 2009年3月10日
2009年3月10日
HibernateShard
多数据库水平分区解决方案。
1. 简介
Hibernate 的一个扩展,用于处理多数据库水平分区架构。
由google工程师 2007年 捐献给 Hibernate社区。
http://www.hibernate.org/414.html
目前版本: 3.0.0 beta2, 未发GA版。
条件:Hibernate Core 3.2, JDK 5.0
2. 水平分区原理
一个库表如 Order 存在于多个数据库实例上。按特定的分区逻辑,将该库表的数据存储在这些实例中,一条记录的主键 PK,在所有实例中不得重复。
水平分区在大型网站,大型企业应用中经常采用。 像
www.sina.com.cn ,www.163.com
www.bt285.cn www.guihua.org
目的出于海量数据分散存储,分散操作,分散查询以便提高数据处理量和整体数据处理性能。
使用:
google工程师的设计还是非常好的,完全兼容 Hibernate本身的主要接口。
- org.hibernate.Session
- org.hibernate.SessionFactory
- org.hibernate.Criteria
- org.hibernate.Query
org.hibernate.Session
org.hibernate.SessionFactory
org.hibernate.Criteria
org.hibernate.Query
因此程序员开发变化不大,甚至不需要关心后台使用了分区数据库。程序迁移问题不大。而且配置上比较简明。
3. 三种策略:
1) ShardAccessStrategy, 查询操作时,到那个分区执行。
默认提供两个实现:
顺序策略:SequentialShardAccessStrategy, 每个query按顺序在所有分区上执行。
平行策略:ParallelShardAccessStrategy, 每个query以多线程方式并发平行的在所有分区上执行。 此策略下,需要使用线程池机制满足特定的性能需要,java.util.concurrent.ThreadPoolExecutor。
2) ShardSelectionStrategy, 新增对象时,存储到哪个分区。
框架默认提供了一个轮询选择策略 RoundRobinShardSelectionStrategy, 但一般不这样使用。
通常采用“attribute-based sharding”机制,基于属性分区。一般是用户根据表自己实现一个基于属性分区的策略类ShardSelectionStrategy ,例如,以下WeatherReport基于continent属性选择分区:
- public class WeatherReportShardSelectionStrategy implements ShardSelectionStrategy {
- public ShardId selectShardIdForNewObject(Object obj) {
- if(obj instanceof WeatherReport) {
- return ((WeatherReport)obj).getContinent().getShardId();
- }
- throw new IllegalArgumentException();
- }
public class WeatherReportShardSelectionStrategy implements ShardSelectionStrategy {
public ShardId selectShardIdForNewObject(Object obj) {
if(obj instanceof WeatherReport) {
return ((WeatherReport)obj).getContinent().getShardId();
}
throw new IllegalArgumentException();
}
}
3) ShardResolutionStrategy, 该策略用于查找单个对象时,判断它在哪个或哪几个分区上。
默认使用 AllShardsShardResolutionStrategy ,可以自定义例如:
- public class WeatherReportShardResolutionStrategy extends AllShardsShardResolutionStrategy {
- public WeatherReportShardResolutionStrategy(List<ShardId> shardIds) {
- super(shardIds);
- }
-
- public List<ShardId> selectShardIdsFromShardResolutionStrategyData(
- ShardResolutionStrategyData srsd) {
- if(srsd.getEntityName().equals(WeatherReport.class.getName())) {
- return Continent.getContinentByReportId(srsd.getId()).getShardId();
- }
- return super.selectShardIdsFromShardResolutionStrategyData(srsd);
- }
- }
public class WeatherReportShardResolutionStrategy extends AllShardsShardResolutionStrategy {
public WeatherReportShardResolutionStrategy(List<ShardId> shardIds) {
super(shardIds);
}
public List<ShardId> selectShardIdsFromShardResolutionStrategyData(
ShardResolutionStrategyData srsd) {
if(srsd.getEntityName().equals(WeatherReport.class.getName())) {
return Continent.getContinentByReportId(srsd.getId()).getShardId();
}
return super.selectShardIdsFromShardResolutionStrategyData(srsd);
}
}
4. 水平分区下的查询
对于简单查询 HibernateShard 可以满足。
水平分区下多库查询是一个挑战。主要存在于以下三种操作:
1) distinct
因为需要遍历所有shard分区,并进行合并判断重复记录。
2) order by
类似 1)
3) aggregation
count,sim,avg等聚合操作先分散到分区执行,再进行汇总。
是不是有点类似于 MapReduce ? 呵呵。
目前 HibernateShard 不支持 1), 2), 对 3) 部分支持
HibernateShard 目前通过 Criteria 接口的实现对 聚合提供了较好的支持, 因为 Criteria 以API接口指定了 Projection 操作,逻辑相对简单。
而HQL,原生 SQL 还不支持此类操作。
5. 再分区和虚拟分区
当数据库规模增大,需要调整分区逻辑和数据存储时, 需要再分区。
两种方式: 1)数据库数据迁移其他分区; 2) 改变记录和分区映射关系。这两种方式都比较麻烦。尤其“改变记录和分区映射关系”,需要调整 ShardResolutionStrategy。
HibernateShard 提供了一种虚拟分区层。当需要调整分区策略时,只需要调整虚拟分区和物理分区映射关系即可。以下是使用虚拟分区时的配置创建过程:
-
- Map<Integer, Integer> virtualShardMap = new HashMap<Integer, Integer>();
- virtualShardMap.put(0, 0);
- virtualShardMap.put(1, 0);
- virtualShardMap.put(2, 1);
- virtualShardMap.put(3, 1);
- ShardedConfiguration shardedConfig =
- new ShardedConfiguration(
- prototypeConfiguration,
- configurations,
- strategyFactory,
- virtualShardMap);
- return shardedConfig.buildShardedSessionFactory();
Map<Integer, Integer> virtualShardMap = new HashMap<Integer, Integer>();
virtualShardMap.put(0, 0);
virtualShardMap.put(1, 0);
virtualShardMap.put(2, 1);
virtualShardMap.put(3, 1);
ShardedConfiguration shardedConfig =
new ShardedConfiguration(
prototypeConfiguration,
configurations,
strategyFactory,
virtualShardMap);
return shardedConfig.buildShardedSessionFactory();
6. 局限:
1)HibernateShard 不支持垂直分区, 垂直+水平混合分区。
2) 水平分区下 查询功能受到一定限制,有些功能不支持。实践中,需要在应用层面对水平分区算法进行更多的考虑。
3) 不支持跨分区的 关系 操作。例如:删除A分区上的 s 表,B分区上的关联子表 t的记录无法进行参照完整性约束检查。 (其实这个相对 跨分区查询的挑战应该说小的多,也许google工程师下个版本会支持,呵呵)
4) 解析策略接口似乎和对象ID全局唯一性有些自相矛盾,
AllShardsShardResolutionStrategy 的接口返回的是给定对象ID所在的 shard ID集合,按理应该是明确的一个 shard ID.
参考资料:HibernateShard 参考指南。
现在正开发的定位模块用到的定位设置是塞格车圣导航设备,发送指令返回的经纬度需要转换成十进制,再到GIS系统获取地理信息描述。以后需要要经常用到这方面的知识,随笔写下。
将经纬度转换成十进制
公式:
Decimal Degrees = Degrees + minutes/60 + seconds/3600
例:57°55'56.6" =57+55/60+56.6/3600=57.9323888888888
如把经纬度 (longitude,latitude) (205.395583333332,57.9323888888888)转换据成坐标(Degrees,minutes,seconds)(205°23'44.1",57°55'56.6")。
步骤如下:
1、 直接读取"度":205
2、(205.395583333332-205)*60=23.734999999920 得到"分":23
3、(23.734999999920-23)*60=44.099999995200 得到"秒":44.1
发送定位指令,终端返回的经纬度信息如下:
(ONE072457A3641.2220N11706.2569E000.000240309C0000400)
按照协议解析

获得信息体的经纬度是主要,其它不要管,直接用String类的substring()方法截掉,获取的经纬度
3641.2220N11706.2569E http://www.bt285.cn
- package com.tdt.test;
-
- import com.tdt.api.gis.LocationInfo;
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- public class LonlatConversion {
-
-
-
-
-
-
-
- public static String xypase(String dms, String type) {
- if (dms == null || dms.equals("")) {
- return "0.0";
- }
- double result = 0.0D;
- String temp = "";
-
- if (type.equals("E")) {
- String e1 = dms.substring(0, 3);
-
- String e2 = dms.substring(3, dms.length());
-
- result = Double.parseDouble(e1);
- result += (Double.parseDouble(e2) / 60.0D);
- temp = String.valueOf(result);
- if (temp.length() > 9) {
- temp = e1 + temp.substring(temp.indexOf("."), 9);
- }
- } else if (type.equals("N")) {
- String n1 = dms.substring(0, 2);
- String n2 = dms.substring(2, dms.length());
-
- result = Double.parseDouble(n1);
- result += Double.parseDouble(n2) / 60.0D;
- temp = String.valueOf(result);
- if (temp.length() > 8) {
- temp = n1 + temp.substring(temp.indexOf("."), 8);
- }
- }
- return temp;
- }
- public static void main(String[] args) {
- String info="(ONE072457A3641.2220N11706.2569E000.000240309C0000400)";
- info=info.substring(11,info.length()-13);
-
- String N = info.substring(0, info.indexOf("N"));
-
- String E = info.substring(info.indexOf("N")+1,info.indexOf("E"));
-
- double x = Double.parseDouble(CoordConversion.xypase(E,"E"));
- double y = Double.parseDouble(CoordConversion.xypase(N,"N"));
- String result =LocationInfo.getLocationInfo("test", x, y);
- System.out.println(result);
- }
- }
package com.tdt.test;
import com.tdt.api.gis.LocationInfo;
/**
* <p>Title:坐标转换 </p>
*
* <p>Description:</p>
*
* <p>Copyright: Copyright (c) 2009</p>
*
* <p>Company:</p>
*
* @author sunnylocus
* @version 1.0 [2009-03-24]
*
*/
public class LonlatConversion {
/**
*
* @param dms 坐标
* @param type 坐标类型
* @return String 解析后的经纬度
*/
public static String xypase(String dms, String type) {
if (dms == null || dms.equals("")) {
return "0.0";
}
double result = 0.0D;
String temp = "";
if (type.equals("E")) {//经度
String e1 = dms.substring(0, 3);//截取3位数字,经度共3位,最多180度
//经度是一伦敦为点作南北两极的线为0度,所有往西和往东各180度
String e2 = dms.substring(3, dms.length());//需要运算的小数
result = Double.parseDouble(e1);
result += (Double.parseDouble(e2) / 60.0D);
temp = String.valueOf(result);
if (temp.length() > 9) {
temp = e1 + temp.substring(temp.indexOf("."), 9);
}
} else if (type.equals("N")) { //纬度,纬度是以赤道为基准,相当于把地球分两半,两个半球面上的点和平面夹角0~90度
String n1 = dms.substring(0, 2);//截取2位,纬度共2位,最多90度
String n2 = dms.substring(2, dms.length());
result = Double.parseDouble(n1);
result += Double.parseDouble(n2) / 60.0D;
temp = String.valueOf(result);
if (temp.length() > 8) {
temp = n1 + temp.substring(temp.indexOf("."), 8);
}
}
return temp;
}
public static void main(String[] args) {
String info="(ONE072457A3641.2220N11706.2569E000.000240309C0000400 http://www.guihua.org )";
info=info.substring(11,info.length()-13);
//纬度
String N = info.substring(0, info.indexOf("N"));
//经度
String E = info.substring(info.indexOf("N")+1,info.indexOf("E"));
//请求gis,获取地理信息描述
double x = Double.parseDouble(CoordConversion.xypase(E,"E"));
double y = Double.parseDouble(CoordConversion.xypase(N,"N"));
String result =LocationInfo.getLocationInfo("test", x, y); //System.out.println("径度:"+x+","+"纬度:"+y);
System.out.println(result);
}
}
运行结果
在济南市,位于轻骑路和八涧堡路附近;在环保科技园国际商务中心和济南市区贤文庄附近。
一、本图片生成器具有以下功能特性:
1、可以设置图片的宽度、高度、外框颜色、背景色;
2、可以设置图片字体的大小、名称、颜色;
3、可以设置输出图片的格式,如JPEG、GIF等;
4、可以将图片存储到一个文件或者存储到一个输出流;
5、可以为图片增加若干条干扰线(在生成随机码图片时可用此特性);
6、打印在图片上的文字支持自动换行;
另外,本图片生成器还用到了模板方法模式。
二、下面列出相关的源代码
1、抽象类AbstractImageCreator的源代码
- public abstract class AbstractImageCreator {
- private static Random rnd = new Random(new Date().getTime());
-
-
- private int width = 200;
-
-
- private int height = 80;
-
-
- private Color rectColor;
-
-
- private Color bgColor;
-
-
- private int lineNum = 0;
-
-
- private String formatName = "JPEG";
-
-
- private Color fontColor = new Color(0, 0, 0);
-
-
- private String fontName = "宋体";
-
-
- private int fontSize = 15;
-
-
-
-
-
-
-
-
- private void drawRandomLine(Graphics graph){
- for(int i=0;i<lineNum;i++){
-
- graph.setColor(getRandomColor(100, 155));
-
-
- int x1 = rnd.nextInt(width);
- int y1 = rnd.nextInt(height);
-
- int x2 = rnd.nextInt(width);
- int y2 = rnd.nextInt(height);
-
-
- graph.drawLine(x1, y1, x2, y2);
- }
- }
-
-
-
-
- private Color getRandomColor(int base, int range){
- if((base + range) > 255) range = 255 - base;
-
- int red = base + rnd.nextInt(range);
- int green = base + rnd.nextInt(range);
- int blue = base + rnd.nextInt(range);
-
- return new Color(red, green, blue);
- }
-
-
- public void drawImage(String text)throws IOException{
- BufferedImage image = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB);
-
- if(rectColor == null) rectColor = new Color(0, 0, 0);
- if(bgColor == null) bgColor = new Color(240, 251, 200);
-
-
- Graphics graph = image.getGraphics();
-
-
- graph.setColor(bgColor);
- graph.fillRect(0, 0, width, height);
-
-
- graph.setColor(rectColor);
- graph.drawRect(0, 0, width-1, height-1);
-
-
- drawRandomLine(graph);
-
-
- drawString(graph, text);
-
-
- graph.dispose();
-
-
- saveImage(image);
- }
-
- protected abstract void drawString(Graphics graph, String text);
-
- protected abstract void saveImage(BufferedImage image)throws IOException;
-
- }
public abstract class AbstractImageCreator {
private static Random rnd = new Random(new Date().getTime());
//图片宽度
private int width = 200;
//图片高度
private int height = 80;
//外框颜色
private Color rectColor;
//背景色
private Color bgColor;
//干扰线数目
private int lineNum = 0;
//图片格式
private String formatName = "JPEG";
//字体颜色
private Color fontColor = new Color(0, 0, 0);
//字体名称
private String fontName = "宋体";
//字体大小
private int fontSize = 15;
//##### 这里省略成员变脸的get、set方法 #####
/**
* 画干扰线
*/
private void drawRandomLine(Graphics graph){
for(int i=0;i<lineNum;i++){
//线条的颜色
graph.setColor(getRandomColor(100, 155));
//线条两端坐标值
int x1 = rnd.nextInt(width);
int y1 = rnd.nextInt(height);
int x2 = rnd.nextInt(width);
int y2 = rnd.nextInt(height);
//画线条
graph.drawLine(x1, y1, x2, y2);
}
}
/**
* 随机获取颜色对象
*/
private Color getRandomColor(int base, int range){
if((base + range) > 255) range = 255 - base;
int red = base + rnd.nextInt(range);
int green = base + rnd.nextInt(range);
int blue = base + rnd.nextInt(range);
return new Color(red, green, blue);
}
//该方法内应用了模板方法模式
public void drawImage(String text)throws IOException{
BufferedImage image = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB);
if(rectColor == null) rectColor = new Color(0, 0, 0);
if(bgColor == null) bgColor = new Color(240, 251, 200);
//获取画布
Graphics graph = image.getGraphics();
//画长方形
graph.setColor(bgColor);
graph.fillRect(0, 0, width, height);
//外框
graph.setColor(rectColor);
graph.drawRect(0, 0, width-1, height-1);
//画干扰线
drawRandomLine(graph);
//画字符串
drawString(graph, text);
//执行
graph.dispose();
//输出图片结果
saveImage(image);
}
protected abstract void drawString(Graphics graph, String text);
protected abstract void saveImage(BufferedImage image)throws IOException;
}
2、类DefaultImageCreator的源代码
该类将生成的图片存储到一个文件中,需要设置outputFilePath成员变量值,该成员变量值表示图片的存储全路径。
- public class DefaultImageCreator extends AbstractImageCreator {
- private String outputFilePath;
-
- public String getOutputFilePath() {
- return outputFilePath;
- }
-
- public void setOutputFilePath(String outputFilePath) {
- this.outputFilePath = outputFilePath;
- }
-
- public DefaultImageCreator(){
-
- }
-
- public DefaultImageCreator(String outputFilePath){
- this.outputFilePath = outputFilePath;
- }
-
- @Override
- protected void drawString(Graphics graph, String text) {
- graph.setColor(getFontColor());
- Font font = new Font(getFontName(), Font.PLAIN, getFontSize());
- graph.setFont(font);
-
- FontMetrics fm = graph.getFontMetrics(font);
- int fontHeight = fm.getHeight();
-
- int offsetLeft = 0;
- int rowIndex = 1;
- for(int i=0;i<text.length();i++){
- char c = text.charAt(i);
- int charWidth = fm.charWidth(c);
-
-
- if(Character.isISOControl(c) || offsetLeft >= (getWidth()-charWidth)){
- rowIndex++;
- offsetLeft = 0;
- }
-
- graph.drawString(String.valueOf(c), offsetLeft, rowIndex * fontHeight);
- offsetLeft += charWidth;
- }
- }
-
- @Override
- protected void saveImage(BufferedImage image)throws IOException{
- ImageIO.write(image, getFormatName(), new File(outputFilePath));
- }
-
- }
public class DefaultImageCreator extends AbstractImageCreator {
private String outputFilePath;
public String getOutputFilePath() {
return outputFilePath;
}
public void setOutputFilePath(String outputFilePath) {
this.outputFilePath = outputFilePath;
}
public DefaultImageCreator(){
}
public DefaultImageCreator(String outputFilePath){
this.outputFilePath = outputFilePath;
}
@Override
protected void drawString(Graphics graph, String text) {
graph.setColor(getFontColor());
Font font = new Font(getFontName(), Font.PLAIN, getFontSize());
graph.setFont(font);
FontMetrics fm = graph.getFontMetrics(font);
int fontHeight = fm.getHeight(); //字符的高度
int offsetLeft = 0;
int rowIndex = 1;
for(int i=0;i<text.length();i++){
char c = text.charAt(i);
int charWidth = fm.charWidth(c); //字符的宽度
//另起一行
if(Character.isISOControl(c) || offsetLeft >= (getWidth()-charWidth)){
rowIndex++;
offsetLeft = 0;
}
graph.drawString(String.valueOf(c), offsetLeft, rowIndex * fontHeight);
offsetLeft += charWidth;
}
}
@Override
protected void saveImage(BufferedImage image)throws IOException{
ImageIO.write(image, getFormatName(), new File(outputFilePath));
}
}
3、类OutputStreamImageCreator的源代码
该类将生成的图片存储到一个输出流中,需要设置out成员变量值。
- public class OutputStreamImageCreator extends DefaultImageCreator {
- private OutputStream out ;
-
- public OutputStream getOut() {
- return out;
- }
-
- public void setOut(OutputStream out) {
- this.out = out;
- }
-
- public OutputStreamImageCreator(){
-
- }
-
- public OutputStreamImageCreator(OutputStream out){
- this.out = out;
- }
-
- @Override
- public String getOutputFilePath() {
- return null;
- }
-
- @Override
- public void setOutputFilePath(String outputFilePath) {
- outputFilePath = null;
- }
-
- @Override
- protected void saveImage(BufferedImage image) throws IOException {
- if(out!=null) ImageIO.write(image, getFontName(), out);
- }
-
- }
public class OutputStreamImageCreator extends DefaultImageCreator {
private OutputStream out ;
public OutputStream getOut() {
return out;
}
public void setOut(OutputStream out) {
this.out = out;
}
public OutputStreamImageCreator(){
}
public OutputStreamImageCreator(OutputStream out){
this.out = out;
}
@Override
public String getOutputFilePath() {
return null;
}
@Override
public void setOutputFilePath(String outputFilePath) {
outputFilePath = null;
}
@Override
protected void saveImage(BufferedImage image) throws IOException {
if(out!=null) ImageIO.write(image, getFontName(), out);
}
}
三、实例代码
1、图片存储到文件
StringBuffer sb = new StringBuffer();
- sb.append("中华人民共和国\n");
- sb.append("中华人民共和国\n");
-
- DefaultImageCreator creator = new DefaultImageCreator("c:\\img.jpeg");
- creator.setWidth(150);
- creator.setHeight(100);
- creator.setLineNum(60);
- creator.setFontSize(20);
- creator.drawImage(sb.toString());
StringBuffer sb = new StringBuffer();
sb.append("中华人民共和国\n");
sb.append("中华人民共和国\n");
DefaultImageCreator creator = new DefaultImageCreator("c:\\img.jpeg");
creator.setWidth(150);
creator.setHeight(100);
creator.setLineNum(60);
creator.setFontSize(20);
creator.drawImage(sb.toString());

Java程序的源代码很容易被别人偷看,只要有一个反编译器,任何人都可以分析别人的代码。本文讨论如何在不修改原有程序的情况下,通过加密技术保护源代码。
一、为什么要加密?
对于传统的C或C++之类的语言来说,要在Web上保护源代码是很容易的,只要不发布它就可以。遗憾的是,Java程序的源代码很容易被别人偷看。只要有一个反编译器,任何人都可以分析别人的代码。Java的灵活性使得源代码很容易被窃取,但与此同时,它也使通过加密保护代码变得相对容易,我们唯一需要了解的就是Java的ClassLoader对象。当然,在加密过程中,有关Java Cryptography Extension(JCE)的知识也是必不可少的。
有几种技术可以“模糊”Java类文件,使得反编译器处理类文件的效果大打折扣。然而,修改反编译器使之能够处理这些经过模糊处理的类文件并不是什么难事,所以不能简单地依赖模糊技术来保证源代码的安全。
我们可以用流行的加密工具加密应用,比如PGP(Pretty Good Privacy)或GPG(GNU Privacy Guard)。这时,最终用户在运行应用之前必须先进行解密。但解密之后,最终用户就有了一份不加密的类文件,这和事先不进行加密没有什么差别。
Java运行时装入字节码的机制隐含地意味着可以对字节码进行修改。JVM每次装入类文件时都需要一个称为ClassLoader的对象,这个对象负责把新的类装入正在运行的JVM。JVM给ClassLoader一个包含了待装入类(比如java.lang.Object)名字的字符串,然后由ClassLoader负责找到类文件,装入原始数据,并把它转换成一个Class对象。
我们可以通过定制ClassLoader,在类文件执行之前修改它。这种技术的应用非常广泛??在这里,它的用途是在类文件装入之时进行解密,因此可以看成是一种即时解密器。由于解密后的字节码文件永远不会保存到文件系统,所以窃密者很难得到解密后的代码。
由于把原始字节码转换成Class对象的过程完全由系统负责,所以创建定制ClassLoader对象其实并不困难,只需先获得原始数据,接着就可以进行包含解密在内的任何转换。
Java 2在一定程度上简化了定制ClassLoader的构建。在Java 2中,loadClass的缺省实现仍旧负责处理所有必需的步骤,但为了顾及各种定制的类装入过程,它还调用一个新的findClass方法。
这为我们编写定制的ClassLoader提供了一条捷径,减少了麻烦:只需覆盖findClass,而不是覆盖loadClass。这种方法避免了重复所有装入器必需执行的公共步骤,因为这一切由loadClass负责。
不过,本文的定制ClassLoader并不使用这种方法。原因很简单。如果由默认的ClassLoader先寻找经过加密的类文件,它可以找到;但由于类文件已经加密,所以它不会认可这个类文件,装入过程将失败。因此,我们必须自己实现loadClass,稍微增加了一些工作量。
二、定制类装入器
每一个运行着的JVM已经拥有一个ClassLoader。这个默认的ClassLoader根据CLASSPATH环境变量的值,在本地文件系统中寻找合适的字节码文件。
应用定制ClassLoader要求对这个过程有较为深入的认识。我们首先必须创建一个定制ClassLoader类的实例,然后显式地要求它装入另外一个类。这就强制JVM把该类以及所有它所需要的类关联到定制的ClassLoader。Listing 1显示了如何用定制ClassLoader装入类文件。
【Listing 1:利用定制的ClassLoader装入类文件】
以下是引用片段:
// 首先创建一个ClassLoader对象 如 http://www.bt285.cn
ClassLoader myClassLoader = new myClassLoader();
// 利用定制ClassLoader对象装入类文件
// 并把它转换成Class对象
Class myClass = myClassLoader.loadClass( "mypackage.MyClass" );
// 最后,创建该类的一个实例
Object newInstance = myClass.newInstance();
// 注意,MyClass所需要的所有其他类,都将通过
// 定制的ClassLoader自动装入 |
如前所述,定制ClassLoader只需先获取类文件的数据,然后把字节码传递给运行时系统,由后者完成余下的任务。
ClassLoader有几个重要的方法。创建定制的ClassLoader时,我们只需覆盖其中的一个,即loadClass,提供获取原始类文件数据的代码。这个方法有两个参数:类的名字,以及一个表示JVM是否要求解析类名字的标记(即是否同时装入有依赖关系的类)。如果这个标记是true,我们只需在返回JVM之前调用resolveClass。
【Listing 2:ClassLoader.loadClass()的一个简单实现】
以下是引用片段:
public Class loadClass( String name, boolean resolve ) 如:http://www.5a520.cn
throws ClassNotFoundException {
try {
// 我们要创建的Class对象
Class clasz = null;
// 必需的步骤1:如果类已经在系统缓冲之中,
// 我们不必再次装入它
clasz = findLoadedClass( name );
if (clasz != null)
return clasz;
// 下面是定制部分
byte classData[] = /* 通过某种方法获取字节码数据 */;
if (classData != null) {
// 成功读取字节码数据,现在把它转换成一个Class对象
clasz = defineClass( name, classData, 0, classData.length );
}
// 必需的步骤2:如果上面没有成功,
// 我们尝试用默认的ClassLoader装入它
if (clasz == null)
clasz = findSystemClass( name );
// 必需的步骤3:如有必要,则装入相关的类
if (resolve && clasz != null)
resolveClass( clasz );
// 把类返回给调用者
return clasz;
} catch( IOException ie ) {
throw new ClassNotFoundException( ie.toString() );
} catch( GeneralSecurityException gse ) {
throw new ClassNotFoundException( gse.toString() );
}
} |
Listing 2显示了一个简单的loadClass实现。代码中的大部分对所有ClassLoader对象来说都一样,但有一小部分(已通过注释标记)是特有的。在处理过程中,ClassLoader对象要用到其他几个辅助方法:
findLoadedClass:用来进行检查,以便确认被请求的类当前还不存在。loadClass方法应该首先调用它。
defineClass:获得原始类文件字节码数据之后,调用defineClass把它转换成一个Class对象。任何loadClass实现都必须调用这个方法。
findSystemClass:提供默认ClassLoader的支持。如果用来寻找类的定制方法不能找到指定的类(或者有意地不用定制方法),则可以调用该方法尝试默认的装入方式。这是很有用的,特别是从普通的JAR文件装入标准Java类时。
resolveClass:当JVM想要装入的不仅包括指定的类,而且还包括该类引用的所有其他类时,它会把loadClass的resolve参数设置成true。这时,我们必须在返回刚刚装入的Class对象给调用者之前调用resolveClass。
三、加密、解密
Java加密扩展即Java Cryptography Extension,简称JCE。它是Sun的加密服务软件,包含了加密和密匙生成功能。JCE是JCA(Java Cryptography Architecture)的一种扩展。
JCE没有规定具体的加密算法,但提供了一个框架,加密算法的具体实现可以作为服务提供者加入。除了JCE框架之外,JCE软件包还包含了SunJCE服务提供者,其中包括许多有用的加密算法,比如DES(Data Encryption Standard)和Blowfish。
为简单计,在本文中我们将用DES算法加密和解密字节码。下面是用JCE加密和解密数据必须遵循的基本步骤:
步骤1:生成一个安全密匙。在加密或解密任何数据之前需要有一个密匙。密匙是随同被加密的应用一起发布的一小段数据,Listing 3显示了如何生成一个密匙。 【Listing 3:生成一个密匙】
以下是引用片段:
// DES算法要求有一个可信任的随机数源
SecureRandom sr = new SecureRandom();
// 为我们选择的DES算法生成一个KeyGenerator对象
KeyGenerator kg = KeyGenerator.getInstance( "DES" );
kg.init( sr );
// 生成密匙
SecretKey key = kg.generateKey();
// 获取密匙数据
byte rawKeyData[] = key.getEncoded();
/* 接下来就可以用密匙进行加密或解密,或者把它保存
为文件供以后使用 */
doSomething( rawKeyData ); |
步骤2:加密数据。得到密匙之后,接下来就可以用它加密数据。除了解密的ClassLoader之外,一般还要有一个加密待发布应用的独立程序(见Listing 4)。 【Listing 4:用密匙加密原始数据】
以下是引用片段:
// DES算法要求有一个可信任的随机数源
SecureRandom sr = new SecureRandom();
byte rawKeyData[] = /* 用某种方法获得密匙数据 */;
// 从原始密匙数据创建DESKeySpec对象
DESKeySpec dks = new DESKeySpec( rawKeyData );
// 创建一个密匙工厂,然后用它把DESKeySpec转换成
// 一个SecretKey对象
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance( "DES" );
SecretKey key = keyFactory.generateSecret( dks );
// Cipher对象实际完成加密操作
Cipher cipher = Cipher.getInstance( "DES" );
// 用密匙初始化Cipher对象
cipher.init( Cipher.ENCRYPT_MODE, key, sr );
// 现在,获取数据并加密
byte data[] = /* 用某种方法获取数据 */
// 正式执行加密操作
byte encryptedData[] = cipher.doFinal( data );
// 进一步处理加密后的数据
doSomething( encryptedData ); |
步骤3:解密数据。运行经过加密的应用时,ClassLoader分析并解密类文件。操作步骤如Listing 5所示。 【Listing 5:用密匙解密数据】
// DES算法要求有一个可信任的随机数源
SecureRandom sr = new SecureRandom();
byte rawKeyData[] = /* 用某种方法获取原始密匙数据 */;
// 从原始密匙数据创建一个DESKeySpec对象
DESKeySpec dks = new DESKeySpec( rawKeyData );
// 创建一个密匙工厂,然后用它把DESKeySpec对象转换成
// 一个SecretKey对象
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance( "DES" );
SecretKey key = keyFactory.generateSecret( dks );
// Cipher对象实际完成解密操作
Cipher cipher = Cipher.getInstance( "DES" );
// 用密匙初始化Cipher对象
cipher.init( Cipher.DECRYPT_MODE, key, sr );
// 现在,获取数据并解密
byte encryptedData[] = /* 获得经过加密的数据 */
// 正式执行解密操作
byte decryptedData[] = cipher.doFinal( encryptedData );
// 进一步处理解密后的数据
doSomething( decryptedData ); |
四、应用实例
前面介绍了如何加密和解密数据。要部署一个经过加密的应用,步骤如下:
步骤1:创建应用。我们的例子包含一个App主类,两个辅助类(分别称为Foo和Bar)。这个应用没有什么实际功用,但只要我们能够加密这个应用,加密其他应用也就不在话下。
步骤2:生成一个安全密匙。在命令行,利用GenerateKey工具(参见GenerateKey.java)把密匙写入一个文件: % java GenerateKey key.data
步骤3:加密应用。在命令行,利用EncryptClasses工具(参见EncryptClasses.java)加密应用的类: % java EncryptClasses key.data App.class Foo.class Bar.class
该命令把每一个.class文件替换成它们各自的加密版本。
步骤4:运行经过加密的应用。用户通过一个DecryptStart程序运行经过加密的应用。DecryptStart程序如Listing 6所示。 【Listing 6:DecryptStart.java,启动被加密应用的程序】
以下是引用片段:
import java.io.*;
import java.security.*;
import java.lang.reflect.*;
import javax.crypto.*;
import javax.crypto.spec.*;
public class DecryptStart extends ClassLoader
{
// 这些对象在构造函数中设置,
// 以后loadClass()方法将利用它们解密类
private SecretKey key;
private Cipher cipher;
// 构造函数:设置解密所需要的对象
public DecryptStart( SecretKey key ) throws GeneralSecurityException,
IOException {
this.key = key;
String algorithm = "DES";
SecureRandom sr = new SecureRandom();
System.err.println( "[DecryptStart: creating cipher]" );
cipher = Cipher.getInstance( algorithm );
cipher.init( Cipher.DECRYPT_MODE, key, sr );
}
// main过程:我们要在这里读入密匙,创建DecryptStart的
// 实例,它就是我们的定制ClassLoader。
// 设置好ClassLoader以后,我们用它装入应用实例,
// 最后,我们通过Java Reflection API调用应用实例的main方法
static public void main( String args[] ) throws Exception {
String keyFilename = args[0];
String appName = args[1];
// 这些是传递给应用本身的参数
String realArgs[] = new String[args.length-2];
System.arraycopy( args, 2, realArgs, 0, args.length-2 );
// 读取密匙
System.err.println( "[DecryptStart: reading key]" );
byte rawKey[] = Util.readFile( keyFilename );
DESKeySpec dks = new DESKeySpec( rawKey );
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance( "DES" );
SecretKey key = keyFactory.generateSecret( dks );
// 创建解密的ClassLoader
DecryptStart dr = new DecryptStart( key );
// 创建应用主类的一个实例
// 通过ClassLoader装入它
System.err.println( "[DecryptStart: loading "+appName+"]" );
Class clasz = dr.loadClass( appName );
// 最后,通过Reflection API调用应用实例
// 的main()方法
// 获取一个对main()的引用
String proto[] = new String[1];
Class mainArgs[] = { (new String[1]).getClass() };
Method main = clasz.getMethod( "main", mainArgs );
// 创建一个包含main()方法参数的数组
Object argsArray[] = { realArgs };
System.err.println( "[DecryptStart: running "+appName+".main()]" );
// 调用main()
main.invoke( null, argsArray );
}
public Class loadClass( String name, boolean resolve )
throws ClassNotFoundException {
try {
// 我们要创建的Class对象
Class clasz = null;
// 必需的步骤1:如果类已经在系统缓冲之中
// 我们不必再次装入它
clasz = findLoadedClass( name );
if (clasz != null)
return clasz;
// 下面是定制部分
try {
// 读取经过加密的类文件
byte classData[] = Util.readFile( name+".class" );
if (classData != null) {
// 解密...
byte decryptedClassData[] = cipher.doFinal( classData );
// ... 再把它转换成一个类
clasz = defineClass( name, decryptedClassData,
0, decryptedClassData.length );
System.err.println( "[DecryptStart: decrypting class "+name+"]" );
}
} catch( FileNotFoundException fnfe )
// 必需的步骤2:如果上面没有成功
// 我们尝试用默认的ClassLoader装入它
if (clasz == null)
clasz = findSystemClass( name );
// 必需的步骤3:如有必要,则装入相关的类
if (resolve && clasz != null)
resolveClass( clasz );
// 把类返回给调用者
return clasz;
} catch( IOException ie ) {
throw new ClassNotFoundException( ie.toString()
);
} catch( GeneralSecurityException gse ) {
throw new ClassNotFoundException( gse.toString()
);
}
}
} |
对于未经加密的应用,正常执行方式如下: % java App arg0 arg1 arg2
对于经过加密的应用,则相应的运行方式为: % java DecryptStart key.data App arg0 arg1 arg2
DecryptStart有两个目的。一个DecryptStart的实例就是一个实施即时解密操作的定制ClassLoader;同时,DecryptStart还包含一个main过程,它创建解密器实例并用它装入和运行应用。示例应用App的代码包含在App.java、Foo.java和Bar.java内。Util.java是一个文件I/O工具,本文示例多处用到了它。完整的代码请从本文最后下载。
五、注意事项
我们看到,要在不修改源代码的情况下加密一个Java应用是很容易的。不过,世上没有完全安全的系统。本文的加密方式提供了一定程度的源代码保护,但对某些攻击来说它是脆弱的。
虽然应用本身经过了加密,但启动程序DecryptStart没有加密。攻击者可以反编译启动程序并修改它,把解密后的类文件保存到磁盘。降低这种风险的办法之一是对启动程序进行高质量的模糊处理。或者,启动程序也可以采用直接编译成机器语言的代码,使得启动程序具有传统执行文件格式的安全性。
另外还要记住的是,大多数JVM本身并不安全。狡猾的黑客可能会修改JVM,从ClassLoader之外获取解密后的代码并保存到磁盘,从而绕过本文的加密技术。Java没有为此提供真正有效的补救措施。
不过应该指出的是,所有这些可能的攻击都有一个前提,这就是攻击者可以得到密匙。如果没有密匙,应用的安全性就完全取决于加密算法的安全性。虽然这种保护代码的方法称不上十全十美,但它仍不失为一种保护知识产权和敏感用户数据的有效方案。
Java 流在处理上分为字符流和字节流。字符流处理的单元为 2 个字节的 Unicode 字符,分别操作字符、字符数组或字符串,而字节流处理单元为 1 个字节,操作字节和字节数组。
Java 内用 Unicode 编码存储字符,字符流处理类负责将外部的其他编码的字符流和 java 内 Unicode 字符流之间的转换。而类 InputStreamReader 和 OutputStreamWriter 处理字符流和字节流的转换。字符流(一次可以处理一个缓冲区)一次操作比字节流(一次一个字节)效率高。
( 一 )以字节为导向的 stream------InputStream/OutputStream
InputStream 和 OutputStream 是两个 abstact 类,对于字节为导向的 stream 都扩展这两个鸡肋(基类 ^_^ ) ;
1、 InputStream
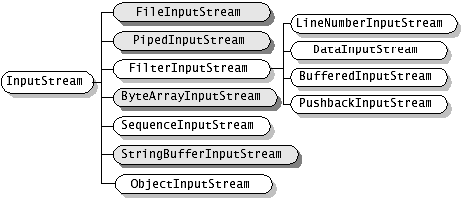
1.1
ByteArrayInputStream -- 把内存中的一个缓冲区作为 InputStream 使用 . 如使用http://www.5a520.cn
construct---
(A)ByteArrayInputStream(byte[]) 创建一个新字节数组输入流( ByteArrayInputStream ),它从指定字节数组中读取数据( 使用 byte 作为其缓冲区数组)
(B)---ByteArrayInputStream(byte[], int, int) 创建一个新字节数组输入流,它从指定字节数组中读取数据。
---mark:: 该字节数组未被复制。
1.2
StringBufferInputStream -- 把一个 String 对象作为 InputStream .
construct---
StringBufferInputStream(String) 据指定串创建一个读取数据的输入流串。
注释:不推荐使用 StringBufferInputStream 方法。 此类不能将字符正确的转换为字节。
同 JDK 1.1 版中的类似,从一个串创建一个流的最佳方法是采用 StringReader 类。
1.3
FileInputStream -- 把一个文件作为 InputStream ,实现对文件的读取操作
construct---
(A)FileInputStream(File name) 创建一个输入文件流,从指定的 File 对象读取数据。
(B)FileInputStream(FileDescriptor) 创建一个输入文件流,从指定的文件描述器读取数据。
(C)-FileInputStream(String name) 创建一个输入文件流,从指定名称的文件读取数据。
method ---- read() 从当前输入流中读取一字节数据。
read(byte[]) 将当前输入流中 b.length 个字节数据读到一个字节数组中。
read(byte[], int, int) 将输入流中 len 个字节数据读入一个字节数组中。
1.4
PipedInputStream :实现了 pipe 的概念,主要在线程中使用 . 管道输入流是指一个通讯管道的接收端。
一个线程通过管道输出流发送数据,而另一个线程通过管道输入流读取数据,这样可实现两个线程间的通讯。
construct---
PipedInputStream() 创建一个管道输入流,它还未与一个管道输出流连接。
PipedInputStream(PipedOutputStream) 创建一个管道输入流 , 它已连接到一个管道输出流。
1.5
SequenceInputStream :把多个 InputStream 合并为一个 InputStream . “序列输入流”类允许应用程序把几个输入流连续地合并起来,
并且使它们像单个输入流一样出现。每个输入流依次被读取,直到到达该流的末尾。
然后“序列输入流”类关闭这个流并自动地切换到下一个输入流。
construct---
SequenceInputStream(Enumeration) 创建一个新的序列输入流,并用指定的输入流的枚举值初始化它。
SequenceInputStream(InputStream, InputStream) 创建一个新的序列输入流,初始化为首先 读输入流 s1, 然后读输入流 s2 。
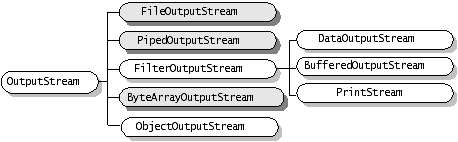
2、 OutputSteam http://www.bt285.cn
2.1
ByteArrayOutputStream : 把信息存入内存中的一个缓冲区中 . 该类实现一个以字节数组形式写入数据的输出流。
当数据写入缓冲区时,它自动扩大。用 toByteArray() 和 toString() 能检索数据。
constructor
(A)--- ByteArrayOutputStream() 创建一个新的字节数组输出流。
(B)--- ByteArrayOutputStream() 创建一个新的字节数组输出流。
(C)--- ByteArrayOutputStream(int) 创建一个新的字节数组输出流,并带有指定大小字节的缓冲区容量。
toString(String) 根据指定字符编码将缓冲区内容转换为字符串,并将字节转换为字符。
write(byte[], int, int) 将指定字节数组中从偏移量 off 开始的 len 个字节写入该字节数组输出流。
write(int) 将指定字节写入该字节数组输出流。
writeTo(OutputStream) 用 out.write(buf, 0, count) 调用输出流的写方法将该字节数组输出流的全部内容写入指定的输出流参数。
2.2
FileOutputStream: 文件输出流是向 File 或 FileDescriptor 输出数据的一个输出流。
constructor
(A)FileOutputStream(File name) 创建一个文件输出流,向指定的 File 对象输出数据。
(B)FileOutputStream(FileDescriptor) 创建一个文件输出流,向指定的文件描述器输出数据。
(C)FileOutputStream(String name) 创建一个文件输出流,向指定名称的文件输出数据。
(D)FileOutputStream(String, boolean) 用指定系统的文件名,创建一个输出文件。
2.3
PipedOutputStream: 管道输出流是指一个通讯管道的发送端。 一个线程通过管道输出流发送数据,
而另一个线程通过管道输入流读取数据,这样可实现两个线程间的通讯。
constructor
(A)PipedOutputStream() 创建一个管道输出流,它还未与一个管道输入流连接。
(B)PipedOutputStream(PipedInputStream) 创建一个管道输出流,它已连接到一个管道输入流。
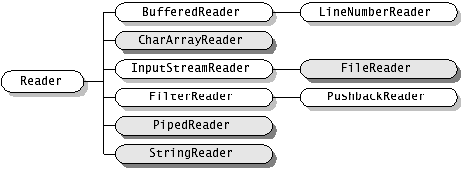
( 二 )以字符为导向的 stream Reader/Writer
以 Unicode 字符为导向的 stream ,表示以 Unicode 字符为单位从 stream 中读取或往 stream 中写入信息。
Reader/Writer 为 abstact 类
以 Unicode 字符为导向的 stream 包括下面几种类型:
1. Reader
1.1
CharArrayReader :与 ByteArrayInputStream 对应此类实现一个可用作字符输入流的字符缓冲区
constructor
CharArrayReader(char[]) 用指定字符数组创建一个 CharArrayReader 。
CharArrayReader(char[], int, int) 用指定字符数组创建一个 CharArrayReader
1.2
StringReader : 与 StringBufferInputStream 对应其源为一个字符串的字符流。
StringReader(String) 创建一新的串读取者。
1.3
FileReader : 与 FileInputStream 对应
1.4
PipedReader :与 PipedInputStream 对应
2. Writer

2.1 CharArrayWrite : 与 ByteArrayOutputStream 对应
2.2 StringWrite :无与之对应的以字节为导向的 stream
2.3 FileWrite : 与 FileOutputStream 对应
2.4 PipedWrite :与 PipedOutputStream 对应
3、两种不同导向的 stream 之间的转换
3.1
InputStreamReader 和 OutputStreamReader :
把一个以字节为导向的 stream 转换成一个以字符为导向的 stream 。
InputStreamReader 类是从字节流到字符流的桥梁:它读入字节,并根据指定的编码方式,将之转换为字符流。
使用的编码方式可能由名称指定,或平台可接受的缺省编码方式。
InputStreamReader 的 read() 方法之一的每次调用,可能促使从基本字节输入流中读取一个或多个字节。
为了达到更高效率,考虑用 BufferedReader 封装 InputStreamReader ,
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
例如: // 实现从键盘输入一个整数
- String s = null;
- InputStreamReader re = new InputStreamReader(System.in);
- BufferedReader br = new BufferedReader(re);
- try {
- s = br.readLine();
- System.out.println("s= " + Integer.parseInt(s));
- br.close();
- }
- catch (IOException e)
- {
- e.printStackTrace();
- }
- catch (NumberFormatException e)
- {
- System.out.println(" 输入的不是数字 ");
- }
InputStreamReader(InputStream) 用缺省的字符编码方式,创建一个 InputStreamReader 。
InputStreamReader(InputStream, String) 用已命名的字符编码方式,创建一个 InputStreamReader 。
OutputStreamWriter 将多个字符写入到一个输出流,根据指定的字符编码将多个字符转换为字节。
每个 OutputStreamWriter 合并它自己的 CharToByteConverter, 因而是从字符流到字节流的桥梁。
(三)Java IO 的一般使用原则 :
一、按数据来源(去向)分类:
1 、是文件: FileInputStream, FileOutputStream, ( 字节流 )FileReader, FileWriter( 字符 )
2 、是 byte[] : ByteArrayInputStream, ByteArrayOutputStream( 字节流 )
3 、是 Char[]: CharArrayReader, CharArrayWriter( 字符流 )
4 、是 String: StringBufferInputStream, StringBufferOuputStream ( 字节流 )StringReader, StringWriter( 字符流 )
5 、网络数据流: InputStream, OutputStream,( 字节流 ) Reader, Writer( 字符流 )
二、按是否格式化输出分:
1 、要格式化输出: PrintStream, PrintWriter
三、按是否要缓冲分:
1 、要缓冲: BufferedInputStream, BufferedOutputStream,( 字节流 ) BufferedReader, BufferedWriter( 字符流 )
四、按数据格式分:
1 、二进制格式(只要不能确定是纯文本的) : InputStream, OutputStream 及其所有带 Stream 结束的子类
2 、纯文本格式(含纯英文与汉字或其他编码方式); Reader, Writer 及其所有带 Reader, Writer 的子类
五、按输入输出分:
1 、输入: Reader, InputStream 类型的子类
2 、输出: Writer, OutputStream 类型的子类
六、特殊需要:
1 、从 Stream 到 Reader,Writer 的转换类: InputStreamReader, OutputStreamWriter
2 、对象输入输出: ObjectInputStream, ObjectOutputStream
3 、进程间通信: PipeInputStream, PipeOutputStream, PipeReader, PipeWriter
4 、合并输入: SequenceInputStream
5 、更特殊的需要: PushbackInputStream, PushbackReader, LineNumberInputStream, LineNumberReader
决定使用哪个类以及它的构造进程的一般准则如下(不考虑特殊需要):
首先,考虑最原始的数据格式是什么: 原则四
第二,是输入还是输出:原则五
第三,是否需要转换流:原则六第 1 点
第四,数据来源(去向)是什么:原则一
第五,是否要缓冲:原则三 (特别注明:一定要注意的是 readLine() 是否有定义,有什么比 read, write 更特殊的输入或输出方法)
第六,是否要格式化输出:原则二
早上帮朋友一台服务器解决了
Mysql cpu 占用 100% 的问题。稍整理了一下,将经验记录在这篇文章里
朋友主机(Windows 2003 + IIS + PHP + MYSQL )近来 MySQL 服务进程 (mysqld-nt.exe) CPU 占用率总为 100% 高居不下。此主机有10个左右的 database, 分别给十个网站调用。据朋友测试,导致 mysqld-nt.exe cpu 占用奇高的是网站A,一旦在 IIS 中将此网站停止服务,CPU 占用就降下来了。一启用,则马上上升。
MYSQL CPU 占用 100% 的解决过程
今天早上仔细检查了一下。目前此小说网站 http://www.5a520.cn 的七日平均日 IP 为2000,PageView 为 3万左右。网站A 用的 database 目前有39个表,记录数 60.1万条,占空间 45MB。按这个数据,MySQL 不可能占用这么高的资源。
于是在服务器上运行命令,将 mysql 当前的环境变量输出到文件 output.txt:
d:\web\mysql> mysqld.exe --help >output.txt
发现 tmp_table_size 的值是默认的 32M,于是修改 My.ini, 将 tmp_table_size 赋值到 200M:
d:\web\mysql> notepad c:\windows\my.ini
[mysqld]
tmp_table_size=200M
然后重启 MySQL 服务。CPU 占用有轻微下降,以前的CPU 占用波形图是 100% 一根直线,现在则在 97%~100%之间起伏。这表明调整 tmp_table_size 参数对 MYSQL 性能提升有改善作用。但问题还没有完全解决。
于是进入 mysql 的 shell 命令行,调用 show processlist, 查看当前 mysql 使用频繁的 sql 语句:
mysql> show processlist;
反复调用此命令,发现网站 A 的两个 SQL 语句经常在 process list 中出现,其语法如下:
SELECT t1.pid, t2.userid, t3.count, t1.date
FROM _mydata AS t1
LEFT JOIN _myuser AS t3 ON t1.userid=t3.userid
LEFT JOIN _mydata_body AS t2 ON t1.pid=t3.pid
ORDER BY t1.pid
LIMIT 0,15
调用 show columns 检查这三个表的结构 :
mysql> show columns from _myuser;
mysql> show columns from _mydata;
mysql> show columns from _mydata_body;
终于发现了问题所在:_mydata 表,只根据 pid 建立了一个 primary key,但并没有为 userid 建立索引。而在这个 SQL 语句的第一个 LEFT JOIN ON 子句中:
LEFT JOIN _myuser AS t3 ON t1.userid=t3.userid
_mydata 的 userid 被参与了条件比较运算。于是我为给 _mydata 表根据字段 userid 建立了一个索引:
mysql> ALTER TABLE `_mydata` ADD INDEX ( `userid` )
建立此索引之后,CPU 马上降到了 80% 左右。看到找到了问题所在,于是检查另一个反复出现在 show processlist 中的 sql 语句:
SELECT COUNT(*)
FROM _mydata AS t1, _mydata_key AS t2
WHERE t1.pid=t2.pid and t2.keywords = '孔雀'
经检查 _mydata_key 表的结构,发现它只为 pid 建了了 primary key, 没有为 keywords 建立 index。_mydata_key 目前有 33 万条记录,在没有索引的情况下对33万条记录进行文本检索匹配,不耗费大量的 cpu 时间才怪。看来就是针对这个表的检索出问题了。于是同样为 _mydata_key 表根据字段 keywords 加上索引:
mysql> ALTER TABLE `_mydata_key` ADD INDEX ( `keywords` )
建立此索引之后,CPU立刻降了下来,在 50%~70%之间震荡。
再次调用 show prosslist,网站A 的sql 调用就很少出现在结果列表中了。但发现此主机运行了几个 Discuz 的论坛程序, Discuz 论坛的好几个表也存在着这个问题。于是顺手一并解决,cpu占用再次降下来了
解决 MYSQL CPU 占用 100% 的经验总结
http://www.bt285.cn BT下载
- 增加 tmp_table_size 值。mysql 的配置文件中,tmp_table_size 的默认大小是 32M。如果一张临时表超出该大小,MySQL产生一个 The table tbl_name is full 形式的错误,如果你做很多高级 GROUP BY 查询,增加 tmp_table_size 值。 这是 mysql 官方关于此选项的解释:
tmp_table_size
This variable determines the maximum size for a temporary table in memory. If the table becomes too large, a MYISAM table is created on disk. Try to avoid temporary tables by optimizing the queries where possible, but where this is not possible, try to ensure temporary tables are always stored in memory. Watching the processlist for queries with temporary tables that take too long to resolve can give you an early warning that tmp_table_size needs to be upped. Be aware that memory is also allocated per-thread. An example where upping this worked for more was a server where I upped this from 32MB (the default) to 64MB with immediate effect. The quicker resolution of queries resulted in less threads being active at any one time, with all-round benefits for the server, and available memory.
- 对 WHERE, JOIN, MAX(), MIN(), ORDER BY 等子句中的条件判断中用到的字段,应该根据其建立索引 INDEX。索引被用来快速找出在一个列上用一特定值的行。没有索引,MySQL不得不首先以第一条记录开始并然后读完整个表直到它找出相关的行。表越大,花费时间越多。如果表对于查询的列有一个索引,MySQL能快速到达一个位置去搜寻到数据文件的中间,没有必要考虑所有数据。如果一个表有1000行,这比顺序读取至少快100倍。所有的MySQL索引(PRIMARY、UNIQUE和INDEX)在B树中存储。
根据 mysql 的开发文档:
索引 index 用于:
开发人员做 SQL 数据表设计的时候,一定要通盘考虑清楚。
摘要: 利用org.apache.commons.net.ftp包实现一个简单的ftp客户端实用类。主要实现一下功能
1.支持上传下载。支持断点续传
2.支持进度汇报
3.支持对于中文目录及中文文件创建的支持。
import java.io.File;
import java.io.FileOutputStream; ...
阅读全文