
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@ubuntu:~# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 3498472 315836 3819540 0 0 0 1 2 0 0 0 100 0
2表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:
root@ubuntu:~# vmstat 2 procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 1 0 0 3499840 315836 3819660 0 0 0 1 2 0 0 0 100 0 0 0 0 3499584 315836 3819660 0 0 0 0 88 158 0 0 100 0 0 0 0 3499708 315836 3819660 0 0 0 2 86 162 0 0 100 0 0 0 0 3499708 315836 3819660 0 0 0 10 81 151 0 0 100 0 1 0 0 3499732 315836 3819660 0 0 0 2 83 154 0 0 100 0 |
这表示vmstat每2秒采集数据,一直采集,直到我结束程序,这里采集了5次数据我就结束了程序。
好了,命令介绍完毕,现在开始实战讲解每个参数的意思。
r 表示运行队列(就是说多少个进程真的分配到CPU),我
测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种
web服务器中,我们一般做
性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
下午内网
测试库同事反应查询更新数据很慢,有时甚至表都打不开,后来通过服务器【linux】的top命令查看了下,cpu和mem占用正常,但wait高达80%多(下面两图显示的就是问题前后观察EM对比的截图,版本是oracle10gR2,EM的效果比oracle11gR2逊色不少哈):
-------------------------------------->>
---------------------------->>
接着通过sqldevelpdev客户端查询有没有锁等待之类会话事件,果然有,而且是两个session持有TX锁,然后通过下面的sql查询从oracle和linux级别kill掉了相应session,以为风波就此平静,结果过了不到一分钟查询又出现,只不过这次只有一个session持有TX锁,于是就去查找对应的sql_txt,找到后发现是个同事写的存储过程,定时任务,当时正在运行,让其确认下是不是任务执行出问题了,结果一查,是程序问题,造成的死循环,它会批量发起会话,kill一个后接着又锁,循环反复,后来他改了下程序后重新运行,一切恢复通畅.
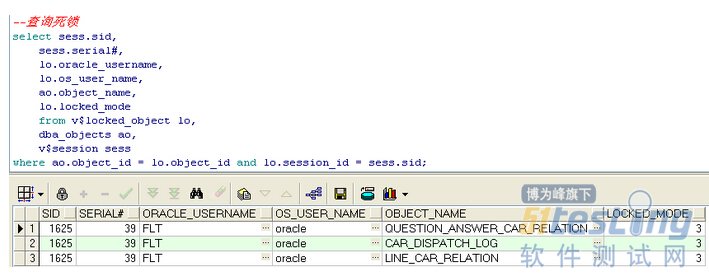
--查询死锁 select sess.sid, sess.serial#, lo.oracle_username, lo.os_user_name, ao.object_name, lo.locked_mode from v$locked_object lo, dba_objects ao,v$session sess where ao.object_id = lo.object_id and lo.session_id = sess.sid; --oracle级别kill session alter system kill session '1627,1'; alter system kill session '1564,64740'; --查询当前连接会话 select s.value,s.sid,a.username,a.MACHINE from v$sesstat S,v$statname N,v$session A where n.statistic#=s.statistic# and name='session pga memory' and s.sid=a.sid and a.sid=1626 order by s.value; --查询造成死锁的sql语句 SELECT a.SID, a.username, s.sql_text FROM v$session a, v$sqltext s WHERE a.sql_address = s.address AND a.sql_hash_value = s.hash_value and a.SID=1626 ORDER BY a.username, a.SID, s.piece; --造成锁等待的操作内容 begin flt_com.p_line_relation_change(:A0,:B0,:C0,:D0,:E0,:ret_errorcode,:ret_errorname); end; --通过sid查找pid,进而通过系统级别kill select spid, osuser, s.program from v$session s,v$process p where s.paddr=p.addr and s.sid=1605; --服务器级别kill kill -9 spid --------------------------------over game |
java中环境变量的设置,主要是设置设置JAVA_HOME,CLASSPATH,在path变量中增加java的bin目录。当然现在都是用工具开发,可以不设置CLASSPATH,可能会有问题,所以还是尽量设置、
JAVA_HOME
C:\Java\jdk1.6.0_30(java的安装目录,)
PATH
C:\Java\jdk1.6.0_30\bin(%JAVA_HOME%\lib)(不要新建path在原来的path路径上新加java到bin的路径就可以了,)
CLASSPATH
.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(注前面的点号和分号一定不能丢,还有中间的,后面的分号也不要丢了)
说明:CLASSPATH可以再增加一些第三方的jar文件,方便手工编译和运行程序。
***********************************************************
在windows中查看环境变量,用set,要查看某一个环境变量的值,可以用set后面跟要查看的值,比如:set classpath ,查看path变量的话,可以直接输入path就可以了。
设置环境变量,可以用set ,比如 set classpath=“新的路径”; 这样就可以了,但只是临时的,doc窗口关闭的时候,设置的临时环境变量就不存在了。
下午内网
测试库同事反应查询更新数据很慢,有时甚至表都打不开,后来通过服务器【linux】的top命令查看了下,cpu和mem占用正常,但wait高达80%多(下面两图显示的就是问题前后观察EM对比的截图,版本是oracle10gR2,EM的效果比oracle11gR2逊色不少哈):
-------------------------------------->>
---------------------------->>
接着通过sqldevelpdev客户端查询有没有锁等待之类会话事件,果然有,而且是两个session持有TX锁,然后通过下面的sql查询从oracle和linux级别kill掉了相应session,以为风波就此平静,结果过了不到一分钟查询又出现,只不过这次只有一个session持有TX锁,于是就去查找对应的sql_txt,找到后发现是个同事写的存储过程,定时任务,当时正在运行,让其确认下是不是任务执行出问题了,结果一查,是程序问题,造成的死循环,它会批量发起会话,kill一个后接着又锁,循环反复,后来他改了下程序后重新运行,一切恢复通畅.
--查询死锁 select sess.sid, sess.serial#, lo.oracle_username, lo.os_user_name, ao.object_name, lo.locked_mode from v$locked_object lo, dba_objects ao,v$session sess where ao.object_id = lo.object_id and lo.session_id = sess.sid; --oracle级别kill session alter system kill session '1627,1'; alter system kill session '1564,64740'; --查询当前连接会话 select s.value,s.sid,a.username,a.MACHINE from v$sesstat S,v$statname N,v$session A where n.statistic#=s.statistic# and name='session pga memory' and s.sid=a.sid and a.sid=1626 order by s.value; --查询造成死锁的sql语句 SELECT a.SID, a.username, s.sql_text FROM v$session a, v$sqltext s WHERE a.sql_address = s.address AND a.sql_hash_value = s.hash_value and a.SID=1626 ORDER BY a.username, a.SID, s.piece; --造成锁等待的操作内容 begin flt_com.p_line_relation_change(:A0,:B0,:C0,:D0,:E0,:ret_errorcode,:ret_errorname); end; --通过sid查找pid,进而通过系统级别kill select spid, osuser, s.program from v$session s,v$process p where s.paddr=p.addr and s.sid=1605; --服务器级别kill kill -9 spid --------------------------------over game |
用CURL命令行测试
REST API 无疑是低效率的,这里把最近使用的两款 Chrome 插件总结下
POSTMAN
简单易用
REST Console
功能强大
使用的话用POSTMAN就够用了,但是我更喜欢 REST Console ,因为她的功能非常强大和全面,一下子就能让你搞清楚你在做的事情,你用不到的功能也可以帮助你更加了解 REST, http请求的过程。
下面是两个的截图界面
1. Authorization
Basic Auth
Digest Auth
OAuth 1.0
2. REQUEST METHOD
GET, PUT, POST, PATCH, DELETE, LINK, UNLINK, COPY, HEAD, OPTIONS, PURGE
3. Request Headers
Content-Type: form-data x-www-form-urlencoded raw Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryVQuD0ghtRqDehBQH Request Payload: ------WebKitFormBoundaryVQuD0ghtRqDehBQH Content-Disposition: form-data; name="image" dddddd ------WebKitFormBoundaryVQuD0ghtRqDehBQH-- Content-Type:application/x-www-form-urlencoded Form Data: image:bbbbbbb Content-Type:text/plain;charset=UTF-8 Request Payload: image=aaaaaaaaaaaaaa |
这3种方法其中 form-data 是不支持 PUT 方法的。而用REST Console中的 Content-Type:multpart/form-data 是支持 PUT 方法的。不知道是不是bug
4. Response Body
支持3种展示方式, 以及常用的XML和JSON格式。
Pretty
Raw
Preview
JSON/XML
5. Response Header
Connection → Connection Options that are desired for the connection Keep-Alive Content-Length →93 Content-Type →application/json; charset=UTF-8 Date →Fri, 01 Aug 2014 05:41:56 GMT Keep-Alive →timeout=5, max=100 Server →Apache/2.2.9 (Win32) PHP/5.4.30 mod_fcgid/2.3.6 X-Powered-By →PHP/5.4.30 |
2. REST Console 测试工具
1. Options
软件相关设置,配色,主题,高亮设置等(说明这个东东功能比较全面)
特别说下一个选项就是 Help Lines, 开启这个选项,对着 REST Console的每一个选项,就很容易搞清楚 http 的 请求和响应中的每一个项目是怎么回事
原创文章,转载请注明 : http://www.cnblogs.com/ganiks/
2. Target
设置下面内容:
Target Request URI : 这个是请求的 URI Request Method : PUT POST ... Request Timeout Accept Accept: (注意区分这个type和后面的content-type) */*(一般都是这个选项) application/atom+xml test/plain application/javascript application/json application/http application/pdf application/rar ... ... Acceptable Language |
3. Body
Content Headers
Content-Type: mime type of the request body(跟PUT和POST方法配合使用)
application/x-www-form-urlencoded
text/plain
multipart/form-data
这3种是在 POSTMAN中支持的3种,但其实有很多很多种,在 REST Console 中的输入框中输入几个字母,会自动匹配库中的很多选项
Acceptable Encoding: 比如 utf-8(参考 HTTP compression)
Content-MD5: 比如 Q2hlY2sgSW50ZWdyaXR5IQ==
Request Payload
RAW BODY: image=ccccccccc
Request Params: key=>value
Attachements: upload files
Custom Headers
Request Parameters
对照个例子:
Accept:*/* Accept-Encoding:gzip,deflate,sdch Accept-Language:zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4 Authorization:Basic MTAwLXRva2VuOg== Cache-Control:no-cache Connection:keep-alive Content-Length:20 Content-Type:text/plain;charset=UTF-8 Host:192.168.4.126 Origin:chrome-extension://fdmmgilgnpjigdojojpjoooidkmcomcm User-Agent:Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36 |
4. Authorization
Basic Auth
Setup oAuth
Refresh oAuth
5. Headers
Headers
Max-Forwards: 10 (限制消息可以穿破 的代理和网关的层数)
Range
From: (发送消息者的邮件地址)
Warning
Pragma
...
Cache (内容太多了)
Common non-standard request headers
6. Response
Response Body: 支持 JSON XML HTML CSS 等高亮格式 { "id": "162", "image": "cccccccc", "link": "dd2", "show_date": "0000-00-00", "state": 1, "show_order": 0 } RAW Body {"id":"162","image":"cccccccc","link":"dd2","show_date":"0000-00-00","state":1,"show_order":0} Response Headers Status Code: 200 Date: Fri, 01 Aug 2014 06:39:00 GMT Server: Apache/2.2.9 (Win32) PHP/5.4.30 mod_fcgid/2.3.6 Connection: Keep-Alive X-Powered-By: PHP/5.4.30 Content-Length: 94 Keep-Alive: timeout=5, max=100 Content-Type: application/json; charset=UTF-8 Response Preview Request Body Request Url: http://192.168.4.126/news/162 Request Method: PUT Status Code: 200 Params: {} Request Headers Content-Type: multipart/form-data Authorization: Basic MTAwLXRva2VuOg== Accept: */* Connection: keep-alive Origin: chrome-extension: //rest-console-id User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36 |
3. http请求的Accept参数
上面提到了一个设置的地方, Accept 和 Content-Type
这两个参数很重要
前者一般如果不设置默认的是 */*, POSTMAN 和 RESTConsole 工具中默认的是 application/json,因此在不设置 Headers:Accept 参数的情况下返回的按照 json格式;
而普通的浏览器中返回的则默认是 application/xml 格式。
后者这个 type 指的是head body 内容的 类型
这就是为什么这两个参数分别被 REST Console 工具分别放在了 2. Target 3. Body 中。
在 yii 中默认支持的 rest api 格式有 xml 和 JSON, yii 会根据 请求的 head 的 Accept 参数来返回对应格式的数据。
这个参数 在chrome 中可以修改默认值吗?
Eclipse自带Junit插件,不用安装就能在项目中编写
测试用例,非常方便。
在项目中添加Junit库
在编写测试用例之前,需要先引入Junit。对项目根目录右键,选择Properties,Java Build Path,Libraries,如图:
Add Library,选择Junit:
点Next选择Junit版本,然后Finish就完成了引入。
编写测试用例
假设有如下类:
package choon.test;
public class Calculate {
public int Add(int x,int y) {
return x + y;
}
}
可以编写测试用例如下:
package choon.test; import static org.junit.Assert.*; import org.junit.Test; public class Test1 { @Test Calculate calculate = new Calculate(); assertEquals(8, calculate.Add(3, 5)); } } |
对test方法右键Run As Junit Test即可运行该测试用例:
如图,绿色状态条表示测试通过,如果是红色,则表示没有通过。
before和after标签
被before标记的方法在每个测试用例执行之前执行,被after标记的方法在每个测试用例执行后执行。
假如编写如下测试用例:
package choon.test; import static org.junit.Assert.*; import org.junit.After; import org.junit.Before; import org.junit.Test; public class Test1 { @Before public void setUp() { System.out.println("---begin test---"); } @Test public void test() { Calculate calculate = new Calculate(); assertEquals(8, calculate.Add(3, 5)); System.out.println("test case"); } @After public void tearDown() { System.out.println("---end test---"); } } |
则会有下面的执行结果:
测试用例的编写很重要,一个不好的测试用例既起不到测试作用又浪费时间,而一个好的测试用例可以很好的指出代码中的问题,避免更大的麻烦。
skipfish是
Google的工程师MIchal Zalewski开发的另一款网站安全检测工具,它完全实现了全自动化操作,所以不需要人工干预,这一点上比RatProxy要好用一些,当然在功能上也强大更多了。
可以从http://code.google.com/p/skipfish/下载它。
安装Cygwin
与ratproxy一样,在windows下需要安装cygwin才能编译它。
下载Cygwin(http://www.cygwin.com/),一路默认下一步直到选择下载站点,考虑到国外的源速度比较慢,所以选择从ntu.edu.tw(速度还是不错的)下载;然后下一步Select Packages,找到以下几个包,并安装它们:
gcc
make
libidn-devel
zlib-devel
openssl-devel
继续下一步直至安装完成。
生成skipfish
1、下载skipfish
2、运行cygwin.bat,并切换到skipfish所在目录(cd “c:\skipfish”)
3、运行make,等它编译完成
使用skipfish
在命令行输入以下命令:
skipfish –o log –W “dictionaries/complete.wl” http://lwme.cnblogs.com
-o参数是输出目录,-W是选择字典,然后就等着它扫描完看报告吧。
使用它的默认参数扫描起来是相当慢的,所以如果有需要的话,可以通过-h参数或者它的在线文档:http://code.google.com/p/skipfish/wiki/SkipfishDoc去研究它。
在
测试领域,很多的测试从业人员都在讨论或者曾经讨论过
自动化测试。支持者认为自动化能够提高测试效率,减少枯燥繁琐的用例执行。持反对意见人的当心自动化测试的引入成本太大,反而没有手工测试来的高效。更有人当心自动化测试无法保证软件的质量,其实能否保证软件的质量,不是由自动化测试决定,而是取决于你的用例的设计。对于新的事物,在没有任何实践的基础上不能轻易地下结论,因为每个人都有惯性的思维,有时候很难跳出固有的思维去考虑新的事物。
自动化测试本身作为一种测试的手段不存在任何的问题。它的好与坏,本质是由其最终结果来决定的。如果自动化测试带来收益大于我们投入的成本,那么自动化测试就是成功的。我们要做的就是在自动化测试实施过程中去提高我们的收益,去降低我们的成本。
何为自动化测试?自动化测试是希望能够通过自动化测试工具或其他手段,按照测试工程师的预定计划进行自动的测试。目的是减轻手工测试的劳动量,腾出更多的时间和精力去测试重要模块,同时又保证已有覆盖自动化测试的模块的质量,从而达到提高软件质量的目的。自动化测试的目的在于发现原有模块引入的新缺陷,保证已有功能的质量。
自动化测试开展的前提
首先部门或者公司要从管理层次上支持你,其次要有专门的测试团队去建立适合自动化测试的测试流程、测试体系,排除上面的因数之外我总结了自动化测试一些前提条件。
1. 长期性
指的是被测产品(或功能)是否需要一个长期的维护,因为短期的项目是没有实现自动化测试的必要的,短期的项目很明显他的投入成本肯定大于其收益。
2. 稳定性
被测产品(或功能)是否有一个相对稳定的产品。如果功能和界面都处于不稳定阶段而且经常发生变化的,那脚本和用例的维护成本是非常高的,
所以也是不具备实施自动化的前提条件。
3. 合适测试工具
(工欲善其事,必先利其器)
假如被测产品(或功能)难以通过工具识别其控件的话
假如使用脚本语言难懂难学,而且扩展性差。
4. 人员
你的产品组内是否具备合适人员去开展自动化,是否具备一定合适的人去做自动化脚本开发。自动化测试实施的好与坏,很大程度上取决于该测试工程师,因为要有效实施自动化测试,单一的测试工具的熟练是远远不够的,他需要其它一些辅助的测试手段,所以同时也就需要该测试工程师具备一定的方案解决能力,能够找到较优的方案来解决现实中碰到的问题。
5. 用例
自动化测试需要好的
测试用例的辅助,这个应该是大家的共识,所以不展开来讲。所以这里希望我们的自动化测试工程师需要与
用例设计者进行密切的合作。
整体来说自动化测试能否有效开展,能否有效的实施,不是单一取决于某一个人或者某自动化测试工程师的能力,他是整个团队合作的结果。
自动化测试成本
这是领导们最关心的问题。因为他们都希望自动化测试带来的收益要远大于所投入的成本。不然怎么体现自动化测试价值?如果没有价值还不如直接手工测试来的干脆。
那么自动化成本有哪些?
1、调研成本
2、脚本开发维护成本
3、自动化用例设计与维护成本
4、资源投入成本
如何有效的降低自动化测试成本呢?
一、 提高调研成本,减少人为因数成本
调研成本省不了,而且要加大投入,如果投入成本不大,选择的工具和框架都不适合自动化的开展,那么自动化测试肯定以失败告终。一旦给自动化测试选好了型,后期的转化成本非常的高,所以一开始就要选择合适的工具和框架。
当然为了尽量减少调研成本,需要选择合适人,需要整个团队的配合。
二、 选择好的测试工具
选择好的测试工具,首先要看其所使用的语言是否容易普及,是否功能强大,在自动化测试工具当中,我认为最重要的是GUI对象的识别能力,第三方接口的处理能力。
三、 构建合适的测试框架
有了好的测试工具之后,我们需要一个合适的测试框架,测试框架应该是一个企业级的应用,而不是单一的产品和功能。它至少可以减少重复代码编写,包含常用的操作,简单的配置或自动配置,运行结果自动收集,运行结果简洁且容易分析。
四、 选择合适的人,减少研究,实施投入成本
这里我主要讲是选择合适的人,做正确的事上。那么什么样的人适合做自动化测试呢,首先的一点肯定要有一定的代码编写能力。其次我觉得需要一定软件工程的思想。没有好的思想,是很难组织起清晰架构的代码来的。
合适人,做正确的事。这里就充分体现管理者能力了,尤其是测试框架上的研究,往往不是靠单一的人所能够做到,因为会受到知识体系,思维,能力等相关的束缚。所以我的意见是这些应该是交给一个组织,该组织内集合测试负责人,测试工程师,自动化测试工程师,来依靠团队的力量来打造合适的测试框架。当然框架的实现上应该交给自动化测试工程师。
那么什么样的人才是合适的呢
1、需要有一定的手工测试经验和自动化测试经验,能知道测试框架为谁而做,需要做什么?
2、能够将复杂的设计简单化,能够充分理解软件工程的思想,将最简单的应用提供给测试工程师
五、 减少用例的设计维护成本
如果有好的框架支撑的话,那么用例的设计维护成本完全是可以减少的。
六、 保持脚本整体架构清晰易懂,易维护
七、 合适的加大资源投入成本
我觉得资源投入成本是值得的,资源投入如果能够减少人力的投入的话。我想是所有管理者都愿意看到的。
自动化测试收益
在如何评价自动化测试收益方面,每个人的角度不通过,得出结果可能也不相同。我想从以下几个方面来看自动化收益:
1、快速测试
测试人员手工测试多个功能,测试执行的并行度总有个上限。而多个并行执行的自动化测试脚本可以更快速地验证版本,一次性地报告问题
2、降低手工测试投入成本
将功能测试人员从繁琐重复的测试中解脱出来,有更多的时间和精力去进行一些探索性的测试。
3、提供了软件的质量
自动化测试能够帮助我们减少生产环境中某种特定类型的缺陷。这些缺陷包括环境或者配置相关的缺陷、在主流程上本来正常但因为后期修改影响到的功能、以及容易被忽略的地方等
4、提高了我们对软件质量的信心
5、自动化测试可以唤起更高的工作热情
这一方面来自于可以部分地将测试人员从大量重复的测试执行中解放出来,另一方面来自于新技术、新工具带来的新鲜感
如何有效地提高自动化测试收益?
要有效的开展自动化,一定程度上来说,成本是很难降低的,只有将收益最大化。增加收益的方式有很多种:
一、提高自动化测试迭代次数,提高自动化的使用频率
要提高自动化的使用频率,就需要将原有观念自动化测试收益往往来源于回归阶段进行更正,实际证明自动化同样可以在日常测试中发挥作用。自动化的使用用例的重复性使用频率越高,其价值也就越大,其收益也会越大。
二、脚本复用,提高脚本对应功能点的用例覆盖率
提高该脚本所覆盖功能点的用例覆盖,也就是我们不但要考虑减少了自动化脚本开发成本以及降低维护成本,同时也要考虑该脚本带来的收益已尽量去最大化。
三、提高自动化用例的覆盖率,最大程度上减少手工重复的劳动
尽可能的提高用例的覆盖率,并通过自动化来代替我们的手工测试,这样不但能在保证软件质量的同时减少手工重复的劳动,
四、建立并维护好测试用例库,帮助我们节省资源并快速培养测试人员
五、推广成功案例到其它产品
从入行一开始就决定了不走技术路线,因为游戏之所以是游戏是因为其游戏性而不是技术性,我爱的是游戏,而不是技术。
1:刚入行的时候:找严重bug,或者操作步骤很多的bug,很有成就感,因为找到别人找不到的bug
2:后来意识到,基础的简单的bug价值不见得比严重的难找的bug价值低,开始转向追求覆盖、不漏基础简单的bug
3:开始关注流程,流程可以减少人为失误导致的bug,开始关注预防bug,特别是通过流程来预防人为bug
4:认为流程最重要,几乎所有的bug都可以通过流程来预防和解决
6:开始认识到信息的重要性,认为测试的职责是提供产品信息,而不是自己掌控决定权
7:开始认识到,测试要做的太多,不可能全部做到,要做取舍
8:测试是辅助,不仅仅辅助产品,而且要辅助团队;团队重要性高于项目
9:测试不仅仅要提供产品的信息,也要提供人的信息,团队的信息
推送并不是什么新技术,这种技术在
互联网时代就已经很流行了。只是随着进入
移动互联网时代,推送技术显得更加重要。因为在智能
手机中,推送从某种程度上,可以取代使用多年的短信,而且与短信相比,还可以向用户展示更多的信息(如图像、表格、声音等)。
推送技术的实现通常会使用服务端向客户端推送消息的方式。也就是说客户端通过用户名、Key等ID注册到服务端后,在服务端就可以将消息向所有活动的客户端发送。
实际上,在很多移动
操作系统中,官方都为其提供了推送方案,例如,
Google的云推送、IOS、
Windows Phone7/8也都提供了类似的推送方案。不过这些推送方案的服务器都在国外,有一些推送服务(如Google的云推送)在国内由于某些原因不太稳定,所以国内近几年涌现出了很多专门为国人打造的推送服务。
本文将从各种流行移动操作系统入手介绍推送技术的各种实现方式。当然,我们的主要目的是讨论
Android的推送技术。
一、iOS的推送技术
Apple为IOS提供了很完美的推送方案,其基本原理是Apple提供了自己的推送服务器,叫APNS(Apple Push Notification Service,
苹果推送通知服务器)。而客户端设备(IPhone、IPad等)直接与APNS建立长连接。不过向客户端设备发送的消息并不是由APNS产生的,而是在需要发送消息的用户自己提供的服务器(称为Provider)中产生的,然后Provider将消息传送给APNS,最后由APNS将消息传送给客户端设备。也就是说,消息最开始由Provider产生,然后Provider将消息传送给APNS,最后再由APNS传送给客户端设备。消息传递的过程如图1所示。
在发送消息到客户端设备接收到消息的过程中,始终伴随这一个令牌的传送(device token)。要想使用APNS提供消息服务,应用程序需要先向IOS注册需要提供的一个必要的信息就是与当前设备有关的device token,IOS在接收到devicetoken后,会向APNS查询这个device token是否在APNS上注册了(所有的IOS设备在第一次使用时都需要向苹果服务器注册一个账号,否则无法从AppleStore下载应用,当然更无法使用推送服务了),如果已经注册,APNS会直接向应用程序返回这个devicetoken。应用程序获得这个devicetoken后,表示APNS已经允许向自己推送消息了,接着还需要将该device token发送给推送服务器(Provider)。到这里应用程序已经成功将自己注册到APNS中了。现在就可以通过Provider产生要推送的消息,然后Provider会将消息发送给APNS服务器,最后APNS服务器会直接向应用程序发送消息。这个过程比较复杂,不过看一下图2的描述就会对这一过程更加了解了。每一个流程描述前面的数字表示发送的时间先后顺序。
二、Windows Phone的推送技术
微软为Window Phone提供的推送方案与IOS类似,也需要自己准备推送服务器(可以称为Cloud Service)。只是表示设备的ID变成了Uri。在Window Phone中有一个Push Client Service(PCS)。所有需要推送服务的应用程序都需要与Push Client Service通信。下面是Window Phone推送的基本步骤,读者可以与图3对照来看这一过程。
第1步:应用程序会向Push Client Service请求一个Push Notification URI(①)。
第2步:如果当前Window Phone设备已经在微软服务器注册了,Push Client Service会从MPNS(Microsoft Push Notification Service ,微软推送通知服务)获取Push Notification URI,并返回给应用程序,表示推送服务可用(②和③)。
第3步:应用程序需要将Push Notification URI发送给自己的推送服务器(Cloud Service)(④)。
第4步:如果需要推送消息,Cloud Service会将消息发送到MPNS,然后MPNS会将消息发送给Push Client Service,最后由Push Client Service将消息传送给应用程序(⑤、⑥和③)。