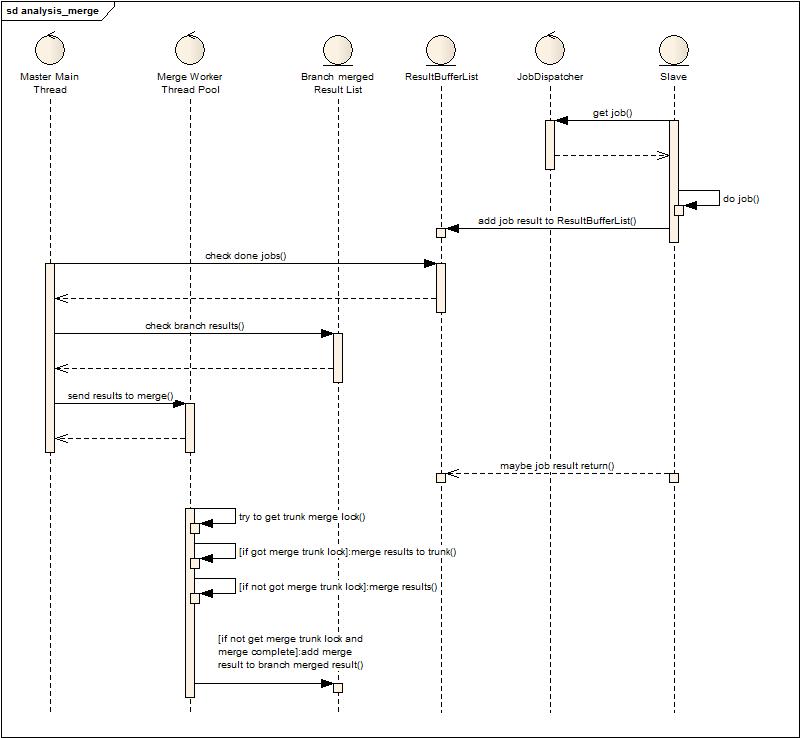
从上图可以发现增加了两个角色:Merge Worker Thread Pool和Branch merged ResultList,与上面设计的差别就在于主线程不再负责合并数据,而是批量的获取数据交给合并线程池来合并,而合并线程池中的工作者在合并的过程中会竞争主干合并锁,成功获得的就和主干合并,不成功的就将结果合并后放到分支合并队列上,等待下次合并时被主干合并或者分支合并获得再次合并。这样改进后,发现由于数据挂在队列没有得到及时处理产生的内存压力大大下降,同时也充分利用了多核,多线程榨干了多核的计算能力(线程池大小根据cpu核来设置的小一点,预留一点给GC用)。这种设计中还多了一些小的调优配置,例如是否允许被合并过的数据多次被再次合并(防止无畏的计算消耗),每次并行合并最小结果数是多少,等待堆积到最小结果数的最大时间等等。(有兴趣看代码)
至上面的优化为止,感觉合并这块已经被榨干了,但分析日志数据的增多,对及时性要求的加强,使得我又要重新审视是否还有能力继续榨出这个流程的水份。因此有了一个大胆的想法,磁盘换内存。因为在调度合并上已经找不到更多可以优化的点了,但是有一点还可以考虑,就是主干的那点数据是否要贯穿于整个合并周期,而且主干的数据随着增量分析不断增大(在最近这次优化的过程中也就是发现GC的频繁导致合并速度下降,合并速度下降导致内存中临时数据保存的时间久,反过来又影响GC,最后变成了恶性循环)。尽管觉得靠谱,但不测试不得而知。于是得到了以下的设计和实现:
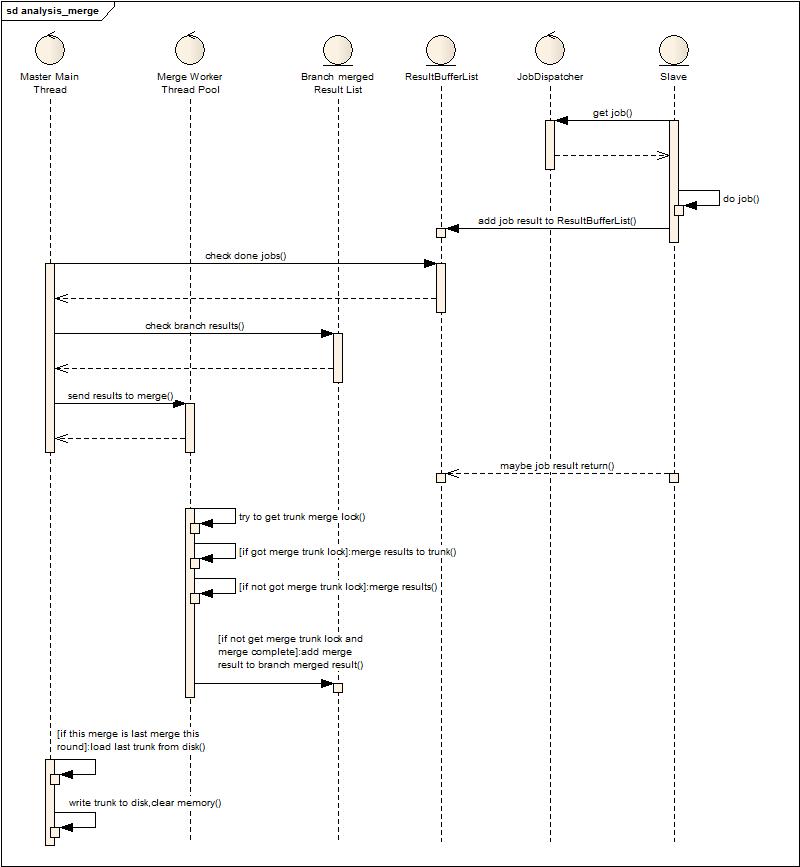
这个流程发现和第二个流程就多了最后两个步骤,判断是否是最后的一次合并,如果是载入磁盘数据,然后合并,合并完后将主干输出到磁盘,清空主干内存。(此时发现导出中间结果原来不是每次必须的,但是这种模式下却成为每次必须的了)
这个改动的优势在什么地方?例如一个分析周期是2分钟,那么在2分钟内,主干庞大的数据被外置到磁盘,内存大量空闲,极大提高了当前时间片结果合并的效率(GC少了)。缺点是什么?会在每个周期产生两次磁盘大量的读写,但配合上优化过的中间结果载入载出(前面的私有序列化)会适当缓和。
由于线下无法模拟,就尝试着线上测试,发现GC减少,合并过程加速达到预期,但是每轮的磁盘和内存的换入换出由于也记入在一轮分析时间之内,每轮写出最大时候70m数据,需要消耗10多秒,甚至20秒,读入最大需要10s,这个时间如果算在要求一轮两分钟内,那也是不可接受的),重新审视是否有疏漏的细节。首先载入是否可以异步,如果可以异步,而不是在最后一轮才载入,那么就不会纳入到分析周期中,因此配置了一个可以调整的比例值,当任务完成到达或者超过这个比例值的时候,将开始并行载入数据,最后一轮等到异步载入后开始分析,发现果然可行,因此这个时间被排除在周期之外(虽然也带来了一点内存消耗)。然后再考虑输出是否可以异步,以前输出不可以异步的原因是这份数据是下一轮分析的主干,如果异步输出,下一轮数据开始处理,很难保证下一轮的第一个任务是否会引发数据修改,导致并发问题,所以一直锁定主干输出,直到完成再开始,但现在每次合并都是空主干开始的,因此输出完全可以异步,主干可以立刻清空,进入下一轮合并,只要在下一个周期开始载入主干前异步导出主干完成即可,这个时间是很长的,完全可以把控,因此输出也可以变成异步,不纳入分析周期。
至此完成了所有的优化,分析器高峰期的指标发生了改变:一轮分析从2分钟左右降低到了1分10秒,JVM的O区在合并过程中从50-80的占用率下降到20-60的占用率,GC次数明显大幅减少。
总结:
<!--[if !supportLists]-->1. <!--[endif]-->利用可横向扩展的系统来分担纵向扩展系统的工作。
<!--[if !supportLists]-->2. <!--[endif]-->流程中中间数据的优化处理。
<!--[if !supportLists]-->3. <!--[endif]-->特殊化处理可以特殊处理的流程。
<!--[if !supportLists]-->4. <!--[endif]-->从整体流程上考虑不同策略的消耗,提高整体处理能力。
<!--[if !supportLists]-->5. <!--[endif]-->资源的快用快放,提高同一类资源利用率。
<!--[if !supportLists]-->6. <!--[endif]-->不同阶段不同资源的互换,提高不同资源的利用率。
其实很多细节也许看了代码才会有更深的体会,分析器只是一个典型的消耗性案例,每一点改进都是在数据和业务驱动下不断的考验。例如纵向的Master也许真的有一天就到了它的极限,那么就交给Slave将数据产出到外部存储,交由其他系统或者另一个分析集群去做二次分析。对于海量数据的处理来说都需要经历初次筛选,再次分析,展示关联几个阶段,Java的应用摆脱不了内存约束带来对计算的影响,因此就要考虑好自己的顶在什么地方。但优化一定是全局的,例如磁盘换内存,磁盘带来的消耗在总体上来说还是可以接受的化,那么就可以被采纳(当然如果用上SSD效果估计会更好)。
最后还是想说的是,很多事情是简单做到复杂,复杂再回归到简单,对系统提出的挑战就是如何能够用最直接的方式简单的搞定,而不是做一个臃肿依赖庞大的系统,简单才看的清楚,看的清楚才有机会不断改进。
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
java反射机制的实现原理
反射机制:
所谓的反射机制就是java语言在运行时拥有一项自观的能力。
通过这种能力可以彻底的了解自身的情况为下一步的动作做准备。
下面具体介绍一下java的反射机制。这里你将颠覆原来对java的理解。
Java的反射机制的实现要借助于4个类:class,Constructor,Field,Method;
其中class代表的时类对象,
Constructor-类的构造器对象,
Field-类的属性对象,
Method-类的方法对象。
通过这四个对象我们可以粗略的看到一个类的各个组 成部分。
Class:程序运行时,java运行时系统会对所有的对象进行运行时类型的处理。
这项信息记录了每个对象所属的类,虚拟机通常使用运行时类型信息选择正 确的方法来执行(摘自:白皮书)。
但是这些信息我们怎么得到啊,就要借助于class类对象了啊。
在Object类中定义了getClass()方法。我 们可以通过这个方法获得指定对象的类对象。然后我们通过分析这个对象就可以得到我们要的信息了。
比如:ArrayList arrayList;
Class clazz = arrayList.getClass();
然后我来处理这个对象clazz。
当然了Class类具有很多的方法,这里重点将和Constructor,Field,Method类有关系的方法。
Reflection 是 Java 程序开发语言的特征之一,它允许运行中的 Java 程序对自身进行检查,或者说“自审”,并能直接操作程序的内部属性。Java 的这一能力在实际应用中也许用得不是很多,但是个人认为要想对java有个更加深入的了解还是应该掌握的。
1.检测类:
reflection的工作机制
考虑下面这个简单的例子,让我们看看 reflection 是如何工作的。
import java.lang.reflect.*;
public class DumpMethods {
public static void main(String args[]) {
try {
//forName("java.lang.String")获取指定的类的对象
Class c = Class.forName("java.lang.String");
Method m[] = c.getDeclaredMethods();
for (int i = 0; i < m.length; i++)
System.out.println(m[i].toString());
} catch (Throwable e) {
System.err.println(e);
}
}
}
按如下语句执行:
java DumpMethods java.util.ArrayList
这个程序使用 Class.forName 载入指定的类,然后调用 getDeclaredMethods 来获取这个类中定义了的方法列表。java.lang.reflect.Methods 是用来描述某个类中单个方法的一个类。
Java类反射中的主要方法
对于以下三类组件中的任何一类来说
-- 构造函数、字段和方法
-- java.lang.Class 提供四种独立的反射调用,以不同的方式来获得信息。调用都遵循一种标准格式。以下是用于查找构造函数的一组反射调用:
Constructor getConstructor(Class[] params) -- 获得使用特殊的参数类型的公共构造函数,
Constructor[] getConstructors() -- 获得类的所有公共构造函数
Constructor getDeclaredConstructor(Class[] params) -- 获得使用特定参数类型的构造函数(与接入级别无关)
Constructor[] getDeclaredConstructors() -- 获得类的所有构造函数(与接入级别无关)
获得字段信息的Class 反射调用不同于那些用于接入构造函数的调用,在参数类型数组中使用了字段名:
Field getField(String name) -- 获得命名的公共字段
Field[] getFields() -- 获得类的所有公共字段
Field getDeclaredField(String name) -- 获得类声明的命名的字段
Field[] getDeclaredFields() -- 获得类声明的所有字段
用于获得方法信息函数:
Method getMethod(String name, Class[] params) -- 使用特定的参数类型,获得命名的公共方法
Method[] getMethods() -- 获得类的所有公共方法
Method getDeclaredMethod(String name, Class[] params) -- 使用特写的参数类型,获得类声明的命名的方法
Method[] getDeclaredMethods() -- 获得类声明的所有方法
使用 Reflection:
用于 reflection 的类,如 Method,可以在 java.lang.relfect 包中找到。使用这些类的时候必须要遵循三个步骤:
第一步是获得你想操作的类的 java.lang.Class 对象。
在运行中的 Java 程序中,用 java.lang.Class 类来描述类和接口等。
下面就是获得一个 Class 对象的方法之一:
Class c = Class.forName("java.lang.String");
这条语句得到一个 String 类的类对象。还有另一种方法,如下面的语句:
Class c = int.class;
或者
Class c = Integer.TYPE;
它们可获得基本类型的类信息。其中后一种方法中访问的是基本类型的封装类 (如 Intege ) 中预先定义好的 TYPE 字段。
第二步是调用诸如 getDeclaredMethods 的方法,以取得该类中定义的所有方法的列表。
一旦取得这个信息,就可以进行第三步了——使用 reflection API 来操作这些信息,如下面这段代码:
Class c = Class.forName("java.lang.String");
Method m[] = c.getDeclaredMethods();
System.out.println(m[0].toString());
它将以文本方式打印出 String 中定义的第一个方法的原型。
处理对象:
a.创建一个Class对象
b.通过getField 创建一个Field对象
c.调用Field.getXXX(Object)方法(XXX是Int,Float等,如果是对象就省略;Object是指实例).
例如:
import java.lang.reflect.*;
import java.awt.*;
class SampleGet {
public static void main(String[] args) throws Exception {
Rectangle r = new Rectangle(100, 325);
printHeight(r);
printWidth( r);
}
static void printHeight(Rectangle r)throws Exception {
//Field属性名
Field heightField;
//Integer属性值
Integer heightValue;
//创建一个Class对象
Class c = r.getClass();
//.通过getField 创建一个Field对象
heightField = c.getField("height");
//调用Field.getXXX(Object)方法(XXX是Int,Float等,如果是对象就省略;Object是指实例).
heightValue = (Integer) heightField.get(r);
System.out.println("Height: " + heightValue.toString());
}
static void printWidth(Rectangle r) throws Exception{
Field widthField;
Integer widthValue;
Class c = r.getClass();
widthField = c.getField("width");
widthValue = (Integer) widthField.get(r);
System.out.println("Height: " + widthValue.toString());
}
}
安全性和反射:
在处理反射时安全性是一个较复杂的问题。反射经常由框架型代码使用,由于这一点,我们可能希望框架能够全面接入代码,无需考虑常规的接入限制。但是,在其它情况下,不受控制的接入会带来严重的安全性风险,例如当代码在不值得信任的代码共享的环境中运行时。
由于这些互相矛盾的需求,Java编程语言定义一种多级别方法来处理反射的安全性。基本模式是对反射实施与应用于源代码接入相同的限制:
从任意位置到类公共组件的接入
类自身外部无任何到私有组件的接入
受保护和打包(缺省接入)组件的有限接入
不过至少有些时候,围绕这些限制还有一种简单的方法。我们可以在我们所写的类中,扩展一个普通的基本类 java.lang.reflect.AccessibleObject 类。这个类定义了一种setAccessible方法,使我们能够启动或关闭对这些类中其中一个类的实例的接入检测。唯一的问题在于如果使用了安全性管理 器,它将检测正在关闭接入检测的代码是否许可了这样做。如果未许可,安全性管理器抛出一个例外。
下面是一段程序,在TwoString 类的一个实例上使用反射来显示安全性正在运行:
public class ReflectSecurity {
public static void main(String[] args) {
try {
TwoString ts = new TwoString("a", "b");
Field field = clas.getDeclaredField("m_s1");
// field.setAccessible(true);
System.out.println("Retrieved value is " +
field.get(inst));
} catch (Exception ex) {
ex.printStackTrace(System.out);
}
}
}
如果我们编译这一程序时,不使用任何特定参数直接从命令行运行,它将在field .get(inst)调用中抛出一个IllegalAccessException异常。如果我们不注释 field.setAccessible(true)代码行,那么重新编译并重新运行该代码,它将编译成功。最后,如果我们在命令行添加了JVM参数 -Djava.security.manager以实现安全性管理器,它仍然将不能通过编译,除非我们定义了ReflectSecurity类的许可权 限。
反射性能:(转录别人的啊)
反射是一种强大的工具,但也存在一些不足。一个主要的缺点是对性能有影响。使用反射基本上是一种解释操作,我们可以告诉JVM,我们希望做什么并且它满足我们的要求。这类操作总是慢于只直接执行相同的操作。
下面的程序是字段接入性能测试的一个例子,包括基本的测试方法。每种方法测试字段接入的一种形式 -- accessSame 与同一对象的成员字段协作,accessOther 使用可直接接入的另一对象的字段,accessReflection 使用可通过反射接入的另一对象的字段。在每种情况下,方法执行相同的计算 -- 循环中简单的加/乘顺序。
程序如下:
public int accessSame(int loops) {
m_value = 0;
for (int index = 0; index < loops; index++) {
m_value = (m_value + ADDITIVE_VALUE) *
MULTIPLIER_VALUE;
}
return m_value;
}
public int acces
sReference(int loops) {
TimingClass timing = new TimingClass();
for (int index = 0; index < loops; index++) {
timing.m_value = (timing.m_value + ADDITIVE_VALUE) *
MULTIPLIER_VALUE;
}
return timing.m_value;
}
public int accessReflection(int loops) throws Exception {
TimingClass timing = new TimingClass();
try {
Field field = TimingClass.class.
getDeclaredField("m_value");
for (int index = 0; index < loops; index++) {
int value = (field.getInt(timing) +
ADDITIVE_VALUE) * MULTIPLIER_VALUE;
field.setInt(timing, value);
}
return timing.m_value;
} catch (Exception ex) {
System.out.println("Error using reflection");
throw ex;
}
}
在上面的例子中,测试程序重复调用每种方法,使用一个大循环数,从而平均多次调用的时间衡量结果。平均值中不包括每种方法第一次调用的时间,因此初始化时间不是结果中的一个因素。下面的图清楚的向我们展示了每种方法字段接入的时间:
图 1:字段接入时间 :
我们可以看出:在前两副图中(Sun JVM),使用反射的执行时间超过使用直接接入的1000倍以上。通过比较,IBM JVM可能稍好一些,但反射方法仍旧需要比其它方法长700倍以上的时间。任何JVM上其它两种方法之间时间方面无任何显著差异,但IBM JVM几乎比Sun JVM快一倍。最有可能的是这种差异反映了Sun Hot Spot JVM的专业优化,它在简单基准方面表现得很糟糕。反射性能是Sun开发1.4 JVM时关注的一个方面,它在反射方法调用结果中显示。在这类操作的性能方面,Sun 1.4.1 JVM显示了比1.3.1版本很大的改进。
如果为为创建使用反射的对象编写了类似的计时测试程序,我们会发现这种情况下的差异不象字段和方法调用情况下那么显著。使用newInstance()调 用创建一个简单的java.lang.Object实例耗用的时间大约是在Sun 1.3.1 JVM上使用new Object()的12倍,是在IBM 1.4.0 JVM的四倍,只是Sun 1.4.1 JVM上的两部。使用Array.newInstance(type, size)创建一个数组耗用的时间是任何测试的JVM上使用new type[size]的两倍,随着数组大小的增加,差异逐步缩小。随着jdk6.0的推出,反射机制的性能也有了很大的提升。期待中….
总结:
Java语言反射提供一种动态链接程序组件的多功能方法。它允许程序创建和控制任何类的对象(根据安全性限制),无需提前硬编码目标类。这些特性使得反射 特别适用于创建以非常普通的方式与对象协作的库。例如,反射经常在持续存储对象为数据库、XML或其它外部格式的框架中使用。Java reflection 非常有用,它使类和数据结构能按名称动态检索相关信息,并允许在运行着的程序中操作这些信息。Java 的这一特性非常强大,并且是其它一些常用语言,如 C、C++、Fortran 或者 Pascal 等都不具备的。
但反射有两个缺点。第一个是性能问题。用于字段和方法接入时反射要远慢于直接代码。性能问题的程度取决于程序中是如何使用反射的。如果它作为程序运行中相 对很少涉及的部分,缓慢的性能将不会是一个问题。即使测试中最坏情况下的计时图显示的反射操作只耗用几微秒。仅反射在性能关键的应用的核心逻辑中使用时性 能问题才变得至关重要。
许多应用中更严重的一个缺点是使用反射会模糊程序内部实际要发生的事情。程序人员希望在源代码中看到程序的逻辑,反射等绕过了源代码的技术会带来维护问 题。反射代码比相应的直接代码更复杂,正如性能比较的代码实例中看到的一样。解决这些问题的最佳方案是保守地使用反射——仅在它可以真正增加灵活性的地方 ——记录其在目标类中的使用。
一下是对应各个部分的例子:
具体的应用:
1、 模仿instanceof 运算符号
class A {}
public class instance1 {
public static void main(String args[])
{
try {
Class cls = Class.forName("A");
boolean b1
= cls.isInstance(new Integer(37));
System.out.println(b1);
boolean b2 = cls.isInstance(new A());
System.out.println(b2);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
2、 在类中寻找指定的方法,同时获取该方法的参数列表,例外和返回值
import java.lang.reflect.*;
public class method1 {
private int f1(
Object p, int x) throws NullPointerException
{
if (p == null)
throw new NullPointerException();
return x;
}
public static void main(String args[])
{
try {
Class cls = Class.forName("method1");
Method methlist[]
= cls.getDeclaredMethods();
for (int i = 0; i < methlist.length;
i++)
Method m = methlist[i];
System.out.println("name
= " + m.getName());
System.out.println("decl class = " +
m.getDeclaringClass());
Class pvec[] = m.getParameterTypes();
for (int j = 0; j < pvec.length; j++)
System.out.println("
param #" + j + " " + pvec[j]);
Class evec[] = m.getExceptionTypes();
for (int j = 0; j < evec.length; j++)
System.out.println("exc #" + j
+ " " + evec[j]);
System.out.println("return type = " +
m.getReturnType());
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
3、 获取类的构造函数信息,基本上与获取方法的方式相同
import java.lang.reflect.*;
public class constructor1 {
public constructor1()
{
}
protected constructor1(int i, double d)
{
}
public static void main(String args[])
{
try {
Class cls = Class.forName("constructor1");
Constructor ctorlist[]
= cls.getDeclaredConstructors();
for (int i = 0; i < ctorlist.length; i++) {
Constructor ct = ctorlist[i];
System.out.println("name
= " + ct.getName());
System.out.println("decl class = " +
ct.getDeclaringClass());
Class pvec[] = ct.getParameterTypes();
for (int j = 0; j < pvec.length; j++)
System.out.println("param #"
+ j + " " + pvec[j]);
Class evec[] = ct.getExceptionTypes();
for (int j = 0; j < evec.length; j++)
System.out.println(
"exc #" + j + " " + evec[j]);
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
4、 获取类中的各个数据成员对象,包括名称。类型和访问修饰符号
import java.lang.reflect.*;
public class field1 {
private double d;
public static final int i = 37;
String s = "testing";
public static void main(String args[])
{
try {
Class cls = Class.forName("field1");
Field fieldlist[]
= cls.getDeclaredFields();
for (int i
= 0; i < fieldlist.length; i++) {
Field fld = fieldlist[i];
System.out.println("name
= " + fld.getName());
System.out.println("decl class = " +
fld.getDeclaringClass());
System.out.println("type
= " + fld.getType());
int mod = fld.getModifiers();
System.out.println("modifiers = " +
Modifier.toString(mod));
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
5、 通过使用方法的名字调用方法
import java.lang.reflect.*;
public class method2 {
public int add(int a, int b)
{
return a + b;
}
public static void main(String args[])
{
try {
Class cls = Class.forName("method2");
Class partypes[] = new Class[2];
partypes[0] = Integer.TYPE;
partypes[1] = Integer.TYPE;
Method meth = cls.getMethod(
"add", partypes);
method2 methobj = new method2();
Object arglist[] = new Object[2];
arglist[0] = new Integer(37);
arglist[1] = new Integer(47);
Object retobj
= meth.invoke(methobj, arglist);
Integer retval = (Integer)retobj;
System.out.println(retval.intValue());
}
catch (Throwable e) {
System.err.println(e);
}
}
}
6、 创建新的对象
import java.lang.reflect.*;
public class constructor2 {
public constructor2()
{
}
public constructor2(int a, int b)
{
System.out.println(
"a = " + a + " b = " + b);
}
public static void main(String args[])
{
try {
Class cls = Class.forName("constructor2");
Class partypes[] = new Class[2];
partypes[0] = Integer.TYPE;
partypes[1] = Integer.TYPE;
Constructor ct
= cls.getConstructor(partypes);
Object arglist[] = new Object[2];
arglist[0] = new Integer(37);
arglist[1] = new Integer(47);
Object retobj = ct.newInstance(arglist);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
7、 变更类实例中的数据的值
import java.lang.reflect.*;
public class field2 {
public double d;
public static void main(String args[])
{
try {
Class cls = Class.forName("field2");
Field fld = cls.getField("d");
field2 f2obj = new field2();
System.out.println("d = " + f2obj.d);
fld.setDouble(f2obj, 12.34);
System.out.println("d = " + f2obj.d);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
使用反射创建可重用代码:
1、 对象工厂
Object factory(String p) {
Class c;
Object o=null;
try {
c = Class.forName(p);// get class def
o = c.newInstance(); // make a new one
} catch (Exception e) {
System.err.println("Can't make a " + p);
}
return o;
}
public class ObjectFoundry {
public static Object factory(String p)
throws ClassNotFoundException,
InstantiationException,
IllegalAccessException {
Class c = Class.forName(p);
Object o = c.newInstance();
return o;
}
}
2、 动态检测对象的身份,替代instanceof
public static boolean
isKindOf(Object obj, String type)
throws ClassNotFoundException {
// get the class def for obj and type
Class c = obj.getClass();
Class tClass = Class.forName(type);
while ( c!=null ) {
if ( c==tClass ) return true;
c = c.getSuperclass();
}
return false;
}
打个比方:一个object就像一个大房子,大门永远打开。房子里有很多房间(也就是方法)。这些房间有上锁的(synchronized方法),和不上锁之分(普通方法)。房门口放着一把钥匙(key),这把钥匙可以打开所有上锁的房间。另外我把所有想调用该对象方法的线程比喻成想进入这房子某个房间的人。所有的东西就这么多了,下面我们看看这些东西之间如何作用的。
在此我们先来明确一下我们的前提条件。该对象至少有一个synchronized方法,否则这个key还有啥意义。当然也就不会有我们的这个主题了。
一个人想进入某间上了锁的房间,他来到房子门口,看见钥匙在那儿(说明暂时还没有其他人要使用上锁的房间)。于是他走上去拿到了钥匙,并且按照自己的计划使用那些房间。注意一点,他每次使用完一次上锁的房间后会马上把钥匙还回去。即使他要连续使用两间上锁的房间,中间他也要把钥匙还回去,再取回来。
因此,普通情况下钥匙的使用原则是:“随用随借,用完即还。”
这时其他人可以不受限制的使用那些不上锁的房间,一个人用一间可以,两个人用一间也可以,没限制。但是如果当某个人想要进入上锁的房间,他就要跑到大门口去看看了。有钥匙当然拿了就走,没有的话,就只能等了。
要是很多人在等这把钥匙,等钥匙还回来以后,谁会优先得到钥匙?Not guaranteed。象前面例子里那个想连续使用两个上锁房间的家伙,他中间还钥匙的时候如果还有其他人在等钥匙,那么没有任何保证这家伙能再次拿到。(JAVA规范在很多地方都明确说明不保证,象Thread.sleep()休息后多久会返回运行,相同优先权的线程那个首先被执行,当要访问对象的锁被释放后处于等待池的多个线程哪个会优先得到,等等。我想最终的决定权是在JVM,之所以不保证,就是因为JVM在做出上述决定的时候,绝不是简简单单根据一个条件来做出判断,而是根据很多条。而由于判断条件太多,如果说出来可能会影响JAVA的推广,也可能是因为知识产权保护的原因吧。SUN给了个不保证就混过去了。无可厚非。但我相信这些不确定,并非完全不确定。因为计算机这东西本身就是按指令运行的。即使看起来很随机的现象,其实都是有规律可寻。学过计算机的都知道,计算机里随机数的学名是伪随机数,是人运用一定的方法写出来的,看上去随机罢了。另外,或许是因为要想弄的确定太费事,也没多大意义,所以不确定就不确定了吧。)
再来看看同步代码块。和同步方法有小小的不同。
1.从尺寸上讲,同步代码块比同步方法小。你可以把同步代码块看成是没上锁房间里的一块用带锁的屏风隔开的空间。
2.同步代码块还可以人为的指定获得某个其它对象的key。就像是指定用哪一把钥匙才能开这个屏风的锁,你可以用本房的钥匙;你也可以指定用另一个房子的钥匙才能开,这样的话,你要跑到另一栋房子那儿把那个钥匙拿来,并用那个房子的钥匙来打开这个房子的带锁的屏风。
记住你获得的那另一栋房子的钥匙,并不影响其他人进入那栋房子没有锁的房间。
为什么要使用同步代码块呢?我想应该是这样的:首先对程序来讲同步的部分很影响运行效率,而一个方法通常是先创建一些局部变量,再对这些变量做一些操作,如运算,显示等等;而同步所覆盖的代码越多,对效率的影响就越严重。因此我们通常尽量缩小其影响范围。如何做?同步代码块。我们只把一个方法中该同步的地方同步,比如运算。
另外,同步代码块可以指定钥匙这一特点有个额外的好处,是可以在一定时期内霸占某个对象的key。还记得前面说过普通情况下钥匙的使用原则吗。现在不是普通情况了。你所取得的那把钥匙不是永远不还,而是在退出同步代码块时才还。
还用前面那个想连续用两个上锁房间的家伙打比方。怎样才能在用完一间以后,继续使用另一间呢。用同步代码块吧。先创建另外一个线程,做一个同步代码块,把那个代码块的锁指向这个房子的钥匙。然后启动那个线程。只要你能在进入那个代码块时抓到这房子的钥匙,你就可以一直保留到退出那个代码块。也就是说你甚至可以对本房内所有上锁的房间遍历,甚至再sleep(10*60*1000),而房门口却还有1000个线程在等这把钥匙呢。很过瘾吧。
在此对sleep()方法和钥匙的关联性讲一下。一个线程在拿到key后,且没有完成同步的内容时,如果被强制sleep()了,那key还一直在它那儿。直到它再次运行,做完所有同步内容,才会归还key。记住,那家伙只是干活干累了,去休息一下,他并没干完他要干的事。为了避免别人进入那个房间把里面搞的一团糟,即使在睡觉的时候他也要把那唯一的钥匙戴在身上。
最后,也许有人会问,为什么要一把钥匙通开,而不是一个钥匙一个门呢?我想这纯粹是因为复杂性问题。一个钥匙一个门当然更安全,但是会牵扯好多问题。钥匙的产生,保管,获得,归还等等。其复杂性有可能随同步方法的增加呈几何级数增加,严重影响效率。
这也算是一个权衡的问题吧。为了增加一点点安全性,导致效率大大降低,是多么不可取啊。
摘自:http://www.54bk.com/more.asp?name=czp&id=2097
一、当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。
二、然而,当一个线程访问object的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该object中的非synchronized(this)同步代码块。
三、尤其关键的是,当一个线程访问object的一个synchronized(this)同步代码块时,其他线程对object中所有其它synchronized(this)同步代码块的访问将被阻塞。
四、第三个例子同样适用其它同步代码块。也就是说,当一个线程访问object的一个synchronized(this)同步代码块时,它就获得了这个object的对象锁。结果,其它线程对该object对象所有同步代码部分的访问都被暂时阻塞。
五、以上规则对其它对象锁同样适用.
举例说明:
一、当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。
package ths;
public class Thread1 implements Runnable {
public void run() {
synchronized(this) {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + " synchronized loop " + i);
}
}
}
public static void main(String[] args) {
Thread1 t1 = new Thread1();
Thread ta = new Thread(t1, "A");
Thread tb = new Thread(t1, "B");
ta.start();
tb.start();
}
}
结果:
A synchronized loop 0
A synchronized loop 1
A synchronized loop 2
A synchronized loop 3
A synchronized loop 4
B synchronized loop 0
B synchronized loop 1
B synchronized loop 2
B synchronized loop 3
B synchronized loop 4
二、然而,当一个线程访问object的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该object中的非synchronized(this)同步代码块。
package ths;
public class Thread2 {
public void m4t1() {
synchronized(this) {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
}
public void m4t2() {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
public static void main(String[] args) {
final Thread2 myt2 = new Thread2();
Thread t1 = new Thread(
new Runnable() {
public void run() {
myt2.m4t1();
}
}, "t1"
);
Thread t2 = new Thread(
new Runnable() {
public void run() {
myt2.m4t2();
}
}, "t2"
);
t1.start();
t2.start();
}
}
结果:
t1 : 4
t2 : 4
t1 : 3
t2 : 3
t1 : 2
t2 : 2
t1 : 1
t2 : 1
t1 : 0
t2 : 0
三、尤其关键的是,当一个线程访问object的一个synchronized(this)同步代码块时,其他线程对object中所有其它synchronized(this)同步代码块的访问将被阻塞。
//修改Thread2.m4t2()方法:
public void m4t2() {
synchronized(this) {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
}
结果:
t1 : 4
t1 : 3
t1 : 2
t1 : 1
t1 : 0
t2 : 4
t2 : 3
t2 : 2
t2 : 1
t2 : 0
四、第三个例子同样适用其它同步代码块。也就是说,当一个线程访问object的一个synchronized(this)同步代码块时,它就获得了这个object的对象锁。结果,其它线程对该object对象所有同步代码部分的访问都被暂时阻塞。
//修改Thread2.m4t2()方法如下:
public synchronized void m4t2() {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
结果:
t1 : 4
t1 : 3
t1 : 2
t1 : 1
t1 : 0
t2 : 4
t2 : 3
t2 : 2
t2 : 1
t2 : 0
五、以上规则对其它对象锁同样适用:
package ths;
public class Thread3 {
class Inner {
private void m4t1() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t1()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
private void m4t2() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t2()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
}
private void m4t1(Inner inner) {
synchronized(inner) { //使用对象锁
inner.m4t1();
}
}
private void m4t2(Inner inner) {
inner.m4t2();
}
public static void main(String[] args) {
final Thread3 myt3 = new Thread3();
final Inner inner = myt3.new Inner();
Thread t1 = new Thread(
new Runnable() {
public void run() {
myt3.m4t1(inner);
}
}, "t1"
);
Thread t2 = new Thread(
new Runnable() {
public void run() {
myt3.m4t2(inner);
}
}, "t2"
);
t1.start();
t2.start();
}
}
结果:
尽管线程t1获得了对Inner的对象锁,但由于线程t2访问的是同一个Inner中的非同步部分。所以两个线程互不干扰。
t1 : Inner.m4t1()=4
t2 : Inner.m4t2()=4
t1 : Inner.m4t1()=3
t2 : Inner.m4t2()=3
t1 : Inner.m4t1()=2
t2 : Inner.m4t2()=2
t1 : Inner.m4t1()=1
t2 : Inner.m4t2()=1
t1 : Inner.m4t1()=0
t2 : Inner.m4t2()=0
现在在Inner.m4t2()前面加上synchronized:
private synchronized void m4t2() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t2()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
结果:
尽管线程t1与t2访问了同一个Inner对象中两个毫不相关的部分,但因为t1先获得了对Inner的对象锁,所以t2对Inner.m4t2()的访问也被阻塞,因为m4t2()是Inner中的一个同步方法。
t1 : Inner.m4t1()=4
t1 : Inner.m4t1()=3
t1 : Inner.m4t1()=2
t1 : Inner.m4t1()=1
t1 : Inner.m4t1()=0
t2 : Inner.m4t2()=4
t2 : Inner.m4t2()=3
t2 : Inner.m4t2()=2
t2 : Inner.m4t2()=1
t2 : Inner.m4t2()=0
同步买票问题
public class TicketsSystem {
public static void main(String[] args) {
SellThread st = new SellThread();
Thread th1 = new Thread(st);
th1.start();
Thread th2 = new Thread(st);
th2.start();
Thread th3 = new Thread(st);
th3.start();
}
}
class SellThread implements Runnable {
private int number=10;
String s = new String();
public void run() {
while (number > 0) {
synchronized (s) {
System.out.println("第" + number + "个人在"
+ Thread.currentThread().getName() + "买票");
}
number--;
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Java线程:线程的同步-同步块
对于同步,除了同步方法外,还可以使用同步代码块,有时候同步代码块会带来比同步方法更好的效果。
追其同步的根本的目的,是控制竞争资源的正确的访问,因此只要在访问竞争资源的时候保证同一时刻只能一个线程访问即可,因此Java引入了同步代码快的策略,以提高性能。
在上个例子的基础上,对oper方法做了改动,由同步方法改为同步代码块模式,程序的执行逻辑并没有问题。
/**
* Java线程:线程的同步-同步代码块
*
* @author leizhimin 2009-11-4 11:23:32
*/
public class Test {
public static void main(String[] args) {
User u = new User("张三", 100);
MyThread t1 = new MyThread("线程A", u, 20);
MyThread t2 = new MyThread("线程B", u, -60);
MyThread t3 = new MyThread("线程C", u, -80);
MyThread t4 = new MyThread("线程D", u, -30);
MyThread t5 = new MyThread("线程E", u, 32);
MyThread t6 = new MyThread("线程F", u, 21);
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
}
}
class MyThread extends Thread {
private User u;
private int y = 0;
MyThread(String name, User u, int y) {
super(name);
this.u = u;
this.y = y;
}
public void run() {
u.oper(y);
}
}
class User {
private String code;
private int cash;
User(String code, int cash) {
this.code = code;
this.cash = cash;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
/**
* 业务方法
*
* @param x 添加x万元
*/
public void oper(int x) {
try {
Thread.sleep(10L);
synchronized (this) {
this.cash += x;
System.out.println(Thread.currentThread().getName() + "运行结束,增加“" + x + "”,当前用户账户余额为:" + cash);
}
Thread.sleep(10L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return "User{" +
"code='" + code + '\'' +
", cash=" + cash +
'}';
}
}
线程E运行结束,增加“32”,当前用户账户余额为:132
线程B运行结束,增加“-60”,当前用户账户余额为:72
线程D运行结束,增加“-30”,当前用户账户余额为:42
线程F运行结束,增加“21”,当前用户账户余额为:63
线程C运行结束,增加“-80”,当前用户账户余额为:-17
线程A运行结束,增加“20”,当前用户账户余额为:3
Process finished with exit code 0
注意:
在使用synchronized关键字时候,应该尽可能避免在synchronized方法或synchronized块中使用sleep或者yield方法,因为synchronized程序块占有着对象锁,你休息那么其他的线程只能一边等着你醒来执行完了才能执行。不但严重影响效率,也不合逻辑。
同样,在同步程序块内调用yeild方法让出CPU资源也没有意义,因为你占用着锁,其他互斥线程还是无法访问同步程序块。当然与同步程序块无关的线程可以获得更多的执行时间。