 2008年11月7日
2008年11月7日
在进行文件下载时liunx下出现中文文件名乱码,windows下却没有.可能是不同操作系统的编码方式不同?(含糊不清的说法),用
Properties initProp = new Properties(System.getProperties());
System.out.println(prop.getProperty("file.encoding"));能得到编码方式都是UTF-8
后来发现用
fileName = new String(fileName.getBytes("UTF-8"), "iso-8859-1");不管linux还是windows 下用火狐都是显示正常的,IE下却显示乱码,所以问题出在浏览器,得在程序中加入判断(分别处理firefox跟Ie):
//判断是否是使用IE的方法
String userAgent = request.getHeader("User-Agent");
boolean isIE = false;
//userAgent.toLowerCase().indexOf("msie")
if(userAgent.indexOf("MSIE") > 0){
isIE = true;
}
if(isIE){
fileName = new String(fileName.getBytes("gb2312"), "iso-8859-1");
}else{
fileName = new String(fileName.getBytes("UTF-8"), "iso-8859-1");
}
一个同学前几天遇到一个问题,今天我试着看了一下。
项目没有错误,在项目部署到tomcat后,tomcat启动时报错:
java.lang.UnsupportedClassVersionError: Bad version number in .class file 。。。
这个问题我原来遇到过,原因应该是编译java时生成的class文件,在运行时用到的JRE和class文件版本不一致造成的。
1 如果是一般的java程序:
可以在MyEclipse中修改JRE的路径和版本。在Window->Preferences中,打开如下位置,就可修改JRE:

修改完之后,最好重新编译一下,选Project->Clean... 选项,然后选择是所有的项目都要重新编译,还是只重新编译指定的项目,然后就应该没问题了。
今天一开始我也是这么做的,但是还是报错,在网上搜了一下之后,因为这是Web项目,程序当然是在Tomcat上运行的,所以我们这么改当然不行。
2 如果是Web 程序
就要修改Tomcat运行时的JDK环境了,如下图:

把JDK的路径和之前Installed JRE的设置成一样的,这个问题就解决了!(虽然这里面设置的是JDK的路径,但是我觉得其实就是在设置JRE的路径,因为java程序运行的时候需要的 是JRE,而不是JDK。我们装JDK的时候,一般都装了2个JRE,一个是JDK里面的JRE,还有一个和JDK平级的JRE,刚才我上网查了一下,这 两个JRE的区别不大,大家也可以去查一下,每次都可以选择任何一个JRE,但是之后配置的吆喝前面的一致。)
如果不清楚JDK和JRE的关系的,可以上网查一下。
一般情况下,我们运行别人的程序可能会遇到这个问题。
再做个小小的延伸。。
这个项目编译并没有报错,如果我们导入别人的项目之后,出现了很多错误,那就是JDK版本的问题了,可以在这里修改:

可以选择1.3,1.4,5.0,6.0.
转 http://apps.hi.baidu.com/share/detail/1776104
http://mayuqi827.javaeye.com/blog/804409
LINUX基本操作命令
基本操作命令
----------------------------------------------------------------------
----------------------------------------------------------------------
ls #以默认方式显示当前目录文件列表
ls –a #显示所有文件包括隐藏文件
ls –l #显示文件属性,包括大小,日期,符号连接,是否可读写及是否可执行
ls --color=never *.so > obj #不显示文字颜色,将所有so文件记录到obj文件中
----------------------------------------------------------------------
cd dir #切换到当前目录下的dir目录
cd / #切换到根目录
cd .. #切换到到上一级目录
cd ../.. #切换到上二级目录
cd ~ #切换到用户目录,比如是root用户,则切换到/root下
----------------------------------------------------------------------
rm file #删除某一个文件
rm -fr dir #删除当前目录下叫dir的整个目录
----------------------------------------------------------------------
cp source target #将文件source 复制为 target
cp /root/source . #将/root下的文件source复制到当前目录
cp –av soure_dir target_dir #将整个目录复制,两目录完全一样
cp –fr source_dir target_dir
#将整个目录复制,并且是以非链接方式复制,当source目录带有符号链接时,两个目录不相同
----------------------------------------------------------------------
mv source target #将文件source更名为target
----------------------------------------------------------------------
diff dir1 dir2 #比较目录1与目录2的文件列表是否相同,但不比较文件的实际内容,不同则列出
diff file1 file2
#比较文件1与文件2的内容是否相同,如果是文本格式的文件,则将不相同的内容显示,如果是二进制代码则只表示两个文件是不同的
comm file1 file2 #比较文件,显示两个文件不相同的内容
----------------------------------------------------------------------
echo message #显示一串字符
echo "message message2" #显示不连续的字符串
cat:
cat file #显示文件的内容,和DOS的type相同
cat file | more #显示文件的内容并传输到more程序实现分页显示,使用命令less file可实现相同的功能
more #分页命令,一般通过管道将内容传给它,如ls | more
----------------------------------------------------------------------
export LC_ALL=zh_CN.GB2312 #将环境变量LC_ALL的值设为zh_CN.GB2312
export DISPLAY=0:0 #通过该设置,当前字符终端下运行的图形程序可直接运行于Xserver
date #显示当前日期时间
date -s 20:30:30 #设置系统时间为20:30:30
date -s 2002-3-5 #设置系统时期为2003-3-5
clock –r #对系统Bios中读取时间参数
clock –w #将系统时间(如由date设置的时间)写入Bios
----------------------------------------------------------------------
eject #umout掉CDROM并将光碟弹出,但cdrom不能处于busy的状态,否则无效
----------------------------------------------------------------------
du #计算当前目录的容量
du -sm /root #计算/root目录的容量并以M为单位
find -name /path file #在/path目录下查找看是否有文件file
grep -ir “chars” #在当前目录的所有文件查找字串chars,并忽略大小写,-i为大小写,-r为下一级目录
----------------------------------------------------------------------
vi file #编辑文件file
vi 原基本使用及命令:
输入命令的方式为先按ctrl+c, 然后输入:x(退出),:x!(退出并保存) :w(写入文件),:w!(不询问方式写入文件), :r
file(读文件file) ,:%s/oldchars/newchars/g(将所有字串oldchars换成newchars)
这一类的命令进行操作
----------------------------------------------------------------------
man ls #读取关于ls命令的帮助
man ls | grep color #读取关于ls命令的帮助并通过grep程序在其中查找color字串
----------------------------------------------------------------------
startx #运行Linux图形有环境
Xfree86 #只运行X图形server
----------------------------------------------------------------------
reboot #重新启动计算机
halt #关闭计算机
init 0 #关闭所有应用程序和服务,进入纯净的操作环境
init 1 #重新启动应用及服务
init 6 #重新启动计算机
----------------------------------------------------------------------
扩展命令
----------------------------------------------------------------------
----------------------------------------------------------------------
tar xfzv file.tgz #将文件file.tgz解压
tar xfzv file.tgz -C target_path #将文件file.tgz解压到target_path目录下
tar cfzv file.tgz source_path #将文件source_path压缩为file.tgz
tar c directory > directory.tar #将目录directory打包成不压缩的directory.tar
gzip directory.tar #将覆盖原文件生成压缩的 directory.tar.gz
gunzip directory.tar.gz #覆盖原文件解压生成不压缩的 directory.tar。
tar xf directory.tar #可将不压缩的文件解包
----------------------------------------------------------------------
dmesg #显示kernle启动及驱动装载信息
uname #显示操作系统的类型
uname -R #显示操作系统内核的version
----------------------------------------------------------------------
strings file 显示file文件中的ASCII字符内容
----------------------------------------------------------------------
rpm -ihv program.rpm #安装程序program并显示安装进程
rpm2targz program.rpm program.tgz #将rpm格式的文件转换成tarball格式
----------------------------------------------------------------------
su root #切换到超级用户
sulogin /dev/tty4 #在tty4即alt+F4终端等待用户登陆或直接登陆开启一个shell
chmod a+x file #将file文件设置为可执行,脚本类文件一定要这样设置一个,否则得用bash file才能执行
chmod 666 file #将文件file设置为可读写
chown user /dir #将/dir目录设置为user所有
----------------------------------------------------------------------
mknod /dev/hda1 b 3 1 #创建块设备hda1,主设备号为3,从设备号为1,即master硬盘的的第一个分区
mknod /dev/tty1 c 4 1 #创建字符设备tty1,主设备号为4,众设备号为1,即第一个tty终端
----------------------------------------------------------------------
touch /tmp/running #在/tmp下创建一个临时文件running,重新启动后消失
----------------------------------------------------------------------
sleep 9 #系统挂起9秒钟的时间
----------------------------------------------------------------------
lpd stop 或 cups stop #停止打印服务程序
lpd start 或 cups start #启动打印服务程序
lpd restart 或 cups restart #重新启动打印服务程序
lpr file.txt #打印文件file.txt
----------------------------------------------------------------------
fdisk /dev/hda #就像执行了dos的fdisk一样
cfdisk /dev/hda #比fdisk界面稍为友好些
mount -t ext2 /dev/hda1 /mnt #把/dev/hda1装载到 /mnt目录
df #显示文件系统装载的相关信息
mount -t iso9660 /dev/cdrom /mnt/cdrom #将光驱加载到/mnt/cdrom目录
mount-t smb //192.168.1.5/sharedir /mnt -o
username=tomlinux,password=tomlinux
#将windows的的共享目录加载到/mnt/smb目录,用户名及密码均为tomlinux
mount -t nfs 192.168.1.1:/sharedir /mnt
#将nfs服务的共享目录sharedir加载到/mnt/nfs目录
umount /mnt #将/mnt目录卸载,/mnt目录必须处于空闲状态
umount /dev/hda1 #将/dev/hda1设备卸载,设备必须处于空亲状态
sync #将cache中的内容与磁盘同步,在Linux中复制文件,一般要系统空闲才去写文件
e2fsck /dev/hda1 #检查/dev/hda1是否有文件系统错误,提示修复方式
e2fsck -p /dev/hda1#检查/dev/hda1是否有错误,如果有则自动修复
e2fsck -y /dev/hda1#检查错误,所有提问均于yes方式执行
e2fsck -c /dev/hda1#检查磁盘是否有坏区
mkfs /dev/hda1 #格式化/dev/hda1为ext2格式
mkfs.minix /dev/hda1 #格式化/dev/hda1为minix格式文件系统
mfks /dev/hda9 #格工化/dev/hda9为Linux swap格式
swapon /dev/hda9 #将swap分区装载当作内存来用
swapoff /dev/hda9 #将swap分区卸载
----------------------------------------------------------------------
lilo #运行lilo程序,程序自动查找/etc/lilo.conf并按该配置生效
lilo -C /root/lilo.conf #lilo程序按/root/lilo.conf配置生效
grub #在Linux shell状态下运行boot loader设置程序
grub-install
#安装grub磁盘引导程序,成功后升级内核无须像lilo一样要重新启动系统,只需修改/etc/grub.conf即可实现新引导配置
rdev bzImage #显示kernel的根分区信息
rdev bzImage /dev/hda1
#将kernel的根分区设置为/dev/hda1,这在没有lilo等引导程序的系统中非常重要.
----------------------------------------------------------------------
dd if=/dev/fd0 of=floppy.fd #将软盘的内容复制成一个镜像,功能与旧石器时代常用的hd-copy相同
dd if=/dev/zero of=root.ram bs=1024,count=1024
#生成一个大小为1M的块设备,可以把它当作硬盘的一个分区来用
mkfs root.ram #将块设备格式化为ext2格式
dd if=root.ram of=/dev/ram0 #将init.rd格式的root.ram的内容导入内存
mount /dev/ram0 /mnt #ramdisk /dev/ram0装载到/mnt 目录
----------------------------------------------------------------------
gcc hello.c #将hello.c编译成名为a.out二进制执行文件
gcc hello.c -o hello #将hello.c编译成名为hello的二进制执行文件
gcc -static -o hello hello.c #将hello.c编译成名为hello的二进制静态执行文件
ldd program #显示程序所使用了哪些库
objcopy -S program #将程序中的符号表及无用的调试信息去掉,可以小很多
----------------------------------------------------------------------
strace netscape
#跟踪程序netscape的执行,看调用的库,环境变量设置,配置文件,使用的设备,调用的其它应用程序等,在strace下,程序干了什么东东一目了
然。
ps #显示当前系统进程信息
ps –ef #显示系统所有进程信息
kill -9 500 #将进程编号为500的程序干掉
killall -9 netscape #将所有名字为netscape的程序杀死,kill不是万能的,对僵死的程序则无效。
top #显示系统进程的活动情况,按占CPU资源百分比来分
free #显示系统内存及swap使用情况
time program #在program程序结束后,将计算出program运行所使用的时间
----------------------------------------------------------------------
chroot . #将根目录切换至当前目录,调试新系统时使用
chroot /tomlinux #将根目录切换至/tomlinux目录
chroot /tomlinux sbin/init #将根目录切换至/tomlinux并执行sbin/init
adduser id #增加一个叫id的用户
userdel id #增除叫id的用户
userlist #显示已登陆的用户列表
passwd id #修改用户id的密码
passwd -d root #将root用户的密码删除
chown id /work #指定/work目录为id用户所拥有
----------------------------------------------------------------------
ifconfig eth0 192.168.1.1 netmask 255.255.255.0
#设置网卡1的地址192.168.1.1,掩码为255.255.255.0,不写netmask参数则默认为255.255.255.0
ifconfig eth0:1 192.168.1.2 #捆绑网卡1的第二个地址为192.168.1.2
ifconfig eth0:x 192.168.1.x #捆绑网卡1的第二个地址为192.168.1.x
ifconfig down eth1 #关闭第二块网卡,使其停止工作
hostname -F tomlinux.com #将主机名设置为tomlinux.com
route #显示当前路由设置情况
route add default gw 192.168.1.1 metric 1 #设置192.168.1.1为默认的路由
route del default #将默认的路由删除
dhcp #启动dhcp服务
dhclient #启动dhcp终端并自动获取IP地址
ping 163.com #测试与163.com的连接
ping 202.96.128.68 #测试与IP 202。96.128.68的连接
----------------------------------------------------------------------
probe rtl8139 #检查驱动程序rtl8139.o是否正常工作
lsmod #显示已装载的驱动程序
insmod rtl8139.o #装载驱动程序rtl8139.o
insmod sb.o io=0x280 irq=7 dma=3 dma16=7 mpu_io=330
#装载驱动程序并设置相关的irq,dma参数
rmmod rtl8139 #删除名为rtl8139的驱动模块
gpm -k #停止字符状态下的mouse服务
gpm -t ps2 #在字符状态下以ps2类型启动mouse的服务
----------------------------------------------------------------------
telnet 192.168.1.1 #登陆IP为192.168.1.1的telnet服务器
telnet iserver.com #登陆域名为iserver.com的telnet服务器
ftp 192.168.1.1 或 ftp iserver.com #登陆到ftp服务
1tomcat 部署网站 去掉端口号和项目名称
去除端口号 conf-->server.xml中查找原始的端口号(如8080),修改为80后,即可在访问时不用输入端口号。不过要注意防止其它程序占用80端口。
项目名称 server.xml <Context path="/myapp" reloadable="true" docBase="D:"myapp" workDir="D:"myapp"work"/>
2 TOMCAT 如何配置多端口
1.修改端口:
在Tomcat的安装目录下的"conf目录下,打开server.xml,
找到
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"/>
将8080改为你想要的端口8081
2.映射路径:
还是在server.xml配置文件中,
在</host>这个结束标签之前加上如下的配置信息:
<Context
path="/myapp"
reloadable="true"
docBase="e:"myApp" />
3.添加端口:
在server.xml中添加以下:
<Connector port="65535" protocol="HTTP/1.1"
connectionTimeout="20000" />
Tomcat的端口号最大到65535.
4.上面的端口对于原来Tomcat中的其他Web应用也可以使用,
下面是独立的,只有你的e:"myApp中的Web应用可用,
也就是在server.xml中的</Service>下另外建立一个Service:
<Service name="test">
<Connector port="65535" protocol="HTTP/1.1"
connectionTimeout="20000" />
<Engine name="myengine" defaultHost="myhost">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
<Host name="myhost" appBase="e:"myApp"
unpackWARs="true" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
</Host>
</Engine>
</Service>
另外:
1818189端口?有这么多位吗?
我印象中端口号范围是0~65535,怎么还有这么多位的端口?
http://ttov.blog.163.com/blog/static/3822715201072692912584/
1、安装VMware workstation。
2、安装guest系统,这里我安装的Red Hat
Linux9,安装过程中确保网络连接选择的是NAT方式,当然可以在安装完后进行修改。
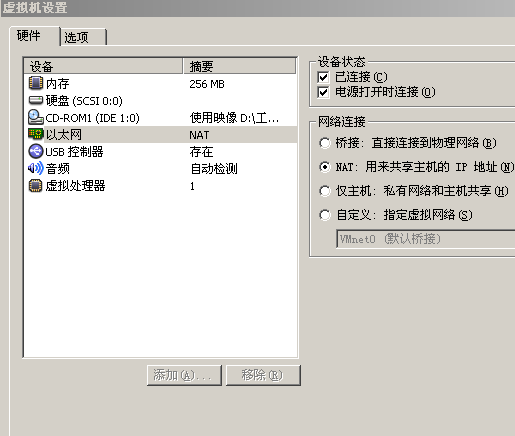
3、到windows XP
中,查看所有的网络连接,你应该发现除了原有的网卡之外,又多了Vmnet1和Vmnet8。
vmnet1是hostonly的接口,而Vmnet8是就是我们要使用的NAT的网络接口。
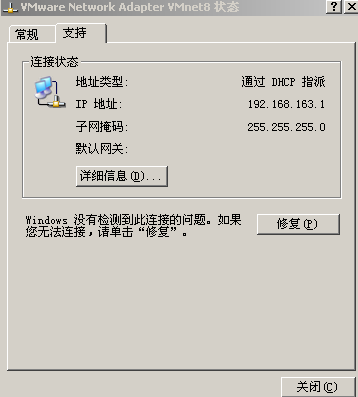
4、在win主机上用ipconfig查看VMnet8的IP地址,
一般是192.168.X.1/255.255.255.0,此时VMnet8的设置应该是自动获取IP,现在改成静态IP,并把此IP直接填入
VMnet8里,不设网关。
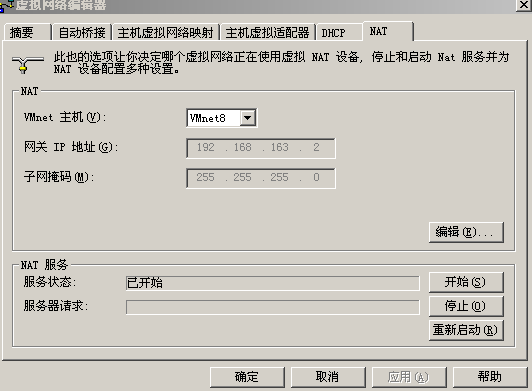
5、同时在VM网络设置里的NAT项中查看VMnet8,一般是
192.168.X.2/255.255.255.0这个地址就是VMnet8,NAT的网关。
6、现在在LINUX下把网卡IP设置成和VMnet8一个网段的
IP(192.168.X.Z/255.255.255.0)
7、网关设置成刚才查看的那个IP192.168.X.2即可。
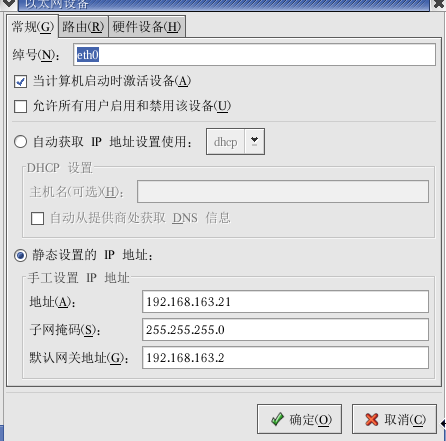
8、DNS和你host主机的一样就可以。
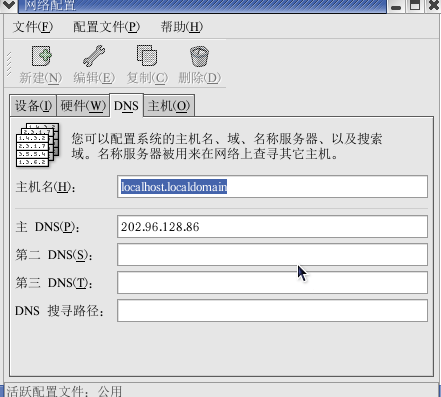
9、设置完成后,重新启动linux的网络服务。
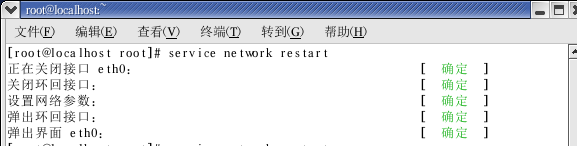
Linux命令
netconfig 设置IP
ifconfig 查看
reboot 重启
services network restart (重启网络)
http://www.cnblogs.com/hakuci/archive/2008/12/07/1349547.html
一般情况下,安装完vmware,不做其他设置,直接使用nat模式就可以与主机共享上网了。但如果你用的是某些精简版,或者你自己做过修改,那么就照下
面的步骤检查一遍吧。
一、先检查nat是否可用及相关服务是否已经打开。
首先打开虚拟机的虚拟网络设置功
能,虚拟机菜单栏——编辑——虚拟网络设置

=700)
window.open('http://bbs.crsky.com/1236983883/Mon_1004/6_194774_887ae060f330442.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图一
如果你发现上面的选项是灰色的,说明你的精简版没有这个功能,想办法换个版本,或者找下载说明,看看是否还
需要装其他东西。
在后面的对话框里检查dhcp和nat服务是否已经打开。

=700)
window.open('http://bbs.crsky.com/1236983883/Mon_1004/6_194774_56d1cfb5e6d2e11.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图二

=700)
window.open('http://bbs.crsky.com/1236983883/Mon_1004/6_194774_da98e19f2ca0e5a.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图三
如果你在上图中按下启动——应用没有用的话,就要考虑是不是相关服务被禁用了。主机开始菜单——运行——
services.msc检查相关服务的情况。正确的应该如下:

=700)
window.open('http://bbs.crsky.com/1236983883/Mon_1004/6_194774_b831307582cc66e.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图四
二、
检查ics是否有打开,既打开ics又打开nat模式,同时作用,会造成混乱的,必须关闭。(ics就是internet connection
share,也就是internent连接共享)

=700)
window.open('http://bbs.crsky.com/1236983883/Mon_1004/6_194774_180e7abade984b8.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图五
三、
检查网络接口模式
看看虚拟机网卡是不是真的用了nat模式,跟虚拟网络设置里是不是用了同一个vmnet号,请确保下图六和图3中用的是
同一个vmnet号。

=700)
window.open('http://bbs.crsky.com/1236983883/Mon_1004/6_194774_88f83d8b3174401.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图六
虚拟机7.0以前的版本,nat都默认使用了vmnet8作为nat的默认端口号,但vm7.0就不同了。

=700)
window.open('http://bbs.crsky.com/1236983883/Mon_1004/6_194774_742811ec5a6daf6.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图七
nat模式用的是vmnet0了,这个时候,保险为妙,虚拟机网卡请使用自定义vmnet0接口。
四、
开虚拟机系统检查是否获取到了ip。检查ip,网关,dns,是否都正常。

=700)
window.open('http://bbs.crsky.com/1236983883/thumb/Mon_1004/6_194774_724219dda00790b.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图八
4.1关于出现网络连接红叉,“电缆被拔出”。在虚拟机里是不存在电缆的,所以肯定是设置问题。
4.1.1
检查图六“打开电源时连接”的钩,或者检查图八里,右下角的虚拟网卡图标是否有叉。
4.1.2
上一条正常的,请安装一遍vmtools,确保虚拟网卡驱动正常。
4.1.3
上2条都正常的,还是有问题的,应该是某些系统的问题了。ubuntu的话多点几次连接看看,redflag的话,本地连接属性里“连接后在通知区域显示
图标”前的钩去掉,眼不见心不烦反而可以连上了。
五、vm7.0还是没有获取到ip的,需要把虚拟网络设置设置为默
认再试一遍。
将虚拟机里的系统关机,打开虚拟网络配置,如图7所示,按下左下角的“resore
default”恢复默认设置,在随后跳出的whql驱动认证里全部选择“始终安装此驱动软件”。

=700)
window.open('http://bbs.crsky.com/1236983883/Mon_1004/6_194774_b329ff341c566c1.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
图九
完
成后,请继续检查前面的检查项目,再检查一遍后再打开虚拟机里的系统。
六、获取了ip还是无法上网的,有以下的几种情况。
6.1 主机是win7或是vista,vmware版本低于6.5.3的,请升级vmware的版本。
这个问题的症状就是能ping通域名,也上不去网。但qq可以上去,这个应该是个兼容问题,请升级vmware版本。
6.2
使用网络命令检查网络。
1.ping nat网关,以图8为利,ping 192.168.47.2
2.ping
物理主机公网ip或内网真实ip,
3.可以继续ping,公网的isp网关或是内网的路由器ip,最后ping下网站域名。
如果都能通,而不是6.1的问题,看是不是浏览器上设置了错误的代理。
如果dns能解析,
但ping所有外网ip都是丢包的,应该是网关问题,检查下是否是双网关,route print检查下默认网关。
如果可以ping通所
有ip,ping不通域名,则应该是nat服务器的dns解析出了问题,重新启动主机(和重启路由器一样的道理)或是在虚拟机里直接填公网dns,或者设
置nat,直接将dns直接填到虚拟机nat里(如图十)。

=700)
window.open('http://bbs.crsky.com/1236983883/thumb/Mon_1004/6_194774_c10769a426e7ab1.jpg');" onload="if(this.offsetWidth>'700')this.width='700';if(this.offsetHeight>'2100')this.height='2100';" border="0">
http://www.xpxzlt.cn/simple/?t161677.html
Q:VMware DHCP Service 服务无法启动 1067 错误
A:打开Virtual Network Editor,选择 Restore Default
Q:VMware Brige 桥接服务无法启动 发生系统错误 2 系统找不到指定的文件
A:替换vmnetbridge.sys
vmnetbridge.dll(下载)
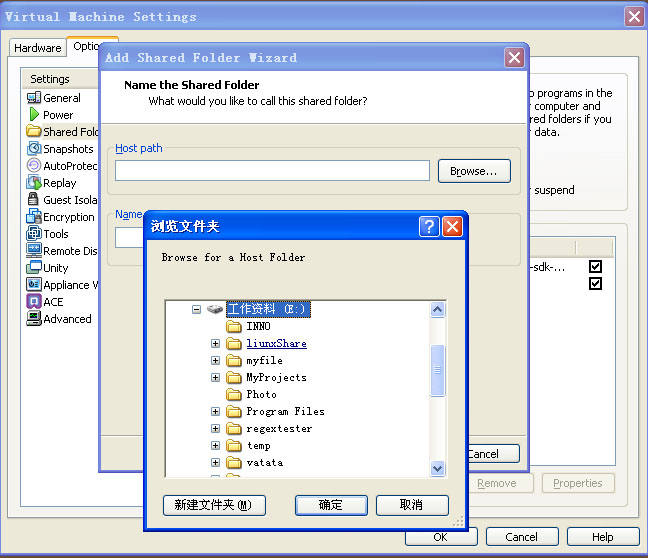
window主机与Ubuntu虚拟机共享文件夹的设置方法:
打开虚拟机,并开启Ubuntu。
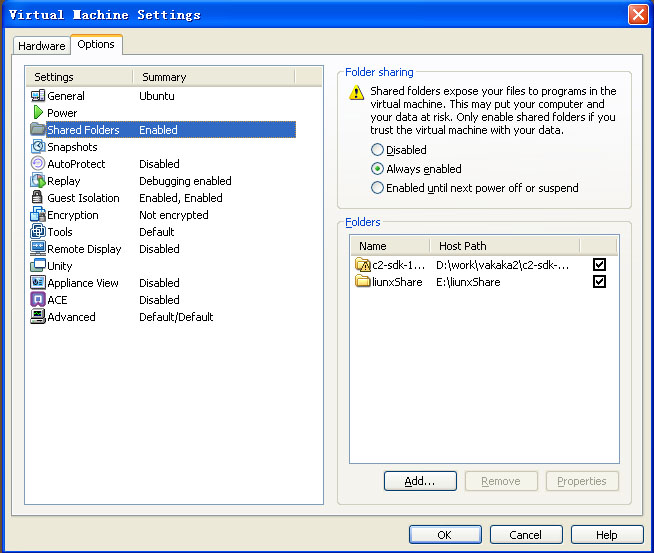
在ubuntu的选项卡右击 --> Settings --> 点击 Options --> 窗口左侧的 Shared
Folders --> 右侧Folder Sharing的 Always enabled --> 右侧 Folders 下面的
Add --> Next --> Brower --> 在 浏览文件夹 中选择自己想要共享的文件夹(如:
E:/linuxshare) --> 确定 --> Enable this share --> Finish 。
文件夹共享设置完成。
需要往 Ubuntu上传什么东西,放在E:/linuxshare 下即可。 linux中的访问路径是: /mnt/hgfs/linuxshare
下面附上截图。

图一
图二
图三
图四
图五

图六
http://www.cnblogs.com/computer/archive/2010/07/21/1781945.html
http://chenjian977355.blog.163.com/blog/static/5544582010229150190/
WIN 7下光盘安装Ubuntu9.10,简单配置并修改启动项~~
先下载最新的Ubuntu9.10版,前几天刚发布的
下载地址:http://www.ubuntu.org.cn/getubuntu/download/
在下载位置处,选择“TAIWAN”(中国好像只有台湾这个选项)

因为觉得光盘安装比较舒服,所以我选择了光盘安装。
用UltraISO或者其他工具把下载下来的镜像刻进一张空的CD盘。
由于偶的小Y从来没碰过Ubuntu系统,所以整个安装过程最主要的就是对硬盘进行分区。
申明:本人安装时并未想到要来写教程,部分截图是9.04版的,但几乎是一样的,不一样处我会指出。
1.将光盘放进光驱后重启,按F12,选择光驱启动,此时光驱开始狂转,等一会便出现界面,选择你看得懂的:简体中文

2.选择第一项“试用Ubuntu而不改计算机中的任何内容”,按回车确认,也可以选择第二项直接安装ubuntu,安装步骤与以下演示相相同。(为什么要选择第一项安装,因为ubuntu
liveCD有个特色,就是可以一台电脑上用光盘来临时体验一下ubutnu的完整系统,进入后进也可安装系统)

3.毫无悬念的,光驱又开始狂转,这下等的时间会稍微长点,一段时间后进入系统。在这里你可以先体验下这个
系统,可以联网;玩够了再考虑装还是不装 。如果装的话,就点击桌面的“安装”
。如果装的话,就点击桌面的“安装”

4.出现以下界面,当然用简体中文,按默认连续三次Forward(下一步),如图



5.然后就到了给硬盘分区了,首先进入到如图的界面(图显示的不是WIN7 ,是XP,这个不重要,只要点击那个“手动指定分区(高级)”就行了)

6.注意:以下内容重要!!!!
我的小Y一共分成了CDEFG,5个区,F盘80G
至今没用过,所以我打算分出20G来装Ubuntu。不一定要20G,10G也行,看自身情况。
选中要改变的分区,点“编辑分区”(9.10版里好像是叫“新建”,都一样,就是“删除分区”选项之前的那个)

7.出现以下提示,点继续将进行硬盘分区,不用担心,你硬盘里的东西不会丢失

8.分区完成,以下我们可以看到硬盘多个一个空闲的空间,这就是我们释放出来安装ubunbu的空间。选中
空闲的空间再点下面的新的分区。

9.下面对这个空闲的空间进行分区,首先来分个swap交换空间,这个相当于windows下的虚拟内存,根据你内存的大小填入,一般填为与内存一样的大小,我的内存2G,因此以下
也填入2048(也有一种说法是:内存小于1G的此处填2倍,大于1G的就填1G就行,自己看着办吧),再选择交换空间按确定。

10.依然选中空闲的空间-新的分区,下面来创建个系统空间,这里我把空闲剩下的全部分配给这个分区,再选
择Ext3日志文件系
统,挂载点选/,再点确定,到这里分区完成。


11.自定义填写用户名和密码,你也可以选择自动登录还是需要密码以登入(这就是决定是否在开机输入密
码),再点下一步,当你密码设置过短时,考虑到安全ubuntu会提示你是否重新设置,我们不用管它,点继续即可。

12.通过下面我们看到两个分区,格式为swap和ext3,这两个分区就是Linux要用到的分区,选中ext3分区再点下一步就行。

13.接下来提示问你是否导入本机WIN 7系统的文档到ubuntu下使用,如果你需要就勾上,我一个没勾,再点下一步。
14.好了,到这里准备安装,现在你要做的是拔掉网线(切记,一定要把网线拔掉),用无线网络的直接把无线开关掰回去先。因为ubuntu在安装过
程上会自动从官方下载一些更新,由于这个“源"地址设在欧洲,对于我们国内用户来说下载特级慢,我们还是把更新放在系统安装后进行操作,下面点击安装即
可!

15.以下进行系统安装中,请不要断来电脑电源!

17.过了十几分钟,系统安装完成,点现在重启,此时电脑会弹出光盘,请取出光盘后敲一下回车。

安装完成,秀下桌面:

==========================================================================================================
第二部分:
简单配置
重启后首次进入ubuntu的桌面,说明系统已安装成功,下面我们来对系统进行更
新(这类似于windows下的打补丁),
首先要做的是换源,什么是源?源可以理解为ubuntu系统更新的服务器地
址,之前我们已经说过,ubuntu默认的源是设在欧洲,这对于我们国内来说更新过程十分慢,因此可见换源十分重要,我们把这个源换成离我们较近的地区来
提高更新速度。先点击右上角的网络标识,连上网络,很简单的,一看就会。
1.选择桌面上方的工具条
依次进入System —— Administration——软件源
——wnloag
from--other,此时提示输入密码(密码就是你刚才安装时设置的密码,以后其它操作会提示都是输入那个密码),然后弹出以下窗口,有世界各地区供
选择,选择Tai w再选tw.archive.ubuntu.com这个源(因为Tai w这个源在国内被公认较快),最后点Choose
Gerver。

此时,系统会连上“源”更新组件之类的,

2.下载语言包:我们发现系统虽安装好了,可是菜单却
大多数是英文,此是要做的是下载并安装简体中文语言包,System —— Administration ——Language
Support,此时系统会自动选好汉语,并弹出以下窗口,直接点Install。

3.此时系统正在下载并安装简体中文语言包中。

语言安装完毕后,我们点Close关闭窗口,再选择桌面右上角的关机按钮,选择Restart...重新启动计算机
4.重启后,你能发现原来英文的菜单已经变为简体中文了,说明简体中文语言包安装成功。

5.我们发现桌面空空的,什么都没有,这时要把平时在windows习惯的几个图标调出来,选择桌面上方的应用程序--
附件--终端,在终端输入gconf-editor再按回车后将弹出配置编辑器窗口。

6.通过以下窗口,依次选择apps—— nautilus—— desktop,从右边选择把需要显示在桌面图标,勾上即可

7.在桌面右键选择更改桌面背景,进入视觉效果选项卡,默认是关闭好像,然后点击正常(或拓展),视个人喜好定,不过这个费显卡的,反正我选择正常很流
畅。

接着,系统会自动联网安装显卡驱动程序,装好后重启,再次进入该处才能正常开启视觉效果选项。
=========================================================================================================
第三部分:修改启动项
ubuntu安装后每次开机都是默认进入ubuntu系统的,对于以windows为主的朋友,每次开机都要守在画面切换到XP启动,可见十分麻
烦,通过下面,你可以设置让你的WIN 7系统为第一启动
我尝试像XP一样打开menu.lst,结果是空白~~~~几番询问后才发现时因为9.10升级为grub2了,于是转而修改grub.cfg文件。
1.左上角-应用程序-附件-终端,输入sudo chmod +w /boot/grub/grub.cfg
将grub.cfg设为可写状态

2.提示输入密码:输入你设的开机密码,此处输入密码不可见,密码输入后直接回车,然后输入sudo gedit
/boot/grub/grub.cfg

3.编辑grub.cfg

4.自习查看,里面有好几段以
###BEGIN**************###开头
###END****************###结尾 的代码
5.将含有WIN 7那段代码剪切至图中位置

6.确认下图的那段代码值=0

7.保存后退出。
8.一切顺利的话,重启的菜单项将是这样的(高亮显示的即为WIN 7)

注意:如果是XP系统,则第一第二部分通用,要调整启动顺序的话
打开终端(应用程序——>附件——>终端),输入sudo gedit
/boot/grub/menu.lst,敲下回车,这时要求输入password,输入登录系统的密码,在终端里不能显示输入的密码,这是正常的,输入
后回车打开编辑窗口。
在其中找到XP的代码,把它剪切到最前头就行了~~~~~
Communications link failure,The last packet successfully received from
the server was *** millisecond ago.The last packet successfully sent to
the server was *** millisecond ago。
最近做测试,发现Mysql 过一段时间会无法连接,导致数据库数据不一至,极其郁闷。
下面是转一哥门的
使用Connector/J连接MySQL数据库,程序运行较长时间后就会报以下错误:
Communications link failure,The last packet successfully received
from the server was *** millisecond ago.The last packet successfully
sent to the server was *** millisecond ago。
其中错误还会提示你修改wait_timeout或是使用Connector/J的autoReconnect属性避免该错误。
后来查了一些资料,才发现遇到这个问题的人还真不少,大部分都是使用连接池方式时才会出现这个问题,短连接应该很难出现这个问题。这个问题的原因:
MySQL服务器默认的“wait_timeout”是28800秒即8小时,意味着如果一个连接的空闲时间超过8个小时,MySQL将自动断开该连接,而连接池却认为该连接还是有效的(因为并未校验连接的有效性),当应用申请使用该连接时,就会导致上面的报错。
1.按照错误的提示,可以在JDBC
URL中使用autoReconnect属性,实际测试时使用了autoReconnect=true&
failOverReadOnly=false,不过并未起作用,使用的是5.1版本,可能真像网上所说的只对4之前的版本有效。
2.没办法,只能修改MySQL的参数了,wait_timeout最大为31536000即1年,在my.cnf中加入:
[mysqld]
wait_timeout=31536000
interactive_timeout=31536000
重启生效,需要同时修改这两个参数。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/cau99/archive/2009/12/11/4987760.aspx
hibernate-HQL语句(1)
http://java.chinaitlab.com/Hibernate/809957.html
当月第一天 select timestamp(concat(year(curdate()),'-',month(curdate()),'-','1')) 如2010-08-01 00:00:00
当前时间 select now()
测试对于保证软件开发质量有着非常重要的作用,单元测试更是必不可少,
JUnit是一个非常强
大的单元测试包,可以对一个/多个类的单个/多个方法测试,还可以将不同的TestCase组合成TestSuit,使测试
任务自动化。Eclipse同样集成了JUnit,可以非常方便地编写TestCase。
我们创
建一个Java工程,添加一个example.Hello类,首先我们给Hello类添加一个abs()方法,作用是返
回绝对值:

(图一)
下一
步,我们准备对这个方法进行测试,确保功能正常。选中Hello.java,右
键点击,选择New->JUnit
Test Case:

(图二)
Eclipse会询问是否添加junit.jar包,确定后新建一个HelloTest类,用来测试Hello类。

(图三)
选中setUp()和tearDown(),然后点击“Next”:

(图
四)
选择要
测试的方法,我们选中abs(int)方法,完成后在HelloTest.java中输入:

(图五)
JUnit会以以下顺序执行测试:(大致的代码)
try {
HelloTest test = new HelloTest(); // 建立测试类实例
test.setUp(); // 初始化测试环境
test.testAbs();
// 测试某个方法
test.tearDown(); // 清理资源
}
catch…
setUp()是建立测试环境,这里创建一个Hello类的实例;tearDown()用于清理资源,如释放打开的文件等等。以test开头的方法被认为是测试方法,JUnit会依次执行testXxx()方法。在testAbs()方法中,我们对abs()的测试分别选择
正数,负数和0,如果方法返回值与期待结果相同,则assertEquals不会产生异常。
如果有
多个testXxx方法,JUnit会创建多个XxxTest实例,每次
运行一个testXxx方法,setUp()和tearDown()会在testXxx前后被调用,因此,不要在一个testA()中依赖testB()。
直接运
行Run->Run
As->JUnit Test,就可
以看到JUnit测试结果:

(图六)
绿色表
示测试通过,只要有1个测试未通过,就会显示红色并列出未通过测试的方法。可以试图改变abs()的代码,故意返回错误的结果(比如return n+1;),然后再运行JUnit就会报告错误。
如果没
有JUnit面板,选择Window->Show View->Other,打开JUnit的View:

(图七)
JUnit通过单元测试,能在开发阶段就找出许多Bug,并且,多个Test Case可以组合成Test Suite,让
整个测试自动完成,尤其适合于XP方法。每增加一个小的新功能或者对代码进行了小的修改,就立刻运行一
遍Test Suite,确保新增和修改的代码不会破坏原有的功能,大大增强软件的可维护
性,避免代码逐渐“腐烂”。
初次学会使用Junit的使用是通过这篇文章的(上文),自己尝试跟着做了一遍,结果发现它上面提供的代码例子是错误
的,不过流程、图片都很清楚。所以你可以先看看它上面是怎么说的,至于测试的代码我稍做了改动,为的是只要说明问题就行——其实不难。
被测试的类代码:
public class HelloJunit {
public static int abs(int n){
return n>=0?n:(-n);
}
}
Junit的测试代码:
import junit.framework.TestCase;
public class HelloJunitTest extends TestCase {
public void testAbs() {
assertEquals(HelloJunit.abs(10),10);
assertEquals(HelloJunit.abs(-10),10);
}
}
主要代码
行为assertEquals(HelloJunit.abs(10),10);
其中参数
的意义为:
HelloJunit.abs(10)执行类HelloJunit的abs方法(参数为10,表示求10的绝对值)。
逗号后面
的10表示为预期的结果(期望值)。
该行表示
将期望值(10)与实际值(类HelloJunit的abs方法执行结果)进行比较,如果不相
等则抛出异常。
这里只是
一个简简单单的例子,Junit被大家称为优秀的白盒自动化测试框架,当然只有自己用过了才会了解。网上有许多的资料介绍这个框架,笔
者也是从自身情况出发来学习它的。当然学习使用它是需要有一定基础的,笔者拥有C和C++的基础,对Java的学习也开始不久,所以在这里将力
所能及的知识共享出来与大家分享,希望能够共同提高。另外笔者是专职的测试人员,所以在描述一些问题时大多都会以测试的角度来阐述。学习此框架的目的在于
能够在工作中进行白盒测试,在以后的介绍中还会介绍白盒测试相关的理论和工具,希望大家能够一起提高进步。
由于MySQL目前字段的默认值不支持函数的形式设置默认值是不可能的。
代替的方案是使用TIMESTAMP类型代替DATETIME类型。
CURRENT_TIMESTAMP
:当我更新这条记录的时候,这条记录的这个字段不会改变。
CURRENT_TIMESTAMP ON UPDATE
CURRENT_TIMESTAMP
:当我更新这条记录的时候,这条记录的这个字段将会改变。即时间变为了更新时候的时间。(注意一个UPDATE设置一个列为它已经有的值,这将不引起
TIMESTAMP列被更新,因为如果你设置一个列为它当前的值,MySQL为了效率而忽略更改。)如果有多个TIMESTAMP列,只有第一个自动更
新。
TIMESTAMP列类型自动地用当前的日期和时间标记INSERT或UPDATE的操作。
如果有多个
TIMESTAMP列,只有第一个自动更新。
自动更新第一个TIMESTAMP列在下列任何条件下发生:
列
值没有明确地在一个INSERT或LOAD DATA INFILE语句中指定。
列值没有明确地在一个UPDATE语句中指定且另
外一些的列改变值。(注意一个UPDATE设置一个列为它已经有的值,这将不引起TIMESTAMP列被更新,因为如果你设置一个列为它当前的
值,MySQL为了效率而忽略更改。)
你明确地设定TIMESTAMP列为NULL.
除第一个以外的
TIMESTAMP列也可以设置到当前的日期和时间,只要将列设为NULL,或NOW()。
另外在5.0以上版本中也可以使用
trigger来实现此功能。
create table test_time (
id int(11),
create_time
datetime
);
delimiter |
create
trigger default_datetime before insert on test_time
for each
row
if new.create_time is null then
set
new.create_time = now();
end if;|
delimiter ;
生成 注释
应该是选取要注释内容后, ctrl+shift+c 按一下注释,按两下取消注释
ctrl+shift+"反注释!能讲ctrl+shift+/ 多行注释掉的内容反注释掉
CTRL+T 查看接口的实现
MyEclipse调试
1.首先在一个java文件中设断点,然后运行debug,当程序走到断点处就会停下。
2.F5键与F6键均为单步调试,
F5是step into,也就是进入本行代码中执行(进入函数执行),
F6是step over,也就是执行本行代码,跳到下一行执行(不进入函数),
3.F7是跳出函数 step return
4.F8是执行到最后。
=====================================
1.Step Into (F5) 跳入
2.Step Over (F6) 跳过
3.Step Return (F7) 执行完当前method,然后return跳出此method
4.step Filter 逐步过滤
一直执行直到遇到未经过滤的位置或断点(设置Filter:window-preferences-java-Debug-step
Filtering)
5.resume 重新开始执行debug,一直运行直到遇到breakpoint
6.hit count 设置执行次数 适合程序中的for循环(设置 breakpoint view-右键hit
count)
7.inspect 检查 运算。执行一个表达式显示执行值
8.watch 实时地监视变量的变化
9.我们常说的断点(breakpoints)是指line breakpoints,除了line
breakpoints,还有其他的断点类型:field(watchpoint)breakpoint,method
breakpoint,exception breakpoint.
10.field breakpoint 也叫watchpoint(监视点) 当成员变量被读取或修改时暂挂
11.添加method breakpoint 进入/离开此方法时暂挂(Run-method breakpoint)
12.添加Exception breakpoint 捕抓到Execption时暂挂(待续...)
断点属性:
1.hit count 执行多少次数后暂挂 用于循环
2.enable condition 遇到符合你输入条件(为ture\改变时)就暂挂
3.suspend thread 多线程时暂挂此线程
4.suspend VM 暂挂虚拟机
13.variables 视图里的变量可以改变变量值,在variables 视图选择变量点击右键--change
value.一次来进行快速调试。
14.debug
过程中修改了某些code后--〉save&build-->resume-->重新暂挂于断点
===========================
例如你有如下程序:
public class debugtest {
来源:(http://blog.sina.com.cn/s/blog_624aa0960100fkrr.html)
- MyEclipse调试_匆匆过客_新浪博客
public String addDays() {
System.out.println("1");//
=============》(3)
String result = "";
//=============》(4)
System.out.println("2");//
=============》(5)
return result;
}
public static void main(String args[]) {
debugtest aa = new
debugtest();
int ii=9;
aa.addDays();//
=============》(1)
System.out.println("eeeeeeeeeeeeeee");//=============》(2)
}
}
你在(1)处加断点,运行到此处时如果Step Into (F5)为跳入(进入函数),则接着执行到(3)。
再执行Step Over (F6)执行本行,则执行到(4)。
最后执行Step Return (also F7),则跳出addDays方法,跳到(2)
转http://blog.sina.com.cn/s/blog_624aa0960100fkrr.html
MyEclipse 中显示行号 要想显示行号,按住 Ctrl + F10 选择 show Line Numbers
eclipse/myeclipse注释模板的修改 alt+shitf+j
Window --> Java --> Code Style --> Code Templates --> Comments --> types --> Edit
/**
*
* 项目名称:${project_name}
* 类名称:${type_name}
* 类描述:
* 创建人:${user}
* 创建时间:${date} ${time}
* 修改人:${user}
* 修改时间:${date} ${time}
* 修改备注:
* @version
*
*/
http://www.javaeye.com/topic/585168
myeclipse中如何配置自定义的代码排版格式 ctrl+shift+f
http://www.blogjava.net/bolo/
http://www.blogjava.net/bolo/archive/2010/04/11/318004.html
com.test.action.user包下:
SaveUserAction.java
SaveUserAction-validation.xml
SaveUserAction.java文件的内容:
package com.test.action.user;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import com.opensymphony.xwork2.ActionSupport;
import com.test.bean.User;
import com.test.service.UserService;
public class SaveUserAction extends ActionSupport
{
private User user;
private UserService service;
public User getUser()
{
return user;
}
public void setUser(User user)
{
this.user = user;
}
public UserService getService()
{
return service;
}
public void setService(UserService service)
{
this.service = service;
}
@Override
public String execute() throws Exception
{
this.service.save(this.user);
return SUCCESS;
}
@Override
@SuppressWarnings("unchecked")
public void validate()
{
Map map = this.getFieldErrors();
Set set = map.keySet();
for (Iterator iter = set.iterator(); iter.hasNext();)
{
System.out.println(map.get(iter.next()));
}
}
}
SaveUserAction-validation.xml的文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE validators PUBLIC "-//OpenSymphony Group//XWork Validator
1.0.2//EN" "http://www.opensymphony.com/xwork/xwork-validator-1.0.2.dtd">
<validators>
<field name="user">
<field-validator type="visitor">
<param name="context">user</param>
<param name="appendPrefix">true</param>
<message>user's </message>
</field-validator>
</field>
</validators>
com.test.bean包下的文件:
User.java;
User-user-validation.xml
User-user-validation.xml文件的内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE validators PUBLIC "-//OpenSymphony Group//XWork Validator
1.0.2//EN" "http://www.opensymphony.com/xwork/xwork-validator-1.0.2.dtd">
<validators>
<field name="firstname">
<field-validator type="requiredstring">
<message>required first name</message>
</field-validator>
</field>
<field name="lastname">
<field-validator type="requiredstring">
<message>required last name</message>
</field-validator>
</field>
<field name="age">
<field-validator type="required">
<message>required age</message>
</field-validator>
<field-validator type="int">
<param name="min">1</param>
<param name="max">150</param>
<message>age should be between ${min} and
${max}</message>
</field-validator>
</field>
</validators>
还有一个问题,就是校验信息会重复,在错误的情况下。由以下代码可以测试:
@Override
@SuppressWarnings("unchecked")
public void validate()
{
Map map = this.getFieldErrors();
Set set = map.keySet();
for (Iterator iter = set.iterator(); iter.hasNext();)
{
System.out.println(map.get(iter.next()));
}
}
}
解决方法:
applicationContext.xml 文件中的配置action中加入:Struts 2.0 的action 是有状态的
在spring 配置的action 中加上 scope="prototype";
配置如下:<bean id="saveUserAction"
class="com.test.action.user.SaveUserAction" scope="prototype">
<property name="service" ref="userService"></property>
</bean>
关键字: struts2,spring2,hibernate3,整合
今天在寝室窝了一天,由于前天老师给了个ss2+toplink的项目源码,要我去消化。直接看那
三个整合具吃力,于是先从ssh2入手吧!
所使用的工具和环境。
jdk6+myeclipse6.5+tomcat6+mysql5+spring2.0+hibernate3+struts2
好了,开始我们的第一个ssh2之旅吧。
首先先分析一下我们的第一个ssh2项目的需求,简单的说就是有一张表单,
让你填写用户名和密码,提交后存入数据库。就这么简单,呵呵。
第一步:。我
们首先新建一张mysql数据表
sql如下
CREATE TABLE mytest.users (
id INT
NOT NULL,
username VARCHAR(50),
password VARCHAR(50),
PRIMARY KEY (id)
数据表创建好后结构如下:

当然我已经有几天数据添加进去了
 第二步
第二步
打开myeclipse,新建一个web项目,
命名为ssh2-2, java ee规范我们选择5,如图
 第三步 务必小心的一步
第三步 务必小心的一步
导
入ssh2的各个jar,步骤如下:
选中当前的项目后,点击菜单烂的myeclipse---project
capablities----add hibernate项,跳出如图

务必按照图示选择,尤其是copy checkde……一项,然后点击next,默认next,去掉specify
database……复选框,next,去掉create session……复选框,finish。
再次选中选中当前的项目后,点击
菜单烂的myeclipse---project capablities----add spring项,跳出如图

依然务必按照如是选择,jar文件选择如下5个:


点击next,
之后按下选择,务必,

next后finsh即可。
然后导入struts2的jar
如下5个放到lib下

然后放入我们的数据库驱动jar mysql-connector-java-5.0.8-bin.jar 没得话附件中有
至
此,包都导入完毕
http://77857.blog.51cto.com/67857/149631
去网上找了一些相关错误的信息看了下说Hibernate core下面的xerces.jar包的问题。删除后正确了。
如果删除后还是错误,看一下项目的lib文件夹下面的是否还有xerces相关jar包,也删掉。
记住把tomcat 里面xerces.jar也要删掉
1:login.JSP
<form action="
login.action" method="post">
username:<input type="text" name="username"> <br/>
password:<input type="text" name="password"> <br/>
<input type="submit" name="submit"/>
</form>
<s:form action="login">
<s:textfield name="username" label="username"></s:textfield>
<s:password name="password" label="password"> </s:password>
<s:submit name="submit"></s:submit>
</s:form>
2:action
package com.test.action;
public class LoginAction {
private String username;
private String password;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String execute() throws Exception {
return "success";
}
}
package com.test.action;
import com.opensymphony.xwork2.ActionSupport;
public class LoginAction extends ActionSupport {
private String username;
private String password;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String execute() throws Exception {
if("smallfa".equals(this.getUsername().trim())&&"smallfa".equals(this.getPassword().trim()))
{
return "success";
}
else
{
this.addFieldError(username, "username or password errors");
return "failer";
}
}
@Override
public void validate() {
if(null==this.getUsername()||"".equals(this.getUsername().trim()))
{
this.addFieldError(username, "username required");
}
if(null==this.getPassword()||"".equals(this.getPassword().trim()))
{
this.addFieldError(username, "username required");
}
}
}
3:struts-xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.1//EN" "http://struts.apache.org/dtds/struts-2.1.dtd">
<struts>
<package name="struts2" namespace="/" extends="struts-default">
<action name="login" class="com.test.action.LoginAction">
<result name="success">/result.jsp</result>
</action>
</package>
</struts>
4:web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<filter>
<!-- 定义核心Filter的名字 -->
<filter-name>struts2</filter-name>
<!-- 定义核心Filter的实现类 -->
<filter-class>org.apache.struts2.dispatcher.FilterDispatcher</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
5:result.jsp
username:${requestScope.username}<br/>
password:${requestScope.password}<br/>
6:参考视频
视频:
Struts2入门与配置 浪曦 J2EE Struts 2应用开发详解系列视频
http://v.youku.com/v_show/id_XNTY4MDUwMzY=.html
离上次打球隔有一段时间了,终于有一个晚上等到好朋友早点下班,到了场地因天气冷,既是场地有照明灯,过来的人比昔日还显得稀少,直到打到后面基本也就我们两队在玩,今天打的还是挺过隐的,外投好多个球,其中最自感有一个是假动作,突跨步一接三步路擦板进,确实好久没进这样的球,只不过有点遗憾的我们队竟有一个超极品的兄台,传球失误、防过老漏人、乱面、无语。让我想了前个晚上比赛那位仁兄。
关于数据库的学习,个人意见,仅供参考,本人也在学习中。
首先需要了解下 数据模型 关系数据库 DBMS 范式 自然运算 等等概念性的东西,可以去书店或者图书馆查阅相关书籍,可以了解下,没必要完全掌握,当然你要能掌握的话,那么对你的以后是非常有帮助的。
其实然后就是SQL标准 对象关系SQL 基本的SQL查询,以及最基本的SELECT/UPDATE/INSERT/DELETE语法,各种不同的数据库大同小异的。
然后就是不同的数据库,不同的用法,你也可以专学一门,比如ORACLE
或者MSSQL MYSQL INFORMIX DB2主要这几种~
这些入门了就可以学习嵌入数据库了,访问数据库的程序
以及数据库的性能优化,完整性,视图,安全 目录 备份 还原等等
当然主要学习ORACLE的话你也可以先直接挑本ORACLE入门看,类似ORACLE10G入门,ORACLE基础的书,不求完全懂,能看一点是一点,学习ORACLE是一个长期的过程,你在懂了一些后,再去看别的书,你会找到很多相同点,那时候就会有恍然大悟的感觉,一点点看就OK了~
到了一定的程度,你就知道自己怎么去学习,需要掌握些什么,像什么方向发展了。
另外在学习的过程中推荐有疑问的就自己做实验操作,或者去各大论坛像CSDN,CNOUG,ITPUB,CNBLOGS查找答案或者提问,也可以下载里面的基础区的教程了,不过大多是达人们整理出来的文档,也很不错的,尤其前面两个论坛你能学到很多东西的,不过还是推荐你先完整的看一本入门的后再说,不管理解了几成,有什么问题记下来,以后慢慢一点点解决。
ORACLE视频教程的话有个中科院的什么绝版培训教程oracle 10g的04年的视频,非常不错,迅雷上搜索中科院oracle 10g培训教程就能搜索到。
数据库开发工具的话 有TOAD(客户端连接工具),POWERDESIGN(数据库设计建模工具,), PL/SQL DESIGNER(PL/SQL开发工具),一般这3个就够用了,可以自己去迅雷搜索下载最新版本,另外的话还有一个叫DBATRIN,E/R 什么的工具,很多的,其实装了ORACLE客户端工具后,自带的JAVA控制台也很好用的。
当然你想一蹴而就的话,可以直接去网上找相关的ORACLE入门资料,那些都是些整理出来的条条,不过不推荐,最好多看书,多做实验。
Hibernate的对象有3种状态,分别为:瞬时态(Transient)、 持久态(Persistent)、脱管态(Detached)。处于持久态的对象也称为PO(Persistence Object),瞬时对象和脱管对象也称为VO(Value Object)。
由new命令开辟内存空间的java对象,
eg. Person person = new Person("amigo", "女");
如果没有变量对该对象进行引用,它将被java虚拟机回收。
瞬时对象在内存孤立存在,它是携带信息的载体,不和数据库的数据有任何关联关系,在Hibernate中,可通过session的save()或saveOrUpdate()方法将瞬时对象与数据库相关联,并将数据对应的插入数据库中,此时该瞬时对象转变成持久化对象。
处于该状态的对象在数据库中具有对应的记录,并拥有一个持久化标识。如果是用hibernate的delete()方法,对应的持久对象就变成瞬时对象,因数据库中的对应数据已被删除,该对象不再与数据库的记录关联。
当一个session执行close()或clear()、evict()之后,持久对象变成脱管对象,此时持久对象会变成脱管对象,此时该对象虽然具有数据库识别值,但它已不在HIbernate持久层的管理之下。
持久对象具有如下特点:
1. 和session实例关联;
2. 在数据库中有与之关联的记录。
当与某持久对象关联的session被关闭后,该持久对象转变为脱管对象。当脱管对象被重新关联到session上时,并再次转变成持久对象。
脱管对象拥有数据库的识别值,可通过update()、saveOrUpdate()等方法,转变成持久对象。
脱管对象具有如下特点:
1. 本质上与瞬时对象相同,在没有任何变量引用它时,JVM会在适当的时候将它回收;
2. 比瞬时对象多了一个数据库记录标识值。
本文摘自孙卫琴的《精通Hibernate:Java对象持久化技术详情》
Hibernate有如下5个核心接口:
- Configuration接口:该对象用于配置并且根启动Hibernate。Hibernate应用通过Configuration实例来指定对象-关系映射文件的位置或动态配置Hibernate的属性,然后创建SessionFactory实例。
- SessionFactory接口:一个SessionFactory实例对应一个数据存储源,应用从SessionFactory中获得Session实例。它具有如下特点:
1)它是线程安全的,这意味着它的同一个实例可以被应用的各个线程共享。
2)它是重量级的,这意味着不能随意创建或销毁它的实例。如果应用只访问一个数据库,只需创建一个SessionFactory实例,在应用初始化的时候创建该实例。如果应用同时访问多个数据库,则需要为每个数据库创建一个单独的SessionFactory实例。
之所以说SessionFactory是重量级的,是因为它需要一个很大的缓存,用来存放预定义的SQL语句以及映射元数据等。用户还可以为SessionFactory配置一个缓存插件,这个缓存插件被称为Hibernate的第二级缓存,该缓存用来存放被工作单元读过的数据,将来其它工作单元可能会重用这些数据,因此这个缓存中的数据能够被所有工作单元共享,一个工作单元通常对应一个数据库事务。
- Session接口:该接口是Hibernate应用使用最广泛的接口。Session也被称为持久化管理器,提供了和持久化相关的操作,如添加、更新、删除、加载和查询对象。Session具有一下特点:
1)不是线程安全的,因此在设计软件架构时,应该避免多个线程共享同一个Session实例;
2)Session实例是轻量级的,所谓轻量级,是指它的创建和销毁不需要消耗太多的资源。这意味着在程序中可以经常创建和销毁Session对象,例如为每个客户请求分配单独的Session实例,或者为每个工作单元分配单独的Session实例。
Session有一个缓存,被称为Hibernate的第一级缓存,它存放被当前工作单元加载的对象。每个Session实例都有自己的缓存,这个Session实例的缓存,这个Session实例的缓存只能被当前工作单元访问。
- Transaction:该接口是Hibernate的数据库事务接口,它对底层的事务接口做了封装,底层事务接口包括:JDBC API、JTA(Java Transaction API)、CORBA(Common Object Requet Broker Architecture) API.
Hibernate应用可通过一致的Transaction接口来声明事务边界,这有助于应用在不同环境或容器中移植。
- Query和Criteria接口:它们是Hibernate的查询接口,用于向数据库查询对象,以及控制执行查询的过程。Query实例封装了一个HQL(Hibernate Query Language)查询语句,HQL是面向对象的,它引用类名及类的属性名,而不是表名及表的字段名。Criteria接口完全封装了基于字符串形式的查询语句,比Query接口更加面向对象,Criteria接口更擅长于执行动态查询。
<set
name="propertyName" (1)
table="table_name" (2)
schema="schema_name" (3)
lazy="true|false" (4)
inverse="true|false" (5)
cascade="all|none|save-update|delete|all-delete-orphan" (6)
sort="unsorted|natural|comparatorClass" (7)
order-by="column_name asc|desc" (8)
where="arbitrary sql where condition" (9)
outer-join="true|false|auto" (10)
batch-size="N" (11)
access="field|property|ClassName" (12)
>
<key .... />
<index .... />
<element .... />
</set>
(1) name 集合属性的名称
(2) table (可选——默认为属性的名称)这个集合表的名称(不能在一对多的关联关系中使用)
(3) schema (可选) 表的schema的名称, 他将覆盖在根元素中定义的schema
(4) lazy (可选——默认为false) lazy(可选--默认为false) 允许延迟加载(lazy initialization )(不能在数组中使用)
(5) inverse (可选——默认为false) 标记这个集合作为双向关联关系中的方向一端。
(6) cascade (可选——默认为none) 让操作级联到子实体
(7) sort(可选)指定集合的排序顺序, 其可以为自然的(natural)或者给定一个用来比较的类。
(8) order-by (可选, 仅用于jdk1.4) 指定表的字段(一个或几个)再加上asc或者desc(可选), 定义Map,Set和Bag的迭代顺序
(9) where (可选) 指定任意的SQL where条件, 该条件将在重新载入或者删除这个集合时使用(当集合中的数据仅仅是所有可用数据的一个子集时这个条件非常有用)
(10) outer-join(可选)指定这个集合,只要可能,应该通过外连接(outer join)取得。在每一个SQL语句中, 只能有一个集合可以被通过外连接抓取(译者注: 这里提到的SQL语句是取得集合所属类的数据的Select语句)
(11) batch-size (可选, 默认为1) 指定通过延迟加载取得集合实例的批处理块大小("batch size")。
(12) access(可选-默认为属性property):Hibernate取得属性值时使用的策略
摘要: 原文出处:http://tech.it168.com/j/d/2007-05-14/200705141007843.shtml
说明:该文不得转载
摘要:本文以详尽的实例展示了hibernate3.x中调用存储过程各步骤,从建立测试表、存储过程的建立、工程的建立以及类的编写和测试一步一步引导用户学习hibernate3.x中调用存储过程的方法.
如果底层数据库(eg. Oracle、mysq...
阅读全文
Hibernate的描述文件可以是一个properties属性文件,也可以是一个xml文件。下面讲一下Hibernate.cfg.xml的配置。配置格式如下:
1. 配置数据源
在Hibernate.cfg.xml中既可以配置JDBC,也可以配置JNDI。在本小节中讲述数据源如何配置。
hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 各属性的配置-->
<!—为true表示将Hibernate发送给数据库的sql显示出来 -->
<property name="show_sql">true</property>
<!-- SQL方言,这边设定的是MySQL -->
<property name="dialect">net.sf.hibernate.dialect.MySQLDialect</property>
<!-- 一次读的数据库记录数 -->
<property name="jdbc.fetch_size">50</property>
<!-- 设定对数据库进行批量删除 -->
<property name="jdbc.batch_size">30</property>
<!—下面为JNDI的配置 -->
<!-- 数据源的名称 -->
<property name="connection.datasource">java:comp/env/jdbc/datasourcename</property>
<!-- Hibernate的连接加载类 -->
<property name="connection.provider_class">net.sf.hibernate.connection.DatasourceConnectionProvider</property>
<property name="dialect">net.sf.hibernate.dialect.SQLServerDialect</property>
<!—映射文件 -->
<mapping resource="com/amigo/pojo/User.hbm.xml"/>
<mapping resource="com/amigo/pojo/Org.hbm.xml"/>
</session-factory>
</hibernate-configuration>
2. c3p0连接池
c3p0连接池是Hibernate推荐使用的连接池,若需要使用该连接池时,需要将c3p0的jar包加入到classpath中。c3p0连接池的配置示例如下:
hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 显示实际操作数据库时的SQL -->
<property name="show_sql">true</property>
<!-- SQL方言,这边设定的是MySQL -->
<property name="dialect">net.sf.hibernate.dialect.MySQLDialect</property>
<!--驱动程序,在后续的章节中将讲述mysql、sqlserver和Oracle数据库的配置 -->
<property name="connection.driver_class">……</property>
<!-- JDBC URL -->
<property name="connection.url">……</property>
<!-- 数据库用户名 -->
<property name="connection.username">user</property>
<!-- 数据库密码 -->
<property name="connection.password">pass</property>
<property name="c3p0.min_size">5</property>
<property name="c3p0.max_size">20</property>
<property name="c3p0.timeout">1800</property>
<property name="c3p0.max_statements">50</property>
<!-- 对象与数据库表格映像文件 -->
<mapping resource="com/amigo/pojo/User.hbm.xml"/>
<mapping resource="com/amigo/pojo/Org.hbm.xml"/>
</session-factory>
</hibernate-configuration>
在上述配置中,Hibernate根据配置文件生成连接,再交给c3p0管理。
3. proxool连接池
proxool跟c3p0以及dbcp不一样,它是自己生成连接的,因此连接信息放在proxool配置文件中。使用它时,需要将proxool-0.8.3.jar加入到classespath中。配置举例如下:
hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 显示实际操作数据库时的SQL -->
<property name="show_sql">true</property>
<!-- SQL方言,这边设定的是MySQL -->
<property name="dialect">net.sf.hibernate.dialect.MySQLDialect</property>
<!—proxool的配置 -->
<property name="proxool.pool_alias">pool1</property>
<property name="proxool.xml">ProxoolConf.xml</property>
<property name="connection.provider_class">net.sf.hibernate.connection.ProxoolConnectionProvider</property>
<!-- 对象与数据库表格映像文件 -->
<mapping resource="com/amigo/pojo/User.hbm.xml"/>
<mapping resource="com/amigo/pojo/Org.hbm.xml"/>
</session-factory>
</hibernate-configuration>
在hibernate.cfg.xml的同目录下编写proxool的配置文件:ProxoolConf.xml,该文件的配置实例如下:
ProxoolConf.xml
<?xml version="1.0" encoding="utf-8"?>
<!-- the proxool configuration can be embedded within your own application's.
Anything outside the "proxool" tag is ignored. -->
<something-else-entirely>
<proxool>
<alias>pool1</alias>
<!--proxool只能管理由自己产生的连接-->
<!-- 驱动的url-->
<!-- jdbc:mysql://localhost:3306/dbname?useUnicode=true&characterEncoding=GBK-->
<driver-url>… </driver-url>
<!-- 驱动类,eg. com.mysql.jdbc.Driver-->
<driver-class>… </driver-class>
<driver-properties>
<!-- 数据库用户名,eg. value为root-->
<property name="user" value="…"/>
<!-- 数据库密码,eg. value为root-->
<property name="password" value="…."/>
</driver-properties>
<!-- proxool自动侦察各个连接状态的时间间隔(毫秒),侦察到空闲的连接就马上回收,超时的销毁-->
<house-keeping-sleep-time>90000</house-keeping-sleep-time>
<!-- 指因未有空闲连接可以分配而在队列中等候的最大请求数,超过这个请求数的用户连接就不会被接受-->
<maximum-new-connections>20</maximum-new-connections>
<!-- 最少保持的空闲连接数-->
<prototype-count>5</prototype-count>
<!-- 允许最大连接数,超过了这个连接,再有请求时,就排在队列中等候,最大的等待请求数由maximum-new-connections决定-->
<maximum-connection-count>100</maximum-connection-count>
<!-- 最小连接数-->
<minimum-connection-count>10</minimum-connection-count>
</proxool>
</something-else-entirely>
4. dbcp连接池
在hibernate3.0中,已经不再支持dbcp了,hibernate的作者在hibernate.org中,明确指出在实践中发现dbcp有 BUG,在某些种情会产生很多空连接不能释放,所以抛弃了对dbcp的支持。若需要使用dbcp,开发人员还需要将commons-pool-1.2.jar 和commons-dbcp-1.2.1.jar两个jar包加入到classpath中。dbcp与c3p0一样,都是由hibernate建立连接的。
在hibernate2.0中的配置建立如下:
hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 2.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 显示实际操作数据库时的SQL -->
<property name="show_sql">true</property>
<!-- SQL方言,这边设定的是MySQL -->
<property name="dialect">net.sf.hibernate.dialect.MySQLDialect</property>
<!--驱动程序,在后续的章节中将讲述mysql、sqlserver和Oracle数据库的配置 -->
<property name="connection.driver_class">……</property>
<!-- JDBC URL -->
<property name="connection.url">……</property>
<!-- 数据库用户名,eg. root -->
<property name="connection.username">…</property>
<!-- 数据库密码, eg. root-->
<property name="connection.password">…</property>
<property name="dbcp.maxActive">100</property>
<property name="dbcp.whenExhaustedAction">1</property>
<property name="dbcp.maxWait">60000</property>
<property name="dbcp.maxIdle">10</property>
<property name="dbcp.ps.maxActive">100</property>
<property name="dbcp.ps.whenExhaustedAction">1</property>
<property name="dbcp.ps.maxWait">60000</property>
<property name="dbcp.ps.maxIdle">10</property>
<!-- 对象与数据库表格映像文件 -->
<mapping resource="com/amigo/pojo/User.hbm.xml"/>
<mapping resource="com/amigo/pojo/Org.hbm.xml"/>
</session-factory>
</hibernate-configuration>
5. MySql连接配置
在hibernate中,可以配置很多种数据库,例如MySql、Sql Server和Oracle,MySql的配置举例如下:
hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 各属性的配置-->
<!—为true表示将Hibernate发送给数据库的sql显示出来 -->
<property name="show_sql">true</property>
<!-- SQL方言,这边设定的是MySQL -->
<property name="dialect">net.sf.hibernate.dialect.MySQLDialect</property>
<!-- 一次读的数据库记录数 -->
<property name="jdbc.fetch_size">50</property>
<!-- 设定对数据库进行批量删除 -->
<property name="jdbc.batch_size">30</property>
<!--驱动程序-->
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<!-- JDBC URL -->
<property name="connection.url">jdbc:mysql://localhost/dbname?characterEncoding=gb2312</property>
<!-- 数据库用户名-->
<property name="connection.username">root</property>
<!-- 数据库密码-->
<property name="connection.password">root</property>
<!—映射文件 -->
<mapping resource="com/amigo/pojo/User.hbm.xml"/>
<mapping resource="com/amigo/pojo/Org.hbm.xml"/>
</session-factory>
</hibernate-configuration>
上面使用的驱动类是com.mysql.jdbc.Driver。需要将MySql的连接器jar包(eg. mysql-connector-java-5.0.4-bin.jar)加入到classpath中。
6. Sql Server连接配置
本小节讲述一下Sql Server数据库的hibernate连接设置,在此只给出连接部分的内容,其余部分与2.2.1.5一样,在此不再赘述。内容如下:
<!--驱动程序-->
<property name="connection.driver_class">net.sourceforge.jtds.jdbc.Driver</property>
<!-- JDBC URL -->
<property name="connection.url">jdbc:jtds:sqlserver://localhost:1433;DatabaseName=dbname</property>
<!-- 数据库用户名-->
<property name="connection.username">sa</property>
<!-- 数据库密码-->
<property name="connection.password"></property>
上例的驱动类使用的是jtds的驱动类,因此读者需要将jtds的jar包(eg. jtds-1.2.jar)加入到classpath中。
7. Oracle连接配置
本小节讲述一下Sql Server数据库的hibernate连接设置,在此只给出连接部分的内容,其余部分与2.2.1.5一样,在此不再赘述。内容如下:
<!--驱动程序-->
<property name="connection.driver_class">oracle.jdbc.driver.OracleDriver</property>
<!-- JDBC URL -->
<property name="connection.url">jdbc:oracle:thin:@localhost:1521:dbname</property>
<!-- 数据库用户名-->
<property name="connection.username">test</property>
<!-- 数据库密码-->
<property name="connection.password">test</property>
上例使用的驱动类为:oracle.jdbc.driver.OracleDriver,开发人员需要将相关的jar包(ojdbc14.jar)加入到classpath中。
http://www.blogjava.net/amigoxie/archive/2007/12/29/171395.html
本节讲述如何使用Hibernate实现记录的增、删、改和查功能。
1 查询
在Hibernate中使用查询时,一般使用Hql查询语句。
HQL(Hibernate Query Language),即Hibernate的查询语言跟SQL非常相像。不过HQL与SQL的最根本的区别,就是它是面向对象的。
使用HQL时需要注意以下几点:
l 大小写敏感
因为HQL是面向对象的,而对象类的名称和属性都是大小写敏感的,所以HQL是大小写敏感的。
Eg.
HQL语句:from Cat as cat where cat.id > 1;与from Cat as cat where cat.ID > 1;是不一样的,这点与SQL不同。
l from子句
Eg. from Cat,该句返回Cat对象实例,开发人员也可以给其加上别名,eg. from Cat as cat,对于多表查询的情况,可参考如下:
from Cat as cat, Dog as dog
其它方面都与SQL类似,在此不再赘述。
接下来讲一个在Hibernate中查询的例子。
1.1简单查询
List list = session.createQuery("from User as user order by user.loginName").list();
1.2带单个参数的查询
List list = session.find("from User as user where user.loginName=?",
loginName,
Hibernate.STRING);
1.3多个参数的查询
Eg1. 此例采用“?”占位符的方式
String hql = "from User as user where user.loginName=? and user.orgId=? ";
Query query = session.createQuery(hql);
query.setParameter(1, 'amigo');
query.setParameter(2, new Long(1)) ;
List list = query .list();
Eg2. 此例采用“:paramName”的方式
String hql = "from User as user where user.loginName=:loginName and user.orgId=:orgId ";
Query query = session.createQuery(hql);
query.setParameter('loginName', 'amigo');
query.setParameter('orgId', new Long(1)) ;
List list = query .list();
1.4查询数量
int count = (Integer) session.createQuery("select count(*) from User").uniqueResult().intValue();
1.5限制查询起始值和数量的查询
这种一般是在记录需要分页的时候需要用到,例如,在如下的代码中,限制查询的开始记录的位置为50,最大查询条数为50。
String hql = "from User as user order by user.loginName";
int firstResult= 50;
int maxResults = 50;
Query query = session.createQuery(hql);
query = query.setFirstResult(firstResult);
query.setMaxResults(maxResults);
1.6子查询
在某些情况下,也需要用到子查询,例如在下面的例子中,User为用户对象,UserRole为用户与角色关联对象。如下HQL语句将没有分配角色的用户对象查找出来。
String hql = "from User user where user.loginName"
+ " not in(select ur.user.loginName from UserRole ur) ";
List list = (session.createQuery(hql)).list();
1.7原生SQL查询
对于某些复杂的查询语句,需要调用某种特定的数据库的特定函数才能解决,Hibernate虽然不推荐使用原生SQL语句来查询,因为这将破坏数据库的易移植性,但是Hibernate中也提供了使用原生SQL进行查询的方法,只需要获得连接即可。
Eg. 在下面的例子中,用到了Sql Server数据库中的原生sql语句,如下所示:
String timeUnit = "13";
String sql = "select count(*) count, CONVERT(VARCHAR(" + timeUnit +"), log.gen_datetime,121) timeUnit " + "from Log log";
SQLQuery query = session.createSQLQuery(sql)
.addScalar("count", Hibernate.INTEGER)
.addScalar("timeUnit", Hibernate.STRING);
List list = query.list();
2 新增
在数据库中新增记录在Hibernate中不需要使用insert命令,只需要构造新增的对象后,调用Session对象的save(…)方法即可。
2.1新增单个对象
新增单个对象的实例如下,该实例将在用户表中新增一条记录。
Session session = HibernateSessionFactory.getSession();
Transaction ts = null;
try {
ts = session.beginTransaction();
User user = new User();
user.setLoginName("amigo");
user.setFullName("阿蜜果");
……
session.save(user) ;
ts.commit();
} catch (Exception e) {
if (ts != null) {
ts.rollback();
}
} finally {
HibernateSessionFactory.closeSession();
}
2.2批量新增对象
对于批量新增对象的情况,需要在新增一部分对象后flush和clear一次,例如,没批量新增20个对象时手动的flush一次,假设在list为一个用户列表,里面包含很多User对象,那么要将实现这些对象的批量新增,可采用如下方法:
Session session = HibernateSessionFactory.getSession();
Transaction ts = null;
try {
ts = session.beginTransaction();
for (int i = 0; i < list.size(); i++) {
User user = (User) list.get(i);
session.save(user) ;
if (i % 20 == 0) {
session.flush();
session.clear();
}
}
ts.commit();
} catch (Exception e) {
if (ts != null) {
ts.rollback();
}
} finally {
HibernateSessionFactory.closeSession();
}
3 更新
在hibernate中,更新对象前不需要使用查询语句:update…,一般需要在取得需要更新的持久化对象后,执行Session对象的update(…)方法。例如:
Session session = HibernateSessionFactory.getSession();
Transaction ts = null;
try {
ts = session.beginTransaction();
//取得持久化对象
User user = session.get(User.class, "amigo");
//对需要修改的属性进行修改
user.setFullName("阿蜜果");
……
session.update(user) ;
ts.commit();
} catch (Exception e) {
if (ts != null) {
ts.rollback();
}
} finally {
HibernateSessionFactory.closeSession();
}
4 删除
4.1删除单个对象
一般在取得某对象后,开发人员可以调用Session对象的delete(…)方法删除该对象。
Eg. 下面的实例中取得loginName(主键)为“amigo”的User对象后,将它删除。
Session session = HibernateSessionFactory.getSession();
Transaction ts = null;
try {
ts = session.beginTransaction();
//取得持久化对象
User user = session.get(User.class, "amigo");
session.delete(user) ;
ts.commit();
} catch (Exception e) {
if (ts != null) {
ts.rollback();
}
} finally {
HibernateSessionFactory.closeSession();
}
4.2批量删除对象
对于批量删除对象的情况,开发人员可以在取得待删除的对象列表后,一个一个的将对象删除,对于每个对象的删除方法,见3.4.1小节。开发人员还可以hql语句来做批量删除。
Eg. 该实例通过delete语句来删除记录,除了loginName为“amigo”的对象为,其余都删除,代码如下所示:
Session session = HibernateSessionFactory.getSession();
Transaction ts = null;
try {
ts = session.beginTransaction();
String hql = "delete User as user where user.loginName != 'amigo'";
Query query = session.createQuery(hql);
int count = query.executeUpdate();
ts.commit();
System.out.println("delete count : " + count); //删除条数
} catch (Exception e) {
if (ts != null) {
ts.rollback();
}
} finally {
HibernateSessionFactory.closeSession();
}
http://www.blogjava.net/amigoxie/archive/2008/01/01/171972.html
本文总结Hibernate中常见的异常。
1. net.sf.hibernate.MappingException
当出现net.sf.hibernate.MappingException: Error reading resource:…异常时一般是因为映射文件出现错误。
当出现net.sf.hibernate.MappingException: Resource: … not found是因为XML配置文件没找到所致,有可能是放置目录不正确,或者没将其加入hibernate.cfg.xml中。
2. net.sf.hibernate.PropertyNotFoundException
当出现net.sf.hibernate.PropertyNotFoundException: Could not find a setter for property name in class …时,原因一般是因为XML映射文件中的属性与对应的Java类中的属性的getter或setter方法不一致。
3. org.hibernate.id.IdentifierGenerationException
当出现org.hibernate.id.IdentifierGenerationException: ids for this class must be manually assigned before calling save():异常时,一般是因为<id>元素配置不正确,<id>元素缺少其子元素<generator></generator>的配置引起。
解决方案:<id>元素映射了相应数据库表的主键字段,对其子元素<generator class="">,其中class的取值可以为increment、identity、sequence、hilo、native……等,更多的可参考hibernate参考文档,一般取其值为native 。具体可参考2.2.2.1小节。
4. a different object with the same identifier value was already associated with the session
当出现a different object with the same identifier value was already associated with the session时,一般是因为在hibernate中同一个session里面有了两个相同标识但是是不同实体。
有如下几种解决方案:
(1)使用session.clean(),如果在clean操作后面又进行了saveOrUpdate(object)等改变数据状态的操作,有可能会报出"Found two representations of same collection"异常。
(2)使用session.refresh(object),当object不是数据库中已有数据的对象的时候,不能使用session.refresh(object)因为该方法是从hibernate的session中去重新取object,如果session中没有这个对象,则会报错所以当你使用saveOrUpdate(object)之前还需要判断一下。
(3)session.merge(object),Hibernate里面自带的方法,推荐使用。
5. SQL Grammer Exception,Could not execute JDBC batch update
当出现SQL Grammer Exception,Could not execute JDBC batch update异常时,一般是由如下问题引起:
(1)SQL语句中存在语法错误或是传入的数据有误;
(2)数据库的配置不合法,或者说是配置有误。较容易出现的有数据表的映射文件(,hbm.xml文件)配置有误;Hibernate.cfg.xml文件配置有误;
(3) 当前的数据库用户权限不足,不能操作数据库。以是以Oracle 数据库为例,这种情况下在错误提示中会显示java.sql.BatchUpdateException: ORA-01031: insufficient privileges这样的信息。
针对上面的各种原因,开发人员可以找出对应的解决方案。
http://www.blogjava.net/amigoxie/category/19976.html
在Hibernate
中,各表的映射文件….hbm.xml
可以通过工具生成,例如在使用MyEclipse
开发时,它提供了自动生成映射文件的工具。本节简单的讲述一下这些配置文件的配置。
配置文件的基本结构如下:
<?xml version="1.0" encoding='UTF-8'?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd" >
<hibernate-mapping package="包名">
<class name="类名" table="表名">
<id name="主键在java类中的字段名" column="对应表中字段" type="类型 ">
<generator class="主键生成策略"/>
</id>
……
</class>
</hibernate-mapping>
1. 主键(id)
Hibernate的主键生成策略有如下几种:
1) assigned
主键由外部程序负责生成,在 save() 之前指定。
2) hilo
通过hi/lo 算法实现的主键生成机制,需要额外的数据库表或字段提供高位值来源。
3) seqhilo
与hilo 类似,通过hi/lo 算法实现的主键生成机制,需要数据库中的 Sequence,适用于支持 Sequence 的数据库,如Oracle。
4) increment
主键按数值顺序递增。此方式的实现机制为在当前应用实例中维持一个变量,以保存着当前的最大值,之后每次需要生成主键的时候将此值加1作为主键。这种方式可能产生的问题是:不能在集群下使用。
5) identity
采用数据库提供的主键生成机制。如DB2、SQL Server、MySQL 中的主键生成机制。
6) sequence
采用数据库提供的 sequence 机制生成主键。如 Oralce 中的Sequence。
7) native
由 Hibernate 根据使用的数据库自行判断采用 identity、hilo、sequence 其中一种作为主键生成方式。
8) uuid.hex
由 Hibernate 基于128 位 UUID 算法 生成16 进制数值(编码后以长度32 的字符串表示)作为主键。
9) uuid.string
与uuid.hex 类似,只是生成的主键未进行编码(长度16),不能应用在 PostgreSQL 数据库中。
10) foreign
使用另外一个相关联的对象的标识符作为主键。
主键配置举例如下:
<id name="id" column="id" type="java.lang.Integer">
<generator class="native"/>
</id>
另外还可以扩展Hibernate的类来做自己的主键生成策略,具体例子见:http://www.javaeye.com/topic/93391。
2. 普通属性(property)
开发人员可以打开网址:http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd
来查看hibernate3.0的dtd信息,可看到property的定义如下:
<!ELEMENT property (meta*,(column|formula)*,type?)>
<!ATTLIST property name CDATA #REQUIRED>
<!ATTLIST property node CDATA #IMPLIED>
<!ATTLIST property access CDATA #IMPLIED>
<!ATTLIST property type CDATA #IMPLIED>
<!ATTLIST property column CDATA #IMPLIED>
<!ATTLIST property length CDATA #IMPLIED>
<!ATTLIST property precision CDATA #IMPLIED>
<!ATTLIST property scale CDATA #IMPLIED>
<!ATTLIST property not-null (true|false) #IMPLIED>
<!ATTLIST property unique (true|false) "false">
<!ATTLIST property unique-key CDATA #IMPLIED>
<!ATTLIST property index CDATA #IMPLIED> <!-- include the columns spanned by this property in an index -->
<!ATTLIST property update (true|false) #IMPLIED>
<!ATTLIST property insert (true|false) #IMPLIED>
<!ATTLIST property optimistic-lock (true|false) "true"> <!-- only supported for properties of a class (not component) -->
<!ATTLIST property formula CDATA #IMPLIED>
<!ATTLIST property lazy (true|false) "false">
<!ATTLIST property generated (never|insert|always) "never">
它的各属性中比较常用的有:name(对应的java类的属性名称)、column(对应的表中的字段)、tyope(属性的类型,eg.java.lang.String)、not-null(设置该属性是否为空,为true时表示非空,默认为false)和length(字段的长度限制)。
Eg1. <property name="accessname" column="accessName" type="java.lang.String" not-null="true" />
Eg2. <property name="state" column="state" type="java.lang.Byte" not-null="true" />
Eg3. <property name="description" column="description" type="java.lang.String" />
3. 一对多关系(<many-to-one…/>和<set…></set>)
一对多关系一般是用在一个表与另一个表存在外键关联的时候,例如用户表的组织id与组织表存在外键关联,则“一”方为组织表,“多”方为用户表,因为一个组织可以包含多个用户,而一个用户只能隶属于一个组织。
对于存在一对多关系和多对一关系的双方,需要在…hbm.xml中进行相应配置,这时在“一”方(例如:组织)需要在映射文件中添加<set…></set>元素,因为它包含多个“多”方的对象,一般的格式如下:
<set name="java映射类中对应的属性" inverse="true" lazy="true">
<key column="表中对应字段"/>
<one-to-many class="多方的类"/>
</set>
Eg.
<set name="userSet" inverse="true" lazy="true">
<key column="orgId"/>
<one-to-many class="User"/>
</set>
“多”方(例如:用户)隶属于一个“一”方对象,一般的格式如下:
<many-to-one name="java映射类中对应的属性" column="表中对应字段" class="类名" not-null="true" />
Eg.
<many-to-one name="org" column="orgId" class="Organization" not-null="true" />
4. 一对一关系(<one-to-one…/>)
一对一关系相对一对多关系来说比较少见,但也在某些情况下要用到,例如有一个用户的基本信息表(USER)和一个用户的密码表(PASSWD)就存在一对一的关系。下面来看一下一对一关系在Hibernate的配置。
其中主表(eg. 用户的基本信息表)的配置如下:
<one-to-one name="主表对象中子表对象的属性名" class="子表对象的类名" cascade="save-update"/>
Eg. <one-to-one name="password" class="com.amigo.dao.pojo.Passwd" cascade="save-update"/>
子表(eg. 用户的密码表)的配置如下:
<one-to-one name="子表对象中主表对象的属性名" class="主表对象的类名" constrained="true" />
Eg. <one-to-one name="user" class="com.amigo.dao.pojo.User " constrained="true" />
5. 多对多关系(<many-to-many…/>)
在数据库设计时,一般将多对多关系转换为两个一对多(或多对一)关系,例如在基于角色的权限系统中,用户和角色存在的关系就是典型的多对多关系,即一个用户可以具有多个角色,而一个角色又可以为多个用户所有,一般在设计时,都会加一个用户与角色的关联表,该表与用户表以及角色表都存在外键关联。
在本小节中讲述的是没有分解的多对多关系在Hibernate中如何配置。设置格式如下:
<set name="java对象的属性名" table="表名" cascade="all" outer-join="false">
<key column="表的对应字段"/>
<many-to-many class="另一个表的对象类" column="另一个表的字段"/>
</set>
Eg. 上述的多对多关系可以表示为:
t_user方:
<set name="roleSet" table="t_user" cascade="all" outer-join="false">
<key column="roleId"/>
<many-to-many class="com.amigo.dao.pojo.Role" column="roleId"/>
</set>
t_role方:
<set name="userSet" table="t_role" cascade="all" outer-join="false">
<key column="roleId"/>
<many-to-many class="com.amigo.dao.pojo.User" column="roleId"/>
</set>
6. 完整实例
在本小节中举一些.hbm.xml映射文件的例子,让开发人员对其有一个感性的认识。接下来讲述一个用户表(tbl_user)、用户与角色关联表(tbl_user_role)、角色表(tbl_role)以及组织表(tbl_organization)的例子。
(1)tbl_user
<?xml version="1.0" encoding='UTF-8'?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd" >
<hibernate-mapping package="com.amigo.dao.pojo">
<class name="User" table="tbl_user">
<id name="loginname" column="loginName" type="java.lang.String">
<generator class="assigned"/>
</id>
<property name="name" column="name" type="java.lang.String" not-null="true" />
<property name="password" column="password" type="java.lang.String" not-null="true" />
<property name="mobile" column="mobile" type="java.lang.String" />
<property name="telephone" column="telephone" type="java.lang.String" />
<property name="email" column="email" type="java.lang.String" />
<property name="createtime" column="createTime" type="java.util.Date" not-null="true" />
<property name="lastlogintime" column="lastLoginTime" type="java.util.Date" />
<property name="logintimes" column="loginTimes" type="java.lang.Long" not-null="true" />
<property name="state" column="state" type="java.lang.Byte" not-null="true" />
<property name="description" column="description" type="java.lang.String" />
<many-to-one name="organization" column="orgId" class="Organization" not-null="true" />
<set name="userRoleSet" inverse="true" cascade="all-delete-orphan" lazy="true">
<key column="loginName"/>
<one-to-many class="UserRole"/>
</set>
</hibernate-mapping>
(2)tbl_organization
<?xml version="1.0" encoding='UTF-8'?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd" >
<hibernate-mapping package="com.amigo.dao.pojo">
<class name="Organization" table="tbl_organization">
<id name="orgid" column="orgId" type="java.lang.Long">
<generator class="native"/>
</id>
<property name="parentorgid" column="parentOrgId" type="java.lang.Long" not-null="true" />
<property name="orgname" column="orgName" type="java.lang.String" not-null="true" />
<property name="orgfullname" column="orgFullName" type="java.lang.String" />
<property name="orglevel" column="orgLevel" type="java.lang.Integer" not-null="true" />
<property name="state" column="state" type="java.lang.Byte" not-null="true" />
<property name="description" column="description" type="java.lang.String" />
<property name="creator" column="creator" type="java.lang.String" />
<property name="createtime" column="createTime" type="java.util.Date" />
<set name="userSet" inverse="true" lazy="true">
<key column="orgId"/>
<one-to-many class="User"/>
</set>
</class>
</hibernate-mapping>
(3)tbl_user_role
<?xml version="1.0" encoding='UTF-8'?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd" >
<hibernate-mapping package="com.cotel.netvote.dao.model">
<class name="UserRole" table="tbl_user_role">
<id name="urid" column="urId" type="java.lang.Integer">
<generator class="native"/>
</id>
<many-to-one name="role" column="roleId" class="Role" not-null="true" />
<many-to-one name="user" column="loginName" class="User" not-null="true" />
</class>
</hibernate-mapping>
(4)tbl_ role
<?xml version="1.0" encoding='UTF-8'?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd" >
<hibernate-mapping package="com.cotel.netvote.dao.model">
<class name="Role" table="tbl_role">
<id name="roleid" column="roleId" type="java.lang.Integer">
<generator class="native"/>
</id>
<property name="rolename" column="roleName" type="java.lang.String" not-null="true" />
<property name="createdate" column="createDate" type="java.util.Date" not-null="true" />
<property name="description" column="description" type="java.lang.String" />
<set name="userRoleSet" inverse="true" lazy="true" cascade="all">
<key column="roleId"/>
<one-to-many class="UserRole"/>
</set>
</class>
</hibernate-mapping>
http://www.blogjava.net/amigoxie/archive/2007/12/31/171831.html
1:spring 跟hibernate版本冲突
2:spring 配置问题
3:找不到对应的类
4:hibernate动态生成sprinDAO生成对应实体的XML映射表需要做一些修改
http://hi.baidu.com/fgfd0/blog/item/1d96232e79a20d524fc22680.html
http://www.javaeye.com/topic/79071
http://hi.baidu.com/fgfd0/blog/item/1d96232e79a20d524fc22680.html
http://www.javaeye.com/topic/79071
ubuntu
TOMCAT昨天突然自己宕掉服务了,怎么重起都不行,后来查看logs中catalina.out 日志发现如下错误
INFO:
The Apache Tomcat Native
library which allows optimal performance in production environments was
not found on the java.
library.
path: /usr/local/jdk1.6.0_01/jre/lib/i386/client:/usr/local/jdk1.6.0_01/jre/lib/i386:/usr/local/jdk1.6.0_01/jre/../lib/i386:/usr/
java/packages/lib/i386:/lib:/usr/lib
Aug 24, 2007 1:20:27 PM org.apache.coyote.http11.Http11Protocol init
SEVERE: Error initializing endpoint
java.net.BindException: Address already in use:8080
....................
netstat -nlp 看到后台
java只有一个8015端口,而且有
127.0.0.1:8080 127.0.0.1:8080 ESTABLISHED的链接
很是奇怪,
google一下提示是要使用apr
由于是debian系统所以很容易安装需要的软件
apt-get install libapr1-dev apache2-utils
可是还是不行,错误照常出现。
重起服务器后一切正常。
win
当我下载Tomcat6.0.16并安装到eclise后,当任意建一个工程后,哪怕只有一个jsp页面的工程,启动Tomcat后都会有一个“警告”的提示(对工程与页面显示没有任何影响)。于是删除工程,只启动Tomcat服务器时,提示信息:
The Apache Tomcat Native
library which allows optimal performance in production environments was
not found on the java.
library.
path: ......,是说在产品环境下可以优化工作性能的Tomcat的本地包没有找到。于是我就把以前所学的有关classpath、
path相关的知识全用上设置一大类键值对,根本无法解决这个问题。
经过几个小时的上网搜索终于找到了解决方法:原来Tomcat从5.5版本后增加了APR技术(Apache Portable
Runtime),这是一个用C语言写成文件包,目的在于提高Tomcat的服务性能,从而使得Tomcat将不仅仅担任一个容器的功能,而是要成为一个
一般的web服务器(general purpose webserver)。现在是什么都涨,Tomcat的野心也在涨啊!
通过上述描述大家也就明白了,我们只要把那个本地文件下载过来,配置好之后,这些问题就会迎刃而解了,首先要到Tomcat网站上去下载:
http://tomcat.apache.org/download-native.cgi 找到
Native 1.1.13 Source Release zip 这是个源文件,如果你要自己编译就下这个,如果想使用已编译好的dll文件就点击这个链接下面的“Here“ 链接,找一个版本号最新的,进去可以下载一个tcnative-1.dll文件。
那么如何配置这个文件呢?简单一点就是把这个文件扔到windows/system32下面,因为我们已经在
path下配置好了这个路径,系统启动后就可以找到这个路径下的文件,如果想放到自己指定的位置,比如话到Tomcat安装路径下,那么就要在
path中指定好这个路径,我是这样做的,首先根据惯例在系统变量中设置CATALINA_HOME变量,然后再把%CATALINA_HOME%\bin加入到
path中,然后再把下载的dll文件放到 bin路径下就一切ok了。当然不做这些工作不会影Tomcat运行,萝卜白菜各有所爱了。
本文参考
http://www.blogjava.net/beansoft/archive/2006/12/22/89577.html
https://webwork.dev.java.net/servlets/ProjectDocumentList下载WebWork压缩包,并将其解压开来,本文中使用的是webwork-2.1.7版本。
其中必须要在lib文件夹中加入的jar文件分别为
webwork-2.1.7.jar
xwork.jar ———— 包含webwork构建所依赖的xwork类库
common-logging.jar ———— 通用日志类库,webwork使用它来提供透明的日志记录
oscore.jar ———— 一个通用功能类库
velocity-dep.jar ———— 依赖的Velocity类库
ognl.jar ———— webwork中使用的表达式语言(ORGL)
除webwork-2.1.7.jar以外的几个jar文件都可以从WebWork压缩包中的lib\core文件夹下找到
而如果需要其他的功能(如:文件上传),则要将lib\core下的相应的jar文件拷贝到WEB-INF\lib目录
配置web.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<display-name>My WebWork Application</display-name>
增加有关servlet定义的节点
<servlet>
<servlet-name>webwork</servlet-name>
<servlet-class>com.opensymphony.webwork.dispatcher.ServletDispatcher
</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
将这个servlet映射至某个URL模式
<servlet-mapping>
<servlet-name>webwork</servlet-name>
<url-pattern>*.action</url-pattern>
</servlet-mapping>
增加webwork标签库的定义节点
<taglib>
<taglib-uri>webwork</taglib-uri>
<taglib-location>/WEB-INF/webwork.tld</taglib-location>
</taglib>
</web-app>
创建xwork.xml配置文件
<!DOCTYPE xwork PUBLIC "-//OpenSymphony Group//XWork 1.0//EN" "http://www.opensymphony.com/xwork/xwork-1.0.dtd">
<xwork>
<include file="webwork-default.xml" />
<package name="example" extends="webwork-default">
<action name="hello" class="org.liky.webwork.liky.HelloWorldAction">
<result name="success" type="dispatcher">index.jsp</result>
</action>
</package>
</xwork>
这几天把hibernate和spring好好看了下,再想想struts的一些东西,决定把3个整合一下一起用,表现层用struts+freemarker,业务层用spring,hibernate处理持久层。在struts中,利用委托,将action的处理委托给spring进行,struts只负责页面逻辑。
前些日子下了Eclipse 3.2+MyEclipse5.0M2,感觉MyEclipse一些东西还是不错的,就用它来做个整合。
首先,建立一个web project:
然后,给新建立的项目附加上struts的一些文件:
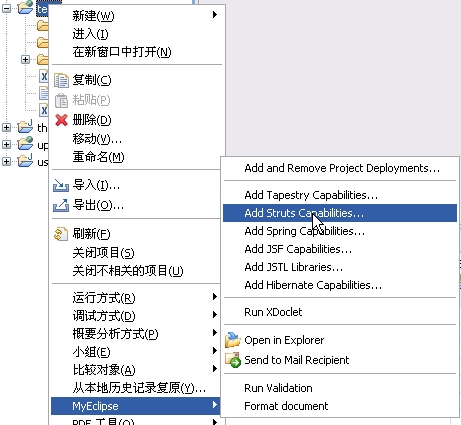

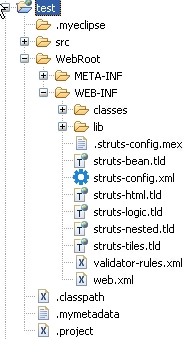
完成后项目结构如下:
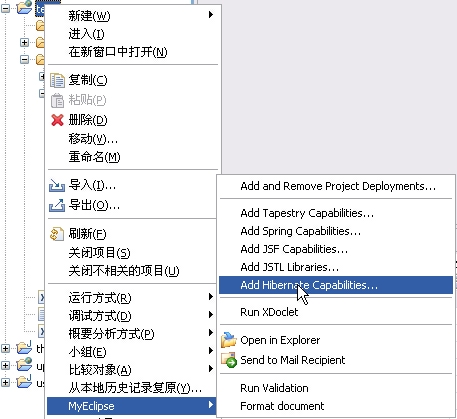
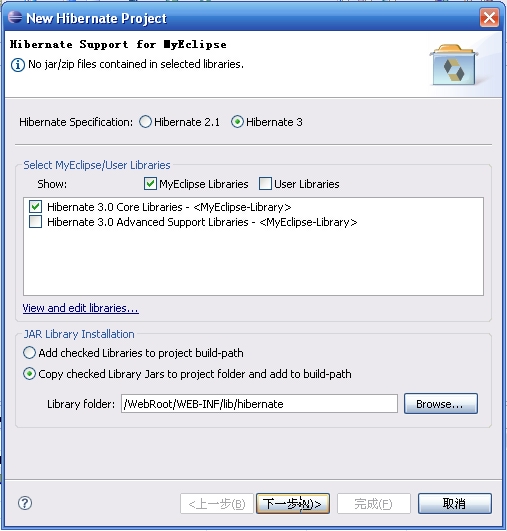
接着加入hibernate需要的文件:
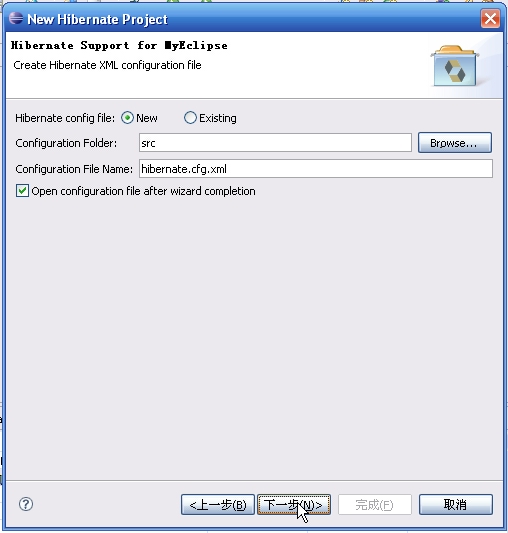

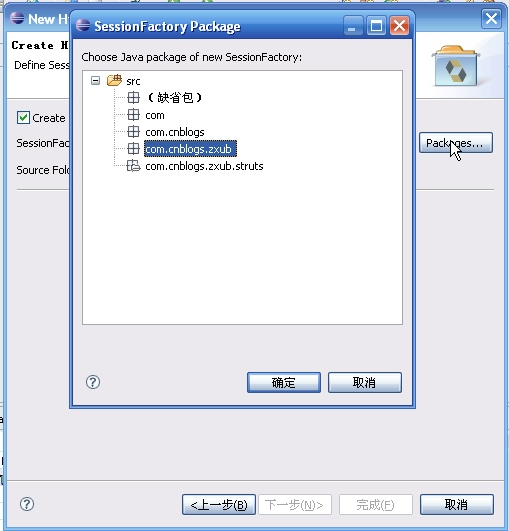
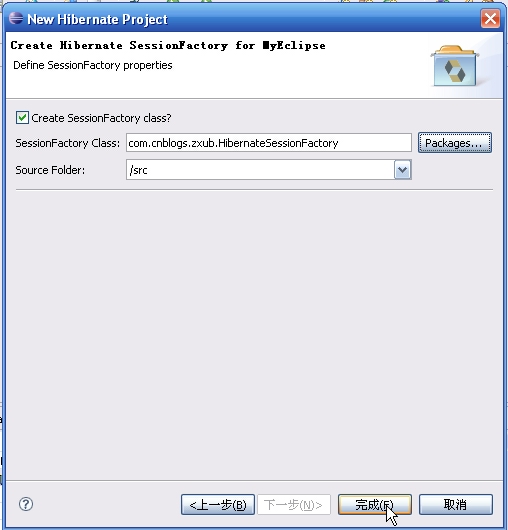
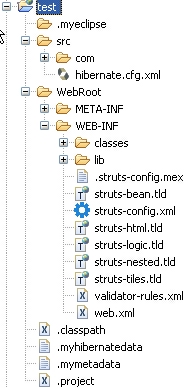
完成后项目结构为:
再加入spring的文件:
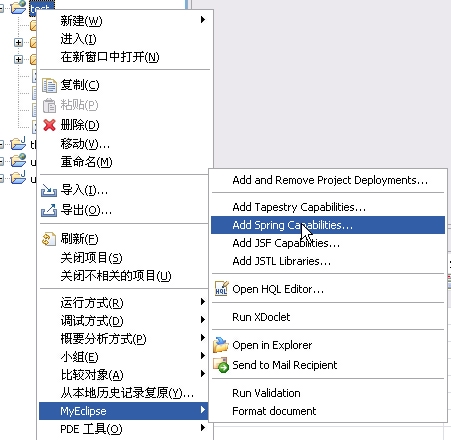
注意下面的选择:
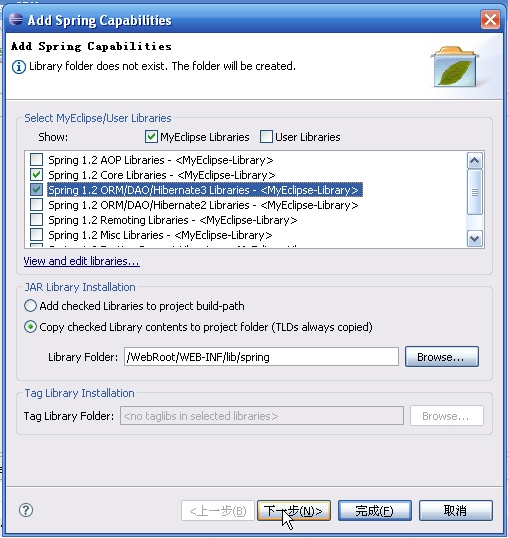
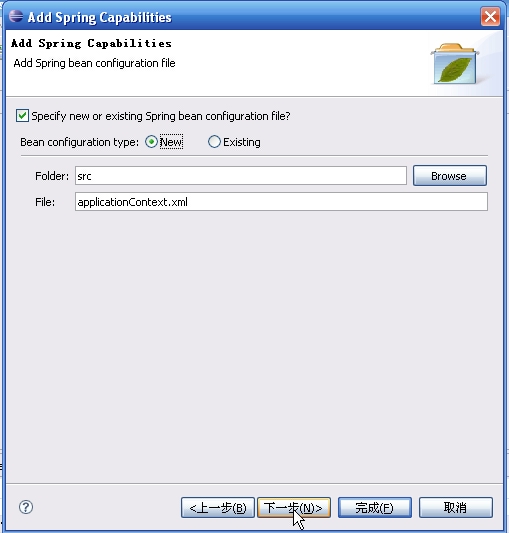
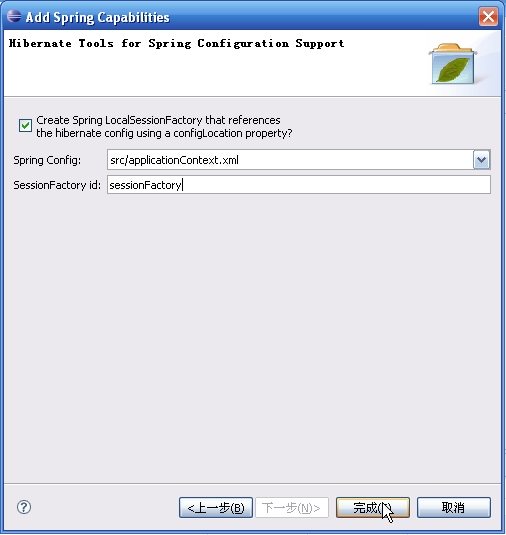
完成后可以看到:
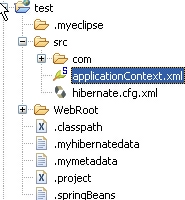
打开那个applicationContext.xml,将

改为:

现在还需要做一些修改,才能在运行的时候不报错,我以前也写过struts+hibernate的时候,会抛一个错,之所以是由于hibernate包含的那个xerces.jar,所以现在直接把它给删掉,没什么问题。
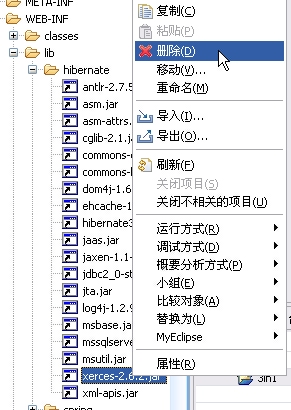
在spring和hibernate那,有2个log4j.jar,老版本不好用,所以删除,换一个新版本。
删除
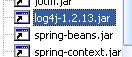
和
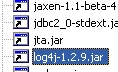
,换上

,然后,在src下加入一个log4j.properties:
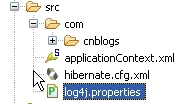
内容如下:
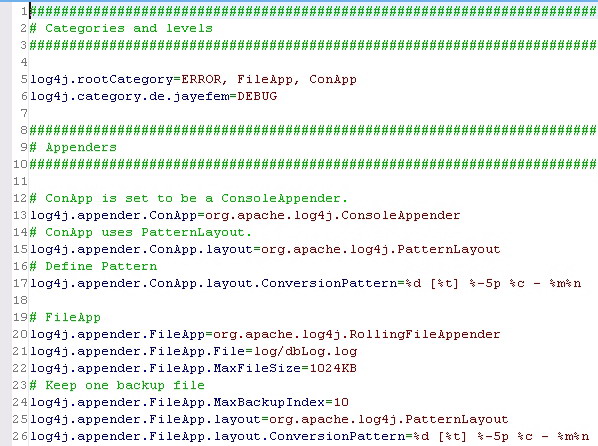
这样log4j就配好了。
接下来是加入FreeMarker,jsp比不上,个人感觉。
先下一个freemarker.jar

,加到WEB-INF下的lib目录,然后,打开web.xml,加入如下内容:


下面来点实战演习。
切换到MyEclipse的hibernate视图。
打开数据库连接:

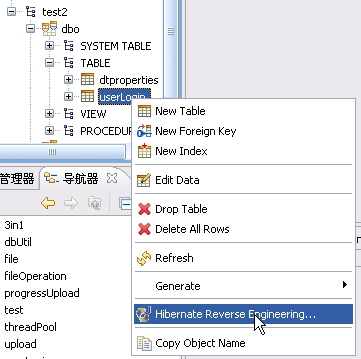
然后,执行
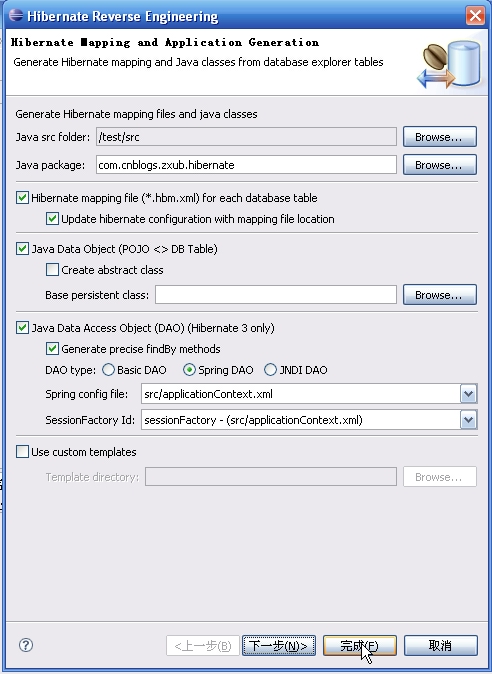
自动生成几个文件:
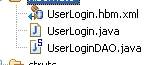
并且,spring的applicationContext.xml自动加入
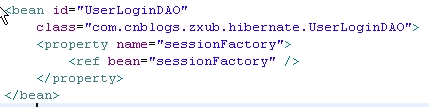
然后,建立ftl页面,根据前面web.xml配置的freemarker设置,需要建立如下目录
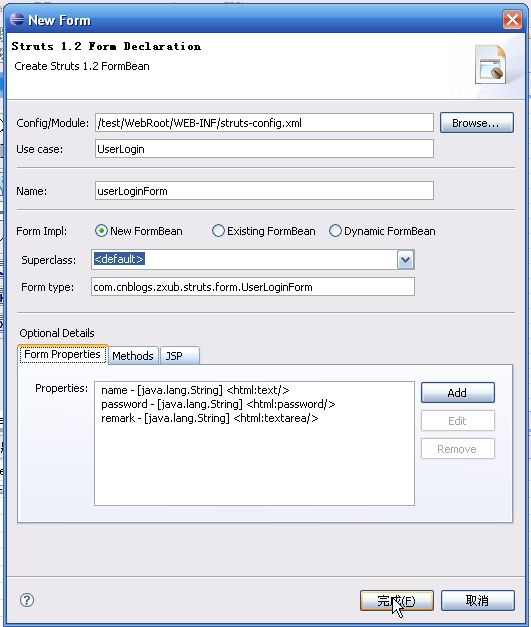
先把页面逻辑处理下,打开struts-config.xml,然后进行如下操作

继续加
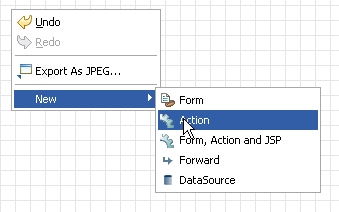
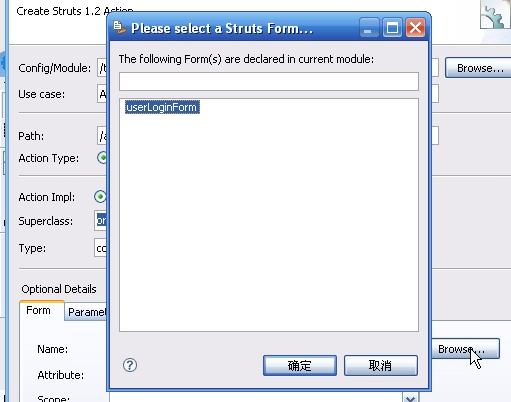
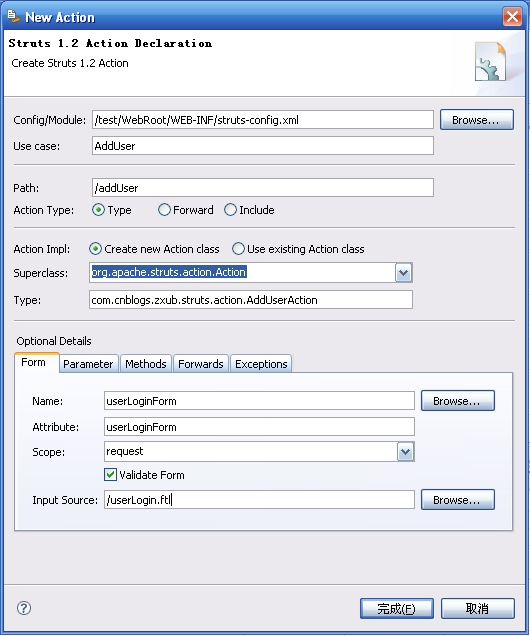
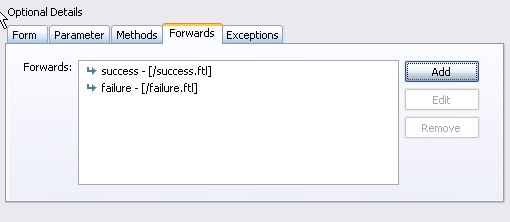
完成后效果如下:
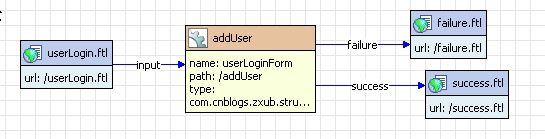
下面是3个页面:

这里注意下前2行,在freemarker中用struts标签。
前面说过action委托给spring做,许要在struts那加入

然后,action类需要修改下

下面的setter是为spring准备的。
struts配置那的action声明需要修改一下,说明用代理:

然后在spring的applicationContext.xml加上:
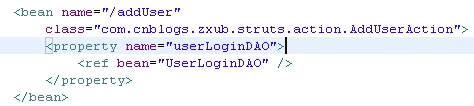
注意是用name,不是id。
发布,运行,结果抛了个错

还好,问题不大,找到

加到WEB-INF/lib下就可以了。
开始测试
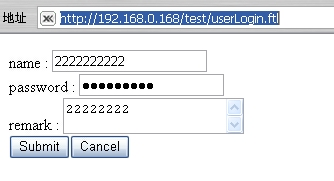
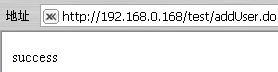
成功的话:
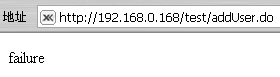
否则:
然后去数据库一看,郁闷,数据没进来,试了N久,最后发现spring里要定义个dataSource。原来sessionFactory的定义变为如下:
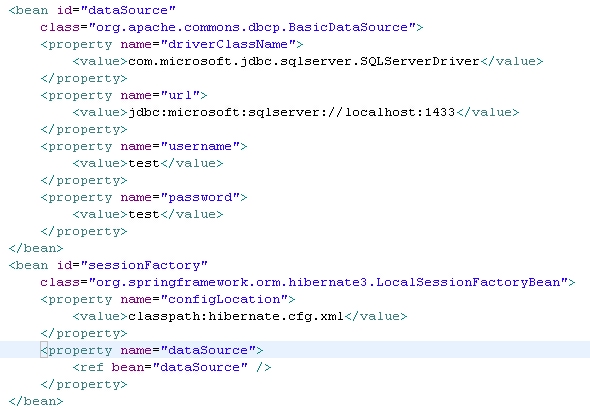
ok,一切正常。到这里,就写完了,只是为说明怎样用MyEclipse进行快速开发,毕竟平时做项目要的是进度,还要监管质量,有了MyEclipse,确实方便不少。
http://www.cnblogs.com/zxub/archive/2006/08/03/466682.html