免费的存储很多,但是真正好用的没几个,我试过163的,联想的,但是总是感觉少一口气,用了不到一个月就忘记了,很早就听说了dropbox,但是一直没下定决心选择它(中国的河蟹太强大了),一次偶然的机会尝试了下,突然发现我们真的可以生活在云端了。
Dropbox 上手指南
Dropbox注册非常简单,点击注册:

简单填写之后可以拥有了免费的2G的空间了。在Dropbox的web界面可以直接上传文件了,但是如果紧紧提供这些功能那么Dropbox也就是紧紧只是一个普通的云存储了,真正贴心的功能在于它的客户端。废话少说,注册之后有用户指南会引引导你到下载客户端页面。一步步安装之后就可以指定某个文件夹同步到云端了。
Dropbox有哪些特色
- 免费的2G空间(目前官方的活动可以将免费空间扩展到5.25G)
- 速度不错(公司电信和家杭州网通都可以达到220K下行和26K的上行速度)
- 贴心的客户端,你只要将文件拖进文件夹,客户端就会自动同步。
- 支持linux,mac,Windows 甚至iphone
- 免费的外链和多人共享空间
Dropbox有哪些不足之处
- 没办法同步多个文件夹(可以通过junction命令将文件夹硬连到同步目录去)
- 客户端同步计划不可编辑,它会在每台机器上都会同步所有的文件,文件大了就麻烦了。
可以改进之处(个人愚见)
- 加强客户端功能,允许用户制定同步计划,在线规划后哪些文件需要同步到哪些机器,哪些文件无需同步到所有机器等。
- 支持多文件夹,以及网络映射
- 支持同步策略制定,比如只上传不下载、只下载不上传等策略。
相关链接
Mark Richards, 主管和高级技术架构师, Collaborative Consulting, LLC
2009 年 7 月 31 日
事务策略系列文章的作者 Mark Richards 将讨论如何在 Java? 平台中为具有高吞吐量和高用户并发性需求的应用程序实现事务策略。理解如何进行折衷将帮助您确保高水平的数据完整性和一致性,并减少随后开发流程中的重构工作。
我在本系列 的前几篇文章中所介绍的 API 层和客户端编排策略事务策略是应用于大多数标准业务应用程序的核心策略。它们简单、可靠、相对易于实现,并且提供了最高水平的数据完整性和一致性。但有时,您可能需要减小事务的作用域以获取吞吐量、改善性能并提高数据库的并发性。您如何才能实现这些目的,同时仍然维持高水平的数据完整性和一致性呢?答案是使用 High Concurrency 事务策略。
High Concurrency 策略源自 API 层 策略。API 层策略虽然非常坚固和可靠,但它存在一些缺点。始终在调用栈的最高层(API 层)启动事务有时会效率低下,特别是对于具有高用户吞吐量和高数据库并发性需求的应用程序。限制特定的业务需求,长时间占用事务和长时间锁定都会消耗过多资源。
与 API 层策略类似,High Concurrency 策略释放了客户机层的任何事务责任。但是,这还意味着,您只能通过客户机层调用一次任何特定的逻辑工作单元(LUW)。High Concurrency 策略旨在减小事务的总体作用域,以便资源锁定的时间更短,从而增加应用程序的吞吐量、并发性以及性能。
通过使用此策略所获取的好处在一定程度上将由您所使用的数据库以及它所采用的配置决定。一些数据库(比如说使用 InnoDB 引擎的 Oracle 和 MySQL)不会保留读取锁,而其他数据库(比如没有 Snapshot Isolation Level 的 SQL Server)则与之相反。保留的锁越多,无论它们是共享还是专用的,它们对数据库(以及应用程序)的并发性、性能和吞吐量的影响就越大。
但是,获取并在数据库中保留锁仅仅是高并发性任务的一个部分。并发性和吞吐量还与您释放锁的时间有关。无论您使用何种数据库,不必要地长时间占用事务将更长地保留共享和专用锁。在高并发性下,这可能会造成数据库将锁级别从低级锁提高到页面级锁,并且在一些极端情况下,从页面级锁切换到表级锁。在多数情况下,您无法控制数据引擎用于选择何时升级锁级别的启发方法。一些数据库(比如 SQL Server)允许您禁用页面级锁,以期它不会从行级锁切换到表级锁。有时,这种赌博有用,但大多数情况下,您都不会实现预期中的并发性改善。
底线是,在高数据库并发性的场景中,数据库锁定(共享或专用)的时间越长,则越有可能出现以下问题:
- 数据库连接耗尽,从而造成应用程序处于等待状态
- 由共享和专用锁造成的死锁,从而造成性能较差以及事务失败
- 从页面级锁升级到表级锁
换句话说,应用程序在数据库中所处的时间越长,应用程序能处理的并发性就越低。我所列出的任何问题都会造成您的应用程序运行缓慢,并且将直接减少总体吞吐量和降低性能 - 以及应用程序处理大型并发性用户负载的能力。
折衷
High Concurrency 策略解决了高并发性需求,因为它能将事务在体系结构中的作用域尽可能减小。其结果是,事务会比在 API 层事务策略中更快地完成(提交或回滚)。但是,就像您从 Vasa 中学到的(见参考资料),您不能同时拥有它们。生活中充满了折衷,事务处理也不例外。您不能期望提供与 API 层策略同样可靠的事务处理,同时提供最大的用户并发性和最高的吞吐量。
因此,您在使用 High Concurrency 事务策略时放弃了什么呢?根据您的应用程序的设计,您可能需要在事务作用域外部执行读取操作,即使读取操作用于更新目的。"等一等!"您说:"您不能这样做 - 您可能会更新在最后一次读取之后发生了变化的数据!"这是合理的担忧,并且也是需要开始考虑折衷的地方。通过此策略,由于您未对数据保持读取锁,因此在执行更新操作时遇到失效数据异常的机率会增加。但是,与 Vasa 的情况一样,所有这些都可以归结为一个问题,即哪个特性更加重要:可靠、坚固的事务策略(如 API 层策略),还是高用户并发性和吞吐量。在高并发性情形中,同时实现两者是极为困难的。如果您尝试这样做,则可能会适得其反。
第二个折衷之处是事务可靠性的总体缺乏。此策略难以实现,并且需要更长的时间进行开发和测试,并且比 API 层或 Client Orchestration 策略更易于出错。考虑到这些折衷,您首先应该分析当前的情形以确定使用此策略是否是正确的方法。由于 High Concurrency 策略派生自 API 层策略,因此一种比较好的方法是先使用 API 层策略,并使用较高的用户负载对应用程序执行负载测试(比您预期的峰值负载更高)。如果您发现吞吐量较低、性能较第、等待次数非常多,或者甚至出现死锁,则要准备迁移到 High Concurrency 策略。
在本文的其余部分,我将向您介绍 High Concurrency 事务策略的其他一些特性,以及实现它的两种方法。
基本结构和特性
图 1 通过我在 事务策略系列中所使用的逻辑应用程序栈展示了 High Concurrency 事务策略。包含事务逻辑的类显示为红色阴影。 图 1 通过我在 事务策略系列中所使用的逻辑应用程序栈展示了 High Concurrency 事务策略。包含事务逻辑的类显示为红色阴影。
图 1. 体系结构层和事务逻辑

一些 API 层策略的特性和规则是有效的 - 但并非所有。注意,图 1 中的客户机层没有事务逻辑,这意味着任何类型的客户机都可以用于此事务策略,包括基于 Web 的客户机、桌面、Web 服务和 Java Message Service (JMS)。并且事务策略遍布于客户机下面的层中,但这不是绝对的。一些事务可能在 API 层中开始,一些在业务层中开始,还有一些甚至在 DAO 层中开始。这种一致性的缺乏是造成策略难以实现、维护和治理的原因之一。
在大多数情况下,您会发现您需要使用Programmatic Transaction 模型 来减小事务作用域,但有时您仍然会使用Declarative Transaction 模型。但是,您通常不能在相同的应用程序中混用 Programmatic 和 Declarative Transaction 模型。在使用这种事务策略时,不应该坚持使用这种 Programmatic Transaction 模型,这样您就不会遇到各种问题。但是,如果您发现自己可以在此策略中使用 Declarative Transaction 模型,那么您应该在使用 REQUIRED 事务属性开始事务的层中标记所有公共写方法(插入、更新和删除)。此属性表示需要一个事务,并且如果事务不存在,则由方法启动。
与其他事务策略一样,无论您选择开始事务的组件或层是什么,启动事务的方法都被认为是事务拥有者。只要可能,事务拥有者应该是对事务执行提交和回滚的唯一方法。
事务策略实现
您可以使用两个主要技巧来实现 High Concurrency 事务策略。先读取(read-first)技巧涉及在尽可能高的应用层(通常为 API 层)对事务作用域范围外的读取操作进行分组。低级(lower-level)技巧涉及在体系结构中尽可能低的层启动事务,同时仍然能够更新操作的原子性和隔离。
先读取技巧
先读取技巧涉及重构(或编写)应用程序逻辑和工作流,以便所有的处理和读取操作在事务作用域的外部首先发生。这种方法消除了不必要的共享或读取锁,但是如果数据在您能够提交工作之前更新或提交,则可能会引入失效数据异常。为了应对可能的这种情况,如果在此事务策略中使用对象关系映射(ORM)框架,则应确保使用了版本验证功能。
为了演示这种先读取技巧,我们从一些实现 API 层事务策略的代码入手。在清单 1 中,事务在 API 层中开始,并且包围了整个工作单元,包括所有的读取、处理和更新操作:
清单 1. 使用 API 层策略
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public void processTrade(TradeData trade) throws Exception {
try {
//first validate and insert the trade
TraderData trader = service.getTrader(trade.getTraderID());
validateTraderEntitlements(trade, trader);
verifyTraderLimits(trade, trader);
performPreTradeCompliance(trade, trader);
service.insertTrade(trade);
//now adjust the account
AcctData acct = service.getAcct(trade.getAcctId());
verifyFundsAvailability(acct, trade);
adjustBalance(acct, trade);
service.updateAcct(trade);
//post processing
performPostTradeCompliance(trade, trader);
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
|
注意在 清单 1 中,所有的处理都包含在 Java Transaction API (JTA) 事务的作用域内,包括所有的确认、验证和兼容性检查(提前和事后)。如果您通过探查器工具来运行 processTrade() 方法,那么就会看到每个方法调用的执行时间将与表 1 相似:
表 1. API 层方法探查 - 事务作用域
| 方法名称 |
执行时间 (ms) |
service.getTrader() |
100 |
validateTraderEntitlements() |
300 |
verifyTraderLimits() |
500 |
performPreTradeCompliance() |
2300 |
service.insertTrade() |
200 |
service.getAcct() |
100 |
verifyFundsAvailability() |
600 |
adjustBalance() |
100 |
service.updateAcct() |
100 |
performPostTradeCompliance() |
1800 |
processTrade() 方法的持续时间稍微长于 6 秒 (6100 ms)。由于事务的起始时间与方法相同,因此事务的持续时间也是 6100 ms。根据您所使用的数据库类型以及特定的配置设计,您将在事务执行过程中保持共享和专用锁(从执行读取操作开始)。此外,在由 processTrade() 方法调用的方法中执行的任何读取操作也可以在数据库中保持一个锁。您可能会猜想,在本例中,在数据库中保持锁持续 6 秒以上将不能扩展以支持高用户负载。
清单 1 中的代码在没有高用户并发性或高吞吐量需求的环境中可能会非常出色地运行。遗憾的是,这只是大多数人用于测试的一种环境。一旦此代码进入生产环境,其中数以百计的交易者(或者是全球的)都在进行交易,则该系统最有可能会运行得非常糟糕,并且极有可能会遇到数据库死锁(根据您所使用的数据库而定)。
现在,我将修复 清单 1 中的代码,方法是应用 High Concurrency 事务策略的先读取技巧。在清单 1 所示的代码中,第一个要注意的地方是总共只用了 300 ms 的更新操作(插入和更新)。(此处,我假定 processTrade() 方法调用的其他方法不执行更新操作。基本技巧是在事务作用域之外执行读取操作和非更新处理,并且仅将更新封装在事务内部。清单 2 中的代码演示了减小事务作用域并仍然维持原子性的必要性:
清单 2. 使用 High Concurrency 策略(先读取技巧)
public void processTrade(TradeData trade) throws Exception {
UserTransaction txn = null;
try {
//first validate the trade
TraderData trader = service.getTrader(trade.getTraderID());
validateTraderEntitlements(trade, trader);
verifyTraderLimits(trade, trader);
performPreTradeCompliance(trade, trader);
//now adjust the account
AcctData acct = service.getAcct(trade.getAcctId());
verifyFundsAvailability(acct, trade);
adjustBalance(acct, trade);
performPostTradeCompliance(trade, trader);
//start the transaction and perform the updates
txn = (UserTransaction)ctx.lookup("UserTransaction");
txn.begin();
service.insertTrade(trade);
service.updateAcct(trade);
txn.commit();
} catch (Exception up) {
if (txn != null) {
try {
txn.rollback();
} catch (Exception t) {
throw up;
}
}
throw up;
}
}
|
注意,我将 insertTrade() 和 updateAcct() 方法移动到了 processTrade() 方法的末尾,并将它们封装在了一个编程事务中。通过这种方法,所有读取操作和相应的处理将在事务的上下文之外执行,因此不会在事务持续时间内在数据库中保持锁。在新代码中,事务持续时间只有 300 ms,这显著低于 清单 1 中的 6100 ms。再次,其目标是减少在数据库中花费的时间,从而减少数据库的总体并发性,以及应用程序处理较大并发用户负载的能力。通过使用 清单 2 中的代码将数据库占用时间减少至 300 ms,从理论上说,吞吐量将实现 20 倍的提升。
如表 2 所示,在事务作用域中执行的代码至减少至 300 ms:
表 2. API 层方法探查 - 修改后的事务作用域
| 方法名称 |
执行时间 (ms) |
service.insertTrade() |
200 |
service.updateAcct() |
100 |
虽然这从数据库并发性的角度来说是一种显著的改善,但先读取技巧带来了一个风险:由于为更新指定的对象上没有任何锁,因此任何人都可以在此 LUW 过程中更新这些未锁定的实体。因此,您必须确保被插入或更新的对象一般情况下不会由多个用户同时更新。在之前的交易场景中,我做了一个安全的假设,即只有一个交易者会在特定的时间操作特定的交易和帐户。但是,并非始终都是这种情况,并且可能会出现失效数据异常。
另外需要注意:在使用 Enterprise JavaBeans (EJB) 3.0 时,您必须通知容器您计划使用编程事务管理。为此,您可以使用 @TransactionManagement(TransactionManagementType.BEAN) 注释。注意,这个注释是类级的(而不是方法级的),这表示您不能在相同的类中结合 Declarative 和 Programmatic 事务模型。选择并坚持其中之一。
低级技巧
假设您希望坚持使用 Declarative Transaction 模型来简化事务处理,但是仍然能在高用户并发性场景中增加吞吐量。同时,您应该在这种事务策略中使用低级技巧。通过此技巧,您通常会遇到与先读取技巧相同的折衷问题:读取操作通常是在事务作用域的外部完成的。并且,实现这种技巧最有可能需要代码重构。
我仍然从 清单 1 中的示例入手。不用在相同的方法中使用编程事务,而是将更新操作移动到调用栈的另一个公共方法中。然后,完成读取操作和处理时,您可以调用更新方法;它会开始一个事务,调用更新方法并返回。清单 3 演示了这个技巧:
清单 3. 使用 High Concurrency 策略(低级技巧)
@TransactionAttribute(TransactionAttributeType.SUPPORTS)
public void processTrade(TradeData trade) throws Exception {
try {
//first validate the trade
TraderData trader = service.getTrader(trade.getTraderID());
validateTraderEntitlements(trade, trader);
verifyTraderLimits(trade, trader);
performPreTradeCompliance(trade, trader);
//now adjust the account
AcctData acct = service.getAcct(trade.getAcctId());
verifyFundsAvailability(acct, trade);
adjustBalance(acct, trade);
performPostTradeCompliance(trade, trader);
//Now perform the updates
processTradeUpdates(trade, acct);
} catch (Exception up) {
throw up;
}
}
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public void processTradeUpdates(TradeData trade, AcctData acct) throws Exception {
try {
service.insertTrade(trade);
service.updateAcct(trade);
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
|
通过此技巧,您可以有效地在调用栈的较低层次开始事务,从而减少花费在数据库中的时间。注意,processTradeUpdates() 方法仅更新在父方法(或以上)中修改中创建的实体。再次,保持事务的时间不再是 6 秒,您只需要 300 ms。
现在是最难的部分。与 API 层策略或 Client Orchestration 策略不同,High Concurrency 策略并未使用一致的实现方法。这便是 图 1 看上去为何像一名经验丰富的曲棍球员(包括缺少的牙齿)的原因。对于一些 API 调用,事务可能会在 API 层的末端开始,而其他时候,它可能仅限于 DAO 层(特别是对于 LUW 中的单表更新)。技巧是确定在多个客户机请求之间共享的方法,并确保如果某个事务是在较高级的方法中开始的,则它将在较低级的方法中使用。遗憾的是,此特性的效果是,作为非事务拥有者的较低级方法可以对异常执行回滚。结果,开始事务的父方法不能对异常采取正确的措施,并且在尝试回滚(或提交)已经标记为回滚的事务时会出现异常。
实现指南
有些情况仅需要稍微小些的事务作用域来满足吞吐量和并发性需求,而另一些情况需要大大缩小事务作用域来实现所需的目的。不管具体情况如何,您都可以遵循以下的实现指导,它们能够帮助您设计和实现 High Concurrency 策略:
- 在着手使用低级别技术之前,首先要从先读技术开始。这样,事务至少包含在应用程序架构的 API 层,并且不扩散到其他层中。
- 当使用声明性事务时,经常使用
REQUIRED 事务属性而不是 MANDATORY 事务属性来获得保护,避免启动某个事务的方法调用另一个事务方法。
- 在采用此事务策略之前,确保您在事务作用域外部执行读取操作时是相对安全的。查看您的实体模型并问自己多个用户同时操作相同的实体是常见的、少见还是不可能的。举例来说,两个用户可以同时修改相同的帐户吗?如果您的回答是常见,则面临着极高的失效数据异常风险,那么这个策略对于您的应用程序探查来说是一个很差的选择。
- 并不需要让所有 读取操作都处于事务作用域之外。如果有一个特定的实体经常会被多个用户同时更改,则应该想尽一切办法将它添加到事务作用域中。但是应该清楚,添加到事务作用域中的读取操作和处理越多,吞吐量和用户负载功能的下降就越大。
结束语
一切都归结于如何在问题之间取得折衷。为了在应用程序或子系统中支持高吞吐量和高用户并发性,您需要高数据库并发性。要支持高数据库并发性,则需要减少数据库锁,并尽可能缩短保持资源的时间。某些数据库类型和配置可以处理一些这种工作,但在大多数情况下,解决方案最终归结为如何设计代码和事务处理。对这些问题有一些了解之后,您在稍后可以更加轻松地完成复杂的重构工作。选择正确的事务策略对应用程序的成功至关重要。对于高用户并发性需求,可以使用 High Concurrency 事务策略作为确保高水平数据完整性,同时维持高并发性和吞吐量需求的解决方案。
参考资料
学习
讨论
转自:http://www.ibm.com/developerworks/cn/java/j-ts5/index.html?ca=drs-cn-0731
1.通过修改/etc/fstab 方式来加载
在/etc/fstab中加入下面一行
192.168.206.232:/opt/share /opt/share nfs rw,async 0 0
然后执行下 mount -a
2.通过命令行临时加载
mount -t cifs //10.1.27.195/linux /opt/other -o username=XXX,password=xxx,rw
通过 umount /opt/other 来卸载共享
具体命令来通过 man mount来查看。
有时候我们需要在网页上展现PPT,Google Docs 是一个好去处,最近发现一款软件iSpring 下一款免费软件可以将PPT直接转换成Flash,方便传播。
官方网址:http://www.ispringsolutions.com/
我们可以下载免费的PPT转换软件:iSpring Free
下载之后,按提示一步步安装,安装完成之后打开PowerPoint可以看见多了一行菜单
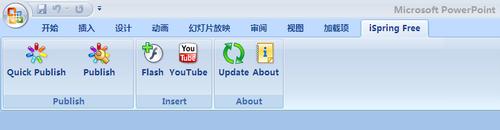
点击Publish就可以将PPT转换成Flash了:
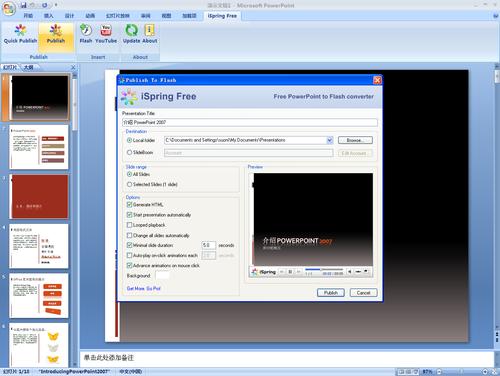
最终我们可以得到我们需求的swf文件,直接嵌入到页面中去就可以访问了:

Flickr : PPT转换成Flash
最近需要用C操作文件,但是使用fopen和fseek的时候,在32位操作系统中,没办法操作2G以上的文件,后面经过多次Google和高手指点之后通过open64、lseek解决这个问题:
1 #include <stdio.h>
2 // #define _LARGEFILE_SOURCE
3 // #define _LARGEFILE64_SOURCE
4 // #define _FILE_OFFSET_BITS 64
5 #include <sys/types.h>
6 #include <sys/stat.h>
7 #include <unistd.h>
8 #include <stdio.h>
9 #include <fcntl.h>
10 #include <errno.h>
11
12 int main(int argc, char *argv[])
13 {
14 off_t file_last_pos;
15 off_t end = 0;
16 // FILE *fp;
17 int fp = open64(argv[1], O_RDONLY);
18 if (fp < 0 ) {
19 printf("can't open file [%s]\n", strerror(errno));
20 return 1;
21 } else {
22 printf("file open success\n");
23 }
24 file_last_pos = lseek(fp, 0, SEEK_END);
25 printf("Size: %1d \n",file_last_pos);
26 close(fp);
27 return 0;
28 }
//这行GCC参数很重要,原来是希望通过define的方式来解决的,但是最后还是只能通过这种方式
gcc -D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64 test.c -o test
Gem 发布了1.3版本,如果你的版本是1.1或者1.2在执行
C:\Documents and Settings\suoni>gem update --system
Updating RubyGems
Nothing to update
可能会出现以上错误,通过以下这种方法安装可以解决这个问题:
C:\Documents and Settings\suoni>gem install rubygems-update
Successfully installed rubygems-update-1.3.1
1 gem installed
(请多执行几次,如果一次不成功的话,我机器上第二次才行)
然后执行
C:\Documents and Settings\suoni>update_rubygems
进行安装