每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
问:每天300w PV 的在单台机器上,这台机器需要多少QPS?
答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
问:如果一台机器的QPS是58,需要几台机器来支持?
答:139 / 58 = 3
现在敏捷开发是越来越火了,人人都在谈敏捷,人人都在学习Scrum和XP...
为了不落后他人,于是我也开始学习Scrum,今天主要是对我最近阅读的相关资料,根据自己的理解,用自己的话来讲述Scrum中的各个环节,主要目的有两个,一个是进行知识的总结,另外一个是觉得网上很多学习资料的讲述方式让初学者不太容易理解;所以我决定写一篇扫盲性的博文,同时试着也与园内的朋友一起分享交流一下,希望对初学者有帮助。
什么是敏捷开发?
敏捷开发(Agile Development)是一种以人为核心、迭代、循序渐进的开发方法。
怎么理解呢?首先,我们要理解它不是一门技术,它是一种开发方法,也就是一种软件开发的流程,它会指导我们用规定的环节去一步一步完成项目的开发;而这种开发方式的主要驱动核心是人;它采用的是迭代式开发;
为什么说是以人为核心?
我们大部分人都学过瀑布开发模型,它是以文档为驱动的,为什么呢?因为在瀑布的整个开发过程中,要写大量的文档,把需求文档写出来后,开发人员都是根据文档进行开发的,一切以文档为依据;而敏捷开发它只写有必要的文档,或尽量少写文档,敏捷开发注重的是人与人之间,面对面的交流,所以它强调以人为核心。
什么是迭代?
迭代是指把一个复杂且开发周期很长的开发任务,分解为很多小周期可完成的任务,这样的一个周期就是一次迭代的过程;同时每一次迭代都可以生产或开发出一个可以交付的软件产品。
关于Scrum和XP
前面说了敏捷它是一种指导思想或开发方式,但是它没有明确告诉我们到底采用什么样的流程进行开发,而Scrum和XP就是敏捷开发的具体方式了,你可以采用Scrum方式也可以采用XP方式;Scrum和XP的区别是,Scrum偏重于过程,XP则偏重于实践,但是实际中,两者是结合一起应用的,这里我主要讲Scrum。
什么是Scrum?
Scrum的英文意思是橄榄球运动的一个专业术语,表示“争球”的动作;把一个开发流程的名字取名为Scrum,我想你一定能想象出你的开发团队在开发一个项目时,大家像打橄榄球一样迅速、富有战斗激情、人人你争我抢地完成它,你一定会感到非常兴奋的。
而Scrum就是这样的一个开发流程,运用该流程,你就能看到你团队高效的工作。
【Scrum开发流程中的三大角色】
产品负责人(Product Owner)
主要负责确定产品的功能和达到要求的标准,指定软件的发布日期和交付的内容,同时有权力接受或拒绝开发团队的工作成果。
流程管理员(Scrum Master)
主要负责整个Scrum流程在项目中的顺利实施和进行,以及清除挡在客户和开发工作之间的沟通障碍,使得客户可以直接驱动开发。
开发团队(Scrum Team)
主要负责软件产品在Scrum规定流程下进行开发工作,人数控制在5~10人左右,每个成员可能负责不同的技术方面,但要求每成员必须要有很强的自我管理能力,同时具有一定的表达能力;成员可以采用任何工作方式,只要能达到Sprint的目标。
Scrum流程图
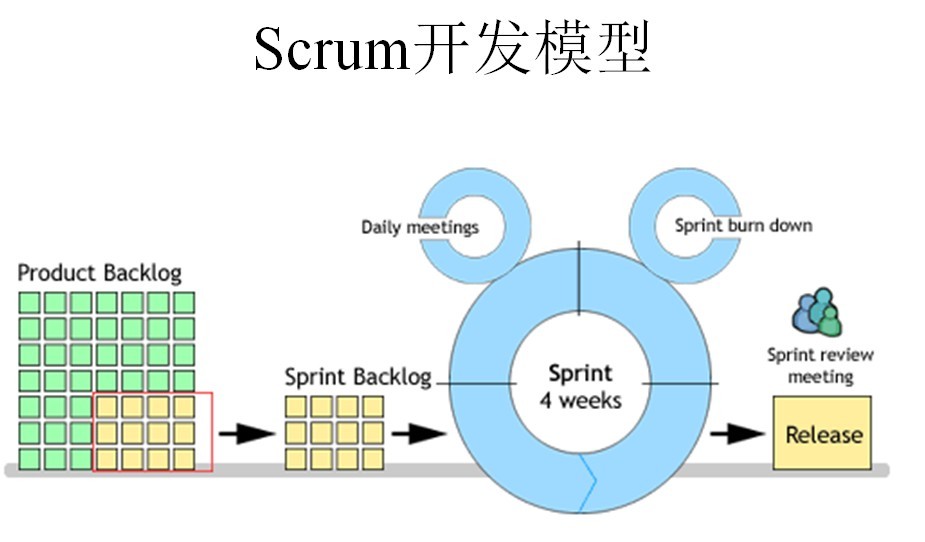
//------------------------
下面,我们开始讲具体实施流程,但是在讲之前,我还要对一个英文单词进行讲解。
什么是Sprint?
Sprint是短距离赛跑的意思,这里面指的是一次迭代,而一次迭代的周期是1个月时间(即4个星期),也就是我们要把一次迭代的开发内容以最快的速度完成它,这个过程我们称它为Sprint。
如何进行Scrum开发?
1、我们首先需要确定一个Product Backlog(按优先顺序排列的一个产品需求列表),这个是由Product Owner 负责的;
2、Scrum Team根据Product Backlog列表,做工作量的预估和安排;
3、有了Product Backlog列表,我们需要通过 Sprint Planning Meeting(Sprint计划会议) 来从中挑选出一个Story作为本次迭代完成的目标,这个目标的时间周期是1~4个星期,然后把这个Story进行细化,形成一个Sprint Backlog;
4、Sprint Backlog是由Scrum Team去完成的,每个成员根据Sprint Backlog再细化成更小的任务(细到每个任务的工作量在2天内能完成);
5、在Scrum Team完成计划会议上选出的Sprint Backlog过程中,需要进行 Daily Scrum Meeting(每日站立会议),每次会议控制在15分钟左右,每个人都必须发言,并且要向所有成员当面汇报你昨天完成了什么,并且向所有成员承诺你今天要完成什么,同时遇到不能解决的问题也可以提出,每个人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃尽图);
6、做到每日集成,也就是每天都要有一个可以成功编译、并且可以演示的版本;很多人可能还没有用过自动化的每日集成,其实TFS就有这个功能,它可以支持每次有成员进行签入操作的时候,在服务器上自动获取最新版本,然后在服务器中编译,如果通过则马上再执行单元测试代码,如果也全部通过,则将该版本发布,这时一次正式的签入操作才保存到TFS中,中间有任何失败,都会用邮件通知项目管理人员;
7、当一个Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,这时,我们要进行 Srpint Review Meeting(演示会议),也称为评审会议,产品负责人和客户都要参加(最好本公司老板也参加),每一个Scrum Team的成员都要向他们演示自己完成的软件产品(这个会议非常重要,一定不能取消);
8、最后就是 Sprint Retrospective Meeting(回顾会议),也称为总结会议,以轮流发言方式进行,每个人都要发言,总结并讨论改进的地方,放入下一轮Sprint的产品需求中;
下面是运用Scrum开发流程中的一些场景图:
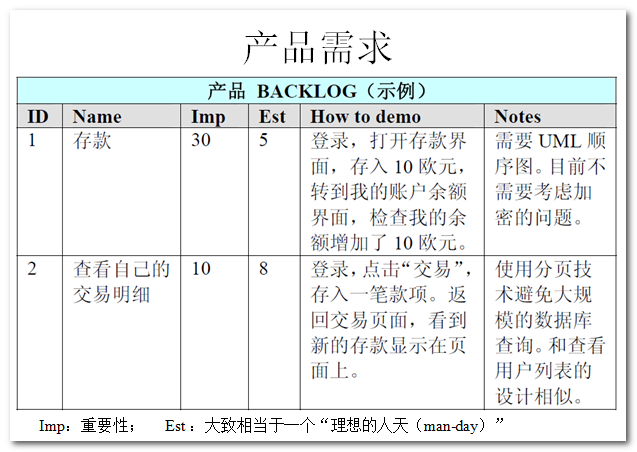
上图是一个 Product Backlog 的示例。

上图就是每日的站立会议了,参会人员可以随意姿势站立,任务看板要保证让每个人看到,当每个人发言完后,要走到任务版前更新自己的燃尽图。
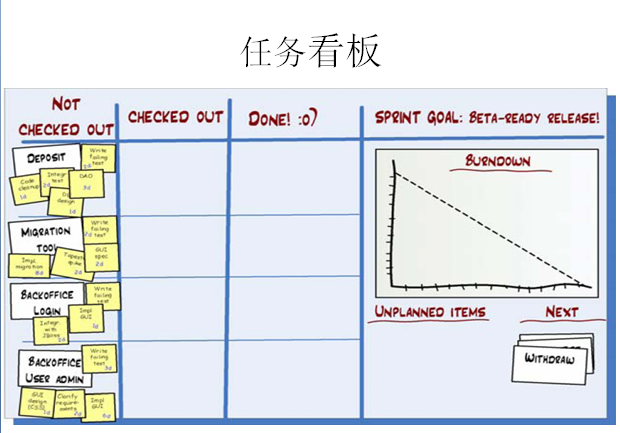
任务看版包含 未完成、正在做、已完成 的工作状态,假设你今天把一个未完成的工作已经完成,那么你要把小卡片从未完成区域贴到已完成区域。

每个人的工作进度和完成情况都是公开的,如果有一个人的工作任务在某一个位置放了好几天,大家都能发现他的工作进度出现了什么问题(成员人数最好是5~7个,这样每人可以使用一种专用颜色的标签纸,一眼就可以从任务版看出谁的工作进度快,谁的工作进度慢)

上图可不是扑克牌,它是计划纸牌,它的作用是防止项目在开发过程中,被某些人所领导。
怎么用的呢?比如A程序员开发一个功能,需要5个小时,B程序员认为只需要半小时,那他们各自取相应的牌,藏在手中,最后摊牌,如果时间差距很大,那么A和B就可以讨论A为什么要5个小时...
转自:http://www.cnblogs.com/taven/archive/2010/10/17/1853386.html
先申明概念:
1、悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
2、乐观锁( Optimistic Locking )
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。而乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
所以悲观锁和乐观锁最大的区别是是否一直锁定资源,悲观锁在事物的全流程锁定数据,乐观锁不锁定数据(用读写锁是阻塞事物,而用乐观锁则会导致回滚。这个是一种事物冲突后的不同锁的表象)。乐观锁的最大特点是在最后检查数据是否被修改,如果已被别人修改过,则回滚数据,避免脏数据。至于事物是否冲突和加锁没有直接联系,该冲突的还是会冲突,不管你加悲观锁和乐观锁都会冲突。
悲观锁和乐观锁都是为了解决丢失更新问题或者是脏读。悲观锁和乐观锁的重点就是是否在读取记录的时候直接上锁。悲观锁的缺点很明显,需要一个持续的数据库连接,这在web应用中已经不适合了。
一个比较清楚的场景
下面这个假设的实际场景可以比较清楚的帮助我们理解这个问题:
a. 假设当当网上用户下单买了本书,这时数据库中有条订单号为001的订单,其中有个status字段是’有效’,表示该订单是有效的;
b. 后台管理人员查询到这条001的订单,并且看到状态是有效的
c. 用户发现下单的时候下错了,于是撤销订单,假设运行这样一条SQL: update order_table set status = ‘取消’ where order_id = 001;
d. 后台管理人员由于在b这步看到状态有效的,这时,虽然用户在c这步已经撤销了订单,可是管理人员并未刷新界面,看到的订单状态还是有效的,于是点击”发货”按钮,将该订单发到物流部门,同时运行类似如下SQL,将订单状态改成已发货:update order_table set status = ‘已发货’ where order_id = 001
观点1:只有冲突非常严重的系统才需要悲观锁;
分析:这是更准确的说法;
“所有悲观锁的做法都适合于状态被修改的概率比较高的情况,具体是否合适则需要根据实际情况判断。”,表达的也是这个意思,不过说法不够准确;的确,之所以用悲观锁就是因为两个用户更新同一条数据的概率高,也就是冲突比较严重的情况下,所以才用悲观锁。
观点2:最后提交前作一次select for update检查,然后再提交update也是一种乐观锁的做法
分析:这是更准确的说法;
的确,这符合传统乐观锁的做法,就是到最后再去检查。但是wiki在解释悲观锁的做法的时候,’It is not appropriate for use in web application development.’, 现在已经很少有悲观锁的做法了,所以我自己将这种二次检查的做法也归为悲观锁的变种,因为这在所有乐观锁里面,做法和悲观锁是最接近的,都是先select for update,然后update
*****除了上面的观点1和观点2是更准确的说法,下面的所有观点都是错误的***********
观点3:这个问题的原因是因为数据库隔离级别是uncommitted read级别;
分析:这个观点是错误的;
这个过程本身就是在read committed隔离级别下发生的,从a到d每一步,尤其是d这步,并不是因为读到了未提交的数据,仅仅是因为用户界面没有刷新[事实上也不可能做自动刷新,这样相当于数据库一发生改变立刻要刷新了,这需要监听数据库了,显然这是简单问题复杂化了];
观点4:悲观锁是指一个用户在更新数据的时候,其他用户不能读取这条记录;也就是update阻塞读才叫悲观锁;
分析:这个观点是错的;
这在db2背景的开发中尤其常见;因为db2默认就是update会阻塞读;但是这是各个数据库对读写的时候上锁的并发处理实现不一样。但这根本不是悲观锁乐观锁的区别。Oracle可以做到写不阻塞读仅仅是因为做了多版本并发控制(Multiversion concurrency control), http://en.wikipedia.org/wiki/Multiversion_concurrency_control;但是在Oracle里面,一样可以做乐观锁和悲观锁的控制。这本质上是应用层面的选择。
观点5:Oracle实际上用的就是乐观锁
分析:这个观点是错的;
前面说了,Oracle的确可以做到写不阻塞读,但是这不是悲观锁和乐观锁的问题。这是因为实现了多版本并发控制。按照wiki的定义,悲观锁和乐观锁是在应用层面选择的。Oracle的应用只要在第二步做了select for update,就是悲观锁的做法;况且Oracle在任何隔离级别下,除了分布式事务两阶段提交的短暂时间,其他所有情况下都不存在写阻塞读的情况,如果按照这个观点的话那Oracle已经不能做悲观锁了-_-
观点6:不需要这么麻烦,只需要在d这步,最后提交更新的时候再做一个普通的select检查一下就可以;[就是double check的做法]
分析:这个观点是错的。
这个做法其实在http://www.hetaoblog.com/database-lost-update-pessimistic-lock/,’3. 传统悲观锁做法的变通’这节已经说明了,如果要这么做的话,仍然需要在最后提交更新前double check的时候做一个select for update, 否则select结束到update提交前的时间仍然有可能记录被修改;
观点7:应该尽可能使用悲观锁;
分析:这个观点是错的;
a. 根据悲观锁的概念,用户在读的时候(b这步)就会将记录锁住,直到更新结束的时候才会将锁释放,所以整个锁的过程时间比较长;
b. 另外,悲观锁需要有一个持续的数据库连接,这在当今的web应用中已经几乎不存在;wiki上也说了, 悲观锁‘is not appropriate for use in web application development.’
所以,现在大部分应用都应该是乐观锁的;
转自:http://zhidao.baidu.com/link?url=MUOUg59oz7-FKwz-zuUviGryfw9J4V63Pd2iWWErorwUpyeL85rznlmYaGDHXjH_ChywA3R1m9XNpx4k7RCCT3rNofjkCxIBYHdsvwr2bVy
1、常规网络访问限制:
a、线上运营设备的SSH端口不允许绑定在公网IP地址上,开发只能登录开发机然后通过内网登录这些服务器;
b、开发机、测试机的SSH端口可以绑定在公网IP地址上,SSH端口(22)可以考虑改为非知名端口;
c、线上运营设备、开发机、测试机的防火墙配置,公网只做80(HTTP)、8080(HTTP)、443(HTTPS)、SSH端口(仅限开发机、测试机)对外授权访问;
d、线上运营设备、开发机、测试机除第c点以外所有服务端口禁止绑定在公网IP地址上,尤其是3306端口(MySQL);
2、DB保护,
a、DB服务器不允许配置公网IP(或用防火墙全部禁止公网访问);
b、DB的root账户不用于业务访问,回收集中管理,开放普通账户做业务逻辑访问,对不同安全要求的库表用不同的账户密码访问;
c、程序不要把DB访问的账户密码写到配置文件中,写入代码或启动时远程到配置中心拉取(此方法比较重,可暂不考虑)。
d、另:DB备份文件可以考虑做加密处理;
3、系统安全:
a、设备的root密码回收集中管理,给开发提供普通用户帐号;
b、密码需要定期修改,有强度要求;
4、业务访问控制:
a、业务服务逻辑和运营平台,尽量不要提供对用户表和订单表的批量访问接口,如果运营平台确实有这样的需求,需要对特定账户做授权;
安全的代价是不方便、效率会下降,需要寻找平衡点。
转自http://www.witwebs.com/aliyun-mount-init/
阿里云的服务器,国内访问速度,稳定性一直都是不错的。至少我在使用的过程中,还未碰到什么问题。我将自己在使用主机过程的安装和环境配置做一个详细的介绍。仅供新手朋友参考!当我们在购买到阿里云服务器之后,会获得相应的IP地址和管理密码。
主要介绍Linux的数据盘的格式化和挂载。
大致步骤是: 登陆Linux > 查看硬盘状况 > 分区数据盘 > 格式化数据盘 > 挂载新分区
将会用到的命令如下:
df -h 查看已挂载硬盘信息
fdisk -l 查看磁盘信息,未挂载的也会列出来
fdisk /dev/xvdb 对数据盘进行分区,回车之后,继续 根据提示,依次输入”n” ,”p”,“1”,两次回车,“wq”, 分区就开始了,很快就会完成
mkfs .ext3 /dev/xvdb1 命令对新分区进行格式化
echo ‘/dev/xvdb1 /www ext3 defaults 0 0′ >> /etc/fstab 添加分区信息
mount -a 命令挂载新分区
1:通过Linux SSH 登陆软件登陆你的linux。登陆之后输入命令:df -lh 的界面如图:

2:输入命令: fdisk -l 查看磁盘状况,可以看到有数据盘: /dev/xvdb 而用df没有查看到这个磁盘。所以需要另外挂载。

3: 用 fdisk /dev/xvdb 对数据盘进行分区。根据提示,输入 n, p, 1, 回车,回车, wq。
完成之后,再用 fdisk -l,就可以看到显示的信息和之前有不同了。

4:格式化磁盘。 mkfs .ext3 /dev/xvdb1 ,格式化磁盘。完成之后,就可以来挂载分区了。

5, 挂载分区,首先建立一个目录用来挂载分区。比如: mkdir /www
然后把分区信息加入到fstab中:一次执行:
echo ‘/dev/xvdb1 /www ext3 defaults 0 0′ >> /etc/fstab 添加分区信息
mount -a 命令挂载新分区
最后用 df -h 命令查看,将会发现数据盘。

OK,希望能帮到各位。
1、需要先安装gcc和tcl
yum install gcc
yum install tcl
2、下载并安装redis
cd /opt
wget http://download.redis.io/releases/redis-3.0.0.tar.gz
tar -zxvf /opt/redis-3.0.0.tar.gz
cd /opt/redis-3.0.0
make
make test
make PREFIX=/opt/redis-3.0.0 install
注:PREFIX一定要大写,装好后,会生成/opt/redis-3.0.0/bin目录,里面有启动命令之类的文件。
3、启动与关闭
redis启动
/opt/redis-3.0.0/bin/redis-server /opt/redis-3.0.0/redis.conf
redis关闭
/opt/redis-3.0.0/bin/redis-cli -h 127.0.0.1 -p 6379 shutdown
客户端启动
/opt/redis-3.0.0/bin/redis-cli
set name test
get name
4、参数修改
/opt/redis-3.0.0/redis.conf文件修改
#后台运行,可以ctrl+c不至于退出
daemonize yes
关于错误提示
(1)编辑/etc/sysctl.conf ,最下面加一行vm.overcommit_memory=1,然后sysctl -p 使配置文件生效
(2)sysctl vm.overcommit_memory=1
注:如果使用了云服务器,要记得打开6379端口,否则无法远程访问
1、svnadmin create /opt/svn/yiss/app/ios1、apache里的httpd.conf配置如下:
每个库单独
<Location /yiss/app/ios>#这个是ios项目url上的访问上下文,对应http://IP/yiss/app/ios/
DAV svn
SVNPath /opt/svn/yiss/app/ios#这个是svn库的绝对路径
AuthType Basic#校验方式
AuthName "please input username/password"#提示信息
AuthUserFile /opt/svn/passwd#密码文件绝对路径
AuthzSVNAccessFile /opt/svn/authz#权限文件绝对路径
Require valid-user
</Location>
<Location /yiss/app/android>#安卓项目访问上下文
DAV svn
SVNPath /opt/svn/yiss/app/android
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
<Location /yiss/web/buildscript>
DAV svn
SVNPath /opt/svn/yiss/web/buildscript
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
2、首先要创建/opt/svn/yiss/app目录和/opt/svn/yiss/web
然后用命令创建svn库
svnadmin create /opt/svn/yiss/app/ios
svnadmin create /opt/svn/yiss/app/android
svnadmin create /opt/svn/yiss/web/buildscript
3、创建apache用户和密码,会提示重复输入2次确认。想改密码就多次输入,以最后一次输入的为准。
htpasswd /opt/svn/passwd wxq
htpasswd /opt/svn/passwd caowei
......
4、配置权限组/opt/svn/authz
[groups]
admin=wxq
web=caowei,luocan,houlei,gengzhuo,huangwei,wuhaiying,leo
app=ssh,golden,shawn,leo
#admin组用户可以访问所有目录
[/]
@admin=rw
#ios,android,srv,doc,buildscript这些都是库名,这里创建了3个库
[ios:/]
@app=rw
[android:/]
@app=rw
[buildscript:/]
@admin=rw
5、给目录及子目录授权,否则会报403forbidden无权限
chmod 777 /opt/svn -R
6、重启svn,启动的时候要以根启动,如果以某个svn库启动,则其他库无法启动。
killall svnserve
svnserve -d -r /opt/svn/yiss
7、重启apache
/opt/apache/bin/apachectl restart
8、浏览测试
http://115.231.94.x/yiss/app/ios/
http://115.231.94.x/yiss/app/android/
http://115.231.94.x/yiss/web/buildscript/