|
|
2011年10月25日
分析: 这个问题是google的面试题。由于一个字符串有很多种二叉表示法,貌似很难判断两个字符串是否可以做这样的变换。 对付复杂问题的方法是从简单的特例来思考,从而找出规律。 先考察简单情况: 字符串长度为1:很明显,两个字符串必须完全相同才可以。 字符串长度为2:当s1="ab", s2只有"ab"或者"ba"才可以。 对于任意长度的字符串,我们可以把字符串s1分为a1,b1两个部分,s2分为a2,b2两个部分,满足((a1~a2) && (b1~b2))或者 ((a1~b2) && (a1~b2)) 如此,我们找到了解决问题的思路。首先我们尝试用递归来写。 解法一(递归) 两个字符串的相似的必备条件是含有相同的字符集。简单的做法是把两个字符串的字符排序后,然后比较是否相同。 加上这个检查就可以大大的减少递归次数。 代码如下: public boolean isScramble(String s1, String s2) {
int l1 = s1.length();
int l2 = s2.length();
if(l1!=l2){
return false;
}
if(l1==0){
return true;
}
char[] c1 = s1.toCharArray();
char[] c2 = s2.toCharArray();
if(l1==1){
return c1[0]==c2[0];
}
Arrays.sort(c1);
Arrays.sort(c2);
for(int i=0;i<l1;++i){
if(c1[i]!=c2[i]){
return false;
}
}
boolean result = false;
for(int i=1;i<l1 && !result;++i){
String s11 = s1.substring(0,i);
String s12 = s1.substring(i);
String s21 = s2.substring(0,i);
String s22 = s2.substring(i);
result = isScramble(s11,s21) && isScramble(s12,s22);
if(!result){
String s31 = s2.substring(0,l1-i);
String s32 = s2.substring(l1-i);
result = isScramble(s11,s32) && isScramble(s12,s31);
}
}
return result;
} 解法二(动态规划) 减少重复计算的方法就是动态规划。动态规划是一种神奇的算法技术,不亲自去写,是很难完全掌握动态规划的。 这里我使用了一个三维数组boolean result[len][len][len],其中第一维为子串的长度,第二维为s1的起始索引,第三维为s2的起始索引。 result[k][i][j]表示s1[i...i+k]是否可以由s2[j...j+k]变化得来。 代码如下,非常简洁优美: public class Solution {
public boolean isScramble(String s1, String s2) {
int len = s1.length();
if(len!=s2.length()){
return false;
}
if(len==0){
return true;
}
char[] c1 = s1.toCharArray();
char[] c2 = s2.toCharArray();
boolean[][][] result = new boolean[len][len][len];
for(int i=0;i<len;++i){
for(int j=0;j<len;++j){
result[0][i][j] = (c1[i]==c2[j]);
}
}
for(int k=2;k<=len;++k){
for(int i=len-k;i>=0;--i){
for(int j=len-k;j>=0;--j){
boolean r = false;
for(int m=1;m<k && !r;++m){
r = (result[m-1][i][j] && result[k-m-1][i+m][j+m]) || (result[m-1][i][j+k-m] && result[k-m-1][i+m][j]);
}
result[k-1][i][j] = r;
}
}
}
return result[len-1][0][0];
}
}
分析: 因为要求结果集是升序排列,所以首先我们要对数组进行排序。 子集的长度可以从0到整个数组的长度。长度为n+1的子集可以由长度为n的子集再加上在之后的一个元素组成。 这里我使用了三个技巧 1。使用了一个index数组来记录每个子集的最大索引,这样添加新元素就很简单。 2。使用了两个变量start和end来记录上一个长度的子集在结果中的起始和终止位置。 3。去重处理使用了一个last变量记录前一次的值,它的初始值设为S[0]-1,这样就保证了和数组的任何一个元素不同。 代码如下: public class Solution {
public ArrayList<ArrayList<Integer>> subsetsWithDup(int[] S) {
Arrays.sort(S);
ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>();
ArrayList<Integer> indexs = new ArrayList<Integer>();
result.add(new ArrayList<Integer>());
indexs.add(-1);
int slen = S.length;
int start=0,end=0;
for(int len=1;len<=slen;++len){
int e = end;
for(int i=start;i<=end;++i){
ArrayList<Integer> ss = result.get(i);
int index = indexs.get(i).intValue();
int last = S[0]-1;
for(int j = index+1;j<slen;++j){
int v = S[j];
if(v!=last){
ArrayList<Integer> newss = new ArrayList<Integer>(ss);
newss.add(v);
result.add(newss);
indexs.add(j);
++e;
last = v;
}
}
}
start = end+1;
end = e;
}
return result;
}
}
分析: 格雷码的序列中应包含2^n个数。这个问题初看起来不容易,我们要想出一个生成方法。 对于n=2,序列是: 00,01,11,10 那对于n=3,如何利用n=2的序列呢?一个方法是,先在n=2的四个序列前加0(这其实是保持不变),然后再考虑把最高位变成1,只需要把方向反过来就可以了 000,001,011,010 100,101,111,110-> 110,111,101,100 把这两行合起来就可以得到新的序列。 想通了,写代码就很容易了。 public class Solution {
public ArrayList<Integer> grayCode(int n) {
ArrayList<Integer> result = new ArrayList<Integer>();
result.add(0);
if(n>0){
result.add(1);
}
int mask = 1;
for(int i=2;i<=n;++i){
mask *= 2;
for(int j=result.size()-1;j>=0;--j){
int v = result.get(j).intValue();
v |= mask;
result.add(v);
}
}
return result;
}
}
解法一:(递归) 一个简单的想法,是遍历s3的每个字符,这个字符必须等于s1和s2的某个字符。如果都不相等,则返回false 我们使用3个变量i,j,k分别记录当前s1,s2,s3的字符位置。 如果s3[k] = s1[i], i向后移动一位。如果s3[k]=s2[j],j向后移动一位。 这个题目主要难在如果s1和s2的字符出现重复的时候,就有两种情况,i,j都可以向后一位。 下面的算法在这种情况使用了递归,很简单的做法。但是效率非常差,是指数复杂度的。 public class Solution {
public boolean isInterleave(String s1, String s2, String s3) {
int l1 = s1.length();
int l2 = s2.length();
int l3 = s3.length();
if(l1+l2!=l3){
return false;
}
char[] c1 = s1.toCharArray();
char[] c2 = s2.toCharArray();
char[] c3 = s3.toCharArray();
int i=0,j=0;
for(int k=0;k<l3;++k){
char c = c3[k];
boolean m1 = i<l1 && c==c1[i];
boolean m2 = j<l2 && c==c2[j];
if(!m1 && !m2){
return false;
}
else if(m1 && m2){
String news3 = s3.substring(k+1);
return isInterleave(s1.substring(i+1),s2.substring(j),news3)
|| isInterleave(s1.substring(i),s2.substring(j+1),news3);
}
else if(m1){
++i;
}
else{
++j;
}
}
return true;
}
} 解法二:(动态规划) 为了减少重复计算,就要使用动态规划来记录中间结果。 这里我使用了一个二维数组result[i][j]来表示s1的前i个字符和s2的前j个字符是否能和s3的前i+j个字符匹配。 状态转移方程如下: result[i,j] = (result[i-1,j] && s1[i] = s3[i+j]) || (result[i,j-1] && s2[j] = s3[i+j]); 其中0≤i≤len(s1) ,0≤j≤len(s2)
这样算法复杂度就会下降到O(l1*l2)
public class Solution {
public boolean isInterleave(String s1, String s2, String s3) {
int l1 = s1.length();
int l2 = s2.length();
int l3 = s3.length();
if(l1+l2!=l3){
return false;
}
char[] c1 = s1.toCharArray();
char[] c2 = s2.toCharArray();
char[] c3 = s3.toCharArray();
boolean[][] result = new boolean[l1+1][l2+1];
result[0][0] = true;
for(int i=0;i<l1;++i){
if(c1[i]==c3[i]){
result[i+1][0] = true;
}
else{
break;
}
}
for(int j=0;j<l2;++j){
if(c2[j]==c3[j]){
result[0][j+1] = true;
}
else{
break;
}
}
for(int i=1;i<=l1;++i){
char ci = c1[i-1];
for(int j=1;j<=l2;++j){
char cj = c2[j-1];
char ck = c3[i+j-1];
result[i][j] = (result[i][j-1] && cj==ck) || (result[i-1][j] && ci==ck);
}
}
return result[l1][l2];
}
}
摘要: 给定一个由n个整数组成的数组S,是否存在S中的三个数a,b,c使得 a+b+c=0?找出所有的不重复的和为0的三元组。
注意:
1.三元组的整数按照升序排列 a 2.给出的结果中不能含有相同的三元组 阅读全文
摘要: 给定两个字符串S和T,计算S的子序列为T的个数。
这里的字符串的子序列指的是删除字符串的几个字符(也可以不删)而得到的新的字符串,但是不能改变字符的相对位置。
比如“ACE”是“ABCDE”的子序列,但是“AEC”就不是。
如果S=“rabbbit” T=“rabit”,有3种不同的子序列为T的构成方法,那么结果应该返回3。 阅读全文
分析: 题目不难,但是在面试时,在有限的时间内,没有bug写出,还是很考验功力的。 解决这个问题的思路是逐层扫描,上一层设置好下一层的next关系,在处理空指针的时候要格外小心。 代码如下,有注释,应该很容易看懂: 使用了三个指针: node:当前节点 firstChild:下一层的第一个非空子节点 lastChild:下一层的最后一个待处理(未设置next)的子节点 public void connect(TreeLinkNode root) {
TreeLinkNode node = root;
TreeLinkNode firstChild = null;
TreeLinkNode lastChild = null;
while(node!=null){
if(firstChild == null){ //记录第一个非空子节点
firstChild = node.left!=null?node.left:node.right;
}
//设置子节点的next关系,3种情况
if(node.left!=null && node.right!=null){
if(lastChild!=null){
lastChild.next = node.left;
}
node.left.next = node.right;
lastChild = node.right;
}
else if(node.left!=null){
if(lastChild!=null){
lastChild.next = node.left;
}
lastChild = node.left;
}
else if(node.right!=null){
if(lastChild!=null){
lastChild.next = node.right;
}
lastChild = node.right;
}
//设置下一个节点,如果本层已经遍历完毕,移到下一层的第一个子节点
if(node.next!=null){
node = node.next;
}
else{
node = firstChild;
firstChild = null;
lastChild = null;
}
}
}
分析: 这道题相比之前的两道题,难度提高了不少。 因为限制了只能交易两次,所以我们可以把n天分为两段,分别计算这两段的最大收益,就可以得到一个最大收益。穷举所有这样的分法,就可以得到全局的最大收益。 为了提高效率,这里使用动态规划,即把中间状态记录下来。使用了两个数组profits,nprofits分别记录从0..i和i..n的最大收益。 代码如下: public int maxProfit(int[] prices) {
int days = prices.length;
if(days<2){
return 0;
}
int[] profits = new int[days];
int min = prices[0];
int max = min;
for(int i=1;i<days;++i){
int p = prices[i];
if(min>p){
max = min = p;
}
else if(max<p){
max = p;
}
int profit = max - min;
profits[i] = (profits[i-1]>profit)?profits[i-1]:profit;
}
int[] nprofits = new int[days];
nprofits[days-1] = 0;
max = min = prices[days-1];
for(int i=days-2;i>=0;--i){
int p = prices[i];
if(min>p){
min =p;
}
else if(max<p){
max = min = p;
}
int profit = max - min;
nprofits[i] = (nprofits[i+1]>profit)?nprofits[i+1]:profit;
}
int maxprofit = 0;
for(int i=0;i<days;++i){
int profit = profits[i]+nprofits[i];
if(maxprofit<profit){
maxprofit = profit;
}
}
return maxprofit;
}
分析:为了得到最大收益,必须在所有上升的曲线段的开始点买入,在最高点卖出。而在下降阶段不出手。  实现代码如下: public class Solution {
public int maxProfit(int[] prices) {
int len = prices.length;
if(len<2){
return 0;
}
int min=0;
int result = 0;
boolean inBuy = false;
for(int i=0;i<len-1;++i){
int p = prices[i];
int q = prices[i+1];
if(!inBuy){
if(q>p){
inBuy = true;
min=p ;
}
}
else{
if(q<p){
result += (p-min);
inBuy = false;
}
}
}
if(inBuy){
result += ((prices[len-1])-min);
}
return result;
}
}
摘要: 假设你有一个数组包含了每天的股票价格,它的第i个元素就是第i天的股票价格。
你只能进行一次交易(一次买进和一次卖出),设计一个算法求出最大的收益。 阅读全文
摘要: 给定一个二叉树,寻找最大的路径和.
路径可以从任意节点开始到任意节点结束。(也可以是单个节点)
比如:对于二叉树
1
/ \
2 3
和最大的路径是2->1->3,结果为6
/**
* Definition for binary tree
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/ 阅读全文
摘要: 给定两个单词(一个开始,一个结束)和一个字典,找出所有的最短的从开始单词到结束单词的变换序列的序列(可能不止一个),并满足:
1.每次只能变换一个字母
2.所有的中间单词必须存在于字典中
比如:
输入:
start = "hit"
end = "cog"
dict = ["hot","dot","dog","lot","log"]
那么最短的变化序列有两个
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]。
注意:
1. 所有单词的长度都是相同的
2. 所有单词都只含有小写的字母。 阅读全文
摘要: 给定两个排序好的数组A和B,把B合并到A并保持排序。
public class Solution {
public void merge(int A[], int m, int B[], int n) {
//write your code here }
}
注意:
假定A有足够的额外的容量储存B的内容,m和n分别为A和B的初始化元素的个数。要求算法复杂度在O(m+n)。 阅读全文
摘要: 给定两个单词(一个开始,一个结束)和一个字典,找出最短的从开始单词到结束单词的变换序列的长度,并满足:
1.每次只能变换一个字母
2.所有的中间单词必须存在于字典中
比如:
输入:
start = "hit"
end = "cog"
dict = ["hot","dot","dog","lot","log"]
那么最短的变化序列是"hit" -> "hot" -> "dot" -> "dog" -> "cog",所以返回长度是5。
注意:
1. 如果找不到这样的序列,返回0
2. 所有单词的长度都是相同的
3. 所有单词都只含有小写的字母。 阅读全文
摘要: 给定一个二叉树,每个节点的值是一个数字(0-9),每个从根节点到叶节点均能组成一个数字。
比如如果从根节点到叶节点的路径是1-2-3,那么这代表了123这个数字。
求出所有这样从根节点到叶节点的数字之和。
比如,对于二叉树
1
/ \
2 3
一共有两条路径1->2和1->3,那么求和的结果就是12+13=25
/**
* Definition for binary tree
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Solution {
public int sumNumbers(TreeNode root) {
//write c 阅读全文
摘要: 给定一个2D的棋盘,含有‘X'和’O',找到所有被‘X'包围的’O',然后把该区域的‘O’都变成'X'。
例子-输入:
X X X X
X O O X
X X O X
X O X X
应该输出:
X X X X
X X X X
X X X X
X O X X
public void solve(char[][] board) {
} 阅读全文
摘要: 给定一个字符串s,切割字符串使得每个子串都是回文的。(比如aba,对称)
要求返回所有可能的分割。
比如,对于字符串s="aab",
返回:
[
["aa","b"],
["a","a","b"]
]
阅读全文
摘要: 给定一个有由数字构成的数组表示的数,求该数加1的结果。
public class Solution {
public int[] plusOne(int[] digits) {
}
} 阅读全文
摘要: 实现 int sqrt(int x);
计算和返回x的平方根。 阅读全文
摘要: 给定一个未排序的整数数组,求最长的连续序列的长度。要求算法的时间复杂度在O(n)
比如对于数组[100, 4, 200, 1, 3, 2],其中最长序列为[1,2,3,4],所以应该返回4
public class Solution {
public int longestConsecutive(int[] num) {
//write your code here
}
} 阅读全文
摘要: 给定一个字符串s,分割s使得每个子串都是回文的(即倒过来和原字符串是一样的,如aba)
求最少的分割次数。 阅读全文
问题描述: Problem Statement THIS PROBLEM WAS TAKEN FROM THE SEMIFINALS OF THE TOPCODER INVITATIONAL TOURNAMENT DEFINITION Class Name: MatchMaker Method Name: getBestMatches Paramaters: String[], String, int Returns: String[] Method signature (be sure your method is public): String[] getBestMatches(String[] members, String currentUser, int sf); PROBLEM STATEMENT A new online match making company needs some software to help find the "perfect couples". People who sign up answer a series of multiple-choice questions. Then, when a member makes a "Get Best Mates" request, the software returns a list of users whose gender matches the requested gender and whose answers to the questions were equal to or greater than a similarity factor when compared to the user's answers. Implement a class MatchMaker, which contains a method getBestMatches. The method takes as parameters a String[] members, String currentUser, and an int sf: - members contains information about all the members. Elements of members are of the form "NAME G D X X X X X X X X X X" * NAME represents the member's name * G represents the gender of the current user. * D represents the requested gender of the potential mate. * Each X indicates the member's answer to one of the multiple-choice questions. The first X is the answer to the first question, the second is the answer to the second question, et cetera. - currentUser is the name of the user who made the "Get Best Mates" request. - sf is an integer representing the similarity factor. The method returns a String[] consisting of members' names who have at least sf identical answers to currentUser and are of the requested gender. The names should be returned in order from most identical answers to least. If two members have the same number of identical answers as the currentUser, the names should be returned in the same relative order they were inputted. TopCoder will ensure the validity of the inputs. Inputs are valid if all of the following criteria are met: - members will have between 1 and 50 elements, inclusive. - Each element of members will have a length between 7 and 44, inclusive. - NAME will have a length between 1 and 20, inclusive, and only contain uppercase letters A-Z. - G can be either an uppercase M or an uppercase F. - D can be either an uppercase M or an uppercase F. - Each X is a capital letter (A-D). - The number of Xs in each element of the members is equal. The number of Xs will be between 1 and 10, inclusive. - No two elements will have the same NAME. - Names are case sensitive. - currentUser consists of between 1 and 20, inclusive, uppercase letters, A-Z, and must be a member. - sf is an int between 1 and 10, inclusive. - sf must be less than or equal to the number of answers (Xs) of the members. NOTES The currentUser should not be included in the returned list of potential mates. EXAMPLES For the following examples, assume members = {"BETTY F M A A C C", "TOM M F A D C A", "SUE F M D D D D", "ELLEN F M A A C A", "JOE M F A A C A", "ED M F A D D A", "SALLY F M C D A B", "MARGE F M A A C C"} If currentUser="BETTY" and sf=2, BETTY and TOM have two identical answers and BETTY and JOE have three identical answers, so the method should return {"JOE","TOM"}. If currentUser="JOE" and sf=1, the method should return {"ELLEN","BETTY","MARGE"}. If currentUser="MARGE" and sf=4, the method should return []. Definition Class: MatchMaker Method: getBestMatches Parameters: String[], String, int Returns: String[] Method signature: String[] getBestMatches(String[] param0, String param1, int param2) (be sure your method is public) ================================================================我的代码============= import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class MatchMaker {
enum GENDER{MALE,FEMALE};
//"NAME G D X X X X X X X X X X"
private static class Member{
String name;
GENDER gender;
GENDER mate;
String[] answers;
int index;
int matched = 0;
}
String[] getBestMatches(String[] members, String currentUser, int sf){
List<Member> allMembers = new ArrayList<Member>();
Member cu = null;
for(int i=0;i<members.length;++i){
String m = members[i];
String[] c = m.split(" ");
Member mem = new Member();
mem.name= c[0];
mem.gender = c[1].equals("M")?GENDER.MALE:GENDER.FEMALE;
mem.mate = c[2].equals("M")?GENDER.MALE:GENDER.FEMALE;
mem.index = i;
mem.matched = 0;
String[] answers = mem.answers = new String[c.length-3];
for(int j=3;j<c.length;++j){
answers[j-3] = c[j];
}
allMembers.add(mem);
if(c[0].equals(currentUser)){
cu = mem;
}
}
List<Member> matched = new ArrayList<Member>();
if(cu!=null){
for(Member mem:allMembers){
if(mem!=cu && mem.gender==cu.mate){
for(int i=0;i<mem.answers.length;++i){
if(mem.answers[i].equals(cu.answers[i])){
++mem.matched;
}
}
if(mem.matched>=sf){
matched.add(mem);
}
}
}
Collections.sort(matched, new Comparator<Member>(){
public int compare(Member ma, Member mb) {
if(ma.matched!=mb.matched){
return mb.matched - ma.matched;
}
return ma.index-mb.index;
}
});
String[] result = new String[matched.size()];
for(int i=0;i<result.length;++i){
result[i] = matched.get(i).name;
}
return result;
}
return new String[0];
}
}
以下是我在上一家公司出的java笔试题,有些难度,感兴趣的同学可以做做看。 ---Question--- 1.What is the output of the following program? public class Foo { public static void main(String[] args){ Map<byte[], String> m = new HashMap<byte[], String>(); byte[] key = "abcd".getBytes(); m.put(key, "abcd"); System.out.println(m.containsKey(key)); System.out.println(m.containsKey("abcd")); System.out.println(m.containsKey("abcd".getBytes())); } } a) true,true,false b)true,false,false c)true,true,true d) false,false,false e)Program throws an exception 2. What is the proper string filled in the following program? Public class Foo { public static void main(String[] args) { String s=”1\\2\\3\\4”; //split the string with “\” String []result = s.split(“____”); for(String r:result){ System.out.println(r); } } } a) \ b) \\ c) \\\ d)\\\\ e)\\\\\ 3. What is the output of the following program? public class Foo { public static void main(String[] args) { char[] c = new char[] { '1' }; String s = new String(c); System.out.println("abcd" + c); System.out.println("abcd" + s); } } a) Compile error b)abcd1,abcd1 c) abcd49,abcd1 d) Program throws an exception e)none of above 4. Which class is threading safe which one object can be used between multi-threads without extra synchronized? a) Vector b) HashMap c) ArrayList d)StringBuilder e)HashSet 5. What is the output of the following program? public class Foo { public static void main(String[] args) throws IOException { ByteArrayOutputStream baos = new ByteArrayOutputStream(); byte[] b = new byte[]{(byte)0x0,(byte)0x1,(byte)0x2}; baos.write(b); baos.write(0x0102); byte[] result = baos.toByteArray(); ByteArrayInputStream bais = new ByteArrayInputStream(result); System.out.println(bais.available()); } } a) 0 b) 1 c)4 d) 5 e) Program throws an exception 6. What is return value of function “calc”? public class Foo { public static int calc() throws IOException{ int ret = 0; try{ ++ret; throw new IOException("try"); } catch(IOException ioe){ --ret; return ret; } finally{ ++ret; return ret; } } } a) 0 b) 1 c)2 d)3 e) throws an exception 7. What is the output of the following program? public class Foo { public static class Value { private int value; public int get(){ return value; } public void set(int v){ value = v; } } public static class Values implements Iterable<Value>{ public Values(int capacity){ this.capacity = capacity; } int count =1 ; int capacity; Value v = new Value(); public Iterator<Value> iterator() { return new Iterator<Value>(){ public boolean hasNext() { return count<=capacity; } public Value next() { v.set(count++); return v; } public void remove() { throw new UnsupportedOperationException(); } }; } } public static void main(String[] args) { Values vs = new Values(10); Value result = null; for(Value v:vs){ if(result == null){ result = v; } else{ result.set(result.get()+v.get()); } } System.out.println(result.get()); } } a) 20 b)40 c)45 d)55 e)throws NullpointerException 8. If add keyword “final” before a class member function, it means: a) The method can’t access the non-final member variable. b) The method can’t modify the member variable. c) The method can’t be override by subclass. d) The method is a thread-safe function. e) The method can’t be accessed by other non-final function. 9. About java memory and garbage collector, which statement is correct? a) Moving variable from locale to class will make GC more effectively. b) When Full GC is executing, all the user threads will be paused. c) If object A contains a reference of object B and object B contains a reference of object A, the two objects can’t be reclaimed by GC. d) When a thread exits, all objects which created by that thread will be reclaimed e) It is recommended that calling “System.gc()” to control the memory usage. 10. About java classpath and classloader, which statement is NOT correct? a) User can specify the classpath by using the option “-cp” in Java command line. b) If user doesn’t specify classpath, the JVM search the class from the current folder by default. c) A JVM can load two different versions of a library. d) To define customized class loader, it is possible to load class from internet at runtime. 11. Which data structure has best performance when remove an element from it? a) Vector b)ArrayList c)LinkedList d)HashMap e)HashSet 12. Which is the correct way to convert bytes from charset “gb2312” to “utf-8”? byte[] src , dst; a) dst = new String(src,”utf-8”).getBytes(“gb2312”); b) dst = new String(src,”gb2312”).getBytes(“utf-8”); c) dst = new String(src,”utf-16”).getBytes(); d) dst = new String(src).getBytes(); e) None of above.
摘要: 准备工作:1. 下载Snappy库Download source code from: http://code.google.com/p/snappy编译并安装./configure & make & sudo make install2. 编译leveldb自带的db_benchmake db_bench注意:在ubuntu 11.04上编译会出错,修改makefile:$(CX... 阅读全文
leveldb读数据 先看看ReadOptions有哪些参数可以指定: // Options that control read operations
struct ReadOptions {
// 是否检查checksum
// Default: false
bool verify_checksums;
// 是否将此次结果放入cache
// Default: true
bool fill_cache;
//是否指定snapshot,否则读取当前版本
// Default: NULL
const Snapshot* snapshot;
ReadOptions()
: verify_checksums(false),
fill_cache(true),
snapshot(NULL) {
}
}; 下面看看读取的详细过程: 查询memtable=>查询previous memtable(imm_)=>查询文件(缓冲) Status DBImpl::Get(const ReadOptions& options,
const Slice& key,
std::string* value) {
Status s;
MutexLock l(&mutex_);
SequenceNumber snapshot;
//设置snapshot
if (options.snapshot != NULL) {
snapshot = reinterpret_cast<const SnapshotImpl*>(options.snapshot)->number_;
} else {
snapshot = versions_->LastSequence();
}
MemTable* mem = mem_;
MemTable* imm = imm_;
Version* current = versions_->current();
mem->Ref();
if (imm != NULL) imm->Ref();
current->Ref();
bool have_stat_update = false;
Version::GetStats stats;
// Unlock while reading from files and memtables
{
mutex_.Unlock();
LookupKey lkey(key, snapshot);
//先查询memtable
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != NULL && imm->Get(lkey, value, &s)) { //然后查询previous memtable:imm_
// Done
} else {
//从文件中读取
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
}
mutex_.Lock();
}
//是否有文件需要被compaction,参见allowed_seek
if (have_stat_update && current->UpdateStats(stats)) {
MaybeScheduleCompaction();
}
mem->Unref();
if (imm != NULL) imm->Unref();
current->Unref();
return s;
} 重点来看看从version中读取: Status Version::Get(const ReadOptions& options,
const LookupKey& k,
std::string* value,
GetStats* stats) {
Slice ikey = k.internal_key();
Slice user_key = k.user_key();
const Comparator* ucmp = vset_->icmp_.user_comparator();
Status s;
stats->seek_file = NULL;
stats->seek_file_level = -1;
FileMetaData* last_file_read = NULL;
int last_file_read_level = -1;
//从level0向高层查找,如果再低级level中查到,则不再查询
std::vector<FileMetaData*> tmp;
FileMetaData* tmp2;
for (int level = 0; level < config::kNumLevels; level++) {
size_t num_files = files_[level].size();
//本层文件数为空,则返回
if (num_files == 0) continue;
// Get the list of files to search in this level
FileMetaData* const* files = &files_[level][0];
if (level == 0) {
//level0特殊处理,因为key是重叠,所有符合条件的文件必须被查找
tmp.reserve(num_files);
for (uint32_t i = 0; i < num_files; i++) {
FileMetaData* f = files[i];
if (ucmp->Compare(user_key, f->smallest.user_key()) >= 0 &&
ucmp->Compare(user_key, f->largest.user_key()) <= 0) {
tmp.push_back(f);
}
}
if (tmp.empty()) continue;
std::sort(tmp.begin(), tmp.end(), NewestFirst);
files = &tmp[0];
num_files = tmp.size();
} else {
// 二分法查找,某个key只可能属于一个文件
uint32_t index = FindFile(vset_->icmp_, files_[level], ikey);
//没有查到
if (index >= num_files) {
files = NULL;
num_files = 0;
} else {
tmp2 = files[index];
if (ucmp->Compare(user_key, tmp2->smallest.user_key()) < 0) {
// All of "tmp2" is past any data for user_key
files = NULL;
num_files = 0;
} else {
files = &tmp2;
num_files = 1;
}
}
}
for (uint32_t i = 0; i < num_files; ++i) { //遍历本层符合条件的文件
if (last_file_read != NULL && stats->seek_file == NULL) {
//seek_file只记录第一个
stats->seek_file = last_file_read;
stats->seek_file_level = last_file_read_level;
}
FileMetaData* f = files[i];
last_file_read = f;
last_file_read_level = level;
//从table cache中读取
Iterator* iter = vset_->table_cache_->NewIterator(
options,
f->number,
f->file_size);
iter->Seek(ikey);
const bool done = GetValue(ucmp, iter, user_key, value, &s);
if (!iter->status().ok()) { //查找到
s = iter->status();
delete iter;
return s;
} else {
delete iter;
if (done) {
return s;
}
}
}
}
return Status::NotFound(Slice()); // Use an empty error message for speed
} 继续跟踪:TableCache Iterator* TableCache::NewIterator(const ReadOptions& options,
uint64_t file_number,
uint64_t file_size,
Table** tableptr) {
if (tableptr != NULL) {
*tableptr = NULL;
}
char buf[sizeof(file_number)];
EncodeFixed64(buf, file_number);
Slice key(buf, sizeof(buf));
//从LRU cache中查找
Cache::Handle* handle = cache_->Lookup(key);
if (handle == NULL) {
/加载文件
std::string fname = TableFileName(dbname_, file_number);
RandomAccessFile* file = NULL;
Table* table = NULL;
Status s = env_->NewRandomAccessFile(fname, &file);
if (s.ok()) {
s = Table::Open(*options_, file, file_size, &table);
}
if (!s.ok()) {
assert(table == NULL);
delete file;
// We do not cache error results so that if the error is transient,
// or somebody repairs the file, we recover automatically.
return NewErrorIterator(s);
}
//插入Cache
TableAndFile* tf = new TableAndFile;
tf->file = file;
tf->table = table;
handle = cache_->Insert(key, tf, 1, &DeleteEntry);
}
Table* table = reinterpret_cast<TableAndFile*>(cache_->Value(handle))->table;
//从Table对象中生成iterator
Iterator* result = table->NewIterator(options);
result->RegisterCleanup(&UnrefEntry, cache_, handle);
if (tableptr != NULL) {
*tableptr = table;
}
return result;
}
总体来说,leveldb的写操作有两个步骤,首先是针对log的append操作,然后是对memtable的插入操作。 影响写性能的因素有: 1. write_buffer_size2. kL0_SlowdownWritesTrigger and kL0_StopWritesTrigger.提高这两个值,能够增加写的性能,但是降低读的性能 看看WriteOptions有哪些参数可以指定 struct WriteOptions {
//设置sync=true,leveldb会调用fsync(),这会降低插入性能
//同时会增加数据的安全性
//Default: false
bool sync;
WriteOptions()
: sync(false) {
}
}; 首先把Key,value转成WriteBatch Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
} 接下来就是真正的插入了 这里使用了两把锁,主要是想提高并发能力,减少上锁的时间。 首先是检查是否可写,然后append log,最后是插入memtable <db/dbimpl.cc> Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
Status status;
//加锁
MutexLock l(&mutex_);
LoggerId self;
//拿到写log的权利
AcquireLoggingResponsibility(&self);
//检查是否可写
status = MakeRoomForWrite(false); // May temporarily release lock and wait
uint64_t last_sequence = versions_->LastSequence();
if (status.ok()) {
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(updates);
// Add to log and apply to memtable. We can release the lock during
// this phase since the "logger_" flag protects against concurrent
// loggers and concurrent writes into mem_.
{
assert(logger_ == &self);
mutex_.Unlock();
//IO操作:写入LOG
status = log_->AddRecord(WriteBatchInternal::Contents(updates));
if (status.ok() && options.sync) {
status = logfile_->Sync();
}
//插入memtable
if (status.ok()) {
status = WriteBatchInternal::InsertInto(updates, mem_);
}
mutex_.Lock();
assert(logger_ == &self);
}
//设置新的seqence number
versions_->SetLastSequence(last_sequence);
}
//释放写LOG锁
ReleaseLoggingResponsibility(&self);
return status;
} 写流量控制: <db/dbimpl.cc> Status DBImpl::MakeRoomForWrite(bool force) {
mutex_.AssertHeld();
assert(logger_ != NULL);
bool allow_delay = !force;
Status s;
while (true) {
if (!bg_error_.ok()) {
// Yield previous error
s = bg_error_;
break;
} else if (
allow_delay &&
versions_->NumLevelFiles(0) >= config::kL0_SlowdownWritesTrigger) {
mutex_.Unlock();
//如果level0的文件大于kL0_SlowdownWritesTrigger阈值,则sleep 1s,这样给compaction更多的CPU
env_->SleepForMicroseconds(1000);
allow_delay = false; // Do not delay a single write more than once
mutex_.Lock();
} else if (!force &&
(mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) {
//可写
break;
} else if (imm_ != NULL) {
// imm_:之前的memtable 没有被compaction,需要等待
bg_cv_.Wait();
} else if (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) {
// level0文件个数大于kL0_StopWritesTrigger,需要等待
Log(options_.info_log, "waiting \n"); \n");
bg_cv_.Wait();
} else {
//生成新的额memtable和logfile,把当前memtable传给imm_
assert(versions_->PrevLogNumber() == 0);
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = NULL;
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
if (!s.ok()) {
break;
}
delete log_;
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.Release_Store(imm_);
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
// 发起compaction,dump imm_
MaybeScheduleCompaction();
}
}
return s;
}
摘要: leveldb 是通过Open函数来打开/新建数据库。Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->static Status Open(const Options& options, &nb... 阅读全文
我们知道,leveldb在写数据的时候,除了log文件,都要在内存中写一份。 先看看SkipList【跳表】这个数据结构: 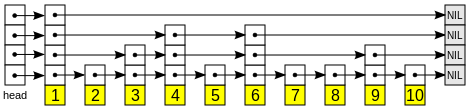 SkipList有如下特点: 1. 本质上一个排序好的链表 2. 分层,上层节点比下层的少,更具有跳跃性 3. 查询的复杂度是O(logn) SkipList跟红黑树等还是比较容易实现和理解的,主要长处是比较容易实现Lock free和遍历。 我们来看看leveldb的实现 插入: //插入一个新的key
template<typename Key, class Comparator>
void SkipList<Key,Comparator>::Insert(const Key& key) {
//查找插入节点,prev为各层的前置节点
Node* prev[kMaxHeight];
Node* x = FindGreaterOrEqual(key, prev);
// Our data structure does not allow duplicate insertion
assert(x == NULL || !Equal(key, x->key));
//生成随机高度
int height = RandomHeight();
if (height > GetMaxHeight()) {
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
//设置当前最大高度
max_height_.NoBarrier_Store(reinterpret_cast<void*>(height));
}
//生成新节点
x = NewNode(key, height);
for (int i = 0; i < height; i++) {
//设置新节点的各层的下一跳
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
//设置前节点的next为当前节点,完成插入
prev[i]->SetNext(i, x);
}
} 查询: template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node* SkipList<Key,Comparator>::FindGreaterOrEqual(const Key& key, Node** prev)
const {
Node* x = head_;
int level = GetMaxHeight() - 1; //从高层开始查找,依次到0 level
while (true) {
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) { //比next key 要大
// Keep searching in this list
x = next;
} else { //比next key小,查找下一层
//标记当前level的前置节点
if (prev != NULL) prev[level] = x;
if (level == 0) {
return next;
} else {
level--;
}
}
}
}
template<typename Key, class Comparator>
bool SkipList<Key,Comparator>::Contains(const Key& key) const {
Node* x = FindGreaterOrEqual(key, NULL);
if (x != NULL && Equal(key, x->key)) {
return true;
} else {
return false;
}
} 接着我们看看leveldb MemTable的实现,很简单了,基本是对SkipList访问一个封装 <db/memtable.h> class MemTable {
public:
explicit MemTable(const InternalKeyComparator& comparator);
//增加引用计数
void Ref() { ++refs_; }
//减少引用计数
void Unref() {
--refs_;
assert(refs_ >= 0);
if (refs_ <= 0) {
delete this;
}
}
//内存使用量
size_t ApproximateMemoryUsage();
//遍历操作
Iterator* NewIterator();
//插入
void Add(SequenceNumber seq, ValueType type,
const Slice& key,
const Slice& value);
//查询
bool Get(const LookupKey& key, std::string* value, Status* s);
private:
~MemTable(); // Private since only Unref() should be used to delete it
//key compartor,用于排序
struct KeyComparator {
const InternalKeyComparator comparator;
explicit KeyComparator(const InternalKeyComparator& c) : comparator(c) { }
int operator()(const char* a, const char* b) const;
};
friend class MemTableIterator;
friend class MemTableBackwardIterator;
typedef SkipList<const char*, KeyComparator> Table;
KeyComparator comparator_;
int refs_; //引用计数
Arena arena_; //内存分配器
Table table_; //数据存放SkipList
// No copying allowed
MemTable(const MemTable&);
void operator=(const MemTable&);
}; 先看看插入 <db/memtable.cc> void MemTable::Add(SequenceNumber s, ValueType type,
const Slice& key,
const Slice& value) {
//数据结构:
//1.internal key size : Varint32 (length of 2+3)
//2.key data
//3.SequenceNumber+Key type: 8 bytes
//4 value size: Varint32
//5 value data
size_t key_size = key.size();
size_t val_size = value.size();
size_t internal_key_size = key_size + 8;
const size_t encoded_len =
VarintLength(internal_key_size) + internal_key_size +
VarintLength(val_size) + val_size;
char* buf = arena_.Allocate(encoded_len);
char* p = EncodeVarint32(buf, internal_key_size);
memcpy(p, key.data(), key_size);
p += key_size;
EncodeFixed64(p, (s << 8) | type);
p += 8;
p = EncodeVarint32(p, val_size);
memcpy(p, value.data(), val_size);
assert((p + val_size) - buf == encoded_len);
table_.Insert(buf);
} 查询 <db/memtable.cc> bool MemTable::Get(const LookupKey& key, std::string* value, Status* s) {
Slice memkey = key.memtable_key();
Table::Iterator iter(&table_);
iter.Seek(memkey.data());
if (iter.Valid()) {
// entry format is:
// klength varint32
// userkey char[klength]
// tag uint64
// vlength varint32
// value char[vlength]
// Check that it belongs to same user key. We do not check the
// sequence number since the Seek() call above should have skipped
// all entries with overly large sequence numbers.
const char* entry = iter.key();
uint32_t key_length;
const char* key_ptr = GetVarint32Ptr(entry, entry+5, &key_length);
if (comparator_.comparator.user_comparator()->Compare(
Slice(key_ptr, key_length - 8),
key.user_key()) == 0) {
// Correct user key
const uint64_t tag = DecodeFixed64(key_ptr + key_length - 8);
switch (static_cast<ValueType>(tag & 0xff)) {
case kTypeValue: {
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
value->assign(v.data(), v.size());
return true;
}
case kTypeDeletion:
*s = Status::NotFound(Slice());
return true;
}
}
}
return false;
}
leveldb 使用 version 来保存数据库的状态。
先看看一个重要的数据结果,sst file的META info
<db/version_edit.h>
struct FileMetaData {
int refs; //引用计数
int allowed_seeks; //允许的seeks次数
uint64_t number;//文件编号
uint64_t file_size; //文件大小
InternalKey smallest; //最小的key
InternalKey largest; //最大的key
FileMetaData() : refs(0), allowed_seeks(1 << 30), file_size(0) { }
};
这里面有一个很有意思的字段: allowed_seeks,代表了可以seek的次数,为0的时候表示这个文件需要被compaction.如何设置seeks次数呢?文件大小除以16k,不到100算100。
f->allowed_seeks = (f->file_size / 16384);
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
原因,请看leveldb的注释:
// We arrange to automatically compact this file after a certain number of seeks. Let's assume:
// (1) One seek costs 10ms
// (2) Writing or reading 1MB costs 10ms (100MB/s)
// (3) A compaction of 1MB does 25MB of IO:
// 1MB read from this level
// 10-12MB read from next level (boundaries may be misaligned)
// 10-12MB written to next level
// This implies that 25 seeks cost the same as the compaction
// of 1MB of data. I.e., one seek costs approximately the
// same as the compaction of 40KB of data. We are a little
// conservative and allow approximately one seek for every 16KB
// of data before triggering a compaction.
接下来看Version的定义,version其实就是一系列的SST file的集合。
class Version {
public:
//生成iterator用于遍历
void AddIterators(const ReadOptions&, std::vector<Iterator*>* iters);
//根据key来查询,若没有查到,更新GetStats
struct GetStats {
FileMetaData* seek_file;
int seek_file_level;
};
Status Get(const ReadOptions&, const LookupKey& key, std::string* val,
GetStats* stats);
//是否需要进行compaction
bool UpdateStats(const GetStats& stats);
//引用计算,避免在被引用时候删除
void Ref();
void Unref();
//查询和key range有关的files
void GetOverlappingInputs(
int level,
const InternalKey* begin, // NULL means before all keys
const InternalKey* end, // NULL means after all keys
std::vector<FileMetaData*>* inputs);
//计算是否level对某个key range是否有overlap
bool OverlapInLevel(int level,
const Slice* smallest_user_key,
const Slice* largest_user_key);
//memtable output应该放到哪个level
int PickLevelForMemTableOutput(const Slice& smallest_user_key,
const Slice& largest_user_key);
//某个level的文件个数
int NumFiles(int level) const { return files_[level].size(); }
// Return a human readable string that describes this version's contents.
std::string DebugString() const;
private:
friend class Compaction;
friend class VersionSet;
class LevelFileNumIterator;
Iterator* NewConcatenatingIterator(const ReadOptions&, int level) const;
VersionSet* vset_; // VersionSet to which this Version belongs
Version* next_; // Next version in linked list
Version* prev_; // Previous version in linked list
int refs_; // Number of live refs to this version
//sst files
std::vector<FileMetaData*> files_[config::kNumLevels];
//下一个要被compaction的文件
FileMetaData* file_to_compact_;
int file_to_compact_level_;
//compaction score:>1表示要compaction
double compaction_score_;
int compaction_level_;
explicit Version(VersionSet* vset)
: vset_(vset), next_(this), prev_(this), refs_(0),
file_to_compact_(NULL),
file_to_compact_level_(-1),
compaction_score_(-1),
compaction_level_(-1) {
}
~Version();
// No copying allowed
Version(const Version&);
void operator=(const Version&);
};
那VersionSet呢?VersionSet 是version组成一个双向循环链表。 class VersionSet{
//. . .
Env* const env_;
const std::string dbname_;
const Options* const options_;
TableCache* const table_cache_;
const InternalKeyComparator icmp_;
uint64_t next_file_number_;
uint64_t manifest_file_number_;
uint64_t last_sequence_;
uint64_t log_number_;
WritableFile* descriptor_file_;
log::Writer* descriptor_log_;
Version dummy_versions_; // Head of circular doubly-linked list of versions.
Version* current_; // == dummy_versions_.prev_
//每层都有一个compact pointer用于指示下次从哪里开始compact,以用于实现循环compact
std::string compact_pointer_[config::kNumLevels];
//. . .
} VersionEdit是version对象的变更记录,用于写入manifest.这样通过原始的version加上一系列的versionedit的记录,就可以恢复到最新状态。 class VersionEdit {
public:
VersionEdit() { Clear(); }
~VersionEdit() { }
void Clear();
void SetComparatorName(const Slice& name) {
has_comparator_ = true;
comparator_ = name.ToString();
}
void SetLogNumber(uint64_t num) {
has_log_number_ = true;
log_number_ = num;
}
void SetPrevLogNumber(uint64_t num) {
has_prev_log_number_ = true;
prev_log_number_ = num;
}
void SetNextFile(uint64_t num) {
has_next_file_number_ = true;
next_file_number_ = num;
}
void SetLastSequence(SequenceNumber seq) {
has_last_sequence_ = true;
last_sequence_ = seq;
}
void SetCompactPointer(int level, const InternalKey& key) {
compact_pointers_.push_back(std::make_pair(level, key));
}
//添加meta file
void AddFile(int level, uint64_t file,
uint64_t file_size,
const InternalKey& smallest,
const InternalKey& largest) {
FileMetaData f;
f.number = file;
f.file_size = file_size;
f.smallest = smallest;
f.largest = largest;
new_files_.push_back(std::make_pair(level, f));
}
//删除特定的文件
void DeleteFile(int level, uint64_t file) {
deleted_files_.insert(std::make_pair(level, file));
}
//编码,解码:用于写入manifest
void EncodeTo(std::string* dst) const;
Status DecodeFrom(const Slice& src);
std::string DebugString() const;
private:
friend class VersionSet;
typedef std::set< std::pair<int, uint64_t> > DeletedFileSet;
std::string comparator_;
uint64_t log_number_;
uint64_t prev_log_number_;
uint64_t next_file_number_;
SequenceNumber last_sequence_;
bool has_comparator_;
bool has_log_number_;
bool has_prev_log_number_;
bool has_next_file_number_;
bool has_last_sequence_;
std::vector< std::pair<int, InternalKey> > compact_pointers_;
DeletedFileSet deleted_files_;
std::vector< std::pair<int, FileMetaData> > new_files_;
};
摘要: leveldb之所以使用level作为数据库名称,精华就在于level的设计。本质是一种归并排序算法。这样设计的好处主要是可以减少compaction的次数和每次的文件个数。Compaction为什么要compaction? compaction可以提高数据的查询效率,没有经过compaction,需要从很多SST file去查找,而做过compaction后,只需要从有限的SST文件去... 阅读全文
所谓snapshot就是一个快照,我们可以从快照中读到旧的数据。 先写一个测试程序来看看snapshot的使用: #include <iostream>
#include "leveldb/db.h"
using namespace std;
using namespace leveldb;
int main() {
DB *db ;
Options op;
op.create_if_missing = true;
Status s = DB::Open(op,"/tmp/testdb",&db);
if(s.ok()){
cout << "create successfully" << endl;
s = db->Put(WriteOptions(),"abcd","1234");
if(s.ok()){
cout << "put successfully" << endl;
string value;
s = db->Get(ReadOptions(),"abcd",&value);
if(s.ok()){
cout << "get successfully,value:" << value << endl;
}
}
if(s.ok()){
string value;
const Snapshot * ss =db->GetSnapshot();
ReadOptions rop;
db->Put(WriteOptions(),"abcd","123456");
db->Get(rop,"abcd",&value);
if(s.ok()){
cout << "get successfully,value:" << value << endl;
}
rop.snapshot = ss;
db->Get(rop,"abcd",&value);
if(s.ok()){
cout << "get from snapshot successfully,value:" << value << endl;
}
db->ReleaseSnapshot(ss);
}
}
delete db;
return 0;
} 程序运行的输出结果是: create successfully
put successfully
get successfully,value:1234
get successfully,value:123456
get from snapshot successfully,value:1234 可以看出,即使在数据更新后,我们仍然可以从snapshot中读到旧的数据。 下面我们来分析leveldb中snapshot的实现。 SequenceNumber(db/dbformat.h) SequenceNumber是leveldb很重要的东西,每次对数据库进行更新操作,都会生成一个新的SequenceNumber,64bits,其中高8位为0,可以跟key的类型(8bits)进行合并成64bits。 typedef uint64_t SequenceNumber;
// We leave eight bits empty at the bottom so a type and sequence#
// can be packed together into 64-bits.
static const SequenceNumber kMaxSequenceNumber =
((0x1ull << 56) - 1); SnapShot(db/snapshot.h),,可以看出snapshot其实就是一个sequence number class SnapshotImpl : public Snapshot {
public:
//创建后保持不变
SequenceNumber number_;
private:
friend class SnapshotList;
//双向循环链表
SnapshotImpl* prev_;
SnapshotImpl* next_;
SnapshotList* list_; // just for sanity checks
}; 创建snapshot: const Snapshot* DBImpl::GetSnapshot() {
MutexLock l(&mutex_);
return snapshots_.New(versions_->LastSequence());
} 删除snapshot: void DBImpl::ReleaseSnapshot(const Snapshot* s) {
MutexLock l(&mutex_);
snapshots_.Delete(reinterpret_cast<const SnapshotImpl*>(s));
}
摘要: leveldb使用SSTable格式来保存数据。格式为:(当前没有META BLOCK)SSTABLE = |DATA BLOCK1|DATA BLOCK2|...|DATA BLOCK N|META BLOCK1|...|META BLOCK N|META INDEX BLOCK|DATA INDEX BLOCK|Footer|DATA BLOCK = |KeyValues|Restart ar... 阅读全文
摘要: leveldb在每次数据库操作之前都会把操作记录下来。
主要实现在db\log_format.h,db\log_reader.h,db\log_reader.cc,db\log_write.h,db\log_write.cc中。我们来具体看看实现。
日志格式
db\log_format.h
log是分块的,每块为32K,每条记录的记录头为7个字节,前四个为CRC,然后是长度(2个字节)... 阅读全文
摘要: 对于一个db来说,存储是至关重要的问题。运行上一篇的测试程序后,会发现leveldb会生成以下文件:SST文件:数据文件 -- sstable格式*.log: 数据库日志文件 -- 顺序记录所有数据库操作,用来恢复数据CURRENT: 文本文件,表明当面的manifest文件LOCK:空文件,数据库锁,防止多进程访问LOG: 日志文件,文本格式LOG.old:上一次的日志文件MANIFEST: 数... 阅读全文
leveldb是 google对bigtable的一个简化版的开源实现,很有研究价值。 我的编译环境:ubuntu 32&g++ 4.6 1.安装git并下载代码 sudo apt-get install git-core
git clone https://code.google.com/p/leveldb/ 2. 编译leveldb cd leveldb
./build_detect_platform
make 为了能够调试,修改Makefile为debug mode(B模式) OPT ?= -g2 编译后会生成库文件:libleveldb.a 3. 编写测试程序 ldbtest.cpp #include <iostream>
#include "leveldb/db.h"
using namespace std;
using namespace leveldb;
int main() {
DB *db ;
Options op;
op.create_if_missing = true;
Status s = DB::Open(op,"/tmp/testdb",&db);
if(s.ok()){
cout << "create successfully" << endl;
s = db->Put(WriteOptions(),"abcd","1234");
if(s.ok()){
cout << "put successfully" << endl;
string value;
s = db->Get(ReadOptions(),"abcd",&value);
if(s.ok()){
cout << "get successfully,value:" << value << endl;
}
else{
cout << "get failed" << endl;
}
}
else{
cout << "put failed" << endl;
}
}
else{
cout << "create failed" << endl;
}
delete db;
return 0;
} 注意link的时候需要加上-lpthread.
运行后得到结果:(Eclipse中运行)
摘要: 和Amazon EC2提供了一系列的命令行工具帮助使用自动化任务,比如创建instance,启动instance等等。步骤:1. 下载:http://developer.amazonwebservices.com/connect/entry.jspa?externalID=3512. 创建一个脚本用于设置环境变量。windows平台:Code highlighting produced by Ac... 阅读全文
学习软件有三个境界,第一个境界是会使用它,第二个境界是懂得背后的原理,明白它的架构体系,第三个境界学习他的所长,为我所用。研究HBase/BigTable架构和源码一段时间后,我总结了一些东西可以供我们在设计分布式系统借鉴使用。 1. 使用可信任的分布式组件来搭建自己的分布式系统。
设 计一个可靠,健壮的分布式系统是比较困难的。我们知道,为了防止SPOF(Single Point Of Failure)问题,我们要分散风险,把数据放在多个nodes上面去,但是这样带来了是数据的同步问题和版本问题,解决这个问题需要运用复杂的 Paxos协议,系统的复杂度自然就升高了。另外一个需要解决的问题是分布式锁和事件通知机制,以及全局信息共享,设计这些都需要大量的精力和仔细的研 究。 HBase就不用考虑这些问题,它把数据的同步和冗余问题交给了Hadoop,把锁机制和全局共享交给了Zookeeper,这大大简化了HBase的设计。 所以我们设计系统的时候,也要尽量利用这些可靠,稳定的组件。目前比较流行和稳定的有:
分布式文件系统 - HDFS
分布式锁和目录 - Zookeeper
缓存 - MemCached
消息队列 - ActiveMQ 2.避免单点问题(SPOF)
设计分布式系统要时刻考虑到失败,不单是软件可能失败,硬件也可能挂掉,所以我们系统里面就不能有不可替代的角色。 HBase 使用Master Server来监控所有的Region Server,一旦其中的一台出现问题,在其上的Region将会被转移到其他的Region Server,避免了服务中断。而Master Server也可以多台备选,一台挂掉之后,其他的备胎则会”继承遗志“,从而让整个系统得以生存。 那 HBase如何做到这个呢,一个是使用”心跳机制”,即Region Server要主动定期向Master汇报状况,另外一个是利用zookeeper里面的”生命节点“,每个server在启动后要在ZK里面注册,一旦 这个server挂掉,它在ZK里面的节点就会消失,监听这个节点的server就会得到通知。 3.利用不变性提高系统的吞吐量
我们知道,很多进程/线程修改同一个东西的时候,我们就需要锁机制来避免冲突。但是锁带来的问题是系统性能下降。如果对于一个只读的对象,就不需要锁了。 HBase 在设计存储的时候考虑到这一点,最新的数据是放在memory里面,以提高性能。但是memory是有限的,我们不可能让数据一直放在memory里面, 所以我们需要定时把这些数据写到HDFS/磁盘上面。一种设计是写到一个可修改的大文件中去,这样对这个文件的读写就需要加锁了。HBase是每次都写到 一个新的文件中,一旦文件创建后,这个文件将不能被修改,就是所谓的create-one-read-many。当然这样也有一个问题,就是时间长了,会 有很多的小文件,每次查找,需要查找这所有的文件,降低了系统的性能,HBase会定时的合并这些小文件生成一个大文件。 4.利用索引块提高文件的查询速度
HBase的存储文件(HFile)是用来存储很多排序后的Key-Value的,如何设计一种支持快速随机查询和压缩的文件是一个有意思的话题。 HFile 在文件的尾部增加了索引块,但是不可能对任何一个rowkey都做索引,这样的话索引块会很大,而且也不利于压缩。HFile的做法是定义一个Data Block的大小,这样就把数据划分了一个一个的Block,索引只针对这些block做,Block是可以被压缩的。当查询一个rowkey的时候,如 果没有cache的话,首先使用二分法定位到具体的block,然后再解压,遍历查询具体的key。 HFile这样的设计兼顾了速度和文件大小的平衡。 5.自定义RPC机制提供更大的灵活性
HBase/Hadoop 都没有利用标准的Java远程调用规范RMI,而是自己搞了一套。这样做的好处有几点,一是减少网络流量,我们知道,java RMI使用了java serlizable来传递参数,java序列化有很多无关的类信息,都占用不少的空间,而且这会带来对java版本的依赖。二是带来更大的灵活性,你可 以在其中加入版本检查,权限认证等。 那 HBase是怎么设计这个RPC呢?首先它定义了一个writable接口,来代替java序列化,实现这个接口就等于告诉HBase,怎么把这个对象写 到RPC流中去。使用RPC的时候,需要先写一个服务器端和客户端共用的interface,这个interface必须继承 VersionedProtocol来处理版本问题 。HBase利用Java的动态反射机制(Proxy.newProxyInstance)来生成代 理对象,这样当Client调用代理对象的时候,Client就会把参数打包,发送到服务器端,然后等待返回结果。服务器会根据interface查找到 具体的实现的对象,调用该对象的方法来执行远程调用。详细的做法可以参考HBase/Hadoop的源码。 6.内嵌Web Server增强系统的透明度
当一个后台进程启动之后,我们如何了解这个进程的内部状态呢?传统方法是通过进程管理器或者Debug log来看进程的情况,但是这些信息很有限。 HBase利用jetty在进程内部启动了一个web server,就可以即时的显示一些系统内部的信息,非常的方便。 利 用Jetty支持jsp非常的容易,下面是一个示例的代码。注意的是,需要把jasper-runtime-5.5.12.jar,jasper- compiler-5.5.12.jar,jasper-compiler-jdt-5.5.12.jar,jsp-2.1.jar,jsp-api- 2.1.jar等jar包放在classpath里面,否则会出现页面解析错误。 server = new Server(port); server.setSendServerVersion(false);
server.setSendDateHeader(false);
server.setStopAtShutdown(true); WebAppContext wac = new WebAppContext();
wac.setContextPath("/");
wac.setWar("./webapps/job");
server.setHandler(wac);
server.setStopAtShutdown(true);
最近开发了一个开源项目peachbox,主要用于监控android上应用程序的行为,目前可以记录发短信,删短信,装应用程序和卸载程序,以及 某些针对Android 的ROOT行为。 项目地址: http://code.google.com/p/peachbox实现的原理主要是修改Android的源码,增加一些Hook点,然后就可以记录行为。 下载地址: http://peachbox.googlecode.com/files/peachbox.zip
Mysql 的latin1 不等于标准的latin1(iso-8859-1) 和cp1252,比iso-8859-1多了0x80-0x9f字符,比cp1252多了0x81,0x8d,0x8f,0x90,0x9d 一共5个字符。
http://dev.mysql.com/doc/refman/5.0/en/charset-we-sets.html
latin1 is the default character set. MySQL's latin1 is the same as the Windows cp1252 character set. This means it is the same as the official ISO 8859-1 or IANA (Internet Assigned Numbers Authority) latin1, except that IANA latin1 treats the code points between 0x80 and 0x9f as “ undefined,” whereas cp1252, and therefore MySQL's latin1, assign characters for those positions. For example, 0x80 is the Euro sign. For the “ undefined” entries in cp1252, MySQL translates 0x81 to Unicode 0x0081, 0x8d to 0x008d, 0x8f to 0x008f, 0x90 to 0x0090, and 0x9d to 0x009d. 这样在Java中,如果使用标准的iso-8859-1或者cp1252解码可能出现乱码。 s.getBytes("iso-8859-1") 或者 s.getBytes("cp1252"); 写了一段代码来解决这个问题 private String convertCharset(String s){
if(s!=null){
try {
int length = s.length();
byte[] buffer = new byte[length];
//0x81 to Unicode 0x0081, 0x8d to 0x008d, 0x8f to 0x008f, 0x90 to 0x0090, and 0x9d to 0x009d.
for(int i=0;i<length;++i){
char c = s.charAt(i);
if(c==0x0081){
buffer[i]=(byte)0x81;
}
else if(c==0x008d){
buffer[i]=(byte)0x8d;
}
else if(c==0x008f){
buffer[i]=(byte)0x8f;
}
else if(c==0x0090){
buffer[i]=(byte)0x90;
}
else if(c==0x009d){
buffer[i]=(byte)0x9d;
}
else{
buffer[i] = Character.toString(c).getBytes("cp1252")[0];
}
}
String result = new String(buffer,"utf-8");
return result;
} catch (UnsupportedEncodingException e) {
logger.error("charset convert error", e);
}
}
return null;
}
摘要: 如何在Java中实现Javascript插件? 阅读全文
最近开发的一个通用网络爬虫平台,主要是想满足自己想从特定网站抓取大量内容的需求,有如下特点: 1. 支持cookie/session,所以支持登录论坛和网站 2. 支持图像识别,可以由人工识别或者机器识别 3. 多线程下载,性能不错 4. 支持代理 5. 支持HTTPS和证书验证 6. 支持可插拔脚本,对特别网站使用特别的脚本(javascript编写)。 7. 有Web界面,操作方便 项目位置: http://code.google.com/p/ssnaker/下载: http://ssnaker.googlecode.com/files/snaker_1.00_b7.zip 最新的版本也实现一个火车票刷票的功能(具体实现都放在engines/train.js)
原题: http://community.topcoder.com/stat?c=problem_statement&pm=164&rd=50 Class Name: Prerequisites Mathod Name: orderClasses Parameters: String[] Returns: String[] You are a student at a college with the most unbelievably complex prerequisite structure ever. To help you schedule your classes, you decided to put together a program that returns the order in which the classes should be taken. Implement a class Prerequisites which contains a method orderClasses. The method takes a String[] that contains the classes you must take and returns a String[] of classes in the order the classes should be taken so that all prerequisites are met. String[] elements will be of the form (and TopCoder will ensure this): "CLASS: PRE1 PRE2 ..." where PRE1 and PRE2 are prerequisites of CLASS. CLASS, PRE1, PRE2, ... consist of a department name (3 or 4 capital letters, A-Z inclusive) followed by a class number (an integer between 100 and 999, inclusive). The department name should be immediately followed by the class number with no additional characters, numbers or spaces (i.e. MATH217). It is not necessary for a class to have prerequisites. In such a case, the colon is the last character in the String. You can only take one class at a time, therefore, use the following rules to determine which class to take : 1) Any prerequisite class(es) listed for a class must be taken before the class can be taken. 2) If multiple classes can be taken at the same time, you take the one with the lowest number first, regardless of department. 3) If multiple classes with the same number can be taken at the same time, you take the department name which comes first in alphabetical order. 4) If the inputted course schedule has errors, return a String[] of length 0. There is an error if it is impossible to return the classes in an order such that all prerequisites are met, or if a prerequisite is a course that does not have its own entry in the inputted String[]. Examples of valid input Strings are: "CSE111: CSE110 MATH101" "CSE110:" Examples of invalid input Strings are: "CS117:" (department name must consist of 3 - 4 capital letters, inclusive) "cs117:" (department name must consist of 3 - 4 capital letters, inclusive) "CS9E11:" (department name must be letters only) "CSE110: " (no trailing spaces allowed) "CSE110: CSE101 " (no trailing spaces allowed) "MATH211: MAM2222" (class number to large) "MATH211: MAM22" (class number to small) "ENGIN517: MATH211" (department name to large) Here is the method signature (be sure your method is public): String[] orderClasses(String[] classSchedule); TopCoder will make sure classSchedule contains between 1 and 20 Strings, inclusive, all of the form above. The Strings will have between 1 and 50 characters, inclusive. TopCoder will check that the syntax of the Strings are correct: The Strings will contain a valid class name, followed by a colon, possibly followed by a series of unique prerequisite classes separated by single spaces. Also, TopCoder will ensure that each class has at most one entry in the String[]. Examples: If classSchedule={ "CSE121: CSE110", "CSE110:", "MATH122:", } The method should return: {"CSE110","CSE121","MATH122"} If classSchedule={ "ENGL111: ENGL110", "ENGL110: ENGL111" } The method should return: {} If classSchedule=[ "ENGL111: ENGL110" } The method should return: {} If classSchedule={ "CSE258: CSE244 CSE243 INTR100" "CSE221: CSE254 INTR100" "CSE254: CSE111 MATH210 INTR100" "CSE244: CSE243 MATH210 INTR100" "MATH210: INTR100" "CSE101: INTR100" "CSE111: INTR100" "ECE201: CSE111 INTR100" "ECE111: INTR100" "CSE243: CSE254" "INTR100:" } The method should return: {"INTR100","CSE101","CSE111","ECE111","ECE201","MATH210","CSE254","CSE221","CSE2 43","CSE244","CSE258"} Definition Class: Prerequisites Method: orderClasses Parameters: String[] Returns: String[] Method signature: String[] orderClasses(String[] param0) (be sure your method is public)
------------------------------------------------------------我的解法如下---------------------------------------- 想法很简单,这道题本质上是一道排序问题,我们只需要定义好排序的逻辑,然后应用快排就可以了。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Prerequisites {
private static final String[] EMPTY = {};
Map<String,Klass> classes = new HashMap<String,Klass>();
static class Klass implements Comparable<Klass>{
String name;
int number;
String dept;
List<Klass> pres = new ArrayList<Klass>();
boolean exist = false;
Klass(String name){
this.name = name;
int len = name.length();
this.number = Integer.parseInt(name.substring(len-3));
this.dept =name.substring(0,len-3);
}
private boolean isPre(Klass k){
if(k==this) return false;
for(Klass p:this.pres){
if(k == p || p.isPre(k)) return true;
}
return false;
}
@Override
public int compareTo(Klass that) {
boolean pre = this.isPre(that);
boolean sub = that.isPre(this);
if(pre && sub){
throw new RuntimeException("circle detected");
}
else if(pre){
return 1;
}
else if(sub){
return -1;
}
if(this.number!=that.number) return this.number-that.number;
return this.dept.compareTo(that.dept);
}
}
private Klass getClass(String name){
Klass k = classes.get(name);
if(k==null){
k = new Klass(name);
classes.put(name, k);
}
return k;
}
public String[] orderClasses(String[] classSchedule){
classes.clear();
//parse the input
for(String s:classSchedule){
int idx = s.indexOf(":");
String name = s.substring(0,idx);
Klass k = getClass(name);
k.exist = true;
if(idx!=s.length()-1){
String[] pres = s.substring(idx+1).split(" ");
for(String pre:pres){
if(pre.length()>0){
Klass p = getClass(pre);
k.pres.add(p);
}
}
}
}
Klass [] sortedClasses = (Klass[]) classes.values().toArray(new Klass[0]);
for(Klass k:sortedClasses){
if(!k.exist){
return EMPTY;
}
}
try {
Arrays.sort(sortedClasses);
} catch (Exception e) {
return EMPTY;
}
String[] result = new String[sortedClasses.length];
int c = 0;
for(Klass k:sortedClasses){
result[c++] = k.name;
}
return result;
}
}
|