
既然做C/S测试,安装/卸载是
测试的很重要的部分之一,所以利用空闲时间写一下自己的安装/卸载
用例设计思路,如果你觉得写的不好或者觉得有需要补充的地方,请大家提出来,大家共同
学习,共同进步,谢谢!
1.1 安装
一、安装方式
1、正常安装,安装方式为‘只有我’
2、正常安装,安装方式为‘任何人’
二、安装路径
1、缺省路径安装
2、自定义安装路径(非C盘)
1)通过浏览,选择自定义路径
2)手动输入路径(存在路径、不存在的路径)
3)输入路径的格式不正确
4)通过浏览的盘符,手动输入不存在的文件夹
5)指定路径下已有同名文件
6)中文路径(中文路径、中英文混合路径)
7)包含空格的路径(空格、下划线等合法路径)
8)非法路径(输入特殊字符)
三、安装环境:
1、没安装过
2、已安装过老版本(系统正在使用、系统未使用)
3、已安装了最新版本
4、卸载系统重新安装
5、安装一半,异常退出(比如:在线安装断网、本地安装点取消、断电等)可重新安装
6、磁盘空间不足
7、删除了部分文件(可正常安装、修复、卸载系统)
9、杀毒软件
10、未达到最低配置时安装
三、修复
1、利用安装软件进行修复
2、利用修复文件进行修复
四、安装时快捷键使用情况
五、安装完成
1、安装成功,检查版本信息是否正确
2、安装完成,文件属性为非只读
3、安装完成,快捷方式检查,创建快捷方式正确
六、安装完成进入系统方式
1、通过桌面快捷方式进入
2、通过‘开始’——‘所有程序’——系统快捷方式进入
1.2 卸载
一、卸载方式
1、通过控制面板卸载
2、通过安装程序卸载
3、通过‘开始’——‘所有程序’——‘XX系统卸载’
二、非法卸载
1、系统正在运行时
2、系统正升级时
三、卸载完成后
1、桌面快捷方式消失
2、‘开始’——‘所有程序’中快捷方式消失
3、安装路径下此文件夹已被删除
请根据下表和页面截图,设计《发表QQ说说》的功能点及
测试用例:
图1 功能列表
图2 QQ空间加载后,说说功能区展开截图
图3 光标进入文本框后截图
图4 文字超出规定后的效果截图
图5. 添加图片的两种模式本地上传和我的相册
图6. 仅发表图片后的效果
图7.删除图片
图8. 发表多张图片
简介
通常来说,
Python不是一种高性能的语言,在某种意义上,这种说法是真的。但是,随着以Numpy为中心的数学和科学软件包的生态圈的发展,达到合理的性能不会太困难。
当性能成为问题时,运行时间通常由几个函数决定。用C重写这些函数,通常能极大的提升性能。
在本系列的第一部分中,我们来看看如何使用NumPy的C API来编写C语言的Python扩展,以改善模型的性能。在以后的
文章中,我们将在这里提出我们的解决方案,以进一步提升其性能。
文件
这篇文章中所涉及的文件可以在Github上获得。
模拟
作为这个练习的起点,我们将在像重力的力的作用下为N体来考虑二维N体的模拟。
以下是将用于存储我们世界的状态,以及一些临时变量的类。
# lib/sim.py class World(object): """World is a structure that holds the state of N bodies and additional variables. threads : (int) The number of threads to use for multithreaded implementations. STATE OF THE WORLD: N : (int) The number of bodies in the simulation. m : (1D ndarray) The mass of each body. r : (2D ndarray) The position of each body. v : (2D ndarray) The velocity of each body. F : (2D ndarray) The force on each body. TEMPORARY VARIABLES: Ft : (3D ndarray) A 2D force array for each thread's local storage. s : (2D ndarray) The vectors from one body to all others. s3 : (1D ndarray) The norm of each s vector. NOTE: Ft is used by parallel algorithms for thread-local storage. s and s3 are only used by the Python implementation. """ def __init__(self, N, threads=1, m_min=1, m_max=30.0, r_max=50.0, v_max=4.0, dt=1e-3): self.threads = threads self.N = N self.m = np.random.uniform(m_min, m_max, N) self.r = np.random.uniform(-r_max, r_max, (N, 2)) self.v = np.random.uniform(-v_max, v_max, (N, 2)) self.F = np.zeros_like(self.r) self.Ft = np.zeros((threads, N, 2)) self.s = np.zeros_like(self.r) self.s3 = np.zeros_like(self.m) self.dt = dt |
在开始模拟时,N体被随机分配质量m,位置r和速度v。对于每个时间步长,接下来的计算有:
合力F,每个体上的合力根据所有其他体的计算。
速度v,由于力的作用每个体的速度被改变。
位置R,由于速度每个体的位置被改变。
第一步是计算合力F,这将是我们的瓶颈。由于世界上存在的其他物体,单一物体上的力是所有作用力的总和。这导致复杂度为O(N^2)。速度v和位置r更新的复杂度都是O(N)。
如果你有兴趣,这篇维基百科的文章介绍了一些可以加快力的计算的近似方法。
纯Python
在纯Python中,使用NumPy数组是时间演变函数的一种实现方式,它为优化提供了一个起点,并涉及测试其他实现方式。
# lib/sim.py def compute_F(w): """Compute the force on each body in the world, w.""" for i in xrange(w.N): w.s[:] = w.r - w.r[i] w.s3[:] = (w.s[:,0]**2 + w.s[:,1]**2)**1.5 w.s3[i] = 1.0 # This makes the self-force zero. w.F[i] = (w.m[i] * w.m[:,None] * w.s / w.s3[:,None]).sum(0) def evolve(w, steps): """Evolve the world, w, through the given number of steps.""" for _ in xrange(steps): compute_F(w) w.v += w.F * w.dt / w.m[:,None] w.r += w.v * w.dt |
合力计算的复杂度为O(N^2)的现象被NumPy的数组符号所掩盖。每个数组操作遍历数组元素。
可视化
这里是7个物体从随机初始状态开始演化的路径图:
性能
为了实现这个基准,我们在项目目录下创建了一个脚本,包含如下内容:
import lib
w = lib.World(101)
lib.evolve(w, 4096)
我们使用cProfile模块来测试衡量这个脚本。
python -m cProfile -scum bench.py
前几行告诉我们,compute_F确实是我们的瓶颈,它占了超过99%的运行时间。
428710 function calls (428521 primitive calls) in 16.836 seconds Ordered by: cumulative time ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 16.837 16.837 bench.py:2(<module>) 1 0.062 0.062 16.756 16.756 sim.py:60(evolve) 4096 15.551 0.004 16.693 0.004 sim.py:51(compute_F) 413696 1.142 0.000 1.142 0.000 {method 'sum' ... 3 0.002 0.001 0.115 0.038 __init__.py:1(<module>) ... |
在Intel i5台式机上有101体,这种实现能够通过每秒257个时间步长演化世界。
简单的C扩展 1
在本节中,我们将看到一个C扩展模块实现演化的功能。当看完这一节时,这可能帮助我们获得一个C文件的副本。文件src/simple1.c,可以在GitHub上获得。
关于NumPy的C API的其他文档,请参阅NumPy的参考。Python的C API的详细文档在这里。
样板
文件中的第一件事情是先声明演化函数。这将直接用于下面的方法列表。
static PyObject *evolve(PyObject *self, PyObject *args);
接下来是方法列表。
static PyMethodDef methods[] = {
{ "evolve", evolve, METH_VARARGS, "Doc string."},
{ NULL, NULL, 0, NULL } /* Sentinel */
};
这是为扩展模块的一个导出方法列表。这只有一个名为evolve方法。
样板的最后一部分是模块的初始化。
PyMODINIT_FUNC initsimple1(void) {
(void) Py_InitModule("simple1", methods);
import_array();
}
另外,正如这里显示,initsimple1中的名称必须与Py_InitModule中的第一个参数匹配。对每个使用NumPy API的扩展而言,调用import_array是有必要的。
数组访问宏
数组访问的宏可以在数组中被用来正确地索引,无论数组被如何重塑或分片。这些宏也使用如下的代码使它们有更高的可读性。
#define m(x0) (*(npy_float64*)((PyArray_DATA(py_m) + \
(x0) * PyArray_STRIDES(py_m)[0])))
#define m_shape(i) (py_m->dimensions[(i)])
#define r(x0, x1) (*(npy_float64*)((PyArray_DATA(py_r) + \
(x0) * PyArray_STRIDES(py_r)[0] + \
(x1) * PyArray_STRIDES(py_r)[1])))
#define r_shape(i) (py_r->dimensions[(i)])
在这里,我们看到访问宏的一维和二维数组。具有更高维度的数组可以以类似的方式被访问。
在这些宏的帮助下,我们可以使用下面的代码循环r:
for(i = 0; i < r_shape(0); ++i) {
for(j = 0; j < r_shape(1); ++j) {
r(i, j) = 0; // Zero all elements.
}
}
命名标记
上面定义的宏,只在匹配NumPy的数组对象定义了正确的名称时才有效。在上面的代码中,数组被命名为py_m和py_r。为了在不同的方法中使用相同的宏,NumPy数组的名称需要保持一致。
计算力
特别是与上面五行的Python代码相比,计算力数组的方法显得颇为繁琐。
static inline void compute_F(npy_int64 N, PyArrayObject *py_m, PyArrayObject *py_r, PyArrayObject *py_F) { npy_int64 i, j; npy_float64 sx, sy, Fx, Fy, s3, tmp; // Set all forces to zero. for(i = 0; i < N; ++i) { F(i, 0) = F(i, 1) = 0; } // Compute forces between pairs of bodies. for(i = 0; i < N; ++i) { for(j = i + 1; j < N; ++j) { sx = r(j, 0) - r(i, 0); sy = r(j, 1) - r(i, 1); s3 = sqrt(sx*sx + sy*sy); s3 *= s3 * s3; tmp = m(i) * m(j) / s3; Fx = tmp * sx; Fy = tmp * sy; F(i, 0) += Fx; F(i, 1) += Fy; F(j, 0) -= Fx; F(j, 1) -= Fy; } } } |
请注意,我们使用牛顿第三定律(成对出现的力大小相等且方向相反)来降低内环范围。不幸的是,它的复杂度仍然为O(N^2)。
演化函数
该文件中的最后一个函数是导出的演化方法。
static PyObject *evolve(PyObject *self, PyObject *args) { // Declare variables. npy_int64 N, threads, steps, step, i; npy_float64 dt; PyArrayObject *py_m, *py_r, *py_v, *py_F; // Parse arguments. if (!PyArg_ParseTuple(args, "ldllO!O!O!O!", &threads, &dt, &steps, &N, &PyArray_Type, &py_m, &PyArray_Type, &py_r, &PyArray_Type, &py_v, &PyArray_Type, &py_F)) { return NULL; } // Evolve the world. for(step = 0; step< steps; ++step) { compute_F(N, py_m, py_r, py_F); for(i = 0; i < N; ++i) { v(i, 0) += F(i, 0) * dt / m(i); v(i, 1) += F(i, 1) * dt / m(i); r(i, 0) += v(i, 0) * dt; r(i, 1) += v(i, 1) * dt; } } Py_RETURN_NONE; } |
在这里,我们看到了Python参数如何被解析。在该函数底部的时间步长循环中,我们看到的速度和位置向量的x和y分量的显式计算。
性能
C版本的演化方法比Python版本更快,这应该不足为奇。在上面提到的相同的i5台式机中,C实现的演化方法能够实现每秒17972个时间步长。相比Python实现,这方面有70倍的提升。
观察
注意,C代码一直保持尽可能的简单。输入参数和输出矩阵可以进行类型检查,并分配一个Python装饰器函数。删除分配,不仅能加快处理,而且消除了由Python对象不正确的引用计数造成的内存泄露(或更糟)。
下一部分
在本系列文章的下一部分,我们将通过发挥C-相邻NumPy矩阵的优势来提升这种实现的性能。之后,我们来看看使用英特尔的SIMD指令和OpenMP来进一步推进。
今天我主要来说下过年时候自己做的一些
性能测试,由于时间紧迫,所以最终选择了全部从log方面入手,从而最终达到一气呵成的效果。
分别有这样几个大项:
我们分别在Activity的生命周期方法内添加Log.e(tag,message),如下效果:
@Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); Log.e("AppStartTime","AppOnCreate"); ... } @Override protected void onResume() { super.onResume(); Log.e("AppStartTime","AppOnResume"); ... } |
,这里的tag我们使用AppStartTime,那么我们需要在应用启动之后在command内输入:
adb logcat -v time -v threadtime *:E | grep ActivityStartTime>StartTimeFile.txt
2. cpu和内存消耗
在command中输入如下命令:
adb
shell top -n 400 | grep <your package name>Cpu_MemoryFile.txt
3. GC
在command中输入如下命令:
adb logcat -v time -v threadtime *:D | grep GC>GCFile.txt
这里需要注意的是,GC分析的时候需要关注三个值。
average_GC_Freed
average_GC_per
average_GC_time
4. 网络流量
在被测应用中增加一个获取所有应用的网络流量的service,添加一个getAppTrafficList( )方法,代码如下:
publicvoidgetAppTrafficList(){ PackageManagerpm=getPackageManager(); List<PackageInfo>pinfos=pm .getInstalledPackages(PackageManager.GET_UNINSTALLED_PACKAGES |PackageManager.GET_PERMISSIONS); for(PackageInfoinfo:pinfos){ String[]premissions=info.requestedPermissions; if(premissions!=null&&premissions.length>0){ for(Stringpremission:premissions){ if("android.permission.INTERNET".equals(premission)){ intuId=info.applicationInfo.uid; longrx=TrafficStats.getUidRxBytes(uId); longtx=TrafficStats.getUidTxBytes(uId); if(rx<0||tx<0){ continue; }else{ Log.e("网络流量",info.applicationInfo.loadLabel(pm)+Formatter.formatFileSize(this,rx+tx) } } } } } } |
如果还要其他数据,那么全部可以按照以上的方法去获取。然后我们来看如何使用python一次性分析这些文件从而直接获取report。
首先引入第三方绘制pdf的模块:
# -*- coding: utf-8 -*-
from reportlab.graphics.shapes import *
from reportlab.graphics.charts.lineplots import LinePlot
from reportlab.graphics.charts.textlabels import Label
from reportlab.graphics import renderPDF
然后我们需要一个读文件的方法:
def FileRead(path):
data_list = []
number_list = []
number = 0
for line in open(path):
data_list.append(line)
number =number+1
number_list.append(number)
return data_list,number_list
接着我们需要一个制作pdf的方法:
def MakePDF(times,list,reportname,pdfname):
drawing = Drawing(500,300) lp = LinePlot() lp.x = 50 lp.y = 50 lp.height = 125 lp.width = 300 lp.data = [zip(times, list)] lp.lines[0].strokeColor = colors.blue lp.lines[1].strokeColor = colors.red lp.lines[2].strokeColor = colors.green drawing.add(lp) drawing.add(String(350,150, reportname,fontSize=14,fillColor=colors.red)) renderPDF.drawToFile(drawing,pdfname,reportname) #这里的times和list两个参数都是list,是时间和监控获取的数据一一对应的关系 这些我们都有了之后,我们来看下分析AppStartTime的方法: def analysisStartFile(list): totalcount =0 totaltime =0 time_list =[] totalcount_list = [] for i in range(len(list)): if 'AppStartTime' in list[i]: totalcount =totalcount+1 totalcount_list.append(totalcount) if float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:])>0: totaltime=totaltime+float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:]) time_list.append(float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:])) return totalcount_list,'%.2f'%float(totaltime/totalcount),time_list |
所有的分析数据的思维都是使用split()方法分隔空格之后做分析。因为读取文件之后是将所有的数据存在list中,但是当我们去用的时候由于空格在其中就变得非常的麻烦,那么我们可以先使用split将空格去掉,然后使用if key in list的方法进行过滤再做分析。
最后在main()方法中基本就是如下的顺序执行方法:
if __name__== '__main__':
list1,list2 = FileRead(<your file path>)
print list1,list2
list_count,average_start_time,time_list = analysisStartFile(list1)
MakePDF(list_count,time_list,'average time:'+str(average_start_time)+'s',"启动性能报告.pdf")
最终我们就能够批量的生成如下图的报告了。
一点点必要的废话
JavaScript的发展大体上经历了下面几个比较大的阶段:
第一阶段:石器时代。
基本上没有任何框架和工具,而且各种浏览器混战,API相当混乱,开发和
测试都非常痛苦。
第二阶段:刀耕火种。
出现了一些简单的、小型的工具,比如prototype/mootools之类的。
第三阶段:农耕文明。
2005年左右,Ajax、JSON等技术开始兴起,并且以非常快的速度普及。这个阶段出现了jQuery之类的神器,但是还是有大量的问题没有解决,开发和测试依然非常痛苦,各种工具很乱,
学习过程漫长。
第四阶段:规模化、结构化。
前端代码的规模越来越大,结构化、模块化的呼声越来越高,开始出现专业的“前端工程师”这样的职业。各个
互联网大佬都开始组建自己的UED部门,比如
腾讯的CDC、淘宝的UED、网易的UEDC。
对于前端开发来说,这一阶段已经发生了思想上飞跃。此时前端考虑的问题已经不仅仅是“如何把界面做得好看”这么简单了,对前端的要求已经提升到了“用户体验”的层次,界面“好看”只是其中一部分,还要做交互设计,怎么让用户操作更方便、怎么让界面更人性化,如此等等。 在这个阶段出现了很多重量级的框架,大体上分2个体系:一个是以jQuery为内核的前端框架,例如jQueryUI之类的各类UI;另一个就是自成体系的ExtJS。
(有人可能会说还有Flex、SilverLight、JavaFX之类的东西呢!这里专门说JS,那些先不管,谢谢。)
第五阶段:工业化、多平台。
JavaScript代码不仅仅规模更加庞大,而且要支持各种平台。2008年之后,安卓异军突起,加上iPhone的强势插入,
移动平台上的UI 设计日益收到重视。移动平台的迅速崛起进一步刺激了桌面UI体系的演进,jQeury推出了jQuery Mobile,ExtJS推出了自己的Touch版本,其它各种衍生框架也都出现了Touch版本。
我们知道,科技领域的工业化是以机器代替人力为核心特征的,对比前端代码的工业化,我们立刻就会发现,自动化程度依然不够。虽然出现了像WebStorm这样的前端开发神器,但是对于
自动化测试、
性能测试之类的需求,依然没有成熟的、统一的工具。
近来TDD(
Test Driving Develop)的概念越来越热,加上来自
Google的AnguarJS框架开始流行,TDD正在被广泛接受。因此,在这个阶段,必须解决工具的问题,而自动化测试工具就是其中需求最强烈的一个工具。
好,废话结束,开始玩儿JsTestDriver。
JsTestDriver简介
完整介绍参见官方的页面
安装Eclipse插件
请使用Eclipse的插件安装工具
注意:
1、Eclipse版本不能太低。
2、如果在线安装不成功,可以把插件下载到本地,然后再用Eclipse的插件安装工具从本地安装。
3、只安装JS Test Driver Plugin for Eclipse,其它的不要安装,否则会报冲突。
安装完成之后,开始配置JsTestDriver,步骤如下:
第一步:配置JsTestDriver服务器
在Eclipse的菜单中选择Window->Preferences,在左侧找到JS Test Driver。
第二步:打开JsTestDriver的控制面板
在Eclipse顶部的菜单中选择Window->Show View,找到JsTestDriver并双击,这样JsTestDriver的控制面板就显示出来了。
好,到这里安装配置就算完成了,接下来我们来做一个最简单的例子试试手感。 最简单的例子
第一步:在Eclipse中新建一个WEB项目,名字随意。
第二步:在WebContent目录下新建js和js-test两个目录。js目录用来放你的js源代码,js-test用来放JsTestDriver的测试用例代码。
第三步:在js目录下新建一个myjs.js,内容如下:
myapp = {};
myapp.Greeter = function() { };
myapp.Greeter.prototype.greet = function(name) {
return "Hello " + name + "!";
};
在js-test的目录下新建一个testMyJS.js,内容如下:
GreeterTest = TestCase("GreeterTest");
GreeterTest.prototype.testGreet = function() {
var greeter = new myapp.Greeter();
assertEquals("Hello World!", greeter.greet("World"));
};
以上测试用例的代码和Java中的JUnit比较类似。这里我们先不管上面代码的具体含义,先想办法让工具跑起来再说,我们继续。
第四步:创建JsTestDriver配置文件。
直接在WebContent目录下创建一个jsTestDriver.conf,内容如下:
server: http://localhost:8259
load:
- jasmine/*.*
- jasmine-adapter/JasmineAdapter.js
- js/*.js
- js-test/*.js
注意上面的端口号,必须和前面设置的端口号一致。
这种配置文件的风格叫做YAML,JsTestDriver配置文件的完整说明
第五步:开始运行。
点击Eclipse工具栏中的运行按钮左侧的小三角,选择Run Configrations,如下图:
配置成以下形式:
一、前言
Web自动化
测试一直是一个比较迫切的问题,对于现在web开发的
敏捷开发,却没有相对应的
敏捷测试,故开此主题,一边研究,一边将Web自动化测试应用于
工作中,进而形成能够独立成章的博文,希望能够为国内web自动化测试的发展做一点绵薄的贡献吧,笑~
二、Watir搭建流程
图1-1 需要安装的工具
因为安装
Ruby还需要用到其他的一些开发工具集,所以建议从网站下载,而且使用该安装包的话,它会帮你把环境变量也设置完毕,我使用的版本是:railsinstaller-2.2.4.exe,建议下载最新版本。
图1-2 RailsInstaller工具包安装界面
开始安装RailsInstaller工具包,安装到默认位置即可。
图1-3 安装完毕界面
这个对勾建议打上,它会帮你配置git和ssh,安装过程中ruby等一系列环境变量也配置OK了,挺好~
图1-4 测试Ruby安装情况
安装好railsinstaller-2.2.4.exe后,打开cmd命令行,输入命令:ruby –v,如果,出现图1-4所示ruby的版本情况,则说明ruby已经安装完毕,我们也可以输入命令测试一下gem的版本:gem –v,如图1-4所示,gem也是安装成功。
图1-5 gem安装情况
使用命令:gem list,查看一下,如图1-5,你会发现,railsinstaller安装完毕后,默认是不包含Watir自动化测试工具的,所以我们现在要开始安装watir。
图1-6 gem命令
先简单看一眼gem怎么用,如上图1-6所示,
图1-7 安装watir命令
使用命令:gem install watir,进行安装watir,如果顺利的话,下面会出现很多的successfully等文字;不过在国内,你一般是看不到successfully等文字的,因为https://rubygems.org/已经被墙了,现在我们要对gem的源进行修改一下,来达到安装watir的目的。
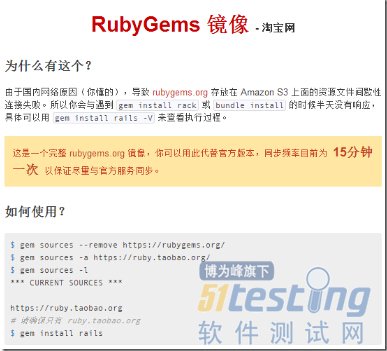
图1-8 RubyGems镜像网址
首先使用命令:gem sources -l,查看一下gem的当前源,一般都是:https://rubygems.org/
然后我们使用命令:gem sources --remove https://rubygems.org/
接着输入命令:gem sources -a https://ruby.taobao.org/
参考上图。
图1-9 查看gem的源
现在再看一下gem的源这是是否正确:gem sources -l,如果只有:https://ruby.taobao.org/,一个源,则说明配置正确。然后再使用命令安装Watir:gem install watir,这次应该就能够安装成功了。
图1-10 commonwatir和watir版本
我们可以再次使用命令:gem list,可以看到,list里面有好多与watir相关的内容,这里主要关心两个工具,如上图所示,commonwatir和watir,这里需要给commonwatir和watir降版本到3.0.0,如果不进行降级,会出现NameError错误,命令如下:
图1-11 watir降级到3.0.0
输入命令:gem uninstall watir -v 5.0.0
输入命令:gem install watir -v 3.0.0
图1-12 commonwatir降级到3.0.0
输入命令:gem uninstall commonwatir -v 4.0.0
输入命令:gem install commonwatir -v 3.0.0
图1-13 ruby测试代码
require "watir"
puts "Open IE..."
ie=Watir::IE.new
ie.goto(http://www.baidu.com/)
puts "IE is opened - enjoy it :)"
在文本编辑器中新建一个test.rb文件,输入以上代码,强烈建议手动输入,空格不慎也会导致运行失败。
图1-14 ruby文件编码
编码也要注意,使用UTF-8编码。
图1-15 测试效果
将test.rb保存完毕后,在cmd命令行输入命令:ruby test.rb如果ruby代码没有报错,程序就会自动打开IE浏览器,自动输入http://www.baidu.com/,打开百度页面。至此,《Windows环境搭建Web自动化测试框架Watir(基于Ruby)第1章》编写完毕。
三、本章总结
我们通过一系列的配置,将ruby和watir部署到windows平台上,下一步,我们就可以编写各种各样的测试脚本,针对不同的web应用,进行不同的测试。
51Testing: 陈晔老师,您好,听说您在工作期间创立了"移动测试会"免费公益沙龙,移动测试会,目前又和网易,cstqb,支付宝等都有深入合作,你是如何合理的分配您的时间,同时能完成这么多事情? 陈晔:说到这个我还是很惭愧的,行业中很多朋友都和我说,要多陪陪女儿,要多陪陪家里,这点上面我的确做的不够。不过关注我微信的都知道,我还兼职美食家,每天都在吃不同的东西,我还是有那么一点点追求的。大家可以去看我自己写的一年的行程,我几乎每周双休日都排满,不是去大会演讲就是去学校给学生公益的做技术指导。最忙的莫过于我开始写书的时候也是我女儿刚出生的那个时间点,在这个过程中其实evernote给了我很大的帮助,我会把每天的事情列出来,然后每天逐个击破。不过也和我小时习惯晚睡有吧,所以几乎那个时候我都是每天2点左右睡的。因为真的有很多事情是晚上做效率比较高。
51Testing: 作为国内Android与iOS最早的工程师之一,您有什么成功的秘诀和我们分享吗? 陈晔:其实要说从我从公司走向行业到现在其实也就2年的时间,并不是很长。当然成功肯定不敢当,现在只是刚开始。至于秘诀的话。我个人总结出来以下几条。
1.考虑问题尽量目光放长远,不要自己局限自己
很多人在公司,忙业务忙技术,但是看问题的角度并没有跳出公司去看。往往最后都是盲人摸象,无法看到一个总体,从而自己在限制自己。
2.定制短期的计划
可以有长期的目标,但是计划肯定是短期的。一方面长期的话很多人无法坚持下去。另外一方面就是,在我整个经历中我已经很强烈的感受到一点,"计划赶不上变化"是有道理的。我们需要的就是很强的
学习能力,然后去以不变应万变。
3.踏实点
不要每天去聊qq,聊薪资,去聊点虚的,更不要想着出名赚外快。无论作为一个测试,你将来转作什么岗位,只要你还是做IT的,那么你还是需要有技术基础,否则都是纸上谈兵罢了。现在行业的发展越来越快,对于技术的要求也越来越高。所以不要去问一些大而全的问题,先好好学习技术基础才是王道。
51Testing: 移动互联网发展非常快,可以说是日新月异。作为移动互联网测试的资深人士,您眼中目前移动互联网的现状是怎样的?未来的发展趋势又是如何? 陈晔:首先第一点,不懂代码,不去看源码的还是不要来移动互联网做测试了,很快就会被淘汰了。
其实从现在来看,可能很多人会觉得大数据、智能家居等会是未来的方向。但我觉得就测试而言,无论方向什么,我们还是要抓住技术的基础,也许Android和iOS哪天都会倒,也许将来又是新的语言和技术,但作为一个移动互联网的测试,我们必须用最快的速度去接收和学习,为什么我一直强调学习能力很重要,就是这个道理。如果作为移动互联网测试的你,每天还是浑浑噩噩,只会用工具,觉得不看代码就能够写
测试用例,那么我劝你要么快点努力学习,要么就快点转行业吧,不用多久肯定淘汰。
随着发展,测试人员需要提升自己的技术,让自己八面玲珑。我个人觉得移动互联网测试未来的战斗就是和数据以及新事物的战斗。任何测试都需要用数据来说,性能、压力、用户体验等,而如何获取更准确的、颗粒度更细的数据来反映问题也是对测试的一种挑战。而随着移动互联网飞速的发展,每天都会有新的技术、新的语言出现,我们随时要用120%的热情和专注去接收这一切。
最后我想说两点。第一点,请客观的认清自己的能力,不要浪费时间在聊天上,请花时间在学习上面,不要觉得好像测试的要求不应该那么高。不是国内要求高,而是大部分测试都在非正常的要求下工作,现在一旦要求回归正轨之后就出现各种抱怨,抱怨不能改变任何事情,请记住。第二点,站在尽量高的高度去看问题,然后给自己做规划吧。不要回头看,自己花了10年一直在重复工作。
51Testing:在您从事移动互联网测试的工作过程中,是否遇到过什么困难?要如何解决?
陈晔:工作过程中遇到的最大的困难莫过于要接触很多自己不懂的东西。移动互联网现在发展非常快,开发技术快,
测试技术更快。在学习一个新技术的时候,我建议大家尽量先去看官方网站,毕竟官方网站的消息是最新的,不要去到qq上去毫无目的的去问。目前国内上google不是很方便,但我依然很推荐大家遇见问题,自主的能够多上google、stackoverflow和github等网站看看。这样慢慢的培养自己自主解决问题的能力,自然而然学习能力就会有提升。
51Testing:如果要做好关于APP的自动化测试,需要注意些什么呢? 陈晔:APP的自动化我就一句话,一定要分层,而且要分的细。不要把所有的风险都压在UI自动化或者手工测试上看,或者说压在打好包的APP上面。分层要讲就非常多了。从界面到代码,可能还涉及到一些软硬件结合。从前端的功能到后端的接口。界面上细分我们还可以看到natvie的测试和webview的测试方式很不同,从接口层面来讲,我们用python的requests或者
java的httpclient直接测试接口,和我们去调用开发的接口去做测试又是两个层面。所以总而言之,一定要分层,将风险平均化,才能够在快速迭代的移动互联网的项目各个阶段保证好质量。
51Testing: 您认为APP测试区别与其他应用测试需要特别关注的内容有哪些?
陈晔: APP的测试目前相对传统互联网的测试需要特别关注的点我觉得有如下一些:
1. 平台特性
Android、iOS,WP等平台各自有各自的特性,不仅仅是表面大家知道的分辨率,还有就是应用每个操作在系统内部有什么变化,这些我们都需要去了解
2. 网络变化
移动的网络变化很大,弱网络情况下我们的应用的逻辑是否会有问题这个很重要。昨天的工作中我还发现我们自己的应用在弱网络下js重复加载的问题。
3. 碎片化
这个就是我第一点中提到的特性,不过还是需要单独拿出来列一下。
4. 移动无线的安全
移动无线的安全随着发展,越来越变的重要。对于APP而言,除了网络层面的安全以外,还有很多和自身特性有关的安全,比如Activity启动参数注入,contentprovider的数据共享,iOS远程ssh登陆等。这些对测试而言挑战也很大
5. 移动无线的性能
很多人在最初很容易就觉得移动无线的性能和服务器的并发是一个东西,很多人都在问一个应用很多人在用的时候怎么测试性能,这个其实还是服务器上的性能问题。而这里我要说的是APP本身的性能问题。其关注点很多,比如电量,流量等,深入的话还有内存泄漏,界面渲染,h5和自定义控件性能等
6. 自动化和持续集成
虽然以前测试也都是有自动化和持续集成。但是为什么我要列在这里呢。原因在于移动互联网的测试中自动化和持续集成要求很高,没有持续集成的项目根本在移动互联网是没有办法很好的运作起来的。而移动互联网目前涉及到的语言和技术又比较杂,故而对测试又是一个很大的挑战。
51Testing: 在移动互联网测试的过程中,往往会用到很多测试工具,目前安卓端和IOS端比较普遍使用的自动化工具是什么? 可以给我们推荐点比较实用的小工具吗?
陈晔: 这个问题,工具实在太多太多了,已经列举不过来了。比较实用的小工具的话,我倒是可以推荐几个:
抓包:fiddler,charles,burpsuite
Android自动化框架:APPium,Robotium,Calabash
iOS:APPium,Calabash,KIF,GHUnit,instruments
51Testing: 很多手机测试人员都会比较困惑,手机APP怎么去做压力测试比较好?您能说一下您的看法吗?
陈晔: 手机APP的压力测试,其实压力测试在这个过程中我觉得分成两部分。一个是实用压力的方式去测试APP的稳定性,这个在Android的monkey和iOS中使用js编写monkey都可以进行ANR和NPE的测试。另外一方面就是和场景紧紧相关的压力测试,这种压力测试就需要自动化去支持。往往对应用施加压力之后,查看应用的使用流畅度、逼近系统分配内存峰值时候的情况,包括控件是否能够正常渲染等。
51Testing:对于APP测试,您有什么独到的区别于教科书的见解?
陈晔: 我不敢说区别于教科书,但我能说下区别于很多人YY中的想法的见解。移动APP的测试现在根本不存在什么全自动化,也不存在非常好的录制回放的工具。要测试好移动APP需要扎实的技术基础,任何抱着"有什么工具,有什么框架能够做自动化,做安全,做性能,做压力测试"想法的都是流氓。在移动APP测试目前更多的是需要用开源的工具和框架,然后结合自己团队的情况以及自己对于被测产品的技术和业务理解去二次开发,最后投入到项目团队和持续集成中去,这是现在很流行的做法,也是我个人觉得最好的做法。也许将来会有好的平台,好的工具,但是多学点来丰富自己也不是什么坏事。
51Testing: 听说您最近也有负责公司测试人员的招募工作,应该对面试方面应该也有一定的经验了,对于正在找工作的测试新人,您有什么面试经验要和他们分享吗?
陈晔: 最近是一直在招聘,基本上这段时间没有停过。其实我觉得移动互联网的测试面试与其他可能还是有点差别的,但是注意点还是一样的。
1. 简历要真实
不要动不动就精通,动不动就各种工具和框架或者语言都往简历上写,简历上写的太多未必是好事儿。我建议还是把真实的情况写上去比较好。所以不要老抱怨面试官问一些不切实际的问题,先看看自己简历写的如何。
2. 技术要扎实
不要太浮躁,对一些技术和业务不能只知其一,觉得了解了一些就很了不起。目前移动互联网仅仅这样肯定是不行的。
3. 了解清楚需求以及知道自己要什么
不要只看到公司名字就觉得高大上,仅仅知道公司是不够的,好好确认自己要去的部门、项目、团队。大公司也有烂部门,小公司也有好项目和好团队。这些都不是固定的,而是需要自己去了解的。
51Testing: 作为一名有丰富经验的测试员,您对想从事手机测试新人有哪些建议?怎么样做可以让新手做的更好,更迅速的成长为这个领域的高手?
陈晔: 1. 不要道听途说。比如什么公司好啦,什么工资高了,什么行业有前景等。别人说终究就是别人说的,要是真的想了解,那么尽量通过自己去体验去感受去了解,要做到不要听风就是雨。
2. 好好学习code基础。在移动互联网做测试,不写code可以,但是要懂,要会。否则对于被测应用的实现都不了解,还谈什么测试呢?我们有一句话"先学开发,后学测试"
3. 锻炼自己的学习能力。包括看原生文档,学习开源工具和代码。不要看到英文就退缩,这样你是无法在移动互联网的路上走出属于自己的路的。
以上这些就是一些前提,如果这些前提做不到,那么就不用谈后面或者其他的事情了。接着我们谈下要怎么做。比如你要开始做android和iOS的应用测试了,那么基本上你要根据如下的顺序。
1). 先看官方文档中的系统介绍,对于平台有一个全面的了解
2). 仔细的查看文档中和测试有关的工具和框架,并自己实践(文档理论上是非常详细的)
3). 学习相关平台的开发技术
4). 仔细了解自己产品项目的需求
5). 仔细审视自己产品的代码(不要说看不到代码什么的,不看代码等于瞎子在测试)
6). 好好看看一些流行框架的原理和实现
7). 用分层的思想好好设计测试策略
简单来讲这样的路线是最好的,目前这些是移动互联网测试的基础要求,代码能力,编写脚本能力,静态分析能力等。我希望大家了解一点,如果你们觉得这些要求很高,那是因为大部分人在国内长期低要求或者被叫兽忽悠已经习惯了,当拿出正常的要求的时候,很多人就会觉得很高。事实是这只是基础要求。
51Testing: 由于时间关系,本次访谈正式结束,非常感谢陈晔老师抽出宝贵时间参加我们的访谈和对小编工作的支持,让小编对移动互联网测试领域了解了不少,相信这次的内容也将会给测试员带来颇多的收益。希望以后能有更多的机会,能让您分享测试心得!
按照常规的做法,当一个缺陷修复完毕后,通常会对修复后的代码进行两种形式的
测试。首先是确认测试,以验证该修复程序实际上已经修复了缺陷,二是
回归测试,以确保修复部分本身没有破坏已有的功能。需要注意的是,当新的功能添加到现有的应用程序时也适用这一相同的原理。在添加新功能的情况下,测试可以验证新功能的
工作是否按要求和设计规范,例如回归测试就可以表明,新的代码并没有破坏任何现有的功能。
也有可能应用程序的新版本同时包含了修复先前报告的缺陷以及具有新的功能。对于“修复”部分,我们通常会有一系列的缺陷的测试脚本(DTS)用来运行以确认是否修复,而对于新的功能,我们将有一系列具体的测试脚本用来测试变更控制通知(CCNS) 。
此外,随着新的功能和更多组件的增加,软件应用程序变得越来越大,回归测试包,也就是一个
测试用例库,被开发并运用于每次应用程序的新版本发布。
选择回归测试包的测试
如先前所述,对于每个应用软件的新版本而言,需要执行三组测试集:回归测试,特定版本的测试和缺陷的测试脚本。选择测试用例的回归测试包不是一件容易的事。选择测试集以及回归测试包需要仔细的思考和注意力。
人们会认为,每一个为特定版本的测试而写的测试用例将成为回归测试包的一部分,并在下个版本出来后用于执行。所以,也就是说,随着程序代码越来越多的新版本的出现,回归测试包会变得越来越大。如果我们将回归测试自动化,这并不应该是一个问题,但对于手动执行一个大的回归测试包,这可能会导致时间上的限制以及新功能可能会因没有时间而无法进行测试。
这些回归测试包通常包含覆盖核心功能的测试,在整个应用程序的演变过程中都不发生改变。话虽如此,一些老的测试用例可能会不再适用,因为有些功能可能已被删除,并通过新的功能所取代。因此,回归测试包需要定期更新,以反映应用程序的更改。
回归测试包是来自于针对早期版本的需求规格软件的脚本测试的组合,也包括随机测试。回归测试包应在最低限度涵盖典型的用例场景的基本工作流程。 “最重要的测试”,即对很重要的应用领域的测试应该总是被包含在回归测试包中。例如,一个银行应用程序应该包含对其安全稳健性的测试,而一个高访问量网站的Web应用程序则应该对其进行性能相关的测试案例。
成功的测试案例,即与应用程序早期版本中的缺陷测试相关的测试也是列入回归测试包的很好的候选对象。
自动化回归测试
在可能情况下,回归测试必须自动化。用相同的变量和条件一遍又一遍的运行相同的测试,不会产生任何新的缺陷。重复的工作会造成执行测试者的丧失兴趣和注意力不集中,可能在执行回归测试的过程中错失发现潜在缺陷的机会。此外自动化回归测试的另一个优点是,可以添加多个测试用例到该回归测试包而不对花费时间产生太大影响。自动回归测试包可以连夜执行或与手动测试并行运行,并能释放资源。
Reporter.ReportEvent EventStatus, ReportStepName, Details [, in]
Argument
Type
Descrīption
EventStatus
Number or pre-defined constant
状态值:
0、或 micPass:将本步骤的运行结果状态设置为“Pass”,并向Result中产生报告信息。
如果想在报告中生成“通过”报告,用本状态值。
1、或 micFail: 将本步骤的运行结果状态设置为“Fail”,并向Result中产生报告信息。当脚本中运行本语句时,整个
测试的结果状态是“fails”。
如果想在报告中生成“失败”报告,用本状态值。如果运行了本语句,则整个测试的状态为“Fail”。
2、或 micDone:仅向Result中产生报告信息,但不影响整个测试的结果状态。
如果想在报告中生成“完成”报告,用本状态值。
3、或 micWarning: S向Result中产生报告信息,但是不会中断测试的运行,也不影响测试的 pass/fail status。
如果想在报告中生成“警告”报告,用本状态值。运行这个语句后,整个测试结果状态为“Warning”。
ReportStepName
String
将在报告中显示的步骤名称(object name).
Details
String
报告的详细信息。这些信息是本条报告的“Details”信息。
我装的是比较新的版本,6.0.5,网上搜到的教程多是针对4.x版本的,装6.0.5还是会碰上不少问题。
主要参考这个文档安装的。但因为yum安装更方便,所以尽量yum安装
mysql:
yum -y install mysql mysql-server
chkconfig mysqld on
service mysqld start
yum install开头是失败。提示GPG key" atomicrocketturtle.com一类的错误。把/etc/yum.repos.d/automic.repo 移到temp目录中,然后yum update,再安装就好了。
为了保险起见,安装jdk6,没有装jdk7.
yum search jdk|grep 1.6
然后安装 java-1.6.0-openjdk
tomcat6:
安装这些
tomcat6,tomcat6-lib,tomcat6-webapps,tomcat6-servlet,tomcat6-javadoc,tomcat6-docs-webapp,tomcat6-jsp,tomcat6-admin-webapps
然后chkconfig,service操作
安装时按照 https://confluence.atlassian.com/display/JIRA060/Using+the+JIRA+Configuration+Tool#UsingtheJIRAConfigurationTool-starting
因为没有图形界面,就借鉴帮助中的图形界面配置我们的命令行界面。
mysql进去
create user jira identified by 'jira';
grant all privileges on jiradb.* to jira@localhost identified by 'jira' with grant option;
flush privileges;
我认为mysql是3306的接口,反复试了几次,老是失败。
netstat|grep mysql
原来mysqld的接口不是3306。这样就成功了,难道3306已经被占用了吗,但是netstat|grep 3306没有找到。
通过“locate java”和ll可以得到java的home,
/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0.x86_64/jre
那就设这个为JAVA_HOME吧。