
1、
测试人员只能修改缺陷状态为:new-->open,fixed-->closed,fiexed-->reopen
2、 开发人员只能修改缺陷状态为:open-->fiexd,open-->rejected
以上状态转换,可以根据实际需要进行定制!
本实验前提:已经设置好相关的组(如项目测试组,组内成员:wyy)
下面以测试人员只能修改的缺陷状态为例,详细介绍如何设置。
1. 在IE浏览器中输入:http://<安装TD的IP地址>/tdbin,回车,打开如图1所示页面。
图1 TestDirector主页面
2. 在图1中点“TestDirector”链接,打开如图2所示页面。
图2 TestDirector登录页面
3.点图2页面右上角的“Customize”链接,打开如图3所示的对话框,选择Domain、Project,输入User ID、Password。(注意:须用管理员权限登录)
图3 TestDirector登录自定义页面
4. 在图3中点“OK”按钮,进入自定义管理页面,如图4所示。
图4 TestDirector自定义页面
5. 点图4中的“Set up Groups”链接,打开Set up Groups对话框,如图5所示。
图5 Set up Groups对话框
6. 选择需要设置的组,如:选择组“项目测试组”,点“Change”,打开“Permission Settings For 项目测试组 Groups ”,如图6所示。
图6 Permission Settings For 项目测试组 Groups(一) 7. 点图6中的“Defects”,并点“Modify Defect”复选框前面的+号展看该项,如图7所示。
图7 Permission Settings For 项目测试组 Groups(二)
8. 点图7中的“Status”项,如图8所示。
图8 Permission Settings For 项目测试组 Groups(三)
9. 点图8中的“Add”、“Edit”、“Delete”按钮即可添加、编辑、删除状态字段的设置。
比如:要设置测试人员可以修改的权限状态为:new-->open,fixed-->closed,fiexed-->reopen。
先删除图8中的fiexed到any,之后点“Add”, 如图9所示,选择From中的下面一个单选按钮,在下拉框中选择New,再选择To的下面一个单选按钮,在下拉框中选择Open,之后点“OK”即可设置成功。
图9 添加缺陷状态转换规则
10.最后的设置如图10所示。
图10 添加缺陷状态转换规则示例
11.点图10中的“OK”即可设置成功,返回到“Set up Groups”对话框界面,点“OK”设置完成,返回到“Customize”页面,到此设置完成。
公司的Web服务器搭建完成,上线在即。它能够承载多大的访问量,响应速度和容错能力等性能指标是否满足要求,所有这些都是我最想知道,也最为担心的。如何才能知晓这一切呢?
通过工具可以有效地测试Web服务器的运行状态和响应时间等性能指标,从而解决上述问题。下面以Web Application Stress Tool(简称WAST)为例,介绍如何进行Web压力
测试。这是由
微软的网站测试人员开发的专门用来进行实际网站
压力测试的一套工具。
测试工具的设置
下载并安装WAST,过程极其简单。在对目标Web服务器进行压力测试之前,首先要对它进行一些必要的设置。
1.设置并行连接数
点击“Defaults→Settings”打开设置面板。在Concurrent Connections下进行并行连接设置。Stress Level(Threads)是最少线程,Stress Multiplier是最大线程。这里的线程是指定程序在后台用多少线程进行请求,也就是相当于模拟多少个客户机的连接,一般填写500~1000。这个线程数是根据本机的承受力来设置的,如果你对自己的机器配置有足够信心的话,那么可以设置得更高一些。
2.设置持续时间
在“Test Run Time”中用来指定一次压力测试需要持续的时间,分为天、小时、分、秒几个单位级别,比如我们设置为1个小时。
3.其余设置
用Rpquest Delay设置延迟时间,我们设置为100~500。用Suspend设置设定挂起时间,Warmup时间是初始化测试运行时间,Cooldown时间是指定结束阶段的测试时间。Bandwith指定带宽瓶颈,允许模拟从14.4 kbps的Modem连接到T1(1.5 Mbps)的Local Area Network(LAN)连接的网络带宽。Redirects设置重定向时间,Throughput用来设置用户、密码页面状态保存等是否启用,Name Resolution用来设置是否进行名称解析。所有以上的选项大家可以根据自己的需要进行设置。
压力测试的步骤
设置完成后就可以进行压力测试。测试的步骤如下:
第一步,点击工具栏上的“New Script”按钮,在打开的面板中点击“Nanual”按钮创建一个新的测试项目。在打开的窗口中对它进行设置,在主选项中的Server中填写要测试的服务器的IP地址。这里我们填写192.168.1.20。在下方选择测试的Web连接方式,这里的方式Verb选择get。Path选择要测试的Web页面路径,这里填写/Index.asp即动网的首页文件,WAST可以设置更多的Path。
第二步,在“Settings”功能设置中将Stress Level (Threads)线程数设置为1000。然后点工具中的灰色三角按钮即可进行测试。测试过程中我们可以从服务器的任务管理器中看到CPU使用率已经达到100%,损耗率达到最大。在CMD窗口中使用命令netstat -an,可以看到客户端的IP地址在服务器上的80端口进行了非常多的连接,而且Web网站已经打不开了,提示过多用户连接。
通过压力测试,管理员对Web服务器的抗压能力有了大概了解,可根据实际需要进行服务器硬件扩展,也为系统设置和软件选择等提供依据。Web服务器在正式发布前进行压力测试是非常必要的。
首先,两者的出发点是一致的,都是保证项目的健壮性、可靠性、正确性而言的。
不同点主要有:
1、时机不一致。
单元测试是在软件编码前期进行的,先于集成测试;集成测试,是在系统即将开发完毕,对系统的是否正常运作进行测试。
2、测试目的不一样。
单元测试是一个高度本地化的东西(个人认为是属于程序员自身的)。主要是针对每一个package下的Class 的功能进行测试。是程序员的生产力的一个表现方式。
集成测试,将系统当成一个黑盒子,仅关注系统的输出、输入。向客户提供质量保证,不专门对单个程序员进行评估。
3、测试工具不一样
单元测试:用junit自动测试框架,专人写测试代码,周期性的进行测试,保证没有隐藏bug的出现。
集成测试:则需要更多人的协调,侧重点会放到业务的处理上来,性能上也会有所考虑
4、测试粒度不同
单元测试的颗粒度是在单只程序上
集成测试的颗粒度则在整个系统上
最近几天在公司里写网络通讯的代码比较多,自然就会涉及到IO事件监测方法的问题。我惊奇的发现select轮训的方法在那里居然还大行其道。我告诉他们现在无论在
Linux系统下,还是windows系统下,select都应该被废弃不用了,其原因是在两个平台上select的系统调用都有一个可以说是致命的坑。
在windows上面单个fd_set中容纳的socket handle个数不能超过FD_SETSIZE(在win32 winsock2.h里其定义为64,以VS2010版本为准),并且fd_set结构使用一个数组来容纳这些socket handle的,每次FD_SET宏都是向这个数组中放入一个socket handle,并且此过程中是限定了不能超过FD_SETSIZE,具体请自己查看winsock2.h中FD_SET宏的定义。
此处的问题是
若本身fd_set中的socket handle已经达到FD_SETSIZE个,那么后续的FD_SET操作实际上是没有效果的,对应socket handle的IO事件将被遗漏!!!
而在Linux系统下面,该问题其实也是处在fd_set的结构和FD_SET宏上。此时fd_set结构是使用bit位序列来记录每一个待检测IO事件的fd。记录的方式稍微复杂,如下
/usr/include/sys/select.h中
1 typedef long int __fd_mask; 2 #define __NFDBITS (8 * sizeof (__fd_mask)) 3 #define __FDELT(d) ((d) / __NFDBITS) 4 5 #define __FDMASK(d) ((__fd_mask) 1 << ((d) % __NFDBITS)) 6 7 typedef struct 8 { 9 /* XPG4.2 requires this member name. Otherwise avoid the name 10 from the global namespace. */ 11 #ifdef __USE_XOPEN 12 __fd_mask fds_bits[__FD_SETSIZE / __NFDBITS]; 13 # define __FDS_BITS(set) ((set)->fds_bits) 14 #else 15 __fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS]; 16 # define __FDS_BITS(set) ((set)->__fds_bits) 17 #endif 18 } fd_set; 19 20 #define FD_SET(fd, fdsetp) __FD_SET (fd, fdsetp) |
/usr/include/bits/select.h中
1 # define __FD_SET(d, set) (__FDS_BITS (set)[__FDELT (d)] |= __FDMASK (d))
可以看出,在上面的过程,实际上每个bit在fd_set的bit序列中的位置对应于fd的值。而fd_set结构中bit位个数是__FD_SETSIZE定义的,__FD_SETSIZE在/usr/include/bits/typesize.h(包含关系如下sys/socket.h -> bits/types.h -> bits/typesizes.h)中被定义为1024。
现在的问题是,当fd>=1024时,FD_SET宏实际上会引起内存写越界。而实际上在man select中对已也有明确的说明,如下
NOTES
An fd_set is a fixed size buffer. Executing FD_CLR() or FD_SET() with a value of fd that is negative or is equal to or
larger than FD_SETSIZE will result in undefined behavior. Moreover, POSIX requires fd to be a valid file descriptor.
这一点包括之前的我,是很多人没有注意到的,并且云风大神有篇博文《一起 select 引起的崩溃》也描述了这个问题。
可以看出在Linux系统select也是不安全的,若想使用,得小心翼翼的确认fd是否达到1024,但这很难做到,不然还是老老实实的用poll或epoll吧。
扯得有点远了,但也引出了本片
文章要叙述的主题,就是Linux系统下fd值是怎么分配确定,大家都知道fd是int类型,但其值是怎么增长的,在下面的内容中我对此进行了一点分析,以2.6.30版本的kernel为例,欢迎拍砖。
首先得知道是哪个函数进行fd分配,对此我以pipe为例,它是分配fd的一个典型的syscall,在fs/pipe.c中定义了pipe和pipe2的syscall实现,如下1 SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags) 2 { 3 int fd[2]; 4 int error; 5 6 error = do_pipe_flags(fd, flags); 7 if (!error) { 8 if (copy_to_user(fildes, fd, sizeof(fd))) { 9 sys_close(fd[0]); 10 sys_close(fd[1]); 11 error = -EFAULT; 12 } 13 } 14 return error; 15 } 16 17 SYSCALL_DEFINE1(pipe, int __user *, fildes) 18 { 19 return sys_pipe2(fildes, 0); 20 } |
进一步分析do_pipe_flags()实现,发现其使用get_unused_fd_flags(flags)来分配fd的,它是一个宏
#define get_unused_fd_flags(flags) alloc_fd(0, (flags)),位于include/linux/fs.h中
好了咱们找到了主角了,就是alloc_fd(),它就是内核章实际执行fd分配的函数。其位于fs/file.c,实现也很简单,如下
1 int alloc_fd(unsigned start, unsigned flags) 2 { 3 struct files_struct *files = current->files; 4 unsigned int fd; 5 int error; 6 struct fdtable *fdt; 7 8 spin_lock(&files->file_lock); 9 repeat: 10 fdt = files_fdtable(files); 11 fd = start; 12 if (fd < files->next_fd) 13 fd = files->next_fd; 14 15 if (fd < fdt->max_fds) 16 fd = find_next_zero_bit(fdt->open_fds->fds_bits, 17 fdt->max_fds, fd); 18 19 error = expand_files(files, fd); 20 if (error < 0) 21 goto out; 22 23 /* 24 * If we needed to expand the fs array we 25 * might have blocked - try again. 26 */ 27 if (error) 28 goto repeat; 29 30 if (start <= files->next_fd) 31 files->next_fd = fd + 1; 32 33 FD_SET(fd, fdt->open_fds); 34 if (flags & O_CLOEXEC) 35 FD_SET(fd, fdt->close_on_exec); 36 else 37 FD_CLR(fd, fdt->close_on_exec); 38 error = fd; 39 #if 1 40 /* Sanity check */ 41 if (rcu_dereference(fdt->fd[fd]) != NULL) { 42 printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd); 43 rcu_assign_pointer(fdt->fd[fd], NULL); 44 } 45 #endif 46 47 out: 48 spin_unlock(&files->file_lock); 49 return error; 50 } |
在pipe的系统调用中start值始终为0,而中间比较关键的expand_files()函数是根据所给的fd值,判断是否需要对进程的打开文件表进行扩容,其函数头注释如下
/*
* Expand files.
* This function will expand the file structures, if the requested size exceeds
* the current capacity and there is room for expansion.
* Return <0 error code on error; 0 when nothing done; 1 when files were
* expanded and execution may have blocked.
* The files->file_lock should be held on entry, and will be held on exit.
*/
此处对其实现就不做深究了,回到alloc_fd(),现在可以看出,其分配fd的原则是
每次优先分配fd值最小的空闲fd,当分配不成功,即返回EMFILE的错误码,这表示当前进程中fd太多。
到此也印证了在公司写的服务端程序(kernel是2.6.18)中,每次打印client链接对应的fd值得变化规律了,假如给一个新连接分配的fd值为8,那么其关闭之后,紧接着的新的链接分配到的fd也是8,再新的链接的fd值是逐渐加1的。
为此,我继续找了一下socket对应fd分配方法,发现最终也是 alloc_fd(0, (flags),调用序列如下
socket(sys_call) -> sock_map_fd() -> sock_alloc_fd() -> get_unused_fd_flags()
open系统调用也是用get_unused_fd_flags(),这里就不列举了。
现在想回头说说开篇的select的问题。由于Linux系统fd的分配规则,实际上是已经保证每次的fd值尽量的小,一般非IO频繁的系统,的确一个进程中fd值达到1024的概率比较小。因而对此到底是否该弃用select,还不能完全地做绝对的结论。如果设计的系统的确有其他措施保证fd值小于1024,那么用select无可厚非。
但在网络通讯程序这种场合是绝不应该作此假设的,所以还是尽量的不用select吧!!
文章开始之前,我先吐槽一下:现在的应届毕业生丫,不知大学四年都干了什么,难道时间都花在恋爱上面,就算你想恋也没得爱可给你恋的,你确实恋了的,我只能认为你在搞基。
虽然我也是从大学四年搞基出来的,至少有些东西还是没丢给老师。
目录:
1. 数据类型
2. 存储引擎
3. 名词解析
4. 实体 VS 类
5. 关系型 VS 面向对象
文章开始之前,还是先吐槽一下:那些从学校步入社会的人们丫,多上点心,别天天还搞基,伤身又伤心,底子薄没事,不肯前进就是大事了,不是每个头头都这么好心,还一点一点给你们写培训文档。
本文都是Mysql为基础。
1. 数据类型
1) 整数型
tinyint
int
bigint
当我问起int(20) 和int (12) 有区别吗?(括号里面是长度)全场沉默了......
2) 数值型
decimal
当我问起decimal 10,当数值长度操过10了,会怎么样? 万一是金融行业呢,你该咋办? 全场沉默了......
3) 字符型
char
varchar
当我问起char(2) 和varchar(2)有区别吗?(括号里面是长度)全场沉默了......
当char字段和varchar字段使用索引的时候,他们有区别吗?全场沉默了......
tinytext
text
mediumtext
text最大的大小是多少?text字段可以用索引吗? 全场沉默了......
4)时间型
datetime
timestamp
datetime跟 timestamp有区别吗?区别在哪里? 全场继续沉默了......
5)枚举型
enum
一位童鞋站起来问到,enum(Y,N) 和 char(1)有区别吗?
2. 存储引擎
innodb
myisam
memory
当我问起 innodb、 myisam有什么区别的时候,一位技术牛人,站起来,一棍子打死一群人,说直接用innodb就是了,现在的版本mysql默认都是推荐你使用innodb。
如果真要说起来,就说到锁了,这又是坑爹的话题。 还是那位技术牛人高....
3. 名词解析
完整性
冗余
实体
实体的关系
关系型
某位童鞋直接站起来说道:都扔给老师。 真的是佩服那位健忘的童鞋,有健忘症真好,我这课我也丢给老师了。
4 实体 VS 类
该篇开始,我要说个知识:现在很多公司都是由下往上开发,今天我给你们讲的是从上往下开发。
当时有位比较资深的人员就说到,由下往上都是老一辈人喜欢的,因为那段时间里他们的思想没受到面向对象编程的侵袭。
从上往下是你们这群90后乐意做的事。
由下往上:数据库关系--->代码编程---->界面
由上往下:界面--->代码编程---->数据库关系
这是要逆天的存在,先不管是否是不是逆天,先看下面的实例:
class Person {
public $name;
public $age;
public $sex;
public $weight;
}
然后找了个童鞋转了下数据结构
id int name varchar(50) age int sex enum("男","女") weight int
这位童鞋确实给力。
然后我又写了.
$person1 = new Person();
$person1->name = "张三';
$person2= new Person();
$person2->name = "李四';
这位童鞋又写出了如下
id int name varchar(50) age int sex enum("男","女") weight int
1 张三
2 李四
我相信当你看到这些,你应该知道发生了什么了吧!
我继续写到:
class Person {
public $name;
public $age;
public $orders = array(new Order(),new Order());
}
class Order {
public $money;
public $items = array(
"手把手教你做关键词匹配项目",
"屌丝的坑人表单神器"
);
}
90后的小伙子很快就完成了:
order表:
order_id person_id money
order_item表:
item_id order_id item_name
看了这个我翻然大悟,原来现在的应届生对类感兴趣,对实体和实体与实体之间的联系免疫了。
我大悟了,不知道那些童鞋了解了没有,毕竟这个培训是给那些童鞋的。
5. 关系型 VS 面向对象
面向对象 =>关系型 (90后太厉害了,不提了)
最终总结:课后,他们希望我下节课讲解下数据库如何优化,我只能吐槽下:尼玛,连tinyint,char,varchar,索引,锁都搞不懂就来学数据库如何优化,这是要整哪样?
当然我也对他们乐于要求感到高兴,毕竟有需求就有动力。
官方介绍
HSSF is the POI Project's pure
Java implementation of the Excel '97(-2007) file format. XSSF is the POI Project's pure Java implementation of the Excel 2007 OOXML (.xlsx) file format.
从官方文档中了解到:POI提供的HSSF包用于操作 Excel '97(-2007)的.xls文件,而XSSF包则用于操作Excel2007之后的.xslx文件。
需要的jar包
POI官网上下载包并解压获取java操作excel文件必须的jar包:
其中dom4j-1.6.1.jar和xbean.jar(下载地址:http://mirror.bjtu.edu.cn/apache/xmlbeans/binaries/ 网站:http://xmlbeans.apache.org
并不包含在POI提供的jar包中,需要单独下载,否则程序会抛出异常:java.lang.ClassNotFoundException:org.apache.xmlbeans.XmlOptions。
具体代码
在Eclipse中创建一个java project,将上面列出来的jar包都加入到工程的classpath中,否则引用不到jar包会报错。
直接上代码(代码基本框架来自Apache POI官方网站,自行调整部分):
创建excel文件并写入内容:
public static void createWorkbook() throws IOException { Workbook wb = new HSSFWorkbook(); String safeName1 = WorkbookUtil.createSafeSheetName("[O'sheet1]"); Sheet sheet1 = wb.createSheet(safeName1); CreationHelper createHelper = wb.getCreationHelper(); // Create a row and put some cells in it. Rows are 0 based. Row row = sheet1.createRow((short) 0); // Create a cell and put a value in it. Cell cell = row.createCell(0); cell.setCellValue(1234); // Or do it on one line. row.createCell(2).setCellValue( createHelper.createRichTextString("This is a string")); row.createCell(3).setCellValue(true); // we style the second cell as a date (and time). It is important to // create a new cell style from the workbook otherwise you can end up // modifying the built in style and effecting not only this cell but // other cells. CellStyle cellStyle = wb.createCellStyle(); cellStyle.setDataFormat(createHelper.createDataFormat().getFormat( "m/d/yy h:mm")); cell = row.createCell(1); cell.setCellValue(new Date()); cell.setCellStyle(cellStyle); // you can also set date as java.util.Calendar CellStyle cellStyle1 = wb.createCellStyle(); cellStyle1.setDataFormat(createHelper.createDataFormat().getFormat( "yyyyMMdd HH:mm:ss")); cellStyle1.setBorderBottom(CellStyle.BORDER_THIN); cellStyle1.setBottomBorderColor(IndexedColors.BLACK.getIndex()); cellStyle1.setBorderLeft(CellStyle.BORDER_THIN); cellStyle1.setLeftBorderColor(IndexedColors.GREEN.getIndex()); cellStyle1.setBorderRight(CellStyle.BORDER_THIN); cellStyle1.setRightBorderColor(IndexedColors.BLUE.getIndex()); cellStyle1.setBorderTop(CellStyle.BORDER_MEDIUM_DASHED); cellStyle1.setTopBorderColor(IndexedColors.BLACK.getIndex()); cell = row.createCell(4); cell.setCellValue(Calendar.getInstance()); cell.setCellStyle(cellStyle1); FileOutputStream fileOut = new FileOutputStream("e:/test/workbook.xls"); wb.write(fileOut); fileOut.close(); } |
读取excel文件的内容:
public static void readExcel() throws InvalidFormatException, IOException { // Use a file Workbook wb1 = WorkbookFactory.create(new File("e:/test/userinfo.xls")); Sheet sheet = wb1.getSheetAt(0); // Decide which rows to process // int rowStart = Math.min(10, sheet.getFirstRowNum()); // int rowEnd = Math.max(40, sheet.getLastRowNum()); int rowStart = sheet.getLastRowNum(); int rowEnd = sheet.getLastRowNum() + 1; logger.info(sheet.getFirstRowNum()); logger.info(sheet.getLastRowNum()); for (int rowNum = rowStart; rowNum < rowEnd; rowNum++) { Row r = sheet.getRow(rowNum); int lastColumn = Math.max(r.getLastCellNum(), 10); logger.info(lastColumn); // To get the contents of a cell, you first need to know what kind // of cell it is (asking a string cell for its numeric contents will // get you a NumberFormatException for example). So, you will want // to switch on the cell's type, and then call the appropriate // getter for that cell. for (int cn = 0; cn < lastColumn; cn++) { // Cell cell = r.getCell(cn, Row.RETURN_BLANK_AS_NULL); Cell cell = r.getCell(cn); switch (cell.getCellType()) { case Cell.CELL_TYPE_STRING: logger.info(cell.getRichStringCellValue().getString()); break; case Cell.CELL_TYPE_NUMERIC: if (DateUtil.isCellDateFormatted(cell)) { logger.info(cell.getDateCellValue()); } else { logger.info(cell.getNumericCellValue()); } break; case Cell.CELL_TYPE_BOOLEAN: logger.info(cell.getBooleanCellValue()); break; case Cell.CELL_TYPE_FORMULA: logger.info(cell.getCellFormula()); break; default: logger.info("empty"); } } } } |
我们的程序要做的事情是:根据第一行标题的顺序来读取每一行文件的内容,实际标题和内容的顺序是不确定的,但是我们要求按照给定的顺序输出文件内容。
代码如下:
public static void readUserInfo() throws InvalidFormatException, IOException { String[] titles = { "收费编号", "收费性质", "姓名", "家庭住址", "工作单位", "电话", "手机", "小区楼号", "单元号", "楼层", "房间号", "建筑面积(㎡)", "面积依据", "A面积", "A超", "A轻体", "B面积", "B超", "B轻体", "用户编号", "所属楼前表表号" }; //用来存储标题和顺序的map,key为标题,value为顺序号 Map<String, Integer> titleMap = new HashMap<String, Integer>(); //将既定顺序写入map for (int i=0 ; i<titles.length; i++) { titleMap.put(titles[i], i); } Workbook wb = WorkbookFactory.create(new File("e:/test/userinfo.xls")); for (int numSheet = 0; numSheet < wb.getNumberOfSheets(); numSheet++) { Sheet xSheet = wb.getSheetAt(numSheet); if (xSheet == null) { continue; } // 获取第一行的标题内容 Row tRow = xSheet.getRow(0); //存储标题顺序的数组 Integer[] titleSort = new Integer[tRow.getLastCellNum()]; //循环标题 for (int titleNum = 0; titleNum < tRow.getLastCellNum(); titleNum++) { Cell tCell = tRow.getCell(titleNum); String title = ""; if (tCell == null || "".equals(tCell)) { } else if (tCell.getCellType() == XSSFCell.CELL_TYPE_BOOLEAN) {// 布尔类型处理 // logger.info(xCell.getBooleanCellValue()); } else if (tCell.getCellType() == XSSFCell.CELL_TYPE_NUMERIC) {// 数值类型处理 title = doubleToString(tCell.getNumericCellValue()); } else {// 其他类型处理 title = tCell.getStringCellValue(); } //通过获取的标题,从map中读取顺讯号,写入保存标题顺序号的数组 Integer ts = titleMap.get(title); if (ts != null) { titleSort[titleNum] = ts; } } // 循环行Row for (int rowNum = 1; rowNum < xSheet.getLastRowNum() + 1; rowNum++) { Row xRow = xSheet.getRow(rowNum); if (xRow == null) { continue; } // 循环列Cell String[] v = new String[titleSort.length]; for (int cellNum = 0; cellNum < titleSort.length; cellNum++) { Cell xCell = xRow.getCell(cellNum); String value = ""; if (xCell == null || "".equals(xCell)) { } else if (xCell.getCellType() == XSSFCell.CELL_TYPE_BOOLEAN) {// 布尔类型处理 logger.info(xCell.getBooleanCellValue()); } else if (xCell.getCellType() == XSSFCell.CELL_TYPE_NUMERIC) {// 数值类型处理 value = doubleToString(xCell.getNumericCellValue()); } else {// 其他类型处理 value = xCell.getStringCellValue(); } //按照标题顺序的编号来存储每一行记录 v[titleSort[cellNum]] = value; // logger.info("v[" + titleSort[cellNum] + "] = " + v[titleSort[cellNum]]); } //循环结果数组,获取的与既定顺序相同 for (int i = 0; i < v.length; i++) { logger.info(v[i]); } } } } |
上段程序中用到的工具类doubleToString(将excel中的double类型转为String类型,处理了科学计数法形式的数):
private static String doubleToString(double d) { String str = Double.valueOf(d).toString(); // System.out.println(str); String result = ""; if (str.indexOf("E") > 2) { int index = str.indexOf("E"); int power = Integer.parseInt(str.substring(index + 1)); BigDecimal value = new BigDecimal(str.substring(0, index)); value = value.movePointRight(power); result = value.toString(); } else { if (str.indexOf(".0") > 0) result = str.substring(0, str.indexOf(".0")); else result = str; } return result; } |
目前对于POI的应用只限于此,并没有再深入,以后写了新的相关内容会继续补充,请大大们批评指正!
1、需求分析前的准备
在
软件开发过程中,需求分析可以说是核心任务之一,就像一支将要远航的船队,要在指定时间内到达目录地,他们需要一条正确的航线,才能到达目的地,如果航线有误,他们将会误时到达,或是不回到原位将永远到达不了,这么重要的东西,但在国内很多团队中缺少,虽然我也做了一些,但在项目完成的时候,回头看看,其实我们做了很多不必要的事,浪费了很多时间、人力和物力,为保证在今后的开发中减少这些错误的发生,现将一些问题记录下来。
为了了解系统需求,先可以从概要式的需求着手,再细化需求,需求分析必须拟定文档,在写文档之前我们必须做好寻求分析的范围,总结为以下几点:
1.1要做一个什么样的系统
这个不说,我想做软件开发的人都知道,拟定这个后,一切才可以扩展开,比如我们要做一个B2C的商城,要卖母婴用品,知道了这些,我们就可以找现在网站有的B2C网站做参考,分析系统构架,系统功能等。
1.2系统将要在什么样的环境下进行
我上次经历的一个系统,就是要用asp.net重新发一个B2C商城,但有一些前提条件,以前公司有网站,是用java+MYSQL开发的,但我们开发的新系统必须兼容以前的数据,如客户信息,商品信息,还有一些资源信息,并且还要兼容
Google,baidu收录的地址路径,还有与原ERP的通讯等条件,这样让我们的开发很受限制,这些需求就是这样,你无法改变,所以在设计新系统的同时你必须考虑,要花时间去了解以前系统的功能,接口等,如果不了解,等你把新系统开发完了才发现系统脱离了公司原有的业务流程,让公司无法运作,那就代表你开发的系统根本没有价值,我想这不是我们想要的结果。
1.3要解决哪些问题
开发出来软件系统就是为了解决客户需求的,一个B2C网站就是卖商品,主要由客户、商品、购物车、定单组成,将这些核心的功能定义好,我想其它的意外都不会太影响到整个系统的进程。
1.4将来可能会有哪些变化
面对将来的发展,我们也许不能完全考虑到,但与公司的战略发展,可以提前考虑些,能想到多少就想多少,多多益善,我们开发一个系统不是只满足当前的需求,如果眼光只放在眼前,那么你这个系统很快就会被淘汰,功能也许不需要现在实现,但接口总得留下吧,不然想改进都是很困难的事,如果一个稍微的小需求都要动系统构架,我想这个系统会越来越不稳定,作为系统分析师,这块也是至关重要的。
1.5系统可以维持任务的周期是多少
系统周期与公司战略发展是紧扣的,一个系统的功能不可能随着社会的变化,能一直满足市场需要的,在设计系统的时候,可以了解一下公司的战略发展,比如公司三年之内要做成什么样,客户多少,网站浏量,可以做下评估,这样就考虑系统构架的问题,你开始就准备构架一个大胖子,但现在需求简单,在实际的运行中,速度缓慢,其实你构架越复杂,系统运行就越缓慢,虽说现在很多大系统运行的都很好,但要想想,人家服务器,网络构架是什么样的,你不可能让你的系统一线就有这么好的环境,就算有,那成本也太大了,一般的公司也吃不消。
1.6系统分几个阶段实施
在开发初期,我们不可能将系统所有的功能都能完成的很好,为了加快开进度,为了系统能尽早上线,我们得像建楼一样,分阶段进行,分段实施,如果我们现在只是要在网上卖商品,那我们就得把客户管理、商品管理、购物车、定单管理这几大块实现,把一个系统根基打好,谁都想让自己的系统变成最强大的系统,但这个想法几乎是不可能完成的,如果我们把根基打好了,再在上面加以改进,添砖添瓦,根据客户或市场的需要来完善,我想这个系统就会慢慢变成一个成功的系统,对于B2C网站来说,能完成商业的需要,能让公司的流程走顺,那就是个好系统,没有最好的系统,只有最适合的系统。
分阶段实施,可以有节约成本,也可以加快实施速度,不管是作为公司的管理人员还是开发人员,能尽快看到成果,会提高信心,可以举个例子,在设计一个B2C商城的时候,我们除了客户管理、商品管理、购物车、定单管理外,还要加入广告管理、促销管理、CPS、统计管理、用户积分、虚拟币、礼品、物流、接口等一些功能,如果开发周期只给两个月,四个人,从系统设计到系统上线,怎么做?怎样如期完成呢?如果你的团队都没接触过B2C这样的系统,开发起来是很难度的,在这样的情况下,我们必须分段实施,抓主干,把核心的东西完成了,系统可以上线,虽然没有理想的那么强大,但最少它能赚钱,再一个两个月可以把客户管理、商品管理、购物车、定单管理这几块主要的功能完善,公司业务可以进行,后面的功能虽然很有必要,但也可以分个先后,系统上线了,能给大家看到东西,能用用,建议也会多些,对于系统的优化改进,这个是无止尽的,如果没有这些基本的东西,天天都会有人在你耳边叫,你们什么时候上线呀,做了这么久,做的怎么样了,让你的团队心里承受着很大的压力,就算你在两个月内把开发任务完成了,那你的
测试通的过吗,功能越多,问题越多,在后期维护问题越多,最后烦了,没办法,重构,那样不是亏大了。
在一个新的环境中,一个新的团队,你说要在某一时间段里完成什么样的系统,你怎样做到让领导相信你,让公司相信你,一个大一点的软件系统,少则几个月,再多一点就一年半载,他们能等吗,再说了他们不懂代码,不会天天跟你的屁股后面问你,系统怎么样了,做了哪些,就算这样,我想你也进了疯人院了,所以我们做系统要打好第一枪,这样才会得到更多人的支持和理解,如果你不能理解,可以去看看商殃变法中的《徒木立信》的典故。
至于软件第一开发第一阶段要做哪些事,这个要根据一个系统的核心功能去了解,只有建立好了框架,不要太急于求成,没什么好处,把根基打好了,再想怎么包装,都不是件难事。
1.8系统开发团队由哪些人组成
一个好的团队,必定是发挥了团队中每个人的优势,在开发团队中,不是你技术能力强,你就是最有价值的人,我相信在开发团队里没有一个从头到尾都能支持的能人,不是不没,是我是觉得不可能存在,也许我么说有些人不服,其实我这么说也有我的理由,一个人也许有机会经历团队中的每个环节,并且都能深入,但绝对不是一个机会,如果有,那就是一个人的开发,一个人的开发我想也不能叫团队,有时候,一个人什么都能做,多了一个人,什么都做不好,但面对大的项目,不得不进行团队合作。
我所在的公司,我进去的时候,接到项目任务,我开始还有些心虚,因为有些工作我也没接触过,但又不得不去做,但我很意外的时候,我们的团队中有一位项目助理,她的出现让我们的团队协调管理得到了很好的实施,计划任务,可以做到很好的按排,但跟踪管理,我能收集分配,但指定到人后,我很难看到进展的情况,因为自身还有很多的工作,开始我部署了项目管理系统的,收集需求和BUG,也指定到人,但反馈往往不及时,因为我有时候隔一天才上去看,后来我将这项目工作交给了项目助理,让她去管理这些,我发现她做的很好,她每天和我只花几分钟的时间做核对,出现意外情况我就出现解决,她的出现把我和团队中的每个开发人员的工作连接起来,让项目管理得以顺利的实施。
开发团队具体由哪些人组成,这是要根据公司实力,项目进度和项目大小来定的,现在说几个工作职则,可来灵活分配一下:
项目经理:对项目的决策性问题进行定位,一个功能做与不做,领导说的算
构架师:控制技术问题,解决技术难题,对分配下来的任务进行分析、评估,反馈给项目经理,再进行确定
项目助理:记录团队会议内容,协调工作中的日常事务
开发组长:调配开发组员,辅助组内开发人员并对成员工作进行监管,一般由主程担任
开发人员:负责编写代码,按需求完成任务
测试人员:对功能进行测试
如果这里的每项目工作按排到个人,我想开发团队的协调管理最好。
1.9系统运行环境是什么样的
在系统构架时,根据需要定义好,系统构架、程序环境、网络环境,如考虑分布式存储,日均访问量、系统安全、成本预算等。
asp.net的开发成本是要比java的开成本低的。
Sql server的运营成本是要oracle低的,但oracle在大型数据处理上要优于SQL Server,如果是SNS站我觉得上Oracle会好些。
选择什么样的环境,在没有特定要求的情况下,根据团队的现状去考虑我觉得就差不多了。
我们有了目的地将要远航,那么就得需要航海图、船、船长、舵手、水手、水和食物,虽然这样我们能保证100%完成任务,因为大海中的意外谁也不会知晓,但我们理想的是我们能安全到达,如果条件不允许,就算我们知道目的地在哪,出了海,我们将面对是一场艰辛冒险旅程。
2、收集需求
需求的收集是个很繁琐的过程,收集的不够,开发过程中变化会很多,特别是你上了一个演示版本后,开始别人一点意见都没,一看你的演示,你就意见一大堆,这样的问题我想在很多项目中都出现过,所以先在收集需求的时候要和客户或相关部门一一确认,我们考虑需求要从种两种角度去考虑,一种是用户角度,另一种是开发者角度,所以在谈需求时,必须边聊边记,把所谈的话记录整理,如果怕遗漏,可以录音,然后将采用文档的方式表达出来,将提出的需求加以分析,做下技术评估,如果有特别的难题可以提前让开发人员做技术预研,在做评估后,需要分段实施的,就做好规划,然后和提需求的人员确认,需求文档的功能可以多写点,根据企业的发展,能考虑的都考虑,这样可以在系统构架时,定位系统的生命周期时,给以更多的参考,在需求定出阶段后,我们得把要马上实施的功能放在当前,加以强化、细化,反复的进行,条件允许的时候应该做些Demo来确认。
1、新建测试项目:
2、生成TestSuite以及LoadTest
以上操作完成以后项目如下:
开始测试:
双击LoadTest1,如下图:
点击左上角绿色三角形即可开始测试
上图中参数设置参见:http://blog.sina.com.cn/s/blog_59ee85870101o1nz.html
TestNG的英文为
Test Next Generation, 听上去好像下一代
测试框架已经无法正常命名了的样子,哈哈,言归正传,啥是TestNG呢,它是一套测试框架,在原来的Junit框架的思想基础上开发的新一代测试框架,既然这么牛b,那果断弄来试试。本文主要从安装步骤-->第一个测试例子-->再多一点例子-->框架分析-->suite文件的书写-->总结结束。
安装步骤:
1. 第一步,当然首先是在你的
java sdk, eclipse ide, system environment,都已经配置好了的情况下进行, 这些本人早就搭建好了,为了体现手把手教学,这里附加上本人的开发环境参数:os: win 8, java_version: 1.7, path: (added), eclipse_version: 4.3.1, 好了,其实只要装好这些就行了,版本么,再说,哈哈,开工
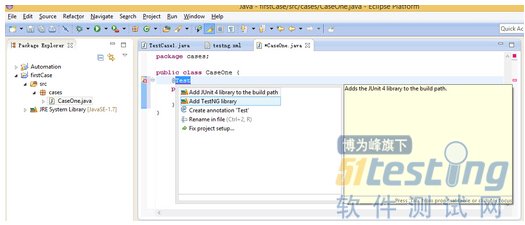
2. 第二步,去官网download一个TestNG插件,这个
工作在eclipse内完成,点击help->install new software,紧接着填上http://beust.com/eclipse
然后一路next到finish。好了TestNG插件装上了,为了check一下是否正常工作,新建一个空的工程,然后再新建一个一个TestNG类试一下,如果能够正常建立,那么就成功了,步骤:file->new->Other,会看到
如果这个看到了,那么okay,恭喜你,可以开工写测试的case了,至此,环境搭建完成。
第一个测试例子:
点击src包上右击,新建一个类,->new->class,包名就叫cases吧,类名就叫CaseOne吧不要main方法,然后finish
写第一个TestNG的带有@Test的方法如图
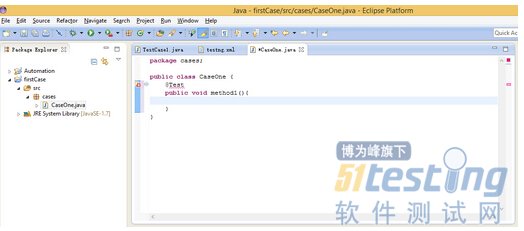
这样前面的case没通过,后面的当然也不会过,比如将注释掉的那句代码去掉就不会通过执行后面两case了。
我们还可以对method进行分组,如
@Test(groups={"group1"})
这样就不用像方法3那样倚赖写一大串了,只需要一个group的名字便可以了。
框架分析
再来看看别的annotation吧!上代码
package cases; import org.testng.annotations.AfterClass; import org.testng.annotations.AfterMethod; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeClass; import org.testng.annotations.BeforeMethod; import org.testng.annotations.BeforeTest; import org.testng.annotations.Test; public class TestCase2 { @BeforeTest public void setUp(){ System.out.println("*******before********"); } @BeforeMethod public void beforeMethod(){ System.out.println("*******beforeMethod********"); } @AfterMethod public void afterMethod(){ System.out.println("*******aftermethod********"); } @Test public void t1(){ System.out.println("*********t1**********"); } @Test public void t2(){ System.out.println("*********t2**********"); } @BeforeClass public void beforeClass(){ System.out.println("*****beforeClass*****"); } @AfterClass public void afterClass(){ System.out.println("*****afterClass*****"); } @AfterTest public void finish(){ System.out.println("*******finish********"); } } |
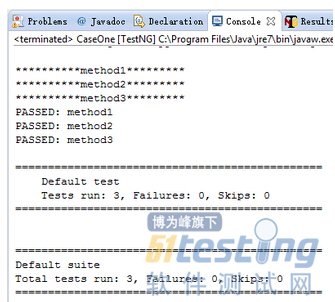
运行得到结果如下
*******before******** *****beforeClass***** *******beforeMethod******** *********t1********** *******aftermethod******** *******beforeMethod******** *********t2********** *******aftermethod******** *****afterClass***** *******finish******** PASSED: t1 PASSED: t2 =============================================== Default test Tests run: 2, Failures: 0, Skips: 0 =============================================== |
这样一来咱们就大概的知道了不同的annotation下的方法的执行顺序了。基本上是@BeforeTest->@BeforeClass->(@BeforeMethod->@Test->@AfterTest)->...重复()内内容...->@AfterClass->@AfterTest.好了,框架基本如下,
再多一点例子:
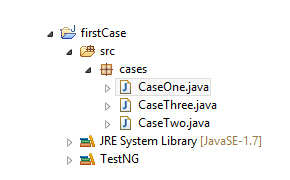
同时建立多个Class,如
如果全部选中,当然会从上当下的执行,但是万一有些文件我们不想执行呢,比如CaseOne中的method1我们想跳过去,那就得写一个控制文件了,在TestNG中使用xml来控制,在顶级目录下建一个build.xml文件,内容如下
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="My Sample Suite"> <test name="First test"> <classes> <class name="cases.CaseOne"></class> </classes> </test> <test name="Second test"> <classes> <class name="cases.CaseTwo"></class> </classes> </test> <test name="Third test"> <classes> <class name="cases.CaseThree"></class> </classes> </test> </suite> 这是按类写的,当然你可以写的更详细,指定方法 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="My Sample Suite"> <test name="First test"> <classes> <class name="cases.CaseOne"></class> <methods> <include name="method1"/> <include name="method2"/> </methods> </classes> </test> <test name="Second test"> <classes> <class name="cases.CaseTwo"></class> </classes> </test> <test name="Third test"> <classes> <class name="cases.CaseThree"></class> </classes> </test> </suite> |
这样类CaseOne中的第三个方法会掠过去不执行。
总结:
在我看来,TestNG是一个非常好用的测试框架,其测试步骤顺序很规范,很强大,当然还有很多东西要去探索。笔者水平较浅,不足之处,大家海涵!
通俗的讲,Wap是
手机网页浏览器使用的网页,
web是电脑网页浏览器使用的网页。(讲得不专业,但方便理解)
在手机上显示的网页不一定能在电脑上正常显示,有些web服务器会对浏览器版本进行判断,并返回信息,如下图是在电脑上打开wap的url提示。
扫描器如果不能正常访问,是不能正常扫描,需要修改user-agent string。把这个参数改成手机浏览器,下图是从firefox上截图。参数可以参考这里的值。
HP webinspect 10的参数修改方法,新建一个任务后,会有如下页面,选择advanced,进入设置对话框,
在Cookies/Headers中添加一个参数
User-Agent: Mozilla/5.0 (
Windows NT 6.1; WOW64) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.43 BIDUBrowser/6.x Safari/537.31
设置完后,就可以在HP Webinspect的浏览器中显示手机的网页,这里拿
百度为例。
http://m.baidu.com/?from=844b&pu=sz%401321_480&wpo=fast