
前段时间在录制,增强,整合
LoadRunner脚本,期间两次遇到了中文乱码问题。在此记录一下中文乱码问题的解决办法。
一、录制回放中文乱码
我录制登陆的脚本,用户名中出现中文,回放的时候总是提示登陆失败。如下图:
图1 LR回放中文乱码
解决中文乱码可以在录制的时候在Virtual User Gen的 Tools->Recoding Options -> Advanced -> Support charset -> UTF-8。重新录制后中文乱码问题得到解决。
二、整合脚本中文乱码
录制增强(参数化,关联,检查点,事务)脚本后决定将几个脚本整合在一起。于是新建了一个空的脚本,将登陆退出公用操作分别放在vuser_init和vuser_end中,其他操作放在各自的Action中。整理完成回放后又出现中文乱码。为解决这个问题,最关键的是要把本地GBK编码的汉字转换成UTF-8编码格式的信息,为此我们引进loadrunner自带的编码函数lr_convert_string_encoding。
int lr_convert_string_encoding ( const char *sourceString, const char *fromEncoding, const char *toEncoding, const char *paramName);
该函数有4个参数,含义如下:
sourceString:被转换的源字符串。
fromEncoding:转换前的字符编码。
toEncoding:要转换成为的字符编码。
paramName:转换后的目标字符串。
实践一:
lr_convert_string_encoding("登陆账号",LR_ENC_SYSTEM_LOCALE, LR_ENC_UTF8, "Account");
web_submit_data("login.quick",
……
"Name=account", "Value={Account}", ENDITEM,
……
LAST);
回放脚本的时候依然报错。查看lr_convert_string_encoding的解释,它会在其转换的字符串末尾加上\x00。在C语言中\X00是一个字符串的结束,而正是这个\x00的存在导致了脚本回放失败。
实践二:
char tmp[100]; lr_convert_string_encoding("登陆账号",LR_ENC_SYSTEM_LOCALE, LR_ENC_UTF8, "Account"); strcpy(tmp,lr_eval_string("{Account}")); lr_save_string(tmp,"Account"); web_submit_data("login.quick", …… "Name=account", "Value={Account}", ENDITEM, …… LAST); |
通过strcpy和lr_save_string的处理屏蔽\x00的影响,
测试结果正常
在做
web项目的自动化端到端
测试时主要使用的是
Selenium WebDriver来驱动浏览器。Selenium WebDriver的优点是支持的语言多,支持的浏览器多。主流的浏览器Chrome、Firefox、IE等都支持,
手机上的浏览器
Android、IPhone等也支持,甚至还支持PhantomJS(由于PhantomJS跑测试时并不需要渲染元素,所以执行速度快)。
但是我在使用Selenium WebDriver时,遇到了很多坑。这些问题,有的是因为Selenium WebDriver与浏览器不同版本之间兼容性的问题,有的是Selenium WebDriver本身的bug,当然也不乏自己对Selenium WebDriver某些功能理解不透彻。我花时间总结了一下,分享给大家,希望大家以后遇到问题可以避过这些坑,少走弯路。另外也总结了一些使用WebDriver的比较好的实践,也一并分享给大家。
WebDriver每次启动一个Firefox的实例时,会生成一个匿名的profile,并不会使用当前Firefox的profile。这点一定要注意。比如如果访问被测试的web服务需要通过代理,你想直接设置Firefox的代理是行不通的,因为WebDriver启动的Firefox实例并不会使用你这个profile,正确的做法是通过FirefoxProfile来设置。
public WebDriver create() { FirefoxProfile firefoxProfile = new FirefoxProfile(); firefoxProfile.setPreference("network.proxy.type",1); firefoxProfile.setPreference("network.proxy.http",yourProxy); firefoxProfile.setPreference("network.proxy.http_port",yourPort); firefoxProfile.setPreference("network.proxy.no_proxies_on",""); return new FirefoxDriver(firefoxProfile); } |
通过FirefoProfile也可以设置Firefox其它各种配置。如果要默认给Firefox安装插件的话,可以将插件放置到Firefox安装目录下的默认的plugin文件夹中,这样即使是使用一个全新的profile也可以应用此plugin。
使用WebDriver点击界面上Button元素时,如果当前Button元素被界面上其他元素遮住了,或没出现在界面中(比如Button在页面底部,但是屏幕只能显示页面上半部分),使用默认的WebElement.Click()可能会触发不了Click事件。
修正方案是找到该页面元素后直接发送一条Click的JavaScript指令。
((JavascriptExecutor)webDriver).executeScript("arguments[0].click();", webElement);
当进行了一些操作发生页面跳转时,最好加一个Wait方法等待page load完成再进行后续操作。方法是在某个时间段内判断document.readyState是不是complete。
protected Function<WebDriver, Boolean> isPageLoaded() { return new Function<WebDriver, Boolean>() { @Override public Boolean apply(WebDriver driver) { return ((JavascriptExecutor) driver).executeScript("return document.readyState").equals("complete"); } }; } public void waitForPageLoad() { WebDriverWait wait = new WebDriverWait(webDriver, 30); wait.until(isPageLoaded()); } |
如果页面有Ajax操作,需要写一个Wait方法等待Ajax操作完成。方式与上一条中的基本相同。比如一个Ajax操作是用于向DropDownList中填充数据,则写一个方法判断该DropDownList中元素是否多余0个。
private Function<WebDriver, Boolean> haveMoreThanOneOption(final By element) { return new Function<WebDriver, Boolean>() { @Override public Boolean apply(WebDriver driver) { WebElement webElement = driver.findElement(element); if (webElement == null) { return false; } else { int size = webElement.findElements(By.tagName("option")).size(); return size >= 1; } } }; } public void waitForDropDownListLoaded() { WebDriverWait wait = new WebDriverWait(webDriver, 30); wait.until(isPageLoaded()); } |
以此类推,我们可以判断某个元素是否呈现、某个class是否append成功等一系列方法来判断ajax是否执行完成。
如果网站使用了JQuery的动画效果,我们在运行测试的时候其实可以disable JQuery的animation,一方面可以加快测试的速度,另一方面可以加强测试的稳定性(如果启用了Animation,使用WebDriver驱动浏览器时可能会出现一些无法预料的异常)。
((JavascriptExecutor)driver).executeScript("jQuery.fx.off=true");
由于WebDriver要驱动浏览器,所以测试运行的时间比较长,我们可以并行跑测试以节省时间。如果你使用的是maven构建工具,可以配置surefire plugin时,在configruation节点加入以下配置。
<parallel>classes</parallel>
<threadCount>3</threadCount>
<perCoreThreadCount>false</perCoreThreadCount>
当测试fail的时候,如果当前使用的WebDriver实现了TakesScreenshot接口,我们就可以调用相应的方法截下当前浏览器呈现的web页面,这样有利于快速定位出错的原因。
public void getScreenShot() { if (webDriver instanceof TakesScreenshot) { TakesScreenshot screenshotTaker = (TakesScreenshot) webDriver; File file = screenshotTaker.getScreenshotAs(savePath); } } |
如果页面弹出了浏览器自带的警告框(使用JavaScript的Alert方法),Selenium WebDriver在点选次警告框时会偶发性失败。具体原因还未查明。解决方案是尽量不使用Alert方法的警告框,而是自己实现模式窗口(比如Jquery UI的模式窗口)来实现警告框效果。这样即保证了测试的稳定性,另外我们自己可以控制警告框的样式,给用户带来更好的体验。
经常更新Selenium的版本。注意经常上Selenium的官网看是否发布了新的版本,新的版本都修复了那些bug,如果包含你遇到的bug,就可以升级到目前的版本。
首先简要介绍一下我们的系统。我们整个系统中,可视化的应用(
web,APP)都是基于后端的saasapi。我们的saasapi采用rest风格,采用http协议,以json作为数据载体。所以,对后端的api接口进行
测试很有必要。
用到的技术包括:maven、junit4,json开发包、hudson、jdbc等等。
1.项目目录结构(采用maven)
2.用例组织和规则约束
用例组织
例如:trackSegListWithTime(轨迹分段)、segTrackData(轨迹点显示)接口属于我的车模块。那么就在src/test/java源文件夹下面建立一个我的车模块包com.cpsdna.saasapi.test.vehicle,然后新建测试接口的类: TrackSegListWithTimeTest.java、 SegTrackDataTest.java
命名规则
测试类命名规则:接口名称+Test,例如SegTrackDataTest.java(轨迹点显示接口的测试类)
方法命名规则:test+方法意义,例如testSegTrackDataWithNoObjId(以没有objId参数方式测试segTrackData接口 )
3.测试方法步骤
1.声明参数变量
3.组装发送的json报文,把参数变量加入其中
4.向服务器端发送json
5.接收从服务器端返回的信息(json或者其它)
6.通过json开发包(json-lib,gson)解析从服务器返回的json
7.添加断言(预期的结果和解析的实际结果是否一致)
下面给一个实例:
我认识一个朋友,也是
程序员出身,他在一家还不错的外企上班,每个月工资收入也就差不多15K,五年的
工作经验了,在他面前,我算是小弟。那天我们几个朋友一起打完球就去附近的饭馆吃饭,环境还不错,于是就边吃边聊工作、赚钱的事情。
那天了解到,他不仅拿着15K的高薪,业余还有着更高的收入,从聊天中,我总结了几点程序员赚钱的技巧,分享给大家,也许你可以参考一下,哪天发财了记得回到这篇
文章中来赞一下。
利用Adsense可以将广告发布到你的网站上去,通过访客点击广告来赚取佣金。这似乎是一个很不错的主意,如果你有一个不错的创意,写一个网站对于程序员的你应该不难,网站放上Adsense广告,推广、引流、收美金。
首先,他的Android应用是免费的,他并不是靠卖App来赚钱,而是通过向App中投放广告来赚取佣金的。如果你对Android技术非常熟悉,或者你的工作就是做Android开发,那么为什么不自己开发一个应用放到Android市场,为自己创造另一份收入。
三、参加一些开发者大赛
这是一种最实在的方法了,拿奖金,只赚不赔,不过前提是你得有足够的实力。他参加过Google的Android开发者大赛,很得瑟的跟我们说那时候他赢得了2000美金,尽管不是很多,但从中也可以学到不少知识,至少,通过
学习,他可以自己开发Android应用来赚取广告费了。
四、承接一些项目
当然这要花费你很大一部分时间,承接时你要考虑时间成本,至少这些时间要和你的工资相当。个人不怎么推荐这种方法,有时候周期会很长,很容易丧失积极性,不过也算是一种方法。
五、刷机、越狱
现在都是智能
手机,有些用久了,卡了,像电脑一样要重装系统,一些小白有教程都搞不定,这时候你可以借此开展刷机业务。还有iOS的越狱,这个需要你对iOS的操作非常熟悉。你可以将此业务挂到淘宝上,帮助买家实现他们要的功能。
六、做黑客
黑入银行,盗取前女友现任老公的所有钱,哈哈,开玩笑了。不过,做一名优秀的计算机黑客确实可以帮你赚取很大一笔收入,比如帮助一些企业提高计算机网络的安全性、做一些抵御攻击的积极措施等。
这是我们讨论结果的几个要点,因人而异,如果你要更好的建议,欢迎在评论中告诉我们。
回答:本期话题分几个要素点,我将根据命题划分的几个关键词:紧急情况,压缩,测试周期,来一起分析探讨。
项目中难免会碰到很多“紧急情况”,如:
1、需求变更
客户是善变的,我们必须伺候好客户,不是么?没有任何理由,他们要变更需求,一般情况下,最为乙方、丙方只有服从。
2、项目外包
很少有人碰到过吧?不过的确存在!项目进行到一半时由于自身团队或者高层决策、成本等方面上的要求,直接将项目外包出去,或者重新让一个项目团队接手。
3、开发设计架构存在明显严重缺陷
显然,架构师、项目经理等没有在前期做好评审和确认,但是很多项目,尤其是政府项目团队成员很随意,反正是有扶持款项。但这不是质量低下的理由!
4、不确定因素造成人员减少
如核心员工跳槽离职、女同事怀孕、家里生老病死等。
5、客户要求提前上线
在交付阶段,再次回到客户,他是老大,出钱的,给项目的!甲方要求提前项目上线,这不得不加快进度,不是么?
关键点把握——“压缩”
综合上述我列举的几个原因,在项目决策和进度上已经批复下来,我们必须得“压缩”进度安排。这里明显不存在沟通、协商的必要了,或者说与相关部门、人员沟通/协商无效了。
但是对于我们测试团队的“测试周期”,个人认为,有必要澄清或者继续不断与相关涉众进行沟通和协商!毕竟整个周期被砍,直接最大影响的是我们测试部门同事!
这里根据之前列举的5大理由,我会有侧重地整理下解决方案:
1、需求一旦变更,项目团队前面阶段也肯定有影响,开发需要重新设计编码,然后才是到测试阶段。由于需求变更是客户方提出的,我们有权利去交涉争取最长“测试周期”。这里作为测试经理必须和项目经理统一战线,和客户方达成共识。因项目后期客户自身提出的临时需求变成要求,本不在合约范围内,所以综合已有的项目计划和人员安排,在强制要求“压缩”进度、或者保证原有进度的情况下,个人认为必须给客户列举出详细的测试风险和影响要素。让客户方明确在进度被压缩的前提下,我们能保证的质量效果和最佳状态!知道风险是多方面必须一起承担的。
2、项目突然被外包给别人,有点不可思议!但是整个项目被第三方接手,这里的交接情况,主要是新项目组对需求的快速把握、理解,开发方对项目架构、设计及代码的熟悉都是不得不去考虑的。这样对于测试团对来说,只能延后开始执行测试时间点,那势必得把握测试要素的重点。个人建议按测试优先级、功能重要等级进行分类和划分,给客户方一个明确能保证质量的测试业务点清单。毕竟不可能在短时间项目被重新分包情况下,让测试团队控制什么进度来交付产品/项目。这个是整个项目进度的问题。
3、开发设计有严重问题。这个是自己团队得承担的责任!但是也因此影响到了测试部门人员。我们在开发人员紧急处理问题时,可以同步参与
单元测试、
接口测试等。因为已经大架构上错误了,测试人员协助开发人员一起确保系统设计、搭建没有问题,其实是不能再出问题!
4、非受迫性减员很普遍,但是各项目组或者总的测试团队负责人/测试项目经理必须分配好冗余资源进行补充,自己得多承担责任。作为缺岗人员的备份者,更加要协调好剩余同事的任务安排,稳定军心。
5、客户要求赶工上线,正常情况下不能保证质量是否完全可靠,同问题1,得让他们承担接受潜在风险!上线交付是个很严肃的过程,对系统功能、性能、安全、稳定性,软、硬件环境要求必须都满足上线的前提,才能正式交付,客户在计划外要求提前上线,除去自己业务方面需求,没有对项目团队有啥合理理由或者要求,我们作为测试团队,得把握其上线要求的最佳业务点,如某个功能模块一定要运行正常稳定,有侧重的去测试该部分,若他们可以接受条件的话。
其实上述方面我还是侧重与责任方进行交流沟通!虽然已经被压缩了进度,但有些情况必须阐明,才能安心工作,对于测试部门,测试经理也有义务进行责任承担的同时,给予同事们最大程度保护!
对于传统的加班加点,加人加米等方式,这里我其实不想多说,因为这些都是非正常的要求,才称之为“紧急情况”,所以除去那些人力、费用、资源等成本不说,在项目进度,这里主要是测试进度加快情况下,只能先理清思路,针对不同要求去协商并沟通,争取最佳的效果吧。尽可能保证项目在预期内打到理想的最好质量状态。
我个人是没有见过被压缩进度下,又要做到很好,又要满足各种要求的!这不现实!这里只是给出最可能的、理想的、较好的处理方式和技巧而已~
希望其他大神补充,指正!
测试代码来自 Progremming Erlang。
Erlang: R13B (erts-5.7.1), 启动参数 +P 5000000
系统: Window XP
CPU: E8200 2.66G 双核
内存: 4G
Erlang R13B (erts-5.7.1) [smp:2:2] [rq:2] [async-threads:0] Eshell V5.7.1 (abort with ^G) 1> c(processes). {ok,processes} 2> processes:max(1000000). Maximum allowed processes:5000000 Process spawn time = 2.703(2.688) microseconds ok 3> processes:max(1000000). Maximum allowed processes:5000000 Process spawn time = 3.203(2.938) microseconds ok 4> processes:max(1000000). Maximum allowed processes:5000000 Process spawn time = 3.25(3.015) microseconds ok |
结果:
创建100W,平均3us左右。因为物理内存比较多。测试时内存高峰在1.2G左右, 由此可以估计一下进程的内存消耗。
测试创建200W, 150W都不能正常运行。测试时,内存到1.8G以上时,werl进程死循环。不能结束。
在WINDOW下,单进程的内存不能超过2G。可见,进程的上限也就100W多一点吧。如果加上其它开销。单个结点能创建的进程数量还会少很多。
看下测试代码 for函数的编写并不是最优化的方式,改成尾递归形式:
for(I, N, F) -> for_h(I, N, F, []).
for_h(_N, _N, _, L) -> L;
for_h(I, N, F, L) -> for_h(I+1, N, F, [F()|L]).
再测试:
5> c(processes). {ok,processes} 6> processes:max(1000000). Maximum allowed processes:5000000 Process spawn time = 1.891(1.64) microseconds ok 7> processes:max(1000000). Maximum allowed processes:5000000 Process spawn time = 2.266(1.641) microseconds ok 8> processes:max(1000000). Maximum allowed processes:5000000 Process spawn time = 2.234(1.625) microseconds ok |
结果在2us左右,看来尾递归还是影响挺大。
回答:与其说考核成果,不如我们来称之为对测试结果的分析更为准确。
主要可以考虑以下几个方面:
1、性能测试需求是否覆盖完整
业务不仅是
功能测试的根本,也是性能测试的前置条件。一个成果性能测试肯定是最大最优化覆盖了业务路径,包括核心业务功能模块和逻辑。
2、性能测试计划是否合理
a)测试前计划所需的软、硬件环境配置
包括服务器CPU/Mem/HD等,还有网络带宽和路由/交换机等网络拓扑。其对整个测试结果起到决定性作用,也对测试代理机和工具等给予支持。
b)测试进度安排是否充分
这里主要指对于测试方案制定、测试脚本开发、测试执行、测试结果分析总结等一系列时间节点是否满足整个项目测试计划和进度。我们知道性能测试比较依赖环境、工具等,若该阶段花费太多时间成本,对整个测试项目会有严重影响。
3、性能测试方案是否有效
测试方案及策略是整个性能测试的指导性纲要,对于测试方法、技术、选择的业务脚本,都得在性能测试方案中体现。
4、性能测试脚本是否高效
这里已经默认选择了充分的业务场景进行测试。对于整个性能测试结果来说,核心部分就是开发的测试脚本,能够用最高效的代码来执行每一个业务功能,充分、完整的覆盖所有路径,则可以保障测试结果的有效和整个性能测试的质量。另外,脚本本身如开发之代码,过多调用进程和不释放内存等低质量语句,会使得测试执行变本加厉,从而影响到整个测试,甚至产生的结果会有严重差异。
5、性能测试执行日志是否加载
这里注意不是整个测试结果数据,是执行测试时每个细节、步骤的日志信息。若性能测试执行时不开启或开发产生日志信息,则丢失了第一时间的问题列表数据,对于日后分析带来不便。
6、性能测试结果分析是否到位
对于完成的性能测试结果,我们基本会使用图表形式来直观查看测试情况,并通过结果数据如CPU/MEM占用率,吞吐量,响应时间等来量化服务器资源消耗和系统性能。但我们更加需要去把握几个峰值或异常数据的节点,分析其产生的原因和当时的状况,然后给出自己建言和想法,帮助开发去进行性能调优。
7、性能测试问题发现和总结
其实不仅仅是性能测试,每次完成测试后对测试整个过程和产生的问题进行整理,并作总结,帮助下次测试时避免再发生相同的问题,是必须进行的步骤,也是成功测试的有效手段。
8、所有过程是否文档化
这个其实也不仅仅是性能测试,对于每次测试过程,无论功能、性能或者安全,都得文档化,通过产生记录、各阶段的测试准入、准出等,来辅助相关测试人员等进行
工作。若有体系标准,如CMMI/ISO9001等,则更佳。
以上大致列举了下性能测试及其成果度量时需要考虑的部分,通过周而复始的操作,比对前后性能测试过程与结果,这样就可以不断改进和提高性能测试的质量。说大点可就能考评自己性能测试是否高效、系统功能更优化的那些成果了。
纯个人想法,请不吝指正。
在编写代码高亮脚本的时候,问了瓶子一个问题,就是在循环里处理删除DOM元素的时候,会动态改变NodeList的length,所以
测试许久, 最后发现是这个问题,狂晕。但是期间谈到了一个关于removeChild的时候在IE下无法回收内存的泄漏问题,他展示了一个EXT里针对IE使用的方 法:
var div=document.getElementById("div"); var first=div.firstChild,next=first; while(next){ var d=document.createElement("div"); d.appendChild(next); d.innerHTML=""; next=div.firstChild; } /////////////////////////////////////////////////// //简单的removeChild方式: var div=document.getElementById("div"); var first=div.firstChild,next=first; while(next){ next.parentNode.removeChild(next); next=div.firstChild; } |
但是经过使用Drip工具(测试IE是否内存泄漏的工具,download),测试还是存在内存泄漏的问题,但是使用IE JS Leaks Detector却啥也检测不出来(全部的测试都检测不出来,就连网上都吹捧的内存泄漏的方式也检测不出来),还有使用了话说是Drip的增强版的sIEve(download),也测试不出来。既然这样,那就暂且信任Drip吧。下面几种传说中的内存泄漏的方式都是在Drip下测试的。
在开始讲述之前,先大概了解一下javascript的GC机制:
垃圾回收进程尝试推断何时可以安全地回收不再使用的变量,通常是通过判定程序是否能够通过变量之间形成的引用网络到达该变量。当确信变量是不可达的,就在它上面标上可以回收的记号,并且在回收器的下一次清理中(可能在未来的任意时刻)释放相关的内存。
也就是说,垃圾回收机制会定时的检查程序中的对象,查看它是否跟别的对象之间已经完全断开了引用链而“孤单一人”,这时,垃圾回收机制就会回收这个 对象的内存,否则,将不会回收。所以说,对象在使用完了之后,就应该被回收内存,而不是一直占用着内存不放,导致浏览器的内存使用量节节飙升。
第一种:既然上面谈到了关于removeChild,那就从它开始吧,通过Drip测试,简单的使用 removeChild删除子节点的方式确实存在内存泄漏,但是使用了上面EXT使用的方式,也还是存在。经过一番搜索,有
文章说需要清除节点的全部属性 来实现内存的正确回收,那就进行了下面的测试。结果通过将节点的属性都delete掉之后,Drip显示没有内存泄漏了。
var div=document.getElementById("div"); var first=div.firstChild,next=first; while(next){ div.removeChild(next); for(var k in next){ delete next[k]; } next=div.firstChild; } |
第二种:将一个DOM对象和一个JS对象相互成为对方的属性。对于这点,IE官方也都有说法:在IE6中,对于 javascript object内部,jscript使用的是mark-and-sweep算法,而对于javascript object与外部object(包括native object和vbscript object等等)的引用时,IE 6使用的才是计数器的算法。也就是说,IE 6对于纯粹的Script Objects间的Circular References是可以正确处理的,可惜它处理不了的是JScript与Native Object(例如Dom、ActiveX Object)之间的Circular References。所以,当我们出现Native对象(例如Dom、ActiveX Object)与Javascript对象间的循环引用时,内存泄露的问题就出现了。当然,这个bug在IE 7中已经被修复了。(Fuck,难怪我用Drip测试不出来(系统是IE8的内核))。下面是我的一个测试:
function Encapsulator(element){ this.elementReference = element; element.expandoProperty = this; } function SetupLeak2(){ var obj=new Encapsulator(document.getElementById("test")); document.body.removeChild(document.getElementById("test")); //alert(document.getElementById("test").expandoProperty); 出现错误 //说明从element.expandoProperty ---> obj的引用已经断开了 //但是从obj.elementReference到element的引用依然存在, //这样的话在IE6下element就无法回收内存,但是其他浏览器的GC机制都会很好的处理了这个问题。 document.body.appendChild(obj.elementReference); } |
第三种:将事件处理函数放在定义它的函数的内部。这种情况之前就看到过,回想下自己以前编写js的方式:外包一个自执行函数,里面定义闭包内的变量和功能函数,也不乏对事件处理程序的处理。这样是否会造成IE下的内存泄漏呢?下面是两个测试程序:
var test=function(){ var div=document.getElementById("test"); var i=0; while((i++) < 20){ (function(index){ var o=document.createElement("p"); o.innerHTML="AAA"; o.onclick=function(){ alert("haha,leap"); } div.appendChild(o); o.onclick=null; div.removeChild(o); })(i); } } function addEvent(){ var div=document.getElementById("event"); div.onclick=function(){ this.parentNode.removeChild(this); } } |
上面的一段程序也是从网上摘录下来做测试的,在闭包中动态生成一个div元素,并给它添加事件,事件处理程序写在闭包里面,也就是内涵在test函数里 面,可是在removeChild的时候,Drip下显示还是内存泄漏了,即使是把它的onclick属性设置为null也不行。第二个测试程序中,在事 件处理程序中通过removeChild删除当前节点的时候,也显示内存泄漏。
第四种:在创建DOM对象时插入script。这个还是第一次看到。即是通过createElement创建DOM元 素的时候,直接在字符串中插入了js代码:document.createElement(“<div onclick=’foo();’>”),但是这种方式只在IE下有效。通过测试下面的程序,在Drip中也确实显示内存泄漏了
var leakMemory=function(){
for(i = 0; i < 5000; i++){
var parentDiv = document.createElement("<div onClick='foo()'>");
}
}
第五种:总是先将新创建的DOM对象插入到文档后,在对其进行其他操作。对于这点,我想象不到它是如何造成内存泄漏 的。而且,它跟页面优化的一些方式可能存在冲突。在某些情况下,在创建了DOM元素之后,先处理DOM的操作,最后才插入到文档中,这样可以避免尽可能的 由于reflow影响性能的情况。这可能就需要一个权衡了吧,因地制宜~
总结:
上面是本人通过使用Drip工具测试的结果,但是由于在sIEVE和JS Leaps Detector下测试都没发现内存泄漏的情况,所以纠结的很。经过这一番折腾,也不枉自己一番倒腾倒腾吧,在以后的编写代码中,可以或多或少的去避免这 些不必要的可能造成内存泄漏的情况出现。
同时,如果有说错的地方,欢迎指正,共同学习~~
一、Appium中,经常会遇到会遇到滑动操作,但往往用各种手势操作后还是滑动不了,今天主要讲下如何正确使用appium的手势操作。系统环境为最新的iOS 7.1+ Xcode 5.1
首先讲下滑动操作的几个基本方法。
1.swipe操作,主要用于缓慢拖动,代码示例
JavascriptExecutor js = (JavascriptExecutor) driver; HashMap<String, Double> swipeObject = new HashMap<String, Double>(); swipeObject.put("startX", startX); swipeObject.put("startY", startY); swipeObject.put("endX", endX); swipebject.put("endY", endY); swipeObject.put("duration", duration); swipeObject.put("element", Double.valueOf(((RemoteWebElement) element).getId())); js.executeScript("mobile: swipe", swipeObject); |
①X,Y可为coordinator,也可以是percent,duration单位为秒
②可以指定的element,也可以不指定
③appium mac端有swipe的按钮可以试下
2.flick操作,类似swipe,但没有duration,用于快速滑动,如ViewController的切换,代码示例
JavascriptExecutor js = (JavascriptExecutor) driver; HashMap<String, Double> flickObject = new HashMap<String, Double>(); flickObject.put("startX", 0.8); flickObject.put("startY", 0.5); flickObject.put("endX", 0.2); flickObject.put("endY", 0.5); flickObject.put("element", Double.valueOf(((RemoteWebElement) element).getId())); js.executeScript("mobile: flick", flickObject);); |
3.scroll操作,专为iOS 7.x而生,官方的解释如下
An unfortunate bug exists in the iOS 7.x Simulator where ScrollViews don't recognize gestures initiated by UIAutomation (which Appium uses under the hood for iOS). To work around this, we have provided access to a different function, scroll, which in many cases allows you to do what you wanted to do with a ScrollView, namely, scroll it!
简而言之,iOS 7的系统ScrollView无法识别手势操作,使用scroll方法可完美替代,代码见例子
二、接下来以三个不同app的引导图为例,分别为看游戏,云阅读和云音乐,演示下不同方法实现的滑动操作
1.看游戏,引导图以ScrollView引导,只需要使用srcoll方法即可
JavascriptExecutor js = (JavascriptExecutor) driver;
HashMap<String, String> scrollObject = new HashMap<String, String>();
scrollObject.put("direction", "right");
js.executeScript("mobile: scroll", scrollObject
2.云音乐,引导图以ScrollView引导,分别为4张image
接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。
接口测试适用于为其他系统提供服务的底层框架系统和中心服务系统,主要测试这些系统对外部提供的接口,验证其正确性和稳定性。接口测试同样适用于一个上层系统中的服务层接口,越往上层,其测试的难度越大。
接口测试实施在多系统多平台的构架下,有着极为高效的成本收益比,接口测试天生为高复杂性的平台带来高效的缺陷监测和质量监督能力。平台越复杂,系统越庞大,接口测试的效果越明显。
基于接口测试的重要性,以及它比较容易自动化的特性,通过持续集成的接口监控能够及时的发现项目中存在的问题,这对持续运营的项目来说,非常重要。
二、接口测试的流程
1、 项目启动后,测试人员要尽早找到开发人员拿到接口测试文档
2、 获取接口测试文档后,就可以进行接口用例的编写和调试
3、 接口用例编写调试完成后,部署到持续集成的测试环境中,
4、 设定脚本运行频率,告警方式等基本参数,进行接口的日常监控
5、 每日进行接口脚本的维护更新,接口异常的处理
三、编写接口测试脚本
大部分性能工具都可以用来进行接口测试,jmeter就是一个好用的
性能测试工具,他也同样可以用来进行接口测试,jmeter比较适用于CGI、webservice、DB等类型的接口测试。下面以websevice api接口为例说明如何编写接口测试用例(本文侧重于接口测试平台的搭建,对于具体工具是使用只进行简单介绍,对于工具不了解的,可以自行
百度):
jimter接口脚本的编写步骤如下:
1、 编写接口请求
通过录制或者查看接口文档,编写接口请求,进行调试,确保接口调试通过
对于http的请求来说,就是正确的填写域名,查询字符串,查询参数等信息
2、 对接口的返回结果进行断言
断言的目的是对输出结果进行判断,确认接口测试结果是否有异常
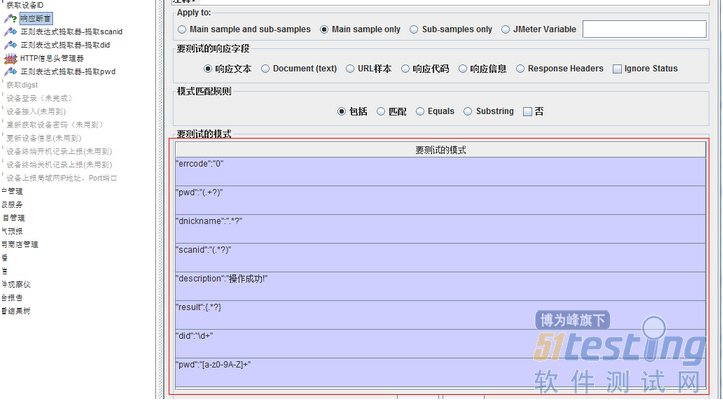
这些
工作完成后,接口测试脚本就准备好了
四、生成接口测试报告
接口测试脚本运行后生成的是JTL(xml)格式的文件,这些文件不具备可读性,因此我们要把他转化为可以阅读的html格式报告。
转化的步骤如下:
1、 安装ant工具
Ant是一个功能强大的打包编译工具。我们使用他的目的是将xml文件转化为html格式的文件
2、 找到jmeter自带的xsl文件
Xml文件要转化为html文件,需要编写xsl文件,实际上,jmeter已经自带了xsl文件,如果你不想自己定义格式的话,可以直接使用自带的格式,这样可以省不少事情。这些文件的位置位于jmeter的extras文件夹下,只需要简单修改一些文件路径配置就可以正常使用。
3、 编写ant的buildfile文件
Ant自带了把XML转化为html的lib库,因此,这个转化也是相当简单的,示例如下:
<target name="xslt-report" depends="_message_xalan"> <tstamp><format property="report.datestamp" pattern="yyyy/MM/dd HH:mm"/></tstamp> <xslt classpathref="xslt.classpath" force="true" in="${resultpath}/${test}-${TODAY}.jtl" out="${resultpath}/${test}-${TODAY}.html" style="${jmeter.extras}/jmeter-results-detail-report${style_version}.xsl"> <param name="showData" expression="${show-data}"/> <param name="titleReport" expression="${report.title}"/> <param name="dateReport" expression="${report.datestamp}"/> </xslt> </target> |
完整的buildfile文件,请自行百度
4、 运行ant命令,生成html文件
Cmd运行ant –buildfile xsl文件,你就可以生成html报告了
生成的测试报告如下:
五、部署到持续集成平台
部署到持续集成平台可以实现脚本的定时运行,这是接口测试的核心。
这里我们选用了jenkins,,jenkins是一个强大的持续集成系统,使用起来也很简单。
使用步骤如下:
1、 安装jenkins
Jenkins的安装是非常简单的
注意:请将jenkins安装到一个空间比较大的系统盘中。因为jenkins运行起来,生成的文件比较占空间。
2、 安装完成后,配置一个项目