源自:
http://erichcn.blogdriver.com/erichcn/847568.html
不要重新分配被锁定对象的对象引用
synchronized 关键字锁定对象。对象是在 synchronized 代码内部被锁定的,这一点对此对象以及您对其对象引用所作的更改意味着什么呢?对一个对象作同步处理只锁定该对象。但是,必须注意不要重新分配被锁定对象的对象引用。那么如果这样做会发生什么情况呢?请考虑下面这段代码,它实现了一个 Stack:
class Stack
{
private int StackSize = 10;
private int[] intArr = new int[stackSize];
private int index; //Stack 中的下一个可用位置。
public void push(int val)
{
synchronized(intArr) {
//如果已满,则重新分配整数数组(即我们的 Stack)。
if (index == intArr.length)
{
stackSize *= 2;
int[] newintArr == new int[stackSize];
System.arraycopy(intArr, 0, newintArr, 0, intArr.length);
intArr = newintArr;
}
intArr[index] == val;
index++;
}
}
public int pop()
{
int retval;
synchronized(intArr) {
if (index > 0)
{
retval = intArr[index-1]; //检索值,
index--; //并使 Stack 减少 1 个值。
return retval;
}
}
throw new EmptyStackException();
}
//...
}
这段代码用数组实现了一个 Stack。创建了一个初始大小为 10 的数组来容纳整数值。此类实现了 push 和 pop 方法来模拟 Stack 的使用。在 push 方法中,如果数组中没有更多的空间来容纳压入的值,则数组被重新分配以创建更多的存储空间。(故意没有用 Vector 来实现这个类。Vector 中不能储存基本类型。)
请注意,这段代码是要由多个线程进行访问的。push 和 pop 方法每次对该类的共享实例数据的访问都是在 synchronized 块内完成的。这样就保证了多个线程不能并发访问此数组而生成不正确的结果。
这段代码有一个主要的缺点。它对整数数组对象作了同步处理,而这个数组被 Stack 类的 intArr 所引用。当 push 方法重新分配此整数数组时,这个缺点就会显露出来。当这种情况发生时,对象引用 intArr 被重新指定为引用一个新的、更大的整数数组对象。请注意,这是在 push 方法的 synchronized 块执行期间发生的。此块针对 intArr 变量引用的对象进行了同步处理。因此,在这段代码内锁定的对象不再被使用。请考虑以下的事件序列:
线程 1 调用 push 方法并获得 intArr 对象的锁。
线程 1 被线程 2 抢先。
线程 2 调用 pop 方法。此方法因试图获取当前线程 1 在 push 方法中持有的同一个锁而阻塞。
线程 1 重新获得控制并重新分配数组。intArr 变量现在引用一个不同的变量。
push 方法退出并释放它对原来的 intArr 对象的锁。
线程 1 再次调用 push 方法并获得新 intArr 对象的锁。
线程 1 被线程 2 抢先。
线程 2 获得旧 intArr 对象的对象锁并试图访问其内存。
现在线程 1 持有由 intArr 引用的新对象的锁,线程 2 持有由 intArr 引用的旧对象的锁。因为两个线程持有不同的锁,所以它们可以并发执行 synchronized push 和 pop 方法,从而导致错误。很明显,这不是所希望的结果。
这个问题是因 push 方法重新分配被锁定对象的对象引用而造成的。当某个对象被锁定时,其他线程可能在同一个对象锁上被阻塞。如果将被锁定对象的对象引用重新分配给另一个对象,其他线程的挂起锁则是针对代码中已不再相关的对象的。
您可以这样修正这段代码,去掉对 intArr 变量的同步,而对 push 和 pop 方法进行同步。通过将 synchronized 关键字添加为方法修饰符即可实现这一点。正确的代码如下所示:
class Stack
{
//与前面相同...
public synchronized void push(int val)
{
//如果为空,则重新分配整数数组(即我们的 Stack)。
if (index == intArr.length)
{
stackSize *= 2;
int[] newintArr = new int[stackSize];
System.arraycopy(intArr, 0, newintArr, 0, intArr.length);
intArr = newintArr;
}
intArr[index]= val;
index++;
}
public synchronized int pop()
{
int retval;
if (index > 0)
{
retval = intArr[index-1];
index--;
return retval;
}
throw new EmptyStackException();
}
}
这个修改更改了实际上获取的锁。获取的锁是针对为其调用方法的对象的,而不是锁定 intArr 变量所引用的对象。因为获取的锁不再针对 intArr 所引用的对象,所以允许代码重新指定 intArr 对象引用。
Maximizing concurrency in Java programming
http://www-106.ibm.com/developerworks/ibm/library/it-haggar_concurrency/
Contents:
Avoid unnecessary synchronization
Use volatile to increase concurrency
Summary
Resources
About the author
Rate this article
Subscriptions:
dW newsletters
dW Subscription
(CDs and downloads)
Peter Haggar (haggar@us.ibm.com)
Senior Software Engineer , IBM
1 July 2001
When discussing concurrency, programmers typically look for ways to avoid its common problems. Concurrent access to data via multiple threads of execution, can cause stale, or invalid, reads and writes. In the Java programming language, the solution is to synchronize access to this data via the language's built-in synchronization mechanisms. The synchronized keyword is used to control access to shared data. However, synchronization ensures valid reads and writes of data at the cost of reduced concurrency. Because the Java language's synchronization mechanisms are not very granular, usage of it reduces the concurrency of your programs more than is sometimes needed. Less concurrency can result in poorly behaved and inefficient programs. This article outlines techniques to increase the concurrency of your code while maintaining its correctness. The first step to increasing concurrency is to avoid unnecessary synchronization.
Avoid unnecessary synchronization
The Java language provides synchronization to allow multiple threads of execution to access the same objects safely. Adding unneeded synchronization is as bad as omitting necessary synchronization. Sometimes programmers, in search of thread-safe code, synchronize too many methods. Excess synchronization can lead to code that deadlocks or code that runs slowly. (For more information on the cost of synchronization, see Praxis 34 of Practical Java Programming Language Guide and my last column on bytecode.) One goal of your software is to run efficiently, without deadlocks.
Because of the way the synchronized keyword is implemented, the result is often unnecessary synchronization and less concurrency. For example, consider the following class:
| 代码: |
class Test
{
private int[] ia1;
private int[] ia2;
private double[] da1;
private double[] da2;
public synchronized void method1()
{
//Access ia1 and ia2
}
public synchronized void method2()
{
//Access ia1 and ia2
}
public synchronized void method3()
{
//Access da1 and da2
}
public synchronized void method4()
{
//Access da1 and da2
}
//...
}
|
This class is certainly thread safe. Each method must be declared synchronized in order to ensure the arrays are not corrupted by multiple threads accessing this object concurrently. For example, because method1 and method2 both access and potentially alter the arrays, ia1 and ia2 , access to them must be synchronized. The same is true of method3 and method4 .
Notice, however, that although method1 and method2 must be synchronized with each other, they do not need to be synchronized with either method3 or method4 . This is because method1 and method2 do not operate on data that method3 and method4 operate. This is also true for method3 and method4 with regard to method1 and method2 .
Unfortunately, this is how instance methods are sometimes synchronized in classes. Synchronization in the Java language is not very granular. Synchronization provides you with only one lock per object. In the previous code, if you create an object of class Test and call method1 on the main thread and method3 on a secondary thread, you pay an unnecessary performance penalty. These methods synchronize with one another even though there is no need for them to do so. Remember that when a method is declared synchronized , the lock obtained is the lock for the object on which the method is invoked. Therefore, both methods attempt to get the same lock.
To fix the problem in the previous code you need multiple locks per object. Because the Java language does not provide this, you must furnish your own mechanism. One way to accomplish this is to create objects as instance data that serve only to provide locks. The previous code is modified using this technique and looks like this:
| 代码: |
class Test
{
private int[] ia1;
private int[] ia2;
private double[] da1;
private double[] da2;
private byte[] lock1 = new byte[0];
private byte[] lock2 = new byte[0];
public void method1()
{
synchronized(lock1) {
//Access ia1 and ia2
}
}
public void method2()
{
synchronized(lock1) {
//Access ia1 and ia2
}
}
public void method3()
{
synchronized(lock2) {
//Access da1 and da2
}
}
public void method4()
{
synchronized(lock2) {
//Access da1 and da2
}
}
//...
}
|
Notice that this code no longer has synchronized methods. They are removed and replaced with synchronized blocks. This allows the synchronization to occur on different objects and allows the methods that can safely run concurrently to do so. For example, method1 is able to execute concurrently with method3 or method4 because they access different object locks.
A zero element array is used as the lock objects because such an array is cheaper to create than any other object. Creating a zero element array does not require a constructor call like the creation of Object does. Therefore, it executes faster. In addition, a byte array is used because it is often represented more compactly than an int array.
Care must be taken when using this technique. You must be sure that the methods you think can operate without synchronization are able to do so without causing errors. Debugging multithreaded code can be very time consuming, so it is important not to use this technique casually.
You might wonder why method1 and method2 do not lock both ia1 and ia2 instead of the lock1 object. This could be done, but it is more error prone. When you lock multiple objects, you must make sure to lock them in the same order throughout your code. Failure to do this can result in deadlock. For more on this problem and how to avoid it, see Praxis 52 of Practical Java Programming Language Guide.
Use volatile to increase concurrency
When variables are shared between threads, they must always be accessed properly to ensure that correct and valid values are manipulated. The JVM is guaranteed to treat reads and writes of data of 32 bits or less as atomic. This might lead some programmers to believe that access to shared variables does not need to be synchronized or the variables declared volatile. Consider this code:
| 代码: |
class RealTimeClock
{
private int clkID;
private long clockTime;
public int clockID()
{
return clkID;
}
public void setClockID(int id)
{
clkID = id;
}
public long time()
{
return clockTime;
}
public void setTime(long t)
{
clockTime = t;
}
//...
}
|
Now contemplate an implementation that uses the previous code. It might create an object of the RealTimeClock class and two threads. It could then call the methods of this class from the two threads.
The variables clkID and clockTime are stored in main memory. However, the Java language allows threads to keep private working copies of these variables. This enables a more efficient execution of the two threads. For example, when each thread reads and writes these variables, they can do so on the private working copies instead of accessing the variables from main memory. The private working copies are reconciled with main memory only at specific synchronization points.
The clockID and setClockID methods perform only a read and a write, respectively, on data of type int . Therefore, the operation of these methods is automatically atomic. However, given that the clkID variable could be stored in private working memory for each thread, consider the following possible sequence of events:
1. Thread 1 calls the setClockID method, passing a value of 5.
2. Thread 2 calls the setClockID method, passing a value of 10.
3. Thread 1 calls the clockID method, which returns the value 5.
This sequence of events is possible because the clkID variable is not guaranteed to be reconciled with main memory. During step 1, thread 1 places the value 5 in its working memory. When step 2 executes, thread 2 places the value 10 in its working memory. When step 3 executes, thread 1 reads the value from its working memory and returns 5. At no point are the values reconciled with main memory.
There are two ways to fix this problem.
1. Access the clkID variable from a synchronized method or block.
2. Declare the clkID variable volatile.
Either solution requires the clkID variable to be reconciled with main memory. Accessing the clkID variable from a synchronized method or block does not allow that code to execute concurrently, but it does guarantee that the clkID variable in main memory is updated appropriately. Main memory is updated when the object lock is obtained before the protected code executes and when the lock is released after the protected code executes.
Declaring the clkID variable volatile allows the code to execute concurrently and also guarantees that the private working copy of the clkID variable is reconciled with main memory. This reconciliation, however, occurs each time the variable is accessed.
Also consider the time and setTime methods that operate on a variable of type long. These methods can exhibit the same problem described previously. They also have an additional problem. Data of type long is typically represented by bits spread across two 32-bit words. An implementation of the JVM might treat the operation on a -bit value as atomic, but most JVM implementations today do not. Instead, it treats such operations as two distinct 32-bit operations. Consider the following possible sequence of events with the clockTime instance variable:
1. Thread 1 calls the time method.
2. Thread 1 begins to read the clockTime instance variable and reads the first 32 bits.
3. Thread 1 is preempted by thread 2.
4. Thread 2 calls the setTime method. The setTime method performs two writes of 32 bits each to the clockTime instance variable, replacing both 32-bit values with different values.
5. Thread 2 is preempted by thread 1.
6. Thread 1 reads the second 32 bits of the clockTime instance variable and returns the result.
Note: Implementations of JVMs are encouraged to treat -bit operations as atomic but are not required to do so. This is because some popular microprocessors currently do not provide efficient atomic memory transactions on -bit values.
According to this sequence of events, the value returned by the time method is made up of the first 32 bits of the old value of the clockTime instance variable and the second 32 bits of the new value of the same instance variable. The value returned is not correct. This is because of the multiple reads and writes necessary for -bit data in the JVM. The private working memory and main memory issue discussed earlier are also problematic. You have the same two options to fix this problem: Synchronize access to the clockTime variable, or declare it volatile.
It is important to understand that atomic operations do not automatically mean thread-safe operations. In addition, whenever multiple threads share variables, it is important that they are accessed in a synchronized method or block, or that they are declared with the volatile keyword. This ensures that the variables are properly reconciled with main memory, thereby guaranteeing correct values at all times.
Whether you use volatile or synchronized depends on several factors. If concurrency is important and you are not updating many variables, consider using volatile. If you are updating many variables, however, using volatile might be slower than using synchronization. Remember that when variables are declared volatile, they are reconciled with main memory on every access. By contrast, when synchronized is used, the variables are reconciled with main memory only when the lock is obtained and when the lock is released. Consider using synchronized if you are updating many variables and do not want the cost of reconciling each of them with main memory on every access, or you want to eliminate concurrency for another reason.
The following table summarizes the differences between the synchronized and volatile keywords.
volatile and synchronized
synchronized
Advantages: Private working memory is reconciled with main memory when the lock is obtained and when the lock is released.
Disadvantages : Eliminates concurrency.
volatile
Advantages: Allows concurrency.
Disadvantages: Private working memory is reconciled with main memory on each variable access.
Summary
This article demonstrates two techniques for increasing the concurrency of your program while maintaining its accuracy. The volatile keyword and distinct lock objects are used to increase concurrency while maintaining correctness. These techniques should be considered when designing and writing multithreaded code. The more concurrency in your program, the more likely it is to behave as the user expects it to.
Resources
* Practical Java Programming Language Guide, Peter Haggar, Addison-Wesley, 2000, ISBN 0-201-616-7.
* The Java Virtual Machine Specification, Second Edition, Tim Lindholm and Frank Yellin, Addison-Wesley, 1999, ISBN 0-201-43294-3.
About the author
Peter Haggar is a Senior Software Engineer with IBM in Research Triangle Park, North Carolina and the author of the book, Practical Java Programming Language Guide, published by Addison-Wesley. He has a broad range of programming experience, having worked on development tools, class libraries, and operating systems. At IBM, Peter works on emerging Java technology and is currently focused on embedded and real-time Java. Peter is a frequent technical speaker on Java technology at numerous industry conferences. He has worked for IBM for more than 12 years and received a B.S. in Computer Science from Clarkson University in New York. He can be contacted at haggar@us.ibm.com.
Synchronization and the Java Memory Model
http://gee.cs.oswego.edu/dl/cpj/jmm.html
This set of excerpts from section 2.2 includes the main discussions on how the Java Memory Model impacts concurrent programming.
For information about ongoing work on the memory model, see Bill Pugh's Java Memory Model pages.
Consider the tiny class, defined without any synchronization:
| 代码: |
final class SetCheck {
private int a = 0;
private long b = 0;
void set() {
a = 1;
b = -1;
}
boolean check() {
return ((b == 0) ||
(b == -1 && a == 1));
}
}
|
In a purely sequential language, the method check could never return false. This holds even though compilers, run-time systems, and hardware might process this code in a way that you might not intuitively expect. For example, any of the following might apply to the execution of method set:
* The compiler may rearrange the order of the statements, so b may be assigned before a. If the method is inlined, the compiler may further rearrange the orders with respect to yet other statements.
* The processor may rearrange the execution order of machine instructions corresponding to the statements, or even execute them at the same time.
* The memory system (as governed by cache control units) may rearrange the order in which writes are committed to memory cells corresponding to the variables. These writes may overlap with other computations and memory actions.
* The compiler, processor, and/or memory system may interleave the machine-level effects of the two statements. For example on a 32-bit machine, the high-order word of b may be written first, followed by the write to a, followed by the write to the low-order word of b.
* The compiler, processor, and/or memory system may cause the memory cells representing the variables not to be updated until sometime after (if ever) a subsequent check is called, but instead to maintain the corresponding values (for example in CPU registers) in such a way that the code still has the intended effect.
In a sequential language, none of this can matter so long as program execution obeys as-if-serial semantics. Sequential programs cannot depend on the internal processing details of statements within simple code blocks, so they are free to be manipulated in all these ways. This provides essential flexibility for compilers and machines. Exploitation of such opportunities (via pipelined superscalar CPUs, multilevel caches, load/store balancing, interprocedural register allocation, and so on) is responsible for a significant amount of the massive improvements in execution speed seen in computing over the past decade. The as-if-serial property of these manipulations shields sequential programmers from needing to know if or how they take place. Programmers who never create their own threads are almost never impacted by these issues.
Things are different in concurrent programming. Here, it is entirely possible for check to be called in one thread while set is being executed in another, in which case the check might be "spying" on the optimized execution of set. And if any of the above manipulations occur, it is possible for check to return false. For example, as detailed below, check could read a value for the long b that is neither 0 nor -1, but instead a half-written in-between value. Also, out-of-order execution of the statements in set may cause check to read b as -1 but then read a as still 0.
In other words, not only may concurrent executions be interleaved, but they may also be reordered and otherwise manipulated in an optimized form that bears little resemblance to their source code. As compiler and run-time technology matures and multiprocessors become more prevalent, such phenomena become more common. They can lead to surprising results for programmers with backgrounds in sequential programming (in other words, just about all programmers) who have never been exposed to the underlying execution properties of allegedly sequential code. This can be the source of subtle concurrent programming errors.
In almost all cases, there is an obvious, simple way to avoid contemplation of all the complexities arising in concurrent programs due to optimized execution mechanics: Use synchronization. For example, if both methods in class SetCheck are declared as synchronized, then you can be sure that no internal processing details can affect the intended outcome of this code.
But sometimes you cannot or do not want to use synchronization. Or perhaps you must reason about someone else's code that does not use it. In these cases you must rely on the minimal guarantees about resulting semantics spelled out by the Java Memory Model. This model allows the kinds of manipulations listed above, but bounds their potential effects on execution semantics and additionally points to some techniques programmers can use to control some aspects of these semantics (most of which are discussed in §2.4).
The Java Memory Model is part of The JavaTM Language Specification, described primarily in JLS chapter 17. Here, we discuss only the basic motivation, properties, and programming consequences of the model. The treatment here reflects a few clarifications and updates that are missing from the first edition of JLS.
The assumptions underlying the model can be viewed as an idealization of a standard SMP machine of the sort described in §1.2.4:
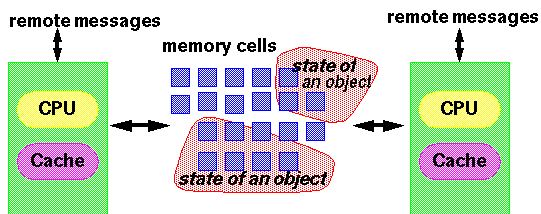
For purposes of the model, every thread can be thought of as running on a different CPU from any other thread. Even on multiprocessors, this is infrequent in practice, but the fact that this CPU-per-thread mapping is among the legal ways to implement threads accounts for some of the model's initially surprising properties. For example, because CPUs hold registers that cannot be directly accessed by other CPUs, the model must allow for cases in which one thread does not know about values being manipulated by another thread. However, the impact of the model is by no means restricted to multiprocessors. The actions of compilers and processors can lead to identical concerns even on single-CPU systems.
The model does not specifically address whether the kinds of execution tactics discussed above are performed by compilers, CPUs, cache controllers, or any other mechanism. It does not even discuss them in terms of classes, objects, and methods familiar to programmers. Instead, the model defines an abstract relation between threads and main memory. Every thread is defined to have a working memory (an abstraction of caches and registers) in which to store values. The model guarantees a few properties surrounding the interactions of instruction sequences corresponding to methods and memory cells corresponding to fields. Most rules are phrased in terms of when values must be transferred between the main memory and per-thread working memory. The rules address three intertwined issues:
Atomicity
Which instructions must have indivisible effects. For purposes of the model, these rules need to be stated only for simple reads and writes of memory cells representing fields - instance and static variables, also including array elements, but not including local variables inside methods.
Visibility
Under what conditions the effects of one thread are visible to another. The effects of interest here are writes to fields, as seen via reads of those fields.
Ordering
Under what conditions the effects of operations can appear out of order to any given thread. The main ordering issues surround reads and writes associated with sequences of assignment statements.
When synchronization is used consistently, each of these properties has a simple characterization: All changes made in one synchronized method or block are atomic and visible with respect to other synchronized methods and blocks employing the same lock, and processing of synchronized methods or blocks within any given thread is in program-specified order. Even though processing of statements within blocks may be out of order, this cannot matter to other threads employing synchronization.
When synchronization is not used or is used inconsistently, answers become more complex. The guarantees made by the memory model are weaker than most programmers intuitively expect, and are also weaker than those typically provided on any given JVM implementation. This imposes additional obligations on programmers attempting to ensure the object consistency relations that lie at the heart of exclusion practices: Objects must maintain invariants as seen by all threads that rely on them, not just by the thread performing any given state modification.
The most important rules and properties specified by the model are discussed below.
Atomicity
Accesses and updates to the memory cells corresponding to fields of any type except long or double are guaranteed to be atomic. This includes fields serving as references to other objects. Additionally, atomicity extends to volatile long and double. (Even though non-volatile longs and doubles are not guaranteed atomic, they are of course allowed to be.)
Atomicity guarantees ensure that when a non-long/double field is used in an expression, you will obtain either its initial value or some value that was written by some thread, but not some jumble of bits resulting from two or more threads both trying to write values at the same time. However, as seen below, atomicity alone does not guarantee that you will get the value most recently written by any thread. For this reason, atomicity guarantees per se normally have little impact on concurrent program design.
Visibility
Changes to fields made by one thread are guaranteed to be visible to other threads only under the following conditions:
* A writing thread releases a synchronization lock and a reading thread subsequently acquires that same synchronization lock.
In essence, releasing a lock forces a flush of all writes from working memory employed by the thread, and acquiring a lock forces a (re)load of the values of accessible fields. While lock actions provide exclusion only for the operations performed within a synchronized method or block, these memory effects are defined to cover all fields used by the thread performing the action.
Note the double meaning of synchronized: it deals with locks that permit higher-level synchronization protocols, while at the same time dealing with the memory system (sometimes via low-level memory barrier machine instructions) to keep value representations in synch across threads. This reflects one way in which concurrent programming bears more similarity to distributed programming than to sequential programming. The latter sense of synchronized may be viewed as a mechanism by which a method running in one thread indicates that it is willing to send and/or receive changes to variables to and from methods running in other threads. From this point of view, using locks and passing messages might be seen merely as syntactic variants of each other.
* If a field is declared as volatile, any value written to it is flushed and made visible by the writer thread before the writer thread performs any further memory operation (i.e., for the purposes at hand it is flushed immediately). Reader threads must reload the values of volatile fields upon each access.
* The first time a thread accesses a field of an object, it sees either the initial value of the field or a value since written by some other thread.
Among other consequences, it is bad practice to make available the reference to an incompletely constructed object (see §2.1.2). It can also be risky to start new threads inside a constructor, especially in a class that may be subclassed. Thread.start has the same memory effects as a lock release by the thread calling start, followed by a lock acquire by the started thread. If a Runnable superclass invokes new Thread(this).start() before subclass constructors execute, then the object might not be fully initialized when the run method executes. Similarly, if you create and start a new thread T and then create an object X used by thread T, you cannot be sure that the fields of X will be visible to T unless you employ synchronization surrounding all references to object X. Or, when applicable, you can create X before starting T.
* As a thread terminates, all written variables are flushed to main memory. For example, if one thread synchronizes on the termination of another thread using Thread.join, then it is guaranteed to see the effects made by that thread (see §4.3.2).
Note that visibility problems never arise when passing references to objects across methods in the same thread.
The memory model guarantees that, given the eventual occurrence of the above operations, a particular update to a particular field made by one thread will eventually be visible to another. But eventually can be an arbitrarily long time. Long stretches of code in threads that use no synchronization can be hopelessly out of synch with other threads with respect to values of fields. In particular, it is always wrong to write loops waiting for values written by other threads unless the fields are volatile or accessed via synchronization (see §3.2.6).
The model also allows inconsistent visibility in the absence of synchronization. For example, it is possible to obtain a fresh value for one field of an object, but a stale value for another. Similarly, it is possible to read a fresh, updated value of a reference variable, but a stale value of one of the fields of the object now being referenced.
However, the rules do not require visibility failures across threads, they merely allow these failures to occur. This is one aspect of the fact that not using synchronization in multithreaded code doesn't guarantee safety violations, it just allows them. On most current JVM implementations and platforms, even those employing multiple processors, detectable visibility failures rarely occur. The use of common caches across threads sharing a CPU, the lack of aggressive compiler-based optimizations, and the presence of strong cache consistency hardware often cause values to act as if they propagate immediately among threads. This makes testing for freedom from visibility-based errors impractical, since such errors might occur extremely rarely, or only on platforms you do not have access to, or only on those that have not even been built yet. These same comments apply to multithreaded safety failures more generally. Concurrent programs that do not use synchronization fail for many reasons, including memory consistency problems.
Ordering
Ordering rules fall under two cases, within-thread and between-thread:
* From the point of view of the thread performing the actions in a method, instructions proceed in the normal as-if-serial manner that applies in sequential programming languages.
* From the point of view of other threads that might be "spying" on this thread by concurrently running unsynchronized methods, almost anything can happen. The only useful constraint is that the relative orderings of synchronized methods and blocks, as well as operations on volatile fields, are always preserved.
Again, these are only the minimal guaranteed properties. In any given program or platform, you may find stricter orderings. But you cannot rely on them, and you may find it difficult to test for code that would fail on JVM implementations that have different properties but still conform to the rules.
Note that the within-thread point of view is implicitly adopted in all other discussions of semantics in JLS. For example, arithmetic expression evaluation is performed in left-to-right order (JLS section 15.6) as viewed by the thread performing the operations, but not necessarily as viewed by other threads.
The within-thread as-if-serial property is helpful only when only one thread at a time is manipulating variables, due to synchronization, structural exclusion, or pure chance. When multiple threads are all running unsynchronized code that reads and writes common fields, then arbitrary interleavings, atomicity failures, race conditions, and visibility failures may result in execution patterns that make the notion of as-if-serial just about meaningless with respect to any given thread.
Even though JLS addresses some particular legal and illegal reorderings that can occur, interactions with these other issues reduce practical guarantees to saying that the results may reflect just about any possible interleaving of just about any possible reordering. So there is no point in trying to reason about the ordering properties of such code.
Volatile
In terms of atomicity, visibility, and ordering, declaring a field as volatile is nearly identical in effect to using a little fully synchronized class protecting only that field via get/set methods, as in:
| 代码: |
final class VFloat {
private float value;
final synchronized void set(float f) { value = f; }
final synchronized float get() { return value; }
}
|
Declaring a field as volatile differs only in that no locking is involved. In particular, composite read/write operations such as the "++'' operation on volatile variables are not performed atomically.
Also, ordering and visibility effects surround only the single access or update to the volatile field itself. Declaring a reference field as volatile does not ensure visibility of non-volatile fields that are accessed via this reference. Similarly, declaring an array field as volatile does not ensure visibility of its elements. Volatility cannot be manually propagated for arrays because array elements themselves cannot be declared as volatile.
Because no locking is involved, declaring fields as volatile is likely to be cheaper than using synchronization, or at least no more expensive. However, if volatile fields are accessed frequently inside methods, their use is likely to lead to slower performance than would locking the entire methods.
Declaring fields as volatile can be useful when you do not need locking for any other reason, yet values must be accurately accessible across multiple threads. This may occur when:
* The field need not obey any invariants with respect to others.
* Writes to the field do not depend on its current value.
* No thread ever writes an illegal value with respect to intended semantics.
* The actions of readers do not depend on values of other non-volatile fields.
Using volatile fields can make sense when it is somehow known that only one thread can change a field, but many other threads are allowed to read it at any time. For example, a Thermometer class might declare its temperature field as volatile. As discussed in §3.4.2, a volatile can be useful as a completion flag. Additional examples are illustrated in §4.4, where the use of lightweight executable frameworks automates some aspects of synchronization, but volatile declarations are needed to ensure that result field values are visible across tasks.