2006年8月5日
#
今天启动Tomcat启动不了,报以下错: org.apache.catalina.core.StandardContext startInternal SEVERE: Error listenerStart org.apache.catalina.core.StandardContext startInternal SEVERE: Context [/******] startup failed due to previous errors 网上找了N多文章,都没有切中要害。 后来在国外网站上搜到一个方法 http://grails.1312388.n4.nabble.com/Deployment-problems-td4628710.html。 我试了一下,是可以的。方案如下。 Tomcat报的错太含糊了,什么错都没报出来,只提示了Error listenerStart。为了调试,我们要获得更详细的日志。可以在WEB-INF/classes目录下新建一个文件叫logging.properties,内容如下 Java代码

- handlers = org.apache.juli.FileHandler, java.util.logging.ConsoleHandler
-
- ############################################################
- # Handler specific properties.
- # Describes specific configuration info for Handlers.
- ############################################################
-
- org.apache.juli.FileHandler.level = FINE
- org.apache.juli.FileHandler.directory = ${catalina.base}/logs
- org.apache.juli.FileHandler.prefix = error-debug.
-
- java.util.logging.ConsoleHandler.level = FINE
- java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
问:每天300w PV 的在单台机器上,这台机器需要多少QPS?
答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
问:如果一台机器的QPS是58,需要几台机器来支持?
答:139 / 58 = 3
现在敏捷开发是越来越火了,人人都在谈敏捷,人人都在学习Scrum和XP...
为了不落后他人,于是我也开始学习Scrum,今天主要是对我最近阅读的相关资料,根据自己的理解,用自己的话来讲述Scrum中的各个环节,主要目的有两个,一个是进行知识的总结,另外一个是觉得网上很多学习资料的讲述方式让初学者不太容易理解;所以我决定写一篇扫盲性的博文,同时试着也与园内的朋友一起分享交流一下,希望对初学者有帮助。
什么是敏捷开发?
敏捷开发(Agile Development)是一种以人为核心、迭代、循序渐进的开发方法。
怎么理解呢?首先,我们要理解它不是一门技术,它是一种开发方法,也就是一种软件开发的流程,它会指导我们用规定的环节去一步一步完成项目的开发;而这种开发方式的主要驱动核心是人;它采用的是迭代式开发;
为什么说是以人为核心?
我们大部分人都学过瀑布开发模型,它是以文档为驱动的,为什么呢?因为在瀑布的整个开发过程中,要写大量的文档,把需求文档写出来后,开发人员都是根据文档进行开发的,一切以文档为依据;而敏捷开发它只写有必要的文档,或尽量少写文档,敏捷开发注重的是人与人之间,面对面的交流,所以它强调以人为核心。
什么是迭代?
迭代是指把一个复杂且开发周期很长的开发任务,分解为很多小周期可完成的任务,这样的一个周期就是一次迭代的过程;同时每一次迭代都可以生产或开发出一个可以交付的软件产品。
关于Scrum和XP
前面说了敏捷它是一种指导思想或开发方式,但是它没有明确告诉我们到底采用什么样的流程进行开发,而Scrum和XP就是敏捷开发的具体方式了,你可以采用Scrum方式也可以采用XP方式;Scrum和XP的区别是,Scrum偏重于过程,XP则偏重于实践,但是实际中,两者是结合一起应用的,这里我主要讲Scrum。
什么是Scrum?
Scrum的英文意思是橄榄球运动的一个专业术语,表示“争球”的动作;把一个开发流程的名字取名为Scrum,我想你一定能想象出你的开发团队在开发一个项目时,大家像打橄榄球一样迅速、富有战斗激情、人人你争我抢地完成它,你一定会感到非常兴奋的。
而Scrum就是这样的一个开发流程,运用该流程,你就能看到你团队高效的工作。
【Scrum开发流程中的三大角色】
产品负责人(Product Owner)
主要负责确定产品的功能和达到要求的标准,指定软件的发布日期和交付的内容,同时有权力接受或拒绝开发团队的工作成果。
流程管理员(Scrum Master)
主要负责整个Scrum流程在项目中的顺利实施和进行,以及清除挡在客户和开发工作之间的沟通障碍,使得客户可以直接驱动开发。
开发团队(Scrum Team)
主要负责软件产品在Scrum规定流程下进行开发工作,人数控制在5~10人左右,每个成员可能负责不同的技术方面,但要求每成员必须要有很强的自我管理能力,同时具有一定的表达能力;成员可以采用任何工作方式,只要能达到Sprint的目标。
Scrum流程图
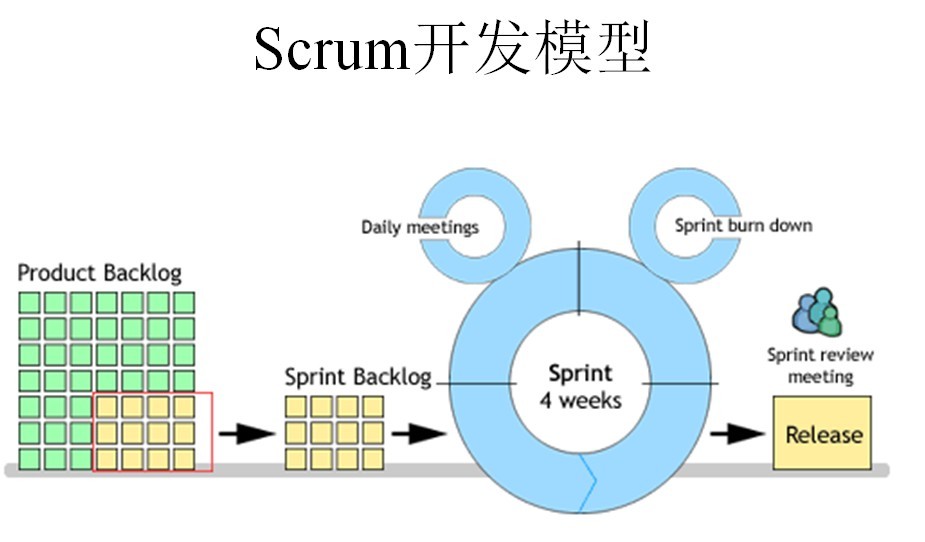
//------------------------
下面,我们开始讲具体实施流程,但是在讲之前,我还要对一个英文单词进行讲解。
什么是Sprint?
Sprint是短距离赛跑的意思,这里面指的是一次迭代,而一次迭代的周期是1个月时间(即4个星期),也就是我们要把一次迭代的开发内容以最快的速度完成它,这个过程我们称它为Sprint。
如何进行Scrum开发?
1、我们首先需要确定一个Product Backlog(按优先顺序排列的一个产品需求列表),这个是由Product Owner 负责的;
2、Scrum Team根据Product Backlog列表,做工作量的预估和安排;
3、有了Product Backlog列表,我们需要通过 Sprint Planning Meeting(Sprint计划会议) 来从中挑选出一个Story作为本次迭代完成的目标,这个目标的时间周期是1~4个星期,然后把这个Story进行细化,形成一个Sprint Backlog;
4、Sprint Backlog是由Scrum Team去完成的,每个成员根据Sprint Backlog再细化成更小的任务(细到每个任务的工作量在2天内能完成);
5、在Scrum Team完成计划会议上选出的Sprint Backlog过程中,需要进行 Daily Scrum Meeting(每日站立会议),每次会议控制在15分钟左右,每个人都必须发言,并且要向所有成员当面汇报你昨天完成了什么,并且向所有成员承诺你今天要完成什么,同时遇到不能解决的问题也可以提出,每个人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃尽图);
6、做到每日集成,也就是每天都要有一个可以成功编译、并且可以演示的版本;很多人可能还没有用过自动化的每日集成,其实TFS就有这个功能,它可以支持每次有成员进行签入操作的时候,在服务器上自动获取最新版本,然后在服务器中编译,如果通过则马上再执行单元测试代码,如果也全部通过,则将该版本发布,这时一次正式的签入操作才保存到TFS中,中间有任何失败,都会用邮件通知项目管理人员;
7、当一个Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,这时,我们要进行 Srpint Review Meeting(演示会议),也称为评审会议,产品负责人和客户都要参加(最好本公司老板也参加),每一个Scrum Team的成员都要向他们演示自己完成的软件产品(这个会议非常重要,一定不能取消);
8、最后就是 Sprint Retrospective Meeting(回顾会议),也称为总结会议,以轮流发言方式进行,每个人都要发言,总结并讨论改进的地方,放入下一轮Sprint的产品需求中;
下面是运用Scrum开发流程中的一些场景图:
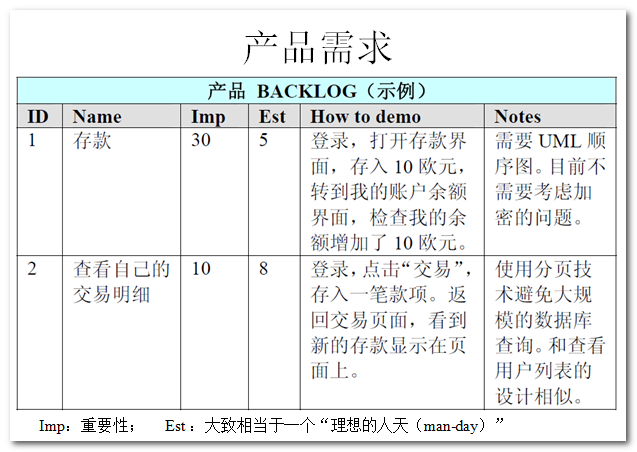
上图是一个 Product Backlog 的示例。

上图就是每日的站立会议了,参会人员可以随意姿势站立,任务看板要保证让每个人看到,当每个人发言完后,要走到任务版前更新自己的燃尽图。
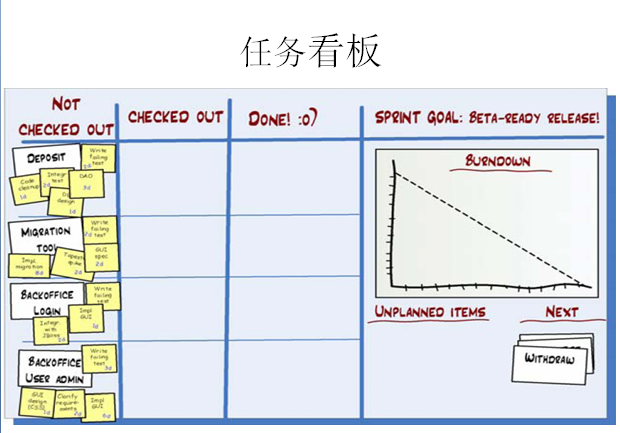
任务看版包含 未完成、正在做、已完成 的工作状态,假设你今天把一个未完成的工作已经完成,那么你要把小卡片从未完成区域贴到已完成区域。

每个人的工作进度和完成情况都是公开的,如果有一个人的工作任务在某一个位置放了好几天,大家都能发现他的工作进度出现了什么问题(成员人数最好是5~7个,这样每人可以使用一种专用颜色的标签纸,一眼就可以从任务版看出谁的工作进度快,谁的工作进度慢)

上图可不是扑克牌,它是计划纸牌,它的作用是防止项目在开发过程中,被某些人所领导。
怎么用的呢?比如A程序员开发一个功能,需要5个小时,B程序员认为只需要半小时,那他们各自取相应的牌,藏在手中,最后摊牌,如果时间差距很大,那么A和B就可以讨论A为什么要5个小时...
转自:http://www.cnblogs.com/taven/archive/2010/10/17/1853386.html
先申明概念:
1、悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
2、乐观锁( Optimistic Locking )
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。而乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
所以悲观锁和乐观锁最大的区别是是否一直锁定资源,悲观锁在事物的全流程锁定数据,乐观锁不锁定数据(用读写锁是阻塞事物,而用乐观锁则会导致回滚。这个是一种事物冲突后的不同锁的表象)。乐观锁的最大特点是在最后检查数据是否被修改,如果已被别人修改过,则回滚数据,避免脏数据。至于事物是否冲突和加锁没有直接联系,该冲突的还是会冲突,不管你加悲观锁和乐观锁都会冲突。
悲观锁和乐观锁都是为了解决丢失更新问题或者是脏读。悲观锁和乐观锁的重点就是是否在读取记录的时候直接上锁。悲观锁的缺点很明显,需要一个持续的数据库连接,这在web应用中已经不适合了。
一个比较清楚的场景
下面这个假设的实际场景可以比较清楚的帮助我们理解这个问题:
a. 假设当当网上用户下单买了本书,这时数据库中有条订单号为001的订单,其中有个status字段是’有效’,表示该订单是有效的;
b. 后台管理人员查询到这条001的订单,并且看到状态是有效的
c. 用户发现下单的时候下错了,于是撤销订单,假设运行这样一条SQL: update order_table set status = ‘取消’ where order_id = 001;
d. 后台管理人员由于在b这步看到状态有效的,这时,虽然用户在c这步已经撤销了订单,可是管理人员并未刷新界面,看到的订单状态还是有效的,于是点击”发货”按钮,将该订单发到物流部门,同时运行类似如下SQL,将订单状态改成已发货:update order_table set status = ‘已发货’ where order_id = 001
观点1:只有冲突非常严重的系统才需要悲观锁;
分析:这是更准确的说法;
“所有悲观锁的做法都适合于状态被修改的概率比较高的情况,具体是否合适则需要根据实际情况判断。”,表达的也是这个意思,不过说法不够准确;的确,之所以用悲观锁就是因为两个用户更新同一条数据的概率高,也就是冲突比较严重的情况下,所以才用悲观锁。
观点2:最后提交前作一次select for update检查,然后再提交update也是一种乐观锁的做法
分析:这是更准确的说法;
的确,这符合传统乐观锁的做法,就是到最后再去检查。但是wiki在解释悲观锁的做法的时候,’It is not appropriate for use in web application development.’, 现在已经很少有悲观锁的做法了,所以我自己将这种二次检查的做法也归为悲观锁的变种,因为这在所有乐观锁里面,做法和悲观锁是最接近的,都是先select for update,然后update
*****除了上面的观点1和观点2是更准确的说法,下面的所有观点都是错误的***********
观点3:这个问题的原因是因为数据库隔离级别是uncommitted read级别;
分析:这个观点是错误的;
这个过程本身就是在read committed隔离级别下发生的,从a到d每一步,尤其是d这步,并不是因为读到了未提交的数据,仅仅是因为用户界面没有刷新[事实上也不可能做自动刷新,这样相当于数据库一发生改变立刻要刷新了,这需要监听数据库了,显然这是简单问题复杂化了];
观点4:悲观锁是指一个用户在更新数据的时候,其他用户不能读取这条记录;也就是update阻塞读才叫悲观锁;
分析:这个观点是错的;
这在db2背景的开发中尤其常见;因为db2默认就是update会阻塞读;但是这是各个数据库对读写的时候上锁的并发处理实现不一样。但这根本不是悲观锁乐观锁的区别。Oracle可以做到写不阻塞读仅仅是因为做了多版本并发控制(Multiversion concurrency control), http://en.wikipedia.org/wiki/Multiversion_concurrency_control;但是在Oracle里面,一样可以做乐观锁和悲观锁的控制。这本质上是应用层面的选择。
观点5:Oracle实际上用的就是乐观锁
分析:这个观点是错的;
前面说了,Oracle的确可以做到写不阻塞读,但是这不是悲观锁和乐观锁的问题。这是因为实现了多版本并发控制。按照wiki的定义,悲观锁和乐观锁是在应用层面选择的。Oracle的应用只要在第二步做了select for update,就是悲观锁的做法;况且Oracle在任何隔离级别下,除了分布式事务两阶段提交的短暂时间,其他所有情况下都不存在写阻塞读的情况,如果按照这个观点的话那Oracle已经不能做悲观锁了-_-
观点6:不需要这么麻烦,只需要在d这步,最后提交更新的时候再做一个普通的select检查一下就可以;[就是double check的做法]
分析:这个观点是错的。
这个做法其实在http://www.hetaoblog.com/database-lost-update-pessimistic-lock/,’3. 传统悲观锁做法的变通’这节已经说明了,如果要这么做的话,仍然需要在最后提交更新前double check的时候做一个select for update, 否则select结束到update提交前的时间仍然有可能记录被修改;
观点7:应该尽可能使用悲观锁;
分析:这个观点是错的;
a. 根据悲观锁的概念,用户在读的时候(b这步)就会将记录锁住,直到更新结束的时候才会将锁释放,所以整个锁的过程时间比较长;
b. 另外,悲观锁需要有一个持续的数据库连接,这在当今的web应用中已经几乎不存在;wiki上也说了, 悲观锁‘is not appropriate for use in web application development.’
所以,现在大部分应用都应该是乐观锁的;
转自:http://zhidao.baidu.com/link?url=MUOUg59oz7-FKwz-zuUviGryfw9J4V63Pd2iWWErorwUpyeL85rznlmYaGDHXjH_ChywA3R1m9XNpx4k7RCCT3rNofjkCxIBYHdsvwr2bVy
JDK1.5以后,在锁机制方面引入了新的锁-Lock,在网上的说法都比较笼统,结合网上的信息和我的理解这里做个总结。 java现有的锁机制有两种实现方式,J.DK1.4前是通过synchronized实现,JDK1.5后加入java.util.concurrent.locks包下的各种lock(以下简称Lock) 先说说代码层的区别。 synchronized:在代码里,synchronized类似“面向对象”,修饰类、方法、对象。 Lock:不作为修饰,类似“面向过程”,在方法中需要锁的时候lock,在结束的时候unlock(一般都在finally块里)。 例如代码: Java代码

- public void method1() {
- synchronized(this){//旧锁,无需人工释放
- System.out.println(1);
- }
- }
-
- public void method2() {
- Lock lock = new ReentrantLock();
- lock.lock();//上锁
- try{
- System.out.println(2);
- }finally{
- lock.unlock();//解锁
- }
- }
之所以起这样一个题目是因为很久以前我曾经写过一篇介绍TIME_WAIT的文章,不过当时基本属于浅尝辄止,并没深入说明问题的来龙去脉,碰巧这段时间反复被别人问到相关的问题,让我觉得有必要全面总结一下,以备不时之需。
讨论前大家可以拿手头的服务器摸摸底,记住「ss」比「netstat」快:
shell> ss -ant | awk ' NR>1 {++s[$1]} END {for(k in s) print k,s[k]} '如果你只是想单独查询一下TIME_WAIT的数量,那么还可以更简单一些:
shell> cat /proc/net/sockstat
我猜你一定被巨大无比的TIME_WAIT网络连接总数吓到了!以我个人的经验,对于一台繁忙的Web服务器来说,如果主要以短连接为主,那么其TIME_WAIT网络连接总数很可能会达到几万,甚至十几万。虽然一个TIME_WAIT网络连接耗费的资源无非就是一个端口、一点内存,但是架不住基数大,所以这始终是一个需要面对的问题。
为什么会存在TIME_WAIT?
TCP在建立连接的时候需要握手,同理,在关闭连接的时候也需要握手。为了更直观的说明关闭连接时握手的过程,我们引用「The TCP/IP Guide」中的例子:

TCP Close
因为TCP连接是双向的,所以在关闭连接的时候,两个方向各自都需要关闭。先发FIN包的一方执行的是主动关闭;后发FIN包的一方执行的是被动关闭。主动关闭的一方会进入TIME_WAIT状态,并且在此状态停留两倍的MSL时长。
穿插一点MSL的知识:MSL指的是报文段的最大生存时间,如果报文段在网络活动了MSL时间,还没有被接收,那么会被丢弃。关于MSL的大小,RFC 793协议中给出的建议是两分钟,不过实际上不同的操作系统可能有不同的设置,以Linux为例,通常是半分钟,两倍的MSL就是一分钟,也就是60秒,并且这个数值是硬编码在内核中的,也就是说除非你重新编译内核,否则没法修改它:
#define TCP_TIMEWAIT_LEN (60*HZ)
如果每秒的连接数是一千的话,那么一分钟就可能会产生六万个TIME_WAIT。
为什么主动关闭的一方不直接进入CLOSED状态,而是进入TIME_WAIT状态,并且停留两倍的MSL时长呢?这是因为TCP是建立在不可靠网络上的可靠的协议。例子:主动关闭的一方收到被动关闭的一方发出的FIN包后,回应ACK包,同时进入TIME_WAIT状态,但是因为网络原因,主动关闭的一方发送的这个ACK包很可能延迟,从而触发被动连接一方重传FIN包。极端情况下,这一去一回,就是两倍的MSL时长。如果主动关闭的一方跳过TIME_WAIT直接进入CLOSED,或者在TIME_WAIT停留的时长不足两倍的MSL,那么当被动关闭的一方早先发出的延迟包到达后,就可能出现类似下面的问题:
- 旧的TCP连接已经不存在了,系统此时只能返回RST包
- 新的TCP连接被建立起来了,延迟包可能干扰新的连接
不管是哪种情况都会让TCP不再可靠,所以TIME_WAIT状态有存在的必要性。
如何控制TIME_WAIT的数量?
从前面的描述我们可以得出这样的结论:TIME_WAIT这东西没有的话不行,不过太多可能也是个麻烦事。下面让我们看看有哪些方法可以控制TIME_WAIT数量,这里只说一些常规方法,另外一些诸如SO_LINGER之类的方法太过偏门,略过不谈。
ip_conntrack:顾名思义就是跟踪连接。一旦激活了此模块,就能在系统参数里发现很多用来控制网络连接状态超时的设置,其中自然也包括TIME_WAIT:
shell> modprobe ip_conntrack shell> sysctl net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait
我们可以尝试缩小它的设置,比如十秒,甚至一秒,具体设置成多少合适取决于网络情况而定,当然也可以参考相关的案例。不过就我的个人意见来说,ip_conntrack引入的问题比解决的还多,比如性能会大幅下降,所以不建议使用。
tcp_tw_recycle:顾名思义就是回收TIME_WAIT连接。可以说这个内核参数已经变成了大众处理TIME_WAIT的万金油,如果你在网络上搜索TIME_WAIT的解决方案,十有八九会推荐设置它,不过这里隐藏着一个不易察觉的陷阱:
当多个客户端通过NAT方式联网并与服务端交互时,服务端看到的是同一个IP,也就是说对服务端而言这些客户端实际上等同于一个,可惜由于这些客户端的时间戳可能存在差异,于是乎从服务端的视角看,便可能出现时间戳错乱的现象,进而直接导致时间戳小的数据包被丢弃。参考:tcp_tw_recycle和tcp_timestamps导致connect失败问题。
tcp_tw_reuse:顾名思义就是复用TIME_WAIT连接。当创建新连接的时候,如果可能的话会考虑复用相应的TIME_WAIT连接。通常认为「tcp_tw_reuse」比「tcp_tw_recycle」安全一些,这是因为一来TIME_WAIT创建时间必须超过一秒才可能会被复用;二来只有连接的时间戳是递增的时候才会被复用。官方文档里是这样说的:如果从协议视角看它是安全的,那么就可以使用。这简直就是外交辞令啊!按我的看法,如果网络比较稳定,比如都是内网连接,那么就可以尝试使用。
不过需要注意的是在哪里使用,既然我们要复用连接,那么当然应该在连接的发起方使用,而不能在被连接方使用。举例来说:客户端向服务端发起HTTP请求,服务端响应后主动关闭连接,于是TIME_WAIT便留在了服务端,此类情况使用「tcp_tw_reuse」是无效的,因为服务端是被连接方,所以不存在复用连接一说。让我们延伸一点来看,比如说服务端是PHP,它查询另一个MySQL服务端,然后主动断开连接,于是TIME_WAIT就落在了PHP一侧,此类情况下使用「tcp_tw_reuse」是有效的,因为此时PHP相对于MySQL而言是客户端,它是连接的发起方,所以可以复用连接。
说明:如果使用tcp_tw_reuse,请激活tcp_timestamps,否则无效。
tcp_max_tw_buckets:顾名思义就是控制TIME_WAIT总数。官网文档说这个选项只是为了阻止一些简单的DoS攻击,平常不要人为的降低它。如果缩小了它,那么系统会将多余的TIME_WAIT删除掉,日志里会显示:「TCP: time wait bucket table overflow」。
需要提醒大家的是物极必反,曾经看到有人把「tcp_max_tw_buckets」设置成0,也就是说完全抛弃TIME_WAIT,这就有些冒险了,用一句围棋谚语来说:入界宜缓。
…
有时候,如果我们换个角度去看问题,往往能得到四两拨千斤的效果。前面提到的例子:客户端向服务端发起HTTP请求,服务端响应后主动关闭连接,于是TIME_WAIT便留在了服务端。这里的关键在于主动关闭连接的是服务端!在关闭TCP连接的时候,先出手的一方注定逃不开TIME_WAIT的宿命,套用一句歌词:把我的悲伤留给自己,你的美丽让你带走。如果客户端可控的话,那么在服务端打开KeepAlive,尽可能不让服务端主动关闭连接,而让客户端主动关闭连接,如此一来问题便迎刃而解了。
参考文档:
- tcp短连接TIME_WAIT问题解决方法大全(1)——高屋建瓴
- tcp短连接TIME_WAIT问题解决方法大全(2)——SO_LINGER
- tcp短连接TIME_WAIT问题解决方法大全(3)——tcp_tw_recycle
- tcp短连接TIME_WAIT问题解决方法大全(4)——tcp_tw_reuse
- tcp短连接TIME_WAIT问题解决方法大全(5)——tcp_max_tw_buckets
1、常规网络访问限制:
a、线上运营设备的SSH端口不允许绑定在公网IP地址上,开发只能登录开发机然后通过内网登录这些服务器;
b、开发机、测试机的SSH端口可以绑定在公网IP地址上,SSH端口(22)可以考虑改为非知名端口;
c、线上运营设备、开发机、测试机的防火墙配置,公网只做80(HTTP)、8080(HTTP)、443(HTTPS)、SSH端口(仅限开发机、测试机)对外授权访问;
d、线上运营设备、开发机、测试机除第c点以外所有服务端口禁止绑定在公网IP地址上,尤其是3306端口(MySQL);
2、DB保护,
a、DB服务器不允许配置公网IP(或用防火墙全部禁止公网访问);
b、DB的root账户不用于业务访问,回收集中管理,开放普通账户做业务逻辑访问,对不同安全要求的库表用不同的账户密码访问;
c、程序不要把DB访问的账户密码写到配置文件中,写入代码或启动时远程到配置中心拉取(此方法比较重,可暂不考虑)。
d、另:DB备份文件可以考虑做加密处理;
3、系统安全:
a、设备的root密码回收集中管理,给开发提供普通用户帐号;
b、密码需要定期修改,有强度要求;
4、业务访问控制:
a、业务服务逻辑和运营平台,尽量不要提供对用户表和订单表的批量访问接口,如果运营平台确实有这样的需求,需要对特定账户做授权;
安全的代价是不方便、效率会下降,需要寻找平衡点。
转自http://www.witwebs.com/aliyun-mount-init/
阿里云的服务器,国内访问速度,稳定性一直都是不错的。至少我在使用的过程中,还未碰到什么问题。我将自己在使用主机过程的安装和环境配置做一个详细的介绍。仅供新手朋友参考!当我们在购买到阿里云服务器之后,会获得相应的IP地址和管理密码。
主要介绍Linux的数据盘的格式化和挂载。
大致步骤是: 登陆Linux > 查看硬盘状况 > 分区数据盘 > 格式化数据盘 > 挂载新分区
将会用到的命令如下:
df -h 查看已挂载硬盘信息
fdisk -l 查看磁盘信息,未挂载的也会列出来
fdisk /dev/xvdb 对数据盘进行分区,回车之后,继续 根据提示,依次输入”n” ,”p”,“1”,两次回车,“wq”, 分区就开始了,很快就会完成
mkfs .ext3 /dev/xvdb1 命令对新分区进行格式化
echo ‘/dev/xvdb1 /www ext3 defaults 0 0′ >> /etc/fstab 添加分区信息
mount -a 命令挂载新分区
1:通过Linux SSH 登陆软件登陆你的linux。登陆之后输入命令:df -lh 的界面如图:

2:输入命令: fdisk -l 查看磁盘状况,可以看到有数据盘: /dev/xvdb 而用df没有查看到这个磁盘。所以需要另外挂载。

3: 用 fdisk /dev/xvdb 对数据盘进行分区。根据提示,输入 n, p, 1, 回车,回车, wq。
完成之后,再用 fdisk -l,就可以看到显示的信息和之前有不同了。

4:格式化磁盘。 mkfs .ext3 /dev/xvdb1 ,格式化磁盘。完成之后,就可以来挂载分区了。

5, 挂载分区,首先建立一个目录用来挂载分区。比如: mkdir /www
然后把分区信息加入到fstab中:一次执行:
echo ‘/dev/xvdb1 /www ext3 defaults 0 0′ >> /etc/fstab 添加分区信息
mount -a 命令挂载新分区
最后用 df -h 命令查看,将会发现数据盘。

OK,希望能帮到各位。
1、需要先安装gcc和tcl
yum install gcc
yum install tcl
2、下载并安装redis
cd /opt
wget http://download.redis.io/releases/redis-3.0.0.tar.gz
tar -zxvf /opt/redis-3.0.0.tar.gz
cd /opt/redis-3.0.0
make
make test
make PREFIX=/opt/redis-3.0.0 install
注:PREFIX一定要大写,装好后,会生成/opt/redis-3.0.0/bin目录,里面有启动命令之类的文件。
3、启动与关闭
redis启动
/opt/redis-3.0.0/bin/redis-server /opt/redis-3.0.0/redis.conf
redis关闭
/opt/redis-3.0.0/bin/redis-cli -h 127.0.0.1 -p 6379 shutdown
客户端启动
/opt/redis-3.0.0/bin/redis-cli
set name test
get name
4、参数修改
/opt/redis-3.0.0/redis.conf文件修改
#后台运行,可以ctrl+c不至于退出
daemonize yes
关于错误提示
(1)编辑/etc/sysctl.conf ,最下面加一行vm.overcommit_memory=1,然后sysctl -p 使配置文件生效
(2)sysctl vm.overcommit_memory=1
注:如果使用了云服务器,要记得打开6379端口,否则无法远程访问
1、svnadmin create /opt/svn/yiss/app/ios1、apache里的httpd.conf配置如下:
每个库单独
<Location /yiss/app/ios>#这个是ios项目url上的访问上下文,对应http://IP/yiss/app/ios/
DAV svn
SVNPath /opt/svn/yiss/app/ios#这个是svn库的绝对路径
AuthType Basic#校验方式
AuthName "please input username/password"#提示信息
AuthUserFile /opt/svn/passwd#密码文件绝对路径
AuthzSVNAccessFile /opt/svn/authz#权限文件绝对路径
Require valid-user
</Location>
<Location /yiss/app/android>#安卓项目访问上下文
DAV svn
SVNPath /opt/svn/yiss/app/android
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
<Location /yiss/web/buildscript>
DAV svn
SVNPath /opt/svn/yiss/web/buildscript
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
2、首先要创建/opt/svn/yiss/app目录和/opt/svn/yiss/web
然后用命令创建svn库
svnadmin create /opt/svn/yiss/app/ios
svnadmin create /opt/svn/yiss/app/android
svnadmin create /opt/svn/yiss/web/buildscript
3、创建apache用户和密码,会提示重复输入2次确认。想改密码就多次输入,以最后一次输入的为准。
htpasswd /opt/svn/passwd wxq
htpasswd /opt/svn/passwd caowei
......
4、配置权限组/opt/svn/authz
[groups]
admin=wxq
web=caowei,luocan,houlei,gengzhuo,huangwei,wuhaiying,leo
app=ssh,golden,shawn,leo
#admin组用户可以访问所有目录
[/]
@admin=rw
#ios,android,srv,doc,buildscript这些都是库名,这里创建了3个库
[ios:/]
@app=rw
[android:/]
@app=rw
[buildscript:/]
@admin=rw
5、给目录及子目录授权,否则会报403forbidden无权限
chmod 777 /opt/svn -R
6、重启svn,启动的时候要以根启动,如果以某个svn库启动,则其他库无法启动。
killall svnserve
svnserve -d -r /opt/svn/yiss
7、重启apache
/opt/apache/bin/apachectl restart
8、浏览测试
http://115.231.94.x/yiss/app/ios/
http://115.231.94.x/yiss/app/android/
http://115.231.94.x/yiss/web/buildscript/
LoadModule auth_basic_module modules/mod_auth_basic.so #基本认证模块
LoadModule auth_digest_module modules/mod_auth_digest.so #使用MD5的用户验证模块
LoadModule authn_file_module modules/mod_authn_file.so #使用文本文件的用户验证
LoadModule authn_alias_module modules/mod_authn_alias.so #在原有的验证方法上提供拓展的验证
LoadModule authn_anon_module modules/mod_authn_anon.so #允许匿名访问已验证的区域
LoadModule authn_dbm_module modules/mod_authn_dbm.so #使用数据库文件验证
LoadModule authn_default_module modules/mod_authn_default.so #认证的撤销模块
LoadModule authz_host_module modules/mod_authz_host.so #基于主机名(或IP)的组授权
LoadModule authz_user_module modules/mod_authz_user.so #用户授权
LoadModule authz_owner_module modules/mod_authz_owner.so #依照文件拥有者的授权
LoadModule authz_groupfile_module modules/mod_authz_groupfile.so #使用明文文件的组授权
LoadModule authz_dbm_module modules/mod_authz_dbm.so #使用数据库的组授权
LoadModule authz_default_module modules/mod_authz_default.so #授权的撤销模块
LoadModule ldap_module modules/mod_ldap.so #LDAP提供其它LADP的连接接和缓存服务模块
LoadModule authnz_ldap_module modules/mod_authnz_ldap.so #允许使用一个LDAP的目录来存放HTTP基本授权文件
LoadModule include_module modules/mod_include.so #服务器端解析HTML语法的模块
LoadModule log_config_module modules/mod_log_config.so #记录服务器请求日志
LoadModule logio_module modules/mod_logio.so #记录每个请求的I/O字节数
LoadModule env_module modules/mod_env.so #设置传递给CGI脚本和SSI页面的环境?
LoadModule ext_filter_module modules/mod_ext_filter.so #在递交给客户端以前通过外部程序发送相应本体
LoadModule mime_magic_module modules/mod_mime_magic.so #通过查看一个文件的一些内容判断MIME类别
LoadModule expires_module modules/mod_expires.so #根据用户的特别设定来生成失效和隐藏控制的http头信息
LoadModule deflate_module modules/mod_deflate.so #传送给客户端以前压缩数据
LoadModule headers_module modules/mod_headers.so #定制响应和回复的HTTP头的内容
LoadModule usertrack_module modules/mod_usertrack.so #在一个站点上跟踪用户的登录信息
LoadModule setenvif_module modules/mod_setenvif.so #允许经过客户编码请求来设定环境变量
LoadModule mime_module modules/mod_mime.so #通过文件的一些属性判读MIME类型
LoadModule dav_module modules/mod_dav.so #基于WEB的创作和版本?
LoadModule status_module modules/mod_status.so #提供服务器运行信息
LoadModule autoindex_module modules/mod_autoindex.so #自动列出一个目录的索引表(类似于UNIX上的ls和DOS下的dir)
LoadModule info_module modules/mod_info.so #提供服务配置的一个综合概况
LoadModule dav_fs_module modules/mod_dav_fs.so #为mod_dav提供文件系统支持
LoadModule vhost_alias_module modules/mod_vhost_alias.so #为虚拟主机提供动态配置
LoadModule negotiation_module modules/mod_negotiation.so #为内容判断提供支持
LoadModule dir_module modules/mod_dir.so #为“/”结尾的重定向和目录文件索引
LoadModule actions_module modules/mod_actions.so #提供了基于请求和媒体类型的CGI脚本执行的支持
LoadModule speling_module modules/mod_speling.so #尝试纠正用户输入错误的网址
LoadModule userdir_module modules/mod_userdir.so #用户特定目录
LoadModule alias_module modules/mod_alias.so #提供主机文件系统不同部分的文件树映射为URL
LoadModule rewrite_module modules/mod_rewrite.so #提供在运行中基于规则的地址重写的支持
LoadModule proxy_module modules/mod_proxy.so #基于HTTP1.1协议的网关或代理服务器
LoadModule proxy_balancer_module modules/mod_proxy_balancer.so #负载均衡的mod_proxy拓展
LoadModule proxy_ftp_module modules/mod_proxy_ftp.so #为mod_proxy提供的ftp支持模块
LoadModule proxy_http_module modules/mod_proxy_http.so #为mod_proxy提供的http支持模块
LoadModule proxy_connect_module modules/mod_proxy_connect.so #mod_proxy的连接处理拓展模块
LoadModule cache_module modules/mod_cache.so #目录隐藏在URL外?
LoadModule suexec_module modules/mod_suexec.so #允许CGI脚本使用特定的用户和组运行
LoadModule disk_cache_module modules/mod_disk_cache.so #管理内容隐藏存放来适合URL的工具?
LoadModule file_cache_module modules/mod_file_cache.so #在内存中缓存一个文件列表
LoadModule mem_cache_module modules/mod_mem_cache.so #隐藏内容于URL
LoadModule cgi_module modules/mod_cgi.so #执行CGI脚本
1.安装apr和apr-util
apr, apr-util: http://apr.apache.org/
tar zxvf apr-1.5.1.tar.gz
cd apr-1.5.1
./configure --prefix=/opt/apr
make && make install
tar zxvf apr-util-1.5.4.tar.gz
cd apr-util-1.5.4
./configure --prefix=/opt/apr-util --with-apr=/opt/apr/
make && make install
2.安装apache下载地址:http://www.apache.org/dist//httpd/httpd-2.2.27.tar.gz
cd /opt
tar -zxvf httpd-2.4.10.tar.gz
cd /opt/httpd-2.4.10
./configure --prefix=/opt/apache --with-apr=/opt/apr/ --with-apr-util=/opt/apr-util/ --with-pcre=/opt/pcre --enable-so --enable-dav --enable-dav-fs
make && make install
其中,–enable-dav允许Apache提供DAV协议支持;–enable-so允许运行时加载DSO模块,前两个参数是必须要加的,–prefix 是安装的位置。如果configure通过,接着执行
数分钟后就完事了,通过 /opt/apache/bin/apachectl start 来启动,在浏览器中访问IP比如本机访问127.0.0.1,如果出现 It’s Works!,那么说明安装成功。
目录授权
chmod 777 /opt/svn
chown -R daemon:daemon /opt/svn
3.安装sqlite,http://www.sqlite.org/download.html
这里下载的是sqlite-autoconf-3080701.tar.gz,我下载到了/root/install并解压
tar zxvf sqlite-autoconf-3080701.tar.gz
cd /root/install/sqlite-autoconf-3080701
./configure --prefix=/opt/sqlite
make && make install
4安装SVN
http://subversion.apache.org/download/下载最新版本,老版本在http://archive.apache.org/dist/subversion/
tar -zxvf subversion-1.8.10.tar.gz
cd /opt/subversion-1.8.10
./configure --prefix=/opt/subversion --with-apr=/opt/apr --with-apr-util=/opt/apr-util --with-apxs=/opt/apache/bin/apxs --with-openssl --with-zlib --enable-maintainer-mode --with-sqlite=/opt/sqlite
有可能需要安装zlib1:
configure: error: subversion requires zlib
去http://zlib.net/下载,http://zlib.net/zlib-1.2.8.tar.gz,上传到/opt
cd /opt
tar zxvf zlib-1.2.8.tar.gz
cd zlib-1.2.8
./configure
make && make install
5.修改Apache配置,httpd.conf最下面追加,直接在根目录下建密码
cd /opt/apache/conf下载httpd.conf
这几个是必须的模块,出了问题检查一下有没有加载
LoadModule authn_file_module modules/mod_authn_file.so
LoadModule authz_host_module modules/mod_authz_host.so
LoadModule dav_module modules/mod_dav.so
#下面2个需要从该目录拷贝过来,并且引入,如果不引入无法和svn协同。
cp /opt/subversion/libexec/mod_authz_svn.so /opt/apache/modules
cp /opt/subversion/libexec/mod_dav_svn.so /opt/apache/modules
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule authz_svn_module modules/mod_authz_svn.so
这个加到最下面用来和svn协同
<Location /svn>
DAV svn
SVNListParentPath on //很重要
SVNParentPath /opt/svn
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
6.svn仓库的创建和权限配置
mkdir -p /opt/svn/
创建apache账户,使通过apache访问url的时候可以浏览该目录
新建一个文件需要-c,以后就不需要加了,passwd文件一定要用命令,明码是不行的
htpasswd -c /opt/svn/passwd wxq
htpasswd /opt/svn/passwd caowei
另外需要建一个群组权限文件到/opt/svn/authz, @代表群组,这里声明了一个admin组,admin组有读写权限
[groups]
admin=wxq
[/]
@admin=rw
[home:/]
@admin=rw
创建子仓库
svnadmin create /opt/svn/home
7.启动/重启/关闭apache
/opt/apache/bin/apachectl start
/opt/apache/bin/apachectl restart
/opt/apache/bin/apachectl stop
8.检测SVN 端口
[root@localhost conf]#netstat -ln |grep 3690
tcp 0 0 0.0.0.0:3690 0.0.0.0:* LISTEN
停止重启SVN
killall svnserve
svnserve -d -r /opt/svn
如果已经有svn在运行,可以换一个端口运行
svnserve -d -r /opt/svn/ --listen-port 3391
查看版本
svnserve --version
查看是否安装了svn
rpm -q subversion
查看是否安装了httpd,可以使用httpd --version检测是否已经卸载
rpm -q httpd
maven是个项目管理工具,集各种功能于一身,下面介绍maven web项目在eclipse种的配置,并于tomcat集成。配置成功后,可以跟一般的web项目一样调试。
一、准备条件
1、安装下载jdk
这里以jdk1.6为例
2、安装eclipse
到eclipse官网下载 Eclipse IDE for Java EE Developers版本的eclipse
http://www.eclipse.org/
3、安装tomcat6
4、安装maven
5、安装eclipse maven插件
这里以在线安装的方式,安装地址为:http://m2eclipse.sonatype.org/sites/m2e
二、配置
1、在eclipse中配置jdk安装位置,tomcat安装位置,maven安装位置,为tomcat指定jdk
在此不详述
2、在eclipse中新建一个maven项目
2-1、新建一个maven项目,选择create a simple project ...

2-2、
点击Next,进入下一个

在此窗口下填写group id,artifact id,可以随便写一个,在Packaging中选择war类型
点击下一步,在以下步骤中一直next,直到最后点击finish
2-3、
右击项目,选择properites,打开以下对话框

在此界面右边导航栏选中 Project Facets,点击超链接Convert Faceted from,进入以下界面
2-4、

在Configuration中选择custom
在下方的Project Facet的Dynamic Web Module中选择2.5版本
在java中选择1.6
注意:这些选择可能根据tomcat版本变化而变化,就tomcat6来说选择以上选项是可以的
此步骤非常重要,只有操作了此步骤,右侧导航栏才会有Deployment Assembly 链接
2-5
接下来点击右边面板的Runtime面板

可以看到下方中有tomcat,如果没有,则点击下面的new,新建一个,新建后选中复选框,然后apply,ok
2-6、
在项目属性面板中的作部导航栏选择Deployment Assembly选项,在右边Web Deployment Assembly
如果看到以下的图示,那么配置就完成了

这里解释一下以上文件夹
src/main/java
该文件夹是存放java源码的,发布项目时会将该文件夹下的class文件复制到WEB-INF/classes目录下
src/main/resources
该文件夹一般放置配置文件,如xml,properties文件等,其实也可以放置java文件,只是一种约定罢了,发布项目时
该文件夹的文件也会复制到WEB-INF/class中
至于test,有些类似,只不过这些是测试代码,用过maven的应该会知道这一点
src/main/webapp
maven中约定是把该文件夹当成是普通web项目中的WebRoot目录,看看右边的deploy path,发布项目时
是发布到根目录/了。该文件夹在建成的maven web项目中,在其内尚没有WEB-INF/classes,WEB-INF/lib文件夹
需要手工建立
注意:有时候由于某种原因,你打开的以上视图可能是下面这样的,

其实,这样也是可以运行项目,调试项目的,但是,如果你运行该项目的pom.xml文件时就会报错,为什么呢,
因为maven会把src/main/webapp文件当成是普通web项目中的WebRoot,而该你的配置里面(上图)却
没有配置,故而会报错。
怎么办呢,分2步
1、选中 WebContent,remove掉它
2、新建一个,Source文件夹为src/main/webapp,deploy path为 /
点击apply,ok即可。
最后还必须将maven库映射到WEB-INF/lib下,具体操作如下,点击add按钮,进入下图

选择java build path entries,点击next,进入下图

选择Maven Dependencies,点击finish,最终如下图

如果不把Maven Dependencies映射到WEB-INF/lib,则在服务端如servlet中用到maven中的库时,则会提示找不到类(虽然你在编写代码时没有红xx,但是运行程序时却会找不到类)
三、运行
在eclipse的server视图中添加你的项目,右键选择的tomcat服务器,选择add and remove,添加刚才新建的web工程,效果如下图

在src/main/java中建立一个servlet,在src/main/webapp中建立一个jsp
启动tomcat,访问你的servlet和jsp,在servlet中你可以定断点,可以调试。
http://zk1878.iteye.com/blog/1222330
在linux下怎么安装.bin的文件。
或者
第一步: sh ./j2sdk-1_4_2-nb-3_5_1-bin-linux.bin
回答YES
第二步: rpm **** |
如何查看是否开启慢查:可看到慢查的设定时间,最下几行
SHOW VARIABLES LIKE '%_query_%';
重新生成慢查询日志文件,不用重启
mysqladmin -u root -p flush-logs(网上都说这种,其实不行)
正确的做法:
1、分析慢查日志输出到digest.log
/usr/local/bin/percona-toolkit-2.2.11/bin/pt-query-digest /data/mysql-slow.log >/data/mysql-digest/digest$(date +%Y-%m-%d-%H:%M).log
2、直接删除mysql-slow.log
rm -fr /data/mysql-slow.log
3、备份并重新生成日志文件:
touch /data/mysql-slow.log
chmod 777 /data/mysql-slow.log
4、重新开启日志记录:
SET GLOBAL slow_query_log = ON;
5、等待就行了,经试验有效
常用工具集:
1、服务器摘要
2、服务器磁盘监测
3、mysql服务状态摘要
- pt-mysql-summary -- --user=root --password=root
4、慢查询日志分析统计
- pt-query-digest /data/logs/mysql/mysql-slow.log
5、表同步工具,和mk-tables-sync功能一样, 用法上 稍有不一样 ,--print的结果更详细
- pt-table-sync --execute --print --no-check-slave --database=world h='127.0.0.1' --user=root --password=123456 h='192.168.0.212' --user=root --password=123456
6、主从状态监测,提供给它一台mysql服务器的IP用户名密码,就可以分析出整个主从架构中每台服务器的信息,包括但不限于mysql版本,IP地址,server ID,mysql服务的启动时间,角色(主/从),Slave Status(落后于主服务器多少秒,有没有错误,slave有没有在运行)。
- [root@RHCE6 ~]# pt-slave-find --host=localhost --user=rhce6 --password=rhce6
- localhost
- Version 5.5.23-log
- Server ID 1
- Uptime 05:16:10 (started 2012-08-08T09:32:03)
- Replication Is not a slave, has 1 slaves connected, is not read_only
- Filters
- Binary logging STATEMENT
- Slave status
- Slave mode STRICT
- Auto-increment increment 1, offset 1
- InnoDB version 1.1.8
- +- 192.168.0.168
- Version 5.5.23-log
- Server ID 10
- Uptime 38:19 (started 2012-08-08T14:09:54)
- Replication Is a slave, has 0 slaves connected, is not read_only
- Filters
- Binary logging STATEMENT
- Slave status 0 seconds behind, running, no errors
- Slave mode STRICT
- Auto-increment increment 1, offset 1
- InnoDB version 1.1.8
7、mysql死锁监测
- pt-deadlock-logger h='127.0.0.1' --user=root --password=123456
8.主键冲突检查
- pt-duplicate-key-checker --database=world h='127.0.0.1' --user=root --password=123456
9.监测从库的复制延迟 ###经过测试 运行这个命令会使从库上的sql线程异常挂掉
- pt-slave-delay --host 192.168.0.206 --user=root --password=123456
更多介绍参考http://www.zhaokunyao.com/archives/3245,命令的使用可以通过--help获知
percona-toolkit简介
percona-toolkit是一组高级命令行工具的集合,用来执行各种通过手工执行非常复杂和麻烦的mysql和系统任务,这些任务包括:
l 检查master和slave数据的一致性
l 有效地对记录进行归档
l 查找重复的索引
l 对服务器信息进行汇总
l 分析来自日志和tcpdump的查询
l 当系统出问题的时候收集重要的系统信息
percona-toolkit源自Maatkit 和Aspersa工具,这两个工具是管理mysql的最有名的工具,现在Maatkit工具已经不维护了,请大家还是使用percona-toolkit吧!这些工具主要包括开发、性能、配置、监控、复制、系统、实用六大类,作为一个优秀的DBA,里面有的工具非常有用,如果能掌握并加以灵活应用,将能极大的提高工作效率。
二、percona-toolkit工具包安装
0.准备工作,先安装:
yum install -y perl-CPAN perl-Time-HiRes
1. 软件包下载
访问http://www.percona.com/downloads/percona-toolkit/下载最新版本的Percona Toolkit 或者通过如下命令行来获取最新的版本:
wget percona.com/get/percona-toolkit.tar.gz
wget percona.com/get/percona-toolkit.rpm
我这里选择直接从网站上找到最新版本下载:
cd /usr/local/bin
wget http://www.percona.com/downloads/percona-toolkit/2.2.11/percona-toolkit-2.2.11.tar.gz
2. 软件包安装
percona-toolkit的编译安装方式
/usr/local/bin
tar xzvf percona-toolkit-2.2.11.tar.gz
cd percona-toolkit-2.2.11
perl Makefile.PL
make
make test
make install
1、INFO: Maximum number of threads (200) created for connector with address null and port 8091
说明:最大线程数错误
解决方案:
使用线程池,用较少的线程处理较多的访问,可以提高tomcat处理请求的能力。使用方式:
首先。打开/conf/server.xml,增加
- <Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
- maxThreads="500" minSpareThreads="20" maxIdleTime="60000" />
最大线程500(一般服务器足以),最小空闲线程数20,线程最大空闲时间60秒。
然后,修改<Connector ...>节点,增加executor属性,如:
- <Connector executor="tomcatThreadPool"
- port="80" protocol="HTTP/1.1"
- connectionTimeout="60000"
- keepAliveTimeout="15000"
- maxKeepAliveRequests="1"
- redirectPort="443"
- ....../>
2、java.net.SocketException: Too many open files
当tomcat并发用户量大的时候,单个jvm进程确实可能打开过多的文件句柄。
使用 #lsof -p 10001|wc -l 查看文件操作数
如下操作:
- (1).ps -ef |grep tomcat 查看tomcat的进程ID,记录ID号,假设进程ID为10001
- (2).lsof -p 10001|wc -l 查看当前进程id为10001的 文件操作数
- (3).使用命令:ulimit -a 查看每个用户允许打开的最大文件数
- 默认是1024.
- (4).然后执行:ulimit -n 65536 将允许的最大文件数调整为65536
ngxin需要增加如下配置和tomcat的session复制配合使用
proxy_redirect off;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
tomcat集群配置:
<Cluster className="org.apache.catalina.cluster.tcp.SimpleTcpCluster"
managerClassName="org.apache.catalina.cluster.session.DeltaManager"
expireSessionsOnShutdown="false"
useDirtyFlag="true"
notifyListenersOnReplication="true">
<Membership
className="org.apache.catalina.cluster.mcast.McastService"
mcastAddr="228.0.0.4"
mcastPort="45564"
mcastFrequency="500"
mcastDropTime="3000"/>
<Receiver
className="org.apache.catalina.cluster.tcp.ReplicationListener"
tcpListenAddress="192.168.1.199"//这里配置局域网IP
tcpListenPort="4001"
tcpSelectorTimeout="100"
tcpThreadCount="6"/>
<Sender
className="org.apache.catalina.cluster.tcp.ReplicationTransmitter"
replicationMode="pooled"
ackTimeout="15000"
waitForAck="true"/>
<Valve className="org.apache.catalina.cluster.tcp.ReplicationValve"
filter=".*\.gif;.*\.js;.*\.jpg;.*\.png;.*\.htm;.*\.html;.*\.css;.*\.txt;"/>
<Deployer className="org.apache.catalina.cluster.deploy.FarmWarDeployer"
tempDir="/tmp/war-temp/"
deployDir="/tmp/war-deploy/"
watchDir="/tmp/war-listen/"
watchEnabled="false"/>
<ClusterListener className="org.apache.catalina.cluster.session.ClusterSessionListener"/>
</Cluster>
web.xml最下面加上这句话
<distributable/>
转自http://hanqunfeng.iteye.com/blog/1920994
1)ip_hash(不推荐使用)
nginx中的ip_hash技术能够将某个ip的请求定向到同一台后端,这样一来这个ip下的某个客户端和某个后端就能建立起稳固的session,ip_hash是在upstream配置中定义的:
- upstream backend {
- server 127.0.0.1:8080 ;
- server 127.0.0.1:9090 ;
- ip_hash;
- }
不推荐使用的原因如下:
1/ nginx不是最前端的服务器。
ip_hash要求nginx一定是最前端的服务器,否则nginx得不到正确ip,就不能根据ip作hash。譬如使用的是squid为最前端,那么nginx取ip时只能得到squid的服务器ip地址,用这个地址来作分流是肯定错乱的。
2/ nginx的后端还有其它方式的负载均衡。
假如nginx后端又有其它负载均衡,将请求又通过另外的方式分流了,那么某个客户端的请求肯定不能定位到同一台session应用服务器上。
3/ 多个外网出口。
很多公司上网有多个出口,多个ip地址,用户访问互联网时候自动切换ip。而且这种情况不在少数。使用 ip_hash 的话对这种情况的用户无效,无法将某个用户绑定在固定的tomcat上 。
2)nginx_upstream_jvm_route(nginx扩展,推荐使用)
nginx_upstream_jvm_route 是一个nginx的扩展模块,用来实现基于 Cookie 的 Session Sticky 的功能。
简单来说,它是基于cookie中的JSESSIONID来决定将请求发送给后端的哪个server,nginx_upstream_jvm_route会在用户第一次请求后端server时,将响应的server标识绑定到cookie中的JSESSIONID中,从而当用户发起下一次请求时,nginx会根据JSESSIONID来决定由哪个后端server来处理。
1/ nginx_upstream_jvm_route安装
下载地址(svn):http://nginx-upstream-jvm-route.googlecode.com/svn/trunk/
假设nginx_upstream_jvm_route下载后的路径为/usr/local/nginx_upstream_jvm_route,
(1)进入nginx源码路径
patch -p0 < /usr/local/nginx_upstream_jvm_route/jvm_route.patch
(2)./configure --with-http_stub_status_module --with-http_ssl_module --prefix=/usr/local/nginx --with-pcre=/usr/local/pcre-8.33 --add-module=/usr/local/nginx_upstream_jvm_route
(3)make & make install
关于nginx的下载与安装参考:http://hanqunfeng.iteye.com/blog/697696
2/ nginx配置
- upstream tomcats_jvm_route
- {
- # ip_hash;
- server 192.168.33.10:8090 srun_id=tomcat01;
- server 192.168.33.11:8090 srun_id=tomcat02;
- jvm_route $cookie_JSESSIONID|sessionid reverse;
- }
3/ tomcat配置
修改192.168.33.10:8090tomcat的server.xml,
- 将
- <Engine name="Catalina" defaultHost="localhost" >
- 修改为:
- <Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat01">
同理,在192.168.33.11:8090server.xml中增加jvmRoute="tomcat02"。
4/ 测试
启动tomcat和nginx,访问nginx代理,使用Google浏览器,F12,查看cookie中的JSESSIONID,
形如:ABCD123456OIUH897SDFSDF.tomcat01 ,刷新也不会变化
今天在安装的时候出现这样的错误。
src/http/modules -I src/mail \
-o objs/addon/nginx-sticky-module-1.1/ngx_http_sticky_misc.o \ ../nginx-sticky-module-1.1/ngx_http_sticky_misc.c
In file included from ../nginx-sticky-module-1.1/ngx_http_sticky_misc.c:11:0: src/core/ngx_sha1.h:19:17: fatal error: sha.h: No such file or directory compilation terminated. make1?: [objs/addon/nginx-sticky-module-1.1/ngx_http_sticky_misc.o] Error 1 make1?: Leaving directory `/etc/nginx/nginx-1.4.1' make: build? Error 2
我的命令是
./configure --prefix=/opt/nginx --with-file-aio --with-http_stub_status_module --add-module=../nginx-sticky-module-1.1
make
提示信息不实很明确,后来安装了openssl之后再次安装就解决了问题。
yum -y install openssl-devel
[root@localhost conf]# /usr/local/nginx/sbin/nginx/usr/local/nginx/sbin/nginx: error while loading shared libraries: libpcre.so.1: cannot open shared object file: No such file or directory
从错误看出是缺少lib文件导致
可以看出 libpcre.so.1 => not found 并没有找到,进入/lib目录中手动链接下[root@localhost lib]# ln -s libpcre.so.0.0.1 libpcre.so.1然后在启动nginx ok 了[root@localhost lib]# /usr/local/nginx/sbin/nginx[root@localhost lib]# ps -ef |grep nginxroot 9539 1 0 19:06 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginxwww 9540 9539 0 19:06 ? 00:00:00 nginx: worker process
安装pcre
PCRE是perl所用到的正则表达式,目的是让所装的软件支持正则表达式。默认情况下,Nginx只处理静态的网页请求,也就是html.如果是来自动态的网页请求,比如*.php,那么Nginx就要根据正则表达式查询路径,然后把*.PHP交给PHP去处理
#rpm -qa | grep pcre //查询系统中有没有安装PCRE,一般装系统是默认装有,所以我们要删掉系统自带的
#cp /lib/libpcre.so.0 / //在删除系统自带的PCRE之前,要先备份一下libpcre.so.0这个文件,因为RPM包的关联性太强,在删除后没libpcre.so.0这个文件时我们装PCRE是装不上的
#rpm -e --nodeps pcre-6.6-1.1 //删除系统自带的PCRE
# tar zxvf pcre-8.00.tar.gz
#cd pcre-8.00
#cp /libpcre.so.0 /lib/ //把我们删除系统自带的PCRE之前备份的libpcre.so.0拷贝到/lib 目录下
#./configure //配置PCRE,因为PCRE是一个库,而不是像pache、php、postfix等这样的程序,所以我们安装时选择默认路径即可,这样会在后面安装其它东西时避免一些不必要的麻烦,执行完这部后会显示出下图,上面显示了我们对PCRE的配置
#make && make install
摘要: 转自http://www.ttlsa.com/nginx/nginx-modules-nginx-sticky-module/在多台后台服务器的环境下,我们为了确保一个客户只和一台服务器通信,我们势必使用长连接。使用什么方式来实现这种连接呢,常见的有使用nginx自带的ip_hash来做,我想这绝对不是一个好的办法,如果前端是CDN,或者说一个局域网的客户同时访问服务器,导致出现服务器分配不均衡,...
阅读全文
CentOS 防火墙开启80端口
网上搜索了很多都没解决问题,下面是正确方法:
#/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT
#/sbin/iptables -I INPUT -p tcp --dport 22 -j ACCEPT
然后保存:
#/etc/rc.d/init.d/iptables save
如果上面的步骤还没好的话,可能是这个iptables文件使用的是包含调用。
一般的在/etc/sysconfig/iptables这个路径上
打开这个文件修改手动添加就行了。
注意需要重启服务哦:执行service iptabels save 与 service iptables restart
端口查看方法:
[root@vcentos ~]# /etc/init.d/iptables status
Table: filter
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:80
2 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
3 RH-Firewall-1-INPUT all -- 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy ACCEPT)
num target prot opt source destination
1 RH-Firewall-1-INPUT all -- 0.0.0.0/0 0.0.0.0/0
运行如下命令:
$ sudo vi /etc/network/interfaces
修改auto eth0下的相关内容为如下:
auto eth0
#iface eth0 inet dhcp -- 这个是自动ip的设置
iface eth0 inet static
address [ip地址]
netmask [子网掩码]
gateway [网关]
运行如下命令重启网络服务:
$ sudo /etc/init.d/networking restart
我是reboot之后才生效
转自:http://blog.163.com/lgh_2002/blog/static/440175262013526113335331/
从“第三天”的性能测试一节中,我们得知了决定性能测试的几个重要指标,它们是:
ü 吞吐量
ü Responsetime
ü Cpuload
ü MemoryUsage
我们也在第三天的学习中对Apache做过了一定的优化,使其最优化上述4大核心指标的读数,那么我们的Apache调优了,我们的Tomcat也作些相应的调整,当完成今的课程后,到时你的“小猫”到时真的会“飞”起来的,所以请用心看完,这篇文章一方面用来向那位曾写过“Tomcat如何承受1000个用户”的作都的敬,一方面又是这篇原文的一个扩展,因为在把原文的知识用到相关的两个大工程中去后解决了:
1) 承受更大并发用户数
2) 取得了良好的性能与改善(系统平均性能提升达20倍,极端一个交易达80倍)。
另外值的一提的是,我们当时工程里用的“小猫”是跑在32位机下的, 也就是我们的JVM最大受到2GB内存的限制,都已经跑成“飞”了。。。。。。如果在64位机下跑这头“小猫”。。。。。。大家可想而知,会得到什么样的效果呢?下面就请请详细的设置吧!

2.1 32位操作系统与64位操作系统中JVM的对比
我们一般的开发人员,基本用的是都是32位的Windows系统,这就导致了一个严重的问题即:32位windows系统对内存限制,下面先来看一个比较的表格:
操作系统 | 操作系统位数 | 内存限制 | 解决办法 |
Winxp | 32 | 4GB | 超级兔子 |
Win7 | 32 | 4GB | 可以通过设置/PAE |
Win2003 | 32 | 可以突破4GB达16GB | 必需要装win2003 advanced server且要打上sp2补丁 |
Win7 | 64 | 无限制 | 机器能插多少内存,系统内存就能支持到多大 |
Win2003 | 64 | 无限制 | 机器能插多少内存,系统内存就能支持到多大 |
Linux | 64 | 无限制 | 机器能插多少内存,系统内存就能支持到多大 |
Unix | 64 | 无限制 | 机器能插多少内存,系统内存就能支持到多大 |
上述问题解决后,我们又碰到一个新的问题,32位系统下JVM对内存的限制:不能突破2GB内存,即使你在Win2003 Advanced Server下你的机器装有8GB-16GB的内存,而你的JAVA,只能用到2GB的内存。
其实我一直很想推荐大家使用Linux或者是Mac操作系统的,而且要装64位,因为必竟我们是开发用的不是打游戏用的,而Java源自Unix归于Unix(Linux只是运行在PC上的Unix而己)。
所以很多开发人员运行在win32位系统上更有甚者在生产环境下都会布署win32位的系统,那么这时你的Tomcat要优化,就要讲究点技巧了。而在64位操作系统上无论是系统内存还是JVM都没有受到2GB这样的限制。
Tomcat的优化分成两块:
ü Tomcat启动命令行中的优化参数即JVM优化
ü Tomcat容器自身参数的优化(这块很像ApacheHttp Server)
这一节先要讲的是Tomcat启动命令行中的优化参数。
Tomcat首先跑在JVM之上的,因为它的启动其实也只是一个java命令行,首先我们需要对这个JAVA的启动命令行进行调优。
需要注意的是:
这边讨论的JVM优化是基于Oracle Sun的jdk1.6版有以上,其它JDK或者低版本JDK不适用。
Tomcat 的启动参数位于tomcat的安装目录\bin目录下,如果你是Linux操作系统就是catalina.sh文件,如果你是Windows操作系统那么你需要改动的就是catalina.bat文件。打开该文件,一般该文件头部是一堆的由##包裹着的注释文字,找到注释文字的最后一段如:
# $Id: catalina.sh 522797 2007-03-27 07:10:29Z fhanik $ # ----------------------------------------------------------------------------- # OS specific support. $var _must_ be set to either true or false. |
敲入一个回车,加入如下的参数
Linux系统中tomcat的启动参数
export JAVA_OPTS="-server -Xms1400M -Xmx1400M -Xss512k -XX:+AggressiveOpts -XX:+UseBiasedLocking -XX:PermSize=128M -XX:MaxPermSize=256M -XX:+DisableExplicitGC -XX:MaxTenuringThreshold=31 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.headless=true " |
Windows系统中tomcat的启动参数
set JAVA_OPTS=-server -Xms1400M -Xmx1400M -Xss512k -XX:+AggressiveOpts -XX:+UseBiasedLocking -XX:PermSize=128M -XX:MaxPermSize=256M -XX:+DisableExplicitGC -XX:MaxTenuringThreshold=31 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.headless=true |
上面参数好多啊,可能有人写到现在都没见一个tomcat的启动命令里加了这么多参数,当然,这些参数只是我机器上的,不一定适合你,尤其是参数后的value(值)是需要根据你自己的实际情况来设置的。
参数解释:
ü -server
我不管你什么理由,只要你的tomcat是运行在生产环境中的,这个参数必须给我加上
因为tomcat默认是以一种叫java –client的模式来运行的,server即意味着你的tomcat是以真实的production的模式在运行的,这也就意味着你的tomcat以server模式运行时将拥有:更大、更高的并发处理能力,更快更强捷的JVM垃圾回收机制,可以获得更多的负载与吞吐量。。。更。。。还有更。。。
Y给我记住啊,要不然这个-server都不加,那是要打屁股了。
ü -Xms–Xmx
即JVM内存设置了,把Xms与Xmx两个值设成一样是最优的做法,有人说Xms为最小值,Xmx为最大值不是挺好的,这样设置还比较人性化,科学化。人性?科学?你个头啊。
大家想一下这样的场景:
一个系统随着并发数越来越高,它的内存使用情况逐步上升,上升到最高点不能上升了,开始回落,你们不要认为这个回落就是好事情,由其是大起大落,在内存回落时它付出的代价是CPU高速开始运转进行垃圾回收,此时严重的甚至会造成你的系统出现“卡壳”就是你在好好的操作,突然网页像死在那边一样几秒甚至十几秒时间,因为JVM正在进行垃圾回收。
因此一开始我们就把这两个设成一样,使得Tomcat在启动时就为最大化参数充分利用系统的效率,这个道理和jdbcconnection pool里的minpool size与maxpool size的需要设成一个数量是一样的原理。
如何知道我的JVM能够使用最大值啊?拍脑袋?不行!
在设这个最大内存即Xmx值时请先打开一个命令行,键入如下的命令:
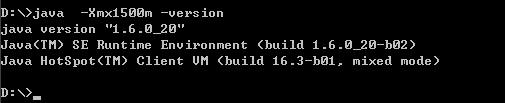
看,能够正常显示JDK的版本信息,说明,这个值你能够用。不是说32位系统下最高能够使用2GB内存吗?即:2048m,我们不防来试试
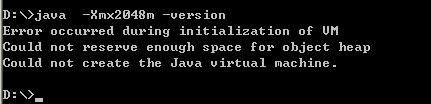
可以吗?不可以!不要说2048m呢,我们小一点,试试1700m如何
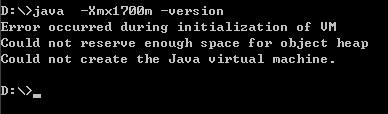
嘿嘿,连1700m都不可以,更不要说2048m了呢,2048m只是一个理论数值,这样说吧我这边有几台机器,有的机器-Xmx1800都没问题,有的机器最高只能到-Xmx1500m。
因此在设这个-Xms与-Xmx值时一定一定记得先这样测试一下,要不然直接加在tomcat启动命令行中你的tomcat就再也起不来了,要飞是飞不了,直接成了一只瘟猫了。
ü –Xmn
设置年轻代大小为512m。整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
ü -Xss
是指设定每个线程的堆栈大小。这个就要依据你的程序,看一个线程 大约需要占用多少内存,可能会有多少线程同时运行等。一般不易设置超过1M,要不然容易出现out ofmemory。
ü -XX:+AggressiveOpts
作用如其名(aggressive),启用这个参数,则每当JDK版本升级时,你的JVM都会使用最新加入的优化技术(如果有的话)
ü -XX:+UseBiasedLocking
启用一个优化了的线程锁,我们知道在我们的appserver,每个http请求就是一个线程,有的请求短有的请求长,就会有请求排队的现象,甚至还会出现线程阻塞,这个优化了的线程锁使得你的appserver内对线程处理自动进行最优调配。
ü -XX:PermSize=128M-XX:MaxPermSize=256M
JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;
在数据量的很大的文件导出时,一定要把这两个值设置上,否则会出现内存溢出的错误。
由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
那么,如果是物理内存4GB,那么64分之一就是64MB,这就是PermSize默认值,也就是永生代内存初始大小;
四分之一是1024MB,这就是MaxPermSize默认大小。
ü -XX:+DisableExplicitGC
在程序代码中不允许有显示的调用”System.gc()”。看到过有两个极品工程中每次在DAO操作结束时手动调用System.gc()一下,觉得这样做好像能够解决它们的out ofmemory问题一样,付出的代价就是系统响应时间严重降低,就和我在关于Xms,Xmx里的解释的原理一样,这样去调用GC导致系统的JVM大起大落,性能不到什么地方去哟!
ü -XX:+UseParNewGC
对年轻代采用多线程并行回收,这样收得快。
ü -XX:+UseConcMarkSweepGC
即CMS gc,这一特性只有jdk1.5即后续版本才具有的功能,它使用的是gc估算触发和heap占用触发。
我们知道频频繁的GC会造面JVM的大起大落从而影响到系统的效率,因此使用了CMS GC后可以在GC次数增多的情况下,每次GC的响应时间却很短,比如说使用了CMS GC后经过jprofiler的观察,GC被触发次数非常多,而每次GC耗时仅为几毫秒。
ü -XX:MaxTenuringThreshold
设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概率。
这个值的设置是根据本地的jprofiler监控后得到的一个理想的值,不能一概而论原搬照抄。
ü -XX:+CMSParallelRemarkEnabled
在使用UseParNewGC 的情况下, 尽量减少 mark 的时间
ü -XX:+UseCMSCompactAtFullCollection
在使用concurrent gc 的情况下, 防止 memoryfragmention, 对live object 进行整理, 使 memory 碎片减少。
ü -XX:LargePageSizeInBytes
指定 Java heap的分页页面大小
ü -XX:+UseFastAccessorMethods
get,set 方法转成本地代码
ü -XX:+UseCMSInitiatingOccupancyOnly
指示只有在 oldgeneration 在使用了初始化的比例后concurrent collector 启动收集
ü -XX:CMSInitiatingOccupancyFraction=70
CMSInitiatingOccupancyFraction,这个参数设置有很大技巧,基本上满足(Xmx-Xmn)*(100- CMSInitiatingOccupancyFraction)/100>=Xmn就不会出现promotion failed。在我的应用中Xmx是6000,Xmn是512,那么Xmx-Xmn是5488兆,也就是年老代有5488 兆,CMSInitiatingOccupancyFraction=90说明年老代到90%满的时候开始执行对年老代的并发垃圾回收(CMS),这时还 剩10%的空间是5488*10%=548兆,所以即使Xmn(也就是年轻代共512兆)里所有对象都搬到年老代里,548兆的空间也足够了,所以只要满 足上面的公式,就不会出现垃圾回收时的promotion failed;
因此这个参数的设置必须与Xmn关联在一起。
ü -Djava.awt.headless=true
这个参数一般我们都是放在最后使用的,这全参数的作用是这样的,有时我们会在我们的J2EE工程中使用一些图表工具如:jfreechart,用于在web网页输出GIF/JPG等流,在winodws环境下,一般我们的app server在输出图形时不会碰到什么问题,但是在linux/unix环境下经常会碰到一个exception导致你在winodws开发环境下图片显示的好好可是在linux/unix下却显示不出来,因此加上这个参数以免避这样的情况出现。
上述这样的配置,基本上可以达到:
ü 系统响应时间增快
ü JVM回收速度增快同时又不影响系统的响应率
ü JVM内存最大化利用
ü 线程阻塞情况最小化
前面我们对Tomcat启动时的命令进行了优化,增加了系统的JVM可使用数、垃圾回收效率与线程阻塞情况、增加了系统响应效率等还有一个很重要的指标,我们没有去做优化,就是吞吐量。
还记得我们在第三天的学习中说的,这个系统本身可以处理1000,你没有优化和配置导致它默认只能处理25。因此下面我们来看Tomcat容器内的优化。
打开tomcat安装目录\conf\server.xml文件,定位到这一行:
<Connector port="8080" protocol="HTTP/1.1" |
这一行就是我们的tomcat容器性能参数设置的地方,它一般都会有一个默认值,这些默认值是远远不够我们的使用的,我们来看经过更改后的这一段的配置:
<Connector port="8080" protocol="HTTP/1.1" URIEncoding="UTF-8" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" disableUploadTimeout="true" connectionTimeout="20000" acceptCount="300" maxThreads="300" maxProcessors="1000" minProcessors="5" useURIValidationHack="false" compression="on" compressionMinSize="2048" compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" redirectPort="8443" /> |
好大一陀唉。。。。。。
没关系,一个个来解释
ü URIEncoding=”UTF-8”
使得tomcat可以解析含有中文名的文件的url,真方便,不像apache里还有搞个mod_encoding,还要手工编译
ü maxSpareThreads
maxSpareThreads 的意思就是如果空闲状态的线程数多于设置的数目,则将这些线程中止,减少这个池中的线程总数。
ü minSpareThreads
最小备用线程数,tomcat启动时的初始化的线程数。
ü enableLookups
这个功效和Apache中的HostnameLookups一样,设为关闭。
ü connectionTimeout
connectionTimeout为网络连接超时时间毫秒数。
ü maxThreads
maxThreads Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可创建的最大的线程数,即最大并发数。
ü acceptCount
acceptCount是当线程数达到maxThreads后,后续请求会被放入一个等待队列,这个acceptCount是这个队列的大小,如果这个队列也满了,就直接refuse connection
ü maxProcessors与minProcessors
在 Java中线程是程序运行时的路径,是在一个程序中与其它控制线程无关的、能够独立运行的代码段。它们共享相同的地址空间。多线程帮助程序员写出CPU最 大利用率的高效程序,使空闲时间保持最低,从而接受更多的请求。
通常Windows是1000个左右,Linux是2000个左右。
ü useURIValidationHack
我们来看一下tomcat中的一段源码:
security if (connector.getUseURIValidationHack()) { String uri = validate(request.getRequestURI()); if (uri == null) { res.setStatus(400); res.setMessage("Invalid URI"); throw new IOException("Invalid URI"); } else { req.requestURI().setString(uri); // Redoing the URI decoding req.decodedURI().duplicate(req.requestURI()); req.getURLDecoder().convert(req.decodedURI(), true); } } |
可以看到如果把useURIValidationHack设成"false",可以减少它对一些url的不必要的检查从而减省开销。
ü enableLookups="false"
为了消除DNS查询对性能的影响我们可以关闭DNS查询,方式是修改server.xml文件中的enableLookups参数值。
ü disableUploadTimeout
类似于Apache中的keeyalive一样
ü 给Tomcat配置gzip压缩(HTTP压缩)功能
compression="on" compressionMinSize="2048" compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" |
HTTP 压缩可以大大提高浏览网站的速度,它的原理是,在客户端请求网页后,从服务器端将网页文件压缩,再下载到客户端,由客户端的浏览器负责解压缩并浏览。相对于普通的浏览过程HTML,CSS,Javascript , Text ,它可以节省40%左右的流量。更为重要的是,它可以对动态生成的,包括CGI、PHP , JSP , ASP , Servlet,SHTML等输出的网页也能进行压缩,压缩效率惊人。
1)compression="on" 打开压缩功能
2)compressionMinSize="2048" 启用压缩的输出内容大小,这里面默认为2KB
3)noCompressionUserAgents="gozilla, traviata" 对于以下的浏览器,不启用压缩
4)compressableMimeType="text/html,text/xml" 压缩类型
最后不要忘了把8443端口的地方也加上同样的配置,因为如果我们走https协议的话,我们将会用到8443端口这个段的配置,对吧?
<!--enable tomcat ssl--> <Connector port="8443" protocol="HTTP/1.1" URIEncoding="UTF-8" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" disableUploadTimeout="true" connectionTimeout="20000" acceptCount="300" maxThreads="300" maxProcessors="1000" minProcessors="5" useURIValidationHack="false" compression="on" compressionMinSize="2048" compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" SSLEnabled="true" scheme="https" secure="true" clientAuth="false" sslProtocol="TLS" keystoreFile="d:/tomcat2/conf/shnlap93.jks" keystorePass="aaaaaa" /> |
好了,所有的Tomcat优化的地方都加上了。结合第三天中的Apache的性能优化,我们这个架构可以“飞奔”起来了,当然这边把有提及任何关于数据库优化的步骤,但仅凭这两步,我们的系统已经有了很大的提升。
举个真实的例子:上一个项目,经过4轮performance testing,第一轮进行了问题的定位,第二轮就是进行了apache+tomcat/weblogic的优化,第三轮是做集群优化,第四轮是sql与codes的优化。
在到达第二轮时,我们的性能已经提升了多少倍呢?我们来看一个loaderrunner的截图吧:


左边第一列是第一轮没有经过任何调优的压力测试报告。
右边这一列是经过了apache优化,tomcat优化后得到的压力测试报告。
大家看看,这就提高了多少倍?这还只是在没有改动代码的情况下得到的改善,现在明白了好好的调优一个apache和tomcat其实是多么的重要了?如果加上后面的代码、SQL的调优、数据库的调优。。。。。。所以我在上一个工程中有单笔交易性能(无论是吞吐量、响应时间)提高了80倍这样的极端例子的存在。
转自:http://blog.csdn.net/lifetragedy/article/details/7708724
查看文件权限的语句: 在终端输入: ls -l xxx.xxx (xxx.xxx是文件名) 那么就会出现相类似的信息,主要都是这些: -rw-rw-r-- 一共有10位数 其中: 最前面那个 - 代表的是类型 中间那三个 rw- 代表的是所有者(user) 然后那三个 rw- 代表的是组群(group) 最后那三个 r-- 代表的是其他人(other) 然后我再解释一下后面那9位数: r 表示文件可以被读(read) w 表示文件可以被写(write) x 表示文件可以被执行(如果它是程序的话) - 表示相应的权限还没有被授予 现在该说说修改文件权限了 在终端输入: chmod o+w xxx.xxx 表示给其他人授予写xxx.xxx这个文件的权限 chmod go-rw xxx.xxx 表示删除xxx.xxx中组群和其他人的读和写的权限 其中: u 代表所有者(user) g 代表所有者所在的组群(group) o 代表其他人,但不是u和g (other) a 代表全部的人,也就是包括u,g和o r 表示文件可以被读(read) w 表示文件可以被写(write) x 表示文件可以被执行(如果它是程序的话) 其中:rwx也可以用数字来代替 r ------------4 w -----------2 x ------------1 - ------------0 行动: + 表示添加权限 - 表示删除权限 = 表示使之成为唯一的权限 当大家都明白了上面的东西之后,那么我们常见的以下的一些权限就很容易都明白了: -rw------- (600) 只有所有者才有读和写的权限 -rw-r--r-- (644) 只有所有者才有读和写的权限,组群和其他人只有读的权限 -rwx------ (700) 只有所有者才有读,写,执行的权限 -rwxr-xr-x (755) 只有所有者才有读,写,执行的权限,组群和其他人只有读和执行的权限 -rwx--x--x (711) 只有所有者才有读,写,执行的权限,组群和其他人只有执行的权限 -rw-rw-rw- (666) 每个人都有读写的权限 -rwxrwxrwx (777) 每个人都有读写和执行的权限
问题解决,解决方法如下:以secureCRT为例,菜单:选项-->会话选项...-->(类别)终端->外观-->字符编码,选择UTF-8,然后确定。。。
安装和设置 OpenSSH Server: sudo apt-get install openssh-server
然后确认sshserver是否启动了: ps -e |grep ssh
如果看到sshd那说明ssh-server已经启动了。
如果没有则可以这样启动: sudo /etc/init.d/ssh start
ssh-server配置文件位于/ etc/ssh/sshd_config
在这里可以定义SSH的服务端口,默认端口是22,你可以自己定义成其他端口号,如222。
然后重启SSH服务:
sudo /etc/init.d/ssh stop
sudo /etc/init.d/ssh start
然后通过Xshell等软件连接。Name为新建连接的名称,选择协议类型(Protocol)为“SSH”,Host为服务器的IP地址,端口(Port Number)为SSH协议的连接端口(默认为22),其他选项按照默认设置。
我在ubuntu12.04系统实际操作中执行了sudo apt-get install openssh-server之后按照提示安装成功。之后直接ssh localhost成功,然后外部机器就可以直接ssh过来了
1.启动Rad Hat 9.0(图形界面方式登陆),并且以管理员的身份登陆。不用管理员身份不能安装。2.在VMware虚拟机的菜单中点击:虚拟机->安装VMware 工具->install。3.Red Hat 9.0自动挂载VMware Tools的虚拟光驱,并显示在桌面。4.进去VMware Tools的虚拟光驱里,把VMwareTools-5.5.1-19175.tar.gz复制到/tmp目录。5.进去/tmp目录,把VMwareTools-5.5.1-19175.tar.gz解压到当前目录下的一个文件夹中(VMwareTools-5文件夹)。6.同时按住Ctrl+Alt+F1三个键,进入字符界面,并以root身份登陆。7.输入以下命令:cp /tmp/VMwareTools-5/vmware-tools-distrib(进入vmware-tools-distrib目录)。8.输入:./vmware-install.pl(执行vmware-install.pl文件)。9.然后一路“回车”,能yes的就yes,就OK。10. 输入reboot命令(重新启动)。11.大功告成。
安装完Ubuntu后忽然意识到没有设置root密码,不知道密码自然就无法进入根用户下。到网上搜了一下,原来是这麽回事。Ubuntu的默认root密码是随机的,即每次开机都有一个新的root密码。我们可以在终端输入命令 sudo passwd,然后输入当前用户的密码,enter,终端会提示我们输入新的密码并确认,此时的密码就是root新密码。修改成功后,输入命令 su root,再输入新的密码就ok了。
摘要: 博客分类: 开发安全框架Shiro 授权即访问控制,它将判断用户在应用程序中对资源是否拥有相应的访问权限。 如,判断一个用户有查看页面的权限,编辑数据的权限,拥有某一按钮的权限,以及是否拥有打印的权限等等。 一、授权的三要素 授权有着三个核心元素:权限、角色和用户。 权限 权限是Apache Shiro安全机制最核心的元素。它在...
阅读全文
mysql-bin文件是数据库的操作日志,例如UPDATE一个表,或者DELETE一些数据,即使该语句没有匹配的数据,这个命令也会存储到日志文件中,还包括每个语句执行的时间,也会记录进去的。
这样做主要有以下两个目的:1:数据恢复:如果你的数据库出问题了,而你之前有过备份,那么可以看日志文件,找出是哪个命令导致你的数据库出问题了,想办法挽回损失。2:主从服务器之间同步数据 主服务器上所有的操作都在记录日志中,从服务器可以根据该日志来进行,以确保两个同步。处理方法分两种情况:
1:只有一个mysql服务器,那么可以简单的注释掉这个选项就行了。
vi /etc/my.cnf把里面的log-bin这一行注释掉,重启mysql服务即可。
2:如果你的环境是主从服务器,那么就需要做以下操作了。
A:在每个从属服务器上,使用SHOW SLAVE STATUS来检查它正在读取哪个日志。
B:使用SHOW MASTER LOGS获得主服务器上的一系列日志。
C:在所有的从属服务器中判定最早的日志,这个是目标日志,如果所有的从属服务器是更新的,就是清单上的最后一个日志。
D:清理所有的日志,但是不包括目标日志,因为从服务器还要跟它同步。
清理日志方法为:
PURGE MASTER LOGS TO 'mysql-bin.010';
PURGE MASTER LOGS BEFORE '2008-12-19 21:00:00';
如果你确定从服务器已经同步过了,跟主服务器一样了,那么可以直接RESET MASTER将这些文件删除。
查看mysql关于mysql-bin的配置
show variables like '%max_binlog_size%'
max_binlog_size 1073741824 默认大小为1G
但是mysql-bin文件过多会占用大量的磁盘空间,所以要对日志文件进行清理,方法如下:
1、
禁止方法: vi /etc/my.cnf把里面的#log-bin=mysql-bin注释掉,重启mysql服务即可.2、mysql> reset master;或flush logs; (清除日志文件)3、mysql> set global expire_logs_days=2;只保留两天的mysql-bin日志4、删除ablelee.000003之前的而没有包含ablelee.000003
mysql> purge binary logs to 'ablelee.000003';
当磁盘大小超过标准时会有报警提示,这时如果掌握df和du命令是非常明智的选择。
df可以查看一级文件夹大小、使用比例、档案系统及其挂入点,但对文件却无能为力。
du可以查看文件及文件夹的大小。
两者配合使用,非常有效。比如用df查看哪个一级目录过大,然后用df查看文件夹或文件的大小,如此便可迅速确定症结。
下面分别简要介绍
df命令可以显示目前所有文件系统的可用空间及使用情形,请看下列这个例子:
以下是代码片段: [yayug@yayu ~]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 3.9G 300M 3.4G 8% /
/dev/sda7 100G 188M 95G 1% /data0
/dev/sdb1 133G 80G 47G 64% /data1
/dev/sda6 7.8G 218M 7.2G 3% /var
/dev/sda5 7.8G 166M 7.2G 3% /tmp
/dev/sda3 9.7G 2.5G 6.8G 27% /usr
tmpfs 2.0G 0 2.0G 0% /dev/shm |
参数 -h 表示使用「Human-readable」的输出,也就是在档案系统大小使用 GB、MB 等易读的格式。
上面的命令输出的第一个字段(Filesystem)及最后一个字段(Mounted on)分别是档案系统及其挂入点。我们可以看到 /dev/sda1 这个分割区被挂在根目录下。
接下来的四个字段 Size、Used、Avail、及 Use% 分别是该分割区的容量、已使用的大小、剩下的大小、及使用的百分比。 FreeBSD下,当硬盘容量已满时,您可能会看到已使用的百分比超过 100%,因为 FreeBSD 会留一些空间给 root,让 root 在档案系统满时,还是可以写东西到该档案系统中,以进行管理。
du:查询文件或文件夹的磁盘使用空间
如果当前目录下文件和文件夹很多,使用不带参数du的命令,可以循环列出所有文件和文件夹所使用的空间。这对查看究竟是那个地方过大是不利的,所以得指定深入目录的层数,参数:--max-depth=,这是个极为有用的参数!如下,注意使用“*”,可以得到文件的使用空间大小.
提醒:一向命令比linux复杂的FreeBSD,它的du命令指定深入目录的层数却是比linux简化,为 -d。
以下是代码片段: [root@bsso yayu]# du -h --max-depth=1 work/testing
27M work/testing/logs
35M work/testing [root@bsso yayu]# du -h --max-depth=1 work/testing/*
8.0K work/testing/func.php
27M work/testing/logs
8.1M work/testing/nohup.out
8.0K work/testing/testing_c.php
12K work/testing/testing_func_reg.php
8.0K work/testing/testing_get.php
8.0K work/testing/testing_g.php
8.0K work/testing/var.php [root@bsso yayu]# du -h --max-depth=1 work/testing/logs/
27M work/testing/logs/ [root@bsso yayu]# du -h --max-depth=1 work/testing/logs/*
24K work/testing/logs/errdate.log_show.log
8.0K work/testing/logs/pertime_show.log
27M work/testing/logs/show.log |
值得注意的是,看见一个针对du和df命令异同的文章:《du df 差异导致文件系统误报解决》。
du 统计文件大小相加
df 统计数据块使用情况
如果有一个进程在打开一个大文件的时候,这个大文件直接被rm 或者mv掉,则du会更新统计数值,df不会更新统计数值,还是认为空间没有释放。直到这个打开大文件的进程被Kill掉。
如此一来在定期删除 /var/spool/clientmqueue下面的文件时,如果没有杀掉其进程,那么空间一直没有释放。
使用下面的命令杀掉进程之后,系统恢复。
fuser -u /var/spool/clientmqueue
http://www.yayu.org/look.php?id=162
查看linux文件目录的大小和文件夹包含的文件数
统计总数大小
du -sh xmldb/
du -sm * | sort -n //统计当前目录大小 并安大小 排序
du -sk * | sort -n
du -sk * | grep guojf //看一个人的大小
du -m | cut -d "/" -f 2 //看第二个/ 字符前的文字
查看此文件夹有多少文件 /*/*/* 有多少文件
du xmldb/
du xmldb/*/*/* |wc -l
40752
解释:
wc [-lmw]
参数说明:
-l :多少行
-m:多少字符
-w:多少字
http://linux.chinaitlab.com/command/734706.html
Linux:ls以K、M、G为单位查看文件大小
#man ls
……
-h, --human-readable
print sizes in human readable format (e.g., 1K 234M 2G)
……
# ls
cuss.war nohup.out
# ls -l
total 30372
-rw-r--r-- 1 root root 31051909 May 24 10:07 cuss.war
-rw------- 1 root root 0 Mar 20 13:52 nohup.out
# ls -lh
total 30M
-rw-r--r-- 1 root root 30M May 24 10:07 cuss.war
-rw------- 1 root root 0 Mar 20 13:52 nohup.out
# ll -h
total 30M
-rw-r--r-- 1 root root 30M May 24 10:07 cuss.war
-rw------- 1 root root 0 Mar 20 13:52 nohup.out
碰到问题先别急,按下面的思路去套,先一步步地定位问题、细化问题。
千万别在论坛、群里问,我的机器好慢怎么回事?我的机器内存泄露了怎么回事?
这类大而空的问题一点意义都没有,其实谁都不知道。你要做的是用下面的思路、方法、工具去定位它
------------------------------
解决问题思路
Java程序问题(运行慢)
先通过 top 查看整个CPU资源使用情况;
通过top -Hp pid查看java进程的每一个线程占用CPU的情况;
如果有一个线程占用CPU过高,有两种可能:
没有内存了,Java垃圾回收线程不停地运行尝试回收内存,但是每次无法收回,确认:
jstat -gcutil pid 1s 观察10多秒钟就能发现了,看是不是内存使用率接近100%了
类似于死循环(hash冲突攻击),就是一个线程一直占用一个核的所有CPU资源(其实一个线程总是暂用一个核超过50%的资源都是不太正常的),解决:
用我课堂的checkPerf脚本,定位这个线程具体执行的任务(能具体到某一行),对应看代码解决。
如果有很多线程,每个线程占用的CPU都不多,那基本是正常的。
如果死锁:
jstack -l pid 多执行几次,统计一下stack中总是在等待哪些锁,可以对锁id进行排序统计(sort uniq grep)
上面列出来的都是明显的瓶颈,最可怕的是哪里都没有明显的瓶颈,哪里都要偷一点点资源走,这是可以试试JProfiler这样更专业一点的工具,同时要配合自己对业务的了解来解决。
Java内存的问题,如果有内存泄露(就是执行完fgc/old gc后不能回收的内存不断地增加):
快速解决:jmap -histo:live pid 来统计所有对象的个数(String/char/Integer/HashEntry 这样的对象很多很正常,主要是盯着你们公司的包名下的那些对象)
每隔一分钟执行一次上面的命令,执行5次以上,看看你们公司报名下的对象数量哪个在一直增加,那基本上就是这个对象引起了泄露;
用课堂上的工具HouseMD来动态监控创建这个对象的地方(一般来说很多时候创建了这些对象把他们丢到一个HashMap然后就不管了),分析一下有没有释放!
上面的方法实在没法定位就用: jmap -dump 导出整个内存(耗时间,需要很大的内存的机器才能对这个导出文件进行分析,会将JVM锁住一段时间)
在Eclipse的插件EMA中打开这个文件(2G的物理文件需要4G以上的内存,5G以上的需要将近20G的内存来分析了)
盯着你们公司报名的那些对象,看看引用关系,谁拿着这些对象没释放(是否是必要的)
MySQL 数据库的性能问题
大部分情况下是磁盘IO的问题(索引没建好、查询太复杂);
索引问题的话分析慢查询日志,explain 他们挨个解决。
偶尔也有数据库CPU不够的情况,如果并发高CPU不够很正常,如果并发不高,那很可能就是group by/order by/random之类的操作严重消耗了数据库的CPU
mysql -e "show full processlist" | grep -v Sleep | sort -rnk6 查看那些SQL语句执行的太长
拿出这个SQL语句分析他们的执行计划: explain SQL 然后改进;
分析慢查询日志,统计top10性能杀手的语句,挨个explain他们,然后改进(具体改进办法具体分析,这里只谈思路)
总结一下数据库问题就只有这三招:show full processlist/分析慢查询日志/explain(然后建好联合索引)
mysql:http:x//mirrors.sohu.com/mysql/MySQL-5.5/mysql-5.5.14.tar.gz
cmake:http://www.cmake.org/cmake/resources/software.html
首先要安装cmake
#tar zxf cmake-2.8.5.tar.gz
#cd cmake-2.8.5
#./bootstrap
#make
#make install
依据源码安装mysql
useradd mysql
tar zxf mysql-5.5.14.tar.g
cd mysql-5.5.14
CFLAGS="-O3" CXX=gcc
CXXFLAGS="-O3 -felide-constructors -fno-exceptions -fno-rtti"
cmake . -LH|more //CMake下查看MySQL的编译配置
/usr/local/bin/cmake -DCMAKE_INSTALL_PREFIX=/opt/mysql \
-DMYSQL_UNIX_ADDR=/opt/mysql/mysql.sock \
-DDEFAULT_CHARSET=utf8 \
-DDEFAULT_COLLATION=utf8_general_ci \
-DWITH_EXTRA_CHARSETS=all \
-DWITH_MYISAM_STORAGE_ENGINE=1 \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DWITH_READLINE=1 \
-DENABLED_LOCAL_INFILE=1 \
-DMYSQL_DATADIR=/opt/mysql/data \
-DMYSQL_TCP_PORT=3306 \
make; make install
cd /opt
chown -R mysql:mysql mysql
cd /opt/mysql
chmod 777 data
./scripts/mysql_install_db
./scripts/mysql_install_db --user=mysql --datadir=/opt/mysql/data
update mysql.user set password=PASSWORD('1234') where User='root';
flush privileges;
show variables like 'character_set_%'; 字符集查看
redhat需要装的库
yum -y install patch make gcc gcc-c++ gcc-g77 flex bison file
yum -y install libtool libtool-libs autoconf kernel-devel
yum -y install libjpeg libjpeg-devel libpng libpng-devel libpng10 libpng10-devel gd gd-devel
yum -y install freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel
yum -y install glib2 glib2-devel bzip2 bzip2-devel libevent libevent-devel
yum -y install ncurses ncurses-devel curl curl-devel e2fsprogs
yum -y install e2fsprogs-devel krb5 krb5-devel libidn libidn-devel
yum -y install openssl openssl-devel vim-minimal nano sendmail
yum -y install fonts-chinese gettext gettext-devel
yum -y install ncurses-devel
yum -y install gmp-devel pspell-devel
yum -y install unzip
注意:如果忘记先安装库,在cmake的时候报错了,得先把库安装一遍,然后删除/opt/mysql-5.6.21/CMakeCache.txt重新cmake一遍就行了.
mysql刚刚装好root初始密码是空的,直接回车就行了
修改授权以便远程机器能够访问
在安装mysql的机器上运行:
1、d:\mysql\bin\>mysql -h localhost -u root //这样应该可以进入MySQL服务器
2、mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION //赋予任何主机访问数据的权限
3、mysql>FLUSH PRIVILEGES //修改生效
4、mysql>EXIT //退出MySQL服务器
众所周知,Spring的事务控制是基于AOP来实现的,一个声明了事务管理的方法(如某个Service的方法)在执行时会被拦截,拦截时执行的“附加”操作集中在:
org.springframework.transaction.interceptor.TransactionInterceptor.invoke(MethodInvocation)
作为一个环绕切面,该方法主要负责在目标方法执行前开始一个事务,在方法执行结束后提交事务。

我们先来深入了解一下事务是如何创建的。从方法createTransactionIfNecessary()上可以看到,创建事务的主要方法是:
org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(TransactionDefinition)
作为抽象类的方法,getTransaction()只处理了一些通用性的检查和设置,实质性的创建事务和开启事务操作都是通过分别调用抽象方法:
org.springframework.transaction.support.AbstractPlatformTransactionManager.doGetTransaction()
和
org.springframework.transaction.support.AbstractPlatformTransactionManager.doBegin(Object,TransactionDefinition)
来完成的,也就是说这些关键性的工作必须由各具体事务管理器来实现,对于hibernate的事务管理器来说,获取事务对象的方法如下:

开始事务的方法如下:

以上是关于事务开始部分的代码,下面我们来看一下事务提交时的代码:
同样的,从方法commitTransactionAfterReturning()我们可以看出执行事务提交的方法主要通过回调
org.springframework.orm.hibernate3.HibernateTransactionManager.doCommit(DefaultTransactionStatus)
来实现的。

补充:
关于方法
org.springframework.transaction.support.TransactionSynchronizationManager.getResource(Object key)
如该方法的注释所说,它主要是通过给定的key找到对应的资源,特别之处是这些资源实例是绑定在线程上的,也就是spring保证一个线程上一个key对应一个资源实例,不同的线程上绑定的是不同的资源实例。对应到Hibernate上来说,key是sessionFactory,资源是sessionHolder!
作者:bluishglc
转自:
http://www.2cto.com/kf/201207/142772.html
摘要: 借助与spring AOP,spring提供了强大的基于声明式事务管理方式,它很好对事务管理代码和具体业务逻辑进行了解藕,使我们在coding过程不要去关心事务管理的逻辑。下面我们借助一个例子来将分析spring内部的实现。1. 例子1.1 datasource配置[html] view plaincopyprint? <bean id="dataS...
阅读全文
基于合理的数据库设计,经过深思熟虑后为表建立索引,是获得高性能数据库系统的基础。而未经合理分析便添加索引,则会降低系统的总体性能。索引虽然说提高了数据的访问速度,但同时也增加了插入、更新和删除操作的处理时间。
是否要为表增加索引、索引建立在那些字段上,是创建索引前必须要考虑的问题。解决此问题的一个比较好的方法,就是分析应用程序的业务处理、数据使用,为经常被用作查询条件、或者被要求排序的字段建立索引。基于优化器对SQL语句的优化处理,我们在创建索引时可以遵循下面的一般性原则:
(1)为经常出现在关键字order by、group by、distinct后面的字段,建立索引。
在这些字段上建立索引,可以有效地避免排序操作。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。
(2)在union等集合操作的结果集字段上,建立索引。其建立索引的目的同上。
(3)为经常用作查询选择的字段,建立索引。
(4)在经常用作表连接的属性上,建立索引。
(5)考虑使用索引覆盖。对数据很少被更新的表,如果用户经常只查询其中的几个字段,可以考虑在这几个字段上建立索引,从而将表的扫描改变为索引的扫描。
除了以上原则,在创建索引时,我们还应当注意以下的限制:
(1)限制表上的索引数目。
对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作。
(2)不要在有大量相同取值的字段上,建立索引。
在这样的字段(例如:性别)上建立索引,字段作为选择条件时将返回大量满足条件的记录,优化器不会使用该索引作为访问路径。
(3)避免在取值朝一个方向增长的字段(例如:日期类型的字段)上,建立索引;对复合索引,避免将这种类型的字段放置在最前面。
由于字段的取值总是朝一个方向增长,新记录总是存放在索引的最后一个叶页中,从而不断地引起该叶页的访问竞争、新叶页的分配、中间分支页的拆分。此外,如果所建索引是聚集索引,表中数据按照索引的排列顺序存放,所有的插入操作都集中在最后一个数据页上进行,从而引起插入“热点”。
(4)对复合索引,按照字段在查询条件中出现的频度建立索引。
在复合索引中,记录首先按照第一个字段排序。对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用。
因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能地使用此索引,发挥索引的作用。
(5)删除不再使用,或者很少被使用的索引。
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再被需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
转自http://www.cnblogs.com/xuhan/archive/2011/07/25/2116156.html
转自:http://www.blogjava.net/cenwenchu/archive/2008/06/30/211712.html
SIP的第四期结束了,因为控制策略的丰富,早先的的压力测试结果已经无法反映在高并发和高压力下SIP的运行状况,因此需要重新作压力测试。跟在测试人员后面做了快一周的压力测试,压力测试的报告也正式出炉,本来也就算是告一段落,但第二天测试人员说要修改报告,由于这次作压力测试的同学是第一次作,有一个指标没有注意,因此需要修改几个测试结果。那个没有注意的指标就是load average,他和我一样开始只是注意了CPU,内存的使用状况,而没有太注意这个指标,这个指标与他们通常的限制(10左右)有差别。重新测试的结果由于这个指标被要求压低,最后的报告显然不如原来的好看。自己也没有深入过压力测试,但是觉得不搞明白对将来机器配置和扩容都会有影响,因此去问了DBA和SA,得到的结果相差很大,看来不得不自己去找找问题的根本所在了。
通过下面的几个部分的了解,可以一步一步的找出Load Average在压力测试中真正的作用。
CPU时间片
为了提高程序执行效率,大家在很多应用中都采用了多线程模式,这样可以将原来的序列化执行变为并行执行,任务的分解以及并行执行能够极大地提高程序的运行效率。但这都是代码级别的表现,而硬件是如何支持的呢?那就要靠CPU的时间片模式来说明这一切。程序的任何指令的执行往往都会要竞争CPU这个最宝贵的资源,不论你的程序分成了多少个线程去执行不同的任务,他们都必须排队等待获取这个资源来计算和处理命令。先看看单CPU的情况。下面两图描述了时间片模式和非时间片模式下的线程执行的情况:
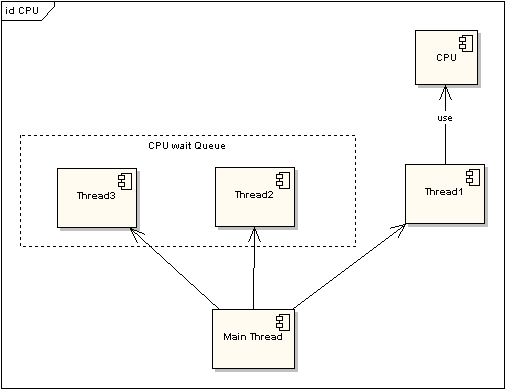
图 1 非时间片线程执行情况
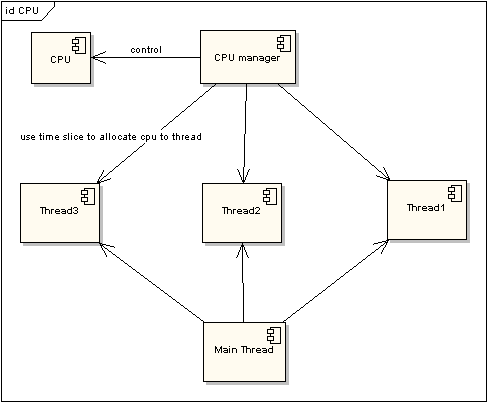
图 2 非时间片线程执行情况
在图一中可以看到,任何线程如果都排队等待CPU资源的获取,那么所谓的多线程就没有任何实际意义。图二中的CPU Manager只是我虚拟的一个角色,由它来分配和管理CPU的使用状况,此时多线程将会在运行过程中都有机会得到CPU资源,也真正实现了在单CPU的情况下实现多线程并行处理。
多CPU的情况只是单CPU的扩展,当所有的CPU都满负荷运作的时候,就会对每一个CPU采用时间片的方式来提高效率。
在Linux的内核处理过程中,每一个进程默认会有一个固定的时间片来执行命令(默认为1/100秒),这段时间内进程被分配到CPU,然后独占使用。如果使用完,同时未到时间片的规定时间,那么就主动放弃CPU的占用,如果到时间片尚未完成工作,那么CPU的使用权也会被收回,进程将会被中断挂起等待下一个时间片。
CPU利用率和Load Average的区别
压力测试不仅需要对业务场景的并发用户等压力参数作模拟,同时也需要在压力测试过程中随时关注机器的性能情况,来确保压力测试的有效性。当服务器长期处于一种超负荷的情况下运行,所能接收的压力并不是我们所认为的可接受的压力。就好比项目经理在给一个人估工作量的时候,每天都让这个人工作12个小时,那么所制定的项目计划就不是一个合理的计划,那个人迟早会垮掉,而影响整体的项目进度。
CPU利用率在过去常常被我们这些外行认为是判断机器是否已经到了满负荷的一个标准,看到50%-60%的使用率就认为机器就已经压到了临界了。CPU利用率,顾名思义就是对于CPU的使用状况,这是对一个时间段内CPU使用状况的统计,通过这个指标可以看出在某一个时间段内CPU被占用的情况,如果被占用时间很高,那么就需要考虑CPU是否已经处于超负荷运作,长期超负荷运作对于机器本身来说是一种损害,因此必须将CPU的利用率控制在一定的比例下,以保证机器的正常运作。
Load Average是CPU的Load,它所包含的信息不是CPU的使用率状况,而是在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。为什么要统计这个信息,这个信息的对于压力测试的影响究竟是怎么样的,那就通过一个类比来解释CPU利用率和Load Average的区别以及对于压力测试的指导意义。
我们将CPU就类比为电话亭,每一个进程都是一个需要打电话的人。现在一共有4个电话亭(就好比我们的机器有4核),有10个人需要打电话。现在使用电话的规则是管理员会按照顺序给每一个人轮流分配1分钟的使用电话时间,如果使用者在1分钟内使用完毕,那么可以立刻将电话使用权返还给管理员,如果到了1分钟电话使用者还没有使用完毕,那么需要重新排队,等待再次分配使用。
图 3 电话使用场景
上图中对于使用电话的用户又作了一次分类,1min的代表这些使用者占用电话时间小于等于1min,2min表示使用者占用电话时间小于等于2min,以此类推。根据电话使用规则,1min的用户只需要得到一次分配即可完成通话,而其他两类用户需要排队两次到三次。
电话的利用率 = sum (active use cpu time)/period
每一个分配到电话的使用者使用电话时间的总和去除以统计的时间段。这里需要注意的是是使用电话的时间总和(sum(active use cpu time)),这与占用时间的总和(sum(occupy cpu time))是有区别的。(例如一个用户得到了一分钟的使用权,在10秒钟内打了电话,然后去查询号码本花了20秒钟,再用剩下的30秒打了另一个电话,那么占用了电话1分钟,实际只是使用了40秒)
电话的Average Load体现的是在某一统计时间段内,所有使用电话的人加上等待电话分配的人一个平均统计。
电话利用率的统计能够反映的是电话被使用的情况,当电话长期处于被使用而没有的到足够的时间休息间歇,那么对于电话硬件来说是一种超负荷的运作,需要调整使用频度。而电话Average Load却从另一个角度来展现对于电话使用状态的描述,Average Load越高说明对于电话资源的竞争越激烈,电话资源比较短缺。对于资源的申请和维护其实也是需要很大的成本,所以在这种高Average Load的情况下电话资源的长期“热竞争”也是对于硬件的一种损害。
低利用率的情况下是否会有高Load Average的情况产生呢?理解占有时间和使用时间就可以知道,当分配时间片以后,是否使用完全取决于使用者,因此完全可能出现低利用率高Load Average的情况。由此来看,仅仅从CPU的使用率来判断CPU是否处于一种超负荷的工作状态还是不够的,必须结合Load Average来全局的看CPU的使用情况和申请情况。
所以回过头来再看测试部对于Load Average的要求,在我们机器为8个CPU的情况下,控制在10 Load左右,也就是每一个CPU正在处理一个请求,同时还有2个在等待处理。看了看网上很多人的介绍一般来说Load简单的计算就是2* CPU个数减去1-2左右(这个只是网上看来的,未必是一个标准)。
补充几点:
1.对于CPU利用率和CPU Load Average的结果来判断性能问题。首先低CPU利用率不表明CPU不是瓶颈,竞争CPU的队列长期保持较长也是CPU超负荷的一种表现。对于应用来说可能会去花时间在I/O,Socket等方面,那么可以考虑是否后这些硬件的速度影响了整体的效率。
这里最好的样板范例就是我在测试中发现的一个现象:SIP当前在处理过程中,为了提高处理效率,将控制策略以及计数信息都放置在Memcached Cache里面,当我将Memcached Cache配置扩容一倍以后,CPU的利用率以及Load都有所下降,其实也就是在处理任务的过程中,等待Socket的返回对于CPU的竞争也产生了影响。
2.未来多CPU编程的重要性。现在服务器的CPU都是多CPU了,我们的服务器处理能力已经不再按照摩尔定律来发展。就我上面提到的电话亭场景来看,对于三种不同时间需求的用户来说,采用不同的分配顺序,我们可看到的Load Average就会有不同。假设我们统计Load的时间段为2分钟,如果将电话分配的顺序按照:1min的用户,2min的用户,3min的用户来分配,那么我们的Load Average将会最低,采用其他顺序将会有不同的结果。所以未来的多CPU编程可以更好的提高CPU的利用率,让程序跑的更快。
load Average
1.1:什么是Load?什么是Load Average?
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)
简单的说是进程队列的长度。Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load。【参考文章:unix Load Average Part1:How It Works】
1.2:查看指令:
w or uptime or procinfo or top
load average: 0.02, 0.27, 0.17
1 per/minute 5 per/minute 15 per/minute
1.3:如何判断系统是否已经Over Load?
对一般的系统来说,根据cpu数量去判断。如果平均负载始终在1.2一下,而你有2颗cup的机器。那么基本不会出现cpu不够用的情况。也就是Load平均要小于Cpu的数量
1.4:Load与容量规划(Capacity Planning)
一般是会根据15分钟那个load 平均值为首先。
1.5:Load误解:
1:系统load高一定是性能有问题。
真相:Load高也许是因为在进行cpu密集型的计算
2:系统Load高一定是CPU能力问题或数量不够。
真相:Load高只是代表需要运行的队列累计过多了。但队列中的任务实际可能是耗Cpu的,也可能是耗i/0奶子其他因素的。
3:系统长期Load高,首先增加CPU
真相:Load只是表象,不是实质。增加CPU个别情况下会临时看到Load下降,但治标不治本。
2:在Load average 高的情况下如何鉴别系统瓶颈。
是CPU不足,还是io不够快造成或是内存不足?
2.1:查看系统负载vmstat
Vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 100152 2436 97200 289740 0 1 34 45 99 33 0 0 99 0
procs
r 列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
cpu 表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比
system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
memory
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si 由内存进入内存交换区数量。
so由内存交换区进入内存数量。
IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
2.2:查看磁盘负载iostat
每隔2秒统计一次磁盘IO信息,直到按Ctrl+C终止程序,-d 选项表示统计磁盘信息, -k 表示以每秒KB的形式显示,-t 要求打印出时间信息,2 表示每隔 2 秒输出一次。第一次输出的磁盘IO负载状况提供了关于自从系统启动以来的统计信息。随后的每一次输出则是每个间隔之间的平均IO负载状况。
# iostat -x 1 10
Linux 2.6.18-92.el5xen 02/03/2009
avg-cpu: %user %nice %system %iowait %steal %idle
1.10 0.00 4.82 39.54 0.07 54.46
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 3.50 0.40 2.50 5.60 48.00 18.48 0.00 0.97 0.97 0.28
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sde 0.00 0.10 0.30 0.20 2.40 2.40 9.60 0.00 1.60 1.60 0.08
sdf 17.40 0.50 102.00 0.20 12095.20 5.60 118.40 0.70 6.81 2.09 21.36
sdg 232.40 1.90 379.70 0.50 76451.20 19.20 201.13 4.94 13.78 2.45 93.16
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘
可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait.
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
另外还可以参考
一般:
svctm < await (因为同时等待的请求的等待时间被重复计算了),
svctm的大小一般和磁盘性能有关:CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。
await: await的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。
如果 svctm 比较接近 await,说明I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明 I/O队列太长,应用得到的响应时间变慢,
如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
别人一个不错的例子.(I/O 系统 vs. 超市排队)
举一个例子,我们在超市排队 checkout 时,怎么决定该去哪个交款台呢? 首当是看排的队人数,5个人总比20人要快吧?除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈,那么可以考虑换个队排了。还有就是收银员的速度了,如果碰上了连钱都点不清楚的新手,那就有的等了。另外,时机也很重要,可能 5分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可是很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义(不过我还没发现什么事情比排队还无聊的)。
I/O 系统也和超市排队有很多类似之处:
r/s+w/s 类似于交款人的总数
平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
平均服务时间(svctm)类似于收银员的收款速度
平均等待时间(await)类似于平均每人的等待时间
平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
I/O 操作率 (%util)类似于收款台前有人排队的时间比例。
我们可以根据这些数据分析出 I/O 请求的模式,以及 I/O 的速度和响应时间。
下面是别人写的这个参数输出的分析
# iostat -x 1
avg-cpu: %user %nice %sys %idle
16.24 0.00 4.31 79.44
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/cciss/c0d0
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p1
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p2
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
上面的 iostat 输出表明秒有 28.57 次设备 I/O 操作: 总IO(io)/s = r/s(读) +w/s(写) = 1.02+27.55 = 28.57 (次/秒) 其中写操作占了主体 (w:r = 27:1)。
平均每次设备 I/O 操作只需要 5ms 就可以完成,但每个 I/O 请求却需要等上 78ms,为什么? 因为发出的 I/O 请求太多 (每秒钟约 29 个),假设这些请求是同时发出的,那么平均等待时间可以这样计算:
平均等待时间 = 单个 I/O 服务时间 * ( 1 + 2 + ... + 请求总数-1) / 请求总数
应用到上面的例子: 平均等待时间 = 5ms * (1+2+...+28)/29 = 70ms,和 iostat 给出的78ms 的平均等待时间很接近。这反过来表明 I/O 是同时发起的。
每秒发出的 I/O 请求很多 (约 29 个),平均队列却不长 (只有 2 个 左右),这表明这 29 个请求的到来并不均匀,大部分时间 I/O 是空闲的。
一秒中有 14.29% 的时间 I/O 队列中是有请求的,也就是说,85.71% 的时间里 I/O 系统无事可做,所有 29 个 I/O 请求都在142毫秒之内处理掉了。
delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s=78.21 * delta(io)/s = 78.21*28.57 =2232.8,表明每秒内的I/O请求总共需要等待2232.8ms。所以平均队列长度应为 2232.8ms/1000ms = 2.23,而iostat 给出的平均队列长度 (avgqu-sz) 却为 22.35,为什么?! 因为 iostat 中有 bug,avgqu-sz值应为 2.23,而不是 22.35。
摘要: 转自:http://zmx.iteye.com/blog/583482Struts2 + JasperReport应用一:导PDF,Excel,HTML显示博客分类: Struts2HTMLExcelStrutsServletXML 我用的是struts2.1.6,从struts2的自带的demo当中可以看到它的web.xml配置与之前的有点不同,有另外一种配置:Xml代码&n...
阅读全文
哈哈!这个问题在我们公司也发生过。经过几天研究终于搞定。
c3p0的connection实现类和我们想象中有出入,最大的出入就是c3p0的connection实现类的close方法不是真的将该链接释放掉,而是将这个链接回收到可用连接池中。于是问题就来了。
c3p0的有一个maxConnection的参数,即最多链接数。还有一个genratNum,即当链接不够用的时候自动每次生成链接的个数。假如将最大连接数设定为50,每次增长数设定为10,初始值为10。假如当前总共产生的链接数已经有49个,但是这49个链接不是可用连接数,那么c3p0就会增长10个。这样一共就产生了59个。
假如你设定最大空闲时间又过长,如一个月,那么就是被close的链接,也不会被释放掉,一直保留链接池中。
所以很快c3p0就将数据库的链接用完。
解决办法是:
1. 在代码中当创建了一个connection(或者从池中取),必须在要在合适的时机将该链接close掉。
2. 合理配置最大连接数,最大空闲时间,每次增长数
3. 可以通过实行ConnectionCustomer接口,来显式的对链接进行关闭,释放资源的操作。
4. 第一点是最重要的,后两点是辅助的。
转自:http://www.oschina.net/question/242388_40477
P6SPY +SQL Profiler 监控JAVAEE SQL
一般大型的javaEE项目开发周期较长,架构,业务逻辑,代码正确性,安全性直接影响着系统的整体性能。由于研发人员技术参差不齐,切人员流动性强,一般大型项目中存在诸多不确定性。要想避免项目后期出现重大变动,失误,不给系统造成严重影响,就要从项目的初期,从代码,注释,对细节严格把控。作为研发人员当然要对自己严格要求,失误最小化。下面介绍一下如果利p6spy ,sql profiler 监控javaEE sql ,至于如何分析sql,如果修改,由于本人对于sql 了解不多,不加追述,当然我也会写,但是仅是写一些简单的。
1)下载p6spy 和sql profiler
2) 将p6spy-install.jar sqlprofiler-0.3-bin中的sqlprofiler.jar 放到项目的lib中
3)将sqlprofiler-0.3-bin中的spy.properties 放到web项目的classes中 ,和tomcat的bin目录中
同时修改spy.properties 中的realdriver=oracle.jdbc.driver.OracleDriver(系统数据库的驱动)
4)将系统的数据源配置文件中的<driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
修改为:<driver-class>com.p6spy.engine.spy.P6SpyDriver</driver-class>
5)java -jar sqlprofiler.jar(是放到系统lib中的那个jar包)
D:\Program Files\Java\jdk1.5.0_17\bin>java -jar D:\nm\NetMessageCDE_BJ_CM\WEB-INF\lib\sqlprofiler.jar
cmd 日志

出现如下试图

6)启系统后,进行操作,sql profiler 出现sql跟踪记录

具体如何使用 sql profler ,上网可以搜一下,东西很多!
1、定义ehcache
<bean id="cacheManager" class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean">
<property name="configLocation" value="classpath:conf/spring/spring_ehcache.xml" />
</bean>
2、在spring中联合oscache
<bean id="cacheFilterBean" class="com.ebizer.framework.core.filter.CacheFilter">
<property name="cacheUris">
<list>
<!--
<value>/index.html</value>
<value>/trend.html</value>
<value>/trend/newest.html</value>
-->
</list>
</property>
</bean>
3、定义ehcache的方法
<!-- Remove the following 3 beans to disable method level data cache -->
<bean id="methodCache" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager" />
<property name="cacheName" value="METHOD_CACHE" />
</bean>
<bean id="methodCacheLong" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager" />
<property name="cacheName" value="METHOD_CACHE_LONG" />
</bean>
<bean id="methodCacheViewHot" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager" />
<property name="cacheName" value="METHOD_CACHE_VIEW_HOT_MATCH_ITEM" />
</bean>
<bean id="methodCacheIndex" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager" />
<property name="cacheName" value="METHOD_CACHE_INDEX" />
</bean>
<bean id="methodCacheInterceptorIndex" class="com.ebizer.framework.core.interceptor.MethodCacheInterceptor">
<property name="cache" ref="methodCacheIndex" />
</bean>
<bean id="methodCacheInterceptor" class="com.ebizer.framework.core.interceptor.MethodCacheInterceptor">
<property name="cache" ref="methodCache" />
</bean>
<bean id="methodCacheInterceptorLong" class="com.ebizer.framework.core.interceptor.MethodCacheInterceptor">
<property name="cache" ref="methodCacheLong" />
</bean>
<bean id="methodCacheInterceptorViewHot" class="com.ebizer.framework.core.interceptor.MethodCacheInterceptor">
<property name="cache" ref="methodCacheViewHot" />
</bean>
<bean id="methodCacheAdvisorTemplate" abstract="true" class="org.springframework.aop.support.NameMatchMethodPointcutAdvisor">
<property name="advice" ref="methodCacheInterceptor" />
</bean>
<bean id="methodCacheAdvisorTemplateLong" abstract="true" class="org.springframework.aop.support.NameMatchMethodPointcutAdvisor">
<property name="advice" ref="methodCacheInterceptorLong" />
</bean>
<bean id="methodCacheAdvisorTemplateViewHot" abstract="true" class="org.springframework.aop.support.NameMatchMethodPointcutAdvisor">
<property name="advice" ref="methodCacheInterceptorViewHot" />
</bean>
摘要: 一、因情制宜,建立“适当”的索引 建立“适当”的索引是实现查询优化的首要前提。 索引(index)是除表之外另一重要的、用户定义的存储在物理介质上的数据结构。当根据索引码的值搜索数据时,索引提供了对数据的快速访问。事实上,没有索引,数据库也能根据SELECT语句成功地检索到结果,但随着表变得越来越大,使用“适当R...
阅读全文
2012年6月23日
今天追踪一个关于页面内存暴涨,页面响应过慢的问题。花了4个多小时,总算找到问题出在哪了。
一、问题描述
最近我们在一台独享服务器上搭建了Tomcat6.0.19环境,发现访问首页时,内存暴涨,一直不退。每次刷新内存增加近10M。一个人狂刷新一分钟就可以把tomcat搞死机。
然后,找各种办法解决问题。整了几天,每天中午轮流监控Tomcat服务器,发现它挂了后就重启。累坏了。
每天到google上面搜索答案,有人说是程序的问题,程序内存泄露。甚至问到“有没有数据库没有释放”、“有没有使用死循环”、有没有写“System.gc()自动释放内存”、有没有“在Service层查询时使用all()方法,查处了所有记录”。等等。
而我一直不承认程序有问题。理由是:我们曾经将这个程序在租用的2个虚拟主机中用了近1个月。不断维护,最后达到一个星期没有出现一个异常的情况。
二、问题分析(关于tomcat内存溢出问题)
分析Tomcat死机的日志,发现是内存耗尽。
大致有这么一段,PSPermGen total 86016K used 86015K
到网上搜了一下,明白了jvm内存分类。然后配置内存,让tomcat自动回收jvm内存。
当然,配置过程也遇到了很多问题,花了一天多。问题是网上的很多人都是抄来抄去,要在一大堆垃圾中选出精品不容易呀。
配了一天都只起到一定作用。比如:给tomcat设置较大内存后,tomcat可以承受到2.19G。只是再刷新就可以把他整崩溃。
最后,请了几个牛人帮忙,一个牛人凌晨帮我们看tomcat配置。问我们,是否加了,-server参数。最后,我同事加上了-server参数。 然后,回去睡觉了,发现java.exe内存真的能回收了。很多问题也解决了。
我们配置如下:(将tomcat6的安装版卸载,换成绿色版)
在catalina.bat的@echo off下面添加(就是第二行)
set JAVA_OPTS=-server -Xms512m -Xmx1024m -XX:MaxNewSize=512m -XX:MaxPermSize=256m
在startup.bat下面添加(让tomcat的工具自动回收内存)
@echo off
set JAVA_OPTS=%JAVA_OPTS%
-Dcom.sun.management.jmxremote.port=1090
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager
-Djava.util.logging.config.file="%CATALINA_HOME%\conf\logging.properties"
三、问题分析(关于页面反应速度异常)
我们的首页显示餐馆的信息,主要根据用户选择地区,然后将该地区的餐馆列表和热卖美食列表显示出来。我们发现一个很奇怪的现象,访问某一学校东校区时:
8个餐馆:Action执行2063ms(获取餐馆列表:1220ms + 获取热卖美食:825ms)。
然后换成其他校区分别为:
3个餐馆:Action执行 51ms (获取餐馆列表:29 + 获取热卖美食: 2)
3个餐馆:Action执行 53ms (32 + 1)
4个餐馆:Action执行 90ms (74 + 1)
看到这个数据,我就很纳闷,怎么时间不成比例呢?
于是,我将8个餐馆删掉4个对比。由于有外键关联,我必须要删除其他的很多的。为了删除一个餐馆记录,我必须删除其他记录多达6个表处,可见外键关系较为复杂。
等我删掉后,发现东校区:
4个餐馆:Action执行111ms(获取餐馆列表:53ms + 获取热卖美食:37ms)。
我发现这个变化太明显了吧。然后,我怀疑那四个餐馆关联了太多东西。我查询出来的不仅仅是餐馆,可能连带查询了另外的6个表的记录。
我就想到了是hbm.xml文件中设置lazy = "true"问题。
通过测试,我发现是 餐馆对应订单时,one-to-many时,lazy = "true"。这个就很明显了。
查询一个餐馆,就把它的上百份订单级联查询出来了,同时把所有菜品也级联查询出来了,把所有菜品分类都查询出来了。
而就东校区的这8家餐馆订单较多,其他校区由于刚开业,订单几乎没有。这下就可以解释为什么东校区这么耗时间(当然也耗内存)。
然后,我将hbm.xml的所有lazy="true"全部去掉,恢复数据库数据。
东校区结果如下:
8个餐馆:Action执行25ms(获取餐馆列表:3ms + 获取热卖美食:8ms)。
四、结论:
lazy="false"使用时要慎重。例如:对与1:1的情况,使用直接影响不大,对于1:n情况就要慎重了。尤其是n成百上千时,问题就相当严重了。我建议最好不用。
第一次,配置和管理服务器,收获真大呀。对我以后的编程风格都造成了深远的影响。我会注意服务器的时间和空间效率问题。
当然测试方法比较土。先将服务器正常上线后,我会学着使用JMeter和roadrunner的工具做压力测试,配置好服务器。
忙里偷闲!记录下来!
转自http://www.cnblogs.com/pyrmkj/archive/2012/06/23/2559375.html
1.第一个例子:
<s:select list="{'aa','bb','cc'}" theme="simple" headerKey="00" headerValue="00"></s:select>
2.第二个例子:
<s:select list="#{1:'aa',2:'bb',3:'cc'}" label="abc" listKey="key" listValue="value" headerKey="0" headerValue="aabb">
3.第三个例子:
<%
java.util.HashMap map = new java.util.LinkedHashMap();
map.put(1,"aaa");
map.put(2,"bbb");
map.put(3,"ccc");
request.setAttribute("map",map);
request.setAttribute("aa","2");
%>
<s:select list="#request.map" label="abc" listKey="key" listValue="value"
value="#request.aa" headerKey="0" headerValue="aabb"></
s:select
>
headerKey headerValue 为设置缺省值
摘抄自 http://www.cnblogs.com/modou/articles/1326683.html
4.第四个例子
public class Program implements Serializable {
/** serialVersionUID */
private static final long serialVersionUID = 1L;
private int programid;
private String programName;
public int getProgramid() {
return programid;
}
public void setProgramid(int programid) {
this.programid = programid;
}
public String getProgramName() {
return programName;
}
public void setProgramName(String programName) {
this.programName = programName;
}
}
在 xxx extends extends ActionSupport {
private List<Program> programs ;
public List<Program> getPrograms() {
return programs;
}
public void setPrograms(List<Program> programs) {
this.programs = programs;
}
}
在jsp页面
<s:select list="programs " listValue="programName " listKey="programid " name="program" id="program"
headerKey="0l" headerValue=" " value="bean.programid "
></s:select>
红色部分为在action里面的list,黄色为<option value="xxx">value</option>对应bean里面的字段programName
绿色为<option value="xxx",对应bean里面的字段programid
紫色为设定select被选中的值,s:select 会自动在 bean选中 key对应的值
转自http://blog.csdn.net/moliqin/article/details/3753570
1.浏览器,只能同时解析一个域名下的6个文件或图片,所以,要区分域名01,02分别解析图片或者cs,js,这样浏览器就可以同时加载很多文件,缩短加载速度,
也就是说每6个文件或图片,就用一个域名css,js可以放到云服务器上
《高性能Linux服务器构建实战:运维监控、性能调优与集群应用》第1章轻量级HTTP服务器Nginx,本章主要介绍了对高性能HTTP服务器Nginx的安装、配置、管理和使用,以及Nginx在性能优化方面的一些经验和技巧,并通过实例分别演示了Nginx与PHP整合,Nginx和Java、Perl整合的过程。本节为大家介绍搭建Nginx+Java环境。
AD:
1.8.4 搭建Nginx+Java环境
Apache对Java的支持很灵活,它们的结合度也很高,例如Apache+Tomcat和Apache+resin等都可以实现对Java应用的支持。Apache一般采用一个内置模块来和Java应用服务器打交道。与Apache相比,Nginx在配合Java应用服务器方面,耦合度很低,它只能通过自身的反向代理功能来实现与Java应用服务器的支持。但这恰恰是Nginx的一个优点,耦合度的降低,可以使Nginx与Java服务器的相互影响降到最低。
接下来通过Nginx+Tomcat的实例来讲解Nginx对Java的支持。Tomcat在高并发环境下处理动态请求时性能很低,而在处理静态页面更加脆弱。虽然Tomcat的最新版本支持epoll,但是通过Nginx来处理静态页面要比通过Tomcat处理在性能方面好很多。
Nginx可以通过以下两种方式来实现与Tomcat的耦合:
将静态页面请求交给Nginx,动态请求交给后端Tomcat处理。
将所有请求都交给后端的Tomcat服务器处理,同时利用Nginx自身的负载均衡功能进行多台Tomcat服务器的负载均衡。
下面通过两个配置实例分别讲述这两种实现Nginx与Tomcat耦合的方式。
1.动态页面与静态页面分离的实例
这里假定Tomcat服务器的IP地址为192.168.12.130,同时Tomcat服务器开放的服务器端口为8080。Nginx相关配置代码如下:
- server {
- listen 80;
- server_name www.ixdba.net;
- root /web/www/html;
-
- location /img/ {
- alias /web/www/html/img/;
- }
-
- location ~ (\.jsp)|(\.do)$ {
- proxy_pass http://192.168.12.130:8080;
- proxy_redirect off;
- proxy_set_header Host $host;
- proxy_set_header X-Real-IP $remote_addr;
- proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
- client_max_body_size 10m;
- client_body_buffer_size 128k;
- proxy_connect_timeout 90;
- proxy_send_timeout 90;
- proxy_read_timeout 90;
- proxy_buffer_size 4k;
- proxy_buffers 4 32k;
- proxy_busy_buffers_size 64k;
- proxy_temp_file_write_size 64k;
- }
-
- }
在这个实例中,首先定义了一个虚拟主机www.ixdba.net,然后通过location指令将/web/www/html/img/目录下的静态文件交给Nginx来完成。最后一个location指令将所有以.jsp、.do结尾的文件都交给Tomcat服务器的8080端口来处理,即http://192.168.12.130:8080。
需要特别注意的是,在location指令中使用正则表达式后,proxy_pass后面的代理路径不能含有地址链接,也就是不能写成http://192.168.12.130:8080/,或者类似http://192.168.12.130:8080/jsp的形式。在location指令不使用正则表达式时,没有此限制。
2.多个Tomcat负载均衡的实例
这里假定有3台Tomcat服务器,分别开放不同的端口,地址如下:
- 192.168.12.131:8000
- 192.168.12.132:8080
- 192.168.12.133:8090
Nginx的相关配置代码如下:
- upstream mytomcats {
- server 192.168.12.131:8000;
- server 192.168.12.132:8080;
- server 192.168.12.133:8090;
- }
-
- server {
- listen 80;
- server_name www.ixdba.net;
-
- location ~* \.(jpg|gif|png|swf|flv|wma|wmv|asf|mp3|mmf|zip|rar)$ {
- root /web/www/html/;
- }
-
- location / {
- proxy_pass http://mytomcats;
- proxy_redirect off;
- proxy_set_header Host $host;
- proxy_set_header X-Real-IP $remote_addr;
- proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
- client_max_body_size 10m;
- client_body_buffer_size 128k;
- proxy_connect_timeout 90;
- proxy_send_timeout 90;
- proxy_read_timeout 90;
- proxy_buffer_size 4k;
- proxy_buffers 4 32k;
- proxy_busy_buffers_size 64k;
- proxy_temp_file_write_size 64k;
- }
-
- }
在这个实例中,先通过upstream定义一个负载均衡组,组名为mytomcats,组的成员就是上面指定的3台Tomcat服务器;接着通过server指令定义一个www.ixdba.net的虚拟主机;然后通过location指令以正则表达式的方式将指定类型的文件全部交给Nginx去处理;最后将其他所有请求全部交给负载均衡组来处理。
这里还有一点需要注意,如果在location指令使用正则表达式后再用alias指令,Nginx是不支持的。
麻烦你再研究一下Varnish,我所希望了解的事项是:
1、 能否设置到URL级别。
你可以以针对“2012潮流”页面的这两个链接进行测试:
[IP]:[Port]/trend.html
[IP]:[Port]/trend/findViewHotItemsAjax.html
注意两个链接后面均可能存在参数,
比如[IP]:[Port]/trend/findViewHotItemsAjax.html?ref=1&np=1
这些参数是查询条件。
可以支持,通过正则表达式区分路径,可以通配到URL级别的访问,在定义了路径后设置一些属性。
2、 能否支持通配符
比如
[IP]:[Port]/trend*
支持
3、能否就每一个独立配置设置独立的缓存时间?
我指的每一个独立配置是指比如某个URL。
比如 /trend.html 缓存4分钟,而另外一个/trend/newest.html则缓存2分钟。
如果不行,那么Varnish的缓存时间允许怎么设置?
可以做到对于不同路径的缓存时间特性设置,但是需要在VCL语言中编写,类似C的语言,按照业务需求来写配置文件和处理流程……
4、 清除Varnish缓存的命令是?
方便做build后,人工或者通过脚本来调用该命令清除Varnish缓存。
首先是要设置了管理的IP,通过Varnish管理端口,使用正则表达式批量清除缓存:
(1)、例:清除类似http://www.elain.org/download/111.html的URL地址):
/elain/apps/varnish/bin/varnishadm -T 172.16.2.223:3500 url.purge /download/
(2)、例:清除类似http://www.elain.org/dl 的URL地址:
/elain/apps/varnish/bin/varnishadm -T 172.16.2.223:3500 url.purge w*$
(3)、例:清除所有缓存:
/elain/apps/varnish/bin/varnishadm -T 172.16.2.223:3500 url.purge *$
5、 如何监控Varnish,有可视化界面查看运行状态,命中率等等吗?
1、查看Varnish服务器连接数与命中率:
/elain/apps/varnish/bin/varnishstat
cache_hit是命中率
2、通过Varnish管理端口进行管理:
用help看看可以使用哪些Varnish命令:
/elain/apps/varnish/bin/varnishadm -T 172.16.2.223:3500 help
[root@vanish ~]# /elain/apps/varnish/bin/varnishadm -T 172.16.2.223:3500 help
help [command]
ping [timestamp]
auth response
quit
banner
status
start
stop
stats
vcl.load <configname> <filename>
vcl.inline <configname> <quoted_VCLstring>
vcl.use <configname>
vcl.discard <configname>
vcl.list
vcl.show <configname>
param.show [-l] [<param>]
param.set <param> <value>
purge.url <regexp>
purge <field> <operator> <arg> [&& <field> <oper> <arg>]...
purge.list
6、 有响应时间统计的报表吗?
比如对某个URL设置了缓存,那么我能否获得该URL的响应时间统计。
可以通过webbench测试URL的相应时间。
root@zhouda webbench-1.5]# webbench -c 100 -t 60 http://10.112.5.219/info.php
Webbench - Simple Web Benchmark 1.5
Copyright (c) Radim Kolar 1997-2004, GPL Open Source Software.
Benchmarking: GET http://10.112.5.219/info.php
100 clients, running 60 sec.
Speed=695 pages/min, 612347 bytes/sec.
Requests: 695 susceed, 0 failed.
每秒钟响应请求数:695 pages/min,每秒钟传输数据量612347 bytes/sec.
CRONTAB利做统计然后通过程序汇总成图表
7、 其它的
如果你在研究过程中,发现有比较有用的功能,也整理一下告诉我。
http://www.oschina.net/question/222919_57985
http://www.oschina.net/question/17_6406
http://www.discuz.net/thread-730015-1-1.html
https://www.varnish-cache.org/docs
https://www.varnish-cache.org/docs/3.0/tutorial/vcl.html
另外,目前最新的测试版本在:http://42.121.12.4
网上的文档写的有些问题,只可以参考,可以按住我下边的总结的,安装外围包,然后再编译安装即可
wget -c http://repo.varnish-cache.org/source/varnish-3.0.2.tar.gz
yum instll -y automake
yum instll -y autoconf
yum instll -y
libtool
yum instll -y ncurses-devel
yum instll -y libxslt
yum instll -y
groff
yum instll -y pcre-devel
yum instll -y pkgconfig
yum instll -y
automake
yum instll -y automake
yum install -y autoconf
yum install -y
libtool
yum install -y ncurses-devel
yum install -y libxslt
yum install
-y groff
yum install -y pcre-devel
yum install -y pkgconfig
groupadd
www
useradd www -g www -s /sbin/nologin
yum -y install patch make gcc gcc-c++ gcc-g77 flex bison file
yum -y
install libtool libtool-libs autoconf kernel-devel
yum -y install libjpeg
libjpeg-devel libpng libpng-devel libpng10 libpng10-devel gd gd-devel
yum -y
install freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel
yum -y
install glib2 glib2-devel bzip2 bzip2-devel libevent libevent-devel
yum -y
install ncurses ncurses-devel curl curl-devel e2fsprogs
yum -y install
e2fsprogs-devel krb5 krb5-devel libidn libidn-devel
yum -y install openssl
openssl-devel vim-minimal nano sendmail
yum -y install fonts-chinese gettext
gettext-devel
yum -y install ncurses-devel
yum -y install gmp-devel
pspell-devel
yum -y install unzip
cd /varnish
./configure --prefix=/opt/varnish
make ;make install
启动:
/opt/varnish/sbin/varnishd -f /opt/varnish/etc/varnish/killwin.vcl -a
42.121.12.4:80 -s malloc,256m -T 127.0.0.1:2000 -p
http_resp_hdr_len=8192
下边的网络转载的
简述:Varnish是一款高性能的开源HTTP加速器,挪威最大的在线报纸 Verdens Gang
使用3台Varnish代替了原来的12台Squid,性能比以前更好。
系统环境:
CentOS release 5.5 (Final) 64-bit
所需软件:
varnish-2.1.4.tar.gz
Varnish官方网站:
http://www.varnish-cache.org/
安装前准备:
创建www用户和组,以及Varnish缓存文件存放目录(/elain/data/vcache):
/usr/sbin/groupadd www -g
600
/usr/sbin/useradd -u 600 -g www www
mkdir -p
/elain/data/vcache
chmod +w /elain/data/vcache
chown -R www:www
/elain/data/vcache
创建Varnish日志目录(/elain/logs/varnish):
mkdir -p
/elain/logs/varnish
chmod +w /elain/logs/varnish
chown -R www:www
/elain/logs/varnish
安装:
wget http://cdnetworks-kr-1.dl.sourceforge.net/project/pcre/pcre/8.12/pcre-8.12.tar.gz
tar
zxvf pcre-8.12.tar.gz
cd pcre-8.12/
./configure
--prefix=/elain/apps/pcre
make && make install
cd ../
wget http://repo.varnish-cache.org/source/varnish-2.1.5.tar.gz
tar
zxvf varnish-2.1.5.tar.gz
cd varnish-2.1.5
export
PKG_CONFIG_PATH=/elain/apps/pcre/lib/pkgconfig
./configure
-prefix=/elain/apps/varnish
make
make install
cd ..
配置:
默认配置文件样板:
/elain/apps/varnish/etc/varnish/default.vcl
cd /elain/apps/varnish/etc/varnish/
cp default.vcl elain_vcl.conf
vi
elain_vcl.conf
#############################
backend www {
.host =
"www.elain.org";
.port = "80";
}
acl purge {
"localhost";
"127.0.0.1";
"172.16.2.0"/24;
}
sub vcl_recv {
if (req.restarts == 0) {
if (req.http.x-forwarded-for)
{
set req.http.X-Forwarded-For =
req.http.X-Forwarded-For ", "
client.ip;
} else {
set req.http.X-Forwarded-For =
client.ip;
}
}
if (req.request != "GET" &&
req.request !=
"HEAD" &&
req.request != "PUT" &&
req.request != "POST"
&&
req.request != "TRACE" &&
req.request != "OPTIONS"
&&
req.request != "DELETE") {
/* Non-RFC2616 or CONNECT which is
weird. */
return (pipe);
}
if (req.request != "GET" &&
req.request != "HEAD") {
/* We only deal with GET and HEAD by default
*/
return (pass);
}
if (req.http.Authorization || req.http.Cookie)
{
/* Not cacheable by default */
return (pass);
}
else {
lookup;
}
return (lookup);
}
sub vcl_pipe {
return (pipe);
}
sub vcl_pass {
return (pass);
}
sub vcl_hash {
set req.hash += req.url;
if (req.http.host) {
set
req.hash += req.http.host;
} else {
set req.hash +=
server.ip;
}
return (hash);
}
sub vcl_hit {
if (!obj.cacheable) {
return (pass);
}
return
(deliver);
}
sub vcl_miss {
return (fetch);
}
sub vcl_fetch {
if (!beresp.cacheable) {
return (pass);
}
if
(beresp.http.Set-Cookie) {
return (pass);
}
return (deliver);
}
sub vcl_deliver {
return (deliver);
}
sub vcl_error {
set obj.http.Content-Type = "text/html;
charset=utf-8";
synthetic {"
<?xml version="1.0"
encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0
Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>"}
obj.status " " obj.response
{"</title>
</head>
<body>
<h1>Error "}
obj.status " " obj.response {"</h1>
<p>"} obj.response
{"</p>
<h3>Guru Meditation:</h3>
<p>XID: "}
req.xid {"</p>
<hr>
<p>Varnish cache
server</p>
</body>
</html>
"};
return
(deliver);
}
###################################
配置文件解释:
(1)、Varnish通过反向代理请求后端IP为172.16.2.223,端口为80的web服务器;
(2)、Varnish允许localhost、127.0.0.1、172.16.2.233
三个来源IP通过PURGE方法清除缓存;
(3)、Varnish对域名为www.elain.org的请求进行处理,非www.elain.org域名的请求则返回“elain
Cache
Server”;
(4)、Varnish对HTTP协议中的GET、HEAD请求进行缓存,对POST请求透过,让其直接访问后端Web服务器。之所以这样配置,是因为POST请求一般是发送数据给服务器的,需要服务器接收、处理,所以不缓存;
(5)、Varnish对以.txt和.js结尾的URL缓存时间设置1小时,对其他的URL缓存时间设置为30天。
启动Varnish
ulimit -SHn 65535
/elain/apps/varnish/sbin/varnishd -f
/elain/apps/varnish/etc/varnish/elain_vcl.conf -a 172.16.2.223:80 -s
file,/elain/data/vcache,1G -w 1024,51200,10 -t 3600 -T 172.16.2.223:3500
参数:
-u 以什么用运行
-g 以什么组运行
-f varnish 配置文件
-a 绑定 IP 和端口
-s
varnish 缓存文件位置与大小
-w 最小,最大线程和超时时间
-T varnish 管理端口,主要用来清除缓存
启动varnishncsa用来将Varnish访问日志写入日志文件:
/elain/apps/varnish/bin/varnishncsa -w
/elain/logs/varnish.log &
停止Varnish
pkill varnish
配置开机自动启动Varnish
vi /etc/rc.local
在末尾增加以下内容:
ulimit -SHn 65535
/elain/apps/varnish/sbin/varnishd -f
/elain/apps/varnish/etc/varnish/elain_vcl.conf -a 172.16.2.223:80 -s
file,/elain/data/vcache,1G -w 1024,51200,10 -t 3600 -T
172.16.2.223:3500
/elain/apps/varnish/bin/varnishncsa -n /elain/data/vcache
-w /elain/logs/varnish.log &
优化Linux内核参数
vi /etc/sysctl.conf
在末尾增加以下内容:
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time =
300
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse =
1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.ip_local_port_range = 5000
65000
sysctl -p
管理Varnish:
1、查看Varnish服务器连接数与命中率:
/elain/apps/varnish/bin/varnishstat
2、通过Varnish管理端口进行管理:
用help看看可以使用哪些Varnish命令:
/elain/apps/varnish/bin/varnishadm
-T 172.16.2.223:3500 help
[root@vanish ~]# /elain/apps/varnish/bin/varnishadm -T 172.16.2.223:3500
help
help [command]
ping [timestamp]
auth
response
quit
banner
status
start
stop
stats
vcl.load
<configname> <filename>
vcl.inline <configname>
<quoted_VCLstring>
vcl.use <configname>
vcl.discard
<configname>
vcl.list
vcl.show <configname>
param.show [-l]
[<param>]
param.set <param> <value>
purge.url
<regexp>
purge <field> <operator> <arg> [&&
<field> <oper> <arg>]...
purge.list
3、通过Varnish管理端口,使用正则表达式批量清除缓存:
(1)、例:清除类似http://www.elain.org/download/111.html的URL地址):
/elain/apps/varnish/bin/varnishadm
-T 172.16.2.223:3500 url.purge /download/
(2)、例:清除类似http://www.elain.org/dl
的URL地址:
/elain/apps/varnish/bin/varnishadm -T 172.16.2.223:3500 url.purge
w*$
(3)、例:清除所有缓存:
/elain/apps/varnish/bin/varnishadm -T 172.16.2.223:3500
url.purge *$
Varnish日志切割脚本
cat /root/scripts/cut_varnish_log.sh
#!/bin/sh
# This script run at 00:00
date=$(date -d "yesterday"
+"%Y-%m-%d")
pkill -9 varnishncsa
mv /elain/logs/varnish/images.log
/elain/logs/varnish/${date}.log
/elain/apps/varnish/bin/varnishncsa -w
/elain/logs/varnish/images.log &
mkdir -p
/elain/logs/varnish/logsbak/
gzip -c /elain/logs/varnish/${date}.log >
/elain/logs/varnish/logsbak/${date}.log.gz
rm -f
/elain/logs/varnish/${date}.log
rm -f /elain/logs/varnish/logsbak/$(date -d
"-1 month" +"%Y-%m*").log.gz
chmod 700 /root/scripts/cut_varnish_log.sh
设置在每天00:00定时执行:
crontab -e
# Info : 每天切割varnish日志
# Author : dingtm
# CTime : 2011.04.08
0 0
* * * /root/scripts/cut_varnish_log.sh
官方文档:
http://www.varnish-cache.org/docs/2.1/
推荐参考文档见附件
好老的文章了,今天把它挖出来了,其实在整个JAVA的学习中偶然性很多,改变你路线的东西也很多,很多东西是跟着工作的变化而变化的,因此关键在于把其中几个学精通,有个主方向,并要懂灵活变化。真个技术生涯还包括架构、做人、团队合作、管人、不断学习新技术,等
第一阶段
2.你需要学习JAVA语言的基础知识以及它的核心类库 (collections,serialization,streams,networking, multithreading,reflection,event,handling,NIO,localization,以及其他)。
5.你需要学习java数据库技术,如JDBCAPI并且会使用至少一种persistence/ORM构架,例如Hibernate,JDO, CocoBase,TopLink,InsideLiberator(国产JDO红工厂软件)或者iBatis。
24.你应该熟练掌握一种JAVAIDE例如sunOne,netBeans,IntelliJIDEA或者Eclipse。(有些人更喜欢VI或EMACS来编写文件。随便你用什么了:)
26.你需要熟悉一种单元测试体系(JNunit),并且学习不同的生成、部署工具(Ant,Maven)。
27.你需要熟悉一些在JAVA开发中经常用到的软件工程过程。例如RUP(RationalUnifiedProcess)andAgilemethodologies。
第二阶段
1.你需要精通面向对象分析与设计(OOA/OOD)、涉及模式(GOF,J2EEDP)以及综合模式。你应该十分了解UML,尤其是class,object,interaction以及statediagrams。
3.你应该了解JVM,classloaders,classreflect,以及垃圾回收的基本工作机制等。你应该有能力反编译一个类文件并且明白一些基本的汇编指令。
6.你还应该了解对象关系的阻抗失配的含义,以及它是如何影响业务对象的与关系型数据库的交互,和它的运行结果,还需要掌握不同的数据库产品运用,比如:oracle,mysql,mssqlserver。
7.你需要学习JAVA的沙盒安全模式(classloaders,bytecodeverification,managers,policyandpermissions,
codesigning, digitalsignatures,cryptography,certification,Kerberos,以及其他)还有不同的安全/认证 API,例如JAAS(JavaAuthenticationandAuthorizationService),JCE (JavaCryptographyExtension),JSSE(JavaSecureSocketExtension),以及JGSS (JavaGeneralSecurityService)。
第三阶段
10.你需要学习如何使用及管理WEB服务器,例如tomcat,resin,Jrun,并且知道如何在其基础上扩展和维护WEB程序。
8.你需要学习Servlets,JSP,以及JSTL(StandardTagLibraries)和可以选择的第三方TagLibraries。
4.如果你将要 写客户端程序,你需要学习WEB的小应用程序(applet),必需掌握GUI设计的思想和方法,以及桌面程序的SWING,AWT, SWT。你还应该对UI部件的JAVABEAN组件模式有所了解。JAVABEANS也被应用在JSP中以把业务逻辑从表现层中分离出来。(这条可有可 无)
9.你需要熟悉主流的网页框架,例如JSF,Struts,Tapestry,Cocoon,WebWork,以及他们下面的涉及模式,如MVC/MODEL2。
14.你应该学习如何利用JAVAAPI和工具来构建WebService。例如JAX- RPC(JavaAPIforXML/RPC),SAAJ (SOAPwithAttachmentsAPIforJava),JAXB(JavaArchitectureforXMLBinding),JAXM(JavaAPIforXMLMessaging), JAXR(JavaAPIforXMLRegistries),或者JWSDP(JavaWebServicesDeveloperPack)。
15.你需要学习一门轻量级应用程序框架,例如Spring,PicoContainer,Avalon,以及它们的IoC/DI风格(setter,constructor,interfaceinjection)。
20.你需要熟悉对不同有用的API和frame work等来为你服务。例如Log4J(logging/tracing),Quartz (scheduling),JGroups(networkgroupcommunication),JCache(distributedcaching), Lucene(full-textsearch),JakartaCommons等等。
25.JAVA(精确的说是有些配置)是冗长的,它需要很多的人工代码(例如EJB),所以你需要熟悉代码生成工具,例如XDoclet
第四阶段
16.你需要熟悉不同的J2EE技术,例如JNDI(JavaNamingandDirectoryInterface),JMS (JavaMessageService),JTA/JTS(JavaTransactionAPI /JavaTransactionService),JMX (JavaManagementeXtensions),以及JavaMail。
11.你需要学习分布式对象以及远程API,例如RMI和RMI/IIOP。
12.你需要掌握各种流行中间件技术标准和与java结合实现,比如Tuxedo、CROBA,当然也包括javaEE本身。
17.你需要学习企业级JavaBeans(EJB)以及它们的不同组件模 式:Stateless/StatefulSessionBeans,EntityBeans(包含Bean- ManagedPersistence[BMP]或者Container-ManagedPersistence[CMP]和它的EJB-QL),或者 Message-DrivenBeans(MDB)。
13.你需要学习最少一种的XMLAPI,例如JAXP(JavaAPIforXMLProcessing),JDOM(JavaforXMLDocumentObjectModel),DOM4J,或JAXR(JavaAPIforXMLRegistries)。
18.你需要学习如何管理与配置一个J2EE应用程序服务器,如WebLogic,JBoss等,并且利用它的附加服务,例如簇类,连接池以及分布式处理支援。你还需要了解如何在它上面封装和配置应用程序并且能够监控、调整它的性能。
第五阶段(优先级低)
19.你需要熟悉面向方面的程序设计以及面向属性的程序设计(这两个都被很容易混淆的缩写为AOP),以及他们的主流JAVA规格和执行。例如AspectJ和AspectWerkz。
21.如果你将要对接或者正和旧的系统或者本地平台,你需要学习JNI (JavaNativeInterface) and JCA (JavaConnectorArchitecture)。
22.你需要熟悉JINI技术以及与它相关的分布式系统,比如掌握CROBA。
23.你需要JavaCommunityProcess(JCP)以及他的不同JavaSpecificationRequests(JSRs),例如Portlets(168),JOLAP(69),DataMiningAPI(73),等等。
28.你需要能够深入了解加熟练操作和配置不同的操作系统,比如GNU/linux,sunsolaris,macOS等,做为跨平台软件的开发者。
29.你还需要紧跟java发展的步伐,比如现在可以深入的学习javaME,以及各种java新规范,技术的运用,如新起的web富客户端技术。
30.你必需要对opensource有所了解,因为至少java的很多技术直接是靠开源来驱动发展的,如java3D技术。
====================================================================
附:
JAVA系统架构师应该看的几本书
Thinking in Java
Effective Java
UML基础、案例与应用
UML入门提高
软件工匠
设计模式——可复用面向对象软件的基础
重构-改善既有代码的设计
敏捷软件开发-原则、模式、实践
企业应用架构模式
Expert One-on-One J2EE Development without EJB
软件工程——实践者的研究方法
软件领导--成功开发软件的指导准则
后面的两本书,其实已经有点属于项目经理的范畴了,不过还不是很深入,看看对做成功的系统架构师是很有好处。
企业应用的系统架构师应该关注的几个方面 (具体情况具体分析,以下未必准确,只是参考)
先来一些基础面试题,您答得出么?
1、说说JVM原理?内存泄露与溢出区别,何时产生内存泄露?
2、用java怎么实现有每天有1亿条记录的DB存储?mysql上亿记录数据量的数据库如何设计?
3、mysql支持事务吗?DB存储引擎有哪些?
4、mvc原理,mvc模式的优缺点,如果让你设计你会怎么改造MVC?
5、hibernate支持集群吗?如何实现集群?
6、tomcat 最多支持并发多少用户?
7、map原理,它是如何快速查找key的?map与set区别?
8、描术算法,如何有效合并两个文件:一个是1亿条的用户基本信息,另一个是用户每天看电影连续剧等的记录,5000万条。内存只有1G???
9、在1亿条用户记录里,如何快速查询统计出看了5个电影以上的用户? ----可以参考 位图索引的原理
10、Spring如何实现IOC与AOP的,说出实现原理?
数据持久层的设计
在Spring和Hibernate,ibatis出来以前,几乎每家公司都有自己的一套方法和架构,而架构师的50%的精力也会集中到这上面,EJB只是增加架构师的负担。在Spring出来以后,基本上,大多数的架构师都从重复设计这个轮子的无用功中解脱出来了。Rod的轮子太好用了,基本上,大家只要套上去就行了,或者,剩下最重要的事情,是选择一个合适的数据库连接池的开源项目吧
MVC架构的具体设计
MVC只是个概要的概念,具体如何实现的具体技术很多,根据项目设计最恰当的架构
大并发性访问
太多了,包括从广域网到服务器到业务层再到架构再到程序、数据库的各种调优,如使用缓存,静态化,静动态server分离,在数据量达到一定程度时,使用集群技术,优先考虑利用服务器的集群,其次是硬件集群,最后才是应用本身加入集群功能
超大数据量返回结果
缓存命中率,分页,优化SQL语句,循环处理数据时尽可能共用对象,只保留关键数据,及时释放内存占用
超大文件的读取和生成
尽可能快的读取大文件,并进行分析。写入大文件时,如何及时释放内存。学会适当利用操作系统的命令行资源来更快完成任务。这方面经验比较少,以后有空研究。
多线程的应用和管理
线程池的管理和监控,线程的启动(包括定时启动),结束,回收,线程资源的释放 ,这句话太简单了,待深入研究
用户界面可用性设计
平衡速度和可用性,恰当的使用异步和同步技术,展现关键数据为重点
分布式的数据交流和集成
选择恰当的数据交互方式,从最泛滥低效的Web Service到最实用的文件共享
群集系统的管理
如何确保缓存的同步?如何确保对象唯一性?如何保证各台机器的同步?
是否采用EJB?如何利用J2EE的特性(例如JNDI)
复杂的业务规则
规则引擎和工作流引擎场景和应用
其实,作为一个真正的系统架构师,不应该局限于企业应用的系统,这种系统往往有数据库的局限性,有时候,应该考虑是否可以横向跨越,直接对其它系统做一些架构考虑,在没有丰富的实战经验的前提下,而只是看了其它人的系统和代码,就能够给出有效的设计指导。
例如对于一个下载软件,可以有如下考虑:
1. 未明和非法url的检验,已经下载失败的容许,信息记录
2. 多线程下载一个文件,文件的切分和拼合,部分切片丢失的拼合可能性
3. 下载线程管理
4. 服务器或者P2P的机器之间的通讯协议
5. 速度监控和限制
6. 下载进度的监控和显示
作为一个在线播放软件,可以做如下考虑
1. 播放速度的保证
机器的问题基本不存在了,关键是网络问题。如何在检测网络速度,根据影片的质量,并缓冲足够多的内容,保证播放一直尽可能顺利的完成。
2. 播放质量的保证
如何利用DirectX等技术,最快的进行渲染,是自己写底层,还是利用已有的API
由于没做过类似的项目,可以写的东西还是少很多了。
系统架构师应该有的素质:
1、 实际的编程经验
最少2年吧,多了就不说了,其实从大学就开始钻研的话,
2、 书面表达能力和口头交流能力
综合利用架构图,UML图,文字和代码片断,表达自己设计思想,至于是Word还是ppt,应该通吃
在开发人员中发现架构师的最有价值标准是有效的沟通。您需要技术娴熟、经验丰富的开发人员,这样的人员需要有就项目中的业务相关问题进行沟通的经历。架构师经常必须对理解方面的差距进行预计,然后才能有所贡献。他们必须愿意克服困难来确保技术和业务观点的融合。他们并不必对意见交换工作进行计划和协调;这仍然主要是项目经理的工作。他们的任务是确定表述系统设计时的最佳工具和构件,以促进有效的意见交换。他们必须能够判断当前方法显得不足而需要采用新方法的情况。写作技能也非常重要,还需要具有制作草图的技能或使用制图软件的能力。
3、 自觉主动;积极解决设计问题
架构师的日常工作目标经常并不明确。很多开发人员直接参考功能规范来列出任务清单。架构师通常则是向这些开发人员提供所需结构的人员,以便尽可能提高工作效率。好的候选者不仅进行沟通方面的工作,而且也会预计各种设计问题并加以解决——通常在没有任何具体指示的情况下自觉进行。无论所分配的职责如何,积极参与项目的开发人员都有机会从一起工作的人员中脱颖而出。
4、 抽象思维能力和总结能力
架构师,顾名思义,在系统未搭建好之前,就要能够有一个草图在心。而如果是对现有系统的改造,那么能在看过系统的文档(如果有的话)和代码后,就能总结出系统的架构特点。
架构师必须能够理解表述模糊的概念并将其变成相关各方能够理解的项目构件。他们必须能够理解抽象概念,并以具体的语言对其进行沟通。开发人员中好的候选者经常要求或自己主动解释开发生命周期中容易混淆的问题。他们能迅速评估各种想法并将其纳入后续工作的操作建议中。
开发人员经常具有很强的数学能力,而好的架构师则倾向于表现出更强的口头表达能力。管理人员经常说开发人员具有“工程意识”,而这是一个用于评估架构师的非常有意义的方面。架构师应该具有很强的解决技术问题的能力,但还必须能够准确获知更为全面的人员如何与技术交互的信息。这要求具有某种形式的抽象思维(而不再是代码的细节),这种思维能力可能较难形成。
5、 全面的技术资讯吸收能力和选择鉴别能力
作为开发人员出身,对于某一个具体问题的研究能力(虽然很多人总结为google能力),已经相当具备了。但是对技术资讯的全面接受和选择性深入了解能力,并且做出正确的判断,那些技术无非是厂家的噱头,而那些技术是真正可以用到项目,提高项目质量的好技术,这种能力确实至关重要的。
转自:http://www.blogjava.net/mrcmd/archive/2007/08/24/138963.html
用java压缩文件夹/文件压缩文件夹代码:
 import java.io.File;
import java.io.File;
import org.apache.tools.zip.ZipOutputStream; //这个包在ant.jar里,要到官方网下载
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.zip.ZipInputStream;
import java.util.zip.ZipEntry;
 public class CompressBook {
public class CompressBook {
 public CompressBook() {}
public CompressBook() {}

/*
* inputFileName 输入一个文件夹
* zipFileName 输出一个压缩文件夹
 */
*/
public void zip(String inputFileName) throws Exception {
String zipFileName = "c:\\test.zip"; //打包后文件名字
System.out.println(zipFileName);
zip(zipFileName, new File(inputFileName));
}
private void zip(String zipFileName, File inputFile) throws Exception {
ZipOutputStream out = new ZipOutputStream(new FileOutputStream(zipFileName));
zip(out, inputFile, "");
System.out.println("zip done");
out.close();
}
private void zip(ZipOutputStream out, File f, String base) throws Exception {
if (f.isDirectory()) {
File[] fl = f.listFiles();
out.putNextEntry(new org.apache.tools.zip.ZipEntry(base + "/"));
base = base.length() == 0 ? "" : base + "/";
for (int i = 0; i < fl.length; i++) {
zip(out, fl[i], base + fl[i].getName());
}
}else {
out.putNextEntry(new org.apache.tools.zip.ZipEntry(base));
FileInputStream in = new FileInputStream(f);
int b;
System.out.println(base);
while ( (b = in.read()) != -1) {
out.write(b);
}
in.close();
}
}
public static void main(String [] temp){
CompressBook book = new CompressBook();
try {
book.zip("c:\\c");//你要压缩的文件夹
}catch (Exception ex) {
ex.printStackTrace();
}
}
 }
}import java.io.*;
import java.util.zip.*;//ZipOutputStream这个流在这里
import java.util.*;
public class ZipOutputStreamTest
{
public static void main(String[] args) throws Exception
{
File f = new File("a.jpg");
FileInputStream fis = new FileInputStream(f);
BufferedInputStream bis = new BufferedInputStream(fis);
byte[] buf = new byte[1024];
int len;
FileOutputStream fos = new FileOutputStream(f.getName()+".zip");
BufferedOutputStream bos = new BufferedOutputStream(fos);
ZipOutputStream zos = new ZipOutputStream(bos);//压缩包
ZipEntry ze = new ZipEntry(f.getName());//这是压缩包名里的文件名
zos.putNextEntry(ze);//写入新的 ZIP 文件条目并将流定位到条目数据的开始处
while((len=bis.read(buf))!=-1)
{
zos.write(buf,0,len);
zos.flush();
}
bis.close();
zos.close();
}
}
摘要: (转)Java操作PDF文件(iText)2009-03-12 01:33:18标签:PDF Java 休闲 iText 文件原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://xiaoduan.blog.51cto.com/502137/137930上次我们用jacob来...
阅读全文
1、public boolean isCacheable(ServletRequest request) {
boolean cachable = false;
if (getTime() > 0) {
/**
* some AJAX application use post to get the page, need to specify a
* cache=true parameter to enable cache. Known url includes:
*/
if ("true".equals(request.getParameter("cache"))) {
cachable = true;
} else if (request.getParameter("noCache") == null
&& (request instanceof HttpServletRequest)) {
HttpServletRequest req = (HttpServletRequest) request;
String uri = req.getRequestURI();
String contextPath = req.getContextPath();
if(contextPath.length()>0)
uri = uri.substring(contextPath.length());
cachable = this.isCacheUris(uri);
}
}
return cachable;
}
public void setCacheUris(List<String> cacheUris) {
this.cacheUris = cacheUris;
}
private boolean isCacheUris(String uri){
for(String _uri:cacheUris){
if(uri.equals(_uri)){
return true;
}
}
return false;
}
2、<bean id="cacheFilterBean" class="com.ebizer.framework.core.filter.CacheFilter">
<property name="cacheUris">
<list>
<value>/trend.html</value>
</list>
</property>
</bean>
tomcat有时报错不准,命名是dtd找不到了,但是却只报找不到action。
本项目把dtd下载到项目中引入,程序直接找的是tomcat/bin目录下
js,css的优化方案基本都搞清楚了。
1.js,css分离出来到静态资源服务器上;
2.优化js,精简;
3.做gzip,客户端缓存;
4.资源服务器,做cdn加速;
2,3,4的优化,互相不冲突
1、 在 页面 ready后调用。jquery有相应的方法。
2、 在前面的方法内,再加个处理,利用setTimeout,在0.5秒后再动态的引入该js文件。
这样就是,等待页面完全装载完毕后,再等待0.5秒才装载该js。
一般而言,真实用户访问每个页面都不会少于1秒,所以也不会影响google的跟踪。
<@s.select id="examineRole" name="examineRole" list=r"#{'0':'无','YWKZ':'业务科长','YWBZ':'业务部长','XSCWBZ':'销售财务部长','KJK':'会计科','ZBZ':'总部长'}" value="'${formEntity.examineRole}'" cssClass="validate-select select"/>
注意value后面的写法,值前面要加单引号代表这是字符串,否则无法与自动选中,因为类型不匹配。数值型的就无需加单引号了。
项目备忘:DefaultViewAction中的printCmsStr方法是初始化block页面的一些参数,
比如:topperMap.put(CoreConstants.YUN_FRONTEND, ConfigHelper.getInstance().getProperties().getProperty("match.yun.frontend"));
1、数据库generator.properties
2、表对象对应的目录PackageNames.properties
3、页面及struts配置的模板PageTemplates.properties
4、codegen/templates/pages/存放一些页面ftl文件和struts-xxx.xml的模板
5、codegen/templates/struts2存放action类以及aciton在spring中的定义
。。。其他目录

要支持ALPHA参数,需要用以下命令
./configure --disable-openmp --disable-opencl --without-magick-plus-plus --disable-deprecated --without-fontconfig --without-tiff --without-x --disable-assert
官网命令
1、convert cyclops.png -bordercolor white -border 1x1 -alpha set -channel RGBA -fuzz 1% -fill none -floodfill +0+0 white -shave 1x1 cyclops_flood_2.png
我的测试命令
2、convert -alpha set -channel RGBA -fuzz 38% -transparent white -trim -adaptive-blur 1.5x0.5 -antialias cyclops.png cyclops_flood_2.png
摘要: ImageMagick开源项目-详细命令解释[ ‑adaptive‑blur• ‑adaptive‑resize• ‑adaptive‑sharpen• ‑adjoin• ‑affine•&nb...
阅读全文
ImageMagick 转换pdf为png 以及png图片透明[转载]
http://xieruilin.javaeye.com/blog/786584
在我写的《基于MoinMoin+ConTeXt实现包含数学内容的Wiki网站》一文中谈到了将 TeX 生成的 pdf 矢量图形转换为背景透明的 png 图片,这是利用 ImageMagick 工具套件中的 convert 命令实现的。
convert 命令有许多选项参数,本文用到的选项如下:
-trim:裁剪图像四周空白区域;
-transparent color:去除图像中指定的颜色;
-density geometry:设定图像的 DPI 值,若不明 DPI 值的概念,可参考《有关pt, px及DPI的知识》;
-antialias:让图像具有抗锯齿的效果;
-quality:图像压缩等级。
下面先由一份 ConTeXt 文档生成 pdf 图形,文档内容如下: (省略)
使用 convert 命令对该 pdf 文档转换:
- $ convert -quality 100 -antialias -density 96 -transparent white -trim test.pdf test.png
经 过测试,关于png透明的需要设定 -transparent white ,即去掉白色背景(其它背景色用相应的颜色名)。 不过对于eps图片,不需要这个命令,因为eps一般是没有背景的。(这里比较奇怪,照说pdf应该也是没有背景色的,eps和pdf都用相同的画图工具 输出。)
对于已经有背景色的png图片,同样可以用下面的命令
convert -transparent white test.png test_new.png
ImageMagick官方网页中,透明色的转换示例较为复杂 :
convert cyclops.png -bordercolor white -border 1x1 -alpha set -channel RGBA -fuzz 20% -fill none -floodfill +0+0 white -shave 1x1 cyclops_flood_2.png
其功能是去掉白色背景,同时进行模糊过渡。
0、利用pd9生成的sql带package会报错,删除即可。比较好的是会自定生成序列和触发器解决主键自增长问题。但是需要注意的是生成的建表sql给table带了"",oracle的表名是对大小写不敏感的,加上""就会区分大小写了。这样在写sql的时候也必须带引号了"tablename",否则会报“表或视图不存在”。
1、hibernate配置需要更改的
jdbc.driverClassName=oracle.jdbc.driver.OracleDriver
jdbc.url=jdbc:oracle:thin:@localhost:1521:orcl
hibernate.dialect=org.hibernate.dialect.OracleDialect
2、主键生成策略需要更改
a)oracle需要增加序列S_SYSTEM_CONFIG
b)oracle创建触发器在insert之前根据序列获取自增长主键值并且插入
3、hibernate的hbm.xml需要更改
<id name="systemConfigId"
column="system_config_id"
type="java.lang.Integer"
length="11">
<generator class="sequence">
<!-- Oracle Sequence的名字 -->
<param name="sequence">S_SYSTEM_CONFIG</param>
场景:一般情况下,我们注册一个用户名,判断是否重复
select count(name) from employee
如果返回值大于0,说明已经存在了,不能用这个用户名注册,但是,并发情况下(load runner并发测试),同时注册十个,会插入多条相同用户名!
这时候,就要找到相应的解决方案了!经过测试,得出正确方法,给name字段添加唯一约束
具体写法:
alter table employees
add constraint CK_st unique(name)
测试通过,不会插入重复记录!
还有一种方法,考虑用事务,插入数据完成后,执行select count(name) from employee,如果>1,则回滚事务,提示注册失败!
由此,总结了一些约束的用法
主键(primary key)约束:
alter table employees
add constraint CK_PrimaryId primary key(EmployeeId)--主键会自动添加约束
核对(check)约束
alter table employees
add constraint CK_EmployeeType check(EmployeeType>1 and EmployeeType<5)--限制EmployeeType取值范围
默认(default)约束
alter table employees
add constraint CK_Pass default'111' for Pass--密码默认为'111'
外键(foreign key)约束
alter table employees
add constraint CK_EmployeeId foreign key(employeeid)
references EmployeeRange(employeeid)
--保持表employees的employeeid字段和表EmployeeRange的employeeid字段一致
唯一(unique)约束
alter table employees
add constraint CK_st unique(name)--唯一约束和主键约束的区别是唯一约束可以为空,主键约束不可以为空,主键约束也是唯一约束
Exception in thread "Image Fetcher 0" java.lang.OutOfMemoryError: Java heap space
解决方法:
在Eclipse里选:Window->Preference->Installed JREs->Edit(选中jre),
在Default VM Arguments里输入-Xms256m -Xmx1024m,表示最小内存256M,最大1G,然后运行就可以了
摘要: [java:showcolumns] view plaincopy·········10········20········30·...
阅读全文
写了很多篇关于图像处理的文章,没有一篇介绍Java 2D的图像处理API,文章讨论和提及的
API都是基于JDK6的,首先来看Java中如何组织一个图像对象BufferedImage的,如图:
一个BufferedImage的像素数据储存在Raster中,ColorModel里面储存颜色空间,类型等
信息,当前Java只支持一下三种图像格式- JPG,PNG,GIF,如何向让Java支持其它格式,首
先要 完成Java中的图像读写接口,然后打成jar,加上启动参数- Xbootclasspath/p
newimageformatIO.jar即可。
Java中如何读写一个图像文件,使用ImageIO对象即可。读图像文件的代码如下:
- File file = new File("D:\\test\\blue_flower.jpg");
- BufferedImage image = ImageIO.read(file);
写图像文件的代码如下:
- File outputfile = new File("saved.png");
- ImageIO.write(bufferedImage, "png",outputfile);
从BufferedImage对象中读取像素数据的代码如下:
- int type= image.getType();
- if ( type ==BufferedImage.TYPE_INT_ARGB || type == BufferedImage.TYPE_INT_RGB )
- return (int [])image.getRaster().getDataElements(x, y, width, height, pixels );
- else
- return image.getRGB( x, y, width, height, pixels, 0, width );
首先获取图像类型,如果不是32位的INT型数据,直接读写RGB值即可,否则需要从Raster
对象中读取。
往BufferedImage对象中写入像素数据同样遵守上面的规则。代码如下:
- int type= image.getType();
- if ( type ==BufferedImage.TYPE_INT_ARGB || type == BufferedImage.TYPE_INT_RGB )
- image.getRaster().setDataElements(x, y, width, height, pixels );
- else
- image.setRGB(x, y, width, height, pixels, 0, width );
读取图像可能因为图像文件比较大,需要一定时间的等待才可以,Java Advance Image
Processor API提供了MediaTracker对象来跟踪图像的加载,同步其它操作,使用方法如下:
- MediaTracker tracker = new MediaTracker(this); //初始化对象
- tracker.addImage(image_01, 1); // 加入要跟踪的BufferedImage对象image_001
- tracker.waitForID(1, 10000) // 等待10秒,让iamge_01图像加载
从一个32位int型数据cARGB中读取图像RGB颜色值的代码如下:
- int alpha = (cARGB >> 24)& 0xff; //透明度通道
- int red = (cARGB >> 16) &0xff;
- int green = (cARGB >> 8) &0xff;
- int blue = cARGB & 0xff;
将RGB颜色值写入成一个INT型数据cRGB的代码如下:
- cRGB = (alpha << 24) | (red<< 16) | (green << 8) | blue;
创建一个BufferedImage对象的代码如下:
- BufferedImage image = newBufferedImage(256, 256, BufferedImage.TYPE_INT_ARGB);
一个完整的源代码Demo如下:
- package com.gloomyfish.swing;
-
- import java.awt.BorderLayout;
- import java.awt.Dimension;
- import java.awt.Graphics;
- import java.awt.Graphics2D;
- import java.awt.RenderingHints;
- import java.awt.image.BufferedImage;
- import java.io.File;
- import java.io.IOException;
-
- import javax.imageio.ImageIO;
- import javax.swing.JComponent;
- import javax.swing.JFrame;
-
- public class PlasmaDemo extends JComponent {
-
- /**
- *
- */
- private static final long serialVersionUID = -2236160343614397287L;
- private BufferedImage image = null;
- private int size = 256;
-
- public PlasmaDemo() {
- super();
- this.setOpaque(false);
- }
-
- protected void paintComponent(Graphics g) {
- Graphics2D g2 = (Graphics2D)g;
- g2.setRenderingHint(RenderingHints.KEY_ANTIALIASING, RenderingHints.VALUE_ANTIALIAS_ON);
- g2.drawImage(getImage(), 5, 5, image.getWidth(), image.getHeight(), null);
- }
-
- private BufferedImage getImage() {
- if(image == null) {
- image = new BufferedImage(size, size, BufferedImage.TYPE_INT_ARGB);
- int[] rgbData = new int[size*size];
- generateNoiseImage(rgbData);
- setRGB(image, 0, 0, size, size, rgbData);
- File outFile = new File("plasma.jpg");
- try {
- ImageIO.write(image, "jpg", outFile);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- return image;
- }
-
- public void generateNoiseImage(int[] rgbData) {
- int index = 0;
- int a = 255;
- int r = 0;
- int g = 0;
- int b = 0;
-
- for(int row=0; row<size; row++) {
- for(int col=0; col<size; col++) {
- // set random color value for each pixel
- r = (int)(128.0 + (128.0 * Math.sin((row + col) / 8.0)));
- g = (int)(128.0 + (128.0 * Math.sin((row + col) / 8.0)));
- b = (int)(128.0 + (128.0 * Math.sin((row + col) / 8.0)));
-
- rgbData[index] = ((clamp(a) & 0xff) << 24) |
- ((clamp(r) & 0xff) << 16) |
- ((clamp(g) & 0xff) << 8) |
- ((clamp(b) & 0xff));
- index++;
- }
- }
-
- }
-
- private int clamp(int rgb) {
- if(rgb > 255)
- return 255;
- if(rgb < 0)
- return 0;
- return rgb;
- }
-
- public void setRGB( BufferedImage image, int x, int y, int width, int height, int[] pixels ) {
- int type = image.getType();
- if ( type == BufferedImage.TYPE_INT_ARGB || type == BufferedImage.TYPE_INT_RGB )
- image.getRaster().setDataElements( x, y, width, height, pixels );
- else
- image.setRGB( x, y, width, height, pixels, 0, width );
- }
-
- public static void main(String[] args) {
- JFrame frame = new JFrame("Noise Art Panel");
- frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
- frame.getContentPane().setLayout(new BorderLayout());
-
- // Display the window.
- frame.getContentPane().add(new PlasmaDemo(), BorderLayout.CENTER);
- frame.setPreferredSize(new Dimension(400 + 25,450));
- frame.pack();
- frame.setVisible(true);
- }
- }
修改 my.ini文件
加入以下语句(在没有设置的前提下)
log-error=d:/log/mysql/mysql_log_err.txt
log=d:/log/mysql/mysql_log.txt
#log-bin=d:/log/mysql/mysql_log_bin
log-slow-queries= d:/log/mysql/mysql_log_slow.txt
使用以下命令查看是否启用了日志
mysql>show variables like ’log_%’;
其他:
参考:http://www.phpfans.net/article/htmls/201008/MjkzMTE0.html
1.
错误日志 记录启动、运行或停止mysqld时出现的问题。
My.ini配置信息:
#Enter a name for the error log file. Otherwise a default name will be used.
#log-error=d:/mysql_log_err.txt
2.
查询日志 记录建立的客户端连接和执行的语句。
My.ini配置信息:
#Enter a name for the query log file. Otherwise a default name will be used.
#log=d:/mysql_log.txt
3.
更新日志 记录更改数据的语句。不赞成使用该日志。
My.ini配置信息:
#Enter a name for the update log file. Otherwise a default name will be used.
#log-update=d:/mysql_log_update.txt
4.
二进制日志 记录所有更改数据的语句。还用于复制。
My.ini配置信息:
#Enter a name for the binary log. Otherwise a default name will be used.
#log-bin=d:/mysql_log_bin
5.
慢日志 记录所有执行时间超过long_query_time秒的所有查询或不使用索引的查询。
My.ini配置信息:
#Enter a name for the slow query log file. Otherwise a default name will be used.
#long_query_time =1
#log-slow-queries= d:/mysql_log_slow.txt
请看下面这段配置就是错误的:
<Host name="www.***.com" debug="0" appBase="webapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false">
<Logger className="org.apache.catalina.logger.FileLogger" directory="logs" prefix="localhost_log." suffix=".txt" timestamp="true" />
<Context path="" docBase="/tomcat/webapps/***" debug="1" />
<Context path="/***2" docBase="/tomcat/webapps/***2" debug="1" />
</Host>
正确的配置如下
<Host name="www.***.com" debug="0" appBase="" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false">
<Logger className="org.apache.catalina.logger.FileLogger" directory="logs" prefix="localhost_log." suffix=".txt" timestamp="true" />
<Context path="" docBase="/tomcat/webapps/***" debug="1" />
<Context path="/***2" docBase="/tomcat/webapps/***2" debug="1" />
</Host>
这两段的区别是第二段去除了appBase="webapps"中的webapps变成了appBase="",因为web应用程序都是放在 webapps这个目录下的,如果不把“webapps“去掉,这里会调用一次quartz的任务调度,在接下来的“<Context path”中又会调用一次quartz的任务调度,所以就重复了2次
tomcat中三种部署项目的方法
第一种方法:在tomcat中的conf目录中,在server.xml中的,<host/>节点中添加:
<Context path="/hello" docBase="D:eclipse3.2.2forwebtoolsworkspacehelloWebRoot" debug="0" privileged="true">
</Context>
至于Context 节点属性,可详细见相关文档。
第二种方法:将web项目文件件拷贝到webapps 目录中。
第三种方法:很灵活,在conf目录中,新建 Catalina(注意大小写)\localhost目录,在该目录中新建一个xml文件,名字可以随意取,只要和当前文件中的文件名不重复就行了,该xml文件的内容为:
<Context path="/hello" docBase="D:eclipse3.2.2forwebtoolsworkspacehelloWebRoot" debug="0" privileged="true">
</Context>
第3个方法有个优点,可以定义别名。服务器端运行的项目名称为path,外部访问的URL则使用XML的文件名。这个方法很方便的隐藏了项目的名称,对一些项目名称被固定不能更换,但外部访问时又想换个路径,非常有效。
第2、3还有优点,可以定义一些个性配置,如数据源的配置等。
还有一篇 详细的
此处主要讲述Tomcat部署发布JSP应用程序的三种方法
1、直接放到Webapps目录下
Tomcat的Webapps目录是Tomcat默认的应用目录,当服务器启动时,会加载所有这个目录下的应用。也可以将JSP程序打包成一个 war包放在目录下,服务器会自动解开这个war包,并在这个目录下生成一个同名的文件夹。一个war包就是有特性格式的jar包,它是将一个Web程序的所有内容进行压缩得到。具体如何打包,可以使用许多开发工具的IDE环境,如Eclipse、NetBeans、ant、JBuilder等。也可以用 cmd 命令:jar -cvf applicationname.war package.*;
甚至可以在程序执行中打包:
try{
string strjavahome = system.getproperty("java.home");
strjavahome = strjavahome.substring(0,strjavahome.lastindexof(\\))+"\\bin\\";
runtime.getruntime().exec("cmd /c start "+strjavahome+"jar cvf hello.war c:\\tomcat5.0\\webapps\\root\\*");
}
catch(exception e){system.out.println(e);}
webapps这个默认的应用目录也是可以改变。打开Tomcat的conf目录下的server.xml文件,找到下面内容:
<Host name="localhost" debug="0" appBase="webapps" unpackWARs="true" autoDeloy="true" xmlValidation="falase" xmlNamespaceAware="false">
2、在server.xml中指定
在Tomcat的配置文件中,一个Web应用就是一个特定的Context,可以通过在server.xml中新建Context里部署一个JSP应用程序。打开server.xml文件,在Host标签内建一个Context,内容如下。
<Context path="/myapp" reloadable="true" docBase="D:\myapp" workDir="D:\myapp\work"/>
其中path是虚拟路径,docBase是JSP应用程序的物理路径,workDir是这个应用的工作目录,存放运行是生成的于这个应用相关的文件。
3、创建一个Context文件
以上两种方法,Web应用被服务器加载后都会在Tomcat的conf\catalina\localhost目录下生成一个XML文件,其内容如下:
<Context path="/admin" docBase="${catalina.home}/server/webapps/admin" debug="0" privileged="true"></Context>
可以看出,文件中描述一个应用程序的Context信息,其内容和server.xml中的Context信息格式是一致的,文件名便是虚拟目录名。您可以直接建立这样的一个xml文件,放在Tomcat的conf\catalina\localhost目录下。例子如下:
注意:删除一个Web应用同时也要删除webapps下相应的文件夹祸server.xml中相应的Context,还要将Tomcat的conf
\catalina\localhost目录下相应的xml文件删除。否则Tomcat仍会岸配置去加载。。。
所以项目最好不要放在webapps下,然后又跑去server.xml下或者catalina目录下再配置一遍,这样就会同时启动2次同一个应用。如果应用中有job,这样会造成并发。
定义一个job:ranJob,设置每秒执行一次,设置不允许覆盖并发执行
- <bean id="rankJob" class="com.chinacache.www.logstat.job.RankJob" />
- <bean id="rankJobDetail"
- class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
- <property name="targetObject" ref="rankJob" />
- <property name="targetMethod" value="execute" />
- <property name="concurrent" value="<span style="color: #ff0000;"><strong>false</strong></span>" />
- </bean>
- <bean id="rankJobTrigger" class="org.springframework.scheduling.quartz.SimpleTriggerBean">
- <property name="jobDetail" ref="rankJobDetail" />
- <!-- 单位 ms,半小时 1800000 ms -->
- <property name="repeatInterval" value="<span style="color: #ff0000;"><strong>1000</strong></span>" />
- </bean>
job代码:
- System.out.println("Start job");
- ExecutorService exec = Executors.newFixedThreadPool(1);
-
- Thread thread = new Thread(new Runnable() {
- @Override
- public void run() {
- System.out.println("thread start");
- try {
- Thread.sleep(3000);
- } catch (InterruptedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- System.out.println("thread end");
- }
- });
- exec.execute(thread);
- System.out.println("end job");
程序输出结果:
- Start job
- end job
- <span style="color: #ff0000;"><strong>thread start</strong></span>
- Start job
- end job
- thread start
- Start job
- end job
- thread start
- Start job
- end job
- thread start
- <strong><span style="color: #ff0000;">thread end</span></strong>
从结果可以看到,job的并发覆盖配置似乎根本没有生效,原因是:job没有关注多线程执行情况
修改job代码,添加如下代码在job访问最后,线程处理完job才结束,
- while (!exec.isTerminated()) {
- // 等待所有子线程结束,才退出主线程
- }
修改代码后程序结果:
- Start job
- thread start
- thread end
可以看到job始终没有结束,说明ExecutorService始终没有终止,看看文档,加入shutdonw()方法,job所有代码如下:
- public void execute() throws InterruptedException {
- System.out.println("Start job");
- ExecutorService exec = Executors.newFixedThreadPool(1);
-
- Thread thread = new Thread(new Runnable() {
- @Override
- public void run() {
- System.out.println("thread start");
- try {
- Thread.sleep(3000);
- } catch (InterruptedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- System.out.println("thread end");
- }
- });
- exec.execute(thread);
- exec.shutdown();
- while (!exec.isTerminated()) {
- // 等待所有子线程结束,才退出主线程
- }
- System.out.println("end job");
- }
打印结果如下:
- Start job
- thread start
- thread end
- end job
-
- Start job
- thread start
- thread end
- end job
-
- Start job
- thread start
- thread end
- end job
OK,至此spring quartz多线程并发问题解决。回顾下,我们要使用isTerminated()方法等多线程结束后在结束job;多线程任务派发结束后,要使用shutdown()方法顺序关闭线程(等待正在执行任务,不接受新任务)
<div class="clearLine"></div>
这段用来清除浮动
得要写在最下面,不可以写在两段div的中间,否则就会错位。
有个bean命名不在指定的拦截范围内,没被事务拦截器拦截,所以没有关闭连接了。 <bean id="mailEngine" parent="txProxyTemplate">
以前没有配置parent,所以不在spring的事务监管之列。
因为当save时,会出错就表示锁了。
比如下面的方法,要catch一下,如果保存报错,就表示另一个线程保存的时候锁住了。
public List<MailQueue> updateStatusAndFindMailList(int numOfEmailsPerTime) {
List<MailQueue> list = this.mailQueueDao.findMailListAndLock(numOfEmailsPerTime);
for(MailQueue mailQueue:list){
try{
mailQueue.setSendStatus(MailQueue.STATUS_SENDING);
this.saveOrUpdate(mailQueue);
}catch(Exception e){
//如果保存失败,表示是给另一个线程保存了。
list.remove(mailQueue);
}
}
return list;
}
在response.sendRedirect()方法后加return语句即可,如下:
response.sendRedirect("index.jsp");
return;
原因是:在程序中两次调用了response.sendRedirect()方法。
jdk5.0文档中很清楚地介绍了出现IllegalStateException异常的可能情况:
1)同一个页面中再次调用response.sendRedirect()方法。
2)提交的URL错误,即不是个有效的URL。
filter中多次chain.doFilter(request, response);也会这样,要保证一个filter只进行一次doFilter
java.lang.IllegalStateException
at org.apache.catalina.connector.ResponseFacade.sendError(ResponseFacade.java:405)
at org.apache.catalina.servlets.DefaultServlet.serveResource(DefaultServlet.java:779)
at org.apache.catalina.servlets.DefaultServlet.doGet(DefaultServlet.java:385)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:627)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:729)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:269)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:188)
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:96)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:76)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:215)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:188)
at com.ebizer.framework.star.filter.CoreUrlRewriteFilter.doFilterInternal(CoreUrlRewriteFilter.java:120)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:76)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:215)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:188)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:213)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:172)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:127)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:117)
at org.apache.catalina.valves.AccessLogValve.invoke(AccessLogValve.java:581)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:108)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:174)
at org.apache.coyote.http11.Http11AprProcessor.process(Http11AprProcessor.java:843)
at org.apache.coyote.http11.Http11AprProtocol$Http11ConnectionHandler.process(Http11AprProtocol.java:679)
at org.apache.tomcat.util.net.AprEndpoint$Worker.run(AprEndpoint.java:1293)
at java.lang.Thread.run(Thread.java:595)
网页缓存
2009-07-09 10:42
网页的缓存是由HTTP消息头中的“Cache-control”来控制的,常见的取值有private、no-cache、max-age、must-revalidate等,默认为private。其作用根据不同的重新浏览方式分为以下几种情况:
(1) 打开新窗口
如果指定cache-control的值为private、no-cache、must-revalidate,那么打开新窗口访问时都会重新访问服务器。而如果指定了max-age值,那么在此值内的时间里就不会重新访问服务器,例如:
Cache-control: max-age=5
表示当访问此网页后的5秒内再次访问不会去服务器
(2) 在地址栏回车
如果值为private或must-revalidate(和网上说的不一样),则只有第一次访问时会访问服务器,以后就不再访问。如果值为no-cache,那么每次都会访问。如果值为max-age,则在过期之前不会重复访问。
(3) 按后退按扭
如果值为private、must-revalidate、max-age,则不会重访问,而如果为no-cache,则每次都重复访问
(4) 按刷新按扭
无论为何值,都会重复访问
项目中使用过滤器来设置网页的缓存
FilterConfig fc;
public void doFilter(ServletRequest req, ServletResponse res,
FilterChain chain) throws IOException, ServletException {
HttpServletResponse response = (HttpServletResponse) res;
// set the provided HTTP response parameters
for (Enumeration e = fc.getInitParameterNames(); e.hasMoreElements();) {
String headerName = (String) e.nextElement();
response.addHeader(headerName, fc.getInitParameter(headerName));
}
// pass the request/response on
chain.doFilter(req, response);
} 配置文件的配置:
<filter>
<filter-name>NoCache</filter-name>
<filter-class>filter.CacheFilter</filter-class>
<init-param>
<param-name>Cache-Control</param-name>
<param-value>no-cache, must-revalidate</param-value>
</init-param>
</filter>
<filter>
<filter-name>CacheForWeek</filter-name>
<filter-class>filter.CacheFilter</filter-class>
<init-param>
<param-name>Cache-Control</param-name>
<param-value>max-age=604800</param-value>
</init-param>
</filter> <filter-mapping>
<filter-name>CacheForWeek</filter-name>
<url-pattern>*.js</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>CacheForWeek</filter-name>
<url-pattern>*.css</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>CacheForWeek</filter-name>
<url-pattern>*.gif</url-pattern>
</filter-mapping> |
JQuery AJAX中遇到这样一个问题,参数中包含特殊字符,比如&'#@等
这是执行AJAX的时候就会出问题,因为所传的参数变了.
看个示例就明白:
$.ajax({
url: '/ashx/ajax.ashx',
type: 'post',
data: 'option=delete&name=11&adb,
success: function (data) {
if (data != 'error') {
}
}
});
上面执行的ajax就是异步删除一个name为 11&abd 的数据
当请求到ajax.ashx页面时,我们获取到的name参数为11
执行操作后会发现其实删除了 name 为 11的数据,而没有删除 name 为 11&abc 的数据
这是由于有&特殊字符,把以前的俩个参数变成了三个参数 option,name,abc
这时就需要用另外一种方法传递参数:
$.ajax({
url: '/ashx/ajax.ashx',
type: 'post',
data:{ 'option':'delete','name':'11&adb'},
success: function (data) {
if (data != 'error') {
}
}
});
采用上面的json格式传递参数就可以避免特殊字符引起的参数错误问题.
1、安装ant,下载ant包,并解压到d盘根目录d:\ant
2、配置环境变量,包括ANT和JAVA_HOME
ANT_HOME:D:\ant
JAVA_HOME:E:\workserver\jdk1.5.0_06
path:D:\ant\bin;E:\workserver\jdk1.5.0_06\bin
3、ant需要jsch-0.1.37.jar包和js-1.6R2.jar包放在ant\lib目录下
4、启动命令行cmd,到该目录:E:\workspace\ebizcenter\metadata\build\scripts
5、执行a、"ant checkout"从svn服务器下载,b、"ant build"编译java类成class文件,c、"ant deploy"部署到服务器(上传)
6、如果是64位系统,参考这篇文章http://www.linuxso.com/linuxbiancheng/13326.html
a、去
http://www.sliksvn.com/en/download下载并安装
b、安装完成后,把安装目录(如:D:\Program Files\SlikSvn\bin) 加入到系统环境变量PATH中 c、
在安装目录下(如:D:\Program Files\SlikSvn\bin)找到“libsvnjavahl-1.dll”这个文件,复制一份后重命名为“svnjavahl-1.dll”,即去掉文件名中前三个字母
1、url转发需要修改响应的字符类型response.setContentType("text/html;charset=UTF-8");2、@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
ajax 是无法实现上传文件的 , ajax与后台通信都是通过传递字符串
-- index.html
- <form action="upload.jsp" id="form1" name="form1" encType="multipart/form-data" method="post" target="hidden_frame" >
- <input type="file" id="file" name="file" style="width:450">
- <input type="submit" value="上传文件"><span id="msg"></span>
- <br>
- <font color="red">支持JPG,JPEG,GIF,BMP,SWF,RMVB,RM,AVI文件的上传</font>
-
- <iframe name='hidden_frame' id="hidden_frame" style='display:none'></iframe>
- </form>
-
- <!-- javascript s -->
- <script type="text/javascript">
- function callback(msg) {
- document.getElementById("file").outerHTML = document.getElementById("file").outerHTML;
- document.getElementById("msg").innerHTML = "<font color=red>"+msg+"</font>";
- }
- </script>
index.html 中主要要做的就是写一个 form 和 iframe ,并把 form 的 target 设为 iframe 的名字,注意要把iframe 设为不可见,其他的都是正常的文件上传的写法,这样刷新的页面就是这个隐藏的 Iframe ,而在 index.html 中是不会有页面刷新的,js的 callback 方法是回调方法。用于清空文件上传框和显示后台信息,注意清空文件上传框的方法,和普通方法有点不一样。
上传的注意事项:
1、<form method="POST" id="matchItemForm" name="formEntity" action="${CoreCtxPath}/gather/gatherAjax.html" enctype="multipart/form-data" target="hidden_frame">
这里的method很重要不能少,enctype也不能少,target代表form和iframe绑定也不能少。
1.Java代码
打开Eclipse的Window菜单,然后Preferences->Java->Code Style->Formatter->Edit/Show(根据不同版本可用的按钮会不一样) ->Line Wrapping->Maximum line width:由默认的80改成自己想要设定的长度
2.Html代码
Window->Preferences->MyEclipse->Files and Editors->Html->Html Source->Line width->加个0以后保存。
3.xml代码
Window->Preferences->MyEclipse->Files and Editors->xml->xml Source->->Line width->999
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
为了能够让终端通过网络访问,需要开启MYSQL远程访问服务。即在MYSQL的user表中进行设置,使任何ip的主机都能够使用用户名为root,密码为“1”访问数据库。在Linux的终端中输入如下命令:
#mysql –uroot -p
Enter password:
#mysql>use mysql;
#mysql>update user set host='%' where user='root';
#mysql>FLUSH PRIVILEGES;
#mysql>select host,user from user ;
当看到Host 这一项中有一个%记录且用户名为root。说明设置已成功。
一般MySQL安装的时候默认是绑定了本机。因此需要在配置文件中取消本机绑定。方能够被远程的主机访问。MySQL配置文件为my.cnf ,位于/etc/mysql/文件夹下。编辑my.cnf,找到bind-address =127.0.0.1。这一句就是将MySQL与本机绑定。所以将此句注释掉。取消与本机的绑定。然后执行 #sudo /etc/init.d/mysql restart 。即重启MySQL服务,重启之后就可进行远程访问。这样就完全搭建好可以在网络中被终端访问的服务器端数据库了。
1、struts2提供的有struts-2.0.9\j4目录,这个下面有工具可以把1.5下编译的包,给编译成兼容1.4的包。
2、spring2是直接支持jre1.4的,其实大部分开源jar包都直接支持。
3、如果你用的是eclipse,你需要在项目--->属性--->构建路径---->库,中进行设置“JRE 系统库[jdk 1.4.2_07]”,当然你也要引入其它编译好了的兼容1.4的包。
4、在项目--->属性--->java编译器,中需要勾选“启用特定与项目的设置”,将“编译器一致性级别”设置为1.4,并且应用。
5、有些jar包不能在1.4环境下跑的,不过这个不好统计,我遇到的有commons-beanutils-1.6.jar不要用1.7以及以后版本的,貌似commons-logging-1.0.4.jar也不要用高版本。
这个是没有设置好的时候报出的错误信息(这里是c3p0,也可能不是这个类报出来):
(C3P0Registry.java:139) jdk1.5 management interfaces unavailable... JMX support disabled.
缓存实现的层面有很多:
1、对象缓存
由ORM框架提供,透明性访问,细颗粒度缓存数据库查询结果,无需业务代码显式编程。当软件结构按照ORM框架的要求进行针对性设计,使用对象缓存将会极大降低web系统对于数据库的访问请求。因为类似Hibernate这样的ORM,良好的设计数据库结构和利用对象缓存,在大负载网站,能够提供极高的性能。因为使用对象缓存也无需显式编程,所以适用范围也最广泛。
2、查询缓存
对数据库查询结果行集进行缓存,适用于一些耗时,但是时效性要求比较低的场景。iBATIS就只能使用查询缓存,而无对象缓存。查询缓存和对象缓存适用的场景不一样,是互为补充的。
3、片断缓存
针对动态页面的局部片断内容进行缓存,适用于一些个性化但不经常更新的页面(例如博客)。OSCache提供了相当简陋的片断缓存,而RoR则提供了相当好的片断缓存机制。
4、Action缓存
针对URL访问返回的页面结果进行缓存,适用于粗粒度的页面缓存,例如新闻发布。OScache提供了相当简陋的Action缓存(通过web.xml中的配置),而RoR提供了相当好的Action缓存。
缓存不能一概而论,以上每种缓存分别适用于各自的场景,缓存不同的层面。当然你可以在应用程序当中把4种缓存一起用上。
相对路径本质上还是绝对路径
因此,归根结底,Java本质上只能使用绝对路径来寻找资源。所有的相对路径寻找资源的方法,都不过是一些便利方法。不过是API在底层帮助我们构建了绝对路径,从而找到资源的!
得到classpath和当前类的绝对路径的一些方法
下面是一些得到classpath和当前类的绝对路径的一些方法。你可能需要使用其中的一些方法来得到你需要的资源的绝对路径。
1.FileTest.class.getResource("")
得到的是当前类FileTest.class文件的URI目录。不包括自己!
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/com/test/
2.FileTest.class.getResource("/")
得到的是当前的classpath的绝对URI路径。
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/
3.Thread.currentThread().getContextClassLoader().getResource("")
得到的也是当前ClassPath的绝对URI路径。
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/
4.FileTest.class.getClassLoader().getResource("")
得到的也是当前ClassPath的绝对URI路径。
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/
5.ClassLoader.getSystemResource("")
得到的也是当前ClassPath的绝对URI路径。
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/
我推荐使用Thread.currentThread().getContextClassLoader().getResource("")来得到当前的classpath的绝对路径的URI表示法。
Web应用程序中资源的寻址
上文中说过,当前用户目录,即相对于System.getProperty("user.dir")返回的路径。
对于JavaEE服务器,这可能是服务器的某个路径,这个并没有统一的规范!
而不是我们发布的Web应用程序的根目录!
这样,在Web应用程序中,我们绝对不能使用相对于当前用户目录的相对路径。
在Web应用程序中,我们一般通过ServletContext.getRealPath("/")方法得到Web应用程序的根目录的绝对路径。
这样,我们只需要提供相对于Web应用程序根目录的路径,就可以构建出定位资源的绝对路径。
这是我们开发Web应用程序时一般所采取的策略。
(本文转载自:http://dev.yesky.com/85/3001085_1.shtml)
如下问题:
java.sql.SQLException: 类型长度大于最大值
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:124)
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:161)
at oracle.jdbc.driver.DatabaseError.check_error(DatabaseError.java:884)
at oracle.jdbc.driver.T4CMAREngine.buffer2Value(T4CMAREngine.java:2230)
at oracle.jdbc.driver.T4CMAREngine.unmarshalUB4(T4CMAREngine.java:1146)
at oracle.jdbc.driver.T4CMAREngine.unmarshalDALC(T4CMAREngine.java:2097)
at oracle.jdbc.driver.T4C8TTIuds.unmarshal(T4C8TTIuds.java:127)
at oracle.jdbc.driver.T4CTTIdcb.receiveCommon(T4CTTIdcb.java:125)
at oracle.jdbc.driver.T4CTTIdcb.receiveFromRefCursor(T4CTTIdcb.java:103)
at oracle.jdbc.driver.T4CResultSetAccessor.unmarshalOneRow(T4CResultSetAccessor.java:165)
at oracle.jdbc.driver.T4CTTIrxd.unmarshal(T4CTTIrxd.java:787)
at oracle.jdbc.driver.T4CTTIrxd.unmarshal(T4CTTIrxd.java:704)
at oracle.jdbc.driver.T4C8Oall.receive(T4C8Oall.java:526)
at oracle.jdbc.driver.T4CCallableStatement.doOall8(T4CCallableStatement.java:179)
at oracle.jdbc.driver.T4CCallableStatement.execute_for_rows(T4CCallableStatement.java:782)
at oracle.jdbc.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:1027)
at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:2887)
at oracle.jdbc.driver.OraclePreparedStatement.execute(OraclePreparedStatement.java:2978)
at oracle.jdbc.driver.OracleCallableStatement.execute(OracleCallableStatement.java:4102)
at getConnection.TestProcedure.main(TestProcedure.java:37)
java.sql.SQLException: 违反协议
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:124)
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:161)
at oracle.jdbc.driver.DatabaseError.check_error(DatabaseError.java:884)
at oracle.jdbc.driver.T4C7Ocommoncall.receive(T4C7Ocommoncall.java:132)
at oracle.jdbc.driver.T4CConnection.logoff(T4CConnection.java:384)
at oracle.jdbc.driver.PhysicalConnection.close(PhysicalConnection.java:1035)
at getConnection.TestProcedure.closeConn(TestProcedure.java:70)
at getConnection.TestProcedure.main(TestProcedure.java:47)
我的数据库是9.2.0.4.0版本1.12M的驱动有问题,必须要下对应的1.13M的驱动。下载网址:http://www.oracle.com/technology/software/tech/java/sqlj_jdbc/htdocs/jdbc9201.html
本文将告诉你学习Java需要达到的30个目标,希望能够对你的学习有所帮助。对比一下自己,你已经掌握了这30条中的多少条了呢?
1.你需要精通面向对象分析与设计(OOA/OOD)、涉及模式(GOF,J2EEDP)以及综合模式。你应该十分了解UML,尤其是class,object,interaction以及statediagrams。
2.你需要学习JAVA语言的基础知识以及它的核心类库(collections,serialization,streams,networking, multithreading,reflection,event,handling,NIO,localization,以及其他)。
3.你应该了解JVM,classloaders,classreflect,以及垃圾回收的基本工作机制等。你应该有能力反编译一个类文件并且明白一些基本的汇编指令。
4.如果你将要写客户端程序,你需要学习WEB的小应用程序(applet),必需掌握GUI设计的思想和方法,以及桌面程序的SWING,AWT, SWT。你还应该对UI部件的JAVABEAN组件模式有所了解。JAVABEANS也被应用在JSP中以把业务逻辑从表现层中分离出来。
5.你需要学习java数据库技术,如JDBCAPI并且会使用至少一种persistence/ORM构架,例如Hibernate,JDO, CocoBase,TopLink,InsideLiberator(国产JDO红工厂软件)或者iBatis。
6.你还应该了解对象关系的阻抗失配的含义,以及它是如何影响业务对象的与关系型数据库的交互,和它的运行结果,还需要掌握不同的数据库产品运用,比如:oracle,mysql,mssqlserver。
7.你需要学习JAVA的沙盒安全模式(classloaders,bytecodeverification,managers,policyandpermissions,
codesigning, digitalsignatures,cryptography,certification,Kerberos,以及其他)还有不同的安全/认证 API,例如JAAS(JavaAuthenticationandAuthorizationService),JCE (JavaCryptographyExtension),JSSE(JavaSecureSocketExtension),以及JGSS (JavaGeneralSecurityService)。
8.你需要学习Servlets,JSP,以及JSTL(StandardTagLibraries)和可以选择的第三方TagLibraries。
9.你需要熟悉主流的网页框架,例如JSF,Struts,Tapestry,Cocoon,WebWork,以及他们下面的涉及模式,如MVC/MODEL2。
10.你需要学习如何使用及管理WEB服务器,例如tomcat,resin,Jrun,并且知道如何在其基础上扩展和维护WEB程序。
11.你需要学习分布式对象以及远程API,例如RMI和RMI/IIOP。
12.你需要掌握各种流行中间件技术标准和与java结合实现,比如Tuxedo、CROBA,当然也包括javaEE本身。
13.你需要学习最少一种的XMLAPI,例如JAXP(JavaAPIforXMLProcessing),JDOM(JavaforXMLDocumentObjectModel),DOM4J,或JAXR(JavaAPIforXMLRegistries)。
14.你应该学习如何利用JAVAAPI和工具来构建WebService。例如JAX-RPC(JavaAPIforXML/RPC),SAAJ (SOAPwithAttachmentsAPIforJava),JAXB(JavaArchitectureforXMLBinding),JAXM(JavaAPIforXMLMessaging), JAXR(JavaAPIforXMLRegistries),或者JWSDP(JavaWebServicesDeveloperPack)。
15.你需要学习一门轻量级应用程序框架,例如Spring,PicoContainer,Avalon,以及它们的IoC/DI风格(setter,constructor,interfaceinjection)。
16.你需要熟悉不同的J2EE技术,例如JNDI(JavaNamingandDirectoryInterface),JMS (JavaMessageService),JTA/JTS(JavaTransactionAPI/JavaTransactionService),JMX (JavaManagementeXtensions),以及JavaMail。
17.你需要学习企业级JavaBeans(EJB)以及它们的不同组件模式:Stateless/StatefulSessionBeans,EntityBeans(包含Bean- ManagedPersistence[BMP]或者Container-ManagedPersistence[CMP]和它的EJB-QL),或者 Message-DrivenBeans(MDB)。
18.你需要学习如何管理与配置一个J2EE应用程序服务器,如WebLogic,JBoss等,并且利用它的附加服务,例如簇类,连接池以及分布式处理支援。你还需要了解如何在它上面封装和配置应用程序并且能够监控、调整它的性能。
19.你需要熟悉面向方面的程序设计以及面向属性的程序设计(这两个都被很容易混淆的缩写为AOP),以及他们的主流JAVA规格和执行。例如AspectJ和AspectWerkz。
20.你需要熟悉对不同有用的API和frame\u001E\u001Ework等来为你服务。例如Log4J(logging/tracing),Quartz (scheduling),JGroups(networkgroupcommunication),JCache(distributedcaching), Lucene(full-textsearch),JakartaCommons等等。
21.如果你将要对接或者正和旧的系统或者本地平台,你需要学习JNI (JavaNativeInterface) and JCA (JavaConnectorArchitecture)。
22.你需要熟悉JINI技术以及与它相关的分布式系统,比如掌握CROBA。
23.你需要JavaCommunityProcess(JCP)以及他的不同JavaSpecificationRequests(JSRs),例如Portlets(168),JOLAP(69),DataMiningAPI(73),等等。
24.你应该熟练掌握一种JAVAIDE例如sunOne,netBeans,IntelliJIDEA或者Eclipse。(有些人更喜欢VI或EMACS来编写文件。随便你用什么了:)
25.JAVA(精确的说是有些配置)是冗长的,它需要很多的人工代码(例如EJB),所以你需要熟悉代码生成工具,例如XDoclet。
26.你需要熟悉一种单元测试体系(JNunit),并且学习不同的生成、部署工具(Ant,Maven)。
27.你需要熟悉一些在JAVA开发中经常用到的软件工程过程。例如RUP(RationalUnifiedProcess)andAgilemethodologies。
28.你需要能够深入了解加熟练操作和配置不同的操作系统,比如GNU/linux,sunsolaris,macOS等,做为跨平台软件的开发者。
29.你还需要紧跟java发展的步伐,比如现在可以深入的学习javaME,以及各种java新规范,技术的运用,如新起的web富客户端技术。
30.你必需要对opensource有所了解,因为至少java的很多技术直接是靠开源来驱动发展的,如java3D技术。
oracle的体系太庞大了,对于初学者来说,难免会有些无从下手的感觉,什么都想学,结果什么都学不好,所以把学习经验共享一下,希望让刚刚入门的人对oracle有一个总体的认识,少走一些弯路。
一、定位
oracle分两大块,一块是开发,一块是管理。开发主要是写写存储过程、触发器什么的,还有就是用Oracle的Develop工具做form。有点类似于程序员,需要有较强的逻辑思维和创造能力,个人觉得会比较辛苦,是青春饭J;管理则需要对oracle数据库的原理有深刻的认识,有全局操纵的能力和紧密的思维,责任较大,因为一个小的失误就会down掉整个数据库,相对前者来说,后者更看重经验。
因为数据库管理的责任重大,很少公司愿意请一个刚刚接触oracle的人去管理数据库。对于刚刚毕业的年轻人来说,可以先选择做开发,有一定经验后转型,去做数据库的管理。当然,这个还是要看人个的实际情况来定。
二、学习方法
我的方法很简单,就是:看书、思考、写笔记、做实验、再思考、再写笔记
看完理论的东西,自己静下心来想想,多问自己几个为什么,然后把所学和所想的知识点做个笔记;在想不通或有疑问的时候,就做做实验,想想怎么会这样,同样的,把实验的结果记下来。思考和做实验是为了深入的了解这个知识点。而做笔记的过程,也是理清自己思路的过程。
学习的过程是使一个问题由模糊到清晰,再由清晰到模糊的过程。而每次的改变都代表着你又学到了一个新的知识点。
学习的过程也是从点到线,从线到网,从网到面的过程。当点变成线的时候,你会有总豁然开朗的感觉。当网到面的时候,你就是高手了
很多网友,特别是初学的人,一碰到问题就拿到论坛上来问,在问前,你有没有查过书,自己有没有研究过,有没有搜索一下论坛?这就叫思维惰性。由别人来回答你的问题,会让你在短时间内不费劲地弄懂这个知识点,然而通过自己的努力去研究它,不但会更深入的了解这个知识点,更重要的是在研究的过程会提高你解决问题和分析问题的能力。总的来说,没有钻研的学习态度,不管学什么东西,都不会成功的。
当然,初学的人很多时候是因为遇到问题时,无从下手,也不知道去哪里找资料,才会到论坛上提问题的。但我认为,在提问的时候,是不是可以问别人是如何分析这个问题?从哪里可以找到相关的资料?而不是这个问题的答案是什么?授人以鱼不如授人以渔。
下面我讲下我处理问题的过程
首先要知道oracle的官方网站:www.oracle.com 这里有oracle的各种版本的数据库、应用工具和权威的官方文档。其次,还要知道http://metalink.oracle.com/这里是买了oracle服务或是oracle的合作伙伴才可以进去的,里面有很多权威的解决方案和补丁。然后就是一些著名网站:asktom.oracle.com www.orafaq.net, www.dbazine.com。这里有很多经验之谈。
遇到问题了。如果是概念上的问题,第一时间可以找tahiti.oracle.com,这里会给你最详细的解释。如果在运行的过程中出了什么错误。可以去metalink看看。如果是想知道事务的处理的经验之谈。可以去asktom。当然。这里只是相对而言。
三、oracle的体系
oracle的体系很庞大,要学习它,首先要了解oracle的框架。在这里,简要的讲一下oracle的架构,让初学者对oracle有一个整体的认识。
1、物理结构(由控制文件、数据文件、重做日志文件、参数文件、归档文件、密码文件组成)
控制文件:包含维护和验证数据库完整性的必要信息、例如,控制文件用于识别数据文件和重做日志文件,一个数据库至少需要一个控制文件
数据文件:存储数据的文件
重做日志文件:含对数据库所做的更改记录,这样万一出现故障可以启用数据恢复。一个数据库至少需要两个重做日志文件
参数文件:定义Oracle 例程的特性,例如它包含调整SGA 中一些内存结构大小的参数
归档文件:是重做日志文件的脱机副本,这些副本可能对于从介质失败中进行恢复很必要。
密码文件:认证哪些用户有权限启动和关闭Oracle例程
2、逻辑结构(表空间、段、区、块)
表空间:是数据库中的基本逻辑结构,一系列数据文件的集合。
段:是对象在数据库中占用的空间
区:是为数据一次性预留的一个较大的存储空间
块:ORACLE最基本的存储单位,在建立数据库的时候指定
3、内存分配(SGA和PGA)
SGA:是用于存储数据库信息的内存区,该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息, 它是在Oracle 服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写。
PGA:包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA 正相反PGA 是只被一个进程使用的区域,PGA 在创建进程时分配在终止进程时回收
4、后台进程(数据写进程、日志写进程、系统监控、进程监控、检查点进程、归档进程、服务进程、用户进程)
数据写进程:负责将更改的数据从数据库缓冲区高速缓存写入数据文件
日志写进程:将重做日志缓冲区中的更改写入在线重做日志文件
系统监控:检查数据库的一致性如有必要还会在数据库打开时启动数据库的恢复
进程监控:负责在一个Oracle 进程失败时清理资源
检查点进程:负责在每当缓冲区高速缓存中的更改永久地记录在数据库中时,更新控制文件和数据文件中的数据库状态信息。
归档进程:在每次日志切换时把已满的日志组进行备份或归档
服务进程:用户进程服务。
用户进程:在客户端,负责将用户的SQL 语句传递给服务进程,并从服务器段拿回查询数据。
5、oracle例程:Oracle 例程由SGA 内存结构和用于管理数据库的后台进程组成。例程一次只能打开和使用一个数据库。
6、SCN(System Change Number):系统改变号,一个由系统内部维护的序列号。当系统需要更新的时候自动增加,他是系统中维持数据的一致性和顺序恢复的重要标志。
四、深入学习
管理:可以考OCP证书,对oracle先有一个系统的学习,然后看Oracle Concepts、oracle online document,对oracle的原理会有更深入的了解,同时可以开始进行一些专题的研究如:RMAN、RAS、STATSPACT、DATAGUARD、TUNING、BACKUP&RECOVER等等。
开发:对于想做Oracle开发的,在了解完Oracle基本的体系结构之后,可以重点关注PL/SQL及Oracle的开发工具这一部分。 PL/SQL主要是包括怎么写SQL语句,怎么使用Oracle本身的函数,怎么写存储过程、存储函数、触发器等。 Oracle的开发工具主要就是Oracle自己的Developer Suite(Oracle Forms Developer and Reports Developer这些),学会如何熟练使用这些工具。
介绍几本oracle入门的好书
oracle官方文档:《concept》上面讲了oracle的体系和概念,很适合初学者看。
OCP的教学用书,也就是STUDY GUIDE(SG)。
Oracle8i 备份恢复手册
Oracle8高级管理与优化
Oracle8i PLSQL程序设计
Oracle8数据库管理员手册
以上书本都是机械工业出版社出版。
介绍几个网站
http://tahiti.oracle.com/ oracle的官方文档
http://metalink.oracle.com/ oracle的技术支持网站。需要购买Oracle服务才能有一个帐号,才能登陆,有大量的Knowledge Base,大量问题解决经验。
http://www.oracle.com/ oracle的官方网站,可以在这里down oracle的软件、官方文档和获得最新的消息
http://www.dbazine.com/ Oracle的杂志
http://asktom.oracle.com/ http://www.orafaq.net/ http://www.ixora.com.au/ http://www.oracle-base.com/ http://www.dba-oracle.com/oracle_links.htm
今天碰见一个问题:
sql-1:
SELECT temp.*, ROWNUM num
FROM (select a.vcCityId,
a.vcCountryId,
a.vcCityName,
a.vcInitial,
a.vcCityDesc,
b.vcCountryName
from web2city a, web2country b
where a.vcCountryId = b.vcCountryId
order by to_number(a.vcCountryId),
a.vcInitial)temp
sql-2:
SELECT temp.*, ROWNUM num
FROM (select a.vcCityId,
a.vcCountryId,
a.vcCityName,
a.vcInitial,
a.vcCityDesc,
b.vcCountryName
from web2city a, web2country b
where a.vcCountryId = b.vcCountryId
order by to_number(a.vcCountryId),
a.vcInitial)temp
where ROWNUM <= 40
这两个sql的前40行结果不一样,为什么呢,其实是因为排序字段的结果不确定的缘故,由于这两个sql出来的结果有很多都是并列的,所以oracle给出的结果集列表不一定都是固定的。oracle会给出他以最快速度查到的满足条件的结果,但是却并不一定满足你的要求。修改需要加入一个唯一的字段进行排就不会出问题。
sql-3:(正解)
SELECT temp.*, ROWNUM num
FROM (select a.vcCityId,
a.vcCountryId,
a.vcCityName,
a.vcInitial,
a.vcCityDesc,
b.vcCountryName
from web2city a, web2country b
where a.vcCountryId = b.vcCountryId
order by to_number(a.vcCountryId),
a.vcInitial,
to_number(a.vccityid)) temp
where ROWNUM <= 40
webwork的xwork.xml里面配置的转发带中文参数就是乱码,这里的vcStatus是中文就乱。
<result name="success" type="redirect">
/haplayadmin/initManageThread.action?vcStatus=${vcStatus}
</result>
1.我们都知道tomcat的默认编码是iso8859
2.webwor的默认编码是iso8859,而webwork.i18n.encoding = utf-8这里配置的是希望转换成的字符集
3.在转换前的action中得到的参数,如果是以get方式得到的那么应该是iso8859(tomcat进行了从utf-8(这个是页面中的contentType决定的)到iso8859的转换)。
如果是post方式得到的则应该是utf-8(因为webwork把从tomcat得到的参数setCharactorEncoding为webwork.properties配置的字符集,通常我们设置的和页面字符集一样)。
4.这样我们在以redirect的方式转换到actionB的时候显然是以get方式提交了,webwork会执行从iso8859到utf-8的转换(webwork.properties里面的配置进行转换)。这时就会出问题:假设前面是以get方式提交的,那么就会从iso8859到utf-8,记住这时我们得到了utf-8编码的字符集.
5.接着,tomcat很老实的把参数按照页面中contentType设定的值(这里是utf-8)转换成iso8859字符集,由于是get方式提交则不会经过webwork的setCharactorEncoding,那么我们得到的是iso8859字符集。
6.在转发后的action中就得到了iso8859编码的字符集,我们只要把这个字符集进行从iso8859到utf-8的转换即可得到需要的参数。
7.然而假设第三步假设是以post方式提交的,我们则得到的是utf-8的字符集编码,在第四步webwork在执行从iso8859到utf-8的转换中就把参数的原始字符集写错了,因为我们得到的是utf-8的原始字符集而不是iso8859。这时转换编码的参数永远也转不回来了。
注:实际上webwork在解析xml中的转发表达式的时候进行的字符集转换,在其他地方则不会出现这样的问题。
一.已知一个类的名字及其class文件,如何使用此类?
1.如果此类位于一个已打包的jar文件中,按如下方法调用:
URL url = new URL("file:/E:/Work/Projects/Output/FrameWork.jar");
URLClassLoader ul = new URLClassLoader(new URL[]{url});
Class aClass = ul.loadClass("com.hdpan.exercise.loader.ProduceObject");
Object obj = aClass.newInstance();
注意的是URLClassLoader.loadClass()方法的参数要包括package的名字,例如这里面如果写成ProduceObject就是错误的。
2.如果此类是一个class文件,位于一个文件夹中,按如下方法调用:
首先要确认的是class的package的名字与目录名应该一致。
URL url = new URL("file:/E:/Work/Projects/FrameWork/bin");
URLClassLoader ul = new URLClassLoader(new URL[]{url});
Class aClass = ul.loadClass("com.hdpan.exercise.loader.ProduceObject");
Object obj = aClass.newInstance();
这里面的URL的路径指到package名的上一层目录位置,例如这里如果写成file:/E:/Work/Projects/FrameWork/bin/com/hdpan/exercise/loader就是错误的
Class这个类中还有许多的get方法可以使用。
二.如何打印class中的所有方法?
Method[] md = aClass.getDeclaredMethods();
for (int i = 0; i < md.length; i++){
System.out.println(md.getName());
}
md.getModifiers();
md.getReturnType();
md.getParameterTypes();
md.getExceptionTypes();
Method这个类中还有许多的属性可以get得到。
如果有两个方法的Name是一样的,但是参数不一样:
Method md = aClass.getMethod("setField1",new Class[]{Integer.TYPE});
第一个参数是方法的名字,第二个参数是一个数组,如果是基本数据类型的话,使用其外覆类的类型,例如int使用Integer.Type,float使用Float.Type
例如,如果类中是这样的定义的:
public void setField1(int field1,String info) {
this.field1 = field1;
System.out.println(info);
}
那么在使用的时候:
Method md = clas.getMethod("setField1",new Class[]{Integer.TYPE,String.class});
三.如何调用class中的方法?
调用方法:
Object obj = aClass.newInstance();
Method mds = aClass.getMethod("setField1",new Class[]{Integer.TYPE});
mds.invoke(obj,new Object[]{new Integer(5)});
对invoke方法,第一个参数是方法所在的对象,如果方法是static的,那么此处可以是null,如果方法不是static的,但是此处是Null的话将会出现NullPointerException
第二参数是方法所需要的参数的对象数组,如果是基本数据类型的话,使用其外覆类的类型,例如int使用Integer.Type,float使用Float.Type
例如,如果类中是这样的定义的::
public void setField1(int field1,String info) {
this.field1 = field1;
System.out.println(info);
}
那么在使用的时候:
Object obj = aClass.newInstance();
Method md = aClass.getMethod("setField1",new Class[]{Integer.TYPE,String.class});
md.invoke(obj,new Object[]{new Integer(5),"This is a Test"});
如果想取得方法的返回值:
public int getField1() {
return field1;
}
那么在使用的时候:
mds = aClass.getMethod("getField1",null);
Integer integer = (Integer)mds.invoke(obj,null);
System.out.println(integer.intValue());
Method方法返回的类型是Object,根据具体的方法返回值类型,将其下溯到具体的类型。
源程序:
ProduceObject.java
=================================
//ProduceObject.java开始
package com.hdpan.exercise.loader;
public class ProduceObject {
public int getField1() {
return field1;
}
public void setField1(int field1) {
this.field1 = field1;
}
public void setField1(int field1,String info) {
this.field1 = field1;
System.out.println(info);
}
public static double getField2() {
return field2;
}
public static void setField2(double field2) {
ProduceObject.field2 = field2;
}
private int field1;
private static double field2;
public static void main(String[] args) {
}
}
//ProduceObject.java结束
=========================
TestLoader.java
=========================
//TestLoader.java开始
package com.hdpan.exercise.loader;
import java.lang.reflect.Method;
import java.net.URL;
import java.net.URLClassLoader;
public class TestLoader {
public static void main(String[] args) throws Exception {
try {
//URL url = new URL("file:/E:/Work/Projects/Output/FrameWork.jar");
URL url = new URL("file:/E:/Work/Projects/FrameWork/bin/com/hdpan/exercise/loader");
URLClassLoader ul = new URLClassLoader(new URL[]{url});
//Class clas = ul.loadClass("ProduceObject");
Class aClass = ul.loadClass("com.hdpan.exercise.loader.ProduceObject");
Object obj = aClass.newInstance();
Method mds = aClass.getMethod("setField1",new Class[]{Integer.TYPE,String.class});
mds.invoke(obj,new Object[]{new Integer(5),"haha"});
mds = aClass.getMethod("getField1",null);
Integer integer = (Integer)mds.invoke(obj,null);
System.out.println(integer.intValue());
//System.out.println(((com.hdpan.exercise.loader.ProduceObject)obj).getField1());
Method[] md = aClass.getDeclaredMethods();
for (int i = 0; i < md.length; i++){
System.out.println(md.getName());
}
} catch (Exception e) {
System.out.println(e);
}
}
}
//TestLoader.java开始
1.什么是pv PV(page view),即页面浏览量,或点击量;通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标。
高手对pv的解释是,一个访问者在24小时(0点到24点)内到底看了你网站几个页面。这里需要强调:同一个人浏览你网站同一个页面,不重复计算pv量,点100次也算1次。说白了,pv就是一个访问者打开了你的几个页面。
PV之于网站,就像收视率之于电视,从某种程度上已成为投资者衡量商业网站表现的最重要尺度。
pv的计算:当一个访问着访问的时候,记录他所访问的页面和对应的IP,然后确定这个IP今天访问了这个页面没有。如果你的网站到了23点,单纯IP有60万条的话,每个访问者平均访问了3个页面,那么pv表的记录就要有180万条。
有一个可以随时查看PV流量以及你的网站世界排名的工具alexa工具条,安装吧!网编们一定要安装这个。
2.什么是uv
uv(unique visitor),指访问某个站点或点击某条新闻的不同IP地址的人数。
在同一天内,uv只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。独立IP访问者提供了一定时间内不同观众数量的统计指标,而没有反应出网站的全面活动。
3.什么是PR值
PR值,即PageRank,网页的级别技术。取自Google的创始人Larry Page,它是***运算法则(排名公式)的一部分,用来标识网页的等级/重要性。级别从1到10级,10级为满分。PR值越高说明该网页越受欢迎(越重要)。
例如:一个PR值为1的网站表明这个网站不太具有流行度,而PR值为7到10则表明这个网站非常受欢迎(或者说极其重要)。
我们可以这样说:一个网站的外部链接数越多其PR值就越高;外部链接站点的级别越高(假如Macromedia的网站链到你的网站上),网站的PR值就越高。例如:如果ABC.COM网站上有一个XYZ.COM网站的链接,那为ABC.COM网站必须提供一些较好的网站内容,从而Google会把来自XYZ.COM的链接作为它对ABC.COM网站投的一票。
你可以下载和安装Google工具条来检查你的网站级别(PR值)。
平原总结:对于网编来说,你的浏览器上有没有alexa工具条,有没有google工具条,是判断一个网编是否懂推广的一个重要标准。如果你没有,那么从今天开始,赶快装上吧!
写这个的文章太多了,为了防止忘记,我还是记一下吧,年纪大了,记性不太好):
1.将tomcat/bin目录下的catalina.sh文件加上这两行:
JAVA_OPTS='-server -Xms512m -Xmx512m -XX:PermSize=32M -XX:MaxNewSize=128m -XX:MaxPermSize=64m -Djava.awt.headless=true'
CATALINA_OPTS="-server -Xms256m -Xmx256m"
设置一下资源大小。
2.如果配了apache的一定要把url转发的转发规则定好,不能全部转发给tomcat去处理。
图片,样式,js等要发给apache去处理:
JkMount /*不能有,有些apache配置了workers.properties的就去掉[uri:/*.jsp]worker=ajp13:localhost:8009
context=/
昨天升级了jre更新到update10,遇到版本不匹配的问题:
bad class file: /usr/java/jdk1.5.0_06/jre/lib/rt.jar(java/lang/Object.class)
class file has wrong version 49.0, should be 48.0
Please remove or make sure it appears in the correct subdirectory of the classpath.
这是因为编译环境和运行环境的不一致造成的,比如tomcat和jdk1.5配合的时候,可能就会出现。解决这个问题的方法:copy jdk1.5的lib/tools.jar到tomcat的common/lib/tools.jar,覆盖掉原有文件就可以了。
做了个简单的测试.
1.用webwork做了个action,直接导入到SUCCESS.
2.用struts做了个action,直接导入到SUCCESS.
然后用LoadRunner测试,设定用户数30个,一开始就30个.开始以后观察发现:
1.webwork的最高His/Second为170
2.struts的最高His/Second为480
有哪位大侠能够告诉我为啥差别这么大,还是可能我的webwork的配置有问题.
我在这个action上面没有添加任何拦截器.
<package name="aaa" extends="webwork-default" namespace="/aaa">
这个模块继承于webwork-default,我将webwork-default.xml里面的<default-interceptor-ref name="defaultStack"/>也删除了,也就是说现在没有经过任何拦截器的.
该贴被javaeye上的前辈们认为是陈年老话题.建议我去搜一下.可是我找不到,真郁闷.
有哪位好心人看到了,请帮我解决一下,不胜感激.http://www.javaeye.com/topic/40306
我对google也在使用webwork的话不置可否,且不论到底是否在用webwork,即时用了你也不知道它被用来在做什么项目,毕竟google的项目太多了.而且确如robbin所说,我所做的测试不是具体应用,不可作为参考.关于测试的结果我感到无所适从,唯有报以苦笑了.
(注:纯属转贴,原出处不明,从一个朋友的QQ拷贝来的。)
随心所遇,自由自在
当你做着你所感兴趣的工作,BOSS发的Money你还满意时,某天,你会发现不知不觉中,自己的生活与工作已溶为一体!
路人甲的生活,是以工作为中心。下班后,当天有没做完的工作,会很习惯无意识的打开本本尝试着把它搞定。正是在工作场所的一切,才构筑了路人甲精神和灵魂的价值。领导的表扬、同事的夸奖、客户的赞美,时时都会调动路人甲自爱和爱人的神经,让路人甲感受到自信和自豪的冲动;即使路人甲遭到批评压制、被人排挤、客户BT发难,也都会激发路人甲的竞争意志、排难决心和尽善尽美的愿望。
工作着是美丽的。
工作着那种繁忙、紧张、充实、兴奋、冲动、疯狂的感觉,棒极了!
工作着,在IT技术日新月异的当今时代,才能体验到与老友共同追求华山论剑、草堂谈诗、雪夜煮酒、桃园看花、共同提高自己的这种绝妙境界与激情人生!
工作着,某一天运气好似乎会发生上网聊天(美其名曰“技术交流”,BOSS一边去!呵呵)、下网见面、一头青蛙、两匹恐龙、哇噻、日子好愉快!(期待这一天的到来)
今天用firefox调试程序,更改了死刷新结果都一样,原来firefox也要手动清缓存。真稀烂的。
其实apache的正则表达式网上很多文章都有做过介绍。但是我配置的时候就是不行,也没有地方求助,只能自己摸索。以下有一点心得,可能会慢慢增加:
1。()括号是分组,这个分组很重要,在整个url链接中的部分使用到正则表达式的地方必须要用这个括号括起来才能表达一个整体的意思,就好像这样:RewriteRule /haplay/team/([a-zA-Z][a-zA-Z_0-9]+) /haplay/group/viewGroup.action?vcGroupId=$1 [PT],这里就是表示在team后的链接必须以第一个字符为字母打头,后面则是任意长度的字母加数字。如果不在最外面加上这么个()括号,那就完全不是这个意思了。
最近在项目中遇到一个棘手的问题,我这项目用的是webwork作为框架,而在配置apache的时候发现所有应用了webwork的ajax标签处都不能正常执行了。
有用过webwork框架的人都知道,webwork集成了dwr作为ajax实现方案。而dwr是通过在web.xml里面配置servlet访问的。想必看到这里大家都清楚了,其实apache配置路径解析的时候肯定要把dwr配置的servlet算进去,于是我就配置了JkMount /*/dwr/* worker1这之类的,试验了好多次,都不行。后来打开页面把源文件查看了一下突然发现自己很蠢,其实webwork是把dwr封装了一层的,这么配置肯定不行了,于是配置成:JkMount /*/webwork/* worker1果然成功了。
最近的一个工作任务就是建立公司的开发团队,看了很多这方面的资料,也思考了很多,希望大家能够提出自己的见解,共同学习共同提高。
一、关于队员选择
根据我自己的价值观我觉得选择队员应该考虑下面几个因素:
1、价值观。我觉得具有相同价值观或者对很多事情有一致看法的人,交流和相处起来比较融洽,甚至对工作、待遇、事业有相同观点。
2、工作态度。这包括工作主动性、积极性、激情、团队精神等方面。
3、工作能力。当然不一定要求队员的工作能力有多高,但是至少得具有基本的一些能力,如果对将要面对的工作丝毫不了解的话,学习起来的剃度是非常大的,对企业、对团队来说,风险都是非常大的。
4、学习能力。无论现在的能力是否出色,但是必须保持一个持续的、超强的学习能力,总是吃老本,迟早要被淘汰。
综合上面的几点,相信大家可以看出,我看重的应该是人,而不是这个人目前具有怎样的能力。我在和应聘者谈话的时候,根本不会去问一些非常具体的问题,例如:Map和Set有什么区别之类的问题,我觉得这不是问题的关键,我需要的是一个合作伙伴,不是一个只为了工作而工作的队员。
此外,我还希望团队中的每一位队友都具有责任心、事业心、热心、虚心的个人魅力。
二、关于团队发展
我的目标是希望能够组建一个稳定的、技术互补的、学习能力强的、具有核心竞争力的团队。当然,组建一个优秀的团队是需要很长时间的,并经历很多过程才来成长起来的。团队的发展离不开个人的发展,我的想法将队员分配在不同的岗位上,这其中必然有大家都不想做的工作岗位,但是并不代表这些岗位不重要或者没有发展前途。这个时候,就是体现一个队员价值观的时候了,从我角度讲,我觉得测试人员、界面开发人员和开发人员是同等重要的,甚至在资源不足的情况下,一个优秀的测试人员和界面开发人员要比一个优秀的开发人员重要的多。所以我觉得,对一个优秀的测试人员和界面开发人员,他们的薪酬和受重视度应该是和开发人员同等的。
只有合理的将人力资源分配在项目涉及到的不同岗位上,并且每个队员在自己的岗位上都能努力的工作并在该领域积累丰富的经验,甚至成为该领域的专家,这无论对企业、对团队还是对个人,都是最成功的。相反,如果大家都根据自己的观点学习某一个或某些领域的话,一种情况是,在某个岗位产生资源浪费,而在大家都不看好的岗位出现资源不足,另一种情况就是大家对很多领域都有涉及,但是在哪个领域都不精通,很难成为某个领域的专家。这样一种模式下,是很难实现技术互补并具有核心竞争力的优秀的团队。
三、关于价值体现
由于队员从事的岗位不同,价值的体现形式就不同,所以需要一种合理的、公平的、公正的奖励机制,这样才能保证团队的良性发展并保持团队的凝聚力。当然,沟通的重要性就不言而喻了,它存在于各个环节的方方面面。
在我们拥有了一支非常优秀的团队后,我想,我们离成功已经不远了。这个时候,团队的稳定性受到了严重的考验,为什么呢?因为这个时候一般的薪酬、奖励已经显得不是非常重要了,随着团队的快速发展,应该让队员们看到自己所能拥有的更大价值,例如给队员提供一定的期权或者股份等,让大家明白并且相信,企业利益最大化的同时也就意味着个人利益的最大化。世界上最伟大的管理原则就是“人们总是会去做受到奖励的事情”。
四、关于人才贮备
无论团队具有怎样的稳定性,人才的流动是无法避免的,所以就要求我们的团队一定要做好人才的贮备工作,这样可以在规避很多风险的同时,也是成本最低的一种方式。
相关的链接地址:
http://www.blogjava.net/coldtear/
前两天鼓弄fck的上传,发现也有中文文件名的问题,翻阅网络的文章似乎还没有关于java版本fck上传的解决文章。仔细研究了一下他上传的类源码SimpleUploaderServlet.java和ConnectorServlet.java。发现并无纰漏。后来一看页面发现都是html页面,于是豁然开朗。分析原因可能是frmupload.html,fck_image.html文件不能被应用服务器很好的解析取得页面的字符集造成(也不知道说的对不对)。于是马上换成jsp后缀,给了个<%@ page contentType="text/html; charset=utf-8" %>刷新页面,效果是立杆见影。
处理完这个问题后我觉得有点疑惑,难道fck开源小组没有意识到这个问题么?fck考虑到国际化的支持,各种语言也都有相应的版本,但是这个却没有想到,令人感到奇怪。