 2012年3月14日
2012年3月14日
select * from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA = 'DBNAME' order by create_time desc;
ps -ef|grep java
kill -9 1231
导出数据库
直接使用命令:
mysqldump -u root -p abc >abc.sql
然后回车输入密码就可以了;
mysqldump -u 数据库链接用户名 -p 目标数据库 > 存储的文件名
文件会导出到当前目录下
导入数据库(sql文件)
mysql -u 用户名 -p 数据库名 < 数据库名.sql
mysql -u abc -p abc < abc.sql
注意sql文件必须在当前目录下,如果不在当前目录下需要在< 之后加上具体sql文件路径
GBK: create database test2 DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;
UTF8: CREATE DATABASE `test2` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
DELIMITER //
CREATE PROCEDURE proc_tmp()
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE product_Id VARCHAR(255);
DECLARE yuanliao VARCHAR(255);
DECLARE miaoshu VARCHAR(255);
DECLARE shazhi VARCHAR(255);
DECLARE midu VARCHAR(255);
DECLARE mf VARCHAR(255);
DECLARE zuzhi VARCHAR(255);
DECLARE quality VARCHAR(255);
DECLARE shuliang VARCHAR(255);
DECLARE jiage VARCHAR(255);
DECLARE price_date VARCHAR(255);
DECLARE idCur CURSOR FOR SELECT productId,yl,ylms,sz,md,fk,zz,qa,amount,price,pricedate FROM sheet1;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1;
OPEN idCur;
REPEAT
FETCH idCur INTO product_Id,yuanliao,miaoshu,shazhi,midu,mf,zuzhi,quality,shuliang,jiage,price_date;
IF NOT done THEN
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'yl',yuanliao,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'ylms',miaoshu,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'sz',shazhi,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'md',midu,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'fk',mf,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'zz',zuzhi,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'qa',quality,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'amount',shuliang,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'price',jiage,product_Id);
INSERT INTO static_data(model_id,dataKey,dataVal,product_id) VALUES(3,'pricedate',price_date,product_Id);
END IF;
UNTIL done END REPEAT;
CLOSE idCur;
END//
DELIMITER ;
CALL proc_tmp();
DROP PROCEDURE proc_tmp;
DELETE FROM sheet1;
定义的变量不能和select里的同名
摘要: 小编整理的“宜兴市主要乡村旅游点瓜果采摘攻略”,希望能成为您瓜果采摘的好帮手!!!农家乐联系人手机采摘项目篱笆园农家乐黄亚云13815118337草莓5月-11月挖笋 野菜 采茶 制乌米饭3-5月桑葚 4月油桃 5月 杨梅 6月下旬-7月中下旬 葡萄 7月-9月 挖百合 8月 板栗 9月底-10月份 绿缘生态农业有限公司陈庆元13701539886挖笋 挖野菜 3-4月 ...
阅读全文
桑葚采
摘
好去处
芳桥
1、绿大地果桑种植基地 13063669929
2、碧园春生态园 13771359607
3、张慕果园 13812203223
4、金沙滩蔬果园 13585035093
建议采摘路线:市区→东氿大道→百合大道→芳塍路往北(详见地图指示)
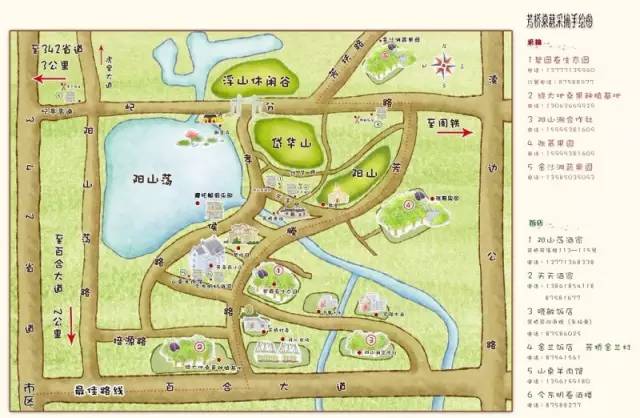
西渚
◆【1】甲有农林生态园
地址:宜兴市西渚镇张戴公路白塔村部旁(近振元南路)
◆【2】白塔云芯林果专业合作社桑葚采摘园
地址:白塔村委入口斜对面张戴公路边
◆【3】小杭采摘园
自驾线路: 宜兴——横山水库
◆【4】白塔瓜果基地
自驾线路:导航即到
徐舍
◆ 苏合农产品销售专业合作联社
自驾线路:麦德龙——G104(行驶16.6公里)——徐舍镇潘东村
湖㳇
◆【1】篱笆园农家乐
地址:宜兴市湖㳇镇洑西村
◆【2】金沙湾农庄
地址:宜兴市湖㳇镇东兴村
【烧烤清单】
1‘.烧烤工具:
烧烤架、网架、木炭、烧烤叉、小毛刷、打火机、助燃剂、竹签、牙签、水果刀、报纸、
一次性筷、一次性碗、一次性盘、一次性隔热手套、纸杯、餐巾纸、湿巾纸、桌布、烧烤围裙、垃圾袋烧烤夹(夹取生食)
2.调料:
调和油、盐、酱油、烧烤酱(汁)、辣椒粉(老干妈)、孜然、五香粉、番茄酱、芝麻、胡萝卜酱、甜面酱、海鲜调料、大蒜、姜、葱花、蜂蜜、
3、食品:
荤菜:鸡翅、排骨、香肠、火腿肠、牛肉、羊肉、五花肉、各式鱼丸肉丸、鸡珍、黄花鱼、秋刀鱼、鲫鱼、鱿鱼、墨鱼仔、虾等
素菜:玉米、韭菜、蘑菇、茄子、土豆、青椒、生菜(生菜包肉)、花菜、香干、臭干子、小镘头、年糕、面包片、棉花糖、皮蛋、胡萝卜/黄瓜、藕片、等
水果:香蕉、木瓜、苹果、梨、菠萝、哈密瓜等
4、饮料:矿泉水、可乐(去油腻)、凉茶(降火)、橙汁、啤酒等

$.ajax({
url:"${base}/bosImg.xml",
dataType:"xml",
success:function(data){
$(data).find("bosPicture[wlbh='"+wlbh+"'][size='800']").find("imgs").each(function (i){
$('#showbox').empty();
$(this).children('img').each(function (ii){
$('#showbox').append('<img src="'+$(this).text()+'" width="280" height="280" />');
})
});
},
error:function(XMLHttpRequest, textStatus, errorThrown) {
alert(XMLHttpRequest.status);
alert(XMLHttpRequest.readyState);
alert(textStatus);
}
grep -rn "2002675" ./catalina.out
在Freemarker中,如果要判断序列中是否包含某个指定的元素,可以使用freemarker的内建函数seq_contains。
注:seq_contains这个内建函数从FreeMarker 2.3.1 版本开始可用。而在2.3 版本中不存在。
使用示例:
Freemarker代码

- <#--声明一个序列,包含若干个元素-->
- <#assign x = ["red", 16, "blue", "cyan"]>
- <#--使用seq_contains判断序列中的元素是否存在-->
- "blue": ${x?seq_contains("blue")?string("yes", "no")}
- "yellow": ${x?seq_contains("yellow")?string("yes", "no")}
- 16: ${x?seq_contains(16)?string("yes", "no")}
- "16": ${x?seq_contains("16")?string("yes", "no")}
输出结果:
Freemarker代码
- "blue": yes
- "yellow": no
- 16: yes
- "16": no
附:seq_前缀在这个内建函数中是需要的,用来和contains 区分开。contains函数用来在字符串中查找子串(因为变量可以同时当作字符串和序列)。
命令行下具体用法如下: mysqldump -u用戶名 -p密码 -d 數據库名 表名 脚本名;
1、导出數據库為dbname的表结构(其中用戶名為root,密码為dbpasswd,生成的脚本名為db.sql)
mysqldump -uroot -pdbpasswd -d dbname >db.sql;
2、导出數據库為dbname某张表(test)结构
mysqldump -uroot -pdbpasswd -d dbname test>db.sql;
3、导出數據库為dbname所有表结构及表數據(不加-d)
mysqldump -uroot -pdbpasswd dbname >db.sql;
4、导出數據库為dbname某张表(test)结构及表數據(不加-d)
mysqldump -uroot -pdbpasswd dbname test>db.sql;
D:\MyDrivers\software\mysql-5.6.26-winx64\bin>mysqldump -h192.168.2.4 -uroot -p -d dy cotton>ee.sql
可以看到solr有哪些子命令,如 start, stop, restart, status, healthcheck, create, create_core, create_collection, delete, version
启动start
bin/solr start -help 查看start帮助
bin/solr start -p 8984 指定端口启动
bin/solr start -cloud 启动分布式版本
bin/solr start -e cloud -noprompt -e表示要启动一个现有的例子,例子名称是cloud,cloud这个例子是以SolrCloud方式启动的
bin/solr restart 重启项目
create
如果是单机版要创建core,如果是分布式的要创建collection
bin/solr create -help 查看create帮助
abc目录的位置创建在solr.solr.home(默认是solr的server/solr目录)目录下
post提交数据生成索引
bin/post -c abc docs/
向名为abc的core或collection提交数据,数据源在docs/目录中
删除
bin/solr delete -c abc 删除一个core或collection
删除索引
bin/post -c abc -d "<delete><id>/home/matthewi/software/solr-5.4.1/docs/solr-morphlines-core/allclasses-noframe.html</id></delete>"
重新执行上面的搜索可以看到搜索结果的数量少了一条:numFound列
bin/post -c abc -d "<delete><query>*:*</query></delete>"
删除所有数据
状态
摘要: nginx.conf配置:location / { proxy_pass http://127.0.0.1:8080/myweb/;proxy_redirect off;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_ad...
阅读全文
摘要: 一,登录要Post的表单数据是什么这部分可以使用Wireshark工具来抓包就可以了,发现需要以下数据:“_xsrf” = xxxx(这是一个变动的数据,需要先活取获取知乎首页源码来获得) “email” = 邮箱 “password” = 密码 “rememberme” ...
阅读全文
public class ClientFormLogin {
public static void main(String[] args) throws Exception {
BasicCookieStore cookieStore = new BasicCookieStore();
CloseableHttpClient httpclient = HttpClients.custom()
.setDefaultCookieStore(cookieStore)
.build();
try {
HttpGet httpget = new HttpGet("http://...");
CloseableHttpResponse response1 = httpclient.execute(httpget);
try {
HttpEntity entity = response1.getEntity();
System.out.println("Login form get: " + response1.getStatusLine());
System.out.println("Initial set of cookies:");
List<Cookie> cookies = cookieStore.getCookies();
if (cookies.isEmpty()) {
System.out.println("None");
} else {
for (int i = 0; i < cookies.size(); i++) {
System.out.println("- " + cookies.get(i).toString());
}
}
//输出网页源码
String result = EntityUtils.toString(response1.getEntity(), "utf-8");
System.out.println(result); EntityUtils.consume(entity);
} finally { response1.close();
}
}
}
package org.yla.test;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.http.Header;
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.Credentials;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.junit.Test;
public class HttpClientTest {
String url = "xxxxxxxxxxxxxxxxxxxxxxxxx";
String ip = "202.107.233.85";
int port = 8080;
String username = "";
String password = "";
/**
* 使用HttpClient4实现代理 202.107.233.85 8080
*
* @throws Exception
*/
@Test
public void test1() throws Exception {
HttpClientBuilder build = HttpClients.custom();
HttpHost proxy = new HttpHost(ip, port);
CloseableHttpClient client = build.setProxy(proxy).build();
HttpGet request = new HttpGet(url);
CloseableHttpResponse response = client.execute(request);
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity));
}
/**
* 使用httpclient3实现代理
*
* @throws Exception
*/
@Test
public void test2() throws Exception {
HttpClient httpClient = new HttpClient();
httpClient.getHostConfiguration().setProxy(ip, port);
GetMethod method = new GetMethod(url);
httpClient.executeMethod(method);
String result = new String(method.getResponseBody());
System.out.println(result);
}
/**
* 使用httpclient4实现代理(带密码的代理)
*
* @throws Exception
*/
@Test
public void test3() throws Exception {
HttpClientBuilder build = HttpClients.custom();
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
AuthScope authscope = new AuthScope(ip, port);
Credentials credentials = new UsernamePasswordCredentials(username,
password);
credentialsProvider.setCredentials(authscope, credentials);
CloseableHttpClient client = build.setDefaultCredentialsProvider(
credentialsProvider).build();
HttpGet request = new HttpGet(url);
CloseableHttpResponse response = client.execute(request);
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity));
}
/**
* 使用httpclient3实现代理(带密码的代理)
*
* @throws Exception
*/
@Test
public void test4() throws Exception {
HttpClient httpClient = new HttpClient();
org.apache.commons.httpclient.auth.AuthScope authscope = new org.apache.commons.httpclient.auth.AuthScope(
ip, port);
org.apache.commons.httpclient.Credentials credentials = new org.apache.commons.httpclient.UsernamePasswordCredentials(
username, password);
httpClient.getState().setProxyCredentials(authscope, credentials);
GetMethod method = new GetMethod(url);
httpClient.executeMethod(method);
String result = new String(method.getResponseBody());
System.out.println(result);
}
/**
* 模拟登录官网(http://mis.pyc.com.cn�?
*
* @throws Exception
*/
@Test
public void testLogin() throws Exception {
HttpClientBuilder build = HttpClients.custom();
CloseableHttpClient client = build.build();
HttpPost post = new HttpPost("http://mis.pyc.com.cn/login.aspx");
List<BasicNameValuePair> params = new ArrayList<BasicNameValuePair>();
params.add(new BasicNameValuePair("__VIEWSTATE",
"/wEPDwUJNjUwNzE0MTM4ZGQzh+vF2xGjdG8Q15kIqgR0CpxhmPucdCqZOPcglRZr/w=="));
params.add(new BasicNameValuePair(
"__EVENTVALIDATION",
"/wEWBQLYtKSdCALEhISFCwKd+7qdDgKC3IeGDAK7q7GGCOqhJpRD8S8yy3ZAlPTSsmPzRUoXMK0mQvGgzlk6hm+G"));
params.add(new BasicNameValuePair("txtName", "xxxxx"));
params.add(new BasicNameValuePair("txtPwd", "xxxxxx"));
params.add(new BasicNameValuePair("btnLogin", "xxxx"));
HttpEntity entity = new UrlEncodedFormEntity(params, "UTF-8");
post.setEntity(entity);
CloseableHttpResponse response = client.execute(post);
int statusCode = response.getStatusLine().getStatusCode();
System.err.println("状态" + statusCode);
if (statusCode == 302) {
Header[] location = response.getHeaders("location");
String rediretUrl = null;
if (location.length == 1) {
rediretUrl = "http://mis.pyc.com.cn" + location[0].getValue();
System.err.println("跳转地址: " + rediretUrl);
}
Header[] allHeaders = response.getAllHeaders();
System.out.println("==================response===================");
for (Header header : allHeaders) {
System.err.println(header.getName() + ": " + header.getValue());
}
Header cookieHeader = response.getFirstHeader("Set-Cookie");
String cookie = cookieHeader.getValue();
System.out.println("cookie: " + cookie);
HttpGet httpGet = new HttpGet(rediretUrl);
httpGet.addHeader("Accept",
"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
// httpGet.addHeader("Accept-Encoding", "gzip, deflate, sdch");
// httpGet.addHeader("Accept-Language", "zh-CN,zh;q=0.8");
httpGet.addHeader("Connection", "keep-alive");
httpGet.addHeader("Cookie", cookie);
httpGet.addHeader("Host", "mis.pyc.com.cn");
httpGet.addHeader("Referer", "http://mis.pyc.com.cn/login.aspx");
httpGet.addHeader(
"User-Agent",
"ozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36");
response = client.execute(httpGet);
HttpEntity entity2 = response.getEntity();
System.out
.println("----------------------------------------------");
System.out.println(EntityUtils.toString(entity2));
}
}
}
一、系统环境
yum update升级以后的系统版本为
[root@yl-web yl]# cat /etc/redhat-release CentOS Linux release 7.1.1503 (Core)
二、mysql安装
# wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm # rpm -ivh mysql-community-release-el7-5.noarch.rpm # yum install mysql-community-server
安装成功后重启mysql服务。
初次安装mysql,root账户没有密码。
[root@yl-web yl]# mysql -u root Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.6.26 MySQL Community Server (GPL) Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | test | +--------------------+ 4 rows in set (0.01 sec) mysql>
设置密码
mysql> set password for 'root'@'localhost' =password('password'); Query OK, 0 rows affected (0.00 sec) mysql> 不需要重启数据库即可生效。
三、配置mysql
1、编码
mysql配置文件为/etc/my.cnf
最后加上编码配置
[mysql] default-character-set =utf8
这里的字符编码必须和/usr/share/mysql/charsets/Index.xml中一致。
2、远程连接设置
把在所有数据库的所有表的所有权限赋值给位于所有IP地址的root用户。
mysql> grant all privileges on *.* to root@'%'identified by 'password';
如果是新用户而不是root,则要先新建用户
mysql>create user 'username'@'%' identified by 'password';
此时就可以进行远程连接了。
linux zip命令
zip -r myfile.zip ./*
将当前目录下的所有文件和文件夹全部压缩成myfile.zip文件,-r表示递归压缩子目录下所有文件.
2.unzip
unzip -o -d /home/sunny myfile.zip
把myfile.zip文件解压到 /home/sunny/
-o:不提示的情况下覆盖文件;
-d:-d /home/sunny 指明将文件解压缩到/home/sunny目录下;
3.其他
zip -d myfile.zip smart.txt
删除压缩文件中smart.txt文件
zip -m myfile.zip ./rpm_info.txt
向压缩文件中myfile.zip中添加rpm_info.txt文件
-------------------------------------------------------------------------------
要使用 zip 来压缩文件,在 shell 提示下键入下面的命令:
zip -r filename.zip filesdir
在这个例子里,filename.zip 代表你创建的文件,filesdir 代表你想放置新 zip 文件的目录。-r 选项指定你想递归地(recursively)包括所有包括在 filesdir 目录中的文件。
要抽取 zip 文件的内容,键入以下命令:
unzip filename.zip
你可以使用 zip 命令同时处理多个文件和目录,方法是将它们逐一列出,并用空格间隔:
zip -r filename.zip file1 file2 file3 /usr/work/school
上面的命令把 file1、file2、 file3、以及 /usr/work/school 目录的内容(假设这个目录存在)压缩起来,然后放入 filename.zip 文件中。
原文链接:
http://caibaojian.com/jquery-each-json.html概述
JSON(javascript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式。同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包。
via在JSON中,有两种结构:对象和数组。原文来自:http://caibaojian.com/jquery-each-json.html
1.对象
一个对象以“{”开始,“}”结束。每个“key”后跟一“:”,“‘key/value’ 对”之间运用 “,”分隔。
packJson = {"name":"caibaojian.com", "password":"111"}
2.数组
packJson = [{"name":"caibaojian.com", "password":"111"}, {"name":"tony", "password":"111"}];
数组是值的有序集合。一个数组以“[”开始,“]”结束。值之间运用 “,”分隔。
JSON对象和JSON字符串的转换
在数据传输流程中,json是以文本,即字符串的形式传递的,而JS操作的是JSON对象,所以,JSON对象和JSON字符串之间的相互转换是关键。例如:
JSON字符串:
var jsonStr = '{"name":"caibaojian", "password":"1111"}';
JSON对象:
var jsonObj = {"name":"caibaojian.com", "password":"1111"};
1、String转换为Json对象
var jsonObj = eval('(' + jsonStr + ')');2.Json对象转换为String字符串
var jsonStr = jsonObj.toJSONString();
grep
<script type='text/javascript' src="/jquery.js"></script> <script type="text/javascript"> $().ready( function(){ var array = [1,2,3,4,5,6,7,8,9]; var filterarray = $.grep(array,function(value){ return value > 5;//筛选出大于5的 }); for(var i=0;i<filterarray.length;i++){ alert(filterarray[i]); } for (key in filterarray){ alert(filterarray[key]); } } ); </script>each
<script type='text/javascript' src="/jquery.js"></script> <script type="text/javascript"> $().ready( function(){ var anObject = {one:1,two:2,three:3};//对json数组each $.each(anObject,function(name,value) { alert(name); alert(value); }); var anArray = ['one','two','three']; $.each(anArray,function(n,value){ alert(n); alert(value); } ); } ); </script>inArray
<script type='text/javascript' src="/jquery.js"></script> <script type="text/javascript"> $().ready( function(){ var anArray = ['one','two','three']; var index = $.inArray('two',anArray); alert(index);//返回该值在数组中的键值,返回1 alert(anArray[index]);//value is two } ); </script>map
<script type='text/javascript' src="/jquery.js"></script> <script type="text/javascript"> $().ready( function(){ var strings = ['0','1','2','3','4','S','6']; var values = $.map(strings,function(value){ var result = new Number(value); return isNaN(result) ? null:result;//isNaN:is Not a Number的缩写 } ); for (key in values) { alert(values[key]); } } ); </script>原生js遍历json对象
遍历json对象:
无规律:
<script> var json = [{dd:'SB',AA:'东东',re1:123},{cccc:'dd',lk:'1qw'}]; for(var i=0,l=json.length;i<l;i++){ for(var key in json[i]){ alert(key+':'+json[i][key]); } } </script>有规律:
packJson = [ {"name":"nikita", "password":"1111"}, {"name":"tony", "password":"2222"} ]; for(var p in packJson){//遍历json数组时,这么写p为索引,0,1 alert(packJson[p].name + " " + packJson[p].password); }也可以用这个:
for(var i = 0; i < packJson.length; i++){ alert(packJson[i].name + " " + packJson[i].password); }遍历json对象
myJson = {"name":"caibaojian", "password":"1111"}; for(var p in myJson){//遍历json对象的每个key/value对,p为key alert(p + " " + myJson[p]); }//code from http://caibaojian.com/jquery-each-json.html 有如下 json对象: var obj ={"name":"冯娟","password":"123456","department":"技术部","sex":"女","old":30}; 遍历方法: for(var p in obj){ str = str+obj[p]+’,'; return str; }
Linux scp命令用于Linux之间复制文件和目录,具体如何使用这里好好介绍一下,从本地复制到远程、从远程复制到本地是两种使用方式。这里有具体举例:
==================
Linux scp 命令
==================
scp 可以在 2个 linux 主机间复制文件;
命令基本格式:
scp [可选参数] file_source file_target
======
从 本地 复制到 远程
======
* 复制文件:
* 命令格式:
scp local_file remote_username@remote_ip:remote_folder
或者
scp local_file remote_username@remote_ip:remote_file
或者
scp local_file remote_ip:remote_folder
或者
scp local_file remote_ip:remote_file
第1,2个指定了用户名,命令执行后需要再输入密码,第1个仅指定了远程的目录,文件名字不变,第2个指定了文件名;
第3,4个没有指定用户名,命令执行后需要输入用户名和密码,第3个仅指定了远程的目录,文件名字不变,第4个指定了文件名;
* 例子:
scp /home/space/music/1.mp3 root@www.cumt.edu.cn:/home/root/others/music
scp /home/space/music/1.mp3 root@www.cumt.edu.cn:/home/root/others/music/001.mp3
scp /home/space/music/1.mp3 www.cumt.edu.cn:/home/root/others/music
scp /home/space/music/1.mp3 www.cumt.edu.cn:/home/root/others/music/001.mp3
* 复制目录:
* 命令格式:
scp -r local_folder remote_username@remote_ip:remote_folder
或者
scp -r local_folder remote_ip:remote_folder
第1个指定了用户名,命令执行后需要再输入密码;
第2个没有指定用户名,命令执行后需要输入用户名和密码;
* 例子:
scp -r /home/space/music/ root@www.cumt.edu.cn:/home/root/others/
scp -r /home/space/music/ www.cumt.edu.cn:/home/root/others/
上面 命令 将 本地 music 目录 复制 到 远程 others 目录下,即复制后有 远程 有 ../others/music/ 目录
======
从 远程 复制到 本地
======
从 远程 复制到 本地,只要将 从 本地 复制到 远程 的命令 的 后2个参数 调换顺序 即可;
例如:
scp root@www.cumt.edu.cn:/home/root/others/music /home/space/music/1.mp3
scp -r www.cumt.edu.cn:/home/root/others/ /home/space/music/
最简单的应用如下 :
scp 本地用户名 @IP 地址 : 文件名 1 远程用户名 @IP 地址 : 文件名 2
[ 本地用户名 @IP 地址 :] 可以不输入 , 可能需要输入远程用户名所对应的密码 .
可能有用的几个参数 :
-v 和大多数 linux 命令中的 -v 意思一样 , 用来显示进度 . 可以用来查看连接 , 认证 , 或是配置错误 .
-C 使能压缩选项 .
-P 选择端口 . 注意 -p 已经被 rcp 使用 .
-4 强行使用 IPV4 地址 .
-6 强行使用 IPV6 地址 .
Linux scp命令的使用方法应该可以满足大家对Linux文件和目录的复制使用了。
package com.demo.json;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import org.json.simple.JSONValue;
public class JsonTest
{
public static void main(String[] args)
{
// -----------------------------------------------------------------------------
// Object 2 JSON
List<Peoper> peopers = new ArrayList<Peoper>();
Peoper p1 = new Peoper("001", "Taki", "中国");
Peoper p2 = new Peoper("002", "DSM", "China");
peopers.add(p1);
peopers.add(p2);
String result = JsonTool.getJsonString("Peopers", peopers);
System.out.println("JSON: " + result);
// 解析PHP json_encode 字符串
String jsonStr = "{\"Name\":\"\u5e0c\u4e9a\",\"Age\":20}";
Object obj = JSONValue.parse(jsonStr);
System.out.println(obj);
System.out.println();
// -----------------------------------------------------------------------------
// JSON 2 Object
String jsonString = "["
+ "{\"author\":\"7\",\"id\":358,\"title\":\"Japan\",\"pictures\":[{\"description\":\"001\",\"imgPath\":\"/cms/u/cms/www/201203/05150720ii68.jpg\"},{\"description\":\"002\",\"imgPath\":\"/cms/u/cms/www/201203/05150720ii67.jpg\"}],\"path\":\"ip\"},"
+ "{\"author\":\"8\",\"id\":359,\"title\":\"China\",\"pictures\":[{\"description\":\"101\",\"imgPath\":\"/cms/u/cms/www/201203/111111111111.jpg\"},{\"description\":\"102\",\"imgPath\":\"/cms/u/cms/www/201203/222222222222.jpg\"}],\"path\":\"ip\"}]";
JSONArray array = JSONArray.fromObject(jsonString);
// Content.class包含pictures.class,需要设置这个参数
Map<String, Class<pictures>> classMap = new HashMap<String, Class<pictures>>();
classMap.put("pictures", pictures.class);
Object[] objs = new Object[array.size()];
for (int i = 0; i < array.size(); i++)
{
JSONObject jsonObject = array.getJSONObject(i);
objs[i] = (Content) JSONObject.toBean(jsonObject, Content.class, classMap);
}
// 转换Content,循环输出所有content
for (int i = 0; i < objs.length; i++)
{
Content content = (Content) objs[i];
System.out.println("author:" + content.getAuthor() + " ID:"
+ content.getId() + " Title:" + content.getTitle() + " Path:" + content.getPath());
// 转换pictures,循环输出所有picture
List<pictures> pictures = content.getPictures();
for (int n = 0; n < pictures.size(); n++)
System.out.println("description:"
+ pictures.get(n).getDescription() + " imgPath:" + pictures.get(n).getImgPath());
}
}
}
package com.demo.json;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import net.sf.json.JSONObject;
public class JsonTool
{
public static String getJsonString(Object key, Object value)
{
//System.out.println("key: " + key);
//System.out.println("value: " + value.toString());
JSONObject obj = new JSONObject();
obj.put(key, value); //添加物件
return obj.toString(); //转换为字符串并返回
}
//解析PHP json_encode 字符串
public static String unescapeUnicode(String str)
{
StringBuffer b=new StringBuffer();
Matcher m = Pattern.compile("\\\\u([0-9a-fA-F]{4})").matcher(str);
while(m.find())
{
b.append((char)Integer.parseInt(m.group(1),16));
}
return b.toString();
}
}
package com.demo.json;
public class People
{
public People()
{
}
public People(String id, String name, String address)
{
this.id = id;
this.name = name;
this.address = address;
}
private String id;
private String name;
private String address;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String toString()
{
return "ID:" + this.id + " Name:" + this.name + " Address:" + this.address;
}
}
package com.demo.json;
import java.util.List;
public class Content {
private String author;
private String id;
private String title;
private List<pictures> pictures;
private String path;
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public List<pictures> getPictures() {
return pictures;
}
public void setPictures(List<pictures> pictures) {
this.pictures = pictures;
}
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
}
package com.demo.json;
public class pictures {
private String description;
private String imgPath;
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public String getImgPath() {
return imgPath;
}
public void setImgPath(String imgPath) {
this.imgPath = imgPath;
}
}
使用jQuery进行DOM元素的操作和遍历
首先确定妳在页面引用的jQuery库,才能使用它。然后简单地使用jQuery()或者它的简化形式$(), 传递一个选择器作为它的第一个参数。选择器通常是一个指定了一个或多个元素的字符串。清单20展示了一些基本的jQuery选择器的使用。
Listing 20. Basic jQuery selectors
| <script type="text/javascript"> var allImages = $("img"); // all IMG elements var allPhotos = $("img.photo"); // all IMG elements with class "photo" var curPhoto = $("img#currentPhoto"); // IMG element with id "currentPhoto" </script> |
需要记住的一点是jQuery方法返回的始终是一个jQuery对象。这种对象支持链式操作(见清单21)。这一特性在其他JavaScript框架中也是通用的。
Listing 21. Basic jQuery operation with chained method calls
| <script type="text/javascript"> $("img").css({"padding":"1px", "border": "1px solid #333"}) .wrap("<div class='img-wrap'/>"); </script> |
上述代码选中页面中所有img元素并设置padding和border, 然后用一个带img-wrap class 的div 来包裹所有这些img.
清单22则展示了jQuery 是如何将前面章节的一个例子进行简化。
Listing 22. Creating and injecting a DOM node with jQuery
| <script type="text/javascript"> alert($("h1:first").html()); // .text() also works and might be better suited here $("#auth").text("Sign Out"); var $li = $("<li>List Item Text</li>"); // $ is used as var prefix to indicate jQuery object $("ul#nav").append($li); </script> |
使用jQuery 处理XML
之前有提到过传递给jQuery $()的第一个参数是一个字符串形式的选择器。第二个不起眼的参数则允许你设置context,或者开始一个jQuery节点,抑或把当前选择的元素当作 一个根节点来使用。默认jQuery会把Document作为当前的Context, 但更好的做法是把context指定得更详细更一些,具体到某个特定的元素身上。在进行XML处理时,需要把context设置为XML的根节点(见清单 23)。
Listing 23. Retrieving values from an XML document with jQuery
| <script type="text/javascript"> // get value of single node (with jQuery) var description = $("description", xmlData).text(); // xmlData was defined in previous section // get values of nodes from a set (with jQuery) var relatedItems = $("related_item", xmlData); var relatedItemVals = []; $.each(relatedItems, function(i, curItem){ relatedItemVals.push(curItem.text()); }); </script> |
上述代码使表示变得相当简洁。通过向jQuery传递节点名称和设置它的context为xmlData,可以很方便地获取想要的节点。取得元素的值,刚需要一翻周折了。
因为innerHTML 对 于非HTML元素不管用,所以就不能使用jQuery的html()方法来获取节点的值。jQuery 虽然提供了一个跨浏览器的方法innerText 来获取元素的值,但当用来处理XML时在浏览器间仍有些差异。比如IE会把包含空值(空格,Tab点位 符,换行)的节点给忽略掉,而处理这样的情况时,FireFox则会把这些节点当作正常节点。为了避免这点不一致性,可以创建一个函数来处理。这个函数里 需要用到一些jQuery函数: contents(), filter() 和 trim()。
Listing 24. Cross-browser JavaScript functions for accurate text value retrieval of a node
| <script type="text/javascript"> /** * Retrieves non-empty text nodes which are children of passed XML node. * Ignores child nodes and comments. Strings which contain only blank spaces * or only newline characters are ignored as well. * @param node {Object} XML DOM object * @return jQuery collection of text nodes */ function getTextNodes(node){ return $(node).contents().filter(function(){ return ( // text node, or CDATA node ((this.nodeName=="#text" && this.nodeType=="3") || this.nodeType=="4") && // and not empty ($.trim(this.nodeValue.replace("\n","")) !== "") ); }); } /** * Retrieves (text) node value * @param node {Object} * @return {String} */ function getNodeValue(node){ var textNodes = getTextNodes(node); var textValue = (node && isNodeComment(node)) ? // isNodeComment is defined above node.nodeValue : (textNodes[0]) ? $.trim(textNodes[0].textContent) : ""; return textValue; } </script> |
现在来看看如何设置节点的值(见清单25)。示例代码中有两点需要注意:一是设置根结果的文本值会重写所有子节点。另外就是如果一个节点之前是没有值的,那么就用 node["textContent"]而不是node.textContent。因为在IE中空节点根本就没有textContent属性。
Listing 25. Cross-browser JavaScript function for accurate setting of the text value of a node
| <script type="text/javascript"> function setNodeValue(node, value){ var textNodes = getTextNodes(node); if (textNodes.get(0)){ textNodes.get(0).nodeValue = value; } else { node["textContent"] = value; } } </script> |
DOM属性与jQuery
在之前的一些例子中已经展示了即使用最原始的JavaScript来处理DOM中的属性也是非常直观明了的了。同样地,jQuery也提供了相应的简化方式。更重要的是,属性可以用在选择器中,非常的强大。
Listing 26. Getting and setting DOM element attributes with jQuery
| <script type="text/javascript"> var item = $("item[content_id='1']", xmlData); // select item node with content_id attribute set to 1 var pubDate = item.attr("date_published"); // get value of date_published attribute item.attr("archive", "true"); // set new attribute called archive, with value set to true </script> |
从代码中可以看出,jQuery的attr()方法即可以设置设置也可以返回属性值。更强大的是jQuery允许在选择器中提供属性来返回特定的元素。下如上面的代码所展示的那样,我们获取到了content_id为1的元素。
通过jQuery的Ajax来装载XML
或许你已经有所了解,Ajax是用JavaScript来异步从服务器获取XML的一种Web技术。Ajax本身是依赖XMLHttpRequest (XHR) 所提供的API来向服务器发送请求和从服务器获取响应的。jQuery除了提供强大的用于遍历和处理DOM元素的方法外,还提供了跨浏览器的Ajax支持。也就是说通过Ajax获取XML简单得就是调用Ajax的get方法。清单27展示了这样的例子。
Listing 27. Loading an external XML file with jQuery's Ajax method
| <script type="text/javascript"> $.ajax({ type : "GET", url : "/path/to/data.xml", dataType : "xml", success : function(xmlData){ var totalNodes = $('*',xmlData).length; // count XML nodes alert("This XML file has " + totalNodes); }, error : function(){ alert("Could not retrieve XML file."); } }); </script> |
$.ajax()方法有一系列丰富的选项设置,并且可以通过其他一些简化的变形方式来调用,比如$.getScript()会导入JavaScript脚本并执行,$.getJSON()会获取JSON数据然后可以在Success回调中使用。当装载XML文件时,妳需要了解一下Ajax的基本语法。如上面代码所示,我们设置类型为get,url设置为从"/path/to/data.xml"这个路径获取XML文件,然后还指明文件类型为XML。当从服务器获取了数据后,success 或error中的一个方法会被触发。本例中,装载成功的话会弹出窗口显示所有节点数目。jQuery的星号选择器表示匹配所有元素。最重要的一点是在回调函数中,第一个参数用来接收从服务器返回的数据。这个参数的名字随便起,接下来的Context就被设置成了这个返回的数据。
在处理Ajax相关的请求时需要注意跨域问题,出于安全性考虑一般不允许从不同的域获取文件。所以上述例子中的代码可能在妳实际的程序中有所不同。
像处理XML一样处理外部的XHTML
因为XHTML是XML的一个子集,所以像XML一样处理XHTML是完全没有问题的。至于为什么妳有处理XHTML的需求是另一回事,但事实是妳确实可以这样做。比如,导入一个XHTML页面然后从中解析数据是可行的,虽然我会建议用另外更强健的方法来实现。
尽管之前讲述了DOM元素的遍历和处理,jQuery同时也可以用来处理XML,虽然需要先将XML文件破费周折地装载进代码中。本节的内容包含了不同的方法和基本的用于完成XML处理的例子。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>省市区三级级联</title>
<script src="jquery-1.8.0.js"></script>
<script>
var d;
$(document).ready(function (){
$.ajax({
url:"city.xml",
dataType:"xml",
success:function(data){
d = data;
$(data).find("province").each(function (i){
//往province中添加值
$("<option></option>").html($(this).attr("name")).attr("value",$(this).attr("name")).appendTo("#province");
});
chpro($("#province").attr("value")); //选中的值传给chpro函数
}
});
});
var c;
function chpro(val){
$("#city").empty(); //清空
//遍历province的name为val下的city
$(d).find("province[name='"+val+"']").find("city").each(function (i){
//往city中添加值 设置属性value的值为当前对象的属性name的值
$("<option></option>").html($(this).attr("name")).attr("value",$(this).attr("name")).appendTo("#city");
c = val;
chcity($("#city").attr("value"));
});
}
function chcity(val){
$("#area").empty();
//遍历province的name为c下的city的name为val下的area
$(d).find("province[name='"+c+"']").find("city[name='"+val+"']").find("area").each(function (i){
$("<option></option>").html($(this).attr("name")).attr("value",$(this).attr("name")).appendTo("#area");
});
}
</script>
</head>
<body>
<form id="myform">
地址:<select id="province" onchange="chpro(this.value)" style="width:150px"></select>
<select id="city" onchange="chcity(this.value)" style="width:150px"></select>
<select id="area" style="width:150px"></select>
</form>
</body>
</html>
文章主要参考于:http://www.ruanyifeng.com/blog/2012/05/responsive_web_design.html(阮一峰的网络日志)
在这篇文章的基础上加上了写自己的理解(文章蓝色部分)。
一. 允许网页宽度自动调整:
"自适应网页设计"到底是怎么做到的?其实并不难。
首先,在网页代码的头部,加入一行viewport元标签。
<meta name="viewport" content="width=device-width, initial-scale=1" />
viewport是网页默认的宽度和高度,上面这行代码的意思是,网页宽度默认等于屏幕宽度(width=device-width),原始缩放比例(initial-scale=1)为1.0,即网页初始大小占屏幕面积的100%。
对于viewport属性,我是真正在接触移动web开发是才遇到的,一般的pc布局都是固定的960px,1000px这种。
下面三篇文章是对viewport属性详细的解释:
Viewport(视区概念)——pc端的理解
Viewport(视区概念)——移动端的应用
viewport ——视区概念(转)
对于老式IE6,7,8浏览器需要js处理,由于主要平台是ios和安卓,所以可以暂时不考虑
二. 不使用绝对宽度
由于网页会根据屏幕宽度调整布局,所以不能使用绝对宽度的布局,也不能使用具有绝对宽度的元素。这一条非常重要。
具体说,CSS代码不能指定像素宽度:
width:xxx px;
只能指定百分比宽度:
width: xx%;
或者:
width:auto;
这里开发是指一个网页不仅能用在pc上,也能同时用于移动端,但是对于webapp这种还是需要单独做一个webapp使用的页面。
对于这个知识点,对于我目前做的项目有用处,主要用于控制限定数据库里读出来的图片宽度。
详见:手机webapp的jquery mobile初次使用心得和解决图片自适应大小问题
三. 相对大小的字体
字体也不能使用绝对大小(px),而只能使用相对大小(em)。
body {
font: normal 100% Helvetica, Arial, sans-serif;
}
上面的代码指定,字体大小是页面默认大小的100%,即16像素。
h1 {
font-size: 1.5em;
}
然后,h1的大小是默认大小的1.5倍,即24像素(24/16=1.5)。
small {
font-size: 0.875em;
}
small元素的大小是默认大小的0.875倍,即14像素(14/16=0.875)。
四. 流动布局(fluid grid)
"流动布局"的含义是,各个区块的位置都是浮动的,不是固定不变的。
.main {
float: right;
width: 70%;
}
.leftBar {
float: left;
width: 25%;
}
float的好处是,如果宽度太小,放不下两个元素,后面的元素会自动滚动到前面元素的下方,不会在水平方向overflow(溢出),避免了水平滚动条的出现。
另外,绝对定位(position: absolute)的使用,也要非常小心。
五. "自适应网页设计"的核心,就是CSS3引入的Media Query模块。
它的意思就是,自动探测屏幕宽度,然后加载相应的CSS文件。
<link rel="stylesheet" type="text/css"
media="screen and (max-device-width: 400px)"
href="tinyScreen.css" />
上面的代码意思是,如果屏幕宽度小于400像素(max-device-width: 400px),就加载tinyScreen.css文件。
<link rel="stylesheet" type="text/css"
media="screen and (min-width: 400px) and (max-device-width: 600px)"
href="smallScreen.css" />
如果屏幕宽度在400像素到600像素之间,则加载smallScreen.css文件。
除了用html标签加载CSS文件,还可以在现有CSS文件中加载。
@import url("tinyScreen.css") screen and (max-device-width: 400px);
六. CSS的@media规则
同一个CSS文件中,也可以根据不同的屏幕分辨率,选择应用不同的CSS规则。
@media screen and (max-device-width: 400px) {
.column {
float: none;
width:auto;
}
#sidebar {
display:none;
}
}
上面的代码意思是,如果屏幕宽度小于400像素,则column块取消浮动(float:none)、宽度自动调节(width:auto),sidebar块不显示(display:none)。
这篇文章有详细的讲解:手机web——自适应网页设计(@media使用)
七. 图片的自适应(fluid image)
除了布局和文本,"自适应网页设计"还必须实现图片的自动缩放。
这只要一行CSS代码:
img { max-width: 100%;}
这行代码对于大多数嵌入网页的视频也有效,所以可以写成:
img, object { max-width: 100%;}
老版本的IE不支持max-width,所以只好写成:
img { width: 100%; }
此外,windows平台缩放图片时,可能出现图像失真现象。这时,可以尝试使用IE的专有命令:
img { -ms-interpolation-mode: bicubic; }
或者,Ethan Marcotte的imgSizer.js。
addLoadEvent(function() {
var imgs = document.getElementById("content").getElementsByTagName("img");
imgSizer.collate(imgs);
});
不过,有条件的话,最好还是根据不同大小的屏幕,加载不同分辨率的图片。有很多方法可以做到这一条,服务器端和客户端都可以实现。
遇到这种问题,请参照这种写法
s|Application {
fontSize:14;
color:blue;
paddingLeft: 10px;
paddingRight: 10px;
paddingTop: 10px;
paddingBottom: 10px;
horizontalAlign: "left";
}