|
|
2011年3月23日
淘宝招聘hadoop工程师若干, 面向在校生(2014年毕业),工作地点:杭州或北京 Hadoop研发工程师
职位描述
您将负责:
1.预研、开发、测试hdfs/mapreduce/hive/hbase的功能、性能和扩展;
2.对有助于提升集群处理能力/高可用性/高扩展性的各种解决方案进行跟踪和落地;
3.解决海量数据不断增长面临的挑战,解决业务需求。 您需要具备:
1、熟练运用java语言;
2、熟悉jvm运行机制、熟悉linux;
3、至少熟悉hadoop、hbase、hive等软件之一;
有意者请发送邮件到 yuling.sh@taobao.com
mapreduce中,一个job的map个数, 每个map处理的数据量是如何决定的呢? 另外每个map又是如何读取输入文件的内容呢? 用户是否可以自己决定输入方式, 决定map个数呢? 这篇文章将详细讲述hadoop中各种InputFormat的功能和如何编写自定义的InputFormat. 简介: mapreduce作业会根据输入目录产生多个map任务, 通过多个map任务并行执行来提高作业运行速度, 但如果map数量过少, 并行量低, 作业执行慢, 如果map数过多, 资源有限, 也会增加调度开销. 因此, 根据输入产生合理的map数, 为每个map分配合适的数据量, 能有效的提升资源利用率, 并使作业运行速度加快. 在mapreduce中, 每个作业都会通过 InputFormat来决定map数量. InputFormat是一个接口, 提供两个方法: InputSplit[] getSplits(JobConf job, int numSplits) throws IOException; RecordReader<K, V> getRecordReader(InputSplit split, JobConf job, Reporter reporter) throws IOException; 其中getSplits方法会根据输入目录产生InputSplit数组, 每个InputSplit会相应产生一个map任务, map的输入定义在InputSplit中. getRecordReader方法返回一个RecordReader对象, RecordReader决定了map任务如何读取输入数据, 例如一行一行的读取还是一个字节一个字节的读取, 等等. 下图是InputFormat的实现类: (暂时无法上传) 这理详细介绍FileInputFormat和CombineFileInputFormat, 其它不常用,有兴趣的可以自己查看hadoop源码.
FileInputFormat(旧接口org.apache.hadoop.mapred) mapreduce默认使用TextInputFormat,TextInputFormat没有实现自己的getSplits方法,它继承于FileInputFormat, 因此使用了FileInputFormat的. org.apache.hadoop.mapred.FileInputFormat的getSplits流程: 两个配置 mapred.min.split.size (一个map最小输入长度), mapred.map.tasks (推荐map数量) 如何决定每个map输入长度呢? 首先获取输入目录下所有文件的长度和, 除以mapred.map.tasks得到一个推荐长度goalSize, 然后通过式子: Math.max(minSize, Math.min(goalSize, blockSize))决定map输入长度. 这里的minSize为mapred.min.split.size, blockSize为相应文件的block长度. 这式子能保证一个map的输入至少大于mapred.min.split.size, 对于推荐的map长度,只有它的长度小于blockSize且大于mapred.min.split.size才会有效果. 由于mapred.min.split.size默认长度为1, 因此通常情况下只要小于blockSize就有效果,否则使用blockSize做为map输入长度. 因此, 如果想增加map数, 可以把mapred.min.split.size调小(其实默认值即可), 另外还需要把mapred.map.tasks设置大. 如果需要减少map数,可以把mapred.min.split.size调大, 另外把mapred.map.tasks调小. 这里要特别指出的是FileInputFormat会让每个输入文件至少产生一个map任务, 因此如果你的输入目录下有许多文件, 而每个文件都很小, 例如几十kb, 那么每个文件都产生一个map会增加调度开销. 作业变慢. 那么如何防止这种问题呢? CombineFileInputFormat能有效的减少map数量.
FileInputFormat(新接口org.apache.hadoop.mapreduce.lib.input) Hadoop 0.20开始定义了一套新的mapreduce编程接口, 使用新的FileInputFormat, 它与旧接口下的FileInputFormat主要区别在于, 它不再使用mapred.map.tasks, 而使用mapred.max.split.size参数代替goalSize, 通过Math.max(minSize, Math.min(maxSize, blockSize))决定map输入长度, 一个map的输入要大于minSize,小于 Math.min(maxSize, blockSize). 若需增加map数,可以把mapred.min.split.size调小,把mapred.max.split.size调大. 若需减少map数, 可以把mapred.min.split.size调大, 并把mapred.max.split.size调小. CombineFileInputFormat 顾名思义, CombineFileInputFormat的作用是把许多文件合并作为一个map的输入. 在它之前,可以使用MultiFileInputFormat,不过其功能太简单, 它以文件为单位,一个文件至多分给一个map处理, 如果某个目录下有许多小文件, 另外还有一个超大文件, 处理大文件的map会严重偏慢. CombineFileInputFormat是一个被推荐使用的InputFormat. 它有三个配置: mapred.min.split.size.per.node, 一个节点上split的至少的大小 mapred.min.split.size.per.rack 一个交换机下split至少的大小 mapred.max.split.size 一个split最大的大小 它的主要思路是把输入目录下的大文件分成多个map的输入, 并合并小文件, 做为一个map的输入. 具体的原理是下述三步: 1.根据输入目录下的每个文件,如果其长度超过mapred.max.split.size,以block为单位分成多个split(一个split是一个map的输入),每个split的长度都大于mapred.max.split.size, 因为以block为单位, 因此也会大于blockSize, 此文件剩下的长度如果大于mapred.min.split.size.per.node, 则生成一个split, 否则先暂时保留. 2. 现在剩下的都是一些长度效短的碎片,把每个rack下碎片合并, 只要长度超过mapred.max.split.size就合并成一个split, 最后如果剩下的碎片比mapred.min.split.size.per.rack大, 就合并成一个split, 否则暂时保留. 3. 把不同rack下的碎片合并, 只要长度超过mapred.max.split.size就合并成一个split, 剩下的碎片无论长度, 合并成一个split. 举例: mapred.max.split.size=1000 mapred.min.split.size.per.node=300 mapred.min.split.size.per.rack=100 输入目录下五个文件,rack1下三个文件,长度为2050,1499,10, rack2下两个文件,长度为1010,80. 另外blockSize为500. 经过第一步, 生成五个split: 1000,1000,1000,499,1000. 剩下的碎片为rack1下:50,10; rack2下10:80 由于两个rack下的碎片和都不超过100, 所以经过第二步, split和碎片都没有变化. 第三步,合并四个碎片成一个split, 长度为150. 如果要减少map数量, 可以调大mapred.max.split.size, 否则调小即可. 其特点是: 一个块至多作为一个map的输入,一个文件可能有多个块,一个文件可能因为块多分给做为不同map的输入, 一个map可能处理多个块,可能处理多个文件。
Yarn做为hadoop下一代集群资源管理和调度平台, 其上能支持多种计算框架, 本文就简要介绍一下这些计算框架.
1. MapReduce 首先是大家熟悉的mapreduce, 在MR2之前, hadoop包括HDFS和mapreduce, 做为hadoop上唯一的分布式计算框架, 其优点是用户可以很方便的编写分布式计算程序, 并支持许多的应用, 如hive, mahout, pig等. 但是其缺点是无法充分利用集群资源, 不支持DAG, 迭代式计算等. 为了解决这些问题, yahoo提出了Yarn (next generation mapreduce), 一个分布式集群集群资源管理和调度平台. 这样除了mapreduce外, 还可以支持各种计算框架. 2. Spark Spark是一种与mapreduce相似的开源计算框架, 不同之处在于Spark在某些工作负载方面表现更优, 因为它使用了内存分布式数据集, 另外除了提供交互式查询外, 它还可以优化迭代工作负载. 3. Apache HAMA Apache Hama 是一个运行在HDFS上的BSP(Bulk Synchronous Parallel大容量同步并行) 计算框架, 主要针对大规模科学计算,如矩阵, 图像, 网络算法等.当前它有一下功能: - 作业提交和管理接口
- 单节点上运行多个任务
- 输入/输出格式化
- 备份恢复
- 支持通过Apache Whirr运行在云端
- 支持与Yarn一起运行
4. Apache Giraph 图像处理平台上运行这大型算法(如page rank, shared connections, personalization-based popularity 等)已经很流行, Giraph采用BSP模型(bulk-synchronous parallel model),可用于等迭代类算法。 5. Open MPI 这是一个高性能计算函数库,通常在HPC(High Performance Computing)中采用,与MapReduce相比,其性能更高,用户可控性更强,但编程复杂,容错性差,可以说,各有所长,在实际应用中,针对不同 该应用会采用MPI或者MapReduce。 6. Apache HBase HBase是一个hadoop数据库, 其特点是分布式,可扩展的,存储大数据。当有需要随机,实时读写的大数据时, 使用HBase很适合.
本文参考: http://wiki.apache.org/hadoop/PoweredByYarn http://www.oschina.net/p/open+mpi
http://incubator.apache.org/hama/ http://incubator.apache.org/giraph/
http://hbase.apache.org/
转载 http://fujun.sinaapp.com/2011/11/02/68.html 第一步,打开终端,看看你的显卡Ubuntu能认出多少显示分辨率设置,输入命令
wufujun@wufujun-VirtualBox:~$ xrandr
系统给出的结果 Screen 0: minimum 64 x 64, current 1024 x 768, maximum 32000 x 32000
VBOX0 connected 1024×768+0+0 0mm x 0mm
1024×768 60.0 + 60.0
1600×1200 60.0
1440×1050 60.0
1280×960 60.0
800×600 60.0
640×480 60.0 这里可以看到,没有16:9的的分辨率设置 第二步,用cvt命令测试1368×768是否可用
wufujun@wufujun-VirtualBox:~$ cvt 1368 768
显示结果如下
# 1368×768 59.88 Hz (CVT) hsync: 47.79 kHz; pclk: 85.86 MHz
Modeline “1368x768_60.00″ 85.25 1368 1440 1576 1784 768 771 781 798 -hsync +vsync 从这个结果里可以到,16:9的分辨率是可以用的 第三步 输入
wufujun@wufujun-VirtualBox:~$ sudo xrandr --newmode "1368x768" 85.86 1368 1440 1576 1784 768 771 781 798 -hsync +vsync
建立新的分辨率模式1368×768,把刚才cvt得到的数据写进参数 第四步 继续输入
sudo xrandr --addmode VBOX0 "1368x768"
给当前显示器VBOX0增加1368×768分辨率设置 做完以上操作后,可以在”显示“设置里面看到显示的分辨率列表中多了一个 1368×768(16:9)的选项。选中这个选项,点击应用,完美的宽屏显示回来了! 经过测试,上面的方法做完以后,每次注销后就又变回了4:3的比例,而且会有的报错,没办法,按上面的修改完毕后,还要再修改一下/etc/X11/xorg.conf这个文件,这个配置文件在现在的版里已经取消了,所以需要我们新建一个
$ sudo gedit /etc/X11/xorg.conf
编辑内容为:
Section "Device"
Identifier "Configured Video Device"
EndSection Section "Monitor"
Identifier "Configured Monitor"
Modeline "1368x768_60.00" 85.86 1368 1440 1584 1800 768 769 772 795 -HSync +Vsync
EndSection Section "Screen"
Identifier "Default Screen"
Monitor "Configured Monitor"
Device "Configured Video Device"
SubSection "Display"
Modes "1368x768@60"
EndSubSection
EndSection
其中 Modeline “1368x768_60.00″ 85.86 1368 1440 1584 1800 768 769 772 795 -HSync +Vsync 就是用$ cvt 1368 768得到的值。也可以用$ gtf 1368 768 60命令来得到这个Modeline的值,这个命令中,1368 768是分辨率 60为刷新率,用这个命令得到的值可能会更为准确一些。
SubSection "Display"
Modes "1368x768@60"
EndSubSection
这段是设置默认显示最佳分辨率。
注意这段文件中的一些规则 Section “Device”区块中,Identifier指定了显卡的唯一名称,这个名称可以随便取,但一定要与Section “Screen”区块中的device选项中的名称相同。在Section “Monitor”区块中,Identifier指定了显示器的唯一名称,这个名称可以随便取,但一定要与Section “Screen”区块中的Monitor选项中所指定的名称相同。Section “Screen”区块中的Identifier选项,指定了这个显卡与显示器相结合的唯一名称。这个名称也可以随便取的。这个名称需要与Section “ServerLayout” 区块中的名称相同。这个Section “ServerLayout” 区块我们一般不必编写
摘要: 最近这些天学习了classLoader的原理, 原因是因为服务器上的一个java进程启动时加载两个不同版本的jar包, 含有相同名字的类, 而且服务端的jar包排在前面, 我上传的jar包排在后面, 于是每次都使用服务端的jar包, 我的jar包便无法生效, 因此希望修改classLader, 让它按相反的顺序加载jar包. ... 阅读全文
摘要: High Availability for the HDFS Namenode Sanjay Radia, Suresh Srinivas Yahoo! Inc (本文为namdnoe HA的设计文档翻译) 1. 问题阐述 有许多方法可以改善HDFS Namednoe(NN)的可用性,包括减少启动时间,更... 阅读全文
本文转自:http://blog.csdn.net/zhouysh/article/details/304767
JAVA代码编写的30条建议
(1) 类名首字母应该大写。字段、方法以及对象(句柄)的首字母应小写。对于所有标识符,其中包含的所有单词都应紧靠在一起,而且大写中间单词的首字母。例如:
ThisIsAClassName
thisIsMethodOrFieldName
若在定义中出现了常数初始化字符,则大写static final基本类型标识符中的所有字母。这样便可标志出它们属于编译期的常数。
Java包(Package)属于一种特殊情况:它们全都是小写字母,即便中间的单词亦是如此。对于域名扩展名称,如com,org,net或者edu等,全部都应小写(这也是Java 1.1和Java 1.2的区别之一)。
(2) 为了常规用途而创建一个类时,请采取"经典形式",并包含对下述元素的定义:
equals()
hashCode()
toString()
clone()(implement Cloneable)
implement Serializable
(3) 对于自己创建的每一个类,都考虑置入一个main(),其中包含了用于测试那个类的代码。为使用一个项目中的类,我们没必要删除测试代码。若进行了任何形式的改动,可方便地返回测试。这些代码也可作为如何使用类的一个示例使用。
(4) 应将方法设计成简要的、功能性单元,用它描述和实现一个不连续的类接口部分。理想情况下,方法应简明扼要。若长度很大,可考虑通过某种方式将其分割成较短的几个方法。这样做也便于类内代码的重复使用(有些时候,方法必须非常大,但它们仍应只做同样的一件事情)。
(5) 设计一个类时,请设身处地为客户程序员考虑一下(类的使用方法应该是非常明确的)。然后,再设身处地为管理代码的人考虑一下(预计有可能进行哪些形式的修改,想想用什么方法可把它们变得更简单)。
(6) 使类尽可能短小精悍,而且只解决一个特定的问题。下面是对类设计的一些建议:
■一个复杂的开关语句:考虑采用"多形"机制
■数量众多的方法涉及到类型差别极大的操作:考虑用几个类来分别实现
■许多成员变量在特征上有很大的差别:考虑使用几个类
(7) 让一切东西都尽可能地"私有"--private。可使库的某一部分"公共化"(一个方法、类或者一个字段等等),就永远不能把它拿出。若强行拿出,就可 能破坏其他人现有的代码,使他们不得不重新编写和设计。若只公布自己必须公布的,就可放心大胆地改变其他任何东西。在多线程环境中,隐私是特别重要的一个 因素--只有private字段才能在非同步使用的情况下受到保护。
(8) 谨惕"巨大对象综合症"。对一些习惯于顺序编程思维、且初涉OOP领域的新手,往往喜欢先写一个顺序执行的程序,再把它嵌入一个或两个巨大的对象里。根据编程原理,对象表达的应该是应用程序的概念,而非应用程序本身。
(9) 若不得已进行一些不太雅观的编程,至少应该把那些代码置于一个类的内部。
(10) 任何时候只要发现类与类之间结合得非常紧密,就需要考虑是否采用内部类,从而改善编码及维护工作(参见第14章14.1.2小节的"用内部类改进代码")。
(11) 尽可能细致地加上注释,并用javadoc注释文档语法生成自己的程序文档。
(12) 避免使用"魔术数字",这些数字很难与代码很好地配合。如以后需要修改它,无疑会成为一场噩梦,因为根本不知道"100"到底是指"数组大小"还是"其他 全然不同的东西"。所以,我们应创建一个常数,并为其使用具有说服力的描述性名称,并在整个程序中都采用常数标识符。这样可使程序更易理解以及更易维护。
(13) 涉及构建器和异常的时候,通常希望重新丢弃在构建器中捕获的任何异常--如果它造成了那个对象的创建失败。这样一来,调用者就不会以为那个对象已正确地创建,从而盲目地继续。
(14) 当客户程序员用完对象以后,若你的类要求进行任何清除工作,可考虑将清除代码置于一个良好定义的方法里,采用类似于cleanup()这样的名字,明确表 明自己的用途。除此以外,可在类内放置一个boolean(布尔)标记,指出对象是否已被清除。在类的finalize()方法里,请确定对象已被清除, 并已丢弃了从RuntimeException继承的一个类(如果还没有的话),从而指出一个编程错误。在采取象这样的方案之前,请确定 finalize()能够在自己的系统中工作(可能需要调用System.runFinalizersOnExit(true),从而确保这一行为)。
(15) 在一个特定的作用域内,若一个对象必须清除(非由垃圾收集机制处理),请采用下述方法:初始化对象;若成功,则立即进入一个含有finally从句的try块,开始清除工作。
(16) 若在初始化过程中需要覆盖(取消)finalize(),请记住调用super.finalize()(若Object属于我们的直接超类,则无此必 要)。在对finalize()进行覆盖的过程中,对super.finalize()的调用应属于最后一个行动,而不应是第一个行动,这样可确保在需要 基础类组件的时候它们依然有效。
(17) 创建大小固定的对象集合时,请将它们传输至一个数组(若准备从一个方法里返回这个集合,更应如此操作)。这样一来,我们就可享受到数组在编译期进行类型检查的好处。此外,为使用它们,数组的接收者也许并不需要将对象"造型"到数组里。
(18) 尽量使用interfaces,不要使用abstract类。若已知某样东西准备成为一个基础类,那么第一个选择应是将其变成一个interface(接 口)。只有在不得不使用方法定义或者成员变量的时候,才需要将其变成一个abstract(抽象)类。接口主要描述了客户希望做什么事情,而一个类则致力 于(或允许)具体的实施细节。
(19) 在构建器内部,只进行那些将对象设为正确状态所需的工作。尽可能地避免调用其他方法,因为那些方法可能被其他人覆盖或取消,从而在构建过程中产生不可预知的结果(参见第7章的详细说明)。
(20) 对象不应只是简单地容纳一些数据;它们的行为也应得到良好的定义。
(21) 在现成类的基础上创建新类时,请首先选择"新建"或"创作"。只有自己的设计要求必须继承时,才应考虑这方面的问题。若在本来允许新建的场合使用了继承,则整个设计会变得没有必要地复杂。
(22) 用继承及方法覆盖来表示行为间的差异,而用字段表示状态间的区别。一个非常极端的例子是通过对不同类的继承来表示颜色,这是绝对应该避免的:应直接使用一个"颜色"字段。
(23) 为避免编程时遇到麻烦,请保证在自己类路径指到的任何地方,每个名字都仅对应一个类。否则,编译器可能先找到同名的另一个类,并报告出错消息。若怀疑自己碰到了类路径问题,请试试在类路径的每一个起点,搜索一下同名的.class文件。
(24) 在Java 1.1 AWT中使用事件"适配器"时,特别容易碰到一个陷阱。若覆盖了某个适配器方法,同时拼写方法没有特别讲究,最后的结果就是新添加一个方法,而不是覆盖现 成方法。然而,由于这样做是完全合法的,所以不会从编译器或运行期系统获得任何出错提示--只不过代码的工作就变得不正常了。
(25) 用合理的设计方案消除"伪功能"。也就是说,假若只需要创建类的一个对象,就不要提前限制自己使用应用程序,并加上一条"只生成其中一个"注释。请考虑将 其封装成一个"独生子"的形式。若在主程序里有大量散乱的代码,用于创建自己的对象,请考虑采纳一种创造性的方案,将些代码封装起来。
(26) 警惕"分析瘫痪"。请记住,无论如何都要提前了解整个项目的状况,再去考察其中的细节。由于把握了全局,可快速认识自己未知的一些因素,防止在考察细节的时候陷入"死逻辑"中。
(27) 警惕"过早优化"。首先让它运行起来,再考虑变得更快--但只有在自己必须这样做、而且经证实在某部分代码中的确存在一个性能瓶颈的时候,才应进行优化。 除非用专门的工具分析瓶颈,否则很有可能是在浪费自己的时间。性能提升的隐含代价是自己的代码变得难于理解,而且难于维护。
(28) 请记住,阅读代码的时间比写代码的时间多得多。思路清晰的设计可获得易于理解的程序,但注释、细致的解释以及一些示例往往具有不可估量的价值。无论对你自 己,还是对后来的人,它们都是相当重要的。如对此仍有怀疑,那么请试想自己试图从联机Java文档里找出有用信息时碰到的挫折,这样或许能将你说服。
(29) 如认为自己已进行了良好的分析、设计或者实施,那么请稍微更换一下思维角度。试试邀请一些外来人士--并不一定是专家,但可以是来自本公司其他部门的人。 请他们用完全新鲜的眼光考察你的工作,看看是否能找出你一度熟视无睹的问题。采取这种方式,往往能在最适合修改的阶段找出一些关键性的问题,避免产品发行 后再解决问题而造成的金钱及精力方面的损失。
(30) 良好的设计能带来最大的回报。简言之,对于一个特定的问题,通常会花较长的时间才能找到一种最恰当的解决方案。但一旦找到了正确的方法,以后的工作就轻松 多了,再也不用经历数小时、数天或者数月的痛苦挣扎。我们的努力工作会带来最大的回报(甚至无可估量)。而且由于自己倾注了大量心血,最终获得一个出色的 设计方案,成功的快感也是令人心动的。坚持抵制草草完工的诱惑--那样做往往得不偿失
在互联网这个领域一直有这样的说法:“如果老二无法战胜老大,那么就把老大赖以生存的东西开源吧”。当年Yahoo!与Google还是处在 强烈竞争关系时候,招聘了Doug(Hadoop创始人),把Google老大赖以生存的DFS与Map-Reduce开源了,开始了Hadoop的童年 时期。差不多在2008年的时候,Hadoop才算逐渐成熟。 从初创到现在,Hadoop经过了至少7年的积累,现在的Hadoop不仅是当年的老二Yahoo的专用产品了,从Hadoop长长的用户名单中, 可以看到Facebook、Linkedin、Amazon,可以看到EMC、eBay、Twitter、IBM、Microsoft,、Apple、 HP…国内的公司有淘宝、百度等等。 
本文将对Hadoop七年(2004-2011)的发展历程进 行梳理。读完本文后,将不难看出,Hadoop的发展基本上经历了这样一个过程:从一个开源的Apache基金会项目,随着越来越多的用户的加入,不断地 使用、贡献和完善,形成一个强大的生态系统,从2009年开始,随着云计算和大数据的发展,Hadoop作为海量数据分析的最佳解决方案,开始受到许多 IT厂商的关注,从而出现了许多Hadoop的商业版以及支持Hadoop的产品,包括软件和硬件。 - 2004年,Google发表论文,向全世界介绍了MapReduce。
- 2005年初,为了支持Nutch搜索引擎项目,Nutch的开发者基于Google发布的MapReduce报告,在Nutch上开发了一个可工作的MapReduce应用。
- 2005年年中,所有主要的Nutch算法被移植到使用MapReduce和NDFS(Nutch Distributed File System )来运行。
- 2006年1月,Doug Cutting加入雅虎,Yahoo!提供一个专门的团队和资源将Hadoop发展成一个可在网络上运行的系统。
- 2006年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
- 2007年,百度开始使用Hadoop做离线处理,目前差不多80%的Hadoop集群用作日志处理。
- 2007年,中国移动开始在“大云”研究中使用Hadoop技术,规模超过1000台。
- 2008年,淘宝开始投入研究基于Hadoop的系统——云梯,并将其用于处理电子商务相关数据。云梯1的总容量大概为9.3PB,包含了1100台机器,每天处理约18000道作业,扫描500TB数据。
- 2008年1月,Hadoop成为Apache顶级项目。
- 2008年2月,Yahoo!宣布其搜索引擎产品部署在一个拥有1万个内核的Hadoop集群上。
- 2008年7月,Hadoop打破1TB数据排序基准测试记录。Yahoo!的一个Hadoop集群用209秒完成1TB数据的排序 ,比上一年的纪录保持者保持的297秒快了将近90秒。
- 2009 年 3 月,Cloudera推出CDH(Cloudera’s Distribution including Apache Hadoop)平台,完全由开放源码软件组成,目前已经进入第3版。
- 2009年5月,Yahoo的团队使用Hadoop对1 TB的数据进行排序只花了62秒时间。
- 2009年7月 ,Hadoop Core项目更名为Hadoop Common;
- 2009年7月 ,MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。
- 2009年7月 ,Avro 和 Chukwa 成为Hadoop新的子项目。
- 2010年5月 ,Avro脱离Hadoop项目,成为Apache顶级项目。
- 2010年5月 ,HBase脱离Hadoop项目,成为Apache顶级项目。
- 2010年5月,IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
- 2010年9月,Hive( Facebook) 脱离Hadoop,成为Apache顶级项目。
- 2010年9月,Pig脱离Hadoop,成为Apache顶级项目。
- 2011年1月,ZooKeeper 脱离Hadoop,成为Apache顶级项目。
- 2011年3月,Apache Hadoop获得Media Guardian Innovation Awards 。
- 2011年3月, Platform Computing 宣布在它的Symphony软件中支持Hadoop MapReduce API。
- 2011年5月,Mapr Technologies公司推出分布式文件系统和MapReduce引擎——MapR Distribution for Apache Hadoop。
- 2011年5月,HCatalog 1.0发布。该项目由Hortonworks 在2010年3月份提出,HCatalog主要用于解决数据存储、元数据的问题,主要解决HDFS的瓶颈,它提供了一个地方来存储数据的状态信息,这使得 数据清理和归档工具可以很容易的进行处理。
- 2011年4月,SGI( Silicon Graphics International )基于SGI Rackable和CloudRack服务器产品线提供Hadoop优化的解决方案。
- 2011年5月,EMC为客户推出一种新的基于开源Hadoop解决方案的数据中心设备——GreenPlum HD,以助其满足客户日益增长的数据分析需求并加快利用开源数据分析软件。Greenplum是EMC在2010年7月收购的一家开源数据仓库公司。
- 2011年5月,在收购了Engenio之后, NetApp推出与Hadoop应用结合的产品E5400存储系统。
- 2011年6月,Calxeda公司(之前公司的名字是Smooth-Stone)发起了“开拓者行动”,一个由10家软件公司组成的团队将为基于Calxeda即将推出的ARM系统上芯片设计的服务器提供支持。并为Hadoop提供低功耗服务器技术。
- 2011年6月,数据集成供应商Informatica发布了其旗舰产品,产品设计初衷是处理当今事务和社会媒体所产生的海量数据,同时支持Hadoop。
- 2011年7月,Yahoo!和硅谷风险投资公司 Benchmark Capital创建了Hortonworks 公司,旨在让Hadoop更加鲁棒(可靠),并让企业用户更容易安装、管理和使用Hadoop。
- 2011年8月,Cloudera公布了一项有益于合作伙伴生态系统的计划——创建一个生态系统,以便硬件供应商、软件供应商以及系统集成商可以一起探索如何使用Hadoop更好的洞察数据。
- 2011年8月,Dell与Cloudera联合推出Hadoop解决方案——Cloudera Enterprise。Cloudera Enterprise基于Dell PowerEdge C2100机架服务器以及Dell PowerConnect 6248以太网交换机 。

在梳理的过程中,笔者发现了上图,它很好地展现了Hadoop生态系统是如何在使用中一步一步成长起来的。
本文转自:http://linuxtoy.org/archives/bash-shortcuts.html
生活在 Bash shell 中,熟记以下快捷键,将极大的提高你的命令行操作效率。 编辑命令 - Ctrl + a :移到命令行首
- Ctrl + e :移到命令行尾
- Ctrl + f :按字符前移(右向)
- Ctrl + b :按字符后移(左向)
- Alt + f :按单词前移(右向)
- Alt + b :按单词后移(左向)
- Ctrl + xx:在命令行首和光标之间移动
- Ctrl + u :从光标处删除至命令行首
- Ctrl + k :从光标处删除至命令行尾
- Ctrl + w :从光标处删除至字首
- Alt + d :从光标处删除至字尾
- Ctrl + d :删除光标处的字符
- Ctrl + h :删除光标前的字符
- Ctrl + y :粘贴至光标后
- Alt + c :从光标处更改为首字母大写的单词
- Alt + u :从光标处更改为全部大写的单词
- Alt + l :从光标处更改为全部小写的单词
- Ctrl + t :交换光标处和之前的字符
- Alt + t :交换光标处和之前的单词
- Alt + Backspace:与 Ctrl + w 相同类似,分隔符有些差别 [感谢 rezilla 指正]
重新执行命令 - Ctrl + r:逆向搜索命令历史
- Ctrl + g:从历史搜索模式退出
- Ctrl + p:历史中的上一条命令
- Ctrl + n:历史中的下一条命令
- Alt + .:使用上一条命令的最后一个参数
控制命令 - Ctrl + l:清屏
- Ctrl + o:执行当前命令,并选择上一条命令
- Ctrl + s:阻止屏幕输出
- Ctrl + q:允许屏幕输出
- Ctrl + c:终止命令
- Ctrl + z:挂起命令
Bang (!) 命令 - !!:执行上一条命令
- !blah:执行最近的以 blah 开头的命令,如 !ls
- !blah:p:仅打印输出,而不执行
- !$:上一条命令的最后一个参数,与 Alt + . 相同
- !$:p:打印输出 !$ 的内容
- !*:上一条命令的所有参数
- !*:p:打印输出 !* 的内容
- ^blah:删除上一条命令中的 blah
- ^blah^foo:将上一条命令中的 blah 替换为 foo
- ^blah^foo^:将上一条命令中所有的 blah 都替换为 foo
友情提示: - 以上介绍的大多数 Bash 快捷键仅当在 emacs 编辑模式时有效,若你将 Bash 配置为 vi 编辑模式,那将遵循 vi 的按键绑定。Bash 默认为 emacs 编辑模式。如果你的 Bash 不在 emacs 编辑模式,可通过
set -o emacs 设置。 - ^S、^Q、^C、^Z 是由终端设备处理的,可用
stty 命令设置。
本文转自 http://trinea.iteye.com/blog/1196400
1、jps的作用 jps类似linux的ps命令,不同的是ps是用来显示进程,而jps只显示java进程,准确的说是当前用户已启动的部分java进程信息,信息包括进程号和简短的进程command。 2、某个java进程已经启动,用jps却显示不了该进程进程号 这个问题已经碰到过两次了,所以在这里总结下。 现象: 用ps -ef|grep java能看到启动的java进程,但是用jps查看却不存在该进程的id。待会儿解释过之后就能知道在该情况下,jconsole、jvisualvm可能无法监控该进程,其他java自带工具也可能无法使用 分析: java程序启动后,默认(请注意是默认)会在/tmp/hsperfdata_userName目录下以该进程的id为文件名新建文件,并在该文件中存储jvm运行的相关信息,其中的userName为当前的用户名,/tmp/hsperfdata_userName目录会存放该用户所有已经启动的java进程信息。对于windows机器/tmp用Windows存放临时文件目录代替。 而jps、jconsole、jvisualvm等工具的数据来源就是这个文件(/tmp/hsperfdata_userName/pid)。所以当该文件不存在或是无法读取时就会出现jps无法查看该进程号,jconsole无法监控等问题 原因: (1)、磁盘读写、目录权限问题 若该用户没有权限写/tmp目录或是磁盘已满,则无法创建/tmp/hsperfdata_userName/pid文件。或该文件已经生成,但用户没有读权限 (2)、临时文件丢失,被删除或是定期清理 对于linux机器,一般都会存在定时任务对临时文件夹进行清理,导致/tmp目录被清空。这也是我第一次碰到该现象的原因 这个导致的现象可能会是这样,用jconsole监控进程,发现在某一时段后进程仍然存在,但是却没有监控信息了。 (3)、java进程信息文件存储地址被设置,不在/tmp目录下 上面我们在介绍时说默认会在/tmp/hsperfdata_userName目录保存进程信息,但由于以上1、2所述原因,可能导致该文件无法生成或是丢失,所以java启动时提供了参数,可以对这个文件的位置进行设置,而jps、jconsole都只会从/tmp目录读取,而无法从设置后的目录读物信息, 这个问题只会在jdk 6u23和6u24上出现,在6u23和6u24上,进程信息会保存在-Djava.io.tmpdir下, 因此如果它被设置为非/tmp目录则会导致 jps,jconsole等无法读取的现象, 但在其他版本的jdk上,即使设置-Djava.io.tmpdir为非/tmp, 也会在/tmp/hsperfdata_userName下保存java进程信息.因此可以说这是6u23和6u24的bug,
以下是jdk对该bug的描述地址:
bug描述:
http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=7021676
bug的修复描述:
http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=7009828
bug修改代码:
http://hg.openjdk.java.net/jdk7/hotspot/hotspot/rev/34d64ad817f4
关于设置该文件位置的参数为-Djava.io.tmpdir
1. 根据上一章配好的集群,现为Myhost1配置backupNode和SecondaryNamenode, 由于机器有限,这里就不为Myhost2配置backupNode和SecondaryNamenode,但是方法相同. 2. 我们选定Myhost4为SecondaryNamenode, Myhost5为backupNode. 配置并启动SecondaryNamenode: 1. 配置:为Myhost1的 hdfs-site.xml 加入如下配置,指定SecondaryNamenode. <property>
<name>dfs.namenode.secondary.http-address</name>
<value> Myhost4:9001</value>
</property> 2. Myhost4的hdfs-site.xml 加入如下配置,指定nn的url和本地的checkpoint.dir. <property>
<name>dfs.federation.nameservice.id</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/yuling.sh/checkpoint-data</value>
</property> 3. 启动SecondaryNamenode. 在Myhost1上运行命令:sbin/star-dfs.sh或者在Myhost4上运行sbin/hadoop-daemo.sh start SecondaryNamenode 即可以启动SecondaryNamenode. 可以通过log或者网页Myhost4:50090查看其状态. 另外在checkpoint.dir下会有元数据信息. 配置并启动backupNode: 1. 配置Myhost5的hdfs-site.xml, 加入如下配置信息: <property>
<name>dfs.namenode.backup.address</name>
<value> Myhost5:9002</value>
</property>
<property>
<name>dfs.namenode.backup.http-address</name>
<value> Myhost5:9003</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/ backup-data</value>
</property> 2. 启动backupNode, 在Myhost5上运行bin/hdfs namenode –backup & 3. 在dfs.namenode.name.dir下查看元数据信息.
下一篇博客将讲述如何搭建hadoop 0.23 的mapreduce
使用hadoop-0.23 搭建hdfs, namenode + datanode 1. HDFS-1052引入了多namenode, HDFS架构变化较大, 可以参考hortonworks的文章: http://hortonworks.com/an-introduction-to-hdfs-federation/. 我将在接下来的博客里把此文章翻译一下(另外还有: http://developer.yahoo.com/blogs/hadoop/posts/2011/03/mapreduce-nextgen-scheduler/). 所有namenode共享datanode, 各个namenode相互独立, 互不影响, 每个namenode都有一个backupNode和SecondaryNamenode,提供主备切换功能和备份元数据的功能. 下文的配置信息主要参考HDFS-2471. 2. 环境: a) 五台机器 ,linux系统, b) 互相添加ssh-key,后应该可以不用密码互连 c) 编译好的0.23版本的包: hadoop-0.23.0-SNAPSHOT.tar.gz d) 每台机器需要安装java1.6或以上版本.并把JAVA_HOME加到$PATH中. e) 最好加上pssh和pscp工具. 这里把五台机器命名为: Myhost1 Myhost2 Myhost3 Myhost4 Myhost5 假设我们需要搭建如下集群: Myhost1和Myhost2开启 namenode, 另外三台机器启动datanode服务. 3. 首先把分配到五台机器上,然后解压.(推荐使用pscp, pssh命令) 4. 然后在五台机器上安装java,并把JAVA_HOME加到$PATH中 5. 进入解压后的hadoop目录, 编辑 etc/hadoop/hdfs-site.xml a) Myhost1的配置如下(其中hadoop存放在/home/yuling.sh/目录下): <property>
<name>fs.defaultFS</name>
<value>hdfs:// Myhost1:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/cluster-data</value>
</property> b) Myhost2的配置如下(其中hadoop存放在/home/yuling.sh/目录下): <property>
<name>fs.defaultFS</name>
<value>hdfs:// Myhost2:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/cluster-data</value>
</property> c) 这里把Myhost1集群起名ns1, Myhost1集群起名ns2, 三台slava的etc/hadoop/hdfs-site.xml配置如下: <property>
<name>dfs.federation.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>hdfs:// Myhost1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>hdfs:// Myhost2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value> Myhost2:50070</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/yuling.sh/datanode</value>
</property>
d) 解释:namenode需要指定两个参数, 用于存放元数据和文件系统的URL. Datanode需指定要连接的namenode 的rpc-address和http-address. 以及数据存放位置dfs.datanode.data.dir. 6. 然后编辑两台namenode的hadoop目录下 etc/hadoop/slaves文件. 加入三台slave机器名: Myhost3 Myhost4 Myhost5 7. 现在需要格式化namenode, 由于namenode共享datanode, 因此它们的clusterid需要有相同的名字.这里我们把名字设为 yuling .命令如下: bin/hdfs namenode –format –clusterid yuling 两台机器格式话之后会在/home/yuling.sh/cluster-data下生成元数据目录. 8. 启动Myhost1和Myhost2上的namenode和slave上datanode服务. 命令如下: sbin/start-hdfs.sh 分别在Myhost1和Myhost2下运行. 9. 启动之后打开浏览器, 分别查看两namenode启动后状态. URL为: Myhost1:50070和Myhost2:50070 10. 这期间可能会遇到许多问题, 但是可以根据抛出的异常自己解决, 我这里就不多说了. 下一篇博客将讲述如何启动backupNode和SecondaryNamenode
编译(环境linux, 需要联网) 1. 首先下载hadoop 0.23版本 svn checkout http://svn.apache.org/repos/asf/hadoop/common/tags/release-0.23.0-rc0/ 2. 进入release-0.23.0-rc0目录下能看到INSTALL.TXT文件, 这里有编译hadoop 0.23的教程. 编译前的准备:. a) * Unix System b) * JDK 1.6 c) * Maven 3.0 d) * Forrest 0.8 (if generating docs) e) * Findbugs 1.3.9 (if running findbugs) f) * ProtocolBuffer 2.4.1+ (for MapReduce) g) * Autotools (if compiling native code) h) * Internet connection for first build (to fetch all Maven and Hadoop dependencies) 可以根据需要安装全部或部分的工具,然后把它们加入到$PATH中. 这里介绍一下ProtocolBuffer的安装方法:下载2.4.1版本后解压,进入目录,运行如下命令即可. $ ./configure --prefile=/usr/local $ make $ sudo make install 3. 经过第二步准备之后,由于从hadoop0.23开始使用Maven编译,因此必需联网,命令如下: mvn package [-Pdist][-Pdocs][-Psrc][-Pnative][-Dtar] 建议先运行命令: mvn package -Pdist -DskipTests –Dtar (前提Maven 3.0和ProtocolBuffer2.4.1以上), 此命令成功之后会在release-0.23.0-rc0/下生成 hadoop-dist/target/hadoop-0.23.0-SNAPSHOT.tar.gz. 可以使用这个包搭建集群. 使用-Pdocs选项可以生成文档,当然前提是安装了Forrest 0.8和Findbugs 1.3.9. 可以参考如下命令手动指定:FORREST_HOME和FINDBUGS_HOME. mvn package -Pdocs -DskipTests -Dtar -Dmaven.test.skip -Denv.FORREST_HOME=/usr/local/apache-forrest-0.9 -Denv.FINDBUGS_HOME=/usr/local/findbugs-1.3.9 生成的文档在各自的target/site目录下.
经过以上步骤,我们已经编译好了hadoop-0.23,现在可以使用hadoop-0.23.0-SNAPSHOT.tar.gz来搭建集群了. 下一篇博客将讲述如何使用hadoop-0.23 搭建hdfs集群
本周末学习zookeeper,原理和安装配置 本文参考: http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ http://zookeeper.apache.org/ Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储,但是 Zookeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。 Zookeeper安装和配置比较简单,可以参考官网. 数据模型 Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如图 1 所示:
图 1 Zookeeper 数据结构

Zookeeper 这种数据结构有如下这些特点: - 每个子目录项如 NameService 都被称作为 znode,这个 znode 是被它所在的路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1
- znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录
- znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据
- znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了
- znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
- znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍
ZooKeeper 典型的应用场景 Zookeeper 从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生 变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式,关于 Zookeeper 的详细架构等内部细节可以阅读 Zookeeper 的源码 下面详细介绍这些典型的应用场景,也就是 Zookeeper 到底能帮我们解决那些问题?下面将给出答案。 统一命名服务(Name Service) 分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形 的名称结构是一个有层次的目录结构,既对人友好又不会重复。说到这里你可能想到了 JNDI(Java Naming and Directory Interface,Java命名和目录接口,是一组在Java应用中访问命名和目录服务的API),没错 Zookeeper 的 Name Service 与 JNDI 能够完成的功能是差不多的,它们都是将有层次的目录结构关联到一定资源上,但是 Zookeeper 的 Name Service 更加是广泛意义上的关联,也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复名称,就像数据库中产生一个唯一的数字主键一样。 Name Service 已经是 Zookeeper 内置的功能,你只要调用 Zookeeper 的 API 就能实现。如调用 create 接口就可以很容易创建一个目录节点。 配置管理(Configuration Management) 配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。 像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
图 2. 配置管理结构图
 集群管理(Group Membership) Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服 务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。 Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。 它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用 getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。 Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server 创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL 目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server 编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL 节点,死去的 Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前 Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。
图 3. 集群管理结构图
 这部分的示例代码如下,完整的代码请看源代码:
清单 3. Leader Election 关键代码
void findLeader() throws InterruptedException { byte[] leader = null; try { leader = zk.getData(root + "/leader", true, null); } catch (Exception e) { logger.error(e); } if (leader != null) { following(); } else { String newLeader = null; try { byte[] localhost = InetAddress.getLocalHost().getAddress(); newLeader = zk.create(root + "/leader", localhost, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); } catch (Exception e) { logger.error(e); } if (newLeader != null) { leading(); } else { mutex.wait(); } } } | 共享锁(Locks) 共享锁在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
图 4. Zookeeper 实现 Locks 的流程图
 同步锁的实现代码如下,完整的代码请看源代码:
清单 4. 同步锁的关键代码
void getLock() throws KeeperException, InterruptedException{ List<String> list = zk.getChildren(root, false); String[] nodes = list.toArray(new String[list.size()]); Arrays.sort(nodes); if(myZnode.equals(root+"/"+nodes[0])){ doAction(); } else{ waitForLock(nodes[0]); } } void waitForLock(String lower) throws InterruptedException, KeeperException { Stat stat = zk.exists(root + "/" + lower,true); if(stat != null){ mutex.wait(); } else{ getLock(); } } | 队列管理 Zookeeper 可以处理两种类型的队列: - 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
- 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
同步队列用 Zookeeper 实现的实现思路如下: 创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。 用下面的流程图更容易理解:
图 5. 同步队列流程图
 同步队列的关键代码如下,完整的代码请看附件:
清单 5. 同步队列
void addQueue() throws KeeperException, InterruptedException{ zk.exists(root + "/start",true); zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); synchronized (mutex) { List<String> list = zk.getChildren(root, false); if (list.size() < size) { mutex.wait(); } else { zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } } } | 当队列没满是进入 wait(),然后会一直等待 Watch 的通知,Watch 的代码如下: public void process(WatchedEvent event) { if(event.getPath().equals(root + "/start") && event.getType() == Event.EventType.NodeCreated){ System.out.println("得到通知"); super.process(event); doAction(); } } | FIFO 队列用 Zookeeper 实现思路如下: 实现的思路也非常简单,就是在特定的目录下创建 SEQUENTIAL 类型的子目录 /queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过 getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证 FIFO。 下面是生产者和消费者这种队列形式的示例代码,完整的代码请看附件:
清单 6. 生产者代码
boolean produce(int i) throws KeeperException, InterruptedException{ ByteBuffer b = ByteBuffer.allocate(4); byte[] value; b.putInt(i); value = b.array(); zk.create(root + "/element", value, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL); return true; } |
清单 7. 消费者代码
int consume() throws KeeperException, InterruptedException{ int retvalue = -1; Stat stat = null; while (true) { synchronized (mutex) { List<String> list = zk.getChildren(root, true); if (list.size() == 0) { mutex.wait(); } else { Integer min = new Integer(list.get(0).substring(7)); for(String s : list){ Integer tempValue = new Integer(s.substring(7)); if(tempValue < min) min = tempValue; } byte[] b = zk.getData(root + "/element" + min,false, stat); zk.delete(root + "/element" + min, 0); ByteBuffer buffer = ByteBuffer.wrap(b); retvalue = buffer.getInt(); return retvalue; } } } } | 总结 Zookeeper 作为 Hadoop 项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop 集群中的 NameNode,还有 Hbase 中 Master Election、Server 之间状态同步等。 本文介绍的 Zookeeper 的基本知识,以及介绍了几个典型的应用场景。这些都是 Zookeeper 的基本功能,最重要的是 Zoopkeeper 提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管 理模型,而不仅仅局限于上面提到的几个常用应用场景。
使用 Linux 系统总是免不了要接触包管理工具。比如,Debian/Ubuntu 的 apt、openSUSE 的 zypp、Fedora 的 yum、Mandriva 的 urpmi、Slackware 的 slackpkg、Archlinux 的 pacman、Gentoo 的 emerge、Foresight 的 conary、Pardus 的 pisi,等等。DistroWatch 针对上述包管理器的主要用法进行了总结,对各位 Linux 用户来说具有很好的参考作用。这个总结还是有一点不足,有空给大家整理一个更全面的版本。 | 任务 | apt
Debian, Ubuntu | zypp
openSUSE | yum
Fedora, CentOS | | 安装包 | apt-get install <pkg> | zypper install <pkg> | yum install <pkg> | | 移除包 | apt-get remove <pkg> | zypper remove <pkg> | yum erase <pkg> | | 更新包列表 | apt-get update | zypper refresh | yum check-update | | 更新系统 | apt-get upgrade | zypper update | yum update | | 列出源 | cat /etc/apt/sources.list | zypper repos | yum repolist | | 添加源 | (edit /etc/apt/sources.list) | zypper addrepo <path> <name> | (add <repo> to /etc/yum.repos.d/) | | 移除源 | (edit /etc/apt/sources.list) | zypper removerepo <name> | (remove <repo> from /etc/yum.repos.d/) | | 搜索包 | apt-cache search <pkg> | zypper search <pkg> | yum search <pkg> | | 列出已安装的包 | dpkg -l | rpm -qa | rpm -qa | | 任务 | urpmi
Mandriva | slackpkg
Slackware | pacman
Arch | | 安装包 | urpmi <pkg> | slackpkg install <pkg> | pacman -S <pkg> | | 移除包 | urpme <pkg> | slackpkg remove <pkg> | pacman -R <pkg> | | 更新包列表 | urpmi.update -a | slackpkg update | pacman -Sy | | 更新系统 | urpmi --auto-select | slackpkg upgrade-all | pacman -Su | | 列出源 | urpmq --list-media | cat /etc/slackpkg/mirrors | cat /etc/pacman.conf | | 添加源 | urpmi.addmedia <name> <path> | (edit /etc/slackpkg/mirrors) | (edit /etc/pacman.conf) | | 移除源 | urpmi.removemedia <media> | (edit /etc/slackpkg/mirrors) | (edit /etc/pacman.conf) | | 搜索包 | urpmf <pkg> | -- | pacman -Qs <pkg> | | 列出已安装的包 | rpm -qa | ls /var/log/packages/ | pacman -Qii | | 任务 | conary
rPath, Foresight | pisi
Pardus | emerge
Gentoo | | 安装包 | conary update <pkg> | pisi install <pkg> | emerge <pkg> | | 移除包 | conary erase <pkg> | pisi remove <pkg> | emerge -C <pkg> | | 更新包列表 | | pisi update-repo | emerge --sync | layman -S [for added repositories] | | 更新系统 | conary updateall | pisi upgrade | emerge -NuDa world | | 列出源 | | pisi list-repo | layman -L | | 添加源 | | pisi add-repo <name> <path> | layman -a | | 移除源 | | pisi remove-repo <name> | layman -d | | 搜索包 | conary query <pkg> | pisi search <pkg> | emerge --search | | 列出已安装的包 | conary query | pisi list-installed | cat /var/lib/portage | more |
本文转自 http://linuxtoy.org/archives/linux-package-management-cheatsheet.html
-Xms256m
-Xmx512m
-Xmn128m
-XX:PermSize=96m
-XX:MaxPermSize=96m
-Xverify:none
-Xnoclassgc
-XX:UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=85 加入以上参数能使eclipse启动速度得到加快.至于各个参数的意义可以在网上查找到,这里不详细赘述.
Eclipse插件开发 1. 下载并安装jdk和eclipse
这里强调一下: 需要下载Eclipse for RCP and RAP Developers, 否则无法新建Plug-in Development 项目.
2. 新建项目
安装好之后打开eclipse, 点击 File->NewProject。选择Plug-in Project,点击Next。新建一个名为com.developer.showtime的项目,所有参数采用默认值. 3. 在com.developer.showtime项目的src下新建一个类: ShowTime,代码如下:
package com.developer.showtime;
import org.eclipse.jface.dialogs.MessageDialog;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.ui.IStartup;
public class ShowTime implements IStartup {
public void earlyStartup() {
Display.getDefault().syncExec(new Runnable() {
public void run(){
long eclipseStartTime = Long.parseLong(System.getProperty("eclipse.startTime"));
long costTime = System.currentTimeMillis() - eclipseStartTime;
Shell shell = Display.getDefault().getActiveShell();
String message = "Eclipse start in " + costTime + "ms";
MessageDialog.openInformation(shell, "Information", message);
}
});
}
}
4. 修改plugin.xml文件如下: <?xml version="1.0" encoding="UTF-8"?>
<?eclipse version="3.4"?>
<plugin>
<extension
point="org.eclipse.ui.startup">
<startup class="com.developer.showtime.ShowTime"/>
</extension>
</plugin> 5. 试运行 右键点击Run as -> Eclipse Application. 此时会运行一个eclipse, 启动之后就能显示启动所需时间. 6. 导出插件. 右键Export -> Deployable plug-ins and fragments. 在Directory中输入需要导出的路径, 点击finish后会在该目录下产生一个plugins的目录, 里面就是插件包: com.developer.showTime_1.0.0.201110161216.jar. 把这个包复制到eclipse目录下的plugin目录下. 然后再启动eclipse 便可以看到eclipse启动所花的时间.
本周学习了mapreduce-64,对map端的spill有了较为深入的了解. 附件描述了修改前后sort的原理.mapreduce-64前spill原理较为简单,打上mapreduce-64后主要流程也不难,需要了解各个参数的意义.
下文翻译自yahoo博客:http://developer.yahoo.com/blogs/hadoop/posts/2011/02/mapreduce-nextgen/
Hadoop的下一代mapreduce 概述 在大数据商业领域中,运行个数少但较大的集群比运行多个小集群更划算,大集群还可以处理更大的数据集并支持更多的作业和用户. Apache Hadoop 的MapReduce框架已经达到4000台机器的扩展极限,我们正在发展下一代MapReduce,使其成为一个通用资源管理,单作业,用户自定义组件,管理着应用程序执行的框架. 由于停机成本更大,高可用必需从一开始就得建立,就如安全性和多用户组,用以支持更多用户使用更大的集群,新的构架在许多地方进行了创新,增加了敏捷性和机器利用率. 背景 当前Apache Hadoop 的MapReduce的接口会显示其年龄. 由于集群大小和工作负载的变化趋势, MapReduce的JobTracker需要彻底的改革以解决其可扩展性,内存消耗,线程模型,可靠性和性能上的不足. 过去五年,我们做了一些小的修复,然而最近,修改框架的的成本越来越高. 结构的缺陷和纠正措施都很好理解,甚至早在2007年,当我们记录下修复建议: https://issues.apache.org/jira/browse/MAPREDUCE-278. 从运营的角度看,目前的Hadoop MapReduce框架面临系统级别的升级,以解决例如bug修复,性能改善和功能的需求. 更糟糕的是,它迫使每个用户也需要同时升级,不顾其利益;这使用户使用新版本的周期变长. 需求 我们考虑改善Hadoop MapReduce框架的方法,重要的是记住最迫切的需求,下一代Hadoop MapReduce框架最迫切的需求是: - 可靠性
- 可用性
- 可扩展性 - 10000台机器,200000核,或者更多
- 向后兼容性 - 确保用户的MapReduce应用程序在下一代框架下不需要改变
- 进展 – 客户端可以控制hadoop软件堆栈的升级.
- 可预测的延迟 – 用户很关注的一点.
- 集群利用率
第二层次需求: - 使MapReduce支持备用编程范式
- 支持短时间的服务
鉴于以上需求,显然我们需要重新考虑使用hadoop成为数据处理的基础设施. 事实上,当前MapReduce结构无法满足我们的需求,因此需要新的创新,这在hadoop社区这已成为共识,查看2008年一月的一个提议,在jira: https://issues.apache.org/jira/browse/MAPREDUCE-279. 下一代MapReduce 重构的基本思想是把jobtracker的两大功能分开,使资源管理和作业分配/监控成为两个部件.新的资源管理器管理提供给应用(一个或多个)的计算资源,应用管理中心管理应用程序的调度和协调,应用程序既是一个经典MapReduce作业也是这类作业的DAG. 资源管理器和每台机器的NodeManager服务,管理该机上的用户进程,形成计算结构. 每个应用程序的ApplicationMaster是一个具体库的架构,负责从资源管理器请求资源,并和NodeManager协同执行和监控任务. 资源管理器支持应用程序的分组,这些组保证使用一定比例集群资源. 它是纯粹的调度,也就是,它运行时并不监控和追踪应用的状态. 此外,它不保证重新启动失败的任务,无论是应用程序或硬件导致的失败. 资源管理器执行调度功能是基于应用的资源需求,每个应用需要多种资源需求,代表对对容器所需的资源,资源需求包括内存,cpu,硬盘,网络等,注意这与当前使用slot模型的MapReduce有很大的不同,slot模型导致集群利用率不高,资源管理器有一个调度策略插件,负责分把集群资源分给各个组,应用等.有基础的调度插件,例如:当前的CapacityScheduler 和FairScheduler. NodeManager是每台机器的框架代理,负责提交应用程序的容器,监控他们的资源利用率(cpu,内存,硬盘,网络),并且报告给调度器. 每个应用程序的ApplicationMaster负责与调度器请求适当的资源容器,提交作业,追踪其状态,监控进度和处理失败任务. 结构 改进当前实现面对面的Hadoop MapReduce 可扩展性 在集群中把资源管理从集群管理器的整个生命周期和他们的部件中分离出来后形成的架构:扩展性更好并且更优雅, Hadoop MapReduce的JobTracker花费很大一部分时间和精力管理应用程序的生命周期,这是导致软件灾难的原因.把它移到应用指定的实体是一个重大的胜利. 可扩展性在当前硬件趋势下更加重要,当前hadoop的MapReduce已经发展到4000台机器,然而4000台机器在2009年(例:8core,16G RAM,4TB硬盘)只有2011年400台机器的一半(16core,48G RAM, 24TB硬盘). 并且,运营成本的因素有助于迫使和巩固我们使用更大的集群:6000台机器或者更多. 可用性 - 资源管理器 – 使用 Apache ZooKeeper 用于故障转移. 当资源管理器发生故障,另外一个可以迅速恢复,这是由于集群状态保存在ZooKeeper中. 资源管理器失败后,重启所有组和正在运行的应用程序.
- 应用中心 - 下一代MapReduce支持应用特殊点的检查功能 ,依靠其把自身状态存储在hdfs上的功能,MapReduce 应用中心可以从失败中恢复,
兼容性 下一代MapReduce使用线兼容协议以允许不同版本的服务端和客户端相互通信,在将来的releases版本,这将使集群滚动升级,一个重要的可操作性便成功了. 创新和敏捷性 提出的构架一个主要优点是MapReduce将更有效,成为user-land library. 计算框架(资源管理器和节点管理器)完全通用并在MapReduce看来是透明的. 这使最终客户在同一个集群使用可用不同版本的MapReduce, 这是微不足道的支持,因为MapReduce的应用中心和运行时的多版本可用于不同的应用. 这为应用提供显著的灵活性,因为整个集群没必要升级,如修复bug,改进和新功能的应用. 它也允许终端用户根据他们自己的安排升级其应用到MapReduce版本,这大大提高了集群的可操作性. 允许用户自定义的Map-Reduce版本的创新不会影响软件的稳定性. 这是微不足道的,就像hadoop在线原型进入用户MapReduce版本而不影响其他用户.( It will be trivial to incorporate features such as the Hadoop Online Prototype into the user’s version of MapReduce without affecting other users.) 集群利用率 下一代MapReduce资源管理器使用通用概念,用于调度和分配给单独的个体. 集群中的每个机器资源是概念性的,例如内存,cpu,I/O带宽等. 每个机器都是可替代的,分配给应用程序就像基于应用指定需求资源的容器.每个容器包括一些处理器,并和其他容器逻辑隔离,提供强有利的多租户支持. 它删除了当前hadoop MapReduce中map和reduce slots概念. Slot会影响集群的利用率,因为在任何时候,无论map和reduce都是稀缺的. 支持MapReduce编程范式 下一代MapReduce提供一个完全通用的计算框架以支持MapReduce和其他的范例. 架构允许终端用户实现应用指定的框架,通过实现用户的ApplicationMaster,可以向资源管理器请求资源并利用他们,因为他们通过隔离并保证资源的情况下看起来是适合的. 因此,在同一个hadoop集群下支持多种编程范式,例如MapReduce, MPI, Master-Worker和迭代模型,并允许为每个应用使用适当的框架.这对自定义框架顺序执行一定数目的MapReduc应用程序(例: K-Means, Page-Rank)很重要. 结论 Apache Hadoop和特定的Hadoop MapReduce,是一个用于处理大数据集的成功开源项目. 我们建议Hadoop的 MapReduce重构以提供高可用性,增加集群利用率,提供编程范例的支持以加快发展. 我们认为,在已存在的选项中如Torque, Condor, Mesos 等,没有一个用于设计解决MapReduce集群规模的问题, 某些功能很新且不成熟, 另外一些没有解决关键问题,如调度在上十万个task,规模的性能,安全和多用户等. 我们将与Apache Hadoop社区合作,为实现这以提升Apache Hadoop以适应下一代大数据空间.
0.23的调度方法: http://developer.yahoo.com/blogs/hadoop/posts/2011/03/mapreduce-nextgen-scheduler/
周末无事,故翻译sheepdog design. 原文地址: https://github.com/collie/sheepdog/wiki/Sheepdog-Design Sheepdog 设计 Sheeepdog采用完全对称的结构,没有类似元数据服务的中心节点. 这种设计有以下的特点. 1) 性能于容量的线性的可扩展性. 当需要提升性能或容量时,只需向集群中增加新的机器便能使Sheeepdog线性成长. 2) 没有单点故障 即使某台机器发生故障,依然可以通过其他机器访问数据. 3) 容易管理 不需要配置机器角色,当管理员在新增的机器开启Sheepdog守护进程时, Sheepdog会自动检测新加入的机器并配置它成为存储系统中的一员. 结构概述  
Sheepdog是一个分布式存储系统.为Sheepdog客户端(QEMU的块驱动程序)提供对象存储(类似于简单的键值对). 接下来几章将更加详细的阐述Sheepdog各个部分. 1) 对象存储(Object对象存储(Object Storage) 2) ) Sheepdog不同于一般的文件系统, Sheepdog进程为QEMU(Sheepdog进程名)创建一个分布式对象存储系统,它可以存储”对象”.这里的”对象”数据大小可变,并有唯一的标识,通过标识可以进行读/写/创建/删除操作.对象存储组成”网关”和”对象管理器”. 3) 网关(getway) Getway接收QEMU块驱动的I/O请求(对象id,偏移,长度和操作类型),通过一直散列算法获得目标节点,然后转发I/O请求至该节点. 4) 对象管理器(Object manager) 对象管理器接收getway转发过来的I/O请求,然后对磁盘执行读/写操作. 5) 集群管理器(Cluster manager) 集群管理器管理管理节点成员(探测失败/新增节点并报告节点成员的变化),以及一些需要节点一致的操作(vdi 创建, 快照 vdi等).当前集群管理器使用corosync集群引擎. 6) QEMU 块驱动 QEMU块驱动把VM image分为固定大小(默认4M),并通过其getway存储到对象存储中 对象存储(Object Storage) 每个对象使用一个64bit的整数作为全局标识,并在多台机器存有备份,QEMU块驱动并不关心存储的位置,对象存储系统负责管理存储的位置. 对象类型(object types) Sheepdog的对象分为以下四种: 1) 数据类型(data object) 它包括虚拟磁盘映射的真实数据,虚拟磁盘映射分为固定大小的数据对象, Sheepdog客户端访问这个对象. 2) vdi object 它包括虚拟磁盘映射的元数据(例:映射名,磁盘大小,创建时间,vdi的数据对象ID等). 3) vmstate object 它存储运行中的VM状态映射.管理员通过它获取实时快照信息. 4) vdi attr object 使用它存储各个vdi的属性,属性为键值对类型,类似于普通文件的扩展信息. 对象ID规则(object ID rules) 1) 0 - 31 (32 bits): 对象类型详细信息 2) 32 - 55 (24 bits): vdi id 3) 56 - 59 ( 4 bits): 预留 4) 60 - 63 ( 4 bits): 对象类型标识符 每个VDI有一个全局唯一的ID(vdi id), 通过VDI名求得的散列值,低三十二位使用如下: | 对象类型 | 低32位的作用 | | 数据类型 | 虚拟磁盘映射的索引号 | | Vdi对象 | 未使用(填0) | | Vm状态对象 | Vm状态映射索引 | | Vdi属性对象 | 键名的散列值 | 对象格式(object format) 1) 数据对象 虚拟磁盘映射的块 2) Vdi对象 1 struct sheepdog_inode {
2 char name[SD_MAX_VDI_LEN]; /* the name of this VDI*/
3 char tag[SD_MAX_VDI_TAG_LEN]; /* the snapshot tag name */
4 uint64_t ctime; /* creation time of this VDI */
5 uint64_t snap_ctime; /* the time snapshot is taken */
6 uint64_t vm_clock_nsec; /* vm clock (used for live snapshot) */
7 uint64_t vdi_size; /* the size of VDI */
8 uint64_t vm_state_size; /* the size of vm state (used for live snapshot) */
9 uint16_t copy_policy; /* reserved */
10 uint8_t nr_copies; /* the number of object redundancy */
11 uint8_t block_size_shift; /* info about the size of the data object */
12 uint32_t snap_id; /* the snapshot id */
13 uint32_t vdi_id; /* the vdi id */
14 uint32_t parent_vdi_id; /* the parent snapshot vdi id of this VDI */
15 uint32_t child_vdi_id[MAX_CHILDREN]; /* the children VDIs of this VDI */
16 uint32_t data_vdi_id[MAX_DATA_OBJS]; /* the data object IDs this VDI contains*/
17 }; 3) Vm状态对象 Vm状态映射块 4) Vdi属性对象 前SD_MAX_VDI_ATTR_KEY_LEN位(256位)为属性的键名,余下的是属性指. 只读/可写对象(read-only/writable objects) 从如何访问对象的角度,我们还可以把Sheepdog对象分为以下两类. 1) 只读对象(例:VDI快照数据对象) 只允许一个VM对其读写,其他vm无法访问 2) 可写对象 不允许任何VM对其写,所有VM都可读 其他功能(other features) Sheepdog对象存储可接收正在写时复制(copy-on-write)的请求.当一个客户端发送一个创建和写的请求时,同时可以指定基本对象(CoW操作的来源),这用于快照和克隆操作. 网关(Gateway) 对象存在哪(where to store objects) Sheepdog使用一致性哈希算法决定存放对象的位置,一致性哈希算法提供哈希表,而且增加或介绍节点不回显著的改变对象映射,通过哈希表能使I/O负载均衡. 副本(replication) Sheepdog的数据副本很简单,我们假设只有一个写,所以写冲突不会发生,客户端可以并行发生请求到目标节点,发生读请求到一个目标节点如果客户端自己处理I/O请求顺序. 写I/O流(write I/O flow) Getway使用一致性哈希算法计算目标节点并发送写请求到所有目标节点,只有所有副本均更新成功写请求才会成功,这是因为如果一个副本未更新,getway有可能从未更新的节点读取旧数据. 读I/O流(read I/O flow) Getway使用一致性哈希算法计算目标节点,并发送读请求到一个目标节点. 1) 修复对象一致性 当某节点在转发I/O请求时crash,有可能破坏副本的一致性,所以当getway第一次读取对象时会试图修复其一致性,从一节点读取整个对象并用它覆盖所有副本. 重试I/O请求(retrying I/O requests) Sheepdog存储所有成员节点的历史信息,我们把历史版本号叫做”epoch”(详见章节’对象恢复’). 如果getway转发I/O请求至目标节点并且getway与目标节点epoch号不相符,I/O请求失败且getway重试请求直到epcho号相符,这就需要保持副本强一致性. I/O重试也可能发生在目标节点挂了导致无法完成I/O操作. 对象管理器(Object Manager) 对象管理器把对象存储到本地磁盘,当前把每个对象存储为一个文件,这中方法简单.我们也可以使用DBMS(例: BerkeleyDB, Tokyo Cabinet等) 作为对象存储器,但还不支持. 路径命名规则(path name rule) 对象存储成如下路径: /store_dir/obj/[epoch number]/[object ID] 所有对象文件有一个扩展属性: 副本数(sheepdog.copies), 写日志(write journaling) 当sheep进程在写操作过程中失败,对象有可能至少部分更新,一般情况这不会有问题,因为如果VM未接收成功消息,不保证所写部分的内容.然而对于vdi对象,我们必须整体更新或整体未更新,因为如果vdi对象只是部分更新,VDI的元数据有可能被破坏. 为例防止这个问题,我们使用日志记录对vdi对象的写操作. 日志过程很简单: 1) 创建日志文件"/store_dir/journal/[epoch]/[vdi object id]" 2) 首先写数据到日志文件 3) 写一个数据到vdi对象 4) 删除日志文件 集群管理器(Cluster Manager) 大多情况, Sheepdo客户端单独访问它们的映射因为我们不允许两个客户端同时访问一个映射,但是某些VDI操作(例:克隆VDI,创建VDI)必须做,因为这些操作更新全局信息,我们使用Corosync集群引擎完成而不是中心服务器. 我们将扩展Sheepdog以支持其他集群管理系统. 本章正在编辑 QEMU 块驱动(QEMU Block Driver) 
Sheepdog卷被分为4M的数据对象,刚创建的对象未分配,也就是说,只有写对象被分配. Open 首先QEMU块驱动通过getway的bdrv_open()从对象存储读取vdi 读/写(read/write) 块驱动通过请求的部分偏移量和大小计算数据对象id, 并向getway发送请求. 当块驱动发送写请求到那些不属于其当前vdi的数据对象是,块驱动发送CoW请求分配一个新的数据对象. 写入快照vdi(write to snapshot vdi) 我们可以把快照VDI附加到QEMU, 当块驱动第一次发送写请求到快照VDI, 块驱动创建一个新的可写VDI作为子快照,并发送请求到新的VDI. VDI操作(VDI Operations) 查找(lookup) 当查找VDI对象时: 1) 通过求vdi名的哈希值得到vdi id 2) 通过vdi id计算di对象 3) 发送读请求到vdi对象 4) 如果此vdi不是请求的那个,增加vdi id并重试发送读请求 快照,克隆(snapshot, cloning) 快照可克隆操作很简单, 1) 读目标VDI 2) 创建一个与目标一样的新VDI 3) 把新vdi的‘'parent_vdi_id''设为目标VDI的id 4) 设置目标vdi的''child_vdi_id''为新vdi的id. 5) 设置目标vdi的''snap_ctime''为当前时间, 新vdi变为当前vdi对象 删除(delete) TODO:当前,回收未使用的数据对象是不会被执行,直到所有相关VDI对象(相关的快照VDI和克隆VDI)被删除. 所有相关VDI被删除后, Sheepdog删除所有此VDI的数据对象,设置此VDI对象名为空字符串. 对象恢复(Object Recovery) epoch Sheepdog把成员节点历史存储在存储路径, 路径名如下: /store_dir/epoch/[epoch number] 每个文件包括节点在epoch的列表信息(IP地址,端口,虚拟节点个数). 恢复过程(recovery process) 1) 从所有节点接收存储对象ID 2) 计算选择那个对象 3) 创建对象ID list文件"/store_dir/obj/[the current epoch]/list" 4) 发送一个读请求以获取id存在于list文件的对象. 这个请求被发送到包含前一次epoch的对象的节点.( The requests are sent to the node which had the object at the previous epoch.) 5) 把对象存到当前epoch路径. 冲突的I/O(conflicts I/Os) 如果QEMU发送I/O请求到某些未恢复的对象, Sheepdog阻塞此请求并优先恢复对象. 协议(Protocol) Sheepdog的所有请求包含固定大小的头部(48位)和固定大小的数据部分,头部包括协议版本,操作码,epoch号,数据长度等. between sheep and QEMU | 操作码 | 描述 | | SD_OP_CREATE_AND_WRITE_OBJ | 发送请求以创建新对象并写入数据,如果对象存在,操作失败 | | SD_OP_READ_OBJ | 读取对象中的数据 | | SD_OP_WRITE_OBJ | 向对象写入数据,如果对象不存在,失败 | | SD_OP_NEW_VDI | 发送vdi名到对象存储并创建新vdi对象, 返回应答vdi的唯一的vdi id | | SD_OP_LOCK_VDI | 与SD_OP_GET_VDI_INFO相同 | | SD_OP_RELEASE_VDI | 未使用 | | SD_OP_GET_VDI_INFO | 获取vdi信息(例:vdi id) | | SD_OP_READ_VDIS | 获取已经使用的vdi id | between sheep and collie | 操作码 | 描述 | | SD_OP_DEL_VDI | 删除VDI | | SD_OP_GET_NODE_LIST | 获取sheepdog的节点列表 | | SD_OP_GET_VM_LIST | 未使用 | | SD_OP_MAKE_FS | 创建sheepdog集群 | | SD_OP_SHUTDOWN | 停止sheepdog集群 | | SD_OP_STAT_SHEEP | 获取本地磁盘使用量 | | SD_OP_STAT_CLUSTER | 获取sheepdog集群信息 | | SD_OP_KILL_NODE | 退出sheep守护进程 | | SD_OP_GET_VDI_ATTR | 获取vdi属性对象id | between sheeps | 操作码 | 描述 | | SD_OP_REMOVE_OBJ | 删除对象 | | SD_OP_GET_OBJ_LIST | 获取对象id列表,并存储到目标节点 |
Ant是什么? Ant是一种基于 Java和XML的build工具. 1 编写build.xml Ant的buildfile是用XML写的.每个buildfile含有一个project. buildfile中每个task元素可以有一个id属性,可以用这个id值引用指定的任务.这个值  是唯一的.(详情请参考下面的Task小节) 1.1 Projects project有下面的属性: | Attribute | Description | Required | | name | 项目名称. | No | | default | 当没有指定target时使用的缺省target | Yes | | basedir | 用于计算所有其他路径的基路径.该属性可以被basedir property覆盖.当覆盖时,该属性被忽略.如果属性和basedir property都没有设定,就使用buildfile文件的父目录. | No |
项目的描述以一个顶级的<description>元素的形式出现(参看description小节).
一个项目可以定义一个或多个target.一个target是一系列你想要执行的.执行Ant时,你可以选择执行那个target.当没有给定target时,使用project的default属性所确定的target.
1.2 Targets
一个target可以依赖于其他的target.例如,你可能会有一个target用于编译程序,一个target用于生成可执行文件.你在生成可执行文件之前先编译通过, 生成可执行文件的target依赖于编译target.Ant会处理这种依赖关系. 生成可执行文件的target依赖于编译target.Ant会处理这种依赖关系.
然而,应当注意到,Ant的depends属性只指定了target应该被执行的顺序-如果被依赖的target无法运行,这种depends对于指定了依赖关系的target就没有影响.
Ant会依照depends属性中target出现的顺序(从左到右)依次执行每个target.然而,要记住的是只要某个target依赖于一个target,后者就会被先执行.
<target name="A"/>
<target name="B" depends="A"/>
<target name="C" depends="B"/>
<target name="D" depends="C,B,A"/>
假定我们要执行target D.从它的依赖属性来看,你可能认为先执行C,然后B, A被执行.错了,C依赖于B,B依赖于A,先执行A,然后B,然后C,D被执行. A被执行.错了,C依赖于B,B依赖于A,先执行A,然后B,然后C,D被执行.
一个target只能被执行一次,即时有多个target依赖于它(看上面的例子).
如 果(或如果不)某些属性被设定,才执行某个target.这样,允许根据系统的状态(java version, OS, 命令行属性定义等等)来更好地控制build的过程.要想让一个target这样做,你就应该在target元素中,加入if(或unless)属性,带 上target因该有所判断的属性.例如:
<target name="build-module-A" if="module-A-present"/>
<target name="build-own-fake-module-A" unless="module-A-present"/>
如果没有if或unless属性,target总会被执行.
可选的description属性可用来提供关于target的一行描述,这些描述可由-projecthelp命令行选项输出. 将你的tstamp task在一个所谓的初始化target是很好的做法,其他的target依赖这个初始化target.要确保初始化target是出现在其他target依赖表中的第一个target.在本手册中大多数的初始化target的名字是"init". target有下面的属性: | Attribute | Description | Required | | name | target的名字 | Yes | | depends | 用逗号分隔的target的名字列表,也就是依赖表. | No | | if | 执行target所需要设定的属性名. | No | | unless | 执行target需要清除设定的属性名. | No | | description | 关于target功能的简短描述. | No |
1.3 Tasks
一个task是一段可执行的代码.
一个task可以有多个属性(如果你愿意的话,可以将其称之为变量).属性只可能包含对property的引用.这些引用会在task执行前被解析.
下面是Task的一般构造形式:
<name attribute1="value1" attribute2="value2" ... />
这里name是task的名字,attributeN是属性名,valueN是属性值.
有一套内置的(built-in)task,以及一些可选task,但你也可以编写自己的task.
所有的task都有一个task名字属性.Ant用属性值来产生日志信息.
可以给task赋一个id属性:
<taskname id="taskID" ... />
这里taskname是task的名字,而taskID是这个task的唯一标识符.通过这个标识符,你可以在脚本中引用相应的task.例如,在脚本中你可以这样:
<script ... >
task1.setFoo("bar");
</script>
设定某个task实例的foo属性.在另一个task中(用java编写),你可以利用下面的语句存取相应的实例.
project.getReference("task1").
注意1:如果task1还没有运行,就不会被生效(例如:不设定属性),如果你在随后配置它,你所作的一切都会被覆盖.
注意2:未来的Ant版本可能不会兼容这里所提的属性, 很有可能根本没有task实例,只有proxies. 很有可能根本没有task实例,只有proxies.
1.4 Properties
一个project可以有很多的properties.可以在buildfile中用 property task来设定,或在Ant之外设定.一个property有一个名字和一个值.property可用于task的属性值.这是通过将属性名放在"${" 和"}"之间并放在属性值的位置来实现的.例如如果有一个property builddir的值是"build",这个property就可用于属性值:${builddir}/classes.这个值就可被解析为build /classes. 内置属性 如果你使用了<property> task 定义了所有的系统属性,Ant允许你使用这些属性.例如,${os.name}对应操作系统的名字. 要想得到系统属性的列表可参考the Javadoc of System.getProperties. 除了Java的系统属性,Ant还定义了一些自己的内置属性: basedir project基目录的绝对路径 (与<project>的basedir属性一样). ant.file buildfile的绝对路径. ant.version Ant的版本. ant.project.name 当前执行的project的名字;由<project>的name属性设定. ant.java.version Ant检测到的JVM的版本; 目前的值有"1.1", "1.2", "1.3" and "1.4". 例子 <project name="MyProject" default="dist" basedir="."> <!-- set global properties for this build --> <property name="src" value="."/> <property name="build" value="build"/> <property name="dist" value="dist"/> <target name="init"> <!-- Create the time stamp --> <tstamp/> <!-- Create the build directory structure used by compile --> <mkdir dir="${build}"/> </target> <target name="compile" depends="init"> <!-- Compile the java code from ${src} into ${build} --> <javac srcdir="${src}" destdir="${build}"/> </target> <target name="dist" depends="compile"> <!-- Create the distribution directory --> <mkdir dir="${dist}/lib"/> <!-- Put everything in ${build} into the MyProject-${DSTAMP}.jar file --> <jar jarfile="${dist}/lib/MyProject-${DSTAMP}.jar" basedir="${build}"/> </target> <target name="clean"> <!-- Delete the ${build} and ${dist} directory trees --> <delete dir="${build}"/> <delete dir="${dist}"/> </target> </project> 1.5 Path-like Structures 你可以用":"和";"作为分隔符,指定类似PATH和CLASSPATH的引用.Ant会把分隔符转换为当前系统所用的分隔符. 当需要指定类似路径的值时,可以使用嵌套元素.一般的形式是 <classpath> <pathelement path="${classpath}"/> <pathelement location="lib/helper.jar"/> </classpath> location属性指定了相对于project基目录的一个文件和目录,而path属性接受逗号或分号分隔的一个位置列表.path属性一般用作预定义的路径--其他情况下,应该用多个location属性. 为简洁起见,classpath标签支持自己的path和location属性. : <classpath> <pathelement path="${classpath}"/> </classpath> 可以被简写作: <classpath path="${classpath}"/> 也可通过<fileset>元素指定路径.构成一个fileset的多个文件加入path-like structure的顺序是未定的. <classpath> <pathelement path="${classpath}"/> <fileset dir="lib"> <include name="**/*.jar"/> </fileset> <pathelement location="classes"/> </classpath> 上面的例子构造了一个路径值包括:${classpath}的路径,跟着lib目录下的所有jar文件,接着是classes目录. 如果你想在多个task中使用相同的path-like structure,你可以用<path>元素定义他们(与target同级),然后通过id属性引用--参考Referencs例子.
path-like structure可能包括对另一个path-like structurede的引用(通过嵌套<path>元素):
<path id="base.path">
<pathelement path="${classpath}"/>
<fileset dir="lib">
<include name="**/*.jar"/>
</fileset>
<pathelement location="classes"/>
</path>
<path id="tests.path">
<path refid="base.path"/>
<pathelement location="testclasses"/>
</path>
前面所提的关于<classpath>的简洁写法对于<path>也是有效的,如:
<path id="tests.path">
<path refid="base.path"/>
<pathelement location="testclasses"/>
</path>
可写成:
<path id="base.path" path="${classpath}"/>
命令行变量
有些task可接受参数,并将其传递给另一个进程.为了能在变量中包含空格字符,可使用嵌套的arg元素.
Attribute Description Required
value 一个命令行变量;可包含空格字符. 只能用一个
line 空格分隔的命令行变量列表.
file 作为命令行变量的文件名;会被文件的绝对名替代.
path 一个作为单个命令行变量的path-like的字符串;或作为分隔符,Ant会将其转变为特定平台的分隔符.
例子
<arg value="-l -a"/>
是一个含有空格的单个的命令行变量.
<arg line="-l -a"/>
是两个空格分隔的命令行变量.
<arg path="/dir;/dir2:dir3"/>
是一个命令行变量,其值在DOS系统上为dir;dir2;dir3;在Unix系统上为/dir:/dir2:/dir3 .
References
buildfile元素的id属性可用来引用这些元素.如果你需要一遍遍的复制相同的XML代码块,这一属性就很有用--如多次使用<classpath>结构.
下面的例子:
<project ... >
<target ... >
<rmic ...>
<classpath>
<pathelement location="lib/"/>
<pathelement path="${java.class.path}/"/>
<pathelement path="${additional.path}"/>
</classpath>
</rmic>
</target>
<target ... >
<javac ...>
<classpath>
<pathelement location="lib/"/>
<pathelement path="${java.class.path}/"/>
<pathelement path="${additional.path}"/> </classpath>
</javac>
</target>
</project>
可以写成如下形式:
<project ... >
<path id="project.class.path">
<pathelement location="lib/"/>
<pathelement path="${java.class.path}/"/>
<pathelement path="${additional.path}"/>
</path>
<target ... >
<rmic ...>
<classpath refid="project.class.path"/>
</rmic>
</target>
<target ... >
<javac ...>
<classpath refid="project.class.path"/>
</javac>
</target>
</project>
所有使用PatternSets, FileSets 或 path-like structures嵌套元素的task也接受这种类型的引用. 转自: http://www.linux521.com/2009/java/200904/1760.html
最近看了hadoop进度显示部分代码,做了个ppt算是一个总结吧. /Files/shenh062326/hadoop进度计算.ppt
本文转自 http://coolshell.cn/articles/3463.html
对于SQL的Join,在学习起来可能是比较乱的。我们知道,SQL的Join语法有很多inner的,有outer的,有left的,有时候,对于Select出来的结果集是什么样子有点不是很清楚。Coding Horror上有一篇文章(实在不清楚为什么Coding Horror也被墙)通过 文氏图 Venn diagrams 解释了SQL的Join。我觉得清楚易懂,转过来。 假设我们有两张表。 - Table A 是左边的表。
- Table B 是右边的表。
其各有四条记录,其中有两条记录是相同的,如下所示: id name id name
-- ---- -- ----
1 Pirate 1 Rutabaga
2 Monkey 2 Pirate
3 Ninja 3 Darth Vader
4 Spaghetti 4 Ninja 下面让我们来看看不同的Join会产生什么样的结果。
SELECT * FROM TableA
INNER JOIN TableB
ON TableA.name = TableB.name
id name id name
-- ---- -- ----
1 Pirate 2 Pirate
3 Ninja 4 Ninja Inner join
产生的结果集中,是A和B的交集。 | 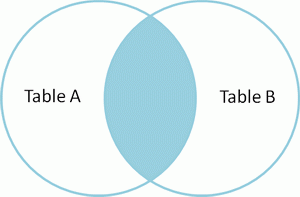 | SELECT * FROM TableA
FULL OUTER JOIN TableB
ON TableA.name = TableB.name
id name id name
-- ---- -- ----
1 Pirate 2 Pirate
2 Monkey null null
3 Ninja 4 Ninja
4 Spaghetti null null
null null 1 Rutabaga
null null 3 Darth Vader Full outer join 产生A和B的并集。但是需要注意的是,对于没有匹配的记录,则会以null做为值。 | 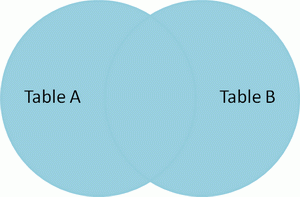 | SELECT * FROM TableA
LEFT OUTER JOIN TableB
ON TableA.name = TableB.name
id name id name
-- ---- -- ----
1 Pirate 2 Pirate
2 Monkey null null
3 Ninja 4 Ninja
4 Spaghetti null null Left outer join 产生表A的完全集,而B表中匹配的则有值,没有匹配的则以null值取代。 | 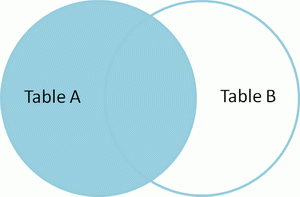 | SELECT * FROM TableA
LEFT OUTER JOIN TableB
ON TableA.name = TableB.name
WHERE TableB.id IS null
id name id name
-- ---- -- ----
2 Monkey null null
4 Spaghetti null null 产生在A表中有而在B表中没有的集合。 | 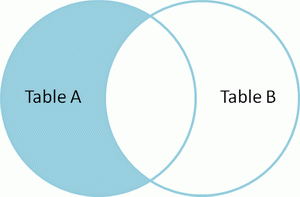 | SELECT * FROM TableA
FULL OUTER JOIN TableB
ON TableA.name = TableB.name
WHERE TableA.id IS null
OR TableB.id IS null
id name id name
-- ---- -- ----
2 Monkey null null
4 Spaghetti null null
null null 1 Rutabaga
null null 3 Darth Vader 产生A表和B表都没有出现的数据集。 | 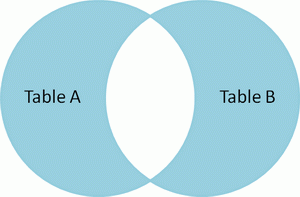 |
还需要注册的是我们还有一个是“交差集” cross join, 这种Join没有办法用文式图表示,因为其就是把表A和表B的数据进行一个N*M的组合,即笛卡尔积。表达式如下: SELECT * FROM TableA
CROSS JOIN TableB 这个笛卡尔乘积会产生 4 x 4 = 16 条记录,一般来说,我们很少用到这个语法。但是我们得小心,如果不是使用嵌套的select语句,一般系统都会产生笛卡尔乘积然再做过滤。这是对于性能来说是非常危险的,尤其是表很大的时候。
简单的jar使用方法
JAR files are packaged with the ZIP file format, so you can use them for "ZIP-like" tasks such as lossless data compression, archiving, decompression, and archive unpacking. These are among the most common uses of JAR files, and you can realize many JAR file benefits using only these basic features.Even if you want to take advantage of advanced functionality provided by the JAR file format such as electronic signing, you'll first need to become familiar with the fundamental operations. To perform basic tasks with JAR files, you use the Java Archive Tool provided as part of the Java Development Kit. Because the Java Archive tool is invoked by using the jar command, for convenience we'll call it the "Jar tool". As a synopsis and preview of some of the topics to be covered in this lesson, the following table summarizes common JAR-file operations: | Operation | Command |
|---|
| To create a JAR file | jar cf jar-file input-file(s) | | To view the contents of a JAR file | jar tf jar-file | | To extract the contents of a JAR file | jar xf jar-file | | To extract specific files from a JAR file | jar xf jar-file archived-file(s) | To run an application packaged as a JAR file
(version 1.1) | jre -cp app.jar MainClass | To run an application packaged as a JAR file
(version 1.2 -- requires Main-Class
manifest header) | java -jar app.jar | | To invoke an applet packaged as a JAR file | <applet code=AppletClassName.class
archive="JarFileName.jar"
width=width height=height>
</applet> |
SIEGE is an http load tester and benchmarking utility. It was designed to let web developers measure the performance of their code under duress, to see how it will stand up to load on the internet. It lets the user hit a web server with a configurable number of concurrent simulated users. Those users place the server "under siege."
|