2008年11月27日
关于大端和小端,自己已经记了很多次了,可每次都忘,今天创新工场笔试,第一道题就是关于大端小端的知识,可惜,自己又忘了,怎么回事,说到底,是自己同时记大端和小端,导致容易混淆,现在只记小端了:小端,是数的高位存在内存地址的高位,小高高!
下面是从网上摘抄的一些东东,帮助理解和记忆,来自http://www.52rd.com/Blog/Detail_RD.Blog_imjacob_14837.html:
端模式(Endian)的这个词出自Jonathan
Swift书写的《格列佛游记》。这本书根据将鸡蛋敲开的方法不同将所有的人分为两类,从圆头开始将鸡蛋敲开的人被归为Big
Endian,从尖头开始将鸡蛋敲开的人被归为Littile
Endian。小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。在计算机业Big
Endian和Little
Endian也几乎引起一场战争。在计算机业界,Endian表示数据在存储器中的存放顺序。下文举例说明在计算机中大小端模式的区别。
如果将一个32位的整数0x12345678存放到一个整型变量(int)中,这个整型变量采用大端或者小端模式在内存中的存储由下表所示。为简单起见,本书使用OP0表示一个32位数据的最高字节MSB(Most Significant Byte),使用OP3表示一个32位数据最低字节LSB(Least Significant Byte)。
|
地址偏移
|
大端模式
|
小端模式
|
|
0x00
|
12(OP0)
|
78(OP3)
|
|
0x01
|
34(OP1)
|
56(OP2)
|
|
0x02
|
56(OP2)
|
34(OP1)
|
|
0x03
|
78(OP3)
|
12(OP0)
|
如果将一个16位的整数0x1234存放到一个短整型变量(short)中。这个短整型变量在内存中的存储在大小端模式由下表所示。
|
地址偏移
|
大端模式
|
小端模式
|
|
0x00
|
12(OP0)
|
34(OP1)
|
|
0x01
|
34(OP1)
|
12(OP0)
|
由上表所知,采用大小模式对数据进行存放的主要区别在于在存放的字节顺序,大端方式将高位存放在低地址,小端方式将
高位存放在高地址。采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。到目前为止,采用大端或者小端进行数据存
放,其孰优孰劣也没有定论。
有的处理器系统采用了小端方式进行数据存放,如Intel的奔腾。有的处理器系统采用了大端方式进行数据存放,如IBM半导体和Freescale的PowerPC处理器。不仅对于处理器,一些外设的设计中也存在着使用大端或者小端进行数据存放的选择。
因此在一个处理器系统中,有可能存在大端和小端模式同时存在的现象。这一现象为系统的软硬件设计带来了不小的麻烦,这要求系统设计工程师,必须深入理解大端和小端模式的差别。大端与小端模式的差别体现在一个处理器的寄存器,指令集,系统总线等各个层次中。
转自:http://jaskell.blogbus.com/logs/3249971.html
一、同余
我们来了解一下什么是“同余”。简单来说就是,如果两个数都除以某个数能够有相同的余数,那么我们就说这两个数“同余”。不过这次我们用严谨的数学概念来表述:
两个整数 a,b,若它们除以整数 m 所得的余数相等,则称 a,b 对于模 m 同余
记作 
读作 a 同余于 b 模 m ,或读作 a 与 b 关于模 m 同余。
比如 
我们再来了解一下相关的性质:
- 如果 ,那么 m | (a − b) ,这里 m | (a − b) 表示 (a − b) 能被 m 整除
- 如果 ,
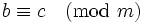 , 那么 , 那么
- 如果 ,
 , 那么 , 那么 , , , ,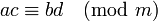 , ,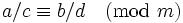
- 如果 , 那么
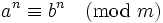
有了这些性质,判断两个数是否同余就可以用更简单的方法了。根据性质一,原来我们需要判断 (a mod m) == (b mod m)
是否为真,现在就可以直接判断 (a - b) mod m == 0
是否为真了。这样就把其中一次求余运算变为减法运算了。一般来说减法要比除法更容易在计算机上实现,运算速度也更快。
二、求余 (a * b * c * d) mod m = ?
由于计算机表示一个整数通常用 32bit 。而大量连乘运算则可能会导致整数溢出,这时我们就要利用求余一些性质来进行处理了。把以上式子转换为:
已知: (a * b) mod m == ((a mod m) * b) mod m
所以: (a * b * c * d) mod m = ((((((a mod m) * b) mod m) * c) mod m) * d) mod m
这样就把连乘运算分解了,每次可以先进行求余运算然后再进行乘法运算。
使用的是Ubuntu 9.10发行版,找了好半天中文输入法,发现目前最好/最新的是ibus(前身是鼎鼎大名的scim-python,对于我这个linux小白来说,并不是鼎鼎大名的...),严格来说它不是一个输入法,而是一个输入法框架,9.10自带的ibus里有N多国家的输入法(基于ibus框架)。ubuntu9.10里面ibus自带的中文PinYin输入法好像一开始不能用...(拿不准...),必须去Preferences里面的IBus Preferences里面的Input Method中自己添加“汉语-PinYin”输入法,如果开始没有,需要安装ibus-pinyin,见下面的第4步。
在网上找了点资料,在ibus已经加入到Ubuntu的源了,如果需要,使用下面的命令进行安装:
- sudo apt-get update 更新软件包列表
- sudo apt-get install ibus 安装ibus框架
- sudo apt-get install ibus ibus-table 安装某些输入法引擎基础,如果仅仅想使用拼音输入法,可以跳过此步,拼音输入法不需要依赖ibus-table。某些输入法,如五笔,依赖ibus-table。
- sudo apt-get install ibus ibus-pinyin 安装拼音输入法引擎,发现很好用啊,哈哈
由于安装和卸载软件是使用的必须前提,所以这里对apt命令进行一些总结。在总结之前,还得对ubuntu的软件源的地址进行说明,为了达到好的下载源的速度,最好选一个最快的软件源,目前来说http://ubuntu.srt.cn是最快的,ubuntu自己提供了检测的功能,可以自动检测(choose a download server -> select best server)。
关于apt-get命令的详细而简单的说明,是《AptGetHowTo》。注意,使用apt-get命令必须要用root权限。这里,摘抄了最常用的命令....如下
Installation commands
apt-get install <package_name> This command installs a new package.apt-get build-dep <package_name>
This command searches the repositories and installs the build dependencies for <package_name>. If the package is not in the repositories it will return an error.
aptitude install <package_name>
Aptitude is a [http://en.wikipedia.org/wiki/Ncurses Ncurses] viewer of packages installed or available. Aptitude can be used from the command line in a similar way to apt-get. See man aptitude for more information.
- APT and aptitude will accept multiple package names as a space delimited list. For example:
apt-get install <package1_name> <package2_name> <package3_nam
Search commands
apt-cache search <search_term>
This command will find packages that include <search_term>.
dpkg -l *<search_term>*
This will find packages whose names contain <search_term>. Similar to apt-cache search, but also shows whether a package is installed on your system by marking it with ii (installed) and un (not installed).
apt-cache show <package_name>
This command shows the description of package <package_name> and other relevant information including version, size, dependencies and conflicts.
Typical usage example
I want to feel the wind in my hair, I want the adrenaline of speed. So lets install a racing game. But what racing games are available?
apt-cache search racing game
It gives me a lot of answers. I see a game named "torcs". Lets get some more information on this game.
apt-cache show torcs
Hmmm... it seems interesting. But is this game not already installed on my computer? And what is the available version? Is it from Universe or main?
apt-cache policy torcs
Ok, so now, let's install it!
apt-get install torcs
What is the command I must type in the console to launch this game? In this example, it's straightforward ("torcs"), but that's not always the case. One way of finding the name of the binary is to look at what files the package has installed in "/usr/bin". For games, the binary will be in "/usr/games". For administrative programs, it's in "/usr/sbin".
dpkg -L torcs | grep /usr/games/
The first part of the command display all files installed by the package "torcs" (try it). With the second part, we ask to only display lines containing "/usr/games/".
Hmmm, that game is cool. Maybe there are some extra tracks?
apt-cache search torcs
But I'm running out of space. I will delete the apt cache!
apt-get clean
Oh no, my mother asked me to remove all games from this computer. But I want to keep the configuration files so I can simply re-install it later.
apt-get remove torcs
If I want to also remove config files :
apt-get purge torcs 文章来源: http://localhost/wp2/?p=180
由于宿舍网络情况比较复杂,想为tattoo搭建一个proxy,没想到在android中没有找到设置proxy的地方。上网查了一篇文章,可以解决这个问题。
转自 http://alexmogurenko.com/blog/programming/android-how-to-set-proxy-for-android-browser/
下面是原文
There are many reasons to make browser serf pages through proxy server:
- someone wanna catch http requests/responses
- someone wanna hide his IP
- so on
What to do if you want set proxy for android browser? there some ways:
- add record to database: /data/data/com.android.providers.settings/databases/settings.db
- pull database to pc add record (using for example sdk tool sqlite3) and replace existing db
- make changes in database directly on device
but as for me there exist simplier way, do it by your Java application using Settings provider:
Settings.System.putString(getContentResolver(), Settings.System.HTTP_PROXY, "proxy_ip:proxy_port");
where proxy_ip/proxy_port = IP/port of proxy that you going to use.
there left one problem, it will not work if we will not add one string to manifest file, here it is:
<uses-permission android:name=”android.permission.WRITE_SETTINGS” />
Thats all, now it works, here is code:
package com.BrowserSettings;
import android.app.Activity;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.provider.Settings;
public class BrowserSettingsUI extends Activity {
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
final Button button = (Button) findViewById(R.id.Button01);
button.setOnClickListener(new Button.OnClickListener() {
public void onClick(View v) {
try
{
Settings.System.putString(getContentResolver(), Settings.System.HTTP_PROXY, "127.0.0.1:100");//enable proxy
}catch (Exception ex){
}
}
});
final Button button2 = (Button) findViewById(R.id.Button02);
button2.setOnClickListener(new Button.OnClickListener() {
public void onClick(View v) {
try
{
Settings.System.putString(getContentResolver(), Settings.System.HTTP_PROXY, "");//disable proxy
}catch (Exception ex){
}
}
});
}
}
manifest file:
<?xml version=”1.0″ encoding=”utf-8″?>
<manifest xmlns:android=”http://schemas.android.com/apk/res/android”
package=”com.BrowserSettings”
android:versionCode=”1″
android:versionName=”1.0.0″>
<application android:icon=”@drawable/icon” android:label=”@string/app_name”>
<activity android:name=”.BrowserSettingsUI”
android:label=”@string/app_name”>
<intent-filter>
<action android:name=”android.intent.action.MAIN” />
<category android:name=”android.intent.category.LAUNCHER” />
</intent-filter>
</activity>
</application>
<uses-permission android:name=”android.permission.WRITE_SETTINGS” />
</manifest>
文章来源: http://localhost/wp2/?p=172
最近在学习《算法导论》时,发现很多证明都用到了数学归纳法,这里查了点资料,把数学归纳法复习一下:
数学归纳法用来在数学上证明与自然数N有关的命题的一种特殊方法,它主要用来研究与正整数有关的数学问题,在高中数学中常用来证明等式成立和数列通项公式成立。
用的最多的是第一数学归纳法和第二数学归纳法,下面详细说明。
第一数学归纳法
- 证明当n(n为自然数)取第一个值时命题成立
- 假设当n=k(k为自然数)时命题成立,证明当n=k+1时命题也成立
由1,2步,可证明命题成立。
第二数学归纳法
对第一数学归纳法进行了扩充
- 证明当n=0时命题成立
- 假设当n<=k(k为自然数)时命题成立,证明当n=k+1时命题也成立
有1,2步,可证明命题成立。
在算法时间复杂度的证明上,由于n取值是一个自然数,所以多用数学归纳法原理进行证明。其实,证明循环正确性的循环不变式就是直接利用的第一数学归纳法。
参考:
百度百科,数学归纳法
文章来源: http://localhost/wp2/?p=165
如题,经典问题,记录于此...
递归实现
思路:如果只有一个节点,则什么都不做。否则,将当前链表(a1,a2...a3)的子链表(a2,...an)进行逆转,返回逆转后的第一个节点的指针,再将a1节点加到a2节点后面。
代码:(这里没有使用头节点)
node * reverse(node * p){
if(p->next == null){
return p;
}
node * q = p->next;
node * head = reverse(q);
p->next = null;
q->next = p;
return head;
}
非递归实现
思路:一个指针进行链表的遍历,一个指针指向逆转后的链表的第一个节点,在遍历的过程中,将当前节点加入逆转后的链表第一个元素即可。返回逆转后的链表的第一个节点的指针。
代码:(这里没有使用头节点)
node * reverse(node * p){
node * p_reverse;
if(p != null){
p_reverse = p;
node * q = p->next;
p->next = null;
}
while(q != null){
p = q->next;
q->next = p_reverse;
p_reverse = q;
q = p;
}
}
对C语言用的太少,上面的代码实现可能有点恶心,不过可以实现功能....
文章来源: http://localhost/wp2/?p=150
摘要: Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
... 阅读全文
对eclipse是用的多,学的少,用了都半年了,连插件都不知道怎么装,搜索了一篇文章《Eclipse 3.4插件安装方式》作为参考吧...
以前安装Eclipse插件无非两种方式, 直接copy插件到features/plugins目录或者在links目录下创建链接文件. 刚刚发布的Eclipse 3.4又推出另一种新的安装途径, 更加灵活。Eclipse 3.4下有个dropins目录, 只要把插件放到该目录下就可以加载, 有几种格式可以选择。
1. 最简单的,直接将jar包放到dropins目录:
eclipse/
dropins/
com.essiembre.eclipse.i18n.resourcebundle_0.7.7
2. 传统格式,统一放到一个eclipse目录下:
eclipse/
dropins/
eclipse/
features/
plugins/
3. 按照插件名称区分:
eclipse/
dropins/
resourcebundleeditor/
features/
plugins/
m2eclipse/
features/
plugins/
4. 类似links方式添加链接:
eclipse/
dropins/
xfire.link
如果只安装一个Eclipse的话建议采用第三种,否则采用第四种。
如果发现安装了没有效果,可以删除eclipse主目录下的\configuration\org.eclipse.update后,再执行eclipse -clean试试。
文章来源: http://localhost/wp2/?p=127
Oracle支持的数据类型可以分为三个基本种类:字符数据类型、数字数据类型以及表示其它数据的数据类型。
字符数据类型
CHAR数据类型存储固定长度的字符值。一个CHAR数据类型可以包括1到2000个字符。如果对CHAR没有明确地说明长度,它的默认长度则设置为1.如果对某个CHAR类型变量赋值,其长度小于规定的长度,那么Oracle自动用空格填充。
VARCHAR2存储可变长度的字符串。虽然也必须指定一个VARCHAR2数据变量的长度,但是这个长度是指对该变量赋值的的最大长度而非实际赋值长度。不需要用空格填充。最多可设置为4000个字节。所以如果存储中文的时候,就不能存储到4000个字符了,因为一个汉字会占有多个字节。
因为VARCHAR2数据类型只存储为该列所赋的字符(不加空格),所以VARCHAR2需要的存储空间比CHAR数据类型要小。
Oracle推荐使用VARCHAR2
NCHAR和NVARCHAR2数据类型分别存储固定长度与可变长度的字符数据,但是它们使用的是和数据库其他类型不同的字符集。在创建数据库时,需要指定所使用的字符集,以便对数据库中数据进行编码。还可以指定一个辅助的字符集[即本地语言集(National Language Set,简称NLS)]。NCHAR和NVARCHAR2类型的列使用辅助字符集。
在Oracle9i中,可以以字符而不是字节为单位来表示NCHAR和NVARCHAR2列的长度。
LONG数据类型可以存放2GB的字符数据,它是从早期版本中继承来的。现在如果想存储大容量的数据,Oracle推荐使用CLOB和NCLOB数据类型。在表和SQL语句中使用LONG类型有许多限制。
CLOB和NCLOB数据类型可以存储多达4GB的字符数据。NCLOB数据类型可存储NLS数据。
数字数据类型
Oracle使用标准、可变长度的内部格式来存储数字。这个内部格式精度可以高达38位。
NUMBER数据类型可以有两个限定符,如:
column NUMBER ( precision, scale)
precision表示数字中的有效位。如果没有指定precision的话,Oracle将使用38作为精度。
scale表示数字小数点右边的位数,scale默认设置为0。如果把scale设成负数,Oracle将把该数字取舍到小数点左边的指定位数。
日期数据类型
Oracle标准日期格式为:DD-MON-YY HH:MI:SS
通过修改实例的参数NLS_DATE_FORMAT,可以改变实例中插入日期的格式。在一个会话期间,可以通过ALTER SESSION SQL命令来修改日期,或者通过使用SQL语句的TO_DATE表达式中的参数来更新一个特定值。
其它的数据类型
RAW和LONG RAW数据类型主要用于对数据库进行解释。指定这两种类型时,Oracle以位的形式来存储数据。RAW数据类型一般用于存储有特定格式的对象,如位图。 RAW数据类型可占用2KB的空间,而LONG RAW数据类型则可以占用2GB大小。
ROWID ROWID是一种特殊的列类型,称之为伪列(pseudocolumn)。ROWID伪列在SQL SELECT语句中可以像普通列那样被访问。Oracle数据库中每行都有一个伪列。ROWID表示行的地址,ROWID伪列用ROWID数据类型定义。
ROWID与磁盘驱动的特定位置有关,因此,ROWID是获得行的最快方法。但是,行的ROWID会随着卸载和重载数据库而发生变化,因此建议不要在事务 中使用ROWID伪列的值。例如,一旦当前应用已经使用完记录,就没有理由保存行的ROWID.不能通过任何SQL语句来设置标准的ROWID伪列的值。
列或变量可以定义成ROWID数据类型,但是Oracle不能保证该列或变量的值是一个有效的ROWID.
LOB
LOB(大型对象)数据类型,可以保存4GB的信息。LOB有以下3种类型:
。CLOB,只能存储字符数据
。NCLOB,保存本地语言字符集数据
。BLOB,以二进制信息保存数据
可以指定将一个LOB数据保存在Oracle数据库内,还是指向一个包含次数据的外部文件。
LOB可以参与事务。管理LOB中的数据必须通过DBMS_LOB PL/SQL内置软件包或者OCI接口。
为了便于将LONG数据类型转换成LOB,Oracle9i包含许多同时支持LOB和LONG的函数,还包括一个ALTER TABLE语句的的新选择,它允许将LONG数据类型自动转换成LOB.
BFILE
BFILE数据类型用做指向存储在Oracle数据库以外的文件的指针。
XMLType
作为对XML支持的一部分,Oracle9i包含了一个新的数据类型XMLType.定义为XMLType的列将存储一个在字符LOB列中的XML文档。有许多内置的功能可以使你从文当中抽取单个节点,还可以在XMLType文档中对任何节点创建索引。
用户自定义数据
从Oracle8以后,用户可以定义自己的复杂数据类型,它们由Oracle基本数据类型组合而成。
AnyType、AnyData和AnyDataSet
Oracle包括3个新的数据类型,用于定义在现有数据类型之外的数据结构。其中每种数据类型必须用程序单元来定义,以便让Oracle9i知道如何处理这些类型的特定实现。
额外的:
类型转换
Oracle会自动将某些数据类型转换成其他的数据类型,转换取决于包括该值的SQL语句。
数据转换还可以通过Oracle的类型转换函数显示地进行。
连接与比较
在大多数平台上Oracle SQL中的连接操作符用两条竖线(||)表示。连接是将两个字符值连接。Oracle的自动类型转换功能使得两个数字值也可以进行连接。
NULL
NULL值是关系数据库的重要特征之一。实际上,NULL不代表任何值,它表示没有值。如果要创建表的一个列,而这个列必须有值,那么应将它指定为NOT NULL,这表示该列不能包含NULL值。
任何数据类型都可以赋予NULL值。NULL值引入了SQL运算的三态逻辑。如果比较的一方是NULL值,那么会出现3种状态:TURE、FALSE以及两者都不是。
因为NULL值不等于0或其他任何值,所以测试某个数据是否为NULL值只能通过关系运算符IS NULL来进行。
NULL值特别适合以下情况:当一个列还未赋值时。如果选择不使用NULL值,那么必须对行的所有列都要赋值。这实际上也取消了某列不需要值的可能性,同时对它赋的值也很容易产生误解。这种情况则可能误导终端用户,并且导致累计操作的错误结果。
参考:
《Oracle数据类型》,http://www.cnblogs.com/cxd4321/archive/2008/04/14/1153201.html
文章来源: http://localhost/wp2/?p=122
如果一个方法后面有“throws InterruptedException”(即会抛出InterruptedException异常的方法),表示这个方法内(或是这个方法中所调用的方法内),可能会抛出InterruptedException异常。在多线程程序设计中,这通常告诉我们两点:
- 这是“需要时间”的方法
- 这是“可以取消”的方法
即,如果一个方法后面有“thorws InterruptedException”表示这个方法可能会花点时间,但是可以取消。
Java中会抛出InterruptException异常的有下面三个方法:
- java.lang.Object类(及其子类)实例的wait方法
- java.lang.Object类(及其子类)实例的sleep方法
- java.lang.Thread类(及其子类)实例的join方法
根据上面的两点,首先,这三个方法都是需要花点时间的方法,这个很好理解。其次,他么都可以被取消,具体怎么取消,下面分别说明。
取消wait
可以调用interrupt方法(这个方法是java.lang.Thread类(及其子类)实例的方法,某个线程都可以在任何时候调用其他线程的interrupt方法)来取消wait方法的等待。即不用再等待notify/notifyAll方法的“通知”了。当对某个wait的线程调用interrupt方法的时候,这个线程会从wait set中出来,先重新获得锁定,再抛出InterruptedException。注意,在获得锁定前,是不会抛出InterruptedException异常的。
为了加深理解,这里对比一下notify/notifyAll方法和interrupt方法。首先,notify/notifyAll方法是java.lang.Object类(及其子类)实例的方法,而interrupt方法是java.lang.Thread类(及其子类)实例的方法。其次,notify/notifyAll方法调用时需要获得锁定,而interrupt方法不用,如前所述,interrupt方法可以在任何时候被调用。最后,被notify/notifyAll方法唤醒的线程是(重新获得锁定后)继续执行wait方法之后的方法,而被interrupt方法唤醒的线程则满足前面所的第二条“可以被取消”,即让被唤醒的线程(重新获得锁定后)在wait方法上抛出InterruptedException。
取消sleep
当sleep中的线程被调用interrupt方法时,会马上(不用想取消wait一样,还要获得锁定)放弃sleep状态,并抛出InterruptedException异常。
取消join
当线程以join方法等待其他线程结束时,可以被调用interrupt方法来马上取消等待其他线程结束。
下面是关于java内部是怎么实现取消上面三个方法的等待的。在线程内部,有一个标志位表示线程的中断状态。有两个方法可以设置这个状态,interrupt方法和interrupted方法,interrupted方法属于java.lang.Thread类(及其子类)的静态方法,用来返回 当前线程的中断状态,并清除这个状态。调用interrupt方法将设置此标志位(表示让被调用线程处于中断状态),调用interrupted方法返回值是当前线程是否被中断,并取消此标志位(表示让当前线程处于非中断状态)。在实现细节上,会抛出InterruptedException异常的sleep,wait和join方法在内部不断的检测这个中断状态,如果发现被设置了,则抛出InterruptedException异常。java.lang.Thread类(及其子类)实例还有一个isInterrupted方法来检测这个标志位,如果被设置了返回true,否则返回false。还需要进一步补充的是:interrupt方法和interrupted方法的区别。可以对任意的一个线程调用interrupt方法,但是只能对当前的线程(即正在运行的线程)调用interrupted方法(此方法是静态方法),所以,在程序中无法清除其他线程的中断状态了。
参考:
《Java多线程设计模式》,中国铁道出版社,2005,结城浩 文章来源: http://localhost/wp2/?p=99
前面的Guarded Suspension Pattern和Balking Pattern都比较极端。一个是“不让?爷不玩了”,另一个是“不行!我一定要玩!”。而,Guarded Timeout Patter就中庸的多了,是“现在不让玩?那我等等吧。如果超过我等待的时间了,我就不玩了”。 还是以代码说话:
class A{
private long timeout; //等待的最长时间
public synchronized void changeState(){
改变状态 通知等待的线程不同再等了(notify/notifyAll)
}
public synchronized void guardedMethod() throws InterruptedException{
long start = System.currentTimeMillis(); //开始时刻
while(条件成立不成立){
long now = System.currentTimeMillis(); //现在时刻
long rest = timeout - (now -start); //还需要等待的时间
if(rest <= 0){throw new InterruptedException("...");} //如果为等待时间为0或者为负数,就不等了。
等着一段时间吧,如果超过我等待的最长时间了,我就不玩了(wait(rest)) //当wait的时间超过rest时,也会抛出InteruptedException。
}
进行处理
}
}
在通常情况下,会对if(rest<=0){...}中抛出的异常进行一下包装,即继承InterruptedException异常,是得调用者知道是超时了(wait(rest),interrupt方法都可能会抛出InterruptedException,所以必须包装一下,让上层程序识别)。
参考: 《Java多线程设计模式》,中国铁道出版社,2005,结城浩
文章来源: http://localhost/wp2/?p=88
Balking Pattern重在“balking”,balking的意思是“退缩不前”,在棒球运动的意思是“当跑垒员在垒时,投手在投手板但’中途放弃‘投球的动作”(呵呵,对棒球不懂...)。另外,这种模式和Guarded Suspension Pattern有点类似,也是有要检测警戒条件是否成立,不过,如果不成立,就不用等待了,直接就放弃了。呵呵,这种模式还是想的比较开啊(不行?那爷不赔你玩了:)),相比之下,Guarded Suspension Pattern就执着的多了:)。 从代码的角度看,如下: class A{ public synchronized void guardedMethod(){ if(警戒条件不成立){ return; } 进行处理 改变状态 } } 下面给出参考书中列出的一个使用Balking Pattern的实例:即文本编辑器的自动保存功能。当在编辑文件的时候,后台有个线程会定期的对文件进行保存,防止程序崩溃时文件内容的丢失。那么,文件是否被修改就是这里的警戒条件。当然,还得有另外一个字段,就是当前的数据。编辑程序会调用synchronized的方法对文件数据进行修改,并设置警戒条件(为什么用synchronized?是因为防止更改操作和保存的冲突,否则,可能保存的不是最新的数据)。那么,后台的定时保存线程,会定时调用保存文件这个guardedMethod(),如果文件已经被(编辑程序)保存了,那么就balking了,否则,就保存。下面是代码:
class Data{
public synchronized void changeData(String content){
this.content = content; changed = true;
}
public synchronized void guardedMethod(){
if(!changed){ return; }
doSave();
changed = false;
}
private vodi doSave(){}
}
注意上面的doSave方法不是synchronized。 Balking Patter的适用场合:
- 不需要可以去执行的时候。如上面说的自动保存的例子。
- 不想等待警戒条件成立时。
- 警戒条件只有一次成立时。比如仅仅需要进行一次初始化(不是在构造函数中)的共享资源类。
参考: 《Java多线程设计模式》,中国铁道出版社,2005,结城浩
文章来源: http://localhost/wp2/?p=86
Guarded Suspension Pattern就是“当访问的共享资源被保护(防卫)时,那么线程就挂起”,生活中的例子就是当你和女朋友准备出去玩,你给女朋友打电话说该走了,女朋友说还没准备好,那你只能等在那里知道你女朋友收拾好了才能出去:)。 相对Single Threaded Pattern的任何线程对共享资源的访问仅仅是多个线程不能同时访问unsafeMethod,Guared Suspension Pattern就稍微复杂点了,它有个概念就是“条件”。当共享资源的条件准备好时,才能让其他线程进行访问,如果条件没有准备好,对不起,先等着吧。所以,这个模式里面还必须有一个改变“条件”使其成立的方法,还得有一个通知等待的线程不用再等的方法,否则,那些线程就在那里死等了...。 Guarded Suspension Pattern中对共享资源叫做Guarded Object(被防卫的对象),unsafeMethod方法称之为guardedMethod。当线程执行guardedMethod方法时,只要满足警戒条件,就会马上执行。当警戒条件不成立时,就要开始等待。警戒条件的成立与否,会随着Guarded Object状态的变化而变化。 从代码的角度看,如下:
class A{
public synchronized void changeState(){
改变状态 通知等待的线程不同再等了(notify/notifyAll)
}
public synchronized void guardedMethod(){
while(条件成立不成立){
//这里不能是if,至于原因就好好想想吧:)(需要重点理解wait/notify/notifyAll的处理过程)
等着吧(wait)
} 进行处理
}
}
这种模式有一些变形: busy wait,即忙碌的等待。即在while循环中不用wait,而用yield;在changeState中不用notify/notifyAll。但是,这种变形的缺点是等待的线程仍然在运行,只不过一直在检测运行时间是否满足。 参考: 《Java多线程设计模式》,中国铁道出版社,2005,结城浩
文章来源: http://localhost/wp2/?p=82
Immutable Pattern的关键在于共享资源是immutable(不会改变的)。即在实例产生后,没有改变字段的方法了,即只有只读的方法(所有的方法都是safeMethod),那么任何线程对共享资源的访问就不可造成冲突了。就算想破坏这个共享资源都没有办法,呵呵。 String类就是Immutable Pattern的典型。String类没有提供任何改变字符串属性的方法。当然就是Immutable Pattern了。 从代码上来看,Immutable Pattern的形式如下:
class A{
public void safeMethod1(){}
publi c void safeMethod2(){}
}
由于没有用到synchronized关键字,那么访问共享资源的效率是很高的。在某些情况下,如果某个共享资源用到了synchronized关键字,即不是immtable。那么,可以根据这个类的具体用处,分为两个类,一个是immutable,另一个是mutable(可变的),如果这两个类可以互相转化,那么在不同的场合用不同的类就可以提高程序的效率了。Java中对字符串这个共享资源提供了两个类:String类和StringBuffer类。他们就是对应的immutable和mutable,两者可以通过构造函数(String有个构造函数的参数是StringBuffer,StringBuffer有个构造函数的参数String)转化。 参考: 《Java多线程设计模式》,中国铁道出版社,2005,结城浩
文章来源: http://localhost/wp2/?p=75
Single Threaded Execution模式的核心就是single,即某个共享资源同时只能被某一个线程访问。可以做如下比喻来理解这个模式:门(共享资源),人(线程)。一个门一次只能由一个人通过。如果一个人正在通过这个门,那么其他人只能等待了。 当然,共享资源中某些方法是线程安全的(SafeMethod),就不用考虑多个线程同时调用的情况了。只有对不安全的方法(UnsafeMethod)才需要考虑多线程访问的问题。 可以对Single Thread Execution模式这样理解:如果另外的线程也行执行被保护的UnsafeMethod,那么就需要判断是否有其他线程正在执行被保护的UnsafeMethod。如果有,则等待;没有,则执行。 对Single Threaded Execution Pattern来说,代码的典型表现形式就是对所有的UnsafeMethod方法加上synchronized关键字。如:
class A{
public void safeMethod(){ }
public synchronized void unsafeMethod1(){ }
publi synchronized void unsafeMethod2(){ }
}
当下面的情况发生时,可能会出现死锁
- 有多个共享资源
- 线程锁定了一个共享资源,但还没有解除锁定就锁定了另外一个共享资源
- 各个线程获取共享资源的顺序不固定
也就是说,打破上面的三个情况的任何一个,就可以避免死锁的发生。 参考: 《Java多线程设计模式》,中国铁道出版社,2005,结城浩
文章来源: http://localhost/wp2/?p=70
Oracle的数据库驱动有两种,oci和thin,没有用过oci,这里用的是thin。 问题描述: 有一张表MESSAGE,里面有个字段是content varchar2(4000)。 如果直接用Statement来更新这个字段,是不会用任何问题的。因为Statement的原理就是直接将整个sql语句发到数据库执行。 但是,如果用PreparedStatement的setString()方法来设置这个字段,就有问题了,当设置的字符串长度大于2000时,就会报错:”java.sql.SQLException: 数据大小超出此类型的最大值“。 问题分析: 这些天学着用iBatis,就遇到了上面的这个问题。因为如果在iBatis中使用内联参数(#做占位符),底层实现的时候就是用的PreparedStatement来实现的,所以就遇到了上面的问题。 至于为什么用PreparedStatement会出先这个问题,JavaEye上的一篇文章《当PreparedStatement中的参数遇到大字符串》给出了很好的解释(牛逼啊!)
现在通过Oracle提供的JDBC文档来详细看看问题的来由。
我们都知道Oracle提供了两种客户端访问方式OCI和thin,
在这两种方式下,字符串转换的过程如下:
1、JDBC OCI driver:
在JDBC文档中是这么说的:
“If the value of NLS_LANG is set to a character set other than US7ASCII or WE8ISO8859P1, then thedriver uses UTF8 as the client character set. This happens automatically and does not require any user intervention. OCI then converts the data from the database character set to UTF8. The JDBC OCI driver then passes the UTF8 data to the JDBC Class Library where the UTF8 data is converted to UTF-16. ”
2、JDBC thin driver:
JDBC文档是这样的:
“If the database character set is neither ASCII (US7ASCII) nor ISO Latin1 (WE8ISO8859P1), then the JDBC thin driver must impose size restrictions for SQL CHAR bind parameters that are more restrictive than normal database size limitations. This is necessary to allow for data expansion during conversion.The JDBC thin driver checks SQL CHAR bind sizes when a setXXX() method (except for the setCharacterStream() method) is called. If the data size exceeds the size restriction, then the driver returns a SQL exception (SQLException: Data size bigger than max size for this type) from the setXXX() call. This limitation is necessary to avoid the chance of data corruption when conversion of character data occurs and increases the length of the data. This limitation is enforced in the following situations:
(1)Using the JDBC thin driver (2)Using binds (not defines) (3)Using SQL CHAR datatypes (4)Connecting to a database whose character set is neither ASCII (US7ASCII) nor ISO Latin1 (WE8ISO8859P1) When the database character set is neither US7ASCII nor WE8ISO8859P1, the JDBC thin driver converts Java UTF-16 characters to UTF-8 encoding bytes for SQL CHAR binds. The UTF-8 encoding bytes are then transferred to the database, and the database converts the UTF-8 encoding bytes to the database character set encoding.” 原来是JDBC在转换过程中对字符串的长度做了限制。这个限制和数据库中字段的实际长度没有关系。 所以,setCharacterStream()方法可以逃过字符转换限制,也就成为了解决此问题的方案之一。 而JDBC对转换字符长度的限制是为了转换过程中的数据扩展。 问题解决: 根据上面的分析,可以用PreparedStatement的setCharacterStream()方法来解决问题。 在iBatis中,可以使用下面的自定义类型处理器来处理(参考文章《用ibatis向oracle数据库的varchar2(4000)列写值的问题》)
/**
* String implementation of TypeHandler
*/
public class StringTypeHandler extends BaseTypeHandler implements TypeHandler {
/**
* 在使用oracle时,如果在一个varchar2(4000)的字段上插入的字符过长(一般只能插入666个汉字,视字符集不同会有所不同),
* 会导致失败,具体报错会因驱动版本不同而不同。
* 如果使用setCharacterStream则可以插入最多的字符。因此,我将这个方法改了一下。
*/
public void setParameter(PreparedStatement ps, int i, Object parameter,
String jdbcType) throws SQLException {
//原来的代码
//ps.setString(i, ((String) parameter));
//以下是我加的代码,为了尽量提高效率,作了一下判断
String s = (String) parameter;
if (s.length() < 667) { //以字符中全是汉字为底线。
ps.setString(i, s);
} else {
ps.setCharacterStream(i, new StringReader(s), s.length());
}
}
public Object getResult(ResultSet rs, String columnName) throws
SQLException {
Object s = rs.getString(columnName);
if (rs.wasNull()) {
return null;
} else {
return s;
}
}
public Object getResult(ResultSet rs, int columnIndex) throws SQLException {
Object s = rs.getString(columnIndex);
if (rs.wasNull()) {
return null;
} else {
return s;
}
}
public Object getResult(CallableStatement cs, int columnIndex) throws
SQLException {
Object s = cs.getString(columnIndex);
if (cs.wasNull()) {
return null;
} else {
return s;
}
}
public Object valueOf(String s) {
return s;
}
}
其实,上面的解决方案是比较麻烦的,今天发现了一个更好的解决方案,就是将oracle jdbc驱动换成用于oracle10g第二版的驱动ojdbc14.jar。就行了,唉,前面折腾了几天的问题竟然可以这么容易地解决...
文章来源: http://localhost/wp2/?p=63
这里对final关键字进行总结。
final类
当类声明为final时,就不能定义这个类的子类。因为final类的类无法定义子类,所以final类声明的所有方法不会被覆盖(override)。
final方法
若将实例方法声明为final时,这个方法无法被子类所覆盖(override)。
若将类方法(static方法)声明为final时,这个方法无法被子类所隐藏(hide)。对隐藏这个术语不熟,本文最后会加上。
final字段(final属性)
final字段的值只能指定一次。
final实例字段的值只能在定义时或者在构造器中指定。
如:
class A{
final int i = 1;
}
class A{
final int i;
public A(){
this.i = 2;
}
}
final类字段的值只能在定义是或者在static块(静态初始化块)中指定。
class A{
static final int i = 12;
}
class A{
static final int i;
static{
i = 12;
}
}
final局部变量和final参数
final局部变量的值只能指定一次。
final参数的值在方法被调用时,由实参指定,不能再次指定(实际上也满足被指定一次的原则)。
下面对java中类的继承中的覆盖(override)和隐藏(hide)进行总结。
在《Java核心技术卷一》中对隐藏是采用的访问限定符(如public,private,protected)来实现的。这里的隐藏不是采用访问限定符来实现的,而是采用子类和父类有同名的类方法和字段(实例字段和静态字段)来实现的。在实际编程中,隐藏一般只用于类方法,即父类的类方法被子类中同名(这里的同名指方法名和参数都一样,其实返回值也必须一样,可以试一试)的类方法隐藏。
这里继续总结一下:
- 子类可以覆盖父类的实例方法(方法名、参数和返回值都一样),另外,这里还有一个重载(overload)的概念,重载是一个静态的概念,是在编译时根据方法名和参数来确定的,重载是一个类自身的一个属性,和继承没有关系。
- 子类可以隐藏父类的类方法(方法名、参数和返回值都一样)
- 子类可以隐藏父类的字段(实例字段和静态字段)(通过在子类中定义字段名相同(类型可和父类不一样)的字段即可)。
覆盖是动态的概念,是在运行时决定的。重载和隐藏是静态的概念,是在编译时决定的。
参考:
- 《Java多线程设计模式》中国铁道出版社 2005
文章来源: http://localhost/wp2/?p=61
编程时你需要考虑的不是内存的物理地址(memory address),而是一种逻辑上的内存模型。
Java虚拟机将其管辖的内存大致分三个逻辑部分:
- 方法区(Method Area)、
- Java栈
- Java堆。
方法区是 静态分配(static allocation)的,编译器将变量在绑定在某个存储位置上,而且这些绑定不会在运行时改变。Java方法区的一个重要部分,也是静态分配最典型的例子,是常数池,源代码中的 命名常量、String常量和static 变量保存在其中。
Java Stack是一个逻辑概念,特点是后进先出,此外没有特别的要求。Java Stack并不代表任何特定的内存区间,也不限制它的实现方式。一个栈的空间可能是连续的,也可能是不连续的。最典型的Stack应用是方法的调 用,Java虚拟机每调用一次方法就创建一个 方法帧(frame),退出该方法则对应的方法帧被弹出(pop)。栈分配存在一些局限:Java栈所处理的方法帧和局部变量,都将随着方法帧弹出而结束,显然局部变量无法从一个帧保持到下一个帧,被调方法的帧不可能比调用方法的寿命更长。因此,从数据保存来看, 栈分配适用于由作用域决定生命周期的局部变量。
Java堆(Heap)堆分配(heap allocation)意味着以随意的顺序,在运行时进行存储空间分配和收回的内存管理模型。堆中存储的数据常常是大小、数量和生命期在编译时无法确定的。 Java对象的内存总是在heap中分配。文章来源: http://localhost/wp2/?p=59
在Java中,为了生成一个线程,有两种方法:
- 继承Thread类,覆盖run方法。在使用时,调用Thread实例的start方法即可启动一个线程,此线程将执行run方法里面的代码。
- 实现Runnable接口,实现run方法。在使用时,调用Thread实例(传入实现Runnable接口的类实例)的start方法,此线程将执行run方法里面的代码。
启动线程的方法只能用start方法,不能用run方法...start方法才会启动一个线程去执行run方法,而run方法仅仅是一个类实例的方法!!!
在此,需要强调的是,线程和Thread类的区别。线程是一个动态的概念,而Thread类(或其实例)是静态的概念。虽然说从代码上看,执行Thread实例的start方法或者run方法(只能在实现Runnable接口时)好像把Thread实例当作了一个线程,当事实上,应该这样理解:Thread类就是一个普通的类,和其他类没有什么两样,但是他的start方法或者run方法比较特殊,可以启动一个新的线程。当新线程启动后,就马上执行Thread类里面run方法的代码或者Runnable接口的run方法。 在Java中,为了实现多线程之间的同步和互斥,提供了一个关键字,synchronized。这个关键字有两个用法:
- 用于方法声明中。如: public synchronized void methd(){ .... } 把这种用法称之为synchronized方法。
- 用于方法体中。如: public void method(){ synchronized(this){ .... } }把这种方法称为synchronized语句。
当不同的线程运行synchronized方法或者synchronized语句时,首先会获得锁,然后再执行,当退出时,会释放锁。当锁还没有被释放时,如果有其他线程访问,那么这些线程会阻塞。如果锁被释放,那么jvm会让所有在此锁上阻塞的所有线程竞争,将有一个线程得到锁,其他线程将继续阻塞。 其实,synchronized方法就是在方法体的最前面加了一个锁,在方法体的最后面释放掉了这个锁。synchronized语句就是在被包含的语句 前加了一个锁,在被包含的语句后释放掉了锁。这里需要强调锁的概念,可以这么认为,Java中每一个对象都有一个锁的,可以使用synchronized 方法和synchronized语句来获得这些锁。 下面通过实例来理解synchronized方法和synchronized语句。 1,下面的两个方法是等价的: public synchronized void methd(){ .... } public void method(){ synchronized(this){ .... } } 怎么理解上面的等价? synchronized方法(只能)获得当前对象的锁,那么,在synchronized语句中显示的指明要获得锁的对象为this就可以使两者等价了。 在synchronized方法中,多个线程同时只能访问某个对象(可能含多个synchronized方法)的一个synchonized方法。 对下面这个银行类来说,使用synchronized方法就可以达到线程的互斥。多个线程同时只能有一个线程访问一个synchronized方法。 public class Bank{ public synchronized void deposite(){ 对某个帐户进行增加 } public synchronized void withdraw(){ 对某个帐户进行减少 } } 如果,我们想对某个对象的方法进行更灵活的线程互斥访问,可以使用synchornized语句,显示的声明要获得的锁的对象。 2, public synchronized static void methd(){ .... } 上面的方法都可以防止多个线程同时访问这个类中的method方法。它可以对类的所有对象实例起作用。他等价于下面的方法。 public static void method(){ synchronized(this.getClass()){ .... } } 这里还需要补充一下,synchronized方法被继承后就不是synchronized的了,除非在子类中再次声明方法为synchronized的。 Object类是Java所有对象的基类,Object类中有几个方法,提供了对多线程编程的支持:
- wait()方法将当前运行的线程阻塞,放置于当前线程锁执行的对象的wait set中,然后取消此线程对锁的获得。
- notify()/notifyAll()方法将把当前线程执行的对象的wait set中的某一个/所有线程拿出来。
注意,wait和notify/notifyAll方法只能在线程已获得对象实例的锁时才能调用,否则,将抛出java.lang.IllegalMonitorStateException。 这篇文章写的好累啊,语言组织能力咋这么弱...
文章来源: http://localhost/wp2/?p=52
由于需要,学习了Oracle日志分析工具LogMiner的使用,在此记录一下:
1,确定你的Oracle安装的目录,下面用%ORALCE_HOME%表示。
2,必须以DBA角色登录,命令如下
SQL>sqlplus /nolog
SQL>conn sys/manager@wymis as sysdba
3,(如果第一次做日志分析)安装LogMiner
SQL> @%ORALCE_HOME%\ora90\rdbms\admin\dbmslm.sql
SQL> @%ORALCE_HOME%\ora90\rdbms\admin\dbmslmd.sql
4,设置UTL_FILE_DIR值,这个值表示存放日志分析相关文件的目录,设置方法可以到Oracle的企业管理器下面设置,这个值的例子如c:\log,注意,最后没有\符号。设置完后,需要重新启动数据库。
5,生成数据字典
SQL> execute dbms_logmnr_d.build(-
> dictionary_filename => 'logminer_dict.dat',-
> dictionary_location => 'c:\import');
注意上面每行代码后有一个'-'符号,表示输入还没有结束。
注意,dictionary_location的值必须与第4步中UTL_FILE_DIR的值一样。
6,创建要分析的日志文件列表,
创建列表
SQL> EXECUTE dbms_logmnr.add_logfile(-
LogFileName=>' e:\Oracle\oradata\sxf\redo01.log',-
Options=>dbms_logmnr.new);
添加其他日志文件到列表
SQL> EXECUTE dbms_logmnr.add_logfile(
LogFileName=>' e:\Oracle\oradata\sxf\redo02.log',
Options=>dbms_logmnr.addfile);
注意,LogFileName的值可以到相应的数据库实例文件夹下面的实例获得。
7,使用LogMiner进行日志分析
SQL> execute dbms_logmnr.start_logmnr(-
> dictfilename => 'c:\import\logminer_dict.dat',-
> starttime => to_date('2001-9-18 00:00:00','YYYY-MM-DD HH24:MI:SS'),-
> endtime => to_date('2009-10-30 00:00:00','YYYY-MM-DD HH24:MI:SS'));
注意,这里的starttime和endtime的范围必须是你的日志文件涉及的范围。如果实在拿不准,可以不用这两个参数。
8,分析结果
LogMiner分析的结果存放在v$LogMnr_Contents表里面。具体的分析,网上有很多好的文章,就不再写了。
再转一篇比较好的文章,来自http://www.oracle.com.cn/viewthread.php?tid=22975的 robertmao_2003
作为Oracle DBA,我们有时候需要追踪数据误删除或用户的恶意操作情况,此时我们不仅需要查出执行这些操作的数据库账号,还需要知道操作是由哪台客户端(IP地址 等)发出的。针对这些问题,一个最有效实用而又低成本的方法就是分析Oracle数据库的日志文件。本文将就Oracle日志分析技术做深入探讨。
一、如何分析即LogMiner解释
从目前来看,分析Oracle日志的唯一方法就是使用Oracle公司提供的LogMiner来进行, Oracle数据库的所有更改都记录在日志中,但是原始的日志信息我们根本无法看懂,而LogMiner就是让我们看懂日志信息的工具。从这一点上看,它 和tkprof差不多,一个是用来分析日志信息,一个则是格式化跟踪文件。通过对日志的分析我们可以实现下面的目的:
1、查明数据库的逻辑更改;
2、侦察并更正用户的误操作;
3、执行事后审计;
4、执行变化分析。
不仅如此,日志中记录的信息还包括:数据库的更改历史、更改类型(INSERT、UPDATE、DELETE、DDL等)、更改对应的SCN号、以及执行 这些操作的用户信息等,LogMiner在分析日志时,将重构等价的SQL语句和UNDO语句(分别记录在V$LOGMNR_CONTENTS视图的 SQL_REDO和SQL_UNDO中)。这里需要注意的是等价语句,而并非原始SQL语句,例如:我们最初执行的是“delete a where c1 <>'cyx';”,而LogMiner重构的是等价的6条DELETE语句。所以我们应该意识到V$LOGMNR_CONTENTS视图中 显示的并非是原版的现实,从数据库角度来讲这是很容易理解的,它记录的是元操作,因为同样是“delete a where c1 <>'cyx';”语句,在不同的环境中,实际删除的记录数可能各不相同,因此记录这样的语句实际上并没有什么实际意义,LogMiner重 构的是在实际情况下转化成元操作的多个单条语句。
另外由于Oracle重做日志中记录的并非原始的对象(如表以及其中的列)名称,而只是它们在Oracle数据库中的内部编号(对于表来说是它们在数据库 中的对象ID,而对于表中的列来说,对应的则是该列在表中的排列序号:COL 1, COL 2 等),因此为了使LogMiner重构出的SQL语句易于识别,我们需要将这些编号转化成相应的名称,这就需要用到数据字典(也就说LogMiner本身 是可以不用数据字典的,详见下面的分析过程),LogMiner利用DBMS_LOGMNR_D.BUILD()过程来提取数据字典信息。
LogMiner包含两个PL/SQL包和几个视图:
1、dbms_logmnr_d包,这个包只包括一个用于提取数据字典信息的过程,即dbms_logmnr_d.build()过程。
2、dbms_logmnr包,它有三个过程:
add_logfile(name varchar2, options number) - 用来添加/删除用于分析的日志文件;
start_logmnr(start_scn number, end_scn number, start_time number,end_time number, dictfilename varchar2, options number) - 用来开启日志分析,同时确定分析的时间/SCN窗口以及确认是否使用提取出来的数据字典信息。
end_logmnr() - 用来终止分析会话,它将回收LogMiner所占用的内存。
与LogMiner相关的数据字典。
1、v$logmnr_dictionary,LogMiner可能使用的数据字典信息,因logmnr可以有多个字典文件,该视图用于显示这方面信息。
2、v$logmnr_parameters,当前LogMiner所设定的参数信息。
3、v$logmnr_logs,当前用于分析的日志列表。
4、v$logmnr_contents,日志分析结果。
二、Oracle9i LogMiner的增强:
1、支持更多数据/存储类型:链接/迁移行、CLUSTER表操作、DIRECT PATH插入以及DDL操作。在V$LOGMNR_CONTENTS的SQL_REDO中可以看到DDL操作的原句(CREATE USER除外,其中的密码将以加密的形式出现,而不是原始密码)。如果TX_AUDITING初始化参数设为TRUE,则所有操作的数据库账号将被记录。
2、提取和使用数据字典的选项:现在数据字典不仅可以提取到一个外部文件中,还可以直接提取到重做日志流中,它在日志流中提供了操作当时的数据字典快照,这样就可以实现离线分析。
3、允许对DML操作按事务进行分组:可以在START_LOGMNR()中设置COMMITTED_DATA_ONLY选项,实现对DML操作的分组,这样将按SCN的顺序返回已经提交的事务。
4、支持SCHEMA的变化:在数据库打开的状态下,如果使用了LogMiner的DDL_DICT_TRACKING选项,Oracle9i的 LogMiner将自动对比最初的日志流和当前系统的数据字典,并返回正确的DDL语句,并且会自动侦察并标记当前数据字典和最初日志流之间的差别,这样 即使最初日志流中所涉及的表已经被更改或者根本已经不存在,LogMiner同样会返回正确的DDL语句。
5、在日志中记录更多列信息的能力:例如对于UPDATE操作不仅会记录被更新行的情况,还可以捕捉更多前影信息。
6、支持基于数值的查询:Oracle9i LogMiner在支持原有基于元数据(操作、对象等)查询的基础上,开始支持基于实际涉及到的数据的查询。例如涉及一个工资表,现在我们可以很容易地查 出员工工资由1000变成2000的原始更新语句,而在之前我们只能选出所有的更新语句。
三、Oracle8i/9i的日志分析过程
LogMiner只要在实例起来的情况下都可以运行,LogMiner使用一个字典文件来实现Oracle内部对象名称的转换,如果没有这个字典文件,则直接显示内部对象编号,例如我们执行下面的语句:
delete from "C"."A" where "C1" = ‘gototop’ and ROWID = 'AAABg1AAFAAABQaAAH';
如果没有字典文件,LogMiner分析出来的结果将是:
delete from "UNKNOWN"."OBJ# 6197" where "COL 1" = HEXTORAW('d6a7d4ae') and ROWID
= 'AAABg1AAFAAABQaAAH';
如果想要使用字典文件,数据库至少应该出于MOUNT状态。然后执行dbms_logmnr_d.build过程将数据字典信息提取到一个外部文件中。下面是具体分析步骤:
1、确认设置了初始化参数:UTL_FILE_DIR,并确认Oracle对改目录拥有读写权限,然后启动实例。示例中UTL_FILE_DIR参数如下:
SQL> show parameter utl
NAME TYPE VALUE
------------------------ ----------- ------------------------------
utl_file_dir string /data6/cyx/logmnr
这个目录主要用于存放dbms_logmnr_d.build过程所产生的字典信息文件,如果不用这个,则可以不设,也就跳过下面一步。
2、生成字典信息文件:
exec dbms_logmnr_d.build(dictionary_filename =>'
dic.ora',dictionary_location => '/data6/cyx/logmnr');
其中dictionary_location指的是字典信息文件的存放位置,它必须完全匹配UTL_FILE_DIR的值,例如:假设 UTL_FILE_DIR=/data6/cyx/logmnr/,则上面这条语句会出错,只因为UTL_FILE_DIR后面多了一个“/”,而在很多 其它地方对这一“/”是不敏感的。
dictionary_filename指的是放于字典信息文件的名字,可以任意取。当然我们也可以不明确写出这两个选项,即写成:
exec dbms_logmnr_d.build('dic.ora','/data6/cyx/logmnr');
如果你第一步的参数没有设,而直接开始这一步,Oracle会报下面的错误:
ERROR at line 1:
ORA-01308: initialization parameter utl_file_dir is not set
ORA-06512: at "SYS.DBMS_LOGMNR_D", line 923
ORA-06512: at "SYS.DBMS_LOGMNR_D", line 1938
ORA-06512: at line 1
需要注意的是,在oracle817 for Windows版中会出现以下错误:
14:26:05 SQL> execute dbms_logmnr_d.build('oradict.ora','c:\oracle\admin\ora\log');
BEGIN dbms_logmnr_d.build('oradict.ora','c:\oracle\admin\ora\log'); END;
*
ERROR at line 1:
ORA-06532: Subscript outside of limit
ORA-06512: at "SYS.DBMS_LOGMNR_D", line 793
ORA-06512: at line 1
解决办法:
编辑"$ORACLE_HOME/rdbms/admindbmslmd.sql"文件,把其中的
TYPE col_desc_array IS VARRAY(513) OF col_description;
改成:
TYPE col_desc_array IS VARRAY(700) OF col_description;
保存文件,然后执行一遍这个脚本:
15:09:06 SQL> @c:\oracle\ora81\rdbms\admin\dbmslmd.sql
Package created.
Package body created.
No errors.
Grant succeeded.
然后重新编译DBMS_LOGMNR_D包:
15:09:51 SQL> alter package DBMS_LOGMNR_D compile body;
Package body altered.
之后重新执行dbms_logmnr_d.build即可:
15:10:06 SQL> execute dbms_logmnr_d.build('oradict.ora','c:\oracle\admin\ora\log');
PL/SQL procedure successfully completed.
3、添加需要分析的日志文件
SQL>exec dbms_logmnr.add_logfile( logfilename=>'
/data6/cyx/rac1arch/arch_1_197.arc', options=>  bms_logmnr.new);
PL/SQL procedure successfully completed.
这里的options选项有三个参数可以用:
NEW - 表示创建一个新的日志文件列表
ADDFILE - 表示向这个列表中添加日志文件,如下面的例子
REMOVEFILE - 和addfile相反。
SQL> exec dbms_logmnr.add_logfile( logfilename=>'
/data6/cyx/rac1arch/arch_2_86.arc', options=> bms_logmnr.addfile);
PL/SQL procedure successfully completed.
4、当你添加了需要分析的日志文件后,我们就可以让LogMiner开始分析了:
SQL> exec dbms_logmnr.start_logmnr(dictfilename=>'/data6/cyx/logmnr/dic.ora');
PL/SQL procedure successfully completed.
如果你没有使用字典信息文件(此时我们只需要启动实例就可以了),那么就不需要跟dictfilename参数:
SQL> exec dbms_logmnr.start_logmnr();
PL/SQL procedure successfully completed.
当然dbms_logmnr.start_logmnr()过程还有其它几个用于定义分析日志时间/SCN窗口的参数,它们分别是:
STARTSCN / ENDSCN - 定义分析的起始/结束SCN号,
STARTTIME / ENDTIME - 定义分析的起始/结束时间。
例如下面的过程将只分析从 '2003-09-21 09:39:00'到'2003-09-21 09:45:00'这段时间的日志:
SQL> exec dbms_logmnr.start_logmnr(dictfilename=>'/data6/cyx/logmnr/dic.ora' , -
starttime => '2003-09-21 09:39:00',endtime => '2003-09-21 09:45:00');
PL/SQL procedure successfully completed.
上面过程第一行结尾的“-”表示转行,如果你在同一行,则不需要。我们可以看到有效日志的时间戳:
SQL> select distinct timestamp from v$logmnr_contents;
TIMESTAMP
-------------------
2003-09-21 09:40:02
2003-09-21 09:42:39
这里需要注意的是,因为我之前已经设置NLS_DATE_FORMAT环境变量,所以上面的日期可以直接按这个格式写就行了,如果你没有设,则需要使用to_date函数来转换一下。
SQL> !env|grep NLS
NLS_LANG=american_america.zhs16cgb231280
NLS_DATE_FORMAT=YYYY-MM-DD HH24:MI:SS
ORA_NLS33=/oracle/oracle9/app/oracle/product/9.2.0/ocommon/nls/admin/data
使用to_date的格式如下:
exec dbms_logmnr.start_logmnr(dictfilename=>'/data6/cyx/logmnr/dic.ora',-
starttime => to_date('2003-09-21 09:39:00','YYYY-MM-DD HH24:MI:SS'),-
endtime => to_date('2003-09-21 09:45:00','YYYY-MM-DD HH24:MI:SS'));
STARTSCN 和ENDSCN参数使用方法类似。
5、好了,在上面的过程执行结束之后,我们就可以通过访问与LogMiner相关的几个视图来提取我们需要的信息了。其中在v$logmnr_logs中 可以看到我们当前分析的日志列表,如果数据库有两个实例(即OPS/RAC),在v$logmnr_logs中会有两个不同的THREAD_ID。
而真正的分析结果是放在v$logmnr_contents中,这里面有很多信息,我们可以根据需要追踪我们感兴趣的信息。后面我将单独列出来讲常见的追踪情形。
6、全部结束之后,我们可以执行dbms_logmnr.end_logmnr过程退出LogMiner分析过程,你也可以直接退出SQL*PLUS,它会自动终止。
四、如何利用LogMiner分析Oracle8的日志文件
虽然说LogMiner是Oracle8i才推出来,但我们同样可以用它来分析Oracle8的日志文件,只不过稍微麻烦了一点,并且有一定的限制,下面是具体做法:
我们首先复制Oracle8i的$ORACLE_HOME/rdbms/admin/dbmslmd.sql脚本到Oracle8数据库所在主机的同样目 录;这个脚本用于创建dbms_logmnr_d包(注意,Oracle9i中还将创建dbms_logmnr包),如果是8.1.5脚本名字为 dbmslogmnrd.sql。然后在Oracle8的数据库上运行这个脚本,之后使用dbms_logmnr_d.build过程创建字典信息文件。 现在我们就可以把Oracle8的归档日志连同这个字典信息文件复制到Oracle8i数据库所在的主机上,之后在Oracle8i数据库中从上面分析过 程的第三步开始分析Oracle8的日志,不过
dbms_logmnr.start_logmnr()中使用的是Oracle8的字典信息文件。
按照我前面所说的那样,如果不是字典文件,我们则可以直接将Oracle8的归档日志复制到Oracle8i数据库所在主机,然后对它进行分析。
其实这里涉及到了一个跨平台使用LogMiner的问题,笔者做过试验,也可以在Oracle9i中来分析Oracle8i的日志。但这些都是有所限制的,主要表现在:
1、LogMiner所使用的字典文件必须和所分析的日志文件是同一个数据库所产生的,并且该数据库的字符集应和执行LogMiner数据库的相同。这很好理解,如果不是同一个数据库所产生就不存在对应关系了。
2、生成日志的数据库硬件平台和执行LogMiner数据库的硬件平台要求一致,操作系统版本可以不一致。笔者做试验时(如果读者有兴趣可以到我网站 http://www.ncn.cn上下载试验全过程,因为太长就不放在这里了),所用的两个数据库操作系统都是Tru64 UNIX,但一个是 V5.1A,另一个则是V4.0F。如果操作系统不一致则会出现下面的错误:
ORA-01284: file /data6/cyx/logmnr/arch_1_163570.arc cannot be opened
ORA-00308: cannot open archived log '/data6/cyx/logmnr/arch_1_163570.arc'
ORA-27048: skgfifi: file header information is invalid
ORA-06512: at "SYS.DBMS_LOGMNR", line 63
ORA-06512: at line 1
五、分析v$logmnr_contents
前面我们已经知道了LogMiner的分析结果是放在v$logmnr_contents中,这里面有很多信息,我们可以根据需要追踪我们感兴趣的信息。那么我们通常感兴趣的有哪些呢?
1、追踪数据库结构变化情况,即DDL操作,如前所述,这个只有Oracle9i才支持:
SQL> select timestamp,sql_redo from v$logmnr_contents2
where upper(sql_redo) like '%CREATE%';
TIMESTAMP
-------------------
SQL_REDO
-------------------------
2003-09-21 10:01:55
create table t (c1 number);
2、追踪用户误操作或恶意操作:
例如我们现实中有这样需求,有一次我们发现一位员工通过程序修改了业务数据库信息,把部分电话的收费类型改成免费了,现在就要求我们从数据库中查出到底是 谁干的这件事?怎么查?LogMiner提供了我们分析日志文件的手段,其中v$logmnr_contents的SESSION_INFO列包含了下面 的信息:
login_username=NEW_97
client_info= OS_username=oracle8 Machine_name=phoenix1
OS_terminal=ttyp3 OS_process_id=8004 OS_program name=sqlplus@phoenix1
(TNS V1-V3)
虽然其中信息已经很多了,但在我们的业务数据库中,程序是通过相同的login_username登录数据库的,这样单从上面的信息是很难判断的。
不过我们注意到,因为公司应用服务器不是每个人都有权限在上面写程序的,一般恶意程序都是直接通过他自己的PC连到数据库的,这就需要一个准确的定位。 IP追踪是我们首先想到的,并且也满足我们的实际要求,因为公司内部IP地址分配是统一管理的,能追踪到IP地址我们就可以准确定位了。但从面的 SESSION_INFO中我们并不能直接看到IP,不过我们还是有办法的,因为这个SESSION_INFO里面的内容其实是日志从V$SESSION 视图里提取的,我们可以在生产数据库中创建一个追踪客户端IP地址的触发器:
create or replace trigger on_logon_trigger
after logon on database
begin
dbms_application_info.set_client_info(sys_context('userenv', 'ip_address'));
end;
/
现在,我们就可以在V$SESSION视图的CLIENT_INFO列中看到新登录的客户端IP地址了。那么上面的提出的问题就可以迎刃而解了。假如被更新的表名为HMLX,我们就可以通过下面的SQL来找到所需信息:
SQL > select session_info ,sql_redo from v$logmnr_contents
2 where upper(operation) = 'UPDATE' and upper(sql_redo) like '%HMLX%'
3 /
SESSION_INFO
-----------------------------------------
SQL_REDO
-----------------------------------------
login_username=C client_info=10.16.98.26 OS_username=sz-xjs-chengyx Machine_name
=GDTEL\SZ-XJS-CHENGYX
update "C"."HMLX" set "NAME" = 'free' where "NAME" = 'ncn.cn' and ROWID = 'AAABhTAA
FAAABRaAAE';
好了,到此为止,这篇文章就要结束了,如果读者朋友还有什么疑问,可以登录我的个人网站(www.ncn.cn)来获得最新消息,也可以通过MSN(gototop_ncn@hotmail.com)直接和我联系。
六、参考资料:
1、Technical White Paper Oracle9i LogMiner
2、Metalink文档:How to Setup LogMiner(文档ID:111886.1) 文章来源: http://localhost/wp2/?p=50
昨天,遇到一件让自己胆战心惊的事情,就是数据库导出的DMP文件由原来的800多M变为了现在的300多M,整整少了500M!
仔细回想,自己平时操作数据库还是很小心的,就算有失误,也不可能造成那么大的损失啊!
在这里记录一下解决过程:
1,首先当然想到了Oracle的重做日志功能,也学习了Oracle自带的日志分析工具LogMiner的使用方法,等会在另外一篇文章里记录一下这个工具的使用方法。
2,在使用LogMiner之前,突然想到,能不能把800M的数据库和300M的数据库的每张表都单独导出为DMP文件,进行一下大小的对比
3,在用exp导出时,有一个log选项设定导出日志的文件路径,此文件记录了所有导出的数据库表名和记录数,用UltraEdit32的正则表达式功能去除了除开表名的其他不相关数据。
4,用Java编写了一个小程序,读入所有表名,对每个表名单独进行exp操作。
5,果然不出所料,其中有一个表被某个管理员清理过,那个表本来就很大,占到了500多M!
至此,问题解决,总结一下,不管碰到什么意外的问题,不要慌张,冷静分析才是王道!
PS:被删除数据的那张表竟然占到了500多M,而整个数据库才800M,很不解,然后看了一下这张表的模式,发现设计的很有问题,这张表里面表达了多对多的关系,所以数据冗余太大,而且这些冗余根本就不是必须的,反而影响了性能!找常理来说,针对多对多的关系应该转化为两个多对一的关系。 文章来源: http://localhost/wp2/?p=48
今天去听了阿里巴巴的一个宣讲会,感受挺深的...
现在的互联网企业对人才的要求越来越明确了,要不,你精通算法,各种算法;要不,你精通某种编程语言,做过多个项目;总之,就是一个字,精通。
精通,对于我们大部分人来说太难了...一是自己所处的学习环境,什么都在用,要精通某一个,无论从时间还是精力上,谈何容易;二是对于行业的确了解太少,确实不知道什么技术是最需要的;三是大部分人都自己的定位都不甚了解,梦想,对大部分人来说都过于飘渺了(哎,浮躁的社会哺育浮躁的人...),大部分人(很不幸,自己也是其中的一员)的梦想,就是寻找自己的梦想,很可悲...
看到一句话,说“什么都去干的企业,最终会被自己干掉”,想想,对个人而言,又何尝不是?如果对什么都有兴趣,但是,精力有限,什么都不精通,真正在找工作的时候,碰到一些细节的、要求准确性的问题,却是束手无策...这时肯定觉得掌握一大堆时髦、前沿的名词还不如踏踏实实掌握某一个东东好...平时聊天时高谈阔论的骄傲这时化作了一腔默默的无奈...实际点,颠颠自己的分量,在精力允许的范围内,精通一个东西...然后再做其他打算...只有一年就要找工作了,该踏实点了... 文章来源: http://localhost/wp2/?p=46
Flash/Flex与Java之间的数据类型映射,来自red5官方文档:
Please note that Red5 performs automatic parameter conversion, e.g. if you pass a number to a method that takes a String as parameter, it is automatically converted.
* = Only available in Flash Player 9 or newer (AMF3)
** = You can map the class to serialize to in Red5 by adding "[RemoteClass(alias="package.to.RemoteClass")]" above your Flex class definition.
文章来源: http://localhost/wp2/?p=39
今天在做red5和flashplayer之间传递数据时,犯了一个让人郁闷的错误,记录下来,让自己今后保持头脑清醒...
昨天晚上还可以正确传递ArrayCollection,但是今天下午却不行...我的解决方法太失败了,我竟然首先没有对比和昨天的差异,而就是在那不停的测啊,改啊,测啊...还以为发现了red5序列化的一个bug...太傻冒了...遇到这种问题,很自然的应该找昨天为什么行,而今天为什么不行...很明显应该从代码入手...唉,而自己只会看现象...很多时候,多看看代码,问题就会解决的...唉,可能是自己的思维定势吧...改正...
在记录一下错误的原因:自己对NetConnection的编码方式设置成了AMF0,由于ArrayCollection的传递需要AMF3,所以出错了... 文章来源: http://localhost/wp2/?p=37
越来越深刻的觉得,从小到大的各个阶段,不能跳跃前行,只能脚踏实地。
这些天师兄们讲找工作只要算法和C/C++基础好,找工作那是一个一帆风顺...回想本科学习时,当时觉得做项目很牛逼,久而久之,就忽略了项目的基础——算法,回过头来,现在还得重新啃算法。算法里面的一些时间复杂度的证明,又是高数极限里面的一些基础知识(还好,高数还没忘光...)。这一个个鲜活而血淋淋的实例再一次向我昭示了脚踏实地的重要性。
既然已经决定先走技术路线,那么就彻底点,卸下那些与技术路线背道而驰的坏毛病,脚踏实地的走吧,人生可不是买东西,没有折扣啊... 文章来源: http://localhost/wp2/?p=34
linux 分区操作试验
=============
一:试验环境
1.vmware虚拟机
2.linux9.0
3.设置两块硬盘
=============
二:试验步骤
1.在linux9.0中安装第二块硬盘;
2.使用fdisk工具对第二块硬盘分区;
3.格式化分区;
4.挂载分区到系统目录;
5.对挂载点进行存取;
6.卸载挂载点;
7.设置系统启动自动挂载分区;
=============
三:分区工具
1.fdisk使用
因为我使用的是两块scsi硬盘,故第二块硬盘被识别为sdb
查看sdb的分区情况,因为是新硬盘,所以没有任何分区信息;
[root@www root]# fdisk -l /dev/sdb
Disk /dev/sdb: 4294 MB, 4294967296 bytes
255 heads, 63 sectors/track, 522 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
2.对sdb硬盘进行分区操作
[root@www root]# fdisk /dev/sdb
Command (m for help): m
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition //删除分区;
l list known partition types
m print this menu //打印操作菜单;
n add a new partition //建立新分区;
o create a new empty DOS partition table
p print the partition table //打印分区表;
q quit without saving changes //不保存分区表,推出;
s create a new empty Sun disklabel
t change a partition's system id //该表分区的id表示;
u change display/entry units
v verify the partition table
w write table to disk and exit //保存分区表,推出;
x extra functionality (experts only)
3.建立主分区
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-522, default 1):
Using default value 1
Last cylinder or +size or +sizeM or +sizeK (1-522, default 522): +500M
Command (m for help): p
Disk /dev/sdb: 4294 MB, 4294967296 bytes
255 heads, 63 sectors/track, 522 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 62 497983+ 83 Linux
4..创建扩展分区,最好将硬盘的所有剩余空间都作为扩展分区
Command (m for help): n
Command action
e extended
p primary partition (1-4)
e
Partition number (1-4): 2
First cylinder (63-522, default 63):
Using default value 63
Last cylinder or +size or +sizeM or +sizeK (63-522, default 522):
Using default value 522
Command (m for help): p
Disk /dev/sdb: 4294 MB, 4294967296 bytes
255 heads, 63 sectors/track, 522 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 62 497983+ 83 Linux
/dev/sdb2 63 522 3694950 5 Extended
5.创建逻辑分区
Command (m for help): n
Command action
l logical (5 or over)
p primary partition (1-4)
l
First cylinder (63-522, default 63):
Using default value 63
Last cylinder or +size or +sizeM or +sizeK (63-522, default 522): +500M
Command (m for help): p
Disk /dev/sdb: 4294 MB, 4294967296 bytes
255 heads, 63 sectors/track, 522 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 62 497983+ 83 Linux
/dev/sdb2 63 522 3694950 5 Extended
/dev/sdb5 63 124 497983+ 83 Linux
Command (m for help):
6.改变分区的系统代码
Command (m for help): t
Partition number (1-5): 5
Hex code (type L to list codes): L
0 Empty 1c Hidden Win95 FA 70 DiskSecure Mult bb Boot Wizard hid
1 FAT12 1e Hidden Win95 FA 75 PC/IX be Solaris boot
2 XENIX root 24 NEC DOS 80 Old Minix c1 DRDOS/sec (FAT-
3 XENIX usr 39 Plan 9 81 Minix / old Lin c4 DRDOS/sec (FAT-
4 FAT16 <32M 3c PartitionMagic 82 Linux swap c6 DRDOS/sec (FAT-
5 Extended 40 Venix 80286 83 Linux c7 Syrinx
6 FAT16 41 PPC PReP Boot 84 OS/2 hidden C: da Non-FS data
7 HPFS/NTFS 42 SFS 85 Linux extended db CP/M / CTOS / .
8 AIX 4d QNX4.x 86 NTFS volume set de Dell Utility
9 AIX bootable 4e QNX4.x 2nd part 87 NTFS volume set df BootIt
a OS/2 Boot Manag 4f QNX4.x 3rd part 8e Linux LVM e1 DOS access
b Win95 FAT32 50 OnTrack DM 93 Amoeba e3 DOS R/O
c Win95 FAT32 (LB 51 OnTrack DM6 Aux 94 Amoeba BBT e4 SpeedStor
e Win95 FAT16 (LB 52 CP/M 9f BSD/OS eb BeOS fs
f Win95 Ext'd (LB 53 OnTrack DM6 Aux a0 IBM Thinkpad hi ee EFI GPT
10 OPUS 54 OnTrackDM6 a5 FreeBSD ef EFI (FAT-12/16/
11 Hidden FAT12 55 EZ-Drive a6 OpenBSD f0 Linux/PA-RISC b
12 Compaq diagnost 56 Golden Bow a7 NeXTSTEP f1 SpeedStor
14 Hidden FAT16 <3 5c Priam Edisk a8 Darwin UFS f4 SpeedStor
16 Hidden FAT16 61 SpeedStor a9 NetBSD f2 DOS secondary
17 Hidden HPFS/NTF 63 GNU HURD or Sys ab Darwin boot fd Linux raid auto
18 AST SmartSleep 64 Novell Netware b7 BSDI fs fe LANstep
1b Hidden Win95 FA 65 Novell Netware b8 BSDI swap ff BBT
Hex code (type L to list codes):b
Changed system type of partition 5 to b (Win95 FAT32)
Command (m for help): p
Disk /dev/sdb: 4294 MB, 4294967296 bytes
255 heads, 63 sectors/track, 522 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 62 497983+ 83 Linux
/dev/sdb2 63 522 3694950 5 Extended
/dev/sdb5 63 124 497983+ b Win95 FAT32
7.创建逻辑分区sdb6,并将其转换为swap类型;
Command (m for help): p
Disk /dev/sdb: 4294 MB, 4294967296 bytes
255 heads, 63 sectors/track, 522 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 62 497983+ 83 Linux
/dev/sdb2 63 522 3694950 5 Extended
/dev/sdb5 63 124 497983+ b Win95 FAT32
/dev/sdb6 125 186 497983+ 82 Linux swap
8.保存分区表信息;重启计算机;
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: If you have created or modified any DOS 6.x
partitions, please see the fdisk manual page for additional
information.
Syncing disks.
[root@www root]# reboot
==============
四:格式化分区
1.格式化linux类型文件系统;
[root@www root]# mkfs -t ext3 /dev/sdb1
mke2fs 1.32 (09-Nov-2002)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
124928 inodes, 497983 blocks
24899 blocks (5.00%) reserved for the super user
First data block=1
61 block groups
8192 blocks per group, 8192 fragments per group
2048 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729, 204801, 221185, 401409
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 32 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
2.格式化 vfat文件系统
[root@www root]# mkfs -t vfat /dev/sdb5
mkfs.vfat 2.8 (28 Feb 2001)
3.格式化swap文件系统;
[root@www root]# mkswap /dev/sdb6
Setting up swapspace version 1, size = 509927 kB
================
五:挂载使用分区
[root@www root]# mkdir /mnt/sdb1
[root@www root]# mount /dev/sdb1 /mnt/sdb1
[root@www root]# cd /mnt/sdb1
[root@www sdb1]# touch testfile
[root@www sdb1]# ll
总用量 12
drwx------ 2 root root 12288 10月 16 19:22 lost+found
-rw-r--r-- 1 root root 0 10月 16 19:25 testfile
[root@www sdb1]# cd
[root@www root]# umount /mnt/sdb1
[root@www root]# ls /mnt/sdb1
==========================
六:让系统启动时自动挂载分区
[root@www root]# vi /etc/fstab
LABEL=/ / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
none /dev/pts devpts gid=5,mode=620 0 0
none /proc proc defaults 0 0
none /dev/shm tmpfs defaults 0 0
/dev/sda3 swap swap defaults 0 0
/dev/cdrom /mnt/cdrom udf,iso9660 noauto,owner,kudzu,ro 0 0
/dev/fd0 /mnt/floppy auto noauto,owner,kudzu 0 0
/dev/sdb1 /mnt/sdb1 auto default 0 0
来自:http://www.moandroid.com/?p=638
DDMS 的全称是Dalvik Debug Monitor Service,它为我们提供例如:为测试设备截屏,针对特定的进程查看正在运行的线程以及堆信息、Logcat、广播状态信息、模拟电话呼叫、接收SMS、虚拟地理坐标等等。
如何启动 DDMS
DDMS 工具存放在SDK – tools/路径下,启动DDMS方法如下:
- 直接双击ddms.bat运行;
- 在Eclipes调试程序的过程中启动DDMS,在Eclipes中的界面如下:

选择“Other”,界面如下:

双击DDMS就可以启动了。
DDMS对Emulator和外接测试机有同等效用。如果系统检测到它们(VM)同时运行,那么DDMS将会默认指向 Emulator。以上2种启动后的操作有些不一样,建议分别尝试下。
DDMS 的工作原理
DDMS将搭建起IDE与测试终端(Emulator 或者connected
device)的链接,它们应用各自独立的端口监听调试器的信息,DDMS可以实时监测到测试终端的连接情况。当有新的测试终端连接后,DDMS将捕捉到
终端的ID,并通过adb建立调试器,从而实现发送指令到测试终端的目的。

DDMS监听第一个终端App进程的端口为8600,APP进程将分配8601,如果有更多终端或者更多APP进程将按照这个顺序依次类推。DDMS通过8700端口(”base port”)接收所有终端的指令。
下边通过GUI详细了解DDMS的一些功能
Devices
在GUI的左上角可以看到标签为”Devices”的面板,这里可以查看到所有与DDMS连
接的终端的详细信息,以及每个终端正在运行的APP进程,每个进程最右边相对应的是与调试器链接的端口。因为Android是基于Linux内核开发的操
作平台,同时也保留了Linux中特有的进程ID,它介于进程名和端口号之间。
在面板的右上角有一排很重要的按键他们分别是Debug the selected process、Update Threads、Update Heap、Stop Process和ScreenShot。
Emulator Control
通过这个面板的一些功能可以非常容易的使测试终端模拟真实手机所具备的一些交互功能,比如:接听电话,根据选项模拟各种不同网络情况,模拟接受SMS消息和发送虚拟地址坐标用于测试GPS功能等。

Telephony Status: 通过选项模拟语音质量以及信号连接模式。
Telephony Actions: 模拟电话接听和发送SMS到测试终端。
Location Control: 模拟地理坐标或者模拟动态的路线坐标变化并显示预设的地理标识,可以通过以下3种方式:
- Manual: 手动为终端发送二维经纬坐标。
- GPX: 通过GPX文件导入序列动态变化地理坐标,从而模拟行进中GPS变化的数值。
- KML: 通过KML文件导入独特的地理标识,并以动态形式根据变化的地理坐标显示在测试终端。
Threads、Heap、File Exporler

这几项,我们在其他开发工具中也经常使用,就在不此详细说明了。通过File Exporler可以查看Android模拟器中的文件,可以很方便的导入/出文件。
Locate、Console

Locate:显示输出的调试信息,详见Android下如何调试程序?;
Console:是Android模拟器输出的信息,加载程序等信息;
使用DDMS模拟发送短信,操作过程如下:
在Emulator Control"Telephony Actions 中输入以下内容

单击发送后,在Android模拟器中打开Messaging,看到下面的短信:

单击新短信,详细查看短信内容:

中文显示为乱码,在未来的开发中,我们必须要注意中文字符的问题。
总结说明
DDMS是我们开发人员最好的调试工具,它将是每个从事Android开发的人员都不可缺少的。
一切从String str = new String("abc")说起...
这行代码形式上很简单,其实很复杂。有一个常见的Java笔试题就是问上面这行代码创建了几个String对象。
我刚开始很自然的觉得应该是创建了一个String对象,后来查阅资料,才发现,实际上创建了两个String对象。下面说明为什么创建了两个String对象。
首先,来了解一下Java中的字符串驻留池的概念。JVM为了提高性能,将一下两种形式的字符串放在一个称之为字符串驻留池的内存块中:
形式一:String str = "abc";
形式二:"abc"
其实,形式一和形式二都是字符串的字面常量。所以,可以这样理解,即把字符串的字面常量都放在了字符串驻留池中。对形式一来说,str其实就是引用的字符串驻留池中"abc"这个String对象。
如果有如下的两行代码:
String str1 = "abc";
String str2 = "abc";
那么,上面的两行代码创建了几个String对象?答案是一个。根据我们刚才所述,那么第一行语句将在池中创建一个String对象,第二行会先在池中寻找是否有值与"abc"相同的String对象,如果有,就直接引用,没有这在池中新建String对象。这下,就明白了为什么上面的两行语句仅仅创建了一个String对象。
然后,让我们来看一看String str = new String("abc")。我们先不讨论到底创建了几个String对象。我们在这里,比较一下这种new的方式和上面的直接赋值方式两种创建String对象的不同,直接赋值的方式是在字符串驻留池中创建对象,但new这种方式是在堆中创建对象。即,new创建的String对象是不会放入字符串驻留池中的。如果一定要把某个通过new创建的字符串对象放入驻留池,可以使用intern()方法。如String strt = str.intern(),将把str的值放在驻留池中(当然,是在驻留池原来没有这个值对应的String对象的情况下),并返回驻留池中String对象的引用。
现在,可以分析String str = new String("abc");创建了几个String对象了:)很明显,传入的"abc"字符串字面常量在驻留池中创建了一个对象,new操作符在堆中创建了一个对象,所以,一共创建了两个String对象。
对于Java中的其他类的对象的创建,应该没有这种问题。看来,String对象还是挺特殊的...追根究底,我觉得还是因为字符串操作太多了,为了优化,不得已而为之。
Java标注(Annotation)是Java语言5.0版本开始支持加入源代码的特殊语法元数据。
Java语言中的类、方法、变量、参数和包等都可以被标注。Java标注和Javadoc不同,标注有自反性。在编译器生成类文件时,标注可以被嵌入到字节码中,由Java虚拟机执行时获取到标注。
Java标注可以用于编译时,也可以用于运行时。下面的讨论主要集中于运行时。
Annotation分类
1,内建Annotation——Java5.0版在java语法中经常用到的内建Annotation:
@Deprecated用于修饰已经过时的方法;
@Override用于修饰此方法覆盖了父类的方法(而非重载);
@SuppressWarnings用于通知java编译器禁止特定的编译警告。
下面代码展示了内建Annotation类型的用法:
1 package com.bjinfotech.practice.annotation;
2
3 /**
4 * 演示如何使用java5内建的annotation
5 * 参考资料:
6 * http://java.sun.com/docs/books/tutorial/java/javaOO/annotations.html
7 * http://java.sun.com/j2se/1.5.0/docs/guide/language/annotations.html
8 * http://mindprod.com/jgloss/annotations.html
9 * @author cleverpig
10 *
11 */
12 import java.util.List;
13
14 public class UsingBuiltInAnnotation {
15 //食物类
16 class Food{}
17 //干草类
18 class Hay extends Food{}
19 //动物类
20 class Animal{
21 Food getFood(){
22 return null;
23 }
24 //使用Annotation声明Deprecated方法
25 @Deprecated
26 void deprecatedMethod(){
27 }
28 }
29 //马类-继承动物类
30 class Horse extends Animal{
31 //使用Annotation声明覆盖方法
32 @Override
33 Hay getFood(){
34 return new Hay();
35 }
36 //使用Annotation声明禁止警告
37 @SuppressWarnings({"deprecation","unchecked"})
38 void callDeprecatedMethod(List horseGroup){
39 Animal an=new Animal();
40 an.deprecatedMethod();
41 horseGroup.add(an);
42 }
43 }
44 }
45
46
2,开发者自定义Annotation:由开发者自定义Annotation类型。
下面是一个使用annotation进行方法测试的sample:
AnnotationDefineForTestFunction类型定义如下:
1
2 package com.bjinfotech.practice.annotation;
3
4 import java.lang.annotation.*;
5 /**
6 * 定义annotation
7 * @author cleverpig
8 *
9 */
10 //加载在VM中,在运行时进行映射
11 @Retention(RetentionPolicy.RUNTIME)
12 //限定此annotation只能标示方法
13 @Target(ElementType.METHOD)
14 public @interface AnnotationDefineForTestFunction{}
15
16
测试annotation的代码如下:
1 package com.bjinfotech.practice.annotation;
2
3 import java.lang.reflect.*;
4
5 /**
6 * 一个实例程序应用前面定义的Annotation:AnnotationDefineForTestFunction
7 * @author cleverpig
8 *
9 */
10 public class UsingAnnotation {
11 @AnnotationDefineForTestFunction public static void method01(){}
12
13 public static void method02(){}
14
15 @AnnotationDefineForTestFunction public static void method03(){
16 throw new RuntimeException("method03");
17 }
18
19 public static void method04(){
20 throw new RuntimeException("method04");
21 }
22
23 public static void main(String[] argv) throws Exception{
24 int passed = 0, failed = 0;
25 //被检测的类名
26 String className="com.bjinfotech.practice.annotation.UsingAnnotation";
27 //逐个检查此类的方法,当其方法使用annotation声明时调用此方法
28 for (Method m : Class.forName(className).getMethods()) {
29 if (m.isAnnotationPresent(AnnotationDefineForTestFunction.class)) {
30 try {
31 m.invoke(null);
32 passed++;
33 } catch (Throwable ex) {
34 System.out.printf("测试 %s 失败: %s %n", m, ex.getCause());
35 failed++;
36 }
37 }
38 }
39 System.out.printf("测试结果: 通过: %d, 失败: %d%n", passed, failed);
40 }
41 }
42
43
3,使用第三方开发的Annotation类型
这也是开发人员所常常用到的一种方式。比如我们在使用Hibernate3.0时就可以利用Annotation生成数据表映射配置文件,而不必使用Xdoclet。
来自:http://www.cnblogs.com/ssqjd/archive/2009/02/08/1386427.html
要玩GPhone的模拟器,当然需要先去google上面下载Android的SDK,解压出来后在SDK的根目录下有一个tools文件夹,里面就是模拟器和一些非常有用的工具。
双击“emulator.exe”,直接启动模拟器,简单吧。当然,如果要对模拟器进行一些定制,还是要从命令行调用,带上参数启动。下面就来介绍一下启动是常用的几个参数:
1.模拟器外观的定制:
480x320, landscape: emulator -skin HVGA-L
320x480, portrait : emulator -skin HVGA-P (default)
320x240, landscape: emulator -skin QVGA-L
240x320, portrait : emulator -skin QVGA-P
2.为模拟器加上SD卡:
emulator -sdcard D:"sdcard.img
下面我们再来说说如何创建"sdcard.img"文件:
“tools”目录下还有另外一个很好用的工具“mksdcard.exe”,一看名字就知道——make sdcard。对,就用它来创建一个“SD卡”。
命令为:
mksdcard 1024M D:"sdcard.img
OK,这样一个容量为1G的SD卡就创建完毕了。
使用SDCard:
创建: mksdcard <1024M> <sdcard.img>
(bytes(default),K,M)
连接到模拟器: emulator -sdcard <目录/sdcard.img>
传文件到SDCard: adb push <目录/audio.mp3> </sdcard/audio.mp3>
玩过手机模拟器的人一般最感兴趣的当然是模拟器能做什么呢?下面一一道来:
GPhone的模拟器有个特有的号码:15555218135,这个就类似我们实体手机的SIM卡号码啦。要实现拨号,用手机?当然不行!
更简单,三步:
1.运行 cmd
2.连接: telnet localhost 5554
3.命令:gsm call 15555218135
look!是不是模拟器上显示来电了?接听/挂断和实体手机一样。
发短信也一样简单,重复上面1,2两步,第三部命令改一下:
sms send 15555218135 Hello,this is a Message.
来说说PC与模拟器文件传输的方法吧。这里需要用到另一个重要工具,也在“tools”目录下,“adb.exe”。
adb:
adb(Android Debug Bridge)是Android 提供的一个通用的调试工具,借助这个工具,我们可以管理设备或手机 模拟器 的状态 。还可以进行以下的操作:
1、快速更新设备或手机模拟器中的代码,如应用或Android系统升级;
2、在设备上运行shell命令;
3、管理设备或手机模拟器上的预定端口;
4、在设备或手机模拟器上复制或粘贴文件
一些常用的操作:
进入Shell: adb shell
通过上面的命令,就可以进入设备或模拟器的shell环境中,在这个Linux Shell中,你可以执行各种Linux 的命令,另外如果只想执行一条shell命令,可以采用以下的方式:
adb shell [command]
如:adb shell dmesg会打印出内核的调试信息。
(Android的linux shell做了大量精简,很多linux常用指令都不支持)
上传文件: adb push <PC文件> </tmp/...>
下载文件: adb pull </tmp/...> <PC文件>
安装程序: adb install <*.apk>
卸载软件: adb shell rm /data/app/<*.apk>
补充一点,通过adb安装的软件(*.apk)都在"/data/app/"目录下,所以安装时不必制定路径,卸载只需要简单的执行"rm"就行。
结束adb: adb kill-server
显示android模拟器状态:
adb devices (端口信息)
adb get-product (设备型号)
adb get-serialno (序列号)
等待正在运行的设备: adb wait-for-device
端口转发: adb forward adb forward tcp:5555 tcp:1234
(将默认端口TCP 5555转发到1234端口上)
查看bug报告: adb bugreport
adb shell sqlite3 访问数据库SQLite3
adb shell logcat -b radio 记录无线通讯日志: 一般来说,无线通讯的日志非常多,在运行时没必要去记录,但我们还是可以通过命令,设置记录:
应用程序配置文件:
"AndroidManifest.xml"中
"<category android:name="android.intent.category.LAUNCHER" />"
决定是否应用程序是否显示在Panel上
-----------------------------------------------------------------------------------
am指令(在shell内使用am来加载android应用):
am [start|instrument]
am start [-a <ACTION>]
[-d <DATA_URI>]
[-t <MIME_TYPE>]
[-c <CATEGORY> [-c <CATEGORY>] ...]
[-e <EXTRA_KEY> <EXTRA_VALUE> [-e <EXTRA_KEY> <EXTRA_VALUE> ...]
[-n <COMPONENT>] [-D] [<URI>]
am instrument [-e <ARG_NAME> <ARG_VALUE>]
[-p <PROF_FILE>]
[-w] <COMPONENT>
启动浏览器:
am start -a android.intent.action.VIEW -d http://www.google.cn/
拨打电话:
am start -a android.intent.action.CALL -d tel:10086
启动google map直接定位到北京:
am start -a android.intent.action.VIEW geo:0,0?q=beijing
-----------------------------------------------------------------------------------
目录:
# ls
ls
sqlite_stmt_jou
cache
sdcard
etc
init
init.goldfish.r
init.rc
data
system
proc
sys
sbin
default.prop
root
dev
这里要说明下,从andorid中得到的文件流的字符串的顺序是按“类型+权限+拥有者+数组+大小+日期+名称+链接到”顺序排列的,其中类型“d”表示的是文件夹,"l"表示的是链接,'-'表示的是文件。
例如d rwxrwx--- system cache 2009-01-09 11:46 cache
上面的目录就是通过解析ls命令返回的字符串进行解析的。
-----------------------------------------------------------------------------------
数据库:
联络人(含通话记录)数据库:/data/data/com.android.providers.contacts/databases/contacts.db
媒体库(貌似记录铃声设置等信息): /data/data/com.android.providers.media/internal.db
系统设置: /data/data/com.android.providers.settings/databases/settings.db
短信库: /data/data/com.android.providers.telephony/databases/mmssms.db
Web设置: /data.data/com.android.settings/databases/webview.db
地图搜索历史记录:/data/data/com.google.android.apps.maps/databases/search_history.db
帐号库?(内含androidId信息) : /data/data/com.google.android.googleapps/databases/accounts.db
铃声: /system/media/audio
时区设置: /data/property/persist.sys.timezone
-----------------------------------------------------------------------------------
目前的安装模式
安装前:
1. emulator -wipe-data
2. adb push busybox ./
3. adb shell ./busybox tar -cf /tmp/data.tar /data
4. adb pull /tmp/data.tar .
5. mkdir original
6. cd original
7. tar -xf ../data.tar
安装后:
1. adb shell ./busybox tar -cf /tmp/data.tar /data
2. adb pull /tmp/data.tar .
3. mkdir after_install
4. cd after_install
5. tar -xf ../data.tar
目前来看,就是/data/app和data/data下多了两个相关文件,同时在/data/system/packages.xml中增加了安装的程序信息。似乎菜单也是从这个文件中得到是否新安装程序,以及如何显示相关信息比如名称什么的。
android模拟器和真机的不同之处:
* 不支持呼叫和接听实际来电;但可以通过控制台模拟电话呼叫(呼入和呼出)
* 不支持USB连接
* 不支持相机/视频捕捉
* 不支持音频输入(捕捉);但支持输出(重放)
* 不支持扩展耳机
* 不能确定连接状态
* 不能确定电池电量水平和交流充电状态
* 不能确定SD卡的插入/弹出
* 不支持蓝牙
andoroid模拟器使用注意:
平时使用emulator测试开发的网友注意应该定期清理下C:"Documents and Settings"sh"Local
Settings"Temp"AndroidEmulator文件夹,由于Android模拟器每次运行时会临时生成几个.tmp后缀的临时文件,没有几
个月功夫简单一看竟然占用磁盘空间高达5GB之多。这些文件网友可以安全的删除。
最近在读高焕堂的《Android应用框架原理与程序设计》,由于高焕堂是台湾省的,所以术语不太一样,这里是网上收集的大陆和台湾的IT术语对比表:
中国台湾省 中国大陆
程式----------->程序
图示----------->图标
功能表--------->菜单
视窗----------->窗口
作业----------->工作
内存----------->记忆体
埠------------->端口
资讯----------->信息
硬盘----------->硬碟
互动----------->交互
光盘----------->光碟
硬碟机--------->硬盘驱动器
光碟机--------->光盘驱动器
变数----------->变量
物件----------->对象
乱数----------->随机数
测验----------->测试
滑鼠----------->鼠标
回应----------->响应
设定----------->设置
撰写----------->编写
列印----------->打印
网路----------->网络
档案----------->文件
位元----------->比特
档名----------->文件名
影像----------->图像
萤屏----------->屏幕
存盘----------->存储
指标----------->指示
影片----------->动画
真伪----------->真假
显示幕--------->显示器
工具列--------->工具栏
重绘----------->刷新
装置----------->设置
游标----------->光标
关於----------->关于
支援----------->支持
软体----------->软件
硬体----------->硬件
著作权--------->版权
整合ssi虽然原理比较简单,但在实际操作的时候还是容易出错的,在这里也记录一下...
各个组件的版本号:struts2.1 spring2.5 ibatis2.3
struts2.1需要的包
首先是struts2.1必须的包:
然后是要与spring集成需要的包:struts2-spring-plugin-2.1.6.jar
spring2.5需要的包
这里用的是集成了spring所有模块的包:spring.jar
ibatis2.3需要的包
ibatis-2.3.*.*.jar
web.xml的配置
1 <?xml version="1.0" encoding="UTF-8"?>
2 <web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
4 xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
5 http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
6 <filter>
7 <filter-name>struts2</filter-name>
8 <filter-class>
9 org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter
10 </filter-class>
11 </filter>
12 <listener>
13 <listener-class>
14 org.springframework.web.context.ContextLoaderListener
15 </listener-class>
16 </listener>
17 <filter-mapping>
18 <filter-name>struts2</filter-name>
19 <url-pattern>/*</url-pattern>
20 </filter-mapping>
21 <welcome-file-list>
22 <welcome-file>login.jsp</welcome-file>
23 </welcome-file-list>
24 </web-app>
25
applicationContext.xml的配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName">
<value>org.gjt.mm.mysql.Driver</value>
</property>
<property name="url">
<value>jdbc:mysql://localhost:3306/test</value>
</property>
<property name="username">
<value>root</value>
</property>
<property name="password">
<value></value>
</property>
</bean>
<bean id="sqlMapClient"
class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="configLocation" value="WEB-INF/sql-map-config.xml" />
</bean>
<bean id="sqlMapClientTemplate" class="org.springframework.orm.ibatis.SqlMapClientTemplate">
<property name="sqlMapClient" ref="sqlMapClient" />
</bean>
<!-- 其他配置,如DAO,Action--/>
</beans>
sql-map-config.xml的配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE sqlMapConfig
PUBLIC "-//ibatis.apache.org//DTD SQL Map Config 2.0//EN"
"http://ibatis.apache.org/dtd/sql-map-config-2.dtd">
<sqlMapConfig>
<settings useStatementNamespaces="true" />
<sqlMap resource="ssi/persistance/sqlmap/user_SqlMap.xml" />
</sqlMapConfig>
具体sql-map文件的配置,这里就不写了,我也是刚刚学习ibatis,呵呵,由于最近马上就要开发了,就找了工具来加快速度,ibatis官方提供的ibator(原来叫abator)这个工具相当猛啊,还在学习中...
在配置过程当中,特别需要注意各个配置文件的存放位置,比如对于applicationContext.xml来说,默认应该存放在WEB-INF文件夹中,如果想放到类路径上去,需要在web.xml里面配置,一般配置在web.xml的开头部分:
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
classpath:applicationContext.xml
</param-value>
</context-param>
来自:http://www.javaeye.com/topic/106626
一、简介:
hsql数据库是一款纯Java编写的免费数据库,许可是BSD-style的协议。
相对其他数据库来说,其体积小,才563kb。
仅一个hsqldb.jar文件就包括了数据库引擎,数据库驱动,还有其他用户界面操作等内容。
下载地址:http://hsqldb.org/
二、使用hsql数据库:
1、hsql数据库引擎有几种服务器模式:常用的Server模式、WebServer模式、Servlet模式、Standlone模式、Memory-On­ly数据库。
2、最为常用的Server模式:
1)首先却换到lib文件夹下,运行java -cp hsqldb.jar
org.hsqldb.Server -database.0 db/mydb -dbname.0 xdb
执行命令后,将会在db文件夹下创建一个数据库mydb,别名(用于访问数据库)是xdb,如果存在mydb数据库,将会打开它。
2)运行数据库界面操作工具:java -cp hsqldb.jar
org.hsqldb.util.DatabaseManager
在Type选项里选上相应的服务器模式,这里选择HSQL
Database Engine
Server模式;Driver不用修改;URL修改为jdbc:hsqldb:hsql://localhost/xdb
(主要这里xdb就是上面我们设置的别名);user里设置用户名,第一次登录时,设置的是管理员的用户名,password设置密码。然后点击Ok。
3)第一次运行数据库引擎,创建数据库完毕。好了,你可以打开db文件夹,会发现里面多了几个文件。
mydb.properties文件:是关于数据库的属性文件。
mydb.script:hsql主要保存的表(这里按hsql的说法是Memory表,就是最为常用的),里面的格式都是文本格式,可以用文本查看,里面的语­句都是sql语句,熟悉sql语句的话,你也可以手动修改它。每次运行数据库引擎的话都是从这里加载进内存的。
mydb.lck表示数据库处于打开状态。
其他的请参看hsqldb包里的手册。
3、WebServer模式和Server运行模式基本一样,只是支持了Http等协议,主要用于防火墙,默认端口是9001。启动Server,java
-cp hsqldb.jar org.hsqldb.WebServer ...剩余的和上面的一致。
4、Servlet模式可以允许你通过Servlet容器来访问数据库,请查看hsqlServlet.java的源代码,和WebServer类似。
5、另一个值得思考的模式是Standalone模式:不能通过网络来访问数据库,主要是在一个JVM中使用,那样的话,访问的速度会更加快。虽然文档里
面提到­主要是用于开发时使用,但是我们可以假设一下,该方法不需要一个引擎类的东西,而类似于打开文件的方式,返回一个
Connection对象:
Connection c = DriverManager.getConnection("jdbc:hsqldb:file:mydb",
"sa", "");
将会在当前目录找到mydb数据库相关文件,打开并返回一个Connection对象。该方式有点好处就是可以不使用引擎,在需要的时候操作数据。所以那
些对数­据库不是特别有要求的,但又需要一个操作数据库的方式的话,可以使用这种方法。对于那些不想额外在数据库引擎花费金钱的话,可以
使用这种方法。但是不推荐使用该­方法。记得Hibernate里SessionFactory可以使用
openSession(Connecttion
c)来获得一个Session对象的,因此,在测试或者实际应用的话都可以这样使用。
6、Memory-Only
数据库:顾名思义,主要是内存中使用,不用于保存数据。可以用于在内存中交换数据。
上面是关于hsqldb的一些基本信息的介绍,可以看到它的一些优势和特性。
我们可以把hsqldb内置在web程序中,除考虑Standalone模式外,最好是采用最为常用的Server模式。
那么Server模式如何和web程序合理搭配使用呢。
可以采用两种方式:
1)采用上面提到的方法,运行java -cp hsqldb.jar
org.hsqldb.Server -database.0 db/mydb -dbname.0 xdb
来启动db,通过设置的URL:jdbc:hsqldb:hsql://localhost/xdb
以达到在程序中访问hsql数据库的
(注:设置URL等信息,可以通过hibernate来配置,例如:
hibernate.dialect org.hibernate.dialect.HSQLDialect
hibernate.connection.driver_class org.hsqldb.jdbcDriver
hibernate.connection.username sa
hibernate.connection.password
hibernate.connection.url jdbc:hsqldb:hsql://localhost/xdb )
2)为了省去第一种方法的琐碎,可以在启动web容器的过程中同时启动hsqldb。具体做法如下:编写一个有关hsql的Listener类,扩展javax­.servlet.ServletContextListener,可以在配置文件中设置dbPath、dbName、port等等hsqldb的信息,启动h­sqldb。
在web.xml中配置
<listener>
<listener-class>com.iplan.portal.framework.web.HsqlListener</listener-class­>
</listener>
这样在启动web容器的时候,同时启动了hsqldb,关闭容器的时候同时也shutdown掉hsqldb。
MyEclipse6.5集成SVN
第一步:安装Mylyn:
打开Myeclipse6.5,依次点击Hellp-->Software Updates-->Find and Install
在弹出的对话框中选择第二项(Search for new features to install),点击next后,在新的对话框中选择New Remote Site...然后填写下面内容:
Name:Mylyn
URL:http://download.eclipse.org/tools/mylyn/update/e3.3
然后一路点击下一步。完成安装后重启workspace。
第二步:安装Subversive:
打开Myeclipse6.5,依次点击Hellp-->Software Updates-->Find and Install
在弹出的对话框中选择第二项(Search for new features to install),点击next后,在新的对话框中选择New Remote Site...然后填写下面内容:
Name:subversive
URL:http://download.eclipse.org/technology/subversive/0.7/update-site/
然后一路点击下一步。完成安装后重启workspace。
第三步:安装Subservice Connectors:
打开MyEclipse6.5,依次点击Hellp-->Software Updates-->Find and Install
在弹出的对话框中选择第二项(Search for new features to install),点击next后,在新的对话框中选择New Remote Site...然后填写下面内容:
Name:subservice connectors
URL:http://www.polarion.org/projects/subversive/download/eclipse/2.0/update-site/
然后一路点击下一步。完成安装后重启workspace。
到这里安装完毕。
然后在MyEclipse6.5点击Window-->Show View-->Other...-->SVN-->SVN Repositories,点击OK,添加SVN Repositories的窗口。
好了,下面就可以新建一个Repository Location了。
在SVN Repositories窗口中右键New-->Repository Location,输入SVN服务端的URL和用户名,密码,点击确定后就完成了。
磁盘命令应该是最基本的命令了。linux下的磁盘命令主要有三个:
df命令用来检查文件系统的磁盘空间占用情况。这里的文件系统指挂载到linux系统上的文件系统。没有挂载上来的是没有包含进来的。
fdisk命令主要用来分区。先复习一下基础知识。一个硬盘可以划分4个区,3个主要分区,一个扩展分区,而扩展分区里可以划分n个逻辑分区,扩展分区本身不能储存任何东西,也不能格式化成某种文件系统,只能用于区分逻辑分区。
sudo fdisk -l
fdisk用来分区比较复杂,Linux有一个图形化的软件gparted来进行分区。
sudo apt-get install gparted 安装
mkfs是格式化的命令,它的形式:sudo mkfs -t 文件系统 存储设备,如:
sudo mkfs -t ext3 /dev/sda6 把该设备格式化成ext3文件系统
mount和umount是挂载和取消挂载命令。
sudo mount [-t 文件系统 ] [-o 选项] 设备 目录
使用这个命令前需要先生成一个用于被挂的目录,创建了这样的目录后有个细节问题就是更改这个目录的权限,最起码要你可读写,这样才能使你挂载的硬盘可读写,当然ntfs的硬盘除外。如:chmod 777 目录。挂载时,也有可以省事的地方,比如说你不知道你的分区是什么文件类型你可以:sudo mount -t auto 设备 目录。sudo mount 设备 目录
ROWNUM的概念
ROWNUM是
一个虚假的列。它将被分配为 1,2,3,4,...N,N 是行的数量。一个ROWNUM值不是被永久的分配给一行
(这是最容易被误解的)。表中的某一行并没有标号;你不可以查询ROWNUM值为5的行——根本没有这个概念。另一个容易搞糊涂的问题是ROWNUM值是
何时被分配的。ROWNUM值的分配是在查询的谓词解析之后,任何排序和聚合之前进行的。ROWNUM值只有当被分配之后才会增长。这就是为什么下面的查
询永远都不会返回结果:
select * from countries where rownum>1;
ROWNUM > 1对于第一行来说并不是真值,ROWNUM没有增长到 2。所以,没有比1大的ROWNUM.永远都不要使用’ROWNUM>?‘和’ROWNUM=2…N’这样的条件。
用rownum显示排序结果的前N条记录
FROM/WHERE子句先被执行.
根据FROM/WHERE子句输出的行, ROWNUM被分配给他们并自增长.
SELECT 被应用.
GROUP BY 被应用.
HAVING is 被应用.
ORDER BY 被应用.
这就是为什么下面的SQL几乎总是错误的:
select rownum,job_title,min_salary
from jobs where rownum<3 order by min_salary;
正确的写法:
select rownum,tmp.* from (
select job_title,min_salary
from jobs order by min_salary) tmp
where rownum<=3;
用ROWNUM实现分页
select * from
(select /*+ FIRST_ROWS(n) */ a.*,
ROWNUM rnum
from (your_query_goes_here, with order by) a
where ROWNUM <=
:MAX_ROW_TO_FETCH )
where rnum >= :MIN_ROW_TO_FETCH;
FIRST_ROWS(N)使优化器考虑最短时间获得前N条记录.
:MAX_ROW_TO_FETCH 某一页中结果集的最后一行。如果你每页显示10行,要显示第6页,那么此值取60。
:MIN_ROW_TO_FETCH 某一页中结果集的第一行。如果你每页显示10行,要显示第6页,那么此值取50。
ROWNUM对性能的影响
ROWNUM可以避免oracle在磁盘上进行排序。rownum无法避免全表扫描的发生,但是它可以避免对整个表数据的排序操作,在指定了rownum后,排序操作在内存中可以轻松完成。
sequence是用来在多用户环境下产生唯一整数的数据库对象。序列产生器顺序生成数字,它可用于自动生成主键值,并能协调多行或者多表的主键操
作。没有sequence,顺序的值只能靠编写程序来生成。先找出最近产生的值然后自增长。这种方法要求一个事务级别的锁,这将导致在多用户并发操作的环
境下,必须有人等待下一个主键值的产生。而且此方法很容易产生主键冲突的错误,如下图:
time a......trans1 begin.........................................................
|
取max value=5
|
time b...... max value+1=6........trans2 begin.....................
| |
other action max value=5
| |
time c..... commit; ...................max value+1=6................
|
commt(ora-00001)
如上图,事务2会报主键冲突的错误,而再刷新一下页面(再执行一边程序),可能就正常了。
还有一个问题,那就是完成生成主键的程序
(一般情况包含plsql块)本身对于并发调用也是一个瓶颈,因为这样的程序段往往是提供给好多程序去调用,如果代码端写的不够优化(比如没有使用邦定变
量等等),或者此代码段存在问题,那么它所影响的是系统的全局。我们应该提倡开发人员使用sequence。sequence消除了序列化问题,而且改善
了应用的并发能力。
创建sequence
sequence的命名最重要的是要统一,命名规则是次要的。
CREATE SEQUENCE emp_sequence
INCREMENT BY 1
START WITH 1
NOMAXVALUE
NOCYCLE
CACHE 10;
这
里需要重点说明的是cache参数,它是为了应对并发访问的。cache参数告诉oracle预先分配一个sequence
numbers的集合,并且保留在内存中,以便sequence
number能够被快速的访问。这个内存的大小就是cache所指定的大小,当多个用户同时访问一个sequence的时候,是在oracle
SGA中读取sequence当前的合理数值,如果并发访问太大,cache的大小不够,那么就会产生sequence
cache相关的等待(enq: SQ - contention),影响系统性能。
既然cache涉及到了内存,那么就会想到oracle实例恢复的问题。如果数据库shutdown abort,sequence会如何呢?当然会有问题,sequence number保存在内存里的但是没有被应用到表中的会丢失!
修改sequence
除了修改sequence的starting number,你什么都能改,如果想改starting number,只能先drop然后create。
ALTER SEQUENCE emp_sequence
INCREMENT BY 10
MAXVALUE 10000
CYCLE
CACHE 20;
修
改很有用,最典型的情况是“需要把sequence 的current value改大一点,避免程序报错!”。你就可以看看current
value是多少,然后修改increment by 足够大的值,然后执行.nextval,最后别忘了再将increnent
by改成原来的值,还要注意做这些工作的前提是当前没有人用此sequence。
使用 sequence
CURRVAL 和 NEXTVAL 能够在以下情况使用:
insert的values字句、select中的select列表、update中的set字句
CURRVAL 和 NEXTVAL 不能够在以下情况使用:
子查询、视图和实体化视图的查询、带distinct的select语句、带
group by和order
by的select语句、带union或intersect或minus的select语句、select中的where字句、create
table与alter table中的default值、check约束条件。
删除sequence
drop sequence seq_a;
当删除sequence后,对应它的同义词会被保留,但是引用时会报错。
oracle rac环境中的sequence
oracle为了在rac环境下为了sequence的一致性,使用了三种锁:row cache lock、SQ锁、SV锁。
row cache lock的目的是在sequence指定nocache的情况下调用sequence.nextval过程中保证序列的顺序性;
SQ锁是应用于指定了cache+noorder的情况下调用sequence.nextval过程中。
SV
锁(dfs lock handel) 是调用sequence.nextval期间拥有的锁。前提是创建sequence时指定了cache
和order属性 (cache+order)。order参数的目的是为了在RAC上节点之间生成sequence的顺序得到保障。
创建sequence赋予的cache值较小时,有enq:sq-contention等待增加的趋势。
cache的缺省值是20.因此创建并发访问多的sequence时,cacheh值应取大一些。否则会发生enq:sq-contention等待事件。
rac上创建sequence时,如果指定了cache大小而赋予noorder属性,则各节点将会把不同范围的sequence值cache到内
存上。若两个节点之间都必须通过依次递增方式使用sequence,必须赋予如下的order属性(一般不需要这样做)"sql> create
sequence seq_b cache 100
order"。如果是已赋予了cache+order属性的sequence,oracle使用SV锁进行同步。SV锁争用问题发生时的解决方法与sq锁
的情况相同,就是将cache 值进行适当调整。
在RAC多节点环境下,Sequence的Cache属性对性能的影响很大。应该尽量赋予cache+noorder属性,并要给予足够的
cache值。如果需要保障顺序,必须赋予cache+order属性。但这时为了保障顺序,实例之间需要不断的交换数据。因此性能稍差。
每次struts的更新,都会发现它的基础jar包不同,下面我就列举最新版的struts2的基础jar包.
struts2.0.14:它们为commons-logging-1.0.4,freemarker-2.3.8,ognl-2.6.11,struts2-core-2.0.14,xwork-2.07.
struts2.1.6:它们为commons-fileupload-1.2.1,commons-io-1.3.2,commons-
logging-1.0.4,freemarker-2.3.13,ognl-2.6.11,struts2-core-2.1.6,xwork-2.1.2.
web.xml
考虑到以后兼容以后的版本,原来的FilterDispatcher和ActionContextCleanUp将在以后的版本中去掉,官方推荐使用
org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter
来自:http://silverw0396.javaeye.com/blog/90554
一.引言
ORACLE数据库字符集,即Oracle全球化支持(Globalization Support),或即国家语言支持(NLS)其作用是用本国语言和格式来存储、处理和检索数据。利用全球化支持,ORACLE为用户提供自己熟悉的数据库母语环境,诸如日期格式、数字格式和存储序列等。Oracle可以支持多种语言及字符集,其中oracle8i支持48种语言、76个国家地域、229种字符集,而oracle9i则支持57种语言、88个国家地域、235种字符集。由于oracle字符集种类多,且在存储、检索、迁移oracle数据时多个环节与字符集的设置密切相关,因此在实际的应用中,数据库开发和管理人员经常会遇到有关oracle字符集方面的问题。本文通过以下几个方面阐述,对oracle字符集做简要分析
二.字符集基本知识
2.1字符集
实质就是按照一定的字符编码方案,对一组特定的符号,分别赋予不同数值编码的集合。Oracle数据库最早支持的编码方案是US7ASCII。
Oracle的字符集命名遵循以下命名规则:
<Language><bit size><encoding>
即: <语言><比特位数><编码>
比如: ZHS16GBK表示采用GBK编码格式、16位(两个字节)简体中文字符集
2.2字符编码方案
2.2.1 单字节编码
(1)单字节7位字符集,可以定义128个字符,最常用的字符集为US7ASCII
(2)单字节8位字符集,可以定义256个字符,适合于欧洲大部分国家
例如:WE8ISO8859P1(西欧、8位、ISO标准8859P1编码)
2.2.2 多字节编码
(1)变长多字节编码
某些字符用一个字节表示,其它字符用两个或多个字符表示,变长多字节编码常用于对亚洲语言的支持,例如日语、汉语、印地语等
例如:AL32UTF8(其中AL代表ALL,指适用于所有语言)、zhs16cgb231280
(2)定长多字节编码
每一个字符都使用固定长度字节的编码方案,目前oracle唯一支持的定长多字节编码是AF16UTF16,也是仅用于国家字符集
2.2.3 unicode编码
Unicode是一个涵盖了目前全世界使用的所有已知字符的单一编码方案,也就是说Unicode为每一个字符提供唯一的编码。UTF-16是unicode的16位编码方式,是一种定长多字节编码,用2个字节表示一个unicode字符,AF16UTF16是UTF-16编码字符集。
UTF-8是unicode的8位编码方式,是一种变长多字节编码,这种编码可以用1、2、3个字节表示一个unicode字符,AL32UTF8,UTF8、UTFE是UTF-8编码字符集
2.3 字符集超级
当一种字符集(字符集A)的编码数值包含所有另一种字符集(字符集B)的编码数值,并且两种字符集相同编码数值代表相同的字符时,则字符集A是字符集B的超级,或称字符集B是字符集A的子集。
Oracle8i和oracle9i官方文档资料中备有子集-超级对照表(subset-superset pairs),例如:WE8ISO8859P1是WE8MSWIN1252的子集。由于US7ASCII是最早的Oracle数据库编码格式,因此有许多字符集是US7ASCII的超集,例如WE8ISO8859P1、ZHS16CGB231280、ZHS16GBK都是US7ASCII的超集。
2.4 数据库字符集(oracle服务器端字符集)
数据库字符集在创建数据库时指定,在创建后通常不能更改。在创建数据库时,可以指定字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。
2.4.1 字符集
(1)用来存储CHAR, VARCHAR2, CLOB, LONG等类型数据
(2)用来标示诸如表名、列名以及PL/SQL变量等
(3)用来存储SQL和PL/SQL程序单元等
2.4.2 国家字符集:
(1)用以存储NCHAR, NVARCHAR2, NCLOB等类型数据
(2)国家字符集实质上是为oracle选择的附加字符集,主要作用是为了增强oracle的字符处理能力,因为NCHAR数据类型可以提供对亚洲使用定长多字节编码的支持,而数据库字符集则不能。国家字符集在oracle9i中进行了重新定义,只能在unicode编码中的AF16UTF16和UTF8中选择,默认值是AF16UTF16
2.4.3查询字符集参数
可以查询以下数据字典或视图查看字符集设置情况
nls_database_parameters、props$、v$nls_parameters
查询结果中NLS_CHARACTERSET表示字符集,NLS_NCHAR_CHARACTERSET表示国家字符集
2.4.4修改数据库字符集
按照上文所说,数据库字符集在创建后原则上不能更改。如果需要修改字符集,通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换,或通过ALTER DATABASE CHARACTER SET语句修改字符集,但创建数据库后修改字符集是有限制的,只有新的字符集是当前字符集的超集时才能修改数据库字符集,例如UTF8是US7ASCII的超集,修改数据库字符集可使用ALTER DATABASE CHARACTER SET UTF8。
2.5 客户端字符集(NLS_LANG参数)
2.5.1 客户端字符集含义
客户端字符集定义了客户端字符数据的编码方式,任何发自或发往客户端的字符数据均使用客户端定义的字符集编码,客户端可以看作是能与数据库直接连接的各种应用,例如sqlplus,exp/imp等。客户端字符集是通过设置NLS_LANG参数来设定的。
2.5.2 NLS_LANG参数格式
NLS_LANG=<language>_<territory>.<client character set>
Language:显示oracle消息,校验,日期命名
Territory:指定默认日期、数字、货币等格式
Client character set:指定客户端将使用的字符集
例如:NLS_LANG=AMERICAN_AMERICA.US7ASCII
AMERICAN是语言,AMERICA是地区,US7ASCII是客户端字符集
2.5.3客户端字符集设置方法
1)UNIX环境
$NLS_LANG=“simplified chinese”_china.zhs16gbk
$export NLS_LANG
编辑oracle用户的profile文件
2)Windows环境
编辑注册表
Regedit.exe---HKEY_LOCAL_MACHINE---SOFTWARE---ORACLE—HOME0
2.5.4 NLS参数查询
Oracle提供若干NLS参数定制数据库和用户机以适应本地格式,例如有NLS_LANGUAGE,NLS_DATE_FORMAT,NLS_CALENDER等,可以通过查询以下数据字典或v$视图查看。
NLS_DATABASE_PARAMETERS--显示数据库当前NLS参数取值,包括数据库字符集取值
NLS_SESSION_PARAMETERS--显示由NLS_LANG 设置的参数,或经过alter session 改变后的参数值(不包括由NLS_LANG 设置的客户端字符集)
NLS_INSTANCE_PARAMETE--显示由参数文件init<SID>.ora 定义的参数V$NLS_PARAMETERS--显示数据库当前NLS参数取值
2.5.5修改NLS参数
使用下列方法可以修改NLS参数
(1)修改实例启动时使用的初始化参数文件
(2)修改环境变量NLS_LANG
(3)使用ALTER SESSION语句,在oracle会话中修改
(4)使用某些SQL函数
NLS作用优先级别:Sql function>alter session>环境变量或注册表>参数文件>数据库默认参数
三.导入/导出与字符集转换
3.1 EXP/IMP
Export 和 Import 是一对读写Oracle数据的工具。Export 将 Oracle 数据库中的数据输出到操作系统文件中, Import 把这些文件中的数据读到Oracle 数据库中,由于使用exp/imp进行数据迁移时,数据从源数据库到目标数据库的过程中有四个环节涉及到字符集,如果这四个环节的字符集不一致,将会发生字符集转换。
EXP
____________ _________________ _____________
|imp导入文件|<-|环境变量NLS_LANG|<-|数据库字符集|
------------ ----------------- -------------
IMP
____________ _________________ _____________
|imp导入文件|->|环境变量NLS_LANG|->|数据库字符集|
------------ ----------------- -------------
四个字符集是
(1)源数据库字符集
(2)Export过程中用户会话字符集(通过NLS_LANG设定)
(3)Import过程中用户会话字符集(通过NLS_LANG设定)
(4)目标数据库字符集
3.2导出的转换过程
在Export过程中,如果源数据库字符集与Export用户会话字符集不一致,会发生字符集转换,并在导出文件的头部几个字节中存储Export用户会话字符集的ID号。在这个转换过程中可能发生数据的丢失。
例:如果源数据库使用ZHS16GBK,而Export用户会话字符集使用US7ASCII,由于ZHS16GBK是16位字符集,而US7ASCII是7位字符集,这个转换过程中,中文字符在US7ASCII中不能够找到对等的字符,所以所有中文字符都会丢失而变成“?? ”形式,这样转换后生成的Dmp文件已经发生了数据丢失。
因此如果想正确导出源数据库数据,则Export过程中用户会话字符集应等于源数据库字符集或是源数据库字符集的超集
3.3导入的转换过程
(1)确定导出数据库字符集环境
通过读取导出文件头,可以获得导出文件的字符集设置
(2)确定导入session的字符集,即导入Session使用的NLS_LANG环境变量
(3)IMP读取导出文件
读取导出文件字符集ID,和导入进程的NLS_LANG进行比较
(4)如果导出文件字符集和导入Session字符集相同,那么在这一步骤内就不需要转换,如果不同,就需要把数据转换为导入Session使用的字符集。可以看出,导入数据到数据库过程中发生两次字符集转换
第一次:导入文件字符集与导入Session使用的字符集之间的转换,如果这个转换过程不能正确完成,Import向目标数据库的导入过程也就不能完成。
第二次:导入Session字符集与数据库字符集之间的转换。
然而,oracle8i的这种转换只能在单字节字符集之间进行,oracle8i导入Session不支持多字节字符集之间的转换,因此为了避免第一次转换,导入Session使用的NLS_LANG与导出文件字符集相同,第二次转换(通过SQL*Net)支持任何两种字符集。以上情况在Oracle9i中略有不同
四.乱码问题
oracle在数据存储、迁移过程中经常发生字符乱码问题,归根到底是由于字符集使用不当引起。下面以使用客户端sqlplus向数据库插入数据和导入/导出(EXP/IMP)过程为例,说明乱码产生的原因。
4.1使用客户端sqlplus向数据库存储数据
这个过程存在3个字符集设置
(1)客户端应用字符集
(2)客户端NLS_LANG参数设置
(3)服务器端数据库字符集(Character Set)设置
客户端应用sqlplus中能够显示什么样的字符取决于客户端操作系统语言环境(客户端应用字符集),但在应用中录入这些字符后,这些字符能否在数据库中正常存储,还与另外两个字符集设置紧密相关,其中客户端NLS_LANG参数主要用于字符数据传输过程中的转换判断。常见的乱码大致有两种情形:
(1)汉字变成问号“?”;
当从字符集A 转换成字符集B时,如果转换字符之间不存在对应关系,NLS_LANG使用替代字符“?”替代无法映射的字符
(2)汉字变成未知字符(虽然有些是汉字,但与原字符含义不同)
转换存在对应关系,但字符集A 中的字符编码与字符集B 中的字符编码代表不同含义
4.2发生乱码原因
乱码产生是由于几个字符集之间转换不匹配造成,分以下几种情况:
(注:字符集之间如果不存在子集、超集对应关系时的情况不予考虑,因为这种情况下字符集之间转换必产生乱码)
1)服务器端数据库字符集与客户端应用字符集相同,与客户端NLS_LANG参数设置不同
如果客户端NLS_LANG字符集是其它两种字符集的子集,转换过程将出现乱码。
解决方法:将三种字符集设置成同一字符集,或NLS_LANG字符集是其它两种字符集的超集
2)服务器端数据库字符集与客户端NLS_LANG参数设置相同,与客户端应用字符集不同
如果客户端应用字符集是其它两种字符集的超集时,转换过程将出现乱码,但对于单字节编码存储中文问题,可参看本文第5章节的分析
3)客户端应用字符集、客户端NLS_LANG参数设置、服务器端数据库字符集互不相同
此种情况较为复杂,但三种字符集之间只要有不能转换的字符,则必产生乱码
4.3导入/导出过程出现乱码原因
这个过程存在4个字符集设置,在3.1章节中已分析
(1)源数据库字符集
(2)EXP过程中NLS_LANG参数
(3)IMP过程中NLS_LANG参数
(4)目标数据库字符集
出现乱码原因
1)当源数据库字符集不等于EXP过程中NLS_LANG参数,且源数据库字符集是EXP过程中NLS_LANG的子集,才能保证导出文件正确,其他情况则导出文件字符乱码
2)EXP过程中NLS_LANG字符集不等于IMP过程中NLS_LANG字符集,且EXP过程中NLS_LANG字符集是IMP过程中NLS_LANG字符集的子级, 才能保证第一次转换正常,否则第一次转换中出现乱码。
3)如果第一次转换正常,IMP过程中NLS_LANG字符集是目标数据库字符集的子集或相同,才能保证第二次转换正常,否则则第二次转换中出现乱码
五.单字节编码存储中文问题
由于历史的原因,早期的oracle没有中文字符集(如oracle6、oracle7、oracle7.1),但有的用户从那时起就使用数据库了,并用US7ASCII字符集存储了中文,或是有的用户在创建数据库时,不考虑清楚,随意选择一个默认的字符集,如WE8ISO8859P1或US7ASCII,而这两个字符集都没有汉字编码,虽然有些时候选用这种字符集好象也能正常使用,但用这种字符集存储汉字信息从原则上说就是错误的,它会给数据库的使用与维护带来一系列的麻烦。
正常情况下,要将汉字存入数据库,数据库字符集必须支持中文,而将数据库字符集设置为US7ASCII等单字节字符集是不合适的。US7ASCII字符集只定义了128个符号,并不支持汉字。另外,如果在SQL*PLUS中能够输入中文,操作系统缺省应该是支持中文的,但如果在NLS_LANG中的字符集设置为US7ASCII,显然也是不正确的,它没有反映客户端的实际情况。但在实际应用中汉字显示却是正确的,这主要是因为Oracle检查数据库与客户端的字符集设置是同样的,那么数据在客户与数据库之间的存取过程中将不发生任何转换,但是这实际上导致了数据库标识的字符集与实际存入的内容是不相符的。而在SELECT的过程中,Oracle同样检查发现数据库与客户端的字符集设置是相同的,所以它也将存入的内容原封不动地传送到客户端,而客户端操作系统识别出这是汉字编码所以能够正确显示。
在这个例子中,数据库与客户端都没有设置成中文字符集,但却能正常显示中文,从应用的角度看好象没问题。然而这里面却存在着极大的隐患,比如在应用length或substr等字符串函数时,就可能得到意外的结果。
对于早期使用US7ASCII字符集数据库的数据迁移到oracle8i/9i中(使用zhs16gbk),由于原始数据已经按照US7ASCII格式存储,对于这种情况,可以通过使用Oracle8i的导出工具,设置导出字符集为US7ASCII,导出后使用UltraEdit等工具打开dmp文件,修改第二、三字符,修改 0001 为0354,这样就可以将US7ASCII字符集的数据正确导入到ZHS16GBK的数据库中。
六.结束语
为了避免在数据库迁移过程中由于字符集不同导致的数据损失,oracle提供了字符集扫描工具(character set scanner),通过这个工具我们可以测试在数据迁移过程中由于字符集转换可能带来的问题,然后根据测试结果,确定数据迁移过程中最佳字符集解决方案。
参考文献
[1]Biju Thomas , Bob Bryla《oracle9i DBA基础I 学习指南》电子工业出版社 2002
过滤器是很多Web层框架(特别是对MVC模式的框架,如Struts2...等等)实现的基础,有必要对其进行了解。
一、Servlet过滤器的概念:
◆Servlet过滤器是在Java Servlet规范2.3中定义的,它能够对Servlet容器的请求和响应对象进行检查和修改。
◆Servlet过滤器本身并不产生请求和响应对象,它只能提供过滤作用。Servlet过期能够在Servlet被调用之前检查Request对象,修改Request Header和Request内容;在Servlet被调用之后检查Response对象,修改Response Header和Response内容。
Servlet过期负责过滤的Web组件可以是Servlet、JSP或者HTML文件。
二、Servlet过滤器的特点:
◆Servlet过滤器可以检查和修改ServletRequest和ServletResponse对象
◆Servlet过滤器可以被指定和特定的URL关联,只有当客户请求访问该URL时,才会触发过滤器
◆Servlet过滤器可以被串联在一起,形成管道效应,协同修改请求和响应对象
三、Servlet过滤器的作用:
◆查询请求并作出相应的行动。
◆阻塞请求-响应对,使其不能进一步传递。
◆修改请求的头部和数据。用户可以提供自定义的请求。
◆修改响应的头部和数据。用户可以通过提供定制的响应版本实现。
◆与外部资源进行交互。
四、Servlet过滤器的适用场合:
◆认证过滤
◆登录和审核过滤
◆图像转换过滤
◆数据压缩过滤
◆加密过滤
◆令牌过滤
◆资源访问触发事件过滤
◆XSL/T过滤
◆Mime-type过滤
五、Servlet过滤器接口的构成:
所有的Servlet过滤器类都必须实现javax.servlet.Filter接口。这个接口含有3个过滤器类必须实现的方法:
◆init(FilterConfig):
这是Servlet过滤器的初始化方法,Servlet容器创建Servlet过滤器实例后将调用这个方法。在这个方法中可以读取web.xml文件中Servlet过滤器的初始化参数
◆doFilter(ServletRequest,ServletResponse,FilterChain):
这个方法完成实际的过滤操作,当客户请求访问于过滤器关联的URL时,Servlet容器将先调用过滤器的doFilter方法。FilterChain参数用于访问后续过滤器
◆destroy():
Servlet容器在销毁过滤器实例前调用该方法,这个方法中可以释放Servlet过滤器占用的资源
六、Servlet过滤器的创建步骤:
◆实现javax.servlet.Filter接口
◆实现init方法,读取过滤器的初始化函数
◆实现doFilter方法,完成对请求或过滤的响应
◆调用FilterChain接口对象的doFilter方法,向后续的过滤器传递请求或响应
◆销毁过滤器
七、Servlet过滤器对请求的过滤:
◆Servlet容器创建一个过滤器实例
◆过滤器实例调用init方法,读取过滤器的初始化参数
◆过滤器实例调用doFilter方法,根据初始化参数的值判断该请求是否合法
◆如果该请求不合法则阻塞该请求
◆如果该请求合法则调用chain.doFilter方法将该请求向后续传递
八、Servlet过滤器对响应的过滤:
◆过滤器截获客户端的请求
◆重新封装ServletResponse,在封装后的ServletResponse中提供用户自定义的输出流
◆将请求向后续传递
◆Web组件产生响应
◆从封装后的ServletResponse中获取用户自定义的输出流
◆将响应内容通过用户自定义的输出流写入到缓冲流中
◆在缓冲流中修改响应的内容后清空缓冲流,输出响应内容
九、Servlet过滤器的发布:
◆发布Servlet过滤器时,必须在web.xml文件中加入﹤filter﹥元素和﹤filter-mapping﹥元素。
◆filter元素用来定义一个过滤器:
- //属性 含义
- filter-name 指定过滤器的名字
- filter-class 指定过滤器的类名
- init-param 为过滤器实例提供初始化参数,可以有多个
◆filter-mapping元素用于将过滤器和URL关联:
- //属性 含义
- filter-name 指定过滤器的名字
- url-pattern 指定和过滤器关联的URL,为”/*”表示所有URL
十一、Servlet过滤器使用的注意事项
◆由于Filter、FilterConfig、FilterChain都是位于javax.servlet包下,并非HTTP包所特有的,所以其中所用到的请求、响应对象ServletRequest、ServletResponse在使用前都必须先转换成HttpServletRequest、HttpServletResponse再进行下一步操作。
◆在web.xml中配置Servlet和Servlet过滤器,应该先声明过滤器元素,再声明Servlet元素
◆如果要在Servlet中观察过滤器生成的日志,应该确保在server.xml的localhost对应的﹤host﹥元素中配置如下﹤logger﹥元素:
- ﹤Logger className = “org.apache.catalina.logger.FileLogger”
- directory = “logs”prefix = “localhost_log.”suffix=”.txt”
- timestamp = “true”/﹥
Servlet过滤器的情况就向你介绍到这里,那么你对Servlet过滤器是否有了了解呢?
来自:http://www.blogjava.net/Unmi/archive/2009/07/01/285020.html
作为 Java 程序员,对于 JavaBean 也许你会说再熟悉不过了,它贯穿在系统的多层中,不同的叫法有
PO、VO、DTO、POJO、DO(Domain Object)。然而它无外乎就是一个 Class 类,带上些属性和它们的
setter/getter 方法,set/get 后面那一个字母大写。虽然我们现在很少把 JavaBean 与那个古老的 2.0 的 EJB
搞混,但为什么明明用 IDE 为属性生成的 getter/setter 方法,应用一运行,还是报找不到某个 bean 属性的 setter 或
getter 方法呢?
要知道,在 Sun 的网站上那个关于 JavaBean 规范的 PDF 文档可是有足足实实的 114 页啊。难免有些规则有点古怪,至使知名的 IDE 都难以应对,所以我们还是有必要了解其中二三,来规范我们的 JavaBean 和解释一些情形。
Sun 的关于 JavaBean 规范见:http://java.sun.com/javase/technologies/desktop/javabeans/docs/spec.html,其中可下载到 JavaBean 规范的 PDF 文档。
实际中的问题
首
先,当然还是要说它的属性及 setter/getter 方法。属性以小写字母开头,驼峰命名格式,相应的 getter/setter 方法是
get/set 接上首字母大写的属性名。多数情况是对的,且当前流行的 IDE(Eclipse、JBuilder) 也都认这个死理,这里
NetBean
值得表扬一下。但要是碰到些遗留的代码中属性名不规范,或者有些人就是顽固,或真是对属性命名犹豫不决时的写下的代码时,那还是有得你研究一下。
这里来看看 Eclipse 为几个属性生成的 getter/setter 方法吧:
sName(从 C 转过来的,受匈牙利的影响,认为 Name 是个字符串,所以加个前缀 s) getSName()/setSName(String name)
URL (平时认为是缩略语/专有名词,理当全部大写,这在我们对待 ID 时经常发生的) getURL()/setURL(String url)
上
面第一个由 Eclipse 为我们生成的 getSName()/setSName(String name) 方法,参照 JavaBean
规范来说,其实是错误的。如果出现这样的方法,放到我们的标签(像 Struts 标签,如 <s:textfield
name="sName"/>),或是进行 Hibernate/iBatis 那种映射时,你就能收到报 找不到 sName 属性相应的 getter/setter 方法 那样的错误。不是明明有 getSName() 和 setSName(String name),可是方法名错了,正确的版本应该是 getsName() 和 setsName(String name)。
前面首先解释了属性命名不规范产生问题的原因,现在就来更仔细的了解关于 JavaBean 属性及其 getter/setter 方法的约定,有些是硬性的。
属性与存取访问的规定
为 JavaBean 创建属性时,必须牢记:缩略语通常被视为一个独立的单词,而不是单个字母。例如,URL 对应的属性名应该用 url,相应的 getUrl()/setUrl(),所以 ID 还是用 id 作为属性吧,相应的 getId()/setId()。
规
范中另一个特别的地方就是,第二个字母为大写的属性名要区别对待。如果属性名的第二个字母是大写的,那么该属性名直接用作 getter/setter
方法中 get/set 的后部分,就是说大小写不变。这就是为什么 sName 对应的存取方法是 getsName()/setsName()
的原因,不能不说这条规则很令人费解。那就更有必要看看下面表格的规范:
| 属性名/类型 |
getter 方法 |
setter 方法 |
| xcoordinate/Double |
public Double getXcoordinate() |
public void setXcoordinate(Double newValue) |
| xCoordinate/Double |
public Double getxCoordinate() |
public void setxCoordinate(Double newValue) |
| XCoordinate/Double |
public Double getXCoordinate() |
public void setXCoordinate(Double newValue) |
| Xcoordinate/Double |
不允许 |
不允许 |
| student/Boolean |
public Boolean getStudent() |
public void setStudent(Boolean newValue) |
| student/boolean |
public boolean getStudent()
public boolean isStudent() |
public void setStudent(boolean newValue) |
属
性是首字母大写,次字母小写是,你永远都找不到它的 getter/setter 方法的,对这个属性的使用是会害人的。对于 boolean
类型属性的 getter 方法是 isXxx() 还是 getXxx() 就自己决定了,isXxx() 应该更接近于自然语言,更顺溜些。
知道了属性及存取方法的规定,那么你即使是面对古老代码,在使用标签来引用或与 Hibernate/iBatis 等进行映射,你就知道该填什么样的属性名了。
还有一个我们很少碰触到的是关于可索引属性的 getter/setter 方法(这方面 C# 表现的比 Java 要优秀),比如有属性
private OrderItem[] orderItem; 那它相应的 getter/setter 除常见的两个外,还有带索引参数的两个版本,如下:
public OrderItem[] getOrderItem();
public void setOrderItem(OrderItem[] newArray);
public OrderItem[] getOrderItem(int index);
public void setOrderItem(int index, OrderItem orderItem);
关于 Bean 导航
最后就是 Bean 导航的规范,通常用点记法(dot notation) 来引用属性,同时也要注意索引属性的访问。在 Web MVC 的表单中,以及标签中, Jarkata-Commons-BeanUtils 中用得很多。看点记法的示例:
| Java 代码 |
点记法 |
| anOrder.getAccount().getUsername() |
anOrder.account.username |
| anOrder.getOrderItem().get(0).getProductId() |
anOrder.orderItem[0].productId |
| anObject.getId() |
anObject.id |
| anObject.getxCoordinate() |
anObject.xCoordinate |
上表应该从右往左边看,点记法中的属性名运行时要被解析成相应的存取方法调用。比如像 Struts1 标签:
<html:text property= "stocks[1].code"/>
会显示出 FormBean 中 stocks 列表的第二个元素的 code 属性,提交就填充到相应的位置上去。
转自:http://blog.csdn.net/ccat/archive/2009/05/14/4180765.aspx
几乎每一个新人在初学关系型数据库设计的时候,都会接触到关系范式。但是,我还是见到了大量很离谱的设计。客观的说,背下关系范式,离一个合格的数据库设
计师还差很远。设计工作总是在理想与现实之,规范与工艺之间妥协。建筑如是,造船如是,操作系统设计如是,数据库设计亦如是。
是的,你记得范式,你还记得反范式建议。你知道范式减少冗余,提高一致性;你还知道反范式可以方便编程。不幸的是,最终的结果总是遵守范式的做法使自己的应用层代码混乱,而反范式的企图使得数据库也陷入混乱。
这是谁的错?
不必太自责,设计工作是一个经验的积累过程。没有人天生就会做设计。天才与勤奋,是乘法关系。并不是你笨,只是天才对面的那个系数还不够大而已。
以下的一些经验,或许在你读完关系范式以后,可以抽空看一看 。世上没有魔法,读完这篇文章,并不会立即让你拥有多年设计经验。但是,这些在设计工作中积累的经验教训,应该可以帮助你少走一些弯路。
关于范式
关系范式并不邪恶,也不要把它想得太神秘,如果书本上的定义不能让你很快理解,不妨试着回答以下的问题:
字段还可以再分吗?分成两个或更多的字段以后,还能不能表达完整的含义?
字段的值是不是有限的几个离散的状态?
两个或若干个字段,能不能提取出来建立为一个数据字典?
如果表中某个字段依赖其他表,被依赖的字段是不是唯一的(最好是主键)?
查询中是否会出现超过两个表的Join?
将数据库设计与系统设计结合起来
数据库设计并不是一个孤立的过程,整个软件生命期中,各方面的工作应该有机结合。这方面我觉得ACCP过去的教材讲得还不错,至少思路是对的:
在做需求分析的时候,做Use Case。
此时可以分析出应用层的功能接口,对于数据库的实体分类可以有一个大概的划定。例如,这个项目会需要一个工作流,这个项目会需要一个订单系统,或者一个文档库,等等。通常,每个子系统可以对应一个
在做概要设计的时候,出类关系和ER简图。
通常来说,此时不能确定所有的字段,但是会有哪些表,有哪些主外键依赖,有哪些地方应该需要存储过程和触发器的辅助,等等。
详细设计时尽可能将数据库结构完全固定。
尽管现代开发工具不断提升XP能力,重构越来越简单。数据库的重构仍然是一件牵一发而动全身的事情,毕竟数据库是信息存储的根本。大厦楼顶加个小花园容易,把地基下面的承重柱子拔出来换两根试试?
重视SQL
近年来ORM发展很快,几乎每个框架都要提供这个功能,以至于会有些菜鸟认为“ORM”会淘汰SQL语言。
这是一块试金石,如果你有这样的感觉,应该考虑认真评估一下自己在这个领域是不是太菜了。
SQL不是一种编程语言这么简单,SQL代表的是一种与应用开发语言完全不同的思想。面向集合,过程无关,着眼于规则定义。可以说,SQL是FP High Order计算的最成功应用,也可以说,SQL是一种静态强类型的MapReduce语言。
看,换上时髦的名词,会不会让你觉得它上等起来了?
在应用层语言惨烈竞争的同时,SQL语言压倒了同时代出现的其他关系型数据库操作语言,在这个拥有巨大利润的领域占据了绝对统治地位。即使桀骜不驯的
Postgres,也在1995年变身为PostgrSQL。这一过程,并非像VC淘汰BC那么多盘外招,而是长时间争议与选择的结果。
对于信息操作规则定义,SQL几乎是最好的表达方式。接近自然语言,高度可读,并且非常利于优化。
打个比方,一个基于过程语言的上帝,这样说:
* 构造一个光源对象
* 构造一个能源对象
* 调用光源对象方法,设置能源
* 调用光源对象的发光方法,传入照明范围内的对象列表
基于SQL的上帝说,要有光。
当然,在这位老兄背后,要有打杂的小弟去完成插电点灯的事情,但是作为上帝,什么活都自己做了,要天使干什么?
看看那些应用层语言的list comprehensions(列表推导式)。不止一次我想要为Python实现一个基于存储层的列表推导式实现,都可耻的失败了。
当然,我承认这跟跟人能力有关,我不是Gudio。
看看LINQ,不管如何吹嘘,它就是一个抽象出I/O的SQL。我见过一些人激烈的贬低SQL,抬高ORM,同时又对LINQ顶礼膜拜,这可真够分裂的。
ORM对应用层编程效率的提升是客观的,无需回避。但是随着你数据操作越来越精细和复杂,就越来越需要通过规则定义来抽象High Order I/O过程。当你转了一圈儿回来,会发现自己又在写SQL。
想想Hibernate的HQL,想想C#的LINQ。
计算机不会变魔术。想让它做事更聪明,就需要你这个驭者更加聪明才行。
好的工具和方法可以给你带来更高的能力系数,但是记住,一个乘法计算,仅有一头大是不够的。
不懂SQL的人,是不能驾驭好ORM的。
与ORM做朋友
ORM对于开发工作,无疑是有好处的。我的朋友沈葳说,人脑能组织和分析的事务是有限的,所以代码越短,越有利于提高代码质量。从这个角度讲,ORM是非常重要的开发工具,其意义不亚于C API 函数集到GUI 框架的进步。
要想让ORM充分发挥威力,有时候需要从数据库设计时就做出一定妥协。
例如,你往往会需要加入自增标识列,会放弃一些精巧但是不利于ORM访问的依赖设定,甚至要放弃一些漂亮的命名(它们在应用层语言中是保留字,但是你用的ORM不懂如何规避)。
但是,这往往是必要的。就像建筑师向气候和建筑材料妥协一样。
在ORM默认的自增字段外,也许你还需要基于业务规则的唯一约束,那么额外加索引。
好的ORM会帮助你方便的查询数据字典,生成对象映射,跟踪数据变更,提供数据完整性的应用层检查,构造两阶段提交事务,减少不必要的I/O。
同样,不懂得运用ORM,也可能会破坏数据完整性,降低数据访问速度,甚至造成数据库死锁。作为项目开发人员,应该将ORM视为朋友而不是负担。
合理分层
过去,流行使用复杂的数据库设计,将业务规则存储于数据库的存储过程。现在,又流行抛弃数据层的一切约束,所有的规则都放在应用层。
这两者都不合理,除了应用需求的影响,前者与Oracle的广告部宣传有关,后者与MySQL阵营的鼓动有关。背后都有一些不合理的力量推动。
每一层应该保证自己的完整性,这才是分层的意义。那么,在数据库层,应该保证数据的完整性。
数据库备份出来,再恢复进去,应该可以得到所有的业务信息。
直接向数据库导入数据,应该可以有完整的数据规则保护。
数据库里保存的,不仅仅是表和记录,应该是完整的持久性信息。
从这个角度讲,配置文件和应用层代码中不应该有任何业务数据定义,这些信息都应该是数据字典表。如果出现了这种配置文件,大多数情况下都是愚蠢的错误。
实际上,包括Web网站常见的附件上传,都应该保存在数据库中。
独立的I/O文件存储、包括将外键约束转移到应用层,往往是因为对性能的妥协。以及,这里面确实存在MySQL阵营在推广过程中的一些不道德的宣传。
有效利用数据库功能,可以提高应用层的开发速度,简化代码结构,使得数据存储更安全。这通常仰赖与设计人员的经验,根据项目的具体需求进行调整。
基于这个原则,合理利用数据库功能,编写存储过程,触发器,调校索引,都是必要的。
我敢打赌,随着MySQL实现越来越多的功能,它的宣传材料上会越来越多的出现以前被MySQL所摒弃的复杂设计理念,并且宣称这是MySQL所独创或一贯倡导的。
收集整理常见的模式
在设计模式提出这么多年,在关系型数据库问世如此之久后,我很惊讶的一件事就是数据库设计模式仍然是一个相当冷门的领域。实际上,关系数据库的模式也有很多
可循之规。例如用户信息(HR或CRM)、工作流,权限管理(如RBAC),订单等等,都有相当成熟的行业经验和时间,往往只要修改一些字段名,或者在关
键架构的基础上加以扩展,就可以很好的用于实践。
每一个有志于成为高水平设计人员的开发者,都应该积极的收集自己体会到的数据库设计模式,积极的与同行交流。
这方面,Oracle的示例Schema,Postgres的示例数据库项目(在Soureforge上可以找到),都是很好的例子。相对来说,微软在MSSQL和Access中提供的示例库更为轻量和简单,也是作为入门的不错借鉴。
来自J道Banq http://www.jdon.com/artichect/dbdead.htm
现代软件和以往传统软件主要区别在于:现代软件基于internet互联网技术,运行于开放的网络环境,不象传统软件只是运行在封闭的局域网,运行环境的区别就决定了软件操作用户的多少,在一个开放互联网环境,
你的软件系统用户是不断增长,特别是那些对所有人群开放的社区网站系统,更是承受前所未有的访问负载。那么,这些软件系统承受的压力主要会集中在软件的哪个环节呢?如果你使用传统软件的设计思路,那么无疑压力都集中在数据库上。
随着用户的爆发量增长,在某个凌晨醒来时,你发现:数据库已死。
传统软件系统实则应该叫数据库软件系统,是一个数据库系统,开发这样的系统非常简单,成本
也非常低廉,只要根据需求先设计好数据表结构,然后,就找一些大学毕业生写大量SQL语句,虽然还使用
JAVA/PHP/.NET等语言,但实际上这些语言只是将SQL送往数据库执行的运输工,没有什么价值和地位。
所以,这样的系统运行在互联网环境下以后,主要负载就集中在数据库的SQL运行上,也就是说:整个软件系统性能关键点就集中在数据库上了,数据库是性能
主角,是王者;虽然你购置了昂贵的Websphere/weblogic等应用服务器,但是由于Java只是运输工,根本起不到性能上负载分担的作用。
著名的社区网站MySpace就是因为一个好的idea,用户疯狂增长,但是系统却不能平滑承受增长的用户访问,这些用户访问网站缓慢、无法访问甚至丢失数据,他们经过几次伤筋动骨的架构升级,在微软SQLServer直接技术支持下,
好容易才勉强应付过去。看看他们痛苦经历,你是否也愿意再来一次呢?详细情况: http://www.jdon.com/jivejdon/thread/34601.html
从中可以看出,数据库性能微调和挖潜总是有限度的,对数据库性能优化提高性能的步伐永远赶不上用户增长量,
有人也提出数据库集群的概念,其实数据库集群是一个骗人概念,一般只是备份,在集群数量和failover上有制约,
否则,数据库巨头Oracle不会跑到JavaEE阵营摇旗呐喊,还最早推出EJB3服务器,并扬言要收购JavaEE过去老大
Bea Weblogic。
很显然,数据库成已经为软件系统的主要性能瓶颈了,单纯依靠数据库自救的方式已经行不通,是宣布数据库退出主角时候了,那么由谁来宣布:教皇数据库已死?无疑是Java。
Java社区早在本世纪初就提出中间件概念,用以取代数据库地位,实则就是将软件系统主要负载从数据库上转移到中间件服务器上,分担负载。
也就是说:Java社区提出:既然数据库已经成为瓶颈,修修补补也无济于事,不如放弃它,不再依赖它。
也就是说:Java不再做SQL的运输工,不再是跑龙套的了,而是主角,那么如何让Java成为主角呢?那必须依赖对象这个概念,对象是生活在中间件服务器内存中,它又是数据库数据的业务封装,它和数据库有着
千丝万缕的关系,但是它又和关系数据库存在天然矛盾,两者水火不容。
过去,我们是将业务逻辑写成SQL送往数据库执行,导致数据库成为业务逻辑主要运行瓶颈,那么,如果我们将
业务逻辑用对象概念表达,而不是SQL,那么我们的业务逻辑就围绕内存中的对象反复计算,这样,负载不是集中在
对象运行的中间件服务器上(也就是应用服务器Weblogic/websphere/JBoss/Tomcat)?而对象/中间件都是用Java
语言表达的,无疑,这样的架构,Java才成为主角。
再进一步想想:如果我们从软件系统开始之初,就使用对象分析设计,不与数据库沾边,整个流程就完全OO,分析设计直至代码都摆脱了数据库影响,这个流程如下:
分析建模 细化设计(通过Evans DDD) 架构设计 代码实现 调试测试 部署运行。
那么数据库在什么时候建立呢?数据库表结构的创建可以延缓到部署运行时,由Hibernate/EJB CMP/JPA等ORM技术自动实现。这样,
整个上游环节就不涉及数据库技术,而是使用更符合自然的表达OO方式,软件质量就更高了。我在J道网站已经大量阐述了如何从OO分析
到OO实现的过程,包括我的Jdon框架也直接支持这样一个自然方式。
现在,很多人已经理解,分析设计要用OO,但是数据库是运行阶段缺少不了的,确实,这是正确观点,我们夺取数据库的王位,不是将它打倒,只是理性和平移交权力重心而已,数据库退出主角地位,让位于Java中间件,也预示着过去数据库为王的时代的结束,
但是数据库会和操作系统一样,成为我们现代软件系统一个不可缺少重要的基础环节。
正是基于这样事实,虽然我早在2005年喊出“数据库时代的终结一文,回帖长达几百贴,
大部分是怀疑论,不信论,其实2003年国外TSS就有一篇“给数据库休息吧”
(休息不代表退休,而是退居幕后,就象操作系统作用一样),由此可见,由于传统观点影响和不及时与国际新思想同步,国内数据库保皇派还是有相当人数的。我
BanQ人微言轻,抛出这些观点被保皇派讥讽为所疯话,那么看看,著名ORM框架Hibernate和SEAM框架创始人Gavin
King的一段观点:
In
almost all enterprise applications, the database is the primary
bottleneck, and the least scalable tier of the runtime environment.
数据库成为了大多数企业应用的主要瓶颈,也成为了运行环境中最不具伸缩性的层。... PHP/Ruby的用户会说什么都不共享(share
nothing)的架构照样具有很好的伸缩性,.... 这些傻瓜真正想的是“除了数据库以外什么都不共享(Share nothing except
for the database)”的架构。更多参看这里
所谓伸缩性,就是弹性,整个软件架构既支持小负载运行,也支持大负载支持,只要增加服务器即可;
由于软件系统负载已经从SQL转移到内存中的对象上,那么我们就可以通过增加这些应用服务器数量,通过分布式计算甚至云计算,达到业务对象在多台应用服务
器之间传递共享,而不必通过数据库这个环节,既减轻数据库负载,又能轻松扩充性能,不必走
集中试大型主机之路,只要添置低廉PC服务器即可。经过权威测试:websphere/weblogic的20台PC服务器集群性能不亚于一台SUN/IBM的中型机,性价比已经一目了然了。
JavaEE的服务器的集群相对于Linux等操作系统集群的好处在于:JavaEE集群能够针对某个繁忙负载大的具体业务功能进行集群,换句话说:
就是做到精确制导,精确解决问题,而显然,Linux操作系统的集群则无法直至业务核心的。
从另外一个方面看:虽然现在PHP号称走上对象路线,Ruby的铁轨开始铺进企业,但是他们的运行环境实则依赖数据库的,
特别是Ruby On Rails还是最适合Evans DDD对象建模路线,但是目前来讲还是"披着羊皮的狼",批着DDD,实则是以数据库中心。当然相信
ROR等将来会提供分布式计算环境,但是JavaEE在2002年时就通过EJB以及分布式缓存成熟稳定地提供分布式计算的中间件,并且已经大量成熟应用。
本文结束以前,我相信大家明白,在众多语言平台竞争中,为什么Java能够击败过去拳王数据库,夺得新的拳王冠军,以及他的特点所在。有人可能会说:你忘记谈.NET了,这个不用我回答你,用微软中国董事长张亚勤的话回答:8年前.NET战略很天真,
你会将你的重要业务企业计算依赖一个很天真不成熟的技术吗?除非你自己也很天真:)。
原作者有版权声明,只能链接到他的页面了。
这篇博文对SQL的连接查询进行了实例化的讲解,适合入门和回顾SQL连接的相关知识...
http://lavasoft.blog.51cto.com/62575/38929
用exp命令导出了一个dmp文件,在导入时遇到了问题,提示说表空间不存在。在网上搜索的方法太复杂,其实,如果需要导入的表比较少,可以直接用二进制编辑器,如UltraEdit32直接编辑dmp文件。把里面的表空间字符串改为被导入的表空间即可。
在多人协同开发项目时,版本控制是非常重要的。
作为一个学习计划来学习SVN,主要的参考资料是《使用Subversion进行版本控制——针对Subversion1.4》,这个资料其实是网上比较流行翻译版本,原作者是Ben Collins-Sussman...。
本文是这个学习计划的开篇:-)。介绍SVN背后的一些知识。
SVN是一个版本控制系统,版本控制系统的核心任务是实现写作编辑和数据共享。
版本控制系统有两个模型:锁定-修改-解锁模型和拷贝-修改=合并模型。
SVN采用的是后者,拷贝-修改-合并模型使得用户可以并行的工作,不必等待别人。但是,这个模型可能会遇到“冲突”的情况,即多个用户对同一个文件进行了修改。在冲突发生时,需要用户交流(:-)交流的重要性!)后再手工更正。但幸运的是,冲突的发生并不频繁。所以,这种模型是很实用的。
图一表明了拷贝-修改-合并模型:

图一
Harry和Sally为同一个项目各自建立了一个工作拷贝,工作是并行的,修改了同一个文件A,Sally首先保存修改到版本库,当Harry想去提交修改的时候,版本库提示文件A已经过期,换句话说,A在他上次更新之后已经更改了,所以当他通过客户端请求合并版本库和他的工作拷贝之后,碰巧Sally的修改和他的修改不冲突,所以一旦他把所有的修改集成到一起,也可以将工作拷贝保存到版本库。
图二表明了拷贝-修改-合并模型下冲突发生:

图二
如果Sally和Harry的修改交迭(:-)对同一块代码进行了修改)怎么办?这种情况叫做冲突。当Harry告诉他的客户端去合并版本库的最新修改到自己的工作拷贝时,他的文件就会处于冲突状态;它可以看到一对冲突的修改集,并手工的选择保留一组修改。需要注意的是软件不能自动解决冲突,只有人可以理解并作出智能的选择,一旦Harry手工的解决了冲突(也许需要和Sally讨论),就可以安全的吧合并的文件保存到版本库。
J2EE,Java2平台企业版(Java2PlatformEnterpriseEdition),是Sun公司为企业级应用推出的标准(Platform)。Java平台共分为三个主要版本JavaEE、JavaSE和JavaME。
Sun公司在1998年发表1.2版本的时候,使用了新名称Java2Platform,即Java2平台,修改后的JDK称为
Java2PlatformSoftwareDevelpingKit,并分为标准版(StandardEdition,J2SE),企业版
(EnterpriseEdition,J2EE),微型版(MicroEdition,J2ME)。J2EE便由此诞生。
Java2平台包括标准版(J2SE)、企业版(J2EE)和微缩版(J2ME)三个版本。他们的范围是:J2SE包含于J2EE中,J2ME包含了J2SE的核心类,但新添加了一些专有类。
随着Java技术的发展,J2EE平台得到了迅速的发展,成为Java语言中最活跃的体系之一。现如今,J2EE不仅仅是指一种标准平台,她更多的表达着一种软件架构和设计思想。
2005年6月,JavaOne大会召开,SUN公司公开JavaSE6。此时,Java的各种版本已经更名以取消其中的数字2:J2EE更名为JavaEE,J2SE更名为JavaSE,J2ME更名为Java ME。
一、配置系统管理(Admin Web Application)
大多数商业化的J2EE服务器都提供一个功能强大的管理界面,且大都采用易于理解的Web应用界面。Tomcat按照自己的方式,同样提供一个成熟
的管理工具,并且丝毫不逊于那些商业化的竞争对手。Tomcat的Admin Web
Application最初在4.1版本时出现,当时的功能包括管理context、data
source、user和group等。当然也可以管理像初始化参数,user、group、role的多种数据库管理等。在后续的版本中,这些功能将得
到很大的扩展,但现有的功能已经非常实用了。Admin Web
Application被定义在自动部署文件:CATALINA_BASE/webapps/admin.xml
。(译者注:CATALINA_BASE即tomcat安装目录下的server目录)
你必须编辑这个文件,以确定Context中的docBase参数是绝对路径。也就是说CATALINA_BASE/webapps
/admin.xml的路径是绝对路径。作为另外一种选择,你也可以删除这个自动部署文件,而在server.xml文件中建立一个Admin Web
Application的context,效果是一样的。你不能管理Admin Web
Application这个应用,换而言之,除了删除CATALINA_BASE/webapps/admin.xml ,你可能什么都做不了。
如果你使用UserDatabaseRealm(默认),你将需要添加一个user以及一个role到CATALINA_BASE/conf/tomcat-users.xml文件中。你编辑这个文件,添加一个名叫“admin”的role 到该文件中,如下:
<role name="admin"/>
你同样需要有一个用户,并且这个用户的角色是“admin”。象存在的用户那样,添加一个用户(改变密码使其更加安全):
<user name="admin"
password="deep_dark_secret"
roles="admin"/>
|
当你完成这些步骤后,请重新启动Tomcat,访问http://localhost:8080/admin,你将看到一个登录界面。Admin
Web Application采用基于容器管理的安全机制,并采用了Jakarta
Struts框架。一旦你作为“admin”角色的用户登录管理界面,你将能够使用这个管理界面配置Tomcat。
二、配置应用管理(Manager Web Application)
Manager Web Application让你通过一个比Admin Web Application更为简单的用户界面,执行一些简单的Web应用任务。Manager Web Application被被定义在一个自动部署文件中:
CATALINA_BASE/webapps/manager.xml
你必须编辑这个文件,以确保context的docBase参数是绝对路径,也就是说CATALINA_HOME/server/webapps/manager的绝对路径。(译者注:CATALINA_HOME即tomcat安装目录)
如果你使用的是UserDatabaseRealm,那么你需要添加一个角色和一个用户到CATALINA_BASE/conf/tomcat-users.xml文件中。接下来,编辑这个文件,添加一个名为“manager”的角色到该文件中:
<role name=”manager”>
你同样需要有一个角色为“manager”的用户。像已经存在的用户那样,添加一个新用户(改变密码使其更加安全):
<user name="manager"
password="deep_dark_secret"
roles="manager"/>
|
然后重新启动Tomcat,访问http://localhost/manager/list,将看到一个很朴素的文本型管理界面,或者访问
http: //localhost/manager/html/list,将看到一个HMTL的管理界面。不管是哪种方式都说明你的Manager
Web Application现在已经启动了。
Manager
application让你可以在没有系统管理特权的基础上,安装新的Web应用,以用于测试。如果我们有一个新的web应用位于/home/user
/hello下在,并且想把它安装到/hello下,为了测试这个应用,我们可以这么做,在第一个文件框中输入“/hello”(作为访问时的
path),在第二个文本框中输入“file:/home/user/hello”(作为Config URL)。
Manager
application还允许你停止、重新启动、移除以及重新部署一个web应用。停止一个应用使其无法被访问,当有用户尝试访问这个被停止的应用时,将
看到一个503的错误??“503 - This application is not currently available”。
移除一个web应用,只是指从Tomcat的运行拷贝中删除了该应用,如果你重新启动Tomcat,被删除的应用将再次出现(也就是说,移除并不是指从硬盘上删除)。
三、部署一个web应用
有两个办法可以在系统中部署web服务。
1.拷贝你的WAR文件或者你的web应用文件夹(包括该web的所有内容)到$CATALINA_BASE/webapps目录下。
2.为你的web服务建立一个只包括context内容的XML片断文件,并把该文件放到$CATALINA_BASE/webapps目录下。这个web应用本身可以存储在硬盘上的任何地方。
如果你有一个WAR文件,你若想部署它,则只需要把该文件简单的拷贝到CATALINA_BASE/webapps目录下即可,文件必须以
“.war” 作为扩展名。一旦Tomcat监听到这个文件,它将(缺省的)解开该文件包作为一个子目录,并以WAR文件的文件名作为子目录的名字。
接下来,Tomcat将在内存中建立一个context,就好象你在server.xml文件里建立一样。当然,其他必需的内容,将从server.xml中的DefaultContext获得。
部署web应用的另一种方式是写一个Context XML片断文件,然后把该文件拷贝到CATALINA_BASE/webapps目录下。一个Context片断并非一个完整的XML文件,而只是一个context元素,以及对该应用的相应描述。
这种片断文件就像是从server.xml中切取出来的context元素一样,所以这种片断被命名为“context片断”。
举个例子,如果我们想部署一个名叫MyWebApp.war的应用,该应用使用realm作为访问控制方式,我们可以使用下面这个片断:
<!--
Context fragment for deploying MyWebApp.war
-->
<Context path="/demo"
docBase="webapps/MyWebApp.war"
debug="0" privileged="true">
<Realm className=
"org.apache.catalina.realm.UserDatabaseRealm”
resourceName="UserDatabase"/>
</Context>
|
四、配置虚拟主机(Virtual Hosts)
关于server.xml中“Host”这个元素,只有在你设置虚拟主机的才需要修改。虚拟主机是一种在一个web服务器上服务多个域名的机制,对
每个域名而言,都好象独享了整个主机。实际上,大多数的小型商务网站都是采用虚拟主机实现的,这主要是因为虚拟主机能直接连接到Internet并提供相
应的带宽,以保障合理的访问响应速度,另外虚拟主机还能提供一个稳定的固定IP。
基于名字的虚拟主机可以被建立在任何web服务器上,建立的方法就是通过在域名服务器(DNS)上建立IP地址的别名,并且告诉web服务器把去往
不同域名的请求分发到相应的网页目录。因为这篇文章主要是讲Tomcat,我们不准备介绍在各种操作系统上设置DNS的方法,如果你在这方面需要帮助,请
参考《DNS and Bind》一书,作者是Paul Albitz and Cricket Liu
(O'Reilly)。为了示范方便,我将使用一个静态的主机文件,因为这是测试别名最简单的方法。
在Tomcat中使用虚拟主机,你需要设置DNS或主机数据。为了测试,为本地IP设置一个IP别名就足够了,接下来,你需要在server.xml中添加几行内容,如下:
<Server port="8005"
shutdown="SHUTDOWN" debug="0">
<Service name="Tomcat-Standalone">
<Connector className=
"org.apache.coyote.tomcat4.CoyoteConnector"
port="8080"
minProcessors="5" maxProcessors="75"
enableLookups="true"
redirectPort="8443"/>
<Connector className=
"org.apache.coyote.tomcat4.CoyoteConnector"
port="8443" minProcessors="5"
maxProcessors="75"
acceptCount="10" debug="0"
scheme="https" secure="true"/>
<Factory className="org.apache.coyote.
tomcat4.CoyoteServerSocketFactory"
clientAuth="false" protocol="TLS" />
</Connector>
<Engine name="Standalone"
defaultHost="localhost" debug="0">
<!-- This Host is the default Host -->
<Host name="localhost"
debug="0" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Context path="" docBase="ROOT" debug="0"/>
<Context path="/orders"
docBase="/home/ian/orders" debug="0"
reloadable="true" crossContext="true">
</Context>
</Host>
<!-- This Host is the first
"Virtual Host": http://www.example.com/ -->
<Host name="www.example.com"
appBase="/home/example/webapp">
<Context path="" docBase="."/>
</Host>
</Engine>
</Service>
</Server>
Tomcat的server.xml文件,在初始状态下,只包括一个虚拟主机,但是它容易被扩充到支持多个虚拟主机。在前面的例子中展示的是一个简
单的
server.xml版本,其中粗体部分就是用于添加一个虚拟主机。每一个Host元素必须包括一个或多个context元素,所包含的context元
素中必须有一个是默认的context,这个默认的context的显示路径应该为空(例如,path=””)。
五、配置基础验证(Basic Authentication)
容器管理验证方法控制着当用户访问受保护的web应用资源时,如何进行用户的身份鉴别。当一个web应用使用了Basic
Authentication(BASIC参数在web.xml文件中auto-method元素中设置),而有用户访问受保护的web应用
时,Tomcat将通过HTTP Basic
Authentication方式,弹出一个对话框,要求用户输入用户名和密码。在这种验证方法中,所有密码将被以64位的编码方式在网络上传输。
注意:使用Basic Authentication通过被认为是不安全的,因为它没有强健的加密方法,除非在客户端和服务器端都使用HTTPS或者其他密码加密码方式(比如,在一个虚拟私人网络中)。若没有额外的加密方法,网络管理员将能够截获(或滥用)用户的密码。
但是,如果你是刚开始使用 Tomcat,或者你想在你的web应用中测试一下基于容器的安全管理,Basic
Authentication还是非常易于设置和使用的。只需要添加<security-constraint>和<login-config>两个元素
到你的web应用的web.xml文件中,并且在CATALINA_BASE/conf/tomcat-users.xml文件中添加适当的<role>
和<user>即可,然后重新启动Tomcat。
下面例子中的web.xml摘自一个俱乐部会员网站系统,该系统中只有member目录被保护起来,并使用Basic Authentication进行身份验证。请注意,这种方式将有效的代替Apache web服务器中的.htaccess文件。
<!--
Define the
Members-only area,
by defining
a "Security Constraint"
on this Application, and
mapping it to the
subdirectory (URL) that we want
to restrict.
-->
<security-constraint>
<web-resource-collection>
<web-resource-name>
Entire Application
</web-resource-name>
<url-pattern>/members/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>member</role-name>
</auth-constraint>
</security-constraint>
<!-- Define the Login
Configuration for
this Application -->
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>My Club
Members-only Area</realm-name>
</login-config>
六、配置单点登录(Single Sign-On)
一旦你设置了realm和验证的方法,你就需要进行实际的用户登录处理。一般说来,对用户而言登录系统是一件很麻烦的事情,你必须尽量减少用户登录验证的次数。作为缺省的情况,当用户第一次请求受保护的资源时,每一个web应用都会要求用户登录。
如果你运行了多个web应用,并且每个应用都需要进行单独的用户验证,那这看起来就有点像你在与你的用户搏斗。用户们不知道怎样才能把多个分离的应用整合成一个单独的系统,所有他们也就不知道他们需要访问多少个不同的应用,只是很迷惑,为什么总要不停的登录。
Tomcat 4的“single sign-on”特性允许用户在访问同一虚拟主机下所有web应用时,只需登录一次。为了使用这个功能,你只需要在Host上添加一个SingleSignOn Valve元素即可,如下所示:
<Valve className=
"org.apache.catalina.
authenticator.SingleSignOn"
debug="0"/>
|
在Tomcat初始安装后,server.xml的注释里面包括SingleSignOn
Valve配置的例子,你只需要去掉注释,即可使用。那么,任何用户只要登录过一个应用,则对于同一虚拟主机下的所有应用同样有效。使用single
sign-on valve有一些重要的限制:
1.value必须被配置和嵌套在相同的Host元素里,并且所有需要进行单点验证的web应用(必须通过context元素定义)都位于该Host下。
2.包括共享用户信息的realm必须被设置在同一级Host中或者嵌套之外。
3.不能被context中的realm覆盖。
4.使用单点登录的web应用最好使用一个Tomcat的内置的验证方式(被定义在web.xml中的<auth-method>中),这比自定义的验证方式强,Tomcat内置的的验证方式包括basic、digest、form和client-cert。
5.如果你使用单点登录,还希望集成一个第三方的web应用到你的网站中来,并且这个新的web应用使用它自己的验证方式,而不使用容器管理安全,那你基本上就没招了。你的用户每次登录原来所有应用时需要登录一次,并且在请求新的第三方应用时还得再登录一次。
当然,如果你拥有这个第三方web应用的源码,而你又是一个程序员,你可以修改它,但那恐怕也不容易做。
6.单点登录需要使用cookies。
七、配置用户定制目录(Customized User Directores)
一些站点允许个别用户在服务器上发布网页。例如,一所大学的学院可能想给每一位学生一个公共区域,或者是一个ISP希望给一些web空间给他的客户,但这又不是虚拟主机。在这种情况下,一个典型的方法就是在用户名前面加一个特殊字符(~),作为每位用户的网站,比如:
http://www.cs.myuniversity.edu/~username
http://members.mybigisp.com/~username
Tomcat提供两种方法在主机上映射这些个人网站,主要使用一对特殊的Listener元素。Listener的className属性应该是
org.apache.catalina.startup.UserConfig,userClass属性应该是几个映射类之一。
如果你的系统是Unix,它将有一个标准的/etc/passwd文件,该文件中的帐号能够被运行中的Tomcat很容易的读取,该文件指定了用户的主目录,使用PasswdUserDatabase 映射类。
<Listener className=
"org.apache.catalina.startup.UserConfig"
directoryName="public_html"
userClass="org.apache.catalina.
startup.PasswdUserDatabase"/>
|
web文件需要放置在像/home/users/ian/public_html或者/users/jbrittain/public_html一样的目录下面。当然你也可以改变public_html 到其他任何子目录下。
实际上,这个用户目录根本不一定需要位于用户主目录下里面。如果你没有一个密码文件,但你又想把一个用户名映射到公共的像/home一样目录的子目录里面,则可以使用HomesUserDatabase类。
<Listener className=
"org.apache.catalina.startup.UserConfig"
directoryName="public_html"
homeBase="/home"
userClass="org.apache.catalina.
startup.HomesUserDatabase"/>
|
这样一来,web文件就可以位于像/home/ian/public_html或者/home/jasonb/public_html一样的目录下。这种形式对Windows而言更加有利,你可以使用一个像c:home这样的目录。
这些Listener元素,如果出现,则必须在Host元素里面,而不能在context元素里面,因为它们都用应用于Host本身。
八、在Tomcat中使用CGI脚本
Tomcat主要是作为Servlet/JSP容器,但它也有许多传统web服务器的性能。支持通用网关接口(Common Gateway Interface,即CGI)就是其中之一,CGI提供一组方法在响应浏览器请求时运行一些扩展程序。
CGI之所以被称为通用,是因为它能在大多数程序或脚本中被调用,包括:Perl,Python,awk,Unix shell scrīpting等,甚至包括Java。
当然,你大概不会把一个Java应用程序当作CGI来运行,毕竟这样太过原始。一般而言,开发Servlet总要比CGI具有更好的效率,因为当用户点击一个链接或一个按钮时,你不需要从操作系统层开始进行处理。
Tomcat包括一个可选的CGI Servlet,允许你运行遗留下来的CGI脚本。
为了使Tomcat能够运行CGI,你必须做如下几件事:
1.把servlets-cgi.renametojar (在CATALINA_HOME/server/lib/目录下)改名为servlets-cgi.jar。处理CGI的servlet应该位于Tomcat的CLASSPATH下。
2.在Tomcat的CATALINA_BASE/conf/web.xml 文件中,把关于<servlet-name> CGI的那段的注释去掉(默认情况下,该段位于第241行)。
3.同样,在Tomcat的CATALINA_BASE/conf/web.xml文件中,把关于对CGI进行映射的那段的注释去掉(默认情况下,该段位于第299行)。注意,这段内容指定了HTML链接到CGI脚本的访问方式。
4.你可以把CGI脚本放置在WEB-INF/cgi
目录下(注意,WEB-INF是一个安全的地方,你可以把一些不想被用户看见或基于安全考虑不想暴露的文件放在此处),或者你也可以把CGI脚本放置在
context下的其他目录下,并为CGI Servlet调整cgiPathPrefix初始化参数。这就指定的CGI
Servlet的实际位置,且不能与上一步指定的URL重名。
5.重新启动Tomcat,你的CGI就可以运行了。
在Tomcat中,CGI程序缺省放置在WEB-INF/cgi目录下,正如前面所提示的那样,WEB-INF目录受保护的,通过客户端的浏览器无法窥探到其中内容,所以对于放置含有密码或其他敏感信息的CGI脚本而言,这是一个非常好的地方。
为了兼容其他服务器,尽管你也可以把CGI脚本保存在传统的/cgi-bin目录,但要知道,在这些目录中的文件有可能被网上好奇的冲浪者看到。另外,在Unix中,请确定运行Tomcat的用户有执行CGI脚本的权限。
九、改变Tomcat中的JSP编译器(JSP Compiler)
在Tomcat 4.1(或更高版本,大概),JSP的编译由包含在Tomcat里面的Ant程序控制器直接执行。这听起来有一点点奇怪,但这正是Ant有意为之的一部分,有一个API文档指导开发者在没有启动一个新的JVM的情况下,使用Ant。
这是使用Ant进行Java开发的一大优势。另外,这也意味着你现在能够在Ant中使用任何javac支持的编译方式,这里有一个关于Apache Ant使用手册的javac page列表。
使用起来是容易的,因为你只需要在<init-param> 元素中定义一个名字叫“compiler”,并且在value中有一个支持编译的编译器名字,示例如下:
<servlet>
<servlet-name>jsp</servlet-name>
<servlet-class>
org.apache.jasper.servlet.JspServlet
</servlet-class>
<init-param>
<param-name>logVerbosityLevel</param-name>
<param-value>WARNING</param-value>
</init-param>
<init-param>
<param-name>compiler</param-name>
<param-value>jikes</param-value>
</init-param>
<load-on-startup>3</load-on-startup>
</servlet>
|
当然,给出的编译器必须已经安装在你的系统中,并且CLASSPATH可能需要设置,那处决于你选择的是何种编译器。
十、限制特定主机访问(Restricting Access to Specific Hosts)
有时,你可能想限制对Tomcat
web应用的访问,比如,你希望只有你指定的主机或IP地址可以访问你的应用。这样一来,就只有那些指定的的客户端可以访问服务的内容了。为了实现这种效
果,Tomcat提供了两个参数供你配置:RemoteHostValve 和RemoteAddrValve。
通过配置这两个参数,可以让你过滤来自请求的主机或IP地址,并允许或拒绝哪些主机/IP。与之类似的,在Apache的httpd文件里有对每个目录的允许/拒绝指定。例如你可以把Admin Web application设置成只允许本地访问,设置如下:
<Context path=
"/path/to/secret_files" ...>
<Valve className="org.apache.
catalina.valves.RemoteAddrValve"
allow="127.0.0.1" deny=""/>
</Context>
|
如果没有给出允许主机的指定,那么与拒绝主机匹配的主机就会被拒绝,除此之外的都是允许的。与之类似,如果没有给出拒绝主机的指定,那么与允许主机匹配的主机就会被允许,除此之外的都是拒绝的。
从JavaEE 5的firstcup文档中得到下面的信息:
A Java EE server is a server application that the implements the Java EE platform APIs and provides
the standard Java EE services. Java EE servers are sometimes called application servers, because they
allow you to serve application data to clients, much as how web servers serve web pages to webbrowsers.
下面的文章来源于互联网,对比了Web服务器和应用服务器:
web服务器可以解析(handles)http协
议。当web服务器接收到一个http请求(request),会返回一个http响应
(response),例如送回一个html页面。为了处理一个请求(request),web服务器可以响应(response)一个静态页面或图片,
进行页面跳转(redirect),或者把动态响应(dynamic
response)的产生委托(delegate)给一些其它的程序例如cgi脚本,jsp(javaserver
pages)脚本,servlets,asp(active server
pages)脚本,服务器端(server-side)javascript,或者一些其它的服务器端(server-side)技术。无论它们(译者
注:脚本)的目的如何,这些服务器端(server-side)的程序通常产生一个html的响应(response)来让浏览器可以浏览。
要知道,web服务器的代理模型(delegation
model)非常简单。当一个请求(request)被送到web服务器里来时,它只单纯的把请求(request)传递给可以很好的处理请求
(request)的程序(译者注:服务器端脚本)。web服务器仅仅提供一个可以执行服务器端(server-side)程序和返回(程序所产生的)响
应(response)的环境,而不会超出职能范围。服务器端(server-side)程序通常具有事务处理(transaction
processing),数据库连接(database connectivity)和消息(messaging)等功能。
虽然web服务器不支持事务处理或数据库连接池,但它可以配置(employ)各种策略(strategies)来实现容错性(fault
tolerance)和可扩展性(scalability),例如负载平衡(load
balancing),缓冲(caching)。集群特征(clustering—features)经常被误认为仅仅是应用程序服务器专有的特征。
应用程序服务器(the application server)
根据我们的定义,作为应用程序服务器,它通过各种协议,可以包括http,把商业逻辑暴露给(expose)客户端应用程序。web服务器主要是处
理向浏览器发送html以供浏览,而应用程序服务器提供访问商业逻辑的途径以供客户端应用程序使用。应用程序使用此商业逻辑就象你调用对象的一个方法
(或过程语言中的一个函数)一样。
应用程序服务器的客户端(包含有图形用户界面(gui)的)可能会运行在一台pc、一个web服务器或者甚至是其它的应用程序服务器上。在应用程序
服务器与其客户端之间来回穿梭(traveling)的信息不仅仅局限于简单的显示标记。相反,这种信息就是程序逻辑(program
logic)。正是由于这种逻辑取得了(takes)数据和方法调用(calls)的形式而不是静态html,所以客户端才可以随心所欲的使用这种被暴露
的商业逻辑。
在大多数情形下,应用程序服务器是通过组件(component)的应用程序接口(api)把商业逻辑暴露(expose)(给客户端应用程序)
的,例如基于j2ee(java 2 platform, enterprise edition)应用程序服务器的ejb(enterprise
javabean)组件模型。此外,应用程序服务器可以管理自己的资源,例如看大门的工作(gate-keeping
duties)包括安全(security),事务处理(transaction processing),资源池(resource
pooling),和消息(messaging)。就象web服务器一样,应用程序服务器配置了多种可扩展(scalability)和容错(fault
tolerance)技术。
一个例子
例如,设想一个在线商店(网站)提供实时定价(real-time
pricing)和有效性(availability)信息。这个站点(site)很可能会提供一个表单(form)让你来选择产品。当你提交查询
(query)后,网站会进行查找(lookup)并把结果内嵌在html页面中返回。网站可以有很多种方式来实现这种功能。我要介绍一个不使用应用程序
服务器的情景和一个使用应用程序服务器的情景。观察一下这两中情景的不同会有助于你了解应用程序服务器的功能。
情景1:不带应用程序服务器的web服务器
在此种情景下,一个web服务器独立提供在线商店的功能。web服务器获得你的请求(request),然后发送给服务器端(server-
side)可以处理请求(request)的程序。此程序从数据库或文本文件(flat file,译者注:flat
file是指没有特殊格式的非二进制的文件,如properties和xml文件等)中查找定价信息。一旦找到,服务器端(server-side)程序
把结果信息表示成(formulate)html形式,最后web服务器把会它发送到你的web浏览器。
简而言之,web服务器只是简单的通过响应(response)html页面来处理http请求(request)。
情景2:带应用程序服务器的web服务器
情景2和情景1相同的是web服务器还是把响应(response)的产生委托(delegates)给脚本(译者注:服务器端(server
-side)程序)。然而,你可以把查找定价的商业逻辑(business
logic)放到应用程序服务器上。由于这种变化,此脚本只是简单的调用应用程序服务器的查找服务(lookup
service),而不是已经知道如何查找数据然后表示为(formulate)一个响应(response)。这时当该脚本程序产生html响应
(response)时就可以使用该服务的返回结果了。
在此情景中,应用程序服务器提供(serves)了用于查询产品的定价信息的商业逻辑。(服务器的)这种功能(functionality)没有指
出有关显示和客户端如何使用此信息的细节,相反客户端和应用程序服务器只是来回传送数据。当有客户端调用应用程序服务器的查找服务(lookup
service)时,此服务只是简单的查找并返回结果给客户端。
通过从响应产生(response-generating)html的代码中分离出来,在应用程序之中该定价(查找)逻辑的可重用性更强了。其他的
客户端,例如收款机,也可以调用同样的服务(service)来作为一个店员给客户结帐。相反,在情景1中的定价查找服务是不可重用的因为信息内嵌在
html页中了。
总而言之,在情景2的模型中,在web服务器通过回应html页面来处理http请求(request),而应用程序服务器则是通过处理定价和有效性(availability)请求(request)来提供应用程序逻辑的。
警告(caveats)
现在,xml web services已经使应用程序服务器和web服务器的界线混淆了。通过传送一个xml有效载荷(payload)给服务器,web服务器现在可以处理数据和响应(response)的能力与以前的应用程序服务器同样多了。
另外,现在大多数应用程序服务器也包含了web服务器,这就意味着可以把web服务器当作是应用程序服务器的一个子集(subset)。虽然应用程
序服务器包含了web服务器的功能,但是开发者很少把应用程序服务器部署(deploy)成这种功能(capacity)(译者注:这种功能是指既有应用
程序服务器的功能又有web服务器的功能)。相反,如果需要,他们通常会把web服务器独立配置,和应用程序服务器一前一后。这种功能的分离有助于提高性
能(简单的web请求(request)就不会影响应用程序服务器了),分开配置(专门的web服务器,集群(clustering)等等),而且给最佳
产品的选取留有余地。
每次听见“眼高手低”,我就庆幸自己不是这样的人。可是,越来越觉得自己就是一个典型的“眼高手低”。
对于未来几年靠技术吃饭的我,眼高手低,意味着以为理解了技术的本质,却不去实践!
悲哀!悲哀!
技术,就是一个实践重于理论的东西。再有理论,却不实践。那是万万不行的!技术,就是来源于实践啊!
看现在这些流行框架,哪个不是由实践来,到实践去?
“实践是检验真理的唯一标准”。
自己要克服这个毛病,必须在今后学习任何一个技术的时候,要实践!花大时间实践!不要认为简单就省掉这个环节,再简单,也得实践!
告诫!
转自:http://semi-sleep.javaeye.com/blog/348768
Red5如何响应rmpt的请求,中间涉及哪些关键类?
1.Red5在启动时会调用RTMPMinaTransport的start()方法,该方法会开启rmtp的socket监听端口(默认是1935),然后使用mina(apache的io操作类库)的api将RTMPMinaIoHandler绑定到该端口。
2.RTMPMinaIoHandler上定义了messageReceived、messageSent、sessionOpened和
sessionClosed等方法,当有socket请求时,相应的方法会被调用,这时RTMPMinaIoHandler会使用当前的socket连接
来创建一个RTMPMinaConnection(或者使用一个之前创建好的RTMPMinaConnection),并将其作为参数传递给定义于
RTMPHandler类上的相应的messageReceived、messageSent、connectionOpened和
connectionClosed方法。
3.RTMPHandler会调用Server类的lookupGlobal获得当前的GlobalScope,然后再利用GlobalScope
找到当前socket请求应该使用的WebScope(这个WebScope就是我们在自己的项目的WEB-INF"red5-web.xml中定义的
啦)。最后,RTMPHandler会调用RTMPMinaConnection的connect方法连接到相应的WebScope。
4.至此,控制流进入了我们自己项目中了,通常来说,WebScope又会将请求转移给ApplicationAdapter,由它来最终响应请求,而我们的项目通过重载ApplicationAdapter的方法来实现自己的逻辑。
1 RTMPMinaIoHandler
2 |--[delegate method call and pass RTMPMinaConnection to]-->RTMPHandler
3 |--[call lookupGlobal method]-->Server
4 |--[use globalScope to lookup webScope]-->GlobalScope
5 |--[call connect method and pass WebScope to]-->RTMPMinaConnection
Red5如何启动?在它的启动过程中如何初始化这些关键类?
这里探讨的是Red5 standalone的启动过程(也就是我们执行red5.bat),关于Red5如何在tomcat中启动,目前仍在研究中。
Red5启动过程如下:
1.编辑red5.bat,找到关键的一行:
C:\Program Files\Java\jre1.5.0_15\bin\java"
-Djava.security.manager
-Djava.security.policy=conf/red5.policy
-cp red5.jar;conf;bin org.red5.server.Standalone
可以看到它是调用org.red5.server.Standalone作为程序启动的入口,这也是为什么使用eclipse在debug模式下启动
Standalone就可以调试Red5代码。需要注意的是,如果你要调试Red5,记得除了源代码(src)之外,把conf和webapps两个文件
夹都拷入项目中,并把conf加入classpath。
2.观察Standalone的main方法,你会看到它使用spring的ContextSingletonBeanFactoryLocator来载
入classpath下面的red5.xml,注意ContextSingletonBeanFactoryLocator还会在下面的步骤中被使用,由
于它是singleton的,所以保证了我们自己的项目中定义的bean可以引用red5.xml中定义的bean,这个下面会有介绍。
try {
ContextSingletonBeanFactoryLocator.getInstance(red5Config).useBeanFactory("red5.common");
} catch (Exception e) {
// Don't raise wrapped exceptions as their stacktraces may confuse people
raiseOriginalException(e);
}
3.查看red5.xml,这个文件首先定义了指向classpath:/red5-common.xml的名字为“red5.common”的
BeanFactory,注意它会是整个BeanFactory层次中的根节点,所以在red5-common.xml中定义的bean可以被其他地方所
引用。
<bean id="red5.common" class="org.springframework.context.support.FileSystemXmlApplicationContext">
<constructor-arg><list><value>classpath:/red5-common.xml</value></list></constructor-arg>
</bean>
这里我们主要留意red5-common.xml中定义的类型为org.red5.server.Server的“red5.server”,它会在接下来很多地方被用到。
<bean id="red5.server" class="org.red5.server.Server"/>
4.回到red5.xml,接着定义指向classpath:/red5-core.xml的名字为“red5.core”的BeanFactory,注意“red5.core”是以“red5.common”为parent context。
<bean id="red5.core" class="org.springframework.context.support.FileSystemXmlApplicationContext">
<constructor-arg><list><value>classpath:/red5-core.xml</value></list></constructor-arg>
<constructor-arg><ref bean="red5.common" /></constructor-arg>
</bean>
查看red5-core.xml,这个文件主要定义了之前说过的RTMPMinaTransport,RMTPMinaIoHandler和
RTMPHandler这些类的Bean。对于RTMPMinaTransport,注意init-method="start"这段代码,这说明
RTMPMinaTransport的start方法会在该Bean初始化时调用,正如上面提到的,该方法会做开启1935端口,绑定
RTMPMinaIoHandler到该端口等等的操作。对于RTMPHandler,注意它的server属性通过“red5.server”引用了定
义在parent
context(red5-common.xml)上面的Server,通过它RTMPHandler能够找到GlobalScope,进而找到
WebScope。
<!-- RTMP Handler -->
<bean id="rtmpHandler"
class="org.red5.server.net.rtmp.RTMPHandler">
<property name="server" ref="red5.server" />
<property name="statusObjectService" ref="statusObjectService" />
</bean>
<!-- RTMP Mina IO Handler -->
<bean id="rtmpMinaIoHandler"
class="org.red5.server.net.rtmp.RTMPMinaIoHandler">
<property name="handler" ref="rtmpHandler" />
<property name="codecFactory" ref="rtmpCodecFactory" />
<property name="rtmpConnManager" ref="rtmpMinaConnManager" />
</bean>
<!-- RTMP Mina Transport -->
<bean id="rtmpTransport" class="org.red5.server.net.rtmp.RTMPMinaTransport" init-method="start" destroy-method="stop">
<property name="ioHandler" ref="rtmpMinaIoHandler" />
<property name="address" value="${rtmp.host}" />
<property name="port" value="${rtmp.port}" />
<property name="receiveBufferSize" value="${rtmp.receive_buffer_size}" />
<property name="sendBufferSize" value="${rtmp.send_buffer_size}" />
<property name="eventThreadsCore" value="${rtmp.event_threads_core}" />
<property name="eventThreadsMax" value="${rtmp.event_threads_max}" />
<property name="eventThreadsQueue" value="${rtmp.event_threads_queue}" />
<property name="eventThreadsKeepalive" value="${rtmp.event_threads_keepalive}" />
<!-- This is the interval at which the sessions are polled for stats. If mina monitoring is not enabled, polling will not occur. -->
<property name="jmxPollInterval" value="1000" />
<property name="tcpNoDelay" value="${rtmp.tcp_nodelay}" />
</bean>
5.再次回到red5.xml,接下来定义类型为org.red5.server.ContextLoader的bean,并在初始化后调用它的init方法。
<bean id="context.loader" class="org.red5.server.ContextLoader" init-method="init">
<property name="parentContext" ref="red5.common" />
<property name="contextsConfig" value="red5.globals" />
</bean>
查看该方法的源代码,可以看到它会读取在classPath下面的red5.globals文件,对于每一行初始化一个以“red5.common”为
parent
context的BeanFactory,具体来说,现在red5.globals中只有一行
default.context=${red5.root}/webapps/red5-default.xml,那么会创建一个名字为
“default.context”的指向webapps/red5-default.xml的Bean
Factory,它以“red5.common”为parent context。
protected void loadContext(String name, String config) {
log.debug("Load context - name: " + name + " config: " + config);
ApplicationContext context = new FileSystemXmlApplicationContext(
new String[] { config }, parentContext);
contextMap.put(name, context);
// add the context to the parent, this will be red5.xml
ConfigurableBeanFactory factory = ((ConfigurableApplicationContext) applicationContext)
.getBeanFactory();
// Register context in parent bean factory
factory.registerSingleton(name, context);
}
查看red5-default.xml,发现它主要是定义了GlobalScope的bean,然后把它注册到“red5.server”上。
<bean id="global.scope" class="org.red5.server.GlobalScope" init-method="register">
<property name="server" ref="red5.server" />
<property name="name" value="default" />
<property name="context" ref="global.context" />
<property name="handler" ref="global.handler" />
<property name="persistenceClass">
<value>org.red5.server.persistence.FilePersistence</value>
</property>
</bean>
6.继续看red5.xml,最后定义类型为org.red5.server.jetty.JettyLoader的bean,并且在初始化后调用它的init方法,查看该方法源代码,很明显它是初始化并且启动jetty这个web server。
<bean id="jetty6.server" class="org.red5.server.jetty.JettyLoader" init-method="init" autowire="byType" depends-on="context.loader">
<property name="webappFolder" value="${red5.root}/webapps" />
</bean>
7.到了这里似乎所有的初始化和启动都完毕了,但是问题就来了,这里仅仅定义了
RTMPMinaIoHandler,RTMPHandler,Server和GlobalScope,但是在我们之前提到过的Red5响应rmpt的请
求的过程中,还需要有WebScope来最终处理RTMPMinaConnection,这个WebScope又是怎么配置并且加进来的呢?
8.查看webapps下的项目,这里以oflaDemo为例,查看WEB-INF下面的web.xml,发现有以下三个参数
contextConfigLocation,locatorFactorySelector和parentContextKey,同时还有一个
org.springframework.web.context.ContextLoaderListener。
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/red5-*.xml</param-value>
</context-param>
<context-param>
<param-name>locatorFactorySelector</param-name>
<param-value>red5.xml</param-value>
</context-param>
<context-param>
<param-name>parentContextKey</param-name>
<param-value>default.context</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
查看这个listener的javadoc,其实这个listener会在web
app(就是我们自己的项目)启动时,创建一个指向contextConfigLocation(其实就是WEB-INF"red5-web.xml)的
Bean Factory,同时为它设置parent context。这个parent
context实际上是使用locatorFactorySelector找到ContextSingletonBeanFactoryLocator,
进而使用parentContextKey找到定义在这个locator里面的Bean
Fanctory,由于ContextSingletonBeanFactoryLocator是singleton的,所以这个
ContextSingletonBeanFactoryLocator对象跟我们在第2步中拿到的对象是一样的,而由于
parentContextKey被设置成“default.context”,这就意味着该parent
context是第5步中定义的名为“default.context”的Bean Factory。基于以上的参数,我们得到这样一个Bean
Factory的链条,由上至下分别是
conf\red5-common.xml -> webapps\red5-default.xml -> webapps\oflaDemo\WEB-INF\red5-web.xml
这就使得red5-web.xml可以使用red5-common.xml和red5-default.xml中定义的bean。
9.最后查看webapps"oflaDemo"WEB-INF"red5-web.xml,它定义了类型为
org.red5.server.WebScope的bean,初始化了它的server(指向“red5.server”),parent(指向
“global.scope”)等属性,最后调用它的register方法初始化,查看该方法源代码,发现它会把自己注册到GlobalScope上面,
至此所有的关键类的初始化完毕。
<bean id="web.scope" class="org.red5.server.WebScope" init-method="register">
<property name="server" ref="red5.server" />
<property name="parent" ref="global.scope" />
<property name="context" ref="web.context" />
<property name="handler" ref="web.handler" />
<property name="contextPath" value="${webapp.contextPath}" />
<property name="virtualHosts" value="${webapp.virtualHosts}" />
</bean>
Spring beanFactory 的层次图
conf\red5-common.xml
|-- conf\red5-core.xml
|-- webapps\red5-default.xml
|-- webapps\root\WEB-INF\red5-web.xml
|-- webapps\SOSample\WEB-INF\red5-web.xml
|-- webapps\oflaDemo\WEB-INF\red5-web.xml
看清了Red5 Standalone的启动过程,感觉为了实现自定义项目集成到Red5的核心服务上,Red5
Standalone非常依赖于spring的多个Bean
Factory之间的复杂层次关系,之所以Red5能建立这样一种层次关系,是因为它能够控制jetty这样一个嵌入式的web
server。问题在于,一旦Red5需要作为一个web app运行在类似Tomcat这样的独立的web
server上面,那么整个过程就很不一样了,所以后很多东西都要改,我想这也是为什么Red5 0.8
RC1为什么只有安装版但还没有war版的原因。
最后,如果哪位成功在Tomcat上配置过Red5 0.7的war版本,还请告诉我一声,我试了0.6的war可以,不知道0.7为什么老不行。。。
最近做了一个小的网站。本来没有什么值得说的。但是在部署的时候遇到的一些问题值得写下来,所有这些问题都是关于Tomcat类加载机制的。
转述一篇文章:
对于只用于某一个web应用的类或资源,放在这个web应用下的/WEB-INF/classes目录下,如果是JAR,就放在这个web应用下的WEB-INF/lib目录下。
对于让所有的web应用共享的类或资源,放在$CATALINA_BASE/shared/classes目录下,如果是JAR,就放在$CATALINA_BASE/shared/lib目录下。
Tomcat中的类加载策略和JDK中的委托模型略有不同。当Tomcat启动的时候,会创建一组类加载器,形成下面的层次关系:
Bootstrap
|
System
|
Common
/ \
Catalina Shared
/ \
webapp1 webapp2 ..
各个类加载器的作用描述如下:
Bootstrap:负责加载由虚拟机提供的基本的运行时类和系统扩展目录($JAVA_HOME/jre/lib/ext)下的JAR包;
System:通常这个加载器用来加载CLASSPATH环境变量中指定的类,但在Tomcat5的标准启动脚本($CATALINA_HOME/bin/catalina.sh或%CATALINA_HOME%/bin/catalina.bat)中改变了它的行为,它只加载下面的类:
$CATALINA_HOME/bin/bootstrap.jar - Contains the main() method that is used to initialize the Tomcat 5 server, and the class loader implementation classes it depends on.
$JAVA_HOME/lib/tools.jar - Contains the "javac" compiler used to convert JSP pages into servlet classes.
$CATALINA_HOME/bin/commons-logging-api.jar - Jakarta commons logging API.
$CATALINA_HOME/bin/commons-daemon.jar - Jakarta commons daemon API.
jmx.jar - The JMX 1.2 implementation.
Common:它负责加载对于Tomcat本身和所有的web应用都需要看到的类,通常,应用的类不应该由他加载。$CATALINA_HOME/common/classes,$CATALINA_HOME/commons/endorsed和$CATALINA_HOME/common/lib下的都由这个加载器加载。缺省的,包括:
ant.jar - Apache Ant.
commons-collection.jar - Jakarta commons collection.
commons-dbcp.jar - Jakarta commons DBCP, providing a JDBC connection pool to web applications.
commons-el.jar - Jakarta commons el, implementing the expression language used by Jasper.
commons-pool.jar - Jakarta commons pool.
jasper-compiler.jar - The JSP 2.0 compiler.
jasper-runtime.jar - The JSP 2.0 runtime.
jsp-api.jar - The JSP 2.0 API.
naming-common.jar - The JNDI implementation used by Tomcat 5 to represent in-memory naming contexts.
naming-factory.jar - The JNDI implementation used by Tomcat 5 to resolve references to enterprise resources (EJB, connection pools).
naming-resources.jar - The specialized JNDI naming context implementation used to represent the static resources of a web application.
servlet-api.jar - The Servlet and JSP API classes.
xerces.jar - The XML parser that is visible by default to Tomcat internal classes and to web applications.
Catalina:用来加载实现Tomcat自己需要的类。由他加载的类对web应用都是不可见的。$CATALINA_HOME/server/classes,$CATALINA_HOME/server/lib,都由这个加载器加载。缺省的,包括:
catalina.jar - Implementation of the Catalina servlet container portion of Tomcat 5.
jakarta-regexp-X.Y.jar - The binary distribution of the Jakarta Regexp regular expression processing library, used in the implementation of request filters.
servlets-xxxxx.jar - The classes associated with each internal servlet that provides part of Tomcat's functionality. These are separated so that they can be completely removed if the corresponding service is not required, or they can be subject to specialized security manager permissions.
tomcat-coyote.jar - Coyote connector for Tomcat 5.
tomcat-http11.jar - Standalone Java HTTP/1.1 connector.
tomcat-jk2.jar - Classes for the Java portion of the JK 2 web server connector, which allows Tomcat to run behind web servers such as Apache and iPlanet iAS and iWS.
tomcat-util.jar - Utility classes required by some Tomcat connectors.
Shared:被所有的web应用共享的类和资源由这个加载器加载。$CATALINA_BASE/shared/classed,$CATALINA_BASE/shared/lib,都由这个加载器加载。
WebappX:对每个Tomcat里的web应用都创建一个加载器,web应用下的WEB-INF/classes,WEB-INF/lib,都由这个加载器加载,由它所加载的类对其他的web应用是不可见的。
web应用的加载器(WebappX)和JDK的委托模型略有不同,这是根据Servlet2.3规范做出的。当WebappX被请求加载一个类时,它首先尝试自己加载,而不是委托给它的父加载器。但是,对于下面的类,仍然要委托给父加载器:
Classes which are part of the JRE base classes cannot be overriden. For some classes (such as the XML parser components in JDK 1.4+), the JDK 1.4 endorsed feature can be used (see the common classloader definition above). In addition, for the following class patterns, the classloader will always delegate first (and load the class itself if no parent classloader loads it):
javax.*
org.xml.sax.*
org.w3c.dom.*
org.apache.xerces.*
org.apache.xalan.*
Last, any JAR containing servlet API classes will be ignored by the classloader.
Tomcat中其他的加载器都是遵循委托模型的。
最后,以web应用的角度,要加载类或者资源时,会以下面的顺序查找:
Bootstrap classes of your JVM
System class loader classses (described above)
/WEB-INF/classes of your web application
/WEB-INF/lib/*.jar of your web application
$CATALINA_HOME/common/classes
$CATALINA_HOME/common/endorsed/*.jar
$CATALINA_HOME/common/lib/*.jar
$CATALINA_BASE/shared/classes
$CATALINA_BASE/shared/lib/*.jar
本文来自CSDN博客:http://blog.csdn.net/findhappy7/archive/2008/05/12/2436702.aspx
第一,谈谈final, finally, finalize的区别。
第二,Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是否可以implements(实现)interface(接口)?
第三,Static Nested Class 和 Inner Class的不同,说得越多越好(面试题有的很笼统)。
第四,&和&&的区别。
第五,HashMap和Hashtable的区别。
第六,Collection 和 Collections的区别。
第七,什么时候用assert。
第八,GC是什么? 为什么要有GC?
第九,String s = new String("xyz");创建了几个String Object?
第十,Math.round(11.5)等於多少? Math.round(-11.5)等於多少?
第十一,short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1 += 1;有什么错?
第十二,sleep() 和 wait() 有什么区别?
第十三,Java有没有goto?
第十四,数组有没有length()这个方法? String有没有length()这个方法?
第十五,Overload和Override的区别。Overloaded的方法是否可以改变返回值的类型?
第十六,Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
第十七,给我一个你最常见到的runtime exception。
第十八,error和exception有什么区别?
第十九,List, Set, Map是否继承自Collection接口?
第二十,abstract class和interface有什么区别?
第二十一,abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?
第二十二,接口是否可继承接口? 抽象类是否可实现(implements)接口? 抽象类是否可继承实体类(concrete class)?
第二十三,启动一个线程是用run()还是start()?
第二十四,构造器Constructor是否可被override?
第二十五,是否可以继承String类?
第二十六,当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?
第二十七,try {}里有一个return语句,那么紧跟在这个try后的finally {}里的code会不会被执行,什么时候被执行,在return前还是后?
第二十八,编程题: 用最有效率的方法算出2乘以8等於几?
第二十九,两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
第三十,当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
第三十一,swtich是否能作用在byte上,是否能作用在long上,是否能作用在String上?
第三十二,编程题: 写一个Singleton出来。
以下是答案
第一,谈谈final, finally, finalize的区别。
final
—修饰符(关键字)如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承。因此一个类不能既被声明为
abstract的,又被声明为final的。将变量或方法声明为final,可以保证它们在使用中不被改变。被声明为final的变量必须在声明时给定
初值,而在以后的引用中只能读取,不可修改。被声明为final的方法也同样只能使用,不能重载
finally—再异常处理时提供 finally 块来执行任何清除操作。如果抛出一个异常,那么相匹配的 catch 子句就会执行,然后控制就会进入 finally 块(如果有的话)。
finalize
—方法名。Java 技术允许使用 finalize()
方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是在
Object 类中定义的,因此所有的类都继承了它。子类覆盖 finalize() 方法以整理系统资源或者执行其他清理工作。finalize()
方法是在垃圾收集器删除对象之前对这个对象调用的。
第二,Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是否可以implements(实现)interface(接口)?
匿名的内部类是没有名字的内部类。不能extends(继承) 其它类,但一个内部类可以作为一个接口,由另一个内部类实现。
第三,Static Nested Class 和 Inner Class的不同,说得越多越好(面试题有的很笼统)。
Nested
Class (一般是C++的说法),Inner Class
(一般是JAVA的说法)。Java内部类与C++嵌套类最大的不同就在于是否有指向外部的引用上。具体可见http:
//www.frontfree.net/articles/services/view.asp?id=704&page=1
注: 静态内部类(Inner Class)意味着1创建一个static内部类的对象,不需要一个外部类对象,2不能从一个static内部类的一个对象访问一个外部类对象
第四,&和&&的区别。
&是位运算符。&&是布尔逻辑运算符。
第五,HashMap和Hashtable的区别。
都属于Map接口的类,实现了将惟一键映射到特定的值上。
HashMap 类没有分类或者排序。它允许一个 null 键和多个 null 值。
Hashtable 类似于 HashMap,但是不允许 null 键和 null 值。它也比 HashMap 慢,因为它是同步的。
第六,Collection 和 Collections的区别。
Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
Collection是个java.util下的接口,它是各种集合结构的父接口。
第七,什么时候用assert。
断言是一个包含布尔表达式的语句,在执行这个语句时假定该表达式为 true。如果表达式计算为 false,那么系统会报告一个 AssertionError。它用于调试目的:
assert(a > 0); // throws an AssertionError if a <= 0
断言可以有两种形式:
assert Expression1 ;
assert Expression1 : Expression2 ;
Expression1 应该总是产生一个布尔值。
Expression2 可以是得出一个值的任意表达式。这个值用于生成显示更多调试信息的 String 消息。
断言在默认情况下是禁用的。要在编译时启用断言,需要使用 source 1.4 标记:
javac -source 1.4 Test.java
要在运行时启用断言,可使用 -enableassertions 或者 -ea 标记。
要在运行时选择禁用断言,可使用 -da 或者 -disableassertions 标记。
要系统类中启用断言,可使用 -esa 或者 -dsa 标记。还可以在包的基础上启用或者禁用断言。
可
以在预计正常情况下不会到达的任何位置上放置断言。断言可以用于验证传递给私有方法的参数。不过,断言不应该用于验证传递给公有方法的参数,因为不管是否
启用了断言,公有方法都必须检查其参数。不过,既可以在公有方法中,也可以在非公有方法中利用断言测试后置条件。另外,断言不应该以任何方式改变程序的状
态。
第八,GC是什么? 为什么要有GC? (基础)。
GC是垃圾收集器。Java 程序员不用担心内存管理,因为垃圾收集器会自动进行管理。要请求垃圾收集,可以调用下面的方法之一:
System.gc()
Runtime.getRuntime().gc()
第九,String s = new String("xyz");创建了几个String Object?
两个对象,一个是“xyx”,一个是指向“xyx”的引用对象s。
第十,Math.round(11.5)等於多少? Math.round(-11.5)等於多少?
Math.round(11.5)返回(long)12,Math.round(-11.5)返回(long)-11;
第十一,short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1 += 1;有什么错?
short s1 = 1; s1 = s1 + 1;有错,s1是short型,s1+1是int型,不能显式转化为short型。可修改为s1 =(short)(s1 + 1) 。short s1 = 1; s1 += 1正确。
第十二,sleep() 和 wait() 有什么区别? 搞线程的最爱
sleep()方法是使线程停止一段时间的方法。在sleep 时间间隔期满后,线程不一定立即恢复执行。这是因为在那个时刻,其它线程可能正在运行而且没有被调度为放弃执行,除非(a)“醒来”的线程具有更高的优先级
(b)正在运行的线程因为其它原因而阻塞。
wait()是线程交互时,如果线程对一个同步对象x 发出一个wait()调用,该线程会暂停执行,被调对象进入等待状态,直到被唤醒或等待时间到。
第十三,Java有没有goto?
Goto—java中的保留字,现在没有在java中使用。
第十四,数组有没有length()这个方法? String有没有length()这个方法?
数组没有length()这个方法,有length的属性。
String有有length()这个方法。
第十五,Overload和Override的区别。Overloaded的方法是否可以改变返回值的类型?
方
法的重写Overriding和重载Overloading是Java多态性的不同表现。重写Overriding是父类与子类之间多态性的一种表现,重
载Overloading是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写
(Overriding)。子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被“屏蔽”了。如果在一个类中定义了多个同名的方
法,它们或有不同的参数个数或有不同的参数类型,则称为方法的重载(Overloading)。Overloaded的方法是可以改变返回值的类型。
第十六,Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
Set里的元素是不能重复的,那么用iterator()方法来区分重复与否。equals()是判读两个Set是否相等。
equals()和==方法决定引用值是否指向同一对象equals()在类中被覆盖,为的是当两个分离的对象的内容和类型相配的话,返回真值。
第十七,给我一个你最常见到的runtime exception。
ArithmeticException,
ArrayStoreException, BufferOverflowException, BufferUnderflowException,
CannotRedoException, CannotUndoException, ClassCastException,
CMMException, ConcurrentModificationException, DOMException,
EmptyStackException, IllegalArgumentException,
IllegalMonitorStateException, IllegalPathStateException,
IllegalStateException,
ImagingOpException,
IndexOutOfBoundsException, MissingResourceException,
NegativeArraySizeException, NoSuchElementException,
NullPointerException, ProfileDataException, ProviderException,
RasterFormatException, SecurityException, SystemException,
UndeclaredThrowableException, UnmodifiableSetException,
UnsupportedOperationException
第十八,error和exception有什么区别?
error 表示恢复不是不可能但很困难的情况下的一种严重问题。比如说内存溢出。不可能指望程序能处理这样的情况。
exception 表示一种设计或实现问题。也就是说,它表示如果程序运行正常,从不会发生的情况。
第十九,List, Set, Map是否继承自Collection接口?
List,Set是
Map不是
第二十,abstract class和interface有什么区别?
声
明方法的存在而不去实现它的类被叫做抽象类(abstract
class),它用于要创建一个体现某些基本行为的类,并为该类声明方法,但不能在该类中实现该类的情况。不能创建abstract
类的实例。然而可以创建一个变量,其类型是一个抽象类,并让它指向具体子类的一个实例。不能有抽象构造函数或抽象静态方法。Abstract
类的子类为它们父类中的所有抽象方法提供实现,否则它们也是抽象类为。取而代之,在子类中实现该方法。知道其行为的其它类可以在类中实现这些方法。
接
口(interface)是抽象类的变体。在接口中,所有方法都是抽象的。多继承性可通过实现这样的接口而获得。接口中的所有方法都是抽象的,没有一个有
程序体。接口只可以定义static
final成员变量。接口的实现与子类相似,除了该实现类不能从接口定义中继承行为。当类实现特殊接口时,它定义(即将程序体给予)所有这种接口的方法。
然后,它可以在实现了该接口的类的任何对象上调用接口的方法。由于有抽象类,它允许使用接口名作为引用变量的类型。通常的动态联编将生效。引用可以转换到
接口类型或从接口类型转换,instanceof 运算符可以用来决定某对象的类是否实现了接口。
第二十一,abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?
都不能
第二十二,接口是否可继承接口? 抽象类是否可实现(implements)接口? 抽象类是否可继承实体类(concrete class)?
接口可以继承接口。抽象类可以实现(implements)接口,抽象类是否可继承实体类,但前提是实体类必须有明确的构造函数。
第二十三,启动一个线程是用run()还是start()?
启动一个线程是调用start()方法,使线程所代表的虚拟处理机处于可运行状态,这意味着它可以由JVM调度并执行。这并不意味着线程就会立即运行。run()方法可以产生必须退出的标志来停止一个线程。
第二十四,构造器Constructor是否可被override?
构造器Constructor不能被继承,因此不能重写Overriding,但可以被重载Overloading。
第二十五,是否可以继承String类?
String类是final类故不可以继承。
第二十六,当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?
不能,一个对象的一个synchronized方法只能由一个线程访问。
第二十七,try {}里有一个return语句,那么紧跟在这个try后的finally {}里的code会不会被执行,什么时候被执行,在return前还是后?
会执行,在return前执行。
第二十八,编程题: 用最有效率的方法算出2乘以8等於几?
有C背景的程序员特别喜欢问这种问题。
2 << 3
第二十九,两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?
不对,有相同的hash code。
第三十,当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
是值传递。Java 编程语言只由值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的内容可以在被调用的方法中改变,但对象的引用是永远不会改变的。
第三十一,swtich是否能作用在byte上,是否能作用在long上,是否能作用在String上?
switch(expr1)中,expr1是一个整数表达式。因此传递给 switch 和 case 语句的参数应该是 int、 short、 char 或者 byte。long,string 都不能作用于swtich。
第三十二,编程题: 写一个Singleton出来。
Singleton模式主要作用是保证在Java应用程序中,一个类Class只有一个实例存在。
一般Singleton模式通常有几种种形式:
第一种形式: 定义一个类,它的构造函数为private的,它有一个static的private的该类变量,在类初始化时实例话,通过一个public的getInstance方法获取对它的引用,继而调用其中的方法。
public class Singleton {
private Singleton(){}
//在自己内部定义自己一个实例,是不是很奇怪?
//注意这是private 只供内部调用
private static Singleton instance = new Singleton();
//这里提供了一个供外部访问本class的静态方法,可以直接访问
public static Singleton getInstance() {
return instance;
}
}
第二种形式:
public class Singleton {
private static Singleton instance = null;
public static synchronized Singleton getInstance() {
//这个方法比上面有所改进,不用每次都进行生成对象,只是第一次
//使用时生成实例,提高了效率!
if (instance==null)
instance=new Singleton();
return instance; }
}
其他形式:
定义一个类,它的构造函数为private的,所有方法为static的。
一般认为第一种形式要更加安全些
第三十三 Hashtable和HashMap
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许
还有就是,HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在
多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap
就必须为之提供外同步。
Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
原来一直对框架这个东东很好奇,认为框架意味着神秘,意味着神通广大。这几天,终于有时间和精力来学习了,借了一本《J2EE开源编程精要15讲》来看,这本书主要是针对学习Structs、Hibernate和Spring框架的新手来讲解的,可以说,是对上面三个框架最基本的入门教材。
首先还是谈谈读后感吧。总的来说,这本书对于Java Web框架的新手来说还是很值得一看的。里面的例子,基本上做到了每一步都有图片,便于操作。而且,总的来说,此书讲的还是比较通俗易懂的。但想通过看这本书对以上三个框架有比较深的认识,通过我自己的体会,那是不可能的。不过就入门来讲,这本书真的很好!至少我觉得自己还是入门了,今后可以再找找各个框架相关的”专著“来看看,应该提高的比较快,如果再来点实践,呵呵,掌握应该可以的,唉,又在说大话了...
粗略看完此书,我最大的体会就是在Java Web的这几个著名框架中,用的最多的就是通过配置文件来进行动态的配置,达到程序各个模块的低耦合,便于代码的重用。按照我目前的理解,我觉得这三个框架主要的工作就是根据配置文件来对应用程序进行配置。应用程序的编写者通过按照框架预先规定的配置文件的格式,把需要降低耦合的模块(Java嘛,当然是类了)写进配置文件中即可,剩下的就是框架的工作了,呵呵,难怪那么多人用框架,如果用熟了,框架真的可以帮程序开发者很多忙啊!
难怪很多人都说学习XML很重要,在框架中,大部分都用的是XML作为配置文件。所以,对XML的操作应该作为一个基本功,平时应该多练习,虽然框架把这一部分工作都做了,但是,基本功可是非常重要的啊。
我还得谈谈对Spring IoC的体会:
在应用程序中,可能需要用到很多资源,如果把这些资源直接放在程序代码中,那么,如果需要把这些资源换了,那么,程序代码中与此资源相关的部分都要修改,不利于重用,于是,通过建立一个映射,及把具体的资源和资源名建立映射,在源程序中仅仅使用资源名,那么如果资源变了,只需要改动那个映射文件即可。而Spring框架的IoC核心的重要功能就是提供这种配置和读取映射的功能。
来自:it168 http://tech.it168.com/a2009/0202/264/000000264124.shtml
现在许许多多的初学者和程序员,都在趋之若鹜地学习Web开发的宝典级框架:Struts2,Spring,Hibernate。似乎这些框架成为了一个人是否精通Java,是否会写J2EE程序的唯一事实标准和找工作的必备基础。
然而,如果在面试的时候问这些程序员,你们为什么要学习这些框架?这些框架的本质到底是什么?似乎很少很少有人能够给我非常满意的答复。因为他们都在为了学习而学习,为了工作而学习,而不是在真正去深入了解一个框架。其实所有的人都应该思考这样的问题: 为什么要学习框架?框架到底给我带来了什么?接下来,我们以登录作为一个最简单的例子,来看看不同的年代,我们是怎么写Web程序的。
在很多年前,我们这么写程序的
很多年前,那是一个贫苦的年代,如果我们要使用Java在网页上做一些动态的交互功能。很多人会告诉你一个技术,叫做JSP。在我还对Java非常困惑的时候,就有人告诉我,JSP是个好东西,它可以在HTML代码里面写Java代码来完成逻辑。
Html代码:
作为一张JSP,它可以接收从别的JSP发送过来的登录请求,并进行处理。这样,我们不需要任何额外的配置文件,也不需要任何框架的帮忙,就能完成逻辑。
后来,我们放弃了在页面上写逻辑
后来,程序写得越来越多,我们发现,这种在HTML代码中编写Java代码来完成逻辑的方式存在着不少问题:
1. Java代码由于混杂在一个HTML环境中而显得混乱不堪,可读性非常差。一个JSP文件有时候会变成几十K,甚至上百K。要找一段逻辑,经常无法定位。
2. 编写代码时非常困惑,不知道代码到底应该写在哪里,也不知道别人是不是已经曾经实现过类似的功能,到哪里去引用。
3. 突然之间,某个需求发生了变化。于是,每个人蒙头开始全程替换,还要小心翼翼的,生怕把别人的逻辑改了。
4. 逻辑处理程序需要自己来维护生命周期,对于类似数据库事务、日志等众多模块无法统一支持。
在这个时候,如果有一个产品,它能够将页面上的那些Java代码抽取出来,让页面上尽量少出现Java代码,该有多好。于是许多人开始使用servlet来处理那些业务逻辑。
Java代码:
在这里,我们需要在web.xml中为这个servlet配置url的请求关系。
Xml代码:

代码重构到这里,我们发现,其实我们的工作量本身并没有减少,只是代码从JSP移动到了Servlet,使得整个流程看上去稍微清楚了一些。然而,为了这么点干净,我们付出的代价是什么?为每个servlet都在web.xml里面去做一个url的请求配置!
再后来,出现框架
时代进一步发展,人们发现简单的JSP和Servlet已经很难满足人们懒惰的要求了。于是,人们开始试图总结一些公用的Java类,来解决Web开发过
程中碰到的问题。这时,横空出世了一个框架,叫做struts。它非常先进地实现了MVC模式,成为了广大程序员的福音。
struts的代码示例我就不贴了,网上随便搜搜你可以发现一堆一堆的。在一定程度上,struts能够解决web开发中的职责分配问题,使得显示与逻辑
分开。不过在很长一段时间内,使用struts的程序员往往无法分别我们到底需要web框架帮我们做什么,我们到底需要它完成点什么功能?
我们到底要什么
在回顾了我们写代码的历史之后,我们回过头来看看,我们到底要什么?
无论是使用JSP,还是使用Struts1,或是Struts2,我们至少都需要一些必须的元素(如果没有这些元素,或许我还真不知道这个程序会写成什么样子):
1. 数据
在这个例子中,就是name和password。他们共同构成了程序的核心载体。事实上,我们往往会有一个User类来封装name和password,这样会使得我们的程序更加OO。无论怎么说,数据会穿插在这个程序的各处,成为程序运行的核心。
2. 页面展示
在这个例子中,就是login.jsp。没有这个页面,一切的请求、验证和错误展示也无从谈起。在页面上,我们需要利用HTML,把我们需要展现的数据都呈现出来。同时我们也需要完成一定的页面逻辑,例如,错误展示,分支判断等等。
3. 处理具体业务的场所
在这里,不同阶段,处理具体业务的场所就不太一样。原来用JSP和Servlet,后来用Struts1或者Struts2的Action。
上面的这些必须出现的元素,在不同的年代,被赋予了不同的表现形式,有的受到时代的束缚,其表现形式非常落后,有的已经不再使用。但是拨开这些外在的表现形式,我们就可以发现,这不就是我们已经熟门熟路的MVC嘛?
数据 ———— Model
页面展示 ———— View
处理具体业务的场所 ———— Control
所以,框架不重要,概念是王道。只要能够深刻理解MVC的概念,框架对你来说,只是一个jar包而已。
MVC的概念其实就那么简单,这些概念其实早已深入我们的内心,而我们所缺乏的是将其本质挖掘出来。我们来看看下面这幅图,这是一副流行了很多年的讲述MVC模型的图:
在这幅图中,MVC三个框框各司其职,结构清晰明朗。不过我觉得这幅图忽略了一个问题,就是数据是动的,数据在View和Control层一旦动起来,就会产生许多的问题:
1. 数据从View层传递到Control层,如何使得一个个扁平的字符串,转化成一个个生龙活虎的Java对象
2. 数据从View层传递到Control层,如何方便的进行数据格式和内容的校验?
3. 数据从Control层传递到View层,一个个生龙活虎的Java对象,又如何在页面上以各种各样的形式展现出来
4. 如果你试图将数据请求从View层发送到Control层,你如何才能知道你要调用的究竟是哪个类,哪个方法?一个Http的请求,又如何与Control层的Java代码建立起关系来?
除此之外,Control层似乎也没有想象中的那么简单,因为它作为一个控制器,至少还需要处理以下的问题:
1. 作为调用逻辑处理程序的facade门面,如果逻辑处理程序发生了异常,我们该如何处理?
2. 对于逻辑处理的结果,我们需要做怎么样的处理才能满足丰富的前台展示需要?
这一个又一个问题的提出,都基于对MVC的基本概念的挖掘。所以,这些问题都需要我们在写程序的时候去一一解决。说到这里,这篇文章开头所提的问题应该可
以有答案了:框架是为了解决一个又一个在Web开发中所遇到的问题而诞生的。不同的框架,都是为了解决不同的问题,但是对于程序员而言,他们只是jar包
而已。框架的优缺点的评论,也完全取决于其对问题解决程度和解决方式的优雅性的评论。所以,千万不要为了学习框架而学习框架,而是要为了解决问题而学习框
架,这才是一个程序员的正确学习之道。
当对一个ArrayList进行remove(Object)操作删除一个元素后,被删除的元素之后的元素会全部向前移动一位!今天编程时没有注意,害的自己好苦啊!
记录!谨记谨记!
|
|
| | 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|
| 26 | 27 | 28 | 29 | 30 | 31 | 1 | | 2 | 3 | 4 | 5 | 6 | 7 | 8 | | 9 | 10 | 11 | 12 | 13 | 14 | 15 | | 16 | 17 | 18 | 19 | 20 | 21 | 22 | | 23 | 24 | 25 | 26 | 27 | 28 | 29 | | 30 | 1 | 2 | 3 | 4 | 5 | 6 |
|
常用链接
留言簿(2)
随笔分类
随笔档案
文章档案
搜索
最新评论

阅读排行榜
评论排行榜
|
|