#
摘要: 借助与spring AOP,spring提供了强大的基于声明式事务管理方式,它很好对事务管理代码和具体业务逻辑进行了解藕,使我们在coding过程不要去关心事务管理的逻辑。下面我们借助一个例子来将分析spring内部的实现。1. 例子1.1 datasource配置[html] view plaincopyprint? <bean id="dataS...
阅读全文
基于合理的数据库设计,经过深思熟虑后为表建立索引,是获得高性能数据库系统的基础。而未经合理分析便添加索引,则会降低系统的总体性能。索引虽然说提高了数据的访问速度,但同时也增加了插入、更新和删除操作的处理时间。
是否要为表增加索引、索引建立在那些字段上,是创建索引前必须要考虑的问题。解决此问题的一个比较好的方法,就是分析应用程序的业务处理、数据使用,为经常被用作查询条件、或者被要求排序的字段建立索引。基于优化器对SQL语句的优化处理,我们在创建索引时可以遵循下面的一般性原则:
(1)为经常出现在关键字order by、group by、distinct后面的字段,建立索引。
在这些字段上建立索引,可以有效地避免排序操作。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。
(2)在union等集合操作的结果集字段上,建立索引。其建立索引的目的同上。
(3)为经常用作查询选择的字段,建立索引。
(4)在经常用作表连接的属性上,建立索引。
(5)考虑使用索引覆盖。对数据很少被更新的表,如果用户经常只查询其中的几个字段,可以考虑在这几个字段上建立索引,从而将表的扫描改变为索引的扫描。
除了以上原则,在创建索引时,我们还应当注意以下的限制:
(1)限制表上的索引数目。
对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作。
(2)不要在有大量相同取值的字段上,建立索引。
在这样的字段(例如:性别)上建立索引,字段作为选择条件时将返回大量满足条件的记录,优化器不会使用该索引作为访问路径。
(3)避免在取值朝一个方向增长的字段(例如:日期类型的字段)上,建立索引;对复合索引,避免将这种类型的字段放置在最前面。
由于字段的取值总是朝一个方向增长,新记录总是存放在索引的最后一个叶页中,从而不断地引起该叶页的访问竞争、新叶页的分配、中间分支页的拆分。此外,如果所建索引是聚集索引,表中数据按照索引的排列顺序存放,所有的插入操作都集中在最后一个数据页上进行,从而引起插入“热点”。
(4)对复合索引,按照字段在查询条件中出现的频度建立索引。
在复合索引中,记录首先按照第一个字段排序。对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用。
因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能地使用此索引,发挥索引的作用。
(5)删除不再使用,或者很少被使用的索引。
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再被需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
转自http://www.cnblogs.com/xuhan/archive/2011/07/25/2116156.html
转自:http://www.blogjava.net/cenwenchu/archive/2008/06/30/211712.html
SIP的第四期结束了,因为控制策略的丰富,早先的的压力测试结果已经无法反映在高并发和高压力下SIP的运行状况,因此需要重新作压力测试。跟在测试人员后面做了快一周的压力测试,压力测试的报告也正式出炉,本来也就算是告一段落,但第二天测试人员说要修改报告,由于这次作压力测试的同学是第一次作,有一个指标没有注意,因此需要修改几个测试结果。那个没有注意的指标就是load average,他和我一样开始只是注意了CPU,内存的使用状况,而没有太注意这个指标,这个指标与他们通常的限制(10左右)有差别。重新测试的结果由于这个指标被要求压低,最后的报告显然不如原来的好看。自己也没有深入过压力测试,但是觉得不搞明白对将来机器配置和扩容都会有影响,因此去问了DBA和SA,得到的结果相差很大,看来不得不自己去找找问题的根本所在了。
通过下面的几个部分的了解,可以一步一步的找出Load Average在压力测试中真正的作用。
CPU时间片
为了提高程序执行效率,大家在很多应用中都采用了多线程模式,这样可以将原来的序列化执行变为并行执行,任务的分解以及并行执行能够极大地提高程序的运行效率。但这都是代码级别的表现,而硬件是如何支持的呢?那就要靠CPU的时间片模式来说明这一切。程序的任何指令的执行往往都会要竞争CPU这个最宝贵的资源,不论你的程序分成了多少个线程去执行不同的任务,他们都必须排队等待获取这个资源来计算和处理命令。先看看单CPU的情况。下面两图描述了时间片模式和非时间片模式下的线程执行的情况:
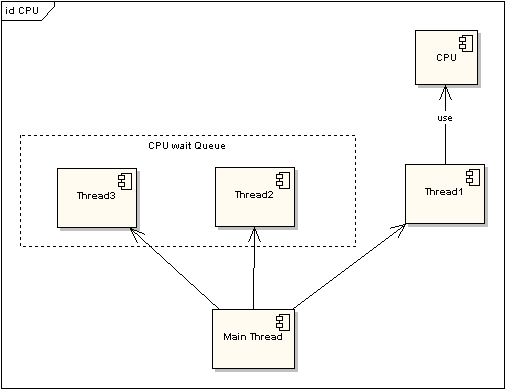
图 1 非时间片线程执行情况
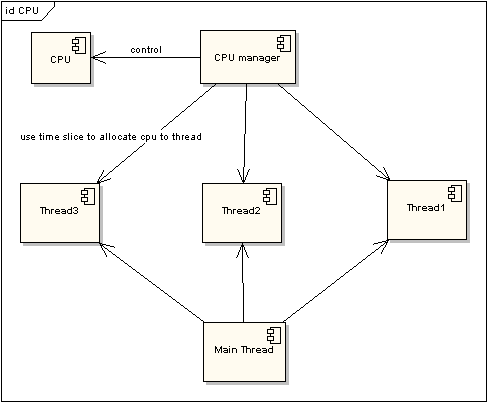
图 2 非时间片线程执行情况
在图一中可以看到,任何线程如果都排队等待CPU资源的获取,那么所谓的多线程就没有任何实际意义。图二中的CPU Manager只是我虚拟的一个角色,由它来分配和管理CPU的使用状况,此时多线程将会在运行过程中都有机会得到CPU资源,也真正实现了在单CPU的情况下实现多线程并行处理。
多CPU的情况只是单CPU的扩展,当所有的CPU都满负荷运作的时候,就会对每一个CPU采用时间片的方式来提高效率。
在Linux的内核处理过程中,每一个进程默认会有一个固定的时间片来执行命令(默认为1/100秒),这段时间内进程被分配到CPU,然后独占使用。如果使用完,同时未到时间片的规定时间,那么就主动放弃CPU的占用,如果到时间片尚未完成工作,那么CPU的使用权也会被收回,进程将会被中断挂起等待下一个时间片。
CPU利用率和Load Average的区别
压力测试不仅需要对业务场景的并发用户等压力参数作模拟,同时也需要在压力测试过程中随时关注机器的性能情况,来确保压力测试的有效性。当服务器长期处于一种超负荷的情况下运行,所能接收的压力并不是我们所认为的可接受的压力。就好比项目经理在给一个人估工作量的时候,每天都让这个人工作12个小时,那么所制定的项目计划就不是一个合理的计划,那个人迟早会垮掉,而影响整体的项目进度。
CPU利用率在过去常常被我们这些外行认为是判断机器是否已经到了满负荷的一个标准,看到50%-60%的使用率就认为机器就已经压到了临界了。CPU利用率,顾名思义就是对于CPU的使用状况,这是对一个时间段内CPU使用状况的统计,通过这个指标可以看出在某一个时间段内CPU被占用的情况,如果被占用时间很高,那么就需要考虑CPU是否已经处于超负荷运作,长期超负荷运作对于机器本身来说是一种损害,因此必须将CPU的利用率控制在一定的比例下,以保证机器的正常运作。
Load Average是CPU的Load,它所包含的信息不是CPU的使用率状况,而是在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。为什么要统计这个信息,这个信息的对于压力测试的影响究竟是怎么样的,那就通过一个类比来解释CPU利用率和Load Average的区别以及对于压力测试的指导意义。
我们将CPU就类比为电话亭,每一个进程都是一个需要打电话的人。现在一共有4个电话亭(就好比我们的机器有4核),有10个人需要打电话。现在使用电话的规则是管理员会按照顺序给每一个人轮流分配1分钟的使用电话时间,如果使用者在1分钟内使用完毕,那么可以立刻将电话使用权返还给管理员,如果到了1分钟电话使用者还没有使用完毕,那么需要重新排队,等待再次分配使用。
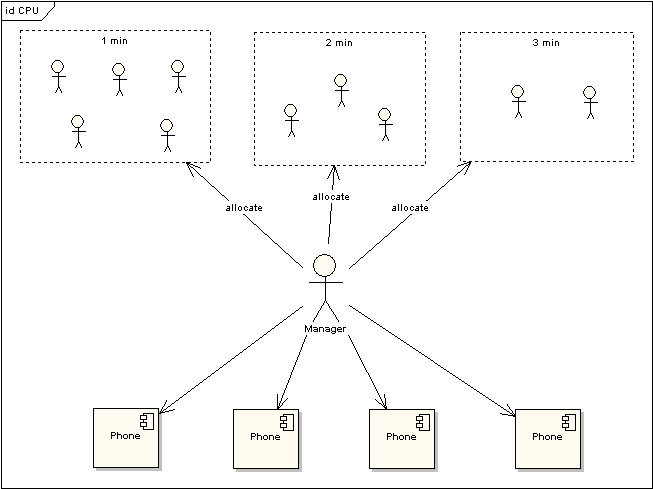
图 3 电话使用场景
上图中对于使用电话的用户又作了一次分类,1min的代表这些使用者占用电话时间小于等于1min,2min表示使用者占用电话时间小于等于2min,以此类推。根据电话使用规则,1min的用户只需要得到一次分配即可完成通话,而其他两类用户需要排队两次到三次。
电话的利用率 = sum (active use cpu time)/period
每一个分配到电话的使用者使用电话时间的总和去除以统计的时间段。这里需要注意的是是使用电话的时间总和(sum(active use cpu time)),这与占用时间的总和(sum(occupy cpu time))是有区别的。(例如一个用户得到了一分钟的使用权,在10秒钟内打了电话,然后去查询号码本花了20秒钟,再用剩下的30秒打了另一个电话,那么占用了电话1分钟,实际只是使用了40秒)
电话的Average Load体现的是在某一统计时间段内,所有使用电话的人加上等待电话分配的人一个平均统计。
电话利用率的统计能够反映的是电话被使用的情况,当电话长期处于被使用而没有的到足够的时间休息间歇,那么对于电话硬件来说是一种超负荷的运作,需要调整使用频度。而电话Average Load却从另一个角度来展现对于电话使用状态的描述,Average Load越高说明对于电话资源的竞争越激烈,电话资源比较短缺。对于资源的申请和维护其实也是需要很大的成本,所以在这种高Average Load的情况下电话资源的长期“热竞争”也是对于硬件的一种损害。
低利用率的情况下是否会有高Load Average的情况产生呢?理解占有时间和使用时间就可以知道,当分配时间片以后,是否使用完全取决于使用者,因此完全可能出现低利用率高Load Average的情况。由此来看,仅仅从CPU的使用率来判断CPU是否处于一种超负荷的工作状态还是不够的,必须结合Load Average来全局的看CPU的使用情况和申请情况。
所以回过头来再看测试部对于Load Average的要求,在我们机器为8个CPU的情况下,控制在10 Load左右,也就是每一个CPU正在处理一个请求,同时还有2个在等待处理。看了看网上很多人的介绍一般来说Load简单的计算就是2* CPU个数减去1-2左右(这个只是网上看来的,未必是一个标准)。
补充几点:
1.对于CPU利用率和CPU Load Average的结果来判断性能问题。首先低CPU利用率不表明CPU不是瓶颈,竞争CPU的队列长期保持较长也是CPU超负荷的一种表现。对于应用来说可能会去花时间在I/O,Socket等方面,那么可以考虑是否后这些硬件的速度影响了整体的效率。
这里最好的样板范例就是我在测试中发现的一个现象:SIP当前在处理过程中,为了提高处理效率,将控制策略以及计数信息都放置在Memcached Cache里面,当我将Memcached Cache配置扩容一倍以后,CPU的利用率以及Load都有所下降,其实也就是在处理任务的过程中,等待Socket的返回对于CPU的竞争也产生了影响。
2.未来多CPU编程的重要性。现在服务器的CPU都是多CPU了,我们的服务器处理能力已经不再按照摩尔定律来发展。就我上面提到的电话亭场景来看,对于三种不同时间需求的用户来说,采用不同的分配顺序,我们可看到的Load Average就会有不同。假设我们统计Load的时间段为2分钟,如果将电话分配的顺序按照:1min的用户,2min的用户,3min的用户来分配,那么我们的Load Average将会最低,采用其他顺序将会有不同的结果。所以未来的多CPU编程可以更好的提高CPU的利用率,让程序跑的更快。
load Average
1.1:什么是Load?什么是Load Average?
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)
简单的说是进程队列的长度。Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load。【参考文章:unix Load Average Part1:How It Works】
1.2:查看指令:
w or uptime or procinfo or top
load average: 0.02, 0.27, 0.17
1 per/minute 5 per/minute 15 per/minute
1.3:如何判断系统是否已经Over Load?
对一般的系统来说,根据cpu数量去判断。如果平均负载始终在1.2一下,而你有2颗cup的机器。那么基本不会出现cpu不够用的情况。也就是Load平均要小于Cpu的数量
1.4:Load与容量规划(Capacity Planning)
一般是会根据15分钟那个load 平均值为首先。
1.5:Load误解:
1:系统load高一定是性能有问题。
真相:Load高也许是因为在进行cpu密集型的计算
2:系统Load高一定是CPU能力问题或数量不够。
真相:Load高只是代表需要运行的队列累计过多了。但队列中的任务实际可能是耗Cpu的,也可能是耗i/0奶子其他因素的。
3:系统长期Load高,首先增加CPU
真相:Load只是表象,不是实质。增加CPU个别情况下会临时看到Load下降,但治标不治本。
2:在Load average 高的情况下如何鉴别系统瓶颈。
是CPU不足,还是io不够快造成或是内存不足?
2.1:查看系统负载vmstat
Vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 100152 2436 97200 289740 0 1 34 45 99 33 0 0 99 0
procs
r 列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
cpu 表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比
system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
memory
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si 由内存进入内存交换区数量。
so由内存交换区进入内存数量。
IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
2.2:查看磁盘负载iostat
每隔2秒统计一次磁盘IO信息,直到按Ctrl+C终止程序,-d 选项表示统计磁盘信息, -k 表示以每秒KB的形式显示,-t 要求打印出时间信息,2 表示每隔 2 秒输出一次。第一次输出的磁盘IO负载状况提供了关于自从系统启动以来的统计信息。随后的每一次输出则是每个间隔之间的平均IO负载状况。
# iostat -x 1 10
Linux 2.6.18-92.el5xen 02/03/2009
avg-cpu: %user %nice %system %iowait %steal %idle
1.10 0.00 4.82 39.54 0.07 54.46
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 3.50 0.40 2.50 5.60 48.00 18.48 0.00 0.97 0.97 0.28
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sde 0.00 0.10 0.30 0.20 2.40 2.40 9.60 0.00 1.60 1.60 0.08
sdf 17.40 0.50 102.00 0.20 12095.20 5.60 118.40 0.70 6.81 2.09 21.36
sdg 232.40 1.90 379.70 0.50 76451.20 19.20 201.13 4.94 13.78 2.45 93.16
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘
可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait.
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
另外还可以参考
一般:
svctm < await (因为同时等待的请求的等待时间被重复计算了),
svctm的大小一般和磁盘性能有关:CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。
await: await的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。
如果 svctm 比较接近 await,说明I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明 I/O队列太长,应用得到的响应时间变慢,
如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
别人一个不错的例子.(I/O 系统 vs. 超市排队)
举一个例子,我们在超市排队 checkout 时,怎么决定该去哪个交款台呢? 首当是看排的队人数,5个人总比20人要快吧?除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈,那么可以考虑换个队排了。还有就是收银员的速度了,如果碰上了连钱都点不清楚的新手,那就有的等了。另外,时机也很重要,可能 5分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可是很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义(不过我还没发现什么事情比排队还无聊的)。
I/O 系统也和超市排队有很多类似之处:
r/s+w/s 类似于交款人的总数
平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
平均服务时间(svctm)类似于收银员的收款速度
平均等待时间(await)类似于平均每人的等待时间
平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
I/O 操作率 (%util)类似于收款台前有人排队的时间比例。
我们可以根据这些数据分析出 I/O 请求的模式,以及 I/O 的速度和响应时间。
下面是别人写的这个参数输出的分析
# iostat -x 1
avg-cpu: %user %nice %sys %idle
16.24 0.00 4.31 79.44
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/cciss/c0d0
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p1
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p2
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
上面的 iostat 输出表明秒有 28.57 次设备 I/O 操作: 总IO(io)/s = r/s(读) +w/s(写) = 1.02+27.55 = 28.57 (次/秒) 其中写操作占了主体 (w:r = 27:1)。
平均每次设备 I/O 操作只需要 5ms 就可以完成,但每个 I/O 请求却需要等上 78ms,为什么? 因为发出的 I/O 请求太多 (每秒钟约 29 个),假设这些请求是同时发出的,那么平均等待时间可以这样计算:
平均等待时间 = 单个 I/O 服务时间 * ( 1 + 2 + ... + 请求总数-1) / 请求总数
应用到上面的例子: 平均等待时间 = 5ms * (1+2+...+28)/29 = 70ms,和 iostat 给出的78ms 的平均等待时间很接近。这反过来表明 I/O 是同时发起的。
每秒发出的 I/O 请求很多 (约 29 个),平均队列却不长 (只有 2 个 左右),这表明这 29 个请求的到来并不均匀,大部分时间 I/O 是空闲的。
一秒中有 14.29% 的时间 I/O 队列中是有请求的,也就是说,85.71% 的时间里 I/O 系统无事可做,所有 29 个 I/O 请求都在142毫秒之内处理掉了。
delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s=78.21 * delta(io)/s = 78.21*28.57 =2232.8,表明每秒内的I/O请求总共需要等待2232.8ms。所以平均队列长度应为 2232.8ms/1000ms = 2.23,而iostat 给出的平均队列长度 (avgqu-sz) 却为 22.35,为什么?! 因为 iostat 中有 bug,avgqu-sz值应为 2.23,而不是 22.35。
摘要: 转自:http://zmx.iteye.com/blog/583482Struts2 + JasperReport应用一:导PDF,Excel,HTML显示博客分类: Struts2HTMLExcelStrutsServletXML 我用的是struts2.1.6,从struts2的自带的demo当中可以看到它的web.xml配置与之前的有点不同,有另外一种配置:Xml代码&n...
阅读全文
哈哈!这个问题在我们公司也发生过。经过几天研究终于搞定。
c3p0的connection实现类和我们想象中有出入,最大的出入就是c3p0的connection实现类的close方法不是真的将该链接释放掉,而是将这个链接回收到可用连接池中。于是问题就来了。
c3p0的有一个maxConnection的参数,即最多链接数。还有一个genratNum,即当链接不够用的时候自动每次生成链接的个数。假如将最大连接数设定为50,每次增长数设定为10,初始值为10。假如当前总共产生的链接数已经有49个,但是这49个链接不是可用连接数,那么c3p0就会增长10个。这样一共就产生了59个。
假如你设定最大空闲时间又过长,如一个月,那么就是被close的链接,也不会被释放掉,一直保留链接池中。
所以很快c3p0就将数据库的链接用完。
解决办法是:
1. 在代码中当创建了一个connection(或者从池中取),必须在要在合适的时机将该链接close掉。
2. 合理配置最大连接数,最大空闲时间,每次增长数
3. 可以通过实行ConnectionCustomer接口,来显式的对链接进行关闭,释放资源的操作。
4. 第一点是最重要的,后两点是辅助的。
转自:http://www.oschina.net/question/242388_40477
P6SPY +SQL Profiler 监控JAVAEE SQL
一般大型的javaEE项目开发周期较长,架构,业务逻辑,代码正确性,安全性直接影响着系统的整体性能。由于研发人员技术参差不齐,切人员流动性强,一般大型项目中存在诸多不确定性。要想避免项目后期出现重大变动,失误,不给系统造成严重影响,就要从项目的初期,从代码,注释,对细节严格把控。作为研发人员当然要对自己严格要求,失误最小化。下面介绍一下如果利p6spy ,sql profiler 监控javaEE sql ,至于如何分析sql,如果修改,由于本人对于sql 了解不多,不加追述,当然我也会写,但是仅是写一些简单的。
1)下载p6spy 和sql profiler
2) 将p6spy-install.jar sqlprofiler-0.3-bin中的sqlprofiler.jar 放到项目的lib中
3)将sqlprofiler-0.3-bin中的spy.properties 放到web项目的classes中 ,和tomcat的bin目录中
同时修改spy.properties 中的realdriver=oracle.jdbc.driver.OracleDriver(系统数据库的驱动)
4)将系统的数据源配置文件中的<driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
修改为:<driver-class>com.p6spy.engine.spy.P6SpyDriver</driver-class>
5)java -jar sqlprofiler.jar(是放到系统lib中的那个jar包)
D:\Program Files\Java\jdk1.5.0_17\bin>java -jar D:\nm\NetMessageCDE_BJ_CM\WEB-INF\lib\sqlprofiler.jar
cmd 日志

出现如下试图

6)启系统后,进行操作,sql profiler 出现sql跟踪记录

具体如何使用 sql profler ,上网可以搜一下,东西很多!
1、定义ehcache
<bean id="cacheManager" class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean">
<property name="configLocation" value="classpath:conf/spring/spring_ehcache.xml" />
</bean>
2、在spring中联合oscache
<bean id="cacheFilterBean" class="com.ebizer.framework.core.filter.CacheFilter">
<property name="cacheUris">
<list>
<!--
<value>/index.html</value>
<value>/trend.html</value>
<value>/trend/newest.html</value>
-->
</list>
</property>
</bean>
3、定义ehcache的方法
<!-- Remove the following 3 beans to disable method level data cache -->
<bean id="methodCache" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager" />
<property name="cacheName" value="METHOD_CACHE" />
</bean>
<bean id="methodCacheLong" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager" />
<property name="cacheName" value="METHOD_CACHE_LONG" />
</bean>
<bean id="methodCacheViewHot" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager" />
<property name="cacheName" value="METHOD_CACHE_VIEW_HOT_MATCH_ITEM" />
</bean>
<bean id="methodCacheIndex" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager" ref="cacheManager" />
<property name="cacheName" value="METHOD_CACHE_INDEX" />
</bean>
<bean id="methodCacheInterceptorIndex" class="com.ebizer.framework.core.interceptor.MethodCacheInterceptor">
<property name="cache" ref="methodCacheIndex" />
</bean>
<bean id="methodCacheInterceptor" class="com.ebizer.framework.core.interceptor.MethodCacheInterceptor">
<property name="cache" ref="methodCache" />
</bean>
<bean id="methodCacheInterceptorLong" class="com.ebizer.framework.core.interceptor.MethodCacheInterceptor">
<property name="cache" ref="methodCacheLong" />
</bean>
<bean id="methodCacheInterceptorViewHot" class="com.ebizer.framework.core.interceptor.MethodCacheInterceptor">
<property name="cache" ref="methodCacheViewHot" />
</bean>
<bean id="methodCacheAdvisorTemplate" abstract="true" class="org.springframework.aop.support.NameMatchMethodPointcutAdvisor">
<property name="advice" ref="methodCacheInterceptor" />
</bean>
<bean id="methodCacheAdvisorTemplateLong" abstract="true" class="org.springframework.aop.support.NameMatchMethodPointcutAdvisor">
<property name="advice" ref="methodCacheInterceptorLong" />
</bean>
<bean id="methodCacheAdvisorTemplateViewHot" abstract="true" class="org.springframework.aop.support.NameMatchMethodPointcutAdvisor">
<property name="advice" ref="methodCacheInterceptorViewHot" />
</bean>
摘要: 一、因情制宜,建立“适当”的索引 建立“适当”的索引是实现查询优化的首要前提。 索引(index)是除表之外另一重要的、用户定义的存储在物理介质上的数据结构。当根据索引码的值搜索数据时,索引提供了对数据的快速访问。事实上,没有索引,数据库也能根据SELECT语句成功地检索到结果,但随着表变得越来越大,使用“适当R...
阅读全文
2012年6月23日
今天追踪一个关于页面内存暴涨,页面响应过慢的问题。花了4个多小时,总算找到问题出在哪了。
一、问题描述
最近我们在一台独享服务器上搭建了Tomcat6.0.19环境,发现访问首页时,内存暴涨,一直不退。每次刷新内存增加近10M。一个人狂刷新一分钟就可以把tomcat搞死机。
然后,找各种办法解决问题。整了几天,每天中午轮流监控Tomcat服务器,发现它挂了后就重启。累坏了。
每天到google上面搜索答案,有人说是程序的问题,程序内存泄露。甚至问到“有没有数据库没有释放”、“有没有使用死循环”、有没有写“System.gc()自动释放内存”、有没有“在Service层查询时使用all()方法,查处了所有记录”。等等。
而我一直不承认程序有问题。理由是:我们曾经将这个程序在租用的2个虚拟主机中用了近1个月。不断维护,最后达到一个星期没有出现一个异常的情况。
二、问题分析(关于tomcat内存溢出问题)
分析Tomcat死机的日志,发现是内存耗尽。
大致有这么一段,PSPermGen total 86016K used 86015K
到网上搜了一下,明白了jvm内存分类。然后配置内存,让tomcat自动回收jvm内存。
当然,配置过程也遇到了很多问题,花了一天多。问题是网上的很多人都是抄来抄去,要在一大堆垃圾中选出精品不容易呀。
配了一天都只起到一定作用。比如:给tomcat设置较大内存后,tomcat可以承受到2.19G。只是再刷新就可以把他整崩溃。
最后,请了几个牛人帮忙,一个牛人凌晨帮我们看tomcat配置。问我们,是否加了,-server参数。最后,我同事加上了-server参数。 然后,回去睡觉了,发现java.exe内存真的能回收了。很多问题也解决了。
我们配置如下:(将tomcat6的安装版卸载,换成绿色版)
在catalina.bat的@echo off下面添加(就是第二行)
set JAVA_OPTS=-server -Xms512m -Xmx1024m -XX:MaxNewSize=512m -XX:MaxPermSize=256m
在startup.bat下面添加(让tomcat的工具自动回收内存)
@echo off
set JAVA_OPTS=%JAVA_OPTS%
-Dcom.sun.management.jmxremote.port=1090
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager
-Djava.util.logging.config.file="%CATALINA_HOME%\conf\logging.properties"
三、问题分析(关于页面反应速度异常)
我们的首页显示餐馆的信息,主要根据用户选择地区,然后将该地区的餐馆列表和热卖美食列表显示出来。我们发现一个很奇怪的现象,访问某一学校东校区时:
8个餐馆:Action执行2063ms(获取餐馆列表:1220ms + 获取热卖美食:825ms)。
然后换成其他校区分别为:
3个餐馆:Action执行 51ms (获取餐馆列表:29 + 获取热卖美食: 2)
3个餐馆:Action执行 53ms (32 + 1)
4个餐馆:Action执行 90ms (74 + 1)
看到这个数据,我就很纳闷,怎么时间不成比例呢?
于是,我将8个餐馆删掉4个对比。由于有外键关联,我必须要删除其他的很多的。为了删除一个餐馆记录,我必须删除其他记录多达6个表处,可见外键关系较为复杂。
等我删掉后,发现东校区:
4个餐馆:Action执行111ms(获取餐馆列表:53ms + 获取热卖美食:37ms)。
我发现这个变化太明显了吧。然后,我怀疑那四个餐馆关联了太多东西。我查询出来的不仅仅是餐馆,可能连带查询了另外的6个表的记录。
我就想到了是hbm.xml文件中设置lazy = "true"问题。
通过测试,我发现是 餐馆对应订单时,one-to-many时,lazy = "true"。这个就很明显了。
查询一个餐馆,就把它的上百份订单级联查询出来了,同时把所有菜品也级联查询出来了,把所有菜品分类都查询出来了。
而就东校区的这8家餐馆订单较多,其他校区由于刚开业,订单几乎没有。这下就可以解释为什么东校区这么耗时间(当然也耗内存)。
然后,我将hbm.xml的所有lazy="true"全部去掉,恢复数据库数据。
东校区结果如下:
8个餐馆:Action执行25ms(获取餐馆列表:3ms + 获取热卖美食:8ms)。
四、结论:
lazy="false"使用时要慎重。例如:对与1:1的情况,使用直接影响不大,对于1:n情况就要慎重了。尤其是n成百上千时,问题就相当严重了。我建议最好不用。
第一次,配置和管理服务器,收获真大呀。对我以后的编程风格都造成了深远的影响。我会注意服务器的时间和空间效率问题。
当然测试方法比较土。先将服务器正常上线后,我会学着使用JMeter和roadrunner的工具做压力测试,配置好服务器。
忙里偷闲!记录下来!
转自http://www.cnblogs.com/pyrmkj/archive/2012/06/23/2559375.html