TSimpleServerTSimpleServer accepts a connection, processes requests from the connection until the client closes the connection, and goes back to accept a new connection. Since
it is all done in a single thread with blocking I/O, it can only serve one client connection, and all the other clients will have to wait until they get accepted. TSimpleServer is mainly used for testing purpose. Don't use it in production!
TSimplerServer接受一个连接,处理连接请求,直到客户端关闭了连接,它才回去接受一个新的连接。正因为它只在一个单独的线程中以阻塞I/O的方式完成这些工作,所以它只能服务一个客户端连接,其他所有客户端在被服务器端接受之前都只能等待。TSimpleServer主要用于测试目的,不要在生产环境中使用它!文章来源:http://www.codelast.com/
TNonblockingServer vs. THsHaServerTNonblockingServer solves the problem with TSimpleServer of one client blocking all the other clients by using non-blocking I/O. It uses
java.nio.channels.Selector, which allows you to get blocked on multiple connections instead of a single connection by calling
select(). The select() call returns when one ore more connections are ready to be accepted/read/written. TNonblockingServer handles those connections either by accepting it, reading data from it, or writing data to it, and calls select() again to wait for the next available connections. This way, multiple clients can be served without one client starving others.
TNonblockingServer使用非阻塞的I/O解决了TSimpleServer一个客户端阻塞其他所有客户端的问题。它使用了java.nio.channels.Selector,通过调用select(),它使得你阻塞在多个连接上,而不是阻塞在单一的连接上。当一或多个连接准备好被接受/读/写时,select()调用便会返回。TNonblockingServer处理这些连接的时候,要么接受它,要么从它那读数据,要么把数据写到它那里,然后再次调用select()来等待下一个可用的连接。通用这种方式,server可同时服务多个客户端,而不会出现一个客户端把其他客户端全部“饿死”的情况。
There is a catch, however. Messages are processed by the same thread that calls select(). Let's say there are 10 clients, and each message takes 100 ms to process. What would be the latency and throughput? While a message is being processed, 9 clients are waiting to be selected, so it takes 1 second for the clients to get the response back from the server, and throughput will be 10 requests / second. Wouldn't it be great if multiple messages can be processed simultaneously?
然而,还有个棘手的问题:所有消息是被调用select()方法的同一个线程处理的。假设有10个客户端,处理每条消息所需时间为100毫秒,那么,latency和吞吐量分别是多少?当一条消息被处理的时候,其他9个客户端就等着被select,所以客户端需要等待1秒钟才能从服务器端得到回应,吞吐量就是10个请求/秒。如果可以同时处理多条消息的话,会很不错吧?
This is where THsHaServer (Half-Sync/Half-Async server) comes into picture. It uses a single thread for network I/O, and a separate pool of worker threads to handle message processing. This way messages will get processed immediately if there is an idle worker threads, and multiple messages can be processed concurrently. Using the example above, now the latency is 100 ms and throughput will be 100 requests / sec.
因此,THsHaServer(半同步/半异步的server)就应运而生了。它使用一个单独的线程来处理网络I/O,一个独立的worker线程池来处理消息。这样,只要有空闲的worker线程,消息就会被立即处理,因此多条消息能被并行处理。用上面的例子来说,现在的latency就是100毫秒,而吞吐量就是100个请求/秒。
To demonstrate this, I ran a benchmark with 10 clients and a modified message handler that simply sleeps for 100 ms before returning. I used THsHaServer with 10 worker threads. The handler looks something like this:
为了演示,我做了一个测试,有10客户端和一个修改过的消息处理器——它的功能仅仅是在返回之前简单地sleep 100毫秒。我使用的是有10个worker线程的THsHaServer。消息处理器的代码看上去就像下面这样:
1 2 3 4 5 6 7 8 | public ResponseCode sleep() throws TException {
try { Thread.sleep(100); } catch (Exception ex) { } return ResponseCode.Success; }
|
The results are as expected. THsHaServer is able to process all the requests concurrently, while TNonblockingServer processes requests one at a time.
结果正如我们想像的那样,THsHaServer能够并行处理所有请求,而TNonblockingServer只能一次处理一个请求。
文章来源:http://www.codelast.com/
THsHaServer vs. TThreadedSelectorServer
Thrift 0.8 introduced yet another server, TThreadedSelectorServer. The main difference between TThreadedSelectorServer and THsHaServer is that TThreadedSelectorServer allows you to have multiple threads for network I/O. It maintains 2 thread pools, one for handling network I/O, and one for handling request processing. TThreadedSelectorServer performs better than THsHaServer when the network io is the bottleneck. To show the difference, I ran a benchmark with a handler that returns immediately without doing anything, and measured the average latency and throughput with varying number of clients. I used 32 worker threads for THsHaServer, and 16 worker threads/16 selector threads for TThreadedSelectorServer.
Thrift 0.8引入了另一种server实现,即TThreadedSelectorServer。它与THsHaServer的主要区别在于,TThreadedSelectorServer允许你用多个线程来处理网络I/O。它维护了两个线程池,一个用来处理网络I/O,另一个用来进行请求的处理。当网络I/O是瓶颈的时候,TThreadedSelectorServer比THsHaServer的表现要好。为了展现它们的区别,我进行了一个测试,令其消息处理器在不做任何工作的情况下立即返回,以衡量在不同客户端数量的情况下的平均latency和吞吐量。对THsHaServer,我使用32个worker线程;对TThreadedSelectorServer,我使用16个worker线程和16个selector线程。
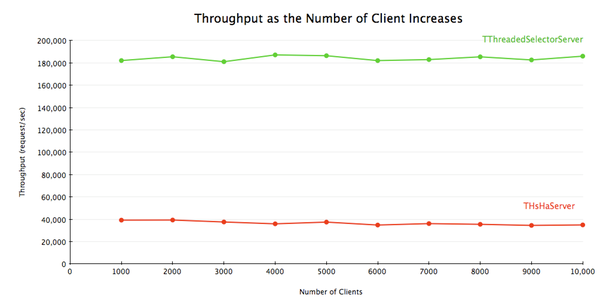
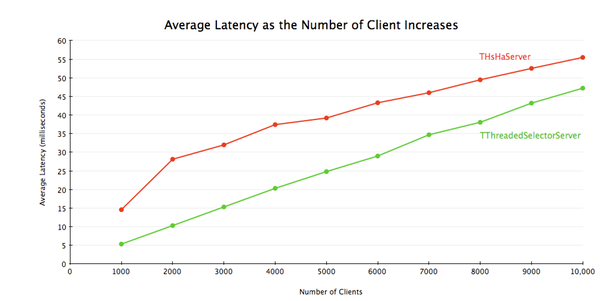
The result shows that TThreadedSelectorServer has much higher throughput than THsHaServer while maintaining lower latency.
结果显示,TThreadedSelectorServer比THsHaServer的吞吐量高得多,并且维持在一个更低的latency上。
文章来源:http://www.codelast.com/
TThreadedSelectorServer vs. TThreadPoolServer
Finally, there is TThreadPoolServer. TThreadPoolServer is different from the other 3 servers in that:
最后,还剩下 TThreadPoolServer。TThreadPoolServer与其他三种server不同的是:
· There is a dedicated thread for accepting connections.
· 有一个专用的线程用来接受连接。
· Once a connection is accepted, it gets scheduled to be processed by a worker thread in ThreadPoolExecutor.
· 一旦接受了一个连接,它就会被放入ThreadPoolExecutor中的一个worker线程里处理。
· The worker thread is tied to the specific client connection until it's closed. Once the connection is closed, the worker thread goes back to the thread pool.
· worker线程被绑定到特定的客户端连接上,直到它关闭。一旦连接关闭,该worker线程就又回到了线程池中。
· You can configure both minimum and maximum number of threads in the thread pool. Default values are 5 and Integer.MAX_VALUE, respectively.
· 你可以配置线程池的最小、最大线程数,默认值分别是5(最小)和Integer.MAX_VALUE(最大)。
This means that if there are 10000 concurrent client connections, you need to run 10000 threads. As such, it is not as resource friendly as other servers. Also, if the number of clients exceeds the maximum number of threads in the thread pool, requests will be blocked until a worker thread becomes available.
这意味着,如果有1万个并发的客户端连接,你就需要运行1万个线程。所以它对系统资源的消耗不像其他类型的server一样那么“友好”。此外,如果客户端数量超过了线程池中的最大线程数,在有一个worker线程可用之前,请求将被一直阻塞在那里。
Having said that, TThreadPoolServer performs very well; on the box I'm using it's able to support 10000 concurrent clients without any problem. If you know the number of clients that will be connecting to your server in advance and you don't mind running a lot of threads, TThreadPoolServer might be a good choice for you.
我们已经说过,TThreadPoolServer的表现非常优异。在我正在使用的计算机上,它可以支持1万个并发连接而没有任何问题。如果你提前知道了将要连接到你服务器上的客户端数量,并且你不介意运行大量线程的话,TThreadPoolServer对你可能是个很好的选择。
文章来源:http://www.codelast.com/
Conclusion
结论
I hope this article helps you decide which Thrift server is right for you. I think TThreadedSelectorServer would be a safe choice for most of the use cases. You might also want to consider TThreadPoolServer if you can afford to run lots of concurrent threads. Feel free to send me email atmapkeeper-users@googlegroups.com or post your comments here if you have any questions/comments.
希望本文能帮你做出决定:哪一种Thrift server适合你。我认为TThreadedSelectorServer对大多数案例来说都是个安全之选。如果你的系统资源允许运行大量并发线程的话,你可能会想考虑使用TThreadPoolServer。(后面的就不翻译了)
Appendix A: Hardware Configuration
1 2 3 4 | Processors: 2 x Xeon E5620 2.40GHz (HT enabled, 8 cores, 16 threads)
Memory: 8GB
Network: 1Gb/s <full-duplex>
OS: RHEL Server 5.4 Linux 2.6.18-164.2.1.el5 x86_64
|
Appendix B: Benchmark DetailsIt's pretty straightforward to run the benchmark yourself. First clone the
MapKeeper repository and compile the
stub java server:
1 2 3 | git clone git://github.com/m1ch1/mapkeeper.git cd mapkeeper/stubjava make
|
Then, start the server you like to benchmark:
1 2 3 4 | make run mode=threadpool # run TThreadPoolServer make run mode=nonblocking # run TNonblockingServer make run mode=hsha # run THsHaServer make run mode=selector # run TThreadedSelectorServer |
Then, clone YCSB repository and compile:
1 2 3 | git clone git://github.com/brianfrankcooper/YCSB.git cd YCSB mvn clean package
|
Once the compilation finishes, you can run YCSB against the stub server:
1 | ./bin/ycsb load mapkeeper -P ./workloads/workloada |
For more detailed information about how to use YCSB, check out their wiki page.