摘要: JDBC模板类 概述 Spring JDBC抽象框架core包提供了JDBC模板类,其中JdbcTemplate是core包的核心类,所以其他模板类都是基于它封装完成的,JDBC模板类是第一种工作模式。 JdbcTemplate类通过模板...
阅读全文
posted @
2012-02-26 09:39 todayx.org 阅读(2719) |
评论 (0) |
编辑 收藏 在软件这个行业里有些规则是很有杀伤力的,比如很有名的摩尔定律。
总结出这些规则的意义在于可以大致的照明方向,免得努力来努力去却走到了阴沟里。
现实中种种利益纷争、观点之争看似纷繁,但在大时间尺度下来看却都是规则的实现手段。
这就好比下围棋,每一手都要为谋得利益而计算,但结局却只有三种:赢、输或和,这就是规则的力量。
民以食为天,所以第一定律从收入开始。
程序员第一定律可以表述为:程序员的收入是技能复杂度和技能实现可能程度的函数。
如果程序员的工资是S,社会平均水平的工资为A,程序员掌握的技能复杂度为C,实现程度为P。
那么S = A x C x P。
这里面的实现程度P不太好理解,额外做点说明。
好比说有人在东北种了很多白菜,并获得了大丰收。与此同时广州也确实需要大白菜,按批发价他的这批白菜可以买10万。
但关键是这个人找不到车皮,大白菜就只能在当地零售,这个时候这批大白菜就只能买1万块钱。
这就是实现程度。
大白菜内蕴了既定的价值,这种价值并不因为卖多少钱而改变,但这种价值能实现到什么程度则依赖于现实的可能性。
这视乎很简单,但其实不是,很多人的一生就笼罩在这条定律下面,我们来基于这第一定律继续做些推导。
技能的复杂度C可以大致等价于掌握一门技术所需要的时间。
各种集成的开发环境,各种容易学习的类库等使软件开发的门槛降得很低,这对整个产业是有利的,但对个体而言则是不利的。
你花5个月可以学会的技术,其他人花5个月也可以学会,而5个月可以学会的东西所蕴含的价值一定是低的。
与之相对5年才可以学会的东西,其内蕴价值一定是高的。
内蕴价值低,所对应的收入必然偏低。
为避免争议,我这里就不写技术的名字了,但大家可以从学习所需要的时间上来对各种技术做个分类。
有时候很多人会有一种错觉,认为越热门的技术收益越好。
这在大多时候是错的。
越热的技术,越成熟的技术越是大众的,而越是大众的技术内蕴价值越低,所以收益越不好。
热度能够帮助找到工作,但对技能复杂度C没有影响。
- 推论2:单纯的涉猎广泛,没有专精,对收入的影响是负面的。
各种技术的复杂度大概是呈指数增长的,越到后面前进一步越困难。
好比说学会5门语言所需要的时间大多时候远比学精一门语言要短。
在特定年纪尚,每样技术都会一点,对提高实现程度P略有帮助,但自身可替代性很强,对技能复杂度C的影响为负面。
长期来看得不偿失。
有些技术领域很窄,上手也慢,实现程度却高,比如显卡驱动,打印驱动等。
但这类工作好比在钢丝上跳舞:只要能实现自己的价值,那么回报大体不错,但最怕技术更迭。
技术一换代,可能多年积累十去六七。
总结来看,程序员要想获得不错的收入,第一要掌握稀缺的技术,即技术的内蕴价值要高;第二要找到实现稀缺技术的场景。
《微软的秘密》一书中提到,微软里面优秀的程序员是可以拥有许多辆保时捷的。
用上面两条做分解,就会发现原因很简单:
一是这样的人是NT的核心开发人员,这类人员内蕴价值极高,处于稀缺状态;二是微软提供了实现这种技能内蕴价值的机会。
这二者缺一不可。
#根据大家的回复做了点修改把"实现可能性"替换成了"实现程度"。
2012世界末日暨环境保护主题站,关注国内外最新2012世界末日信息,旨在通过关注,收集,展示2012世界末日相关资料的方式,唤醒并提高人们保护环境与爱护地球的意识,引导人类保护环境.
posted @
2012-02-14 22:03 todayx.org 阅读(553) |
评论 (4) |
编辑 收藏什么是HTTP协议
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器
目前我们使用的是HTTP/1.1 版本
Web服务器,浏览器,代理服务器
当我们打开浏览器,在地址栏中输入URL,然后我们就看到了网页。 原理是怎样的呢?
实际上我们输入URL后,我们的浏览器给Web服务器发送了一个Request, Web服务器接到Request后进行处理,生成相应的Response,然后发送给浏览器, 浏览器解析Response中的HTML,这样我们就看到了网页,过程如下图所示

我们的Request 有可能是经过了代理服务器,最后才到达Web服务器的。
过程如下图所示

代理服务器就是网络信息的中转站,有什么功能呢?
1. 提高访问速度, 大多数的代理服务器都有缓存功能。
2. 突破限制, 也就是翻-墙了
3. 隐藏身份。
URL详解
URL(Uniform Resource Locator) 地址用于描述一个网络上的资源, 基本格式如下
schema://host[:port#]/path/.../[?query-string][#anchor]
scheme 指定低层使用的协议(例如:http, https, ftp)
host HTTP服务器的IP地址或者域名
port# HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如 http://www.cnblogs.com:8080/
path 访问资源的路径
query-string 发送给http服务器的数据
anchor- 锚
URL 的一个例子
http://www.mywebsite.com/sj/test/test.aspx?name=sviergn&x=true#stuff Schema: http host: www.mywebsite.com path: /sj/test Query String: name=sviergn&x=true Anchor: stuff
HTTP协议是无状态的
http协议是无状态的,同一个客户端的这次请求和上次请求是没有对应关系,对http服务器来说,它并不知道这两个请求来自同一个客户端。 为了解决这个问题, Web程序引入了Cookie机制来维护状态.
HTTP消息的结构
先看Request 消息的结构, Request 消息分为3部分,第一部分叫Request line, 第二部分叫Request header, 第三部分是body. header和body之间有个空行, 结构如下图

第一行中的Method表示请求方法,比如"POST","GET", Path-to-resoure表示请求的资源, Http/version-number 表示HTTP协议的版本号
当使用的是"GET" 方法的时候, body是为空的
比如我们打开博客园首页的request 如下
GET http://www.cnblogs.com/ HTTP/1.1 Host: www.cnblogs.com
下面我们打开Fiddler 捕捉一个博客园登录的Request 然后分析下它的结构, 在Inspectors tab下以Raw的方式可以看到完整的Request的消息, 如下图

我们再看Response消息的结构, 和Request消息的结构基本一样。 同样也分为三部分,第一部分叫Response line, 第二部分叫Response header,第三部分是body. header和body之间也有个空行, 结构如下图

HTTP/version-number表示HTTP协议的版本号, status-code 和message 请看下节[状态代码]的详细解释.
我们用Fiddler 捕捉一个博客园首页的Response然后分析下它的结构, 在Inspectors tab下以Raw的方式可以看到完整的Response的消息, 如下图

Get和Post方法的区别
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
我们看看GET和POST的区别
1. GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
2. GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
3. GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
4. GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
状态码
Response 消息中的第一行叫做状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
状态码用来告诉HTTP客户端,HTTP服务器是否产生了预期的Response.
HTTP/1.1中定义了5类状态码, 状态码由三位数字组成,第一个数字定义了响应的类别
1XX 提示信息 - 表示请求已被成功接收,继续处理
2XX 成功 - 表示请求已被成功接收,理解,接受
3XX 重定向 - 要完成请求必须进行更进一步的处理
4XX 客户端错误 - 请求有语法错误或请求无法实现
5XX 服务器端错误 - 服务器未能实现合法的请求
看看一些常见的状态码
200 OK
最常见的就是成功响应状态码200了, 这表明该请求被成功地完成,所请求的资源发送回客户端
如下图, 打开博客园首页

302 Found
重定向,新的URL会在response 中的Location中返回,浏览器将会自动使用新的URL发出新的Request
例如在IE中输入, http://www.google.com. HTTP服务器会返回304, IE取到Response中Location header的新URL, 又重新发送了一个Request.

304 Not Modified
代表上次的文档已经被缓存了, 还可以继续使用,
例如打开博客园首页, 发现很多Response 的status code 都是304

提示: 如果你不想使用本地缓存可以用Ctrl+F5 强制刷新页面
400 Bad Request 客户端请求与语法错误,不能被服务器所理解
403 Forbidden 服务器收到请求,但是拒绝提供服务
404 Not Found
请求资源不存在(输错了URL)
比如在IE中输入一个错误的URL, http://www.cnblogs.com/tesdf.aspx

500 Internal Server Error 服务器发生了不可预期的错误
503 Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
HTTP Request header
使用Fiddler 能很方便的查看Reques header, 点击Inspectors tab ->Request tab-> headers 如下图所示.

header 有很多,比较难以记忆,我们也按照Fiddler那样把header 进行分类,这样比较清晰也容易记忆。
Cache 头域
If-Modified-Since
作用: 把浏览器端缓存页面的最后修改时间发送到服务器去,服务器会把这个时间与服务器上实际文件的最后修改时间进行对比。如果时间一致,那么返回304,客户端 就直接使用本地缓存文件。如果时间不一致,就会返回200和新的文件内容。客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示在浏览器中.
例如:If-Modified-Since: Thu, 09 Feb 2012 09:07:57 GMT
实例如下图

If-None-Match
作用: If-None-Match和ETag一起工作,工作原理是在HTTP Response中添加ETag信息。 当用户再次请求该资源时,将在HTTP Request 中加入If-None-Match信息(ETag的值)。如果服务器验证资源的ETag没有改变(该资源没有更新),将返回一个304状态告诉客户端使用 本地缓存文件。否则将返回200状态和新的资源和Etag. 使用这样的机制将提高网站的性能
例如: If-None-Match: "03f2b33c0bfcc1:0"
实例如下图

Pragma
作用: 防止页面被缓存, 在HTTP/1.1版本中,它和Cache-Control:no-cache作用一模一样
Pargma只有一个用法, 例如: Pragma: no-cache
注意: 在HTTP/1.0版本中,只实现了Pragema:no-cache, 没有实现Cache-Control
Cache-Control
作用: 这个是非常重要的规则。 这个用来指定Response-Request遵循的缓存机制。各个指令含义如下
Cache-Control:Public 可以被任何缓存所缓存()
Cache-Control:Private 内容只缓存到私有缓存中
Cache-Control:no-cache 所有内容都不会被缓存
还有其他的一些用法, 我没搞懂其中的意思, 请大家参考其他的资料
Client 头域
Accept
作用: 浏览器端可以接受的媒体类型,
例如: Accept: text/html 代表浏览器可以接受服务器回发的类型为 text/html 也就是我们常说的html文档,
如果服务器无法返回text/html类型的数据,服务器应该返回一个406错误(non acceptable)
通配符 * 代表任意类型
例如 Accept: */* 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)
Accept-Encoding:
作用: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate),(注意:这不是只字符编码);
例如: Accept-Encoding: gzip, deflate
Accept-Language
作用: 浏览器申明自己接收的语言。
语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等;
例如: Accept-Language: en-us
User-Agent
作用:告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.
我们上网登陆论坛的时候,往往会看到一些欢迎信息,其中列出了你的操作系统的名称和版本,你所使用的浏览器的名称和版本,这往往让很多人感到很神 奇,实际上,服务器应用程序就是从User-Agent这个请求报头域中获取到这些信息User-Agent请求报头域允许客户端将它的操作系统、浏览器 和其它属性告诉服务器。
例如: User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; InfoPath.2; .NET4.0E)
Accept-Charset
作用:浏览器申明自己接收的字符集,这就是本文前面介绍的各种字符集和字符编码,如gb2312,utf-8(通常我们说Charset包括了相应的字符编码方案);
例如:
Cookie/Login 头域
Cookie:
作用: 最重要的header, 将cookie的值发送给HTTP 服务器
Entity头域
Content-Length
作用:发送给HTTP服务器数据的长度。
例如: Content-Length: 38
Content-Type
作用:
例如:Content-Type: application/x-www-form-urlencoded
Miscellaneous 头域
Referer:
作用: 提供了Request的上下文信息的服务器,告诉服务器我是从哪个链接过来的,比如从我主页上链接到一个朋友那里,他的服务器就能够从HTTP Referer中统计出每天有多少用户点击我主页上的链接访问他的网站。
例如: Referer:http://translate.google.cn/?hl=zh-cn&tab=wT
Transport 头域
Connection
例如: Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
例如: Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭, 当客户端再次发送Request,需要重新建立TCP连接。
Host(发送请求时,该报头域是必需的)
作用: 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的
例如: 我们在浏览器中输入:http://www.guet.edu.cn/index.html
浏览器发送的请求消息中,就会包含Host请求报头域,如下:
Host:http://www.guet.edu.cn
此处使用缺省端口号80,若指定了端口号,则变成:Host:指定端口号
HTTP Response header
同样使用Fiddler 查看Response header, 点击Inspectors tab ->Response tab-> headers 如下图所示

我们也按照Fiddler那样把header 进行分类,这样比较清晰也容易记忆。
Cache头域
Date
作用: 生成消息的具体时间和日期
例如: Date: Sat, 11 Feb 2012 11:35:14 GMT
Expires
作用: 浏览器会在指定过期时间内使用本地缓存
例如: Expires: Tue, 08 Feb 2022 11:35:14 GMT
Vary
作用:
例如: Vary: Accept-Encoding
Cookie/Login 头域
P3P
作用: 用于跨域设置Cookie, 这样可以解决iframe跨域访问cookie的问题
例如: P3P: CP=CURa ADMa DEVa PSAo PSDo OUR BUS UNI PUR INT DEM STA PRE COM NAV OTC NOI DSP COR
Set-Cookie
作用: 非常重要的header, 用于把cookie 发送到客户端浏览器, 每一个写入cookie都会生成一个Set-Cookie.
例如: Set-Cookie: sc=4c31523a; path=/; domain=.acookie.taobao.com

Entity头域
ETag
作用: 和If-None-Match 配合使用。 (实例请看上节中If-None-Match的实例)
例如: ETag: "03f2b33c0bfcc1:0"
Last-Modified:
作用: 用于指示资源的最后修改日期和时间。(实例请看上节的If-Modified-Since的实例)
例如: Last-Modified: Wed, 21 Dec 2011 09:09:10 GMT
Content-Type
作用:WEB服务器告诉浏览器自己响应的对象的类型和字符集,
例如:
Content-Type: text/html; charset=utf-8
Content-Type:text/html;charset=GB2312
Content-Type: image/jpeg
Content-Length
指明实体正文的长度,以字节方式存储的十进制数字来表示。在数据下行的过程中,Content-Length的方式要预先在服务器中缓存所有数据,然后所有数据再一股脑儿地发给客户端。
例如: Content-Length: 19847
Content-Encoding
WEB服务器表明自己使用了什么压缩方法(gzip,deflate)压缩响应中的对象。
例如:Content-Encoding:gzip
Content-Language
作用: WEB服务器告诉浏览器自己响应的对象的语言者
例如: Content-Language:da
Miscellaneous 头域
Server:
作用:指明HTTP服务器的软件信息
例如:Server: Microsoft-IIS/7.5
X-AspNet-Version:
作用:如果网站是用ASP.NET开发的,这个header用来表示ASP.NET的版本
例如: X-AspNet-Version: 4.0.30319
X-Powered-By:
作用:表示网站是用什么技术开发的
例如: X-Powered-By: ASP.NET
Transport头域
Connection
例如: Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
例如: Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭, 当客户端再次发送Request,需要重新建立TCP连接。
Location头域
Location
作用: 用于重定向一个新的位置, 包含新的URL地址
实例请看304状态实例
HTTP协议是无状态的和Connection: keep-alive的区别
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系
HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)
从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间
posted @
2012-02-14 21:58 todayx.org 阅读(326) |
评论 (3) |
编辑 收藏 作为一个开发者,尤其是web开发人员,我想你有必要去了解这一系列的处理流程,在这期间,浏览器和服务器到底是如何打交道的?服务器又是如何处理的?浏览器又是如何将网页显示给用户的呢?......
疑惑和细节真是太多了。坦白讲,要想彻彻底底的弄清楚以上每个疑惑和处理细节,至少需要十本书的厚度,所谓“底层无极限”嘛,而且不同的web服务 器和服务器端编程语言的实现和处理流程不尽相同(但本质都是相通的)。本文中,我将根据http协议的有关知识,跟大家讲解一些web开发的本质。不管你 是从事.NET,还是J2EE或者php开发等等,都离不开这些本质。希望你读完本文,能有新的收获和见解。由于本人水平和经验有限,难免有误,望读者见 谅。
何为http协议(Hypertext Transfer Protocol,超文本传输协议)?
所谓协议,就是指双方遵循的规范。http协议,就是浏览器和服务器之间进行“沟通”的一种规范。我们在看空间,刷微博...都是在使用http协议,当然,远远不止这些应用。
笔者一直听说http是属于“应用层的协议”,而且是基于TCP/IP协议的。这个不难理解,如果你上大学时候学过“计算机网络”的课程,就一定知 道OSI七层参考协议(我当时是死记硬背的)。如果你接触过socket网络编程,就应该明白TCP和UDP这两种使用广泛的通信协议(建立连接、三次握 手等等,当然,这不是本文讨论的重点)。如图:

既然TCP/UDP是广泛使用的网络通信协议,那为啥有多出个http协议来呢?
笔者曾自己动手写过一个简单的web服务器处理软件,根据我的推断(不一定准确)。UDP协议具有不可靠性和不安全性,显然这很难满足web应用的需要。
而TCP协议是基于连接和三次握手的,虽然具有可靠性,但人具有一定的缺陷。但试想一下,普通的C/S架构软件,顶多上千个Client同时连接,而B/S架构的网站,十万人同时在线也是很平常的事儿。如果十万个客户端和服务器一直保持连接状态,那服务器如何满足承载呢?
这就衍生出了http协议。基于TCP的可靠性连接。通俗点说,就是在请求之后,服务器端立即关闭连接、释放资源。这样既保证了资源可用,也吸取了TCP的可靠性的优点。
正因为这点,所以大家通常说http协议是“无状态”的,也就是“服务器不知道你客户端干了啥”,其实很大程度上是基于性能考虑的。以至于后来有了session之类的玩意。
实战准备工作:
在监视网络方面,windows平台上有一款叫做Sniffer的优秀软件,这也是很多“黑客”经常使用的嗅探工具。 在研究http协议时,推荐大家使用一款
叫作httpwatch的工具。(遗憾的是,该工具是收费的。该咋办就咋办,你懂的)。安装完成后,可以在IE浏览器的tools中直接打开(目前也支持firefox)。如图所示:

点击Record,就可以开始监视并记录http消息了。stop、Clear等等按钮的功能,这里就不一一介绍了。拿实例来说话,下面就是我记录访问main.aspx页面的时候记录的,能够清晰的看到http报文消息的详细信息,如图:

学习http协议,主要需要了解http的请求和响应(当然,还有get、post等请求方式,状态码、URI、MIME等)
首先看看http请求消息(就是浏览器丢给服务器的):
一个http请求代表客户端浏览器向服务器发送的数据。一个完整的http请求消息,包含一个请求行,若干个消息头(请求头),换行,实体内容
请求行:描述客户端的请求方式、请求资源的名称、http协议的版本号。 例如: GET/BOOK/JAVA.HTML HTTP/1.1
请求头(消息头)包含(客户机请求的服务器主机名,客户机的环境信息等):
Accept:用于告诉服务器,客户机支持的数据类型 (例如:Accept:text/html,image/*)
Accept-Charset:用于告诉服务器,客户机采用的编码格式
Accept-Encoding:用于告诉服务器,客户机支持的数据压缩格式
Accept-Language:客户机语言环境
Host:客户机通过这个服务器,想访问的主机名
If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间
Referer:客户机通过这个头告诉服务器,它(客户端)是从哪个资源来访问服务器的(防盗链)
User-Agent:客户机通过这个头告诉服务器,客户机的软件环境(操作系统,浏览器版本等)
Cookie:客户机通过这个头,将Coockie信息带给服务器
Connection:告诉服务器,请求完成后,是否保持连接
Date:告诉服务器,当前请求的时间
(换行)
实体内容:
就是指浏览器端通过http协议发送给服务器的实体数据。例如:name=dylan&id=110
(get请求时,通过url传给服务器的值。post请求时,通过表单发送给服务器的值)
再看看HTTP响应消息(服务器返回给浏览器的):
一个http响应代表服务器端向客户端回送的数据,它包括:
一个状态行,若干个消息头,以及实体内容
响应头(消息头)包含:
Location:这个头配合302状态吗,用于告诉客户端找谁
Server:服务器通过这个头,告诉浏览器服务器的类型
Content-Encoding:告诉浏览器,服务器的数据压缩格式
Content-Length:告诉浏览器,回送数据的长度
Content-Type:告诉浏览器,回送数据的类型
Last-Modified:告诉浏览器当前资源缓存时间
Refresh:告诉浏览器,隔多长时间刷新
Content- Disposition:告诉浏览器以下载的方式打开数据。例如: context.Response.AddHeader("Content-Disposition","attachment:filename=aa.jpg"); context.Response.WriteFile("aa.jpg");
Transfer-Encoding:告诉浏览器,传送数据的编码格式
ETag:缓存相关的头(可以做到实时更新)
Expries:告诉浏览器回送的资源缓存多长时间。如果是-1或者0,表示不缓存
Cache-Control:控制浏览器不要缓存数据 no-cache
Pragma:控制浏览器不要缓存数据 no-cache
Connection:响应完成后,是否断开连接。 close/Keep-Alive
Date:告诉浏览器,服务器响应时间
理解了以上的http请求消息和响应消息,相信你对于http协议已经理解得足够深刻了。关于http协议的更多具体细节,可以参照http RFC文档。
大致步骤就是:浏览器先向服务器发送请求,服务器接收到请求后,做相应的处理,然后封装好响应报文,再回送给浏览器。浏览器拿到响应报文后,再通过 浏览器引擎去渲染网页,解析DOM树,javascript引擎解析并执行脚本操作,插件去干插件该干的事儿...关于浏览器渲染、解析的原理,可以参考 http://kb.cnblogs.com/page/129756/
说白了,所谓web的本质,无非是:请求/处理/响应 ,任何的web服务器,任何的服务端编程语言,都没法脱离这个本质。 而浏览器端解析html、图片等静态内容,呈现给用户,脚本引擎执行脚本代码,完成脚本代码要做的事儿(例如dom操作,css属性更改,发送ajax请 求等等)。
笔者浅浅的认为,其实浏览器就是一种特殊的Client,而B/S架构也是一种特殊的C/S架构。这里值得一提的是,不同的web服务器和编程语 言,又是如何接收用户http请求。如何处理,如何响应的呢?笔者拿熟悉的ASP.NET为例,通过反编译工具查看源代码(微软这家伙实在封装的太好了) 从底层进行了剖析,如图:

由于篇幅有限,无法再继续将asp.net、iis web服务器的细节及底层实现再做进一步地进行剖析了。因为微软的asp.net技术体系实在庞大,而且很复杂。有时间笔者会继续更新系列文章,欢迎读者继续关注。
posted @
2012-02-14 21:56 todayx.org 阅读(272) |
评论 (0) |
编辑 收藏 2012世界末日暨环境保护主题站,关注国内外最新2012世界末日信息,旨在通过关注,收集,展示2012世界末日相关资料的方式,唤醒并提高人们保护环境与爱护地球的意识,引导人类保护环境.
最近一直比较忙,所以一连几天都没有更新。本来觉得没什么,后来有几个网友都问起为什么没有更新,才觉得大家对我的博客还是比较关心的。于是觉得挺对不起大家的。终于到了周末,昨天晚上忙乎了一晚上,写了个Swing演示,今天把它共享出来,算是弥补。
收到一个朋友的邮件说如何在Swing中实现组件的动画效果,就像JIDE的那些组件一样。的确Swing框架的灵活性和可扩展性,使得它非常适合做这样Makeover工作。我简单总结一了以下,这种组件不外乎要有以下三种元素:
1.外观华丽。这包括使用渐变色,线条和字体反走样,图标设计漂亮抢眼,界面变化要柔和等等。但要避免设计太花哨,给人华而不实的感觉。原则上避免颜色太 碎,图标应以简洁为主,不可滥用图片等。技术上没有多大要求,主要是美工,你需要掌握各种做图工具,自己最好有好的审美和设计能力。
2.动画效果。组件行为变化要柔和化,尽量使用动画效果,如淡入淡出、滚动弹出等等。技术上最常用的方法是使用javax.swing.Timer。为什 么要使用javax.swing.Timer,这是因为javax.swing.Timer触发的事件都在EDT上执行,是线程安全的。除此外还需掌握 Java 2D的常用接口及图像处理的常见技巧。
3.空间布局。这种组件空间布局的特点是立体、动态、拖拽式的。这和人的认知能力有关。人类认知的特点是具体到抽象。二维、静态和键盘式操作对普通用户来 说太过抽象和专业化,需要一定的辅助学习才能理解的。而三维、动态、拖拽式操作更贴近于感性的认知范畴。因此这类组件经常有浮动式窗口、组件布局动态变化 及拖拽式操作等特征。实现技术包括布局管理器(LayoutManager)、Swing组件分层结构、Swing事件体系结构以及DnD接口等。
美工对于java程序员来说可能比较缺乏,但是华丽外观不仅仅是美工技术,这包括一些宏观设计原则。java程序员完全可以通过掌握这些方针原则来提高自 己的设计水平。前面文章介绍那个《Swing外观设计方针》就是一本这样的书。至于美工,我觉得如果你有美术天分,那就要充分利用;如果没有,那么你可以 模仿,熟悉几种的图形工具就完全可以不用自己的画图做出比较漂亮的图标、图片(当然没有考虑版权问题)。我就是后者,但是我发现我平时只需要PrScrn 键(抓图)、Paint(Windows 画图工具,切图、剪裁、转换格式)、PowerPoint/OpenOffice Imprise(画图)、Google Image(搜索图片)就已经足够了。其他所需的技术就需要你掌握Swing和Java 2D方方面面的技术了。当然复杂的组件不仅仅是靠掌握这些技术能解决的,可能你还需要能比较好地熟悉各种编程模式。
这个朋友特别提到Windows上的折叠式操作面板,他说:
另外,我对JIDE中两个东西很感兴趣,一个是CollapsiblePanel(Windows Explorer左边的常见任务),点击后折叠、展开子面板,而且是动画效果

因此昨晚就特地试了一下。虽然以前就大概明白使用Timer和布局管理器以及图像处理就可以实现这些东西,但一直没有做。昨晚的实验还是很成功的,大概花 了两个小时就实现了这个面板。工作过程大概就是分解这些面板组件、解析那部分需要动画、应该在哪儿触发何种事件。另外就是编写这些组件,不断调试。这个过 程的大部分时间都被效果调整占去了。你需要不断的运行程序,抓取屏幕,然后将它帖到Paint中,然后放大,然后和Windows上的抓图比较,包括大 小、尺寸、颜色、字体、微观变化等等。最后算是基本实现了Windows这个折叠式的面板组件。下面的是我的演示程序的一个抓图:

这个是淡出淡入动画效果:

下面的Enable Animation的JCheckBox可以设置是否使用动画效果。选择上折叠和展开就具有动画效果。
这个组件的类名是dyno.swing.beans.FolderPane。使用比较简单:
FolderPane fp=new FolderPane();//设置是否有动画效果,缺省没有
fp.setAnimated(true);//添加子面板
fp.addFolder("文件和文件夹任务", getFileFolderPane());
fp.addFolder("其他位置", getOtherPlacePane());
fp.addFolder("详细信息", getDetailsPane());
add(fp, BorderLayout.CENTER); |
主要接口有两个:
设置是否要动画效果
public void setAnimated(boolean b)
添加面板,title是面板标题文字,content是应用程序组件
public void addFolder(String title, JComponent content) |
这个演示的源码可以从这儿下载,是一个NetBeans工程。编译之后,直接双击foldered_pane.jar既可观看效果。源代码中有详细的注解。 更新:刚刚修改了一下,现在可以支持JScrollPane,即能放到JScrollPane,并能在动画时动态的更新JScrollPane状态。

posted @
2012-02-08 21:26 todayx.org 阅读(357) |
评论 (2) |
编辑 收藏程序员到底可以做多久,这个职业是否真的到35岁就终止?带着这个问题,和所有有此疑问和忧虑的朋友们探讨。先说说我自己的观点吧。要回答这个问题,我们首先要回答另外几个问题。
1. 人得学习能力是否会随着年龄的增长而变差?
可能是如此,我两岁的儿子一首唐诗说两遍就记住了,很长绕口的儿歌《小熊过桥》几乎能一字不差的唱完;而我是显然办不到的。不过发现一个事实,就是人的学 习能力不仅仅是靠记忆能力,跟逻辑思维能力,还有人的经验也有很大的关系;我们每个人也许都发现,你如果只是个优秀的Java程序员,如果要你去维护一 个.net的系统,不出两个月, 你马上就是一个.net专家。因为你知道相关的知识怎么学习,知道如何才能最快定位问题的一般方法。我个人是个完全不懂php得人,结果被强拉过去搞了个 php的项目,结果被认为是php expert! 所以我的最终答案是,人得记忆力更年龄成反比,但是学习能力跟年龄成正比。
2. 人的年龄越大,精力会跟不上程序员这样高强度的工作吗?
我的答案也是否定的。首先这是个伪命题,没有哪件事情是轻松的;你觉得别人比你轻松,那也只是你觉得而已。大体上个人的回报跟付出是成正比的。其实随着你 的年龄增长,知识积累越多,经验越丰富,你的工作效率会更高。5年前你修一个Bug要一个星期,现在也许10分钟就够了,并且是又快又好。难道不是这样 吗?所以你的工作强度事实上会变得更低,因为你的效率更高,你会有更多时间喝咖啡,也会遭你邻桌的同事低语“这家伙每天无所事事,咋工资比我高那么多?” 因为你的10分钟就抵别人的一个星期。
3. 人的年龄越大,就没有激情学习新知识了吗?
对有些人是,对有些人不是。计算机科学日新月异,确实更新相当快。你真的会跟不上脚步吗?可能会,如果你自己不学习。但我一定要亦步亦趋吗?也不见得,无 论如何,即便是软件开发,也还是有方向,有领域,你只要更上你需要更上的节奏就够了。今天请我的一个兄弟给我讲了下Struts应用,就是给我搞个最小化 的Struts项目,包含所有Struct的重要知识点,然后搬个椅子坐我旁边,花上半个小时跟我讲解;我现在俨然Struts专家了,不信,我跟你讲讲 看? 呵呵,开玩笑了。
如果我们觉得每天吃饭不是件枯燥无趣的事,我们应该也不太会拒绝不断学习;如果我们一定会因为自然规律而失去某些优势,记得你其实有更多的优势可以弥补;最重要的是,做你喜欢的事,做你能做的事情。
正月十五,明月高悬;祝福各位龙图大展!
posted @
2012-02-07 13:46 todayx.org 阅读(589) |
评论 (0) |
编辑 收藏--核心类主要有:
org.jfree.chart.JFreeChart :图表对象,任何类型的图表的最终表现形式都是在该对象进行一些属性的定制。JFreeChart引擎本身提供了一个工厂类用于创建不同类型的图表对象
org.jfree.data.category.XXXDataSet: 数据集对象,用于提供显示图表所用的数据。根据不同类型的图表对应着很多类型的数据集对象类
org.jfree.chart.plot.XXXPlot :图表区域对象,基本上这个对象决定着什么样式的图表,创建该对象的时候需要Axis、Renderer以及数据集对象的支持
org.jfree.chart.axis.XXXAxis :用于处理图表的两个轴:纵轴和横轴
org.jfree.chart.render.XXXRender :负责如何显示一个图表对象
org.jfree.chart.urls.XXXURLGenerator: 用于生成Web图表中每个项目的鼠标点击链接
XXXXXToolTipGenerator: 用于生成图象的帮助提示,不同类型图表对应不同类型的工具提示类
JFreeChart类:
void setAntiAlias(boolean flag) 字体模糊边界
void setBackgroundImage(Image image) 背景图片
void setBackgroundImageAlignment(int alignment) 背景图片对齐方式(参数常量在org.jfree.ui.Align类中定义)
void setBackgroundImageAlpha(float alpha) 背景图片透明度(0.0~1.0)
void setBackgroundPaint(Paint paint) 背景色
void setBorderPaint(Paint paint) 边界线条颜色
void setBorderStroke(Stroke stroke) 边界线条笔触
void setBorderVisible(boolean visible) 边界线条是否可见
-----------------------------------------------------------------------------------------------------------
TextTitle类:
void setFont(Font font) 标题字体
void setPaint(Paint paint) 标题字体颜色
void setText(String text) 标题内容
-----------------------------------------------------------------------------------------------------------
StandardLegend(Legend)类:
void setBackgroundPaint(Paint paint) 图示背景色
void setTitle(String title) 图示标题内容
void setTitleFont(Font font) 图示标题字体
void setBoundingBoxArcWidth(int arcWidth) 图示边界圆角宽
void setBoundingBoxArcHeight(int arcHeight) 图示边界圆角高
void setOutlinePaint(Paint paint) 图示边界线条颜色
void setOutlineStroke(Stroke stroke) 图示边界线条笔触
void setDisplaySeriesLines(boolean flag) 图示项是否显示横线(折线图有效)
void setDisplaySeriesShapes(boolean flag) 图示项是否显示形状(折线图有效)
void setItemFont(Font font) 图示项字体
void setItemPaint(Paint paint) 图示项字体颜色
void setAnchor(int anchor) 图示在图表中的显示位置(参数常量在Legend类中定义)
-----------------------------------------------------------------------------------------------------------
Axis类:
void setVisible(boolean flag) 坐标轴是否可见
void setAxisLinePaint(Paint paint) 坐标轴线条颜色(3D轴无效)
void setAxisLineStroke(Stroke stroke) 坐标轴线条笔触(3D轴无效)
void setAxisLineVisible(boolean visible) 坐标轴线条是否可见(3D轴无效)
void setFixedDimension(double dimension) (用于复合表中对多坐标轴的设置)
void setLabel(String label) 坐标轴标题
void setLabelFont(Font font) 坐标轴标题字体
void setLabelPaint(Paint paint) 坐标轴标题颜色
void setLabelAngle(double angle) 坐标轴标题旋转角度(纵坐标可以旋转)
void setTickLabelFont(Font font) 坐标轴标尺值字体
void setTickLabelPaint(Paint paint) 坐标轴标尺值颜色
void setTickLabelsVisible(boolean flag) 坐标轴标尺值是否显示
void setTickMarkPaint(Paint paint) 坐标轴标尺颜色
void setTickMarkStroke(Stroke stroke) 坐标轴标尺笔触
void setTickMarksVisible(boolean flag) 坐标轴标尺是否显示
ValueAxis(Axis)类:
void setAutoRange(boolean auto) 自动设置数据轴数据范围
void setAutoRangeMinimumSize(double size) 自动设置数据轴数据范围时数据范围的最小跨度
void setAutoTickUnitSelection(boolean flag) 数据轴的数据标签是否自动确定(默认为true)
void setFixedAutoRange(double length) 数据轴固定数据范围(设置100的话就是显示MAXVALUE到MAXVALUE-100那段数据范围)
void setInverted(boolean flag) 数据轴是否反向(默认为false)
void setLowerMargin(double margin) 数据轴下(左)边距
void setUpperMargin(double margin) 数据轴上(右)边距
void setLowerBound(double min) 数据轴上的显示最小值
void setUpperBound(double max) 数据轴上的显示最大值
void setPositiveArrowVisible(boolean visible) 是否显示正向箭头(3D轴无效)
void setNegativeArrowVisible(boolean visible) 是否显示反向箭头(3D轴无效)
void setVerticalTickLabels(boolean flag) 数据轴数据标签是否旋转到垂直
void setStandardTickUnits(TickUnitSource source) 数据轴的数据标签(可以只显示整数标签,需要将AutoTickUnitSelection设false)
NumberAxis(ValueAxis)类:
void setAutoRangeIncludesZero(boolean flag) 是否强制在自动选择的数据范围中包含0
void setAutoRangeStickyZero(boolean flag) 是否强制在整个数据轴中包含0,即使0不在数据范围中
void setNumberFormatOverride(NumberFormat formatter) 数据轴数据标签的显示格式
void setTickUnit(NumberTickUnit unit) 数据轴的数据标签(需要将AutoTickUnitSelection设false)
DateAxis(ValueAxis)类:
void setMaximumDate(Date maximumDate) 日期轴上的最小日期
void setMinimumDate(Date minimumDate) 日期轴上的最大日期
void setRange(Date lower,Date upper) 日期轴范围
void setDateFormatOverride(DateFormat formatter) 日期轴日期标签的显示格式
void setTickUnit(DateTickUnit unit) 日期轴的日期标签(需要将AutoTickUnitSelection设false)
void setTickMarkPosition(DateTickMarkPosition position) 日期标签位置(参数常量在org.jfree.chart.axis.DateTickMarkPosition类中定义)
CategoryAxis(Axis)类:
void setCategoryMargin(double margin) 分类轴边距
void setLowerMargin(double margin) 分类轴下(左)边距
void setUpperMargin(double margin) 分类轴上(右)边距
void setVerticalCategoryLabels(boolean flag) 分类轴标题是否旋转到垂直
void setMaxCategoryLabelWidthRatio(float ratio) 分类轴分类标签的最大宽度
-----------------------------------------------------------------------------------------------------------
Plot类:
void setBackgroundImage(Image image) 数据区的背景图片
void setBackgroundImageAlignment(int alignment) 数据区的背景图片对齐方式(参数常量在org.jfree.ui.Align类中定义)
void setBackgroundPaint(Paint paint) 数据区的背景图片背景色
void setBackgroundAlpha(float alpha) 数据区的背景透明度(0.0~1.0)
void setForegroundAlpha(float alpha) 数据区的前景透明度(0.0~1.0)
void setDataAreaRatio(double ratio) 数据区占整个图表区的百分比
void setOutLinePaint(Paint paint) 数据区的边界线条颜色
void setOutLineStroke(Stroke stroke) 数据区的边界线条笔触
void setNoDataMessage(String message) 没有数据时显示的消息
void setNoDataMessageFont(Font font) 没有数据时显示的消息字体
void setNoDataMessagePaint(Paint paint) 没有数据时显示的消息颜色
CategoryPlot(Plot)类:
void setDataset(CategoryDataset dataset) 数据区的2维数据表
void setColumnRenderingOrder(SortOrder order) 数据分类的排序方式
void setAxisOffset(Spacer offset) 坐标轴到数据区的间距
void setOrientation(PlotOrientation orientation) 数据区的方向(PlotOrientation.HORIZONTAL或PlotOrientation.VERTICAL)
void setDomainAxis(CategoryAxis axis) 数据区的分类轴
void setDomainAxisLocation(AxisLocation location) 分类轴的位置(参数常量在org.jfree.chart.axis.AxisLocation类中定义)
void setDomainGridlinesVisible(boolean visible) 分类轴网格是否可见
void setDomainGridlinePaint(Paint paint) 分类轴网格线条颜色
void setDomainGridlineStroke(Stroke stroke) 分类轴网格线条笔触
void setRangeAxis(ValueAxis axis) 数据区的数据轴
void setRangeAxisLocation(AxisLocation location) 数据轴的位置(参数常量在org.jfree.chart.axis.AxisLocation类中定义)
void setRangeGridlinesVisible(boolean visible) 数据轴网格是否可见
void setRangeGridlinePaint(Paint paint) 数据轴网格线条颜色
void setRangeGridlineStroke(Stroke stroke) 数据轴网格线条笔触
void setRenderer(CategoryItemRenderer renderer) 数据区的表示者(详见Renderer组)
void addAnnotation(CategoryAnnotation annotation) 给数据区加一个注释
void addRangeMarker(Marker marker,Layer layer) 给数据区加一个数值范围区域
PiePlot(Plot)类:
void setDataset(PieDataset dataset) 数据区的1维数据表
void setIgnoreNullValues(boolean flag) 忽略无值的分类
void setCircular(boolean flag) 饼图是否一定是正圆
void setStartAngle(double angle) 饼图的初始角度
void setDirection(Rotation direction) 饼图的旋转方向
void setExplodePercent(int section,double percent) 抽取的那块(1维数据表的分类下标)以及抽取出来的距离(0.0~1.0),3D饼图无效
void setLabelBackgroundPaint(Paint paint) 分类标签的底色
void setLabelFont(Font font) 分类标签的字体
void setLabelPaint(Paint paint) 分类标签的字体颜色
void setLabelLinkMargin(double margin) 分类标签与图的连接线边距
void setLabelLinkPaint(Paint paint) 分类标签与图的连接线颜色
void setLabelLinkStroke(Stroke stroke) 分类标签与图的连接线笔触
void setLabelOutlinePaint(Paint paint) 分类标签边框颜色
void setLabelOutlineStroke(Paint paint) 分类标签边框笔触
void setLabelShadowPaint(Paint paint) 分类标签阴影颜色
void setMaximumLabelWidth(double width) 分类标签的最大长度(0.0~1.0)
void setPieIndex(int index) 饼图的索引(复合饼图中用到)
void setPieIndex(int index) 饼图的索引(复合饼图中用到)
void setSectionOutlinePaint(int section,Paint paint) 指定分类饼的边框颜色
void setSectionOutlineStroke(int section,Stroke stroke) 指定分类饼的边框笔触
void setSectionPaint(int section,Paint paint) 指定分类饼的颜色
void setShadowPaint(Paint paint) 饼图的阴影颜色
void setShadowXOffset(double offset) 饼图的阴影相对图的水平偏移
void setShadowYOffset(double offset) 饼图的阴影相对图的垂直偏移
void setLabelGenerator(PieSectionLabelGenerator generator) 分类标签的格式,设置成null则整个标签包括连接线都不显示
void setToolTipGenerator(PieToolTipGenerator generator) MAP中鼠标移上的显示格式
void setURLGenerator(PieURLGenerator generator) MAP中钻取链接格式
PiePlot3D(PiePlot)类:
void setDepthFactor(double factor) 3D饼图的Z轴高度(0.0~1.0)
MultiplePiePlot(Plot)类:
void setLimit(double limit) 每个饼图之间的数据关联(详细比较复杂)
void setPieChart(JFreeChart pieChart) 每个饼图的显示方式(见JFreeChart类个PiePlot类)
-----------------------------------------------------------------------------------------------------------
AbstractRenderer类:
void setItemLabelAnchorOffset(double offset) 数据标签的与数据点的偏移
void setItemLabelsVisible(boolean visible) 数据标签是否可见
void setItemLabelFont(Font font) 数据标签的字体
void setItemLabelPaint(Paint paint) 数据标签的字体颜色
void setItemLabelPosition(ItemLabelPosition position) 数据标签位置
void setPositiveItemLabelPosition(ItemLabelPosition position) 正数标签位置
void setNegativeItemLabelPosition(ItemLabelPosition position) 负数标签位置
void setOutLinePaint(Paint paint) 图形边框的线条颜色
void setOutLineStroke(Stroke stroke) 图形边框的线条笔触
void setPaint(Paint paint) 所有分类图形的颜色
void setShape(Shape shape) 所有分类图形的形状(如折线图的点)
void setStroke(Stroke stroke) 所有分类图形的笔触(如折线图的线)
void setSeriesItemLabelsVisible(int series,boolean visible) 指定分类的数据标签是否可见
void setSeriesItemLabelFont(int series,Font font) 指定分类的数据标签的字体
void setSeriesItemLabelPaint(int series,Paint paint) 指定分类的数据标签的字体颜色
void setSeriesItemLabelPosition(int series,ItemLabelPosition position) 数据标签位置
void setSeriesPositiveItemLabelPosition(int series,ItemLabelPosition position) 正数标签位置
void setSeriesNegativeItemLabelPosition(int series,ItemLabelPosition position) 负数标签位置
void setSeriesOutLinePaint(int series,Paint paint) 指定分类的图形边框的线条颜色
void setSeriesOutLineStroke(int series,Stroke stroke) 指定分类的图形边框的线条笔触
void setSeriesPaint(int series,Paint paint) 指定分类图形的颜色
void setSeriesShape(int series,Shape shape) 指定分类图形的形状(如折线图的点)
void setSeriesStroke(int series,Stroke stroke) 指定分类图形的笔触(如折线图的线)
AbstractCategoryItemRenderer(AbstractRenderer)类:
void setLabelGenerator(CategoryLabelGenerator generator) 数据标签的格式
void setToolTipGenerator(CategoryToolTipGenerator generator) MAP中鼠标移上的显示格式
void setItemURLGenerator(CategoryURLGenerator generator) MAP中钻取链接格式
void setSeriesLabelGenerator(int series,CategoryLabelGenerator generator) 指定分类的数据标签的格式
void setSeriesToolTipGenerator(int series,CategoryToolTipGenerator generator) 指定分类的MAP中鼠标移上的显示格式
void setSeriesItemURLGenerator(int series,CategoryURLGenerator generator) 指定分类的MAP中钻取链接格式
BarRenderer(AbstractCategoryItemRenderer)类:
void setDrawBarOutline(boolean draw) 是否画图形边框
void setItemMargin(double percent) 每个BAR之间的间隔
void setMaxBarWidth(double percent) 每个BAR的最大宽度
void setMinimumBarLength(double min) 最短的BAR长度,避免数值太小而显示不出
void setPositiveItemLabelPositionFallback(ItemLabelPosition position) 无法在BAR中显示的正数标签位置
void setNegativeItemLabelPositionFallback(ItemLabelPosition position) 无法在BAR中显示的负数标签位置
BarRenderer3D(BarRenderer)类:
void setWallPaint(Paint paint) 3D坐标轴的墙体颜色
StackedBarRenderer(BarRenderer)类:
没有特殊的设置
StackedBarRenderer3D(BarRenderer3D)类:
没有特殊的设置
GroupedStackedBarRenderer(StackedBarRenderer)类:
void setSeriesToGroupMap(KeyToGroupMap map) 将分类自由的映射成若干个组(KeyToGroupMap.mapKeyToGroup(series,group))
LayeredBarRenderer(BarRenderer)类:
void setSeriesBarWidth(int series,double width) 设定每个分类的宽度(注意设置不要使某分类被覆盖)
WaterfallBarRenderer(BarRenderer)类:
void setFirstBarPaint(Paint paint) 第一个柱图的颜色
void setLastBarPaint(Paint paint) 最后一个柱图的颜色
void setPositiveBarPaint(Paint paint) 正值柱图的颜色
void setNegativeBarPaint(Paint paint) 负值柱图的颜色
IntervalBarRenderer(BarRenderer)类:
需要传IntervalCategoryDataset作为数据源
GanttBarRenderer(IntervalBarRenderer)类:
void setCompletePaint(Paint paint) 完成进度颜色
void setIncompletePaint(Paint paint) 未完成进度颜色
void setStartPercent(double percent) 设置进度条在整条中的起始位置(0.0~1.0)
void setEndPercent(double percent) 设置进度条在整条中的结束位置(0.0~1.0)
StatisticBarRenderer(BarRenderer)类:
需要传StatisticCategoryDataset作为数据源
LineAndShapeRenderer(AbstractCategoryItemRenderer)类:
void setDrawLines(boolean draw) 是否折线的数据点之间用线连
void setDrawShapes(boolean draw) 是否折线的数据点根据分类使用不同的形状
void setShapesFilled(boolean filled) 所有分类是否填充数据点图形
void setSeriesShapesFilled(int series,boolean filled) 指定分类是否填充数据点图形
void setUseFillPaintForShapeOutline(boolean use) 指定是否填充数据点的Paint也被用于画数据点形状的边框
LevelRenderer(AbstractCategoryItemRenderer)类:
void setItemMargin(double percent) 每个分类之间的间隔
void setMaxItemWidth(double percent) 每个分类的最大宽度
CategoryStepRenderer(AbstractCategoryItemRenderer)类:
void setStagger(boolean shouldStagger) 不同分类的图是否交错
MinMaxCategoryRenderer(AbstractCategoryItemRenderer)类:
void setDrawLines(boolean drawLines) 是否在每个分类线间画连接线
void setGroupPaint(Paint groupPaint) 一组图形连接线的颜色
void setGroupStroke(Stroke groupStroke) 一组图形连接线的笔触
void setMaxIcon(Icon maxIcon) 最大值的ICON
void setMinIcon(Icon minIcon) 最小值的ICON
void setObjectIcon(Icon objectIcon) 所有值的ICON
AreaRender(AbstractCategoryItemRenderer)类:
没有特殊的设置
StackedAreaRender(AreaRender)类:
没有特殊的设置
posted @
2012-02-07 13:46 todayx.org 阅读(259) |
评论 (0) |
编辑 收藏
摘要: 历史上的今天回顾历史的今天,历史就像生活的一面镜子;可以了解历史的这一天发生的事件;借古可以鉴今;历史是不能忘记的.要记住历史的每一天http://www.todayx.org/每天在写Java程序, 其实里面有一些细节大家可能没怎么注意, 这不, 有人总结了一个我们编程中常见的问题. 虽然一般没有什么大问题, 但是最好别这样做. 另外这里提到的很多问题其实可以通过Findbugs( http:/...
阅读全文
posted @
2012-02-05 22:56 todayx.org 阅读(230) |
评论 (0) |
编辑 收藏今天我不谈抱负理想,也不谈具体的技术,我来谈几个看法上的典型错误。下面的这些问题都是我曾经遇到,或者是我的朋友们遇到过的问题,这些都是我个人的理解,希望对大家有帮助。
关于设计模式、设计原则
有人认为,熟悉了设计模式、设计原则,就学会了设计。其实,设计模式和设计原则,只是前人根据设计实践做的总结和提炼,设计,归根到底是要解决问题的,把具体问题的解决办法,经过一定的抽象,变成程序员的语言。
我见过一些人,他们知识渊博、见识广博,甚至理论可以给你阐述得冠冕堂皇,但是到了实际需要解决问题的时候,他们却拿不出巧妙的、优雅的办法,这是典型的象牙塔人。
另一方面,也有一些人看不起学习设计模式的人,他们觉得他们已经掌握了软件设计的奥义,这些对他们来说是毫无意义的词汇,对此大可以一笑置之。
有时候我们反而被设计模式或设计原则粗暴的掌握束缚了手脚,譬如我遇到这样一件事情,某位努力的程序员,设计的代码用遍了组合(例如把User对象 放置到Administrator里面),我好奇地问,有一些类和对象之间的关系很明显符合继承的特征,为什么不愿意用它?他说,设计原则告诉我们,要多 用组合,少用继承。我想,对这些优秀的模式、原则、方法论,如果不能透彻地掌握,不能根据实际场景合适地运用,是不是反而不如对其不了解来的好呢?
关于多种计算机语言的学习
有人觉得学习一种语言就可以了,学习那么多语言没有必要。事实上,多掌握一门合适的计算机语言不仅仅是多掌握一种谋生的工具,如果一种新的语言能够很大程度上改变你对编程、对设计的看法,那么兴许它就值得你去学习。
譬如C语言,可以培养严谨的思维;譬如动态语言,它可以帮助程序员更好地做面向对象的coding;譬如函数式语言,它在工业生产、运算领域有着不可替代的作用。
当然话说回来,所谓术业有专攻,对于某一门计算机语言(包括该语言所需的运行时环境、其中的编译或解释的原理)深入的掌握,是很有必要的。
另外,我们时常看到诸多计算机语言孰优孰劣的争论,计算机语言归根到底是一种工具,工具是随着时代发展升级和变更的,单纯的优劣争论没有太大意义。
关于英语
中国人为什么要学英语,程序员为什么要学英语,当我把那些方法名、变量名全部取成拼音,一样可以,谁下的这个破规定?
遗憾的是,诸多学习材料、论文、技术资料(尤其是一些刚出不久的技术),都是英语的;另一方面,国际标准、程序员交流的通用方式,都是英文的,我想肯定很难想象,那些有名的framework、lib的源码,如果用拼音来写变量名会成什么样子。
所以,如果你的英语不好(至少读写不好),就不要给自己找太借口,英语是一个掌握其他工具的工具,除非你坚信,中文很快就会在计算机界变成世界第一通用的语言。
关于算法
算法有多重要,这一件事的争议一直都很大。
软件归根到底是用来解决问题的,提到算法就不能不提到数学(这也是为什么很多软件领域的大师都具备相当的数学背景),对于解决问题,这里可以简单归纳成两步:
(1)把实际的问题抽象成简化的数学模型
(2)用算法去解决这个数学问题
算法,在这里应该是一个广义的概念(这里的算法并不仅仅指大学里学习的狭义的具体算法),算法是解决上述数学问题的办法。如果工作中你并未意识到它的存在,那只是说明,你抽象出的数学模型比较简单,解决这个模型的办法也很简单,或者有现成的方式可以模仿,或者有现成的框架帮你完成了,以至于你不去关注它、在乎它。
如果你做的事情是充满创新意义的,是别人从没有做过的,这时候算法兴许就成了决定你成败的因素。
在当前中国的环境下,视野广阔和经历丰富的人很好找,但是企业要招到具备上述两点能力来解决问题的人,其实是非常困难的。
关于经验
唯经验论者的人有很多,他们认为,在软件企业的职位、薪水、甚至决策能力,都取决于经验,一个5年经验的工程师,肯定比3年经验的工程师能找到更好的饭碗:
“我是老员工,我工作5年了,凭什么工作3年的他薪水比我高那么多”
实际上,很多因素,包括领域积累(这是业务上的,例如互联网领域、传统软件领域,这和所谓的纯技术没有直接关系)、视野、承受压力的能力等等往往都 在很大程度上取决于“经验”的积累,但是,这并不是绝对的。有句话叫做“事业一半是干出来的,一半是总结出来的”,也确实有一些出色的程序员,他们善于总 结、善于观察和积累,并且善于不断地思考,这样的程序员就是拥有更多优秀的经验。
另一方面,程序员是要来解决问题的,经验不能代替解决问题,有的人具备更优秀的解决问题的能力,他为什么就不能得到更优厚的薪水?
posted @
2012-02-05 22:53 todayx.org 阅读(250) |
评论 (0) |
编辑 收藏越来越多人开始使用Java,但是他们大多数人没有做好足够的思想准备(没有接受OO思想体系相关培训),以致不能很好驾驭Java项目,甚至导致 开发后的Java系统性能缓慢甚至经常当机。很多人觉得这是Java复杂导致,其实根本原因在于:我们原先掌握的关于软件知识(OO方面)不是太贫乏就是 不恰当,存在认识上和方法上的误区。
软件的生命性
软件是有生命的,这可能是老调重弹了,但是因为它事关分层架构的原由,反复强调都不过分。
一个有生命的软件首先必须有一个灵活可扩展的基础架构,其次才是完整的功能。
目前很多人对软件的思想还是焦点落在后者:完整的功能,觉得一个软件功能越完整越好,其实关键还是架构的灵活性,就是前者,基础架构好,功能添 加只是时间和工作量问题,但是如果架构不好,功能再完整,也不可能包括未来所有功能,软件是有生命的,在未来成长时,更多功能需要加入,但是因为基础架构 不灵活不能方便加入,死路一条。
正因为普通人对软件存在短视误区,对功能追求高于基础架构,很多吃了亏的老程序员就此离开软件行业,带走宝贵的失败经验,新的盲目的年轻程序员 还是使用老的思维往前冲。其实很多国外免费开源框架如ofbiz compiere和slide也存在这方面陷阱,貌似非常符合胃口,其实类似国内那些几百元的盗版软件,扩展性以及持续发展性严重不足。
那么选择现在一些流行的框架如Hibernate、Spring/Jdonframework是否就表示基础架构打好了呢?其实还不尽然,关键还是取决于你如何使用这些框架来搭建你的业务系统。
存储过程和复杂SQL语句的陷阱
首先谈谈存储过程使用的误区,使用存储过程架构的人以为可以解决性能问题,其实它正是导致性能问题的罪魁祸首之一,打个比喻:如果一个人频临死亡,打一针可以让其延长半年,但是打了这针,其他所有医疗方案就全部失效,请问你会使用这种短视方案吗?
为什么这样说呢?如果存储过程都封装了业务过程,那么运行负载都集中在数据库端,要中间J2EE应用服务器干什么?要中间服务器的分布式计算和 集群能力做什么?只能回到过去集中式数据库主机时代。现在软件都是面向互联网的,不象过去那样局限在一个小局域网,多用户并发访问量都是无法确定和衡量, 依靠一台数据库主机显然是不能够承受这样恶劣的用户访问环境的。(当然搞数据库集群也只是五十步和百步的区别)。
从分层角度来看,现在三层架构:表现层、业务层和持久层,三个层次应该分割明显,职责分明:持久层职责持久化保存业务模型对象,业务层对持久层 的调用只是帮助我们激活曾经委托其保管的对象,所以,不能因为持久层是保管者,我们就以其为核心围绕其编程,除了要求其归还模型对象外,还要求其做其做复 杂的业务组合。打个比喻:你在火车站将水果和盘子两个对象委托保管处保管,过了两天来取时,你还要求保管处将水果去皮切成块,放在盘子里,做成水果盘给 你,合理吗?
上面是谈过分依赖持久层的一个现象,还有一个正好相反现象,持久层散发出来,开始挤占业务层,腐蚀业务层,整个业务层到处看见的是数据表的影子 (包括数据表的字段),而不是业务对象。这样程序员应该多看看OO经典PoEAA.PoEAA 认为除了持久层,不应该在其他地方看到数据表或表字段名。
当然适量使用存储过程,使用数据库优点也是允许的。按照Evans DDD理论,可以将SQL语句和存储过程作为规则Specification一部分。
Hibernate等ORM问题
现在使用Hibernate人也不少,但是他们发现Hibernate性能缓慢,所以寻求解决方案,其实并不是 Hibernate性能缓慢,而是我们使用方式发生错误:
"最近本人正搞一个项目,项目中我们用到了struts1.2+hibernate3, 由于关系复杂表和表之间的关系很多,在很多地方把lazy都设置false,所以导致数据一加载很慢,而且查询一条数据更是非常的慢。"
Hibernate是一个基于对象模型持久化的技术,因此,关键是我们需要设计出高质量的对象模型,遵循DDD领域建模原则,减少降低关联,通 过分层等有效办法处理关联。如果采取围绕数据表进行设计编程,加上表之间关系复杂(没有科学方法处理、侦察或减少这些关系),必然导致 系统运行缓慢,其实同样问题也适用于当初对EJB的实体Bean的CMP抱怨上,实体Bean是Domain Model持久化,如果不首先设计Domain Model,而是设计数据表,和持久化工具设计目标背道而驰,能不出问题吗?关于这个问题N多年就在Jdon争论过。
这里同样延伸出另外一个问题:数据库设计问题,数据库是否需要在项目开始设计?
如果我们进行数据库设计,那么就产生了一系列问题:当我们使用Hibernate实现持久保存时,必须考虑事先设计好的数据库表结构以及他们的关系如何和业务对象实现映射,这实际上是非常难实现的,这也是很多人觉得使用ORM框架棘手根本原因所在。
当然,也有脑力相当发达的人可以实现,但是这种围绕数据库实现映射的结果必然扭曲业务对象,这类似于两个板块(数据表和业务对象)相撞,必然产 生地震,地震的结果是两败俱伤,软的一方吃亏,业务对象是代码,相当于数据表结构,属于软的一方,最后导致业务对象变成数据传输对象DTO, DTO满天飞,性能和维护问题随之而来。
领域建模解决了上述众多不协调问题,特别是ORM痛苦使用问题,关于 ORM/Hibernate使用还是那句老话:如果你不掌握领域建模方法,那么就不要用Hibernate,对于这个层次的你:也许No ORM 更是一个简单之道: No ORM: The simplest solution
Spring分层矛盾问题
Spring是以挑战EJB面貌出现,其本身拥有的强大组件定制功能是优点,但是存在实战的一些问题,Spring作为业务层框架,不支持业务层Session 功能。
具体举例如下:当我们实现购物车之类业务功能时,需要将购物场合保存到 Session中,由于业务层没有方便的Session支持,我们只得将购物车保存到 HttpSession,而HttpSession只有通过HttpRequest才能获得,再因为在Spring业务层容器中是无法访问到 HttpRequest这个对象的,所以,最后我们只能将"购物车保存到HttpSession"这个功能放在表现层中实现,而这个功能明显应该属于业务 层功能,这就导致我们的Java项目层次混乱,维护性差。 违背了使用Spring和分层架构最初目的。
领域驱动设计DDD
现在回到我们讨论的重点上来,分层架构是我们使用Java的根本原因之一,域建模专家Eric Evans在他的"Domain Model Design"一书中开篇首先强调的是分层架构,整个DDD理论实际是告诉我们如何使用模型对象oo技术和分层架构来设计实现一个Java项目。
我们现在很多人知道Java项目基本有三层:表现层 业务层和持久层,当我们执着于讨论各层框架如何选择之时,实际上我们真正的项目开发工作还没有开始,就是我们选定了某种框架的组合(如 Struts+Spring+Hibernate或Struts+EJB或Struts+ JdonFramework),我们还没有意识到业务层工作还需要大量工作,DDD提供了在业务层中再划分新的层次思想,如领域层和服务层,甚至再细分为 作业层、能力层、策略层等等。通过层次细化方式达到复杂软件的松耦合。DDD提供了如何细分层次的方式
当我们将精力花费在架构技术层面的讨论和研究上时,我们可能忘记以何种依据选择这些架构技术?选择标准是什么?领域驱动设计DDD 回答了这样的问题,DDD会告诉你如果一个框架不能协助你实现分层架构,那就抛弃它,同时,DDD也指出选择框架的考虑目的,使得你不会人云亦云,陷入复 杂的技术细节迷雾中,迷失了架构选择的根本方向。
现在也有些人误以为DDD是一种新的理论,其实DDD和设计模式一样,不是一种新的理论,而是实战经验的总结,它将前人 使用面向模型设计的方法经验提炼出来,供后来者学习,以便迅速找到驾驭我们软件项目的根本之道。
posted @
2012-02-04 23:21 todayx.org 阅读(182) |
评论 (0) |
编辑 收藏 其实写这篇博客的想法在年前已经有了,但一直在犹豫要不要写,一是因为写出来肯定会有人骂的了,刚过完春节的,在自己地头找骂,实在是晦气;二是因为我对 行业趋势的眼光向来不准,估计今天的想法也是十有八九会错,错了日后自己的看着也不爽。但是又觉得如果心里有想法,不记录下来,思绪就飘远了,年代久了之 后,都忘记自己曾经也有过“看法”,应该会为自己的庸碌后悔吧?所以还是写了。写了归写了,请各位看官往下读之前,先整理好心情,做到:一是自己对世界有 自己的看法;二是认同别人的看法可以跟自己不同;三是对别人的看法跟自己不同时不要生气因为气的是你自己别人替不了。如果做到了这三点,再往下读,因为下 文的观点会很偏激、很有态度,我欢迎你留言讨论、发表不同的见解,如果纯粹是谩骂(或有很多脏词),建议你自己开一篇博客或发到你的微博,不要评论本文, 因为我会删除“纯粹是谩骂(或有很多脏词)”的评论。
ActionScript/MXML
其实就是说 Adobe Flash 平台不值得进入。在 2011 年,Flash 终于能够开发 iOS/Android 应用,再加上网页游戏市场火爆,估计很多人会想要进入这个平台。但我有不同的看法,列几点理由:
1、 Adobe 是市场导向的,没有技术领袖气质。视频网站兴起后,Flash Player 的新版本就加强视频播放;网页游戏兴起后,新版本就加强图形渲染;移动设备开发兴起后,新版本就是能够运行在更多的平台上。一直在跟随,从来不能领导;选 择 Flash 平台就意味着你永远都不能走在时代前缘,只能吃别人吃剩下的;选择 Flash 平台就意味着你最急切的需求无法满足,比如最近他们都在忙着支持移动设备,我们做网页游戏的希望他们加强实时性小数据包网络传输的需求就根本没有人理会。
2、 HTML5 出来以后,Adobe 这个本来也没有多少技术人员的公司还分心去支持它,出把 swf 转为 html+js+css 工具,出图形化 html5+css3+js 编程的工具。它乐于革掉自己的命,因为它只是个卖工具的,支持 html5 就像是 photoshop 支持多一种图像格式;但是程序员你呢,你被革命后你的未来在哪里,见过当年的“中年下岗工人”不?
3、从 ActionScript 3 发布之后,这门语言基本上没有什么变化。你看从 Flash Player 9 发布 AS3 以来,连 C++、C 语言都出了新的标准,java/c# 这类有大公司支持的语言变化巨大,甚至 python 也出了 python 3,更别提 google 公司新出的 go 和 dart 两门优秀的语言。AS3 作为 ECMAScript 的一种方言,现在 ECMA-262 都发布到 5.1 版本了,它仍然没有想要跟进的样子。
4、Flex SDK 类库狗血地照抄了早期版本的 java 类库的设计,连缺陷也照抄不误。你有多少次为了截取 Array 的一部分元素而去看它的手册的?这也就算了,还有一堆的 bugs。你知不知道 Application.application 是会变的?
5、 虚拟机方面,javascript 都有了 V8 引擎,而 AVM 还是那个 AVM,无数用户抱怨它慢都没有用的,优先级高的需求永远是更能够直接赚钱的特性。选择 Flash 就好像你是一个赛车手选了一辆小马力的车,虽然你弯道转得很好,也从不撞车,但可能一辆大马力的车还是从容地超越你。js 有了 V8 后开发出了 Node.js 从前端转到后端,拓展了更加广阔的应用领域,AS 在可以预见的未来,还是逃脱不了“写点小动画”的命运。
6、Stage 3D 不是救世主。不要忘记“low-level”这个定语,如果你直接使用 Stage 3D APIs 来编写程序,你知道那得多么痛苦。选择 A3D、Away3D 能够减轻一定的工作量,但使用开源引擎支持较差、特性较少。客观地说,写 3D 应用现在应该选择 Unity3D 或 Unrel Engine 3,反正它们也能编译成 swf 了。
7、2012 年,网页游戏的冬天不来,起码也是秋天。网页游戏的增长将会放缓,其实从 2011 年第四季度可以看到各大公司都开始压缩产品线,开始不再大量招工,而是转向消化之前已经招到的技术人员。在 2012 年,将会有更多的页游创业公司倒闭或转向移动设备游戏开发,AS 开发人员将会过剩,薪资下降。如果你在 2012 年上半年开始进入 AS 领域,那么下半年刚有所成的时候,就会遇到一大批刚下岗的竞争者,高薪梦肯定要落空。
8、移动设备应用或游戏开发在 2012 年还会受到资本的热捧,但 AS 在这个领域的竞争力我心存疑虑。Flash 优势就是跨平台,而 Unity3D 和 UDK 同样可以跨平台,同样可以使用脚本语言开发,而且性能、效果都更加优秀。随着 Unity3D 和 UDK 可以编译成 swf 在 Flash Player 上运行,学习 AS 的必要性进一步降低。
综上 8 点,可以看到没有技术基因的 Adobe 公司引导下的 Flash 开发路线图缺乏方向,前景模糊,再加上 ActionScript 和 Flex SDK 本身的缺陷,又遇上 Unity3D 和 UDK 这样的强劲外敌,再加上网页游戏大盘下滑,内忧外患之下,实在不是明智之选。Adobe Flash 当然不会死掉,也不会在 2012 年大量失去市场份额,但 Flash 程序员的 2012 不好过,想活得轻松点,注意距离。线程
线程是指进程中的一个单一顺序的控制流,是操作系统能够调度的最小单位,一个进程中可以有多条线程,分别执行不同的任务。线程有内核线程和用户线程之分,但在本文中仅指内核线程。在软件开发中,使用线程有以下好处:
1、在多核或多路 CPU 的机器上多线程程序能够并发执行,提高运算速度;
2、把 I/O,人机交互等与密集运算部分分离,提升 I/O 吞吐量和增进用户体验。
线程的缺点也很明显:
1、创建一条线程需要较大的内存开销,导致不能创建海量的线程;
2、线程由操作系统调度(分配时间片),线程切换的 CPU 成本比较高,导致大量线程存在时大量 CPU 资源消耗在线程切换上;
3、同一进程的多条线程共享全部系统资源,在多线程间共享资源需要进入加锁,大量的锁开销不提,重要的是加大了编写程序的复杂性,这一点你看看有多少书名含有“多线程”三个字就明白写个多线程应用有多难了;
4、 I/O 方面,多线程帮助有限,以 TCP Socket Server 为例,如果每一个 client connection 由一条专属的线程服务,那么这个 server 可能并发量很难超过 1000。为了进一步解决并发带来的问题,现代服务器都使用 event-driven i/o 了。
event-driven i/o 解决了并发量的问题,但引入了“代码被回调函数分割得零零碎碎”的问题。特别是当 event-driven i/o 跟 multi-threading 结合在一起的时候,麻烦就倍增了。解决这个问题的办法就使用绿色线程,绿色线程可以在同一个进程中成千上万地存在,从而可以在异步 I/O 上封装出同步的 APIs,典型的就是用基于 greenlet + libevent 开发的 python 库 gevent。绿色线程的缺陷在于操作系统不知道它的存在,需要用户进行调度,也就无法利用到多核或多路 CPU 了。为了解决这个问题,很多大牛都做出了巨大的努力,并且成果斐然,scala、google go 和 rust 都较好地解决了问题,下文以 rust 的并发模型为例讲一下。
rust 提出一个 Task 的概念,Task 有一个入口函数,也有自己的栈,并拥有进程堆内存的一部分,为方便理解,你可以把它看作一条绿色线程。rust 进程可以创建成千上万个 Tasks,它们由内建的调度器进行调度,因为 Tasks 之间并不共享数据,只通过 channels/ports 通信,所以它们是可并行程度很高。rust 程序启动时会生成若干条(数量由 CPU 核数决定或运行时指定)线程,这些线程并行执行 Tasks,从而利用多个 CPU 核心。
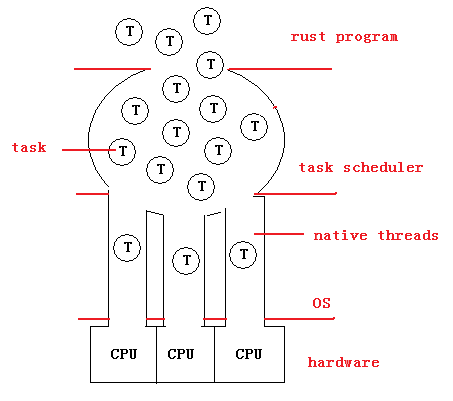
如 上图,rust 应用程序不停地 spawn 出一个又一个 Tasks,它们由 tasks 调度器管理,在适当的时机,调度器会把某一个 Task 分配给原生线程执行,如果这个 Task 进入 I/O 等待或主动让出 CPU(sleep),那么这个 Task 会被交回给调度器,而相应的原生线程会执行另一个新分派的 Task。尽管使用 rust 编程语言是不能创建线程的(直接调用 C 函数不算),但 rust 应用程序实际上是多线程的(一般情况下),它能够充分地利用多核或多路 CPU。
综上,类似 rust 的 Task 的概念是比线程更好的并发模型,更安全,编写的代码也更加容易维护(关于维护性,我相信写过 gevent 程度或 go 程序的同学会认同的)。线程当然不会消亡,但随着 scala/go/rust 的成熟,在可以预见的将来,线程会退到它呆着的角落:远离普通程序员,只有少数人需要了解它的细节。
C++
C++ 在 2011 年其实风头甚劲,C++2011 标准出台,gcc/msvc/clang 都很快速地支持了许多新特性,新兴的移动设备的性能较差,更是 C++ 的新舞台,在这个时候唱衰 C++,压力很大。我使用 C++ 年头不少,但除了在校的时候写过两个小游戏参加过两个比赛(分别是面向社会和面向大学生的)弄些证书好找工作以外,在工作中只用过大概不到一年半,做《斩 魂》(http://zh.163.com)的早期版本,写了服务器端的几条进程和客户端的 GameAI 部分。经验少,而且写得不好,所以基本上有人在 weibo 上问我 C++ 的问题,我都是转发给 @bnu_chenshuo 和 @miloyip 等真正的行家去回答的。所以实际上今天写这一篇,我底气很是不足,但是朋友们给前两篇很大面子,弄得我骑虎难下,只好硬着头皮写了。
前 文提到 C++ 的新标准,很有必要提一下标准化对 C++ 的影响。首先我们要肯定标准定制对 C++ 的积极作用,但标准化过程中的超长流程,一次次将 C++ 推向深渊。C++ 的第一个标准是 1998 年的 ISO/IEC 14882:1998,距离整个 90 年代最流行的 C++ 程序库 MFC(Microsoft Foundation Class Library)的第一个版本发行时间已经整整 6 年。1998 年,MFC 版本号为 6.0,与其一起发布的 Visual C++ 6.0 占有了巨大的市场。因为 MFC 发布得标准制定的时间早,所以 MFC 内部实现了许多后来标准库里也有的组件,比如各种数据结构容器。VC6 的市场占有率让 windows 平台下开发的许多 C++ 程序员甚至不知道有 STL,同时也无视 C++98 标准,从更兼容标准的 VC2002/2003 的市场占有率就可以看出来,直到今天,我知道国内不少公司还是只用 VC6 的。
其实在 90 年代,计算机的运算能力有限,市场上非常需要一款性能较高、抽象较强的编程语言,C++ 获得了成功,但它标准化的时间过长,造成各种编译器有各自互不兼容的“方言”,成了它的第一个软肋。第一个瞄准这个软肋的就是 java,java 在 1995 年推出,虽然性能稍逊,但它有更高的抽象能力、也更安全,并且更容易跨平台,所以迅速获得了成功;第二个瞄准这个软肋的是 C#,微软不能推动 C++ 发展,又不愿 C++ 的市场被 java 鲸吞,于是在 2001 年推出了 C#,经过 10 年的发展和微软大量的金钱推广,C# 已经成功获得了它应有的江湖地位。
虽然 java/c# 都不是善类,但 C++ 在 21 世纪的第一个十年里仍然地位稳固,这是因为 Linux 和 MacOS X 大获成功,在这两个平台上 C++ 都是非常有竞争力的编程语言,C++ 自然水涨船高。但随着 web2.0 和 web app 概念的兴起,以及 CPU 的主频进一步提升,服务器端编程语言渐渐地对执行效率不再敏感,而是更在意程序员的开发效率,众多的脚本语言开始蚕食 C++ 的市场份额,从早期的 perl 到后期的 python/php/ruby,在 2005 年以后,C++/java/C# 等静态类型的编译型语言的市场份额都下降了,新兴的贵族是动态语言。面对动态语言在开发效率上的强劲挑战,C++ 社区除了在 2003 年对 C++98 做了小小的 patch,基本上睡着了,完全没有应对之策,哦不,连应用的姿态都没有。
进入 21 世纪的第二个十年,市场又发生了变化,云计算越走越近,也许我们中的大部分人今天还可以说只闻其声不见其形,但 The Data Center Is the Computer 这句话大家应该觉得很务实:完成一个用户操作,在服务器端的进程间通信次数前所未有地多。在这个十年,我们需要这样的编程语言:
1、能充分利用现代 CPU 的计算能力,不仅仅是多个核心,更是巨大的 L1/L2/L3 Cache、超线程等;
2、能够大量减小异步 I/O 的性能提升的同时带来的副作用:异步编程的复杂性以及对可维护性的伤害;
两 句话其实也可以压缩为一句:需要有更好的并发模型的语言。一开始大家都在已有的编程语言中寻找,然后找到了 erlang,实践证明 erlang 自有其局限,所以 google go/scala/rust 等新语言如同雨后春笋般拨地而出。C++2011 标准努力降低 C++ 的编程难度,并提供了线程库以支持现代 CPU,如果在 2005 年,这个标准绝对有竞争力,但在今天,它只能成为新的编程语言的垫脚石。正如 IE 最大的用处是用来下载其它浏览器,不久之后,也许会流行新的冷笑话:C++ 最大的用处就是用来实现其它编程语言。
市场一直在寻找一门中间的高级 语言,它上承 C 语言和汇编语言,下启脚本语言。C++ 最先抢占了高地,并在与 java/c# 的争斗中不落下风,但新的十年,它的对手又增加了 google go/scala/rust 等新锐,并且新的标准不可能在两三年内再次出台,两三年内新锐成长起来后,留给它的位置就不多了。
上 文讨论的基本上都是服务器编程,有必要再来看一下桌面和移动设备领域。首先看桌面软件,rust 是 mozilla 基金会开发系统程序语言的,它的定位是部分取代 C++ 开发 firefox 的浏览器,所以 rust 会进入桌面开发,google go 肯定会顺道啃一口。移动设备方面,主要是 android、ios 和 windows phone,随着移动设备性能增强,编译型语言加脚本的模式就会占大头,编译型语言方面主要是 C++ 和 Objective-C 在竞争,C++ 会占上风(但需求量远远小于脚本,从 lua 在 2011 年的增长速度可以印证),但是谁知道 rust 之类的会不会进入移动设备呢,毕竟移动设备的 CPU 核心也越来越多了呀,C++ 还是前景堪忧。
回首 C++ 的 30 年,展望它的未来,总结起来可能就是:标准化流程拖死人了。如果不是 15 年不能标准化,java/c# 的搅局可能不会出现;如果在 2005 年能够应对动态语言……如果云时代有更好的并发模型……
题 外话:java/c# 不会有 C++ 的问题,因为它们有自己的平台,有巨大的财富支撑。特别是平台的作用非常巨大,你可以想像一下如果 Adobe 有自己的浏览器或手机操作系统 ActionScript/MXML 会不会是今天的境地;也可以想像一下 google go 的飞速发展动力是什么。
两点解释
1、 我觉得有必要解释“不宜进入”一下这四个字,我想要表达的意思就是如果你现在不是这三个技术点的专家,并且手上没有使用这三个技术点的项目,进入这三个技 术点仅为技术储备,那么就“不宜进入”。另外我不是说用了这三个技术点的项目就死,学了这三个技术点的人就找不到工作,或者这三个技术点明天或明年就 game over,渣都没得剩,不是这样的意思,它们还会存在很长一段时间。本文不是叫专家自废武功,也不是叫已经做好技术造型的项目赶紧儿换技术,举例说,如果 你选择了用 java 做服务器端,flash 做客户端开发一个 webgame,那你最好玩命儿地把 ActionScript/MXML 和 java 多线程编程(及异步 I/O)给钻透,不然可能随时掉陷阱里。
2、新年新气象,工作和家庭都有很重要的事情压在肩上,大家的评论我不逐条回复了,我会在一两个星期后再统一写一篇《2012 不宜进入的三个技术点(Q&A)》统一回答,还请见谅。
posted @
2012-02-04 23:19 todayx.org 阅读(193) |
评论 (0) |
编辑 收藏劳动密集型公司
这样的公司以业务为导向,市场团队在公司中占据较高的地位。每一个技术人员最终被折算到了“人天”里面去,团队规模相对较大,所有技术人员都比较容 易被替代,能力强的可以做更多的事情,能力弱的就少做一些。通过强有力的制度、政策和流程的规约,团队有条不紊地运作起来。业务氛围强势,技术通道升级较 慢,需要非常长期的积累才可以获得丰厚的回报,诸多优秀人才脱离编码,而潜心转管理、谈需求并获得回报。愿意招纳毕业生编码,以减小运营成本。只鼓励小范 围、浅层次的创新,对于优秀的创意、想法,必须转化为生产力才能够被认可。
技术密集型公司
这样的公司较为重视技术和创新,敢于在产品中使用预期能够带来收益的技术。公司非常愿意招聘一些有丰富研发经验、有广泛阅历的程序员加入,同时也能 吸引一些比较优秀的技术人才,并且长期为公司工作。团队人员较少,研发过程无论是从时间还是环境来看,通常比较宽松,用较少约束、任务驱动的形式,鼓励程 序员按期完成下发的任务。技术人员层次划分较多,不同层次技术人员在一起办公,往往都不脱离编码,和项目结合紧密。愿意招不同层次的研发人员,不愿意招经 验丰富但脱离技术的人到研发团队。
思维密集型公司
这样的公司对研发人员思辨能力要求较高,愿意做一些创造性的产品。公司技术人员的招聘较为严格,更看重人员的创新气质、解决问题的思路、建模和抽象 的能力,而对于具体的某种技术实现,并没有很高的要求。团队人员不多,项目压力不大,任务给定的要求和流程约束较少,需要团队成员较强的自主能力来解决问 题。技术人员层次划分不多,讨论气氛浓厚,设计精益求精,创新的点子容易得到认可并尝试实现。
你所在的公司,属于哪一种?
posted @
2012-02-04 01:10 todayx.org 阅读(3305) |
评论 (5) |
编辑 收藏 渔夫 蛇 青蛙的故事
渔夫看到船边有条蛇,口中正衔着一只青蛙。渔夫动了恻隐之心,把青蛙从蛇的口中救了出来。但渔夫又为蛇将挨饿而难过,便拿出一瓶酒,往蛇的口中滴了几滴。 蛇高兴地游走了,青蛙也为重获新生而高兴,渔夫则为自己的善举而感到快乐。他想,这真是皆大欢喜!没料到,仅仅过了几分钟,渔夫听到有东西在叩击他的船 板。他低头一看,那条蛇又回来了,而且嘴里咬着两只青蛙——它来讨要更多酒的奖赏!
渔夫的本意是希望蛇不再捕捉青蛙,但是由于怜悯而给了它几滴酒——这是奖励而不是惩罚,结果事与愿违。你奖励了什么行为,就会得到更多这样的行为。所以,这则寓言要告诉我们的是,别去奖励那些错误的行为。
我们再讲一个企业奖励错误行为的故事
一家企业制定了一个规定,如果该企业的员工加班到晚上7 点可以获得10元钱的晚餐补助,如果加班到8点可以打出租车回家(平常5点下班)。该奖励制度执行了一段时间之后,公司管理者竟然发现,有很多员工在正常 下班前或者很早就已经完成了工作,但是他们居然不正常下班而是留下来继续加班,有的待到七点,有的待到八点以后。一个管理者亲眼看见一个员工在下午4点前 就完成了文档整理,然后一直在那里上网聊天一直到晚上8点。
你也行会认为这些员工钻公司的空子有些不太好,但是这不能完全怪他们,因为早早的完成工作不见的会得到公司的奖励,相反有意把工作拖到晚上8点之后就可以拿到打车费,并且能免费获得一顿饭钱,多划算呀!
管理者一定要牢记住这句话"受到奖励的事情人们都喜欢去做" 为此管理者应该仔细检测奖励制度,哪些是积极的 ,哪些可能带来消极的影响,修改掉哪些不合理的部分,通过奖励正确的行为来获得自己想要的结果。
美国管理专家拉伯福认为,企业在奖励员工方面最常范的十个错误.
1、需要好的结果,却奖励了那些看上去最忙碌,工作时间最长的人
2、要求工作的质量,却设下了不合理的完成工期
3、希望从根本上解决问题,却奖励那些治标不治本的人
4、要求员工对公司忠诚,却支付高薪给新来的员工或威胁要离职的员工
5、要求事情简单化,却奖励制造琐碎和使事情复杂化的人
6、想要创造和谐的工作环境,却奖励那些光说不做并且经常抱怨的人
7、要求员工有创意,却指责那些公司里有特立独行的人
8、要求节俭,却奖励那些浪费资源的人
9、要求员工有团队精神,却牺牲团队利益奖励那些投机取巧的人
10、要求创新,却奖励保守的人,责罚未能完成的创意
如何改进我们的奖励行为
孔子云:举一而不能以三反,不可教也。每一个治理者都可以对照拉伯福所说的这十种错误,举一反三,验照一下自己是不是犯过类似的错误。例如:
1、 我们 是不是口头上公布讲究实绩、注重实效,却往往奖励了那些专会做表面文章、投机取巧之人?
2、 我们是不是口头上公布员工考核以业绩为主,却往往凭主观印象评价和奖励员工?
3、 我们是不是口头上公布鼓励创新,却往往处罚了敢于创新之人?
4、 我们是不是口头上公布鼓励不同意见,却往往处罚了敢于发表不同意见之人?
5、 我们是不是口头上公布按章办事,却往往处罚了坚持原则的员工?
6、 我们是不是口头上鼓励员工勤奋工作、努力奉献,却往往奖励了不干实事、专事捣鬼、钻营之人?
总结
总之,我们每一个治理者都要牢记:“在表现与奖励之间建立起正确的连带关系,是改进组织运作的唯一要诀”。在考核和奖励员工时非凡要注重的是,要注重其实 际业绩,而不要注重其口头上怎么说。不能奖励了投机取巧,冷落了埋头实干,否则以后我们指望谁来做事呢?
治理大师卡耐基说过:我年纪越大,就越不重视别人说些什么,我只看他们做些什么。其实中国古贤更早就说过这样的话:“始吾于人也,听其言而信其行;今吾于 人也,听其言而观其行”。在奖罚问题上,每个治理者确实不可粗心大意,草率行事。否则,“种瓜得瓜,种豆得豆”,种下了苦果可是要自己吃的!
posted @
2012-02-04 01:08 todayx.org 阅读(1332) |
评论 (3) |
编辑 收藏博士
有一个博士分到一家研究所,成为学历最高的一个人。
有一天他到单位后面的小池塘去钓鱼,正好正副所长在他的一左一右,也在钓鱼。
他只是微微点了点头,这两个本科生,有啥好聊的呢?
不一会儿,正所长放下钓竿,伸伸懒腰,蹭蹭蹭从水面上如飞地走到对面上厕所。
博士眼睛睁得都快掉下来了。水上飘?不会吧?这可是一个池塘啊。
正所长上完厕所回来的时候,同样也是蹭蹭蹭地从水上飘回来了。
怎么回事?博士生又不好去问,自己是博士生哪!
过一阵,副所长也站起来,走几步,蹭蹭蹭地飘过水面上厕所。这下子博士更是差点昏倒:不会吧,到了一个江湖高手集中的地方?
博士生也内急了。这个池塘两边有围墙,要到对面厕所非得绕十分钟的路,而回单位上又太远,怎么办?
博士生也不愿意去问两位所长,憋了半天后,也起身往水里跨:我就不信本科生能过的水面,我博士生不能过。
只听咚的一声,博士生栽到了水里。
两位所长将他拉了出来,问他为什么要下水,他问:“为什么你们可以走过去呢?”
两所长相视一笑:“这池塘里有两排木桩子,由于这两天下雨涨水正好在水面下。我们都知道这木桩的位置,所以可以踩着桩子过去。你怎么不问一声呢?”
这个故事告诉我们:学历代表过去,只有学习力才能代表将来。尊重经验的人,才能少走弯路。一个好的团队,也应该是学习型的团队。
个人理解和感悟:看学历更要看能力
招聘广告上面我们经常会看到“要求本科以上学历”,很少有企业招聘的时候 是不在乎学历的,而且在一些正规的企业里,如果没有足够的学历,是不予以考虑加薪升职的。企业在人才的竞争上面出现了一种盲目攀比学历的不良倾向,现在经 常可以看到在某些企业的官方介绍上面写“公司的本科以上学历占有xx比例”的字眼,,似乎聘用的人才学历越高
越好,在职员工高学历的越多越好。有一则消息称研究生学历的人比本科学历的人平均年薪要高出2w元,从这里看出,学历在企业招聘和考核中的重要性。
现在越来越多的人坚持考研或者读MBA,他们认为一旦有了高的学历就可以“春风得意马蹄疾,一页看遍长安花”了。目前学历仍然是一个隐形的、力量巨大的“杀手”,生生的把没有一纸文凭的人拒之门外。
有文凭不等于有水平,没有学历不等于没有能力,大量的事实说明, 不少才华横溢、能力卓越的人才,他们并没有高的学历,有的甚至没有大学文凭,例如爱迪生、高尔基诺贝尔 比尔盖茨 乔布斯等,这些人虽然没有高的学历,但是他们取得的成就是非凡的,同样现实中生活中也能轻易的发现,很多拥有高学历的人在工作中能力平平、毫无建树、庸庸 碌碌的过万了一生,管理者在选择人才时,只能把学历当作一种参考条件,更重要的是要看这个人的实际能力。如果企业不从实际出发,竞相制定一些高学历的规 定,对学历的要求过为严格,甚至唯学历取人,很难选拔出优秀的人才,衡量人才既要有文化程度方面的要求,更总要视履行岗位职责的能力,真正使那些有学历, 有智慧又有能力的人得到重用.
伯 乐相马,主要是看马能否跑千里而不是看马的出身。近有消息说,有些用人单位招聘人才的取向已更加务实,选才标准正在由“学历型”向“能力型”转变,这是一 种令人欣慰的转变。毕竟,千里马是跑出来的,人才是干出来的。创造业绩主要不是靠职前的学历,而是靠任职后的实践经历和创造性努力。但愿我们公开选拔干部 时,能够更重任职的能力而不是更重职前的学历。
一个人是否真正的有才能,并不能以学历作为衡量的唯一标准,管理者在选人、用人时,不要被学历遮住了视野,二应该把有实际能力的员工放在最重要的位置上
posted @
2012-02-03 00:00 todayx.org 阅读(1462) |
评论 (3) |
编辑 收藏春节前和同事在回家的路上看到了建筑工地,不由的感慨建筑业相比软件业来讲实在是成熟太多了! 想想看,建筑师设计好图纸,交给建筑公司(大包工头), 大包工头再报给小包工头, 小包工头随便抓一些农民工就可以干活了! 农民工们可不懂得那么多高深的建筑原理, 对整个建筑也并不了解,可是他们只需要把自己的一砖一瓦做好,整个建筑就能做成了 -- 当然也有豆腐渣工程-- 但毕竟是少数,排除在外。
更重要的是他们根本不用担心项目的后期客户突然想改设计方案,客户不会也不可能要求你把朝北的窗户挪到南边去,也不会要求把10层楼中的第3层和第7层扒掉重盖。
我们这些苦苦挣扎的码农们肯定会想, 什么时候软件业也能这样啊,什么时候我们也能快乐编程,按时上下班,或者以后这些底层的Labor work都让机器人做了, 我们都去做需求,架构,设计, 然后项目按进度,高质量的完成, 大家都很happy...
但是无数的无情现实告诉教育我们:别做梦了,这是绝对不可能的, 至少在可以预见的时间段(比如50年)是不可能的, 原因就在于软件的复杂性,在现有的技术情况下, 软件的固有复杂性无法解决, 只有依靠我们这么码农们去弥补。
为什么软件这么复杂, 为什么我们无法像建筑业盖房子,汽车业装配汽车一样去写软件?
布鲁克斯 在著名的《人月神话》中提到软件的内在复杂性, 的确,软件系统的复杂性远远超过建筑业和制造业, 软件的需求是在人的脑子中的, 用自然语言都很难完整、准备的表达出来,更不用说用计算机(好吧,更好听的名字是”电脑“)这种原始的工具了。 不错,我用的正是”原始“这个词, 从二进制语言,到汇编语言,再到高级语言,其最基本的、最核心的东西依然是顺序,循环,分支, 即使加上面向对象,动态语言,库, 框架,计算机语言的本质仍然没有改变,我们只是在已经建好的大厦上做装饰而已。 使用这种原始的工具,怎么能够表示复杂的需求?
程序员的出现正是为了填充这之间的巨大鸿沟,程序员需要用自己的大脑,使用极其”原始“的工具, 把无法准确表述的,尚在脑子中的需求映射到代码上,其难度可想而知!
当然我们程序员也不笨, 在长期的斗争中,我们学会了把一个问题用划分为一个一个的模块, 让这些模块低耦合,高内聚, 我们还学会了分层,让各个部分的联系达到最小, 可是所有的这些努力只是把复杂性降低了一点, 本质的复杂性依然存在。
未完待续。。。
posted @
2012-02-02 23:59 todayx.org 阅读(1559) |
评论 (2) |
编辑 收藏酒宴开始。
酒杯盛酒,酒杯碰撞,这是物理层;
你要根据不同人的外貌特征找到你要敬酒的人所坐的位置,这是IP协议(网络层);
你明白,敬酒的实际目的是加深感情,这在应用层,而这酒中的感情,才是报文的数据部分。
你和某位新见面的兄弟互相来回敬酒,这叫TCP;
你给同一位好兄弟敬酒好多次,死命灌他,他也不回礼,这叫UDP;
你对全桌的人说,来,咱们同归于尽,这叫广播;
你在对这一桌的人顺序挨个敬酒,这叫令牌环。
你对该兄弟说,初次见面,请多关照,请问阁下尊姓大名,敬酒一杯,这叫SYN报文;
这位兄弟说,同是天涯沦落人,相逢何必曾相识,喝!这叫ACK报文;
你一看,对方的啤酒怎么没有气泡啊,不行,你怎么能拿茶水当啤酒呢?这叫数据校验。
有一个兄弟过来给你桌上的领导敬酒,你说不行,领导喝多了,不能再喝了,这叫防火墙;
有一位兄弟过来敬酒,你说10分钟里面已经喝了5杯了,达到我极限了,这叫带宽;
而且我还没回礼呢,现在喝不下了,先缓缓,这叫拥塞控制;
你现在要给你最好的兄弟敬酒,于是你先找到了他所在的桌子(网络号),再找到他本人的位置(主机号);
从你要准备敬酒到敬酒完成,这叫时延,其中要经历倒酒(发送时延)、碰杯(传播时延)、你的兄弟被灌下(处理时延)这几个过程。
终于,你醉了,你吐了一地,不省人事,这叫缓冲区溢出。
posted @
2012-02-01 23:19 todayx.org 阅读(1706) |
评论 (3) |
编辑 收藏 故事一
去过庙的人都知道,一进庙门,首先是弥陀佛,笑脸迎客,而在他的北面,则是黑口黑脸的韦陀。
但相传在很久以前,他们并不在同一个庙里,而是分别掌管不同的庙。 弥乐佛热情快乐,所以来的人非常多,但他什么都不在乎,丢三拉四,没有好好的管理账务,所以依然入不敷出。而韦陀虽然管账是一把好手,但成天阴着个脸,太 过严肃,搞得人越来越少,最后香火断绝。
佛祖在查香火的时候发现了这个问题,就将他们俩放在同一个庙里,由弥乐佛负责公关,笑迎八方客,于是香火大旺。而韦陀铁面无私,锱珠必较,则让他负责财务,严格把关。在两人的分工合作中,庙里一派欣欣向荣景象。
故事二
在动物园里的小骆驼问妈妈:"妈妈妈妈,为什么我们的睫毛那么地长?"
骆驼妈妈说:"当风沙来的时候,长长的睫毛可以让我们在风暴中都能看得到方向。"
小骆驼又问:"妈妈妈妈,为什么我们的背那么驼,丑死了!"
骆驼妈妈说:"这个叫驼峰,可以帮我们储存大量的水和养分,让我们能在沙漠里耐受十几天的无水无食条件。"
小骆驼又问:"妈妈妈妈,为什么我们的脚掌那么厚?"
骆驼妈妈说:"那可以让我们重重的身子不至于陷在软软的沙子里,便于长途跋涉啊。"
小骆驼高兴坏了:"哗,原来我们这么有用啊!!可是妈妈,为什么我们还在动物园里,不去沙漠远足呢?"
故事三
有个鲁国人擅长编草鞋,他妻子擅长织白绢。他想迁到越国去。友人对他说:“你到越国去,一定会贫穷的。”“为什么?”“草鞋,是用来穿着走路的,但越国人 习惯于赤足走路;白绢,是用来做帽子的,但越国人习惯于披头散发。凭着你的长处,到用不到你的地方去,这样,要使自己不贫穷,难道可能吗?”
故事一告诉我们:其实在用人大师的眼里,没有废人,正如武功高手,不需名贵宝剑,摘花飞叶即可伤人,关键看如何运用。
故事二告诉我们:天生我才必有用,可惜现在没人用。一个好的心态+一本成功的教材+一个无限的舞台=成功。每个人的潜能是无限的,关键是要找到一个能充分发挥潜能的舞台。
故事二告诉我们:一个人要发挥其专长,就必须适合社会环境需要。如果脱离社会环境的需要,其专长也就失去了价值
个人理解和感悟:充分发挥员工的长处
管理者的任务,简单的说就是找到对的人,把他们放到对的地方,然后鼓励他们充分发挥自己的创意,完成本职工作,在这个过程中管理者既要用人职场,又要容忍之短,使员工最大限度的发挥自己的才能,达到合理使用人才的目的。
正确的用人之道,就是用人的长处,即让一个人的长处和优势得到充分的发挥,让一个人的短处和劣势得到有效的避免,正所谓“人尽其才,物尽其用”“木匠手中 无烂木”“智者不用其短,而用愚人之所长也”,从某种意义上说天下没有无用之人,一个擅长用人的管理者,能将每个人都派上用场
如何才能扬人之所长
1、管理者必须做到客观公正。每个人都不可避免的会有自己的好恶,也会收到成见、偏见影响、管理者一定要待人宽容,心胸开阔,一切从公司的利益出发,不可错过一个人才
2、管理者应该充分利用科学方法。人才入冰山,其优秀特质浮出水面的只有1/3 ,如果不运用一些科学的方法很难看出来,方法有很多,笔试、面试、心理测试、情景模拟、评价中心等,在使用的过程中要注意灵活运用
3、将人才放到对的位置上。根据其特点,为其提供充分展示自己能力的平台,让其在实际的工作中不断锻炼
4、适时展开具有针对性、个性化的培训。培训不但要补员工所短,同时应该培训员工长处,让员工之“长”根突出、更醒目。并让其在你的公司里面形成一定的品牌
5、优化配置、平衡互补,取各家之“长”溶于一炉,并相互扬“长”,相互促“长”
posted @
2012-02-01 23:19 todayx.org 阅读(1500) |
评论 (0) |
编辑 收藏
摘要: 历史上的今天回顾历史的今天,历史就像生活的一面镜子;可以了解历史的这一天发生的事件;借古可以鉴今;历史是不能忘记的.要记住历史的每一天http://www.todayx.org/jdk1.5以后用Integer举例Integer a = 3; ...
阅读全文
posted @
2012-02-01 00:23 todayx.org 阅读(1684) |
评论 (0) |
编辑 收藏等于还是不等于?
看来看下面的一段代码:
代码片段1
Java代码

- public static void main(final String[] args) {
- Integer a = new Integer(100);
- Integer b = 100;
- System.out.println(a == b);
- }
这段代码的输出是什么?相信很多人都会很容易的猜到:false,因为a、b两个对象的地址不同,用“==”比较时是false。恭喜你,答对了。
再看下面的一段代码:
代码片段2
Java代码
- public static void main(final String[] args) {
- Integer a = 100;
- Integer b = 100;
- System.out.println(a == b);
- }
你可能会回答,这没什么不一样啊,所以还是false。很遗憾,如果你执行上面的一段代码,结果是true。
上面的代码可能让你有些意外,那好吧,再看看下面的这段代码:
代码片段3
Java代码
- public static void main(final String[] args) {
- Integer a = 156;
- Integer b = 156;
- System.out.println(a == b);
- }
结果是true吗?很遗憾,如果你执行上面的一段代码,结果是false。
感到吃惊吗?那最后再看下面的一段代码:
代码片段4
Java代码
- public static void main(final String[] args) {
- Integer a = Integer.valueOf(100);
- Integer b = 100;
- System.out.println(a == b);
- }
最后的结果,可能你已经猜到了,是true。
为什么会这样?
现在我们分析一下上面的代码。可以很容易的看出,这一系列代码的最终目的都是用“==”对两个对象进行比较。Java中,如果用“==”比较两个对象结果为true,说明这两个对象实际上是同一个对象,false说明是两个对象。
现在,我们来看看为什么会出现上面的现象。
我们先看代码片段4:最后的运行结果是true,说明a、b两个对象实际上是同一个对象。但是a对象是通过调用Integer的valueOf方法创建的,而b对象是通过自动装箱创建出来的,怎么会是同一个对象呢?难道问题在字节码那里,毕竟Java程序是依靠虚拟器运行字节码来实现的。
通过jdk中自带的工具javap,解析字节码,核心的部分摘取如下:
Java代码
- 0: bipush 100
- 2: invokestatic #16; //Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
- 5: astore_1
- 6: bipush 100
- 8: invokestatic #16; //Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
代码中我们只调用了一次Integer.valueOf方法,但是字节码中出现了两次对Integer.valueOf方法的调用。那么另一次是哪里呢?只可能在自动装箱时调用的。因此这段代码实际上等价于:
Java代码
- public static void main(final String[] args) {
- Integer a = Integer.valueOf(100);
- Integer b = Integer.valueOf(100);
- System.out.println(a == b);
- }
现在问题就简单了:看jdk源代码,查看valueOf方法的具体实现:
Java代码
- public static Integer valueOf(int i) {
- final int offset = 128;
- if (i >= -128 && i <= 127) { // must cache
- return IntegerCache.cache[i + offset];
- }
- return new Integer(i);
- }
看到这儿,上面的代码就很明确了:对于-128到127的数字,valueOf返回的是缓存中的对象。所以两次调用Integer.valueOf(100)返回的都是同一个对象。
我们再先看代码片段3:根据上面的分析,代码片段3实际上等价于以下代码:
Java代码
- public static void main(final String[] args) {
- Integer a = Integer.valueOf(156);
- Integer b = Integer.valueOf(156);
- System.out.println(a == b);
- }
由于156不在-128到127范围内,所以两个对象都是通过new Integer()的方式创建的,所以最后结果为false。
片段1和片段2就不做具体分析了,相信读者可以自行分析。
最后,请大家思考一下问题:通过上面的分析,了解到整数的自动装箱是通过Integer.valueOf(int number)实现的,那么自动拆箱是如何实现的呢?
posted @
2012-02-01 00:21 todayx.org 阅读(1975) |
评论 (3) |
编辑 收藏posted @
2012-01-30 23:00 todayx.org 阅读(2777) |
评论 (0) |
编辑 收藏已经是到北京的第五个年头了,从最开始的想做手机游戏而学习编程,到后来做 Web 开发,又开始做日志分析,接触到了 Hadoop ,最终确定下来自己的技术方向。曾经以为五年的时间,差不多都应该做出自己的产品来,而实际情况却是:一直在用的技术还了解的只是皮毛。所以,虽然在 IT 这个行业已经可以说自己工作了五年时间,但感觉自己还只是刚刚起步,跑在前面的大有人在,自己还要继续努力。
从去年开始接触的 Hadoop ,当时的日志分析已经遇到了瓶颈,用 Hadoop 一试,确实性能提高不少,只可惜,当时的公司因为各方面的原因,开始关注云存储这个方向,虽然即使到了现在我也不太好判定这个战略方向的转变 是对还是错,但是对于当时只是普通员工的我来说,刚好发现了一个实用的技术却没有时间和机会研究、应用,让人都有点恼火。可能像我这样的凡夫俗子,还没有 达到能站在和老板相同高度看待问题的程度,而我能做的,换家公司,找一个能应用自己感兴趣的技术的公司。于是, 2011 年,就又以跳槽开始了。
但 是我并没有想到今年会跳两次,我一直都感觉自己是个踏踏实实的人,但实际情况却是这几年北京这几个同学我换的工作最多。我也很明白:频繁的换工作,害的其 实是自己。每一份工作,都需要花一定的时间去适应,就拿试用期来说,一般的都应该是三个月吧,一年换两份工作,光试用期就半年出去了,真正能踏踏实实做点 事的时间,又能有多少呢?本来在年初换工作时,打算结婚也被拿了出来说事,还想着有上一年的时间,在老家付个首付,没有想到,造化弄人,六月份的时候,一 边看着转正的通知邮件,一边和主管协商着什么时候离职。
但 我并不后悔去了这家公司,虽然只有短短两个月的时间,却让我学到了很多东西,开阔了视野。原来还有这样让人认同的企业文化,原来还有经历这么丰富的同事, 原来还有这么爱带着兄弟们吃喝玩乐的主管,原来程序员的生活,不一定就是加班加班,原来我们可以让自己的生活更精彩。尤其是在去了一趟杭州之后。第一次坐 飞机,下飞机的时候耳膜难受的要死,声音都快听不见了,而我们只有一天的时间,第二天就又要飞回北京,我是想着赶紧休息休息,而同事是一边说着西湖、苏堤 啥的就双眼冒光,大晚上的整个绕西湖走了一圈,没把我累死。不过也确实感受到了和北京不一样的生活方式和态度,那些就在岸边上的茶庄,彰显着和北京烧烤摊 不一样的韵味。只是,当终于下了飞机,换了快轨,出了地铁之后,又一次回到北京的地面上时,我竟然都有种过年时候回到了老家的感觉,原来,在一个城市生活 上一段时间,哪怕只是几年,或多或少的,竟然会产生感情。
可 惜的是,我还没有体会的多深,因为公司内部的原因,我们的项目没用做成,大家因为这个项目聚在了一起,项目没了,大家也就都散了。而且散的那么快,快的都 不可思议。应聘到了一个公司,一个项目做不成,那还可以做别的,一个公司可以有好多项目,而我们这个项目组的成员,明显大家都很有自己的想法,只想做自己 想做的事,而并不是到了一个公司后就开始混日子。那么既然是这样,我想我应该祝福他们,后来一个月后,主管又联系我们聚了一次,大家果然都在做自己擅长、 喜欢的工作,虽然已经不在一个团队,但由衷的为他们感到高兴。
应该说,今年我本来是起了一个好头,在项目组中有这些有着共同理想的同事,但因为中间的变故,团队散了,我也慢慢的走向了堕落。现在回想起来,简直都觉得有点不可思议。
在等待离职的日子里,我看完了《七龙珠》全集,还有《盗墓笔记》,看到最新的更新 ( 当时还没有完结 ) ,每天去了之后就是看漫画、看小说,本来之前因为项目的原因,一个月的时间把 Demo 写的差不多都可以进行演示了,结果变故一来,立马就好像泄了气的皮球一样,什么准备结婚,什么钻研技术,一概不管,完全就把上班当成了去网 吧。自然,白天都成这样了,晚上还期望能老老实实的看书吗,不可能了,再然后,等再到了新公司之后,看书的习惯就怎么也没用再培养起来。
到 了新公司,这个应该老实点了吧,毕竟当时都已经六月份了,半年的时间都已经过去了,如果再折腾折腾,整个一年就过去了,技术这玩意,要说看看书就能学会, 我还真是做不到,必须得有实际的东西去做,在项目上应用,才能快速的掌握。道理也都明白,可就是中间经历了那么一档子事之后,整个人都浮躁了起来,再想回 到以前的状态,真的很难,只能是慢慢的适应。
这 一适应就又是三个月,十一假期时候,交接过来的老版本的日志分析系统出了次问题,正好赶上在唐山参加同学婚礼,三十号下午到的唐山,晚上和同学侃到一两 点,四五点又起来接新娘盘头,参加一天的婚礼下午又坐车回北京,休息了一个晚上之后,从二号早上七点开始恢复数据,一直到三号早上六点,之前也加班搞过通 宵,但像这次这样整还真是头一次,完事之后啥感觉?要说程序写的不好能害死人,程序交接的不好,更能害死人。
假期之后,替换老系统的计划提上了日程,和之前的不一样,也不用再写什么 Demo 先演示啥的,论证已经通过,直接开始用就是。 Hadoop 、 HBase 、 Hive 、 Chukwa 、 Sqoop ,一个都不能少,有很多时候其他组的同事看到我在整 Hive 都奇怪:你们组就每天调 SQL ?
有的时候我自己都快搞不清业务关系,以及写好的 hql 的执行条件,以至于写了一大堆的脚本,而其他同事在某一处想调试时,光这个执行顺序我就得好好解释一遍,突然发现,我现在的这套程序,虽然听 上去比之前老版本的简单,但实际执行的步骤复杂,随着考虑问题的增多,我的脚本也越来越多,慢慢的,可能就和老系统差不多了,只不过,老系统是一个脚本执 行 N 多程序,我是 N 多程序对应着自己的脚本。原来,程序员看别人的程序与看自己的程序,在最开始的时候,是有私心的。
把 HBase 中表的存储空间从 150G 优化到了 120G , hql 分析时间由两个小时优化到了半个小时,好像有那么点成果,可是自己一直对执行效率不是很满意,捣鼓了一个多月一直都没啥进展,直到在和同事的讨论中,听取了别人的建议,再结合自己的业务,存储一下从 120G 优化到了不到 5G ,执行时间也从三个小时优化到了十分钟。但是,这样就已经可以了吗?不行, 2012 ,还得继续。此外,明白了一个道理:和别人多沟通、多分享,比自己一个人埋头苦干要强百倍。
剩下的,对来年做个规划吧, 2012 了,该办的事必须得抓紧时间办啊。
关 于看书,之前看过一篇文章,提到程序员都是自学成才,通过项目,通过好书,尤其是精读一本好书。只是可惜,计算机类的图书,越是好书块头越大,看前头几章 的时候压力最大,“这得啥时候才能看完呢?”虽然这是个错误的观点吧,但有时候还是忍不住会去想,这个时候,毅力、恒心真的很重要,当然,如果是结合项目 需要来看,那就更好了,一边看一边能解决实际问题,这样看书肯定是效率百倍。如果能再按照书中给出的练习强度来检查学习程度,那就更加 OK 了,只是,结合自身实际来看,这个也需要点恒心。
列下书单吧,希望自己能坚持完成。
《深入理解计算机系统》
《 Java 编程思想》
《 C++ 编程思想》
《微积分学教程》
关 于英语,快放假了无所事事时,看到了篇讲如何学习英语的文章,很受启发,英语这玩意,先别说它重不重要,要想学,关键还是看自己有没有兴趣,有兴趣,再结 合合理的学习方法,如果能坚持一段时间,我想,应该是能见到点效果的吧。这个事情想了很长时间,但一直都只是停留在想想的阶段,从来就没有说实际行动过一 次。如果再不抓住这一年的时间,恐怕以后自己会找到更多的借口,所以,把这个也写上吧,一年的时间,说长不长,说短不短,多给自己安排点事,别再留出看漫 画的时间来。
列下目标吧,希望自己能坚持完成。
能看完一本原版英文小说
能听懂一部无字幕英文电影的对白
关于技术, Hadoop 现在只是应用,对它的源码还没有怎么看,接下来打算从比较简单入手,慢慢的,由浅入深吧,希望能对它的底层实现有更加清晰的认识。这个在日常工作中天天都用的到,按说应该是花时间最多的,希望能比前两个成绩多点吧。
目标的话,能分析一遍 Hadoop 及其子项目的源码。
计划列了不少,能全部完成的话还真得拜了佛,但不管怎样,能坚持完成二三,也算是对 2012 有个交代,一年的时间,激情会慢慢消磨殆尽,但如果能时不时的绷紧这根弦,把它养成习惯,或许也就省了烧香了。
posted @
2012-01-30 23:00 todayx.org 阅读(1687) |
评论 (3) |
编辑 收藏有了创业的想法,如何迈出第一步?曾经我跟朋友讲过很多次,我告诉他:如果你有想法,一定要立即执行,不要考虑能不能成功的问题。
但是轮到自己的时候就会很犹豫,我本质上来说也是很喜欢研究技术的人所以创业的话我会希望完全自己编写程序,但是自己写所要学习的知识太多了,花费的时间太长了,一开始考虑的太多,反而忘了如何走出第一步。
这 么多年来一直想做一个网站,但是目的并不太明确,现在终于有了一点头绪,于是全身都燃烧起来了,但是接下来的事情,放假,结婚,南北两地跑,一刻不能清 闲,连续两周没有上网。虽然激情没有冷却,但是已经比刚开始思考的东西多了很多,各种奇思妙想,创新点子都冒出来了,只是苦恼了,一直都无法付诸实践。其 中很多想法都是到了网站达到一定程度才能做的。
这段时间考虑了太多的东西,不懂得如何推广网站,需要学习,网站的内容需要用户来创造,如何才能吸引用户来这里落地安家,如何保证安全,如何定位、规范内容,起个什么名字,申请什么域名,选择什么语言,投资多少钱,找人合作吗,如何应对竞争,如何盈利.....
各 种考虑纷至沓来,脑子乱糟糟,反而不知道如何走出第一步了,只感觉自己成功的希望很渺小,那股子激情越来越弱,现实太残酷,勇气已经快要消失了,唯一剩下 的一个念头是:做这个网站可以逼自己学到东西,所以不论能不能挣钱,都有做这个网站的价值。于是还是鼓起勇气对自己说,一定要把这个网站做出来。
现在看的太远也不是什么好事,当务之急应该是把网站搭起来。我觉得应该是边做边学。如果暂时做不到就先放下来,把它当做自己的一个目标。
再想想网站的详细定位,想个好名字就去申请域名和空间。哪怕只有一个主页,第一步一定要迈起来。面对困难不敢迈步的人,永远不能成功。
posted @
2012-01-29 13:15 todayx.org 阅读(1513) |
评论 (3) |
编辑 收藏数据库安全涉及的问题
数据库安全是当今最重要的问题。您的数据库可能允许顾客通过互联网购买产品,它也可能包含用来预测业务趋势的历史数据;无论是哪种情况,公司都需要可靠的数据库安全计划。
数据库安全计划应该定义:
允许谁访问实例和/或数据库
在哪里以及如何检验用户的密码
用户被授予的权限级别
允许用户运行的命令
允许用户读取和/或修改的数据
允许用户创建、修改和/或删除的数据库对象
DB2安全机制
DB2中有三种主要的安全机制,可以帮助 DBA 实现数据库安全计划:身份验证(authentication)、授权(authorization) 和特权(privilege)。
身份验证是用户在尝试访问DB2实例或数据库时遇到的第一种安全特性。DB2身份验证与底层操作系统的安全特性紧密协作来检验用户ID和密码。DB2还可以利用Kerberos这样的安全协议对用户进行身份验证。
授权决定用户和/或用户组可以执行的操作以及他们可以访问的数据对象。用户执行高级数据库和实例管理操作的能力由指派给他们的权限决定。在 DB2 中有5种不同的权限级别:SYSADM、SYSCTRL、SYSMAINT、DBADM和LOAD。
特权的粒度比授权要细,可以分配给用户和/或用户组。特权定义用户可以创建或删除的对象。它们还定义用户可以用来访问对象(比如表、视图、索引和包)的命 令。DB2 9中新增的一个概念是基于标签的访问控制(LBAC),它允许以更细的粒度控制谁有权访问单独的行和/或列。
客户机、服务器、网关和主机
数据库环境常常由几台不同的机器组成;必须在所有潜在的数据访问点上保护数据库。在处理 DB2 身份验证时客户机、服务器、网关和主机的概念尤其重要。
数据库服务器是数据库实际所在的机器(在分区的数据库系统上可能是多台机器)。DB2数据库客户机是对服务器上的数据库执行查询的机器。这些客户机可以是本地的(驻留在与数据库服务器相同的物理机器上),也可以是远程的(驻留在单独的机器上)。
如果数据库驻留在运行AS/400(iSeries)或OS/390(zSeries)的大型机上,它就称为主机或主机服务器。
网关是一台运行DB2 Connect产品的机器。DB2客户机可以通过网关连接驻留在主机上的DB2数据库。
网关也称为DB2 Connect服务器。安装了 Enterprise Server Edition产品的系统也内置了DB2 Connect功能。
DB2身份验证
DB2 身份验证控制数据库安全计划的以下方面:
谁有权访问实例和/或数据库
在哪里以及如何检验用户的密码
在发出attach或connect命令时,它在底层操作系统安全特性的帮助下完成这个任务。attach命令用来连接DB2实例,connect命令用来连接DB2实例中的数据库。下面的示例展示了DB2对发出这些命令的用户进行身份验证的不同方式。具体如下
用创建 DB2 实例时使用的用户ID登录到安装 DB2 的机器上。发出以下命令:
$ db2 attach to db2inst1
Instance Attachment Information
Instance server = DB2/LINUX 9.7.5
Authorization ID = DB2INST1
Local instance alias = DB2INST1
在这里,隐式地执行身份验证。使用登录机器的用户ID,并假设这个ID已经经过了操作系统的检验。
$ db2 connect to sample user db2inst1 using a
Database Connection Information
Database server = DB2/LINUX 9.7.5
SQL authorization ID = DB2INST1
Local database alias = SAMPLE
在这里,显式地执行身份验证。用户db2inst1和密码a由操作系统进行检验。用户db2inst1成功地连接到示例数据库。
db2 connect to sample user test1 using password new chgpass confirm chgpass
与上例中一样,用户ID db2inst1和密码password由操作系统进行检验。然后,操作系统将db2inst1的密码从a改为chgpass。因此,如果再次发出例 2 中的命令,它就会失败。
DB2身份验证类型
DB2使用身份验证类型决定在什么地方进行身份验证。例如,在客户机---服务器环境中,是客户机还是服务器检验用户的 ID和密码?在客户机---网关---主机环境中,是客户机还是主机检验用户的ID和密码?
DB2 9能够根据用户是试图连接数据库,还是执行实例连接和实例级操作,指定不同的身份验证机制。在默认情况下,实例对于所有实例级和连接级请求使用一种身份验 证类型。这由数据库管理程序配置参数AUTHENTICATION来指定。V9.1 中引入了数据库管理程序配置参数 SRVCON_AUTH。这个参数专门处理对数据库的连接。例如,如果在DBM CFG 中进行以下设置:
$ db2 get dbm cfg|grep -i auth
Server Connection Authentication (SRVCON_AUTH) = KERBEROS
Database manager authentication (AUTHENTICATION) = SERVER_ENCRYPT
那么在连接实例时会使用SERVER_ENCRYPT。但是在连接数据库时会使用KERBEROS身份验证。如果在服务器上没有正确地初始化KERBEROS,但是提供了有效的用户ID/密码,那么允许这个用户连接实例,但是不允许他连接数据库。
下表总结了可用的 DB2 身份验证类型。在客户机---网关---主机环境中,这些身份验证选项在客户机和网关上设置,而不是在主机上。本节将详细讨论如何设置这些选项。
| 类型 | 描述 |
| SERVER | 身份验证在服务器上进行。 |
| SERVER_ENCRYPT | 身份验证在服务器上进行。密码在客户机上进行加密,然后再发送到服务器。 |
| CLIENT | 身份验证在客户机上进行(例外情况见 处理不可信的客户机 )。 |
| *KERBEROS | 由 Kerberos 安全软件执行身份验证。 |
| *KRB_SERVER_ENCRYPT | 如果客户机设置是 KERBEROS,那么由 Kerberos 安全软件执行身份验证。否则使用 SERVER_ENCRYPT。 |
| DATA_ENCRYPT | 身份验证在服务器上进行。服务器接受加密的用户 ID 和密码,并对数据进行加密。这个选项的操作方式与 SERVER_ENCRYPT 相同,但是数据也要加密。 |
| DATA_ENCRYPT_CMP | 身份验证方式与 DATA_ENCRYPT 相同,但是允许不支持 DATA_ENCRYPT 的老式客户机使用 SERVER_ENCRYPT 身份验证进行连接。在这种情况下,数据不进行加密。如果进行连接的客户机支持 DATA_ENCRYPT,就会进行数据加密,而不能降级到 SERVER_ENCRYPT 身份验证。这个身份验证类型只在服务器的数据库管理程序配置文件中是有效的,而且在客户机或网关实例上使用 CATALOG DATABASE 时是无效的。 |
| GSSPLUGIN | 身份验证方式由一个外部 GSS-API 插件决定。 |
| GSS_SERVER_ENCRYPT | 身份验证方式由一个外部 GSS-API 插件决定。在客户机不支持服务器的 GSS-API 插件之一的情况下,使用 SERVER_ENCRYPT 身份验证。 |
注意:这些设置只对 Windows 2000、AIX、Solaris 和 Linux® 操作系统有效。
在服务器上设置身份验证
在数据库服务器上,在数据库管理程序配置(DBM CFG)文件中使用 AUTHENTICATION 参数设置身份验证。请记住,DBM CFG文件是一个实例级配置文件。因此,AUTHENTICATION参数影响这个实例中的所有数据库。以下命令演示如何修改这个参数。
要查看配置文件中的身份验证参数:
$db2 get dbm cfg
要将身份验证参数修改为 server_encrypt :
$ db2 update dbm cfg using authentication server
$db2stop
$db2start
注:虽然更新完注册表参数后,直接执行 db2 get dbm cfg|grep -i auth可以看到注册表参数已经修改完毕。但是为使其生效,还是需要重启实例。
某些身份验证类型(比如GSSPLUGIN、KERBEROS 和 CLIENT)要求设置其他数据库管理程序配置参数,比如 TRUST_ALLCLNTS、SRV_PLUGIN_MODE 和 SRVCON_PW_PLUGIN。关于这些设置的更多细节见下文。
在网关上设置身份验证
使用catalog database命令在网关上设置身份验证。在这里的示例中,我们将使用名为myhostdb 的主机数据库。
要将网关身份验证类型设置为 SERVER,应该在网关机器上发出以下命令:
db2 catalog database myhostdb at node nd1 authentication SERVER
db2 terminate
注意,身份验证不会在网关本身执行。在DB2 Version 8中,身份验证必须在客户机或主机数据库服务器上执行。
在客户机上设置身份验证
我们来考虑两台单独的客户机上的两种情况。我们将一个客户机配置为连接服务器机器上的数据库(DB2 UDB LUW 分布式平台),另一个客户机连接主机上的数据库(例如 DB2 for zSeries)。
连接服务器数据库的客户机: 在针对要连接的数据库的数据库目录项中,客户机身份验证设置必须匹配数据库服务器上的设置(但是 KRB_SERVER_ENCRYPT、DATA_ENCRYPT_CMP 和 GSS_SERVER_ENCRYPT 例外)。
我们假设服务器身份验证类型设置为 SERVER。在客户机上发出以下命令对名为 sample 的服务器数据库进行编目:
$db2 catalog database sample at node nd1 authentication SERVER
注:如果没有指定身份验证类型,客户机将默认使用 SERVER_ENCRYPT。
连接主机数据库的客户机: 我们假设网关上的身份验证类型设置为SERVER。如果没有指定身份验证类型,那么在通过 DB2 Connect访问数据库时假设采用SERVER_ENCRYPT身份验证。身份验证在主机数据库服务器上进行。从客户机发出以下命令会导致客户机向网关 发送未加密的用户 ID 和密码:
db2 catalog database myhostdb at node nd1 authentication SERVER
现在假设网关上的身份验证类型设置为SERVER_ENCRYPT。身份验证同样在主机数据库服务器上进行。用户ID和密码在客户机上进行加密,然后再发送到网关,并在网关上进行加密,然后再发送到主机。这是默认的做法。
处理不可信的客户机
如果服务器或网关将身份验证类型设置为CLIENT,那么这意味着期望客户机对 用户的ID和密码进行身份验证。但是,一些客户机的操作系统没有本机安全特性。这种不可信的客户机包括在Windows 98和Windows ME上运行的DB2。DB2 V9.1不支持 Windows 98 或 Windows ME,但是它支持低版本的客户机,所以仍然可能必须处理不可信的V8客户机。
在 DBM CFG 文件中有两个额外参数,用于在服务器或网关身份验证方法设置为CLIENT,而不可信的客户机试图连接数据库或DB2实例时,决定应该在哪里进行身份验证。这些参数是 TRUST_ALLCLNTS和TRUST_CLNTAUTH 参数。
当服务器或网关身份验证类型为CLIENT 时,除了TRUST_ALLCLNTS和 TRUST_CLNTAUTH 参数之外,还有两个因素会起作用。第一个因素是用户 ID 和密码是否是显式提供的,第二个因素是进行连接的客户机的类型。有三种DB2客户机:
不可信的客户机 :如上所述
主机客户机 :运行在 zSeries 这样的主机操作系统上的客户机
可信客户机 :运行在具有本机安全特性的非主机操作系统(比如 Windows NT、2000、2003、XP 以及所有形式的 Unix / Linux)上的客户机
当身份验证设置为 CLIENT 时
下表总结了如果服务器的身份验证类型设置为 CLIENT,那么在每种类型的客户机向服务器发出连接命令时将在哪里进行身份验证。
| 是否提供了 ID/密码? | TRUST_ALLCLNTS | TRUST_CLNTAUTH | 不可信的客户机 | 可信的客户机 | 主机客户机 |
| No | Yes | CLIENT | CLIENT | CLIENT | CLIENT |
| No | Yes | SERVER | CLIENT | CLIENT | CLIENT |
| No | No | CLIENT | SERVER | CLIENT | CLIENT |
| No | No | SERVER | SERVER | CLIENT | CLIENT |
| No | DRDAONLY | CLIENT | SERVER | SERVER | CLIENT |
| No | DRDAONLY | SERVER | SERVER | SERVER | CLIENT |
| Yes | Yes | CLIENT | CLIENT | CLIENT | CLIENT |
| Yes | Yes | SERVER | SERVER | SERVER | SERVER |
| Yes | No | CLIENT | SERVER | CLIENT | CLIENT |
| Yes | No | SERVER | SERVER | SERVER | SERVER |
| Yes | DRDAONLY | CLIENT | SERVER | SERVER | CLIENT |
| Yes | DRDAONLY | SERVER | SERVER | SERVER | SERVER |
DRDAONLY 意味着只信任主机客户机,而不管使用 DRDA 进行连接的 DB2 Version 8 客户机。
下面的示例说明如何在服务器和客户机上设置身份验证类型和参数:
在服务器上设置身份验证:
$db2 update dbm cfg using authentication client
$db2 update dbm cfg using trust_allclnts yes
$db2 update dbm cfg using trust_clntauth server
$db2stop
$db2start
在客户机上设置身份验证:
$db2 catalog database sample at node nd1 authentication client
在上面的示例中,如果从任何客户机发出命令
db2 connect to sample
那么身份验证在客户机上进行。如果从任何客户机发出命令
db2 connect to sample user test1 using password
那么身份验证在服务器上进行。
DB2的安全插件架构
DB2 V8.2引入了安全插件的概念。这个概念在DB2 V9.1中得到了进一步增强。通过使用标准的 GSS-API 调用,用户可以编写一个安全插件并将对用户 ID 进行身份验证的工作交给一个外部安全程序。这种方式的一个示例是DB2本身的KERBEROS身份验证。在一台机器上安装 DB2 ESE或应用程序开发客户机时,安装过程中将有一些示例应用程序代码放入实例目录,如果查看 samples\security\plugins 目录,就会看到如何编写安全插件的示例。本节将概述如何在 DB2 安全架构中使用插件,但是不讨论如何编写或编译插件本身。关于这个主题的详细描述,请参考 DB2 UDB 安全性: 理解 DB2 Universal Database 安全性插件 。
Kerberos 身份验证
Kerberos 身份验证为DB2提供了一种无需通过网络发送用户ID和密码的用户身份验证方法。Kerberos安全协议作为第三方身份验证服务执行身份验证,它使用传 统的密码术创建一个共享的密钥。这个密钥成为用户的凭证,在请求本地或网络服务时在所有情况下都使用它检验用户的身份。通过使用Kerberos安全协 议,可以实现对远程DB2数据库服务器的单点登录。
首先,讨论如何设置DB2来使用Kerberos身份验证。如上所述,Kerberos身份验证在DB2 中是使用插件架构实现的。默认的kerberos 插件的源代码在samples/security/plugins 目录中,称为IBMkrb5.c 。在DB2 中使用Kerberos之前,必须在客户机和服务器上启用和支持 Kerberos。为此,必须满足以下条件:
1、客户机和服务器必须属于同一个域(用 Windows 术语来说,是可信域)。
2、必须设置适当的主体(Kerberos 中的用户 ID)。
3、必须创建服务器的keytab文件,实例所有者必须能够读这个文件。
4、所有机器必须有同步的时钟。
可以在 Kerberos 产品附带的文档中找到关于设置 Kerberos 的更多信息。
为了在 DB2 中启用 Kerberos 身份验证,必须先告诉客户机在哪里寻找将使用的Kerberos 插件。在客户机上,运行以下命令:
DB2 UPDATE DBM CFG USING CLNT_KRB_PLUGIN IBMkrb5
DB2 TERMINATE
在这个示例中,使用默认的 KERBEROS 插件。如果使用的Kerberos实现需要特殊功能的话,DBA可以修改这个插件来执行特殊功能。
还可以告诉客户机它正在针对哪个服务器主体进行身份验证。这个选项可以避免Kerberos身份验证的第一步,即客户机寻找它要连接的实例的服务器主体。在客户机上对数据库进行编目时可以指定AUTHENTICATION参数。它的格式是:
DB2 CATALOG DB dbname AT NODE node name AUTHENTICATION KERBEROS TARGET PRINCIPAL service/host@REALM
这一步是可选的。
DB2 CATALOG DB sample AT NODE testnd AUTHENTICATION KERBEROS TARGET PRINCIPAL gmilne/gmilne02.torolab.ibm.com@TOROLAB.IBM.COM
设置 Kerberos 身份验证的下一步是设置服务器。srvcon_gssplugin_list 参数可以设置为支持的GSS-API插件的列表,但是只允许有一个Kerberos 插件。如果这个列表中没有Kerberos 插件,那么自动地使用默认的IBMkrb5插件。如果希望允许所有身份验证(实例连接和数据库连接)使用Kerberos,那么执行以下命令:
DB2 UPDATE DBM CFG USING AUTHENTICATION KERBEROS
或者
DB2 UPDATE DBM CFG USING AUTHENTICATION KRB_SERVER_ENCRYPT
如果只希望 DB2 使用 Kerberos 对数据库连接进行身份验证(对实例连接使用 SERVER),那么执行以下命令:
DB2 UPDATE DBM CFG USING SVRCON_AUTH KERBEROS
或者
DB2 UPDATE DBM CFG USING SVRCON_AUTH KRB_SERVER_ENCRYPT
根据实例的位长度(32 或 64 位),DB2将在实例启动时自动地装载 IBMkrb5 插件。
其他身份验证设置
如果查看 V9.1 实例中的DBM CFG,会看到影响DB2对用户ID进行身份验证的方式的各种设置。正如前面提到的,有针对标准操作系统用户ID身份验证的设置(CLIENT、 SERVER、SERVER_ENCRYPT、DATA_ENCRYPT、DATA_ENCRYPT_CMP),还有将身份验证工作交给外部程序的插件 (KERBEROS、KRB_SERVER_ENCRYPT、GSSPLUGIN、 GSS_SERVER_ENCRYPT)。本节专门介绍其他一些配置变量如何影响对用户的身份验证。
Client Userid-Password Plugin (CLNT_PW_PLUGIN) =
Group Plugin (GROUP_PLUGIN) =
GSS Plugin for Local Authorization (LOCAL_GSSPLUGIN) =
Server Plugin Mode (SRV_PLUGIN_MODE) = UNFENCED
Server List of GSS Plugins (SRVCON_GSSPLUGIN_LIST) =
Server Userid-Password Plugin (SRVCON_PW_PLUGIN) =
Cataloging allowed without authority (CATALOG_NOAUTH) = NO
Bypass federated authentication (FED_NOAUTH) = NO
在上面的列表中,去掉了已经讨论过的参数。
| CLNT_PW_PLUGIN | 这个参数在客户端的 DBM CFG 中指定。它指定用来进行客户机和本地身份验证的客户机插件的名称。 |
| GROUP_PLUGIN | 默认值是空(NULL)。将它设置为用户定义的插件就会调用这个插件进行所有组枚举,而不依赖于操作系统的组查找。这与后面讨论的授权部分相关。 |
| LOCAL_GSSPLUGIN | 这个参数指定默认的 GSS-API 插件库的名称,当数据库管理程序配置的身份验证参数值设置为GSSPLUGIN 或 GSS_SERVER_ENCRYPT 时,这个库用来进行实例级的本地授权。 |
| SRV_PLUGIN_MODE | (YES/NO) 这个参数的默认设置是 NO。当改为 YES 时,以 FENCED 模式启动 GSS-API 插件,其工作方式类似于 FENCED 存储过程。FENCED 插件的崩溃不会导致 DB2 实例崩溃。在插件还处于开发阶段时,建议以 fenced 模式运行它们,这样的话插件中的逻辑问题和内存泄漏就不会导致实例崩溃。在确定插件是可靠的之后,应该以 unfenced 模式运行以提高性能。 |
| SRVCON_GSSPLUGIN_LIST | 一 个插件列表,当使用 KERBEROS、KRB_SERVER_ENCRYPT、GSSPLUGIN 或 GSS_SERVER_ENCRYPT 时,服务器上的数据库管理程序在身份验证期间将使用这些插件。列表中的每个插件应该用逗号(‘,’)分隔,它们之间没有空格。插件按照优先次序列出,首先 使用列表中的第一个插件对发送的用户 ID/密码进行身份验证。只有当列出的所有插件都返回了错误时,DB2 才会向用户返回身份验证错误。 |
| SRVCON_PW_PLUGIN | 在指定 CLIENT、SERVER 或 SERVER_ENCRYPT 身份验证时,这个参数允许用户修改 DB2 用来检验用户 ID 和密码的默认身份验证方法。在默认情况下,它的值是 NULL,因此使用默认的 DB2 方法。 |
| CATALOG_NOAUTH | (YES/NO) 默认值是 NO。将这个参数修改为 YES 就允许不属于 SYSADM、SYSCTRL 或 SYSMAINT 组成员的用户修改机器上的 Database、Node、Admin 和 DCS 编目。如果登录的用户使用不可信客户机(定义见上文),或者登录所用的用户 ID 不允许连接数据库或实例,但是用户又必须在客户机上进行编目,只有在这种情况下这个参数才是有用的。 |
| FED_NOAUTH | 如 果 fed_noauth 设置为 yes,身份验证设置为 server 或 server_encrypt,联邦设置为 yes,那么在实例上避免进行身份验证。它假设身份验证在数据源上进行。当 fed_noauth 设置为 yes 时系统会发出警告。在客户机和 DB2 服务器上都不进行身份验证。知道SYSADM身份验证名称的任何用户都拥有联邦服务器的 SYSADM 权限。 |
转自 iteye
posted @
2012-01-29 13:14 todayx.org 阅读(1137) |
评论 (1) |
编辑 收藏 coffeescrip是目前前端MVC开发中的一个不错的框架,特分享一本好书,
来自动物出版社的O'Reilly.The.Little.Book.on.CoffeeScript.Jan.2012.pdf
posted @
2012-01-29 13:13 todayx.org 阅读(1152) |
评论 (0) |
编辑 收藏 一、问题:铁路的售票系统的数据量是海量吗?
不是。因为数据量不大,真不大。
每一个车次与车次间是独立的,每车次不超过2000张票,一天发车不超过50万车次;
以预售期15天来讲,15*0.1亿张不超过1.5亿笔的热线数据,称不上海量数据的。
再加上可以按线路分库,更是不到千万级的单表容量。已经发车完成的进入归档分析。
即数据库按路线使用不同的服务器,不同的车次放在不同的表中。并发量锁真不大。
当然,如果不分库分表,再加上不归档处理,铁路的售票系统的数据量看起来是海量的;
关键是这海量的数据没有意义。
二、如何分库分表?
2.1 分库,考虑数据间没有直接关系和服务器如何部署
铁路的售票系统为例来说,按路线分库,再按车次分表是合理的。
设路线有1万条,按每1000条需要两台服务器(一台热机沉余),不到20台服务器
如果使用SAN存储,则使用SAN作为存储,本机作为热机沉余,只需要10台。
当然使用mySQL这种经济型数据库,服务器需要更多来防灾;
即可以采用双写或多写的方式来保证数据的绝对安全。
2.2分表,考虑数据间不存在重叠,即数据满足二分原则
铁路的售票系统的任意两个车次是没有关系的,所以可以分表。
电信的某个用户的通话和其它用户的通话记录,也是没有关系,所以可以分表处理
(实际上电信的系统,分库分表后也是不大的,难在后台的计费、结算等规则)
三、数据库访问接口
1. 元数据:如何识别到当前要处理的数量在哪张表?
铁路的售票系统会有一个车次管理系统,例2012年2月12日 D3206 车次,
按预先设计的在哪台服务器的哪个库,建哪个表。
2.建立元数据的规则:即具体如何分库分表的规则
这个就是数据库的访问接口。
3.数据库访问接口的透明程度
即哪个层知道哪些元数据信息。
例,是否让窗口售票的客户端来解析元数据的规则然后缓存,还是通过中间件来解析缓存的
具体各层使用怎样透明程度,和业务性质、节点和数据中心的拓扑等有关。
四、历史数据归档与分析
1.使用分库分表后,数据需要归档,分析处理的程序变得复杂,但使联机交易变得简单
2.分析:要注意是针对热线数据分析、归档数据分析、混合分析有关,
通过分库分表和归档,更方便使用分布式的统计方案。
具体可以参考,淘宝的开放平台架构师写的文章:
结论:分库分表跟不分库分表,整个架构是完全不一样的。
像铁票的售票系统、淘宝、电信、银行等,绝对要采用分库分表的数据存储方案,
来解决数据量的增长而不影响性能的问题。
像淘宝等互联网应用还要解决带宽即CDN问题。
posted @
2012-01-16 21:01 todayx.org 阅读(2478) |
评论 (4) |
编辑 收藏新版谷歌分析增加了好几个实用功能,包括即时分析报告,访问者流(参见《“访问者流”功能添加入Google Analytics中》),还有“多渠道通路分析”。从专业到专家,差别有时候就是一个工具,多渠道通路分析,就是让你变成专家的好工具。之前转发的博客《转发整理:究竟哪种营销手段为B2C网站带来订单》,如果要了解到底哪种营销手段为小明带来订单,用多渠道通路可以很直观的看出来。
单渠道通路分析,在老版本的google analytics已经存在,很多电子商务网站都使用过,如下图:

这 就是常说的可视化通路(或者叫转化率漏斗),4887个用户将商品放入购物车,最后854个用户购买,购物流程的转化率是17.47%。超过80%的用 户,在购物过程中流失了。通过这个漏斗,我们可以分析购物流程哪个环节出了问题,然后改造对应的页面,提升用户购物体验,从而达成更高的转化率。
上 面的可视化通路被称作单渠道通路,对于网站本身的UED(用户体验设计)很有用。那么有没有一种方法,能够帮我们分析出各种推广渠道的效率和效果呢?一个 更直接的问题是:我的EDM电子邮件营销的效果好,还是Google Adwords的效果好呢?或者我该尝试一下社会化媒体facebook?——这就是多渠道通路解决的问题。
多渠道通路谷歌的介绍文字
https://support.google.com/analytics/bin/answer.py?hl=zh-Hans&answer=1191180&topic=1191164&ctx=topic
引用上面文字的定义:
在 Google Analytics(分析)中,转化和电子商务交易会在访问者完成转化后计入引荐该访问者的最近一个广告系列、搜索或广告。但是,在此之前的网站引荐、搜索字词和广告对此次转化有何贡献?访问者从最初表现出购物意愿到最终决定购买,经历了多长时间?
“多渠道路径”报告可以为您展示各营销渠道(即网站流量来源)如何共同发挥作用来实现销售和转化,从而解答这些问题和其他问题。
例 如,许多人可能会在 Google 上搜索您的品牌后,进入您的网站进行购买。不过,他们可能是在阅读博客文章时发现了您的品牌,也可能是在搜索某些产品或服务时发现的。利用“多渠道路径” 报告,您可以了解先前的引荐网址、搜索字词以及在其他渠道的展示对您的销售有何帮助。
我们结合几个实例来看:

上图是多渠道通路的总览界面,位于“转化”-“多渠道通路”-“Overview”

上图的数据可以看出,73.55%的实际购买用户,都是通过自然排名到达的。42.32%的用户,通过直接访问网址的方法到达的。两者加起来超过100%,因为有交集(见红色框)。交集部分有19.9%用户。从这个图可以直观看出购买用户的来源情况。
而在老版本的谷歌分析中,如果一个用户有了购买行为,你只能从数据中观察到这个用户这一次购买的进入途径。举例:某用户第一次在google搜索“cheap gadgets free shipping”,进入了 buyonme.com 网站,然后收藏了这个网站。两天后,该用户通过收藏夹再次访问buyonme.com,然后下了一个订单达成预设转化目标,老版本GA只能统计这个目标来自于Direct Visit,而新版本GA可以追溯历史,判断这个转化目标的实现与当时的搜索有关。
再看看更直观的一个图:

上面的图显示了实际购买用户的购买路径。
排在第一位的是单次自然排名搜索用户,第二位的是直接访问用户(包括收藏夹访问),第三位是用户两次通过搜索引擎自然排名搜索后购买,第四位是用户先搜索找到网站第二次通过收藏夹或直接输入网址产生的购买。
以上数据,对于广告投放策略以及用户购买行为分析,非常有用。
作者: 谭砚耘@用户体验与可用性设计-科研笔记
版权属于: 谭砚耘 (TOTHETOP至尚国际 )
版权所有。转载时必须以链接形式注明作者和原始出处
http://www.webusability.cn/google-analytics-multi-channel-funnels-800/
如果你希望与作者交流,请发送邮件到 tanyanyun/at/163.com 别忘了修改小老鼠
posted @
2012-01-16 20:59 todayx.org 阅读(1657) |
评论 (1) |
编辑 收藏