
2007年1月13日
var fixgeometry = function() {
/* Some orientation changes leave the scroll position at something
* that isn't 0,0. This is annoying for user experience. */
scroll(0, 0);
/* Calculate the geometry that our content area should take */
var header = $(".header:visible");
var footer = $(".footer:visible");
var content = $(".content:visible");
var viewport_height = $(window).height();
var content_height = viewport_height - header.outerHeight() - footer.outerHeight();
/* Trim margin/border/padding height */
content_height -= (content.outerHeight() - content.height());
content.height(content_height);
}; /* fixgeometry */
$(document).ready(function() {
$(window).bind("orientationchange resize pageshow", fixgeometry);
});
posted @
2013-01-28 10:59 The Matrix 阅读(5189) |
评论 (1) |
编辑 收藏posted @
2012-05-14 14:28 The Matrix 阅读(1210) |
评论 (0) |
编辑 收藏环境:
Centos6.2(安装在Vmware7.0中)
Magento1.6.2
Apache Httpd Server 2.2.15
MySql 5.1.61
PHP5.3.3
安装过程:
apache http、mysql、php及相关扩展安装:
其中apache http、Mysql、php都是利用centos的添加/删除软件功能进行安装。同时使用该功能安装"php-xml"、"php-gd"、"php-pdo"、"php-mbstring"、"php-mysql"扩展。
使用chkconfig配置httpd和mysql为系统服务。命令如下:
chkconfig httpd on
chkconfig -add mysqld
chkconfig mysqld on
使用chkconfig --list 可以查看所有的服务配置状态
使用service httpd start、service mysqld start启动httpd和mysqld服务。可以通过service httpd restart重启相关服务。
此时访问本机的http://localhost可以看到apache的欢迎界面,同时编辑index.php文件,其内容如下:
<?php
phpinfo();
?>
并将该文件置于/var/www/html目录下,访问http://localhost/index.php,此时应该不能看到php版本信息,仅能看到index.php的静态文本内容。
修改/etc/httpd/conf/httpd.conf文件,修改如下:
DirectoryIndex index.html index.html.var -> DirectoryIndex index.html index.htm index.php
增加:
AddType application/x-httpd-php .php
AddDefaultCharset -> AddDefaultCharset off (解决中文乱码问题)
增加一段VirtualHost描述,如下(在配置文件的最后):
<VirtualHost *:80>
DocumentRoot /var/www/smallfive
ServerName smallfive
ServerAlias smallfive.com *.smallfive.com
</VirtualHost>
此时访问http://localhost/index.php,应该一切正常
设置数据库:
使用mysqladmin -u root password 'newpassword'设置mysql数据库的默认密码
让数据库更安全:
mysql -u root -p 进入mysql
mysql> DROP DATABASE test; 删除test数据库
mysql> DELETE FROM mysql.user WHERE user = ''; 删除匿名帐户
mysql> FLUSH PRIVILEGES; 重载权限
创建magento数据库
mysql> CR 访问magento数据库,确保一切正常
配置Magento:
解压缩magento1.6.2版本至/var/www/smallfive/magento目录
解压命令:
EATE DATABASE magento;
mysql> GRANT ALL PRIVILEGES ON magento.* TO 'root'@'localhost' IDENTIFIED BY 'newpassword';
tar zxvf magento1.6.2.tar.gz
此时访问http://localhost/magento,可根据magento的设置进行配置
注意如下问题:
1、确保当前用户拥有对/var/www/smallfive/magento可读可写权限
2、还需安装mcrypt库,安装这个库比较繁琐,mcrypt依赖于Libmcrypt库和mhash库,我们需要下载Libmcrypt库和mhash库安装它们,然后再编译Mcrypt。
在编译之前,先做好如下准备工作:
a、安装phpize:yum -y install php-devel
b、安装C++脚本编译模块:
yum -y install gcc gcc-g++
yum -y install gcc gcc-c++
安装mcrypt库过程,如下:
a、下载libmcrypt和mhash库
Libmcrypt:http://sourceforge.net/project/showfiles.php?group_id=87941&package_id=91774&release_id=487459
mhash:http://sourceforge.net/project/showfiles.php?group_id=4286&package_id=4300&release_id=645636
b、将上述两个下载后,分别解压,并执行如下命令编译:
./configure
make && make install
c、下载php对应的源代码,解压,
进入php源代码的 /ext/mcrypt目录
执行phpize命令
./configure –with-php-config=/usr/bin/php-config
make && make install
d、在php.ini文件中增加如下内容:
extension=/usr/lib/php/modules/mcrypt.so
mcrypt.so文件路径在php-config文件中可以找到
e、service httpd restart
end!
参考文章:
http://www.eexu.com/article.asp?id=1730
http://www.ruiwant.com/centos-6-0%E4%B8%8Bmagento%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE%E6%80%BB%E7%BB%93.html
http://zixun.www.net.cn/qita/2344.html
http://os.qudong.com/Linux/2010/0210/64441.html
posted @
2012-04-04 17:09 The Matrix 阅读(3126) |
评论 (1) |
编辑 收藏有时在vmware里面安装的系统或应用有License时间的限制,可以通过修改虚拟机时间的方法来防止过期,此时需在.vmx文件中加入下面的内容:
tools.syncTime = "FALSE"time.synchronize.continue = "FALSE"time.synchronize.restore = "FALSE"time.synchronize.resume.disk = "FALSE"time.synchronize.shrink = "FALSE"rtc.startTime = 1183431600 #这是用来指定虚拟机启动后的时间。数字是自1970年1月1日零时零分零秒以来的秒数,可以通过如下网址将某个时间转换为该数字(Unix时间戳):http://www.onlineconversion.com/unix_time.htm
注意:同时还需在虚拟机操作系统的服务中,停用“VMware Tools Service”的服务。
在Windows Server 2003中操作系统自身也有时间同步功能,需在时间设定中停用,同时停用“Windows Timer”服务。
posted @
2012-03-02 10:51 The Matrix 阅读(8670) |
评论 (0) |
编辑 收藏
主要参见:
http://blog.chenlb.com/2011/03/install-apache-php-wordpress-windows.html
在安装好apache http server后,如果端口不正确,则修改"apache安装目录/conf/httpd.conf"文件中的如下信息:
#ServerName localhost:80 -> ServerName localhost:8060
Apache HTTP Server版本:2.2
PHP版本:5.3.8
WordPress版本:3.2.1
posted @
2011-11-27 21:28 The Matrix 阅读(651) |
评论 (0) |
编辑 收藏1. 打开工具Oracle SQL Plus 以dba身份登录sys用户
sqlplus /nolog
conn sys@url as sysdba
2. 创建用户并指定表空间
使用客户端工具或者Web管理控制台创建表空间以及用户
给用户赋予connect、resource、dba权限
grant connect,resource,dba to username;
注意:给oracle用户分配connect、resource角色时,此时connect 角色中有一个 UNLIMITED TABLESPACE 权限,也就是username这个用户可以在其他表空间里随意建表。
alter user username quota 0 on users; --alter username quota 0 on Users; // 还不是很清楚具体含义???
alter user username quota unlimited on tablespacename; --赋予username用户在tablespacename表空间任意建表的权限;
3. 使用imp工具导入dmp数据文件
imp username/password@url file=c:\db.dmp fromuser=username1 touser=username log=c:\log.txt
-------------------------------------------------------------------------------------------------------------
其它命令:
select * from dba_users; --查询用户
select * from dba_tables; --查询表
select * from dba_views; --查询视图
select * from dba_tablespaces; --查询表空间
oracle 10g,查询表空间使用率
Select * from sys.DBA_TABLESPACE_USAGE_METRICS;
-------------------------------------------------------------------------------------------------------------
drop user username cascade;
ORA-01940:无法删除当前已连接的用户
select username, sid, serial# from v$session where username='username';
alter system kill session'sid,serial#'
posted @
2011-05-31 16:43 The Matrix 阅读(3894) |
评论 (0) |
编辑 收藏环境:Windows7 professional
1、下载redmine1.1.3.zip、ruby1.8.7、rubygems-1.3.7.zip、mysql 5.0
2、安装MySQL5.0,cmd窗口下使用mysql -u root -p 登录MySQL数据库,执行如下语句创建redmine数据库及用户:
create database redmine character set utf8;
create user 'redmine'@'localhost' identified by 'my_password';
grant all privileges on redmine.* to 'redmine'@'localhost';
注:
使用MySQL5.5在后面进行初始数据时Ruby会提示连接有问题
在安装完MySQL后,先不要进行配置,至“MySQL安装路径\bin”目录下,修改MySQLInstanceConfig.exe为“以管理员成分执行此程序”,“以兼容模式运行该程序”
进行数据库配置时,选择字符集为utf8
3、运行ruby1.8.7安装包,解压至d:/ruby187,将d:/ruby187/bin添加至path环境变量中
安装后可执行 ruby -v查看ruby版本以检验安装是否正确
4、解压rubygems-1.3.7.zip至d:/rubygems-1.3.7
进入d:/rubygems-1.3.7目录,执行ruby setup.rb
注:Redmine需要rubygems 1.3.1 - 1.5.x,肯定不能用1.8.2版本
5、执行gem install rails -v=2.3.5 远程安装rails2.3.5版本
gem install mysql
gem install -v=0.4.2 i18n
6、解压缩redmine1.1.3至d:/redmine1.1.3目录
进入d:/redmine-1.1.3/config目录,修改database.yml.example文件为database.yml,并修改该文件中的production数据库连接配置为如下:
production:
adapter: mysql
database: redmine
host: localhost
username: redmine
password: my_password
encoding: utf8
进入d:/redmine1.1.3目录,执行
rake config/initializers/session_store.rb
rake db:migrate RAILS_ENV="production"
7、加载默认配置数据
rake redmine:load_default_data RAILS_ENV="production"
默认语言选择"zh"
8、运行
ruby script/server webrick -e production
9、访问:http://localhost:3000
使用admin/admin进行登入
进入设置,把默认语言设为“简体中文”,然后设置当前用户的默认语言设为“简体中文”,这样就是中文界面了
-----------------------------------------
继续,将redmine设置为windows 7的服务
1、首先需要配置mysql为windows 7的服务
2、Ruby提供一个安装Ruby程序为服务的包:mongrel_service。安装其实很简单,运行:gem install mongrel_service
3、安装redmine为服务,执行mongrel_rails service::install -N RedMine -c C:\redmine-1.1.3 -p 3000 –e production
注意:此处打开cmd窗口时,需要输入cmd后,不是直接按Enter,而是按 Ctrl+Shift+Enter打开Cmd窗口,此时以管理员身份打开,否则安装为服务时会提示拒绝访问。
4、安装服务后,需检查服务-e后的参数是不是production,如果不是production而是development,则在注册表中把参数手动改为production。修改方法是:打开“注册表编辑器”,展开分支“HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services”,选择redmine服务,找到ImagePath项,修改保存后在服务列表中启动服务,并把服务设置自动启动。
OK!
posted @
2011-05-20 10:25 The Matrix 阅读(2788) |
评论 (0) |
编辑 收藏
参见如下链接:
posted @
2011-03-25 21:33 The Matrix 阅读(1203) |
评论 (0) |
编辑 收藏
没仔细研究,先把项目地址记下:
http://arshaw.com/fullcalendar/
这个博客中另有几个推荐的类似项目:
http://hi.baidu.com/freezesoul/blog/item/15c5d73fe4a315c17d1e71ec.html
posted @
2010-11-09 20:37 The Matrix 阅读(1280) |
评论 (0) |
编辑 收藏这几天在看郎咸平的《谁在谋杀中国经济》,这本书我基本看过一遍了,认为全书的重点在于中华文化的四大茫然,整本书都是围绕这四大茫然展开论述,中华文化的四大茫然如下:
茫然之一:就知道赚钱
茫然之二:不了解世界
茫然之三:不了解别人为什么那么看你
茫然之四:不了解自己的缺点
大家有时间可以看看这本书,我觉得写的不错,至少我自己看完深有感触,我觉得完全可以将这几点套用到我们生活的很多方面,比如对于我们搞IT的技术人员来说,我认为现在很多人也存在四大茫然:
茫然之一:只知道完成任务。也许是我年龄大了点,但我觉得现在很多小朋友,尤其是85年以后出生的,工作的时候只是在完成任务,事情做完了,有时也不测试,或者就是匆匆测试,匆匆结束,并没有好好的想为什么这件事老大要让我这样做,这样做有什么好处,会不会有缺点,我是不是有更好的方法。当你不去想的时候,意味着你少了很多提高的机会。
茫然之二:不追究为什么。很多人做事情就象第一条说的那样,只是完成任务,并不去想其中的原理是什么。面试过很多人,对于目前工作两三年的大部分人来说(当然我面试的不是好的学校毕业的,基本学校为中等偏下点),一旦涉及到Spring、Hibernate、Struts等框架深入点东西的时候,大都回答不上来,只是对框架能熟练应用而已。这样够么?计算机的很多知识,当你熟悉了其运作原理,框架对于你来说,只是手到擒来,看看学学就会用了。我问过好几个同事,平时晚上回去都干嘛,很多人都回答我晚上回去看看电视,稍微看看书就睡觉了。我有点惊讶,我想如果你想成为一个技术高手,一个能拿高薪的程序员,你又没有天份,又不付出超过常人的努力,凭什么你比别人强呢?
茫然之三:不善于总结。很多人(又是很多人)过着做一天和尚撞一天钟的日子,日子一天一天过去,基本不去总结,只是过了好长一段时间会发觉,原来最近我啥也没有进步,啥也没学到,还是老样子。知识在于积累,你只有不断总结,知识才能更好的积累,才能更好的为你服务。
茫然之四:没有明确的目标。一个人没有目标就决定了他不会有长足的进步。你都没有想过自己要成为一个架构师,一个项目经理,一个部门经理,一个技术总监,都没有想过要成为这样的人需要具备什么样的条件,你怎么可能知道自己欠缺什么?需要补充什么呢?长远目标要明确,然后根据长远目标进行分析,我要达到这样的目标,还有什么欠缺,据此制定短期目标,短期目标一定要可实现可操作。这样随着你目标的一步一步实现,你各方面的能力也随之提高了。
写了几点,也作为对自己的鞭策。
posted @
2010-04-14 22:05 The Matrix 阅读(6158) |
评论 (10) |
编辑 收藏2010年已经过去一个月了,赶在农历春节前列一下今年的读书清单,不能总把精力放在工作中了,也需要补充点新知识了,否则没有新东西能贡献出来了。
1、《OSGI原理与最佳实践》,结合这本书并研究SpringDM,做一些实例。
2、《SQL语言艺术》
3、《Oracle9i&10g编程艺术》
4、《架构之美》
5、《UML和模式应用》
6、《UML彩色建模》
7、《领域驱动设计与模式实战》
8、《敏捷软件开发 原则、模式与实践》
9、《软件开发的边界》
10、《软件随想录》
11、《走出软件作坊》
就这么多了,9、10、11去年都看过一遍了,但好多地方粗粗过了一下,还要仔细阅读。
另外也对自己提个要求,看书要做读书笔记。
2010年-我的读书年!
posted @
2010-02-03 23:27 The Matrix 阅读(2768) |
评论 (6) |
编辑 收藏摘自《软件随想录》
看了软件随想录中下面一段话,觉得非常棒,作为一名软件从业人员,不一定有机会能实现描述中的优秀软件产品,但这样的理念需要贯穿我们每个人的心田,时刻记在心中:
【创造一个有使用价值的软件,你必须时时刻刻都在奋斗,每一次的修补,每一个功能,每一处小小的改进,你都在奋斗,目的只是为了再多创造一点空间,可以再多吸引一个用户加入。没有捷径可走。你需要一点运气,但是这不取决于你是否幸运。你之所以会有好运气,那是因为你寸土必争。
每天你前进一小步,将一件东西做得比昨天好一点点。这样的改进几乎看不出可以让谁获益,几乎没有变化。但是,你前进了一小步。
有无数个要做的这样微小的改进。
为了发现可以改进的地方。你必须有一个思维定势,始终如一的用批判的眼光看世界。随便找一样东西,如果你看不出它的缺点,那么你的思维转型还没有成功。当你成功的时候,你身边亲密的人会被你逼得发疯。你的家人恨不得杀了你。当你步行上班的时候,看到一个司机漫不经心地开车,你几乎用了所有的意志力才勉强忍不住冲上去告诉那个司机,他这样开车差点儿要了旁边坐在轮椅上的那个可怜小孩的命。
当你改正了一个又一个这样的小细节后,当你磨光、定型、擦亮、修饰你的产品的每一个小边角后,就会有神奇的事情发生。厘米变成分米,分米变成米,米变成了千米。你最后拿出来的是一件真正优秀的产品。它第一眼就让人觉得震撼,出类拔萃,工作起来完全符合直觉。就算100万个用户中有一个用户某天突然要用到一个他100万次使用中才会用到一次的罕见功能,他发现了这个功能不仅能用,而且还很没:在你的软件中,即使是看门人的小屋都铺着大理石的地板,配有实心的橡木门和桃花心木的壁板。
就是在这个时候,你意识到这是一个优秀软件。】
posted @
2010-01-05 21:25 The Matrix 阅读(2292) |
评论 (11) |
编辑 收藏http://www.insideria.com/2009/05/flex-4-custom-layouts.html
http://www.insideria.com/2009/10/easy-flex-skinning-with-firewo.html
posted @
2009-11-25 12:25 The Matrix 阅读(589) |
评论 (0) |
编辑 收藏在Flash Builder 4 Beta 2版本中,使用mxml方式实现state的切换有了很大改进,使用起来更方便,具体可参见下文:
http://onflex.org/learn/fx4/index.php?page=States
看完这篇文章后,想到一个问题,如何用编程的方式实现切换呢,找了参考资料,实现了一个例子,代码如下:
开发环境:Flash Builder 4 Beta2
<?xml version="1.0" encoding="utf-8"?>
<s:Application
xmlns:fx="http://ns.adobe.com/mxml/2009"
xmlns:s="library://ns.adobe.com/flex/spark"
creationComplete="creationCompleteHandler(event)">
<fx:Script>
<![CDATA[
import mx.core.UIComponent;
import mx.events.FlexEvent;
import mx.states.SetProperty;
import mx.states.State;
import spark.components.Label;
import spark.components.Panel;
private var stateArray : Array;
private var state1 : State;
private var state2 : State;
protected function creationCompleteHandler(event:FlexEvent):void
{
state1 = new State();
state1.name="state1";
state2 = new State();
state2.name="state2";
var stateArray1:Array = new Array();
var stateArray2:Array = new Array();
state1.overrides = stateArray1;
state2.overrides = stateArray2;
stateArray = new Array();
stateArray.push(state1);
stateArray.push(state2);
this.states = stateArray;
var panel:Panel = new Panel();
group.addElement(panel);
var label:Label = new Label();
panel.addElement(label);
buildStates(stateArray1, stateArray2, panel, label);
this.currentState = "state1";
}
private function buildStates(stateArray1:Array, stateArray2:Array,
compenent1:UIComponent, compenent2:UIComponent) : void{
stateArray1.push(makeSetProp(compenent1, "title", "Panel1"));
stateArray1.push(makeSetProp(compenent2, "text", "One"));
stateArray2.push(makeSetProp(compenent1, "title", "Panel2"));
stateArray2.push(makeSetProp(compenent2, "text", "Two"));
}
private function makeSetProp(target:UIComponent, name:String, value:*):SetProperty{
var sp:SetProperty = new SetProperty();
sp.target = target;
sp.name = name;
sp.value = value;
return sp;
}
]]>
</fx:Script>
<s:VGroup autoLayout="true" horizontalAlign="center">
<s:HGroup horizontalCenter="0">
<s:Button label="One"
click="this.currentState='state1'"/>
<s:Button label="Two"
click="this.currentState='state2'"/>
</s:HGroup>
<s:HGroup id="group" horizontalCenter="0">
</s:HGroup>
</s:VGroup>
</s:Application>
posted @
2009-11-11 21:59 The Matrix 阅读(1625) |
评论 (0) |
编辑 收藏 这是前几天在别人的BLog上看到的一幅图,觉得不错,基本涵盖了IT人员需要掌握的基础知识这块,从这幅图中可以看出语言并不重要,关键是要搞明白整个环节,这样遇到任何问题就能有目的、有方法的学习了。

posted @
2009-10-22 08:32 The Matrix 阅读(966) |
评论 (0) |
编辑 收藏1、下载Ruby并安装,下载地址:http://rubyforge.org/frs/?group_id=167
下载了1.8.6-27 Release Candidate 2(ruby186-27_rc2.exe)版本
2、在windows的命令行下,输入 ruby –v,检查ruby是否正确安装,应该出现如下信息:
ruby 1.8.6 (2008-08-11 patchlevel 287) [i386-mswin32]
3、安装rails,执行gem install rails命令,安装成功后,执行rails -v检查。
我安装了Rails2.3.2版本。使用gem install -version rails可以指定安装的rails版本,具体如何使用gem,可以用gem help install查看帮助。
参考:Ruby On Rails(ROR)安装(http://enjoylog.cn/?p=8)
装好了便到Ruby On Rails的官方网站(http://rubyonrails.org/),找到了
Getting Started with Rails(http://guides.rubyonrails.org/getting_started.html)
开始一步一步follow up。
RubyOnRails的中文站上的翻译文档没有完全跟进,还是看英文的吧。
我使用的是MySQL的数据库,操作系统:Vista。
到创建POSTS应用的时候遇到了问题,创建数据后数据库中有数据,但是到Listing posts界面无法查看,总是报错。
网上Google了一下,果然有人遇到相同的问题,参照了如下解决方案,到
http://instantrails.rubyforge.org/svn/trunk/InstantRails-win/InstantRails/mysql/bin/ 上下载了libmySQL.dll文件放到RUBY_HOME/bin/目录下,问题解决。
参考:升级2.2后mysql驱动的问题(http://www.javaeye.com/topic/283871?page=1)
感叹一下,当Listing Posts这个CRUD小应用跑起来后,觉得Ruby On Rails的开发是比Java开发要快一些,看了一下它生成的代码,貌似也不多。
今天晚了,明天继续。
posted @
2009-07-19 00:42 The Matrix 阅读(1798) |
评论 (0) |
编辑 收藏 最近在做一个很小的项目的功能改进,小小的项目中原来连接的是MySQL数据库,现在需要新连接一个数据库(Oracle),仅仅从一张表查询数据即可,没有添加、修改、删除等等功能。本来这个小小的项目中用的是Hibernate,现在又要增加一个数据库连接,觉得配置起来有点麻烦,忽然想起来,我干吗还要用Hibernate呢,直接用JDBC不也挺好使么,想了便做,果然写起JDBC来,很是快捷,一会就搞好了。
做好了以后,忽然觉得有点迷茫,感觉不用Hibernate不也挺好的么,咱为什么现在开口闭口都是Hibernate呢,于是便有了今天的题目。
很久以前没有Hibernate的时候:
第一阶段:我们写程序都是直接用JDBC,甚至在JSP页面中直接去createConnection,然后执行查询,输出到页面。
第二阶段:后来觉得每次都是创建一个连接,好像效率不高,于是看了别人的介绍,要用数据库连接池,好的,那便用数据库连接池吧,每次都从pool中获得一个Connection,然后查询数据。
第三阶段:用了连接池,还是效率不高,那怎么办呢?用缓存吧,自己实现缓存?可以,也可以用开源的缓存框架。
第四阶段:到了OO大流行的时代了,一切都要OO,恰逢Hibernate降临人世,于是一切都用Hibernate来实现了,其实同期还是有不少其它ORMAP框架的,比如(TOPLINK、JDO、IBatis等,IBatis国内用的还比较多,另外两个好像用的比较少)。
第五阶段:忽然EJB大流行,事务的概念被广为传播(并不是原来没有事务的概念,只是实现起来比较麻烦),借助EJB的广为传播,Spring+Hibernate的组合也慢慢占据了大半市场。此时事务用Spring AOP的声明式事务来解决,缓存可以用开源的缓存框架(已经和Hibernate无缝集成了),数据库连接池也是通过配置的方式在SpringContext.xml文件中配置,貌似一切都很完美。
真的到了第五阶段,一切是不是真的完美了呢,如果一个很小的应用,需要从好几个数据库查询数据,但是每个数据库仅需要查询那么一两张表的数据,偶尔添加、删除几条数据,数据量也不大,此时我们是不是还用第一阶段的方式会更好呢,好像有时配置多数据源也不是那么方便的事情。或者使用Spring中的JDBCTemplate,貌似也不错。
再往后看,难道Spring+Hibernate的组合就天下无敌了么?难道就没有新的框架了么?前段时间,JavaEye上关于充血模型、贫血模型的讨论吸引了多少眼球,以后是不是会有这么一个框架用于实现充血模型呢?
说了这么多,最终只是想说明白这么一句:用恰当的技术做恰当的事情,这真是一个艰难的选择……,至于未来,更是迷茫,因为我们只是跟随者,而不是领导者。
posted @
2009-07-06 22:06 The Matrix|
编辑 收藏前两天出差在外,利用空余时间将《深入浅出EXT JS》这本书的前五章翻了一遍,后面的章节粗粗浏览了一下,觉得这本书写的不错,写下自己的一点感悟:
1、适合的读者
a、是一名Java开发程序员,做过WEB开发
b、对Ajax开发的基础知识有所了解
2、书评:
这本书我觉得应该改成这个名字:《EXT JS CookBook》,可能使得书的内容和名称更贴切,呵呵。
书中对Ext JS的基础类、Grid、Form、Tree、布局管理器、数据获取等各方面都做了详细的描述,基本上开发中需要用到的知识点,在书中都会提到,而且书中的很多例子和实际工作还是非常贴切的,对于工作中需要用到EXT JS或者需要学习EXT JS的程序员来说还是会很有帮助的。
最后提点缺点,这本书中对EXT JS的知识点都做了比较详细的描述,但是缺乏对EXT JS的框架的深入分析。
posted @
2009-04-19 13:36 The Matrix 阅读(2402) |
评论 (2) |
编辑 收藏前两天在InfoQ上看到一篇文章:利用Clear Toolkit连接Flex与Java开发,今天下载了说明文档粗略了翻了一遍,Clear Toolkit包含五个部分,分别是:
- Clear Data Builder,这是个Eclipse插件,可以根据SQL语句或Java数据传输对象为BlazeDS或LCDS自动生成CRUD应用。
- DTO2Fx,该插件会根据Java类型自动生成对应的ActionScript类。
- Log4Fx是个构建于Flex logging API之上的Eclipse插件,它会自动化日志处理并且更加灵活,也更加友好。
- Fx2Ant插件会为Flex Builder项目生成优化的Ant构建脚本。
- clear.swc是个增强的Flex组件库。
暂时用不到这个工具,记录留待备查。
posted @
2009-04-12 20:57 The Matrix 阅读(671) |
评论 (0) |
编辑 收藏这篇Blog是原来写在别的地方的,今天将其转到BlogJava上来。
-------------------------------------------------------------------------------
今天仔仔细细的看了一下Hibernate的缓存,并做了实例实践了一把。google一下,网上的教程、文章很多。
自己小结一下:
Hibernate的缓存分为:
- 一级缓存:在Session级别的,在Session关闭的时候,一级缓存就失效了。
- 二级缓存:在SessionFactory级别的,它可以使用不同的缓存实现,如EhCache、JBossCache、OsCache等。
缓存的注释写法如下,加在Entity的java类上:
- @Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
缓存的方式有四种,分别为:
- CacheConcurrencyStrategy.NONE
- CacheConcurrencyStrategy.READ_ONLY,只读模式,在此模式下,如果对数据进行更新操作,会有异常;
- CacheConcurrencyStrategy.READ_WRITE,读写模式在更新缓存的时候会把缓存里面的数据换成一个锁,其它事务如果去取相应的缓存数据,发现被锁了,直接就去数据库查询;
- CacheConcurrencyStrategy.NONSTRICT_READ_WRITE,不严格的读写模式则不会的缓存数据加锁;
- CacheConcurrencyStrategy.TRANSACTIONAL,事务模式指缓存支持事务,当事务回滚时,缓存也能回滚,只支持JTA环境。
另外还有如下注意事项:
1、查询缓存需要在Query的相应方法执行前加上这么一句:
query.setCacheable(true);
在使用Hibernate时,获得的query有setCacheable方法,可以设置使用缓存,但当使用JPA时,javax.persistence.Query并没有setCacheable方法,此时如果JPA的实现是Hibernate时,可以将其进行如下转化,再调用setCacheable方法(如果JPA的实现是其它ORMAP框架,就不知道怎么做了)。
if (query instanceof org.hibernate.ejb.QueryImpl) {
((org.hibernate.ejb.QueryImpl) query).getHibernateQuery().setCacheable(true);
}
2、还有就是查询缓存的查询执行后,会将查询结果放入二级缓存中,但是放入的形式是以ID为Key,实例作为一个Value。
3、hibernate的配置文件中需加入如下信息:
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.EhCacheProvider" />
<property name="hibernate.cache.use_second_level_cache" value="true" />
<property name="hibernate.cache.use_query_cache" value="true" />
posted @
2009-04-07 22:54 The Matrix 阅读(10133) |
评论 (3) |
编辑 收藏
摘要: 前段时间对Spring的事务配置做了比较深入的研究,在此之间对Spring的事务配置虽说也配置过,但是一直没有一个清楚的认识。通过这次的学习发觉Spring的事务配置只要把思路理清,还是比较好掌握的。
总结如下:
Spring配置文件中关于事务配置总是由三个组成部分,分别是Data...
阅读全文
posted @
2009-04-05 16:38 The Matrix 阅读(332549) |
评论 (85) |
编辑 收藏今天在Javaeye的新闻频道看到一个界面原型绘制工具,叫做“wireframesketcher”,下载试了试,感觉有如下几个好处:
1、使用方便,可以很容易的做tree和table,比visio中的tree和table好用
2、集成在eclipse中,对于开发人员来说用起来更直接
3、其界面原型文件为xml格式,可以使用比较工具比较
唯一的缺点:
不是免费开源的工具,但是现在可以申请免费的license
随便画了一个图,如下:
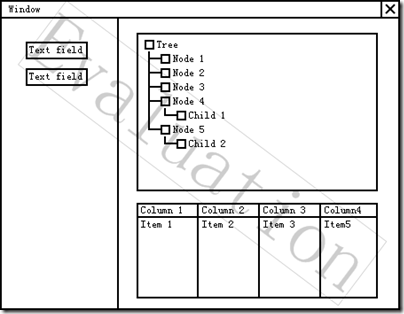
感兴趣的兄弟姐妹们可以到如下地址看看:
http://wireframesketcher.com/index.html
posted @
2009-03-28 21:55 The Matrix 阅读(4604) |
评论 (1) |
编辑 收藏由于要写一个Spring的培训教材,要做Spring的事务样例,于是开始写样例,写好了一测,控制台有SQL输出,数据库却查询不到数据,查亚查亚,花了一个多小时,原来是获取的Service不是经过代理的Service,自然事务不起作用,数据库里就没有数据了,鄙视一下自己。
配置文件样例如下(已经修改了dao和service的命名,减少了写错的可能性,以后命名问题一定要注意):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<context:annotation-config />
<context:component-scan base-package="com.*" />
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="configLocation" value="classpath:hibernate.cfg.xml" />
<property name="configurationClass" value="org.hibernate.cfg.AnnotationConfiguration" />
</bean>
<!-- 定义事务管理器(声明式的事务) -->
<bean id="transactionManager"
class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<!-- 配置DAO -->
<bean id="generatorDaoTarget" class="com.*.spring.dao.GeneratorDaoImpl">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<bean id="generatorDao"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<!-- 配置事务管理器 -->
<property name="transactionManager"><ref bean="transactionManager" /></property>
<property name="target"><ref bean="generatorDaoTarget" /></property>
<property name="proxyInterfaces"><value>com.*.spring.dao.GeneratorDao</value></property>
<!-- 配置事务属性 -->
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
<bean id="plantDaoTarget" class="com.*.spring.dao.PlantDaoImpl">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<bean id="plantDao"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<!-- 配置事务管理器 -->
<property name="transactionManager"><ref bean="transactionManager" /></property>
<property name="target"><ref bean="plantDaoTarget" /></property>
<property name="proxyInterfaces"><value>com.*.spring.dao.PlantDao</value></property>
<!-- 配置事务属性 -->
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
<!-- 配置Service -->
<bean id="plantGeneratorServiceTarget"
class="com.*.spring.service.PlantGeneratorServiceImpl">
<property name="plantDao">
<ref bean="plantDao" />
</property>
<property name="generatorDao">
<ref bean="generatorDao" />
</property>
</bean>
<bean id="plantGeneratorService"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<!-- 配置事务管理器 -->
<property name="transactionManager"><ref bean="transactionManager" /></property>
<property name="target"><ref bean="plantGeneratorServiceTarget" /></property>
<property name="proxyInterfaces"><value>com.*.spring.service.PlantGeneratorService</value></property>
<!-- 配置事务属性 -->
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
</beans>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 各属性的配置-->
<!-- 为true表示将Hibernate发送给数据库的sql显示出来 -->
<property name="hibernate.show_sql">true</property>
<property name="hibernate.hbm2ddl.auto">none</property>
<!-- SQL方言,这边设定的是MySQL -->
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<!--连接数据库的Driver-->
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<!--数据库连接url-->
<property name="connection.url">jdbc:mysql://localhost:3306/test</property>
<!--用户名-->
<property name="connection.username">root</property>
<!--密码-->
<property name="connection.password">123456</property>
<!-- 映射文件 -->
<mapping class="com.*.spring.domain.Generator" />
<mapping class="com.*.spring.domain.Plant" />
</session-factory>
</hibernate-configuration>
public interface GeneratorDao {
/**
* 获取所有机组数据
* @return
*/
public List<Generator> listGenerators();
/**
* 保存机组数据
* @param generator 机组数据
*/
public void save(Generator generator);
}
public class GeneratorDaoImpl extends HibernateDaoSupport implements GeneratorDao {
@SuppressWarnings("unchecked")
public List<Generator> listGenerators() {
return this.getSession().createQuery("from Generator").list();
}
public void save(Generator generator) {
this.getSession().save(generator);
}
}
posted @
2009-03-16 22:24 The Matrix 阅读(1549) |
评论 (0) |
编辑 收藏 给自己做的这个程序起了个名字叫EasyWork,代码可以从Google Code上下载,具体地址如下:
http://easywork.googlecode.com/svn/trunk/
由于时间关系,这个程序还存在不少问题,所以只能供大家参考,有问题不要骂我就行了:)
简要使用说明:
1、开发环境+运行环境:MyEclipse6.0,JDK1.5,Tomcat6.0.14,MySQL5.0
2、准备好上述环境后,使用下载代码sql目录中的easywork_init.sql脚本创建数据库表和初始数据。
3、将项目导入Eclipse后,运行Tomcat(此过程就不详细描述了)。
4、使用http://localhost/easywork/system/login.jsp访问登录页面,目前还没有做index.html,默认用户名/密码:admin/1。
存在问题如下:
1、任务管理功能还没有完全完成,日志记录还没有做。
2、超时或者没有登录访问页面时,只是报不能访问的异常,没有转入登录页面。
3、对资源类型(菜单、URL、字段、操作)的访问限制还没有做。
4、很多界面的输入信息校验没有做。
5、基本没有美工。
6、总而言之,目前这个项目中的代码只能做Struts2 + ExtJS如何使用的借鉴:)
posted @
2009-03-01 11:03 The Matrix 阅读(6283) |
评论 (28) |
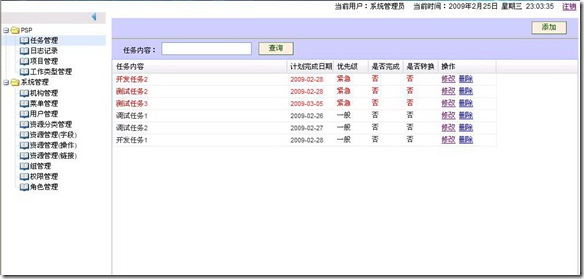
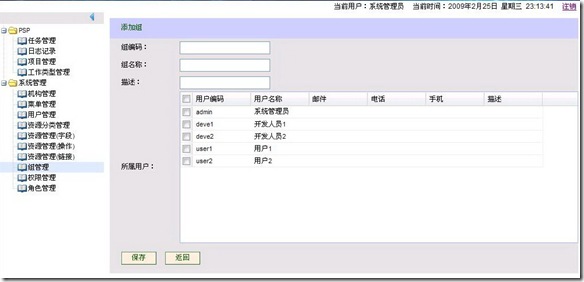
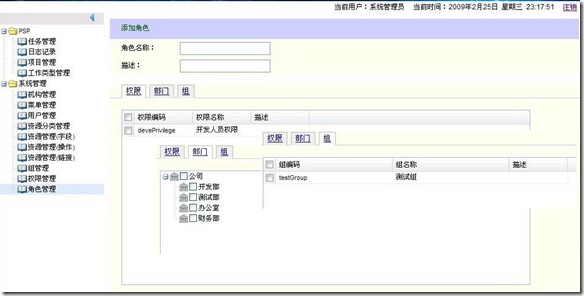
编辑 收藏 很近没有更新BLog了,这一阵子忙着学习Struts2和ExtJS,使用这两者做了一个小程序,使用RBAC实现了基本的权限管理功能,还做了一个任务管理和日志记录,任务管理用于记录当前需要处理的事情,日志记录用于记录每天的工作情况。
用下来Struts2和ExtJS还是挺好用的。先贴几张图,后续再把学习过程中遇到的问题整理出来。
任务管理
添加组
添加权限

添加角色
posted @
2009-02-26 07:14 The Matrix 阅读(4328) |
评论 (15) |
编辑 收藏 由于前段时间使用JSF做了一个项目,不少使用JSF的兄弟们对JSF评价并不好,因此在学习的过程中一直在想,JSF究竟是不是应该继续学习继续研究使用下去,在看完Seam In Action的第三章后,这个星期又对Struts2简单学习了一下,终于决定结束JSF和JBoss Seam的学习了。
因为从JSF的学习和Struts2的学习对比中明显觉得JSF复杂,对于一个技术力量不是非常强的项目组来说,使用JSF当你遇到一些问题时,绝对是一件痛苦的事情。
从自己的实践中觉得JSF至少有两个致命伤:
1、觉得JSF貌似把简单的事情搞得复杂化了,在传统的MVC框架如Struts中,从request中获取param很容易,也可以将param封装为对象,在JSF中,希望将这一切都模型化,一切都以组件为中心,类似于Swing的架构,但是http的无状态以及web的本质,使得一般JSF只能将组件树存放在服务端,同时又不能象CS程序那样方便的查看组件的状态、属性等信息。对于通常情况来说,JSF将其封装的很好,不用我们开发者操心,但是当遇到一些问题时,对于开发者想去调试查看问题时,问题就显得很复杂了。
2、JSF的自定义组件感觉超复杂,难度应该比当年自定义JSP标签更要高,试想一下,如果哪个组件不合意了,想改一下,还是比较困难的,除非对JSF组件有相当的深入了解。
顺便把项目中遇到的一个RichFaces的缺点列出来:
RichFaces在生成组件的html时,大量使用了Div,曾经有过一个页面有1千多行(在一个table中),页面上还有一个RichFaces的下拉菜单,从而导致菜单响应非常之慢,后来只有将rich:datatable换为普通的html:table,就没有问题了。
再看看Seam In Action中总结的JSF的缺点:
1、在JSF中初次请求的处理流程太过简单,而后续请求则执行了完整的复杂的处理流程。在JSF中假设第一个调用应该是在页面被渲染后执行,但实际中有时我们需要在第一次请求时就执行某些操作。在JSF中缺少象Struts中的Controller。
2、所有的请求都是POST。浏览器处理POST请求是比较草率,当用户执行了一个JSF Action操作后,点击浏览器的刷新按钮时,浏览器会询问用户是否重新提交,这会令用户非常困惑。
3、仅仅拥有简单基础的页面导向机制。
4、过度复杂的生命周期。
JBossSeam宣称对于JSF存在的缺点都提供了解决方法,但是有一种更复杂的感觉。
在Seam中,生成选择的项目时,有EAR和WAR的选项,如果选择了EAR选项,那么Seam会生成四个项目,分别为war、ear、ejb、test四个类型的项目。有一次我将生成的项目从一个目录拷贝到另一个目录,切换了Eclipse的workspace,此时问题来了,ejb项目提示编译错误,提示无法找到某些class,找来找去找来找去......后来将项目关闭了一下,再打开错误提示就没有了。
由这个问题我忽然想到,使用Seam集成JSF、EJB是不是太重量级了,如果采用EJB作为替代普通的POJO,对于一个小型的项目组来说,一般的规模就是三至五个人(我个人的理解),开发人员本来就不多,还要面对Seam划分的四个项目,好像比较繁琐,当然采用war模式另当别论。
相比较而言,这个星期看了一些Struts2的资料,觉得Struts2的架构非常清晰,易于理解。
翻了很早之前的JavaEye上的一个帖子,提到JSF是面向开发工具的,如果能做到象VB那样,就大有前途了,4年过去了,不要提JSF的开发工具了,就是Java各个方面的GUI开发工具,又有哪个能和VB相比呢,看来选择JSF作为一个方向不是一个好选择........还是及早放弃吧,哎...
最后我觉得可以用这么一句话可以形容JSF,看起来很美,用起来不爽。
posted @
2008-12-25 23:35 The Matrix 阅读(2328) |
评论 (6) |
编辑 收藏这个事情去年做过一次,不过没有留下记录,今天又要做一次,记录下来,呵呵
环境:
Spring版本为1.2,Tomcat为5.5.26,JDK为Jdk1.5.0_11。
1、下载Axis1.4,解压后将其jar文件添加到web项目的lib目录中。
2、配置Axis Servlet,在web.xml文件中加入如下信息:
<servlet>
<servlet-name>AxisServlet</servlet-name>
<servlet-class>
org.apache.axis.transport.http.AxisServlet
</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>AxisServlet</servlet-name>
<url-pattern>/servlet/AxisServlet</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>AxisServlet</servlet-name>
<url-pattern>*.jws</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>AxisServlet</servlet-name>
<url-pattern>/services/*</url-pattern>
</servlet-mapping>
3、编写java类,样例如下。
接口:
public interface InterchangeDataService {
public String getMonthInterchange(String marketDate);
}
实现类:
public class InterchangeDataServiceImpl extends ServletEndpointSupport implements InterchangeDataService {
public InterchangeDataServiceImpl() {
}
public String getMonthInterchange(String marketDate) {
return "getMonthInterchange";
}
}
注意实现类需要继承ServletEndpointSupport类,该类是由Spring提供的。
4、配置service-config.wsdd。
<?xml version="1.0" encoding="utf-8"?>
<deployment xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java">
<handler name="LocalResponder" type="java:org.apache.axis.transport.local.LocalResponder"/>
<handler name="URLMapper" type="java:org.apache.axis.handlers.http.URLMapper"/>
<service name="interchangeDataService" provider="java:RPC" style="rpc" use="literal">
<parameter name="wsdlTargetNamespace" value="urn:soap.axisspring"/>
<parameter name="className" value="com.ecgit.eccm.webservice.InterchangeDataServiceImpl"/>
<parameter name="allowedMethods" value="*"/>
</service>
<transport name="http">
<requestFlow>
<handler type="URLMapper"/>
<handler type="java:org.apache.axis.handlers.http.HTTPAuthHandler"/>
</requestFlow>
<parameter name="qs:list" value="org.apache.axis.transport.http.QSListHandler"/>
<parameter name="qs:wsdl" value="org.apache.axis.transport.http.QSWSDLHandler"/>
<parameter name="qs:method" value="org.apache.axis.transport.http.QSMethodHandler"/>
</transport>
<transport name="local">
<responseFlow>
<handler type="LocalResponder"/>
</responseFlow>
</transport>
</deployment>
5、测试web service服务,代码如下。
至项目的WEB-INF目录下,执行如下命令:
Java -Djava.ext.dirs=lib org.apache.axis.wsdl.WSDL2Java http://localhost:8080/axis/services/interchangeDataService?WSDL
会在WEB-INF目录中生成四个JAVA文件,它们分别是:
- InterchangeDataServiceImpl.java 定义了Web服务接口,接口中的方法与InterchangeDataService中的方法一致。
- InterchangeDataServiceImplService.java 定义了用于获取Web服务接口的方法。
- InterchangeDataServiceImplServiceLocator.java 接口InterchangeDataServiceImplService的具体实现。
- InterchangeDataServiceImplSoapBindingStub.java Web服务客户端桩,通过该类与服务器交互。
最后编写一个Main方法,调用如下方法即可进行测试:
InterchangeDataServiceImplServiceLocator serviceLocator = new InterchangeDataServiceImplServiceLocator();
InterchangeDataServiceImpl service = serviceLocator.getinterchangeDataService();
String monthSchedule = service.getMonthInterchange("2008-05-30");
posted @
2008-12-19 17:16 The Matrix 阅读(3413) |
评论 (1) |
编辑 收藏 上次使用Seam自动生成了一个CRUD的例子,后来想还是自己白手起家做一个例子看看,于是开始动手。
首先使用JBossTools工具生成项目,在生成项目的向导中,如果项目类型选择ear,则会生成四个项目,分别对应war、ear、ejb、test,觉得这样太过繁琐,还是选择war类型,又想要不使用tomcat作为运行服务器吧,因为JBoss也不太熟悉。没想到这一试倒试出问题来了,如果完全使用向导生成项目,选择tomcat作为运行服务器,则项目根本无法运行起来,总是提示缺少这个jar,那个jar。好,又换回JBoss,没问题了。仔细看了一下,原来在自动生成项目的WebContent/WEB-INF/lib目录中,只有大概十几个jar,连Hibernate的jar都没有,而在JBoss的Server/default/lib目录下则什么jar都有,怪不得不出错。
第一个教训:还是先使用JBoss作为运行环境,等整个Seam都搞熟了,再配一个Tomcat的运行环境。
继续,将原来项目中的一个通用DAO和一个UserService拷贝过来,代码如下,启动服务器报错。分别为如下错误信息:
第二个错误解决:Caused by: java.lang.IllegalArgumentException: @PersistenceContext may only be used on session bean or message driven bean components: genericDao
既然提示@PersistenceContext只能用在SessionBean中,因为原来的代码是使用的Spring框架,想了好长时间,在WebContent/WEB-INF/component.xml中看到这么一段,那么是不是通过@In来注入entityManager呢,修改@PersistenceContext为@In,编辑器自动提示没有发现名称为em的Component(这点好像不错),于是再修改为@In("entityManager") ,重启服务器,该问题解决。
<persistence:managed-persistence-context name="entityManager" auto-create="true" entity-manager-factory="#{testEntityManagerFactory}"/>
第三个错误解决:Caused by org.jboss.seam.RequiredException with message: "@In attribute requires non-null value: userService.genericDao"
将UserService中的@In修改为@In(create = true, required = true)解决此问题。
解决上述几个问题后,自己的例子终于运行起来了 :-)
下一篇关于Seam In Action中对JSF的介绍及Seam如何增强JSF。
-------------------------------------------------------------------------------------------------
项目生成的代码被分为两个目录,分别为Action和Model目录,检查JBoss中项目部署的目录,发觉Action目录下的代码编译生成的class文件被存放至WEB-INF/dev目录下,Model目录下的代码编译生成的class文件被存放至WEB-INF/classes目录下,google了一下,发现在Seam Reference中提到这是Seam的增量式重部署,支持对JavaBean组件的增量重部署,可以加快编辑/编译/测试的速度。
代码如下:
public interface GenericDao {
public Object get(Class clazz, Serializable id);
public void save(Object object);
public void update(Object object);
public void remove(Class clazz, Serializable id);
public void remove(Object obj);

}
@Name("genericDao")
public class GenericDaoImpl implements GenericDao {
@PersistenceContext ----> @In("entityManager")
private EntityManager em;
public Object get(Class clazz, Serializable id) {
if (id == null) return null;
else return em.find(clazz, id);
}
}
public interface UserService {
public void findAllUsers();
}
@Name("userService")
public class UserServiceImpl implements UserService, SecurityUserService {
@In ----> @In(create = true, required = true)
protected GenericDao genericDao;
private List<User> resultList = null;
public List<User> getResultList() {
if (resultList == null) {
this.findAllUsers();
}
return resultList;
}
public void setResultList(List<User> resultList) {
this.resultList = resultList;
}
public void findAllUsers() {
String hql = "from User order by userCode";
resultList = this.genericDao.query(hql);
}
}
// 实体类
@Entity
@Table(name = "USER")
public class User implements IUser, Serializable {
// 用户编码
@Id
private String userCode;
// 用户姓名
private String userName;
}
<!DOCTYPE composition PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<ui:composition xmlns="http://www.w3.org/1999/xhtml"
xmlns:s="http://jboss.com/products/seam/taglib"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:rich="http://richfaces.org/rich"
template="layout/template.xhtml">
<ui:define name="body">
<rich:panel>
<f:facet name="header">User Search Results</f:facet>
<rich:dataTable id="userServiceTable"
var="user"
value="#{userService.resultList}">
<h:column>
<f:facet name="header">
<h:outputText value="UserCode"/>
</f:facet>
<h:outputText value="#{user.userCode}"/>
</h:column>
<h:column>
<f:facet name="header">
<h:outputText value="UserName"/>
</f:facet>
<h:outputText value="#{user.userName}"/>
</h:column>
</rich:dataTable>
</rich:panel>
</ui:define>
</ui:composition>
通过这个实践,小结一下:
1、发觉Seam确实简化了JSF开发,但由于它涉及的新东西相对较多,与传统的SSH走的路线不太一致,还是觉得其学习曲线比较陡峭,需要对Seam熟练掌握后(包括开发环境的搭建等)才能真正提高开发效率。
2、Seam提供了IOC的功能,有时需要跳出Spring,从一个新的角度去审视Seam。
posted @
2008-12-18 23:46 The Matrix 阅读(2163) |
评论 (0) |
编辑 收藏 这个星期的后半周主要搞了kettle的试验,做了两个例子出来,在后续工作中这两个例子应该也能派上用场,本来以为kettle的文档不多,后来单独下载了kettle的doc压缩包,发觉里面的内容还是不少的,真要将kettle搞熟的话,这些文档还是需要仔细研读一番的。另外kettle doc解压后文档目录挺奇怪的,都是数字命名的目录名,不知有啥具体含义。
下周的学习重点还是要转回到JBoss Seam中了 :-)
posted @
2008-12-14 22:13 The Matrix 阅读(1276) |
评论 (3) |
编辑 收藏需求:
kettletest1数据库中有table_source数据表,结构如下:
- Id 主键
- t_id 数据时间
- part_id 实例ID
- yg 数据字段1
- wg 数据字段2
该表中的数据对于不同的实例ID,一分钟一条数据,t_id字段表示数据的时间,精确到分钟。
kettletest2数据库中有table_target数据表,结构如下:
- Id 主键
- marketdate 数据日期,格式为 yyyy-MM-dd
- pointtime 时间,格式为 HH:mm
- pointnumber 时间的数字表示,00:01表示为1,00:00表示为1440
- plantcode 实例Code
- yg 数据字段1
- wg 数据字段2
需定期将table_source表中的数据获取至table_target表中,并进行如下处理:
1、将t_id数据时间字段拆分为三个字段,分别为marketdate、pointtime、pointnumber。
a、marketdate取t_id的日期部分。
b、pointtime取t_id的时间部分。
c、pointnumber为时间的数字表示,等于hour*60+minute。
d、但当t_id的时间为某日的00:00时,需将其转化为24:00,并且marketdate需取日期的前一天。如t_id为2008-12-04 00:00,则marketdate为2008-12-03,pointtime为24:00,pointnumber为1440。
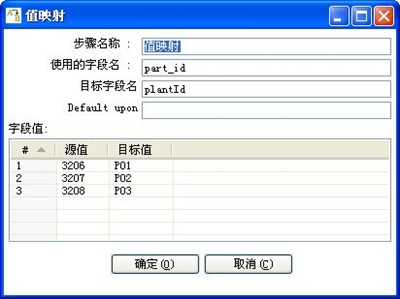
2、将part_id字段映射为plantcode字段,并根据如下规则进行转换:
part_id plantcode
3206 P01
3207 P02
3208 P03
测试中使用的数据库均为mysql数据库。
实战:
整个转换工作共分为三个步骤,如下图:
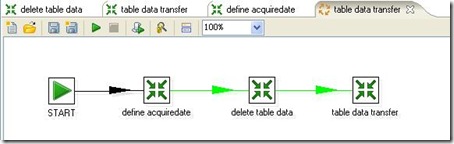
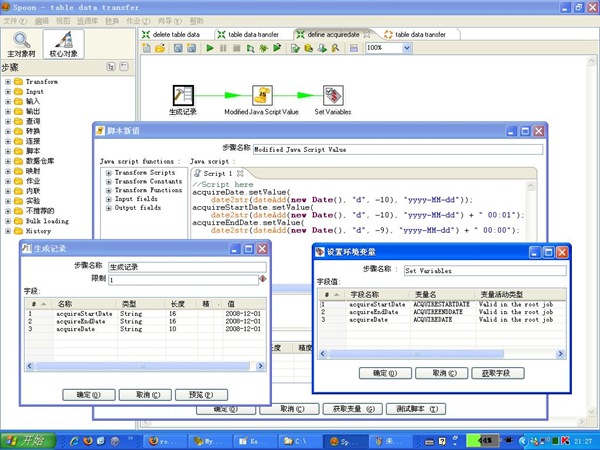
1、定义需获取的数据的日期
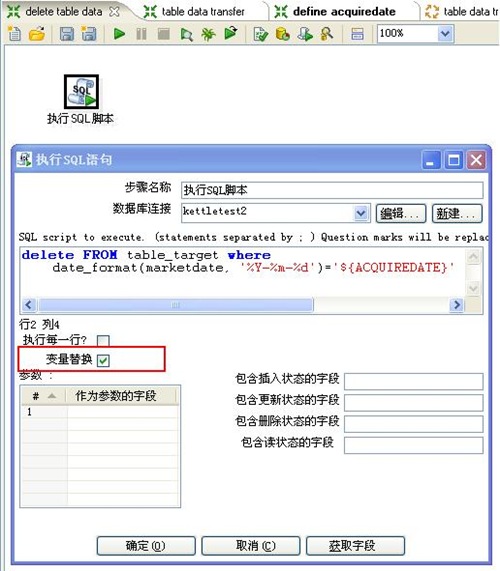
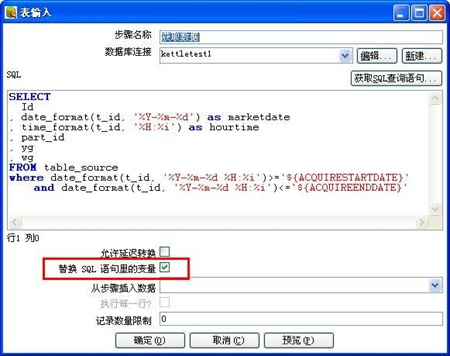
2、删除table_target表中已有数据,注意一定要将“执行SQl语句”面板中的“变量替换”要选上,否则SQL语句中的变量不会被替换,我刚开始没注意到这个地方,找问题找了半天。
3、获取table_source中的数据,并将其插入table_target表
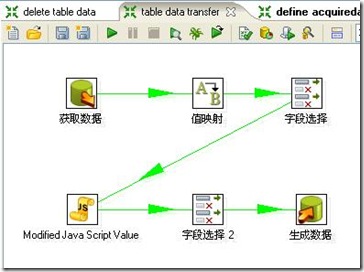
3-1、获取table_source表的数据
3-2、值映射
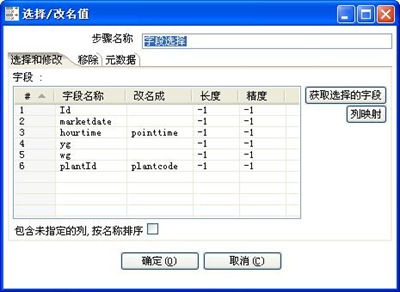
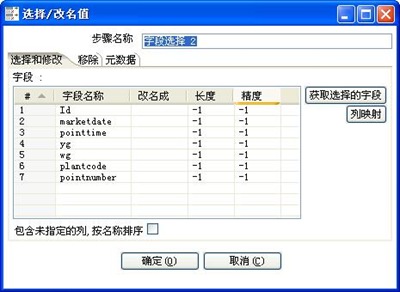
3-3、字段选择
3-4、对t_id字段进行处理,增加了pointnumber字段。在这一步骤中发现kettle的一个bug,就是不能在JavaScript中使用str2date函数,错误的具体信息参见:http://jira.pentaho.com/browse/PDI-1827。这个问题也折腾了好长时间,刚开始怎么也想不通这个函数使用时怎么会报错呢,后来只好从字符串中截取年、月、日信息。
该步骤中还存在另外一个使人困惑的问题,就是点击“测试脚本”按钮,会报错,但是执行job和transformation时则不会报错。
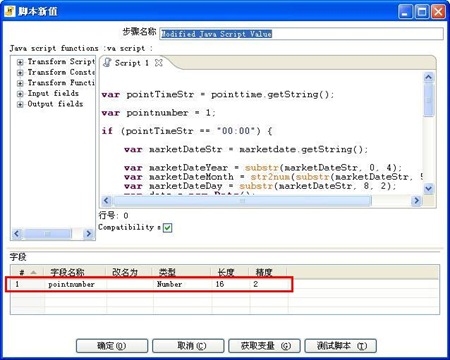
3-5、增加pointnumber字段至输出结果中
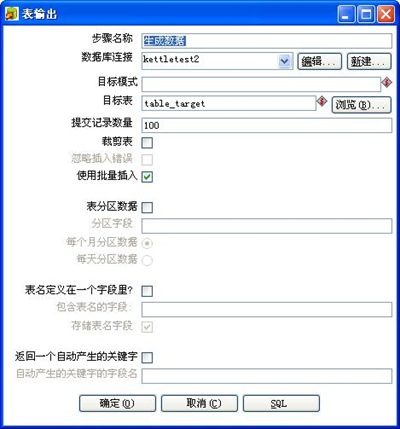
3-6、插入数据至table_target表
3-4步骤中的JavaScript代码如下:
var pointTimeStr = pointtime.getString();
var pointnumber = 1;
if (pointTimeStr == "00:00") {
var marketDateStr = marketdate.getString();
var marketDateYear = substr(marketDateStr, 0, 4);
var marketDateMonth = str2num(substr(marketDateStr, 5, 2))-1;
var marketDateDay = substr(marketDateStr, 8, 2);
var date = new Date();
date.setYear(marketDateYear);
date.setMonth(marketDateMonth);
date.setDate(marketDateDay);
var temp1 = dateAdd(date, "d", -1);
marketdate.setValue(date2str(temp1, "yyyy-MM-dd"));
pointtime.setValue("24:00");
pointnumber = 1440;
} else {
var hourStr = pointTimeStr.substr(0, 2);
var hour = str2num(hourStr);
var minuteStr = pointTimeStr.substr(3, 5);
var minute = str2num(minuteStr);
pointnumber = hour * 60 + minute;
}
至此,整个转换工作完成,小结一下:
如果对kettle等etl工具比较熟悉的话,使用etl工具进行数据转换、抽取等事情还是比较方便的,比起写程序还是有优势的。但是这个转换过程中遇到的kettle的两个bug比较让人头疼,觉得kettle好像还不是很稳定。
posted @
2008-12-14 21:55 The Matrix 阅读(34327) |
评论 (5) |
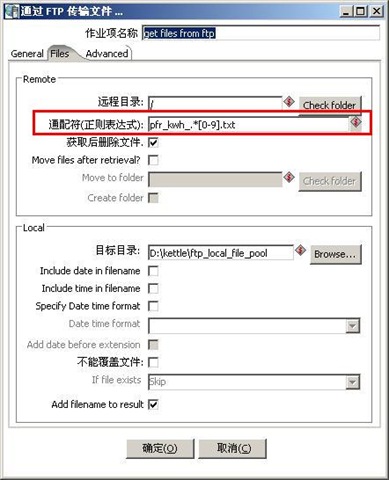
编辑 收藏这个实践其实不难,主要是有一个地方要注意,就是文件名通配符的写法,如果文件名格式为“TRANS_yyyymmdd.txt”,如TRANS_20081101.txt。如果想匹配所有以TRANS开头的文本文件,在kettle中要写成这样:TRANS_.*[0-9].txt。
最后在windows操作系统中配置定时任务就可以定期执行该Job了。
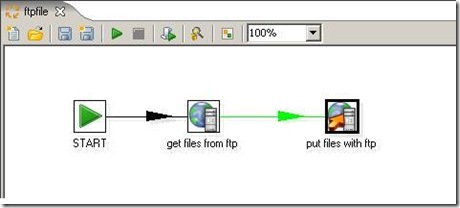
Job的图:
FTP配置信息:
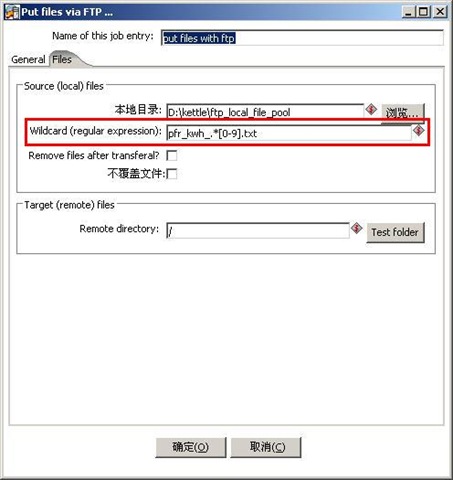
posted @
2008-12-12 15:20 The Matrix 阅读(17061) |
评论 (0) |
编辑 收藏一定要给SQL Server2000打上sp3a补丁,打上补丁后,使用telnet访问1433端口一切正常。
另外学了一个查询SQL Server版本的语句:select @@version
posted @
2008-12-12 12:07 The Matrix 阅读(1446) |
评论 (1) |
编辑 收藏DATE_FORMAT(date,format)
根据format字符串格式化date值。下列修饰符可以被用在format字符串中: %M 月名字(January……December)
%W 星期名字(Sunday……Saturday)
%D 有英语前缀的月份的日期(1st, 2nd, 3rd, 等等。)
%Y 年, 数字, 4 位
%y 年, 数字, 2 位
%a 缩写的星期名字(Sun……Sat)
%d 月份中的天数, 数字(00……31)
%e 月份中的天数, 数字(0……31)
%m 月, 数字(01……12)
%c 月, 数字(1……12)
%b 缩写的月份名字(Jan……Dec)
%j 一年中的天数(001……366)
%H 小时(00……23)
%k 小时(0……23)
%h 小时(01……12)
%I 小时(01……12)
%l 小时(1……12)
%i 分钟, 数字(00……59)
%r 时间,12 小时(hh:mm:ss [AP]M)
%T 时间,24 小时(hh:mm:ss)
%S 秒(00……59)
%s 秒(00……59)
%p AM或PM
%w 一个星期中的天数(0=Sunday ……6=Saturday )
%U 星期(0……52), 这里星期天是星期的第一天
%u 星期(0……52), 这里星期一是星期的第一天
%% 一个文字“%”。
posted @
2008-12-10 09:18 The Matrix 阅读(736) |
评论 (0) |
编辑 收藏 看了Seam的例子,也看了Seam的简介,禁不住手痒,还是先做一个例子吧,遵照《seam_reference》第三章中的指导,使用JBossTool生成了自己的第一个例子,过程如下:
1、生成Sem web项目

2、输入项目的相关信息,如下图:
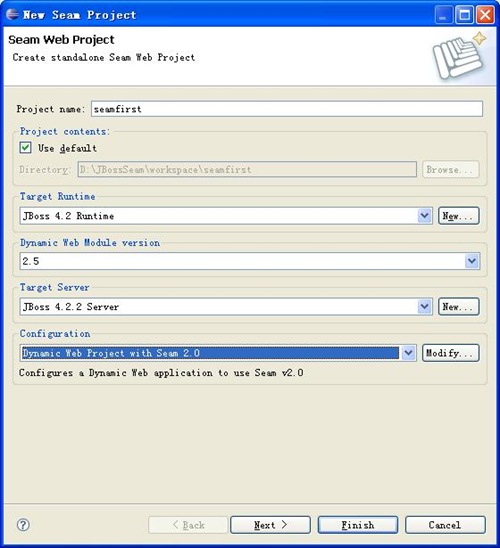
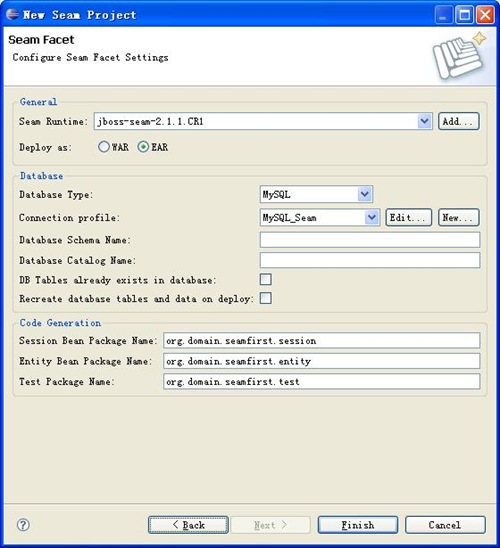
注意,如果是第一次使用Eclipse,需要配置Target Runtime和Target Server。
3、然后一路next,到最后一步时,如果是第一次使用,也要注意配置Seam Runtime和Connection Profile,如下图。最后点击finish按钮,即可创建Seam项目。
4、生成项目后,在Eclipse中共出现了四个项目,如下:
- seamfirst (web项目)
- seamfirst-ear (ear项目,集成web和ejb)
- seamfirst-jar (ejb项目)
- seamfirst-test (测试项目,进行单元测试)
此时运行JBossServer服务器,访问http://localhost:8080/seamfirst链接,出现如下图页面,此时Seam帮我们生成了一个框架,包含了基本的登录和退出功能,还有一个首页。
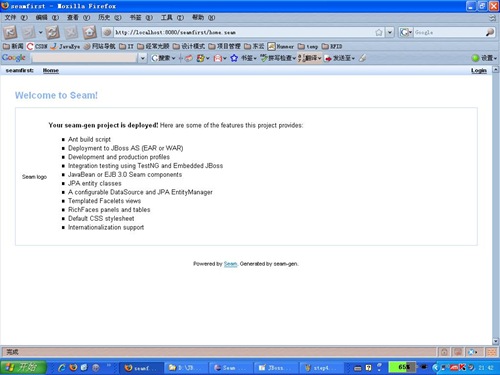
5、继续!使用Seam生成单表的CRUD操作。本步骤前提,有一个mysql数据库,数据库中有一个Customer表,该表有ID(int类型)、customername(varchar2类型)、customerdesc(varchar2类型)、createdate(date类型)、email(varchar2类型)五个字段。在seamfirst项目上点击右键,选择Seam Generate Entities菜单,弹出界面如下图:
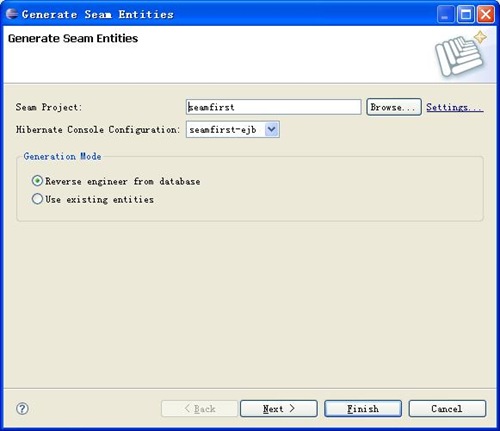
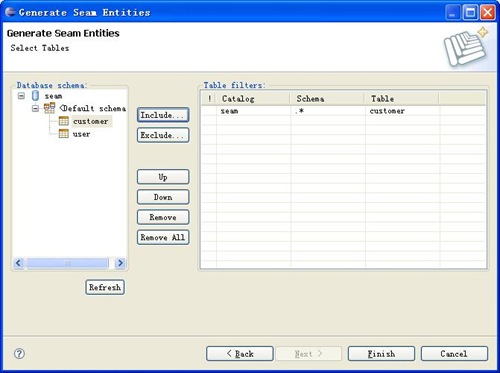
单击finish按钮后,再运行JBoss Server服务器,访问http://localhost:8080/seamfirst,发觉菜单栏上多了一个Customer List菜单,单击此链接,即可进行Customer的添加、删除、修改、查询操作,虽然生成的界面不是很好看,也不是很符合我自己的操作习惯,但是功能倒是完备。
以后若是修改了Seam提供的代码自动生成的模板,然后再使用该功能,想必生成的页面就符合自己的项目要求了,记下一笔,先不管它。
生成的代码分析:
生成的代码主要有两部分,一部分为Java代码,一部分为页面代码。
Java代码包括如下三个类:
- Customer.java ---- 实体类,映射到数据库中的Customer表。
- CustomerHome.java ---- SessionBean,提供了Customer类的创建、更新、删除功能。继承了org.jboss.seam.framework.EntityHome类,EntityHome类中提供创建、更新、删除等基本功能。
- CustomerList.java ---- SessionBean,提供了Customer类的查询功能。继承了org.jboss.seam.framework.EntityQuery类,EntityQuery类中提供了查询功能。
CustomerHome和CustomerList类中都使用了@Name annotation,这样在页面中就可以直接访问Session Bean中的方法了,达到了Seam将表现层和业务层直接融合的目标。
页面代码包括如下文件:
- Customer.xhtml
- Customer.page.xml
- CustomerEdit.xhtml
- CustomerEdit.page.xml
- CustomerList.xhtml
- CustomerList.page.xml
刚开始看这段代码时,困惑我的有两个地方
- 一个是CustomerList.xhtml中rich:dataTable的value为"#{customerList.resultList}",customerList我明白指的是CustomerList SessionBean,但是我看遍了其代码,也没有发现有resultList属性,后来仔细一看,才发觉该属性在其父类EntityQuery中。
- 另一个是每一个xhtml文件都有一个对应的page.xml文件,想了半天也没整明白这是怎么回事,后来只好继续看Seam in Action的第三章,看着看着终于明白了,原来这是Seam对JSF的一个扩展,增强了JSF的功能,具体含义后面详细解释。
至此第一个使用JBossTools生成的Seam例子完成了,好像很简单 :-)
posted @
2008-12-09 22:40 The Matrix 阅读(2136) |
评论 (1) |
编辑 收藏需求:Oracle的数据库文件都存放在C盘,由于数据文件越来越大,所以想把一些数据文件移至D盘
环境:Oracle9i
操作步骤:
- sqlplus /nolog
- connect / as sysdba;
- shutdown immediate;
- startup mount;
- alter database rename file 'c:\ora92\oradata\trans\trans.dbf' to 'd:\ora92\oradata\trans\trans.dbf';
- alter database open;
注意点:
附Oracle的几种启动方式
1、startup nomount
非安装启动,这种方式启动下可执行:重建控制文件、重建数据库。
读取init.ora文件,启动instance,即启动SGA和后台进程,这种启动只需要init.ora文件。
2、startup mount dbname
安装启动,这种方式启动下可执行:数据库日志归档、数据库介质恢复、使数据文件联机或脱机、重新定位数据文件、重做日志文件。
执行“nomount”,然后打开控制文件,确认数据文件和联机日志文件的位置,但此时不对数据文件和日志文件进行校验检查。
3、startup open dbname
先执行“nomount”,然后执行“mount”,再打开包括Redo log文件在内的所有数据库文件,这种方式下可访问数据库中的数据。
4、startup,等于以下三个命令
startup nomount
alter database mount
alter database open
posted @
2008-12-09 10:16 The Matrix 阅读(2766) |
评论 (1) |
编辑 收藏用JBossTools生成项目,生成CRUD的代码,然后访问就报了如下异常:
Exception during request processing:
Caused by java.lang.IllegalStateException with message: "No phase id bound to current thread (make sure you do not have two SeamPhaseListener instances installed)"
org.jboss.seam.contexts.PageContext.getPhaseId(PageContext.java:163)
org.jboss.seam.contexts.PageContext.isBeforeInvokeApplicationPhase(PageContext.java:175)
org.jboss.seam.contexts.PageContext.getCurrentWritableMap(PageContext.java:91)
org.jboss.seam.contexts.PageContext.remove(PageContext.java:105)
org.jboss.seam.Component.newInstance(Component.java:2102)
org.jboss.seam.Component.getInstance(Component.java:1987)
org.jboss.seam.Component.getInstance(Component.java:1966)
org.jboss.seam.Component.getInstance(Component.java:1960)
org.jboss.seam.Component.getInstance(Component.java:1933)
org.jboss.seam.Component.getInstance(Component.java:1928)
org.jboss.seam.faces.FacesPage.instance(FacesPage.java:92)
org.jboss.seam.core.ConversationPropagation.restorePageContextConversationId(ConversationPropagation.java:84)
org.jboss.seam.core.ConversationPropagation.restoreConversationId(ConversationPropagation.java:57)
org.jboss.seam.jsf.SeamPhaseListener.afterRestoreView(SeamPhaseListener.java:389)
org.jboss.seam.jsf.SeamPhaseListener.afterServletPhase(SeamPhaseListener.java:228)
org.jboss.seam.jsf.SeamPhaseListener.afterPhase(SeamPhaseListener.java:194)
com.sun.faces.lifecycle.Phase.handleAfterPhase(Phase.java:175)
com.sun.faces.lifecycle.Phase.doPhase(Phase.java:114)
com.sun.faces.lifecycle.RestoreViewPhase.doPhase(RestoreViewPhase.java:104)
com.sun.faces.lifecycle.LifecycleImpl.execute(LifecycleImpl.java:118)
javax.faces.webapp.FacesServlet.service(FacesServlet.java:265)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:290)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
org.jboss.seam.servlet.SeamFilter$FilterChainImpl.doFilter(SeamFilter.java:83)
org.jboss.seam.web.IdentityFilter.doFilter(IdentityFilter.java:38)
org.jboss.seam.servlet.SeamFilter$FilterChainImpl.doFilter(SeamFilter.java:69)
org.jboss.seam.web.MultipartFilter.doFilter(MultipartFilter.java:90)
org.jboss.seam.servlet.SeamFilter$FilterChainImpl.doFilter(SeamFilter.java:69)
org.jboss.seam.web.ExceptionFilter.doFilter(ExceptionFilter.java:64)
org.jboss.seam.servlet.SeamFilter$FilterChainImpl.doFilter(SeamFilter.java:69)
org.jboss.seam.web.RedirectFilter.doFilter(RedirectFilter.java:45)
org.jboss.seam.servlet.SeamFilter$FilterChainImpl.doFilter(SeamFilter.java:69)
org.ajax4jsf.webapp.BaseXMLFilter.doXmlFilter(BaseXMLFilter.java:177)
org.ajax4jsf.webapp.BaseFilter.handleRequest(BaseFilter.java:267)
org.ajax4jsf.webapp.BaseFilter.processUploadsAndHandleRequest(BaseFilter.java:380)
org.ajax4jsf.webapp.BaseFilter.doFilter(BaseFilter.java:507)
org.jboss.seam.web.Ajax4jsfFilter.doFilter(Ajax4jsfFilter.java:56)
org.jboss.seam.servlet.SeamFilter$FilterChainImpl.doFilter(SeamFilter.java:69)
org.jboss.seam.web.LoggingFilter.doFilter(LoggingFilter.java:58)
org.jboss.seam.servlet.SeamFilter$FilterChainImpl.doFilter(SeamFilter.java:69)
org.jboss.seam.debug.hot.HotDeployFilter.doFilter(HotDeployFilter.java:54)
org.jboss.seam.servlet.SeamFilter$FilterChainImpl.doFilter(SeamFilter.java:69)
org.jboss.seam.servlet.SeamFilter.doFilter(SeamFilter.java:158)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:235)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
org.jboss.web.tomcat.filters.ReplyHeaderFilter.doFilter(ReplyHeaderFilter.java:96)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:235)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:230)
org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:175)
org.jboss.web.tomcat.security.SecurityAssociationValve.invoke(SecurityAssociationValve.java:182)
org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:432)
org.jboss.web.tomcat.security.JaccContextValve.invoke(JaccContextValve.java:84)
org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:127)
org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:102)
org.jboss.web.tomcat.service.jca.CachedConnectionValve.invoke(CachedConnectionValve.java:157)
org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:109)
org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:262)
org.apache.coyote.http11.Http11Processor.process(Http11Processor.java:844)
org.apache.coyote.http11.Http11Protocol$Http11ConnectionHandler.process(Http11Protocol.java:583)
org.apache.tomcat.util.net.JIoEndpoint$Worker.run(JIoEndpoint.java:446)
java.lang.Thread.run(Thread.java:619)
Google了一下,有人讲是JBoss4.2.3GA版本的BUG,赶紧下载了JBoss4.2.2GA,再测试一切正常!
不知还会不会有其它莫名的BUG了......
posted @
2008-12-07 22:03 The Matrix 阅读(1027) |
评论 (0) |
编辑 收藏 把环境配好之后,Seam的例子也运行起来了,看了seam_reference第一章中如下几个例子讲解:
- the registration example
- the messages example
- the todo list example
- the numberguess example
又在满江红的网站上找了seam_reference2.0的中文文档,主要看了《the contextual component model》一章,看完以后感觉Seam最核心的地方就是其contextual component model了,不过看完这一章以后只是对Seam有个大概的了解,对其具体的内容,细节还缺乏进一步的了解,对其优点、缺点也缺乏进一步的认识。
然后又找到了《Seam in Action》的电子书,看了一点之后还是觉得这本电子书写得好,内容组织的很好,不象seam_reference后面的章节仅仅是罗列seam的各项功能。
今天把Seam in Action的第一章草草看了一遍,将第一章讲述的内容总结如下:
1、什么是Seam
在Seam in Action中,没有将Seam称之为web framework,而是将其称为application stack。Seam将Java EE中的EJB3、JSF、JPA/Hibernate、JAAS等技术融合在一起,提供了更容易使用的方式,比如conversation、page flows、buisness precesses、rule-based security、JavaScript(Ajax) remoting、PDF rendering、email组合、charting、file uploads、Groovy integration等,用以简化web开发。
2、Seam的目标
简化web开发
3、Seam如何集成各类技术
 Seam集成了JSF、JPA和POJO Component
Seam集成了JSF、JPA和POJO Component
 在Seam中将EJB3.0中的Session Bean作为JSF的managed bean,直接将表现层和业务层衔接在一起,使得Session Bean可以直接访问web相关数据,比如request、session、application、JSF的FacesMessage、Component Tree等。而在不使用Seam时,一般都是使用JSF back bean来作为表现层和业务层之间的中介。
在Seam中将EJB3.0中的Session Bean作为JSF的managed bean,直接将表现层和业务层衔接在一起,使得Session Bean可以直接访问web相关数据,比如request、session、application、JSF的FacesMessage、Component Tree等。而在不使用Seam时,一般都是使用JSF back bean来作为表现层和业务层之间的中介。
使用annotation中的@Name标注替代了JSF的faces-config.xml中关于managed bean的配置。
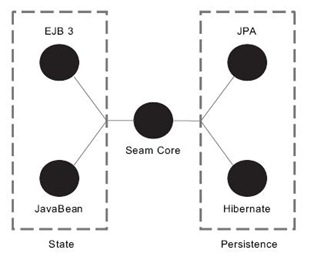
Seam不一定必须使用EJB和JPA,也可以使用POJO、Hibernate作为替代。如下图:
上下文相关的组件模型(Seam中的核心概念)
Seam提供了7种类型的上下文,其中属于Seam特有的两种上下文类型分别为:Conversation Context、Business process Context。
Seam提供了统一的组件注册、annotation、异常配置、方法拦截、统一的EL表达式等功能。其中Seam对其管理的组件拦截过程如下图:

4、Seam的核心竞争力
更好的JSF
增强的JSF
- Seam对JSF最被认可的改进就是消除了在配置文件中声明managed bean。
- Prerender page actions
- Managed request parameters (for a given page)
- Intelligent stateless and stateful navigation
- Transparent JSF data model and data model selection handling
- Fine-grained exception handling
- Page-level security (per view ID)
- 基于Annotation的表单验证
- Bookmarkable command links (solving the “everything is a POST” problem)
- Entity converter for pick lists
- Conversation controls
- Support for preventing lazy initialization exceptions and nontransactional data access in the view
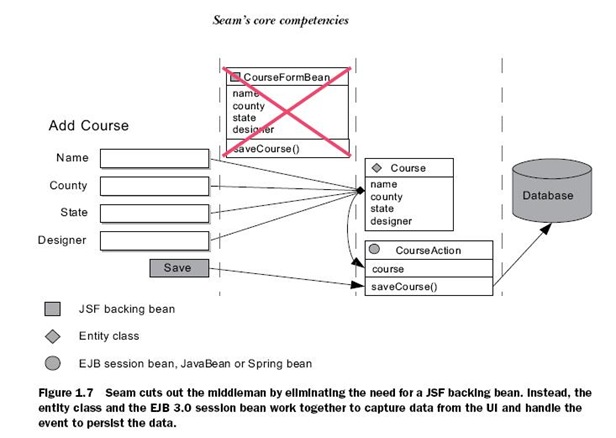
消除了连接Bean(ELIMINATING CONNECTOR BEANS)
用一幅图可以很好的说明这句话的含义
引入了有状态的变量范围(INTRODUCING STATEFUL VARIABLE SCOPES)
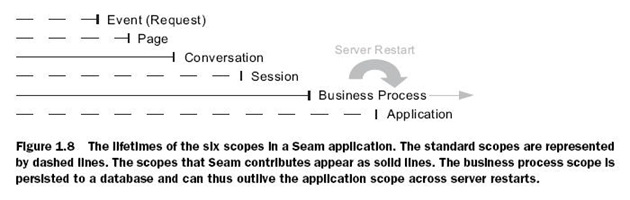
扩展的Persistence Context
Spring中提供了The Session In View Filter,使得persistence manage可以在一个请求中存在,避免了常见的LazyInitializationException。在Seam中,扩展的Persistence Context可以跨越多个请求。其实扩展的Persistence Context是Conversation Context、Business Process Context的基础。
get rich quick
Seam提供了两种方式将Ajax集成到Seam应用中,一种是使用具有Ajax特性的JSF组件,如RichFaces和ICEFaces,另一种是可以在浏览器中使用JavaScript直接调用服务端的组件。
Seam还提供了另外一种意义上的Rich,即将PDF、mail等功能集成到Seam应用中。
提供了一个快速开发环境
代码自动生成
热部署
Seam调试页面
不部署即可以进行单元测试
从目前我个人的理解来看,Seam的作用与能力如下:
- Seam将EJB3与JSF整合在一起,消除了JSF与业务代码之间的间隙,直接将表现层与业务层衔接在一起
- Seam提出了Conversation Context的概念,将Stateful EJB引入到web开发中,直接与Conversation Context对应
- Seam提供了与Jbpm、itext、mail等一系列开源框架的整合,对于需要使用的相关功能的用户来说,提供了便利性
- 提供了开发工具的整合(Seam Gen与IDE),还可以自动生成部分代码
但由于Seam整合了如此多的框架,带来的一个最大的缺点:学习曲线陡峭,在SSH非常流行的今天,需要面对很多新技术(JSF、EJB3、JPA等),对于一个新手来说难度比较大,如果想使Seam被更多的开发人员使用,必须加强它的文档,目前的文档还是太少了。
posted @
2008-12-06 23:51 The Matrix 阅读(2282) |
评论 (0) |
编辑 收藏 今天早上在网上看到了kettle发布了最新的版本,忽然想起最近其实做了不少工作应该是ETL工具的拿手好戏,赶紧下载下来看看,看是否能够在实际的工作中应用起来。
顺便讲一下,为啥看到kettle会两眼发光。
最近写了好几个小程序,用于从一个ftp去获取数据,然后转发至另一个ftp去,或者是从一个数据库获取数据然后保存至本地的数据库中,使用的是jdk中的Timer实现的定时调度,本来也没什么问题,连续运行几个月都不会出错。
可是最近网络不是太好,周期性抽风,ping包时,每5分钟大概会丢7-8个包,从而导致程序也会假死,过一段时间后就不正常干活了,估计是因为用了数据库连接池的问题,要是每次发起数据库连接可能就不会有问题了,偷懒也不想改了,因为网络最终肯定是会修好的 :-) 但是想试试ETL工具,因为后面还有一些类似的东西要处理,不想写代码了,用别人的轮子感觉比较好,呵呵
首先下载了kettle的最新版,kettle3.1,解压后即可运行,一般的开发人员稍微摸索一下,看看例子简单的转换还是会做的,今天小试了一把,有几个注意点记下来。
- 使用资源库(repository)登录时,默认的用户名和密码是admin/admin
- 当job是存放在资源库(一般资源库都使用数据库)中时,使用Kitchen.bat执行job时,需使用如下的命令行:
Kitchen.bat /rep kettle /user admin /pass admin /job job名
- 当job没有存放在资源库而存放在文件系统时,使用Kitchen.bat执行job时,需使用如下的命令行:
Kitchen.bat /norep /file user-transfer-job.kjb
- 可以使用命令行执行job后,就可以使用windows或linux的任务调度来定时执行任务了
在一开始使用命令行方式执行job时,总是报如下的错误,琢磨了好长时间总算整明白正确的方式了。
Unexpected error during transformation metadata load
No repository defined!
下一步准备按照实际情况定制Job,做好了再写小结。
posted @
2008-12-04 22:48 The Matrix 阅读(10356) |
评论 (13) |
编辑 收藏 JBoss Envers目的是根据对实体的设置,提供记录执行数据变更历史的功能(数据变更版本)。Envers的配置非常简单,如果需要对某个实例进行历史数据版本记录,只需要在实例上配置@Versioned annotation即可。针对每个实体的版本的历史数据,Envers都会创建一个单独的数据表进行存储。
目前Envers支持Hibernate和Hibernate-entitymanager(JPA实现).
这个特点在需要对历史数据进行存档时很实用,而且目前Envers已经合并到Hibernate的新版本中去了,使用起来更方便,具体Hibernate哪个不太清楚。
留个印记..............
posted @
2008-12-04 09:04 The Matrix 阅读(295) |
评论 (0) |
编辑 收藏准备深入学习JBossSeam,好好研究研究,具体学习路线基本遵循jboss-seam-2.1.1.CR1中的<<seam_reference.pdf>>。
学习JBossSeam之前最好对相关技术有一定的了解,比如:
然后下载相关的软件,如下:
- jboss-seam-2.1.1.CR1
- jboss-4.2.3.GA
- JBossTools-3.0.0.Beta1-R200810311334-ALL-win32(开发环境)
- eclipse-jee-ganymede-SR1-win32(开发环境)
- apache-ant-1.7.0
- jdk1.6.0_06
环境的配置都比较简单,基本都是解压即可,有如下注意事项:
- 在系统的环境变量中设置JAVA_HOME、ANT_HOME
- JBossTools解压后需拷贝至eclipse解压后的目录中。
- jboss-seam-2.1.1.CR1解压后,需设置其bulid目录下的default.build.properties文件中的jboss.home为JBOSS_HOME(假定为jboss-4.2.3GA的安装目录)。
上述配置好后,启动JBoss Server,然后至SEAM_HOME(假定为Seam的安装目录)/examples/registration目录下,运行ant explode命令,即可编译部署registration应用至JBoss Server中,最后访问:http://localhost:8080/seam-registration 即可体验Seam提供的第一个example程序 :-)
posted @
2008-12-03 23:03 The Matrix 阅读(961) |
评论 (0) |
编辑 收藏考核系统快结束了,将此项目的经历回忆如下,也小结一下,先谈这个项目中值得提倡的地方:
1、在开发之前进行了完整的需求分析,形成了系统的需求文档,需求文档中最有用的部分感觉就是界面原型,还有系统的菜单,这样给了用户一个初步的直观的印象,同时文档中的一些对于界面原型的描述以及计算规则等内容在后期的开发中也起了指导作用。
2、在需求分析完成之后,进行了概要设计,包括完整的数据库设计,这样在后期的开发中对数据库表结构方面没有大的修改了,只是添加了一些表和视图。
再谈谈项目中的缺点吧:
1、首先就说说需求文档,虽说需求文档写了很多,大概有100页左右(word),但由于一篇文档中集中的内容太多,对于用户来说只是关注了界面原型,系统菜单等部分,对于其它内容用户关注度不高;同时由于篇幅太大,开发人员打开查看或者后续修改也比较麻烦。
对于以后的需求文档是否可以这样编写:首先有一个正文,正文中包括大纲,然后将每一个具体的需求放在单独的一个文档中,最好能类似html链接那样,这样查看也方便,也一目了然。
原来用RobotHelp写过帮助,照此看来,岂不可以用来写需求文档了,呵呵
2、再说数据库设计,还不够细致,很多应用场景由于设计的不够细致,导致数据库表也有所欠缺,因此对于以后的项目设计有两个注意点:
a、加强应用场景设计,具体可以用流程图,甚至序列图描述清晰的业务流程,完善数据库表设计。
b、要求一定先修改模型(这里指PowerDesigner中的数据库设计),然后再去修改POJO类等具体代码,最好不要先改代码,再修改模型,这样难免会有遗漏,时间久了,就会导致模型和代码的不一致,慢慢的,模型文档就没有人看,也没有人维护了。
c、顺便提一下,模型文档的好处一是方便后来者,二是可以方便的导出数据字典。
3、对于命名规范没有在开发前考虑全面,虽然在开发前对命名规范有一定的规定,但是不够全面,造成了后期开发中各人各人的命名有所偏差。
4、分层架构中的dao层和service层处理的不够好,导致service层实际上是混杂了dao和service的功能,业务代码不够清晰。以后的项目考虑dao就是dao,提供数据访问的操作,service层则提供业务处理方法,service与dao的关系应该是多对多的关系。
5、考核系统中使用了JSF/Richfaces做为表现层,好像不太好使,经常会出现多次重复访问方法的问题,后续还需要加强对JSF的学习,避免类似问题。另外Richfaces在生成大数据量的页面时,一个表格有1440行数据,页面巨慢无比:(,后来没有使用RichaFaces的表格,直接使用jstl+html标签,速度倒是很快。
6、项目中的日志输出、异常处理不够明晰,这个和命名规范一样应该在项目开始时给出清晰的思路,在具体开发中应该经常检查。
posted @
2008-12-03 19:50 The Matrix 阅读(1024) |
评论 (0) |
编辑 收藏具体内容参见如下链接:
http://www.javaworld.com.tw/roller/ingramchen/entry/2005_9_20_JBossSeamKingofStateful_
posted @
2008-12-03 13:11 The Matrix 阅读(632) |
评论 (0) |
编辑 收藏今天在http://refcardz.dzone.com/上下载了《Getting Started with Hibernate Search》,乍一看标题,以为是讲如何使用Hibernate进行查询操作什么的,下载好以后打开一看,原来是Hibernate集成了lucene,用来对自己的数据库进行全文检索,真是厉害!
没有仔细研究具体内容,先记下一笔,日后有时间时,可以实践一把。
posted @
2008-12-01 12:59 The Matrix 阅读(463) |
评论 (0) |
编辑 收藏 Template设计模式主要适用于需要按一定的步骤执行的场合,但有的步骤在不同的场合执行的内容有不相同。如下类图中的TemplateClass中的execute()方法会按照如下的顺序进行调用:
public void execute() {
step1();
step2();
}
但由于step1在不同的场合执行的内容不一样,此时就将step1设为抽象方法,在TemplateConcreteClass1和TemplateConcreteClass2中分别实现,这样就形成了Template设计模式,step1()方法也称为模板方式。
类图如下:
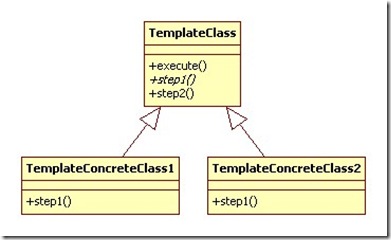
posted @
2008-11-29 22:54 The Matrix 阅读(807) |
评论 (0) |
编辑 收藏1、在菜单中选择“Weblog”,然后选择“Another Weblog Service”。
2、在Weblog Homepage URL中输入你的Blog主页地址。
3、输入用户名与密码。
4、在“Type of weblog that you are using”中选择“Custom(Metaweblog API)”。
5、“Remote posting URL for your weblog”中输入“http://www.cnblogs.com/用户名/services/metaweblog.aspx”。
posted @
2008-11-28 22:56 The Matrix 阅读(228) |
评论 (0) |
编辑 收藏
具体过程参见:http://coenraets.org/flex-spring/
简要描述一下:
1、首先要继承FlexFactory,实现Spring与Flex的集成,上文中已经提供了具体实现,下载即可。
2、在web.xml中配置Spring,如下:
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/applicationContext.xml</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
3、在service-config.xml配置文件中添加
<factories>
<factory id="spring" class="flex.samples.factories.SpringFactory"/>
</factories>
4、修改remote-config.xml中原有的destination配置,原为:
<properties>
<source>com.bluesky.flexpsp.PsPDataService</source>
</properties>
修改为:
<properties>
<factory>spring</factory><!-- spring为第三步中的factoryID-->
<source>pspDataService</source><!-- pspDataService为bean的id -->
</properties>
posted @
2008-08-09 23:58 The Matrix 阅读(843) |
评论 (0) |
编辑 收藏
1、使用HTTPService
使用HTTPService可以直接访问ASP.NET、JSP、Servlet、PHP等页面,此种方式最为简单直接。
2、使用WebService
使用WebService可以直接访问互联网上各大公司提供的WebService服务,该种方式对做互联网应用开发可能用的比较多。
3、使用RemoteObject
此种方式可以直接访问Java Class的method,可以采用此种方式构建 Flex + Spring + Hibernate的应用。
4、使用Message
此种方式弥补了WEB应用的缺点,使得浏览器和Server端可以进行双向交互,可以用于构建复杂的C/S方式的企业应用。
不同方式的具体访问方法在BlazeDS的Test中都有样例。
第一、第二种方式不需要服务端有特殊设置,只要客户端能够解析服务端返回的信息即可。
第三、第四种方式需要使用BlazeDS进行配置后方可使用,或者使用ColdFusion。
posted @
2008-07-30 12:39 The Matrix 阅读(484) |
评论 (0) |
编辑 收藏
至
http://opensource.adobe.com/ 可以下载BlazeDS,下载后解压至本地。
BlazeDS includes the following Web Application Archive (WAR) files:
- blazeds.war - The primary BlazeDS WAR file: use this as a starting point for building your BlazeDS application.
- samples.war - Sample BlazeDS applications.
- ds-console.war - Simple monitoring application for BlazeDS deployments.
在访问BlazeDS的Sample前,需要首先运行install_root/sampledb目录下的HSQLDB数据库,运行方式为启动startdb.bat脚本
然后启动tomcat,即可访问http://localhost:8400/,体验BlazeDS了。
如果没有下载tomcat和BlazeDS的整合包,直接安装BlazeDS的话,对于不同的应用服务器需要进行一些额外的配置,具体参见如下链接:
http://opensource.adobe.com/wiki/display/blazeds/Installation+Guide
posted @
2008-07-30 12:38 The Matrix 阅读(2030) |
评论 (0) |
编辑 收藏 今天忽然想到这个题目----快速高效的开发软件项目,将个人的一点体会记下来:
1、需求分析要做的充分,使用原型法和用户进行沟通,这样可以更好的把握用户需求。
2、架构设计一定要做,解决项目中可能遇到的难点问题,其实架构设计也可以看作一个抽象的过程,从系统需求中抽取出共性的内容,然后进行设计。
3、多周期迭代,每次迭代的时间控制在两个星期至一个月,每次迭代结束后一定需要进行测试。要牢记项目经理的职责不是编写代码,不是关注编码的细节,要有全局观,与用户要有良好的沟通。
4、困难的问题、基础的问题要先解决。
5、要有测试人员全程参与,并且测试人员对项目的目标、范围、质量要求与项目主管、用户理解一致。
6、确保开发人员理解需要解决的问题后才进行开发,可采用复述法、提问法确保理解。
7、不要采用大家不熟悉的技术,如果采用,那么需要对该技术尽早预研,并开展培训工作。
8、建立一个强有力的、关系融洽的团队。团队中最好能有一个技术高手,最好能有一个活跃气氛的人。
9、确保能够有效的沟通,尤其是后期测试人员参与集成测试时。
10、不要把项目时间排的很满,要留出机动的时间和资源。
11、对项目组成员能够进行考核奖励。
12、没有完美的产品,只有合适的产品。
13、项目启动前就编码规范、沟通方式、在项目中采取何种管理方式等与项目组成员进行沟通。项目组每周召开简短的例会,讨论完成情况,分析存在问题,交流沟通其他技术问题。
14、不能姑息项目组中犯错误的同事,有问题要指出,方式要恰当。
15、最后一点,不要拘泥于形式,要能够洞悉项目中已经存在、正在出现、即将发生的问题和风险,并采取适当的方法去解决,最近很喜欢孙子兵法中的一
句话“故兵无常势,水无常形。能因敌变化而取胜者,谓之神。”。当然这不是说各项知识不需了解,仅凭感觉,这样是做不好项目的。
posted @
2008-07-18 21:24 The Matrix 阅读(531) |
评论 (0) |
编辑 收藏
1、专注于构建一个强有力的团队,这一团队能够解决困难的问题,并为客户创造真正的价值
团队的定义:团队就是一群拥有互补技能的人,他们为了一个共同的目标而努力,达成目的并固守相互间的责任
2、领导者鼓舞;管理者授权。要同时成为优秀的领导者和管理者,你需要就愿景进行沟通并理解其细节。
3、对可能出现的障碍有所准备,防微杜渐,在这些障碍尚未壮大时就清除它们。
4、花时间来仔细倾听别人的意见,但不要过于担心其他人的想法。
5、专注于事实。
6、充当一个衰减器,而不是放大器,为团队提供稳定性。
7、永远不要将不能解释的事情归咎于蓄意破坏。
8、培养幽默意识来作为严肃认真的一种平衡;对于工作一丝不苟,对自己轻松自如。
9、除了工作,还应该懂得享受生活,而且每年要读25本书。
10、相信你的直觉:如果你感觉不妙,那么很可能预感就会成真。
摘自《软件开发的边界-管理成功的项目》
posted @
2008-07-06 21:26 The Matrix 阅读(194) |
评论 (0) |
编辑 收藏如何编写高质量的Java代码:
1、
养成良好的习惯及良好的编码风格,比如当有代码没有彻底完成前,通过TODO、FIXME等方式进行标注,比如良好的命名规则、注释、行间距等
2、
秉承设计模式的一个基本原则:单一职责,一个类不应过于庞大,如果过于庞大,则应分解
3、
避免Ctrl+C、Ctrl+V,当发生这样的事情后,需要进行重构
4、
要敢于重构,敢于重构的一个质量保证手段就是要对代码进行充分的测试
5、
注意异常处理、注意事务控制的范围
6、
遇到问题不能总是求助于Google、其他同事,要自己能够分析问题,解决问题
7、
不能仅仅满足于编码速度快,要时刻牢记需要编写的是高质量的代码,易于维护的代码。一定要深刻理解高质量、易于维护。高质量就是说代码需要在各种情况下都能正常工作,而不仅仅是正常流程no problem,易于维护就是说如果换了一个开发人员来修改代码,是否能够很容易的阅读代码,理解代码,还是他会觉得这段代码无药可救了,重写是最佳选择,如果是后一种状况的话,那么这段代码就是最糟糕的了。
以下为摘自IBM <Java代码质量专题>的一段话:
高质量的软件通常具备了这样一些特性:
- 满足用户的需求。
- 合理进度、成本、功能关系。
- 具备扩展性和灵活性,能够适应一定程度的需求变化。
- 能够足够的强壮、足够的鲁棒,能够有效的处理例外的情况。
- 保持成本和性能的平衡。
-
能够可持续的发展。
posted @
2008-06-15 22:05 The Matrix 阅读(893) |
评论 (0) |
编辑 收藏
首先需要明白的是,什么是架构设计,看了以前的培训资料,也google了,也自己想了,总结下来:
架构设计:软件系统是由组件以及它们之间的连接关系组成的,同时架构设计还要满足软件系统的易变性、可扩展性、可维护性等特性。
搞清楚了什么是架构设计之后,再想想怎么才能做好架构设计呢?
架构设计可大可小,回顾一下自己做过的项目,细想再小的项目其实也有一个架构设计,只不过这个架构设计可能很小,三言两语就能描述清楚了,比如一个很小的BS系统,可能也要划分一下,功能模块如何划分,哪些是公用的,目录或package如何划分,这个我觉得也是架构设计。
但是当系统变大时,架构设计就变得复杂了,因为需要考虑的东西就多了,一方面从系统的功能来说,系统功能点已经上百成千个了,光是搞清楚这些功能点就已经不容易了,如何从这些功能点中发掘共性,划分组件,如何设计组件之间的联系,实现分而治之就更复杂了,另一方面,系统变大了,系统的非功能性需求或约束更多了,一个小系统,可能不需要考虑大用户量、并发、大数据量等问题,但一个大系统,即使用户不提这些约束条件,一个好的项目经理或者架构师,必须替用户考虑这些约束条件,有几年的数据以后,系统会不会变慢,采取什么样的方式可以解决这样的问题,用户如果要求5秒内,系统必须有响应,那么目前的架构设计能不能满足这样的要求呢?
同时从软件系统的架构与建筑设计的类比来看,一个建筑设计,必定是先把建筑结构定下来,然后再按图施工,如果想有创新性的设计,则必须广闻博见,同时还必须功力深厚,否则怎么设计的出鸟巢呢?呵呵
同样对于一个软件架构的设计者来说,第一个层次,丰富的实践知识,达到这样,至少在一定的范围内可以依葫芦画瓢了,同时还可以有一些局部性的创新设计。
第二个层次建立在第一个层次的基础上,广闻博见,精通十八般武艺,无论哪种兵器都能使得很趁手,比如BS架构很熟悉,CS架构很熟悉,银行系统的架构设计做过,电信系统的架构见过研究过,嵌入式系统的架构也熟悉,操作系统、数据库等基础知识那更是不用说,至少熟悉多种主流编程语言,还能紧跟潮流趋势,更要有自己的思想,理解能力深厚,这样的大师我想应该能做出创新性的设计了。
回顾一下自己,只能是第一个层次了,其实第一个层次也不算很好,第二个层次只能算刚刚入门,看来要成为一个大师,很难,@_@
posted @
2008-06-01 13:18 The Matrix 阅读(520) |
评论 (0) |
编辑 收藏
今天将以前参加的一个架构设计的培训教材拿出来又翻了翻,忽然发现当时培训的教材其实是按照RUP的开发思路来安排的。
首先来看看RUP的核心工作流,分别是:
- 商业建模(业务建模)
- 需求
- 分析与设计
- 实现
- 测试
- 发布
- 配置与变更管理
- 项目管理
- 环境
后面几项与架构设计的关系不大,重点看前面几个:商业建模、需求、分析与设计。
回过头来再看看培训教材的大纲:
- 架构师必备的全局观
- 架构设计导论
- 架构设计过程概览
- 需求分析 ---- RUP ---- 需求
- 领域建模 ---- RUP ---- 商业建模
- 打通软件需求到架构师设计之墙 ---- RUP ---- 需求、分析与设计
- 概念性架构设计 ---- RUP ---- 分析与设计
- 细化架构设计 ---- RUP ---- 分析与设计
- 非功能需求设计方法论 ---- RUP ---- 分析与设计(重点在非功能需求的架构设计)
- 架构验证 ---- RUP ---- 分析与设计(重点在验证)
- UML实践指南
- 面向对象架构设计
- 架构模式实践
- 框架技术实践
除了实践部分与前面概要性的部分之外,其余部分基本可以对应起来。
有时候,会觉得写小说是件容易的事情,设计好大纲,一篇一篇往里填充不就行了么,但是换做真的是自己动笔的话,确万万也写不出来。
架构设计也是如此,简单点说是如此简单:熟悉需求、商业建模、分析与设计。但是真的遇到一个需要实现的系统时,确发现千头万绪,要想做一个好的架构,不是一件容易的事情。
要想做好架构设计,重点还在一个
分析,学习架构设计也是如此,那就是得分析开源框架、别人的代码为什么要这么做?要分析我从中可以体会到什么?
架构设计师的知识面一定要广,否则应用面就比较窄了。
说了半天,回头一看,乱七八糟,其实最近在琢磨的一个问题是,如何才能搞好架构设计 ^_^
再想想,这是一个长期工程,需要不断的分析积累。
posted @
2008-05-31 22:54 The Matrix 阅读(483) |
评论 (0) |
编辑 收藏
今天假借儿子的名义买了个变形金刚,了却了多年的心愿,哈哈
posted @
2008-05-25 01:30 The Matrix 阅读(273) |
评论 (0) |
编辑 收藏
在startup.sh开始处中增加如下内容:
declare -x CATALINA_OPTS="-server -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8788"
然后启动Tomcat即可。
windows下是增加如下内容:
SET CATALINA_OPTS=-server -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8788
posted @
2008-05-22 16:13 The Matrix 阅读(504) |
评论 (0) |
编辑 收藏
在终端中切换到root用户,然后执行如下命令:
yum install scim scim-lang-chinese scim-pinyin -y
安装完成后,注销再登录系统即可。
posted @
2008-05-21 13:24 The Matrix 阅读(334) |
评论 (0) |
编辑 收藏
时间过的真快,上次写随笔已经是四个月前的事情了。
四个月过去了,有什么进步呢?但工作还是要做,不知什么时候是个尽头。
posted @
2007-10-29 21:48 The Matrix 阅读(317) |
评论 (0) |
编辑 收藏
使用flash.utils.getDefinitionByName()函数可以根据类名创建类的实例,具体可以参照API文档。
posted @
2007-06-15 23:16 The Matrix 阅读(525) |
评论 (0) |
编辑 收藏
今天看了《最后期限》的前几章,好书!
posted @
2007-05-12 23:17 The Matrix 阅读(297) |
评论 (0) |
编辑 收藏
今天才了解到,Hibernate3.2已经全面支持EJB3.0中的JPA规范。
看来对新技术了解不够,只顾了看EJB3.0的规范了

感觉Hibernate3.2全面支持EJB3.0的规范对于EJB3的推广来说是件好事,至少在ORM这方面,一般程序员积累的经验可以很快速的适应EJB3.0的开发。只要继续加强对EJB容器、事务处理等方面的学习,就可以对EJB3有全面完整的了解。比起以前EJB2.1和常用技术的格格不入而言,真的是很大的进步了。
posted @
2007-05-10 21:08 The Matrix 阅读(765) |
评论 (0) |
编辑 收藏 EntityManager的定义
EntityManager的定义
The EntityManager manages the O/R mapping between a fixed set of entity classes and an underlying data source.
It provides APIs for creating queries, finding objects, synchronizing objects, and inserting objects into the database.
It also can provide caching and manage the interaction between an entity and transactional services in a Java EE environment such as JTA.
The EntityManager is tightly integrated with Java EE and EJB but is not limited to this environment; it can be used in plain Java programs.
An EntityManager maps a fixed set of classes to a particular database. This set of classes is called a persistence unit .
In Java SE, entity managers are created using a javax.persistence.EntityManagerFactory
Example:
EntityManagerFactory factory = Persistence.createEntityManagerFactory("titan", map);
EntityManager manager = factory.createEntityManager();
在Java SE环境中,使用完EntityManagerFactory后,最好将其关闭,以释放其占有的资源。
和Java SE环境不一样,在Java EE中,一个注入的EntityManagerFactory会被EJB容器自动关闭,实际上,如果你调用EntityManagerFactory的clost()方法时,会抛出IllegalStateException异常。
public interface EntityManager {
public void persist(Object entity);
public <T> T find(Class <T> entityClass, Object primaryKey);
public <T> T getReference(Class <T> entityClass, Object primaryKey);
public <T> T merge(T entity);
public void remove(Object entity);
public void lock(Object entity, LockModeType lockMode);
public void refresh(Object entity);
public boolean contains(Object entity);
public void clear( );
public void joinTransaction( );
public void flush( );
public FlushModeType getFlushMode( );
public void setFlushMode(FlushModeType type);
public Query createQuery(String queryString);
public Query createNamedQuery(String name);
public Query createNativeQuery(String sqlString);
public Query createNativeQuery(String sqlString, String resultSetMapping);
public Query createNativeQuery(String sqlString, Class resultClass);
public Object getDelegate( );
public void close( );
public boolean isOpen( );
}
Persistence context的定义
A persistence context is a set of managed entity object instances.
Persistence contexts are managed by an entity manager.
There are two types of persistence contexts: transaction-scoped and extended persistence contexts.
A persistence context can be created by calling the EntityManagerFactory.createEntityManager( ) method. The returned EntityManager instance represents an extended persistence context. If the EntityManagerFactory is JTA-enabled, then you have to explicitly enlist the EntityManager instance within a transaction by calling the EntityManager.joinTransaction( ) method. If you do not enlist the EntityManager within the JTA transaction, then changes you make to your entities are not synchronized with the database.
FlushModeType的含义
FlushModeType默认为AUTO模式,当为AUTO时,在一个查询被执行前,会自动将变化提交到数据库中,即调用flush()方法。但是调用find()或getreference()方法时,并不会执行自动提交。当为COMMIT模式时,仅仅在事务提交时,会将变化提交到数据库中。
EJB3中的实体注解规范参见如下链接
http://wiki.redsaga.com/confluence/display/HART/Home
posted @
2007-05-07 23:42 The Matrix 阅读(597) |
评论 (0) |
编辑 收藏
1、查找数组中的元素可以使用ascb.util.ArrayUtilities中的
findMatchIndex()、findLastMatchIndex()、findMatchIndices()方法,具体参考API。
2、使用splice()方法可以移除数组中间的元素,使用pop()方法移除数组的最后一个元素,使用shift()方法移除数组的第一个元素。也可以使用splice()方法向数组中增加元素。
3、将数组转化为String,可以使用join()方法。
例:
var letters:Array = ["a", "b", "c"];
trace(letters.join()); // Displays: a,b,c
posted @
2007-01-16 22:35 The Matrix 阅读(765) |
评论 (0) |
编辑 收藏
flash.system.Capabilities类提供了很多静态方法返回运行flash的player、计算机的信息,比如操作系统、语言、声音、视频能力等。
还有一些其它的类比如:
flash.display.Stage和flash.system.Security允许你控制播放器的右键弹出菜单和设置对话框。
flash.display.Stage还可以控制播放器播放的视频的缩放比例和位置。
flash.system.Capabilities.os 返回操作系统信息。代码如下:
var os:String = System.capabilities.os.substr(0, 3);
if (os == "Win") {
// Windows-specific code goes here
} else if (os == "Mac") {
// Mac-specific code goes here
} else {
// Must be Unix or Linux
}
flash.system.Capabilities.playerType 不同的类型包括:
Browser plug-in that runs in web browsers such as Mozilla or Firefox
ActiveX Control used by Internet Explorer
Standalone player, which plays .swfs outside of the browser
External player, which is the player integrated in the Flash IDE
flash.system.capabilities.screenResolutionX 和 screenResolutionY获取屏幕分辨率。
stage.scaleMode属性可以设置一个movie如何填充播放器,包括比例等。
有四种模式,以静态常量的方法定义在flash.display.StageScaleMode类中,分别为:EXACT_FIT、NO_BORDER、NO_SCALE、SHOW_ALL。
stage.align属性可以设置一个movie的排列方式,也以静态常量的方式定义在flash.display.StageAlign类中。
如下:
Vertical Horizontal
StageAlign.TOP Top Center
StageAlign.BOTTOM Bottom Center
StageAlign.LEFT Center Left
StageAlign.RIGHT Center Right
StageAlign.TOP_LEFT Top Left
StageAlign.TOP_RIGHT Top Right
StageAlign.BOTTOM_LEFT Bottom Left
StageAlign.BOTTOM_RIGHT Bottom Right
flash.system.Capabilities的hasAudio和hasMP3属性可以判断flash player所在设备的音频能力。
stage.showDefaultContextMenu属性设为false,可以隐藏掉一些系统默认菜单。
posted @
2007-01-13 15:42 The Matrix 阅读(683) |
评论 (0) |
编辑 收藏事件是实现对象通讯的一个重要手段,对于构建一个灵活的系统来说是非常必要的。在Flash Player 9中,将事件发送机制内建在了flash.events.EventDispatcher类中。所有需要发送事件的类都必须继承EventDispatcher类。
调用EventDispatcher类中的addEventListener( ) and removeEventListener( )方法,就可以注册或者移除事件监听器。EventDispatcher中还定义了dispatchEvent()方法,可以使用该方法发送事件。dispatchEvent()方法至少需要一个参数,即flash.events.Event对象或者它的子类。
原文如下:
Events are an important way for objects to communicate. They are essential for creating flexible systems. Flash Player 9, for example, has a built-in event dispatching mechanism in the flash.events.EventDispatcher class. All classes that dispatch events inherit from EventDispatcher (e.g., NetStream and Sprite). If you want to define a class that dispatches events, you can extend EventDispatcher, as follows:
package {
import flash.events.EventDispatcher;
public class Example extends EventDispatcher {
}
}
The EventDispatcher class has public methods called addEventListener( ) and removeEventListener( ) that you can call from any instance of an EventDispatcher subclass to register event listeners. EventDispatcher also defines a protected method called dispatchEvent( ), which you can call from within a subclass to dispatch an event. The dispatchEvent( ) method requires at least one parameter as a flash.events.Event object or a subclass of Event.
posted @
2007-01-13 15:09 The Matrix 阅读(461) |
评论 (0) |
编辑 收藏
Another option is to use implicit getters and setters. Implicit getters and setters are declared as methods, but they look like properties. The syntax for a getter is as follows:
public function get name( ):Datatype {
}
The syntax for a setter is as follows:
public function set name(value:Datatype):void {
}
这样在代码中调用counter.count=5时相当于调用了set count(5)方法。
Counter类如下:
public class Counter {
private var _count:uint;
public function Counter( ) {
_count = 0;
}
public function get count( ):uint {
return _count;
}
public function set count(value:uint):void {
if(value < 100) {
_count = value;
}
else {
throw Error( );
}
}
}
posted @
2007-01-13 14:53 The Matrix 阅读(570) |
评论 (0) |
编辑 收藏