
下面是stackoverflow中关于数组方法的相关问题中,获得最多票数的12个数组操作方法。
1. 声明一个数组
String[] aArray = new String[5];
String[] bArray = {"a","b","c", "d", "e"};
String[] cArray = new String[]{"a","b","c","d","e"};
2. 输出一个数组
int[] intArray = { 1, 2, 3, 4, 5 };
String intArrayString = Arrays.toString(intArray);
// print directly will print reference value
System.out.println(intArray);
// [I@7150bd4d
System.out.println(intArrayString);
// [1, 2, 3, 4, 5]
3. 从一个数组创建数组列表
String[] stringArray = { "a", "b", "c", "d", "e" };
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(stringArray));
System.out.println(arrayList);
// [a, b, c, d, e]
4. 检查一个数组是否包含某个值
String[] stringArray = { "a", "b", "c", "d", "e" };
boolean b = Arrays.asList(stringArray).contains("a");
System.out.println(b);
// true
5. 连接两个数组
int[] intArray = { 1, 2, 3, 4, 5 };
int[] intArray2 = { 6, 7, 8, 9, 10 };
// Apache Commons Lang library
int[] combinedIntArray = ArrayUtils.addAll(intArray, intArray2);
6. 声明一个内联数组(Array inline)
method(new String[]{"a", "b", "c", "d", "e"});
7. 把提供的数组元素放入一个字符串
// containing the provided list of elements
// Apache common lang
String j = StringUtils.join(new String[] { "a", "b", "c" }, ", ");
System.out.println(j);
// a, b, c
8. 将一个数组列表转换为数组
String[] stringArray = { "a", "b", "c", "d", "e" };
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(stringArray));
String[] stringArr = new String[arrayList.size()];
arrayList.toArray(stringArr);
for (String s : stringArr)
System.out.println(s);
9. 将一个数组转换为集(set)
Set<String> set = new HashSet<String>(Arrays.asList(stringArray));
System.out.println(set);
//[d, e, b, c, a]
10. 逆向一个数组
int[] intArray = { 1, 2, 3, 4, 5 };
ArrayUtils.reverse(intArray);
System.out.println(Arrays.toString(intArray));
//[5, 4, 3, 2, 1]
11. 移除数组中的元素
int[] intArray = { 1, 2, 3, 4, 5 };
int[] removed = ArrayUtils.removeElement(intArray, 3);//create a new array
System.out.println(Arrays.toString(removed));
12. 将整数转换为字节数组
byte[] bytes = ByteBuffer.allocate(4).putInt(8).array();
for (byte t : bytes) {
System.out.format("0x%x ", t);
}
前几天看了一下Spring的部分源码,发现回调机制被大量使用,觉得有必要把Java回调机制的理解归纳总结一下,以方便在研究类似于Spring源码这样的代码时能更加得心应手。
注:本文不想扯很多拗口的话来充场面,我的目的是希望以最简明扼要的语言将Java回调的大概机制说清楚。好了,言归正传。
一句话,回调是一种双向调用模式,什么意思呢,就是说,被调用方在被调用时也会调用对方,这就叫回调。“If you call me, i will call back”。
不理解?没关系,先看看这个可以说比较经典的使用回调的方式:
class A实现接口InA ——背景1
class A中包含一个class B的引用b ——背景2
class B有一个参数为InA的方法
test(InA a) ——背景3
A的对象a调用B的方法传入自己,test(a) ——这一步相当于you call me
然后b就可以在test方法中调用InA的方法 ——这一步相当于i call you back
是不是清晰一点了?下面再来看一个完全符合这个方式模板的例子
(PS:这个例子来源于网络,由于这个例子表现的功能极度拉风,令我感觉想想出一个超越它的例子确实比较困难,所以直接搬过来)
//相当于接口InA public interface BoomWTC{ //获得拉登的决定 public benLaDengDecide(); // 执行轰炸世贸 public void boom(); } //相当于class A public class At$911 implements BoomWTC{//相当于【背景1】 private boolean decide; private TerroristAttack ta;//相当于【背景2】 public At$911(){ Date now=new Date(); SimpleDateFormat myFmt1=new SimpleDateFormat("yy/MM/dd HH:mm"); this.dicede= myFmt.format(dt).equals("01/09/11 09:44"); this.ta=new TerroristAttack(); } //获得拉登的决定 public boolean benLaDengDecide(){ return decide; } // 执行轰炸世贸 public void boom(){ ta.attack(new At$911);//class A调用class B的方法传入自己的对象,相当于【you call me】 } } //相当于class B public class TerroristAttack{ public TerroristAttack(){ } public attack(BoomWTC bmw){——这相当于【背景3】 if(bmw.benLaDengDecide()){//class B在方法中回调class A的方法,相当于【i call you back】 //let's go......... } } } |
现在应该对回调有一点概念了吧。
可是问题来了,对于上面这个例子来说,看不出用回调有什么好处,直接在调用方法不就可以了,为什么要使用回调呢?
事实上,很多需要进行回调的操作是比较费时的,被调用者进行费时操作,然后操作完之后将结果回调给调用者。看这样一个例子:
//模拟Spring中HibernateTemplate回调机制的代码 interface CallBack{ public void doCRUD(); } public class HibernateTemplate { public void execute(CallBack action){ getConnection(); action.doCRUD(); releaseConnection(); } public void add(){ execute(new CallBack(){ public void doCRUD(){ System.out.println("执行add操作..."); } }); } public void getConnection(){ System.out.println("获得连接..."); } public void releaseConnection(){ System.out.println("释放连接..."); } } |
可能上面这个例子你不能一眼看出个所以然来,因为其实这里A是作为一个内部匿名类存在的。好,不要急,让我们把这个例子来重构一下:
interface CallBack{ //相当于接口InA public void doCRUD(); } public class A implements CallBack{//【背景1】 private B b;//【背景2】 public void doCRUD(){ System.out.println("执行add操作..."); } public void add(){ b.execute(new A());//【you call me】 } } public class B{ public void execute(CallBack action){ //【背景3】 getConnection(); action.doCRUD(); //【i call you back】 releaseConnection(); } public void getConnection(){ System.out.println("获得连接..."); } public void releaseConnection(){ System.out.println("释放连接..."); } } |
好了,现在就明白多了吧,完全可以转化为上面所说的回调使用方式的模板。
现在在来看看为什么要使用回调,取得连接getConnection();是费时操作,A希望由B来进行这个费时的操作,执行完了之后通知A即可(即所谓的i call you back)。这就是这里使用回调的原因。
在网上看到了一个比喻,觉得很形象,这里借用一下:
你有一个复杂的问题解决不了,打电话给你的同学,你的同学说可以解决这个问题,但是需要一些时间,那么你不可能一直拿着电话在那里等,你会把你的电话号码告诉他,让他解决之后打电话通知你。回调就是体现在你的同学又反过来拨打你的号码。
结合到前面所分析的,你打电话给你同学就是【you call me】,你同学解决完之后打电话给你就是【i call you back】。
怎么样,现在理解了吧?
---------------------------------以下为更新----------------------------------
看了有些朋友的回帖,我又思考了一下,感觉自己之前对回调作用的理解的确存在偏差。
下面把自己整理之后的想法共享一下,如果有错误希望指出!多谢!
先说上面这段代码,本来完全可以用模板模式来进行实现:
public abstract class B{ public void execute(){ getConnection(); doCRUD(); releaseConnection(); } public abstract void doCRUD(); public void getConnection(){ System.out.println("获得连接..."); } public void releaseConnection(){ System.out.println("释放连接..."); } } public class A extends B{ public void doCRUD(){ System.out.println("执行add操作..."); } public void add(){ doCRUD(); } } public class C extends B{ public void doCRUD(){ System.out.println("执行delete操作..."); } public void delete(){ doCRUD(); } } 如果改为回调实现是这样的: interface CallBack{ public void doCRUD(); } public class HibernateTemplate { public void execute(CallBack action){ getConnection(); action.doCRUD(); releaseConnection(); } public void add(){ execute(new CallBack(){ public void doCRUD(){ System.out.println("执行add操作..."); } }); } public void delete(){ execute(new CallBack(){ public void doCRUD(){ System.out.println("执行delete操作..."); } }); } public void getConnection(){ System.out.println("获得连接..."); } public void releaseConnection(){ System.out.println("释放连接..."); } } |
可见摒弃了继承抽象类方式的回调方式更加简便灵活。不需要为了实现抽象方法而总是继承抽象类,而是只需要通过回调来增加一个方法即可,更加的直观简洁灵活。这算是回调的好处之一。
下面再给出一个关于利用回调配合异步调用的很不错的例子
回调接口:
public interface CallBack { /** * 执行回调方法 * @param objects 将处理后的结果作为参数返回给回调方法 */ public void execute(Object... objects ); } 消息的发送者: /** * 这个类相当于你自己 */ public class Local implements CallBack,Runnable{ private Remote remote; /** * 发送出去的消息 */ private String message; public Local(Remote remote, String message) { super(); this.remote = remote; this.message = message; } /** * 发送消息 */ public void sendMessage() { /**当前线程的名称**/ System.out.println(Thread.currentThread().getName()); /**创建一个新的线程发送消息**/ Thread thread = new Thread(this); thread.start(); /**当前线程继续执行**/ System.out.println("Message has been sent by Local~!"); } /** * 发送消息后的回调函数 */ public void execute(Object... objects ) { /**打印返回的消息**/ System.out.println(objects[0]); /**打印发送消息的线程名称**/ System.out.println(Thread.currentThread().getName()); /**中断发送消息的线程**/ Thread.interrupted(); } public static void main(String[] args) { Local local = new Local(new Remote(),"Hello"); local.sendMessage(); } public void run() { remote.executeMessage(message, this); //这相当于给同学打电话,打完电话之后,这个线程就可以去做其他事情了,只不过等到你的同学打回电话给你的时候你要做出响应 } } |
消息的接收者:
/** * 这个类相当于你的同学 */ public class Remote { /** * 处理消息 * @param msg 接收的消息 * @param callBack 回调函数处理类 */ public void executeMessage(String msg,CallBack callBack) { /**模拟远程类正在处理其他事情,可能需要花费许多时间**/ for(int i=0;i<1000000000;i++) { } /**处理完其他事情,现在来处理消息**/ System.out.println(msg); System.out.println("I hava executed the message by Local"); /**执行回调**/ callBack.execute(new String[]{"Nice to meet you~!"}); //这相当于同学执行完之后打电话给你 } } |
由上面这个例子可见,回调可以作为异步调用的基础来实现异步调用。
git作为源码管理工具出于流行趋势。这里和大家一起分享下我们是如何用git的分支(branch)功能管理不同规模的项目
小型项目
推荐工具:TortoiseGit
开发阶段(第一版上线前):2个分支 develop和master
由于是项目参与人员不多,基本上很少会有不同角色的人员出现职责冲突,需求变更也不会很繁冗。这种情况值我们只需要主要功能分支。
其中develop负责开发版本,master相当于预上线版本。
develop过程如果出现代码冲突,手工merge就好。
开发阶段(第一版上线后):3个分支 develop、master、hotfix
多处于来的hotfix用于紧急上线(bug,新需求等)。hotfix基于master,因为develop已经越走越远,基于develop的hotfix会将带上一些当前不想上线的新功能。
hotfix完成后hotfix要merge到master上,因为线上不管何种情况都是master版本。qa完成
测试并且上线后要将master版本merge到develop避免hotfix的修改在develop中丢失。
维护阶段(停止常规开发):2个分支 master、hotfix。
这个阶段就相当于针对上线版本的各种打补丁了。
中型项目
推荐工具: sourcetree
开发阶段(第一版上线前):3个分支 feature、develop和master
相对于小型项目多了feature分支的概念。feature分支基于develop分支,当功能开发完成后merge回develop。
这样做的好处是将develop分支从小型项目中去中心化。举个例子,因为是中型项目,我们可能有5 6个在并行开发,如果这个过程中客户说某个功能我们不要了,我们可以很轻松的丢掉某个feature分支而不必污染develop。
但是如果是开发时间很久的feature分支,很可能会因为不定时的merge develop或者需求的不断变更等导致当前分支的commit比较肮脏。所以对于feature分析的力度要控制好。
如图所示:
开发阶段(第一版上线后):4个分支 feature、develop、master和hotfix
和上面小心项目一样 hotfix基于master版本。
维护阶段(停止常规开发): 和小型项目一样 大型项目
推荐工具:sourcetree
大型项目相对于中型项目又多了release版本。这个版本的作用只要是控制需求的更新以及当前版本bug的fix处理。
点击查看大图:
对于这种情景sourcetree自带git-flow的功能
并且给出各种引导提示
和中型项目相比,hotfix分支在大型项目中只处理线上的bug问题。对于需求的控制,都会发生在release分支中。一个release版本的生成并不意味着它可以直接提交master,qa的介入在中小型项目中属于master分支,
但是在这个流程下,qa的介入属于release分支,包括对于bug的修复操作也是直接在release版本完成。当qa对于release版本确认完成后,release版本merge到master预上线并且merge回develop保持代码一致性。
2007年8月13日,在刚刚开始我
工作的第七个年头时,终于顺利的进入了M公司,并得到了一个
测试管理方面的职位。虽然之前的六年工作中,我一直在偏技术和偏管理的角色中游移,自信自己在两个方面都有一些积累,足以胜任技术管理工作。可是在M公司的这一个半月,的确又真的让我重新开始思考自己的工作。
零零碎碎想到一些东西,先写下来,以后继续慢慢补充,也欢迎大家一起讨论。另外,虽然我的视角是从 Test Team 的角度出发的,但是也应该可以适用于其他想进一步提升自己价值的Team。
在大多数情况下,Test Team并不是以软件的直接生产者的身份出现的,而是作为一个附属的功能团队承担开发过程中的一部分职责。这也决定了Test Team 的工作并不不能直接的体现出价值,而是只有当Test Team的工作成果被其他人或Team所使用,为其他人或Team带来价值时,才能真正的体现出Test Team的价值。
换句话说,当我们的“产品”能够服务于他人时,我们的工作才有了价值;而当接受或使用我们的“服务”的组织越多时,则我们的Test Team的价值也就越大。
举个例子。当一个 Test Team 仅仅认为自己的工作只是“尽早的找到bug,并确认每个bug都得到合理的解决(这是对
软件测试工作的经典定义)”时,一个Test Team产生的价值仅仅作用于某个Develop Team甚至某个Developer。这时,Test Team的大多数工作都属于Team内部的工作,与其他Team的接口可能仅仅限于一个bug tracking system,所产生交互的工作也仅仅限于对bug的讨论和状态的跟踪。这种情况下的 Test Team的工作甚至存在的理由都无法被项目之外或部门之外的人或组织所了解。
但是当我们留意到我们可以为整个项目中的多个Team,甚至整个部门的多个项目或者企业中的多个部门提供我们的“服务”时,一切都会变得完全不同了。例如
为项目团队提供每个版本的bug趋势分析数据,让项目中的每个人都了解项目当前的状态
通过分析bug数据来建立或完善各种Checklist,帮助项目团队更好的完成需求评审、设计评审以及代码评审,减少bug出现的机会。同时,可以定期将多个项目的Checklist进行合并,使单个项目的经验可以通过Test Team快速的流动起来,及时的作用于其他项目
主动为Architect Team提供每个项目的
性能测试数据,帮助他们获取更多的实际项目信息,减少踏入“陷阱”的几率
……
我们可以做得事情还可以有很多,而关键在于我们是否有积极主动的与其他部门内或部门外的Team进行沟通,去努力了解他们的工作和需求,并开发我们已有的“产品”所能提供的价值。也只有当我们把自己成功的“推销”出去,并与更多的Team在工作上有了越来越深的融合,我们为别人提供的价值也越来越大时,我们自己的价值也才会变得越来越大,并且逐渐成为组织中无可替代的部分!
git作为源码管理工具出于流行趋势。这里和大家一起分享下我们是如何用git的分支(branch)功能管理不同规模的项目
小型项目
推荐工具:TortoiseGit
开发阶段(第一版上线前):2个分支 develop和master
由于是项目参与人员不多,基本上很少会有不同角色的人员出现职责冲突,需求变更也不会很繁冗。这种情况值我们只需要主要功能分支。
其中develop负责开发版本,master相当于预上线版本。
develop过程如果出现代码冲突,手工merge就好。
开发阶段(第一版上线后):3个分支 develop、master、hotfix
多处于来的hotfix用于紧急上线(bug,新需求等)。hotfix基于master,因为develop已经越走越远,基于develop的hotfix会将带上一些当前不想上线的新功能。
hotfix完成后hotfix要merge到master上,因为线上不管何种情况都是master版本。qa完成
测试并且上线后要将master版本merge到develop避免hotfix的修改在develop中丢失。
维护阶段(停止常规开发):2个分支 master、hotfix。
这个阶段就相当于针对上线版本的各种打补丁了。
中型项目
推荐工具: sourcetree
开发阶段(第一版上线前):3个分支 feature、develop和master
相对于小型项目多了feature分支的概念。feature分支基于develop分支,当功能开发完成后merge回develop。
这样做的好处是将develop分支从小型项目中去中心化。举个例子,因为是中型项目,我们可能有5 6个在并行开发,如果这个过程中客户说某个功能我们不要了,我们可以很轻松的丢掉某个feature分支而不必污染develop。
但是如果是开发时间很久的feature分支,很可能会因为不定时的merge develop或者需求的不断变更等导致当前分支的commit比较肮脏。所以对于feature分析的力度要控制好。
如图所示:
开发阶段(第一版上线后):4个分支 feature、develop、master和hotfix
和上面小心项目一样 hotfix基于master版本。
维护阶段(停止常规开发): 和小型项目一样 大型项目
推荐工具:sourcetree
大型项目相对于中型项目又多了release版本。这个版本的作用只要是控制需求的更新以及当前版本bug的fix处理。
点击查看大图:
对于这种情景sourcetree自带git-flow的功能
并且给出各种引导提示
和中型项目相比,hotfix分支在大型项目中只处理线上的bug问题。对于需求的控制,都会发生在release分支中。一个release版本的生成并不意味着它可以直接提交master,qa的介入在中小型项目中属于master分支,
但是在这个流程下,qa的介入属于release分支,包括对于bug的修复操作也是直接在release版本完成。当qa对于release版本确认完成后,release版本merge到master预上线并且merge回develop保持代码一致性。
<pluginRepositories> <pluginRepository> <id>apache.snapshots</id> <url> http://people.apache.org/repo/m2-snapshot-repository/ </url> </pluginRepository> </pluginRepositories> </dependencies> <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId> <version>5.5</version> <scope>test</scope> <classifier>jdk15</classifier> </dependency> </dependencies> |
经测试这种方法可以正常运行。
其他几种方法:
其他的方法没有测试过,因为现在只是简单的用例还没有涉及太多。以后再试。
参考这个吧。http://maven.apache.org/plugins/maven-surefire-plugin/testng.html
多数人知道
SQL注入,也知道SQL参数化查询可以防止SQL注入,可为什么能防止注入却并不是很多人都知道的。
首先:我们要了解SQL收到一个指令后所做的事情:
在这里,简单的表示为: 收到指令 -> 编译SQL生成执行计划 ->选择执行计划 ->执行执行计划。
具体可能有点不一样,但大致的步骤如上所示。
接着我们来分析为什么拼接SQL 字符串会导致SQL注入的风险呢?
首先创建一张表Users:
CREATE TABLE [dbo].[Users]( [Id] [uniqueidentifier] NOT NULL, [UserId] [int] NOT NULL, [UserName] [varchar](50) NULL, [Password] [varchar](50) NOT NULL, CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] 3F3ECD42B7A24B139ECA0A7D584CA195 |
插入一些数据:
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),1,'name1','pwd1');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),2,'name2','pwd2');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),3,'name3','pwd3');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),4,'name4','pwd4');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),5,'name5','pwd5');
假设我们有个用户登录的页面,代码如下:
验证用户登录的sql 如下:
select COUNT(*) from Users where Password = 'a' and UserName = 'b'
这段代码返回Password 和UserName都匹配的用户数量,如果大于1的话,那么就代表用户存在。
本文不讨论SQL 中的密码策略,也不讨论代码规范,主要是讲为什么能够防止SQL注入,请一些同学不要纠结与某些代码,或者和SQL注入无关的主题。
可以看到执行结果:
这个是SQL profile 跟踪的SQL 语句。
注入的代码如下:
select COUNT(*) from Users where Password = 'a' and UserName = 'b' or 1=1—'
这里有人将UserName设置为了 “b' or 1=1 –”.
实际执行的SQL就变成了如下:
可以很明显的看到SQL注入成功了。很多人都知道参数化查询可以避免上面出现的注入问题,比如下面的代码:
class Program { private static string connectionString = "Data Source=.;Initial Catalog=Test;Integrated Security=True"; static void Main(string[] args) { Login("b", "a"); Login("b' or 1=1--", "a"); } private static void Login(string userName, string password) { using (SqlConnection conn = new SqlConnection(connectionString)) { conn.Open(); SqlCommand comm = new SqlCommand(); comm.Connection = conn; //为每一条数据添加一个参数 comm.CommandText = "select COUNT(*) from Users where Password = @Password and UserName = @UserName"; comm.Parameters.AddRange( new SqlParameter[] { new SqlParameter("@Password", SqlDbType.VarChar) {Value = password}, new SqlParameter("@UserName", SqlDbType.VarChar) {Value = userName}, }); comm.ExecuteNonQuery(); } } } |
实际执行的SQL 如下所示:
exec sp_executesql N'select COUNT(*) from Users where Password = @Password and UserName = @UserName',N'@Password varchar(1),@UserName varchar(1)',@Password='a',@UserName='b'
exec sp_executesql N'select COUNT(*) from Users where Password = @Password and UserName = @UserName',N'@Password varchar(1),@UserName varchar(11)',@Password='a',@UserName='b'' or 1=1—'
可以看到参数化查询主要做了这些事情:
1:参数过滤,可以看到 @UserName='b'' or 1=1—'
2:执行计划重用
因为执行计划被重用,所以可以防止SQL注入。
首先分析SQL注入的本质,
用户写了一段SQL 用来表示查找密码是a的,用户名是b的所有用户的数量。
通过注入SQL,这段SQL现在表示的含义是查找(密码是a的,并且用户名是b的) 或者1=1 的所有用户的数量。
可以看到SQL的语意发生了改变,为什么发生了改变呢?,因为没有重用以前的执行计划,因为对注入后的SQL语句重新进行了编译,因为重新执行了语法解析。所以要保证SQL语义不变,即我想要表达SQL就是我想表达的意思,不是别的注入后的意思,就应该重用执行计划。
如果不能够重用执行计划,那么就有SQL注入的风险,因为SQL的语意有可能会变化,所表达的查询就可能变化。
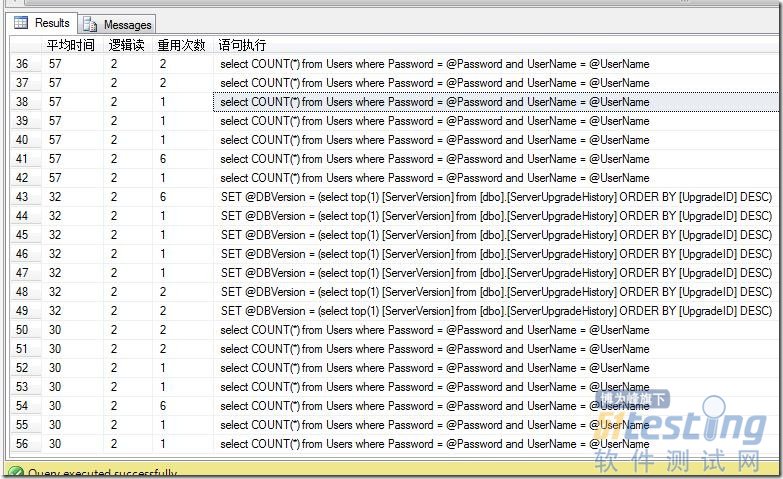
在SQL Server 中查询执行计划可以使用下面的脚本:
DBCC FreeProccache select total_elapsed_time / execution_count 平均时间,total_logical_reads/execution_count 逻辑读, usecounts 重用次数,SUBSTRING(d.text, (statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(text) ELSE statement_end_offset END - statement_start_offset)/2) + 1) 语句执行 from sys.dm_exec_cached_plans a cross apply sys.dm_exec_query_plan(a.plan_handle) c ,sys.dm_exec_query_stats b cross apply sys.dm_exec_sql_text(b.sql_handle) d --where a.plan_handle=b.plan_handle and total_logical_reads/execution_count>4000 ORDER BY total_elapsed_time / execution_count DESC; 18EFAED775BF4DB9A36C57B39EC6913D |
在这篇文章中有这么一段:
这里作者有一句话:”不过这种写法和直接拼SQL执行没啥实质性的区别”
任何拼接SQL的方式都有SQL注入的风险,所以如果没有实质性的区别的话,那么使用exec 动态执行SQL是不能防止SQL注入的。
比如下面的代码:
private static void TestMethod() { using (SqlConnection conn = new SqlConnection(connectionString)) { conn.Open(); SqlCommand comm = new SqlCommand(); comm.Connection = conn; //使用exec动态执行SQL //实际执行的查询计划为(@UserID varchar(max))select * from Users(nolock) where UserID in (1,2,3,4) //不是预期的(@UserID varchar(max))exec('select * from Users(nolock) where UserID in ('+@UserID+')') comm.CommandText = "exec('select * from Users(nolock) where UserID in ('+@UserID+')')"; comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4" }); //comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4); delete from Users;--" }); comm.ExecuteNonQuery(); } } |
执行的SQL 如下:
exec sp_executesql N'exec(''select * from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID varchar(max) ',@UserID='1,2,3,4'
可以看到SQL语句并没有参数化查询。
如果你将UserID设置为”1,2,3,4); delete from Users;—-”,那么执行的SQL就是下面这样:
exec sp_executesql N'exec(''select * from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID varchar(max) ',@UserID='1,2,3,4); delete from Users;--'
不要以为加了个@UserID 就代表能够防止SQL注入,实际执行的SQL 如下:
任何动态的执行SQL 都有注入的风险,因为动态意味着不重用执行计划,而如果不重用执行计划的话,那么就基本上无法保证你写的SQL所表示的意思就是你要表达的意思。
这就好像小时候的填空题,查找密码是(____) 并且用户名是(____)的用户。
不管你填的是什么值,我所表达的就是这个意思。
最后再总结一句:因为参数化查询可以重用执行计划,并且如果重用执行计划的话,SQL所要表达的语义就不会变化,所以就可以防止SQL注入,如果不能重用执行计划,就有可能出现SQL注入,存储过程也是一样的道理,因为可以重用执行计划。
本文主要介绍使用
Python语言编写Socket协议Server及Client的简单实现方法。
1. Python Socket编程简介
Socket通常也称作"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求。
三种流行的套接字类型是:stream,datagram和raw。stream和datagram套接字可以直接与TCP协议进行接口,而raw套接字则接口到IP协议。
Python Socket模块提供了对低层BSD套接字样式网络的访问,使用该模块建立具有TCP和流套接字的简单服务器。详见https://docs.python.org/2/library/socket.html
2. Python Socket Server
实现代码如下
# -*- coding:utf-8 -*- from socket import * def SocketServer(): try: Colon = ServerUrl.find(':') IP = ServerUrl[0:Colon] Port = int(ServerUrl[Colon+1:]) #建立socket对象 print 'Server start:%s'%ServerUrl sockobj = socket(AF_INET, SOCK_STREAM) sockobj.setsockopt(SOL_SOCKET,SO_REUSEADDR, 1) #绑定IP端口号 sockobj.bind((IP, Port)) #监听,允许5个连结 sockobj.listen(5) #直到进程结束时才结束循环 while True: #等待client连结 connection, address = sockobj.accept( ) print 'Server connected by client:', address while True: #读取Client消息包内容 data = connection.recv(1024) #如果没有data,跳出循环 if not data: break #发送回复至Client RES='200 OK' connection.send(RES) print 'Receive MSG:%s'%data.strip() print 'Send RES:%s\r\n'%RES #关闭Socket connection.close( ) except Exception,ex: print ex ServerUrl = "192.168.16.15:9999" SocketServer() |
注:需要注意的是Socket对象建立后需要加上sockobj.setsockopt(SOL_SOCKET,SO_REUSEADDR, 1),否则会出现Python脚本重启后Socket Server端口不会立刻关闭,出现端口占用错误。
3. Python Socket Client
实现代码如下
# -*- coding:utf-8 -*- from socket import * def SocketClient(): try: #建立socket对象 s=socket(AF_INET,SOCK_STREAM,0) Colon = ServerUrl.find(':') IP = ServerUrl[0:Colon] Port = ServerUrl[Colon+1:] #建立连接 s.connect((IP,int(Port))) sdata='GET /Test HTTP/1.1\r\n\ Host: %s\r\n\r\n'%ServerUrl print "Request:\r\n%s\r\n"%sdata s.send(sdata) sresult=s.recv(1024) print "Response:\r\n%s\r\n" %sresult #关闭Socket s.close() except Exception,ex: print ex ServerUrl = "192.168.16.15:9999" SocketClient() |
4. 运行结果
Socket Server端运行截图如下:
Socket-Server
Socket Client端运行截图如下:
开发环境
1. jdk1.7
2. Eclipse
3. selenium(selenium-java-2.42.2.zip)
将下载下来的 selenium-java-2.42.2.zip 解压, 解压后文件目录:
1. 将上面加压出来的文件复制到新建的项目目录下:
2. 添加build path,项目目录右键 >> Build Path >> config build path >> Java Build Path >> Libraries >> Add JARs
把libs文件夹下的jar包全部添加上,再添加selenium-java-2.42.2和selenium-java-2.42.2-srcs
3、添加完之后目录结构如下图,多了Referenced Libraries,这里就是上面那一步添加进去的jar包
常用的一些选项有:
问题类型
JIRA系统中用优先级来表示问题的严重级别,有以下几种级别:
优先级 block>critical>major>minor>trivial
状态
每个问题有一个状态,用来表明问题所处的阶段,问题通过开始于open状态,然后开始处理/progress,再解决到/resolved,然后关闭/closed.根据情况的不同,可以文具项目来制定问题状态.
解决
一个问题可以用多种方式解决,系统管理员是可以在JIRA系统中定制解决方式.JIRA系统默认的解决方式如下: