|
|
2012年7月2日
在用 extjs editorgridpanel 进行输入编辑的时候, 默认情况下只支持使用 tab 键可以实现焦点切换, 如果想让editorgridpanel 在编辑时通过方向键来实现焦点跳转切换,只需加上以下代码: //让grid支持方向键盘 by liongis@163.com
Ext.override(Ext.grid.CellSelectionModel, {
onEditorKey : function(field, e) {
var smodel = this;
var k = e.getKey(), newCell, g = smodel.grid, ed = g.activeEditor;
switch(k){
case e.TAB:
e.stopEvent();
ed.completeEdit();
if (e.shiftKey) {
newCell = g.walkCells(ed.row, ed.col-1, -1, smodel.acceptsNav, smodel);
} else {
newCell = g.walkCells(ed.row, ed.col+1, 1, smodel.acceptsNav, smodel);
}
if (ed.col == 1) {
if (e.shiftKey) {
newCell = g.walkCells(ed.row, ed.col+1, -1, smodel.acceptsNav, smodel);
} else {
newCell = g.walkCells(ed.row, ed.col+1, 1, smodel.acceptsNav, smodel);
}
}
break;
case e.UP:
e.stopEvent();
ed.completeEdit();
newCell = g.walkCells(ed.row-1, ed.col, -1, smodel.acceptsNav, smodel);
break;
case e.DOWN:
e.stopEvent();
ed.completeEdit();
newCell = g.walkCells(ed.row+1, ed.col, 1, smodel.acceptsNav, smodel);
break;
case e.LEFT:
e.stopEvent();
ed.completeEdit();
newCell = g.walkCells(ed.row, ed.col-1, -1, smodel.acceptsNav, smodel);
break;
case e.RIGHT:
e.stopEvent();
ed.completeEdit();
newCell = g.walkCells(ed.row, ed.col+1, 1, smodel.acceptsNav, smodel);
break;
}
if (newCell) {
g.startEditing(newCell[0], newCell[1]);
}
}
}); 注意:这里重写的是:CellSelectionModel ,而不是RowSelectionMode 原文出自: http://www.cnblogs.com/liongis/p/3284620.html
序言: 1.本文摘自网络,看控件命名像是4.0以前的版本,但控件属性配置仍然可以借鉴(不足之处,以后项目用到时再续完善)。 Ext.form.TimeField: 配置项:
maxValue:列表中允许的最大时间
maxText:当时间大于最大值时的错误提示信息
minValue:列表中允许的最小时间
minText:当时间小于最小值时的错误提示信息
increment:两个相邻选项间的时间间隔,默认为15分钟
format:显示格式,默认为“g:i A”。一般使用“H:i:s”
H:带前缀0的24小时
i:带前缀0的分钟
s:带前缀0的秒
invalidText:当时间值非法时显示的提示信息
altFormats:多个时间输入格式组成的字符串,不同的格式之间使用“|”进行分割 Ext.form.FieldSet animCollapse:动画折叠,默认为false
checkboxToggle:设置是否显示字段集的checkbox选择框,默认为false
checkboxName:指定字段集中用于展开或隐藏字段集面板的checkbox的名字,该属性只有在checkboxToggle为true时生效
labelWidth:字段标签的宽度,可以级联到子容器
layout:布局,默认为form Ext.form.DateFied maxValue:允许选择的最大日期
maxText:当日期大于最大值时的错误提示信息
minValue:允许选择的最小时间
minText:当日期小于最小值时的错误提示信息
format:日期显示格式,默认为“m/d/y”,一般使用“Y-m-d”
Y:四位年份
m:带前缀0的月份
d:带前缀0的日期
y:两位年份
n:不带前缀0的月份
j:不带前缀0的日期
w:星期的数字,0表示星期日,1代表星期一
showToday:是否显示今天按钮,默认为true
altFormats:多个日期输入格式组成的字符串,不同的格式之间使用“|”进行分割,默认值为'm/d/Y|n/j/Y|n/j/y|m/j /y|n/d/y|m/j/Y|n/d/Y|m-d-y|m-d-Y|m/d|m-d|md|mdy|mdY|d|Y-m-d'
disabledDates:禁止选择的日期组成的数组
disabledDatesText:选择禁选日期时显示的提示信息
disabledDays:禁止选择的星期组成的数组,0代表星期日,1代表星期一
disabledDaysText:选择禁选星期时显示的提示信息
invalidText:当日期值非法时显示的提示信息
方法:
getValue():取得日期值 Ext.form.ComboBox displayField:被显示在下拉框中的字段名
editable:是否可编辑,默认为true
forceSelection:输入值是否严格为待选列表中存在的值。如果输入不存在的值,会自动选择第一个最接近的值。
hiddenName:隐藏字段的名字,如果提供该参数则一个隐藏字段将被创建,用来存储所选值,当表单提交时在服务器端可以通过该名字取得列表中的所选值
listWidth:下拉列表的宽度
minListWidth:下拉列表的最小宽度,默认为70像素
loadingText:当下拉框加载数据时显示的提示信息,只有当mode='remote'时才会生效
maxHeight:下拉列表框的最大高度,默认为300像素
minChars:下拉列表框自动选择前用户需要输入的最小字符数量。mode='remote'默认为4,mode='local'默认为0
mode:下拉列表框的数据读取模式。remote读取远程数据,local读取本地数据
pageSize:下拉列表框的分页大小。该项设置只在mode='remote'时生效
queryParam:查询的名字,默认为'query',将被传递到查询字符串中
allQuery:一个发往服务器用来查询全部信息的查询字符串,默认为空字符串''
selectOnFocus:当获得焦点时立刻选择一个已存在的列表项。默认为false,此项只有在editable=true时才会生效
store:列表框绑定的数据源
transform:将页面中已存在的元素转换为组合框
lazyInit:延时初始化下拉列表,默认为true
lazyRender:延时渲染,默认为false
triggerAction:设置单击触发按钮时执行的默认操作,有效值包括all和query,默认为query,如果设置为all则会执行allQuery中设置的查询
typeAhead:设置在输入过程中是否自动选择匹配的剩余部分文本(选择第一个满足条件的),默认为false
value:初始化组合框中的值
valueField:组合框的值字段
valueNotFoundText:值不存在时的提示信息
tpl:Ext模板字符串或模板对象,可以通过该配置项自定义下拉列表的显示方式
方法:
clearValue():清空字段当前值
doQuery( String query, Boolean forceAll ):
getValue():
getStore():
setValue( String value ): Ext.from.RadioGroup allowBlank:
blankText: Ext.form.Radio; getGroupValue():
setValue( value {String/Boolean} ): Ext.form.CheckboxGroup allowBlank:是否允许不选择,默认为true
blankText:
columns:显示的列数,可选值包括:固定值auto、数值、数组(整数、小数)
items:对象数组
vertical:是否垂直方向显示对象,默认为false Ext.form.Checkbox boxLabel:复选框的文字描述
checked:复选框是否被选择,默认为false
handler:当checked值改变时触发的函数,函数包含两个参数:checkbox、checked
inputValue:
方法:
getValue():返回复选框的checked状态
setValue( Boolean/String checked ): Ext.form.NumberField allowDecimals:是否允许输入小数,默认为true
allowNegative:是否允许输入负数,默认为true
baseChars:输入的有效数字集合,默认为'0123456789'
decimalPrecision:数字的精度,默认保留小数点后2位
decimalSeparator:十进制分隔符,默认为'.'
maxValue:允许输入的最大数值
maxText:超过最大值之后的提示信息
minValue:允许输入的最小数值
minText:超过最小值之后的提示信息
nanText:输入非有效数值之后的提示信息 Ext.form.TextArea preventScrollbars:是否禁止出现滚动条,默认为false Ext.form.TextField allowBlank:是否允许为空,默认为true
blankText:空验证失败后显示的提示信息
emptyText:在一个空字段中默认显示的信息
grow:字段是否自动伸展和收缩,默认为false
growMin:收缩的最小宽度
growMax:伸展的最大宽度
inputType:字段类型:默认为text
maskRe:用于过滤不匹配字符输入的正则表达式
maxLength:字段允许输入的最大长度
maxLengthText:最大长度验证失败后显示的提示信息
minLength:字段允许输入的最小长度
minLengthText:最小长度验证失败后显示的提示信息
regex:正则表达式
regexText:正则表达式验证失败后显示的提示信息
vtype:验证类型的名字
alpha:限制只能输入字母
alphanum:限制只能输入字母和数字
email
url
vtypeText:验证失败时的提示信息
validator:自定义验证函数
selectOnFocus:当字段得到焦点时自动选择已存在的文本,默认为false Ext.form.Field name:字段名
value:字段的初始化值
disabled:字段是否不可用,默认为false
fieldLabel:字段标签说明
hideLabel:隐藏字段标签,默认为false
labelSeparator:字段标签与字段之间的分隔符,默认为':'
labelStyle:字段标签样式
inputType:默认为text
invalidClass:默认为x-form-invalid
invalidText:字段非法文本提示
msgTarget:错误信息显示的位置,默认为qtip
qtip:显示一个浮动的提示信息
title:显示一个浏览器的浮动提示信息
under:在字段下方显示一个提示信息
side:在字段右边显示一个提示信息
readOnly:字段是否只读,默认为false
validateOnBlur:字段在失去焦点时被验证,默认为true
方法:
clearInvalid():
getRawValue()
setRawValue( Mixed value )
getValue()
setValue( Mixed value )
isDirty():字段值在装载后是否被修改过
isValid( Boolean preventMark ):当前字段值是否合法
markInvalid( [String msg] )
validate()
reset() Ext.form.FormPanel items:一个元素或元素数组
buttons:一个按钮配置对象的数组,按钮将被添加到表单页脚中
buttonAlign:按钮的对齐方式,可选值有left、center、right,默认为center
labelWidth:表单标签的宽度
labelAlign:表单标签的对齐方式,可选值有left、top、right,默认为left
labelSeparator:字段标签与字段之间的分隔符,默认为':'
minButtonWidth:按钮的最小宽度,默认为75
方法:
getForm() : Ext.form.BasicForm
load( Object options )
startMonitoring()
stopMonitoring() Ext.form.BaseicForm baseParams:传递到请求中的参数
method:表单的提交方式,有效值包括GET、POST
url:表单默认的提交路径
fileUpload:表单是否进行文件上传
timeout:表单动作的超时时间,默认为30秒
trackResetOnLoad:是否在表单初次创建时清楚数据
方法:
doAction( String/Object actionName, [Object options] ):执行一个预订的动作,可用选项包括:
url:动作提交的路径
method:表单的提交方式,有效值包括GET、POST
params:传递到请求中的参数
headers:
success:执行成功后回调的函数,包括两个参数:form和action
failure:执行失败后回调的函数,包括两个参数:form和action
clientValidation:是否客户端验证
clearInvalid():清除表单中所有的无效验证信息
findField( String id ):查找表单字段
getValues( [Boolean asString] ):
isDirty():表单数据是否被更改过
isValid():客户端验证是否成功
load( Object options ):执行表单读取动作
loadRecord( Record record ):从一个数据记录中读取数据到表单中
markInvalid( Array/Object errors ):成批设置表单字段为验证无效
reset():重置表单
setValues( Array/Object values ):成批设置表单字段值
submit( Object options ):执行表单提交动作
updateRecord( Record record ):持久化表单数据到记录集中 Ext.form.Action success:执行成功后回调的函数,包括两个参数:form和action
failure:执行失败后回调的函数,包括两个参数:form和action
method:表单的提交方式,有效值包括GET、POST
params:传递到请求中的参数
url:动作提交的路径
waitMsg:动作执行时显示的等待信息
属性:
Action.CLIENT_INVALID:客户端验证错误
Action.CONNECT_FAILURE:通信错误
Action.LOAD_FAILURE:加载数据时,没有包含data属性的字段被返回
Action.SERVER_INVALID:服务端验证错误
failureType:错误类型
result:包含布尔类型的success属性和其他属性,如{success: true, msg: 'ok'}
type:动作类型,可选值有submit和load
Ext.form.Action.Submit:返回的信息中要包含一个布尔类型的success属性和一个可选的errors属性
Ext.form.Action.Load:返回的信息中要包含一个布尔类型的success属性和一个data属性 Ext.grid.EditorGridPanel clicksToEdit:设置点击单元格进入编辑模式的点击次数,默认为2
autoEncode:是否自动编码/解码HTML内容,默认为false
selModel:默认为Ext.grid.CellSelectionModel
主要方法:
startEditing( Number rowIndex, Number colIndex ):开始编辑指定单元格
stopEditing( [Boolean cancel] ):结束编辑操作 Ext.grid.GroupinView enableGroupingMenu:是否在表头菜单中进行分组控制,默认为true groupByText:表头菜单中分组控制的菜单文字,默认为'Group By This Field' enableNoGroups:是否允许用户关闭分组功能,默认为true showGroupsText:在表头菜单中启用分组和禁用分组的菜单文字,默认为'Show in Groups' groupTextTpl:用于渲染分组信息的模板,默认为'{text}',常用的可选值有: text:列标题:组字段值 gvalue:组字段的值 startRow:组行索引 enableGrouping:是否对数据分组,默认为true hideGroupedColumn:是否隐藏分组列,默认为false ignoreAdd:在向表格中添加数据时是否刷新表格,默认为false showGroupName:是否在分组行上显示分组字段的名字,默认为true startCollapsed:初次显示时分组是否处于收缩状态,默认为false 主要方法: collapseAllGroups():收缩所有分组行 expandAllGroups():展开所有分组行 getGroupId( String value ):根据分组字段值取得组id toggleAllGroups( [Boolean expanded] ):切换所有分组行的展开或收缩状态 toggleGroup( String groupId, [Boolean expanded] ):切换指定分组行的展开或收缩状态 2、Ext.data.GroupingStore groupField:分组字段 groupOnSort:是否在分组字段上排序,默认为false remoteGroup:是否远程分组数据,默认为false。如果是远程分组数据,则通过groupBy参数发送分组字段名 Ext.grid.GridPanel: store:表格的数据集
columns:表格列模式的配置数组,可自动创建ColumnModel列模式
autoExpandColumn:自动充满表格未用空间的列,参数为列id,该id不能为0
stripeRows:表格是否隔行换色,默认为false
cm、colModel:表格的列模式,渲染表格时必须设置该配置项
sm、selModel:表格的选择模式,默认为Ext.grid.RowSelectionModel
enableHdMenu:是否显示表头的上下文菜单,默认为true
enableColumnHide:是否允许通过标题中的上下文菜单隐藏列,默认为true
loadMask:是否在加载数据时显示遮罩效果,默认为false
view:表格视图,默认为Ext.grid.GridView
viewConfig:表格视图的配置对象
autoExpandMax:自动扩充列的最大宽度,默认为1000
autoExpandMin:自动扩充列的最小宽度,默认为50
columnLines:是否显示列分割线,默认为false
disableSelection:是否禁止行选择,默认为false
enableColumnMove:是否允许拖放列,默认为true
enableColumnResize:是否允许改变列宽,默认为true
hideHeaders:是否隐藏表头,默认为false
maxHeight:最大高度
minColumnWidth:最小列宽,默认为25
trackMouseOver:是否高亮显示鼠标所在的行,默认为true
主要方法:
getColumnModel():取得列模式
getSelectionModel():取得选择模式
getStore():取得数据集
getView():取得视图对象
reconfigure( Ext.data.Store store, Ext.grid.ColumnModel colModel ):使用一个新的数据集和列模式重新配置表格组件
2、Ext.grid.Column
主要配置项:
id:列id
header:表头文字
dataIndex:设置列与数据集中数据记录的对应关系,值为数据记录中的字段名称。如果没有设置该项则使用列索引与数据记录中字段的索引进行对应
width:列宽
align:列数据的对齐方式
hidden:是否隐藏列,默认为false
fixed:是否固定列宽,默认为false
menuDisabled:是否禁用列的上下文菜单,默认为false
resizable:是否允许改变列宽,默认为true
sortable:是否允许排序,默认为true
renderer:设置列的自定义单元格渲染函数
传入函数的参数有:
value:数据的原始值
metadata:元数据对象,用于设置单元格的样式和属性,该对象包含的属性有:
css:应用到单元格TD元素上的样式名称
attr:一个HTML属性定义字符串,例如'style="color:blue"'
record:当前数据记录对象
rowIndex:单元格的行索引
colIndex:单元格的列索引
store:数据集对象
xtype:列渲染器类型,默认为gridcolumn,其它可选值有booleancolumn、numbercolumn、datecolumn、templatecolumn等
editable:是否可编辑,默认为true
editor:编辑器
groupName:
emptyGroupText:
groupable:
3、Ext.grid.ColumnModel
主要配置项:
columns:字段数组
defaultSortable:是否进行默认排序,默认为false
defaultWidth:默认宽度
主要方法:
findColumnIndex( String col ):根据给定的dataIndex查找列索引
getColumnById( String id ):取得指定id对应的列
getColumnCount( Boolean visibleOnly ):取得列总数
getColumnHeader( Number col ):取得列的表头
getColumnId( Number index ):取得列id
getDataIndex( Number col ):取得列对应的数据字段名
getIndexById( String id ):取得列索引
getTotalWidth( Boolean includeHidden )
isCellEditable( Number colIndex, Number rowIndex )
isFixed()
isHidden( Number colIndex )
setColumnHeader( Number col, String header )
setColumnWidth( Number col, Number width, Boolean suppressEvent )
setDataIndex( Number col, String dataIndex )
setEditable( Number col, Boolean editable )
setEditor( Number col, Object editor )
setHidden( Number colIndex, Boolean hidden )
setRenderer( Number col, Function fn )
4、Ext.grid.AbstractSelectionModel
主要方法:
lock():锁定选择区域
unlock():解锁选择区域
isLocked():当前选择区域是否被锁定
5、Ext.grid.CellSelectionModel
主要方法:
clearSelections( Boolean preventNotify ):清除选择区域
getSelectedCell():取得当前选择的单元格,返回一数组,其格式:[rowIndex, colIndex]
hasSelection():当前是否有选择区域
select( Number rowIndex, Number colIndex, [Boolean preventViewNotify], [Boolean preventFocus], [Ext.data.Record r] ):选择指定单元格
6、Ext.grid.RowSelectionModel
主要配置项:
singleSelect:是否单选模式,默认为false,即可以选择多条数据
主要方法:
clearSelections( [Boolean fast] ):清除所有选择区域
deselectRange( Number startRow, Number endRow ):取消范围内的行选择
deselectRow( Number row, [Boolean preventViewNotify] ):取消指定行的选择状态
each( Function fn, [Object scope] ):遍历所有选择行,并调用指定函数。当前被选行将传入该函数中
getCount():得到选择的总行数
getSelected():得到第一个被选记录
getSelections():得到所有被选记录的数组
hasNext():判断当前被选行之后是否还有记录可以选择
hasPrevious():判断当前被选行之前是否还有记录可以选择
hasSelection():是否已选择了数据
isIdSelected( String id ):判断指定id的记录是否被选择
isSelected( Number/Record index ):判断指定记录或记录索引的数据是否被选择
selectAll():选择所有行
selectFirstRow():选择第一行
selectLastRow( [Boolean keepExisting] ):选择最后行
keepExisting:是否保持已有的选择
selectNext( [Boolean keepExisting] ):选择当前选择行的下一行
selectPrevious( [Boolean keepExisting] ):选择当前选择行的上一行
selectRange( Number startRow, Number endRow, [Boolean keepExisting] ):选择范围内的所有行
selectRecords( Array records, [Boolean keepExisting] ):选择一组指定记录
selectRow( Number row, [Boolean keepExisting], [Boolean preventViewNotify] ):选择一行
row:行索引
selectRows( Array rows, [Boolean keepExisting] ):选择多行
rows:行索引数组
7、Ext.grid.CheckboxSelectionModel
主要配置项:
singleSelect:是否单选模式,默认为false,即可以选择多条数据
checkOnly:是否只能通过点击checkbox列进行选择,默认为false
sortable:是否允许checkbox列排序,默认为false
width:checkbox列的宽度,默认为20
8、Ext.grid.RowNumberer
主要配置项:
header:行号列表头显示的内容
width:列宽,默认为23
9、Ext.grid.GridView
主要配置项:
enableRowBody:是否包含行体
sortAscText:表格标题菜单中升序的文字描述
sortDescText:表格标题菜单中降序的文字描述
columnsText:表格标题菜单中列对应的文字描述
autoFill:是否自动扩展列以充满整个表格,默认为false
forceFit:是否强制调整表格列宽以适用表格的整体宽度,防止出现水平滚动条,默认为false
主要方法:
focusCell( Number row, Number col ):将焦点移到指定单元格
focusRow( Number row ):将焦点移动指定行
getCell( Number row, Number col ):取得指定单元格对应的td元素
getHeaderCell( Number index ):取得指定表头对应的td元素
getRow( Number index ):取得指定行对应的tr元素
getRowClass( Record record, Number index, Object rowParams, Store store ):得到附加到表格行上的样式名
record:当前行的数据记录对象
index:当前行的索引
rowParams:渲染时传入到行模板中的配置对象,通过它可以为行体定制样式,该对象只在enableRowBody为true时才生效,可能的属性如下:
body:渲染到行体中的HTML代码片段
bodyStyle:应用到行体tr元素style属性的字符串
cols:应用到行体td元素colspan属性的值,默认为总列数
store:表格数据集
refresh( [Boolean headersToo] ):刷新表格组件
scrollToTop():滚动表格到顶端 Ext.TabPanel: activeTab:初始激活的tab,索引或者id值,默认为none autoTabs:是否自动将带有'x-tab'样式类的div转成tabs添加到TabPanel中,默认为false。 当该配置项设为true时,需要设置deferredRender为false,还必须使用applyTo。 deferredRender:是否延迟渲染,默认为true。 autoTabSelector:默认为'div.x-tab'。 resizeTabs:是否可以改变tab的尺寸,默认为false。 minTabWidth:tab的最小宽度,默认为30。 tabWidth:每个新增加的tab宽度,默认为120。 tabTip:tab的提示信息 tabPosition:tab位置,可选值有top、bottom,默认为top。 enableTabScroll:是否允许Tab溢出时可以滚动,默认为false。 closable:tab是否可关闭,默认为false scrollDuration:每次的滚动时长,默认为0.35毫秒。 scrollIncrement:每次的滚动步长,默认为100像素。 wheelIncrement:每次鼠标滑轮的滚动步长,默认为20像素。 2、主要方法: activate( String/Panel tab ) getActiveTab():获取当前活动的tab get( String/Number key ):根据组件id或者索引获取组件 getItem(String id):根据tab id获取tab setActiveTab( String/Number item ) remove( Component/String component, [Boolean autoDestroy] ) removeAll( [Boolean autoDestroy] ) 在使用TabPanel时需要注意: 1、在创建Ext.TabPanel时deferredRender配置项经常会被忽略。该配置项的默认值是true。true表示只有在用户第一次访问 选项卡时,该选项卡的panel才会被渲染。 所以当我们有可能使用脚本操作选项卡时,谨记将该配置项设置为false。 2、在FormPanel中使用TabPanel,如果在TabPanel中不定义deferredRender的值为false,那么,当你使用 Load方法为Form加载数据,或使用setValue为没有激活过的Panel的控件赋值时,将会发生错误。原因是,在默认设置下 deferredRender为true,TabPanel并不会渲染所有Panel上的控件,只有在该Panel被激活时才渲染控件,所以当你为这些控 件设置数据时,将会找不到这些控件,会出现错误。因而,在FormPanel中使用TabPanel,一定要在TabPanel中设置 deferredRender的值为false,强制TabPanel在Layout渲染时同时渲染所有Panel上的控件。 本文转自: http://www.cnblogs.com/knowledgesea/p/3284404.html
摘要: 前言:最近公司有个Web要发布,但是以前都是由实施到甲方去发布,配置,这几天有点闲,同事让我搞一个一键发布,就和安装软件那样的程序,好让实施直接 配置一下数据库就可以了,然后到网上搜了下,找到一些相关的教程,现在整理了一下,花了一个下午的时间来写笔记,写好了,首先奉献给博客园的小伙伴们,和 大伙儿分享一下,好了,下面进入主题~~~ 1,首先打开VS2010,新建一个项目,如图1-1所示: &nbs... 阅读全文
大家可以参考下这个网站http://eoffice.im.fju.edu.tw/phpbb/viewtopic.php?p=28685
1.先启动项目上的h2/bin下的h2.bat或h2w.bat文件,把h2数据库启动起来 2.SSH2框架和h2数据库整合方法 2.1先在数据库下创建 schema目录(相当于一个数据库实例) create schema fdrkftcode 目的是解决这种异常org.h2.jdbc.JdbcSQLException: Schema "fdrkftcode" not found; ...
2.2在schema目录下创建表,如创建系统用户表admin create table fdrkftcode.admin( id int primary key, adminname varchar(50), username varchar(50), userpwd varchar(50), adminrights varchar(50), createdate datetime, usedtimes int, lastlogin datetime, curstatus int, remark varchar(200) ) 3.为了使用hibernate操作h2,需要作如下设置,在sql编辑窗口输入下面这些脚本 对于实体pojo对象的映射,我是用的annotation,关键是id主键的映射,如下: @Column(name = "ID", nullable = false) @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "ABC_ID_SEQ") @SequenceGenerator(name = "ABC_ID_SEQ", sequenceName = "ABC_ID_SEQ") protected Long id; 注意这里的GeneratedValue和SequenceGenerator的使用,这属于JPA规范,全部来自javax.persisten 4.配置applicationContext.xml文件,主要有三个地方要注意: 4.1修改连接数据库的JDBC驱动 driverClass的值为org.h2.Driver 4.2修改连接数据库所用的URL字符串 jdbcUrl的值为jdbc:h2:tcp://localhost/~/FDRKFTCODE;MODE=MySQL;AUTO_SERVER=TRUE 4.3修改Hibernate的数据库方言hibernate.dialect为org.hibernate.dialect.H2Dialect 5.h2数据库一些常用操作 5.1帮助命令help 5.2表中某字段重命名 ALTER TABLE fdrkftcode.admin ALTER COLUMN usepwd rename to userpwd 5.3表中新增字段 ALTER TABLE fdrkftcode.admin ADD IF NOT EXISTS abc varchar(50) 5.4表中删除字段 ALTER TABLE fdrkftcode.admin DROP COLUMN IF EXISTS abc 5.5查找表中记录 SELECT * from fdrkftcode.admin 5.6往表中插入记录 INSERT INTO fdrkftcode.admin VALUES (1,'管理员','admin','admin','10000000000000000000','2013-05-1 00:12:34',3,'2013-05-1 15:32:57',1,'超过级管理员') 5.7修改表中某记录 UPDATE fdrkftcode.admin SET fdrkftcode.admin.adminname='超级管理员' where fdrkftcode.admin.id=1 5.8删除表中某记录 DELETE FROM fdrkftcode.admin WHERE fdrkftcode.admin.id=1
6.下面是我项目的applicationContext.xml配置方法,大家可以参考下 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd"> <!-- 定义使用C3P0连接池的数据源 --> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <!-- 指定连接数据库的JDBC驱动 --> <property name="driverClass"> <value>org.h2.Driver</value> </property> <!-- 连接数据库所用的URL --> <property name="jdbcUrl"> <value>jdbc:h2:tcp://localhost/~/FDRKFTCODE;MODE=MySQL;AUTO_SERVER=TRUE</value> </property> <!-- 连接数据库的用户名 --> <property name="user"> <value>sa</value> </property> <!-- 连接数据库的密码 --> <property name="password"> <value></value> </property> <!-- 设置数据库连接池的最大连接数 --> <property name="maxPoolSize"> <value>50</value> </property> <!-- 设置数据库连接池的最小连接数 --> <property name="minPoolSize"> <value>5</value> </property> <!-- 设置数据库连接池的初始化连接数 --> <property name="initialPoolSize"> <value>5</value> </property> <!-- 设置数据库连接池的连接的最大空闲时间,单位为秒 --> <property name="maxIdleTime"> <value>20</value> </property> </bean> <!-- 定义Hibernate的SessionFactory --> <bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean"> <!-- 依赖注入上面定义的数据源dataSource --> <property name="dataSource" ref="dataSource"/> <!-- 注册Hibernate的ORM映射文件 --> <property name="mappingResources"> <list> <value>com/sungoal/ORM/Admin.hbm.xml</value> </list> </property> <!-- 设置Hibernate的相关属性 --> <property name="hibernateProperties"> <props> <!-- 设置Hibernate的数据库方言 --> <prop key="hibernate.dialect">org.hibernate.dialect.H2Dialect</prop> <!-- 设置Hibernate是否在控制台输出SQL语句,开发调试阶段通常设为true --> <prop key="show_sql">true</prop> <!-- 设置Hibernate一个提交批次中的最大SQL语句数 --> <prop key="hibernate.jdbc.batch_size">50</prop> </props> </property> </bean> <!--定义Hibernate的事务管理器HibernateTransactionManager --> <bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager"> <!-- 依赖注入上面定义的sessionFactory --> <property name="sessionFactory" ref="sessionFactory"/> </bean> <!-- 装配通用数据库访问类BaseDAOImpl --> <bean id="dao" class="com.sungoal.DAO.BaseDAOImpl"> <!-- 依赖注入上面定义的sessionFactory --> <property name="sessionFactory" ref="sessionFactory"/> </bean> <!-- 部署系统用户管理业务控制器AdminAction --> <bean id="adminAction" class="com.sungoal.struts.action.AdminAction" scope="prototype"> <property name="dao" ref="dao"/> </bean> </beans>
hibernate.properties ######################
### Query Language ###
###################### ## define query language constants / function names hibernate.query.substitutions yes 'Y', no 'N'
## select the classic query parser
#hibernate.query.factory_class org.hibernate.hql.classic.ClassicQueryTranslatorFactory
#################
### Platforms ###
#################
## JNDI Datasource #hibernate.connection.datasource jdbc/test
#hibernate.connection.username db2
#hibernate.connection.password db2
## HypersonicSQL
hibernate.dialect org.hibernate.dialect.HSQLDialect
hibernate.connection.driver_class org.hsqldb.jdbcDriver
hibernate.connection.username sa
hibernate.connection.password
hibernate.connection.url jdbc:hsqldb:./build/db/hsqldb/hibernate
#hibernate.connection.url jdbc:hsqldb:hsql://localhost
#hibernate.connection.url jdbc:hsqldb:test ## H2 (www.h2database.com)
#hibernate.dialect org.hibernate.dialect.H2Dialect
#hibernate.connection.driver_class org.h2.Driver
#hibernate.connection.username sa
#hibernate.connection.password
#hibernate.connection.url jdbc:h2:mem:./build/db/h2/hibernate
#hibernate.connection.url jdbc:h2:testdb/h2test
#hibernate.connection.url jdbc:h2:mem:imdb1
#hibernate.connection.url jdbc:h2:tcp://dbserv:8084/sample;
#hibernate.connection.url jdbc:h2:ssl://secureserv:8085/sample;
#hibernate.connection.url jdbc:h2:ssl://secureserv/testdb;cipher=AES ## MySQL #hibernate.dialect org.hibernate.dialect.MySQLDialect
#hibernate.dialect org.hibernate.dialect.MySQLInnoDBDialect
#hibernate.dialect org.hibernate.dialect.MySQLMyISAMDialect
#hibernate.connection.driver_class com.mysql.jdbc.Driver
#hibernate.connection.url jdbc:mysql:///test
#hibernate.connection.username gavin
#hibernate.connection.password
## Oracle
#hibernate.dialect org.hibernate.dialect.OracleDialect
#hibernate.dialect org.hibernate.dialect.Oracle9Dialect
#hibernate.connection.driver_class oracle.jdbc.driver.OracleDriver
#hibernate.connection.username ora
#hibernate.connection.password ora
#hibernate.connection.url jdbc:oracle:thin:@localhost:1521:orcl
#hibernate.connection.url jdbc:oracle:thin:@localhost:1522:XE
## PostgreSQL
#hibernate.dialect org.hibernate.dialect.PostgreSQLDialect
#hibernate.connection.driver_class org.postgresql.Driver
#hibernate.connection.url jdbc:postgresql:template1
#hibernate.connection.username pg
#hibernate.connection.password
## DB2
#hibernate.dialect org.hibernate.dialect.DB2Dialect
#hibernate.connection.driver_class com.ibm.db2.jcc.DB2Driver
#hibernate.connection.driver_class COM.ibm.db2.jdbc.app.DB2Driver
#hibernate.connection.url jdbc:db2://localhost:50000/somename
#hibernate.connection.url jdbc:db2:somename
#hibernate.connection.username db2
#hibernate.connection.password db2 ## TimesTen #hibernate.dialect org.hibernate.dialect.TimesTenDialect
#hibernate.connection.driver_class com.timesten.jdbc.TimesTenDriver
#hibernate.connection.url jdbc:timesten:direct:test
#hibernate.connection.username
#hibernate.connection.password ## DB2/400 #hibernate.dialect org.hibernate.dialect.DB2400Dialect
#hibernate.connection.username user
#hibernate.connection.password password ## Native driver
#hibernate.connection.driver_class COM.ibm.db2.jdbc.app.DB2Driver
#hibernate.connection.url jdbc:db2://systemname ## Toolbox driver
#hibernate.connection.driver_class com.ibm.as400.access.AS400JDBCDriver
#hibernate.connection.url jdbc:as400://systemname
## Derby (not supported!)
#hibernate.dialect org.hibernate.dialect.DerbyDialect
#hibernate.connection.driver_class org.apache.derby.jdbc.EmbeddedDriver
#hibernate.connection.username
#hibernate.connection.password
#hibernate.connection.url jdbc:derby:build/db/derby/hibernate;create=true
## Sybase
#hibernate.dialect org.hibernate.dialect.SybaseDialect
#hibernate.connection.driver_class com.sybase.jdbc2.jdbc.SybDriver
#hibernate.connection.username sa
#hibernate.connection.password sasasa
#hibernate.connection.url jdbc:sybase:Tds:co3061835-a:5000/tempdb
## Mckoi SQL
#hibernate.dialect org.hibernate.dialect.MckoiDialect
#hibernate.connection.driver_class com.mckoi.JDBCDriver
#hibernate.connection.url jdbc:mckoi:///
#hibernate.connection.url jdbc:mckoi:local://C:/mckoi1.0.3/db.conf
#hibernate.connection.username admin
#hibernate.connection.password nimda
## SAP DB
#hibernate.dialect org.hibernate.dialect.SAPDBDialect
#hibernate.connection.driver_class com.sap.dbtech.jdbc.DriverSapDB
#hibernate.connection.url jdbc:sapdb://localhost/TST
#hibernate.connection.username TEST
#hibernate.connection.password TEST
#hibernate.query.substitutions yes 'Y', no 'N'
## MS SQL Server
#hibernate.dialect org.hibernate.dialect.SQLServerDialect
#hibernate.connection.username sa
#hibernate.connection.password sa ## JSQL Driver
#hibernate.connection.driver_class com.jnetdirect.jsql.JSQLDriver
#hibernate.connection.url jdbc:JSQLConnect://1E1/test ## JTURBO Driver
#hibernate.connection.driver_class com.newatlanta.jturbo.driver.Driver
#hibernate.connection.url jdbc:JTurbo://1E1:1433/test ## WebLogic Driver
#hibernate.connection.driver_class weblogic.jdbc.mssqlserver4.Driver
#hibernate.connection.url jdbc:weblogic:mssqlserver4:1E1:1433 ## Microsoft Driver (not recommended!)
#hibernate.connection.driver_class com.microsoft.jdbc.sqlserver.SQLServerDriver
#hibernate.connection.url jdbc:microsoft:sqlserver://1E1;DatabaseName=test;SelectMethod=cursor ## The New Microsoft Driver
#hibernate.connection.driver_class com.microsoft.sqlserver.jdbc.SQLServerDriver
#hibernate.connection.url jdbc:sqlserver://localhost ## jTDS (since version 0.9)
#hibernate.connection.driver_class net.sourceforge.jtds.jdbc.Driver
#hibernate.connection.url jdbc:jtds:sqlserver://1E1/test ## Interbase #hibernate.dialect org.hibernate.dialect.InterbaseDialect
#hibernate.connection.username sysdba
#hibernate.connection.password masterkey ## DO NOT specify hibernate.connection.sqlDialect ## InterClient #hibernate.connection.driver_class interbase.interclient.Driver
#hibernate.connection.url jdbc:interbase://localhost:3060/C:/firebird/test.gdb ## Pure Java #hibernate.connection.driver_class org.firebirdsql.jdbc.FBDriver
#hibernate.connection.url jdbc:firebirdsql:localhost/3050:/firebird/test.gdb
## Pointbase
#hibernate.dialect org.hibernate.dialect.PointbaseDialect
#hibernate.connection.driver_class com.pointbase.jdbc.jdbcUniversalDriver
#hibernate.connection.url jdbc:pointbase:embedded:sample
#hibernate.connection.username PBPUBLIC
#hibernate.connection.password PBPUBLIC
## Ingres
## older versions (before Ingress 2006) #hibernate.dialect org.hibernate.dialect.IngresDialect
#hibernate.connection.driver_class ca.edbc.jdbc.EdbcDriver
#hibernate.connection.url jdbc:edbc://localhost:II7/database
#hibernate.connection.username user
#hibernate.connection.password password ## Ingres 2006 or later #hibernate.dialect org.hibernate.dialect.IngresDialect
#hibernate.connection.driver_class com.ingres.jdbc.IngresDriver
#hibernate.connection.url jdbc:ingres://localhost:II7/database;CURSOR=READONLY;auto=multi
#hibernate.connection.username user
#hibernate.connection.password password ## Mimer SQL #hibernate.dialect org.hibernate.dialect.MimerSQLDialect
#hibernate.connection.driver_class com.mimer.jdbc.Driver
#hibernate.connection.url jdbc:mimer:multi1
#hibernate.connection.username hibernate
#hibernate.connection.password hibernate
## InterSystems Cache
#hibernate.dialect org.hibernate.dialect.Cache71Dialect
#hibernate.connection.driver_class com.intersys.jdbc.CacheDriver
#hibernate.connection.username _SYSTEM
#hibernate.connection.password SYS
#hibernate.connection.url jdbc:Cache://127.0.0.1:1972/HIBERNATE
#################################
### Hibernate Connection Pool ###
#################################
hibernate.connection.pool_size 1
###########################
### C3P0 Connection Pool###
###########################
#hibernate.c3p0.max_size 2
#hibernate.c3p0.min_size 2
#hibernate.c3p0.timeout 5000
#hibernate.c3p0.max_statements 100
#hibernate.c3p0.idle_test_period 3000
#hibernate.c3p0.acquire_increment 2
#hibernate.c3p0.validate false
##############################
### Proxool Connection Pool###
##############################
## Properties for external configuration of Proxool hibernate.proxool.pool_alias pool1 ## Only need one of the following #hibernate.proxool.existing_pool true
#hibernate.proxool.xml proxool.xml
#hibernate.proxool.properties proxool.properties
#################################
### Plugin ConnectionProvider ###
#################################
## use a custom ConnectionProvider (if not set, Hibernate will choose a built-in ConnectionProvider using hueristics) #hibernate.connection.provider_class org.hibernate.connection.DriverManagerConnectionProvider
#hibernate.connection.provider_class org.hibernate.connection.DatasourceConnectionProvider
#hibernate.connection.provider_class org.hibernate.connection.C3P0ConnectionProvider
#hibernate.connection.provider_class org.hibernate.connection.ProxoolConnectionProvider
#######################
### Transaction API ###
#######################
## Enable automatic flush during the JTA beforeCompletion() callback
## (This setting is relevant with or without the Transaction API) #hibernate.transaction.flush_before_completion
## Enable automatic session close at the end of transaction
## (This setting is relevant with or without the Transaction API)
#hibernate.transaction.auto_close_session
## the Transaction API abstracts application code from the underlying JTA or JDBC transactions
#hibernate.transaction.factory_class org.hibernate.transaction.JTATransactionFactory
#hibernate.transaction.factory_class org.hibernate.transaction.JDBCTransactionFactory
## to use JTATransactionFactory, Hibernate must be able to locate the UserTransaction in JNDI
## default is java:comp/UserTransaction
## you do NOT need this setting if you specify hibernate.transaction.manager_lookup_class
#jta.UserTransaction jta/usertransaction
#jta.UserTransaction javax.transaction.UserTransaction
#jta.UserTransaction UserTransaction
## to use the second-level cache with JTA, Hibernate must be able to obtain the JTA TransactionManager
#hibernate.transaction.manager_lookup_class org.hibernate.transaction.JBossTransactionManagerLookup
#hibernate.transaction.manager_lookup_class org.hibernate.transaction.WeblogicTransactionManagerLookup
#hibernate.transaction.manager_lookup_class org.hibernate.transaction.WebSphereTransactionManagerLookup
#hibernate.transaction.manager_lookup_class org.hibernate.transaction.OrionTransactionManagerLookup
#hibernate.transaction.manager_lookup_class org.hibernate.transaction.ResinTransactionManagerLookup
##############################
### Miscellaneous Settings ###
##############################
## print all generated SQL to the console #hibernate.show_sql true
## format SQL in log and console
hibernate.format_sql true
## add comments to the generated SQL
#hibernate.use_sql_comments true
## generate statistics
#hibernate.generate_statistics true
## auto schema export
#hibernate.hbm2ddl.auto create-drop
#hibernate.hbm2ddl.auto create
#hibernate.hbm2ddl.auto update
#hibernate.hbm2ddl.auto validate
## specify a default schema and catalog for unqualified tablenames
#hibernate.default_schema test
#hibernate.default_catalog test
## enable ordering of SQL UPDATEs by primary key
#hibernate.order_updates true
## set the maximum depth of the outer join fetch tree
hibernate.max_fetch_depth 1
## set the default batch size for batch fetching
#hibernate.default_batch_fetch_size 8
## rollback generated identifier values of deleted entities to default values
#hibernate.use_identifer_rollback true
## enable bytecode reflection optimizer (disabled by default)
#hibernate.bytecode.use_reflection_optimizer true
#####################
### JDBC Settings ###
#####################
## specify a JDBC isolation level #hibernate.connection.isolation 4
## enable JDBC autocommit (not recommended!)
#hibernate.connection.autocommit true
## set the JDBC fetch size
#hibernate.jdbc.fetch_size 25
## set the maximum JDBC 2 batch size (a nonzero value enables batching)
#hibernate.jdbc.batch_size 5
#hibernate.jdbc.batch_size 0
## enable batch updates even for versioned data
hibernate.jdbc.batch_versioned_data true
## enable use of JDBC 2 scrollable ResultSets (specifying a Dialect will cause Hibernate to use a sensible default)
#hibernate.jdbc.use_scrollable_resultset true
## use streams when writing binary types to / from JDBC
hibernate.jdbc.use_streams_for_binary true
## use JDBC 3 PreparedStatement.getGeneratedKeys() to get the identifier of an inserted row
#hibernate.jdbc.use_get_generated_keys false
## choose a custom JDBC batcher
# hibernate.jdbc.factory_class
## enable JDBC result set column alias caching
## (minor performance enhancement for broken JDBC drivers)
# hibernate.jdbc.wrap_result_sets
## choose a custom SQL exception converter
#hibernate.jdbc.sql_exception_converter
##########################
### Second-level Cache ###
##########################
## optimize chache for minimal "puts" instead of minimal "gets" (good for clustered cache) #hibernate.cache.use_minimal_puts true
## set a prefix for cache region names
hibernate.cache.region_prefix hibernate.test
## disable the second-level cache
#hibernate.cache.use_second_level_cache false
## enable the query cache
#hibernate.cache.use_query_cache true
## store the second-level cache entries in a more human-friendly format
#hibernate.cache.use_structured_entries true
## choose a cache implementation
#hibernate.cache.provider_class org.hibernate.cache.EhCacheProvider
#hibernate.cache.provider_class org.hibernate.cache.EmptyCacheProvider
hibernate.cache.provider_class org.hibernate.cache.HashtableCacheProvider
#hibernate.cache.provider_class org.hibernate.cache.TreeCacheProvider
#hibernate.cache.provider_class org.hibernate.cache.OSCacheProvider
#hibernate.cache.provider_class org.hibernate.cache.SwarmCacheProvider
## choose a custom query cache implementation
#hibernate.cache.query_cache_factory
############
### JNDI ###
############
## specify a JNDI name for the SessionFactory #hibernate.session_factory_name hibernate/session_factory
## Hibernate uses JNDI to bind a name to a SessionFactory and to look up the JTA UserTransaction;
## if hibernate.jndi.* are not specified, Hibernate will use the default InitialContext() which
## is the best approach in an application server
#file system
#hibernate.jndi.class com.sun.jndi.fscontext.RefFSContextFactory
#hibernate.jndi.url file:/ #WebSphere
#hibernate.jndi.class com.ibm.websphere.naming.WsnInitialContextFactory
#hibernate.jndi.url iiop://localhost:900/
摘要: 这几天学习了一下Spring Security3.1,从官网下载了Spring Security3.1版本进行练习,经过多次尝试才摸清了其中的一些原理。本人不才,希望能帮助大家。还有,这次我第二次写博客啊,文体不是很行。希望 能让观看者不产生疲惫的感觉,我已经心满意足了。 一、数据库结构 先来看一下数据库结构,采用的是基于角色-资源-用户的权限... 阅读全文
我们知道,EXT的全部js是比较大的,一个ext-all-debug.js就达2m多,它的压缩版(去掉js中的换行及空格),也达600多k,这对于在网速不太快的时,下载js就得漫长的等待。
JOffice中的日历任务控件,js多达四五个,每个js大小都达70多k,尽管我们采用了后加载的方式,则当用户点击我的任务功能时,才下载该js,但这样仍然很慢,因为下载的js很慢
,鉴于此,在互联网上使用类似Joffice类似的程序,速度会使很多开发商不敢选用ext作为开发技术。据本人当时参与移动一个内部采购平台的开发,就是因为其运行程序慢,遭到移动的终端用户的弃骂,
所以,要想用EXT来开发应用,需要解决其运行慢的特点。
我们可以从以下几种方法来提高应用程序的运行速度:
一.前期尽量少加载js.
这点在Joffice中有比较好的运用,采用的是由ScriptMgr.load方法来完成,加载完成后,其会在body中插入一个div,只要当前页面不被刷新,下次再访问该功能时,不需要再加载js function $ImportJs(viewName,callback) {
var b = document.getElementById(viewName+'-hiden');
if (b != null) {
var view = eval('new ' + viewName + '()');
callback.call(this, view);
} else {
var jsArr = eval('App.importJs.' + viewName);
if(jsArr==undefined){
var view = eval('new ' + viewName + '()');
callback.call(this, view);
return ;
}
ScriptMgr.load({
scripts : jsArr,
callback : function() {
Ext.DomHelper.append(document.body,"<div id='"
+ viewName
+ "-hiden' style='display:none'></div>");
var view = eval('new ' + viewName + '()');
callback.call(this, view);
}
});
}
} package com.htsoft.core.web.filter;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class GzipJsFilter implements Filter {
Map headers = new HashMap();
public void destroy() {
}
public void doFilter(ServletRequest req, ServletResponse res,
FilterChain chain) throws IOException, ServletException {
if(req instanceof HttpServletRequest) {
doFilter((HttpServletRequest)req, (HttpServletResponse)res, chain);
}else {
chain.doFilter(req, res);
}
}
public void doFilter(HttpServletRequest request,
HttpServletResponse response, FilterChain chain)
throws IOException, ServletException {
request.setCharacterEncoding("UTF-8");
for(Iterator it = headers.entrySet().iterator();it.hasNext();) {
Map.Entry entry = (Map.Entry)it.next();
response.addHeader((String)entry.getKey(),(String)entry.getValue());
}
chain.doFilter(request, response);
}
public void init(FilterConfig config) throws ServletException {
String headersStr = config.getInitParameter("headers");
String[] headers = headersStr.split(",");
for(int i = 0; i < headers.length; i++) {
String[] temp = headers[i].split("=");
this.headers.put(temp[0].trim(), temp[1].trim());
}
}
}
3.在WEB.xml 文件中,添加以下配置: <filter>
<filter-name>GzipJsFilter</filter-name>
<filter-class>com.htsoft.core.web.filter.GzipJsFilter</filter-class>
<init-param>
<param-name>headers</param-name>
<param-value>Content-Encoding=gzip</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>GzipJsFilter</filter-name>
<url-pattern>*.gzjs</url-pattern>
lt;/filter-mapping>
<servlet-mapping>
4.在index.jsp中引入该压缩文件:
<script type="text/javascript" src="<%=request.getContextPath()%>/ext3/ext-all.gzjs"></script>  可以看到浏览器解压后,其代码是一样的: 
大家可以看到以上,这块是在外网使用的,其速度是比较快的。当然,浏览器解压这个文件需要一点时间,不过在本地解压是非常快的,可以不用管。 三、通过Js缓存,更加可以提高EXT的加载速度,关于缓存,本文不作讨论。 原文出自: http://man1900.iteye.com/blog/515058
我们常常在代码中读取一些资源文件(比如图片,音乐,文本等等)。在单独运行的时候这些简单的处理当然不会有问题。但是,如果我们把代码打成一个jar包以后,即使将资源文件一并打包,这些东西也找不出来了。看看下面的代码: //源代码1:
package edu.hxraid;
import java.io.*;
public class Resource {
public void getResource() throws IOException{
File file=new File("bin/resource/res.txt");
BufferedReader br=new BufferedReader(new FileReader(file));
String s="";
while((s=br.readLine())!=null)
System.out.println(s);
}
}
这段代码写在Eclipse建立的java Project中,其目录为:(其中将资源文件res.txt放在了bin目录下,以便打成jar包)
1、src/
src/edu/hxraid/Resource.java
2、bin/
bin/resource/res.txt
bin/edu/hxraid/Resource.class 很显然运行源代码1是能够找到资源文件res.txt。但当我们把整个工程打成jar包以后(ResourceJar.jar),这个jar包内的目录为:
edu/hxraid/Resource.class
resource/res.txt 而这时jar包中Resource.class字节 码:ldc <String "bin/resource/res.txt"> [20] 将无法定位到jar包中的res.txt位置上。就算把bin/目录去掉:ldc <String "resource/res.txt"> [20] 仍然无法定位到jar包中res.txt上。 这主要是因为jar包是一个单独的文件而非文件夹,绝对不可能通过"file:/e:/.../ResourceJar.jar/resource /res.txt"这种形式的文件URL来定位res.txt。所以即使是相对路径,也无法定位到jar文件内的txt文件(读者也许对这段原因解释有些费解,在下面我们会用一段代码运行的结果来进一步阐述)。 那么把资源打入jar包,无论ResourceJar.jar在系统的什么路径下,jar包中的字节码程序都可以找到该包中的资源。这会是幻想吗?
当然不是,我们可以用类装载器(ClassLoader)来做到这一点: (1) ClassLoader 是类加载器的抽象类。它可以在运行时动态的获取加载类的运行信息。 可以这样说,当我们调用ResourceJar.jar中的Resource类时,JVM加载进Resource类,并记录下Resource运行时信息 (包括Resource所在jar包的路径信息)。而ClassLoader类中的方法可以帮助我们动态的获取这些信息:
● public URL getResource(String name)
查找具有给定名称的资源。资源是可以通过类代码以与代码基无关的方式访问的一些数据(图像、声音、文本等)。并返回资源的URL对象。
● public InputStream getResourceAsStream(String name);
返回读取指定资源的输入流。这个方法很重要,可以直接获得jar包中文件的内容。 (2) ClassLoader是abstract的,不可能实例化对象,更加不可能通过ClassLoader调用上面两个方法。所以我们真正写代码的时候,是通过Class类中的getResource()和getResourceAsStream()方法,这两个方法会委托ClassLoader中的getResource()和getResourceAsStream()方法 。好了,现在我们重新写一段Resource代码,来看看上面那段费解的话是什么意思了: //源代码2:
package edu.hxraid;
import java.io.*;
import java.net.URL;
public class Resource {
public void getResource() throws IOException{
//查找指定资源的URL,其中res.txt仍然开始的bin目录下
URL fileURL=this.getClass().getResource("/resource/res.txt");
System.out.println(fileURL.getFile());
}
public static void main(String[] args) throws IOException {
Resource res=new Resource();
res.getResource();
}
} 运行这段源代码结果:/E:/Code_Factory/WANWAN/bin/resource/res.txt (../ Code_Factory/WANWAN/.. 是java project所在的路径) 我们将这段代码打包成ResourceJar.jar ,并将ResourceJar.jar放在其他路径下(比如 c:\ResourceJar.jar)。然后另外创建一个java project并导入ResourceJar.jar,写一段调用jar包中Resource类的测试代码: import java.io.IOException;
import edu.hxraid.Resource;
public class TEST {
public static void main(String[] args) throws IOException {
Resource res=new Resource();
res.getResource();
}
} 这时的运行结果是:file:/C:/ResourceJar.jar!/resource/res.txt 我们成功的在运行时动态获得了res.txt的位置。然而,问题来了,你是否可以通过下面这样的代码来得到res.txt文件?
File f=new File("C:/ResourceJar.jar!/resource/res.txt");
当然不可能,因为".../ResourceJar.jar!/resource/...."并不是文件资源定位符的格式 (jar中资源有其专门的URL形式: jar:<url>!/{entry} )。所以,如果jar包中的类源代码用File f=new File(相对路径);的形式,是不可能定位到文件资源的。这也是为什么源代码1打包成jar文件后,调用jar包时会报出FileNotFoundException的症结所在了。 (3) 我们不能用常规操作文件的方法来读取ResourceJar.jar中的资源文件res.txt,但可以通过Class类的getResourceAsStream()方法来获取 ,这种方法是如何读取jar中的资源文件的,这一点对于我们来说是透明的。我们将Resource.java改写成: //源代码3:
package edu.hxraid;
import java.io.*;
public class Resource {
public void getResource() throws IOException{
//返回读取指定资源的输入流
InputStream is=this.getClass().getResourceAsStream("/resource/res.txt");
BufferedReader br=new BufferedReader(new InputStreamReader(is));
String s="";
while((s=br.readLine())!=null)
System.out.println(s);
}
} 我们将java工程下/bin目录中的edu/hxraid /Resource.class和资源文件resource/res.txt一并打包进ResourceJar.jar中,不管jar包在系统的任何目录 下,调用jar包中的Resource类都可以获得jar包中的res.txt资源,再也不会找不到res.txt文件了。 原文出自: http://www.iteye.com/topic/483115
编辑代码常用快捷键 格式化代码的快捷键 Ctrl + Shift + F 格式化缩进的快捷键是 Ctrl + I,只能对选中的文本进行缩进 删除一行的快捷键是 Ctrl + D 当前窗口最大化最小化切换 Ctrl + M 转到最后进行修改的位置 Ctrl + Q 快速查找选中的字符 Ctrl + K(向下) Ctrl + Shift + K(向上) 光标放到一个括号,切换到另一个成对的括号 Ctrl + Shirt + P 在编辑过的位置进行切换 Alt + 左右方向键 阅读代码常用的快捷键 F3不解释(一些人喜欢用Ctrl + 鼠标左键) 选中方法或者变量 Ctrl + Alt + H,查找在哪些地方调用,快速阅读代码和评估代码修改必须要用到的 继承关系 F4,了解代码的框架 快速查找函数和变量 Ctrl + O,输入函数或变量的名字,比在Outline中一个一个找要快很多,但是要对代码有了解 全工程查找 Ctrl + H,代码巨多的情况下必不可少。 由于水平有限,笔者只用到了这些快捷键 如果想知道其他的快捷键 Ctrl + Shift + L 自定义格式化代码 在Preference中打开Java的Format 
内建的模版是不能修改的,点击New...,随便输入一个名字,新建一个自己的模板,弹出自定义Edit窗口 
可以定义的项目非常丰富,在右边还可以进行预览,就算对英文不感冒,也可以捉摸出大致的意思。对代码进行格式化的好处是不仅仅是美观,便于阅读,在 进行团队开发的时候,使用统一的格式,在合并代码的时候可以避免许多的冲突。修改完成的模版就是使用Ctrl + Shift + F格式化时的模板 自动去除无用的import,自动补全@Override和@deprecated,eclipse的Clean up 在Code Style中,除了Format还有Clean Up 
和Format进行同样的操作,新建一个模板,有几个地方我决定有必要改一下 在Code Organizing标签选择Remove trailing whitespace(移除尾部的空格) 和Organzie imports 选择Organzie imports前效果 选择Organzie imports后效果 
切换到Code Style标签 
Use blocks in if/while/for/do statements 为if/while/for/do自动添加括号,这个因人而异,我决定即使只用一行,也应该添加括号。 点击菜单里的Source - Clean up,可以对代码进行清理,清理代码最大的好处是——移除没用的import,自动添加@Deprecated和@Override
特别是自动添加@Override,可以很清楚的明白那些函数是继承的。
代码提示 用过visual assistx的一定非常系统它的代码提示功能,我是个没有代码提示就无法Coding的人,点击菜单Windows-Preference,切换到以下窗口 
找到Auto Activation,也就是红色方框中的部分,将Auto activation delay(ms): 修改为 50 将Auto activation triggers for Java:修改为 .abcdefghigklmnoprstuvwxyz,这样就能随时提示了。 最后介绍两个工具,Search Everything 根据文件名快速查找文件,ClipX剪贴板历史记录。 原文出自:http://www.cnblogs.com/sw926/p/3209615.html
1 @Entity
2 @Table(name="T_ADM_USER")
3 public class User extends GenericEntity implements Serializable {
4
5 @OneToOne(cascade = CascadeType.PERSIST)
6 @JoinColumn(name="grade_id")
7 public Grade getGrade() {
8 return grade;
9 }
10 public void setGrade(Grade grade) {
11 this.grade = grade;
12 }
13 @Column(name="user_name", insertable = true, updatable = true, nullable = true)
14 public String getUsername() {
15 return username;
16 }
17 public void setUsername(String username) {
18 this.username = username;
19 }
20
21 }
1 public class TableUtil {
2
3 public static void main(String[] args) {
4 try{
5
6 AnnotationConfiguration cfg = new AnnotationConfiguration();
7 cfg.addAnnotatedClass(com.mygogo.grade.user.entity.User.class);
9 SchemaExport se = new SchemaExport(cfg);
10 se.setDelimiter(";");
11 se.drop(true, true);
12 se.create(true, true);
13 }catch(Exception e){
14 e.printStackTrace();
15 }
16
17 }
18 }
Servlet和Filter的url匹配以及url-pattern详解
Servlet和filter是J2EE开发中常用的技术,使用方便,配置简单,老少皆宜。估计大多数朋友都是直接配置用,也没有关心过具体的细节,今天 遇到一个问题,上网查了servlet的规范才发现,servlet和filter中的url-pattern还是有一些文章在里面的,总结了一些东西, 放出来供大家参考,以免遇到问题又要浪费时间。一 servlet容器对url的匹配过当一个请求发送到servlet容器的时候,容器先会将请求的url减去当前应用上下文的路径作为servlet的映射url,比如我访问的是http://localhost/test/aaa.html,我的应用上下文是test,容器会将http://localhost/test去掉,剩下的/aaa.html部分拿来做servlet的映射匹配。这个映射匹配过程是有顺序的,而且当有一个servlet匹配成功以后,就不会去理会剩下的servlet了(filter不同,后文会提到)。其匹配规则和顺序如下:<o:p></o:p>
1. 精确路径匹配。例子:比如servletA 的url-pattern为 /test,servletB的url-pattern为 /* ,这个时候,如果我访问的url为http://localhost/test ,这个时候容器就会先进行精确路径匹配,发现/test正好被servletA精确匹配,那么就去调用servletA,也不会去理会其他的servlet了。<o:p></o:p>
2. 最长路径匹配。例子:servletA的url-pattern为/test/*,而servletB的url-pattern为/test/a/*,此时访问http://localhost/test/a时,容器会选择路径最长的servlet来匹配,也就是这里的servletB。<o:p></o:p>
3. 扩展匹配,如果url最后一段包含扩展,容器将会根据扩展选择合适的servlet。例子:servletA的url-pattern:*.action<o:p></o:p>
4. 如果前面三条规则都没有找到一个servlet,容器会根据url选择对应的请求资源。如果应用定义了一个default servlet,则容器会将请求丢给default servlet(什么是default servlet?后面会讲)。
根据这个规则表,就能很清楚的知道servlet的匹配过程,所以定义servlet的时候也要考虑url-pattern的写法,以免出错。 对于filter,不会像servlet那样只匹配一个servlet,因为filter的集合是一个链,所以只会有处理的顺序不同,而不会出现只选择一 个filter。Filter的处理顺序和filter-mapping在web.xml中定义的顺序相同。 二 url-pattern详解- 在web.xml文件中,以下语法用于定义映射:
- 以”/’开头和以”/*”结尾的是用来做路径映射的。
- 以前缀”*.”开头的是用来做扩展映射的。
- “/” 是用来定义default servlet映射的。
- 剩下的都是用来定义详细映射的。比如: /aa/bb/cc.action
所以,为什么定义”/*.action”这样一个看起来很正常的匹配会错?因为这个匹配即属于路径映射,也属于扩展映射,导致容器无法判断 出自: http://foxty.iteye.com/blog/39332
oracle监听不能启动的问题及处理过程! oracle环境如下: SQL> select * from V$version 2 ; BANNER ---------------------------------------------------------------- Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod PL/SQL Release 10.2.0.1.0 - Production CORE 10.2.0.1.0 Production TNS for 32-bit Windows: Version 10.2.0.1.0 - Production NLSRTL Version 10.2.0.1.0 - Production 出错过程回忆:在此之前用windows优化大师对系统注册表进行了修复! Q:链接oracle时报错:ORA-12541: TNS: 无监听程序 A: 1〉查看监听有没有启动: 一:运行lsnrctl C:\Documents and Settings\Admin>lsnrctl LSNRCTL for 32-bit Windows: Version 10.2.0.1.0 - Production on 20-4月 -2007 09: 1:43 Copyright (c) 1991, 2005, Oracle. All rights reserved. 欢迎来到LSNRCTL, 请键入"help"以获得信息。 二:查看stauts LSNRCTL> status 正在连接到 (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1))) TNS-12541: TNS: 无监听程序 TNS-12560: TNS: 协议适配器错误 TNS-00511: 无监听程序 32-bit Windows Error: 2: No such file or directory 正在连接到 (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=zxt)(PORT=1521))) TNS-12541: TNS: 无监听程序 TNS-12560: TNS: 协议适配器错误 TNS-00511: 无监听程序 32-bit Windows Error: 61: Unknown error 三:发现监听没有启动,现在启动监听 LSNRCTL> start 启动tnslsnr: 请稍候... Failed to start service, error 3. TNS-12560: TNS: 协议适配器错误 TNS-00530: 协议适配器错误 2〉发现监听启动不起来,估计是注册表有点问题,登录注册表 C:\Documents and Settings\Admin>regedit 进入注册表到HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\OracleOraDb10g_home1TNSListener 发现ImagePath关键值没有了,增加可扩充字符串值,取名为ImagePathImagePath,编辑字符串的数值数据为:G:\oracle\product\10.2.0\db_2\BIN\TNSLSNR(对应oracle的TNSLSNR的位置) ,退出注册表。 3〉启动监听 LSNRCTL> start 启动tnslsnr: 请稍候... TNSLSNR for 32-bit Windows: Version 10.2.0.1.0 - Production 系统参数文件为d:\oracle\product\10.2.0\db_1\network\admin\listener.ora 写入d:\oracle\product\10.2.0\db_1\network\log\listener.log的日志信息 监听: (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(PIPENAME=\\.\pipe\EXTPROC1ipc))) 监听: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=zxt)(PORT=1521))) 正在连接到 (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1))) LISTENER 的 STATUS ------------------------ 别名 LISTENER 版本 TNSLSNR for 32-bit Windows: Version 10.2.0.1.0 - Produ ction 启动日期 20-4月 -2007 09:41:29 正常运行时间 0 天 0 小时 0 分 3 秒 跟踪级别 off 安全性 ON: Local OS Authentication SNMP OFF 监听程序参数文件 d:\oracle\product\10.2.0\db_1\network\admin\listener.o ra 监听程序日志文件 d:\oracle\product\10.2.0\db_1\network\log\listener.log 监听端点概要... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(PIPENAME=\\.\pipe\EXTPROC1ipc))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=zxt)(PORT=1521))) 服务摘要.. 服务 "PLSExtProc" 包含 1 个例程。 例程 "PLSExtProc", 状态 UNKNOWN, 包含此服务的 1 个处理程序... 命令执行成功 4>监听启动成功后尝试登录 C:\Documents and Settings\Admin>sqlplus zxt@orcl SQL*Plus: Release 10.2.0.1.0 - Production on 星期五 4月 20 09:42:33 2007 Copyright (c) 1982, 2005, Oracle. All rights reserved. 输入口令: 连接到: Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production With the Partitioning, OLAP and Data Mining options 登录成功! 总结:估计是windows优化大师或者别的工具在修复注册表时候删掉了ImagePath字段,补上后就可以了! 补充:登录sqlplus时报 ORA-12514: TNS: 监听程序当前无法识别连接描述符中请求的服务错误! 处理办法: 1〉oracle_home\NETWORK\ADMIN\tnsnames.ora中修改(ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) 为(ADDRESS = (PROTOCOL = TCP)(HOST = 本地计算机名)(PORT = 1521)),保存即可。 2〉有的人介绍oracle_home\NETWORK\ADMIN\sqlnet.ora中修改SQLNET.AUTHENTICATION_SERVICES = (NTS)为 SQLNET.AUTHENTICATION_SERVICES = (NONE) 这2种方法,第一个最佳!
Ext GridPanel实现复选框选择框: 1 var selectModel = new Ext.grid.CheckboxSelectionModel({
2 singleSelect : false
3 });
4 但是这样每一行都会有复选框,如果需求为:某行数据的某个列满足什么条件我才有复选框选项就不太好实现了,
这样就需要重写Ext.grid.CheckboxSelectionModel的渲染,行点击涵数来实现. 1 var selectModel = new Ext.grid.CheckboxSelectionModel({
2 singleSelect : false,
3 renderer : function(v, p, record){
4 if (record.data['结果状态'] == '0'){
5 return '';
6 }
7 return '<div class="x-grid3-row-checker"> </div>';
8 },
9 onHdMouseDown : function(e, t) {
10 if (t.className == 'x-grid3-hd-checker') {
11 e.stopEvent();
12 var hd = Ext.fly(t.parentNode);
13 var isChecked = hd.hasClass('x-grid3-hd-checker-on');
14 if (isChecked){
15 hd.removeClass('x-grid3-hd-checker-on');
16 this.clearSelections();
17 }else {
18 hd.addClass('x-grid3-hd-checker-on');
19 if (this.locked){
20 return;
21 }
22 this.selections.clear();
23 for (var i = 0, len = this.grid.store.getCount(); i < len; i++ ){
24 if (this.grid.store.getAt(i).data["结果状态"] != '0'){
25 this.selectRow(i, true);
26 }
27 }
28 }
29 }
30 },
31 handleMouseDown : function(g, rowIndex, e){
32 if (e.button !== 0 || this.isLocked()) {
33 return;
34 }
35 var view = this.grid.getView();
36 if (e.shiftKey && !this.singleSelect && this.last != false ) {
37 var last = this.last;
38 this.selectRange(last, rowIndex, e.ctrlKey);
39 this.last = last;
40 view.focusRow(rowIndex);
41 }else{
42 var isSelected = this.isSelected(rowIndex);
43 if (e.ctrlKey && isSelected) {
44 this.deselectRow(rowIndex);
45 }else if(!isSelected || this.getCount() > 1){
46 if(this.grid.store.getAt(rowIndex).data["结果状态"] != '0'){
47 this.selectRow(rowIndex, e.ctrlKey || e.shiftKey);
48 }
49 view.focusRow(rowIndex);
50 }
51 }
52 }
53 }); 原文: http://fordream.iteye.com/blog/1179252
摘要: 在学习中Ext.grid.EditorGridPanel 的时候碰到一个知识点,如何用复选框来表示真假值,当然我们可以直接这样 Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->1 {2 heade... 阅读全文
Ext.grid.GridPanel可以设置stripeRows: true的属性来实现隔行换颜色的效果,如果你想自定义每行的颜色,那么你可以按照下边地方法来实现: Ext.ux.GridView=Ext.extend(
Ext.grid.GridView,
{
getRowClass:function(record,index)
{
if(index%2==0)
return 'red';
else
return 'green';
}
}
)
使用自定义的view
var grid = new Ext.grid.GridPanel({
//other code
store: store,
view:new Ext.ux.GridView(),
//other code
});
样式定义: .red {
background-color:#FF0000;
}
.green {
background-color:#00FF00;
}
 通过firebug可以看到,给每行的div添加了自定义的样式  原文出自: http://love4j.iteye.com/blog/516007
摘要: 先上图 grid分页: 把grid和page工具绑定在一起 // create the Data Store var store = new Ext.data.Store... 阅读全文
http://yourgame.iteye.com/blog/252853
Ext中的combobox有属性typeAhead:true 可以实现模糊匹配,但是是从开始匹配的,如果需要自定的的匹配,则需要监听beforequery方法,实现自己的匹配查询方法: 代码如下: var gfxmComb = new Ext.form.ComboBox({
id : 'gfxmComb',
store : gfxmStore,
typeAhead : true,
mode : 'local',
editable : true,
displayField :'xmMc',
valueField :'xmBm',
triggerAction : 'all',
selectOnFocus : true,
listeners : {
'beforequery':function(e){
var combo = e.combo;
if(!e.forceAll){
var input = e.query;
// 检索的正则
var regExp = new RegExp(".*" + input + ".*");
// 执行检索
combo.store.filterBy(function(record,id){
// 得到每个record的项目名称值
var text = record.get(combo.displayField);
return regExp.test(text);
});
combo.expand();
return false;
}
}
}
}); 原文出自:http://weibaojun.iteye.com/blog/1098731
Javascript是一门非常灵活的语言,我们可以随心所欲的书写各种风格的代码,不同风格的代码也必然也会导致执行效率的差异,开发过程中零零散散地接触到许多提高代码性能的方法,整理一下平时比较常见并且容易规避的问题 Javascript自身执行效率 Javascript中的作用域链、闭包、原型继承、eval等特性,在提供各种神奇功能的同时也带来了各种效率问题,用之不慎就会导致执行效率低下。 1、全局导入 我们在编码过程中多多少少会使用到一些全局变量(window,document,自定义全局变量等等),了解javascript作用域链的人都 知道,在局部作用域中访问全局变量需要一层一层遍历整个作用域链直至顶级作用域,而局部变量的访问效率则会更快更高,因此在局部作用域中高频率使用一些全 局对象时可以将其导入到局部作用域中,例如: 1 //1、作为参数传入模块
2 (function(window,$){
3 var xxx = window.xxx;
4 $("#xxx1").xxx();
5 $("#xxx2").xxx();
6 })(window,jQuery);
7
8 //2、暂存到局部变量
9 function(){
10 var doc = document;
11 var global = window.global;
12 } 2、eval以及类eval问题 我们都知道eval可以将一段字符串当做js代码来执行处理,据说使用eval执行的代码比不使用eval的代码慢100倍以上(具体效率我没有测试,有兴趣同学可以测试一下) JavaScript 代码在执行前会进行类似“预编译”的操作:首先会创建一个当前执行环境下的活动对象,并将那些用 var 申明的变量设置为活动对象的属性,但是此时这些变量的赋值都是 undefined,并将那些以 function 定义的函数也添加为活动对象的属性,而且它们的值正是函数的定义。但是,如果你使用了“eval”,则“eval”中的代码(实际上为字符串)无法预先识 别其上下文,无法被提前解析和优化,即无法进行预编译的操作。所以,其性能也会大幅度降低 其实现在大家一般都很少会用eval了,这里我想说的是两个类eval的场景(new Function{},setTimeout,setInterver) setTimtout("alert(1)",1000);
setInterver("alert(1)",1000);
(new Function("alert(1)"))(); 上述几种类型代码执行效率都会比较低,因此建议直接传入匿名方法、或者方法的引用给setTimeout方法 3、闭包结束后释放掉不再被引用的变量var f = (function(){
var a = {name:"var3"};
var b = ["var1","var2"];
var c = document.getElementByTagName("li");
//****其它变量
//***一些运算
var res = function(){
alert(a.name);
}
return res;
})() 上述代码中变量f的返回值是由一个立即执行函数构成的闭包中返回的方法res,该变量保留了对于这个闭包中所有变量(a,b,c等)的引用,因此这两个变 量会一直驻留在内存空间中,尤其是对于dom元素的引用对内存的消耗会很大,而我们在res中只使用到了a变量的值,因此,在闭包返回前我们可以将其它变 量释放 var f = (function(){
var a = {name:"var3"};
var b = ["var1","var2"];
var c = document.getElementByTagName("li");
//****其它变量
//***一些运算
//闭包返回前释放掉不再使用的变量
b = c = null;
var res = function(){
alert(a.name);
}
return res;
})() 在web开发过程中,前端执行效率的瓶颈往往都是在dom操作上面,dom操作是一件很耗性能的事情,如何才能在dom操作过程中尽量节约性能呢? 1、减少reflow 什么是reflow? 当 DOM 元素的属性发生变化 (如 color) 时, 浏览器会通知 render 重新描绘相应的元素, 此过程称为 repaint。 如果该次变化涉及元素布局 (如 width), 浏览器则抛弃原有属性, 重新计算并把结果传递给 render 以重新描绘页面元素, 此过程称为 reflow。 减少reflow的方法 -
先将元素从document中删除,完成修改后再把元素放回原来的位置(当对某元素及其子元素进行大量reflow操作时,1,2两种方法效果才会比较明显) -
将元素的display设置为”none”,完成修改后再把display修改为原来的值 - 修改多个样式属性时定义class类代替多次修改style属性(for certain同学推荐)
-
大量添加元素到页面时使用documentFragment
例如 for(var i=0;i<100:i++){
var child = docuemnt.createElement("li");
child.innerHtml = "child";
document.getElementById("parent").appendChild(child);
} 上述代码会多次操作dom,效率比较低,可以改为下面的形式 创建documentFragment,将所有元素加入到docuemntFragment不会改变dom结构,最后将其添加到页面,只进行了一次reflow var frag = document.createDocumentFragment();
for(var i=0;i<100:i++){
var child = docuemnt.createElement("li");
child.innerHtml = "child";
frag.appendChild(child);
}
document.getElementById("parent").appendChild(frag); 2、暂存dom状态信息 当代码中需要多次访问元素的状态信息,在状态不变的情况下我们可以将其暂存到变量中,这样可以避免多次访问dom带来内存的开销,典型的例子就是: var lis = document.getElementByTagName("li");
for(var i=1;i<lis.length;i++){
//***
}
上述方式会在每一次循环都去访问dom元素,我们可以简单将代码优化如下
var lis = document.getElementByTagName("li");
for(var i=1,j=lis.length ;i<j;i++){
//***
} 3、缩小选择器的查找范围 查找dom元素时尽量避免大面积遍历页面元素,尽量使用精准选择器,或者指定上下文以缩小查找范围,以jquery为例 - 少用模糊匹配的选择器:例如
$("[name*='_fix']"),多用诸如id以及逐步缩小范围的复合选择器$("li.active")等 - 指定上下文:例如
$("#parent .class"),$(".class",$el)等
4、使用事件委托 使用场景:一个有大量记录的列表,每条记录都需要绑定点击事件,在鼠标点击后实现某些功能,我们通常的做法是给每条记录都绑定监听事件,这种做法会导致页面会有大量的事件监听器,效率比较低下。 基本原理:我们都知道dom规范中事件是会冒泡的,也就是说在不主动阻止事件冒泡的情况下任何一个元素的事件都 会按照dom树的结构逐级冒泡至顶端。而event对象中也提供了event.target(IE下是srcElement)指向事件源,因此我们即使在 父级元素上监听该事件也可以找到触发该事件的最原始的元素,这就是委托的基本原理。废话不多说,上示例 $("ul li").bind("click",function(){
alert($(this).attr("data"));
}) 上述写法其实是给所有的li元素都绑定了click事件来监听鼠标点击每一个元素的事件,这样页面上会有大量的事件监听器。 根据上面介绍的监听事件的原理我们来改写一下 $("ul").bind("click",function(e){
if(e.target.nodeName.toLowerCase() ==="li"){
alert($(e.target).attr("data"));
}
}) 这样一来,我们就可以只添加一个事件监听器去捕获所有li上触发的事件,并做出相应的操作。 当然,我们不必每次都做事件源的判断工作,可以将其抽象一下交给工具类来完成。jquery中的delegate()方法就实现了该功能 语法是这样的$(selector).delegate(childSelector,event,data,function),例如: $("div").delegate("button","click",function(){
$("p").slideToggle();
}); 参数说明(引自w3school)
| 参数 | 描述 |
|---|
| childSelector | 必需。规定要附加事件处理程序的一个或多个子元素。 | | event | 必需。规定附加到元素的一个或多个事件。由空格分隔多个事件值。必须是有效的事件。 | | data | 可选。规定传递到函数的额外数据。 | | function | 必需。规定当事件发生时运行的函数。 | Tips:事件委托还有一个好处就是,即使在事件绑定之后动态添加的元素上触发的事件同样可以监听到哦,这样就不用在每次动态加入元素到页面后都为其绑定事件了 原文出自: http://www.cnblogs.com/gewei/archive/2013/03/29/2988180.html
摘要: 在Java中,它的内存管理包括两方面:内存分配(创建Java对象的时候)和内存回收,这 两方面工作都是由JVM自动完成的,降低了Java程序员的学习难度,避免了像C/C++直接操作内存的危险。但是,也正因为内存管理完全由JVM负责, 所以也使Java很多程序员不再关心内存分配,导致很多程序低效,耗内存。因此就有了Java程序员到最后应该去了解JVM,才能写出更高效,充分利用有 限的内存的程序。 1... 阅读全文
在设计产品时,要考虑到到很多的因素,其中一个重要的是配色方案。不同的颜色可以使您的产品创造出不同的效果。请务必检查颜色在一般和特定的文化含义,以获得最佳使用效果。 在这篇文章中,我想向大家介绍一些有用的设计工具将帮助您选择合适的调色板为您的设计。这里有15个在线工具分析和收集的色彩组合。 














转自:http://www.cnblogs.com/58top/archive/2013/01/15/useful-color-combination-apps-for-designers.html
转: http://www.cnblogs.com/58top/archive/2013/01/11/free-jquery-tooltip-plugins.html
textarea元素已被广泛用于网页Web的IDE。通常网站自带的textarea编辑器不能满足我们的需求,作为一名开发者我们经常需要进行代码的在线编辑,高亮显示代码等,因此,通过其他的开源项目,我们可以添加一些实用的功能, 在这篇文章中,我将使用 JavaScript库 ACE来创建一个输入框效果。这是一个完全开源的脚本。该脚本允许开发人员创建支持语法高亮的输入框。然后你可以代码嵌入到网站中的任何地方 下载库 首先我们需要Github上下载ACE代码。 下载完成后解压缩,在你的header部分引入js文件 <script src="src-min/ace.js" type="text/javascript" charset="utf-8"></script> 添加代码到编辑器 首先设置一个id为editor的div 然后在script里面调用ace.edit()方法,代码如下
var editor = ace.edit("editor");
editor.getSession().setMode("ace/mode/javascript"); 您可以重命名变量,为了方便起见,我定义了var editor作为变量,你也可以定义var demoeditor作为变量。第二行声明使用哪种类型的语言高亮显示。您可以从 src 目录选择其他语言集合。这里是一些支持支持的语言集合: - SQL
- Ruby
- SASS
- PHP
- Objectivec
- Csharp
- Java
- JSON
使用额外的参数editor.setTheme("ace/theme/dawn");
editor.getSession().setTabSize(2);
editor.getSession().setUseWrapMode(true); 这3行代码是关于文本输入效果的,第一行改变代码默认的语法颜色和主题,在src目录下个有几十个新的主题,你可以从中任意选择 另外两个选项是关于用户体验。通常情况下,按一个键盘上的Tab键将输入4个空格,这里我设置成2个空格,此外,该文本在默认情况下将不会自动换行,超了会追加一个水平滚动条向外延伸。但使用这种方法setUseWrapMode(true),我们可以修复自动换行的问题。 还有一些其他的命令,你可以参考ACE向导。这里面包含了改变光标的位置,动态添加新内容,或复制的文本的全部内容。 CSS代码 #editor {
margin-left: 15px;
margin-top: 15px;
width: 1000px;
height: 400px; } 原文出自: http://www.cnblogs.com/58top/archive/2013/01/28/building-a-syntax-highlighted-input-box-with-javascript.html
Aspect Oriented Programming 面向切面编程。解耦是程序员编码开发过程中一直追求的。AOP也是为了解耦所诞生。 具体思想是:定义一个切面,在切面的纵向定义处理方法,处理完成之后,回到横向业务流。 AOP 在Spring框架中被作为核心组成部分之一,的确Spring将AOP发挥到很强大的功能。最常见的就是事务控制。工作之余,对于使用的工具,不免需要了解其所以然。学习了一下,写了些程序帮助理解。 AOP 主要是利用代理模式的技术来实现的。 1、静态代理:就是设计模式中的proxy模式 a、业务接口 /**
* 抽象主题角色:声明了真实主题和代理主题的共同接口。
*
* @author yanbin
*
*/
public interface ITalk {
public void talk(String msg);
} b、业务实现 /**
* 真实主题角色:定义真实的对象。
*
* @author yanbin
*
*/
public class PeopleTalk implements ITalk {
public String username;
public String age;
public PeopleTalk(String username, String age) {
this.username = username;
this.age = age;
}
public void talk(String msg) {
System.out.println(msg + "!你好,我是" + username + ",我年龄是" + age);
}
public String getName() {
return username;
}
public void setName(String name) {
this.username = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
} c、代理对象 /**
* 代理主题角色:内部包含对真实主题的引用,并且提供和真实主题角色相同的接口。
*
* @author yanbin
*
*/
public class TalkProxy implements ITalk {
private ITalk talker;
public TalkProxy(ITalk talker) {
// super();
this.talker = talker;
}
public void talk(String msg) {
talker.talk(msg);
}
public void talk(String msg, String singname) {
talker.talk(msg);
sing(singname);
}
private void sing(String singname) {
System.out.println("唱歌:" + singname);
}
} d、测试类 /**
* 代理测试类,使用代理
*
* @author yanbin
*
*/
public class ProxyPattern {
public static void main(String[] args) {
// 不需要执行额外方法的。
ITalk people = new PeopleTalk("AOP", "18");
people.talk("No ProXY Test");
System.out.println("-----------------------------");
// 需要执行额外方法的(切面)
TalkProxy talker = new TalkProxy(people);
talker.talk("ProXY Test", "代理");
}
} 从这段代码可以看出来,代理模式其实就是AOP的雏形。 上端代码中talk(String msg, String singname)是一个切面。在代理类中的sing(singname)方法是个后置处理方法。 这样就实现了,其他的辅助方法和业务方法的解耦。业务不需要专门去调用,而是走到talk方法,顺理成章的调用sing方法 再从这段代码看:1、要实现代理方式,必须要定义接口。2、每个业务类,需要一个代理类。 2、动态代理:jdk1.5中提供,利用反射。实现InvocationHandler接口。 业务接口还是必须得,业务接口,业务类同上。 a、代理类: /**
* 动态代理类
*
* @author yanbin
*
*/
public class DynamicProxy implements InvocationHandler {
/** 需要代理的目标类 */
private Object target;
/**
* 写法固定,aop专用:绑定委托对象并返回一个代理类
*
* @param delegate
* @return
*/
public Object bind(Object target) {
this.target = target;
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), this);
}
/**
* @param Object
* target:指被代理的对象。
* @param Method
* method:要调用的方法
* @param Object
* [] args:方法调用时所需要的参数
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = null;
// 切面之前执行
System.out.println("切面之前执行");
// 执行业务
result = method.invoke(target, args);
// 切面之后执行
System.out.println("切面之后执行");
return result;
}
} b、测试类 /**
* 测试类
*
* @author yanbin
*
*/
public class Test {
public static void main(String[] args) {
// 绑定代理,这种方式会在所有的方法都加上切面方法
ITalk iTalk = (ITalk) new DynamicProxy().bind(new PeopleTalk());
iTalk.talk("业务说明");
}
} 输出结果会是: 切面之前执行
people talk业务说法
切面之后执行 说明只要在业务调用方法切面之前,是可以动态的加入需要处理的方法。 从代码来看,如果再建立一个业务模块,也只需要一个代理类。ITalk iTalk = (ITalk) new DynamicProxy().bind(new PeopleTalk()); 将业务接口和业务类绑定到动态代理类。 但是这种方式:还是需要定义接口。 3、利用cglib CGLIB是针对类来实现代理的,他的原理是对指定的目标类生成一个子类,并覆盖其中方法实现增强。采用的是继承的方式。不细说,看使用 a、业务类 /**
* 业务类
*
* @author yanbin
*
*/
public class PeopleTalk {
public void talk(String msg) {
System.out.println("people talk" + msg);
}
} b、cglib代理类 /**
* 使用cglib动态代理
*
* @author yanbin
*
*/
public class CglibProxy implements MethodInterceptor {
private Object target;
/**
* 创建代理对象
*
* @param target
* @return
*/
public Object getInstance(Object target) {
this.target = target;
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(this.target.getClass());
// 回调方法
enhancer.setCallback(this);
// 创建代理对象
return enhancer.create();
}
@Override
public Object intercept(Object proxy, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
Object result = null;
System.out.println("事物开始");
result = methodProxy.invokeSuper(proxy, args);
System.out.println("事物结束");
return result;
}
} c.测试类 /**
* 测试类
*
* @author yanbin
*
*/
public class Test {
public static void main(String[] args) {
PeopleTalk peopleTalk = (PeopleTalk) new CglibProxy().getInstance(new PeopleTalk());
peopleTalk.talk("业务方法");
peopleTalk.spreak("业务方法");
}
} 最后输出结果: 事物开始
people talk业务方法
事物结束
事物开始
spreak chinese业务方法
事物结束 由于篇幅有限,这篇主要对AOP的原理简单实现做了演示和阐述,有助自己理解。至于Spring的AOP实现上面无外乎其右,不过实现方面复杂的多。 原文出自: http://www.cnblogs.com/yanbincn/archive/2012/06/01/2530377.html
摘要: 摘要:ComboBox是常用控件之一,但由于其数据来源分两种形式:本地和远程,故写的形式难度并不亚于ExtJS中的TreePanel和 GridPanel。鄙人也经常提醒自己的师弟师妹,ExtJS本身是面向对象写的,不能在应用的时候却不按照面向对象来写,面向对象最起码的好处就是代 码的复用,对于网页来讲,代码复用的好处就是加载的JS会少很多,这样网页渲染时就不会很慢。下面我将分别介绍扩展的四种Co... 阅读全文
首先定义一数据源,一般使用simpleStore,jsonStore。需要注意的是simpleStore用于读取二维数组的数据,而jsonStroe用于读取json数据格式。 Combox使用simpleStore 代码如下所示: var subjectField = new Ext.form.ComboBox({
fieldLabel : '分类名称',
hiddenName : 'drug.subjectCode',// 传递到后台的参数
store : new Ext.data.SimpleStore({
autoLoad : true,
url :'xxx',
fields : ['subjectCode', 'subjectName']
}),
valueField : 'subjectCode',// 域的值,对应于store里的fields
displayField : 'subjectName',// 显示的域,对应于store里的fields
typeAhead : true,// 设置true,完成自动提示
mode : 'local', // 设置local,combox将从本地加载数据
triggerAction : 'all',// 触发此表单域时,查询所有
selectOnFocus : true,
anchor : '90%',
forceSelection : true
});
服务端返回的数据结构如下所示: [ ["00000003","硬膏剂"], ["00000005","滴眼剂"], ["00000016","栓剂"], ["00000017","注射剂"], ["00000018","软膏剂"] ] 当combox使用jsonStore时,一般运用于分页查询。页面效果如下所示:   示例代码如下所示: // 药品商品名 var itemNameField = new Ext.form.ComboBox({
width : 200,
fieldLabel : '药品商品名',
hiddenName : 'drug.itemName',
store : advanceStore,
valueField : 'itemName',
displayField : 'itemName',
typeAhead : true,
mode : 'remote',// 分页查询必须设置为 remote,当我们点击下一页的时候是从服务端取数据,而不是本地
triggerAction : 'all',
emptyText : '请选择一个分类名',
selectOnFocus : true,
minChars : 0, // 完成自动提示,当mode为‘local’时,默认为0,当mode为‘remote’时候,默认为4,这里设置为0
pageSize : 10,// 每页显示的记录数字
queryParam :'drug.itemName' // 在combox内敲入字符时候,combox向后台查询传递的参数,这里设置为'drug.itemName'是为了更好的封装,默认传递参数‘query’
});
这里还有一个问题,就是Combox设置初始值。 我是采用如下做法的,不知道各位知不知道其他用法? var subjectField = new Ext.form.ComboBox({
fieldLabel : '分类名称',
hiddenName : 'drug.subjectCode',
store : new Ext.data.SimpleStore({
autoLoad : true,
url : 'xxx',
fields : ['subjectCode', 'subjectName'],
listeners : {
load : function(){ subjectField.setValue(record.get("drug.subjectCode"));
}
}
}),
valueField : 'subjectCode',
displayField : 'subjectName',
typeAhead : true,
mode : 'local',
triggerAction : 'all',
emptyText : '请选择一个分类名',
selectOnFocus : true,
anchor : '90%',
forceSelection : true
});
原文出自: http://www.iteye.com/topic/296710
所有的事件回调函数都有两个参数: event和 ui,浏览器自有event对象,和经过封装的ui对象 ui.helper - 表示sortable元素的JQuery对象,通常是当前元素的克隆对象 ui.position - 表示相对当前对象,鼠标的坐标值对象{top,left} ui.offset - 表示相对于当前页面,鼠标的坐标值对象{top,left} ui.item - 表示当前拖拽的元素
ui.placeholder - 占位符(如果有定义的话) ui.sender - 当前拖拽元素的所属sortable对象(仅当元素是从另一个sortable对象传递过来时有用) ·参数(参数名 : 参数类型 : 默认值) appendTo : String : 'parent' Defines where the helper that moves with the mouse is being appended to during the drag (for example, to resolve overlap/zIndex issues). 初始:$('.selector').sortable({ appendTo: 'body' }); 获取:var appendTo = $('.selector').sortable('option', 'appendTo'); 设置:$('.selector').sortable('option', 'appendTo', 'body'); axis : String : false 如果有设置,则元素仅能横向或纵向拖动。可选值:'x', 'y' 初始:$('.selector').sortable({ axis: 'x' }); 获取:var axis = $('.selector').sortable('option', 'axis'); 设置:$('.selector').sortable('option', 'axis', 'x'); cancel : Selector : ':input,button' 阻止排序动作在匹配的元素上发生。 初始:$('.selector').sortable({ cancel: 'button' }); 获取:var cancel = $('.selector').sortable('option', 'cancel'); 设置:$('.selector').sortable('option', 'cancel', 'button'); connectWith : Selector : false 允许sortable对象连接另一个sortable对象,可将item元素拖拽到另一个中。 初始:$('.selector').sortable({ connectWith: '.otherlist' }); 获取:var connectWith = $('.selector').sortable('option', 'connectWith'); 设置:$('.selector').sortable('option', 'connectWith', '.otherlist'); containment : Element, String, Selector : false 约束排序动作只能在一个指定的范围内发生。可选值:DOM对象, 'parent', 'document', 'window', 或jQuery对象 初始:$('.selector').sortable({ containment: 'parent' }); 获取:var containment = $('.selector').sortable('option', 'containment'); 设置:$('.selector').sortable('option', 'containment', 'parent'); cursor : String : 'auto' 定义在开始排序动作时,如果的样式。 初始:$('.selector').sortable({ cursor: 'crosshair' }); 获取:var cursor = $('.selector').sortable('option', 'cursor'); 设置:$('.selector').sortable('option', 'cursor', 'crosshair'); cursorAt : Object : false 当开始移动时,鼠标定位在的某个位置上(最多两个方向)。可选值:{ top, left, right, bottom }. 初始:$('.selector').sortable({ cursorAt: 'top' }); 获取:var cursorAt = $('.selector').sortable('option', 'cursorAt'); 设置:$('.selector').sortable('option', 'cursorAt', 'top'); delay : Integer : 0 以毫秒为单位,设置延迟多久才激活排序动作。此参数可防止误点击。 初始:$('.selector').sortable({ delay: 500 }); 获取:var delay = $('.selector').sortable('option', 'delay'); 设置:$('.selector').sortable('option', 'delay', 500); distance : Integer : 1 决定至少要在元素上面拖动多少像素后,才正式触发排序动作。 初始:$('.selector').sortable({ distance: 30 }); 获取:var distance = $('.selector').sortable('option', 'distance'); 设置:$('.selector').sortable('option', 'distance', 30); dropOnEmpty : Boolean : true 是否允許拖拽到一個空的sortable对象中。 初始:$('.selector').sortable({ dropOnEmpty: false }); 获取:var dropOnEmpty = $('.selector').sortable('option', 'dropOnEmpty'); 设置:$('.selector').sortable('option', 'dropOnEmpty', false); forceHelperSize : Boolean : false If true, forces the helper to have a size. 初始:$('.selector').sortable({ forceHelperSize: true }); 获取:var forceHelperSize = $('.selector').sortable('option', 'forceHelperSize'); 设置:$('.selector').sortable('option', 'forceHelperSize', true); forcePlaceholderSize : Boolean : false If true, forces the placeholder to have a size. 初始:$('.selector').sortable({ forcePlaceholderSize: true }); 获取:var forcePlaceholderSize = $('.selector').sortable('option', 'forcePlaceholderSize'); 设置:$('.selector').sortable('option', 'forcePlaceholderSize', true); grid : Array : false 将排序对象的item元素视为一个格子处理,每次移动都按一个格子大小移动,数组值:[x,y] 初始:$('.selector').sortable({ grid: [50, 20] }); 获取:var grid = $('.selector').sortable('option', 'grid'); 设置:$('.selector').sortable('option', 'grid', [50, 20]); handle : Selector, Element : false 限制排序的动作只能在item元素中的某个元素开始。 初始:$('.selector').sortable({ handle: 'h2' }); 获取:var handle = $('.selector').sortable('option', 'handle'); 设置:$('.selector').sortable('option', 'handle', 'h2'); helper : String, Function : 'original' 设置是否在拖拽元素时,显示一个辅助的元素。可选值:'original', 'clone' 初始:$('.selector').sortable({ helper: 'clone' }); 获取:var helper = $('.selector').sortable('option', 'helper'); 设置:$('.selector').sortable('option', 'helper', 'clone'); items : Selector : '> *' 指定在排序对象中,哪些元素是可以进行拖拽排序的。 初始:$('.selector').sortable({ items: 'li' }); 获取:var items = $('.selector').sortable('option', 'items'); 设置:$('.selector').sortable('option', 'items', 'li'); opacity : Float : false 定义当排序时,辅助元素(helper)显示的透明度。 初始:$('.selector').sortable({ opacity: 0.6 }); 获取:var opacity = $('.selector').sortable('option', 'opacity'); 设置:$('.selector').sortable('option', 'opacity', 0.6); placeholderType: StringDefault: false 设置当排序动作发生时,空白占位符的CSS样式。 初始:$('.selector').sortable({ placeholder: 'ui-state-highlight' }); 获取:var placeholder = $('.selector').sortable('option', 'placeholder'); 设置:$('.selector').sortable('option', 'placeholder', 'ui-state-highlight'); revert : Boolean : false 如果设置成true,则被拖拽的元素在返回新位置时,会有一个动画效果。 初始:$('.selector').sortable({ revert: true }); 获取:var revert = $('.selector').sortable('option', 'revert'); 设置:$('.selector').sortable('option', 'revert', true); scroll : Boolean : true 如果设置成true,则元素被拖动到页面边缘时,会自动滚动。 初始:$('.selector').sortable({ scroll: false }); 获取:var scroll = $('.selector').sortable('option', 'scroll'); 设置:$('.selector').sortable('option', 'scroll', false); scrollSensitivity : Integer : 20 设置当元素移动至边缘多少像素时,便开始滚动页面。 初始:$('.selector').sortable({ scrollSensitivity: 40 }); 获取:var scrollSensitivity = $('.selector').sortable('option', 'scrollSensitivity'); 设置:$('.selector').sortable('option', 'scrollSensitivity', 40); scrollSpeed : Integer : 20 设置页面滚动的速度。 初始:$('.selector').sortable({ scrollSpeed: 40 }); 获取:var scrollSpeed = $('.selector').sortable('option', 'scrollSpeed'); 设置:$('.selector').sortable('option', 'scrollSpeed', 40); tolerance : String : 'intersect' 设置当拖动元素越过其它元素多少时便对元素进行重新排序。可选值:'intersect', 'pointer' intersect:至少重叠50% pointer:鼠标指针重叠元素 初始:$('.selector').sortable({ tolerance: 'pointer' }); 获取:var tolerance = $('.selector').sortable('option', 'tolerance'); 设置:$('.selector').sortable('option', 'tolerance', 'pointer'); zIndex : Integer : 1000 设置在排序动作发生时,元素的z-index值。 初始:$('.selector').sortable({ zIndex: 5 }); 获取:var zIndex = $('.selector').sortable('option', 'zIndex'); 设置:$('.selector').sortable('option', 'zIndex', 5); ·事件
start 当排序动作开始时触发此事件。 定义:$('.selector').sortable({ start: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortstart', function(event, ui) { ... }); sort 当元素发生排序时触发此事件。 定义:$('.selector').sortable({ sort: function(event, ui) { ... } }); 绑定:$('.selector').bind('sort', function(event, ui) { ... }); change 当元素发生排序且坐标已发生改变时触发此事件。 定义:$('.selector').sortable({ change: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortchange', function(event, ui) { ... }); beforeStop 当排序动作结束之前触发此事件。此时占位符元素和辅助元素仍有效。 定义:$('.selector').sortable({ beforeStop: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortbeforeStop', function(event, ui) { ... }); stop 当排序动作结束时触发此事件。 定义:$('.selector').sortable({ stop: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortstop', function(event, ui) { ... }); update 当排序动作结束时且元素坐标已经发生改变时触发此事件。 定义:$('.selector').sortable({ update: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortupdate', function(event, ui) { ... }); receive 当一个已连接的sortable对象接收到另一个sortable对象的元素后触发此事件。 定义:$('.selector').sortable({ receive: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortreceive', function(event, ui) { ... }); over 当一个元素拖拽移入另一个sortable对象后触发此事件。 定义:$('.selector').sortable({ over: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortover', function(event, ui) { ... }); out 当一个元素拖拽移出sortable对象移出并进入另一个sortable对象后触发此事件。 定义:$('.selector').sortable({ out: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortout', function(event, ui) { ... }); activate 当一个有使用连接的sortable对象开始排序动作时,所有允许的sortable触发此事件。 定义:$('.selector').sortable({ activate: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortactivate', function(event, ui) { ... }); deactivate 当一个有使用连接的sortable对象结束排序动作时,所有允许的sortable触发此事件。 定义:$('.selector').sortable({ deactivate: function(event, ui) { ... } }); 绑定:$('.selector').bind('sortdeactivate', function(event, ui) { ... }); ·方法
destory 从元素中移除拖拽功能。 用法:.sortable( 'destroy' ) disable 禁用元素的拖拽功能。 用法:.sortable( 'disable' ) enable 启用元素的拖拽功能。 用法:.sortable( 'enable' ) option 获取或设置元素的参数。 用法:.sortable( 'option' , optionName , [value] ) serialize 获取或设置序列化后的每个item元素的id属性。 用法:.sortable( 'serialize' , [options] ) toArray 获取序列化后的每个item元素的id属性的数组。 用法:.sortable( 'toArray' ) refresh 手动重新刷新当前sortable对象的item元素的排序。 用法:.sortable( 'refresh' ) refreshPositions 手动重新刷新当前sortable对象的item元素的坐标,此方法可能会降低性能。 用法:.sortable( 'refreshPositions' ) cancel 取消当前sortable对象中item元素的排序改变。 用法:.sortable( 'cancel' ) 排序后保存有两种方法, 一是cookie,二是 数据库配置文件等。 这个是cookie 的例子 大家可以参考 http://www.cnblogs.com/tianxiangbing/archive/2010/01/26/jquery_sortable.html 下面是数据库的部分代码 原作: $(function() { var show = $(".loader"); var orderlist = $(".orderlist"); var listleft = $("div[id = 'column_left']"); var listcenter = $("div[id = 'column_center']"); var listright = $("div[id = 'column_right']"); $( ".column" ).sortable({ opacity: 0.5,//拖动的透明度 revert: true, //缓冲效果 cursor: 'move', //拖动的时候鼠标样式 connectWith: ".column", //开始用update 结果执行两次,浪费资源,古改成stop //但是stop在元素没有改变位置的时候也会执行, //用update其他js会有问题,^_^ stop: function(){ var new_order_left = []; //左栏布局 var new_order_center = [];//中栏布局 var new_order_right = [];//右栏布局 listleft.children(".portlet").each(function() { new_order_left.push(this.title); }); listcenter.children(".portlet").each(function() { new_order_center.push(this.title); }); listright.children(".portlet").each(function() { new_order_right.push(this.title); }); var newleftid = new_order_left.join(','); var newcenterid = new_order_center.join(','); var newrightid = new_order_right.join(','); $.ajax({ type: "post", url: jsonUrl, //服务端处理程序 data: { leftid: newleftid, centerid: newcenterid, rightid:newrightid}, //id:新的排列对应的ID,order:原排列顺序 // beforeSend: function() { // show.html(" 正在更新"); // }, success: function(msg) { //alert(msg); show.html(""); } }); } }); 原文出自: http://hb-keepmoving.iteye.com/blog/1154618
图片预加载
1 (function($) {
2 var cache = [];
3 // Arguments are image paths relative to the current page.
4 $.preLoadImages = function() {
5 var args_len = arguments.length;
6 for (var i = args_len; i--;) {
7 var cacheImage = document.createElement('img');
8 cacheImage.src = arguments[i];
9 cache.push(cacheImage);
10 }
11 }
12
13 jQuery.preLoadImages("image1.gif", "/path/to/image2.png"); 在新窗口打开链接 (target=”blank”)1 $('a[@rel$='external']').click(function(){
2 this.target = "_blank";
3 });
4
5 /*
6 Usage:
7 <a href="http://www.catswhocode.com" rel="external">catswhocode.com</a>
8 */ 当支持 JavaScript 时为 body 增加 class1 /* 该代码只有1行,但是最简单的用来检测浏览器是否支持 JavaScript 的方法,如果支持 JavaScript 就在 body 元素增加一个 hasJS 的 class */
2 $('body').addClass('hasJS'); 平滑滚动页面到某个锚点 1 $(document).ready(function() {
2 $("a.topLink").click(function() {
3 $("html, body").animate({
4 scrollTop: $($(this).attr("href")).offset().top + "px"
5 }, {
6 duration: 500,
7 easing: "swing"
8 });
9 return false;
10 });
11 }); 鼠标滑动时的渐入和渐出1 $(document).ready(function(){
2 $(".thumbs img").fadeTo("slow", 0.6); // This sets the opacity of the thumbs to fade down to 60% when the page loads
3
4 $(".thumbs img").hover(function(){
5 $(this).fadeTo("slow", 1.0); // This should set the opacity to 100% on hover
6 },function(){
7 $(this).fadeTo("slow", 0.6); // This should set the opacity back to 60% on mouseout
8 });
9 }); 制作等高的列1 var max_height = 0;
2 $("div.col").each(function(){
3 if ($(this).height() > max_height) { max_height = $(this).height(); }
4 });
5 $("div.col").height(max_height); 在一些老的浏览器上启用 HTML5 的支持 1 (function(){
2 if(!/*@cc_on!@*/0)
3 return;
4 var e = "abbr,article,aside,audio,bb,canvas,datagrid,datalist,details,dialog,eventsource,figure,footer,header,hgroup,mark,menu,meter,nav,output,progress,section,time,video".split(','),i=e.length;while(i--){document.createElement(e[i])}
5 })()
6
7 //然后在head中引入该js
8 <!--[if lt IE 9]>
9 <script src="http://html5shim.googlecode.com/svn/trunk/html5.js"></script>
10 <![endif]--> 测试浏览器是否支持某些 CSS3 属性 1 var supports = (function() {
2 var div = document.createElement('div'),
3 vendors = 'Khtml Ms O Moz Webkit'.split(' '),
4 len = vendors.length;
5
6 return function(prop) {
7 if ( prop in div.style ) return true;
8
9 prop = prop.replace(/^[a-z]/, function(val) {
10 return val.toUpperCase();
11 });
12
13 while(len--) {
14 if ( vendors[len] + prop in div.style ) {
15 // browser supports box-shadow. Do what you need.
16 // Or use a bang (!) to test if the browser doesn't.
17 return true;
18 }
19 }
20 return false;
21 };
22 })();
23
24 if ( supports('textShadow') ) {
25 document.documentElement.className += ' textShadow'; 获取 URL 中传递的参数1 $.urlParam = function(name){
2 var results = new RegExp('[\\?&]' + name + '=([^&#]*)').exec(window.location.href);
3 if (!results) { return 0; }
4 return results[1] || 0;
5 } 禁用表单的回车键提交1 $("#form").keypress(function(e) {
2 if (e.which == 13) {
3 return false;
4 }
5 });
摘要: 为什么需要元数据模型 您已经熟悉使用 Cognos 来创建报表,进行自助式设计分析,然而这些需要的创建的应用都依赖于对应的元数据模型,用户使用元数据模型对他们的数据源进行分析和报告。元数据模型是整 个 Cognos 应用的基础,它是一个或多个数据源中信息的业务演示。基于这个基础,您才能够创建报表,进行自助式设计分析。 Cognos 能支持多种数据源,包括关系型的和多维的数据库。元数据模型能隐藏底... 阅读全文
什么是自助式设计分析 自助式设计分析是指在业务人员在同一工具做即席查询、报表和分析,完全由业务用户自助式制作。并且能和自助式仪表盘、专业报表工具紧密集成。通过业务人员进行自助式设计分析可以提升业务敏捷度、提升客户满意度、快速报表制作、降低 IT 管理成本。 IBM Cognos Business Insight Advanced 是用于创建报表和分析数据的基于 Web 的工具。商业用户可通过此用户界面了解其业务。IBM Cognos Business Insight Advanced 属于一种新型报表使用环境,将为商业用户带来全面的商业智能体验。 在《第一个自助式仪表盘》介绍了使用 IBM Cognos Business Insight 创建复杂的交互式仪表盘并以预定义的方式浏览内容。在 Business Insight 仪表盘中,可处理现有的内容并进行基本分析、数据浏览和协作性决策的制定。如果要执行深入分析并要创建报表,可以切换到 Business Insight Advanced 来执行更高级的数据浏览,例如添加附加度量、条件格式化和高级计算。 在 IBM Cognos BI 10.1 版本以前,IBM Cognos Report Studio 中的“专业”和“快速”两种创建模式,从 IBM Cognos BI 10.1 版本开始,“快速”创建模式现已替换为 IBM Cognos Business Insight Advanced,专业 IT 报表创建者仍使用 Report Studio 工具创建高级报表。 Business Insight Advanced 由业务人员使用,提供比原来“快速”创建模式的功能更为强大,例如完全支持列表报表、图表和关系数据源,而且还提供了专用于数据浏览的全新用户体验。 Business Insight Advanced 用户界面重点是在浏览数据。因此某些默认行为与以前版本的 IBM Cognos Report Studio 中“快速”创建模有所不同。例如,默认情况下,在 Business Insight Advanced 双击项目现将执行向下追溯。 不论是 IBM Cognos BI 的 Report Studio、Query Studio、Analysis Studio 制作的报表,IBM Cognos Business Insight Advanced 都可以打开,并且可以由业务人员进行自助式设计分析。而 Query Studio、Analysis Studio 功能已经被 Business Insight Advanced 取代,所以 Cognos BI 10 的业务用户只需要使用 Business Insight Advanced 就足够了。Report Studio 则留给专业人员使用。 创建第一个自助式设计分析 - 在开始菜单中启动 IBM Cognos BI Developer Edition,运行 Developer Edition Manager,在确保左侧的服务都正常的情况下,点击右上角的启动,选择 Business Insight Advanced。
- 在“Cognos > 公共文件夹 > 示样 > 多维数据集”路径下,选择“Great Outdoors Sales (cube)”数据包,进入 IBM Cognos Business Insight Advanced 后选择“新建”。在选择报表类型的时候,选择“交叉表”,点击确定。
如果载入数据包报错,例如在内容存储库中找不到数据源“great_outdoors_sales_en”,则需要按照《第一次安装》的步骤检查是否正确建立了 PowerCube 数据源。 - 在右侧的“可插入对象”窗格中的“来源”选项卡显示了面向成员的数据视图。您可以看到维度数据源,也就是包括多维数据源或者按维度建模的关系数据源,在本教程中使用的是 PowerCube 多维数据源。
- 数据包是模型的子集,其中包含可以插入到报表中的项目。
- 维度是有关业务主要方面(如产品、日期或市场)的描述性数据的概括分组。
- 级别层级是维度内更具体的分组。例如,对于“年份”维度,可以将数据组织为较小的组,如“年份”、“当前月份”和“上一个月份”。
- 成员文件夹包含可用于层级或级别的成员。例如,“年”级别层级的“成员”文件夹包含“年”、“季度”和“月份”级别中的所有内容。
- 级别是包含相同详细程度信息并具有共同属性的维度层级内的位置。一个级别层级内可以存在多个级别,从根级别开始。例如,“年份”级别层级具有以下相关级别。
- 成员属性是每个成员所具有的属性。例如,性别可以是所有员工成员的属性。
图 1. 可插入对象

- 对于维度模型数据源,您可以通过单击树面板顶部的按钮来交替查看元数据树和面向成员的数据树。在本教程中选择“查看成员树”。然后把 Years 拖动到列,把 Products 拖动到行,把 Revenue 拖动到度量,如图 2 所示。
图 2. 查看成员树

- 接下来您可以了解一下在 Business Insight Advanced 展示数据的功能。使用维度数据源或按维度建模的关系数据源时,您可以向下追溯到较低级别数据集或向上追溯到较高级别数据集的报表。向上追溯和向下追溯允许 您在预定义的维度层级(例如“年 - 年 - 季度 - 月”)内查看有关数据的更加全面或更加详细的信息,而无需创建其他报表。
左键点击交叉表中的产品“Golf Equipment”两次,可以实现向下追溯的功能。双击第一列最后一行汇总标题上的“Golf Equipment”可以实现向上追溯的功能。 其实在交叉表里面的任意数据都可以实现向下追溯的功能,而选择汇总标题上的数据都可以实现向上追溯的功能。 - 在“Golf Equipment”的向下追溯的效果下,单击成员“Golf Accessories”,在数据菜单下选择“浏览”,再单击“替换”,然后单击“使用级别成员”,如图 3 所示。
图 3. 替换成员

这样就把“Golf Accessories”替换为相同级别的成员。为了帮助理解,可以参看图 4,展开面向成员的数据树,和“Golf Accessories”相同级别的成员是标注红色的那些数据项。
图 4. 级别成员

- 等待报表刷新后,右键选择任意产品类型,点击菜单“最高或最低”,选择“最高 5 (基于 Revenue, Years)”,这样就筛选出最高的 5 个产品类型。
图 5. 最高或最低

- 右键选择汇总标题上的“Golf Equipment”,点击“删除”,这样就可以把不需要的汇总行除去,如图 6 所示。
图 6. 删除汇总行

- 按住 Ctrl 键选择“Tents”和“Packs”两个产品类型,右键选择“排除成员 > 从初始集”,如图 7 所示。您会发现仍然是 5 个产品类型,但是已经不是原来的 5 个,“Tents”和“Packs”两个产品类型已经被换成另外两个。
而如果您刚才选择“排除成员 > 从当前集”,则就会剩下 3 个产品类型。
图 7. 排除成员

- 在右侧的“可插入对象”窗格中的“来源”选项卡中选择“Personal Accessories”产品类型下的后面四个成员拖拽到报表的最后一行后面,如图 8 所示。
图 8. 添加成员

- 您会看到报表有 9 个产品类型,它们分别来自两个数据集。其中 Watches 和 Eyewear 这两个产品类型在两个数据集里面都有,属于重复的产品类型。
您按住 Ctrl 键可以选择两个数据集的 Eyewear,这样就等同于选择了两个数据集。然后在数据菜单下选择“浏览”,再单击“合并到一个集中”,选择“删除重复项”,如图 9 所示。
图 9. 合并数据集

- 这样就剩下合并在一个数据集中的 7 个产品类型,Watches 和 Eyewear 也没有重复了。
右键选择任意产品类型,点击菜单“最高或最低”,选择“最低 5 (基于 Revenue, Years)”,这样就筛选出最低的 5 个产品类型。 - 按住 Ctrl 键选择 Packs 和 Navigation 两个产品类型,右键选择“移动成员”,点击 “到顶部”,如图 10 所示。Packs 和 Navigation 两个产品类型就会被放到报表的头两行。
图 10. 移动成员

- 刚才您做了很多数据集的操作,这些操作包括:
- 排除成员
- 将成员移到集的顶部或底部
- 联接多个集
- 应用最高或最低过滤器
- 过滤集
- 展开或折叠集合中的成员
在 IBM Cognos Business Insight Advanced 可以查看集定义,从而了解、更改、添加或删除可对该集执行的操作,集的定义以图形树的形式为您显示了对集执行的所有操作的历史记录。 您可以任意选择数据项,比如 Packs ,然后右键菜单选择“编辑集”。或者您也可以在“数据”菜单下选择“浏览”,找到“编辑集”的菜单项。 图形树显示了对成员集合执行的所有操作,如图 11 所示。您可以执行以下操作,在这里选择“取消”即可。 - 要查看操作详情,请将鼠标悬停在操作节点上。
- 要更改操作的顺序,请单击操作节点,然后单击向右箭头或向左箭头。
- 要编辑操作,请单击操作节点,然后单击“编辑”按钮。
- 要添加新操作,请单击“新建”按钮。
图 11. 编辑集

- 任意选择报表的数据项,右键选择“显示属性”,这样会展开报表的属性页。您可以设置报表的属性。
图 12. 设置属性

- 保存您的分析结果在“我的文件夹”下,命名为“第一个自助式设计分析”。
使用图表 IBM Cognos Business Insight Advanced 包含一种默认图表技术,该技术不同于 10.1 之前版本中使用的原始图表技术。“使用原始图表创建”选项,让您能够使用老版本的原始图表技术的报表,而不是默认的 Business Insight Advanced 图表来创建新的报表。 在《第一张交互式离线报表》,您已经去掉“使用原始图表创建”的选择,这里可以再检查一下。您可以在“工具”菜单中点击“选项”,在“高级选项”标签中,检查是否已经去掉“使用原始图表创建”的选择。 IBM Cognos Business Insight Advanced 包含丰富的图表类型: - 柱形图:对于比较离散数据或显示随时间变化的趋势非常有用。
- 折线图:对于显示随时间变化的趋势和比较多个数据序列非常有用。
- 饼形图:对于突出显示比例非常有用。
- 条形图:对于显示随时间变化的趋势和绘制多个数据序列非常有用。
- 面积图:对于强调随时间变化的更改量非常有用,堆积面积图还用于显示部分与整体的关系。
- 点状图:对于以非群集样式显示定量数据非常有用。
- 组合图:通过在一个图表内使用柱形图、面积图和折线图的组合,绘出多个数据序列。组合图对于突出显示各种数据序列之间的关系非常有用。
- 散点图:使用数据点来沿刻度的任何位置(不仅在常规刻度线处)绘出两个度量,对于浏览不同数据集之间的相互关系非常有用。
- 泡形图:使用数据点和气泡沿某一刻度的任意位置绘出度量,就像散点图一样,气泡的大小表示第三个度量,对于表示财务数据非常有用。
- 项目符号图表:是条形图的一个变体。它们可以将特色度量(项目符号)与目标度量(目标)进行对比,也可以将比对度量与背景中提供其他定性度量(如“非常满意”、“满意”和“不满意”)的彩色区域联系到一起,通常用于代替执行仪表盘中的仪表板图。
- 仪表板图:使用指针将信息显示为表盘上的读数。在有颜色的数据范围或图表轴上读取每个指针的值非常容易。此图表类型常用于执行仪表盘报表,以显示关键业务指示器。
- 排列图:通过标识事件的主要原因来帮助您改善这些过程。排列图按照从最频繁到最不频繁的顺序对类别进行排名。这些图表常用于质量控制数据,以便您确定并减少问题的主要来源。
- 渐进图:类似于堆积图,单个堆积的各分段都从下一分段垂直偏移,对于强调各分段占整体的比例非常有用。
- 象限图:将背景分成四个等区域的泡形图。象限图对于绘出包含三个度量(使用 X 轴、Y 轴和表示第三个度量值的气泡大小)的数据很有用。
- Marimekko 图表:是百分堆积图,其中列的宽度与列值的总和成正比,各个分段高度是各自列总值的百分比。
- 雷达图:将多个轴组合成一个放射状的图形。对于每个数字,均沿着从图表中心开始的单独轴绘出数据。
- 盈亏图表:是一种 Microchart 图,其中每列的值为 1 或 -1,通常表示盈利或亏损。
- 极坐标图:对于显示科学计算数据非常有用,是使用值和角度将信息显示为极坐标的圆形图。
- 在工具栏中找到“页面布局”,为报表选择预定义的页面布局。您选择 1x2 的布局,这样就能在报表旁边放置图表,如图 13 所示。页面刷新后,报表出现在左侧的单元格,而右侧的单元格是空着的。
图 13. 页面布局

- 在右侧的“工具箱”中选择图表,拖拽到右侧的单元格中。当“插入图表”提示出现时,选择饼形图,如图 14 所示。
图 14. 插入图表

- 在右侧的“来源”中选择 Gross Profit 拖拽到默认度量,把 Sales Regions 拖拽到序列(饼形图扇区)。
- 您可以尝试在饼形图上进行向下追溯和向上追溯的功能。右键选择饼形扇区,然后单击“向下追溯”或者“向上追溯”。
- 您可以将饼形扇区拉离剩余的饼形图,以突出显示饼形扇区。右键选择要拉出的饼形扇区,然后单击“分解扇区”。此时扇区会从图表中拉出。要使已拉出的扇区返回到饼形图中,请右键选择饼形图图表对象,然后单击“删除已分解的扇区”。
- 您在“查看”菜单下可以切换“页面设计”和“页面预览”,其中“页面预览”是缺省选择,这是给业务人员进行自助式设计分析用的,所见即所得,可以直接看到数据结果。而“页面设计”功能是给专业人员用的,界面类似即将在后面介绍的 Report Studio。
- 保存并退出 Business Insight Advanced。
在自助式仪表盘中打开 - 在开始菜单中启动 IBM Cognos BI Developer Edition,运行 Developer Edition Manager,在确保左侧的服务都正常的情况下,点击右上角的启动,选择 Business Insight。在 IBM Cognos Business Insight 的启动页上选择“新建”。
- 在右侧的可插入对象中选择下面的“内容”,在“我的文件夹”下,可以找到刚才保存的“第一个自助式设计分析”,展开可以发现有两个对象,分别是“交叉表 1”和“饼形图 1”。右键选择“第一个自助式设计分析”报表,选择“插入”。
- 在自助式仪表盘中,您如果想看除了报表里面 5 个产品类型以外的产品,比如想把 Lanterns 产品类型也添加到报表中。那就不能直接在 Business Insight 里面完成,可以通过选择菜单的齿轮形状的按钮“完成更多”来启动 Business Insight Advanced,如图 15 所示。等待一会以后,Business Insight Advanced 界面就出现了。
图 15. 完成更多

- 默认情况下,当您使用 IBM Cognos Business Insight Advanced 将源目录树中的成员插入到报表中时,成员将与其子项一起以集 [ 创建成员集 ] 的形式插入。您可以更改成员的插入方式。因为现在只想添加 Lanterns 产品类型,所以想要插入不带子项的成员。
为此,在“可插入对象”窗格的“来源”选项卡上,单击“插入带子项的成员”按钮,并选择插入成员的方式,选择“插入单个成员”,如图 16 所示。
图 16. 插入单个成员

- 然后在 Products > Camping Equipment 路径下,把 Lanterns 拖拽到报表的最后一行,注意等到有闪烁行线出现时再松开鼠标。
- 这样就有 6 个产品类型出现在报表中,Lanterns 产品类型出现在报表的最后一行。点击右上角的“完成”回到 Business Insight 的仪表盘窗口。
- 值得注意的是,现在修改的报表仅仅是改变自助式仪表盘的数据,而不影响原先的报表“第一个自助式设计分析”。因此您可以在自助式仪表盘里面引用自助式设计 分析的结果,也可以随时利用自助式设计分析的强大功能来弥补自助式仪表盘的不足。Business Insight 和 Business Insight Advanced 两者无缝集成,不需要切换。
总结 您可以使用两种不同的方式打开 Business Insight Advanced: - 从执行报表高级编辑(“完成更多”)的 Business Insight 仪表盘中打开。这种方式适合业务人员在自助式仪表盘里面想进一步进行自助分析。
- 从 IBM Cognos Connection 的“启动”菜单中打开或从欢迎页面(“创建者业务报表”)中打开。这种方式适合业务人员进行自助设计分析。
Business Insight Advanced 是给业务人员进行自助式设计分析用的。在《第一次安装》中,您曾经用 Report Studio 构建了第一张简单报表,而 Report Studio 是给专业人士使用的报表工具。 您可以用 Report Studio 来打开刚才保存的“第一个自助式设计分析”。 在开始菜单中启动 IBM Cognos BI Developer Edition,运行 Developer Edition Manager,在确保左侧的服务都正常的情况下,点击右上角的启动,选择 Report Studio。在“Cognos > 公共文件夹 > 示样 > 多维数据集”路径下,选择“Great Outdoors Sales (cube)”数据包,进入 IBM Report Studio 后选择“打开现有的”。在“我的文件夹”下,可以找到刚才保存的“第一个自助式设计分析”,点击“打开”。 您可以看到 Report Studio 提供了给专业报表创建者的许多功能,下面举例说明 Business Insight Advanced 不能实现而 Report Studio 可以完成的功能。 - 在 Report Studio 中间的“查询资源管理器”,您可以创建或修改关系报表 [ 使用关系查询 ] 或维度报表 [ 使用维度查询 ] 中的查询,以及执行复杂任务,如定义合并联接和写入 SQL 语句,如图 17 所示。在 Business Insight Advanced,您不能看到也不能操控查询。
图 17. 查询资源管理器

- 点击交叉表的左上方的三个小红点,选择交叉表,您可以看到交叉表的属性,如图 18 所示。这里有一些属性是 Business Insight Advanced 无法编辑的。比如在“其他”类别里面的“名称”,这里的名称就是您刚才在 Business Insight 中进行自助式仪表盘时候看到的对象名称。您可以在 Report Studio 把它修改成更有意义的名字,比如“产品线收入表”。
图 18. 交叉表属性

摘要: 熟悉 Report Studio Report Studio 是用来制作更加精细的专有报表的工具。IBM Cognos Report Studio 是一个基于 Web 的报表创建工具,专业报表创建者和开发人员可使用此工具针对多个数据库创建复杂的、具有多页并且可以进行多项查询的报表。使用 Report Studio,您可以创建公司所需的任何报表,如发票报表、财务报表以及每周销售和库存报表。报表... 阅读全文
什么是自助式仪表盘 IBM Cognos Business Insight 基于网页的界面可以让您建立先进的交互式的仪表盘,来提供见解并使协同决策变得简单。在 IBM Cognos Business Insight 中创建的仪表盘可以让业务用户将集成的商业智能体验与协作决策相结合。用户可以快速而轻松地完成绝大部分任务。例如可以查看并与报表交互、排列数据或者执 行额外的计算、或者与团队中其他成员共享信息。因为用户对报表和数据有不同的需求,所以可以利用自由形式布局也可以重新排列报表或添加新报表。 定制化内容 当启动 IBM Cognos Business Insight 的时候,您可以选择打开一个已存在的仪表盘或是创建一个仪表盘。在打开的工作区域中,您都可以添加或重新排列新小工具,所有仪表盘都是可编辑的。业务用户 可以将有权限访问各种系统内容组合成一个指定的仪表盘,并可以进行分析。高级业务用户或报表作者可以为一组业务用户创建报表和基础仪表盘,来包含该组用户 工作所需的所有信息。这样,业务用户就能定制仪表盘来契合特殊的需求。这些需求可能包括重排布局,更改图形,将数据排序,添加计算,新建过滤等以及搜索一 份补充报表并添加其到工作区域。 添加新内容 您可以从内容或工具箱标签拖拽新小工具到仪表盘来。使用相同的方式,你可以添加报表、报表组件、度量列表或独立度量、TM1 项目、或者任何小工具中描述的项目。您可以使用 IBM Cognos Business Insight 中增强的搜索功能来寻找并添加相关内容到仪表盘。这个功能是一种全文搜索,类似于流行的搜索引擎。 交互分析能力 除了更改报表中数据的显示,你也可以与报表交互,并自定义其排列。此外,你还可以利用报表中的数据添加基础性运算,可以过滤数据。 高级过滤 使用过滤小工具可以过滤报表中所有与其关联的报表。这样,如果你有一个地区选择过滤器,它过滤所有该地区一项的报表。当然,它只过滤那些与这个过滤器关联的报表中的数据。当你在过滤小工具上选择一个值,报表就会重新刷新来显示你选择的过滤好的数据项。
其他内容 除了报表内容之外,您也可以添加其他内容到仪表盘,例如 Web 页面、图像、我的收件箱、文本、RSS 订阅。 创建注释 对于仪表盘上的一份报表中的内容,评论或注释有助于用户与团队中其他成员进行合作。这些注释可以让其他查看相同报表的用户看见。这些用户也可以添加 关于此报表的进一步注释,来提供额外的信息。例如,注释可以提醒在某个地区调查销售较低的结果,也可以是某些异常数据的一个解释,例如一个最近发布且已在 市场上有数月的产品的销售数据较小。您可以注释实时报表并保存输出版本。当打印一个报表的 PDF 版本或是导出报表为 PDF 或 Excel 输出时,注释也会被包括在其中。
创建第一个自助式仪表盘 - 在开始菜单中启动 IBM Cognos BI Developer Edition,运行 Developer Edition Manager,在确保左侧的服务都正常的情况下,点击右上角的启动,选择 Business Insight。在 IBM Cognos Business Insight 的启动页上选择“新建”。
- 在右侧的可插入对象中选择下面的“内容”,在“公共文件夹 > 示样 > 模型 > GO 数据仓库 ( 查询 ) > Business Insight 源报表 > 收入数据”路径下,右键选择“Revenue by Country – bar - chart”报表,选择“插入”,如图 1 所示。再用同样的方式,把另外的 Revenue by Product Type - Combination Chart 和 Revenue by Order method - Pie Chart 两张报表插入到仪表盘中。
图 1. 选择报表

- 在仪表盘空白处点击右键,选择“排列所有小工具以符合内容的显示尺寸”来调整三张报表在仪表盘的大小和位置。您也可以单独调整每个报表的大小和位置,方法是鼠标移动到报表上,等到小工具菜单显示后选择“调整大小以适合内容”,如图 2 所示。
图 2. 调整大小

- 在右侧的可插入对象中选择下面的“工具箱”,可以看到有很多小工具,比如可以添加公司的 Web 页面,添加公司商标图像等。这里我们选择“文本”,输入“公司收入仪表盘”,选择合适的大小,把它添加到仪表盘中,如图 3 所示。
图 3. 添加文本

- 点击上方工具栏的保存按钮,保存到我的文件夹中,命名为“第一个交互式仪表盘”。不要关闭 IBM Cognos Business Insight。
您可以在 Business Insight 中保存的任意仪表盘设置为主页。在保存按钮旁边有“主页”按钮,您可以在旁边单击箭头,找到“将仪表盘设为主页”这个选项。
查看仪表盘的数据 - 选择“Revenue by Country – bar - chart”报表,在上方的小工具操作中选择“更改显示类型”,更改为“列表”,如图 4 所示。在“更改显示类型”旁边的按钮是“更改调色板”,您可以根据喜好来选择不同风格不同类型的显示方式来展现数据。
图 4. 更改显示类型

- 在列表中选择“中国”、“巴西”、“加拿大”和“法国”,然后在上方小工具操作中选择“过滤器”,过滤条件是“包含中国、巴西、加拿大、法国”,如图 5 所示。 。
图 5. 添加本地过滤条件

- 在上方的小工具操作中选择“更改显示类型”,更改为“条形图”。这样新的“Revenue by Country – bar - chart”报表就仅仅包含中国、巴西、加拿大、法国了。
- 点击左上方的展开按钮,可以查看已应用过滤器和已应用排序,如图 6 所示。点击过滤器右边的删除按钮,把刚才建立的“包含中国、巴西、加拿大、法国”过滤器删除。
图 6. 查看本地过滤条件

- 在右侧的可插入对象中选择下面的“工具箱”,右键点击“幻灯片过滤器”选择“插入”,把它添加到仪表盘中。在幻灯片过滤器属性窗口中,选择三张报表都有的数据项“收入”,把过滤器的内容设为值范围,修改描述文本后确定,如图 7 所示。
图 7. 幻灯片过滤器属性

- 您可以试着调整页面布局,使得仪表盘更美观。在页面的右上角有一个“内容”按钮,点击可以隐藏或者显示右侧的可插入对象,隐藏右侧的可插入对象可以让仪变盘区域变得更大一些。
您还可以试着拖拽幻灯片过滤器的滑条杆,仪表盘的三张报表图形都会随着变化。
图 8. 调整全局过滤条件

选择一张报表点击左上方的展开按钮,可以查看已应用过滤器和已应用排序,如图 9 所示。刚才建立的全局过滤条件已经显示在已应用过滤器中了,如果在这里删除过滤器,那么只会影响当前报表,而不会影响仪表盘中的其他报表,这是和本地过滤条件的区别所在。
图 9. 查看全局过滤条件

仪表盘的数据交互 - 在右侧的可插入对象中选择下面的“内容”,在“公共文件夹 > 示样 > 模型 > GO 数据仓库 ( 分析 ) > Report Studio 报表示样”路径下,右键选择“预算与实际”报表,选择“在新仪表盘中打开”。如果提示“是否保存仪表盘”,选择“是”。
- 点击上方工具栏的保存按钮,保存到我的文件夹中,命名为“数据交互”。
- 右键选择您需要评注的数据,比如美洲户外用品商店的差额百分比 69.16%,选择添加注释,如图 10 所示。
图 10. 添加注释

- 注释内容填写“69.16% - 增加预算”,确定以后可以看到在 69.16% 数据项上有红色三角形标记,表明有注释。您要查看注释,可将指针悬停于注释(由红色三角形标记指明)上。具有报表读取权限的所有用户都可以查看注释。 如果同一单元格或报表小工具有多个注释,它们将按逆时序显示。 对于每个注释,您可以看到撰写注释的用户的用户名、撰写日期和时间。
图 11. 查看注释

- 点击上方小工具操作的菜单,可以将包含报表内容的报表小工具导出为多种格式。要保存数据的快照,您可以创建报表小工具的 PDF 版本,刚才添加的注释也会保留在导出的 PDF 文件中。当您导出到 PDF 时,小工具将出现在 Adobe Reader 中,因此您必须在计算机上安装 Adobe Reader。
图 12. 将仪表盘小工具导出为不同格式

- 您可以查看报表数据项的 lineage 信息,以了解该报表数据项所代表的内容。Lineage 信息通过数据包和数据包使用的数据源追溯项目的元数据。Lineage 还显示报表创建者添加的或在数据模型中定义的所有数据项过滤器。
IBM Cognos BI Lineage 工具包括两种视图:业务视图和技术视图。业务视图显示了高级语篇信息,该信息描述了数据项及其所来自的数据包。技术视图是选定数据项的 lineage 的图形表示。Lineage 从数据包中的数据项一直跟踪到数据包使用的数据源。
图 13. 查看报表数据项的传承信息

- 下面按住 CTRL 键选中您关心的地区门店,比如“美洲 > 户外用品商店”、“美洲 > 直销”和“美洲 > 百货商店”,然后点击上方小工具操作的计算按钮,选择“+ > 直销 + 户外用品商店 + 百货商店”。您会发现刷新后的仪表盘把计算结果显示在新行中。默认情况下,将使用计算中所用的表达式作为标题名称。计算结果不会存储在基础数据源中。相 反,IBM Cognos Business Insight 会在每次刷新报表时重新运行计算。计算结果始终以数据源中的最新数据为基础。
图 14. 增加计算

您在上方小工具操作的按钮里面还能找到“分组 / 取消分组”、排序等按钮。如果是灰色,表示该功能不适用您目前的报表和数据。 排序按字母或数字的升序或降序组织数据。例如,您可以对列出产品销售额的列按降序进行排序,以便对产品销售额从高到低进行排序。 如果列表报表中的同一列多次出现同一个值,那么您可以将这些相同的值归为一组。分组操作将对选定报表项目的行进行重新排序,这样相同值会一起显示并抑制重 复显示的情况。由于分组的列会显示在未分组的列之前,因此分组和取消分组操作可能会更改报表项目的顺序。但是您可以对列表中的列重新排序来提高报表的可读 性。
总结 在本系列教程的“第 1 部分,第一次安装”中,您安装了样例数据和样例档案。您可以在“公共文件夹 > 示样 > 模型 > Business Insight 示样”目录下找到六个样例仪表盘。您可以依次打开来进行更深一步地研究和学习。 - 员工满意度仪表盘
该报表显示员工满意度的不同度量,例如培训投资、员工调查结果(按部门和按主题,包括与计划调查结果的比较),以及员工奖金列表(按国家 / 地区排序)。滑块过滤器适用于奖金列表。 - 市场营销仪表盘
该仪表盘显示不同促销活动的结果。活动名称的选择值过滤器适用于前两个图表。产品系列选择值过滤器适用于广告费图表,年份滑块过滤器适用于广告费交叉表。 - 招聘仪表盘
该仪表盘显示针对不同指标(根据组织、部门、分部)的招聘结果(填充职位的平均天数)、年份和有关不同招聘技巧的成功的详细信息。两个选择值过滤器控制其中三个小工具。 - 收入数据仪表盘
该仪表盘按区域、国家 / 地区(由选择值过滤器控制)、产品类型(由选择值过滤器控制)及订购方法显示收入。 - 销售(按年)仪表盘
该仪表盘显示由滑块过滤器控制的一年范围内不同的销售指标:利润率、毛利润、产品成本、销售数量、区域收入以及实际收入与计划收入之间的比较。滑块过滤器控制所有小工具。 - 销售仪表盘(交互式)
该仪表盘显示销售的不同方面:月毛利润、地区毛利润和产品系列毛利润,区域收入以及对该销售做出贡献的销售代表的数目。 该源对象基于“Go 数据仓库 ( 分析 )”数据包和“Go 数据仓库 ( 查询 )”数据包。 该销售仪表盘是交互式的,可以支持向上追溯和向下追溯的功能。 您可以在报表或报表组成部分中向上追溯或向下追溯。在 IBM Cognos Business Insight 中,对于列表和交叉表,将指针悬停在数据项上时,超链接会标识可追溯项目。在图表中,当您将指针悬停在可追溯项目上时,指针将变为手形,并且工具提示将指 明您将追溯的内容。在 Business Insight 中,仅当您使用按维度结构化的数据时,才能执行向上追溯和向下追溯。
什么是交互式离线报表 IBM Cognos Active Report 是可以与用户交互的离线报表,包含了数据和展现内容,它在无法访问企业内部网络和数据库的情况下仍然可以通过此类报表分析数据,获得有价值的信息。 IBM Cognos Active Report 非常适合移动办公的情况,如销售体系。使用者在离线的条件下浏览报表,深入挖掘数据,获取额外的信息。IBM Cognos Active Report 拓展了商务智能的应用场景,并让系统户的更好的性能和支持更大的使用规模。 用户使用 IBM Cognos Report Studio 来创建 Active Report。IBM Cognos Active Report 具有很强的交互性和易用性,报表的设计从用户需求出发,并确保的简洁美观流畅的用户体验。 IBM Cognos Active Report 是 IBM Cognos Report Studio 报表的拓展。数据需要以一种简洁易懂的组织方式呈现给客户。有些用户习惯于数字,而另一些则偏好于图表。为了方便设计人员设计出更简洁的报表,IBM Cognos Report Studio 在保持原有功能的同时加入了一些交互式的控件 , 如选项卡、下拉菜单等,用于定义交互报表,对数据进行排序和过滤。 作为一个高级业务人员,可以将刚刚完成的动态报表下载成为本地文件,并转发给公司其它成员 . 文件最终以 mht 格式保存 , 并可以以邮件附件形式发送给同事。 如果正在使用 Microsoft Internet Explorer 6.0,则无法将 MHT 格式的活动报表作为文件打开,交互式离线报表需要 Microsoft Internet Explorer 7 版本以上。要在 Mozilla Firefox 中查看 MHT 格式的活动报表,必须先下载一个 UnMHT 附加组件。
创建第一张交互式离线报表 - 在开始菜单中启动 IBM Cognos BI Developer Edition,运行 Developer Edition Manager,在确保左侧的服务都正常的情况下,点击右上角的启动,选择 Report Studio。
- 在“Cognos > 公共文件夹 > 示样 > 模型”路径下,选择“ GO 数据仓库 ( 查询 ) ”数据包,进入 IBM Report Studio 后选择“新建”。
图 1. 选择数据包

在选择报表类型的时候,选择“活动报表”,点击确定。
图 2. 选择报表类型

- 在左侧的可插入对象中先插入一个列表,然后展开“销售和市场营销(查询)”目录,再展开“销售(查询)”命名空间,按住 Control 键后选择“产品”下的产品类型以及“销售资料”下的收入和计划收入,拖动到右边报表页中,如图 3 所示。
 
准备工作 IBM Cognos Business Intelligence 10.1 是最新的商业智能解决方案,用于提供查询、报表、分析、仪表板和记分卡功能,并且可通过规划、方案建模、预测分析等功能进行扩展。它可以在人们尝试了解业绩并使用工具做出决策时,在思考和工作方式方面提供支持,以便人们可以搜索和组合与业务相关的所有方面,并与之进行交互。 - 查询和报表功能为用户提供根据事实做出决策所需的信息。
- 仪表板使任何用户都能够以支持其做出决策的方式来访问内容、与之交互,并对其进行个性化设置。
- 分析功能使您能够从多个角度和方面对信息进行访问,从而可以查看和分析信息,帮助您做出明智的决策。
- 协作功能包括通信工具和社交网络,用于推动决策过程中的意见交流。
- 记分卡功能可实现业务指标的捕获、管理和监控的自动化,使您可将其与自己的战略和运营目标进行比较。
在开始体验 Cognos BI 10.1 之前,您需要到 IBM developerWorks 去下载 Cognos 10.1 的试用版。IBM Cognos BI Developer Edition V10.1.0 下载地址是:http://www.ibm.com/developerworks/cn/downloads/im/cognosbi/。 您需要下载两个文件,IBM Cognos BI Developer Edition 10.1.0 Windows English 的下载文件名是 CZS56EN.tar.gz,IBM Cognos Business Intelligence Samples V10.1.0 for DB2 LUW Windows English 的下载文件名是 CZQ90EN.tar.gz。IBM Cognos BI Developer Edition V10.1.0 有 30 天的使用时间,足够让您完成本教程的学习了。 根据试用版的系统需求,您需要用 Windows 操作系统来进行安装,要求 Windows XP SP3 或者更高的版本。另外您要安装 Windows 的 Internet 信息服务 IIS,并且把浏览器 IE 升级到 7 版本以上。建议内存有 2G 以上,有 1.5 G 以上的临时空间和 2G 以上的磁盘空间来进行安装。 由于本教程需要数据库来存放 Cognos BI 10.1 的样例数据,所以您还需要到 IBM developerWorks 去下载 DB2 的社区版。DB2 Express-C 9.7.4 for Windows 下载地址是:http://www.ibm.com/developerworks/cn/downloads/im/udbexp/。下载文件名是 db2exc_974_WIN_x86.exe。 安装 DB2
双击 db2exc_974_WIN_x86.exe 然后选择任意目录进行解压缩。解压成功后点击 setup.exe 进入 DB2 安装启动板。
图 1. DB2 安装启动板

点击“安装新产品”,进入到安装向导界面,点击“下一步”继续。阅读并接受许可协议,点击“下一步”继续。
图 2. 选择安装类型

本教程选择典型安装,这个选项将安装 DB2 的主要部件和功能。
图 3. 选择创建响应文件

选择不创建响应文件而只进行安装,点击“下一步”继续。
图 4. 选择安装文件夹

一般使用默认的驱动器和目录设置就可以了,确保有 560 MB 可用空间,点击“下一步”继续。
图 5. 设置用户信息

安装 DB2 之后,某些 DB2 进程会作为系统服务运行。为了运行这些服务,需要一个操作系统帐户。在本教程中,使用默认的 db2admin 用户帐户,密码为 cognos,DB2 安装程序会在操作系统中创建它。当然您也可以指定使用一个现有的帐户,但是这个帐户必须具有本地管理员权力。点击“下一步”继续。
图 6. 配置 DB2 实例

可以认为 DB2 实例是数据库的容器。必须有一个实例,然后才能创建数据库。在 Windows 上进行安装时,会自动创建一个称为 DB2 的实例。在默认情况下,DB2 实例监听端口 50000 上的 TCP/IP 连接。可以点击配置来查看,在本教程中一切保持默认配置即可。点击“下一步”继续。
图 7. 开始复制文件

检查前面选择的安装选项。单击“安装”。结束以后,点击“完成”即可。
安装 Cognos 解压文件 CZS56EN.tar.gz,然后点击运行 Cognos 10 BI Server 安装程序 install.exe。
图 8. IBM Cognos BI Developer Edition 安装界面

选择简体中文后,点击“OK”。在简介这一步骤中,阅读许可协议并选择接受协议条款。
图 9. 选择安装文件夹

选择缺省文件夹即可以,要保证有可用空间。快捷方式文件夹是指产品图标的程序组,也可以采用缺省的 IBM Cognos BI Developer Edition。
图 10. 配置

在配置界面中可使用默认的端口。然后给 Cognos 的管理员设定用户名和密码,在本教程中设定管理员为 administrator,密码为 cognos。
图 11. 安装摘要

在安装摘要中可以看到整个安装需要 1.5G 以上的磁盘空间,点击“安装”继续。
图 12. 完成安装

完成安装界面时候,勾选启动 IBM Cognos BI Developer Edition Manager,然后点击“完成”。IBM Cognos BI Developer Edition Manager 是开发版特有的组件,可以用来安装和配置 IBM Cognos BI 和 Framework Manager,也可以用来管理用户和启动停止服务。
图 13. IBM Cognos Developer Edition Manager 第一次启动界面

第一次启动 IBM Cognos BI Developer Edition Manager,点击“完成”让 Manager 进行初始化的安装和配置。
图 14. 安装 IBM Cognos Developer Edition Manager

安装过程可能需要十几分钟,耐心等待直到登陆界面出现。
图 15. 登陆 IBM Cognos Developer Edition Manager

在登陆界面中输入在 图 10所示的用户名和密码,在本教程中是 administrator 和 cognos,然后点击确定。
图 16. 安装 Cogos BI Suite

选择 BI Suite,然后进行安装。IBM Cognos BI Suite 赋予了您完整的自助服务报告和即席查询能力,使其可以访问、修改和创建报表。访问任意类型的数据,包括关系 OLAP、分析 OLAP 或桌面文件。并通过 Web、PDF、Excel、电子邮件或门户发送您的报表。安装过程可能需要半小时,耐心等待直到直到登陆界面出现。在登陆界面中输入在图 10 所示的用户名和密码,在本教程中是 administrator 和 cognos,然后点击确定。
图 17. 安装 Framework Manager

选择 Framework Manager,然后进行安装,这个步骤非常快就完成了。Framework Manager 是元数据建模工具。它使得建模者可以创建和管理业务相关的元数据,以便在所有 Cognos BI 应用程序中使用。Framework Manager 的主要用户为数据仓库开发人员和数据建模者。
配置 Cognos 首先需要把 C:\Program Files\IBM\SQLLIB\java 目录下的 db2jcc.jar 和 db2jcc_license_cu.jar 拷贝到 C:\Program Files\IBM\Cognos Developer\tomcat\lib 目录下,然后在 IBM Cognos Developer Edition Manager 重启 Cognos 服务。 安装样例数据 解压文件 CZQ90EN.tar.gz,然后点击运行 install_DB2_samples.exe 进行安装。在 Instruction 这一步骤中,阅读许可协议并选择接受协议条款。
图 18. 选择安装路径

安装路径采用缺省的,这样会和 IBM Cognos BI Developer Edition 安装在同一目录下。完成安装后,样例数据文件会放在 C:\Program Files\IBM\Cognos Developer\webcontent\samples\datasources\db2,找到数据文件 GS_DB.tar.gz,并进行解压缩。 然后在点击开始菜单,选择运行,输入 db2cmd 再确定,进入到 DB2CLP 的窗口。安装过程可能需要五分钟,具体操作命令和显示参见清单 1。在这个过程中需要输入 DB2 的用户名和密码,在本教程是 db2admin 和 cognos。
清单 1. 创建数据库并导入数据
>CD C:\Program Files\IBM\Cognos Developer\webcontent\samples\datasources\db2\GS_DB\win >GOSalesConfig.bat >setupGSDB.bat ------------------------------------------------------------------- DB2 version 9 or later detected - using DB2 Version 9 syntax ------------------------------------------------------------------- Press Enter at the prompts to accept the default value shown Default values can be specifed in the file GOSalesConfig.sh ------------------------------------------------------------------- Please enter the name of the database ( or the alias ) to be used for the GOSales sample data (default=GS_DB) : ------------------------------------------------------------------- This script can create the GS_DB database. Creating the database will cause any existing databases with the same name to be dropped. If you choose not to recreate the database, existing objects within the database will be dropped. Would you like to create the database GS_DB (Y/N) Default=Y : Please wait ... Starting GOSALES_RUN_SCRIPTS Dropping existing database GS_DB if found Creating database GS_DB Please wait ... Starting GOSALES_RUN_SCRIPTS Connecting to GS_DB 输入 db2admin 的当前密码:cognos 数据库连接信息 数据库服务器 = DB2/NT 9.7.4 SQL 授权标识 = DB2ADMIN 本地数据库别名 = GS_DB Error dropping existing tables Creating tables. Loading data. Creating primary keys Creating indexes Creating constraints. Creating stored procedures Creating views Granting permissions Updating statistics Verifying row counts Table row count validation successful Adding table comments |
创建数据源连接 在开始菜单中启动 IBM Cognos BI Developer Edition,运行 Developer Edition Manager,在确保左侧的服务都正常的情况下,点击右上角的启动,如图 19 所示选择 IBM Cognos Administration。
图 19. 启动 Cognos Administration

在 IBM Cognos Administration 界面中选择配置页,选中“数据源连接”,点击右上角的图标,如图 20 所示新建数据源。
图 20. 在 Cognos Administration 中添加数据源

- 在指定名称和说明 - 新建数据源向导中,名称中输入“great_outdoors_sales”,点击下一步。
- 在指定连接 - 新建数据源向导中,选择类型为“IBM DB2”,点击下一步。
- 在指定 IBM DB2 连接字符串 - 新建数据源向导中,DB2 数据库名称写为“GS_DB”,在登陆勾选“密码”,用户 ID 中写为 “db2admin”,密码和确认密码写为 “cognos”。然后点击“测试连接”如图 21 所示。测试成功后点击下一步。如果测试有问题的时候,可以重启 Cognos 服务或者重启系统。
图 21. 指定 IBM DB2 连接字符串

- 在指定命令 - 新建数据源向导中,保持缺省,点击完成。
- 重复 1 到 4 的步骤,再创建“great_outdoors_warehouse”数据源,即名称为“great_outdoors_warehouse”,其余内容“great_outdoors_sales”一样。
- 在指定名称和说明 - 新建数据源向导中,名称中输入“sales_and_marketing”,点击下一步。
- 在指定连接 - 新建数据源向导中,选择类型为“IBM Cognos PowerCube”,点击下一步。
- 指定 IBM Cognos PowerCube 连接字符串 - 新建数据源向导中,Windows 位置输入“C:\Program Files\IBM\Cognos Developer\webcontent\samples\datasources\cubes\PowerCubes\EN \sales_and_marketing.mdc”。然后点击“测试连接”,测试成功后点击完成。
- 重复 6 到 8 的步骤,再创建“great_outdoors_sales_en”数据源,即名称为 “great_outdoors_sales_en”,Windows 位置输入“C:\Program Files\IBM\Cognos Developer\webcontent\samples\datasources\cubes\PowerCubes\EN \great_outdoors_sales_en.mdc”。
- 重复 6 到 8 的步骤,再创建“employee_expenses”数据源,即名称为“employee_expenses”,Windows 位置输入“C:\Program Files\IBM\Cognos Developer\webcontent\samples\datasources\cubes\PowerCubes\EN\ employee_expenses.mdc”。
- 重复 6 到 8 的步骤,再创建“go_accessories”数据源,即名称为“go_accessories”,Windows 位置输入“C:\Program Files\IBM\Cognos Developer\webcontent\samples\datasources\cubes\PowerCubes\EN\ go_accessories.mdc”。
- 重复 6 到 8 的步骤,再创建“go_americas”数据源,即名称为“go_americas”,Windows 位置输入“C:\Program Files\IBM\Cognos Developer\webcontent\samples\datasources\cubes\PowerCubes\EN\ go_americas.mdc”。
- 重复 6 到 8 的步骤,再创建“go_asia_pacific”数据源,即名称为“go_asia_pacific”,Windows 位置输入“C:\Program Files\IBM\Cognos Developer\webcontent\samples\datasources\cubes\PowerCubes\EN\ go_asia_pacific.mdc”。
回页首 导入示例档案库 接下来要把示例的部署档案库导入到 Cognos 环境中来。这些档案库的位置在 C:\Program Files\IBM\Cognos Developer\webcontent\samples\content\db2 目录下。选择拷贝三个文件到 C:\Program Files\IBM\Cognos Developer\deployment 目录下准备进行部署。 这三个文件是 IBM_Cognos_Samples.zip,本教程主要的 Great Outdoors 公司例子; IBM_Cognos_DrillThroughSamples.zip, Great Outdoors 公司显示钻透功能的例子; IBM_Cognos_PowerCube.zip 多维立方体的例子。 - 在 IBM Cognos Administration 界面中选择配置页,选中“内容管理”,点击右上角的图标,如图 22 所示新建导入。
图 22. 新建导入向导

- 在部署档案库中,首先选择 IBM_Cognos_Samples,点击下一步。
- 在指定名称和说明 - 新建导入向导,按照默认的名字,点击下一步。
- 在公共文件夹内容中,勾选档案库的内容“示样”,点击下一步。
- 在指定常规选项 - 新建导入向导,保留默认选项,点击下一步。
- 复查汇总 - 新建导入向导,点击下一步。
- 在选择操作 - 新建导入向导中,选择“保存并运行一次” ,点击完成。
- 在运行使用选项 - IBM_Cognos_Samples 中,选择“现在”,点击运行。
- 重复 1 到 8 的步骤,选择 IBM_Cognos_PowerCube 进行导入。
10. 重复 1 到 8 的步骤,选择 IBM_Cognos_DrillThroughSamples 进行导入。 第一张简单报表 在开始菜单中启动 IBM Cognos BI Developer Edition,运行 Developer Edition Manager,在确保左侧的服务都正常的情况下,点击右上角的启动,选择 Report Studio,如 图 19所示。 在“Cognos > 公共文件夹 > 示样 > 模型”路径下,选择“ GO 数据仓库 ( 查询 ) ”数据包,进入 IBM Report Studio 后选择“新建”。
图 23. 选择数据包

在选择报表类型的时候,选择“列表”,点击确定。
图 24. 选择报表类型

在左侧的可插入对象中,展开“销售和市场营销(查询)”目录,再展开“销售(查询)”命名空间,选择“产品”下的产品系列、产品类型和产品,选择“销售资料”下的数量和收入,一个一个拖动到右边的列表中。
图 25. 选择项目

剩下的工作就是点击工具栏的运行按钮,来等待您的第一张简单报表出炉了,如图 26 所示。
图 26. 运行报表

报表运行结果如图 27 所示。
图 27. 第一张简单报表

总结 在整个安装过程中,DB2 是用户数据源,我们把本教程的样例数据放在了 DB2 的 GS_DB 数据库中,并在 Cognos Administration 进行了数据源的配置。 Cognos Connection 是 Cognos 门户,提供信息的集成和用户访问的统一入口。管理员可以通过他实现用户、角色管理,服务器配置,权限控制等各种管理功能;最终用户可以通过 Cognos Connection 访问到文件夹、报表、个性化展现、访问 Cognos Viewer、Report Studio、Business Insight 和 Event Studio 的内容。 Report Studio 是专业的报表制作模块。报表制作人员可以通过他制作各种类型的报表,包括中国特色的非平衡报表,地图,动态仪表盘,KPI 报表等。报表制作人员可以分页面设计,每页可以有多个查询,每个查询可以连接多个数据源,甚至异构数据源。报表的内容采用的是化繁为简的方式,可以精确控 制报表中每一个对象的各种属性。 Business Insight 是业务用户的自定义仪表盘工具,用户可以拖拽任意 Cognos BI 内容(包含查询,报表,分析,TM1 数据集等)形成自定义的仪表盘。 Cognos Framework Manager 是一个专门对元数据进行管理的客户端开发工具。他可以连接多个数据源,能够连接 OLAP 和数据库等各种数据源,并提供对元数据的定制和管理以及安全性控制等相关控制。
图 28. IBM Cognos BI Developer Edition 架构和工作原理

当您运行第一张简单报表的时候,IBM Cognos BI Developer Edition 是按照下面步骤来运行的: - 在 IBM Cognos Framework Manager 工具中,建模人员确保元数据是按照业务人员可以理解的方式来进行组织的。建模人员把元数据从一个或多个数据库中导入,并按照业务需求添加到模型中。
- 建模人员把模型数据包发布到 IBM Cognos Connection,这样开发报表人员就可以利用它们来进行创建报表和仪表盘了。比如在本教程中的“ GO 数据仓库 ( 查询 ) ”数据包。
- 业务人员和报表开发人员利用已经发布的数据包来理解业务数据。
- 用户在 IBM Cognos Connection 运行、查看和管理他们的内容。根据不同的权限,他们可以简单运行和查看报表,或者管理计划、门户展示等。
源文出自:http://blog.csdn.net/thy822/article/details/7608305
两种方法一样,只是写法不同 第一种写法 1 listeners:{
2 beforeedit:function(e){
3 if(...) e.cancel = true;//true表示不可编辑
4 }
5 } 第二种写法 1 grid.on('beforeedit',function(e)){
2 var record = e.record;
3 if(...){
4 e.cancel = true;//true表示不可编辑
5 }
6 }
1.首先看效果 2.需要一个合计插件GridSummary.js GridSummary 插件,下载后将后缀名该为 js 3.页面需要引用的文件 1 <link rel="stylesheet" type="text/css" href="include/ext-3.4.0/resources/css/ext-all.css" />
2 <link rel="stylesheet" type="text/css" href="include/ext-3.4.0/ux/css/ux-all.css" />
3 <script type="text/javascript" src="include/ext-3.4.0/adapter/ext/ext-base.js"></script>
4 <script type="text/javascript" src="include/ext-3.4.0/ext-all.js"></script>
5 <script type="text/javascript" src="include/ext-3.4.0/ux/ux-all.js"></script>
6 <script type="text/javascript" src="include/ext-3.4.0/locale/ext-lang-zh_CN.js"></script>
7 <script type="text/javascript" src="include/ext-3.4.0/ux/GridSummary.js"></script> <!-- 合计插件 -->
8 <script type="text/javascript" src="demo.js"></script> <!-- 示例js -->
4.Grid代码 var url = "RequestAction/AT/Req_CT_SHIPMENTS.aspx?Action=GetDetailAll&S_SHIPMENTS_M_GUID=" + guid;
//复选框
var sm = new Ext.grid.CheckboxSelectionModel();
var textFileldVehicle = new Ext.form.TextField
({
allowBlank: false,
blankText: "请输入车号",
maxLength: 50
});
var numField = new Ext.form.NumberField({
allowNegative: false,
allowDecimals: true,
allowFormat: true,
decimalPrecision: 2,
allowBlank: false,
blankText: '金额必须大于零'
});
//字段集合
var fields =
[
{ name: 'S_VEHICLE_NUMBER' },
{ name: 'N_QUANTITY' },
{ name: 'N_FREIGHT' },
{ name: 'S_GUID' },
{ name: 'S_SHIPMENTS_M_GUID' }
];
var proxy = new Ext.data.HttpProxy({ url: url });
//数据读取器
var reader = new Ext.data.JsonReader({
totalProperty: "totalPorperty", //数据总条数
root: "rows", //将要显示数据的数组
id: "S_GUID", //每一行数据的唯一记录
fields: fields
});
//列集合 其中 summaryType: 'sum' 为求和
var cm = new Ext.grid.ColumnModel
({ columns: [sm,
new Ext.grid.RowNumberer({ header: 'NO', width: 30, align: 'center' }),
{ header: '车号', dataIndex: 'S_VEHICLE_NUMBER', editor: textFileldVehicle, summaryRenderer: function (v, params, data) { return '合计'; } },
{ header: '重量', dataIndex: 'N_QUANTITY', summaryType: 'sum', renderer: formatNumberDefault, align: 'right', editor: numField },
{ header: '运费', dataIndex: 'N_FREIGHT', summaryType: 'sum', renderer: formatNumberDefault, align: 'right', editor: numField}
]
});
//如果全部列都可排序否则单个设置
cm.defaultSortable = false;
//创建一个store
var shipmentsDetailstore = new Ext.data.Store({
proxy: proxy,
reader: reader,
autoDestroy: true,
autoLoad: { params: { start: 0, limit: pageSize} }
});
//插入行按钮
var btn_Insert = new Ext.Button({ text: '插入行', iconCls: 'insert', handler: function () {
//定义一个recode对象
var initValue = createShipmentDetailRow();
grid.stopEditing();
var maxRowIndex = grid.getStore().getCount();
grid.getStore().insert(maxRowIndex, initValue); //在第一个位置插入
grid.view.refresh();
grid.getSelectionModel().selectLastRow();
grid.getView().focusRow(maxRowIndex); //焦点标记行
grid.startEditing(maxRowIndex, 2); //单元格转换成编辑状态
}
});
//删除行按钮
var btn_Remove = new Ext.Button({ text: '删除行', iconCls: 'delete', handler: function () {
grid.stopEditing();
var rows = grid.getSelectionModel().getSelections();
if (rows == undefined || rows.length == 0) {
setShipmentStatusBarText('error', '请选择需要删除的行!');
return; //判断记录集是否为空,为空返回
}
grid.getStore().remove(rows);
grid.view.refresh();
}
});
//工具栏
var tbar = new Ext.Toolbar({
cls: 'top-toolbar',
items: [btn_Insert, '-', btn_Remove]
});
var summary = new Ext.ux.grid.GridSummary();
//创建GRID
var grid = new Ext.grid.EditorGridPanel
({
id: 'ShipmentsDetailGirdPanel',
deferredRender: false,
enableColumnHide: false,
enableHdMenu: false,
columnLines: true,
enableColumnMove: false,
store: shipmentsDetailstore,
sm: sm,
cm: cm,
loadMask: true,
//自适应宽度 参数为列数
// autoExpandColumn: 4,
//超过长度带自动滚动条
autoScroll: true,
border: false,
nocache: false,
timeout: 10,
clicksToEdit: 1,
scripts: true,
loadMask: { msg: '正在加载数据,请稍侯……' },
tbar: tbar,
view: new Ext.ux.grid.BufferView({
rowHeight: 25,
scrollDelay: true,
forceFit: true,
deferEmptyText: true,
emptyText: "无数据"
}),
plugins: summary
}); 5.此时会看到合计行字体偏小 添加样式 .x-grid3-summary-row .x-grid3-cell-inner {
FONT: 12.5px tahoma,arial,helvetica,sans-serif
} 6.此示例Ext版本为 3.4.0
人们对软件架构存在非常多的误解,其中一个最为普遍的误解就是:将架构(Architecture)和框架(Framework)混为一谈。  框架是一种特殊的软件,它并不能提供完整无缺的解决方案,而是为你构建解决方案提供良好的基础。框架是半成品。典型地,框架是系统或子系统的半成品;框架中的服务可以被最终应用直接调用,而框架中的扩展点是供应用开发人员定制的“可变化点”。 软件架构不是软件,而是关于软件如何设计的重要决策。软件架构决策涉及到如何将软件系统分解成不同的部分、各部分之间的静态结构关系和动态交互关系等。经 过完整的开发过程之后,这些架构决策将体现在最终开发出的软件系统中;当然,引入软件框架之后,整个开发过程变成了“分两步走”,而架构决策往往会体现在 框架之中。或许,人们常把架构和框架混为一谈的原因就在于此吧! 节选自《软件架构设计》书稿 原文出自: http://blog.csdn.net/lovingprince/article/details/3347248
Web集群是由多个同时运行同一个web应用的服务器组成,在外界看来就像一个服务器一样,这多台服务器共同来为客户提供更高性能的服务。集群更标准的定 义是:一组相互独立的服务器在网络中表现为单一的系统,并以单一系统的模式加以管理,此单一系统为客户工作站提供高可靠性的服务。 而负载均衡的任务就是负责多个服务器之 间(集群内)实现合理的任务分配,使这些服务器(集群)不会出现因某一台超负荷、而其他的服务器却没有充分发挥处理能力的情况。负载均衡有两个方面的含 义:首先,把大量的并发访问或数据流量分担到多台节点上分别处理,减少用户等待响应的时间;其次,单个高负载的运算分担到多台节点上做并行处理,每个节点 设备处理结束后,将结果汇总,再返回给用户,使得信息系统处理能力可以得到大幅度提高 因此可以看出,集群和负载均衡有本质上的不同,它们是解决两方面问题的不同方案,不要混淆。 集群技术可以分为三大类: 1、高性能性集群(HPC Cluster) 2、高可用性集群(HA Cluster) 3、高可扩展性集群 一、高性能性集群(HPC Cluster) 指以提高科学计算能力为目标的集群技术。该集群技术主要用于科学计算,这里不打算介绍,如果感兴趣可以参考相关的资料。 二、高可用性集群(HA Cluster) 指为了使群集的整体服务尽可能可用,减少服务宕机时间为目的的集群技术。如果高可用性集群中的某节点发生了故障,那么这段时间内将由其他节点代替它的工作。当然对于其他节点来讲,负载相应的就增加了。 为了提高整个系统的可用性,除了提高计算机各个部件的可靠性以外,一般情况下都会采用该集群的方案。 对于该集群方案,一般会有两种工作方式: ①主-主(Active-Active)工作方式 这是最常用的集群模型,它提供了高可用性,并且在只有一个节点时也能提供可以接受的性能,该模型允许最大程度的利用硬件资源。每个节点都通过网络对客户机 提供资源,每个节点的容量被定义好,使得性能达到最优,并且每个节点都可以在故障转移时临时接管另一个节点的工作。所有的服务在故障转移后仍保持可用,但 是性能通常都会下降。  这是目前运用最为广泛的双节点双应用的Active/Active模式。 支撑用户业务的应用程序在正常状态下分别在两台节点上运行,各自有自己的资源,比如IP地址、磁盘阵列上的卷或者文件系统。当某一方的系统或者资源出现故障时,就会将应用和相关资源切换到对方的节点上。 这种模式的最大优点是不会有服务器的“闲置”,两台服务器在正常情况下都在工作。但如果有故障发生导致切换,应用将放在同一台服务器上运行,由于服务器的处理能力有可能不能同时满足数据库和应用程序的峰值要求,这将会出现处理能力不够的情况,降低业务响应水平。 ②主-从(Active-Standby)工作方式 为了提供最大的可用性,以及对性能最小的影响,主-从工作方式需要一个在正常工作时处于备用状态的节点,主节点处理客户机的请求,而备用节点处于空闲状态,当主节点出现故障时,备用节点会接管主节点的工作,继续为客户机提供服务,并且不会有任何性能上影响。  两节点的Active/Standby模式是HA中最简单的一种,两台服务器通过双心跳线路组成一个集群。应用Application联合各个可选的系统组件如:外置共享的磁盘阵列、文件系统和浮动IP地址等组成业务运行环境。 PCL为此环境提供了完全冗余的服务器配置。这种模式的优缺点: - 缺点:Node2在Node1正常工作时是处于“闲置”状态,造成服务器资源的浪费。
- 优点:当Node1发生故障时,Node2能完全接管应用,并且能保证应用运行时的对处理能力要求。
三、高可扩展性集群 这里指带有负载均衡策略(算法)的服务器群集技术。带负载均衡集群为企业需求提供了更实用的方案,它使负载可以在计算机集群中尽可能平均地分摊处理。而需 要均衡的可能是应用程序处理负载或是网络流量负载。该方案非常适合于运行同一组应用程序的节点。每个节点都可以处理一部分负载,并且可以在节点之间动态分 配负载, 以实现平衡。对于网络流量也是如此。通常,单个节点对于太大的网络流量无法迅速处理,这就需要将流量发送给在其它节点。还可以根据每个节点上不同的可用资 源或网络的特殊环境来进行优化。 负载均衡集群在多节点之间按照一定的策略(算法)分发网络或计算处理负载。负载均衡建立在现有网络结构之上,它提供了一种廉价有效的方法来扩展服务器带宽,增加吞吐量,提高数据处理能力,同时又可以避免单点故障。 前面已经说过负载均衡的作用是在多个节点之间按照一定的策略(算法)分发网络或计算处理负载。负载均衡可以采用软件和硬件来实现。一般的框架结构可以参考下图。  后 台的多个Web节点上面有相同的Web应用,用户的访问请求首先进入负载均衡分配节点(可能是软件或者硬件),由它根据负载均衡策略(算法)合理地分配给 某个Web应用节点。每个Web节点相同的内容做起来不难,所以选择负载均衡策略(算法)是个关键问题。下面会专门介绍均衡算法。 web 负载均衡的作用就是把请求均匀的分配给各个节点,它是一种动态均衡,通过一些工具实时地分析数据包,掌握网络中的数据流量状况,把请求理分配出去。对于不 同的应用环境(如电子商务网站,它的计 算负荷大;再如网络数据库应用,读写频繁,服务器的存储子系统系统面临很大压力;再如视频服务应用,数据传输量大,网络接口负担重压。),使用的均衡策略 (算法)是不同的。 所以均衡策略(算法)也就有了多种多样的形式,广义上的负载均衡既可以设置专门的网关、负载均衡器,也可以通过一些专用软件与协议来实现。在OSI七层协 议模型中的第二(数据链路层)、第三(网络层)、第四(传输层)、第七层(应用层)都有相应的负载均衡策略(算法),在数据链路层上实现负载均衡的原理是 根据数据包的目的MAC地址选择不同的路径;在网络层上可利用基于IP地址的分配方式将数据流疏通到多个节点;而传输层和应用层的交换(Switch), 本身便是一种基于访问流量的控制方式,能够实现负载均衡。 目前,基于负载均衡的算法主要有三种:轮循(Round-Robin)、最小连接数(Least Connections First),和快速响应优先(Faster Response Precedence)。 ①轮循算法,就是将来自网络的请求依次分配给集群中的节点进行处理。 ②最小连接数算法,就是为集群中的每台服务器设置一个记数器,记录每个服务器当前的连接数,负载均衡系统总是选择当前连接数最少的服务器分配任务。 这要比"轮循算法"好很多,因为在有些场合中,简单的轮循不能判断哪个节点的负载更低,也许新的工作又被分配给了一个已经很忙的服务器了。 ③快速响应优先算法,是根据群集中的节点的状态(CPU、内存等主要处理部分)来分配任务。 这一点很难做到,事实上到目前为止,采用这个算法的负载均衡系统还很少。尤其对于硬件负载均衡设备来说,只能在TCP/IP协议方面做工作,几乎不可能深入到服务器的处理系统中进行监测。但是它是未来发展的方向。 上面是负载均衡常用的算法,基于以上负载均衡算法的使用方式上,又分为如下几种: 1、DNS轮询 最早的负载均衡技术是通过DNS来实现的,在DNS中为多个地址配置同一个名字,因而查询这个名字的客户机将得到其中一个地址,从而使得不同的客户访问不同的服务器,达到负载均衡的目的。 DNS负载均衡是一种简单而有效的方法,但是它不能区分服务器的差异,也不能反映服务器的当前运行状态。当使用DNS负载均衡的时候,必须尽量保证不同的 客户计算机能均匀获得不同的地址。由于DNS数据具备刷新时间标志,一旦超过这个时间限制,其他DNS服务器就需要和这个服务器交互,以重新获得地址数 据,就有可能获得不同IP地址。因此为了使地址能随机分配,就应使刷新时间尽量短,不同地方的DNS服务器能更新对应的地址,达到随机获得地址,然而将过 期时间设置得过短,将使DNS流量大增,而造成额外的网络问题。DNS负载均衡的另一个问题是,一旦某个服务器出现故障,即使及时修改了DNS设置,还是 要等待足够的时间(刷新时间)才能发挥作用,在此期间,保存了故障服务器地址的客户计算机将不能正常访问服务器 2、反向代理服务器 使用代理服务器,可以将请求转发给内部的服务器,使用这种加速模式显然可以提升静态网页的访问速度。然而,也可以考虑这样一种技术,使用代理服务器将请求均匀转发给多台服务器,从而达到负载均衡的目的。 这种代理方式与普通的代理方式有所不同,标准代理方式是客户使用代理访问多个外部服务器,而这种代理方式是代理多个客户访问内部服务器,因此也被称为反向代理模式。虽然实现这个任务并不算是特别复杂,然而由于要求特别高的效率,实现起来并不简单。 使用反向代理的好处是,可以将负载均衡和代理服务器的高速缓存技术结合在一起,提供有益的性能。然而它本身也存在一些问题,首先就是必须为每一种服务都专门开发一个反向代理服务器,这就不是一个轻松的任务。 代理服务器本身虽然可以达到很高效率,但是针对每一次代理,代理服务器就必须维护两个连接,一个对外的连接,一个对内的连接,因此对于特别高的连接请求, 代理服务器的负载也就非常之大。反向代理方式下能应用优化的负载均衡策略,每次访问最空闲的内部服务器来提供服务。但是随着并发连接数量的增加,代理服务 器本身的负载也变得非常大,最后反向代理服务器本身会成为服务的瓶颈。 3、地址转换网关 支持负载均衡的地址转换网关,可以将一个外部IP地址映射为多个内部IP地址,对每次TCP连接请求动态使用其中一个内部地址,达到负载均衡的目的。很多 硬件厂商将这种技术集成在他们的交换机中,作为他们第四层交换的一种功能来实现,一般采用随机选择、根据服务器的连接数量或者响应时间进行选择的负载均衡 策略来分配负载。由于地址转换相对来讲比较接近网络的低层,因此就有可能将它集成在硬件设备中,通常这样的硬件设备是局域网交换机。 原文出自: http://blog.csdn.net/lovingprince/article/details/3290871
//修复办法,谷歌浏览器中,table的单元格实际宽度=指定宽度+padding,所以只要重写gridview里的一个方法,如下:
1 //修复办法,谷歌浏览器中,table的单元格实际宽度=指定宽度+padding,所以只要重写gridview里的一个方法,如下:
2 Ext.override(Ext.grid.GridView,{
3 getColumnStyle : function(colIndex, isHeader) {
4 var colModel = this.cm,
5 colConfig = colModel.config,
6 style = isHeader ? '' : colConfig[colIndex].css || '',
7 align = colConfig[colIndex].align;
8
9 if(Ext.isChrome){
10 style += String.format("width: {0};", parseInt(this.getColumnWidth(colIndex))-2+'px');
11 }else{
12 style += String.format("width: {0};", this.getColumnWidth(colIndex));
13 }
14
15 if (colModel.isHidden(colIndex)) {
16 style += 'display: none; ';
17 }
18
19 if (align) {
20 style += String.format("text-align: {0};", align);
21 }
22
23 return style;
24 },
25 });
26 [代码] [JavaScript]代码//看看修复过后的效果
原文出自:http://www.oschina.net/code/snippet_201314_15163
使用AES加密时,当密钥大于128时,代码会抛出java.security.InvalidKeyException: Illegal key size or default parameters Illegal key size or default parameters是指密钥长度是受限制的,java运行时环境读到的是受限的policy文件。文件位于${java_home}/jre/lib/security 这种限制是因为美国对软件出口的控制。
解决办法:
去掉这种限制需要下载Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files.网址如下。 下载包的readme.txt 有安装说明。就是替换${java_home}/jre/lib/security/ 下面的local_policy.jar和US_export_policy.jar
jdk 5: http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-archive-downloads-java-plat-419418.html#jce_policy-1.5.0-oth-JPR jdk6: http://www.oracle.com/technetwork/java/javase/downloads/jce-6-download-429243.html
参考http://stackoverflow.com/questions/6481627/java-security-illegal-key-size-or-default-parameters 原文出自:http://blog.csdn.net/shangpusp/article/details/7416603
随笔- 50 文章- 0 评论- 180 jQuery中所支持的异步模型为: - Callbacks,回调函数列队。
- Deferred,延迟执行对象。
- Promise,是Deferred只暴露非状态改变方法的对象。
这些模型都很漂亮,但我想要一种更帅气的异步模型。 Thread? 我们知道链式操作是可以很好的表征运行顺序的(可以参考我的文章《jQuery链式操作》),然而通常基于回调函数或者基于事件监听的异步模型中,代码的执行顺序不清晰。 Callbacks模型实际上类似一个自定义事件的回调函数队列,当触发该事件(调用Callbacks.fire())时,则回调队列中的所有回调函数。 Deferred是个延迟执行对象,可以注册Deferred成功、失败或进行中状态的回调函数,然后通过触发相应的事件来回调函数。 这两种异步模型都类似于事件监听异步模型,实质上顺序依然是分离的。 当然Promise看似能提供我需要的东西,比如Promise.then().then().then()。但是,Promise虽然成功用链式操作明确了异步编程的顺序执行,但是没有循环,成功和失败分支是通过内部代码确定的。 个人认为,Promise是为了规范化后端nodejs中I/O操作异步模型的,因为I/O状态只有成功和失败两种状态,所以他是非常成功的。 但在前端,要么只有成功根本没有失败,要么不止只有两种状态,不应当固定只提供三种状态的方案,我觉得应该提供可表征多状态的异步方案。 这个大家可以在something more看到。 我想要一种类似于线程的模型,我们在这里称为Thread,也就是他能顺序执行、也能循环执行、当然还有分支执行。 顺序执行 线程的顺序执行流程,也就是类似于: 这样就是依次执行do1,do2,do3。因为这是异步模型,所以我们希望能添加wait方法,即类似于: do1(); wait(1000); //等待1000ms
do2(); wait(1000); //等待1000ms
do3(); wait(1000); //等待1000ms
不使用编译方法的话,使用链式操作来表征顺序,则实现后的样子应当是这样的: 1 Thread(). //获取线程
2 then(do1). //然后执行do1
3 wait(1000). //等待1000ms
4 then(do2). //然后执行do2
5 wait(1000). //等待1000ms
6 then(do3). //然后执行do3
7 wait(1000); //等待1000ms 循环执行 循环这很好理解,比如for循环: 1 for(; true;){
2 dosomething();
3 wait(1000);
4 } 进行无限次循环执行do,并且每次都延迟1000ms。则其链式表达应当是这样的: 1 Thread(). //获取线程
2 loop(-1). //循环开始,正数则表示循环正数次,负数则表示循环无限次
3 then(dosomething). //然后执行do
4 wait(1000). //等待1000ms
5 loopEnd(); //循环结束 这个可以参考后面的例子。 分支执行 分支也就是if...else,比如: 1 if(true){
2 doSccess();
3 }else{
4 doFail();
5 }
6
7 那么其链式实现应当是: 1 Thread(). //获得线程
2 right(true). //如果表达式正确
3 then(doSccess). //执行doSccess
4 left(). //否则
5 then(doFail). //执行doFail
6 leftEnd(). //left分支结束
7 rightEnd(); //right分支结束 声明变量 声明变量也就是: 可被其它函数使用。那么我们的实现是:
1 Thread(). //得到线程
2 define("hello world!"). //将回调函数第一个参数设为hello world!
3 then(function(a){alert(a);}); //获取变量a,alert出来 顺序执行实现方案  Thread实际上是一个打包函数Fn队列。 Thread实际上是一个打包函数Fn队列。
所谓打包函数就是将回调函数打包后产生的新的函数,举个例子: 1 function package(callback){
2 return function(){
3 callback();
4 // 干其他事情
5 }
6 } 这样我们就将callback函数打包起来了。 Thread提供一个fire方法来触发线程取出一个打包函数然后执行,打包函数执行以后回调Thread的fire方法。 
那么我们就可以顺序执行函数了。 现在只要打包的时候设置setTimeout执行,则这个线程就能实现wait方法了。 循环执行实现方案 循环Loop是一个Thread的变形,只不过在执行里面的打包函数的时候使用另外一种方案,通过添加一个指针取出,执行完后触发Loop继续,移动指针取出下一个打包函数。 
分支执行实现方案 分支Right和Left也是Thread的一种变形,开启分支的时候,主Thread会创建两个分支Right线程和Left线程,打包一个触发分支Thread的函数推入队列,然后当执行到该函数的时候判断触发哪个分支执行。 
其中一个队列执行结束后回调主Thread,通知进行下一步。 例子 由于该方案和wind-asycn非常相似,所以我们拿wind.js中的clock例子进行改造看看其中的差别吧。 wind.js中的例子: 我的例子: Something more? 我们提供了on方法将事件转成分支来执行。 举个例子页面有个按钮“点我”,但是我们希望打开页面5秒内单击没有效,5秒后显示“请点击按钮”后,单击才会出现“你成功点击了”。 使用on分支是这样的:
1 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
2 <html>
3 <head>
4 <title>on - asThread.js Sample</title>
5 <meta http-equiv="X-UA-Compatible" content="IE=9" />
6 <script src="asThread.js"></script>
7 </head>
8 <body>
9 <button id = "b">点我</button>
10 <script>
11 var ele = document.getElementById("b");
12
13 Thread(). // 获得线程
14 then(function(){alert("请点击按钮")}, 5000). //然后等5秒显示"请点击按钮"
15 on(ele, "click"). // 事件分支On开始,如果ele触发了click事件
16 then(function(){alert("你成功点击了")}). //那么执行你成功点击了
17 onEnd(). // 事件分支On结束
18 then(function(){alert("都说可以的了")}). // 然后弹出"都说可以的了"
19 run(); //启动线程
20 </script>
21 </body>
22 </html> 自定义事件也可以哦,只要在.on时候传进去注册监听函数,和删除监听函数就行了。比如: 1 function addEvent(__elem, __type, __handler){
2 //添加监听
3 }
4
5 function removeEvent(__elem, __type, __handler){
6 //删除监听
7 }
8
9 Thread().
10 on(ele, "success", addEvent, removeEvent).
11 then(function(){alert("成功!")}).
12 onEnd().
13 run(); 当然实际上我们还可以注册多个事件分支。事件分支是并列的,也就是平级的事件分支没有现有顺序,所以我们能这样: 1 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
2 <html>
3 <head>
4 <title>on - asThread.js Sample</title>
5 <meta http-equiv="X-UA-Compatible" content="IE=9" />
6 <script src="asThread.js"></script>
7 </head>
8 <body>
9 <button id = "b">点我</button>
10 <button id = "c">点我</button>
11 <script>
12 var ele0 = document.getElementById("b"),
13 ele1 = document.getElementById("c");
14
15 Thread(). // 获得线程
16 then(function(){alert("请点击按钮")}, 5000). //然后等5秒显示"请点击按钮"
17 on(ele0, "click"). // 事件分支On开始,如果ele0触发了click事件
18 then(function(){alert("你成功点击了")}). //那么执行你成功点击了
19 onEnd(). // 事件分支On结束
20 on(ele1, "click"). // 事件分支On开始,如果ele1触发了click事件
21 then(function(){alert("你成功点击了")}). //那么执行你成功点击了
22 onEnd(). // 事件分支On结束
23 then(function(){alert("都说可以的了")}). // 然后弹出"都说可以的了"
24 run(); //启动线程
25 </script>
26 </body>
27 </html> 一个线程不够用?只要输入名字就能开辟或者得到线程了。 系统会自动初始化一个主线程,当不传参数时就直接返回主线程: 但如果主线程正在用想开辟一个线程时,只要给个名字就行,比如: Thread("hello") //得到名字是hello的线程 那么下次再想用该线程时只要输入相同的名字就行了: Thread("hello") //得到hello线程 默认只最多只提供10个线程,所以用完记得删掉: IE10已经提供了setImmediate方法,而其他现代浏览器也可以模拟该方法,其原理是推倒线程末端,使得浏览器画面能渲染,得到比setTimeout(0)更快的响应。 我们通过接口.imm来提供这一功能。比如: Thread(). imm(function(){alert("hello world")}). run(); 这方法和.then(fn)不太一样,.then(fn)是可能阻塞当前浏览器线程的,但.imm(fn)是将处理推到浏览器引擎列队末端,排到队了在运行。 所以如果你使用多个Thread(伪多线程),而又希望确保线程是并行运行的,那么请使用.imm来替代.then。 当然对于老版IE,只能用setTimeout(0)替代了。 分支Right传的参数如果只是布尔值肯定很不爽,因为这意味着分支是静态的,在初始化时候就决定了,但我们希望分支能在执行到的时候再判断是走 Right还是Left,所以我们提供了传参可以是函数(但是函数返回值需要是布尔值,否则……╮(╯▽╰)╭也会转成布尔值的……哈哈)。比如: 1 fucntion foo(boolean){
2 return !boolean;
3 }
4
5 Thread().
6 define(true).
7 right(foo).
8 then(function(){/*这里不会运行到*/}).
9 rightEnd().
10 run(); Enjoy yourself!! 项目地址 https://github.com/miniflycn/asThread 原问出自: http://www.cnblogs.com/justany/archive/2013/01/25/2874602.html
如何在 WebSphere 中解决 jar 包冲突 郝 爱丽, 高级软件工程师, IBM 中国软件开发中心 简介: Jar 包冲突问题是在大型 Java 软件开发中经常遇到的问题,系统开发人员经常会为解决类似的问题耗费大量的时间进行调试和测试,本文根据各种际情况,结合 WebSphere 中类加载器,讨论了几种解决 jar 包冲突问题的办法,并给出了具体实现的步骤及源代码。 读者定位为具有 Java 和 WebSphere 开发经验的开发人员。 读者可以学习到在 WebSphere 中类加载器的定义以及解决 jar 包冲突问题的几种办法,并可以直接使用文章中提供的 Java 代码,从而节省他们的开发和调试时间,提高效率。 大型的基于 WebSphere 的项目开发中,同一个 WebSphere Application Server(以下简称 WAS)上会部署多个应用程序,而这多个应用程序必然会共用一些 jar 包,包括第三方提供的工具和项目内部的公共 jar 等。把这些共用的 jar 包提取出来在多个应用程序之间共享,不仅可以统一对这些 jar 包进行维护,同时也提高了 WAS 的性能。但是随着应用的不断扩大,新的应用程序的不断增加,新的应用程序会希望使用一些更高版本的共享 jar 包,而由于系统运行维护的需要,老的应用程序仍然希望用老版本的共享 jar 包,这样就必然造成了共享 jar 包的版本冲突。jar 包版本冲突问题是在大型应用项目的开发中经常遇到的问题,本文试图从 WebSphere 的类加载器入手,讨论几种在不同情况下解决 jar 包冲突问题的办法。 WebSphere 中类加载器介绍 Jar 包冲突实际上是应用程序运行时不能找到真正所需要的类,而影响类的查找和加载的是 JVM 以及 WebSphere 中的类加载器(class loader),为此,我们首先介绍一下 WebSphere 中的类加载器以及一些相关的概念。 WebSphere 中类加载器层次结构 Java 应用程序运行时,在 class 执行和被访问之前,它必须通过类加载器加载使之有效,类加载器是 JVM 代码的一部分,负责在 JVM 虚拟机中查找和加载所有的 Java 类和本地的 lib 库。类加载器的不同配置影响到应用程序部署到应用程序服务器上运行时的行为。JVM 和 WebSphere 应用程序服务器提供了多种不同的类加载器配置, 形成一个具有父子关系的分层结构。WebSphere 中类加载器的层次结构图 1 所示: 图 1:WebSphere 中类加载器的层次结构  如上图所示,WebSphere 中类加载器被组织成一个自上而下的层次结构,最上层是系统的运行环境 JVM,最下层是具体的应用程序,上下层之间形成父子关系。 - JVM Class loader:位于整个层次结构的最上层,它是整个类加载器层次结构的根,因此它没有父类加载器。这个类加载器负责加载 JVM 类, JVM 扩展类,以及定义在 classpath 环境变量上的所有的 Java 类。
- WebSphere Extensions Class loader:WebSphere 扩展类加载器 , 它将加载 WebSphere 的一些 runtime 类,资源适配器类等。
- WebSphere lib/app Class loader:WebSphere 服务器类加载器,它将加载 WebSphere 安装目录下 $(WAS_HOME)/lib/app 路径上的类。 在 WAS v4 版本中,WAS 使用这个路径在所有的应用程序之间共享 jar 包。从 WAS v5 开始, 共享库功能提供了一种更好的方式,因此,这个类加载器主要用于一些原有的系统的兼容。
- WebSphere "server" Class loader:WebSphere 应用服务器类加载器。 它定义在这个服务器上的所有的应用程序之间共享的类。WAS v5 中有了共享库的概念之后,可以为应用服务器定义多个与共享库相关联的类加载器,他们按照定义的先后顺序形成父子关系。
- Application Module Class Loader:应用程序类加载器,位于层次结构的最后一层,用于加载 J2EE 应用程序。根据应用程序的类加载策略的不同,还可以为 Web 模块定义自己的类加载器。
关于 WebSphere 的类加载器的层次结构,以下的几点说明可能更有助于进一步的理解类的查找和加载过程: - 每个类加载器负责在自身定义的类路径上进行查找和加载类。
- 一个子类加载器能够委托它的父类加载器查找和加载类,一个加载类的请求会从子类加载器发送到父类加载器,但是从来不会从父类加载器发送到子类加载器。
- 一旦一个类被成功加载,JVM 会缓存这个类直至其生命周期结束,并把它和相应的类加载器关联在一起,这意味着不同的类加载器可以加载相同名字的类。
- 如果一个加载的类依赖于另一个或一些类,那么这些被依赖的类必须存在于这个类的类加载器查找路径上,或者父类加载器查找路径上。
- 如果一个类加载器以及它所有的父类加载器都无法找到所需的类,系统就会抛出 ClassNotFoundExecption 异常或者 NoClassDefFoundError 的错误。
类加载器的委托模式 类加载器有一个重要的属性:委托模式(Delegation Mode,有时也称为加载方式:Classloader mode)。委托模式决定了类加载器在查找一个类的时候, 是先查找类加载器自身指定的类路径还是先查找父类加载器上的类路径。 类加载器的委托模式有两个取值: - Parent_First:在加载类的时候,在从类加载器自身的类路径上查找加载类之前,首先尝试在父类加载器的类路径上查找和加载类。
- Parent_Last:在加载类的时候,首先尝试从自己的类路径上查找加载类,在找不到的情况下,再尝试父类加载器类路径。
有了委托模式的概念,我们可以更加灵活的配置在类加载器的层次结构中类的加载和查找方式。表 1 中给出了在 WebSphere 的类加载器层次结构中各个类加载器的委托模式的定义,并给出了不同的类加载器内类的生命周期。  注意:在上表中,"JVM Class loader" 因为在类加载器的最顶层,它没有父类加载器,因此其委托模式为 N/A,"WebSphere Extensions Class loader"和"WebSphere lib/app Class loader"的委托模式固定为表中的取值,不可配置,其它的类加载器的委托模式都是可以配置的。 WebSphere 中的类加载器策略 WebSphere 中对类加载器有一些相关的配置,称为类加载器策略(class loader policy)。类加载器策略指类加载器的独立策略(class loader isolation policy), 通过类加载器策略设置,我们可以为 WAS 和应用程序的类加载器进行独立定义。 每个 WAS 可以配置自己的应用程序类加载器策略,WAS 中的每个应用程序也可以配置自己的 Web 模块类加载器策略,下面我们对这两种策略分别介绍。 1 .应用服务器(WAS)配置:应用程序类加载器策略 应用服务器对应用程序类加载器策略有两种配置: - Single:整个应用服务器上的所有应用程序使用同一个类加载器。在这种配置下,每个应用程序不再有自己的类加载器。
- Multiple:应用服务器上的每个应用程序使用自己的类加载器。
2 .应用程序配置:Web 模块类加载器策略 应用程序中对 Web 模块类加载器有两种配置: - Application:整个应用程序内的所有的实用程序 jar 包和 Web 模块使用同一个类加载器。
- Module:应用程序内的每个 Web 模块使用自己的类加载器。应用程序的类加载器仍然存在,负责加载应用程序中 Web 模块以外的其它类,包括所有的实用程序 jar 包。
从上面的定义可以看出,不同的类加载器策略的配置下,类加载器的层次结构上的某些类加载器可能不存在。比如在应用程序服务器的应用程序类加载 器策略定义为 single 的情况下,应用程序的类加载器将不存在,同一个应用服务器上的所有应用程序将共用同一个类加载器,这也就意味着不同的应用程序之间的类是共享的,应用程序 间不能存在同名的类。 回页首 在 WebSphere 中解决 jar 包冲突 Jar 包冲突问题实际上就是应用程序希望用某一个确定版本的 jar 包中的类,但是类加载器却找到并加载了另外一个版本的 jar 包中的类。在上一部分介绍了 WebSphere 中类加载器的基本概念和相关配置之后,我们来看如何在 WebSphere 中解决 jar 包冲突。 在 WAS v5 版本之前,使用共享 jar 包的方式是将 jar 包放在 $(WAS_HOME)/lib/app 路径下,从上一部分中,我们可以看到,这个路径正是"WebSphere lib/app Class loader" 类加载器的类查找路径,WebSphere 会查找这个路径以取得相应得 jar 包中的 Java 类,从而做到在 WebSphere ND 上的多个应用程序之间共享 jar 包的目的。但是这样做的一个缺点就是这些共享 jar 包暴露给 WebSphere ND 上所有的应用程序,对于那些希望使用 jar 包其它版本的应用程序,这些 jar 包也同样存在在了它们的类加载器类路径上,因此,就不可避免的会造成版本的冲突。在 WAS v5 版本及之后,增加了共享库(shared library)的概念,推荐的在多个应用程序间共享 jar 包并避免 jar 包冲突的方式是使用共享库。 具体分析引起 jar 包冲突的情况,主要有三种: - 多个应用程序间 jar 包冲突:多个应用程序间由于使用了共享 jar 包的不同版本而造成 jar 包版本冲突。
- 应用程序中多个 Web 模块间 jar 包冲突:同一个应用程序内部,不同的 Web 模块间同时使用一个 jar 包的不同版本而造成 jar 包版本冲突。
- 应用程序中同一个 Web 模块内 jar 包冲突:同一个应用程序内部,同一个 Web 模块内,由于需要同时使用同一个 jar 包的两个版本而造成的 jar 包冲突
本部分根据这三种 jar 包冲突的情况,讨论三种解决 jar 包冲突的办法,并具体讨论三种解决办法的实现步骤和适用情况: - 共享库方式解决 jar 包冲突:主要解决应用程序间的 jar 包冲突问题
- 打包到 Web 模块中解决 jar 包冲突:主要解决应用程序中多个 Web 模块间 jar 包冲突问题
- 命令行运行方式解决 jar 包冲突:主要解决应用程序中同一个 Web 模块内 jar 包冲突问题
共享库方式解决 jar 包冲突 在 WAS v5 中,提供了一种很好的机制,使得 jar 包只存在于需要这个 jar 包的应用程序的类加载器的路径上,而其它的应用程序不受它的任何影响,这就是共享库(Shared library)。共享库可以用在应用服务器级别和应用程序级别,使用应用程序级别的共享库,其好处就是在不同的应用程序之间使用共享 jar 包的不同版本。我们可以为一些通用 jar 包的每个不同版本定义成不同的共享库,应用程序希望使用哪个版本,就把这个版本的共享库放到应用程序的类加载器的类路径上,这种方式有效的解决了应用程序 之间 jar 包冲突的问题。 下面举例介绍定义和使用共享库的具体方法,本例中,假设存在 xerces.jar 包版本冲突。 1 . 定义共享库 系统管理员可以在 WebSphere 的 Admin console 中定义共享库,可以分别在 Cell、Node 以及 server 的级别上定义。 步骤一 : 进入 Admin console,选择 Environment > Shared Library > new。如图 2 所示: 
图 2:WebSphere Admin Console 中进入共享库页面 步骤二: 给出共享库的名字,并指定共享的文件和目录。多个不同的文件 / 目录之间通过"Enter"键分隔,且不能有路径分隔符,如":"和";"等。如图 3 所示: 
图 3:WebSphere Admin Console 中添加共享库 步骤三:点击 Apply 或者 OK 之后,就添加了一个名字为 Xerces V2.0 的共享库。记住添加完成后一定要在 admin console 保存配置。如图 4 所示: 
图 4:WebSphere Admin Console 中共享库列表-
2 .安装应用程序 进入 Admin console,选择 Applications > Install New Application 安装应用程序。请参照 IBM WebSphere 的 Admin console 使用手册进行安装新的应用程序,此处不再详细介绍。 3 .将共享库关联到应用程序 步骤一:进入 Admin console,选择 Applications > Enterprise applications ,并选择需要使用共享库的应用程序。注意:因为要改变应用程序的设置,所以如果应用程序已经运行,需要先停掉应用程序。如图 5 所示: 
图 5:WebSphere Admin Console 中选择需要配置的应用程序 步骤二 : 点击应用程序,进入后,选择 Libraries。如图 6 所示: 
图 6:WebSphere Admin Console 中选择应用程序库属性步骤三 : 点击 Add,为应用程序添加共享库。如图 7 所示: 
图 7:WebSphere Admin Console 中应用程序添加库 步骤四 : 从下拉列表中选择所需要的共享库,点击 OK。如图 8 所示:
图 8:WebSphere Admin Console 中应用程序添加库页面指定所用的共享库
这样,Xerces V2.0 共享库定义的 xerces 版本就存在于了应用程序类加载器的类加载路径上。注意,在添加完成后要保存服务器的设置。 4 .设置应用程序的类加载器的委托模式为 Parent_Last 为了进一步防止共享库定义的 jar 包的其它版本已经存在于 JVM 或者 WebSphere 的类加载器路径上,还需要设置应用程序的类加载器的委托方式为 Parent_Last。 通过上面的配置,即使 xerces 的其它版本已经存在于系统中,应用程序在运行时,其类加载器也会首先查找并加载指定的共享库中的 xerces 版本。这样我们就通过使用共享库的方式,解决了 jar 包版本冲突问题。 打包到 Web 模块中解决 jar 包冲突 共享库的方式,只是在应用程序的层次上,在多个应用程序之间解决了共享 jar 包造成的版本冲突问题,如果一个应用程序的内部,其中一个 Web 模块使用了一个 jar 包的 A 版本,而另一个 Web 模块使用这个 jar 包的 B 版本,在这种情况下造成的 jar 包冲突,共享库的方式是无法解决的,我们可以考虑将其中一个在多个应用程序间共享的 jar 包版本,比如 A 版本,定义成共享库,或者放在"WebSphere lib/app Class loader"类加载器路径上供多个应用程序使用,而将 B 版本的 jar 包打包到使用它的 Web 模块中的方式来解决冲突。 其次,目前很多在线的系统是 WAS v4 的遗留系统,其上运行的应用程序已经使用了"WebSphere lib/app Class loader"类加载器,将 jar 包放在 $(WAS_HOME)/lib/app 目录下进行共享。如果由于其中某个应用程序的升级或者新增加某个应用程序,需要使用某个共享 jar 包的其它版本,在这种情况下,为了减少对系统的影响,也可以考虑将这个共享 jar 包的新版本打包到升级(或新增)的应用程序中的方式来解决 jar 包冲突。 由于 Web 模块的 WebContent/WEB-INFO/lib 目录在应用程序 Web 模块的类加载器查找路径上,因此,我们可以把 jar 包放在这个目录下,Web 模块的类加载器将自动查找并加载这个 jar 包中的类。 步骤一:在 WSAD IE 集成开发环境中,将冲突 jar 包放在 Web 模块的 WebContent/WEB-INFO/lib 目录下。如图 11 所示: 
图 11:WSAD IE 中为 Web 模块添加库步骤二:在 Admin console 中,将应用程序部署到 WebSphere server 上之后,进入 Applications > Enterprise Applications, 选择相应的应用程序,并确认应用程序不在运行状态 ( 参见前面章节中选择应用程序的步骤 )。点击进入应用程序,确认应用程序的类加载器的委托模式为 Parent_First, 应用程序的类加载器策略为 Module。如图 12 所示: 
图 12:WebSphere Admin Console 中应用程序属性配置页面步骤三:在同一个页面上,选择 Web Modules,点击进入。如图 13 所示: 
图 13:WebSphere Admin Console 中选择应用程序 Web 模块属性步骤四:点击相应的包含冲突 jar 包的 Web 模块,设置 Web 模块的类加载器的委托模式为 Parent_Last。注意:在设置完成后要保存服务器配置,并启动应用程序。如图 14 所示:  图 14:WebSphere Admin Console 中为 Web 模块指定类加载器委托模式 图 14:WebSphere Admin Console 中为 Web 模块指定类加载器委托模式
将冲突 jar 包打包到 Web 模块中,并设置相应 Web 模块的类加载器的委托模式为 Parent_Last,应用程序在运行过程中加载类的时候,这个 Web 模块的类加载器会首先查找 WebContent/WEB-INFO/lib 目录下的 jar 包进行类的加载;而对于其它的 Web 模块,由于其类加载器的委托模式仍然为缺省的 Parent_First,它们的类加载器仍然首先从应用程序的共享库或者 WebSphere 的共享路径上加载 jar 包中的类,从而解决了 jar 包冲突的问题。 命令行运行方式解决 jar 包冲突 不论是设置共享库,还是将冲突 jar 包打包到应用程序中,其解决的问题都是在应用程序的一个 Web 模块中只使用了冲突 jar 包的一个版本的情况。我们在开发中曾经遇到过这样的情况:应用程序的 Web 模块中已经使用了 1.4 版本的 xerces.jar,由于 Web 功能的扩展,在这个模块中又引入一个新的第三方工具,而这个第三方工具需要使用 2.0 版本的 xerces.jar 才能正常工作,这种情况下的 jar 包冲突如何解决呢? 在前面类加载器的部分已经介绍过,每个应用程序的一个 Web 模块最多只能有一个类加载器,而 Web 模块的类加载器中加载的类的生命周期为整个应用程序的运行期,也就是说,Web 模块加载器不可能同时加载一个类的两个版本,同时,Web 模块的类加载器的委托模式也是在应用程序运行前设置的,在应用程序运行期内无法改变的,因此,上面描述的在一个 Web 模块中同时使用两个版本的 jar 包的问题,象前两种方法那样配置运行在一个 JVM 内的类加载器的设置的方法是无法解决的。 唯一的解决办法就是在应用程序运行的 JVM 外,启动另外一个 JVM 来运行调用冲突 jar 包的代码,因为两个不同的 JVM 可以加载各自的类,从而解决 jar 包冲突问题。 这种情况下,原来使用 jar 包的老版本的方式(包括 jar 包放置路径,共享库设置方式,类加载器的委托模式等)不变,将对 jar 包新版本的调用通过命令行运行方式实现。具体做法是:将对 jar 包新版本内功能的调用,封装到一个可以单独运行的类中,在 Web 模块中以命令行方式运行这个类。同时把这个类以及 jar 包的新版本放在任意一个 was 可访问的路径上(比如 /usr/WebSphere),在命令行的 classpath 参数中包含这个路径(比如 /usr/WebSphere)。 下面通过举例说明命令行运行方式的编程过程,在本例中,假设 TestEar 应用程序的 Web 模块 TestWar 中,已经使用了 conflict_v1.jar,由于新添功能需要使用 conflict_v2.jar 中的 exampleCall() 功能。 冲突 jar 包 conflict_v2.jar 提供的功能: 代码 1:冲突 jar 包 conflict_v2.jar 功能 1 Package com.ibm.conflict;
2
3 Public class ConflictClass{
4 …… .
5 Public static String exampleCall(string param){
6 String rs;
7 …… ;
8 Return rs;
9 }
10 …… 不存在冲突问题时的编码举例: 如果没有 jar 包冲突问题,则对这个功能的调用是简单的,只需要将 conflict_v2.jar 放在应用程序自身或者其父类加载器的查找路径上,然后在 Web 模块中直接调用即可,如下: 代码 2:不存在冲突时的调用方式1 Public String methodA(String param){
2 ……
3 String rs = ConflictClass.exampleCall(param);
4 ……
5 Return rs;
6 }
存在冲突后的命令行运行方式编码举例 针对 jar 包冲突问题,我们需要在 Web 模块中做如下的修改: - 步骤一:将冲突 jar 包放在 was 可访问的路径上,比如 /usr/WebSphere/conflict_v2.jar。
步骤二:将对包含冲突代码的调用封装到一组可单独运行的类中,它们将调用冲突 jar 包的功能,并将结果以系统输出的方式打印到系统标准输出上。 将这些类封装到一个单独的 jar 文件中,比如 workAroundConflict.jar,并将其放在 was 可访问的路径上,比如 /usr/WebSphere/workAroundConflict.jar。
1 Package com.ibm.test;
2
3 Import com.ibm.ConflictClass;
4
5 Public class WorkAround{
6 Public static void main(String[] args){
7 String param1=args[0];
8 String returnStr=ConflictClass.exampleCall ();
9 System.out.println("<RTStr>"+returnStr+"</RTStr>");
10 Return;
11 }
12 }
代码 3:将对冲突代码的调用写入一个单独的类 WorkAround 步骤三:在 Web 模块中通过命令行方式调用封装的类,通过 classpath 指定所有依赖的 jar 包和类路径。运行封装类,从系统标准输出中取得运行结果。
1 Public static String methodA (String param){
2 ……
3 String rtStr = "";
4 String lStr="<RTStr>";
5 String rStr="<RTStr>";
6 //put all the dependency jar here
7 String classPath=
8 "/usr/WebSphere/conflict_v2.jar;
9 /usr/WebSphere/workaroundConflict.jar; ……";
10 String className="com.ibm.test.WorkAround";
11 String cmdLine="java -classpath " +classPath +" " +className + " "+ param;
12 Try{
13 Process process = Runtime.getRuntime().exec(cmdLine,null);
14 process.waitFor();
15 BufferedReader br= new BufferedReader(
16 new InputStreamReader(process.getInputStream()));
17 while ((s = br.readLine())!=null) {
18 if (null == out)
19 out=s;
20 else
21 out+=s;
22 }
23 //get result from out
24 if (null != out){
25 int lIndex = out.lastIndexOf(lStr);
26 int rIndex = out.lastIndexOf(rStr);
27 rsStr = out.substring(lIndex+lStr.length, rIndex);
28 }
29
30 } catch (Exception e){
31 e.printStackTrace();
32 }
33 …… .
34 return rsStr;
35 }
代码 4:在应用程序中通过命令行方式运行 WorkAround -
命令行运行方式通过启动另外一个 JVM 的方式运行冲突代码,在一个不同的 JVM 中加载冲突的类,从而解决了 jar 包冲突问题。 但是命令行运行方式毕竟不是一个很好的方式,它存在以下的弊端: - 命令行运行方式只适用于对冲突 jar 包的使用只是运行一段代码,或者只要求返回简单的字符串结果的情况。对于复杂的交互,命令行方式无法做到。但是如果在别无他法的情况下,可以适当地划分封 装对冲突代码调用的 jar 包的包含范围,尽量将命令行运行的代码接口简单化。
- 命令行运行方式因为启动了另外一个 JVM 来运行,降低了 WebSphere 的性能。
因此,命令行方式只适用于一些极为特殊的情况下解决 jar 包冲突问题。 回页首 结论 本文对基于 WebSphere 的大型项目开发中遇到的 jar 包冲突问题,结合 WebSphere 中类加载器的概念,给出了三种解决办法以及相应的操作步骤和实现代码,并分析了各种方式所适用的具体情况。 项目开发过程中的 jar 包冲突,主要存在以下三种情况: - 多个应用程序间的 jar 包冲突
- 应用程序内多个 Web 模块间的 jar 包冲突
- 应用程序内同一个 Web 模块内部 jar 包冲突
通过对类加载器的分析我们知道,解决 jar 包冲突问题的根本在于合理配置类加载器。在深入理解 WebSphere 中类加载器的层次结构的基础上,我们给出了"共享库解决 jar 包冲突"以及"打包到 Web 模块中解决 jar 包冲突"的办法,通过合理地配置 WebSphere 中类加载器及其委托模式,可以解决大多数的 jar 包冲突问题。但是由于这个层次结构中类加载器只配置到 Web 模块,因此,对于 Web 模块内部的 jar 包冲突问题,类加载器的配置是无法解决的,为此我们给出了"命令行运行方式解决 jar 包冲突"的办法。 表 2 中列出了在不同的 WAS 版本下,三种解决 jar 包冲突问题的办法所适用的 jar 包冲突情况。 表 2:Jar 包冲突解决办法适用的 jar 包冲突情况总结  参考资料 - IBM WebSphere Application Server V5 ClassloaderNamingSpace Guide。
- IBM WebSphere Application Server V5.1 System Management and Configuration。
作者简介 郝爱丽是一位 IBM CSDL 的软件工程师,从事多年 J2EE 开发工作,有丰富的 J2EE 开发经验。目前从事企业电子商务应用的开发和支持。 常红平是一位 IBM CSDL 的软件工程师,IBM certified DB2 DBA 和 IBM certified DB2 developer。他目前正在从事企业电子商务应用的开发。您可以通过 changhp@cn.ibm.com 和他联系。
CXF和Spring结合的非常紧密,默认发布Server端是需要用到Spring的,但是项目中用到的Spring jar包比较老2.0,CXF版本2.3.1,跟Spring不兼容,需要换乘Spring2.5,但是换jar包对原来的项目存在风险,上网搜了一个脱 离Spring运行的方法。 写一个类继承CXFNonSpringServlet,重写loadBus方法。 1 @SuppressWarnings("unchecked")
2 public void loadBus(ServletConfig servletConfig) throws ServletException {
3 super.loadBus(servletConfig);
4 Bus bus = this.getBus();
5 BusFactory.setDefaultBus(bus);
6
7 Enumeration<String> enums = getInitParameterNames();
8 while (enums.hasMoreElements()) {
9 String key = enums.nextElement();
10 String value = getInitParameter(key);
11 try {
12 Class clz = Class.forName(value);
13 try {
14 Endpoint.publish(key, clz.newInstance());
15 } catch (InstantiationException e) {
16 e.printStackTrace();
17 } catch (IllegalAccessException e) {
18 e.printStackTrace();
19 }
20 } catch (ClassNotFoundException e) {
21 e.printStackTrace();
22 }
23 }
24 } 在web.xml里将要发布的类配置一下,可以配置多个 1 <servlet>
2 <servlet-name>CXFServlet</servlet-name>
3 <servlet-class>
4 com.infodms.ws.util.MyCXFNoSpringServlet
5 </servlet-class>
6 <init-param>
7 <param-name>/TestService</param-name>
8 <param-value>com.infodms.ws.test.TestServiceImpl</param-value>
9 </init-param>
10 <init-param>
11 <param-name>/HelloWorld</param-name>
12 <param-value>com.infodms.ws.test.HelloWorldImpl</param-value>
13 </init-param>
14 </servlet>
15 <servlet-mapping>
16 <servlet-name>CXFServlet</servlet-name>
17 <url-pattern>/ws/*</url-pattern>
18 </servlet-mapping>
配置完成,启动tomcat,报错,还是加载了spring,但是代码确实走了刚刚加的MyCXFNoSpringServlet
1 java.lang.RuntimeException: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.apache.cxf.bus.spring.BusApplicationListener' defined in class path resource [META-INF/cxf/cxf.xml]: Initialization of bean failed; nested exception is java.lang.NoSuchMethodError: org.springframework.context.support.AbstractApplicationContext.addApplicationListener(Lorg/springframework/context/ApplicationListener;)V
2 org.apache.cxf.bus.spring.SpringBusFactory.createBus(SpringBusFactory.java:96)
调试了一下源码,内部需要从环境变量中取得org.apache.cxf.bus.factory的值,如果为空就默认按照spring的方式加载。于是在类的最开始加入一行代码 1 System.setProperty("org.apache.cxf.bus.factory", "org.apache.cxf.bus.CXFBusFactory");
再次启动tomcat,报错,由异常可知WoodstoxValidationImpl类没有默认构造方法,通过反射实例化对象报错,看了一下这个类的源码,确实没有无参构造方法
1 Caused by: java.lang.InstantiationException: org.apache.cxf.wstx_msv_validation.WoodstoxValidationImpl
2 at java.lang.Class.newInstance0(Class.java:340)
3 at java.lang.Class.newInstance(Class.java:308)
4 at org.apache.cxf.bus.extension.Extension.load(Extension.java:110)
原文出自: http://liuqiang5151.iteye.com/blog/840496
摘要: 一、解决基本问题: 在做 RCP 项目的时候经常会遇到一个问题,就是要将一些控制信息输出到 RCP 自身的控制台,那么我们就可以扩展 Eclipse 扩展点 org.eclipse.ui.console.consoleFactories ,来实现我们自己的控制台,解决方法如下: 首先 ,在 plugin.xml 中定义扩展点: plugin.xml: <extension &n... 阅读全文
今天整理系统,发现系统很多页面,只有在IE6下显示正常,其它的都不正常,很是奇怪。所以上网找了一些关于浏览器兼容的问题和解决办法,在此我觉得大牛们总结的比较精彩,分享给网友们! 一、CSS兼容 以下两种方法几乎能解决现今所有兼容. 1, !important (不是很推荐,用下面的一种感觉最安全) 随着IE7对!important的支持, !important 方法现在只针对IE6的兼容.(注意写法.记得该声明位置需要提前.) 代码:
<style>
#wrapper {
width: 100px!important; /* IE7+FF */
width: 80px; /* IE6 */
}
</style> 2, IE6/IE77对FireFox <from 针对firefox ie6 ie7的css样式> *+html 与 *html 是IE特有的标签, firefox 暂不支持.而*+html 又为 IE7特有标签. 代码:
<style>
#wrapper { width: 120px; } /* FireFox */
*html #wrapper { width: 80px;} /* ie6 fixed */
*+html #wrapper { width: 60px;} /* ie7 fixed, 注意顺序 */
</style> 注意:
*+html 对IE7的兼容 必须保证HTML顶部有如下声明: 代码:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://w3.org/TR/html4/loose.dtd"> 二、解决DIV错乱(非常重要) 可以用这个解决多个div对齐时的间距不对, 关于 clear float 的原理可参见 [How To Clear Floats Without Structural Markup]
将以下代码加入Global CSS 中,给需要闭合的div加上 class=”clearfix” 即可,屡试不爽. 代码:
<style>
/* Clear Fix */
.clearfix:after {
content:".";
display:block;
height:0;
clear:both;
visibility:hidden;
}
.clearfix {
display:inline-block;
}
/* Hide from IE Mac \*/
.clearfix {display:block;}
/* End hide from IE Mac */
/* end of clearfix */
</style> 三、其它零碎(不容忽视,细节决定成败) 1. 文字本身的大小不兼容。同样是font-size:14px的宋体文字,在不同浏览器下占的空间是不一样的,ie下实际占高16px,下留白3px,ff 下实际占高17px,上留白1px,下留白3px,opera下就更不一样了。解决方案:给文字设定 line-height 。确保所有文字都有默认的 line-height 值。这点很重要,在高度上我们不能容忍1px 的差异。
2.ff下容器高度限定,即容器定义了height之后,容器边框的外形就确定了,不会被内容撑大,而ie下是会被内容撑大,高度限定失效。所以不要轻易给容器定义height。
3.横向上的撑破容器问题,。如果float 容器未定义宽度,ff下内容会尽可能撑开容器宽度,ie下则会优先考虑内容折行。故,内容可能撑破的浮动容器需要定义width。
小实验:有兴趣大家可以看看这段实验。在不同浏览器下分别测试以下各项代码。
a.<div style=”border:1px solid red;height:10px”></div> b. <div style=”border:1px solid red;width:10px”></div>
c. <div style=”border:1px solid red;float:left”></div> d. <div style=”border:1px solid red;overflow:hidden”></div>
上 面的代码在不同浏览器中是不一样的,实验起源于对小height 值div 的运用,<div style=”height:10px;overflow:hidden”></div>,小height 值要配合overflow:hidden一起使用。实验好玩而已,想说明的是,浏览器对容器的边界解释是大不相同的,容器内容的影响结果各不相同。
4.最被痛恨的,double-margin bug。ie6下给浮动容器定义margin-left 或者margin-right 实际效果是数值的2倍。解决方案,给浮动容器定义display:inline。
5.mirror margin bug,当外层元素内有float元素时,外层元素如定义margin-top:14px,将自动生成margin-bottom:14px。 padding也会出现类似问题,都是ie6下的特产,该类bug 出现的情况较为复杂,远不只这一种出现条件,还没系统整理。解决方案:外层元素设定border 或 设定float。
引申:ff 和ie 下对容器的margin-bottom,padding-bottom的解释有时不一致,似乎与之相关。
6. 吞吃现象。还是ie6,上下两个div,上面的div设置背景,却发现下面没有设置背景的div 也有了背景,这就是吞吃现象。对应上面的背景吞吃现象,还有滚动下边框缺失的现象。解决方案:使用zoom:1。这个zoom好象是专门为解决ie6 bug而生的。
7.注释也能产生bug~~~“多出来的一只猪。”这是前人总结这个bug使用的文案,ie6的这个bug 下,大家会在页面看到猪字出现两遍,重复的内容量因注释的多少而变。解决方案:用“<!–[if !IE]> picRotate start <![endif]–>”方法写注释。
8.img 下的留白,大家看这段代码有啥问题:
<div>
< img src=”" mce_src=”" />
< /div>
把div的border打开,你发现图片底部不是紧贴着容器底部的,是img后面的空白字符造成,要消除必须这样写
<div>
<img src=”" mce_src=”" /></div>
后面两个标签要紧挨着。ie7下这个bug 依然存在。解决方案:给img设定 display:block。
9. 失去line-height。<div style=”line-height:20px”><img />文字</div>,很遗憾,在ie6下单行文字 line-height 效果消失了。。。,原因是<img />这个inline-block元素和inline元素写在一起了。解决方案:让img 和文字都 float起来。
引申:大家知道img 的align 有 text-top,middle,absmiddle啊什么的,你可以尝试去调整img 和文字让他们在ie和ff下能一致,你会发现怎么调都不会让你满意。索性让img 和文字都 float起来,用margin 调整。
10.clear层应该单独使用。也许你为了节省代码把clear属性直接放到下面的一个内容层,这样有问题,不仅仅是ff和op下失去margin效果,ie下某些margin值也会失效
<div style=”background:red;float:left;”>dd</div>
< div style=”clear:both;margin-top:18px;background:green”>ff</div>
11.ie 下overflow:hidden对其下的绝对层position:absolute或者相对层 position:relative无效。解决方案:给overflow:hidden加position:relative或者position: absolute。另,ie6支持overflow-x或者overflow-y的特性,ie7、ff不支持。
12.ie6下严重的bug,float元素如没定义宽度,内部如有div定义了height或zoom:1,这个div就会占满一整行,即使你给了宽度。float元素如果作为布局用或复杂的容器,都要给个宽度的。
13.ie6下的bug,绝对定位的div下包含相对定位的div,如果给内层相对定位的div高度height具体值,内层相对层将具有100%的width值,外层绝对层将被撑大。解决方案给内层相对层float属性。
14.width:100%这个东西在ie里用很方便,会向上逐层搜索width值,忽视浮动层的影响,ff下搜索至浮动层结束,如此,只能给中间的所有浮动层加width:100%才行,累啊。opera这点倒学乖了跟了ie。 四、一句话解决所有兼容性问题(懒人有懒人的办法奥!) 在网站头部加上一句: 1. Google Chrome Frame也可以让IE用上Chrome的引擎: <meta http-equiv=“X-UA-Compatible” content=“chrome=1″/> 2.强制IE8使用IE7模式来解析 <meta http-equiv=“X-UA-Compatible”content=“IE=EmulateIE7″><!– IE7 mode –> //或者 <metahttp-equiv=“X-UA-Compatible”content=“IE=7″><!– IE7 mode –> 3.强制IE8使用IE6或IE5模式来解析 <metahttp-equiv=“X-UA-Compatible”content=“IE=6″><!– IE6 mode –> <metahttp-equiv=“X-UA-Compatible”content=“IE=5″><!– IE5 mode –> 4.如果一个特定版本的IE支持所要求的兼容性模式多于一种,如: <metahttp-equiv=“X-UA-Compatible”content=“IE=5; IE=8″/> 我用的是最后一种,不过还是没有彻底解决问题,我也在寻求方法,恳求大牛们帮忙解决! 原文出自: http://www.cnblogs.com/sybboy/archive/2013/01/19/2868153.html
1. Javascript没有类的概念。一般使用原型链继承(prototypal inheritance)来模拟类。
2. 除了null和undefined之外的任何数据类型都能表现成Object (behave like an object),包括Number类型和Function类型。 var n = 42;
function f() { alert("foo"); };
alert("n is " + n.toString()); // "n is 42"
alert(f.name + " is a function"); // "f is a function"
注意,是“表现为object”,而不是“是object”。事实上,number, string和boolean是基本类型(primitives),除了这三个之外的都可以算作object,比如一个正则表达式也是一个object。 当需要访问基本类型变量的属性时,那些基本类型变量将被临时转换成object。 例如: "foobar".big();
// is equivalent to
new String("foobar").big();
.14.toFixed();
// is equivalent to
new Number(3.14).toFixed()
另外,不能强行给基本类型变量(number, string, boolean)加上私有属性。
var a = "mystring",
b = new String( "mystring" );
Object.defineProperty( b, 'foo', { value: 42, enumerable: false });
console.log(b.foo); // 42
Object.defineProperty( a, 'foo', { value: 42, enumerable: false });
// TypeError: Object.defineProperty called on non-object
// trying another way:
a.foo = 42;
// remember, this is equivalent to:
// new Number(a).foo = 42;
// …so the 'foo' property is defined on the wrapper, not on 'a'
console.log(a.foo); // undefined 3. 如果变量名前不加上var,那么这个变量就是全局的。
function setGlobal() {
a = 42;
}
function setLocal() {
var b = 23;
}
setGlobal();
alert(a); // 42
setLocal();
alert(b); // ReferenceError: b is not defined
4. this指针是由调用函数赋予的, 而不是由被调函数自身定义的。 例如: var a = {}, b = {};
a.foo = 42;
b.foo = 18;
a.alertFoo = function() { alert(this.foo); };
a.alertFoo(); // 42
a.alertFoo.call(b); // 18
5. 严格的相等判断应该使用===。例如 : 0 == false 为真, 但是 0 === false 为假。
6. 0, undefined, null, "", NaN 都是假值 (falsy)。 这些值全都等同于false,但他们之间不能相互替换。
7. 变量声明会被提升到当前作用域的顶端。 例如:下述代码中,你认为调用foo函数会返回什么?
var a = 2;
function foo() {
return a;
var a = 5;
}
它将返回undefined。 上述代码等同于下述代码: var a = 2;
function foo() {
var a; // 'a' declaration is moved to top
return a;
a = 5;
} 另一个例子: 下述代码中,调用函数foo后变量a的值是什么? var a = 42;
function foo() {
a = 12;
return a;
function a(){}
} 答案是42。因为foo函数中变相声明了a变量,因此a成了局部变量了。 function foo() {
function a() {} // local 'a' is a function
a = 12; // local 'a' is now a number (12)
return a; // return the local 'a' (12)
} 8. 参数在函数声明中可以省略, 例如: function hello(name, age) {
alert("Hello "+name+", you’re "+age+" years old!");
}
hello("Anon", 42); // "hello Anon, you’re 42 years old!"
hello("Baptiste"); // "hello Baptiste, you’re undefined years old!"
hello("Bulat", 24, 42); // "hello Bulat, you’re 24 years old!" 9. 对于字符串,使用双引号""和单引号''的效果是一样的。
10. Javascript代码可以在浏览器环境之外运行, 比如在Terminal或者HTTP服务器上。(例如 Node.js)
原文出自:http://www.cnblogs.com/newyorker/archive/2013/01/18/2865820.html
本篇介绍可以在C#中使用的1D/2D编码解码器。条形码的应用已经非常普遍,几乎所有超市里面的商品上面都印有条形码;二维码也开始应用到很多场合,如火车票有二维码识别、网易的首页有二维码图标,用户只需要用手机扫描一下就可以看到手机版网易的网址,免去了输入长串字符的麻烦。 条形码的标准: 条形码的标准有ENA条形码、UPC条形码、二五条形码、交叉二五条形码、库德巴条形码、三九条形码和128条形码等,而商品上最常使用的就是EAN商品条形码。EAN商品条形码亦称通用商品条形码,由国际物品编码协会制定,通用于世界各地,是目前国际上使用最广泛的一种商品条形码。我国目前在国内推行使用的也是这种商品条形码。EAN商品条形码分为EAN-13(标准版)和EAN-8(缩短版)两种。 二维码的编码标准: 全球现有的二维码多达200种以上,其中常见的技术标准有PDF417(美系标准),QRCode(日系标准),Code49,Code16K,CodeOne,DM(韩系标准),GM(中国标准),CM(中国标准)等20余种。用得最多的是QRcode。 下面借助google的开源项目zxing来实现1D/2D的编码和解码,测试效果如下:  
zxing的官方地址是:http://code.google.com/p/zxing/ zxing的功能还是很强大的,最初是用java编写,并支持Android、ios、symbian等手机操作系统。 不过不知是何原因,该官网连一个例子也没有,文档也是字典式的把所有类列出来,一点都没为读者考虑。 下面我把如果使用zxing完成上图所示例子讲解一遍,供初学者参考: 1.我们新建一个Winform测试项目; 2.从官网下载zxing开源项目,大概16m的样子,解压缩后打开zxing-2.1\csharp目录,将该目录拷贝到我们新建的Winform项目下(方便调试和看源码,并非一定要如此); 
3.winform项目中添加对zxing项目的引用; 4.按上图所示例子建好控件,“生成条形码”的代码如下:
1 //生成条形码
2 private void button1_Click(object sender, EventArgs e)
3 {
4 lbshow.Text = "";
5 Regex rg = new Regex("^[0-9]{13}$");
6 if (!rg.IsMatch(txtMsg.Text))
7 {
8 MessageBox.Show("本例子采用EAN_13编码,需要输入13位数字");
9 return;
10 }
11
12 try
13 {
14 MultiFormatWriter mutiWriter = new com.google.zxing.MultiFormatWriter();
15 ByteMatrix bm = mutiWriter.encode(txtMsg.Text, com.google.zxing.BarcodeFormat.EAN_13, 363, 150);
16 Bitmap img= bm.ToBitmap();
17 pictureBox1.Image =img;
18
19 //自动保存图片到当前目录
20 string filename = System.Environment.CurrentDirectory + "\\EAN_13" + DateTime.Now.Ticks.ToString() + ".jpg";
21 img.Save(filename, System.Drawing.Imaging.ImageFormat.Jpeg);
22 lbshow.Text = "图片已保存到:" + filename;
23 }
24 catch(Exception ee)
25 { MessageBox.Show(ee.Message); }
26 } 其中需要注意BarcodeFormat参数,可以打开定义看到具体的编码方式,自己百度每种编码方式对输入的要求。 这里EAN_13编码要求是13位长度的数字,并且满足:把所有偶数序号位上的数相加求和,用求出的和乘3,再把所有奇数序号上的数相加求和,用求出的和加上刚才偶数序号上的数,然后得出和能被10整除。(这个规则校验在UPCEANReader类的checkStandardUPCEANChecksum方法里面,如果不需要,可以去掉) 生成二维码的代码与上面相似:
1 //生成二维码
2 private void button2_Click(object sender, EventArgs e)
3 {
4 lbshow.Text = "";
5 try
6 {
7 MultiFormatWriter mutiWriter = new com.google.zxing.MultiFormatWriter();
8 ByteMatrix bm = mutiWriter.encode(txtMsg.Text, com.google.zxing.BarcodeFormat.QR_CODE, 300, 300);
9 Bitmap img = bm.ToBitmap();
10 pictureBox1.Image = img;
11
12 //自动保存图片到当前目录
13 string filename = System.Environment.CurrentDirectory + "\\QR" + DateTime.Now.Ticks.ToString() + ".jpg";
14 img.Save(filename, System.Drawing.Imaging.ImageFormat.Jpeg);
15 lbshow.Text = "图片已保存到:" + filename;
16 }
17 catch (Exception ee)
18 { MessageBox.Show(ee.Message); }
19 } 注意编码问题,在com.google.zxing.qrcode.encoder.Encoder类中修改默认编码为utf-8,否则解码出现的是乱码。 System.String DEFAULT_BYTE_MODE_ENCODING = "UTF-8"; 此处之前是"ISO-8859-1",之所以改成UTF-8是因为,在解码的时候程序会猜测可能的编码,如果猜测失败则默认是UTF-8,代码在com.google.zxing.qrcode.decoder.DecodedBitStreamParser类的guessEncoding方法中。 所以此开源项目也缺少全局性思考,连编码和解码的默认编码方式都不一致。 4.实现图片解码,即把条形码或二维码图片解码成其真实内容,当然在pc上应用不大,但可能只是还没发现而已,代码如下: 1 //解码操作
2 private void button3_Click(object sender, EventArgs e)
3 {
4 MultiFormatReader mutiReader = new com.google.zxing.MultiFormatReader();
5 Bitmap img = (Bitmap)Bitmap.FromFile(opFilePath);
6 if (img == null)
7 return;
8 LuminanceSource ls = new RGBLuminanceSource(img, img.Width, img.Height);
9 BinaryBitmap bb = new BinaryBitmap(new com.google.zxing.common.HybridBinarizer(ls));
10
11 Result r= mutiReader.decode(bb);
12 txtMsg.Text = r.Text;
13 } opFilePath是图片路径,你可以用openFileDialog控件打开文件来得到路径。 原文出自: http://www.cnblogs.com/tuyile006/archive/2013/01/16/2863367.html
很多人都知道SQL注入,也知道SQL参数化查询可以防止SQL注入,可为什么能防止注入却并不是很多人都知道的。 本文主要讲述的是这个问题,也许你在部分文章中看到过这块内容,当然了看看也无妨。 首先:我们要了解SQL收到一个指令后所做的事情: 具体细节可以查看文章:Sql Server 编译、重编译与执行计划重用原理 在这里,我简单的表示为: 收到指令 -> 编译SQL生成执行计划 ->选择执行计划 ->执行执行计划。 具体可能有点不一样,但大致的步骤如上所示。 接着我们来分析为什么拼接SQL 字符串会导致SQL注入的风险呢? 首先创建一张表Users: CREATE TABLE [dbo].[Users]( [Id] [uniqueidentifier] NOT NULL, [UserId] [int] NOT NULL, [UserName] [varchar](50) NULL, [Password] [varchar](50) NOT NULL, CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] 
插入一些数据: INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),1,'name1','pwd1'); INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),2,'name2','pwd2'); INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),3,'name3','pwd3'); INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),4,'name4','pwd4'); INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),5,'name5','pwd5'); 假设我们有个用户登录的页面,代码如下: 验证用户登录的sql 如下: select COUNT(*) from Users where Password = 'a' and UserName = 'b' 这段代码返回Password 和UserName都匹配的用户数量,如果大于1的话,那么就代表用户存在。 本文不讨论SQL 中的密码策略,也不讨论代码规范,主要是讲为什么能够防止SQL注入,请一些同学不要纠结与某些代码,或者和SQL注入无关的主题。 可以看到执行结果: 
这个是SQL profile 跟踪的SQL 语句。 
注入的代码如下: select COUNT(*) from Users where Password = 'a' and UserName = 'b' or 1=1—' 这里有人将UserName设置为了 “b' or 1=1 –”. 实际执行的SQL就变成了如下: 

可以很明显的看到SQL注入成功了。 很多人都知道参数化查询可以避免上面出现的注入问题,比如下面的代码: class Program { private static string connectionString = "Data Source=.;Initial Catalog=Test;Integrated Security=True"; static void Main(string[] args) { Login("b", "a"); Login("b' or 1=1--", "a"); } private static void Login(string userName, string password) { using (SqlConnection conn = new SqlConnection(connectionString)) { conn.Open(); SqlCommand comm = new SqlCommand(); comm.Connection = conn; //为每一条数据添加一个参数 comm.CommandText = "select COUNT(*) from Users where Password = @Password and UserName = @UserName"; comm.Parameters.AddRange( new SqlParameter[]{ new SqlParameter("@Password", SqlDbType.VarChar) { Value = password}, new SqlParameter("@UserName", SqlDbType.VarChar) { Value = userName}, }); comm.ExecuteNonQuery(); } } } 实际执行的SQL 如下所示: exec sp_executesql N'select COUNT(*) from Users where Password = @Password and UserName = @UserName',N'@Password varchar(1),@UserName varchar(1)',@Password='a',@UserName='b' exec sp_executesql N'select COUNT(*) from Users where Password = @Password and UserName = @UserName',N'@Password varchar(1),@UserName varchar(11)',@Password='a',@UserName='b'' or 1=1—' 可以看到参数化查询主要做了这些事情: 1:参数过滤,可以看到 @UserName='b'' or 1=1—' 2:执行计划重用 因为执行计划被重用,所以可以防止SQL注入。 首先分析SQL注入的本质, 用户写了一段SQL 用来表示查找密码是a的,用户名是b的所有用户的数量。 通过注入SQL,这段SQL现在表示的含义是查找(密码是a的,并且用户名是b的,) 或者1=1 的所有用户的数量。 可以看到SQL的语意发生了改变,为什么发生了改变呢?,因为没有重用以前的执行计划,因为对注入后的SQL语句重新进行了编译,因为重新执行了语法解析。所以要保证SQL语义不变,即我想要表达SQL就是我想表达的意思,不是别的注入后的意思,就应该重用执行计划。 如果不能够重用执行计划,那么就有SQL注入的风险,因为SQL的语意有可能会变化,所表达的查询就可能变化。 在SQL Server 中查询执行计划可以使用下面的脚本: DBCC FreeProccache select total_elapsed_time / execution_count 平均时间,total_logical_reads/execution_count 逻辑读, usecounts 重用次数,SUBSTRING(d.text, (statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(text) ELSE statement_end_offset END - statement_start_offset)/2) + 1) 语句执行 from sys.dm_exec_cached_plans a cross apply sys.dm_exec_query_plan(a.plan_handle) c ,sys.dm_exec_query_stats b cross apply sys.dm_exec_sql_text(b.sql_handle) d --where a.plan_handle=b.plan_handle and total_logical_reads/execution_count>4000 ORDER BY total_elapsed_time / execution_count DESC; 
博客园有篇文章: Sql Server参数化查询之where in和like实现详解 在这篇文章中有这么一段: 
这里作者有一句话:”不过这种写法和直接拼SQL执行没啥实质性的区别” 任何拼接SQL的方式都有SQL注入的风险,所以如果没有实质性的区别的话,那么使用exec 动态执行SQL是不能防止SQL注入的。 比如下面的代码: private static void TestMethod() { using (SqlConnection conn = new SqlConnection(connectionString)) { conn.Open(); SqlCommand comm = new SqlCommand(); comm.Connection = conn; //使用exec动态执行SQL //实际执行的查询计划为(@UserID varchar(max))select * from Users(nolock) where UserID in (1,2,3,4) //不是预期的(@UserID varchar(max))exec('select * from Users(nolock) where UserID in ('+@UserID+')') comm.CommandText = "exec('select * from Users(nolock) where UserID in ('+@UserID+')')"; comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4" }); //comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4); delete from Users;--" }); comm.ExecuteNonQuery(); } } 执行的SQL 如下: exec sp_executesql N'exec(''select * from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID varchar(max) ',@UserID='1,2,3,4' 
可以看到SQL语句并没有参数化查询。 如果你将UserID设置为” 1,2,3,4); delete from Users;—- ”,那么执行的SQL就是下面这样: exec sp_executesql N'exec(''select * from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID varchar(max) ',@UserID='1,2,3,4); delete from Users;--' 不要以为加了个@UserID 就代表能够防止SQL注入,实际执行的SQL 如下: 
任何动态的执行SQL 都有注入的风险,因为动态意味着不重用执行计划,而如果不重用执行计划的话,那么就基本上无法保证你写的SQL所表示的意思就是你要表达的意思。 这就好像小时候的填空题,查找密码是(____) 并且用户名是(____)的用户。 不管你填的是什么值,我所表达的就是这个意思。 最后再总结一句:因为参数化查询可以重用执行计划,并且如果重用执行计划的话,SQL所要表达的语义就不会变化,所以就可以防止SQL注入,如果不能重用执行计划,就有可能出现SQL注入,
存储过程也是一样的道理,因为可以重用执行计划。 原文出自: http://www.cnblogs.com/LoveJenny/archive/2013/01/15/2860553.html
背景 : 在使用搜索引擎和电商的搜索功能时,大家一定遇到过这样的情景:我想搜索电影“十二生肖”,可不小心输成“十二生效”了,不用担心搜不到你想要的结果,因为建立在大数据上的搜索引擎会帮你自动纠错,就这个例子Google和Baidu返回给我的分别是: 显示以下查询字词的结果: 十二生肖 和 您要找的是不是: 十二生肖 ,他们都做到了自动纠错,关于自动纠错我之前也写过一篇陋文,当时是自己实现的N-Gram模型,但是效果不是太好,主要是针对不同的语料库算法的精确度是不一样的,我想换个算法试试看,目前主流的计算串间的距离(相反的,你也可以理解为相似度)是Levenshtein,当要实现时,发现lucene已经做了这个事,那咱就站在巨人的肩膀上成长吧。 引用包: lucene-core-3.1.0.jar + lucene-spellchecker-3.1.0.jar,你可以在这里得到 使用示例: 在类SpellCorrector的main方法中加入以下代码 1 //创建目录
2 File dict = new File("");
3 Directory directory = FSDirectory.open(dict);
4
5 //实例化拼写检查器
6 SpellChecker sp = new SpellChecker(directory);
7
8
9 //创建词典
10 File dictionary = new File(SpellCorrecter.class.getResource("dictionary.txt").getFile());
11
12 //对词典进行索引
13 sp.indexDictionary(new PlainTextDictionary(dictionary));
14
15
16 //有错别字的搜索
17 String search = "非常勿扰";
18
19
20 //建议个数,这里我只想要最接近的那一个,你可以设置成别的数字,如3
21 int suggestionNumber = 1;
22
23
24 //获取建议的关键字
25 String[] suggestions = sp.suggestSimilar(search, suggestionNumber);
26
27
28 //显示结果
29 System.out.println("搜索:" + search);
30
31
32 for (String word : suggestions) {
33 System.out.println("你要找的是不是:" + word);
34 }
注:这之前你需要有个语料库,我这里是个存放正确视频名称的文件,格式如下:
红颜血泪
冰上火一般的激情
在敌之手
驰风竞艇王第二部
钓金龟
潇湘路一号
戏里戏外第二季
草原狼爵士乐
拯救大兵瑞恩 好了,接下来就直接运行吧,例如我搜索“十二生效”,则提示说是不是要找“十二生肖” 
原文出自: http://www.cnblogs.com/wuren/archive/2013/01/16/2862873.html
严重: Exception sending context initialized event to listener instance of class org.springframework.web.context.ContextLoaderListener org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'ResourceService': Invocation of init method failed; nested exception is javax.xml.ws.WebServiceException: java.lang.IllegalArgumentException: An operation with name [####] already exists in this service 可能是因为WebService 存在重载的方法,因此初始化时Spring无法找到对应的方法 使用的插件为: javax.jws-1.0.0_JDK1.5_1.0.0.jar cxf-bundle-2.5.2.jar spring-webmvc-3.1.1.RELEASE.jar
一般我们的前台代码Ext.grid.ColumnModel里会这样写,以便显示日期格式: ////////////////////////////////////////////////////////////// Js代码
....
{ header:"birthday", dataIndex:"birthday" .... renderer:new Ext.util.Format.dateRenderer("Y-m-d"),
.... } .... ////////////////////////////////////////////////////////////// 如果你前台这样写的话,那恭喜你,你的显示日期那列将不再正确显示时间, 而是显示为"NaN-NaN-NaN",是吧? 呵呵,问我怎么知道的?因为最开始我也是这么错的。 为什么会是错的呢? 让我们来看看Ext.format.dateRenderer的源代码(开源的东西就是好), 它的源代码是这样的: Js代码 //////////////////////////////////////////////////////////////
dateRenderer : function(format) {
return function(v) {
return Ext.util.Format.date(v, format);、
}
} //////////////////////////////////////////////////////////////
可以看出,我们传会来的值,被当做日期又被格式化了一次,我们传回来的是日期吗?
以前是,经过昨天后台代码的修改,我们传回来的仅仅是个字符串了,至于为什么要这么改, 请看昨天写的“Extjs日期格式问题(一) ”,那咋办?有的朋友应该已经想到了,既然是字符串, 那就直接显示呗,不用renderer了,于是前台代码Ext.grid.ColumnModel里就变成了: Js代码 //////////////////////////////////////////////////////////////
....
{header:"birthday",dataIndex:"birthday".......),
....
////////////////////////////////////////////////////////////// 可以负责任的告诉你,这样写,绝对可以正确显示了,这样是不是感觉更简单了呢? 但是,基于我项目里的要求,这个问题并没有解决完,因为在这里不是一个简单的gridpanel, 而是一个editgridpanel,所以还得定义一个editor,于是有了下面这样一段代码: Js代码 //////////////////////////////////////////////////////////////
....
{header:"birthday",dataIndex:"birthday".......,
editor:new Ext.grid.GridEditor(new Ext.form.DateField({format:"Y-m-d"})),
..... //////////////////////////////////////////////////////////////
加了这个DateField控件后,每次可以正常的选择日期,但是选择完日期后, grid里显示的格式就又不正确了,这次显示的内容成了: "Wed Mar 04 1970......", 这样的格式一看就是个日期,这样显示的原因当然是因为我们没有写renderer进行格式化处理的缘故。。。 说到这里,有人应该已经想到解决办法了,另外有些人可能就抓狂了,这renderer加了不能正常显示, 不加也不能正常显示,这很矛盾啊。。 问题往往到了最矛盾的时候,也是到了解决的时候,现在我把解决代码贴出来,大家一看就明白了。 多的不说,看代码: Js代码
////////////////////////////////////////////////////////////// renderer:function(value){
if(value instanceof Date){
return new Date(value).format("Y-m-d");
}else{
return value;
}
}
////////////////////////////////////////////////////////////// 简单吧?自己写renderer就是了。 原文出自:http://ks2144634.blog.163.com/blog/static/133585503201081544950656/
错误”ora-04031 无法分配XXX字节的共享内存(XXX)”的解决办法: oracle 9i:
sys用户以sysdba身份登录
先查看当前shared_pool_size值
sql>show parameter shared_pool_size;
然后
sql>alter system set shared_pool_size=’比原先值适当增加’ scope=spfile;
然后
sql>shutdown immediate
sql>startup oracle 10g:
oracle 10g shared_pool_size默认值为0,也就是系统自动管理shared pool内存,这时可以适当增加shared_pool_reserved_size的值,仍然让系统自动管理这部分内存 sql>alter system set shared_pool_reserved_size=’比原先值适当增加’ scope=spfile;
sql>shutdown immediate
sql>startup 原文出自:http://openwares.net/database/cant_alloc_share_memory.html
对依赖注入( http://www.oschina.net/code/snippet_871522_15682) 的进一步加强. 作为基本功能的注册,使用语法是:registration.register<Interface,Implementation>(). 可以到了实际的项目中,要注册的接口和类可能不止一个两个,会成百上千。无论是用C#代码来注册,还是用XML文件来配置,都是开发者的噩梦。 这里,让我们来个思维的反转: 变集中配置为分散声明。 1 为要注册的类,加入RegisterInContainer的声明 2 在系统启动的时候,扫描所有的类,对有RegisterInContainer的类,找到它所有实现的接口,把这些接口和该类绑定注册。 用于装饰要注入类的Attribute. 1 using System;
2 using System.Linq;
3 using Skight.eLiteWeb.Domain.BasicExtensions;
4
5 namespace Skight.eLiteWeb.Domain.Containers
6 {
7 [AttributeUsage(AttributeTargets.Class)]
8 public class RegisterInContainerAttribute : Attribute
9 {
10 public RegisterInContainerAttribute(LifeCycle life_cycle) {
11 this.life_cycle = life_cycle;
12 }
13
14 public LifeCycle life_cycle { get; set; }
15 public Type type_to_register_in_container { get; set; }
16
17 public void register_using(Registration registration) {
18 DiscreteItemResolver resolver = new TypeResolver(type_to_register_in_container);
19 if (life_cycle == LifeCycle.singleton) resolver = new SingletonResolver(resolver);
20 registration.register(resolver,type_to_register_in_container.all_interface().ToArray());
21 }
22 }
23 } 注入声明Attribute参数,指定是否单件方式生成注册类。1 namespace Skight.eLiteWeb.Domain.Containers
2 {
3 public enum LifeCycle
4 {
5 single_call,
6 singleton
7 }
8 } 注册声明Attribute的使用示例 1 //调用Container.get_an<FrontController>()将会得到FrontControllerImpl的对象
2
3 using Skight.eLiteWeb.Domain.Containers;
4
5 namespace Skight.eLiteWeb.Presentation.Web.FrontControllers
6 {
7 [RegisterInContainer(LifeCycle.single_call)]
8 public class FrontControllerImpl : FrontControllers.FrontController
9 {
10 private CommandResolver command_resolver;
11
12 public FrontControllerImpl(CommandResolver commandResolver)
13 {
14 command_resolver = commandResolver;
15 }
16
17 public void process(WebRequest request)
18 {
19 command_resolver.get_command_to_process(request).process(request);
20 }
21 }
22 } Registration添加一个方法:反过来,为一个解析器(实现类)注册多个接口。1 void register(DiscreteItemResolver resolver, params Type[] contracts);
2 扫描注册机,在系统启动时调用一次。 1 using System.Collections.Generic;
2 using System.Reflection;
3 using Skight.eLiteWeb.Domain.BasicExtensions;
4 using Skight.eLiteWeb.Domain.Containers;
5
6 namespace Skight.eLiteWeb.Application.Startup
7 {
8 public class RegistrationScanner:StartupCommand
9 {
10 private readonly Registration registration;
11 private readonly IEnumerable<Assembly> assemblies;
12
13 public RegistrationScanner(Registration registration, params Assembly[] assemblies)
14 {
15 this.registration = registration;
16 this.assemblies = assemblies;
17 }
18
19 public void run()
20 {
21 assemblies
22 .each(assembly =>
23 assembly.GetTypes()
24 .each(type =>
25 type.run_againste_attribute<RegisterInContainerAttribute>(
26 attribute =>
27 {
28 attribute.type_to_register_in_container = type;
29 attribute.register_using(registration);
30 })));
31 }
32 }
33 } 系统启动:创建注册类,然后传入必要的Assembly,调用注册机注册所有加了Attribute的类。 1 using System;
2 using System.Collections.Generic;
3 using System.Reflection;
4 using Skight.eLiteWeb.Domain.Containers;
5 using Skight.eLiteWeb.Presentation.Web.FrontControllers;
6
7 namespace Skight.eLiteWeb.Application.Startup
8 {
9 public class ApplicationStartup
10 {
11 public void run()
12 {
13 var registration = create_registration();
14 new RegistrationScanner(registration,
15 Assembly.GetAssembly(typeof (Container)),
16 Assembly.GetAssembly(typeof (FrontController)),
17 Assembly.GetAssembly(typeof (StartupCommand)))
18 .run();
19
20 }
21
22 private Registration create_registration()
23 {
24 IDictionary<Type, DiscreteItemResolver> item_resolvers = new Dictionary<Type, DiscreteItemResolver>();
25 Container.initialize_with(new ResolverImpl(item_resolvers));
26 return new RegistrationImpl(item_resolvers);
27 }
28 }
29 } Global.asax系统入口,把所有的代码串起来。 1 <%@ Application Language="C#" %>
2 <%@ Import Namespace="Skight.eLiteWeb.Application.Startup" %>
3 <script RunAt="server">
4
5 private void Application_Start(object sender, EventArgs e)
6 {
7 new ApplicationStartup().run();
8 }
9
10 </script> 原文出自: http://www.oschina.net/code/snippet_871522_16735
摘要: http://www.umlchina.com/Tools/Newindex1.htmUML相关工具一览(截止2012年10月) 整理 本文的PDF版本在此下载>> 以下总结了全世界的各种UML相关工具,按工具名称字母排序。 工具(最新版本) 厂商&地址 版权 ... 阅读全文
1.活动图、用例图、类图 http://yuml.me/diagram/scruffy/class/draw 2.序列图 http://www.websequencediagrams.com/ 3.序列图、协作图 http://www.diagrammr.com/
摘要: Container注入框架的进入点Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> 1 namespace Skight.LightWeb.Domain 2 { 3 &n... 阅读全文
在这里我们总结了Oracle临时表的集中用法,临时表创建之后基本不占用表空间,如果你没有指定临时表存放的表空的时候,你插入到临时表的数据是存在系统的临时表空间中。 Oracle临时表可以说是提高数据库处理性能的好方法,在没有必要存储时,只存储在Oracle临时表空间中。希望本文能对大家有所帮助。 1 、前言 目前所有使用 Oracle 作为数据库支撑平台的应用,大部分数据量比较庞大的系统,即表的数据量一般情况下都是在百万级以上的数据量。 当然在 Oracle 中创建分区是一种不错的选择,但是当你发现你的应用有多张表关联的时候,并且这些表大部分都是比较庞大,而你关联的时候发现其中的某一张或者某几张表关联 之后得到的结果集非常小并且查询得到这个结果集的速度非常快,那么这个时候我考虑在 Oracle 中创建“临时表”。 我对临时表的理解:在 Oracle 中创建一张表,这个表不用于其他的什么功能,主要用于自己的软件系统一些特有功能才用的,而当你用完之后表中的数据就没用了。 Oracle 的临时表创建之后基本不占用表空间,如果你没有指定临时表(包括临时表的索引)存放的表空的时候,你插入到临时表的数据是存放在 ORACLE 系统的临时表空间中( TEMP )。 2 、临时表的创建 创建Oracle 临时表,可以有两种类型的临时表: 会话级的临时表 事务级的临时表 。 1) 会话级的临时表因为这这个临时表中的数据和你的当前会话有关系,当你当前SESSION 不退出的情况下,临时表中的数据就还存在,而当你退出当前SESSION 的时候,临时表中的数据就全部没有了,当然这个时候你如果以另外一个SESSION 登陆的时候是看不到另外一个SESSION 中插入到临时表中的数据的。即两个不同的SESSION 所插入的数据是互不相干的。当某一个SESSION 退出之后临时表中的数据就被截断(truncate table ,即数据清空)了。会话级的临时表创建方法: 1 Create Global Temporary Table Table_Name
2 (Col1 Type1,Col2 Type2 ) On Commit Preserve Rows ; ) On Commit Preserve Rows ;
举例: 1 create global temporary table Student
2 (Stu_id Number(5),
3 Class_id Number(5),
4 Stu_Name Varchar2(8),
5 Stu_Memo varchar2(200)) on Commit Preserve Rows ;
2) 事务级临时表是指该临时表与事务相关,当进行事务提交或者事务回滚的时候,临时表中的数据将自行被截断,其他的内容和会话级的临时表的一致(包括退出SESSION 的时候,事务级的临时表也会被自动截断)。事务级临时表的创建方法: 1 Create Global Temporary Table Table_Name
2 (Col1 Type1,Col2 Type2) On Commit Delete Rows ;
举例: 1 create global temporary table Classes
2 (Class_id Number(5),
3 Class_Name Varchar2(8),
4 Class_Memo varchar2(200)) on Commit delete Rows ;
3) 两中类型临时表的区别 会话级临时表采用 on commit preserve rows ;而事务级则采用 on commit delete rows ;用法上,会话级别只有当会话结束临时表中的数据才会被截断,而且事务级临时表则不管是 commit 、 rollback 或者是会话结束,临时表中的数据都将被截断 4 )什么时候使用临时表 1 )、当某一个 SQL 语句关联的表在 2 张及以上,并且和一些小表关联。可以采用将大表进行分拆并且得到比较小的结果集合存放在临时表中 2 )、程序执行过程中可能需要存放一些临时的数据,这些数据在整个程序的会话过程中都需要用的等等。 3 . 例子:略 4 .临时表的不足之处 1 )不支持 lob 对象,这也许是设计者基于运行效率的考虑,但实际应用中确实需要此功能时就无法使用临时表了。 2 )不支持主外键关系 所以,由于以上原因,我们可以自己创建临时表,以弥补 oracle 临时表的不足之处 上面的都是本人经过测试的,但下面是在网上搜索到的方法,本人具体没有测试过,不过觉得可行性很强,有时间测试下 创建方法: 1 、以常规表的形式创建临时数据表的表结构,但要在每一个表的主键中加入一个 SessionID 列以区分不同的会话。(可以有 lob 列和主外键) 2 、写一个用户注销触发器,在用户结束会话的时候删除本次会话所插入的所有记录 (SessionID 等于本次会话 ID 的记录 ) 。 3 、程序写入数据时,要顺便将当前的会话 ID(SessionID) 写入表中。 4 、程序读取数据时,只读取与当前会话 ID 相同的记录即可。 功能增强的扩展设计: 1 、可以在数据表上建立一个视图,视图对记录的筛选条件就是当前会话的SessionID 。 2 、数据表中的SessionID 列可以通过Trigger 实现,以实现对应用层的透明性。 3 、高级用户可以访问全局数据,以实现更加复杂的功能。 扩展临时表的优点: 1 、实现了与Oracle 的基于会话的临时表相同的功能。 2 、支持SDO_GEOMETRY 等lob 数据类型。 3 、支持表间的主外键连接,且主外键连接也是基于会话的。 4 、高级用户可以访问全局数据,以实现更加复杂的功能 原文出自: http://database.51cto.com/art/201001/180851.htm
Heritrix绑定主机IP 关键字:Heritrix 127.0.0.1 IP 主机 Heritrix默认绑定的IP是127.0.0.1。 在org.archive.crawler.Heritrix中 | … final private static Collection<String> LOCALHOST_ONLY = Collections.unmodifiableList(Arrays.asList(new String[] { "127.0.0.1" })); … private static Collection<String> guiHosts = LOCALHOST_ONLY; protected static String doCmdLineArgs(final String [] args) throws Exception { … // Now look at options passed. for (int i = 0; i < options.length; i++) { switch(options[i].getId()) { … case 'b': Heritrix.guiHosts = parseHosts(options[i].getValue()); break; … default: assert false: options[i].getId(); } } … } | 首先定义了默认IP:127.0.0.1,然后赋给guiHost主机变量。当指定-b或--bind参数时,才会把指定的IP赋给主机变量。 另外,中间还有一步参数处理,对于--xxxx参数会转为-x的形式统一处理,所以--bind和-b有一样的效果。 Heritrix启动参数 关键字:Heritrix 启动 参数 bind admin properties Heritrix的启动参数,除了--bind外,都可以在heritrix.properties设置,而不用每次都在命令行中输入。 如常用的--port, --admin等。 | heritrix.cmdline.admin = admin:admin heritrix.cmdline.port = 8080 heritrix.cmdline.run = false heritrix.cmdline.nowui = false heritrix.cmdline.order = heritrix.cmdline.jmxserver = false heritrix.cmdline.jmxserver.port = 8081 | 关于Heritrix的Extractor中文乱码 关键字:Heritrix 中文 乱码 GB2312 Extractor 继承从org.archive.crawler.extractor.Extractor的子类,在extract方法中可以从参数CrawlURI中取出要解析的内容。 | curi.getHttpRecorder().getReplayCharSequence.toString() | 有中文时,不做处理会输出乱码。可以在取到的HttpRecorder后设置编码: | HttpRecorder hr = curi.getHttpRecorder(); if ( hr == null ) { throw new IOException( "Why is recorder null here?" ); } hr.setCharacterEncoding( "gb2312" ); cs = hr.getReplayCharSequence(); System.out.println( cs.toString() ); | 原文出自: http://blog.chinaunix.net/uid-8464637-id-2461166.html
原文出自: http://blog.csdn.net/jbxiaozi/article/details/7351768
1.右键项目-》属性-》java bulid path-》jre System Library-》access rules-》resolution选择accessible,下面填上** 点击确定即可!!! 2. 在MyEclipse中编写Java代码时,用到了BASE64Decoder,import sun.misc.BASE64Decoder;可是Eclipse提示:
Access restriction: The type BASE64Decoder is not accessible due to restriction on required library C:\Program
files\java\jre6\lib\rt.jar
Access restriction : The constructor BASE64Decoder() is not accessible due to restriction on required library C:\Program files\java\jre6\lib\rt.jar
解决方案1(推荐):
只需要在project build path中先移除JRE System Library,再添加库JRE System Library,重新编译后就一切正常了。
解决方案2:
Windows -> Preferences -> Java -> Compiler -> Errors/Warnings ->
Deprecated and trstricted API -> Forbidden reference (access rules): -> change to warning
项目中有时需要用到起始日期和结束日期,要做到起始日期必须小于结束日期。在extjs中已经有现成的函数,摘录如下: 1 Ext.apply(Ext.form.VTypes, {
2 daterange : function(val, field) {
3 var date = field.parseDate(val);
4 if (!date) {
5 return;
6 }
7 if (field.startDateField
8 && (!this.dateRangeMax || (date.getTime() != this.dateRangeMax
9 .getTime()))) {
10 var start = Ext.getCmp(field.startDateField);
11 start.setMaxValue(date);
12 start.validate();
13 this.dateRangeMax = date;
14 } else if (field.endDateField
15 && (!this.dateRangeMin || (date.getTime() != this.dateRangeMin
16 .getTime()))) {
17 var end = Ext.getCmp(field.endDateField);
18 end.setMinValue(date);
19 end.validate();
20 this.dateRangeMin = date;
21 }
22 /*
23 * Always return true since we're only using this vtype to set
24 * the min/max allowed values (these are tested for after the
25 * vtype test)
26 */
27 return true;
28 }
29 }); 然后分别定义起始日期和结束日期控件: 1 var startDate = new Ext.form.DateField({
2 fieldLabel : '开始日期',
3 emptyText : '请选择',
4 disabledDays : [1, 2, 5],//将星期一,二,五禁止.数值为0-6,0为星期日,6为星期六
5 labelWidth : 100,
6 readOnly : true,
7 allowBlank : false,
8 format : 'Y-m-d',//日期格式
9 name : 'startdt',
10 id : 'startdt',
11 vtype : 'daterange',//daterange类型为上代码定义的类型
12 endDateField : 'endDate'//必须跟endDate的id名相同
13 })
14 var endDate = new Ext.form.DateField({
15 fieldLabel : '结束日期',
16 emptyText : '请选择',
17 disabledDays : [1, 2, 5],//将星期一,二,五禁止.数值为0-6,0为星期日,6为星期六
18 readOnly : true,
19 allowBlank : false,
20 format : 'Y-m-d',//日期格式
21 name : 'enddt',
22 id : 'endDate',
23 vtype : 'daterange',//daterange类型为上代码定义的类型
24 startDateField : 'startdt'//必须跟startDate的id名相同
25 }) 效果如下两图: 
图1.选择开始日期 
图2.选择结束日期 原文出自: http://blog.csdn.net/security08/article/details/5070749
工作流管理联盟: 定义: 创建并完善了工作流的相关标准,开拓了相关市场,是唯一的致力于工作流标准化的专业组织。该组织推出了工作流XML(Wf-XML)和XML过程定义语言(XPDL) ,现在有超过80种有名的解决方案中使用了这两种语言来存储和交换过程模型。发布了用于工作流管理系统之间互操作的工作流参考模型,并且为了实现不同工作流产品之间的互操作,WfMC在工作流管理系统的相关术语、体系结构及应用编程接口等方面制定了一系列标准 工作流: 定义: 工作流是一类能够完全或者部分自动执行的经营过程,根据一系列过程规则,文档、信息或任务能够在不同的执行者之间传递、执行。从工作流的定义可以看出:(1)、有多个参与者:(2)、按照一定的规则进行活动(传递文档、信息、任务等);(3)、活动的推进是自动的或部分自动的。【工作流管理联盟】 工作流管理系统: 定义: 工作流管理系统是一个软件系统,它负责工作流的定义和管理,并按照在计算机中预先定义好的工作流逻辑推进过程实例的执行。工作流管理系统(Workflow Management System,WFMS)是通过对工作流程中涉及各步骤的人员和IT资 源的合理调整,从而起到对工作流的定义、管理和实现的确定性作用。工作流管理系统是支持企业实现业务过程管理和自动化的强有力的软件工具,它能完成工作流 的定义和管理,并按照在计算机中预先定义好的工作流逻辑推进工作流实例的执行。所以工作流是工作流管理系统的最重要的被管理的元素,就像表、试图是数据库 管理系统的管理对象一样。【工作流管理联盟】 工作流参考模型: 
定义: 1.通用的工作流系统实现模型 2.把工作流系统中的主要功能组件和这些组件间的接口一起看成抽象的模型 作用: 1.这个模型可以与市场上的大多数产品相匹配,因此为开发协同工作的工作流系统奠定了基础 2.工作流参考模型的引入为人们讨论工作流技术提供了一一个规范的术语表,为在一般意义上讨论工作流系统的体系结构提供了基础:工作流参考模型为工作流管理系统的关键软件部件提供了功能描述,并描述了关键软件部件交互,而 且这个描述是独立于特定产品或技术的实现的:从功能的角度定义五个关键软件部件的交互接口,推动了信息交换的标准化,使得不同产品间的互操作成为可能。 组成: 1.软件组件:为工作流系统的各种功能提供支持。 2.各中类型的系统定义数据和控制数据:系统中的一个或多个软件构件使用的数据。 3.应用程序与应用程序数据库:外部系统或数据,被系统调用来完成整个或部分工作流管理的功能。 五类接口(WorkflowAPI,WAPI) 接口l:工作流执行服务与工作流建模工具间的接口,为实现对工作流过程定义的访问(如建立、修改、删除等)提供了一致的方法。 接口2:工作流服务和用户应用之间的接口,这是最主要的接口规范,它约定所有客户方应用和工作流服务之间的功能访问方式。 接口3:工作流引擎和应用服务间的直接接口,其目标是集成工作流和其它应用服务而无需考虑原有工作流管理系统。 接口4:工作流管理系统之间的互操作接口,用于描述不同工作流产品的互操作性。 一般必须的互操作有两个主要方面: (1)流程定义或子集的公共解释; (2)运行时间对各种控制信息转换,和在不同实施服务之间传递工作流相关数据和应用数据的支持。_个工作流引擎可以选择、实例化和执行其他工作流引擎所约定的流程定义。 接口5:工作流服务和工作流管理工具之间的接口,用于系统管理、应用访问工作流执行服务。 通用工作流系统各部分功能: 
1.工作流执行服务 工作流执行服务是指由一个或者多个工作流引擎组成,以创建,管理和执行工作流实例,应用程序可能通过工作流应用程序接口(WAPI))与这个服务进行交互。工作流执行服务的主要功能是:解释流程定义,生成过程实例,并管理其实施过程;依据工作流相关数据实现流程活动导航,包括顺序或并行操作、期限设置等;与外部资源交互,完成各项活动;维护工作流控制数据和工作流相关数据,并向用户传送必要的相关数据。 工作流执行服务使用外部资源的两种途径: 1.用户应用接口:工作流引擎通过任务项列表管理资源,任务项列表管理器负责从任务项列表中选择并监督工作项的完成。任务项列表管理器或用户负责调用应用工具。 2.直接调用应用接口:工作流引擎直接调用相应的应用来完成一项任务。这主要是针对基于服务器的无需用户参与的应用,那些需要用户操作的活动则通过任务列表管理器来调用。 2.工作流引擎 工作流引擎是指为工作流实例提供运行时执行环境的软件服务或“引擎”。 主要提供以下功能:对过程定义进行解释;控制过程实例的生成、激活、挂起、终止等;控制过程活动间的转换,包括串行或并行的操作、工作流相关数据的解释 等;支持用户操作的界面;维护工作流控制数据和工作流相关数据,在应用或用户间传递工作流相关数据;提供用于激活外部应用并提供工作流相关数据的界面;提 供控制、管理和监督的功能。 3.过程定义工具 过程定义工具是管理流程定义的工具,它可以通过图形方式把复杂的流程定义显示出来并加以操作。流程定义工具同工作流执行服务交互,为用户提供一种对实际业务过程进行分析、建模的手段,并生成业务过程的可被计算机处理的形式化描述(过程定义)。这也是工作流系统建立阶段的主要任务。不同的工作流产品,其建模工具输出格式是不同的。接口l不仅使工作流的定义阶段和运行阶段分离,使用户可以分别选择建模工具和执行产品,并且提供了对工作流过程进行协同定义的潜在能力,这些产品提供了分布的运行服务。 4.管理和监控工具 管理和监控工具主要负责对组织机构、角色等数据的维护管理和工作流实例的运行进行监控。管理员可以通过工作流管理工具获得目前各个活动的运行情况报告,并可干预实例的推进。 5.客户端应用 客户端应用是通过请求的方式同工作流执行服务交互的应用,也就是说是客户端应用调用工作流执行服务,客户端应用同工作流执行服务交互。它提供给用户一种手段,以处理实例运行过程中需要人工参与的任务。 6.调用的应用 调用的应用指工作流执行服务在过程实例运行过程中调用的、用以对应用数据进行处理的应用程序和Web服务 原文出自: http://www.cnblogs.com/yuziyan/archive/2012/12/08/2809346.html
类图画法 类之间的几种关系:泛化(Generalization)、实现(Realization)、关联(Association)(又分一般关联、聚合(Aggregation)、组合(Composition))、依赖(Dependency) 一、类图画法 1、 类图的概念 A、显示出类、接口以及它们之间的静态结构和关系 B、用于描述系统的结构化设计 2、 类图的元素 类、接口、协作、关系,我们只简单介绍一下这四种元素。 同其他的图一样,类图也可以包含注解和限制。 类图中也可以包含包和子系统,这两者用来将元素分组。 有时候你也可以将类的实例放到类图中。 3、 类 A、 类是对一组具有相同属性、操作、关系和语义的对象的抽象,它是面向对象系统组织结构的核心,包括名称部分(Name)、属性部分(Attribute)和操作部分(Operation),见下图。 
B、 类属性的语法为: [可见性] 属性名 [:类型] [=初始值] [{属性字符串}] 可见性:公有(Public)“+”、私有(Private)“-”、受保护(Protected)“#” 类操作的语法为: [可见性] 操作名 [(参数表)] [:返回类型] [{属性字符串}] 可见性:公有(Public)“+”、私有(Private)“-”、受保护(Protected)“#”、包内公有(Package)“~” 参数表: 定义方式:“名称:类型”;若存在多个参数,将各个参数用逗号隔开;参数可以具有默认值; 属性字符串: 在操作的定义中加入一些除了预定义元素之外的信息。 4、 接口 在没有给出对象的实现和状态的情况下对对象行为的描述。 一个类可以实现一个或多个接口。 使用两层矩形框表示,与类图的区别主要是顶端有<<interface>>显示: 
也可以用一个空心圆表示: 
5、 协作 协作是指一些类、接口和其他的元素一起工作提供一些合作的行为,这些行为不是简单地将元素 加能得到的。例如:当你为一个分布式的系统中的事务处理过程建模型时,你不可能只通过一个类来明白事务是怎样进行的,事实上这个过程的执行涉及到一系列的 类的协同工作。使用类图来可视化这些类和他们的关系。 6、 关系 这篇文章的重点,详见第二部分。 二、类之间的几种关系 1、 泛化(Generalization) A、 是一种继承关系,表示一般与特殊的关系,它指定了子类如何特化父类的所有特征和行为,描述了一种“is a kind of” 的关系。例如:老虎是动物的一种,即有老虎的特性也有动物的共性。 B、 用带空心箭头的实线表示,箭头指向父类,如下图: 
2、 实现(Realization) A、 是一种类与接口的关系,表示类是接口所有特征和行为的实现。 B、 用带空心箭头的虚线表示,箭头指向接口,如下图: 
3、 关联(Association) A、 一般关联 a、 关联关系是类与类之间的联结,它使一个类知道另一个类的属性和方法,指明了事物的对象之间的联系,如:老师与学生、丈夫与妻子。关联可以是双向的,也可以是单向的,还有自身关联。 b、 用带普通箭头的实心线表示。双向的关联可以有两个箭头或者没有箭头,单向的关联有一个箭头,如下图: 
B、 聚合(Aggregation) a、 它是整体与部分(整体 has a 部分)的关系,且部分可以离开整体而单独存在,如车和轮胎是整体和部分的关系,轮胎离开车仍然可以存在。聚合关系是关联关系的一种,是强的关联关系,关联和聚合在语法上无法区分,必须考察具体的逻辑关系。 b、 用带空心菱形的实线表示,菱形指向整体,如下图: 
C、 组合(Composition) a、 它是整体与部分的关系,但部分不能离开整体而单独存在。如公司和部门是整体和部分的关系,没有公司就不存在部门。组合关系是关联关系的一种,是比聚合关系还要强的关系,它要求普通的聚合关系中代表整体的对象负责代表部分的对象的生命周期。 b、 用带实心菱形的实线表示,菱形指向整体,如下图: 
4、 依赖(Dependency) A、 元素A的变化会影响元素B,那么B和A的关系是依赖关系,B依赖A。要避免双向依赖,一般来说,不应该存在双向依赖。关联、实现、泛化都是依赖关系。 B、 用带箭头的虚线表示,箭头指向被依赖元素。 
5、 总结 各种关系的强弱顺序如下: 泛化 = 实现 > 组合 > 聚合 > 关联 > 依赖 下面这张UML图,比较形象地展现了各种类图关系: 
原文出自: http://www.cnblogs.com/fuhongxue2011/archive/2012/12/09/2810408.html
摘要: 近日来对Ext特别感兴趣,也许是它那种OO的设计思想吸引了我,也可以追溯到第一次见到EXT那种漂亮的界面开始吧.求神拜佛不如自食其力,为了一点小的问题找遍了GOOGLE也没个结果,自己甚少去BBS混,也不熟悉规矩,只能硬着头皮自己干了.翻源代码是一道必不可少的工序,说来惭愧,自己对JS的认识还停留在入门阶段.这里说说自己对于Ext验证这里浅薄的理解:首先看看如下一段代码Code highlight... 阅读全文
由于HTTP协议的无状态特性,导致在ASP.NET编程中,每个请求都会在服务端从头到执行一次管线过程, 对于ASP.NET页面来说,Page对象都会重新创建,所有控件以及内容都会重新生成, 因此,如果希望上一次的页面状态能够在后续页面中保留,则必需引入状态管理功能。 ASP.NET为了实现状态管理功能,提供了8种方法,可帮助我们在页面之间或者整个用户会话期间保留状态数据。 这些方法分为二类:视图状态、控件状态、隐藏域、Cookie 和查询字符串会以不同方式将数据发送到客户端上。 而应用程序状态、会话状态和配置文件属性(Profile)则会将数据存储到服务端。 虽然每种方法都有不同的优点和缺点,对于小的项目来说,可以选择自己认为最容易使用的方法, 然而,对于有着较高要求的程序,尤其是对于性能与扩展性比较关注的程序来说, 选择不同的方法最终导致的差别可能就非常大了。 在这篇博客中,我将谈谈自己对ASP.NET状态管理方面的一些看法。
注意:本文的观点可能并不合适开发小型项目,因为我关注的不是易用性。 hidden-input hidden-input 这个名字我是取的,表示所有type="hidden"的input标签元素。 在中文版的MSDN中,也称之为 隐藏域 。 hidden-input通常存在于HTML表单之内,它不会显示到页面中, 但可以随表单一起提交,因此,经常用于维护当前页面的相关状态,在服务端我们可以使用Request.Form[]来访问这些数据。 一般说来,我通常使用hidden-input来保存一些中间结果,用于在多次提交中维持一系列状态, 或者用它来保存一些固定参数用来提交给其它页面(或网站)。 在这些场景中,我不希望用户看到这些数据,因此,使用hidden-input是比较方便的。 关于表单的更多介绍可参考我的博客:细说 Form (表单) 在ASP.NET WebForm框架中,我们可以使用HiddenField控件来创建一个hidden-input控件,并可以在服务端操作它, 还可以直接以手写的方式使用隐藏域,例如: <input type="hidden" name="hidden-1" value="aaaaaaa" /> <input type="hidden" name="hidden-2" value="bbbbbbb" /> <input type="hidden" name="hidden-3" value="ccccccc" /> 另外,我们还可以调用ClientScript.RegisterHiddenField()方法来创建隐藏域: ClientScript.RegisterHiddenField("hidden-4", "ddddddddd"); 输出结果: <input type="hidden" name="hidden-4" id="hidden-4" value="ddddddddd" /> 这三种方法对于生成的HTML代码来说,主要差别在于它们出现位置不同:
1. HiddenField控件:由HiddenField的出现位置来决定(在form内部)。
2. RegisterHiddenField方法:在form标签的开头位置。
3. hidden-input:你写在哪里就是哪里。 优点:
1. 不需要任何服务器资源:隐藏域随页面一起发送到客户端。
2. 广泛的支持:几乎所有浏览器和客户端设备都支持具有隐藏域的表单。
3. 实现简单:隐藏域是标准的 HTML 控件,不需要复杂的编程逻辑。 缺点:
1. 不能在多页面跳转之间维持状态。
2. 用户可见,保存敏感数据时需要加密。 QueryString 查询字符串是存在于 URL 结尾的一段数据。下面是一个典型的查询字符串示例(红色部分文字): http://www.abc.com/demo.aspx?k1=aaa&k2=bbb&k3=ccc 查询字符串经常用于页面的数据过滤,例如:
1. 给列表页面增加分页参数,list.aspx?page=2
2. 给列表页面增加过虑范围,Product.aspx?categoryId=5
3. 显示特定记录,ProductInfo.aspx?page=3 关于查询字符串的用法,我补充二点:
1. 可以调用HttpUtility.ParseQueryString()来解析查询字符串。
2. 允许参数名重复:list.aspx?page=2&page=3,因此在修改URL参数时,使用替换方式而不是追加。
关于参数重名的读取问题,请参考我的博客:细说 Request[]与Request.Params[] 优点:
1. 不需要任何服务器资源:查询字符串的数据包含在每个URL中。
2. 广泛的支持:几乎所有的浏览器和客户端设备均支持使用查询字符串传递参数值。
3. 实现简单:在服务端直接访问Request.QueryString[]可读取数据。
4. 页面传值简单:<a href="url">或者 Response.Redirect(url) 都可以实现。 缺点:
1. 有长度限制。
2. 用户可见,不能保存敏感数据。 Cookie 由于HTTP协议是无状态的,对于一个浏览器发出的多次请求,WEB服务器无法区分它们是不是来源于同一个浏览器。所以,需要额外的数据用于维护会话。 Cookie 正是这样的一段随HTTP请求一起被传递的额外数据。 Cookie 是一小段文本信息,它的工作方式就是伴随着用户请求和页面在 Web 服务器和浏览器之间传递。Cookie 包含每次用户访问站点时 Web 应用程序都可以读取的信息。 与hidden-input, QueryString相比,Cookie有更多的属性,许多浏览器可以直接查看这些信息: 
由于Cookie拥有这些属性,因此在客户端状态管理中可以实现更多的功能,尤其是在实现客户端会话方面具有不可替代的作用。 关于Cookie的更多讲解,请参考我的另一篇博客:细说Cookie 优点:
1. 可配置到期规则:Cookie可以在客户端长期存在,也可以在浏览器关闭时清除。
2. 不需要任何服务器资源:Cookie 存储在客户端。
3. 简单性:Cookie 是一种基于文本的轻量结构,包含简单的键值对。
4. 数据持久性:与其它的客户端状态数据相比,Cookie可以实现长久保存。
5. 良好的扩展性:Cookie的读写要经过ASP.NET管线,拥有无限的扩展性。 这里我要解释一下Cookie 【良好的扩展性】是个什么概念,比如:
1. 我可以实现把Cookie保存到数据库中而不需要修改现有的项目代码。
2. 把SessionId这样由ASP.NET产生的临时Cookie让它变成持久保存。 缺点:
1. 大小受到限制。
2. 增加请求头长度。
3. 用户可见,保存敏感数据时需要加密。 ApplicationState 应用程序状态是指采用HttpApplicationState实现的状态维持方式,使用代码如下: Application.Lock(); Application["PageRequestCount"] = ((int)Application["PageRequestCount"]) + 1; Application.UnLock(); 对于这种方法,我不建议使用,因为:
1. 与使用静态变量差不多,直接使用静态变量可以不需要字典查找。
2. 选择强类型的集合或者变量可以避免装箱拆箱。 ViewState,ControlState 视图状态,控件状态,二者是类似,在页面中表现为一个hidden-input元素: <input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="......................" /> 控件状态是ASP.NET 2.0中引入,与视图状态相比,它不允许关闭。
由于它们使用方式一致,而且视图状态是基于控件状态的实现逻辑,所以我就不区分它们了。 在ASP.NET的早期,微软为了能帮助广大开发人员提高开发效率,引用入一大批的服务端控件,并为了能将事件编程机制引入ASP.NET中,又发明了ViewState。 这种方式虽然可以简化开发工作量,然而却有一些限制和缺点:
1. 视图状态的数据只能用于回发(postback)。
2. 视图状态的【滥用】容易导致生成的HTML较大,这会引起一个恶性循环:
a. 过大的ViewState在序列化过程中会消耗较多的服务器CPU资源,
b. 过大的ViewState最终生成的HTML输出也会很大,它会浪费服务端网络资源,
c. 过大的ViewState输出导致表单在下次提交时,会占用客户端网络资源。
d. 过大的ViewState数据上传到服务端后,反序列化又会消耗较多的服务器CPU资源。
因此,整个交互过程中,用户一直在等待,用户体验极差。 在ASP.NET兴起的年代,ViewState绝对是个了不起的发明。
然而,现在很多关于ASP.NET性能优化的方法中,都会将【关闭ViewState】放在头条位置。
为什么会这样呢,大家可以自己思考一下了。 有些人认为:我现在做的程序只是在局域网内使用,使用ViewState完全没有问题!
然而,那些人或许没有想过:
1. 未来用户可能会把它部署在互联网上运行(对于产品来说就是遇到大客户了)。
2. 项目早期的设计与规划,对后期的开发与维护来说,影响是巨大的,因为许多基础部分通常是在早期开发的。
当这二种情况的任何一种发生时,想再禁用ViewState,可能已经晚了。 对于视图状态,我认为它解决的问题比它引入的问题要多要复杂,
因此,我不想花时间整理它的优缺点,我只想说一句:把它关了,在web.config中关了。 另外,我不排斥使用服务器控件,我认为:你可以使用服务端控件显示数据,但不要用它处理回发。 如果你仍然认为视图状态是不可缺少的,那我还是建议你看看ASP.NET MVC框架,看看没有视图状态是不是照样可以写ASP.NET程序。 Session Session是ASP.NET实现的一种服务端会话技术,它允许我们方便地在服务端保存与用户有关的会话数据。 我认为Session只有一个优点:最简单的服务端会话实现方式。 缺点:
1. 当mode="InProc"时,容易丢失数据,为什么?因为网站会因为各种原因重启。
2. 当mode="InProc"时,Session保存的东西越多,就越占用服务器内存,对于用户在线人数较多的网站,服务器的内存压力会比较大。
3. 当mode="InProc"时,程序的扩展性会受到影响,原因很简单:服务器的内存不能在多台服务器间共享。
4. 当采用进程外模式时,在每次请求中,不管你用不用会话数据,所有的会话数据都为你准备好了(反序列化),这其实很是浪费资源的。
5. 如果你没有关闭Session,SessionStateModule就一直在工作中,尤其是全采用默认设置时,会对每个请求执行一系列的调用,浪费资源。
6. 阻塞同一客户端发起的多次请求(默认方式)。
7. 无Cookie会话可能会丢失数据(重新生成已过期的会话标识符)。 Session的这些缺点也提醒我们:
1. 当网站的在线人数较多时,一定不要用Session保存较大的对象。
2. 在密集型的AJAX型网站或者大量使用iframe的网站中,要关注Session可能引起的服务端阻塞问题。
3. 当采用进程外模式时,不需要访问Session的页面,一定要关闭,否则会浪费服务器资源。 如果想了解更多的Session特点,以及我对Session的看法,可以浏览我的博客:Session,有没有必要使用它? Session的本质有二点:
1. SessionId + 服务端字典:服务端字典保存了某个用户的所有会话数据。
2. 用SessionId识别不同的客户端:SessionId通常以Cookie形式发送到客户端。 我认为了解Sesssion本质非常有用,因为可以借鉴并实现自己的服务端会话方法。 关于Session我还想说一点:
有些新手喜欢用Session来实现身份认证功能,这是一种【不正确】的方法。
如果你的ASP.NET应用程序需要身份认证功能,请使用 Forms身份认证 或者 Windows身份认证 Profile Profile 在中文版的MSDN中被称为 配置文件属性,这个功能是在 ASP.NET 2.0 中引入的。 ASP.NET提供这个功能主要是为了简化与用户相关的个性化信息的读写方式。
简化主要体现在3个方面:
1. 自动与某个用户关联,已登录用户或者未登录都支持。
2. 不需要我们设计用户的个性化信息的保存表结构,只要修改配置文件就够了。
3. 不需要我们实现数据的加载与保存逻辑,ASP.NET框架替我们实现好了。 为了使用Profile,我们首先在web.config中定义所需要的用户个性化信息: <profile> <properties> <add name="Address"/> <add name="Tel"/> </properties> </profile> 然后,就可以在页面中使用了: 
为什么会这样呢?
原因是ASP.NET已经根据web.config为我们创建了一个新类型: using System; using System.Web.Profile; public class ProfileCommon : ProfileBase { public ProfileCommon(); public virtual string Address { get; set; } public virtual string Tel { get; set; } public virtual ProfileCommon GetProfile(string username); } 有了这个类型后,当我们访问HttpContext.Profile属性时,ASP.NET会创建一个ProfileCommon的实例。 也正是由于Profile的强类型机制,在使用Profile时才会有智能提示功能。 如果我们希望为未登录的匿名用户也提供这种支持,需要将配置修改成: <profile> <properties> <add name="Address" allowAnonymous="true" /> <add name="Tel" allowAnonymous="true"/> </properties> </profile> <anonymousIdentification enabled="true" /> Profile中的每个属性还允许指定类型和默认值,以及序列化方式,因此,扩展性还是比较好的。 尽管Profile看上去很美,然而,使用Profile的人却很少。
比如我就不用它,我也没见有人有过它。
为什么会这样?
我个人认为:它与MemberShip一样,是个鸡肋。
通常说来,我们会为用户信息创建一张User表,增加用户信息时,会通过增加字段的方式解决。
我认为这样集中的数据才会更好,而不是说,有一部分数据由我维护,另一部分数据由ASP.NET维护。
另一个特例是:我们根本不创建User表,直接使用MemberShip,那么Profile用来保存MemberShip没有信息是有必要的。 还是给Profile做个总结吧:
优点:使用简单。
缺点:不实用。 各种状态管理的对比与总结 前面分别介绍了ASP.NET的8种状态管理技术,这里打算给它们做个总结。
| 客户端 | 服务端 | | 数据安全性 | 差 | 好 | | 数据长度限制 | 有 | 受硬件限制 | | 占用服务器资源 | 否 | 是 | | 集群扩展性 | 好 | 差 | 表格中主要考察了数据保存与服务端水平扩展的相关重要指标。 下面我来解释表格的结果。
1. 客户端方式的状态数据(hidden-input, QueryString, Cookie):
a. 数据对用户来说,可见可修改,因此数据不安全。
b. QueryString, Cookie 都有长度限制。
c. 数据在客户端,因此不占用服务端资源。这个特性对于在线人数很多的网站非常重要。
d. 数据在客户端,因此和服务端没有耦合关系,WEB服务器可以更容易实现水平扩展。
2. 服务端方式的状态数据(ApplicationState,ViewState,ControlState,Session,Profile):
a. 数据对用户不可见,因此安全性好。(ApplicationState,Session,Profile)
b. 数所长度只受硬件限制,因此,对于在线人数较多的网站,需谨慎选择。
c. 对于存放在内存中的状态数据,由于不能共享内存,因此会限制水平扩展能力。
d. 如果状态数据保存到一台机器,会有单点失败的可能,也会限制了水平扩展能力。 从这个表格我们还可以得到以下结论:
1. 如果很关注数据的安全性,应该首选服务端的状态管理方法。
2. 如果你关注服务端的水平扩展性,应该首选客户端的状态管理方法。 会话状态的选择 接下来,我们再来看看会话状态,它与状态管理有着一些关系,属于比较类似的概念。 谈到会话状态,首先我要申明一点:会话状态与状态不是一回事。 本文前面所说的状态分为二种:
1. 页面之间的状态。
2. 应用程序范围内的状态。 而会话状态是针对某个用户来说,他(她)在多次操作之间的状态。
在用户的操作期间,有可能状态需要在页面之间持续使用,
也有可能服务端程序做过重启,但数据仍然有效。
因此,这种状态数据更持久。 在ASP.NET中,使用会话状态有二个选择:Session 或者 Cookie 。
前者由ASP.NET实现,并有可能依赖后者。
后者则由浏览器实现,ASP.NET提供读写方法。 那么到底选择哪个呢?
如果你要问我这个问题,我肯定会说:我选 Cookie ! 下面是我选择Cookie实现会话状态的理由:
1. 不会有服务端阻塞问题。
2. 不占用服务端资源。
3. 水平扩展没有限制。
4. 也支持过期设置,而且更灵活。
5. 可以在客户端直接使用会话数据。
6. 可以实现更灵活的会话数据加载策略。
7. 扩展性较好(源于ASP.NET管线的扩展性) 如果选择使用Cookie实现会话状态,有3点需要特别注意:
1. 不建议保存敏感数据,除非已加密。
2. 只适合保存短小简单的数据。
3. 如果会话数据较大,可以在客户端保存用户标识,由服务端实现数据的加载保存逻辑。 或许有些人认为:每种技术都有它们的优缺点,有各自的适用领域。
我表示赞同这句话。
但是,我们要清楚一点:每个项目的规模不一样,性能以及扩展性要求也不同。
对于一个小的项目来说,选择什么方法都不是问题,
但是,对于规模较大的项目,我们一定需要取舍。
取舍的目标是:包装越少越好,因为人家做了过多的包装,就会有较多的限制,
所以,不要只关注现在的调用是否方便,其实只要你愿意包装,你也可以让复杂的调用简单化。 改变开发方式,发现新方法 回想一下:为什么在ASP.NET中需要状态管理?
答:因为与HTTP协议有关,服务端没有保存每个请求的上次页面状态。 为什么Windows计算器(这类)程序不用考虑会话问题呢?
答:因为这类程序的界面不需要重新生成,任何变量都可表示状态。 再来看这样一个场景: 
图片左边是一个列表页面,允许调整每条记录的优先级,但是有2个要求:
1. 在移动每条记录时,必须输入一个调整理由。
2. 只要输入理由后,那条记录可以任意调整多次。 显然,完成这个任务必须要有状态才能实现。 面对这个问题,你可以思考一下:选择哪种ASP.NET支持的状态管理方法都很麻烦。 怎么办? 我的解决方法:创建一个JavaScript数组,用每个数组元素保存每条记录的状态,
所有用户交互操作用AJAX方式实现,这样页面不会刷新,JavaScript变量中的状态一直有效。
因此,很容易就能解决这个问题。 这个案例也提醒我们:当发现ASP.NET提供的状态管理功能全部不合适时, 我们需要改变开发方式了。 为什么WEB编程都有【无状态】问题,而桌面程序没有?
我认为与HTTP协议有关,但没有绝对的关系。
只要你能保证页面不刷新,也能像桌面程序那样,用JavaScript变量就能维护页面状态。 原文出自: http://www.cnblogs.com/fish-li/archive/2012/11/21/2780086.html
1.本地库导出
mysqldump -u 用户名 -p 数据库名 > 存放位置
例: mysqldump -uroot -p1234 testdb > /root/db/testdb.sql
2.从远程库导出
mysqldump -h 主机IP -u 用户名 -p 数据库名 > 存放位置
例: mysqldump -h192.168.30.30 -uroot -p1234 testdb > /root/db/testdb.sql
3.导出表结构及数据
mysqldump -u 用户名 -p 数据库名 表名 > 导出的文件名
例: mysqldump -uroot -p1234 testdb tab > /root/db/testdb.tab.sql
4.导入数据库
mysql -u用户名 -p密码 数据库名 < 数据库名
例: mysql -uroot -p1234 testdb < /root/db/back.sql
注意:testdb 要事先创建好.
原文出自: http://www.cnblogs.com/natgeo/archive/2012/12/08/2809027.html
在formPanel里加个Key事件 1 keys : [{
2 key : Ext.EventObject.ENTER,
3 fn : function(keyCode, e) {
4 var field = Ext.getCmp(e.target.id);
5 if (Ext.isDefined(field) && field != null) {
6 if (Ext.isDefined(field.xtype)) {
7 if (field.isXType('datefield')) {
8 field.setValue(field.getValue());
9 }
10 }
11 }
12 if (Ext.isIE) {
13 e.browserEvent.keyCode = Ext.EventObject.TAB;
14 } else {
15 var currentfield = Ext.getCmp(e.target.id);
16 var fields = refThis.HusbandView
17 .findByType('field');
18 var i = 0;
19 for (; i < fields.length; i++) {
20 if (fields[i].id == currentfield.id)
21 break;
22 }
23 while (true) {
24 i++;
25 if (fields.length <= i)
26 break;
27 if (!fields[i].disabled
28 && fields[i].xtype != 'hidden'
29 && !fields[i].hidden)
30 break;
31 }
32 if (fields.length <= i)
33 return;
34 if (!fields[i].disabled) {
35 fields[i].focus();
36 if (Ext.isDefined(fields[i].selectText))
37 fields[i].selectText();
38 }
39 }
40 }
41 }]
原文出自:http://xlong224.blog.163.com/blog/static/601214932011102810201224/
原先的EditGrid无法解决回车控制问题,它的回车控制是向下跑的。而我想让它横着走。搞了半天终于实现了。 1 Ext.override(Ext.grid.RowSelectionModel, {
2 onEditorKey : function(field, e) {
3 // alert('go');
4 var k = e.getKey(), newCell, g = this.grid, ed = g.activeEditor;
5 var shift = e.shiftKey;
6 Ext.log('k:' + k);
7 if (k == e.ENTER) {
8 e.stopEvent();
9 ed.completeEdit();
10 if (shift) {
11 newCell = g.walkCells(ed.row, ed.col - 1, -1,
12 this.acceptsNav, this);
13 } else {
14 // alert('go');
15 newCell = g.walkCells(ed.row, ed.col + 1, 1,
16 this.acceptsNav, this);
17 }
18 } else if (k == e.TAB) {
19 e.stopEvent();
20 ed.completeEdit();
21 if (this.moveEditorOnEnter !== false) {
22 if (shift) {
23 newCell = g.walkCells(ed.row - 1, ed.col, -1,
24 this.acceptsNav, this);
25 } else {
26 // alert('go');
27 newCell = g.walkCells(ed.row + 1, ed.col, 1,
28 this.acceptsNav, this);
29 }
30 }
31 } else if (k == e.ESC) {
32 ed.cancelEdit();
33 }
34 if (newCell) {
35 g.startEditing(newCell[0], newCell[1]);
36 }
37 }
38 });
39 var sm2 = new Ext.grid.RowSelectionModel({
40 moveEditorOnEnter : true,
41 singleSelect : true,
42 listeners : {
43 rowselect : function(sm, row, rec) {
44 centerForm.getForm().loadRecord(rec);
45 }
46 }
47
48 });
原文出自:http://erichua.iteye.com/blog/234698 2. 默认extjs中editorgrid编辑单元格的时候按回车是将焦点向下移动,按照一般的逻辑应该是向右移动。 其实只要将原先rowSelectionModel中onEditorKey方法override一下即可。 代码如下: 1 Ext.override(Ext.grid.RowSelectionModel, {
2
3 onEditorKey : function(field, e) {
4 var k = e.getKey(), newCell, g = this.grid, last = g.lastEdit, ed = g.activeEditor, shift = e.shiftKey, ae, last, r, c;
5
6 if (k == e.TAB) {
7 e.stopEvent();
8 ed.completeEdit();
9 if (shift) {
10 newCell = g.walkCells(ed.row, ed.col - 1, -1, this.acceptsNav,
11 this);
12 } else {
13 newCell = g.walkCells(ed.row, ed.col + 1, 1, this.acceptsNav,
14 this);
15 }
16 } else if (k == e.ENTER) {
17 if (this.moveEditorOnEnter !== false) {
18 if (shift) {
19 newCell = g.walkCells(last.row, last.col - 1, -1,
20 this.acceptsNav, this);
21 } else {
22 newCell = g.walkCells(last.row, last.col + 1, 1,
23 this.acceptsNav, this);
24 }
25 }
26 }
27 if (newCell) {
28 r = newCell[0];
29 c = newCell[1];
30
31 this.onEditorSelect(r, last.row);
32
33 if (g.isEditor && g.editing) { // *** handle tabbing while
34 // editorgrid is in edit mode
35 ae = g.activeEditor;
36 if (ae && ae.field.triggerBlur) {
37 // *** if activeEditor is a TriggerField, explicitly call
38 // its triggerBlur() method
39 ae.field.triggerBlur();
40 }
41 }
42 g.startEditing(r, c);
43 }
44 }
45 })
方法1: JMX 很多人询问如何通过 JMX 来管理 Quertz,很奇怪的是 Quartz 的文档完全没有提及这方面的问题,你可以在 quartz.properties 中通过以下配置来启用 JMX 的支持: org.quartz.scheduler.jmx.export = true
然后你就可以使用标准的 JMX 客户端,例如 $JAVA_HOME/bin/jconsole 来连接到 Quartz 并进行远程管理。 方法2: RMI 另外一个远程管理 Quartz 的方法就是启用 RMI。如果你用的是 RMI 的方式,就会自动一个 Quartz 实例来作为 RMI 服务器,然后你可启动第二个 Quartz 实例来作为 RMI 客户端,二者通过 TCP 端口进行通讯。 服务器端调度实例配置方法(quartz.properties): org.quartz.scheduler.rmi.export = true
org.quartz.scheduler.rmi.createRegistry = true
org.quartz.scheduler.rmi.registryHost = localhost
org.quartz.scheduler.rmi.registryPort = 1099
org.quartz.scheduler.rmi.serverPort = 1100
客户端调度器配置(quartz.properties): org.quartz.scheduler.rmi.proxy = true
org.quartz.scheduler.rmi.registryHost = localhost
org.quartz.scheduler.rmi.registryPort = 1099
关于 Quartz 的 RMI 特性的文档描述请看 这里. Quartz 不提供客户端 API,服务器端和客户端都是使用 org.quartz.Scheduler,只是配置不同而已。通过不同的配置来执行不同的行为。对服务器端来说,调度器用来执行所有的作业;而客户端只 是一个简单的代理,不运行任何作业,在关闭客户端的时候必须小心,因为它允许你也同时关闭服务器端。 这些配置都在我的示例程序 MySchedule 中有着重说明,如果你运行的是 Web 应用,你可以看到 这个演示,你将看到我们提供了很多 quartz 的示例配置用来做远程管理。 如果使用 RMI 方法,你可以用 MySchedule Web UI 做为一个代理来管理 Quartz,你可以查看作业,可停止服务器的运行。 根据我的经验,使用 RMI 方法的弊端就是创建一个新的单点故障,如果你的服务器端口宕掉了,就无法恢复。 原文出自: http://www.oschina.net/question/12_67413
1、Scheduler的配置 <bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref bean="testTrigger"/>
</list>
</property>
<property name="autoStartup" value="true"/>
</bean>
说明:Scheduler包含一个Trigger列表,每个Trigger表示一个作业。 2、Trigger的配置 <bean id="testTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean">
<property name="jobDetail" ref="testJobDetail"/>
<property name="cronExpression" value="*/1 * * * * ?"/>
<!-- 每隔1秒钟触发一次 -->
</bean>
说明: 1)Cron表达式的格式:秒 分 时 日 月 周 年(可选)。 字段名 允许的值 允许的特殊字符 秒 0-59 , - * / 分 0-59 , - * / 小时 0-23 , - * / 日 1-31 , - * ? / L W C 月 1-12 or JAN-DEC , - * / 周几 1-7 or SUN-SAT , - * ? / L C # 年 (可选字段) empty, 1970-2099 , - * / “?”字符:表示不确定的值 “,”字符:指定数个值 “-”字符:指定一个值的范围 “/”字符:指定一个值的增加幅度。n/m表示从n开始,每次增加m “L”字符:用在日表示一个月中的最后一天,用在周表示该月最后一个星期X “W”字符:指定离给定日期最近的工作日(周一到周五) “#”字符:表示该月第几个周X。6#3表示该月第3个周五 2)Cron表达式范例: 每隔5秒执行一次:*/5 * * * * ? 每隔1分钟执行一次:0 */1 * * * ? 每天23点执行一次:0 0 23 * * ? 每天凌晨1点执行一次:0 0 1 * * ? 每月1号凌晨1点执行一次:0 0 1 1 * ? 每月最后一天23点执行一次:0 0 23 L * ? 每周星期天凌晨1点实行一次:0 0 1 ? * L 在26分、29分、33分执行一次:0 26,29,33 * * * ? 每天的0点、13点、18点、21点都执行一次:0 0 0,13,18,21 * * ? 3、JobDetail的配置 <bean id="testJobDetail" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="testJob"/>
<property name="targetMethod" value="execute"/>
<property name="concurrent" value="false"/>
<!-- 是否允许任务并发执行。当值为false时,表示必须等到前一个线程处理完毕后才再启一个新的线程 -->
</bean>
4、业务类的配置 <bean id="testJob" class="com.cjm.web.service.quartz.TestJob"/> 5、业务类源代码 public class TestJob {
public void execute(){
try{
//.
}catch(Exception ex){
ex.printStackTrace();
}
}
}
说明:业务类不需要继承任何父类,也不需要实现任何接口,只是一个普通的java类。 注意: 在Spring配置和Quartz集成内容时,有两点需要注意 1、在<Beans>中不能够设置default-lazy-init="true",否则定时任务不触发,如果不明确指明default-lazy-init的值,默认是false。 2、在<Beans>中不能够设置default-autowire="byName"的属性,否则后台会报 org.springframework.beans.factory.BeanCreationException错误,这样就不能通过Bean名称自 动注入,必须通过明确引用注入
原文出自: http://www.oschina.net/question/8676_9032
缓存在 Solr 中充当了一个非常重要的角色,Solr 中主要有这三种缓存: - Filter cache(过滤器缓存),用于保存过滤器(fq 参数)和层面搜索的结果
- Document cache(文档缓存),用于保存 lucene 文档存储的字段
- Query result(查询缓存),用于保存查询的结果
还有第四种缓存,lucene 内部的缓存,不过该缓存外部无法控制到。 通过这 3 种缓存,可以对 solr 的搜索实例进行调优。调整这些缓存,需要根据索引库中文档的数量,每次查询结果的条数等。 在调整参数前,需要事先得到 solr 示例中的以下信息: - 索引中文档的数量
- 每秒钟搜索的次数
- 过滤器的数量
- 一次查询返回最大的文档数量
- 不同查询和不同排序的个数
这些数量可以在 solr admin 页面的日志模块找到。假设以上的值分别为: - 索引中文档的数量:1000000
- 每秒钟搜索的次数:100
- 过滤器的数量:200
- 一次查询返回最大的文档数量:100
- 不同查询和不同排序的个数:500
然后可以开始修改 solrconfig.xml 中缓存的配置了,第一个是过滤器缓存: <filterCache class="solr.FastLRUCache" size="200" initialSize="200" autowarmCount="100"/> 第二个是查询结果缓存: <queryResultCache class="solr.FastLRUCache" size="500" initialSize="500" autowarmCount="250"/> 第三个是文档缓存: <documentCache class="solr.FastLRUCache" size="11000" initialSize="11000" /> 这几个配置是基于以上的几个假设的值进行调优的。 原文出自: http://insolr.com/forum.php?mod=viewthread&tid=7&reltid=880&pre_thread_id=19&pre_pos=5&ext=
一.首先准备好solr的dataimport功能需要的东西,在solr的下载包中。分别在: 1》Solr-1.3.0\dist\apache-solr-dataimporthandler-1.3.0.jar 2》E:\education\search\Solr-1.3.0\example\example-DIH\solr\ 3》你是哪种数据库,提供该数据库的jdbc驱动。 二.如果你还不会运行solr,请参考本人的前几篇博客。这里要做的是,先把E:\education\search\Solr-1.3.0 \example\example-DIH\solr\下面的东西拷贝到solr的HOME目录,然后删除rss,这个是另外一个功能是导入rss订阅信 息到solr中,确实很强,这都想到了。将jar文件,实际就两个拷贝到tomcat的webapps下面的solr的WEB-INF的lib文件夹下 面。 三.更改solr Home目录下的conf/solrconfig.xml,其实就是提交一个solrRequestHandler,代码如下: - <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
- <lst name="defaults">
- <str name="config">C:\solr-tomcat\solr\db\conf\db-data-config.xml</str>
- </lst>
- </requestHandler>
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">C:\solr-tomcat\solr\db\conf\db-data-config.xml</str> </lst> </requestHandler> 四.将solr Home目录下面的solrconfig.xml和schema.xml拷贝到db文件夹下面的conf中。 五.修改db\conf\db-data-config.xml - <dataConfig>
- <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/tuitui" user="root" password="mysql"/>
- <document name="shop">
- <entity name="tuitui_shop" pk="shopId" query="select * from tuitui_shop">
- <field column="shopid" name="shopId" />
- <field column="shopName" name="shopName" />
- <field column="shopUrl" name="shopUrl" />
- <field column="keyword" name="keyword" />
- <field column="synopsis" name="synopsis" />
- <field column="province" name="province" />
- <field column="city" name="city" />
- <field column="domain" name="domain" />
- <field column="address" name="address" />
- <field column="coordinate" name="coordinate" />
- <field column="shopSspn" name="shopSspn" />
- <field column="phone" name="phone" />
- <field column="createTime" name="createTime" />
- </entity>
- </document>
- </dataConfig>
<dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/tuitui" user="root" password="mysql"/> <document name="shop"> <entity name="tuitui_shop" pk="shopId" query="select * from tuitui_shop"> <field column="shopid" name="shopId" /> <field column="shopName" name="shopName" /> <field column="shopUrl" name="shopUrl" /> <field column="keyword" name="keyword" /> <field column="synopsis" name="synopsis" /> <field column="province" name="province" /> <field column="city" name="city" /> <field column="domain" name="domain" /> <field column="address" name="address" /> <field column="coordinate" name="coordinate" /> <field column="shopSspn" name="shopSspn" /> <field column="phone" name="phone" /> <field column="createTime" name="createTime" /> </entity> </document></dataConfig> 其中的意思我做简单解释,具体大家可以去看看官方wiki。 document:一个文档也就是lucene的document这个没什么解释的; entity:主要针对的是一个数据库表; filed:属性column是数据库的字段,name是filed的名字,即schema中的field name http://wiki.apache.org/solr/DataImportHandler 六.启动TOMCAT,输入地址进行导入,导入分为很多模式:我选用的全部倒入模式。 http://localhost/solr/dataimport?command=full-import 原文出自: http://insolr.com/forum.php?mod=viewthread&tid=128&reltid=880&pre_thread_id=19&pre_pos=4&ext=
先从网址 http://labs.mop.com/apache-mirror/lucene/solr/3.6.1/apache-solr-3.6.1.zip 下载程序文件 1.解压开找到apache-solr-3.6.1\apache-solr-3.6.1\dist目录下的apache-solr-3.6.1.war 直接放到tomcat/webapps下面 2.先别急着启动慢慢来,修改配置文件apache-solr-3.6.1\WEB-INF\web.xml 找到: <!-- People who want to hardcode their "Solr Home" directly into the WAR File can set the JNDI property here... --> <!-- <env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>/put/your/solr/home/here</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry> --> 更改这为 <!-- People who want to hardcode their "Solr Home" directly into the WAR File can set the JNDI property here... --> <env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>d:/solr_work/solr</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry> 注:红色字体的文件夹为apache-solr-3.6.1\example\solr 该应用(此为单核应用,多核以后会讲到)放大D盘的新建空目录solr_work目录下就可以 3.启动tomcat,输入 http://localhost:8080/solr solr应用搭建成功 原文出自: http://insolr.com/forum.php?mod=viewthread&tid=3&reltid=880&pre_thread_id=19&pre_pos=6&ext=
本文只是Solr 4.0的基础教程,本人不经常写东西,写的不好请见谅,欢迎到群233413850进行讨论学习。 先说一点部署之后肯定会有人用solrj,solr 4.0好像添加了不少东西,其中CommonsHttpSolrServer这个类改 名为HttpSolrServer,我是找了半天才发现,大家以后可以注意。 部署前准备: Solr 4.0 目录:  这里是我的部署方式,Tomcat安装好之后把apache-solr-4.0.0\example\webapps下的solr.war文件拷贝到Tomcat下的 Tomcat7.0\webapps目录下,然后启动Tomcat 报错不用管,solr.war会自动解压,之后打开Tomcat7.0\webapps\solr\WEB- INF\web.xml,把下面代码复制进去放到后面: - <env-entry>
- <env-entry-name>solr/home</env-entry-name>
- <env-entry-value>E:\SolrHome</env-entry-value>
- <env-entry-type>java.lang.String</env-entry-type>
- </env-entry>
其中 E:\SolrHome 是存放solr配置文件等,修改为自己文件的位置,为了看着更清晰直观,你可以这样放: E:\Tomcat7.0 E:\apache-solr-4.0.0 E:\SolrHome 现在可以重新启动Tomcat了,没有报错,通过这个地址进入Solr4.0页面:http://localhost:8080/solr  如果进入以上界面说明成功了,没有成功的话页面会有ERROR提示。 如图:左侧core0,core1等是solr 4.0中的示例,core0和core1位于apache-solr-4.0.0\example\multicore所有文件都下拷贝 到E:\SoleHome下,core0和core1可以理解为两个库,都是独立的,用来存放索引以及生成这些索引文件所需要的配置文件,solrtest是我测试建立的目录,如图: 
没添加一个库都需要在solr.xml里面进行配置,这个比较简单 - <solr persistent="false">
- <cores adminPath="/admin/cores" host="${host:}" hostPort="${jetty.port:}">
- <core name="core0" instanceDir="core0" />
- <core name="core1" instanceDir="core1" />
- <core name="collection1" instanceDir="collection1" />
- <core name="solrtest" instanceDir="solrtest"/>
- </cores>
- </solr>
每个目录下包含两个文件夹conf和data,data下有两个文件夹index和tlog,index是存放生成的索引文件,tlog存放log, conf下是必要的配置文件schema.xml和solrconfig.xml,可以参考官方或者core里面的配置文件: - <?xml version="1.0" ?>
- <schema name="example solr test" version="1.1">
- <types>
- <fieldtype name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
- <fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
- </types>
- <fields>
- <!-- general -->
- <field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
- <field name="type" type="string" indexed="true" stored="true" multiValued="false" />
- <field name="name" type="string" indexed="true" stored="true" multiValued="false" />
- <field name="_version_" type="long" indexed="true" stored="true"/>
- </fields>
- <!-- field to use to determine and enforce document uniqueness. -->
- <uniqueKey>id</uniqueKey>
- <!-- field for the QueryParser to use when an explicit fieldname is absent -->
- <defaultSearchField>name</defaultSearchField>
- <!-- SolrQueryParser configuration: defaultOperator="AND|OR" -->
- <solrQueryParser defaultOperator="OR"/>
- </schema>
solrconfig.xml我还不是很懂,在这里就不讲了,但是必须配置(好像是必须配): - <?xml version="1.0" encoding="UTF-8" ?>
- <!-- 可以从core文件中copy过来 -->
- <config>
- <luceneMatchVersion>LUCENE_40</luceneMatchVersion>
-
- <directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.StandardDirectoryFactory}"/>
- <dataDir>${solr.solrtest.data.dir:}</dataDir> 这里solr.后面名字改掉
- <updateHandler class="solr.DirectUpdateHandler2">
- <updateLog>
- <str name="dir">${solr.solrtest.data.dir:}</str>
- </updateLog>
- </updateHandler>
- <requestHandler name="/get" class="solr.RealTimeGetHandler">
- <lst name="defaults">
- <str name="omitHeader">true</str>
- </lst>
- </requestHandler>
-
- <requestHandler name="/replication" class="solr.ReplicationHandler" startup="lazy" />
- <requestDispatcher handleSelect="true" >
- <requestParsers enableRemoteStreaming="false" multipartUploadLimitInKB="2048" />
- </requestDispatcher>
-
- <requestHandler name="standard" class="solr.StandardRequestHandler" default="true" />
- <requestHandler name="/analysis/field" startup="lazy" class="solr.FieldAnalysisRequestHandler" />
- <requestHandler name="/update" class="solr.UpdateRequestHandler" />
- <requestHandler name="/admin/" class="org.apache.solr.handler.admin.AdminHandlers" />
- <requestHandler name="/admin/ping" class="solr.PingRequestHandler">
- <lst name="invariants">
- <str name="q">solrpingquery</str>
- </lst>
- <lst name="defaults">
- <str name="echoParams">all</str>
- </lst>
- </requestHandler>
- <!-- config for the admin interface -->
- <admin>
- <defaultQuery>solr</defaultQuery>
- </admin>
- </config>
之后在exampledocs目录下手动创建一个solr1.xml文件: - <?xml version="1.0" ?>
- <add>
- <doc>
- <field name="id">solr1</field>
- <field name="type">type1</field>
- <field name="name">my solr test</field>
- </doc>
- </add>
跟schema.xml中的字段对应,好了现在可以提交数据了,这里在window命令窗口提交数据,把E:\apache-solr- 4.0.0\example\exampledocs下的post.jar复制到 E:\SolrHome\exampledocs下 打开命令窗口CD 到E:\SolrHome\exampledocs下使用命令,Tomcat不要忘了开: java -Durl=http://localhost:8080/solr/solrtest/update -Ddata=files -jar post.jar solr1.xml
如图成功的添加的索引,看下E:\SolrHome\solrtest\data\index下的文件: 
进入solr页面:
点击Executu Query查询,右侧生成了地址可以打开查看,到此结束。
Debug视图 认识debug视图,红色部分框为线程堆栈视图,黄色部分框为表达式、断点、变量视图,蓝色部分为代码视图。

线程堆栈视图
分别介绍一下这几个按钮的含义: 1.表示当前实现继续运行直到下一个断点,快捷键为F8。 2.表示打断整个进程 3.表示进入当前方法,快捷键为F5。 4.表示运行下一行代码,快捷键为F6。 5.表示退出当前方法,返回到调用层,快捷键为F7。 6.表示当前线程的堆栈,从中可以看出在运行哪些代码,并且整个调用过程,以及代码行号

变量视图 1.为变量名视图,显示当前代码行中所有可以访问的实例变量和局部变量 2.显示所有的变量值 3.可以通过该窗口来改变变量值

断点视图 1.显示所有断点 2. 将当前窗口1中选中的端口失效,再次点击启用。 3.异常断点

表达式视图 表达式视图:表达式视图是Debug过程中较为常用的一个视图,可以对自己的感兴趣的一些变量进行观察,也可以增加一些自己的表达式,也可以查看一行代码的运行结果。 1.表达式 2. 点击此可以新增一个表达式

代码视图 代码视图:用来显示具体的代码。其中绿色部分是指当前将要执行的代码

场景一:小明辛苦了两天终于将自己的负责的任务完成了,第二天转测后,测试找到了小明说,小明的程序有bug,可以是小明经过仔细调试,发现本地没有任何问题,但是测试的环境上确实有问题,所以小明遇到了难题,测试的环境linux,又不能上去linux去debug,小明这个时候想要是Linux也可以debug就好了. 远程debug 远程debug:远程debug顾名思义,能够将远程操作系统上的任何java进行debug,但是有前提是本地需要有同步的代码。 1.远程debug的步骤是在远程操作系统上启动java进程时增加特殊的 -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=$DEBUG_PORT,server=y,suspend=n 2.在Eclipse中新建一个Remote Java Application 远程debug 1.打开Debug Configurations视图 2.右击Remote Java Application, New 3.选择源码工程 4.输入远程IP和端口,端口即服务 端的$DEBUG_PORT,点击OK。

场 景一:小明写了一个任务执行者,该执行者不间断的执行一些任务,在现网上运行了一段时间后,发现有概率的出现一些故障,发现运行一段时间后,该任务者异常 退出了,退出的因为是空指针,可以小明想要在本地debug,不知道断点打在哪里,该问题是概率事件,不一定会出现,所以小明debug几遍下来后,头晕 眼花,连代码都看不清楚了,小明想要是能有个断点每当出现空指针异常的时候就停下来让他发现问题,那该多好呀。 异常断点 异常断点:在定位问题的过程中,常常会遇到断点无法打到合适的位置,以至于和问题的触发点千差万别,所以这个时候不妨试试异常断点,顾名思义,异常断点是指抛出某种异常后自动挂起的断点。 点击红色部位,增加一个异常断点

输入想要定位的异常类型,例如NullPointerException,这样系统中抛出任何NullPointerException异常后,都会挂起当前线程,给你机会去定位问题。 场景一:小明写了一个巨大的循环,在调测代码时,小明发现每当循环到第100000次的时候,就是出现问题,没有达到自己的预期,于是小明在循环里打了个断点,想看看到底怎么回事,可小明万万没有想到,想要到达100000次循环是多么的困难,小明这个时候已经开始浮想联翩,如果能有这样的断点: If 循环次数== 100000,线程停下来 条件断点 如右图,循环1000次,如果想要在循环到500 次的时候停下来,可以创建一个条件断点,右 击断点悬着Breakpoint Properties。

选中Enable Condition 在空白处,添加你自己的条件,如果条件返回true,线程会被挂起,如果为false,则忽略该异常 Hit Count为该断点经过多少次后,正式挂起线程,如果设置为500,则表达前499次,经过该断点都不会停下,当第500次,该断点会挂起当前线程。

表达式 表达式可以查看一些在当前代码中没有的命令行,方便定位问题。 场景一:小明最近遇到一个难题,在调用一个第三方插件时总是会有问题,小明怀疑是第三方插件的bug,但小明没有找到源码不能进行debug,小明该怎么办呢? Debug定位第三方插件的问题 1.使用反编译工具将代码反编译 2.将反编译后的源码进行过滤 3.修复源码编译错误 4.进行debug Debug一些经验 1.尽量减少debug,少用debug,优秀的程序员总是花80%的时间来思考如何解决问题,20%的时间来动手完成代码,而糟糕的程序员总是用20%的时间去写代码,80%的时间去调试代码,动手之前尽量想好如何去做,并且已经为你自己的思路做了充分的实验。 2.尽可能的提高debug的效率,设置合适的断点,使用快捷键。 3.debug的F6快捷键经常用到,它与金山词霸的快捷键冲突,所以在debug的时候最好将金山词霸关掉。 4.debug的表达式是可执行代码,将会对代码结果产生永久性影响,在调试时注意,经常将不用的表达式清除掉。 原文出自: http://mgoann.iteye.com/blog/1396637
1 import java.io.File;
2
3 public class FileTest {
4
5 public static void main(String[] args) throws Exception {
6
7 System.out.println(Thread.currentThread().getContextClassLoader()
8 .getResource(""));
9
10 System.out.println(FileTest.class.getClassLoader().getResource(""));
11
12 System.out.println(ClassLoader.getSystemResource(""));
13
14 System.out.println(FileTest.class.getResource(""));
15
16 System.out.println(FileTest.class.getResource("/"));
17
18 // Class文件所在路径
19
20 System.out.println(new File("/").getAbsolutePath());
21
22 System.out.println(System.getProperty("user.dir"));
23
24 System.out.println(System.getProperty("file.encoding"));
25
26
27 }
28
29 }
当我们启动一个tomcat的服务的时候,jar包和claess文件是是以怎么样的顺序被加载进来的? 加载顺序: 1. $java_home/lib 目录下的java核心api 2. $java_home/lib/ext 目录下的java扩展jar包 3. java -classpath/-Djava.class.path所指的目录下的类与jar包 4. $CATALINA_HOME/common目录下按照文件夹的顺序从上往下依次加载 5. $CATALINA_HOME/server目录下按照文件夹的顺序从上往下依次加载 6. $CATALINA_BASE/shared目录下按照文件夹的顺序从上往下依次加载 7. 我们的项目路径/WEB-INF/classes下的class文件 8. 我们的项目路径/WEB-INF/lib下的jar文件 在同一个文件夹下,jar包是按顺序从上到下依次加载 由ClassLoader的双亲委托模式加载机制我们可以知道,假设两个包名和类名完全相同的class文件不再同一个jar包,如果一个class文件已经被加载java虚拟机里了,那么后面的相同的class文件就不会被加载了。 原文 : http://xiaomogui.iteye.com/blog/847686
多站点共享Session常见的作法有: - 使用.net自动的状态服务(Asp.net State Service);
- 使用.net的Session数据库;
- 使用Memcached。
- 使用Cookie方式实现多个站点间的共享(这种方式只限于几个站点都在同一域名的情况下);
这里我们就 演练一下 以数据库的形来存储Session,来实现多站点共享Session。 首先我们 建好一下站点,如下图: 
Default.aspx 
其中 有二个Button ,SetSession 主要是用于给一个 Session 赋值(如:Session["ShareValue"] = “abcd” ) , GetSession 主要就是获得 一个 Session 值。 具体代码如下: 
代码部分就这么多就行了… 下面就是要配置一下 Web.config了 , 其实主要就是在 <system.web> 这个节点中 增加 machineKey 及 sessionState 这两个节点, 1.增加machineKey 主要作用是: “按照MSDN的标准说法:“对密钥进行配置,以便将其用于对 Forms 身份验证 Cookie 数据和视图状态数据进行加密和解密,并将其用于对进程外会话状态标识进行验证。”也就是说Asp.Net的很多加密,都是依赖于machineKey里面 的值,例如Forms 身份验证 Cookie、ViewState的加密。默认情况下,Asp.Net的配置是自己动态生成,如果单台服务器当然没问题,但是如果多台服务器负载均 衡,machineKey还采用动态生成的方式,每台服务器上的machinekey值不一致,就导致加密出来的结果也不一致,不能共享验证和 ViewState,所以对于多台服务器负载均衡的情况,一定要在每台站点配置相同的machineKey。“ ,具体可以查一下其它资料。 2.增加 sessionState 主要是让 Session 保存在数据库中。 具体配置如下: <machineKey validationKey="86B6275BA31D3D713E41388692FCA68F7D20269411345AA1C17A7386DACC9C46E7CE5F97F556F3CF0A07159659E2706B77731779D2DA4B53BC47BFFD4FD48A54" decryptionKey="9421E53E196BB56DB11B9C25197A2AD470638EFBC604AC74CD29DBBCF79D6046" validation="SHA1" decryption="AES"/>
<sessionState mode="SQLServer" sqlConnectionString="Data Source=PC-07195;Initial Catalog=AWBUISession;Persist Security Info=True;User ID=jins;Password=js@#$1234" allowCustomSqlDatabase="true" cookieless="false" timeout="100"/> 网站部分 这样就好了。。。 下面就是要配置据库了….. 数据库配置: 使用aspnet_regsql.exe工具 ASP.NET 2.0版本后微软提供了aspnet_regsql.exe工具可以方便的配置Session数据库.该工具位于 Web 服务器上的"系统根目录\Microsoft.NET\Framework\版本号"文件夹中. 使用举例:
aspnet_regsql.exe -S . -U sa -P 123456 -ssadd -sstype p -S参数: 表示数据库实例名称. 可以用"."表示本机. -U和-P参数: 表示用户名和密码. -E参数: 可以再-U –P 与 -E中选择一组. –E表示以当前系统用户通过windows身份验证登录数据库, -U -P则是使用SqlServer用户登录数据库. -ssadd / –ssremove 参数: -ssadd表示是添加Session数据库, -ssremove表示移除Session数据库. sstype 参数说明: | t | 将会话数据存储到 SQL Server tempdb 数据库中。这是默认设置。如果将会话数据存储到 tempdb 数据库中,则在重新启动 SQL Server 时将丢失会话数据。 | | p | 将会话数据存储到 ASPState 数据库中,而不是存储到 tempdb 数据库中。 | | c | 将会话数据存储到自定义数据库中。如果指定 c 选项,则还必须使用 -d 选项包括自定义数据库的名称。 | 我的设置是:aspnet_regsql.exe -S . - E -d AWBUISession -ssadd -sstype c 好了。基本的 我们就已经搞定了。。
现在 我们分别把我们刚建的一个网站 部署 到 IIS 中。不过我们既然要负载。至少也的部署两份 我们把 其中一个 服务器中的 defaut.aspx 中 “服务器 1” 改成 “服务器 2” ,这样做的主要目地是 做一下 区别! 具体如下: 两个网站的 URL分别是: server 1:127.0.0.1:8081; server 2:127.0.0.1:8080; OK。下面我们就是 配置 Nignx了。 首先 在 nginx\conf 配置 文件中找到 nginx.conf 这个文件 ,就记事本打开, 做如上的 设置: OK。 nginx 这样配置 就算OK 了。 我们启动一下 nginx .. 在浏览器中 输入我们 在 nginx 中配置的 URL 如:127.0.0.1:8090
我们会看到 服务器 1 已经开始为我们服务了,我们再点一下 “SetSession”来设置一下一个 会话值, 我们会看到 服务器 2 开始 工作。这时我们再点一下 “GetSesion”看一下 刚才在 服务器 1 设置 的会话值,结果如下 : 出现这种情况 ,主要就是在数据库中存储 一个会话时 没有做到 服务器1 和服务2的Session 共享,主要是 在ASPStateTempSessions 这个表中的 一个SessionID,其中的SessionId包括两个部分:网站生成的24位SessionID及8位AppName对于不同的站点,其AppName不同,在能够在不同站点下使24位SessionID相同的情况下,要保证经过组合加上AppName后的SessionID相同,可以通过修改存储过程TempGetAppID,使其得到的SessionID与AppName无关,修改TempGetAppID如下: ALTER PROCEDURE [dbo].[TempGetAppID]
@appName tAppName,
@appId int OUTPUT
AS
SET @appName = 'Test' --LOWER(@appName) 修改这里,使多个站点的APPname ,为一个固定值。
SET @appId = NULL
SELECT @appId = AppId
FROM [AWBUISession].dbo.ASPStateTempApplications
WHERE AppName = @appName
IF @appId IS NULL BEGIN
BEGIN TRAN
SELECT @appId = AppId
FROM [AWBUISession].dbo.ASPStateTempApplications WITH (TABLOCKX)
WHERE AppName = @appName
IF @appId IS NULL
BEGIN
EXEC GetHashCode @appName, @appId OUTPUT
INSERT [AWBUISession].dbo.ASPStateTempApplications
VALUES
(@appId, @appName)
IF @@ERROR = 2627
BEGIN
DECLARE @dupApp tAppName
SELECT @dupApp = RTRIM(AppName)
FROM [AWBUISession].dbo.ASPStateTempApplications
WHERE AppId = @appId
RAISERROR('SQL session state fatal error: hash-code collision between applications ''%s'' and ''%s''. Please rename the 1st application to resolve the problem.', 18, 1, @appName, @dupApp)
END
END
COMMIT
END
RETURN 0
经过以上修改之后,下面要实现多个站点共用同一个SessionID. 重启一下各站点。再在浏览一下网站点 “SetSession”, 再点:“GetSession” 这样 我们就看到 服务器2 给出了我们 刚才在 服务器 1 中设置 的会话值了。 我们 再点:“GetSession”,可以看到 服务器1 和服务器 2 返回的是相同的结果,达到了 “多站点共享Session” 附加一点: Session 过期删除,主要是 在 SQL server 代理中的作业完成,具体的可以,查一下其它相关资料. 原文出自: http://www.cnblogs.com/red-fox/archive/2012/11/05/2755271.html
摘要: 1.加载JDBC驱动程序 Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> 1 import java.sql.DriverManager; ... 阅读全文
Apache Shiro 架构 ApacheShiro的设计目标是使程序的安全变得简单直观而易于实现,shiro的核心设计参照大多数用户对安全的思考模式--如何对某人(或某事)在与程序交互的环境中的进行安全控制。 程序设计通常都以用户为基础,换句话说,你经常以用户可以(或者应该)如何与软件交互为基础来设计用户接口或者服务API,例如,你可能说,“如果当前与我程序交互的用户已经登录了,我将展示一个按钮给他,他可以点击去查看自己的账户住处,如果他们没有登录,我将显示一个注册按钮。” 这个陈述例子指出我们开发程序很大程度上是为了满足用户的需求,即使“用户(User)”是另外一个软件系统而并非一个人,你仍然要写代码对当前与你软件交互的谁(或者什么)的动作进行回应。 shiro从它的设计中表现了这种理念,为了与软件开发者的直觉相配合,Apache Shiro在几乎所有程序中保留了直观和易用的特性。 概览 在概念层,shiro架构包含三个主要的理念:Subject,SecurityManager和Realm。下面的图展示了这些组件如何相互作用,我们将在下面依次对其进行描述。 
subject:就像我们在上一章示例中提到的那样,subject本质上是当前运行用户特定的'view',而单词“user”经常暗指一个人,subject可以是一个人,但也可以是第三方服务、守护进程帐户、时钟守护任务或者其它--当前和软件交互的任何事件。 subject实例都和(也需要)一个SecurityManager绑定,当你和一个subject进行交互,这些交互动作被转换成SecurityManager下subject特定的交互动作。 SecurityManager:SecurityManager是Shiro架构的核心,配合内部安全组件共同组成安全伞。然而,一旦一个程序配置好了SecurityManager和它的内部对象,SecurityManager通常独自留下来,程序开发人员几乎花费的所有时间都集中在Subjet API上。 我们将在以后详细讨论SecurityManager,但当你和一个Subject互动时了解它是很重要的。任何Subject的安全操作中SecurityManager是幕后真正的举重者,这在上面的图表中可以反映出来。 Realms:Reamls是Shiro和你的程序安全数据之间的“桥”或者“连接”,它用来实际和安全相关的数据如用户执行身份认证(登录)的帐号和授权(访问控制)进行交互,shiro从一个或多个程序配置的Realm中查找这些东西。 Realm本质上是一个特定的安全DAO:它封装与数据源连接的细节,得到shiro所需的相关的数据。在配置shiro的时候,你必须指定至少一个Realm来实现认证(authentication)和/或授权(authorization)。SecurityManager可以配置多个复杂的Realm,但是至少有一个是需要的。 Shiro提供out-of-the-box Realms来连接安全数据源(或叫地址)如LDAP、JDBC、文件配置如INI和属性文件等,如果已有的Realm不能满足你的需求你也可以开发自己的Realm实现。 和其它内部组件一样,ShiroSecurityManager管理如何使用Realms获取Subject实例所代表的安全和身份信息。 详细架构 下面的图表展示了Shiro的核心架构思想,下面有简单的解释。 
Subject (org.apache.shiro.subject.Subject) 正在与软件交互的一个特定的实体“view”(用户、第三方服务、时钟守护任务等)。 SecurityManager(org.apache.shiro.mgt.SecurityManager) 如同上面提到的,SecurityManager 是Shiro的核心,它基本上就是一把“伞”用来协调它管理的组件使之平稳地一起工作,它也管理着Shiro中每一个程序用户的视图,所以它知道每个用户如何执行安全操作。 Authenticator(org.apache.shiro.authc.Authenticator) Authenticator是一个组件,负责执行和反馈用户的认证(登录),如果一个用户尝试登录,Authenticator就开始执行。Authenticator知道如何协调一个或多个保存有相关用户/帐号信息的Realm,从这些Realm中获取这些数据来验证用户的身份以确保用户确实是其表述的那个人。 Authentication Strategy(org.apache.shiro.authc.pam.AuthenticationStrategy) 如果配置了多个Realm,AuthenticationStrategy将会协调Realm确定在一个身份验证成功或失败的条件(例如,如果在一个方面验证成功了但其他失败了,这次尝试是成功的吗?是不是需要所有方面的验证都成功?还是只需要第一个?) Authorizer(org.apache.shiro.authz.Authorizer) Authorizer是负责程序中用户访问控制的组件,它是最终判断一个用户是否允许做某件事的途径,像Authenticator一样,Authorizer也知道如何通过协调多种后台数据源来访问角色和权限信息,Authorizer利用这些信息来准确判断一个用户是否可以执行给定的动作。 SessionManager(org.apache.shiro.session.mgt.SessionManager) SessionManager知道如何创建并管理用户Session生命周期而在所有环境中为用户提供一个强有力的Session体验。这在安全框架领域是独一无二--Shiro具备管理在任何环境下管理用户Session的能力,即使没有Web/Servlet或者EJB容器。默认情况下,Shiro将使用现有的session(如Servlet Container),但如果环境中没有,比如在一个独立的程序或非web环境中,它将使用它自己建立的session提供相同的作用,sessionDAO用来使用任何数据源使session持久化。 SessionDAO(org.apache.shiro.session.mgt.eis.SessionDAO) SessionDAO代表SessionManager执行Session持久(CRUD)动作,它允许任何存储的数据挂接到session管理基础上。 CacheManager(org.apache.shiro.cache.CacheManager) CacheManager创建并管理其它shiro组件的catch实例生命周期,因为shiro要访问许多后端数据源来实现认证、授权和session管理,caching已经成为提升性能的一流的框架特征,任何一个现在开源的和/或企业级的caching产品都可以插入到shiro中实现一个快速而有效的用户体验。 Cryptography (org.apache.shiro.crypto.*) Cryptography在安全框架中是一个自然的附加产物,shiro的crypto包包含了易用且易懂的加密方式,Hashes(亦即digests)和不同的编码实现。该包里所有的类都亦于理解和使用,曾经用过Java自身的加密支持的人都知道那是一个具有挑战性的工作,而shiro的加密API简化了java复杂的工作方式,将加密变得易用。 Realms (org.apache.shiro.realm.Realm) 如同上面提到的,Realm是shiro和你的应用程序安全数据之间的“桥”或“连接”,当实际要与安全相关的数据进行交互如用户执行身份认证(登录)和授权验证(访问控制)时,shiro从程序配置的一个或多个Realm中查找这些数据,你需要配置多少个Realm便可配置多少个Realm(通常一个数据源一个),shiro将会在认证和授权中协调它们。 SecurityManager 因为shiro API鼓励以Subject为中心的开发方式,大部分开发人员将很少会和SecurityManager直接交互(尽管框架开发人员也许发现它非常有用),尽管如此,知道SecurityManager如何工作,特别是当在一个程序中进行配置的时候,是非常重要的。 设计 如前所述,程序中SecurityManager执行操作并且管理所有程序用户的状态,在shiro基础的SecurityManager实现中,包含以下内容: 认证(Authentication) 授权(Authorization) 会话管理(Session Management) 缓存管理(Cache Management) Realm协调(Realm coordination) 事件传导(Event propagation ) "RememberMe" 服务("Remember Me" Services) 建立Subject(Subject creation) 退出登录(Logout) 及其它。 但这些功能都在一个单独的组件中管理,并且,当所有功能集中在一个类中实现是灵活和可定制是非常困难的。 为了实现配置的简单、灵活、可插拔,shiro在设计时实现了高模块化--尽管模块化,SecurityManager(包括它的继承类)并没有做到,相反地,SecurityManager实现更像一个轻量级的‘容器(container)’,代表几乎所有嵌套/封装组件的行为,这种‘封装(wrapper)’设计在上面的架构图表中已有反映。 当组件执行逻辑的时候,SecurityManager知道如何以及何时去协调组件做出正确的动作。 SecurityManager和JavaBean兼容,这允许你(或者配置途径)通过标准的JavaBean访问/设置方法(get*/set*)很容易地定制插件,这意味着shiro模块可以根据用户行为转化成简易的配置。 简易的配置 因为适合JavaBean,任何支持Javabean配置的组件都有非常简单的途径配置SecurityManager,如Spring、Guice、JBoss,等等。 我们将在下一节讨论配置(Configuration ) 为文档加把手 我们希望这篇文档可以帮助你使用Apache Shiro进行工作,社区一直在不断地完善和扩展文档,如果你希望帮助shiro项目,请在你认为需要的地方考虑更正、扩展或添加文档,你提供的任何点滴帮助都将扩充社区并且提升Shiro。 提供你的文档的最简单的途径是将它发送到用户论坛(http://shiro-user.582556.n2.nabble.com/)或邮件列表(http://shiro.apache.org/mailing-lists.html) 原文地址:http://shiro.apache.org/architecture.html
摘要: 1.上下文Context、面向切面编程AOP模型分析 在本人的“.NET面向上下文、AOP架构模式(概述)” 一文中,我们大概了解了上下文如何辅助对象在运行时的管理。在很多时候我们急需在运行时能把对象控制在一定的逻辑范围内,在必要的时候能让他们体现出集中 化的概念,如人群、车辆、动物等等。而Context与AOP有着密切的联系,Context表示逻辑抽象的范围而AOP描述了... 阅读全文
摘要: 前段时间一直在学习和研究.NET事务处理,慢慢的我发现可以使用事务处理来实现一种可逆的系统框架。这种框架在一些IT社区似乎还没有见过,但是在我们日常开发中确实有这个需求。所以我花了点时间深入的研究了一下事务的原理和使用,实现了以事务为纽带,以资源为操作对象的可逆框架。 这里我假设您对事务有了整体的认识,也对自定义事务管理器有过了解。[王清培版权所有,转载请给出署名] (可以参考本人的:.NET简谈... 阅读全文
1. 上下文概述 上下文:其实就是一个逻辑上的业务、功能区域。在这个逻辑区域里可以有效的进行管理,算是一种制度的约束,也可以理解为某种范围类的数据共享。 其实在很多应用框架中到处可以看见上下文的概念,包括.NET本身的设计就建立在这种思想上的。实例化的对象默认存在于系统中的默认上下文中,我们可以构建自己的上下文将对象在运行时进行合理的管理。 在ASP.NET框架中比较经典的就是HttpContext上下文对象。所有的运行时对象都会逻辑归属到HttpContext上下文中来,如:我们可以使用Request、Response等对象访问HTTP处理的生命周期数据。 在Remoting中跨AppDomin访问也是建立在上下文基础上的,请求的消息通过隧道后序列化到达调用发。王清培版权所有,转载请给出署名 在这些强大的应用框架背后总有着让人难以琢磨的设计秘方,诸多的设计原则、设计模式、丰富的实践经验都将是框架稳定运行的基石。Context算是一个比较完美的逻辑范围设计模式。[王清培版权所有,转载请给出署名] 那么就让我们来领略一下上下文的奥秘吧! 2. 上下文的一般应用 上下文的设计思想绝对的美妙,很多地方一旦进行上下文抽象就能解决很多问题。比如在Remoting中我们可以动态的在上下文中加入很 多扩展对上下文中的所有对象进行强制管理,比如:调用某一个方法我们需要进行安全检查,我们可以编写一个满足自己当前项目需求的安全认证插件动态的注入到 上下文管理器区域中,在这个地方就体现出上下文的设计优势。 在Web编程中,由于它有着与Winfrom编程很大的差异性,需要将同一组对象同时服务于N个客户端进行使用,而在Winfrom中基本上都是属于单线程的,当然可以手动的开启多线程并行操作。对于ASP.NET每当有新的请求处理时,框架会自动开启新的线程去处理当前的调用,然后这个时候就是需要一个相对于之前操作的独立上下文数据环境,而不是在同一个服务器上的所有线程都是共享的。王清培版权所有,转载请给出署名 那么我们就需要将当前的HTTP处理的相关数据纳入到一个逻辑的上下文进行管理和数据共享。 这么多的优势存在,看来我们是有必要尝试一下这中设计模式了。那么就目前系统开发框架而言我们的上下文能用在哪里呢?我想当务之急就是将分层架构中的所有单条线上的对象进行上下文管理。[王清培版权所有,转载请给出署名] 典型的三层架构: 
在一般的三层架构开发过程中我们的调用关系基本都是这样的,利用上下文设计模式我们可以将本来鼓励的对象进行合理的管理。上图中User对象线将是属于User上下文的,Order对象线将是属于Order上下文的。大家互不干扰,可以在这个逻辑上下文中共享数据、设置调用安全策略、设计日志记录方式、甚至可以计算每个方法的性能。 BLL的调用代码: - View Code
- /***
- * author:深度训练
- * blog:http://wangqingpei557.blog.51cto.com/
- * **/
- using System;
- using System.Collections.Generic;
- using System.Text;
- using System.Reflection;
-
- namespace ConsoleApplication1.BLL
- {
- [ContextModule.ContextEveningBound(IsEvening = true)]
- public class BLL_Order : ContextModule.ContextModuleBaseObject<BLL_Order>
- {
- DAL.DAL_Order dal_order = new DAL.DAL_Order();
-
- [ContextModule.ContextExceptionHandler(OperationSort = 1)]
- public Model.Model_Order InsertOrderSingle(Model.Model_Order ordermodel)
- {
- return ContextModule.ContextAction.PostMethod<DAL.DAL_Order, Model.Model_Order>(
- dal_order, dal_order.GetMethodInfo("InsertOrderSingle"), ordermodel);
- }
- [ContextModule.ContextExceptionHandler(OperationSort = 1)]
- public void SendOrder(Model.Model_Order ordermodel)
- {
- ContextModule.ContextAction.PostMethod<DAL.DAL_Order, object>(
- dal_order, dal_order.GetMethodInfo("SendOrder"), ordermodel);
- }
- }
- }
DAL的执行代码:
- View Code
- /***
- * author:深度训练
- * blog:http://wangqingpei557.blog.51cto.com/
- * **/
- using System;
- using System.Collections.Generic;
- using System.Text;
-
- namespace ConsoleApplication1.DAL
- {
- [ContextModule.ContextEveningBound(IsEvening = true)]
- public class DAL_Order : ContextModule.ContextModuleBaseObject<DAL_Order>
- {
- [ContextModule.ContextLogHandler(OperationSort = 1)]
- [ContextModule.ContextSecurityHanlder(OperationSort = 2)]
- public Model.Model_Order InsertOrderSingle(Model.Model_Order ordermodel)
- {
- return new Model.Model_Order() { OrderGuid = Guid.NewGuid(), OrderTime = DateTime.Now };
- }
- [ContextModule.ContextLogHandler(OperationSort = 1)]
- public void SendOrder(Model.Model_Order ordermodel)
- {
- Console.WriteLine("订单发送成功!");
- }
- }
- }
上述代码是我模拟一个上下文的执行过程。 3. 上下文共享区域 在每个独立的上下文环境中应该有一片共享的数据存储区域,以备多个上下文对象访问。这种方便性多半存在于项目比较紧张的修改需求的时候或者加新业务的时候扩展方法用的。 BLL调用代码: - View Code
- [ContextModule.ContextExceptionHandler(OperationSort = 1)]
- public void UpdateOrderSingle()
- {
- Model.Model_Order ordermodel = new Model.Model_Order() { OrderGuid = Guid.NewGuid(), OrderTime = DateTime.Now };
- //放入上下文共享对象池
- ContextModule.ContextRuntime.CurrentContextRuntime.SetValue("updateorder", ordermodel);
- ContextModule.ContextAction.PostMethod<DAL.DAL_Order, object>(
- dal_order, dal_order.GetMethodInfo("UpdateOrderSingle"), null);
- }
DAL执行代码:DAL执行代码:DAL执行代码:DAL执行代码:
- [ContextModule.ContextLogHandler(OperationSort = 1)]
- public void UpdateOrderSingle()
- {
- Model.Model_Order ordermodel =
- ContextModule.ContextRuntime.CurrentContextRuntime.GetValue("updateorder") as Model.Model_Order;
- }
4. 上下文运行时环境 对于上下文运行时环境的构建需要考虑到运行时是共享的上下文对象。对于纳入上下文管理的所有对象都需要共享或者说是受控于上下文运行时。 上下文构建:
- /***
- * author:深度训练
- * blog:http://wangqingpei557.blog.51cto.com/
- * **/
- using System;
- using System.Collections.Generic;
- using System.Text;
-
- namespace ContextModule
- {
- /// <summary>
- /// 上下文运行时环境。
- /// 上下文逻辑运行时环境,环境中的功能都是可以通过附加进来的。
- /// </summary>
- public class ContextRuntime : IDisposable
- {
- #region IDisposable成员
- void IDisposable.Dispose()
- {
- _currentContextRuntime = null;
- }
- #endregion
-
- protected ContextRuntime() { }
- private DateTime _initTime = DateTime.Now;
- /// <summary>
- /// 获取运行时创建上下文的时间
- /// </summary>
- public virtual DateTime InitTime { get { return _initTime; } }
- private Dictionary<object, object> _runTimeResource = new Dictionary<object, object>();
- private ContextFilterHandlerMap _filterMap = new ContextFilterHandlerMap();
- /// <summary>
- /// 获取上下文中的方法、类过滤器映射表
- /// </summary>
- public ContextFilterHandlerMap FilterMap { get { return _filterMap; } }
- private Guid _initPrimaryKey = Guid.NewGuid();
- /// <summary>
- /// 获取运行时创建上下文的唯一标识
- /// </summary>
- public virtual Guid InitPrimaryKey { get { return _initPrimaryKey; } }
- /// <summary>
- /// 获取上下文共享区域中的数据
- /// </summary>
- /// <param name="key">数据Key</param>
- /// <returns>object数据对象</returns>
- public virtual object GetValue(object key)
- {
- return _runTimeResource[key];
- }
- /// <summary>
- /// 设置上下文共享区域中的数据
- /// </summary>
- /// <param name="key">数据Key</param>
- /// <param name="value">要设置的数据对象</param>
- public virtual void SetValue(object key, object value)
- {
- _runTimeResource[key] = value;
- }
-
- [ThreadStatic]
- private static ContextRuntime _currentContextRuntime;
- /// <summary>
- /// 获取当前上下文运行时对象.
- /// </summary>
- public static ContextRuntime CurrentContextRuntime { get { return _currentContextRuntime; } }
- /// <summary>
- /// 开始运行时上下文
- /// </summary>
- /// <returns>ContextRuntime</returns>
- public static ContextRuntime BeginContextRuntime()
- {
- //可以通过配置文件配置上下文运行时环境的参数。这里只是实现简单的模拟。
- _currentContextRuntime = new ContextRuntime();
- return _currentContextRuntime;
- }
- }
- }
对于上下文的入口构建: - //开启上下文
- using (ContextModule.ContextRuntime.BeginContextRuntime())
- {
-
- }
通过Using的方式我们开始上下文生命周期。 5. 上下文活动对象 上下文对象的绑定需要延后,不能在对象的构建时就创建上下文。 使用后期绑定动态的切入到执行的上下文中。 调用代码,上下文入口: - /***
- * author:深度训练
- * blog:http://wangqingpei557.blog.51cto.com/
- * **/
- using System;
- using System.Collections.Generic;
- using System.Text;
- using System.Data;
- using ConsoleApplication1.BLL;
- using ConsoleApplication1.Model;
-
- namespace ConsoleApplication1
- {
- public class Program
- {
- public static void Main(string[] args)
- {
- BLL.BLL_Order order = new BLL.BLL_Order();
- using (ContextModule.ContextRuntime.BeginContextRuntime())
- {
- Model.Model_Order ordermodel = new Model_Order() { OrderGuid = Guid.NewGuid(), OrderTime = DateTime.Now };
- Model.Model_Order resultmodel = ContextModule.ContextAction.PostMethod<BLL.BLL_Order, Model.Model_Order>(order, order.GetMethodInfo("InsertOrderSingle"), ordermodel);
- ContextModule.ContextAction.PostMethod<BLL.BLL_Order, object>(order, order.GetMethodInfo("SendOrder"), ordermodel);
- }
-
- }
- }
- }
6. 上下文在分层架构中的运用 有了上下文的核心原型之后我们可以扩展到分层架构中来,对于分层架构的使用其实很有必要,一般的大型业务系统都是混合的使用模式,可能有C/S、B/S、Mobile终端等等。 对于加入Service层之后BLL、DAL将位于服务之后,对于来自客户端的调用需要经过一些列的身份验证及权限授予。有了WCF之后面向SOA的架构开发变的相对容易点,对安全、性能、负载等等都很完美,所以大部分的情况下我们很少需要控制BLL、DAL的执行运行。 那么没有使用WCF构建分布式的系统时或者是没有分布式的需求就是直接的调用,如WEB的一般开发,从UI到BLL到DAL。或者是普通的Winfrom的项目、控制台项目属于内网的使用,可能就需要控制到代码的执行。 下面我通过演示一个具体的实例来看看到底效果如何。 我以控制台的程序作为演示项目类型,也使用简单的三层架构。 
这个再简单不过了吧,为了演示越简单越好,关键是突出重点。 需求: 在DAL对象里面加入一个插入Order实体对象的方法: - /***
- * author:深度训练
- * blog:http://wangqingpei557.blog.51cto.com/
- * **/
- using System;
- using System.Collections.Generic;
- using System.Text;
-
- namespace ConsoleApplication1.DAL
- {
- [ContextModule.ContextEveningBound(IsEvening = true)]
- public class DAL_Order : ContextModule.ContextModuleBaseObject<DAL_Order>
- {
- [ContextModule.ContextLogHandler(OperationSort = 1)]
- [ContextModule.ContextSecurityHanlder(OperationSort = 2)]
- public Model.Model_Order InsertOrderSingle(Model.Model_Order ordermodel)
- {
- return new Model.Model_Order() { OrderGuid = Guid.NewGuid(), OrderTime = DateTime.Now };
- }
- }
- }
在这个类的上面有一个特性ContextEveningBound,该是用来表示当前对象属于后期绑定到上下文的对象。同时该类也继承自一个ContextModuleBaseObject<DAL_Order>泛型类,主要作用是将对象强制的绑定到上下文进行管理。 在方法InsertOrderSingle上面有两个特性,ContextLogHandler是用来记录方法的执行日志,ContextSecurityHanlder是用来在方法执行的过程中强制要求管理员认证。 BLL对象代码: - /***
- * author:深度训练
- * blog:http://wangqingpei557.blog.51cto.com/
- * **/
- using System;
- using System.Collections.Generic;
- using System.Text;
- using System.Reflection;
-
- namespace ConsoleApplication1.BLL
- {
- [ContextModule.ContextEveningBound(IsEvening = true)]
- public class BLL_Order : ContextModule.ContextModuleBaseObject<BLL_Order>
- {
- DAL.DAL_Order dal_order = new DAL.DAL_Order();
-
- [ContextModule.ContextExceptionHandler(OperationSort = 1)]
- public Model.Model_Order InsertOrderSingle(Model.Model_Order ordermodel)
- {
- return ContextModule.ContextAction.PostMethod<DAL.DAL_Order, Model.Model_Order>(
- dal_order, dal_order.GetMethodInfo("InsertOrderSingle"), ordermodel);
- }
- }
- }
在BLL对象里面有一个调用DAL对象方法的实例对象,为了演示简单这里没有加入层的依赖注入设计方案,通过直接调 用方式。在BLL方法体中有一个专门用来在上下文中调用方法的接口,这是约束目的是为了能让框架切入到方法的执行之前先执行。具体的设计原理我将在下一篇 文章中详细讲解。 在方法的上面有一个ContextExceptionHandler特性,目的是安全的调用DAL对象的方法,在有异常的情况下能通过上下文的方式人性化的提示错误信息。这样我们就不需要频繁的编写捕获异常的代码,看起来也不爽,我们要的是代码的整洁、美丽。 UI调用: - /***
- * author:深度训练
- * blog:http://wangqingpei557.blog.51cto.com/
- * **/
- using System;
- using System.Collections.Generic;
- using System.Text;
- using System.Data;
- using ConsoleApplication1.BLL;
- using ConsoleApplication1.Model;
-
- namespace ConsoleApplication1
- {
- public class Program
- {
- public static void Main(string[] args)
- {
- BLL.BLL_Order order = new BLL.BLL_Order();
- //开启上下文
- using (ContextModule.ContextRuntime.BeginContextRuntime())
- {
- Model.Model_Order ordermodel = new Model_Order() { OrderGuid = Guid.NewGuid(), OrderTime = DateTime.Now };
-
- Model.Model_Order resultmodel =
- ContextModule.ContextAction.PostMethod<BLL.BLL_Order, Model.Model_Order>(
- order, order.GetMethodInfo("InsertOrderSingle"), ordermodel);
- }
-
- }
- }
- }
执行效果: 
会先执行日志的记录,然后要求我们输入用户凭证才能继续执行下面的方法。
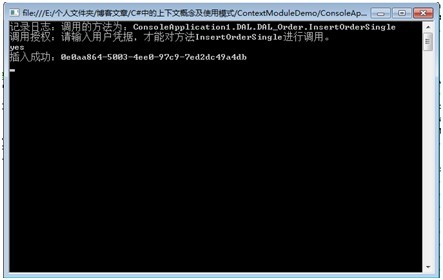
我输入YES才能继续执行插入的方法。我们可以通过很简单的实现上下文的管理接口,对方法进行控制。 总结:该篇文章只是介绍上下文的作用、原理、优势。下篇文章:“.NET 面向上下文架构模式(实现)”将详细的介绍上下文框架如何开发。[王清培版权所有,转载请给出署名]
有关SSL的原理和介绍在网上已经有不少,对于Java下使用keytool生成证书,配置SSL通信的教程也非常多。但如果我们不能够亲自动 手做一个SSL Sever和SSL Client,可能就永远也不能深入地理解Java环境下,SSL的通信是如何实现的。对SSL中的各种概念的认识也可能会仅限于可以使用的程度。本文通 过构造一个简单的SSL Server和SSL Client来讲解Java环境下SSL的通信原理。 首先我们先回顾一下常规的Java Socket编程。在Java下写一个Socket服务器和客户端的例子还是比较简单的。以下是服务端的代码:
Java代码
1.package org.bluedash.tryssl;
2.
3.import java.io.BufferedReader;
4.import java.io.IOException;
5.import java.io.InputStbreamReader;
6.import java.io.PrintWriter;
7.import java.net.ServerSocket;
8.import java.net.Socket;
9.
10.public class Server extends Thread {
11. private Socket socket;
12.
13. public Server(Socket socket) {
14. this.socket = socket;
15. }
16.
17. public void run() {
18. try {
19. BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
20. PrintWriter writer = new PrintWriter(socket.getOutputStream());
21.
22. String data = reader.readLine();
23. writer.println(data);
24. writer.close();
25. socket.close();
26. } catch (IOException e) {
27.
28. }
29. }
30.
31. public static void main(String[] args) throws Exception {
32. while (true) {
33. new Server((new ServerSocket(8080)).accept()).start();
34. }
35. }
36.}
package org.bluedash.tryssl;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.ServerSocket;
import java.net.Socket; public class Server extends Thread {
private Socket socket; public Server(Socket socket) {
this.socket = socket;
} public void run() {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter writer = new PrintWriter(socket.getOutputStream()); String data = reader.readLine();
writer.println(data);
writer.close();
socket.close();
} catch (IOException e) { }
}
public static void main(String[] args) throws Exception {
while (true) {
new Server((new ServerSocket(8080)).accept()).start();
}
}
}
服务端很简单:侦听8080端口,并把客户端发来的字符串返回去。下面是客户端的代码:
Java代码
1.package org.bluedash.tryssl;
2.
3.import java.io.BufferedReader;
4.import java.io.InputStreamReader;
5.import java.io.PrintWriter;
6.import java.net.Socket;
7.
8.public class Client {
9.
10. public static void main(String[] args) throws Exception {
11.
12. Socket s = new Socket("localhost", 8080);
13.
14. PrintWriter writer = new PrintWriter(s.getOutputStream());
15. BufferedReader reader = new BufferedReader(new InputStreamReader(s.getInputStream()));
16. writer.println("hello");
17. writer.flush();
18. System.out.println(reader.readLine());
19. s.close();
20. }
21.
22.}
package org.bluedash.tryssl;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.Socket; public class Client { public static void main(String[] args) throws Exception { Socket s = new Socket("localhost", 8080); PrintWriter writer = new PrintWriter(s.getOutputStream());
BufferedReader reader = new BufferedReader(new InputStreamReader(s.getInputStream()));
writer.println("hello");
writer.flush();
System.out.println(reader.readLine());
s.close();
} }
客户端也非常简单:向服务端发起请求,发送一个"hello"字串,然后获得服务端的返回。把服务端运行起来后,执行客户端,我们将得到"hello"的返回。
就是这样一套简单的网络通信的代码,我们来把它改造成使用SSL通信。在SSL通信协议中,我们都知道首先服务端必须有一个数字证书,当客户端连接 到服务端时,会得到这个证书,然后客户端会判断这个证书是否是可信的,如果是,则交换信道加密密钥,进行通信。如果不信任这个证书,则连接失败。 因此,我们首先要为服务端生成一个数字证书。Java环境下,数字证书是用keytool生成的,这些证书被存储在store的概念中,就是证书仓库。我们来调用keytool命令为服务端生成数字证书和保存它使用的证书仓库:
Bash代码
1.keytool -genkey -v -alias bluedash-ssl-demo-server -keyalg RSA -keystore ./server_ks -dname "CN=localhost,OU=cn,O=cn,L=cn,ST=cn,C=cn" -storepass server -keypass 123123
keytool -genkey -v -alias bluedash-ssl-demo-server -keyalg RSA -keystore ./server_ks -dname "CN=localhost,OU=cn,O=cn,L=cn,ST=cn,C=cn" -storepass server -keypass 123123
这样,我们就将服务端证书bluedash-ssl-demo-server保存在了server_ksy这个store文件当中。有关keytool的用法在本文中就不再多赘述。执行上面的命令得到如下结果:
Bash代码
1.Generating 1,024 bit RSA key pair and self-signed certificate (SHA1withRSA) with a validity of 90 days
2. for: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
3.[Storing ./server_ks]
Generating 1,024 bit RSA key pair and self-signed certificate (SHA1withRSA) with a validity of 90 days
for: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
[Storing ./server_ks]
然后,改造我们的服务端代码,让服务端使用这个证书,并提供SSL通信:
Java代码
1.package org.bluedash.tryssl;
2.
3.import java.io.BufferedReader;
4.import java.io.FileInputStream;
5.import java.io.IOException;
6.import java.io.InputStreamReader;
7.import java.io.PrintWriter;
8.import java.net.ServerSocket;
9.import java.net.Socket;
10.import java.security.KeyStore;
11.
12.import javax.net.ServerSocketFactory;
13.import javax.net.ssl.KeyManagerFactory;
14.import javax.net.ssl.SSLContext;
15.import javax.net.ssl.SSLServerSocket;
16.
17.public class SSLServer extends Thread {
18. private Socket socket;
19.
20. public SSLServer(Socket socket) {
21. this.socket = socket;
22. }
23.
24. public void run() {
25. try {
26. BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
27. PrintWriter writer = new PrintWriter(socket.getOutputStream());
28.
29. String data = reader.readLine();
30. writer.println(data);
31. writer.close();
32. socket.close();
33. } catch (IOException e) {
34.
35. }
36. }
37.
38. private static String SERVER_KEY_STORE = "/Users/liweinan/projs/ssl/src/main/resources/META-INF/server_ks";
39. private static String SERVER_KEY_STORE_PASSWORD = "123123";
40.
41. public static void main(String[] args) throws Exception {
42. System.setProperty("javax.net.ssl.trustStore", SERVER_KEY_STORE);
43. SSLContext context = SSLContext.getInstance("TLS");
44.
45. KeyStore ks = KeyStore.getInstance("jceks");
46. ks.load(new FileInputStream(SERVER_KEY_STORE), null);
47. KeyManagerFactory kf = KeyManagerFactory.getInstance("SunX509");
48. kf.init(ks, SERVER_KEY_STORE_PASSWORD.toCharArray());
49.
50. context.init(kf.getKeyManagers(), null, null);
51.
52. ServerSocketFactory factory = context.getServerSocketFactory();
53. ServerSocket _socket = factory.createServerSocket(8443);
54. ((SSLServerSocket) _socket).setNeedClientAuth(false);
55.
56. while (true) {
57. new SSLServer(_socket.accept()).start();
58. }
59. }
60.}
package org.bluedash.tryssl;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.ServerSocket;
import java.net.Socket;
import java.security.KeyStore; import javax.net.ServerSocketFactory;
import javax.net.ssl.KeyManagerFactory;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLServerSocket; public class SSLServer extends Thread {
private Socket socket; public SSLServer(Socket socket) {
this.socket = socket;
} public void run() {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter writer = new PrintWriter(socket.getOutputStream()); String data = reader.readLine();
writer.println(data);
writer.close();
socket.close();
} catch (IOException e) { }
} private static String SERVER_KEY_STORE = "/Users/liweinan/projs/ssl/src/main/resources/META-INF/server_ks";
private static String SERVER_KEY_STORE_PASSWORD = "123123"; public static void main(String[] args) throws Exception {
System.setProperty("javax.net.ssl.trustStore", SERVER_KEY_STORE);
SSLContext context = SSLContext.getInstance("TLS");
KeyStore ks = KeyStore.getInstance("jceks");
ks.load(new FileInputStream(SERVER_KEY_STORE), null);
KeyManagerFactory kf = KeyManagerFactory.getInstance("SunX509");
kf.init(ks, SERVER_KEY_STORE_PASSWORD.toCharArray());
context.init(kf.getKeyManagers(), null, null); ServerSocketFactory factory = context.getServerSocketFactory();
ServerSocket _socket = factory.createServerSocket(8443);
((SSLServerSocket) _socket).setNeedClientAuth(false); while (true) {
new SSLServer(_socket.accept()).start();
}
}
}
可以看到,服务端的Socket准备设置工作大大增加了,增加的代码的作用主要是将证书导入并进行使用。此外,所使用的Socket变成了 SSLServerSocket,另外端口改到了8443(这个不是强制的,仅仅是为了遵守习惯)。另外,最重要的一点,服务端证书里面的CN一定和服务 端的域名统一,我们的证书服务的域名是localhost,那么我们的客户端在连接服务端时一定也要用localhost来连接,否则根据SSL协议标 准,域名与证书的CN不匹配,说明这个证书是不安全的,通信将无法正常运行。
有了服务端,我们原来的客户端就不能使用了,必须要走SSL协议。由于服务端的证书是我们自己生成的,没有任何受信任机构的签名,所以客户端是无法 验证服务端证书的有效性的,通信必然会失败。所以我们需要为客户端创建一个保存所有信任证书的仓库,然后把服务端证书导进这个仓库。这样,当客户端连接服 务端时,会发现服务端的证书在自己的信任列表中,就可以正常通信了。 因此现在我们要做的是生成一个客户端的证书仓库,因为keytool不能仅生成一个空白仓库,所以和服务端一样,我们还是生成一个证书加一个仓库(客户端证书加仓库):
Bash代码
1.keytool -genkey -v -alias bluedash-ssl-demo-client -keyalg RSA -keystore ./client_ks -dname "CN=localhost,OU=cn,O=cn,L=cn,ST=cn,C=cn" -storepass client -keypass 456456
keytool -genkey -v -alias bluedash-ssl-demo-client -keyalg RSA -keystore ./client_ks -dname "CN=localhost,OU=cn,O=cn,L=cn,ST=cn,C=cn" -storepass client -keypass 456456
结果如下:
Bash代码
1.Generating 1,024 bit RSA key pair and self-signed certificate (SHA1withRSA) with a validity of 90 days
2. for: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
3.[Storing ./client_ks]
Generating 1,024 bit RSA key pair and self-signed certificate (SHA1withRSA) with a validity of 90 days
for: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
[Storing ./client_ks]
接下来,我们要把服务端的证书导出来,并导入到客户端的仓库。第一步是导出服务端的证书:
Bash代码
1.keytool -export -alias bluedash-ssl-demo-server -keystore ./server_ks -file server_key.cer
keytool -export -alias bluedash-ssl-demo-server -keystore ./server_ks -file server_key.cer
执行结果如下:
Bash代码
1.Enter keystore password: server
2.Certificate stored in file <server_key.cer>
Enter keystore password: server
Certificate stored in file <server_key.cer>
然后是把导出的证书导入到客户端证书仓库:
Bash代码
1.keytool -import -trustcacerts -alias bluedash-ssl-demo-server -file ./server_key.cer -keystore ./client_ks
keytool -import -trustcacerts -alias bluedash-ssl-demo-server -file ./server_key.cer -keystore ./client_ks
结果如下:
Bash代码
1.Enter keystore password: client
2.Owner: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
3.Issuer: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
4.Serial number: 4c57c7de
5.Valid from: Tue Aug 03 15:40:14 CST 2010 until: Mon Nov 01 15:40:14 CST 2010
6.Certificate fingerprints:
7. MD5: FC:D4:8B:36:3F:1B:30:EA:6D:63:55:4F:C7:68:3B:0C
8. SHA1: E1:54:2F:7C:1A:50:F5:74:AA:63:1E:F9:CC:B1:1C:73:AA:34:8A:C4
9. Signature algorithm name: SHA1withRSA
10. Version: 3
11.Trust this certificate? [no]: yes
12.Certificate was added to keystore
Enter keystore password: client
Owner: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
Issuer: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
Serial number: 4c57c7de
Valid from: Tue Aug 03 15:40:14 CST 2010 until: Mon Nov 01 15:40:14 CST 2010
Certificate fingerprints:
MD5: FC:D4:8B:36:3F:1B:30:EA:6D:63:55:4F:C7:68:3B:0C
SHA1: E1:54:2F:7C:1A:50:F5:74:AA:63:1E:F9:CC:B1:1C:73:AA:34:8A:C4
Signature algorithm name: SHA1withRSA
Version: 3
Trust this certificate? [no]: yes
Certificate was added to keystore
好,准备工作做完了,我们来撰写客户端的代码:
Java代码
1.package org.bluedash.tryssl;
2.
3.import java.io.BufferedReader;
4.import java.io.InputStreamReader;
5.import java.io.PrintWriter;
6.import java.net.Socket;
7.
8.import javax.net.SocketFactory;
9.import javax.net.ssl.SSLSocketFactory;
10.
11.public class SSLClient {
12.
13. private static String CLIENT_KEY_STORE = "/Users/liweinan/projs/ssl/src/main/resources/META-INF/client_ks";
14.
15. public static void main(String[] args) throws Exception {
16. // Set the key store to use for validating the server cert.
17. System.setProperty("javax.net.ssl.trustStore", CLIENT_KEY_STORE);
18.
19. System.setProperty("javax.net.debug", "ssl,handshake");
20.
21. SSLClient client = new SSLClient();
22. Socket s = client.clientWithoutCert();
23.
24. PrintWriter writer = new PrintWriter(s.getOutputStream());
25. BufferedReader reader = new BufferedReader(new InputStreamReader(s
26. .getInputStream()));
27. writer.println("hello");
28. writer.flush();
29. System.out.println(reader.readLine());
30. s.close();
31. }
32.
33. private Socket clientWithoutCert() throws Exception {
34. SocketFactory sf = SSLSocketFactory.getDefault();
35. Socket s = sf.createSocket("localhost", 8443);
36. return s;
37. }
38.}
package org.bluedash.tryssl;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.Socket; import javax.net.SocketFactory;
import javax.net.ssl.SSLSocketFactory; public class SSLClient { private static String CLIENT_KEY_STORE = "/Users/liweinan/projs/ssl/src/main/resources/META-INF/client_ks"; public static void main(String[] args) throws Exception {
// Set the key store to use for validating the server cert.
System.setProperty("javax.net.ssl.trustStore", CLIENT_KEY_STORE);
System.setProperty("javax.net.debug", "ssl,handshake"); SSLClient client = new SSLClient();
Socket s = client.clientWithoutCert(); PrintWriter writer = new PrintWriter(s.getOutputStream());
BufferedReader reader = new BufferedReader(new InputStreamReader(s
.getInputStream()));
writer.println("hello");
writer.flush();
System.out.println(reader.readLine());
s.close();
} private Socket clientWithoutCert() throws Exception {
SocketFactory sf = SSLSocketFactory.getDefault();
Socket s = sf.createSocket("localhost", 8443);
return s;
}
}
可以看到,除了把一些类变成SSL通信类以外,客户端也多出了使用信任证书仓库的代码。以上,我们便完成了SSL单向握手通信。即:客户端验证服务端的证书,服务端不认证客户端的证书。
以上便是Java环境下SSL单向握手的全过程。因为我们在客户端设置了日志输出级别为DEBUG:
Java代码
1.System.setProperty("javax.net.debug", "ssl,handshake");
System.setProperty("javax.net.debug", "ssl,handshake");
因此我们可以看到SSL通信的全过程,这些日志可以帮助我们更具体地了解通过SSL协议建立网络连接时的全过程。 结合日志,我们来看一下SSL双向认证的全过程: 第一步: 客户端发送ClientHello消息,发起SSL连接请求,告诉服务器自己支持的SSL选项(加密方式等)。
Bash代码
1.*** ClientHello, TLSv1
*** ClientHello, TLSv1
第二步: 服务器响应请求,回复ServerHello消息,和客户端确认SSL加密方式:
Bash代码
1.*** ServerHello, TLSv1
*** ServerHello, TLSv1
第三步: 服务端向客户端发布自己的公钥。
第四步: 客户端与服务端的协通沟通完毕,服务端发送ServerHelloDone消息:
Bash代码
1.*** ServerHelloDone
*** ServerHelloDone
第五步: 客户端使用服务端给予的公钥,创建会话用密钥(SSL证书认证完成后,为了提高性能,所有的信息交互就可能会使用对称加密算法),并通过ClientKeyExchange消息发给服务器:
Bash代码
1.*** ClientKeyExchange, RSA PreMasterSecret, TLSv1
*** ClientKeyExchange, RSA PreMasterSecret, TLSv1
第六步: 客户端通知服务器改变加密算法,通过ChangeCipherSpec消息发给服务端:
Bash代码
1.main, WRITE: TLSv1 Change Cipher Spec, length = 1
main, WRITE: TLSv1 Change Cipher Spec, length = 1
第七步: 客户端发送Finished消息,告知服务器请检查加密算法的变更请求:
Bash代码
1.*** Finished
*** Finished
第八步:服务端确认算法变更,返回ChangeCipherSpec消息
Bash代码
1.main, READ: TLSv1 Change Cipher Spec, length = 1
main, READ: TLSv1 Change Cipher Spec, length = 1
第九步:服务端发送Finished消息,加密算法生效:
Bash代码
1.*** Finished
*** Finished
那么如何让服务端也认证客户端的身份,即双向握手呢?其实很简单,在服务端代码中,把这一行:
Java代码
1.((SSLServerSocket) _socket).setNeedClientAuth(false);
((SSLServerSocket) _socket).setNeedClientAuth(false);
改成:
Java代码
1.((SSLServerSocket) _socket).setNeedClientAuth(true);
((SSLServerSocket) _socket).setNeedClientAuth(true);
就可以了。但是,同样的道理,现在服务端并没有信任客户端的证书,因为客户端的证书也是自己生成的。所以,对于服务端,需要做同样的工作:把客户端的证书导出来,并导入到服务端的证书仓库:
Bash代码
1.keytool -export -alias bluedash-ssl-demo-client -keystore ./client_ks -file client_key.cer
2.Enter keystore password: client
3.Certificate stored in file <client_key.cer>
keytool -export -alias bluedash-ssl-demo-client -keystore ./client_ks -file client_key.cer
Enter keystore password: client
Certificate stored in file <client_key.cer>
Bash代码
1.keytool -import -trustcacerts -alias bluedash-ssl-demo-client -file ./client_key.cer -keystore ./server_ks
2.Enter keystore password: server
3.Owner: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
4.Issuer: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
5.Serial number: 4c57c80b
6.Valid from: Tue Aug 03 15:40:59 CST 2010 until: Mon Nov 01 15:40:59 CST 2010
7.Certificate fingerprints:
8. MD5: DB:91:F4:1E:65:D1:81:F2:1E:A6:A3:55:3F:E8:12:79
9. SHA1: BF:77:56:61:04:DD:95:FC:E5:84:48:5C:BE:60:AF:02:96:A2:E1:E2
10. Signature algorithm name: SHA1withRSA
11. Version: 3
12.Trust this certificate? [no]: yes
13.Certificate was added to keystore
keytool -import -trustcacerts -alias bluedash-ssl-demo-client -file ./client_key.cer -keystore ./server_ks
Enter keystore password: server
Owner: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
Issuer: CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn
Serial number: 4c57c80b
Valid from: Tue Aug 03 15:40:59 CST 2010 until: Mon Nov 01 15:40:59 CST 2010
Certificate fingerprints:
MD5: DB:91:F4:1E:65:D1:81:F2:1E:A6:A3:55:3F:E8:12:79
SHA1: BF:77:56:61:04:DD:95:FC:E5:84:48:5C:BE:60:AF:02:96:A2:E1:E2
Signature algorithm name: SHA1withRSA
Version: 3
Trust this certificate? [no]: yes
Certificate was added to keystore
完成了证书的导入,还要在客户端需要加入一段代码,用于在连接时,客户端向服务端出示自己的证书:
Java代码
1.package org.bluedash.tryssl;
2.
3.import java.io.BufferedReader;
4.import java.io.FileInputStream;
5.import java.io.InputStreamReader;
6.import java.io.PrintWriter;
7.import java.net.Socket;
8.import java.security.KeyStore;
9.import javax.net.SocketFactory;
10.import javax.net.ssl.KeyManagerFactory;
11.import javax.net.ssl.SSLContext;
12.import javax.net.ssl.SSLSocketFactory;
13.
14.public class SSLClient {
15. private static String CLIENT_KEY_STORE = "/Users/liweinan/projs/ssl/src/main/resources/META-INF/client_ks";
16. private static String CLIENT_KEY_STORE_PASSWORD = "456456";
17.
18. public static void main(String[] args) throws Exception {
19. // Set the key store to use for validating the server cert.
20. System.setProperty("javax.net.ssl.trustStore", CLIENT_KEY_STORE);
21. System.setProperty("javax.net.debug", "ssl,handshake");
22. SSLClient client = new SSLClient();
23. Socket s = client.clientWithCert();
24.
25. PrintWriter writer = new PrintWriter(s.getOutputStream());
26. BufferedReader reader = new BufferedReader(new InputStreamReader(s.getInputStream()));
27. writer.println("hello");
28. writer.flush();
29. System.out.println(reader.readLine());
30. s.close();
31. }
32.
33. private Socket clientWithoutCert() throws Exception {
34. SocketFactory sf = SSLSocketFactory.getDefault();
35. Socket s = sf.createSocket("localhost", 8443);
36. return s;
37. }
38.
39. private Socket clientWithCert() throws Exception {
40. SSLContext context = SSLContext.getInstance("TLS");
41. KeyStore ks = KeyStore.getInstance("jceks");
42.
43. ks.load(new FileInputStream(CLIENT_KEY_STORE), null);
44. KeyManagerFactory kf = KeyManagerFactory.getInstance("SunX509");
45. kf.init(ks, CLIENT_KEY_STORE_PASSWORD.toCharArray());
46. context.init(kf.getKeyManagers(), null, null);
47.
48. SocketFactory factory = context.getSocketFactory();
49. Socket s = factory.createSocket("localhost", 8443);
50. return s;
51. }
52.}
package org.bluedash.tryssl;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.Socket;
import java.security.KeyStore;
import javax.net.SocketFactory;
import javax.net.ssl.KeyManagerFactory;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSocketFactory; public class SSLClient {
private static String CLIENT_KEY_STORE = "/Users/liweinan/projs/ssl/src/main/resources/META-INF/client_ks";
private static String CLIENT_KEY_STORE_PASSWORD = "456456";
public static void main(String[] args) throws Exception {
// Set the key store to use for validating the server cert.
System.setProperty("javax.net.ssl.trustStore", CLIENT_KEY_STORE);
System.setProperty("javax.net.debug", "ssl,handshake");
SSLClient client = new SSLClient();
Socket s = client.clientWithCert();
PrintWriter writer = new PrintWriter(s.getOutputStream());
BufferedReader reader = new BufferedReader(new InputStreamReader(s.getInputStream()));
writer.println("hello");
writer.flush();
System.out.println(reader.readLine());
s.close();
} private Socket clientWithoutCert() tbhrows Exception {
SocketFactory sf = SSLSocketFactory.getDefault();
Socket s = sf.createSocket("localhost", 8443);
return s;
} private Socket clientWithCert() throws Exception {
SSLContext context = SSLContext.getInstance("TLS");
KeyStore ks = KeyStore.getInstance("jceks");
ks.load(new FileInputStream(CLIENT_KEY_STORE), null);
KeyManagerFactory kf = KeyManagerFactory.getInstance("SunX509");
kf.init(ks, CLIENT_KEY_STORE_PASSWORD.toCharArray());
context.init(kf.getKeyManagers(), null, null);
SocketFactory factory = context.getSocketFactory();
Socket s = factory.createSocket("localhost", 8443);
return s;
}
} 通过比对单向认证的日志输出,我们可以发现双向认证时,多出了服务端认证客户端证书的步骤:
Bash代码
1.*** CertificateRequest
2.Cert Types: RSA, DSS
3.Cert Authorities:
4.<CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn>
5.<CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn>
6.*** ServerHelloDone
*** CertificateRequest
Cert Types: RSA, DSS
Cert Authorities:
<CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn>
<CN=localhost, OU=cn, O=cn, L=cn, ST=cn, C=cn>
*** ServerHelloDone
Bash代码
1.*** CertificateVerify
2.main, WRITE: TLSv1 Handshake, length = 134
3.main, WRITE: TLSv1 Change Cipher Spec, length = 1
*** CertificateVerify
main, WRITE: TLSv1 Handshake, length = 134
main, WRITE: TLSv1 Change Cipher Spec, length = 1
在 @*** ServerHelloDone@ 之前,服务端向客户端发起了需要证书的请求 @*** CertificateRequest@ 。
在客户端向服务端发出 @Change Cipher Spec@ 请求之前,多了一步客户端证书认证的过程 @*** CertificateVerify@ 。 客户端与服务端互相认证证书的情景
Java代码  - 在项目中经常遇见这样的问题:修改应用的配置文件web.xml后,无论重启应用还是重启WebSphere服务器,都不能重新加载web.xml,导致修改的内容无效。
-
- 这 个问题困扰了我好久,即使删除了${was安装目录}\IBM\WebSphere\AppServer\profiles\AppSrv01\下的 temp和wstemp两个缓存文件夹下的临时文件,重启后还是无效。几经折腾,后来终于找到了问题所在——还是由于was的缓存机制导致的。
-
- 找 到${was安装目录}\AppServer\profiles\AppSrv01\config\cells\xxxNode01Cell \applications\${应用名}.ear\deployments\目录下,有一个与应用相同名称的缓存文件夹,删除或修改该文件夹的 web.xml,重启was即可。
Java代码 - 在websphere中修改了jsp后,有时会出现修改的jsp没有起作用,特别是改变了某jsp的样式后,在页面中没看到效果,这主要就是由于websphere中缓存的缘故,这就要清除WebSphere中jsp缓存,如我的应用部署的目录为:
- E:\IBM\WebSphere\AppServer\profiles\AppSrv01\installedApps\nbxzfwNode01Cell\项目名_war.ear\项目名.war
- 在这个目录下更新了某个jsp页面,后在浏览器里面查看的时候,发现页面没有改变。基于此,我查看了一下目录,存放应用临时文件的地方:
- E:\IBM\WebSphere\AppServer\profiles\AppSrv01\temp\nbxzfwNode01\server1\项目名_war\项目名.war
- 在这目录下,可以看到有很多class文件,都是jsp编译过来的,对应我们应用目录下的jsp文件,于是找到对应jsp的class文件删除,再到浏览器中查看,发现已经改变了。。
- 还有一种办法,就是把这个jsp从项目中删除或重命名,再到浏览器里面查看那个页面,这时可能会报错,之后,再把对应的jsp添加上或名字改过来,再次到浏览器里面查看应用的时候,就发现这jsp的更新效果出来了,呵呵…
Java代码 - 前两天去客户那里给系统做升级,同时协助解决几个使用中的问题。到了现场第一件事情是把以前的应用导出做备份, 结果居然遇到返回null。查看日志发现系统报告空间不足,以前遇到这个问题是因为WAS出现oom(Out of Memory)之后,会生成javacore和dump文件供分析内存,这两个文件通常都比较大,30多M。如果多次出现oom,生成的文件就会占用大量空间。难道最近经常内存溢出?我心抽搐。
- 快马赶到Profile目录,没有发现导出文件,询问客户也没有出现系统宕机的情况,大石落地。仔细查看之后发现profile下的wstemp目录体积巨大,接近1.7G。这是个临时目录,每当管理员通过console登录之后,wstemp会生成一个新文件夹,保存管理员的所有操作记录,在管理员登出之后会删除该目录。但是wstemp下一堆的临时文件夹都没有被删掉,看来是was 5的bug又遗留到was 6了,真是搞不明白,was的这一堆补丁怎么都没解决掉这么明显的一个问题。N多RMB的was啊,越来越觉得还不如免费的jboss。
- 回公司之后查看了自己的was版本,wstemp目录2.4G,不过分区够大才没出问题。直接删之了事
转: http://dsr-22.iteye.com/blog/1258831
简介: Gang of Four 的解释器设计模式 (Interpreter design pattern) 鼓励在一个语言的基础上构建一个新的语言来实现扩展。大多数函数式语言都能够让您以多种方式(如操作符重载和模式匹配)对语言进行扩展。尽管 Java™ 不支持这些技术,下一代 JVM 语言均支持这些技术,但其具体实现细则有所不同。在本文中,Neal Ford 将探讨 Groovy、Scala 和 Clojure 如何通过以 Java 无法支持的方式来实现函数式扩展,从而实现解释器设计模式的目的。 在本期 函数式思维 的文章中,我将继续研究 Gang of Four (GoF) 设计模式(参阅 参考资料)的函数式替代解决方案。在本文中,我将研究最少人了解,但却是最强大的模式之一:解释器 (Interpreter)。 解释器的定义是: 给定一个语言,定义其语法表示,以及一个使用该表示来解释语言中的句子的解释器。 换句话说,如果您正在使用的语言不适用于解决问题,那么用它来构建一个适用的语言。关于该方法的一个很好的示例出现在 Web 框架中,如 Grails 和 Ruby on Rails(参阅 参考资料),它们扩展了自己的基础语言(分别是 Groovy 和 Ruby),使编写 Web 应用程序变得更容易。 这种模式最少人了解,因为构建一种新的语言并不常见,需要专业的技能和惯用语法。它是最强大的 设计模式,因为它鼓励您针对正在解决的问题扩展自己的编程语言。这在 Lisp(因此 Clojure 也同样)世界是一个普遍的特质,但在主流语言中不太常见。 当使用禁止对语言本身进行扩展的语言(如 Java)时,开发人员往往将自己的思维塑造成该语言的语法;这是您的惟一选择。然而,当您渐渐习惯使用允许轻松扩展的语言时,您就会开始将语言折向解决问题的方向,而不是其他折衷的方式。 Java 缺乏直观的语言扩展机制,除非您求助于面向方面的编程。然而,下一代的 JVM 语言(Groovy、Scala 和 Clojure)(参阅 参考资料)均支持以多种方式进行扩展。通过这样做,它们可以达到解释器设计模式的目的。首先,我将展示如何使用这三种语言实现操作符重载,然后演示 Groovy 和 Scala 如何让您扩展现有的类。 操作符重载(operator overloading) 操作符重载 是函数式语言的一个常见特性,能够重定义操作符(如 +、- 或 *)配合新的类型工作,并表现出新的行为。操作符重载的缺失是 Java 形成时期的一个有意识的决定,但现在几乎每一个现代语言都具备这个特性,包括在 JVM 上 Java 的天然接班人。 Groovy Groovy 尝试更新 Java 的语法,使其跟上潮流,同时保留其自然语义。因此,Groovy 通过将操作符自动映射到方法名称实现操作符重载。例如,如果您想重载 Integer 的 + 操作符,那么您要重写 Integer 类的 plus() 方法。完整的映射列表已在线提供(参阅 参考资料);表 1 显示了列表的一部分: 表 1. Groovy 的操作符/方法映射列表的一部分 | 操作符 | 方法 |
|---|
x + y | x.plus(y) | x * y | x.multiply(y) | x / y | x.div(y) | x ** y | x.power(y) |
作为一个操作符重载的示例,我将在 Groovy 和 Scala 中都创建一个 ComplexNumber 类。复数 是一个数学概念,由一个实数 和虚数 部分组成,一般写法是,例如 3 + 4i。复数在许多科学领域中都很常用,包括工程学、物理学、电磁学和混沌理论。开发人员在编写这些领域的应用程序时,大大受益于能够创建反映其问题域的操作符。(有关复数的更多信息,请参阅 参考资料。) 清单 1 中显示了一个 Groovy ComplexNumber 类: 清单 1. Groovy 中的 ComplexNumber package complexnums class ComplexNumber { def real, imaginary public ComplexNumber(real, imaginary) { this.real = real this.imaginary = imaginary } def plus(rhs) { new ComplexNumber(this.real + rhs.real, this.imaginary + rhs.imaginary) } def multiply(rhs) { new ComplexNumber( real * rhs.real - imaginary * rhs.imaginary, real * rhs.imaginary + imaginary * rhs.real) } String toString() { real.toString() + ((imaginary < 0 ? "" : "+") + imaginary + "i").toString() } } |
在 清单 1 中,我创建一个类,保存实数和虚数部分,并且我创建重载的 plus() 和 multiply() 操作符。两个复数的相加是非常直观的:plus() 操作符将两个数各自的实数和虚数分别进行相加,并产生结果。两个复数的相乘需要以下公式: (x + yi)(u + vi) = (xu - yv) + (xv + yu)i |
在 清单 1 中的 multiply() 操作符复制该公式。它将两个数字的实数部分相乘,然后减去虚数部分相乘的积,再加上实数和虚数分别彼此相乘的积。 清单 2 测试复数运算符: 清单 2. 测试复数运算符 package complexnums import org.junit.Test import static org.junit.Assert.assertTrue import org.junit.Before class ComplexNumberTest { def x, y @Before void setup() { x = new ComplexNumber(3, 2) y = new ComplexNumber(1, 4) } @Test void plus_test() { def z = x + y; assertTrue 3 + 1 == z.real assertTrue 2 + 4 == z.imaginary } @Test void multiply_test() { def z = x * y assertTrue(-5 == z.real) assertTrue 14 == z.imaginary } } |
在 清单 2 中,plus_test() 和 multiply_test() 方法对重载操作符的使用(两者都以该领域专家使用的相同符号代表)与类似的内置类型用法没什么区别。 Scala(和 Clojure) Scala 通过放弃操作符和方法之间的区别来实现操作符重载:操作符仅仅是具有特殊名称的方法。因此,要使用 Scala 重写乘法运算,您要重写 * 方法。在清单 3 中,我用 Scala 创建复数。 清单 3. Scala 中的复数 class ComplexNumber(val real:Int, val imaginary:Int) { def +(operand:ComplexNumber):ComplexNumber = { new ComplexNumber(real + operand.real, imaginary + operand.imaginary) } def *(operand:ComplexNumber):ComplexNumber = { new ComplexNumber(real * operand.real - imaginary * operand.imaginary, real * operand.imaginary + imaginary * operand.real) } override def toString() = { real + (if (imaginary < 0) "" else "+") + imaginary + "i" } } |
清单 3 中的类包括熟悉的 real 和 imaginary 成员,以及 + 和 * 操作符/方法。如清单 4 所示,我可以自然地使用 ComplexNumber : 清单 4. 在 Scala 中使用复数 val c1 = new ComplexNumber(3, 2) val c2 = new ComplexNumber(1, 4) val c3 = c1 + c2 assert(c3.real == 4) assert(c3.imaginary == 6) val res = c1 + c2 * c3 printf("(%s) + (%s) * (%s) = %s\n", c1, c2, c3, res) assert(res.real == -17) assert(res.imaginary == 24) |
通过统一操作符和方法,Scala 使操作符重载变成一件小事。Clojure 使用相同的机制来重载操作符。例如,以下 Clojure 代码定义了一个重载的 ** 操作符: (defn ** [x y] (Math/pow x y)) |
回页首 扩展类 类似于操作符重载,下一代的 JVM 语言允许您扩展类(包括核心 Java 类),扩展的方式在 Java 语言本身是不可能实现的。这些设施通常用于构建领域特定的语言 (DSL)。虽然 GOF 从来没有考虑过 DSL(因为它们与当时流行的语言没有共同点),DSL 却体现了解释器设计模式的初衷。 通过将计量单位和其他修饰符添加给 Integer 等核心类,您可以(就像添加操作符一样)更紧密地对现实问题进行建模。Groovy 和 Scala 都支持这样做,但它们使用不同的机制。 Groovy 的 Expando 和类别类 Groovy 包括两种对现有类添加方法的机制:ExpandoMetaClass 和类别。(在 函数式思维:函数设计模式,第 2 部分 中,我在适配器模式的上下文中详细介绍过 ExpandoMetaClass。) 比方说,您的公司由于离奇的遗留原因,需要以浪(furlongs,英国的计量单位)/每两周而不是以英里/每小时 (MPH) 的方法来表达速度,开发人员发现自己经常要执行这种转换。使用 Groovy 的 ExpandoMetaClass,您可以添加一个 FF 属性给处理转换的 Integer ,如清单 5 所示: 清单 5. 使用 ExpandoMetaClass 添加一个浪/两周的计量单位给 Integer static { Integer.metaClass.getFF { -> delegate * 2688 } } @Test void test_conversion_with_expando() { assertTrue 1.FF == 2688 } |
ExpandoMetaClass 的替代方法是,创建一个类别 包装器类,这是从 Objective-C 借来的概念。在清单 6 中,我添加了一个(小写) ff 属性给 Integer: 清单 6. 通过一个类别类添加计量单位 class FFCategory { static Integer getFf(Integer self) { self * 2688 } } @Test void test_conversion_with_category() { use(FFCategory) { assertTrue 1.ff == 2688 } } |
一个类别类是一个带有一组静态方法集合的普通类。每个方法接受至少一个参数;第一个参数是这种方法增强的类型。例如,在 清单 6 中, FFCategory 类拥有一个 getFf() 方法,它接受一个 Integer 参数。当这个类别类与 use 关键字一起使用时,代码块内所有相应类型都被增强。在单元测试中,我可以在代码块内引用 ff 属性(记住,Groovy 自动将 get 方法转换为属性引用),如在 清单 6 的底部所示。 有两种机制可供选择,让您可以更准确地控制增强的范围。例如,如果整个系统使用 MPH 作为速度的默认单位,但也需要频繁转换为浪/每两周,那么使用 ExpandoMetaClass 进行全局修改将是适当的。 您可能对重新开放核心 JVM 类的有效性持怀疑态度,担心会产生广泛深远的影响。类别类让您限制潜在危险性增强的范围。以下是一个来自真实世界的开源项目示例,它极好地利用了这一机制。 easyb 项目(参阅 参考资料)让您可以编写测试,以验证正接受测试的类的各个方面。请研究清单 7 所示的 easyb 测试代码片段: 清单 7. easyb 测试一个 queue 类 it "should dequeue items in same order enqueued", { [1..5].each {val -> queue.enqueue(val) } [1..5].each {val -> queue.dequeue().shouldBe(val) } } |
queue 类不包括 shouldBe() 方法,这是我在测试的验证阶段所调用的方法。easyb 框架已为我添加了该方法;清单 8 中所显示的在 easyb 源代码中的 it() 方法定义,演示了该过程: 清单 8. easyb 的 it() 方法定义 def it(spec, closure) { stepStack.startStep(BehaviorStepType.IT, spec) closure.delegate = new EnsuringDelegate() try { if (beforeIt != null) { beforeIt() } listener.gotResult(new Result(Result.SUCCEEDED)) use(categories) { closure() } if (afterIt != null) { afterIt() } } catch (Throwable ex) { listener.gotResult(new Result(ex)) } finally { stepStack.stopStep() } } class BehaviorCategory { // ... static void shouldBe(Object self, value) { shouldBe(self, value, null) } //... } |
在 清单 8中,it() 方法接受了一个 spec (描述测试的一个字符串)和一个代表测试的主体的闭包块。在方法的中间,闭包会在 BehaviorCategory 块内执行,该块出现在清单的底部。BehaviorCategory 增强 Object,允许 Java 世界中的任何 实例验证其值。 通过允许选择性增强驻留在层次结构顶层的 Object,Groovy 的开放类机制可以轻松地实现为任何实例验证结果,但它限制了对 use 块主体的修改。 Scala 的隐式转换 Scala 使用隐式转换 来模拟现有类的增强。隐式转换不会对类添加方法,但允许语言自动将一个对象转换成拥有所需方法的相应类型。例如,我不能将 isBlank() 方法添加到 String 类中,但我可以创建一个隐式转换,将 String 自动转换为拥有这种方法的类。 作为一个示例,我想将 append() 方法添加到 Array,这让我可以轻松地将 Person 实例添加到适当类型的数组,如清单 9 所示: 清单 9.将一个方法添加到 Array 中,以增加人员 case class Person (firstName: String, lastName: String) {} class PersonWrapper(a: Array[Person]) { def append(other: Person) = { a ++ Array(other) } def +(other: Person) = { a ++ Array(other) } } implicit def listWrapper(a: Array[Person]) = new PersonWrapper(a) |
在 清单 9中,我创建一个简单的 Person 类,它带有若干个属性。为了使 Array[Person](在 Scala 中,一般使用 [ ] 而不是 < > 作为分隔符)Person 可知,我创建一个 PersonWrapper 类,它包括所需的 append() 方法。在清单的底部,我创建一个隐式转换,当我在数组上调用 append() 方法时,隐式转换会自动将一个 Array[Person] 转换为 PersonWrapper。清单 10 测试该转换: 清单 10. 测试对现有类的自然扩展 val p1 = new Person("John", "Doe") var people = Array[Person]() people = people.append(p1) |
在 清单 9中,我也为 PersonWrapper 类添加了一个 + 方法。清单 11 显示了我如何使用操作符的这个漂亮直观的版本: 清单 11. 修改语言以增强可读性 people = people + new Person("Fred", "Smith") for (p <- people) printf("%s, %s\n", p.lastName, p.firstName) |
Scala 实际上并未对原始的类添加一个方法,但它通过自动转换成一个合适的类型,提供了这样做的外观。使用 Groovy 等语言进行元编程所需要的相同工作在 Scala 中也需要,以避免过多使用隐式转换而产生由相互关联的类所组成的令人费解的网。但是,在正确使用时,隐式转换可以帮助您编写表达非常清晰的代码。 回页首 结束语 来自 GoF 的原始解释器设计模式建议创建一个新语言,但其基础语言并不支持我们今天所掌握的良好扩展机制。下一代 Java 语言都通过使用多种技术来支持语言级别的可扩展性。在本期文章中,我演示了操作符重载如何在 Groovy、Scala 和 Clojure 中工作,并研究了在 Groovy 和 Scala 中的类扩展。 在下期文章中,我将展示 Scala 风格的模式匹配和泛型的组合如何取代一些传统的设计模式。该讨论的中心是一个在函数式错误处理中也起着作用的概念,这一概念将是我们下期文章的主题。 参考资料 学习 获得产品和技术 讨论 关于作者  Neal Ford 是一家全球性 IT 咨询公司 ThoughtWorks 的软件架构师和 Meme Wrangler。他的工作还包括设计和开发应用程序、教材、杂志文章、课件和视频/DVD 演示,而且他是各种技术书籍的作者或编辑,包括最近的新书 The Productive Programmer 。他主要的工作重心是设计和构建大型企业应用程序。他还是全球开发人员会议上的国际知名演说家。请访问他的 Web 站点。
http://www.ibm.com/developerworks/cn/views/java/libraryview.jsp?view_by=search&sort_by=Date&sort_order=desc&view_by=Search&search_by=%E5%87%BD%E6%95%B0%E5%BC%8F%E6%80%9D%E7%BB%B4&dwsearch.x=18&dwsearch.y=11
摘要: 简介 目的 本文将描述 IBM Cognos Active Report 内可用的各种功能,以及如何使用它们创建和分发交互式报告应用程序。 本文假设您对 IBM Cognos Active Report 功能有一定的基本了解。有关入门资料,请参阅 http://publib.boulder.ibm.com/infocenter/cbi/v10r1m1/index.jsp 上 Au... 阅读全文
摘要: 在Word 给段落编号时,有时某些段落编号后会突然增大缩进1.选择更改样式-段落间距-自定义段落间距2.选择编辑选项卡,点击修改按钮3.设置相应的样式即可 阅读全文
Project 默认字体是11号宋体,显然有点太大了,但每次输入一个任务都要去格式化太麻烦 可以统一设置一个默认字体,步骤如下: 1.选择格式选项卡,点击文本样式 2.选择需要的样式,并将要修改的项选择全部,单击确定就搞定了
好的网站设计需要有好的效果技巧组合,无论你是一个自由者,设计师,要想使网站效果突出,绚丽,jquery是你一个不二的选择,利用jQuery,你可以很容易地创建自己的图像幻灯片,UI设计界面,完全与众不同的风格以达到惊人的过渡效果。有了这些功能,它可以帮助您的网上脱颖而出,提升您的品牌标识。今天的这些jquery插件,今天他被在60%的网站上使用,如果你正在创建web项目,这个是不错的选择 TN3 Gallery – jQuery Slider and Image Gallery 
Take a Tour 下载 Easy Slider 1.7 – Numeric Navigation jQuery Slider 
演示 下载 Easy Slider 是一个滑动门插件,支持任何图片或内容,当点击时实现横向或纵向滑动。它拥有一系列丰富的参数设置,可通过CSS来进行完全的控制。所以,基本上你只需要链接这个插件文件后,设置好内容,然后样式化CSS就可以了。 RoyalSlider – Touch-Enabled jQuery Image Gallery 
演示 下载 SlideDeck 
演示 下载 slideViewer (a jQuery image slider built on a single unordered list) 1.2 
演示 下载 利用这个jQuery插件,只需几行代码就能够将一组无序的图片列表转换成可导航控制的相册。 jqFancyTransitions – slideshow with strip effects 
演示 下载 jqFancyTransitions这个jQuery插件能够以奇特的切换效果幻灯展示图片。它支持三种切换效果包括:波浪、拉链和卷帘。可以为图片设置标题,切换速度等。 AviaSlider – jQuery Slideshow 
演示 下载 AviaSlider是一个独特的slidershow插件,支持8种不同的图片切换效果。支持图片预加载,图片自动播放当用户交互时停止。 Presentation Cycle – Cycle with a progressbar 
演示 下载 Nivo Slider 
演示 下载 Nivo Slider是一款出色的jQuery幻灯片插件,支持多种切换效果,可定制性强. jQuery Easy Slides v1.1 
演示 下载 Advanced Slider – jQuery XML slider 
演示 下载 Horinaja 
演示 下载 Horinaja是一个可定制、易于安装、跨浏览器的Slideshow控件。当鼠标移到Slideshow区域时,内容项目停止滚动切换。当鼠标移开时,内容项目自动滚动切换。提供基于scriptaculous/prototype和jQuery两种版本 mbSlider 
演示 下载 by mike182uk
Dragdealer JS 
演示 下载 Smooth Div Scroll 
演示 下载 Supersized jQuery Plugin 
演示 下载 Pikachoose 
演示 下载 PikaChoose是一个超轻量级的图片画廊jQuery插件,它是可以轻而易举地使用在您的网站。 有许多的网站使用了他,在他的主页上可以看到这些网站。 UnoSlider – Responsive Touch Enabled Slider 
演示 下载 bxSlider 
演示 下载 bxSlider是一个jQuery插件用于创建简单的内容滑动变换容器。可以设置是否自动滑动,滑动速度等。 slideViewerPro 1.5 
演示 下载 Slides 
演示 下载 Simple Controls Gallery v1.4 
演示 下载 jQuery OneByOne Slider Plugin 
演示 下载 s3Slider jQuery plugin 
演示 下载 jQuery s3Slider 就是一个效果非常棒的产品展示用 Plugin ,它让我们单纯使用 HTML 就能达到如同 Flash 般的动画效果,而且配合适当的 CSS 时,更能在展示产品呈现一流的设计感。 JCoverflip 
演示 下载 jCoverflip是一个jQuery插件用于创建类似于Coverflow的界面,可以展示图片或其它任意内容。内容既可以单击其中的某个项目进行浏览,也可以拖动Slider(jQuery UI slider)浏览。 Elastislide – A Responsive jQuery Carousel Plugin 
演示 下载 Orbit: A Slick jQuery Image Slider Plugin 
演示 下载 LayerSlider – The Parallax Effect Slider 
演示 下载 jQuery UI Slider 
演示 下载 FLEXSLIDER 
演示 下载 simpleSlide 
演示 下载 Sliding Image Gallery jQuery Plugin 
演示 下载 Translucent – jQuery Banner Rotator / Slideshow 
演示 下载 Blueberry Slider 
演示 下载 Coin Slider 
演示 下载 jQuery.popeye 
演示 下载 Query.popeye这个插件能够将一组无序的图片列表转换成一个简单的相册。当点击图片时将以Lightbox风格放大图片。图片展示框提供 向前/ 向后控制并能够为每一张图片添加备注说明信息。jQuery.popeye能够根据图片大小自动调整展示框的高度和宽度。 Colorbox 
演示 下载 这个是jquery的弹窗效果插件 jQuery Slider Evolution 
演示 下载 Coda-Slider 
演示 下载 AnythingSlider jQuery Plugin 
演示 下载 jQuery Multimedia Portfolio 
演示 下载 jQuery Multimedia Portfolio支持多种多媒体格式,包括:图片,视频(flv), 音频(mp3), 并能自动侦测每个文件的扩展名再分别调用合适的播放。 jQuery Cycle Plugin 
演示 下载 jCycle 是一种新的插件jQuery致力于添加影像的平稳过渡。它支持6个不同的过渡类型而且很容易使用。自由职业者,相信您的客户会喜欢它的! Estro – jQuery Ken Burns & swipe effect slider 
演示 下载 ResponsiveSlides.js 
演示 下载 ResponsiveSlides.js 是一个微型的 jQuery 插件用来创建响应式的幻灯展示效果,对 <ul> 标签中的图片进行自动幻灯展示,支持几乎所有浏览器包括 IE6。也可设置 max-width 属性并对 IE6 有效。 wmuSlider 
演示 下载 FSS – Full Screen Sliding Website Plugin 
演示 下载 Agile Carousel 
演示 下载 jQuery Slider plugin 
演示 下载 jQuery Carousel Evolution 
演示 下载 Skitter Slideshow 
演示 下载 转自: http://www.cnblogs.com/web8cn/archive/2012/08/03/2622060.html
摘要: 1.新建插件工程,选择从已存在的Jar包创建2.选择本地的jar包3.输入工程名称,点击完成4.在Eclipse 资源管理器看到新建的插件工程5.双击MANIFEST.MF文件6.在编辑器中打开的设计界面,点击导出按钮7.选择插件依赖工程,和导出路径8.点击完成,在指定的位置看到导出的jar插件包 阅读全文
是自己编写的一个jar文件,每次添加单个jar到maven本地仓库的操作如下: 1.建立一个新的文件夹,将jar文件存放在该文件夹下。 注意文件夹下最好只存放该文件。 2.在该文件夹下建立一个pom.xml文件,在pom文件中定义其maven坐标。 3.在cmd窗口中执行以下命令: mvn install:install-file -Dfile=<path-to-file> -DgroupId=<group-id> -DartifactId=<artifact-id> -Dversion=<version> -Dpackaging=<packaging> 例如 mvn install:install-file -Dfile=/home/xx.jar -DgroupId=xx -DartifactId=xx -Dversion=1.0 -Dpackaging=jar
摘要: Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> 1 using System; 2 using System.Collections.Generic; &n... 阅读全文
http://hb.qq.com/a/20110624/001008.htm http://blog.163.com/popfei3707@126/blog/static/12297648420107542344500/ http://www.iteye.com/problems/30192 http://hi.baidu.com/guorabbit/item/dddca00b7521eb813d42e279
修改 apache-tomcat-6.0.33\bin\catalina.bat 文件 @echo off if "%OS% " == "Windows_NT " setlocal rem --------------------------------------------------------------------------- rem Start script for the CATALINA Server rem rem $Id: startup.bat,v 1.4 2002/08/04 18:19:43 patrickl Exp $ rem --------------------------------------------------------------------------- set JAVA_HOME=c:\jdk set CATALINA_HOME=c:\apache-tomcat-6.0.33 rem Guess CATALINA_HOME if not defined if not "%CATALINA_HOME% " == " " goto gotHome JAVA_HOME=c:\jdk set CATALINA_HOME=c:\apache-tomcat-6.0.33 中 c:\jdk 是你jdk工具包的目录, c:\apache-tomcat-6.0.33 是tomcat 安装目录
jquery的功能总是那么的强大,用他可以开发任何web和移动框架,在浏览器市场,他一直是占有重要的份额,今天,就给大家分享20惊人的jQuery插件为设计师和开发人员。 比方说The-M-Project 可能就是你正在等待的一个开源的手机的 HTML5 的 JavaScript 框架,通过它可编写 HTML5/CSS3/SVG 应用,并支持多数数据平台,包括 iOS, Android, Palm webOS, 和 Blackberry OS。 jShowOff:jQuery的内容肩 - jQuery插件 ShowOff 是一个基于 jQuery 的内容幻灯插件,之所以叫内容插件而不是图片幻灯插件,是因为jShowOff不仅支持图片,同时也支持任何HTML代码。jShowOff很易于使用, 对HTML结构的要求很简单,有一个父元素包裹的元素集合就可以了,并且jShowOff提供了丰富实用的配置参数。 预览:
 下载jQuery的内容肩插件 要求: jQuery的兼容性:所有主要浏览器下载:http://github.com/ekallevig/jShowOff
使用jQuery - Zoomy快速和方便的缩放 zoomy是简单的。zoomy是很容易实现和定制。Zoomy是一个快速简便的插件,使图片放大或缩小。你只需要两个副本图像和一个大的图像显示,然后缩放图像。大多数CMS系统保存或创建多个大小的图像,所以它很容易成立。只是链接上显示图片的放大图片,并告诉插件使用变焦时的链接。只需点点的脚本。Zoomy是一个很容易实现的jQuery插件,它可以帮助创建图像放大功能。 预览:
 要求: jQuery的下载:http://redeyeoperations.com/plugins/zoomy/zoomy0.5.zip 使用php /jquery /image 图像裁剪插件 jQuery上传/图像上传工具的使用和作物不同类型的图像,JPG,GIF和PNG和你现在可以上传图片,并有一个随机的文件名 (此修复一些有缓存的问题)你需要“ 图片区选择 “插件。 我们需要的是一种方式来上传一个JPG图像,调整其大小,如果需要的话,那么裁剪给定的高度和宽度。 preivew:
 要求:jQuery的,PHP PHP的GD
Demo: http://www.webmotionuk.co.uk/jquery/image_upload_crop.php
Download: http://www.webmotionuk.co.uk/jquery/jquery_upload_crop.zip ProcessWire:PHP的CMS的框架与jQuery ProcessWire是一个开源的内容管理系统(CMS)和Web应用程序框架,针对设计师,开发人员和他们的客户的需求。ProcessWire给你更多的控制领域,模板和标记比其他平台,并提供了强大的模板系统,ProcessWire的API使您的内容轻松,愉快的工作。相比,你可以用来管理和发展在ProcessWire的网站是惊人的简单。 预览:
 要求: PHP 5.2.4 +的MySQL 5.0.15 + 演示:http://processwire.com/demo/ 下载:https://github.com/ryancramerdesign/ProcessWire
jRating - 灵活的jQuery的Ajax评分插件 jRating是一个非常灵活的jQuery插件,用于快速创建一个Ajaxed星级评级制度。它是可以配置的每一个细节,从“数星星”,“如果星星可以代表小数或不”。还有一个选项,以显示大或小的恒星和图像可以很容易改变的任何其他文件。 预览:
 要求: jQuery的兼容性:所有主要
The-M-Project HTML5的跨平台移动应用的JavaScript框架 The-M-Project 可能就是你正在等待的一个开源的手机的 HTML5 的 JavaScript 框架,通过它可编写 HTML5/CSS3/SVG 应用,并支持多数数据平台,包括 iOS, Android, Palm webOS, 和 Blackberry OS。The-M-Project是一个令人兴奋的HTML5的JavaScript框架建立跨平台的移动网络应用程序(IOSAndroid,Palm的webOS,黑莓)。它使用jquery的JavaScript部分,并包含所有UI +像脱机支持,国际化和功能的核心文件。 预览:
 要求: Git的nodeJS 兼容性:所有主要的移动
arbor.js:使用Web和jQuery的图形可视化图书馆 arbor.js 是一个利用 Web Works 和 jQuery 创建的可视化图形库,它为图形组织和屏幕刷新处理提供了一个高效的、力导向的布局算法。 预览:
 要求: jQuery的兼容性:所有现代浏览器下载:https://github.com/samizdatco/arbor
jQuery.validval插件简化定制的表单验证 jQuery.validVal是一个插件,旨在简化和定制的验证形式。它是高度可定制,功能非常丰富,可以很容易地在任何类型的HTML形式(甚至AJAX的形式),。它可用于任何一种HTML表单(包括Ajaxed)的验证,并通过在类名定义的规则。 预览:
 要求: jQuery的兼容性:所有主要浏览器演示:http://validval.frebsite.nl/examples.php
FancyMoves Jquery的产品滑块 FancyMoves 是一个漂亮的产品图片滚动展播jQuery插件。支持键盘或点击图片导航浏览,当点击具体图片会弹出一个Lightbox模式对话框来显示原始图片。他有三种展现方式:使用键盘箭头,使用滑块两侧的左,右箭头,或在滑块只需点击下一个或最后一个项目。 FancyMoves,为您的网站或博客的一个新的jQuery滑块产品 预览:
 要求:
Demo: http://webdesignandsuch.com/posts/jquery-product-slider/jQuery-productSlider/index.html
Download: http://webdesignandsuch.com/posts/jquery-product-slider/jQuery-productSlider/FancyMoves.zip
jquery 自动复制插件sheepIt SheepIt!是一个能够动态复制表单元素的jQuery插件,可以批量增加、删除某一个表单元素。在增加表单元素前/后都可以添加回调函数。 有时候,一个静态的形式是不够的,因为我们可能希望使人们有可能为用户定义灵活的地址,电话,电子邮件等 这是SheepIt!
预览:
 要求: jQuery的1.4 + 的兼容性:所有主要
jquery Overlay Effect Menu Overlay Effect Menu是一款基于jquery的菜单插件,当鼠标经过菜单时候,将会产生遮罩,遮挡除了菜单的任何部分,并且展开子菜单. 预览:
 要求: jQuery的兼容性:所有主要的浏览器演示:
http://tympanus.net/Tutorials/OverlayEffectMenu/
Download: http://tympanus.net/Tutorials/OverlayEffectMenu/OverlayEffectMenu.zip File Download jQuery Plugin: jDownload jDownload是一个jQuery插件,其目的是要下载有关文件的说明 一旦下载链接被点击时,它发送一个Ajax查询到一个PHP文件,它返回一个模态窗口中的文件的名称,类型和大小。 预览:
 要求: jQuery的jQuery UI的兼容性:所有主要浏览器下载:http://code.google.com/p/jquery-jdownload/downloads/list
创意与jQuery自由基Web版式 - Lettering.js lettering.js,重量轻,易于使用JavaScript <SPAN>插件用来实现比较激进的网页排版。 它只是简单地划分成片<SPAN>小号的任何给定的元素包装一个自定义类的每个字母。 preivew:
 要求: jQuery的兼容性:所有主要浏览器下载:http://github.com/davatron5000/Lettering.js
SlideNote:滑动通知的jQuery插件 SlideNote是一个可定制的,灵活jquery插件,可以很容易地显示在您的网站或在你的web应用滑动通知。欲了解更多信息或看到一个演示中,向下滚动。插件显示任何URL的内容,可选它可以显示该网址内的元素的内容。 预览:
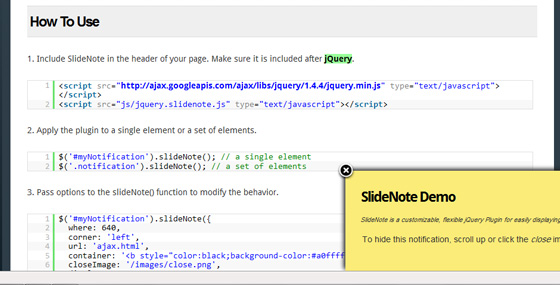 要求: jQuery的兼容性:所有主要浏览器下载:http://github.com/tommcfarlin/slidenote~~V
jQuery的水平手风琴 -Easy Accordion Easy Accordion是一个高度灵活的jQuery插件用于快速创建水平可折叠手风琴(Accordion),它支持在同一个页面中创建多个实例。可折叠任意内容如:图片、列表、Flash等,外观也完全可以通过CSS自定义。 预览:
 要求: jQuery的兼容性:所有主要
carouFredSel - 无限的jQuery传送带滚动水平和垂直插件 carouFredSel是一个内容无限循环播放容器jQuery,可以展示任何类型的HTML元素。支持水平和垂直两个方向。项目的高度和宽度可以不相同。可以动态从容器中删除/添加项目,可以利用向前/向后按纽播放项目或设置成自动播放。 Slick jQuery Image Slider Plugin “Orbit” Orbit是一个设计良好并且容易使用的jQuery图片滑动幻灯片插件,它除了支持图片滚动切换展示外,还支持针对内容的滚动。插件的定制性相当高,它提供了多个参数的设置,通过设置你可以将它打造成完全符合你要求的样式。 预览:
 要求: jQuery的兼容性:所有主要浏览器网址:http://www.zurb.com/playground/jquery-image-slider-plugin/Orbit_Kit.zip 转自:http://www.cnblogs.com/web8cn/archive/2012/07/30/2614795.html
摘要: 今天在网上看到了一篇关于JAVA图像处理的文章,博主贴出了一个处理类:特点是高品质缩小,具体代码如下: import java.awt.image.BufferedImage; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import&n... 阅读全文
一、需要用到的类 java.awt.image.BufferedImage; javax.imageio.ImageIO; java.io.*; 二、为什么要将BufferedImage转为byte数组 在传输中,图片是不能直接传的,因此需要把图片变为字节数组,然后传输比较方便;只需要一般输出流的write方法即可; 而字节数组变成BufferedImage能够还原图像; 三、如何取得BufferedImage BufferedImage image = ImageIO.read(new File("1.gif")); 四、BufferedImage ---->byte[] ImageIO.write(BufferedImage image,String format,OutputStream out);方法可以很好的解决问题; 参数image表示获得的BufferedImage; 参数format表示图片的格式,比如“gif”等; 参数out表示输出流,如果要转成Byte数组,则输出流为ByteArrayOutputStream即可; 执行完后,只需要toByteArray()就能得到byte[]; 五、byte[] ------>BufferedImage ByteArrayInputStream in = new ByteArrayInputStream(byte[]b); //将b作为输入流; BufferedImage image = ImageIO.read(InputStream in); //将in作为输入流,读取图片存入image中,而这里in可以为ByteArrayInputStream(); 六、显示BufferedImage public void paint(Graphics g){ super.paint(g); g.drawImage(image); //image为BufferedImage类型 } 七、实例 要求:编写一个网络程序,通过Socket将图片从服务器端传到客户端,并存入文件系统; Server端: package org.exam3;
import java.awt.image.BufferedImage;
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.net.ServerSocket;
import java.net.Socket;
import javax.imageio.ImageIO;
public class T6Server {
public static void main(String[] args) throws Exception {
ServerSocket server = new ServerSocket(8888);
Socket s = server.accept();
DataOutputStream dout = new DataOutputStream(s.getOutputStream());
BufferedImage image = ImageIO.read(new File("1.gif"));
ByteArrayOutputStream out = new ByteArrayOutputStream();
boolean flag = ImageIO.write(image, "gif", out);
byte[] b = out.toByteArray();
dout.write(b);
s.close();
}
}
Client端:
package org.exam3;
import java.awt.BorderLayout;
import java.awt.Graphics;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import java.io.File;
import java.io.PrintWriter;
import java.net.Socket;
import javax.imageio.ImageIO;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JPanel;
public class T6Client extends JFrame {
JButton button;
MyPanel panel;
public T6Client() {
setSize(300, 400);
button = new JButton("获取图像");
add(button,BorderLayout.NORTH);
button.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent event) {
try {
Socket s = new Socket("localhost",8888);
PrintWriter out = new PrintWriter(s.getOutputStream());
out.print("a");
DataInputStream in = new DataInputStream(s.getInputStream());
byte[]b = new byte[1000000];
in.read(b);
ByteArrayInputStream bin = new ByteArrayInputStream(b);
BufferedImage image = ImageIO.read(bin);
ImageIO.write(image, "gif", new File("2.gif"));
s.close();
} catch (Exception e) {
}
}
});
panel = new MyPanel();
add(panel);
}
public static void main(String[] args) throws Exception {
T6Client frame = new T6Client();
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setVisible(true);
}
} 转自:
这两个概念是早些时候Martin Fowler总结出来的两种常见模型设计类型,没有说谁好谁不好,为不同的模型类别选择合适的场景是设计者的工作。没有工具本身的问题,只有工具使用者的问题。 贫血模型是指领域对象里只有get和set方法(POJO),所有的业务逻辑都不包含在内而是放在Business Logic层。

优点是系统的层次结构清楚,各层之间单向依赖,Client->(Business Facade)->Business Logic->Data Access Object。可见,领域对象几乎只作传输介质之用,不会影响到层次的划分。 该模型的缺点是不够面向对象,领域对象只是作为保存状态或者传递状态使用,它是没有生命的,只有数据没有行为的对象不是真正的对象,在Business Logic里面处理所有的业务逻辑,对于细粒度的逻辑处理,通过增加一层Facade达到门面包装的效果。 在使用Spring的时候,通常暗示着你使用了贫血模型,我们把Domain类用来单纯地存储数据,Spring管不着这些类的注入和管理,Spring关心的逻辑层(比如单例的被池化了的Business Logic层)可以被设计成singleton的bean。 假使我们这里逆天而行,硬要在Domain类中提供业务逻辑方法,那么我们在使用Spring构造这样的数据bean的时候就遇到许多麻烦,比如:bean之间的引用,可能引起大范围的bean之间的嵌套构造器的调用。 贫血模型实施的最大难度在于如何梳理好Business Logic层内部的划分关系,由于该层会比较庞大,边界不易控制,内部的各个模块之间的依赖关系不易管理,可以考虑这样这样的实现思路: (1)铺设扁平的原子业务逻辑层,即简单的CRUD操作(含批量数据操作); (2)特定业务清晰的逻辑通过Facade层来组装原子操作实现。 (3)给业务逻辑层实施模块划分,保持模块之间的松耦合的关系。 举例说明: 原子业务逻辑层(Service)提供了用户模型的条件查询方法: List<User> queryUser(Condition con) Facade层则提供了一种特定的业务场景的分子接口,满足18岁的中国公民,内部实现调用的正是上述的原子接口: List<User> queryAdultChinese() Facade、Service层纵向划分为几个大的领域包:用户、内容和产品。 充血模型层次结构和上面的差不多,不过大多业务逻辑和持久化放在 Domain Object里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成Client->(Business Facade)->Business Logic->Domain Object->Data Access Object。

它的优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。 缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。即使划分好了业务逻辑,由于分散在Business Logic和Domain Object层中,不能更好的分模块开发。熟悉业务逻辑的开发人员需要渗透到Domain Logic中去,而在Domian Logic又包含了持久化,对于开发者来说这十分混乱。 其次,如果Business Logic要控制事务并且为上层提供一个统一的服务调用入口点,它就必须把在Domain Logic里实现的业务逻辑全部重新包装一遍,完全属于重复劳动。 使用RoR开发时, 每一个领域模型对象都可以具备自己的基础业务方法,通常满足充血模型的特征。充血模型更加适合较复杂业务逻辑的设计开发。 充血模型的层次和模块的划分是一门学问,对开发人员要求亦较高,可以考虑定义这样的一些规则: (1)事务控制不要放在领域模型的对象中实现,可以放在facade中完成。 (2)领域模型对象中只保留该模型驱动的一般方法,对于业务特征明显的特异场景方法调用放在facade中完成。 万事都不是绝对的,也有一些看起来不易解决的问题。例如,考虑到性能的需要,我需要一次查询出满足某种条件的用户和某种条件的产品,他们二者之间通过订购关系关联起来,可能发现这种情形下,上述的模型层次划分变得无解了…… 怎么办呢?包括以上种种,欢迎大家讨论。
转自: http://raychase.iteye.com/blog/1328224
简介: EhCache 是一个纯 Java 的进程内缓存框架,具有快速、精干等特点,是 Hibernate 中默认的 CacheProvider。本文充分的介绍了 EhCache 缓存系统对集群环境的支持以及使用方法。 发布日期: 2010 年 4 月 01 日
级别: 初级
访问情况 : 13809 次浏览
评论: 1 (查看 | 添加评论 - 登录) EhCache 缓存系统简介 EhCache 是一个纯 Java 的进程内缓存框架,具有快速、精干等特点,是 Hibernate 中默认的 CacheProvider。 下图是 EhCache 在应用程序中的位置: 图 1. EhCache 应用架构图  EhCache 的主要特性有: - 快速;
- 简单;
- 多种缓存策略;
- 缓存数据有两级:内存和磁盘,因此无需担心容量问题;
- 缓存数据会在虚拟机重启的过程中写入磁盘;
- 可以通过 RMI、可插入 API 等方式进行分布式缓存;
- 具有缓存和缓存管理器的侦听接口;
- 支持多缓存管理器实例,以及一个实例的多个缓存区域;
- 提供 Hibernate 的缓存实现;
- 等等 …
由于 EhCache 是进程中的缓存系统,一旦将应用部署在集群环境中,每一个节点维护各自的缓存数据,当某个节点对缓存数据进行更新,这些更新的数据无法在其它节点中共享, 这不仅会降低节点运行的效率,而且会导致数据不同步的情况发生。例如某个网站采用 A、B 两个节点作为集群部署,当 A 节点的缓存更新后,而 B 节点缓存尚未更新就可能出现用户在浏览页面的时候,一会是更新后的数据,一会是尚未更新的数据,尽管我们也可以通过 Session Sticky 技术来将用户锁定在某个节点上,但对于一些交互性比较强或者是非 Web 方式的系统来说,Session Sticky 显然不太适合。所以就需要用到 EhCache 的集群解决方案。 EhCache 从 1.7 版本开始,支持五种集群方案,分别是: - Terracotta
- RMI
- JMS
- JGroups
- EhCache Server
本文主要介绍其中的三种最为常用集群方式,分别是 RMI、JGroups 以及 EhCache Server 。 回页首 RMI 集群模式 RMI 是 Java 的一种远程方法调用技术,是一种点对点的基于 Java 对象的通讯方式。EhCache 从 1.2 版本开始就支持 RMI 方式的缓存集群。在集群环境中 EhCache 所有缓存对象的键和值都必须是可序列化的,也就是必须实现 java.io.Serializable 接口,这点在其它集群方式下也是需要遵守的。 下图是 RMI 集群模式的结构图: 图 2. RMI 集群模式结构图  采用 RMI 集群模式时,集群中的每个节点都是对等关系,并不存在主节点或者从节点的概念,因此节点间必须有一个机制能够互相认识对方,必须知道其它节点的信息,包括 主机地址、端口号等。EhCache 提供两种节点的发现方式:手工配置和自动发现。手工配置方式要求在每个节点中配置其它所有节点的连接信息,一旦集群中的节点发生变化时,需要对缓存进行重 新配置。 由于 RMI 是 Java 中内置支持的技术,因此使用 RMI 集群模式时,无需引入其它的 Jar 包,EhCache 本身就带有支持 RMI 集群的功能。使用 RMI 集群模式需要在 ehcache.xml 配置文件中定义 cacheManagerPeerProviderFactory 节点。假设集群中有两个节点,分别对应的 RMI 绑定信息是: | 节点 1 | 192.168.0.11 | 4567 | /oschina_cache | | 节点 2 | 192.168.0.12 | 4567 | /oschina_cache | | 节点 3 | 192.168.0.13 | 4567 | /oschina_cache |
那么对应的手工配置信息如下: <cacheManagerPeerProviderFactory
class="net.sf.ehcache.distribution.RMICacheManagerPeerProviderFactory"
properties="hostName=localhost,
port=4567,
socketTimeoutMillis=2000,
peerDiscovery=manual,
rmiUrls=//192.168.0.12:4567/oschina_cache|//192.168.0.13:4567/oschina_cache" />
其它节点配置类似,只需把 rmiUrls 中的两个 IP 地址换成另外两个节点对应的 IP 地址即可。 接下来在需要进行缓存数据复制的区域(Region)上配置如下即可: <cache name="sampleCache2"
maxElementsInMemory="10"
eternal="false"
timeToIdleSeconds="100"
timeToLiveSeconds="100"
overflowToDisk="false">
<cacheEventListenerFactory
class="net.sf.ehcache.distribution.RMICacheReplicatorFactory"
properties="replicateAsynchronously=true,
replicatePuts=true,
replicateUpdates=true,
replicateUpdatesViaCopy=false,
replicateRemovals=true "/>
</cache>
具体每个参数代表的意义请参考 EhCache 的手册,此处不再详细说明。 EhCache 的 RMI 集群模式还有另外一种节点发现方式,就是通过多播( multicast )来维护集群中的所有有效节点。这也是最为简单而且灵活的方式,与手工模式不同的是,每个节点上的配置信息都相同,大大方便了节点的部署,避免人为的错漏出现。 在上述三个节点的例子中,配置如下: <cacheManagerPeerProviderFactory
class="net.sf.ehcache.distribution.RMICacheManagerPeerProviderFactory"
properties="peerDiscovery=automatic,
multicastGroupAddress=230.0.0.1,
multicastGroupPort=4446, timeToLive=32" />
其中需要指定节点发现模式 peerDiscovery 值为 automatic 自动;同时组播地址可以指定 D 类 IP 地址空间,范围从 224.0.1.0 到 238.255.255.255 中的任何一个地址。 回页首 JGroups 集群模式 EhCache 从 1.5. 版本开始增加了 JGroups 的分布式集群模式。与 RMI 方式相比较, JGroups 提供了一个非常灵活的协议栈、可靠的单播和多播消息传输,主要的缺点是配置复杂以及一些协议栈对第三方包的依赖。 JGroups 也提供了基于 TCP 的单播 ( Unicast ) 和基于 UDP 的多播 ( Multicast ) ,对应 RMI 的手工配置和自动发现。使用单播方式需要指定其它节点的主机地址和端口,下面是两个节点,并使用了单播方式的配置: <cacheManagerPeerProviderFactory
class="net.sf.ehcache.distribution.jgroups.JGroupsCacheManagerPeerProviderFactory"
properties="connect=TCP(start_port=7800):
TCPPING(initial_hosts=host1[7800],host2[7800]; port_range=10;timeout=3000;
num_initial_members=3;up_thread=true;down_thread=true):
VERIFY_SUSPECT(timeout=1500;down_thread=false;up_thread=false):
pbcast.NAKACK(down_thread=true;up_thread=true;gc_lag=100;
retransmit_timeout=3000):
pbcast.GMS(join_timeout=5000;join_retry_timeout=2000;shun=false;
print_local_addr=false;down_thread=true;up_thread=true)" propertySeparator="::" />
使用多播方式配置如下: <cacheManagerPeerProviderFactory
class="net.sf.ehcache.distribution.jgroups.JGroupsCacheManagerPeerProviderFactory"
properties="connect=UDP(mcast_addr=231.12.21.132;mcast_port=45566;):PING:MERGE2:FD_SOCK:VERIFY_SUSPECT:pbcast.NAKACK:UNICAST:pbcast.STABLE:FRAG:pbcast.GMS" propertySeparator="::" />
从上面的配置来看,JGroups 的配置要比 RMI 复杂得多,但也提供更多的微调参数,有助于提升缓存数据复制的性能。详细的 JGroups 配置参数的具体意义可参考 JGroups 的配置手册。 JGroups 方式对应缓存节点的配置信息如下: <cache name="sampleCache2"
maxElementsInMemory="10"
eternal="false"
timeToIdleSeconds="100"
timeToLiveSeconds="100"
overflowToDisk="false">
<cacheEventListenerFactory
class="net.sf.ehcache.distribution.jgroups.JGroupsCacheReplicatorFactory"
properties="replicateAsynchronously=true,
replicatePuts=true,
replicateUpdates=true,
replicateUpdatesViaCopy=false, replicateRemovals=true" />
</cache>
使用组播方式的注意事项 使用 JGroups 需要引入 JGroups 的 Jar 包以及 EhCache 对 JGroups 的封装包 ehcache-jgroupsreplication-xxx.jar 。 在一些启用了 IPv6 的电脑中,经常启动的时候报如下错误信息: java.lang.RuntimeException: the type of the stack (IPv6) and the user supplied addresses (IPv4) don't match: /231.12.21.132. 解决的办法是增加 JVM 参数:-Djava.net.preferIPv4Stack=true。如果是 Tomcat 服务器,可在 catalina.bat 或者 catalina.sh 中增加如下环境变量即可: SET CATALINA_OPTS=-Djava.net.preferIPv4Stack=true
经过实际测试发现,集群方式下的缓存数据都可以在 1 秒钟之内完成到其节点的复制。 回页首 EhCache Server 与前面介绍的两种集群方案不同的是, EhCache Server 是一个独立的缓存服务器,其内部使用 EhCache 做为缓存系统,可利用前面提到的两种方式进行内部集群。对外提供编程语言无关的基于 HTTP 的 RESTful 或者是 SOAP 的数据缓存操作接口。 下面是 EhCache Server 提供的对缓存数据进行操作的方法: OPTIONS /{cache}} 获取某个缓存的可用操作的信息。 HEAD /{cache}/{element} 获取缓存中某个元素的 HTTP 头信息,例如: curl --head http://localhost:8080/ehcache/rest/sampleCache2/2
EhCache Server 返回的信息如下: HTTP/1.1 200 OK X-Powered-By: Servlet/2.5
Server: GlassFish/v3 Last-Modified: Sun, 27 Jul 2008 08:08:49 GMT
ETag: "1217146129490" Content-Type: text/plain; charset=iso-8859-1
Content-Length: 157 Date: Sun, 27 Jul 2008 08:17:09 GMT
GET /{cache}/{element} 读取缓存中某个数据的值。 PUT /{cache}/{element} 写缓存。 由于这些操作都是基于 HTTP 协议的,因此你可以在任何一种编程语言中使用它,例如 Perl、PHP 和 Ruby 等等。 下图是 EhCache Server 在应用中的架构: 图 3. EhCache Server 应用架构图  EhCache Server 同时也提供强大的安全机制、监控功能。在数据存储方面,最大的 Ehcache 单实例在内存中可以缓存 20GB。最大的磁盘可以缓存 100GB。通过将节点整合在一起,这样缓存数据就可以跨越节点,以此获得更大的容量。将缓存 20GB 的 50 个节点整合在一起就是 1TB 了。 回页首 总结 以上我们介绍了三种 EhCache 的集群方案,除了第三种跨编程语言的方案外,EhCache 的集群对应用程序的代码编写都是透明的,程序人员无需考虑缓存数据是如何复制到其它节点上。既保持了代码的轻量级,同时又支持庞大的数据集群。 EhCache 可谓是深入人心。 2009 年年中,Terracotta 宣布收购 EhCache 产品。Terracotta 公司的产品 Terracotta 是一个 JVM 级的开源群集框架,提供 HTTP Session 复制、分布式缓存、POJO 群集、跨越集群的 JVM 来实现分布式应用程序协调。最近 EhCache 主要的改进都集中在跟 Terracotta 框架的集成上,这是一个真正意义上的企业级缓存解决方案。 参考资料 学习 获得产品和技术 讨论 关于作者 刘柄成,开源中国社区(http://www.oschina.net)站长,DLOG4J 作者,十年的 Java 开发经验,热衷于开源软件的开发和应用。 http://www.ibm.com/developerworks/cn/java/j-lo-ehcache/
Ehcache 是现在最流行的纯Java开源缓存框架,配置简单、结构清晰、功能强大,最初知道它,是从Hibernate的缓存开始的。网上中文的EhCache材料 以简单介绍和配置方法居多,如果你有这方面的问题,请自行google;对于API,官网上介绍已经非常清楚,请参见官网;但是很少见到特性说明和对实现 原理的分析,因此在这篇文章里面,我会详细介绍和分析EhCache的特性,加上一些自己的理解和思考,希望对缓存感兴趣的朋友有所收获。 一、特性一览,来自官网,简单翻译一下: 1、快速轻量
过去几年,诸多测试表明Ehcache是最快的Java缓存之一。
Ehcache的线程机制是为大型高并发系统设计的。
大量性能测试用例保证Ehcache在不同版本间性能表现得一致性。
很多用户都不知道他们正在用Ehcache,因为不需要什么特别的配置。
API易于使用,这就很容易部署上线和运行。
很小的jar包,Ehcache 2.2.3才668kb。
最小的依赖:唯一的依赖就是SLF4J了。
2、伸缩性
缓存在内存和磁盘存储可以伸缩到数G,Ehcache为大数据存储做过优化。
大内存的情况下,所有进程可以支持数百G的吞吐。
为高并发和大型多CPU服务器做优化。
线程安全和性能总是一对矛盾,Ehcache的线程机制设计采用了Doug Lea的想法来获得较高的性能。
单台虚拟机上支持多缓存管理器。
通过Terracotta服务器矩阵,可以伸缩到数百个节点。
3、灵活性
Ehcache 1.2具备对象API接口和可序列化API接口。
不能序列化的对象可以使用除磁盘存储外Ehcache的所有功能。
除了元素的返回方法以外,API都是统一的。只有这两个方法不一致:getObjectValue和getKeyValue。这就使得缓存对象、序列化对象来获取新的特性这个过程很简单。
支持基于Cache和基于Element的过期策略,每个Cache的存活时间都是可以设置和控制的。
提供了LRU、LFU和FIFO缓存淘汰算法,Ehcache 1.2引入了最少使用和先进先出缓存淘汰算法,构成了完整的缓存淘汰算法。
提供内存和磁盘存储,Ehcache和大多数缓存解决方案一样,提供高性能的内存和磁盘存储。
动态、运行时缓存配置,存活时间、空闲时间、内存和磁盘存放缓存的最大数目都是可以在运行时修改的。
4、标准支持
Ehcache提供了对JSR107 JCACHE API最完整的实现。因为JCACHE在发布以前,Ehcache的实现(如net.sf.jsr107cache)已经发布了。
实现JCACHE API有利于到未来其他缓存解决方案的可移植性。
Ehcache的维护者Greg Luck,正是JSR107的专家委员会委员。
5、可扩展性
监听器可以插件化。Ehcache 1.2提供了CacheManagerEventListener和CacheEventListener接口,实现可以插件化,并且可以在ehcache.xml里配置。
节点发现,冗余器和监听器都可以插件化。
分布式缓存,从Ehcache 1.2开始引入,包含了一些权衡的选项。Ehcache的团队相信没有什么是万能的配置。
实现者可以使用内建的机制或者完全自己实现,因为有完整的插件开发指南。
缓存的可扩展性可以插件化。创建你自己的缓存扩展,它可以持有一个缓存的引用,并且绑定在缓存的生命周期内。
缓存加载器可以插件化。创建你自己的缓存加载器,可以使用一些异步方法来加载数据到缓存里面。
缓存异常处理器可以插件化。创建一个异常处理器,在异常发生的时候,可以执行某些特定操作。
6、应用持久化
在VM重启后,持久化到磁盘的存储可以复原数据。
Ehcache是第一个引入缓存数据持久化存储的开源Java缓存框架。缓存的数据可以在机器重启后从磁盘上重新获得。
根据需要将缓存刷到磁盘。将缓存条目刷到磁盘的操作可以通过cache.flush()方法来执行,这大大方便了Ehcache的使用。
7、监听器
缓存管理器监听器。允许注册实现了CacheManagerEventListener接口的监听器:
notifyCacheAdded()
notifyCacheRemoved()
缓存事件监听器。允许注册实现了CacheEventListener接口的监听器,它提供了许多对缓存事件发生后的处理机制:
notifyElementRemoved/Put/Updated/Expired
8、开启JMX
Ehcache的JMX功能是默认开启的,你可以监控和管理如下的MBean:
CacheManager、Cache、CacheConfiguration、CacheStatistics
9、分布式缓存
从Ehcache 1.2开始,支持高性能的分布式缓存,兼具灵活性和扩展性。
分布式缓存的选项包括:
通过Terracotta的缓存集群:设定和使用Terracotta模式的Ehcache缓存。缓存发现是自动完成的,并且有很多选项可以用来调试缓存行为和性能。
使用RMI、JGroups或者JMS来冗余缓存数据:节点可以通过多播或发现者手动配置。状态更新可以通过RMI连接来异步或者同步完成。
Custom:一个综合的插件机制,支持发现和复制的能力。
可用的缓存复制选项。支持的通过RMI、JGroups或JMS进行的异步或同步的缓存复制。
可靠的分发:使用TCP的内建分发机制。
节点发现:节点可以手动配置或者使用多播自动发现,并且可以自动添加和移除节点。对于多播阻塞的情况下,手动配置可以很好地控制。
分布式缓存可以任意时间加入或者离开集群。缓存可以配置在初始化的时候执行引导程序员。
BootstrapCacheLoaderFactory抽象工厂,实现了BootstrapCacheLoader接口(RMI实现)。
缓存服务端。Ehcache提供了一个Cache Server,一个war包,为绝大多数web容器或者是独立的服务器提供支持。
缓存服务端有两组API:面向资源的RESTful,还有就是SOAP。客户端没有实现语言的限制。
RESTful缓存服务器:Ehcached的实现严格遵循RESTful面向资源的架构风格。
SOAP缓存服务端:Ehcache RESTFul Web Services API暴露了单例的CacheManager,他能在ehcache.xml或者IoC容器里面配置。
标准服务端包含了内嵌的Glassfish web容器。它被打成了war包,可以任意部署到支持Servlet 2.5的web容器内。Glassfish V2/3、Tomcat 6和Jetty 6都已经经过了测试。
10、搜索
标准分布式搜索使用了流式查询接口的方式,请参阅文档。
11、Java EE和应用缓存
为普通缓存场景和模式提供高质量的实现。
阻塞缓存:它的机制避免了复制进程并发操作的问题。
SelfPopulatingCache在缓存一些开销昂贵操作时显得特别有用,它是一种针对读优化的缓存。它不需要调用者知道缓存元素怎样被返回,也支持在不阻塞读的情况下刷新缓存条目。
CachingFilter:一个抽象、可扩展的cache filter。
SimplePageCachingFilter:用于缓存基于request URI和Query String的页面。它可以根据HTTP request header的值来选择采用或者不采用gzip压缩方式将页面发到浏览器端。你可以用它来缓存整个Servlet页面,无论你采用的是JSP、 velocity,或者其他的页面渲染技术。
SimplePageFragmentCachingFilter:缓存页面片段,基于request URI和Query String。在JSP中使用jsp:include标签包含。
已经使用Orion和Tomcat测试过,兼容Servlet 2.3、Servlet 2.4规范。
Cacheable命令:这是一种老的命令行模式,支持异步行为、容错。
兼容Hibernate,兼容Google App Engine。
基于JTA的事务支持,支持事务资源管理,二阶段提交和回滚,以及本地事务。
12、开源协议
Apache 2.0 license 二、Ehcache的加载模块列表,他们都是独立的库,每个都为Ehcache添加新的功能,可以在此下载 : - ehcache-core:API,标准缓存引擎,RMI复制和Hibernate支持
- ehcache:分布式Ehcache,包括Ehcache的核心和Terracotta的库
- ehcache-monitor:企业级监控和管理
- ehcache-web:为Java Servlet Container提供缓存、gzip压缩支持的filters
- ehcache-jcache:JSR107 JCACHE的实现
- ehcache-jgroupsreplication:使用JGroup的复制
- ehcache-jmsreplication:使用JMS的复制
- ehcache-openjpa:OpenJPA插件
- ehcache-server:war内部署或者单独部署的RESTful cache server
- ehcache-unlockedreadsview:允许Terracotta cache的无锁读
- ehcache-debugger:记录RMI分布式调用事件
- Ehcache for Ruby:Jruby and Rails支持
Ehcache的结构设计概览: 
三、核心定义: cache manager:缓存管理器,以前是只允许单例的,不过现在也可以多实例了 cache:缓存管理器内可以放置若干cache,存放数据的实质,所有cache都实现了Ehcache接口 element:单条缓存数据的组成单位 system of record(SOR):可以取到真实数据的组件,可以是真正的业务逻辑、外部接口调用、存放真实数据的数据库等等,缓存就是从SOR中读取或者写入到SOR中去的。 代码示例: Java代码  - CacheManager manager = CacheManager.newInstance("src/config/ehcache.xml");
- manager.addCache("testCache");
- Cache test = singletonManager.getCache("testCache");
- test.put(new Element("key1", "value1"));
- manager.shutdown();
当然,也支持这种类似DSL的配置方式,配置都是可以在运行时动态修改的: Java代码 - Cache testCache = new Cache(
- new CacheConfiguration("testCache", maxElements)
- .memoryStoreEvictionPolicy(MemoryStoreEvictionPolicy.LFU)
- .overflowToDisk(true)
- .eternal(false)
- .timeToLiveSeconds(60)
- .timeToIdleSeconds(30)
- .diskPersistent(false)
- .diskExpiryThreadIntervalSeconds(0));
事务的例子: Java代码 - Ehcache cache = cacheManager.getEhcache("xaCache");
- transactionManager.begin();
- try {
- Element e = cache.get(key);
- Object result = complexService.doStuff(element.getValue());
- cache.put(new Element(key, result));
- complexService.doMoreStuff(result);
- transactionManager.commit();
- } catch (Exception e) {
- transactionManager.rollback();
- }
四、一致性模型: 说到一致性,数据库的一致性是怎样的?不妨先来回顾一下数据库的几个隔离级别: 未提交读(Read Uncommitted):在读数据时不会检查或使用任何锁。因此,在这种隔离级别中可能读取到没有提交的数据。会出现脏读、不可重复读、幻象读。
已提交读(Read Committed):只读取提交的数据并等待其他事务释放排他锁。读数据的共享锁在读操作完成后立即释放。已提交读是数据库的默认隔离级别。会出现不可重复读、幻象读。
可重复读(Repeatable Read):像已提交读级别那样读数据,但会保持共享锁直到事务结束。会出现幻象读。
可序列化(Serializable):工作方式类似于可重复读。但它不仅会锁定受影响的数据,还会锁定这个范围,这就阻止了新数据插入查询所涉及的范围。 基于以上,再来对比思考下面的一致性模型: 1、强一致性模型:系统中的某个数据被成功更新(事务成功返回)后,后续任何对该数据的读取操作都得到更新后的值。这是传统关系数据库提供的一致性模型,也是关系数据库深受人们喜爱的原因之一。强一致性模型下的性能消耗通常是最大的。 2、弱一致性模型:系统中的某个数据被更新后,后续对该数据的读取操作得到的不一定是更新后的值,这种情况下通常有个“不一致性时间窗口”存在:即数据更新完成后在经过这个时间窗口,后续读取操作就能够得到更新后的值。 3、最终一致性模型:属于弱一致性的一种,即某个数据被更新后,如果该数据后续没有被再次更新,那么最终所有的读取操作都会返回更新后的值。 最终一致性模型包含如下几个必要属性,都比较好理解: - 读写一致:某线程A,更新某条数据以后,后续的访问全部都能取得更新后的数据。
- 会话内一致:它本质上和上面那一条是一致的,某用户更改了数据,只要会话还存在,后续他取得的所有数据都必须是更改后的数据。
- 单调读一致:如果一个进程可以看到当前的值,那么后续的访问不能返回之前的值。
- 单调写一致:对同一进程内的写行为必须是保序的,否则,写完毕的结果就是不可预期的了。
4、Bulk Load:这种模型是基于批量加载数据到缓存里面的场景而优化的,没有引入锁和常规的淘汰算法这些降低性能的东西,它和最终一致性模型很像,但是有批量、高速写和弱一致性保证的机制。 这样几个API也会影响到一致性的结果: 1、显式锁(Explicit Locking ):如果我们本身就配置为强一致性,那么自然所有的缓存操作都具备事务性质。而如果我们配置成最终一致性时,再在外部使用显式锁API,也可以达到事务的效果。当然这样的锁可以控制得更细粒度,但是依然可能存在竞争和线程阻塞。 2、无锁可读取视图(UnlockedReadsView):一个允许脏读的decorator,它只能用在强一致性的配置下,它通过申请一个特殊的写锁来比完全的强一致性配置提升性能。 举例如下,xml配置为强一致性模型: Xml代码 - <cache name="myCache"
- maxElementsInMemory="500"
- eternal="false"
- overflowToDisk="false"
- <terracotta clustered="true" consistency="strong" />
- </cache>
但是使用UnlockedReadsView: Java代码 - Cache cache = cacheManager.getEhcache("myCache");
- UnlockedReadsView unlockedReadsView = new UnlockedReadsView(cache, "myUnlockedCache");
3、原子方法(Atomic methods):方法执行是原子化 的,即CAS操作(Compare and Swap)。CAS最终也实现了强一致性的效果,但不同的是,它是采用乐观锁而不是悲观锁来实现的。在乐观锁机制下,更新的操作可能不成功,因为在这过程 中可能会有其他线程对同一条数据进行变更,那么在失败后需要重新执行更新操作。现代的CPU都支持CAS原语了。 Java代码 - cache.putIfAbsent(Element element);
- cache.replace(Element oldOne, Element newOne);
- cache.remove(Element);
五、缓存拓扑类型: 1、独立缓存(Standalone Ehcache):这样的缓存应用节点都是独立的,互相不通信。 2、分布式缓存(Distributed Ehcache):数据存储在Terracotta的服务器阵列(Terracotta Server Array,TSA)中,但是最近使用的数据,可以存储在各个应用节点中。 逻辑视角: 
L1缓存就在各个应用节点上,而L2缓存则放在Cache Server阵列中。
组网视角:
 模型存储视角: 
L1级缓存是没有持久化存储的。另外,从缓存数据量上看,server端远大于应用节点。
3、复制式缓存(Replicated Ehcache):缓存数据时同时存放在多个应用节点的,数据复制和失效的事件以同步或者异步的形式在各个集群节点间传播。上述事件到来时,会阻塞写线程的操作。在这种模式下,只有弱一致性模型。 它有如下几种事件传播机制:RMI、JGroups、JMS和Cache Server。 RMI模式下,所有节点全部对等: 
JGroup模式:可以配置单播或者多播,协议栈和配置都非常灵活。 Xml代码 - <cacheManagerPeerProviderFactory
- class="net.sf.ehcache.distribution.jgroups.JGroupsCacheManagerPeerProviderFactory"
- properties="connect=UDP(mcast_addr=231.12.21.132;mcast_port=45566;):PING:
- MERGE2:FD_SOCK:VERIFY_SUSPECT:pbcast.NAKACK:UNICAST:pbcast.STABLE:FRAG:pbcast.GMS"
- propertySeparator="::"
- />
JMS模式:这种模式的核心就是一个消息队列,每个应用节点都订阅预先定义好的主题,同时,节点有元素更新时,也会发布更新元素到主题中去。JMS规范实现者上,Open MQ和Active MQ这两个,Ehcache的兼容性都已经测试过。 
Cache Server模式:这种模式下存在主从节点,通信可以通过RESTful的API或者SOAP。 
无论上面哪个模式,更新事件又可以分为updateViaCopy或updateViaInvalidate,后者只是发送一个过期消息,效率要高得多。 复制式缓存容易出现数据不一致的问题,如果这成为一个问题,可以考虑使用数据同步分发的机制。 即便不采用分布式缓存和复制式缓存,依然会出现一些不好的行为,比如: 缓存漂移(Cache Drift):每个应用节点只管理自己的缓存,在更新某个节点的时候,不会影响到其他的节点,这样数据之间可能就不同步了。这在web会话数据缓存中情况尤甚。 数据库瓶颈(Database Bottlenecks ):对于单实例的应用来说,缓存可以保护数据库的读风暴;但是,在集群的环境下,每一个应用节点都要定期保持数据最新,节点越多,要维持这样的情况对数据库的开销也越大。 六、存储方式: 1、堆内存储:速度快,但是容量有限。 2、堆外(OffHeapStore)存储:被称为 BigMemory,只在企业版本的Ehcache中提供,原理是利用nio的DirectByteBuffers实现,比存储到磁盘上快,而且完全不受 GC的影响,可以保证响应时间的稳定性;但是direct buffer的在分配上的开销要比heap buffer大,而且要求必须以字节数组方式存储,因此对象必须在存储过程中进行序列化,读取则进行反序列化操作,它的速度大约比堆内存储慢一个数量级。 (注:direct buffer不受GC影响,但是direct buffer归属的的JAVA对象是在堆上且能够被GC回收的,一旦它被回收,JVM将释放direct buffer的堆外空间。) 3、磁盘存储。 七、缓存使用模式: cache-aside:直接操作。先询问cache某条缓存数据是否存在,存在的话直接从cache中返回数据,绕过SOR;如果不存在,从SOR中取得数据,然后再放入cache中。 Java代码 - public V readSomeData(K key)
- {
- Element element;
- if ((element = cache.get(key)) != null) {
- return element.getValue();
- }
- if (value = readDataFromDataStore(key)) != null) {
- cache.put(new Element(key, value));
- }
- return value;
- }
cache-as-sor:结合了read-through、write-through或write-behind操作,通过给SOR增加了一层代理,对外部应用访问来说,它不用区别数据是从缓存中还是从SOR中取得的。 read-through。 write-through。 write-behind(write-back):既将写的过程变为异步的,又进一步延迟写入数据的过程。 Copy Cache的两个模式:CopyOnRead和CopyOnWrite。 CopyOnRead指的是在读缓存数据的请求到达时,如果发现数据已经过期,需要重新从源处获取,发起的copy element的操作(pull); CopyOnWrite则是发生在真实数据写入缓存时,发起的更新其他节点的copy element的操作(push)。 前者适合在不允许多个线程访问同一个element的时候使用,后者则允许你自由控制缓存更新通知的时机。 更多push和pull的变化和不同,也可参见这里。 八、多种配置方式: 包括配置文件、声明式配置、编程式配置,甚至通过指定构造器的参数来完成配置,配置设计的原则包括: 所有配置要放到一起 缓存的配置可以很容易在开发阶段、运行时修改 错误的配置能够在程序启动时发现,在运行时修改出错则需要抛出运行时异常 提供默认配置,几乎所有的配置都是可选的,都有默认值 九、自动资源控制(Automatic Resource Control,ARC): 它是提供了一种智能途径来控制缓存,调优性能。特性包括: 内存内缓存对象大小的控制,避免OOM出现 池化(cache manager级别)的缓存大小获取,避免单独计算缓存大小的消耗 灵活的独立基于层的大小计算能力,下图中可以看到,不同层的大小都是可以单独控制的 可以统计字节大小、缓存条目数和百分比 优化高命中数据的获取,以提升性能,参见下面对缓存数据在不同层之间的流转的介绍 
缓存数据的流转包括了这样几种行为: Flush:缓存条目向低层次移动。 Fault:从低层拷贝一个对象到高层。在获取缓存的过程中,某一层发现自己的该缓存条目已经失效,就触发了Fault行为。 Eviction:把缓存条目除去。 Expiration:失效状态。 Pinning:强制缓存条目保持在某一层。 下面的图反映了数据在各个层之间的流转,也反映了数据的生命周期: 
十、监控功能: 监控的拓扑: 
每个应用节点部署一个监控探针,通过TCP协议与监控服务器联系,最终将数据提供给富文本客户端或者监控操作服务器。
十一、广域网复制: 缓存数据复制方面,Ehcache允许两个地理位置各异的节点在广域网下维持数据一致性,同时它提供了这样几种方案(注:下面的示例都只绘制了两个节点的情形,实际可以推广到N个节点): 第一种方案:Terracotta Active/Mirror Replication。 
这种方案下,服务端包含一个活跃节点,一个备份节点;各个应用节点全部靠该活跃节点提供读写服务。这种方式最简单,管理容易;但是,需要寄希望于理想的网络状况,服务器之间和客户端到服务器之间都存在走WAN的情况,这样的方案其实最不稳定。
第二种方案:Transactional Cache Manager Replication。 
这 种方案下,数据读取不需要经过WAN,写入数据时写入两份,分别由两个cache manager处理,一份在本地Server,一份到其他Server去。这种方案下读的吞吐量较高而且延迟较低;但是需要引入一个XA事务管理器,两个 cache manager写两份数据导致写开销较大,而且过WAN的写延迟依然可能导致系统响应的瓶颈。
第三种方案:Messaging based (AMQ) replication。 
这 种方案下,引入了批量处理和队列,用以减缓WAN的瓶颈出现,同时,把处理读请求和复制逻辑从Server Array物理上就剥离开,避免了WAN情况恶化对节点读取业务的影响。这种方案要较高的吞吐量和较低的延迟,读/复制的分离保证了可以提供完备的消息分 发保证、冲突处理等特性;但是它较为复杂,而且还需要一个消息总线。
有一些Ehcache特性应用较少或者比较边缘化,没有提到,例如对于JMX的支持;还有一些则是有类似的特性和介绍了,例如对于WEB的支持,请参见我这篇关于OSCache的解读,其中的“web支持”一节有详细的原理分析。 最后,关于Ehcache的性能比对,下面这张图来自Ehcache的创始人Greg Luck的blog: 
put/get上Ehcache要500-1000倍快过Memcached。原因何在?他自己分析道:“In-process caching and asynchronous replication are a clear performance winner”。有关它详细的内容还是请参阅他的blog吧。
转自: http://raychase.iteye.com/blog/1545906
Windows 7,在使用 JGroups 的时候提示错误: java.lang.RuntimeException: the type of the stack (IPv6) and the user supplied addresses (IPv4) don't match: /xxx.xxx.xxx.xxx. 在操作系统中禁用 IPv6 是没用的,这个需要在 JVM 中禁用 IPv6 特性,加入以下参数即可: -Djava.net.preferIPv4Stack=true
摘要: Spring框架提供了构造Web应用程序的全能MVC模块。Spring MVC分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行制定。是一个标准的MVC框架。 那你猜一猜哪一部分应该是哪一部分? SpringMVC框架图 SpringMVC接口解释 DispatcherServlet接口: Spring提供的前端... 阅读全文
原文: http://www.cnblogs.com/web8cn/archive/2012/07/19/2598745.html
引子 “请写一个Singleton。”面试官微笑着和我说。 “这可真简单。”我心里想着,并在白板上写下了下面的Singleton实现: class Singleton {
public: static Singleton& Instance() {
static Singleton singleton;
return singleton;
}
private: Singleton() { };
}; “那请你讲解一下该实现的各组成。”面试官的脸上仍然带着微笑。 “首先要说的就是Singleton的构造函数。由于Singleton限制其类型实例有且只能有一个,因此我们应通过将构造函数设置为非公有 来保证其不会被用户代码随意创建。而在类型实例访问函数中,我们通过局部静态变量达到实例仅有一个的要求。另外,通过该静态变量,我们可以将该实例的创建 延迟到实例访问函数被调用时才执行,以提高程序的启动速度。” 保护 “说得不错,而且更可贵的是你能注意到对构造函数进行保护。毕竟中间件代码需要非常严谨才能防止用户代码的误用。那么,除了构造函数以外,我们还需要对哪些组成进行保护?” “还需要保护的有拷贝构造函数,析构函数以及赋值运算符。或许,我们还需要考虑取址运算符。这是因为编译器会在需要的时候为这些成员创建一个默认的实现。” “那你能详细说一下编译器会在什么情况下创建默认实现,以及创建这些默认实现的原因吗?”面试官继续问道。 “在这些成员没有被声明的情况下,编译器将使用一系列默认行为:对实例的构造就是分配一部分内存,而不对该部分内存做任何事情;对实例的拷贝也 仅仅是将原实例中的内存按位拷贝到新实例中;而赋值运算符也是对类型实例所拥有的各信息进行拷贝。而在某些情况下,这些默认行为不再满足条件,那么编译器 将尝试根据已有信息创建这些成员的默认实现。这些影响因素可以分为几种:类型所提供的相应成员,类型中的虚函数以及类型的虚基类。” “就以构造函数为例,如果当前类型的成员或基类提供了由用户定义的构造函数,那么仅进行内存拷贝可能已经不是正确的行为。这是因为该成员的构造 函数可能包含了成员初始化,成员函数调用等众多执行逻辑。此时编译器就需要为这个类型生成一个默认构造函数,以执行对成员或基类构造函数的调用。另外,如 果一个类型声明了一个虚函数,那么编译器仍需要生成一个构造函数,以初始化指向该虚函数表的指针。如果一个类型的各个派生类中拥有一个虚基类,那么编译器 同样需要生成构造函数,以初始化该虚基类的位置。这些情况同样需要在拷贝构造函数中考虑:如果一个类型的成员变量拥有一个拷贝构造函数,或者其基类拥有一 个拷贝构造函数,位拷贝就不再满足要求了,因为拷贝构造函数内可能执行了某些并不是位拷贝的逻辑。同时如果一个类型声明了虚函数,拷贝构造函数需要根据目 标类型初始化虚函数表指针。如基类实例经过拷贝后,其虚函数表指针不应指向派生类的虚函数表。同理,如果一个类型的各个派生类中拥有一个虚派生,那么编译 器也应为其生成拷贝构造函数,以正确设置各个虚基类的偏移。” “当然,析构函数的情况则略为简单一些:只需要调用其成员的析构函数以及基类的析构函数即可,而不需要再考虑对虚基类偏移的设置及虚函数表指针的设置。” “在这些默认实现中,类型实例的各个原生类型成员并没有得到初始化的机会。但是这一般被认为是软件开发人员的责任,而不是编译器的责任。”说完这些,我长出一口气,心里也暗自庆幸曾经研究过该部分内容。 “你刚才提到需要考虑保护取址运算符,是吗?我想知道。” “好的。首先要声明的是,几乎所有的人都会认为对取址运算符的重载是邪恶的。甚至说,boost为了防止该行为所产生的错误更是提供了 addressof()函数。而另一方面,我们需要讨论用户为什么要用取址运算符。Singleton所返回的常常是一个引用,对引用进行取址将得到相应 类型的指针。而从语法上来说,引用和指针的最大区别在于是否可以被delete关键字删除以及是否可以为NULL。但是Singleton返回一个引用也 就表示其生存期由非用户代码所管理。因此使用取址运算符获得指针后又用delete关键字删除Singleton所返回的实例明显是一个用户错误。综上所 述,通过将取址运算符设置为私有没有多少意义。” 重用 “好的,现在我们换个话题。如果我现在有几个类型都需要实现为Singleton,那我应怎样使用你所编写的这段代码呢?” 刚刚还在洋洋自得的我恍然大悟:这个Singleton实现是无法重用的。没办法,只好一边想一边说:“一般来说,较为流行的重用方法一共有三 种:组合、派生以及模板。首先可以想到的是,对Singleton的重用仅仅是对Instance()函数的重用,因此通过从Singleton派生以继 承该函数的实现是一个很好的选择。而Instance()函数如果能根据实际类型更改返回类型则更好了。因此奇异递归模板(CRTP,The Curiously Recurring Template Pattern)模式则是一个非常好的选择。”于是我在白板上飞快地写下了下面的代码: 1 template <typename T> 2 class Singleton 3 { 4 public: 5 static T& Instance() 6 { 7 static T s_Instance; 8 return s_Instance; 9 } 10 11 protected: 12 Singleton(void) {} 13 ~Singleton(void) {} 14 15 private: 16 Singleton(const Singleton& rhs) {} 17 Singleton& operator = (const Singleton& rhs) {} 18 }; 同时我也在白板上写下了对该Singleton实现进行重用的方法: 1 class SingletonInstance : public Singleton<SingletonInstance>… “在需要重用该Singleton实现时,我们仅仅需要从Singleton派生并将Singleton的泛型参数设置为该类型即可。” 生存期管理 “我看你在实现中使用了静态变量,那你是否能介绍一下上面Singleton实现中有关生存期的一些特征吗?毕竟生存期管理也是编程中的一个重要话题。”面试官提出了下一个问题。 “嗯,让我想一想。我认为对Singleton的生存期特性的讨论需要分为两个方面:Singleton内使用的静态变量的生存期以及 Singleton外在用户代码中所表现的生存期。Singleton内使用的静态变量是一个局部静态变量,因此只有在Singleton的 Instance()函数被调用时其才会被创建,从而拥有了延迟初始化(Lazy)的效果,提高了程序的启动性能。同时该实例将生存至程序执行完毕。而就 Singleton的用户代码而言,其生存期贯穿于整个程序生命周期,从程序启动开始直到程序执行完毕。当然,Singleton在生存期上的一个缺陷就 是创建和析构时的不确定性。由于Singleton实例会在Instance()函数被访问时被创建,因此在某处新添加的一处对Singleton的访问 将可能导致Singleton的生存期发生变化。如果其依赖于其它组成,如另一个Singleton,那么对它们的生存期进行管理将成为一个灾难。甚至可 以说,还不如不用Singleton,而使用明确的实例生存期管理。” “很好,你能提到程序初始化及关闭时单件的构造及析构顺序的不确定可能导致致命的错误这一情况。可以说,这是通过局部静态变量实现 Singleton的一个重要缺点。而对于你所提到的多个Singleton之间相互关联所导致的生存期管理问题,你是否有解决该问题的方法呢?” 我突然间意识到自己给自己出了一个难题:“有,我们可以将Singleton的实现更改为使用全局静态变量,并将这些全局静态变量在文件中按照特定顺序排序即可。” “但是这样的话,静态变量将使用eager initialization的方式完成初始化,可能会对性能影响较大。其实,我想听你说的是,对于具有关联的两个Singleton,对它们进行使用的 代码常常局限在同一区域内。该问题的一个解决方法常常是将对它们进行使用的管理逻辑实现为Singleton,而在内部逻辑中对它们进行明确的生存期管 理。但不用担心,因为这个答案也过于经验之谈。那么下一个问题,你既然提到了全局静态变量能解决这个问题,那是否可以讲解一下全局静态变量的生命周期是怎 样的呢?” “编译器会在程序的main()函数执行之前插入一段代码,用来初始化全局变量。当然,静态变量也包含在内。该过程被称为静态初始化。” “嗯,很好。使用全局静态变量实现Singleton的确会对性能造成一定影响。但是你是否注意到它也有一定的优点呢?” 见我许久没有回答,面试官主动帮我解了围:“是线程安全性。由于在静态初始化时用户代码还没有来得及执行,因此其常常处于单线程环境下,从而保 证了Singleton真的只有一个实例。当然,这并不是一个好的解决方法。所以,我们来谈谈Singleton的多线程实现吧。” 多线程 “首先请你写一个线程安全的Singleton实现。” 我拿起笔,在白板上写下早已烂熟于心的多线程安全实现: 1 template <typename T> 2 class Singleton 3 { 4 public: 5 static T& Instance() 6 { 7 if (m_pInstance == NULL) 8 { 9 Lock lock; 10 if (m_pInstance == NULL) 11 { 12 m_pInstance = new T(); 13 atexit(Destroy); 14 } 15 return *m_pInstance; 16 } 17 return *m_pInstance; 18 } 19 20 protected: 21 Singleton(void) {} 22 ~Singleton(void) {} 23 24 private: 25 Singleton(const Singleton& rhs) {} 26 Singleton& operator = (const Singleton& rhs) {} 27 28 void Destroy() 29 { 30 if (m_pInstance != NULL) 31 delete m_pInstance; 32 m_pInstance = NULL; 33 } 34 35 static T* volatile m_pInstance; 36 }; 37 38 template <typename T> 39 T* Singleton<T>::m_pInstance = NULL; “写得很精彩。那你是否能逐行讲解一下你写的这个Singleton实现呢?” “好的。首先,我使用了一个指针记录创建的Singleton实例,而不再是局部静态变量。这是因为局部静态变量可能在多线程环境下出现问题。” “我想插一句话,为什么局部静态变量会在多线程环境下出现问题?” “这是由局部静态变量的实际实现所决定的。为了能满足局部静态变量只被初始化一次的需求,很多编译器会通过一个全局的标志位记录该静态变量是否已经被初始化的信息。那么,对静态变量进行初始化的伪码就变成下面这个样子:”。 1 bool flag = false; 2 if (!flag) 3 { 4 flag = true; 5 staticVar = initStatic(); 6 } “那么在第一个线程执行完对flag的检查并进入if分支后,第二个线程将可能被启动,从而也进入if分支。这样,两个线程都将执行对静态变量 的初始化。因此在这里,我使用了指针,并在对指针进行赋值之前使用锁保证在同一时间内只能有一个线程对指针进行初始化。同时基于性能的考虑,我们需要在每 次访问实例之前检查指针是否已经经过初始化,以避免每次对Singleton的访问都需要请求对锁的控制权。” “同时,”我咽了口口水继续说,“因为new运算符的调用分为分配内存、调用构造函数以及为指针赋值三步,就像下面的构造函数调用:” 1 SingletonInstance pInstance = new SingletonInstance(); “这行代码会转化为以下形式:” 1 SingletonInstance pHeap = __new(sizeof(SingletonInstance)); 2 pHeap->SingletonInstance::SingletonInstance(); 3 SingletonInstance pInstance = pHeap; “这样转换是因为在C++标准中规定,如果内存分配失败,或者构造函数没有成功执行, new运算符所返回的将是空。一般情况下,编译器不会轻易调整这三步的执行顺序,但是在满足特定条件时,如构造函数不会抛出异常等,编译器可能出于优化的 目的将第一步和第三步合并为同一步:” 1 SingletonInstance pInstance = __new(sizeof(SingletonInstance)); 2 pInstance->SingletonInstance::SingletonInstance(); “这样就可能导致其中一个线程在完成了内存分配后就被切换到另一线程,而另一线程对Singleton的再次访问将由于pInstance已经 赋值而越过if分支,从而返回一个不完整的对象。因此,我在这个实现中为静态成员指针添加了volatile关键字。该关键字的实际意义是由其修饰的变量 可能会被意想不到地改变,因此每次对其所修饰的变量进行操作都需要从内存中取得它的实际值。它可以用来阻止编译器对指令顺序的调整。只是由于该关键字所提 供的禁止重排代码是假定在单线程环境下的,因此并不能禁止多线程环境下的指令重排。” “最后来说说我对atexit()关键字的使用。在通过new关键字创建类型实例的时候,我们同时通过atexit()函数注册了释放该实例的 函数,从而保证了这些实例能够在程序退出前正确地析构。该函数的特性也能保证后被创建的实例首先被析构。其实,对静态类型实例进行析构的过程与前面所提到 的在main()函数执行之前插入静态初始化逻辑相对应。” 引用还是指针 “既然你在实现中使用了指针,为什么仍然在Instance()函数中返回引用呢?”面试官又抛出了新的问题。 “这是因为Singleton返回的实例的生存期是由Singleton本身所决定的,而不是用户代码。我们知道,指针和引用在语法上的最大区 别就是指针可以为NULL,并可以通过delete运算符删除指针所指的实例,而引用则不可以。由该语法区别引申出的语义区别之一就是这些实例的生存期意 义:通过引用所返回的实例,生存期由非用户代码管理,而通过指针返回的实例,其可能在某个时间点没有被创建,或是可以被删除的。但是这两条 Singleton都不满足,因此在这里,我使用指针,而不是引用。” “指针和引用除了你提到的这些之外,还有其它的区别吗?” “有的。指针和引用的区别主要存在于几个方面。从低层次向高层次上来说,分为编译器实现上的,语法上的以及语义上的区别。就编译器的实现来说, 声明一个引用并没有为引用分配内存,而仅仅是为该变量赋予了一个别名。而声明一个指针则分配了内存。这种实现上的差异就导致了语法上的众多区别:对引用进 行更改将导致其原本指向的实例被赋值,而对指针进行更改将导致其指向另一个实例;引用将永远指向一个类型实例,从而导致其不能为NULL,并由于该限制而 导致了众多语法上的区别,如dynamic_cast对引用和指针在无法成功进行转化时的行为不一致。而就语义而言,前面所提到的生存期语义是一个区别, 同时一个返回引用的函数常常保证其返回结果有效。一般来说,语义区别的根源常常是语法上的区别,因此上面的语义区别仅仅是列举了一些例子,而真正语义上的 差别常常需要考虑它们的语境。” “你在前面说到了你的多线程内部实现使用了指针,而返回类型是引用。在编写过程中,你是否考虑了实例构造不成功的情况,如new运算符运行失败?” “是的。在和其它人进行讨论的过程中,大家对于这种问题有各自的理解。首先,对一个实例的构造将可能在两处抛出异常:new运算符的执行以及构 造函数抛出的异常。对于new运算符,我想说的是几点。对于某些操作系统,例如Windows,其常常使用虚拟地址,因此其运行常常不受物理内存实际大小 的限制。而对于构造函数中抛出的异常,我们有两种策略可以选择:在构造函数内对异常进行处理,以及在构造函数之外对异常进行处理。在构造函数内对异常进行 处理可以保证类型实例处于一个有效的状态,但一般不是我们想要的实例状态。这样一个实例会导致后面对它的使用更为繁琐,例如需要更多的处理逻辑或再次导致 程序执行异常。反过来,在构造函数之外对异常进行处理常常是更好的选择,因为软件开发人员可以根据产生异常时所构造的实例的状态将一定范围内的各个变量更 改为合法的状态。举例来说,我们在一个函数中尝试创建一对相互关联的类型实例,那么在一个实例的构造函数抛出了异常时,我们不应该在构造函数里对该实例的 状态进行维护,因为前一个实例的构造是按照后一个实例会正常创建来进行的。相对来说,放弃后一个实例,并将前一个实例删除是一个比较好的选择。” 我在白板上比划了一下,继续说到:“我们知道,异常有两个非常明显的缺陷:效率,以及对代码的污染。在太小的粒度中使用异常,就会导致异常使用次数的增加,对于效率以及代码的整洁型都是伤害。同样地,对拷贝构造函数等组成常常需要使用类似的原则。” “反过来说,Singleton的使用也可以保持着这种原则。Singleton仅仅是一个包装好的全局实例,对其的创建如果一旦不成功,在较高层次上保持正常状态同样是一个较好的选择。” Anti-Patten “既然你提到了Singleton仅仅是一个包装好的全局变量,那你能说说它和全局变量的相同与不同么?” “单件可以说是全局变量的替代品。其拥有全局变量的众多特点:全局可见且贯穿应用程序的整个生命周期。除此之外,单件模式还拥有一些全局变量所 不具有的性质:同一类型的对象实例只能有一个,同时适当的实现还拥有延迟初始化(Lazy)的功能,可以避免耗时的全局变量初始化所导致的启动速度不佳等 问题。要说明的是,Singleton的最主要目的并不是作为一个全局变量使用,而是保证类型实例有且仅有一个。它所具有的全局访问特性仅仅是它的一个副 作用。但正是这个副作用使它更类似于包装好的全局变量,从而允许各部分代码对其直接进行操作。软件开发人员需要通过仔细地阅读各部分对其进行操作的代码才 能了解其真正的使用方式,而不能通过接口得到组件依赖性等信息。如果Singleton记录了程序的运行状态,那么该状态将是一个全局状态。各个组件对其 进行操作的调用时序将变得十分重要,从而使各个组件之间存在着一种隐式的依赖。” “从语法上来讲,首先Singleton模式实际上将类型功能与类型实例个数限制的代码混合在了一起,违反了SRP。其次Singleton模式在Instance()函数中将创建一个确定的类型,从而禁止了通过多态提供另一种实现的可能。” “但是从系统的角度来讲,对Singleton的使用则是无法避免的:假设一个系统拥有成百上千个服务,那么对它们的传递将会成为系统的一个灾 难。从微软所提供的众多类库上来看,其常常提供一种方式获得服务的函数,如GetService()等。另外一个可以减轻Singleton模式所带来不 良影响的方法则是为Singleton模式提供无状态或状态关联很小的实现。” “也就是说,Singleton本身并不是一个非常差的模式,对其使用的关键在于何时使用它并正确的使用它。” 面试官抬起手腕看了看时间:“好了,时间已经到了。你的C++功底已经很好了。我相信,我们会在不久的将来成为同事。” 笔者注:这本是Writing Patterns Line by Line的一篇文章,但最后想想,写模式的人太多了,我还是省省吧。。。 下一篇回归WPF,环境刚好。可能中间穿插些别的内容,比如HTML5,JS,安全等等。 头一次写小品文,不知道效果是不是好。因为这种文章的特点是知识点分散,而且隐藏在文章的每一句话中。。。好处就是写起来轻松,呵呵。。。
错误
Server Tomcat v6.0 Server at localhost was unable to start within 45 seconds. If the server requires more time, try increasing the timeout in the server editor.
修改 workspace\.metadata\.plugins\org.eclipse.wst.server.core\servers.xml文件。
<servers>
<server hostname="localhost" id="JBoss v5.0 at localhost" name="JBoss v5.0 at
localhost" runtime-id="JBoss v5.0" server-type="org.eclipse.jst.server.generic.jboss5"
server-type-id="org.eclipse.jst.server.generic.jboss5" start-timeout="1000" stop-
timeout="15" timestamp="0">
<map jndiPort="1099" key="generic_server_instance_properties" port="8090"
serverAddress="127.0.0.1" serverConfig="default"/>
</server>
</servers>
把 start-timeout="45" 改为 start-timeout="1000" 或者更长
重启eclipse就可以了。
这个原因就是:启动tomcat需要的时间比45秒大了,Eclipse会判断tomcat在默认的时间是否启动了,如果在默认45秒没有启动就会报错了。
在看java performance的时候看到一些同步的名词,偏向锁、轻量级锁之类的,于是想先了解一下虚拟机中的锁机制,于是找到了这篇文章。发现是《深入理解Java虚拟机:JVM高级特性与最佳实践》一书的章节,讲得干脆好懂,差点就有要去买一本的冲动-----还是明天吧。以下是文章转载: ------------------------------------------------------------------------------------------------------------------------------------------------------------------
高效并发是JDK1.6的一个重要主题,HotSpot虚拟机开发团队在这个版本上花费了大量的精力去实现各种锁优化技术,如适应性自旋 (AdaptiveSpinning)、锁削除(Lock Elimination)、锁膨胀(Lock Coarsening)、轻量级锁(LightweightLocking)、偏向锁(BiasedLocking)等,这些技术都是为了在线程之间更高 效地共享数据,以及解决竞争问题,从而提高程序的执行效率。 13.3.1 自旋锁与自适应自旋 前面我们讨论互斥同步的时候,提到了互斥同步对性能最大的影响是阻塞的实现,挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给系统的并发 性能带来了很大的压力。同时,虚拟机的开发团队也注意到在许多应用上,共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和恢复线程并不值 得。如果物理机器有一个以上的处理器,能让两个或以上的线程同时并行执行,我们就可以让后面请求锁的那个线程“稍等一会”,但不放弃处理器的执行时间,看 看持有锁的线程是否很快就会释放锁。为了让线程等待,我们只须让线程执行一个忙循环(自旋),这项技术就是所谓的自旋锁。 自旋锁在JDK 1.4.2中就已经引入,只不过默认是关闭的,可以使用-XX:+UseSpinning参数来开启,在JDK1.6中就已经改为默认开启了。自旋等待不 能代替阻塞,且先不说对处理器数量的要求,自旋等待本身虽然避免了线程切换的开销,但它是要占用处理器时间的,所以如果锁被占用的时间很短,自旋等待的效 果就会非常好,反之如果锁被占用的时间很长,那么自旋的线程只会白白消耗处理器资源,而不会做任何有用的工作,反而会带来性能的浪费。因此自旋等待的时间 必须要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程了。自旋次数的默认值是10次,用户可以使用参数 -XX:PreBlockSpin来更改。 在JDK1.6中引入了自适应的自旋锁。自适应意味着自旋的时间不再固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同 一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而它将允许自旋等待持续相对更 长的时间,比如100个循环。另一方面,如果对于某个锁,自旋很少成功获得过,那在以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器资源。有了 自适应自旋,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测就会越来越准确,虚拟机就会变得越来越“聪明”了。 13.3.2 锁削除 锁削除是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行削除。锁削除的主要判定依据来源于逃逸分析 的数据支持(第11章已经讲解过逃逸分析技术),如果判断到一段代码中,在堆上的所有数据都不会逃逸出去被其他线程访问到,那就可以把它们当作栈上数据对 待,认为它们是线程私有的,同步加锁自然就无须进行。 也许读者会有疑问,变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是程序员自己应该是很清楚的,怎么会在明知道不存在数据争用的情况下要 求同步呢?答案是有许多同步措施并不是程序员自己加入的,同步的代码在Java程序中的普遍程度也许超过了大部分读者的想象。我们来看看下面代码清单 13-6中的例子,这段非常简单的代码仅仅是输出三个字符串相加的结果,无论是源码字面上还是程序语义上都没有同步。 代码清单 13-6 一段看起来没有同步的代码 Java代码   - public String concatString(String s1, String s2, String s3) {
- return s1 + s2 + s3;
- }
- public String concatString(String s1, String s2, String s3) {
- return s1 + s2 + s3;
- }
我们也知道,由于String是一个不可变的类,对字符串的连接操作总是通过生成新的String对象来进行的,因此Javac编译器会对String 连接做自动优化。在JDK 1.5之前,会转化为StringBuffer对象的连续append()操作,在JDK1.5及以后的版本中,会转化为StringBuilder对象 的连续append()操作。即代码清单13-6中的代码可能会变成代码清单13-7的样子 。 代码清单 13-7 Javac转化后的字符串连接操作 Java代码 - public String concatString(String s1, String s2, String s3) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- sb.append(s3);
- return sb.toString();
- }
- public String concatString(String s1, String s2, String s3) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- sb.append(s3);
- return sb.toString();
- }
现在大家还认为这段代码没有涉及同步吗?每个StringBuffer.append()方法中都有一个同步块,锁就是sb对象。虚拟机观察变量 sb,很快就会发现它的动态作用域被限制在concatString()方法内部。也就是sb的所有引用永远不会“逃逸”到concatString() 方法之外,其他线程无法访问到它,所以这里虽然有锁,但是可以被安全地削除掉,在即时编译之后,这段代码就会忽略掉所有的同步而直接执行了。 13.3.3 锁膨胀 原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制得尽量小——只在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待锁的线程也能尽快地拿到锁。 大部分情况下,上面的原则都是正确的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,甚至加锁操作是出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗。 上面代码清单13-7中连续的append()方法就属于这类情况。如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围 扩展(膨胀)到整个操作序列的外部,以代码清单13-7为例,就是扩展到第一个append()操作之前直至最后一个append()操作之后,这样只需 要加锁一次就可以了。 13.3.4 轻量级锁 轻量级锁是JDK1.6之中加入的新型锁机制,它名字中的“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的,因此传统的锁机制就被称为“重 量级”锁。首先需要强调一点的是,轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的 性能消耗。 要理解轻量级锁,以及后面会讲到的偏向锁的原理和运作过程,必须从HotSpot虚拟机的对象(对象头部分)的内存布局开始介绍。HotSpot虚拟 机的对象头(ObjectHeader)分为两部分信息,第一部分用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄 (Generational GCAge)等,这部分数据的长度在32位和64位的虚拟机中分别为32个和64个Bits,官方称它为“MarkWord”,它是实现轻量级锁和偏向锁 的关键。另外一部分用于存储指向方法区对象类型数据的指针,如果是数组对象的话,还会有一个额外的部分用于存储数组长度。 对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,MarkWord被设计成一个非固定的数据结构以便在极小的空间内存 储尽量多的信息,它会根据对象的状态复用自己的存储空间。例如在32位的HotSpot虚拟机中对象未被锁定的状态下,MarkWord的32个Bits 空间中的25Bits用于存储对象哈希码(HashCode),4Bits用于存储对象分代年龄,2Bits用于存储锁标志位,1Bit固定为0,在其他 状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如表13-1所示。 表13-1 HotSpot虚拟机对象头Mark Word | 存储内容 | 标志位 | 状态 | | 对象哈希码、对象分代年龄 | 01 | 未锁定 | | 指向锁记录的指针 | 00 | 轻量级锁定 | | 指向重量级锁的指针 | 10 | 膨胀(重量级锁定) | | 空,不需要记录信息 | 11 | GC标记 | | 偏向线程ID、偏向时间戳、对象分代年龄 | 01 | 可偏向 | 简单地介绍完了对象的内存布局,我们把话题返回到轻量级锁的执行过程上。在代码进入同步块的时候,如果此同步对象没有被锁定(锁标志位为“01”状 态),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的MarkWord的拷贝(官方把这份拷贝加了一个Displaced前缀,即Displaced MarkWord),这时候线程堆栈与对象头的状态如图13-3所示。  图13-3 轻量级锁CAS操作之前堆栈与对象的状态 图13-3 轻量级锁CAS操作之前堆栈与对象的状态 然后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向LockRecord的指针。如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位(MarkWord的最后两个Bits)将转变为“00”,即表示此对象处于轻量级锁定状态,这时候线程堆栈与对象头的状态如图 13-4所示。  图13-4 轻量级锁CAS操作之后堆栈与对象的状态 图13-4 轻量级锁CAS操作之后堆栈与对象的状态 ( 注2:图13-3和图13-4来源于HotSpot虚拟机的一位Senior Staff Engineer——Paul Hohensee所写的PPT《The Hotspot Java Virtual Machine》) 如果这个更新操作失败了,虚拟机首先会检查对象的MarkWord是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直 接进入同步块继续执行,否则说明这个锁对象已经被其他线程抢占了。如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁,锁标志的 状态值变为“10”,MarkWord中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。 上面描述的是轻量级锁的加锁过程,它的解锁过程也是通过CAS操作来进行的,如果对象的MarkWord仍然指向着线程的锁记录,那就用CAS操作把 对象当前的Mark Word和线程中复制的Displaced MarkWord替换回来,如果替换成功,整个同步过程就完成了。如果替换失败,说明有其他线程尝试过获取该锁,那就要在释放锁的同时,唤醒被挂起的线 程。 轻量级锁能提升程序同步性能的依据是“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用CAS 操作避免了使用互斥量的开销,但如果存在锁竞争,除了互斥量的开销外,还额外发生了CAS操作,因此在有竞争的情况下,轻量级锁会比传统的重量级锁更慢。 13.3.5 偏向锁 偏向锁也是JDK1.6中引入的一项锁优化,它的目的是消除数据在无竞争情况下的同步原语,进一步提高程序的运行性能。如果说轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量,那偏向锁就是在无竞争的情况下把整个同步都消除掉,连CAS操作都不做了。 偏向锁的“偏”,就是偏心的“偏”、偏袒的“偏”。它的意思是这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。 如果读者读懂了前面轻量级锁中关于对象头MarkWord与线程之间的操作过程,那偏向锁的原理理解起来就会很简单。假设当前虚拟机启用了偏向锁(启 用参数-XX:+UseBiasedLocking,这是JDK1.6的默认值),那么,当锁对象第一次被线程获取的时候,虚拟机将会把对象头中的标志位 设为“01”,即偏向模式。同时使用CAS操作把获取到这个锁的线程的ID记录在对象的MarkWord之中,如果CAS操作成功,持有偏向锁的线程以后 每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(例如Locking、Unlocking及对Mark Word的Update等)。 当有另外一个线程去尝试获取这个锁时,偏向模式就宣告结束。根据锁对象目前是否处于被锁定的状态,撤销偏向(RevokeBias)后恢复到未锁定 (标志位为“01”)或轻量级锁定(标志位为“00”)的状态,后续的同步操作就如上面介绍的轻量级锁那样执行。偏向锁、轻量级锁的状态转化及对象 Mark Word的关系如图13-5所示。  图13-5 偏向锁、轻量级锁的状态转化及对象Mark Word的关系 图13-5 偏向锁、轻量级锁的状态转化及对象Mark Word的关系 偏向锁可以提高带有同步但无竞争的程序性能。它同样是一个带有效益权衡(TradeOff)性质的优化,也就是说它并不一定总是对程序运行有 利,如果程序中大多数的锁都总是被多个不同的线程访问,那偏向模式就是多余的。在具体问题具体分析的前提下,有时候使用参数 -XX:-UseBiasedLocking来禁止偏向锁优化反而可以提升性能。
作者:icyfenix@gmail.com 来源: 《深入理解Java虚拟机:JVM高级特性与最佳实践》
比onload更快获取图片尺寸 文章更新:2011-05-31
lightbox类效果为了让图片居中显示而使用预加载,需要等待完全加载完毕才能显示,体验不佳(如filick相册的全屏效果)。javascript无法获取img文件头数据,真的是这样吗?本文通过一个巧妙的方法让javascript获取它。 这是大部分人使用预加载获取图片大小的例子: 01 | var imgLoad = function (url, callback) { |
02 | var img = new Image(); |
06 | callback(img.width, img.height); |
08 | img.onload = function () { |
09 | callback(img.width, img.height); |
可以看到上面必须等待图片加载完毕才能获取尺寸,其速度不敢恭维,我们需要改进。 web应用程序区别于桌面应用程序,响应速度才是最好的用户体验。如果想要速度与优雅兼得,那就必须提前获得图片尺寸,如何在图片没有加载完毕就能获取图片尺寸? 十多年的上网经验告诉我:浏览器在加载图片的时候你会看到图片会先占用一块地然后才慢慢加载完毕,并且不需要预设width与height属性,因 为浏览器能够获取图片的头部数据。基于此,只需要使用javascript定时侦测图片的尺寸状态便可得知图片尺寸就绪的状态。 当然实际中会有一些兼容陷阱,如width与height检测各个浏览器的不一致,还有webkit new Image()建立的图片会受以处在加载进程中同url图片影响,经过反复测试后的最佳处理方式: 02 | // 05.27: 1、保证回调执行顺序:error > ready > load;2、回调函数this指向img本身 |
03 | // 04-02: 1、增加图片完全加载后的回调 2、提高性能 |
06 | * 图片头数据加载就绪事件 - 更快获取图片尺寸 |
10 | * @param {String} 图片路径 |
11 | * @param {Function} 尺寸就绪 |
12 | * @param {Function} 加载完毕 (可选) |
13 | * @param {Function} 加载错误 (可选) |
15 | alert('size ready: width=' + this.width + '; height=' + this.height); |
18 | var imgReady = (function () { |
19 | var list = [], intervalId = null, |
24 | for (; i < list.length; i++) { |
25 | list[i].end ? list.splice(i--, 1) : list[i](); |
27 | !list.length && stop(); |
32 | clearInterval(intervalId); |
36 | return function (url, ready, load, error) { |
37 | var onready, width, height, newWidth, newHeight, |
45 | load && load.call(img); |
53 | img.onerror = function () { |
54 | error && error.call(img); |
56 | img = img.onload = img.onerror = null; |
60 | onready = function () { |
62 | newHeight = img.height; |
63 | if (newWidth !== width || newHeight !== height || |
64 | // 如果图片已经在其他地方加载可使用面积检测 |
65 | newWidth * newHeight > 1024 |
74 | img.onload = function () { |
75 | // onload在定时器时间差范围内可能比onready快 |
76 | // 这里进行检查并保证onready优先执行 |
77 | !onready.end && onready(); |
79 | load && load.call(img); |
81 | // IE gif动画会循环执行onload,置空onload即可 |
82 | img = img.onload = img.onerror = null; |
88 | // 无论何时只允许出现一个定时器,减少浏览器性能损耗 |
89 | if (intervalId === null) intervalId = setInterval(tick, 40); |
调用例子: 2 | alert('size ready: width=' + this.width + '; height=' + this.height); |
是不是很简单?这样的方式获取摄影级别照片尺寸的速度往往是onload方式的几十多倍,而对于web普通(800×600内)浏览级别的图片能达到秒杀效果。看了这个再回忆一下你见过的web相册,是否绝大部分都可以重构一下呢?好了,请观赏令人愉悦的 DEMO : http://www.planeart.cn/demo/imgReady/ (通过测试的浏览器:Chrome、Firefox、Safari、Opera、IE6、IE7、IE8) planeArt.cn原创文章,原文地址:http://www.planeart.cn/?p=1121 其他文章: 1、再谈IE6之Fixed定位
2、简易的全屏透明遮罩(lightBox)解决方案
http://www.cnblogs.com/lhb25/archive/2011/03/09/1964344.html 您可能还喜欢 对于Web设计和开发人员来说,CSS是非常重要的一部分,随着越来越多的浏览器对CSS3的支持及不断完善,设计师和开发者们有了更多的选 择。如今,用纯CSS就可以实现各种各样很酷的效果,甚至是动画。今天这篇文章向大家推荐24款非常优秀的CSS3工具,为了获得更佳的效果,请在 Chrome 4+, Safari 4+, Firefox 3.6+, IE9+, Opera 10.5+版本浏览器中浏览如下在线工具。 使用CSS3 Pie可以让IE6至IE8版本实现大多数的CSS3修饰特性,如圆角、阴影、渐变等等。 
非常好的CSS3效果演示,提供了示例代码。 
非常帅的一款CSS3工具,可修改代码,即时预览。 
一个非常不错的CSS3按钮制作工具。 
非常不错的CSS3代码生成器,带预览效果。 
非常不错的CSS3菜单制作工具。 
一款非常棒的CSS3渐变效果演示工具。 
一份不错的CSS3属性速查手册(PDF格式)。 
非常不错的CSS3选择器测试工具 
一款强大的CSS3旋转动画效果演示工具,即时生成代码。 
CSS3特性介绍及效果预览。 
一款非常不错的CSS3代码生成工具。 
CSS3颜色命名对照表。 
CSS3书签工具。 
一款在线CSS3圆角工具,四个角输入值就能生成对应的效果和代码。 
很炫的CSS3桌面。 
非常详尽的浏览器对CSS支持情况,包括CSS2.1和CSS3。 
让元素以键盘风格显示的样式表。 
一款在线CSS3圆角和阴影效果演示及代码生成工具。 
CSS3包装阴影效果。 
模仿内阴影效果,可输入内容查看效果,中文也可以噢。 
这工具名字太奇怪了,一款文本阴影效果工具,可即时生成代码。 
在线CSS3学习工具,可即时预览效果。 
最后压轴的这款工具非常强大,可在线演示渐变、阴影、旋转、动画等非常多的效果,并生成对应效果的代码,赶紧体验一下吧! 
您可能还喜欢 (编译来源:梦想天空 原文来自:Ultimate Collection of CSS3 Tools For Your Next Web Development)
工具提示(Tooltip)在网站中的一个小功能,但却有很重要的作用,常用于显示一些温馨的提示信息。如果网站中的工具提示功能做得非常有创意的话能够加深用户对网站印象。因此,今天这篇文章向大家推荐的20款优秀的 jQuery Tooltip 插件就是用于帮助你制作漂亮的工具提示效果。 
















您你可能还喜欢
jQuery的易扩展性吸引了来自全球的开发者来共同编写jQuery插件。jQuery插件不仅能够增强网站的可用性,有效地改善用户体验,还可以大大减少开发时间。现在的jQuery插件很多,可以根据您的项目需要来选择。这里为您介绍20款非常不错的插件。 Creative Radical Web Typography Lettering.js是一个轻量经的、易于使用的jQuery插件,可创造出极具个性的网页排版,是2010年最佳jQuery插件之一。 
演示 | 下载 New FancyMoves Jquery Product Slider Jquery Product Slider是一款效果很不错的产品幻灯片插件。 
演示 | 下载 Jquery Space Gallery Jquery Space Gallery是一款很有空间感的图片库插件。 
演示 | 下载 Fancy Thumbnail Hover Effect 这是一款非常不错的Hover效果插件。 
演示 | 下载 Jquery Inline Form Validation 这是一款表单验证插件。 
演示 | 下载 Site Switcher 这是一款站点切换插件。 
演示 | 下载 AnythingSlider 这是一款效果很棒的幻灯片插件。 
演示 | 下载 Jquery Tooltip Coda Bubble 这是一款简洁的jQuery信息提示插件。 
演示 | 下载 Jquery Upload and Crop Image 这是一款图片上传和裁剪插件。 
演示 | 下载 jQuery Carts 这是一款jQuery图表插件。 
演示 | 下载 Twitter-like login box 这是一款类似Twitter登陆框效果的插件。 
演示 | 下载 File Download 这是一款文件下载插件。 
演示 | 下载 Polaroid Photo Viewer 这是一款宝丽莱效果图片浏览插件。 
演示 | 下载 jquery Hover Sub Tag Cloud 这是一款子标签云显示插件。 
演示 | 下载 Graph Visualization 这是一款图标可视化插件。 
演示 | 下载 Show/Hide Jquery Panel 这是一款控制面板显示和隐藏的插件。 
演示 | 下载 Drop Down with CSS and jQuery 这是一款下拉菜单插件。 
演示 | 下载 Quick & Easy Zooming With jQuery – Zoomy 这是一款非常好用的缩放插件。 
演示 | 下载 Horizontal Accordions 这是一款横向手风琴效果插件。 
演示 | 下载 Flexible Rating 这是一款非常灵活的评分插件。 
演示 | 下载 (编译来源:梦想天空 原文来自:20 Useful jQuery Plugins Every Developer Should Know About)
流体布局(一) jQuery插件:jQuery.Waterfall.js, js的计算方法 jQuery1.4.4,IE8.0,opera,firefox,chrome测试通过 围观请点击:http://3vke.com 下载地址:Waterfall on github 1.使用方法: ①.加载jQuery库;
②.加载jQuery.Waterfull.js , 必须在jQuery库之后;
③.调用接口: $node.waterfull({/* 此处为设置选项, 可留空 */}) , 如: $('#container').waterfall({}) 2.设置选项: {
itemSelector:'.post-home', // 子元素id/class, 可留空
columnCount:4, // 列数, 纯数字, 可留空
columnWidth:300 // 列宽度, 纯数字, 可留空
isResizable: false, // 自适应浏览器宽度, 默认false
isAnimated: false, // 元素动画, 默认false
Duration: 500, // 动画时间
Easing: "swing", // 动画效果, 配合 jQuery Easing Plugin 使用
endFn: function(){} // 回调函数
} 3.Ajax说明: $.ajax({
url: Url,
beforeSend: function() {},
success: function(date) {
$('#container').append(date).waterfall({});
}
}) 流体布局(二) 固定宽度的流体布局的个人思路:参考文献:@qiqiboy javascript 图片预加载 思路如下: 1.imgReady可以在图片没有加载完成之前,通过头信息获取到图片的大小(这种方法相当天才),于是我建立一个局部的数组,将图片高度储存起来:(div的高度亦可) var argg= new Array()//例如有10篇文章,就是一个length=10的数组 2.通过浏览器的宽度,来判断一行可以放几张图(假定3张),再建立一个全局数组,保存数据: var args= new Array()//初始化数据,全部设定为0 args=[0,0,0]; 3.排序,用for循环,每一次通过比较argg[i]和args的最小值,来确定下一个div放置的位置,放完之后,把args的最小值重新赋值: 新版iphoto主题,采用如上方法布局,包含ajax后只有8Kb,相当廉价,新版首页观光地址:http://icold.me/photo 1.流体布局主题iPhoto新版首页观光地址:http://icold.me/photo 2.流体布局js计算方法以及js源代码下载:流体布局(三)
流体布局(三) 本文主要写固定宽度流体布局中的处理办法(全文以iphoto主题为例) 1.先看看Html结构
<div id="container">
<div class="post-home">xxoo..</div>
<div class="post-home">xxoo..</div>
<div class="post-home">xxoo..</div>
<div class="post-home">xxoo..</div>
<div class="post-home">xxoo..</div>
</div> #container宽度我设定为1050px, .post-home宽度设定为350px,具体的css就不写了(也就是3列) 2.js的算法 jQuery(document).ready(function($) {
var args = [0, 0, 0];
/*储存已排列的最后3个.post-home的top值, 初始时为[0,0,0];
没有储存left值, 因为left已经是知道的, [0,350,700];
*/
sort($('#container > .post-home'));
function sort(elem) { // elem是传入的DOM
var r, // setTimeout相关变量
m = 0,// 初始变量
n = elem.length,// .post-home的数量
topArgs = new Array(); // 建立一个局部数组
Array.prototype.min = function() {
/*返回数组中最小值的序号
0 ==>第一列(left = 0*350px)
1 ==>第二列(left = 1*350px)
2 ==>第三列(left = 2*350px)
*/
var e,d = 0,b = this[0],c = this.length;
for (e = 1; e < c; e++) {
if (this[e] < b) {b = this[e];d = e}
}
return d
};
Array.prototype.max = function() { // 返回数组中的最大值
var d, b = this[0],c = this.length;
for (d = 1; d < c; d++) {
if (this[d] > b) {b = this[d]}
}
return b
};
getHeight();
function getHeight() {
if (m < n) { // 用来判断是不是获取了所有的.post-home的高度
var $this = elem.eq(m), // 第m个.post-home
h = parseInt($this.height()) + 16; // 第m个.post-home高度 + 16, 16是与下一个div的距高
topArgs.push(h); // 把第m个.post-home高度, 放到数组中去
m++; // m累加
r = setTimeout(getHeight, 10) // setTimeout来循环函数, 直到m==n 获取所有的高度
}
if (m >= n) {
clearTimeout(r); // 清除循环
r = null;
var d, e = topArgs.length; //初始化数据
for (d = 0; d < e; d++) { // for循环来给topleft赋值
var minNum = args.min(), // 获得args的最小值的序号
newTop = args[minNum],// 获得args的最小值
$that = elem.eq(d); // 第d个.post-home
$that.css({ // for循环来给topleft赋值
position: "absolute",
top: newTop,
left: 350 * minNumber
});
args[minNum] = newTop + topArgs[d];
/*改变args数组最小值的大小
这样args[minNum]就不是最小了
而是这一列下一个.post-home的高度
如此循环,下一个args[minNum],就是第二列的下一个.post-home的高度
*/
}
$('#container').css({
height: args.max() //给$('#container')的高度赋值
});
}
}
}
});
3.最重要的问题 假如不能及时得到img的高度,将会错位,所以这里推荐再谈javascript图片预加载技术, 如果你嫌麻烦,可以用$(window).load(function(){})把上面的代码包括起来,$(window).load可以在图片加载完成之后执行内部的代码。 http://3vke.com/2012/03/09/%E6%B5%81%E4%BD%93%E5%B8%83%E5%B1%80%E6%8F%92%E4%BB%B6waterfall/
MySQL性能优化的21个最佳实践 今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显。关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我 们程序员需要去关注的事情。当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能。这里,我们不会讲过 多的SQL语句的优化,而只是针对MySQL这一Web应用最多的数据库。希望下面的这些优化技巧对你有用。 1. 为查询缓存优化你的查询 大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。 这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让MySQL不使用缓存。请看下面的示例: 
上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而 开启缓存。
2. EXPLAIN 你的 SELECT 查询 使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。 EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。 挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id索引,并且有表联接: 
当我们为 group_id 字段加上索引后: 
我们可以看到,前一个结果显示搜索了 7883 行,而后一个只是搜索了两个表的 9 和 16 行。查看rows列可以让我们找到潜在的性能问题。 3. 当只要一行数据时使用 LIMIT 1 当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。 在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。 下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1) 
4. 为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。 
从上图你可以看到那个搜索字串 “last_name LIKE ‘a%’”,一个是建了索引,一个是没有索引,性能差了4倍左右。 另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%’”,索引可能是没有意义的。你可能需要使用MySQL全文索引 或是自己做一个索引(比如说:搜索关键词或是Tag什么的) 5. 在Join表的时候使用相当类型的例,并将其索引 如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。 而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样) 
6. 千万不要 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。 如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得 不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序) 下面的示例是随机挑一条记录 
7. 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。 所以,你应该养成一个需要什么就取什么的好的习惯。 
8. 永远为每张表设置一个ID 我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。 就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。 而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区…… 在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比 如: 有一个“学生表”有学生的ID,有一个“课程表”有课程ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生ID和课程 ID叫“外键”其共同组成主键。 9. 使用 ENUM 而不是 VARCHAR ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。 如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。 MySQL也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个 VARCHAR 字段时,这个建议会告诉你把其改成 ENUM 类型。使用 PROCEDURE ANALYSE() 你可以得到相关的建议。 10. 从 PROCEDURE ANALYSE() 取得建议 PROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。 例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。 在phpmyadmin里,你可以在查看表时,点击 “Propose table structure” 来查看这些建议 
一定要注意,这些只是建议,只有当你的表里的数据越来越多时,这些建议才会变得准确。一定要记住,你才是最终做决定的人。 11. 尽可能的使用 NOT NULL 除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。 首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!) 不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。 12. Prepared Statements Prepared Statements很像存储过程,是一种运行在后台的SQL语句集合,我们可以从使用 prepared statements 获得很多好处,无论是性能问题还是安全问题。 Prepared Statements 可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL注入式”攻击。当然,你也可以手动地检查你的这些变量,然而,手动的检查容易出问题, 而且很经常会被程序员忘了。当我们使用一些framework或是ORM的时候,这样的问题会好一些。 在性能方面,当一个相同的查询被使用多次的时候,这会为你带来可观的性能优势。你可以给这些Prepared Statements定义一些参数,而MySQL只会解析一次。 虽然最新版本的MySQL在传输Prepared Statements是使用二进制形势,所以这会使得网络传输非常有效率。 当然,也有一些情况下,我们需要避免使用Prepared Statements,因为其不支持查询缓存。但据说版本5.1后支持了。 在PHP中要使用prepared statements,你可以查看其使用手册:mysqli 扩展 或是使用数据库抽象层,如: PDO. 
13. 无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个SQL语句的时候,你的程序会停在那里直到没这个SQL语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。 mysql_unbuffered_query() 发送一个SQL语句到MySQL而并不像mysql_query()一样去自动fethch和缓存结果。这会相当节约很多可观的内存,尤其是那些会产生大 量结果的查询语句,并且,你不需要等到所有的结果都返回,只需要第一行数据返回的时候,你就可以开始马上开始工作于查询结果了。 然而,这会有一些限制。因为你要么把所有行都读走,或是你要在进行下一次的查询前调用 mysql_free_result() 清除结果。而且, mysql_num_rows() 或 mysql_data_seek() 将无法使用。所以,是否使用无缓冲的查询你需要仔细考虑。 14. 把IP地址存成 UNSIGNED INT 很多程序员都会创建一个 VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当 你需要使用这样的WHERE条件:IP between ip1 and ip2。 我们必需要使用UNSIGNED INT,因为 IP地址会使用整个32位的无符号整形。 而你的查询,你可以使用 INET_ATON() 来把一个字符串IP转成一个整形,并使用 INET_NTOA() 把一个整形转成一个字符串IP。在PHP中,也有这样的函数 ip2long() 和 long2ip()。 
15. 固定长度的表会更快 如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。 固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。 并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。 使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。 16. 垂直分割 “垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有100多个字段,很恐怖) 示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改 写这 个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有 好的性能。 示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户 ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。 另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。 17. 拆分大的 DELETE 或 INSERT 语句 如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。 Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。 如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上掛了。 所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例: 
18. 越小的列会越快 对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。 参看 MySQL 的文档 Storage Requirements 查看所有的数据类型。 如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。 当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009年11月06日),一个简单的ALTER TABLE语句花了3个多小时,因为里面有一千六百万条数据。 19. 选择正确的存储引擎 在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。酷壳以前文章《MySQL: InnoDB 还是 MyISAM?》讨论和这个事情。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都 无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。 InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。 下面是MySQL的手册
target=”_blank”MyISAM Storage Engine InnoDB Storage Engine 20. 使用一个对象关系映射器(Object Relational Mapper) 使用 ORM (Object Relational Mapper),你能够获得可靠的性能增涨。一个ORM可以做的所有事情,也能被手动的编写出来。但是,这需要一个高级专家。 ORM 的最重要的是“Lazy Loading”,也就是说,只有在需要的去取值的时候才会去真正的去做。但你也需要小心这种机制的副作用,因为这很有可能会因为要去创建很多很多小的查询反而会降低性能。 ORM 还可以把你的SQL语句打包成一个事务,这会比单独执行他们快得多得多。 目前,个人最喜欢的PHP的ORM是:Doctrine。 21. 小心“永久链接” “永久链接”的目的是用来减少重新创建MySQL链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自 从我 们的Apache开始重用它的子进程后——也就是说,下一次的HTTP请求会重用Apache的子进程,并重用相同的 MySQL 链接。 PHP手册:mysql_pconnect() 在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存问题,文件句柄数,等等。 而且,Apache 运行在极端并行的环境中,会创建很多很多的了进程。这就是为什么这种“永久链接”的机制工作地不好的原因。在你决定要使用“永久链接”之前,你需要好好地考虑一下你的整个系统的架构。 转自: http://3vke.com/2012/05/14/mysql%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E7%9A%8421%E4%B8%AA%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5/
一、起始之语 我一直都是在PC上折腾网页的,这会儿怎么风向周边捣鼓起手机网页开发呢?原因是公司原先使用Java开发的产品,耗了不少人力财力,但是最后的效果却不怎么好。因为,Android系统一套东西,iPhone又是新的一套,折腾死人呐。 于是总监发狠,让我把手上的活都交出去,专心折腾web版的,看看最后效果如何。 加上我觊觎手机上的开发学习很久了,于是,一拍即合,搞起了手机开发方面的学习。 分享是很好的提高自身学习的方法。因为分享过程中梳理了所学,往往会有些意想不到的心得与收获。如此利人利已的事情,自然乐意为之。于是,自己在文 章id > 2000 的这一历史性时刻,新建了一个“mobile相关”的分类目录,把移动相关的一些东西总结,整理,分享出去,大家共勉。 二、我的选择 显然,当下手机web开发移不开CSS3 + HTML5以及JavaScript。目前,也应运而生了很多开发的框架,有胶水层的,也有显示层的(不罗列)。因为个人偏好以及筛选,决定使用PhoneGap实现与设备相机,通讯录等交互,jQuery Mobile实现页面UI的显示以及相关交互。 如果时间足够,我想我会针对项目本身重新搞个更轻便灵活的交互框架。考虑到现实情况,还是决定使用他人的UI框架。 下截图为今儿个上午(2011-11-1 11:11)跑通的第一个PhoneGap下的Android手机程序:
 不过PhoneGap是与胶水层打交道的东西,要说到这东西还需要些时日。我们可以先把目前投向与页面显示相关的UI框架上。例如,本文要说起的jQuery Mobile。 三、我眼中的jQuery Mobile 目前为止,jQuery Mobile的正式版还没有出来,但是这并不妨碍对其的使用。官方首页上说其代码轻量(lightweight code)。可能跟Sencha Touch相比确实轻量。但是,在我看来(本身为框架的原因),其实代码还是蛮啰嗦的(例如CSS文件min后有49K之多)。对于实际的项目而言,皮肤风格不可能几种并存的,所以,其a~e的五种模板选择实际有些多余,很多都是打酱油的命。 
而且,实际项目中的设计师设计东东的时候不可能是总是跟着jQuery Mobile的UI来的。因此,我们难免会碰到对其模板进行修改或是新添加的情况。 不过,我可以确信的是,如果在个人网站或是其他一些非对外的中小项目上使用jQuery Mobile的话,一定会爽歪的! 然后,还有一点我得承认。jQuery Mobile的上手可比Sencha Touch快多了。其UI显示基本上就是基于HTML5的data-自定义属性来的,跟它的老爸爸jQuery一样,确实是write less, do more. 页面元素的UI显示完全可以根据HTML代码内容和属性而来,不需要任何额外的JavaScript代码或是CSS代码,有模有样的手机页面效果就可以出炉。而且,要出效果页面,你只要静下心花个1整天的时间把官方的介绍文档看一篇就可以了。真这么简单。 例如下面这个纯显示的页面们(PC建议使用Chrome浏览器围观)。
您可以狠狠地点击这里:jQuery Mobile的UI展示页面 手机可以访问以下地址:http://www.zhangxinxu.com/jq/mobile/ 这是在桌面版opera 10.1 mobile下的显示效果:
默认进入:
 选择“文章搜索”项 → 点击搜索框后:
 如果是在Android系统或是iPhone上,渐变效果,平滑切换效果都会显露出来的。 上面加起来差不多有10多个HTML页面,捣鼓了几个小时就出来的,当然是在无敌模式下。为什么快呢?因为基本上没有动一点新的CSS代码或是JavaScript代码。直接write HTML即可。如果你对jQuery Mobile熟悉的话,可以更快。 语义化
要想使用jQuery Mobile,很重要的一点就是要注意语义化。到不是使用HTML5之类的标签(考虑到渐进增强,jQuery Mobile使用的还是XHTML时代的标签),而是div, p, ul ,li, h1~6等的使用。 在jQuery Mobile标签下,不同的标签所对应的UI效果很多都已经定死了。例如: <div data-role="header"> <h1>鑫空间-鑫生活</h1> <a href="#" data-icon="arrow-r" data-iconpos="right">中文</a> </div> 上面这段data-role为header的div中,h1标签不仅仅是个标题了,而是直接会修改当下页面的title值,因此,上面几行代码对应的页面的title就是“鑫空间-鑫生活”,即使你头部的title写的是“今天是小光棍节,呼啦啦~~”。 而后面的a标签文字虽然没有指定data-role="button",但是,谁叫他生在data-role="header"的div下呢,于是,它就是个显示按钮的命。而且,JMobile自动将其定位到右侧了。 语义化的标签决定了其位置,显示等。确实方便,但是有所限制。可谓有利有弊。 还有列表li标签中的第一个图片,会自动变成列表缩略图等,好多好多,你试一下就会发现这东西还是挺有意思的。 嘛,不过吗,不用急,冰冻三尺非一日之寒,什么东西都是慢慢积累的。才刚开始,说多了未必是好。所以,本文就唠叨这么多。 转自 张鑫旭-鑫空间-鑫生活[ http://www.zhangxinxu.com]
本系列意在记录Windwos线程的相关知识点,包括线程基础、线程调度、线程同步、TLS、线程池等 信号量内核对象 信号量内核对象用来进行资源计数,它包含一个使用计数、最大资源数、当前资源计数。最大资源数表示信号量可以控制的最大资源数量,当前资源数表示信号当前可用的资源数量。 设想一个场景:需要开发一个服务器进程,最多同时运行5个线程来响应客户端请求,应该设计一个“线程池”。最开始的时候,5个线程都应该在等待状 态,如果有一个客户端请求到来,那么唤醒其中的一个线程以处理客户端请求,如果同时的请求数量为5,那么5个线程将全部投入使用,再多的请求应该被放弃。 也就是说,随着客户端请求的增加,当前资源计数随之递减。 我们可能需要这样的一个内核对象来实现这个功能:初始化5个线程并同时等待一个内核对象触发,当一个客户端请求到来时,试图触发内核对象,这样5个 线程中随机一个被唤醒,并且自动使内核对象变为未触发。外部判断上限是否到达5。表面看来似乎用“自动重置的事件对象”即可实现这个功能啊,为什么要涉及 到信号量呢?因为信号量还可以控制一次唤醒多少个线程!!而且这个例子只是信号量的一个用途,后面我们会看到一个更实际的用途。 总结一下,信号量内核对象是这样的一种对象:它维护一个资源计数,当资源计数大于0,处于触发状态;资源计数等于0时,处于未触发状态;资源计数不可能小于0,也绝不可能大于资源计数上限。下图展示了这种内核对象的特点: 
如上图,只有资源计数>0时才是触发状态,资源=0时为未触发状态,而WaitForSingleObject成功将递减资源计数,调用ReleaseSemaphore将增加资源计数。 下面两个函数CreateSemaphore和CreateSemaphoreEx用于创建信号量对象: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | HANDLE WINAPI CreateSemaphore(
__in_opt LPSECURITY_ATTRIBUTES lpSemaphoreAttributes,//内核对象安全描述符
__in LONG lInitialCount,//资源计数的初始值
__in LONG lMaximumCount,//资源计数的最大值
__in_opt LPCTSTR lpName //内核对象命名
);
HANDLE WINAPI CreateSemaphoreEx(
__in_opt LPSECURITY_ATTRIBUTES lpSemaphoreAttributes,
__in LONG lInitialCount,
__in LONG lMaximumCount,
__in_opt LPCTSTR lpName,
__reserved DWORD dwFlags,
__in DWORD dwDesiredAccess
);
|
任何进程可以用OpenSemaphore来得到一个命名的信号量: 1 2 3 4 5 | HANDLE WINAPI OpenSemaphore(
__in DWORD dwDesiredAccess,
__in BOOL bInheritHandle,
__in LPCTSTR lpName
);
|
线程通过调用ReleaseSemaphore来递增资源计数,不一定每次只递增1,可以设置递增任意值。当将要超过资源上限值的时候,ReleaseSemaphore会返回FALSE。 1 2 3 4 5 | BOOL WINAPI ReleaseSemaphore(
__in HANDLE hSemaphore,
__in LONG lReleaseCount,//可以设置递增的值
__out_opt LPLONG lpPreviousCount//返回先前的资源计数
);
|
互斥量内核对象 互斥量(mutex)用来确保一个线程独占对一个资源的访问。互斥量包含一个使用计数、线程ID和一个递归计数,互斥量与关键段的行为几乎相同(因 为它记录了线程ID和递归计数,使得互斥量可以支持递归调用的情况)。互斥量的规则十分简单:如果线程ID为0(即没有线程独占它),那么它处于触发状 态,任何试图等待该对象的线程都将获得资源的独占访问;如果线程ID不为0,那么它处于未触发状态,任何试图等待该对象的线程都将等待。 可以使用CreateMutex或者CreateMutexEx创建互斥对象: 1 2 3 4 5 6 7 8 9 10 11 12 | HANDLE WINAPI CreateMutex(
__in_opt LPSECURITY_ATTRIBUTES lpMutexAttributes,
__in BOOL bInitialOwner,//初始化对象的状态,如果传入FALSE则会初始化为触发状态,如果传入TRUE,那么对象的线程ID会被设置成当前调用线程,并初始化为未触发
__in_opt LPCTSTR lpName
);
HANDLE WINAPI CreateMutexEx(
__in_opt LPSECURITY_ATTRIBUTES lpMutexAttributes,
__in_opt LPCTSTR lpName,
__in DWORD dwFlags,
__in DWORD dwDesiredAccess
);
|
一如既往,OpenMutex用于打开一个已经命名的互斥量内核对象: 1 2 3 4 5 | HANDLE WINAPI OpenMutex(
__in DWORD dwDesiredAccess,
__in BOOL bInheritHandle,
__in LPCTSTR lpName
);
|
线程在获得对独占资源的访问权限之后,可以正常执行相关的逻辑,当需要释放互斥对象的时候可以调用ReleaseMutex: 1 2 3 | BOOL WINAPI ReleaseMutex(
__in HANDLE hMutex
);
|
互斥量与其他内核对象不同,它会记录究竟是哪个线程占用了共享资源,结合递归计数,同一个线程可以在获得共享资源之后继续访问共享资源,这个行为就像关键段一样。然而互斥量和关键段从本质上是不同的,关键段是用户模式的线程同步方法,而互斥量是内核模式的线程同步方式。 介绍完这两个内核对象后,我们思考一下前面在【Windows】线程漫谈——线程同步之Slim读/写锁中 设计的一个场景:有一个共享的队列,2个服务端线程负责读取队列中的条目以处理,2个客户端线程负责写入队列中的条目以使服务先端线程处理,当队列中没有 条目的时候应当挂起服务端线程,直到有条目进入时才被唤醒,另一方面,当队列已满时,客户端线程应当挂起直到服务端至少处理了一个条目,以释放至少一个条 目的空间。 现在我们来用信号量和互斥量来实现同样的功能,下面的流程图分别是客户端写入线程和服务端读取线程的逻辑: 1.首先创建一个互斥量对象m_hmtxQ,并初始化为未触发状态;之后创建一个信号量对象,并设置最大资源计数为队列的长度,初始化资源计数为0,正好表征队列元素的个数。 1 2 | m_hmtxQ = CreateMutex(NULL,FALSE,NULL);
m_hsemNumElements = CreateSemaphore(NULL,0,nMaxElements,NULL);
|
2.设计客户端核心逻辑如下图: 
WatiForSingleObject:试图获得队列的独占访问权限,对于这个队列无论是读还是写都应该是线程独占的。因此,使用互斥量对象来同步; ReleaseSemaphore:试图增加一个资源计数,表征客户端想要向队列中增加一个元素,当然队列可能现在已经满了,对应的资源计数已达到 计数上限,此时ReleaseSemaphore会返回FALSE,这样客户端就不能像队列中插入元素。反之,如果ReleaseSemaphore返回 TRUE,表示队列没有满,客户端可以向队列中插入元素。 ReleaseMutex:无论客户端是否能够像队列中插入元素,在结束访问后,都应该释放互斥对象,以便其他线程能够进入临界资源。 3.设计服务端核心逻辑如下图: 
WatiForSingleObject:试图获得队列的独占访问权限,对于这个队列无论是读还是写都应该是线程独占的。因此,使用互斥量对象来同步; WaitForSingleObject(m_hsemNumElements…):试图检查信号量对象是否是触发状态。只有是触发状态的信号量对 象,线程才能进入;也就意味着:队列中只要有元素(资源>0,触发状态),服务端就能读取。反之,如果队列中没有元素(资源=0,未触发状态),服 务端将暂时不能访问队列,这时应该立即释放Mutex。 ReleaseMutex:无论客户端是否能够像队列中插入元素,在结束访问后,都应该释放互斥对象,以便其他线程能够进入临界资源。 原文:http://www.cnblogs.com/P_Chou/archive/2012/07/13/semaphore-and-mutex-in-thread-sync.html
摘要: 操作系统:WIN7数据库:oracle11g 64bit数据库客户端:32bit在网上找了很多解决方案,很多人说要将应用程序池改为启用32位应用程序。虽然能进入登录页面,但是在连接数据库时报错:尝试加载 Oracle 客户端库时引发 BadImageFormatException。如果在安装 32 位 Oracle 客户端组件的情况下以 64 位模式运行,将出现此问题。正确的解决方案:1.以管理员... 阅读全文
http://www.oschina.net/news/30791/opensource-projects-of-chinese?from=20120708 http://www.oschina.net/project/zh
http://www.oschina.net/news/30661/15-most-popular-jquery-plugins-of-june?from=20120708
Google 图片搜索功能 在谷歌图片搜索中, 用户可以上传一张图片, 谷歌显示因特网中与此图片相同或者相似的图片. 
比如我上传一张照片试试效果: 
原理讲解 参考Neal Krawetz博士的这篇文章, 实现这种功能的关键技术叫做"感知哈希算法"(Perceptual Hash Algorithm), 意思是为图片生成一个指纹(字符串格式), 两张图片的指纹越相似, 说明两张图片就越相似. 但关键是如何根据图片计算出"指纹"呢? 下面用最简单的步骤来说明一下原理: 第一步 缩小图片尺寸 将图片缩小到8x8的尺寸, 总共64个像素. 这一步的作用是去除各种图片尺寸和图片比例的差异, 只保留结构、明暗等基本信息.  第二步 转为灰度图片 将缩小后的图片, 转为64级灰度图片.  第三步 计算灰度平均值 计算图片中所有像素的灰度平均值 第四步 比较像素的灰度 将每个像素的灰度与平均值进行比较, 如果大于或等于平均值记为1, 小于平均值记为0. 第五步 计算哈希值 将上一步的比较结果, 组合在一起, 就构成了一个64位的二进制整数, 这就是这张图片的指纹. 第六步 对比图片指纹 得到图片的指纹后, 就可以对比不同的图片的指纹, 计算出64位中有多少位是不一样的. 如果不相同的数据位数不超过5, 就说明两张图片很相似, 如果大于10, 说明它们是两张不同的图片. 代码实现 (C#版本) 下面我用C#代码根据上一节所阐述的步骤实现一下. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 | using System;
using System.IO;
using System.Drawing;
namespace SimilarPhoto
{
class SimilarPhoto
{
Image SourceImg;
public SimilarPhoto(string filePath)
{
SourceImg = Image.FromFile(filePath);
}
public SimilarPhoto(Stream stream)
{
SourceImg = Image.FromStream(stream);
}
public String GetHash()
{
Image image = ReduceSize();
Byte[] grayValues = ReduceColor(image);
Byte average = CalcAverage(grayValues);
String reslut = ComputeBits(grayValues, average);
return reslut;
}
// Step 1 : Reduce size to 8*8
private Image ReduceSize(int width = 8, int height = 8)
{
Image image = SourceImg.GetThumbnailImage(width, height, () => { return false; }, IntPtr.Zero);
return image;
}
// Step 2 : Reduce Color
private Byte[] ReduceColor(Image image)
{
Bitmap bitMap = new Bitmap(image);
Byte[] grayValues = new Byte[image.Width * image.Height];
for(int x = 0; x<image.Width; x++)
for (int y = 0; y < image.Height; y++)
{
Color color = bitMap.GetPixel(x, y);
byte grayValue = (byte)((color.R * 30 + color.G * 59 + color.B * 11) / 100);
grayValues[x * image.Width + y] = grayValue;
}
return grayValues;
}
// Step 3 : Average the colors
private Byte CalcAverage(byte[] values)
{
int sum = 0;
for (int i = 0; i < values.Length; i++)
sum += (int)values[i];
return Convert.ToByte(sum / values.Length);
}
// Step 4 : Compute the bits
private String ComputeBits(byte[] values, byte averageValue)
{
char[] result = new char[values.Length];
for (int i = 0; i < values.Length; i++)
{
if (values[i] < averageValue)
result[i] = '0';
else
result[i] = '1';
}
return new String(result);
}
// Compare hash
public static Int32 CalcSimilarDegree(string a, string b)
{
if (a.Length != b.Length)
throw new ArgumentException();
int count = 0;
for (int i = 0; i < a.Length; i++)
{
if (a[i] != b[i])
count++;
}
return count;
}
}
}
|
谷歌服务器里的图片数量是百亿级别的, 我电脑里的图片数量当然没法比, 但以前做过爬虫程序, 电脑里有40,000多人的头像照片, 就拿它们作为对比结果吧! 我计算出这些图片的"指纹", 放在一个txt文本中, 格式如下. 
用ASP.NET写一个简单的页面, 允许用户上传一张图片, 后台计算出该图片的指纹, 并与txt文本中各图片的指纹对比, 整理出结果显示在页面中, 效果如下: 
本文地址: http://www.cnblogs.com/technology/archive/2012/07/12/Perceptual-Hash-Algorithm.html 原文:http://www.cnblogs.com/technology/archive/2012/07/12/Perceptual-Hash-Algorithm.html
Flyweight定义:
避免大量拥有相同内容的小类的开销(如耗费内存),使大家共享一个类(元类). 为什么使用?
面向对象语言的 原则就是一切都是对象,但是如果真正使用起来,有时对象数可能显得很庞大,比如,字处理软件,如果以每个文字都作为一个对象,几千个字,对象数就是几千, 无疑耗费内存,那么我们还是要"求同存异",找出这些对象群的共同点,设计一个元类,封装可以被共享的类,另外,还有一些特性是取决于应用 (context),是不可共享的,这也Flyweight中两个重要概念内部状态intrinsic和外部状态extrinsic之分. 说白点,就是先捏一个的原始模型,然后随着不同场合和环境,再产生各具特征的具体模型,很显然,在这里需要 产生不同的新对象,所以Flyweight模式中常出现Factory模式.Flyweight的内部状态是用来共享的,Flyweight factory负责维护一个Flyweight pool(模式池)来存放内部状态的对象. Flyweight模式是一个提高程序效率和性能的模式,会大大加快程序的运行速度.应用场合很多:比如你要从一个数据库中读取一系列字符串,这些字符串中有许多是重复的,那么我们可以将这些字符串储存在Flyweight池(pool)中. 如何使用? 我们先从Flyweight抽象接口开始: | public interface Flyweight
{
public void operation( ExtrinsicState state );
} //用于本模式的抽象数据类型(自行设计)
public interface ExtrinsicState { } | 下面是接口的具体实现(ConcreteFlyweight) ,并为内部状态增加内存空间, ConcreteFlyweight必须是可共享的,它保存的任何状态都必须是内部(intrinsic),也就是说,ConcreteFlyweight必须和它的应用环境场合无关. | public class ConcreteFlyweight implements Flyweight {
private IntrinsicState state;
public void operation( ExtrinsicState state )
{
//具体操作
} } | 当然,并不是所有的Flyweight具体实现子类都需要被共享的,所以还有另外一种不共享的ConcreteFlyweight: | public class UnsharedConcreteFlyweight implements Flyweight { public void operation( ExtrinsicState state ) { } } | Flyweight factory负责维护一个Flyweight池(存放内部状态),当客户端请求一个共享Flyweight时,这个factory首先搜索池中是否已经 有可适用的,如果有,factory只是简单返回送出这个对象,否则,创建一个新的对象,加入到池中,再返回送出这个对象.池 | public class FlyweightFactory {
//Flyweight pool
private Hashtable flyweights = new Hashtable();
public Flyweight getFlyweight( Object key ) { Flyweight flyweight = (Flyweight) flyweights.get(key); if( flyweight == null ) {
//产生新的ConcreteFlyweight
flyweight = new ConcreteFlyweight();
flyweights.put( key, flyweight );
} return flyweight;
}
} | 至此,Flyweight模式的基本框架已经就绪,我们看看如何调用: FlyweightFactory factory = new FlyweightFactory();
Flyweight fly1 = factory.getFlyweight( "Fred" );
Flyweight fly2 = factory.getFlyweight( "Wilma" );
...... 从调用上看,好象是个纯粹的Factory使用,但奥妙就在于Factory的内部设计上. Flyweight模式在XML等数据源中应用
我们上面已经提到,当大量从数据源中读取字符串,其中肯定有重复的,那么我们使用Flyweight模式可以提高效率,以唱片CD为例,在一个XML文件中,存放了多个CD的资料. 每个CD有三个字段:
1.出片日期(year)
2.歌唱者姓名等信息(artist)
3.唱片曲目 (title) 其中,歌唱者姓名有可能重复,也就是说,可能有同一个演唱者的多个不同时期 不同曲目的CD.我们将"歌唱者姓名"作为可共享的ConcreteFlyweight.其他两个字段作为UnsharedConcreteFlyweight. 首先看看数据源XML文件的内容: |
<?xml version="1.0"?>
<collection>
<cd>
<title>Another Green World</title>
<year>1978</year>
<artist>Eno, Brian</artist>
</cd> <cd>
<title>Greatest Hits</title>
<year>1950</year>
<artist>Holiday, Billie</artist>
</cd> <cd>
<title>Taking Tiger Mountain (by strategy)</title>
<year>1977</year>
<artist>Eno, Brian</artist>
</cd> ....... </collection> |
虽然上面举例CD只有3张,CD可看成是大量重复的小类,因为其中成分只有三个字段,而且有重复的(歌唱者姓名).
CD就是类似上面接口 Flyweight: |
public class CD {
private String title;
private int year;
private Artist artist;
public String getTitle() { return title; }
public int getYear() { return year; }
public Artist getArtist() { return artist; }
public void setTitle(String t){ title = t;}
public void setYear(int y){year = y;}
public void setArtist(Artist a){artist = a;}
} | 将"歌唱者姓名"作为可共享的ConcreteFlyweight: | public class Artist { //内部状态
private String name; // note that Artist is immutable.
String getName(){return name;} Artist(String n){
name = n;
}
} | 再看看Flyweight factory,专门用来制造上面的可共享的ConcreteFlyweight:Artist | public class ArtistFactory { Hashtable pool = new Hashtable();
Artist getArtist(String key){ Artist result;
result = (Artist)pool.get(key);
////产生新的Artist
if(result == null) {
result = new Artist(key);
pool.put(key,result);
}
return result;
}
} | 当你有几千张甚至更多CD时,Flyweight模式将节省更多空间,共享的flyweight越多,空间节省也就越大.
摘要: =============C#.Net 篇目录============== 一、程序集的加载 程序集是 .NET Framework 应用程序的构造块;程序集构成了部署、版本控制、重复使用、激活范围控制和安全权限的基本单元。 绑定是查找与唯一指定的类型相对应的声明(即实现)的过程。根据此过程是发生在编译时还是运行时分为: a) ... 阅读全文
1. 概述 将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化; 对请求排队或记录请求日志,以及支持可撤销的操作。 2. 解决的问题 在软件系统中,行为请求者与行为实现者通常是一种紧耦合的关系,但某些场合,比如需要对行为进行记录、撤销或重做、事务等处理时,这种无法抵御变化的紧耦合的设计就不太合适。 3. 模式中角色 3.1 抽象命令(Command):定义命令的接口,声明执行的方法。 3.2 具体命令(ConcreteCommand):具体命令,实现要执行的方法,它通常是“虚”的实现;通常会有接收者,并调用接收者的功能来完成命令要执行的操作。 3.3 接收者(Receiver):真正执行命令的对象。任何类都可能成为一个接收者,只要能实现命令要求实现的相应功能。 3.4 调用者(Invoker):要求命令对象执行请求,通常会持有命令对象,可以持有很多的命令对象。这个是客户端真正触发命令并要求命令执行相应操作的地方,也就是说相当于使用命令对象的入口。 3.5 客户端(Client):命令由客户端来创建,并设置命令的接收者。 4. 模式解读 4.1 命令模式的类图  4.2 命令模式的实现代码 /// <summary>
/// 接收者类,知道如何实施与执行一个请求相关的操作,任何类都可能作为一个接收者。
/// </summary>
public class Receiver
{
/// <summary>
/// 真正的命令实现
/// </summary>
public void Action()
{
Console.WriteLine("Execute request!");
}
}
/// <summary>
/// 抽象命令类,用来声明执行操作的接口
/// </summary>
public interface ICommand
{
void Execute();
}
/// <summary>
/// 具体命令类,实现具体命令。
/// </summary>
public class ConcereteCommand : ICommand
{
// 具体命令类包含有一个接收者,将这个接收者对象绑定于一个动作
private Receiver receiver;
public ConcereteCommand(Receiver receiver)
{
this.receiver = receiver;
}
/// <summary>
/// 说这个实现是“虚”的,因为它是通过调用接收者相应的操作来实现Execute的
/// </summary>
public void Execute()
{
receiver.Action();
}
}
/// <summary>
/// 调度类,要求该命令执行这个请求
/// </summary>
public class Invoker
{
private ICommand command;
/// <summary>
/// 设置命令
/// </summary>
/// <param name="command"></param>
public void SetCommand(ICommand command)
{
this.command = command;
}
/// <summary>
/// 执行命令
/// </summary>
public void ExecuteCommand()
{
command.Execute();
}
} 4.3 客户端代码 class Program
{
static void Main(string[] args)
{
Receiver receiver = new Receiver();
ICommand command = new ConcereteCommand(receiver);
Invoker invoker = new Invoker();
invoker.SetCommand(command);
invoker.ExecuteCommand();
Console.Read();
}
} 执行结果  4.4 模式分析 4.4.1 本质:对命令进行封装,将发出命令与执行命令的责任分开。 4.4.2 每一个命令都是一个操作:请求的一方发出请求,要求执行一个操作;接收的一方收到请求,并执行操作。 4.4.3 请求方和接收方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求是怎么被接收,以及操作是否被执行、何时被执行,以及是怎么被执行的。 4.4.4 使请求本身成为一个对象,这个对象和其它对象一样可以被存储和传递。 4.4.5 命令模式的关键在于引入了抽象命令接口,且发送者针对抽象命令接口编程,只有实现了抽象命令接口的具体命令才能与接收者相关联。 5. 模式总结 5.1 优点 5.1.1 解除了请求者与实现者之间的耦合,降低了系统的耦合度。 5.1.2 对请求排队或记录请求日志,支持撤销操作。 5.1.3 可以容易地设计一个组合命令。 5.1.4 新命令可以容易地加入到系统中。 5.2 缺点 5.2.1 因为针对每一个命令都需要设计一个具体命令类,使用命令模式可能会导致系统有过多的具体命令类。 5.3 适用场景 5.3.1 当需要对行为进行“记录、撤销/重做”等处理时。 5.3.2 系统需要将请求者和接收者解耦,使得调用者和接收者不直接交互。 5.3.3 系统需要在不同时间指定请求、请求排队和执行请求。 5.3.4 系统需要将一组操作组合在一起,即支持宏命令。 6. 应用举例:银行帐号的存款、提款 6.1 类图  6.2 代码实现 /// <summary>
/// 银行帐号
/// </summary>
public class Account
{
/// <summary>
/// 帐号总金额
/// </summary>
private decimal totalAmount { get; set; }
/// <summary>
/// 存钱
/// </summary>
/// <param name="amount"></param>
public void MoneyIn(decimal amount)
{
this.totalAmount += amount;
}
/// <summary>
/// 取钱
/// </summary>
/// <param name="amount"></param>
public void MoneyOut(decimal amount)
{
this.totalAmount -= amount;
}
public decimal GetTotalAmout()
{
return totalAmount;
}
}
public abstract class Command
{
protected Account account;
public Command(Account account)
{
this.account = account;
}
public abstract void Execute();
}
/// <summary>
/// 存款命令
/// </summary>
public class MoneyInCommand : Command
{
private decimal amount;
public MoneyInCommand(Account account, decimal amount)
: base(account)
{
this.amount = amount;
}
/// <summary>
/// 实现存钱命令
/// </summary>
public override void Execute()
{
account.MoneyIn(amount);
}
}
/// <summary>
/// 取款命令类
/// </summary>
public class MoneyOutCommand : Command
{
private decimal amount;
public MoneyOutCommand(Account account, decimal amount)
: base(account)
{
this.amount = amount;
}
/// <summary>
/// 实现取钱命令
/// </summary>
public override void Execute()
{
account.MoneyOut(amount);
}
}
public class Invoker
{
private Command command;
public void SetCommand(Command command)
{
this.command = command;
}
public void ExecuteCommand()
{
command.Execute();
}
} 6.3 客户端代码 class Program
{
static void Main(string[] args)
{
// 创建银行帐号
Account account = new Account();
// 创建一个存入500元的命令
Command commandIn = new MoneyInCommand(account,500);
// 创建一个调度者
BankAccount.Invoker invoker = new BankAccount.Invoker();
// 设置存钱命令
invoker.SetCommand(commandIn);
// 执行
invoker.ExecuteCommand();
Console.WriteLine("The current amount is " + account.GetTotalAmout().ToString("N2"));
// 再次存入500
Command commandIn2 = new MoneyInCommand(account, 500);
invoker.SetCommand(commandIn2);
invoker.ExecuteCommand();
Console.WriteLine("The current amount is " + account.GetTotalAmout().ToString("N2"));
// 取出300
Command commandOut = new MoneyOutCommand(account, 300);
invoker.SetCommand(commandOut);
invoker.ExecuteCommand();
Console.WriteLine("The current amount is " + account.GetTotalAmout().ToString("N2"));
Console.Read();
}
} 执行结果  转自: http://www.cnblogs.com/wangjq/archive/2012/07/11/2585930.html
需求场景: 1. 页面内有多级iframe嵌套。 2. iframe内部某些按钮点击后需要弹出浮层。 3. 浮层需要将整个浏览器窗口遮罩,且浮层位于浏览窗口中部。 效果如下: 
解决思路: - 顶层页面内预留用于显示浮层的div(命名为popdiv),且该div内有一预留的iframe,该iframe用于加载浮层内容,命名为popiframe
- 提供可以直接访问浮层内容的url连接
- iframe触发显示浮层事件时,通过window.top 设置顶层窗口的popiframe.src。
- 通过计算浮层内容的长宽及当前窗口的长宽设置popdiv的位置,使其在窗口中央显示。
实现: 顶层页面相关html代码: | <div id="mask" style="display:none;"></div> <div id="id_popdiv" style="display:none;" class="popup"> <iframe id="id_popiframe" src="" frameborder="0" scrolling="no" width="100%" height="100%"> </iframe> </div> | iframe有点击按钮的html代码 | <script type="text/javascript" src="js/popmanager.js"></script> <a href="javascript:pop('popcontenturl',782,600);" class="link" rel="1">show pop content</a><br /> | popcontenturl 页面中的关闭的主要代码: | <script type="text/javascript" src="js/showhide.js" charset="utf-8"></script> <div class="pop_container"> <a href="javascript:unpop();" title="关闭" class="close"></a> <h2 class="title">浮层标题</h2> <div class="pop_content"> 浮层内容 … </div> </div> | 主要js代码(popmanager.js) | function getWindowScrollTop(win){ var scrollTop=0; if(win.document.documentElement&&win.document.documentElement.scrollTop){ scrollTop=win.document.documentElement.scrollTop; }else if(win.document.body){ scrollTop=win.document.body.scrollTop; } return scrollTop; } function setWindowScrollTop(win, topHeight) { if(win.document.documentElement) { win.document.documentElement.scrollTop = topHeight; } if(win.document.body){ win.document.body.scrollTop = topHeight; } } function getWindowScrollLeft(win){ var scrollLeft=0; if(win.document.documentElement&&win.document.documentElement.scrollLeft){ scrollLeft=win.document.documentElement.scrollLeft; } else if(win.document.body){ scrollLeft=win.document.body.scrollLeft; } return scrollLeft; } function getWindowHeight(win){ var clientHeight=0; if(win.document.body.clientHeight&&win.document.documentElement.clientHeight){ clientHeight = (win.document.body.clientHeight<win.document.documentElement.clientHeight)? win.document.body.clientHeight:win.document.documentElement.clientHeight; }else{ clientHeight = (win.document.body.clientHeight>win.document.documentElement.clientHeight)? win.document.body.clientHeight:win.document.documentElement.clientHeight; } return clientHeight; } function getWindowWidth(win){ var clientWidth=0; if(win.document.body.clientWidth&&win.document.documentElement.clientWidth){ clientWidth = (win.document.body.clientWidth<win.document.documentElement.clientWidth)? win.document.body.clientWidth:win.document.documentElement.clientWidth; }else{ clientWidth = (win.document.body.clientWidth>win.document.documentElement.clientWidth)? win.document.body.clientWidth:win.document.documentElement.clientWidth; } return clientWidth; } function unpop() { try{ var win = (top && top!=self)?top:window; } catch(e) { return ; } win.document.getElementById('mask').style.display = "none"; win.document.getElementById("id_popdiv").style.display = "none"; win.document.getElementById("id_iframe_pop").setAttribute('src', ''); } function pop(url,width,height) { try{ var win = (top && top!=self)?top:window; } catch(e) { return ; } var topWindowHeight = getWindowHeight(win); var topWindowWidth = getWindowWidth(win); var lvTop=parseInt((topWindowHeight-height)/2)+parseInt(getWindowScrollTop(win)); var lvLeft=parseInt((topWindowWidth-width)/2)+parseInt(getWindowScrollLeft(win)); lvTop = lvTop<=0?1:lvTop; lvLeft = lvLeft<=0?1:lvLeft; win.document.getElementById("id_popdiv").style.top=lvTop+"px"; win.document.getElementById("id_popdiv").style.left=lvLeft+"px"; win.document.getElementById("id_popdiv").style.margin="0"; win.document.getElementById("id_iframe_pop").setAttribute('src', url); win.document.getElementById("id_iframe_pop").setAttribute('width', width); win.document.getElementById("id_iframe_pop").setAttribute('height', height); win.document.getElementById('mask').style.display = "block"; win.document.getElementById("id_popdiv").style.display = "block"; } | 附: 应用较多的div浮层技术为基于jquery的blockUI技术。详情请参考相关文档。 转自: http://www.cnblogs.com/zhanghairong/archive/2012/07/11/2586050.html
软件测试要求开发人员避免测试自己开发的程序。从心理学角度讲,这是很有道理的。特别是一个相对复杂的系统,开发人员在刚刚开发完成的时候,尚沉浸于对自己设计的回味之中。此时去测试的话往往会侧重于程序本身的功能通过性测试。很难发现错误。
测试是为发现错误而执行程序的错误。一个人发现别人身上的不足很容易,但发现自己身上的错误便不那么容易了。所谓“吾能指人之失而不能见己之失,吾能指 人之小失而不能见己之大失”者是也。一个软件开发人员需要养成一种习惯,正视自己开发的软件,特别是刚刚完成的软件。要看到它的不足,知道他能做什么,不 能做什么。在不能做的时候是如何处理的。对边界条件是否做了严格的判断及约束。其实大道相通,有没有这样的意识往往跟一个人为人处世的心态,对自己的认知 有密切的联系。一个追求完美,经常反思自己的人往往有一种虚怀若谷的情怀,“战战兢兢、如履薄冰、如临深渊”者是也。所谓的方法、套路仅仅是方便于那些不 怎么思考,只会人云亦云、亦步亦趋的人设计的。
说了一些心态方面的,再来从方法学上说一下软件测试的要点,对开发人员来说,白盒测试要比黑盒测试更重要,这决定着你的系统上线后你能不能安心的睡觉; 测试的阶段主要在单元测试与集成测试方面。 先看一张测试相关的图: 
按照测试的过程,分为单元测试、集成测试、系统测试、验收测试四点。对于开发人员来说,我只强调前面两点。
单元测试主要测试编写的类、类中的函数等。这是测试的最小单元。常用的测试工具有java的JUnit、BoostTest等。
集成测试侧重于系统的整体功能性测试,这需要模拟各种可能的请求情况,特别是边界条件。在多系统中,单个系统的测试完了后还需要各个系统之间的联调。
测试目标方面,除了一般的功能测试之外还需要稳定性测试、性能测试、可靠性测试、适用性测试、易用性测试、安全性测试。
下面详细介绍一下各个测试要点的测试内容。
1. 功能性测试: 在软件测试领域的通用理解是:“功能测试是基于产品功能说明书,是在已知产品所应具有的功能,从用户角度来进行功能验证,以确认每个功能是否都能正常使 用、是否实现了产品规格说明书的要求、是否能适当地接收输入数锯而产生正确的输出结果等。功能测试,包括用户界面测试、各种操作的测试、不同的数据输入、 逻辑思路、数据输出和存储等的测试。” 对于开发人员来说,功能性测试主要是对系统所支持的功能点的测试,对数据的测试,包括数据边界的测试、数据包长度限制的测试、各个功能模块数据的正确性测 试以及容错处理。该项测试要先把系统的功能点全部列出来,对异常数据的处理也算在内。
2. 稳定性测试: 测试在压力情况下内存使用情况,cpu使用情况,是否有内存泄露,各个模块功能是否正常,能否正常提供服务,是否会在高压情况下卡死等。这也需要用各种可 能数据进行压力测试,要测试边界条件下,收到攻击时还能否正常工作,系统有没有自清理功能等。个人的理解,该项测试类似于可靠性测试,要点在于测试系统在 极端情况下是否正常。比如一个房子在高强度地震下的抗震能力。
3. 性能测试: 测试程序(一般是服务器),每秒能正常处理的请求数。这项测试一般是寻找系统的性能瓶颈,看看能否满足实际的需求。当下,一个服务器每天处理5000万的请求便可以了。当然,通过优化对性能的追求是没有止境的。
4. 安全性测试: 安全性测试的主要目的是 确保软件不会去完成没有预先设计的功能。这一点很重要,需要开发人员在开发时对可能出现的情况作细致的判断。常见的安全性测试内容有:畸形的文件结构、畸 形的数据包、用户输入的验证、验证资源之间的依赖关系、配置文件等的格式等。因为开发人员常常假定他所获取的资源内容是符合一定标准或规则的。附录十常见 的web安全性测试的内容。
5. 适用性测试: 在软件测试领域的通用理解是“适用性主要是用户体验的评估活动”。个人理解,对于开发人员,这方面主要跟易用性测试联系起来,开发软件产品是为了更方便的 为人服务,一个系统要尽可能的简单,尽可能减少人工的操作。比如,在配置文件方面,有配置是为了减少代码的改动性,但是配置要尽可能的简单,可以由一个配 置项解决的问题不要再添加另外一项配置。 附: WEB安全性测试 一个完整的WEB安全性测试可以从部署与基础结构、输入验证、身份验证、授权、配置管理、敏感数据、会话管理、加密。参数操作、异常管理、审核和日志记录等几个方面入手。1. 安全体系测试1) 部署与基础结构l 网络是否提供了安全的通信l 部署拓扑结构是否包括内部的防火墙l 部署拓扑结构中是否包括远程应用程序服务器l 基础结构安全性需求的限制是什么l 目标环境支持怎样的信任级别2) 输入验证l 如何验证输入A. 是否清楚入口点B. 是否清楚信任边界C. 是否验证Web页输入D. 是否对传递到组件或Web服务的参数进行验证E. 是否验证从数据库中检索的数据F. 是否将方法集中起来G. 是否依赖客户端的验证H. 应用程序是否易受SQL注入攻击I. 应用程序是否易受XSS攻击l 如何处理输入3) 身份验证l 是否区分公共访问和受限访问l 是否明确服务帐户要求l 如何验证调用者身份l 如何验证数据库的身份l 是否强制试用帐户管理措施4) 授权l 如何向最终用户授权l 如何在数据库中授权应用程序l 如何将访问限定于系统级资源5) 配置管理l 是否支持远程管理l 是否保证配置存储的安全l 是否隔离管理员特权6) 敏感数据l 是否存储机密信息l 如何存储敏感数据l 是否在网络中传递敏感数据l 是否记录敏感数据7) 会话管理l 如何交换会话标识符l 是否限制会话生存期l 如何确保会话存储状态的安全8) 加密l 为何使用特定的算法l 如何确保加密密钥的安全性9) 参数操作l 是否验证所有的输入参数l 是否在参数过程中传递敏感数据l 是否为了安全问题而使用HTTP头数据10) 异常管理l 是否使用结构化的异常处理l 是否向客户端公开了太多的信息11) 审核和日志记录l 是否明确了要审核的活动l 是否考虑如何流动原始调用这身份2. 应用及传输安全WEB应用系统的安全性从使用角度可以分为应用级的安全与传输级的安全,安全性测试也可以从这两方面入手。应用级的安全测试的主要目的是查找Web系统自身程序设计中存在的安全隐患,主要测试区域如下。l 注册与登陆:现在的Web应用系统基本采用先注册,后登录的方式。A. 必须测试有效和无效的用户名和密码B. 要注意是否存在大小写敏感,C. 可以尝试多少次的限制D. 是否可以不登录而直接浏览某个页面等。l 在线超时:Web应用系统是否有超时的限制,也就是说,用户登陆一定时间内(例如15分钟)没有点击任何页面,是否需要重新登陆才能正常使用。l 操作留痕:为了保证Web应用系统的安全性,日志文件是至关重要的。需要测试相关信息是否写进入了日志文件,是否可追踪。l 备份与恢复:为了防范系统的意外崩溃造成的数据丢失,备份与恢复手段是一个Web系统的必备功能。备份与恢复根据Web系统对安全性的要求可以采用多种手 段,如数据库增量备份、数据库完全备份、系统完全备份等。出于更高的安全性要求,某些实时系统经常会采用双机热备或多级热备。除了对于这些备份与恢复方式 进行验证测试以外,还要评估这种备份与恢复方式是否满足Web系统的安全性需求。传输级的安全测试是考虑到Web系统的传输的特殊性,重点测试数据经客户端传送到服务器端可能存在的安全漏洞,以及服务器防范非法访问的能力。一般测试项目包括以下几个方面。l HTTPS和SSL测试:默认的情况下,安全HTTP(Soure HTTP)通过安全套接字SSL(Source Socket Layer)协议在端口443上使用普通的HTTP。HTTPS使用的公共密钥的加密长度决定的HTTPS的安全级别,但从某种意义上来说,安全性的保证 是以损失性能为代价的。除了还要测试加密是否正确,检查信息的完整性和确认HTTPS的安全级别外,还要注意在此安全级别下,其性能是否达到要求。l 服务器端的脚本漏洞检查:存在于服务器端的脚本常常构成安全漏洞,这些漏洞又往往被黑客利用。所以,还要测试没有经过授权,就不能在服务器端放置和编辑脚本的问题。l 防火墙测试:防火墙是一种主要用于防护非法访问的路由器,在Web系统中是很常用的一种安全系统。防火墙测试是一个很大很专业的课题。这里所涉及的只是对防火墙功能、设置进行测试,以判断本Web系统的安全需求。转自: http://hi.baidu.com/yelangdefendou/blog/item/a4ce5c472d8b632b8794738c.html
最近在给客户做项目的时候客户提出要求要给图片加水印, 在添加文字水印时,让用户自定义自体,当用户在选择字体时,如果勾选了删除线和下划线选项,而java.awt.Font不支持下划线和删除线的style, 这怎么办呢? 
还好,Java提供了 AttributedString 类, 通过 attributedString.addAttribute(TextAttribute.STRIKETHROUGH, TextAttribute.STRIKETHROUGH_ON); attributedString.addAttribute(TextAttribute.UNDERLINE, TextAttribute.UNDERLINE_ON); 即可给文字添加删除线和下划线,再通过 graphics2D.drawString(as.getIterator(), x, y); 就可以显示下划线和删除线的效果了。 
- import java.awt.Font;
- import java.awt.Graphics;
- import java.awt.Graphics2D;
- import java.awt.RenderingHints;
- import java.awt.font.TextAttribute;
- import java.text.AttributedString;
-
- import javax.swing.JFrame;
- import javax.swing.JPanel;
-
- public class IteratorUnderStrike extends JPanel{
- public void paint(Graphics g) {
- Graphics2D g2 = (Graphics2D) g;
-
- String s = "/"www.java2s.com/" is great.";
-
- g2.setRenderingHint(RenderingHints.KEY_ANTIALIASING,
- RenderingHints.VALUE_ANTIALIAS_ON);
- Font plainFont = new Font("Times New Roman", Font.PLAIN, 24);
-
- AttributedString as = new AttributedString(s);
- as.addAttribute(TextAttribute.FONT, plainFont);
- as.addAttribute(TextAttribute.UNDERLINE, TextAttribute.UNDERLINE_ON, 1, 15);
- as.addAttribute(TextAttribute.STRIKETHROUGH, TextAttribute.STRIKETHROUGH_ON, 18, 25);
-
- g2.drawString(as.getIterator(), 24, 70);
- }
-
- public static void main(String[] args) {
- JFrame f = new JFrame();
- f.getContentPane().add(new IteratorUnderStrike());
- f.setSize(850, 250);
- f.show();
- }
- }
http://yanghuidang.iteye.com/blog/1203582
图形上下文导论(Introduction to SWT Graphics) 摘要: org.eclipse.swt.graphics包(package),包含了管理图形资源的类。只要实现了org.eclipse.swt.graphics.Drawable接口,就可在上面绘画,包括 org.eclipse.swt.widgets.Control 和 org.eclipse.swt.graphics.Image 。 org.eclipse.swt.graphics.GC封装了全部绘画API,包括如何绘制线条、图形、如何绘制文本、图像以及填充图形。 本篇将展示如何使用GC在图像上绘画, 控件的绘画事件(paintEvent)回调。画布(Canvas)控件,因为不同的绘画操作,拥有很多构造风格常量允许你指定何时以及如何产生绘画,本篇也将展示这些东西。 英文原文:Graphics Context - Quick on the draw http://www.eclipse.org/articles/Article-SWT-graphics/SWT_graphics.html 作者: Joe Winchester, IBM 2003年7月3日(July 3, 2003) 2007.5.30 Copyright 2003 International Business Machines Corp. 目录: SWT图形系统使用了与控件(Control)相同的坐标习惯,即客户区最左上角开始的点为原点(0,0),x轴坐标向右增加,y轴坐标向下增加。Point 类被用于描述位置(坐标系统中的位置)以及偏移量(SWT中并没有Dimension类,矩形(rectangle)的大小是由Point类捕获的x、y坐标点偏移量到原点坐标来描述的)。 " src="/CuteSoft_Client/CuteEditor/Images/anchor.gif">图形上下文(Graphics Context) 图形能够被画在任何实现了org.eclipse.swt.graphics.Drawable接口的东西上,比如控件(Control)、图像(Image)、显示设备或者打印设备。 org.eclipse.swt.graphics.GC 就是封装了执行绘画操作的图形上下文(graphics context)。一般有两种使用GC的方法:一种是让Drawable 实例作为GC构造函数的参数获取的GC,另外一种是绘画事件(paintEvent)回调提供的GC。 在图像(Image)上绘画 以下代码是把一个图像作为构造参数获取图像的GC,然后在它上面绘制线条。  从左上角顶点(0,0)处向右下角顶点画线条 从左上角顶点(0,0)处向右下角顶点画线条  从右上角顶点向左下角顶点画线条。 从右上角顶点向左下角顶点画线条。 Image image = new Image(display,"C:/devEclipse_02/eclipse/plugins/org.eclipse.platform_2.0.2/eclipse_lg.gif");
GC gc = new GC(image);
Rectangle bounds = image.getBounds();
 gc.drawLine(0,0,bounds.width,bounds.height); gc.drawLine(0,0,bounds.width,bounds.height);
 gc.drawLine(0,bounds.height,bounds.width,0); gc.drawLine(0,bounds.height,bounds.width,0);
 gc.dispose(); gc.dispose();
image.dispose();
| 原始图像 | 绘制线条后的图像 |  |  |  由你创建的GC,就得由你负责销毁它。调用 dispose()方法。关于怎样管理 SWT 资源的更多信息请参见 SWT: The Standard Widget Toolkit 。一个 GC 实例应该在使用完后就尽可能快的释放,这是因为每一个GC 都需要占用底层系统平台资源,而在某些操作系统平台中,这些资源是相当匮乏的,例如Windows 98仅仅提供了5个GC 对象。 由你创建的GC,就得由你负责销毁它。调用 dispose()方法。关于怎样管理 SWT 资源的更多信息请参见 SWT: The Standard Widget Toolkit 。一个 GC 实例应该在使用完后就尽可能快的释放,这是因为每一个GC 都需要占用底层系统平台资源,而在某些操作系统平台中,这些资源是相当匮乏的,例如Windows 98仅仅提供了5个GC 对象。 在控件(Control)上绘画 org.eclipse.swt.widgets.Control 实现了Drawable接口,所以你可以在控件(Control)上绘画,图像(Image)上绘画方法与控件相同(把控件或图像作为参数传给GC获取控件或图像的GC,然后在其上进行绘画)。但是,图像(Image)上的绘画与控件有所不同是图像的修改是永恒不变的。如果使用GC在控件上进行绘画,操作系统自身在绘制控件时会覆盖你所做的绘画操作。正确的方法的是为控件添加一个绘画监听器,这个监听器类就是org.eclipse.swt.events.PaintListener,然后在监听器中回调方法参数就是org.eclipse.swt.events.PaintEvent的一个实例。PaintEvent 包含了一GC,这样在控件上面或者是指定区域里面进行绘画的环境就准备好了 以下代码  给Shell添加了一个绘画监听, 给Shell添加了一个绘画监听, 然后在paintControl()方法中画一条连接原点到底部右下角的直线。 然后在paintControl()方法中画一条连接原点到底部右下角的直线。 Shell shell = new Shell(display);
 shell.addPaintListener(new PaintListener(){ shell.addPaintListener(new PaintListener(){
public void paintControl(PaintEvent e){
Rectangle clientArea = shell.getClientArea();
 e.gc.drawLine(0,0,clientArea.width,clientArea.height); e.gc.drawLine(0,0,clientArea.width,clientArea.height);
}
});
shell.setSize(150,150)  虽然Shell的大小设置为(150,150), 但实际上可绘画的区域比这还要再小一些,因为Shell还包括了边框、工具栏以及菜单栏,这也就是我们所要了解的客户区域。任何面板(Composite)都是使用getClientArea()方法获取客户区域的。 因为应用程序总是在底层OS绘制完控件后才得到绘画事件,所以绘画事件中的GC进行绘画后的效果就可以最终显示在控件上面了。当然也有例外,比如工具栏区域就不能在上面进行绘画。org.eclipse.swt.widgets.Canvas 能够用来进行多方面的图形绘画操作。 剪切(Clipping) 一个GC的剪切区域就是发生绘画的那部分,这里有个例子,如果你要填充出一个有缺口的三角形形状,一种方法是画出多个三角形和矩形组合出这么一个形状;当然也有另一种方法,就是利用GC的剪切操作。 shell.addPaintListener(new PaintListener() {
public void paintControl(PaintEvent e) {
Rectangle clientArea = shell.getClientArea();
int width = clientArea.width;
int height = clientArea.height;
 e.gc.setClipping(20,20,width - 40, height - 40); e.gc.setClipping(20,20,width - 40, height - 40);
e.gc.setBackground(display.getSystemColor(SWT.COLOR_CYAN));
 e.gc.fillPolygon(new int[] {0,0,width,0,width/2,height}); e.gc.fillPolygon(new int[] {0,0,width,0,width/2,height});
}
}); 这段代码在Shell上画了一个三角形。 左上角和右上角连接到底部边缘的中间。使用一个矩形CG对其进行剪切。 左上角和右上角连接到底部边缘的中间。使用一个矩形CG对其进行剪切。 最后显示出被剪切的矩形区域。 最后显示出被剪切的矩形区域。  当控件发生绘画事件,GC总是剪切需要重绘的那部分区域。例如,另一个窗口移到了一个SWT shell的前面,随后又移走。那么需要重新显示的就是GUI被损坏的那部分(shell被覆盖的那部分),一个绘画事件就是事件队列。当绘画事件发生,paintControl(PaintEvent evt) 在上面的例子中每当 paintControl(PaintEvent)被调用的时候, 就将在PaintEvent's area中寻找一个优化。绘画事件(paint event)很可能不交叉在绘画的形状(shape)中,在这种情况下,就不需要绘画(painting)或者指使需要一部分重画而已。依靠绘画的类型,就可以解决GC所选择的绘画部分,但事实上这要比GC剪切花费更多开销,而且在实践中常常忽视这些被损坏的区域让GC重新绘画全部,只有在刷新操作中才会依赖剪切。 如果程序需要手工损坏控件的某部分区域,可以使用Control.redraw(int x, int y, int width, int height)或者使用Control.redraw()损坏整个客户区域。此区域就被打上了标记然后包含在下一个绘画事件中,产生闪屏后,就会立即使用Control.update()方法强制处理控件的绘画请求。如果无绘画请求(也就是客户区域无损坏), update()就什么不做。
(译者注:此处的Control并不单指Control类,而是指所有继承了Control类的控件类,比如button,canvas,shell等等)
画布(Canvas) 虽然任何控件都可以通过绘画事件(paintEvent)在其上进行绘制, 但是org.eclipse.swt.widgets.Canvas Canvas的默认行为是使用当前背景色填充自身的整个客户区域。这样会引起屏闪,因为绘画事件也是在GC上绘画,所以用户就会看到被填充的原始背 景色和产生绘画之间的闪烁。有一种方法可避免此类情况,在创建Canvas时使用SWT.NO_BACKGROUND样式。这样就防止了绘画背景,意思就 是程序要负责绘画客户区域的每一个像素。 当部件调整大小时,客户区域会重复绘画,这就会出现屏幕闪烁。使用SWT.NO_REDRAW_RESIZE 可减少这样的情况,控件会减少不必要的重绘。比如改变尺寸大小,绘画事件GC只会剪切需要重绘的部分即底部区域和右边区域,就像一个反方向的“L”。 在固定大小的GC上绘画NO-REDRAW_RESIZE样式能很好的减少屏闪。但是错误的使用NO_REDRAW_RESIZE 可以导致图形成扁圆形。扁圆形是个大概的说法,事实上是指部件没有随大小的调整而进行正确的更新。下面的例子就演示了这样的情况。 填充椭圆形。因为在窗口大小改变时没有产生绘画事件,因为GC只剪切受损的(发生改变的)区域,而上一个绘画又没有被抹去,这就产生了扁圆形状。( 即使用NO_REDRAW_RESIZE 绘画事件只处理扩大的那部分区域,原先部分它就不管了). 填充椭圆形。因为在窗口大小改变时没有产生绘画事件,因为GC只剪切受损的(发生改变的)区域,而上一个绘画又没有被抹去,这就产生了扁圆形状。( 即使用NO_REDRAW_RESIZE 绘画事件只处理扩大的那部分区域,原先部分它就不管了). shell.setLayout(new FillLayout());
 final Canvas canvas = new Canvas(shell,SWT.NO_REDRAW_RESIZE); final Canvas canvas = new Canvas(shell,SWT.NO_REDRAW_RESIZE);
canvas.addPaintListener(new PaintListener() {
public void paintControl(PaintEvent e) {
Rectangle clientArea = canvas.getClientArea();
e.gc.setBackground(display.getSystemColor(SWT.COLOR_CYAN));
 e.gc.fillOval(0,0,clientArea.width,clientArea.height); e.gc.fillOval(0,0,clientArea.width,clientArea.height);
}
});
canvas的大小被增大,GC只剪切需要重绘的地方,扁圆形状就产生了。 
问题出在 ,应该使用SWT.NONE 样式,这样GC就不会只剪切扩大的部分了。所以当Shell大小增大时整个椭圆形都会被重绘。 ,应该使用SWT.NONE 样式,这样GC就不会只剪切扩大的部分了。所以当Shell大小增大时整个椭圆形都会被重绘。  final Canvas canvas = new Canvas(shell,SWT.NONE); final Canvas canvas = new Canvas(shell,SWT.NONE);
任何SWT部件,如果超过一个矩形区域被“损坏”,平台会把它们合并成一个,也就是说SWT程序只能处理一个绘画事件。在Canvas上使用NO_MERGE_PAINTS 样式可以覆盖这样的行为,可以为每一个被“损坏”的矩形区域调用绘画事件监听。 风格常量NO_BACKGROUND, NO_REDRAW_RESIZE 以及NO_MERGE_PAINTS 能够被使用在任何面板(Composite)以及子类中, 包括Canvas、Shell以及Group。 虽然这是被SWT允许的(不会由异常抛出),但在Composite 类的Javadoc中关于风格有这样的警告 "... 如果在其他的Composite子类中(除了Canvas)使用其行为是不明确的。"。所以实现图形绘画操作Canvas应该是首选。 另一种减少屏幕闪烁的方法,就是使用双缓冲技术。你可以先根据Canvas客户区域大小创建Image对象,然后使用GC(Image)将其绘画到Canvas上; 在绘画事件GC中调用drawImage(Image image, int x, int y)。 在一些平台上已经为你实现了双缓冲,所以你可以根据情况考虑使用三缓冲。" src="/CuteSoft_Client/CuteEditor/Images/anchor.gif"> 绘制线条和形状(Drawing lines and shapes) GC 拥有很多绘画线条的方法,比如画连接两个坐标点的直线、连接多个坐标点的直线或者是预先定义好的形状,线条颜色就是GC的前景色,可以通过风格样式常量来 决定线条的粗细胖瘦。绘画事件其GC也有很多相同的属性(前景色、背景色、以及颜色),并且线条的默认宽度是1像素。 GC.drawLine(int x1, int y1, int x2, int y2);
画一条从坐标点(x1,y1)到坐标点(x2,y2)的直线,如果两点的坐标值相同就相当于画一个圆点。 GC.drawPolyline(int[] pointArray);
画一条连接多个坐标点的直线,int[] 存放着要连接的x、y坐标值。代码如下:
gc.drawPolyline(new int[] { 25,5,45,45,5,45 });
先是从坐标点25,5到45,45,然后从45,45到5,45。 
GC.drawPolygon(int[] pointArray);
drawPolyline(int[])的使用与gc.drawPolyline很相似,不同的是最后一个点(5,45)连接了第一个点(25,5)。
gc.drawPolygon(new int[] { 25,5,45,45,5,45 });
相当于用三条线段链接三角形的单个端点,从而形成了一个三角形区域。 
GC.drawRectangle(int x, int y, int width, int height);
画一个矩形区域,int x,int y是矩形左上角的坐标点,int width,int heighy分别是矩形的宽和高。
gc.drawRectangle(5,5,90,45);
左上角坐标点为(5,5),对角坐标点为(95,50)。
你可以将Rectangle作为一个单独的参数传送给绘画方法。GC.drawRectangle(Rectangle); GC.drawRoundedRectangle(int x, int y, int width, int height, int arcWidth, int arcHeight);
圆角矩形不同于标准矩形,它的四角呈圆形。每一个圆角实际上就是一个1/4的椭圆形,其弧宽和弧高就是完整椭圆形的宽和高。 gc.drawRoundedRectangle(5,5,90,45,25,15)
画了一个圆角矩形,左顶角坐标值(5,5)。下面是圆角矩形的右下角放大图,其宽和高分别是25、15。 
虽然调用4次drawArc()和4次drawLine()完全可以实现一个圆角矩形。但在一些平台下,例如Windows或者Photon,SWT就可以使用非常优秀的平台API。
GC.drawOval(int x, int y, int width, int height);
一个椭圆形是画在矩形里的,所以由矩形的左顶点坐标以及宽和高来定义。定义一个正圆形同样使用这个方法。
gc.drawOval(5,5,90,45);
GC.drawArc(int x, int y, int width, int height, int startAngle, int endAngle);
一个弧形是被画在一个指明了高和宽以及左顶角x,y坐标的矩形区域内。int startAngle是个角度,是开始画弧形的位置,开始点就是此角度与X轴坐标线相交的那个点。int endAngle同样是角度,它是弧形结束的位置,道理和int startAngle相同。
gc.drawArc(5,5,90,45,90,200);
这里画了一个弧形,从90度垂线和X轴坐标相交处开始,然后持续画200度。 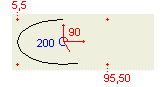
GC.setLineStyle(int style);
线条(Lines)拥有多种风格, org.eclipse.swt.SWT中提供了定义线条风格的常量,这些线条风格常量以LINE_开头。
| SWT.LINE_SOLID |  | | SWT.LINE_DOT |  | | SWT.LINE_DASH |  | | SWT.LINE_DASHDOT |  | | SWT.LINE_DASHDOTDOT |  | GC.setLineWidth(int width);
线条的默认宽度是1像素(pixel), 当然也可以使用GC的lineWidth字段设置线条宽。
| gc.setLineWidth(2); |  | | gc.setLineWidth(4); |  | 因为线条风格影响着所有的绘画操作,所以这也就使你可以画出不同边线风格的矩形或椭圆等图形。 gc.setLineWidth(3);
gc.drawOval(5,5,40,40);
gc.setLineWidth(1);
gc.setLineStyle(SWT.LINE_DOT);
gc.setForeground(display.getSystemColor(SWT.COLOR_BLUE));
gc.drawRectangle(60,5,60,40);
当GC的属性被改变,比如像线条的宽度、线条的风格或者是颜色,这些变化都会影响到后续的绘画操作。以上代码片段中,首先设置线条的宽度为3画了一个椭圆,随后重新设置线条属性画了一个边线是虚线的矩形。在SWT图形编程中,忘记重新设置这些字段属性的值是经常会犯的错误。
绘制文本(Drawing text) GC之上同样可以绘制文本,文字的轮廓可通过GC的foreground color和font确定。你需要定义它的左上角坐标(就是字体的位置)以及字体的高和宽。绘制文本有两种设置方法:第一种是在drawText()绘制 方法里直接输入文本它将处理行分隔符和tabs制表符,常用来模仿一个Label。第二种是在drawString()绘制方法中输入字符串,没有tab 以及回车处理,常用于更加复杂的控件,就像StyledText常用于Eclipse Java editor那样。 GC.drawText(String text, int x, int y);
Font font = new Font(display,"Arial",14,SWT.BOLD | SWT.ITALIC);
// ...
gc.drawText("Hello World",5,5);
gc.setForeground(display.getSystemColor(SWT.COLOR_BLUE));
gc.setFont(font);
gc.drawText("Hello\tThere\nWide\tWorld",5,25);
// ...
font.dispose();

drawText API 支持控制转义字符,\t 就是tab,\n就是回车换行。 GC.drawString(String text, int x, int y);
Font font = new Font(display,"Arial",14,SWT.BOLD | SWT.ITALIC); // ... gc.drawString("Hello World",5,5); gc.setForeground(display.getSystemColor(SWT.COLOR_BLUE)); gc.setFont(font); gc.drawString("Hello\tThere\nWide\tWorld",5,25); // ... font.dispose() 
使用drawString时,tab 和回车换行转义字符没有被处理。在GC绘制时字符串所占的大小基于它的内容和GC所设置的字体。获取字符串所占宽度可以分别使用GC.stringExtent(String text)和GC.textExtent(String text)这两个方法。 它们所返回的Point的x,y坐标值分别就是宽和高。
GC.drawText(String text, int x, int y, boolean isTransparent);
drawText(String text, int x, int y)绘制的文本使用的是GC的当前foreground color。当你希望文本透过背景色在最顶层显示的画,你可设置它的isTransparent这个布尔型的参数为true。此方法在图像(image) 上绘制时特别有用。
Font font = new Font(display,"Arial",12,SWT.BOLD | SWT.ITALIC);
Image image = new Image(display,"C:/devEclipse_02/eclipse/plugins/org.eclipse.platform_2.0.2/eclipse_lg.gif");
GC gc = new GC(image);
gc.drawText("Hello World",5,5);
gc.setFont(font);
gc.setForeground(display.getSystemColor(SWT.COLOR_WHITE));
gc.drawText("Hello World",5,25,true);
gc.dispose();
image.dispose();
font.dispose();

GC.drawText(String text, int x, int y, int flags);
int flags指的是SWT.DRAW_DELIMITER, SWT.DRAW_TAB, SWT.DRAW_TRANSPARENT 以及 SWT.DRAW_MNEMONIC 样式常量。这些常量用来确定是否处理 \n , \t , 是否使用背景色透明,是否处理 &。
gc.drawImage(image,0,0);
gc.drawText("Hello\t&There\nWide\tWorld",5,5,SWT.DRAW_TRANSPARENT);
gc.drawText("Hello\t&There\nWide\tWorld",5,25,SWT.DRAW_DELIMITER | SWT.DRAW_TAB | SWT.DRAW_MNEMONIC );

" src="/CuteSoft_Client/CuteEditor/Images/anchor.gif">填充形状(Filling shapes)使用GC的foreground color画线条(边线), 使用GC的background color填充形状。 GC.fillPolygon(int[]);
gc.setBackground(display.getSystemColor(SWT.COLOR_BLUE)); gc.fillPolygon(new int[] { 25,5,45,45,5,45 }) 
GC.fillRectangle(int x, int y, int width, int height);
gc.fillRectangle(5,5,90,45);  填充矩形的时候,底部边线和右边线是不包含在内的。虽然点(5,5)被包含在填充矩形的代码中,但右下角点 95,50 (5+90 , 45+5) 不在填充区域的范围里,右下角的填充点是94,49。这不同于drawRectangle(5,5,90,45),drawRectangle指的是整个形状,所以其右下角点是95,50。 举例说明一下,下面的代码填充了一个矩形,但是填充的颜色并没有覆盖边线。填充区域的右上角点坐标以及宽和高都减小了1像素。
gc.drawRectangle(5,5,90,45);
gc.setBackground(display.getSystemColor(SWT.COLOR_CYAN));
gc.fillRectangle(6,6,89,44);
GC.fillRoundedRectangle(int x, int y, int width, int height, int arcWidth, int arcHeight);
gc.fillRoundRectangle(5,5,90,45,25,15); 
有点像 GC.fillRectangle(...)方法。底部边框和右边框都被排除在填充范围之内,所以底部右下角坐标变成了(94,49)而不是(95,50)
GC.fillOval(int x, int y, int width, int height);
gc.fillOval(5,5,90,45);
与其他的填充APIs相似 GC.fillArc(int x, int y, int widt4h., int height, int startAngle, int endAngle);
gc.fillArc(5,5,90,45,90,200);
fillArc(...) 方法中的参数和drawArc(...)中的参数很相似。fillArc(...)遵守着和其他填充方法一样的模式,底部边框和右边框不在填充范围之内。
GC.fillGradientRectangle(int x, int y, int width. int height, vertical boolean);
对矩形进行由前景色到背景色的渐变填充。Vertical为true表示垂直渐变,反之则表示水平渐变。
gc.setBackgrouind(display,getSystemColor(SWT.COLOR_BLUE));
gc.fillGradientRectangle(5,5,90,45,false);
水平渐变从左边的黑色前景色开始向右边蓝色背景色变化。正如其他的填充方法,底部和右边框是被排除在外的,所以底部右下角会由1像素插入。 
gc.setBackground(display.getSystemColor(SWT.COLOR_BLUE));
gc.setForeground(display.getSystemColor(SWT.COLOR_CYAN));
gc.fillGradientRectangle(5,5,90,45,true);
垂直渐变从上而下,由前景色向背景色变化。 
异或(XOR)当GC的绘画发生时你可以在绘画表面上编辑图形的像素值,设置GC的异或(XOR)模式为true,每种颜色都是三原色红、绿、蓝经过异或(XOR)操作后的结果,那么你就可以将几种颜色经过异或(XOR)操作后得到新的颜色。
shell.setBackground(display.getSystemColor(SWT.COLOR_WHITE));
// ...
gc.setBackground(display.getSystemColor(SWT.COLOR_BLUE));
gc.fillRectangle(5,5,90,45);
gc.setXORMode(true);
gc.setBackground(display.getSystemColor(SWT.COLOR_WHITE));
gc.fillRectangle(20,20,50,50);
gc.setBackground(display.getSystemColor(SWT.COLOR_RED));
gc.fillOval(80,20,50,50);

被填充的背景色是白色的(255,255,255)矩形,当在上面覆盖一层蓝色(0,0,255),或(XOR)后的颜色就是黄色(25,255,0)。白背景的部分和黄色异或后就成了黑色(0,0,0)。一个红色背景的圆,它覆盖在蓝色上面异或(XOR)后就成了紫色(255,0,255)。盖在白色上面异或(XOR)后就成了青色(0,255,255)。 (译者注: SWT API帮助文档中对setXORMode()方法是这样描述的“此方法在某些平台下是不被支持的,显著表现的有Mac OS X,如果你希望你的代码可运行在所有平台,应该尽量避免使用此方法。”) " src="/CuteSoft_Client/CuteEditor/Images/anchor.gif">绘制图像(Drawing Images)org.eclipse.swt.graphics.Image 表示一个已经准备好在显示设备或打印设备上显示的图像。创建一个image对象最简单的方式就是从经过验证的文件格式中加载文件。支持的文件格式有 GIF, BMP (Windows 位图), JPG, PNG, 新的Eclipse releases版还支持TIFF格式。
Image image = new Image(display,"C:/eclipse/eclipse/plugins/org.eclipse.platform_2.0.2/eclipse_lg.gif");
GC.drawImage(Image image, int x, int y);
每一个图像(image)都有一个由它自身范围所决定的大小。例如图像 eclipse_lg.gif的大小就是115,164 ,可以使用 image.getBounds()获取。当绘画了一个图像,此图像就会以它自身范围的宽度和高度显示出来。
gc.drawImage(image,5,5);

GC.drawImage(Image image, int srcX, int srcY, int srcWidth, int srcHeight, int dstX, int dstY, int dstWidth, int dstHeight);
根据原始图像的宽度和高度,不但可以绘画出不同大小的图像还可以只绘画原始图像的局部。 src 参数联系图像本身,要画完整的图像,srcX、srcY 使用0,0,宽高就使用图像的宽高。dst 参数表示图像被画在哪里以及画成多大。原始图像的大小是115,164,若要把图像宽度增加2倍,高度减低一半,可以使用下面的语句:
gc.drawImage(image,0,0,115,164,5,5,230,82);

使用src坐标可以使你只画出图像的局部。例如,如果你只想画出图像的右上角部分,你可以设定src坐标为20,0,宽度和高度为95,82。下面的代码中dst 宽度和高度同样使用95,82。通过指定不同大小就可以对图像进行拉长或收缩操作。
gc.drawImage(image,20,0,95,82,5,5,95,82);
还能完成一些其他的图像效果,比如图像透明度、animation以及alpha通道。但这些不属于本篇的讨论范围,我希望在以后的文章中能够涉及到这些东西。 总结(Conclusion) 本文已经展示了如何使用GC画线条、文本和填充形状。给构造器传入一个drawable参数就能够创建其GC,例如一个图像、或者给控件(control)使用绘画事件(paintEvent)回调。 GC 的API允许设置前景色绘画出线条并使用背景色填充。Canvas 控件允许通过绘画事件(paintEvent)绘画,并且当绘画事件发生时它有很多的构造常量可以使用。GC 的剪切操作允许你控制只想显示的部分,还有如何绘画出不同风格的线条以及显示文本和图像。
恐怕现在用过电脑的人,一定都知道大部分带文本编辑功能的软件都有一个快捷键ctrl+f 吧(比如word)。这个功能主要来完成“查找”,“替换”和“全部替换”功能的,其实这就是典型的模式匹配的应用,即在文本文件中查找串。 1.模式匹配 模式匹配的模型大概是这样的:给定两个字符串变量S和P,其中S成为目标串,其中包含n个字符,P称为模式串,包含m个字符,其中m<=n。从S的 给定位置(通常是S的第一个位置)开始搜索模式P。如果找到,则返回模式P在目标串中的位置(即:P的第一个字符在S中的下标)。如果在目标串S中没有找 到模式串P,则返回-1.这就是模式匹配的定义啦,下面来看看怎么实现模式匹配算法吧。 2.朴素的模式匹配 朴素的模式匹配算法非常简单,容易理解,大概思路是这样的:从S的第一个字符S0开始,将P中的字符依次和S中字符比较,若S0=P0 && …… && Sm-1 = Pm-1,则证明匹配成功,剩下的匹配无需进行了,返回下标0。若在某一步Si != Pi 则P中剩下的字符也不用比较了,不可能匹配成功了,然后从S中第二个字符开始与P中第一个字符进行比较,同理,也是知道Sm = Pm-1或者找到某个i使得Si != S-1为止。依次类推若知道以S中第n-m个开始字符为止,还没有匹配成功则证明S中不存模式P。(想想为什么这里强调是n-m)这个代码实现应该是非常 简单的,具体开始参考strstr函数的内部实现。可以看看百度百科,给个链接http://baike.baidu.com/view/745156.htm,这里不写出来了,还得赶紧进入正题KMP呢。 3.快速模式匹配算法(KMP) 朴素的模式匹配效率不高的主要原因是进行了重复的字符比较。下一次比较和上一次比较没有任何的联系,是朴素模式匹配的缺点,其实上一次比较的比较结果是可 以利用的,这就产生了快速模式匹配。在朴素的模式匹配中,目标串S的下标移动是一步一步的,这其实并不好,移动步数没有必要为1。 现在不妨假设,当前匹配情况是这样的:S0 …… St St+1 …… St+j 与 P0 P1…… Pj ,现在正在尝试匹配的字符是St+j+1和Pj+1,并且St+j+1 != Pj+1,言外之意就是说S St+1……St+j和P0 P1……Pj是完全匹配的。那么这个时候,S中下一次匹配开始位置应该是什么呢??按照朴素的模式匹配,下次比较应该从St+1开始,并且令St+1和 P0比较,但是在快速模式匹配中并不是这样,快速模式匹配选择St+j+1和Pk比较,K是什么呢?K是这样的一个值,使得P0 P1……Pk 和 Pj-k Pj-k+1……Pj完全匹配,不妨设k=next[j],因此P0 P1……Pk和St+j-k St+j-k+1 ……St+j完全匹配。那么下一次要进行匹配的两个字符应为St+j+1和Pk+1。S和P都没有回溯到下标0在进行比较,这就是KMP之所以快的原因 啦。 现在关键问题来了,这个K怎么能得到呢?如果得到这个K值复杂度高,那这个思路就不好了,其实这个K呢,只和模式串P有关系,并且要求m个k,k = next[j],因此只要算一次存储到next数组中就可以了,并且时间复杂度和m有关系(线性关系)。看看具体怎么求next数组的值,即求k。 用归纳法求next[]:设next(0) = -1,若已知next(j) = k,欲求得next[j+1]。 (1)如果Pk+1 = Pj+1,显然next[j+1] = k+1.如果Pk+1 != Pj+1,则next[j+1] < next[j],于是寻找h < k 使得P0 P1……Ph = Pj-h Pj-h+1……Pj = Pk-h Pk-h+1……Pk。也就是说h = next(k);看出来了吧,这是个迭代的过程。(也就是以前的结果对求以后的值有用) (2)如果不存这样的h,说明P0 P1……Pj+1中没有前后相等的子串,因此next[j+1] =-1. (3)如果存在这样的h,继续检验Ph和Pj是否相等。知道找到这中相等的情况,或者确定为-1求next[j+1]的过程结束。 看看实现的代码:  View Code 1 int next[20] ={0};
2 //注意返回结果是一个数组next,保存m个k值得地方,即若next[j]=k
3 //则str[0]str[1]…str[k] = str[j-k]str[j-k+1]…str[j]
4 //这样当des[t+j+1]和pat[j+1]匹配失败时,下一个匹配位置为des[t+j+1]和next[j]+1
5 void Next(char str[],int len)
6 {
7 next[0] = -1;
8 for(int j = 1 ; j < len ; j++)
9 {
10 int i = next[j-1];
11 while(str[j] != str[i+1] && i >= 0)//迭代的过程
12 {
13 i = next[i];
14 }
15 if(str[j] == str[i+1])
16 {
17 next[j] = i+1;
18 }
19 else
20 {
21 next[j] = -1;
22 }
23 }
24 } 现在有了next数组保存的k值,就可以实现KMP算法了: View Code 1 View Code
2
3 //des是目标串,pat是模式串,len1和len2是串的长度
4 int kmp(char des[],int len1,char pat[],int len2)
5 {
6 Next(str2,len2);
7 int p=0,s=0;
8 while(p < len2 && s < len1)
9 {
10 if(pat[p] == des[s])
11 {
12 p++;s++;
13 }
14 else
15 {
16 if(p==0)
17 {
18 s++;//若第一个字符就匹配失败,则从des的下一个字符开始
19 }
20 else
21 {
22 p = next[p-1]+1;//用失败函数确定pat应回溯到的字符
23 }
24 }
25 }
26 if(p < len2)//整个过程匹配失败
27 {
28 return -1;
29 }
30 return s-len2;
31 } 时间复杂度:
对于Next函数近似接近O(m),KMP算法的时间复杂度为O(n),所以整个算法的时间复杂度为O(n+m) 空间复杂度: 多引入了O(m)的空间复杂度。 4.应用KMP的一道面试题 给定两个字符串是s1和s2,要判定s2是否能够被s1做循环移位得到的字符串包含。例如s1=AABCD,s2 =CDAA,返回true,因为s1循环移位可以变成CDAAB。给定s1=ACBD和s2=ACBD则返回false。 分析:不难发现对s2移位得到的字符串都将是字符串s1s1的子串,如果s2可以有s1循环移位得到,那么s2一定是s1s1的子串,这时KMP算法是不是就很管用了呢。 思考:有没有比KMP更好的思路呢??
1 OpenEJB概述 Tomcat本不支持部署EJB,通过向其安装OpenEjb,可使其支持。 2 安装 2.1 下载 http://www.apache.org/dyn/closer.cgi/openejb/3.1.3/openejb.war 2.2 安装 1、将下载的openejb.war 放在Tomcat的安装目录 webapps下。 2、启动Tomcat。 3、在IE中输入:http://localhost:8080/openejb 回车后显示如下信息: Welcome to the OpenEJB/Tomcat integration! Now that OpenEJB has been installed, click on the "Testing your setup" link below to verify it. When everything is setup well, feel free to play around with the tools provided below! OK!安装成功,就这么简单! 4、测试一下:http://localhost:8080/openejb/viewjndi.jsp 3 部署 像往常一样,开发一个Ejb工程。 接口: @Remote public interface GreeterRemote { public String greet(String message); public List<Greeting> getAllGreetings(); } 实现类: @Stateless public class GreeterBean implements GreeterRemote,GreeterLocal{ public List<Greeting> getAllGreetings(){ List<Greeting> greetings = new ArrayList<Greeting>(); Greeting greeting = new Greeting(); greeting.setId(12); greeting.setName("bill gates"); greetings.add(greeting); greeting = new Greeting(); greeting.setId(334); greeting.setName("李宁"); greetings.add(greeting); return greetings; } public String greet(String message){ return "您好"+ message; } } 将此EJB工程打成jar包,比如放在D:\Tomcat\ejb下。注:“D:\Tomcat\ejb”是我自己建的。 然后打开:Tomcat\conf\openejb.xml,将</openejb>前的内容改为: <!-- # # The <Deployments> element can be used to configure file # paths where OpenEJB should look for ejb jars or ear files. # # See http://openejb.apache.org/deployments.html # # The below entry is simply a default and can be changed or deleted <Deployments dir="apps/" />原来是这句,我们用不到,可以用下面的语句直接加载指定的ejb jar包。 --> <Deployments jar="D:/Tomcat/ejb/OpenEjbTest.jar" /> 重启Tomcat,在浏览器输入:http://127.0.0.1:8089/openejb/invokeobj.jsp  点击其中的”Browse for an EJB”,转到如下界面:  如果在其中能看到自己的EJB Bean,那就成功了。 4 客户端调用 按照官方给出的说明:http://openejb.apache.org/3.0/clients.html,此处使用“Remote Client with HTTP (in tomcat)”方式。对上面部署的EJB调用的客户端代码如下: public class GreeterBeanTest{ public static void main(String[] args) throws NamingException { Properties p = new Properties(); p.put("java.naming.factory.initial", "org.apache.openejb.client.RemoteInitialContextFactory"); p.put("java.naming.provider.url", "http://localhost:8089/openejb/ejb"); InitialContext initialContext = new InitialContext(p); GreeterRemote greeterRemote =(GreeterRemote) initialContext.lookup("GreeterBeanRemote"); String str="屈剑峰"; System.out.println(greeterRemote.greet(str)); } } 原文地址: http://qujianfeng.iteye.com/blog/793409
简介 Eclipse 平台允许使用可插入组件 —— 插件 —— 帮助创建丰富的图形用户界面(graphical user interface,GUI)应用程序。例如,插件可以向 GUI 提供视图。但是,在现实的应用程序中,UI 视图不能是孤立的。它们需要根据其他视图的状态进行交互和对本身进行更新。 一个简单的例子是描述世界各地的主要旅游目的地的 GUI 应用程序。这个 GUI 可能有一个 Select City 视图,用于显示旅游景点和公共交通信息。 图 1. 视图链接的例子  本文介绍在 Eclipse 中结合视图的方式以及如何对其他视图的状态做出响应。还讨论链接视图方式在哪些情况下可能比其他方式合适。 Eclipse 开发人员可以依赖以下方法对视图进行链接: - 选择提供器 - 选择监听器(selection provider-selection listener)模式,从而让视图对其他视图中的选择做出反应
-
IAdaptable 接口,与某些事件结合使用 - 属性改变监听器,它允许视图将属性改变事件告之已注册的监听器
选择提供器 - 选择监听器范型 选择提供器 - 选择监听器模式能够方便地创建对其他视图中的改变做出响应的视图。例如,当用户点击代表城市名的 UI 项时,另一个视图可能需要显示这个城市的景点详情。这样的视图可以使用 UI 选择对象(可能是代表城市名的字符串对象)中包含的信息,并使用它从模型中获取和显示其他信息。 视图应该能够识别并利用 UI 选择事件。org.eclipse.ui.ISelectionListener 是接收 UI 选择事件的监听器接口。选择监听器必须注册到工作台页面。工作台页面实现 org.eclipse.ui.ISelectionService 接口定义的服务,从而将 UI 选择事件告之监听器。选择监听器必须注册到选择服务。 用于显示可选择的 UI 项的视图还应该能够公布 UI 选择。视图通过将 “选择提供器” 注册到它们各自的工作台站点来实现这一点。Eclipse 中的每个 UI 部分通过 org.eclipse.ui.IWorkbenchPartSite 引用与工作台站点联络。选择提供器注册到工作台站点。 在使用选择提供器 - 选择监听器模式链接视图时,视图可以将本身作为监听器添加到工作台页面,而希望公布选择的其他视图必须将选择提供器添加到它们各自的工作台站点。org.eclipse.ui.ISelectionListener 接口如下所示。 public void selectionChanged(IWorkbenchPart part, ISelection selection);
|
要使视图能够监听选择改变,视图必须实现 ISelectionListener 接口并必须将自己注册到工作台页面。清单 1 显示一个例子。 清单 1. 将选择监听器添加到工作台页面 1 public class MyView extends ViewPart implements ISelectionListener {
2 public void createPartControl(Composite parent) {
3 // add this view as a selection listener to the workbench page
4 getSite().getPage().addSelectionListener((ISelectionListener) this);
5 }
6
7 // Implement the method defined in ISelectionListener, to consume UI
8 // selections
9 public void selectionChanged(IWorkbenchPart part, ISelection selection) {
10 // Examine selection and act on it!
11 }
12 } |
使用 UI 选择的更好的方法是,将消费者视图作为监听器注册到特定的视图部分。正如在下面的例子中可以看到的,源视图部分的视图 ID 在注册选择监听器期间被作为一个参数。 getSite().getPage().addSelectionListener("SampleViewId",(ISelectionListener)this);
这种方式可以避免对消费者视图进行多余的回调,如果视图被注册为非特定的监听器,就会出现这种情况。 清单 2 中的代码片段显示一个视图的 createPartControl() 方法,这个方法创建一个 JFace TableViewer 并将它作为选择提供器添加到工作台站点。这些代码使 TableViewer 中的任何 UI 选择改变能够传播到页面,并最终传播到对这种事件感兴趣的消费者视图。 清单 2. 设置选择提供器 1 public void createPartControl(Composite parent) {
2 // Set up a JFace Viewer
3 viewer = new TableViewer(parent, SWT.MULTI | SWT.H_SCROLL | SWT.V_SCROLL);
4 viewer.setContentProvider(new ViewContentProvider());
5 viewer.setLabelProvider(new ViewLabelProvider());
6 viewer.setSorter(new NameSorter());
7 viewer.setInput(getViewSite());
8 // ADD the JFace Viewer as a Selection Provider to the View site.
9 getSite().setSelectionProvider(viewer);
10 } 这个视图将它创建的 JFace TableViewer 注册为选择提供器有两个原因: - 这个视图打算使用这个 TableViewer 显示信息,而且用户将与 TableViewer 进行交互。
- TableViewer 实现了选择提供器接口并能够向工作台部分站点传播选择事件。
因为 JFace 查看器是选择提供器,所以在大多数情况下就不必创建选择提供器了。视图只需使用众多的 JFace 查看器之一来显示信息,并将 JFace 查看器注册为选择提供器。 另一种链接方式 某些情况需要另一种视图链接方式: - 信息量可能太大,由于内存使用量增加,UI 选择对象无法有效地容纳它。
- 视图可能希望公布其他信息,而不只是公布可视化选择信息。公布的信息可能是根据选择进行某些后期处理的结果。
- 视图可能希望使用来自另一个插件的信息,而这个插件可能根本没有提供视图(使用包含的 JFace 查看器)。在这种情况下,使用基于 UI 选择的链接是不可能的。
可以使用 org.eclipse.core.runtime.IAdaptable 接口来缓解第一个问题,这个接口使选择对象能够在需要时传播更多信息。第二个和第三个问题需要用手工方式解决,属性改变监听器模式是合适的解决方案。 使用 IAdaptable 接口 实现 IAdaptable 接口的类能够动态地返回某些类型的适配器,然后可以使用这些适配器获取更多信息。如果查看器中的选择对象实现了 IAdaptable 接口,那么根据它们可以返回的适配器类型,可以有效地获取更多信息或相关信息。org.eclipse.core.runtime.IAdaptable 接口如下所示。 public void object getAdapter(Class adapter);
显然,调用者应该知道它期望选择返回的适配器接口类型。考虑一个 JFace TreeViewer,它在一个单层的树中显示城市。代表城市的对象是 CityClass 类型的。CityClass 对象应该包含关于此城市的基本信息,并只在需要时返回详细信息。在清单 3 中要注意,CityClass 支持的适配器类型使调用者能够在需要时获得更多信息。 清单 3. JFace TreeViewer 中的 CityClass 1 class CityClass implements IAdaptable {
2 private String cityName;
3
4 public CityClass(String name) {
5 this.name = name;
6 }
7
8 public String getName() {
9 return name;
10 }
11
12 public CityClass getParent() {
13 return parent;
14 }
15
16 public String toString() {
17 return getName();
18 }
19
20 public Object getAdapter(Class key) {
21 if (key.getName().equals("ITransportationInfo"))
22 return CityPlugin.getInstance().getTransportAdapter();
23 else (key.getName().equals("IPlacesInfo"))
24 return CityPlugin.getInstance().getPlacesAdapter();
25 return null; }
26 }
27 熟悉 Eclipse IDE 工作台的开发人员都了解 Outline 视图,这个视图提供了编辑器中打开的文件的结构化视图。这个 Outline 视图展示了 IAdaptable 接口如何与某些事件类型结合使用,从而有效地根据其他视图的内容对视图进行初始化。编辑器必须为用户打开的文件创建一个 Content Outline 页面。Content Outline 页面符合 IContentOutlinePage 接口。编辑器还必须实现 IAdaptable 接口,这样就能够向编辑器查询 IContentOutlinePage 类型的适配器。使用这个适配器来获取和显示文件的大纲信息。 IAdaptable 接口的另一个例子是 Properties 视图。Properties 视图跟踪对活动部分的选择,并调用当前选择对象上的 getAdapter 方法。查询的适配器类型是 IPropertySource。然后,Properties 视图使用 IPropertySource 适配器来获取要显示的信息。 在这些视图链接例子中,应用程序在接到 Selection Changed 或 Part Activation 通知时,通过 IAdaptable 获取信息。因此,如果选择对象实现了 IAdaptable,那么与从选择对象本身获取的信息量相比,用户可以通过适配器获得多得多的信息。
属性改变监听器范型 可以使用属性改变监听器类型的交互来解决前面提到的另外两个问题:视图如何使用来自未提供视图的插件的信息,以及视图如何公布在可视化选择之后某些处理所生成的信息? 可以建立一个插件来接受属性改变监听器的注册,并在需要时通知注册的监听器。应用程序可以将定制的事件告之监听器,事件中还可以包含要共享的信息。 与选择提供器的情况不同,属性改变提供器不需要实现特定的接口。您必须决定将监听器注册到提供器的语义。清单 4 中的代码片段是一些方法,它们允许在属性提供器视图或插件类中添加或删除属性改变监听器。 清单 4. 添加和删除属性改变监听器1 //To add a listener for property changes to this notifier:
2 public void addPropertyChangeListener(IPropertyChangeListener listener);
3 //To remove the given content change listener from this notifier:
4 public void removePropertyChangeListener(IPropertyChangeListener listener);
|
属性提供器应该使用 org.eclipse.jface.util.PropertyChangeEvent 来创建一个可以有效填充和传播的事件。另外,属性提供器要负责维护监听器列表并对它们进行回调。 作为一个例子,请考虑一个每小时调用 World Weather Web Service 来查询主要城市的气象的插件,它要使这些信息可供其他插件和视图使用。CityWeatherPlugin 可以公开一个称为 CitiesWeatherXML 的属性,消费者可以将本身作为 PropertyChange 监听器注册到 CityWeatherPlugin。为此,监听器必须了解 CityWeatherPlugin 中的注册方法,这样才能将本身注册为气象数据事件的监听器。CityWeatherPlugin 应该跟踪并通知监听器。它使用 PropertyChangeEvent 向监听器提供数据。 清单 5. 创建属性提供器 1 class CityPopulationPlugin {
2 ArrayList myListeners; // A public method that allows listener registration
3
4 public void addPropertyChangeListener(IPropertyChangeListener listener) {
5 if (!myListeners.contains(listener))
6 myListeners.add(listener);
7 }
8
9 // A public method that allows listener registration
10 public void removePropertyChangeListener(IPropertyChangeListener listener) {
11 myListeners.remove(listener);
12 }
13
14 public CityPopulationPlugin() {
15 // method to start the thread that invokes the population \ web service
16 // once every hour
17 // and then notifies the listeners via the propertyChange() callback
18 // method.
19 initWebServiceInvokerThread(myListeners);
20 }
21
22 void initWebServiceInvokerThread(ArrayList listeners) {
23 // Code to Invoke Web Service Periodically, and retrieve information
24 // Post Invocation, inform listeners
25 for (Iterator iter = listeners.iterator(); iter.hasNext();) {
26 IPropertyChangeListener element = (IPropertyChangeListener) iter.next();
27 element.propertyChange(new PropertyChangeEvent(this, "CitiesWeatherXML", null,
28 CityWeatherXMLObj));
29 }
30 }
31 } 属性改变监听器必须实现 org.eclipse.jface.util.IPropertyChangeListener 接口,以便允许属性改变提供器对它进行回调。这个接口有一个方法
public void propertyChange(PropertyChangeEvent event)
清单 6. 实现 IPropertyChangeListener 1 class MyView implements IPropertyChangeListener {
2 public void createPartControl() {
3 // register with a Known Plugin that sources Population Data
4 CityPopulationPlugin.getInstance().addPropertyChangeListener(this);
5 }
6
7 public void propertyChange(PropertyChangeEvent event) {
8 // This view is interested in the Population Counts of the Cities.
9 // The population data is being sourced by another plugin in the
10 // background.
11 if (event.getProperty().equals("CitiesWeatherXML")) {
12 Object val = event.getNewValue();
13 // do something with val
14 }
15 }
16 } 这种方式的灵活性在于,应用程序可以在需要时通知监听器,并根据各种场景向它们传递信息。传递的信息不必直接与 UI 选择相关;这些信息可以是某些后期处理的结果。另外,它可以与其他后台作业的状态相关,或者是定期从模型中获取的最新信息。例如,City Selector View 可能不只是传播选择的城市,还使用 PropertyChange 范型将当前选择的城市的气象信息异步地传播给其他消费者。
结束语 本文讨论了使视图相互协作和响应的各种方式。如果 UI 选择本身不够,可以使用 IAdaptable 接口加强它们。属性改变监听器也为满足非 UI 场景提供了更大的灵活性。 http://www.ibm.com/developerworks/cn/opensource/os-ecllink/ http://www.cnblogs.com/zephyr/archive/2008/05/30/1210477.html http://www.eclipse.org/articles/Article-Integrating-EMF-GMF-Editors/
http://sishuok.com/forum/blogCategory/showByCategory.html?categories_id=51&user_id=4249 http://sishuok.com/forum/blogCategory/showByCategory.html?categories_id=49&user_id=2
http://sishuok.com/forum/blogCategory/showByCategory/7.html?user_id=183
http://sishuok.com/forum/blogCategory/showByCategory.html?categories_id=82&user_id=6091
maven是什么 maven这个词可以翻译为“知识的积累”,也可以翻译为“专家”或“内行”。作为apache组织中的一个颇为成功的开源项目,maven主要服务于基于java平台的项目构建、依赖管理和项目信息管理。 maven能干什么 使项目构建构成更容易; 提供统一构建系统(编译、测试、持续整合...); 提供高质量的项目信息(依赖、报告、site...); 提供开发的最佳实践指南; 能无缝的加入新的特性; maven有什么【maven的核心概念】 项目对象模型(Project Object Model), 坐标(Coordinates), 项目生命周期(ProjectLifecycle), 插件(plugin)和目标(goal), 依赖管理系统(Dependency Management System), 仓库管理(Repositories)。 准备我们需要的环境 下载maven的安装包apache-maven-3.0.3-bin.tar.gz,解压至任何目录。 设置环境变量M2_HOME,设置为maven的安装路径;同时把maven的bin目录增加至环境变量path里。【我们可以看到,跟java的安装几乎一模一样】。 正常情况下,maven会到中央仓库去下载我们需要的构件或者插件;但是,现在在教室不能上网,所以需要将老师的私服加入到下载的配置中。建立 C:\Documents and Settings\Administrator\.m2文件夹,其中Administrator为当前登录的用户。拷入准备好的 settings.xml。其中 java代码: - <profile>
- 。
- <url>http://10.83.1.111:10080/nexus-webapp-1.9.1.1/content/groups/public/</url>
- <url>http://10.83.1.111::10080/nexus-webapp-1.9.1.1/content/groups/public/</url>
- </profile>
代表老师的私服 工程描述文件pom java代码: - <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <groupId>cn.javass.study</groupId>
- <artifactId>hello-world</artifactId>
- <version>1.0-SNAPSHOT</version>
- <name>Maven Quick Start Archetype</name>
- <dependencies>
- <dependency>
- <groupId>junit</groupId>
- <artifactId>junit</artifactId>
- <version>3.7.1</version>
- <scope>test</scope>
- </dependency>
- </dependencies>
- </project>
常见的mvn命令 java代码: - mvn clean test
- mvn clean package
- mvn clean install
mvn是命令名 clean说明要清空所有的配置文件 test说明要运行单元测试 package说明要打包 install安装到本地仓库 坐标 Maven的世界中拥有数量非常巨大的构件,也就是我们平时用的一些jar、war等文件。Maven定义了这样一组规则:世界上任何一个构件都可以使用 Maven坐标唯一标识。Maven坐标的元素包括groupId、artifactId、version、packaging、classifier。 groupId:定义当前Maven项目隶属的实际项目。groupId的表示方式与java包名的表示方式类似,通常与域名反向一一对应。 artifactId:该元素定义实际项目中的一个Maven项目/模块。 version:版本【可以分成稳定版本和快照版本】。 packaging:打包方式。如:jar、war。 classifier:不能直接定义,用来表示构件到底用于何种jdk版本。 pom POM(Project Object Model):Maven的核心文件,位于每个工程的根目录中,指示Maven如何工作的元数据文件,类似于Ant中的build.xml文件。 依赖(Dependency) 为了能够构建或运行,Java工程一般会依赖其它的包。在Maven中,这些被依赖的包就被称为dependency。dependency一般是其它工程的坐标。 依赖具有传递性。 生命周期 项目的生命周期是指软件开发人员每天都在对项目进行清理、编译以及部署。虽然大家都在不停的做构建工作,但公司和公司间、项目和项目间,往往使用不同的方式做类似的工作。 Maven的生命周期就是为了所有的构建过程进行抽象和统一。这个生命周期包含了项目的清理、初始化、编译、测试、打包、集成测试、验证、部署和站点生成等几乎所有构建步骤。 Maven拥有三套相互独立的生命周期,他们分别为clean、default和site。clean生命周期的目的是清理项目,default生命周期的目的是构建项目,而site生命周期的目的是建立项目站点。 阶段【phase】 每个生命周期包含一些阶段,这些阶段是有顺序的,并且后面的阶段依赖于前面的阶段,用户和Maven最直接的交互方式就是调用这些生命周期阶段。 较之于生命周期阶段的前后依赖关系,三套生命周期本身是相互独立的,用户可以仅仅调用clean生命周期的某个阶段,或者仅仅调用default生命周期的某个阶段,而不会对其他生命周期产生任何影响。 clean生命周期包含三个阶段: pre-clean、clean、post-clean default生命周期包含很多阶段: site生命周期包含四个阶段: pre-site、site、post-site、site-deploy 插件及其目标【goal】 Maven的核心仅仅定义了抽象的生命周期,具体的任务是交由插件完成的,插件以独立的构建形式存在。 对于插件本身,为了能够复用代码,它往往能够完成多个任务。例如maven-dependency-plugin插件,能够基于项目以来做很多事情。比 如,能够分析项目依赖,找到无用的或者重复的依赖;还能够列出项目的依赖树。这些功能往往背后有很多可以复用的代码,因此,可以把这些功能聚集在一个插件 里,每个功能就是一个插件目标。 我们原来仅仅学过通过前缀调用插件,现在可以用冒号来指定调用插件的某个具体目标了,比如:mvn dependency:tree。冒号前面是插件的前缀,冒号后是该插件的目标。 在Maven世界中,任何一个依赖、插件或者项目的构建输出,都可以称为构件。任何一个构件都有一组坐标唯一标识。 得益于坐标机制,任何Maven项目使用任何一个构件的方式都是完全相同的。在此基础上,Maven可以在某个位置统一存储所有Maven项目共享的构件,这个统一的位置就是仓库。 对于Maven来说,仓库只分为两大类:本地仓库和远程仓库。当Maven根据坐标寻找构件的时候,它首先会查看本地仓库,如果本地仓库存在此构件,则直 接使用;如果本地仓库部存在此构件,Maven就会去远程仓库查找,发现需要的构件之后,下载到本地仓库再使用。 【以上概念,对比一下hibernate中的一级缓存。】 私服是一种特殊的远程仓库,它是架设在局域网内的仓库服务,私服代理广域网上的远程仓库,供局域网内的Maven用户使用。 登录时其默认的用户名为admin,密码为admin123。 使用nexus的时候,如果想支持搜索;可以从远程仓库下载其索引,这当然非常慢,我们可以使用gui的方式在下载好的构件基础上重建索引。 exus支持非常全面的搜索方式。GAV搜索:通过GroupId、ArtifactId和Version进行搜索;全类名搜索;关键词搜索。 配置客户机使用nexus时,需要在settings.xml文件中加入相应的配置,从nexus的仓库组中下载构件和插件。【在helloworld中已经说明,这里不再举例】 WTP项目【也就是咱们的eclipse下的dynamic web project】 src/main/java:源码目录 src/main/resources:资源目录(如存放log4j.properties) src/main/webapp:web目录【它下面就是WEB-INF】 src/test/java:测试源码目录 src/test/resources:测试资源目录 target:编译结果目录 安装插件 将获得的m2eclipse.rar解压到eclipse的dropins文件夹下,重启eclipse,就可以看到maven插件了。 新建项目 选择【New】->【Project】->【Maven Project】,选择create a simple project,填入GAV,选择打包方式jar/war。 如果要新建web工程,请选择打包方式为war,为了让项目能在eclipse相关的tomcat下运行,还需要一点点麻烦的配置。选择项目的属性,添加 dynamic web project支持【project facets】;再次选择项目的属性,重整项目的部署【deployment assembly】。这部分操作非常非常麻烦,请注意看老师的演示。 添加依赖 在项目上右击【maven】->【add dependency】。 运行命令行 在项目上右击【Run as】。
|