原文链接:http://www.cnblogs.com/juandx/p/4962089.html
python中对文件、文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块。
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split()
eg os.path.split(‘/home/swaroop/byte/code/poem.txt’)
结果:(‘/home/swaroop/byte/code’, ‘poem.txt’)
分离扩展名:os.path.splitext()
获取路径名:os.path.dirname()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取和设置环境变量:os.getenv() 与os.putenv()
给出当前平台使用的行终止符:os.linesep Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’
指示你正在使用的平台:os.name 对于Windows,它是’nt’,而对于Linux/Unix用户,它是’posix’
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
终止当前进程:os.exit()
获取文件大小:os.path.getsize(filename)
文件操作:
os.mknod(“test.txt”) 创建空文件
fp = open(“test.txt”,w) 直接打开一个文件,如果文件不存在则创建文件
关于open 模式:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
fp.read([size]) #size为读取的长度,以byte为单位
fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
fp.flush() #把缓冲区的内容写入硬盘
fp.fileno() #返回一个长整型的”文件标签“
fp.isatty() #文件是否是一个终端设备文件(unix系统中的)
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
目录操作:
os.mkdir(“file”) 创建目录
复制文件:
shutil.copyfile(“oldfile”,”newfile”) oldfile和newfile都只能是文件
shutil.copy(“oldfile”,”newfile”) oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
复制文件夹:
shutil.copytree(“olddir”,”newdir”) olddir和newdir都只能是目录,且newdir必须不存在
重命名文件(目录)
os.rename(“oldname”,”newname”) 文件或目录都是使用这条命令
移动文件(目录)
shutil.move(“oldpos”,”newpos”)
删除文件
os.remove(“file”)
删除目录
os.rmdir(“dir”)只能删除空目录
shutil.rmtree(“dir”) 空目录、有内容的目录都可以删
转换目录
os.chdir(“path”) 换路径
Python读写文件
1.open
使用open打开文件后一定要记得调用文件对象的close()方法。比如可以用try/finally语句来确保最后能关闭文件。
file_object = open(‘thefile.txt’)
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法。
2.读文件
读文本文件
input = open('data', 'r')
#第二个参数默认为r
input = open('data')
1
2
3
读二进制文件
input = open('data', 'rb')
1
读取所有内容
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
1
2
3
4
5
读固定字节
file_object = open('abinfile', 'rb')
try:
while True:
chunk = file_object.read(100)
if not chunk:
break
do_something_with(chunk)
finally:
file_object.close( )
1
2
3
4
5
6
7
8
9
读每行
list_of_all_the_lines = file_object.readlines( )
1
如果文件是文本文件,还可以直接遍历文件对象获取每行:
for line in file_object:
process line
1
2
3.写文件
写文本文件
output = open('data', 'w')
1
写二进制文件
output = open('data', 'wb')
1
追加写文件
output = open('data', 'w+')
1
写数据
file_object = open('thefile.txt', 'w')
file_object.write(all_the_text)
file_object.close( )
1
2
3
写入多行
file_object.writelines(list_of_text_strings)
1
注意,调用writelines写入多行在性能上会比使用write一次性写入要高。
在处理日志文件的时候,常常会遇到这样的情况:日志文件巨大,不可能一次性把整个文件读入到内存中进行处理,例如需要在一台物理内存为 2GB 的机器上处理一个 2GB 的日志文件,我们可能希望每次只处理其中 200MB 的内容。
在 Python 中,内置的 File 对象直接提供了一个 readlines(sizehint) 函数来完成这样的事情。以下面的代码为例:
file = open('test.log', 'r')sizehint = 209715200 # 200Mposition = 0lines = file.readlines(sizehint)while not file.tell() - position < 0: position = file.tell() lines = file.readlines(sizehint)
1
每次调用 readlines(sizehint) 函数,会返回大约 200MB 的数据,而且所返回的必然都是完整的行数据,大多数情况下,返回的数据的字节数会稍微比 sizehint 指定的值大一点(除最后一次调用 readlines(sizehint) 函数的时候)。通常情况下,Python 会自动将用户指定的 sizehint 的值调整成内部缓存大小的整数倍。
file在python是一个特殊的类型,它用于在python程序中对外部的文件进行操作。在python中一切都是对象,file也不例外,file有file的方法和属性。下面先来看如何创建一个file对象:
file(name[, mode[, buffering]])
1
file()函数用于创建一个file对象,它有一个别名叫open(),可能更形象一些,它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。name是文件的名字。
mode是打开的模式,可选的值为r w a U,分别代表读(默认) 写 添加支持各种换行符的模式。用w或a模式打开文件的话,如果文件不存在,那么就自动创建。此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清空,因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。由于历史的原因,换行符在不同的系统中有不同模式,比如在 unix中是一个\n,而在windows中是‘\r\n’,用U模式打开文件,就是支持所有的换行模式,也就说‘\r’ ‘\n’ ‘\r\n’都可表示换行,会有一个tuple用来存贮这个文件中用到过的换行符。不过,虽说换行有多种模式,读到python中统一用\n代替。在模式字符的后面,还可以加上+ b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
buffering如果为0表示不进行缓冲;如果为1表示进行“行缓冲“;如果是一个大于1的数表示缓冲区的大小,应该是以字节为单位的。
file对象有自己的属性和方法。先来看看file的属性。
closed #标记文件是否已经关闭,由close()改写
encoding #文件编码
mode #打开模式
name #文件名
newlines #文件中用到的换行模式,是一个tuple
softspace #boolean型,一般为0,据说用于print
1
2
3
4
5
6
file的读写方法:
F.read([size]) #size为读取的长度,以byte为单位
F.readline([size])
#读一行,如果定义了size,有可能返回的只是一行的一部分
F.readlines([size])
#把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
F.write(str)
#把str写到文件中,write()并不会在str后加上一个换行符
F.writelines(seq)
#把seq的内容全部写到文件中。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
file的其他方法:
F.close()
#关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。如果一个文件在关闭后还对其进行操作会产生ValueError
F.flush()
#把缓冲区的内容写入硬盘
F.fileno()
#返回一个长整型的”文件标签“
F.isatty()
#文件是否是一个终端设备文件(unix系统中的)
F.tell()
#返回文件操作标记的当前位置,以文件的开头为原点
F.next()
#返回下一行,并将文件操作标记位移到下一行。把一个file用于for ... in file这样的语句时,就是调用next()函数来实现遍历的。
F.seek(offset[,whence])
#将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
F.truncate([size])
#把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
http://www.cnblogs.com/allenblogs/archive/2010/09/13/1824842.html
http://www.cnblogs.com/rollenholt/archive/2012/04/23/2466179.html
首先 dfs.replication这个参数是个client参数,即node level参数。需要在每台datanode上设置。
其实默认为3个副本已经够用了,设置太多也没什么用。
一个文件,上传到hdfs上时指定的是几个副本就是几个。以后你修改了副本数,对已经上传了的文件也不会起作用。可以再上传文件的同时指定创建的副本数
Hadoop dfs -D dfs.replication=1 -put 70M logs/2
可以通过命令来更改已经上传的文件的副本数:
hadoop fs -setrep -R 3 /
查看当前hdfs的副本数
hadoop fsck -locations
FSCK started by hadoop from /172.18.6.112 for path / at Thu Oct 27 13:24:25 CST 2011
....................Status: HEALTHY
Total size: 4834251860 B
Total dirs: 21
Total files: 20
Total blocks (validated): 82 (avg. block size 58954290 B)
Minimally replicated blocks: 82 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Thu Oct 27 13:24:25 CST 2011 in 10 milliseconds
The filesystem under path '/' is HEALTHY
某个文件的副本数,可以通过ls中的文件描述符看到
hadoop dfs -ls
-rw-r--r-- 3 hadoop supergroup 153748148 2011-10-27 16:11 /user/hadoop/logs/201108/impression_witspixel2011080100.thin.log.gz
如果你只有3个datanode,但是你却指定副本数为4,是不会生效的,因为每个datanode上只能存放一个副本。
参考:http://blog.csdn.net/lskyne/article/details/8898666
转自:https://www.cnblogs.com/shabbylee/p/6792555.html
由于历史原因,Python有两个大的版本分支,Python2和Python3,又由于一些库只支持某个版本分支,所以需要在电脑上同时安装Python2和Python3,因此如何让两个版本的Python兼容,如何让脚本在对应的Python版本上运行,这个是值得总结的。
对于Ubuntu 16.04 LTS版本来说,Python2(2.7.12)和Python3(3.5.2)默认同时安装,默认的python版本是2.7.12。
当然你也可以用python2来调用。
如果想调用python3,就用python3.
对于Windows,就有点复杂了。因为不论python2还是python3,python可执行文件都叫python.exe,在cmd下输入python得到的版本号取决于环境变量里哪个版本的python路径更靠前,毕竟windows是按照顺序查找的。比如环境变量里的顺序是这样的:
那么cmd下的python版本就是2.7.12。
反之,则是python3的版本号。
这就带来一个问题了,如果你想用python2运行一个脚本,一会你又想用python3运行另一个脚本,你怎么做?来回改环境变量显然很麻烦。
网上很多办法比较简单粗暴,把两个python.exe改名啊,一个改成python2.exe,一个改成python3.exe。这样做固然可以,但修改可执行文件的方式,毕竟不是很好的方法。
我仔细查找了一些python技术文档,发现另外一个我觉得比较好的解决办法。
借用py的一个参数来调用不同版本的Python。py -2调用python2,py -3调用的是python3.
当python脚本需要python2运行时,只需在脚本前加上,然后运行py xxx.py即可。
#! python2
当python脚本需要python3运行时,只需在脚本前加上,,然后运行py xxx.py即可。
#! python3
就这么简单。
同时,这也完美解决了在pip在python2和python3共存的环境下报错,提示Fatal error in launcher: Unable to create process using '"'的问题。
当需要python2的pip时,只需
py -2 -m pip install xxx
当需要python3的pip时,只需
py -3 -m pip install xxx
python2和python3的pip package就这样可以完美分开了。
Sentry权限控制通过Beeline(Hiveserver2 SQL 命令行接口)输入Grant 和 Revoke语句来配置。语法跟现在的一些主流的关系数据库很相似。需要注意的是:当sentry服务启用后,我们必须使用beeline接口来执行hive查询,Hive Cli并不支持sentry。
CREATE ROLE Statement
CREATE ROLE语句创建一个可以被赋权的角色。权限可以赋给角色,然后再分配给各个用户。一个用户被分配到角色后可以执行该角色的权限。
只有拥有管理员的角色可以create/drop角色。默认情况下,hive、impala和hue用户拥有管理员角色。
CREATE ROLE [role_name];
DROP ROLE Statement
DROP ROLE语句可以用来从数据库中移除一个角色。一旦移除,之前分配给所有用户的该角色将会取消。之前已经执行的语句不会受到影响。但是,因为hive在执行每条查询语句之前会检查用户的权限,处于登录活跃状态的用户会话会受到影响。
DROP ROLE [role_name];
GRANT ROLE Statement
GRANT ROLE语句可以用来给组授予角色。只有sentry的管理员用户才能执行该操作。
GRANT ROLE role_name [, role_name]
TO GROUP (groupName) [,GROUP (groupName)]
REVOKE ROLE Statement
REVOKE ROLE语句可以用来从组移除角色。只有sentry的管理员用户才能执行该操作。
REVOKE ROLE role_name [, role_name]
FROM GROUP (groupName) [,GROUP (groupName)]
GRANT (PRIVILEGE) Statement
授予一个对象的权限给一个角色,该用户必须为sentry的管理员用户。
GRANT
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
TO ROLE (roleName) [,ROLE (roleName)]
REVOKE (PRIVILEGE) Statement
因为只有认证的管理员用户可以创建角色,从而只有管理员用户可以取消一个组的权限。
REVOKE
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
FROM ROLE (roleName) [,ROLE (roleName)]
GRANT (PRIVILEGE) ... WITH GRANT OPTION
在cdh5.2中,你可以委托给其他角色来授予和解除权限。比如,一个角色被授予了WITH GRANT OPTION的权限可以GRANT/REVOKE同样的权限给其他角色。因此,如果一个角色有一个库的所有权限并且设置了 WITH GRANT OPTION,该角色分配的用户可以对该数据库和其中的表执行GRANT/REVOKE语句。
GRANT
(PRIVILEGE)
ON (OBJECT) (object_name)
TO ROLE (roleName)
WITH GRANT OPTION
只有一个带GRANT选项的特殊权限的角色或者它的父级权限可以从其他角色解除这种权限。一旦下面的语句执行,所有跟其相关的grant权限将会被解除。
REVOKE
(RIVILEGE)
ON (BJECT) (bject_name)
FROM ROLE (roleName)
Hive目前不支持解除之前赋予一个角色 WITH GRANT OPTION 的权限。要想移除WITH GRANT OPTION、解除权限,可以重新去除 WITH GRANT OPTION这个标记来再次附权。
SET ROLE Statement
SET ROLE语句可以给当前会话选择一个角色使之生效。一个用户只能启用分配给他的角色。任何不存在的角色和当前用户不能使用的角色是不能生效的。如果没有使用任何角色,用户将会使用任何一个属于他的角色的权限。
选择一个角色使用:
To enable a specific role:
使用所有的角色:
To enable a specific role:
关闭所有角色
SET ROLE NONE;
SHOW Statement
显示当前用户拥有库、表、列相关权限的数据库:
SHOW DATABASES;
显示当前用户拥有表、列相关权限的表;
SHOW TABLES;
显示当前用户拥有SELECT权限的列:
SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name];
显示当前系统中所有的角色(只有管理员用户可以执行):
SHOW ROLES;
显示当前影响当前会话的角色:
SHOW CURRENT ROLES;
显示指定组的被分配到的所有角色(只有管理员用户和指定组内的用户可以执行)
SHOW ROLE GRANT GROUP (groupName);
SHOW语句可以用来显示一个角色被授予的权限或者显示角色的一个特定对象的所有权限。
显示指定角色的所有被赋予的权限。(只有管理员用户和指定角色分配到的用户可以执行)。下面的语句也会显示任何列级的权限。
SHOW GRANT ROLE (roleName);
显示指定对象的一个角色的所有被赋予的权限(只有管理员用户和指定角色分配到的用户可以执行)。下面的语句也会显示任何列级的权限。
SHOW GRANT ROLE (roleName) on (OBJECT) (objectName);
----------------------------我也是有底线的-----------------------------
摘要: Python 里面的编码和解码也就是 unicode 和 str 这两种形式的相互转化。编码是 unicode -> str,相反的,解码就是 str -> unicode。剩下的问题就是确定何时需要进行编码或者解码了.关于文件开头的"编码指示",也就是 # -*- codin...
摘要: 我们每次执行hive的hql时,shell里都会提示一段话:[python] view plaincopy... Number of reduce tasks not specified. Estimated from input data size: 50...
摘要: spark 累加历史主要用到了窗口函数,而进行全部统计,则需要用到rollup函数
1 应用场景:
1、我们需要统计用户的总使用时长(累加历史)
2、前台展现页面需要对多个维度进行查询,如:产品、地区等等
3、需要展现的表格头如: 产品、2015-04、2015-05、2015-06
2 原始数据:
product_code |event_date |dur...
摘要: Spark1.4发布,支持了窗口分析函数(window functions)。在离线平台中,90%以上的离线分析任务都是使用Hive实现,其中必然会使用很多窗口分析函数,如果SparkSQL支持窗口分析函数,
那么对于后面Hive向SparkSQL中的迁移的工作量会大大降低,使用方式如下:
1、初始化数据
创建表
[sql] view plain cop...
如果用传统SCP远程拷贝,速度是比较慢的。现在采用lz4压缩传输。LZ4是一个非常快的无损压缩算法,压缩速度在单核300MB/S,可扩展支持多核CPU。它还具有一个非常快速的解码器,速度单核可达到和超越1GB/S。通常能够达到多核系统上的RAM速度限制。
你PV 全命为Pipe Viewer,利用它我们可以查看到命令执行的进度。
下面介绍下lz4和pv的安装,下载软件:
下载pv-1.1.4.tar.gz wget http://sourceforge.jp/projects/sfnet_pipeviewer/downloads/pipeviewer/1.1.4/pv-1.1.4.tar.bz2/
下lz4的包难一些,可能要FQ:https://dl.dropboxusercontent.com/u/59565338/LZ4/lz4-r108.tar.gz
安装灰常简单:
pv安装:
[root ~]$ tar jxvf pv-1.1.4.tar.bz2
[root ~]$ cd pv-1.1.4
[root pv-1.1.4]$ ./configure && make && make install
lz4安装:
[root ~]$ tar zxvf lz4-r108.tar.gz
[root ~]$ cd lz4-r108
[root lz4-r108]$ make && make install
用法:(-c 后指定要传输的文件,ssh -p 是指定端口,后面的ip是目标主机的ip, -xC指定传到目标主机下的那个目录下,别的不用修改):
tar -c mysql-slave-3307 |pv|lz4 -B4|ssh -p10022 -c arcfour128 -o"MACs umac-64@openssh.com" 192.168.100.234 "lz4 -d |tar -xC /data"
下面是我线上传一个从库的效果:
看到了吧,25.7G 只需要接近3分钟,这样远比scp速度快上了好几倍,直接scp拷贝离散文件,很消耗IO,而使用LZ4快速压缩,对性能影响不大,传输速度快
PS:下次补充同机房不同网段的传输效果及跨机房的传输效果^0^
作者:陆炫志
出处:xuanzhi的博客 http://www.cnblogs.com/xuanzhi201111
您的支持是对博主最大的鼓励,感谢您的认真阅读。本文版权归作者所有,欢迎转载,但请保留该声明。
王 腾腾 和 邵 兵
2015 年 11 月 26 日发布
WeiboGoogle+用电子邮件发送本页面
Comments 1
引子
随着云时代的来临,大数据(Big data)也获得了越来越多的关注。著云台的分析师团队认为,大数据(Big data)通常用来形容一个公司创造的大量非结构化和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像 MapReduce 一样的框架来向数十、数百或甚至数千的电脑分配工作。
“大数据”在互联网行业指的是这样一种现象:互联网公司在日常运营中生成、累积的用户网络行为数据。这些数据的规模是如此庞大,以至于不能用 G 或 T 来衡量。所以如何高效的处理分析大数据的问题摆在了面前。对于大数据的处理优化方式有很多种,本文中主要介绍在使用 Hadoop 平台中对数据进行压缩处理来提高数据处理效率。
压缩简介
Hadoop 作为一个较通用的海量数据处理平台,每次运算都会需要处理大量数据,我们会在 Hadoop 系统中对数据进行压缩处理来优化磁盘使用率,提高数据在磁盘和网络中的传输速度,从而提高系统处理数据的效率。在使用压缩方式方面,主要考虑压缩速度和压缩文件的可分割性。综合所述,使用压缩的优点如下:
1. 节省数据占用的磁盘空间;
2. 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度。
压缩格式
Hadoop 对于压缩格式的是自动识别。如果我们压缩的文件有相应压缩格式的扩展名(比如 lzo,gz,bzip2 等)。Hadoop 会根据压缩格式的扩展名自动选择相对应的解码器来解压数据,此过程完全是 Hadoop 自动处理,我们只需要确保输入的压缩文件有扩展名。
Hadoop 对每个压缩格式的支持, 详细见下表:
表 1. 压缩格式
压缩格式 工具 算法 扩展名 多文件 可分割性
DEFLATE 无 DEFLATE .deflate 不 不
GZIP gzip DEFLATE .gzp 不 不
ZIP zip DEFLATE .zip 是 是,在文件范围内
BZIP2 bzip2 BZIP2 .bz2 不 是
LZO lzop LZO .lzo 不 是
如果压缩的文件没有扩展名,则需要在执行 MapReduce 任务的时候指定输入格式。
1
2
3
4
5
hadoop jar /usr/home/hadoop/hadoop-0.20.2/contrib/streaming/
hadoop-streaming-0.20.2-CD H3B4.jar -file /usr/home/hadoop/hello/mapper.py -mapper /
usr/home/hadoop/hello/mapper.py -file /usr/home/hadoop/hello/
reducer.py -reducer /usr/home/hadoop/hello/reducer.py -input lzotest -output result4 -
jobconf mapred.reduce.tasks=1*-inputformatorg.apache.hadoop.mapred.LzoTextInputFormat*
性能对比
Hadoop 下各种压缩算法的压缩比,压缩时间,解压时间见下表:
表 2. 性能对比
压缩算法 原始文件大小 压缩文件大小 压缩速度 解压速度
gzip 8.3GB 1.8GB 17.5MB/s 58MB/s
bzip2 8.3GB 1.1GB 2.4MB/s 9.5MB/s
LZO-bset 8.3GB 2GB 4MB/s 60.6MB/s
LZO 8.3GB 2.9GB 49.3MB/s 74.6MB/s
因此我们可以得出:
1) Bzip2 压缩效果明显是最好的,但是 bzip2 压缩速度慢,可分割。
2) Gzip 压缩效果不如 Bzip2,但是压缩解压速度快,不支持分割。
3) LZO 压缩效果不如 Bzip2 和 Gzip,但是压缩解压速度最快!并且支持分割!
这里提一下,文件的可分割性在 Hadoop 中是很非常重要的,它会影响到在执行作业时 Map 启动的个数,从而会影响到作业的执行效率!
所有的压缩算法都显示出一种时间空间的权衡,更快的压缩和解压速度通常会耗费更多的空间。在选择使用哪种压缩格式时,我们应该根据自身的业务需求来选择。
下图是在本地压缩与通过流将压缩结果上传到 BI 的时间对比。
图 1. 时间对比
图 1. 时间对比
使用方式
MapReduce 可以在三个阶段中使用压缩。
1. 输入压缩文件。如果输入的文件是压缩过的,那么在被 MapReduce 读取时,它们会被自动解压。
2.MapReduce 作业中,对 Map 输出的中间结果集压缩。实现方式如下:
1)可以在 core-site.xml 文件中配置,代码如下
图 2. core-site.xml 代码示例
图 2. core-site.xml 代码示例
2)使用 Java 代码指定
1
2
conf.setCompressMapOut(true);
conf.setMapOutputCompressorClass(GzipCode.class);
最后一行代码指定 Map 输出结果的编码器。
3.MapReduce 作业中,对 Reduce 输出的最终结果集压。实现方式如下:
1)可以在 core-site.xml 文件中配置,代码如下
图 3. core-site.xml 代码示例
图 3. core-site.xml 代码示例
2)使用 Java 代码指定
1
2
conf.setBoolean(“mapred.output.compress”,true);
conf.setClass(“mapred.output.compression.codec”,GzipCode.class,CompressionCodec.class);
最后一行同样指定 Reduce 输出结果的编码器。
压缩框架
我们前面已经提到过关于压缩的使用方式,其中第一种就是将压缩文件直接作为入口参数交给 MapReduce 处理,MapReduce 会自动根据压缩文件的扩展名来自动选择合适解压器处理数据。那么到底是怎么实现的呢?如下图所示:
图 4. 压缩实现情形
图 4. 压缩实现情形
我们在配置 Job 作业的时候,会设置数据输入的格式化方式,使用 conf.setInputFormat() 方法,这里的入口参数是 TextInputFormat.class。
TextInputFormat.class 继承于 InputFormat.class,主要用于对数据进行两方面的预处理。一是对输入数据进行切分,生成一组 split,一个 split 会分发给一个 mapper 进行处理;二是针对每个 split,再创建一个 RecordReader 读取 split 内的数据,并按照
的形式组织成一条 record 传给 map 函数进行处理。此类在对数据进行切分之前,会首先初始化压缩解压工程类 CompressionCodeFactory.class,通过工厂获取实例化的编码解码器 CompressionCodec 后对数据处理操作。
下面我们来详细的看一下从压缩工厂获取编码解码器的过程。
压缩解压工厂类 CompressionCodecFactory
压缩解压工厂类 CompressionCodeFactory.class 主要功能就是负责根据不同的文件扩展名来自动获取相对应的压缩解压器 CompressionCodec.class,是整个压缩框架的核心控制器。我们来看下 CompressionCodeFactory.class 中的几个重要方法:
1. 初始化方法
图 5. 代码示例
图 5. 代码示例
① getCodeClasses(conf) 负责获取关于编码解码器 CompressionCodec.class 的配置信息。下面将会详细讲解。
② 默认添加两种编码解码器。当 getCodeClass(conf) 方法没有读取到相关的编码解码器 CompressionCodec.class 的配置信息时,系统会默认添加两种编码解码器 CompressionCodec.class,分别是 GzipCode.class 和 DefaultCode.class。
③ addCode(code) 此方法用于将编码解码器 CompressionCodec.class 添加到系统缓存中。下面将会详细讲解。
2. getCodeClasses(conf)
图 6. 代码示例
图 6. 代码示例
① 这里我们可以看,系统读取关于编码解码器 CompressionCodec.class 的配置信息在 core-site.xml 中 io.compression.codes 下。我们看下这段配置文件,如下图所示:
图 7. 代码示例
图 7. 代码示例
Value 标签中是每个编码解码 CompressionCodec.class 的完整路径,中间用逗号分隔。我们只需要将自己需要使用到的编码解码配置到此属性中,系统就会自动加载到缓存中。
除了上述的这种方式以外,Hadoop 为我们提供了另一种加载方式:代码加载。同样最终将信息配置在 io.compression.codes 属性中,代码如下:
1
2
conf.set("io.compression.codecs","org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,com.hadoop.compression.lzo.LzopCodec");)
3. addCode(code) 方法添加编码解码器
图 8. 代码示例
图 8. 代码示例
addCodec(codec) 方法入口参数是个编码解码器 CompressionCodec.class,这里我们会首先接触到它的一个方法。
① codec.getDefaultExtension() 方法看方法名的字面意思我们就可以知道,此方法用于获取此编码解码所对应文件的扩展名,比如,文件名是 xxxx.gz2,那么这个方法的返回值就是“.bz2”,我们来看下 org.apache.hadoop.io.compress.BZip2Codec 此方法的实现代码:
图 9. 代码示例
图 9. 代码示例
② Codecs 是一个 SortedMap 的示例。这里有个很有意思的地方,它将 Key 值,也就是通过 codec.getDefaultExtension() 方法获取到的文件扩展名进行了翻转,举个例子,比如文件名扩展名“.bz2”,将文件名翻转之后就变成了“2zb.”。
系统加载完所有的编码解码器后,我们可以得到这样一个有序映射表,如下:
图 10. 代码示例
图 10. 代码示例
现在编码解码器都有了,我们怎么得到对应的编码解码器呢?看下面这个方法。
4. getCodec() 方法
此方法用于获取文件所对应的的编码解码器 CompressionCodec.class。
图 11. 代码示例
图 11. 代码示例
getCodec(Path) 方法的输入参数是 Path 对象,保存着文件路径。
① 将文件名翻转。如 xxxx.bz2 翻转成 2zb.xxxx。
② 获取 codecs 集合中最接近 2zb.xxxx 的值。此方法有返回值同样是个 SortMap 对象。
在这里对返回的 SortMap 对象进行第二次筛选。
编码解码器 CompressionCodec
刚刚在介绍压缩解压工程类 CompressionCodeFactory.class 的时候,我们多次提到了压缩解压器 CompressionCodecclass,并且我们在上文中还提到了它其中的一个用于获取文件扩展名的方法 getDefaultExtension()。
压缩解压工程类 CompressionCodeFactory.class 使用的是抽象工厂的设计模式。它是一个接口,制定了一系列方法,用于创建特定压缩解压算法。下面我们来看下比较重要的几个方法:
1. createOutputStream() 方法对数据流进行压缩。
图 12. 代码示例
图 12. 代码示例
此方法提供了方法重载。
① 基于流的压缩处理;
② 基于压缩机 Compress.class 的压缩处理
2. createInputStream() 方法对数据流进行解压。
图 13. 代码示例
图 13. 代码示例
这里的解压方法同样提供了方法重载。
① 基于流的解压处理;
② 基于解压机 Decompressor.class 的解压处理;
关于压缩/解压流与压缩/解压机会在下面的文章中我们会详细讲解。此处暂作了解。
3. getCompressorType() 返回需要的编码器的类型。
getDefaultExtension() 获取对应文件扩展名的方法。前文已提到过,不再敖述。
压缩机 Compressor 和解压机 Decompressor
前面在编码解码器部分的 createInputStream() 和 createInputStream() 方法中我们提到过 Compressor.class 和 Decompressor.class 对象。在 Hadoop 的实现中,数据编码器和解码器被抽象成了两个接口:
1. org.apache.hadoop.io.compress.Compressor;
2. org.apache.hadoop.io.compress.Decompressor;
它们规定了一系列的方法,所以在 Hadoop 内部的编码/解码算法实现都需要实现对应的接口。在实际的数据压缩与解压缩过程,Hadoop 为用户提供了统一的 I/O 流处理模式。
我们看一下压缩机 Compressor.class,代码如下:
图 14. 代码示例
图 14. 代码示例
① setInput() 方法接收数据到内部缓冲区,可以多次调用;
② needsInput() 方法用于检查缓冲区是否已满。如果是 false 则说明当前的缓冲区已满;
③ getBytesRead() 输入未压缩字节的总数;
④ getBytesWritten() 输出压缩字节的总数;
⑤ finish() 方法结束数据输入的过程;
⑥ finished() 方法用于检查是否已经读取完所有的等待压缩的数据。如果返回 false,表明压缩器中还有未读取的压缩数据,可以继续通过 compress() 方法读取;
⑦ compress() 方法获取压缩后的数据,释放缓冲区空间;
⑧ reset() 方法用于重置压缩器,以处理新的输入数据集合;
⑨ end() 方法用于关闭解压缩器并放弃所有未处理的输入;
⑩ reinit() 方法更进一步允许使用 Hadoop 的配置系统,重置并重新配置压缩器;
为了提高压缩效率,并不是每次用户调用 setInput() 方法,压缩机就会立即工作,所以,为了通知压缩机所有数据已经写入,必须使用 finish() 方法。finish() 调用结束后,压缩机缓冲区中保持的已经压缩的数据,可以继续通过 compress() 方法获得。至于要判断压缩机中是否还有未读取的压缩数据,则需要利用 finished() 方法来判断。
压缩流 CompressionOutputStream 和解压缩流 CompressionInputStream
前文编码解码器部分提到过 createInputStream() 方法返回 CompressionOutputStream 对象,createInputStream() 方法返回 CompressionInputStream 对象。这两个类分别继承自 java.io.OutputStream 和 java.io.InputStream。从而我们不难理解,这两个对象的作用了吧。
我们来看下 CompressionInputStream.class 的代码:
图 15. 代码示例
图 15. 代码示例
可以看到 CompressionOutputStream 实现了 OutputStream 的 close() 方法和 flush() 方法,但用于输出数据的 write() 方法以及用于结束压缩过程并将输入写到底层流的 finish() 方法和重置压缩状态的 resetState() 方法还是抽象方法,需要 CompressionOutputStream 的子类实现。
Hadoop 压缩框架中为我们提供了一个实现了 CompressionOutputStream 类通用的子类 CompressorStream.class。
图 16. 代码示例
图 16. 代码示例
CompressorStream.class 提供了三个不同的构造函数,CompressorStream 需要的底层输出流 out 和压缩时使用的压缩器,都作为参数传入构造函数。另一个参数是 CompressorStream 工作时使用的缓冲区 buffer 的大小,构造时会利用这个参数分配该缓冲区。第一个可以手动设置缓冲区大小,第二个默认 512,第三个没有缓冲区且不可使用压缩器。
图 17. 代码示例
图 17. 代码示例
在 write()、compress()、finish() 以及 resetState() 方法中,我们发现了压缩机 Compressor 的身影,前面文章我们已经介绍过压缩机的的实现过程,通过调用 setInput() 方法将待压缩数据填充到内部缓冲区,然后调用 needsInput() 方法检查缓冲区是否已满,如果缓冲区已满,将调用 compress() 方法对数据进行压缩。流程如下图所示:
图 18. 调用流程图
图 18. 调用流程图
结束语
本文深入到 Hadoop 平台压缩框架内部,对其核心代码以及各压缩格式的效率进行对比分析,以帮助读者在使用 Hadoop 平台时,可以通过对数据进行压缩处理来提高数据处理效率。当再次面临海量数据处理时, Hadoop 平台的压缩机制可以让我们事半功倍。
相关主题
Hadoop 在线 API
《Hadoop 技术内幕深入解析 HADOOP COMMON 和 HDFS 架构设计与实现原理》
developerWorks 开源技术主题:查找丰富的操作信息、工具和项目更新,帮助您掌握开源技术并将其用于 IBM 产品。
posted @
2017-09-14 17:35 xzc 阅读(555) |
评论 (0) |
编辑 收藏Linux系统查看当前主机CPU、内存、机器型号及主板信息:
查看CPU信息(型号)
# cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看内存信息
# cat /proc/meminfo
查看主板型号:
# dmidecode |grep -A16 "System Information$"
查看机器型号
# dmidecode | grep "Product Name"
查看当前操作系统内核信息
# uname -a
查看当前操作系统发行版信息
# cat /etc/issue | grep Linux
posted @
2017-09-10 16:37 xzc 阅读(240) |
评论 (0) |
编辑 收藏posted @
2017-09-07 11:37 xzc 阅读(272) |
评论 (0) |
编辑 收藏posted @
2017-08-30 21:05 xzc 阅读(305) |
评论 (0) |
编辑 收藏1. 日期输出格式化
所有日期、时间的api都在datetime模块内。
1. datetime => string
now = datetime.datetime.now()
now.strftime('%Y-%m-%d %H:%M:%S')
#输出2012-03-05 16:26:23.870105
strftime是datetime类的实例方法。
2. string => datetime
t_str = '2012-03-05 16:26:23'
d = datetime.datetime.strptime(t_str, '%Y-%m-%d %H:%M:%S')
strptime是datetime类的静态方法。
2. 日期比较操作
在datetime模块中有timedelta类,这个类的对象用于表示一个时间间隔,比如两个日期或者时间的差别。
构造方法:
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
所有的参数都有默认值0,这些参数可以是int或float,正的或负的。
可以通过timedelta.days、tiemdelta.seconds等获取相应的时间值。
timedelta类的实例,支持加、减、乘、除等操作,所得的结果也是timedelta类的实例。比如:
year = timedelta(days=365)
ten_years = year *10
nine_years = ten_years - year
同时,date、time和datetime类也支持与timedelta的加、减运算。
datetime1 = datetime2 +/- timedelta
timedelta = datetime1 - datetime2
这样,可以很方便的实现一些功能。
1. 两个日期相差多少天。
d1 = datetime.datetime.strptime('2012-03-05 17:41:20', '%Y-%m-%d %H:%M:%S')
d2 = datetime.datetime.strptime('2012-03-02 17:41:20', '%Y-%m-%d %H:%M:%S')
delta = d1 - d2
print delta.days
输出:3
2. 今天的n天后的日期。
now = datetime.datetime.now()
delta = datetime.timedelta(days=3)
n_days = now + delta
print n_days.strftime('%Y-%m-%d %H:%M:%S')
输出:2012-03-08 17:44:50
#coding=utf-8
import datetime
now=datetime.datetime.now()
print now
#将日期转化为字符串 datetime => string
print now.strftime('%Y-%m-%d %H:%M:%S')
t_str = '2012-03-05 16:26:23'
#将字符串转换为日期 string => datetime
d=datetime.datetime.strptime(t_str,'%Y-%m-%d %H:%M:%S')
print d
#在datetime模块中有timedelta类,这个类的对象用于表示一个时间间隔,比如两个日#期或者时间的差别。
#计算两个日期的间隔
d1 = datetime.datetime.strptime('2012-03-05 17:41:20', '%Y-%m-%d %H:%M:%S')
d2 = datetime.datetime.strptime('2012-03-02 17:41:20', '%Y-%m-%d %H:%M:%S')
delta = d1 - d2
print delta.days
print delta
#今天的n天后的日期。
now=datetime.datetime.now()
delta=datetime.timedelta(days=3)
n_days=now+delta
print n_days.strftime('%Y-%m-%d %H:%M:%S')
posted @
2017-08-14 23:09 xzc 阅读(1363) |
评论 (0) |
编辑 收藏Shell中并没有真正意义的多线程,要实现多线程可以启动多个后端进程,最大程度利用cpu性能。
直接看代码示例吧。
(1) 顺序执行的代码
1 #!/bin/bash 2 date 3 for i in `seq 1 5` 4 do 5 { 6 echo "sleep 5" 7 sleep 5 8 } 9 done 10 date 输出:
Sat Nov 19 09:21:51 CST 2016 sleep 5 sleep 5 sleep 5 sleep 5 sleep 5 Sat Nov 19 09:22:16 CST 2016
(2) 并行代码
使用'&'+wait 实现“多进程”实现
1 #!/bin/bash 2 date 3 for i in `seq 1 5` 4 do 5 { 6 echo "sleep 5" 7 sleep 5 8 } & 9 done 10 wait ##等待所有子后台进程结束 11 date输出:
Sat Nov 19 09:25:07 CST 2016 sleep 5 sleep 5 sleep 5 sleep 5 sleep 5 Sat Nov 19 09:25:12 CST 2016
(3) 对于大量处理任务如何实现启动后台进程的数量可控?
简单的方法可以使用2层for/while循环实现,每次wait内层循环的多个后台程序执行完成。
但是这种方式的问题是,如果内层循环有“慢节点”可能导致整个任务的执行执行时间长。
更高级的实现可以看(4)
(4) 使用命名管道(fifo)实现每次启动后台进程数量可控。
1 #!/bin/bash 2 3 function my_cmd(){ 4 t=$RANDOM 5 t=$[t%15] 6 sleep $t 7 echo "sleep $t s" 8 } 9 10 tmp_fifofile="/tmp/$$.fifo" 11 mkfifo $tmp_fifofile # 新建一个fifo类型的文件 12 exec 6<>$tmp_fifofile # 将fd6指向fifo类型 13 rm $tmp_fifofile #删也可以 14 15 thread_num=5 # 最大可同时执行线程数量 16 job_num=100 # 任务总数 17 18 #根据线程总数量设置令牌个数 19 for ((i=0;i<${thread_num};i++));do 20 echo 21 done >&6 22 23 for ((i=0;i<${job_num};i++));do # 任务数量 24 # 一个read -u6命令执行一次,就从fd6中减去一个回车符,然后向下执行, 25 # fd6中没有回车符的时候,就停在这了,从而实现了线程数量控制 26 read -u6 27 28 #可以把具体的需要执行的命令封装成一个函数 29 { 30 my_cmd 31 } & 32 33 echo >&6 # 当进程结束以后,再向fd6中加上一个回车符,即补上了read -u6减去的那个 34 done 35 36 wait 37 exec 6>&- # 关闭fd6 38 echo "over"
参考:http://lawrence-zxc.github.io/2012/06/16/shell-thread/
posted @
2017-08-02 17:01 xzc 阅读(341) |
评论 (0) |
编辑 收藏 之前在论坛看到一个关于HDFS权限的问题,当时无法回答该问题。无法回答并不意味着对HDFS权限一无所知,而是不能准确完整的阐述HDFS权限,因此决定系统地学习HDFS文件权限。HDFS的文件和目录权限模型共享了POSIX(Portable Operating System Interface,可移植操作系统接口)模型的很多部分,比如每个文件和目录与一个拥有者和组相关联,文件或者目录对于拥有者、组内的其它用户和组外的其它用户有不同的权限等。与POSIX模型不同的是,HDFS中的文件没有可执行文件的概念,因而也没有setuid和setgid,虽然目录依然保留着可执行目录的概念(x),但对于目录也没有setuid和setgid。粘贴位(sticky bit)可以用在目录上,用于阻止除超级用户,目录或文件的拥有者外的任何删除或移动目录中的文件,文件上的粘贴位不起作用。
当创建文件或目录时,拥有者为运行客户端进程的用户,组为父目录所属的组。每个访问HDFS的客户端进程有一个由用户姓名和组列表两部分组的成标识,无论何时HDFS必须对由客户端进程访问的文件或目录进行权限检查,规则如下:
- 如果进程的用户名匹配文件或目录的拥有者,那么测试拥有者权限
- 否则如果文件或目录所属的组匹配组列表中任何组,那么测试组权限
- 否则测试其它权限
如果权限检查失败,则客户端操作失败。
从hadoop-0.22开始,hadoop支持两种不同的操作模式以确定用户,分别为simple和kerberos具体使用哪个方式由参数hadoop.security.authentication设置,该参数位于core-site.xml文件中,默认值为simple。在simple模式下,客户端进程的身份由主机的操作系统确定,比如在类Unix系统中,用户名为命令whoami的输出。在kerberos模式下,客户端进程的身份由Kerberos凭证确定,比如在一个Kerberized环境中,用户可能使用kinit工具得到了一个Kerberos ticket-granting-ticket(TGT)且使用klist确定当前的principal。当映射一个Kerberosprincipal到HDFS的用户名时,除了最主要的部分外其余部分都被丢弃,比如一个principal为todd/foobar@CORP.COMPANY.COM,将映射为HDFS上的todd。无论哪种操作模式,对于HDFS来说用户标识机制都是外部的,HDFS本身没有创建用户标,建立组或者处理用户凭证的规定。
上面讨论了确定用户的两种模式,即simple和kerberos,下面学习如何确定用户组。用户组是通过由参数hadoop.security.group.mapping设置的组映射服务确定的,默认实现是org.apache.hadoop.security.JniBasedUnixGroupsMappingWithFallback,该实现首先确定Java本地接口(JNI)是否可用,如果JNI可用,该实现将使用hadoop中的API为用户解析用户组列表。如果JNI不可用,那么使用ShellBasedUnixGroupsMapping,该实现将使用Linux/Unix中的bash –cgroups命令为用户解析用户组列表。其它实现还有LdapGroupsMapping,通过直接连接LDAP服务器来解析用户组列表。对HDFS来说,用户到组的映射是在NameNode上执行的,因而NameNode的主机系统配置决定了用户的组映射。HDFS将文件或目录的用户和组存储为字符串,并且不像Linux/Unix那样可以将用户和组转换为数字。
每个针对文件或者目录的操作都将全路径名称传递到NameNode,然后对该路径的每次操作都将应用权限检查。客户端隐含地关联用户身份到NameNode的连接,减少改变现存客户端API的需要。总是存在这么一种情景,当在一个文件上的操作成功后,当重复该操作时可能失败,因为该文件或者路径中的某些目录已经不再存在。例如,当客户端第一次开始读取一个文件时,它向NameNode发出的第一个请求来发现该文件第一个块的位置,第二个寻找其他块的请求可能失败。另一方面,对于已经知道文件块的客户端来说,删除文件不会取消访问。通过添加权限,客户端对文件的访问在请求之间可能撤回,对于已经知道文件块的客户端来说,改变权限不会取消客户端的访问。
HDFS中超级用户与通常熟悉的Linux或Unix中的root用户不同,HDFS的超级用户是与NameNode进程有相同标示的用户,更简单易懂些,启动NameNode的用户就为超级用户。对于谁是超级用户没有固定的定义,当NameNode启动后,该进程的标示决定了谁是超级用户。HDFS的超级用户不必是NameNode主机的超级用户,也需用所有的集群使用相同的超级用户,出于实验目的在个人工作站上运行HDFS的人自然而然的称为超级用户而不需要任何配置。另外参数dfs.permissions.superusergroup设置了超级用户,该组中的所有用户也为超级用户。超级用户在HDFS中可以执行任何操作而针对超级用户的权限检查永远不会失败。
HDFS也提供了对POSIX ACL(访问控制列表)支持来为特定的用户或者用户组提供更加细粒度的文件权限。ACL是不同于用户和组的自然组织层次的有用的权限控制方式,ACL可以为特定的用户和组设置不同的权限,而不仅仅是文件的拥有者和文件所属的组。默认情况下,HDFS禁用ACL,因此NameNode禁止ACL的创建,为了启用ACL,需要在hdfs-site.xml中将参数dfs.namenode.acls.enabled设置为true。
访问控制列表由一组ACL项组成,每个ACL项命名了特定的用户或组,并为其授予或拒绝读,写和执行的权限,例如:
user::rw- user:bruce:rwx #effective:r-- group::r-x #effective:r-- group:sales:rwx #effective:r-- mask::r-- other::r--
每个ACL项由类型,可选的名称和权限字符串组成,它们之间使用冒号(:)。在上面的例子中文件的拥有者具有读写权限,文件所属的组具有读和执行的权限,其他用户具有读权限,这些设置与将文件设置为654等价(6表示拥有者的读写权限,5表示组的读和执行权限,4表示其他用户的读权限)。除此之外,还有两个扩展的ACL项,分别为用户bruce和组sales,并都授予了读写和执行的权限。mask项是一个特殊的项,用于过滤授予所有命名用户,命名组及未命名组的权限,即过滤除文件拥有者和其他用户(other)之外的任何ACL项。在该例子中,mask值有读权限,则bruce用户、sales组和文件所属的组只具有读权限。每个ACL必须有mask项,如果用户在设置ACL时没有使用mask项,一个mask项被自动加入到ACL中,该mask项是通过计算所有被mask过滤项的权限与(&运算)得出的。对拥有ACL的文件执行chmod实际改变的是mask项的权限,因为mask项扮演的是过滤器的角色,这将有效地约束所有扩展项的权限,而不是仅改变组的权限而可能漏掉其它扩展项的权限。
访问控制列表和默认访问控制列表存在着不同,前者定义了在执行权限检查实施的规则,后者定义了新文件或者子目录创建时自动接收的ACL项,例如:
user::rwx group::r-x other::r-x default:user::rwx default:user:bruce:rwx #effective:r-x default:group::r-x default:group:sales:rwx #effective:r-x default:mask::r-x default:other::r-x
只有目录可能拥有默认访问控制列表,当创建新文件或者子目录时,自动拷贝父辈的默认访问控制列表到自己的访问控制列表中,新的子目录也拷贝父辈默认的访问控制列表到自己的默认访问控制列表中。这样,当创建子目录时默认ACL将沿着文件系统树被任意深层次地拷贝。在新的子ACL中,准确的权限由模式参数过滤。默认的umask为022,通常新目录权限为755,新文件权限为644。模式参数为未命名用户(文件的拥有者),mask及其他用户过滤拷贝的权限值。在上面的例子中,创建权限为755的子目录时,模式对最终结果没有影响,但是如果创建权限为644的文件时,模式过滤器导致新文件的ACL中文件拥有者的权限为读写,mask的权限为读以及其他用户权限为读。mask的权限意味着用户bruce和组sales只有读权限。拷贝ACL发生在文件或子目录的创建时,后面如果修改父辈的默认ACL将不再影响已存在子类的ACL。
默认ACL必须包含所有最小要求的ACL项,包括文件拥有者项,文件所属的组项和其它用户项。如果用户没有在默认ACL中配置上述三项中的任何一个,那么该项将通过从访问ACL拷贝对应的权限来自动插入,或者如果没有访问ACL则自动插入权限位。默认ACL也必须拥有mask,如果mask没有被指定,通过计算所有被mask过滤项的权限与(&运算)自动插入mask。当一个文件拥有ACL时,权限检查的算法变为:
- 如果用户名匹配文件的拥有者,则测试拥有者权限
- 否则,如果用户名匹配命名用户项中的用户名,则测试由mask权限过滤后的该项的权限
- 否则,如果文件所属的组匹配组列表中的任何组,并且如果这些被mask过滤的权限具有访问权限,那么使用这么权限
- 否则,如果存在命名组项匹配组列表中的成员,并且如果这些被mask过滤的权限具有访问权限,那么使用这么权限
- 否则,如果文件所属的组或者任何命名组项匹配组列表中的成员,但不具备访问权限,那么访问被拒绝
- 否则测试文件的其他用户权限
最佳实践时基于传统的权限位设置大部分权限要求,然后定义少量带有特殊规则的ACL增加权限位。相比较只是用权限位的文件,使用ACL的文件会在NameNode中产生额外的内存消耗。
上面学习了HDFS中的文件权限和访问控制列表,最后学习一下如何针对权限和ACL进行配置,下表列出了其中的重要参数:
| 参数名 | 位置 | 用途 |
| dfs.permissions.enabled | hdfs-site.xml | 默认值为true,即启用权限检查。如果为 false,则禁用权限检查。 |
| hadoop.http.staticuser.user | core-site.xml | 默认值为dr.who,查看web UI的用户 |
| dfs.permissions.superusergroup | hdfs-site.xml | 超级用户的组名称,默认为supergroup |
| <fs.permissions.umask-mode | core-site.xml | 创建文件和目录时使用的umask,默认值为八进制022,每位数字对应了拥有者,组和其他用户。该值既可以使用八进制数字,如022,也可以使用符号,如u=rwx,g=r-x,o=r-x(对应022) |
| dfs.cluster.administrators | hdfs-site.xml | 被指定为ACL的集群管理员 |
| dfs.namenode.acls.enabled | hdfs-site.xml | 默认值为false,禁用ACL,设置为true则启用ACL。当ACL被禁用时,NameNode拒绝设置或者获取ACL的请求 |
posted @
2017-07-28 10:55 xzc 阅读(968) |
评论 (0) |
编辑 收藏1. crontab 命令:用于在某个时间,系统自动执行你所希望的程序文件或命令。
2. crontab 的参数
-e (edit user's crontab)
-l (list user's crontab)
-r (delete user's crontab)
-i (prompt before deleting user's crontab)
3.下面进行一个例子:在8月6号18时每隔3分钟执行以下命令:who >> /apple/test_crontab.log
步骤一:先创建一个文件cronfile:内容为如下:
*/3 18 6 8 * who >> /apple/test_crontab_log
步骤二:将文件cronfile 加入到cron守护进行(命令为:crontab cronfile)
4. 检查是否加入到守护进程cron中,用命令:crontab -l
如何出来的内容中包含你刚刚的内容,则加入成功。每隔3分钟查看下test_crontab.log文件,看看是否有内容。
5. 对crontab内容格式的解释:f1 f2 f3 f4 f5 program
f1 是表示分钟(0-59),f2 表示小时(0-23),f3 表示一个月份中的第几日(1-(31、30、29、28)),f4 表示月份(1-12),f5 表示一个星期中的第几天(0-6(0表示周日))。program 表示要执行的程式(可以理解为文件或命令)
f1:为*时候表示每隔1分钟,如果为*/n 表示每隔n分钟,如果为3,4 表示第3,4分钟,如果为2-6表示第2分钟到第6分钟。
f2:为*时候表示每隔1小说。如果为*/n 表示每隔n小时,如果为3,4 表示第3,4小时,如果为2-6表示第2小时到第6小时
f3: 为*时候表示每天。n 表示第n天
f4: 为*时候表示每月。n 表示第n个月
f5: 为*时候表示每周。0表示周日,6表示周六,1-4表示周一到周六
6. 具体例子:(来自crontab百度百科)
a. 每月每天每小时的第 0 分钟执行一次 /bin/ls : 0 * * * * /bin/ls
b. 在 12 月内, 每天的早上 6 点到 12 点中,每隔 20 分钟执行一次 /usr/bin/backup :
*/20 6-12 * 12 * /usr/bin/backup
c. 周一到周五每天下午 5:00 寄一封信给 alex_mail_name :
0 17 * * 1-5 mail -s "hi" alex_mail_name < /tmp/maildata
d. 每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha"
20 0-23/2 * * * echo "haha"
e. 晚上11点到早上8点之间每两个小时和早上8点 显示日期 0 23-7/2,8 * * * date
posted @
2017-07-27 18:59 xzc 阅读(299) |
评论 (0) |
编辑 收藏最近一段时间,在处理Shell 脚本时候,遇到时间的处理问题。 时间的加减,以及时间差的计算。
1。 时间加减
这里处理方法,是将基础的时间转变为时间戳,然后,需要增加或者改变时间,变成 秒。
如:1990-01-01 01:01:01 加上 1小时 20分
处理方法:
a.将基础时间转为时间戳
time1=$(date +%s -d '1990-01-01 01:01:01')
echo $time1
631126861 【时间戳】
b.将增加时间变成秒
[root@localhost ~]# time2=$((1*60*60+20*60))
[root@localhost ~]# echo $time2
4800
c.两个时间相加,计算出结果时间
time1=$(($time1+$time2))
time1=$(date +%Y-%m-%d\ %H:%M:%S -d "1970-01-01 UTC $time1 seconds");
echo $time1
1990-01-01 02:21:01
2。时间差计算方法
如:2010-01-01 与 2009-01-01 11:11:11 时间差
原理:同样转成时间戳,然后计算天,时,分,秒
time1=$(($(date +%s -d '2010-01-01') - $(date +%s -d '2009-01-01 11:11:11')));
echo time1
将time1 / 60 秒,就变成分了。
补充说明:
shell 单括号运算符号:
a=$(date);
等同于:a=`date`;
双括号运算符:
a=$((1+2));
echo $a;
等同于:
a=`expr 1 + 2`
posted @
2017-07-06 16:33 xzc 阅读(3322) |
评论 (1) |
编辑 收藏可参照:http://www.voidcn.com/blog/Vindra/article/p-4917667.html
一、get请求
curl "http://www.baidu.com" 如果这里的URL指向的是一个文件或者一幅图都可以直接下载到本地
curl -i "http://www.baidu.com" 显示全部信息
curl -l "http://www.baidu.com" 只显示头部信息
curl -v "http://www.baidu.com" 显示get请求全过程解析
wget "http://www.baidu.com"也可以
二、post请求
curl -d "param1=value1¶m2=value2" "http://www.baidu.com"
三、json格式的post请求
curl -l -H "Content-type: application/json" -X POST -d '{"phone":"13521389587","password":"test"}' http://domain/apis/users.json
例如:
curl -l -H "Content-type: application/json" -X POST -d '{"ver": "1.0","soa":{"req":"123"},"iface":"me.ele.lpdinfra.prediction.service.PredictionService","method":"restaurant_make_order_time","args":{"arg2":"\"stable\"","arg1":"{\"code\":[\"WIND\"],\"temperature\":11.11}","arg0":"{\"tracking_id\":\"100000000331770936\",\"eleme_order_id\":\"100000000331770936\",\"platform_id\":\"4\",\"restaurant_id\":\"482571\",\"dish_num\":1,\"dish_info\":[{\"entity_id\":142547763,\"quantity\":1,\"category_id\":1,\"dish_name\":\"[0xe7][0x89][0xb9][0xe4][0xbb][0xb7][0xe8][0x85][0x8a][0xe5][0x91][0xb3][0xe5][0x8f][0x89][0xe7][0x83][0xa7][0xe5][0x8f][0x8c][0xe6][0x8b][0xbc][0xe7][0x85][0xb2][0xe4][0xbb][0x94][0xe9][0xa5][0xad]\",\"price\":31.0}],\"merchant_location\":{\"longitude\":\"121.47831425\",\"latitude\":\"31.27576153\"},\"customer_location\":{\"longitude\":\"121.47831425\",\"latitude\":\"31.27576153\"},\"created_at\":1477896550,\"confirmed_at\":1477896550,\"dishes_total_price\":0.0,\"food_boxes_total_price\":2.0,\"delivery_total_price\":2.0,\"pay_amount\":35.0,\"city_id\":\"1\"}"}}' http://vpcb-lpdinfra-stream-1.vm.elenet.me:8989/rpc
ps:json串内层参数需要格式化
posted @
2017-05-18 11:28 xzc 阅读(1641) |
评论 (1) |
编辑 收藏
1)统计80端口连接数
netstat -nat|grep -i "80"|wc -l
2)统计httpd协议连接数
ps -ef|grep httpd|wc -l
3)、统计已连接上的,状态为“established
netstat -na|grep ESTABLISHED|wc -l
4)、查出哪个IP地址连接最多,将其封了.
netstat -na|grep ESTABLISHED|awk {print $5}|awk -F: {print $1}|sort|uniq -c|sort -r +0n
netstat -na|grep SYN|awk {print $5}|awk -F: {print $1}|sort|uniq -c|sort -r +0n
---------------------------------------------------------------------------------------------
1、查看apache当前并发访问数:
netstat -an | grep ESTABLISHED | wc -l
对比httpd.conf中MaxClients的数字差距多少。
2、查看有多少个进程数:
ps aux|grep httpd|wc -l
3、可以使用如下参数查看数据
server-status?auto
#ps -ef|grep httpd|wc -l
1388
统计httpd进程数,连个请求会启动一个进程,使用于Apache服务器。
表示Apache能够处理1388个并发请求,这个值Apache可根据负载情况自动调整。
#netstat -nat|grep -i "80"|wc -l
4341
netstat -an会打印系统当前网络链接状态,而grep -i "80"是用来提取与80端口有关的连接的,wc -l进行连接数统计。
最终返回的数字就是当前所有80端口的请求总数。
#netstat -na|grep ESTABLISHED|wc -l
376
netstat -an会打印系统当前网络链接状态,而grep ESTABLISHED 提取出已建立连接的信息。 然后wc -l统计。
最终返回的数字就是当前所有80端口的已建立连接的总数。
netstat -nat||grep ESTABLISHED|wc - 可查看所有建立连接的详细记录
查看Apache的并发请求数及其TCP连接状态:
Linux命令:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果示例:
LAST_ACK 5
SYN_RECV 30
ESTABLISHED 1597
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057
其中的
SYN_RECV表示正在等待处理的请求数;
ESTABLISHED表示正常数据传输状态;
TIME_WAIT表示处理完毕,等待超时结束的请求数。
---------------------------------------------------------------------------------------------
查看httpd进程数(即prefork模式下Apache能够处理的并发请求数):
Linux命令:
ps -ef | grep httpd | wc -l
查看Apache的并发请求数及其TCP连接状态:
Linux命令:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果示例:
LAST_ACK 5
SYN_RECV 30
ESTABLISHED 1597
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057
说明:
SYN_RECV表示正在等待处理的请求数;
ESTABLISHED表示正常数据传输状态;
TIME_WAIT表示处理完毕,等待超时结束的请求数。
posted @
2017-05-17 23:12 xzc 阅读(1463) |
评论 (2) |
编辑 收藏一、回收站简介:
在HDFS里,删除文件时,不会真正的删除,其实是放入回收站/trash,回收站里的文件可以快速恢复。
可以设置一个时间阀值,当回收站里文件的存放时间超过这个阀值或是回收站被清空时,文件才会被彻底删除,并且释放占用的数据块。
二、实例:
Hadoop的回收站trash功能默认是关闭的,所以需要在core-site.xml中手动开启。
1、修改core-site.xml,增加:
<property> <name>fs.trash.interval</name> <value>1440</value> <description>Number of minutes between trash checkpoints. If zero, the trash feature is disabled. </description> </property>
默认是0,单位是分钟,这里设置为1天。
删除数据rm后,会将数据move到当前文件夹下的.Trash目录。
2、测试
1)、新建目录input
hadoop/bin/hadoop fs -mkdir input
2)、上传文件
root@master:/data/soft# hadoop/bin/hadoop fs -copyFromLocal /data/soft/file0* input
3)、删除目录input
[root@master data]# hadoop fs -rmr input Moved to trash: hdfs://master:9000/user/root/input
4)、查看当前目录
[root@master data]# hadoop fs -ls Found 2 items drwxr-xr-x - root supergroup 0 2011-02-12 22:17 /user/root/.Trash
发现input删除了,多了一个目录.Trash
5)、恢复刚刚删除的目录
[root@master data]# hadoop fs -mv /user/root/.Trash/Current/user/root/input /user/root/input
6)、查看恢复的数据
[root@master data]# hadoop fs -ls input Found 2 items -rw-r--r-- 3 root supergroup 22 2011-02-12 17:40 /user/root/input/file01 -rw-r--r-- 3 root supergroup 28 2011-02-12 17:40 /user/root/input/file02
7)、删除.Trash目录(清理垃圾)
[root@master data]# hadoop fs -rmr .Trash Deleted hdfs://master:9000/user/root/.Trash
posted @
2017-05-12 11:20 xzc 阅读(214) |
评论 (0) |
编辑 收藏posted @
2017-05-10 10:49 xzc 阅读(316) |
评论 (0) |
编辑 收藏
一、为什么需要消息系统
1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 3.扩展性: 因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。 4.灵活性 & 峰值处理能力: 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 5.可恢复性: 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 6.顺序保证: 在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性) 7.缓冲: 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。 8.异步通信: 很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
二、kafka 架构
2.1 拓扑结构
如下图:
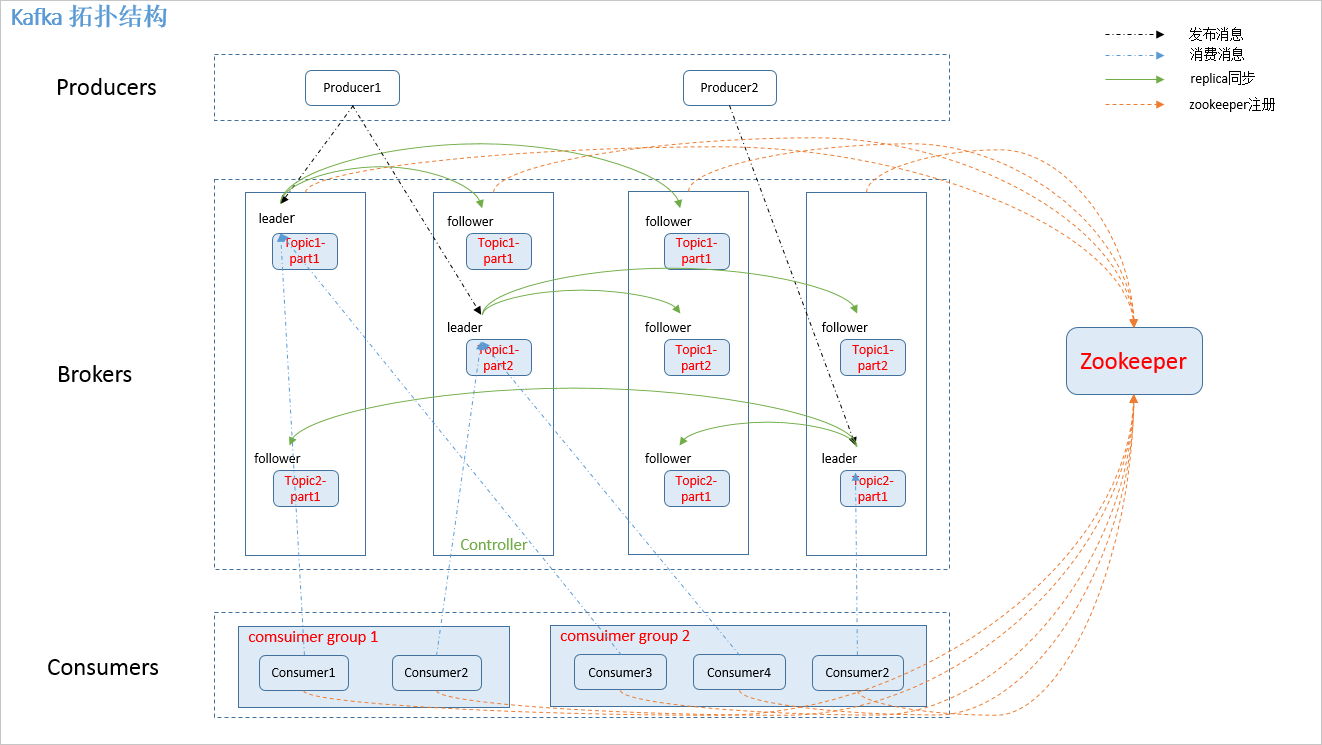
图.1
2.2 相关概念
如图.1中,kafka 相关名词解释如下:
1.producer: 消息生产者,发布消息到 kafka 集群的终端或服务。 2.broker: kafka 集群中包含的服务器。 3.topic: 每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。 4.partition: partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。 5.consumer: 从 kafka 集群中消费消息的终端或服务。 6.Consumer group: high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。 7.replica: partition 的副本,保障 partition 的高可用。 8.leader: replica 中的一个角色, producer 和 consumer 只跟 leader 交互。 9.follower: replica 中的一个角色,从 leader 中复制数据。 10.controller: kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。 12.zookeeper: kafka 通过 zookeeper 来存储集群的 meta 信息。
2.3 zookeeper 节点
kafka 在 zookeeper 中的存储结构如下图所示:

图.2
三、producer 发布消息
3.1 写入方式
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。
3.2 消息路由
producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。其路由机制为:
1. 指定了 patition,则直接使用; 2. 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition 3. patition 和 key 都未指定,使用轮询选出一个 patition。
附上 java 客户端分区源码,一目了然:

//创建消息实例 public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) { if (topic == null) throw new IllegalArgumentException("Topic cannot be null"); if (timestamp != null && timestamp < 0) throw new IllegalArgumentException("Invalid timestamp " + timestamp); this.topic = topic; this.partition = partition; this.key = key; this.value = value; this.timestamp = timestamp; } //计算 patition,如果指定了 patition 则直接使用,否则使用 key 计算 private int partition(ProducerRecord<K, V> record, byte[] serializedKey , byte[] serializedValue, Cluster cluster) { Integer partition = record.partition(); if (partition != null) { List<PartitionInfo> partitions = cluster.partitionsForTopic(record.topic()); int lastPartition = partitions.size() - 1; if (partition < 0 || partition > lastPartition) { throw new IllegalArgumentException(String.format("Invalid partition given with record: %d is not in the range [0...%d].", partition, lastPartition)); } return partition; } return this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); } // 使用 key 选取 patition public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (keyBytes == null) { int nextValue = counter.getAndIncrement(); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) { int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { return DefaultPartitioner.toPositive(nextValue) % numPartitions; } } else { //对 keyBytes 进行 hash 选出一个 patition return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } }3.3 写入流程
producer 写入消息序列图如下所示:

图.3
流程说明:
1. producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader 2. producer 将消息发送给该 leader 3. leader 将消息写入本地 log 4. followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK 5. leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
3.4 producer delivery guarantee
一般情况下存在三种情况:
1. At most once 消息可能会丢,但绝不会重复传输 2. At least one 消息绝不会丢,但可能会重复传输 3. Exactly once 每条消息肯定会被传输一次且仅传输一次
当 producer 向 broker 发送消息时,一旦这条消息被 commit,由于 replication 的存在,它就不会丢。但是如果 producer 发送数据给 broker 后,遇到网络问题而造成通信中断,那 Producer 就无法判断该条消息是否已经 commit。虽然 Kafka 无法确定网络故障期间发生了什么,但是 producer 可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了 Exactly once,但目前还并未实现。所以目前默认情况下一条消息从 producer 到 broker 是确保了 At least once,可通过设置 producer 异步发送实现At most once。
四、broker 保存消息
4.1 存储方式
物理上把 topic 分成一个或多个 patition(对应 server.properties 中的 num.partitions=3 配置),每个 patition 物理上对应一个文件夹(该文件夹存储该 patition 的所有消息和索引文件),如下:
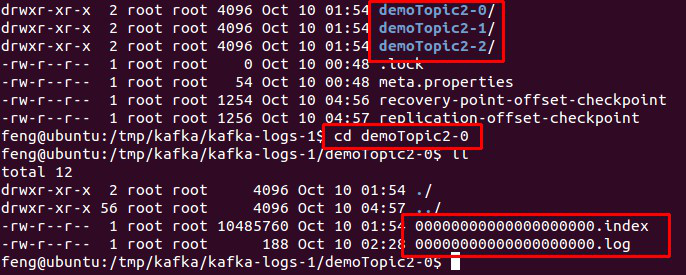
图.4
4.2 存储策略
无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据:
1. 基于时间:log.retention.hours=168 2. 基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
4.3 topic 创建与删除
4.3.1 创建 topic
创建 topic 的序列图如下所示:
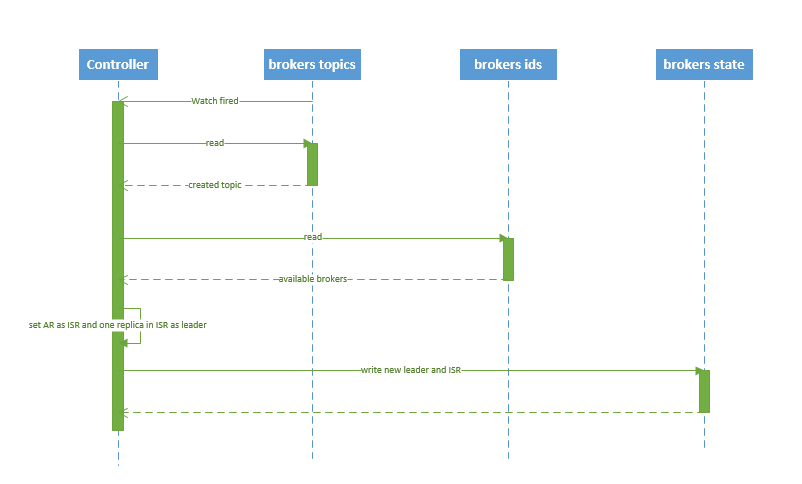
图.5
流程说明:
1. controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。 2. controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition: 2.1 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR 2.2 将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state 3. controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。
4.3.2 删除 topic
删除 topic 的序列图如下所示:
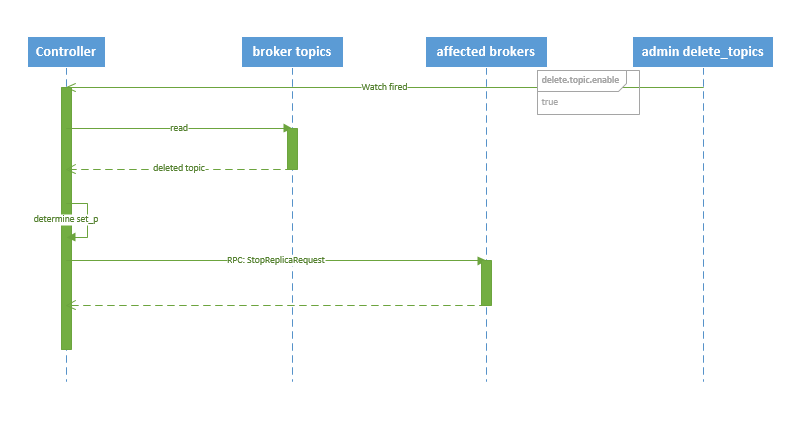
图.6
流程说明:
1. controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。 2. 若 delete.topic.enable=false,结束;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest。
五、kafka HA
5.1 replication
如图.1所示,同一个 partition 可能会有多个 replica(对应 server.properties 配置中的 default.replication.factor=N)。没有 replica 的情况下,一旦 broker 宕机,其上所有 patition 的数据都不可被消费,同时 producer 也不能再将数据存于其上的 patition。引入replication 之后,同一个 partition 可能会有多个 replica,而这时需要在这些 replica 之间选出一个 leader,producer 和 consumer 只与这个 leader 交互,其它 replica 作为 follower 从 leader 中复制数据。
Kafka 分配 Replica 的算法如下:
1. 将所有 broker(假设共 n 个 broker)和待分配的 partition 排序 2. 将第 i 个 partition 分配到第(i mod n)个 broker 上 3. 将第 i 个 partition 的第 j 个 replica 分配到第((i + j) mode n)个 broker上
5.2 leader failover
当 partition 对应的 leader 宕机时,需要从 follower 中选举出新 leader。在选举新leader时,一个基本的原则是,新的 leader 必须拥有旧 leader commit 过的所有消息。
kafka 在 zookeeper 中(/brokers/.../state)动态维护了一个 ISR(in-sync replicas),由3.3节的写入流程可知 ISR 里面的所有 replica 都跟上了 leader,只有 ISR 里面的成员才能选为 leader。对于 f+1 个 replica,一个 partition 可以在容忍 f 个 replica 失效的情况下保证消息不丢失。
当所有 replica 都不工作时,有两种可行的方案:
1. 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长。 2. 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短。
kafka 0.8.* 使用第二种方式。
kafka 通过 Controller 来选举 leader,流程请参考5.3节。
5.3 broker failover
kafka broker failover 序列图如下所示:
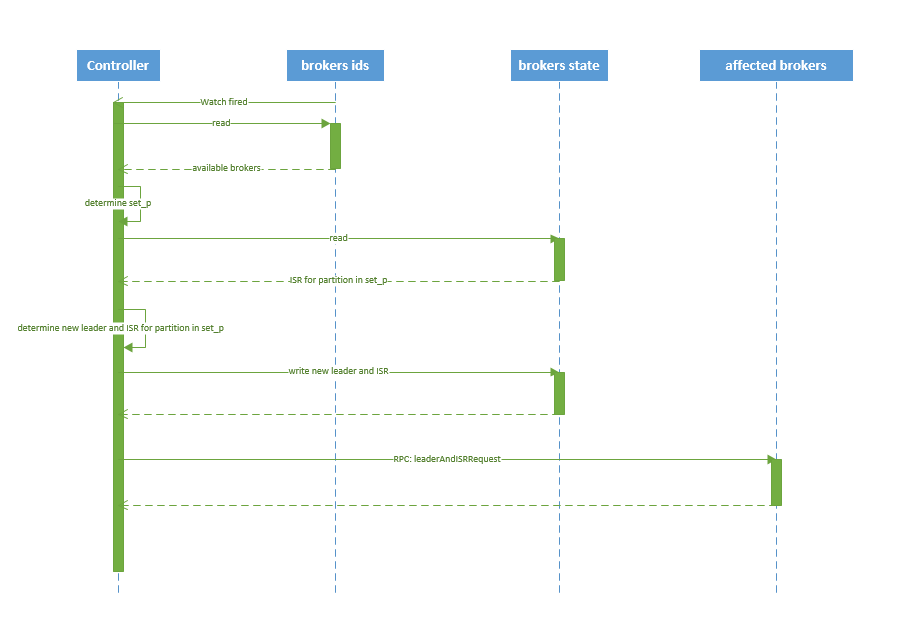
图.7
流程说明:
1. controller 在 zookeeper 的 /brokers/ids/[brokerId] 节点注册 Watcher,当 broker 宕机时 zookeeper 会 fire watch 2. controller 从 /brokers/ids 节点读取可用broker 3. controller决定set_p,该集合包含宕机 broker 上的所有 partition 4. 对 set_p 中的每一个 partition 4.1 从/brokers/topics/[topic]/partitions/[partition]/state 节点读取 ISR 4.2 决定新 leader(如4.3节所描述) 4.3 将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点 5. 通过 RPC 向相关 broker 发送 leaderAndISRRequest 命令
5.4 controller failover
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher,当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
当新的 controller 当选时,会触发 KafkaController.onControllerFailover 方法,在该方法中完成如下操作:
1. 读取并增加 Controller Epoch。 2. 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注册 watcher。 3. 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注册 watcher。 4. 通过 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注册 watcher。 5. 若 delete.topic.enable=true(默认值是 false),则 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注册 watcher。 6. 通过 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注册Watch。 7. 初始化 ControllerContext 对象,设置当前所有 topic,“活”着的 broker 列表,所有 partition 的 leader 及 ISR等。 8. 启动 replicaStateMachine 和 partitionStateMachine。 9. 将 brokerState 状态设置为 RunningAsController。 10. 将每个 partition 的 Leadership 信息发送给所有“活”着的 broker。 11. 若 auto.leader.rebalance.enable=true(默认值是true),则启动 partition-rebalance 线程。 12. 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,则删除相应的Topic。
6. consumer 消费消息
6.1 consumer API
kafka 提供了两套 consumer API:
1. The high-level Consumer API 2. The SimpleConsumer API
其中 high-level consumer API 提供了一个从 kafka 消费数据的高层抽象,而 SimpleConsumer API 则需要开发人员更多地关注细节。
6.1.1 The high-level consumer API
high-level consumer API 提供了 consumer group 的语义,一个消息只能被 group 内的一个 consumer 所消费,且 consumer 消费消息时不关注 offset,最后一个 offset 由 zookeeper 保存。
使用 high-level consumer API 可以是多线程的应用,应当注意:
1. 如果消费线程大于 patition 数量,则有些线程将收不到消息 2. 如果 patition 数量大于线程数,则有些线程多收到多个 patition 的消息 3. 如果一个线程消费多个 patition,则无法保证你收到的消息的顺序,而一个 patition 内的消息是有序的
6.1.2 The SimpleConsumer API
如果你想要对 patition 有更多的控制权,那就应该使用 SimpleConsumer API,比如:
1. 多次读取一个消息 2. 只消费一个 patition 中的部分消息 3. 使用事务来保证一个消息仅被消费一次
但是使用此 API 时,partition、offset、broker、leader 等对你不再透明,需要自己去管理。你需要做大量的额外工作:
1. 必须在应用程序中跟踪 offset,从而确定下一条应该消费哪条消息 2. 应用程序需要通过程序获知每个 Partition 的 leader 是谁 3. 需要处理 leader 的变更
使用 SimpleConsumer API 的一般流程如下:
1. 查找到一个“活着”的 broker,并且找出每个 partition 的 leader 2. 找出每个 partition 的 follower 3. 定义好请求,该请求应该能描述应用程序需要哪些数据 4. fetch 数据 5. 识别 leader 的变化,并对之作出必要的响应
以下针对 high-level Consumer API 进行说明。
6.2 consumer group
如 2.2 节所说, kafka 的分配单位是 patition。每个 consumer 都属于一个 group,一个 partition 只能被同一个 group 内的一个 consumer 所消费(也就保障了一个消息只能被 group 内的一个 consuemr 所消费),但是多个 group 可以同时消费这个 partition。
kafka 的设计目标之一就是同时实现离线处理和实时处理,根据这一特性,可以使用 spark/Storm 这些实时处理系统对消息在线处理,同时使用 Hadoop 批处理系统进行离线处理,还可以将数据备份到另一个数据中心,只需要保证这三者属于不同的 consumer group。如下图所示:

图.8
6.3 消费方式
consumer 采用 pull 模式从 broker 中读取数据。
push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
对于 Kafka 而言,pull 模式更合适,它可简化 broker 的设计,consumer 可自主控制消费消息的速率,同时 consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
6.4 consumer delivery guarantee
如果将 consumer 设置为 autocommit,consumer 一旦读到数据立即自动 commit。如果只讨论这一读取消息的过程,那 Kafka 确保了 Exactly once。
但实际使用中应用程序并非在 consumer 读取完数据就结束了,而是要进行进一步处理,而数据处理与 commit 的顺序在很大程度上决定了consumer delivery guarantee:
1.读完消息先 commit 再处理消息。 这种模式下,如果 consumer 在 commit 后还没来得及处理消息就 crash 了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于 At most once 2.读完消息先处理再 commit。 这种模式下,如果在处理完消息之后 commit 之前 consumer crash 了,下次重新开始工作时还会处理刚刚未 commit 的消息,实际上该消息已经被处理过了。这就对应于 At least once。 3.如果一定要做到 Exactly once,就需要协调 offset 和实际操作的输出。 精典的做法是引入两阶段提交。如果能让 offset 和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,consumer 拿到数据后可能把数据放到 HDFS,如果把最新的 offset 和数据本身一起写到 HDFS,那就可以保证数据的输出和 offset 的更新要么都完成,要么都不完成,间接实现 Exactly once。(目前就 high-level API而言,offset 是存于Zookeeper 中的,无法存于HDFS,而SimpleConsuemr API的 offset 是由自己去维护的,可以将之存于 HDFS 中)
总之,Kafka 默认保证 At least once,并且允许通过设置 producer 异步提交来实现 At most once(见文章《kafka consumer防止数据丢失》)。而 Exactly once 要求与外部存储系统协作,幸运的是 kafka 提供的 offset 可以非常直接非常容易得使用这种方式。
更多关于 kafka 传输语义的信息请参考《Message Delivery Semantics》。
6.5 consumer rebalance
当有 consumer 加入或退出、以及 partition 的改变(如 broker 加入或退出)时会触发 rebalance。consumer rebalance算法如下:
1. 将目标 topic 下的所有 partirtion 排序,存于PT 2. 对某 consumer group 下所有 consumer 排序,存于 CG,第 i 个consumer 记为 Ci 3. N=size(PT)/size(CG),向上取整 4. 解除 Ci 对原来分配的 partition 的消费权(i从0开始) 5. 将第i*N到(i+1)*N-1个 partition 分配给 Ci
在 0.8.*版本,每个 consumer 都只负责调整自己所消费的 partition,为了保证整个consumer group 的一致性,当一个 consumer 触发了 rebalance 时,该 consumer group 内的其它所有其它 consumer 也应该同时触发 rebalance。这会导致以下几个问题:
1.Herd effect 任何 broker 或者 consumer 的增减都会触发所有的 consumer 的 rebalance 2.Split Brain 每个 consumer 分别单独通过 zookeeper 判断哪些 broker 和 consumer 宕机了,那么不同 consumer 在同一时刻从 zookeeper 看到的 view 就可能不一样,这是由 zookeeper 的特性决定的,这就会造成不正确的 reblance 尝试。 3. 调整结果不可控 所有的 consumer 都并不知道其它 consumer 的 rebalance 是否成功,这可能会导致 kafka 工作在一个不正确的状态。
基于以上问题,kafka 设计者考虑在0.9.*版本开始使用中心 coordinator 来控制 consumer rebalance,然后又从简便性和验证要求两方面考虑,计划在 consumer 客户端实现分配方案。(见文章《Kafka Detailed Consumer Coordinator Design》和《Kafka Client-side Assignment Proposal》),此处不再赘述。
七、注意事项
7.1 producer 无法发送消息的问题
最开始在本机搭建了kafka伪集群,本地 producer 客户端成功发布消息至 broker。随后在服务器上搭建了 kafka 集群,在本机连接该集群,producer 却无法发布消息到 broker(奇怪也没有抛错)。最开始怀疑是 iptables 没开放,于是开放端口,结果还不行(又开始是代码问题、版本问题等等,倒腾了很久)。最后没办法,一项一项查看 server.properties 配置,发现以下两个配置:
# The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = security_protocol://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
以上说的就是 advertised.listeners 是 broker 给 producer 和 consumer 连接使用的,如果没有设置,就使用 listeners,而如果 host_name 没有设置的话,就使用 java.net.InetAddress.getCanonicalHostName() 方法返回的主机名。
修改方法:
1. listeners=PLAINTEXT://121.10.26.XXX:9092 2. advertised.listeners=PLAINTEXT://121.10.26.XXX:9092
修改后重启服务,正常工作。关于更多 kafka 配置说明,见文章《Kafka学习整理三(borker(0.9.0及0.10.0)配置)》。
八、参考文章
1. 《Kafka剖析(一):Kafka背景及架构介绍》
2. 《Kafka设计解析(二):Kafka High Availability (上)》
3. 《Kafka设计解析(二):Kafka High Availability (下)》
4. 《Kafka设计解析(四):Kafka Consumer解析》
5. 《Kafka设计解析(五):Kafka Benchmark》
6. 《Kafka学习整理三(borker(0.9.0及0.10.0)配置)》
7. 《Using the High Level Consumer》
8. 《Using SimpleConsumer》
9. 《Consumer Client Re-Design》
10. 《Message Delivery Semantics》
11. 《Kafka Detailed Consumer Coordinator Design》
12. 《Kafka Client-side Assignment Proposal》
13. 《Kafka和DistributedLog技术对比》
14. 《kafka安装和启动》
15. 《kafka consumer防止数据丢失》
本文版权归作者和博客园共有,欢迎转载,未经同意须保留此段声明,且在文章页面明显位置给出原文连接。欢迎指正与交流。
posted @
2017-04-28 10:37 xzc 阅读(305) |
评论 (0) |
编辑 收藏1. Kerberos简介
1.1. 功能
一个安全认证协议
用tickets验证
避免本地保存密码和在互联网上传输密码
包含一个可信任的第三方
使用对称加密
客户端与服务器(非KDC)之间能够相互验证
Kerberos只提供一种功能——在网络上安全的完成用户的身份验证。它并不提供授权功能或者审计功能。
1.2. 概念
首次请求,三次通信方
- the Authentication Server
- the Ticket Granting Server
- the Service or host machine that you’re wanting access to.

图 1‑1 角色
其他知识点
- 每次通信,消息包含两部分,一部分可解码,一部分不可解码
- 服务端不会直接有KDC通信
- KDC保存所有机器的账户名和密码
- KDC本身具有一个密码
2. 3次通信

我们这里已获取服务器中的一张表(数据)的服务以为,为一个http服务。
2.1. 你和验证服务
如果想要获取http服务,你首先要向KDC表名你自己的身份。这个过程可以在你的程序启动时进行。Kerberos可以通过kinit获取。介绍自己通过未加密的信息发送至KDC获取Ticket Granting Ticket (TGT)。
(1)信息包含
Authentication Server收到你的请求后,会去数据库中验证,你是否存在。注意,仅仅是验证是否存在,不会验证对错。
如果存在,Authentication Server会产生一个随机的Session key(可以是一个64位的字符串)。这个key用于你和Ticket Granting Server (TGS)之间通信。
(2)回送信息
Authentication Server同样会发送两部分信息给你,一部分信息为TGT,通过KDC自己的密码进行加密,包含:
- 你的name/ID
- TGS的name/ID
- 时间戳
- 你的IP地址
- TGT的生命周期
- TGS session key
另外一部分通过你的密码进行加密,包含的信息有
- TGS的name/ID
- 时间戳
- 生命周期
- TGS session key

图 2‑1 第一次通信
如果你的密码是正确的,你就能解密第二部分信息,获取到TGS session key。如果,密码不正确,无法解密,则认证失败。第一部分信息TGT,你是无法解密的,但需要展示缓存起来。
2.2. 你和TGS
如果第一部分你已经成功,你已经拥有无法解密的TGT和一个TGS Session Key。
(1) 请求信息
a) 通过TGS Session Key加密的认证器部分:
b) 明文传输部分:
- 请求的Http服务名(就是请求信息)
- HTTP Service的Ticket生命周期
c) TGT部分
Ticket Granting Server收到信息后,首先检查数据库中是否包含有你请求的Http服务名。如果无,直接返回错误信息。
如果存在,则通过KDC的密码解密TGT,这个时候。我们就能获取到TGS Session key。然后,通过TGS Session key去解密你传输的第一部分认证器,获取到你的用户名和时间戳。
TGS再进行验证:
- 对比TGT中的用户名与认证器中的用户名
- 比较时间戳(网上有说认证器中的时间错和TGT中的时间错,个人觉得应该是认证器中的时间戳和系统的时间戳),不能超过一定范围
- 检查是否过期
- 检查IP地址是否一致
- 检查认证器是否已在TGS缓存中(避免应答攻击)
- 可以在这部分添加权限认证服务
TGS随机产生一个Http Service Session Key, 同时准备Http Service Ticket(ST)。
(2) 回答信息
a) 通过Http服务的密码进行加密的信息(ST):
- 你的name/ID
- Http服务name/ID
- 你的IP地址
- 时间戳
- ST的生命周期
- Http Service Session Key
b) 通过TGS Session Key加密的信息
- Http服务name/ID
- 时间戳
- ST的生命周期
- Http Service Session Key
你收到信息后,通过TGS Session Key解密,获取到了Http Service Session Key,但是你无法解密ST。

图 2‑2 第二次通信
2.3. 你和Http服务
在前面两步成功后,以后每次获取Http服务,在Ticket没有过期,或者无更新的情况下,都可直接进行这一步。省略前面两个步骤。
(1) 请求信息
a) 通过Http Service Session Key,加密部分
b) ST
Http服务端通过自己的密码解压ST(KDC是用Http服务的密码加密的),这样就能够获取到Http Service Session Key,解密第一部分。
服务端解密好ST后,进行检查
- 对比ST中的用户名(KDC给的)与认证器中的用户名
- 比较时间戳(网上有说认证器中的时间错和TGT中的时间错,个人觉得应该是认证器中的时间戳和系统的时间戳),不能超过一定范围
- 检查是否过期
- 检查IP地址是否一致
- 检查认证器是否已在HTTP服务端的缓存中(避免应答攻击)
(2) 应答信息
a) 通过Http Service Session Key加密的信息

图 2‑3 第三次通信
你在通过缓存的Http Service Session Key解密这部分信息,然后验证是否是你想要的服务器发送给你的信息。完成你的服务器的验证。
至此,整个过程全部完成。
posted @
2017-04-25 15:56 xzc 阅读(252) |
评论 (2) |
编辑 收藏posted @
2017-04-14 11:25 xzc 阅读(545) |
评论 (2) |
编辑 收藏问题导读
1.CM的安装目录在什么位置?
2.hadoop配置文件在什么位置?
3.Cloudera manager运行所需要的信息存在什么位置?4.CM结构和功能是什么? 1. 相关目录
1. 相关目录- /var/log/cloudera-scm-installer : 安装日志目录。
- /var/log/* : 相关日志文件(相关服务的及CM的)。
- /usr/share/cmf/ : 程序安装目录。
- /usr/lib64/cmf/ : Agent程序代码。
- /var/lib/cloudera-scm-server-db/data : 内嵌数据库目录。
- /usr/bin/postgres : 内嵌数据库程序。
- /etc/cloudera-scm-agent/ : agent的配置目录。
- /etc/cloudera-scm-server/ : server的配置目录。
- /opt/cloudera/parcels/ : Hadoop相关服务安装目录。
- /opt/cloudera/parcel-repo/ : 下载的服务软件包数据,数据格式为parcels。
- /opt/cloudera/parcel-cache/ : 下载的服务软件包缓存数据。
- /etc/hadoop/* : 客户端配置文件目录。
2. 配置Hadoop配置文件
配置文件放置于/var/run/cloudera-scm-agent/process/目录下。如:/var/run/cloudera-scm-agent/process/193-hdfs-NAMENODE/core-site.xml。这些配置文件是通过Cloudera Manager启动相应服务(如HDFS)时生成的,内容从数据库中获得(即通过界面配置的参数)。
在CM界面上更改配置是不会立即反映到配置文件中,这些信息会存储于数据库中,等下次重启服务时才会生成配置文件。且每次启动时都会产生新的配置文件。
CM Server主要数据库为scm基中放置配置的数据表为configs。里面包含了服务的配置信息,每一次配置的更改会把当前页面的所有配置内容添加到数据库中,以此保存配置修改历史。
scm数据库被配置成只能从localhost访问,如果需要从外部连接此数据库,修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
查看配置内容
- 直接查询scm数据库的configs数据表的内容。
- 访问REST API: http://hostname:7180/api/v4/cm/deployment,返回JSON格式部署配置信息。
3. 数据库Cloudera manager主要的数据库为scm,存储Cloudera manager运行所需要的信息:配置,主机,用户等。
4. CM结构CM分为Server与Agent两部分及数据库(自带更改过的嵌入Postgresql)。它主要做三件事件:
- 管理监控集群主机。
- 统一管理配置。
- 管理维护Hadoop平台系统。
实现采用C/S结构,Agent为客户端负责执行服务端发来的命令,执行方式一般为使用python调用相应的服务shell脚本。Server端为Java REST服务,提供REST API,Web管理端通过REST API调用Server端功能,Web界面使用富客户端技术(Knockout)。
- Server端主体使用Java实现。
- Agent端主体使用Python, 服务的启动通过调用相应的shell脚本进行启动,如果启动失败会重复4次调用启动脚本。
- Agent与Server保持心跳,使用Thrift RPC框架。
5. 升级在CM中可以通过界面向导升级相关服务。升级过程为三步:
- 下载服务软件包。
- 把所下载的服务软件包分发到集群中受管的机器上。
- 安装服务软件包,使用软链接的方式把服务程序目录链接到新安装的软件包目录上。
6. 卸载sudo /usr/share/cmf/uninstall-scm-express.sh, 然后删除/var/lib/cloudera-scm-server-db/目录,不然下次安装可能不成功。
7. 开启postgresql远程访问CM内嵌数据库被配置成只能从localhost访问,如果需要从外部查看数据,数据修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
posted @
2017-04-13 14:36 xzc 阅读(314) |
评论 (0) |
编辑 收藏- 新版本的 hbck 可以修复各种错误,修复选项是:
- (1)-fix,向下兼容用,被-fixAssignments替代
- (2)-fixAssignments,用于修复region assignments错误
- (3)-fixMeta,用于修复meta表的问题,前提是HDFS上面的region info信息有并且正确。
- (4)-fixHdfsHoles,修复region holes(空洞,某个区间没有region)问题
- (5)-fixHdfsOrphans,修复Orphan region(hdfs上面没有.regioninfo的region)
- (6)-fixHdfsOverlaps,修复region overlaps(区间重叠)问题
- (7)-fixVersionFile,修复缺失hbase.version文件的问题
- (8)-maxMerge <n> (n默认是5),当region有重叠是,需要合并region,一次合并的region数最大不超过这个值。
- (9)-sidelineBigOverlaps ,当修复region overlaps问题时,允许跟其他region重叠次数最多的一些region不参与(修复后,可以把没有参与的数据通过bulk load加载到相应的region)
- (10)-maxOverlapsToSideline <n> (n默认是2),当修复region overlaps问题时,一组里最多允许多少个region不参与
- 由于选项较多,所以有两个简写的选项
- (11) -repair,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps
- (12)-repairHoles,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans
-
-
-
- 新版本的 hbck
- (1)缺失hbase.version文件
- 加上选项 -fixVersionFile 解决
- (2)如果一个region即不在META表中,又不在hdfs上面,但是在regionserver的online region集合中
- 加上选项 -fixAssignments 解决
- (3)如果一个region在META表中,并且在regionserver的online region集合中,但是在hdfs上面没有
- 加上选项 -fixAssignments -fixMeta 解决,( -fixAssignments告诉regionserver close region),( -fixMeta删除META表中region的记录)
- (4)如果一个region在META表中没有记录,没有被regionserver服务,但是在hdfs上面有
- 加上选项 -fixMeta -fixAssignments 解决,( -fixAssignments 用于assign region),( -fixMeta用于在META表中添加region的记录)
- (5)如果一个region在META表中没有记录,在hdfs上面有,被regionserver服务了
- 加上选项 -fixMeta 解决,在META表中添加这个region的记录,先undeploy region,后assign
- (6)如果一个region在META表中有记录,但是在hdfs上面没有,并且没有被regionserver服务
- 加上选项 -fixMeta 解决,删除META表中的记录
- (7)如果一个region在META表中有记录,在hdfs上面也有,table不是disabled的,但是这个region没有被服务
- 加上选项 -fixAssignments 解决,assign这个region
- (8)如果一个region在META表中有记录,在hdfs上面也有,table是disabled的,但是这个region被某个regionserver服务了
- 加上选项 -fixAssignments 解决,undeploy这个region
- (9)如果一个region在META表中有记录,在hdfs上面也有,table不是disabled的,但是这个region被多个regionserver服务了
- 加上选项 -fixAssignments 解决,通知所有regionserver close region,然后assign region
- (10)如果一个region在META表中,在hdfs上面也有,也应该被服务,但是META表中记录的regionserver和实际所在的regionserver不相符
- 加上选项 -fixAssignments 解决
-
- (11)region holes
- 需要加上 -fixHdfsHoles ,创建一个新的空region,填补空洞,但是不assign 这个 region,也不在META表中添加这个region的相关信息
- (12)region在hdfs上面没有.regioninfo文件
- -fixHdfsOrphans 解决
- (13)region overlaps
- 需要加上 -fixHdfsOverlaps
-
-
- 说明:
- (1)修复region holes时,-fixHdfsHoles 选项只是创建了一个新的空region,填补上了这个区间,还需要加上-fixAssignments -fixMeta 来解决问题,( -fixAssignments 用于assign region),( -fixMeta用于在META表中添加region的记录),所以有了组合拳 -repairHoles 修复region holes,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans
- (2) -fixAssignments,用于修复region没有assign、不应该assign、assign了多次的问题
- (3)-fixMeta,如果hdfs上面没有,那么从META表中删除相应的记录,如果hdfs上面有,在META表中添加上相应的记录信息
- (4)-repair 打开所有的修复选项,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps
-
- 新版本的hbck从(1)hdfs目录(2)META(3)RegionServer这三处获得region的Table和Region的相关信息,根据这些信息判断并repair
新版本的 hbck 可以修复各种错误,修复选项是: (1)-fix,向下兼容用,被-fixAssignments替代 (2)-fixAssignments,用于修复region assignments错误 (3)-fixMeta,用于修复meta表的问题,前提是HDFS上面的region info信息有并且正确。 (4)-fixHdfsHoles,修复region holes(空洞,某个区间没有region)问题 (5)-fixHdfsOrphans,修复Orphan region(hdfs上面没有.regioninfo的region) (6)-fixHdfsOverlaps,修复region overlaps(区间重叠)问题 (7)-fixVersionFile,修复缺失hbase.version文件的问题 (8)-maxMerge <n> (n默认是5),当region有重叠是,需要合并region,一次合并的region数最大不超过这个值。 (9)-sidelineBigOverlaps ,当修复region overlaps问题时,允许跟其他region重叠次数最多的一些region不参与(修复后,可以把没有参与的数据通过bulk load加载到相应的region) (10)-maxOverlapsToSideline <n> (n默认是2),当修复region overlaps问题时,一组里最多允许多少个region不参与 由于选项较多,所以有两个简写的选项 (11) -repair,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps (12)-repairHoles,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans 新版本的 hbck (1)缺失hbase.version文件 加上选项 -fixVersionFile 解决 (2)如果一个region即不在META表中,又不在hdfs上面,但是在regionserver的online region集合中 加上选项 -fixAssignments 解决 (3)如果一个region在META表中,并且在regionserver的online region集合中,但是在hdfs上面没有 加上选项 -fixAssignments -fixMeta 解决,( -fixAssignments告诉regionserver close region),( -fixMeta删除META表中region的记录) (4)如果一个region在META表中没有记录,没有被regionserver服务,但是在hdfs上面有 加上选项 -fixMeta -fixAssignments 解决,( -fixAssignments 用于assign region),( -fixMeta用于在META表中添加region的记录) (5)如果一个region在META表中没有记录,在hdfs上面有,被regionserver服务了 加上选项 -fixMeta 解决,在META表中添加这个region的记录,先undeploy region,后assign (6)如果一个region在META表中有记录,但是在hdfs上面没有,并且没有被regionserver服务 加上选项 -fixMeta 解决,删除META表中的记录 (7)如果一个region在META表中有记录,在hdfs上面也有,table不是disabled的,但是这个region没有被服务 加上选项 -fixAssignments 解决,assign这个region (8)如果一个region在META表中有记录,在hdfs上面也有,table是disabled的,但是这个region被某个regionserver服务了 加上选项 -fixAssignments 解决,undeploy这个region (9)如果一个region在META表中有记录,在hdfs上面也有,table不是disabled的,但是这个region被多个regionserver服务了 加上选项 -fixAssignments 解决,通知所有regionserver close region,然后assign region (10)如果一个region在META表中,在hdfs上面也有,也应该被服务,但是META表中记录的regionserver和实际所在的regionserver不相符 加上选项 -fixAssignments 解决 (11)region holes 需要加上 -fixHdfsHoles ,创建一个新的空region,填补空洞,但是不assign 这个 region,也不在META表中添加这个region的相关信息 (12)region在hdfs上面没有.regioninfo文件 -fixHdfsOrphans 解决 (13)region overlaps 需要加上 -fixHdfsOverlaps 说明: (1)修复region holes时,-fixHdfsHoles 选项只是创建了一个新的空region,填补上了这个区间,还需要加上-fixAssignments -fixMeta 来解决问题,( -fixAssignments 用于assign region),( -fixMeta用于在META表中添加region的记录),所以有了组合拳 -repairHoles 修复region holes,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans (2) -fixAssignments,用于修复region没有assign、不应该assign、assign了多次的问题 (3)-fixMeta,如果hdfs上面没有,那么从META表中删除相应的记录,如果hdfs上面有,在META表中添加上相应的记录信息 (4)-repair 打开所有的修复选项,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps 新版本的hbck从(1)hdfs目录(2)META(3)RegionServer这三处获得region的Table和Region的相关信息,根据这些信息判断并repair
示例:
- 查看hbasemeta情况
- hbase hbck
- 1.重新修复hbase meta表(根据hdfs上的regioninfo文件,生成meta表)
- hbase hbck -fixMeta
- 2.重新将hbase meta表分给regionserver(根据meta表,将meta表上的region分给regionservere)
- hbase hbck -fixAssignments
查看hbasemeta情况 hbase hbck 1.重新修复hbase meta表(根据hdfs上的regioninfo文件,生成meta表) hbase hbck -fixMeta 2.重新将hbase meta表分给regionserver(根据meta表,将meta表上的region分给regionservere) hbase hbck -fixAssignments
- 当出现漏洞
- hbase hbck -fixHdfsHoles (新建一个region文件夹)
- hbase hbck -fixMeta (根据regioninfo生成meta表)
- hbase hbck -fixAssignments (分配region到regionserver上)
当出现漏洞 hbase hbck -fixHdfsHoles (新建一个region文件夹) hbase hbck -fixMeta (根据regioninfo生成meta表) hbase hbck -fixAssignments (分配region到regionserver上)
- 一、故障原因
- IP为10.191.135.3的服务器在2013年8月1日出现服务器重新启动的情况,导致此台服务器上的所有服务均停止。从而造成NTP服务停止。当NTP服务停止后,导致HBase集群中大部分机器时钟和主机时间不一致,造成regionserver服务中止。并在重新启动后,出现region的hole。需要对数据进行重新修复,以正常提供插入数据的服务。
-
- 二、恢复方式
- 1、集群50个regionserver,宕掉服务41个,namenode所在机器10.191.135.3不明重启(原因查找中)导致本机上的namenode、zookeeper、时间同步服务器服务挂掉。
- 2、重启hbase服务时,没能成功stop剩余的9个regionserver服务,进行了人为kill进程,
- 3、在hdfs上移走了hlog(避免启动时split log花费过多时间影响服务),然后重启hbase。发现10.191.135.30机器上的时间与时间同步服务器10.191.135.3不同步。手工同步后重启成功。hbase可以正常提供查询服务。
- 4、运行mapreduce put数据。抛出异常,数据无法正常插入;
- 5、执行/opt/hbase/bin/hbase hbck -fixAssignments,尝试重新分配region。结果显示hbase有空洞,即region之间数据不连续了;
- 6、通过上述操作可以定位是在regionserver服务宕掉的后重启的过程中丢了数据。需要进行空洞修复。然而hbase hbck命令总是只显示三条空洞。
- 7、通过编写的regionTest.jar工具进行进一步检测出空洞所在的regionname然后停掉hbase,进而进行region合并修复空洞;
- 8、合并的merge 操作需要先去.META.表里读取该region的信息,由于.META.表也在regionserver宕机过程中受到损坏,所以部分region的.META.信息没有,merge操作时就抛出空指针异常。因此只能将hdfs这些region进行移除,然后通过regionTest.jar 检测新的空洞所在的regionname,进行合并操作修复空洞;
- 9、关于region重叠,即regionname存在.META.表内,但是在hdfs上被错误的移出,并进行了region合并。这种情况下需要通过regionTest.jar检测重叠的regionname然后手动去.META.表删除,.META.表修改之后需要flush;
- 10、最后再次执行 hbase hbck 命令,hbase 所有表status ok。
-
- 三、相关命令及页面报错信息
- 1.手工同步时间命令
service ntpd stop
ntpdate -d 192.168.1.20
service ntpd start
-
-
- 2.org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException: Failed 2 actions: WrongRegionException: 2 times, servers with issues: datanode10:60020,
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.processBatchCallback(HConnectionManager.java:1641)
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.processBatch(HConnectionManager.java:1409)
at org.apache.hadoop.hbase.client.HTable.flushCommits(HTable.java:949)
at org.apache.hadoop.hbase.client.HTable.doPut(HTable.java:826)
at org.apache.hadoop.hbase.client.HTable.put(HTable.java:801)
at org.apache.hadoop.hbase.mapreduce.TableOutputFormat$TableRecordWriter.write(TableOutputFormat.java:123)
at org.apache.hadoop.hbase.mapreduce.TableOutputFormat$TableRecordWriter.write(TableOutputFormat.java:84)
at org.apache.hadoop.mapred.MapTask$NewDirectOutputCollector.write(MapTask.java:533)
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:88)
at o
-
- 3.13/08/01 18:30:02 DEBUG util.HBaseFsck: There are 22093 region info entries
ERROR: There is a hole in the region chain between +8615923208069cmnet201303072132166264580 and +861592321. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
ERROR: There is a hole in the region chain between +8618375993383cmwap20130512235639430 and +8618375998629cmnet201305040821436779670. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
ERROR: There is a hole in the region chain between +8618725888080cmnet201212271719506311400 and +8618725889786cmnet201302131646431671140. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
ERROR: Found inconsistency in table cqgprs
Summary:
-ROOT- is okay.
Number of regions: 1
Deployed on: datanode14,60020,1375330955915
.META. is okay.
Number of regions: 1
Deployed on: datanode21,60020,1375330955825
cqgprs is okay.
Number of regions: 22057
Deployed on: datanode1,60020,1375330955761 datanode10,60020,1375330955748 datanode11,60020,1375330955736 datanode12,60020,1375330955993 datanode13,60020,1375330955951 datanode14,60020,1375330955915 datanode15,60020,1375330955882 datanode16,60020,1375330955892 datanode17,60020,1375330955864 datanode18,60020,1375330955703 datanode19,60020,1375330955910 datanode2,60020,1375330955751 datanode20,60020,1375330955849 datanode21,60020,1375330955825 datanode22,60020,1375334479752 datanode23,60020,1375330955835 datanode24,60020,1375330955932 datanode25,60020,1375330955856 datanode26,60020,1375330955807 datanode27,60020,1375330955882 datanode28,60020,1375330955785 datanode29,60020,1375330955799 datanode3,60020,1375330955778 datanode30,60020,1375330955748 datanode31,60020,1375330955877 datanode32,60020,1375330955763 datanode33,60020,1375330955755 datanode34,60020,1375330955713 datanode35,60020,1375330955768 datanode36,60020,1375330955896 datanode37,60020,1375330955884 datanode38,60020,1375330955918 datanode39,60020,1375330955881 datanode4,60020,1375330955826 datanode40,60020,1375330955770 datanode41,60020,1375330955824 datanode42,60020,1375449245386 datanode43,60020,1375330955880 datanode44,60020,1375330955902 datanode45,60020,1375330955881 datanode46,60020,1375330955841 datanode47,60020,1375330955790 datanode48,60020,1375330955848 datanode49,60020,1375330955849 datanode5,60020,1375330955880 datanode50,60020,1375330955802 datanode6,60020,1375330955753 datanode7,60020,1375330955890 datanode8,60020,1375330955967 datanode9,60020,1375330955948
test1 is okay.
Number of regions: 1
Deployed on: datanode43,60020,1375330955880
test2 is okay.
Number of regions: 1
Deployed on: datanode21,60020,1375330955825
35 inconsistencies detected.
Status: INCONSISTENT
-
- 4.hadoop jar regionTest.jar com.region.RegionReaderMain /hbase/cqgprs 检测cqgprs表里的空洞所在的regionname。
-
- 5.==================================
first endKey = +8615808059207cmnet201307102326567966800
second startKey = +8615808058578cmnet201212251545557984830
first regionNmae = cqgprs,+8615808058578cmnet201212251545557984830,1375241186209.0f8266ad7ac45be1fa7233e8ea7aeef9.
second regionNmae = cqgprs,+8615808058578cmnet201212251545557984830,1362778571889.3552d3db8166f421047525d6be39c22e.
==================================
first endKey = +8615808060140cmnet201303051801355846850
second startKey = +8615808059207cmnet201307102326567966800
first regionNmae = cqgprs,+8615808058578cmnet201212251545557984830,1362778571889.3552d3db8166f421047525d6be39c22e.
second regionNmae = cqgprs,+8615808059207cmnet201307102326567966800,1375241186209.09d489d3df513bc79bab09cec36d2bb4.
==================================
-
- 6.Usage: bin/hbase org.apache.hadoop.hbase.util.Merge [-Dfs.default.name=hdfs://nn:port] <table-name> <region-1> <region-2>
./hbase org.apache.hadoop.hbase.util.Merge -Dfs.defaultFS=hdfs://bdpha cqgprs cqgprs,+8615213741567cmnet201305251243290802280,1369877465524.3c13b460fae388b1b1a70650b66c5039. cqgprs,+8615213745577cmnet201302141725552206710,1369534940433.5de80f59071555029ac42287033a4863. &
-
- 7.13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618225125357cmnet201212290358070667800
ERROR: (regions cqgprs,+8618225123516cmnet201304131404096748520,1375363774655.b3cf5cc752f4427a4e699270dff9839e. and cqgprs,+8618225125357cmnet201212290358070667800,1364421610707.7f7038bfbe2c0df0998a529686a3e1aa.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618225127504cmnet201302182135452100210
13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618285642723cmnet201302031921019768070
ERROR: (regions cqgprs,+8618285277826cmnet201306170027424674330,1375363962312.9d1e93b22cec90fd75361fa65b1d20d2. and cqgprs,+8618285642723cmnet201302031921019768070,1360873307626.f631cd8c6acc5e711e651d13536abe94.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618286275556cmnet201212270713444340110
13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618323968833cmnet201306010239025175240
ERROR: (regions cqgprs,+8618323967956cmnet201306091923411365860,1375364143678.665dba6a14ebc9971422b39e079b00ae. and cqgprs,+8618323968833cmnet201306010239025175240,1372821719159.6d2fecc1b3f9049bbca83d84231eb365.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618323992353cmnet201306012336364819810
ERROR: There is a hole in the region chain between +8618375993383cmwap20130512235639430 and +8618375998629cmnet201305040821436779670. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618723686187cmnet201301191433522129820
ERROR: (regions cqgprs,+8618723683087cmnet201301300708363045080,1375364411992.4ee5787217c1da4895d95b3b92b8e3a2. and cqgprs,+8618723686187cmnet201301191433522129820,1362003066106.70b48899cc753a0036f11bb27d2194f9.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618723689138cmnet201301051742388948390
13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618723711808cmnet201301031139206225900
ERROR: (regions cqgprs,+8618723710003cmnet201301250809235976320,1375364586329.40eed10648c9a43e3d5ce64e9d63fe00. and cqgprs,+8618723711808cmnet201301031139206225900,1361216401798.ebc442e02f5e784bce373538e06dd232.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618723714626cmnet201302122009459491970
ERROR: There is a hole in the region chain between +8618725888080cmnet201212271719506311400 and +8618725889786cmnet201302131646431671140. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
-
- 8. delete '.META.','regionname','info:serverstartcode'
- delete '.META.','regionname','info:regionserver'
- delete '.META.','regionname','info:regioninfo'
-
- 9. flush '.META.'
major_compact '.META.'
posted @
2017-04-11 16:01 xzc 阅读(445) |
评论 (0) |
编辑 收藏自从开源中国的maven仓库挂了之后就一直在用国外的仓库,慢得想要砸电脑的心都有了。如果你和我一样受够了国外maven仓库的龟速下载?快试试阿里云提供的maven仓库,从此不在浪费生命……
仓库地址:http://maven.aliyun.com/nexus/#view-repositories;public~browsestorage
仓库配置
在maven的settings.xml文件里的mirrors节点,添加如下子节点:
<mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>
或者直接在profiles->profile->repositories节点,添加如下子节点:
<repository> <id>nexus-aliyun</id> <name>Nexus aliyun</name> <layout>default</layout> <url>http://maven.aliyun.com/nexus/content/groups/public</url> <snapshots> <enabled>false</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository>
settings文件的路径
settings.xml的默认路径就:个人目录/.m2/settings.xml
如:
windowns: C:\Users\你的用户名\.m2\settings.xml
linux: /home/你的用户名/.m2/settings.xml
posted @
2017-04-11 10:08 xzc 阅读(256) |
评论 (0) |
编辑 收藏所谓BOM,全称是Byte Order Mark,它是一个Unicode字符,通常出现在文本的开头,用来标识字节序(Big/Little Endian),除此以外还可以标识编码(UTF-8/16/32),如果出现在文本中间,则解释为zero width no-break space。 注:Unicode相关知识的详细介绍请参考UTF-8, UTF-16, UTF-32 & BOM。
对于UTF-8/16/32而言,它们名字中的8/16/32指的是编码单位是多少位的,也就是说,它们的编码单位分别是8/16/32位,换算成字节就
是1/2/4字节,如果是多字节,就要牵扯到字节序,UTF-8以单字节为编码单位,所以不存在字节序。
UTF-8主要的优点是可以兼容ASCII,但如果使用BOM的话,这个好处就荡然无存了,除此以外,BOM的存在还可能引发一些问题,比如下面错误便都
有可能是BOM导致的:
- Shell: No such file or directory
- PHP: Warning: Cannot modify header information – headers already sent
在详细讨论UTF-8编码中BOM的检测与删除问题前,不妨先通过一个例子热热身:
shell> curl -s http://phone.10086.cn/ | head -1 | sed -n l
\357\273\277<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional\
//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\r$
如上所示,前三个字节分别是357、273、277,这就是八进制的BOM。
shell> curl -s http://phone.10086.cn/ | head -1 | hexdump -C
00000000 ef bb bf 3c 21 44 4f 43 54 59 50 45 20 68 74 6d |...<!DOCTYPE htm|
00000010 6c 20 50 55 42 4c 49 43 20 22 2d 2f 2f 57 33 43 |l PUBLIC "-//W3C|
00000020 2f 2f 44 54 44 20 58 48 54 4d 4c 20 31 2e 30 20 |//DTD XHTML 1.0 |
00000030 54 72 61 6e 73 69 74 69 6f 6e 61 6c 2f 2f 45 4e |Transitional//EN|
00000040 22 20 22 68 74 74 70 3a 2f 2f 77 77 77 2e 77 33 |" "http://www.w3|
00000050 2e 6f 72 67 2f 54 52 2f 78 68 74 6d 6c 31 2f 44 |.org/TR/xhtml1/D|
00000060 54 44 2f 78 68 74 6d 6c 31 2d 74 72 61 6e 73 69 |TD/xhtml1-transi|
00000070 74 69 6f 6e 61 6c 2e 64 74 64 22 3e 0d 0a |tional.dtd">..|
如上所示,前三个字节分别是EF、BB、BF,这就是十六进制的BOM。 注:用到了第三方网站的页面,不能保证例子始终可用。
实际做项目开发时,可能会面对成百上千个文本文件,如果有几个文件混入了BOM,那么很难察觉,如果没有带BOM的UTF-8文本文件,可以用vi杜撰几
个,相关命令如下:
设置UTF-8编码:
:set fileencoding=utf-8
添加BOM:
:set bomb
删除BOM:
:set nobomb
查询BOM:
:set bomb?
如何检测UTF-8编码中的BOM呢?
shell> grep -r -I -l $'^\xEF\xBB\xBF' /path
如何删除UTF-8编码中的BOM呢?
shell> grep -r -I -l $'^\xEF\xBB\xBF' /path | xargs sed -i 's/^\xEF\xBB\xBF//;q'
推荐:如果你使用SVN的话,可以在pre-commit钩子里加上相关代码用以杜绝BOM。
#!/bin/bash
REPOS="$1"
TXN="$2"
SVNLOOK=/usr/bin/svnlook
for FILE in $($SVNLOOK changed -t "$TXN" "$REPOS" | awk '/^[AU]/ {print $NF}'); do
if $SVNLOOK cat -t "$TXN" "$REPOS" "$FILE" | grep -q $'^\xEF\xBB\xBF'; then
echo "Byte Order Mark be found in $FILE" 1>&2
exit 1
fi
done
本文用到了很多shell命令,篇幅所限,恕不详述,如果有不明白的就请自己搜索吧。
posted @
2016-09-18 09:38 xzc 阅读(943) |
评论 (0) |
编辑 收藏当我们需要把二进制转成c语言中使用的16进制字符数组时,命令xxd是很有用的。
xxd 帮助信息如下:关键选项标黑。
[root@localhost ]# xxd --help
Usage:
xxd [options] [infile [outfile]]
or
xxd -r [-s [-]offset] [-c cols] [-ps] [infile [outfile]]
Options:
-a toggle autoskip: A single '*' replaces nul-lines. Default off.
-b binary digit dump (incompatible with -p,-i,-r). Default hex.
-c cols format <cols> octets per line. Default 16 (-i: 12, -ps: 30).
-E show characters in EBCDIC. Default ASCII.
-g number of octets per group in normal output. Default 2. 每个goup的字节数,默认为2,可设置。
-h print this summary.
-i output in C include file style. :输出为c包含文件的风格,数组方式存在。
-l len stop after <len> octets. :转换到len个字节后停止转换。
-ps output in postscript plain hexdump style.
-r reverse operation: convert (or patch) hexdump into binary.
-r -s off revert with <off> added to file positions found in hexdump.
-s [+][-]seek start at <seek> bytes abs. (or +: rel.) infile offset.
-u use upper case hex letters. : 字节大写方式
-v show version: "xxd V1.10 27oct98 by Juergen Weigert".
比如运行:
> xxd -g 1 -i -u -l 10000000 nm.ts > xxd_test.txt
生成的文本显示:
unsigned char __0513_1634_ch32_666_10_ts[] = {
0X47, 0X02, 0X03, 0X13, 0XF8, 0X5A, 0XC5, 0X40, 0X26, 0XE4, 0XD0, 0XDE,
0XAD, 0XB8, 0X76, 0X89, 0X85, 0X23, 0X06, 0X04, 0X6E, 0X05, 0X8B, 0X09,
0XC0, 0X5C, 0X96, 0X4F, 0X18, 0X51, 0X41, 0XC8, 0X40, 0X9F, 0X06, 0X93,
0X38, 0XC1, 0XBB, 0X1A, 0XBC, 0XAC, 0X47, 0XFF, 0X5E, 0X54, 0XEB, 0XA7,
0X14, 0X36, 0X85, 0X8A, 0X90, 0X14, 0X17, 0XA2, 0X9D, 0XC0, 0X84, 0X56,
0XCB, 0X97, 0X78, 0XC8, 0X57, 0X15, 0X3E, 0X61, 0X6F, 0XFE, 0XC9, 0X39,
0XEF, 0XD3, 0XB6, 0X6A, 0XD2, 0XE4, 0XFB, 0X4C, 0X05, 0XF6, 0X03, 0XED,
0X50, 0XB3, 0XE7, 0X46, 0X57, 0X24, 0X71, 0X16, 0X38, 0X45, 0X53, 0X19,
0X56, 0X25, 0X3C, 0X8D, 0X4C, 0XA9, 0X28, 0X9A, 0XB2, 0X99, 0X76, 0X52,
0X28, 0XE9, 0XD6, 0XD6, 0X11, 0X94, 0X89, 0X19, 0X4D, 0XEA, 0X68, 0X76,
0X53, 0XC6, 0XAA, 0X3A, 0XD4, 0XA1, 0X25, 0XA5, 0X03, 0XB0, 0X73, 0XA0,
0XAE, 0X11, 0XC9, 0XBD, 0X37, 0X17, 0X11, 0X5F, 0X30, 0X34, 0X34, 0X0B
.....
};
unsigned int nm.ts_len = 10000000;
另外,在vim中也可以把文件转换为16进制来显示:
:%!xxd
返回正常显示:
:%!xxd -r
linux下查看二进制文件
以十六进制格式输出:
od [选项] 文件
od -d 文件 十进制输出
-o 文件 八进制输出
-x 文件 十六进制输出
xxd 文件 输出十六进制
在vi命令状态下:
:%!xxd :%!od 将当前文本转化为16进制格式
:%!xxd -c 12 每行显示12个字节
:%!xxd -r 将当前文本转化回文本格式
posted @
2016-09-18 09:38 xzc 阅读(2524) |
评论 (0) |
编辑 收藏一、IFS 介绍
Shell 脚本中有个变量叫 IFS(Internal Field Seprator) ,内部域分隔符。完整定义是The shell uses the value stored in IFS, which is the space, tab, and newline characters by default, to delimit words for the read and set commands, when parsing output from command substitution, and when performing variable substitution.
Shell 的环境变量分为 set, env 两种,其中 set 变量可以通过 export 工具导入到 env 变量中。其中,set 是显示设置shell变量,仅在本 shell 中有效;env 是显示设置用户环境变量 ,仅在当前会话中有效。换句话说,set 变量里包含了 env 变量,但 set 变量不一定都是 env 变量。这两种变量不同之处在于变量的作用域不同。显然,env 变量的作用域要大些,它可以在 subshell 中使用。
而 IFS 是一种 set 变量,当 shell 处理"命令替换"和"参数替换"时,shell 根据 IFS 的值,默认是 space, tab, newline 来拆解读入的变量,然后对特殊字符进行处理,最后重新组合赋值给该变量。
二、IFS 简单实例
1、查看变量 IFS 的值。
- $ echo $IFS
-
- $ echo "$IFS" | od -b
- 0000000 040 011 012 012
- 0000004
$ echo $IFS $ echo "$IFS" | od -b 0000000 040 011 012 012 0000004
直接输出IFS是看不到的,把它转化为二进制就可以看到了,"040"是空格,"011"是Tab,"012"是换行符"\n" 。最后一个 012 是因为 echo 默认是会换行的。
2、$* 和 $@ 的细微差别
从下面的例子中可以看出,如果是用冒号引起来,表示这个变量不用IFS替换!!所以可以看到这个变量的"原始值"。反之,如果不加引号,输出时会根据IFS的值来分割后合并输出! $* 是按照IFS中的第一个值来确定的!下面这两个例子还有细微的差别!
- $ IFS=:;
- $ set x y z
- $ echo $*
- x y z
- $ echo "$*"
- x:y:z
- $ echo $@
- x y z
- $ echo "$@"
- x y z
$ IFS=:; $ set x y z $ echo $* x y z $ echo "$*" x:y:z $ echo $@ x y z $ echo "$@" x y z
上例 set 变量其实是3个参数,而下面这个例子实质是2个参数,即 set "x y z" 和 set x y z 是完全不同的。
- $ set "x" "y z"
- $ echo $*
- x y z
- $ echo "$*"
- x:y z
- $ echo $@
- x y z
- $ echo "$@"
- x y z
- $ echo $* |od -b
- 0000000 170 040 171 040 172 012
- 0000006
- $ echo "$*" |od -b
- 0000000 170 072 171 040 172 012
- 0000006
$ set "x" "y z" $ echo $* x y z $ echo "$*" x:y z $ echo $@ x y z $ echo "$@" x y z $ echo $* |od -b 0000000 170 040 171 040 172 012 0000006 $ echo "$*" |od -b 0000000 170 072 171 040 172 012 0000006
小结:$* 会根据 IFS 的不同来组合值,而 $@ 则会将值用" "来组合值!
3、for 循环中的奇怪现象
- $ for x in $var ;do echo $x |od -b ;done
- 0000000 012
- 0000001
- 0000000 040 141 012
- 0000003
- 0000000 142 012
- 0000002
- 0000000 012
- 0000001
- 0000000 143 012
- 0000002
$ for x in $var ;do echo $x |od -b ;done 0000000 012 0000001 0000000 040 141 012 0000003 0000000 142 012 0000002 0000000 012 0000001 0000000 143 012 0000002
先暂且不解释 for 循环的内容!看下面这个输出!IFS 的值同上! var=": a:b::c:",
- $ echo $var |od -b
- 0000000 040 040 141 040 142 040 040 143 012
- 0000011
- $ echo "$var" |od -b
- 0000000 072 040 141 072 142 072 072 143 072 012
- 0000012
$ echo $var |od -b 0000000 040 040 141 040 142 040 040 143 012 0000011 $ echo "$var" |od -b 0000000 072 040 141 072 142 072 072 143 072 012 0000012
"$var"的值应该没做替换,所以还是 ": a:b::c:" (注 "072" 表示冒号),但是$var 则发生了变化!注意输出的最后一个冒号没有了,也没有替换为空格!Why?
使用 $var 时是经历了这样一个过程!首先,按照这样的规则 [变量][IFS][变量][IFS]……根据原始 var 值中所有的分割符(此处是":")划分出变量,如果IFS的值是有多个字符组成,如IFS=":;",那么此处的[IFS]指的是IFS中的任意一个字符($* 是按第一个字符来分隔!),如 ":" 或者 ";" ,后面不再对[IFS]做类似说明!(注:[IFS]会有多个值,多亏 #blackold 的提醒);然后,得到类似这样的 list, "" " a" "b" "" "c" 。如果此时 echo $var,则需要在这些变量之间用空格隔开,也就是"" [space] " a" [space] "b" [space] "" [space] "c" ,忽略掉空值,最终输出是 [space][space]a[space]b[space][space]c !
如果最后一个字符不是分隔符,如 var="a:b",那么最后一个分隔符后的变量就是最后一个变量!
这个地方要注意下!!如果IFS就是空格,那么类似于" [space][space]a[space]b[space][space]c "会合并重复的部分,且去头空格,去尾空格,那么最终输出会变成类似 a[space]b[space]c ,所以,如果IFS是默认值,那么处理的结果就很好算出来,直接合并、忽略多余空格即可!
另外,$* 和 $@ 在函数中的处理过程是这样的(只考虑"原始值"!)!"$@",就是像上面处理后赋值,但是 "$*" 却不一样!它的值是用分隔符(如":")而不是空格隔开!具体例子见最后一个例子!
好了,现在来解释 for 循环的内容。for 循环遍历上面这个列表就可以了,所以 for 循环的第一个输出是空!("012"是echo输出的换行符 )。。。。后面的依次类推!不信可以试试下面这个例子,结果是一样的!
- $ for x in "" " a" "b" "" "c" ;do echo $x |od -b ;done
- 0000000 012
- 0000001
- 0000000 040 141 012
- 0000003
- 0000000 012
- 0000001
- 0000000 142 012
- 0000002
- 0000000 012
- 0000001
- 0000000 143 012
- 0000002
$ for x in "" " a" "b" "" "c" ;do echo $x |od -b ;done 0000000 012 0000001 0000000 040 141 012 0000003 0000000 012 0000001 0000000 142 012 0000002 0000000 012 0000001 0000000 143 012 0000002
三、IFS的其他实例
Example 1:
- $ IFS=:
- $ var=ab::cd
- $ echo $var
- ab cd
- $ echo "$var"
- ab::cd
$ IFS=: $ var=ab::cd $ echo $var ab cd $ echo "$var" ab::cd
解释下:x 的值是 "ab::cd",当进行到 echo $x 时,因为$符,所以会进行变量替换。Shell 根据 IFS 的值将 x 分解为 ab "" cd,然后echo,插入空隔,ab[space]""[space]cd,忽略"",输出 ab cd 。
Example 2 :
- $ read a
- xy z
- $ echo $a
- xy z
$ read a xy z $ echo $a xy z
解释:这是 http://bbs.chinaunix.net/thread-207178-1-1.html 上的一个例子。此时IFS是默认值,本希望把所有的输入(包括空格)都放入变量a中,但是输出的a却把前面的空格给忽略了!!原因是:默认的 IFS 会按 space tab newline 来分割。这里需要注意的一点是,read 命令的实现过程,即在读入时已经替换了。解决办法是在开头加上一句 IFS=";" ,这里必须加上双引号,因为分号有特殊含义。
Example 3 :
- $ tmp=" xy z"
- $ a=$tmp
- $ echo $a
- $ echo "$a"
$ tmp=" xy z" $ a=$tmp $ echo $a $ echo "$a"
解释:什么时候会根据 IFS 来"处理"呢?我觉得是,对于不加引号的变量,使用时都会参考IFS,但是要注意其原始值!
Example 4 :
- #!/bin/bash
- IFS_old=$IFS #将原IFS值保存,以便用完后恢复
- IFS=$’\n’ #更改IFS值为$’\n’ ,注意,以回车做为分隔符,IFS必须为:$’\n’
- for i in $((cat pwd.txt)) #pwd.txt 来自这个命令:cat /etc/passwd >pwd.txt
- do
- echo $i
- done
- IFS=$IFS_old #恢复原IFS值
#!/bin/bash IFS_old=$IFS #将原IFS值保存,以便用完后恢复 IFS=$’\n’ #更改IFS值为$’\n’ ,注意,以回车做为分隔符,IFS必须为:$’\n’ for i in $((cat pwd.txt)) #pwd.txt 来自这个命令:cat /etc/passwd >pwd.txt do echo $i done IFS=$IFS_old #恢复原IFS值
另外一个例子,把IP地址逆转输出:
Example 5 :
- #!/bin/bash
-
- IP=220.112.253.111
- IFS="."
- TMPIP=$(echo $IP)
- IFS=" " # space
- echo $TMPIP
- for x in $TMPIP ;do
- Xip="${x}.$Xip"
- done
- echo ${Xip%.}
#!/bin/bash IP=220.112.253.111 IFS="." TMPIP=$(echo $IP) IFS=" " # space echo $TMPIP for x in $TMPIP ;do Xip="${x}.$Xip" done echo ${Xip%.}Complex_Example 1: http://bbs.chinaunix.net/forum.php?mod=viewthread&tid=3660898&page=1#pid21798049
- function output_args_ifs(){
- echo "=$*"
- echo "="$*
- for m in $* ;do
- echo "[$m]"
- done
- }
-
- IFS=':'
- var='::a:b::c:::'
- output_args_ifs $var
function output_args_ifs(){ echo "=$*" echo "="$* for m in $* ;do echo "[$m]" done } IFS=':' var='::a:b::c:::' output_args_ifs $var
输出为:
- =::a:b::c:: # 少了最后一个冒号!看前面就知道为什么了
- = a b c
- []
- []
- [a]
- [b]
- []
- [c]
- []
=::a:b::c:: # 少了最后一个冒号!看前面就知道为什么了 = a b c [] [] [a] [b] [] [c] []
由于 "output_args_ifs $var" 中 $var 没有加引号,所以根据IFS替换!根据IFS划分出变量: "" "" "a" "b" "" "c" "" ""(可以通过输出 $# 来测试参数的个数!),重组的结果为
"$@" 的值是 "" [space] "" [space] "a" [space] "b" [space] "" [space] "c" [space] "" [space] "",可以通过,echo==>" a b c "
"$*" 的值是 "" [IFS] "" [IFS] "a" [IFS] "b" [IFS] "" [IFS] "c" [IFS] "" [IFS] "",忽略"",echo=>"::a:b::c::"
注意, $* 和 $@ 的值都是 "" "" "a" "b" "" "c" "" "" 。可以说是一个列表……因为他们本来就是由 $1 $2 $3……组成的。
所以,《Linux程序设计》里推荐使用 $@,而不是$*
总结:IFS 其实还是很麻烦的,稍有不慎就会产生很奇怪的结果,因此使用的时候要注意!我也走了不少弯路,只希望能给后来者一些帮助。本文若有问题,欢迎指正!!谢谢!
如有转载,请注明blog.csdn.net/whuslei
参考:
http://blog.chinaunix.net/space.php?uid=20543672&do=blog&id=94358
http://smilejay.com/2011/12/bash_ifs/#comment-51
posted @
2016-04-01 15:00 xzc 阅读(275) |
评论 (1) |
编辑 收藏MYSQL 获取当前日期及日期格式
获取系统日期: NOW()
格式化日期: DATE_FORMAT(date, format)
注: date:时间字段
format:日期格式
返回系统日期,输出 2009-12-25 14:38:59
select now();
输出 09-12-25
select date_format(now(),'%y-%m-%d');
根据format字符串格式化date值:
%S, %s 两位数字形式的秒( 00,01, ..., 59)
%I, %i 两位数字形式的分( 00,01, ..., 59)
%H 两位数字形式的小时,24 小时(00,01, ..., 23)
%h 两位数字形式的小时,12 小时(01,02, ..., 12)
%k 数字形式的小时,24 小时(0,1, ..., 23)
%l 数字形式的小时,12 小时(1, 2, ..., 12)
%T 24 小时的时间形式(hh:mm:ss)
%r 12 小时的时间形式(hh:mm:ss AM 或hh:mm:ss PM)
%p AM或PM
%W 一周中每一天的名称(Sunday, Monday, ..., Saturday)
%a 一周中每一天名称的缩写(Sun, Mon, ..., Sat)
%d 两位数字表示月中的天数(00, 01,..., 31)
%e 数字形式表示月中的天数(1, 2, ..., 31)
%D 英文后缀表示月中的天数(1st, 2nd, 3rd,...)
%w 以数字形式表示周中的天数( 0 = Sunday, 1=Monday, ..., 6=Saturday)
%j 以三位数字表示年中的天数( 001, 002, ..., 366)
%U 周(0, 1, 52),其中Sunday 为周中的第一天
%u 周(0, 1, 52),其中Monday 为周中的第一天
%M 月名(January, February, ..., December)
%b 缩写的月名( January, February,...., December)
%m 两位数字表示的月份(01, 02, ..., 12)
%c 数字表示的月份(1, 2, ...., 12)
%Y 四位数字表示的年份
%y 两位数字表示的年份
%% 直接值“%”
curdate()
MySQL 获得当前日期时间 函数
1.1 获得当前日期+时间(date + time)函数:now()
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2008-08-08 22:20:46 |
+---------------------+
除了 now() 函数能获得当前的日期时间外,MySQL 中还有下面的函数:
current_timestamp()
,current_timestamp
,localtime()
,localtime
,localtimestamp -- (v4.0.6)
,localtimestamp() -- (v4.0.6)
这些日期时间函数,都等同于 now()。鉴于 now() 函数简短易记,建议总是使用 now() 来替代上面列出的函数。
1.2 获得当前日期+时间(date + time)函数:sysdate()
sysdate() 日期时间函数跟 now() 类似,不同之处在于:now() 在执行开始时值就得到了, sysdate() 在函数执行时动态得到值。看下面的例子就明白了:
mysql> select now(), sleep(3), now();
+---------------------+----------+---------------------+
| now() | sleep(3) | now() |
+---------------------+----------+---------------------+
| 2008-08-08 22:28:21 | 0 | 2008-08-08 22:28:21 |
+---------------------+----------+---------------------+mysql> select sysdate(), sleep(3), sysdate();
+---------------------+----------+---------------------+
| sysdate() | sleep(3) | sysdate() |
+---------------------+----------+---------------------+
| 2008-08-08 22:28:41 | 0 | 2008-08-08 22:28:44 |
+---------------------+----------+---------------------+
可以看到,虽然中途 sleep 3 秒,但 now() 函数两次的时间值是相同的; sysdate() 函数两次得到的时间值相差 3秒。MySQL Manual 中是这样描述 sysdate() 的:Return the time at which the functionexecutes。
sysdate() 日期时间函数,一般情况下很少用到。
2. 获得当前日期(date)函数:curdate()
mysql> select curdate();
+------------+
| curdate() |
+------------+
| 2008-08-08 |
+------------+
其中,下面的两个日期函数等同于 curdate():
current_date()
,current_date
3. 获得当前时间(time)函数:curtime()
mysql> select curtime();
+-----------+
| curtime() |
+-----------+
| 22:41:30 |
+-----------+
其中,下面的两个时间函数等同于 curtime():
current_time()
,current_time
4. 获得当前 UTC 日期时间函数:utc_date(), utc_time(), utc_timestamp()
mysql> select utc_timestamp(), utc_date(), utc_time(), now()
+---------------------+------------+------------+---------------------+
| utc_timestamp() | utc_date() | utc_time() | now() |
+---------------------+------------+------------+---------------------+
| 2008-08-08 14:47:11 | 2008-08-08 | 14:47:11 | 2008-08-08 22:47:11 |
+---------------------+------------+------------+---------------------+
因为我国位于东八时区,所以本地时间 = UTC 时间 + 8 小时。UTC 时间在业务涉及多个国家和地区的时候,非常有用。
二、MySQL 日期时间 Extract(选取) 函数。
1. 选取日期时间的各个部分:日期、时间、年、季度、月、日、小时、分钟、秒、微秒
set @dt = '2008-09-10 07:15:30.123456';
select date(@dt); -- 2008-09-10
select time(@dt); -- 07:15:30.123456
select year(@dt); -- 2008
select quarter(@dt); -- 3
select month(@dt); -- 9
select week(@dt); -- 36
select day(@dt); -- 10
select hour(@dt); -- 7
select minute(@dt); -- 15
select second(@dt); -- 30
select microsecond(@dt); -- 123456
2. MySQL Extract() 函数,可以上面实现类似的功能:
set @dt = '2008-09-10 07:15:30.123456';
select extract(year from @dt); -- 2008
select extract(quarter from @dt); -- 3
select extract(month from @dt); -- 9
select extract(week from @dt); -- 36
select extract(day from @dt); -- 10
select extract(hour from @dt); -- 7
select extract(minute from @dt); -- 15
select extract(second from @dt); -- 30
select extract(microsecond from @dt); -- 123456select extract(year_month from @dt); -- 200809
select extract(day_hour from @dt); -- 1007
select extract(day_minute from @dt); -- 100715
select extract(day_second from @dt); -- 10071530
select extract(day_microsecond from @dt); -- 10071530123456
select extract(hour_minute from @dt); -- 715
select extract(hour_second from @dt); -- 71530
select extract(hour_microsecond from @dt); -- 71530123456
select extract(minute_second from @dt); -- 1530
select extract(minute_microsecond from @dt); -- 1530123456
select extract(second_microsecond from @dt); -- 30123456
MySQLExtract() 函数除了没有date(),time() 的功能外,其他功能一应具全。并且还具有选取‘day_microsecond’等功能。注意这里不是只选取 day 和 microsecond,而是从日期的 day 部分一直选取到 microsecond 部分。够强悍的吧!
MySQL Extract() 函数唯一不好的地方在于:你需要多敲几次键盘。
3. MySQL dayof… 函数:dayofweek(), dayofmonth(), dayofyear()
分别返回日期参数,在一周、一月、一年中的位置。
set @dt = '2008-08-08';
select dayofweek(@dt); -- 6
select dayofmonth(@dt); -- 8
select dayofyear(@dt); -- 221
日期 ‘2008-08-08′ 是一周中的第 6 天(1 = Sunday, 2 = Monday, …, 7 = Saturday);一月中的第 8 天;一年中的第 221 天。
4. MySQL week… 函数:week(), weekofyear(), dayofweek(), weekday(), yearweek()
set @dt = '2008-08-08';
select week(@dt); -- 31
select week(@dt,3); -- 32
select weekofyear(@dt); -- 32
select dayofweek(@dt); -- 6
select weekday(@dt); -- 4
select yearweek(@dt); -- 200831
MySQL week() 函数,可以有两个参数,具体可看手册。 weekofyear() 和 week() 一样,都是计算“某天”是位于一年中的第几周。 weekofyear(@dt) 等价于 week(@dt,3)。
MySQLweekday() 函数和 dayofweek() 类似,都是返回“某天”在一周中的位置。不同点在于参考的标准, weekday:(0 =Monday, 1 = Tuesday, …, 6 = Sunday); dayofweek:(1 = Sunday, 2 = Monday,…, 7 = Saturday)
MySQL yearweek() 函数,返回 year(2008) + week 位置(31)。
5. MySQL 返回星期和月份名称函数:dayname(), monthname()
set @dt = '2008-08-08';
select dayname(@dt); -- Friday
select monthname(@dt); -- August
思考,如何返回中文的名称呢?
6. MySQL last_day() 函数:返回月份中的最后一天。
select last_day('2008-02-01'); -- 2008-02-29
select last_day('2008-08-08'); -- 2008-08-31
MySQL last_day() 函数非常有用,比如我想得到当前月份中有多少天,可以这样来计算:
mysql> select now(), day(last_day(now())) as days;
+---------------------+------+
| now() | days |
+---------------------+------+
| 2008-08-09 11:45:45 | 31 |
+---------------------+------+ 三、MySQL 日期时间计算函数
1. MySQL 为日期增加一个时间间隔:date_add()
set @dt = now();
select date_add(@dt, interval 1 day); -- add 1 day
select date_add(@dt, interval 1 hour); -- add 1 hour
select date_add(@dt, interval 1 minute); -- ...
select date_add(@dt, interval 1 second);
select date_add(@dt, interval 1 microsecond);
select date_add(@dt, interval 1 week);
select date_add(@dt, interval 1 month);
select date_add(@dt, interval 1 quarter);
select date_add(@dt, interval 1 year);select date_add(@dt, interval -1 day); -- sub 1 day
MySQL adddate(), addtime()函数,可以用 date_add() 来替代。下面是 date_add() 实现 addtime() 功能示例:
mysql> set @dt = '2008-08-09 12:12:33';
mysql>
mysql> select date_add(@dt, interval '01:15:30' hour_second);
+------------------------------------------------+
| date_add(@dt, interval '01:15:30' hour_second) |
+------------------------------------------------+
| 2008-08-09 13:28:03 |
+------------------------------------------------+mysql> select date_add(@dt, interval '1 01:15:30' day_second);
+-------------------------------------------------+
| date_add(@dt, interval '1 01:15:30' day_second) |
+-------------------------------------------------+
| 2008-08-10 13:28:03 |
+-------------------------------------------------+
date_add() 函数,分别为 @dt 增加了“1小时 15分 30秒” 和 “1天 1小时 15分 30秒”。建议:总是使用 date_add() 日期时间函数来替代 adddate(), addtime()。
2. MySQL 为日期减去一个时间间隔:date_sub()
mysql> select date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second);
+----------------------------------------------------------------+
| date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second) |
+----------------------------------------------------------------+
| 1997-12-30 22:58:59 |
+----------------------------------------------------------------+
MySQL date_sub() 日期时间函数 和 date_add() 用法一致,不再赘述。另外,MySQL 中还有两个函数 subdate(), subtime(),建议,用 date_sub() 来替代。
3. MySQL 另类日期函数:period_add(P,N), period_diff(P1,P2)
函数参数“P” 的格式为“YYYYMM” 或者 “YYMM”,第二个参数“N” 表示增加或减去 N month(月)。
MySQL period_add(P,N):日期加/减去N月。
mysql> select period_add(200808,2), period_add(20080808,-2)
+----------------------+-------------------------+
| period_add(200808,2) | period_add(20080808,-2) |
+----------------------+-------------------------+
| 200810 | 20080806 |
+----------------------+-------------------------+
MySQL period_diff(P1,P2):日期 P1-P2,返回 N 个月。
mysql> select period_diff(200808, 200801);
+-----------------------------+
| period_diff(200808, 200801) |
+-----------------------------+
| 7 |
+-----------------------------+
在 MySQL 中,这两个日期函数,一般情况下很少用到。
4. MySQL 日期、时间相减函数:datediff(date1,date2), timediff(time1,time2)
MySQL datediff(date1,date2):两个日期相减 date1 - date2,返回天数。
select datediff('2008-08-08', '2008-08-01'); -- 7
select datediff('2008-08-01', '2008-08-08'); -- -7
MySQL timediff(time1,time2):两个日期相减 time1 - time2,返回 time 差值。
select timediff('2008-08-08 08:08:08', '2008-08-08 00:00:00'); -- 08:08:08
select timediff('08:08:08', '00:00:00'); -- 08:08:08
注意:timediff(time1,time2) 函数的两个参数类型必须相同。
四、MySQL 日期转换函数、时间转换函数
1. MySQL (时间、秒)转换函数:time_to_sec(time), sec_to_time(seconds)
select time_to_sec('01:00:05'); -- 3605
select sec_to_time(3605); -- '01:00:05'
2. MySQL (日期、天数)转换函数:to_days(date), from_days(days)
select to_days('0000-00-00'); -- 0
select to_days('2008-08-08'); -- 733627select from_days(0); -- '0000-00-00'
select from_days(733627); -- '2008-08-08'
3. MySQL Str to Date (字符串转换为日期)函数:str_to_date(str, format)
select str_to_date('08/09/2008', '%m/%d/%Y'); -- 2008-08-09
select str_to_date('08/09/08' , '%m/%d/%y'); -- 2008-08-09
select str_to_date('08.09.2008', '%m.%d.%Y'); -- 2008-08-09
select str_to_date('08:09:30', '%h:%i:%s'); -- 08:09:30
select str_to_date('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30
可以看到,str_to_date(str,format) 转换函数,可以把一些杂乱无章的字符串转换为日期格式。另外,它也可以转换为时间。“format” 可以参看 MySQL 手册。
4. MySQL Date/Time to Str(日期/时间转换为字符串)函数:date_format(date,format), time_format(time,format)
mysql> select date_format('2008-08-08 22:23:00', '%W %M %Y');
+------------------------------------------------+
| date_format('2008-08-08 22:23:00', '%W %M %Y') |
+------------------------------------------------+
| Friday August 2008 |
+------------------------------------------------+mysql> select date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s');
+----------------------------------------------------+
| date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s') |
+----------------------------------------------------+
| 20080808222301 |
+----------------------------------------------------+mysql> select time_format('22:23:01', '%H.%i.%s');
+-------------------------------------+
| time_format('22:23:01', '%H.%i.%s') |
+-------------------------------------+
| 22.23.01 |
+-------------------------------------+
MySQL 日期、时间转换函数:date_format(date,format), time_format(time,format) 能够把一个日期/时间转换成各种各样的字符串格式。它是 str_to_date(str,format) 函数的 一个逆转换。
5. MySQL 获得国家地区时间格式函数:get_format()
MySQL get_format() 语法:
get_format(date|time|datetime, 'eur'|'usa'|'jis'|'iso'|'internal'
MySQL get_format() 用法的全部示例:
select get_format(date,'usa') ; -- '%m.%d.%Y'
select get_format(date,'jis') ; -- '%Y-%m-%d'
select get_format(date,'iso') ; -- '%Y-%m-%d'
select get_format(date,'eur') ; -- '%d.%m.%Y'
select get_format(date,'internal') ; -- '%Y%m%d'
select get_format(datetime,'usa') ; -- '%Y-%m-%d %H.%i.%s'
select get_format(datetime,'jis') ; -- '%Y-%m-%d %H:%i:%s'
select get_format(datetime,'iso') ; -- '%Y-%m-%d %H:%i:%s'
select get_format(datetime,'eur') ; -- '%Y-%m-%d %H.%i.%s'
select get_format(datetime,'internal') ; -- '%Y%m%d%H%i%s'
select get_format(time,'usa') ; -- '%h:%i:%s %p'
select get_format(time,'jis') ; -- '%H:%i:%s'
select get_format(time,'iso') ; -- '%H:%i:%s'
select get_format(time,'eur') ; -- '%H.%i.%s'
select get_format(time,'internal') ; -- '%H%i%s'
MySQL get_format() 函数在实际中用到机会的比较少。
6. MySQL 拼凑日期、时间函数:makdedate(year,dayofyear), maketime(hour,minute,second)
select makedate(2001,31); -- '2001-01-31'
select makedate(2001,32); -- '2001-02-01'select maketime(12,15,30); -- '12:15:30' 五、MySQL 时间戳(Timestamp)函数
1. MySQL 获得当前时间戳函数:current_timestamp, current_timestamp()
mysql> select current_timestamp, current_timestamp();
+---------------------+---------------------+
| current_timestamp | current_timestamp() |
+---------------------+---------------------+
| 2008-08-09 23:22:24 | 2008-08-09 23:22:24 |
+---------------------+---------------------+
2. MySQL (Unix 时间戳、日期)转换函数:
unix_timestamp(),
unix_timestamp(date),
from_unixtime(unix_timestamp),
from_unixtime(unix_timestamp,format)
下面是示例:
select unix_timestamp(); -- 1218290027
select unix_timestamp('2008-08-08'); -- 1218124800
select unix_timestamp('2008-08-08 12:30:00'); -- 1218169800select from_unixtime(1218290027); -- '2008-08-09 21:53:47'
select from_unixtime(1218124800); -- '2008-08-08 00:00:00'
selectfrom_unixtime(1218169800); -- '2008-08-08 12:30:00'selectfrom_unixtime(1218169800, '%Y %D %M %h:%i:%s %x'); -- '2008 8th August12:30:00 2008'
3. MySQL 时间戳(timestamp)转换、增、减函数:
timestamp(date) -- date to timestamp
timestamp(dt,time) -- dt + time
timestampadd(unit,interval,datetime_expr) --
timestampdiff(unit,datetime_expr1,datetime_expr2) --
请看示例部分:
select timestamp('2008-08-08'); -- 2008-08-08 00:00:00
select timestamp('2008-08-08 08:00:00', '01:01:01'); -- 2008-08-08 09:01:01
selecttimestamp('2008-08-08 08:00:00', '10 01:01:01'); -- 2008-08-1809:01:01select timestampadd(day, 1, '2008-08-08 08:00:00'); --2008-08-09 08:00:00
select date_add('2008-08-08 08:00:00', interval 1 day); -- 2008-08-09 08:00:00
MySQL timestampadd() 函数类似于 date_add()。
select timestampdiff(year,'2002-05-01','2001-01-01'); -- -1
select timestampdiff(day ,'2002-05-01','2001-01-01'); -- -485
select timestampdiff(hour,'2008-08-08 12:00:00','2008-08-08 00:00:00'); -- -12
select datediff('2008-08-08 12:00:00', '2008-08-01 00:00:00'); -- 7
MySQL timestampdiff() 函数就比 datediff() 功能强多了,datediff() 只能计算两个日期(date)之间相差的天数。
六、MySQL 时区(timezone)转换函数convert_tz(dt,from_tz,to_tz)selectconvert_tz('2008-08-08 12:00:00', '+08:00', '+00:00'); -- 2008-08-0804:00:00
时区转换也可以通过 date_add, date_sub, timestampadd 来实现。
select date_add('2008-08-08 12:00:00', interval -8 hour); -- 2008-08-08 04:00:00
select date_sub('2008-08-08 12:00:00', interval 8 hour); -- 2008-08-08 04:00:00
select timestampadd(hour, -8, '2008-08-08 12:00:00'); -- 2008-08-08 04:00:00
posted @
2016-03-30 10:33 xzc 阅读(336) |
评论 (2) |
编辑 收藏在项目中遇到一个奇怪的bug,是由一行简单代码引起的。
代码作用:比较两个UNIX文本文件,找出并打印文本2比文本1新增加的内容。
代码调用了diff命令,例如:
# temp1.txt文件内容
$> cat temp1.txt
20110224
20110225
20110228
20110301
20110302
# temp2.txt文件内容
$> cat temp2.txt
20110228
20110301
20110302
20110303
20110304
# diff命令输出结果
$> diff temp1.txt temp2.txt
1,2d0
< 20110224
< 20110225
5a4,5
> 20110303
> 20110304
# 只输出temp2.txt文件独有的内容
$> diff temp1.txt temp2.txt | grep "> " | sed 's/> //g'
20110303
20110304
说明:输出结果去掉了两个文件的共同内容,只输出了temp2.txt的新增部分,和预想的结果一样。
但是,随着temp1.txt文件内容的增加,diff命令出现了不同预期的结果:
$> cat temp1.txt
20101216
20101217
20101220
20101221
20101223
20101224
20101227
20101228
20101229
20101230
20101231
20110103
20110104
20110105
20110106
20110107
20110110
20110111
20110112
20110113
20110114
20110117
20110118
20110119
20110120
20110121
20110124
20110125
20110126
20110127
20110128
20110131
20110201
20110202
20110203
20110204
20110207
20110208
20110209
20110210
20110211
20110214
20110215
20110216
20110217
20110218
20110221
20110222
20110223
20110224
20110225
20110228
20110301
20110302
20110303
$> cat temp2.txt
20110228
20110301
20110302
20110303
20110304
20110307
20110308
20110309
20110310
20110311
20110314
$> diff temp1.txt temp2.txt
1,55c1,11
< 20101216
< 20101217
< 20101220
< 20101221
< 20101223
< 20101224
< 20101227
< 20101228
< 20101229
< 20101230
< 20101231
< 20110103
< 20110104
< 20110105
< 20110106
< 20110107
< 20110110
< 20110111
< 20110112
< 20110113
< 20110114
< 20110117
< 20110118
< 20110119
< 20110120
< 20110121
< 20110124
< 20110125
< 20110126
< 20110127
< 20110128
< 20110131
< 20110201
< 20110202
< 20110203
< 20110204
< 20110207
< 20110208
< 20110209
< 20110210
< 20110211
< 20110214
< 20110215
< 20110216
< 20110217
< 20110218
< 20110221
< 20110222
< 20110223
< 20110224
< 20110225
< 20110228
< 20110301
< 20110302
< 20110303
---
> 20110228
> 20110301
> 20110302
> 20110303
> 20110304
> 20110307
> 20110308
> 20110309
> 20110310
> 20110311
> 20110314
$> diff temp1.txt temp2.txt | grep "> " | sed 's/> //g'
20110228
20110301
20110302
20110303
20110304
20110307
20110308
20110309
20110310
20110311
20110314
可以看到,diff命令不但输出了temp2.txt文件的新增部分(20110304-20110314),也同时输出了两个文件的共同内容(20110228-20110303),从而导致了与预期不一致的结果。
查看diff命令的man手册发现,diff的作用是比较两个文件的内容,并输出两个文件之间的差异,产生一个能够将两个文件互相转换的列表,但这个列表并不能100%保证是最小集。
于是,以上例子中,可以看到diff给出了temp1.txt和temp2.txt文件的比较差异结果,但其中包含了两个文件的共同部分,因此与预期不一样。
解决方法:
用comm命令代替diff,例如:
$> comm -13 temp1.txt temp2.txt
20110304
20110307
20110308
20110309
20110310
20110311
20110314
comm命令用来比较两个文件,具体用法:
comm [-123] file1 file2
-1 过滤file1独有的内容
-2 过滤file2独有的内容
-3 过滤file1和file2重复的内容
备注:
diff的输出格式,主要有以下几种:
n1 a n3,n4
n1,n2 d n3
n1,n2 c n3,n4
例如"1,2d0" "5a4,5" "1,55c1,11"等。
其中n1和n2指第一个文件的行数,n3和n4指第二个文件的行数。"a"代表add增加,"d"代表delete删除,"c"代表change整块变动。
有了diff的输出结果,可以使用patch命令将一个文件恢复成另一个,例如:
$> cat temp1.txt
20110224
20110225
20110228
20110301
20110302
$> cat temp2.txt
20110228
20110301
20110302
20110303
20110304
$> diff temp1.txt temp2.txt > temp.diff
$> cat temp.diff
1,2d0
< 20110224
< 20110225
5a4,5
> 20110303
> 20110304
# 使用temp.diff和temp1.txt恢复temp2文件
$> patch -i temp.diff -o temp2_restore.txt temp1.txt
Looks like a normal diff.
done
# 完成后temp2_restore和原temp2文件内容一致
$> cat temp2_restore.txt
20110228
20110301
20110302
20110303
20110304
posted @
2016-03-24 12:09 xzc 阅读(1070) |
评论 (1) |
编辑 收藏 status=`ftp -v -n $ip<<END_SCRIPT
user $name $code
binary
cd $remote_dir
lcd $local_dir
prompt
mget *.txt
#mdelete *.txt
close
bye
END_SCRIPT`
echo $status|grep "226 Transfer complete"
if [ $? -eq 0 ]
then
echo "Connect Succeed!!!"
exit 0
else
echo $status|grep "530 Login incorrect"
if [ $? -eq 0 ]
then
echo "FTP Connect Error!!!"
exit 1
else
echo "No data transferred!!!"
exit 0
posted @
2016-03-24 12:08 xzc 阅读(1173) |
评论 (0) |
编辑 收藏获得当前日期+时间(date + time)函数:now()
mysql> select now(); +---------------------+ | now() | +---------------------+ | 2008-08-08 22:20:46 | +---------------------+
获得当前日期+时间(date + time)函数:sysdate()
sysdate() 日期时间函数跟 now() 类似,不同之处在于:now() 在执行开始时值就得到了, sysdate() 在函数执行时动态得到值。看下面的例子就明白了:
mysql> select now(), sleep(3), now(); +---------------------+----------+---------------------+ | now() | sleep(3) | now() | +---------------------+----------+---------------------+ | 2008-08-08 22:28:21 | 0 | 2008-08-08 22:28:21 | +---------------------+----------+---------------------+
sysdate() 日期时间函数,一般情况下很少用到。
MySQL 获得当前时间戳函数:current_timestamp, current_timestamp()
mysql> select current_timestamp, current_timestamp(); +---------------------+---------------------+ | current_timestamp | current_timestamp() | +---------------------+---------------------+ | 2008-08-09 23:22:24 | 2008-08-09 23:22:24 | +---------------------+---------------------+
MySQL 日期转换函数、时间转换函数
MySQL Date/Time to Str(日期/时间转换为字符串)函数:date_format(date,format), time_format(time,format)
mysql> select date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s'); +----------------------------------------------------+ | date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s') | +----------------------------------------------------+ | 20080808222301 | +----------------------------------------------------+MySQL 日期、时间转换函数:date_format(date,format), time_format(time,format) 能够把一个日期/时间转换成各种各样的字符串格式。它是 str_to_date(str,format) 函数的 一个逆转换。
MySQL Str to Date (字符串转换为日期)函数:str_to_date(str, format)
select str_to_date('08/09/2008', '%m/%d/%Y'); -- 2008-08-09 select str_to_date('08/09/08' , '%m/%d/%y'); -- 2008-08-09 select str_to_date('08.09.2008', '%m.%d.%Y'); -- 2008-08-09 select str_to_date('08:09:30', '%h:%i:%s'); -- 08:09:30 select str_to_date('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30可以看到,str_to_date(str,format) 转换函数,可以把一些杂乱无章的字符串转换为日期格式。另外,它也可以转换为时间。“format” 可以参看 MySQL 手册。
MySQL (日期、天数)转换函数:to_days(date), from_days(days)
select to_days('0000-00-00'); -- 0 select to_days('2008-08-08'); -- 733627
MySQL (时间、秒)转换函数:time_to_sec(time), sec_to_time(seconds)
select time_to_sec('01:00:05'); -- 3605 select sec_to_time(3605); -- '01:00:05'
MySQL 拼凑日期、时间函数:makdedate(year,dayofyear), maketime(hour,minute,second)
select makedate(2001,31); -- '2001-01-31' select makedate(2001,32); -- '2001-02-01' select maketime(12,15,30); -- '12:15:30'
MySQL (Unix 时间戳、日期)转换函数
unix_timestamp(), unix_timestamp(date), from_unixtime(unix_timestamp), from_unixtime(unix_timestamp,format)
下面是示例:
select unix_timestamp(); -- 1218290027 select unix_timestamp('2008-08-08'); -- 1218124800 select unix_timestamp('2008-08-08 12:30:00'); -- 1218169800 select from_unixtime(1218290027); -- '2008-08-09 21:53:47' select from_unixtime(1218124800); -- '2008-08-08 00:00:00' select from_unixtime(1218169800); -- '2008-08-08 12:30:00' select from_unixtime(1218169800, '%Y %D %M %h:%i:%s %x'); -- '2008 8th August 12:30:00 2008'
MySQL 日期时间计算函数
MySQL 为日期增加一个时间间隔:date_add()
set @dt = now(); select date_add(@dt, interval 1 day); -- add 1 day select date_add(@dt, interval 1 hour); -- add 1 hour select date_add(@dt, interval 1 minute); -- ... select date_add(@dt, interval 1 second); select date_add(@dt, interval 1 microsecond); select date_add(@dt, interval 1 week); select date_add(@dt, interval 1 month); select date_add(@dt, interval 1 quarter); select date_add(@dt, interval 1 year); select date_add(@dt, interval -1 day); -- sub 1 day
MySQL adddate(), addtime()函数,可以用 date_add() 来替代。下面是 date_add() 实现 addtime() 功能示例:
mysql> set @dt = '2008-08-09 12:12:33'; mysql> mysql> select date_add(@dt, interval '01:15:30' hour_second); +------------------------------------------------+ | date_add(@dt, interval '01:15:30' hour_second) | +------------------------------------------------+ | 2008-08-09 13:28:03 | +------------------------------------------------+ mysql> select date_add(@dt, interval '1 01:15:30' day_second); +-------------------------------------------------+ | date_add(@dt, interval '1 01:15:30' day_second) | +-------------------------------------------------+ | 2008-08-10 13:28:03 | +-------------------------------------------------+
MySQL 为日期减去一个时间间隔:date_sub()
mysql> select date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second); +----------------------------------------------------------------+ | date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second) | +----------------------------------------------------------------+ | 1997-12-30 22:58:59 | +----------------------------------------------------------------+MySQL date_sub() 日期时间函数 和 date_add() 用法一致,不再赘述。
MySQL 日期、时间相减函数:datediff(date1,date2), timediff(time1,time2)
MySQL datediff(date1,date2):两个日期相减 date1 - date2,返回天数。 select datediff('2008-08-08', '2008-08-01'); -- 7 select datediff('2008-08-01', '2008-08-08'); -- -7MySQL timediff(time1,time2):两个日期相减 time1 - time2,返回 time 差值。
select timediff('2008-08-08 08:08:08', '2008-08-08 00:00:00'); -- 08:08:08 select timediff('08:08:08', '00:00:00'); -- 08:08:08注意:timediff(time1,time2) 函数的两个参数类型必须相同。
MySQL 时间戳(timestamp)转换、增、减函数:
timestamp(date) -- date to timestamp timestamp(dt,time) -- dt + time timestampadd(unit,interval,datetime_expr) -- timestampdiff(unit,datetime_expr1,datetime_expr2) --
请看示例部分:
select timestamp('2008-08-08'); -- 2008-08-08 00:00:00 select timestamp('2008-08-08 08:00:00', '01:01:01'); -- 2008-08-08 09:01:01 select timestamp('2008-08-08 08:00:00', '10 01:01:01'); -- 2008-08-18 09:01:01 select timestampadd(day, 1, '2008-08-08 08:00:00'); -- 2008-08-09 08:00:00 select date_add('2008-08-08 08:00:00', interval 1 day); -- 2008-08-09 08:00:00 MySQL timestampadd() 函数类似于 date_add()。 select timestampdiff(year,'2002-05-01','2001-01-01'); -- -1 select timestampdiff(day ,'2002-05-01','2001-01-01'); -- -485 select timestampdiff(hour,'2008-08-08 12:00:00','2008-08-08 00:00:00'); -- -12 select datediff('2008-08-08 12:00:00', '2008-08-01 00:00:00'); -- 7MySQL timestampdiff() 函数就比 datediff() 功能强多了,datediff() 只能计算两个日期(date)之间相差的天数。
MySQL 时区(timezone)转换函数
convert_tz(dt,from_tz,to_tz) select convert_tz('2008-08-08 12:00:00', '+08:00', '+00:00'); -- 2008-08-08 04:00:00时区转换也可以通过 date_add, date_sub, timestampadd 来实现。
select date_add('2008-08-08 12:00:00', interval -8 hour); -- 2008-08-08 04:00:00 select date_sub('2008-08-08 12:00:00', interval 8 hour); -- 2008-08-08 04:00:00 select timestampadd(hour, -8, '2008-08-08 12:00:00'); -- 2008-08-08 04:00:00
更多参考 http://www.cnblogs.com/she27/archive/2009/01/16/1377089.html
posted @
2016-02-22 14:46 xzc 阅读(355) |
评论 (1) |
编辑 收藏[转载]http://www.blogjava.net/hongqiang/archive/2012/07/12/382939.html
假如你要在linux下删除大量文件,比如100万、1000万,像/var/spool/clientmqueue/的mail邮件,
像/usr/local/nginx/proxy_temp的nginx缓存等,那么rm -rf *可能就不好使了。
rsync提供了一些跟删除相关的参数
rsync --help | grep delete
--del an alias for --delete-during
--delete delete files that don't exist on the sending side
--delete-before receiver deletes before transfer (default)
--delete-during receiver deletes during transfer, not before
--delete-after receiver deletes after transfer, not before
--delete-excluded also delete excluded files on the receiving side
--ignore-errors delete even if there are I/O errors
--max-delete=NUM don't delete more than NUM files
其中--delete-before 接收者在传输之前进行删除操作
可以用来清空目录或文件,如下:
1、先建立一个空目录
mkdir /data/blank
2、用rsync删除目标目录
rsync --delete-before -d /data/blank/ /var/spool/clientmqueue/
这样目标目录很快就被清空了
又假如你有一些特别大的文件要删除,比如nohup.out这样的实时更新的文件,动辄都是几十个G上百G的,也可
以用rsync来清空大文件,而且效率比较高
1、创建空文件
touch /data/blank.txt
2、用rsync清空文件
rsync -a --delete-before --progress --stats /root/blank.txt /root/nohup.out
building file list ...
1 file to consider
blank.txt
0 100% 0.00kB/s 0:00:00 (xfer#1, to-check=0/1)
Number of files: 1
Number of files transferred: 1
Total file size: 0 bytes
Total transferred file size: 0 bytes
Literal data: 0 bytes
Matched data: 0 bytes
File list size: 27
File list generation time: 0.006 seconds
File list transfer time: 0.000 seconds
Total bytes sent: 73
Total bytes received: 31
sent 73 bytes received 31 bytes 208.00 bytes/sec
total size is 0 speedup is 0.00
tips:
当SRC和DEST文件性质不一致时将会报错
当SRC和DEST性质都为文件【f】时,意思是清空文件内容而不是删除文件
当SRC和DEST性质都为目录【d】时,意思是删除该目录下的所有文件,使其变为空目录
最重要的是,它的处理速度相当快,处理几个G的文件也就是秒级的事
最核心的内容是:rsync实际上用的就是替换原理
另外一种方式:利用xagr与ls结合
ls | xargs -n 20 rm -fr
ls当然是输出所有的文件名(用空格分割)
xargs就是将ls的输出,每20个为一组(以空格为分隔符),作为rm -rf的参数
也就是说将所有文件名20个为一组,由rm -rf删除,这样就不会超过命令行的长度了
posted @
2016-02-14 11:05 xzc 阅读(356) |
评论 (1) |
编辑 收藏Cloudera Manager分析
目录
1. 相关目录
2. 配置
3. 数据库
4. CM结构
5. 升级
6. 卸载
7. 开启postgresql远程访问
/var/log/cloudera-scm-installer : 安装日志目录。/var/log/* : 相关日志文件(相关服务的及CM的)。/usr/share/cmf/ : 程序安装目录。/usr/lib64/cmf/ : Agent程序代码。/var/lib/cloudera-scm-server-db/data : 内嵌数据库目录。/usr/bin/postgres : 内嵌数据库程序。/etc/cloudera-scm-agent/ : agent的配置目录。/etc/cloudera-scm-server/ : server的配置目录。/opt/cloudera/parcels/ : Hadoop相关服务安装目录。/opt/cloudera/parcel-repo/ : 下载的服务软件包数据,数据格式为parcels。/opt/cloudera/parcel-cache/ : 下载的服务软件包缓存数据。/etc/hadoop/* : 客户端配置文件目录。
Hadoop配置文件
配置文件放置于/var/run/cloudera-scm-agent/process/目录下。如:/var/run/cloudera-scm-agent/process/193-hdfs-NAMENODE/core-site.xml。这些配置文件是通过Cloudera Manager启动相应服务(如HDFS)时生成的,内容从数据库中获得(即通过界面配置的参数)。
在CM界面上更改配置是不会立即反映到配置文件中,这些信息会存储于数据库中,等下次重启服务时才会生成配置文件。且每次启动时都会产生新的配置文件。
CM Server主要数据库为scm基中放置配置的数据表为configs。里面包含了服务的配置信息,每一次配置的更改会把当前页面的所有配置内容添加到数据库中,以此保存配置修改历史。
scm数据库被配置成只能从localhost访问,如果需要从外部连接此数据库,修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
查看配置内容
- 直接查询scm数据库的configs数据表的内容。
- 访问REST API:
http://hostname:7180/api/v4/cm/deployment,返回JSON格式部署配置信息。
配置生成方式
CM为每个服务进程生成独立的配置目录(文件)。所有配置统一在服务端查询数据库生成(因为scm数据库只能在localhost下访问)生成配置文件,再由agent通过网络下载包含配置文件的zip包到本地解压到指定的目录。
配置修改
CM对于需要修改的配置预先定义,对于没有预先定义的配置,则通过在高级配置项中使用xml配置片段的方式进行配置。而对于/etc/hadoop/下的配置文件是客户端的配置,可以在CM通过部署客户端生成客户端配置。
Cloudera manager主要的数据库为scm,存储Cloudera manager运行所需要的信息:配置,主机,用户等。
CM分为Server与Agent两部分及数据库(自带更改过的嵌入Postgresql)。它主要做三件事件:
- 管理监控集群主机。
- 统一管理配置。
- 管理维护Hadoop平台系统。
实现采用C/S结构,Agent为客户端负责执行服务端发来的命令,执行方式一般为使用python调用相应的服务shell脚本。Server端为Java REST服务,提供REST API,Web管理端通过REST API调用Server端功能,Web界面使用富客户端技术(Knockout)。
- Server端主体使用Java实现。
- Agent端主体使用Python, 服务的启动通过调用相应的shell脚本进行启动,如果启动失败会重复4次调用启动脚本。
- Agent与Server保持心跳,使用Thrift RPC框架。
在CM中可以通过界面向导升级相关服务。升级过程为三步:
- 下载服务软件包。
- 把所下载的服务软件包分发到集群中受管的机器上。
- 安装服务软件包,使用软链接的方式把服务程序目录链接到新安装的软件包目录上。
sudo /usr/share/cmf/uninstall-scm-express.sh, 然后删除/var/lib/cloudera-scm-server-db/目录,不然下次安装可能不成功。
CM内嵌数据库被配置成只能从localhost访问,如果需要从外部查看数据,数据修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
posted @
2015-12-25 17:28 xzc 阅读(434) |
评论 (0) |
编辑 收藏除了在一个目录结构下查找文件这种基本的操作,你还可以用find命令实现一些实用的操作,使你的命令行之旅更加简易。
本文将介绍15种无论是于新手还是老鸟都非常有用的Linux find命令。
首先,在你的home目录下面创建下面的空文件,来测试下面的find命令示例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # vim create_sample_files.sh
touch MybashProgram.sh
touch mycprogram.c
touch MyCProgram.c
touch Program.c
mkdir backup
cd backup
touch MybashProgram.sh
touch mycprogram.c
touch MyCProgram.c
touch Program.c
# chmod +x create_sample_files.sh
# ./create_sample_files.sh
# ls -R
.:
backup MybashProgram.sh MyCProgram.c
create_sample_files.sh mycprogram.c Program.c
./backup:
MybashProgram.sh mycprogram.c MyCProgram.c Program.c
|
1. 用文件名查找文件
这是find命令的一个基本用法。下面的例子展示了用MyCProgram.c作为查找名在当前目录及其子目录中查找文件的方法。
1 2 3 | # find -name "MyCProgram.c"
./backup/MyCProgram.c
./MyCProgram.c
|
2.用文件名查找文件,忽略大小写
这是find命令的一个基本用法。下面的例子展示了用MyCProgram.c作为查找名在当前目录及其子目录中查找文件的方法,忽略了大小写。
1 2 3 4 5 | # find -iname "MyCProgram.c"
./mycprogram.c
./backup/mycprogram.c
./backup/MyCProgram.c
./MyCProgram.c
|
3. 使用mindepth和maxdepth限定搜索指定目录的深度
在root目录及其子目录下查找passwd文件。
1 2 3 4 5 | # find / -name passwd
./usr/share/doc/nss_ldap-253/pam.d/passwd
./usr/bin/passwd
./etc/pam.d/passwd
./etc/passwd
|
在root目录及其1层深的子目录中查找passwd. (例如root — level 1, and one sub-directory — level 2)
1 2 | # find -maxdepth 2 -name passwd
./etc/passwd
|
在root目录下及其最大两层深度的子目录中查找passwd文件. (例如 root — level 1, and two sub-directories — level 2 and 3 )
1 2 3 4 | # find / -maxdepth 3 -name passwd
./usr/bin/passwd
./etc/pam.d/passwd
./etc/passwd
|
在第二层子目录和第四层子目录之间查找passwd文件。
1 2 3 | # find -mindepth 3 -maxdepth 5 -name passwd
./usr/bin/passwd
./etc/pam.d/passwd
|
4. 在find命令查找到的文件上执行命令
下面的例子展示了find命令来计算所有不区分大小写的文件名为“MyCProgram.c”的文件的MD5验证和。{}将会被当前文件名取代。
1 2 3 4 5 | find -iname "MyCProgram.c" -exec md5sum {} \;
d41d8cd98f00b204e9800998ecf8427e ./mycprogram.c
d41d8cd98f00b204e9800998ecf8427e ./backup/mycprogram.c
d41d8cd98f00b204e9800998ecf8427e ./backup/MyCProgram.c
d41d8cd98f00b204e9800998ecf8427e ./MyCProgram.c
|
5. 相反匹配
显示所有的名字不是MyCProgram.c的文件或者目录。由于maxdepth是1,所以只会显示当前目录下的文件和目录。
1 2 3 4 5 6 | find -maxdepth 1 -not -iname "MyCProgram.c"
.
./MybashProgram.sh
./create_sample_files.sh
./backup
./Program.c
|
6. 使用inode编号查找文件
任何一个文件都有一个独一无二的inode编号,借此我们可以区分文件。创建两个名字相似的文件,例如一个有空格结尾,一个没有。
1 2 3 4 5 6 | touch "test-file-name"
# touch "test-file-name "
[Note: There is a space at the end]
# ls -1 test*
test-file-name
test-file-name
|
从ls的输出不能区分哪个文件有空格结尾。使用选项-i,可以看到文件的inode编号,借此可以区分这两个文件。
1 2 3 | ls -i1 test*
16187429 test-file-name
16187430 test-file-name
|
你可以如下面所示在find命令中指定inode编号。在此,find命令用inode编号重命名了一个文件。
1 2 3 4 5 | find -inum 16187430 -exec mv {} new-test-file-name \;
# ls -i1 *test*
16187430 new-test-file-name
16187429 test-file-name
|
你可以在你想对那些像上面一样的糟糕命名的文件做某些操作时使用这一技术。例如,名为file?.txt的文件名字中有一个特殊字符。若你想执行“rm file?.txt”,下面所示的所有三个文件都会被删除。所以,采用下面的步骤来删除”file?.txt”文件。
1 2 | ls
file1.txt file2.txt file?.txt
|
找到每一个文件的inode编号。
1 2 3 4 | ls -i1
804178 file1.txt
804179 file2.txt
804180 file?.txt
|
如下所示:?使用inode编号来删除那些具有特殊符号的文件名。
1 2 3 4 | find -inum 804180 -exec rm {} \;
# ls
file1.txt file2.txt
[Note: The file with name "file?.txt" is now removed]
|
7. 根据文件权限查找文件
下面的操作时合理的:
- 找到具有指定权限的文件
- 忽略其他权限位,检查是否和指定权限匹配
- 根据给定的八进制/符号表达的权限搜索
此例中,假设目录包含以下文件。注意这些文件的权限不同。
1 2 3 4 5 6 7 8 | ls -l
total 0
-rwxrwxrwx 1 root root 0 2009-02-19 20:31 all_for_all
-rw-r--r-- 1 root root 0 2009-02-19 20:30 everybody_read
---------- 1 root root 0 2009-02-19 20:31 no_for_all
-rw------- 1 root root 0 2009-02-19 20:29 ordinary_file
-rw-r----- 1 root root 0 2009-02-19 20:27 others_can_also_read
----r----- 1 root root 0 2009-02-19 20:27 others_can_only_read
|
找到具有组读权限的文件。使用下面的命令来找到当前目录下对同组用户具有读权限的文件,忽略该文件的其他权限。
1 2 3 4 5 | find . -perm -g=r -type f -exec ls -l {} \;
-rw-r--r-- 1 root root 0 2009-02-19 20:30 ./everybody_read
-rwxrwxrwx 1 root root 0 2009-02-19 20:31 ./all_for_all
----r----- 1 root root 0 2009-02-19 20:27 ./others_can_only_read
-rw-r----- 1 root root 0 2009-02-19 20:27 ./others_can_also_read
|
找到对组用户具有只读权限的文件。
1 2 | find . -perm g=r -type f -exec ls -l {} \;
----r----- 1 root root 0 2009-02-19 20:27 ./others_can_only_read
|
找到对组用户具有只读权限的文件(使用八进制权限形式)。
1 2 | find . -perm 040 -type f -exec ls -l {} \;
----r----- 1 root root 0 2009-02-19 20:27 ./others_can_only_read
|
8. 找到home目录及子目录下所有的空文件(0字节文件)
下面命令的输出文件绝大多数都是锁定文件盒其他程序创建的place hoders
只列出你home目录里的空文件。
1 | find . -maxdepth 1 -empty
|
只列出当年目录下的非隐藏空文件。
1 | find . -maxdepth 1 -empty -not -name ".*"
|
9. 查找5个最大的文件
下面的命令列出当前目录及子目录下的5个最大的文件。这会需要一点时间,取决于命令需要处理的文件数量。
1 | find . -type f -exec ls -s {} \; | sort -n -r | head -5
|
10. 查找5个最小的文件
方法同查找5个最大的文件类似,区别只是sort的顺序是降序。
1 | find . -type f -exec ls -s {} \; | sort -n | head -5
|
上面的命令中,很可能你看到的只是空文件(0字节文件)。如此,你可以使用下面的命令列出最小的文件,而不是0字节文件。
1 | find . -not -empty -type f -exec ls -s {} \; | sort -n | head -5
|
11. 使用-type查找指定文件类型的文件
只查找socket文件
查找所有的目录
查找所有的一般文件
查找所有的隐藏文件
1 | find . -type f -name ".*"
|
查找所有的隐藏目录
12. 通过和其他文件比较修改时间查找文件
显示在指定文件之后做出修改的文件。下面的find命令将显示所有的在ordinary_file之后创建修改的文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | ls -lrt
total 0
-rw-r----- 1 root root 0 2009-02-19 20:27 others_can_also_read
----r----- 1 root root 0 2009-02-19 20:27 others_can_only_read
-rw------- 1 root root 0 2009-02-19 20:29 ordinary_file
-rw-r--r-- 1 root root 0 2009-02-19 20:30 everybody_read
-rwxrwxrwx 1 root root 0 2009-02-19 20:31 all_for_all
---------- 1 root root 0 2009-02-19 20:31 no_for_all
# find -newer ordinary_file
.
./everybody_read
./all_for_all
./no_for_all
|
13. 通过文件大小查找文件
使用-size选项可以通过文件大小查找文件。
查找比指定文件大的文件
查找比指定文件小的文件
查找符合给定大小的文件
注意: – 指比给定尺寸小,+ 指比给定尺寸大。没有符号代表和给定尺寸完全一样大。
14. 给常用find操作取别名
若你发现有些东西很有用,你可以给他取别名。并且在任何你希望的地方执行。
常用的删除a.out文件。
1 2 | alias rmao="find . -iname a.out -exec rm {} \;"
# rmao
|
删除c程序产生的core文件。
1 2 | alias rmc="find . -iname core -exec rm {} \;"
# rmc
|
15. 用find命令删除大型打包文件
下面的命令删除大于100M的*.zip文件。
1 | find / -type f -name *.zip -size +100M -exec rm -i {} \;"
|
用别名rm100m删除所有大雨100M的*.tar文件。使用同样的思想可以创建rm1g,rm2g,rm5g的一类别名来删除所有大于1G,2G,5G的文件。
1 2 3 4 5 6 7 8 9 | alias rm100m="find / -type f -name *.tar -size +100M -exec rm -i {} \;"
# alias rm1g="find / -type f -name *.tar -size +1G -exec rm -i {} \;"
# alias rm2g="find / -type f -name *.tar -size +2G -exec rm -i {} \;"
# alias rm5g="find / -type f -name *.tar -size +5G -exec rm -i {} \;"
# rm100m
# rm1g
# rm2g
# rm5g
|
Find命令示例(第二部分)
若你喜欢这篇关于find命令的Mommy文章,别忘了看看第二部分的关于find命令的Daddy文章。《爹地,我找到了!15个极好的Linux find命令示例》
posted @
2015-12-23 10:34 xzc 阅读(398) |
评论 (3) |
编辑 收藏posted @
2015-12-21 15:54 xzc 阅读(2573) |
评论 (1) |
编辑 收藏一:需要包含的包
import java.security.*;
import java.io.*;
import java.util.*;
import java.security.*;
import java.security.cert.*;
import sun.security.x509.*
import java.security.cert.Certificate;
import java.security.cert.CertificateFactory;
二:从文件中读取证书
用keytool将.keystore中的证书写入文件中,然后从该文件中读取证书信息
CertificateFactory cf=CertificateFactory.getInstance("X.509");
FileInputStream in=new FileInputStream("out.csr");
Certificate c=cf.generateCertificate(in);
String s=c.toString();
三:从密钥库中直接读取证书
String pass="123456";
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,pass.toCharArray());
java.security.cert.Certificate c=ks.getCertificate(alias);//alias为条目的别名
四:JAVA程序中显示证书指定信息
System.out.println("输出证书信息:\n"+c.toString());
System.out.println("版本号:"+t.getVersion());
System.out.println("序列号:"+t.getSerialNumber().toString(16));
System.out.println("主体名:"+t.getSubjectDN());
System.out.println("签发者:"+t.getIssuerDN());
System.out.println("有效期:"+t.getNotBefore());
System.out.println("签名算法:"+t.getSigAlgName());
byte [] sig=t.getSignature();//签名值
PublicKey pk=t.getPublicKey();
byte [] pkenc=pk.getEncoded();
System.out.println("公钥");
for(int i=0;i<pkenc.length;i++)System.out.print(pkenc[i]+",");
五:JAVA程序列出密钥库所有条目
String pass="123456";
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,pass.toCharArray());
Enumeration e=ks.aliases();
while(e.hasMoreElements())
java.security.cert.Certificate c=ks.getCertificate((String)e.nextElement());
六:JAVA程序修改密钥库口令
String oldpass="123456";
String newpass="654321";
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,oldpass.toCharArray());
in.close();
FileOutputStream output=new FileOutputStream(".keystore");
ks.store(output,newpass.toCharArray());
output.close();
七:JAVA程序修改密钥库条目的口令及添加条目
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,storepass.toCharArray());
Certificate [] cchain=ks.getCertificate(alias);获取别名对应条目的证书链
PrivateKey pk=(PrivateKey)ks.getKey(alias,oldkeypass.toCharArray());获取别名对应条目的私钥
ks.setKeyEntry(alias,pk,newkeypass.toCharArray(),cchain);向密钥库中添加条目
第一个参数指定所添加条目的别名,假如使用已存在别名将覆盖已存在条目,使用新别名将增加一个新条目,第二个参数为条目的私钥,第三个为设置的新口令,第四个为该私钥的公钥的证书链
FileOutputStream output=new FileOutputStream("another");
ks.store(output,storepass.toCharArray())将keystore对象内容写入新文件
八:JAVA程序检验别名和删除条目
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,storepass.toCharArray());
ks.containsAlias("sage");检验条目是否在密钥库中,存在返回true
ks.deleteEntry("sage");删除别名对应的条目
FileOutputStream output=new FileOutputStream(".keystore");
ks.store(output,storepass.toCharArray())将keystore对象内容写入文件,条目删除成功
九:JAVA程序签发数字证书
(1)从密钥库中读取CA的证书
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,storepass.toCharArray());
java.security.cert.Certificate c1=ks.getCertificate("caroot");
(2)从密钥库中读取CA的私钥
PrivateKey caprk=(PrivateKey)ks.getKey(alias,cakeypass.toCharArray());
(3)从CA的证书中提取签发者的信息
byte[] encod1=c1.getEncoded();提取CA证书的编码
X509CertImpl cimp1=new X509CertImpl(encod1); 用该编码创建X509CertImpl类型对象
X509CertInfo cinfo1=(X509CertInfo)cimp1.get(X509CertImpl.NAME+"."+X509CertImpl.INFO); 获取X509CertInfo对象
X500Name issuer=(X500Name)cinfo1.get(X509CertInfo.SUBJECT+"."+CertificateIssuerName.DN_NAME); 获取X509Name类型的签发者信息
(4)获取待签发的证书
CertificateFactory cf=CertificateFactory.getInstance("X.509");
FileInputStream in2=new FileInputStream("user.csr");
java.security.cert.Certificate c2=cf.generateCertificate(in);
(5)从待签发的证书中提取证书信息
byte [] encod2=c2.getEncoded();
X509CertImpl cimp2=new X509CertImpl(encod2); 用该编码创建X509CertImpl类型对象
X509CertInfo cinfo2=(X509CertInfo)cimp2.get(X509CertImpl.NAME+"."+X509CertImpl.INFO); 获取X509CertInfo对象
(6)设置新证书有效期
Date begindate=new Date(); 获取当前时间
Date enddate=new Date(begindate.getTime()+3000*24*60*60*1000L); 有效期为3000天
CertificateValidity cv=new CertificateValidity(begindate,enddate); 创建对象
cinfo2.set(X509CertInfo.VALIDITY,cv); 设置有效期
(7)设置新证书序列号
int sn=(int)(begindate.getTime()/1000);以当前时间为序列号
CertificateSerialNumber csn=new CertificateSerialNumber(sn);
cinfo2.set(X509CertInfo.SERIAL_NUMBER,csn);
(8)设置新证书签发者
cinfo2.set(X509CertInfo.ISSUER+"."+CertificateIssuerName.DN_NAME,issuer);应用第三步的结果
(9)设置新证书签名算法信息
AlgorithmId algorithm=new AlgorithmId(AlgorithmId.md5WithRSAEncryption_oid);
cinfo2.set(CertificateAlgorithmId.NAME+"."+CertificateAlgorithmId.ALGORITHM,algorithm);
(10)创建证书并使用CA的私钥对其签名
X509CertImpl newcert=new X509CertImpl(cinfo2);
newcert.sign(caprk,"MD5WithRSA"); 使用CA私钥对其签名
(11)将新证书写入密钥库
ks.setCertificateEntry("lf_signed",newcert);
FileOutputStream out=new FileOutputStream("newstore");
ks.store(out,"newpass".toCharArray()); 这里是写入了新的密钥库,也可以使用第七条来增加条目
十:数字证书的检验
(1)验证证书的有效期
(a)获取X509Certificate类型对象
CertificateFactory cf=CertificateFactory.getInstance("X.509");
FileInputStream in1=new FileInputStream("aa.crt");
java.security.cert.Certificate c1=cf.generateCertificate(in1);
X509Certificate t=(X509Certificate)c1;
in2.close();
(b)获取日期
Date TimeNow=new Date();
(c)检验有效性
try{
t.checkValidity(TimeNow);
System.out.println("OK");
}catch(CertificateExpiredException e){ //过期
System.out.println("Expired");
System.out.println(e.getMessage());
}catch((CertificateNotYetValidException e){ //尚未生效
System.out.println("Too early");
System.out.println(e.getMessage());}
(2)验证证书签名的有效性
(a)获取CA证书
CertificateFactory cf=CertificateFactory.getInstance("X.509");
FileInputStream in2=new FileInputStream("caroot.crt");
java.security.cert.Certificate cac=cf.generateCertificate(in2);
in2.close();
(c)获取CA的公钥
PublicKey pbk=cac.getPublicKey();
(b)获取待检验的证书(上步已经获取了,就是C1)
(c)检验证书
boolean pass=false;
try{
c1.verify(pbk);
pass=true;
}catch(Exception e){
pass=false;
System.out.println(e);
}
posted @
2015-12-11 11:40 xzc 阅读(400) |
评论 (0) |
编辑 收藏原文地址:http://www.itwis.com/html/os/linux/20100202/7360.html
linux中用shell获取昨天、明天或多天前的日期:
在Linux中对man date -d 参数说的比较模糊,以下举例进一步说明:
# -d, --date=STRING display time described by STRING, not `now’
- [root@Gman root]# date -d next-day +%Y%m%d #明天日期
- 20091024
- [root@Gman root]# date -d last-day +%Y%m%d #昨天日期
- 20091022
- [root@Gman root]# date -d yesterday +%Y%m%d #昨天日期
- 20091022
- [root@Gman root]# date -d tomorrow +%Y%m%d # 明天日期
- 20091024
- [root@Gman root]# date -d last-month +%Y%m #上个月日期
- 200909
- [root@Gman root]# date -d next-month +%Y%m #下个月日期
- 200911
- [root@Gman root]# date -d next-year +%Y #明年日期
- 2010
DATE=$(date +%Y%m%d --date '2 days ago') #获取昨天或多天前的日期
名称 : date
使用权限 : 所有使用者
使用方式 : date [-u] [-d datestr] [-s datestr] [--utc] [--universal] [--date=datestr] [--set=datestr] [--help] [--version] [+FORMAT] [MMDDhhmm[[CC]YY][.ss]]
说明 : date 能用来显示或设定系统的日期和时间,在显示方面,使用者能设定欲显示的格式,格式设定为一个加号后接数个标记,其中可用的标记列表如下 :
- 时间方面 :
- % : 印出
- % %n : 下一行
- %t : 跳格
- %H : 小时(00..23)
- %I : 小时(01..12)
- %k : 小时(0..23)
- %l : 小时(1..12)
- %M : 分钟(00..59)
- %p : 显示本地 AM 或 PM
- %r : 直接显示时间 (12 小时制,格式为 hh:mm:ss [AP]M)
- %s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数 %S : 秒(00..61)
- %T : 直接显示时间 (24 小时制)
- %X : 相当于 %H:%M:%S
- %Z : 显示时区
- 日期方面 :
- %a : 星期几 (Sun..Sat)
- %A : 星期几 (Sunday..Saturday)
- %b : 月份 (Jan..Dec)
- %B : 月份 (January..December)
- %c : 直接显示日期和时间
- %d : 日 (01..31)
- %D : 直接显示日期 (mm/dd/yy)
- %h : 同 %b
- %j : 一年中的第几天 (001..366)
- %m : 月份 (01..12)
- %U : 一年中的第几周 (00..53) (以 Sunday 为一周的第一天的情形)
- %w : 一周中的第几天 (0..6)
- %W : 一年中的第几周 (00..53) (以 Monday 为一周的第一天的情形)
- %x : 直接显示日期 (mm/dd/yy)
- %y : 年份的最后两位数字 (00.99)
- %Y : 完整年份 (0000..9999)
若是不以加号作为开头,则表示要设定时间,而时间格式为 MMDDhhmm[[CC]YY][.ss],
其中 MM 为月份,
DD 为日,
hh 为小时,
mm 为分钟,
CC 为年份前两位数字,
YY 为年份后两位数字,
ss 为秒数
把计 :
-d datestr : 显示 datestr 中所设定的时间 (非系统时间)
--help : 显示辅助讯息
-s datestr : 将系统时间设为 datestr 中所设定的时间
-u : 显示目前的格林威治时间
--version : 显示版本编号
例子 :
显示时间后跳行,再显示目前日期 : date +%T%n%D
显示月份和日数 : date +%B %d
显示日期和设定时间(12:34:56) : date --date 12:34:56
设置系统当前时间(12:34:56):date --s 12:34:56
注意 : 当你不希望出现无意义的 0 时(比如说 1999/03/07),则能在标记中插入 - 符号,比如说 date +%-H:%-M:%-S 会把时分秒中无意义的 0 给去掉,像是原本的 08:09:04 会变为 8:9:4。另外,只有取得权限者(比如说 root)才能设定系统时间。 当你以 root 身分更改了系统时间之后,请记得以 clock -w 来将系统时间写入 CMOS 中,这样下次重新开机时系统时间才会持续抱持最新的正确值。
ntp时间同步
linux系统下默认安装了ntp服务,手动进行ntp同步如下
ntpdate ntp1.nl.net
当然,也能指定其他的ntp服务器
-------------------------------------------------------------------
扩展功能
date 工具可以完成更多的工作,不仅仅只是打印出当前的系统日期。您可以使用它来得到给定的日期究竟是星期几,并得到相对于当前日期的相对日期。了解某一天是星期几
GNU 对 date 命令的另一个扩展是 -d 选项,当您的桌上没有日历表时(UNIX 用户不需要日历表),该选项非常有用。使用这个功能强大的选项,通过将日期作为引号括起来的参数提供,您可以快速地查明一个特定的日期究竟是星期几:
$ date -d "nov 22"
Wed Nov 22 00:00:00 EST 2006
$
在本示例中,您可以看到今年的 11 月 22 日是星期三。
所以,假设在 11 月 22 日召开一个重大的会议,您可以立即了解到这一天是星期三,而这一天您将赶到驻地办公室。
获得相对日期
d 选项还可以告诉您,相对于 当前日期若干天的究竟是哪一天,从现在开始的若干天或若干星期以后,或者以前(过去)。通过将这个相对偏移使用引号括起来,作为 -d 选项的参数,就可以完成这项任务。
例如,您需要了解两星期以后的日期。如果您处于 Shell 提示符处,那么可以迅速地得到答案:
$ date -d ’2 weeks’
- 关于使用该命令,还有其他一些重要的方法。使用 next/last指令,您可以得到以后的星期几是哪一天:
- $ date -d 'next monday' (下周一的日期)
- $ date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
- $ date -d last-day +%Y%m%d(昨天的日期) 或者:date -d yesterday +%Y%m%d
- $ date -d last-month +%Y%m(上个月是几月)
- $ date -d next-month +%Y%m(下个月是几月)
- 使用 ago 指令,您可以得到过去的日期:
- $ date -d '30 days ago' (30天前的日期)
- 您可以使用负数以得到相反的日期:
- $ date -d 'dec 14 -2 weeks' (相对:dec 14这个日期的两周前的日期)
- $ date -d '-100 days' (100天以前的日期)
- $ date -d '50 days'(50天后的日期)
这个技巧非常有用,它可以根据将来的日期为自己设置提醒,可能是在脚本或 Shell 启动文件中,如下所示:
DAY=`date -d '2 weeks' +"%b %d"`
if test "`echo $DAY`" = "Aug 16"; then echo 'Product launch is now two weeks away!'; fi
posted @
2015-12-08 09:33 xzc 阅读(950) |
评论 (0) |
编辑 收藏LINUX - awk命令之NF和$NF区别
LINUX - awk命令之NF和$NF区别
NF和$NF 区别问答:
1.awk中$NF是什么意思?
#pwd
/usr/local/etc
~# echo $PWD | awk -F/ '{print $NF}'
etc
NF代表:浏览记录的域的个数
$NF代表 :最后一个Field(列)
2.awk下面的变量NF和$NF有什么区别?
{print NF} 也有{print $NF}
前者是输出了域个数,后者是输出最后一个字段的内容
如:~# echo $PWD | awk -F/ '{print $NF}'
posted @
2015-12-07 10:23 xzc 阅读(1502) |
评论 (0) |
编辑 收藏bash shell 脚本执行的方法有多种,本文作一个总结,供大家学习参考。
假设我们编写好的shell脚本的文件名为hello.sh,文件位置在/data/shell目录中并已有执行权限。
方法一:切换到shell脚本所在的目录(此时,称为工作目录)执行shell脚本:
cd /data/shell
./hello.sh
./的意思是说在当前的工作目录下执行hello.sh。如果不加上./,bash可能会响应找到不到hello.sh的错误信息。因为目前的工作目录(/data/shell)可能不在执行程序默认的搜索路径之列,也就是说,不在环境变量PASH的内容之中。查看PATH的内容可用 echo $PASH 命令。现在的/data/shell就不在环境变量PASH中的,所以必须加上./才可执行。
方法二:以绝对路径的方式去执行bash shell脚本:
/data/shell/hello.sh
方法三:直接使用bash 或sh 来执行bash shell脚本:
cd /data/shell
bash hello.sh
或
cd /data/shell
sh hello.sh
注意,若是以方法三的方式来执行,那么,可以不必事先设定shell的执行权限,甚至都不用写shell文件中的第一行(指定bash路径)。因为方法三是将hello.sh作为参数传给sh(bash)命令来执行的。这时不是hello.sh自己来执行,而是被人家调用执行,所以不要执行权限。那么不用指定bash路径自然也好理解了啊,呵呵……。
方法四:在当前的shell环境中执行bash shell脚本:
cd /data/shell
. hello.sh
或
cd /data/shell
source hello.sh
前三种方法执行shell脚本时都是在当前shell(称为父shell)开启一个子shell环境,此shell脚本就在这个子shell环境中执行。shell脚本执行完后子shell环境随即关闭,然后又回到父shell中。而方法四则是在当前shell中执行的。
假设shell脚本文件为hello.sh
放在/root目录下。
下面介绍几种在终端执行shell脚本的方法:
复制代码代码如下:
[root@localhost home]# cd /root/
[root@localhost ~]#vim hello.sh
#! /bin/bash
cd /tmp
echo "hello guys!"
echo "welcome to my Blog:linuxboy.org!"
1.切换到shell脚本所在的目录,执行:
复制代码代码如下:
[root@localhost ~]# ./hello.sh
-bash: ./ hello.sh: 权限不够
2.以绝对路径的方式执行:
复制代码代码如下:
[root@localhost ~]# /root/Desktop/hello.sh
-bash: /root/Desktop/ hello.sh: 权限不够
3.直接用bash或sh执行:
复制代码代码如下:
[root@localhost ~]# bash hello.sh
hello guys!
welcome to my Blog:linuxboy.org!
[root@localhost ~]# pwd
/root
[root@localhost ~]# sh hello.sh
hello guys!
welcome to my Blog:linuxboy.org!
[root@localhost ~]# pwd
/root
注意:用以上三种方法执行shell脚本,现行的shell会开启一个子shell环境,去执行shell脚本,前两种必须要有执行权限才能够执行。也可以让shell脚本在现行的shell中执行:
4.现行的shell中执行
复制代码代码如下:
[root@localhost ~]# . hello.sh
hello guys!
welcome to my Blog:linuxboy.org!
[root@localhost tmp]# pwd
/tmp
[root@localhost ~]# source hello.sh
hello guys!
welcome to my Blog:linuxboy.org!
[root@localhost tmp]# pwd
/tmp
对于第4种不会创建子进程,而是在父进程中直接执行。
上面的差异是因为子进程不能改变父进程的执行环境,所以CD(内建命令,只有内建命令才可以改变shell 的执行环境)没有成功,但是第4种没有子进程,所以CD成功。
posted @
2015-12-02 10:33 xzc 阅读(383) |
评论 (0) |
编辑 收藏posted @
2015-11-26 23:35 xzc 阅读(285) |
评论 (0) |
编辑 收藏posted @
2015-11-26 23:20 xzc 阅读(376) |
评论 (0) |
编辑 收藏Python语法简单,而且通过缩进的方式来表现层次结构,代码非常简明易懂,对初学者来说,比较容易上手。
Perl的模式匹配非常强大,同时匹配的符号有很多种,难以阅读和维护。
在文本处理方面,python通过加载re模块来实现模式匹配的查找和替换。而Perl内置就有模式匹配功能。
note:内置命令和外部命令的区别。
通过代码来直接做比较。
python版:
#!/usr/bin/python
import re
import fileinput
exists_re = re.compile(r'^(.*?) INFO.*Such a record already exists', re.I)
location_re = re.compile(r'^AwbLocation (.*?) insert into', re.I)
for line in fileinput.input():
fn = fileinput.filename()
currline = line.rstrip()
mprev = exists_re.search(currline)
if(mprev):
xlogtime = mprev.group(1)
mcurr = location_re.search(currline)
if(mcurr):
print fn, xlogtime, mcurr.group(1)
Perl版:
#!/usr/bin/perl
while (<>) {
chomp;
if (m/^(.*?) INFO.*Such a record already exists/i) {
$xlogtime = $1;
}
if (m/^AwbLocation (.*?) insert into/i) {
print "$ARGV $xlogtime $1\n";
}
}
time process_file.py *log > summarypy.log
real 0m8.185s
user 0m8.018s
sys 0m0.092s
time process_file.pl *log > summaypl.log
real 0m1.481s
user 0m1.294s
sys 0m0.124s
在文本处理方面,Perl 比Python快8倍左右。
所以在处理大文件如大日志方面,用perl更好,因为更快。
如果对速度要求不是很严格的话,用python更好,因为python简洁易懂,容易维护和阅读。
为什么在文本处理时,Perl比Python快很多呢?
这是因为Perl的模式匹配是其内置功能,而Python需要加载re模块,使用内置命令比外部命令要快很多。
内置命令和外部命令的区别
Linux命令有内置命令和外部命令之分,功能基本相同,但是调用有些细微差别。
内置命令实际上是shell程序的一部分,其中包含的是一些简单的linux系统命令,这些命令在shell程序识别并在shell程序内部完成运行,通常在linux系统加载运行时shell就被加载并驻留在系统内存中。内部命令是设在bash源代码里面的,其执行速度比外部命令快,因为解析内部命令shell不需要创建子进程,比如exit,cd,pwd,echo,history等。
外部命令是linux系统中的实用应用程序,因为实用程序的功能通常比较强大,其包含的程序量也很大,在系统加载的时候并不随系统一起被加载到内存中,而是在需要的时候才将其调入内存。通常外部命令的实体并不包含在shell中,但是其命令执行过程是由shell程序控制的。shell程序管理外部命令执行的路径查找,加载存放,并控制命令的执行。外部命令是在bash之外额外安装的,通常放在/bin, /usr/bin, /sbin, /usr/sbin,....等。
用type命令可以分辨内部命令与外部命令。

posted @
2015-11-26 23:15 xzc 阅读(1568) |
评论 (0) |
编辑 收藏转自:
http://blog.csdn.net/caihaijiang/article/details/5903154Eclipse下Debug时,弹出错误提示:“Unable to install breakpoint due to missing line number attributes. Modify compiler options to generate line number attributes”,无法进行调试。
遇到这个错误时找到的解答方案汇总:
1、修改Eclipse的java编译器使用jdk,而不是jre;
2、使用Ant编译时,未打开debug开关,在写javac 任务时,设置debug="true",否则不能调试。THe settings for the eclipse compiler don't affect the ant build and even if you launch the ant build from withineclipse. ant controls it's own compiler settings.you can tell ant to generate debugging info like this 'javac ... debug="true".../>;(我遇到的问题,是采用这个办法解决的)
3、编译器的设置问题,window->preferences->java->Compiler在compiler起始页,classfile Generation区域中确认已经勾选了All line number attributes to generated class files。如果已经勾选,从新来一下再Apply一下。或者从项目层次进行设定,项目属性->java compiler同样在起始页,确定已经勾选。
Eclipse编译时出现Outof Memory问题,解决办法如下:
window->preferences->java->Installed JREs,选择安装的jre(如jdk1.5.0),单击右边按钮“Edit”,弹出“Edit JRE”的对话框,在Default VM Argument的输入框中输入:-Xmx512m,然后按确定,即可。(-Xms是设定最小内存,-Xmx是设定最大内存)
posted @
2015-11-26 15:56 xzc 阅读(756) |
评论 (0) |
编辑 收藏一:前言
防火墙,其实说白了讲,就是用于实现Linux下访问控制的功能的,它分为硬件的或者软件的防火墙两种。无论是在哪个网络中,防火墙工作的地方一定是在网络的边缘。而我们的任务就是需要去定义到底防火墙如何工作,这就是防火墙的策略,规则,以达到让它对出入网络的IP、数据进行检测。
目前市面上比较常见的有3、4层的防火墙,叫网络层的防火墙,还有7层的防火墙,其实是代理层的网关。
对于TCP/IP的七层模型来讲,我们知道第三层是网络层,三层的防火墙会在这层对源地址和目标地址进行检测。但是对于七层的防火墙,不管你源端口或者目标端口,源地址或者目标地址是什么,都将对你所有的东西进行检查。所以,对于设计原理来讲,七层防火墙更加安全,但是这却带来了效率更低。所以市面上通常的防火墙方案,都是两者结合的。而又由于我们都需要从防火墙所控制的这个口来访问,所以防火墙的工作效率就成了用户能够访问数据多少的一个最重要的控制,配置的不好甚至有可能成为流量的瓶颈。
二:iptables 的历史以及工作原理
1.iptables的发展:
iptables的前身叫ipfirewall (内核1.x时代),这是一个作者从freeBSD上移植过来的,能够工作在内核当中的,对数据包进行检测的一款简易访问控制工具。但是ipfirewall工作功能极其有限(它需要将所有的规则都放进内核当中,这样规则才能够运行起来,而放进内核,这个做法一般是极其困难的)。当内核发展到2.x系列的时候,软件更名为ipchains,它可以定义多条规则,将他们串起来,共同发挥作用,而现在,它叫做iptables,可以将规则组成一个列表,实现绝对详细的访问控制功能。
他们都是工作在用户空间中,定义规则的工具,本身并不算是防火墙。它们定义的规则,可以让在内核空间当中的netfilter来读取,并且实现让防火墙工作。而放入内核的地方必须要是特定的位置,必须是tcp/ip的协议栈经过的地方。而这个tcp/ip协议栈必须经过的地方,可以实现读取规则的地方就叫做 netfilter.(网络过滤器)
作者一共在内核空间中选择了5个位置,
1.内核空间中:从一个网络接口进来,到另一个网络接口去的
2.数据包从内核流入用户空间的
3.数据包从用户空间流出的
4.进入/离开本机的外网接口
5.进入/离开本机的内网接口
2.iptables的工作机制
从上面的发展我们知道了作者选择了5个位置,来作为控制的地方,但是你有没有发现,其实前三个位置已经基本上能将路径彻底封锁了,但是为什么已经在进出的口设置了关卡之后还要在内部卡呢? 由于数据包尚未进行路由决策,还不知道数据要走向哪里,所以在进出口是没办法实现数据过滤的。所以要在内核空间里设置转发的关卡,进入用户空间的关卡,从用户空间出去的关卡。那么,既然他们没什么用,那我们为什么还要放置他们呢?因为我们在做NAT和DNAT的时候,目标地址转换必须在路由之前转换。所以我们必须在外网而后内网的接口处进行设置关卡。
这五个位置也被称为五个钩子函数(hook functions),也叫五个规则链。
1.PREROUTING (路由前)
2.INPUT (数据包流入口)
3.FORWARD (转发管卡)
4.OUTPUT(数据包出口)
5.POSTROUTING(路由后)
这是NetFilter规定的五个规则链,任何一个数据包,只要经过本机,必将经过这五个链中的其中一个链。
3.防火墙的策略
防火墙策略一般分为两种,一种叫“通”策略,一种叫“堵”策略,通策略,默认门是关着的,必须要定义谁能进。堵策略则是,大门是洞开的,但是你必须有身份认证,否则不能进。所以我们要定义,让进来的进来,让出去的出去,所以通,是要全通,而堵,则是要选择。当我们定义的策略的时候,要分别定义多条功能,其中:定义数据包中允许或者不允许的策略,filter过滤的功能,而定义地址转换的功能的则是nat选项。为了让这些功能交替工作,我们制定出了“表”这个定义,来定义、区分各种不同的工作功能和处理方式。
我们现在用的比较多个功能有3个:
1.filter 定义允许或者不允许的
2.nat 定义地址转换的
3.mangle功能:修改报文原数据
我们修改报文原数据就是来修改TTL的。能够实现将数据包的元数据拆开,在里面做标记/修改内容的。而防火墙标记,其实就是靠mangle来实现的。
小扩展:
对于filter来讲一般只能做在3个链上:INPUT ,FORWARD ,OUTPUT
对于nat来讲一般也只能做在3个链上:PREROUTING ,OUTPUT ,POSTROUTING
而mangle则是5个链都可以做:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
iptables/netfilter(这款软件)是工作在用户空间的,它可以让规则进行生效的,本身不是一种服务,而且规则是立即生效的。而我们iptables现在被做成了一个服务,可以进行启动,停止的。启动,则将规则直接生效,停止,则将规则撤销。
iptables还支持自己定义链。但是自己定义的链,必须是跟某种特定的链关联起来的。在一个关卡设定,指定当有数据的时候专门去找某个特定的链来处理,当那个链处理完之后,再返回。接着在特定的链中继续检查。
注意:规则的次序非常关键,谁的规则越严格,应该放的越靠前,而检查规则的时候,是按照从上往下的方式进行检查的。
三.规则的写法:
iptables定义规则的方式比较复杂:
格式:iptables [-t table] COMMAND chain CRETIRIA -j ACTION
-t table :3个filter nat mangle
COMMAND:定义如何对规则进行管理
chain:指定你接下来的规则到底是在哪个链上操作的,当定义策略的时候,是可以省略的
CRETIRIA:指定匹配标准
-j ACTION :指定如何进行处理
比如:不允许172.16.0.0/24的进行访问。
iptables -t filter -A INPUT -s 172.16.0.0/16 -p udp --dport 53 -j DROP
当然你如果想拒绝的更彻底:
iptables -t filter -R INPUT 1 -s 172.16.0.0/16 -p udp --dport 53 -j REJECT
iptables -L -n -v #查看定义规则的详细信息
四:详解COMMAND:
1.链管理命令(这都是立即生效的)
-P :设置默认策略的(设定默认门是关着的还是开着的)
默认策略一般只有两种
iptables -P INPUT (DROP|ACCEPT) 默认是关的/默认是开的
比如:
iptables -P INPUT DROP 这就把默认规则给拒绝了。并且没有定义哪个动作,所以关于外界连接的所有规则包括Xshell连接之类的,远程连接都被拒绝了。
-F: FLASH,清空规则链的(注意每个链的管理权限)
iptables -t nat -F PREROUTING
iptables -t nat -F 清空nat表的所有链
-N:NEW 支持用户新建一个链
iptables -N inbound_tcp_web 表示附在tcp表上用于检查web的。
-X: 用于删除用户自定义的空链
使用方法跟-N相同,但是在删除之前必须要将里面的链给清空昂了
-E:用来Rename chain主要是用来给用户自定义的链重命名
-E oldname newname
-Z:清空链,及链中默认规则的计数器的(有两个计数器,被匹配到多少个数据包,多少个字节)
iptables -Z :清空
2.规则管理命令
-A:追加,在当前链的最后新增一个规则
-I num : 插入,把当前规则插入为第几条。
-I 3 :插入为第三条
-R num:Replays替换/修改第几条规则
格式:iptables -R 3 …………
-D num:删除,明确指定删除第几条规则
3.查看管理命令 “-L”
附加子命令
-n:以数字的方式显示ip,它会将ip直接显示出来,如果不加-n,则会将ip反向解析成主机名。
-v:显示详细信息
-vv
-vvv :越多越详细
-x:在计数器上显示精确值,不做单位换算
--line-numbers : 显示规则的行号
-t nat:显示所有的关卡的信息
五:详解匹配标准
1.通用匹配:源地址目标地址的匹配
-s:指定作为源地址匹配,这里不能指定主机名称,必须是IP
IP | IP/MASK | 0.0.0.0/0.0.0.0
而且地址可以取反,加一个“!”表示除了哪个IP之外
-d:表示匹配目标地址
-p:用于匹配协议的(这里的协议通常有3种,TCP/UDP/ICMP)
-i eth0:从这块网卡流入的数据
流入一般用在INPUT和PREROUTING上
-o eth0:从这块网卡流出的数据
流出一般在OUTPUT和POSTROUTING上
2.扩展匹配
2.1隐含扩展:对协议的扩展
-p tcp :TCP协议的扩展。一般有三种扩展
--dport XX-XX:指定目标端口,不能指定多个非连续端口,只能指定单个端口,比如
--dport 21 或者 --dport 21-23 (此时表示21,22,23)
--sport:指定源端口
--tcp-fiags:TCP的标志位(SYN,ACK,FIN,PSH,RST,URG)
对于它,一般要跟两个参数:
1.检查的标志位
2.必须为1的标志位
--tcpflags syn,ack,fin,rst syn = --syn
表示检查这4个位,这4个位中syn必须为1,其他的必须为0。所以这个意思就是用于检测三次握手的第一次包的。对于这种专门匹配第一包的SYN为1的包,还有一种简写方式,叫做--syn
-p udp:UDP协议的扩展
--dport
--sport
-p icmp:icmp数据报文的扩展
--icmp-type:
echo-request(请求回显),一般用8 来表示
所以 --icmp-type 8 匹配请求回显数据包
echo-reply (响应的数据包)一般用0来表示
2.2显式扩展(-m)
扩展各种模块
-m multiport:表示启用多端口扩展
之后我们就可以启用比如 --dports 21,23,80
六:详解-j ACTION
常用的ACTION:
DROP:悄悄丢弃
一般我们多用DROP来隐藏我们的身份,以及隐藏我们的链表
REJECT:明示拒绝
ACCEPT:接受
custom_chain:转向一个自定义的链
DNAT
SNAT
MASQUERADE:源地址伪装
REDIRECT:重定向:主要用于实现端口重定向
MARK:打防火墙标记的
RETURN:返回
在自定义链执行完毕后使用返回,来返回原规则链。
练习题1:
只要是来自于172.16.0.0/16网段的都允许访问我本机的172.16.100.1的SSHD服务
分析:首先肯定是在允许表中定义的。因为不需要做NAT地址转换之类的,然后查看我们SSHD服务,在22号端口上,处理机制是接受,对于这个表,需要有一来一回两个规则,如果我们允许也好,拒绝也好,对于访问本机服务,我们最好是定义在INPUT链上,而OUTPUT再予以定义就好。(会话的初始端先定义),所以加规则就是:
定义进来的: iptables -t filter -A INPUT -s 172.16.0.0/16 -d 172.16.100.1 -p tcp --dport 22 -j ACCEPT
定义出去的: iptables -t filter -A OUTPUT -s 172.16.100.1 -d 172.16.0.0/16 -p tcp --dport 22 -j ACCEPT
将默认策略改成DROP:
iptables -P INPUT DROP
iptables -P OUTPUT DROP
iptables -P FORWARD DROP
七:状态检测:
是一种显式扩展,用于检测会话之间的连接关系的,有了检测我们可以实现会话间功能的扩展
什么是状态检测?对于整个TCP协议来讲,它是一个有连接的协议,三次握手中,第一次握手,我们就叫NEW连接,而从第二次握手以后的,ack都为1,这是正常的数据传输,和tcp的第二次第三次握手,叫做已建立的连接(ESTABLISHED),还有一种状态,比较诡异的,比如:SYN=1 ACK=1 RST=1,对于这种我们无法识别的,我们都称之为INVALID无法识别的。还有第四种,FTP这种古老的拥有的特征,每个端口都是独立的,21号和20号端口都是一去一回,他们之间是有关系的,这种关系我们称之为RELATED。
所以我们的状态一共有四种:
NEW
ESTABLISHED
RELATED
INVALID
所以我们对于刚才的练习题,可以增加状态检测。比如进来的只允许状态为NEW和ESTABLISHED的进来,出去只允许ESTABLISHED的状态出去,这就可以将比较常见的反弹式木马有很好的控制机制。
对于练习题的扩展:
进来的拒绝出去的允许,进来的只允许ESTABLISHED进来,出去只允许ESTABLISHED出去。默认规则都使用拒绝
iptables -L -n --line-number :查看之前的规则位于第几行
改写INPUT
iptables -R INPUT 2 -s 172.16.0.0/16 -d 172.16.100.1 -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -R OUTPUT 1 -m state --state ESTABLISHED -j ACCEPT
此时如果想再放行一个80端口如何放行呢?
iptables -A INPUT -d 172.16.100.1 -p tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -R INPUT 1 -d 172.16.100.1 -p udp --dport 53 -j ACCEPT
练习题2:
假如我们允许自己ping别人,但是别人ping自己ping不通如何实现呢?
分析:对于ping这个协议,进来的为8(ping),出去的为0(响应).我们为了达到目的,需要8出去,允许0进来
在出去的端口上:iptables -A OUTPUT -p icmp --icmp-type 8 -j ACCEPT
在进来的端口上:iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT
小扩展:对于127.0.0.1比较特殊,我们需要明确定义它
iptables -A INPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT
iptables -A OUTPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT
八:SNAT和DNAT的实现
由于我们现在IP地址十分紧俏,已经分配完了,这就导致我们必须要进行地址转换,来节约我们仅剩的一点IP资源。那么通过iptables如何实现NAT的地址转换呢?
1.SNAT基于原地址的转换
基于原地址的转换一般用在我们的许多内网用户通过一个外网的口上网的时候,这时我们将我们内网的地址转换为一个外网的IP,我们就可以实现连接其他外网IP的功能。
所以我们在iptables中就要定义到底如何转换:
定义的样式:
比如我们现在要将所有192.168.10.0网段的IP在经过的时候全都转换成172.16.100.1这个假设出来的外网地址:
iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -j SNAT --to-source 172.16.100.1
这样,只要是来自本地网络的试图通过网卡访问网络的,都会被统统转换成172.16.100.1这个IP.
那么,如果172.16.100.1不是固定的怎么办?
我们都知道当我们使用联通或者电信上网的时候,一般它都会在每次你开机的时候随机生成一个外网的IP,意思就是外网地址是动态变换的。这时我们就要将外网地址换成 MASQUERADE(动态伪装):它可以实现自动寻找到外网地址,而自动将其改为正确的外网地址。所以,我们就需要这样设置:
iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -j MASQUERADE
这里要注意:地址伪装并不适用于所有的地方。
2.DNAT目标地址转换
对于目标地址转换,数据流向是从外向内的,外面的是客户端,里面的是服务器端通过目标地址转换,我们可以让外面的ip通过我们对外的外网ip来访问我们服务器不同的服务器,而我们的服务却放在内网服务器的不同的服务器上。
如何做目标地址转换呢?:
iptables -t nat -A PREROUTING -d 192.168.10.18 -p tcp --dport 80 -j DNAT --todestination 172.16.100.2
目标地址转换要做在到达网卡之前进行转换,所以要做在PREROUTING这个位置上
九:控制规则的存放以及开启
注意:你所定义的所有内容,当你重启的时候都会失效,要想我们能够生效,需要使用一个命令将它保存起来
1.service iptables save 命令
它会保存在/etc/sysconfig/iptables这个文件中
2.iptables-save 命令
iptables-save > /etc/sysconfig/iptables
3.iptables-restore 命令
开机的时候,它会自动加载/etc/sysconfig/iptabels
如果开机不能加载或者没有加载,而你想让一个自己写的配置文件(假设为iptables.2)手动生效的话:
iptables-restore < /etc/sysconfig/iptables.2
则完成了将iptables中定义的规则手动生效
十:总结
Iptables是一个非常重要的工具,它是每一个防火墙上几乎必备的设置,也是我们在做大型网络的时候,为了很多原因而必须要设置的。学好Iptables,可以让我们对整个网络的结构有一个比较深刻的了解,同时,我们还能够将内核空间中数据的走向以及linux的安全给掌握的非常透彻。我们在学习的时候,尽量能结合着各种各样的项目,实验来完成,这样对你加深iptables的配置,以及各种技巧有非常大的帮助。
附加iptables比较好的文章:
posted @
2015-11-24 17:17 xzc 阅读(235) |
评论 (0) |
编辑 收藏如果你的IPTABLES基础知识还不了解,建议先去看看.
开始配置
我们来配置一个filter表的防火墙.
(1)查看本机关于IPTABLES的设置情况
[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain RH-Firewall-1-INPUT (0 references)
target prot opt source destination
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmp type 255
ACCEPT esp -- 0.0.0.0/0 0.0.0.0/0
ACCEPT ah -- 0.0.0.0/0 0.0.0.0/0
ACCEPT udp -- 0.0.0.0/0 224.0.0.251 udp dpt:5353
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:631
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:80
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:25
REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited
可以看出我在安装linux时,选择了有防火墙,并且开放了22,80,25端口.
如果你在安装linux时没有选择启动防火墙,是这样的
[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
什么规则都没有.
(2)清除原有规则.
不管你在安装linux时是否启动了防火墙,如果你想配置属于自己的防火墙,那就清除现在filter的所有规则.
[root@tp ~]# iptables -F 清除预设表filter中的所有规则链的规则
[root@tp ~]# iptables -X 清除预设表filter中使用者自定链中的规则
我们在来看一下
[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
什么都没有了吧,和我们在安装linux时没有启动防火墙是一样的.(提前说一句,这些配置就像用命令配置IP一样,重起就会失去作用),怎么保存.
[root@tp ~]# /etc/rc.d/init.d/iptables save
这样就可以写到/etc/sysconfig/iptables文件里了.写入后记得把防火墙重起一下,才能起作用.
[root@tp ~]# service iptables restart
现在IPTABLES配置表里什么配置都没有了,那我们开始我们的配置吧
(3)设定预设规则
[root@tp ~]# iptables -p INPUT DROP
[root@tp ~]# iptables -p OUTPUT ACCEPT
[root@tp ~]# iptables -p FORWARD DROP
上面的意思是,当超出了IPTABLES里filter表里的两个链规则(INPUT,FORWARD)时,不在这两个规则里的数据包怎么处理呢,那就是DROP(放弃).应该说这样配置是很安全的.我们要控制流入数据包
而对于OUTPUT链,也就是流出的包我们不用做太多限制,而是采取ACCEPT,也就是说,不在着个规则里的包怎么办呢,那就是通过.
可以看出INPUT,FORWARD两个链采用的是允许什么包通过,而OUTPUT链采用的是不允许什么包通过.
这样设置还是挺合理的,当然你也可以三个链都DROP,但这样做我认为是没有必要的,而且要写的规则就会增加.但如果你只想要有限的几个规则是,如只做WEB服务器.还是推荐三个链都是DROP.
注:如果你是远程SSH登陆的话,当你输入第一个命令回车的时候就应该掉了.因为你没有设置任何规则.
怎么办,去本机操作呗!
(4)添加规则.
首先添加INPUT链,INPUT链的默认规则是DROP,所以我们就写需要ACCETP(通过)的链
为了能采用远程SSH登陆,我们要开启22端口.
[root@tp ~]# iptables -A INPUT -p tcp --dport 22 -j ACCEPT
[root@tp ~]# iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT (注:这个规则,如果你把OUTPUT 设置成DROP的就要写上这一部,好多人都是望了写这一部规则导致,始终无法SSH.在远程一下,是不是好了.
其他的端口也一样,如果开启了web服务器,OUTPUT设置成DROP的话,同样也要添加一条链:
[root@tp ~]# iptables -A OUTPUT -p tcp --sport 80 -j ACCEPT ,其他同理.)
如果做了WEB服务器,开启80端口.
[root@tp ~]# iptables -A INPUT -p tcp --dport 80 -j ACCEPT
如果做了邮件服务器,开启25,110端口.
[root@tp ~]# iptables -A INPUT -p tcp --dport 110 -j ACCEPT
[root@tp ~]# iptables -A INPUT -p tcp --dport 25 -j ACCEPT
如果做了FTP服务器,开启21端口
[root@tp ~]# iptables -A INPUT -p tcp --dport 21 -j ACCEPT
[root@tp ~]# iptables -A INPUT -p tcp --dport 20 -j ACCEPT
如果做了DNS服务器,开启53端口
[root@tp ~]# iptables -A INPUT -p tcp --dport 53 -j ACCEPT
如果你还做了其他的服务器,需要开启哪个端口,照写就行了.
上面主要写的都是INPUT链,凡是不在上面的规则里的,都DROP
允许icmp包通过,也就是允许ping,
[root@tp ~]# iptables -A OUTPUT -p icmp -j ACCEPT (OUTPUT设置成DROP的话)
[root@tp ~]# iptables -A INPUT -p icmp -j ACCEPT (INPUT设置成DROP的话)
允许loopback!(不然会导致DNS无法正常关闭等问题)
IPTABLES -A INPUT -i lo -p all -j ACCEPT (如果是INPUT DROP)
IPTABLES -A OUTPUT -o lo -p all -j ACCEPT(如果是OUTPUT DROP)
下面写OUTPUT链,OUTPUT链默认规则是ACCEPT,所以我们就写需要DROP(放弃)的链.
减少不安全的端口连接
[root@tp ~]# iptables -A OUTPUT -p tcp --sport 31337 -j DROP
[root@tp ~]# iptables -A OUTPUT -p tcp --dport 31337 -j DROP
有些些特洛伊木马会扫描端口31337到31340(即黑客语言中的 elite 端口)上的服务。既然合法服务都不使用这些非标准端口来通信,阻塞这些端口能够有效地减少你的网络上可能被感染的机器和它们的远程主服务器进行独立通信的机会
还有其他端口也一样,像:31335、27444、27665、20034 NetBus、9704、137-139(smb),2049(NFS)端口也应被禁止,我在这写的也不全,有兴趣的朋友应该去查一下相关资料.
当然出入更安全的考虑你也可以包OUTPUT链设置成DROP,那你添加的规则就多一些,就像上边添加
允许SSH登陆一样.照着写就行了.
下面写一下更加细致的规则,就是限制到某台机器
如:我们只允许192.168.0.3的机器进行SSH连接
[root@tp ~]# iptables -A INPUT -s 192.168.0.3 -p tcp --dport 22 -j ACCEPT
如果要允许,或限制一段IP地址可用 192.168.0.0/24 表示192.168.0.1-255端的所有IP.
24表示子网掩码数.但要记得把 /etc/sysconfig/iptables 里的这一行删了.
-A INPUT -p tcp -m tcp --dport 22 -j ACCEPT 因为它表示所有地址都可以登陆.
或采用命令方式:
[root@tp ~]# iptables -D INPUT -p tcp --dport 22 -j ACCEPT
然后保存,我再说一边,反是采用命令的方式,只在当时生效,如果想要重起后也起作用,那就要保存.写入到/etc/sysconfig/iptables文件里.
[root@tp ~]# /etc/rc.d/init.d/iptables save
这样写 !192.168.0.3 表示除了192.168.0.3的ip地址
其他的规则连接也一样这么设置.
在下面就是FORWARD链,FORWARD链的默认规则是DROP,所以我们就写需要ACCETP(通过)的链,对正在转发链的监控.
开启转发功能,(在做NAT时,FORWARD默认规则是DROP时,必须做)
[root@tp ~]# iptables -A FORWARD -i eth0 -o eth1 -m state --state RELATED,ESTABLISHED -j ACCEPT
[root@tp ~]# iptables -A FORWARD -i eth1 -o eh0 -j ACCEPT
丢弃坏的TCP包
[root@tp ~]#iptables -A FORWARD -p TCP ! --syn -m state --state NEW -j DROP
处理IP碎片数量,防止攻击,允许每秒100个
[root@tp ~]#iptables -A FORWARD -f -m limit --limit 100/s --limit-burst 100 -j ACCEPT
设置ICMP包过滤,允许每秒1个包,限制触发条件是10个包.
[root@tp ~]#iptables -A FORWARD -p icmp -m limit --limit 1/s --limit-burst 10 -j ACCEPT
我在前面只所以允许ICMP包通过,就是因为我在这里有限制.
二,配置一个NAT表放火墙
1,查看本机关于NAT的设置情况
[root@tp rc.d]# iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
SNAT all -- 192.168.0.0/24 anywhere to:211.101.46.235
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
我的NAT已经配置好了的(只是提供最简单的代理上网功能,还没有添加防火墙规则).关于怎么配置NAT,参考我的另一篇文章
当然你如果还没有配置NAT的话,你也不用清除规则,因为NAT在默认情况下是什么都没有的
如果你想清除,命令是
[root@tp ~]# iptables -F -t nat
[root@tp ~]# iptables -X -t nat
[root@tp ~]# iptables -Z -t nat
2,添加规则
添加基本的NAT地址转换,(关于如何配置NAT可以看我的另一篇文章),
添加规则,我们只添加DROP链.因为默认链全是ACCEPT.
防止外网用内网IP欺骗
[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 10.0.0.0/8 -j DROP
[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 172.16.0.0/12 -j DROP
[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 192.168.0.0/16 -j DROP
如果我们想,比如阻止MSN,QQ,BT等的话,需要找到它们所用的端口或者IP,(个人认为没有太大必要)
例:
禁止与211.101.46.253的所有连接
[root@tp ~]# iptables -t nat -A PREROUTING -d 211.101.46.253 -j DROP禁用FTP(21)端口
[root@tp ~]# iptables -t nat -A PREROUTING -p tcp --dport 21 -j DROP
这样写范围太大了,我们可以更精确的定义.
[root@tp ~]# iptables -t nat -A PREROUTING -p tcp --dport 21 -d 211.101.46.253 -j DROP
这样只禁用211.101.46.253地址的FTP连接,其他连接还可以.如web(80端口)连接.
按照我写的,你只要找到QQ,MSN等其他软件的IP地址,和端口,以及基于什么协议,只要照着写就行了.
最后:
drop非法连接
[root@tp ~]# iptables -A INPUT -m state --state INVALID -j DROP
[root@tp ~]# iptables -A OUTPUT -m state --state INVALID -j DROP
[root@tp ~]# iptables-A FORWARD -m state --state INVALID -j DROP
允许所有已经建立的和相关的连接
[root@tp ~]# iptables-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
[root@tp ~]# iptables-A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
[root@tp ~]# /etc/rc.d/init.d/iptables save
这样就可以写到/etc/sysconfig/iptables文件里了.写入后记得把防火墙重起一下,才能起作用.
[root@tp ~]# service iptables restart
别忘了保存,不行就写一部保存一次.你可以一边保存,一边做实验,看看是否达到你的要求,上面的所有规则我都试过,没有问题.
写这篇文章,用了我将近1个月的时间.查找资料,自己做实验,希望对大家有所帮助.如有不全及不完善的地方还请提出.
因为本篇文章以配置为主.关于IPTABLES的基础知识及指令命令说明等我会尽快传上,当然你可以去网上搜索一下,还是很多的.
posted @
2015-11-24 16:15 xzc 阅读(198) |
评论 (0) |
编辑 收藏posted @
2015-11-19 18:08 xzc 阅读(1392) |
评论 (0) |
编辑 收藏 echo "Cfoo'barxml" | sed "s/'/::/g" | sed 's/::/\\:/g' | sed "s/:/'/g" 替换单引号为 \'
------------------------
sed 替换单引号'
echo "mmm'sss" > test
cat test
把test内容中单引号替换成双引号
sed 's/'"'"/'"''/g' test ==> sed 's/' " ' " / ' " ' '/g' test
解析下:
's/' => 要进行替换操作,后紧跟匹配字符
"'" => 用双引号包裹着单引号
/ =>分割符
'"' => 用单引号包裹着双引号
'/g' =>分隔符,全局替换
当然还可以使用下面这两种方法替换:
sed s#\'#\"#g test 最外层使用#分隔,里面使用转义单引号,转义双引号
sed "s/'/\"/g" test 最外层使用双引号,里面使用单引号,转义双引号
echo "mmm'sss" | sed 's/'"'"/'"''/g'
echo "mmm'sss" | sed s#\'#\"#g
echo "mmm'sss" | sed "s/'/\"/g"
awk '{print "sed '\''s/"$1"\\t/"$2"\\t/g'\'' ref_Zv9_top_level.bed.chrom"}' ref_Zv9_top_level.gff3_transID
sed 's/rna10004\t/XR_223343.1\t/g' ref_Zv9_top_level.bed.chrom
sed 's/rna10000\t/XR_223342.1\t/g' ref_Zv9_top_level.bed.chrom
sed 's/\]/\"/g' 替换]为“
sed 's/\[/\"/g' 替换[为“
posted @
2015-10-29 19:52 xzc 阅读(1827) |
评论 (1) |
编辑 收藏shell中${}的妙用
1. 截断功能
${file#*/}: 拿掉第一条/及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##*/}: 拿掉最后一条/及其左边的字符串:my.file.txt
${file#*.}: 拿掉第一个.及其左边的字符串:file.txt
${file##*.}: 拿掉最后一个.及其左边的字符串:txt
${file%/*}: 拿掉最后条/及其右边的字符串:/dir1/dir2/dir3
${file%%/*}: 拿掉第一条/及其右边的字符串:(空值)
${file%.*}: 拿掉最后一个.及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}: 拿掉第一个.及其右边的字符串:/dir1/dir2/dir3/my
记忆的方法为:
[list]#是去掉左边, ##最后一个
%是去掉右边, %%第一个
2. 字符串提取
单一符号是最小匹配﹔两个符号是最大匹配。
${file:0:5}:提取最左边的 5 个字节:/dir1
${file:5:5}:提取第 5 个字节右边的连续 5 个字节:/dir2
3. 字符串替换
${file/dir/path}:将第一个 dir 提换为 path:/path1/dir2/dir3/my.file.txt
${file//dir/path}:将全部 dir 提换为 path:/path1/path2/path3/my.file.txt
4. 针对不同的变量状态赋值(没设定、空值、非空值):
${file-my.file.txt}: 若$file没有设定,则使用my.file.txt作返回值。(空值及非空值时不作处理)
${file:-my.file.txt}:若$file没有设定或为空值,则使用my.file.txt作返回值。(非空值时不作处理)
${file+my.file.txt}: 若$file设为空值或非空值,均使用my.file.txt作返回值。(没设定时不作处理)
${file:+my.file.txt}:若$file为非空值,则使用my.file.txt作返回值。(没设定及空值时不作处理)
${file=my.file.txt}: 若$file没设定,则使用my.file.txt作返回值,同时将$file 赋值为 my.file.txt。(空值及非空值时不作处理)
${file:=my.file.txt}:若$file没设定或为空值,则使用my.file.txt作返回值,同时将 $file 赋值为 my.file.txt。(非空值时不作处理)
${file?my.file.txt}: 若$file没设定,则将my.file.txt输出至 STDERR。(空值及非空值时不作处理)
${file:?my.file.txt}:若$file没设定或为空值,则将my.file.txt输出至STDERR。(非空值时不作处理)
注意:
":+"的情况是不包含空值的.
":-", ":="等只要有号就是包含空值(null).
5. 变量的长度
${#file}
6. 数组运算
A=(a b c def)
${A[@]} 或 ${A[*]} 可得到 a b c def (全部组数)
${A[0]} 可得到 a (第一个组数),${A[1]} 则为第二个组数...
${#A[@]} 或 ${#A[*]} 可得到 4 (全部组数数量)
${#A[0]} 可得到 1 (即第一个组数(a)的长度),${#A[3]} 可得到 3 (第四个组数(def)的长度)
posted @
2015-10-29 16:18 xzc 阅读(153) |
评论 (0) |
编辑 收藏在linux操作系统中,find命令非常强大,在文件与目录的查找方面可谓无所不至其极,如果能结合xargs命令使得,更是强大无比。
以下来看看find命令忽略目录查找的用法吧。
例1,根据文件属性查找:
find . -type f -name "*config*" ! -path "./tmp/*" ! -path "./scripts/*" ! -path "./node_modules/*"
Explanation:
find . - Start find from current working directory (recursively by default)
-type f - Specify to find that you only want files in the results
-name "*_peaks.bed" - Look for files with the name ending in _peaks.bed
! -path "./tmp/*" - Exclude all results whose path starts with ./tmp/
! -path "./scripts/*" - Also exclude all results whose path starts with ./scripts/
例2,根据文件内容查找:
grep -n -r --exclude-dir='node_modules' --exclude-dir='logs' --exclude="nohup.out" 192 *
使用find命令在linux系统中查找文件时,有时需要忽略某些目录,可以使用 -prune 参数来进行过滤。
不过必须注意:要忽略的路径参数要紧跟着搜索的路径之后,否则该参数无法起作用。
例如:指定搜索/home/zth目录下的所有文件,但是会忽略/home/zth/astetc的路径:
find /home/zth -path "/home/zth/astetc" -prune -o -type f -print
按照文件名来搜索则为:
find /home/zth -path "/home/zth/astetc" -prune -o -type f -name "cdr_*.conf" -print
要忽略两个以上的路径如何处理?
find /home/zth /( -path "/home/zth/astetc" -o -path "/home/zth/etc" /) -prune -o -type f -print
find /home/zth /( -path "/home/zth/astetc" -o -path "/home/zth/etc" /) -prune -o -type f -name "cdr_*.conf" -print
注意:/( 和/) 前后都有空格。
查找某个文件包含内容,以下语句可以解决目录带空格的问题:
find ./ -name "mysql*" -print0 |xargs -0 grep "SELECT lead_id FROM vicidial_list where vendor_lead_code"
如果目录不带空格,可以这样:
find ./ -name "mysql*" |xargs grep "SELECT lead_id FROM vicidial_list where vendor_lead_code"
通过以上的例子,大家应该可以掌握find命令查找文件时,忽略相关目录的方法了。
posted @
2015-10-28 11:33 xzc 阅读(1371) |
评论 (1) |
编辑 收藏X509 文件扩展名
首先我们要理解文件的扩展名代表什么。DER、PEM、CRT和CER这些扩展名经常令人困惑。很多人错误地认为这些扩展名可以互相代替。尽管的确有时候有些扩展名是可以互换的,但是最好你能确定证书是如何编码的,进而正确地标识它们。正确地标识证书有助于证书的管理。
编码 (也用于扩展名)
- .DER = 扩展名DER用于二进制DER编码的证书。这些证书也可以用CER或者CRT作为扩展名。比较合适的说法是“我有一个DER编码的证书”,而不是“我有一个DER证书”。
- .PEM = 扩展名PEM用于ASCII(Base64)编码的各种X.509 v3 证书。文件开始由一行"—– BEGIN …“开始。
常用的扩展名
- .CRT = 扩展名CRT用于证书。证书可以是DER编码,也可以是PEM编码。扩展名CER和CRT几乎是同义词。这种情况在各种unix/linux系统中很常见。
- CER = CRT证书的微软型式。可以用微软的工具把CRT文件转换为CER文件(CRT和CER必须是相同编码的,DER或者PEM)。扩展名为CER的文件可以被IE识别并作为命令调用微软的cryptoAPI(具体点就是rudll32.exe cryptext.dll, CyrptExtOpenCER),进而弹出一个对话框来导入并/或查看证书内容。
- .KEY = 扩展名KEY用于PCSK#8的公钥和私钥。这些公钥和私钥可以是DER编码或者PEM编码。
CRT文件和CER文件只有在使用相同编码的时候才可以安全地相互替代。
posted @
2015-10-01 10:12 xzc 阅读(450) |
评论 (0) |
编辑 收藏原文地址: http://www.thegeekstuff.com/2012/04/curl-examples/
下载单个文件,默认将输出打印到标准输出中(STDOUT)中
curl http://www.centos.org
通过-o/-O选项保存下载的文件到指定的文件中:
-o:将文件保存为命令行中指定的文件名的文件中
-O:使用URL中默认的文件名保存文件到本地
1 # 将文件下载到本地并命名为mygettext.html
2 curl -o mygettext.html http://www.gnu.org/software/gettext/manual/gettext.html
3
4 # 将文件保存到本地并命名为gettext.html
5 curl -O http://www.gnu.org/software/gettext/manual/gettext.html
同样可以使用转向字符">"对输出进行转向输出
同时获取多个文件
若同时从同一站点下载多个文件时,curl会尝试重用链接(connection)。
通过-L选项进行重定向
默认情况下CURL不会发送HTTP Location headers(重定向).当一个被请求页面移动到另一个站点时,会发送一个HTTP Loaction header作为请求,然后将请求重定向到新的地址上。
例如:访问google.com时,会自动将地址重定向到google.com.hk上。
1 curl http://www.google.com
2 <HTML>
3 <HEAD>
4 <meta http-equiv="content-type" content="text/html;charset=utf-8">
5 <TITLE>302 Moved</TITLE>
6 </HEAD>
7 <BODY>
8 <H1>302 Moved</H1>
9 The document has moved
10 <A HREF="http://www.google.com.hk/url?sa=p&hl=zh-CN&pref=hkredirect&pval=yes&q=http://www.google.com.hk/&ust=1379402837567135amp;usg=AFQjCNF3o7umf3jyJpNDPuF7KTibavE4aA">here</A>.
11 </BODY>
12 </HTML>
上述输出说明所请求的档案被转移到了http://www.google.com.hk。
这是可以通过使用-L选项进行强制重定向
1 # 让curl使用地址重定向,此时会查询google.com.hk站点
2 curl -L http://www.google.com
断点续传
通过使用-C选项可对大文件使用断点续传功能,如:
1 # 当文件在下载完成之前结束该进程
2 $ curl -O http://www.gnu.org/software/gettext/manual/gettext.html
3 ############## 20.1%
4
5 # 通过添加-C选项继续对该文件进行下载,已经下载过的文件不会被重新下载
6 curl -C - -O http://www.gnu.org/software/gettext/manual/gettext.html
7 ############### 21.1%
对CURL使用网络限速
通过--limit-rate选项对CURL的最大网络使用进行限制
1 # 下载速度最大不会超过1000B/second
2
3 curl --limit-rate 1000B -O http://www.gnu.org/software/gettext/manual/gettext.html
下载指定时间内修改过的文件
当下载一个文件时,可对该文件的最后修改日期进行判断,如果该文件在指定日期内修改过,就进行下载,否则不下载。
该功能可通过使用-z选项来实现:
1 # 若yy.html文件在2011/12/21之后有过更新才会进行下载
2 curl -z 21-Dec-11 http://www.example.com/yy.html
CURL授权
在访问需要授权的页面时,可通过-u选项提供用户名和密码进行授权
1 curl -u username:password URL
2
3 # 通常的做法是在命令行只输入用户名,之后会提示输入密码,这样可以保证在查看历史记录时不会将密码泄露
4 curl -u username URL
从FTP服务器下载文件
CURL同样支持FTP下载,若在url中指定的是某个文件路径而非具体的某个要下载的文件名,CURL则会列出该目录下的所有文件名而并非下载该目录下的所有文件
1 # 列出public_html下的所有文件夹和文件
2 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/
3
4 # 下载xss.php文件
5 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/xss.php
上传文件到FTP服务器
通过 -T 选项可将指定的本地文件上传到FTP服务器上
# 将myfile.txt文件上传到服务器
curl -u ftpuser:ftppass -T myfile.txt ftp://ftp.testserver.com
# 同时上传多个文件
curl -u ftpuser:ftppass -T "{file1,file2}" ftp://ftp.testserver.com
# 从标准输入获取内容保存到服务器指定的文件中
curl -u ftpuser:ftppass -T - ftp://ftp.testserver.com/myfile_1.txt获取更多信息
通过使用 -v 和 -trace获取更多的链接信息
通过字典查询单词
1 # 查询bash单词的含义
2 curl dict://dict.org/d:bash
3
4 # 列出所有可用词典
5 curl dict://dict.org/show:db
6
7 # 在foldoc词典中查询bash单词的含义
8 curl dict://dict.org/d:bash:foldoc
为CURL设置代理
-x 选项可以为CURL添加代理功能
1 # 指定代理主机和端口
2 curl -x proxysever.test.com:3128 http://google.co.in
其他网站整理
保存与使用网站cookie信息
1 # 将网站的cookies信息保存到sugarcookies文件中
2 curl -D sugarcookies http://localhost/sugarcrm/index.php
3
4 # 使用上次保存的cookie信息
5 curl -b sugarcookies http://localhost/sugarcrm/index.php
传递请求数据
默认curl使用GET方式请求数据,这种方式下直接通过URL传递数据
可以通过 --data/-d 方式指定使用POST方式传递数据
1 # GET
2 curl -u username https://api.github.com/user?access_token=XXXXXXXXXX
3
4 # POST
5 curl -u username --data "param1=value1¶m2=value" https://api.github.com
6
7 # 也可以指定一个文件,将该文件中的内容当作数据传递给服务器端
8 curl --data @filename https://github.api.com/authorizations
注:默认情况下,通过POST方式传递过去的数据中若有特殊字符,首先需要将特殊字符转义在传递给服务器端,如value值中包含有空格,则需要先将空格转换成%20,如:
1 curl -d "value%201" http://hostname.com
在新版本的CURL中,提供了新的选项 --data-urlencode,通过该选项提供的参数会自动转义特殊字符。
1 curl --data-urlencode "value 1" http://hostname.com
除了使用GET和POST协议外,还可以通过 -X 选项指定其它协议,如:
1 curl -I -X DELETE https://api.github.cim
上传文件
1 curl --form "fileupload=@filename.txt" http://hostname/resource
http://curl.haxx.se/docs/httpscripting.html
posted @
2015-09-23 16:55 xzc 阅读(307) |
评论 (2) |
编辑 收藏方法一: 使用全局变量
- g_result=""
-
- function testFunc()
- {
- g_result='local value'
- }
-
- testFunc
- echo $g_result
方法二: 把shell函数作为子程序调用,将其结果写到子程序的标准输出- function testFunc()
- {
- local_result='local value'
- echo $local_result
- }
-
- result=$(testFunc)
- echo $result
看到一篇关于函数返回值的好文章,分享一下: http://www.linuxjournal.com/content/return-values-bash-functions
posted @
2015-09-21 10:20 xzc 阅读(4431) |
评论 (2) |
编辑 收藏posted @
2015-09-15 20:07 xzc 阅读(242) |
评论 (0) |
编辑 收藏posted @
2015-09-15 14:52 xzc 阅读(1989) |
评论 (1) |
编辑 收藏posted @
2015-09-10 11:24 xzc 阅读(545) |
评论 (1) |
编辑 收藏posted @
2015-09-09 15:11 xzc 阅读(506) |
评论 (0) |
编辑 收藏posted @
2015-09-09 11:54 xzc 阅读(354) |
评论 (0) |
编辑 收藏posted @
2015-09-09 11:54 xzc 阅读(340) |
评论 (0) |
编辑 收藏posted @
2015-09-09 11:21 xzc 阅读(498) |
评论 (0) |
编辑 收藏自从Hadoop集群搭建以来,我们一直使用的是Gzip进行压缩
当时,我对gzip压缩过的文件和原始的log文件分别跑MapReduce测试,最终执行速度基本差不多
而且Hadoop原生支持Gzip解压,所以,当时就直接采用了Gzip压缩的方式
关于Lzo压缩,twitter有一篇文章,介绍的比较详细,见这里:
Lzo压缩相比Gzip压缩,有如下特点:
- 压缩解压的速度很快
- Lzo压缩是基于Block分块的,这样,一个大的文件(在Hadoop上可能会占用多个Block块),就可以由多个MapReduce并行来进行处理
虽然Lzo的压缩比没有Gzip高,不过由于其前2个特性,在Hadoop上使用Lzo还是能整体提升集群的性能的
我测试了12个log文件,总大小为8.4G,以下是Gzip和Lzo压缩的结果:
- Gzip压缩,耗时480s,Gunzip解压,耗时180s,压缩后大小为2.5G
- Lzo压缩,耗时160s,Lzop解压,耗时110s,压缩后大小为4G
以下为在Hadoop集群上使用Lzo的步骤:
1. 在集群的所有节点上安装Lzo库,可从这里下载
cd /opt/ysz/src/lzo-2.04
./configure –enable-shared
make
make install
#编辑/etc/ld.so.conf,加入/usr/local/lib/后,执行/sbin/ldconfig
或者cp /usr/local/lib/liblzo2.* /usr/lib64/
#如果没有这一步,最终会导致以下错误:
lzo.LzoCompressor: java.lang.UnsatisfiedLinkError: Cannot load liblzo2.so.2 (liblzo2.so.2: cannot open shared object file: No such file or directory)!
2. 编译安装Hadoop Lzo本地库以及Jar包,从这里下载
export CFLAGS=-m64
export CXXFLAGS=-m64
ant compile-native tar
#将本地库以及Jar包拷贝到hadoop对应的目录下,并分发到各节点上
cp lib/native/Linux-amd64-64/* /opt/sohuhadoop/hadoop/lib/native/Linux-amd64-64/
cp hadoop-lzo-0.4.10.jar /opt/sohuhadoop/hadoop/lib/
3. 设置Hadoop,启用Lzo压缩
vi core-site.xml
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
vi mapred-site.xml
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
4. 安装lzop,从这里下载
下面就是使用lzop压缩log文件,并上传到Hadoop上,执行MapReduce操作,测试的Hadoop是由3个节点组成集群
lzop -v 2011041309.log
hadoop fs -put *.lzo /user/pvlog
#给Lzo文件建立Index
hadoop jar /opt/sohuhadoop/hadoop/lib/hadoop-lzo-0.4.10.jar com.hadoop.compression.lzo.LzoIndexer /user/pvlog/
写一个简单的MapReduce来测试,需要指定InputForamt为Lzo格式,否则对单个Lzo文件仍不能进行Map的并行处理
job.setInputFormatClass(com.hadoop.mapreduce.LzoTextInputFormat.class);
可以通过下面的代码来设置Reduce的数目:
job.setNumReduceTasks(8);
最终,12个文件被切分成了36个Map任务来并行处理,执行时间为52s,如下图:

我们配置Hadoop默认的Block大小是128M,如果我们想切分成更多的Map任务,可以通过设置其最大的SplitSize来完成:
FileInputFormat.setMaxInputSplitSize(job, 64 *1024 * 1024);
最终,12个文件被切分成了72个Map来处理,但处理时间反而长了,为59s,如下图:

而对于Gzip压缩的文件,即使我们设置了setMaxInputSplitSize,最终的Map数仍然是输入文件的数目12,执行时间为78s,如下图:
.jpg)
从以上的简单测试可以看出,使用Lzo压缩,性能确实比Gzip压缩要好不少
posted @
2015-09-09 11:19 xzc 阅读(405) |
评论 (0) |
编辑 收藏posted @
2015-08-06 17:36 xzc 阅读(692) |
评论 (0) |
编辑 收藏最近在看《Hadoop:The Definitive Guide》,对其分布式文件系统HDFS的Streaming data access不能理解。基于流的数据读写,太抽象了,什么叫基于流,什么是流?Hadoop是Java语言写的,所以想理解好Hadoop的Streaming Data Access,还得从Java流机制入手。流机制也是JAVA及C++中的一个重要的机制,通过流使我们能够自由地操作包括文件,内存,IO设备等等中的数据。
首先,流是什么?
流是个抽象的概念,是对输入输出设备的抽象,Java程序中,对于数据的输入/输出操作都是以“流”的方式进行。设备可以是文件,网络,内存等。

流具有方向性,至于是输入流还是输出流则是一个相对的概念,一般以程序为参考,如果数据的流向是程序至设备,我们成为输出流,反之我们称为输入流。
可以将流想象成一个“水流管道”,水流就在这管道中形成了,自然就出现了方向的概念。

当程序需要从某个数据源读入数据的时候,就会开启一个输入流,数据源可以是文件、内存或网络等等。相反地,需要写出数据到某个数据源目的地的时候,也会开启一个输出流,这个数据源目的地也可以是文件、内存或网络等等。
流有哪些分类?
可以从不同的角度对流进行分类:
1. 处理的数据单位不同,可分为:字符流,字节流
2.数据流方向不同,可分为:输入流,输出流
3.功能不同,可分为:节点流,处理流
1. 和 2. 都比较好理解,对于根据功能分类的,可以这么理解:
节点流:节点流从一个特定的数据源读写数据。即节点流是直接操作文件,网络等的流,例如FileInputStream和FileOutputStream,他们直接从文件中读取或往文件中写入字节流。

处理流:“连接”在已存在的流(节点流或处理流)之上通过对数据的处理为程序提供更为强大的读写功能。过滤流是使用一个已经存在的输入流或输出流连接创建的,过滤流就是对节点流进行一系列的包装。例如BufferedInputStream和BufferedOutputStream,使用已经存在的节点流来构造,提供带缓冲的读写,提高了读写的效率,以及DataInputStream和DataOutputStream,使用已经存在的节点流来构造,提供了读写Java中的基本数据类型的功能。他们都属于过滤流。

举个简单的例子:
public static void main(String[] args) throws IOException {
// 节点流FileOutputStream直接以A.txt作为数据源操作
FileOutputStream fileOutputStream = new FileOutputStream("A.txt");
// 过滤流BufferedOutputStream进一步装饰节点流,提供缓冲写
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(
fileOutputStream);
// 过滤流DataOutputStream进一步装饰过滤流,使其提供基本数据类型的写
DataOutputStream out = new DataOutputStream(bufferedOutputStream);
out.writeInt(3);
out.writeBoolean(true);
out.flush();
out.close();
// 此处输入节点流,过滤流正好跟上边输出对应,读者可举一反三
DataInputStream in = new DataInputStream(new BufferedInputStream(
new FileInputStream("A.txt")));
System.out.println(in.readInt());
System.out.println(in.readBoolean());
in.close();
}流结构介绍:
Java所有的流类位于java.io包中,都分别继承字以下四种抽象流类型。
| | 字节流 | 字符流 |
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
1.继承自InputStream/OutputStream的流都是用于向程序中输入/输出数据,且数据的单位都是字节(byte=8bit),如图,深色的为节点流,浅色的为处理流。


2.继承自Reader/Writer的流都是用于向程序中输入/输出数据,且数据的单位都是字符(2byte=16bit),如图,深色的为节点流,浅色的为处理流。


常见流类介绍:
节点流类型常见的有:
对文件操作的字符流有FileReader/FileWriter,字节流有FileInputStream/FileOutputStream。
处理流类型常见的有:
缓冲流:缓冲流要“套接”在相应的节点流之上,对读写的数据提供了缓冲的功能,提高了读写效率,同事增加了一些新的方法。
字节缓冲流有BufferedInputStream/BufferedOutputStream,字符缓冲流有BufferedReader/BufferedWriter,字符缓冲流分别提供了读取和写入一行的方法ReadLine和NewLine方法。
对于输出地缓冲流,写出的数据,会先写入到内存中,再使用flush方法将内存中的数据刷到硬盘。所以,在使用字符缓冲流的时候,一定要先flush,然后再close,避免数据丢失。
转换流:用于字节数据到字符数据之间的转换。
仅有字符流InputStreamReader/OutputStreamWriter。其中,InputStreamReader需要与InputStream“套接”,OutputStreamWriter需要与OutputStream“套接”。
数据流:提供了读写Java中的基本数据类型的功能。
DataInputStream和DataOutputStream分别继承自InputStream和OutputStream,需要“套接”在InputStream和OutputStream类型的节点流之上。
对象流:用于直接将对象写入写出。
流类有ObjectInputStream和ObjectOutputStream,本身这两个方法没什么,但是其要写出的对象有要求,该对象必须实现Serializable接口,来声明其是可以序列化的。否则,不能用对象流读写。
还有一个关键字比较重要,transient,由于修饰实现了Serializable接口的类内的属性,被该修饰符修饰的属性,在以对象流的方式输出的时候,该字段会被忽略。
posted @
2015-07-16 11:36 xzc 阅读(379) |
评论 (0) |
编辑 收藏Hive:
利用squirrel-sql 连接hive
add driver -> name&example url(jdbc:hive2://xxx:10000)->extra class path ->Add
{hive/lib/hive-common-*.jar
hive/lib/hive-contrib-*.jar
hive/lib/hive-jdbc-*.jar
hive/lib/libthrift-*.jar
hive/lib/hive-service-*.jar
hive/lib/httpclient-*.jar
hive/lib/httpcore-*.jar
hadoop/share/hadoop/common/hadoop-common--*.jar
hadoop/share/hadoop/common/lib/common-configuration-*.jar
hadoop/share/hadoop/common/lib/log4j-*.jar
hadoop/share/hadoop/common/lib/slf4j-api-*.jar
hadoop/share/hadoop/common/lib/slf4j-log4j-*.jar}
->List Drivers(wait ..then class name will auto set org.apache.hive.jdbc/HiveDriver)->OK->Add aliases ->chose the hive driver->done
Hive数据迁移
1.导出表
EXPORT TABLE <table_name> TO 'path/to/hdfs';
2.复制数据到另一个hdfs
hadoop distcp hdfs://:8020/path/to/hdfs hdfs:///path/to/hdfs
3.导入表
IMPORT TABLE <table_name> FROM 'path/to/another/hdfs';
Hive 输出查询结果到文件
输出到本地文件:
insert overwrite local directory './test-04'
row format delimited
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
select * from src;
输出到hdfs:
输出到hdfs好像不支持 row format,只能另辟蹊径了
INSERT OVERWRITE DIRECTORY '/outputable.txt'
select concat(col1, ',', col2, ',', col3) from myoutputtable;
当然默认的分隔符是\001
若要直接对文件进行操作课直接用stdin的形式
eg. hadoop fs -cat ../000000_0 |python doSomeThing.py
#!/usr/bin/env python
import sys
for line in sys.stdin:
(a,b,c)=line.strip().split('\001')
Hive 语法:
hive好像不支持select dicstinct col1 as col1 from table group by col1
需要用grouping sets
select col1 as col1 from table group by col1 grouping sets((col1))
Beeline:
文档:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
利用jdbc连接hive:
hive2='JAVA_HOME=/opt/java7 HADOOP_HOME=/opt/hadoop /opt/hive/bin/beeline -u jdbc:hive2://n1.hd2.host.dxy:10000 -n hadoop -p fake -d org.apache.hive.jdbc.HiveDriver --color=true --silent=false --fastConnect=false --verbose=true'
beeline利用jdbc连接hive若需要执行多条命令使用
hive2 -e "xxx" -e "yyy" -e...
posted @
2015-06-13 16:48 xzc 阅读(3429) |
评论 (0) |
编辑 收藏posted @
2015-04-28 11:48 xzc 阅读(253) |
评论 (0) |
编辑 收藏
show tables like '*name*';
2.查看表结构信息
desc formatted table_name;
desc table_name;
3.查看分区信息
show partitions table_name;
4.根据分区查询数据
select table_coulm from table_name where partition_name = '2014-02-25';
5.查看hdfs文件信息
dfs -ls /user/hive/warehouse/table02;
6.从文件加载数据进表(OVERWRITE覆盖,追加不需要OVERWRITE关键字)
LOAD DATA LOCAL INPATH 'dim_csl_rule_config.txt' OVERWRITE into table dim.dim_csl_rule_config;
--从查询语句给table插入数据
INSERT OVERWRITE TABLE test_h02_click_log PARTITION(dt) select *
from stage.s_h02_click_log where dt='2014-01-22' limit 100;
7.导出数据到文件
insert overwrite directory '/tmp/csl_rule_cfg' select a.* from dim.dim_csl_rule_config a;
hive -e "select day_id,pv,uv,ip_count,click_next_count,second_bounce_rate,return_visit,pg_type from tmp.tmp_h02_click_log_baitiao_ag_sum where day_id in ('2014-03-06','2014-03-07','2014-03-08','2014-03-09','2014-03-10');"> /home/jrjt/testan/baitiao.dat;
8.自定义udf函数
1.继承UDF类
2.重写evaluate方法
3.把项目打成jar包
4.hive中执行命令add jar /home/jrjt/dwetl/PUB/UDF/udf/GetProperty.jar;
5.创建函数create temporary function get_pro as 'jd.Get_Property'//jd.jd.Get_Property为类路径;
9.查询显示列名 及 行转列显示
set hive.cli.print.header=true; // 打印列名
set hive.cli.print.row.to.vertical=true; // 开启行转列功能, 前提必须开启打印列名功能
set hive.cli.print.row.to.vertical.num=1; // 设置每行显示的列数
10.查看表文件大小,下载文件到某个目录,显示多少行到某个文件
dfs -du hdfs://BJYZH3-HD-JRJT-4137.jd.com:54310/user/jrjt/warehouse/stage.db/s_h02_click_log;
dfs -get /user/jrjt/warehouse/ods.db/o_h02_click_log_i_new/dt=2014-01-21/000212_0 /home/jrjt/testan/;
head -n 1000 文件名 > 文件名
11.杀死某个任务 不在hive shell中执行
hadoop job -kill job_201403041453_58315
12.hive-wui路径
http://172.17.41.38/jobtracker.jsp
13.删除分区
alter table tmp_h02_click_log_baitiao drop partition(dt='2014-03-01');
alter table d_h02_click_log_basic_d_fact drop partition(dt='2014-01-17');
14.hive命令行操作
执行一个查询,在终端上显示mapreduce的进度,执行完毕后,最后把查询结果输出到终端上,接着hive进程退出,不会进入交互模式。
hive -e 'select table_cloum from table'
-S,终端上的输出不会有mapreduce的进度,执行完毕,只会把查询结果输出到终端上。这个静音模式很实用,,通过第三方程序调用,第三方程序通过hive的标准输出获取结果集。
hive -S -e 'select table_cloum from table'
执行sql文件
hive -f hive_sql.sql
15.hive上操作hadoop文件基本命令
查看文件大小
dfs -du /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-15;
删除文件
dfs -rm /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-15;
16.插入数据sql、导出数据sql
1.insert 语法格式为:
基本的插入语法:
INSERT OVERWRITE TABLE tablename [PARTITON(partcol1=val1,partclo2=val2)]select_statement FROM from_statement
insert overwrite table test_insert select * from test_table;
对多个表进行插入操作:
FROM fromstatte
INSERT OVERWRITE TABLE tablename1 [PARTITON(partcol1=val1,partclo2=val2)]select_statement1
INSERT OVERWRITE TABLE tablename2 [PARTITON(partcol1=val1,partclo2=val2)]select_statement2
from test_table
insert overwrite table test_insert1
select key
insert overwrite table test_insert2
select value;
insert的时候,from子句即可以放在select 子句后面,也可以放在 insert子句前面。
hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。
2.通过查询将数据保存到filesystem
INSERT OVERWRITE [LOCAL] DIRECTORY directory SELECT.... FROM .....
导入数据到本地目录:
insert overwrite local directory '/home/zhangxin/hive' select * from test_insert1;
产生的文件会覆盖指定目录中的其他文件,即将目录中已经存在的文件进行删除。
导出数据到HDFS中:
insert overwrite directory '/user/zhangxin/export_test' select value from test_table;
同一个查询结果可以同时插入到多个表或者多个目录中:
from test_insert1
insert overwrite local directory '/home/zhangxin/hive' select *
insert overwrite directory '/user/zhangxin/export_test' select value;
17.mapjoin的使用 应用场景:1.关联操作中有一张表非常小 2.不等值的链接操作
select /*+ mapjoin(A)*/ f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802)
18.perl启动任务
perl /home/jrjt/dwetl/APP/APP/A_H02_CLICK_LOG_CREDIT_USER/bin/a_h02_click_log_credit_user.pl
APP_A_H02_CLICK_LOG_CREDIT_USER_20140215.dir >& /home/jrjt/dwetl/LOG/APP/20140306/a_h02_click_log_credit_user.pl.4.log
19.查看perl进程
ps -ef|grep perl
20.hive命令移动表数据到另外一张表目录下并添加分区
dfs -cp /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-18 /user/jrjt/warehouse/ods.db/o_h02_click_log/;
dfs -cp /user/jrjt/warehouse/tmp.db/tmp_h02_click_log_baitiao/* /user/jrjt/warehouse/dw.db/d_h02_click_log_baitiao_basic_d_fact/;--复制所有分区数据
alter table d_h02_click_log_baitiao_basic_d_fact add partition(dt='2014-03-11') location '/user/jrjt/warehouse/dw.db/d_h02_click_log_baitiao_basic_d_fact/dt=2014-03-11';
21.导出白条数据
hive -e "select day_id,pv,uv,ip_count,click_next_count,second_bounce_rate,return_visit,pg_type from tmp.tmp_h02_click_log_baitiao_ag_sum where day_id like '2014-03%';"> /home/jrjt/testan/baitiao.xlsx;
22.hive修改表名
ALTER TABLE o_h02_click_log_i RENAME TO o_h02_click_log_i_bk;
23.hive复制表结构
CREATE TABLE d_h02_click_log_baitiao_ag_sum LIKE tmp.tmp_h02_click_log_baitiao_ag_sum;
24.hive官网网址
https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-InstallationandConfiguration
http://www.360doc.com/content/12/0111/11/7362_178698714.shtml
25.hive添加字段
alter table tmp_h02_click_log_baitiao_ag_sum add columns(current_session_timelenth_count bigint comment '页面停留总时长');
ALTER TABLE tmp_h02_click_log_baitiao CHANGE current_session_timelenth current_session_timelenth bigint comment '当前会话停留时间';
26.hive开启简单模式不启用mr
set hive.fetch.task.conversion=more;
27.以json格式输出执行语句会读取的input table和input partition信息
Explain dependency query
posted @
2015-02-13 15:20 xzc 阅读(362) |
评论 (0) |
编辑 收藏转自:http://www.aboutyun.com/forum.php?mod=viewthread&tid=8590&highlight=hive
问题导读:
1.如何查看hive表结构?
2.如何查看表结构信息?
3.如何查看分区信息?
4.哪个命令可以模糊搜索表
1.hive模糊搜索表
show tables like '*name*';
2.查看表结构信息
desc formatted table_name;
desc table_name;
3.查看分区信息
show partitions table_name;
4.根据分区查询数据
select table_coulm from table_name where partition_name = '2014-02-25';
5.查看hdfs文件信息
dfs -ls /user/hive/warehouse/table02;
6.从文件加载数据进表(OVERWRITE覆盖,追加不需要OVERWRITE关键字)
LOAD DATA LOCAL INPATH 'dim_csl_rule_config.txt' OVERWRITE into table dim.dim_csl_rule_config;
--从查询语句给table插入数据
INSERT OVERWRITE TABLE test_h02_click_log PARTITION(dt) select *
from stage.s_h02_click_log where dt='2014-01-22' limit 100;
7.导出数据到文件
insert overwrite directory '/tmp/csl_rule_cfg' select a.* from dim.dim_csl_rule_config a;
hive -e "select day_id,pv,uv,ip_count,click_next_count,second_bounce_rate,return_visit,pg_type from tmp.tmp_h02_click_log_baitiao_ag_sum where day_id in ('2014-03-06','2014-03-07','2014-03-08','2014-03-09','2014-03-10');"> /home/jrjt/testan/baitiao.dat;
8.自定义udf函数
1.继承UDF类
2.重写evaluate方法
3.把项目打成jar包
4.hive中执行命令add jar /home/jrjt/dwetl/PUB/UDF/udf/GetProperty.jar;
5.创建函数create temporary function get_pro as 'jd.Get_Property'//jd.jd.Get_Property为类路径;
9.查询显示列名 及 行转列显示
set hive.cli.print.header=true; // 打印列名
set hive.cli.print.row.to.vertical=true; // 开启行转列功能, 前提必须开启打印列名功能
set hive.cli.print.row.to.vertical.num=1; // 设置每行显示的列数
10.查看表文件大小,下载文件到某个目录,显示多少行到某个文件
dfs -du hdfs://BJYZH3-HD-JRJT-4137.jd.com:54310/user/jrjt/warehouse/stage.db/s_h02_click_log;
dfs -get /user/jrjt/warehouse/ods.db/o_h02_click_log_i_new/dt=2014-01-21/000212_0 /home/jrjt/testan/;
head -n 1000 文件名 > 文件名
11.杀死某个任务 不在hive shell中执行
hadoop job -kill job_201403041453_58315
12.hive-wui路径
http://172.17.41.38/jobtracker.jsp
13.删除分区
alter table tmp_h02_click_log_baitiao drop partition(dt='2014-03-01');
alter table d_h02_click_log_basic_d_fact drop partition(dt='2014-01-17');
14.hive命令行操作
执行一个查询,在终端上显示mapreduce的进度,执行完毕后,最后把查询结果输出到终端上,接着hive进程退出,不会进入交互模式。
hive -e 'select table_cloum from table'
-S,终端上的输出不会有mapreduce的进度,执行完毕,只会把查询结果输出到终端上。这个静音模式很实用,,通过第三方程序调用,第三方程序通过hive的标准输出获取结果集。
hive -S -e 'select table_cloum from table'
执行sql文件
hive -f hive_sql.sql
15.hive上操作hadoop文件基本命令
查看文件大小
dfs -du /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-15;
删除文件
dfs -rm /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-15;
16.插入数据sql、导出数据sql
1.insert 语法格式为:
基本的插入语法:
INSERT OVERWRITE TABLE tablename [PARTITON(partcol1=val1,partclo2=val2)]select_statement FROM from_statement
insert overwrite table test_insert select * from test_table;
对多个表进行插入操作:
FROM fromstatte
INSERT OVERWRITE TABLE tablename1 [PARTITON(partcol1=val1,partclo2=val2)]select_statement1
INSERT OVERWRITE TABLE tablename2 [PARTITON(partcol1=val1,partclo2=val2)]select_statement2
from test_table
insert overwrite table test_insert1
select key
insert overwrite table test_insert2
select value;
insert的时候,from子句即可以放在select 子句后面,也可以放在 insert子句前面。
hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。
2.通过查询将数据保存到filesystem
INSERT OVERWRITE [LOCAL] DIRECTORY directory SELECT.... FROM .....
导入数据到本地目录:
insert overwrite local directory '/home/zhangxin/hive' select * from test_insert1;
产生的文件会覆盖指定目录中的其他文件,即将目录中已经存在的文件进行删除。
导出数据到HDFS中:
insert overwrite directory '/user/zhangxin/export_test' select value from test_table;
同一个查询结果可以同时插入到多个表或者多个目录中:
from test_insert1
insert overwrite local directory '/home/zhangxin/hive' select *
insert overwrite directory '/user/zhangxin/export_test' select value;
17.mapjoin的使用 应用场景:1.关联操作中有一张表非常小 2.不等值的链接操作
select /*+ mapjoin(A)*/ f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802)
18.perl启动任务
perl /home/jrjt/dwetl/APP/APP/A_H02_CLICK_LOG_CREDIT_USER/bin/a_h02_click_log_credit_user.pl
APP_A_H02_CLICK_LOG_CREDIT_USER_20140215.dir >& /home/jrjt/dwetl/LOG/APP/20140306/a_h02_click_log_credit_user.pl.4.log
19.查看perl进程
ps -ef|grep perl
20.hive命令移动表数据到另外一张表目录下并添加分区
dfs -cp /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-18 /user/jrjt/warehouse/ods.db/o_h02_click_log/;
dfs -cp /user/jrjt/warehouse/tmp.db/tmp_h02_click_log_baitiao/* /user/jrjt/warehouse/dw.db/d_h02_click_log_baitiao_basic_d_fact/;--复制所有分区数据
alter table d_h02_click_log_baitiao_basic_d_fact add partition(dt='2014-03-11') location '/user/jrjt/warehouse/dw.db/d_h02_click_log_baitiao_basic_d_fact/dt=2014-03-11';
21.导出白条数据
hive -e "select day_id,pv,uv,ip_count,click_next_count,second_bounce_rate,return_visit,pg_type from tmp.tmp_h02_click_log_baitiao_ag_sum where day_id like '2014-03%';"> /home/jrjt/testan/baitiao.xlsx;
22.hive修改表名
ALTER TABLE o_h02_click_log_i RENAME TO o_h02_click_log_i_bk;
23.hive复制表结构
CREATE TABLE d_h02_click_log_baitiao_ag_sum LIKE tmp.tmp_h02_click_log_baitiao_ag_sum;
24.hive官网网址
https://cwiki.apache.org/conflue ... ionandConfiguration
http://www.360doc.com/content/12/0111/11/7362_178698714.shtml
25.hive添加字段
alter table tmp_h02_click_log_baitiao_ag_sum add columns(current_session_timelenth_count bigint comment '页面停留总时长');
ALTER TABLE tmp_h02_click_log_baitiao CHANGE current_session_timelenth current_session_timelenth bigint comment '当前会话停留时间';
26.hive开启简单模式不启用mr
set hive.fetch.task.conversion=more;
27.以json格式输出执行语句会读取的input table和input partition信息
Explain dependency query
posted @
2015-02-13 15:19 xzc 阅读(3904) |
评论 (0) |
编辑 收藏posted @
2015-02-09 10:52 xzc 阅读(659) |
评论 (0) |
编辑 收藏 JAVA 命令参数详解:
1、-D<name>=<value> set a system property 设置系统属性。
java命令引入jar时可以-cp参数,但时-cp不能用通配符(多个jar时什么烦要一个个写,不能*.jar),面通常的jar都在同一目录,且多于1个。前些日子找到(发现)-Djava.ext.dirs太好。
如:
java -Djava.ext.dirs=lib MyClass
可以在运行前配置一些属性,比如路径什么的。
java -Dconfig="d:/config/config.xml" Abc
这样在Abc中就可以通过System.getProperty("config");获得这个值了。
在虚拟机的系统属性中设置属性名/值对,运行在此虚拟机之上的应用程序可用
当虚拟机报告类找不到或类冲突时可用此参数来诊断来查看虚拟机从装入类的情况。
另外,javac -d <目录> 指定存放生成的类文件的位置
Standard System Properties
| Key | Meaning |
"file.separator" | Character that separates components of a file path. This is "/" on UNIX and "\" on Windows. |
"java.class.path" | Path used to find directories and JAR archives containing class files. Elements of the class path are separated by a platform-specific character specified in the path.separator property. |
"java.home" | Installation directory for Java Runtime Environment (JRE) |
"java.vendor" | JRE vendor name |
"java.vendor.url" | JRE vender URL |
"java.version" | JRE version number |
"line.separator" | Sequence used by operating system to separate lines in text files |
"os.arch" | Operating system architecture |
"os.name" | Operating system name |
"os.version" | Operating system version |
"path.separator" | Path separator character used in java.class.path |
"user.dir" | User working directory |
"user.home" | User home directory |
"user.name" | User account name |
所谓的 system porperty,system 指的是 JRE (runtime)system,不是指 OS。
System.setProperty("net.jxta.tls.principal", "client");
System.setProperty("net.jxta.tls.password", "password");
System.setProperty("JXTA_HOME",System.getProperty("JXTA_HOME","client"));
可以利用系统属性来加载多个驱动
posted @
2015-01-21 10:09 xzc 阅读(863) |
评论 (0) |
编辑 收藏在linux系统下进程遇到查看文件的权限、修改文件的权限以及修改文件的所有者等操作,主要涉及到chmod、chgrp、chown三个命令。本文简单讲述下这三个命令的使用。
- chgrp 修改文件所属组
- chown 修改文件所有者
- chmod 修改文件属性
一、chgrp 使用说明
用法:chgrp [-cfhRv][--help][--version][所属群组][文件或目录...]
或者:chgrp [-cfhRv][--help][--reference=参考文件或目录][--version][文件或目录...]
参数[-R] 用于整个目录下递归
参数[-h] 有且只有改变符号连接的用户组
参数[-c]与[-v]类似,但是v表示无论如何也要显示结果,c表示只有更改组之后才显示结果
实例:chgrp [-R] test test.txt
表示把test.txt文件的群组修改成test
二、chown 使用说明
用法:chown [选项]... 所有者[:[组]] 文件...
或:chown [选项]... :组 文件...
或:chown [选项]... --reference=参考文件 文件...
chown [-cfhvR] [--help] [--version] user[:group] file...
<参数>[-cfvR] 类似上面的chgrp的用法
范例
chown test:users test.txt
将档案 test.txt 的拥有者设为 users 群的使用者 test
chown -R test:users *
将目前目录下的所有档案与子目录的拥有者皆设为 users 群体的使用者 test
chgrp和chown 的都是转移文件属主 但是chown只能在同一个用户组里面转换而chgrp可以转移到不同的用户组
三、chmod 使用说明
用法:chmod [选项]... 模式[,模式]... 文件...
或:chmod [选项]... 八进制模式 文件...
或:chmod [选项]... --reference=参考文件 文件...
<模式>由三部份组成:一个或以上的 ugoa 字母,一个或以上的 +-= 符号,
和一个或以上的 rwxXstugo 字母。
<参数>[-cfvR] 类似上面的chgrp的用法
具体比如 chmod [-R] u/g/o/a +/-/= rwx 檔案或目錄
【u/g/o/a】说明
- u:user表示该档案的拥有者
- g:group表示与该档案的拥有者属于同一个群体(group)者
- o:other表示其他以外的人
- a:all表示这三者皆是
【+-=】说明
【rwx】说明
- r:read表示可读取
- w:write表示可写入
- x:excute表示可执行
- X 表示只有当该档案是个子目录或者该档案已经被设定过为可执行
当然rwx这些权限也可以用数字来代替
r:4 w:2 x:1 -:0
比如执行:chmod u=rwx,g=rx,o=r filename
就等同于: chmod u=7,g=5,o=4 filename
范例:
chmod o-r test.txt
表示给其他人撤销test.txt这个文件的读权限
chmod -R a+r *
将目前目录下的所有档案与子目录皆设为任何人可读取
chmod ug+w,o-w test1.txt test2.txt
将档案 test1.txt 与 test2.txt 设为该档案拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入
chmod ug=rwx,o=x file 效果等同于 chmod 771 file
chmod a=rwx file 效果等同于 chmod 777 file
posted @
2015-01-20 11:33 xzc 阅读(237) |
评论 (0) |
编辑 收藏posted @
2015-01-15 19:57 xzc 阅读(385) |
评论 (3) |
编辑 收藏本文总结了Linux添加或者删除用户和用户组时常用的一些命令和参数。
1、建用户:
adduser phpq //新建phpq用户
passwd phpq //给phpq用户设置密码
2、建工作组
groupadd test //新建test工作组
3、新建用户同时增加工作组
useradd -g test phpq //新建phpq用户并增加到test工作组
注::-g 所属组 -d 家目录 -s 所用的SHELL
4、给已有的用户增加工作组
usermod -G groupname username
或者:gpasswd -a user group
5、临时关闭:在/etc/shadow文件中属于该用户的行的第二个字段(密码)前面加上*就可以了。想恢复该用户,去掉*即可。
或者使用如下命令关闭用户账号:
passwd peter –l
重新释放:
passwd peter –u
6、永久性删除用户账号
userdel peter
groupdel peter
usermod –G peter peter (强制删除该用户的主目录和主目录下的所有文件和子目录)
7、从组中删除用户
编辑/etc/group 找到GROUP1那一行,删除 A
或者用命令
gpasswd -d A GROUP
8、显示用户信息
id user
cat /etc/passwd
更详细的用户和用户组的解说请参考
Linux 用户和用户组详细解说
本文主要讲述在Linux 系统中用户(user)和用户组(group)管理相应的概念;用户(user)和用户组(group)相关命令的列举;其中也对单用户多任务,多用户多任务也做以解说。
本篇文章来源于 PHP资讯 原文链接:http://www.phpq.net/linux/linux-add-delete-user-group.html
Linux 用户(user)和用户组(group)管理概述
、理解Linux的单用户多任务,多用户多任务概念;
Linux 是一个多用户、多任务的操作系统;我们应该了解单用户多任务和多用户多任务的概念;
1、Linux 的单用户多任务;
单用户多任务;比如我们以beinan 登录系统,进入系统后,我要打开gedit 来写文档,但在写文档的过程中,我感觉少点音乐,所以又打开xmms 来点音乐;当然听点音乐还不行,MSN 还得打开,想知道几个弟兄现在正在做什么,这样一样,我在用beinan 用户登录时,执行了gedit 、xmms以及msn等,当然还有输入法fcitx ;这样说来就有点简单了,一个beinan用户,为了完成工作,执行了几个任务;当然beinan这个用户,其它的人还能以远程登录过来,也能做其它的工作。
2、Linux 的多用户、多任务;
有时可能是很多用户同时用同一个系统,但并不所有的用户都一定都要做同一件事,所以这就有多用户多任务之说;
举个例子,比如LinuxSir.Org 服务器,上面有FTP 用户、系统管理员、web 用户、常规普通用户等,在同一时刻,可能有的弟兄正在访问论坛;有的可能在上传软件包管理子站,比如luma 或Yuking 兄在管理他们的主页系统和FTP ;在与此同时,可能还会有系统管理员在维护系统;浏览主页的用的是nobody 用户,大家都用同一个,而上传软件包用的是FTP用户;管理员的对系统的维护或查看,可能用的是普通帐号或超级权限root帐号;不同用户所具有的权限也不同,要完成不同的任务得需要不同的用户,也可以说不同的用户,可能完成的工作也不一样;
值得注意的是:多用户多任务并不是大家同时挤到一接在一台机器的的键盘和显示器前来操作机器,多用户可能通过远程登录来进行,比如对服务器的远程控制,只要有用户权限任何人都是可以上去操作或访问的;
3、用户的角色区分;
用户在系统中是分角色的,在Linux 系统中,由于角色不同,权限和所完成的任务也不同;值得注意的是用户的角色是通过UID和识别的,特别是UID;在系统管理中,系统管理员一定要坚守UID 唯一的特性;
root 用户:系统唯一,是真实的,可以登录系统,可以操作系统任何文件和命令,拥有最高权限;
虚拟用户:这类用户也被称之为伪用户或假用户,与真实用户区分开来,这类用户不具有登录系统的能力,但却是系统运行不可缺少的用户,比如bin、daemon、adm、ftp、mail等;这类用户都系统自身拥有的,而非后来添加的,当然我们也可以添加虚拟用户;
普通真实用户:这类用户能登录系统,但只能操作自己家目录的内容;权限有限;这类用户都是系统管理员自行添加的;
4、多用户操作系统的安全;
多用户系统从事实来说对系统管理更为方便。从安全角度来说,多用户管理的系统更为安全,比如beinan用户下的某个文件不想让其它用户看到,只是设置一下文件的权限,只有beinan一个用户可读可写可编辑就行了,这样一来只有beinan一个用户可以对其私有文件进行操作,Linux 在多用户下表现最佳,Linux能很好的保护每个用户的安全,但我们也得学会Linux 才是,再安全的系统,如果没有安全意识的管理员或管理技术,这样的系统也不是安全的。
从服务器角度来说,多用户的下的系统安全性也是最为重要的,我们常用的Windows 操作系统,它在系纺权限管理的能力只能说是一般般,根本没有没有办法和Linux或Unix 类系统相比;
二、用户(user)和用户组(group)概念;
1、用户(user)的概念;
通过前面对Linux 多用户的理解,我们明白Linux 是真正意义上的多用户操作系统,所以我们能在Linux系统中建若干用户(user)。比如我们的同事想用我的计算机,但我不想让他用我的用户名登录,因为我的用户名下有不想让别人看到的资料和信息(也就是隐私内容)这时我就可以给他建一个新的用户名,让他用我所开的用户名去折腾,这从计算机安全角度来说是符合操作规则的;
当然用户(user)的概念理解还不仅仅于此,在Linux系统中还有一些用户是用来完成特定任务的,比如nobody和ftp 等,我们访问LinuxSir.Org 的网页程序,就是nobody用户;我们匿名访问ftp 时,会用到用户ftp或nobody ;如果您想了解Linux系统的一些帐号,请查看 /etc/passwd ;
2、用户组(group)的概念;
用户组(group)就是具有相同特征的用户(user)的集合体;比如有时我们要让多个用户具有相同的权限,比如查看、修改某一文件或执行某个命令,这时我们需要用户组,我们把用户都定义到同一用户组,我们通过修改文件或目录的权限,让用户组具有一定的操作权限,这样用户组下的用户对该文件或目录都具有相同的权限,这是我们通过定义组和修改文件的权限来实现的;
举例:我们为了让一些用户有权限查看某一文档,比如是一个时间表,而编写时间表的人要具有读写执行的权限,我们想让一些用户知道这个时间表的内容,而不让他们修改,所以我们可以把这些用户都划到一个组,然后来修改这个文件的权限,让用户组可读,这样用户组下面的每个用户都是可读的;
用户和用户组的对应关系是:一对一、多对一、一对多或多对多;
一对一:某个用户可以是某个组的唯一成员;
多对一:多个用户可以是某个唯一的组的成员,不归属其它用户组;比如beinan和linuxsir两个用户只归属于beinan用户组;
一对多:某个用户可以是多个用户组的成员;比如beinan可以是root组成员,也可以是linuxsir用户组成员,还可以是adm用户组成员;
多对多:多个用户对应多个用户组,并且几个用户可以是归属相同的组;其实多对多的关系是前面三条的扩展;理解了上面的三条,这条也能理解;
三、用户(user)和用户组(group)相关的配置文件、命令或目录;
1、与用户(user)和用户组(group)相关的配置文件;
1)与用户(user)相关的配置文件;
/etc/passwd 注:用户(user)的配置文件;
/etc/shadow 注:用户(user)影子口令文件;
2)与用户组(group)相关的配置文件;
/etc/group 注:用户组(group)配置文件;
/etc/gshadow 注:用户组(group)的影子文件;
2、管理用户(user)和用户组(group)的相关工具或命令;
1)管理用户(user)的工具或命令;
useradd 注:添加用户
adduser 注:添加用户
passwd 注:为用户设置密码
usermod 注:修改用户命令,可以通过usermod 来修改登录名、用户的家目录等等;
pwcov 注:同步用户从/etc/passwd 到/etc/shadow
pwck 注:pwck是校验用户配置文件/etc/passwd 和/etc/shadow 文件内容是否合法或完整;
pwunconv 注:是pwcov 的立逆向操作,是从/etc/shadow和 /etc/passwd 创建/etc/passwd ,然后会删除 /etc/shadow 文件;
finger 注:查看用户信息工具
id 注:查看用户的UID、GID及所归属的用户组
chfn 注:更改用户信息工具
su 注:用户切换工具
sudo 注:sudo 是通过另一个用户来执行命令(execute a command as another user),su 是用来切换用户,然后通过切换到的用户来完成相应的任务,但sudo 能后面直接执行命令,比如sudo 不需要root 密码就可以执行root 赋与的执行只有root才能执行相应的命令;但得通过visudo 来编辑/etc/sudoers来实现;
visudo 注:visodo 是编辑 /etc/sudoers 的命令;也可以不用这个命令,直接用vi 来编辑 /etc/sudoers 的效果是一样的;
sudoedit 注:和sudo 功能差不多;
2)管理用户组(group)的工具或命令;
groupadd 注:添加用户组;
groupdel 注:删除用户组;
groupmod 注:修改用户组信息
groups 注:显示用户所属的用户组
grpck
grpconv 注:通过/etc/group和/etc/gshadow 的文件内容来同步或创建/etc/gshadow ,如果/etc/gshadow 不存在则创建;
grpunconv 注:通过/etc/group 和/etc/gshadow 文件内容来同步或创建/etc/group ,然后删除gshadow文件;
3、/etc/skel 目录;
/etc/skel目录一般是存放用户启动文件的目录,这个目录是由root权限控制,当我们添加用户时,这个目录下的文件自动复制到新添加的用户的家目录下;/etc/skel 目录下的文件都是隐藏文件,也就是类似.file格式的;我们可通过修改、添加、删除/etc/skel目录下的文件,来为用户提供一个统一、标准的、默认的用户环境;
[root@localhost beinan]# ls -la /etc/skel/
总用量 92
drwxr-xr-x 3 root root 4096 8月 11 23:32 .
drwxr-xr-x 115 root root 12288 10月 14 13:44 ..
-rw-r--r-- 1 root root 24 5月 11 00:15 .bash_logout
-rw-r--r-- 1 root root 191 5月 11 00:15 .bash_profile
-rw-r--r-- 1 root root 124 5月 11 00:15 .bashrc
-rw-r--r-- 1 root root 5619 2005-03-08 .canna
-rw-r--r-- 1 root root 438 5月 18 15:23 .emacs
-rw-r--r-- 1 root root 120 5月 23 05:18 .gtkrc
drwxr-xr-x 3 root root 4096 8月 11 23:16 .kde
-rw-r--r-- 1 root root 658 2005-01-17 .zshrc
/etc/skel 目录下的文件,一般是我们用useradd 和adduser 命令添加用户(user)时,系统自动复制到新添加用户(user)的家目录下;如果我们通过修改 /etc/passwd 来添加用户时,我们可以自己创建用户的家目录,然后把/etc/skel 下的文件复制到用户的家目录下,然后要用chown 来改变新用户家目录的属主;
4、/etc/login.defs 配置文件;
/etc/login.defs 文件是当创建用户时的一些规划,比如创建用户时,是否需要家目录,UID和GID的范围;用户的期限等等,这个文件是可以通过root来定义的;
比如Fedora 的 /etc/logins.defs 文件内容;
# *REQUIRED*
# Directory where mailboxes reside, _or_ name of file, relative to the
# home directory. If you _do_ define both, MAIL_DIR takes precedence.
# QMAIL_DIR is for Qmail
#
#QMAIL_DIR Maildir
MAIL_DIR /var/spool/mail 注:创建用户时,要在目录/var/spool/mail中创建一个用户mail文件;
#MAIL_FILE .mail
# Password aging controls:
#
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_MIN_LEN Minimum acceptable password length.
# PASS_WARN_AGE Number of days warning given before a password expires.
#
PASS_MAX_DAYS 99999 注:用户的密码不过期最多的天数;
PASS_MIN_DAYS 0 注:密码修改之间最小的天数;
PASS_MIN_LEN 5 注:密码最小长度;
PASS_WARN_AGE 7 注:
#
# Min/max values for automatic uid selection in useradd
#
UID_MIN 500 注:最小UID为500 ,也就是说添加用户时,UID 是从500开始的;
UID_MAX 60000 注:最大UID为60000;
#
# Min/max values for automatic gid selection in groupadd
#
GID_MIN 500 注:GID 是从500开始;
GID_MAX 60000
#
# If defined, this command is run when removing a user.
# It should remove any at/cron/print jobs etc. owned by
# the user to be removed (passed as the first argument).
#
#USERDEL_CMD /usr/sbin/userdel_local
#
# If useradd should create home directories for users by default
# On RH systems, we do. This option is ORed with the -m flag on
# useradd command line.
#
CREATE_HOME yes 注:是否创用户家目录,要求创建;
5、/etc/default/useradd 文件;
通过useradd 添加用户时的规则文件;
# useradd defaults file
GROUP=100
HOME=/home 注:把用户的家目录建在/home中;
INACTIVE=-1 注:是否启用帐号过期停权,-1表示不启用;
EXPIRE= 注:帐号终止日期,不设置表示不启用;
SHELL=/bin/bash 注:所用SHELL的类型;
SKEL=/etc/skel 注: 默认添加用户的目录默认文件存放位置;也就是说,当我们用adduser添加用户时,用户家目录下的文件,都是从这个目录中复制过去的;
后记:
关于用户(user)和用户组(group)管理内容大约就是这么多;只要把上面所说的内容了解和掌握,用户(user)和用户组(group)管理就差不多了;由于用户(user)和用户组(group)是和文件及目录权限联系在一起的,所以文件及目录权限的操作也会独立成文来给大家介绍;
摘自 http://fedora.linuxsir.org/main/?q=node/91
posted @
2015-01-09 18:18 xzc 阅读(343) |
评论 (0) |
编辑 收藏posted @
2015-01-06 17:01 xzc 阅读(430) |
评论 (0) |
编辑 收藏posted @
2014-12-29 16:53 xzc 阅读(411) |
评论 (1) |
编辑 收藏posted @
2014-12-08 21:13 xzc 阅读(495) |
评论 (1) |
编辑 收藏hbase(main):001:0> scan '-ROOT-'
ROW COLUMN+CELL
.META.,,1 column=info:regioninfo, timestamp=1340249081981, value={NAME => '.META.,,
1', STARTKEY => '', ENDKEY => '', ENCODED => 1028785192,}
.META.,,1 column=info:server, timestamp=1341304672637, value=Hadoop46:60020
.META.,,1 column=info:serverstartcode, timestamp=1341304672637, value=1341301228326
.META.,,1 column=info:v, timestamp=1340249081981, value=\x00\x00
1 row(s) in 1.3230 seconds
hbase(main):002:0> import java.util.Date
=> Java::JavaUtil::Date
hbase(main):003:0> Date.new(1341304672637).toString()
=> "Tue Jul 03 16:37:52 CST 2012"
hbase(main):004:0> Date.new(1341301228326).toString()
=> "Tue Jul 03 15:40:28 CST 2012"
在shell中,如果有可读日期,能否转成long类型呢?
hbase(main):005:0> import java.text.SimpleDateFormat
=> Java::JavaText::SimpleDateFormat
hbase(main):006:0> import java.text.ParsePosition
=> Java::JavaText::ParsePosition
hbase(main):015:0> SimpleDateFormat.new("yy/MM/dd").parse("12/07/03",ParsePosition.new(0)).getTime()
=> 1341244800000
参考
http://abloz.com/hbase/book.html
posted @
2014-12-01 09:39 xzc 阅读(5109) |
评论 (1) |
编辑 收藏posted @
2014-09-27 12:53 xzc 阅读(2153) |
评论 (0) |
编辑 收藏HBase 为用户提供了一个非常方便的使用方式, 我们称之为“HBase Shell”。
HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建、删除及修改表, 还可以向表中添加数据、列出表中的相关信息等。
备注:写错 HBase Shell 命令时用键盘上的“Delete”进行删除,“Backspace”不起作用。
在启动 HBase 之后,用户可以通过下面的命令进入 HBase Shell 之中,命令如下所示:
hadoop@ubuntu:~$ hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.94.3, r1408904, Wed Nov 14 19:55:11 UTC 2012
hbase(main):001:0>
具体的 HBase Shell 命令如下表 1.1-1 所示:

下面我们将以“一个学生成绩表”的例子来详细介绍常用的 HBase 命令及其使用方法。

这里 grad 对于表来说是一个列,course 对于表来说是一个列族,这个列族由三个列组成 china、math 和 english,当然我们可以根据我们的需要在 course 中建立更多的列族,如computer,physics 等相应的列添加入 course 列族。(备注:列族下面的列也是可以没有名字的。)
1). create 命令
创建一个具有两个列族“grad”和“course”的表“scores”。其中表名、行和列都要用单引号括起来,并以逗号隔开。
hbase(main):012:0> create 'scores', 'name', 'grad', 'course'
2). list 命令
查看当前 HBase 中具有哪些表。
hbase(main):012:0> list
3). describe 命令
查看表“scores”的构造。
hbase(main):012:0> describe 'scores'
4). put 命令
使用 put 命令向表中插入数据,参数分别为表名、行名、列名和值,其中列名前需要列族最为前缀,时间戳由系统自动生成。
格式: put 表名,行名,列名([列族:列名]),值
例子:
a. 加入一行数据,行名称为“xiapi”,列族“grad”的列名为”(空字符串)”,值位 1。
hbase(main):012:0> put 'scores', 'xiapi', 'grad:', '1'
hbase(main):012:0> put 'scores', 'xiapi', 'grad:', '2' --修改操作(update)
b. 给“xiapi”这一行的数据的列族“course”添加一列“<china,97>”。
hbase(main):012:0> put 'scores', 'xiapi', 'course:china', '97'
hbase(main):012:0> put 'scores', 'xiapi', 'course:math', '128'
hbase(main):012:0> put 'scores', 'xiapi', 'course:english', '85'
5). get 命令
a.查看表“scores”中的行“xiapi”的相关数据。
hbase(main):012:0> get 'scores', 'xiapi'
b.查看表“scores”中行“xiapi”列“course :math”的值。
hbase(main):012:0> get 'scores', 'xiapi', 'course :math'
或者
hbase(main):012:0> get 'scores', 'xiapi', {COLUMN=>'course:math'}
hbase(main):012:0> get 'scores', 'xiapi', {COLUMNS=>'course:math'}
备注:COLUMN 和 COLUMNS 是不同的,scan 操作中的 COLUMNS 指定的是表的列族, get操作中的 COLUMN 指定的是特定的列,COLUMNS 的值实质上为“列族:列修饰符”。COLUMN 和 COLUMNS 必须为大写。
6). scan 命令
a. 查看表“scores”中的所有数据。
hbase(main):012:0> scan 'scores'
注意:
scan 命令可以指定 startrow,stoprow 来 scan 多个 row。
例如:
scan 'user_test',{COLUMNS =>'info:username',LIMIT =>10, STARTROW => 'test', STOPROW=>'test2'}
b.查看表“scores”中列族“course”的所有数据。
hbase(main):012:0> scan 'scores', {COLUMN => 'grad'}
hbase(main):012:0> scan 'scores', {COLUMN=>'course:math'}
hbase(main):012:0> scan 'scores', {COLUMNS => 'course'}
hbase(main):012:0> scan 'scores', {COLUMNS => 'course'}
7). count 命令
hbase(main):068:0> count 'scores'
8). exists 命令
hbase(main):071:0> exists 'scores'
9). incr 命令(赋值)
10). delete 命令
删除表“scores”中行为“xiaoxue”, 列族“course”中的“math”。
hbase(main):012:0> delete 'scores', 'xiapi', 'course:math'
11). truncate 命令
hbase(main):012:0> truncate 'scores'
12). disbale、drop 命令
通过“disable”和“drop”命令删除“scores”表。
hbase(main):012:0> disable 'scores' --enable 'scores'
hbase(main):012:0> drop 'scores'
13). status命令
hbase(main):072:0> status
14). version命令
hbase(main):073:0> version
另外,在 shell 中,常量不需要用引号引起来,但二进制的值需要双引号引起来,而其他值则用单引号引起来。HBase Shell 的常量可以通过在 shell 中输入“Object.constants”。
posted @
2014-09-27 11:53 xzc 阅读(974) |
评论 (0) |
编辑 收藏 最近在hadoop实际使用中有以下几个小细节分享: i=m5M��]Ef
1 中文问题
从url中解析出中文,但hadoop中打印出来仍是乱码?我们曾经以为hadoop是不支持中文的,后来经过查看源代码,发现hadoop仅仅是不支持以gbk格式输出中文而己。
这是TextOutputFormat.class中的代码,hadoop默认的输出都是继承自FileOutputFormat来的,FileOutputFormat的两个子类一个是基于二进制流的输出,一个就是基于文本的输出TextOutputFormat。
public class TextOutputFormat<K, V> extends FileOutputFormat<K, V> {
protected static class LineRecordWriter<K, V> &E��{CQ#k
implements RecordWriter<K, V> {
private static final String utf8 = “UTF-8″;//这里被写死成了utf-8 2� kP0/�/
private static final byte[] newline; �k�TC'�`xv
static { ��:�h��tz]
try { �0 _!�')+
newline = “/n”.getBytes(utf8); R�y$zF~[ �
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException(”can’t find ” + utf8 + ” encoding”);
}
}
… k��-:wM`C�
public LineRecordWriter(DataOutputStream out, String keyValueSeparator) {
this.out = out;
try {
this.keyValueSeparator = keyValueSeparator.getBytes(utf8);
} catch (UnsupportedEncodingException uee) { �@r.�w�+E=
throw new IllegalArgumentException(”can’t find ” + utf8 + ” encoding”);
}
} ab�}��Kt($
…
private void writeObject(Object o) throws IOException {
if (o instanceof Text) {
Text to = (Text) o;
out.write(to.getBytes(), 0, to.getLength());//这里也需要修改 q&�D�M*!Jq
} else { �5 O't�-'�
out.write(o.toString().getBytes(utf8));
}
}
… qxQuXF�>:#
} |3bCq(ZR/P
可以看出hadoop默认的输出写死为utf-8,因此如果decode中文正确,那么将Linux客户端的character设为utf-8是可以看到中文的。因为hadoop用utf-8的格式输出了中文。
因为大多数数据库是用gbk来定义字段的,如果想让hadoop用gbk格式输出中文以兼容数据库怎么办? _.{I1*6�Y2
我们可以定义一个新的类: .c5�)�`�
public class GbkOutputFormat<K, V> extends FileOutputFormat<K, V> { sTS �N��u+
protected static class LineRecordWriter<K, V>
implements RecordWriter<K, V> {
//写成gbk即可 F"�ua`ercI
private static final String gbk = “gbk”;
private static final byte[] newline;
static {
try {
newline = “/n”.getBytes(gbk);
} catch (UnsupportedEncodingException uee) { @}�<b���42
throw new IllegalArgumentException(”can’t find ” + gbk + ” encoding”);
}
}
… S�jL&/�),�
public LineRecordWriter(DataOutputStream out, String keyValueSeparator) { P?o|N<4��6
this.out = out; X�-<�l�+WP
try { 0,]m.�)w�s
this.keyValueSeparator = keyValueSeparator.getBytes(gbk); J�s'j��}w�
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException(”can’t find ” + gbk + ” encoding”);
}
} �J|aU}Z�8m
… �/��(&UDG$
private void writeObject(Object o) throws IOException {
if (o instanceof Text) {
// Text to = (Text) o;
// out.write(to.getBytes(), 0, to.getLength()); �+A-z>T(��
// } else { @h,3"2W{Ev
out.write(o.toString().getBytes(gbk));
}
} ��is�U4D�
… �e�L_Il.�:
}
然后在mapreduce代码中加入conf1.setOutputFormat(GbkOutputFormat.class)
即可以gbk格式输出中文。
2 关于计算过程中的压缩和效率的对比问题 h�f//2V�l
之前曾经介绍过对输入文件采用压缩可以提高部分计算效率。现在作更进一步的说明。
为什么压缩会提高计算速度?这是因为mapreduce计算会将数据文件分散拷贝到所有datanode上,压缩可以减少数据浪费在带宽上的时间,当这些时间大于压缩/解压缩本身的时间时,计算速度就会提高了。
hadoop的压缩除了将输入文件进行压缩外,hadoop本身还可以在计算过程中将map输出以及将reduce输出进行压缩。这种计算当中的压缩又有什么样的效果呢?
测试环境:35台节点的hadoop cluster,单机2 CPU,8 core,8G内存,redhat 2.6.9, 其中namenode和second namenode各一台,namenode和second namenode不作datanode
输入文件大小为2.5G不压缩,records约为3600万条。mapreduce程序分为两个job: ��;R]~9Aan
job1:map将record按user字段作key拆分,reduce中作外连接。这样最后reduce输出为87亿records,大小540G
job2:map读入这87亿条数据并输出,reduce进行简单统计,最后的records为2.5亿条,大小16G
计算耗时54min
仅对第二个阶段的map作压缩(第一个阶段的map输出并不大,没有压缩的必要),测试结果:计算耗时39min
可见时间上节约了15min,注意以下参数的不同。 U&W/���Nj
不压缩时:
Local bytes read=1923047905109 :3[;9xC�Hj
Local bytes written=1685607947227 "j8`�)XXa(
压缩时: /U>|^$4 #5
Local bytes read=770579526349 ��|RL/�2j|
Local bytes written=245469534966
本地读写的的数量大大降低了
至于对reduce输出的压缩,很遗憾经过测试基本没有提高速度的效果。可能是因为第一个job的输出大多数是在本地机上进行map,不经过网络传输的原因。
附:对map输出进行压缩,只需要添加 jobConf.setMapOutputCompressorClass(DefaultCodec.class)
3 关于reduce的数量设置问题
reduce数量究竟多少是适合的。目前测试认为reduce数量约等于cluster中datanode的总cores的一半比较合适,比如 cluster中有32台datanode,每台8 core,那么reduce设置为128速度最快。因为每台机器8 core,4个作map,4个作reduce计算,正好合适。 �u�/�(�>a�
附小测试:对同一个程序 j�&[u�$P*K
reduce num=32,reduce time = 6 min
reduce num=128, reduce time = 2 min
reduce num=320, reduce time = 5min
4某次正常运行mapreduce实例时,抛出错误
java.io.IOException: All datanodes xxx.xxx.xxx.xxx:xxx are bad. Aborting…
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream.processDatanodeError(DFSClient.java:2158)
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream.access$1400(DFSClient.java:1735)
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream$DataStreamer.run(DFSClient.java:1889)
java.io.IOException: Could not get block locations. Aborting…
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream.processDatanodeError(DFSClient.java:2143)
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream.access$1400(DFSClient.java:1735)
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream$DataStreamer.run(DFSClient.java:1889)
经查明,问题原因是linux机器打开了过多的文件导致。用命令ulimit -n可以发现linux默认的文件打开数目为1024,修改/ect/security/limit.conf,增加hadoop soft 65535
再重新运行程序(最好所有的datanode都修改),问题解决
P.S:据说hadoop dfs不能管理总数超过100M个文件,有待查证
5 运行一段时间后hadoop不能stop-all.sh的问题,显示报错
no tasktracker to stop ,no datanode to stop
问题的原因是hadoop在stop的时候依据的是datanode上的mapred和dfs进程号。而默认的进程号保存在/tmp下,linux 默认会每隔一段时间(一般是一个月或者7天左右)去删除这个目录下的文件。因此删掉hadoop-hadoop-jobtracker.pid和 hadoop-hadoop-namenode.pid两个文件后,namenode自然就找不到datanode上的这两个进程了。
在配置文件中的export HADOOP_PID_DIR可以解决这个问题
posted @
2013-10-17 17:14 xzc 阅读(4716) |
评论 (0) |
编辑 收藏 linux中用shell获取昨天、明天或多天前的日期:
在Linux中对man date -d 参数说的比较模糊,以下举例进一步说明:
# -d, --date=STRING display time described by STRING, not `now’
[root@Gman root]# date -d next-day +%Y%m%d #明天日期
20091024
[root@Gman root]# date -d last-day +%Y%m%d #昨天日期
20091022
[root@Gman root]# date -d yesterday +%Y%m%d #昨天日期
20091022
[root@Gman root]# date -d tomorrow +%Y%m%d # 明天日期
20091024
[root@Gman root]# date -d last-month +%Y%m #上个月日期
200909
[root@Gman root]# date -d next-month +%Y%m #下个月日期
200911
[root@Gman root]# date -d next-year +%Y #明年日期
2010
DATE=$(date +%Y%m%d --date ’2 days ago’) #获取昨天或多天前的日期
名称 : date
使用权限 : 所有使用者
使用方式 : date [-u] [-d datestr] [-s datestr] [--utc] [--universal] [--date=datestr] [--set=datestr] [--help] [--version] [+FORMAT] [MMDDhhmm[[CC]YY][.ss]]
说明 : date 能用来显示或设定系统的日期和时间,在显示方面,使用者能设定欲显示的格式,格式设定为一个加号后接数个标记,其中可用的标记列表如下 :
时间方面 :
% : 印出
% %n : 下一行
%t : 跳格
%H : 小时(00..23)
%I : 小时(01..12)
%k : 小时(0..23)
%l : 小时(1..12)
%M : 分钟(00..59)
%p : 显示本地 AM 或 PM
%r : 直接显示时间 (12 小时制,格式为 hh:mm:ss [AP]M)
%s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数 %S : 秒(00..61)
%T : 直接显示时间 (24 小时制)
%X : 相当于 %H:%M:%S
%Z : 显示时区
日期方面 :
%a : 星期几 (Sun..Sat)
%A : 星期几 (Sunday..Saturday)
%b : 月份 (Jan..Dec)
%B : 月份 (January..December)
%c : 直接显示日期和时间
%d : 日 (01..31)
%D : 直接显示日期 (mm/dd/yy)
%h : 同 %b
%j : 一年中的第几天 (001..366)
%m : 月份 (01..12)
%U : 一年中的第几周 (00..53) (以 Sunday 为一周的第一天的情形)
%w : 一周中的第几天 (0..6)
%W : 一年中的第几周 (00..53) (以 Monday 为一周的第一天的情形)
%x : 直接显示日期 (mm/dd/yy)
%y : 年份的最后两位数字 (00.99)
%Y : 完整年份 (0000..9999)
若是不以加号作为开头,则表示要设定时间,而时间格式为 MMDDhhmm[[CC]YY][.ss],
其中 MM 为月份,
DD 为日,
hh 为小时,
mm 为分钟,
CC 为年份前两位数字,
YY 为年份后两位数字,
ss 为秒数
把计 :
-d datestr : 显示 datestr 中所设定的时间 (非系统时间)
--help : 显示辅助讯息
-s datestr : 将系统时间设为 datestr 中所设定的时间
-u : 显示目前的格林威治时间
--version : 显示版本编号
例子 :
显示时间后跳行,再显示目前日期 : date +%T%n%D
显示月份和日数 : date +%B %d
显示日期和设定时间(12:34:56) : date --date 12:34:56
设置系统当前时间(12:34:56):date --s 12:34:56
注意 : 当你不希望出现无意义的 0 时(比如说 1999/03/07),则能在标记中插入 - 符号,比如说 date +%-H:%-M:%-S 会把时分秒中无意义的 0 给去掉,像是原本的 08:09:04 会变为 8:9:4。另外,只有取得权限者(比如说 root)才能设定系统时间。 当你以 root 身分更改了系统时间之后,请记得以 clock -w 来将系统时间写入 CMOS 中,这样下次重新开机时系统时间才会持续抱持最新的正确值。
ntp时间同步
linux系统下默认安装了ntp服务,手动进行ntp同步如下
ntpdate ntp1.nl.net
当然,也能指定其他的ntp服务器
-------------------------------------------------------------------
扩展功能
date 工具可以完成更多的工作,不仅仅只是打印出当前的系统日期。您可以使用它来得到给定的日期究竟是星期几,并得到相对于当前日期的相对日期。了解某一天是星期几
GNU 对 date 命令的另一个扩展是 -d 选项,当您的桌上没有日历表时(UNIX 用户不需要日历表),该选项非常有用。使用这个功能强大的选项,通过将日期作为引号括起来的参数提供,您可以快速地查明一个特定的日期究竟是星期几:
$ date -d "nov 22"
Wed Nov 22 00:00:00 EST 2006
$
在本示例中,您可以看到今年的 11 月 22 日是星期三。
所以,假设在 11 月 22 日召开一个重大的会议,您可以立即了解到这一天是星期三,而这一天您将赶到驻地办公室。
获得相对日期
d 选项还可以告诉您,相对于 当前日期若干天的究竟是哪一天,从现在开始的若干天或若干星期以后,或者以前(过去)。通过将这个相对偏移使用引号括起来,作为 -d 选项的参数,就可以完成这项任务。
例如,您需要了解两星期以后的日期。如果您处于 Shell 提示符处,那么可以迅速地得到答案:
$ date -d ’2 weeks’
关于使用该命令,还有其他一些重要的方法。使用 next/last指令,您可以得到以后的星期几是哪一天:
$ date -d ’next monday’ (下周一的日期)
$ date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
$ date -d last-day +%Y%m%d(昨天的日期) 或者:date -d yesterday +%Y%m%d
$ date -d last-month +%Y%m(上个月是几月)
$ date -d next-month +%Y%m(下个月是几月)
使用 ago 指令,您可以得到过去的日期:
$ date -d ’30 days ago’ (30天前的日期)
您可以使用负数以得到相反的日期:
$ date -d ’dec 14 -2 weeks’ (相对:dec 14这个日期的两周前的日期)
$ date -d ’-100 days’ (100天以前的日期)
$ date -d ’50 days’(50天后的日期)
这个技巧非常有用,它可以根据将来的日期为自己设置提醒,可能是在脚本或 Shell 启动文件中,如下所示:
DAY=`date -d ’2 weeks’ +"%b %d"`
if test "`echo $DAY`" = "Aug 16"; then echo ’Product launch is now two weeks away!’; fi
posted @
2013-02-07 12:28 xzc 阅读(5012) |
评论 (0) |
编辑 收藏Sybase 函数
Sybase字符串函数
长度和语法分析
datalength(char_expr)
在char_expr中返回字符的长度值,忽略尾空
substring(expression,start,length)
返回部分字符串
right(char_expr,int_expr)
返回char_expr右边的int_expr字符
基本字符串运算
upper(char_expr)
把char_expr转换成大写形式
lower(char_expr)
把char_expr转换成小写形式
space(int_expr)
生成有int_expr个空格的字符串
replicate(char_expr,int_expr)
重复char_expr,int_expr次
stuff(expr1,start,length,expr2)
用expr2代替epxr1中start起始长为length的字符串
reverse(char_expr)
反写char_expr中的文本
ltrim(char_expr)
删除头空
rtrim(char_expr)
删除尾空
格式转换
ascii(char_expr)
返回char_expr中第一个字符的ASCII值
char(int_expr)
把ASCII码转换为字符
str(float_expr[,length[,decimal]])
进行数值型到字符型转换
soundex(char_expr)
返回char_expr的soundex值
difference(char_expr1,char_expr2)
返回表达式soundex值之差
串内搜索
charindex(char_expr,expression)
返回指定char_expr的开始位置,否则为0
patindex("%pattern%",expression)
返回指定样式的开始位置,否则为0
datalength用于确定可变字符串的长度
soundex用于确定字符串是否发音相似
difference返回0-4之间的值,0表示最不相似,4表示最相似
通配符
% 匹配任何数量的字符或无字符
_ 匹配任何单个字符(空间占位符)
[] 规定有效范围,或某个"OR"条件
[ABG] A,B,G
[A-C] A,B,C
[A-CE-G] A,B,C,E,F,G
[^ABG] 除了A,B,G
[^A-C] 除了A,B,C
escape子句
用某个转义字符可在搜索字符串时将通配符作为文字来包含。
ANSI-89 SQL标准定义了escape子句指定某个转义字符
缺省情况下,[]来转义某个通配符,例:
select * from test_tab
where description like "%20[%]%"
语法:
like char_expression escape escape_character
例
select * from test_tab
where description like "%20#%%" escape "#"
+ 可用于串接字符
select au_laname+","+au_fname from authors
数学函数
abs(numeric_expr)
返回指定值的绝对值
ceiling(numeric_expr)
返回大于或等于指定值的最小整数
exp(float_expr)
给出指定值的指数值
floor(numeric_expr)
返回小于或等于指定值的最大整数
pi()
返回常数3.1415926
power(numeric_expr,power)
返回numeric_expr的值给power的幂
rand([int_expr])
返回0-1之间的随机浮点数,可指定基值
round(numeric_expr,int_expr)
把数值表达式圆整到int_expr指定的精度
sign(int_expr)
返回正+1,零0或负-1
sqrt(float_expr)
返回指定值的平方根
SQL SERVER支持所有标准的三角函数和其他有用的函数
日期函数
getdate()
返回当前的系统日期和时间
datename(datepart,date_expr)
以字符串形式返回date_expr指定部分的值,转换成合适的名字
datepart(datepart,date_expr)
作为整数返回date_expr值的指定部分
datediff(datepart,date_expr1,date_expr2)
返回date_expr2-date_expr1,通过指定的datepart度量
dateadd(datepart,number,date_expr)
返回日期,通过在date_expr上增加指定number的日期部件而产生的
datepart
日期部件 缩写 值范围
年 yy 1753-9999
季度 qq 1-4
月 mm 1-12
每年中的天 dy 1-366
天 dd 1-31
星期 wk 1-54
星期天 dw 1-7(1=sunday)
小时 hh 0-23
分钟 mi 0-59
秒 ss 0-59
毫秒 ms 0-999
例:
select invoice_no,
datediff(dd,date_shipped,getdate())
from invoices
where balance_due>0
转换函数convert
此函数把值从一种类型改变成另一种类型
convert(datetype [(length)],expression)
select "Advance="+convert(char(12),advance)
from titles
日期转换
convert(datetype[(length)],expression,format)
format指定将日期转换为什么格式,有以下值:
没有世纪 有世纪 转换字符串中日期格式
0 or 100 mon dd yyy hh:miAM(or PM)
1 101 mm/dd/yy
2 102 yy.mm.dd
3 103 dd/mm/yy
4 104 dd.mm.yy
5 105 dd-mm-yy
6 106 dd mon yy
7 107 mon dd,yy
8 108 hh:mm:ss
9 or 109 mon dd,yyyy hh:mi:ss:mmmAM(or PM)
10 110 mm-dd-yy
11 111 yy/mm/dd
12 112 yymmdd
系统函数
函数 定义
访问和安全性信息
host_id() 客户进程的当前主机进程ID号
host_name() 客户进程的当前主计算机名
suser_id(["login_name"]) 用户的SQL Server ID号
suser_name([server_user_id]) 用户的SQL Server登录名
user_id(["name_in_db"]) 用户在数据库中的ID号
user_name([user_id]) 用户在数据库中的名字
user 用户在数据库中的名字
show_role() 用户的当前活动角色
数据库和对象信息
db_id(["db_name"]) 数据库ID号
db_name([db_id]) 数据库名
object_id("objname") 数据库对象ID号
object_name(obj_id]) 数据库对象号
col_name(obj_id,col_id) 对象的栏名
col_length("objname","colname") 栏的长度
index_col("objname",index_id,key#) 已索引的栏名
valid_name(char_expr) 若char_expr不是有效标识符,则返回0
数据函数
datalength(expression) 按字节返回expression的长度
tsequal(timestamp1,timestamp2) 比较时戳值,若时戳值不匹配,则返回出错消息
isnull()
isnull函数用指定的值代替查询栏或合计中的空值
例:
select avg(isnull(total_order,$0))
from invoices
posted @
2012-08-21 10:49 xzc 阅读(5166) |
评论 (1) |
编辑 收藏日期函数
getdate()
得到当前时间,可以设置得到各种时间格式.
datepart(日期部分,日期)
取指定时间的某一个部分,年月天时分秒.
datediff(日期部分,日期1,日期2)
计算指定的日期1和日期2的时间差多少.
dateadd(日期部分,数值表达式,日期)
计算指定时间,再加上表达式指定的时间长度.
--取时间的某一个部分
select datepart(yy,getdate()) --year
select datepart(mm,getdate()) --month
select datepart(dd,getdate()) --day
select datepart(hh,getdate()) --hour
select datepart(mi,getdate()) --min
select datepart(ss,getdate()) --sec
--取星期几
set datefirst 1
select datepart(weekday,getdate()) --weekday
--字符串时间
select getdate() -- '03/11/12'
select convert(char,getdate(),101) -- '09/27/2003'
select convert(char,getdate(),102) -- '2003.11.12'
select convert(char,getdate(),103) -- '27/09/2003'
select convert(char,getdate(),104) -- '27.09.2003'
select convert(char,getdate(),105) -- '27-09-2003'
select convert(char,getdate(),106) -- '27 Sep 2003'
select convert(char,getdate(),107) --'Sep 27, 2003'
select convert(char,getdate(),108) --'11:16:06'
select convert(char,getdate(),109) --'Sep 27 2003 11:16:28:746AM'
select convert(char,getdate(),110) --'09-27-2003'
select convert(char,getdate(),111) --'2003/09/27'
select convert(char,getdate(),112) --'20030927'
select rtrim(convert(char,getdate(),102))+' '+(convert(char,getdate(),108)) -- '2003.11.12 11:03:41'
--整数时间
select convert(int,convert(char(10),getdate(),112)) -- 20031112
select datepart(hh,getdate())*10000 + datepart(mi,getdate())*100 + datepart(ss,getdate()) -- 110646
--时间格式 "YYYY.MM.DD HH:MI:SS" 转换为 "YYYYMMDDHHMISS"
declare @a datetime,@tmp varchar(20),@tmp1 varchar(20)
select @a=convert(datetime,'2004.08.03 12:12:12')
select @tmp=convert(char(10),@a,112)
select @tmp
select @tmp1=convert(char(10),datepart(hh,@a)*10000 + datepart(mi,@a)*100 + datepart(ss,@a))
select @tmp1
select @tmp=@tmp+@tmp1
select @tmp
--当月最后一天
declare
@tmpstr varchar(10)
@mm int,
@premm int,
@curmmlastday varchar(10)
begin
select @mm=datepart(month,getdate())--当月
select @premm=datepart(month,dateadd(month,-1,getdate())) --上个月
if (@mm>=1 and @mm<=8)
select @tmpstr=convert(char(4),datepart(year,getdate()))+'.0'+convert(char(1),datepart(month,dateadd(month,1,getdate())))+'.'+'01'
else if (@mm>=9 and @mm<=11)
select @tmpstr=convert(char(4),datepart(year,getdate()))+'.'+convert(char(2),datepart(month,dateadd(month,1,getdate())))+'.'+'01'
else
select @tmpstr=convert(char(4),datepart(year,dateadd(year,1,getdate())))+'.0'+convert(char(1),datepart(month,dateadd(month,1,getdate())))+'.'+'01'
select @curmmlastday=convert(char(10),dateadd(day,-1,@tmpstr),102) --当月最后一天
end
源文档 <http://hi.baidu.com/hwaspf/blog/item/a0ef87be66326e0d18d81f17.html>
posted @
2012-08-21 10:49 xzc 阅读(5055) |
评论 (0) |
编辑 收藏posted @
2012-07-24 13:45 xzc 阅读(4619) |
评论 (0) |
编辑 收藏
心得和大家分享,希望对大家会有帮助。
1、字母大小写比对不敏感,也就是在值比对判断时大小写字母都一样;
2、等值,或<>判断,系统默认对等式两边比对值去右边空格再进行比较;
3、GROUP BY 可以根据SELECT字段或表达式的别名来 汇总,在编写时也尽量避免SELECT 语句的别
名与FROM表中的字段有重复,不然会出现莫名其妙的错误;
4、FROM后的子查询 要定义别名才可使用;
5、存储过程要返回IQ系统错误信息 SQLCODE || ERRORMSG(*) :(两者都为EXCEPTION后第一条SQL
语句才有效果);
6、IQ中若采用 FULL JOIN 连接则不能使用 WHERE 条件,否则FULL JOIN将失效,要筛选条件则用
子查询先过滤记录后再FULL JOIN;
7、建表时,字段默认为非空;
8、UPDATE语句,如果与目标表关联的表有多条,则不会报错,而是随机取一条更新(第一条);
9、RANK() OVER(PARTITION BY .. ORDER BY ..) 分组分析函数,相同的ORDER BY值,返回顺序值
一样,且PARTITION BY 只支持一个字段或一个字段组(需多个字段分组的则要用 || 拼为一个字
段(待确认,该问题以前碰过一次,再次验证却不存在这问题))
10、返回可读的 全局唯一字符:UUIDTOSTR(NEWID())
11、存储过程隐式游标语法:
FOR A AS B CURSOR FOR SELECT ... FROM ...
DO
.... 过程语句
END FOR;
需要注意的时,这边的A 和 B 在 过程语句中都不能引用,所以为避免过程语句其他字段名与FOR
SELECT 语句的字段名称重复,FOR SELECT 语句的字段最好都定义别名区分
12、根据SELECT 语句建立[临时]表的方法(ORACLE的CREATE TABLE)为 SELECT ..[*] INTO [#]
table_name FROM ..; 其中如果在table_name加前缀#,则为会话级临时表,否则为实体表;
13、因Sybase为列存储模式,在执行上INSERT语句会比UPDATE语句慢,尤其表数据越多INSERT效率
就越慢;所以在ETL时建议多用UPDATE而不是INSERT
14、虽说Sybase为列存储模式,每个字段上都有默认索引,但对于经常的两表的关联键还是要建立
索引否则会经常报QUERY_TEMP_SPACE_LIMIT不足的错误;
15、存储过程中也可以显示的执行DDL语句,这点与Oracle不同;
16、空字符串''在Sybase中也是个字符而不是null值,这点要注意;
17、调整SESSION的临时空间SET TEMPORARY OPTION QUERY_TEMP_SPACE_LIMIT = '150000'; 15000
为大小,如写0则没限制大小
==================================常用函数===========================================
字符串函数
1)ISNULL(EXP1,EXP2,EXP3,...) :返回第一个非空值,用法与COALESCE(exp1,exp2[,exp3...])相
同
3)TRIM(exp) :去除两边空格
4)DATEFORMAT(date_exp,date_format) :日期型转字符型;
5)STRING(exp):转为字符型;
6)SUBSTRING(exp,int-exp1,[int-exp2]):截取exp从int-exp1开始,截取int-exp2个字符;
7)REPLACE(o-exp,search-exp,replace-exp):从o-exp搜索search-exp,替换为replace-exp;
8)SPACE(int_exp):返回int个空格;
8)UPPER(exp):转为大写字母,等价于UCASE(exp);
8)LOWER(exp):转为小写字母,
8)CHARINDEX(exp1,exp2):返回exp2字符串中exp1的位置!定位,exp1 查找的字符,exp2 被查找
的字符串;
8)DATALENGTH(CHAR_EXPR):在char_expr中返回字符的长度值,忽略尾空;
8)RIGHT(char_expr,int_expr):返回char_expr右边的int_expr个字符;
8)LEFT(char_expr,int_expr):返回char_expr左边的int_expr个字符;
8)REPLICATE(char_expr,int_expr):重复char_expr,int_expr次;
8)STUFF(expr1,start,length,expr2):用expr2代替epxr1中start起始长为length的字符串;
8)REVERSE(char_expr):反写char_expr中的文本;
8)LTRIM(char_expr):删除头空;
8)RTRIM(char_expr):删除尾空;
8)STR(float_expr[,length[,decimal]]):进行数值型到字符型转换;
8)PATINDEX("%pattern%",expression):返回指定样式的开始位置,否则为0;
8)NULLIF(exp1,exp1):比较两个表达式,如果相等则返回null值,否则返回exp1
8)NUMBER(*):返回序号,相当于ORACLE的rowid,但有区别;
其他函数
8)RANK() OVER(PARTITION BY .. ORDER BY ..) 分组分析函数,相同的ORDER BY值,返回顺序值
一样,且PARTITION BY 只支持一个字段或一个字段组(需多个字段分组的则要用 || 拼为一个字
段(待确认))
8)返回可读的 全局ID UUIDTOSTR(NEWID())
8)COL_LENGTH(tab_name,col_name):返回定义的列长度;兼容性:IQ&ASE
8)LENGTH(exp):返回exp的长度;兼容性:IQ
转换函数
8)CONVERT(datetype,exp[,format-style]):字符转日期型 或DATE(exp);兼容性:IQ&ASE
format-style值 输出:
112 yyyymmdd
120 yyyy-mm-dd hh:nn:ss
SELECT CONVERT(date,'20101231',112),CONVERT(varchar(10),getdate(),120) ;
--结果
2010-12-31 2011-04-07
8)CAST(exp AS data-type):返回转换为提供的数据类型的表达式的值; 兼容性:IQ
日期函数
8)DAY(date_exp):返回日期天值,DAYS(date_exp,int):返回日期date_exp加int后的日期;MONTH
与MONTHS、YEAR与YEARS同理;
8)DATE(exp):将表达式转换为日期,并删除任何小时、分钟或秒;兼容性:IQ
8)DATEPART(date-part,date-exp): 返回日期分量的对应值(整数);
8)GETDATE():返回系统时间;
8)DATENAME(datepart,date_expr):以字符串形式返回date_expr指定部分的值,转换成合适的名字
;
8)DATEDIFF(datepart,date_expr1,date_expr2):返回date_expr2-date_expr1,通过指定的
datepart度量;
8)DATEADD(date-part,num-exp,date-exp):返回按指定date-part分量加num-exp值后生成的
date-exp值;兼容性:IQ&ASE
date-part日期分量代表值:
缩写 值
YY 0001-9999
QQ 1-4
MM 1-12
WK 1-54
DD 1-31
DY 1--366
DW 1-7(周日-周六)
HH 0-23
MI 0-59
SS 0-59
MS 0-999
数值函数
8)CEIL(num-exp):返回大于或等于指定表达式的最小整数;兼容性:IQ&ASE;
8)FLOOR(numeric_expr):返回小于或等于指定值的最大整数;
8)ABS(num-exp):返回数值表达式的绝对值;兼容性:IQ&ASE;
8)TRUNCNUM(1231.1251,2):截取数值;不四舍五入;
8)ROUND(numeric_expr,int_expr):把数值表达式圆整到int_expr指定的精度;
8)RAND([int_expr]):返回0-1之间的随机浮点数,可指定基值;
8)SIGN(int_expr):返回正+1,零0或负-1;
8)SQRT(float_expr):返回指定值的平方根;
8)PI():返回常数3.1415926;
8)POWER(numeric_expr,power):返回numeric_expr的值给power的幂;
8)EXP(float_expr):给出指定值的指数值;
==================================常用DDL语句
===========================================
Sybase中DDL语句不能修改字段的数据类型,只能修改空与非空:
1.删除列:
ALTER TABLE table_name DELETE column_name;
2.增加列:
ALTER TABLE table_name ADD (column_name DATA_TYPE [NOT] NULL);
3.修改列的空与非空:
ALTER TABLE table_name MODIFY column_name [NOT] NULL;
4.修改列名:
ALTER TABLE table_name RENAME old_column_name TO new_column_name;
5.快速建立临时表:
SELECT * INTO [#]table_name FROM .....;
6、修改表名:
ALTER TABLE old_table_name RENAME new_table_name
7.增加主键约束:
ALTER TABLE tb_name ADD CONSTRAINT pk_name PRIMARY KEY(col_name,..)
8.删除主键约束:
ALTER TABLE tb_name DROP CONSTRAINT pk_name;
9.建立自增长字段,与Oracle的SEQUENCE类似:
CREATE TABLE TMP_001 (RES_ID INTEGER IDENTITY NOT NULL);
10.添加表注释:
COMMENT ON TABLE table_name IS '....';
11.创建索引:
CREATE INDEX index_name ON table_name(column_name);
posted @
2012-06-18 10:57 xzc 阅读(5659) |
评论 (0) |
编辑 收藏posted @
2012-03-20 09:09 xzc 阅读(4683) |
评论 (0) |
编辑 收藏posted @
2012-03-10 15:44 xzc 阅读(8216) |
评论 (0) |
编辑 收藏将ociuldr.exe复制到H:\oracle\product\10.2.0\db_1\BIN下, 或者path中的某个文件夹中
用法:
C:\Documents and Settings\tgm>ociuldr
Usage: ociuldr user=... query=... field=... record=... file=...
(@) Copyright Lou Fangxin 2004/2005, all rights reserved.
Notes:
-si = enable logon as SYSDBA
user = username/password@tnsname
sql = SQL file name,one sql per file, do not include ";"
query = select statement
field = seperator string between fields
record= seperator string between records
file = output file name(default: uldrdata.txt)
read = set DB_FILE_MULTIBLOCK_READ_COUNT at session level
sort = set SORT_AREA_SIZE & SORT_AREA_RETAINED_SIZE at session level (UNIT:MB)
hash = set HASH_AREA_SIZE at session level (UNIT:MB)
serial= set _serial_direct_read to TRUE at session level
trace = set event 10046 to given level at session level
table = table name in the sqlldr control file
mode = sqlldr option, INSERT or APPEND or REPLACE or TRUNCATE
log = log file name, prefix with + to append mode
long = maximum long field size
array = array fetch size
head = 第一行是否为字段名(head=on), 默认为off
for field and record, you can use '0x' to specify hex character code,
\r=0x0d \n=0x0a |=0x7c ,=0x2c \t=0x09
一、导出数据
d:\>ociuldr user=test/test@acf query="select * from test" file=test.txt table=test
二、查看导出内容
1,a
2,b
3,c
4,d
5,e
6,f
三、查看自动生成的控制文件
--
-- Generated by OCIULDR
--
OPTIONS(BINDSIZE=8388608,READSIZE=8388608,ERRORS=-1,ROWS=50000)
LOAD DATA
INFILE 'test.txt' "STR X'0a'"
INTO TABLE test
FIELDS TERMINATED BY X'2c' TRAILING NULLCOLS
(
ID CHAR(40),
NAME CHAR(10)
)
四、可以尝试使用这个控制文件将数据加载到数据库中
d:\>sqlldr test/test@acf control=test_sqlldr.ctl
这样数据就加载到数据库中。对于大数据库表的导出ociuldr工具还支持按照不同的批量导出数据,这通过一个参数batch来实现,默认一个batch是50万条记录,如果不指定batch为2就表示100万条记录换一个文件,默认这个选项值是0,就是指不生成多个文件。
在指定batch选项后,需要指定file选项来定义生成的文件名,文件名中间需要包含“%d”字样,在生成文件时,“%d”会打印成序号,请看以下一个测试:
D:\>ociuldr user=test/test@acf query="select * from test" batch=1 file=test_%d.txt table=test
刚才测试了一下,果然是强悍, 用spool按要求导出10万条记录要好几分钟, 用ociuldr导出来用了一秒,或许一秒都不到, NB!
posted @
2012-03-03 15:39 xzc 阅读(6000) |
评论 (1) |
编辑 收藏在ajax应用流行时,有时我们可能为了降低服务器的负担,把动态内容生成静态html页面或者是xml文件,供客户端访问!但是在我们的网站或系统中往住页面中某些部分是在后台没有进行修改时,其内容不会发生变化的。但是页面中也往往有部分内容是动态的更新的,比如一个新闻页面,新闻内容往往生成了之后就是静态的,但是新闻的最新评论往往是变化的,在这个时候有几种解决方案:
1、重新生成该静态页面,优点是用户访问时页面上的肉容可以实现全静态,不与服务器程序及数据库后端打交道!缺点是每次用户对页面任何部分更新都必须重新生成。
2、js调用请求动态内容,优点是静态页面只生成一次,动态部分才动态加载,却点是服务器端要用输出一段js代码并用js代码输出网页内容,也不利于搜索引擎收录。
3、ajax调用动态内容,和js基本相似,只是与服务器交互的方式不同!并且页面显示不会受到因动态调用速度慢而影响整个页面的加载速度!至于ajax不利于搜索收录,当然在《ajax in acation》等相关书籍中也介绍有变向的解决方案!
4、在服务器端ssl动态内容,用服务器端优化及缓存解决是时下最流行的方法!
对于第二种和第三种方法都是我最青睐的静态解决方法,适合以内容为主的中小型网站。那么在有时候可能会有js读取url参数的需求,事实证明的确也有很多时候有这种需求,特别是在胖客户端的情况下!以前也写过这样的代码,其实原理很简单就是利用javascript接口提供location对像得到url地址,然后通过分析url以取得参数,以下是我收录的一些优秀的url参数读取代码:
一、字符串分割分析法。
这里是一个获取URL+?带QUESTRING参数的JAVASCRIPT客户端解决方案,相当于asp的request.querystring,PHP的$_GET
函数:
<script>
function GetRequest()
{
var url = location.search; //获取url中"?"符后的字串
var theRequest = new Object();
if(url.indexOf("?") != -1)
{
var str = url.substr(1);
strs = str.split("&");
for(var i = 0; i < strs.length; i ++)
{
theRequest[strs[i].split("=")[0]]=unescape(strs[i].split("=")[1]);
}
}
return theRequest;
}
</script>
然后我们通过调用此函数获取对应参数值:
<script>
var Request=new Object();
Request=GetRequest();
var 参数1,参数2,参数3,参数N;
参数1=Request['参数1'];
参数2=Request['参数2'];
参数3=Request['参数3'];
参数N=Request['参数N'];
</script>
以此获取url串中所带的同名参数
二、正则分析法。
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
alert(GetQueryString("参数名1"));
alert(GetQueryString("参数名2"));
alert(GetQueryString("参数名3"));
posted @
2011-12-12 17:15 xzc 阅读(5063) |
评论 (0) |
编辑 收藏
转自:http://blog.csdn.net/wh62592855/article/details/4988336
例如说吧,对DEPTNO 10中的每个员工,确定聘用他们的日期及聘用下一个员工(可能是其他部门的员工)的日期之间相差的天数。
SQL> select ename,hiredate,deptno from emp order by hiredate;
ENAME HIREDATE DEPTNO
---------- --------------- ----------
SMITH 17-DEC-80 20
ALLEN 20-FEB-81 30
WARD 22-FEB-81 30
JONES 02-APR-81 20
BLAKE 01-MAY-81 30
CLARK 09-JUN-81 10
TURNER 08-SEP-81 30
MARTIN 28-SEP-81 30
KING 17-NOV-81 10
JAMES 03-DEC-81 30
FORD 03-DEC-81 20
ENAME HIREDATE DEPTNO
---------- --------------- ----------
MILLER 23-JAN-82 10
SCOTT 19-APR-87 20
ADAMS 23-MAY-87 20
14 rows selected.
SQL> select ename,hiredate,next_hd,
2 next_hd-hiredate diff
3 from
4 (
5 select deptno,ename,hiredate,
6 lead(hiredate) over(order by hiredate) next_hd
7 from emp
8 )
9 where deptno=10;
ENAME HIREDATE NEXT_HD DIFF
---------- --------------- --------------- ----------
CLARK 09-JUN-81 08-SEP-81 91
KING 17-NOV-81 03-DEC-81 16
MILLER 23-JAN-82 19-APR-87 1912
这里的LEAD OVER非常有用,它能够访问“未来的”行(“未来的”行相对于当前行,由ORDER BY子句决定)。这种无需添加联接就能够访问当前行附近行的功能,提高了代码的可读性和有效性。在采用窗口函数时,一定要记住,它在WHERE子句之后求值,因此在该解决方案中,需要使用内联视图。如果把对DEPTNO的筛选移到内联视图,则结果会发生改变(仅考虑了DETPNO 10中的HIREDATE)。
所以下面的结果是错误的:
SQL> select ename,hiredate,next_hd,
2 next_hd-hiredate diff
3 from
4 (
5 select deptno,ename,hiredate,
6 lead(hiredate) over(order by hiredate) next_hd
7 from emp
8 where deptno=10
9 );
ENAME HIREDATE NEXT_HD DIFF
---------- --------------- --------------- ----------
CLARK 09-JUN-81 17-NOV-81 161
KING 17-NOV-81 23-JAN-82 67
MILLER 23-JAN-82
对于ORACLE的LEAD和LAG函数还需要特别注意,它们的结果中可能会有重复。在上面的例子中表EMP内不包含重复的HIREDATE,所以“看起来”似乎没有什么问题。下面我们向表中插入4个重复值来看看
SQL> insert into emp(empno,ename,deptno,hiredate)
2 values(1,'a',10,to_date('17-NOV-1981'));
1 row created.
SQL> insert into emp(empno,ename,deptno,hiredate)
2 values(2,'b',10,to_date('17-NOV-1981'));
1 row created.
SQL> insert into emp(empno,ename,deptno,hiredate)
2 values(3,'c',10,to_date('17-NOV-1981'));
1 row created.
SQL> insert into emp(empno,ename,deptno,hiredate)
2 values(4,'d',10,to_date('17-NOV-1981'));
1 row created.
SQL> select ename,hiredate
2 from emp
3 where deptno=10
4 order by 2;
ENAME HIREDATE
---------- ---------------
CLARK 09-JUN-81
b 17-NOV-81
c 17-NOV-81
a 17-NOV-81
d 17-NOV-81
KING 17-NOV-81
MILLER 23-JAN-82
7 rows selected.
现在还是用以前那个查询语句来试试
SQL> select ename,hiredate,next_hd,
2 next_hd-hiredate diff
3 from
4 (
5 select deptno,ename,hiredate,
6 lead(hiredate) over(order by hiredate) next_hd
7 from emp
8 )
9 where deptno=10;
ENAME HIREDATE NEXT_HD DIFF
---------- --------------- --------------- ----------
CLARK 09-JUN-81 08-SEP-81 91
d 17-NOV-81 17-NOV-81 0
c 17-NOV-81 17-NOV-81 0
a 17-NOV-81 17-NOV-81 0
b 17-NOV-81 17-NOV-81 0
KING 17-NOV-81 03-DEC-81 16
MILLER 23-JAN-82 19-APR-87 1912
7 rows selected.
可以看到其中有4个员工的DIFF列值都是0,这是错误的,同一天聘用的所有员工都应该跟下一个聘用其他员工的HIREDATE进行计算。
幸运的是ORACLE针对这类情况提供了一个非常简单的措施:当调用LEAD函数时,可以给LEAD传递一个参数,以便准确的指定“未来的”行(是下一行?10行之后?等等)。
select ename,hiredate,next_hd,
next_hd-hiredate diff
from
(
select deptno,ename,hiredate,
lead(hiredate,cnt-rn+1) over(order by hiredate) next_hd
from
(
select deptno,ename,hiredate,
count(*) over(partition by hiredate) cnt,
row_number() over(partition by hiredate order by empno) rn
from emp
where deptno=10
)
)
posted @
2011-12-09 10:40 xzc 阅读(4195) |
评论 (1) |
编辑 收藏Java 定义的位运算(bitwise operators )直接对整数类型的位进行操作,这些整数类型包括long,int,short,char,and byte 。表4-2 列出了位运算:
表4.2 位运算符及其结果
运算符 结果
~ 按位非(NOT)(一元运算)
& 按位与(AND)
| 按位或(OR)
^ 按位异或(XOR)
>> 右移
>>> 右移,左边空出的位以0填充
运算符 结果
<< 左移
&= 按位与赋值
|= 按位或赋值
^= 按位异或赋值
>>= 右移赋值
>>>= 右移赋值,左边空出的位以0填充
<<= 左移赋值
续表
既然位运算符在整数范围内对位操作,因此理解这样的操作会对一个值产生什么效果是重要的。具体地说,知道Java 是如何存储整数值并且如何表示负数的是有用的。因此,在继续讨论之前,让我们简短概述一下这两个话题。
所有的整数类型以二进制数字位的变化及其宽度来表示。例如,byte 型值42的二进制代码是00101010 ,其中每个位置在此代表2的次方,在最右边的位以20开始。向左下一个位置将是21,或2,依次向左是22,或4,然后是8,16,32等等,依此类推。因此42在其位置1,3,5的值为1(从右边以0开始数);这样42是21+23+25的和,也即是2+8+32 。
所有的整数类型(除了char 类型之外)都是有符号的整数。这意味着他们既能表示正数,又能表示负数。Java 使用大家知道的2的补码(two’s complement )这种编码来表示负数,也就是通过将与其对应的正数的二进制代码取反(即将1变成0,将0变成1),然后对其结果加1。例如,-42就是通过将42的二进制代码的各个位取反,即对00101010 取反得到11010101 ,然后再加1,得到11010110 ,即-42 。要对一个负数解码,首先对其所有的位取反,然后加1。例如-42,或11010110 取反后为00101001 ,或41,然后加1,这样就得到了42。
如果考虑到零的交叉(zero crossing )问题,你就容易理解Java (以及其他绝大多数语言)这样用2的补码的原因。假定byte 类型的值零用00000000 代表。它的补码是仅仅将它的每一位取反,即生成11111111 ,它代表负零。但问题是负零在整数数学中是无效的。为了解决负零的问题,在使用2的补码代表负数的值时,对其值加1。即负零11111111 加1后为100000000 。但这样使1位太靠左而不适合返回到byte 类型的值,因此人们规定,-0和0的表示方法一样,-1的解码为11111111 。尽管我们在这个例子使用了byte 类型的值,但同样的基本的原则也适用于所有Java 的整数类型。
因为Java 使用2的补码来存储负数,并且因为Java 中的所有整数都是有符号的,这样应用位运算符可以容易地达到意想不到的结果。例如,不管你如何打算,Java 用高位来代表负数。为避免这个讨厌的意外,请记住不管高位的顺序如何,它决定一个整数的符号。
4.2.1 位逻辑运算符
位逻辑运算符有“与”(AND)、“或”(OR)、“异或(XOR )”、“非(NOT)”,分别用“&”、“|”、“^”、“~”表示,4-3 表显示了每个位逻辑运算的结果。在继续讨论之前,请记住位运算符应用于每个运算数内的每个单独的位。
表4-3 位逻辑运算符的结果
A 0 1 0 1 B 0 0 1 1 A | B 0 1 1 1 A & B 0 0 0 1 A ^ B 0 1 1 0 ~A 1 0 1 0
按位非(NOT)
按位非也叫做补,一元运算符NOT“~”是对其运算数的每一位取反。例如,数字42,它的二进制代码为:
00101010
经过按位非运算成为
11010101
按位与(AND)
按位与运算符“&”,如果两个运算数都是1,则结果为1。其他情况下,结果均为零。看下面的例子:
00101010 42 &00001111 15
00001010 10
按位或(OR)
按位或运算符“|”,任何一个运算数为1,则结果为1。如下面的例子所示:
00101010 42 | 00001111 15
00101111 47
按位异或(XOR)
按位异或运算符“^”,只有在两个比较的位不同时其结果是 1。否则,结果是零。下面的例子显示了“^”运算符的效果。这个例子也表明了XOR 运算符的一个有用的属性。注意第二个运算数有数字1的位,42对应二进制代码的对应位是如何被转换的。第二个运算数有数字0的位,第一个运算数对应位的数字不变。当对某些类型进行位运算时,你将会看到这个属性的用处。
00101010 42 ^ 00001111 15
00100101 37
位逻辑运算符的应用
下面的例子说明了位逻辑运算符:
// Demonstrate the bitwise logical operators.
class BitLogic {
public static void main(String args[]) {
String binary[] = {"0000", "0001", "0010", "0011", "0100", "0101", "0110", "0111", "1000", "1001", "1010", "1011", "1100", "1101", "1110", "1111"
};
int a = 3; // 0 + 2 + 1 or 0011 in binary
int b = 6; // 4 + 2 + 0 or 0110 in binary
int c = a | b;
int d = a & b;
int e = a ^ b;
int f = (~a & b) | (a & ~b);
int g = ~a & 0x0f;
System.out.println(" a = " + binary[a]);
System.out.println(" b = " + binary[b]);
System.out.println(" a|b = " + binary[c]);
System.out.println(" a&b = " + binary[d]);
System.out.println(" a^b = " + binary[e]);
System.out.println("~a&b|a&~b = " + binary[f]);
System.out.println(" ~a = " + binary[g]);
}
}
在本例中,变量a与b对应位的组合代表了二进制数所有的 4 种组合模式:0-0,0-1,1-0 ,和1-1 。“|”运算符和“&”运算符分别对变量a与b各个对应位的运算得到了变量c和变量d的值。对变量e和f的赋值说明了“^”运算符的功能。字符串数组binary 代表了0到15 对应的二进制的值。在本例中,数组各元素的排列顺序显示了变量对应值的二进制代码。数组之所以这样构造是因为变量的值n对应的二进制代码可以被正确的存储在数组对应元素binary[n] 中。例如变量a的值为3,则它的二进制代码对应地存储在数组元素binary[3] 中。~a的值与数字0x0f (对应二进制为0000 1111 )进行按位与运算的目的是减小~a的值,保证变量g的结果小于16。因此该程序的运行结果可以用数组binary 对应的元素来表示。该程序的输出如下:
a = 0011 b = 0110 a|b = 0111 a&b = 0010 a^b = 0101 ~a&b|a&~b = 0101 ~a = 1100
4.2.2 左移运算符
左移运算符<<使指定值的所有位都左移规定的次数。它的通用格式如下所示:
value << num
这里,num 指定要移位值value 移动的位数。也就是,左移运算符<<使指定值的所有位都左移num位。每左移一个位,高阶位都被移出(并且丢弃),并用0填充右边。这意味着当左移的运算数是int 类型时,每移动1位它的第31位就要被移出并且丢弃;当左移的运算数是long 类型时,每移动1位它的第63位就要被移出并且丢弃。
在对byte 和short类型的值进行移位运算时,你必须小心。因为你知道Java 在对表达式求值时,将自动把这些类型扩大为 int 型,而且,表达式的值也是int 型。对byte 和short类型的值进行移位运算的结果是int 型,而且如果左移不超过31位,原来对应各位的值也不会丢弃。但是,如果你对一个负的byte 或者short类型的值进行移位运算,它被扩大为int 型后,它的符号也被扩展。这样,整数值结果的高位就会被1填充。因此,为了得到正确的结果,你就要舍弃得到结果的高位。这样做的最简单办法是将结果转换为byte 型。下面的程序说明了这一点:
// Left shifting a byte value.
class ByteShift {
public static void main(String args[]) {
byte a = 64, b;
int i;
i = a << 2;
b = (byte) (a << 2);
System.out.println("Original value of a: " + a);
System.out.println("i and b: " + i + " " + b);
}
}
该程序产生的输出下所示:
Original value of a: 64
i and b: 256 0
因变量a在赋值表达式中,故被扩大为int 型,64(0100 0000 )被左移两次生成值256 (10000 0000 )被赋给变量i。然而,经过左移后,变量b中惟一的1被移出,低位全部成了0,因此b的值也变成了0。
既然每次左移都可以使原来的操作数翻倍,程序员们经常使用这个办法来进行快速的2 的乘法。但是你要小心,如果你将1移进高阶位(31或63位),那么该值将变为负值。下面的程序说明了这一点:
// Left shifting as a quick way to multiply by 2.
class MultByTwo {
public static void main(String args[]) {
int i;
int num = 0xFFFFFFE;
for(i=0; i<4; i++) {
num = num << 1;
System.out.println(num);
}
}
这里,num 指定要移位值value 移动的位数。也就是,左移运算符<<使指定值的所有位都左移num位。每左移一个位,高阶位都被移出(并且丢弃),并用0填充右边。这意味着当左移的运算数是int 类型时,每移动1位它的第31位就要被移出并且丢弃;当左移的运算数是long 类型时,每移动1位它的第63位就要被移出并且丢弃。
在对byte 和short类型的值进行移位运算时,你必须小心。因为你知道Java 在对表达式求值时,将自动把这些类型扩大为 int 型,而且,表达式的值也是int 型。对byte 和short类型的值进行移位运算的结果是int 型,而且如果左移不超过31位,原来对应各位的值也不会丢弃。但是,如果你对一个负的byte 或者short类型的值进行移位运算,它被扩大为int 型后,它的符号也被扩展。这样,整数值结果的高位就会被1填充。因此,为了得到正确的结果,你就要舍弃得到结果的高位。这样做的最简单办法是将结果转换为byte 型。下面的程序说明了这一点:
// Left shifting a byte value.
class ByteShift {
public static void main(String args[]) {
byte a = 64, b;
int i;
i = a << 2;
b = (byte) (a << 2);
System.out.println("Original value of a: " + a);
System.out.println("i and b: " + i + " " + b);
}
}
该程序产生的输出下所示:
Original value of a: 64
i and b: 256 0
因变量a在赋值表达式中,故被扩大为int 型,64(0100 0000 )被左移两次生成值256 (10000 0000 )被赋给变量i。然而,经过左移后,变量b中惟一的1被移出,低位全部成了0,因此b的值也变成了0。
既然每次左移都可以使原来的操作数翻倍,程序员们经常使用这个办法来进行快速的2 的乘法。但是你要小心,如果你将1移进高阶位(31或63位),那么该值将变为负值。下面的程序说明了这一点:
// Left shifting as a quick way to multiply by 2.
class MultByTwo {
public static void main(String args[]) {
int i;
int num = 0xFFFFFFE;
for(i=0; i<4; i++) {
num = num << 1;
System.out.println(num);
}
}
}
该程序的输出如下所示:
536870908
1073741816
2147483632
-32
初值经过仔细选择,以便在左移 4 位后,它会产生-32。正如你看到的,当1被移进31 位时,数字被解释为负值。
4.2.3 右移运算符
右移运算符>>使指定值的所有位都右移规定的次数。它的通用格式如下所示:
value >> num
这里,num 指定要移位值value 移动的位数。也就是,右移运算符>>使指定值的所有位都右移num位。下面的程序片段将值32右移2次,将结果8赋给变量a:
int a = 32;
a = a >> 2; // a now contains 8
当值中的某些位被“移出”时,这些位的值将丢弃。例如,下面的程序片段将35右移2 次,它的2个低位被移出丢弃,也将结果8赋给变量a:
int a = 35;
a = a >> 2; // a still contains 8
用二进制表示该过程可以更清楚地看到程序的运行过程:
00100011 35
>> 2
00001000 8
将值每右移一次,就相当于将该值除以2并且舍弃了余数。你可以利用这个特点将一个整数进行快速的2的除法。当然,你一定要确保你不会将该数原有的任何一位移出。
右移时,被移走的最高位(最左边的位)由原来最高位的数字补充。例如,如果要移走的值为负数,每一次右移都在左边补1,如果要移走的值为正数,每一次右移都在左边补0,这叫做符号位扩展(保留符号位)(sign extension ),在进行右移操作时用来保持负数的符号。例如,–8 >> 1 是–4,用二进制表示如下:
11111000 –8 >>1 11111100 –4
一个要注意的有趣问题是,由于符号位扩展(保留符号位)每次都会在高位补1,因此-1右移的结果总是–1。有时你不希望在右移时保留符号。例如,下面的例子将一个byte 型的值转换为用十六
进制表示。注意右移后的值与0x0f进行按位与运算,这样可以舍弃任何的符号位扩展,以便得到的值可以作为定义数组的下标,从而得到对应数组元素代表的十六进制字符。
// Masking sign extension.
class HexByte {
static public void main(String args[]) {
char hex[] = {
’0’, ’1’, ’2’, ’3’, ’4’, ’5’, ’6’, ’7’,
’8’, ’9’, ’a’, ’b’, ’c’, ’d’, ’e’, ’f’’
};
byte b = (byte) 0xf1;
System.out.println("b = 0x" + hex[(b >> 4) & 0x0f] + hex[b & 0x0f]);}}
该程序的输出如下:
b = 0xf1
4.2.4 无符号右移
正如上面刚刚看到的,每一次右移,>>运算符总是自动地用它的先前最高位的内容补它的最高位。这样做保留了原值的符号。但有时这并不是我们想要的。例如,如果你进行移位操作的运算数不是数字值,你就不希望进行符号位扩展(保留符号位)。当你处理像素值或图形时,这种情况是相当普遍的。在这种情况下,不管运算数的初值是什么,你希望移位后总是在高位(最左边)补0。这就是人们所说的无符号移动(unsigned shift )。这时你可以使用Java 的无符号右移运算符>>> ,它总是在左边补0。
下面的程序段说明了无符号右移运算符>>> 。在本例中,变量a被赋值为-1,用二进制表示就是32位全是1。这个值然后被无符号右移24位,当然它忽略了符号位扩展,在它的左边总是补0。这样得到的值255被赋给变量a。
int a = -1; a = a >>> 24;
下面用二进制形式进一步说明该操作:
11111111 11111111 11111111 11111111 int型-1的二进制代码>>> 24 无符号右移24位00000000 00000000 00000000 11111111 int型255的二进制代码
由于无符号右移运算符>>> 只是对32位和64位的值有意义,所以它并不像你想象的那样有用。因为你要记住,在表达式中过小的值总是被自动扩大为int 型。这意味着符号位扩展和移动总是发生在32位而不是8位或16位。这样,对第7位以0开始的byte 型的值进行无符号移动是不可能的,因为在实际移动运算时,是对扩大后的32位值进行操作。下面的例子说明了这一点:
// Unsigned shifting a byte value.
class ByteUShift {
static public void main(String args[]) {
进制表示。注意右移后的值与0x0f进行按位与运算,这样可以舍弃任何的符号位扩展,以便得到的值可以作为定义数组的下标,从而得到对应数组元素代表的十六进制字符。
// Masking sign extension.
class HexByte {
static public void main(String args[]) {
char hex[] = {
’0’, ’1’, ’2’, ’3’, ’4’, ’5’, ’6’, ’7’,
’8’, ’9’, ’a’, ’b’, ’c’, ’d’, ’e’, ’f’’
};
byte b = (byte) 0xf1;
System.out.println("b = 0x" + hex[(b >> 4) & 0x0f] + hex[b & 0x0f]);}}
该程序的输出如下:
b = 0xf1
4.2.4 无符号右移
正如上面刚刚看到的,每一次右移,>>运算符总是自动地用它的先前最高位的内容补它的最高位。这样做保留了原值的符号。但有时这并不是我们想要的。例如,如果你进行移位操作的运算数不是数字值,你就不希望进行符号位扩展(保留符号位)。当你处理像素值或图形时,这种情况是相当普遍的。在这种情况下,不管运算数的初值是什么,你希望移位后总是在高位(最左边)补0。这就是人们所说的无符号移动(unsigned shift )。这时你可以使用Java 的无符号右移运算符>>> ,它总是在左边补0。
下面的程序段说明了无符号右移运算符>>> 。在本例中,变量a被赋值为-1,用二进制表示就是32位全是1。这个值然后被无符号右移24位,当然它忽略了符号位扩展,在它的左边总是补0。这样得到的值255被赋给变量a。
int a = -1; a = a >>> 24;
下面用二进制形式进一步说明该操作:
11111111 11111111 11111111 11111111 int型-1的二进制代码>>> 24 无符号右移24位00000000 00000000 00000000 11111111 int型255的二进制代码
由于无符号右移运算符>>> 只是对32位和64位的值有意义,所以它并不像你想象的那样有用。因为你要记住,在表达式中过小的值总是被自动扩大为int 型。这意味着符号位扩展和移动总是发生在32位而不是8位或16位。这样,对第7位以0开始的byte 型的值进行无符号移动是不可能的,因为在实际移动运算时,是对扩大后的32位值进行操作。下面的例子说明了这一点:
// Unsigned shifting a byte value.
class ByteUShift {
static public void main(String args[]) {
int b = 2;
int c = 3;
a |= 4;
b >>= 1;
c <<= 1;
a ^= c;
System.out.println("a = " + a);
System.out.println("b = " + b);
System.out.println("c = " + c);
}
}
该程序的输出如下所示:
a = 3
b = 1
c = 6
posted @
2011-11-04 11:56 xzc 阅读(267) |
评论 (1) |
编辑 收藏- import java.net.*;
- String key=URLEncoder.encode("中文key","GBK");
- String value=URLEncoder.encode("中文value","GBK");
- Cookie cook=new Cookie(key,value);
- String key=cook.getName(),value=cook.getValue();
- key=URLDecoder.decode(key,"GBK");
- value=URLDecoder.decode(value,"GBK");
String value = java.net.URLEncoder.encode("中文","utf-8");
Cookie cookie = new Cookie("chinese_code",value);
cookie.setMaxAge(60*60*24*6);
response.addCookie(cookie);
encode() 只有一个参数的已经过时了,现在可以设置编码格式, 取cookie值的时候 也不用解码了。
posted @
2011-10-03 11:29 xzc 阅读(6366) |
评论 (3) |
编辑 收藏
<servlet>
<servlet-name>dwr-invoker</servlet-name>
<servlet-class>org.directwebremoting.servlet.DwrServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>true</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>dwr-invoker</servlet-name>
<url-pattern>/dwr/*</url-pattern>
</servlet-mapping>
我们注意到它里面包含了这段配置:<load-on-startup>1</load-on-startup>,那么这个配置有什么作用呢?
贴一段英文原汁原味的解释如下:
Servlet specification:
The load-on-startup element indicates that this servlet should be loaded (instantiated and have its init() called) on the startup of the web application. The optional contents of these element must be an integer indicating the order in which the servlet should be loaded. If the value is a negative integer, or the element is not present, the container is free to load the servlet whenever it chooses. If the value is a positive integer or 0, the container must load and initialize the servlet as the application is deployed. The container must guarantee that servlets marked with lower integers are loaded before servlets marked with higher integers. The container may choose the order of loading of servlets with the same load-on-start-up value.
翻译过来的意思大致如下:
1)load-on-startup元素标记容器是否在启动的时候就加载这个servlet(实例化并调用其init()方法)。
2)它的值必须是一个整数,表示servlet应该被载入的顺序
2)当值为0或者大于0时,表示容器在应用启动时就加载并初始化这个servlet;
3)当值小于0或者没有指定时,则表示容器在该servlet被选择时才会去加载。
4)正数的值越小,该servlet的优先级越高,应用启动时就越先加载。
5)当值相同时,容器就会自己选择顺序来加载。
所以,<load-on-startup>x</load-on-startup>,中x的取值1,2,3,4,5代表的是优先级,而非启动延迟时间。
如下题目:
2.web.xml中不包括哪些定义(多选)
a.默认起始页
b.servlet启动延迟时间定义
c.error处理页面
d.jsp文件改动后重新载入时间
答案:b,d
通常大多数Servlet是在用户第一次请求的时候由应用服务器创建并初始化,但<load-on-startup>n</load-on-startup> 可以用来改变这种状况,根据自己需要改变加载的优先级!
posted @
2011-09-29 15:22 xzc 阅读(149931) |
评论 (22) |
编辑 收藏Keytool是一个Java数据证书的管理工具 ,Keytool将密钥(key)和证书(certificates)存在一个称为keystore的文件中在keystore里,包含两种数据:
密钥实体(Key entity)——密钥(secret key)又或者是私钥和配对公钥(采用非对称加密)
可信任的证书实体(trusted certificate entries)——只包含公钥
ailas(别名)每个keystore都关联这一个独一无二的alias,这个alias通常不区分大小写
JDK中keytool常用命令:
-genkey 在用户主目录中创建一个默认文件".keystore",还会产生一个mykey的别名,mykey中包含用户的公钥、私钥和证书
(在没有指定生成位置的情况下,keystore会存在用户系统默认目录,如:对于window xp系统,会生成在系统的C:\Documents and Settings\UserName\文件名为“.keystore”)
-alias 产生别名
-keystore 指定密钥库的名称(产生的各类信息将不在.keystore文件中)
-keyalg 指定密钥的算法 (如 RSA DSA(如果不指定默认采用DSA))
-validity 指定创建的证书有效期多少天
-keysize 指定密钥长度
-storepass 指定密钥库的密码(获取keystore信息所需的密码)
-keypass 指定别名条目的密码(私钥的密码)
-dname 指定证书拥有者信息 例如: "CN=名字与姓氏,OU=组织单位名称,O=组织名称,L=城市或区域名称,ST=州或省份名称,C=单位的两字母国家代码"
-list 显示密钥库中的证书信息 keytool -list -v -keystore 指定keystore -storepass 密码
-v 显示密钥库中的证书详细信息
-export 将别名指定的证书导出到文件 keytool -export -alias 需要导出的别名 -keystore 指定keystore -file 指定导出的证书位置及证书名称 -storepass 密码
-file 参数指定导出到文件的文件名
-delete 删除密钥库中某条目 keytool -delete -alias 指定需删除的别 -keystore 指定keystore -storepass 密码
-printcert 查看导出的证书信息 keytool -printcert -file yushan.crt
-keypasswd 修改密钥库中指定条目口令 keytool -keypasswd -alias 需修改的别名 -keypass 旧密码 -new 新密码 -storepass keystore密码 -keystore sage
-storepasswd 修改keystore口令 keytool -storepasswd -keystore e:\yushan.keystore(需修改口令的keystore) -storepass 123456(原始密码) -new yushan(新密码)
-import 将已签名数字证书导入密钥库 keytool -import -alias 指定导入条目的别名 -keystore 指定keystore -file 需导入的证书
下面是各选项的缺省值。
-alias "mykey"
-keyalg "DSA"
-keysize 1024
-validity 90
-keystore 用户宿主目录中名为 .keystore 的文件
-file 读时为标准输入,写时为标准输出
1、keystore的生成:
分阶段生成:
keytool -genkey -alias yushan(别名) -keypass yushan(别名密码) -keyalg RSA(算法) -keysize 1024(密钥长度) -validity 365(有效期,天单位) -keystore
e:\yushan.keystore(指定生成证书的位置和证书名称) -storepass 123456(获取keystore信息的密码);回车输入相关信息即可;
一次性生成:
keytool -genkey -alias yushan -keypass yushan -keyalg RSA -keysize 1024 -validity 365 -keystore e:\yushan.keystore -storepass 123456 -dname "CN=(名字与
姓氏), OU=(组织单位名称), O=(组织名称), L=(城市或区域名称), ST=(州或省份名称), C=(单位的两字母国家代码)";(中英文即可)
2、keystore信息的查看:
keytool -list -v -keystore e:\keytool\yushan.keystore -storepass 123456
显示内容:
---------------------------------------------------------------------
Keystore 类型: JKS
Keystore 提供者: SUN
您的 keystore 包含 1 输入
别名名称: yushan
创建日期: 2009-7-29
项类型: PrivateKeyEntry
认证链长度: 1
认证 [1]:
所有者:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
签发人:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
序列号:4a6f29ed
有效期: Wed Jul 29 00:40:13 CST 2009 至Thu Jul 29 00:40:13 CST 2010
证书指纹:
MD5:A3:D7:D9:74:C3:50:7D:10:C9:C2:47:B0:33:90:45:C3
SHA1:2B:FC:9E:3A:DF:C6:C4:FB:87:B8:A0:C6:99:43:E9:4C:4A:E1:18:E8
签名算法名称:SHA1withRSA
版本: 3
--------------------------------------------------------------------
缺省情况下,-list 命令打印证书的 MD5 指纹。而如果指定了 -v 选项,将以可读格式打印证书,如果指定了 -rfc 选项,将以可打印的编码格式输出证书。
keytool -list -rfc -keystore e:\yushan.keystore -storepass 123456
显示:
-------------------------------------------------------------------------------------------------------
Keystore 类型: JKS
Keystore 提供者: SUN
您的 keystore 包含 1 输入
别名名称: yushan
创建日期: 2009-7-29
项类型: PrivateKeyEntry
认证链长度: 1
认证 [1]:
-----BEGIN CERTIFICATE-----
MIICSzCCAbSgAwIBAgIESm8p7TANBgkqhkiG9w0BAQUFADBqMQ8wDQYDVQQGDAbkuK3lm70xDzAN
BgNVBAgMBua5luWNlzEPMA0GA1UEBwwG5rmY5r2tMREwDwYDVQQKDAh4eOWNj+S8mjERMA8GA1UE
CwwIeHjlhazlj7gxDzANBgNVBAMTBnl1c2hhbjAeFw0wOTA3MjgxNjQwMTNaFw0xMDA3MjgxNjQw
MTNaMGoxDzANBgNVBAYMBuS4reWbvTEPMA0GA1UECAwG5rmW5Y2XMQ8wDQYDVQQHDAbmuZjmva0x
ETAPBgNVBAoMCHh45Y2P5LyaMREwDwYDVQQLDAh4eOWFrOWPuDEPMA0GA1UEAxMGeXVzaGFuMIGf
MA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCJoru1RQczRzTnBWxefVNspQBykS220rS8Y/oX3mZa
hjL4wLfOURzUuxxuVQR2jx7QI+XKME+DHQj9r6aAcLBCi/T1jwF8mVYxtpRuTzE/6KEZdhowEe70
liWLVE+hytLBHZ03Zhwcd6q5HUMu27du3MPQvqiwzTY7MrwIvQQ8iQIDAQABMA0GCSqGSIb3DQEB
BQUAA4GBAGoQQ1/FnTfkpQh+Ni6h3fZdn3sR8ZzDMbOAIYVLAhBb85XDJ8QZTarHbZMJcIdHxAl1
i08ct3E8U87V9t8GZFWVC4BFg/+zeFEv76SFpVE56iX7P1jpsu78z0m69hHlds77VJTdyfMSvtXv
sYHP3fxfzx9WyhipBwd8VPK/NgEP
-----END CERTIFICATE-----
-------------------------------------------------------------------------------------------------------
3、证书的导出:
keytool -export -alias yushan -keystore e:\yushan.keystore -file e:\yushan.crt(指定导出的证书位置及证书名称) -storepass 123456
4、查看导出的证书信息
keytool -printcert -file yushan.crt
显示:(在windows下可以双击yushan.crt查看)
-----------------------------------------------------------------------
所有者:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
签发人:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
序列号:4a6f29ed
有效期: Wed Jul 29 00:40:13 CST 2009 至Thu Jul 29 00:40:13 CST 2010
证书指纹:
MD5:A3:D7:D9:74:C3:50:7D:10:C9:C2:47:B0:33:90:45:C3
SHA1:2B:FC:9E:3A:DF:C6:C4:FB:87:B8:A0:C6:99:43:E9:4C:4A:E1:18:E8
签名算法名称:SHA1withRSA
版本: 3
-----------------------------------------------------------------------
5、证书的导入:
准备一个导入的证书:
keytool -genkey -alias shuany -keypass shuany -keyalg RSA -keysize 1024 -validity 365 -keystore e:\shuany.keystore -storepass 123456 -dname "CN=shuany,
OU=xx, O=xx, L=xx, ST=xx, C=xx";
keytool -export -alias shuany -keystore e:\shuany.keystore -file e:\shuany.crt -storepass 123456
现在将shuany.crt 加入到yushan.keystore中:
keytool -import -alias shuany(指定导入证书的别名,如果不指定默认为mykey,别名唯一,否则导入出错) -file e:\shuany.crt -keystore e:\yushan.keystore -storepass
123456
keytool -list -v -keystore e:\keytool\yushan.keystore -storepass 123456
显示:
------------------------------------------------------------------------------
Keystore 类型: JKS
Keystore 提供者: SUN
您的 keystore 包含 2 输入
别名名称: yushan
创建日期: 2009-7-29
项类型: PrivateKeyEntry
认证链长度: 1
认证 [1]:
所有者:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
签发人:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
序列号:4a6f29ed
有效期: Wed Jul 29 00:40:13 CST 2009 至Thu Jul 29 00:40:13 CST 2010
证书指纹:
MD5:A3:D7:D9:74:C3:50:7D:10:C9:C2:47:B0:33:90:45:C3
SHA1:2B:FC:9E:3A:DF:C6:C4:FB:87:B8:A0:C6:99:43:E9:4C:4A:E1:18:E8
签名算法名称:SHA1withRSA
版本: 3
*******************************************
*******************************************
别名名称: shuany
创建日期: 2009-7-29
输入类型: trustedCertEntry
所有者:CN=shuany, OU=xx, O=xx, L=xx, ST=xx, C=xx
签发人:CN=shuany, OU=xx, O=xx, L=xx, ST=xx, C=xx
序列号:4a6f2cd9
有效期: Wed Jul 29 00:52:41 CST 2009 至Thu Jul 29 00:52:41 CST 2010
证书指纹:
MD5:15:03:57:9B:14:BD:C5:50:21:15:47:1E:29:87:A4:E6
SHA1:C1:4F:8B:CD:5E:C2:94:77:B7:42:29:35:5C:BB:BB:2E:9E:F0:89:F5
签名算法名称:SHA1withRSA
版本: 3
*******************************************
*******************************************
------------------------------------------------------------------------------
6、证书条目的删除:
keytool -delete -alias shuany(指定需删除的别名) -keystore yushan.keystore -storepass 123456
7、证书条目口令的修改:
keytool -keypasswd -alias yushan(需要修改密码的别名) -keypass yushan(原始密码) -new 123456(别名的新密码) -keystore e:\yushan.keystore -storepass 123456
8、keystore口令的修改:
keytool -storepasswd -keystore e:\yushan.keystore(需修改口令的keystore) -storepass 123456(原始密码) -new yushan(新密码)
9、修改keystore中别名为yushan的信息
keytool -selfcert -alias yushan -keypass yushan -keystore e:\yushan.keystore -storepass 123456 -dname "cn=yushan,ou=yushan,o=yushan,c=us
posted @
2011-09-15 08:30 xzc 阅读(416) |
评论 (0) |
编辑 收藏转自:
http://www.iteye.com/topic/255397
1.那即将离我远去的
用buffalo作为我的ajax类库也有些历史了,几乎是和Spring同时开始接触的.
按照官方的方式,Buffalo与Spring的集成是很简单:
在Spring中配置一个BuffaloServiceConfigure bean,把spring托管的服务在其中声明即可,Buffalo可以通过ServletContext得到Spring的WebApplicationContext,进而得到所需的服务:
- <bean name="buffaloConfigBean"
- class="net.buffalo.service.BuffaloServiceConfigurer">
- <property name="services">
- <map>
- <entry key="springSimpleService">
- <ref bean="systemService" />
- </entry>
- <entry key="springSimpleService2">
- <ref bean="systemService2" />
- </entry>
- </map>
- </property>
- </bean>
<bean name="buffaloConfigBean"
class="net.buffalo.service.BuffaloServiceConfigurer">
<property name="services">
<map>
<entry key="springSimpleService">
<ref bean="systemService" />
</entry>
<entry key="springSimpleService2">
<ref bean="systemService2" />
</entry>
</map>
</property>
</bean>
似乎很简单,但,有没有觉得似乎很傻?只是把Spring里已经配置好的bean再引用一次而已,
一旦面临协作开发,和所有的全局配置文件一样,BuffaloServiceConfigure bean下面就会囊括几十上百个service ref,一大堆人围着这个配置文件转,CVS冲突就成了家常便饭了,苦恼不已.当然,按我们这么多年的开发经验是不会出现这种低级错误的,早早的在项目设计阶段就会按模块划分出多个配置文件,一人独用,无需和别人共享配置,轻松面对冲突问题,带来的局面就是每个包里都塞着一个buffalo.xml,一个项目里配置文件到处有,不断得copy/paste,层层套套,那可不是硕果累累的满足感.
当然,Spring本身在2.5之前也因XML配置繁琐而让人诟病,Guice才能异军突起,那时Spring比Buffalo的配置更多,所以Buffalo的问题也就不是问题了.但有一天,我终于要正式升级到Spring2.5.
世界清静了!使用annotation,看到怎么多配置文件消失,看到简洁的Bean/MVC配置,呵呵,还真是令人心情愉悦的.
诶,等等,怎么还有大堆XML?哦?原来是Buffalo...
Buffalo像个刺头,傻愣愣地杵在XML里.
2.于是我开始把Buffalo也Annotation化.
话说Spring的扩展能力还是ganggang的,一天时间,就有成果了.
先写个注解:
- package cn.tohot.common.annotation;
-
- import java.lang.annotation.ElementType;
- import java.lang.annotation.Retention;
- import java.lang.annotation.RetentionPolicy;
- import java.lang.annotation.Target;
-
-
-
-
-
-
- @Retention(RetentionPolicy.RUNTIME)
- @Target(ElementType.TYPE)
- public @interface Buffalo {
-
-
-
- String value();
- }
package cn.tohot.common.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* buffalo扩展接口,用于表明该类是一个buffalo服务.
* @author tedeyang
*
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Buffalo {
/**
* @return 远程调用时的服务名.
*/
String value();
}
接着再写Spring的扩展
-
-
-
- package cn.tohot.common.annotation;
-
- import java.util.HashMap;
-
- import net.buffalo.service.BuffaloServiceConfigurer;
-
- import org.apache.log4j.Logger;
- import org.springframework.beans.BeansException;
- import org.springframework.beans.factory.DisposableBean;
- import org.springframework.beans.factory.FactoryBean;
- import org.springframework.beans.factory.InitializingBean;
- import org.springframework.beans.factory.config.BeanPostProcessor;
-
-
-
-
-
-
- @SuppressWarnings("unchecked")
- public class BuffaloAnnotationServiceFactoryBean implements FactoryBean, InitializingBean, DisposableBean, BeanPostProcessor {
- private static final Logger log = Logger.getLogger(BuffaloAnnotationServiceFactoryBean.class);
-
- private BuffaloServiceConfigurer buffaloConfigurer = null;
-
- public BuffaloAnnotationServiceFactoryBean() {
- buffaloConfigurer = new BuffaloServiceConfigurer();
- buffaloConfigurer.setServices(new HashMap());
- }
-
- private void addBuffaloBean(String buffaloServiceName,Object bean) {
- buffaloConfigurer.getServices().put(buffaloServiceName, bean);
- log.info("Add a buffalo service :"+buffaloServiceName);
- }
-
- public Object getObject() throws Exception {
- return this.buffaloConfigurer;
- }
-
- public Class getObjectType() {
- return BuffaloServiceConfigurer.class;
- }
-
- public boolean isSingleton() {
- return true;
- }
-
- public void afterPropertiesSet() throws Exception {
- }
-
- public void destroy() throws Exception {
- if (buffaloConfigurer != null)
- buffaloConfigurer.setServices(null);
- buffaloConfigurer = null;
- }
-
- public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
- return bean;
- }
-
- public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
- log.debug("find a bean:"+beanName);
- if (bean.getClass().isAnnotationPresent(Buffalo.class)) {
- Buffalo buffalo = bean.getClass().getAnnotation(Buffalo.class);
- addBuffaloBean(buffalo.value(), bean);
- }
- return bean;
- }
-
- }
/**
*
*/
package cn.tohot.common.annotation;
import java.util.HashMap;
import net.buffalo.service.BuffaloServiceConfigurer;
import org.apache.log4j.Logger;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.FactoryBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.config.BeanPostProcessor;
/**
* 该类作为FactoryBean可以无缝替换buffalo 2.0自带的配置类,并使用annotation进行配置.
* @author tedeyang
*
*/
@SuppressWarnings("unchecked")
public class BuffaloAnnotationServiceFactoryBean implements FactoryBean, InitializingBean, DisposableBean, BeanPostProcessor {
private static final Logger log = Logger.getLogger(BuffaloAnnotationServiceFactoryBean.class);
private BuffaloServiceConfigurer buffaloConfigurer = null;
public BuffaloAnnotationServiceFactoryBean() {
buffaloConfigurer = new BuffaloServiceConfigurer();
buffaloConfigurer.setServices(new HashMap());
}
private void addBuffaloBean(String buffaloServiceName,Object bean) {
buffaloConfigurer.getServices().put(buffaloServiceName, bean);
log.info("Add a buffalo service :"+buffaloServiceName);
}
public Object getObject() throws Exception {
return this.buffaloConfigurer;
}
public Class getObjectType() {
return BuffaloServiceConfigurer.class;
}
public boolean isSingleton() {
return true;
}
public void afterPropertiesSet() throws Exception {
}
public void destroy() throws Exception {
if (buffaloConfigurer != null)
buffaloConfigurer.setServices(null);
buffaloConfigurer = null;
}
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
log.debug("find a bean:"+beanName);
if (bean.getClass().isAnnotationPresent(Buffalo.class)) {
Buffalo buffalo = bean.getClass().getAnnotation(Buffalo.class);
addBuffaloBean(buffalo.value(), bean);
}
return bean;
}
}
主要思路是用FactoryBean替换原BuffaloServiceConfigurer,并挂上BeanPostProcessor的钩子,检测一下annotation,发现buffalo服务就添加到原BuffaloServiceConfigurer中去.
3.今天我这样配置Buffalo:
- <?xml version="1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
- xmlns:tx="http://www.springframework.org/schema/tx" xmlns:context="http://www.springframework.org/schema/context"
- xsi:schemaLocation="http:
- http:
- http:
- http:
-
- <!-- Spring Annotation配置, 自动搜索组件 -->
- <context:component-scan base-package="cn.tohot.demo"/>
- <bean id="buffalo" class="cn.tohot.common.annotation.BuffaloAnnotationServiceFactoryBean" />
- </beans>
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<!-- Spring Annotation配置, 自动搜索组件 -->
<context:component-scan base-package="cn.tohot.demo"/>
<bean id="buffalo" class="cn.tohot.common.annotation.BuffaloAnnotationServiceFactoryBean" />
</beans>
服务端的Buffalo bean 类:
- package cn.tohot.demo;
-
- import org.springframework.stereotype.Service;
-
- import cn.tohot.common.annotation.Buffalo;
-
- @Service
- @Buffalo("testbean")
- public class BuffaloBeanTestService {
- public String run() {
- System.out.println("run");
- return "run";
- }
- }
package cn.tohot.demo;
import org.springframework.stereotype.Service;
import cn.tohot.common.annotation.Buffalo;
@Service //声明Spring bean,
@Buffalo("testbean") //声明一个名为"testbean"的Buffalo service
public class BuffaloBeanTestService {
public String run() {
System.out.println("run");
return "run";
}
}
很简洁,不是吗?
posted @
2011-08-26 09:21 xzc 阅读(232) |
评论 (0) |
编辑 收藏转自:
http://www.iteye.com/topic/11738前几天解释了Spring的抽象事务机制。这次讲讲Spring中的DataSource 事务。
DataSource事务相关的类比较多,我们一步步来拨开其中的密团。
1 如何获得连接
看DataSourceUtils代码
- protected static Connection doGetConnection(DataSource dataSource, boolean allowSynchronization);
- throws SQLException {
-
- ConnectionHolder conHolder = (ConnectionHolder); TransactionSynchronizationManager.getResource(dataSource);;
- if (conHolder != null); {
- conHolder.requested();;
- return conHolder.getConnection();;
- }
-
-
- Connection con = dataSource.getConnection();;
- if (allowSynchronization && TransactionSynchronizationManager.isSynchronizationActive();); {
- conHolder = new ConnectionHolder(con);;
- TransactionSynchronizationManager.bindResource(dataSource, conHolder);;
- TransactionSynchronizationManager.registerSynchronization(new ConnectionSynchronization(conHolder, dataSource););;
- conHolder.requested();;
- }
-
- return con;
- }
protected static Connection doGetConnection(DataSource dataSource, boolean allowSynchronization);
throws SQLException {
ConnectionHolder conHolder = (ConnectionHolder); TransactionSynchronizationManager.getResource(dataSource);;
if (conHolder != null); {
conHolder.requested();;
return conHolder.getConnection();;
}
Connection con = dataSource.getConnection();;
if (allowSynchronization && TransactionSynchronizationManager.isSynchronizationActive();); {
conHolder = new ConnectionHolder(con);;
TransactionSynchronizationManager.bindResource(dataSource, conHolder);;
TransactionSynchronizationManager.registerSynchronization(new ConnectionSynchronization(conHolder, dataSource););;
conHolder.requested();;
}
return con;
}原来连接是从TransactionSynchronizationManager中获取,如果TransactionSynchronizationManager中已经有了,那么拿过来然后调用conHolder.requested()。否则从原始的DataSource这创建一个连接,放到一个ConnectionHolder,然后再调用TransactionSynchronizationManager.bindResource绑定。
好,我们又遇到两个新的类TransactionSynchronizationManager和ConnectionHolder和。继续跟踪
2 TransactionSynchronizationManager
看其中的一些代码
- private static ThreadLocal resources = new ThreadLocal();;
- public static Object getResource(Object key); {
- Map map = (Map); resources.get();;
- if (map == null); {
- return null;
- }
- Object value = map.get(key);;
- return value;
- }
- public static void bindResource(Object key, Object value); throws IllegalStateException {
- Map map = (Map); resources.get();;
- if (map == null); {
- map = new HashMap();;
- resources.set(map);;
- }
- map.put(key, value);;
- }
private static ThreadLocal resources = new ThreadLocal();;
public static Object getResource(Object key); {
Map map = (Map); resources.get();;
if (map == null); {
return null;
}
Object value = map.get(key);;
return value;
}
public static void bindResource(Object key, Object value); throws IllegalStateException {
Map map = (Map); resources.get();;
if (map == null); {
map = new HashMap();;
resources.set(map);;
}
map.put(key, value);;
}原来TransactionSynchronizationManager内部建立了一个ThreadLocal的resources,这个resources又是和一个map联系在一起的,这个map在某个线程第一次调用bindResource时生成。
联系前面的DataSourceUtils代码,我们可以总结出来。
某个线程使用DataSourceUtils,当第一次要求创建连接将在TransactionSynchronizationManager中创建出一个ThreadLocal的map。然后以DataSource作为键,ConnectionHolder为值放到map中。等这个线程下一次再请求的这个DataSource的时候,就从这个map中获取对应的ConnectionHolder。用map是为了解决同一个线程上多个DataSource。
然后我们来看看ConnectionHolder又是什么?
3 对连接进行引用计数
看ConnectionHolder代码,这个类很简单,看不出个所以然,只好再去看父类代码ResourceHolderSupport,我们感兴趣的是这两个方法
- public void requested(); {
- this.referenceCount++;
- }
-
- public void released(); {
- this.referenceCount--;
- }
public void requested(); {
this.referenceCount++;
}
public void released(); {
this.referenceCount--;
}看得出这是一个引用计数的技巧。原来Spring中对Connection是竟量使用已创建的对象,而不是每次都创建一个新对象。这就是DataSourceUtils中
- if (conHolder != null); {
- conHolder.requested();;
- return conHolder.getConnection();;
- }
if (conHolder != null); {
conHolder.requested();;
return conHolder.getConnection();;
}的原因
4 释放连接
完成事物后DataSourceTransactionManager有这样的代码
- protected void doCleanupAfterCompletion(Object transaction); {
- DataSourceTransactionObject txObject = (DataSourceTransactionObject); transaction;
-
-
- TransactionSynchronizationManager.unbindResource(this.dataSource);;
- txObject.getConnectionHolder();.clear();;
-
-
- }
protected void doCleanupAfterCompletion(Object transaction); {
DataSourceTransactionObject txObject = (DataSourceTransactionObject); transaction;
// Remove the connection holder from the thread.
TransactionSynchronizationManager.unbindResource(this.dataSource);;
txObject.getConnectionHolder();.clear();;
//... DataSourceUtils.closeConnectionIfNecessary(con, this.dataSource);;
}DataSourceUtils
- protected static void doCloseConnectionIfNecessary(Connection con, DataSource dataSource); throws SQLException {
- if (con == null); {
- return;
- }
-
- ConnectionHolder conHolder = (ConnectionHolder); TransactionSynchronizationManager.getResource(dataSource);;
- if (conHolder != null && con == conHolder.getConnection();); {
-
- conHolder.released();;
- return;
- }
-
-
-
- if (!(dataSource instanceof SmartDataSource); || ((SmartDataSource); dataSource);.shouldClose(con);); {
- logger.debug("Closing JDBC connection");;
- con.close();;
- }
- }
protected static void doCloseConnectionIfNecessary(Connection con, DataSource dataSource); throws SQLException {
if (con == null); {
return;
}
ConnectionHolder conHolder = (ConnectionHolder); TransactionSynchronizationManager.getResource(dataSource);;
if (conHolder != null && con == conHolder.getConnection();); {
// It's the transactional Connection: Don't close it.
conHolder.released();;
return;
}
// Leave the Connection open only if the DataSource is our
// special data source, and it wants the Connection left open.
if (!(dataSource instanceof SmartDataSource); || ((SmartDataSource); dataSource);.shouldClose(con);); {
logger.debug("Closing JDBC connection");;
con.close();;
}
}恍然大悟。如果事物完成,那么就
TransactionSynchronizationManager.unbindResource(this.dataSource);将当前的ConnectionHolder
从TransactionSynchronizationManager上脱离,然后doCloseConnectionIfNecessary。最后会把连接关闭掉。
5 两个辅助类JdbcTemplate和TransactionAwareDataSourceProxy
JdbcTemplate中的execute方法的第一句和最后一句
- public Object execute(PreparedStatementCreator psc, PreparedStatementCallback action);
- throws DataAccessException {
-
- Connection con = DataSourceUtils.getConnection(getDataSource(););;
-
- DataSourceUtils.closeConnectionIfNecessary(con, getDataSource(););;
- }
- }
public Object execute(PreparedStatementCreator psc, PreparedStatementCallback action);
throws DataAccessException {
Connection con = DataSourceUtils.getConnection(getDataSource(););;
//其他代码
DataSourceUtils.closeConnectionIfNecessary(con, getDataSource(););;
}
}作用不言自明了吧
从TransactionAwareDataSourceProxy中获取的连接是这个样子的
- public Connection getConnection(); throws SQLException {
- Connection con = DataSourceUtils.doGetConnection(getTargetDataSource();, true);;
- return getTransactionAwareConnectionProxy(con, getTargetDataSource(););;
- }
public Connection getConnection(); throws SQLException {
Connection con = DataSourceUtils.doGetConnection(getTargetDataSource();, true);;
return getTransactionAwareConnectionProxy(con, getTargetDataSource(););;
}万变不离其宗,不过我们还是看看getTransactionAwareConnectionProxy
- protected Connection getTransactionAwareConnectionProxy(Connection target, DataSource dataSource); {
- return (Connection); Proxy.newProxyInstance(
- ConnectionProxy.class.getClassLoader();,
- new Class[] {ConnectionProxy.class},
- new TransactionAwareInvocationHandler(target, dataSource););;
- }
protected Connection getTransactionAwareConnectionProxy(Connection target, DataSource dataSource); {
return (Connection); Proxy.newProxyInstance(
ConnectionProxy.class.getClassLoader();,
new Class[] {ConnectionProxy.class},
new TransactionAwareInvocationHandler(target, dataSource););;
}原来返回的是jdk的动态代理。继续看TransactionAwareInvocationHandler
- public Object invoke(Object proxy, Method method, Object[] args); throws Throwable {
-
- if (this.dataSource != null); {
- DataSourceUtils.doCloseConnectionIfNecessary(this.target, this.dataSource);;
- }
- return null;
- }
-
- }
public Object invoke(Object proxy, Method method, Object[] args); throws Throwable {
//... if (method.getName();.equals(CONNECTION_CLOSE_METHOD_NAME);); {
if (this.dataSource != null); {
DataSourceUtils.doCloseConnectionIfNecessary(this.target, this.dataSource);;
}
return null;
}
}TransactionAwareDataSourceProxy会先从DataSourceUtils获取连接。然后将这个连接用jdk的动态代理包一下返回。外部代码如果调用的这个冒牌的Connection,就会先调用TransactionAwareInvocationHandler的invoke,在这个invoke 中,完成原来调用DataSourceUtils的功能。
总结上面的流程
Spring 对DataSource进行事务管理的关键在于ConnectionHolder和TransactionSynchronizationManager。
0.先从TransactionSynchronizationManager中尝试获取连接
1.如果前一步失败则在每个线程上,对每个DataSouce只创建一个Connection
2.这个Connection用ConnectionHolder包装起来,由TransactionSynchronizationManager管理
3.再次请求同一个连接的时候,从TransactionSynchronizationManager返回已经创建的ConnectionHolder,然后调用ConnectionHolder的request将引用计数+1
4.释放连接时要调用ConnectionHolder的released,将引用计数-1
5.当事物完成后,将ConnectionHolder从TransactionSynchronizationManager中解除。当谁都不用,这个连接被close
以上所有都是可以调用DataSourceUtils化简代码,而JdbcTemplate又是调用DataSourceUtils的。所以在Spring文档中要求尽量首先使用JdbcTemplate,其次是用DataSourceUtils来获取和释放连接。至于TransactionAwareDataSourceProxy,那是下策的下策。不过可以将Spring事务管理和遗留代码无缝集成。
所以如某位朋友说要使用Spring的事务管理,但是又不想用JdbcTemplate,那么可以考虑TransactionAwareDataSourceProxy。这个类是原来DataSource的代理。
其次,想使用Spring事物,又不想对Spring进行依赖是不可能的。与其试图自己模拟DataSourceUtils,不如直接使用现成的。
posted @
2011-08-09 14:59 xzc 阅读(4007) |
评论 (1) |
编辑 收藏
在HP-UX文件系统中,系统默认的是小文件系统(即不支持大于2GB的文件),如果用户希望当前的文件系统能支持大于2GB的文件时,我们可以这样做:
1、新建文件系统时:
mkfs -F vxfs -o largefiles /dev/vg02/rlvol1
或者
newfs -F vxfs -o largefiles /dev/vg02/rlvol1
2、文件系统内有数据文件时:
fsadm -F vxfs -o largefiles /inffile
当然,你也可以将大文件系统转换为小文件系统,不过要注意的是这个大文件系统中不能有大于2GB的文件,否则无法转换成功。示例如下:
fsadm -F vxfs -o nolargefiles /inffile
posted @
2011-08-08 16:57 xzc 阅读(767) |
评论 (2) |
编辑 收藏SELECT ename
FROM scott.emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
--得到结果为:
KING
JONES
SCOTT
ADAMS
FORD
SMITH
BLAKE
ALLEN
WARD
MARTIN
TURNER
JAMES
而:
SELECT SYS_CONNECT_BY_PATH(ename, '>') "Path"
FROM scott.emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
--得到结果为:
>KING
>KING>JONES
>KING>JONES>SCOTT
>KING>JONES>SCOTT>ADAMS
>KING>JONES>FORD
>KING>JONES>FORD>SMITH
>KING>BLAKE
>KING>BLAKE>ALLEN
>KING>BLAKE>WARD
>KING>BLAKE>MARTIN
>KING>BLAKE>TURNER
>KING>BLAKE>JAMES
>KING>CLARK
>KING>CLARK>MILLER
SELECT ename
FROM scott.emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
--得到结果为:
KING
JONES
SCOTT
ADAMS
FORD
SMITH
BLAKE
ALLEN
WARD
MARTIN
TURNER
JAMES
而:
SELECT SYS_CONNECT_BY_PATH(ename, '>') "Path"
FROM scott.emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
--得到结果为:
>KING
>KING>JONES
>KING>JONES>SCOTT
>KING>JONES>SCOTT>ADAMS
>KING>JONES>FORD
>KING>JONES>FORD>SMITH
>KING>BLAKE
>KING>BLAKE>ALLEN
>KING>BLAKE>WARD
>KING>BLAKE>MARTIN
>KING>BLAKE>TURNER
>KING>BLAKE>JAMES
>KING>CLARK
>KING>CLARK>MILLER
其实SYS_CONNECT_BY_PATH这个函数是oracle9i才新提出来的!
它一定要和connect by子句合用!
第一个参数是形成树形式的字段,第二个参数是父级和其子级分隔显示用的分隔符!
START WITH 代表你要开始遍历的的节点!
CONNECT BY PRIOR 是标示父子关系的对应!
如下例子:
view plaincopy to clipboardprint?
select max(
substr(
sys_connect_by_path(column_name,',')
,2)
)
from (select column_name,rownum rn from user_tab_columns where table_name ='AA_TEST')
start with rn=1 connect by rn=rownum ;
select max(
substr(
sys_connect_by_path(column_name,',')
,2)
)
from (select column_name,rownum rn from user_tab_columns where table_name ='AA_TEST')
start with rn=1 connect by rn=rownum ;
是将列用,进行分割成为一行,然后将首个,去掉,只取取最大的那个数据。
---------------------------------------------
下面是别人的例子:
1、带层次关系
view plaincopy to clipboardprint?
SQL> create table dept(deptno number,deptname varchar2(20),mgrno number);
Table created.
SQL> insert into dept values(1,'总公司',null);
1 row created.
SQL> insert into dept values(2,'浙江分公司',1);
1 row created.
SQL> insert into dept values(3,'杭州分公司',2);
1 row created.
SQL> commit;
Commit complete.
SQL> select max(substr(sys_connect_by_path(deptname,','),2)) from dept connect by prior deptno=mgrno;
MAX(SUBSTR(SYS_CONNECT_BY_PATH(DEPTNAME,','),2))
--------------------------------------------------------------------------------
总公司,浙江分公司,杭州分公司
SQL> create table dept(deptno number,deptname varchar2(20),mgrno number);
Table created.
SQL> insert into dept values(1,'总公司',null);
1 row created.
SQL> insert into dept values(2,'浙江分公司',1);
1 row created.
SQL> insert into dept values(3,'杭州分公司',2);
1 row created.
SQL> commit;
Commit complete.
SQL> select max(substr(sys_connect_by_path(deptname,','),2)) from dept connect by prior deptno=mgrno;
MAX(SUBSTR(SYS_CONNECT_BY_PATH(DEPTNAME,','),2))
--------------------------------------------------------------------------------
总公司,浙江分公司,杭州分公司
2、行列转换
如把一个表的所有列连成一行,用逗号分隔:
view plaincopy to clipboardprint?
SQL> select max(substr(sys_connect_by_path(column_name,','),2))
from (select column_name,rownum rn from user_tab_columns where table_name ='DEPT')
start with rn=1 connect by rn=rownum ;
MAX(SUBSTR(SYS_CONNECT_BY_PATH(COLUMN_NAME,','),2))
--------------------------------------------------------------------------------
DEPTNO,DEPTNAME,MGRNO
posted @
2011-08-05 11:03 xzc 阅读(1399) |
评论 (3) |
编辑 收藏posted @
2011-07-18 18:51 xzc 阅读(620) |
评论 (0) |
编辑 收藏转自:
http://blog.csdn.net/tianlesoftware/article/details/4680230
在Oracle中建库,通常有两种方法。一是使用Oracle的建库工
且DBCA,这是一个图形界面工且,使用起来方便且很容易理解,因为它的界面友好、美观,而且提示也比较齐全。在Windows系统中,这个工具可以在Oracle程序组中打开(”开始”—“程序”—“ Oracle OraDb10g_home1”—“ Configuration and Migration Tools”—“ Database ConfigurationAssistant”),也可以在命令行(”开始”—“运行”—“cmd”)工具中直接输入dbca来打开。另一种方法就是手工建库,这也就是下面所要讲的内容。 手工建库比起使用DBCA建库来说,是比较麻烦的,但是如果我们学好了手工建库的话,就可以使我们更好地理解Oracle数据库的体系结构。手工建库须要经过几个步骤,每一个步骤都非常关键。它包括:
1、 创建必要的相关目录
2、 创建初始化参数文件
3、 设置环境变量Oracle_sid
4、 创建实例
5、 创建口令文件
6、 启动数据库到nomount(实例)状态
7、 执行建库脚本
8、 执行catalog脚步本创建数据字典
9、 执行catproc创建package包
10、 执行pupbld
11、 由初始化参数文件创建spfile文件
12、 执行scott脚本创建scott模式
做完了以上的步骤之后就可以使用“SQL>alterdatabase open;”打开数据库正常的使用了。下面,我将具体地把以上的几个步骤用实验展开来讲。 实验系统平台:Windows Server 2000 数据库系统版本:Oracle Database 10G Oracle的安装路径:D盘 .创建的数据库名称:book 1、打开命令行工具,创建必要有相关目录
C:/>mkdir D:/oracle/product/10.1.0/admin/book
C:/>mkdir D:/oracle/product/10.1.0/admin/book/bdump
C:/>mkdir D:/oracle/product/10.1.0/admin/book/udump
C:/>mkdir D:/oracle/product/10.1.0/admin/book/cdump
C:/>mkdir D:/oracle/product/10.1.0/admin/book/pfile
C:/>mkdir D:/oracle/product/10.1.0/admin/book/create
C:/>mkdir D:/oracle/product/10.1.0/oradata/book
上面创建目录的过程也可以在Windows的图形界面中去创建。其中
D:/oracle/product/10.1.0/admin/book目录下的几个子目录主要用于存放数据库运行过程中的跟踪信息。最重要的两上子目录是bdump和udump目录,bdump目录存放的是数据库动行过程中的各个后台进程的跟踪信息,当中alert文件是警告文件,其文件名称为alert_book.log,当数据库出现问题时,首先就可以去查看此文件以找出原因,手工创建过程中出现的各种问题往往也可以通过查看这个文件找到原因。Udump目录存放特定会话相关的跟踪信息D:/oracle/product/10.1.0/oradata/book目录存放各种数据库文件,包括控制文件、数据文件、重做日志文件。
2、创建初始化参数文件
数据库系统启动时须要用初始化参数文件的设置分配内存、启动必要的后台进程的。因此,初始化参数文件创建的是否正确、参数设置是否正确关系着整个建库的“命运”。 创建初始化参数文件可以通过拷贝现在的初始化参数文件并将其做适当的修改即可,从而不必要用
手工去一句一句地写出来,因为初始化参数文件的结构体系基本上都是一样的。在我们安装Oracle的时候,系统已经为我们安装了一个名为orcl的数据库,于是我们可以从它那里得到一份初始化参数文件。打开D:/oracle/product/10.1.0/admin/orcl/pfile,找到init.ora文件,把它拷贝到D:/oracle/product/10.1.0/bd_1/databse下,并将其改名为initbook.ora。接着用记事本的方式打开initbook.ora,修改以下的内容: db_domain=""
db_name=book
control_files=("D:/oracle/product/10.1.0/oradata/book/control01.ctl",
"D:/oracle/product/10.1.0/oradata/book/control02.ctl",
"D:/oracle/product/10.1.0/oradata/book/control03.ctl") undo_management=AUTO
undo_tablespace=UNDOTBS1
――注意此处的“UNDOTBS1”要和建库脚步本中对应
background_dump_dest=D:/oracle/product/10.1.0/admin/book/bdump
core_dump_dest=D:/oracle/product/10.1.0/admin/book/cdump
user_dump_dest=D:/oracle/product/10.1.0/admin/book/udump
3、打开命令行,设置环境变量oracle_sid
C:/>set oracle_sid=book 设置环境变量的目地是在默认的情况下,指定命令行中所操作的数据库实例是book。
4、创建实例(即后台控制服务)
C:/>oradim –new –sid book oradim是创建实例的工具程序名称,-new表明执行新建实例,-delete表明执行删掉实例,-sid指定害例的名称。 5、创建口令文件
C:/>orapwd file=D:/oracle/product/10.1.0/db_1/database/pwdbook.ora password=bookstore entries=2
orapwd是创建口令文件的工肯程序各称,file参数指定口令文件所在的目录和文件名称,password参数指定sys用户的口令,entries参数指定数据库拥用DBA权限的用户的个数,当然还有一个force参数,相信您不指即明,这里就不再细述。 请注意,这里的命令要一行输入,中间不得换行,否则会出现不必要的错误。 口令文件是专门存放sys用户的口令,因为sys用户要负责建库、启动数据库、关闭数据库等特殊任务,把以sys用户的中令单独存放于口令文件中,这样数据库末打开时也能进行口令验证。
6、启动数据
库到nomount(实例)状态 C:/>sqlplus /nolog SQL*Plus:Release 10.1.0.2.0 - Production on 星期三 6月 29
23:09:35 2005 Copyright 1982,2004,Oracle. All rights reserved. SQL>connect sys/bookstore as sysdba
---这里是用sys连接数据库 已连接到空闲例程
SQL>startup nomount ORACLE 例程已经启动。
Total System Global Area 319888364
bytes Fixed Size 453612bytes
Variable Size 209715200bytes
DatabaseBuffers 109051904bytes
Redo Buffers 667648bytes
SQL>
7、执行建库脚本
执行建库脚本,首先要有建库的脚本。(去哪找建库脚本呢?我又没有!)不用着急,请接着往下看。 得到一个符合自己要求的建库脚本有两种方法,一种方法是在自己的电脑上用DBCA来建,接照它的提示一步步地去做,在做到第十二步的时候,请选择“生成建库脚本”,然后就大功告成,你就可以到相应的目录上去找到那个脚本并适当地修它便可便用。另一种方法就是自己手工去写一份建库脚本,这也是这里要见意使用的方法,用记事本编辑如下的内容,并将其保存为文件名任取而后缀名为(*.sql)的SQL脚本,这里保存到E盘根本录下且文件名称为book.sql。
Create database book datafile 'D:/oracle/product/10.1.0/oradata/book/system01.dbf' size 300M reuse
autoextend on next 10240Kmaxsize unlimited extent management local sysaux datafile
'D:/oracle/product/10.1.0/oradata/book/sysaux01.dbf' size 120M reuse autoextend on next 10240K
maxsize unlimited default temporary tablespace temp tempfile
'D:/oracle/product/10.1.0/oradata/book/temp01.dbf' size 20M reuse autoextend on next 640Kmaxsize unlimited undo tablespace "UNDOTBS1"
--请注意这里的undo表空间要和参数文件对应 datafile
'D:/oracle/product/10.1.0/oradata/book/undotbs01.dbf' size 200M reuse autoextend on next 5120K
maxsize unlimited logfile
group 1 ('D:/oracle/product/10.1.0/oradata/book/redo01.log') size 10240K,
group 2 ('D:/oracle/product/10.1.0/oradata/book/redo02.log') size 10240K, group 3('D:/oracle/product/10.1.0/oradata/book/redo03.log') size 10240K 接着就执行刚建的建库脚本:
SQL>start E:/book.sql
8、执行catalog脚步本创建数据字典
SQL>start D:/oracle/product/10.1.0/db_1/rdbms/admin/catalog.sql
9、执行catproc创建package包 SQL>start
D:/oracle/product/10.1.0/db_1/rdbms/admin/catproc.sql
10、执行pupbld
在执行pupbld之前要把当前用户(sys)转换成system,即以system账户连接数据库。因为此数据库是刚建的,所以system的口令是系统默认的口令,即manager。你可以在数据库建好以后再来重新设置此账户的口令。
SQL>connectsystem/manager
SQL>start D:/oracle/product/10.1.0/db_1/sqlplus/admin/pupbld.sql
11、由初始化参
数文件创建spfile文件 SQL>create spfile from pfile;
12、执行scott脚本创建scott模式 SQL>start
D:/oracle/product/10.1.0/db_1/rdbms/admin/scott.sql
13、把数据库打开到正常状态 SQL>alterdatabase open;
14、以scott连接到数据库(口令为tiger),测试新建数据库是否可以正常运行 至此,整个数据库就已经建好了。接着你就可以在此数据库上建立自己的账户和表空间啦以及数据库对象,这里就不再作更
多地叙述。
附:本意是想在linux上创建个oracle实例的,用这个文档捣鼓了半天,都快结束了才发现这个方法只能在window上使用。晕死了。自己机子上装的oracle 11i的,看了下与oracle 10g还是有点区别的:
没仔细研究,就发现amin下目录不一样:
Oracle 10G下有bdump ,udump ,cdump,pfile,create
Oracle 11i 只有 adump,dpdump,pfile 三个。有空在研究吧。
还是想在linux下手动创建个。
unix和linux下没有oradim命令,因为没用,oradim主要就是用来控制服务的,unix/linux上oracle 实例不需要建立服务,所以就没有。
posted @
2011-07-18 18:50 xzc 阅读(680) |
评论 (0) |
编辑 收藏WINDOWS是很脆弱的系统,可能装完没几天就会崩溃,如果你在WINDOWS下装有oracle,那怎么来恢复这个数据库呢?
一种方法是重装数据库后用IMP来导入原来的数据,但使用这种方法的前提是你有以前数据的备份,并且这种方法还有许多不足的地方,如备份过旧,可能会丢失许多数据、导入数据太长等。
一般情况下我们可以采用重用原来的数据库的方法来恢复。在讲步骤前先说说这种方法的原理。
数据库与实例对应,当数据库服务启动后,我们可以用SQLPLUS "/AS SYSDBA"方法连接到一个空闲的例程,当执行startup启动数据库时,首先会在%ORACLE_HOME%/database下找当前SID对应的参数文件(PFILE或者SPFILE)和密码文件,然后启动例程;接着根据参数文件记录的信息找到控制文件,读取控制文件的信息,这就是mount数据库了;最终根据控制文件的信息打开数据库。这个过程相当于对数据库着了一次冷备份的恢复。
下面的具体步骤:(我们假设原库的所有相关文件都存在)
1、安装数据库软件
只需安装同版本的数据库软件即可,不需要创建数据库。最好安装在和原来数据库同样的%ORACLE_HOME%下,省得还要修改参数文件路径等。(直接覆盖原来的oracle即可)
再次强调,只安装软件,不创建数据库,否则将数据库软件安装在同样的目录下旧的部分数据文件会被覆盖,这样数据库也不能被恢复了。
2、新建一个实例
在cmd窗口执行
oradim -new -sid oracle9i
注意,这个SID名称最好与你以前的SID一样,否则在启动的数据需要指明pfile,并且需要重建密码文件,比较麻烦。(当然,如果你就不想用原来的SID也可以,把参数文件、密码文件的名称都改成与新SID对应的名称)。
3、启动数据库
做完以上两步,就可以启动数据库了。
用net start 检查oracle服务是否已经启动,如果oracle服务没有启动,则在cmd下运行如下命令:
net start oracleserviceoracle9i
然后设定必要的环境变量,在cmd窗口运行
set ORACLE_SID=oracle9i
接着连接数据库
sqlplus "/as sysdba"
startup
如果正常的话,数据库应该就能起来了
4、启动监听
lsnrctl start
5、后续工作
经过以上几步后,基本上就可以使用oracle了,但是使用起来有点不方便,如每次在cmd中启动数据库都需要先SET ORACLE_SID、在本机连接数据库也都需要加上@TNSNAME等。我们可以修改注册表,添加ORACLE_SID的信息,避免这些麻烦。
在注册表的HKEY_LOCAL_MACHINESOFTWAREORACLE下新建字符串值,名称为ORACLE_SID,值为oracle9i。
也可以将以下内容保持成一个后缀名为reg的文件(文件名随便起),然后双击,即可将信息导入到注册表中。
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESOFTWAREORACLE]
"ORACLE_SID"="oracle9i"
注意,以上步骤都是在%ORACLE_HOME%、%ORACLE_SID%都与原库一样的情况下讨论的,虽然%ORACLE_HOME%和%ORACLE_SID%可以与原库不一样,但为了减少麻烦和出错的几率,建议不要改变则两个值。
posted @
2011-07-17 13:45 xzc 阅读(569) |
评论 (1) |
编辑 收藏
研究发现:属性(变量)可分为三类(对象属性、全局变量和局部变量)
对象属性:声明时以“this.”开头,只能被“类的实例”即对象所调用,不能被“类内部(对外不对内)”调用;全局变量:声明时直接以变量名开头,可以任意调用(对内对外);局部变量:只能被
“类内部(对内不对外)”调用。
JS函数的声明与访问原理
<script type="text/javascript">
//类
var testClass = function(){
//对象属性(对外不对内,类调用)
this.age ="25";
//全局变量(对内对外)
name="jack";
//局部变量(对内不对外)
var address = "beijing";
//全局函数(对内对外)
add = function(a,b){
//可访问:全局变量和局部变量
multiply(a,b);
return a+b;
}
//实例函数(由类的对象调用)
this.minus = function(a,b){
//可以访问:对象属性、全局变量和局部变量
return a-b;
}
//局部函数(内部直接调用)
var multiply = function(a,b){
//只能访问:全局变量和局部变量
return a*b;
}
}
//类函数(由类名直接调用)
testClass.talk= function(){
//只能访问:全局变量和全局函数
this.what = function(){
alert("What can we talk about?");
about();
}
var about = function(){
alert("about name:"+name);
alert("about add(1,1):"+add(1,1));
}
}
//原型函数(由类的对象调用)
testClass.prototype.walk = function(){
//只能访问:全局变量和全局函数
this.where = function(){
alert("Where can we go?");
go();
}
var go = function(){
alert("go name:"+name);
alert("go add(1,1):"+add(1,1));
}
}
</script>
下面看看如何调用:
<script type="text/javascript">
//获取一个cbs类的实例
var cbs= new testClass();
//调用类的对象属性age
alert("age:"+cbs.age);
//获取类函数talk的实例
var talk = new testClass.talk();
//调用类函数的实例函数
talk.what();
//获取原型函数walk的实例
var walk = new cbs.walk();
//调用原型函数的实例函数
walk.where();
</script>
posted @
2011-07-09 11:34 xzc 阅读(1005) |
评论 (2) |
编辑 收藏常用命令
Maven2 的运行命令为 : mvn ,
常用命令为 :
mvn archetype:create :创建 Maven 项目
mvn compile :编译源代码
mvn test-compile :编译测试代码
mvn test : 运行应用程序中的单元测试
mvn site : 生成项目相关信息的网站
mvn clean :清除目标目录中的生成结果
mvn package : 依据项目生成 jar 文件
mvn install :在本地 Repository 中安装 jar
mvn eclipse:eclipse :生成 Eclipse 项目文件
生成项目
建一个 JAVA 项目 : mvn archetype:create -DgroupId=com.demo -DartifactId=App
建一个 web 项目 : mvn archetype:create -DgroupId=com.demo -DartifactId=web-app -DarchetypeArtifactId=maven-archetype-webapp
简单解释一下:
archetype 是一个内建插件,他的create任务将建立项目骨架
archetypeArtifactId 项目骨架的类型
DartifactId 项目名称
可用项目骨架有:
* maven-archetype-archetype
* maven-archetype-j2ee-simple
* maven-archetype-mojo
* maven-archetype-portlet
* maven-archetype-profiles (currently under development)
* maven-archetype-quickstart
* maven-archetype-simple (currently under development)
* maven-archetype-site
* maven-archetype-site-simple, and
* maven-archetype-webapp
附maven2 生成项目标准目录布局
src/main/java Application/Library sources
src/main/resources Application/Library resources
src/main/filters Resource filter files
src/main/assembly Assembly descriptors
src/main/config Configuration files
src/main/webapp Web application sources
src/test/java Test sources
src/test/resources Test resources
src/test/filters Test resource filter files
src/site Site
LICENSE.txt Project's license
README.txt Project's readme
posted @
2011-07-08 11:20 xzc 阅读(3893) |
评论 (0) |
编辑 收藏
如果你想定义一个maven工程模板,有一种很快的方法:
1.定义你开发环境的目录结构,写一个pom.xml.
2.使用命令,mvn archetype:create-from-project 创建一个工程模板。
3.在target目录下执行mvn install.执行完之后你就可以使用你的模板了。
4.执行命令,mvn archetype:generate -DarchetypeCatalog=local就可以开始使用你定义的模板创建工程。
例子:
1.创建目录结构如下:
Demo
--src
--main
--resources
--test
--webapp
pom.xml
pom.xml内容:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>gDemo</groupId>
<artifactId>demo</artifactId>
<packaging>jar</packaging>
<version>1.0</version>
<name>Maven Quick Start Archetype</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
2.在Demo目录下执行命令,mvn archetype:create-from-project
3.在创建的target\generated-sources\archetype目录下执行,mvn install.
到此你的工程模板创建完成。在以后开发中就可以使用它。
4.执行mvn archetype:generate -DarchetypeCatalog=local会看到模板选项,选择刚才创建的模板,然后进行下面的设置。
到此恭喜你,成功使用。
posted @
2011-07-08 10:13 xzc 阅读(1564) |
评论 (0) |
编辑 收藏总体解释:
DML(data manipulation language):
它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言
DDL(data definition language):
DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
DCL(Data Control Language):
是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权力执行DCL
详细解释:
一、DDL is Data Definition Language statements. Some examples:数据定义语言,用于定义和管理 SQL 数据库中的所有对象的语言
1.CREATE - to create objects in the database 创建
2.ALTER - alters the structure of the database 修改
3.DROP - delete objects from the database 删除
4.TRUNCATE - remove all records from a table, including all spaces allocated for the records are removed
TRUNCATE TABLE [Table Name]。
下面是对Truncate语句在MSSQLServer2000中用法和原理的说明:
Truncate table 表名 速度快,而且效率高,因为:
TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。
DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 DROP TABLE 语句。
对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
TRUNCATE TABLE 不能用于参与了索引视图的表。
5.COMMENT - add comments to the data dictionary 注释
6.GRANT - gives user's access privileges to database 授权
7.REVOKE - withdraw access privileges given with the GRANT command 收回已经授予的权限
二、DML is Data Manipulation Language statements. Some examples:数据操作语言,SQL中处理数据等操作统称为数据操纵语言
1.SELECT - retrieve data from the a database 查询
2.INSERT - insert data into a table 添加
3.UPDATE - updates existing data within a table 更新
4.DELETE - deletes all records from a table, the space for the records remain 删除
5.CALL - call a PL/SQL or Java subprogram
6.EXPLAIN PLAN - explain access path to data
Oracle RDBMS执行每一条SQL语句,都必须经过Oracle优化器的评估。所以,了解优化器是如何选择(搜索)路径以及索引是如何被使用的,对优化SQL语句有很大的帮助。Explain可以用来迅速方便地查出对于给定SQL语句中的查询数据是如何得到的即搜索路径(我们通常称为Access Path)。从而使我们选择最优的查询方式达到最大的优化效果。
7.LOCK TABLE - control concurrency 锁,用于控制并发
三、DCL is Data Control Language statements. Some examples:数据控制语言,用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等
1.COMMIT - save work done 提交
2.SAVEPOINT - identify a point in a transaction to which you can later roll back 保存点
3.ROLLBACK - restore database to original since the last COMMIT 回滚
4.SET TRANSACTION - Change transaction options like what rollback segment to use 设置当前事务的特性,它对后面的事务没有影响.
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/level_level/archive/2009/06/08/4248685.aspx
posted @
2011-06-27 10:53 xzc 阅读(503) |
评论 (0) |
编辑 收藏
1,REGEXP_LIKE :与LIKE的功能相似
2,REGEXP_INSTR :与INSTR的功能相似
3,REGEXP_SUBSTR :与SUBSTR的功能相似
4,REGEXP_REPLACE :与REPLACE的功能相似
它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法相同,
但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
POSIX 正则表达式由标准的元字符(metacharacters)所构成:
'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹
配 '\n' 或 '\r'。
'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的
字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少
出现m次。
\num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
各种操作符的运算优先级
\转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
|
*/
--创建表
create table fzq
(
id varchar(4),
value varchar(10)
);
--数据插入
insert into fzq values
('1','1234560');
insert into fzq values
('2','1234560');
insert into fzq values
('3','1b3b560');
insert into fzq values
('4','abc');
insert into fzq values
('5','abcde');
insert into fzq values
('6','ADREasx');
insert into fzq values
('7','123 45');
insert into fzq values
('8','adc de');
insert into fzq values
('9','adc,.de');
insert into fzq values
('10','1B');
insert into fzq values
('10','abcbvbnb');
insert into fzq values
('11','11114560');
insert into fzq values
('11','11124560');
--regexp_like
--查询value中以1开头60结束的记录并且长度是7位
select * from fzq where value like '1____60';
select * from fzq where regexp_like(value,'1....60');
--查询value中以1开头60结束的记录并且长度是7位并且全部是数字的记录。
--使用like就不是很好实现了。
select * from fzq where regexp_like(value,'1[0-9]{4}60');
-- 也可以这样实现,使用字符集。
select * from fzq where regexp_like(value,'1[[:digit:]]{4}60');
-- 查询value中不是纯数字的记录
select * from fzq where not regexp_like(value,'^[[:digit:]]+$');
-- 查询value中不包含任何数字的记录。
select * from fzq where regexp_like(value,'^[^[:digit:]]+$');
--查询以12或者1b开头的记录.不区分大小写。
select * from fzq where regexp_like(value,'^1[2b]','i');
--查询以12或者1b开头的记录.区分大小写。
select * from fzq where regexp_like(value,'^1[2B]');
-- 查询数据中包含空白的记录。
select * from fzq where regexp_like(value,'[[:space:]]');
--查询所有包含小写字母或者数字的记录。
select * from fzq where regexp_like(value,'^([a-z]+|[0-9]+)$');
--查询任何包含标点符号的记录。
select * from fzq where regexp_like(value,'[[:punct:]]');
/*
理解它的语法就可以了。其它的函数用法类似。
作者:tshfang
来源: 泥胚文章写作http://www.nipei.com原文地址:http://www.nipei.com/article/9865
posted @
2011-06-21 15:39 xzc 阅读(1495) |
评论 (0) |
编辑 收藏
早起的国内互联网都使用GBK编码,久之,所有项目都以GBK来编码了。对于J2EE项目,为了减少编码的干扰通常都是设置一个编码的Filter,强制将Request/Response编码改为GBK。例如一个Spring的常见配置如下:
<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>GBK</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
毫无疑问,这在GBK编码的页面访问、提交数据时是没有乱码问题的。但是遇到Ajax就不一样了。Ajax强制将中文内容进行UTF-8编码,这样导致进入后端后使用GBK进行解码时发生乱码。网上的所谓的终极解决方案都是扯淡或者过于复杂,例如下面的文章:
这样的文章很多,显然:
- 使用VB进行UTF-8转换成GBK提交是完全不可行(多浏览器、多平台完全不可用)
- 使用复杂的js函数进行一次、多次编码,后端进行一次、多次解码也是不靠谱的,成本太高,无法重复使用
如果提交数据的时候能够告诉后端传输的编码信息是否就可以避免这种问题?比如Ajax请求告诉后端是UTF-8,其它请求告诉后端是GBK,这样后端分别根据指定的编码进行解码是不是就解决问题了。
有两个问题:
- 如何通过Ajax告诉后端的编码?Header过于复杂,Cookie成本太高,使用参数最方便。
- 后端何时进行解码?每一个请求进行解码,过于繁琐;获取参数时解码,此时已经乱码;在Filter里面动态设置编码是最完善的方案。
- 如何从参数中获取编码?如果是POST的body显然无法获取,因此在获取之前所有参数就已经按照某种编码解码过了,无法还原。所以通过URL传递编码最有效。支持GET/POST,同时成本很低。
解决了上述问题,来看具体实现方案。 列一段Java代码:
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.util.ClassUtils;
import org.springframework.web.filter.OncePerRequestFilter;
/** 自定义编码过滤器
* @author imxylz (imxylz#gmail.com)
* @sine 2011-6-9
*/
public class MutilCharacterEncodingFilter extends OncePerRequestFilter {
static final Pattern inputPattern = Pattern.compile(".*_input_encode=([\\w-]+).*");
static final Pattern outputPattern = Pattern.compile(".*_output_encode=([\\w-]+).*");
// Determine whether the Servlet 2.4 HttpServletResponse.setCharacterEncoding(String)
// method is available, for use in the "doFilterInternal" implementation.
private final static boolean responseSetCharacterEncodingAvailable = ClassUtils.hasMethod(HttpServletResponse.class,
"setCharacterEncoding", new Class[] { String.class });
private String encoding;
private boolean forceEncoding = false;
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
String url = request.getQueryString();
Matcher m = null;
if (url != null && (m = inputPattern.matcher(url)).matches()) {//输入编码
String inputEncoding = m.group(1);
request.setCharacterEncoding(inputEncoding);
m = outputPattern.matcher(url);
if (m.matches()) {//输出编码
response.setCharacterEncoding(m.group(1));
} else {
if (this.forceEncoding && responseSetCharacterEncodingAvailable) {
response.setCharacterEncoding(this.encoding);
}
}
} else {
if (this.encoding != null && (this.forceEncoding || request.getCharacterEncoding() == null)) {
request.setCharacterEncoding(this.encoding);
if (this.forceEncoding && responseSetCharacterEncodingAvailable) {
response.setCharacterEncoding(this.encoding);
}
}
}
filterChain.doFilter(request, response);
}
public void setEncoding(String encoding) {
this.encoding = encoding;
}
public void setForceEncoding(boolean forceEncoding) {
this.forceEncoding = forceEncoding;
}
}
解释下:
- 如果URL的QueryString中包含_input_encode就使用此编码进行设置Request编码,以后参数按照此编码进行解析,例如如果是Ajax就传入UTF-8,如果是普通的GBK请求则无视此参数。
- 如果无视此参数,则按照web.xml中配置的编码规则进行反编码,如果是GBK就按照GBK规则解析。
- 对于输出编码同样使用上述规则。需要输出编码依赖输入编码,也就是说如果有一个_output_encode的输出编码,则同时需要有一个_input_encode编码来指定输入编码。当然你可以改造成不依赖输入编码。
- 完全兼容Spring的org.springframework.web.filter.CharacterEncodingFilter编码规则,只需要替换类即可。
- 没有继承org.springframework.web.filter.CharacterEncodingFilter类的原因是,org.springframework.web.filter.CharacterEncodingFilter里面的encoding参数和forceEncoding参数是private,子类无法使用。在有_input_encode而无_output_encode的时候想依然保持Spring的Response解析规则的话无法做到,所以将里面的代码拷贝过来使用。(为了展示方便,注释都删掉了)
- 正则表达式可以改进成只需要匹配一次,从而可以提高一点点效率。
- 所有后端请求将无视编码的存在,前端Ajax的GET/POST请求也将无视编码的存在,只是在URL地址中加上一个_input_encode=UTF-8的参数。仅此而已。
- 如果想输出的编码也是UTF-8,比如手机端请求、跨站请求等,则需要URL地址参数_input_encode=UTF-8&_output_encode=UTF-8。
- 对于POST请求,编码参数不能写在body里面,否则无法解析。
- 显然,这种终极解决方案,在任何编码中都可以解决,GBK/UTF-8/ISO8859-1等编码任何组合都可以实现。
- 唯一局限性是,此解决方案限制在J2EE项目中,其它平台不知是否有类似Filter这样的组件能够设置编码的概念。
posted @
2011-06-21 11:54 xzc 阅读(2103) |
评论 (1) |
编辑 收藏
下载地址:http://sourceforge.net/project/showfiles.php?group_id=178867
1.buffalo-2.0.jar
在buffalo-2.0-bin里,把它加到Web应用程序里的lib
2.buffalo.js和prototype.js
我把这两个文件放到Web应用程序的scripts/目录下,buffalo.js在buffalo-2.0-bin里,prototype.js在buffalo-demo.war里找
4.web.xml内容
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<servlet>
<servlet-name>bfapp</servlet-name>
<servlet-class>net.buffalo.web.servlet.ApplicationServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>bfapp</servlet-name>
<url-pattern>/bfapp/*</url-pattern>
</servlet-mapping>
</web-app>
5.index.jsp文件
<%@ page language="java" pageEncoding="UTF-8"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>第一个 buffalo 示例程序</title>
<script language="JavaScript" src="scripts/prototype.js"></script>
<script language="JavaScript" src="scripts/buffalo.js"></script>
<script type="text/javascript">
var endPoint="<%=request.getContextPath()%>/bfapp";
var buffalo = new Buffalo(endPoint);
function hello(me) {
buffalo.remoteCall("demoService.getHello", [me.value], function(reply) {
alert(reply.getResult());
})
}
</script>
</head>
<body>
输入你的名字:<input type="text" name="myname">
<input type="button" value="Buffao远程调用" onclick="hello($('myname'));"><br>
</body>
</html>
说明:remoteCall是远程调用方法,demoService是buffalo-service.properties文件的键,getHello是被调用java类方法名,me.value是传给getHello方法的参数,reply.getResult()是getHello返回的值。
6.DemoService.java文件
package demo.buffalo;
/**
*
* @文件名 demo.buffalo.DemoService.java
* @作者 chenlb
* @创建时间 2007-7-14 下午12:42:17
*/
public class DemoService {
public String getHello(String name) {
return "Hello , "+name +" 这是第一个buffalo示例程序";
}
}
7.buffalo-service.properties文件放到WEB-INF/classes/目录下
demoService=demo.buffalo.DemoService
说明:框架是通过此文件来查找远程调用的类的。
8.现在可以运行了。
示例下载
注意:Eclipse项目,文件编码是UTF-8
官方地址:
Buffalo中文论坛:http://groups.google.com/group/amowa
http://buffalo.sourceforge.net/tutorial.html
http://confluence.redsaga.com/pages/viewpage.action?pageId=1643
JavaScript API :http://confluence.redsaga.com/display/BUFFALO/JavaScript+API
http://www.amowa.net/buffalo/zh/index.html
posted @
2011-06-16 16:44 xzc 阅读(380) |
评论 (0) |
编辑 收藏转自:http://dingyu.me/blog/posts/view/flowchart-howtos
一个哥们在MSN上告诉我,他们公司的交互设计师只产出流程图,并问我用什么标准评价流程图的好坏。他的说法把我彻底震了-这分工也太细了吧!也不知道该说他们那里这样是好还是不好。
不过仔细想来,我倒的确没有仔细考虑过流程图的好坏,正好借此机会自我总结一下。
1、各司其职的形状
在我的流程图中,适用于不同目的和功能的形状都有各自确定的规范。到目前为止,我一共定义了以下一些形状:
(1)开始和结束

作为整张流程图的头和尾,必须标清楚到底具体指哪个页面,以免日后出现歧义。
(2)网页

如你所见,网页的形状是一个带有漂亮的淡蓝色过渡效果的长方形,它的边框为深蓝色,中间写明了这个网页的用途,括号中的数字代表这个形状所对应的demo文件的名称(比如这里是2.html),我有时会把流程图输出为网页的形式,并把每个网页形状和它所对应的demo文件链接起来,这样查看起来非常方便。对OmniGraffle来说这是小菜一碟,如果你被迫用Visio,嗯……
另外,所有从形状出来的线条,都具有和此形状边框一样的颜色。这样的做法不仅看起来漂亮,在复杂的流程图中还能轻易地标明各形状的关系。我没有见过类似的做法,所以这是由我首创也说不定,呵。
(3)后台判断

很常见的一个形状。我在用法上有一点和其他人的不同在于,我几乎总是让‘是’的分支往下流动,让‘否’的分支向右流动。因为流程图一般都是从上向下、从左到右绘制的,遵循上述规则一方面可以让绘制者不用为选择方向操心,另一方面也方便了读者阅读。
(4)表单错误页

既然有表单,当然会有错误信息。其实这个信息很重要,用户出错时惶恐不安,就靠着错误提示来解决问题了。你不在流程图里说什么时候显示错误页、不在demo里提供错误页,有些程序员会直接在网页上写个“错误,请检查”,所以UI设计师一定要对这个东西重视起来。
但一般来说也没必要把每种错误都在流程图中表示出来,因为含有两个文本框的表单就有三种出错情况了,多了就更不用说了。所以我都是把错误页变为表单的附属页,比如表单页的编号为2,那么此表单错误页的编号就从2.1开始排下去,每种错误放到一个附属页中,这样程序员在拿到demo时也能搞清楚什么意思。
结合网页和表单的形状,一个表单验证的流程图就是这样的:

(5)后台动作

并非所有后台动作都绘入流程图中(否则流程图就会变成庞然大物了),只有需要特别强调的后台动作(和用户体验直接相关的)才使用此形状。
(6)多重分支

多重分支指的是几种并列的情况,每种情况都有发生的可能,发生哪种取决于分支起始处的判断结果。
(7)对话框

有时候一些操作可以利用对话框来完成, 这些对话框由js生成,显示在父界面之上。
(8)注释

这个形状(比如页面)详细的内容,或者需要解释的业务逻辑,甚至用户此处的情况等,我都会放到注释中,这样既降低沟通成本,又可作为备忘。
(9)跳转点

在一个复杂的流程图中,往往出现跳转到另外一个远处结点的情况,此时如果直接用线连过去,未免使得流程图显得凌乱,用一个跳转点就解决问题了。在点内标明跳转到的形状的编号,画起来容易,看起来也清楚。
此外,也可以利用跳转点来分割篇幅巨大的流程图,Yahoo!就这么用。
(10)子流程

分割篇幅巨大的流程图,更好的办法是用子流程。
要注意的是,如果你在流程图中使用了子流程这一形状,一定记得同时附上子流程图,以消除影响项目质量的不确定性因素。另外,在子流程图中也可以标明其所属关系。
(11)流程块


可以用流程块将整张流程图分隔为几个部分,并为每个部分单独命名(比如“流程块1”等)。这样做的目的在于从视觉上使复杂的流程图变得更为清晰,在沟通时也方便。
2、图例和流程图信息

在团队合作中,图例是必须的,否则没人知道你画出来的东西到底是什么。即使流程图只给自己看,也最好养成标注图例的好习惯。其实这道理有点类似程序中的注释。
流程图信息也是必备的。其内容至少应包括作者、时间、流程图名称和版本(如下图)。这一方面可以让读者(其他同事)在有问题时能够方便地找到作者你,也起到了meta的作用。
3、绘制流程图的工具
Mac下首选OmniGraffle,Windows下除了Visio,似乎没有更好的选择(虽然Visio已经很难用了)。
4、评价流程图的好坏
我觉得一个好的流程图至少应做到以下几点:
- 密切地迎合了用户的心理状态、如实的反映了用户的操作习惯。流程图是要指导UI设计的,是UI设计的参照物,如果流程图本身无法正确描绘出用户的情况的话,UI十有八九会出问题;
- 覆盖了各种可能的情况和细节。这非常重要。任何在先期不确定的因素,都会在项目中成为随时引爆的地雷,都会直接降低最终上线的UI质量。此种情况真是屡见不鲜。但同时这条又很难做到,因为它不仅要求设计师熟悉用户,也要设计师充分知晓产品的商业逻辑,还要了解系统的运作机制,落下以上任何一个方面,都会在流程图中留下死角。这个问题我不知道有没有更好的解决方案,不过与PD和系分反复沟通是个行之有效的方法;
- 考虑到系统的设计和承受能力。系统的运作机制和承受能力必须在绘制流程图过程中考虑进去,以免出现流程图被开发人员枪毙的情况。我的习惯是,在绘制流程图时和系统分析师频繁沟通和交流,确保每一个环节都是可行的;
- 确保别人看得懂你的流程图。别人现在看不懂,你自己以后也一样看不懂。为了降低沟通成本,把流程图画清楚吧。
5、其它
(1)想办法把流程图绘制得漂亮些。谁不喜欢漂亮的东西呢?
这是我做过的一些流程图,当然文字全部模糊掉了(放图之前犹豫了好长时间-这样做不知是否有损我的职业道德。我特意请教了Fenng,他觉得没事。如果谁觉得有问题请直言不讳地告诉我)。


(2)如果你在公司里不是一锤定音式的人物的话,你就需要对你的文档进行版本管理。流程图也不例外,什么时间发布的什么版本,都要清楚地标出来,“ 最新”是个用不得的词。
我就说这么多了,抛砖引玉而已,蓉儿等人看你们的了!
噢对了,问个事儿:大家有没有觉得我每次写的文章都太长了?
posted @
2011-05-27 17:07 xzc 阅读(687) |
评论 (1) |
编辑 收藏从ftp定时下载按日期生成的文件
1、下载脚本get.bat如下
f:
cd f:/beifen (脚本所在目录)
set cicdate=%date:~0,4%%date:~5,2%%date:~8,2%
(echo open ftp地址
echo 用户名
echo 密码
echo prompt
echo get %cicdate%.txt
echo bye) > ftp_beifen.src
ftp -s:ftp_beifen.src
echo %date%导出数据库备份结束,时间:%time% >> getftp_beifen.log
2、在xp上定时自动运行批处理文件
AT命令是Windows XP中内置的命令,它也可以媲美Windows中的“计划任务”,而且在计划的安排、任务的管理、工作事务的处理方面,
AT命令具有更强大更神通的功能。AT命令可在指定时间和日期、在指定计算机上运行命令和程序。
查看所有安排的计划 at
取消已经安排的计划 at 5 /Delete
在dos下运行一下命令,系统就会在每天的16:46分自动运行批处理文件get.bat
net stop schedule
net start schedule
at 16:46 /every:Monday,Tuesday,Wednesday,Thursday,Friday,Saturday,Sunday F:\beifen\get.bat
posted @
2011-05-21 12:11 xzc 阅读(4690) |
评论 (1) |
编辑 收藏转自:http://blog.csdn.net/tianlesoftware/archive/2009/12/01/4915223.aspx
一、什么是Oracle字符集
Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。
影响Oracle数据库字符集最重要的参数是NLS_LANG参数。
它的格式如下: NLS_LANG = language_territory.charset
它有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中:
Language: 指定服务器消息的语言, 影响提示信息是中文还是英文
Territory: 指定服务器的日期和数字格式,
Charset: 指定字符集。
如:AMERICAN _ AMERICA. ZHS16GBK
从NLS_LANG的组成我们可以看出,真正影响数据库字符集的其实是第三部分。
所以两个数据库之间的字符集只要第三部分一样就可以相互导入导出数据,前面影响的只是提示信息是中文还是英文。
二.字符集的相关知识:
2.1 字符集
实质就是按照一定的字符编码方案,对一组特定的符号,分别赋予不同数值编码的集合。Oracle数据库最早支持的编码方案是US7ASCII。
Oracle的字符集命名遵循以下命名规则:
<Language><bit size><encoding>
即: <语言><比特位数><编码>
比如: ZHS16GBK表示采用GBK编码格式、16位(两个字节)简体中文字符集
2.2 字符编码方案
2.2.1 单字节编码
(1)单字节7位字符集,可以定义128个字符,最常用的字符集为US7ASCII
(2)单字节8位字符集,可以定义256个字符,适合于欧洲大部分国家
例如:WE8ISO8859P1(西欧、8位、ISO标准8859P1编码)
2.2.2 多字节编码
(1)变长多字节编码
某些字符用一个字节表示,其它字符用两个或多个字符表示,变长多字节编码常用于对亚洲语言的支持, 例如日语、汉语、印地语等
例如:AL32UTF8(其中AL代表ALL,指适用于所有语言)、zhs16cgb231280
(2)定长多字节编码
每一个字符都使用固定长度字节的编码方案,目前oracle唯一支持的定长多字节编码是AF16UTF16,也是仅用于国家字符集
2.2.3 unicode编码
Unicode是一个涵盖了目前全世界使用的所有已知字符的单一编码方案,也就是说Unicode为每一个字符提供唯一的编码。UTF-16是unicode的16位编码方式,是一种定长多字节编码,用2个字节表示一个unicode字符,AF16UTF16是UTF-16编码字符集。
UTF-8是unicode的8位编码方式,是一种变长多字节编码,这种编码可以用1、2、3个字节表示一个unicode字符,AL32UTF8,UTF8、UTFE是UTF-8编码字符集
2.3 字符集超级
当一种字符集(字符集A)的编码数值包含所有另一种字符集(字符集B)的编码数值,并且两种字符集相同编码数值代表相同的字符时,则字符集A是字符集B的超级,或称字符集B是字符集A的子集。
Oracle8i和oracle9i官方文档资料中备有子集-超级对照表(subset-superset pairs),例如:WE8ISO8859P1是WE8MSWIN1252的子集。由于US7ASCII是最早的Oracle数据库编码格式,因此有许多字符集是US7ASCII的超集,例如WE8ISO8859P1、ZHS16CGB231280、ZHS16GBK都是US7ASCII的超集。
2.4 数据库字符集(oracle服务器端字符集)
数据库字符集在创建数据库时指定,在创建后通常不能更改。在创建数据库时,可以指定字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。
2.4.1字符集
(1)用来存储CHAR, VARCHAR2, CLOB, LONG等类型数据
(2)用来标示诸如表名、列名以及PL/SQL变量等
(3)用来存储SQL和PL/SQL程序单元等
2.4.2国家字符集:
(1)用以存储NCHAR, NVARCHAR2, NCLOB等类型数据
(2)国家字符集实质上是为oracle选择的附加字符集,主要作用是为了增强oracle的字符处理能力,因为NCHAR数据类型可以提供对亚洲使用定长多字节编码的支持,而数据库字符集则不能。国家字符集在oracle9i中进行了重新定义,只能在unicode编码中的AF16UTF16和UTF8中选择,默认值是AF16UTF16
2.4.3查询字符集参数
可以查询以下数据字典或视图查看字符集设置情况
nls_database_parameters、props$、v$nls_parameters
查询结果中NLS_CHARACTERSET表示字符集,NLS_NCHAR_CHARACTERSET表示国家字符集
2.4.4修改数据库字符集
按照上文所说,数据库字符集在创建后原则上不能更改。不过有2种方法可行。
1. 如果需要修改字符集,通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换。
2. 通过ALTER DATABASE CHARACTER SET语句修改字符集,但创建数据库后修改字符集是有限制的,只有新的字符集是当前字符集的超集时才能修改数据库字符集,例如UTF8是US7ASCII的超集,修改数据库字符集可使用ALTER DATABASE CHARACTER SET UTF8。
2.5 客户端字符集(NLS_LANG参数)
2.5.1客户端字符集含义
客户端字符集定义了客户端字符数据的编码方式,任何发自或发往客户端的字符数据均使用客户端定义的字符集编码,客户端可以看作是能与数据库直接连接的各种应用,例如sqlplus,exp/imp等。客户端字符集是通过设置NLS_LANG参数来设定的。
2.5.2 NLS_LANG参数格式
NLS_LANG=<language>_<territory>.<client character set>
Language: 显示oracle消息,校验,日期命名
Territory:指定默认日期、数字、货币等格式
Client character set:指定客户端将使用的字符集
例如:NLS_LANG=AMERICAN_AMERICA.US7ASCII
AMERICAN是语言,AMERICA是地区,US7ASCII是客户端字符集
2.5.3客户端字符集设置方法
1)UNIX环境
$NLS_LANG=“simplified chinese”_china.zhs16gbk
$export NLS_LANG
编辑oracle用户的profile文件
2)Windows环境
编辑注册表
Regedit.exe ---》 HKEY_LOCAL_MACHINE ---》SOFTWARE ---》 ORACLE-HOME
2.5.4 NLS参数查询
Oracle提供若干NLS参数定制数据库和用户机以适应本地格式,例如有NLS_LANGUAGE,NLS_DATE_FORMAT,NLS_CALENDER等,可以通过查询以下数据字典或v$视图查看。
NLS_DATABASE_PARAMETERS:显示数据库当前NLS参数取值,包括数据库字符集取值
NLS_SESSION_PARAMETERS: 显示由NLS_LANG 设置的参数,或经过alter session 改变后的参数值(不包括由NLS_LANG 设置的客户端字符集)
NLS_INSTANCE_PARAMETE: 显示由参数文件init<SID>.ora 定义的参数
V$NLS_PARAMETERS:显示数据库当前NLS参数取值
2.5.5修改NLS参数
使用下列方法可以修改NLS参数
(1)修改实例启动时使用的初始化参数文件
(2)修改环境变量NLS_LANG
(3)使用ALTER SESSION语句,在oracle会话中修改
(4)使用某些SQL函数
NLS作用优先级别:Sql function > alter session > 环境变量或注册表 > 参数文件 > 数据库默认参数
三.EXP/IMP 与 字符集
3.1 EXP/IMP
Export 和 Import 是一对读写Oracle数据的工具。Export 将 Oracle 数据库中的数据输出到操作系统文件中, Import 把这些文件中的数据读到Oracle 数据库中,由于使用exp/imp进行数据迁移时,数据从源数据库到目标数据库的过程中有四个环节涉及到字符集,如果这四个环节的字符集不一致,将会发生字符集转换。
EXP
____________ _________________ _____________
|imp导入文件|<-|环境变量NLS_LANG|<-|数据库字符集|
------------ ----------------- -------------
IMP
____________ _________________ _____________
|imp导入文件|->|环境变量NLS_LANG|->|数据库字符集|
------------ ----------------- -------------
四个字符集是
(1)源数据库字符集
(2)Export过程中用户会话字符集(通过NLS_LANG设定)
(3)Import过程中用户会话字符集(通过NLS_LANG设定)
(4)目标数据库字符集
3.2导出的转换过程
在Export过程中,如果源数据库字符集与Export用户会话字符集不一致,会发生字符集转换,并在导出文件的头部几个字节中存储Export用户会话字符集的ID号。在这个转换过程中可能发生数据的丢失。
例:如果源数据库使用ZHS16GBK,而Export用户会话字符集使用US7ASCII,由于ZHS16GBK是16位字符集,而US7ASCII是7位字符集,这个转换过程中,中文字符在US7ASCII中不能够找到对等的字符,所以所有中文字符都会丢失而变成“?? ”形式,这样转换后生成的Dmp文件已经发生了数据丢失。
因此如果想正确导出源数据库数据,则Export过程中用户会话字符集应等于源数据库字符集或是源数据库字符集的超集
3.3导入的转换过程
(1)确定导出数据库字符集环境
通过读取导出文件头,可以获得导出文件的字符集设置
(2)确定导入session的字符集,即导入Session使用的NLS_LANG环境变量
(3)IMP读取导出文件
读取导出文件字符集ID,和导入进程的NLS_LANG进行比较
(4)如果导出文件字符集和导入Session字符集相同,那么在这一步骤内就不需要转换, 如果不同,就需要把数据转换为导入Session使用的字符集。可以看出,导入数据到数据库过程中发生两次字符集转换
第一次:导入文件字符集与导入Session使用的字符集之间的转换,如果这个转换过程不能正确完成,Import向目标数据库的导入过程也就不能完成。
第二次:导入Session字符集与数据库字符集之间的转换。
四. 查看数据库字符集
涉及三方面的字符集,
1. oracel server端的字符集;
2. oracle client端的字符集;
3. dmp文件的字符集。
在做数据导入的时候,需要这三个字符集都一致才能正确导入。
4.1 查询oracle server端的字符集
有很多种方法可以查出oracle server端的字符集,比较直观的查询方法是以下这种:
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
SQL>select userenv(‘language’) from dual;
AMERICAN _ AMERICA. ZHS16GBK
4.2 如何查询dmp文件的字符集
用oracle的exp工具导出的dmp文件也包含了字符集信息,dmp文件的第2和第3个字节记录了dmp文件的字符集。如果dmp文件不大,比如只有几M或几十M,可以用UltraEdit打开(16进制方式),看第2第3个字节的内容,如0354,然后用以下SQL查出它对应的字符集:
SQL> select nls_charset_name(to_number('0354','xxxx')) from dual;
ZHS16GBK
如果dmp文件很大,比如有2G以上(这也是最常见的情况),用文本编辑器打开很慢或者完全打不开,可以用以下命令(在unix主机上):
cat exp.dmp |od -x|head -1|awk '{print $2 $3}'|cut -c 3-6
然后用上述SQL也可以得到它对应的字符集。
4.3 查询oracle client端的字符集
在windows平台下,就是注册表里面相应OracleHome的NLS_LANG。还可以在dos窗口里面自己设置,
比如: set nls_lang=AMERICAN_AMERICA.ZHS16GBK
这样就只影响这个窗口里面的环境变量。
在unix平台下,就是环境变量NLS_LANG。
$echo $NLS_LANG
AMERICAN_AMERICA.ZHS16GBK
如果检查的结果发现server端与client端字符集不一致,请统一修改为同server端相同的字符集。
补充:
(1).数据库服务器字符集
select * from nls_database_parameters
来源于props$,是表示数据库的字符集。
(2).客户端字符集环境
select * from nls_instance_parameters
其来源于v$parameter,表示客户端的字符集的设置,可能是参数文件,环境变量或者是注册表
(3).会话字符集环境
select * from nls_session_parameters
来源于v$nls_parameters,表示会话自己的设置,可能是会话的环境变量或者是alter session完成,如果会话没有特殊的设置,将与nls_instance_parameters一致。
(4).客户端的字符集要求与服务器一致,才能正确显示数据库的非Ascii字符。
如果多个设置存在的时候,NLS作用优先级别:Sql function > alter session > 环境变量或注册表 > 参数文件 > 数据库默认参数
字符集要求一致,但是语言设置却可以不同,语言设置建议用英文。如字符集是zhs16gbk,则nls_lang可以是American_America.zhs16gbk。
五. 修改oracle的字符集
按照上文所说,数据库字符集在创建后原则上不能更改。因此,在设计和安装之初考虑使用哪一种字符集十分重要。对数据库server而言,错误的修改字符集将会导致很多不可测的后果,可能会严重影响数据库的正常运行,所以在修改之前一定要确认两种字符集是否存在子集和超集的关系。一般来说,除非万不得已,我们不建议修改oracle数据库server端的字符集。特别说明,我们最常用的两种字符集ZHS16GBK和ZHS16CGB231280之间不存在子集和超集关系,因此理论上讲这两种字符集之间的相互转换不受支持。
不过修改字符集有2种方法可行。
1. 通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换。
2. 通过ALTER DATABASE CHARACTER SET语句修改字符集,但创建数据库后修改字符集是有限制的,只有新的字符集是当前字符集的超集时才能修改数据库字符集,例如UTF8是US7ASCII的超集,修改数据库字符集可使用ALTER DATABASE CHARACTER SET UTF8。
5.1 修改server端字符集(不建议使用)
1. 关闭数据库
SQL>SHUTDOWN IMMEDIATE
2. 启动到Mount
SQL>STARTUP MOUNT;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;
SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
SQL>ALTER DATABASE CHARACTER SET ZHS16GBK;
SQL>ALTER DATABASE national CHARACTER SET ZHS16GBK;
SQL>SHUTDOWN IMMEDIATE;
SQL>STARTUP
注意:如果没有大对象,在使用过程中进行语言转换没有什么影响,(切记设定的字符集必须是ORACLE支持,不然不能start) 按上面的做法就可以。
若出现‘ORA-12717: Cannot ALTER DATABASE NATIONAL CHARACTER SET when NCLOB data exists’ 这样的提示信息,
要解决这个问题有两种方法
1. 利用INTERNAL_USE 关键字修改区域设置,
2. 利用re-create,但是re-create有点复杂,所以请用internal_use
SQL>SHUTDOWN IMMEDIATE;
SQL>STARTUP MOUNT EXCLUSIVE;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;
SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
SQL>ALTER DATABASE NATIONAL CHARACTER SET INTERNAL_USE UTF8;
SQL>SHUTDOWN immediate;
SQL>startup;
如果按上面的做法做,National charset的区域设置就没有问题
5.2 修改dmp文件字符集
上文说过,dmp文件的第2第3字节记录了字符集信息,因此直接修改dmp文件的第2第3字节的内容就可以‘骗’过oracle的检查。这样做理论上也仅是从子集到超集可以修改,但很多情况下在没有子集和超集关系的情况下也可以修改,我们常用的一些字符集,如US7ASCII,WE8ISO8859P1,ZHS16CGB231280,ZHS16GBK基本都可以改。因为改的只是dmp文件,所以影响不大。
具体的修改方法比较多,最简单的就是直接用UltraEdit修改dmp文件的第2和第3个字节。
比如想将dmp文件的字符集改为ZHS16GBK,可以用以下SQL查出该种字符集对应的16进制代码: SQL> select to_char(nls_charset_id('ZHS16GBK'), 'xxxx') from dual;
0354
然后将dmp文件的2、3字节修改为0354即可。
如果dmp文件很大,用ue无法打开,就需要用程序的方法了。
5.3客户端字符集设置方法
1)UNIX环境
$NLS_LANG=“simplified chinese”_china.zhs16gbk
$export NLS_LANG
编辑oracle用户的profile文件
2)Windows环境
编辑注册表
Regedit.exe ---》 HKEY_LOCAL_MACHINE ---》SOFTWARE ---》 ORACLE-HOME
或者在窗口设置:
set nls_lang=AMERICAN_AMERICA.ZHS16GBK
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/tianlesoftware/archive/2009/12/01/4915223.aspx
posted @
2011-04-15 10:58 xzc 阅读(907) |
评论 (0) |
编辑 收藏
从10g开始,oracle开始提供Shrink的命令,假如我们的表空间中支持自动段空间管理 (ASSM),就可以使用这个特性缩小段,即降低HWM。这里需要强调一点,10g的这个新特性,仅对ASSM表空间有效,否则会报 ORA-10635: Invalid segment or tablespace type。
有关ASSM的详细信息,请参考我的Blog:Oracle 自动段空间管理
http://blog.csdn.net/tianlesoftware/archive/2009/12/07/4958989.aspx
如果经常在表上执行DML操作,会造成数据库块中数据分布稀疏,浪费大量空间。同时也会影响全表扫描的性能,因为全表扫描需要访问更多的数据块。从oracle10g开始,表可以通过shrink来重组数据使数据分布更紧密,同时降低HWM释放空闲数据块。
segment shrink分为两个阶段:
1、数据重组(compact):通过一系列insert、delete操作,将数据尽量排列在段的前面。在这个过程中需要在表上加RX锁,即只在需要移动的行上加锁。由于涉及到rowid的改变,需要enable row movement.同时要disable基于rowid的trigger.这一过程对业务影响比较小。
2、HWM调整:第二阶段是调整HWM位置,释放空闲数据块。此过程需要在表上加X锁,会造成表上的所有DML语句阻塞。在业务特别繁忙的系统上可能造成比较大的影响。
shrink space语句两个阶段都执行。
shrink space compact只执行第一个阶段。
如果系统业务比较繁忙,可以先执行shrink space compact重组数据,然后在业务不忙的时候再执行shrink space降低HWM释放空闲数据块。
shrink必须开启行迁移功能。
alter table table_name enable row movement ;
注意:alter table XXX enable row movement语句会造成引用表XXX的对象(如存储过程、包、视图等)变为无效。执行完成后,最好执行一下utlrp.sql来编译无效的对象。
语法:
alter table <table_name> shrink space [ <null> | compact | cascade ];
alter table <table_name> shrink space compcat;
收缩表,相当于把块中数据打结实了,但会保持 high water mark;
alter table <tablespace_name> shrink space;
收缩表,降低 high water mark;
alter table <tablespace_name> shrink space cascade;
收缩表,降低 high water mark,并且相关索引也要收缩一下下。
alter index idxname shrink space;
回缩索引
1:普通表
Sql脚本,改脚本会生成相应的语句
select'alter table '||table_name||' enable row movement;'||chr(10)||'alter table '||table_name||' shrink space;'||chr(10)from user_tables;
select'alter index '||index_name||' shrink space;'||chr(10)from user_indexes;
2:分区表的处理
进行shrink space时 发生ORA-10631错误.shrink space有一些限制.
在表上建有函数索引(包括全文索引)会失败。
Sql脚本,改脚本会生成相应的语句
select 'alter table '||table_name||' enable row movement;'||chr(10)||'alter table '||table_name||' shrink space;'||chr(10) from user_tables where ;
select 'alter index '||index_name||' shrink space;'||chr(10) from user_indexes where uniqueness='NONUNIQUE' ;
select 'alter table '||segment_name||' modify subpartition '||partition_name||' shrink space;'||chr(10) from user_segments where segment_type='TABLE SUBPARTITION' ';
详细测试:
我们用系统视图all_objects来在上个测试的tablespace ASSM上创建测试表my_objects
/* Formatted on 2009-12-7 20:42:45 (QP5 v5.115.810.9015) */
CREATE TABLESPACE ASSM DATAFILE 'd:\ASSM01.dbf' SIZE 100M EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO;
/* Formatted on 2009-12-7 20:39:26 (QP5 v5.115.810.9015) */
SELECT TABLESPACE_NAME,
BLOCK_SIZE,
EXTENT_MANAGEMENT,
ALLOCATION_TYPE,
SEGMENT_SPACE_MANAGEMENT
FROM dba_tablespaces
WHERE TABLESPACE_NAME = 'ASSM';
TABLESPACE_NAME BLOCK_SIZE EXTENT_MAN ALLOCATIO SEGMEN
--------------------- ---------- ---------- --------- ------
ASSM 8192 LOCAL SYSTEM AUTO
1 row selected.
/* Formatted on 2009-12-7 20:44:15 (QP5 v5.115.810.9015) */
CREATE TABLE my_objects
TABLESPACE assm
AS
SELECT * FROM all_objects;
然后我们随机地从table MY_OBJECTS中删除一部分数据:
SQL> SELECT COUNT ( * ) FROM my_objects;
COUNT(*)
----------
49477
SQL> delete from my_objects where object_name like '%C%';
SQL> delete from my_objects where object_name like '%U%';
SQL> delete from my_objects where object_name like '%A%';
现在我们使用show_space()来看看my_objects的数据存储状况:
注: show_space() 存储过程代码参看一下连接的附件
http://blog.csdn.net/tianlesoftware/archive/2009/12/07/4958989.aspx
SQL>exec show_space('my_objects','auto','T','Y');
Total Blocks............................768
Total Bytes.............................6291456
Unused Blocks...........................68
Unused Bytes............................557056
Last Used Ext FileId....................8
Last Used Ext BlockId...................649
Last Used Block.........................60
*************************************************
The segment is analyzed
0% -- 25% free space blocks.............41
0% -- 25% free space bytes..............335872
25% -- 50% free space blocks............209
25% -- 50% free space bytes.............1712128
50% -- 75% free space blocks............190
50% -- 75% free space bytes.............1556480
75% -- 100% free space blocks...........229
75% -- 100% free space bytes............1875968
Unused Blocks...........................0
Unused Bytes............................0
Total Blocks............................11
Total bytes.............................90112
PL/SQL 过程已成功完成。
这里,table my_objects的HWM下有767个block,其中,free space为25-50%的block有209个,free space为50-75%的block有190个,free space为75-100%的block有229个. Total blocks 11个。
这种情况下,我们需要对这个table的现有数据行进行重组。
要使用assm上的shink,首先我们需要使该表支持行移动,可以用这样的命令来完成:
alter table my_objects enable row movement;
现在,就可以来降低my_objects的HWM,回收空间了,使用命令:
alter table bookings shrink space;
我们具体的看一下实验的结果:
SQL> alter table my_objects enable row movement;
表已更改。
SQL> alter table my_objects shrink space;
表已更改。
SQL>exec show_space('my_objects','auto','T','Y');
Total Blocks............................272
Total Bytes.............................2228224
Unused Blocks...........................0
Unused Bytes............................0
Last Used Ext FileId....................8
Last Used Ext BlockId...................265
Last Used Block.........................16
*************************************************
The segment is analyzed
0% -- 25% free space blocks.............0
0% -- 25% free space bytes..............0
25% -- 50% free space blocks............0
25% -- 50% free space bytes.............0
50% -- 75% free space blocks............1
50% -- 75% free space bytes.............8192
75% -- 100% free space blocks...........0
75% -- 100% free space bytes............0
Unused Blocks...........................0
Unused Bytes............................0
Total Blocks............................257
Total bytes.............................2105344
在执行玩shrink命令后,我们可以看到,table my_objects的HWM现在降到了271的位置,而且HWM下的block的空间使用状况,Total blocks 的block有257个,free space 为25-50% Block只有0个。
Shrink 的实现机制:
我们接下来讨论一下shrink的实现机制,我们同样使用讨论move机制的那个实验来观察。
/* Formatted on 2009-12-7 20:58:40 (QP5 v5.115.810.9015) */
CREATE TABLE TEST_HWM (id INT, name CHAR (2000))
TABLESPACE ASSM;
INSERT INTO TEST_HWM VALUES (1, 'aa');
INSERT INTO TEST_HWM VALUES (2, 'bb');
INSERT INTO TEST_HWM VALUES (2, 'cc');
INSERT INTO TEST_HWM VALUES (3, 'dd');
INSERT INTO TEST_HWM VALUES (4, 'ds');
INSERT INTO TEST_HWM VALUES (5, 'dss');
INSERT INTO TEST_HWM VALUES (6, 'dss');
INSERT INTO TEST_HWM VALUES (7, 'ess');
INSERT INTO TEST_HWM VALUES (8, 'es');
INSERT INTO TEST_HWM VALUES (9, 'es');
INSERT INTO TEST_HWM VALUES (10, 'es');
我们来看看这个table的rowid和block的ID和信息:
/* Formatted on 2009-12-7 21:00:02 (QP5 v5.115.810.9015) */
SQL>SELECT ROWID, id, name FROM TEST_HWM;ROWID ID NAME
ROWID ID NAME
------------------------------------- ---------- --------
AAANMEAAIAAAAEcAAA 3 dd
AAANMEAAIAAAAEcAAB 4 ds
AAANMEAAIAAAAEcAAC 5 dss
AAANMEAAIAAAAEdAAA 6 dss
AAANMEAAIAAAAEdAAB 7 ess
AAANMEAAIAAAAEdAAC 8 es
AAANMEAAIAAAAEeAAA 9 es
AAANMEAAIAAAAEeAAB 10 es
AAANMEAAIAAAAEgAAA 1 aa
AAANMEAAIAAAAEgAAB 2 bb
AAANMEAAIAAAAEgAAC 2 cc
/* Formatted on 2009-12-7 21:00:49 (QP5 v5.115.810.9015) */
SQL>SELECT EXTENT_ID,
FILE_ID,
RELATIVE_FNO,
BLOCK_ID,
BLOCKS
FROM dba_extents
WHERE segment_name = 'TEST_HWM';
EXTENT_ID FILE_ID RELATIVE_FNO BLOCK_ID BLOCKS
---------- ---------- ------------ ---------- ----------
0 8 8 281 8
1 row selected.
然后从table test_hwm中删除一些数据:
delete from TEST_HWM where id = 2;
delete from TEST_HWM where id = 4;
delete from TEST_HWM where id = 3;
delete from TEST_HWM where id = 7;
delete from TEST_HWM where id = 8;
观察table test_hwm的rowid和blockid的信息:
SQL> select rowid , id,name from TEST_HWM;
ROWID ID NAME
------------------------------------------ ---------- ---------
AAANMEAAIAAAAEcAAC 5 dss
AAANMEAAIAAAAEdAAA 6 dss
AAANMEAAIAAAAEeAAA 9 es
AAANMEAAIAAAAEeAAB 10 es
AAANMEAAIAAAAEgAAA 1 aa
/* Formatted on 2009-12-7 21:00:49 (QP5 v5.115.810.9015) */
SQL>SELECT EXTENT_ID,
FILE_ID,
RELATIVE_FNO,
BLOCK_ID,
BLOCKS
FROM dba_extents
WHERE segment_name = 'TEST_HWM';
EXTENT_ID FILE_ID RELATIVE_FNO BLOCK_ID BLOCKS
---------- ---------- ------------ ---------- ----------
0 8 8 281 8
1 row selected.
从以上的信息,我们可以看到,在table test_hwm中,剩下的数据是分布在AAAAEc,AAAAEd,AAAAEf,AAAAEg这样四个连续的block中。
SQL> exec show_space('TEST_HWM','auto','T','Y');
Total Blocks............................8
Total Bytes.............................65536
Unused Blocks...........................0
Unused Bytes............................0
Last Used Ext FileId....................8
Last Used Ext BlockId...................281
Last Used Block.........................8
*************************************************
The segment is analyzed
0% -- 25% free space blocks.............0
0% -- 25% free space bytes..............0
25% -- 50% free space blocks............1
25% -- 50% free space bytes.............8192
50% -- 75% free space blocks............3
50% -- 75% free space bytes.............24576
75% -- 100% free space blocks...........1
75% -- 100% free space bytes............8192
Unused Blocks...........................0
Unused Bytes............................0
Total Blocks............................0
Total bytes.............................0
我们可以看到目前这四个block的空间使用状况,AAAAEc,AAAAEd,AAAAEf,AAAAEg上各有一行数据,我们猜测free space为50-75%的3个block是这三个block,那么free space为25-50%的1个block就是AAAAEg了,剩下free space为 75-100% 的3个block,是HWM下已格式化的尚未使用的block。(在extent不大于于16个block时,是以一个extent为单位来移动的)
然后,我们对table my_objects执行shtink的操作:
SQL> alter table test_hwm enable row movement;
Table altered
SQL> alter table test_hwm shrink space;
Table altered
SQL> select rowid ,id,name from TEST_HWM;
ROWID ID NAME
------------------ ---------- ------------
AAANMEAAIAAAAEcAAA 10 es
AAANMEAAIAAAAEcAAC 5 dss
AAANMEAAIAAAAEcAAD 1 aa
AAANMEAAIAAAAEcAAE 9 es
AAANMEAAIAAAAEdAAA 6 dss
/* Formatted on 2009-12-7 21:00:49 (QP5 v5.115.810.9015) */
SQL>SELECT EXTENT_ID,
FILE_ID,
RELATIVE_FNO,
BLOCK_ID,
BLOCKS
FROM dba_extents
WHERE segment_name = 'TEST_HWM';
EXTENT_ID FILE_ID RELATIVE_FNO BLOCK_ID BLOCKS
---------- ---------- ------------ ---------- ----------
0 8 8 281 8
1 row selected.
当执行了shrink操作后,有意思的现象出现了。我们来看看oracle是如何移动行数据的,这里的情况和move已经不太一样了。我们知道,在move操作的时候,所有行的rowid都发生了变化,table所位于的block的区域也发生了变化,但是所有行物理存储的顺序都没有发生变化,所以我们得到的结论是,oracle以block为单位,进行了block间的数据copy。那么shrink后,我们发现,部分行数据的rowid发生了变化,同时,部分行数据的物理存储的顺序也发生了变化,而table所位于的block的区域却没有变化,这就说明,shrink只移动了table其中一部分的行数据,来完成释放空间,而且,这个过程是在table当前所使用的block中完成的。
那么Oracle具体移动行数据的过程是怎样的呢?我们根据这样的实验结果,可以来猜测一下:
Oracle是以行为单位来移动数据的。Oracle从当前table存储的最后一行数据开始移动,从当前table最先使用的block开始搜索空间,所以,shrink之前,rownum=10的那行数据(10,es),被移动到block AAAAEc上,写到(1,aa)这行数据的后面,所以(10,es)的rownum和rowid同时发生改变。然后是(9,es)这行数据,重复上述过程。这是oracle从后向前移动行数据的大致遵循的规则,那么具体移动行数据的的算法是比较复杂的,包括向ASSM的table中insert数据使用block的顺序的算法也是比较复杂的,大家有兴趣的可以自己来研究,在这里我们不多做讨论。
在shrink table的同时shrink这个table上的index:
alter table my_objects shrink space cascade;
同样地,这个操作只有当table上的index也是ASSM时,才能使用。
Move 和 Shrink 产生日志的对比
我们对比了同样数据量和分布状况的两张table,在move和shrink下生成的redo size(table上没有index的情况下):
/* Formatted on 2009-12-7 21:20:43 (QP5 v5.115.810.9015) */
SQL>SELECT tablespace_name, SEGMENT_SPACE_MANAGEMENT
FROM dba_tablespaces
WHERE tablespace_name IN ('ASSM', 'HWM');
TABLESPACE_NAME SEGMENT_SPACE_MANAGEMENT
------------------------------ ------------------------
ASSM AUTO
HWM MANUAL
SQL> create table my_objects tablespace ASSM as select * from all_objects where rownum<20000;
Table created
SQL> create table my_objects1 tablespace HWM as select * from all_objects where rownum<20000;
Table created
SQL> select bytes/1024/1024 from user_segments where segment_name = 'MY_OBJECTS';
BYTES/1024/1024
---------------
2.1875
SQL> delete from my_objects where object_name like '%C%';
7278 rows deleted
SQL> delete from my_objects1 where object_name like '%C%';
7278 rows deleted
SQL> delete from my_objects where object_name like '%U%';
2732 rows deleted
SQL> delete from my_objects1 where object_name like '%U%';
2732 rows deleted
SQL> commit;
Commit complete
SQL> alter table my_objects enable row movement;
Table altered
/* Formatted on 2009-12-7 21:21:48 (QP5 v5.115.810.9015) */
SQL>SELECT VALUE
FROM v$mystat, v$statname
WHERE v$mystat.statistic# = v$statname.statistic#
AND v$statname.name = 'redo size';
VALUE
----------
27808792
SQL> alter table my_objects shrink space;
Table altered
SQL>SELECT VALUE
FROM v$mystat, v$statname
WHERE v$mystat.statistic# = v$statname.statistic#
AND v$statname.name = 'redo size';
VALUE
----------
32579712
SQL> alter table my_objects1 move;
Table altered
SQL>SELECT VALUE
FROM v$mystat, v$statname
WHERE v$mystat.statistic# = v$statname.statistic#
AND v$statname.name = 'redo size';
VALUE
----------
32676784
对于table my_objects,进行shrink,产生了32579712 – 27808792=4770920,约4.5M的redo ;对table my_objects1进行move,产生了32676784-32579712= 97072,约95K的redo size。
结论:与move比较起来,shrink的日志写要大得多。
Shrink的几点问题:
1. shrink后index是否需要rebuild:
因为shrink的操作也会改变行数据的rowid,那么,如果table上有index时,shrink table后index会不会变为UNUSABLE呢?
我们来看这样的实验,同样构建my_objects的测试表:
create table my_objects tablespace ASSM as select * from all_objects where rownum<20000;
create index i_my_objects on my_objects (object_id);
delete from my_objects where object_name like '%C%';
delete from my_objects where object_name like '%U%';
现在我们来shrink table my_objects:
SQL> alter table my_objects enable row movement;
Table altered
SQL> alter table my_objects shrink space;
Table altered
SQL> select index_name,status from user_indexes where index_name='I_MY_OBJECTS';
INDEX_NAME STATUS
------------------------------ --------
I_MY_OBJECTS VALID
我们发现,table my_objects上的index的状态为VALID,估计shrink在移动行数据时,也一起维护了index上相应行的数据rowid的信息。我们认为,这是对于move操作后需要rebuild index的改进。但是如果一个table上的index数量较多,我们知道,维护index的成本是比较高的,shrink过程中用来维护index的成本也会比较高。
2. shrink时对table的lock
在对table进行shrink时,会对table进行怎样的锁定呢?当我们对table MY_OBJECTS进行shrink操作时,查询v$locked_objects视图可以发现,table MY_OBJECTS上加了row-X (SX) 的lock:
SQL>select OBJECT_ID, SESSION_ID,ORACLE_USERNAME,LOCKED_MODE from v$locked_objects;
OBJECT_ID SESSION_ID ORACLE_USERNAME LOCKED_MODE
---------- ---------- ------------------ -----------
55422 153 DLINGER 3
SQL> select object_id from user_objects where object_name = 'MY_OBJECTS';
OBJECT_ID
----------
55422
那么,当table在进行shrink时,我们对table是可以进行DML操作的。
3. shrink对空间的要求
我们在前面讨论了shrink的数据的移动机制,既然oracle是从后向前移动行数据,那么,shrink的操作就不会像move一样,shrink不需要使用额外的空闲空间。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/tianlesoftware/archive/2009/11/04/4764254.aspx
posted @
2011-04-15 10:57 xzc 阅读(9345) |
评论 (0) |
编辑 收藏转自:http://blog.csdn.net/rein07/archive/2010/11/25/6033937.aspx
1.SQL>shutdown abort 如果数据库是打开状态,强行关闭
2.SQL>sqlplus / as sysdba
3.SQL>startup
ORACLE 例程已经启动。
Total System Global Area 293601280 bytes
Fixed Size 1248624 bytes
Variable Size 121635472 bytes
Database Buffers 167772160 bytes
Redo Buffers 2945024 bytes
数据库装载完毕。
ORA-01122: 数据库文件 1 验证失败
ORA-01110: 数据文件 1:
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\SYSTEM01.DBF'
ORA-01207: 文件比控制文件更新 - 旧的控制文件
4.SQL>alter database backup controlfile to trace as 'f:\aa';
数据库已更改。
5.SQL>shutdown immediate 如果数据库是打开状态,则关闭
ORA-01109: 数据库未打开
已经卸载数据库
6.SQL>startup nomount;
ORACLE 例程已经启动。
Total System Global Area 105979576 bytes
Fixed Size 454328 bytes
Variable Size 79691776 bytes
Database Buffers 25165824 bytes
Redo Buffers 667648 bytes
7.Editplus之类的编辑器打开在第四步生成的f:\aa文件;
其实在这个文件中的已经告诉你咋样恢复你的数据库了,找到STARTUP NOMOUNT字样,然后下面可以看到类似语句,这个文件有好几个类似的生成控制文件语句,主要针对不懂的环境执行不同的语句,象我的数据库没有做任何备份,也不是在归档模式,就执行这句
CREATE CONTROLFILE REUSE DATABASE "ORCLDW" NORESETLOGS NOARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\REDO01.LOG' SIZE 50M,
GROUP 2 'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\REDO02.LOG' SIZE 50M,
GROUP 3 'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\REDO03.LOG' SIZE 50M
DATAFILE
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\SYSTEM01.DBF',
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\UNDOTBS01.DBF',
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\SYSAUX01.DBF',
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\USERS01.DBF',
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\EXAMPLE01.DBF'
CHARACTER SET ZHS16GBK
;
执行上面这段语句,这个语句重建控制文件,然后你可以看着f:\aa文件完成下面的恢复工作了,
8.SQL>RECOVER DATABASE (恢复指定表空间、数据文件或整个数据库)
9.SQL>ALTER DATABASE OPEN 打开数据库
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/rein07/archive/2010/11/25/6033937.aspx
posted @
2011-04-15 10:56 xzc 阅读(6988) |
评论 (0) |
编辑 收藏引用
trailblizer 的 Oracle:Rank,Dense_Rank,Row_Number比较
Oracle:Rank,Dense_Rank,Row_Number比较
一个员工信息表
Create Table EmployeeInfo (CODE Number(3) Not Null,EmployeeName varchar2(15),DepartmentID Number(3),Salary NUMBER(7,2),
Constraint PK_EmployeeInfo Primary Key (CODE));
Select * From EMPLOYEEINFO

现执行SQL语句:
Select EMPLOYEENAME,SALARY,
RANK() OVER (Order By SALARY Desc) "RANK",
DENSE_RANK() OVER (Order By SALARY Desc ) "DENSE_RANK",
ROW_NUMBER() OVER(Order By SALARY Desc) "ROW_NUMBER"
From EMPLOYEEINFO
结果如下:

Rank,Dense_rank,Row_number函数为每条记录产生一个从1开始至N的自然数,N的值可能小于等于记录的总数。这3个函数的唯一区别在于当碰到相同数据时的排名策略。
①ROW_NUMBER:
Row_number函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
②DENSE_RANK:
Dense_rank函数返回一个唯一的值,除非当碰到相同数据时,此时所有相同数据的排名都是一样的。
③RANK:
Rank函数返回一个唯一的值,除非遇到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
同时也可以分组排序,也就是在Over从句内加入Partition by groupField:
Select DEPARTMENTID,EMPLOYEENAME,SALARY,
RANK() OVER ( Partition By DEPARTMENTID Order By SALARY Desc) "RANK",
DENSE_RANK() OVER ( Partition By DEPARTMENTID Order By SALARY Desc ) "DENSE_RANK",
ROW_NUMBER() OVER( Partition By DEPARTMENTID Order By SALARY Desc) "ROW_NUMBER"
From EMPLOYEEINFO
结果如下:

现在如果插入一条工资为空的记录,那么执行上述语句,结果如下:

会发现空值的竟然排在了第一位,这显然不是想要的结果。解决的办法是在Over从句Order By后加上 NULLS Last即:
Select EMPLOYEENAME,SALARY,
RANK() OVER (Order By SALARY Desc Nulls Last) "RANK",
DENSE_RANK() OVER (Order By SALARY Desc Nulls Last) "DENSE_RANK",
ROW_NUMBER() OVER(Order By SALARY Desc Nulls Last ) "ROW_NUMBER"
From EMPLOYEEINFO
结果如下:

posted @
2011-04-03 21:46 xzc 阅读(639) |
评论 (0) |
编辑 收藏Oracle Sql Loader中文字符导入乱码的解决方案
服务器端字符集NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK
控制文件ctl:
LOAD DATA
CHARACTERSET ZHS16GBK
INFILE 'c:\testfile.txt'
id name desc
FIELDS TERMINATED BY ","
(id,name ,desc )
导入成功
其中c:\testfile.txt文件中有中文,在将此文件导入到oracle数据库中时,需要设置字符集CHARACTERSET ZHS16GBK
(1)查看服务器端字符集
通过客户端或服务器端的sql*plus登录ORACLE的一个合法用户,执行下列SQL语句:
SQL > select * from V$NLS_PARAMETERS
------------------------
(2)控制文件ctl:
LOAD DATA
CHARACTERSET ZHS16GBK
INFILE '/inffile/vac/subs-vac.csv'
TRUNCATE
INTO TABLE INF_VAC_SUBS_PRODUCT
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
(
USER_NUMBER,
PRODUCT_ID,
EFFECTIVE_DATE DATE "YYYY/MM/DD HH24:MI:SS",
EXPIRATION_DATE DATE "YYYY/MM/DD HH24:MI:SS"
)
posted @
2011-03-08 17:20 xzc 阅读(9062) |
评论 (2) |
编辑 收藏
要测试sql loader 以及快速产生大量测试数据
生成大量测试数据思路。
一,用plsql developer 生成csv 文件
二,用>>输出重定向,追加到一个cvs 文件里。
三,再用sql loader 快速载入。
在plsql developer 执行
- SELECT object_id,object_name FROM dba_objects;
SELECT object_id,object_name FROM dba_objects;
右键plsql developer 导出csv 格式 1.csv。在linux 上执行下面的脚本
- #!/bin/bash
-
- for((i=1;i<200;i=i+1))
- do
- cat 1.csv >> 2.csv;
- echo $i;
- done
#!/bin/bash
for((i=1;i<200;i=i+1))
do
cat 1.csv >> 2.csv;
echo $i;
done
这样 50000 * 200 差不到就有一千万的数据了。我测试的 11047500 392M
可以用:
wc -l 2.csv
查看csv 里有多少条数据。现在测试数据有了。我们来试一下sql loader 的载入效果吧。
创建sqlloader 控制文件如下,保存为1.ctl
- load data
- infile '2.csv'
- into table my_objects
- fields terminated by ','optionally enclosed by '"'
- (object_id,
- object_name
- );
load data
infile '2.csv'
into table my_objects
fields terminated by ','optionally enclosed by '"'
(object_id,
object_name
);
控制文件简要说明:
-- INFILE 'n.csv' 导入多个文件
-- INFILE * 要导入的内容就在control文件里 下面的BEGINDATA后面就是导入的内容
--BADFILE '1.bad' 指定坏文件地址
--apend into table my_objects 追加
-- INSERT 装载空表 如果原先的表有数据 sqlloader会停止 默认值
-- REPLACE 原先的表有数据 原先的数据会全部删除
-- TRUNCATE 指定的内容和replace的相同 会用truncate语句删除现存数据
--可以指定位置加载
--(object_id position(1:3) char,object_name position(5:7) char)
--分别指定分隔符
--(object_id char terminated by ",", object_name char terminated by ",")
--执行sqlldr userid=scott/a123 control=1.ctl log=1.out direct=true
--30秒可以载入200万的测试数据 79MB
--sqlldr userid=/ control=result1.ctl direct=true parallel=true
--sqlldr userid=/ control=result2.ctl direct=true parallel=true
--sqlldr userid=/ control=result2.ctl direct=true parallel=true
--当加载大量数据时(大约超过10GB),最好抑制日志的产生:
--SQLALTER TABLE RESULTXT nologging;
--这样不产生REDO LOG,可以提高效率。然后在CONTROL文件中load data上面加一行:unrecoverable
--此选项必须要与DIRECT共同应用。
--在并发操作时,ORACLE声称可以达到每小时处理100GB数据的能力!其实,估计能到1-10G就算不错了,开始可用结构
--相同的文件,但只有少量数据,成功后开始加载大量数据,这样可以避免时间的浪费
下面就是执行了
- sqlldr userid=scott/a123 control=1.ctl log=1.out direct=true
sqlldr userid=scott/a123 control=1.ctl log=1.out direct=true
结果:30秒可以载入200万的测试数据 79MB
226秒载入1100万的测试数据 392Mb
我的环境是在虚拟机,测得的结果
MemTotal: 949948 kB
model name : Intel(R) Pentium(R) D CPU 2.80GHz
stepping : 8
cpu MHz : 2799.560
cache size : 1024 KB
还是挺快的:)
posted @
2011-03-08 16:47 xzc 阅读(3996) |
评论 (0) |
编辑 收藏一、构造字符串
直接构造
STR_ZERO=hello
STR_FIRST="i am a string"
STR_SECOND='success'
重复多次
#repeat the first parm($1) by $2 times
strRepeat()
{
local x=$2
if [ "$x" == "" ]; then
x=0
fi
local STR_TEMP=""
while [ $x -ge 1 ];
do
STR_TEMP=`printf "%s%s" "$STR_TEMP" "$1"`
x=`expr $x - 1`
done
echo $STR_TEMP
}
举例:
STR_REPEAT=`strRepeat "$USER_NAME" 3`
echo "repeat = $STR_REPEAT"
二、赋值与拷贝
直接赋值
与构造字符串一样
USER_NAME=terry
从变量赋值
ALIASE_NAME=$USER_NAME
三、联接
直接联接两个字符串
STR_TEMP=`printf "%s%s" "$STR_ZERO" "$USER_NAME"`
使用printf可以进行更复杂的联接
四、求长
获取字符串变量的长度:${#string}
求字符数(char)
COUNT_CHAR=`echo "$STR_FIRST" | wc -m`
echo $COUNT_CHAR
求字节数(byte)
COUNT_BYTE=`echo "$STR_FIRST" | wc -c`
echo $COUNT_BYTE
求字数(word)
COUNT_WORD=`echo "$STR_FIRST" | wc -w`
echo $COUNT_WORD
五、比较
相等比较 str1 = str2
不等比较 str1 != str2
举例:
if [ "$USER_NAME" = "terry" ]; then
echo "I am terry"
fi
小于比较
#return 0 if the two string is equal, return 1 if $1 < $2, else 2strCompare() { local x=0 if [ "$1" != "$2" ]; then x=2 localTEMP=`printf "%s\n%s" "$1" "$2"` local TEMP2=`(echo "$1"; echo "$2") |sort` if [ "$TEMP" = "$TEMP2" ]; then x=1 fi fi echo $x }
六、测试
判空 -z str
判非空 -n str
是否为数字
# return 0 if the string is num, otherwise 1
strIsNum()
{
local RET=1
if [ -n "$1" ]; then
local STR_TEMP=`echo "$1" | sed 's/[0-9]//g'`
if [ -z "$STR_TEMP" ]; then
RET=0
fi
fi
echo $RET
}
举例:
if [ -n "$USER_NAME" ]; then
echo "my name is NOT empty"
fi
echo `strIsNum "9980"`
七、分割
以符号+为准,将字符分割为左右两部分
使用sed
举例:
命令 date --rfc-3339 seconds 的输出为
2007-04-14 15:09:47+08:00
取其+左边的部分
date --rfc-3339 seconds | sed 's/+[0-9][0-9]:[0-9][0-9]//g'
输出为
2007-04-14 15:09:47
取+右边的部分
date --rfc-3339 seconds | sed 's/.*+//g'
输出为
08:00
以空格为分割符的字符串分割
使用awk
举例:
STR_FRUIT="Banana 0.89 100"
取第3字段
echo $STR_FRUIT | awk '{ print $3; }'
八、子字符串
字符串1是否为字符串2的子字符串
# return 0 is $1 is substring of $2, otherwise 1
strIsSubstring()
{
local x=1
case "$2" in
*$1*) x=0;;
esac
echo $x
}
Shell字符串截取
一、Linux shell 截取字符变量的前8位,有方法如下:
1.expr substr “$a” 1 8
2.echo $a|awk ‘{print substr(,1,8)}’
3.echo $a|cut -c1-8
4.echo $
5.expr $a : ‘\(.\\).*’
6.echo $a|dd bs=1 count=8 2>/dev/null
二、按指定的字符串截取
1、第一种方法:
- ${varible##*string} 从左向右截取最后一个string后的字符串
- ${varible#*string}从左向右截取第一个string后的字符串
- ${varible%%string*}从右向左截取最后一个string后的字符串
- ${varible%string*}从右向左截取第一个string后的字符串
“*”只是一个通配符可以不要
例子:
$ MYVAR=foodforthought.jpg
$ echo ${MYVAR##*fo}
rthought.jpg
$ echo ${MYVAR#*fo}
odforthought.jpg
2、第二种方法:${varible:n1:n2}:截取变量varible从n1开始的n2个字符,组成一个子字符串。可以根据特定字符偏移和长度,使用另一种形式的变量扩展,来选择特定子字符串。试着在 bash 中输入以下行:
$ EXCLAIM=cowabunga
$ echo ${EXCLAIM:0:3}
cow
$ echo ${EXCLAIM:3:7}
abunga
这种形式的字符串截断非常简便,只需用冒号分开来指定起始字符和子字符串长度。
三、按照指定要求分割:
比如获取后缀名
ls -al | cut -d “.” -f2
shell (bash) 比较运算符
| 运算符 |
描述 |
示例 |
| 文件比较运算符 |
| -efilename |
如果filename存在,则为真 |
[ -e /var/log/syslog ] |
| -dfilename |
如果filename为目录,则为真 |
[ -d /tmp/mydir ] |
| -ffilename |
如果filename为常规文件,则为真 |
[ -f /usr/bin/grep ] |
| -Lfilename |
如果filename为符号链接,则为真 |
[ -L /usr/bin/grep ] |
| -rfilename |
如果filename可读,则为真 |
[ -r /var/log/syslog ] |
| -wfilename |
如果filename可写,则为真 |
[ -w /var/mytmp.txt ] |
| -xfilename |
如果filename可执行,则为真 |
[ -L /usr/bin/grep ] |
| filename1-ntfilename2 |
如果filename1比filename2新,则为真 |
[ /tmp/install/etc/services -nt /etc/services ] |
| filename1-otfilename2 |
如果filename1比filename2旧,则为真 |
[ /boot/bzImage -ot arch/i386/boot/bzImage ] |
| 字符串比较运算符[size=-1](请注意引号的使用,这是防止空格扰乱代码的好方法) |
| -zstring |
如果string长度为零,则为真 |
[ -z "$myvar" ] |
| -nstring |
如果string长度非零,则为真 |
[ -n "$myvar" ] |
| string1=string2 |
如果string1与string2相同,则为真 |
[ "$myvar" = "one two three" ] |
| string1!=string2 |
如果string1与string2不同,则为真 |
[ "$myvar" != "one two three" ] |
| 算术比较运算符 |
| num1-eqnum2 |
等于 |
[ 3 -eq $mynum ] |
| num1-nenum2 |
不等于 |
[ 3 -ne $mynum ] |
| num1-ltnum2 |
小于 |
[ 3 -lt $mynum ] |
| num1-lenum2 |
小于或等于 |
[ 3 -le $mynum ] |
| num1-gtnum2 |
大于 |
[ 3 -gt $mynum ] |
| num1-genum2 |
大于或等于 |
[ 3 -ge $mynum ] |
posted @
2011-03-04 18:13 xzc 阅读(9080) |
评论 (2) |
编辑 收藏#!/sbin/sh
######################################
## 名称: infuser_load.sh
## 描述: 通用接口文件 导入数据库
## 参数: owner table_name
## 作者: xxx
## 日期: 2011-03-04
######################################
##owner
owner=$1
##table_name
table_name=$2
##batchId
batchId=$3
##day_id
day_id=$4
##日期[YYYYMMDD]
DAYID=`date +'%Y%m%d'`
##月份[YYYYMM]
MONTHID=`date +'%Y%m'`
##shell文件目录
sh_dir=/inffile/shell/
cd ${sh_dir}
##load文件###########################
##file_name
file_name=`sqlplus -s infuser/xxx@DATACK <<EOF
set heading off feedback off pagesize 0 verify off echo off
select replace(replace(to_char(file_name), '@DAYID@', '${DAYID}'), '@MONTHID@', '${MONTHID}')
from datackdb.inf_file_def
where owner = '${owner}'
and table_name = '${table_name}'
and state = '00A'
and rownum <= 1;
exit
EOF`
#echo "${file_name}"
##ctl_file
ctl_file=`sqlplus -s infuser/xxx@DATACK <<EOF
set heading off feedback off pagesize 0 verify off echo off
select replace(replace(to_char(ctl_file), '@DAYID@', '${DAYID}'), '@MONTHID@', '${MONTHID}')
from datackdb.inf_file_def
where owner = '${owner}'
and table_name = '${table_name}'
and state = '00A'
and rownum <= 1;
exit
EOF`
#echo "${ctl_file}"
infile=""
for fname in $file_name
do
if [ -r ${fname} ]
then
infile=$infile"INFILE '${fname}'\n"
fi
done
#是否包含@INFILE@字符串的判断
if echo "$ctl_file"|grep -q "@INFILE@"
then
#分隔符前字符串
echo "${ctl_file%%@INFILE@*}" >${table_name}.ctl
#文件名
echo "${infile}" >>${table_name}.ctl
#分隔符后字符串
echo "${ctl_file##*@INFILE@}" >>${table_name}.ctl
else
echo "${ctl_file}" >${table_name}.ctl
fi
#导入数据
sqlldr infuser/infuser@DATACK control=${table_name}.ctl direct=y errors=1000
#删除控制文件
#rm ${table_name}.ctl
#rm ${table_name}.log
##写消息
sqlplus infuser/infuser@DATACK <<EOF
insert into datackdb.inf_data_msg (OWNER, TABLE_NAME, FWF_NO, LAN_ID, DAY_ID, STATE, STATE_DATE, COMMENTS)
values ('${owner}', '${table_name}', '${batchId}', -1, '${day_id}', '00A', sysdate, '');
exit
EOF
date +'%Y-%m-%d %T' >>param.txt
echo "$0 $*" >>param.txt
echo "$0 $* -- 成功"
posted @
2011-03-04 15:23 xzc 阅读(550) |
评论 (0) |
编辑 收藏#! /bin/bash
var1="hello"
var2="he"
#方法1
if [ ${var1:0:2} = $var2 ]
then
echo "1:include"
fi
#方法2
echo "$var1" |grep -q "$var2"
if [ $? -eq 0 ]
then
echo "2:include"
fi
#方法3
echo "$var1" |grep -q "$var2" && echo "include" ||echo "not"
#方法4
[[ "${var1/$var2/}" != "$var2" ]] && echo "include" || echo "not"
其他方法:
expr或awk的index函数
${var#...}
${var%...}
${var/.../...}
posted @
2011-03-04 15:16 xzc 阅读(26421) |
评论 (1) |
编辑 收藏shell判断文件,目录是否存在或者具有权限
www.firnow.com 时间 : 2009-03-04 作者:匿名 编辑:sky 点击: 1632 [ 评论 ]
-
-
shell判断文件,目录是否存在或者具有权限
#!/bin/sh
myPath="/var/log/httpd/"
myFile="/var /log/httpd/access.log"
#这里的-x 参数判断$myPath是否存在并且是否具有可执行权限
if [ ! -x "$myPath"]; then
mkdir "$myPath"
fi
#这里的-d 参数判断$myPath是否存在
if [ ! -d "$myPath"]; then
mkdir "$myPath"
fi
#这里的-f参数判断$myFile是否存在
if [ ! -f "$myFile" ]; then
touch "$myFile"
fi
#其他参数还有-n,-n是判断一个变量是否是否有值
if [ ! -n "$myVar" ]; then
echo "$myVar is empty"
exit 0
fi
#两个变量判断是否相等
if [ "$var1" = "$var2" ]; then
echo '$var1 eq $var2'
else
echo '$var1 not eq $var2'
fi
posted @
2011-03-04 15:14 xzc 阅读(1365) |
评论 (1) |
编辑 收藏shell字符串的截取的问题:
一、Linux shell 截取字符变量的前8位,有方法如下:
1.expr substr “$a” 1 8
2.echo $a|awk ‘{print substr(,1,8)}’
3.echo $a|cut -c1-8
4.echo $
5.expr $a : ‘\(.\\).*’
6.echo $a|dd bs=1 count=8 2>/dev/null
二、按指定的字符串截取
1、第一种方法:
${varible##*string} 从左向右截取最后一个string后的字符串
${varible#*string}从左向右截取第一个string后的字符串
${varible%%string*}从右向左截取最后一个string后的字符串
${varible%string*}从右向左截取第一个string后的字符串
“*”只是一个通配符可以不要
例子:
$ MYVAR=foodforthought.jpg
$ echo ${MYVAR##*fo}
rthought.jpg
$ echo ${MYVAR#*fo}
odforthought.jpg
2、第二种方法:${varible:n1:n2}:截取变量varible从n1到n2之间的字符串。
可以根据特定字符偏移和长度,使用另一种形式的变量扩展,来选择特定子字符串。试着在 bash 中输入以下行:
$ EXCLAIM=cowabunga
$ echo ${EXCLAIM:0:3}
cow
$ echo ${EXCLAIM:3:7}
abunga
这种形式的字符串截断非常简便,只需用冒号分开来指定起始字符和子字符串长度。
三、按照指定要求分割:
比如获取后缀名
ls -al | cut -d “.” -f2
应用心得:
$MYVAR="12|dadg"
echo ${MYVAR##*|} #打印分隔符后的字符串
dafa
echo ${MYVAR%%|*} #打印分隔符前的字符串
12
posted @
2011-03-04 15:09 xzc 阅读(3602) |
评论 (1) |
编辑 收藏
awk内置字符串函数详解(转)
awk提供了许多强大的字符串函数,见下表:
awk内置字符串函数
gsub(r,s) 在整个$0中用s替代r
gsub(r,s,t) 在整个t中用s替代r
index(s,t)
返回s中字符串t的第一位置
length(s)
返回s长度
match(s,r)
测试s是否包含匹配r的字符串
split(s,a,fs) 在fs上将s分成序列a
sprint(fmt,exp) 返回经fmt格式化后的exp
sub(r,s)
用$0中最左边最长的子串代替s
substr(s,p) 返回字符串s中从p开始的后缀部分
substr(s,p,n)
返回字符串s中从p开始长度为n的后缀部分
详细说明一下各个函数的使用方法。
gsub函数有点类似于sed查找和替换。它允许替换一个字符串或字符为另一个字符串或字符,并以正则表达式的形式执行。第一个函数作用于记录$0,第二个gsub函数允许指定目标,然而,如果未指定目标,缺省为$0。
index(s,t)函数返回目标字符串s中查询字符串t的首位置。length函数返回字符串s字符
长度。match函数测试字符串s是否包含一个正则表达式r定义的匹配。split使用域分隔符fs将
字符串s划分为指定序列a。sprint函数类似于printf函数(以后涉及),返回基本输出格式fmt的
结果字符串exp。sub(r,s)函数将用s替代$0中最左边最长的子串,该子串被(r)匹配。
sub(s,p)返回字符串s在位置p后的后缀。substr(s,p,n)同上,并指定子串长度为n。
现在看一看awk中这些字符串函数的功能。
1.gsub
要在整个记录中替换一个字符串为另一个,使用正则表达式格式,/目标模式/,替换模式
/。例如改变学生序号4842到4899:
$ awk 'gsub('4842/, 4899) {print $0}' grade.txt
J.Troll 07/99 4899 Brown-3 12 26 26
2.index
查询字符串s中t出现的第一位置。必须用双引号将字符串括起来。例如返回目标字符串
Bunny中ny出现的第一位置,即字符个数。
$ awk 'BEGIN {print index("Bunny", "ny")} grade.txt
4
3.length
返回所需字符串长度,例如检验字符串J.Troll返回名字及其长度,即人名构成的字符个
数。
$ awk '$1=="J.Troll" {print length($1) " "$1}' grade.txt
7 J.Troll
还有一种方法,这里字符串加双引号。
$ awk 'BEGIN {print length("A FEW GOOD MEN")}'
14
4.match
match测试目标字符串是否包含查找字符的一部分。可以对查找部分使用正则表达式,返
回值为成功出现的字符排列数。如果未找到,返回0,第一个例子在ANCD中查找d。因其不
存在,所以返回0。第二个例子在ANCD中查找D。因其存在,所以返回ANCD中D出现的首位
置字符数。第三个例子在学生J.Lulu中查找u。
$ awk '{BEGIN {print match("ANCD", /d/)}'
0
$ awk '{BEGIN {print match("ANCD", /C/)}'
3
$ awk '$1=="J.Lulu" {print match($1, "u")} grade.txt
4
5.split
使用split返回字符串数组元素个数。工作方式如下:如果有一字符串,包含一指定分隔
符-,例如AD2-KP9-JU2-LP-1,将之划分成一个数组。使用split,指定分隔符及数组名。此
例中,命令格式为("AD2-KP9-JU2-LP-1",parts_array,"-"),split然后返回数组下标数,这
里结果为4。
还有一个例子使用不同的分隔符。
$ awk '{BEGIN {print split("123#456#678", myarray, "#")}'
3
这个例子中,split返回数组myarray的下标数。数组myarray取值如下:
Myarray[1]="123"
Myarray[2]="456"
Myarray[3]="789"
6.sub
使用sub发现并替换模式的第一次出现位置。字符串STR包含‘popedpopopill’,执行下
列sub命令sub(/op/,"op",STR)。模式op第一次出现时,进行替换操作,返回结果如下:
‘pOPedpopepill’。
假如grade.txt文件中,学生J.Troll的记录有两个值一样,“目前级别分”与“最高级别分”。只
改变第一个为29,第二个仍为24不动,操作命令为sub(/26/,"29",$0),只替换第一个出现
24的位置。
$ awk '$1=="J.Troll" sub(/26/, "29", $0)' grade.txt
L.Troll 07/99 4842 Brown-3 12 29 26
L.Transley 05/99 4712 Brown-2 12 30 28
7.substr
substr是一个很有用的函数。它按照起始位置及长度返回字符串的一部分。例子如下:
$ awk '$1=="L.Transley" {print substr($1, 1,5)}' grade.txt
L.Tan
上面例子中,指定在域1的第一个字符开始,返回其前面5个字符。
如果给定长度值远大于字符串长度, awk将从起始位置返回所有字符,要抽取L.Tansley的姓,只需从第3个字符开始返回长度为7。可以输入长度99,awk返回结果相同。
$ awk '{$1=="L.Transley" {print substr($1, 3,99)}' grade.txt
Transley
substr的另一种形式是返回字符串后缀或指定位置后面字符。这里需要给出指定字符串及其返回字串的起始位置。例如,从文本文件中抽取姓氏,需操作域1,并从第三个字符开始:
$ awk '{print substr($1, 3)}' grade.txt
Troll
Transley
还有一个例子,在BEGIN部分定义字符串,在END部分返回从第t个字符开始抽取的子串。
$ awk '{BEGIN STR="A FEW GOOD MEN"} END {print substr(STR,7)) grade.txt
GOOD MEN
8.从shell中向awk传入字符串
awk脚本大多只有一行,其中很少是字符串表示的,这一点通过将变量传入awk命令行会变得很容易。现就其基本原理讲述一些例子。
使用管道将字符串stand-by传入awk,返回其长度。
$ echo "Stand-by" | awk '{print length($0)}'
8
设置文件名为一变量,管道输出到awk,返回不带扩展名的文件名。
$ STR="mydoc.txt"
$ echo $STR | awk '{print subst($STR, 1, 5)}'
mydoc
设置文件名为一变量,管道输出到awk,只返回其扩展名。
$ STR="mydoc.txt"
$ echo $STR | awk '{print substr($STR, 7)}'
txt
posted @
2011-03-03 17:18 xzc 阅读(1581) |
评论 (2) |
编辑 收藏作者:北南南北
来自:LinuxSir.Org
摘要: 本文讲述几种常用文件内容的查看工具,比如cat、more、less、head、tail等,把这些工具最常用的参数、动作介绍给新手,能让新手在短短的几分钟内上手运用。此文献给面对黑色的控制台不知所措的弟兄。
目录
+++++++++++++++++++++++++++++++++++++
正文
+++++++++++++++++++++++++++++++++++++
1、cat 显示文件连接文件内容的工具;
cat 是一个文本文件查看和连接工具。查看一个文件的内容,用cat比较简单,就是cat 后面直接接文件名。
比如:
[root@localhost ~]# cat /etc/fstab
为了便于新手弟兄灵活掌握这个工具,我们多说一点常用的参数;
1.0 cat 语法结构;
cat [选项] [文件]...
选项
-A, --show-all 等价于 -vET
-b, --number-nonblank 对非空输出行编号
-e 等价于 -vE
-E, --show-ends 在每行结束处显示 $
-n, --number 对输出的所有行编号
-s, --squeeze-blank 不输出多行空行
-t 与 -vT 等价
-T, --show-tabs 将跳格字符显示为 ^I
-u (被忽略)
-v, --show-nonprinting 使用 ^ 和 M- 引用,除了 LFD 和 TAB 之外
--help 显示此帮助信息并离开
1.1 cat 查看文件内容实例;
[root@localhost ~]# cat /etc/profile 注:查看/etc/目录下的profile文件内容;
[root@localhost ~]# cat -b /etc/fstab 注:查看/etc/目录下的profile内容,并且对非空白行进行编号,行号从1开始;
[root@localhost ~]# cat -n /etc/profile 注:对/etc目录中的profile的所有的行(包括空白行)进行编号输出显示;
[root@localhost ~]# cat -E /etc/profile 注:查看/etc/下的profile内容,并且在每行的结尾处附加$符号;
cat 加参数-n 和nl工具差不多,文件内容输出的同时,都会在每行前面加上行号;
[root@localhost ~]# cat -n /etc/profile
[root@localhost ~]# nl /etc/profile
cat 可以同时显示多个文件的内容,比如我们可以在一个cat命令上同时显示两个文件的内容;
[root@localhost ~]# cat /etc/fstab /etc/profile
cat 对于内容极大的文件来说,可以通过管道|传送到more 工具,然后一页一页的查看;
[root@localhost ~]# cat /etc/fstab /etc/profile | more
1.2 cat 的创建、连接文件功能实例;
cat 有创建文件的功能,创建文件后,要以EOF或STOP结束;
[root@localhost ~]# cat > linuxsir.org.txt << EOF 注:创建linuxsir.org.txt文件;
> 我来测试 cat 创建文件,并且为文件输入内容; 注:这是为linuxsir.org.txt文件输入内容;
> 北南南北 测试; 注:这是为linuxsir.org.txt文件输入内容;
> EOF 注:退出编辑状态;
[root@localhost ~]# cat linuxsir.org.txt 注:我们查看一下linuxsir.org.txt文件的内容;
我来测试 cat 创建文件,并且为文件输入内容;
北南南北 测试;
cat 还有向已存在的文件追加内容的功能;
[root@localhost ~]# cat linuxsir.txt 注:查看已存在的文件linuxsir.txt 内容;
I am BeiNanNanBei From LinuxSir.Org . 注:内容行
我正在为cat命令写文档
[root@localhost ~]# cat >> linuxsir.txt << EOF 注:我们向linuxsir.txt文件追加内容;
> 我来测试cat向文档追加内容的功能; 注:这是追回的内容
> OK?
> OK~
> 北南 呈上
> EOF 注:以EOF退出;
[root@localhost ~]# cat linuxsir.txt 注:查看文件内容,看是否追回成功。
I am BeiNanNanBei From LinuxSir.Org .
我正在为cat命令写文档
我来测试cat向文档追加内容的功能;
OK?
OK~
北南 呈上
cat 连接多个文件的内容并且输出到一个新文件中;
假设我们有sir01.txt、sir02.tx和sir03.txt ,并且内容如下;
[root@localhost ~]# cat sir01.txt
123456
i am testing
[root@localhost ~]# cat sir02.txt
56789
BeiNan Tested
[root@localhost ~]# cat sir03.txt
09876
linuxsir.org testing
我想通过cat 把sir01.txt、sir02.txt及sir03.txt 三个文件连接在一起(也就是说把这三个文件的内容都接在一起)并输出到一个新的文件sir04.txt 中。
注意:其原理是把三个文件的内容连接起来,然后创建sir04.txt文件,并且把几个文件的内容同时写入sir04.txt中。特别值得一提的是,如果您输入到一个已经存在的sir04.txt 文件,会把sir04.txt内容清空。
[root@localhost ~]# cat sir01.txt sir02.txt sir03.txt > sir04.txt
[root@localhost ~]# more sir04.txt
123456
i am testing
56789
BeiNan Tested
09876
linuxsir.org testing
cat 把一个或多个已存在的文件内容,追加到一个已存在的文件中
[root@localhost ~]# cat sir00.txt
linuxsir.org forever
[root@localhost ~]# cat sir01.txt sir02.txt sir03.txt >> sir00.txt
[root@localhost ~]# cat sir00.txt
linuxsir.org forever
123456
i am testing
56789
BeiNan Tested
09876
linuxsir.org testing
警告:我们要知道>意思是创建,>>是追加。千万不要弄混了。造成失误可不是闹着玩的;
2、more 文件内容或输出查看工具;
more 是我们最常用的工具之一,最常用的就是显示输出的内容,然后根据窗口的大小进行分页显示,然后还能提示文件的百分比;
[root@localhost ~]# more /etc/profile
2.1 more 的语法、参数和命令;
more [参数选项] [文件]
参数如下:
+num 从第num行开始显示;
-num 定义屏幕大小,为num行;
+/pattern 从pattern 前两行开始显示;
-c 从顶部清屏然后显示;
-d 提示Press space to continue, 'q' to quit.(按空格键继续,按q键退出),禁用响铃功能;
-l 忽略Ctrl+l (换页)字符;
-p 通过清除窗口而不是滚屏来对文件进行换页。和-c参数有点相似;
-s 把连续的多个空行显示为一行;
-u 把文件内容中的下划线去掉
退出more的动作指令是q
2.2 more 的参数应用举例;
[root@localhost ~]# more -dc /etc/profile 注:显示提示,并从终端或控制台顶部显示;
[root@localhost ~]# more +4 /etc/profile 注:从profile的第4行开始显示;
[root@localhost ~]# more -4 /etc/profile 注:每屏显示4行;
[root@localhost ~]# more +/MAIL /etc/profile 注:从profile中的第一个MAIL单词的前两行开始显示;
2.3 more 的动作指令;
我们查看一个内容较大的文件时,要用到more的动作指令,比如ctrl+f(或空格键) 是向下显示一屏,ctrl+b是返回上一屏; Enter键可以向下滚动显示n行,要通过定,默认为1行;
我们只说几个常用的; 自己尝试一下就知道了;
Enter 向下n行,需要定义,默认为1行;
Ctrl+f 向下滚动一屏;
空格键 向下滚动一屏;
Ctrl+b 返回上一屏;
= 输出当前行的行号;
:f 输出文件名和当前行的行号;
v 调用vi编辑器;
! 命令 调用Shell,并执行命令;
q 退出more
当我们查看某一文件时,想调用vi来编辑它,不要忘记了v动作指令,这是比较方便的;
2.4 其它命令通过管道和more结合的运用例子;
比如我们列一个目录下的文件,由于内容太多,我们应该学会用more来分页显示。这得和管道 | 结合起来,比如:
[root@localhost ~]# ls -l /etc |more
3、less 查看文件内容 工具;
less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大;您是初学者,我建议您用less。由于less的内容太多,我们把最常用的介绍一下;
3.1 less的语法格式;
less [参数] 文件
常用参数
-c 从顶部(从上到下)刷新屏幕,并显示文件内容。而不是通过底部滚动完成刷新;
-f 强制打开文件,二进制文件显示时,不提示警告;
-i 搜索时忽略大小写;除非搜索串中包含大写字母;
-I 搜索时忽略大小写,除非搜索串中包含小写字母;
-m 显示读取文件的百分比;
-M 显法读取文件的百分比、行号及总行数;
-N 在每行前输出行号;
-p pattern 搜索pattern;比如在/etc/profile搜索单词MAIL,就用 less -p MAIL /etc/profile
-s 把连续多个空白行作为一个空白行显示;
-Q 在终端下不响铃;
比如:我们在显示/etc/profile的内容时,让其显示行号;
[root@localhost ~]# less -N /etc/profile
3.2 less的动作命令;
进入less后,我们得学几个动作,这样更方便 我们查阅文件内容;最应该记住的命令就是q,这个能让less终止查看文件退出;
动作
回车键 向下移动一行;
y 向上移动一行;
空格键 向下滚动一屏;
b 向上滚动一屏;
d 向下滚动半屏;
h less的帮助;
u 向上洋动半屏;
w 可以指定显示哪行开始显示,是从指定数字的下一行显示;比如指定的是6,那就从第7行显示;
g 跳到第一行;
G 跳到最后一行;
p n% 跳到n%,比如 10%,也就是说比整个文件内容的10%处开始显示;
/pattern 搜索pattern ,比如 /MAIL表示在文件中搜索MAIL单词;
v 调用vi编辑器;
q 退出less
!command 调用SHELL,可以运行命令;比如!ls 显示当前列当前目录下的所有文件;
就less的动作来说,内容太多了,用的时候查一查man less是最好的。在这里就不举例子了;
4、head 工具,显示文件内容的前几行;
head 是显示一个文件的内容的前多少行;
用法比较简单;
head -n 行数值 文件名;
比如我们显示/etc/profile的前10行内容,应该是:
[root@localhost ~]# head -n 10 /etc/profile
5、tail 工具,显示文件内容的最后几行;
tail 是显示一个文件的内容的前多少行;
用法比较简单;
tail -n 行数值 文件名;
比如我们显示/etc/profile的最后5行内容,应该是:
[root@localhost ~]# tail -n 5 /etc/profile
posted @
2011-01-18 14:43 xzc 阅读(1150) |
评论 (4) |
编辑 收藏Oracle中不同启动和关闭方式的区别
Oracle数据库提供了几种不同的数据库启动和关闭方式,本文将周详介绍这些启动和关闭方式之间的区别连同他们各自不同的功能。
一、启动和关闭Oracle数据库
对于大多数Oracle DBA来说,启动和关闭Oracle数据库最常用的方式就是在命令行方式下的Server Manager。从Oracle 8i以后,系统将Server Manager的任何功能都集中到了SQL*Plus中,也就是说从8i以后对于数据库的启动和关闭能够直接通过SQL*Plus来完成,而不再另外需要Server Manager,但系统为了保持向下兼容,依旧保留了Server Manager工具。另外也可通过图像用户工具(GUI)的Oracle Enterprise Manager来完成系统的启动和关闭,图像用户界面Instance Manager很简单,这里不再详述。
要启动和关闭数据库,必须要以具备Oracle 管理员权限的用户登陆,通常也就是以具备SYSDBA权限的用户登陆。一般我们常用INTERNAL用户来启动和关闭数据库(INTERNAL用户实际上是SYS用户以SYSDBA连接的同义词)。Oracle数据库的新版本将逐步淘汰INTERNAL这个内部用户,所以我们最好还是配置DBA用户具备SYSDBA权限。
二、数据库的启动(STARTUP)
启动一个数据库需要三个步骤:
1、 创建一个Oracle实例(非安装阶段)
2、 由实例安装数据库(安装阶段)
3、 打开数据库(打开阶段)
在Startup命令中,能够通过不同的选项来控制数据库的不同启动步骤。
1、STARTUP NOMOUNT
NOMOUNT选项仅仅创建一个Oracle实例。读取init.ora初始化参数文档、启动后台进程、初始化系统全局区(SGA)。Init.ora文档定义了实例的配置,包括内存结构的大小和启动后台进程的数量和类型等。实例名根据Oracle_SID配置,不一定要和打开的数据库名称相同。当实例打开后,系统将显示一个SGA内存结构和大小的列表,如下所示:
SQL> startup nomount
ORACLE 例程已启动。
Total System Global Area 35431692 bytes
Fixed Size 70924 bytes
Variable Size 18505728 bytes
Database Buffers 16777216 bytes
Redo Buffers 77824 bytes
2、STARTUP MOUNT
该命令创建实例并且安装数据库,但没有打开数据库。Oracle系统读取控制文档中关于数据文档和重作日志文档的内容,但并不打开该文档。这种打开方式常在数据库维护操作中使用,如对数据文档的更名、改变重作日志连同打开归档方式等。在这种打开方式下,除了能够看到SGA系统列表以外,系统还会给出"数据库装载完毕"的提示。
3、STARTUP
该命令完成创建实例、安装实例和打开数据库的任何三个步骤。此时数据库使数据文档和重作日志文档在线,通常还会请求一个或是多个回滚段。这时系统除了能够看到前面Startup Mount方式下的任何提示外,还会给出一个"数据库已打开"的提示。此时,数据库系统处于正常工作状态,能够接受用户请求。
假如采用STARTUP NOMOUNT或是STARTUP MOUNT的数据库打开命令方式,必须采用ALTER DATABASE命令来执行打开数据库的操作。例如,假如您以STARTUP NOMOUNT方式打开数据库,也就是说实例已创建,但是数据库没有安装和打开。这是必须运行下面的两条命令,数据库才能正确启动。
ALTER DATABASE MOUNT;
ALTER DATABASE OPEN;
而假如以STARTUP MOUNT方式启动数据库,只需要运行下面一条命令即能够打开数据库:
ALTER DATABASE OPEN.
4、其他打开方式
除了前面介绍的三种数据库打开方式选项外,更有另外其他的一些选项。
(1) STARTUP RESTRICT
这种方式下,数据库将被成功打开,但仅仅允许一些特权用户(具备DBA角色的用户)才能够使用数据库。这种方式常用来对数据库进行维护,如数据的导入/导出操作时不希望有其他用户连接到数据库操作数据。
(2) STARTUP FORCE
该命令其实是强行关闭数据库(shutdown abort)和启动数据库(startup)两条命令的一个综合。该命令仅在关闭数据库碰到问题不能关闭数据库时采用。
(3) ALTER DATABASE OPEN READ ONLY;
该命令在创建实例连同安装数据库后,以只读方式打开数据库。对于那些仅仅提供查询功能的产品数据库能够采用这种方式打开。
三、数据库的关闭(SHUTDOWN)
对于数据库的关闭,有四种不同的关闭选项,下面对其进行一一介绍。
1、SHUTDOWN NORMAL
这是数据库关闭SHUTDOWN命令的确省选项。也就是说假如您发出SHUTDOWN这样的命令,也即是SHUTDOWN NORNAL的意思。
发出该命令后,任何新的连接都将再不允许连接到数据库。在数据库关闭之前,Oracle将等待现在连接的任何用户都从数据库中退出后才开始关闭数据库。采用这种方式关闭数据库,在下一次启动时无需进行任何的实例恢复。但需要注意一点的是,采用这种方式,也许关闭一个数据库需要几天时间,也许更长。
2、SHUTDOWN IMMEDIATE
这是我们常用的一种关闭数据库的方式,想很快地关闭数据库,但又想让数据库干净的关闭,常采用这种方式。
当前正在被Oracle处理的SQL语句立即中断,系统中任何没有提交的事务全部回滚。假如系统中存在一个很长的未提交的事务,采用这种方式关闭数据库也需要一段时间(该事务回滚时间)。系统不等待连接到数据库的任何用户退出系统,强行回滚当前任何的活动事务,然后断开任何的连接用户。
3、SHUTDOWN TRANSACTIONAL
该选项仅在Oracle 8i后才能够使用。该命令常用来计划关闭数据库,他使当前连接到系统且正在活动的事务执行完毕,运行该命令后,任何新的连接和事务都是不允许的。在任何活动的事务完成后,数据库将和SHUTDOWN IMMEDIATE同样的方式关闭数据库。
4、SHUTDOWN ABORT
这是关闭数据库的最后一招,也是在没有任何办法关闭数据库的情况下才不得不采用的方式,一般不要采用。假如下列情况出现时能够考虑采用这种方式关闭数据库。
1、 数据库处于一种非正常工作状态,不能用shutdown normal或shutdown immediate这样的命令关闭数据库;
2、 需要立即关闭数据库;
3、 在启动数据库实例时碰到问题;
任何正在运行的SQL语句都将立即中止。任何未提交的事务将不回滚。Oracle也不等待现在连接到数据库的用户退出系统。下一次启动数据库时需要实例恢复,因此,下一次启动可能比平时需要更多的时间。
表1能够清楚地看到上述四种不同关闭数据库的区别和联系。
关闭方式 A I T N
允许新的连接 × × × ×
等待直到当前会话中止 × × × √
等待直到当前事务中止 × × √ √
强制CheckPoint,关闭任何文档 × √ √ √
其中:A-Abort I-Immediate T-Transaction N-Nornal
pl/sql developer的Commander Windows下执行shutdown命令报“ORA-00900: 无效 SQL 语句”,
但在服务器本地sqlplus下却可以执行关闭数据库命令,PL/SQL DEVELOPER只支持部分的sql*plus命令?
另外在数据库unmount(instance 已经启动)的情况下,PL/SQL DEVELOPER无法连接上,
报“ORA-12528: TNS:监听程序:所有适用例程都无法建立新连接”。
在instance已经启动但数据库还没mount的情况下PL/SQL DEVELOPER等客户端都无法连接到实例上
如何查看Oracle当前数据库实例名
数据库实例名在编程的很多地方都需要用到,配置数据库的jdbc:oracle:thin:@192.168.2.1:1521:WW ,还有sqlPlus的连接字符串中也需要用到 conn sys/password@WW as sysdba; 如何查看当前数据库实例名呢?方式有三:
·使用SQL语句:select instance_name from v$instance;
·使用show命令:show parameter instance
·查看参数文件:查看init.ora文件
posted @
2011-01-04 10:32 xzc 阅读(2454) |
评论 (0) |
编辑 收藏[摘要] 在实际的应用中,有时候工作数据库需要重新启动。本文介绍了一个特别实用的操作步骤,希望对大家有所帮助。
[关键字]
Oracle 重启
在实际的应用中,有时候工作数据库需要重新启动。本文介绍了一个特别实用的操作步骤,希望对大家有所帮助。
1. 停应用层的各种程序
2. 停Oralce的监听进程
$ lsnrctl stop
3. 在独占的系统用户下,备份控制文件:
$ sqlplus "/as sysdba"
SQL> alter database backup controlfile to trace;
4. 在独占的系统用户下,手工切换重作日志文件,确保当前已修改过的数据存入文件:
SQL> alter system switch logfile;
5. 在独占的系统用户下,运行下面SQL语句,生成杀数据库用户连接的kill_all_session.sql文件:
SQL> set head off;
SQL> set feedback off;
SQL> set newpage none;
SQL> spool ./kill_session.sql
SQL> select 'alter system kill session ''' sid ',' serial# ''';' from v$session where username is not null;
SQL> spool off;
6. 在独占的系统用户下,执行杀数据库用户连接的kill_session.sql文件
SQL> @./kill_session.sql
7. 在独占的系统用户下,用immediate方式关闭数据库:
SQL> shutdown immediate;
或者
SVRMGRL> shutdown immediate;
8. 启动oralce的监听进程
$ lsnrctl start
9. 进入独占的系统用户下,启动Oralce数据库
$ sqlplus /nolog
SQL> connect / as sysdba
SQL> startup;
或者
$ svrmgrl
SVRMGRL> connect internal;
SVRMGRL> startup;
10.启动应用层的各种程序
posted @
2011-01-04 10:10 xzc 阅读(747) |
评论 (3) |
编辑 收藏
方案理念--四化理念
- 数据规格化
- 处理自动化
- 信息集中化
- 操作人性化
架构
通过视图实现来至两个不同数据库的表的结构完全一致, 在结构完全相同的两个表之间进行数据同步, 问题变得相当简单. 同步代码如下.
ETL
---初始同步
delete from ods_table;
insert into v_table
select * from db_table;
commit;
---新增同步
insert into v_table
select * from db_table t
where t.id not in (select id from v_table);
commit;
---变更同步
update ods_table t
set t.c_number = (select db.c_number from db_table db where db.id = t.id)
where t.c_number != (select db.c_number from db_table db where db.id = t.id);
commit;
实现两个表结构完全一致的方法如下
---建表
CREATE SEQUENCE SEQ_ETL_INCREASE_ID
INCREMENT BY 1
START WITH 1
NOCACHE;
/*==============================================================*/
/* Table: ETL_TABLES */
/*==============================================================*/
CREATE TABLE ETL_TABLES (
"ID" NUMBER DEFAULT -1 NOT NULL,
"TABLE_NAME" VARCHAR2(100) NOT NULL,
"TABLE_TYPE" VARCHAR2(30) NOT NULL,
"TABLE_ROOT_IN" VARCHAR2(30),
"TABLE_NEED_CREATE_VIEW" NUMBER DEFAULT 1,
"TABLE_CREATE_VIEW_NAME_PREFIX" VARCHAR2(30) DEFAULT 'v',
"DB_LINK_NAME" VARCHAR2(100),
"CURRENT_VERSION" NUMBER DEFAULT 1 NOT NULL,
"VERSION_HISTORY" VARCHAR2(3000) DEFAULT 'init input' NOT NULL,
"DEVELOP_DATE" DATE DEFAULT SYSDATE NOT NULL,
"DEVELOP_BY" VARCHAR2(100) DEFAULT 'cyyan@isoftstone' NOT NULL,
"LAST_MAINTAIN_DATE" DATE DEFAULT SYSDATE NOT NULL,
"LAST_MAINTAIN_BY" VARCHAR2(100) DEFAULT 'cyyan@isoftstone' NOT NULL,
"MEMO" VARCHAR2(500),
"STATUS" NUMBER DEFAULT 1,
CONSTRAINT PK_ETL_TABLES PRIMARY KEY ("ID")
);
COMMENT ON TABLE ETL_TABLES IS
'此表用于维护ETL涉及到所有表, 包括:
1, db---业务系统数据库
2, ods---操作数据数据库
3, dw---数据仓库';
/*==============================================================*/
/* Table: ETL_VIEWS */
/*==============================================================*/
CREATE TABLE ETL_VIEWS (
"ID" NUMBER DEFAULT -1 NOT NULL,
"VIEW_NAME" VARCHAR2(100) NOT NULL,
"VIEW_TYPE" VARCHAR2(30) NOT NULL,
"VIEW_ROOT_IN" VARCHAR2(30),
"VIEW_SELECT" VARCHAR2(4000) NOT NULL,
"VIEW_FROM" VARCHAR2(600) NOT NULL,
"VIEW_WHERE" VARCHAR2(2000),
"VIEW_ORDER_BY" VARCHAR2(600),
"VIEW_GROUP_BY" VARCHAR2(600),
"VIEW_HAVING" VARCHAR2(600),
"VIEW_DB_LINK_NAME" VARCHAR2(100),
"CURRENT_VERSION" NUMBER DEFAULT 1 NOT NULL,
"VERSION_HISTORY" VARCHAR2(3000) DEFAULT 'init input' NOT NULL,
"DEVELOP_DATE" DATE DEFAULT SYSDATE NOT NULL,
"DEVELOP_BY" VARCHAR2(100) DEFAULT 'cyyan@isoftstone' NOT NULL,
"LAST_MAINTAIN_DATE" DATE DEFAULT SYSDATE NOT NULL,
"LAST_MAINTAIN_BY" VARCHAR2(100) DEFAULT 'cyyan@isoftstone' NOT NULL,
"MEMO" VARCHAR2(500),
"STATUS" NUMBER DEFAULT 1,
CONSTRAINT PK_ETL_VIEWS PRIMARY KEY ("ID")
);
COMMENT ON TABLE ETL_VIEWS IS
'此表用于维护ETL涉及到所有视图, 包括:
1, v1---db表中与ods对应到视图
2, v2---ods表中与db对应到视图
3, v3---ods表中与dw对应到视图
4, v4---dw表中与ods中对应到视图';
/*==============================================================*/
/* Table: ETLS */
/*==============================================================*/
CREATE TABLE ETLS (
"ID" NUMBER NOT NULL,
"ETL_NAME" VARCHAR2(300) NOT NULL,
"ETL_TYPE" VARCHAR2(30) NOT NULL,
"ETL_SRC_VIEW_OR_TABLE" NUMBER NOT NULL,
"ETL_DES_VIEW_OR_TABLE" NUMBER NOT NULL,
"ETL_INIT_ENABLE" NUMBER(1) DEFAULT 1 NOT NULL,
"ETL_ADD_ENABLE" NUMBER(1) DEFAULT 1 NOT NULL,
"ETL_CHARGE_ENABLE" NUMBER(1) DEFAULT 1 NOT NULL,
"CURRENT_VERSION" NUMBER DEFAULT 1 NOT NULL,
"VERSION_HISTORY" VARCHAR2(3000) DEFAULT 'init input' NOT NULL,
"DEVELOP_DATE" DATE DEFAULT SYSDATE NOT NULL,
"DEVELOP_BY" VARCHAR2(100) DEFAULT 'cyyan@isoftstone' NOT NULL,
"LAST_MAINTAIN_DATE" DATE DEFAULT SYSDATE NOT NULL,
"LAST_MAINTAIN_BY" VARCHAR2(100) DEFAULT 'cyyan@isoftstone' NOT NULL,
"MEMO" VARCHAR2(500),
"STATUS" NUMBER DEFAULT 1,
CONSTRAINT PK_ETLS PRIMARY KEY ("ID")
);
COMMENT ON TABLE ETLS IS
'此表用于维护ETL转换时设计到源表和目的表
源表(或视图)--->目的表(或视图)-
(推荐全部使用视图, 视图具有更过到灵活性, 而且更统一)
整体架构是在完全相同两张表(或视图)之间进行同步处理
规范:
1, 源表(或视图)-和目的表(或视图)-完全相同
2, 目的视图必须是单表';
--存储过程
/*==============================================================*/
/* Database name: %DATABASE% */
/* DBMS name: ORACLE Version 10g */
/* Created on: 2009-2-1 23:29:27 */
/*==============================================================*/
-- INTEGRITY PACKAGE DECLARATION
CREATE OR REPLACE PACKAGE INTEGRITYPACKAGE AS
PROCEDURE INITNESTLEVEL;
FUNCTION GETNESTLEVEL RETURN NUMBER;
PROCEDURE NEXTNESTLEVEL;
PROCEDURE PREVIOUSNESTLEVEL;
END INTEGRITYPACKAGE;
/
-- INTEGRITY PACKAGE DEFINITION
CREATE OR REPLACE PACKAGE BODY INTEGRITYPACKAGE AS
NESTLEVEL NUMBER;
-- PROCEDURE TO INITIALIZE THE TRIGGER NEST LEVEL
PROCEDURE INITNESTLEVEL IS
BEGIN
NESTLEVEL := 0;
END;
-- FUNCTION TO RETURN THE TRIGGER NEST LEVEL
FUNCTION GETNESTLEVEL RETURN NUMBER IS
BEGIN
IF NESTLEVEL IS NULL THEN
NESTLEVEL := 0;
END IF;
RETURN(NESTLEVEL);
END;
-- PROCEDURE TO INCREASE THE TRIGGER NEST LEVEL
PROCEDURE NEXTNESTLEVEL IS
BEGIN
IF NESTLEVEL IS NULL THEN
NESTLEVEL := 0;
END IF;
NESTLEVEL := NESTLEVEL + 1;
END;
-- PROCEDURE TO DECREASE THE TRIGGER NEST LEVEL
PROCEDURE PREVIOUSNESTLEVEL IS
BEGIN
NESTLEVEL := NESTLEVEL - 1;
END;
END INTEGRITYPACKAGE;
/
CREATE OR REPLACE PROCEDURE PRO_CREATE_VIEW_BY_ETL_VIEWS
AS
--------------PRO_CREATE_VIEW_BY_ETL_VIEWS------------------------
-- CREATED ON 2009-2-1 BY CYYAN@ISOFTSTONE
-- 功能 : 根据ETL_VIEWS中到数据生成视图
------------------------------------------------------------------------------
VIEW_CREATE_CODE VARCHAR2(10000); --生成视图到代码
VIEW_NAME VARCHAR2(100); --视图名称
VIEW_SELECT VARCHAR2(4000); --视图的SELECT部分
VIEW_FROM VARCHAR2(300); --视图的FROM部分
VIEW_WHERE VARCHAR2(3000); --视图的WHERE部分
VIEW_ORDER_BY VARCHAR2(600); --视图的ORDER BY部分
VIEW_GROUP_BY VARCHAR2(600); --视图的GROUP BY部分
VIEW_HAVING VARCHAR2(600); --视图的HAVING部分
VIEW_DB_LINK_NAME VARCHAR2(100); --视图的DB LINK部分
ROW_COUNT NUMBER; --行数
CURSOR ETL_VIEWS_CURSOR IS --提取创建视图需要到信息
SELECT VIEW_NAME, VIEW_SELECT, VIEW_FROM, VIEW_WHERE, VIEW_ORDER_BY, VIEW_GROUP_BY, VIEW_HAVING, VIEW_DB_LINK_NAME FROM ETL_VIEWS T WHERE T.CURRENT_VERSION = (SELECT MAX(T2.CURRENT_VERSION) FROM ETL_VIEWS T2 WHERE T.VIEW_NAME = T2.VIEW_NAME);
BEGIN
-- 统计行数
SELECT COUNT(*) INTO ROW_COUNT FROM ETL_VIEWS T WHERE T.CURRENT_VERSION = (SELECT MAX(T2.CURRENT_VERSION) FROM ETL_VIEWS T2 WHERE T.VIEW_NAME = T2.VIEW_NAME);
OPEN ETL_VIEWS_CURSOR; --打开游标
FOR I IN 1 .. ROW_COUNT LOOP --遍历
FETCH ETL_VIEWS_CURSOR
INTO VIEW_NAME, VIEW_SELECT, VIEW_FROM, VIEW_WHERE, VIEW_ORDER_BY, VIEW_GROUP_BY, VIEW_HAVING, VIEW_DB_LINK_NAME;
---拼接创建视图到语句
VIEW_CREATE_CODE := 'create or replace view ' || VIEW_NAME || ' as select ' || VIEW_SELECT || ' from ' || VIEW_FROM;
IF VIEW_DB_LINK_NAME IS NOT NULL THEN
VIEW_CREATE_CODE := VIEW_CREATE_CODE || '@' || VIEW_DB_LINK_NAME;
END IF;
IF VIEW_WHERE IS NOT NULL THEN
VIEW_CREATE_CODE := VIEW_CREATE_CODE || ' where ' || VIEW_WHERE;
END IF;
IF VIEW_ORDER_BY IS NOT NULL THEN
VIEW_CREATE_CODE := VIEW_CREATE_CODE || ' order by ' || VIEW_ORDER_BY;
END IF;
IF VIEW_GROUP_BY IS NOT NULL THEN
VIEW_CREATE_CODE := VIEW_CREATE_CODE || ' group by ' || VIEW_GROUP_BY;
END IF;
IF VIEW_HAVING IS NOT NULL THEN
VIEW_CREATE_CODE := VIEW_CREATE_CODE || ' having ' || VIEW_HAVING;
END IF;
--输出创建语句
--DBMS_OUTPUT.PUT_LINE(VIEW_CREATE_CODE);
--DBMS_OUTPUT.PUT_LINE('');
--执行创建视图
EXECUTE IMMEDIATE VIEW_CREATE_CODE;
END LOOP;
CLOSE ETL_VIEWS_CURSOR; --关闭游标
END;
/
CREATE OR REPLACE PROCEDURE PRO_INSERT_INTO_ETL_VIEWS
AS
--ADD BY CYYAN@ISOFTSTONE
--2009年2月1日21:33:37
---此存储过程用于 将ETL_TABLE中标识需要创建VIEW 到TABLE, 进行自动提起转换到ETL_VIEWS中.
--处理过程用到啦系统表COL从此表中获取列名
TABLE_NAME VARCHAR2(100); --表名
COL_NAME VARCHAR2(100); --列名
TABLE_COUNT NUMBER; --表到行数
--COL_COUNT NUMBER; --列数
ETL_VIEWS_INSERT_CODE VARCHAR2(600); --插入语句到 INSERT部分
ETL_VIEWS_VALUES_CODE VARCHAR2(16000); --插入语句到VALUES部分
--ETL_VIEWS的到列
VIEW_NAME_PREFIX VARCHAR2(30);--实体名到前缀
TABLE_TYPE VARCHAR2(30); --表类型 如 DB, ODS, DW
TABLE_ROOT_IN VARCHAR2(30); --表来源, 来自那个系统, 如资金系统"NHZJ", 财务系统"NHCW"
VIEW_SELECT VARCHAR2(10000); --VIEW 语句到SELECT部分, 这个需要遍历一个表到所有列
DB_LINK_NAME VARCHAR2(100);
CURRENT_VERSION VARCHAR2(600); --版本部分, 这里没更新, 只要全部删除, 或不断插入, 此字段定义了版本, 没有变更都形成新到版本, 取值是取最大值
CURSOR_NUMBER NUMBER;
COL_SELECT_SQL VARCHAR2(100);
RETURN_VALUE NUMBER;
--从ETL_TABLES中查询需要生成视图到表
CURSOR DB_TABLES_CURSOR IS
SELECT UPPER(TABLE_NAME), T.TABLE_TYPE, T.TABLE_ROOT_IN, T.TABLE_CREATE_VIEW_NAME_PREFIX, DB_LINK_NAME FROM ETL_TABLES T WHERE (UPPER(T.TABLE_TYPE) = 'DB' OR UPPER(T.TABLE_TYPE) = 'DW' ) AND T.TABLE_NEED_CREATE_VIEW = 1;
--CURSOR_NUMBER NUMBER; --游标 OLD WAY 执行需要, NEW WAY 不需要
--RETURN_VALUE NUMBER; --执行后返回值 OLD WAY 执行需要, NEW WAY 不需要
BEGIN
-- TEST STATEMENTS HERE
SELECT COUNT(*) INTO TABLE_COUNT FROM ETL_TABLES T WHERE (UPPER(T.TABLE_TYPE) = 'DB' OR UPPER(T.TABLE_TYPE) = 'DW' ) AND T.TABLE_NEED_CREATE_VIEW = 1;
--构造INSERT部分
ETL_VIEWS_INSERT_CODE := 'insert into etl_views(view_name, view_type, view_root_in, view_select, view_from, current_version, VIEW_DB_LINK_NAME) ';
OPEN DB_TABLES_CURSOR;
FOR I IN 1 .. TABLE_COUNT LOOP --表遍历
FETCH DB_TABLES_CURSOR
INTO TABLE_NAME, TABLE_TYPE, TABLE_ROOT_IN, VIEW_NAME_PREFIX, DB_LINK_NAME;
--构造VALUES部分
ETL_VIEWS_VALUES_CODE := 'values(''' || VIEW_NAME_PREFIX || TABLE_NAME || ''', ''' || TABLE_TYPE || ''', ''' || TABLE_ROOT_IN || '''';
DBMS_OUTPUT.PUT(TABLE_NAME);
/* 使用CURSOR遍历列到方法 不适用于DB_LINK
--准备遍历列
SELECT COUNT(*) INTO COL_COUNT FROM COL@DB_LINK_NHZJ WHERE COL.TNAME = UPPER(TABLE_NAME);
DBMS_OUTPUT.PUT_LINE(' table has ' || COL_COUNT || ' cols');
DECLARE
CURSOR COLS_CURSOR IS
SELECT C.CNAME FROM COL@DB_LINK_NHZJ C WHERE C.TNAME = UPPER(TABLE_NAME);
BEGIN
OPEN COLS_CURSOR;
VIEW_SELECT := '';
--下面用逗号拼接列
FETCH COLS_CURSOR --遍历第一列
INTO COL_NAME;
VIEW_SELECT := VIEW_SELECT || COL_NAME;
FOR J IN 2 .. COL_COUNT LOOP --遍历后面到列
FETCH COLS_CURSOR
INTO COL_NAME;
DBMS_OUTPUT.PUT_LINE(' ' || COL_NAME);
VIEW_SELECT := VIEW_SELECT || ', ' || COL_NAME;
END LOOP;
CLOSE COLS_CURSOR;
END;
--DBMS_OUTPUT.PUT_LINE(VIEW_SELECT);
-- DBMS_OUTPUT.PUT_LINE(ETL_VIEWS_VALUES_CODE);
*/
/* 使用 DBMS_SQL */
-- ANOTHER WAY USER DBMS_SQL PACKAGE
COL_SELECT_SQL := 'select t.cname from sys.col@' || DB_LINK_NAME || ' T where T.tname = ''' || TABLE_NAME || '''';
--SQL_CODE := 'select t.cname from sys.col T where T.tname = ''' || TABLE_NAME || '''';
CURSOR_NUMBER := DBMS_SQL.OPEN_CURSOR();
DBMS_SQL.PARSE(CURSOR_NUMBER, COL_SELECT_SQL, DBMS_SQL.NATIVE);
DBMS_SQL.DEFINE_COLUMN(CURSOR_NUMBER,1,COL_NAME, 100);
RETURN_VALUE := DBMS_SQL.EXECUTE(CURSOR_NUMBER);
DBMS_OUTPUT.PUT_LINE(' RETURN_VALUE = ' || RETURN_VALUE);
RETURN_VALUE := DBMS_SQL.FETCH_ROWS(CURSOR_NUMBER); --获取第一列
DBMS_SQL.COLUMN_VALUE(CURSOR_NUMBER,1,COL_NAME);
VIEW_SELECT := COL_NAME;
WHILE DBMS_SQL.FETCH_ROWS(CURSOR_NUMBER)<>0 LOOP ---遍历其它到列
DBMS_SQL.COLUMN_VALUE(CURSOR_NUMBER,1,COL_NAME);
DBMS_OUTPUT.PUT_LINE(COL_NAME);
VIEW_SELECT := VIEW_SELECT || ', ' || COL_NAME;
END LOOP;
-- DBMS_OUTPUT.PUT_LINE('VIEW_SELECT : ' || VIEW_SELECT);
DBMS_SQL.CLOSE_CURSOR(CURSOR_NUMBER);
--生成最新到版本号: 视图名称是唯一的
SELECT NVL(MAX(CURRENT_VERSION),0) + 1 INTO CURRENT_VERSION FROM ETL_VIEWS V WHERE V.VIEW_NAME = VIEW_NAME_PREFIX || TABLE_NAME;
ETL_VIEWS_VALUES_CODE := ETL_VIEWS_VALUES_CODE || CHR(10) || ', ''' || VIEW_SELECT || '''' || CHR(10) || ', ''' || TABLE_NAME || ''', ''' || CURRENT_VERSION || ''', ''' || DB_LINK_NAME || ''')';
--输出插入到语句
--DBMS_OUTPUT.PUT_LINE(ETL_VIEWS_INSERT_CODE);
--DBMS_OUTPUT.PUT_LINE(ETL_VIEWS_VALUES_CODE);
--DBMS_OUTPUT.PUT_LINE('');
--DBMS_STANDARD.
--执行插入语句
-- NEW WAY
EXECUTE IMMEDIATE ETL_VIEWS_INSERT_CODE || ETL_VIEWS_VALUES_CODE;
/*
-- OLD WAY
CURSOR_NUMBER := DBMS_SQL.OPEN_CURSOR();
DBMS_SQL.PARSE(CURSOR_NUMBER, ETL_VIEWS_INSERT_CODE, DBMS_SQL.NATIVE);
RETURN_VALUE := DBMS_SQL.EXECUTE(CURSOR_NUMBER);
DBMS_SQL.CLOSE_CURSOR(CURSOR_NUMBER);
*/
END LOOP;
COMMIT; --提交
CLOSE DB_TABLES_CURSOR; --关闭游标
--EXCEPTION
--ROLLBACK;
END;
/
CREATE OR REPLACE TRIGGER TRG_ID_ON_ETLS
BEFORE INSERT ON ETLS
FOR EACH ROW
DECLARE
-- NOTHING
BEGIN
SELECT SEQ_ETL_INCREASE_ID.NEXTVAL INTO :NEW.ID FROM DUAL;
END TRIGGER_ID_INCREASE;
/
CREATE OR REPLACE TRIGGER TRG_ID_ON_ETL_TABLES
BEFORE INSERT ON ETL_TABLES
FOR EACH ROW
DECLARE
-- NOTHING
BEGIN
SELECT SEQ_ETL_INCREASE_ID.NEXTVAL INTO :NEW.ID FROM DUAL;
END TRIGGER_ID_INCREASE;
/
CREATE OR REPLACE TRIGGER TRG_ID_ON_ETL_VIEWS
BEFORE INSERT ON ETL_VIEWS
FOR EACH ROW
DECLARE
-- NOTHING
BEGIN
SELECT SEQ_ETL_INCREASE_ID.NEXTVAL INTO :NEW.ID FROM DUAL;
END TRIGGER_ID_INCREASE;
/
posted @
2010-12-31 10:42 xzc 阅读(1628) |
评论 (0) |
编辑 收藏
sed -e ‘s/[ ]*$//g’ 文件名
1. Sed简介
sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。以下介绍的是Gnu版本的Sed 3.02。
2. 定址
可以通过定址来定位你所希望编辑的行,该地址用数字构成,用逗号分隔的两个行数表示以这两行为起止的行的范围(包括行数表示的那两行)。如1,3表示1,2,3行,美元符号($)表示最后一行。范围可以通过数据,正则表达式或者二者结合的方式确定 。
3. Sed命令
调用sed命令有两种形式:
*
sed [options] ’command’ file(s)
*
sed [options] -f scriptfile file(s)
a\
在当前行后面加入一行文本。
b lable
分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
c\
用新的文本改变本行的文本。
d
从模板块(Pattern space)位置删除行。
D
删除模板块的第一行。
i\
在当前行上面插入文本。
h
拷贝模板块的内容到内存中的缓冲区。
H
追加模板块的内容到内存中的缓冲区
g
获得内存缓冲区的内容,并替代当前模板块中的文本。
G
获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l
列表不能打印字符的清单。
n
读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N
追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p
打印模板块的行。
P(大写)
打印模板块的第一行。
q
退出Sed。
r file
从file中读行。
t label
if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
T label
错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file
写并追加模板块到file末尾。
W file
写并追加模板块的第一行到file末尾。
!
表示后面的命令对所有没有被选定的行发生作用。
s/re/string
用string替换正则表达式re。
=
打印当前行号码。
#
把注释扩展到下一个换行符以前。
以下的是替换标记
*
g表示行内全面替换。
*
p表示打印行。
*
w表示把行写入一个文件。
*
x表示互换模板块中的文本和缓冲区中的文本。
*
y表示把一个字符翻译为另外的字符(但是不用于正则表达式)
4. 选项
-e command, –expression=command
允许多台编辑。
-h, –help
打印帮助,并显示bug列表的地址。
-n, –quiet, –silent
取消默认输出。
-f, –filer=script-file
引导sed脚本文件名。
-V, –version
打印版本和版权信息。
5. 元字符集^
锚定行的开始 如:/^sed/匹配所有以sed开头的行。
$
锚定行的结束 如:/sed$/匹配所有以sed结尾的行。
.
匹配一个非换行符的字符 如:/s.d/匹配s后接一个任意字符,然后是d。
*
匹配零或多个字符 如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[]
匹配一个指定范围内的字符,如/[Ss]ed/匹配sed和Sed。
[^]
匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
\(..\)
保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。
&
保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。
\<
锚定单词的开始,如:/\<love/匹配包含以love开头的单词的行。
\>
锚定单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\}
重复字符x,m次,如:/0\{5\}/匹配包含5个o的行。
x\{m,\}
重复字符x,至少m次,如:/o\{5,\}/匹配至少有5个o的行。
x\{m,n\}
重复字符x,至少m次,不多于n次,如:/o\{5,10\}/匹配5–10个o的行。
6. 实例
删除:d命令
*
$ sed ’2d’ example—–删除example文件的第二行。
*
$ sed ’2,$d’ example—–删除example文件的第二行到末尾所有行。
*
$ sed ’$d’ example—–删除example文件的最后一行。
*
$ sed ’/test/’d example—–删除example文件所有包含test的行。
替换:s命令
*
$ sed ’s/test/mytest/g’ example—–在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest。
*
$ sed -n ’s/^test/mytest/p’ example—–(-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的test被替换成mytest,就打印它。
*
$ sed ’s/^192.168.0.1/&localhost/’ example—–&符号表示替换换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加 localhost,变成192.168.0.1localhost。
*
$ sed -n ’s/\(love\)able/\1rs/p’ example—–love被标记为1,所有loveable会被替换成lovers,而且替换的行会被打印出来。
*
$ sed ’s#10#100#g’ example—–不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。
选定行的范围:逗号
*
$ sed -n ’/test/,/check/p’ example—–所有在模板test和check所确定的范围内的行都被打印。
*
$ sed -n ’5,/^test/p’ example—–打印从第五行开始到第一个包含以test开始的行之间的所有行。
*
$ sed ’/test/,/check/s/$/sed test/’ example—–对于模板test和west之间的行,每行的末尾用字符串sed test替换。
多点编辑:e命令
*
$ sed -e ’1,5d’ -e ’s/test/check/’ example—–(-e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除1至5行,第二条命令用check替换test。命令的执 行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
*
$ sed –expression=’s/test/check/’ –expression=’/love/d’ example—–一个比-e更好的命令是–expression。它能给sed表达式赋值。
从文件读入:r命令
*
$ sed ’/test/r file’ example—–file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面。
写入文件:w命令
*
$ sed -n ’/test/w file’ example—–在example中所有包含test的行都被写入file里。
追加命令:a命令
*
$ sed ’/^test/a\\—>this is a example’ example<—–’this is a example’被追加到以test开头的行后面,sed要求命令a后面有一个反斜杠。
插入:i命令
$ sed ’/test/i\\
new line
————————-’ example
如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。
下一个:n命令
*
$ sed ’/test/{ n; s/aa/bb/; }’ example—–如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。
变形:y命令
*
$ sed ’1,10y/abcde/ABCDE/’ example—–把1–10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。
退出:q命令
*
$ sed ’10q’ example—–打印完第10行后,退出sed。
保持和获取:h命令和G命令
*
$ sed -e ’/test/h’ -e ’$G example—–在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保 持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中 的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。
保持和互换:h命令和x命令
*
$ sed -e ’/test/h’ -e ’/check/x’ example —–互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换。
7. 脚本
Sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
posted @
2010-12-28 11:55 xzc 阅读(11277) |
评论 (1) |
编辑 收藏
一、ORACLE10g自动收集统计信息--自动analyze
从Oracle Database 10g开始,Oracle在建库后就默认创建了一个名为GATHER_STATS_JOB的定时任务,用于自动收集CBO的统计信息。
这个自动任务默认情况下在工作日晚上10:00-6:00和周末全天开启。调用DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC收集统计信息。该过程首先检测统计信息缺失和陈旧的对象。然后确定优先级,再开始进行统计信息。
可以通过以下查询这个JOB的运行情况:
select * from Dba_Scheduler_Jobs where JOB_NAME ='GATHER_STATS_JOB'
其实同在10点运行的Job还有一个AUTO_SPACE_ADVISOR_JOB:
SQL> select JOB_NAME,LAST_START_DATE from dba_scheduler_jobs;
JOB_NAME LAST_START_DATE
------------------------------ --------------------------------------
AUTO_SPACE_ADVISOR_JOB 04-DEC-07 10.00.00.692269 PM +08:00
GATHER_STATS_JOB 04-DEC-07 10.00.00.701152 PM +08:00
FGR$AUTOPURGE_JOB
PURGE_LOG 05-DEC-07 03.00.00.169059 AM PRC
然而这个自动化功能已经影响了很多系统的正常运行,晚上10点对于大部分生产系统也并非空闲时段。
而自动分析可能导致极为严重的闩锁竞争,进而可能导致数据库Hang或者Crash。
所以建议最好关闭这个自动统计信息收集功能:
exec DBMS_SCHEDULER.DISABLE('GATHER_STATS_JOB');
自动化永远而严重的隐患相伴随!
关闭及开启自动搜集功能,有两种方法,分别如下:
方法一:
exec dbms_scheduler.disable('SYS.GATHER_STATS_JOB');
exec dbms_scheduler.enable('SYS.GATHER_STATS_JOB');
方法二:
alter system set "_optimizer_autostats_job"=false scope=spfile;
alter system set "_optimizer_autostats_job"=true scope=spfile;
Pfile可以直接修改初始化参数文件,重新启动数据库。
二、AWR默认通过MMON及MMNL进程来每小自动运行一次,为了节省空间,采集的数据在 7 天后自动清除。
快照频率和保留时间都可以由用户修改。要查看当前的设置,您可以使用下面的语句:
select snap_interval, retention
from dba_hist_wr_control;
SNAP_INTERVAL RETENTION
------------------- -------------------
+00000 01:00:00.0 +00007 00:00:00.0
这些 SQL 语句显示快照每小时采集一次,采集的数据保留 7 天。要修改设置 — 例如,快照时间间隔为 20 分钟,保留时间为两天 — 您可以发出以下命令。参数以分钟为单位。
begin
dbms_workload_repository.modify_snapshot_settings (
interval => 20,
retention => 2*24*60
);end;
AWR 使用几个表来存储采集的统计数据,所有的表都存储在新的名称为 SYSAUX 的特定表空间中的 SYS 模式下,并且以 WRM$_* 和 WRH$_* 的格式命名。前一种类型存储元数据信息(如检查的数据库和采集的快照),后一种类型保存实际采集的统计数据。(您可能已经猜到,H 代表“历史数据 (historical)”而 M 代表“元数据 (metadata)”。)在这些表上构建了几种带前缀 DBA_HIST_ 的视图,这些视图可以用来编写您自己的性能诊断工具。视图的名称直接与表相关;例如,视图 DBA_HIST_SYSMETRIC_SUMMARY 是在WRH$_SYSMETRIC_SUMMARY 表上构建的。
您的处理计划一般是有规律的,并且通常基于您对各种事件的了解和您处理它们的经验。现在设想相同的事情由一个引擎来完成,这个引擎采集量度并根据预先确定的逻辑来推出可能的计划。您的工作不就变得更轻松了吗? 现在在 Oracle Database 10g 中推出的这个引擎称为自动数据库诊断监控程序 (ADDM)。为了作出决策,ADDM 使用了由 AWR 采集的数据。
在 AWR 进行的每一次快照采集之后,调用 ADDM 来检查量度并生成建议。因此,实际上您拥有了一个一天二十四小时工作的自动数据库管理员,它主动地分析数据并生成建议,从而把您解放出来,使您能够关注更具有战略意义的问题。
快照默认是自动采集的,但您也可以按需要采集它们。所有的 AWR 功能都在程序包 DBMS_WORKLOAD_REPOSITORY 中实施。要采集一次快照,只需发出下面的命令:
execute dbms_workload_repository.create_snapshot它立即采集一次快照,快照被记录在表 WRM$_SNAPSHOT 中。采集的量度是针对 TYPICAL 级别的。如果您想采集更详细的统计数据,您可以在上面的过程中将参数 FLUSH_LEVEL 设置为 ALL。统计数据自动删除,但也可以通过调用过程 drop_snapshot_range() 来手动删除。
posted @
2010-12-15 15:12 xzc 阅读(2784) |
评论 (0) |
编辑 收藏
1、 大数据量的表,比如大于2GB。一方面2GB文件对于32位os是一个上限,另外备份时间长。
2、 包括历史数据的表,比如最新的数据放入到最新的分区中。典型的例子:历史表,只有当前月份的数据可以被修改,而其他月份只能read-on
ly
ORACLE只支持以下分区:tables, indexes on tables, materialized views, and indexes on materialized views
分区对SQL和DML是透明的(应用程序不必知道已经作了分区),但是DDL可以对不同的分区进行管理。
不同的分区之间必须有相同的逻辑属性,比如共同的表名,列名,数据类型,约束;
但是可以有不同的物理属性,比如pctfree, pctused, and tablespaces.
分区独立性:即使某些分区不可用,其他分区仍然可用。
最多可以分成64000个分区,但是具有LONG or LONG RAW列的表不可以,但是有CLOB or BLOB列的表可以。
可以不用to_date函数,比如:
alter session set nls_date_format='mm/dd/yyyy';
CREATE TABLE sales_range
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
(
PARTITION sales_jan2000 VALUES LESS THAN('02/01/2000'),
PARTITION sales_feb2000 VALUES LESS THAN('03/01/2000'),
PARTITION sales_mar2000 VALUES LESS THAN('04/01/2000'),
PARTITION sales_apr2000 VALUES LESS THAN('05/01/2000')
);
Partition Key:最多16个columns,可以是nullable的
非分区的表可以有分区或者非分区的索引;
分区表可以有分区或者非分区的索引;
Partitioning 方法:
Range Partitioning
List Partitioning
Hash Partitioning
Composite Partitioning
Composite Partitioning:组合,以及 range-hash and range-list composite partitioning
Range Partitioning:
每个分区都有VALUES LESS THAN子句,表示这个分区小于(<)某个上限,而大于等于(>=)前一个分区的VALUES LESS THAN值。
MAXVALUE定义最高的分区,他表示一个虚拟的无限大的值。这个分区包括null值。
CREATE TABLE sales_range
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
(
PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('01/02/2000','DD/MM/YYYY')),
PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('01/03/2000','DD/MM/YYYY')),
PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('01/04/2000','DD/MM/YYYY')),
PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('01/05/2000','DD/MM/YYYY')),
PARTITION sales_2000 VALUES LESS THAN(MAXVALUE)
);
插入数据:
Insert into sales_range values(1,2,3,to_date('21-04-2000','DD-MM-YYYY'));
Insert into sales_range values(1,2,3,sysdate);
选择数据:
select * from sales_range;
select * from sales_range partition(sales_apr2000);
select * from sales_range partition(sales_mar2000);
select * from sales_range partition(sales_2000);
按照多个列分区:
CREATE TABLE sales_range1
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date, sales_amount)
(
PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('01/02/2000','DD/MM/YYYY'),1000),
PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('01/03/2000','DD/MM/YYYY'),2000),
PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('01/04/2000','DD/MM/YYYY'),3000),
PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('01/05/2000','DD/MM/YYYY'),4000),
PARTITION sales_2000 VALUES LESS THAN(MAXVALUE, MAXVALUE)
)
Insert into sales_range1 values(1,2,500, TO_DATE('21/01/2000','DD/MM/YYYY'));
Insert into sales_range1 values(2,3,1500, sysdate);
如果多个分区列的值冲突,则按照从左到右的优先级。
List Partitioning:
可以组织无序的,或者没有关系的数据在相同的分区。
不支持多列的(multicolumn) partition keys,只能是一个列。
DEFAULT表示不满足条件的都放在这个分区。
CREATE TABLE sales_list
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_state VARCHAR2(20),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY LIST(sales_state)
(
PARTITION sales_west VALUES('California', 'Hawaii'),
PARTITION sales_east VALUES ('New York', 'Virginia', 'Florida'),
PARTITION sales_central VALUES('Texas', 'Illinois'),
PARTITION sales_other VALUES(DEFAULT)
);
Hash Partitioning:
不可以作splitting, dropping or merging操作。但是可以added and coalesced.
当我们无法判断有多少数据映射或者怎样映射到各个分区时,可以使用这种方法。分区数据最好是2的幂,这样可以平均分配数据。
CREATE TABLE sales_hash1
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
week_no NUMBER(2))
PARTITION BY HASH(salesman_id)
PARTITIONS 4
STORE IN (users, TOOLS, TEST, TABLESPACE1); --表空间
CREATE TABLE sales_hash
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
week_no NUMBER(2))
PARTITION BY HASH(salesman_id)
(
PARTITION p1 tablespace users,
PARTITION p2 tablespace system
);
Composite Partitioning:
先按照range分区,每个子分区又按照list or hash分区。
CREATE TABLE sales_composite
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
SUBPARTITION BY HASH(salesman_id) --子分区
SUBPARTITION TEMPLATE(
SUBPARTITION sp1 TABLESPACE data1,
SUBPARTITION sp2 TABLESPACE data2,
SUBPARTITION sp3 TABLESPACE data3,
SUBPARTITION sp4 TABLESPACE data4)
(PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','DD/MM/YYYY'))
PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','DD/MM/YYYY'))
PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','DD/MM/YYYY'))
PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','DD/MM/YYYY'))
PARTITION sales_may2000 VALUES LESS THAN(TO_DATE('06/01/2000','DD/MM/YYYY')));
使用TEMPLATE,oracle会这样命名子分区:分区_子分区,比如sales_jan2000_sp1表示将数据放在data1表空间
Range-list:
CREATE TABLE bimonthly_regional_sales
(deptno NUMBER,
item_no VARCHAR2(20),
txn_date DATE,
txn_amount NUMBER,
state VARCHAR2(2))
PARTITION BY RANGE (txn_date)
SUBPARTITION BY LIST (state)
SUBPARTITION TEMPLATE(
SUBPARTITION east VALUES('NY', 'VA', 'FL') TABLESPACE system,
SUBPARTITION west VALUES('CA', 'OR', 'HI') TABLESPACE users,
SUBPARTITION central VALUES('IL', 'TX', 'MO') TABLESPACE tools)
( PARTITION janfeb_2000 VALUES LESS THAN (TO_DATE('1-03-2000','DD-Mm-YYYY')), PARTITION marapr_2000 VALUES LESS THAN (TO_DATE('1-05-2000','DD-Mm-YYYY')), PARTITION mayjun_2000 VALUES LESS THAN (TO_DATE('1-07-2000','DD-Mm-YYYY')) )
posted @
2010-12-13 15:19 xzc 阅读(293) |
评论 (0) |
编辑 收藏
第一、使用en_GB.roman8。因为xmanager这个字体与hpux的字体相同,所以使用en_GB.roman8就不会产生乱码。
在/etc/dt/config/Xconfig中Dtlogin*language: en_GB.roman8即可;
第二、使用HP_UNIX的zh_CN.hp15CN字体。
1.在你的装有Xmanager的微机中新建文件夹:
mkdir c:\program fils/Xmanager1.3.8/font/hpux,
2.拷贝/usr/lib/X11/fonts/hp_chinese_s/75dpi/*pcf至此目录。
3.用Xmanager的mkfntdir生成font.dir文件。
cd c:\program files\Xmanager1.3.8/font/hpux
c:\profram files\Xmanager1.3.8\Mkfntdir
4.将此字体目录添加到Xmanager的字体目录中去。(在Xconfig中的font directory中添加新生成的目录,并删除其他目录,但是要留下hp目录)。
posted @
2010-12-13 14:33 xzc 阅读(1243) |
评论 (0) |
编辑 收藏alter table test nologging
insert /*+ append */ into test select
ask tom上有过一篇文章,是说Oracle实际上需要满足表是nologging和insert /*+append*/两个条件才真正实现nologging的
在insert数据量很大的时候(千万级),减少redo的产生对性能应该有很大的提高。
这是一个使用append和nologging对redo产生情况的实验。
结论:
-------------------------------
一、非归档模式下:
没有优化前 (1281372 redo size)
1、单一的使用nologging参数,对redo的产生没有什么影响。 (1214836 redo size)
2、单一的使用append提示,redo的减少很显著 (43872 redo size)
3、nologging+append,更显著 (1108 redo size)
二、归档模式下:
没有优化前:
1、单独使用nologging参数,(1231904 redo size)
2、单独使用append提示, (1245804 redo size)
3、nologging + append, (3748 redo size)
a、使用nologging参数并不代表在dml操作中,oracle不产生redo,只是对于指定表的更新数据不产生redo,但是oracle还是要记录这些操作,所以无论怎么优化,dml操作肯定要产生redo,但是使用这些参数对redo size的影响还是非常可观的。
b、单独使用nologging参数,对redo size没有多少影响,只有和append配合时,才能产生效果。
c、单独使用append提示,对redo的产生影响很大,这是我到现在都不明白的道理,按说append是绕过freelists,直接去寻找新块,能减少对freelists的争用,为什么会少这么多redo呢?
d、归档模式和非归档模式下,参数影响不一样,尤其是单独使用append参数时,看来oracle对归档模式下出于安全考虑还是要多一些。
文章出处:
http://www.diybl.com/course/7_databases/oracle/Oracleshl/2008810/135707.html
1.Nologging的设置跟数据库的运行模式有关
a.数据库运行在非归档模式下:
SQL> archive log list;
Database log mode No Archive Mode
Automatic archival Enabled
Archive destination /opt/oracle/oradata/hsjf/archive
Oldest online log sequence 155
Current log sequence 157
SQL> @redo
SQL> create table test as select * from dba_objects where 1=0;
Table created.
SQL> select * from redo_size;
VALUE
----------
63392
SQL>
SQL> insert into test select * from dba_objects;
10470 rows created.
SQL> select * from redo_size;
VALUE
----------
1150988
SQL>
SQL> insert into test select * from dba_objects;
10470 rows created.
SQL> select * from redo_size;
VALUE
----------
1152368
SQL> select (1152368 -1150988) redo_append,(1150988 -63392) redo from dual;
REDO_APPEND REDO
----------- ----------
1380 1087596
SQL> drop table test;
Table dropped.
我们看到在Noarchivelog模式下,对于常规表的insert append只产生少量redo
b.在归档模式下
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 235999908 bytes
Fixed Size 451236 bytes
Variable Size 201326592 bytes
Database Buffers 33554432 bytes
Redo Buffers 667648 bytes
Database mounted.
SQL> alter database archivelog;
Database altered.
SQL> alter database open;
Database altered.
SQL> @redo
SQL> create table test as select * from dba_objects where 1=0;
Table created.
SQL> select * from redo_size;
VALUE
----------
56288
SQL>
SQL> insert into test select * from dba_objects;
10470 rows created.
SQL> select * from redo_size;
VALUE
----------
1143948
SQL>
SQL> insert into test select * from dba_objects;
10470 rows created.
SQL> select * from redo_size;
VALUE
----------
2227712
SQL> select (2227712 -1143948) redo_append,(1143948 -56288) redo from dual;
REDO_APPEND REDO
----------- ----------
1083764 1087660
SQL> drop table test;
Table dropped.
我们看到在归档模式下,对于常规表的insert append产生和insert同样的redo
此时的insert append实际上并不会有性能提高.
但是此时的append是生效了的
通过Logmnr分析日志得到以下结果:
SQL> select operation,count(*)
2 from v$logmnr_contents
3 group by operation;
OPERATION COUNT(*)
-------------------------------- ----------
COMMIT 17
DIRECT INSERT 10470
INTERNAL 49
START 17
我们注意到这里是DIRECT INSERT,而且是10470条记录,也就是每条记录都记录了redo.
2.对于Nologging的table的处理
a. 在归档模式下:
SQL> create table test nologging as select * from dba_objects where 1=0;
Table created.
SQL> select * from redo_size;
VALUE
----------
2270284
SQL>
SQL> insert into test select * from dba_objects;
10470 rows created.
SQL> select * from redo_size;
VALUE
----------
3357644
SQL>
SQL> insert into test select * from dba_objects;
10470 rows created.
SQL> select * from redo_size;
VALUE
----------
3359024
SQL> select (3359024 -3357644) redo_append,(3357644 - 2270284) redo from dual;
REDO_APPEND REDO
----------- ----------
1380 1087360
SQL> drop table test;
Table dropped.
我们注意到,只有append才能减少redo
b.在非归档模式下:
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 235999908 bytes
Fixed Size 451236 bytes
Variable Size 201326592 bytes
Database Buffers 33554432 bytes
Redo Buffers 667648 bytes
Database mounted.
SQL> alter database noarchivelog;
Database altered.
SQL> alter database open;
Database altered.
SQL> @redo
SQL> create table test nologging as select * from dba_objects where 1=0;
Table created.
SQL> select * from redo_size;
VALUE
----------
56580
SQL>
SQL> insert into test select * from dba_objects;
10470 rows created.
SQL> select * from redo_size;
VALUE
----------
1144148
SQL>
SQL> insert into test select * from dba_objects;
10470 rows created.
SQL> select * from redo_size;
VALUE
----------
1145528
SQL> select (1145528 -1144148) redo_append,(1144148 -56580) redo from dual;
REDO_APPEND REDO
----------- ----------
1380 1087568
SQL>
posted @
2010-12-07 17:24 xzc 阅读(1887) |
评论 (0) |
编辑 收藏oracle 10g for hp HP-UX Itanium 11.31 installation
标签:hp-ux上安装oracle10g
1,硬件信息检验:
/usr/sbin/dmesg | grep "Physical:" 确定物理RAM高于1000M
/usr/sbin/swapinfo -a 确定交换分区有没有空间
bdf /tmp 确定tmp的空闲空间,要保障在400M以上
(扩展/tmp要到init 1但用户状态去umount掉,
lvextend -L 800 /dev/vg00/lvol5(/tmp所在的lv) /dev/dsk/盘号)
extendfs -F vxfs /dev/vg00/lvol5)
bdf 确定磁盘大小,需要2个大于4.7G的磁盘系统
# /bin/getconf KERNEL_BITS 确定系统是否64位
2,检查软件需求:
uname -a 检查操作系统版本:必须是hp-ux 11i v3
show_patches|grep PHKL_40240
show_patches|grep PHKL_39624
show_patches|grep PHKL_39625
注:hp Unix patch 每个季度都会有更新
确定hp 系统patch已经打上,如果没有,到itrc找到patch打上。
(swinstall -s 完全路径。先解析,再install)
3,java -version 查看java版本。必须安装Java版本SDK1.4.2。
(如果不能直接打出,把/opt/java1.4/bin/:加入 /.profile的PATH=中,再加入
export JAVA_HOME=/opt/java1.4)
4,创建需要的UNIX组和用户
#/usr/sbin/groupadd oinstall
#/usr/sbin/groupadd dba
创建oracle用户:
#/usr/sbin/useradd -g oinstall -G dba –m oracle
passwd oracle
5,创建必需目录:
mkdir /orabin
mkdir -p /orabin/oracle
mkdir /archive
chmod -R 775 /orabin /archive
chown oracle:dba /orabin
chown oracle:dba /archive
6,配置内核参数:
6.1 Kernel需求表:
Parameter Recommended Formula or Value
ksi_alloc_max (nproc*8) --32768
max_thread_proc 256
maxdsiz 1073741824 (1 GB)
maxdsiz_64bit 2147483648 (2 GB)
Oracle Database 21
maxssiz 134217728 (128 MB)
maxssiz_64bit 1073741824 (1 GB)
maxswapchunks 16384 --
maxuprc ((nproc*9)/10) --3687
msgmap (2+msgmni)
msgmni 4096
msgseg 32767
msgtql 4096
ncsize (ninode+vx_ncsize) 34816
nfile (15*nproc+2048) 61664
nflocks 4096
ninode (8*nproc+2048) 34816
nkthread (((nproc*7)/4)+16) 7184
nproc 4096
semmap (semmni+2)
semmni 4096
semmns (semmni*2)
semmnu (nproc-4)
semvmx 32767
shmmax The size of physical memory (0X40000000) or
1073741824, whichever is greater.
shmmni 512
shmseg 120
vps_ceiling 64
(参数含义请看参数说明)
#调整内核参数
6.2 #kctune 查内核参数
kctune -h -B nproc="4200"
kctune -h -B ksi_alloc_max="33600"
kctune -h -B max_thread_proc="1100"
kctune -h -B maxdsiz="1073741824"
kctune -h -B maxdsiz_64bit="4294967296"
kctune -h -B maxssiz="134217728"
kctune -h -B maxssiz_64bit="1073741824"
kctune -h -B maxuprc="3688"
kctune -h -B msgmni="4096"
kctune -h -B msgtql="4096"
kctune -h -B ncsize="35840"
kctune -h -B nflocks="4096"
kctune -h -B ninode="34816"
kctune -h -B nkthread="8416"
kctune -h -B semmni="8192"
kctune -h -B semmns="16384"
kctune -h -B semmnu="4092"
kctune -h -B semvmx="32767"
kctune -h -B shmmax="34359738368"
kctune -h -B shmmni="512"
kctune -h -B shmseg="300"
kctune -h -B vps_ceiling="64"
如果更改了制定的static参数。需重建kernel和重起系统。
重起系统,用root登录
7,把安装盘mount上(把安装介质传上去)
用oracle用户登录,并修改oracle用户的环境(shell)
7.1、打开另一个会话终端
7.2、输入命令并确定是否可以用在终端输出图形化界面:
$ xhost +
7.3、完成一下步骤:
在这里安装oracle,切换到oracle用户。$ su - oracle
7.4、输入命令确定oracle的默认SHELL
#echo $SHELL
/sbin/sh(每个用户所使用的sh都不一样)
8,更改环境变量:
$ vi .profile
加入以下行:
export ORACLE_BASE=/orabin/oracle
export ORACLE_HOME=$ORACLE_BASE/product/10.2.0.1/db_1
export PATH=:$ORACLE_HOME/bin:$PATH:$ORACLE_HOME/OPatch
export NLS_LANG=american_america.zhs16gbk
export ORACLE_SID=oracle
9,编辑好之后logout再 su – oracle
$echo $ORACLE_HOME
输出ORACLE_HOME的路径
安装ORACLE软件:
拷贝文件到一个文件系统下,例如:/file/database
注意到用户和组为oracle:dba
如果不是执行:
chown –R oracle:dba database 把他所属用户为oracle所属组为dba
chmod –R 775 databse 更改他的执行权限为755
export DISPLAY= 192.168.61.222:0.0
xhost +
su – oracle 切换到oracle用户
echo $DISPLAY 查看输出目录
如果不是本机的IP地址,执行:
export DISPLAY=LOCALHOST_IP:0.0
然后进入oracle_databse所在目录,进行安装oracle
cd /file/databse
./ runInstaller -ignoreSysPreReqs
10,如果提示swap分区不够大,做如下操作:
vgdisplay –v 看看哪个disk上还有空余的空间。(free要*pe值)
lvcreate –L xxx(需要临时swap分区的大小) –n myswap(lv名字) vg00(所在的vg名)
newfs -F vxfs -o largefiles /dev/vg01/rmyswap(注意lv名前有r)
swapon /dev/vg00 /myswap
11,安装完成之后,需要用root用户run两个脚本
再打开一个会话窗口,执行:
/orabin/oracle/oraInventory/orainstRoot.sh
/orabin/oracle/product/10.2.0.1/root.sh
12,上传 oracle 10.2.0.4补丁
以同样的方法安装oracle 10.2.0.4 补丁
13,配置监听:
netca
14, 建库
dbca
使用裸设备
14.1 先创建裸设备
lvcreate -L 6000 -n system01.dbf vg00
lvcreate -L 5000 -n users01.dbf vg00
lvcreate -L 5000 -n temp01.dbf vg00
lvcreate -L 2000 -n undotbs01.dbf vg00
lvcreate -L 2000 -n undotbs02.dbf vg00
lvcreate -L 50 -n control01.ctl vg00
lvcreate -L 50 -n control02.ctl vg00
lvcreate -L50 -n control03.ctl vg00
lvcreate -L 500 -n redo01.log vg00
lvcreate -L 500 -n redo02.log vg00
lvcreate -L 500 -n redo03.log vg00
lvcreate -L 5000 -n sysaux01.dbf vg00
lvcreate -L 50 -n spfileoracle.ora vg00
14.2 改变裸设备的权限为oracle:dba
chown oracle:dba /dev/vg00/rsystem01.dbf
chown oracle:dba /dev/vg00/rusers01.dbf
chown oracle:dba /dev/vg00/rtemp01.dbf
chown oracle:dba /dev/vg00/rundotbs01.dbf
chown oracle:dba /dev/vg00/rcontrol01.ctl
chown oracle:dba /dev/vg00/rcontrol02.ctl
chown oracle:dba /dev/vg00/rcontrol03.ctl
chown oracle:dba /dev/vg00/rredo01.log
chown oracle:dba /dev/vg00/rredo02.log
chown oracle:dba /dev/vg00/rredo03.log
chown oracle:dba /dev/vg00/rsysaux01.dbf
chown oracle:dba /dev/vg00/rspfileoracle.ora
14.3 创建软连接
ln -s /dev/vg00/rspfileoracle.ora /orabin/product/10.2.0.1/db_1/dbs/spfileoracle .ora
ln -s /dev/vg00/rsystem01.dbf /orabin/oradata/oracle/system01.dbf
ln -s /dev/vg00/rusers01.dbf /orabin/oradata/oracle/users01.dbf
ln -s /dev/vg00/rtemp01.dbf /orabin/oradata/oracle/temp01.dbf
ln -s /dev/vg00/rundotbs01.dbf /orabin/oradata/oracle/undotbs01.dbf
ln -s /dev/vg00/rundotbs02.dbf /orabin/oradata/oracle/undotbs02.dbf
ln -s /dev/vg00/rcontrol01.ctl /orabin/oradata/oracle/control01.ctl
ln -s /dev/vg00/rcontrol02.ctl /orabin/oradata/oracle/control02.ctl
ln -s /dev/vg00/rcontrol03.ctl /orabin/oradata/oracle/control03.ctl
ln -s /dev/vg00/rredo01.log /orabin/oradata/oracle/redo01.log
ln -s /dev/vg00/rredo02.log /orabin/oradata/oracle/redo02.log
ln -s /dev/vg00/rredo03.log /orabin/oradata/oracle/redo03.log
ln -s /dev/vg00/rsysaux01.dbf /orabin/oradata/oracle/sysaux01.dbf
14.4 查看裸设备的权限和属组
# ll /dev/vg00/r*
crw-r----- 1 root sys 64 0x000017 Dec 3 15:26 /dev/vg00/rarchive
crw-r----- 1 oracle dba 64 0x00000f Dec 3 15:10 /dev/vg00/rcontrol01.ctl
crw-r----- 1 oracle dba 64 0x000010 Dec 3 15:10 /dev/vg00/rcontrol02.ctl
crw-r----- 1 oracle dba 64 0x000011 Dec 3 15:10 /dev/vg00/rcontrol03.ctl
brw-r----- 1 oracle dba 64 0x000012 Dec 3 15:10 /dev/vg00/redo01.log
brw-r----- 1 oracle dba 64 0x000013 Dec 3 15:10 /dev/vg00/redo02.log
brw-r----- 1 oracle dba 64 0x000014 Dec 3 15:10 /dev/vg00/redo03.log
crw-r----- 1 root sys 64 0x000001 Dec 3 11:44 /dev/vg00/rlvol1
crw-r----- 1 root sys 64 0x000002 Dec 3 11:44 /dev/vg00/rlvol2
crw-r----- 1 root sys 64 0x000003 Dec 3 11:44 /dev/vg00/rlvol3
crw-r----- 1 root sys 64 0x000004 Dec 3 11:44 /dev/vg00/rlvol4
crw-r----- 1 root sys 64 0x000005 Dec 3 11:44 /dev/vg00/rlvol5
crw-r----- 1 root sys 64 0x000006 Dec 3 11:44 /dev/vg00/rlvol6
crw-r----- 1 root sys 64 0x000007 Dec 3 11:44 /dev/vg00/rlvol7
crw-r----- 1 root sys 64 0x000008 Dec 3 11:44 /dev/vg00/rlvol8
crw-r----- 1 root sys 64 0x000009 Dec 3 15:10 /dev/vg00/roraclebin
crw-r----- 1 oracle dba 64 0x000012 Dec 3 15:10 /dev/vg00/rredo01.log
crw-r----- 1 oracle dba 64 0x000013 Dec 3 15:10 /dev/vg00/rredo02.log
crw-r----- 1 oracle dba 64 0x000014 Dec 3 15:10 /dev/vg00/rredo03.log
crw-r----- 1 oracle dba 64 0x000016 Dec 3 15:10 /dev/vg00/rspfileoracle.ora
crw-r----- 1 oracle dba 64 0x000015 Dec 3 15:10 /dev/vg00/rsysaux01.dbf
crw-r----- 1 oracle dba 64 0x00000a Dec 3 15:10 /dev/vg00/rsystem01.dbf
crw-r----- 1 oracle dba 64 0x00000c Dec 3 15:10 /dev/vg00/rtemp01.dbf
crw-r----- 1 oracle dba 64 0x00000d Dec 3 15:10 /dev/vg00/rundotbs01.dbf
crw-r----- 1 oracle dba 64 0x00000e Dec 3 15:10 /dev/vg00/rundotbs02.dbf
crw-r----- 1 oracle dba 64 0x00000b Dec 3 15:10 /dev/vg00/rusers01.dbf
14.5 查看链接文件的权限和属组
/orabin/oradata/oracle
# ll
total 0
lrwxrwxrwx 1 oracle oinstall 24 Dec 4 11:09 control01.ctl -> /dev/vg00/rcontrol01.ctl
lrwxrwxrwx 1 oracle oinstall 24 Dec 4 11:09 control02.ctl -> /dev/vg00/rcontrol02.ctl
lrwxrwxrwx 1 oracle oinstall 24 Dec 4 11:09 control03.ctl -> /dev/vg00/rcontrol03.ctl
lrwxrwxrwx 1 oracle oinstall 21 Dec 4 11:09 redo01.log -> /dev/vg00/rredo01.log
lrwxrwxrwx 1 oracle oinstall 21 Dec 4 11:09 redo02.log -> /dev/vg00/rredo02.log
lrwxrwxrwx 1 oracle oinstall 21 Dec 4 11:09 redo03.log -> /dev/vg00/rredo03.log
lrwxrwxrwx 1 oracle oinstall 23 Dec 4 11:09 sysaux01.dbf -> /dev/vg00/rsysaux01.dbf
lrwxrwxrwx 1 oracle oinstall 23 Dec 4 11:09 system01.dbf -> /dev/vg00/rsystem01.dbf
lrwxrwxrwx 1 oracle oinstall 21 Dec 4 11:09 temp01.dbf -> /dev/vg00/rtemp01.dbf
lrwxrwxrwx 1 oracle oinstall 24 Dec 4 11:09 undotbs01.dbf -> /dev/vg00/rundotbs01.dbf
lrwxrwxrwx 1 oracle oinstall 24 Dec 4 11:09 undotbs02.dbf -> /dev/vg00/rundotbs02.dbf
lrwxrwxrwx 1 oracle oinstall 22 Dec 4 11:09 users01.dbf -> /dev/vg00/rusers01.dbf
根据提示选择数据库名(oracle),sys密码(和主机名一样),选择control,datafile,redofile以及spfile的路径
15 把数据库变为归档模式
sqlplus 下执行:
alter system set log_archive_start= TRUE scope=spfile;
alter system set log_archive_dest_1="LOCATION=/archive" scope=spfile;
shutdown immediate;
alter database archivelog;
alter database open ;
show parameter archive;
测试:
alter system switch logfile;
/
/
/
到/archive 目录下查看是否已经归档
16 用客户端和网页或者第三方软件连接oracle
测试成功!
finish!
archive log list;
shutdown immediate;
startup mount;
alter database archivelog;
alter database open
alter system set LOG_ARCHIVE_DEST_1='LOCATION=/oracle/oradata/express/archive';
shutdown immediate;
startup
如果是oracle9i,还需要更改如下参数:
alter system set log_archive_start=true scope=spfile;
但是如果在10g中也更改这些参数,数据库重启时会有如下提示:
ORA-32004: obsolete and/or deprecated parameter(s) specified
alter system set log_archive_format='%t_%s.dbf' scope=spfile;
但是如果在10g中也更改这些参数,数据库会不能启动,如下提示:
ORA-32004: obsolete and/or deprecated parameter(s) specified
ORA-19905: log_archive_format must contain %s, %t and %r
posted @
2010-12-03 20:45 xzc 阅读(1107) |
评论 (0) |
编辑 收藏HP--UX查看内存、CPU的使用率
1、运行/usr/contrib/bin/crashinfo(根据第二步实际情况) | more,信息中注意类似如下内容:
==================
= Memory Globals =
==================
Note: "freemem" was resynced with freemem caches: was 169536, now 168628
Physical Memory = 2096640 pages (8.00 GB) //物理内存总量
Free Memory = 168628 pages (658.70 MB)//空闲内存
Average Free Memory = 169403 pages (661.73 MB)//平均空闲内存
gpgslim = 7168 pages (28.00 MB)
lotsfree = 32768 pages (128.00 MB)
desfree = 7168 pages (28.00 MB)
minfree = 3328 pages (13.00 MB)
**************物理内存使用率=(物理内存总量-空闲内存)/物理内存总量***************
========================
= Buffer Cache Globals =
========================
dbc_max_pct = 50 %
dbc_min_pct = 5 %
dbc current pct = 50.0 %
bufpages = 1048320 pages (4.00 GB)
Number of buf headers = 557940
fixed_size_cache = 0
dbc_parolemem = 0
dbc_stealavg = 0
dbc_ceiling = 1048320 pages (4.00 GB)
dbc_nbuf = 52416
dbc_bufpages = 104832 pages (409.50 MB)
dbc_vhandcredit = 11403
orignbuf = 0
origbufpages = 0 pages
====================
= Swap Information =
====================
swapinfo -mt emulation
======================
Mb Mb Mb PCT START/ Mb
TYPE AVAIL USED FREE USED LIMIT RESERVE PRI NAME
dev 16384 0 16098 0% 0 - 1 LVM vg00/lv2
reserve - 2141 -2141
memory 6460 4928 1532 76%
total 22844 7069 15489 31% - 0 -
*****************SWAP内存使用率就是total的PCT值:31%*************************
2、CPU的使用率可以从top参数得出:
System: JXCNMD1 Fri Aug 17 10:25:02 2007
Load averages: 0.35, 0.41, 0.44
311 processes: 257 sleeping, 53 running, 1 zombie
Cpu states:
CPU LOAD USER NICE SYS IDLE BLOCK SWAIT INTR SSYS
0 0.74 8.8% 3.8% 2.0% 85.5% 0.0% 0.0% 0.0% 0.0%
1 0.17 4.4% 6.2% 10.2% 79.3% 0.0% 0.0% 0.0% 0.0%
2 0.12 3.8% 1.0% 1.0% 94.2% 0.0% 0.0% 0.0% 0.0%
3 0.36 0.0% 70.9% 28.1% 1.0% 0.0% 0.0% 0.0% 0.0%
--- ---- ----- ----- ----- ----- ----- ----- ----- -----
avg 0.35 4.2% 20.6% 10.2% 65.1% 0.0% 0.0% 0.0% 0.0%
*****************系统一共4个CPU,每个CPU的使用率=100%-IDLE值*******************
3、top命令的一些解释
问:
top中的几个参数的意义能帮忙解释一下吗?
主要是对 free的计算方法不太理解,机器的物理内存有256M,free中的33M是怎么计算出来
的呢?
Memory: 92764K (15880K) real, 65796K (13316K) virtual, 33684K free Page# 1/5
另外,SAM中有如下有关信息
xx x Processor xx Memory xx Operating System xx Network xx Dynamic x x
xx lqqqqqqqqqqqq/ qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqk x
xx xlqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqkx x
xx xxPhysical Memory: 256.2 MB xx x
xx xxReal Memory: xx x
xx xx Active: 21113.5 KB xx x
xx xx Total: 97083.5 KB xx x
xx xxVirtual Memory: xx x
xx xx Active: 16247.3 KB xx x
xx xx Total: 68390.7 KB xx x
xx xxFree Memory Pages: 6738 at 4 KB/page xx x
xx xxSwap Space: xx x
xx xx Avail: 1024 MB xx x
xx xx Used: 231 MB xxvx
xmqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqjx
其中的Virtual Memory和 Swap Space是什么关系呢?我想计算虚拟内存的利用率该如何计算呢?
答:
top 只能看到进程所使用的内存量,所以你看到的 92764K (15880K) real 就是所有进程所使用的内存总和,这个内存是指物理内存,括号前那个值是Total Real Memory,括号内是Active Real Memory, 这两者的区别就在于Active Real Memory的值只是分配给那些已经在run queue或者正在运行的进程的Real Memory,而Total Real Memory 包括所有的进程。
对于后一项值 65796K (13316K) virtual 的解释也是同样的,不过这个值代表了Virtual Memory(一般为建在Disk上的Swap空间,当然你要问了,我的Swap空间可不止这么些啊 by executing ‘swapinfo‘, 没错,Swap空间是大于这里的Total Vitual Memory的,但我前面说了,这里的值只是计算的分配给进程的),最后一项33684K free 到确确实实是Free 的Memory,它等于Physical Mem - kernel used - user used - buffer cache。
下面是对SAM->;Performance Monitor ->; System Property ->; Memory的显示结果的解释
Physical Memory 256.2 MB 实际物理内存大小
Real Memory
Active: 21113.5 KB 同 top (当然这里举的例子由于有时间差,所以看上去不大一致)
Total: 97083.5 KB 同 top
Virtual Memory:
Active: 16247.3 KB 同 top
Total: 68390.7 KB 同 top
Free Memory Pages: 6738 at 4 KB/page 6738 * 4 就是 top 显示出来的结果
Swap Space:
Avail: 1024 MB 同Swapinfo中 dev filesystem 总和(一般不会用到Pseudo Memory),为实际Swap Space 的大小。
Used: 231 MB 同Swapinfo中的Reserve, 为系统在创建进程时为该进程预留的Swap 空间总和)
posted @
2010-12-03 20:43 xzc 阅读(6568) |
评论 (1) |
编辑 收藏
1. 以root用户修改/etc/lvmrc文件
对应需要做成共享的VG,先要求关闭其开机自动active的设置。
你必须保证这些VG在SG启动的时候激活。
备份/etc/lvmrc文件
# cp /etc/lvmrc /etc/lvmrc_orig
修改/etc/lvmrc文件
From:
AUTO_VG_ACTIVATE=1
To:
AUTO_VG_ACTIVATE=0
在文件/etc/lvmrc 中添加custom_vg_activation功能模块,
此处为非shared的VG设置。(也可以不做)
custom_vg_activation()
{
# e.g. /sbin/vgchange -a y -s
# parallel_vg_sync "/dev/vg00 /dev/vg01"
# parallel_vg_sync "/dev/vg02 /dev/vg03"
/sbin/vgchange -a y vg00
/sbin/vgchange -a y vg01
/sbin/vgchange -a y vg02
/sbin/vgchange -a y vg03
return 0
}
2.创建共享逻辑卷组
主节点上:
# 初始化PV
pvcreate -f /dev/rdsk/c0t12d0
# 在/dev目录添加用于VG的目录
mkdir /dev/vg_ops
# Major number必须为64,minor number是2为16进制数字,作为唯一标识
mknod /dev/vg_ops/group c 64 0x060000
# 创建VG
vgcreate /dev/vg_ops /dev/dsk/c0t12d0
# 激活VG
vgchange -a y vg_ops
# 创建LV
lvcreate -n P901_control_01.ctl -L 110 /dev/vg_ops
lvcreate -n P901_control_02.ctl -L 110 /dev/vg_ops
lvcreate -n P901_control_03.ctl -L 110 /dev/vg_ops
lvcreate -n P901_system_01.dbf -L 400 /dev/vg_ops
lvcreate -n P901_log1_01.log -L 120 /dev/vg_ops
lvcreate -n P901_log1_02.log -L 120 /dev/vg_ops
lvcreate -n P901_log1_03.log -L 120 /dev/vg_ops
lvcreate -n P901_log2_01.log -L 120 /dev/vg_ops
lvcreate -n P901_log2_02.log -L 120 /dev/vg_ops
lvcreate -n P901_log2_03.log -L 120 /dev/vg_ops
lvcreate -n P901_spfile1.dbf -L 5 /dev/vg_ops
lvcreate -n P901_users_01.dbf -L 120 /dev/vg_ops
lvcreate -n P901_temp_01.dbf -L 100 /dev/vg_ops
lvcreate -n P901_undotbs_01.dbf -L 312 /dev/vg_ops
lvcreate -n P901_undotbs_02.dbf -L 312 /dev/vg_ops
lvcreate -n P901_example_01.dbf -L 160 /dev/vg_ops
lvcreate -n P901_cwmlite_01.dbf -L 100 /dev/vg_ops
lvcreate -n P901_indx_01.dbf -L 70 /dev/vg_ops
lvcreate -n P901_tools_01.dbf -L 20 /dev/vg_ops
lvcreate -n P901_drsys_01.dbf -L 90 /dev/vg_ops
# 解除VG的active状态
vgchange -a n vg_ops
# 创建LV的map文件
vgexport -v -s -p -m /tmp/vg_ops.map /dev/vg_ops
# 复制map文件到其它节点
rcp /tmp/vg_ops.map opcbhp2:/tmp/vg_ops.mapOn the other nodes:
mkdir /dev/vg_ops
mknod /dev/vg_ops/group c 64 0x060000
# 在其它节点创建VG和LV
vgimport -v -s -m /tmp/vg_ops.map /dev/vg_ops
# 在所有节点配置相应VG和LV的权限和属主
# chown oracle:dba /dev/vg_ops/r*
# remsh nodehp2 chown oracle:dba /dev/vg_ops/r*
# chmod 777 /dev/vg_ops
# remsh nodehp2 chmod 777 /dev/vg_ops
# chmod 660 /dev/vg_ops/r*
# remsh nodehp2 chmod 660 /dev/vg_ops/r*
Note: 在创建VG的时候,要注意minor number的唯一性,常用以下命令:
# find /dev -name group -exec ls -l {} ;
crw------- 1 root sys 64 0x060000 May 6 07:52 /dev/vg_ops/group
在该例子中"vg_ops"为"0x060000",所以"0x060000"不能用于创建其它VG,合法的minor numbers的范围是从"0x010000"到"0xFF0000"。
3.集群软件ServiceGuard的安装
由供应商安装,Oracle 10gR2的RAC要求Serviceguard Extension for RAC的版本必须A.11.16.00以上,也包含A.11.16.00版本。
4.规划集群环境
1)配置集群:
使用cmquerycl去创建一个集群配置文件
Cmquerycl命令必须在主节点上进行
# cmquerycl -v -C /etc/cmcluster/cmclconf.ascii -n nodehp1 -n nodehp2
2)修改集群配置文件
CLUSTER_NAME # example nodehp
FIRST_CLUSTER_LOCK # /dev/vg_ops
FIRST_CLUSTER_PV # /dev/dsk/c0t12d0
OPS_VOLUME_GROUP # /dev/vg_ops
DLM_ENABLED # NO
GMS_ENABLED # NO
FIRST_CLUSTER_LOCK, FIRST_CLUSTER_PV = 集群lock卷组和磁盘作为表决用途。表决VG和磁盘必须能被所有节点访问(用共享VG就可以)。一个节点倒掉,会要求表决VG的处理。
OPS_VOLUME_GROUP = 所有共享VG
DLM_ENABLED and GMS_ENABLED = NO (8.1.7版本以后均设为NO)
3)使用cmcheckconf命令验证集群配置文件
# cmcheckconf -v -C /etc/cmcluster/cmclconf.ascii
4)使用vgchange来激活lock卷组
# vgchange -a y vg_ops
5)使用cmapplyconf复制集群配置文件到所有节点
# cmapplyconf -v -C /etc/cmcluster/cmclconf.ascii
6)使用vgchange解除lock卷组的激活状态
# vgchange -a n vg_ops
5.基本集群管理
1)启动集群:
# cmruncl
2)使用vgchange在主节点设置共享VG
# vgchange -S y -c y vg_ops
3)使用vgchange在每个节点激活共享VG
# vgchange -a s vg_ops
# remsh nodehp2 /usr/sbin/vgchange -a s vg_ops
4)使用cmhaltcl关闭集群或者使用cmhaltnode从集群移除节点
# cmhaltnode
5)使用cmrunnode添加节点到集群
# cmrunnode
6)使用cmhaltpkg,cmrunpkg及cmmodpkg管理集群的pkg,也可用于集群节点的恢复,可参照在线手册使用。
6.Log Files for Cluster
/var/adm/syslog/syslog.log包含HP Serviceguard Extension for RAC的系统信息
posted @
2010-12-01 20:22 xzc 阅读(410) |
评论 (0) |
编辑 收藏“SQL TRACE”是Oracle提供的用于进行SQL跟踪的手段,是强有力的辅助诊断工具。在日常的数据库问题诊断和解决中,“SQL TRACE”是非常常用的方法。
一般,一次跟踪可以分为以下几步:
1、界定需要跟踪的目标范围,并使用适当的命令启用所需跟踪。
2、经过一段时间后,停止跟踪。此时应该产生了一个跟踪结果文件。
3、找到跟踪文件,并对其进行格式化,然后阅读或分析。
本文就“SQL TRACE”的这些使用作简单探讨,并通过具体案例对SQL_TRACE的使用进行说明。
一、“SQL TRACE”的启用。
(A)SQL_TRACE说明
SQL_TRACE可以作为初始化参数在全局启用,也可以通过命令行方式在具体session启用。
1.在全局启用
在参数文件(pfile/spfile)中指定: SQL_TRACE = true
在全局启用SQL_TRACE会导致所有进程的活动被跟踪,包括后台进程及所有用户进程,这通常会导致比较严重的性能问题,所以在生产环境中要谨慎使用。
提示: 通过在全局启用SQL_TRACE,我们可以跟踪到所有后台进程的活动,很多在文档中的抽象说明,通过跟踪文件的实时变化,我们可以清晰的看到各个进程之间的紧密协调。
2.在当前session级设置
大多数时候我们使用SQL_TRACE跟踪当前会话的进程。通过跟踪当前进程可以发现当前操作的后台数据库递归活动(这在研究数据库新特性时尤其有效),研究SQL执行,发现后台错误等。
在session级启用和停止SQL_TRACE方式如下:
启用当前session的跟踪:
SQL> alter session set SQL_TRACE=true;
Session altered.
此时的SQL操作将被跟踪:
SQL> select count(*) from dba_users;
COUNT(*)
----------
34
结束跟踪:
SQL> alter session set SQL_TRACE=false;
Session altered.
3.跟踪其它用户进程
在很多时候我们需要跟踪其他用户的进程,而不是当前用户,这可以通过Oracle提供的系统包DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION来完成
通过v$session我们可以获得sid、serial#等信息:
获得进程信息,选择需要跟踪的进程:
SQL> select sid,serial#,username from v$session where username =’***’
SID SERIAL# USERNAME
---------- ---------- ------------------------------
8 2041 SYS
9 437 EYGLE
设置跟踪:
SQL> exec dbms_system.set_SQL_TRACE_in_session(9,437,true)
PL/SQL procedure successfully completed.
….
可以等候片刻,跟踪session执行任务,捕获sql操作…
….
停止跟踪:
SQL> exec dbms_system.set_SQL_TRACE_in_session(9,437,false)
PL/SQL procedure successfully completed.
(B) 10046事件说明
10046事件是Oracle提供的内部事件,是对SQL_TRACE的增强.
10046事件可以设置以下四个级别:
1 - 启用标准的SQL_TRACE功能,等价于SQL_TRACE。
4 - Level 1 加上绑定值(bind values)
8 - Level 1 + 等待事件跟踪
12 - Level 1 + Level 4 + Level 8
类似SQL_TRACE方法,10046事件可以在全局设置,也可以在session级设置。
对于10046事件的设置,涉及到了oracle的“诊断事件”的概念。
可以参考以下链接了解详情。http://www.itpub.net/323537,1.html
1. 在全局设置
在参数文件中增加:
EVENT="10046 trace name context forever,level 12"
此设置对所有用户的所有进程生效、包括后台进程.
2. 对当前session设置
通过alter session的方式修改,需要alter session的系统权限:
SQL> alter session set events '10046 trace name context forever';
Session altered.
SQL> alter session set events '10046 trace name context forever, level 8';
Session altered.
SQL> alter session set events '10046 trace name context off';
Session altered.
3. 对其他用户session设置
通过DBMS_SYSTEM.SET_EV系统包来实现:
SQL> desc DBMS_SYSTEM.SET_EV;
Parameter Type Mode Default?
--------- -------------- ---- --------
SI BINARY_INTEGER IN
SE BINARY_INTEGER IN
EV BINARY_INTEGER IN
LE BINARY_INTEGER IN
NM VARCHAR2 IN
其中的参数SI、SE来自v$session视图:
查询获得需要跟踪的session信息:
SQL> select sid,serial#,username from v$session where username is not null;
SID SERIAL# USERNAME
---------- ---------- ------------------------------
8 2041 SYS
9 437 EYGLE
执行跟踪:
SQL> exec dbms_system.set_ev(9,437,10046,8,'eygle');
PL/SQL procedure successfully completed.
结束跟踪:
SQL> exec dbms_system.set_ev(9,437,10046,0,'eygle');
PL/SQL procedure successfully completed.
(C)对启用方法的一些总结。
因为trace的目标范围不同,导致必须使用不同的方法。
?nbsp; 作用于数据库全局的,就改初始化参数。
?nbsp; 只作用于本session的,就用alter session 命令。
?nbsp; 作用于其它session的,就用DBMS_SYSTEM包。
再加上10046诊断事件,是SQL_TRACE的增强,又多了一套方法。
二、获取跟踪文件
以上生成的跟踪文件位于“user_dump_dest”参数所指定的目录中,位置及文件名可以通过以下SQL查询获得:
1.如果是查询当前session的跟踪文件,使用如下查询:
SELECT d.value||'/'||lower(rtrim(i.instance, chr(0)))||'_ora_'||p.spid||'.trc' trace_file_name
from
( select p.spid from v$mystat m,v$session s, v$process p
where m.statistic# = 1 and s.sid = m.sid and p.addr = s.paddr) p,
( select t.instance from v$thread t,v$parameter v
where v.name = 'thread' and (v.value = 0 or t.thread# = to_number(v.value))) i,
( select value from v$parameter where name = 'user_dump_dest') d
TRACE_FILE_NAME
-------------------------------------------------------------------------------
D:\ORACLE\PRODUCT\10.2.0\ADMIN\MYORACLE\UDUMP\hsjf_ora_1026.trc
2.如果是查询其他用户session的跟踪文件,则根据用户的sid和#serial使用如下查询:
SELECT d.value||'/'||lower(rtrim(i.instance, chr(0)))||'_ora_'||p.spid||'.trc' trace_file_name
from
( select p.spid from v$session s, v$process p
where s.sid=’’ and s. SERIAL#='' and p.addr = s.paddr) p,
( select t.instance from v$thread t,v$parameter v
where v.name = 'thread' and (v.value = 0 or t.thread# = to_number(v.value))) i,
( select value from v$parameter where name = 'user_dump_dest') d
TRACE_FILE_NAME
-------------------------------------------------------------------------------
D:\ORACLE\PRODUCT\10.2.0\ADMIN\MYORACLE\UDUMP\hsjf_ora_1026.trc
三、格式化跟踪文件。
原始的跟踪文件是很难读懂的。需要使用oracle自带的tkprof命令行工具格式化一下。
SQL>$tkprof D:\ORACLE\PRODUCT\10.2.0\ADMIN\MYORACLE\UDUMP\hsjf_ora_1026.trc D:\ORACLE\PRODUCT\10.2.0\ADMIN\MYORACLE\UDUMP\hsjf_ora_1026.txt
这个就可以方便的阅读了。可以在hsjf_ora_1026.txt文件中看到所有的sql语句执行次数,CPU使用时间等数据。
备注:可以通过以下方法读取当前已经设置的参数
对于全局的SQL_TRACE参数的设置,可以通过show parameter命令获得。
当我们通过alter session的方式设置了SQL_TRACE,这个设置是不能通过show parameter的方式得到的,我们需要通过dbms_system.read_ev来获取:
SQL> set feedback off
SQL> set serveroutput on
SQL> declare
2 event_level number;
3 begin
4 for event_number in 10000..10999 loop
5 sys.dbms_system.read_ev(event_number, event_level);
6 if (event_level > 0) then
7 sys.dbms_output.put_line(
8 'Event ' ||
9 to_char(event_number) ||
10 ' is set at level ' ||
11 to_char(event_level)
12 );
13 end if;
14 end loop;
15 end;
16 /
Event 10046 is set at level 1
引用:http://blog.sina.com.cn/s/blog_4cae4a25010008do.html
posted @
2010-11-13 14:31 xzc 阅读(8612) |
评论 (2) |
编辑 收藏写HINT目的
手工指定SQL语句的执行计划
hints是oracle提供的一种机制,用来告诉优化器按照我们的告诉它的方式生成执行计划。我们可以用hints来实现:
1) 使用的优化器的类型
2) 基于代价的优化器的优化目标,是all_rows还是first_rows。
3) 表的访问路径,是全表扫描,还是索引扫描,还是直接利用rowid。
4) 表之间的连接类型
5) 表之间的连接顺序
6) 语句的并行程度
2、HINT可以基于以下规则产生作用
表连接的顺序、表连接的方法、访问路径、并行度
3、HINT应用范围
dml语句
查询语句
4、语法
{DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */
or
{DELETE|INSERT|SELECT|UPDATE} --+ hint [text] [hint[text]]...
如果语(句)法不对,则ORACLE会自动忽略所写的HINT,不报错
1. /*+ALL_ROWS*/
表明对语句块选择基于开销的优化方法,并获得最佳吞吐量,使资源消耗最小化.
例如:
SELECT /*+ALL_ROWS*/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT';
2. /*+FIRST_ROWS*/
表明对语句块选择基于开销的优化方法,并获得最佳响应时间,使资源消耗最小化.
例如:
SELECT /*+FIRST_ROWS*/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT';
3. /*+CHOOSE*/
表明如果数据字典中有访问表的统计信息,将基于开销的优化方法,并获得最佳的吞吐量;
表明如果数据字典中没有访问表的统计信息,将基于规则开销的优化方法;
例如:
SELECT /*+CHOOSE*/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT';
4. /*+RULE*/
表明对语句块选择基于规则的优化方法.
例如:
SELECT /*+ RULE */ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT';
5. /*+FULL(TABLE)*/
表明对表选择全局扫描的方法.
例如:
SELECT /*+FULL(A)*/ EMP_NO,EMP_NAM FROM BSEMPMS A WHERE EMP_NO='SCOTT';
6. /*+ROWID(TABLE)*/
提示明确表明对指定表根据ROWID进行访问.
例如:
SELECT /*+ROWID(BSEMPMS)*/ * FROM BSEMPMS WHERE ROWID>='AAAAAAAAAAAAAA'
AND EMP_NO='SCOTT';
7. /*+CLUSTER(TABLE)*/
提示明确表明对指定表选择簇扫描的访问方法,它只对簇对象有效.
例如:
SELECT /*+CLUSTER */ BSEMPMS.EMP_NO,DPT_NO FROM BSEMPMS,BSDPTMS
WHERE DPT_NO='TEC304' AND BSEMPMS.DPT_NO=BSDPTMS.DPT_NO;
8. /*+INDEX(TABLE INDEX_NAME)*/
表明对表选择索引的扫描方法.
例如:
SELECT /*+INDEX(BSEMPMS SEX_INDEX) USE SEX_INDEX BECAUSE THERE ARE FEWMALE BSEMPMS */ FROM BSEMPMS WHERE SEX='M';
9. /*+INDEX_ASC(TABLE INDEX_NAME)*/
表明对表选择索引升序的扫描方法.
例如:
SELECT /*+INDEX_ASC(BSEMPMS PK_BSEMPMS) */ FROM BSEMPMS WHERE DPT_NO='SCOTT';
10. /*+INDEX_COMBINE*/
为指定表选择位图访问路经,如果INDEX_COMBINE中没有提供作为参数的索引,将选择出位图索引的布尔组合方式.
例如:
SELECT /*+INDEX_COMBINE(BSEMPMS SAL_BMI HIREDATE_BMI)*/ * FROM BSEMPMS
WHERE SAL<5000000 AND HIREDATE
11. /*+INDEX_JOIN(TABLE INDEX_NAME)*/
提示明确命令优化器使用索引作为访问路径.
例如:
SELECT /*+INDEX_JOIN(BSEMPMS SAL_HMI HIREDATE_BMI)*/ SAL,HIREDATE
FROM BSEMPMS WHERE SAL<60000;
12. /*+INDEX_DESC(TABLE INDEX_NAME)*/
表明对表选择索引降序的扫描方法.
例如:
SELECT /*+INDEX_DESC(BSEMPMS PK_BSEMPMS) */ FROM BSEMPMS WHERE DPT_NO='SCOTT';
13. /*+INDEX_FFS(TABLE INDEX_NAME)*/
对指定的表执行快速全索引扫描,而不是全表扫描的办法.
例如:
SELECT /*+INDEX_FFS(BSEMPMS IN_EMPNAM)*/ * FROM BSEMPMS WHERE DPT_NO='TEC305';
14. /*+ADD_EQUAL TABLE INDEX_NAM1,INDEX_NAM2,...*/
提示明确进行执行规划的选择,将几个单列索引的扫描合起来.
例如:
SELECT /*+INDEX_FFS(BSEMPMS IN_DPTNO,IN_EMPNO,IN_SEX)*/ * FROM BSEMPMS WHERE EMP_NO='SCOTT' AND DPT_NO='TDC306';
15. /*+USE_CONCAT*/
对查询中的WHERE后面的OR条件进行转换为UNION ALL的组合查询.
例如:
SELECT /*+USE_CONCAT*/ * FROM BSEMPMS WHERE DPT_NO='TDC506' AND SEX='M';
16. /*+NO_EXPAND*/
对于WHERE后面的OR 或者IN-LIST的查询语句,NO_EXPAND将阻止其基于优化器对其进行扩展.
例如:
SELECT /*+NO_EXPAND*/ * FROM BSEMPMS WHERE DPT_NO='TDC506' AND SEX='M';
17. /*+NOWRITE*/
禁止对查询块的查询重写操作.
18. /*+REWRITE*/
可以将视图作为参数.
19. /*+MERGE(TABLE)*/
能够对视图的各个查询进行相应的合并.
例如:
SELECT /*+MERGE(V) */ A.EMP_NO,A.EMP_NAM,B.DPT_NO FROM BSEMPMS A (SELET DPT_NO
,AVG(SAL) AS AVG_SAL FROM BSEMPMS B GROUP BY DPT_NO) V WHERE A.DPT_NO=V.DPT_NO
AND A.SAL>V.AVG_SAL;
20. /*+NO_MERGE(TABLE)*/
对于有可合并的视图不再合并.
例如:
SELECT /*+NO_MERGE(V) */ A.EMP_NO,A.EMP_NAM,B.DPT_NO FROM BSEMPMS A (SELECT DPT_NO,AVG(SAL) AS AVG_SAL FROM BSEMPMS B GROUP BY DPT_NO) V WHERE A.DPT_NO=V.DPT_NO AND A.SAL>V.AVG_SAL;
21. /*+ORDERED*/
根据表出现在FROM中的顺序,ORDERED使ORACLE依此顺序对其连接.
例如:
SELECT /*+ORDERED*/ A.COL1,B.COL2,C.COL3 FROM TABLE1 A,TABLE2 B,TABLE3 C WHERE A.COL1=B.COL1 AND B.COL1=C.COL1;
22. /*+USE_NL(TABLE)*/
将指定表与嵌套的连接的行源进行连接,并把指定表作为内部表.
例如:
SELECT /*+ORDERED USE_NL(BSEMPMS)*/ BSDPTMS.DPT_NO,BSEMPMS.EMP_NO,BSEMPMS.EMP_NAM FROM BSEMPMS,BSDPTMS WHERE BSEMPMS.DPT_NO=BSDPTMS.DPT_NO;
23. /*+USE_MERGE(TABLE)*/
将指定的表与其他行源通过合并排序连接方式连接起来.
例如:
SELECT /*+USE_MERGE(BSEMPMS,BSDPTMS)*/ * FROM BSEMPMS,BSDPTMS WHERE BSEMPMS.DPT_NO=BSDPTMS.DPT_NO;
24. /*+USE_HASH(TABLE)*/
将指定的表与其他行源通过哈希连接方式连接起来.
例如:
SELECT /*+USE_HASH(BSEMPMS,BSDPTMS)*/ * FROM BSEMPMS,BSDPTMS WHERE BSEMPMS.DPT_NO=BSDPTMS.DPT_NO;
25. /*+DRIVING_SITE(TABLE)*/
强制与ORACLE所选择的位置不同的表进行查询执行.
例如:
SELECT /*+DRIVING_SITE(DEPT)*/ * FROM BSEMPMS,DEPT@BSDPTMS WHERE BSEMPMS.DPT_NO=DEPT.DPT_NO;
26. /*+LEADING(TABLE)*/
将指定的表作为连接次序中的首表.
27. /*+CACHE(TABLE)*/
当进行全表扫描时,CACHE提示能够将表的检索块放置在缓冲区缓存中最近最少列表LRU的最近使用端
例如:
SELECT /*+FULL(BSEMPMS) CAHE(BSEMPMS) */ EMP_NAM FROM BSEMPMS;
28. /*+NOCACHE(TABLE)*/
当进行全表扫描时,CACHE提示能够将表的检索块放置在缓冲区缓存中最近最少列表LRU的最近使用端
例如:
SELECT /*+FULL(BSEMPMS) NOCAHE(BSEMPMS) */ EMP_NAM FROM BSEMPMS;
29. /*+APPEND*/
直接插入到表的最后,可以提高速度.
insert /*+append*/ into test1 select * from test4 ;
30. /*+NOAPPEND*/
通过在插入语句生存期内停止并行模式来启动常规插入.
insert /*+noappend*/ into test1 select * from test4 ;
31. NO_INDEX: 指定不使用哪些索引
/*+ NO_INDEX ( table [index [index]...] ) */
select /*+ no_index(emp ind_emp_sal ind_emp_deptno)*/ * from emp where deptno=200 and sal>300;
32. parallel
select /*+ parallel(emp,4)*/ * from emp where deptno=200 and sal>300;
另:每个SELECT/INSERT/UPDATE/DELETE命令后只能有一个/*+ */,但提示内容可以有多个,可以用逗号分开,空格也可以。
如:/*+ ordered index() use_nl() */
---------
类似如下的一条语句:insert into xxxx select /*+parallel(a) */ * from xxx a;数据量大约在75G左右,这位兄弟从上午跑到下午还没跑完,过来问我咋回事,说平常2hrs能跑完的东西跑了好几个小时还撒动静。查看系统性能也比较 正常,cpu,io都不繁忙,平均READ速度在80M/s左右(勉强凑合),但平均写速度只有10M不到。等待事件里面大量的‘ ‘PX Deq Credit: send blkd’,这里能看出并行出了问题,从而最后得知是并行用法有问题,修改之后20分钟完成了该操作。正确的做法应该是:
alter session enable dml parallel;
insert /*+parallel(xxxx,4) */ into xxxx select /*+parallel(a) */ * from xxx a;
因为oracle默认并不会打开PDML,对DML语句必须手工启用。 另外不得不说的是,并行不是一个可扩展的特性,只有在数据仓库或作为DBA等少数人的工具在批量数据操作时利于充分利用资源,而在OLTP环境下使用并行 需要非常谨慎。事实上PDML还是有比较多的限制的,例如不支持触发器,引用约束,高级复制和分布式事务等特性,同时也会带来额外的空间占用,PDDL同 样是如此。有关Parallel excution可参考官方文档,在Thomas Kyte的新书《Expert Oracle Database architecture》也有精辟的讲述。
---------
select count(*)
From wid_serv_prod_mon_1100 a
where a.acct_month = 201010
and a.partition_id = 10
and serv_state not in ('2HB', '2HL', '2HJ', '2HP', '2HF')
and online_flag in (0)
and incr_product_id in (2000020)
and product_id in (2020966, 2020972, 2100297, 2021116)
and billing_mode_id = 1
and exp_date > to_date('201010', 'yyyymm')
and not exists (select /*+no_index (b IDX_W_CDR_MON_SERV_ID_1100)*/
1
from wid_cdr_mon_1100 b
where b.acct_month = 201010
and b.ANA_EVENT_TYPE_4 in
('10201010201', '10202010201', '10203010201', '10203010202', '10203030201', '10203030202', '10204010201', '10204010202', '10204030201')
and a.serv_id = b.serv_id)
posted @
2010-11-05 18:02 xzc 阅读(736) |
评论 (0) |
编辑 收藏这段代码同样是执行了1000条insert语句,但是每一条语句都是不同的,因此ORACLE会把每条语句硬解析一次,其效率就比前面那段就低得多了。如果要提高效率,不妨使用绑定变量将循环中的语句改为
sqlstr:='insert into 测试表 (:i,:i+1,:i*1,:i*2,:i-1) ';
execute immediate sqlstr using i,i,i,i,i;
这样执行的效率就高得多了。
我曾试着使用绑定变量来代替表名、过程名、字段名等,结果是语句错误,结论就是绑定变量不能当作嵌入的字符串来使用,只能当作语句中的变量来用。
从效率来看,由于oracle10G放弃了RBO,全面引入CBO,因此,在10G中使用绑定变量效率的提升比9i中更为明显。
最后,前面说到绑定变量是在通常情况下能提升效率,那哪些是不通常的情况呢?
答案是:在字段(包括字段集)建有索引,且字段(集)的集的势非常大(也就是有个值在字段中出现的比例特别的大)的情况下,使用绑定变量可能会导致查询计划错误,因而会使查询效率非常低。这种情况最好不要使用绑定变量。
EXECUTE IMMEDIATE代替了以前Oracle8i中DBMS_SQL package包.它解析并马上执行动态的SQL语句或非运行时创建的PL/SQL块.动态创建和执行SQL语句性能超前,EXECUTE IMMEDIATE的目标在于减小企业费用并获得较高的性能,较之以前它相当容易编码.尽管DBMS_SQL仍然可用,但是推荐使用EXECUTE IMMEDIATE,因为它获的收益在包之上。
使用技巧
1. EXECUTE IMMEDIATE将不会提交一个DML事务执行,应该显式提交
如果通过EXECUTE IMMEDIATE处理DML命令,那么在完成以前需要显式提交或者作为EXECUTE IMMEDIATE自己的一部分. 如果通过EXECUTE IMMEDIATE处理DDL命令,它提交所有以前改变的数据
2. 不支持返回多行的查询,这种交互将用临时表来存储记录(参照例子如下)或者用REF cursors.
3. 当执行SQL语句时,不要用分号,当执行PL/SQL块时,在其尾部用分号.
4. 在Oracle手册中,未详细覆盖这些功能。下面的例子展示了所有用到Execute immediate的可能方面.希望能给你带来方便.
5. 对于Forms开发者,当在PL/SQL 8.0.6.3.版本中,Forms 6i不能使用此功能.
EXECUTE IMMEDIATE用法例子
1. 在PL/SQL运行DDL语句
begin
execute immediate 'set role all';
end;
2. 给动态语句传值(USING 子句)
declare
l_depnam varchar2(20) := 'testing';
l_loc varchar2(10) := 'Dubai';
begin
execute immediate 'insert into dept values (:1, :2, :3)'
using 50, l_depnam, l_loc;
commit;
end;
3. 从动态语句检索值(INTO子句)
declare
l_cnt varchar2(20);
begin
execute immediate 'select count(1) from emp'
into l_cnt;
dbms_output.put_line(l_cnt);
end;
4. 动态调用例程.例程中用到的绑定变量参数必须指定参数类型.黓认为IN类型,其它类型必须显式指定
declare
l_routin varchar2(100) := 'gen2161.get_rowcnt';
l_tblnam varchar2(20) := 'emp';
l_cnt number;
l_status varchar2(200);
begin
execute immediate 'begin ' || l_routin || '(:2, :3, :4); end;'
using in l_tblnam, out l_cnt, in out l_status;
if l_status != 'OK' then
dbms_output.put_line('error');
end if;
end;
5. 将返回值传递到PL/SQL记录类型;同样也可用%rowtype变量
declare
type empdtlrec is record (empno number(4),
ename varchar2(20),
deptno number(2));
empdtl empdtlrec;
begin
execute immediate 'select empno, ename, deptno ' ||
'from emp where empno = 7934'
into empdtl;
end;
6. 传递并检索值.INTO子句用在USING子句前
declare
l_dept pls_integer := 20;
l_nam varchar2(20);
l_loc varchar2(20);
begin
execute immediate 'select dname, loc from dept where deptno = :1'
into l_nam, l_loc
using l_dept ;
end;
7. 多行查询选项.对此选项用insert语句填充临时表,用临时表进行进一步的处理,也可以用REF cursors纠正此缺憾.
declare
l_sal pls_integer := 2000;
begin
execute immediate 'insert into temp(empno, ename) ' ||
' select empno, ename from emp ' ||
' where sal > :1'
using l_sal;
commit;
end;
对于处理动态语句,EXECUTE IMMEDIATE比以前可能用到的更容易并且更高效.当意图执行动态语句时,适当地处理异常更加重要.应该关注于捕获所有可能的异常.
posted @
2010-11-01 14:42 xzc 阅读(954) |
评论 (0) |
编辑 收藏insert append需要注意的
2010-07-28 11:34
1. append方式添加记录对insert into ... values语句不起作用。
2. 以append方式批量插入的记录,其存储位置在hwm 之上,即使hwm之下存在空闲块也不能使用。
3. 以append方式插入记录后,要执行commit,才能对表进行查询。否则会出现错误:
ORA-12838: 无法在并行模式下修改之后读/修改对象
4. 在归档模式下,要把表设置为nologging,然后以append方式批量添加记录,才会显著减少redo数量。在非归档模式下,不必设置表的nologging属性,即可减少redo数量。如果表上有索引,则append方式批量添加记录,不会减少索引上产生的redo数量,索引上的redo数量可能比表的redo数量还要大。
用insert append可以实现直接路径加载,速度比常规加载方式快。但有一点需要注意: insert append时在表上加“6”类型的锁,会阻塞表上的所有DML语句。因此在有业务运行的情况下要慎重使用。若同时执行多个insert append对同一个表并行加载数据,并不一定会提高速度。因为每一时刻只能有一个进程在加载(排它锁造成)。
SQL> create table test as select * from dba_objects where 1=2;
表已创建。
SQL> insert into test select * from dba_objects;
已创建11344行。
SQL> set lines 150
SQL> col object_type for a10
SQL> col object for a30
SQL> col username for a10
SQL> col osuser for a10
SQL> col program for a30
SQL> col sid for 99,999
SQL> col locked_mode for 99
SQL> col spid for 999,999
SQL> select o.object_type,o.owner||'.'||o.object_name object,s.sid,s.serial#,p.spid,s.username,s.osuser,s.program,l.lock
ed_mode
2 from v$locked_object l,dba_objects o,v$session s,v$process p
3 where l.object_id = o.object_id
4 and s.sid=l.session_id
5 and s.paddr=p.addr
6 and o.object_name = upper('&obj');
输入 obj 的值: test
原值 6: and o.object_name = upper('&obj')
新值 6: and o.object_name = upper('test')
OBJECT_TYP OBJECT SID SERIAL# SPID USERNAME OSUSER PROGRAM
LOCKED_MODE
---------- ------------------------------ ------- ---------- ------------ ---------- ---------- ------------------------
------ -----------
TABLE SYS.TEST 147 19 784 SYS CNPEKALT02 sqlplus.exe
3
2\jyu
可以看到,insert 时在表上加的是“3”类型的锁。
SQL> rollback;
回退已完成。
SQL> insert /*+ append */ into test select * from dba_objects;
已创建11344行。
SQL> set lines 150
SQL> col object_type for a10
SQL> col object for a30
SQL> col username for a10
SQL> col osuser for a10
SQL> col program for a30
SQL> col sid for 99,999
SQL> col locked_mode for 99
SQL> col spid for 999,999
SQL> select o.object_type,o.owner||'.'||o.object_name object,s.sid,s.serial#,p.spid,s.username,s.osuser,s.program,l.lock
ed_mode
2 from v$locked_object l,dba_objects o,v$session s,v$process p
3 where l.object_id = o.object_id
4 and s.sid=l.session_id
5 and s.paddr=p.addr
6 and o.object_name = upper('&obj');
输入 obj 的值: test
原值 6: and o.object_name = upper('&obj')
新值 6: and o.object_name = upper('test')
OBJECT_TYP OBJECT SID SERIAL# SPID USERNAME OSUSER PROGRAM
LOCKED_MODE
---------- ------------------------------ ------- ---------- ------------ ---------- ---------- ------------------------
------ -----------
TABLE SYS.TEST 147 19 784 SYS CNPEKALT02 sqlplus.exe
6
2\jyu
而执行insert append时在表上加的是“6”类型的锁。
insert append与一般的insert在表上加的锁不一样。insert append加的是exclusive的锁。因此要注意在执行insert append尽快提交,否则会阻塞其它事务对同一张表的DML语句。
此外, ORA-12838:是由于在执行insert append之后没有提交或回滚,接着又执行DML语句造成的。解决办法是在insert append 之后加上commit或rollback。
请看下面的测试:
SQL> delete from test;
已删除9831行。
SQL> insert /*+ append */ into test select * from temp_fsum_od;
已创建3277行。
SQL> insert into test select * from temp_fsum_od;
insert into test select * from temp_fsum_od
*
第 1 行出现错误:
ORA-12838: 无法在并行模式下修改之后读/修改对象
SQL> update test set OD_CODE=upper(OD_CODE) ;
update test set OD_CODE=upper(OD_CODE)
*
第 1 行出现错误:
ORA-12838: 无法在并行模式下修改之后读/修改对象
SQL> delete from test;
delete from test
*
第 1 行出现错误:
ORA-12838: 无法在并行模式下修改之后读/修改对象
SQL>
SQL> insert /*+ append */ into test select * from temp_fsum_od;
insert /*+ append */ into test select * from temp_fsum_od
*
第 1 行出现错误:
ORA-12838: 无法在并行模式下修改之后读/修改对象
注意,我先执行了一个delete语句,又执行了insert append. 这个delete语句并没有造成后面的insert append报错。
但在我执行了一个insert append之后,再执行任何DML语句都会报错。
这说明,在执行了insert append 之后,必须commit或rollback,才能再执行其它DML语句。
但在insert append之前可以执行DML语句,而不会对insert append造成影响。
所以我们注意一点就可以了,即只要业务允许,在执行insert
insert append方法的使用
大家众所周知,向 数据库里插入数据有很多种方法,insert、sqlloader、for update等。每种方法都有其不同的特点。 但是每一种方法在其 服务器设置不同的情况下也是有不同的执行情况的。例如:insert。 insert 属于DML语言(即数据操作语言,还包括select,delete,update)。网上介绍过一种insert append方法,语句格式为 insert /* +append+ */ into table_name select column_name1…… from table_name2 ; 这种方法据说可以占用很少的redo表空间,占用很少的redo表空间也就是省略了一些归档的时间,这样是可以提高insert的执行效率的!但是经过测试我发现insert append并不是在任何时候都可以节省时间的。
第一种情况:database为archivelog状态,这种情况下,就算你用insert append也是不一定提高插入效率的。但是如果你在建表的时候,将目标表建成nologging的,然后再使用insert append就会很快。
第二种情况:database为noarchivelog状态,这种情况下,如果情况下采用insert方法向表中插入数据,占用的redo空间的大小与archivelog状态下占用的大小是相当的,不论表是否为nologging。但是如果采用insert append方法的话,通过redo的占用值大家可以发现,不论表是否为nologging,所占用的redo的大小都是很小的。也就说明:在数据库为noarchivelog的状态下,采用insert append方法,如果表不是nologging,系统也会自动将表转换为nologging(即在执行insert append之前,先执行一个alter table arch1 nologging;)。
以下为测试的具体过程:
-------- 数据库为归档模式
create table arch (status varchar(2)) nologging; ----- create a nologging table
Table created
create table arch1 (status varchar(2)) ; ----- create a logging table
Table created
select a.name, b.value
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
and a.name = 'redo size'
and b.value > 0; ----- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 1332780
insert into arch select 'ok' from dba_objects
29514 rows inserted
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 1744516 ----- +411736
insert into arch1 select 'ok' from dba_objects
29514 rows inserted
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 2156000 ------ +411484
insert /*+append*/ into arch select 'ok' from dba_objects
29514 rows inserted
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 2169864 ----- +13864
insert /*+append*/ into arch1 select 'ok' from dba_objects
29514 rows inserted
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 2555448 ----- +385584
spool off;
-------- 数据库为非归档模式
create table arch (status varchar(2)) nologging; ----- create a nologging table
Table created
create table arch1 (status varchar(2)) ; ----- create a logging table
Table created
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 33208
insert into arch select 'ok' from dba_objects
29514 rows inserted
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 444704 ----- +411496
insert into arch1 select 'ok' from dba_objects
29514 rows inserted
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 856160 ----- +411456
insert /*+append*/ into arch select 'ok' from dba_objects
29514 rows inserted
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 870024 ----- +13864
insert /*+append*/ into arch1 select 'ok' from dba_objects
29514 rows inserted
---- view redo engross space
NAME VALUE
---------------------------------------------------------------- ----------
redo size 884004----- +13980
spool off;
|
posted @
2010-10-28 14:56 xzc 阅读(3595) |
评论 (0) |
编辑 收藏
- shell判断文件,目录是否存在或者具有权限
- #!/bin/sh
-
- myPath="/var/log/httpd/"
- myFile="/var /log/httpd/access.log"
-
- #这里的-x 参数判断$myPath是否存在并且是否具有可执行权限
- if [ ! -x "$myPath"]; then
- mkdir "$myPath"
- fi
-
- #这里的-d 参数判断$myPath是否存在
- if [ ! -d "$myPath"]; then
- mkdir "$myPath"
- fi
-
- #这里的-f参数判断$myFile是否存在
- if [ ! -f "$myFile" ]; then
- touch "$myFile"
- fi
-
- #其他参数还有-n,-n是判断一个变量是否是否有值
- if [ ! -n "$myVar" ]; then
- echo "$myVar is empty"
- exit 0
- fi
-
- #两个变量判断是否相等
- if [ "$var1" = "$var2" ]; then
- echo '$var1 eq $var2'
- else
- echo '$var1 not eq $var2'
- fi
posted @
2010-09-29 19:34 xzc 阅读(600) |
评论 (1) |
编辑 收藏posted @
2010-09-29 15:56 xzc 阅读(4427) |
评论 (0) |
编辑 收藏 #!/bin/bash
IFS=:
read aa bb cc < /etc/passwd
echo $aa $bb $cc
(注:默认shell是无法将/etc/passwd中那些以冒号分割的字符串分割的,通过设置IFS可以实现这一点,详情见本文底部)
我们将看到的结果是前两个变量被赋予了正确的值,最后一个变量被赋予了文件第一行剩下的所有值。(因为read一次只能读一行)
而现实中如果一个文件保存了这样一个电话本:
路人甲 13900000000
主角A 23320000
神秘人 12x0x0x0000
旁白 85600000
……
如果我们要写一个脚本来实现该电话本的查询,通常会这样写:
#!/bin/bash
while read name num
do
if [ $name = $1 ]
then echo $num
fi
done
当我们把想查询的人名作为参数来启动脚本,就可以看到他的号码,然后给他打骚扰电话……
(关于while等流程控制语句,我会在稍后整理)
抽取行
head -x 文件 //抽取前x行
tail -x 文件 //抽取末尾x行
sed -n xp 文件 //抽取文件中的第x行 注:这里的-n就是-n,不代表别的。
抽取列
cut -fx -dy 文件 //以y作为分隔符,抽取第x列
awk -Fy '{print $x}' 文件 //以y作为分隔符,抽取第x列
注:awk可以抽取多列,在指令中使用逗号分割,例:
awk -F: '{print $3,$5}' /etc/passwd
将会抽取文件中的第3列和第5列
排序
sort -ty +xn 文件 //以y作为分隔符,以第1+x列为基准排序
注:如果使用了该指令,则不能在同一语句内使用其它参数,如有需要,只能在管道中再sort一次,如: sort +4n /etc/fstab | sort -r
其它参数: n 对数字排序
d 对字母排序
M 对月份排序(诸如JAN,FEB....DEC之类)
r 逆向
$IFS
很多时候我们并不需要指定分隔符,因为$IFS默认包含了空格,\t和换行符。
只有遇到其它分隔符是我们才需要特别指定,比如$PATH和/etc/passwd中就是以冒号分割,遇到类似这种情况,我们才需要对$IFS进行指定。
posted @
2010-09-17 16:05 xzc 阅读(731) |
评论 (0) |
编辑 收藏这段时间学习shell整理的笔记
第1章 文件安全与权限
显示文件
ls -l
d 目录。
l 符号链接(指向另一个文件
s 套接字文件。
b 块设备文件。
c 字符设备文件。
p 命名管道文件。
创建一个文件:
touch myfile
更改文件权限:
chmod [who] operator [permission] filenam
who: u g o a
operator:+ - =
operator: r(4) w(2) x(1)
chown -R owner file
chgrp groupname file
id 自己信息
umask 002
ln [-s] source_path target_path
ln -s /usr/opt/monitor/regstar/reg.log /var/adm/logs/monitor.log
$ H O M E中查找文件名符合* . t x t的文件
$ find ~ -name "*.txt" -print
$ H O M E中查找文件名以一个大写字母开头的文件
$ find . -name "[A-Z]*" -print
/etc目录中查找文件名以host开头的文件
$ find /etc -name "host*" -print
查找文件权限位为 7 5 5的文件
$ find . -perm 755 -print
在/apps目录下查找文件,但不希望在/ a p p s / b i n目录下查找
$ find /apps -name "/apps/bin" -prune -o -print
在 $ H O M E目录中查找文件属主为d a v e的文件
$ find ~ -user dave -print
在/apps目录下查找属于a c c t s用户组的文件
$ find /apps -group accts -print
查找没有有效所属用户组的所有文件
$ fine/-nogroup-print
查找属主帐户已经被删除的文件(在/ e t c / p a s s w d文件中没有有效帐户的文件)
$ find /home -nouser -print
查找更改时间在5日以内的文件
$ find / -mtime -5 -print
在/var/ a d m目录下查找更改时间在3日以前的文件
$ find /var/adm -mtime +3 -print
假设现在的时间是2 3 : 4 0,希望查找更改时间在两个小时以内的文件
$ touch -t 03111750 file
$ ls -l file
$ find . -newer file -print
为了在/ e t c目录下查找所有的符号链接文件
$ find /etc -type l -print
为了在当前目录下查找除目录以外的所有类型的文件
$ find . ! -type d -print
查找文件长度大于1 M字节的文件
$ find . -size +1000000c -print
查找文件长度恰好为1 0 0字节的文件
$ find /home/apache -size 100c -print
查找长度超过1 0块的文件(一块等于5 1 2字节)
$ find . -size +10 -print
在当前的文件系统中查找文件(不进入其他文件系统)
$ find . -name "*.XC" -mount -print
首先匹配所有的文件然后再进入子目录中查找
$ find / -name "CON.FILE" -depth -print
crontab 举例: *(分钟) *(小时) *(每月的几日) *(月) *(每周星期几)
第1列 分钟1~5 9
第2列 小时1~2 3(0表示子夜)
第3列 日1~3 1
第4列 月1~1 2
第5列 星期0~6(0表示星期天)
第6列 要运行的命令
-u 用户名。
-e 编辑c r o n t a b文件。
-l 列出c r o n t a b文件中的内容。
-r 删除c r o n t a b文件。
表示每晚的2 1 : 3 0运行/ a p p s / b i n目录下的c l e a n u p . s h
30 21* * * /apps/bin/cleanup.sh
每月1、1 0、2 2日的4 : 4 5运行/ a p p s / b i n目录下的b a c k u p . s h
45 4 1,10,22 * * /apps/bin/backup.sh
在每天1 8 : 0 0至2 3 : 0 0之间每隔3 0分钟运行/ a p p s / b i n目录下的d b c h e c k . sh
0,30 18-23 * * * /apps/bin/dbcheck.sh
表示每星期六的11 : 0 0 p m运行/ a p p s / b i n目录下的q t r e n d . s h
0 23 * * 6 /apps/bin/qtrend.sh
linux系统重起cron服务的方法为:/sbin/service crond restart
aix系统重起cron服务的方法为:kill -9 pid(cron服务),cron服务后自动重起。
创建一个新的crontab文件:
在 $ H O M E目录下的. p r o f i l e文件
加入 EDITOR=vi; export EDITOR
vi davecron 建一个新的crontab文件
$ crontab davecron 提交crontab
如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用n o h u p命令
nohup command &
echo string
定义变量:
read name
输入hello
echo $name
输入文件—标准输入 0
输出文件—标准输出 1
错误输出文件—标准错误 2
command > filename 把把标准输出重定向到一个新文件中
command > filename 2>&1 把把标准输出和标准错误一起重定向到一个文件中
command 2 > filename 把把标准错误重定向到一个文件中
command >> filename 2>&1 把把标准输出和标准错误一起重定向到一个文件中 (追加)
&&左边的命令(命令1)返回真(即返回0,成功被执行后,&&右边的命令(命令2)才能够被执行
mv who.ini awho.ini && echo "it's success
sort file.txt 对文件排序
--------------------------------------------------
正则表达式介绍:
^ 只只匹配行首
$ 只只匹配行尾
* 只一个单字符后紧跟*,匹配0个或多个此单字符
[ ] 只匹配[ ]内字符。可以是一个单字符,也可以是字符序列。可以使用 -
表示[ ]内字符序列范围,如用[ 1 - 5 ]代替[ 1 2 3 4 5 ]
\ 只用来屏蔽一个元字符的特殊含义。因为有时在 s h e l l中一些元字符有
特殊含义。\可以使其失去应有意义
. 只匹配任意单字符
pattern \ { n \ } 只用来匹配前面pattern出现次数。n为次数
pattern \ { n,\ } m 只含义同上,但次数最少为n
pattern \ { n,m \ } 只含义同上,但pattern出现次数在n与m之间
匹配以单词t r o u b l e结尾的所有行
t r o u b l e $
要匹配所有空行
^ $
^ . $
使用\屏蔽一个特殊字符的含义
下列字符可以认为是特殊字符
$ . ' " * [ ] ^ | () \ + ?
注意^符号的使用,当直接用在第一个括号里,意指否定或不匹配括号里内容
[ ^ 0 - 9 ] 匹配任一非数字型字符
匹配字母A出现两次,并以B结尾
A \ { 2 \ } B
匹配A至少4次
A \ { 4 , \ } B
A出现2次到4次之间
A \ { 2 , 4 \ } B
grep 查匹配的字符
-c 只输出匹配行的计数。
-i 不区分大小写(只适用于单字符)。
-h 查询多文件时不显示文件名。
-l 查询多文件时只输出包含匹配字符的文件名。
-n 显示匹配行及行号。
-s 不显示不存在或无匹配文本的错误信息。
-v 显示不包含匹配文本的所有行。
所有. d o c文件中查找字符串“s o r t”
$ grep "sort" *.doc
精确匹配
$ grep "sort<tab>" *.doc
抽取包含S e p t的所有月份,不管其大小写,并且此行包含字符串 4 8 3
$ grep "[Ss]ept' data.f | grep 483
对一个字符串使用grep
str="hello every one"
echo $str | grep "one"
测试是否已设置或初始化变量。如果未设置或初始化,就可以使用另一值:
$ { v a r i a b l e : - v a l u e }
$ cu='chen'
$ echo "the ask is ${cu:-hi} today" (如果未设置或初始化,就可以使用hi)
readonly 变量 变量设置为只读
设置环境变量:
VARIABLE-NAME = v a l u e
Export VARIABLE-NAME
pg 分页显示
变量 ARIABLE-NAME ='chen' 输出'chen'
变量 ARIABLE-NAME ="chen" 输出 chen
打印当前系统上用户数目:
echo "ther are 'who | wc -l' users on the system "
test测试:
- d 目录 - s 文件长度大于0、非空
- f 正规文件 - w 可写
- L 符号连接 - u 文件有s u i d位设置
- r 可读 - x 可执行
test -r tt.txt
echo $? (正确显示0,错误显示1)
确定当前的运行级别:
$ who -r
$ runlevel
查看doc_part文件是否被打开,有哪些进程在使用:
$ fuser -m /root/doc_part
该命令可以显示当前所使用的登录用户名
$ logname
可以使用tty来报告所连接的设备或终端
$tty
记录当前会话
$script. 文件名
exit
意味着系统在10秒钟之内不进行任何操作
$sleep 10
可以看二进制文件中所包含的文本
$strings 文件名
whereis命令能够给出系统命令的二进制文件及其在线手册的路径
$whereis 命令
tr用法(字符转换)
# tr -s "[a-z]" < a.txt >b.txt a.txt的字符有重复的小写转为b.txt文件
# cat da|tr -s "[a-z]"
# tr -s "[\012]" < a.txt 去掉空行
# tr -s "[\n]" < a.txt
# tr -s "[\015\032]" "[\012*]" < input_file 一般的dos到unix转换命令
# echo "may May"|tr "[a-z]" "[A-Z]" 小写转大小
# cat a.txt|tr "[a-z]" "[A-Z]" >b.txt
# cat a.txt|tr "[A-Z]" "[a-z]" > b.txt 大小转小写
# tr -cs "[a-z][A-Z]" "[\012*]" < a.txt 只保留大小字母,并分行
sort分类:
# sort a.txt > b.txt
# uniq a.txt > b.txt 消除重复的行(只在行连续重复时才有效)
# uniq -u a.txt 只显示不重复行
# uniq -d a.txt 只显示有重复数据行
join(将来自两个分类文本文件的行连在一起)
# join a.txt b.txt
# join -a1 a.txt b.txt 当有不匹配时,只显示a.txt
# join -a1 -a2 a.txt b.txt 当有不匹配时,都显示出来
split用来将大文件分割成小文件(将文件按每个最多1000行分割)
# split 文件
# split -100 文件 指定每个文件100行分割
paste按行将不同文件行信息放在一行
# ls | paste -d "" 以一列格式显示输出
# paste a.txt b.txt
cut用来从标准输入或文本文件中剪切列或
# cut -c 1-3 c.txt 显示每行从开头算起1到3的字母
# cut -c 1-2,5-10 c.txt 显示从1到2,还有5到10的字母
# cut -f 1,3 c.txt 显示1和3栏的字符(使用tab分隔)
sed用法:文本编辑器(强大的文本过滤工具)
删除:d命令
$ sed '2d' example-----删除example文件的第二行。
$ sed '2,$d' example-----删除example文件的第二行到末尾所有行。
$ sed '$d' example-----删除example文件的最后一行。
$ sed '/test/'d example-----删除example文件所有包含test的行。
替换:s命令
$ sed 's/test/mytest/g' example-----在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest
$ sed 's/^192.168.0.1/&localhost/' example-----&符号表示替换换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加 localhost,变成192.168.0.1localhost
写入文件:w命令
$ sed -n '/test/w file' example 在example中所有包含test的行都被写入file里
# sed '/^kai/a\\ this is a example' b.txt " this is a example"被插入到以kai开头后面的新一行
# sed '/^kai/i\\ this is a example' b.txt " this is a example"被插入到以kai开头后面的前一行
posted @
2010-09-17 15:43 xzc 阅读(212) |
评论 (0) |
编辑 收藏转自:http://linuxtoy.org/archives/sed-awk.html
sed 和 awk 都是 Linux 下常用的流编辑器,他们各有各的特色,本文并不是要做什么对比,而是权当好玩,把《SED 单行脚本快速参考》这文章,用 awk 做了一遍~ 至于孰好孰坏,那真是很难评论了。一般来说,sed 的命令会更短小一些,同时也更难读懂;而 awk 稍微长点,但是 if、while 这样的,逻辑性比较强,更加像“程序”。到底喜欢用哪个,就让各位看官自己决定吧!
文本间隔:
# 在每一行后面增加一空行
sed G
awk '{printf("%s\n\n",$0)}'
# 将原来的所有空行删除并在每一行后面增加一空行。
# 这样在输出的文本中每一行后面将有且只有一空行。
sed '/^$/d;G'
awk '!/^$/{printf("%s\n\n",$0)}'
# 在每一行后面增加两行空行
sed 'G;G'
awk '{printf("%s\n\n\n",$0)}'
# 将第一个脚本所产生的所有空行删除(即删除所有偶数行)
sed 'n;d'
awk '{f=!f;if(f)print $0}'
# 在匹配式样“regex”的行之前插入一空行
sed '/regex/{x;p;x;}'
awk '{if(/regex/)printf("\n%s\n",$0);else print $0}'
# 在匹配式样“regex”的行之后插入一空行
sed '/regex/G'
awk '{if(/regex/)printf("%s\n\n",$0);else print $0}'
# 在匹配式样“regex”的行之前和之后各插入一空行
sed '/regex/{x;p;x;G;}'
awk '{if(/regex/)printf("\n%s\n\n",$0);else print $0}'
编号:
# 为文件中的每一行进行编号(简单的左对齐方式)。这里使用了“制表符”
# (tab,见本文末尾关于’\t’的用法的描述)而不是空格来对齐边缘。
sed = filename | sed 'N;s/\n/\t/'
awk '{i++;printf("%d\t%s\n",i,$0)}'
# 对文件中的所有行编号(行号在左,文字右端对齐)。
sed = filename | sed 'N; s/^/ /; s/ *\(.\{6,\}\)\n/\1 /'
awk '{i++;printf("%6d %s\n",i,$0)}'
# 对文件中的所有行编号,但只显示非空白行的行号。
sed '/./=' filename | sed '/./N; s/\n/ /'
awk '{i++;if(!/^$/)printf("%d %s\n",i,$0);else print}'
# 计算行数 (模拟 “wc -l”)
sed -n '$='
awk '{i++}END{print i}'
文本转换和替代:
# Unix环境:转换DOS的新行符(CR/LF)为Unix格式。
sed 's/.$//' # 假设所有行以CR/LF结束
sed 's/^M$//' # 在bash/tcsh中,将按Ctrl-M改为按Ctrl-V
sed 's/\x0D$//' # ssed、gsed 3.02.80,及更高版本
awk '{sub(/\x0D$/,"");print $0}'
# Unix环境:转换Unix的新行符(LF)为DOS格式。
sed "s/$/`echo -e \\\r`/" # 在ksh下所使用的命令
sed 's/$'"/`echo \\\r`/" # 在bash下所使用的命令
sed "s/$/`echo \\\r`/" # 在zsh下所使用的命令
sed 's/$/\r/' # gsed 3.02.80 及更高版本
awk '{printf("%s\r\n",$0)}'
# DOS环境:转换Unix新行符(LF)为DOS格式。
sed "s/$//" # 方法 1
sed -n p # 方法 2
DOS环境的略过
# DOS环境:转换DOS新行符(CR/LF)为Unix格式。
# 下面的脚本只对UnxUtils sed 4.0.7 及更高版本有效。要识别UnxUtils版本的
# sed可以通过其特有的“–text”选项。你可以使用帮助选项(“–help”)看
# 其中有无一个“–text”项以此来判断所使用的是否是UnxUtils版本。其它DOS
# 版本的的sed则无法进行这一转换。但可以用“tr”来实现这一转换。
sed "s/\r//" infile >outfile # UnxUtils sed v4.0.7 或更高版本
tr -d \r <infile >outfile # GNU tr 1.22 或更高版本
DOS环境的略过
# 将每一行前导的“空白字符”(空格,制表符)删除
# 使之左对齐
sed 's/^[ \t]*//' # 见本文末尾关于'\t'用法的描述
awk '{sub(/^[ \t]+/,"");print $0}'
# 将每一行拖尾的“空白字符”(空格,制表符)删除
sed 's/[ \t]*$//' # 见本文末尾关于'\t'用法的描述
awk '{sub(/[ \t]+$/,"");print $0}'
# 将每一行中的前导和拖尾的空白字符删除
sed 's/^[ \t]*//;s/[ \t]*$//'
awk '{sub(/^[ \t]+/,"");sub(/[ \t]+$/,"");print $0}'
# 在每一行开头处插入5个空格(使全文向右移动5个字符的位置)
sed 's/^/ /'
awk '{printf(" %s\n",$0)}'
# 以79个字符为宽度,将所有文本右对齐
# 78个字符外加最后的一个空格
sed -e :a -e 's/^.\{1,78\}$/ &/;ta'
awk '{printf("%79s\n",$0)}'
# 以79个字符为宽度,使所有文本居中。在方法1中,为了让文本居中每一行的前
# 头和后头都填充了空格。 在方法2中,在居中文本的过程中只在文本的前面填充
# 空格,并且最终这些空格将有一半会被删除。此外每一行的后头并未填充空格。
sed -e :a -e 's/^.\{1,77\}$/ & /;ta' # 方法1
sed -e :a -e 's/^.\{1,77\}$/ &/;ta' -e 's/\( *\)\1/\1/' # 方法2
awk '{for(i=0;i<39-length($0)/2;i++)printf(" ");printf("%s\n",$0)}' #相当于上面的方法二
# 在每一行中查找字串“foo”,并将找到的“foo”替换为“bar”
sed 's/foo/bar/' # 只替换每一行中的第一个“foo”字串
sed 's/foo/bar/4' # 只替换每一行中的第四个“foo”字串
sed 's/foo/bar/g' # 将每一行中的所有“foo”都换成“bar”
sed 's/\(.*\)foo\(.*foo\)/\1bar\2/' # 替换倒数第二个“foo”
sed 's/\(.*\)foo/\1bar/' # 替换最后一个“foo”
awk '{gsub(/foo/,"bar");print $0}' # 将每一行中的所有“foo”都换成“bar”
# 只在行中出现字串“baz”的情况下将“foo”替换成“bar”
sed '/baz/s/foo/bar/g'
awk '{if(/baz/)gsub(/foo/,"bar");print $0}'
# 将“foo”替换成“bar”,并且只在行中未出现字串“baz”的情况下替换
sed '/baz/!s/foo/bar/g'
awk '{if(/baz$/)gsub(/foo/,"bar");print $0}'
# 不管是“scarlet”“ruby”还是“puce”,一律换成“red”
sed 's/scarlet/red/g;s/ruby/red/g;s/puce/red/g' #对多数的sed都有效
gsed 's/scarlet\|ruby\|puce/red/g' # 只对GNU sed有效
awk '{gsub(/scarlet|ruby|puce/,"red");print $0}'
# 倒置所有行,第一行成为最后一行,依次类推(模拟“tac”)。
# 由于某些原因,使用下面命令时HHsed v1.5会将文件中的空行删除
sed '1!G;h;$!d' # 方法1
sed -n '1!G;h;$p' # 方法2
awk '{A[i++]=$0}END{for(j=i-1;j>=0;j--)print A[j]}'
# 将行中的字符逆序排列,第一个字成为最后一字,……(模拟“rev”)
sed '/\n/!G;s/\(.\)\(.*\n\)/&\2\1/;//D;s/.//'
awk '{for(i=length($0);i>0;i--)printf("%s",substr($0,i,1));printf("\n")}'
# 将每两行连接成一行(类似“paste”)
sed '$!N;s/\n/ /'
awk '{f=!f;if(f)printf("%s",$0);else printf(" %s\n",$0)}'
# 如果当前行以反斜杠“\”结束,则将下一行并到当前行末尾
# 并去掉原来行尾的反斜杠
sed -e :a -e '/\\$/N; s/\\\n//; ta'
awk '{if(/\\$/)printf("%s",substr($0,0,length($0)-1));else printf("%s\n",$0)}'
# 如果当前行以等号开头,将当前行并到上一行末尾
# 并以单个空格代替原来行头的“=”
sed -e :a -e '$!N;s/\n=/ /;ta' -e 'P;D'
awk '{if(/^=/)printf(" %s",substr($0,2));else printf("%s%s",a,$0);a="\n"}END{printf("\n")}'
# 为数字字串增加逗号分隔符号,将“1234567”改为“1,234,567”
gsed ':a;s/\B[0-9]\{3\}\>/,&/;ta' # GNU sed
sed -e :a -e 's/\(.*[0-9]\)\([0-9]\{3\}\)/\1,\2/;ta' # 其他sed
#awk的正则没有后向匹配和引用,搞的比较狼狈,呵呵。
awk '{while(match($0,/[0-9][0-9][0-9][0-9]+/)){$0=sprintf("%s,%s",substr($0,0,RSTART+RLENGTH-4),substr($0,RSTART+RLENGTH-3))}print $0}'
# 为带有小数点和负号的数值增加逗号分隔符(GNU sed)
gsed -r ':a;s/(^|[^0-9.])([0-9]+)([0-9]{3})/\1\2,\3/g;ta'
#和上例差不多
awk '{while(match($0,/[^\.0-9][0-9][0-9][0-9][0-9]+/)){$0=sprintf("%s,%s",substr($0,0,RSTART+RLENGTH-4),substr($0,RSTART+RLENGTH-3))}print $0}'
# 在每5行后增加一空白行 (在第5,10,15,20,等行后增加一空白行)
gsed '0~5G' # 只对GNU sed有效
sed 'n;n;n;n;G;' # 其他sed
awk '{print $0;i++;if(i==5){printf("\n");i=0}}'
选择性地显示特定行:
# 显示文件中的前10行 (模拟“head”的行为)
sed 10q
awk '{print;if(NR==10)exit}'
# 显示文件中的第一行 (模拟“head -1”命令)
sed q
awk '{print;exit}'
# 显示文件中的最后10行 (模拟“tail”)
sed -e :a -e '$q;N;11,$D;ba'
#用awk干这个有点亏,得全文缓存,对于大文件肯定很慢
awk '{A[NR]=$0}END{for(i=NR-9;i<=NR;i++)print A[i]}'
# 显示文件中的最后2行(模拟“tail -2”命令)
sed '$!N;$!D'
awk '{A[NR]=$0}END{for(i=NR-1;i<=NR;i++)print A[i]}'
# 显示文件中的最后一行(模拟“tail -1”)
sed '$!d' # 方法1
sed -n '$p' # 方法2
#这个比较好办,只存最后一行了。
awk '{A=$0}END{print A}'
# 显示文件中的倒数第二行
sed -e '$!{h;d;}' -e x # 当文件中只有一行时,输出空行
sed -e '1{$q;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,显示该行
sed -e '1{$d;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,不输出
#存两行呗(当文件中只有一行时,输出空行)
awk '{B=A;A=$0}END{print B}'
# 只显示匹配正则表达式的行(模拟“grep”)
sed -n '/regexp/p' # 方法1
sed '/regexp/!d' # 方法2
awk '/regexp/{print}'
# 只显示“不”匹配正则表达式的行(模拟“grep -v”)
sed -n '/regexp/!p' # 方法1,与前面的命令相对应
sed '/regexp/d' # 方法2,类似的语法
awk '!/regexp/{print}'
# 查找“regexp”并将匹配行的上一行显示出来,但并不显示匹配行
sed -n '/regexp/{g;1!p;};h'
awk '/regexp/{print A}{A=$0}'
# 查找“regexp”并将匹配行的下一行显示出来,但并不显示匹配行
sed -n '/regexp/{n;p;}'
awk '{if(A)print;A=0}/regexp/{A=1}'
# 显示包含“regexp”的行及其前后行,并在第一行之前加上“regexp”所在行的行号 (类似“grep -A1 -B1”)
sed -n -e '/regexp/{=;x;1!p;g;$!N;p;D;}' -e h
awk '{if(F)print;F=0}/regexp/{print NR;print b;print;F=1}{b=$0}'
# 显示包含“AAA”、“BBB”和“CCC”的行(任意次序)
sed '/AAA/!d; /BBB/!d; /CCC/!d' # 字串的次序不影响结果
awk '{if(match($0,/AAA/) && match($0,/BBB/) && match($0,/CCC/))print}'
# 显示包含“AAA”、“BBB”和“CCC”的行(固定次序)
sed '/AAA.*BBB.*CCC/!d'
awk '{if(match($0,/AAA.*BBB.*CCC/))print}'
# 显示包含“AAA”“BBB”或“CCC”的行 (模拟“egrep”)
sed -e '/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d # 多数sed
gsed '/AAA\|BBB\|CCC/!d' # 对GNU sed有效
awk '/AAA/{print;next}/BBB/{print;next}/CCC/{print}'
awk '/AAA|BBB|CCC/{print}'
# 显示包含“AAA”的段落 (段落间以空行分隔)
# HHsed v1.5 必须在“x;”后加入“G;”,接下来的3个脚本都是这样
sed -e '/./{H;$!d;}' -e 'x;/AAA/!d;'
awk 'BEGIN{RS=""}/AAA/{print}'
awk -vRS= '/AAA/{print}'
# 显示包含“AAA”“BBB”和“CCC”三个字串的段落 (任意次序)
sed -e '/./{H;$!d;}' -e 'x;/AAA/!d;/BBB/!d;/CCC/!d'
awk -vRS= '{if(match($0,/AAA/) && match($0,/BBB/) && match($0,/CCC/))print}'
# 显示包含“AAA”、“BBB”、“CCC”三者中任一字串的段落 (任意次序)
sed -e '/./{H;$!d;}' -e 'x;/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d
gsed '/./{H;$!d;};x;/AAA\|BBB\|CCC/b;d' # 只对GNU sed有效
awk -vRS= '/AAA|BBB|CCC/{print "";print}'
# 显示包含65个或以上字符的行
sed -n '/^.\{65\}/p'
cat ll.txt | awk '{if(length($0)>=65)print}'
# 显示包含65个以下字符的行
sed -n '/^.\{65\}/!p' # 方法1,与上面的脚本相对应
sed '/^.\{65\}/d' # 方法2,更简便一点的方法
awk '{if(length($0)<=65)print}'
# 显示部分文本——从包含正则表达式的行开始到最后一行结束
sed -n '/regexp/,$p'
awk '/regexp/{F=1}{if(F)print}'
# 显示部分文本——指定行号范围(从第8至第12行,含8和12行)
sed -n '8,12p' # 方法1
sed '8,12!d' # 方法2
awk '{if(NR>=8 && NR<12)print}'
# 显示第52行
sed -n '52p' # 方法1
sed '52!d' # 方法2
sed '52q;d' # 方法3, 处理大文件时更有效率
awk '{if(NR==52){print;exit}}'
# 从第3行开始,每7行显示一次
gsed -n '3~7p' # 只对GNU sed有效
sed -n '3,${p;n;n;n;n;n;n;}' # 其他sed
awk '{if(NR==3)F=1}{if(F){i++;if(i%7==1)print}}'
# 显示两个正则表达式之间的文本(包含)
sed -n '/Iowa/,/Montana/p' # 区分大小写方式
awk '/Iowa/{F=1}{if(F)print}/Montana/{F=0}'
选择性地删除特定行:
# 显示通篇文档,除了两个正则表达式之间的内容
sed '/Iowa/,/Montana/d'
awk '/Iowa/{F=1}{if(!F)print}/Montana/{F=0}'
# 删除文件中相邻的重复行(模拟“uniq”)
# 只保留重复行中的第一行,其他行删除
sed '$!N; /^\(.*\)\n\1$/!P; D'
awk '{if($0!=B)print;B=$0}'
# 删除文件中的重复行,不管有无相邻。注意hold space所能支持的缓存大小,或者使用GNU sed。
sed -n 'G; s/\n/&&/; /^\([ -~]*\n\).*\n\1/d; s/\n//; h; P' #bones7456注:我这里此命令并不能正常工作
awk '{if(!($0 in B))print;B[$0]=1}'
# 删除除重复行外的所有行(模拟“uniq -d”)
sed '$!N; s/^\(.*\)\n\1$/\1/; t; D'
awk '{if($0==B && $0!=l){print;l=$0}B=$0}'
# 删除文件中开头的10行
sed '1,10d'
awk '{if(NR>10)print}'
# 删除文件中的最后一行
sed '$d'
#awk在过程中并不知道文件一共有几行,所以只能通篇缓存,大文件可能不适合,下面两个也一样
awk '{B[NR]=$0}END{for(i=0;i<=NR-1;i++)print B[i]}'
# 删除文件中的最后两行
sed 'N;$!P;$!D;$d'
awk '{B[NR]=$0}END{for(i=0;i<=NR-2;i++)print B[i]}'
# 删除文件中的最后10行
sed -e :a -e '$d;N;2,10ba' -e 'P;D' # 方法1
sed -n -e :a -e '1,10!{P;N;D;};N;ba' # 方法2
awk '{B[NR]=$0}END{for(i=0;i<=NR-10;i++)print B[i]}'
# 删除8的倍数行
gsed '0~8d' # 只对GNU sed有效
sed 'n;n;n;n;n;n;n;d;' # 其他sed
awk '{if(NR%8!=0)print}' |head
# 删除匹配式样的行
sed '/pattern/d' # 删除含pattern的行。当然pattern可以换成任何有效的正则表达式
awk '{if(!match($0,/pattern/))print}'
# 删除文件中的所有空行(与“grep ‘.’ ”效果相同)
sed '/^$/d' # 方法1
sed '/./!d' # 方法2
awk '{if(!match($0,/^$/))print}'
# 只保留多个相邻空行的第一行。并且删除文件顶部和尾部的空行。
# (模拟“cat -s”)
sed '/./,/^$/!d' #方法1,删除文件顶部的空行,允许尾部保留一空行
sed '/^$/N;/\n$/D' #方法2,允许顶部保留一空行,尾部不留空行
awk '{if(!match($0,/^$/)){print;F=1}else{if(F)print;F=0}}' #同上面的方法2
# 只保留多个相邻空行的前两行。
sed '/^$/N;/\n$/N;//D'
awk '{if(!match($0,/^$/)){print;F=0}else{if(F<2)print;F++}}'
# 删除文件顶部的所有空行
sed '/./,$!d'
awk '{if(F || !match($0,/^$/)){print;F=1}}'
# 删除文件尾部的所有空行
sed -e :a -e '/^\n*$/{$d;N;ba' -e '}' # 对所有sed有效
sed -e :a -e '/^\n*$/N;/\n$/ba' # 同上,但只对 gsed 3.02.*有效
awk '/^.+$/{for(i=l;i<NR-1;i++)print "";print;l=NR}'
# 删除每个段落的最后一行
sed -n '/^$/{p;h;};/./{x;/./p;}'
#很长,很ugly,应该有更好的办法
awk -vRS= '{B=$0;l=0;f=1;while(match(B,/\n/)>0){print substr(B,l,RSTART-l-f);l=RSTART;sub(/\n/,"",B);f=0};print ""}'
特殊应用:
# 移除手册页(man page)中的nroff标记。在Unix System V或bash shell下使
# 用’echo’命令时可能需要加上 -e 选项。
sed "s/.`echo \\\b`//g" # 外层的双括号是必须的(Unix环境)
sed 's/.^H//g' # 在bash或tcsh中, 按 Ctrl-V 再按 Ctrl-H
sed 's/.\x08//g' # sed 1.5,GNU sed,ssed所使用的十六进制的表示方法
awk '{gsub(/.\x08/,"",$0);print}'
# 提取新闻组或 e-mail 的邮件头
sed '/^$/q' # 删除第一行空行后的所有内容
awk '{print}/^$/{exit}'
# 提取新闻组或 e-mail 的正文部分
sed '1,/^$/d' # 删除第一行空行之前的所有内容
awk '{if(F)print}/^$/{F=1}'
# 从邮件头提取“Subject”(标题栏字段),并移除开头的“Subject:”字样
sed '/^Subject: */!d; s///;q'
awk '/^Subject:.*/{print substr($0,10)}/^$/{exit}'
# 从邮件头获得回复地址
sed '/^Reply-To:/q; /^From:/h; /./d;g;q'
#好像是输出第一个Reply-To:开头的行?From是干啥用的?不清楚规则。。
awk '/^Reply-To:.*/{print;exit}/^$/{exit}'
# 获取邮件地址。在上一个脚本所产生的那一行邮件头的基础上进一步的将非电邮地址的部分剃除。(见上一脚本)
sed 's/ *(.*)//; s/>.*//; s/.*[:<] *//'
#取尖括号里的东西吧?
awk -F'[<>]+' '{print $2}'
# 在每一行开头加上一个尖括号和空格(引用信息)
sed 's/^/> /'
awk '{print "> " $0}'
# 将每一行开头处的尖括号和空格删除(解除引用)
sed 's/^> //'
awk '/^> /{print substr($0,3)}'
# 移除大部分的HTML标签(包括跨行标签)
sed -e :a -e 's/<[^>]*>//g;/</N;//ba'
awk '{gsub(/<[^>]*>/,"",$0);print}'
# 将分成多卷的uuencode文件解码。移除文件头信息,只保留uuencode编码部分。
# 文件必须以特定顺序传给sed。下面第一种版本的脚本可以直接在命令行下输入;
# 第二种版本则可以放入一个带执行权限的shell脚本中。(由Rahul Dhesi的一
# 个脚本修改而来。)
sed '/^end/,/^begin/d' file1 file2 ... fileX | uudecode # vers. 1
sed '/^end/,/^begin/d' "$@" | uudecode # vers. 2
#我不想装个uudecode验证,大致写个吧
awk '/^end/{F=0}{if(F)print}/^begin/{F=1}' file1 file2 ... fileX
# 将文件中的段落以字母顺序排序。段落间以(一行或多行)空行分隔。GNU sed使用
# 字元“\v”来表示垂直制表符,这里用它来作为换行符的占位符——当然你也可以
# 用其他未在文件中使用的字符来代替它。
sed '/./{H;d;};x;s/\n/={NL}=/g' file | sort | sed '1s/={NL}=//;s/={NL}=/\n/g'
gsed '/./{H;d};x;y/\n/\v/' file | sort | sed '1s/\v//;y/\v/\n/'
awk -vRS= '{gsub(/\n/,"\v",$0);print}' ll.txt | sort | awk '{gsub(/\v/,"\n",$0);print;print ""}'
# 分别压缩每个.TXT文件,压缩后删除原来的文件并将压缩后的.ZIP文件
# 命名为与原来相同的名字(只是扩展名不同)。(DOS环境:“dir /b”
# 显示不带路径的文件名)。
echo @echo off >zipup.bat
dir /b *.txt | sed "s/^\(.*\)\.TXT/pkzip -mo \1 \1.TXT/" >>zipup.bat
DOS 环境再次略过,而且我觉得这里用 bash 的参数 ${i%.TXT}.zip 替换更帅。
下面的一些 SED 说明略过,需要的朋友自行查看原文。
posted @
2010-09-17 15:23 xzc 阅读(344) |
评论 (1) |
编辑 收藏
1.以sysdba身份登陆,查看数据文件路径
- C:\Documents and Settings\Administrator>sqlplus / as sysdba
-
- SQL*Plus: Release 10.2.0.1.0 - Production on 星期三 4月 14 10:51:41 2010
-
- Copyright (c) 1982, 2005, Oracle. All rights reserved.
-
-
- 连接到:
- Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
- With the Partitioning, OLAP and Data Mining options
-
- sys@AAA>show user;
- USER 为 "SYS"
- sys@AAA>select file_name from dba_data_files;
-
- FILE_NAME
-
- D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\USERS01.DBF
- D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\SYSAUX01.DBF
- D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\UNDOTBS01.DBF
- D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\SYSTEM01.DBF
- D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\BBB.DBF
- D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\PERFSTAT.DBF
-
- 已选择6行。
C:\Documents and Settings\Administrator>sqlplus / as sysdba
SQL*Plus: Release 10.2.0.1.0 - Production on 星期三 4月 14 10:51:41 2010
Copyright (c) 1982, 2005, Oracle. All rights reserved.
连接到:
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
With the Partitioning, OLAP and Data Mining options
sys@AAA>show user;
USER 为 "SYS"
sys@AAA>select file_name from dba_data_files;
FILE_NAME
--------------------------------------------------
D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\USERS01.DBF
D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\SYSAUX01.DBF
D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\UNDOTBS01.DBF
D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\SYSTEM01.DBF
D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\BBB.DBF
D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\PERFSTAT.DBF
已选择6行。
2.创建statspack存储数据的表空间,(注:statspack往往会产生大量的分析数据,所以表空间还是大点为好)。
- create tablespace perfstat datafile 'D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\PERFSTAT.DBF' size 2G;
create tablespace perfstat datafile 'D:\ORACLE\PRODUCT\10.2.0\ORADATA\AAA\PERFSTAT.DBF' size 2G;
3.运行statspack安装脚本。默认位置在$oracle_home\rdbms\admin\spcreate.sql
- sys@AAA> @D:\oracle\product\10.2.0\db_1\RDBMS\ADMIN\spcreate.sql
-
- ...................
-
- 输入 perfstat_password 的值: perfstat
-
- ...
-
- 输入 default_tablespace 的值: perfstat
- ..........
- ..........
- 输入 temporary_tablespace 的值: temp
- ..........
- ..........
sys@AAA> @D:\oracle\product\10.2.0\db_1\RDBMS\ADMIN\spcreate.sql
...................
输入 perfstat_password 的值: perfstat
...
输入 default_tablespace 的值: perfstat
..........
..........
输入 temporary_tablespace 的值: temp
..........
..........
安装完之后 会自动切换用户到perfstat下:
- PERFSTAT@AAA> show user;
-
- USER is "PERFSTAT"
PERFSTAT@AAA> show user;
USER is "PERFSTAT"
安装完毕!
4.接下来采样分析,设定一个job,每小时执行一次采样。
首先查看当前DB中有没有正在运行的JOB:
- perfstat@AAA>select job,schema_user,next_date,interval,what from user_jobs;
-
- 未选定行
perfstat@AAA>select job,schema_user,next_date,interval,what from user_jobs;
未选定行
创建statspack采样的job,没每个小时采样一次。
- perfstat@AAA>variable job number;
- perfstat@AAA>begin
- 2 dbms_job.submit(:job,'statspack.snap;',trunc(sysdate+1/24,'hh24'),'trunc(sysdate+1/24,''hh24'')');
- 3 commit;
- 4 end;
- 5 /
-
- PL/SQL 过程已成功完成。
perfstat@AAA>variable job number;
perfstat@AAA>begin
2 dbms_job.submit(:job,'statspack.snap;',trunc(sysdate+1/24,'hh24'),'trunc(sysdate+1/24,''hh24'')');
3 commit;
4 end;
5 /
PL/SQL 过程已成功完成。
查看当前正在运行的job有哪些?
- perfstat@AAA>select job as j,schema_user,next_date,interval,what from user_jobs;
- J SCHEMA_USER NEXT_DATE INTERVAL WHAT
-
- 1 PERFSTAT 14-4月 -10 trunc(sysd statspack.
- ate+1/24,' snap;
- hh24')
perfstat@AAA>select job as j,schema_user,next_date,interval,what from user_jobs;
J SCHEMA_USER NEXT_DATE INTERVAL WHAT
---------- ------------------------------ -------------- ---------- ----------
1 PERFSTAT 14-4月 -10 trunc(sysd statspack.
ate+1/24,' snap;
hh24')
5.由于statspack的采集和分析会做很多DB的分析,产生大量的分析数据,所以频繁的采样肯定会消耗系统性能,特别是在生产库中,所以当你建立了上面每小时执行一次的那个job,请务必在不需要的时候停止它。不然的话,这个失误可能会是致命的( statspack job每小时都会跑,永不停的跑下去,呵呵。),尤其在生产库中。
明天凌晨,系统比较清闲,采样已经没多大意义(采样分析的最终目的是分析高峰时段的系统瓶颈),所以停止这个job.
- perfstat@AAA>variable job number;
- perfstat@AAA>begin
- 2 dbms_job.submit(:job,'dbms_job.broken(1,true);',trunc(sysdate+1),'null');
- 3 commit;
- 4 end;
- 5 /
-
- PL/SQL 过程已成功完成。
perfstat@AAA>variable job number;
perfstat@AAA>begin
2 dbms_job.submit(:job,'dbms_job.broken(1,true);',trunc(sysdate+1),'null');
3 commit;
4 end;
5 /
PL/SQL 过程已成功完成。
6.几个小时候后,看看生成的哪些快照。
- perfstat@AAA>select snap_id,snap_time,startup_time from stats$snapshot;
-
- SNAP_ID SNAP_TIME STARTUP_TIME
-
- 1 14-4月 -10 14-4月 -10
- 2 14-4月 -10 14-4月 -10
perfstat@AAA>select snap_id,snap_time,startup_time from stats$snapshot;
SNAP_ID SNAP_TIME STARTUP_TIME
---------- -------------- --------------
1 14-4月 -10 14-4月 -10
2 14-4月 -10 14-4月 -10
7.设定任意两个快照,产生这段时间内的性能分析报告(此时需要跑spreport脚本,路径和刚才那个脚本一致)。
- perfstat@AAA>@D:\oracle\product\10.2.0\db_1\RDBMS\ADMIN\spreport.sql
-
- Current Instance
- ~~~~~~~~~~~~~~~~
- DB Id DB Name Inst Num Instance
-
- 1858440386 AAA 1 aaa
-
-
-
- Instances in this Statspack schema
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
- DB Id Inst Num DB Name Instance Host
-
- 1858440386 1 AAA aaa 6979580041BD
- 490
-
- Using 1858440386 for database Id
- Using 1 for instance number
-
-
- Specify the number of days of snapshots to choose from
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Entering the number of days (n) will result in the most recent
- (n) days of snapshots being listed. Pressing <return> without
- specifying a number lists all completed snapshots.
-
-
-
- Listing all Completed Snapshots
-
- Snap
- Instance DB Name Snap Id Snap Started Level Comment
-
- aaa AAA 1 14 4月 2010 09:5 5
- 2
- 2 14 4月 2010 09:5 5
- 3
- 3 14 4月 2010 11:0 5
- 0
-
-
-
- Specify the Begin and End Snapshot Ids
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- 输入 begin_snap 的值: 1
- Begin Snapshot Id specified: 1
-
- 输入 end_snap 的值: 2
- End Snapshot Id specified: 2
-
-
-
- Specify the Report Name
- ~~~~~~~~~~~~~~~~~~~~~~~
- The default report file name is sp_1_2. To use this name,
- press <return> to continue, otherwise enter an alternative.
-
- 输入 report_name 的值: d:\myreport.txt
perfstat@AAA>@D:\oracle\product\10.2.0\db_1\RDBMS\ADMIN\spreport.sql
Current Instance
~~~~~~~~~~~~~~~~
DB Id DB Name Inst Num Instance
----------- ------------ -------- ------------
1858440386 AAA 1 aaa
Instances in this Statspack schema
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
DB Id Inst Num DB Name Instance Host
----------- -------- ------------ ------------ ------------
1858440386 1 AAA aaa 6979580041BD
490
Using 1858440386 for database Id
Using 1 for instance number
Specify the number of days of snapshots to choose from
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Entering the number of days (n) will result in the most recent
(n) days of snapshots being listed. Pressing <return> without
specifying a number lists all completed snapshots.
Listing all Completed Snapshots
Snap
Instance DB Name Snap Id Snap Started Level Comment
------------ ------------ --------- ----------------- ----- -------------
aaa AAA 1 14 4月 2010 09:5 5
2
2 14 4月 2010 09:5 5
3
3 14 4月 2010 11:0 5
0
Specify the Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
输入 begin_snap 的值: 1
Begin Snapshot Id specified: 1
输入 end_snap 的值: 2
End Snapshot Id specified: 2
Specify the Report Name
~~~~~~~~~~~~~~~~~~~~~~~
The default report file name is sp_1_2. To use this name,
press <return> to continue, otherwise enter an alternative.
输入 report_name 的值: d:\myreport.txt
...回车
8.完成后,会产生一个分析报告(d:\myreport.txt)。
附件:报告的截取片段:
- STATSPACK report for
-
- Database DB Id Instance Inst Num Startup Time Release RAC
- ~~~~~~~~
- 1858440386 aaa 1 14-4月 -10 09:2 10.2.0.1.0 NO
- 2
-
- Host Name: 6979580041BD490 Num CPUs: 2 Phys Memory (MB): 3,326
- ~~~~
-
- Snapshot Snap Id Snap Time Sessions Curs/Sess Comment
- ~~~~~~~~
- Begin Snap: 1 14-4月 -10 09:52:22 15 4.3
- End Snap: 2 14-4月 -10 09:53:20 15 5.8
- Elapsed: 0.97 (mins)
-
- Cache Sizes Begin End
- ~~~~~~~~~~~
- Buffer Cache: 184M Std Block Size: 8K
- Shared Pool Size: 380M Log Buffer: 6,860K
-
- Load Profile Per Second Per Transaction
- ~~~~~~~~~~~~
- Redo size: 10,075.66 584,388.00
- Logical reads: 58.41 3,388.00
- Block changes: 18.81 1,091.00
- Physical reads: 0.22 13.00
- Physical writes: 0.00 0.00
- User calls: 0.52 30.00
- Parses: 2.83 164.00
- Hard parses: 0.72 42.00
- Sorts: 1.76 102.00
- Logons: 0.02 1.00
- Executes: 10.88 631.00
- Transactions: 0.02
-
- % Blocks changed per Read: 32.20 Recursive Call %: 99.69
- Rollback per transaction %: 0.00 Rows per Sort: 70.69
-
- Instance Efficiency Percentages
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Buffer Nowait %: 100.00 Redo NoWait %: 100.00
- Buffer Hit %: 99.62 In-memory Sort %: 100.00
- Library Hit %: 90.06 Soft Parse %: 74.39
- Execute to Parse %: 74.01 Latch Hit %: 100.00
- Parse CPU to Parse Elapsd %: 14.29 % Non-Parse CPU: 98.41
-
- Shared Pool Statistics Begin End
-
- Memory Usage %: 21.05 20.98
- % SQL with executions>1: 54.05 60.06
- % Memory for SQL w/exec>1: 80.51 83.00
-
- Top 5 Timed Events Avg %Total
- ~~~~~~~~~~~~~~~~~~ wait Call
- Event Waits Time (s) (ms) Time
-
- CPU time 1 70.7
- control file sequential read 189 0 1 23.6
- db file sequential read 8 0 3 2.5
- control file parallel write 27 0 1 1.9
- log file sync 1 0 5 .6
-
- .....................
- .........................
- ...........................
STATSPACK report for
Database DB Id Instance Inst Num Startup Time Release RAC
~~~~~~~~ ----------- ------------ -------- --------------- ----------- ---
1858440386 aaa 1 14-4月 -10 09:2 10.2.0.1.0 NO
2
Host Name: 6979580041BD490 Num CPUs: 2 Phys Memory (MB): 3,326
~~~~
Snapshot Snap Id Snap Time Sessions Curs/Sess Comment
~~~~~~~~ ---------- ------------------ -------- --------- -------------------
Begin Snap: 1 14-4月 -10 09:52:22 15 4.3
End Snap: 2 14-4月 -10 09:53:20 15 5.8
Elapsed: 0.97 (mins)
Cache Sizes Begin End
~~~~~~~~~~~ ---------- ----------
Buffer Cache: 184M Std Block Size: 8K
Shared Pool Size: 380M Log Buffer: 6,860K
Load Profile Per Second Per Transaction
~~~~~~~~~~~~ --------------- ---------------
Redo size: 10,075.66 584,388.00
Logical reads: 58.41 3,388.00
Block changes: 18.81 1,091.00
Physical reads: 0.22 13.00
Physical writes: 0.00 0.00
User calls: 0.52 30.00
Parses: 2.83 164.00
Hard parses: 0.72 42.00
Sorts: 1.76 102.00
Logons: 0.02 1.00
Executes: 10.88 631.00
Transactions: 0.02
% Blocks changed per Read: 32.20 Recursive Call %: 99.69
Rollback per transaction %: 0.00 Rows per Sort: 70.69
Instance Efficiency Percentages
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Buffer Nowait %: 100.00 Redo NoWait %: 100.00
Buffer Hit %: 99.62 In-memory Sort %: 100.00
Library Hit %: 90.06 Soft Parse %: 74.39
Execute to Parse %: 74.01 Latch Hit %: 100.00
Parse CPU to Parse Elapsd %: 14.29 % Non-Parse CPU: 98.41
Shared Pool Statistics Begin End
------ ------
Memory Usage %: 21.05 20.98
% SQL with executions>1: 54.05 60.06
% Memory for SQL w/exec>1: 80.51 83.00
Top 5 Timed Events Avg %Total
~~~~~~~~~~~~~~~~~~ wait Call
Event Waits Time (s) (ms) Time
----------------------------------------- ------------ ----------- ------ ------
CPU time 1 70.7
control file sequential read 189 0 1 23.6
db file sequential read 8 0 3 2.5
control file parallel write 27 0 1 1.9
log file sync 1 0 5 .6
.....................
.........................
...........................
9.若想删除某个快照,制定snapid直接delete
- delete stats$snapshot where snap_id=1;
delete stats$snapshot where snap_id=1;
若想删除所有快照 ,只保留statspack结构,执行@sptrunc。脚本路径也在rdbms/admin下。若想连statspack一起干掉,也可以,请执行下面的脚本:@spdrop
从此你也可以利用statspack来了解当前数据库的运行状况了。
posted @
2010-08-07 11:18 xzc 阅读(1347) |
评论 (0) |
编辑 收藏偶然间发现,几年前,冯老师关于statspack的一篇文章,写的不错,收下了先。
http://www.dbanotes.net/Oracle/AboutStatspack.htm
Statspack 是 Oracle 提供的一个实例级的Tuning工具。很多DBA都喜欢用这个工具来进行数据库的优化调整。不过在交流中发现很多朋友对这个工具的的运用还有一些 问题。下面就其中比较容易出问题的几个方面进行一下简单的分析。
快照的采样时间间隔问题
我们知道,Statspack的report实际上也就是对比两个快照 (Snapshot,也就是数据库当前状态 ) 得出的结果。
一般情况下,专家建议生成Statspack报告的快照时间间隔为15-30分钟。
试想,一个人去医院看病,医生对其测量体温,一般也就是5-10分钟左右就可以了, 为什么是这麽长的时间?因为5-10分钟这段时间基本可以近似的得到你的体温。如果时间过短,可能达不到既定的目的,测到的体温会偏低,时间过长,甚至长达几 个小时的话(假设有这种情况),病人可能都昏迷几次了 ;) 。
对生成Statspack报告的快照时间间隔也是这样,如果两个Snap Time时间过短,数据 库的一些主要周期性事务可能还没有运行,信息收集不完全。如果间隔过长,数据一样会有偏差。
假设如下的情况:系统一直正常,但是最近几天有用户反映,在A时间段应用程序执行 很慢。B时间段正常,而 A时间段有一个主要的事务X运行(也是用户使用到的事务)。 B时间段有另外一个比较消耗资源的事务Y在运行。A和B时间段的跨度比较大。本来你的 快照如果覆盖A时间段内就已经能够的收集到比较准确的数据了,但不巧的是,你的Report 所用的两个Snap ID的时间跨度太长,从而把B时间段内的统计数据也收集了进来。 Statspack 经过比较,“认为”事务Y是对系统有主要影响(这也会在Report上体现出来),而你,经过分析,认为Y才是罪魁祸首,接下来,你不遗余力的对Y进行了tuning......
问题出现了!调整了B之后,用户继续报告,A时间段内系统不但没有变快,反而变得更慢,甚至不可忍受。这种情况是很危险 的,可能会对系统造成不同程序的损害。在比较严格的环境中,这已经构成了一次比较严重的事故。
或许你也要承认,Statspack的快照的采样时间间隔还真需要重视呢......
这是一个Oracle 8.1.7.0.1 版本下的Statspack报告:
Snap Id Snap Time Sessions
------- ------------------ --------
Begin Snap: 637 04-Aug-03 11:59:33 25
End Snap: 646 04-Aug-03 16:29:06 25
Elapsed: 269.55 (mins)
从中可以看到快照637和快照646之间为269.55 (mins)。这么长的时间跨度,即使数据库在一定时间间隔内有问题,在这里的体现也会有偏差。
下面的这个Statspack 报告的时间有点不靠谱了:
Snap Length
Start Id End Id Start Time End Time (Minutes)
-------- -------- -------------------- -------------------- -----------
314 1053 11-Dec-03 18:07:13 19-Dec-03 10:53:02 11,085.82
11,085.82分钟? 这么长时间内的数据采集分析,怕是绝大部分内容都是不能相信的了。
还要注意的是,我们说的时间间隔,是Begin Snap和End Snap之间的间隔,而不是相邻两个Snap 之间的间隔。对于Snap收集的间隔,建议以不要影响性能为准,收集的太过于频繁,会对性能和 存储都造成压力。对于所谓的15-30分钟,不能墨守成规。具体的环境下应该加以调整。
以偏概全
Statspack从本质上说,是对系统的性能统计数据进行采样,然后进行分析,采样,就会有偏差。如何消除偏差?统计学指出差值随样品个数的增加而降低。所以,只凭借一个Report文档就断定数据库的性能问题出在某处,是比较武断的做法(个别情况除外)。需要DBA创建多个Report,包括不同时间段,对比进行分析,这样才会起到很好的效果。在寻求技术支持的时候也最好能够多提交几份Report,便于支持人员迅速帮助解决问题。
有关Timed_statistics参数
虽然这算是一个低级的错误,还是很遗憾,常常看到一些朋友对这个参数的忽略.如果在 Timed_statistics的值设置为False的时候进行收集,可以说,收集到的东西用处不是很大 (我想你不会只想看一些实例名字、初始化参数之类的信息吧)。甚至可以说,如果该参数不设置为True,性能分析无从说起。
你成了泄密者?
Statspack 报告会汇集到你的数据库系统比较全面的信息,如果不对报告加以"伪装"就随意发布到一些技术论坛上寻求支持,无疑给一些黑客以可乘之机。你的数据库名字、实例名字、主机名、数据库版本号、兼容参数、关键的表名字、文件路径等等,尤其是关键的SQL都是黑客们或是恶意入侵者的最好的参考信息。
商业竞争对手也可能正在对你的数据库虎视眈眈。
如果你有意积极配合这些恶意窥探者,那么就把你的Statspack公之于众吧 :-)
posted @
2010-08-07 11:18 xzc 阅读(121) |
评论 (0) |
编辑 收藏大家在平时开发中,有时意外的删除过表,可能就是直接重新创建该表。在oracle10g中,可以用Flashback drop恢复用一个被删除(drop)了的对象,oracle自动将该对象放入回收站。Flashback drop恢复的原理也是利用oracle的回收站来恢复被删除(drop)的对象。
回收站,是一个虚拟的容器,用于存放所有被删除的对象。其实,对于一个对象的删除,数据库仅仅是简单的重命名操作。
数据库参数recyclebin设置为on.(即默认设置)。参数recyclebin为on,则表示把Drop的对象放入回收站。为off,则表示直接删除对象而不放入回收站。
查看recyclebin值命令如:
SQL> show parameter bin;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
recyclebin string on
在系统或会话级别中修改参数recyclebin值的命令为:
SQL>alter system set recyclebin = on|off;
SQL>alter session set recyclebin = on|off;
查看回收站的相关信息视图有:recyclebin/user_recyclebin/dba_recyclebin.
手动清除回收站的信息为:purge recyclebin(或purge table original_name);
删除一张表而不想放入回收站的命令为:drop table table_name purge;
示例1:
1.查看用户下回收站的信息,此时回收站为空
SQL>selectOBJECT_NAME,ORIGINAL_NAME,TYPEfromuser_recyclebin;
OBJECT_NAME ORIGINAL_NAME TYPE
------------------------------ ------------- ------
2.创建测试表tab_test,并为该表增加ind_test索引
SQL>createtabletab_testasselect*fromall_objects;
Tablecreated
SQL>createindexind_testontab_test(object_id);
Indexcreated
SQL> select count(*) from tab_test;
COUNT(*)
----------
40699
3。用drop命令删除tab_test表
SQL>droptabletab_test;
Tabledropped
4。查看用户回收站信息,此时会记录删除后的对象在回收站中的相关信息,此时还能正常操作回收站中的对象,但不能操作DDL/DML语句
SQL>selectOBJECT_NAME,ORIGINAL_NAME,TYPEfromuser_recyclebin;
OBJECT_NAME ORIGINAL_NAME TYPE
------------------------------ ------------- ------
BIN$a+iPOcq+QXiwUT8B3c3QoA==$0 IND_TEST INDEX
BIN$zFJjV8zFSlqbLecXbDeANQ==$0 TAB_TEST TABLE
SQL>selectcount(*)from"BIN$zFJjV8zFSlqbLecXbDeANQ==$0";
COUNT(*)
----------
40699
SQL>deletefrom"BIN$zFJjV8zFSlqbLecXbDeANQ==$0";
deletefrom"BIN$zFJjV8zFSlqbLecXbDeANQ==$0"
ORA-38301:无法对回收站中的对象执行DDL/DML
5.用flashback恢复表到删除之前的状态
SQL>flashbacktabletab_testtobeforedrop;
Done
SQL> select count(*) from tab_test;
COUNT(*)
----------
40699
6.恢复表的索引(此时表中的索引同时也被恢复了,只不过该索引还是保留回收站中的索引名称)
SQL> select index_name from user_indexes where table_name = 'TAB_TEST';
INDEX_NAME
------------------------------
BIN$a+iPOcq+QXiwUT8B3c3QoA==$0
SQL> alter index "BIN$a+iPOcq+QXiwUT8B3c3QoA==$0" rename to ind_test;
Index altered
SQL> select index_name from user_indexes where table_name = 'TAB_TEST';
INDEX_NAME
------------------------------
IND_TEST
示例2:
1.查看用户下回收站的信息,此时回收站为空
SQL>selectOBJECT_NAME,ORIGINAL_NAME,TYPEfromuser_recyclebin;
OBJECT_NAME ORIGINAL_NAME TYPE
------------------------------ ------------- ------
2.创建测试表test1,并输入数据
SQL> create table test1(id number);
Table created
SQL> insert into test1 values(1);
1 row inserted
SQL> insert into test1 values(2);
1 row inserted
SQL> insert into test1 values(3);
1 row inserted
SQL> insert into test1 values(4);
1 row inserted
SQL> commit;
Commit complete
SQL> select count(*) from test1;
COUNT(*)
----------
4
3.删除test1表,然后在重新创建test1表
SQL> drop table test1;
Table dropped
SQL> create table test1(id number);
Table created
SQL> insert into test1 values(1);
1 row inserted
SQL> commit;
Commit complete
SQL> select count(*) from test1;
COUNT(*)
----------
1
4.再次删除test1表
SQL> drop table test1;
Table dropped
5.查询回收站信息(此时回收站中有两条test1表的数据)
SQL>select*fromuser_recyclebin;
OBJECT_NAME ORIGINAL_NAME TYPE
------------------------------ --------------------
BIN$Uk69X077TQWqQ0OQ3u1FdQ==$0 TEST1 TABLE
BIN$kpG5ZWdlRUi/jO6X0EYP+A==$0 TEST1 TABLE
5.用flashback恢复表到删除之前的状态
SQL> flashback table test1 to before drop;
Done
SQL> select count(*) from test1;
COUNT(*)
----------
1
此时查看恢复后的test1,发现恢复到最近一次的信息,因此可说明多次删除后,在回收站中会存在多条与test1有关的数据,而用flashback table test1 to before drop命令恢复到的是test1表中最近一次删除的信息
posted @
2010-08-04 20:40 xzc 阅读(764) |
评论 (0) |
编辑 收藏Flashback query(闪回查询)原理
Oracle根据undo信息,利用undo数据,类似一致性读取方法,可以把表置于一个删除前的时间点(或SCN),从而将数据找回。
Flashback query(闪回查询)前提:
SQL> show parameter undo;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS1
其中undo_management = auto,设置自动undo管理(AUM),该参数默认设置为:auto;
Undo_retention = n(秒),设置决定undo最多的保存时间,其值越大,就需要越多的undo表空间的支持。修改undo_retention的命令如下:
SQL> alter system set undo_retention = 3600;
System altered
闪回实现方式
1. 获取数据删除前的一个时间点或scn,如下:
SQL>select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') time, to_char(dbms_flashback.get_system_change_number) scn from dual;
TIME SCN
------------------- ----------------------------------------
2010-06-29 23:03:14 1060499
2. 查询该时间点(或scn)的数据,如下:
SQL> select * from t as of timestamp to_timestamp('2010-06-29 22:57:47', 'yyyy-mm-dd hh24:mi:ss');
SQL> select * from t as of scn 1060174;
3. 将查询到的数据,新增到表中。也可用更直接的方法,如:
SQL>create table tab_test as select * from t of timestamp to_timestamp('2010-06-29 22:57:47', 'yyyy-mm-dd hh24:mi:ss');
SQL>insert into tab_test select * from1060174;
示例:
Create table t(id number);
insertinto t values(1);
insert into t values(2);
insert into t values(3);
insert into t values(4);
insert into t values(5);
1.查看t表中的原始数据
SQL> select * from t;
ID
---------
1
2
3
4
5
2.获取数据删除前的一个时间点或scn
SQL> select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') time, to_char(dbms_flashback.get_system_change_number) scn from dual;
TIME SCN
------------------- ----------------------------------------
2010-06-29 23:23:33 1061279
3.删除t表中的数据,并提交事物
SQL> delete from t;
5 rows deleted
SQL> commit;
Commit complete
4.在查看t表,此时t表中数据以删除
SQL> select * from t;
ID
----------
5.查看t表中scn为1061279(或时间点为2010-06-29 23:23:33)时的数据
SQL> select * from t as of scn 1061279;
ID
----------
1
2
3
4
5
6.确认要恢复后,将t表中的数据还原到scn为1061279(或时间点为2010-06-29 23:23:33)时的数据,并提交事物
SQL> insert into t select * from t as of scn 1061279;
5 rows inserted
SQL> commit;
Commit complete
7.确认t表数据的还原情况
SQL> select * from t;
ID
----------
1
2
3
4
5
注:推荐使用scn,由于oracle9i中,因为scn与时间点的同步需要5分钟,如果最近5分钟之内的数据需要Falshback query查询,可能会查询丢失,而scn则不存在这个问题。Oracle10g中这个问题已修正(scn与时间点的大致关系,可以通过logmnr分析归档日志获得)。
Falshback query查询的局限:
1. 不能Falshback到5天以前的数据。
2. 闪回查询无法恢复到表结构改变之前,因为闪回查询使用的是当前的数据字典。
3. 受到undo_retention参数的影响,对于undo_retention之前的数据,Flashback不保证能Flashback成功。
4. 对drop,truncate等不记录回滚的操作,不能恢复。
5. 普通用户使用dbms_flashback包,必须通过管理员授权。命令如下:
SQL>grant execute on dbms_flashback to scott;
posted @
2010-08-04 20:39 xzc 阅读(27783) |
评论 (0) |
编辑 收藏上一回演示了运用闪回表查询恢复delete删除的数据以及其原理,今天了解下闪回表。
原理:
闪回表(Flashback table)与闪回查询(Flashback query)的原理大致相同,也是利用undo信息来恢复表对象到以前的某一个时间点(一个快照),因此也要确保AUM有足够的Retention值。但闪回表不等于闪回查询,其区别如下:
闪回查询只是查询以前的一个快照而已,并不改变当前表的状态。
闪回表则是将恢复当前表及附属对象一起回到以前的时间点。
特性:
1. 在线操作
2. 恢复到指定的时间点(或者SCN)的任何数据
3. 自动恢复相关属性
4. 满足分布式的一致性
5. 数据的一致性,所有相关对象将自动一致。
语法:
SQL> flashback table tab_test to timestamp to_timestamp('2010-06-30 22:43:07', 'yyyy-mm-dd hh24:mi:ss');
SQL> flashback table tab_test to scn 1154953;
SQL> flashback table tab_test to timestamp to_timestamp('2010-06-30 22:43:07', 'yyyy-mm-dd hh24:mi:ss') enable triggers;
运用闪回表前提
1.普通用户中需要有Flashback any table的系统权限。命令如:
SQL>grant flashback any table to scott;
2.有该表的select、insert、delete、alter权限。
3.必须保证该表有row movement(行移动)。
示例:
1.创建tab_test表
SQL> create table tab_test as select * from all_objects;
Table created
2.查询tab_test表中数据量
SQL> select count(*) from tab_test;
COUNT(*)
----------
40699
3.为tab_test表创建索引和触发器(触发器为null,不做任何操作)
SQL> create index ind_test on tab_test(object_name);
Index created
SQL> create or replace trigger tr_test
2 after update on tab_test
3 for each row
4 begin
5 null;
6
7 end tr_test;
8 /
Trigger created
4.记录当时的时间点,试图恢复到该时间点
SQL> select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') time, to_char(dbms_flashback.get_system_change_number) scn from dual;
TIME SCN
------------------- ----------------------------------------
2010-06-30 23:02:37 1160764
5.删除tab_test表中数据
SQL> delete from tab_test;
40699 rows deleted
SQL> commit;
Commit complete
6.查询删除数据后的tab_test,确定其表中已没有数据
SQL> select count(*) from tab_test;
COUNT(*)
----------
7.删除tab_test表中索引ind_test
SQL> drop index ind_test;
Index dropped
8.更改tr_test触发器
SQL> create or replace trigger tr_test
2 after insert on tab_test
3 for each row
4 begin
5 null;
6
7 end tr_test;
8 /
Trigger created
9.确保该表中的行迁移(row movement)功能
SQL> alter table tab_test enable row movement;
Table altered
10.恢复tab_test表到刚记录的时间点(或scn),由于表中存在触发器,因此使用了关键字enable triggers;
SQL> flashback table tab_test to timestamp to_timestamp('2010-06-30 23:02:37', 'yyyy-mm-dd hh24:mi:ss') enable triggers;
Done
11.查看恢复结果如下:
SQL> select count(*) from tab_test;
COUNT(*)
----------
40699
SQL> select index_name from user_indexes where table_name = 'TAB_TEST';
INDEX_NAME
------------------------------
SQL> select object_name, status from user_objects where object_name in('TR_TEST', 'IND_TEST');
OBJECT_NAME STATUS
------------------ -------
TR_TEST VALID
SQL> set pages 0
SQL> set lines 1000
Cannot SET LINES
SQL> set long 2000
SQL> select text from user_source t where t.name = 'TR_TEST' order by line;
trigger tr_test
after insert on tab_test
for each row
begin
null;
end tr_test;
总结:
1. Flashback table在真正的高可用环境中,使用意义不大,受限比较多,要必须确保行迁移功能
2. Flashback table过程中,阻止写操作
3. 表中数据能恢复,而表中索引确不能正常恢复
4. 恢复的触发器本身还是修改后的,并不随表flashback到修改以前的时间点。说明关键字enable triggers只能保证触发器的状态正常,而不是内容回滚.
5. 由于原理利用其undo信息,来恢复其对象,因此也是不能恢复truncate数据
6. 恢复数据用flashback query实现比较好
posted @
2010-08-04 20:39 xzc 阅读(3080) |
评论 (0) |
编辑 收藏在数据库的日常学习中,发现公司生产数据库的默认临时表空间temp使用情况达到了30G,使用率达到了100%;待调整为32G后,使用率还是为100%,导致磁盘空间使用紧张。根据临时表空间的主要是对临时数据进行排序和缓存临时数据等特性,待重启数据库后,temp会自动释放。于是想通过重启数据库的方式来缓解这种情况,但是重启数据库之后,发现临时表空间temp的使用率还是100%,一点没变。虽然运行中应用暂时没有报什么错误,但是这在一定程度上存在一定的隐患,有待解决该问题。由于临时表空间主要使用在以下几种情况:
1、order by or group by (disc sort占主要部分);
2、索引的创建和重创建;
3、distinct操作;
4、union & intersect & minus sort-merge joins;
5、Analyze 操作;
6、有些异常也会引起TEMP的暴涨。
Oracle临时表空间暴涨的现象经过分析可能是以下几个方面的原因造成的:
1. 没有为临时表空间设置上限,而是允许无限增长。但是如果设置了一个上限,最后可能还是会面临因为空间不够而出错的问题,临时表空间设置太小会影响性能,临时表空间过大同样会影响性能,至于需要设置为多大需要仔细的测试。
2.查询的时候连表查询中使用的表过多造成的。我们知道在连表查询的时候,根据查询的字段和表的个数会生成一个迪斯卡尔积,这个迪斯卡尔积的大小就是一次查询需要的临时空间的大小,如果查询的字段过多和数据过大,那么就会消耗非常大的临时表空间。
3.对查询的某些字段没有建立索引。Oracle中,如果表没有索引,那么会将所有的数据都复制到临时表空间,而如果有索引的话,一般只是将索引的数据复制到临时表空间中。
针对以上的分析,对查询的语句和索引进行了优化,情况得到缓解,但是需要进一步测试。
总结:
1.SQL语句是会影响到磁盘的消耗的,不当的语句会造成磁盘暴涨。
2.对查询语句需要仔细的规划,不要想当然的去定义一个查询语句,特别是在可以提供用户自定义查询的软件中。
3.仔细规划表索引。如果临时表空间是temporary的,空间不会释放,只是在sort结束后被标记为free的,如果是permanent的,由SMON负责在sort结束后释放,都不用去手工释放的。查看有哪些用户和SQL导致TEMP增长的两个重要视图:v$sort_usage和v$sort_segment。
通过查询相关的资料,发现解决方案有如下几种:
一、重建临时表空间temp
Temporary tablespace是不能直接drop默认的临时表空间的,不过我们可以通过以下方法达到。
查看目前的Temporary Tablespace
SQL> select name from v$tempfile;
NAME
———————————————————————
D:\ORACLE\ORADATA\ORCL\TEMP01.DBF
SQL> select username,temporary_tablespace from dba_users;
USERNAME TEMPORARY_TABLESPACE
------------------------------ ------------------------------
MGMT_VIEW TEMP
SYS TEMP
SYSTEM TEMP
DBSNMP TEMP
SYSMAN TEMP
1.创建中转临时表空间
create temporary tablespace TEMP1 TEMPFILE 'D:\ORACLE\ORADATA\ORCL\temp02.DBF' SIZE 512M REUSE AUTOEXTEND ON NEXT 1M
MAXSIZE UNLIMITED;
2.改变缺省临时表空间 为刚刚创建的新临时表空间temp1
alter database default temporary tablespace temp1;
3.删除原来临时表空间
drop tablespace temp including contents and datafiles;
4.重新创建临时表空间
create temporary tablespace TEMP TEMPFILE 'D:\ORACLE\ORADATA\ORCL\temp01.DBF' SIZE 512M REUSE AUTOEXTEND ON NEXT 1M MAXSIZE
UNLIMITED;
5.重置缺省临时表空间为新建的temp表空间
alter database default temporary tablespace temp;
6.删除中转用临时表空间
drop tablespace temp1 including contents and datafiles;
以上的方法只是暂时释放了临时表空间的磁盘占用空间,是治标但不是治本的方法,真正的治本的方法是找出数据库中消耗资源比较大的sql语句,然后对其进行优化处理。下面是查询在sort排序区使用的执行耗时的SQL:
Select se.username,se.sid,su.extents,su.blocks*to_number(rtrim(p.value))as Space,tablespace,segtype,sql_text
from v$sort_usage su,v$parameter p,v$session se,v$sql s
where p.name='db_block_size' and su.session_addr=se.saddr and s.hash_value=su.sqlhash and s.address=su.sqladdr order by se.username,se.sid;
或是:
Select su.username,su.Extents,tablespace,segtype,sql_text
From v$sort_usage su,v$sql s
Where su.SQL_ID = s.SQL_ID;
注:如果原临时表空间无用户使用(select tablespace_name,current_users,total_blocks,used_blocks,free_blocks,free_blocks/total_blocks from v$sort_segment;),如果是文件系统可以看看文件的时间戳。
我们可以删除该表空间:如果原临时表空间还有用户在使用,你是删除不了这个表空间的!在一次生产环境的临时表空间切换中,原临时表空间始终有用户在上面,即使我关闭了前台程序,也还是有用户,新的临时表空间已经没有用户在使用了。我估计用户进程已经死在原临时表空间了,后来只有重新启动数据库才能把原来旧的临时表空间给删除。
二、修改参数(这个方案紧适用于8i及8i以下的版本)
修改一下TEMP表空间的storage参数,让Smon进程观注一下临时段,从而达到清理和TEMP表空间的目的。
SQL>alter tablespace temp increase 1;
SQL>alter tablespace temp increase 0;
三、Kill session
1、 使用如下语句a查看一下认谁在用临时段
SELECT se.username, se.SID, se.serial#, se.sql_address, se.machine, se.program, su.TABLESPACE,su.segtype, su.CONTENTS FROM
v$session se, v$sort_usage su WHERE se.saddr = su.session_addr
2、kill正在使用临时段的进程
SQL>Alter system kill session 'sid,serial#';
3、把TEMP表空间回缩一下
SQL>Alter tablespace TEMP coalesce;
注:这处方法只能针对字典管理表空间(Dictionary Managed Tablespace)。于本地管理表空间(LMT:Local Managed Tablespace),不需要整理的。9i以后只能创建本地管理的表空间。
CREATE TABLESPACE TEST DATAFILE 'D:\TEST01.dbf' SIZE 5M EXTENT MANAGEMENT DICTIONARY
CREATE TABLESPACE TEST DATAFILE 'D:\TEST01.dbf' SIZE 5M EXTENT MANAGEMENT LOCAL;
四、使用诊断事件,也是相对有效的一种方法
1、查询事件代码
SQL>select ts#, name from sys.ts$ ;
TS# NAME
---------- ------------------------------
0 SYSTEM
1 UNDOTBS1
2 SYSAUX
3 TEMP
4 USERS
5 UNDOTBS2
2、 执行清理操作
SQL>alter session set events 'immediate trace name DROP_SEGMENTS level 4';
说明:temp表空间的TS# 为 3, So TS#+ 1= 4。
oracle临时表空间过大的原因
2009-05-12 11:22
Oracle临时表空间主要是用来做查询和存放一些缓存的数据的,磁盘消耗的一个主要原因是需要对查询的结果进行排序,如果没有猜错的话,在磁盘空间的(内存)的分配上,Oracle使用的是贪心算法,如果上次磁盘空间消耗达到1GB,那么临时表空间就是1GB,如果还有增长,那么依此类推,临时表空间始终保持在一个最大的上限。Oracle临时表空间暴涨的现象经过分析可能是以下几个方面的原因造成的。
1. 没有为临时表空间设置上限,而是允许无限增长。但是如果设置了一个上限,最后可能还是会面临因为空间不够而出错的问题,临时表空间设置太小会影响性能,临时表空间过大同样会影响性能,至于需要设置为多大需要仔细的测试。
2.查询的时候连表查询中使用的表过多造成的。我们知道在连表查询的时候,根据查询的字段和表的个数会生成一个迪斯卡尔积,这个迪斯卡尔积的大小就是一次查询需要的临时空间的大小,如果查询的字段过多和数据过大,那么就会消耗非常大的临时表空间。
3.对查询的某些字段没有建立索引。Oracle中,如果表没有索引,那么会将所有的数据都复制到临时表空间,而如果有索引的话,一般只是将索引的数据复制到临时表空间中。
针对以上的分析,对查询的语句和索引进行了优化,情况得到缓解,但是需要进一步测试。
总结:
1.SQL语句是会影响到磁盘的消耗的,不当的语句会造成磁盘暴涨。
2.对查询语句需要仔细的规划,不要想当然的去定义一个查询语句,特别是在可以提供用户自定义查询的软件中。
3.仔细规划表索引。
如果临时表空间是temporary的,空间不会释放,只是在sort结束后被标记为free的,如果是permanent的,由SMON负责在sort结束后释放,都不用去手工释放的。查看有哪些用户和SQL导致TEMP增长的两个重要视图:
v$sort_usage和v$sort_segment
对于非LMT管理方式的TEMP表空间,最简单的方法是Metalink给出的一个方法:
修改一下TEMP表空间的storage参数,让Smon进程观注一下临时段,从而达到清理和TEMP表空间的目的。
SQL>alter tablespace temp default storage(pctincrease 1);
SQL>alter tablespace temp default storage(pctincrease 0);
而对于LMT管理方式的TEMP表空间,需要重新建立一个新的临时表空间,将所有用户的默认临时表空间指定到新的表空间上,然后offline旧的临时表空间,并drop掉。具体步骤如下:
首先查询用户的缺省临时表空间:
[oracle@jumper oracle]$ sqlplus "/ as sysdba"
SQL*Plus: Release 9.2.0.4.0 - Production on Wed Apr 12 11:11:43 2006
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning option
JServer Release 9.2.0.4.0 - Production
SQL> select username,temporary_tablespace from dba_users;
USERNAME TEMPORARY_TABLESPACE
------------------------------ ------------------------------
SYS TEMP2
SYSTEM TEMP2
OUTLN TEMP2
EYGLE TEMP2
CSMIG TEMP2
TEST TEMP2
REPADMIN TEMP2
......
13 rows selected.
SQL> select name from v$tempfile;
NAME
---------------------------------------------------------------------
/opt/oracle/oradata/conner/temp02.dbf
/opt/oracle/oradata/conner/temp03.dbf
重建新的临时表空间并进行切换:
SQL> create temporary tablespace temp tempfile '/opt/oracle/oradata/conner/temp1.dbf' size 10M;
Tablespace created.
SQL> alter tablespace temp add tempfile '/opt/oracle/oradata/conner/temp2.dbf' size 20M;
Tablespace altered.
SQL> alter database default temporary tablespace temp;
Database altered.
SQL> select username,temporary_tablespace from dba_users;
USERNAME TEMPORARY_TABLESPACE
------------------------------ ------------------------------
SYS TEMP
SYSTEM TEMP
OUTLN TEMP
EYGLE TEMP
CSMIG TEMP
TEST TEMP
REPADMIN TEMP
.......
13 rows selected.
如果原临时表空间无用户使用(select tablespace_name,current_users,total_blocks,used_blocks,free_blocks,free_blocks/total_blocks from v$sort_segment;),如果是文件系统可以看看文件的时间戳。
我们可以删除该表空间:(如果原临时表空间还有用户在用,你是删除不了这个表空间的!在一次生产环境的临时表空间切换中,原临时表空间始终有用户在上面,即使我关闭了前台程序,也还是有用户,新的临时表空间已经没有用户在使用了。我估计用户进程已经死在原临时表空间了。后来只有重新启动数据库才能把原来旧的临时表空间给删除。)
SQL> drop tablespace temp2;
Tablespace dropped.
SQL>
SQL> select name from v$tempfile;
NAME
---------------------------------------------------------------
/opt/oracle/oradata/conner/temp1.dbf
/opt/oracle/oradata/conner/temp2.dbf
SQL> select file_name,tablespace_name,bytes/1024/1024 MB,autoextensible
2 from dba_temp_files
3 /
FILE_NAME TABLESPACE_NAME MB AUTOEXTENSIBLE
-------------------------------------- -------------------- ---------- --------------
/opt/oracle/oradata/conner/temp2.dbf TEMP 20 NO
/opt/oracle/oradata/conner/temp1.dbf TEMP 10 NO
drop tablespace temp including contents and datafiles; --将表空间的内容和数据文件一起删除。
下面是查询在sort排序区使用的执行耗时的SQL:
Select se.username,se.sid,su.extents,su.blocks*to_number(rtrim(p.value))as Space,tablespace,segtype,sql_text
from v$sort_usage su,v$parameter p,v$session se,v$sql s
where p.name='db_block_size' and su.session_addr=se.saddr and s.hash_value=su.sqlhash and s.address=su.sqladdr
order by se.username,se.sid
或是:
Select su.username,su.Extents,tablespace,segtype,sql_text
From v$sort_usage su,v$sql s
Where su.SQL_ID = s.SQL_ID
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/xiaozhang0731/archive/2010/05/05/5557856.aspx
posted @
2010-08-04 17:13 xzc 阅读(2887) |
评论 (2) |
编辑 收藏此文从以下几个方面来整理关于分区表的概念及操作:
1.表空间及分区表的概念
2.表分区的具体作用
3.表分区的优缺点
4.表分区的几种类型及操作方法
5.对表分区的维护性操作.
(1.) 表空间及分区表的概念
表空间:
是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表, 所以称作表空间。
分区表:
当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
( 2).表分区的具体作用
Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。
分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。
什么时候使用分区表:
1、表的大小超过2GB。
2、表中包含历史数据,新的数据被增加都新的分区中。
(3).表分区的优缺点
表分区有以下优点:
1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能。
(4).表分区的几种类型及操作方法
一.范围分区:
范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期。举个例子:你可能会将销售数据按照月份进行分区。
当使用范围分区时,请考虑以下几个规则:
1、每一个分区都必须有一个VALUES LESS THEN子句,它指定了一个不包括在该分区中的上限值。分区键的任何值等于或者大于这个上限值的记录都会被加入到下一个高一些的分区中。
2、所有分区,除了第一个,都会有一个隐式的下限值,这个值就是此分区的前一个分区的上限值。
3、在最高的分区中,MAXVALUE被定义。MAXVALUE代表了一个不确定的值。这个值高于其它分区中的任何分区键的值,也可以理解为高于任何分区中指定的VALUE LESS THEN的值,同时包括空值。
例一:
假设有一个CUSTOMER表,表中有数据200000行,我们将此表通过CUSTOMER_ID进行分区,每个分区存储100000行,我们将每个分区保存到单独的表空间中,这样数据文件就可以跨越多个物理磁盘。下面是创建表和分区的代码,如下:
CREATE TABLE CUSTOMER
(
CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,
FIRST_NAME VARCHAR2(30) NOT NULL,
LAST_NAME VARCHAR2(30) NOT NULL,
PHONE VARCHAR2(15) NOT NULL,
EMAIL VARCHAR2(80),
STATUS CHAR(1)
)
PARTITION BY RANGE (CUSTOMER_ID)
(
PARTITION CUS_PART1 VALUES LESS THAN (100000) TABLESPACE CUS_TS01,
PARTITION CUS_PART2 VALUES LESS THAN (200000) TABLESPACE CUS_TS02
)
例二:按时间划分
CREATE TABLE ORDER_ACTIVITIES
(
ORDER_ID NUMBER(7) NOT NULL,
ORDER_DATE DATE,
TOTAL_AMOUNT NUMBER,
CUSTOTMER_ID NUMBER(7),
PAID CHAR(1)
)
PARTITION BY RANGE (ORDER_DATE)
(
PARTITION ORD_ACT_PART01 VALUES LESS THAN (TO_DATE('01- MAY -2003','DD-MON-YYYY')) TABLESPACEORD_TS01,
PARTITION ORD_ACT_PART02 VALUES LESS THAN (TO_DATE('01-JUN-2003','DD-MON-YYYY')) TABLESPACE ORD_TS02,
PARTITION ORD_ACT_PART02 VALUES LESS THAN (TO_DATE('01-JUL-2003','DD-MON-YYYY')) TABLESPACE ORD_TS03
)
例三:MAXVALUE
CREATE TABLE RangeTable
(
idd INT PRIMARY KEY ,
iNAME VARCHAR(10),
grade INT
)
PARTITION BY RANGE (grade)
(
PARTITION part1 VALUES LESS THEN (1000) TABLESPACE Part1_tb,
PARTITION part2 VALUES LESS THEN (MAXVALUE) TABLESPACE Part2_tb
);
二.列表分区:
该分区的特点是某列的值只有几个,基于这样的特点我们可以采用列表分区。
例一
CREATE TABLE PROBLEM_TICKETS
(
PROBLEM_ID NUMBER(7) NOT NULL PRIMARY KEY,
DESCRIPTION VARCHAR2(2000),
CUSTOMER_ID NUMBER(7) NOT NULL,
DATE_ENTERED DATE NOT NULL,
STATUS VARCHAR2(20)
)
PARTITION BY LIST (STATUS)
(
PARTITION PROB_ACTIVE VALUES ('ACTIVE') TABLESPACE PROB_TS01,
PARTITION PROB_INACTIVE VALUES ('INACTIVE') TABLESPACE PROB_TS02
例二
CREATE TABLE ListTable
(
id INT PRIMARY KEY ,
name VARCHAR (20),
area VARCHAR (10)
)
PARTITION BY LIST (area)
(
PARTITION part1 VALUES ('guangdong','beijing') TABLESPACE Part1_tb,
PARTITION part2 VALUES ('shanghai','nanjing') TABLESPACE Part2_tb
);
)
三.散列分区:
这类分区是在列值上使用散列算法,以确定将行放入哪个分区中。当列的值没有合适的条件时,建议使用散列分区。
散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,使得这些分区大小一致。
例一:
CREATE TABLE HASH_TABLE
(
COL NUMBER(8),
INF VARCHAR2(100)
)
PARTITION BY HASH (COL)
(
PARTITION PART01 TABLESPACE HASH_TS01,
PARTITION PART02 TABLESPACE HASH_TS02,
PARTITION PART03 TABLESPACE HASH_TS03
)
简写:
CREATE TABLE emp
(
empno NUMBER (4),
ename VARCHAR2 (30),
sal NUMBER
)
PARTITION BY HASH (empno) PARTITIONS 8
STORE IN (emp1,emp2,emp3,emp4,emp5,emp6,emp7,emp8);
hash分区最主要的机制是根据hash算法来计算具体某条纪录应该插入到哪个分区中,hash算法中最重要的是hash函数,Oracle中如果你要使用hash分区,只需指定分区的数量即可。建议分区的数量采用2的n次方,这样可以使得各个分区间数据分布更加均匀。
四.组合范围散列分区
这种分区是基于范围分区和列表分区,表首先按某列进行范围分区,然后再按某列进行列表分区,分区之中的分区被称为子分区。
CREATE TABLE SALES
(
PRODUCT_ID VARCHAR2(5),
SALES_DATE DATE,
SALES_COST NUMBER(10),
STATUS VARCHAR2(20)
)
PARTITION BY RANGE(SALES_DATE) SUBPARTITION BY LIST (STATUS)
(
PARTITION P1 VALUES LESS THAN(TO_DATE('2003-01-01','YYYY-MM-DD'))TABLESPACE rptfact2009
(
SUBPARTITION P1SUB1 VALUES ('ACTIVE') TABLESPACE rptfact2009,
SUBPARTITION P1SUB2 VALUES ('INACTIVE') TABLESPACE rptfact2009
),
PARTITION P2 VALUES LESS THAN (TO_DATE('2003-03-01','YYYY-MM-DD')) TABLESPACE rptfact2009
(
SUBPARTITION P2SUB1 VALUES ('ACTIVE') TABLESPACE rptfact2009,
SUBPARTITION P2SUB2 VALUES ('INACTIVE') TABLESPACE rptfact2009
)
)
五.复合范围散列分区:
这种分区是基于范围分区和散列分区,表首先按某列进行范围分区,然后再按某列进行散列分区。
create table dinya_test
(
transaction_id number primary key,
item_id number(8) not null,
item_description varchar2(300),
transaction_date date
)
partition by range(transaction_date)subpartition by hash(transaction_id) subpartitions 3 store in (dinya_space01,dinya_space02,dinya_space03)
(
partition part_01 values less than(to_date(‘2006-01-01’,’yyyy-mm-dd’)),
partition part_02 values less than(to_date(‘2010-01-01’,’yyyy-mm-dd’)),
partition part_03 values less than(maxvalue)
);
(5).有关表分区的一些维护性操作:
一、添加分区
以下代码给SALES表添加了一个P3分区
ALTER TABLE SALES ADD PARTITION P3 VALUES LESS THAN(TO_DATE('2003-06-01','YYYY-MM-DD'));
注意:以上添加的分区界限应该高于最后一个分区界限。
以下代码给SALES表的P3分区添加了一个P3SUB1子分区
ALTER TABLE SALES MODIFY PARTITION P3 ADD SUBPARTITION P3SUB1 VALUES('COMPLETE');
二、删除分区
以下代码删除了P3表分区:
ALTER TABLE SALES DROP PARTITION P3;
在以下代码删除了P4SUB1子分区:
ALTER TABLE SALES DROP SUBPARTITION P4SUB1;
注意:如果删除的分区是表中唯一的分区,那么此分区将不能被删除,要想删除此分区,必须删除表。
三、截断分区
截断某个分区是指删除某个分区中的数据,并不会删除分区,也不会删除其它分区中的数据。当表中即使只有一个分区时,也可以截断该分区。通过以下代码截断分区:
ALTER TABLE SALES TRUNCATE PARTITION P2;
通过以下代码截断子分区:
ALTER TABLE SALES TRUNCATE SUBPARTITION P2SUB2;
四、合并分区
合并分区是将相邻的分区合并成一个分区,结果分区将采用较高分区的界限,值得注意的是,不能将分区合并到界限较低的分区。以下代码实现了P1 P2分区的合并:
ALTER TABLE SALES MERGE PARTITIONS P1,P2 INTO PARTITION P2;
五、拆分分区
拆分分区将一个分区拆分两个新分区,拆分后原来分区不再存在。注意不能对HASH类型的分区进行拆分。
ALTER TABLE SALES SBLIT PARTITION P2 AT(TO_DATE('2003-02-01','YYYY-MM-DD')) INTO (PARTITION P21,PARTITION P22);
六、接合分区(coalesca)
结合分区是将散列分区中的数据接合到其它分区中,当散列分区中的数据比较大时,可以增加散列分区,然后进行接合,值得注意的是,接合分区只能用于散列分区中。通过以下代码进行接合分区:
ALTER TABLE SALES COALESCA PARTITION;
七、重命名表分区
以下代码将P21更改为P2
ALTER TABLE SALES RENAME PARTITION P21 TO P2;
八、相关查询
跨分区查询
select sum( *) from
(select count(*) cn from t_table_SS PARTITION (P200709_1)
union all
select count(*) cn from t_table_SS PARTITION (P200709_2)
);
查询表上有多少分区
SELECT * FROM useR_TAB_PARTITIONS WHERE TABLE_NAME='tableName'
查询索引信息
select object_name,object_type,tablespace_name,sum(value)
from v$segment_statistics
where statistic_name IN ('physical reads','physical write','logical reads')and object_type='INDEX'
group by object_name,object_type,tablespace_name
order by 4 desc
--显示数据库所有分区表的信息:
select * from DBA_PART_TABLES
--显示当前用户可访问的所有分区表信息:
select * from ALL_PART_TABLES
--显示当前用户所有分区表的信息:
select * from USER_PART_TABLES
--显示表分区信息 显示数据库所有分区表的详细分区信息:
select * from DBA_TAB_PARTITIONS
--显示当前用户可访问的所有分区表的详细分区信息:
select * from ALL_TAB_PARTITIONS
--显示当前用户所有分区表的详细分区信息:
select * from USER_TAB_PARTITIONS
--显示子分区信息 显示数据库所有组合分区表的子分区信息:
select * from DBA_TAB_SUBPARTITIONS
--显示当前用户可访问的所有组合分区表的子分区信息:
select * from ALL_TAB_SUBPARTITIONS
--显示当前用户所有组合分区表的子分区信息:
select * from USER_TAB_SUBPARTITIONS
--显示分区列 显示数据库所有分区表的分区列信息:
select * from DBA_PART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的分区列信息:
select * from ALL_PART_KEY_COLUMNS
--显示当前用户所有分区表的分区列信息:
select * from USER_PART_KEY_COLUMNS
--显示子分区列 显示数据库所有分区表的子分区列信息:
select * from DBA_SUBPART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的子分区列信息:
select * from ALL_SUBPART_KEY_COLUMNS
--显示当前用户所有分区表的子分区列信息:
select * from USER_SUBPART_KEY_COLUMNS
--怎样查询出oracle数据库中所有的的分区表
select * from user_tables a where a.partitioned='YES'
--删除一个表的数据是
truncate table table_name;
--删除分区表一个分区的数据是
alter table table_name truncate partition p5;
posted @
2010-07-31 17:53 xzc 阅读(196) |
评论 (0) |
编辑 收藏posted @
2010-07-29 11:15 xzc 阅读(169) |
评论 (0) |
编辑 收藏表压缩是如何工作的
在Orcle9i第2版中,表压缩特性通过删除在数据库表中发现的重复数据值来节省空间。压缩是在数据库的数据块级别上进行的。当确定一个表要被压缩后,数据库便在每一个数据库数据块中保留空间,以便储存在该数据块中的多个位置上出现的数据的单一拷贝。这一被保留的空间被称作符号表(symbol table)。被标识为要进行压缩的数据只存储在该符号表中,而不是在数据库行本身内。当在一个数据库行中出现被标识为要压缩的数据时,该行在该符号表中存储一个指向相关数据的指针,而不是数据本身。节约空间是通过删除表中数据值的冗余拷贝而实现的。
对于用户或应用程序开发人员来说,表压缩的效果是透明的。无论表是否被压缩,开发人员访问表的方式都是相同的,所以当你决定压缩一个表时,不需要修改SQL查询。表压缩的设置通常由数据库管理人员或设计人员进行配置,几乎不需要开发人员或用户参与。
1.表级别:
1.1 创建一个压缩表:
创建表时使用COMPRESS关键字,COMPRESS关键字指示Oracle数据库尽可能以压缩的格式存储该表中的行。
SQL> create table tmp_test
(id number,phone varchar2(20),create_time date)
compress;
1.2 修改现有表为压缩表:
SQL> alter table tmp_test compress;
取消表的压缩:
SQL> alter table tmp_test nocompress;
1.3 确定表是否被压缩:
确定一个表是否使用了压缩,查询user_tables,compression字段表明表是否被压缩.
SQL> select table_name,compression from user_tables where table_name not like 'BIN%';
TABLE_NAME COMPRESS
------------------------------ --------
CLASSES ENABLED
ROOMS ENABLED
STUDENTS DISABLED
MAJOR_STATS DISABLED
2.表空间级别:
2.1 创建表压缩空间:
可以在表空间级别上定义COMPRESS属性,既可以在生成时利用CREATE TABLESPACE来定义,也可以稍后时间利用ALTER TABLESPACE来定义。
与其他存储参数类似,COMPRESS属性也具有一些继承特性。当在一个表空间中创建一个表时,它从该表空间继承COMPRESS属性。
可以在一个表空间直接压缩或解压缩一个表,而不用考虑表空间级别上的COMPRESS属性。
2.2 使现有表空间转换为压缩表空间 SQL> alter tablespace sms default compress;
SQL> alter tablespace sms default nocompress;
2.3 确定是否已经利用COMPRESS对一个表空间进行了定义,可查询USER_TABLESPACES数据字典视图并查看DEF_TAB_COMPRESSION列
SQL> select tablespace_name,def_tab_compression from user_tablespaces;
TABLESPACE DEF_TAB_
---------- --------
USERS DISABLED
TEST DISABLED
UNDOTBS01 DISABLED
STATPACK DISABLED
3.向一个压缩的表中加载数据
注:当像上面那样指定compress时,其它表中(表空间)的数据并没有压缩,它只是修改了数据字典的设置;只有在向一个表中加裁/插入数据时,才会压缩数据.
只有在使用下面4种方法时,表中的数据才会被压缩存放:
4.压缩一个已经存在但并未压缩的表
使用alter table .. move compress使一个已存在但未压缩的表转换为压缩表.
SQL> alter table tmp_test move compress;
同样,也可以使用alter table.. move nocompress来解压一个已经压缩的表:
SQL> alter table tmp_test move nocompress;
5.压缩一个物化视图
使用用于压缩表的类似方式来压缩物化视图。
基于多个表的联接生成的物化视图通常很适于压缩,因为它们通常拥有大量的重复数据项。
SQL> create materialized view mv_tmp_test
compress
as
select a.phone,b.create_time from tmp_test a,recv_stat b
where a.id=b.id;
可以使用ALTER MATERIALIZED VIEW命令来改变一个物化视图的压缩属性。
当你使用此命令时,请注意通常是在下一次刷新该物化视图时才会进行实际的压缩。
SQL> alter materialized view mv_temp_test compress;
6.压缩一个已分区的表
在对已分区的表应用压缩时,可以有很多种选择。你可以在表级别上应用压缩,也可以在分区级别上应用压缩。
你可以利用ALTER TABLE ...MOVE PARTITION命令对此分区进行压缩
SQL> alter table tmp_test move partition create_200606 compress;
要找出一个表中的哪些分区被压缩了,可以查询数据字典视图USER_TAB_PARTITIONS
SQL>SELECT TABLE_NAME, PARTITION_NAME,COMPRESSION FROM USER_TAB_PARTITIONS;
7.压缩表的性能开销
一个压缩的表可以存储在更少的数据块中,从而节省了储存空间,而使用更少的数据块也意味着性能的提高。 在一个I/O受到一定限制的环境中对一个压缩的表进行查询通常可以更快速地完成,因为他们需要阅读的数据库数据块要少得多。
使用sql*load加载100万数据:
|
表名
|
行数
|
路径
|
是否是压缩的
|
消耗的时间
|
|
test_nocom
|
1000000
|
直接
|
非压缩的
|
00:00:21.12
|
|
test_comp
|
1000000
|
直接
|
压缩的
|
00:00:47.77
|
由此可以看出,向压缩表中加入数据的时间是正常表的一倍.加载压缩的表所需要的额外时间来自于在数据加载过程中所执行的压缩操作。
可以得出的结论是:在很少改变的表上使用压缩技术还是可以的.表中数据经常变动的情况下,尽量不要使用表压缩,它影响插入操作.
posted @
2010-07-16 14:58 xzc 阅读(5510) |
评论 (2) |
编辑 收藏一、Linux压缩工具概述
在Linux系统中,提供了许多压缩工具,虽然方便,但也难免造成一些混乱。笔者通过一段时间的整理,将它们理一理顺,希望能够对大家有所帮助:
首先,我们看一下下面这张“压缩包扩展名与压缩工具对应表”,大家通过这张表,就知道网上下载的压缩包,该用什么软件来解了。
工具名 压缩包扩展名
gzip/gunzip “.gz”
compress/uncompress “.Z”
zip/unzip “.zip”
bzip2/bunzip2 “.bz2”
lha “.lzh”
接下来,我们通过实例,来测量一下它们的压缩效率与性能:
测试一:
测试数据:源文件是一个数据库文件,其大小为5,244,928;
测试结果:
gzip:19,136,2秒
compress:17,769,1秒
zip:19,261,2秒
bzip2:1902,2秒
测试二:
测试数据:源文件是一个/etc目录的tar包,其大小为2,631,680;
测试结果:
gzip:551,736,2秒
compress:877,391,3秒
zip:551,856,3秒
bzip2:478,512,11秒
测试三:
测试数据:源文件是一个avi视频文件,其大小为23,157,760;
测试结果:
gzip:17,151,395,43秒
compress:压缩失败,43秒
zip:17,151,509,42秒
bzip2:16,587,991,2分40秒
通过上面的实验,我认为如果你需要高压缩率,就选择bzip2;否则最佳选择就是gzip,它的性价比较好,而且是纯正的自由软件:gzip就是GNU zip!
在LINUX/UNIX系统下,用这些压缩软件是不能直接对一个目录进行打包,当您需要这样做时,通常先使用tar进行归档,将整个目录打包成为一个tar包,然后用压缩软件来压缩。下面我们以备份/etc目录下的所有文件为例,说明一下:
tar –cvf etc /etc (将在当前目录生成一个etc.tar)
gzip etc.tar (将会把etc.tar压缩成为etc.tar.gz)
关于tar的更多信息,我们将专文说明。
好了,说了这么多,下面我们就一起逐一看一下这些压缩工具的用法。
二、Linux压缩工具概述
1.gzip和gunzip
压缩包扩展名:“.gz”
特点:
1)它是纯正的自由软件,性能不错!
2)若没有加上任何参数,生成压缩文件后,会删除原始文件;
命令使用:
1) 压缩一个文件:
gzip file 这样将生成file.gz,删除原文件file;
2) 压缩一个文件,并保留源文件:
gzip –c a > a.gz
3) 提高压缩率:gzip –9 file
注:压缩等级可以从1-9,数字越大压缩效果越好,但要花的时间也越长,默认值为6。
4) 解压缩:
gzip –d file.gz 或
gunzip file.gz
5) 显示详细信息:
gzip –v file
6) 显示版本信息:
gzip –V
2.bzip2和bunzip2
压缩包扩展名:“.bz2”
特点:
1)它采用了新的压缩演算法,压缩效果比传统的LZ77/LZ78压缩演算法来得好;
2)若没有加上任何参数,生成压缩文件后,会删除原始文件;
命令使用:
1) 压缩一个文件:
bzip2 file 这样将生成file.bz2,删除原文件file;
2) 压缩一个文件,并保留源文件:
bzip2 –k file
3) 提高压缩率:bzip –9 file
注:压缩等级可以从1-9,数字越大压缩效果越好,但要花的时间也越长。
4) 解压缩:
bzip2 –d file.bz2 或
bunzip2 file.bz2
5) 显示详细信息:
bzip2 –v file
6) 显示版本信息:
bzip2 –V
相关工具:
如果用bzip2压缩的文件出错的话,你可以尝试使用bzip2recover来恢复:
bzip2recover file-bad.bz2
3.compress和uncompress
压缩包扩展名:“.Z”
特点:
1)它是一个历史悠久的压缩程序,在许多UNIX系统中都可以找到;
2)默认情况下,生成压缩文件后,会删除原始文件。
命令使用:
1) 压缩一个文件:
compress file
2) 压缩一个文件,并保留源文件:
compress –c a > a.Z
3) 提高压缩率:compress –b9 file
注:压缩等级可以从9-16,数字越大压缩效果越好,但要花的时间也越长。预设值是16。
4) 解压缩:
compress –d file.Z 或
uncompress a.Z
5) 显示详细信息:
compress –v file
6) 显示版本信息:
compress –V
4.zip和unzip
压缩包扩展名:“.zip”
特点:
1)它是一个使用广泛的压缩程序,其版本横跨十多种操作系统与硬件结构平台;
2)默认情况下,生成压缩文件后,不会删除原始文件。
命令使用:
1) 压缩一个文件:
注意:如果要压缩的是个文件夹,则要加上-r参数,表示调用递归压缩,如:
zip -r temp.zip temp
zip zipfile file (zipfile是压缩后的文件名,file要压缩的文件名)
2) 压缩一个文件,并删除源文件:
zip –m file
3) 提高压缩率:zip –9 file
注:压缩等级可以从1-9,数字越大压缩效果越好,但要花的时间也越长。预设值是6。
4) 解压缩:
zip –d file.zip 或
unzip file.zip
5) 显示详细信息:
zip –v file
6) 显示版本信息:
zip –V
相关工具:
在Linux中,还提供了一个叫zipinfo的工具,能够察看zip压缩文件的详细信息:
zipinfo file.zip
三、其它压缩/解压缩工具
除了这四对压缩/解压缩工具外,在Linux下还有以下三种压缩/解压缩工具:
1.lha
lha是从lharc演变而来的压缩程序,文件经它压缩后,会产生一个具有“.lzh”的扩展名。使用起来还是比较简单的,而且它是可以直接将一个目录打包的:
1) 压缩一个文件:
lha –a lhzfile file (lhzfile是压缩后的文件名,file要压缩的文件名)
2) 解压缩:
lha –xiw=/tmp lhzfile (其中/tmp是解压缩后的存放目录,lhzfile是压缩文件名)
3) 压缩一个目录:
lha –a lhzfile directory
2.gzexe
这是一个十分特殊的压缩工具,它用来压缩可执行文件。当您执行被gzexe压缩过的可执行文件时,该文件会自动解压后继续执行,和执行一般的可执行文件一样。
当然这一过程会多占用一些系统资源,只有你的可用磁盘空间十分有限时才建议使用。
1) 压缩
gzexe program
这样会生成一个program~,为的是万一压缩失败还能够恢复,当你确定压缩后可以使用后,应删掉它,否则不就白压缩了吗?
2) 解压缩
gzexe –d program
3.unarj
如果你有一些用arj压缩的包的话,你可以使用unarj解开它,不过它只能够解,却无法执行压缩。在Linux没有提供arj压缩工具。
解压时,很简单:unarj e arjfile
posted @
2010-07-13 11:28 xzc 阅读(533) |
评论 (0) |
编辑 收藏
[root@linux ~]# tar [-cxtzjvfpPN] 文件与目录 ....
参数:
-c :建立一个压缩文件的参数指令(create 的意思);
-x :解开一个压缩文件的参数指令!
-t :查看 tarfile 里面的文件!
特别注意,在参数的下达中, c/x/t 仅能存在一个!不可同时存在!
因为不可能同时压缩与解压缩。
-z :是否同时具有 gzip 的属性?亦即是否需要用 gzip 压缩?
-j :是否同时具有 bzip2 的属性?亦即是否需要用 bzip2 压缩?
-v :压缩的过程中显示文件!这个常用,但不建议用在背景执行过程!
-f :使用档名,请留意,在 f 之后要立即接档名喔!不要再加参数!
例如使用『 tar -zcvfP tfile sfile』就是错误的写法,要写成
『 tar -zcvPf tfile sfile』才对喔!
-p :使用原文件的原来属性(属性不会依据使用者而变)
-P :可以使用绝对路径来压缩!
-N :比后面接的日期(yyyy/mm/dd)还要新的才会被打包进新建的文件中!
--exclude FILE:在压缩的过程中,不要将 FILE 打包!
范例:
范例一:将整个 /etc 目录下的文件全部打包成为 /tmp/etc.tar
[root@linux ~]# tar -cvf /tmp/etc.tar /etc <==仅打包,不压缩!
[root@linux ~]# tar -zcvf /tmp/etc.tar.gz /etc <==打包后,以 gzip 压缩
[root@linux ~]# tar -jcvf /tmp/etc.tar.bz2 /etc <==打包后,以 bzip2 压缩
# 特别注意,在参数 f 之后的文件档名是自己取的,我们习惯上都用 .tar 来作为辨识。
# 如果加 z 参数,则以 .tar.gz 或 .tgz 来代表 gzip 压缩过的 tar file ~
# 如果加 j 参数,则以 .tar.bz2 来作为附档名啊~
# 上述指令在执行的时候,会显示一个警告讯息:
# 『tar: Removing leading `/' from member names』那是关於绝对路径的特殊设定。
范例二:查阅上述 /tmp/etc.tar.gz 文件内有哪些文件?
[root@linux ~]# tar -ztvf /tmp/etc.tar.gz
# 由於我们使用 gzip 压缩,所以要查阅该 tar file 内的文件时,
# 就得要加上 z 这个参数了!这很重要的!
范例三:将 /tmp/etc.tar.gz 文件解压缩在 /usr/local/src 底下
[root@linux ~]# cd /usr/local/src
[root@linux src]# tar -zxvf /tmp/etc.tar.gz
# 在预设的情况下,我们可以将压缩档在任何地方解开的!以这个范例来说,
# 我先将工作目录变换到 /usr/local/src 底下,并且解开 /tmp/etc.tar.gz ,
# 则解开的目录会在 /usr/local/src/etc 呢!另外,如果您进入 /usr/local/src/etc
# 则会发现,该目录下的文件属性与 /etc/ 可能会有所不同喔!
范例四:在 /tmp 底下,我只想要将 /tmp/etc.tar.gz 内的 etc/passwd 解开而已
[root@linux ~]# cd /tmp
[root@linux tmp]# tar -zxvf /tmp/etc.tar.gz etc/passwd
# 我可以透过 tar -ztvf 来查阅 tarfile 内的文件名称,如果单只要一个文件,
# 就可以透过这个方式来下达!注意到! etc.tar.gz 内的根目录 / 是被拿掉了!
范例五:将 /etc/ 内的所有文件备份下来,并且保存其权限!
[root@linux ~]# tar -zxvpf /tmp/etc.tar.gz /etc
# 这个 -p 的属性是很重要的,尤其是当您要保留原本文件的属性时!
范例六:在 /home 当中,比 2005/06/01 新的文件才备份
[root@linux ~]# tar -N '2005/06/01' -zcvf home.tar.gz /home
范例七:我要备份 /home, /etc ,但不要 /home/dmtsai
[root@linux ~]# tar --exclude /home/dmtsai -zcvf myfile.tar.gz /home/* /etc
范例八:将 /etc/ 打包后直接解开在 /tmp 底下,而不产生文件!
[root@linux ~]# cd /tmp
[root@linux tmp]# tar -cvf - /etc | tar -xvf -
# 这个动作有点像是 cp -r /etc /tmp 啦~依旧是有其有用途的!
# 要注意的地方在於输出档变成 - 而输入档也变成 - ,又有一个 | 存在~
# 这分别代表 standard output, standard input 与管线命令啦!
# 这部分我们会在 Bash shell 时,再次提到这个指令跟大家再解释啰!
gzip, zcat 命令
[root@linux ~]# gzip [-cdt#] 档名
[root@linux ~]# zcat 档名.gz
参数:
-c :将压缩的资料输出到萤幕上,可透过资料流重导向来处理;
-d :解压缩的参数;
-t :可以用来检验一个压缩档的一致性~看看文件有无错误;
-# :压缩等级,-1 最快,但是压缩比最差、-9 最慢,但是压缩比最好!预设是 -6 ~
范例:
范例一:将 /etc/man.config 複制到 /tmp ,并且以 gzip 压缩
[root@linux ~]# cd /tmp
[root@linux tmp]# cp /etc/man.config .
[root@linux tmp]# gzip man.config
# 此时 man.config 会变成 man.config.gz !
范例二:将范例一的文件内容读出来!
[root@linux tmp]# zcat man.config.gz
# 此时萤幕上会显示 man.config.gz 解压缩之后的文件内容!!
范例三:将范例一的文件解压缩
[root@linux tmp]# gzip -d man.config.gz
范例四:将范例三解开的 man.config 用最佳的压缩比压缩,并保留原本的文件
[root@linux tmp]# gzip -9 -c man.config > man.config.gz
bzip2, bzcat 命令
[root@linux ~]# bzip2 [-cdz] 档名
[root@linux ~]# bzcat 档名.bz2
参数:
-c :将压缩的过程产生的资料输出到萤幕上!
-d :解压缩的参数
-z :压缩的参数
-# :与 gzip 同样的,都是在计算压缩比的参数, -9 最佳, -1 最快!
范例:
范例一:将刚刚的 /tmp/man.config 以 bzip2 压缩
[root@linux tmp]# bzip2 -z man.config
# 此时 man.config 会变成 man.config.bz2 !
范例二:将范例一的文件内容读出来!
[root@linux tmp]# bzcat man.config.bz2
# 此时萤幕上会显示 man.config.bz2 解压缩之后的文件内容!!
范例三:将范例一的文件解压缩
[root@linux tmp]# bzip2 -d man.config.bz2
范例四:将范例三解开的 man.config 用最佳的压缩比压缩,并保留原本的文件
[root@linux tmp]# bzip2 -9 -c man.config > man.config.bz2
compress 命令
[root@linux ~]# compress [-dcr] 文件或目录
参数:
-d :用来解压缩的参数
-r :可以连同目录下的文件也同时给予压缩呢!
-c :将压缩资料输出成为 standard output (输出到萤幕)
范例:
范例一:将 /etc/man.config 複制到 /tmp ,并加以压缩
[root@linux ~]# cd /tmp
[root@linux tmp]# cp /etc/man.config .
[root@linux tmp]# compress man.config
[root@linux tmp]# ls -l
-rw-r--r-- 1 root root 2605 Jul 27 11:43 man.config.Z
范例二:将刚刚的压缩档解开
[root@linux tmp]# compress -d man.config.Z
范例三:将 man.config 压缩成另外一个文件来备份
[root@linux tmp]# compress -c man.config > man.config.back.Z
[root@linux tmp]# ll man.config*
-rw-r--r-- 1 root root 4506 Jul 27 11:43 man.config
-rw-r--r-- 1 root root 2605 Jul 27 11:46 man.config.back.Z
# 这个 -c 的参数比较有趣!他会将压缩过程的资料输出到萤幕上,而不是写入成为
# file.Z 文件。所以,我们可以透过资料流重导向的方法将资料输出成为另一个档名。
# 关於资料流重导向,我们会在 bash shell 当中详细谈论的啦!
dd 命令
[root@linux ~]# dd if="input_file" of="outptu_file" bs="block_size" \
count="number"
参数:
if :就是 input file 啰~也可以是装置喔!
of :就是 output file 喔~也可以是装置;
bs :规划的一个 block 的大小,如果没有设定时,预设是 512 bytes
count:多少个 bs 的意思。
范例:
范例一:将 /etc/passwd 备份到 /tmp/passwd.back 当中
[root@linux ~]# dd if=/etc/passwd of=/tmp/passwd.back
3+1 records in
3+1 records out
[root@linux ~]# ll /etc/passwd /tmp/passwd.back
-rw-r--r-- 1 root root 1746 Aug 25 14:16 /etc/passwd
-rw-r--r-- 1 root root 1746 Aug 29 16:57 /tmp/passwd.back
# 仔细的看一下,我的 /etc/passwd 文件大小为 1746 bytes,因为我没有设定 bs ,
# 所以预设是 512 bytes 为一个单位,因此,上面那个 3+1 表示有 3 个完整的
# 512 bytes,以及未满 512 bytes 的另一个 block 的意思啦!
# 事实上,感觉好像是 cp 这个指令啦~
范例二:备份 /dev/hda 的 MBR
[root@linux ~]# dd if=/dev/hda of=/tmp/mbr.back bs=512 count=1
1+0 records in
1+0 records out
# 这就得好好瞭解一下啰~我们知道整颗硬盘的 MBR 为 512 bytes,
# 就是放在硬盘的第一个 sector 啦,因此,我可以利用这个方式来将
# MBR 内的所有资料都纪录下来,真的很厉害吧! ^_^
范例三:将整个 /dev/hda1 partition 备份下来。
[root@linux ~]# dd if=/dev/hda1 of=/some/path/filenaem
# 这个指令很厉害啊!将整个 partition 的内容全部备份下来~
# 后面接的 of 必须要不是在 /dev/hda1 的目录内啊~否则,怎么读也读不完~
# 这个动作是很有效用的,如果改天你必须要完整的将整个 partition 的内容填回去,
# 则可以利用 dd if=/some/file of=/dev/hda1 来将资料写入到硬盘当中。
# 如果想要整个硬盘备份的话,就类似 Norton 的 ghost 软体一般,
# 由 disk 到 disk ,嘿嘿~利用 dd 就可以啦~厉害厉害!
cpio 命令
[root@linux ~]# cpio -covB > [file|device] <==备份
[root@linux ~]# cpio -icduv < [file|device] <==还原
参数:
-o :将资料 copy 输出到文件或装置上
-i :将资料自文件或装置 copy 出来系统当中
-t :查看 cpio 建立的文件或装置的内容
-c :一种较新的 portable format 方式储存
-v :让储存的过程中文件名称可以在萤幕上显示
-B :让预设的 Blocks 可以增加至 5120 bytes ,预设是 512 bytes !
这样的好处是可以让大文件的储存速度加快(请参考 i-nodes 的观念)
-d :自动建立目录!由於 cpio 的内容可能不是在同一个目录内,
如此的话在反备份的过程会有问题! 这个时候加上 -d 的话,
就可以自动的将需要的目录建立起来了!
-u :自动的将较新的文件覆盖较旧的文件!
范例:
范例一:将所有系统上的资料通通写入磁带机内!
[root@linux ~]# find / -print | cpio -covB > /dev/st0
# 一般来说,使用 SCSI 介面的磁带机,代号是 /dev/st0 喔!
范例二:检查磁带机上面有什么文件?
[root@linux ~]# cpio -icdvt < /dev/st0
[root@linux ~]# cpio -icdvt < /dev/st0 > /tmp/content
# 第一个动作当中,会将磁带机内的档名列出到萤幕上面,而我们可以透过第二个动作,
# 将所有的档名通通纪录到 /tmp/content 文件去!
范例三:将磁带上的资料还原回来~
[root@linux ~]# cpio -icduv < /dev/st0
# 一般来说,使用 SCSI 介面的磁带机,代号是 /dev/st0 喔!
范例四:将 /etc 底下的所有『文件』都备份到 /root/etc.cpio 中!
[root@linux ~]# find /etc -type f | cpio -o > /root/etc.cpio
# 这样就能够备份啰~您也可以将资料以 cpio -i < /root/etc.cpio
# 来将资料捉出来!!!!
posted @
2010-07-12 16:47 xzc 阅读(236) |
评论 (0) |
编辑 收藏一.tar命令
tar可以为文件和目录创建档案。利用tar,用户可以为某一特定文件创建档案(备份文件),也可以在档案中改变文件,或者向档案中加入新的文件。tar 最初被用来在磁带上创建档案,现在,用户可以在任何设备上创建档案,如软盘。利用tar命令,可以把一大堆的文件和目录全部打包成一个文件,这对于备份文 件或将几个文件组合成为一个文件以便于网络传输是非常有用的。Linux上的tar是GNU版本的。
语法:tar [主选项+辅选项] 文件或者目录
使用该命令时,主选项是必须要有的,它告诉tar要做什么事情,辅选项是辅助使用的,可以选用。
主选项:
c 创建新的档案文件。如果用户想备份一个目录或是一些文件,就要选择这个选项。
r 把要存档的文件追加到档案文件的未尾。例如用户已经作好备份文件,又发现还有一个目录或是一些文件忘记备份了,这时可以使用该选项,将忘记的目录或文件追加到备份文件中。
t 列出档案文件的内容,查看已经备份了哪些文件。
u 更新文件。就是说,用新增的文件取代原备份文件,如果在备份文件中找不到要更新的文件,则把它追加到备份文件的最后。
x 从档案文件中释放文件。
辅助选项:
b 该选项是为磁带机设定的。其后跟一数字,用来说明区块的大小,系统预设值为20(20*512 bytes)。
f 使用档案文件或设备,这个选项通常是必选的。
k 保存已经存在的文件。例如我们把某个文件还原,在还原的过程中,遇到相同的文件,不会进行覆盖。
m 在还原文件时,把所有文件的修改时间设定为现在。
M 创建多卷的档案文件,以便在几个磁盘中存放。
v 详细报告tar处理的文件信息。如无此选项,tar不报告文件信息。
w 每一步都要求确认。
z 用gzip来压缩/解压缩文件,加上该选项后可以将档案文件进行压缩,但还原时也一定要使用该选项进行解压缩。
二.Linux下的压缩文件剖析
对于刚刚接触Linux的人来说,一定会给Linux下一大堆各式各样的文件名 给搞晕。别个不说,单单就压缩文件为例,我们知道在Windows下最常见的压缩文件就只有两种,一是,zip,另一个是.rar。可是Linux就不同 了,它有.gz、.tar.gz、tgz、bz2、.Z、.tar等众多的压缩文件名,此外windows下的.zip和.rar也可以在Linux下使 用,不过在Linux使用.zip和.rar的人就太少了。本文就来对这些常见的压缩文件进行一番小结,希望你下次遇到这些文件时不至于被搞晕:)
在具体总结各类压缩文件之前,首先要 弄清两个概念:打包和压缩。打包是指将一大堆文件或目录什么的变成一个总的文件,压缩则是将一个大的文件通过一些压缩算法变成一个小文件。为什么要区分这 两个概念呢?其实这源于Linux中的很多压缩程序只能针对一个文件进行压缩,这样当你想要压缩一大堆文件时,你就得先借助另外的工具将这一大堆文件先打 成一个包,然后再就原来的压缩程序进行压缩。
Linux下最常用的打包程序就是tar了,使用tar程序打出来的包我们常称为tar包,tar包文件的命令通常都是以.tar结尾的。生成tar包后,就可以用其它的程序来进行压缩了,所以首先就来讲讲tar命令的基本用法:
tar命令的选项有很多(用man tar可以查看到),但常用的就那么几个选项,下面来举例说明一下:
# tar -cf all.tar *.jpg
这条命令是将所有.jpg的文件打成一个名为all.tar的包。-c是表示产生新的包,-f指定包的文件名。
# tar -rf all.tar *.gif
这条命令是将所有.gif的文件增加到all.tar的包里面去。-r是表示增加文件的意思。
# tar -uf all.tar logo.gif
这条命令是更新原来tar包all.tar中logo.gif文件,-u是表示更新文件的意思。
# tar -tf all.tar
这条命令是列出all.tar包中所有文件,-t是列出文件的意思
# tar -xf all.tar
这条命令是解出all.tar包中所有文件,-x是解包的意思
以上就是tar的最基本的用法。为了方便用户在打包解包的同时可以压缩或解压文件,tar提供了一种特殊的功能。这就是tar可以在打包或解包的同时调用其它的压缩程序,比如调用gzip、bzip2等。
1) tar调用gzip
gzip是GNU组织开发的一个压缩程序,.gz结尾的文件就是gzip压缩的结果。与gzip相对的解压程序是gunzip。tar中使用-z这个参数来调用gzip。下面来举例说明一下:
# tar -czf all.tar.gz *.jpg
这条命令是将所有.jpg的文件打成一个tar包,并且将其用gzip压缩,生成一个gzip压缩过的包,包名为all.tar.gz
# tar -xzf all.tar.gz
这条命令是将上面产生的包解开。
2) tar调用bzip2
bzip2是一个压缩能力更强的压缩程序,.bz2结尾的文件就是bzip2压缩的结果。与bzip2相对的解压程序是bunzip2。tar中使用-j这个参数来调用bzip2。下面来举例说明一下:
# tar -cjf all.tar.bz2 *.jpg
这条命令是将所有.jpg的文件打成一个tar包,并且调用bzip2压缩,生成一个bzip2压缩过的包,包名为all.tar.bz2
# tar -xjf all.tar.bz2
这条命令是将上面产生的包解开。
3)tar调用compress
compress也是一个压缩程序,但是好象使用compress的人不如gzip和bzip2的人多。.Z结尾的文件就是bzip2压缩的结果。与compress相对的解压程序是uncompress。tar中使用-Z这个参数来调用gzip。下面来举例说明一下:
# tar -cZf all.tar.Z *.jpg
这条命令是将所有.jpg的文件打成一个tar包,并且调用compress压缩,生成一个uncompress压缩过的包,包名为all.tar.Z
# tar -xZf all.tar.Z
这条命令是将上面产生的包解开
有了上面的知识,你应该可以解开多种压缩文件了,下面对于tar系列的压缩文件作一个小结:
1)对于.tar结尾的文件
tar -xf all.tar
2)对于.gz结尾的文件
gzip -d all.gz
gunzip all.gz
3)对于.tgz或.tar.gz结尾的文件
tar -xzf all.tar.gz
tar -xzf all.tgz
4)对于.bz2结尾的文件
bzip2 -d all.bz2
bunzip2 all.bz2
5)对于tar.bz2结尾的文件
tar -xjf all.tar.bz2
6)对于.Z结尾的文件
uncompress all.Z
7)对于.tar.Z结尾的文件
tar -xZf all.tar.z
另外对于Window下的常见压缩文件.zip和.rar,Linux也有相应的方法来解压它们:
1)对于.zip
linux下提供了zip和unzip程序,zip是压缩程序,unzip是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法:
# zip all.zip *.jpg
这条命令是将所有.jpg的文件压缩成一个zip包
注意:如果要压缩的是个文件夹,则要加上-r参数,表示调用递归压缩,如:
zip -r temp.zip temp
# unzip all.zip
这条命令是将all.zip中的所有文件解压出来
2)对于.rar
要在linux下处理.rar文件,需要安装RAR for Linux,可以从网上下载,但要记住,RAR for Linux
不是免费的;然后安装:
# tar -xzpvf rarlinux-3.2.0.tar.gz
# cd rar
# make
这样就安装好了,安装后就有了rar和unrar这两个程序,rar是压缩程序,unrar是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法:
# rar a all *.jpg
这条命令是将所有.jpg的文件压缩成一个rar包,名为all.rar,该程序会将.rar 扩展名将自动附加到包名后。
# unrar e all.rar
这条命令是将all.rar中的所有文件解压出来
到此为至,我们已经介绍过linux下的tar、gzip、gunzip、bzip2、bunzip2、compress、uncompress、 zip、unzip、rar、unrar等程式,你应该已经能够使用它们对.tar、.gz、.tar.gz、.tgz、.bz2、.tar.bz2、. Z、.tar.Z、.zip、.rar这10种压缩文件进行解压了,以后应该不需要为下载了一个软件而不知道如何在Linux下解开而烦恼了。而且以上方 法对于Unix也基本有效。
本文介绍了linux下的压缩程式tar、gzip、gunzip、bzip2、bunzip2、 compress、uncompress、zip、unzip、rar、unrar等程式,以及如何使用它们对.tar、.gz、.tar.gz、. tgz、.bz2、.tar.bz2、.Z、.tar.Z、.zip、.rar这10种压缩文件进行操作。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/hbcui1984/archive/2007/04/25/1583796.aspx
posted @
2010-07-12 16:42 xzc 阅读(7192) |
评论 (0) |
编辑 收藏6.2.1 Pfile文件
Pfile(Parameter File)文件是基于文本格式的参数文件,含有数据库的配置参数。
Oracle 9i在安装时为每个数据库建立了一个Pfile,默认的名称为“init+例程名.ora”,这是一个文本文件,可以用任何文本编辑工具打开。
表6.1 数据库的初始化参数文件分析
| 内容 |
说明 |
| # Copyright (c) 1991, 2001 by Oracle Corporation |
Oracle公司版权标识 |
| # MTS |
多线程服务器配置标识,在Oracle 9i里称为共享服务器配置 |
|
dispatchers="(PROTOCOL=TCP)(SER=MODOSE)", "(PROTOCOL=TCP)
(PRE=oracle.aurora.server.GiopServer)", "(PROTOCOL=TCP)
(PRE=oracle.aurora.server.SGiopServer)"
|
多线程服务器配置 |
| # 其他 |
配置其他参数 |
| compatible=9.0.0 |
兼容版本9.0.0 |
| db_name=myoracle |
数据库名称为myoracle |
| # 分布式, 复制和快照 |
配置分布式、复制和快照参数 |
| db_domain=mynet |
数据库域名为mynet,加上数据库名称db_name构成全局数据库名称 |
| remote_login_passwordfile=EXCLUSIVE |
指定操作系统或口令文件是否具有检查用户口令的权限。设置为EXCLUSIVE, 将使用数据库的口令文件对每个具有权限的用户进行验证。 |
| # 排序, 散列联接, 位图索引 |
配置排序、散列联接、位图索引参数 |
| sort_area_size=524288 |
指定排序区使用的最大内存量为512KB。排序完成后, 各行将返回, 并且内存将释放。增大该值可以提高大型排序的效率。 |
| # 文件配置 |
文件配置参数 |
control_files=("C:\oracle\oradata\myoracle\CONTROL01.CTL",
"C:\oracle\oradata\myoracle\CONTROL02.CTL",
"C:\oracle\oradata\myoracle\CONTROL03.CTL") |
指定控制文件的路径及文件名 |
| # 池 |
内存配置参数 |
| Java_pool_size=33554432 |
指定Java存储池的大小为32MB,用于存储 Java 的方法、类定义和Java对象。 |
| large_pool_size=1048576 |
指定大型池的大小为1MB, 用于共享服务器的会话内存、并行执行的消息缓冲区以及RMAN备份和恢复的磁盘 I/O 缓冲区。 |
| shared_pool_size=33554432 |
指定共享池的大小为32MB,用于存储共享游标、存储的过程、控制结构和并行执行消息缓冲区等对象。较大的值能改善多用户系统的性能 |
| # 游标和库高速缓存 |
配置游标和高速缓存参数 |
| open_cursors=300 |
指定一个会话一次可以打开的游标的最大数量为300,应将该值设置得足够高,这样才能防止应用程序耗尽打开的游标 |
| # 系统管理的撤消和回退段 |
配置系统管理撤消和回滚段参数 |
| undo_management=AUTO |
指定系统使用的撤消空间管理方式为SMU 方式,在SMU方式下, 撤消空间会像撤消表空间一样在外部分配 |
| undo_tablespace=UNDOTBS |
指定回滚表空间为UNDOTBS |
| # 网络注册 |
配置网络注册参数 |
| instance_name=myoracle |
例程名称为myoracle |
| # 诊断和统计 |
配置诊断和统计参数 |
| background_dump_dest=C:\oracle\admin\myoracle\bdump |
后台进程跟踪文件目录 |
| core_dump_dest=C:\oracle\admin\myoracle\cdump |
核心转储跟踪文件目录 |
| timed_statistics=TRUE |
收集操作系统的计时信息,这些信息可被用来优化数据库和 SQL 语句 |
| user_dump_dest=C:\oracle\admin\myoracle\udump |
用户进程跟踪文件目录 |
| # 进程和会话 |
配置进程和会话信息 |
| processes=150 |
指定可同时连接到一个Oracle Server上的操作系统用户进程的最大数量为150 |
| # 重做日志和恢复 |
重做日志和恢复参数设置 |
| Fast_start_mttr_target=300 |
指定从单个数据库例程崩溃中恢复所需的时间为300秒 |
| # 高速缓存和 I/O |
配置高速缓存和I/O参数 |
| db_block_size=4096 |
指定数据块大小为4KB |
| db_cache_size=33554432 |
指定数据缓冲区为32MB,该值越大,可以减少对数据库文件的I/O次数,提高效率 |
6.2.2 SPfile文件
SPfile(Server Parameter File,服务器参数文件)是基于二进制格式的参数文件,含有数据库及例程的参数和数值,但不能用文本编辑工具打开。
下面对两种初始化参数文件进行比较如表6.2所示。
表6.2 Spfile和Pfile文件的比较
| 比较内容 |
SPfile |
Pfile |
| 格式 |
二进制格式 |
文本格式 |
| 编辑方式 |
(1)利用企业管理器对Pfile进行修改,然后转换为Spfile (2)在SQL Plus里使用ALTER SYSTEM语句进行修改 |
(1)利用文本工具直接进行修改 (2)在企业管理器里修改配置后导出形成 |
| 默认名称 |
SPfile+例程名.ora |
Init+例程名.ora 实际参数文件Init.ora |
| 默认路径 |
Oracle\ora90\database\ |
Oracle\ora90\database\ Init.ora位于Oracle\admin\数据库例程名\pfile\ |
| 启动次序 |
SPfile优先于Pfile |
Pfile低于Spfile |
posted @
2010-06-28 10:43 xzc 阅读(155) |
评论 (0) |
编辑 收藏 专用服务器模式下:一种方式是监听进程接收到用户进程请求后,产生一个新的专用服务器进程,并且将对用户进程的所有控制信息传给此服务器进程,也就是说新建的服务器进程继承了监听进程的信息,然后服务器进程给用户进程发一个RESEND包,通知用户进程可以开始给它发信息了,用户进程给这个新建的服务器进程发一个CONNECT包,服务器进程再以ACCEPT包回应用户进程,致此,用户进程正式与服务器进程确定连接。我们把这种连接叫做HAND-OFF连接,也叫转换连接。另一种方式是监听进程接收到用户进程的请求后产生一个新的专用服务器进程,这个服务器进程选用一个TCP/IP端口来控制与用户进程的交互,然后将此信息回传给监听进程,监听进程再将此信息传给用户进程,用户进程使用这个端口给服务器进程发送一个CONNECT包,服务器进程再给用户进程发送一个ACCEPT包,致此,用户进程可以正式向服务器进程发送信息了。这种方式我们叫做重定向连接。HAND-OFF连接需要系统平台具有进程继承的能力,为了使WINDOWS NT/2000支持HAND-OFF必须在HKEY_LOCAL_MACHINE>SOFTWARE>ORACLE>HOMEX中设置USE_SHARED_SOCKET。
共享服务器模式下:只有重定向连接的方式,工作方式是监听进程接收到用户进程的请求后产生一个新的调度进程,这个调度进程选用一个TCP/IP端口来控制与用户进程的交互,然后将此信息回传给监听进程,监听进程再将此信息传给用户进程,用户进程使用这个端口给调度进程发送一个CONNECT包,调度进程再给用户进程发送一个ACCEPT包,致此,用户进程可以正式向调度进程发送信息了。可以通过设置MAX_DISPIATCHERS这个参数来确定调度进程的最大数目,如果调度进程的个数已经达到了最大,或者已有的调度进程不是满负荷,监听进程将不再创建新的调度进程,而是让其中一个调度进程选用一个TCP/IP端口来与此用户进程交互。调度进程每接收一个用户进程请求都会在监听进程处作一个登记,以便监听进程能够均衡每个调度进程的负荷,所有的用户进程请求将分别在有限的调度进程中排队,所有调度进程再顺序的把各自队列中的部分用户进程请求放入同一个请求队列,等候多个ORACLE的共享服务器进程进行处理(可以通过SHARED_SERVERS参数设置共享服务器进程的个数),也就是说所有的调度进程共享同一个请求队列,共享服务器模式下一个实例只有一个请求队列,共享服务器进程处理完用户进程的请求后将根据用户进程请求取自不同的调度进程将返回结果放入不同的响应队列,也就是说有多少调度进程就有多少响应队列,然后各个调度进程从各自的响应队列中将结果取出再返回给用户进程。
以上我们讲完了用户与ORACLE的连接方式,下面我们要讲ORACLE服务器进程如可处理用户进程的请求,当一个用户进程发出了一条SQL语名:UPDATE TABBLEA SET SALARY=SALARY*2;首先,服务器进程把这条语句的字符转换成ASCII等效数字码,接着这个ASCII码被传递给一个HASH函数,并返回一个HASH值,服务器进程将到SHARED POOL 的共享PL/SQL区去查找是否存在同样的HASH值,如果存在,服务器进程将使用这条语句已高速缓存在SHARED POOL中的已分析过的版本来执行,如果不存在,服务器进程将对该语句进行语法分析,首先检查该语句的语法的正确性,接着对语句中涉及的表、索引、视图等对象进行解析,并对照数据字典检查这些对象的名称以及相关结构,并根据ORACLE选用的优化模式以及数据字典中是否存在相应对象的统计数据和是否使用了存储大纲来生成一个执行计划或从存储大纲中选用一个执行计划,然后再用数据字典核对此用户对相应对象的执行权限,最后生成一个编译代码。ORACLE将这条语名的本身实际文本、HASH值、编译代码、与此语名相关联的任何统计数据和该语句的执行计划缓存在SHARED POOL的共享PL/SQL区。服务器进程通过SHARED POOL 锁存器来申请可以向哪些共享PL/SQL区中缓存这此内容,也就是说被SHARED POOL锁存器锁定的PL/SQL区中的块不可被覆盖,因为这些块可能被其它进程所使用。在SQL分析阶段将用到LIBRARY CACHE,从数据字典中核对表、视图等结构的时候,需要将数据字典从磁盘读入LIBRARY CACHE,因此,在读入之前也要使用LIBRARY CACHE锁存器来申请用于缓存数据字典。
生成编译代码之后,接着下一步服务器进程要准备开始更新数据,服务器进程将到DB BUFFER中查找是否有相关对象的缓存数据,下面分两个可能进行解释:
如果没有,服务器进程将在表头部请求一些行锁,如果成功加锁,服务器进程将从数据文件中读这些行所在的数据块放入DB BUFFER中空闲的区域或者覆盖已被挤出LRU列表的非脏数据块缓冲区,并且排列在LRU列表的头部,如果这些非脏数据缓冲区写完也不能满足新数据的请求时,会立即触发DBWN进程将脏数据列表中指向的缓冲块写入数据文件,并且清洗掉这些缓冲区,来腾出空间缓冲新读入的数据,也就是在放入DB BUFFER之前也是要先申请DB BUFFER中的锁存器,成功锁定后,再写入DB BUFFER,然后服务器程将该语句影响的被读入DB BUFFER块中的这些行的ROWID及将要更新的原值和新值及SCN等信息逐条的写入REDO LOG BUFFER,在写入REDO LOG BUFFER之前也是先请求REDO LOG BUFFER块的锁存器,成功锁定之后才开始写入,当写入达到REDO LOG BUFFER大小的三分之一或写入量达到1M或超过三秒后或发生检查点时或者DBWN之前发生,LGWR将把REDO LOG BUFFER中的数据写入磁盘上的重做日志文件,已被写入重做日志文件的REDO LOG BUFFER中的块上的锁存器被释放,并可被后来写入的信息所覆盖,REDO LOG BUFFER以循环的方式工作。当一个重做日志文件写满后,LGWR将切换到下一个重做日志文件,如果是归档模式,归档进程还将前一个写满的重做日志进程写入归档日志文件,重做日志文件也是循环工作方式。写完所有的REDO LOG BUFFER之后,服务器进程开始改写这个DB BUFFER块头部的事务列表并写入SCN,然后COPY包含这个块的头部事务列表及SCN信息的数据副本放入回滚段中,我们将回滚段中的副本称为数据块的“前映像”。(回滚段可以存储在专门的回滚表空间中,这个表空间由一个或多个物理文件组成,并专用于回滚表空间,回滚段也可在其它表空间中的数据文件中开辟。)然后改写这个DB BUFFER块的数据,并在其头部写入对应的回滚段地址,如果对一行数据多次UPDATE而不COMMIT则在回滚段中将会有多个“前映像”,除第一个“前映像”含有SCN信息外,其它的每个“前映像”的头部还含有SCN信息和“前前映像”的回滚段地址。一次UPDATE操作只对应一个SCN。然后服务器进程在脏数据列表中建立一条指向此缓冲块的指针。接着服务器进程会从数据文件读入第二个块重复以上读入,记日志,建立回滚段,修改,放入脏列表的动作,当脏数据列表达到一定长度时,DBWN进程将脏数据列表中指向的缓冲块全部写入数据文件,也就是释放加在这些DB BUFER 块上的锁存器。其实ORACLE可以一次从数据文件中读入几个块放入DB BUFFER,可以通过参数DB_FILE_MULTIBLOCK_READ_COUNT来设置一次读入的块的个数。
如果要查找的数据已缓存,则根据用户的SQL操作类型决定如何操作,如果是SELECT 则查看DB BUFFER块的头部是否有事务,如果有,将从回滚段读取,如果没有则比较SELECT 的SCN与DB BUFFER块头部的SCN如果比自己大,仍然从回滚段读取,如果比自己小则认这是一个非脏缓存,可以直接从这个DB BUFFER块中读取。如果是UPDATE则即使在DB BUFFER中找到一个没有事务,而且SCN比自己小的非脏缓存数据块,服务器进程仍然要到表的头部对这条记录申请加锁,加锁成功则进行后续动作,如果不成功,则要等待前面的进程解锁后才能进行动作。
只有当SQL语句影响的所有行所在的最后一个块被读入DB BUFFER并且重做信息被写入REDO LOG BUFFER(仅是指重做日志缓冲,而非重做日志文件)之后,用户才可以发出COMMIT,COMMIT触发LGRW,但并不强制立即DBWN来释放所有相应的DB BUFFER块上的锁,也就是说有可能出现已COMMIT,但在随后的一段时间内DBWN还在写这条语句涉及的数据块的情形,表头部的行锁,并不是在COMMIT一发出就马上释放,实际上要等到相应的DBWN进程结束才会释放。一个用户请求锁定另一个用户已COMMIT的资源不成功的机会是存在的,从COMMIT到DBWN进程结束之间的时间很短,如果恰巧在这个时间断电,由于COMMIT已触发LGWR进程,所以这些未来得及写入数据文件的改变会在实例重启后由SMON进程根据重做日志文件来前滚。如果未COMMIT就断电,由于DBWN之前触发LGWR,所有DBWN在数据文件上的修改都会被先一步记入重做日志文件,实例重启后,SMON进程再根据重做日志文件来回滚。
如果用户ROOLBACK,则服务器进程会根据数据文件块和DB BUFFER中块的头部的事务列表和SCN以及回滚段地址找到回滚段中相应的修改前的副本,并且用这些原值来还原当前数据文件中已修改但未提交的改变。如果有多个“前映像”,服务器进程会在一个“前映像”的头部找到“前前映像”的回滚段地址,一直找到同一事务下的最早的一个“前映像”为止。一旦发出了COMMIT,用户就不能ROOLBACK,这使得COMMIT后DBWN进程还没有全部完成的后续动作得到了保障。
下面我们要提到检查点的作用,当一个全部检查点发生的时候,首先让LGWR进程将REDO LOG BUFFER中的所有缓冲(包含未提交的重做信息)写入重做日志文件,然后让DBWN进程将DB BUFFER中所有已提交的缓冲写入数据文件(不强制写未提交的)。然后更新控制文件和数据文件头部的SCN,表明当前数据库是一致的,如果在发生检点之前断电,并且当时有一个未提交的改变正在进行,实例重启之后,SMON进程将从上一个检查点开始核对这个检查点之后记录在重做日志文件中已提交的和未提交改变,因为DBWN之前会触发LGWR,所以DBWN对数据文件的修改一定会被先记录在重做日志文件中。因此,断电前被DBWN写进数据文件的改变将通过重做日志文件中的记录进行还原,叫做回滚,如果断电时有一个已提交,但DBWN动作还没有完全完成的改变存在,因为已经提交,提交会触发LGWR进程,所以不管DBWN动作是否已完成,该语句将要影响的行及其产生的结果一定已经记录在重做日志文件中了,则实例重启后,SMON进程根据重做日志文件进行前滚。由此可见,实例失败后用于恢复的时间由两个检查点之间的间隔大小来决定,我们可以通个四个参数设置检查点执行的频率,LOG_CHECKPOINT_IMTERVAL决定了两个检查点之间写入重做日志文件的系统物理块的大小,LOG_CHECKPOINT_TIMEOUT决定了两个检查点之间的时间长度,FAST_START_IO_TARGET决定了用于恢复时需要处理的块的大小,FAST_START_MTTR_TARGET直接决定了用于恢复的时间的长短。SMON进程执行的前滚和回滚与用户的回滚是不同的,SMON是根据重做日志文件进行前滚或回滚,而用户的回滚一定是根据回滚段的内容进行回滚的。在这里我们要说一下回滚段存储的数据,假如是delete操作,则回滚段将会记录整个行的数据,假如是update,则回滚段只记录被修改了的字段的变化前的数据(前映像),也就是没有被修改的字段是不会被记录的,假如是insert,则回滚段只记录插入记录的rowid。这样假如事务提交,那回滚段中简单标记该事务已经提交;假如是回退,则如果操作是是delete,回退的时候把回滚段中数据重新写回数据块,操作如果是update,则把变化前数据修改回去,操作如果是insert,则根据记录的rowid 把该记录删除。
下面我们要讲DBWN如何来写数据文件,在写数据文件前首先要找到可写的空闲数据块,ORACLE中空闲数据块可以通过FREELIST或BITMAP来维护,它们位于一个段的头部用来标识当前段中哪些数据块可以进行INSERT。在本地管理表空间中ORACLE自动管理分配给段的区的大小,区的分配信息存储在组成表空间的数据文件的头部,而数据字典管理的表空间用户可以在创建时决定区的大小,并且区的分配信息是存储在数据字典中的,只在本地管理的表空间中才能选用段自动管理,采用自动段空间管理的本地管理表空间中的段中的空闲数据块的信息就存放在段的头部并且使用位图来管理,采用手动管理的本地管理表空间中的段和数据字典管理的表空间中的段中的空闲数据块的管理都使用位于段头部的空闲列表来管理,空闲列表的工作方式:首先一个空的数据块被加入空闲列表,当其中空闲空间小于PCTFREE设置的值之后,这个块从空闲列表删除,当这个块中的内容降至PCTUSED设置的值之下后,这个数据块被再次加入空闲列表,位于空闲列表中的数据块都是可以向其中INSERT的块,当一个块移出了空闲列表,但只要其中还有保留空间就可以进行UPDATE,当对其中一行UPDATE一个大数据时,如果当前块不能完全放下整个行,只会把整个行迁移到一个新的数据块,并在原块位置留下一个指向新块的指针,这叫行迁移。如果一个数据块可以INSERT,当插入一个当前块装不下的行时,这个行会溢出到两个或两个几上的块中,这叫行链接。如果用户的动作是INSERT 则服务器进程会先锁定FREELIST,然后找到空闲块的地址,再释放FREELIST,当多个服务器进程同时想要锁定FREELIST时即发生FREELIST的争用,可以在非采用自动段空间管理的表空间中创建表时指定FREELIST的个数,默认为1,如果是在采用自动段空间管理的表空间中创建表,即使指定了FREELIST也会被忽略,因为此时将使用BITMAP而不是FREELIST来管理段中的空闲空间。如果用户动作是UPDATE服务器进程将不会使用到FREELIST和BITMAP,因为不要去寻找一个空闲块,而使用锁的队列。
下面来讲一下ORACLE锁的机制,ORACLE分锁存器和锁两种。锁存器是用来保护对内存结构的访问,比如对DB BUFFER中块的锁存器申请,只有在DBWN完成后,这些DB BUFFER块被解锁。然后用于其它的申请。锁存器不可以在进程间共享,锁存器的申请要么成功要么失败,没有锁存器申请队列。主要的锁存器有SHARED POOL锁存器,LIBRARY CACHE锁存器,CACHE BUFFERS LRU CHAIN锁存器,CACHE BUFFERS CHAINS 锁存器,REDO ALLOCATION 锁存器,REDO COPY 锁存器。ORACLE的锁是用来保护数据访问的,锁的限制比锁存器要更宽松,比如,多个用户在修改同一表的不同行时,可以共享一个表上的一个锁,锁的申请可以按照被申请的顺序来排队等候,然后依次应用,这种排队机制叫做队列(ENPUEUE),如果两个服务器进程试图对同一表的同一行进行加锁,则都进入锁的申请队列,先进的加锁成功,后面的进程要等待,直到前一个进程解锁才可以加锁,这叫做锁的争用,而且一旦加锁成功,这个锁将一直保持到用户发出COMMIT或ROOLBACK命令为止。如果两个用户锁定各自的一行并请求对方锁定的行的时候将发生无限期等待即死锁,死锁的发生都是由于锁的争用而不是锁存器的争用引起的,ORACLE在遇到死锁时,自动释放其中一个用户的锁并回滚此用户的改变。正常情况下发生锁的争用时,数据的最终保存结果由SCN来决定哪个进程的更改被最终保存。两个用户的服务器进程在申请同一表的多个行的锁的时候是可以交错进入锁的申请队列的。只有其中发生争用才会进行等待。创建表时指定的MAXTRANS参数决了,表中的一个数据块最多可以被几个事务同时锁定。
下面是几个关于回滚段和死锁的事例:
有表:Test (id number(10)) 有记录1000000条
一,大SELECT,小UPDATE
A会话----Select * from test;----设scn=101----执行时间09:10:11
B会话-----Update test set id=9999999 where id=1000000----设scn=102-----执行时间09:10:12
我们会发现B会话会在A会话前完成,A会话中显示的ID=100000是从回滚段中读取的,因为A会话在读到ID=1000000所在的BLOCK时发现BLOCK上有事务信息,因此要从回滚段中读,如果UPDATE在SELECT读到此BLOCK之前已经COMMIT,则SELECT 读到此BLOCK时发现其BLOCK上没有事务信息,但是会发现其BLICK的SCN比SELECT自己的SCN大,因此也会从回滚段中读取。因此是否从回滚段读一是看是否有事务信息二是比较SCN大小。如果B会话在A会话结束前连续多次对同一条记录UPDATE并COMMIT,那么在回滚段中将记录多个“前映像”,而每个“前映像”中不但包括了原BLOCK的数据和SCN也记录了“前前映像”的回滚段地址,因此A会话在查询到被UPDATE过的BLOCK时,会根据BLOCK记录的回滚段的地址,找到回滚段中的“前映像”,发现这个“前映像”的SCN也比自己的大,因此将根据这个“前映像”中记录的“前前映像”的回滚段地址,在回滚段中找到“前前映像”,再与这个“前前映像”比较SCN,如果比自己小就读取,如果还比自己大,则重复以上步骤,直到找到比自己SCN小的“前…前映像”为止,如果找不到,就会报ORA-01555快照太旧这个错误。
二、大UPDATE,小SELECT
A会话----Update test set id=1;----设scn=101----执行时间09:10:11
B会话-----select * from test where id=1000000----设scn=102-----执行时间09:10:12
我们会发现B会话会在A会话前完成,B会话中显示的ID=1000000是从BLOCK中直接读取的,因为B会话在读到ID=1000000所在的BLOCK时,A会话还没有来得及对其锁定,因此B会话既不会发现BLOCK上有事务信息,也不会发现BLOCK上的SCN比SELECT的大,因此会从BLOCK中直接读取,如果SELECT在UPDATE锁定此BLOCK后才发出,B会话读到此BLOCK时发现其BLOCK上有事务信息,因此会从回滚段中读取。
三、大UPDATE,小UPDATE
A会话----Update test set id=1;----设scn=101----执行时间09:10:11
B会话1-----Update test set id=999999 where id=1000000----设scn=102-----执行时间09:10:12
B会话2----- select * from test where id=2----设scn=103-----执行时间09:10:14
B会话3----- update test set id=3 where id=2----设scn=104-----执行时间09:10:15
我们会发现B会话1会完成,A会话将一直等待,因为B会话1会先于A会话锁定ID=1000000所在的BLOCK,并改写头部的事务信息,A会话在试图锁定此BLOCK时,发现其上有事务信息,将会一直等待B会话1事务结束后再行锁定, B会话2查询到的ID=2是从回滚段中读取的而不是从BLOCK中直接读出来的。因为A会话已将ID=2的BLOCK锁定,并写入了回滚段,从B会话3可以证明这一点,B会话3发出后,B会话3会收到死锁的信息,死锁的原因是A会话在等待B会话对ID=1000000所在的BLOCK解锁,现在B会话又在等待A会话对ID=2所在的BLOCK解锁,因此形成死锁,因此证明ID=2所在的BLOCK已被A会话锁定,然后A会话也会收到死锁的信息
posted @
2010-06-28 10:42 xzc 阅读(169) |
评论 (0) |
编辑 收藏
file_count=`wc -l /odsstatfs/groupfile/${file_name} | awk '{print $1}'`
echo "文件行数:${file_count}"
#文件大小
file_size=`ls -l /odsstatfs/groupfile/${file_name} | awk '{print $5}'`
echo "文件大小:${file_size}"
总结了一下有五种方法:
现在有一个a文件,共有55行
第一种:
# awk '{print NR}' a|tail -n1
55
第二种:
begincwcw兄的这个:
# awk 'END{print NR}' a
55
第三种:
# grep -n "" a|awk -F: '{print '}|tail -n1
55
第四种:
honbj兄的也不错:
# sed -n '$=' a
55
第五种
# wc -l a|awk '{print }'
55
第六种
#cat a |wc -l
55
| 文件内容统计命令:wc |
| http://www.fanqiang.com (2001-05-08 14:24:15) |
wc命令的功能为统计指定文件中的字节数、字数、行数, 并将统计结果显示输出。
语法:wc [选项] 文件…
说明:该命令统计给定文件中的字节数、字数、行数。如果没有给出文件名,则从标准输入读取。wc同时也给出所有指定文件的总统计数。字是由空格字符区分开的最大字符串。
该命令各选项含义如下:
- c 统计字节数。
- l 统计行数。
- w 统计字数。
这些选项可以组合使用。
输出列的顺序和数目不受选项的顺序和数目的影响。总是按下述顺序显示并且每项最多一列。
行数、字数、字节数、文件名
如果命令行中没有文件名,则输出中不出现文件名。
例如:
$ wc - lcw file1 file2
4 33 file1
7 52 file2
11 11 85 total
省略任选项-lcw,wc命令的执行结果与上面一样。 |
|
posted @
2010-04-22 14:56 xzc 阅读(4045) |
评论 (0) |
编辑 收藏一、特殊符号ascii定义
制表符 chr(9)
换行符 chr(10)
回车符 chr(13)
二、嵌套使用repalce,注意每次只能提交一个符号,如先回车再换行
select REPLACE(gg, chr(10), '') from dual
要注意chr(13) | | chr(10) 此类结合使用的情况比较多,回车换行在notepad中是比较好看点的,所以要考虑此种情况
select translate(string,chr(13)||chr(10),',') from dual;
1、例子一
create table TEST_1
(
VA VARCHAR2(10),
VB NUMBER(2),
VC VARCHAR2(10),
VD NUMBER(11,2),
VE NUMBER(11,4),
VCL CLOB
);
SQL> select vb,vc,replace(vc,chr(10),'') as TT, translate(vc,chr(10),',') from test_1;
VB VC TT TRANSLATE(VC,CHR(10),',')
--- ---------- ---------- -------------------------
0 Aaaaaaaaa Aaaaaaaaa Aaaaaaaaa
1 Aaaaaaaaa Aaaaaaaaa Aaaaaaaaa
2 大Ba 大Babc带 大Ba,b,c带
b
c带
3 C C C
1 D D D
5 A A A
5 A A A
0 A A A
0 A A A
2、例子二
要注意chr(13) | | chr(10) 此类结合使用的情况比较多,回车换行在notepad中是比较好看点的,所以要考虑此种情况
select vb,vc,replace(vc,chr(10),'') as TT, translate(vc,chr(13)||chr(10),',') from test_1;
SQL> select vb,vc,replace(vc,chr(10),'') as TT, translate(vc,chr(13)||chr(10),',') from test_1;
VB VC TT TRANSLATE(VC,CHR(13)||CHR(10),
--- ---------- ---------- ------------------------------
0 Aaaaaaaaa Aaaaaaaaa Aaaaaaaaa
1 Aaaaaaaaa Aaaaaaaaa Aaaaaaaaa
2 大Ba 大Babc带 大Babc带
b
c带
3 C C C
1 D D D
5 A A A
5 A A A
0 A A A
0 A A A
11 rows selected
三、对于字符大对象的符号处理
对于clob字段中的符号处理,先to_char然后一样的处理
SQL> select to_char(vcl),replace(to_char(vcl),chr(10),'[]') from test_1;
TO_CHAR(VCL) REPLACE(TO_CHAR(VCL),CHR(10),'
-------------------------------------------------------------------------------- --------------------------------------------------------------------------------
嵌套使用repalce,注意每次只能提交一个符号,如先回车再换行 嵌套使用repalce,注意每次只能提交一个符号,如先回车再换行[]select REPLACE(gg, chr(10), '') from dual[]sel
select REPLACE(gg, chr(10), '') from dual
select translate(string,chr(13)||chr(10),',') from dual;
func:
2.2.1 单记录字符函数
函 数 说 明
ASCII 返回对应字符的十进制值
CHR 给出十进制返回字符
CONCAT 拼接两个字符串,与 || 相同
INITCAT 将字符串的第一个字母变为大写
INSTR 找出某个字符串的位置
INSTRB 找出某个字符串的位置和字节数
LENGTH 以字符给出字符串的长度
LENGTHB 以字节给出字符串的长度
LOWER 将字符串转换成小写
LPAD 使用指定的字符在字符的左边填充
LTRIM 在左边裁剪掉指定的字符
RPAD 使用指定的字符在字符的右边填充
RTRIM 在右边裁剪掉指定的字符
REPLACE 执行字符串搜索和替换
SUBSTR 取字符串的子串
SUBSTRB 取字符串的子串(以字节)
SOUNDEX 返回一个同音字符串
TRANSLATE 执行字符串搜索和替换
TRIM 裁剪掉前面或后面的字符串
UPPER 将字符串变为大写
NVL 以一个值来替换空值
ASCII(<c1>)
<c1>是字符串。返回与指定的字符对应的十进制数。
SQL> select ascii('A') A,ascii('a') a,ascii('0') zero,ascii(' ') space from dual;
A a ZERO SPACE
---------- ---------- ---------- ----------
65 97 48 32
SQL> select ascii('赵') zhao,length('赵') leng from dual;
ZHAO LENG
---------- ----------
54740 1
CHR(<I>[NCHAR])
给出整数,返回对应字符。如:
SQL> select chr(54740) zhao,chr(65) chr65 from dual;
ZH C
-- -
赵 A
CONCAT(<c1>,<c2>)
SQL> select concat('010-','8801 8159')||'转23' 赵元杰电话 from dual;
赵元杰电话
-----------------
010-8801 8159 转23
INITCAP(<c1>)
返回字符串c1 并第一个字母变为大写。例如:
SQL> select initcap('simth') upp from dual;
UPP
-----
Simth
INSTR(<c1>,<c2>[,<I>[,<j>] ] )
在一个字符串中搜索指定的字符,返回发现指定的字符的位置。
C1: 被搜索的字符串
C2: 希望搜索的字符串
I: 搜索的开始位置,缺省是1
J: 出现的位置,缺省是1。
SQL> SELECT INSTR ('Oracle Training', 'ra', 1, 2) "Instring" FROM DUAL;
Instring
----------
9
INSTRB(<c1>,<c2>[,<I>[,<j>] ] )
除了返回的字节外 ,与INSTR 相同,
LENGTH( <c> )
返回字符串 c 的长度。
SQL> l
1 select name,length(name),addr,length(addr),sal,length(to_char(sal))
2* from nchar_tst
SQL> /
NAME LENGTH(NAME) ADDR LENGTH(ADDR) SAL LENGTH(TO_CHAR(SAL))
------ ------------ ---------------- ------------ ---------- ----------------
赵元杰 3 北京市海淀区 6 99999.99 8
LENGTHB( <c> )
以字节返回字符串的字节数。
SQL> select name,lengthb(name),length(name) from nchar_tst;
NAME LENGTHB(NAME) LENGTH(NAME)
------ ------------- ------------
赵元杰 6 3
LOWER ( <c> )
返回字符串并将所有字符变为小写。
SQL> select lower('AaBbCcDd') AaBbCcDd from dual;
AABBCCDD
--------
aabbccdd
UPPER( <c>)
与 LOWER 相反,将给出字符串变为大写。如:
SQL> select upper('AaBbCcDd') AaBbCcDd from dual;
AABBCCDD
--------
AABBCCDD
RPAD 和LPAD(粘贴字符)
RPAD(string,Length[,'set'])
LPAD(string,Length[,'set'])
RPAD在列的右边粘贴字符;
LPAD在列的左边粘贴字符。
例 1:
SQL>select RPAD(City,35,'.'),temperature from weather;
RPAD(City,35,'.') temperature
-------------------------- ----------------
CLEVELAND...... 85
LOS ANGELES.. 81
.........................
(即不够 35 个字符用'.'填满)
LTRIM(左截断)RTRIM(右截断) 函数
LTRIM (string [,’set’])
Left TRIM (左截断)删去左边出现的任何set 字符。
RTRIM (string [,’set’])
Right TRIM (右截断)删去右边出现的任何set 字符。
例1:
SELECT RTRIM (‘Mother Theresa, The’, ‘The’) “Example of Right
Trimming” FROM DUAL;
Example of Right
----------------
Mother Theresa,
SUBSTR Substr(string,start[,Count])
取子字符串中函数
对字串 (或字段),从 start字符 开始,连续取 count 个字符并返回结果,如果没有指 count
则一直取到尾。
select phone,substr(phone,1,3) || ‘0’ || substr(phone,4)
from telecommunication where master ’中国电信’;
SUBSTRB(string,start[,Count])
对字串 (或字段),从 start字节 开始,连续取 count 个字节并返回结果,如果没有指 count
则一直取到尾。
REPLACE (‘string’ [,’string_in’,’string_out’])
String: 希望被替换的字符串或变量。
String_in: 被替换字符串。
String_out: 要替换字符串。
SQL> select replace('Informaix 中国公司','Informaix','IBM Informix')
2 IBM 数据库 from dual;
IBM 数据库
--------------------
IBM Informix 中国公司
SOUNDEX( <c> )
返回一个与给定的字符串读音相同的字符串(不管拼写是否一样)。
SELECT DPL_NAME FROM DENIED_PARTIES_LIST WHERE
SOUNDEX(DPL_NAME) = SOUNDEX(‘Saddam Hussain’) ;
DPL_NAME
----------------------------------------------
Al Husseni
Sadda Al Sada.
REPLACE (‘string’ [,’string_in’,’string_out’])
String:希望被替换的字符串或变量。
String_in: 被替换字符串。
String_out: 要替换字符串。
SELECT REPLACE (‘Oracle’, ‘Or’, ‘Mir’) “Example “ FROM DUAL;
Example
-------
Miracle
TRIM ( [<leading>] <trailing> FROM <trim_char> )
RIM可以使你对给定的字符串进行裁剪(前面,后面或前后)。
z 如果指定 LEADING, Oracle 从trim_char 中裁剪掉前面的字符;
z 如果指定TRAILING, Oracle 从trim_char 中裁剪掉尾面的字符;
z 如果指定两个都指定或一个都没有给出,Oracle从trim_char 中裁剪掉前面及尾面的字
符;
z 如果不指定 trim_character, 缺省为空格符;
z 如果只指定trim_source, Oracle Oracle从trim_char 中裁剪掉前面及尾面的字符。
例子:将下面字符串中的前面和后面的‘0 ‘字符都去掉:
SELECT TRIM (0 FROM 0009872348900) "TRIM Example" FROM DUAL;
TRIM example
--------------------------------
98723489
语法:TRANSLATE(expr,from,to)
om,to) expr: 代表一串字符,
expr: 代表一串字符,from 与 to 是从左到右一一对应的关系,如果不能对应,则视为空值。
举例:
select translate('abcbbaadef','ba','#@') from dual (b将被#替代,a将被@替代)
select translate(ab
select translate('abcbbaadef','bad','#@') from dual (b将被#替代,a将被@替代,d对应的值是空值,将被移走)
因此:结果依次为:@#c##@@def 和@#c##@@ef
posted @
2010-04-22 11:10 xzc 阅读(10664) |
评论 (0) |
编辑 收藏一个大型文件(总之不小),要求删除该文件的最后一行,求一种效率比较高的解决方法。
测试用的文本文件800M
1.用sed解决,此法最易想,但也是最笨的一个,
解决方法来自问题的提出者:
sed -e '$d' input.file > output.file
用time测试了一下,效率是相当的低!
real 2m51.099s
user 2m1.268s
sys 0m4.260s
2.用head解决,此法比sed有一个质的的提升,提升来自增大了缓存,不过依然没有抓住问题的本质,还是做了不少无用功!解决方法来时cu上的热心网友。
head -n-1 input.file > output.file
real 0m23.687s
user 0m0.212s
sys 0m4.668s
3.用vim解决,此法很别处心裁,这应该是遇到这个问题的最先想到的一种。解决方法来自我加的unix like群里的一个叫石仔的管理员!
vim + result
dd
这个没测试,感觉效率和head法差不多,加载太慢!
4.重量级要到场了,感谢cu版主的这个脚本,只能用四个字形容!五体投地!
:|dd of=input.file seek=1 bs=$(($(find input.file -printf "%s")-$(tail -1 input.file|wc -c)))
或者是
:|dd of=input.file seek=1 bs=$(($(stat -c%s input.file)-$(tail -1 input.file|wc -c)))
测试了一下!
real 0m0.123s
user 0m0.004s
sys 0m0.012s
5.感觉这个用c写效率最高,但显然,代码也是最长的,我实现了代码,
测试了一下,
real 0m0.002s
user 0m0.000s
sys 0m0.000s
代码如下:
|
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <stdlib.h>
#define GUESS_LINE_SIZE 80
int get_line_size(char *ptr);
int
main(int argc, char *argv[])
{
char buf[GUESS_LINE_SIZE];
int line_len, fd;
struct stat stat_buf;
fd = open(argv[1], O_RDWR);
lstat(argv[1], &stat_buf);
lseek(fd, -GUESS_LINE_SIZE, SEEK_END);
read(fd, buf, GUESS_LINE_SIZE) ;
line_len = get_line_size(buf);
truncate(argv[1], stat_buf.st_size - line_len);
exit(0);
}
int
get_line_size(char *ptr)
{
int line_len = 0, i = GUESS_LINE_SIZE - 2;/*buf中的最后一个字符为'\n'*/
while (*(ptr + i) != '\n') {
//printf("%c", *(ptr + i));
i--;
line_len++;
}
return line_len;
}
|
posted @
2010-04-21 18:45 xzc 阅读(3285) |
评论 (2) |
编辑 收藏在linux下获取时间字符串
命令 date
# 以yyyymmdd格式输出23天之前现在这个时刻的时间
$ date +%Y%m%d –date=’23 days ago’
$ date -u
Thu Sep 28 09:32:04 UTC 2006
$ date -R
Thu, 28 Sep 2006 17:32:28 +0800
# 测试十亿分之一秒
$ date +’%Y%m%d %H:%M:%S.%N’;date +’%Y%m%d %H:%M:%S.%N’;date +’%Y%m%d %H:%M:%S.%N’;date +’%Y%m%d %H:%M:%S.%N’
20060928 17:44:20.906805000
20060928 17:44:20.909188000
20060928 17:44:20.911535000
20060928 17:44:20.913886000
date 参考
$ date –help
Usage: date [OPTION]… [+FORMAT]
or: date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
Display the current time in the given FORMAT, or set the system date.
-d, –date=STRING display time described by STRING, not `now’
# such as ‘n days ago |1 month ago|n years ago’
-f, –file=DATEFILE like –date once for each line of DATEFILE
-ITIMESPEC, –iso-8601[=TIMESPEC] output date/time in ISO 8601 format.
TIMESPEC=`date’ for date only,
`hours’, `minutes’, or `seconds’ for date and
time to the indicated precision.
–iso-8601 without TIMESPEC defaults to `date’.
-r, –reference=FILE display the last modification time of FILE
-R, –rfc-2822 output RFC-2822 compliant date string
-s, –set=STRING set time described by STRING
-u, –utc, –universal print or set Coordinated Universal Time
–help display this help and exit
–version output version information and exit
FORMAT controls the output. The only valid option for the second form
specifies Coordinated Universal Time. Interpreted sequences are:
%% 输出%符号 a literal %
%a 当前域的星期缩写 locale’s abbreviated weekday name (Sun..Sat)
%A 当前域的星期全写 locale’s full weekday name, variable length (Sunday..Saturday)
%b 当前域的月份缩写 locale’s abbreviated month name (Jan..Dec)
%B 当前域的月份全称 locale’s full month name, variable length (January..December)
%c 当前域的默认时间格式 locale’s date and time (Sat Nov 04 12:02:33 EST 1989)
%C n百年 century (year divided by 100 and truncated to an integer) [00-99]
%d 两位的天 day of month (01..31)
%D 短时间格式 date (mm/dd/yy)
%e 短格式天 day of month, blank padded ( 1..31)
%F 文件时间格式 same as %Y-%m-%d
%g the 2-digit year corresponding to the %V week number
%G the 4-digit year corresponding to the %V week number
%h same as %b
%H 24小时制的小时 hour (00..23)
%I 12小时制的小时 hour (01..12)
%j 一年中的第几天 day of year (001..366)
%k 短格式24小时制的小时 hour ( 0..23)
%l 短格式12小时制的小时 hour ( 1..12)
%m 双位月份 month (01..12)
%M 双位分钟 minute (00..59)
%n 换行 a newline
%N 十亿分之一秒 nanoseconds (000000000..999999999)
%p 大写的当前域的上下午指示 locale’s upper case AM or PM indicator (blank in many locales)
%P 小写的当前域的上下午指示 locale’s lower case am or pm indicator (blank in many locales)
%r 12小时制的时间表示(时:分:秒,双位) time, 12-hour (hh:mm:ss [AP]M)
%R 24小时制的时间表示 (时:分,双位)time, 24-hour (hh:mm)
%s 自基础时间 1970-01-01 00:00:00 到当前时刻的秒数 seconds since `00:00:00 1970-01-01 UTC’ (a GNU extension)
%S 双位秒 second (00..60); the 60 is necessary to accommodate a leap second
%t 横向制表位(tab) a horizontal tab
%T 24小时制时间表示 time, 24-hour (hh:mm:ss)
%u 数字表示的星期(从星期一开始 1-7)day of week (1..7); 1 represents Monday
%U 一年中的第几周星期天为开始 week number of year with Sunday as first day of week (00..53)
%V 一年中的第几周星期一为开始 week number of year with Monday as first day of week (01..53)
%w 一周中的第几天 星期天为开始 0-6 day of week (0..6); 0 represents Sunday
%W 一年中的第几周星期一为开始 week number of year with Monday as first day of week (00..53)
%x 本地日期格式 locale’s date representation (mm/dd/yy)
%X 本地时间格式 locale’s time representation (%H:%M:%S)
%y 两位的年 last two digits of year (00..99)
%Y 年 year (1970…)
%z RFC-2822 标准时间格式表示的域 RFC-2822 style numeric timezone (-0500) (a nonstandard extension)
%Z 时间域 time zone (e.g., EDT), or nothing if no time zone is determinable
By default, date pads numeric fields with zeroes. GNU date recognizes
the following modifiers between `%’ and a numeric directive.
`-’ (hyphen) do not pad the field
`_’ (underscore) pad the field with spaces
posted @
2010-04-20 10:55 xzc 阅读(6957) |
评论 (1) |
编辑 收藏
Oracle中的锁定可以分为几类:
1、DML lock(data lock),
2、DDL lock(dictionary lock)
3、internal lock/latch。
DML lock又可以分为row lock和table lock。row lock在select.. for update/insert/update/delete时隐式自动产生,而table lock除了隐式产生,也可以调用lock table <table_name> in </table_name> name来显示锁定。
如果不希望别的session lock/insert/update/delete表中任意一行,只允许查询,可以用lock table table_name in exclusive mode。(X)这个锁定模式级别最高,并发度最小。
如果允许别的session查询或用select for update锁定记录,不允许insert/update/delete,可以用
lock table table_name in share row exclusive mode。(SRX)
如果允许别的session查询或select for update以及lock table table_name in share mode,只是不允许insert/update/delete,可以用
lock table table_name in share mode。(share mode和share row exclusive mode的区别在于一个是非抢占式的而另一个是抢占式的。进入share row exclusive mode后其他session不能阻止你insert/update/delete,而进入share mode后其他session也同样可以进入share mode,进而阻止你对表的修改。(S)
还有两种锁定模式,row share(RS)和row exclusive(RX)。他们允许的并发操作更多,一般直接用DML语句自动获得,而不用lock语句。
详细参考concepts文档中的"Type Of Locks":
http://download-uk.oracle.com/docs/cd/B10501_01/server.920/a96524/c21cnsis.htm#2937
-------------------------------------
怎么unlock table 解锁
方法一、kill session:
SQL> select object_id,session_id from v$locked_object; //注意session_id 就是上锁的 session标志
SQL> select username,sid,SERIAL# from v$session where sid=。。; //这里的SID = session_id
SQL> alter system kill session 'id,serial#'; //杀死该session
方法二、rollback/commit 终止事务处理
posted @
2010-04-02 16:05 xzc 阅读(7234) |
评论 (1) |
编辑 收藏二元比较操作符,比较变量或者比较数字.注意数字与字符串的区别.
整数比较
-eq 等于,如:if [ "$a" -eq "$b" ]
-ne 不等于,如:if [ "$a" -ne "$b" ]
-gt 大于,如:if [ "$a" -gt "$b" ]
-ge 大于等于,如:if [ "$a" -ge "$b" ]
-lt 小于,如:if [ "$a" -lt "$b" ]
-le 小于等于,如:if [ "$a" -le "$b" ]
< 小于(需要双括号),如:(("$a" < "$b"))
<= 小于等于(需要双括号),如:(("$a" <= "$b"))
> 大于(需要双括号),如:(("$a" > "$b"))
>= 大于等于(需要双括号),如:(("$a" >= "$b"))
字符串比较
= 等于,如:if [ "$a" = "$b" ]
== 等于,如:if [ "$a" == "$b" ],与=等价
注意:==的功能在[[]]和[]中的行为是不同的,如下:
1 [[ $a == z* ]] # 如果$a以"z"开头(模式匹配)那么将为true
2 [[ $a == "z*" ]] # 如果$a等于z*(字符匹配),那么结果为true
3
4 [ $a == z* ] # File globbing 和word splitting将会发生
5 [ "$a" == "z*" ] # 如果$a等于z*(字符匹配),那么结果为true
一点解释,关于File globbing是一种关于文件的速记法,比如"*.c"就是,再如~也是.
但是file globbing并不是严格的正则表达式,虽然绝大多数情况下结构比较像.
!= 不等于,如:if [ "$a" != "$b" ]
这个操作符将在[[]]结构中使用模式匹配.
< 小于,在ASCII字母顺序下.如:
if [[ "$a" < "$b" ]]
if [ "$a" \< "$b" ]
注意:在[]结构中"<"需要被转义.
> 大于,在ASCII字母顺序下.如:
if [[ "$a" > "$b" ]]
if [ "$a" \> "$b" ]
注意:在[]结构中">"需要被转义.
具体参考Example 26-11来查看这个操作符应用的例子.
-z 字符串为"null".就是长度为0.
-n 字符串不为"null"
注意:
使用-n在[]结构中测试必须要用""把变量引起来.使用一个未被""的字符串来使用! -z
或者就是未用""引用的字符串本身,放到[]结构中。虽然一般情况下可
以工作,但这是不安全的.习惯于使用""来测试字符串是一种好习惯.
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/zhrmghl/archive/2006/10/22/1345115.aspx
posted @
2010-04-02 14:17 xzc 阅读(1188) |
评论 (0) |
编辑 收藏
一、最简单的shell里调用sqlplus.
$ vi test1.sh
#!/bin/bash
sqlplus -S /nolog > result.log <<EOF
set heading off feedback off pagesize 0 verify off echo off
conn u_test/iamwangnc
select * from tab;
exit
EOF
$ chmod +x test1.sh
$ ./test1.sh
二、把sqlplus执行结果传递给shell方法一
注意sqlplus段使用老板键`了, 赋变量的等号两侧不能有空格.
$ vi test2.sh
#!/bin/bash
VALUE=`sqlplus -S /nolog <<EOF
set heading off feedback off pagesize 0 verify off echo off numwidth 4
conn u_test/iamwangnc
select count(*) from tab;
exit
EOF`
if [ "$VALUE" -gt 0 ]; then
echo "The number of rows is $VALUE."
exit 0
else
echo "There is no row in the table."
fi
$ chmod +x test2.sh
$ ./test2.sh
三、把sqlplus执行结果传递给shell方法二
注意sqlplus段使用 col .. new_value .. 定义了变量并带参数exit, 然后自动赋给了shell的$?
$ vi test3.sh
#!/bin/bash
sqlplus -S /nolog > result.log <<EOF
set heading off feedback off pagesize 0 verify off echo off numwidth 4
conn u_test/iamwangnc
col coun new_value v_coun
select count(*) coun from tab;
exit v_coun
EOF
VALUE="$?"
echo "The number of rows is $VALUE."
$ chmod +x test3.sh
$ ./test3.sh
四、把shell程序参数传递给sqlplus
$1表示第一个参数, sqlplus里可以直接使用, 赋变量的等号两侧不能有空格不能有空格.
$ vi test4.sh
#!/bin/bash
NAME="$1"
sqlplus -S u_test/iamwangnc <<EOF
select * from tab where tname = upper('$NAME');
exit
EOF
$ chmod +x test4.sh
$ ./test4.sh ttt
五、为了安全要求每次执行shell都手工输入密码
$ vi test5.sh
#!/bin/bash
echo -n "Enter password for u_test:"
read PASSWD
sqlplus -S /nolog <<EOF
conn u_test/$PASSWD
select * from tab;
exit
EOF
$ chmod +x test5.sh
$ ./test5.sh
六、为了安全从文件读取密码
对密码文件设置权限, 只有用户自己才能读写.
$ echo 'iamwangnc' > u_test.txt
$ chmod g-rwx,o-rwx u_test.txt
$ vi test6.sh
#!/bin/bash
PASSWD=`cat u_test.txt`
sqlplus -S /nolog <<EOF
conn u_test/$PASSWD
select * from tab;
exit
EOF
$ chmod +x test6.sh
$ ./test6.sh
--End--
posted @
2010-04-01 12:05 xzc 阅读(4788) |
评论 (0) |
编辑 收藏
shell中数组的下标默认是从0开始的
1. 将字符串存放在数组中,获取其长度
#!/bin/bash
str="a b --n d"
array=($str)
length=${#array[@]}
echo $length
for ((i=0; i<$length; i++))
do
echo ${array[$i]}
done
along@along-laptop:~/code/shell/shell/mycat/testfile$ ./test.sh
4
a
b
--n
d
打印字符串:
[root@mc2 tmp]# cat test.sh
#!/bin/bash
str="a b c"
for i in $str
do
echo $i
done
[root@mc2 tmp]# cat array.sh
#!/bin/bash
str="a b c"
array=($str)
for ((i=0;i<${#array[@]};i++))
do
echo ${array[$i]}
done
结果:
a
b
c
2. 字符串用其他字符分隔时
#!/bin/bash
str2="a#b#c"
a=($(echo $str2 | tr '#' ' ' | tr -s ' '))
length=${#a[@]}
for ((i=0; i<$length; i++))
do
echo ${a[$i]}
done
#echo ${a[2]}
along@along-laptop:~/code/shell/shell/mycat/testfile$ ./test.sh
a
b
c
3. 数组的其他操作
#!/bin/bash
str="a b --n dd"
array=($str)
length=${#array[@]}
#直接输出的是数组的第一个元素
echo $array
#用下标的方式访问数组元素
echo ${array[1]}
#输出这个数组
echo ${array[@]}
#输出数组中下标为3的元素的长度
echo ${#array[3]}
#输出数组中下标为1到3的元素
echo ${array[@]:1:3}
#输出数组中下标大于2的元素
echo ${array[@]:2}
#输出数组中下标小于2的元素
echo ${array[@]::2}
along@along-laptop:~/code/shell/shell/mycat/testfile$ ./test.sh
a
b
a b --n dd
2
b --n dd
--n dd
a b
4. 遍历访问一个字符串(默认是以空格分开的,当字符串是由其他字符分隔时可以参考 2)
#!/bin/bash
str="a --m"
for i in $str
do
echo $i
done
along@along-laptop:~/code/shell/shell/mycat/testfile$ ./para_test.sh
a
--m
5. 如何用echo输出一个 字符串str="-n". 由于-n是echo的一个参数,所以一般的方法echo "$str"是无法输出的.
解决方法可以有:
echo x$str | sed 's/^x//'
echo -ne "$str\n"
echo -e "$str\n\c"
printf "%s\n" $str (这样也可以) |
posted @
2010-03-31 15:28 xzc 阅读(2983) |
评论 (1) |
编辑 收藏来源地址: http://hi.bccn.net/space-21499-do-blog-id-13524.html
shell for 循环指令使用
2008-11-02 22:34
for可以使一些不支持通配符的命令对一系列文件进行操作。在WIN9X中,TYPE命令(显示文件内容)是不支持*.txt这种格式的(WIN2K开始TYPE已支持通配)。遇到类似情况就可以用FOR:
for %a in (*.txt) do type %a
这些还不是FOR最强大的功能。我认为它最强大的功能,表现在以下这些高级应用:
1. 可以用 /r 参数遍历整个目录树
2. 可以用 /f 参数将文本文件内容作为循环范围
3. 可以用 /f 参数将某一命令执行结果作为循环范围
4. 可以用 %~ 操作符将文件名分离成文件名、扩展名、盘符等独立部分
现分别举例说明如下:
1. 用 /r 遍历目录树
当用 *.* 或 *.txt 等文件名通配符作为 for /r 的循环范围时,可以对当前目录下所有文件(包括子目录里面的文件)进行操作。举个例子,你想在当前目录的所有txt文件(包括子目录)内容中查找"bluebear"字样,但由于find本身不能遍历子目录,所以我们用for:
for /r . %a in (*.txt) do @find "bluebear" %a
find 前面的 @ 只是让输出结果不包括 find 命令本身。这是DOS很早就有的功能。和FOR无关。
当用 . 作为循环范围时,for 只将子目录的结构(目录名)作为循环范围,而不包括里面的文件。有点象 TREE 命令,不过侧重点不同。TREE 的重点是用很漂亮易读的格式输出,而FOR的输出适合一些自动任务,例如,我们都知道用CVS管理的项目中,每个子目录下都会有一个CVS目录,有时在软件发行时我们想把这些CVS目录全部去掉:
for /r . %a in (.) do @if exist %aCVS rd /s /q %aCVS
先用 if exist 判断一下,是因为 for 只是机械的对每个目录进行列举,如果有些目录下面没有CVS也会被执行到。用 if exist 判断一下比较安全。
这种删除命令威力太大,请小心使用。最好是在真正执行以上的删除命令前,将 rd /s /q 换成 @echo 先列出要删出的目录,确认无误后再换回rd /s /q:
for /r . %a in (.) do @if exist %aCVS @echo %aCVS
可能目录中会多出一层 ".",比如 c:proj elease.CVS ,但不会影响命令的执行效果。
2. 将某一文件内容或命令执行结果作为循环范围:
假如你有一个文件 todel.txt,里面是所有要删除的文件列表,现在你想将里面列出的每个文件都删掉。假设这个文件是每个文件名占一行,象这样:
c: empa1.txt
c: empa2.txt
c: empsubdir3.txt
c: empsubdir4.txt
那么可以用FOR来完成:
for /f %a in (todel.txt) do del %a
这个命令还可以更强大。比如你的 todel.txt 并不是象上面例子那么干净,而是由DIR直接生成,有一些没用的信息,比如这样:
Volume in drive D is DATA
Volume Serial Number is C47C-9908
Directory of D: mp
09/26/2001 12:50 PM 18,426 alg0925.txt
12/02/2001 04:29 AM 795 bsample.txt
04/11/2002 04:18 AM 2,043 invitation.txt
4 File(s) 25,651 bytes
0 Dir(s) 4,060,700,672 bytes free
for 仍然可以解出其中的文件名并进行操作:
for /f "skip=5 tokens=5" %a in (todel.txt) do @if exist %a DEL %a
当然,上面这个命令是在进行删除,如果你只是想看看哪些文件将被操作,把DEL换成echo:
for /f "skip=5 tokens=5" %a in (todel.txt) do @if exist %a echo %a
你将看到:
alg0925.txt
bsample.txt
invitation.txt
skip=5表示跳过前5行(就是DIR输出的头部信息),tokens=5表示将每行的第5列作为循环值放入%a,正好是文件名。在这里我加了一个文件存在判断,是因为最后一行的"free"刚好也是第5列,目前还想不出好的办法来滤掉最后两行,所以检查一下可保万无一失。
3. 可以用 /f 参数将某一命令执行结果作为循环范围
非常有用的功能。比如,我们想知道目前的环境变量有哪些名字(我们只要名字,不要值)。可是SET命令的输出是“名字=值”的格式,现在可以用FOR来只取得名字部分:
FOR /F "delims==" %i IN ('set') DO @echo %i
将看到:
ALLUSERSPROFILE
APPDATA
CLASSPATH
CommonProgramFiles
COMPUTERNAME
ComSpec
dircmd
HOMEDRIVE
......
这里是将set命令执行的结果拿来作为循环范围。delims==表示用=作为分隔符,由于FOR /F默认是用每行第一个TOKEN,所以可以分离出变量名。如果是想仅列出值:
FOR /F "delims== tokens=2" %i IN ('set') DO @echo %i
tokens=2和前例相同,表示将第二列(由=作为分隔符)作为循环值。
再来个更有用的例子:
我们知道 date /t (/t表示不要询问用户输入)的输出是象这样的:
Sat 07/13/2002
现在我想分离出日期部分,也就是13:
for /f "tokens=3 delims=/ " %a in ('date /t') do @echo %a
实际上把 tokens后面换成1,2,3或4,你将分别得到Sat, 07, 13和2002。注意delims=/后面还有个空格,表示/和空格都是分隔符。由于这个空格delims必须是/f选项的最后一项。
再灵活一点,象本文开头提到的,将日期用2002-07-13的格式输出:
for /f "tokens=2,3,4 delims=/ " %a in ('date /t') do @echo %c-%a-%b
当tokens后跟多个值时,将分别映射到%a, %b, %c等。实际上跟你指定的变量有关,如果你指定的是 %i, 它们就会用%i, %j, %k等。
灵活应用这一点,几乎没有做不了的事。
4. 可以用 %~ 操作符将文件名分离成文件名、扩展名、盘符等独立部分
这个比较简单,就是说将循环变量的值自动分离成只要文件名,只要扩展名,或只要盘符等等。
例:要将 c:mp3下所有mp3的歌名列出,如果用一般的 dir /b/s 或 for /r ,将会是这样:
g:mp3Archived�-18-01-A游鸿明-下沙游鸿明-01 下沙.mp3
g:mp3Archived�-18-01-A游鸿明-下沙游鸿明-02 21个人.mp3
......
g:mp3Archived�-18-01-A王菲-寓言王菲-阿修罗.mp3
g:mp3Archived�-18-01-A王菲-寓言王菲-彼岸花.mp3
g:mp3Archived�-18-01-A王菲-寓言王菲-不爱我的我不爱.mp3
......
如果我只要歌名(不要路径和".mp3"):
游鸿明-01 下沙
游鸿明-02 21个人
......
王菲-阿修罗
王菲-彼岸花
王菲-不爱我的我不爱
......
那么可以用FOR命令:
for /r g:mp3 %a in (*.mp3) do @echo %~na
凡是 %~ 开头的操作符,都是文件名的分离操作。具体请看 for /? 帮助。
本文举的例子有些可能没有实际用处,或可用其它办法完成。仅用于体现FOR可以不借助其它工具,仅用DOS命令组合,就可完成相当灵活的任务。
posted @
2010-03-31 14:41 xzc 阅读(2985) |
评论 (0) |
编辑 收藏
--简单Case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
这两种方式,可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。
还有一个需要注意的问题,Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
--比如说,下面这段SQL,你永远无法得到“第二类”这个结果
CASE WHEN col_1 IN ( 'a', 'b') THEN '第一类'
WHEN col_1 IN ('a') THEN '第二类'
ELSE'其他' END
下面我们来看一下,使用Case函数都能做些什么事情。
一,已知数据按照另外一种方式进行分组,分析。
有如下数据:(为了看得更清楚,我并没有使用国家代码,而是直接用国家名作为Primary Key)
国家(country) 人口(population)
中国 600
美国 100
加拿大 100
英国 200
法国 300
日本 250
德国 200
墨西哥 50
印度 250
根据这个国家人口数据,统计亚洲和北美洲的人口数量。应该得到下面这个结果。
洲 人口
亚洲 1100
北美洲 250
其他 700
想要解决这个问题,你会怎么做?生成一个带有洲Code的View,是一个解决方法,但是这样很难动态的改变统计的方式。
如果使用Case函数,SQL代码如下:
SELECT SUM(population),
CASE country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END
FROM Table_A
GROUP BY CASE country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END;
同样的,我们也可以用这个方法来判断工资的等级,并统计每一等级的人数。SQL代码如下;
SELECT
CASE WHEN salary <= 500 THEN '1'
WHEN salary > 500 AND salary <= 600 THEN '2'
WHEN salary > 600 AND salary <= 800 THEN '3'
WHEN salary > 800 AND salary <= 1000 THEN '4'
ELSE NULL END salary_class,
COUNT(*)
FROM Table_A
GROUP BY
CASE WHEN salary <= 500 THEN '1'
WHEN salary > 500 AND salary <= 600 THEN '2'
WHEN salary > 600 AND salary <= 800 THEN '3'
WHEN salary > 800 AND salary <= 1000 THEN '4'
ELSE NULL END;
二,用一个SQL语句完成不同条件的分组。
有如下数据
国家(country) 性别(sex) 人口(population)
中国 1 340
中国 2 260
美国 1 45
美国 2 55
加拿大 1 51
加拿大 2 49
英国 1 40
英国 2 60
按照国家和性别进行分组,得出结果如下
国家 男 女
中国 340 260
美国 45 55
加拿大 51 49
英国 40 60
普通情况下,用UNION也可以实现用一条语句进行查询。但是那样增加消耗(两个Select部分),而且SQL语句会比较长。
下面是一个是用Case函数来完成这个功能的例子
SELECT country,
SUM( CASE WHEN sex = '1' THEN
population ELSE 0 END), --男性人口
SUM( CASE WHEN sex = '2' THEN
population ELSE 0 END) --女性人口
FROM Table_A
GROUP BY country;
这样我们使用Select,完成对二维表的输出形式,充分显示了Case函数的强大。
三,在Check中使用Case函数。
在Check中使用Case函数在很多情况下都是非常不错的解决方法。可能有很多人根本就不用Check,那么我建议你在看过下面的例子之后也尝试一下在SQL中使用Check。
下面我们来举个例子
公司A,这个公司有个规定,女职员的工资必须高于1000块。如果用Check和Case来表现的话,如下所示
CONSTRAINT check_salary CHECK
( CASE WHEN sex = '2'
THEN CASE WHEN salary > 1000
THEN 1 ELSE 0 END
ELSE 1 END = 1 )
如果单纯使用Check,如下所示
CONSTRAINT check_salary CHECK
( sex = '2' AND salary > 1000 )
女职员的条件倒是符合了,男职员就无法输入了。
posted @
2010-03-26 18:14 xzc 阅读(162) |
评论 (0) |
编辑 收藏Oracle 的SQL*LOADER可以将外部数据加载到数据库表中。下面是SQL*LOADER的基本特点:
1)能装入不同数据类型文件及多个数据文件的数据
2)可装入固定格式,自由定界以及可度长格式的数据
3)可以装入二进制,压缩十进制数据
4)一次可对多个表装入数据
5)连接多个物理记录装到一个记录中
6)对一单记录分解再装入到表中
7)可以用 数对制定列生成唯一的KEY
8)可对磁盘或 磁带数据文件装入制表中
9)提供装入错误报告
10)可以将文件中的整型字符串,自动转成压缩十进制并装入列表中。
1.2控制文件
控制文件是用一种语言写的文本文件,这个文本文件能被SQL*LOADER识别。SQL*LOADER根据控制文件可以找到需要加载的数据。并且分析和解释这些数据。控制文件由三个部分组成:
l 全局选件,行,跳过的记录数等;
l INFILE子句指定的输入数据;
l 数据特性说明。
1.3输入文件
对于 SQL*Loader, 除控制文件外就是输入数据。SQL*Loader可从一个或多个指定的文件中读出数据。如果 数据是在控制文件中指定,就要在控制文件中写成 INFILE * 格式。当数据固定的格式(长度一样)时且是在文件中得到时,要用INFILE "fix n"
load data
infile 'example.dat' "fix 11"
into table example
fields terminated by ',' optionally enclosed by '"'
(col1 char(5),
col2 char(7))
example.dat:
001, cd, 0002,fghi,
00003,lmn,
1, "pqrs",
0005,uvwx,
当数据是可变格式(长度不一样)时且是在文件中得到时,要用INFILE "var n"。如:
load data
infile 'example.dat' "var 3"
into table example
fields terminated by ',' optionally enclosed by '"'
(col1 char(5),
col2 char(7))
example.dat:
009hello,cd,010world,im,
012my,name is,
1.4坏文件
坏文件包含那些被SQL*Loader拒绝的记录。被拒绝的记录可能是不符合要求的记录。
坏文件的名字由 SQL*Loader命令的BADFILE 参数来给定。
1.5日志文件及日志信息
当SQL*Loader 开始执行后,它就自动建立 日志文件。日志文件包含有加载的总结,加载中的错误信息等。
控制文件语法
控制文件的格式如下:
OPTIONS ( { [SKIP=integer] [ LOAD = integer ]
[ERRORS = integer] [ROWS=integer]
[BINDSIZE=integer] [SILENT=(ALL|FEEDBACK|ERROR|DISCARD) ] )
LOAD[DATA]
[ { INFILE | INDDN } {file | * }
[STREAM | RECORD | FIXED length [BLOCKSIZE size]|
VARIABLE [length] ]
[ { BADFILE | BADDN } file ]
{DISCARDS | DISCARDMAX} integr ]
[ {INDDN | INFILE} . . . ]
[ APPEND | REPLACE | INSERT ]
[RECLENT integer]
[ { CONCATENATE integer |
CONTINUEIF { [THIS | NEXT] (start[: end])LAST }
Operator { 'string' | X 'hex' } } ]
INTO TABLE [user.]table
[APPEND | REPLACE|INSERT]
[WHEN condition [AND condition]...]
[FIELDS [delimiter] ]
(
column {
RECNUM | CONSTANT value |
SEQUENCE ( { integer | MAX |COUNT} [, increment] ) |
[POSITION ( { start [end] | * [ + integer] }
) ]
datatype
[TERMINATED [ BY ] {WHITESPACE| [X] 'character' } ]
[ [OPTIONALLY] ENCLOSE[BY] [X]'charcter']
[NULLIF condition ]
[DEFAULTIF condotion]
}
[ ,...]
)
[INTO TABLE...]
[BEGINDATA]
1)要加载的数据文件:
1.INFILE 和INDDN是同义词,它们后面都是要加载的数据文件。如果用 * 则表示数据就在控制文件内。在INFILE 后可以跟几个文件。
2.STRAM 表示一次读一个字节的数据。新行代表新物理记录(逻辑记录可由几个物理记录组成)。
3.RECORD 使用宿主操作系统文件及记录管理系统。如果数据在控制文件中则使用这种方法。
3. FIXED length 要读的记录长度为length字节,
4. VARIABLE 被读的记录中前两个字节包含的长度,length 记录可能的长度。缺伤为8k字节。
5. BADFILE和BADDN同义。Oracle 不能加载数据到数据库的那些记录。
6. DISCARDFILE和DISCARDDN是同义词。记录没有通过的数据。
7. DISCARDS和DISCARDMAX是同义词。Integer 为最大放弃的文件个数。
2)加载的方法:
1.APPEND 给表添加行。
2.INSERT 给空表增加行(如果表中有记录则退出)。
3.REPLACE 先清空表在加载数据。
4. RECLEN 用于两种情况,1)SQLLDR不能自动计算记录长度,2)或用户想看坏文件的完整记录时。对于后一种,Oracle只能按常规把坏记录部分写到错误的地方。如果看整条记录,则可以将整条记录写到坏文件中。
3)指定最大的记录长度:
1. CONCATENATE 允许用户设定一个整数,表示要组合逻辑记录的数目。
4)建立逻辑记录:
1.THIS 检查当前记录条件,如果为真则连接下一个记录。
2.NEXT 检查下一个记录条件。如果为真,则连接下一个记录到当前记录来。
2. Start: end 表示要检查在THIS或NEXT字串是否存在继续串的列,以确定是否进行连接。如:continueif next(1-3)='WAG' 或continueif next(1-3)=X'0d03if'
5)指定要加载的表:
1.INTO TABLE 要加的表名。
2.WHEN 和select WHERE类似。用来检查记录的情况,如:when(3-5)='SSM' and (22)='*"
6)介绍并括起记录中的字段:
1. FIELDS给出记录中字段的分隔符,FIELDS格式为:
FIELDS [TERMIALED [BY] {WHITESPACE | [X] 'charcter'} ]
[ [ OPTIONALLY] ENCLOSE [BY] [X]'charcter' ]
TERMINATED 读完前一个字段即开始读下一个字段直到介绍。
WHITESPACE 是指结束符是空格的意思。包括空格、Tab、换行符、换页符及回车符。如果是要判断但字符,可以用单引号括起,如X'1B'等。
OPTIONALLY ENCLOSED 表示数据应由特殊字符括起来。也可以括在TERMINATED字符内。使用OPTIONALLY要同时用TERMINLATED。
ENCLOSED 指两个分界符内的数据。如果同时用 ENCLOSED和TERMINAED ,则它们的顺序决定计算的顺序。
7)定义列:
column 是表列名。列的取值可以是:
BECHUM 表示逻辑记录数。第一个记录为1,第2个记录为2。
CONSTANT 表示赋予常数。
SEQUENCE 表示序列可以从任意序号开始,格式为:
SEQUENCE ( { integer | MAX |COUNT} [,increment]
POSITION 给出列在逻辑记录中的位置。可以是绝对的,或相对前一列的值。格式为:
POSITION ( {start[end] | * [+integer] } )
Start 开始位置
* 表示前字段之后立刻开始。
+ 从前列开始向后条的位置数。
8)定义数据类型:
可以定义14种数据类型:
CHAR
DATE
DECIMAL EXTERNAL
DECIMAL
DOUBLE
FLOAT
FLOAT EXTERNAL
GRAPHIC EXTERNAL
INTEGER
INTEGER EXTERNAL
SMALLINT
VARCHAR
VARGRAPHIC
1.字符类型数据
CHAR[ (length)] [delimiter]
length缺省为 1.
2.日期类型数据
DATE [ ( length)]['date_format' [delimiter]
使用to_date函数来限制。
3.字符格式中的十进制
DECIMAL EXTERNAL [(length)] [delimiter]
用于常规格式的十进制数(不是二进制=> 一个位等于一个bit)。
4.压缩十进制格式数据
DECIMAL (digtial [,precision])
5.双精度符点二进制
DOUBLE
6.普通符点二进制
FLOAT
7.字符格式符点数
FLOAT EXTERNAL [ (length) ] [delimiter]
8.双字节字符串数据
GRAPHIC [ (legth)]
9.双字节字符串数据
GRAPHIC EXTERNAL[ (legth)]
10.常规全字二进制整数
INTEGER
11.字符格式整数
INTEGER EXTERNAL
12.常规全字二进制数据
SMALLINT
13.可变长度字符串
VARCHAR
14.可变双字节字符串数据
VARGRAPHIC
2.2写控制文件CTL
1. 各数据文件的文件名;
2.各数据文件格式;
3.各数据文件里各数据记录字段的属性;
4.接受数据的ORACLE表列的属性;
5.数据定义;
6.其它
数据文件的要求:
数据类型的指定
CHAR 字符型
INTEGER EXTERNAL 整型
DECIMAL EXTERNAL 浮点型
3.1数据文件的内容
可以在OS下的一个文件;或跟在控制文件下的具体数据。数据文件可以是:
1、 二进制与字符格式:LOADER可以把二进制文件读(当成字符读)列表中
2、 固定格式:记录中的数据、数据类型、 数据长度固定。
3、 可变格式:每个记录至少有一个可变长数据字段,一个记录可以是一个连续的字符串。
数据段的分界(如姓名、年龄)如用“,”作字段的 分 ;用,"’作数据
括号等
4、 LOADER可以使用多个连续字段的物理记录组成一个逻辑记录,记录文件运行情况文件:包括以下内容:
1、 运行日期:软件版本号
2、 全部输入,输出文件名;对命令行的展示信息,补充信息,
3、 对每个装入信息报告:如表名,装入情况;对初始装入, 加截入或更新装
入的选择情况,栏信息
4、 数据错误报告:错误码;放弃记录报告
5、 每个装X报告:装入行;装入行数,可能跳过行数;可能拒绝行数;可能放
弃行数等
6、 统计概要:使用空间(包大小,长度);读入记录数,装入记录数,跳过记
录数;拒绝记录数,放弃记录数;运行时间等。
==========================================================================================================
sql load的一点小总结
sqlldr userid=lgone/tiger control=a.ctl
LOAD DATA
INFILE 't.dat' // 要导入的文件
// INFILE 'tt.date' // 导入多个文件
// INFILE * // 要导入的内容就在control文件里 下面的BEGINDATA后面就是导入的内容
INTO TABLE table_name // 指定装入的表
BADFILE 'c:bad.txt' // 指定坏文件地址
************* 以下是4种装入表的方式
APPEND // 原先的表有数据 就加在后面
// INSERT // 装载空表 如果原先的表有数据 sqlloader会停止 默认值
// REPLACE // 原先的表有数据 原先的数据会全部删除
// TRUNCATE // 指定的内容和replace的相同 会用truncate语句删除现存数据
************* 指定的TERMINATED可以在表的开头 也可在表的内部字段部分
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
// 装载这种数据: 10,lg,"""lg""","lg,lg"
// 在表中结果: 10 lg "lg" lg,lg
// TERMINATED BY X '09' // 以十六进制格式 '09' 表示的
// TERMINATED BY WRITESPACE // 装载这种数据: 10 lg lg
TRAILING NULLCOLS ************* 表的字段没有对应的值时允许为空
************* 下面是表的字段
(
col_1 , col_2 ,col_filler FILLER // FILLER 关键字 此列的数值不会被装载
// 如: lg,lg,not 结果 lg lg
)
// 当没声明FIELDS TERMINATED BY ',' 时
// (
// col_1 [interger external] TERMINATED BY ',' ,
// col_2 [date "dd-mon-yyy"] TERMINATED BY ',' ,
// col_3 [char] TERMINATED BY ',' OPTIONALLY ENCLOSED BY 'lg'
// )
// 当没声明FIELDS TERMINATED BY ','用位置告诉字段装载数据
// (
// col_1 position(1:2),
// col_2 position(3:10),
// col_3 position(*:16), // 这个字段的开始位置在前一字段的结束位置
// col_4 position(1:16),
// col_5 position(3:10) char(8) // 指定字段的类型
// )
BEGINDATA // 对应开始的 INFILE * 要导入的内容就在control文件里
10,Sql,what
20,lg,show
=====================================================================================
//////////// 注意begindata后的数值前面不能有空格
1 ***** 普通装载
LOAD DATA
INFILE *
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
(DEPTNO,
DNAME,
LOC
)
BEGINDATA
10,Sales,"""USA"""
20,Accounting,"Virginia,USA"
30,Consulting,Virginia
40,Finance,Virginia
50,"Finance","",Virginia // loc 列将为空
60,"Finance",,Virginia // loc 列将为空
2 ***** FIELDS TERMINATED BY WHITESPACE 和 FIELDS TERMINATED BY x'09' 的情况
LOAD DATA
INFILE *
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY WHITESPACE
-- FIELDS TERMINATED BY x'09'
(DEPTNO,
DNAME,
LOC
)
BEGINDATA
10 Sales Virginia
3 ***** 指定不装载那一列
LOAD DATA
INFILE *
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
( DEPTNO,
FILLER_1 FILLER, // 下面的 "Something Not To Be Loaded" 将不会被装载
DNAME,
LOC
)
BEGINDATA
20,Something Not To Be Loaded,Accounting,"Virginia,USA"
4 ***** position的列子
LOAD DATA
INFILE *
INTO TABLE DEPT
REPLACE
( DEPTNO position(1:2),
DNAME position(*:16), // 这个字段的开始位置在前一字段的结束位置
LOC position(*:29),
ENTIRE_LINE position(1:29)
)
BEGINDATA
10Accounting Virginia,USA
5 ***** 使用函数 日期的一种表达 TRAILING NULLCOLS的使用
LOAD DATA
INFILE *
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS // 其实下面的ENTIRE_LINE在BEGINDATA后面的数据中是没有直接对应
// 的列的值的 如果第一行改为 10,Sales,Virginia,1/5/2000,, 就不用TRAILING NULLCOLS了
(DEPTNO,
DNAME "upper(:dname)", // 使用函数
LOC "upper(:loc)",
LAST_UPDATED date 'dd/mm/yyyy', // 日期的一种表达方式 还有'dd-mon-yyyy' 等
ENTIRE_LINE ":deptno||:dname||:loc||:last_updated"
)
BEGINDATA
10,Sales,Virginia,1/5/2000
20,Accounting,Virginia,21/6/1999
30,Consulting,Virginia,5/1/2000
40,Finance,Virginia,15/3/2001
6 ***** 使用自定义的函数 // 解决的时间问题
create or replace
function my_to_date( p_string in varchar2 ) return date
as
type fmtArray is table of varchar2(25);
l_fmts fmtArray := fmtArray( 'dd-mon-yyyy', 'dd-month-yyyy',
'dd/mm/yyyy',
'dd/mm/yyyy hh24:mi:ss' );
l_return date;
begin
for i in 1 .. l_fmts.count
loop
begin
l_return := to_date( p_string, l_fmts(i) );
exception
when others then null;
end;
EXIT when l_return is not null;
end loop;
if ( l_return is null )
then
l_return :=
new_time( to_date('01011970','ddmmyyyy') + 1/24/60/60 *
p_string, 'GMT', 'EST' );
end if;
return l_return;
end;
/
LOAD DATA
INFILE *
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED "my_to_date( :last_updated )" // 使用自定义的函数
)
BEGINDATA
10,Sales,Virginia,01-april-2001
20,Accounting,Virginia,13/04/2001
30,Consulting,Virginia,14/04/2001 12:02:02
40,Finance,Virginia,987268297
50,Finance,Virginia,02-apr-2001
60,Finance,Virginia,Not a date
7 ***** 合并多行记录为一行记录
LOAD DATA
INFILE *
concatenate 3 // 通过关键字concatenate 把几行的记录看成一行记录
INTO TABLE DEPT
replace
FIELDS TERMINATED BY ','
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED date 'dd/mm/yyyy'
)
BEGINDATA
10,Sales, // 其实这3行看成一行 10,Sales,Virginia,1/5/2000
Virginia,
1/5/2000
// 这列子用 continueif list="," 也可以
告诉sqlldr在每行的末尾找逗号 找到逗号就把下一行附加到上一行
LOAD DATA
INFILE *
continueif this(1:1) = '-' // 找每行的开始是否有连接字符 - 有就把下一行连接为一行
// 如 -10,Sales,Virginia,
// 1/5/2000 就是一行 10,Sales,Virginia,1/5/2000
// 其中1:1 表示从第一行开始 并在第一行结束 还有continueif next 但continueif list最理想
INTO TABLE DEPT
replace
FIELDS TERMINATED BY ','
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED date 'dd/mm/yyyy'
)
BEGINDATA // 但是好象不能象右面的那样使用
-10,Sales,Virginia, -10,Sales,Virginia,
1/5/2000 1/5/2000
-40, 40,Finance,Virginia,13/04/2001
Finance,Virginia,13/04/2001
8 ***** 载入每行的行号
load data
infile *
into table t
replace
( seqno RECNUM //载入每行的行号
text Position(1:1024))
BEGINDATA
fsdfasj //自动分配一行号给载入 表t 的seqno字段 此行为 1
fasdjfasdfl // 此行为 2 ...
9 ***** 载入有换行符的数据
注意: unix 和 windows 不同 n & /n
< 1 > 使用一个非换行符的字符
LOAD DATA
INFILE *
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED "my_to_date( :last_updated )",
COMMENTS "replace(:comments,'n',chr(10))" // replace 的使用帮助转换换行符
)
BEGINDATA
10,Sales,Virginia,01-april-2001,This is the SalesnOffice in Virginia
20,Accounting,Virginia,13/04/2001,This is the AccountingnOffice in Virginia
30,Consulting,Virginia,14/04/2001 12:02:02,This is the ConsultingnOffice in Virginia
40,Finance,Virginia,987268297,This is the FinancenOffice in Virginia
< 2 > 使用fix属性
LOAD DATA
INFILE demo17.dat "fix 101"
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED "my_to_date( :last_updated )",
COMMENTS
)
demo17.dat
10,Sales,Virginia,01-april-2001,This is the Sales
Office in Virginia
20,Accounting,Virginia,13/04/2001,This is the Accounting
Office in Virginia
30,Consulting,Virginia,14/04/2001 12:02:02,This is the Consulting
Office in Virginia
40,Finance,Virginia,987268297,This is the Finance
Office in Virginia
// 这样装载会把换行符装入数据库 下面的方法就不会 但要求数据的格式不同
LOAD DATA
INFILE demo18.dat "fix 101"
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED "my_to_date( :last_updated )",
COMMENTS
)
demo18.dat
10,Sales,Virginia,01-april-2001,"This is the Sales
Office in Virginia"
20,Accounting,Virginia,13/04/2001,"This is the Accounting
Office in Virginia"
30,Consulting,Virginia,14/04/2001 12:02:02,"This is the Consulting
Office in Virginia"
40,Finance,Virginia,987268297,"This is the Finance
Office in Virginia"
< 3 > 使用var属性
LOAD DATA
INFILE demo19.dat "var 3"
// 3 告诉每个记录的前3个字节表示记录的长度 如第一个记录的 071 表示此记录有 71 个字节
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED "my_to_date( :last_updated )",
COMMENTS
)
demo19.dat
07110,Sales,Virginia,01-april-2001,This is the Sales
Office in Virginia
07820,Accounting,Virginia,13/04/2001,This is the Accounting
Office in Virginia
08730,Consulting,Virginia,14/04/2001 12:02:02,This is the Consulting
Office in Virginia
07140,Finance,Virginia,987268297,This is the Finance
Office in Virginia
< 4 > 使用str属性
// 最灵活的一中 可定义一个新的行结尾符 win 回车换行 : chr(13)||chr(10)
此列中记录是以 a|rn 结束的
select utl_raw.cast_to_raw('|'||chr(13)||chr(10)) from dual;
结果 7C0D0A
LOAD DATA
INFILE demo20.dat "str X'7C0D0A'"
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED "my_to_date( :last_updated )",
COMMENTS
)
demo20.dat
10,Sales,Virginia,01-april-2001,This is the Sales
Office in Virginia|
20,Accounting,Virginia,13/04/2001,This is the Accounting
Office in Virginia|
30,Consulting,Virginia,14/04/2001 12:02:02,This is the Consulting
Office in Virginia|
40,Finance,Virginia,987268297,This is the Finance
Office in Virginia|
==============================================================================
象这样的数据 用 nullif 子句
10-jan-200002350Flipper seemed unusually hungry today.
10510-jan-200009945Spread over three meals.
id position(1:3) nullif id=blanks // 这里可以是blanks 或者别的表达式
// 下面是另一个列子 第一行的 1 在数据库中将成为 null
LOAD DATA
INFILE *
INTO TABLE T
REPLACE
(n position(1:2) integer external nullif n='1',
v position(3:8)
)
BEGINDATA
1 10
20lg
------------------------------------------------------------
如果是英文的日志 格式,可能需要修改环境变量 nls_lang or nls_date_format
==========================================================================================================
Oracle SQL*Loader 使用指南(转载)
SQL*Loader是Oracle数据库导入外部数据的一个工具.它和DB2的Load工具相似,但有更多的选择,它支持变化的加载模式,可选的加载及多表加载.
如何使用 SQL*Loader 工具
我们可以用Oracle的sqlldr工具来导入数据。例如:
sqlldr scott/tiger control=loader.ctl
控制文件(loader.ctl) 将加载一个外部数据文件(含分隔符). loader.ctl如下:
load data
infile 'c:datamydata.csv'
into table emp
fields terminated by "," optionally enclosed by '"'
( empno, empname, sal, deptno )
mydata.csv 如下:
10001,"Scott Tiger", 1000, 40
10002,"Frank Naude", 500, 20
下面是一个指定记录长度的示例控制文件。"*" 代表数据文件与此文件同名,即在后面使用BEGINDATA段来标识数据。
load data
infile *
replace
into table departments
( dept position (02:05) char(4),
deptname position (08:27) char(20)
)
begindata
COSC COMPUTER SCIENCE
ENGL ENGLISH LITERATURE
MATH MATHEMATICS
POLY POLITICAL SCIENCE
Unloader这样的工具
Oracle 没有提供将数据导出到一个文件的工具。但是,我们可以用SQL*Plus的select 及 format 数据来输出到一个文件:
set echo off newpage 0 space 0 pagesize 0 feed off head off trimspool on
spool oradata.txt
select col1 || ',' || col2 || ',' || col3
from tab1
where col2 = 'XYZ';
spool off
另外,也可以使用使用 UTL_FILE PL/SQL 包处理:
rem Remember to update initSID.ora, utl_file_dir='c:oradata' parameter
declare
fp utl_file.file_type;
begin
fp := utl_file.fopen('c:oradata','tab1.txt','w');
utl_file.putf(fp, '%s, %sn', 'TextField', 55);
utl_file.fclose(fp);
end;
/
当然你也可以使用第三方工具,如SQLWays ,TOAD for Quest等。
加载可变长度或指定长度的记录
如:
LOAD DATA
INFILE *
INTO TABLE load_delimited_data
FIELDS TERMINATED BY "," OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
( data1,
data2
)
BEGINDATA
11111,AAAAAAAAAA
22222,"A,B,C,D,"
下面是导入固定位置(固定长度)数据示例:
LOAD DATA
INFILE *
INTO TABLE load_positional_data
( data1 POSITION(1:5),
data2 POSITION(6:15)
)
BEGINDATA
11111AAAAAAAAAA
22222BBBBBBBBBB
跳过数据行:
可以用 "SKIP n" 关键字来指定导入时可以跳过多少行数据。如:
LOAD DATA
INFILE *
INTO TABLE load_positional_data
SKIP 5
( data1 POSITION(1:5),
data2 POSITION(6:15)
)
BEGINDATA
11111AAAAAAAAAA
22222BBBBBBBBBB
导入数据时修改数据:
在导入数据到数据库时,可以修改数据。注意,这仅适合于常规导入,并不适合 direct导入方式.如:
LOAD DATA
INFILE *
INTO TABLE modified_data
( rec_no "my_db_sequence.nextval",
region CONSTANT '31',
time_loaded "to_char(SYSDATE, 'HH24:MI')",
data1 POSITION(1:5) ":data1/100",
data2 POSITION(6:15) "upper(:data2)",
data3 POSITION(16:22)"to_date(:data3, 'YYMMDD')"
)
BEGINDATA
11111AAAAAAAAAA991201
22222BBBBBBBBBB990112
LOAD DATA
INFILE 'mail_orders.txt'
BADFILE 'bad_orders.txt'
APPEND
INTO TABLE mailing_list
FIELDS TERMINATED BY ","
( addr,
city,
state,
zipcode,
mailing_addr "decode(:mailing_addr, null, :addr, :mailing_addr)",
mailing_city "decode(:mailing_city, null, :city, :mailing_city)",
mailing_state
)
将数据导入多个表:
如:
LOAD DATA
INFILE *
REPLACE
INTO TABLE emp
WHEN empno != ' '
( empno POSITION(1:4) INTEGER EXTERNAL,
ename POSITION(6:15) CHAR,
deptno POSITION(17:18) CHAR,
mgr POSITION(20:23) INTEGER EXTERNAL
)
INTO TABLE proj
WHEN projno != ' '
( projno POSITION(25:27) INTEGER EXTERNAL,
empno POSITION(1:4) INTEGER EXTERNAL
)
导入选定的记录:
如下例: (01) 代表第一个字符, (30:37) 代表30到37之间的字符:
LOAD DATA
INFILE 'mydata.dat' BADFILE 'mydata.bad' DISCARDFILE 'mydata.dis'
APPEND
INTO TABLE my_selective_table
WHEN (01) <> 'H' and (01) <> 'T' and (30:37) = '19991217'
(
region CONSTANT '31',
service_key POSITION(01:11) INTEGER EXTERNAL,
call_b_no POSITION(12:29) CHAR
)
导入时跳过某些字段:
可用 POSTION(x:y) 来分隔数据. 在Oracle8i中可以通过指定 FILLER 字段实现。FILLER 字段用来跳过、忽略导入数据文件中的字段.如:
LOAD DATA
TRUNCATE INTO TABLE T1
FIELDS TERMINATED BY ','
( field1,
field2 FILLER,
field3
)
导入多行记录:
可以使用下面两个选项之一来实现将多行数据导入为一个记录:
CONCATENATE: - use when SQL*Loader should combine the same number of physical records together to form one logical record.
CONTINUEIF - use if a condition indicates that multiple records should be treated as one. Eg. by having a '#' character in column 1.
SQL*Loader 数据的提交:
一般情况下是在导入数据文件数据后提交的。
也可以通过指定 ROWS= 参数来指定每次提交记录数。
提高 SQL*Loader 的性能:
1) 一个简单而容易忽略的问题是,没有对导入的表使用任何索引和/或约束(主键)。如果这样做,甚至在使用ROWS=参数时,会很明显降低数据库导入性能。
2) 可以添加 DIRECT=TRUE来提高导入数据的性能。当然,在很多情况下,不能使用此参数。
3) 通过指定 UNRECOVERABLE选项,可以关闭数据库的日志。这个选项只能和 direct 一起使用。
4) 可以同时运行多个导入任务.
常规导入与direct导入方式的区别:
常规导入可以通过使用 INSERT语句来导入数据。Direct导入可以跳过数据库的相关逻辑(DIRECT=TRUE),而直接将数据导入到数据文件中。
posted @
2010-03-24 21:04 xzc 阅读(17780) |
评论 (2) |
编辑 收藏
oracle sql loader全攻略(一)
一:sql loader 的特点
oracle自己带了很多的工具可以用来进行数据的迁移、备份和恢复等工作。但是每个工具都有自己的特点。
比如说exp和imp可以对数据库中的数据进行导出和导出的工作,是一种很好的数据库备份和恢复的工具,因此主要用在数据库的热备份和恢复方面。有着速度快,使用简单,快捷的优点;同时也有一些缺点,比如在不同版本数据库之间的导出、导入的过程之中,总会出现这样或者那样的问题,这个也许是oracle公司自己产品的兼容性的问题吧。
sql loader 工具却没有这方面的问题,它可以把一些以文本格式存放的数据顺利的导入到oracle数据库中,是一种在不同数据库之间进行数据迁移的非常方便而且通用的工具。缺点就速度比较慢,另外对blob等类型的数据就有点麻烦了。
二:sql loader 的帮助
C:\>sqlldr
SQL*Loader: Release 9.2.0.1.0 - Production on 星期六 10月 9 14:48:12 2004
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
用法: SQLLDR keyword=value [,keyword=value,...]
有效的关键字:
userid -- ORACLE username/password
control -- Control file name
log -- Log file name
bad -- Bad file name
data -- Data file name
discard -- Discard file name
discardmax -- Number of discards to allow (全部默认)
skip -- Number of logical records to skip (默认0)
load -- Number of logical records to load (全部默认)
errors -- Number of errors to allow (默认50)
rows -- Number of rows in conventional path bind array or between direct p
ath data saves
(默认: 常规路径 64, 所有直接路径)
bindsize -- Size of conventional path bind array in bytes(默认256000)
silent -- Suppress messages during run (header,feedback,errors,discards,part
itions)
direct -- use direct path (默认FALSE)
parfile -- parameter file: name of file that contains parameter specification
s
parallel -- do parallel load (默认FALSE)
file -- File to allocate extents from
skip_unusable_indexes -- disallow/allow unusable indexes or index partitions(默
认FALSE)
skip_index_maintenance -- do not maintain indexes, mark affected indexes as unus
able(默认FALSE)
readsize -- Size of Read buffer (默认1048576)
external_table -- use external table for load; NOT_USED, GENERATE_ONLY, EXECUTE(
默认NOT_USED)
columnarrayrows -- Number of rows for direct path column array(默认5000)
streamsize -- Size of direct path stream buffer in bytes(默认256000)
multithreading -- use multithreading in direct path
resumable -- enable or disable resumable for current session(默认FALSE)
resumable_name -- text string to help identify resumable statement
resumable_timeout -- wait time (in seconds) for RESUMABLE(默认7200)
date_cache -- size (in entries) of date conversion cache(默认1000)
PLEASE NOTE: 命令行参数可以由位置或关键字指定
。前者的例子是 'sqlload
scott/tiger foo'; 后一种情况的一个示例是 'sqlldr control=foo
userid=scott/tiger'.位置指定参数的时间必须早于
但不可迟于由关键字指定的参数。例如,
允许 'sqlldr scott/tiger control=foo logfile=log', 但是
不允许 'sqlldr scott/tiger control=foo log', 即使
参数 'log' 的位置正确。
C:\>
三:sql loader使用例子
a)SQLLoader将 Excel 数据导出到 Oracle
1.创建SQL*Loader输入数据所需要的文件,均保存到C:\,用记事本编辑:
控制文件:input.ctl,内容如下:
load data --1、控制文件标识
infile 'test.txt' --2、要输入的数据文件名为test.txt
append into table test--3、向表test中追加记录
fields terminated by X'09'--4、字段终止于X'09',是一个制表符(TAB)
(id,username,password,sj) -----定义列对应顺序
a、insert,为缺省方式,在数据装载开始时要求表为空
b、append,在表中追加新记录
c、replace,删除旧记录,替换成新装载的记录
d、truncate,同上
在DOS窗口下使用SQL*Loader命令实现数据的输入
C:\>sqlldr userid=system/manager control=input.ctl
默认日志文件名为:input.log
默认坏记录文件为:input.bad
2.还有一种方法
可以把EXCEL文件另存为CSV(逗号分隔)(*.csv),控制文件就改为用逗号分隔
LOAD DATA
INFILE 'd:\car.csv'
APPEND INTO TABLE t_car_temp
FIELDS TERMINATED BY ","
(phoneno,vip_car)
b)在控制文件中直接导入数据
1、控制文件test.ctl的内容
-- The format for executing this file with SQL Loader is:
-- SQLLDR control= Be sure to substitute your
-- version of SQL LOADER and the filename for this file.
LOAD DATA
INFILE *
BADFILE 'C:\Documents and Settings\Jackey\桌面\WMCOUNTRY.BAD'
DISCARDFILE 'C:\Documents and Settings\Jackey\桌面\WMCOUNTRY.DSC'
INSERT INTO TABLE EMCCOUNTRY
Fields terminated by ";" Optionally enclosed by '"'
(
COUNTRYID NULLIF (COUNTRYID="NULL"),
COUNTRYCODE,
COUNTRYNAME,
CONTINENTID NULLIF (CONTINENTID="NULL"),
MAPID NULLIF (MAPID="NULL"),
CREATETIME DATE "MM/DD/YYYY HH24:MI:SS" NULLIF (CREATETIME="NULL"),
LASTMODIFIEDTIME DATE "MM/DD/YYYY HH24:MI:SS" NULLIF (LASTMODIFIEDTIME="NULL")
)
BEGINDATA
1;"JP";"Japan";1;9;"09/16/2004 16:31:32";NULL
2;"CN";"China";1;10;"09/16/2004 16:31:32";NULL
3;"IN";"India";1;11;"09/16/2004 16:31:32";NULL
4;"AU";"Australia";6;12;"09/16/2004 16:31:32";NULL
5;"CA";"Canada";4;13;"09/16/2004 16:31:32";NULL
6;"US";"United States";4;14;"09/16/2004 16:31:32";NULL
7;"MX";"Mexico";4;15;"09/16/2004 16:31:32";NULL
8;"GB";"United Kingdom";3;16;"09/16/2004 16:31:32";NULL
9;"DE";"Germany";3;17;"09/16/2004 16:31:32";NULL
10;"FR";"France";3;18;"09/16/2004 16:31:32";NULL
11;"IT";"Italy";3;19;"09/16/2004 16:31:32";NULL
12;"ES";"Spain";3;20;"09/16/2004 16:31:32";NULL
13;"FI";"Finland";3;21;"09/16/2004 16:31:32";NULL
14;"SE";"Sweden";3;22;"09/16/2004 16:31:32";NULL
15;"IE";"Ireland";3;23;"09/16/2004 16:31:32";NULL
16;"NL";"Netherlands";3;24;"09/16/2004 16:31:32";NULL
17;"DK";"Denmark";3;25;"09/16/2004 16:31:32";NULL
18;"BR";"Brazil";5;85;"09/30/2004 11:25:43";NULL
19;"KR";"Korea, Republic of";1;88;"09/30/2004 11:25:43";NULL
20;"NZ";"New Zealand";6;89;"09/30/2004 11:25:43";NULL
21;"BE";"Belgium";3;79;"09/30/2004 11:25:43";NULL
22;"AT";"Austria";3;78;"09/30/2004 11:25:43";NULL
23;"NO";"Norway";3;82;"09/30/2004 11:25:43";NULL
24;"LU";"Luxembourg";3;81;"09/30/2004 11:25:43";NULL
25;"PT";"Portugal";3;83;"09/30/2004 11:25:43";NULL
26;"GR";"Greece";3;80;"09/30/2004 11:25:43";NULL
27;"IL";"Israel";1;86;"09/30/2004 11:25:43";NULL
28;"CH";"Switzerland";3;84;"09/30/2004 11:25:43";NULL
29;"A1";"Anonymous Proxy";0;0;"09/30/2004 11:25:43";NULL
30;"A2";"Satellite Provider";0;0;"09/30/2004 11:25:43";NULL
31;"AD";"Andorra";3;0;"09/30/2004 11:25:43";NULL
32;"AE";"United Arab Emirates";1;0;"09/30/2004 11:25:43";NULL
33;"AF";"Afghanistan";1;0;"09/30/2004 11:25:43";NULL
34;"AG";"Antigua and Barbuda";7;0;"09/30/2004 11:25:43";NULL
35;"AI";"Anguilla";7;0;"09/30/2004 11:25:43";NULL
36;"AL";"Albania";3;0;"09/30/2004 11:25:43";NULL
37;"AM";"armenia";3;0;"09/30/2004 11:25:43";NULL
38;"AN";"Netherlands Antilles";3;0;"09/30/2004 11:25:43";NULL
39;"AO";"Angola";2;0;"09/30/2004 11:25:43";NULL
40;"AP";"Asia/Pacific Region";2;0;"09/30/2004 11:25:43";NULL
41;"AQ";"Antarctica";8;0;"09/30/2004 11:25:43";NULL
42;"AR";"Argentina";5;0;"09/30/2004 11:25:43";NULL
43;"AS";"American Samoa";6;0;"09/30/2004 11:25:43";NULL
44;"AW";"Aruba";5;0;"09/30/2004 11:25:43";NULL
45;"AZ";"Azerbaijan";1;0;"09/30/2004 11:25:43";NULL
46;"BA";"Bosnia and Herzegovina";3;0;"09/30/2004 11:25:43";NULL
47;"BB";"Barbados";5;0;"09/30/2004 11:25:43";NULL
48;"BD";"Bangladesh";1;0;"09/30/2004 11:25:43";NULL
49;"BF";"Burkina Faso";2;0;"09/30/2004 11:25:43";NULL
50;"BG";"Bulgaria";3;0;"09/30/2004 11:25:43";NULL
51;"BH";"Bahrain";1;0;"09/30/2004 11:25:43";NULL
52;"BI";"Burundi";2;0;"09/30/2004 11:25:43";NULL
53;"BJ";"Benin";2;0;"09/30/2004 11:25:43";NULL
54;"BM";"Bermuda";4;0;"09/30/2004 11:25:43";NULL
55;"BN";"Brunei Darussalam";1;0;"09/30/2004 11:25:43";NULL
56;"BO";"Bolivia";5;0;"09/30/2004 11:25:43";NULL
57;"BS";"Bahamas";7;0;"09/30/2004 11:25:43";NULL
58;"BT";"Bhutan";1;0;"09/30/2004 11:25:43";NULL
59;"BV";"Bouvet Island";5;0;"09/30/2004 11:25:43";NULL
60;"BW";"Botswana";2;0;"09/30/2004 11:25:43";NULL
61;"BY";"Belarus";3;0;"09/30/2004 11:25:43";NULL
2、执行导入命令
C:\>sqlldr userid=system/manager control=test.ct
part ii
SQL*Loader是Oracle数据库导入外部数据的一个工具.它和DB2的Load工具相似,但有更多的选择,它支持变化的加载模式,可选的加载及多表加载.
如何使用 SQL*Loader 工具
我们可以用Oracle的sqlldr工具来导入数据。例如:
sqlldr scott/tiger control=loader.ctl
控制文件(loader.ctl) 将加载一个外部数据文件(含分隔符). loader.ctl如下:
load data
infile 'c:\data\mydata.csv'
into table emp
fields terminated by "," optionally enclosed by '"'
( empno, empname, sal, deptno )
mydata.csv 如下:
10001,"Scott Tiger", 1000, 40
10002,"Frank Naude", 500, 20
下面是一个指定记录长度的示例控制文件。"*" 代表数据文件与此文件同名,即在后面使用BEGINDATA段来标识数据。
load data
infile *
replace
into table departments
( dept position (02:05) char(4),
deptname position (08:27) char(20)
)
begindata
COSC COMPUTER SCIENCE
ENGL ENGLISH LITERATURE
MATH MATHEMATICS
POLY POLITICAL SCIENCE
Unloader这样的工具
Oracle 没有提供将数据导出到一个文件的工具。但是,我们可以用SQL*Plus的select 及 format 数据来输出到一个文件:
set echo off newpage 0 space 0 pagesize 0 feed off head off trimspool on
spool oradata.txt
select col1 || ',' || col2 || ',' || col3
from tab1
where col2 = 'XYZ';
spool off
另外,也可以使用使用 UTL_FILE PL/SQL 包处理:
rem Remember to update initSID.ora, utl_file_dir='c:\oradata' parameter
declare
fp utl_file.file_type;
begin
fp := utl_file.fopen('c:\oradata','tab1.txt','w');
utl_file.putf(fp, '%s, %s\n', 'TextField', 55);
utl_file.fclose(fp);
end;
/
当然你也可以使用第三方工具,如SQLWays ,TOAD for Quest等。
加载可变长度或指定长度的记录
如:
LOAD DATA
INFILE *
INTO TABLE load_delimited_data
FIELDS TERMINATED BY "," OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
( data1,
data2
)
BEGINDATA
11111,AAAAAAAAAA
22222,"A,B,C,D,"
下面是导入固定位置(固定长度)数据示例:
LOAD DATA
INFILE *
INTO TABLE load_positional_data
( data1 POSITION(1:5),
data2 POSITION(6:15)
)
BEGINDATA
11111AAAAAAAAAA
22222BBBBBBBBBB
跳过数据行:
可以用 "SKIP n" 关键字来指定导入时可以跳过多少行数据。如:
LOAD DATA
INFILE *
INTO TABLE load_positional_data
SKIP 5
( data1 POSITION(1:5),
data2 POSITION(6:15)
)
BEGINDATA
11111AAAAAAAAAA
22222BBBBBBBBBB
导入数据时修改数据:
在导入数据到数据库时,可以修改数据。注意,这仅适合于常规导入,并不适合 direct导入方式.如:
LOAD DATA
INFILE *
INTO TABLE modified_data
( rec_no "my_db_sequence.nextval",
region CONSTANT '31',
time_loaded "to_char(SYSDATE, 'HH24:MI')",
data1 POSITION(1:5) ":data1/100",
data2 POSITION(6:15) "upper(:data2)",
data3 POSITION(16:22)"to_date(:data3, 'YYMMDD')"
)
BEGINDATA
11111AAAAAAAAAA991201
22222BBBBBBBBBB990112
LOAD DATA
INFILE 'mail_orders.txt'
BADFILE 'bad_orders.txt'
APPEND
INTO TABLE mailing_list
FIELDS TERMINATED BY ","
( addr,
city,
state,
zipcode,
mailing_addr "decode(:mailing_addr, null, :addr, :mailing_addr)",
mailing_city "decode(:mailing_city, null, :city, :mailing_city)",
mailing_state
)
将数据导入多个表:
如:
LOAD DATA
INFILE *
REPLACE
INTO TABLE emp
WHEN empno != ' '
( empno POSITION(1:4) INTEGER EXTERNAL,
ename POSITION(6:15) CHAR,
deptno POSITION(17:18) CHAR,
mgr POSITION(20:23) INTEGER EXTERNAL
)
INTO TABLE proj
WHEN projno != ' '
( projno POSITION(25:27) INTEGER EXTERNAL,
empno POSITION(1:4) INTEGER EXTERNAL
)
导入选定的记录:
如下例: (01) 代表第一个字符, (30:37) 代表30到37之间的字符:
LOAD DATA
INFILE 'mydata.dat' BADFILE 'mydata.bad' DISCARDFILE 'mydata.dis'
APPEND
INTO TABLE my_selective_table
WHEN (01) <> 'H' and (01) <> 'T' and (30:37) = '19991217'
(
region CONSTANT '31',
service_key POSITION(01:11) INTEGER EXTERNAL,
call_b_no POSITION(12:29) CHAR
)
导入时跳过某些字段:
可用 POSTION(x:y) 来分隔数据. 在Oracle8i中可以通过指定 FILLER 字段实现。FILLER 字段用来跳过、忽略导入数据文件中的字段.如:
LOAD DATA
TRUNCATE INTO TABLE T1
FIELDS TERMINATED BY ','
( field1,
field2 FILLER,
field3
)
导入多行记录:
可以使用下面两个选项之一来实现将多行数据导入为一个记录:
CONCATENATE: - use when SQL*Loader should combine the same number of physical records together to form one logical record.
CONTINUEIF - use if a condition indicates that multiple records should be treated as one. Eg. by having a '#' character in column 1.
SQL*Loader 数据的提交:
一般情况下是在导入数据文件数据后提交的。
也可以通过指定 ROWS= 参数来指定每次提交记录数。
提高 SQL*Loader 的性能:
1) 一个简单而容易忽略的问题是,没有对导入的表使用任何索引和/或约束(主键)。如果这样做,甚至在使用ROWS=参数时,会很明显降低数据库导入性能。
2) 可以添加 DIRECT=TRUE来提高导入数据的性能。当然,在很多情况下,不能使用此参数。
3) 通过指定 UNRECOVERABLE选项,可以关闭数据库的日志。这个选项只能和 direct 一起使用。
4) 可以同时运行多个导入任务.
常规导入与direct导入方式的区别:
常规导入可以通过使用 INSERT语句来导入数据。Direct导入可以跳过数据库的相关逻辑(DIRECT=TRUE),而直接将数据导入到数据文件中。
posted @
2010-03-24 15:34 xzc 阅读(784) |
评论 (1) |
编辑 收藏
异常的处理是每个Java程序员时常面对的问题,但是很多人没有原则,遇到异常也不知道如何去处理,于是遇到检查异常就胡乱try...catch...一把,然后e.printStackTrace()一下了事,这种做法通常除了调试排错有点作用外,没任何价值。对于运行时异常,则干脆置之不理。
原因是很多开发者缺乏对异常的认识和分析,首先应该明白Java异常体系结构,一种分层继承的关系,你必须对层次结构熟烂于心:
Throwable(必须检查)
Error(非必须检查)
Exception(必须检查)
RuntimeException(非必须检查)
一般把Exception异常及其直接子类(除了RuntimeException之外)的异常称之为检查异常。把RuntimeException以及其子类的异常称之为非检查异常,也叫运行时异常。
对于Throwable和Error,则用的很少,一般会用在一些基础框架中,这里不做讨论。
下面针对J2EE的分层架构:DAO层、业务层、控制层、展示层的异常处理做个分析,并给出一般处理准则。
一、DAO层异常处理
如果你用了Spring的DAO模板来实现,则DAO层没有检查异常抛出,代码非常的优雅。但是,如果你的DAO采用了原始的JDBC来写,这时候,你不能不对异常做处理了,因为难以避免的SQLException会如影随形的跟着你。对已这种DAO级别的异常,异常了你又能如何呢?与其这样胡乱try...catch...,囫囵吞枣消灭了异常不如让异常以另外一种非检查的方式向外传递。这样做好处有二:
1)、DAO的接口不被异常所污染,假设你抛出了SQLException,以后要是换了Spring DAO模板,那DAO接口就不再抛出了SQLException,这样,你的接口抛出异常就是对接口的污染。
2)、DAO异常向外传播给更高层处理,以便异常的错误原因不丢失,便于排查错误或进行捕获处理。
这里还有一个设计上常常令人困扰的问题:很多人会问,那定义一个什么样的异常抛出呢,或者是直接抛出一个throw RuntimeException(e)? 对于这个问题,需要分场合,如果系统小,你可以直接抛出一个throw RuntimeException(e),但对于一个庞大的多模块系统来说,不要抛这种原生的非检查异常,而要抛出自定义的非检查异常,这样不但利于排错,而且有利于系统异常的处理,通常针对每一个模块,粗粒度的定义一个运行时DAO异常。比如:throw new ModelXxxDAORuntimeException(".....",e),对于msg信息,你可写也可不写,根据需要灵活抛出。
这里常见一个很愚昧的处理方式,为每个DAO定义一个异常,呵呵,这样累不累啊,有多大意义,在Service层中调用时候,如果要捕获,还要捕获出一堆异常。这样致命的问题是代码混乱,维护困难,阅读也困难,DAO的异常应该是粗粒度的。
二、业务层异常处理
习惯上把业务层称之为Service层或者服务层,Service层的代表的是业务逻辑,不要迷信分太多太多层有多大好处,除非需要,否则别盲目划分不必要的层,层越多,效率越差,根据需要够用就行了。
Service接口中的每个方法代表一个特定的业务,而这个业务一定是一个完整的业务,通常会看到一些傻X的做法,数据库事务配置在Service层,而Service的实现就是DAO的直接调用,然后在控制层(Action)中,调用了好多Service去完成一个业务,你气得已经无语了,低头找砖头去!!!
搞明白以上两个问题后再回过头看异常怎么处理,Service层通常依赖DAO,而Service层的通常也会因为调用别的非检查异常方法而必须面对异常处理的问题,这里和DAO层又有所不同,彼一时,此一时嘛!
一般来说一个小模块对应一个Service,当然也许有两个或多个,针对这个模块的Service定义一个非检查异常,以应付那些不可避免的异常检查,这个自定义异常可以简单的命名为XxxServiceRuntimeException,将捕获到的异常顺势转译为非检查异常后抛出。我喜欢这么做,因为前台是J2EE应用,前台是web页面,它们的Struts2等框架会自动捕获所有Service层的异常,并把异常交给开发者去自由处理。
但是还有一种情况,由于一些特殊的限制,如果某个异常一旦发生,必须做什么什么处理,而这种处理时硬性要求,或者调用某个Service方法,必须检查处理什么异常,也可以抛出非检查的自定义异常,往往出现这种情况的是政治原因。不推崇这种做法,但也不排斥。
总之,对于接口,尽可能不去用异常污染她!
三、控制层异常
控制层说的简单些就是常见的Action层,主要是控制页面请求的处理。控制层通常都依赖于Service层,现在比较流行的框架对控制层做得都相当的到位,比如Struts2、SpringMVC等等,他们的控制层框架会捕获业务层的所有异常,并在控制层中声明可能抛出Exception,因此控制层一般不处理什么异常。
如果是控制层中因为调用了一些非检查异常的方法,比如IO操作等,可以简单处理下异常,保证流的安全,这才是目的。
四、显示层异常处理
对于页面异常,处理的方式多种多样,一是不处理异常,一旦异常了,页面就报错。二是定义出错页面,根据异常的类型以及所在的模块,导航到出错页面。
一般来说,出错页面是更友好的做法。
另外还有特殊的处理方式,展示页面的模板可以捕获异常,并根据情况将异常信息铺到相应的位置,这样就更友好了,不过复杂度较高。
怎么处理,就看需要了。
五、总结
1)、对于异常处理,应该从设计、需要、维护等多个角度综合考虑,有一个通用准则:千万别捕获了异常什么事情都不干,这样一旦出现异常了,你没法依据异常信息来排错。
2)、对于J2EE多层架构系统来说,尽可能避免(因抛出异常带来的)接口污染。
posted @
2010-03-13 11:59 xzc 阅读(622) |
评论 (0) |
编辑 收藏平时工作中可能会遇到当试图对库表中的某一列或几列创建唯一索引时,系统提示 ORA-01452 :不能创建唯一索引,发现重复记录。
下面总结一下几种查找和删除重复记录的方法(以表CZ为例):
表CZ的结构如下:
SQL> desc cz
Name Null? Type
----------------------------------------- -------- ------------------
C1 NUMBER(10)
C10 NUMBER(5)
C20 VARCHAR2(3)
删除重复记录的方法原理:
(1).在Oracle中,每一条记录都有一个rowid,rowid在整个数据库中是唯一的,rowid确定了每条记录是在Oracle中的哪一个数据文件、块、行上。
(2).在重复的记录中,可能所有列的内容都相同,但rowid不会相同,所以只要确定出重复记录中那些具有最大rowid的就可以了,其余全部删除。
重复记录判断的标准是:
C1,C10和C20这三列的值都相同才算是重复记录。
经查看表CZ总共有16条记录:
SQL>set pagesize 100
SQL>select * from cz;
C1 C10 C20
---------- ---------- ---
1 2 dsf
1 2 dsf
1 2 dsf
1 2 dsf
2 3 che
1 2 dsf
1 2 dsf
1 2 dsf
1 2 dsf
2 3 che
2 3 che
2 3 che
2 3 che
3 4 dff
3 4 dff
3 4 dff
4 5 err
5 3 dar
6 1 wee
7 2 zxc
20 rows selected.
1.查找重复记录的几种方法:
(1).SQL>select * from cz group by c1,c10,c20 having count(*) >1;
C1 C10 C20
---------- ---------- ---
1 2 dsf
2 3 che
3 4 dff
(2).SQL>select distinct * from cz;C1 C10 C20
---------- ---------- ---
1 2 dsf
2 3 che
3 4 dff
(3).SQL>select * from cz a where rowid=(select max(rowid) from cz where c1=a.c1 and c10=a.c10 and c20=a.c20);
C1 C10 C20
---------- ---------- ---
1 2 dsf
2 3 che
3 4 dff
2.删除重复记录的几种方法:
(1).适用于有大量重复记录的情况(在C1,C10和C20列上建有索引的时候,用以下语句效率会很高):
SQL>delete cz where (c1,c10,c20) in (select c1,c10,c20 from cz group by c1,c10,c20 having count(*)>1) and rowid not in
(select min(rowid) from cz group by c1,c10,c20 having count(*)>1);
SQL>delete cz where rowid not in(select min(rowid) from cz group by c1,c10,c20);
(2).适用于有少量重复记录的情况(注意,对于有大量重复记录的情况,用以下语句效率会很低):
SQL>delete from cz a where a.rowid!=(select max(rowid) from cz b where a.c1=b.c1 and a.c10=b.c10 and a.c20=b.c20);
SQL>delete from cz a where a.rowid<(select max(rowid) from cz b where a.c1=b.c1 and a.c10=b.c10 and a.c20=b.c20);
SQL>delete from cz a where rowid <(select max(rowid) from cz where c1=a.c1 and c10=a.c10 and c20=a.c20);
(3).适用于有少量重复记录的情况(临时表法) --超级土的办法
SQL>create table test as select distinct * from cz; (建一个临时表test用来存放重复的记录)
SQL>truncate table cz; (清空cz表的数据,但保留cz表的结构)
SQL>insert into cz select * from test; (再将临时表test里的内容反插回来)
(4).适用于有大量重复记录的情况(Exception into 子句法): --很有意思的一个办法
采用alter table 命令中的 Exception into 子句也可以确定出库表中重复的记录。这种方法稍微麻烦一些,为了使用“excepeion into ”子句,必须首先创建 EXCEPTIONS 表。创建该表的 SQL 脚本文件为 utlexcpt.sql 。对于win2000系统和 UNIX 系统, Oracle 存放该文件的位置稍有不同,在win2000系统下,该脚本文件存放在$ORACLE_HOME\Ora90\rdbms\admin 目录下;而对于 UNIX 系统,该脚本文件存放在$ORACLE_HOME/rdbms/admin 目录下。
具体步骤如下:
SQL>@?/rdbms/admin/utlexcpt.sql
Table created.
SQL>desc exceptions
Name Null? Type
----------------------------------------- -------- --------------
ROW_ID ROWID
OWNER VARCHAR2(30)
TABLE_NAME VARCHAR2(30)
CONSTRAINT VARCHAR2(30)
SQL>alter table cz add constraint cz_unique unique(c1,c10,c20) exceptions into exceptions;
*
ERROR at line 1:
ORA-02299: cannot validate (TEST.CZ_UNIQUE) - duplicate keys found
SQL>create table dups as select * from cz where rowid in (select row_id from exceptions);
Table created.
SQL>select * from dups;
C1 C10 C20
---------- ---------- ---
1 2 dsf
1 2 dsf
1 2 dsf
1 2 dsf
2 3 che
1 2 dsf
1 2 dsf
1 2 dsf
1 2 dsf
2 3 che
2 3 che
2 3 che
2 3 che
3 4 dff
3 4 dff
3 4 dff
16 rows selected.
SQL>select row_id from exceptions;
ROW_ID
------------------
AAAHD/AAIAAAADSAAA
AAAHD/AAIAAAADSAAB
AAAHD/AAIAAAADSAAC
AAAHD/AAIAAAADSAAF
AAAHD/AAIAAAADSAAH
AAAHD/AAIAAAADSAAI
AAAHD/AAIAAAADSAAG
AAAHD/AAIAAAADSAAD
AAAHD/AAIAAAADSAAE
AAAHD/AAIAAAADSAAJ
AAAHD/AAIAAAADSAAK
AAAHD/AAIAAAADSAAL
AAAHD/AAIAAAADSAAM
AAAHD/AAIAAAADSAAN
AAAHD/AAIAAAADSAAO
AAAHD/AAIAAAADSAAP
16 rows selected.
SQL>delete from cz where rowid in ( select row_id from exceptions);
16 rows deleted.
SQL>insert into cz select distinct * from dups;
3 rows created.
SQL>select *from cz;
C1 C10 C20
---------- ---------- ---
1 2 dsf
2 3 che
3 4 dff
4 5 err
5 3 dar
6 1 wee
7 2 zxc
7 rows selected.
从结果里可以看到重复记录已经删除。
posted @
2010-03-06 12:03 xzc 阅读(1015) |
评论 (8) |
编辑 收藏Oracle中start with…connect by prior子句用法
connect by 是结构化查询中用到的,其基本语法是:
select … from tablename
start with 条件1
connect by 条件2
where 条件3;
例:
select * from table
start with org_id = ‘HBHqfWGWPy’
connect by prior org_id = parent_id;
简单说来是将一个树状结构存储在一张表里,比如一个表中存在两个字段:
org_id,parent_id那么通过表示每一条记录的parent是谁,就可以形成一个树状结构。
用上述语法的查询可以取得这棵树的所有记录。
其中:
条件1 是根结点的限定语句,当然可以放宽限定条件,以取得多个根结点,实际就是多棵树。
条件2 是连接条件,其中用PRIOR表示上一条记录,比如 CONNECT BY PRIOR org_id = parent_id;就是说上一条记录的org_id 是本条记录的parent_id,即本记录的父亲是上一条记录。
条件3 是过滤条件,用于对返回的所有记录进行过滤。
简单介绍如下:
在扫描树结构表时,需要依此访问树结构的每个节点,一个节点只能访问一次,其访问的步骤如下:
第一步:从根节点开始;
第二步:访问该节点;
第三步:判断该节点有无未被访问的子节点,若有,则转向它最左侧的未被访问的子节,并执行第二步,否则执行第四步;
第四步:若该节点为根节点,则访问完毕,否则执行第五步;
第五步:返回到该节点的父节点,并执行第三步骤。
总之:扫描整个树结构的过程也即是中序遍历树的过程。
1.树结构的描述
树结构的数据存放在表中,数据之间的层次关系即父子关系,通过表中的列与列间的关系来描述,如EMP表中的EMPNO和MGR。EMPNO表示该雇员的编号,MGR表示领导该雇员的人的编号,即子节点的MGR值等于父节点的EMPNO值。在表的每一行中都有一个表示父节点的MGR(除根节点外),通过每个节点的父节点,就可以确定整个树结构。
在SELECT命令中使用CONNECT BY 和START WITH 子句可以查询表中的树型结构关系。其命令格式如下:
SELECT . . .
CONNECT BY {PRIOR 列名1=列名2|列名1=PRIOR 裂名2}
[START WITH];
其中:CONNECT BY子句说明每行数据将是按层次顺序检索,并规定将表中的数据连入树型结构的关系中。PRIOR运算符必须放置在连接关系的两列中某一个的前面。对于节点间的父子关系,PRIOR运算符在一侧表示父节点,在另一侧表示子节点,从而确定查找树结构是的顺序是自顶向下还是自底向上。
在连接关系中,除了可以使用列名外,还允许使用列表达式。START WITH 子句为可选项,用来标识哪个节点作为查找树型结构的根节点。若该子句被省略,则表示所有满足查询条件的行作为根节点。
START WITH:不但可以指定一个根节点,还可以指定多个根节点。
2.关于PRIOR
运算符PRIOR被放置于等号前后的位置,决定着查询时的检索顺序。
PRIOR被置于CONNECT BY子句中等号的前面时,则强制从根节点到叶节点的顺序检索,即由父节点向子节点方向通过树结构,我们称之为自顶向下的方式。如:
CONNECT BY PRIOR EMPNO=MGR
PIROR运算符被置于CONNECT BY 子句中等号的后面时,则强制从叶节点到根节点的顺序检索,即由子节点向父节点方向通过树结构,我们称之为自底向上的方式。例如:
CONNECT BY EMPNO=PRIOR MGR
在这种方式中也应指定一个开始的节点。
3.定义查找起始节点
在自顶向下查询树结构时,不但可以从根节点开始,还可以定义任何节点为起始节点,以此开始向下查找。这样查找的结果就是以该节点为开始的结构树的一枝。
4.使用LEVEL
在具有树结构的表中,每一行数据都是树结构中的一个节点,由于节点所处的层次位置不同,所以每行记录都可以有一个层号。层号根据节点与根节点的距离确定。不论从哪个节点开始,该起始根节点的层号始终为1,根节点的子节点为2, 依此类推。图1.2就表示了树结构的层次。
5.节点和分支的裁剪
在对树结构进行查询时,可以去掉表中的某些行,也可以剪掉树中的一个分支,使用WHERE子句来限定树型结构中的单个节点,以去掉树中的单个节点,但它却不影响其后代节点(自顶向下检索时)或前辈节点(自底向顶检索时)。
6.排序显示
象在其它查询中一样,在树结构查询中也可以使用ORDER BY 子句,改变查询结果的显示顺序,而不必按照遍历树结构的顺序。
posted @
2010-03-05 18:02 xzc 阅读(49581) |
评论 (2) |
编辑 收藏【转】PowerDesigner 中将Comment(注释)及Name(名称)内容互相COPY的VBS代码
2009-12-03 15:06
posted @
2010-03-03 16:09 xzc 阅读(1037) |
评论 (0) |
编辑 收藏
问题一:
ERROR at line 1: ORA-29538: Java not installed
解决方法
1.检查有没有安装JAVA组件
select * from v$option t where t.PARAMETER='Java';
如果返回行说明已安装,如果没有返回行,运行Oracle Universal Installer安装JAVA组件
2.如果在第1步返回行,则检查oracle中有没有dbms_java.
select distinct owner,name from dba_source where lower(NAME)='dbms_java';
如果没有返回行,执行第3步
3.在sqlplus下以sys登陆,执行$ORACLE_HOME/javavm/install/initjvm.sql
SQL>@?/javavm/install/initjvm.sql;
问题二:
ERROR at line 1:
ORA-29532: Java call terminated by uncaught Java exception:
java.security.AccessControlException: the Permission (java.io.FilePermission
/home/accmgrctl/src/server read) has not been granted to SQLVIEW. The PL/SQL to
grant this is dbms_java.grant_permission( 'SQLVIEW',
'SYS:java.io.FilePermission', '/home/accmgrctl/src/server', 'read' )
ORA-06512: at "SQLVIEW.PKG_FILE_API", line 1
解决方法:
这是由于oracle用户没有访问那个目录的权限,把源代码入在oracle有权限访问的目录下
或者用以下语句授权
EXEC Dbms_Java.Grant_Permission('oracle_username','java.io.FilePermission', '*','read ');
问题三:
ERROR at line 1:
ORA-29913: error in executing ODCIEXTTABLEOPEN callout
ORA-29400: data cartridge error
KUP-00552: internal XAD package failed to load
ORA-06512: at "SYS.ORACLE_LOADER", line 19
解决方法:
这是110202 上的又一新BUG(外部表的读取)
Need to replace the language specific (non-english) kup<lang>.msb file
with the english version.
1. cd $ORACLE_HOME/rdbms/mesg
2. Replace <lang> with your installed languages file.
mv KUP<lang>.msb to KUP<lang>.msb.BAK
3. Copy <us> version over current <lang> copy of kup msb file.
cp kupus.msb to KUP<lang>.msb
4. re-run the select against the external table
我实际的操作过程,就是:
该目录:$ORACLE_HOME/rdbms/mesg 下有两个文件:
kupzhs.msb 和 kupus.msb, 其默认使用了kupzhs.msb
此时,我把kupzhs.msb 重新命名为 kupzhs.msb.bak
之后在测试, OK:
人生有三宝:终身运动,终身学习,终身反醒.吸收新知,提高效率,懂得相处,成就自己,也成就他人,创造最高价值。
posted @
2010-02-09 17:43 xzc 阅读(2262) |
评论 (0) |
编辑 收藏posted @
2010-01-30 12:02 xzc 阅读(1991) |
评论 (0) |
编辑 收藏
-
- <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.url">jdbc:mysql://localhost:3306/struts?useUnicode=true&characterEncoding=GBK</property>
- <property name="connection.username">root</property>
- <property name="connection.password">8888</property>
<!-- JDBC驱动程序 --> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.url">jdbc:mysql://localhost:3306/struts?useUnicode=true&characterEncoding=GBK</property> <!-- 数据库用户名 --> <property name="connection.username">root</property> <!-- 数据库密码 --> <property name="connection.password">8888</property>
上面的一段配置,在c3p0和dbcp中,都是必需的,因为hibernate会根据上述的配置来生成connections,再交给c3p0或dbcp管理.
1 C3P0
只需在hibernate.cfg.xml中加入
- <property name="c3p0.min_size">5</property>
- <property name="c3p0.max_size">30</property>
- <property name="c3p0.time_out">1800</property>
- <property name="c3p0.max_statement">50</property>
<property name="c3p0.min_size">5</property> <property name="c3p0.max_size">30</property> <property name="c3p0.time_out">1800</property> <property name="c3p0.max_statement">50</property>
还有在classespath中加入c3p0-0.8.4.5.jar
2 dbcp
在hibernate.cfg.xml中加入
- <property name="dbcp.maxActive">100</property>
- <property name="dbcp.whenExhaustedAction">1</property>
- <property name="dbcp.maxWait">60000</property>
- <property name="dbcp.maxIdle">10</property>
-
- <property name="dbcp.ps.maxActive">100</property>
- <property name="dbcp.ps.whenExhaustedAction">1</property>
- <property name="dbcp.ps.maxWait">60000</property>
- <property name="dbcp.ps.maxIdle">10</property>
<property name="dbcp.maxActive">100</property> <property name="dbcp.whenExhaustedAction">1</property> <property name="dbcp.maxWait">60000</property> <property name="dbcp.maxIdle">10</property> <property name="dbcp.ps.maxActive">100</property> <property name="dbcp.ps.whenExhaustedAction">1</property> <property name="dbcp.ps.maxWait">60000</property> <property name="dbcp.ps.maxIdle">10</property>
还有在classespath中加入commons-pool-1.2.jar 和commons-dbcp-1.2.1.jar.
3 proxool
由于数据库connection在较长时间没有访问下会自动断开连接,导致浏览出错,增加proxool作为数据库pool。它有自动连接功能。
1)、从http://proxool.sourceforge...下载proxool,释放proxool.jar到WEB-INF/lib
2)、在hibernate.cfg.xml中增加:
- <property name="hibernate.proxool.pool_alias">dbpool</property>
- <property name="hibernate.proxool.xml">proxool.xml</property>
- <property name="connection.provider_class">org.hibernate.connection.ProxoolConnectionProvider</property>
<property name="hibernate.proxool.pool_alias">dbpool</property> <property name="hibernate.proxool.xml">proxool.xml</property> <property name="connection.provider_class">org.hibernate.connection.ProxoolConnectionProvider</property>
3)、在与hibernate.cfg.xml同级目录(src根目录下)增加proxool.xml文件:
- <?xml version="1.0" encoding="utf-8"?>
- <!-- the proxool configuration can be embedded within your own application's.
- Anything outside the "proxool" tag is ignored. -->
- <something-else-entirely>
- <proxool>
- <alias>dbpool</alias>
-
- <driver-url>
- jdbc:mysql://127.0.0.1:3306/wlsh?characterEncoding=GBK&useUnicode=true&autoReconnect=true </driver-url>
- <driver-class>com.mysql.jdbc.Driver</driver-class>
- <driver-properties>
- <property name="user" value="root" />
- <property name="password" value="123456" />
- </driver-properties>
-
- <house-keeping-sleep-time>90000</house-keeping-sleep-time>
-
- <prototype-count>5</prototype-count>
-
- <maximum-connection-count>100</maximum-connection-count>
-
- <minimum-connection-count>10</minimum-connection-count>
- </proxool>
- </something-else-entirely>
<?xml version="1.0" encoding="utf-8"?> <!-- the proxool configuration can be embedded within your own application's. Anything outside the "proxool" tag is ignored. --> <something-else-entirely> <proxool> <alias>dbpool</alias> <!--proxool只能管理由自己产生的连接--> <driver-url> jdbc:mysql://127.0.0.1:3306/wlsh?characterEncoding=GBK&useUnicode=true&autoReconnect=true </driver-url> <driver-class>com.mysql.jdbc.Driver</driver-class> <driver-properties> <property name="user" value="root" /> <property name="password" value="123456" /> </driver-properties> <!-- proxool自动侦察各个连接状态的时间间隔(毫秒),侦察到空闲的连接就马上回收,超时的销毁--> <house-keeping-sleep-time>90000</house-keeping-sleep-time> <!-- 最少保持的空闲连接数--> <prototype-count>5</prototype-count> <!-- 允许最大连接数,超过了这个连接,再有请求时,就排在队列中等候,最大的等待请求数由maximum-new-connections决定--> <maximum-connection-count>100</maximum-connection-count> <!-- 最小连接数--> <minimum-connection-count>10</minimum-connection-count> </proxool></something-else-entirely>
于在hibernate3.0中,已经不再支持dbcp了,hibernate的作者在hibernate.org中,明确指出在实践中发现dbcp有 BUG,在某些种情会产生很多空连接不能释放,所以抛弃了对dbcp的支持。至于c3p0,有评论说它的算法不是最优的,因为网上查资料得知:有网友做了一个实验,在同一项目中分别用了几个常用的连接池,然后测试其性能,发现c3p0占用资源比较大,效率也不高。所以,基于上述原因,proxool不少行家推荐使用,而且暂时来说,是负面评价是最少的一个。在三星中也有项目是用proxool的。从性能和出错率来说,proxool稍微比前两种好些。C3P0,稳定性似乎不错,在这方面似乎有很好的口碑。至于性能,应该不是最好的,算是中规中矩的类型。
Proxool的口碑似乎很好,不大见到负面的评价,从官方资料上来看,有许多有用的特性和特点,也是许多人推荐的。
posted @
2010-01-30 12:00 xzc 阅读(3962) |
评论 (0) |
编辑 收藏JDK工具 java命令详解
一、查看用法
C:\>java -help
Usage: java [-options] class [args...]
(to execute a class)
or java [-options] -jar jarfile [args...]
(to execute a jar file)
where options include:
-client to select the "client" VM
-server to select the "server" VM
-hotspot is a synonym for the "client" VM [deprecated]
The default VM is client.
-cp <class search path of directories and zip/jar files>
-classpath <class search path of directories and zip/jar files>
A ; separated list of directories, JAR archives,
and ZIP archives to search for class files.
-D<name>=<value>
set a system property
-verbose[:class|gc|jni]
enable verbose output
-version print product version and exit
-version:<value>
require the specified version to run
-showversion print product version and continue
-jre-restrict-search | -jre-no-restrict-search
include/exclude user private JREs in the version search
-? -help print this help message
-X print help on non-standard options
-ea[:<packagename>...|:<classname>]
-enableassertions[:<packagename>...|:<classname>]
enable assertions
-da[:<packagename>...|:<classname>]
-disableassertions[:<packagename>...|:<classname>]
disable assertions
-esa | -enablesystemassertions
enable system assertions
-dsa | -disablesystemassertions
disable system assertions
-agentlib:<libname>[=<options>]
load native agent library <libname>, e.g. -agentlib:hprof
see also, -agentlib:jdwp=help and -agentlib:hprof=help
-agentpath:<pathname>[=<options>]
load native agent library by full pathname
-javaagent:<jarpath>[=<options>]
load Java programming language agent, see java.lang.instrument
这个命令帮助是英文的,不知道JDK咋搞的,也不妨碍使用。
另外,这个命令的非标准选项也是很重要的,常常在JVM优化配置方面很关键,可以参看本人的JVM参数配置文章。
C:\myproject>java -X
-Xmixed mixed mode execution (default)
-Xint interpreted mode execution only
-Xbootclasspath:<directories and zip/jar files separated by ;>
set search path for bootstrap classes and resources
-Xbootclasspath/a:<directories and zip/jar files separated by ;>
append to end of bootstrap class path
-Xbootclasspath/p:<directories and zip/jar files separated by ;>
prepend in front of bootstrap class path
-Xnoclassgc disable class garbage collection
-Xincgc enable incremental garbage collection
-Xloggc:<file> log GC status to a file with time stamps
-Xbatch disable background compilation
-Xms<size> set initial Java heap size
-Xmx<size> set maximum Java heap size
-Xss<size> set java thread stack size
-Xprof output cpu profiling data
-Xfuture enable strictest checks, anticipating future default
-Xrs reduce use of OS signals by Java/VM (see documentation)
-Xcheck:jni perform additional checks for JNI functions
-Xshare:off do not attempt to use shared class data
-Xshare:auto use shared class data if possible (default)
-Xshare:on require using shared class data, otherwise fail.
二、实践
老规矩,主要看看里面的参数(也叫开关)的使用。环境接着上篇javac的环境。
1、无参数情况
2、-cp
运行Java要使用类的全名来运行。如果遇到文件夹,则需要-cp设置到顶级包下面,例如
3、-D
设置一个系统属性,在运行时候,可以通过System.getProperties()来获取到。例如写一段代码:
package com.lavasoft;
import java.util.Properties;
/**
* 列举系统的属性
* User: leizhimin
* Date: 2008-11-12 21:25:08
*/
public class TestProperty {
public static void main(String[] args) {
//获取系统属性
Properties prop = System.getProperties();
//输出所有到一个流上,
prop.list(System.out);
}
}
如果在运行的时候加上一个参数-DmyProp=999999999,注意,中间不要添加任何空格。这样就相当于设置了一个系统属性myProp,其值为999999999。
一旦通过-DmyProp=999999999设置了这个系统属性,在程序中就可以获取到这个属性。
3、程序入参
是在运行的时候,给main方法传递参数。为了测试先写一个测试类。
package com.lavasoft;
/**
* 测试main方法的入参
* User: leizhimin
* Date: 2008-11-12 21:46:21
*/
public class TestMainVar {
public static void main(String[] args) {
System.out.println("入参列表如下:");
for(String arg:args){
System.out.println(arg);
}
}
}
4、其他的选项
有关选择 客户端/服务端VM、版本、运行在哪个版本下、是否使用断言等一些不常用的选项。还可以查看
5、-verbose[:class|gc|jni]
查看虚拟机内部动作。
posted @
2009-12-04 17:15 xzc 阅读(17986) |
评论 (4) |
编辑 收藏结构
javac [ options ] [ sourcefiles ] [ @files ]
参数可按任意次序排列。
options
- 命令行选项。
sourcefiles
- 一个或多个要编译的源文件(例如 MyClass.java)。
@files
- 一个或多个对源文件进行列表的文件。
说明
javac
有两种方法可将源代码文件名传递给 javac:
- 如果源文件数量少,在命令行上列出文件名即可。
- 如果源文件数量多,则将源文件名列在一个文件中,名称间用空格或回车行来进行分隔。然后在 javac 命令行中使用该列表文件名,文件名前冠以 @ 字符。
源代码文件名称必须含有 .java 后缀,类文件名称必须含有 .class 后缀,源文件和类文件都必须有识别该类的根名。例如,名为 MyClass 的类将写在名为 MyClass.java的源文件中,并被编译为字节码类文件 MyClass.class。
内部类定义产生附加的类文件。这些类文件的名称将内部类和外部类的名称结合在一起,例如 MyClass$MyInnerClass.class。
应当将源文件安排在反映其包树结构的目录树中。例如,如果将所有的源文件放在 /workspace 中,那么 com.mysoft.mypack.MyClass 的代码应该在 \workspace\com\mysoft\mypack\MyClass.java 中。
缺省情况下,编译器将每个类文件与其源文件放在同一目录中。可用 -d 选项(请参阅后面的
选项)指定其它目标目录。
工具读取用 Java 编程语言编写的类和接口定义,并将它们编译成字节码类文件。
查找类型
当编译源文件时,编译器常常需要它还没有识别出的类型的有关信息。对于源文件中使用、扩展或实现的每个类或接口,编译器都需要其类型信息。这包括在源文件中没有明确提及、但通过继承提供信息的类和接口。
例如,当扩展 java.applet.Applet 时还要用到 Applet 的祖先类:java.awt.Panel 、 java.awt.Container、 java.awt.Component 和 java.awt.Object。
当编译器需要类型信息时,它将查找定义类型的源文件或类文件。编译器先在自举类及扩展类中查找,然后在用户类路径中查找。用户类路径通过两种途径来定义:通过设置 CLASSPATH 环境变量或使用 -classpath 命令行选项。(有关详细资料,请参阅设置类路径)。如果使用 -sourcepath 选项,则编译器在 sourcepath 指定的路径中查找源文件;否则,编译器将在用户类路径中查找类文件和源文件。可用-bootclasspath 和 -extdirs 选项来指定不同的自举类或扩展类;参阅下面的联编选项。
成功的类型搜索可能生成类文件、源文件或两者兼有。以下是 javac 对各种情形所进行的处理:
- 搜索结果只生成类文件而没有源文件: javac 使用类文件。
- 搜索结果只生成源文件而没有类文件: javac 编译源文件并使用由此生成的类文件。
- 搜索结果既生成源文件又生成类文件: 确定类文件是否过时。若类文件已过时,则 javac 重新编译源文件并使用更新后的类文件。否则, javac 直接使用类文件。
缺省情况下,只要类文件比源文件旧, javac 就认为它已过时。( -Xdepend 选项指定相对来说较慢但却比较可靠的过程。)
javac
注意: javac 可以隐式编译一些没有在命令行中提及的源文件。用 -verbose 选项可跟踪自动编译。
文件列表
为缩短或简化 javac 命令,可以指定一个或多个每行含有一个文件名的文件。在命令行中,采用 '@' 字符加上文件名的方法将它指定为文件列表。当 javac 遇到以 `@' 字符开头的参数时,它对那个文件中所含文件名的操作跟对命令行中文件名的操作是一样的。这使得 Windows 命令行长度不再受限制。
例如,可以在名为 sourcefiles 的文件中列出所有源文件的名称。该文件可能形如:
MyClass1.java
MyClass2.java
MyClass3.java
然后可用下列命令运行编译器:
C:> javac @sourcefiles
选项
编译器有一批标准选项,目前的开发环境支持这些标准选项,将来的版本也将支持它。还有一批附加的非标准选项是目前的虚拟机实现所特有的,将来可能要有变化。非标准选项以 -X 打头。
标准选项
- -classpath 类路径
- 设置用户类路径,它将覆盖 CLASSPATH 环境变量中的用户类路径。若既未指定 CLASSPATH 又未指定 -classpath,则用户类路径由当前目录构成。有关详细信息,请参阅设置类路径。
若未指定 -sourcepath 选项,则将在用户类路径中查找类文件和源文件。
- -d 目录
- 设置类文件的目标目录。如果某个类是一个包的组成部分,则 javac 将把该类文件放入反映包名的子目录中,必要时创建目录。例如,如果指定 -d c:\myclasses 并且该类名叫
com.mypackage.MyClass,那么类文件就叫作 c:\myclasses\com\mypackage\MyClass.class。
若未指定 -d 选项,则 javac 将把类文件放到与源文件相同的目录中。
注意: -d 选项指定的目录不会被自动添加到用户类路径中。
- -deprecation
- 显示每种不鼓励使用的成员或类的使用或覆盖的说明。没有给出 -deprecation 选项的话, javac 将显示这类源文件的名称:这些源文件使用或覆盖不鼓励使用的成员或类。
- -encoding
- 设置源文件编码名称,例如
EUCJIS/SJIS。若未指定 -encoding 选项,则使用平台缺省的转换器。
- -g
- 生成所有的调试信息,包括局部变量。缺省情况下,只生成行号和源文件信息。
- -g:none
- 不生成任何调试信息。
- -g:{关键字列表}
- 只生成某些类型的调试信息,这些类型由逗号分隔的关键字列表所指定。有效的关键字有:
- source
- 源文件调试信息
- lines
- 行号调试信息
- vars
- 局部变量调试信息
- -nowarn
- 禁用警告信息。
- -O
- 优化代码以缩短执行时间。使用 -O 选项可能使编译速度下降、生成更大的类文件并使程序难以调试。
在 JDK 1.2 以前的版本中,javac 的 -g 选项和 -O 选项不能一起使用。在 JDK 1.2 中,可以将 -g 和 -O 选项结合起来,但可能会得到意想不到的结果,如丢失变量或重新定位代码或丢失代码。-O 选项不再自动打开 -depend 或关闭 -g 选项。同样, -O 选项也不再允许进行跨类内嵌。
- -sourcepath 源路径
- 指定用以查找类或接口定义的源代码路径。与用户类路径一样,源路径项用分号 (;) 进行分隔,它们可以是目录、JAR 归档文件或 ZIP 归档文件。如果使用包,那么目录或归档文件中的本地路径名必须反映包名。
注意:通过类路径查找的类,如果找到了其源文件,则可能会自动被重新编译。
- -verbose
- 冗长输出。它包括了每个所加载的类和每个所编译的源文件的有关信息。
联编选项
缺省情况下,类是根据与 javac 一起发行的 JDK 自举类和扩展类来编译。但 javac 也支持联编,在联编中,类是根据其它 Java平台实现的自举类和扩展类来进行编译的。联编时, -bootclasspath 和 -extdirs 的使用很重要;请参阅下面的联编程序示例。
- -target 版本
- 生成将在指定版本的虚拟机上运行的类文件。缺省情况下生成与 1.1 和 1.2 版本的虚拟机都兼容的类文件。JDK 1.2 中的 javac 所支持的版本有:
- 1.1
- 保证所产生的类文件与 1.1 和 1.2 版的虚拟机兼容。这是缺省状态。
- 1.2
- 生成的类文件可在 1.2 版的虚拟机上运行,但不能在 1.1 版的虚拟机上运行。
- -bootclasspath 自举类路径
- 根据指定的自举类集进行联编。和用户类路径一样,自举类路径项用分号 (;) 进行分隔,它们可以是目录、JAR 归档文件或 ZIP 归档文件。
- -extdirs 目录
- 根据指定的扩展目录进行联编。目录是以分号分隔的目录列表。在指定目录的每个 JAR 归档文件中查找类文件。
非标准选项
- -X
- 显示非标准选项的有关信息并退出。
- -Xdepend
- 递归地搜索所有可获得的类,以寻找要重编译的最新源文件。该选项将更可靠地查找需要编译的类,但会使编译进程的速度大为减慢。
- -Xstdout
- 将编译器信息送到
System.out 中。缺省情况下,编译器信息送到 System.err 中。
- -Xverbosepath
- 说明如何搜索路径和标准扩展以查找源文件和类文件。
- -J选项
- 将选项传给 javac 调用的 java 启动器。例如, -J-Xms48m 将启动内存设为 48 兆字节。虽然它不以 -X 开头,但它并不是 javac 的‘标准选项’。用 -J 将选项传给执行用 Java 编写的应用程序的虚拟机是一种公共约定。
注意: CLASSPATH 、 -classpath 、 -bootclasspath 和 -extdirs 并 不 指定用于运行 javac 的类。如此滥用编译器的实现通常没有任何意义而且总是很危险的。如果确实需要这样做,可用 -J 选项将选项传给基本的 java 启动器。
程序示例
编译简单程序
一个源文件 Hello.java ,它定义了一个名叫 greetings.Hello 的类。greetings 目录是源文件和类文件两者的包目录,且它不是当前目录。这让我们可以使用缺省的用户类路径。它也使我们没必要用 -d 选项指定单独的目标目录。
C:> dir
greetings/
C:> dir greetings
Hello.java
C:> cat greetings\Hello.java
package greetings;
public class Hello {
public static void main(String[] args) {
for (int i=0; i < args.length; i++) {
System.out.println("Hello " + args[i]);
}
}
}
C:> javac greetings\Hello.java
C:> dir greetings
Hello.class Hello.java
C:> java greetings.Hello World Universe Everyone
Hello World
Hello Universe
Hello Everyone
编译多个源文件
该示例编译 greetings 包中的所有源文件。
C:> dir
greetings\
C:> dir greetings
Aloha.java GutenTag.java Hello.java Hi.java
C:> javac greetings\*.java
C:> dir greetings
Aloha.class GutenTag.class Hello.class Hi.class
Aloha.java GutenTag.java Hello.java Hi.java
指定用户类路径
对前面示例中的某个源文件进行更改后,重新编译它:
C:> cd
\examples
C:> javac greetings\Hi.java
由于 greetings.Hi 引用了 greetings 包中其它的类,编译器需要找到这些其它的类。上面的示例能运行是因为缺省的用户类路径刚好是含有包目录的目录。但是,假设我们想重新编译该文件并且不关心我们在哪个目录中的话, 我们需要将 \examples 添加到用户类路径中。可以通过设置 CLASSPATH 达到此目的,但这里我们将使用 -classpath 选项来完成。
C:>javac -classpath \examples \examples\greetings\Hi.java
如果再次将 greetings.Hi 改为使用标题实用程序,该实用程序也需要通过用户类路径来进行访问:
C:>javac -classpath \examples:\lib\Banners.jar \
\examples\greetings\Hi.java
要执行 greetings 中的类,需要访问 greetings 和它所使用的类。
C:>java -classpath \examples:\lib\Banners.jar greetings.Hi
将源文件和类文件分开
将源文件和类文件置于不同的目录下经常是很有意义的,特别是在大型的项目中。我们用 -d 选项来指明单独的类文件目标位置。由于源文件不在用户类路径中,所以用 -sourcepath 选项来协助编译器查找它们。
C:> dir
classes\ lib\ src\
C:> dir src
farewells\
C:> dir src\farewells
Base.java GoodBye.java
C:> dir lib
Banners.jar
C:> dir classes
C:> javac -sourcepath src -classpath classes:lib\Banners.jar \
src\farewells\GoodBye.java -d classes
C:> dir classes
farewells\
C:> dir classes\farewells
Base.class GoodBye.class
注意:编译器也编译了 src\farewells\Base.java,虽然我们没有在命令行中指定它。要跟踪自动编译,可使用 -verbose 选项。
联编程序示例
这里我们用 JDK 1.2 的 javac 来编译将在 1.1 版的虚拟机上运行的代码。
C:> javac -target 1.1 -bootclasspath jdk1.1.7\lib\classes.zip \
-extdirs "" OldCode.java
-target 1.1
JDK 1.2 javac 在缺省状态下也将根据 1.2 版的自举类来进行编译,因此我们需要告诉 javac 让它根据 JDK 1.1 自举类来进行编译。可用 -bootclasspath 和 -extdirs 选项来达到此目的。不这样做的话,可能会使编译器根据 1.2 版的 API 来进行编译。由于 1.1 版的虚拟机上可能没有该 1.2 版的 API,因此运行时将出错。
选项可确保生成的类文件与 1.1 版的虚拟机兼容。在 JDK1.2 中, 缺省情况下 javac 编译生成的文件是与 1.1 版的虚拟机兼容的,因此并非严格地需要该选项。然而,由于别的编译器可能采用其它的缺省设置,所以提供这一选项将不失为是个好习惯。
posted @
2009-12-04 17:13 xzc 阅读(403) |
评论 (0) |
编辑 收藏Java命令行命令详解
rmic
功能说明:
rmic 为远程对象生成 stub 和 skeleton。
语法:
rmic [ options ] package-qualified-class-name(s)
补充说明:
rmic 编译器根据编译后的 Java 类(含有远程对象实现)名,为远程对象生成 stub 和 skeleton(远程对象是指实现 java.rmi.Remote 接口的对象)。在 rmic 命令中所给的类必须是经 javac 命令成功编译且是完全包限定的类。
命令选项
-classpath[路径] 指定 rmic 用于查询类的路径。如果设置了该选项,它将覆盖缺省值或 CLASSPATH 环境变量。目录用冒号分隔。
-d[目录] 指定类层次的根目录。此选项可用来指定 stub 和 skeleton 文件的目标目录。
-depend 使编译器考虑重新编译从其它类引用的类。 一般来说,它只重新编译从源代码引用的遗漏或过期的类。
-g 允许生成调试表格。调试表格含有行号和局部变量的有关信息,即 Java 调试工具所使用的信息。缺省情况下,只生成行号。
-J 与 -D 选项联用,它将紧跟其后的选项( -J 与 -D 之间无空格)传给 java 解释器。
-keepgenerated 为 stub 和 skeleton 文件保留所生成的 .java 源文件,并将这些源文件写到与 .class 文件相同的目录中,如果要指定目录,则使用 -d 选项。
-nowarn 关闭警告。如果使用该选项,则编译器不输出任何警告信息。
-show 显示 rmic 编译器的 GUI(图形用户界面)。输入一个或多个包限定类名(以空格分隔),并按回车键或“显示”按钮,创建 stub 和 skeleton。
-vcompat (缺省值)创建与 JDK 1.1 和 1.2 stub 协议版本都兼容的 stub 和 skeleton。
-verbose 使编译器和链接器输出关于正在编译哪些类和正在加载哪些类文件的信息。
-v1.1 创建 JDK 1.1 stub 协议版本的 stub 和 skeleton。
-v1.2 只创建 JDK 1.2 stub 协议版本的 stub。
rmid
功能说明:
rmid 启动激活系统守护进程,以便能够在 Java 虚拟机上注册和激活对象。
语法:
rmid [-port port] [-log dir]
补充说明:
rmid 工具启动激活系统守护进程。必须先启动激活系统守护进程,才能向激活系统注册可被激活的对象或在 Java 虚拟机上激活可被激活的对象。
命令选项
-C<某些命令行选项> 指定一个选项,在创建每个 rmid 的子守护进程(激活组)时,该选项以命令行参数的形式传给该子守护进程。
-log[目录] 指定目录的名称,激活系统守护进程在该目录中写入其数据库及相关信息。缺省状态下,将在执行 rmid 命令的目录中创建一个 log 目录。
-port[端口] 指定 rmid 的注册服务程序所使用的端口。激活系统守护进程将 ActivationSystem 与该注册服务程序中的名称java.rmi.activation.ActivationSystem 捆绑在一起。
-stop 停止 -port 选项所指定端口上的当前 rmid 调用。若未指定端口,则将停止在端口 1098 上运行的 rmid。
rmiregistry
功能说明:
rmiregistry 命令可在当前主机的指定端口上启动远程对象注册服务程序。
语法:
rmiregistry [port]
补充说明:
rmiregistry 命令在当前主机的指定 port 上创建并启动远程对象注册服务程序。如果省略 port,则注册服务程序将在 1099 端口上启动。rmiregistry 命令不产生任何输出而且一般在后台运行。远程对象注册服务程序是自举命名服务。主机上的 RMI 服务器将利用它将远程对象绑定到名字上。客户机即可查询远程对象并进行远程方法调用。注册服务程序一般用于定位应用程序需调用其方法的第一个远程对象。该 对象反过来对各应用程序提供相应的支持,用于查找其它对象。
java.rmi.registry.LocateRegistry 类的方法可用于在某台主机或主机和端口上获取注册服务程序操作。java.rmi.Naming 类的基于 URL 的方法将对注册服务程序进行操作,并可用于查询远程对象、将简单(字符串)名称绑定到远程对象、将新名称重新绑定到远程对象(覆盖旧绑定)、取消远程对象 的绑定以及列出绑定在注册服务程序上的 URL。
serialver
功能说明:
serialver 命令返回 serialVersionUID。
语法:
serialver [ 命令选项 ]
补充说明:
serialver 以适于复制到演变类的形式返回一个或多个类的 serialVersionUID。不带参数调用时,它输出用法行。
命令选项
-show 显示一个简单的用户界面。输入完整的类名并按回车键或“显示”按钮可显示 serialVersionUID。
jarsigner
功能说明:
为 Java 归档 (JAR) 文件产生签名,并校验已签名的 JAR 文件的签名。
语法:
jarsigner [ 命令选项 ] jar-file alias
jarsigner -verify [ 命令选项 ] jar-file
补充说明:
jarsigner 工具用于两个目的:
1:为 Java 归档 (JAR) 文件签名
2:校验已签名的 JAR 文件的签名和完整性
命令选项
-keystore[url] 指定密钥仓库的 URL。缺省值是用户的宿主目录中的 .keystore 文件,它由系统属性“user.home”决定。
-storetype[storetype] 指定要被实例化的密钥仓库类型。默认的密钥仓库类型是安全属性文件中 "keystore.type" 属性值所指定的那个类型,由 java.security.KeyStore 中的静态方法 getDefaultType 返回。
-storepass[password] 指定访问密钥仓库所需的口令。这仅在签名(不是校验)JAR 文件时需要。在这种情况下,如果命令行中没有提供 -storepass 选项,用户将被提示输入口令。
-keypass[password] 指定用于保护密钥仓库项(由命令行中指定的别名标出)的私钥的口令。使用 jarsigner 为 JAR 文件签名时需要该口令。如果命令行中没有提供口令,且所需的口令与密钥仓库的口令不同,则将提示用户输入它。
-sigfile[file] 指定用于生成 .SF 和 .DSA 文件的基本文件名。
-signedjar[file] 指定用于已签名的 JAR 文件的名称。
-verify 如果它出现在命令行中,则指定的 JAR 文件将被校验,而不是签名。如果校验成功,将显示“jar verified”。如果试图校验未签名的 JAR 文件,或校验被不支持的算法(例如未安装 RSA 提供者时使用的 RSA)签名的 JAR 文件,则将有如下显示: "jar is unsigned. (signatures missing or not parsable)" 。
-certs 如果它与 -verify 和 -verbose 选项一起出现在命令行中,则输出将包括 JAR 文件的每个签名人的证书信息。
-verbose 如果它出现在命令行中,则代表“verbose”模式,它使 jarsigner 在 JAR 签名或校验过程中输出额外信息。
-internalsf 过去,JAR 文件被签名时产生的 .DSA(签名块)文件包含一个同时产生的 .SF 文件(签名文件)的完整编码副本。这种做法已被更改。为了减小输出 JAR 文件的整个大小,缺省情况下 .DSA 文件不再包含 .SF 文件的副本。但是如果 -internalsf 出现在命令行中,将采用旧的做法。该选项主要在测试时有用;实际上不应使用它,因为这样将消除有用的优化。
-sectionsonly 如果它出现在命令行中,则 JAR 文件被签名时生成的 .SF 文件(签名文件)将不包括含有整个清单文件的散列的头。它仅包含 与 JAR 中每个单独的源文件相关的信息和散列。该选项主要在测试时有用;实际上不应使用它,因为这样将消除有用的优化。
-J [javaoption] 将指定的 javaoption 串直接传递到 Java 解释器。((jarsigner 实际上是解释器的一个 “wrapper”)。该选项不应含有任何空格。它有助于调整执行环境或内存使用。要获得可用的解释器选项的清单,可在命令行键入 java -h 或 java -X。
keytool
功能说明:
管理由私钥和认证相关公钥的 X.509 证书链组成的密钥仓库(数据库)。还管理来自可信任实体的证书。
语法:
keytool [ 命令 ]
补充说明:
keytool 是个密钥和证书管理工具。它使用户能够管理自己的公钥/私钥对及相关证书,用于(通过数字签名)自我认证(用户向别的用户/服务认证自己)或数据完整性以及认证服务。它还允许用户储存他们的通信对等者的公钥(以证书形式)。
native2ascii
功能说明:
将含有本地编码字符(既非 Latin1 又非 Unicode 字符)的文件转换为 Unicode 编码字符的文件。
语法:
native2ascii [options] [inputfile [outputfile]]
补充说明:
Java 编译器和其它 Java 工具只能处理含有 Latin-1 和/或 Unicode 编码(udddd 记号)字符的文件。native2ascii 将含有其它字符编码的文件转换成含 Latin-1 和/或 Unicode 编码字符的文件。若省略 outputfile,则使用标准输出设备输出。此外,如果也省略 inputfile,则使用标准输入设备输入。
命令选项
-reverse 执行相反的操作:将含 Latin-1 和/或 Unicode 编码字符的文件转换成含本地编码字符的文件。
-encoding[encoding_name] 指定转换过程使用的编码名称。缺省的编码从系统属性 file.encoding 中得到。
appletviewer
功能说明:
Java applet 浏览器。appletviewer 命令可在脱离万维网浏览器环境的情况下运行 applet。
语法:
appletviewer [ threads flag ] [ 命令选项 ] urls ...
补充说明:
appletviewer 命令连接到 url 所指向的文档或资源上,并在其自身的窗口中显示文档引用的每个 applet。注意:如果 url 所指向的文档不引用任何带有 OBJECT、EMBED 或 APPLET 标记的 applet,那么 appletviewer 就不做任何事情。
命令选项
-debug 在 Java 调试器 jdb 中启动 appletviewer,使您可以调试文档中的 applet。
-encoding[编码名称] 指定输入 HTML 文件的编码名称。
-J[javaoption] 将 javaoption 字符串作为单个参数传给运行 appletviewer 的 Java 解释器。参数不能含有空格。由多重参数组成的字符串,其中的每个参数都必须以前缀 -J 开头,该前缀以后将被除去。这在调整编译器的执行环境或内存使用时将很有用。
extcheck
功能说明:
extcheck 检测目标 jar 文件与当前安装方式扩展 jar 文件间的版本冲突。
语法:
extcheck [ -verbose ] targetfile.jar
补充说明:
extcheck 实用程序检查指定 Jar 文件的标题和版本与 JDK TM 软件中所安装的扩展是否有冲突。在安装某个扩展前,可以用该实用程序查看是否已安装了该扩展的相同版本或更高的版本。
extcheck 实用程序将 targetfile.jar 文件清单的 specification-title 和 specification-version 头与当前安装在扩展目录下所有 Jar 文件的相对应的头进行比较(缺省扩展目录为 jre/lib/ext)。extcheck 实用程序比较版本号的方式与 java.lang.Package.isCompatibleWith 方法相同。若未检测到冲突,则返回代码为 0。如果扩展目录中任何一个 jar 文件的清单有相同的 specification-title 和相同的或更新的 specification-version 号,则返回非零错误代码。如果 targetfile.jar 的清单中没有 specification-title 或 specification-version 属性,则同样返回非零错误代码。
命令选项
-verbose 对扩展目录中的 Jar 文件进行检查时,列出文件。此外,还报告目标 jar 文件的清单属性及所有冲突的 jar 文件。
jar
功能说明:
Java归档工具
语法:
jar [ 命令选项 ] [manifest] destination input-file [input-files]
补充说明:
jar工具是个java应用程序,可将多个文件合并为单个JAR归档文件。jar是个多用途的存档及压缩工具,它基于ZIP和ZLIB压缩格式。然而, 设计jar的主要目的是便于将java applet或应用程序打包成单个归档文件。将applet或应用程序的组件(.class 文件、图像和声音)合并成单个归档文件时,可以用java代理(如浏览器)在一次HTTP事务处理过程中对它们进行下载,而不是对每个组件都要求一个新连 接。这大大缩短了下载时间。jar还能压缩文件,从而进一步提高了下载速度。此外,它允许applet的作者对文件中的各个项进行签名,因而可认证其来 源。jar工具的语法基本上与tar命令的语法相同。
命令选项
-c 在标准输出上创建新归档或空归档。
-t 在标准输出上列出内容表。
-x[file] 从标准输入提取所有文件,或只提取指定的文件。如果省略了file,则提取所有文件;否则只提取指定文件。
-f 第二个参数指定要处理的jar文件。在-c(创建)情形中,第二个参数指的是要创建的jar文件的名称(不是在标准输出上)。在-t(表(或-x(抽取)这两种情形中,第二个参数指定要列出或抽取的jar文件。
-v 在标准错误输出设备上生成长格式的输出结果。
-m 包括指定的现有清单文件中的清单信息。用法举例:“jar cmf myManifestFile myJarFile *.class”
-0 只储存,不进行 ZIP 压缩。
-M 不创建项目的清单文件。
-u 通过添加文件或更改清单来更新现有的 JAR 文件。例如:“jar -uf foo.jar foo.class”将文件 foo.class 添加到现有的JAR文件foo.jar中,而“jar umf manifest foo.jar”则用manifest中的信息更新foo.jar的清单。
-C 在执行 jar 命令期间更改目录。例如:“jar -uf foo.jar -C classes *”将classes目录内的所有文件加到foo.jar中,但不添加类目录本身。
程序示例
1:将当前目录下所有CLASS文件打包成新的JAR文件:
jar cf file.jar *.class
2:显示一个JAR文件中的文件列表
jar tf file.jar
3:将当前目录下的所有文件增加到一个已经存在的JAR文件中
jar cvf file.jar *
javadoc
功能说明
Java API文档生成器从Java源文件生成API文档HTML页。
语法:
javadoc [ 命令选项 ] [ 包名 ] [ 源文件名 ] [ @files ]
其中[ 包名 ]为用空格分隔的一系列包的名字,包名不允许使用通配符,如(*)。[ 源文件名 ]为用空格分隔的一系列的源文件名,源文件名可包括路径和通配符,如(*)。[ @files ]是以任何次序包含包名和源文件的一个或多个文件。
补充说明
Javadoc解析Java源文件中的声明和文档注释,并产生相应的HTML页缺省),描述公有类、保护类、内部类、接口、构造函数、方法和域。
在实现时,Javadoc要求且依赖于java编译器完成其工作。Javadoc调用部分javac编译声明部分,忽略成员实现。它建立类的内容丰富的 内部表示,包括类层次和“使用”关系,然后从中生成HTML。Javadoc还从源代码的文档注释中获得用户提供的文档。
当Javadoc建立其内部文档结构时,它将加载所有引用的类。由于这一点,Javadoc必须能查找到所有引用的类,包括引导类、扩展类和用户类。
命令选项
-overview i>path/filename 指定javadoc应该从path/filename所指定的“源”文件中获取概述文档,并将它放到概述页中(overview- summary.html)。其中path/filename 是相对于-sourcepath的相对路径名。
-public 只显示公有类及成员。
-protected 只显示受保护的和公有的类及成员。这是缺省状态。
-package 只显示包、受保护的和公有的类及成员。
-private 显示所有类和成员。
-help 显示联机帮助,它将列出这些javadoc和doclet命令行选项。
-doclet class 指定启动用于生成文档的docle 的类文件。该doclet定义了输出的内容和格式。如果未使用-doclet选项,则javadoc使用标准doclet生成缺省HTML格式。该类必须 包含start(Root)法。该启动类的路径由 -docletpath选项定义。
-docletpath classpathlist 指定doclet类文件的路径,该类文件用-doclet选项指定。如果doclet已位于搜索路径中,则没有必要使用该选项。
-1.1 生成具有用Javadoc 1.1生成的文档的外观和功能的文档。也就是说,页的背景为灰色,用图像做页眉,使用bullet列表而不是表格,具有单层目的目录结构,不包含继承 API,不使?*** TML框架,并且不支持内部类。该选项还自动将索引分割成每个字母一个文件。如果想要这种外观,则该选项比javadoc 1.1优越之处等于修正了一些错误。
-sourcepath sourcepathlist
当将包名传递到 javadoc命令中时,指定定位源文件(.java)的搜索路径。注意只有当用 javadoc命令指定包名时才能使用sourcepath选项 -- 它将不会查找传递到javadoc命令中的.java文件。如果省略-sourcepath,则javadoc使用类路径查找源文件。
-classpath classpathlist 指定javadoc将在其中查找引用类的路径 -- 引用类是指带文档的类加上它们引用的任何类。Javadoc将搜索指定路径的所有子目录。classpathlist可以包括多个路径,彼此用逗号分隔。
-bootclasspath classpathlist 指定自举类所在路径。它们名义上是Java平台类。这个bootclasspath是Javadoc将用来查找源文件和类文件的搜索路径的一部分。在 classpathlist中用冒号(:)分隔目录。
-extdirs dirlist 指定扩展类所在的目录。它们是任何使用Java扩展机制的类。这个 extdirs是Javadoc将用来查找源文件和在文件的搜索路径的一部分。在dirlist中用冒号(:)分隔目录。
-verbose 在javadoc运行时提供更详细的信息。不使用verbose选项时,将显示加载源文件、生成文档(每个源文件一条信息)和排序的信息。verbose选项导致打印额外的信息,指定解析每个java源文件的毫秒数。
-locale language_country_variant 指定javadoc在生成文档时使用的环境。
-encoding name 指定源文件编码名,例如EUCJIS/SJIS。如果未指定该选项,则使用平台缺省转换器。
-J[flag] 将flag直接传递给运行javadoc的运行时系统java。注意在J和flag之间不能有空格。
标准 Doclet 提供的选项
-d directory 指定javadoc保存生成的HTML件的目的目录。省略该选项将导致把文件保存到当前目录中。其中directory可以是绝对路径或相对当前工作目录的相对路径。
-use 对每个带文档类和包包括一个“用法”页。该页描述使用给定类或包的任何 API 的包、类、方法、构造函数和域。对于给定类 C,使用类 C 的任何东西将包括 C 的子类、声明为 C 的域、返回 C 的方法以及具有 C 类型参数的方法和构造函数。
-version 在生成文档中包括 @version 文本。缺省地将省略该文本。
-author 在生成文档中包括 @author 文本。
-splitindex 将索引文件按字母分割成多个文件,每个字母一个文件,再加上一个包含所有以非字母字符开头的索引项的文件。
-windowtitle[title] 指定放入 HTML
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/smile_dyf/archive/2008/09/04/2882247.aspx
posted @
2009-12-04 17:12 xzc 阅读(905) |
评论 (0) |
编辑 收藏转自:http://www.blogjava.net/Todd/archive/2009/09/15/295112.html
方法一:在初始化时保存ApplicationContext对象
代码:
ApplicationContext ac = new FileSystemXmlApplicationContext("applicationContext.xml");
ac.getBean("beanId");
说明:这种方式适用于采用Spring框架的独立应用程序,需要程序通过配置文件手工初始化Spring的情况。
方法二:通过Spring提供的工具类获取ApplicationContext对象
代码:
import org.springframework.web.context.support.WebApplicationContextUtils;
ApplicationContext ac1 = WebApplicationContextUtils.getRequiredWebApplicationContext(ServletContext sc);
ApplicationContext ac2 = WebApplicationContextUtils.getWebApplicationContext(ServletContext sc);
ac1.getBean("beanId");
ac2.getBean("beanId");
说明:
这种方式适合于采用Spring框架的B/S系统,通过ServletContext对象获取ApplicationContext对象,然后在通过它获取需要的类实例。
上面两个工具方式的区别是,前者在获取失败时抛出异常,后者返回null。
其中 servletContext sc 可以具体 换成 servlet.getServletContext()或者 this.getServletContext() 或者 request.getSession().getServletContext(); 另外,由于spring是注入的对象放在ServletContext中的,所以可以直接在ServletContext取出 WebApplicationContext 对象: WebApplicationContext webApplicationContext = (WebApplicationContext) servletContext.getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE);
方法三:继承自抽象类ApplicationObjectSupport
说明:抽象类ApplicationObjectSupport提供getApplicationContext()方法,可以方便的获取到ApplicationContext。
Spring初始化时,会通过该抽象类的setApplicationContext(ApplicationContext context)方法将ApplicationContext 对象注入。
方法四:继承自抽象类WebApplicationObjectSupport
说明:类似上面方法,调用getWebApplicationContext()获取WebApplicationContext
方法五:实现接口ApplicationContextAware
说明:实现该接口的setApplicationContext(ApplicationContext context)方法,并保存ApplicationContext 对象。
Spring初始化时,会通过该方法将ApplicationContext对象注入。
在web应用中一般用ContextLoaderListener加载webapplication,如果需要在action之外或者control类之外获取webapplication思路之一是,单独写个类放在static变量中,
类似于:
public class AppContext {
private static AppContext instance;
private AbstractApplicationContext appContext;
public synchronized static AppContext getInstance() {
if (instance == null) {
instance = new AppContext();
}
return instance;
}
private AppContext() {
this.appContext = new ClassPathXmlApplicationContext(
"/applicationContext.xml");
}
public AbstractApplicationContext getAppContext() {
return appContext;
}
}
不过这样,还是加载了2次applicationcontext,servlet一次,路径加载一次;觉得不如直接用路径加载,舍掉servlet加载
在网上也找了些其他说法:实现ApplicationContextAware,,, 接口,或者servletcontextAware接口,还要写配置文件。有的竟然要把配置文件里的listener,换成自己的类,这样纯粹多此一举。不过有的应用不是替换,是在补一个listener,
我在一版的jpetstore(具体那一版不知道)里发现了这个:
[web.xml]里
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<listener>
<listener-class>com.ibatis.jpetstore.util.SpringInit</listener-class>
</listener>
其中SpringInit实现接口ServletContextListener :
package com.ibatis.jpetstore.util;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import org.springframework.context.ApplicationContext;
import org.springframework.web.context.WebApplicationContext;
import org.springframework.web.context.support.WebApplicationContextUtils;
public class SpringInit implements ServletContextListener {
private static WebApplicationContext springContext;
public SpringInit() {
super();
}
public void contextInitialized(ServletContextEvent event) {
springContext = WebApplicationContextUtils.getWebApplicationContext(event.getServletContext());
}
public void contextDestroyed(ServletContextEvent event) {
}
public static ApplicationContext getApplicationContext() {
return springContext;
}
}
在其中的一个bean的构造里SpringInit获取applicationcontext,代码:
public OrderBean() {
this(
(AccountService) SpringInit.getApplicationContext().getBean("accountService"),
(OrderService) SpringInit.getApplicationContext().getBean("orderService") );
}
恩,这种在action,servlet之外的bean里获取applicationcontext的方法值得参考,应该有用
posted @
2009-10-22 18:02 xzc 阅读(2368) |
评论 (0) |
编辑 收藏
- 摘要:在生产中常会遇到需要将数量比较大的表值导入到本地文本文件中. 方法有很多种,比较常用的就是spool命令,本文将为大家介绍这个命令的实现,以及两种实现方法的对比。
- 标签:Oracle spool 比较
-
要输出符合要求格式的数据文件只需在select时用字符连接来规范格式。比如有如下表
SQL>; select id,username,password from myuser;//测试表
1 John 1234
2 Jack 12345
3 Rose 2345
4 Joe 384657
5 Tom 384655
6 Jordan 384455
|
要输出符合1,John,1234,这样的数据格式就用select id||','||username||','||password||',' from myuser这样的语句。
SQL>; select id||','||username||','||password||',' from myuser;
1,John,1234,
2,Jack,12345,
|
写个下面这样的脚本就行可以输出符合要求格式的数据至文件中,不会含有其它不需要东西,只有数据部分。
--脚本文件名为expmyusr.sql,存数据的文件名为e:\exp.txt
set echo on --是否显示执行的命令内容
set feedback off --是否显示 * rows selected
set heading off --是否显示字段的名称
set verify off --是否显示替代变量被替代前后的语句。fil
set trimspool off --去字段空格
set pagesize 1000 --页面大小
set linesize 50//linesize设定尽量根据需要来设定,大了生成的文件也大
define fil= 'e:\exp.txt'
prompt *** Spooling to &fil
spool &fil
select id||','||username||','||'"'||password||'"' from myuser;
spool off;
--执行过程
SQL>; @e:\expmyusr.sql
*** Spooling to e:\exp.txt
1,John,"1234"
2,Jack,"12345"
3,Rose,"2345"
4,Joe,"384657"
5,Tom,"384655"
6,Jordan,"384455"
|
检查可知结果符合要求。
Oracle SPOOL的两种方法之对比
通常情况下,我们使用SPOOL方法,将数据库中的表导出为文本文件的时候会采用两种方法,如下述:
方法一:采用以下格式脚本
set colsep '' ------设置列分隔符
set trimspool on
set linesize 120
set pagesize 2000
set newpage 1
set heading off
set term off
spool 路径+文件名
select * from tablename;
spool off
|
方法二:采用以下脚本
set trimspool on
set linesize 120
set pagesize 2000
set newpage 1
set heading off
set term off
spool 路径+文件名
select col1||','||col2||','||col3||','||col4||'..' from tablename;
spool off
|
比较以上方法,即方法一采用设定分隔符然后由sqlplus自己使用设定的分隔符对字段进行分割,方法二将分隔符拼接在SELECT语句中,即手工控制输出格式。
在实践中,我发现通过方法一导出来的数据具有很大的不确定性,这种方法导出来的数据再由sql ldr导入的时候出错的可能性在95%以上,尤其对大批量的数据表,如100万条记录的表更是如此,而且导出的数据文件狂大。
而方法二导出的数据文件格式很规整,数据文件的大小可能是方法一的1/4左右。经这种方法导出来的数据文件再由sqlldr导入时,出错的可能性很小,基本都可以导入成功。
因此,实践中我建议大家使用方法二手工去控制spool文件的格式,这样可以减小出错的可能性,避免走很多弯路。
posted @
2009-09-27 09:20 xzc 阅读(1339) |
评论 (3) |
编辑 收藏
| General Information |
| Note: O/S permissions are those of the user 'Oracle' ... not the schema owner or connected user |
| Source |
{ORACLE_HOME}/rdbms/admin/utlfile.sql |
| First Availability |
7.3.4 |
| init.ora Parameters |
utl_file_dir |
utl_file_dir=c:\oraload
utl_file_dir=c:\temp
utl_file_dir=* |
| Open Modes |
| A |
Append Text |
| AB |
Append Byte Mode |
| R |
Read Text |
| RB |
Read Byte Mode |
| W |
Write Text |
| WB |
Write Byte Mode |
|
| FCLOSE |
| Close A File Opened By UTL_FILE |
utl_file.fclose(<file_handle>) |
| see FOPEN demo |
|
| FCLOSE_ALL |
| Close All Files Opened By UTL_FILE |
utl_file.fclose_all; |
set serveroutput on
DECLARE
vInHandle utl_file.file_type;
vOutHandle utl_file.file_type;
BEGIN
vInHandle := utl_file.fopen('ORALOAD', 'test.txt', 'R');
vOutHandle := utl_file.fopen('ORALOAD', 'out.txt', 'W');
IF utl_file.is_open(vInHandle) THEN
utl_file.fclose_all;
dbms_output.put_line('Closed All');
END IF;
END fopen;
/ |
|
| FCOPY |
| Copies a contiguous portion of a file to a newly created file |
utl_file.fcopy (
location IN VARCHAR2,
filename IN VARCHAR2,
dest_dir IN VARCHAR2,
dest_file IN VARCHAR2,
start_line IN PLS_INTEGER DEFAULT 1,
end_line IN PLS_INTEGER DEFAULT NULL); |
-- demo requires creating directory CTEMP ... see link at bottom of page
BEGIN
utl_file.fcopy('ORALOAD', 'dump.txt', 'ORALOAD', 'didit.txt');
END;
/ |
|
| FFLUSH |
| Physically writes pending data to the file identified by the file handle |
utl_file.fflush (<file_handle>); |
| See Write demo |
|
| FGETATTR |
| Reads and returns the attributes of a disk file |
utl_file.fgetattr(
location IN VARCHAR2,
filename IN VARCHAR2,
exists OUT BOOLEAN,
file_length OUT NUMBER,
blocksize OUT NUMBER); |
set serveroutput on
DECLARE
ex BOOLEAN;
flen NUMBER;
bsize NUMBER;
BEGIN
utl_file.fgetattr('ORALOAD', 'test.txt', ex, flen, bsize);
IF ex THEN
dbms_output.put_line('File Exists');
ELSE
dbms_output.put_line('File Does Not Exist');
END IF;
dbms_output.put_line('File Length: ' || TO_CHAR(flen));
dbms_output.put_line('Block Size: ' || TO_CHAR(bsize));
END fgetattr;
/ |
|
| FGETPOS |
| Returns the current relative offset position within a file, in bytes |
utl_file.fgetpos(fileid IN file_type) RETURN PLS_INTEGER; |
| See Read-Write demo |
|
| FOPEN |
| Open A File For Read Operations |
utl_file.fopen(
<file_location IN VARCHAR2>,
<file_name IN VARCHAR2>,
<open_mode IN VARCHAR2>,
<max_linesize IN BINARY_INTEGER>)
RETURN <file_type_package_data_type; |
DECLARE
vInHandle utl_file.file_type;
vNewLine VARCHAR2(250);
BEGIN
vInHandle := utl_file.fopen('ORALOAD', 'test.txt', 'R');
LOOP
BEGIN
utl_file.get_line(vInHandle, vNewLine);
dbms_output.put_line(vNewLine);
EXCEPTION
WHEN OTHERS THEN
EXIT;
END;
END LOOP;
utl_file.fclose(vInHandle);
END fopen;
/ |
| Open A File For Write Operations |
<file_handle> := utl_file.fopen(<file_location, file_name, 'w') |
|
| FOPEN_NCHAR |
| Open a file to read or write a text file in Unicode instead of in the database charset |
|
| FREMOVE |
| Delete An Operating System File |
utl_file.fremove (location IN VARCHAR2, filename IN VARCHAR2); |
BEGIN
utl_file.fremove('ORALOAD', 'dump.txt');
END fremove;
/ |
|
| FRENAME |
| Rename An Operating System File |
utl_file.frename (
location IN VARCHAR2,
filename IN VARCHAR2,
dest_dir IN VARCHAR2,
dest_file IN VARCHAR2,
overwrite IN BOOLEAN DEFAULT FALSE); |
BEGIN
utl_file.frename('ORALOAD','test.txt','ORALOAD','x.txt',TRUE);
END frename;
/ |
|
| FSEEK |
| Adjusts the file pointer forward or backward within the file by the number of bytes specified |
utl_file.fseek (
fid IN utl_file.file_type,
absolute_offset IN PL_INTEGER DEFAULT NULL,
relative_offset IN PLS_INTEGER DEFAULT NULL); |
| See Read-Write demo |
|
| GETLINE |
| Read a Line from a file |
utl_file.getline (
file IN FILE_TYPE,
buffer OUT VARCHAR2,
linesize IN NUMBER,
len IN PLS_INTEGER DEFAULT NULL); |
| See Read demos |
|
| GETLINE_NCHAR |
| Same as GETLINE except can be used to read Unicode rather than the database's character set |
|
| GET_RAW |
| Reads a RAW string value from a file and adjusts the file pointer ahead by the number of bytes read |
utl_file.get_raw (
fid IN utl_file.file_type,
r OUT NOCOPY RAW,
len IN PLS_INTEGER DEFAULT NULL); |
| See UTL_MAIL demo |
|
| IS_OPEN |
| Returns True If A File Handle Is Open: Otherwise False |
utl_file.is_open (file IN FILE_TYPE) RETURN BOOLEAN; |
| See FCLOSE_ALL Demo |
|
| NEW_LINE |
| Writes one or more operating system-specific line terminators to a file |
utl_file.NEW_LINE (file IN FILE_TYPE, lines IN NATURAL := 1); |
| See Read Demo |
|
| PUT |
| Writes a string to a file |
utl_file.put(
file IN FILE_TYPE,
buffer IN VARCHAR2); |
| See Write demo |
|
| PUTF |
| A PUT procedure with formatting |
utl_file.putf(
file IN FILE_TYPE,
format IN VARCHAR2,
[arg1 IN VARCHAR2 DEFAULT NULL,
. . .
arg5 IN VARCHAR2 DEFAULT NULL]); |
| See Write demo |
|
| PUT_LINE |
| Writes a line to a file. Appends an operating system-specific line terminator |
utl_file.put_line(
file IN FILE_TYPE,
buffer IN VARCHAR2,
autoflush IN BOOLEAN DEFAULT FALSE); |
| See Read-Write demo |
|
| PUT_NCHAR |
| Writes a Unicode string to a file |
|
| PUT_RAW |
| Accepts as input a RAW data value and writes the value to the output buffer |
utl_file.PUT_RAW (
fid IN utl_file.file_type,
r IN RAW,
autoflush IN BOOLEAN DEFAULT FALSE); |
| See extract_blob Demo |
|
| PUT_LINE_NCHAR |
| Writes a Unicode line to a file |
|
| PUTF_NCHAR |
| Writes a Unicode string to a file |
from: http://www.psoug.org/reference/utl_file.html
--End--
|
posted @
2009-09-25 16:18 xzc 阅读(3137) |
评论 (2) |
编辑 收藏转:本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/huanghui22/archive/2007/05/03/1595166.aspx
有些时候我们希望得到指定数据中的前n列,示例如下:
得到每个部门薪水最高的三个雇员:
先创建示例表
create table emp
as
select * from scott.emp;
alter table emp
add constraint emp_pk
primary key(empno);
create table dept
as
select * from scott.dept;
alter table dept
add constraint dept_pk
primary key(deptno);
先看一下row_number() /rank()/dense_rank()三个函数之间的区别
select emp.deptno,emp.sal,emp.empno,row_number() over (partition by deptno order by sal desc) row_number, --1,2,3
rank() over (partition by deptno order by sal desc) rank, --1,1,3
dense_rank() over (partition by deptno order by sal desc) dense_rank from emp --1,1,2
结果如下:
10 5000.00 7839 1 1 1
10 2450.00 7782 2 2 2
10 1300.00 7934 3 3 3
20 3000.00 7788 1 1 1
20 3000.00 7902 2 1 1
20 2975.00 7566 3 3 2
20 1100.00 7876 4 4 3
20 800.00 7369 5 5 4
30 2850.00 7698 1 1 1
30 1600.00 7499 2 2 2
取每个部门的薪水前三位雇员:
select t.deptno,t.rank,t.sal from
(
select emp.*,row_number() over (partition by deptno order by sal desc) row_number, --1,2,3
rank() over (partition by deptno order by sal desc) rank, --1,1,3
dense_rank() over (partition by deptno order by sal desc) dense_rank from emp --1,1,2
) t
where t.rank<=3
结果如下:
10 1 5000.00
10 2 2450.00
10 3 1300.00
20 1 3000.00
20 1 3000.00
20 3 2975.00
30 1 2850.00
30 2 1600.00
30 3 1500.00
如果想输出成deptno sal1 sal2 sal3这种类型的格式
步骤一(decode):
select t.deptno,decode(row_number,1,sal) sal1,decode(row_number,2,sal) sal2,decode(row_number,3,sal) sal3 from
(
select emp.*,row_number() over (partition by deptno order by sal desc) row_number, --1,2,3
rank() over (partition by deptno order by sal desc) rank, --1,1,3
dense_rank() over (partition by deptno order by sal desc) dense_rank from emp --1,1,2
) t
where t.rank<=3
结果如下:
10 5000
10 2450
10 1300
20 3000
20 3000
20 2975
30 2850
30 1600
30 1500
步骤二(使用聚合函数去除null,得到最终结果):
select t.deptno,max(decode(row_number,1,sal)) sal1,max(decode(row_number,2,sal)) sal2,max(decode(row_number,3,sal)) sal3 from
(
select emp.*,row_number() over (partition by deptno order by sal desc) row_number, --1,2,3
rank() over (partition by deptno order by sal desc) rank, --1,1,3
dense_rank() over (partition by deptno order by sal desc) dense_rank from emp --1,1,2
) t
where t.rank<=3
group by t.deptno
结果如下:
10 5000 2450 1300
20 3000 3000 2975
30 2850 1600 1500
posted @
2009-09-07 16:45 xzc 阅读(414) |
评论 (0) |
编辑 收藏
24/05/2005 14:37 FP 在数据仓库中的转换和装载过程中,经常会使用MERGE语句,这里简单总结一下。
MERGE语句是Oracle9i新增的语法,用来合并UPDATE和INSERT语句。通过MERGE语句,根据一张表或子查询的连接条件对另外一张表进行查询,连接条件匹配上的进行UPDATE,无法匹配的执行INSERT。这个语法仅需要一次全表扫描就完成了全部工作,执行效率要高于INSERT+UPDATE。
下面看个具体的例子:
SQL> CREATE TABLE T AS SELECT ROWNUM ID, A.* FROM DBA_OBJECTS A;
表已创建。
SQL> CREATE TABLE T1 AS
2 SELECT ROWNUM ID, OWNER, TABLE_NAME, CAST('TABLE' AS VARCHAR2(100)) OBJECT_TYPE
3 FROM DBA_TABLES;
表已创建。
SQL> MERGE INTO T1 USING T
2 ON (T.OWNER = T1.OWNER AND T.OBJECT_NAME = T1.TABLE_NAME AND T.OBJECT_TYPE = T1.OBJECT_TYPE)
3 WHEN MATCHED THEN UPDATE SET T1.ID = T.ID
4 WHEN NOT MATCHED THEN INSERT VALUES (T.ID, T.OWNER, T.OBJECT_NAME, T.OBJECT_TYPE);
6165 行已合并。
SQL> SELECT ID, OWNER, OBJECT_NAME, OBJECT_TYPE FROM T
2 MINUS
3 SELECT * FROM T1;
未选定行
MERGE语法其实很简单,下面稍微修改一下例子。
SQL> DROP TABLE T;
表已丢弃。
SQL> DROP TABLE T1;
表已丢弃。
SQL> CREATE TABLE T AS SELECT ROWNUM ID, A.* FROM DBA_OBJECTS A;
表已创建。
SQL> CREATE TABLE T1 AS SELECT ROWNUM ID, OWNER, TABLE_NAME FROM DBA_TABLES;
表已创建。
SQL> MERGE INTO T1 USING T
2 ON (T.OWNER = T1.OWNER AND T.OBJECT_NAME = T1.TABLE_NAME)
3 WHEN MATCHED THEN UPDATE SET T1.ID = T.ID
4 WHEN NOT MATCHED THEN INSERT VALUES (T.ID, T.OWNER, T.OBJECT_NAME);
MERGE INTO T1 USING T
*
ERROR 位于第 1 行:
ORA-30926: 无法在源表中获得一组稳定的行
这个错误是使用MERGE最常见的错误,造成这个错误的原因是由于通过连接条件得到的T的记录不唯一。最简单的解决方法类似:
SQL> MERGE INTO T1
2 USING (SELECT OWNER, OBJECT_NAME, MAX(ID) ID FROM T GROUP BY OWNER, OBJECT_NAME) T
3 ON (T.OWNER = T1.OWNER AND T.OBJECT_NAME = T1.TABLE_NAME)
4 WHEN MATCHED THEN UPDATE SET T1.ID = T.ID
5 WHEN NOT MATCHED THEN INSERT VALUES (T.ID, T.OWNER, T.OBJECT_NAME);
5775 行已合并。
另外,MERGE语句的UPDATE不能修改用于连接的列,否则会报错,详细信息可以参考:http://blog.itpub.net/post/468/14844
===============================================================
ref: http://tomszrp.itpub.net/post/11835/263865
在Oracle 10g之前,merge语句支持匹配更新和不匹配插入2种简单的用法,在10g中Oracle对merge语句做了增强,增加了条件选项和DELETE操作。下面我通过一个demo来简单介绍一下10g中merge的增强和10g前merge的用法。
参考Oracle 的SQL Reference,大家可以看到Merge Statement的语法如下:
MERGE [hint] INTO [schema .] table [t_alias] USING [schema .]
{ table | view | subquery } [t_alias] ON ( condition )
WHEN MATCHED THEN merge_update_clause
WHEN NOT MATCHED THEN merge_insert_clause;
下面我在windows xp 下10.2.0.1版本上做一个测试看看
SQL> select * from v$version;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod
PL/SQL Release 10.2.0.1.0 - Production
CORE 10.2.0.1.0 Production
TNS for 32-bit Windows: Version 10.2.0.1.0 - Production
NLSRTL Version 10.2.0.1.0 - Production
SQL>
一、创建测试用的表
SQL> create table subs(msid number(9),
2 ms_type char(1),
3 areacode number(3)
4 );
表已创建。
SQL> create table acct(msid number(9),
2 bill_month number(6),
3 areacode number(3),
4 fee number(8,2) default 0.00);
表已创建。
SQL>
SQL> insert into subs values(905310001,0,531);
已创建 1 行。
SQL> insert into subs values(905320001,1,532);
已创建 1 行。
SQL> insert into subs values(905330001,2,533);
已创建 1 行。
SQL> commit;
提交完成。
SQL>
二、下面先演示一下merge的基本功能
1) matched 和not matched clauses 同时使用
merge into acct a
using subs b on (a.msid=b.msid)
when MATCHED then
update set a.areacode=b.areacode
when NOT MATCHED then
insert(msid,bill_month,areacode)
values(b.msid,'200702',b.areacode);
2) 只有not matched clause,也就是只插入不更新
merge into acct a
using subs b on (a.msid=b.msid)
when NOT MATCHED then
insert(msid,bill_month,areacode)
values(b.msid,'200702',b.areacode);
3) 只有matched clause, 也就是只更新不插入
merge into acct a
using subs b on (a.msid=b.msid)
when MATCHED then
update set a.areacode=b.areacode
Connected to Oracle Database 10g Enterprise Edition Release 10.2.0.1.0
Connected as study
SQL> select * from subs;
MSID MS_TYPE AREACODE
---------- ------- --------
905310001 0 531
905320001 1 532
905330001 2 533
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
SQL>
SQL> merge into acct a
2 using subs b on (a.msid=b.msid)
3 when MATCHED then
4 update set a.areacode=b.areacode
5 when NOT MATCHED then
6 insert(msid,bill_month,areacode)
7 values(b.msid,'200702',b.areacode);
Done
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
905320001 200702 532 0.00
905330001 200702 533 0.00
905310001 200702 531 0.00
SQL> insert into subs values(905340001,3,534);
1 row inserted
SQL> select * from subs;
MSID MS_TYPE AREACODE
---------- ------- --------
905340001 3 534
905310001 0 531
905320001 1 532
905330001 2 533
SQL>
SQL> merge into acct a
2 using subs b on (a.msid=b.msid)
3 when NOT MATCHED then
4 insert(msid,bill_month,areacode)
5 values(b.msid,'200702',b.areacode);
Done
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
905320001 200702 532 0.00
905330001 200702 533 0.00
905310001 200702 531 0.00
905340001 200702 534 0.00
SQL> update subs set areacode=999;
4 rows updated
SQL> select * from subs;
MSID MS_TYPE AREACODE
---------- ------- --------
905340001 3 999
905310001 0 999
905320001 1 999
905330001 2 999
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
905320001 200702 532 0.00
905330001 200702 533 0.00
905310001 200702 531 0.00
905340001 200702 534 0.00
SQL>
SQL> merge into acct a
2 using subs b on (a.msid=b.msid)
3 when MATCHED then
4 update set a.areacode=b.areacode;
Done
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
905320001 200702 999 0.00
905330001 200702 999 0.00
905310001 200702 999 0.00
905340001 200702 999 0.00
SQL>
三、10g中增强一:条件操作
1) matched 和not matched clauses 同时使用
merge into acct a
using subs b on (a.msid=b.msid)
when MATCHED then
update set a.areacode=b.areacode
where b.ms_type=0
when NOT MATCHED then
insert(msid,bill_month,areacode)
values(b.msid,'200702',b.areacode)
where b.ms_type=0;
2) 只有not matched clause,也就是只插入不更新
merge into acct a
using subs b on (a.msid=b.msid)
when NOT MATCHED then
insert(msid,bill_month,areacode)
values(b.msid,'200702',b.areacode)
where b.ms_type=0;
3) 只有matched clause, 也就是只更新不插入
merge into acct a
using subs b on (a.msid=b.msid)
when MATCHED then
update set a.areacode=b.areacode
where b.ms_type=0;
Connected to Oracle Database 10g Enterprise Edition Release 10.2.0.1.0
Connected as study
SQL> select * from subs;
MSID MS_TYPE AREACODE
---------- ------- --------
905310001 0 531
905320001 1 532
905330001 2 533
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
SQL>
SQL> merge into acct a
2 using subs b on (a.msid=b.msid)
3 when MATCHED then
4 update set a.areacode=b.areacode
5 where b.ms_type=0
6 when NOT MATCHED then
7 insert(msid,bill_month,areacode)
8 values(b.msid,'200702',b.areacode)
9 where b.ms_type=0;
Done
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
905310001 200702 531 0.00
SQL> insert into subs values(905360001,0,536);
1 row inserted
SQL> select * from subs;
MSID MS_TYPE AREACODE
---------- ------- --------
905360001 0 536
905310001 0 531
905320001 1 532
905330001 2 533
SQL>
SQL> merge into acct a
2 using subs b on (a.msid=b.msid)
3 when NOT MATCHED then
4 insert(msid,bill_month,areacode)
5 values(b.msid,'200702',b.areacode)
6 where b.ms_type=0;
Done
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
905310001 200702 531 0.00
905360001 200702 536 0.00
SQL> update subs set areacode=888 where ms_type=0;
2 rows updated
SQL> select * from subs;
MSID MS_TYPE AREACODE
---------- ------- --------
905360001 0 888
905310001 0 888
905320001 1 532
905330001 2 533
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
905310001 200702 531 0.00
905360001 200702 536 0.00
SQL>
SQL> merge into acct a
2 using subs b on (a.msid=b.msid)
3 when MATCHED then
4 update set a.areacode=b.areacode
5 where b.ms_type=0;
Done
SQL> select * from acct;
MSID BILL_MONTH AREACODE FEE
---------- ---------- -------- ----------
905310001 200702 888 0.00
905360001 200702 888 0.00
SQL>
四、10g中增强二:删除操作
An optional DELETE WHERE clause can be used to clean up after a
merge operation. Only those rows which match both the ON clause
and the DELETE WHERE clause are deleted.
merge into acct a
using subs b on (a.msid=b.msid)
when MATCHED then
update set a.areacode=b.areacode
delete where (b.ms_type!=0);
SQL> select * from subs;
MSID MS_TYPE AREACODE
---------- ------- --------
905310001 0 531
905320001 1 532
905330001 2 533
SQL> select * from acct;
MSID MS_TYPE AREACODE
---------- ------- --------
905310001 0 531
905320001 1 532
905330001 2 533
SQL>
SQL> merge into acct a
2 using subs b on (a.msid=b.msid)
3 when MATCHED then
4 update set a.areacode=b.areacode
5 delete where (b.ms_type!=0);
Done
SQL> select * from acct;
MSID MS_TYPE AREACODE
---------- ------- --------
905310001 0 531
SQL>
更为详尽的语法,请参考Oracle SQL Reference手册!
posted @
2009-08-25 21:42 xzc 阅读(267) |
评论 (0) |
编辑 收藏
awk处理文本总结 - Alex.Wang 2008-2-19 15:55
作为技术支持工程我们最最经常的工作就是经常碰到要处理文本文件,不管是什么数据库最后都可以导成文本,我们就可以对他进行处理了,这样即使你不是对所有数据库操作都很熟悉也可以对他的数据进行处理了。
我们必须的工具有两个一个是shell一个是awk,awk对于处理文本文件是最最适合的掌握了awk我们就可以很方便的处理文本文件再借助一些shell命令我们可以很方便得到自己想要的结果。现在从简单的例子来总结一下我觉得会经常碰到的问题。
--------------------------------------------------------------------------------
awk入门篇
awk入门,文本内容example1.txt.
user1 password1 username1 unit1 10
user2 password2 username2 unit2 20
user3 password3 username3 unit3 30
在unix环境中我们可以使用一下命令来打印出第一列
[root@mail awk]# awk '{print $1}' example1.txt
得到的结果是如下,解释一下"'{" 单引号大括号包含awk语句是为了和shell 命令区别,$1的意思就是文本文件的第一列,正常的awk命令跟随-F参数指定间隔符号,如果是空格或tab键就可以省略了。
user1
user2
user3
[root@mail awk]# awk '{if($5>20) {print $1}}' example1.txt
这行命令和上一行比较增加了“if($5>20)”,得到的结果是
user3
这个if语句就没有必要更详细的解释了吧!就是第5列大于20的显示出满足条件的第一列
[root@mail awk]# awk '{if($5>20 || $5==10) {print $1}}' example1.txt
user1
user3
在来一个初级的又增加了一个“if($5>20 || $5==10)” 做逻辑判断逻辑判断的三个“|| && !” 或、与、非三个可以任意加到里面,这个语句的意思是如果第5列大于20或者等于10的都显示处理,在我们的工作中可能有用户会要求找出所有空间大于多少的或者是空间等于多少的账户然后再做批量修改。
if是awk循环中的一个还有其他很多,man awk可以看到,
Control Statements
The control statements are as follows:
if (condition) statement [ else statement ]
while (condition) statement
do statement while (condition)
for (expr1; expr2; expr3) statement
for (var in array) statement
break
continue
delete array[index]
delete array
exit [ expression ]
{ statements }
学习awk可以经常使用一下man awk 可以看到所有的函数和使用方法。
了解每个符号的意义我们才能更好的使用awk,最开始先记住几个命令知道他可实现的结果我们慢慢的再去理解。
--------------------------------------------------------------------------------
awk中级篇
这里顺便介绍一下vi的一个替换命令,现在我们要把example1.txt文本里的空格都替换为“:”冒号这里在vi里使用的命令就是:
%s/ /:/g
这个命令对于使用vi的人来说是用得最多的。我们现在做了一个新的文件example2.txt。
user1:password1:username1:unit1:10
user2:password2:username2:unit2:20
user3:password3:username3:unit3:30
现在我们来做一个awk脚本,之前都是在命令行操作,实际上所有的操作在命令行上是可以都实现的,已我们最经常使用的批量添加用户来开始!
script1.awk
#!/bin/awk -f # 当文件有可执行权限的时候你可以直接执行
# ./script1.awk example2.txt
# 如果没有以上这行可能会出现错误,或者
# awk -f script1.awk example2.txt 参数f指脚本文件
BEGIN { # “BEGIN{”是awk脚本开始的地方
FS=":"; # FS 是在awk里指分割符的意思
}
{ # 接下来的“{” 是内容部分
print "add {"; # 以下都是使用了一个awk函数print
print "uid=" $1;
print "userPassword=" $2;
print "domain=eyou.com" ;
print "bookmark=1";
print "voicemail=1";
print "securemail=1"
print "storage=" $5;
print "}";
print ".";
} # “}” 内容部分结束
END { # “END{” 结束部分
print "exit";
}
执行结果
[root@mail awk]# awk -f script1.awk example2.txt
add {
uid=user1
userPassword=password1
domain=eyou.com
bookmark=1
voicemail=1
securemail=1
storage=10
}
.
.
.
.
.
.
exit
文本操作就是更方便一些。
下面给两个返回效果一样的例子
[root@mail awk]# awk -F: '{print $1"@"$2}' example2.txt
[root@mail awk]# awk -F: '{printf "%s@%s\n",$1,$2}' example2.txt
user1@password1
这里的区别是使用print 和printf的区别,printf格式更自由一些,我们可以更加自由的指定要输出的数据,print会自动在行尾给出空格,而printf是需要给定" \n"的,如果感兴趣你可以把“\n”去掉看一下结果。%s代表字符串%d 代表数字,基本上%s都可以处理了因为在文本里一切都可以看成是字符串,不像C语言等其他语言还要区分数字、字符、字符串等。
awk还有一些很好的函数细细研究一下还是很好用的。
这次碰到了一个问题客户有一个用户列表,大概有2w用户,他有一个有趣的工作要做,就是把每个账户目录放到特定的目录下,例如13910011234这个目录要放到139/10/这个目录下,从这里可以看出规律是手机号码的前三位是二级目录名,手机的第3、4为是三级目录名,我们有的就只有一个用户列表,规律找到了我们现在开始想办法处理吧。
example3.txt
13910011234
15920312343
13922342134
15922334422
......
第一步是要找到一个方法来吧,就是要把每一个手机号分开,最初可能你就会想到这个也没有任何间隔,我们怎么用awk分开他们呢?说实话最初我也考虑了20多分钟,后来想起原来学习python的时候有split函数可以分就想找找awk里是不是有类似的函数,man awk 发现substr 这个函数子串,
[root@mail awk]# awk '{print substr($1,1,3)}' example3.txt
[root@mail awk]# awk '{printf "%s/%s\n",substr($1,1,3),substr($1,4,2)}' example3.txt
[root@mail awk]# awk '{printf "mv %s %s/%s\n",$1,substr($1,1,3),substr($1,4,2)}' example3.txt
以上的两步的返回自己做一下,最后我们就得到了我们想要的结果。
mv 13910011234 139/10
mv 15920312343 159/20
mv 13922342134 139/22
mv 15922334422 159/22
把这部分输出拷贝到一个shell脚本里,在数据当前目录下执行就可以了!
substr(s, i [, n]) Returns the at most n-character substring of s
starting at i. If n is omitted, the rest of s
is used.
substr函数解释,s代表我们要处理的字符串,i 是我们从这个字符串的第几个位置上开始,n 是我们从开始的位置取多少个字符。多看看man英文也会有所提高的。
awk有很多有趣的函数如果感兴趣可以自己去查查看,
man awk
String Functions 字符串函数,举几个觉得常用的函数
length([s]) Returns the length of the string s, or the
length of $0 if s is not supplied.
length 你可以得到字符串的长度,这个是比较常用的一个函数
split(s, a [, r]) Splits the string s into the array a on the
regular expression r, and returns the number of
fields. If r is omitted, FS is used instead.
The array a is cleared first. Splitting
behaves identically to field splitting,
described above.
tolower(str) Returns a copy of the string str, with all the
upper-case characters in str translated to
their corresponding lower-case counterparts.
Non-alphabetic characters are left unchanged.
toupper(str) Returns a copy of the string str, with all the
lower-case characters in str translated to
their corresponding upper-case counterparts.
Non-alphabetic characters are left unchanged.
Time Functions 时间函数,我们最最常用到的是时间戳转换函数
strftime([format [, timestamp]])
Formats timestamp according to the specification in format.
The timestamp should be of the same form as returned by sys-
time(). If timestamp is missing, the current time of day is
used. If format is missing, a default format equivalent to
the output of date(1) is used. See the specification for the
strftime() function in ANSI C for the format conversions that
are guaranteed to be available. A public-domain version of
strftime(3) and a man page for it come with gawk; if that
version was used to build gawk, then all of the conversions
described in that man page are available to gawk.
这里举例说明时间戳函数是如何使用的
[root@ent root]# date +%s | awk '{print strftime("%F %T",$0)}'
2008-02-19 15:59:19
我们先使用date命令做一个时间戳,然后再把他转换为时间
还有一些我们现在可能不经常用到的函数,详细内容man awk 自己可以看一下。
Bit Manipulations Functions 二进制函数
Internationalization Functions 国际标准化函数
USER-DEFINED FUNCTIONS 用户也可以自己定义自己的函数,感兴趣自己可以再深入研究一下。
For example:
function f(p, q, a, b) # a and b are local
{
...
}
/abc/ { ... ; f(1, 2) ; ... }
DYNAMICALLY LOADING NEW FUNCTIONS 动态加载新函数,这个可能就更高级一些了!
--------------------------------------------------------------------------------
awk高级篇
不管学习任何语言,我们学到的都是工具,工具知道的越多,我们做起工作来就越方便,但是工具在你的手里并不一定能造出好的产品,编辑脚本和编程序也是一样的重要的是算法,别人不知道怎么处理的问题你要知道如何处理。这才能证明你比别人更高,工具只要你慢慢练习都会使用。
下面给大家一个我认为是比较高级的问题了,感兴趣的可以自己再想想更好的解决办法。问题是这样的我们有一个从ldap里导出的文件,它都是一行一个字段来说明的,每个用户的数据是已空行分割的。我们必须把对应的uid 和userPassword找出来而且是对应的。
例子:example4.txt
dn: uid=cailiying,domain=ccc.com.cn,o=mail.ccc.com.cn
uid: cailiying
userPassword:: e21kNX0zREl4VEIwODBJdXZkTnU3WFFtS3lRPT0=
letters: 300
quota: 100
dn: uid=caixiaoning,domain=ccc.com.cn,o=mail.ccc.com.cn
userPassword:: e21kNX1kejFXU0doZWprR2RNYnV5ajJJRWl3PT0=
letters: 300
quota: 100
uid: chenzheng
domain: cqc.com.cn
dn: uid=caixiaoning,domain=ccc.com.cn,o=mail.ccc.com.cn
userPassword:: e21kNX1kejFXU0doZWprR2RNYnV5ajJJRWl3PT0=
letters: 300
quota: 100
dn: uid=caixiaoning,domain=ccc.com.cn,o=mail.ccc.com.cn
userPassword:: e21kNX1kejFXU0doZWprR2RNYnV5ajJJRWl3PT0=
letters: 300
quota: 100
uid: chenzheng
domain: cqc.com.cn
处理这个文本我们需要考虑的问题是:
1 uid 和userPassword 并不是每一个段落里都有
2 在每一段里面uid和userPassword 先后顺序是随机的
3 有的段落里可能只有uid 或者只有userPassword
从文本上分析可以看出必须使用的间隔符号,一个是空行,一个是冒号。
冒号我们awk -F:就可以了,不过空行我们不好判断现在想到length()这个函数,在unix里空行最多只有一个\n字符,如果一行字符数小于2我们判断为空行,好现在间隔符号问题解决,空行只能通过循环来实现对空行的判断。
现在碰到的另外一个问题是我们的某个段里的信息是不完全的,我们就要放弃这段这儿如何来做,就是要做两个标记变量u 和 p 再做一个循环如果u 和 p 同事满足我们才输出结果下面的awk脚本就是通过这个思考来解决ldif文本的处理的!
# 此脚本的目的是方便我们以后导ldap的其他邮件的数据,
# 我们之前使用slapdcat -l 导出所有信息,然后我们需要
# 整理出uid password , 这里的设置都是默认以":" 间隔的
# 例slapcat -l user.ldif 如果想得到一份uid 和userPassword 对应的文件,
# 修改username = "dn"; password = "userpassword"; awk -f ldap2txt.awk user.ldif | grep uid | more 可以查看结果 (有可能是多域的邮件)
# 如果想得到domain 所对应的密码,修改username = "dn"; password = "userpassword"; 运行 awk -f ldap2txt.awk user.ldif |grep domain | more
#!/bin/awk -f
# File name: ldap2txt.awk
BEGIN {
FS = ":";
username = "uid";
password = "userPassword";
}
{
if(length($0) == 0 )
{
if (name != "u" && pword != "p")
{
printf ("%s:%s\n", name,pword);
name = "u";
pword = "p";
}
}
else
{
if ($1 == username)
{
name = "u";
name = $0;
}
else if($1 == password)
{
pword = "p";
pword = $0;
}
}
}
END {
}
实际上对于学习语言首先是熟悉一些常用的函数,然后就是试着去解决别人解决过的问题,然后自己再思考一下是不是有更好,速度更快的解决办法,实际上大部分的程序员都是在重复的使用着别人好的解决办法,把别人的方法转变为自己的方法,就是反复练习解决不同的问题,思考更好的方法!
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/blackbillow/archive/2009/01/21/3847425.aspx
posted @
2009-08-21 14:09 xzc 阅读(374) |
评论 (0) |
编辑 收藏posted @
2009-08-17 18:01 xzc 阅读(308) |
评论 (0) |
编辑 收藏【适用范围】IE,JSP
【问题描述和定位】业务需要把一个html页面中的内容导出到excle文件里面,一个常用的方法是在需要导出的jsp页面中增加:
response.setContentType("application/vnd.ms-Excel; charset=gb2312");
response.setHeader("Content-disposition","attachment;filename=excel文件名.xls");
但是经常遇到会把身份证等数字比较长的数据改成科学计数法来显示。
【解决方案和步骤】
在html页面里面加上如下css,然后在出现问题的字段应用这种style就可以了。
<style type="text/css">
<!--
td {
background-color: #FFFFFF;
}
.txt
{padding-top:1px;
padding-right:1px;
padding-left:1px;
mso-ignore:padding;
color:black;
font-size:11.0pt;
font-weight:400;
font-style:normal;
text-decoration:none;
font-family:宋体;
mso-generic-font-family:auto;
mso-font-charset:134;
mso-number-format:"\@"; //关键是这里
text-align:general;
vertical-align:middle;
mso-background-source:auto;
mso-pattern:auto;
white-space:nowrap;}
-->
</style>
示例:
<TD class="txt" align="center">
<bean:write id="ResultSet" property="VW_SETTLHINT/DEALBILLID"/>
</TD>
posted @
2009-08-07 16:26 xzc 阅读(2222) |
评论 (0) |
编辑 收藏
试共同条件:
数据总数为110011条,每条数据条数为19个字段。
电脑配置为:P4 2.67GHz,1G内存。
一、POI、JXL、FastExcel比较
POI、JXL、FastExcel均为java第三方开源导出Excel的开源项目。
导出方案一:一次性全部导出到一个Excel文件中。
实际情况均报OutOfMemery错误,以下数据为报OutOfMemery数据时,数据到的最大数据数目,如表1所示:
表1:报OutOfMemery错误时所能处理的数据量
|
FastExecl |
POI |
JXL |
| 10000数据/sheet |
37465 |
28996 |
42270 |
| 5000数据/sheet |
39096 |
31487 |
46270 |
| 3000数据/sheet |
39000 |
32493 |
47860 |
小结:
多分sheet能一定程度上减少内存的使用,但是均因为程序中创建的Cell(即为Excel中的一个单元格)无法释放,消耗大量内存,导致OutOfMemery错误;JXL表现最好,创建Cell内存使用较少。
导出方案二:先分多个Excel文件将数据全部导出,然后对多个Excel文件进行合并。
首先,测试将全部数据导出所用的时间,如表2所示,数据均测试三次取平均。
表2:导出全部数据所用时间
|
FastExecl |
POI |
JXL |
| 10000数据/文件 |
68s |
33s |
30s |
| 5000数据/文件 |
68s |
32s |
33s |
| 3000数据/文件 |
59s |
33s |
39s |
小结:
均成功导出Excel文件,原因是导出一个Excel文件,释放所占用的创建Cell的内存。
FastExecl表现最差,POI表现稳定,JXL随着数据的增大,速度一定程度上增快。
然后,进行整合,由于将多Excel合并成一个Excel文件的功能只有POI所有,故使用POI测试,结果如表3所示。
注:数据量大合并还会报OutOfMemery错误,故合并总数据量以5万为准。
表3:合并5万数据所用时间
|
时间 |
| 10000数据/文件 |
11s |
| 5000数据/文件 |
11s |
| 3000数据/文件 |
11s |
小结:
使用POI对文件进行合并速度较快,但有数据量的限制。
总结:方案二比较可行,但是数据量有限制,为5万条。
二、导出XML 的电子表格
导出的格式类似为纯文本,能实现大数据量的存储,并能实现分Sheet查看,且能添加简单的样式,符合项目要求。经实际测试Excel2003和Excel2007均能识别并正常打开查看。使用时间测试如表4所示,数据均测试3次取平均。
表4:生成全部数据所用时间
|
时间 |
| 10000数据/sheet |
28.0秒 |
| 20000数据/sheet |
30.1秒 |
| 30000数据/sheet |
28.1秒 |
| 40000数据/sheet |
26.5秒 |
| 50000数据/shee |
28.2秒 |
| 55000数据/sheet |
26.8秒 |
| 59000数据/sheet |
30.1秒 |
| 59500数据/sheet |
发生假死机现象 |
| 60000数据/sheet |
发生假死机现象 |
但是导出的数据为XML不是纯正的Excel文件,如使用Excel文件的xls后缀保存,打开文件会弹出警告,但不影响阅读。
且经实际测试,在Access2007和Access2003中可通过导入外部数据的方式,将导出的XML导入进Access数据库。
三、总结
项目要求是大数据量导出Excel文件,POI、JXL、FastExcel不能完全满足要求;使用XML 的电子表格导出实现了大数据量导出,但是格式为XML不是纯正的Excel文件,为曲线救国。两种导出形式的比较,如表5所示。
表5:合并5万数据所用时间
|
POI、JXL、FastExcel |
XML 的电子表格 |
| 导出数据格式 |
为纯Execl文件 |
为XML文件 |
| 导出数据量 |
小 |
较大 |
| 能否分Sheet |
能 |
能 |
| 能否添加样式 |
能 |
能 |
| 能否添加图片 |
POI 能 |
不能 |
| 导出数据能否导入Access |
能 |
能 |
|
posted @
2009-08-07 15:57 xzc 阅读(1784) |
评论 (0) |
编辑 收藏研究了很久新出的 Spring 2.5, 总算大致明白了如何用标注定义 Bean, 但是如何定义和注入类型为 java.lang.String 的 bean 仍然未解决, 希望得到高人帮助.
总的来看 Java EE 5 的标注开发方式开来是得到了大家的认可了.
@Service 相当于定义 bean, 自动根据 bean 的类名生成一个首字母小写的 bean
@Autowired 则是自动注入依赖的类, 它会在类路径中找成员对应的类/接口的实现类, 如果找到多个, 需要用 @Qualifier("chineseMan") 来指定对应的 bean 的 ID.
一定程度上大大简化了代码的编写, 例如一对一的 bean 映射现在完全不需要写任何额外的 bean 定义了.
下面是代码的运行结果:
man.sayHello()=抽你丫的
SimpleMan said: Hi
org.example.EnglishMan@12bcd4b said: Fuck you!
代码:
beans.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<context:annotation-config/>
<context:component-scan base-package="org.example"/>
</beans>
测试类:
import org.example.IMan;
import org.example.SimpleMan;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class SpringTest {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("beans.xml");
SimpleMan dao = (SimpleMan) ctx.getBean("simpleMan");
System.out.println(dao.hello());
IMan man = (IMan) ctx.getBean("usMan");
System.out.println(man.sayHello());
}
}
自动探测和注入bean的类:
package org.example;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
@Service
public class SimpleMan {
// 自动注入名称为 Man 的 Bean
@Autowired(required = false)
@Qualifier("chineseMan")
//@Qualifier("usMan")
private IMan man;
/**
* @return the man
*/
public IMan getMan() {
return man;
}
/**
* @param man the man to set
*/
public void setMan(IMan man) {
this.man = man;
}
public String hello() {
System.out.println("man.sayHello()=" + man.sayHello());
return "SimpleMan said: Hi";
}
}
一个接口和两个实现类:
package org.example;
/**
* 抽象的人接口.
* @author BeanSoft
* @version 1.0
*/
public interface IMan {
/**
* 打招呼的抽象定义.
* @return 招呼的内容字符串
*/
public String sayHello();
}
package org.example;
import org.springframework.stereotype.Service;
/**
* 中国人的实现.
* @author BeanSoft
*/
@Service
public class ChineseMan implements IMan {
public String sayHello() {
return "抽你丫的";
}
}
package org.example;
import org.springframework.stereotype.Service;
/**
* @author BeanSoft
* 美国大兵
*/
@Service("usMan")
// 这里定义了一个 id 为 usMan 的 Bean, 标注里面的属性是 bean 的 id
public class EnglishMan implements IMan {
public String sayHello() {
return this + " said: Fuck you!";
}
}
posted @
2009-06-25 15:06 xzc 阅读(325) |
评论 (0) |
编辑 收藏
Spring中autowire属性
|
 |
default-autowire="x"
x有4个选择:byName,byType,constructor和autodetect
我感觉byName和byType用的多点
1. byName:
Service.java
|
public class Service
{
Source source;
public void setSource(Source source)
{
this.source = source;
}
}
|
applicationContext.xml
|
<beans
...
default-autowire="byName">
<bean id="source" class="cn.hh.spring.DBCPSource" scope="prototype"/>
<bean id="service" class="cn.hh.spring.Service" scope="prototype">
</bean>
</beans>
|
cn.hh.spring.DBCPSource实现了Source接口
xml中并没有给 bean service配Source属性,但在beans中设置了autowire="byName",这样配置文件会自动根据 cn.hh.spring.Service 中的setSource找bean id="Source"的bean ,然后自动配上去,如果没找到就不装配。
注意:byName的name是java中setXxxx 的Xxxx, 和上面设置的Source source中source拼写毫无关系,完全可以是
|
public class Service
{
Source source1;
public void setSource(Source source1)
{
this.source1 = source1;
}
}
|
结果相同。
2. byType:
Service.java同上
applicationContext.xml
|
<beans
...
default-autowire="byType">
<bean id="dbcpSource" class="cn.hh.spring.DBCPSource" scope="prototype"/>
<bean id="service" class="cn.hh.spring.Service" scope="prototype">
</bean>
</beans>
|
同样没有配置setSource,autowire改成 "byType",配置文件会找实现了Source接口的bean,这里 cn.hh.spring.DBCPSource 实现了Source接口,所以自动装配,如果没找到则不装配。
如果同个配制文件中两个bean实现了Source接口,则报错。
这里的 Type是指setSource(Source source)中参数的类型。
3. constructor:
试图在容器中寻找与需要自动装配的bean的构造函数参数一致的一个或多个bean,如果没找到则抛出异常。
4. autodetect:
首先尝试使用constructor来自动装配,然后再使用 byType方式。
|
|
posted @
2009-06-25 09:44 xzc 阅读(2030) |
评论 (0) |
编辑 收藏posted @
2009-06-18 15:09 xzc 阅读(996) |
评论 (1) |
编辑 收藏有关表分区的一些维护性操作:
一、添加分区
以下代码给SALES表添加了一个P3分区
ALTER TABLE SALES ADD PARTITION P3 VALUES LESS THAN(TO_DATE('2003-06-01','YYYY-MM-DD'));
注意:以上添加的分区界限应该高于最后一个分区界限。
以下代码给SALES表的P3分区添加了一个P3SUB1子分区
ALTER TABLE SALES MODIFY PARTITION P3 ADD SUBPARTITION P3SUB1 VALUES('COMPLETE');
二、删除分区
以下代码删除了P3表分区:
ALTER TABLE SALES DROP PARTITION P3;
在以下代码删除了P4SUB1子分区:
ALTER TABLE SALES DROP SUBPARTITION P4SUB1;
注意:如果删除的分区是表中唯一的分区,那么此分区将不能被删除,要想删除此分区,必须删除表。
三、截断分区
截断某个分区是指删除某个分区中的数据,并不会删除分区,也不会删除其它分区中的数据。当表中即使只有一个分区时,也可以截断该分区。通过以下代码截断分区:
ALTER TABLE SALES TRUNCATE PARTITION P2;
通过以下代码截断子分区:
ALTER TABLE SALES TRUNCATE SUBPARTITION P2SUB2;
四、合并分区
合并分区是将相邻的分区合并成一个分区,结果分区将采用较高分区的界限,值得注意的是,不能将分区合并到界限较低的分区。以下代码实现了P1 P2分区的合并:
ALTER TABLE SALES MERGE PARTITIONS P1,P2 INTO PARTITION P2;
五、拆分分区
拆分分区将一个分区拆分两个新分区,拆分后原来分区不再存在。注意不能对HASH类型的分区进行拆分。
ALTER TABLE SALES SBLIT PARTITION P2 AT(TO_DATE('2003-02-01','YYYY-MM-DD'))
INTO (PARTITION P21,PARTITION P22);
六、接合分区(coalesca)
结合分区是将散列分区中的数据接合到其它分区中,当散列分区中的数据比较大时,可以增加散列分区,然后进行接合,值得注意的是,接合分区只能用于散列分区中。通过以下代码进行接合分区:
ALTER TABLE SALES COALESCA PARTITION;
七、重命名表分区
以下代码将P21更改为P2
ALTER TABLE SALES RENAME PARTITION P21 TO P2;
九、跨分区查询
select sum( *) from (
(select count(*) cn from t_table_SS PARTITION (P200709_1)
union all
select count(*) cn from t_table_SS PARTITION (P200709_2));
十、查询表上有多少分区
SELECT * FROM useR_TAB_PARTITIONS WHERE TABLE_NAME='tableName'
十一、查询索引信息
select object_name,object_type,tablespace_name,sum(value)
from v$segment_statistics
where statistic_name IN ('physical reads','physical write','logical reads')and object_type='INDEX'
group by object_name,object_type,tablespace_name
order by 4 desc
--显示数据库所有分区表的信息:
select * from DBA_PART_TABLES
--显示当前用户可访问的所有分区表信息:
select * from ALL_PART_TABLES
--显示当前用户所有分区表的信息:
select * from USER_PART_TABLES
--显示表分区信息 显示数据库所有分区表的详细分区信息:
select * from DBA_TAB_PARTITIONS
--显示当前用户可访问的所有分区表的详细分区信息:
select * from ALL_TAB_PARTITIONS
--显示当前用户所有分区表的详细分区信息:
select * from USER_TAB_PARTITIONS
--显示子分区信息 显示数据库所有组合分区表的子分区信息:
select * from DBA_TAB_SUBPARTITIONS
--显示当前用户可访问的所有组合分区表的子分区信息:
select * from ALL_TAB_SUBPARTITIONS
--显示当前用户所有组合分区表的子分区信息:
select * from USER_TAB_SUBPARTITIONS
--显示分区列 显示数据库所有分区表的分区列信息:
select * from DBA_PART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的分区列信息:
select * from ALL_PART_KEY_COLUMNS
--显示当前用户所有分区表的分区列信息:
select * from USER_PART_KEY_COLUMNS
--显示子分区列 显示数据库所有分区表的子分区列信息:
select * from DBA_SUBPART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的子分区列信息:
select * from ALL_SUBPART_KEY_COLUMNS
--显示当前用户所有分区表的子分区列信息:
select * from USER_SUBPART_KEY_COLUMNS
--怎样查询出oracle数据库中所有的的分区表
select * from user_tables a where a.partitioned='YES'
--删除一个表的数据是
truncate table table_name;
--删除分区表一个分区的数据是
alter table table_name truncate partition p5;
注:分区根据具体情况选择。
表分区有以下优点:
1、数据查询:数据被存储到多个文件上,减少了I/O负载,查询速度提高。
2、数据修剪:保存历史数据非常的理想。
3、备份:将大表的数据分成多个文件,方便备份和恢复。
4、并行性:可以同时向表中进行DML操作,并行性性能提高。
================================================
索引:
1、一般索引:
create index index_name on table(col_name);
2、Oracle 分区索引详解
语法:Table Index
CREATE [UNIQUE|BITMAP] INDEX [schema.]index_name
ON [schema.]table_name [tbl_alias]
(col [ASC | DESC]) index_clause index_attribs
index_clauses:
分以下两种情况
1. Local Index
就是索引信息的存放位置依赖于父表的Partition信息,换句话说创建这样的索引必须保证父表是Partition
1.1 索引信息存放在父表的分区所在的表空间。但是仅可以创建在父表为HashTable或者composite分区表的。
LOCAL STORE IN (tablespace)
1.2 仅可以创建在父表为HashTable或者composite分区表的。并且指定的分区数目要与父表的分区数目要一致
LOCAL STORE IN (tablespace) (PARTITION [partition [LOGGING|NOLOGGING] [TABLESPACE {tablespace|DEFAULT}] [PCTFREE int] [PCTUSED int] [INITRANS int] [MAXTRANS int] [STORAGE storage_clause] [STORE IN {tablespace_name|DEFAULT] [SUBPARTITION [subpartition [TABLESPACE tablespace]]]])
1.3 索引信息存放在父表的分区所在的表空间,这种语法最简单,也是最常用的分区索引创建方式。
Local
1.4 并且指定的Partition 数目要与父表的Partition要一致
LOCAL (PARTITION [partition
[LOGGING|NOLOGGING]
[TABLESPACE {tablespace|DEFAULT}]
[PCTFREE int]
[PCTUSED int]
[INITRANS int]
[MAXTRANS int]
[STORAGE storage_clause]
[STORE IN {tablespace_name|DEFAULT]
[SUBPARTITION [subpartition [TABLESPACE tablespace]]]])
Global Index
索引信息的存放位置与父表的Partition信息完全不相干。甚至父表是不是分区表都无所谓的。语法如下:
GLOBAL PARTITION BY RANGE (col_list)
( PARTITION partition VALUES LESS THAN (value_list)
[LOGGING|NOLOGGING]
[TABLESPACE {tablespace|DEFAULT}]
[PCTFREE int]
[PCTUSED int]
[INITRANS int]
[MAXTRANS int]
[STORAGE storage_clause] )
但是在这种情况下,如果父表是分区表,要删除父表的一个分区都必须要更新Global Index ,否则索引信息不正确
ALTER TABLE TableName DROP PARTITION PartitionName Update Global Indexes
--查询索引
select object_name,object_type,tablespace_name,sum(value)
from v$segment_statistics
where statistic_name IN ('physical reads','physical write','logical reads')and object_type='INDEX'
group by object_name,object_type,tablespace_name
order by 4 desc
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/thinker28754/archive/2009/03/06/3962309.aspx
posted @
2009-06-18 11:08 xzc 阅读(2219) |
评论 (1) |
编辑 收藏I、关系数据库设计范式介绍
1.1 第一范式(1NF)无重复的列
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
1.2 第二范式(2NF)属性完全依赖于主键[消除部分子函数依赖]
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是属性完全依赖于主键。
1.3 第三范式(3NF)属性不依赖于其它非主属性[消除传递依赖]
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。
II、范式应用实例剖析
下面以一个学校的学生系统为例分析说明,这几个范式的应用。首先第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
首先我们确定一下要设计的内容包括那些。学号、学生姓名、年龄、性别、课程、课程学分、系别、学科成绩,系办地址、系办电话等信息。为了简单我们暂时只考虑这些字段信息。我们对于这些信息,说关心的问题有如下几个方面。
- 学生有那些基本信息
- 学生选了那些课,成绩是什么
- 每个课的学分是多少
- 学生属于那个系,系的基本信息是什么。
2.1 第二范式(2NF)实例分析
首先我们考虑,把所有这些信息放到一个表中(学号,学生姓名、年龄、性别、课程、课程学分、系别、学科成绩,系办地址、系办电话)下面存在如下的依赖关系。
(学号)→ (姓名, 年龄,性别,系别,系办地址、系办电话)
(课程名称) → (学分)
(学号,课程)→ (学科成绩)
2.1.1 问题分析
因此不满足第二范式的要求,会产生如下问题
数据冗余: 同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。
更新异常:
1)若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
2)假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据库。
删除异常 : 假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
2.1.2 解决方案
把选课关系表SelectCourse改为如下三个表:
- 学生:Student(学号,姓名, 年龄,性别,系别,系办地址、系办电话);
- 课程:Course(课程名称, 学分);
- 选课关系:SelectCourse(学号, 课程名称, 成绩)。
2.2 第三范式(3NF)实例分析
接着看上面的学生表Student(学号,姓名, 年龄,性别,系别,系办地址、系办电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号)→ (姓名, 年龄,性别,系别,系办地址、系办电话)
但是还存在下面的决定关系
(学号) → (所在学院)→(学院地点, 学院电话)
即存在非关键字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况。 (數據的更新,刪除異常這里就不分析了,可以參照2.1.1進行分析)
根据第三范式把学生关系表分为如下两个表就可以滿足第三范式了:
学生:(学号, 姓名, 年龄, 性别,系别);
系别:(系别, 系办地址、系办电话)。
总结
上面的数据库表就是符合I,II,III范式的,消除了数据冗余、更新异常、插入异常和删除异常。
posted @
2009-01-04 11:53 xzc 阅读(44824) |
评论 (17) |
编辑 收藏 一、Java中文问题的由来
Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,Java和JSP文件本身编译时产生的乱码问题和Java程序于其他媒介交互产生的乱码问题。
首先Java(包括JSP)源文件中很可能包含有中文,而Java和JSP源文件的保存方式是基于字节流的,如果Java和JSP编译成class文件过程中,使用的编码方式与源文件的编码不一致,就会出现乱码。基于这种乱码,建议在Java文件中尽量不要写中文(注释部分不参与编译,写中文没关系),如果必须写的话,尽量手动带参数-ecoding GBK或-ecoding gb2312编译;对于JSP,在文件头加上<%@ page contentType="text/html;charset=GBK"%>或<%@ page contentType="text/html;charset=gb2312"%>基本上就能解决这类乱码问题。
本文要重点讨论的是第二类乱码,即Java程序与其他存储媒介交互时产生的乱码。很多存储媒介,如数据库,文件,流等的存储方式都是基于字节流的,Java程序与这些媒介交互时就会发生字符(char)与字节(byte)之间的转换,例如从页面提交表单中提交的数据在Java程序里显示乱码等情况。
如果在以上转换过程中使用的编码方式与字节原有的编码不一致,很可能就会出现乱码。
二、解决方法
对于流行的Tomcat来说,有以下两种解决方法:
1) 更改 D:\Tomcat\conf\server.xml,指定浏览器的编码格式为“简体中文”:
方法是找到 server.xml 中的
<Connector port="8080" maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" URIEncoding='GBK' />
标记,粗体字是我添加的。
可以这样验证你的更改是否成功:在更改前,在你出现乱码的页面的IE浏览器,点击菜单“查看|编码”,会发现“西欧(ISO)”处于选中状态。而更改后,点击菜单“查看|编码”,会发现“简体中文(GB2312)”处于选中状态。
b)更该 Java 程序,我的程序是这样的:
public class ThreeParams extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html; charset=GBK");
...
}
}
粗体字是必需要有的,它的作用是让浏览器把Unicode字符转换为GBK字符。这样页面的内容和浏览器的显示模式都设成了GBK,就不会乱码了。
posted @
2008-11-22 20:39 xzc 阅读(684) |
评论 (0) |
编辑 收藏
3.8.1. 利用MessageSource实现国际化
ApplicationContext接口扩展了MessageSource接口,因而提供了消息处理的功能(i18n或者国际化)。与HierarchicalMessageSource一起使用,它还能够处理嵌套的消息,这些是Spring提供的处理消息的基本接口。让我们快速浏览一下它所定义的方法:
-
String getMessage(String code, Object[] args, String default, Locale loc):用来从MessageSource获取消息的基本方法。如果在指定的locale中没有找到消息,则使用默认的消息。args中的参数将使用标准类库中的MessageFormat来作消息中替换值。
-
String getMessage(String code, Object[] args, Locale loc):本质上和上一个方法相同,其区别在:没有指定默认值,如果没找到消息,会抛出一个NoSuchMessageException异常。
-
String getMessage(MessageSourceResolvable resolvable, Locale locale):上面方法中所使用的属性都封装到一个MessageSourceResolvable实现中,而本方法可以指定MessageSourceResolvable实现。
当一个ApplicationContext被加载时,它会自动在context中查找已定义为MessageSource类型的bean。此bean的名称须为messageSource。如果找到,那么所有对上述方法的调用将被委托给该bean。否则ApplicationContext会在其父类中查找是否含有同名的bean。如果有,就把它作为MessageSource。如果它最终没有找到任何的消息源,一个空的StaticMessageSource将会被实例化,使它能够接受上述方法的调用。
Spring目前提供了两个MessageSource的实现:ResourceBundleMessageSource和StaticMessageSource。它们都继承NestingMessageSource以便能够处理嵌套的消息。StaticMessageSource很少被使用,但能以编程的方式向消息源添加消息。ResourceBundleMessageSource会用得更多一些,为此提供了一下示例:
<beans>
<bean id="messageSource"
class="org.springframework.context.support.ResourceBundleMessageSource">
<property name="basenames">
<list>
<value>format</value>
<value>exceptions</value>
<value>windows</value>
</list>
</property>
</bean>
</beans>
这段配置假定在你的classpath中有三个资源文件(resource bundle),它们是format, exceptions和windows。通过ResourceBundle,使用JDK中解析消息的标准方式,来处理任何解析消息的请求。出于示例的目的,假定上面的两个资源文件的内容为…
# in 'format.properties'
message=Alligators rock!
# in 'exceptions.properties'
argument.required=The '{0}' argument is required.
下面是测试代码。因为ApplicationContext实现也都实现了MessageSource接口,所以能被转型为MessageSource接口
public static void main(String[] args) {
MessageSource resources = new ClassPathXmlApplicationContext("beans.xml");
String message = resources.getMessage("message", null, "Default", null);
System.out.println(message);
}
上述程序的输出结果将会是...
Alligators rock!
总而言之,我们在'beans.xml'的文件中(在classpath根目录下)定义了一个messageSource bean,通过它的basenames属性引用多个资源文件;而basenames属性值由list元素所指定的三个值传入,它们以文件的形式存在并被放置在classpath的根目录下(分别为format.properties,exceptions.properties和windows.properties)。
再分析个例子,这次我们将着眼于传递参数给查找的消息,这些参数将被转换为字符串并插入到已查找到的消息中的占位符(译注:资源文件中花括号里的数字即为占位符)。
<beans>
<!-- this MessageSource is being used in a web application -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource">
<property name="baseName" value="WEB-INF/test-messages"/>
</bean>
<!-- let's inject the above MessageSource into this POJO -->
<bean id="example" class="com.foo.Example">
<property name="messages" ref="messageSource"/>
</bean>
</beans>
public class Example {
private MessageSource messages;
public void setMessages(MessageSource messages) {
this.messages = messages;
}
public void execute() {
String message = this.messages.getMessage("argument.required",
new Object [] {"userDao"}, "Required", null);
System.out.println(message);
}
}
调用execute()方法的输出结果是...
The 'userDao' argument is required.
对于国际化(i18n),Spring中不同的MessageResource实现与JDK标准ResourceBundle中的locale解析规则一样。比如在上面例子中定义的messageSource bean,如果你想解析British (en-GB) locale的消息,那么需要创建format_en_GB.properties,exceptions_en_GB.properties和windows_en_GB.properties三个资源文件。
Locale解析通常由应用程序根据运行环境来指定。出于示例的目的,我们对将要处理的(British)消息手工指定locale参数值。
# in 'exceptions_en_GB.properties'
argument.required=Ebagum lad, the '{0}' argument is required, I say, required.
public static void main(final String[] args) {
MessageSource resources = new ClassPathXmlApplicationContext("beans.xml");
String message = resources.getMessage("argument.required",
new Object [] {"userDao"}, "Required", Locale.UK);
System.out.println(message);
}
上述程序运行时的输出结果是...
Ebagum lad, the 'userDao' argument is required, I say, required.
MessageSourceAware接口还能用于获取任何已定义的MessageSource引用。任何实现了MessageSourceAware接口的bean将在创建和配置的时候与MessageSource一同被注入。
posted @
2008-11-22 16:51 xzc 阅读(4090) |
评论 (3) |
编辑 收藏
照抄appfuse,折腾了很久后才发现appfuse式的sample总是只顾着演示自己的一亩三分地而忽略了很多其他东西。
1.从基础开始,没有Spring时,Java的i18n是这样的:
1.1 jsp环境
首先写一个messages.zh_CN.properties文件,放在class-path也就是/WEB-INF/classes里 welcome=欢迎 然后用native2ascii.exe把它转为 welcome=\u6b22\u8fce
在web.xml中定义messages文件
<context-param>
<param-name>javax.servlet.jsp.jstl.fmt.localizationContext</param-name>
<param-value>messages</param-value>
</context-param>
最后在jsp里使用
<%@ taglib uri="http://java.sun.com/jstl/fmt" prefix="fmt" %>
<fmt:message key="welcome"/>
如果有多个Resource Bundle文件, 就要在jsp里用<ftm:bundle>定义了.
1.2 pure Java环境
ResourceBundle rb = ResourceBundle.getBundle("messages");
String welcome = rb.getString("welcome");
2.Spring的增强及appfuse的做法
Spring增加了MessageSource的概念,一是ApplicationContext将充当一个单例的角色,不再需要每次使用i18时都初始化一次ResourceBundle,二是可以代表多个Resource Bundle.
在ApplicationContext的定义文件中,增加如下节点:
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource">
<property name="basename" value="messages"/>
</bean>
则在pure java环境中。 context.getMessage("welcome", null, Locale.CHINA)
而在jsp环境中,Controller调用JSTL viewResolver再调用Jsp时,<fmt:message>将继续发挥它的功效。
因此,appfuse等sample都是在appfuse-servlet.xml 中定义一个<messageSource>。
3.Better Practice
3.1 要不要定义javax.servlet.jsp.jstl.fmt.localizationContext[定义]
Appfuse等sample,都是假定大家完全使用Controller作访问入口,jsp甚至藏在了/web-inf/中。而很不幸,大家的项目可能还是有很多直接访问jsp的地方,而直接访问jsp时,<messageSource>节点是没有作用的。
但如果定义了javax...localizationContext, 又会让MessageSource失效......
3.2 messageSource定义在ApplicationContext.xml还是appfuse-servlet.xml
ApplicationContext*.xml由ContextLoaderListener载入,而appfuse-servlet.xml靠dispatchServlet载入,并拥有一个指向ApplcationContex*.xml指针。所以,appfuse-servlet.xml能看到定义在ApplcationContext里的东西,而反之做不到。
明显, 把<messageSource>定义在ApplicationContext.xml 能获得更好的可见性。
但是appfuse没有在pure Java代码中使用i18n,也就没有考虑这个问题。
3.3 坚决不用鸡肋级<spring:message> tag
连appfuse也不用它,可见多么鸡肋。因为fmt在找不到资源时,最多显示???welcome???,而<spring:message>则会抛出异常,谁会喜欢这种定时炸弹阿。
3.4 有趣的theme 解决"做成图片的文字"的国际化
theme也就是把message的原理发挥了一下,让不同语言的美术字图片的路径也可以定义在theme_zh_CN.properties和theme_en_US.properties中。终于有一个不那么鸡肋的spring tag了。
4.简单归纳
1. jstl中仍然使用标准的<ftm:message>及其定义?
2.java中使用spring的<messageSource>实现单例
3.用<spring:theme>解决那些做成图片的文字的国际化问题
4.Spring 还有session,cookie locale resolver, 到时可以看一下.
posted @
2008-11-22 16:40 xzc 阅读(1466) |
评论 (3) |
编辑 收藏
Posted on 2007-10-25 23:53
Raylong 阅读(3747)
评论(10) 编辑 收藏 所属分类:
Java语法总结 
Java语法总结 - 线程
一提到线程好像是件很麻烦很复杂的事,事实上确实如此,涉及到线程的编程是很讲究技巧的。这就需要我们变换思维方式,了解线程机制的比较通用的技巧,写出高效的、不依赖于某个JVM实现的程序来。毕竟仅仅就Java而言,各个虚拟机的实现是不同的。学习线程时,最令我印象深刻的就是那种不确定性、没有保障性,各个线程的运行完全是以不可预料的方式和速度推进,有的一个程序运行了N次,其结果差异性很大。
1、什么是线程?线程是彼此互相独立的、能独立运行的子任务,并且每个线程都有自己的调用栈。所谓的多任务是通过周期性地将CPU时间片切换到不同的子任务,虽然从微观上看来,单核的CPU上同时只运行一个子任务,但是从宏观来看,每个子任务似乎是同时连续运行的。(但是JAVA的线程不是按时间片分配的,在本文的最后引用了一段网友翻译的JAVA原著中对线程的理解。)
2、在java中,线程指两个不同的内容:一是java.lang.Thread类的一个对象;另外也可以指线程的执行。线程对象和其他的对象一样,在堆上创建、运行、死亡。但不同之处是线程的执行是一个轻量级的进程,有它自己的调用栈。
可以这样想,每个调用栈都对应一个线程,每个线程又对应一个调用栈。
我们运行java程序时有一个入口函数main()函数,它对应的线程被称为主线程。一个新线程一旦被创建,就产生一个新调用栈,从原主线程中脱离,也就是与主线程并发执行。
4、当提到线程时,很少是有保障的。我们必须了解到什么是有保障的操作,什么是无保障的操作,以便设计的程序在各种jvm上都能很好地工作。比如,在某些jvm实现中,把java线程映射为本地操作系统的线程。这是java核心的一部分。
5、线程的创建。
创建线程有两种方式:
A、继承java.lang.Thread类。
class ThreadTest extends Thread{
public void run() {
System.out.println ("someting run here!");
}
public void run(String s){
System.out.println ("string in run is " + s);
}
public static void main (String[] args) {
ThreadTest tt = new ThreadTest();
tt.start();
tt.run("it won't auto run!");
}
}
输出的结果比较有趣:
string in run is it won't auto run!
someting run here!
注意输出的顺序:好像与我们想象的顺序相反了!为什么呢?
一旦调用start()方法,必须给JVM点时间,让它配置进程。而在它配置完成之前,重载的run(String s)方法被调用了,结果反而先输出了“string in run is it won't auto run!”,这时tt线程完成了配置,输出了“someting run here!”。
这个结论是比较容易验证的:
修改上面的程序,在tt.start();后面加上语句for (int i = 0; i<10000; i++); 这样主线程开始执行运算量比较大的for循环了,只有执行完for循环才能运行后面的tt.run("it won't auto run!");语句。此时,tt线程和主线程并行执行了,已经有足够的时间完成线程的配置!因此先到一步!修改后的程序运行结果如下:
someting run here!
string in run is it won't auto run!
注意:这种输出结果的顺序是没有保障的!不要依赖这种结论!
没有参数的run()方法是自动被调用的,而带参数的run()是被重载的,必须显式调用。
这种方式的限制是:这种方式很简单,但不是个好的方案。如果继承了Thread类,那么就不能继承其他的类了,java是单继承结构的,应该把继承的机会留给别的类。除非因为你有线程特有的更多的操作。
Thread类中有许多管理线程的方法,包括创建、启动和暂停它们。所有的操作都是从run()方法开始,并且在run()方法内编写需要在独立线程内执行的代码。run()方法可以调用其他方法,但是执行的线程总是通过调用run()。
B、实现java.lang.Runnable接口。
class ThreadTest implements Runnable {
public void run() {
System.out.println ("someting run here");
}
public static void main (String[] args) {
ThreadTest tt = new ThreadTest();
Thread t1 = new Thread(tt);
Thread t2 = new Thread(tt);
t1.start();
t2.start();
//new Thread(tt).start();
}
}
比第一种方法复杂一点,为了使代码被独立的线程运行,还需要一个Thread对象。这样就把线程相关的代码和线程要执行的代码分离开来。
另一种方式是:参数形式的匿名内部类创建方式,也是比较常见的。
class ThreadTest{
public static void main (String[] args) {
Thread t = new Thread(new Runnable(){
public void run(){
System.out.println ("anonymous thread");
}
});
t.start();
}
}
如果你对此方式的声明不感冒,请参看本人总结的内部类。
第一种方式使用无参构造函数创建线程,则当线程开始工作时,它将调用自己的run()方法。
第二种方式使用带参数的构造函数创建线程,因为你要告诉这个新线程使用你的run()方法,而不是它自己的。
如上例,可以把一个目标赋给多个线程,这意味着几个执行线程将运行完全相同的作业。
6、什么时候线程是活的?
在调用start()方法开始执行线程之前,线程的状态还不是活的。测试程序如下:
class ThreadTest implements Runnable {
public void run() {
System.out.println ("someting run here");
}
public static void main (String[] args) {
ThreadTest tt = new ThreadTest();
Thread t1 = new Thread(tt);
System.out.println (t1.isAlive());
t1.start();
System.out.println (t1.isAlive());
}
}
结果输出:
false
true
isAlive方法是确定一个线程是否已经启动,而且还没完成run()方法内代码的最好方法。
7、启动新线程。
线程的启动要调用start()方法,只有这样才能创建新的调用栈。而直接调用run()方法的话,就不会创建新的调用栈,也就不会创建新的线程,run()方法就与普通的方法没什么两样了!
8、给线程起个有意义的名字。
没有该线程命名的话,线程会有一个默认的名字,格式是:“Thread-”加上线程的序号,如:Thread-0
这看起来可读性不好,不能从名字分辨出该线程具有什么功能。下面是给线程命名的方式。
第一种:用setName()函数
第二种:选用带线程命名的构造器
class ThreadTest implements Runnable{
public void run(){
System.out.println (Thread.currentThread().getName());
}
public static void main (String[] args) {
ThreadTest tt = new ThreadTest();
//Thread t = new Thread (tt,"eat apple");
Thread t = new Thread (tt);
t.setName("eat apple");
t.start();
}
}
9、“没有保障”的多线程的运行。下面的代码可能令人印象深刻。
class ThreadTest implements Runnable{
public void run(){
System.out.println (Thread.currentThread().getName());
}
public static void main (String[] args) {
ThreadTest tt = new ThreadTest();
Thread[] ts =new Thread[10];
for (int i =0; i < ts.length; i++)
ts[i] = new Thread(tt);
for (Thread t : ts)
t.start();
}
}
在我的电脑上运行的结果是:
Thread-0
Thread-1
Thread-3
Thread-5
Thread-2
Thread-7
Thread-4
Thread-9
Thread-6
Thread-8
而且每次运行的结果都是不同的!继续引用前面的话,一旦涉及到线程,其运行多半是没有保障。这个保障是指线程的运行完全是由调度程序控制的,我们没法控制它的执行顺序,持续时间也没有保障,有着不可预料的结果。
10、线程的状态。
A、新状态。
实例化Thread对象,但没有调用start()方法时的状态。
ThreadTest tt = new ThreadTest();
或者Thread t = new Thread (tt);
此时虽然创建了Thread对象,如前所述,但是它们不是活的,不能通过isAlive()测试。
B、就绪状态。
线程有资格运行,但调度程序还没有把它选为运行线程所处的状态。也就是具备了运行的条件,一旦被选中马上就能运行。
也是调用start()方法后但没运行的状态。此时虽然没在运行,但是被认为是活的,能通过isAlive()测试。而且在线程运行之后、或者被阻塞、等待或者睡眠状态回来之后,线程首先进入就绪状态。
C、运行状态。
从就绪状态池(注意不是队列,是池)中选择一个为当前执行进程时,该线程所处的状态。
D、等待、阻塞、睡眠状态。
这三种状态有一个共同点:线程依然是活的,但是缺少运行的条件,一旦具备了条就就可以转为就绪状态(不能直接转为运行状态)。另外,suspend()和stop()方法已经被废弃了,比较危险,不要再用了。
E、死亡状态。
一个线程的run()方法运行结束,那么该线程完成其历史使命,它的栈结构将解散,也就是死亡了。但是它仍然是一个Thread对象,我们仍可以引用它,就像其他对象一样!它也不会被垃圾回收器回收了,因为对该对象的引用仍然存在。
如此说来,即使run()方法运行结束线程也没有死啊!事实是,一旦线程死去,它就永远不能重新启动了,也就是说,不能再用start()方法让它运行起来!如果强来的话会抛出IllegalThreadStateException异常。如:
t.start();
t.start();
放弃吧,人工呼吸或者心脏起搏器都无济于事……线程也属于一次性用品。
11、阻止线程运行。
A、睡眠。sleep()方法
让线程睡眠的理由很多,比如:认为该线程运行得太快,需要减缓一下,以便和其他线程协调;查询当时的股票价格,每睡5分钟查询一次,可以节省带宽,而且即时性要求也不那么高。
用Thread的静态方法可以实现Thread.sleep(5*60*1000); 睡上5分钟吧。sleep的参数是毫秒。但是要注意sleep()方法会抛出检查异常InterruptedException,对于检查异常,我们要么声明,要么使用处理程序。
try {
Thread.sleep(20000);
}
catch (InterruptedException ie) {
ie.printStackTrace();
}
既然有了sleep()方法,我们是不是可以控制线程的执行顺序了!每个线程执行完毕都睡上一觉?这样就能控制线程的运行顺序了,下面是书上的一个例子:
class ThreadTest implements Runnable{
public void run(){
for (int i = 1; i<4; i++){
System.out.println (Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException ie) { }
}
}
public static void main (String[] args) {
ThreadTest tt = new ThreadTest();
Thread t0 = new Thread(tt,"Thread 0");
Thread t1 = new Thread(tt,"Thread 1");
Thread t2 = new Thread(tt,"Thread 2");
t0.start();
t1.start();
t2.start();
}
}
并且给出了结果:
Thread 0
Thread 1
Thread 2
Thread 0
Thread 1
Thread 2
Thread 0
Thread 1
Thread 2
也就是Thread 0 Thread 1 Thread 2 按照这个顺序交替出现,作者指出虽然结果和我们预料的似乎相同,但是这个结果是不可靠的。果然被我的双核电脑验证了:
Thread 0
Thread 1
Thread 2
Thread 2
Thread 0
Thread 1
Thread 1
Thread 0
Thread 2
看来线程真的很不可靠啊。但是尽管如此,sleep()方法仍然是保证所有线程都有运行机会的最好方法。至少它保证了一个线程进入运行之后不会一直到运行完位置。
时间的精确性。再强调一下,线程醒来之后不会进入运行状态,而是进入就绪状态。因此sleep()中指定的时间不是线程不运行的精确时间!不能依赖sleep()方法提供十分精确的定时。我们可以看到很多应用程序用sleep()作为定时器,而且没什么不好的,确实如此,但是我们一定要知道sleep()不能保证线程醒来就能马上进入运行状态,是不精确的。
sleep()方法是一个静态的方法,它所指的是当前正在执行的线程休眠一个毫秒数。看到某些书上的Thread.currentThread().sleep(1000); ,其实是不必要的。Thread.sleep(1000);就可以了。类似于getName()方法不是静态方法,它必须针对具体某个线程对象,这时用取得当前线程的方法Thread.currentThread().getName();
B、线程优先级和让步。
线程的优先级。在大多数jvm实现中调度程序使用基于线程优先级的抢先调度机制。如果一个线程进入可运行状态,并且它比池中的任何其他线程和当前运行的进程的具有更高的优先级,则优先级较低的线程进入可运行状态,最高优先级的线程被选择去执行。
于是就有了这样的结论:当前运行线程的优先级通常不会比池中任何线程的优先级低。但是并不是所有的jvm的调度都这样,因此一定不能依赖于线程优先级来保证程序的正确操作,这仍然是没有保障的,要把线程优先级用作一种提高程序效率的方法,并且这种方法也不能依赖优先级的操作。
另外一个没有保障的操作是:当前运行的线程与池中的线程,或者池中的线程具有相同的优先级时,JVM的调度实现会选择它喜欢的线程。也许是选择一个去运行,直至其完成;或者用分配时间片的方式,为每个线程提供均等的机会。
优先级用正整数设置,通常为1-10,JVM从不会改变一个线程的优先级。默认情况下,优先级是5。Thread类具有三个定义线程优先级范围的静态最终常量:Thread.MIN_PRIORITY (为1) Thread.NORM_PRIORITY (为5) Thread.MAX_PRIORITY (为10)
静态Thread.yield()方法。
它的作用是让当前运行的线程回到可运行状态,以便让具有同等优先级的其他线程运行。用yield()方法的目的是让同等优先级的线程能适当地轮转。但是,并不能保证达到此效果!因为,即使当前变成可运行状态,可是还有可能再次被JVM选中!也就是连任。
非静态join()方法。
让一个线程加入到另一个线程的尾部。让B线程加入A线程,意味着在A线程运行完成之前,B线程不会进入可运行状态。
Thread t = new Thread();
t.start();
t.join;
这段代码的意思是取得当前的线程,把它加入到t线程的尾部,等t线程运行完毕之后,原线程继续运行。书中的例子在我的电脑里效果很糟糕,看不出什么效果来。也许是CPU太快了,而且是双核的;也许是JDK1.6的原因?
12、没总结完。线程这部分很重要,内容也很多,看太快容易消化不良,偶要慢慢地消化掉……
附: java原著中对线程的解释。
e文原文:
Thread Scheduling
In Java technology,threads are usually preemptive,but not necessarily Time-sliced(the process of giving each thread an equal amount of CPU time).It is common mistake to believe that "preemptive" is a fancy word for "does time-slicing".
For the runtime on a Solaris Operating Environment platform,Java technology does not preempt threads of the same priority.However,the runtime on Microsoft Windows platforms uses time-slicing,so it preempts threads of the same priority and even threads of higher priority.Preemption is not guaranteed;however,most JVM implementations result in behavior that appears to be strictly preemptive.Across JVM implementations,there is no absolute guarantee of preemption or time-slicing.The only guarantees lie in the coder’s use of wait and sleep.
The model of a preemptive scheduler is that many threads might be runnable,but only one thread is actually running.This thread continues to run until it ceases to be runnable or another thread of higher priority becomes runnable.In the latter case,the lower priority thread is preempted by the thread of higher priority,which gets a chance to run instead.
A thread might cease to runnable (that is,because blocked) for a variety of reasons.The thread’s code can execute a Thread.sleep() call,deliberately asking the thread to pause for a fixed period of time.The thread might have to wait to access a resource and cannot continue until that resource become available.
All thread that are runnable are kept in pools according to priority.When a blocked thread becomes runnable,it is placed back into the appropriate runnable pool.Threads from the highest priority nonempty pool are given CPU time.
The last sentence is worded loosed because:
(1) In most JVM implementations,priorities seem to work in a preemptive manner,although there is no guarantee that priorities have any meaning at all;
(2) Microsoft Window’s values affect thread behavior so that it is possible that a Java Priority 4 thread might be running,in spite of the fact that a runnable Java Priority 5 thread is waiting for the CPU.
In reality,many JVMs implement pool as queues,but this is not guaranteed hehavior.
热心网友翻译的版本:
在java技术中,线程通常是抢占式的而不需要时间片分配进程(分配给每个线程相等的cpu时间的进程)。一个经常犯的错误是认为“抢占”就是“分配时间片”。
在Solaris平台上的运行环境中,相同优先级的线程不能相互抢占对方的cpu时间。但是,在使用时间片的windows平台运行环境中,可以抢占相同甚至更高优先级的线程的cpu时间。抢占并不是绝对的,可是大多数的JVM的实现结果在行为上表现出了严格的抢占。纵观JVM的实现,并没有绝对的抢占或是时间片,而是依赖于编码者对wait和sleep这两个方法的使用。
抢占式调度模型就是许多线程属于可以运行状态(等待状态),但实际上只有一个线程在运行。该线程一直运行到它终止进入可运行状态(等待状态)或是另一个具有更高优先级的线程变成可运行状态。在后一种情况下,底优先级的线程被高优先级的线程抢占,高优先级的线程获得运行的机会。
线程可以因为各种各样的原因终止并进入可运行状态(因为堵塞)。例如,线程的代码可以在适当时候执行Thread.sleep()方法,故意让线程中止;线程可能为了访问资源而不得不等待直到该资源可用为止。
所有可运行的线程根据优先级保持在不同的池中。一旦被堵塞的线程进入可运行状态,它将会被放回适当的可运行池中。非空最高优先级的池中的线程将获得cpu时间。
最后一个句子是不精确的,因为:
(1)在大多数的JVM实现中,虽然不能保证说优先级有任何意义,但优先级看起来象是用抢占方式工作。
(2)微软windows的评价影响线程的行为,以至尽管一个处于可运行状态的优先级为5的java线程正在等待cpu时间,但是一个优先级为4的java线程却可能正在运行。
实际上,许多JVM用队列来实现池,但没有保证行为。
posted @
2008-11-21 18:01 xzc 阅读(200) |
评论 (0) |
编辑 收藏
- 摘要:本文通过java代码启动多个java子进程。必如在Java中通过Runtime中的exec方法执行java classname。如果执行成功,这个方法返回一个Process对象,如果执行失败,将抛出一个IOException错误。
- 标签:Java 多进程 模式 分析
-
一般我们在java中运行其它类中的方法时,无论是静态调用,还是动态调用,都是在当前的进程中执行的,也就是说,只有一个java虚拟机实例在运行。而有的时候,我们需要通过java代码启动多个java子进程。这样做虽然占用了一些系统资源,但会使程序更加稳定,因为新启动的程序是在不同的虚拟机进程中运行的,如果有一个进程发生异常,并不影响其它的子进程。
在Java中我们可以使用两种方法来实现这种要求。最简单的方法就是通过Runtime中的exec方法执行java classname。如果执行成功,这个方法返回一个Process对象,如果执行失败,将抛出一个IOException错误。下面让我们来看一个简单的例子。
// Test1.java文件
import java.io.*;
public class Test
{
public static void main(String[] args)
{
FileOutputStream fOut = new FileOutputStream("c:\\Test1.txt");
fOut.close();
System.out.println("被调用成功!");
}
}
// Test_Exec.java
public class Test_Exec
{
public static void main(String[] args)
{
Runtime run = Runtime.getRuntime();
Process p = run.exec("java test1");
}
}
|
通过java Test_Exec运行程序后,发现在C盘多了个Test1.txt文件,但在控制台中并未出现“被调用成功!”的输出信息。因此可以断定,Test已经被执行成功,但因为某种原因,Test的输出信息未在Test_Exec的控制台中输出。这个原因也很简单,因为使用exec建立的是Test_Exec的子进程,这个子进程并没有自己的控制台,因此,它并不会输出任何信息。
如果要输出子进程的输出信息,可以通过Process中的getInputStream得到子进程的输出流(在子进程中输出,在父进程中就是输入),然后将子进程中的输出流从父进程的控制台输出。具体的实现代码如下如示:
// Test_Exec_Out.java
import java.io.*;
public class Test_Exec_Out
{
public static void main(String[] args)
{
Runtime run = Runtime.getRuntime();
Process p = run.exec("java test1");
BufferedInputStream in = new BufferedInputStream(p.getInputStream());
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String s;
while ((s = br.readLine()) != null)
System.out.println(s);
}
}
|
从上面的代码可以看出,在Test_Exec_Out.java中通过按行读取子进程的输出信息,然后在Test_Exec_Out中按每行进行输出。上面讨论的是如何得到子进程的输出信息。那么,除了输出信息,还有输入信息。既然子进程没有自己的控制台,那么输入信息也得由父进程提供。我们可以通过Process的getOutputStream方法来为子进程提供输入信息(即由父进程向子进程输入信息,而不是由控制台输入信息)。我们可以看看如下的代码:
// Test2.java文件
import java.io.*;
public class Test
{
public static void main(String[] args)
{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
System.out.println("由父进程输入的信息:" + br.readLine());
}
}
// Test_Exec_In.java
import java.io.*;
public class Test_Exec_In
{
public static void main(String[] args)
{
Runtime run = Runtime.getRuntime();
Process p = run.exec("java test2");
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(p.getOutputStream()));
bw.write("向子进程输出信息");
bw.flush();
bw.close(); // 必须得关闭流,否则无法向子进程中输入信息
// System.in.read();
}
}
|
从以上代码可以看出,Test1得到由Test_Exec_In发过来的信息,并将其输出。当你不加bw.flash()和bw.close()时,信息将无法到达子进程,也就是说子进程进入阻塞状态,但由于父进程已经退出了,因此,子进程也跟着退出了。如果要证明这一点,可以在最后加上System.in.read(),然后通过任务管理器(在windows下)查看java进程,你会发现如果加上bw.flush()和bw.close(),只有一个java进程存在,如果去掉它们,就有两个java进程存在。这是因为,如果将信息传给Test2,在得到信息后,Test2就退出了。
在这里有一点需要说明一下,exec的执行是异步的,并不会因为执行的某个程序阻塞而停止执行下面的代码。因此,可以在运行test2后,仍可以执行下面的代码。
exec方法经过了多次的重载。上面使用的只是它的一种重载。它还可以将命令和参数分开,如exec(“java.test2”)可以写成exec(“java”, “test2”)。exec还可以通过指定的环境变量运行不同配置的java虚拟机。
除了使用Runtime的exec方法建立子进程外,还可以通过ProcessBuilder建立子进程。ProcessBuilder的使用方法如下:
// Test_Exec_Out.java
import java.io.*;
public class Test_Exec_Out
{
public static void main(String[] args)
{
ProcessBuilder pb = new ProcessBuilder("java", "test1");
Process p = pb.start();
… …
}
}
|
在建立子进程上,ProcessBuilder和Runtime类似,不同的ProcessBuilder使用start()方法启动子进程,而Runtime使用exec方法启动子进程。得到Process后,它们的操作就完全一样的。
ProcessBuilder和Runtime一样,也可设置可执行文件的环境信息、工作目录等。下面的例子描述了如何使用ProcessBuilder设置这些信息。
ProcessBuilder pb = new ProcessBuilder("Command", "arg2", "arg2", ''');
// 设置环境变量
Map<String, String> env = pb.environment();
env.put("key1", "value1");
env.remove("key2");
env.put("key2", env.get("key1") + "_test");
pb.directory("..\abcd"); // 设置工作目录
Process p = pb.start(); // 建立子进程
|
posted @
2008-11-17 19:56 xzc 阅读(681) |
评论 (3) |
编辑 收藏1.基本概念的理解
绝对路径:绝对路径就是你的主页上的文件或目录在硬盘上真正的路径,(URL和物理路径)例如:
C:xyz est.txt 代表了test.txt文件的绝对路径。http://www.sun.com/index.htm也代表了一个URL绝对路径。
相对路径:相对与某个基准目录的路径。包含Web的相对路径(HTML中的相对目录),例如:在
Servlet中,"/"代表Web应用的跟目录。和物理路径的相对表示。例如:"./" 代表当前目录,"../"代表上级目录。这种类似的表示,也是属于相对路径。
另外关于URI,URL,URN等内容,请参考RFC相关文档标准。
RFC 2396: Uniform Resource Identifiers (URI): Generic Syntax,
(http://www.ietf.org/rfc/rfc2396.txt)
2.关于JSP/Servlet中的相对路径和绝对路径。
2.1服务器端的地址
服务器端的相对地址指的是相对于你的web应用的地址,这个地址是在服务器端解析的(不同于html和javascript中的相对地址,他们是由客户端浏览器解析的)也就是说这时候在jsp和servlet中的相对地址应该是相对于你的web应用,即相对于http: //192.168.0.1/webapp/的。
其用到的地方有:
forward:servlet中的request.getRequestDispatcher(address);这个address是在服务器端解析的,所以,你要forward到a.jsp应该这么写:request.getRequestDispatcher(“/user/a.jsp”)这个/ 相对于当前的web应用webapp,其绝对地址就是:http://192.168.0.1/webapp/user/a.jsp。 sendRedirect:在jsp中<%response.sendRedirect("/rtccp/user/a.jsp");%>
2.22、客户端的地址
所有的html页面中的相对地址都是相对于服务器根目录(http://192.168.0.1/)的,而不是(跟目录下的该Web应用的目录) http://192.168.0.1/webapp/的。 Html中的form表单的action属性的地址应该是相对于服务器根目录(http://192.168.0.1/)的,所以,如果提交到a.jsp 为:action="/webapp/user/a.jsp"或action="<%=request.getContextPath()% >"/user/a.jsp;
提交到servlet为actiom="/webapp/handleservlet" Javascript也是在客户端解析的,所以其相对路径和form表单一样。
因此,一般情况下,在JSP/HTML页面等引用的CSS,Javascript.Action等属性前面最好都加上
<%=request.getContextPath()%>,以确保所引用的文件都属于Web应用中的目录。另外,应该尽量避免使用类似".","./","../../"等类似的相对该文件位置的相对路径,这样当文件移动时,很容易出问题。
3. JSP/Servlet中获得当前应用的相对路径和绝对路径
3.1 JSP中获得当前应用的相对路径和绝对路径
根目录所对应的绝对路径:request.getRequestURI()
文件的绝对路径 :application.getRealPath(request.getRequestURI());
当前web应用的绝对路径 :application.getRealPath("/");
取得请求文件的上层目录:new File(application.getRealPath(request.getRequestURI())).getParent()
3.2 Servlet中获得当前应用的相对路径和绝对路径
根目录所对应的绝对路径:request.getServletPath();
文件的绝对路径 :request.getSession().getServletContext().getRealPath
(request.getRequestURI())
当前web应用的绝对路径 :servletConfig.getServletContext().getRealPath("/");
(ServletContext对象获得几种方式:
javax.servlet.http.HttpSession.getServletContext()
javax.servlet.jsp.PageContext.getServletContext()
javax.servlet.ServletConfig.getServletContext()
)
4.java 的Class中获得相对路径,绝对路径的方法
4.1单独的Java类中获得绝对路径
根据java.io.File的Doc文挡,可知:
默认情况下new File("/")代表的目录为:System.getProperty("user.dir")。
一下程序获得执行类的当前路径
- package org.cheng.file;
-
- import java.io.File;
-
- public class FileTest {
- public static void main(String[] args) throws Exception {
- System.out.println(Thread.currentThread().getContextClassLoader().getResource(""));
-
- System.out.println(FileTest.class.getClassLoader().getResource(""));
-
- System.out.println(ClassLoader.getSystemResource(""));
- System.out.println(FileTest.class.getResource(""));
- System.out.println(FileTest.class.getResource("/"));
- Class
- System.out.println(new File("/").getAbsolutePath());
- System.out.println(System.getProperty("user.dir"));
- }
- }
4.2服务器中的Java类获得当前路径(来自网络)
(1).Weblogic
WebApplication的系统文件根目录是你的weblogic安装所在根目录。
例如:如果你的weblogic安装在c:�eaweblogic700.....
那么,你的文件根路径就是c:.
所以,有两种方式能够让你访问你的服务器端的文件:
a.使用绝对路径:
比如将你的参数文件放在c:yourconfigyourconf.properties,
直接使用 new FileInputStream("yourconfig/yourconf.properties");
b.使用相对路径:
相对路径的根目录就是你的webapplication的根路径,即WEB-INF的上一级目录,将你的参数文件放
在yourwebappyourconfigyourconf.properties,
这样使用:
new FileInputStream("./yourconfig/yourconf.properties");
这两种方式均可,自己选择。
(2).Tomcat
在类中输出System.getProperty("user.dir");显示的是%Tomcat_Home%/bin
(3).Resin
不是你的JSP放的相对路径,是JSP引擎执行这个JSP编译成SERVLET
的路径为根.比如用新建文件法测试File f = new File("a.htm");
这个a.htm在resin的安装目录下
(4).如何读相对路径哪?
在Java文件中getResource或getResourceAsStream均可
例:getClass().getResourceAsStream(filePath);//filePath可以是"/filename",这里的/代表web
发布根路径下WEB-INF/classes
默认使用该方法的路径是:WEB-INF/classes。已经在Tomcat中测试。
5.读取文件时的相对路径,避免硬编码和绝对路径的使用。(来自网络)
5.1 采用Spring的DI机制获得文件,避免硬编码。
参考下面的连接内容:
http://www.javajia.net/viewtopic.php?p=90213&
5.2 配置文件的读取
参考下面的连接内容:
http://dev.csdn.net/develop/article/39/39681.shtm
5.3 通过虚拟路径或相对路径读取一个xml文件,避免硬编码
参考下面的连接内容:
http://club.gamvan.com/club/clubPage.jsp?iPage=1&tID=10708&ccID=8
6.Java中文件的常用操作(复制,移动,删除,创建等)(来自网络)
常用 java File 操作类
http://www.easydone.cn/014/200604022353065155.htm
Java文件操作大全(JSP中)
http://www.pconline.com.cn/pcedu/empolder/gj/java/0502/559401.html
java文件操作详解(Java中文网)
http://www.51cto.com/html/2005/1108/10947.htm
JAVA 如何创建删除修改复制目录及文件
http://www.gamvan.com/developer/java/2005/2/264.html
总结:
通过上面内容的使用,可以解决在Web应用服务器端,移动文件,查找文件,复制
删除文件等操作,同时对服务器的相对地址,绝对地址概念更加清晰。
建议参考URI,的RFC标准文挡。同时对Java.io.File. Java.net.URI.等内容了解透彻
对其他方面的理解可以更加深入和透彻。
posted @
2008-11-11 11:54 xzc 阅读(640) |
评论 (0) |
编辑 收藏
<%@ page import="java.io.*" %>
<%
// 得到文件名字和路径
String filename = request.getParameter("filename");
String filepath = request.getSession().getServletContext().getgetRealPath("/download/excel/");
//String filepath = request.getRealPath("/download/excel/");
//读到流中
InputStream inputStream = new FileInputStream(filepath+"/"+filename);
//设置输出的格式
response.reset();
response.setContentType("bin");
response.addHeader("Content-Disposition","attachment;filename=\"" + filename + "\"");
//循环取出流中的数据
byte[] bytes = new byte[1000];
int len = inputStream.read(bytes);
while (len > 0){
response.getOutputStream().write(bytes,0,len);
len = inputStream.read(bytes);
}
inputStream.close();
%>
posted @
2008-11-03 17:58 xzc 阅读(384) |
评论 (0) |
编辑 收藏posted @
2008-10-31 11:33 xzc 阅读(428) |
评论 (0) |
编辑 收藏
最近不少Web技术圈内的朋友在讨论协议方面的事情,有的说web开发者应该熟悉web相关的协议,有的则说不用很了解。个人认为这要分层次来看待这个问题,对于一个新手或者刚入门的web开发人员而言,研究协议方面的东西可能会使得web开发失去趣味性、抹煞学习积极性,这类人应该更多的了解基本的Web技术使用。而对于在该行业工作多年的老鸟来说,协议相关的内容、标准相关内容应该尽量多些的了解,因为只有这样才能使得经手的web系统更加优秀(安全、漂亮、快速、兼容性好、体验好……)。本文我们来说一下MIME 协议的一个扩展Content-disposition。
我们在开发web系统时有时会有以下需求:
- 希望某类或者某已知MIME 类型的文件(比如:*.gif;*.txt;*.htm)能够在访问时弹出“文件下载”对话框
- 希望以原始文件名(上传时的文件名,例如:山东省政府1024号文件.doc)提供下载,但服务器上保存的地址却是其他文件名(如:12519810948091234_asdf.doc)
- 希望某文件直接在浏览器上显示而不是弹出文件下载对话框
- ……………………
要解决上述需求就可以使用Content-disposition来解决。第一个需求的解决办法是
Response.AddHeader "content-disposition","attachment; filename=fname.ext"
将上述需求进行归我给出如下例子代码:
public static void ToDownload(string serverfilpath,string filename)
{
FileStream fileStream = new FileStream(serverfilpath, FileMode.Open);
long fileSize = fileStream.Length;
HttpContext.Current.Response.ContentType = "application/octet-stream";
HttpContext.Current.Response.AddHeader("Content-Disposition", "attachment; filename=\"" + UTF_FileName(filename) + "\";");
////attachment --- 作为附件下载
////inline --- 在线打开
HttpContext.Current.Response.AddHeader("Content-Length", fileSize.ToString());
byte[] fileBuffer = new byte[fileSize];
fileStream.Read(fileBuffer, 0, (int)fileSize);
HttpContext.Current.Response.BinaryWrite(fileBuffer);
fileStream.Close();
HttpContext.Current.Response.End();
}
public static void ToOpen(string serverfilpath, string filename)
{
FileStream fileStream = new FileStream(serverfilpath, FileMode.Open);
long fileSize = fileStream.Length;
HttpContext.Current.Response.ContentType = "application/octet-stream";
HttpContext.Current.Response.AddHeader("Content-Disposition", "inline; filename=\"" + UTF_FileName(filename) + "\";");
HttpContext.Current.Response.AddHeader("Content-Length", fileSize.ToString());
byte[] fileBuffer = new byte[fileSize];
fileStream.Read(fileBuffer, 0, (int)fileSize);
HttpContext.Current.Response.BinaryWrite(fileBuffer);
fileStream.Close();
HttpContext.Current.Response.End();
}
private static string UTF_FileName(string filename)
{
return HttpUtility.UrlEncode(filename, System.Text.Encoding.UTF8);
}
简单的对上述代码做一下解析,ToDownload方法为将一个服务器上的文件(serverfilpath为服务器上的物理地址),以某文件名(filename)在浏览器上弹出“文件下载”对话框,而ToOpen是将服务器上的某文件以某文件名在浏览器中显示/打开的。注意其中我使用了UTF_FileName方法,该方法很简单,主要为了解决包含非英文/数字名称的问题,比如说文件名为“衣明志.doc”,使用该方法客户端就不会出现乱码了。
需要注意以下几个问题:
- Content-disposition是MIME协议的扩展,由于多方面的安全性考虑没有被标准化,所以可能某些浏览器不支持,比如说IE4.01
- 我们可以使用程序来使用它,也可以在web服务器(比如IIS)上使用它,只需要在http header上做相应的设置即可
可参看以下几篇文档:
posted @
2008-10-30 16:07 xzc 阅读(363) |
评论 (0) |
编辑 收藏posted @
2008-09-03 15:01 xzc 阅读(345) |
评论 (1) |
编辑 收藏
在程序中,文本文件经常用来存储标准的ASCII码文本,比如英文、加减乘除等号这些运算符号。文本文件也可能用于存储一些其他非ASCII字符,如基于GBK的简体中文,基于GIG5的繁体中文等等。在存储这些字符时需要正确指定文件的编码格式;而在读取这些文本文件时,有时候就需要自动判定文件的编码格式。
按照给定的字符集存储文本文件时,在文件的最开头的三个字节中就有可能存储着编码信息,所以,基本的原理就是只要读出文件前三个字节,判定这些字节的值,就可以得知其编码的格式。其实,如果项目运行的平台就是中文操作系统,如果这些文本文件在项目内产生,即开发人员可以控制文本的编码格式,只要判定两种常见的编码就可以了:GBK和UTF-8。由于中文Windows默认的编码是GBK,所以一般只要判定UTF-8编码格式。
对于UTF-8编码格式的文本文件,其前3个字节的值就是-17、-69、-65,所以,判定是否是UTF-8编码格式的代码片段如下:
- java.io.File f=new java.io.File("待判定的文本文件名");
- try{
- java.io.InputStream ios=new java.io.FileInputStream(f);
- byte[] b=new byte[3];
- ios.read(b);
- ios.close();
- if(b[0]==-17&&b[1]==-69&&b[2]==-65)
- System.out.println(f.getName()+"编码为UTF-8");
- else System.out.println(f.getName()+"可能是GBK");
- }catch(Exception e){
- e.printStackTrace();
- }
java.io.File f=new java.io.File("待判定的文本文件名");
try{
java.io.InputStream ios=new java.io.FileInputStream(f);
byte[] b=new byte[3];
ios.read(b);
ios.close();
if(b[0]==-17&&b[1]==-69&&b[2]==-65)
System.out.println(f.getName()+"编码为UTF-8");
else System.out.println(f.getName()+"可能是GBK");
}catch(Exception e){
e.printStackTrace();
}
上述代码只是简单判定了是否是UTF-8格式编码的文本文件,如果项目对要判定的
文本文件编码不可控(比如用户上传的一些HTML、XML等文本),可以采用一个现成的开源项目:cpdetector,它所在的网址是:
http://cpdetector.sourceforge.net/。它的类库很小,只有500K左右,利用该类库判定文本文件的代码如下:
-
-
-
-
-
-
-
- cpdetector.io.CodepageDetectorProxy detector =
- cpdetector.io.CodepageDetectorProxy.getInstance();
-
-
-
-
- detector.add(new cpdetector.io.ParsingDetector(false));
-
-
-
-
-
- detector.add(cpdetector.io.JChardetFacade.getInstance());
-
- detector.add(cpdetector.io.ASCIIDetector.getInstance());
-
- detector.add(cpdetector.io.UnicodeDetector.getInstance());
- java.nio.charset.Charset charset = null;
- File f=new File("待测的文本文件名");
- try {
- charset = detector.detectCodepage(f.toURL());
- } catch (Exception ex) {ex.printStackTrace();}
- if(charset!=null){
- System.out.println(f.getName()+"编码是:"+charset.name());
- }else
- System.out.println(f.getName()+"未知");
/*------------------------------------------------------------------------
detector是探测器,它把探测任务交给具体的探测实现类的实例完成。
cpDetector内置了一些常用的探测实现类,这些探测实现类的实例可以通过add方法
加进来,如ParsingDetector、 JChardetFacade、ASCIIDetector、UnicodeDetector。
detector按照“谁最先返回非空的探测结果,就以该结果为准”的原则返回探测到的
字符集编码。
--------------------------------------------------------------------------*/
cpdetector.io.CodepageDetectorProxy detector =
cpdetector.io.CodepageDetectorProxy.getInstance();
/*-------------------------------------------------------------------------
ParsingDetector可用于检查HTML、XML等文件或字符流的编码,构造方法中的参数用于
指示是否显示探测过程的详细信息,为false不显示。
---------------------------------------------------------------------------*/
detector.add(new cpdetector.io.ParsingDetector(false));
/*--------------------------------------------------------------------------
JChardetFacade封装了由Mozilla组织提供的JChardet,它可以完成大多数文件的编码
测定。所以,一般有了这个探测器就可满足大多数项目的要求,如果你还不放心,可以
再多加几个探测器,比如下面的ASCIIDetector、UnicodeDetector等。
---------------------------------------------------------------------------*/
detector.add(cpdetector.io.JChardetFacade.getInstance());
//ASCIIDetector用于ASCII编码测定
detector.add(cpdetector.io.ASCIIDetector.getInstance());
//UnicodeDetector用于Unicode家族编码的测定
detector.add(cpdetector.io.UnicodeDetector.getInstance());
java.nio.charset.Charset charset = null;
File f=new File("待测的文本文件名");
try {
charset = detector.detectCodepage(f.toURL());
} catch (Exception ex) {ex.printStackTrace();}
if(charset!=null){
System.out.println(f.getName()+"编码是:"+charset.name());
}else
System.out.println(f.getName()+"未知");
上面代码中的detector不仅可以用于探测文件的编码,也可以探测任意输入的文本流的编码,方法是调用其重载形式:
- charset=detector.detectCodepage(待测的文本输入流,测量该流所需的读入字节数);
charset=detector.detectCodepage(待测的文本输入流,测量该流所需的读入字节数);
上面的字节数由程序员指定,字节数越多,判定越准确,当然时间也花得越长。要注意,字节数的指定不能超过文本流的最大长度。
判定文件编码的具体应用举例:
属性文件(.properties)是Java程序中的常用文本存储方式,象STRUTS框架就是利用属性文件存储程序中的字符串资源。它的内容如下所示:
#注释语句
属性名=属性值
读入属性文件的一般方法是:
- FileInputStream ios=new FileInputStream("属性文件名");
- Properties prop=new Properties();
- prop.load(ios);
- ios.close();
FileInputStream ios=new FileInputStream("属性文件名");
Properties prop=new Properties();
prop.load(ios);
ios.close();
利用java.io.Properties的load方法读入属性文件虽然方便,但如果属性文件中有中文,在读入之后就会发现出现乱码现象。发生这个原因是load方法使用字节流读入文本,在读入后需要将字节流编码成为字符串,而它使用的编码是“iso-8859-1”,这个字符集是ASCII码字符集,不支持中文编码,所以这时需要使用显式的转码:
- String value=prop.getProperty("属性名");
- String encValue=new String(value.getBytes("iso-8859-1"),"属性文件的实际编码");
String value=prop.getProperty("属性名");
String encValue=new String(value.getBytes("iso-8859-1"),"属性文件的实际编码");
在上面的代码中,属性文件的实际编码就可以利用上面的方法获得。当然,象这种属性文件是项目内部的,我们可以控制属性文件的编码格式,比如约定采用Windows内定的GBK,就直接利用"gbk"来转码,如果约定采用UTF-8,也可以是使用"UTF-8"直接转码。如果想灵活一些,做到自动探测编码,就可利用上面介绍的方法测定属性文件的编码,从而方便开发人员的工作。
posted @
2008-06-16 14:44 xzc 阅读(832) |
评论 (1) |
编辑 收藏第一章 目录及文件操作命令
1.1 ls
[语法]: ls [-RadCxmlnogrtucpFbqisf1] [目录或文件......]
[说明]: ls 命令列出指定目录下的文件,缺省目录为当前目录 ./,缺省输出顺序为纵向按字符顺序排列。
-R 递归地列出每个子目录的内容
-a 列出所有文件,包括第一个字符为“.”的隐藏文件
-d 若后面参数是目录,则只列出目录名而不列出目录内容,常与-l选项连
用以显示目录状态。
-C 输出时多列显示
-x 横向按字符顺序排列
-m 输出按流式格式横向排列,文件名之间用逗号(,)分隔
-l 长列表输出,显示文件详细信息,每行一个文件,从左至右依次是:
文件存取模式 链接数 文件主 文件组 文件字节数 上次修改时间
其中文件存取模式用10个字母表示,从左至右的意义如下:
第一个字母表示文件种类,可以是以下几种情况:
d 为目录文件
l 为链接
b 为块文件
c 为字符型文件
p 为命名管道(FIFO)
- 为普通文件
后面9个字母分别表示文件主、同组用户、其他用户对文件的权力,用r表示可读,w 表示可写,x 表示可执行。如果是设备文件,则在文件字节数处显示:主设备 从设备。
-n 与-l选项相同,只是文件主用数字(即UID)显示,文件组用数字
(即GID)表示
-o 与-l选项相同,只是不显示文件组
-g 与-l选项相同,只是不显示文件主
-r 逆序排列
-t 按时间顺序排列而非按名字
-u 显示时间时使用上次访问时间而非上次修改时间
-c 显示时间时使用上次修改i节点时间而非上次修改时间
-p 若所列文件是目录文件,则在其后显示斜杠(/)
-F 在目录文件后加’/’,在可执行文件后加’*’
-b 文件名中若有非打印字符,则用八进制显示该字符
-q 文件名中的打印字符用’?’表示
-i 显示节点号
-s 显示文件长度时使用块长度而非字节长度
-f 将后面的参数解释为目录并列出其中的每一项
-1 每行仅列一项
[例子]:
ls 列出当前目录下的文件
ls -al /bin 以长列表的形式列出目录 /bin 下的所有文件,包括隐藏文件
1.2 pwd
[语法]: pwd
[说明]: 本命令用于显示当前的工作目录
[例子]:
pwd 显示出当前的工作目录
1.3 cd
[语法]: cd [目录]
[说明]:本命令用于改变当前的工作目录,无参数时使用环境变量$HOME 作为其参数,$HOME 一般为注册时进入的路径。
[例子]:
cd 回到注册进入时的目录
cd /tmp 进入 /tmp 目录
cd ../ 进入上级目录
1.4 mkdir
[语法]: mkdir [-m 模式] [-p] 目录名
[说明]: 本命令用于建立目录,目录的存取模式由掩码(umask)决定,要求对其父目录具有写权限,目录的UID和GID为实际UID和GID
-m 按指定存取模式建立目录
-p 建立目录时建立其所有不存在的父目录
[例子]:
mkdir tmp 在当前目录下建立子目录 tmp
mkdir -m 777 /tmp/abc 用所有用户可读可写可执行的存取模式
建立目录 /tmp/aaa ,存取模式参看命令 chmod
mkdir -p /tmp/a/b/c 建立目录 /tmp/a/b/c ,若不存在目录 /tmp/a
及/tmp/a/b 则建立之
1.5 rmdir
[语法]: rmdir [-p] [-s] 目录名
[说明]: 本命令用于删除目录
-p 删除所有已经为空的父目录
-s 当使用-p 选项时,出现错误不提示
[例子]:
rmdir /tmp/abc 删除目录 /tmp/abc
rmdir -p /tmp/a/b/c 删除目录 /tmp/a/b/c ,若目录 /tmp/a /b
及/tmp/a 空,则删除
1.6 cat
[语法]: cat [-u] [-s] [-v[-t] [-e]] 文件...
[说明]: 显示和连接一个或多个文件至标准输出
-u 无缓冲的输出(缺省为有缓冲输出)
-s 对不存在的文件不作提示
-v 显示出文件中的非打印字符,控制字符显示成^n ,n为八进制数字,
其他非打印字符显示成M-x , x 为该字符低7位的8进制数值
-t 在使用-v 选项时,将制表符(tab) 显示成 ^I,将换页符
(formfeed)显示成 ^ L
-e 在使用-v 选项时,在每一行的行尾显示 $
[例子]:
cat file 显示文件
cat -s -v -e file1 file2 file3 逐个显示文件 file1 file2 file3
1.7 head
[语法]: head [-n] [文件 ...]
[说明]: 将文件的头n 行显示输出,缺省值为 10 行,显示多个文件时,在每个文件的前面加上 ==> 文件名 <==
[例子]:
head -9999 file1 file2 显示文件 file1 和 file2 的头 9999 行
1.8 more
[语法]: more [-cdflrsuw] [- 行数] [+ 行数] [+ / 模式 ] [ 文件 ... ]
[说明]: 将文件显示在终端上,每次一屏,在左下部显示 --more--,若是从文件读出而非从管道,则在后面显示百分比,表示已显示的部分,按回车键则上滚一行,按空格键则上滚一屏,未显示完时可以使用more 命令中的子命令。
-c 显示文件之前先清屏
-d 当输错命令时显示错误信息而不是响铃(bell)
-f 不折叠显示长的行
-l 不将分页控制符(CTRL D)当作页结束
-r 一般情况下,more 不显示控制符,本选项使more 显示控制符,
例如,将 (CTRL C) 显示成 ^ C
-s 将多个空行转换成一个空行显示
-u 禁止产生下划线序列
-w 一般情况下 more 显示完后立即推出,本选项在显示完后作提
示,敲任意键后推出
-n 行数 指定每屏显示的行数
+ 行号 从指定行号开始显示
+/模式 在文件中搜索指定模式,从模式出现行的上两行开始显示 文件未显示完时,可以使用more 命令中的子命令,命令中除了! 和 / 以外均不回显,也不用敲回车,当命令破坏 more 提示行时,可用退格键恢复提示行。在以下子命令操作中,i 表示数字,缺省值为 1。
i 空格 上滚一屏多 i 行
i 回车 上滚 i 行
i CTRL+D i 缺省时上滚 11 行,否则上滚 i 行
id i 缺省时上滚 11 行,否则上滚 i 行
iz i 缺省时上滚一屏,否则定义每屏为 i 行
is 跳过 i 行后显示一屏
if 跳过 i 屏后显示一屏
i CTRL+B 跳回 i 屏后显示一屏
b 跳回 一屏后显示一屏
q 或 Q 推出 more
= 显示当前行号
v 从当前行开始编辑当前文件编辑器由环境变量
$EDITOR定义
h 显示帮助信息
i / 模式 向前搜索,直至模式的第 i 次出现 , 从该行的上 两行开始显示一屏
in 向前搜索,直至上一模式的第 i 次出现 , 从该行 的上两行开始显示一屏
单引号 回到上次搜索的出发点,若无搜索则回到开始位置
! 命令 激活一个sh 去执行指定的命令
i : n 跳到后面第 i 个文件,若不存在则跳到最后一个文件
:f 显示当前文件名和行号
:q 或 :Q 推出 more
. (点) 重复上次命令
[ 例子]:
more -c +50 file 清屏后,从第50行开始显示文件 file
more -s -w file1 file2 file3 显示文件 file1 file2 file3
1.9 cp
[语法]: cp [ -p ] [ -r ] 文件 1 [ 文件 2 ...] 目标
[说明]: 将文件1(文件2 ...)拷贝到目标上,目标不能与文件同名, 若目标是文件名,则拷贝的文件只能有一个,若目标是目录, 则拷贝的文件可以有多个,若目标文件不存在,则建立这个文件,若存在,则覆盖其以前的内容,若目标是目录,则将文件拷贝到这个目录下。
- i 在覆盖已存在文件时作提示,若回答 y 则覆盖,其他则中止
- p 不仅拷贝文件内容,还有修改时间,存取模式,存取控制表, 但不拷贝
UID 及 GID
- r 若文件名为目录,则拷贝目录下所有文件及子目录和它们的文件,此时
目标必须为目录
[例子]:
cp file1 file2 将文件 file1 拷贝到文件 file2
cp file1 file2 /tmp 将文件 file1 和文件 file2 拷贝到目录 /tmp 下
cp -r /tmp /mytmp 将目录 /tmp 下所有文件及其子目录拷贝至目录/mytmp
1.10 mv
[语法]: mv [-f] [-i] 文件1 [文件2...] 目标
[说明]: 将文件移动至目标,若目标是文件名,则相当于文件改名
- i 在覆盖已存在文件时作提示,若回答 y 则覆盖,其他则中止
- f 覆盖前不作任何提示
[例子]:
mv file1 file2 将文件 file1 改名为 file2
mv file1 file2 /tmp 将文件 file1 和文件 file2 移动到目录 /tmp 下
1.11 rm
[语法]: rm [-f] [-i] 文件...
或 rm -r [-f] [-i] 目录名... [文件]
[说明]: 用来删除文件或目录
- f 删除文件时不作提示
- r 递归地删除目录及其所有子目录
- i 删除文件之前先作提示
[例子]:
rm file1 删除文件 file1
rm -i /tmp/* 删除目录 /tmp 下的所有文件
rm -r /mytmp 递归地删除目录 /mytmp
1.12 chmod
[语法]: chmod [-R] 模式 文件...
或 chmod [ugoa] {+|-|=} [rwxst] 文件...
[说明]: 改变文件的存取模式,存取模式可表示为数字或符号串,例如:
chmod nnnn file , n为0-7的数字,意义如下:
4000 运行时可改变UID
2000 运行时可改变GID
1000 置粘着位
0400 文件主可读
0200 文件主可写
0100 文件主可执行
0040 同组用户可读
0020 同组用户可写
0010 同组用户可执行
0004 其他用户可读
0002 其他用户可写
0001 其他用户可执行
nnnn 就是上列数字相加得到的,例如 chmod 0777 file 是指将文件 file 存取权限置为所有用户可读可写可执行。
-R 递归地改变所有子目录下所有文件的存取模式
u 文件主
g 同组用户
o 其他用户
a 所有用户
+ 增加后列权限
- 取消后列权限
= 置成后列权限
r 可读
w 可写
x 可执行
s 运行时可置UID
t 运行时可置GID
[例子]:
chmod 0666 file1 file2 将文件 file1 及 file2 置为所有用户可读可写
chmod u+x file 对文件 file 增加文件主可执行权限
chmod o-rwx 对文件file 取消其他用户的所有权限
1.13 chown
[语法]: chown [-R] 文件主 文件...
[说明]: 文件的UID表示文件的文件主,文件主可用数字表示, 也可用一个有效的用户名表示,此命令改变一个文件的UID,仅当此文件的文件主或超级用户可使用。
-R 递归地改变所有子目录下所有文件的存取模式
[例子]:
chown mary file 将文件 file 的文件主改为 mary
chown 150 file 将文件 file 的UID改为150
1.14 chgrp
[语法]: chgrp [-R] 文件组 文件...
[说明]: 文件的GID表示文件的文件组,文件组可用数字表示, 也可用一个有效的组名表示,此命令改变一个文件的GID,可参看chown。
-R 递归地改变所有子目录下所有文件的存取模式
[例子]:
chgrp group file 将文件 file 的文件组改为 group
1.15 cmp
[语法]: cmp [-l] [-s] 文件1 文件2
[说明]: 比较两个文件,若文件1 为 - ,则使用标准输入, 两个文件相同则无提示,不同则显示出现第一个不同时的字符数和行号。
-l 显示每个不同处的字节数(10进制)和不同的字节(8进制)
-s 不作任何提示,只返回码
[例子]:
cmp file1 file2 比较文件 file1 和 file2
cmp -l file1 file2 比较文件file1 和 file2 的每处不同
1.16 diff
[语法]: diff [-be] 文件1 文件2
[说明]: 本命令比较两个文本文件,将不同的行列出来
-b 将一串空格或TAB转换成一个空格或TAB
-e 生成一个编辑角本,作为ex或ed的输入可将文件1转换成文件2
[例子]:
diff file1 file2
diff -b file1 file2
diff -e file1 file2 >edscript
1.17 wc
[语法]: wc [-lwc] 文件...
[说明]: 统计文件的行、字、字符数,若无指定文件,则统计标准输入
-l 只统计行数
-w 只统计字数
-c 只统计字符数
[例子]:
wc -l file1 file2 统计文件file1和file2 的行数
1.18 split
[语法]: split [-n] [ 文件 [名字]]
[说明]: split 将指定大文件分解为若干个小文件,每个文件长度为n行(n 缺省时为1000),第一个小文件名为指定的名字后跟aa,直至zz,名字缺省值为x,若未指定大文件名,则使用标准输入
[例子]:
split -500 largefile little
将文件largefile 每500行写入一个文件,第一个文件名为littleaa
1.19 touch
[语法]: touch [-amc] [mmddhhmm[yy]] 文件...
[说明]: 将指定文件的访问时间和修改时间改变,若指定文件不存在则创建之,若无指定时间,则使用当前时间,返回值是未成功改变时间的文件个数,包括不存在而又未能创建的文件。
-a 只改变访问时间
-m 只改变修改时间
-c 若文件不存在,不创建它且不作提示
mmddhhmm[yy] 两位表示 月日时分[年]
[例子]:
touch file
更新文件file的时间
touch 0701000097 HongKong
将文件HongKong的时间改为97年7月1日0时0分
1.20 file
[语法]: file [-f 文件名文件] 文件...
[说明]: file 对指定文件进行测试,尽量猜测出文件类型并显示出来
-f 文件名文件 文件名文件是一个包含了文件名的文本文件, -f 选项测试
文件名文件中所列出的文件
[例子]:
file * 显示当前目录下所有文件的类型
1.21 pack
[语法]: pack 文件...
[说明]: pack 将指定文件转储为压缩格式,文件名后加 .z , 文件存取模式,访问时间,修改时间等均不变
[例子]:
pack largefile 将largefile 压缩后转储为largefile.z
1.22 pcat 显示压缩文件
[语法]: pcat 文件...
[说明]: pcat 显示输出压缩文件
[例子]:
pcat largefile.z 显示压缩前的largefile
pcat largefile.z > oldfile 显示压缩前的laregfile,并将其重定向到
文件oldfile中
1.23 unpack
[语法]: unpack 文件...
[说明]: 将压缩后的文件解压后转储为压缩前的格式
[例子]:
unpack largefile.z 将压缩文件largefile.z解压后转储为largefile
1.24 find
[语法]: find 路径名... 表达式
[说明]: find 命令递归地遍历指定路径下的每个文件和子目录,看该文件是否能使表达式值为真,以下 n 代表一个十进制整数,+n 代表打印 n , -n 代表小于 n ,下面是合法表达式说明:
-name 模式 文件名与模式匹配则为真,(\ 为转意符)
-perm [-]八进制数 文件存取模式与八进制数相同则为真若有- 选项,则文件存
取模式含有八进制数规定模式即为真
-size n[c] 文件块长度为 n 则真(一块为512字节),若
有c 选项,则文件字节长度为 n 则真
-atime n 若文件的最近访问时间为 n 天前则为真,
find 命令将改变其访问的目录的访问时间
-mtime n 若文件的最近修改时间为 n 天前则为真
-ctime n 若文件状态为 n 天前改变则为真
-exec 命令 { }\; 若命令返回值为0则真,{ }内为命令参数,
此命令必须以 \; 为结束
-ok 命令 { }\; 与 exec 相同,只是在命令执行前先提示,若
回答 y 则执行命令
-print 显示输出使表达式为真的文件名
-newer 文件 若文件的访问时间比newer 指定的文件新则真
-depth 先下降到搜索目录的子目录,然后才至其自身
-mount 仅查找包含指定目录的文件系统
-local 文件在当前文件系统时为真
-type c 文件类型为 c 则真,c 取值可为 b(块文件) c (字符文件)
d(目录) l (符号链接) p (命名管道) f (普通文件)
\( 表达式 \) 表达式为真则真
-links n 文件链接数为 n 时为真
-user 用户 当文件属于用户时为真,用户可用数字表示UID
-nouser 当文件不属于 /etc/passwd 中的一个用户时为真
-group 文件组 当文件属于文件组时为真,文件组可用数字表示GID
-nogroup 当文件不属于 /etc/group 中的一个组时为真
-fstype 类型 当文件所属文件系统类型为指定类型时真
-inum n 当文件 i 节点号为 n 时为真
-prune 当目录名与模式匹配时,不再搜索其子目录
可以用逻辑操作符将简单表达式连接成复杂表达式
逻辑操作符有 ! 表示非操作, -o 表示或操作,两个表达式并列则表示
与操作
[例子]:
find / -name find* -print
从根目录开始搜索文件名如 find* 的文件并显示之
find ./ -exec sleep{1}\; -print
每秒显示一个当前目录下的文件
find $HOME \(-name a.out -o -name '*.o' \) -atime +7 -exec rm {} \;
从$HOME目录开始搜索,删除所有文件名为a.out 或 *.o 且访问时间在7天前的文件
1.25 grep
[语法]: grep [选项] 模式 [文件...]
[说明]: 在指定的文件中搜索模式,并显示所有包含模式的行,模式是一个正规表达式,在使用正规表达式时,最好将其引在单引号(') 中,若指定文件为缺省,则使用标准输入,正规表达式可以是:
. 匹配任意一个字符
* 匹配0个或多个*前的字符
^ 匹配行开头
$ 匹配行结尾
[] 匹配[ ]中的任意一个字符,[]中可用 - 表示范围,
例如[a-z]表示字母a 至z 中的任意一个
\ 转意字符
命令中的选项为:
-b 显示块号
-c 仅显示各指定文件中包含模式的总行数
-i 模式中字母不区分大小写
-h 不将包含模式的文件名显示在该行上
-l 仅显示包含模式的文件名
-n 显示模式所在行的行号
-s 指定文件若不存在或不可读,不提示错误信息
-v 显示所有不包含模式的行
[例子]:
grep 'good' * 在所有文件中搜索含有字符串 good 的行
grep '^myline' mytext 在文件mytext中搜索行首出现myline字符串的行
1.26 vi
[语法]:vi [-wn] [-R] 文件...
[说明]: vi 是一个基于行编辑器 ex 上的全屏幕编辑器,可以在vi 中使用 ex,ed的全部命令,vi选项中 -wn 指将编辑窗口大小置为n行,-R 为将编辑的文件置为只读模式, vi 工作模式分为命令模式和输入模式,一般情况下在命令模式下,可敲入vi命令,进入输入模式下时可以编辑要编辑的文本,命令 a A i I o O c C s S R 可进入输入模式,在输入模式下按 ESC 键可推出输入模式,回到命令模式,在命令模式中敲入: 命令,则可进入ex方式,在屏幕底部出现提示符 : ,此时可使用任意ex命令,屏幕底行也用来作/ ? ! 命令的提示行,大多数命令可以在其前面加数字,表示命令执行的重复次数,下面简单介绍一下vi 的命令集,^ 表示(CTRL)键
^B 退回前一页,前面加数字表示重复次数,每次换页时
保留上一页的两行
^D 在命令模式下,表示下滚屏幕的一半,在输入模式下,表示回退至
左边的自动缩进处
^E 显示屏幕底线之下的一行
^F 前进一页,前面加数字表示重复次数,每次换页时
保留上一页的两行
^G 显示当前文件名,当前行号和文件总行数,并用百分号当前行在
整个文件中的位置
^H(退格) 在命令模式下,光标左移一格;在输入模式下,删去前面的字符
^I(TAB) 在输入模式下,产生一串空格
^J(LF) 光标下移一行
^L 刷新屏幕,即将屏幕重新显示
^M(回车) 在命令模式下,光标移动至下行开头
在输入模式下,开辟一新行
^N 光标下移一行
^P 光标上移一行
^Q 在输入模式下,将其后的非打印字符作为正文插入
^R 刷新屏幕
^U 屏幕上滚一半,前面加数字时表示上滚的行数,此数字对
以后的^D ^U 命令有效
^V 在输入模式下,将其后的非打印字符作为正文插入
^W 在输入模式下,使光标回退一个字
^Y 显示屏幕底线之上的一行
^Z 暂停编辑,退回上层Shell
^[(ESC) 退出输入模式,回到命令模式
! 暂时退出编辑,执行Shell命令
(双引号) 用于标志有名缓冲区,编号缓冲区1-9用于保存被删去的正文,字
母名缓冲区a-z供用户存放自定义的正文
$ 将光标移动到当前行尾,前加数字则表示前移行数,如2$表示移动
到下一行行尾
% 将光标移动到配对的小括号()或大括号{}上去
( 退回句子开头
) 前移到句子开头
- 退到上一行第一个非空格字符
. 重复上一次改变缓冲区内容的命令
/ 模式 向前搜索模式,将光标移动到模式出现处,模式是一个正规
表达式,(参看 grep)
: 在屏幕底部提示:,其后可使用ex命令
? 功能同 / ,但方向是向前查找
[[ 光标回退至前一节分界处
\ 转意符
]] 光标前移至节分界处
^(不是CTRL) 光标移至当前行第一个非空字符上
' 连续两个''表示将光标移至其移动前的位置,'后跟字母表示光标字
母标记的行首(参看 m 命令)
A 在行尾插入正文,进入输入模式
B 光标回退一个字
C 替换光标后的内容
D 删除光标后的内容
E 光标前移到字尾
F 字符 在当前行向左查找指定字符
G 光标移动到其前面数字指定的行,若未指定则移动到最后一行
H 光标移动到屏幕顶行,若前面有数字,则移动到屏幕上该数字
指定的行
I 在行开头插入正文
J 连接两行,若前面有数字则连接数字指定的行
L 光标移动到屏幕底行,若前面有数字,则移动到屏幕底线往上数该
数字指定的行
M 光标移动到屏幕中线
N 使用模式查找/或?时,重复找下一个匹配的模式,但方向与上次相
反,其功能同 n ,但方向相反
O 在当前行上开辟一新行
P 将上次被删除的正文插入光标前面,可在其前面加缓冲区编号,编
号1-9用于保存被删去的正文,字母名缓冲区a-z供用户存放自定
义的正文
Q 从vi 推出进入ex命令状态
R 替换字符串
S 替换整行
T 字符 向左查找字符
U 将当前行恢复至第一次修改前的状态
W 光标移至下一个字首
X 删除光标前的字符
Y 将当前行存入无名缓冲区,前面加数字表示存入的行数,也可用有
名缓冲区来保存,以后可用命令p或P将其取出
ZZ 存盘退出vi
a 光标后插入正文
b 光标回退至上一个字首
cw 替换当前字
c) 替换当前句子
dw 删除一个字
dd 删除一行
e 光标移到下一个字末
f 字符 在当前行向前查找字符
h 光标左移一格
i 在光标前插入正文
j 光标下移一行
k 光标上移一行
l 光标右移一格
m 字母 用字母标记当前行,以后可用 '字母使光标移动到当前行,
(参看'命令)
n 重复上次 / 或 ? 命令
o 在当前行下开辟一新行
p 将用户缓冲区内容放到光标位置(参看P命令)
r 替换当前字符
s 用一串字符替换当前字符
t 字符 光标移动至字符前
u 取消上次操作
w 光标移至下一字首
x 删除当前字符
yw 将当前字存入无名缓冲区,前面可加x,表示存入名字为x的有名
缓冲区(x为a-z),也可加数字表示存入的字数,以后可用P或p命
令取出
yy 将当前行存入无名缓冲区,用法参看yw
{ 光标移动至前一段开头
| 光标移至行首,若前面加数字,则移到数字指定行的行首
} 光标移至下一段开头
在:提示符下,常用命令如下:
:w 当前文件存盘
:w! 强制存盘
:w 文件 将内容写入指定文件
:w! 文件 强制写入指定文件
:x,y w 文件 将 x至 y 行写入指定文件中
:r 文件 将文件读到光标位置
:r ! 命令 将系统命令的输出读到光标位置
:q 退出编辑
:q! 强制退出
:x 与命令ZZ相同
:e 文件名 编辑另一文件
:e ! 重新编辑文件,放弃任何改变
:sh 执行sh,结束后回到编辑
:! 命令 执行命令后回到编辑
:n 编辑下一文件
:n 文件表 重新定义待编辑文件表
:set 设置 vi 的选项,例如 set nu 表示每行前显示行号,在选项前
加no则表示清除该选项,例如 set nonu 表示每行前不显示行
号,下面是一些常用的选项:
ai 自动缩进
aw 编辑下一文件前自动存盘
ic 查找字符串时不区分大小写
nu 每行前显示行号
sm 输入)及}时显示与之配对的( 或 {
slow 插入时延迟屏幕刷新
ws 使查找能绕过文件尾从头进行
wa 写文件之前不作对文件的检查
第二章 设备管理
2.1 stty
[语法]: stty [-a] [-g] [选项]
[说明]: 本命令设置终端,无参数时报告终端设置,本命令功能十分强大,应谨慎使用,下面仅介绍部分常用功能
-a 显示当前终端所有设置
-g 以能作为 stty 命令参数的方式显示终端设置
以下是终端常用设置,在设置前加-表示清除设置:
1.控制方式
ispeed 0 110 300 600 1200 1800 2400 4800 9600 19200 38400
本命令设置终端输入波特率,若为0则使用缺省波特率。
例如 stty ispeed 9600
ospeed 0 110 300 600 1200 1800 2400 4800 9600 19200 38400
本命令设置终端输出波特率,参看 ispeed。
2.输入方式
ingbrk(-ignbrk) 忽略(不忽略)中断(BREAK)
brkint(-brkint) 设置(清除)信号INTR为中断信号
inlcr(-inlcr) 将换行转换(不转换)成回车
icrnl( -icrnl) 将回车转换(不转换)成换行
igncr(-ignrc) 忽略(不忽略)回车
iuclc( -iuclc) 将大写字母转换(不转换)成小写字母
3.输出方式
olcut(-olcut) 将小写字母转换(不转换)为大写字母
onlcr(-onlcr) 输出时将换行符转换(不转换)为回车换行
ocrnl(-ocrnl) 输出时将回车符转换(不转换)为换行符
4.本地方式
echo (-echo) 设置(清除)回显
stwrap(-stwrap) 截断(不截断)大于79个字符的行
echoctl(-echoctr) 将控制键回显为^
2.2 tty
[语法]: tty
[说明]: 显示出终端的设备名
[例子]:
tty
2.3 lp
[语法]: lp 文件...
[说明]: 将文件送打印机打印
[例子]:
lp myfile 将文件myfile 送打印机输出
2.4 lpstat
[语法]: lpstat [选项] [打印任务号]
[说明]: 显示打印机状态,选项的意义如下:
-a [打印机表] 显示打印机表中指定的打印机可否接收打印请求
-c [打印机类名] 显示打印机种类及在该打印机种类下的成员
-d 显示系统预设的打印机
-p [打印机表] 显示打印机表中打印机状态
-r 显示lp 请求程序表( lp request scheduler)
-s 打印系统统计表
-t 打印所有状态信息
-u [用户] 显示由用户发出的打印请求
-v [打印机名表] 显示每个打印机名称,是对应于该打印机设备文件的路径名
[例子]:
lpstat -t 打印所有状态信息
2.5 cancel
[语法]: cancel 打印任务号
cancel 打印机名
cancel -u 用户名 [打印机]
[说明]: 本命令可按打印机名,打印任务,用户来取消打印任务
[例子]:
cancel -u mary 取消用户 mary 的所有打印请求
2.6 enable
[语法]: enable 打印机表
[说明]: 本命令可激活一个或多个打印机
2.7 disable
[语法]: disable [-cw] 打印机表
[说明]: 使一个或多个打印机不能打印
-c 立即取消正在打印的打印请求
-w 等正在打印的内容打完后,才禁止打印机
2.8 sync
[语法]: sync
[说明]: 将磁盘缓冲区内容写回磁盘
2.9 mount
[语法]: mount [-r] 设备 目录
[说明]: 将设备安装到目录下
-r 以只读方式安装
2.10 umount
[语法]: umount 设备
[说明]: 将已安装的文件系统卸下
2.11 tar
[语法]: tar -c[vwfbL] [设备] [块] 文件...
tar -r[vwfbL] [设备] [块] 文件...
tar -t[vfL] [设备] [文件...]
tar -u[vwfbL] [设备] [块] 文件...
tar -x[lmovwfL] [设备] [文件...]
[说明]: 将多个文件归档,命令中各参数的意义为:
r 附加方式归档
x 抽取文件
t 显示文件
u 附加方式归档,同时删除旧版文件
c 建立新档案文件
v 显示所处理的文件名
w 处理文件前,要求用户确认
f 文件名 使用指定文件名作为档案文件
bn 每次读写 n 块,缺省值为1,最大值为20
m 将新的文件修改时间设为获取时的时间
o 获取出来的文件以下达tar指令的UID和GID存储
[例子]:
tar cvf file.tar *
tar tvf file.tar
2.12 df
[语法]: df [-t] [文件系统]
[说明]: 显示剩余 i 节点和块数,使用 -t 选项,还显示总块数和 i 节点数
[例子]: df -t
2.13 du
[语法]: du [-ars] [目录]
[说明]: 显示磁盘空间专用情况
-r 提供无法打开的文件信息
-s 仅显示指定目录所占空间的总和
-a 显示文件大小及目录总空间,其后可根文件名作参数
第三章 进程管理
3.1 sleep
[语法]: sleep 时间
[说明]: 挂起参数指定的秒数
3.2 ps
[语法]: ps [ -efl] [ -t 终端表] [ -u 用户表] [ -g 组表]
[说明]: 显示出有关进程的状态
-e 显示出现在正在运行的所有进程
-f 显示所有信息
-l 产生一个长列表
-t 显示指定终端进程
-u 显示指定用户进程
-g 显示指定组进程
3.3 at
[语法]: at [-f 命令文件] [-m] [-q 队列] -t 时间
[说明]: at命令由cron管理,在未来一个指定的时间内执行一组命令,命令可以从指定文件读入,也可从键盘读入,从键盘读入时以EOF结束,(通常为CTRL D)
-f 从指定命令文件中读入命令
-m 命令执行完后给用户发邮件
-q 将命令放入指定队列
-t 指定时间 指定的时间格式为 [[CC]YY]MMDDhhmm[.ss],CC表示
年的前两位,YY表示年的后两位,MM表示月,DD表示日,hh表
示时,mm表示分,ss表示秒
3.4 kill
[语法]: kill -信号 进程号
[说明]: kill 将信号传递给指定进程,信号意义如下:
1 暂停(hangup)
2 中断(interrupt)
3 退出(quit)
4 非法指令(illeqgal instruction)
5 跟踪中断(trace trap)
6 Abort
7 EMT 指令(Emulation trap)
8 浮点格式异常(floating point exception)
9 kill(不可忽略)
10 通道错误(bus error)
11 不合法内存段
12 错误的系统调用参数
13 写入不可读的连通管道
14 alarm clock
15 软件结束信号
16 用户定义信号一
17 用户定义信号二
[例子]:
kill -9 444 杀死进程号为 444 的进程
第四章 系统管理和用户管理
4.1 who
[语法]: who
who am i
[说明]: 列出现在系统中的用户,who am i 显示自己
4.2 whodo
[语法]: whodo [-h] [-l] [用户]
[说明]: 显示系统中用户及进程,若指定用户,则只列出该用户的信息
-h 不显示头部信息
-l 长列表格式输出
4.3 passwd
[语法]: passwd [用户]
[说明]: 修改密码,指定用户则修改指定用户密码
4.4 logname
[语法]: logname
[说明]: 取得当前用户注册名
4.5 su
[语法]: su [- ] [用户名]
[说明]: su 命令使当前用户成为指定用户,若无指定,则成为超级用户,但必须输入该用户的密码,-选项表示用该用户的注册环境成为该用户
4.6 time
[语法]: time 命令
[说明]: 执行命令,并在执行完后显示其运行的时间
4.7 date
[语法]: date
date mmddhhmm[yy]
[说明]: date 无参数时用于显示系统时间,修改时间时参数形式为
月日时分[年]
4.8 shutdown
[语法]: shutdown [-y] [-gn] [-in]
[说明]: UNIX 系统必须先关闭系统,再关电源
-y 对提示的所有问题都回答 y
-gn 给其他用户n 秒的时间退出,缺省值为60秒
-in 系统退到第n种方式,方式如下:
0 关机
1 单用户模式
2 多用户模式
3 网络下的多用户模式
6 关机并重新启动
4.9 fsck
[语法]: fsck [-y]
[说明]: 本命令用于检查和修复文件系统,当文件系统出现混乱时,可使用本命令,-y选项表示对所有提问都回答YES
第五章 通信和邮件
5.1 wall
[语法]: wall
[说明]: 向所有用户广播通知信息,常用于警告所有用户
5.2 mesg
[语法]: mesg [-n] [-y]
[说明]: mesg 用 -n 参数则禁止其他用户用 write 发消息,用 -y 参数则允许接收消息,若无参数则报告现在的状况
5.3 write
[语法]: write 用户 终端
[说明]: write 与指定的终端上的用户直接对话,直到接收到文件结束符
[例子]:
write mary console
5.4 mailx
[语法]: mailx [选项] [名字]
[说明]: 本命令用于发送和接收邮件,名字是收信人的用户名,本命令有许多内部命令,选项说明如下:
-e 检查是否有邮件,若有则返回0
-f 文件名 从文件中读取邮件而非从邮箱中
-H 只显示信件标题
-s 标题 设定标题为指定标题
[命令说明]
. 当前信件
n 第 n 封信
^ 第一封未被处理的信
$ 最后一封信
* 所有的信
n-m 第n 封至第m封信
用户 由指定用户发出的信
/ 字符串 标题中包含字符串的信
:c 满足指定类型c的信,类型可为
d 已删除的信
n 信传送的信
o 旧信件
r 已读过的信
u 未读过的信
p 一次显示多封信
t 显示某封信的前若干行
si 显示信件字符数
h 显示信件标题
d 删除信件
u 恢复信件
s [信件表] 文件名
将信件存入指定文件中
q 退出
r 回信
~e 编辑信件
~r 文件 从文件中读取信件
[例子]:
mailx mary < myletter
第六章 Shell 编程
shell 不但是 Unix 的用户交互界面,还是一门程序设计语言,系统注册进入时就会执行一个shell命令文件 .profile ,下面对shell中的常用命令作简单介绍。
$n shell 程序命令行中的第n 个参数,n为0-9,当n 为0时表示命令名
$# 命令行中参数的个数
$$ 本shell 命令的进程号
$! 最后一个后台进程的代号
$* 所有命令行参数
$@ 与$*相似,但其值不同
$HOME 注册时进入的目录
$PATH 命令的搜索目录
$PS1 系统第一个提示符,一般为$
$PS2 系统第二个提示符,一般为>
shift [n] 将命令行参数往左移一位,但$0不变
变量名=字符串 将字符串赋予变量名,以后可用$变量名引用该变量
export 变量名表 将变量名表所列变量传递给子进程
read 变量名表 从标准输入读字符串,传给指定变量
echo 变量名表 将变量名表指定的变量显示到标准输出
set 显示设置变量
env 显示目前所有变量
if 条件执行,语法是: if 条件
then 指令
fi
case 分支执行,语法是: case 字符串变量 in
值1) 指令...
值2) 指令...
...
esac
while 条件为真时循环,语法是:
while 条件
do
指令...
done
until 条件为假时循环,语法是:
until 条件
do
指令...
done
for 变量在表中时循环,语法是:
for 变量名 in 字组表
do
指令...
done
break 从循环中退出,语法:
break n
n 表示跳出循环的层数
continue 继续循环,语法:
continue n
n 表示退到包含continue 语句的第n 层继续循环
exit 退出shell
func shell内部可定义函数,语法: func 函数名()
{
指令...
}
expr 将其后的串解释为表达式并计算其值,运算符前后需有空格
trap 捕获信号,语法 trap n ,捕获信号 n (信号说明参见kill)
test 条件测试,语法 test [选项] 参数
选项 -f 文件 若文件存在且可读则真
-w 文件 若文件存在且可写则真
-x 文件 若文件存在且可执行则真
-f 文件 若文件存在且为普通文件则真
-d 文件 若文件存在且为目录文件则真
-p 文件 若文件存在且为fifo文件则真
-s 文件 若文件存在且不空则真
-z 串 若串长度为0则真
-n 串 若串长度不为0则真
串 若串不是空串则真
串1=串2 若串1等于串2则真
串1!=串2 若串1不等于串2则真
n1 -eq n2 若n1与n2数值相当则真
n1 -ne n2 若n1与n2数值不相当则真
n1 -lt n2 若n1小于n2则真
n1 -le n2 若n1小于等于n2则真
n1 -gt n2 若n1大于n2则真
n1 -ge n2 若n1大于等于n2则真
可用 与 -a 或 -o 非 ! 将条件表达式连接起来
第七章 数学计算命令
[语法]: bc [-c] [-l] [文件...]
[说明]: bc是一个交互式的高精度计算工具,采用类似于C语言的语法,能够从指定文件指定文件中读出命令执行,然后再进入交互式执行,事实上,bc是dc的预编译器,它自动激活dc,将语句经预编译后传递给dc,退出bc的命令是quit,bc中的ibase,obase,scale分别表示输入基数,输出基数,小数点右边的位数。
-c bc 只编译,而不将编译结果送dc,将其送到标准输出上
-l 预定义一个数学函数库,可在bc中使用以下函数
s(x) sine
c(x) cosine
e(x) exponential
l(x) log
a(x) arctangent
j(n,x) Bessel
[例子]:
bc -l 进入bc
scale=10 将小数位定为10位
e(1) 计算e的小数点后10位
quit 退出bc
附录 UNIX 常用命令简单说明
UNIX 命令大多数可用联机帮助手册 man 获得帮助,下面是常用命令及简单说明,可供用户快速查找使用。
命令 功能简述
acctcom 等于进程记帐文件
accton 启动或中止记帐进程
adb 汇编语言调试工具
admin 创建和管理SCCS文件
ar 档案文件和库文件管理程序
as 汇编器
asa 回车控制
at 在指定时间执行程序
awk 模式搜索和处理语言
banner 制作标题
basename 生成文件基本名(无前。后缀)
batch 命令的延迟执行
bc 计算器
bdiff 大型文件比较
bfs 大文件搜索
break 退出循环
cal 打印日历表
calendar 打印日历表
cancel 取消打印任务
case 分支语句
cb C语言整理程序
cd 改变当前目录
cc C语言编译器
cdc SCCS实用程序
cflow 生成C语言流程图
checkeq 数学公式排版命令
chgrp 改变文件组
chmod 改变文件存取模式
chown 改变文件主
chroot 改变根目录
cksum 显示校验和
clri 清除指定的I节点
cmp 文件比较
col 过滤反向换行
comb SCCS实用程序
comm 显示两个排序文件的公共行
command 执行简单命令
continue 进入下一循环
cp 复制文件
cpio 复制文件档案
cpp C语言预处理程序
crash 检查系统内存映象
create 建立临时文件
cref 生成交叉引用表
cron 在指定时间执行一组命令
crontab 为命令cron 准备crontab文件
crypt 加密/解密
csplit 将一个文件分解
ct 远程终端注册
ctags 创建供vi使用的标识符
cu 呼叫另一UNIX系统
cut 断开一文件中所选择的字段
cxref 生成C程序交叉访问表
date 打印和设置时间
dc 桌面计算器
dd 转换和复制文件
delta SCCS实用程序
deroff 去掉排版格式
devnm 标识设备名
df 显示可用磁盘空间
diff 显示两个文件的差异
diff3 显示三个文件的差异
dircmp 目录比较
dis 反汇编程序
du 显示对磁盘的占用情况
dump 对指定文件备份
echo 回显指定参数
ed 行编辑器
edit 文本编辑器
egrep 在文件中查找指定模式
env 设置命令执行环境
eqn 数学公式排版命令
eval 执行指定命令
ex 行编辑器
exec 执行指定命令
exit 进程中止
expand 使表格占满行宽
export 将变量传递给子程序
expr 计算表达式值
factor 因式分解
false 返回FALSE
fgrep 在文件中查找指定模式
file 确定文件类型
find 查找符号条件的文件
fmt 安排简单的文本格式
fold 折行
for 循环语句
fsck 文件系统检查和修复
fsdb 文件系统调试程序
fumount 强制性拆协指定资源
function 函数说明
fuser 列出使用文件的进程
fwtmp 产生记帐记录
get SCCS实用程序
getconf 查找配置参数
getopt 获得命令中的选择项
getopts 获得命令中的选择项
getty 设置终端类型、模式、行律等
grep 在文件中查找指定模式
head 打印文件的头若干行
hexdump 按十六进制转储文件
id 显示用户号
if 条件语句
init UNIX 初启进程
install 安装一个文件到文件系统
ipcrm 删除IPC队列
ipcs 显示IPC状态
join 连接两个文件(关系操作〕
kill 中止指定进程
killall 中止所有活动进程
labelit 给文件系统提供标号
ld 目标文件链接编辑器
lex 词法分析程序
line 读一行
link 连接文件
lint C程序检查程序
ln 链接文件
local 建立局部变量
logger 显示注册信息
login 注册
logname 获取注册名
look 在排序文件中查找某行
lorder 查找目标库的次序关系
lp 打印文件
lpr 打印文件
lpstat 显示打印队列状态
ls 目录列表
mail 发送或接收电子邮件
mailx 发送、接收或处理电子邮件
make 执行有选择的编译
makekey 生成加密码
man 显示命令用法
mesg 接收或取消对话方式
mkdir 建立目录
mkfifo 建立FIFO文件
mkfs 建立文件系统
mknod 建立文件系统的I节点
mount 安装文件系统
mv 移动文件
mvdir 移动目录
ncheck 按节点号生成节点名清单
neqn 数学公式排版命令
newgrp 把用户加入到新组
news 打印消息
nice 改变命令执行优先级
nl 给文件加行号
nm 显示目标文件符号表
nohup 忽略挂起或退出执行命令
nroff 文本文件排版
od 按八进制转储文件
pack 压缩文件
passwd 改变口令
paste 文件合并
pax 可移植档案管理程序
pcat 显示压缩格式文件
pg 分屏显示
pr 按打印格式显示文件
pstat 报告系统信息
pwck 口令文件校验程序
pwd 显示当前工作目录
quot 检查文件系统所有权
ratfor 转换成标准FORTRANC程序
read 从标准输入读一行
readonly 标记变量为只读
red 文本编辑器
regcmp 正规表达式编辑
restor 文件系统恢复程序
restore 文件系统恢复程序
return 返回语句
rev 颠倒文件中每行字符次序
rm 删除文件
rmdel SCCS使用程序
rmdir 删除目录
rsh(net) 远程SHELL
rsh(sec) 受限SHELL
runacct 运行日常记帐程序
sact SCCS实用程序
sag 打印系统活动图
sar 报告系统活动
sccsdiff SCCS实用程序
sdb 符号调试器
sdiff 并列显示两个文件的差别
sed 流编辑器
sendto 发送邮件
set 设置选项或参数
setmnt 建立文件系统安装表
sh SHELL解释器
shift 命令行参数移位
shl SHELL层(layer)管理程序
shutdown 关机
size 显示目标文件长度
sleep 挂起进程一段时间
sort 文件排序和合并
spell 拼写错误检查程序
spellin 拼写错误检查
spellout 拼写错误检查
spline 按平滑曲线输出数据
split 分解一个文件
strings 在目标文件中寻找可打印字符
strip 删除符号表
stty 设置终端模式
su 改变用户
sum 显示文件校验和及块数
sync 更新磁盘
tabs 设置制表符
tbl 表格排版
tee 在管道上建立多通路
tic 终端数据库编译程序
time 打印执行命令所花时间
tiemx 报告命令所花时间及活动
touch 更新文件时间
tput 恢复终端或查询数据库
tr 转换字符
trap 捕获信号
troff 文本文件排版
true 返回TRUE
tsort 拓扑排序
tty 显示终端设备名
umask 设置文件掩码
umount 拆卸文件系统
uname 显示系统名
unget SCCS实用程序
uniq 删除文件中重复行
units 度量单位转换
unlink 删除文件
unpack 将压缩文件还原
until 循环语句
update 更新磁盘
val SCCS实用程序
vc SCCS实用程序
vi 全屏幕编辑器
volcopy 文件系统的文字拷贝
wait 等待所有字进程结束
while 循环语句
who 显示谁在使用系统
whodo 显示哪些用户在做什么
write 和另一用户直接对话
xargs 建立参数表并执行命令
yacc 语法分析程序生成器
posted @
2008-06-13 23:16 xzc 阅读(841) |
评论 (2) |
编辑 收藏时间:2006-02-10 00:55:40 类别:其他, 技术 RSS 2.0 引用
1.登录工作站
1.1 透过 PC 登录工作站
执行格式:telnet hostname (在 dos 下执行)
telnet ip-address
Example:
telnet doc telnet 140.122.77.120
注: 可利用指令 arp hostname 或 arp domain_name 查询 ip_address
1.2 登录步骤
login : _______ > 输入 username
password : _______ > 输入密码
1.3 登出步骤
% logout
或 % exit
或 %
1.4 更改帐号密码
% yppasswd > 执行后将会出现下列信息
Changing NIS password for user on ice.
Old password: ______ > 输入旧密码
New password: ______ > 输入新密码(最好6-8字,英文字母与数字混合)
Retype new password: ______ > 再输入一次密码
1.5 在线帮助指令说明
执行格式: man command-name
Example: % man ls
1.6 进入远端电脑系统
执行格式:rlogin hostname [-1 username]
Example:
%rlogin doc
remote login 进入工作站 doc 中。
%rlogin doc -l user
使用 user 帐号进入工作站 doc 中。
执行格式:telnet hostname 或 telnet IP address
Example:
%telnet doc or %telnet 140.109.20.251
2. 文件或目录处理
2.1 列出文件或目录下之文件名称
执行格式: ls [-atFlgR] [name] ( name 可为文件名或目录名称。)
Example :
ls 列出目前目录下之文件名。
ls –a 列出包含以.起始的隐藏档所有文件名。
ls –t 依照文件最后修改时间之顺序,依序列出文件名。
ls –F 列出目前目录下之文件名及其类型。"/" 结尾表示为目录名称,
"*" 结尾表示为执行档,"@" 结尾表示为 symblic link。
ls –l 列出目录下所有文件之许可权、拥有者、文件大小、修改时间及名称。
ls –lg 同上,并显示出文件之拥有者群组名称。
ls –R 显示出目录下,以及其所有子目录之文件名。( recursive listing )
2.2 目录之缩写:
~ 使用者 login 时的 working directory ( 起始目录 )
~username 指定某位 user 的 working directory ( 起始目录 )
.. 目前的工作目录 ( current working directory )
.. 目前目录的上一层目录 ( parent of working directory)
2.3 改变工作目录位置
执行格式:cd [name] :name 可为目录名称、路径或目录缩写。
Example:
cd 改变目录位置,至使用者 login 时的 working directory (起始目录)。
cd dir1 改变目录位置,至 dir1 之目录位置下。
cd ~user 改变目录位置,至使用者的 working directory (起始目录)。
cd .. 改变目录位置,至目前目录的上层( 即 parent of working directory)
cd ../user 改变目录位置,至相对路径 user 之目录位置下。
cd /../.. 改变目录位置,至绝对路径( Full path ) 之目录位置下。
2.4 复制文件
执行格式: cp [-r] source destination
Example:
cp file1 file2 将文件 file1 复制成 file2
cp file1 dir1 将文件 file1 复制到目录 dir1 下,文件名仍为 file1。
cp /tmp/file1 将目录 /tmp 下的文件 file1 复制到现行目录下,文件名仍为 file1。
cp /tmp/file1 file2 将目录 /tmp 下的文件 file1 复制到现行目录下,文件名为 file2
cp -r dir1 dir2 (recursive copy) 复制整个目录。
若目录 dir2 不存在,则将目录 dir1,及其所有文件和子目录,复制到目录 dir2 下,新目录名称为 dir1。若目录 dir2 不存在,则将dir1,及其所有文件和子目录,复制为目录 dir2。
2.5 移动或更改文件、目录名称
执行格式: mv source destination
Example:
mv file1 file2 将文件 file1,更改文件名为 file2。
mv file1 dir1 将文件 file1,移到目录 dir1下,文件名仍为 file1。
mv dir1 dir2 若目录 dir2 不存在,则将目录 dir1,及其所有文件和子目录,移到目录 dir2 下,新目录名称为 dir1。若目录 dir2 不存在,则将dir1,及其所有文件和子目录,更改为目录 dir2。
2.6 建立新目录
执行格式: mkdir directory-name
Exmaple :
mkdir dir1 建立一新目录 dir1。
2.7 删除目录
执行格式: rmdir directory-name 或 rm directory-name
Example :
rmdir dir1 删除目录 dir1,但 dir1 下必须没有文件存在,否则无法删除。
rm -r dir1 删除目录 dir1,及其下所有文件及子目录。
2.8 删除文件
执行格式: rm filename (filename 可为文件名,或文件名缩写符号。)
Example :
rm file1 删除文件名为 file1 之文件。
rm file? 删除文件名中有五个字符,前四个字符为file 之所有文件。
rm f* 删除文件名中,以 f 为字首之所有文件。
2.9 文件名的缩写符号
? 代表文件名称中之单一字符。
* 代表文件名称中之一字串。
2.10 列出目前所在之目录位置
执行格式: pwd
2.11 查看文件内容
执行格式: cat filename
Example :
cat file1 以连续显示方式,查看文件名 file1 之内容。
执行格式: more filename 或 cat filename | more
Example :
more file1 以分页方式,查看文件名 file1 之内容。
cat file1 | more 同上。
2.12 查看目录所占磁盘容量
执行格式: du [-s] directory
Example :
du dir1 显示目录 dir1 的总容量及其次目录的容量(以 k byte 为容量)。
du -s dir1 显示目录 dir1 的总容量。
2.13 查看自己的 disk quota 使用状况
disk quota : 工作站磁盘空间的使用限额。
执行格式: quota -v
Example :
quota -v 将会显示下列信息
Filesystem usage quota limit timeleft files quota limit timelef.
/home/ice/u01 9344 8192 12288 1.9 days 160 0 0
栏位解说:
usage : 目前的磁盘用量。
quota : 你的磁盘使用额度。当你的 usage 超过 quota 时,虽然可以继续使用,但是必须七天之内降到 quota 以下,否则即使用量没有超 limit(最高限额),也无法再写入或复制任何文件。
limit : 最高使用额度。当你的 usage 达到 limit 时,无法再写入或复制任何文件。
3. 文件传输
3.1 拷贝文件或目录至远端工作站
执行格式: rcp [-r] source hostnome:destination
source 可为文件名、目录名或路径,hostnome 为工作站站名,destination 为路径名称.
Example :
rcp file1 doc:/home/user
将文件 file1,拷贝到工作站 doc 路径 /home/user 之目录下。
rcp -r dir1 doc:/home/user
将目录 dir1,拷贝到工作站 doc 路径/home/user 之目录下。
3.2 自远端工作站,拷贝文件或目录
执行格式: rcp [-r] hostname:source destination
( hostname 为工作站名,source 为路径名,destination 可为文件名、目录名或路径 )。
Example :
rcp doc:/home/user/file1 file2
将工作站 doc 中,位于 /home/user 目录下之目录 dir1,拷贝到目前工作站之目录下,目录名称仍为 dir1。
rcp -r doc:/home/user/dir1 .
将工作站 iis1 中,位于 /home/user 目录下之目录 dir1,拷贝到目前工作站之目录下目录名称仍为 dir1。
3.3 本地工作站与远端工作站之间文件传输
( 必须拥有远端工作站之帐号及密码,才可进行传输工作 )
执行格式: ftp hostname or ftp ip_address
Example :
ftp doc 与远端工作站 doc ,进行文件传输
Name (doc:user-name) : 输入帐号
Password (doc:user-name): 输入密码
ftp> help 列出 ftp 文件传输,可使用之任何命令。
ftp> !ls 列出本地工作站,目前目录下之所有文件名。
ftp> !pwd 列出本地工作站,目前所在之工作目录位置。
ftp> ls 列出远端工作站目前目录下之所有文件名。
ftp> dir 列出远端工作站目前目录下之所有文件名(略同于 UNIX 的 ls -l 指令).
ftp> dir . |more 同上,但每页会暂停(可能不适用 Unix 以外的 ftp)。
ftp> pwd 列出远端工作站目前所在之目录位置。
ftp> cd dir1 更改远端工作站之工作目录位置至 dir1 之下。
ftp> get file1 将远端工作站之文件 file1 ,拷贝到本地工作站中。
ftp> put file2 将本地工作站之文件 file2 ,拷贝到远端工作站中。
ftp> mget *.c 将远端工作站中,副文件名为 c 之所有文件,拷贝到本地工作站中。
ftp> mput *.txt 将本地工作站中,副文件名为 txt 之所有文件,拷贝远端工作站中。
ftp> prompt 切换交谈式指令(使用 mput/mget 时不用每个文件皆询问yes/no)。
ftp> quit 结束 ftp 工作。
ftp> bye 结束 ftp 工作。
注: 从PC与工作站间的文件传输也可透过在 PC端的 FTP指令进行文件传输,指令用法与上所述大致相同。
4. 文件模式之设定
4.1 改变文件或目录之读、写、执行之允许权
执行格式:chmod [-R] mode name
( name 可为文件名或目录名;mode可为 3 个 8 位元之数字,或利用ls -l 命令,列出文件或目录之读、写、执行允许权之文字缩写。)
mode : rwx rwx rwx r:read w:write x:execute
user group other
缩写 : (u) (g) (o)
Example :
%chmod 755 dir1
将目录dir1,设定成任何使用者,皆有读取及执行之权利,但只有拥有者可做修改。
%chmod 700 file1
将文件file1,设定只有拥有者可以读、写和执行。
%chmod o+x file2
将文件file2,增加拥有者可以执行之权利。
%chmod g+x file3
将文件file3,增加群组使用者可执行之权利。
%chmod o-r file4
将文件file4,除去其它使用者可读取之权利。
4.2 改变文件或目录之拥有权
执行格式:chown [-R] username name ( name 可为文件名或目录名。)
Example :
%chown user file1
将文件 file1 之拥有权,改为使用者 user 所有。
%chown -R user dir1
将目录 dir1,及其下所有文件和子目录之拥有权,改为使用者 user 所有。
4.3 检查自己所属之群组名称
执行格式:groups
4.4 改变文件或目录之群组拥有权
执行格式:chgrp [-R] groupname name ( name 可为文件名或目录名 )
Example :
%chgrp vlsi file1
将文件 file1 之群组拥有权,改为 vlsi 群组。
%chgrp -R image dir1
将目录dir1,及其下所有文件和子目录,改为 image 群组。
4.5 改变文件或目录之最后修改时间
执行格式:touch name ( name 可为文件或目录名称。)
4.6 文件之连结
同一文件,可拥有一个以上之名称,可将文件做数个连结。
执行格式:ln oldname newname ( Hard link )
Example :
ln file1 file2 将名称 file2,连结至文件 file1。
执行格式:ln -s oldname newname ( Symblick link )
Example :
ln -s file3 file4 将名称 file4,连结至文件file3。
4.7 文件之字串找寻
执行格式:grep string file
Example :
grep abc file1
寻找文件file1中,列出字串 abc 所在之整行文字内容。
4.8 找寻文件或命令之路径
执行格式:whereis command ( 显示命令之路径。)
执行格式:which command ( 显示命令之路径,及使用者所定义之别名。)
执行格式:whatis command ( 显示命令功能之摘要。)
执行格式:find search-path -name filename -print
( 搜寻指定路径下,某文件之路径 。)
Example :
%find / -name file1 -print ( 自根目录下,寻找文件名为 file1 之路径。.
4.9 比较文件或目录之内容
执行格式:diff [-r] name1 name2 ( name1 name2 可同时为文件名,或目录名称。)
Example :
%diff file1 file2
比较文件 file1 与 file2 内,各行之不同处。
%diff -r dir1 dir2
比较目录 dir1 与 dir2 内,各文件之不同处。
4.10 文件打印输出
使用者可用 .login 档中之 setenv PRINTER,来设定打印资料时的打印机名。
printername :sp1 或 sp2
Example :
%setenv PRINTER sp2 设定自 sp2 打印资料。
4.11 一般文件之打印
执行格式:lpr [-Pprinter-name] filename
%lpr file1 或 lpr -Psp2 file1
自 sp2,打印文件 file1。
执行格式:enscript [-Pprinter-name] filename
%enscript file3 或 enscript -Psp1 file3
自 sp1 打印文件 file3。
4.12 troff 文件之打印
执行格式:ptroff [-Pprinter-name] [-man][-ms] filename
%ptroff -man /usr/local/man/man1/ptroff.1
以 troff 格式,自 Apple laser writer 打印 ptroff 命令之使用说明。
%ptroff -Psp2 -man /usr/man/man1/lpr1
以 troff 格式,自 sp2 打印 lpr 命令之使用说明。
5. 打印机控制命令
5.1 检查打印机状态,及打印工作顺序编号和使用者名称
执行格式:lpq [-Pprinter -name]
%lpq 或 lpq -Psp1
检查 sp1 打印机之状态。
5.2 删除打印机内之打印工作 (使用者仅可删除自己的打印工作 )
执行格式:lprm [-Pprinter -name] username 或 job number
%lprm user 或 lprm -Psp1 user
删除 sp1 中,使用者 user 的打印工作,此时使用者名称必须为 user。
%lprm -Psp2 456
删除 sp2 编号为 456 之打印工作。
6. Job 之控制
UNIX O.S.,可于 foregrourd 及 background 同时处理多个 process。
一般使用者执行命令时,皆是在 foreground 交谈式地执行 process,亦可将 process置于 background 中,以非交谈式来执行 process。
6.1 查看系统之 process
执行格式:ps [-aux]
Example:
%ps 或 ps –x (查看系统中,属于自己的 process。)
%ps –au (查看系统中,所有使用者的 process。)
%ps –aux (查看系统中,包含系统内部,及所有使用者的 process。)
6.2 结束或终止 process
执行格式:kill [-9] PID ( PID 为利用 ps 命令所查出之 process ID。)
Example:
%kill 456 或 kill -9 456
终止 process ID 为 456 之 process。
6.3 在 background 执行 process 的方式
执行格式:command & (于 command 后面加入一 "&" 符号即可。)
Example:
%cc file1.c &
将编译 file1.c 文件之工作,置于 background 执行。
执行格式:按下 "Control Z" 键,暂停正在执行的 process。键入 "bg" 命令,将所暂停的 process,置入 background 中继续执行。
Example:
%cc file2.c
^Z
Stopped
%bg
6.4 查看正在 background 中执行的 process
执行格式:jobs
6.5 结束或终止在 background 中的 process
执行格式:kill %n
(n 为利用 "jobs" 命令,所查看出的 background job 编号)
Example:
%kill % 终止在 background 中的第一个 job。
%kill %2 终止在 background 中的第二个 job。
7. shell varialbe
7.1 查看 shell variable 之设定值
执行格式:set 查看所有 shell variable 之设定值。
%set
执行格式:echo $variable-name 显示指定的 shell variable 之设定值。
%echo $PRINTER
sp1
7.2 设定 shell variable
执行格式:set var value
Example:
%set termvt100
设定 shell variable "term" 为 VT100 终端机之型式。
7.3 删除 shell variable
执行格式:unset var
Example:
%unset PRINTER
删除 shell variable "PRINTER" 之设定值。
8. environment variable
8.1 查看 environment variable 之设定值
执行格式:setenv 查看所有 environment variable 之设定值。
Example: %setenv
执行格式:echo $NAME 显示指定的 environment variable "NAME" 之设定值。
Example:
%echo $PRINTER
显示 environment variable "PRINTER" 打印机名称之设定值。
8.2 设定 environment variable
执行格式:setenv NAME word
Example:
%setenv PRINTER sp1
设定 environment variable "PRINTER" 打印机名称为 sp1。
8.3 删除 environment variable
执行格式:unsetenv NAME
Example:
%unsetenv PRINTER
删除 environment variable "PRINTER" 打印机名称之设定值。
9. alias
9.1 查看所定义的命令之 alias
执行格式: alias 查看自己目前定义之所有命令,及所对应之 alias 名称。
执行格式: alias name 查看指定之 alias 名称所定义之命令。
Example:
%alias dir (查看别名 dir 所定义之命令)
ls -atl
9.2 定义命令之 alias
执行格式: alias name \'command line\'
Example:
% alias dir \'ls -l\'
将命令 "ls - l" 定义别名为 dir。
9.3 删除所定义之 alias
执行格式: unalias name
Example:
%unalias dir (删除别名为 dir 之定义。)
%unalias * (删除所有别名之设定。)
10. history
10.1 设定命令记录表之长度
执行格式: set history n
Example:
%set history 40
设定命令记录表之长度为 40 (可记载执行过之前面 40 个命令)。
10.2查看命令记录表之内容
执行格式: history
10.3 使用命令记录表
执行格式: !!
Example: %!! (重复执行前一个命令)
执行格式: !n ( n 为命令记录表之命令编号。)
Example: %!5 ( 执行命令记录表中第五个命令。)
执行格式: !string ( 重复前面执行过以 string 为起始字符之命令。)
Example: %!cat ( 重复前面执行过,以 cat 为起始字符之命令。)
10.4 显示前一个命令之内容
执行格式: !!:p
10.5 更改前一命令之内容并执行之
执行格式: ^oldstring ^newstring
将前一命令中 oldstring 的部份,改成 newstring,并执行之。
Example:
%find . -name file1.c -print
^file1.c^core
%find . -name core -print
注:文件 core 为执行程序或命令发生错误时,系统所产生的文件。作为侦错(debug)之,因其所占空间极大,通常将之删除。
11. 资料之压缩
为了避免不常用的文件或资料,占用太大的磁盘空间,请使用者将之压缩。欲使用压缩过的文件或资料前,将之反压缩,即可还原成原来之资料型式。凡是经过压缩处理之文件,会在文件名后面附加 " .Z " 之字符,表示此为一压缩文件。
11.1 压缩资料
执行格式:compress filename 压缩文件
执行格式:compressdir directory-name 压缩目录
11.2 解压缩还原资料
执行格式:uncompress filename 反压缩文件
执行格式:uncompressdir directory-name 反压缩目录
12. pipe-line 之使用
执行格式:command1 | command2
将 command1 执行结果,送到 command2 做为 command2 的输入。
Example:
%ls -Rl | more
以分页方式,列出目前目录下所有文件,及子目录之名称。
%cat file1 | more
以分页方式,列出文件 file1 之内容。
13. I/O control
13.1 标准输入之控制
执行格式:command-line < file
将 file 做为 command-line 之输入。
Example:
%mail -s "mail test" user@iis.sinica.edu.tw < file1
将文件 file1 当做信件之内容,Subject 名称为 mail test,送给收信人。
13.2 标准输出之控制
执行格式:command > filename
将 command 之执行结果,送至指定的 filename 中。
Example: %ls -l > list
将执行 "ls -l" 命令之结果,写入文件 list 中。
执行格式:command >! filename
同上,若 filename 之文件已经存在,则强迫 overwrite。
Example: %ls -lg >! list
将执行 "ls - lg" 命令之结果,强迫写入文件 list 中。
执行格式:command >& filename
将 command 执行时,屏幕上所产生的任何信息,写入指定的 filename 中。
Example: %cc file1.c >& error
将编译 file1.c 文件时,所产生之任何信息,写入文件 error 中。
执行格式:command >> filename
将 command 执行结果,附加(append)到指定的 filename 中。
Example: %ls - lag >> list
将执行 "ls - lag" 命令之结果,附加(append)到文件 list 中。
执行格式:command >>& filename
将 command 执行时,屏幕上所产生的任何信息,附加于指定的 filename中。
Example: %cc file2.c >>& error
将编译 file2.c 文件时,屏幕所产生之任何信息,附加于文件 error 中。
14. 查看系统中的使用者
执行格式: who 或 finger
执行格式: w
执行格式: finger username or finger username@domainname
15. 改变自己的 username 进入其他使用者的帐号,拥有其使用权利。
执行格式: su username
Example:
%su user 进入使用者 user 之帐号
passwrod: 输入使用者 user 之密码
16. 查看 username
执行格式: whoami 查看 login 时,自己的 username。
执行格式: whoami 查看目前的 username。若已执行过 "su"命令tch user),则显示出此 user 之 username。
17. 查看目前本地所有工作站的使用者
执行格式: rusers
> 结束
18. 与某工作站上的使用者交谈
执行格式: talk username@hostname 或 talk username@ip_address
Example:
1. 可先利用 rusers 指令查看网路上的使用者
2. 假设自己的帐号是 u84987 ,在工作站 indian 上使用,现在想要与 doc 上的u84123 交谈。
%talk u84123@doc > 此时屏幕上将会出现等待画面
在对方(u84123)屏幕上将会出现下列信息
Message from Talk_Daemon@Local_host_name at xx:xx
talk: connection requested by u84987@indian
talk: respond with: talk u84987@indian
此时对方(u84123) 必须执行 talk u84987@indian 即可互相交谈。最后可按结束。
19. 检查远端电脑系统是否正常
执行格式:ping hostname 或 ping IP-Address
Example:
%ping doc
20. 电子邮件(E-mail)的使用简介
20.1将文件当做 E-mail 的内容送出
执行格式:mail -s "Subject-string" username@address < filename
%mail -s "program" user < file.c
将 file.c 当做 mail 的内容,送至 user, subject name 为 program。
20.2 传送 E-mail 给本地使用者
执行格式:mail username
%mail user
20.3 传送 E-mail 至 外地
执行格式: mail username@receiver-address
Example
%mail paul@gate.sinica.edu.tw
Subject : mail test
:
:
键入信文内容
:
:
按下 "Control D" 键或 " . " 键结束信文。
连按两次 "Control C" 键,则中断工作,不送此信件。
Cc:
( Carbon copy : 复制一份信文,给其他的收信人 )
20.4 检查所传送之 E-mail 是否送出,或滞留于本所之邮件伺服站中
执行格式:/usr/lib/sendmail -bp
( 若屏幕显示为 "Mail queue is empty" 之信息,表示 mail 已送出。
若为其它错误信息,表示 E-mail 因故尚未送出。)
20.5 读取信件
执行格式: mail
常用指令如下:
cd [directory] chdir to directory or home if none given
d [message list] delete messages
h print out active message headers
m [user list] mail to specific users
n goto and type next message
p [message list] print messages
q quit, saving unresolved messages in mbox
r [message list] reply to sender (only) of messages
R [message list] reply to sender and all recipients of messages
s [message list] file append messages to file
t [message list] type messages (same as print)
u [message list] undelete messages
v [message list] edit messages with display editor
w [message list] file append messages to file, without from line
x quit, do not change system mailbox
z [-] display next [previous] page of headers
! shell escape
21.文件编辑器 vi 之使用方法简介
vi、celvis(cvi) 是在工作站上被广大使用的中英文编辑软体。对初学者而言,常因其特殊的使用方法,而不得其门而入;对已经在使用 vi 的使用者来说,也常见因对 vi 的不熟悉或不够了解,而无法发挥出 vi 强大的编辑能力,以下将介绍 vi 之使用方法简介。
21.1本文内容大纲
进入 vi
离开 vi
输入模式
如何进入输入模式
如何离开输入模式
指令模式
光标的移动
视窗的移动
删除、复制及修改指令介绍(delete、change、yank)
删除与修改(delete、replace)
移动与复制(delete/put、yank/put)
指令重复
取消前一动作(undo)
字串搜寻
资料的连接与分行
环境的设定
ex 指令
其它方面
中文编辑
恢复编辑时被中断的文件
编辑多个文件
vi 是 visual editor 的缩写,是 UNIX 所提供的编辑器之一。它提供使用者一个视窗的编辑环境,在此视窗下,使用者可编辑所要的文件。
21.2 进入vi
直接执行 vi编辑程序即可:
%vi test
此刻屏幕上会出现 vi 的编辑视窗,同时 vi 会将文件复制一份至记忆体中的缓冲区 (buffer) 。 vi会保留在磁盘中的文件不变,而先对缓冲区的文件作编辑,编辑完成后,使用者可决定是否要取代原来旧有的文件。
--------------------------------------------------------------------------------
-- 作者:itvue
-- 发布时间:2005-5-11 10:17:42
--
21.3 离开vi
若在输入模式下,则先利用《ESC》进入指令模式,而后即可选用下列指令
离开vi。
:q! 离开vi,并放弃刚在缓冲区内编辑的内容。
:wq 将缓冲区内的资料写入磁盘中,并离开vi。
:ZZ 同wq。
:x 同wq。
:w 将缓冲区内的资料写入磁盘中,但并不离开vi。
:q 离开vi,若文件被修改过,则会被要求确认是否放弃修改的内容。
此指令可与:w 配合使用。
21.4 vi 的操作模式
vi 提供两种操作模式:输入模式(insert mode)和指令模式(command mode)。当使用者进入 vi 后,即处在指令模式下,此刻键入之任何字符皆被视为指令。在此模式下可进行删除、修改等动作。若要输入资料,则需进入输入模式。
21.5 输入模式
如何进入输入模式
l a (append) 由光标之后加入资料。
l A 由该行之末加入资料。
l i (insert) 由光标之前加入资料。
l I 由该行之首加入资料。
l o (open) 新增一行于该行之下供输入资料之用。
l 新增一行于该行之上供输入资料之用。
如何离开输入模式
l 《ESC》 结束输入模式。
21.6 指令模式
光标之移动
l h 向左移一个字符。
l J 向上移一个字符。
l K 向下移一个字符。
l L 向右移一个字符。
l 移至该行之首
l $ 移至该行之末。
l ^ 移至该行的第一个字符处。
l H 移至视窗的第一列。
l M 移至视窗的中间那列。
l L 移至视窗的最后一列。
l G 移至该文件的最后一列。
l + 移至下一列的第一个字符处。
l - 移至上一列的第一个字符处。
l ( 移至该句之首。 (注一)
l ) 移至该句之末。
l { 移至该段落之首。 (注二)
l } 移至该段落之末。
l nG 移至该文件的第 n 列。
l n+ 移至光标所在位置之后的第 n 列。
l 移至光标所在位置之前的第 n 列。
l 会显示该行之行号、文件名称、文件中最末行之行号、光标所在行号占总行号之百分比。
注一:句子(sentence)在vi中是指以『!』、『.』或『?』结束的一串字。
注二:段落(paragraph)在vi中是指以空白行隔开的文字。
21.7 视窗的移动
l 视窗往下卷一页。
l 视窗往上卷一页。
l 视窗往下卷半页。
l 视窗往上卷半页。
l 视窗往下卷一行。
l 视窗往上卷一行。
21.8 删除、复制及修改指令介绍 (此单元较少使用)
d(delete)、c(change)和y(yank)这一类的指令在 vi 中的指令格式为:
Operator + Scope command
(运算子) (范围)
运算子:
l d 删除指令。删除资料,但会将删除资料复制到记忆体缓冲区。
l y 将资料(字组、行列、句子或段落)复制到缓冲区。
l p 放置(put)指令,与 d 和 y 配和使用。可将最后delete或yank的资料放置于光标所在位置之行列下。
l c 修改(change)指令,类似delete与insert的组和。删除一个字组、句子等之资料,并插入新键资料。
范围:
l e 由光标所在位置至该字串的最后一个字符。
l w 由光标所在位置至下一个字串的第一个字符。
l b 由光标所在位置至前一个字串的第一个字符。
l $ 由光标所在位置至该行的最后一个字符。
l 由光标所在位置至该行的第一个字符。
l ) 由光标所在位置至下一个句子的第一个字符。
l ( 由光标所在位置至该句子的第一个字符。
l { 由光标所在位置至该段落的最后一个字符。
l } 由光标所在位置至该段落的第一个字符。
整行动作:
l dd 删除整行。
l D 以行为单位,删除光标后之所有字符。
l cc 修改整行的内容。
l yy yank整行,使光标所在该行复制到记忆体缓冲区。
21.9 删除与修改
l x 删除光标所在该字符。
l X 删除光标所在之前一字符。
l dd 删除光标所在该行。
l r 用接于此指令之后的字符取代(replace)光标所在字符。如: ra 将光标所在字符以 a 取代之。
l R 进入取代状态,直到《ESC》为止。
l s 删除光标所在之字符,并进入输入模式直到《ESC》。
l S 删除光标所在之该行资料,并进入输入模式直到《ESC》。
21.10 移动与复制
利用 delete 及 put 指令可完成资料移动之目的。
利用 yank 及 put 指令可完成资料复制之目的。
yank 和 delete 可将指定的资料复制到记忆体缓冲区,而藉由 put 指令可将缓冲区内的资料复制到屏幕上。
例:
移动一行 .在该行执行 dd
.光标移至目的地
.执行 p
复制一行 .在该行执行 yy
.光标移至目的地
.执行 p
21.11 指令重复
在指令模式中,可在指令前面加入一数字 n,则此指令动作会重复执行 n次。
例:
删除10行 .10dd
复制10行 .10yy
指标往下移10行 .10j
21.12 取消前一动作(Undo)
即复原执行上一指令前的内容。
u 恢复最后一个指令之前的结果。
U 恢复光标该行之所有改变。
21.13 搜寻
在vi中可搜寻某一字串,使光标移至该处。
/字串 往光标之后寻找该字串。
?字串 往光标之前寻找该字串。
n 往下继续寻找下一个相同的字串。
N 往上继续寻找下一个相同的字串。
21.14资料的连接
J 句子的连接。将光标所在之下一行连接至光标该行的后面。
若某行资料太长亦可将其分成两行,只要将光标移至分开点,进入输入模式 (可利用 a、i等指令)再按《Enter》即可。
21.15 环境的设定
:set nu 设定资料的行号。
:set nonu 取消行号设定。
:set ai 自动内缩。
:set noai 取消自动内缩。
自动内缩(automatic indentation)
在编辑文件或程序时,有时会遇到需要内缩的状况,『:set ai』即提供自动内缩的功能,用下例解释之:
.vi test
.(进入编辑视窗后)
this is the test for auto indent
《Tab》start indent ← :set ai (设自动内缩)
《Tab》data
《Tab》data
《Tab》data ← :set noai (取消自动内缩)
the end of auto indent.
.注: 可删除《Tab》字符。
21.16 ex指令
读写资料
:w 将缓冲区的资料写入磁盘中。
:10,20w test 将第10行至第20行的资料写入test文件。
:10,20w>>test 将第10行至第20行的资料加在test文件之后。
:r test 将test文件的资料读入编辑缓冲区的最后。
删除、复制及移动
:10,20d 删除第10行至第20行的资料。
:10d 删除第10行的资料。
:%d 删除整个编辑缓冲区。
:10,20co30 将第10行至第20行的资料复制至第30行之后。
:10,20mo30 将第10行至第20行的资料移动至第30行之后。
字串搜寻与取代
s(substitute)指令可搜寻某行列范围。g(global)指令则可搜寻整个编辑缓冲区的资料。
s指令以第一个满足该条件的字串为其取代的对象,若该行有数个满足该条件的字串,也仅能取代第一个,若想取代所有的字串则需加上g参数。
:1,$s/old/new/g 将文件中所有的『old』改成『new』。
:10,20s/^/ / 将第10行至第20行资料的最前面插入5个空白。
:%s/old/new/g 将编辑缓冲区中所有的『old』改成『new』。
21.17 恢复编辑时被中断的文件
在编辑过程中,若系统当掉或连线中断,而缓冲区的资料并还未被写回磁盘时,当再度回到系统,执行下列指令即可回复中断前的文件内容。
%vi -r filename
21.18 编辑多个文件
vi亦提供同时编辑多个文件的功能,方法如下:
%vi file1 file2 ...
当第一个文件编修完成后,可利用『:w』将该缓冲区存档,而后再利用 『:n』载入下一个文件。
posted @
2008-06-13 23:13 xzc 阅读(419) |
评论 (0) |
编辑 收藏
以下是详解Spring的applicationContext.xml文件代码:
<!-- 头文件,主要注意一下编码 -->
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<!-- 建立数据源 -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<!-- 数据库驱动,我这里使用的是Mysql数据库 -->
<property name="driverClassName">
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 数据库地址,这里也要注意一下编码,不然乱码可是很郁闷的哦! -->
<property name="url">
<value>
jdbc:mysql://localhost:3306/tie?useUnicode=true&characterEncoding=utf-8
</value>
</property>
<!-- 数据库的用户名 -->
<property name="username">
<value>root</value>
</property>
<!-- 数据库的密码 -->
<property name="password">
<value>123</value>
</property>
</bean>
<!-- 把数据源注入给Session工厂 -->
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource">
<ref bean="dataSource" />
</property>
<!-- 配置映射文件 -->
<property name="mappingResources">
<list>
<value>com/alonely/vo/User.hbm.xml</value>
</list>
</property>
</bean>
<!-- 把Session工厂注入给hibernateTemplate -->
<!-- 解释一下hibernateTemplate:hibernateTemplate提供了很多方便的方法,在执行时自动建立 HibernateCallback 对象,例如:load()、get()、save、delete()等方法。 -->
<bean id="hibernateTemplate"
class="org.springframework.orm.hibernate3.HibernateTemplate">
<constructor-arg>
<ref local="sessionFactory" />
</constructor-arg>
</bean>
<!-- 把DAO注入给Session工厂 -->
<bean id="userDAO" class="com.alonely.dao.UserDAO">
<property name="sessionFactory">
<ref bean="sessionFactory" />
</property>
</bean>
<!-- 把Service注入给DAO -->
<bean id="userService" class="com.alonely.service.UserService">
<property name="userDAO">
<ref local="userDAO" />
</property>
</bean>
<!-- 把Action注入给Service -->
<bean name="/user" class="com.alonely.struts.action.UserAction">
<property name="userService">
<ref bean="userService" />
</property>
</bean>
</beans> |
以上Spring的applicationContext.xml文件我是用的SSH架构,如果您用Spring的MVC架构,其原理也是一样的。
posted @
2008-06-07 13:48 xzc 阅读(18079) |
评论 (3) |
编辑 收藏一:理解多线程
多线程是这样一种机制,它允许在程序中并发执行多个指令流,每个指令流都称为一个线程,彼此间互相独立。
线程又称为轻量级进程,它和进程一样拥有独立的执行控制,由操作系统负责调度,区别在于线程没有独立的存储空间,而是和所属进程中的其它线程共享一个存储空间,这使得线程间的通信远较进程简单。
多个线程的执行是并发的,也就是在逻辑上“同时”,而不管是否是物理上的“同时”。如果系统只有一个CPU,那么真正的“同时”是不可能的,但是由于CPU的速度非常快,用户感觉不到其中的区别,因此我们也不用关心它,只需要设想各个线程是同时执行即可。
多线程和传统的单线程在程序设计上最大的区别在于,由于各个线程的控制流彼此独立,使得各个线程之间的代码是乱序执行的,由此带来的线程调度,同步等问题,将在以后探讨。
二:在Java中实现多线程
我们不妨设想,为了创建一个新的线程,我们需要做些什么?很显然,我们必须指明这个线程所要执行的代码,而这就是在Java中实现多线程我们所需要做的一切!
真是神奇!Java是如何做到这一点的?通过类!作为一个完全面向对象的语言,Java提供了类 java.lang.Thread 来方便多线程编程,这个类提供了大量的方法来方便我们控制自己的各个线程,我们以后的讨论都将围绕这个类进行。
那么如何提供给 Java 我们要线程执行的代码呢?让我们来看一看 Thread 类。Thread 类最重要的方法是 run() ,它为Thread 类的方法 start() 所调用,提供我们的线程所要执行的代码。为了指定我们自己的代码,只需要覆盖它!
方法一:继承 Thread 类,覆盖方法 run()
我们在创建的 Thread 类的子类中重写 run() ,加入线程所要执行的代码即可。
下面是一个例子:
public class MyThread extends Thread {
int count= 1, number;
public MyThread(int num) {
number = num;
System.out.println("创建线程 " + number);
}
public void run() {
while(true) {
System.out.println("线程 " + number + ":计数 " + count);
if(++count== 6) return;
}
}
public static void main(String args[]) {
for(int i = 0; i < 5; i++) new MyThread(i+1).start();
}
}
这种方法简单明了,符合大家的习惯,但是,它也有一个很大的缺点,那就是如果我们的类已经从一个类继承(如小程序必须继承自 Applet 类),则无法再继承 Thread 类,这时如果我们又不想建立一个新的类,应该怎么办呢?
我们不妨来探索一种新的方法:我们不创建 Thread 类的子类,而是直接使用它,那么我们只能将我们的方法作为参数传递给 Thread 类的实例,有点类似回调函数。但是 Java 没有指针,我们只能传递一个包含这个方法的类的实例。那么如何限制这个类必须包含这一方法呢?当然是使用接口!(虽然抽象类也可满足,但是需要继承,而我们之所以要采用这种新方法,不就是为了避免继承带来的限制吗?)
Java 提供了接口 java.lang.Runnable 来支持这种方法。
方法二:实现 Runnable 接口
Runnable 接口只有一个方法 run(),我们声明自己的类实现 Runnable 接口并提供这一方法,将我们的线程代码写入其中,就完成了这一部分的任务。
但是 Runnable 接口并没有任何对线程的支持,我们还必须创建 Thread 类的实例,这一点通过 Thread 类的构造函数
public Thread(Runnable target);来实现。
下面是一个例子:
public class MyThread implements Runnable {
int count= 1, number;
public MyThread(int num) {
number = num;
System.out.println("创建线程 " + number);
}
public void run() {
while(true) {
System.out.println("线程 " + number + ":计数 " + count);
if(++count== 6) return;
}
}
public static void main(String args[]) {
for(int i = 0; i < 5; i++) new Thread(new MyThread(i+1)).start();
}
}
严格地说,创建 Thread 子类的实例也是可行的,但是必须注意的是,该子类必须没有覆盖 Thread 类的 run 方法,否则该线程执行的将是子类的 run 方法,而不是我
们用以实现Runnable 接口的类的 run 方法,对此大家不妨试验一下。
使用 Runnable 接口来实现多线程使得我们能够在一个类中包容所有的代码,有利于封装,它的缺点在于,我们只能使用一套代码,若想创建多个线程并使各个线程执行不同的代码,则仍必须额外创建类,如果这样的话,在大多数情况下也许还不如直接用多个类分别继承 Thread 来得紧凑。
综上所述,两种方法各有千秋,大家可以灵活运用。
下面让我们一起来研究一下多线程使用中的一些问题。
三:线程的四种状态
1. 新状态:线程已被创建但尚未执行(start() 尚未被调用)。
2. 可执行状态:线程可以执行,虽然不一定正在执行。CPU 时间随时可能被分配给该线程,从而使得它执行。
3. 死亡状态:正常情况下 run() 返回使得线程死亡。调用 stop()或 destroy() 亦有同样效果,但是不被推荐,前者会产生异常,后者是强制终止,不会释放锁。
4. 阻塞状态:线程不会被分配 CPU 时间,无法执行。
四:线程的优先级
线程的优先级代表该线程的重要程度,当有多个线程同时处于可执行状态并等待获得 CPU 时间时,线程调度系统根据各个线程的优先级来决定给谁分配 CPU 时间,优先级高的线程有更大的机会获得 CPU 时间,优先级低的线程也不是没有机会,只是机会要小一些罢了。
你可以调用 Thread 类的方法 getPriority() 和 setPriority()来存取线程的优先级,线程的优先级界于1(MIN_PRIORITY)和10(MAX_PRIORITY)之间,缺省是5(NORM_PRIORITY)。
五:线程的同步
由于同一进程的多个线程共享同一片存储空间,在带来方便的同时,也带来了访问冲突这个严重的问题。Java语言提供了专门机制以解决这种冲突,有效避免了同一个数据对象被多个线程同时访问。
由于我们可以通过 private 关键字来保证数据对象只能被方法访问,所以我们只需针对方法提出一套机制,这套机制就是 synchronized 关键字,它包括两种用法:synchronized 方法和 synchronized 块。
1. synchronized 方法:通过在方法声明中加入 synchronized关键字来声明 synchronized 方法。如:
public synchronized void accessVal(int newVal);
synchronized 方法控制对类成员变量的访问:每个类实例对应一把锁,每个 synchronized 方法都必须获得调用该方法的类实例的锁方能执行,否则所属线程阻塞,方
法一旦执行,就独占该锁,直到从该方法返回时才将锁释放,此后被阻塞的线程方能获得该锁,重新进入可执行状态。这种机制确保了同一时刻对于每一个类实例,其所有声明为 synchronized 的成员函数中至多只有一个处于可执行状态(因为至多只有一个能够获得该类实例对应的锁),从而有效避免了类成员变量的访问冲突(只要所有可能访问类成员变量的方法均被声明为 synchronized)。
在 Java 中,不光是类实例,每一个类也对应一把锁,这样我们也可将类的静态成员函数声明为 synchronized ,以控制其对类的静态成员变量的访问。
synchronized 方法的缺陷:若将一个大的方法声明为synchronized 将会大大影响效率,典型地,若将线程类的方法 run() 声明为 synchronized ,由于在线程的整个生命期内它一直在运行,因此将导致它对本类任何 synchronized 方法的调用都永远不会成功。当然我们可以通过将访问类成员变量的代码放到专门的方法中,将其声明为 synchronized ,并在主方法中调用来解决这一问题,但是 Java 为我们提供了更好的解决办法,那就是 synchronized 块。
2. synchronized 块:通过 synchronized关键字来声明synchronized 块。语法如下:
synchronized(syncObject) {
//允许访问控制的代码
}
synchronized 块是这样一个代码块,其中的代码必须获得对象 syncObject (如前所述,可以是类实例或类)的锁方能执行,具体机制同前所述。由于可以针对任意代码块,且可任意指定上锁的对象,故灵活性较高。
六:线程的阻塞
为了解决对共享存储区的访问冲突,Java 引入了同步机制,现在让我们来考察多个线程对共享资源的访问,显然同步机制已经不够了,因为在任意时刻所要求的资源不一定已经准备好了被访问,反过来,同一时刻准备好了的资源也可能不止一个。为了解决这种情况下的访问控制问题,Java 引入了对阻塞机制的支持。
阻塞指的是暂停一个线程的执行以等待某个条件发生(如某资源就绪),学过操作系统的同学对它一定已经很熟悉了。Java 提供了大量方法来支持阻塞,下面让我们逐一分析。
1. sleep() 方法:sleep() 允许 指定以毫秒为单位的一段时间作为参数,它使得线程在指定的时间内进入阻塞状态,不能得到CPU 时间,指定的时间一过,线程重新进入可执行状态。
典型地,sleep() 被用在等待某个资源就绪的情形:测试发现条件不满足后,让线程阻塞一段时间后重新测试,直到条件满足为止。
2. suspend() 和 resume() 方法:两个方法配套使用,suspend()使得线程进入阻塞状态,并且不会自动恢复,必须其对应的resume() 被调用,才能使得线程重新进入可执行状态。典型地,suspend() 和 resume() 被用在等待另一个线程产生的结果的情形:测试发现结果还没有产生后,让线程阻塞,另一个线程产生了结果后,调用 resume() 使其恢复。
3. yield() 方法:yield() 使得线程放弃当前分得的 CPU 时间,但是不使线程阻塞,即线程仍处于可执行状态,随时可能再次分得 CPU 时间。调用 yield() 的效果等价于调度程序认为该线程已执行了足够的时间从而转到另一个线程。
4. wait() 和 notify() 方法:两个方法配套使用,wait() 使得线程进入阻塞状态,它有两种形式,一种允许 指定以毫秒为单位的一段时间作为参数,另一种没有参数,前者当对应的 notify() 被调用或者超出指定时间时线程重新进入可执行状态,后者则必须对应的 notify() 被调用。
初看起来它们与 suspend() 和 resume() 方法对没有什么分别,但是事实上它们是截然不同的。区别的核心在于,前面叙述的所有方法,阻塞时都不会释放占用的锁(如果占用了的话),而这一对方法则相反。
上述的核心区别导致了一系列的细节上的区别。
首先,前面叙述的所有方法都隶属于 Thread 类,但是这一对却直接隶属于 Object 类,也就是说,所有对象都拥有这一对方法。初看起来这十分不可思议,但是实际上却是很自然的,因为这一对方法阻塞时要释放占用的锁,而锁是任何对象都具有的,调用任意对象的 wait() 方法导致线程阻塞,并且该对象上的锁被释放。而调用 任意对象的notify()方法则导致因调用该对象的 wait() 方法而阻塞的线程中随机选择的一个解除阻塞(但要等到获得锁后才真正可执行)。
其次,前面叙述的所有方法都可在任何位置调用,但是这一对方法却必须在 synchronized 方法或块中调用,理由也很简单,只有在synchronized 方法或块中当前线程才占有锁,才有锁可以释放。同样的道理,调用这一对方法的对象上的锁必须为当前线程所拥有,这样才有锁可以释放。因此,这一对方法调用必须放置在这样的 synchronized 方法或块中,该方法或块的上锁对象就是调用这一对方法的对象。若不满足这一条件,则程序虽然仍能编译,但在运行时会出现IllegalMonitorStateException 异常。
wait() 和 notify() 方法的上述特性决定了它们经常和synchronized 方法或块一起使用,将它们和操作系统的进程间通信机制作一个比较就会发现它们的相似性:synchronized方法或块提供了类似于操作系统原语的功能,它们的执行不会受到多线程机制的干扰,而这一对方法则相当于 block 和wakeup 原语(这一对方法均声明为 synchronized)。它们的结合使得我们可以实现操作系统上一系列精妙的进程间通信的算法(如信号量算法),并用于解决各种复杂的线程间通信问题。
关于 wait() 和 notify() 方法最后再说明两点:
第一:调用 notify() 方法导致解除阻塞的线程是从因调用该对象的 wait() 方法而阻塞的线程中随机选取的,我们无法预料哪一个线程将会被选择,所以编程时要特别小心,避免因这种不确定性而产生问题。
第二:除了 notify(),还有一个方法 notifyAll() 也可起到类似作用,唯一的区别在于,调用 notifyAll() 方法将把因调用该对象的 wait() 方法而阻塞的所有线程一次性全部解除阻塞。当然,只有获得锁的那一个线程才能进入可执行状态。
谈到阻塞,就不能不谈一谈死锁,略一分析就能发现,suspend() 方法和不指定超时期限的 wait() 方法的调用都可能产生死锁。遗憾的是,Java 并不在语言级别上支持死锁的避免,我们在编程中必须小心地避免死锁。
以上我们对 Java 中实现线程阻塞的各种方法作了一番分析,我们重点分析了 wait() 和 notify() 方法,因为它们的功能最强大,使用也最灵活,但是这也导致了它们的效率较低,较容易出错。实际使用中我们应该灵活使用各种方法,以便更好地达到我们的目的。
七:守护线程
守护线程是一类特殊的线程,它和普通线程的区别在于它并不是应用程序的核心部分,当一个应用程序的所有非守护线程终止运行时,即使仍然有守护线程在运行,应用程序也将终止,反之,只要有一个非守护线程在运行,应用程序就不会终止。守护线程一般被用于在后台为其它线程提供服务。
可以通过调用方法 isDaemon() 来判断一个线程是否是守护线程,也可以调用方法 setDaemon() 来将一个线程设为守护线程。
八:线程组
线程组是一个 Java 特有的概念,在 Java 中,线程组是类ThreadGroup 的对象,每个线程都隶属于唯一一个线程组,这个线程组在线程创建时指定并在线程的整个生命期内都不能更改。你可以通过调用包含 ThreadGroup 类型参数的 Thread 类构造函数来指定线程属的线程组,若没有指定,则线程缺省地隶属于名为 system 的系统线程组。
在 Java 中,除了预建的系统线程组外,所有线程组都必须显式创建。
在 Java 中,除系统线程组外的每个线程组又隶属于另一个线程组,你可以在创建线程组时指定其所隶属的线程组,若没有指定,则缺省地隶属于系统线程组。这样,所有线程组组成了一棵以系统线程组为根的树。
Java 允许我们对一个线程组中的所有线程同时进行操作,比如我们可以通过调用线程组的相应方法来设置其中所有线程的优先级,也可以启动或阻塞其中的所有线程。
Java 的线程组机制的另一个重要作用是线程安全。线程组机制允许我们通过分组来区分有不同安全特性的线程,对不同组的线程进行不同的处理,还可以通过线程组的分层结构来支持不对等安全措施的采用。Java 的 ThreadGroup 类提供了大量的方法来方便我们对线程组树中的每一个线程组以及线程组中的每一个线程进行操作。
九:总结
在这一讲中,我们一起学习了 Java 多线程编程的方方面面,包括创建线程,以及对多个线程进行调度、管理。我们深刻认识到了多线程编程的复杂性,以及线程切换开销带来的多线程程序的低效性,这也促使我们认真地思考一个问题:我们是否需要多线程?何时需要多线程?
多线程的核心在于多个代码块并发执行,本质特点在于各代码块之间的代码是乱序执行的。我们的程序是否需要多线程,就是要看这是否也是它的内在特点。
假如我们的程序根本不要求多个代码块并发执行,那自然不需要使用多线程;假如我们的程序虽然要求多个代码块并发执行,但是却不要求乱序,则我们完全可以用一个循环来简单高效地实现,也不需要使用多线程;只有当它完全符合多线程的特点时,多线程机制对线程间通信和线程管理的强大支持才能有用武之地,这时使用多线程才是值得的。
posted @
2008-06-07 13:42 xzc 阅读(245) |
评论 (0) |
编辑 收藏
- jdbcTemplate.execute("CREATE TABLE USER (user_id integer, name varchar(100))");
jdbcTemplate.execute("CREATE TABLE USER (user_id integer, name varchar(100))");
2、如果是UPDATE或INSERT,可以用update()方法。
- jdbcTemplate.update("INSERT INTO USER VALUES('"
- + user.getId() + "', '"
- + user.getName() + "', '"
- + user.getSex() + "', '"
- + user.getAge() + "')");
jdbcTemplate.update("INSERT INTO USER VALUES('"
+ user.getId() + "', '"
+ user.getName() + "', '"
+ user.getSex() + "', '"
+ user.getAge() + "')");
3、带参数的更新
- jdbcTemplate.update("UPDATE USER SET name = ? WHERE user_id = ?", new Object[] {name, id});
jdbcTemplate.update("UPDATE USER SET name = ? WHERE user_id = ?", new Object[] {name, id});
- jdbcTemplate.update("INSERT INTO USER VALUES(?, ?, ?, ?)", new Object[] {user.getId(), user.getName(), user.getSex(), user.getAge()});
jdbcTemplate.update("INSERT INTO USER VALUES(?, ?, ?, ?)", new Object[] {user.getId(), user.getName(), user.getSex(), user.getAge()});
4、使用JdbcTemplate进行查询时,使用queryForXXX()等方法
- int count = jdbcTemplate.queryForInt("SELECT COUNT(*) FROM USER");
int count = jdbcTemplate.queryForInt("SELECT COUNT(*) FROM USER");
- String name = (String) jdbcTemplate.queryForObject("SELECT name FROM USER WHERE user_id = ?", new Object[] {id}, java.lang.String.class);
String name = (String) jdbcTemplate.queryForObject("SELECT name FROM USER WHERE user_id = ?", new Object[] {id}, java.lang.String.class);
- List rows = jdbcTemplate.queryForList("SELECT * FROM USER");
List rows = jdbcTemplate.queryForList("SELECT * FROM USER");
- List rows = jdbcTemplate.queryForList("SELECT * FROM USER");
- Iterator it = rows.iterator();
- while(it.hasNext()) {
- Map userMap = (Map) it.next();
- System.out.print(userMap.get("user_id") + "\t");
- System.out.print(userMap.get("name") + "\t");
- System.out.print(userMap.get("sex") + "\t");
- System.out.println(userMap.get("age") + "\t");
- }
List rows = jdbcTemplate.queryForList("SELECT * FROM USER");
Iterator it = rows.iterator();
while(it.hasNext()) {
Map userMap = (Map) it.next();
System.out.print(userMap.get("user_id") + "\t");
System.out.print(userMap.get("name") + "\t");
System.out.print(userMap.get("sex") + "\t");
System.out.println(userMap.get("age") + "\t");
}
JdbcTemplate将我们使用的JDBC的流程封装起来,包括了异常的捕捉、SQL的执行、查询结果的转换等等。spring大量使用Template Method模式来封装固定流程的动作,XXXTemplate等类别都是基于这种方式的实现。
除了大量使用Template Method来封装一些底层的操作细节,spring也大量使用callback方式类回调相关类别的方法以提供JDBC相关类别的功能,使传统的JDBC的使用者也能清楚了解spring所提供的相关封装类别方法的使用。
JDBC的PreparedStatement
- final String id = user.getId();
- final String name = user.getName();
- final String sex = user.getSex() + "";
- final int age = user.getAge();
-
- jdbcTemplate.update("INSERT INTO USER VALUES(?, ?, ?, ?)",
- new PreparedStatementSetter() {
- public void setValues(PreparedStatement ps) throws SQLException {
- ps.setString(1, id);
- ps.setString(2, name);
- ps.setString(3, sex);
- ps.setInt(4, age);
- }
- });
final String id = user.getId();
final String name = user.getName();
final String sex = user.getSex() + "";
final int age = user.getAge();
jdbcTemplate.update("INSERT INTO USER VALUES(?, ?, ?, ?)",
new PreparedStatementSetter() {
public void setValues(PreparedStatement ps) throws SQLException {
ps.setString(1, id);
ps.setString(2, name);
ps.setString(3, sex);
ps.setInt(4, age);
}
});
- final User user = new User();
- jdbcTemplate.query("SELECT * FROM USER WHERE user_id = ?",
- new Object[] {id},
- new RowCallbackHandler() {
- public void processRow(ResultSet rs) throws SQLException {
- user.setId(rs.getString("user_id"));
- user.setName(rs.getString("name"));
- user.setSex(rs.getString("sex").charAt(0));
- user.setAge(rs.getInt("age"));
- }
- });
final User user = new User();
jdbcTemplate.query("SELECT * FROM USER WHERE user_id = ?",
new Object[] {id},
new RowCallbackHandler() {
public void processRow(ResultSet rs) throws SQLException {
user.setId(rs.getString("user_id"));
user.setName(rs.getString("name"));
user.setSex(rs.getString("sex").charAt(0));
user.setAge(rs.getInt("age"));
}
});
- class UserRowMapper implements RowMapper {
- public Object mapRow(ResultSet rs, int index) throws SQLException {
- User user = new User();
-
- user.setId(rs.getString("user_id"));
- user.setName(rs.getString("name"));
- user.setSex(rs.getString("sex").charAt(0));
- user.setAge(rs.getInt("age"));
-
- return user;
- }
- }
-
- public List findAllByRowMapperResultReader() {
- String sql = "SELECT * FROM USER";
- return jdbcTemplate.query(sql, new RowMapperResultReader(new UserRowMapper()));
- }
class UserRowMapper implements RowMapper {
public Object mapRow(ResultSet rs, int index) throws SQLException {
User user = new User();
user.setId(rs.getString("user_id"));
user.setName(rs.getString("name"));
user.setSex(rs.getString("sex").charAt(0));
user.setAge(rs.getInt("age"));
return user;
}
}
public List findAllByRowMapperResultReader() {
String sql = "SELECT * FROM USER";
return jdbcTemplate.query(sql, new RowMapperResultReader(new UserRowMapper()));
}
在getUser(id)里面使用UserRowMapper
- public User getUser(final String id) throws DataAccessException {
- String sql = "SELECT * FROM USER WHERE user_id=?";
- final Object[] params = new Object[] { id };
- List list = jdbcTemplate.query(sql, params, new RowMapperResultReader(new UserRowMapper()));
-
- return (User) list.get(0);
- }
public User getUser(final String id) throws DataAccessException {
String sql = "SELECT * FROM USER WHERE user_id=?";
final Object[] params = new Object[] { id };
List list = jdbcTemplate.query(sql, params, new RowMapperResultReader(new UserRowMapper()));
return (User) list.get(0);
}
网上收集
org.springframework.jdbc.core.PreparedStatementCreator 返回预编译SQL 不能于Object[]一起用
- public PreparedStatement createPreparedStatement(Connection con) throws SQLException {
- return con.prepareStatement(sql);
- }
public PreparedStatement createPreparedStatement(Connection con) throws SQLException {
return con.prepareStatement(sql);
}
1.增删改
org.springframework.jdbc.core.JdbcTemplate 类(必须指定数据源dataSource)
- template.update("insert into web_person values(?,?,?)",Object[]);
template.update("insert into web_person values(?,?,?)",Object[]);
或
- template.update("insert into web_person values(?,?,?)",new PreparedStatementSetter(){ 匿名内部类 只能访问外部最终局部变量
-
- public void setValues(PreparedStatement ps) throws SQLException {
- ps.setInt(index++,3);
- });
template.update("insert into web_person values(?,?,?)",new PreparedStatementSetter(){ 匿名内部类 只能访问外部最终局部变量
public void setValues(PreparedStatement ps) throws SQLException {
ps.setInt(index++,3);
});
org.springframework.jdbc.core.PreparedStatementSetter 接口 处理预编译SQL
- public void setValues(PreparedStatement ps) throws SQLException {
- ps.setInt(index++,3);
- }
public void setValues(PreparedStatement ps) throws SQLException {
ps.setInt(index++,3);
}
2.查询JdbcTemplate.query(String,[Object[]/PreparedStatementSetter],RowMapper/RowCallbackHandler)
org.springframework.jdbc.core.RowMapper 记录映射接口 处理结果集
- public Object mapRow(ResultSet rs, int arg1) throws SQLException { int表当前行数
- person.setId(rs.getInt("id"));
- }
- List template.query("select * from web_person where id=?",Object[],RowMapper);
public Object mapRow(ResultSet rs, int arg1) throws SQLException { int表当前行数
person.setId(rs.getInt("id"));
}
List template.query("select * from web_person where id=?",Object[],RowMapper);
org.springframework.jdbc.core.RowCallbackHandler 记录回调管理器接口 处理结果集
- template.query("select * from web_person where id=?",Object[],new RowCallbackHandler(){
- public void processRow(ResultSet rs) throws SQLException {
- person.setId(rs.getInt("id"));
- });
posted @
2008-06-07 13:37 xzc 阅读(460) |
评论 (0) |
编辑 收藏一.读取xml配置文件
(一)新建一个java bean(HelloBean.java)
java 代码
- package chb.demo.vo;
-
- public class HelloBean {
- private String helloWorld;
-
- public String getHelloWorld() {
- return helloWorld;
- }
-
- public void setHelloWorld(String helloWorld) {
- this.helloWorld = helloWorld;
- }
- }
-
(二)构造一个配置文件(beanConfig.xml)
xml 代码
- xml version="1.0" encoding="UTF-8"?>
- >
- <beans>
- <bean id="helloBean" class="chb.demo.vo.HelloBean">
- <property name="helloWorld">
- <value>Hello!chb!value>
- property>
- bean>
- beans>
(三)读取xml文件
1.利用ClassPathXmlApplicationContext
java 代码
- ApplicationContext context = new ClassPathXmlApplicationContext("beanConfig.xml");
- HelloBean helloBean = (HelloBean)context.getBean("helloBean");
- System.out.println(helloBean.getHelloWorld());
2.利用FileSystemResource读取
java 代码
- Resource rs = new FileSystemResource("D:/software/tomcat/webapps/springWebDemo/WEB-INF/classes/beanConfig.xml");
- BeanFactory factory = new XmlBeanFactory(rs);
- HelloBean helloBean = (HelloBean)factory.getBean("helloBean");\
- System.out.println(helloBean.getHelloWorld());
值得注意的是:利用FileSystemResource,则配置文件必须放在project直接目录下,或者写明绝对路径,否则就会抛出找不到文件的异常
二.读取properties配置文件
这里介绍两种技术:利用spring读取properties 文件和利用java.util.Properties读取
(一)利用spring读取properties 文件
我们还利用上面的HelloBean.java文件,构造如下beanConfig.properties文件:
properties 代码
- helloBean.class=chb.demo.vo.HelloBean
- helloBean.helloWorld=Hello!chb!
属性文件中的"helloBean"名称即是Bean的别名设定,.class用于指定类来源。
然后利用org.springframework.beans.factory.support.PropertiesBeanDefinitionReader来读取属性文件
java 代码
- BeanDefinitionRegistry reg = new DefaultListableBeanFactory();
- PropertiesBeanDefinitionReader reader = new PropertiesBeanDefinitionReader(reg);
- reader.loadBeanDefinitions(new ClassPathResource("beanConfig.properties"));
- BeanFactory factory = (BeanFactory)reg;
- HelloBean helloBean = (HelloBean)factory.getBean("helloBean");
- System.out.println(helloBean.getHelloWorld());
(二)利用java.util.Properties读取属性文件
比如,我们构造一个ipConfig.properties来保存服务器ip地址和端口,如:
properties 代码
则,我们可以用如下程序来获得服务器配置信息:
java 代码
- InputStream inputStream = this.getClass().getClassLoader().getResourceAsStream("ipConfig.properties");
- Properties p = new Properties();
- try {
- p.load(inputStream);
- } catch (IOException e1) {
- e1.printStackTrace();
- }
- System.out.println("ip:"+p.getProperty("ip")+",port:"+p.getProperty("port"));
本文只介绍了一些简单操作,不当之处希望大家多多指教
posted @
2008-06-06 15:56 xzc 阅读(1071) |
评论 (0) |
编辑 收藏一、数据库名
数据库名是数据库的“身份证号码”,用于标示一个数据库。在参数文件中用DB_NAME表示。
数据库名是在安装数据库、创建新的数据库、创建数据库控制文件、修改数据库结构、备份与恢复数据库时都需要使用到的。
如何查看数据库名呢?方式有三:
·使用SQL语句:select name from v$database;
·使用show命令:show parameter db_name;
·查看参数文件:查看init.ora文件
二、数据库实例名:
数据库实例名是用于和操作系统进行联系的标识,也就是说数据库和操作系统之间的交互使用的是数据库实例名。
实例名也被写入参数文件中,该参数为instance_name,在winnt平台中,实例名同时也被写入注册表。
数据库名和实例名可以相同也可以不同。在一般情况下,数据库名和实例名是一对一的关系,但如果在oracle并行服务器架构(即oracle实时应用集群)中,数据库名和实例名是一对多的关系。
如何查看当前数据库实例名呢?方式有三:
·使用SQL语句:select instance_name from v$instance;
·使用show命令:show parameter instance
·查看参数文件:查看init.ora文件
数据库实例名与ORACLE_SID两者都表示oracle实例,但是有区别的。instance_name是oracle数据库参数。而ORACLE_SID是操作系统的环境变量。ORACLD_SID用于与操作系统交互,也就是说,从操作系统的角度访问实例名,必须通过ORACLE_SID。
ORACLE_SID必须与instance_name的值一致。否则,你将会收到一个错误。在unix平台,是“ORACLE not available”,在winnt平台,是“TNS:协议适配器错误”。
三、数据库域名与全局数据库名
随着由多个数据库构成的分布式数据库的普及,这种命令数据库的方法给数据库的管理造成一定的负担,因为各个数据库的名字可能一样,造成管理上的混乱。
为了解决这种情况,引入了Db_domain参数,这样在数据库的标识是由Db_name(数据库名)和 Db_domain(数据库域名)两个参数共同决定的,避免了因为数据库重名而造成管理上的混乱。这类似于互连网上的机器名的管理。
我们将Db_name和 Db_domain两个参数用‘.’连接起来,表示一个数据库,并将该数据库的名称称为Global_name(全局数据库名),即它扩展了Db_name。Db_name参数只能由字母、数字、’_’、’#’、’$’组成,而且最多8个字符。
对一个网络数据库(Oracle database)的唯一标识,oracle建议用此种方法命令数据库。该值是在创建数据库是决定的,缺省值为Db_name. Db_domain。在以后对参数文件中Db_name与Db_domain参数的任何修改不影响Global_name的值,如果要修改 Global_name,只能用ALTER DATABASE RENAME GLOBAL_NAME TO 命令进行修改,然后修改相应参数。
如何查询数据库域名呢?方法有三:
·使用SQL命令:select value from v$parameter where name = ´db_domain´;
·使用show命令:show parameter domain
·查看参数文件:在参数文件中查询。
四、数据库服务名
该参数是oracle8i新引进的。在8i以前,我们用SID来表示标识数据库的一个实例,但是在Oracle的并行环境中,一个数据库对应多个实例,这样就需要多个网络服务名,设置繁琐。为了方便并行环境中的设置,引进了Service_name参数。该参数对应一个数据库,而不是一个实例。
该参数的缺省值为Db_name. Db_domain,即等于Global_name。如果数据库有域名,则数据库服务名就是全局数据库名;否则,数据库服务名与数据库名相同。
如何查询数据库服务名呢?方法有三:
·使用SQL语句:select value from v$parameter where name = ´service_name´;
·使用show命令:show parameter service_name
·查看参数文件:在参数文件中查询。
从oracle8i开如的oracle网络组件,数据库与客户端的连接主机串使用数据库服务名。之前用的是ORACLE_SID,即数据库实例名。
五、网络服务名
网络服务名,又可以称为数据库别名(database alias)。是客户端程序访问数据库时所需要,屏蔽了客户端如何连接到服务器端的细节,实现了数据库的位置透明的特性。网络服务名被记录在tnsnames.ora文件中。
网络服务名是从客户端的角度出发,当客户端连接远程数据库或其他服务时,可以指定Net服务名。因此需要使用一个或多个命名方法将此Net服务名解析为连接数据库或其他服务的连接描述符。
通常选择的是[本地]-将存储在本地客户机的tnsnames.ora文件中的网络服务名解析为连接描述符。
[Oracle Names]-由Oracle名字服务器提供为网络上的每个Oracle Net服务提供解析方法
[主机名]-通过TCP/IP环境中的主机别名连接到Oracle数据库服务
[Sun NIS]/[DCE CDS]-专用系统用的,在Windows 2000系统环境下不适用
六、总结
Oracle中各种命名的比较名称查询方式
|
名称
|
查询方式
|
| DB_NAME |
select name from v$database |
| INSTANCE_NAME |
select instance_name from v$instance |
| ORACLE_SID |
值和INSTANCE_NAME相同 |
| DB_DOMAIN |
select value from v$parameter where name="db_domain" |
| GLOBAL_NAME |
DB_NAME.DB_DOMAIN |
| SERVICE_NAME |
select value from v$parameter where name="service_name" |
| NET_SERVICE_NAME |
检查tnsnames.ora文件 |
posted @
2008-05-31 15:18 xzc 阅读(540) |
评论 (2) |
编辑 收藏
统一建模语言(Unified Modeling Language,UML)
一些术语:
系统(system)指的是硬件和软件的结合体,它能提供业务问题的解决方案。
系统开发(system development)是为客户建立一个系统的过程。
客户(client)是需要解决问题的人。
系统分析员(analyst)将客户所要解决的问题编制成文档,并将该文档转交给开发人员。
开发人员(developer)是为了及决客户的问题而构造软件并在计算机硬件上实施该软件的程序员。
UML的组成
UML包括了一些可以相互组合图表的图形元素。
1.类图
一个类(class)是一类或一组具有类似属性和共同行为的事物。
矩形方框代表类的图标,它被分成3个区域。最上面的区域中是类名,中间区域是类的属性,最下面区域里列的是类的操作。
举一个例子,属于洗衣机(washing machine)类的事物都具有诸如品牌(brand name)、型号(model name)、序列号(serial number)和容量(capacity)等属性。这类事物的行为包括“加衣物(add clothes)”、“加洗涤剂(add detergent)”、“开机(turn on)”和“取出衣物(remove clothes)”等操作。

2.对象图
对象(object)是一个类的实例,是具有具体属性值和行为的一个具体事物。例如,洗衣机的品牌可能是“Laundatorium”,型号为“Washmeister”,序列号为“GL57774”,一次最多可以洗涤重量为16磅的衣物。
对象的图标也是一个矩形,和类的图标一样,但是对象名下面要带下划线。具体实例的名字位于冒号的左边而该实例所属的类名位于冒号的右边。

3.用例图
用例(use case)是从用户的观点对系统行为的一个描述。
例,一个人使用一台洗衣机,显然是为了洗衣服(wash clothes)。
代表洗衣机用户的智力小人形被称为参与者(actor)。椭圆形代表用例。
参与者(它是发起用例的实体)可以是一个人也可以是另一个系统。

4.状态图
一台洗衣机可以处于浸泡(soak)、洗涤(Wash)、漂洗(Rinse)、脱水(Spin)或者关机(off)状态。

最顶端的符号代表起始状态,最底端的符号表示终止状态。
5.顺序图
类图和对象图标大的实系统的静态结构。在一个运行的系统中,对象之间要发生交互,并且这些交互要经历一定的时间。UML顺序图所表达的正式这种基于时间的动态交互。
例,洗衣机的构件包括一个注水的进水管(Water Pipe)、一个用来装衣物的洗涤缸(Drum)以一个排水管(Drain)。假设已经完成了“加衣物”、“加洗涤剂”和“开机”操作。洗衣服这个用例被执行时按照如下顺序进行:
1通过进水管想洗涤缸中注水。
2洗涤缸保持5分钟静止状态。
3水注满,停止注水。
4洗涤缸往返旋转15分钟。
5通过排水管排掉洗涤后的脏水。
6重新开始注水。
7洗涤缸继续往返旋转洗涤。
8停止向洗衣机中注水。
9通过排水管排掉漂洗衣物的水。
10洗涤缸加快速度单方向旋转5分钟。
11洗涤缸停止旋转,洗衣过程结束。
图中,对象之间发送的消息有:注入新水(Send fresh water)、保持静止(Remain stationary)、停止注水(Stop)、往返旋转(Ratate back and forth)、排掉洗涤后的脏水(Send soapy water)、排掉漂洗过的水(Send rinse water)等。

6.活动图
用例和对象的行为中的各个活动之间通常具有时间顺序。

7.协作图
系统的工作目标是由系统中各组成元素相互协作完成的。例子中洗衣机构件的类集中又增加了一个内部计时器(Internal Timer)。在经过一段时间后,定时器停止注水,然后启动洗涤缸往返旋转。图中的序号代表命令消息的发送顺序。

8.构件图
构件图和部署图和整个计算机系统密切相关。

9.部署图
UML部署图显示了基于计算机系统的物理体系结构。它可以描述计算机和设备,展示它们之间的连接,以及驻留在每台机器中的软件。每台计算机用一个立方体来表示,立方体之间的连线表示这些计算机之间的通信关系。

如果需要将图中的组织元素分组,或者在图中说明一些类或构件是某个特定子系统的一部分,可以通过将这些元素组织成包(package)来达到此目的。包用一边突起的公文夹形图标来表示。

注释(note)的图标是一个带折角的矩形,矩形框中是解释性文字。注释和被注释的图元素之间用一条虚线连接。

构造型(stereotype)能够使用现有的UML元素来定制新的元素。构造型用尖对括号括起来的一个名称来表示,这个括号叫双尖括号(guillemets)。

v
posted @
2008-05-30 21:03 xzc 阅读(415) |
评论 (0) |
编辑 收藏
功能:
1、 允许/限制对表的修改
2、 自动生成派生列,比如自增字段
3、 强制数据一致性
4、 提供审计和日志记录
5、 防止无效的事务处理
6、 启用复杂的业务逻辑
开始
create trigger biufer_employees_department_id
before insert or update
of department_id
on employees
referencing old as old_value
new as new_value
for each row
when (new_value.department_id<>80 )
begin
:new_value.commission_pct :=0;
end;
/
触发器的组成部分:
1、 触发器名称
2、 触发语句
3、 触发器限制
4、 触发操作
1、 触发器名称
create trigger biufer_employees_department_id
命名习惯:
biufer(before insert update for each row)
employees 表名
department_id 列名
2、 触发语句
比如:
表或视图上的DML语句
DDL语句
数据库关闭或启动,startup shutdown 等等
before insert or update
of department_id
on employees
referencing old as old_value
new as new_value
for each row
说明:
1、 无论是否规定了department_id ,对employees表进行insert的时候
2、 对employees表的department_id列进行update的时候
3、 触发器限制
when (new_value.department_id<>80 )
限制不是必须的。此例表示如果列department_id不等于80的时候,触发器就会执行。
其中的new_value是代表更新之后的值。
4、 触发操作
是触发器的主体
begin
:new_value.commission_pct :=0;
end;
主体很简单,就是将更新后的commission_pct列置为0
触发:
insert into employees(employee_id,
last_name,first_name,hire_date,job_id,email,department_id,salary,commission_pct )
values( 12345,’Chen’,’Donny’, sysdate, 12, ‘donny@hotmail.com’,60,10000,.25);
select commission_pct from employees where employee_id=12345;
触发器不会通知用户,便改变了用户的输入值。
触发器类型:
1、 语句触发器
2、 行触发器
3、 INSTEAD OF 触发器
4、 系统条件触发器
5、 用户事件触发器
1、 语句触发器
是在表上或者某些情况下的视图上执行的特定语句或者语句组上的触发器。能够与INSERT、UPDATE、DELETE或者组合上进行关联。但是无论使用什么样的组合,各个语句触发器都只会针对指定语句激活一次。比如,无论update多少行,也只会调用一次update语句触发器。
例子:
需要对在表上进行DML操作的用户进行安全检查,看是否具有合适的特权。
Create table foo(a number);
Create trigger biud_foo
Before insert or update or delete
On foo
Begin
If user not in (‘DONNY’) then
Raise_application_error(-20001, ‘You don’t have access to modify this table.’);
End if;
End;
/
即使SYS,SYSTEM用户也不能修改foo表
[试验]
对修改表的时间、人物进行日志记录。
1、 建立试验表
create table employees_copy as select *from hr.employees
2、 建立日志表
create table employees_log(
who varchar2(30),
when date);
3、 在employees_copy表上建立语句触发器,在触发器中填充employees_log 表。
Create or replace trigger biud_employee_copy
Before insert or update or delete
On employees_copy
Begin
Insert into employees_log(
Who,when)
Values( user, sysdate);
End;
/
4、 测试
update employees_copy set salary= salary*1.1;
select *from employess_log;
5、 确定是哪个语句起作用?
即是INSERT/UPDATE/DELETE中的哪一个触发了触发器?
可以在触发器中使用INSERTING / UPDATING / DELETING 条件谓词,作判断:
begin
if inserting then
-----
elsif updating then
-----
elsif deleting then
------
end if;
end;
if updating(‘COL1’) or updating(‘COL2’) then
------
end if;
[试验]
1、 修改日志表
alter table employees_log
add (action varchar2(20));
2、 修改触发器,以便记录语句类型。
Create or replace trigger biud_employee_copy
Before insert or update or delete
On employees_copy
Declare
L_action employees_log.action%type;
Begin
if inserting then
l_action:=’Insert’;
elsif updating then
l_action:=’Update’;
elsif deleting then
l_action:=’Delete’;
else
raise_application_error(-20001,’You should never ever get this error.’);
Insert into employees_log(
Who,action,when)
Values( user, l_action,sysdate);
End;
/
3、 测试
insert into employees_copy( employee_id, last_name, email, hire_date, job_id)
values(12345,’Chen’,’Donny@hotmail’,sysdate,12);
select *from employees_log
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=1711633
posted @
2008-05-27 15:22 xzc 阅读(895) |
评论 (1) |
编辑 收藏下面就是例子程序
--明细表打印予处理 通用报表:
procedure mx_print_common(pd_id in mx_pd_syn.pd_id%type,
p_pd_mxb_id IN mx_pd_mxb_syn.p_mxb_id%type,
p_dept_no IN sc_mxk.dept_code%type,
p1 sc_bz_syn.bz_code%type,
p2 sc_cjjc_syn.cjjc_code%type,
p3 sc_mxk.warehouse_num%type)
is
sql2 varchar2(500); --存储查询语句
sql3 varchar2(500); --存储查询条件
str1 sc_print_syn.a%type; --存储车间进程
str2 sc_print_syn.b%type; --存储班组(工艺、工序)进程
s_ip sc_print_syn.ip%type;
type cursor_type is ref cursor;
c1 cursor_type;
type record_type is record(
pbom_id sc_mxk.pbom_id%type
);
r_c1 record_type;
/*
注意上面红色的两行和蓝色的两行
红色的两行定义一个游标
蓝色的两行定义一个游标中将要返回的数据的数据结构
*/
cursor c2(p_pbom_id sc_mxk.pbom_id%type) is
select a.dd_count,b.gx_name,c.bz_name,d.cjjc_name
from sc_p_gx_syn a,sc_gx_syn b,sc_bz_syn c,sc_cjjc_syn d
where pbom_id = p_pbom_id
and a.gx_code=b.gx_code(+) and b.dept_code=p_dept_no
and a.bz_code=c.bz_code(+) and b.dept_code=p_dept_no
and a.cjjc_code=d.cjjc_code(+) and b.dept_code=p_dept_no;
r_c2 c2%rowtype;
BEGIN
s_ip :=sys_context('USERENV','IP_ADDRESS');
delete from sc_print_syn where ip=s_ip and p_id=pd_id;
commit;
--下面开始构造查询语句
sql2:='select distinct a.pbom_id from sc_mxk a';
sql3:=' where a.p_id=' || pd_id || ' and a.dept_code= ''' || p_dept_no || '''';
if p_pd_mxb_id >0 then
sql2:=sql3 || ',mxk c ';
sql3:=sql3 || ' and c.m_mxb_id= ' || p_pd_mxb_id || ' and a.mxb_id = c.mxb_id';
end if;
if p1 is not null then
sql2:=sql2 || ',sc_p_gx_syn b';
sql3:=sql3 || ' and a.pbom_id=b.pbom_id and b.bz_code = ''' || p1 || '''';
end if;
if p2 is not null then
sql2:=sql2 || ',sc_p_gx_syn b';
sql3:=sql3 || ' and a.pbom_id=b.pbom_id and b.cjjc_code = ''' || p2 || '''';
end if;
if p3 is not null then
sql3:=sql3 || ' and a.warehouse_num = ''' || p3 || '''';
end if;
sql2:=sql2 || sql3;
--打开动态游标,再往下就都一样了
open c1 for sql2;
loop
fetch c1 into r_c1;
exit when c1%notfound;
str1:='';
str2:='';
--打开工序表进行处理
open c2(r_c1.pbom_id);
loop
fetch c2 into r_c2;
exit when c2%notfound; --没有记录退出
if r_c2.cjjc_name is not null then
str1 :=str1 || to_char(r_c2.cjjc_name);
end if;
if r_c2.bz_name is not null then
str2 := str2 || r_c2.bz_name || to_char(r_c2.dd_count);
elsif r_c2.gx_name is not null then
str2 := str2 || to_char(r_c2.gx_name) || to_char(r_c2.dd_count);
end if;
end loop;
close c2;
insert into sc_print_syn(a,b,ip,p_id,r_id)
values(str1,str2,s_ip,pd_id,r_c1.pbom_id);
COMMIT;
end loop;
close c1;
END mx_print_common;
当然,实现的方法一定很多,甚至可以用隐式游标。但是隐式游标中用动态查询语句也要费一些周折的。
作者:Northsnow
电子邮件:northsnow@163.com
blog:http://blog.csdn.net/precipitant
posted @
2008-05-27 09:17 xzc 阅读(10538) |
评论 (3) |
编辑 收藏1、 Loggers
Loggers组件在此系统中被分为五个级别:DEBUG、INFO、WARN、ERROR和FATAL。这五个级别是有顺序的,DEBUG < INFO < WARN < ERROR < FATAL,明白这一点很重要,这里Log4j有一个规则:假设Loggers级别为P,如果在Loggers中发生了一个级别Q比P高,则可以启动,否则屏蔽掉。
Java程序举例来说:
//建立Logger的一个实例,命名为“com.foo”
Logger logger = Logger.getLogger("com.foo");
//设置logger的级别。通常不在程序中设置logger的级别。一般在配置文件中设置。
logger.setLevel(Level.INFO);
Logger barlogger = Logger.getLogger("com.foo.Bar");
//下面这个请求可用,因为WARN >= INFO
logger.warn("Low fuel level.");
//下面这个请求不可用,因为DEBUG < INFO
logger.debug("Starting search for nearest gas station.");
//命名为“com.foo.bar”的实例barlogger会继承实例“com.foo”的级别。因此,下面这个请求可用,因为INFO >= INFO
barlogger.info("Located nearest gas station.");
//下面这个请求不可用,因为DEBUG < INFO
barlogger.debug("Exiting gas station search");
这里“是否可用”的意思是能否输出Logger信息。
在对Logger实例进行命名时,没有限制,可以取任意自己感兴趣的名字。一般情况下建议以类的所在位置来命名Logger实例,这是目前来讲比较有效的Logger命名方式。这样可以使得每个类建立自己的日志信息,便于管理。比如:
static Logger logger = Logger.getLogger(ClientWithLog4j.class.getName());
2、 Appenders
禁用与使用日志请求只是Log4j其中的一个小小的地方,Log4j日志系统允许把日志输出到不同的地方,如控制台(Console)、文件(Files)、根据天数或者文件大小产生新的文件、以流的形式发送到其它地方等等。
其语法表示为:
org.apache.log4j.ConsoleAppender(控制台),
org.apache.log4j.FileAppender(文件),
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件),
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
配置时使用方式为:
log4j.appender.appenderName = fully.qualified.name.of.appender.class
log4j.appender.appenderName.option1 = value1
…
log4j.appender.appenderName.option = valueN
这样就为日志的输出提供了相当大的便利。
3、 Layouts
有时用户希望根据自己的喜好格式化自己的日志输出。Log4j可以在Appenders的后面附加Layouts来完成这个功能。Layouts提供了四种日志输出样式,如根据HTML样式、自由指定样式、包含日志级别与信息的样式和包含日志时间、线程、类别等信息的样式等等。
其语法表示为:
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
配置时使用方式为:
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
log4j.appender.appenderName.layout.option1 = value1
…
log4j.appender.appenderName.layout.option = valueN
以上是从原理方面说明Log4j的使用方法,在具体Java编程使用Log4j可以参照以下示例:
1、 建立Logger实例:
语法表示:public static Logger getLogger( String name)
实际使用:static Logger logger = Logger.getLogger (ServerWithLog4j.class.getName ()) ;
2、 读取配置文件:
获得了Logger的实例之后,接下来将配置Log4j使用环境:
语法表示:
BasicConfigurator.configure():自动快速地使用缺省Log4j环境。
PropertyConfigurator.configure(String configFilename):读取使用Java的特性文件编写的配置文件。
DOMConfigurator.configure(String filename):读取XML形式的配置文件。
实际使用:PropertyConfigurator.configure("ServerWithLog4j.properties");
3、 插入日志信息
完成了以上连个步骤以后,下面就可以按日志的不同级别插入到你要记录日志的任何地方了。
语法表示:
Logger.debug(Object message);
Logger.info(Object message);
Logger.warn(Object message);
Logger.error(Object message);
实际使用:logger.info("ServerSocket before accept: " + server);
在实际编程时,要使Log4j真正在系统中运行事先还要对配置文件进行定义。定义步骤就是对Logger、Appender及Layout的分别使用,具体如下:
1、 配置根Logger,其语法为:
log4j.rootLogger = [ level ] , appenderName, appenderName, …
这里level指Logger的优先级,appenderName是日志信息的输出地,可以同时指定多个输出地。如:log4j.rootLogger= INFO,A1,A2
2、 配置日志信息输出目的地,其语法为:
log4j.appender.appenderName = fully.qualified.name.of.appender.class
可以指定上面所述五个目的地中的一个。
3、 配置日志信息的格式,其语法为:
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
这里上面三个步骤是对前面Log4j组件说明的一个简化;下面给出一个具体配置例子,在程序中可以参照执行:
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=
%-4r %-5p %d{yyyy-MM-dd HH:mm:ssS} %c %m%n
这里需要说明的就是日志信息格式中几个符号所代表的含义:
-X号: X信息输出时左对齐;
%p: 日志信息级别
%d{}: 日志信息产生时间
%c: 日志信息所在地(类名)
%m: 产生的日志具体信息
%n: 输出日志信息换行
根据上面的日志格式,某一个程序的输出结果如下:
0 INFO 2003-06-13 13:23:46968 ClientWithLog4j Client socket: Socket[addr=localhost/127.0.0.1,port=8002,localport=2014]
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j Server says: 'Java server with log4j, Fri Jun 13 13:23:46 CST 2003'
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j GOOD
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j Server responds: 'Command 'HELLO' not understood.'
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j HELP
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j Server responds: 'Vocabulary: HELP QUIT'
16 DEBUG 2003-06-13 13:23:46984 ClientWithLog4j QUIT
posted @
2008-05-21 10:36 xzc 阅读(427) |
评论 (0) |
编辑 收藏
在强调可重用组件开发的今天,除了自己从头到尾开发一个可重用的日志操作类外,Apache为我们提供了一个强有力的日志操作包-Log4j。
Log4j是Apache的一个开放源代码项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等;我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
此外,通过Log4j其他语言接口,您可以在C、php、C++、.Net、PL/SQL程序中使用Log4j,其语法和用法与在Java程序中一样,使得多语言分布式系统得到一个统一一致的日志组件模块。而且,通过使用各种第三方扩展,您可以很方便地将Log4j集成到J2EE、JINI甚至是SNMP应用中。
Log4j配置文件详细说明(*.properties和*.xml)
属性文件Properties
properties属性文件
编号 配置项 配置项描述 示例
1 log4j.threshold 阈值项 log4j.threshold = error
2 log4j.rootLogger 根日志属性项 log4j.rootLogger = info,stdout1,stdout2
3 log4j.category. 子日志属性项(旧) log4j.category.com.eos = NULL,stdout1
4 log4j.logger. 子日志属性项(新) log4j.logger.com.eos.log = debug,stdout2
5 log4j.additivity. appender是否继承设置 log4j.additivity.com.eos = false
6 log4j.appender. 输出目的地定义项 log4j.appender.stdout2 = org.apache.log4j.ConsoleAppender
7 log4j.appender.A.layout 输出格式定义项 log4j.appender.stdout2.layout = org.apache.log4j.PatternLayout
xml文件
编号 配置项 配置项描述 示例
1 threshold 阈值项
2 root 根日志属性项
3 priority 级别项(旧)
4 level 级别项(新)
5 category 子日志属性项(旧)
6 logger 子日志属性项(新)
7 appender-ref 输出端控制项
8 additivity appender是否继承设置
9 appender 输出目的地定义项
10 layout 输出格式定义项
详细说明(只针对Log4j常用的,用户可以自定义)Appender
Appender继承关系
Appender基本种类
org.apache.log4j.ConsoleAppender(控制台)
org.apache.log4j.FileAppender(文件)
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
· ConsoleAppender选项
Threshold=WARN:指定日志消息的输出最低层次。
ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。
Target=System.err:默认情况下是:System.out,指定输出控制台
· FileAppender 选项
Threshold=WARN:指定日志消息的输出最低层次。
ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。
File=mylog.txt:指定消息输出到mylog.txt文件。
Append=false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。
· DailyRollingFileAppender 选项
Threshold=WARN:指定日志消息的输出最低层次。
ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。
File=mylog.txt:指定消息输出到mylog.txt文件。
Append=false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。
DatePattern='.'yyyy-ww:每周滚动一次文件,即每周产生一个新的文件。当然也可以指定按月、周、
天、时和分。即对应的格式如下:
1)'.'yyyy-MM: 每月
2)'.'yyyy-ww: 每周
3)'.'yyyy-MM-dd: 每天
4)'.'yyyy-MM-dd-a: 每天两次
5)'.'yyyy-MM-dd-HH: 每小时
6)'.'yyyy-MM-dd-HH-mm: 每分钟
n RollingFileAppender 选项
Threshold=WARN:指定日志消息的输出最低层次。
ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。
File=mylog.txt:指定消息输出到mylog.txt文件。
Append=false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。
MaxFileSize=100KB: 后缀可以是KB, MB 或者是 GB. 在日志文件到达该大小时,将会自动滚动,即将原来
的内容移到mylog.log.1文件。
MaxBackupIndex=2:指定可以产生的滚动文件的最大数。
详细说明(只针对Log4j,用户可以自定义)Layout
Log4j的Layout基本种类
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
· HTMLLayout选项
LocationInfo=true:默认值是false,输出java文件名称和行号
Title=my app file: 默认值是 Log4J Log Messages.
n PatternLayout 选项
log4j.appender.A1.layout.ConversionPattern=%-4r %-5p %d{yyyy-MM-dd HH:mm:ssS} %c %m%n
这里需要说明的就是日志信息格式中几个符号所代表的含义:
%X: 信息输出时左对齐;
%p: 输出日志信息优先级,即DEBUG,INFO,WARN,ERROR,FATAL,
%d: 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%r: 输出自应用启动到输出该log信息耗费的毫秒数
%c: 输出日志信息所属的类目,通常就是所在类的全名
%t: 输出产生该日志事件的线程名
%l: 输出日志事件的发生位置,相当于%C.%M(%F:%L)的组合,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main(TestLog4.java:10)
%x: 输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
%%: 输出一个"%"字符
%F: 输出日志消息产生时所在的文件名称
%L: 输出代码中的行号
%m: 输出代码中指定的消息,产生的日志具体信息
%n: 输出一个回车换行符,Windows平台为"\r\n",Unix平台为"\n"输出日志信息换行,可以在%与模式字符之间加上修饰符来控制其最小宽度、最大宽度、和文本的对齐方式。如:
1)%20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,默认的情况下右对齐。
2)%-20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,"-"号指定左对齐。
3)%.30c:指定输出category的名称,最大的宽度是30,如果category的名称大于30的话,就会将左边多出的字符截掉,但小于30的话也不会有空格。
4)%20.30c:如果category的名称小于20就补空格,并且右对齐,如果其名称长于30字符, 就从左边交远销出的字符截掉。
· XMLLayout 选项
LocationInfo=true:默认值是false,输出java文件和行号
日志配置文件内容范例
log4j.properties
#注意:在属性配置文件中,属性值的第一个一定是级别,输出端可有可无,以逗号分割。(而xml文件格式没有这种限制)
log4j.xml
- < xml version="1.0" encoding="UTF-8" >
- <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
- <log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/" debug="false" threshold="null">
-
-
- <appender class="org.apache.log4j.ConsoleAppender" name="CONSOLE">
- <param name="Target" value="System.out"/>
- <param name="Threshold" value="INFO"/>
- <layout class="org.apache.log4j.PatternLayout">
- <param name="ConversionPattern" value="%d [%p] - %m%n "/>
- </layout>
- <filter class="org.apache.log4j.varia.DenyAllFilter"/>
- <errorHandler class="org.apache.log4j.varia. FallbackErrorHandler"/>
- </appender>
-
- <appender class="org.apache.log4j.FileAppender" name="FILE">
- <param name="File" value="file.log"/>
- <param name="Append" value="false"/>
- <param name="Threshold" value="INFO"/>
- <layout class="org.apache.log4j.PatternLayout">
- <param name="ConversionPattern" value="%d [%p] - %m%n "/>
- </layout>
- </appender>
-
- <appender class="org.apache.log4j.RollingFileAppender" name="ROLLING_FILE">
- <param name="Threshold" value="INFO"/>
- <param name="File" value="rolling.log"/>
- <param name="Append" value="false"/>
- <param name="MaxFileSize" value="10KB"/>
- <param name="MaxBackupIndex" value="1"/>
- <layout class="org.apache.log4j.PatternLayout">
- <param name="ConversionPattern" value="%d [%p] - %m%n "/>
- </layout>
- </appender>
-
- <logger additivity="false" name="com.eos">
- <level value="info"/>
- <appender-ref ref="CONSOLE"/>
- </logger>
-
- <category additivity="true" name="com.eos.log">
- <priority value="warn"/>
- </category>
-
- <root>
- <priority value="info"/>
- <appender-ref ref="CONSOLE"/>
- </root>
- </log4j:configuration>
posted @
2008-05-21 10:35 xzc 阅读(3988) |
评论 (1) |
编辑 收藏发布日期:2006年07月30日,更新日期:2006年07月30日
1996年初,欧洲安全电子市场(EU SEMPER)项目组决定编写自己的日志记录API,后来这个API演变成了Log4j。Log4j是一个开放源码项目,一个非常流行的Java日志记录包。它允许开发者向代码中插入日志记录语句,还允许在不修改应用程序源码的情况下修改记录日志的行为。
1996年初,欧洲安全电子市场(EU SEMPER)项目组决定编写自己的日志记录API,后来这个API演变成了Log4j。Log4j是一个开放源码项目,一个非常流行的Java日志记录包。它允许开发者向代码中插入日志记录语句,还允许在不修改应用程序源码的情况下修改日志记录的行为。
几乎每一个项目都会使用日志记录,但是由于日志记录不是项目的核心,因此受重视的程度一般不是很高。我们认为使用日志记录是一件非常严肃的事情,而且做好使用日志记录的规划比单纯记录日志本身更加重要。
本文将比较全面的阐述Log4j的设计原理和使用方法。
日志记录记录的是应用程序运行的轨迹。我们可以通过查看这些轨迹来调试应用程序,这可能也是日志记录最为流行的用法了。但是我们必须意识到规划良好的日志记录中还含有丰富的信息,通过手工的方式或借助一些工具(大多数时候需要自己来书写这些工具)来分析挖掘这些信息。
例如,如果我们在规划中指出必须记录用户的每一次操作,记录的样式为 [日志信息]-[操作开始的时间]-[日志级别]-[日志类别]-[用户名]-[操作名]-[消息],这只是我们假设的一种样式,实际的日志中一般会含有比这更加丰富的信息。为了更好的理解,我们根据该样式构造了一些日志记录(其中日志类别org.solol.Main、org.solol.Parser和org.solol.UserOperator使用了不同的样式):
[日志信息]-[2006-07-30 08:54:20]-[INFO]-[org.solol.Main]-[具体的消息]
[日志信息]-[2006-07-30 08:55:20]-[INFO]-[org.solol.UserOperator]-[User1]-[查询报表1]-[具体的消息]
[日志信息]-[2006-07-30 08:55:30]-[INFO]-[org.solol.UserOperator]-[User1]-[查询报表2]-[具体的消息]
[日志信息]-[2006-07-30 08:56:01]-[INFO]-[org.solol.Parser]-[具体的消息]
[日志信息]-[2006-07-30 08:57:26]-[INFO]-[org.solol.UserOperator]-[User2]-[添加用户User3]-[具体的消息]
[日志信息]-[2006-07-30 08:58:20]-[INFO]-[org.solol.UserOperator]-[User1]-[查询报表3]-[具体的消息]
[日志信息]-[2006-07-30 08:59:38]-[INFO]-[org.solol.UserOperator]-[User3]-[查询报表1]-[具体的消息]
[日志信息]-[2006-07-30 08:59:39]-[INFO]-[org.solol.UserOperator]-[User2]-[退出系统]-[具体的消息]
从上面的日志记录中我们很容易抽取出某一用户的操作列表,如对于用户User1我们的结果为:
[日志信息]-[2006-07-30 08:55:20]-[INFO]-[org.solol.UserOperator]-[User1]-[查询报表1]-[具体的消息]
[日志信息]-[2006-07-30 08:55:30]-[INFO]-[org.solol.UserOperator]-[User1]-[查询报表2]-[具体的消息]
[日志信息]-[2006-07-30 08:58:20]-[INFO]-[org.solol.UserOperator]-[User1]-[查询报表3]-[具体的消息]
这样我们就得到了某一时间段中User1的操作列表,可以利用这一列表来进行安全分析。
我们还可以从另外的角度来分析上面的日志记录,如我们很容易统计出操作(日志类别为org.solol.UserOperator)发生的总次数(6次),其中操作[查询报表1]为2次,[查询报表2]为1次,[查询报表3]为1次,[添加用户User3]为1次,[退出系统]为1次。这样我们就可以得出系统中的那些操作用户使用的比较频繁。
以上我们从两个角度对日记记录中的信息进行了简单的挖掘,实际中待挖掘的方面要丰富的多,这取决于您的意图和您的想象力。
这里我们还要特别强调一下:所有这一切都需要有使用日志记录的良好规划。如果规划不好(即日志记录没有规律性),那么我们挖掘时的任务就会非常繁重或者使挖掘成为一个不可能的任务。
文章到了这里我们要来描述日志记录的最为流行的用法了,即调试应用程序。我们在调试应用程序时一般会使用两种方法,除了日志记录之外,还有debugger调试器。
我们不想把他们放到一起来描述,因为这是两个完全不同的问题,虽然他们都用来调试应用程序。使用debugger调试器我们可以清楚的知道引发错误的上下文及其相关信息,也可以使用单步执行、设置断点、检查变量以及暂挂和恢复线程等等比较高级的能力,但是尽管这样它也不能替代日志记录,同样日志记录也不能替代debugger调试器。我们要结合使用这两种方法,不同的场景使用不同的方法会有更好的效果。
我们认为使用日志记录来调试应用程也应该充分考虑软件的开发周期。这里我们只考虑软件开发周期中的与日志记录有关的两个阶段:
- 开发阶段,用来记录应用程序的方方面面和各种细节,非常详细,使得一看到它就知道那里出了问题,出了什么样的问题。
- 出品阶段,要能够记录各种级别的错误和警告,同时也要适度记录应用程序正常运行的关键信息,这些信息可以给相关人员(开发人员、测试人员、用户等)极大的信心,使他们可以毫不犹豫的告诉您--瞧我们的软件在正常的运行。如一个好的web服务器的启动日志记录不仅要包含错误和警告,还要包含服务器正在启动,正在加载某某组件等等,最后还要提示启动是成功还是失败。
阅读到这里我们就应该着手实现我们的日志记录了。比较幸运的是我们有好多日志记录软件包可选,这就使我们不必关心日志记录的细节,只要把主要的精力放到日志记录的规划上就好了。我们选择的是Log4j,文章的余下部分将主要介绍这个Java日志记录软件包。
log4j的特性列表:
- 在运行速度方面进行了优化
- 使用基于名称的日志(logger)层次结构
- 是fail-stop的
- 是线程安全的
- 不受限于预定义的实用工具集
- 可以在运行时使用property和xml两种格式的文件来配置日志记录的行为
- 在一开始就设计为能够处理Java异常
- 能够定向输出到文件(file)、控制台(console)、java.io.OutputStream、java.io.Writer、远程服务器、远程Unix Syslog守护者、远程JMS监听者、NT EventLog或者发送e-mail
- 使用DEBUG、INFO、WARN、ERROR和FATAL五5个级别
- 可以容易的改变日志记录的布局(Layout)
- 输出日志记录的目的地和写策略可以通过实现Appender接口来改变
- 支持为每个日志(logger)附加多个目的地(appender)
- 提供国际化支持
Log4j有三个主要的组件:Logger、Appender和Layout。这三个组件相互配合使得我们可以获得非常强大的日志记录的能力。
Logger的名称是区分大小写的,依据名称可以确定其层次结构(即父子关系),规则如下:
- 如果Logger A的名称后跟一个点(.)是Logger B的名称的前缀就认为Logger A是Logger B的祖先。
- 如果在Logger A和Logger B之间,Logger B没有任何其它的祖先就认为Logger A是Logger B的父亲。
在Logger的层次结构的最顶层是root logger,它会永远存在,而且不能通过名字取到。
上面文字的描述可能不好的理解,为此我们给出了一张图,Logger的层次结构图,从中可以非常直观的看出三种主要组件的关系和各自所起的作用。
图示 1. Logger的层次结构图

Loger x.y是Logger x.y.z的祖先,因为x.y.是x.y.z的前缀,这符合规则的前一条。另外在Logger x.y和Logger x.y.z之间,Logger x.y.z没有其它的祖先,因此Logger x.y是Logger x.y.z的父亲,这符合规则的后一条。这样我们依据上面的规则就可以构造出如图1所示的Logger的层次结构。
从图1中我们还可以看到每一个Logger都有一个Level,根据该Level的值Logger决定是否处理对应的日志请求。如果Level没有被设置,就象图1中的Logger x.y一样,又该怎么办呢?答案是可以从祖先那里继承。
如果Logger C没有被设置Level,那么它将沿着它的层次结构向上查找,如果找到就继承并结束,否则会一直查找到root logger结束。因为log4j在设计时保证root logger会被设置一个默认的Level,所以任何logger都可以继承到Level。
图1中的Logger x.y没有被设置Level,但是根据上面的继承规则,Logger x.y继承了root logger的Level。
我们在来看看Logger选择日志记录请求(log request)的规则:
假设Logger M具有q级的Level,这个Level可能是设置的也可能是继承到的。
如果向Logger M发出一个Level为p的日志记录请求,那么只有满足p>=q时这个日志记录请求才会被处理。
org.apache.log4j.Logger中的不同方法发出不同Level的日志记录请求,如下:
- public void debug(Object message),发出Level为DEBUG的日志记录请求
- public void info(Object message),发出Level为INFO的日志记录请求
- public void warn(Object message),发出Level为WARN的日志记录请求
- public void error(Object message),发出Level为ERROR日志记录请求
- public void fatal(Object message),发出Level为FATAL的日志请求
- public void log(Level l, Object message),发出指定Level的日志记录请求
其中的静态常量DEBUG、INFO、WARN、ERROR、FATAL是在org.apache.log4j.Level中定义的,除了使用这些预定义的Level之外,Log4j还支持自定义Level。
注:org.apache.log4j.Level中还预定义了一些其它的Level。
在Log4j中,Appender指的是日志记录输出的目的地。当前支持的Appender(目的地)有文件(file)、控制台(console)、java.io.OutputStream、java.io.Writer、远程服务器、远程Unix Syslog守护者、远程JMS监听者、NT EventLog或者发送e-mail。如果您在上面没有找到适合的Appender,那就需要考虑实现自己的自定义Appender了。
每个Logger可以有多个Appender,但是相同的Appender只会被添加一次。
Appender的附加性意味着Logger C会将日志记录发给它的和它祖先的所有Appender。在图1中Logger a会将日志记录发给它自己的JDBCAppender和它的祖先root logger的ConsoleAppender和FileAppender。Logger x.y.z自己没有Appender,它将把日志记录发给它的祖先root logger的ConsoleAppender和FileAppender,如果Logger x.y也含有Appender,那么它们也会包括在内。
Appender的附加性是可以被中断的。假设Logger C的一个祖先为Logger P,如果Logger P的附加性标志(additivity flag)设置为假,那么Logger C会将日志记录只发给它的和在它和Logger P之间的祖先(包括Logger P)的Appender,而不会发给Logger P的祖先的Appender。Logger的附加性标志(additivity flag)默认值为ture。
在图1中如果没有设置Logger a的附加性标志(additivity flag),而是使用默认值true,那么Logger a会将日志记录发给它自己的JDBCAppender和它祖先root logger的ConsoleAppender和FileAppender,这和上面的描述相同。如果设置Logger a的附加性标志(additivity flag)的值false,那么Logger a会将日志记录发给它自己的JDBCAppender而不会在发给它祖先root logger的ConsoleAppender和FileAppender了。
Appender定制了输出目的地,通常我们还需要定制日志记录的输出格式,在Log4j中是通过将Layout和Appender关联到一起来实现的。Layout依据用户的要求来格式化日志记录。PatternLayout(标准Log4j组件)让用户依据类似于C语言printf函数的转换模式来指定输出格式。
例如,转换模式(conversion pattern)为"%r [%t] %-5p %c - %m%n"的PatternLayout将生成类似于以下内容的输出:
176 [main] INFO org.foo.Bar - Located nearest gas station.
在上面的输出中:
- 第一个字段表示自程序开始到发出日志记录请求时所消耗的毫秒数
- 第二个字段表示发出日志记录请求的线程
- 第三个字段表示日志记录请求的Level
- 第四个字段表示发出日志记录请求的Logger的名称
- 第五个字段(-后的文本)表示日志记录请求的消息
Log4j中还提到了一些其它的Layout,包括HTMLLayout、SimpleLayout、XMLLayout、TTCCLayout和DateLayout。如果这些不能满足您的要求,还可以自定义自己的Layout。
依据既有的经验显示用于日志记录的代码大约是全部代码量的4%。如果应用程序具有一定的规模,日志记录语句的数量还是比较巨大的,因此必须有效的管理这些语句。
在Log4j中我们可以通过配置Log4j环境来有效的管理日志记录。配置的方式有三种:
- 通过程序配置
- 通过Property文件配置
- 通过XML文件配置
通过程序配置Log4j环境实际上就是在应用程序的代码中改变Logger的Level或增加减少Appender等等。
Log4j提供了BasicConfigurator,它只是为root logger添加Appender。其中,
- BasicConfigurator.configure()为root logger添加一个关联着PatternLayout.TTCC_CONVERSION_PATTERN的ConsoleAppender
- BasicConfigurator.configure(Appender appender)为root logger添加指定的Appender
我们可以把BasicConfigurator看成是一个简单的使用程序配置Log4j环境的示例。例如,要给root logger添加两个Appender(A和B),下面的代码分别完成了这个要求。
不使用BasicConfigurator:
//示例代码,不能直接使用
Logger root = Logger.getRootLogger();
root.addAppender(A);
root.addAppender(B);
使用BasicConfigurator:
//示例代码,不能直接使用
BasicConfigurator.configure(A);
BasicConfigurator.configure(B);
这里要使用PropertyConfigurator来分析配置文件并设置日志记录,但是要注意日志记录先前的配置不会被清除和重设。
Property文件是由key=value这样的键值对所组成的,可以使用#或!作为注释行的开始。下面给出了两个简单的示例:
非常简单的示例1:
log4j.rootLogger=DEBUG, A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
稍显复杂的示例2:
log4j.rootLogger=, A1, A2
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%d %-5p [%t] %-17c{2} (%13F:%L) %3x - %m%n
log4j.appender.A2=org.apache.log4j.FileAppender
log4j.appender.A2.File=filename.log
log4j.appender.A2.Append=false
log4j.appender.A2.layout=org.apache.log4j.PatternLayout
log4j.appender.A2.layout.ConversionPattern=%-5r %-5p [%t] %c{2} - %m%n
上面的两个示例只是让您对配置文件的格式有一个大体的认识,我们将在后面详细的描述各个配置元素的语法。
Repository-wide threshold:
Repository-wide threshold指定的Level的优先级高于Logger本身的Level。语法为log4j.threshold=[level],level可以为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL。也可以使用自定义Level,这时的语法为log4j.threshold=[level#classname]。默认为ALL。
依据上面的规则,我们有这样的结论:如果log4j.threshold=ERROR,Logger C的Level=DEBUG,这时只有高于等于ERROR的日志记录请求会被Logger C处理。
Appender的配置:
Appender的配置语法为
# For appender named appenderName, set its class.
# Note: The appender name can contain dots.
log4j.appender.appenderName=fully.qualified.name.of.appender.class
# Set appender specific options.
log4j.appender.appenderName.option1=value1
...
log4j.appender.appenderName.optionN=valueN
#For each named appender you can configure its Layout.
#The syntax for configuring an appender's layout is:
log4j.appender.appenderName.layout=fully.qualified.name.of.layout.class
log4j.appender.appenderName.layout.option1=value1
....
log4j.appender.appenderName.layout.optionN=valueN
Logger的配置:
root logger的配置语法:
log4j.rootLogger=[level], appenderName, appenderName, ...,其中level可以为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL。也可以使用自定义Level,这时的语法为[level#classname]。
如果Level被指定那么root logger的Level将被配置为指定值。如果Level没有被指定那么root logger的Level不会被修改。从上面的语法中我们可以看出通过用,分隔的列表可以为root logger指定多个Appender。
对于root logger之外的logger语法是相似的,为log4j.logger.logger_name=[level|INHERITED|NULL], appenderName, appenderName, ...
上面只有INHERITED和NULL需要说明一下,其它部分和root logger相同。INHERITED和NULL的意义是相同的。如果我们使用了它们,意味着这个logger将不在使用自己的Level而是从它的祖先那里继承。
Logger的附加性标志(additivity flag)可以使用log4j.additivity.logger_name=[false|true]来配置。
ObjectRenderer配置:
我们可以通过ObjectRenderer来定义将消息对象转换成字符串的方式。语法为log4j.renderer.fully.qualified.name.of.rendered.class=fully.qualified.name.of.rendering.class。如:
//my.Fruit类型的消息对象将由my.FruitRenderer转换成字符串
log4j.renderer.my.Fruit=my.FruitRenderer
对上面的各个配置元素的语法理解之后,在来看示例1和2就很容易了。
PropertyConfigurator不支持Filter的配置。如果要支持Filter您可以使用DOMConfigurator,即使用XML文件的方式配置。
要使用DOMConfigurator.configure()来读取XML格式的配置文件。XML文件格式的定义是通过org/apache/log4j/xml/log4j.dtd来完成的,各个配置元素的嵌套关系如下:
<!ELEMENT log4j:configuration (renderer*, appender*,(category|logger)*,root?,categoryFactory?)>
这里没有给出更为详细的内容,要了解详细的内容需要查阅log4j.dtd。
下面这个简单的示例可以使您对XML配置文件的格式有一个基本的认识:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j SYSTEM "log4j.dtd">
<log4j>
<appender name="A1" class="org.apache.log4j.FileAppender">
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%-5p %c{2} - %m\n"/>
</layout>
</appender>
<appender name="A2" class="org.apache.log4j.FileAppender">
<layout class="org.apache.log4j.TTCCLayout">
<param name="DateFormat" value="ISO8601" />
</layout>
<param name="File" value="warning.log" />
<param name="Append" value="false" />
</appender>
<category name="org.apache.log4j.xml" priority="debug">
<appender-ref ref="A1" />
</category>
<root priority="debug">
<appender-ref ref="A1" />
<appender-ref ref="A2" />
</root>
</log4j>
默认初始化过程在LogManager类的静态初始化器中完成。具体步骤如下:
- 检查系统属性log4j.defaultInitOverride,如果值为false则执行初始化过程,否则跳过初始化过程。
- 将系统属性log4j.configuration的值赋给变量resource。如果log4j.configuration没有被定义则使用默认值log4j.properties。
- 试图转换变量resource到一个url。
- 如果变量resource不能转换成一个url,那么将使用org.apache.log4j.helpers.Loader.getResource(resource, Logger.class)得到一个url。
- 如果还是得不到url,将忽略默认初始化过程。如果得到url将使用PropertyConfigurator或DOMConfigurator来配置,也可以使用自定义的XXXConfigurator。
posted @
2008-05-21 10:20 xzc 阅读(1962) |
评论 (0) |
编辑 收藏posted @
2007-12-04 11:37 xzc 阅读(1279) |
评论 (0) |
编辑 收藏
至于UTF-8编码则是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24位(三个字节)来编码。对于英文字符较多的论坛则用UTF-8节省空间。
GBK包含全部中文字符,
UTF-8则包含全世界所有国家需要用到的字符。
GBK是在国家标准GB2312基础上扩容后兼容GB2312的标准(好像还不是国家标准)
UTF-8编码的文字可以在各国各种支持UTF8字符集的浏览器上显示。
比如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,而无需他们下载IE的中文语言支持包。
所以,对于英文比较多的论坛 ,使用GBK则每个字符占用2个字节,而使用UTF-8英文却只占一个字节。
posted @
2007-11-21 17:35 xzc 阅读(290) |
评论 (0) |
编辑 收藏
索引是建立在表的一列或多个列上的辅助对象,目的是加快访问表中的数据;
Oracle存储索引的数据结构是B*树,位图索引也是如此,只不过是叶子节点不同B*数索引;
索引由根节点、分支节点和叶子节点组成,上级索引块包含下级索引块的索引数据,叶节点包含索引数据和确定行实际位置的rowid。
使用索引的目的
加快查询速度
减少I/O操作
消除磁盘排序
何时使用索引
查询返回的记录数
排序表<40%
非排序表 <7%
表的碎片较多(频繁增加、删除)
索引的种类
非唯一索引(最常用)
唯一索引
位图索引
局部有前缀分区索引
局部无前缀分区索引
全局有前缀分区索引
散列分区索引
基于函数的索引
管理索引的准则
在表中插入数据后创建索引
。在用SQL*Loader或import工具插入或装载数据后,建立索引比较有效;
索引正确的表和列
。经常检索排序大表中40%或非排序表7%的行,建议建索引;
。为了改善多表关联,索引列用于联结;
。列中的值相对比较唯一;
。取值范围(大:B*树索引,小:位图索引);
。Date型列一般适合基于函数的索引;
。列中有许多空值,不适合建立索引
为性能而安排索引列
。经常一起使用多个字段检索记录,组合索引比单索引更有效;
。把最常用的列放在最前面,例:dx_groupid_serv_id(groupid,serv_id),在where条件中使用groupid或groupid,serv_id,查询将使用索引,若仅用到serv_id字段,则索引无效;
。合并/拆分不必要的索引。
限制每个表索引的数量
。一个表可以有几百个索引(你会这样做吗?),但是对于频繁插入和更新表,索引越多系统CPU,I/O负担就越重;
。建议每张表不超过5个索引。
删除不再需要的索引
。索引无效,集中表现在该使用基于函数的索引或位图索引,而使用了B*树索引;
。应用中的查询不使用索引;
。重建索引之前必须先删除索引,若用alter index … rebuild重建索引,则不必删除索引。
索引数据块空间使用
。创建索引时指定表空间,特别是在建立主键时,应明确指定表空间;
。合理设定pctfress,注意:不能给索引指定pctused;
。估计索引的大小和合理地设置存储参数,默认为表空间大小,或initial与next设置成一样大。
考虑并行创建索引
。对大表可以采用并行创建索引,在并行创建索引时,存储参数被每个查询服务器进程分别使用,例如:initial为1M,并行度为8,则创建索引期间至少要消耗8M空间;
考虑用nologging创建索引
。对大表创建索引可以使用nologging来减少重做日志;
。节省重做日志文件的空间;
。缩短创建索引的时间;
。改善了并行创建大索引时的性能。
怎样建立最佳索引
明确地创建索引
create index index_name on table_name(field_name)
tablespace tablespace_name
pctfree 5
initrans 2
maxtrans 255
storage
(
minextents 1
maxextents 16382
pctincrease 0
);
创建基于函数的索引
。常用与UPPER、LOWER、TO_CHAR(date)等函数分类上,例:
create index idx_func on emp (UPPER(ename)) tablespace tablespace_name;
创建位图索引
。对基数较小,且基数相对稳定的列建立索引时,首先应该考虑位图索引,例:
create bitmap index idx_bitm on class (classno) tablespace tablespace_name;
明确地创建唯一索引
。可以用create unique index语句来创建唯一索引,例:
create unique index dept_unique_idx on dept(dept_no) tablespace idx_1;
创建与约束相关的索引
。可以用using index字句,为与unique和primary key约束相关的索引,例如:
alter table table_name
add constraint PK_primary_keyname primary key (field_name)
using index tablespace tablespace_name;
如何创建局部分区索引
。基础表必须是分区表;
。分区数量与基础表相同;
。每个索引分区的子分区数量与相应的基础表分区相同;
。基础表的子分区中的行的索引项,被存储在该索引的相应的子分区中,例如:
Create Index TG_CDR04_SERV_ID_IDX On TG_CDR04(SERV_ID)
Pctfree 5
Tablespace TBS_AK01_IDX
Storage (
MaxExtents 32768
PctIncrease 0
FreeLists 1
FreeList Groups 1
)
local
/
如何创建范围分区的全局索引
。基础表可以是全局表和分区表。
create index idx_start_date on tg_cdr01(start_date)
global partition by range(start_date)
(partition p01_idx vlaues less than (‘0106’)
partition p01_idx vlaues less than (‘0111’)
…
partition p01_idx vlaues less than (‘0401’ ))
/
重建现存的索引
重建现存的索引的当前时刻不会影响查询;
重建索引可以删除额外的数据块;
提高索引查询效率;
alter index idx_name rebuild nologging;
对于分区索引:
alter index idx_name rebuild partition partiton_name nologging;
要删除索引的原因
。不再需要的索引;
。索引没有针对其相关的表所发布的查询提供所期望的性能改善;
。应用没有用该索引来查询数据;
。该索引无效,必须在重建之前删除该索引;
。该索引已经变的太碎了,必须在重建之前删除该索引;
。语句:drop index idx_name;drop index idx_name drop partition partition_name;
建立索引的代价
基础表维护时,系统要同时维护索引,不合理的索引将严重影响系统资源,主要表现在CPU和I/O上;
插入、更新、删除数据产生大量db file sequential read锁等待;
SQL优化器简介
基于规则的优化器
。总是使用索引
。总是从驱动表开始(from子句最右边的表)
。只有在不可避免的情况下,才使用全表扫描
。任何索引都可以
基于成本的优化器
。需要表、索引的统计资料
Analyze table customer compute statistics;
Analyze table customer estimate statistics sample 5000 rows;
。表中设置并行度、表分区
优化器模式
rule模式
。总忽略CBO和统计信息而基于规则
choose模式
。Oracle根据情况选择rule or first_rows or all_rows
first_rows 模式
。基于成本,以最快的速度返回记录,会造成总体查询速度的下降或消耗更多的资源,倾向索引扫描,适合OLTP系统
all_rows模式
。基于成本,确保总体查询时间最短,倾向并行全表扫描
例如:
Select last_name from customer order by last_name;用first_rows时,迅速返回记录,但I/O量大,用all_rows时,返回记录慢,但使用资源少。
调整SQL表访问
全表扫描
。返回记录:未排序表>40%,排序表>7%,建议采用并行机制来提高访问速度,DDS;
索引访问
。最常用的方法,包括索引唯一扫描和索引范围扫描,OLTP;
快速完全索引扫描
。访问索引中所有数据块,结果相当于全表扫描,可以用索引扫描代替全表扫描,例如:
Select serv_id,count(* ) from tg_cdr01 group by serv_id;
评估全表扫描的合法性
如何实现并行扫描
。永久并行化(不推荐)
alter table customer parallel degree 8;
。单个查询并行化
select /*+ full(emp) parallel(emp,8)*/ * from emp;
分区表效果明显
优化SQL语句排序
排序的操作:
。order by 子句
。group by 子句
。select distinct子句
。创建索引时
。union或minus
。排序合并连接
如何避免排序
。添加索引
。在索引中使用distinct子句
。避免排序合并连接
使用提示进行调整
使用提示的原则
。语法:/*+ hint */
。使用表别名:select /*+ index(e dept_idx)*/ * from emp e
。检验提示
常用的提示
。rule
。all_rows
。first_rows
。use_nl
。use_hash
。use_merge
。index
。index_asc
。no_index
。index_desc(常用于使用max内置函数)
。index_combine(强制使用位图索引)
。index_ffs(索引快速完全扫描)
。use_concat(将查询中所有or条件使用union all)
。parallel
。noparallel
。full
。ordered(基于成本)
调整表连接
表连接的类型
。等连接
where 条件中用等式连接;
。外部连接(左、右连接)
在where条件子句的等式谓词放置一个(+)来实现,例如:
select a.ename,b.comm from emp a,bonus b where a.ename=b.ename(+);
该语句返回所有emp表的记录;
。自连接
Select a.value total, B.value hard, (A.value - b.value) soft ,
Round((b.value/a.value)*100,1) perc
From v$sysstat a,v$sysstat b
Where a.statistic# = 179
and B.statistic# = 180;
反连接
反连接常用于not in or not exists中,是指在查询中找到的任何记录都不包含在结果集中的子查询;不建议使用not in or not exists;
。半连接
查询中使用exists,含义:即使在子查询中返回多条重复的记录,外部查询也只返回一条记录。
嵌套循环连接
。被连接表中存在索引的情况下使用;
。使用use_nl。
hash连接
。Hash连接将驱动表加载在内存中,并使用hash技术连接第二个表,提高等连接速度。
。适合于大表和小表连接;
。使用use_hash。
排序合并连接
。排序合并连接不使用索引
。使用原则:
连接表子段中不存在可用索引;
查询返回两个表中大部分的数据快;
CBO认为全表扫描比索引扫描执行的更快。
。使用use_merge
使用临时/中间表
多个大表关联时,可以分别把满足条件的结果集存放到中间表,然后用中间表关联;
SQL子查询的调整
关联与非关联子查询
。关联:子查询的内部引用的是外部表,每行执行一次;
。非关联:子查询只执行一次,存放在内存中。
调整not in 和not exists语句
。可以使用外部连接优化not in子句,例如:
select ename from emp where dept_no not in
(select dept_no from dept where dept_name =‘Math’);
改为:
select ename from emp,dept
where emp.dept_no=dept.dept_no
and dept.dept_name is null;
使用索引调整SQL
Oracle 为什么不使用索引
。检查被索引的列或组合索引的首列是否出现在PL/SQL语句的WHERE子句中,这是“执行计划”能用到相关索引的必要条件。
。看采用了哪种类型的连接方式。ORACLE的共有Sort Merge Join(SMJ)、Hash Join(HJ)和Nested Loop Join(NL)。在两张表连接,且内表的目标列上建有索引时,只有Nested Loop才能有效地利用到该索引。SMJ即使相关列上建有索引,最多只能因索引的存在,避免数据排序过程。HJ由于须做HASH运算,索引的存在对数据查询速度几乎没有影响。
。看连接顺序是否允许使用相关索引。假设表emp的deptno列上有索引,表dept的列deptno上无索引,WHERE语句有emp.deptno=dept.deptno条件。在做NL连接时,emp做为外表,先被访问,由于连接机制原因,外表的数据访问方式是全表扫描,emp.deptno上的索引显然是用不上,最多在其上做索引全扫描或索引快速全扫描。
。是否用到系统数据字典表或视图。由于系统数据字典表都未被分析过,可能导致极差的“执行计划”。但是不要擅自对数据字典表做分析,否则可能导致死锁,或系统性能下降。
。索引列是否函数的参数。如是,索引在查询时用不上。
。是否存在潜在的数据类型转换。如将字符型数据与数值型数据比较,ORACLE会自动将字符型用to_number()函数进行转换,从而导致上一种现象的发生。
。是否为表和相关的索引搜集足够的统计数据。对数据经常有增、删、改的表最好定期对表和索引进行分析,可用SQL语句“analyze table xxxx compute statistics for all indexes;”。ORACLE掌握了充分反映实际的统计数据,才有可能做出正确的选择。
。索引列的选择性不高。 我们假设典型情况,有表emp,共有一百万行数据,但其中的emp.deptno列,数据只有4种不同的值,如10、20、30、40。虽然emp数据行有很多,ORACLE缺省认定表中列的值是在所有数据行均匀分布的,也就是说每种deptno值各有25万数据行与之对应。假设SQL搜索条件DEPTNO=10,利用deptno列上的索引进行数据搜索效率,往往不比全表扫描的高。
。索引列值是否可为空(NULL)。如果索引列值可以是空值,在SQL语句中那些要返回NULL值的操作,将不会用到索引,如COUNT(*),而是用全表扫描。这是因为索引中存储值不能为全空。
。看是否有用到并行查询(PQO)。并行查询将不会用到索引。
。如果从以上几个方面都查不出原因的话,我们只好用采用在语句中加hint的方式强制ORACLE使用最优的“执行计划”。 hint采用注释的方式,有行注释和段注释两种方式。 如我们想要用到A表的IND_COL1索引的话,可采用以下方式: “SELECT /*+ INDEX(A IND_COL1)*/ * FROM A WHERE COL1 = XXX;"
如何屏蔽索引
语句的执行计划中有不良索引时,可以人为地屏蔽该索引,方法:
。数值型:在索引字段上加0,例如
select * from emp where emp_no+0 = v_emp_no;
。字符型:在索引字段上加‘’,例如
select * from tg_cdr01 where msisdn||’’=v_msisdn;
posted @
2007-11-21 15:05 xzc 阅读(645) |
评论 (1) |
编辑 收藏转自:http://tb.blog.csdn.net/TrackBack.aspx?PostId=1729625
1、各种索引的创建方法
(1)*tree索引
create index indexname on tablename(columnname);
(2)反向索引
create index indexname on tablename(columnname) reverse;
(3)降序索引
create index indexname on tablename(columnname DESC);
(4)位图索引
create BITMAP index indexname on tablename(columnname);
(5)函数索引
create index indexname on tablename(functionname(columnname));
创建索引后要分析才能使用
analyze table test compute statistics for table for all indexed columns for all indexes;
analyze index test validate structure;
select name,lf_rows from index_stats;用这条语句可以查询保存了多少条索引
analyze index test compute statistics;
从字面理解validate structure 主要在于校验对象的有效性. compute statistics在于统计相关的信息..
查询索引
select index_name,index_type from user_indexes where table_name='TEST';
2、打开autotrace功能
执行$ORACLE_HOME/rdbms/admin/utlxplan.sql和$ORACLE_HOME/sqlplus/admin/plustrce.sql
然后给相关用户授予plustrace角色,然后这些用户就可以使用autotrace功能了
3、无效索引
(1)类型不匹配
create table test(a varchar(2),b number);
insert into test values('1',1);
create index test_index on test(a);
analyze table test compute statistics for table for all indexed columns for all indexes;
set autotrace on;
类型匹配的情况
select /*+ RULE */ * from test where a='1';
A B
-- ----------
1 1
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST'
2 1 INDEX (RANGE SCAN) OF 'TEST_INDEX' (NON-UNIQUE) 使用了索引
类型不匹配的情况
select /*+ RULE */ * from test where a=1;
A B
-- ----------
1 1
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (FULL) OF 'TEST' 选择了全表扫描
(2)条件包含函数但没有创建函数索引
alter system set QUERY_REWRITE_ENABLED=true;
alter system set query_rewrite_integrity=enforced;
insert into test values('a',2);
select /*+ RULE */ * from test where upper(a) = 'A';
A B
-- ----------
a 2
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (FULL) OF 'TEST'
由于没有创建函数索引,所以选择全表扫描
create index test_index_fun on test(upper(a));
analyze table test compute statistics for table for all indexed columns for all indexes;
select /*+ RULE */ * from test where upper(a) = 'A';
A B
-------------------------------------------------- ----------
a 2
a 3
a 4
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (FULL) OF 'TEST'
虽然创建了函数索引,但由于工作于RBO模式,所以函数索引没用,选择了全表扫描
select * from test where upper(a) = 'A';
A B
-------------------------------------------------- ----------
a 2
a 3
a 4
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=9)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST' (Cost=2 Card=1 Byt
es=9)
2 1 INDEX (RANGE SCAN) OF 'TEST_INDEX_FUN' (NON-UNIQUE) (Cos
t=1 Card=1)
当函数索引工作于CBO模式下,选择了基于函数的索引,上面创建的索引函数TEST_INDEX_FUN已经用到
(3)符合索引中的前导列没有被作为查询条件
create index test_index_com on test(a,b);
select /*+ RULE */ * from test where a = '1';
A B
-- ----------
1 1
前导列a作为了查询条件,但由于之前创建了a的索引,所以使用了TEST_INDEX而没有使用test_index_com
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST'
2 1 INDEX (RANGE SCAN) OF 'TEST_INDEX' (NON-UNIQUE)
select /*+ RULE */ * from test where b = '1';
A B
-- ----------
1 1
2 1
3 1
4 1
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (FULL) OF 'TEST'
前导列a没有作为查询条件,所以选择全部扫描
select /*+ RULE */ * from test where b = '1' and a= '1';
A B
-- ----------
1 1
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 INDEX (RANGE SCAN) OF 'TEST_INDEX_COM' (NON-UNIQUE)
前导列a作为了查询条件,使用了索引
(4)CBO模式下选择的行数比例过大,优化器选择全表扫描
declare
i number;
j number;
begin
for i in 1 .. 10 loop
for j in 1 .. 10000 loop
insert into test values(to_char(j),i);
end loop;
end loop;
end;
/
declare i number;
begin
for i in 1 .. 100 loop
insert into test values(to_char(i),i);
end loop;
end;
/
SQL> select count(*) from test;
COUNT(*)
----------
200000
select * from test where a = '1';
已选择10000行。
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=27 Card=9333 Bytes=7
4664)
1 0 TABLE ACCESS (FULL) OF 'TEST' (Cost=27 Card=9333 Bytes=746
64)
比例过大,选择全表扫描
select * from test where a = '99';
已选择10行。
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=2 Bytes=16)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST' (Cost=2 Card=2 Byt
es=16)
2 1 INDEX (RANGE SCAN) OF 'TEST_INDEX' (NON-UNIQUE) (Cost=1
Card=2)
比例小,选择索引
select /*+ RULE */ * from test where a = '1';
已选择10000行。
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST'
2 1 INDEX (RANGE SCAN) OF 'TEST_INDEX' (NON-UNIQUE)
如果指定为RBO优化器,肯定就用索引了
(5)在CBO模式下表很久没分析,表的增长明显,优化器采取了全表扫描
(6)索引条件中使用了<>、!=、not\not in、not like等操作符,导致查询不使用索引
先做一个测试在一个表中插入130万条数据,其中不等于1的数据有30万条,以下是几种语句执行的结果
序号 语句 时间 代价
1 select * from test where b<>1; 00: 00: 03.04 398
2 select * from test where b not like 1; 00: 00: 03.03 398
3 select * from test where b !=1; 00: 00: 03.01 398
4 select * from test where b not in(1); 00: 00: 03.00 398
5 select * from test where b<1 union select * from test where b>1; 00: 00: 03.01 264
6 select * from test where b<1 union all select * from test where b>1; 00: 00: 02.09 132
7 select * from test where b<1 or b>1; 00: 00: 02.08 96
从以上可以看出最优化的语句是7,在查询过程中使用索引的有5、6、7
所以,如果建立了索引,在语句中尽量不要使用<>、!=、not、not in、not like操作,如果非要使用,请尽量用or和union操作替换
(7)索引对空值的影响
我们首先做一些测试数据:
SQL> create table t(x int, y int);
请注意,这里我对表t做了一个唯一(联合)索引:
SQL> create unique index t_idx on t(x,y);
SQL> insert into t values(1,1);
SQL> insert into t values(1,NULL);
SQL> insert into t values(NULL,1);
SQL> insert into t values(NULL,NULL);
SQL> commit;
下面我们分析一下索引:
SQL> analyze index t_idx validate structure;
SQL> select name,lf_rows from index_stats;
NAME LF_ROWS
------------------------------ ----------
T_IDX 3
然后,我们就可以看到,当前的索引中仅仅保存了3行数据。
请注意,上面我们插入并提交了四行数据。
所以,这里就有一个结论:
Oracle的索引不保存该索引包含的列中全部为空的行。
这同时也带来个好处,但当一个表中的某一列大部分为空值,至少90%以上是空值的时候,就可以为该列建立索引。
比如该表为t,该列为x
select * from t where x is null;
此时会选择全表扫描
select * from t where x=1;
此时就会使用索引,而且索引中不保存值为空的行,所以索引中只有10%左右的行,因此在这10%的行中找出x=1的行比在全表中找出x=1的行要快的多
我们继续插入数据,现在再插入几行全部为空的行:
SQL> insert into t values(NULL,NULL);
SQL> insert into t values(NULL,NULL);
我们看到这样的插入,居然没有违反前面我们设定的唯一约束(unique on t(x,y)),
所以,这里我们又得出一个结论:
Oracle认为 NULL<>NULL ,进而 (NULL,NULL)<>(NULL,NULL)
换句话说,Oracle认为空值(NULL)不等于任何值,包括空值也不等于空值。
我们看到下面的插入会违反唯一约束(DEMO.T_IDX),这个很好理解了,因为它不是全部为空的值,即它不是(NULL,NULL),只有全部为空的行才被认为是不同的行:
SQL> insert into t values(1,null);
ORA-00001: 违反唯一约束条件 (DEMO.T_IDX)
SQL> insert into t values(null,1);
ORA-00001: 违反唯一约束条件 (DEMO.T_IDX)
SQL>
请看下面的例子:
SQL> select x,y,count(*) from t group by x,y;
X Y COUNT(*)
----- -------- ----------
3
1 1
1 1
1 1 1
Executed in 0.03 seconds
SQL> select x,y,count(*) from t where x is null and y is null group by x,y;
X Y COUNT(*)
---- ------- ----------
3
Executed in 0.01 seconds
SQL>
SQL> select x,y,count(*) from t group by x,y having count(*)>1;
X Y COUNT(*)
------ -------------------- ----------
3
Executed in 0.02 seconds
SQL>
可以看见,完全为空的行有三行,这里我们又可以得出一个结论:
oracle在group by子句中认为完全为空的行是相同的行
换句话说,在group by子句中,oracle认为(NULL,NULL)=(NULL,NULL)
SQL> select * from t where x is null;
X Y
---------- ----------
1
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=4 Bytes=8)
1 0 TABLE ACCESS (FULL) OF 'T' (Cost=2 Card=4 Bytes=8)
SQL> select * from t where x=1;
X Y
---------- ----------
1 1
1
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=1 Card=2 Bytes=4)
1 0 INDEX (RANGE SCAN) OF 'T_IDX' (UNIQUE) (Cost=1 Card=2 Byte
s=4)
从以上可以看出,在使用IS NULL 和 IS NOT NULL条件的时候,Oracle不使用索引
那么我们如何使用空值的比较条件呢?
首先,尽量不在前导列上使用空值,其次我们在创建表的时候,为每个列都指定为非空约束(NOT NULL),并且在必要的列上使用default值
8、不要为所有的列建立索引
我们知道,建立索引是为了提高查询的效率,但是同时也应该注意到,索引增加了对DML操作(insert, update, delete)的代价,而且,一给中的索引如果太多,那么多数的索引是根本不会被使用到的,而另一方面我们维护这些不被使用的所以还要大幅度降低系统的性能。所以,索引不是越多越好,而是要恰到好处的使用。
比如说,有些列由于使用了函数,我们要使用已有的索引(如一些复合索引)是不可能的,那么就必须建立单独的函数索引,如果说这个函数索引很少会被应用(仅仅在几个特别的sql中会用到),我们就可以尝试改写查询,而不去建立和维护那个函数索引,例如:
1,trunc函数
SQL> select empno,ename,deptno from emp where trunc(hiredate)='2004-01-01';
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (FULL) OF 'EMP'
将上面的查询转换为:
SQL> select empno,ename,deptno from emp
2 where hiredate >= to_date('2004-01-01','yyyy-mm-dd')
3 and hiredate<to_date('2004-01-01','yyyy-mm-dd')+0.999;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMP_ID3' (NON-UNIQUE)
2,to_char函数
SQL> select empno,ename,deptno from emp
2 where to_char(hiredate,'yyyy-mm-dd')='2003-09-05';
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (FULL) OF 'EMP'
SQL> select empno,ename,deptno from emp
2 where hiredate=to_date('2003-09-05','yyyy-mm-dd');
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMP_ID3' (NON-UNIQUE)
3,substr函数
SQL> select dname from dept where substr(dname,1,3)='abc';
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (FULL) OF 'DEPT'
SQL> select dname from dept where dname like 'abc%';
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 INDEX (RANGE SCAN) OF 'DEPT_ID1' (NON-UNIQUE)
通常,为了均衡查询的效率和DML的效率,我们要仔细的分析应用,找出来出现频率相对较多、字段内容较少(比如varchar2(1000)就不适合建立索引,而varchar2(10)相对来说就适合建立索引)的列,合理的建立索引,比如有时候我们希望建立复合索引,有时候我们更希望建立单键索引。
posted @
2007-11-21 10:20 xzc 阅读(424) |
评论 (0) |
编辑 收藏转自:http://www.blogjava.net/hadeslee/archive/2007/11/20/161770.html
2. <body onselectstart="return false"> 取消选取、防止复制
3. onpaste="return false" 不准粘贴
4. oncopy="return false;" oncut="return false;" 防止复制
5. <link rel="Shortcut Icon" href="favicon.ico"> IE地址栏前换成自己的图标
6. <link rel="Bookmark" href="favicon.ico"> 可以在收藏夹中显示出你的图标
7. <input style="ime-mode:disabled"> 关闭输入法
8. 永远都会带着框架
<script language="JavaScript"><!--
if (window == top)top.location.href = "frames.htm"; //frames.htm为框架网页
// --></script>
9. 防止被人frame
<SCRIPT LANGUAGE=JAVASCRIPT><!--
if (top.location != self.location)top.location=self.location;
// --></SCRIPT>
10. 网页将不能被另存为
<noscript><iframe src="/*.html>";</iframe></noscript>
11. <input type=button value=查看网页源代码
onclick="window.location = "view-source:"+ "http://www.pconline.com.cn"">
12.删除时确认
<a href="javascript:if(confirm("确实要删除吗?"))location="boos.asp?&areyou=删除&page=1"">删除</a>
13. 取得控件的绝对位置
//Javascript
<script language="Javascript">
function getIE(e){
var t=e.offsetTop;
var l=e.offsetLeft;
while(e=e.offsetParent){
t+=e.offsetTop;
l+=e.offsetLeft;
}
alert("top="+t+"/nleft="+l);
}
</script>
//VBScript
<script language="VBScript"><!--
function getIE()
dim t,l,a,b
set a=document.all.img1
t=document.all.img1.offsetTop
l=document.all.img1.offsetLeft
while a.tagName<>"BODY"
set a = a.offsetParent
t=t+a.offsetTop
l=l+a.offsetLeft
wend
msgbox "top="&t&chr(13)&"left="&l,64,"得到控件的位置"
end function
--></script>
14. 光标是停在文本框文字的最后
<script language="javascript">
function cc()
{
var e = event.srcElement;
var r =e.createTextRange();
r.moveStart("character",e.value.length);
r.collapse(true);
r.select();
}
</script>
<input type=text name=text1 value="123" onfocus="cc()">
15. 判断上一页的来源
javascript:
document.referrer
16. 最小化、最大化、关闭窗口
<object id=hh1 classid="clsid:ADB880A6-D8FF-11CF-9377-00AA003B7A11">
<param name="Command" value="Minimize"></object>
<object id=hh2 classid="clsid:ADB880A6-D8FF-11CF-9377-00AA003B7A11">
<param name="Command" value="Maximize"></object>
<OBJECT id=hh3 classid="clsid:adb880a6-d8ff-11cf-9377-00aa003b7a11">
<PARAM NAME="Command" VALUE="Close"></OBJECT>
<input type=button value=最小化 onclick=hh1.Click()>
<input type=button value=最大化 onclick=hh2.Click()>
<input type=button value=关闭 onclick=hh3.Click()>
本例适用于IE
17.屏蔽功能键Shift,Alt,Ctrl
<script>
function look(){
if(event.shiftKey)
alert("禁止按Shift键!"); //可以换成ALT CTRL
}
document.onkeydown=look;
</script>
18. 网页不会被缓存
<META HTTP-EQUIV="pragma" CONTENT="no-cache">
<META HTTP-EQUIV="Cache-Control" CONTENT="no-cache, must-revalidate">
<META HTTP-EQUIV="expires" CONTENT="Wed, 26 Feb 1997 08:21:57 GMT">
或者<META HTTP-EQUIV="expires" CONTENT="0">
19.怎样让表单没有凹凸感?
<input type=text style="border:1 solid #000000">
或
<input type=text style="border-left:none; border-right:none; border-top:none; border-bottom:
1 solid #000000"></textarea>
20.<div><span>&<layer>的区别?
<div>(division)用来定义大段的页面元素,会产生转行
<span>用来定义同一行内的元素,跟<div>的唯一区别是不产生转行
<layer>是ns的标记,ie不支持,相当于<div>
21.让弹出窗口总是在最上面:
<body onblur="this.focus();">
22.不要滚动条?
让竖条没有:
<body style="overflow:scroll;overflow-y:hidden">
</body>
让横条没有:
<body style="overflow:scroll;overflow-x:hidden">
</body>
两个都去掉?更简单了
<body scroll="no">
</body>
23.怎样去掉图片链接点击后,图片周围的虚线?
<a href="#" onFocus="this.blur()"><img src="/logo.jpg" border=0></a>
24.电子邮件处理提交表单
<form name="form1" method="post" action="mailto:****@***.com" enctype="text/plain">
<input type=submit>
</form>
25.在打开的子窗口刷新父窗口的代码里如何写?
window.opener.location.reload()
26.如何设定打开页面的大小
<body onload="top.resizeTo(300,200);">
打开页面的位置<body onload="top.moveBy(300,200);">
27.在页面中如何加入不是满铺的背景图片,拉动页面时背景图不动
<STYLE>
body
{background-image:url(/logo.gif); background-repeat:no-repeat;
background-position:center;background-attachment: fixed}
</STYLE>
28. 检查一段字符串是否全由数字组成
<script language="Javascript"><!--
function checkNum(str){return str.match(//D/)==null}
alert(checkNum("1232142141"))
alert(checkNum("123214214a1"))
// --></script>
29. 获得一个窗口的大小
document.body.clientWidth; document.body.clientHeight
30. 怎么判断是否是字符
if (/[^/x00-/xff]/g.test(s)) alert("含有汉字");
else alert("全是字符");
31.TEXTAREA自适应文字行数的多少
<textarea rows=1 name=s1 cols=27 onpropertychange="this.style.posHeight=this.scrollHeight">
</textarea>
32. 日期减去天数等于第二个日期
<script language=Javascript>
function cc(dd,dadd)
{
//可以加上错误处理
var a = new Date(dd)
a = a.valueOf()
a = a - dadd * 24 * 60 * 60 * 1000
a = new Date(a)
alert(a.getFullYear() + "年" + (a.getMonth() + 1) + "月" + a.getDate() + "日")
}
cc("12/23/2002",2)
</script>
33. 选择了哪一个Radio
<HTML><script language="vbscript">
function checkme()
for each ob in radio1
if ob.checked then
window.alert ob.value
next
end function
</script><BODY>
<INPUT name="radio1" type="radio" value="style" checked>Style
<INPUT name="radio1" type="radio" value="barcode">Barcode
<INPUT type="button" value="check" onclick="checkme()">
</BODY></HTML>
34.脚本永不出错
<SCRIPT LANGUAGE="JavaScript">
<!-- Hide
function killErrors() {
return true;
}
window.onerror = killErrors;
// -->
</SCRIPT>
35.ENTER键可以让光标移到下一个输入框
<input onkeydown="if(event.keyCode==13)event.keyCode=9">
36. 检测某个网站的链接速度:
把如下代码加入<body>区域中:
<script language=Javascript>
tim=1
setInterval("tim++",100)
b=1
var autourl=new Array()
autourl[1]="www.njcatv.net"
autourl[2]="javacool.3322.net"
autourl[3]="www.sina.com.cn"
autourl[4]="www.nuaa.edu.cn"
autourl[5]="www.cctv.com"
function butt(){
document.write("<form name=autof>")
for(var i=1;i<autourl.length;i++)
document.write("<input type=text name=txt"+i+" size=10 value=测试中……> =》<input type=text
name=url"+i+" size=40> =》<input type=button value=GO
onclick=window.open(this.form.url"+i+".value)><br>")
document.write("<input type=submit value=刷新></form>")
}
butt()
function auto(url){
document.forms[0]["url"+b].value="/url
if(tim>200)
{document.forms[0]["txt"+b].value="/链接超时"}
else
{document.forms[0]["txt"+b].value=""时间"+tim/10+"秒"}
b++
}
function run(){for(var i=1;i<autourl.length;i++)document.write("<img src=http://"+autourl+"/"+Math.random()+" width=1 height=1
onerror=auto("http://"+autourl+"")>")}
run()</script>
37. 各种样式的光标
auto :标准光标
default :标准箭头
hand :手形光标
wait :等待光标
text :I形光标
vertical-text :水平I形光标
no-drop :不可拖动光标
not-allowed :无效光标
help :?帮助光标
all-scroll :三角方向标
move :移动标
crosshair :十字标
e-resize
n-resize
nw-resize
w-resize
s-resize
se-resize
sw-resize
38.页面进入和退出的特效
进入页面<meta http-equiv="Page-Enter" content="revealTrans(duration=x, transition=y)">
推出页面<meta http-equiv="Page-Exit" content="revealTrans(duration=x, transition=y)">
这个是页面被载入和调出时的一些特效。duration表示特效的持续时间,以秒为单位。transition表示使用哪种特效,取值为1-23:
0 矩形缩小
1 矩形扩大
2 圆形缩小
3 圆形扩大
4 下到上刷新
5 上到下刷新
6 左到右刷新
7 右到左刷新
8 竖百叶窗
9 横百叶窗
10 错位横百叶窗
11 错位竖百叶窗
12 点扩散
13 左右到中间刷新
14 中间到左右刷新
15 中间到上下
16 上下到中间
17 右下到左上
18 右上到左下
19 左上到右下
20 左下到右上
21 横条
22 竖条
23 以上22种随机选择一种
39.在规定时间内跳转
<META http-equiv=V="REFRESH" content="5;URL=http://www.51js.com">
40.网页是否被检索
<meta name="ROBOTS" content="属性值">
其中属性值有以下一些:
属性值为"all": 文件将被检索,且页上链接可被查询;
属性值为"none": 文件不被检索,而且不查询页上的链接;
属性值为"index": 文件将被检索;
属性值为"follow": 查询页上的链接;
属性值为"noindex": 文件不检索,但可被查询链接;
属性值为"nofollow": 文件不被检索,但可查询页上的链接。
41、email地址的分割
把如下代码加入<body>区域中
<a href="webmaster@sina.commailto:webmaster@sina.com">webmaster@sina.com</a>
42、流动边框效果的表格
把如下代码加入<body>区域中
<SCRIPT>
l=Array(6,7,8,9,'a','b','b','c','d','e','f')
Nx=5;Ny=35
t="<table border=0 cellspacing=0 cellpadding=0 height="+((Nx+2)*16)+"><tr>"
for(x=Nx;x<Nx+Ny;x++)
t+="<td width=16 id=a_mo"+x+"> </td>"
t+="</tr><tr><td width=10 id=a_mo"+(Nx-1)+"> </td><td colspan="+(Ny-2)+" rowspan="+(Nx)+"> </td><td width=16 id=a_mo"+(Nx+Ny)+"></td></tr>"
for(x=2;x<=Nx;x++)
t+="<tr><td width=16 id=a_mo"+(Nx-x)+"> </td><td width=16 id=a_mo"+(Ny+Nx+x-1)+"> </td></tr>"
t+="<tr>"
for(x=Ny;x>0;x--)
t+="<td width=16 id=a_mo"+(x+Nx*2+Ny-1)+"> </td>"
document.write(t+"</tr></table>")
var N=Nx*2+Ny*2
function f1(y){
for(i=0;i<N;i++){
c=(i+y)%20;if(c>10)c=20-c
document.all["a_mo"+(i)].bgColor="'#0000"+l[c]+l[c]+"'"}
y++
setTimeout('f1('+y+')','1')}
f1(1)
</SCRIPT>
43、JavaScript主页弹出窗口技巧
窗口中间弹出
<script>
window.open("http://www.cctv.com","","width=400,height=240,top="+(screen.availHeight-240)/2+",left="+(screen.availWidth-400)/2);
</script>
============
<html>
<head>
<script language="LiveScript">
function WinOpen() {
msg=open("","DisplayWindow","toolbar=no,directories=no,menubar=no");
msg.document.write("<HEAD><TITLE>哈 罗!</TITLE></HEAD>");
msg.document.write("<CENTER><H1>酷 毙了!</H1><h2>这 是<B>JavaScript</B>所 开 的 视窗!</h2></CENTER>");
}
</script>
</head>
<body>
<form>
<input type="button" name="Button1" value="Push me" onclick="WinOpen()">
</form>
</body>
</html>
==============
一、在下面的代码中,你只要单击打开一个窗口,即可链接到赛迪网。而当你想关闭时,只要单击一下即可关闭刚才打开的窗口。
代码如下:
<SCRIPT language="JavaScript">
<!--
function openclk() {
another=open('http://www.ccidnet.com','NewWindow');
}
function closeclk() {
another.close();
}
//-->
</SCRIPT>
<FORM>
<INPUT TYPE="BUTTON" NAME="open" value="打开一个窗口" onClick="openclk()">
<BR>
<INPUT TYPE="BUTTON" NAME="close" value="关闭这个窗口" onClick="closeclk()">
</FORM>
二、上面的代码也太静了,为何不来点动感呢?如果能给页面来个降落效果那该多好啊!
代码如下:
<script>
function drop(n) {
if(self.moveBy){
self.moveBy (0,-900);
for(i = n; i > 0; i--){
self.moveBy(0,3);
}
for(j = 8; j > 0; j--){
self.moveBy(0,j);
self.moveBy(j,0);
self.moveBy(0,-j);
self.moveBy(-j,0);
}
}
}
</script>
<body onLoad="drop(300)">
三、讨厌很多网站总是按照默认窗口打开,如果你能随心所欲控制打开的窗口那该多好。
代码如下:
<SCRIPT LANGUAGE="JavaScript">
<!-- Begin
function popupPage(l, t, w, h) {
var windowprops = "location=no,scrollbars=no,menubars=no,toolbars=no,resizable=yes" +
",left=" + l + ",top=" + t + ",width=" + w + ",height=" + h;
var URL = "http://www.80cn.com";
popup = window.open(URL,"MenuPopup",windowprops);
}
// End -->
</script>
<table>
<tr>
<td>
<form name=popupform>
<pre>
打开页面的参数<br>
离开左边的距离: <input type=text name=left size=2 maxlength=4> pixels
离开右边的距离: <input type=text name=top size=2 maxlength=4> pixels
窗口的宽度: <input type=text name=width size=2 maxlength=4> pixels
窗口的高度: <input type=text name=height size=2 maxlength=4> pixels
</pre>
<center>
<input type=button value="打开这个窗口!" onClick="popupPage(this.form.left.value, this.form.top.value, this.form.width.value, this.form.height.value)">
</center>
</form>
</td>
</tr>
</table>你只要在相对应的对话框中输入一个数值即可,将要打开的页面的窗口控制得很好。
44、页面的打开移动
把如下代码加入<body>区域中
<SCRIPT LANGUAGE="JavaScript">
<!-- Begin
for (t = 2; t > 0; t--) {
for (x = 20; x > 0; x--) {
for (y = 10; y > 0; y--) {
parent.moveBy(0,-x);
}
}
for (x = 20; x > 0; x--) {
for (y = 10; y > 0; y--) {
parent.moveBy(0,x);
}
}
for (x = 20; x > 0; x--) {
for (y = 10; y > 0; y--) {
parent.moveBy(x,0);
}
}
for (x = 20; x > 0; x--) {
for (y = 10; y > 0; y--) {
parent.moveBy(-x,0);
}
}
}
//-->
// End -->
</script>
45、显示个人客户端机器的日期和时间
<script language="LiveScript">
<!-- Hiding
today = new Date()
document.write("现 在 时 间 是: ",today.getHours(),":",today.getMinutes())
document.write("<br>今 天 日 期 为: ", today.getMonth()+1,"/",today.getDate(),"/",today.getYear());
// end hiding contents -->
</script>
46、自动的为你每次产生最後修改的日期了:
<html>
<body>
This is a simple HTML- page.
<br>
Last changes:
<script language="LiveScript">
<!-- hide script from old browsers
document.write(document.lastModified)
// end hiding contents -->
</script>
</body>
</html>
47、不能为空和邮件地址的约束:
<html>
<head>
<script language="JavaScript">
<!-- Hide
function test1(form) {
if (form.text1.value == "")
alert("您 没 写 上 任 何 东 西, 请 再 输 入 一 次 !")
else {
alert("嗨 "+form.text1.value+"! 您 已 输 入 完 成 !");
}
}
function test2(form) {
if (form.text2.value == "" ||
form.text2.value.indexOf('@', 0) == -1)
alert("这 不 是 正 确 的 e-mail address! 请 再 输 入 一 次 !");
else alert("您 已 输 入 完 成 !");
}
// -->
</script>
</head>
<body>
<form name="first">
Enter your name:<br>
<input type="text" name="text1">
<input type="button" name="button1" value="输 入 测 试" onClick="test1(this.form)">
<P>
Enter your e-mail address:<br>
<input type="text" name="text2">
<input type="button" name="button2" value="输 入 测 试" onClick="test2(this.form)">
</body>
48、跑马灯
<html>
<head>
<script language="JavaScript">
<!-- Hide
var scrtxt="怎麽样 ! 很酷吧 ! 您也可以试试."+"Here goes your message the visitors to your page will "+"look at for hours in pure fascination...";
var lentxt=scrtxt.length;
var width=100;
var pos=1-width;
function scroll() {
pos++;
var scroller="";
if (pos==lentxt) {
pos=1-width;
}
if (pos<0) {
for (var i=1; i<=Math.abs(pos); i++) {
scroller=scroller+" ";}
scroller=scroller+scrtxt.substring(0,width-i+1);
}
else {
scroller=scroller+scrtxt.substring(pos,width+pos);
}
window.status = scroller;
setTimeout("scroll()",150);
}
//-->
</script>
</head>
<body onLoad="scroll();return true;">
这里可显示您的网页 !
</body>
</html>
49、在网页中用按钮来控制前页,后页和主页的显示。
<html>
<body>
<FORM NAME="buttonbar">
<INPUT TYPE="button" VALUE="Back" onClick="history.back()">
<INPUT TYPE="button" VALUE="JS- Home" onClick="location='script.html'">
<INPUT TYPE="button" VALUE="Next" onCLick="history.forward()">
</FORM>
</body>
</html>
50、查看某网址的源代码
把如下代码加入<body>区域中
<SCRIPT>
function add()
{
var ress=document.forms[0].luxiaoqing.value
window.location="view-source:"+ress;
}
</SCRIPT>
输入要查看源代码的URL地址:
<FORM><input type="text" name="luxiaoqing" size=40 value="http://"></FORM>
<FORM><br>
<INPUT type="button" value="查看源代码" onClick=add()>
</FORM>
51、title显示日期
把如下代码加入<body>区域中:
<script language="JavaScript1.2">
<!--hide
var isnMonth = new
Array("1月","2月","3月","4月","5月","6月","7月","8月","9月","10月","11月","12月");
var isnDay = new
Array("星期日","星期一","星期二","星期三","星期四","星期五","星期六","星期日");
today = new Date () ;
Year=today.getYear();
Date=today.getDate();
if (document.all)
document.title="今天是: "+Year+"年"+isnMonth[today.getMonth()]+Date+"日"+isnDay[today.getDay()]
//--hide-->
</script>
52、显示所有链接
把如下代码加入<body>区域中
<script language="JavaScript1.2">
<!--
function extractlinks(){
var links=document.all.tags("A")
var total=links.length
var win2=window.open("","","menubar,scrollbars,toolbar")
win2.document.write("<font size='2'>一共有"+total+"个连接</font><br>")
for (i=0;i<total;i++){
win2.document.write("<font size='2'>"+links[i].outerHTML+"</font><br>")
}
}
//-->
</script>
<input type="button" onClick="extractlinks()" value="显示所有的连接">
53、回车键换行
把如下代码加入<body>区域中
<script type="text/javascript">
function handleEnter (field, event) {
var keyCode = event.keyCode ? event.keyCode : event.which ? event.which : event.charCode;
if (keyCode == 13) {
var i;
for (i = 0; i < field.form.elements.length; i++)
if (field == field.form.elements[i])
break;
i = (i + 1) % field.form.elements.length;
field.form.elements[i].focus();
return false;
}
else
return true;
}
</script>
<form>
<input type="text" onkeypress="return handleEnter(this, event)"><br>
<input type="text" onkeypress="return handleEnter(this, event)"><br>
<textarea>回车换行
54、确认后提交
把如下代码加入<body>区域中
<SCRIPT LANGUAGE="JavaScript">
<!--
function msg(){
if (confirm("你确认要提交嘛!"))
document.lnman.submit()
}
//-->
</SCRIPT>
<form name="lnman" method="post" action="">
<p>
<input type="text" name="textfield" value="确认后提交">
</p>
<p>
<input type="button" name="Submit" value="提交" onclick="msg();">
</p>
</form>
55、改变表格的内容
把如下代码加入<body>区域中
<script language=javascript>
var arr=new Array()
arr[0]="一一一一一";
arr[1]="二二二二二";
arr[2]="三三三三三";
</script>
<select onchange="zz.cells[this.selectedIndex].innerHTML=arr[this.selectedIndex]">
<option value=a>改变第一格</option>
<option value=a>改变第二格</option>
<option value=a>改变第三格</option>
</select>
<table id=zz border=1>
<tr height=20>
<td width=150>第一格</td>
<td width=150>第二格</td>
<td width=150>第三格</td>
</tr>
</table>
posted @
2007-11-20 16:44 xzc 阅读(323) |
评论 (0) |
编辑 收藏
Sun Varchar2(1000);
i Number;
Begin
For i In (Select Table_Name From Dba_Tables Where Owner = 'NEWWSS') Loop
Begin
Sun := i.Table_Name;
Execute Immediate 'create or replace synonym WSS_' || Sun ||
' for NEWWSS.' || Sun || '@WSS_LINK.US.ORACLE.COM';
Exception
When Others Then
Null;
End;
End Loop;
End Create_Synonym;
posted @
2007-10-24 11:05 xzc 阅读(2193) |
评论 (0) |
编辑 收藏JSP动作利用XML语法格式的标记来控制Servlet引擎的行为。利用JSP动作可以动态地插入文件、重用JavaBean组件、把用户重定向到另外的页面、为Java插件生成HTML代码。
JSP动作包括:
jsp:include:在页面被请求的时候引入一个文件。
jsp:useBean:寻找或者实例化一个JavaBean。
jsp:setProperty:设置JavaBean的属性。
jsp:getProperty:输出某个JavaBean的属性。
jsp:forward:把请求转到一个新的页面。
jsp:plugin:根据浏览器类型为Java插件生成OBJECT或EMBED标记。
13.1 jsp:include动作
该动作把指定文件插入正在生成的页面。其语法如下:
<jsp:include page="relative URL" flush="true" />
前面已经介绍过include指令,它是在JSP文件被转换成Servlet的时候引入文件,而这里的jsp:include动作不同,插入文件的时间是在页面被请求的时候。jsp:include动作的文件引入时间决定了它的效率要稍微差一点,而且被引用文件不能包含某些JSP代码(例如不能设置HTTP头),但它的灵活性却要好得多。
例如,下面的JSP页面把4则新闻摘要插入一个“What s New ?”页面。改变新闻摘要时只需改变这四个文件,而主JSP页面却可以不作修改:
WhatsNew.jsp
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE>What s New</TITLE>
</HEAD>
<BODY BGCOLOR="#FDF5E6" TEXT="#000000" LINK="#0000EE"
VLINK="#551A8B" ALINK="#FF0000">
<CENTER>
<TABLE BORDER=5 BGCOLOR="#EF8429">
<TR><TH CLASS="TITLE">
What s New at JspNews.com</TABLE>
</CENTER>
<P>
Here is a summary of our four most recent news stories:
<OL>
<LI><jsp:include page="news/Item1.html" flush="true"/>
<LI><jsp:include page="news/Item2.html" flush="true"/>
<LI><jsp:include page="news/Item3.html" flush="true"/>
<LI><jsp:include page="news/Item4.html" flush="true"/>
</OL>
</BODY>
</HTML>
13.2 jsp:useBean动作
jsp:useBean动作用来装载一个将在JSP页面中使用的JavaBean。这个功能非常有用,因为它使得我们既可以发挥Java组件重用的优势,同时也避免了损失JSP区别于Servlet的方便性。jsp:useBean动作最简单的语法为:
<jsp:useBean id="name" class="package.class" />
这行代码的含义是:“创建一个由class属性指定的类的实例,然后把它绑定到其名字由id属性给出的变量上”。不过,就象我们接下来会看到的,定义一个scope属性可以让Bean关联到更多的页面。此时,jsp:useBean动作只有在不存在同样id和scope的Bean时才创建新的对象实例,同时,获得现有Bean的引用就变得很有必要。
获得Bean实例之后,要修改Bean的属性既可以通过jsp:setProperty动作进行,也可以在Scriptlet中利用id属性所命名的对象变量,通过调用该对象的方法显式地修改其属性。这使我们想起,当我们说“某个Bean有一个类型为X的属性foo”时,就意味着“这个类有一个返回值类型为X的getFoo方法,还有一个setFoo方法以X类型的值为参数”。
有关jsp:setProperty动作的详细情况在后面讨论。但现在必须了解的是,我们既可以通过jsp:setProperty动作的value属性直接提供一个值,也可以通过param属性声明Bean的属性值来自指定的请求参数,还可以列出Bean属性表明它的值
1Y0-327 应该来自请求参数中的同名变量。
在JSP表达式或Scriptlet中读取Bean属性通过调用相应的getXXX方法实现,或者更一般地,使用jsp:getProperty动作。
注意包含Bean的类文件应该放到服务器正式存放Java类的目录下,而不是保留给修改后能够自动装载的类的目录。例如,对于Java Web Server来说,Bean和所有Bean用到的类都应该放入classes目录,或者封装进jar文件后放入lib目录,但不应该放到servlets下。
下面是一个很简单的例子,它的功能是装载一个Bean,然后设置/读取它的message属性。
BeanTest.jsp
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE>Reusing JavaBeans in JSP</TITLE>
</HEAD>
<BODY>
<CENTER>
<TABLE BORDER=5>
<TR><TH CLASS="TITLE">
Reusing JavaBeans in JSP</TABLE>
</CENTER>
<P>
<jsp:useBean id="test" class="hall.SimpleBean" />
<jsp:setProperty name="test"
property="message"
value="Hello WWW" />
<H1>Message: <I>
<jsp:getProperty name="test" property="message" />
</I></H1>
</BODY>
</HTML>
SimpleBean.java
BeanTest页面用到了一个SimpleBean。SimpleBean的代码如下:
package hall;
public class SimpleBean {
private String message = "No message specified";
public String getMessage() {
return(message);
}
public void setMessage(String message) {
this.message = message;
}
}
13.3 关于jsp:useBean的进一步说明
使用Bean最简单的方法是先用下面的代码装载Bean:
<jsp:useBean id="name" class="package.class" />
然后通过jsp:setProperty和jsp:getProperty修改和提取Bean的属性。不过有两点必须注意。第一,我们还可以用下面这种格式实例化Bean:
<jsp:useBean ...>
Body
</jsp:useBean>
它的意思是,只有当第一次实例化Bean时才执行Body部分,如果是利用现有的Bean实例则不执行Body部分。正如
jn0-140 下面将要介绍的,jsp:useBean并非总是意味着创建一个新的Bean实例。
第二,除了id和class外,jsp:useBean还有其他三个属性,即:scope,type,beanName。下表简要说明这些属性的用法。 属性 用法
id 命名引用该Bean的变量。如果能够找到id和scope相同的Bean实例,jsp:useBean动作将使用已有的Bean实例而不是创建新的实例。
class 指定Bean的完整包名。
scope 指定Bean在哪种上下文内可用,可以取下面的四个值之一:page,request,session和application。
默认值是page,表示该Bean只在当前页面内可用(保存在当前页面的PageContext内)。
request表示该Bean在当前的客户请求内有效(保存在ServletRequest对象内)。
session表示该Bean对当前HttpSession内的所有页面都有效。
最后,如果取值application,则表示该Bean对所有具有相同ServletContext的页面都有效。
scope之所以很重要,是因为jsp:useBean只有在不存在具有相同id和scope的对象时才会实例化新的对象;如果已有id和scope都相同的对象则直接使用已有的对象,此时jsp:useBean开始标记和结束标记之间的任何内容都将被忽略。
type 指定引用该对象的变量的类型,它必须是Bean类的名字、超类名字、该类所实现的接口名字之一。请记住变量的名字是由id属性指定的。
beanName 指定Bean的名字。如果提供了type属性和beanName属性,允许省略class属性。
13.4 jsp:setProperty动作
jsp:setProperty用来设置已经实例化的Bean对象的属性,有两种用法。首先,你可以在jsp:useBean元素的外面(后面)使用jsp:setProperty,如下所示:
<jsp:useBean id="myName" ... />
...
<jsp:setProperty name="myName"
property="someProperty" ... />
此时,不管jsp:useBean是找到了一个现有的Bean,还是新创建了一个Bean实例,jsp:setProperty都会执行。第二种用法是把jsp:setProperty放入jsp:useBean元素的内部,如下所示:
<jsp:useBean id="myName" ... >
...
<jsp:setProperty name="myName"
property="someProperty" ... />
</jsp:useBean>
此时,jsp:setProperty只有在新建Bean实例时才会执行,如果是使用现有实例则不执行jsp:setProperty。
jsp:setProperty动作有下面四个属性: 属性 说明
name name属性是必需的。它表示要设置属性的是哪个Bean。
property property属性是必需的。它表示要设置哪个属性。有一个特殊用法:如果property的值是“*”,表示所有名字和Bean属性名字匹配的请求参数都将被传递给相应的属性set方法。
value value属性是可选的。该属性用来指定Bean属性的值。字符串数据会在目标类中通过标准的valueOf方法自动转换成数字、boolean、Boolean、byte、Byte、char、Character。例如,boolean和Boolean类型的属性值(比如“true”)通过Boolean.valueOf转换,int和Integer类型的属性值(比如“42”)通过Integer.valueOf转换。
value和param不能同时使用,但可以使用其中任意一个。
param param是可选的。它指定用哪个请求参数作为Bean属性的值。如果当前请求没有参数,则什么事情也不做,系统不会把null传递给Bean属性的set方法。因此,你可以让Bean自己提供默认属性值,只有当请求参数明确指定了新值时才修改默认属性值。
例如,下面的代码片断表示:如果存在numItems请求参数的话,把numberOfItems属性的值设置为请求参数numItems的值;否则什么也不做。
<jsp:setProperty name="orderBean"
property="numberOfItems"
param="numItems" />
如果同时省略value和param,其效果相当于提供一个param且其值等于property的值。进一步利用这种借助请求参数和属性名字相同进行自动赋值的思想,你还可以在property(Bean属性的名字)中指定“*”,然后省略value和param。此时,服务器会查看所有的Bean属性和请求参数,如果两者名字相同则自动赋值。
下面是一个利用JavaBean计算素数的例子。如果请求中有一个numDigits参数,则该值被传递给Bean的numDigits属性;numPrimes也类似。
JspPrimes.jsp
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE>在JSP中使用JavaBean</TITLE>
</HEAD>
<BODY>
<CENTER>
<TABLE BORDER=5>
<TR><TH CLASS="TITLE">
在JSP中使用JavaBean</TABLE>
</CENTER>
<P>
<jsp:useBean id="primeTable" class="hall.NumberedPrimes" />
<jsp:setProperty name="primeTable" property="numDigits" />
<jsp:setProperty name="primeTable" property="numPrimes" />
Some <jsp:getProperty name="primeTable" property="numDigits" />
digit primes:
<jsp:getProperty name="primeTable" property="numberedList" />
</BODY>
</HTML>
注:NumberedPrimes的代码略。
13.5 jsp:getProperty动作
jsp:getProperty动作提取指定Bean属性的值,转换成字符串,然后输出。jsp:getProperty有两个必需的属性,即:name,表示Bean的名字;property,表示要提取哪个属性的值。下面是一个例子,更多的例子可以在前文找到。
<jsp:useBean id="itemBean" ... />
...
<UL>
<LI>Number of items:
<jsp:getProperty name="itemBean" property="numItems" />
<LI>Cost of each:
<jsp:getProperty name="itemBean" property="unitCost" />
</UL>
13.6 jsp:forward动作
jsp:forward动作把请求转到另外的页面。jsp:forward标记只有一个属性page。page属性包含的是一个相对URL。page的值既可以直接给出,也可以在请求的时候动态计算,如下面的例子所示:
<jsp:forward page="/utils/errorReporter.jsp" />
<jsp:forward page="<%= someJavaExpression %>" />
13.7 jsp:plugin动作
jsp:plugin动作用来根据浏览器的类型,插入通过Java插件 运行Java Applet所必需的OBJECT或EMBED元素。
附录:JSP注释和字符引用约定
下面是一些特殊的标记或字符,你可以利用它们插入注释或可能被视为具有特殊含义的字符。 语法 用途
<%-- comment --%> JSP注释,也称为“隐藏注释”。JSP引擎将忽略它。标记内的所有JSP脚本元素、指令和动作都将不起作用。
<!-- comment --> HTML注释,也称为“输出的注释”,直接出现在结果HTML文档中。标记内的所有JSP脚本元素、指令和动作正常执行。
<\% 在模板文本(静态HTML)中实际上希望出现“<%”的地方使用。
%\> 在脚本元素内实际上希望出现“%>”的地方使用。
\ 使用单引号的属性内的单引号。不过,你既可以使用单引号也可以使用双引号,而另外一种引号将具有普通含义。
\" 使用双引号的属性内的双引号。参见“\ ”的说明。
posted @
2007-10-19 12:57 xzc 阅读(341) |
评论 (0) |
编辑 收藏网络收集:PLSQL常用方法汇总
在SQLPLUS下,实现中-英字符集转换
alter session set nls_language='AMERICAN';
alter session set nls_language='SIMPLIFIED CHINESE';
主要知识点:
一、有关表的操作
1)建表
create table test as select * from dept; --从已知表复制数据和结构
create table test as select * from dept where 1=2; --从已知表复制结构但不包括数据
2)插入数据:
insert into test select * from dept;
二、运算符
算术运算符:+ - * / 可以在select 语句中使用
连接运算符:|| select deptno|| dname from dept;
比较运算符:> >= = != < <= like between is null in
逻辑运算符:not and or
集合运算符: intersect(交),union(并 不重复), union all(并 重复), minus(差)
要求:对应集合的列数和数据类型相同
查询中不能包含long 列
列的标签是第一个集合的标签
使用order by时,必须使用位置序号,不能使用列名
例:集合运算符的使用:
intersect ,union, union all, minus
select * from emp intersect select * from emp where deptno=10 ;
select * from emp minus select * from emp where deptno=10;
select * from emp where deptno=10 union select * from emp where deptno in (10,20); --不包括重复行
select * from emp where deptno=10 union all select * from emp where deptno in (10,20); --包括重复行三,常用 ORACLE 函数
sysdate为系统日期 dual为虚表
一)日期函数[重点掌握前四个日期函数]
-----------------------------------------
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
Time:
HH24:MI:SS
HH12:MI:SS
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
-----------------------------------------
1,add_months[返回日期加(减)指定月份后(前)的日期]
select sysdate S1, add_months(sysdate, 10) S2, add_months(sysdate, 5) S3
from dual;
2,last_day [返回该月最后一天的日期]
select sysdate,last_day(sysdate) from dual;
3,months_between[返回日期之间的月份数]
select sysdate S1,
months_between('1-4月-04', sysdate) S2,
months_between('1-4月-04', '1-2月-04') S3
from dual
4,next_day(d,day): 返回下个星期的日期,day为1-7或星期日-星期六,1表示星期日
select sysdate S1, next_day(sysdate, 1) S2, next_day(sysdate, '星期日') S3
FROM DUAL
5,round[舍入到最接近的日期](day:舍入到最接近的星期日)
select sysdate S1,
round(sysdate) S2,
round(sysdate, 'year') YEAR,
round(sysdate, 'month') MONTH,
round(sysdate, 'day') DAY
from dual
6,trunc[截断到最接近的日期]
select sysdate S1,
trunc(sysdate) S2,
trunc(sysdate, 'year') YEAR,
trunc(sysdate, 'month') MONTH,
trunc(sysdate, 'day') DAY
from dual
7,返回日期列表中最晚日期
select greatest('01-1月-04', '04-1月-04', '10-2月-04') from dual
二)字符函数(可用于字面字符或数据库列)
1,字符串截取
select substr('abcdef',1,3) from dual
2,查找子串位置
select instr('abcfdgfdhd','fd') from dual
3,字符串连接
select 'HELLO'||'hello world' from dual;
4, 1)去掉字符串中的空格
select ltrim(' abc') s1, rtrim('zhang ') s2, trim(' zhang ') s3 from dual
2)去掉前导和后缀
select trim(leading 9 from 9998767999) s1,
trim(trailing 9 from 9998767999) s2,
trim(9 from 9998767999) s3
from dual;
5,返回字符串首字母的Ascii值
select ascii('a') from dual
6,返回ascii值对应的字母
select chr(97) from dual
7,计算字符串长度
select length('abcdef') from dual
8,initcap(首字母变大写) ,lower(变小写),upper(变大写)
select lower('ABC') s1,
upper('def') s2,
initcap('efg') s3 from dual;
9,Replace
select replace('abc','b','xy') from dual;
10,translate
select translate('abc','b','xx') from dual; -- x是1位
11,lpad [左添充] rpad [右填充](用于控制输出格式)
select lpad('func',15,'=') s1, rpad('func',15,'-') s2 from dual;
select lpad(dname,14,'=') from dept;
12, decode[实现if ..then 逻辑]
select deptno,decode(deptno,10,'1',20,'2',30,'3','其他') from dept;
三)数字函数
1,取整函数(ceil 向上取整,floor 向下取整)
select ceil(66.6) N1,floor(66.6) N2 from dual;
2, 取幂(power) 和 求平方根(sqrt)
select power(3,2) N1,sqrt(9) N2 from dual;
3,求余
select mod(9,5) from dual;
4,返回固定小数位数 (round:四舍五入,trunc:直接截断)
select round(66.667,2) N1,trunc(66.667,2) N2 from dual;
5,返回值的符号(正数返回为1,负数为-1)
select sign(-32),sign(293) from dual;
四)转换函数
1,to_char()[将日期和数字类型转换成字符类型]
1) select to_char(sysdate) s1,
to_char(sysdate,'yyyy-mm-dd') s2,
to_char(sysdate,'yyyy') s3,
to_char(sysdate,'yyyy-mm-dd hh12:mi:ss') s4,
to_char(sysdate, 'hh24:mi:ss') s5,
to_char(sysdate,'DAY') s6 from dual;
2) select sal,to_char(sal,'$99999') n1,to_char(sal,'$99,999') n2 from emp
2, to_date()[将字符类型转换为日期类型]
insert into emp(empno,hiredate) values(8000,to_date('2004-10-10','yyyy-mm-dd'));
3, to_number() 转换为数字类型
select to_number(to_char(sysdate,'hh12')) from dual; //以数字显示的小时数
五)其他函数
user:
返回登录的用户名称
select user from dual;
vsize:
返回表达式所需的字节数
select vsize('HELLO') from dual;
nvl(ex1,ex2):
ex1值为空则返回ex2,否则返回该值本身ex1(常用)
例:如果雇员没有佣金,将显示0,否则显示佣金
select comm,nvl(comm,0) from emp;
nullif(ex1,ex2):
值相等返空,否则返回第一个值
例:如果工资和佣金相等,则显示空,否则显示工资
select nullif(sal,comm),sal,comm from emp;
coalesce:
返回列表中第一个非空表达式
select comm,sal,coalesce(comm,sal,sal*10) from emp;
nvl2(ex1,ex2,ex3) :
如果ex1不为空,显示ex2,否则显示ex3
如:查看有佣金的雇员姓名以及他们的佣金
select nvl2(comm,ename,'') as HaveCommName,comm from emp;
六)分组函数
max min avg count sum
1,整个结果集是一个组
1) 求部门30 的最高工资,最低工资,平均工资,总人数,有工作的人数,工种数量及工资总和
select max(ename),max(sal),
min(ename),min(sal),
avg(sal),
count(*) ,count(job),count(distinct(job)) ,
sum(sal) from emp where deptno=30;
2, 带group by 和 having 的分组
1)按部门分组求最高工资,最低工资,总人数,有工作的人数,工种数量及工资总和
select deptno, max(ename),max(sal),
min(ename),min(sal),
avg(sal),
count(*) ,count(job),count(distinct(job)) ,
sum(sal) from emp group by deptno;
2)部门30的最高工资,最低工资,总人数,有工作的人数,工种数量及工资总和
select deptno, max(ename),max(sal),
min(ename),min(sal),
avg(sal),
count(*) ,count(job),count(distinct(job)) ,
sum(sal) from emp group by deptno having deptno=30;
3, stddev 返回一组值的标准偏差
select deptno,stddev(sal) from emp group by deptno;
variance 返回一组值的方差差
select deptno,variance(sal) from emp group by deptno;
4, 带有rollup和cube操作符的Group By
rollup 按分组的第一个列进行统计和最后的小计
cube 按分组的所有列的进行统计和最后的小计
select deptno,job ,sum(sal) from emp group by deptno,job;
select deptno,job ,sum(sal) from emp group by rollup(deptno,job);
cube 产生组内所有列的统计和最后的小计
select deptno,job ,sum(sal) from emp group by cube(deptno,job);七、临时表
只在会话期间或在事务处理期间存在的表.
临时表在插入数据时,动态分配空间
create global temporary table temp_dept
(dno number,
dname varchar2(10))
on commit delete rows;
insert into temp_dept values(10,'ABC');
commit;
select * from temp_dept; --无数据显示,数据自动清除
on commit preserve rows:在会话期间表一直可以存在(保留数据)
on commit delete rows:事务结束清除数据(在事务结束时自动删除表的数据)
Oracle时间日期操作
sysdate+(5/24/60/60) 在系统时间基础上延迟5秒
sysdate+5/24/60 在系统时间基础上延迟5分钟
sysdate+5/24 在系统时间基础上延迟5小时
sysdate+5 在系统时间基础上延迟5天
add_months(sysdate,-5) 在系统时间基础上延迟5月
add_months(sysdate,-5*12) 在系统时间基础上延迟5年
上月末的日期:select last_day(add_months(sysdate, -1)) from dual;
本月的最后一秒:select trunc(add_months(sysdate,1),'MM') - 1/24/60/60 from dual
本周星期一的日期:select trunc(sysdate,'day')+1 from dual
年初至今的天数:select ceil(sysdate - trunc(sysdate, 'year')) from dual;
今天是今年的第几周 :select to_char(sysdate,'fmww') from dual
今天是本月的第几周:SELECT TO_CHAR(SYSDATE,'WW') - TO_CHAR(TRUNC(SYSDATE,'MM'),'WW') + 1 AS "weekOfMon" FROM dual
本月的天数
SELECT to_char(last_day(SYSDATE),'dd') days FROM dual
今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
下个星期一的日期
SELECT Next_day(SYSDATE,'monday') FROM dual
============================================
--计算工作日方法
create table t(s date,e date);
alter session set nls_date_format = 'yyyy-mm-dd';
insert into t values('2003-03-01','2003-03-03');
insert into t values('2003-03-02','2003-03-03');
insert into t values('2003-03-07','2003-03-08');
insert into t values('2003-03-07','2003-03-09');
insert into t values('2003-03-05','2003-03-07');
insert into t values('2003-02-01','2003-03-31');
-- 这里假定日期都是不带时间的,否则在所有日期前加trunc即可。
select s,e,e-s+1 total_days,
trunc((e-s+1)/7)*5 + length(replace(substr('01111100111110',to_char(s,'d'),mod(e-s+1,7)),'0','')) work_days
from t;
-- drop table t;
引此:http://www.itpub.net/showthread.php?s=1635506cd5f48b1bc3adbe4cde96f227&threadid=104060&perpage=15&pagenumber=1
================================================================================
判断当前时间是上午下午还是晚上
SELECT CASE
WHEN to_number(to_char(SYSDATE,'hh24')) BETWEEN 6 AND 11 THEN '上午'
WHEN to_number(to_char(SYSDATE,'hh24')) BETWEEN 11 AND 17 THEN '下午'
WHEN to_number(to_char(SYSDATE,'hh24')) BETWEEN 17 AND 21 THEN '晚上'
END
FROM dual;
================================================================================
Oracle 中的一些处理日期
将数字转换为任意时间格式.如秒:需要转换为天/小时
SELECT to_char(floor(TRUNC(936000/(60*60))/24))||'天'||to_char(mod(TRUNC(936000/(60*60)),24))||'小时' FROM DUAL
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' | | :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from dual
日期 返回的是天 然后 转换为ss
转此:http://www.onlinedatabase.cn/leadbbs/Announce/Announce.asp?BoardID=42&ID=1769
将数字转换为任意时间格式.如秒:需要转换为天/小时
SELECT to_char(floor(TRUNC(936000/(60*60))/24))||'天'||to_char(mod(TRUNC(936000/(60*60)),24))||'小时' FROM DUAL
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' | | :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from dual
日期 返回的是天 然后 转换为ss
转此:http://www.onlinedatabase.cn/leadbbs/Announce/Announce.asp?BoardID=42&ID=1769
将数字转换为任意时间格式.如秒:需要转换为天/小时
SELECT to_char(floor(TRUNC(936000/(60*60))/24))||'天'||to_char(mod(TRUNC(936000/(60*60)),24))||'小时' FROM DUAL
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' | | :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from dual
日期 返回的是天 然后 转换为ss
转此:http://www.onlinedatabase.cn/leadbbs/Announce/Announce.asp?BoardID=42&ID=1769
将数字转换为任意时间格式.如秒:需要转换为天/小时
SELECT to_char(floor(TRUNC(936000/(60*60))/24))||'天'||to_char(mod(TRUNC(936000/(60*60)),24))||'小时' FROM DUAL
TO_DATE格式
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' | | :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from dual
日期 返回的是天 然后 转换为ss
posted @
2007-10-18 14:03 xzc 阅读(2162) |
评论 (2) |
编辑 收藏
 import java.util.GregorianCalendar;
import java.util.GregorianCalendar;

 public class Date
public class Date {
{

 public static void main(String[] args){
public static void main(String[] args){
 //获取今天的年月日星期
//获取今天的年月日星期
Calendar dt = new GregorianCalendar();
int year = dt.get(Calendar.YEAR);
int month = dt.get(Calendar.MONTH)+1;
int day= dt.get(Calendar.DAY_OF_MONTH);
int dayOfWeek= dt.get(Calendar.DAY_OF_WEEK)-1;
System.out.println("今天是"+year+"年"+month+"月"+day+"
日,星期"+dayOfWeek);
//获取指定月份的最大天数
int days = dt.getActualMaximum(month);
System.out.println("本月共有"+days+"天");
//判断是否是闰年
GregorianCalendar da = new GregorianCalendar();
boolean b = da.isLeapYear(2004);
System.out.println(b);
 }
}
 }
}
import java.util.Properties;
import java.io.FileInputStream;
import java.io.IOException;
public class Files{
public static void main(String[] args){
try{
Properties files = new Properties();
files.load(new FileInputStream("Files.Properties"));
String a = files.getProperty("a");
System.out.println(a);
}catch (IOException e) {
}
}
}
//求昨天的当前时间
import java.util.Calendar;
import java.util.GregorianCalendar;
import java.util.Date;
import java.text.SimpleDateFormat;
public class Date1{
public static void main(String[] args){
Calendar date = new GregorianCalendar();
date.add(Calendar.DAY_OF_MONTH,-1);
Date yesterday= date.getTime();
String yesterday2 = new SimpleDateFormat("yyyy.MM.dd.HH.mm.ss").format(yesterday);
System.out.println(yesterday2);
}
}
posted @
2007-09-14 09:43 xzc 阅读(582) |
评论 (1) |
编辑 收藏
1. MySQL(http://www.mysql.com)mm.mysql-2.0.2-bin.jar
Class.forName( "org.gjt.mm.mysql.Driver" );
cn = DriverManager.getConnection( "jdbc:mysql://MyDbComputerNameOrIP:3306/myDatabaseName", sUsr, sPwd );
2. PostgreSQL(http://www.de.postgresql.org)pgjdbc2.jar
Class.forName( "org.postgresql.Driver" );
cn = DriverManager.getConnection( "jdbc:postgresql://MyDbComputerNameOrIP/myDatabaseName", sUsr, sPwd );
3. Oracle(http://www.oracle.com/ip/deploy/database/oracle9i/)classes12.zip
Class.forName( "oracle.jdbc.driver.OracleDriver" );
cn = DriverManager.getConnection( "jdbc:oracle:thin:@MyDbComputerNameOrIP:1521:ORCL", sUsr, sPwd );
4. Sybase(http://jtds.sourceforge.net)jconn2.jar
Class.forName( "com.sybase.jdbc2.jdbc.SybDriver" );
cn = DriverManager.getConnection( "jdbc:sybase:Tds:MyDbComputerNameOrIP:2638", sUsr, sPwd );
//(Default-Username/Password: "dba"/"sql")
5. Microsoft SQLServer(http://jtds.sourceforge.net)
Class.forName( "net.sourceforge.jtds.jdbc.Driver" );
cn = DriverManager.getConnection( "jdbc:jtds:sqlserver://MyDbComputerNameOrIP:1433/master", sUsr, sPwd );
6. Microsoft SQLServer(http://www.microsoft.com)
Class.forName( "com.microsoft.jdbc.sqlserver.SQLServerDriver" );
cn = DriverManager.getConnection( "jdbc:microsoft:sqlserver://MyDbComputerNameOrIP:1433;databaseName=master", sUsr, sPwd );
7. ODBC
Class.forName( "sun.jdbc.odbc.JdbcOdbcDriver" );
Connection cn = DriverManager.getConnection( "jdbc:odbc:" + sDsn, sUsr, sPwd );
8.DB2(新添加)
Class.forName("com.ibm.db2.jdbc.net.DB2Driver");
String url="jdbc:db2://192.9.200.108:6789/SAMPLE"
cn = DriverManager.getConnection( url, sUsr, sPwd );
9.Microsoft SQL Server series (6.5, 7.x and 2000) and Sybase 10
JDBC Name: jTDS
URL: http://jtds.sourceforge.net/
Version: 0.5.1
Download URL: http://sourceforge.net/project/showfiles.php?group_id=33291
语法:
Class.forName("net.sourceforge.jtds.jdbc.Driver ");
Connection con = DriverManager.getConnection("jdbc:jtds:sqlserver://host:port/database","user","password");
or
Connection con = DriverManager.getConnection("jdbc:jtds:sybase://host:port/database","user","password");
10.Postgresql
JDBC Name: PostgreSQL JDBC
URL: http://jdbc.postgresql.org/
Version: 7.3.3 build 110
Download URL: http://jdbc.postgresql.org/download.html
语法:
Class.forName("org.postgresql.Driver");
Connection con=DriverManager.getConnection("jdbc:postgresql://host:port/database","user","password");
11.IBM AS400主机在用的JDBC语法
有装V4R4以上版本的Client Access Express
可以在C:\Program Files\IBM\Client Access\jt400\lib
找到 driver 档案 jt400.zip,并更改扩展名成为 jt400.jar
语法:
java.sql.DriverManager.registerDriver (new com.ibm.as400.access.AS400JDBCDriver ());
Class.forName("com.ibm.as400.access.AS400JDBCConnection");
con = DriverManager.getConnection("jdbc:as400://IP","user","password");
12.informix
Class.forName("com.informix.jdbc.IfxDriver").newInstance();
String url =
"jdbc:informix-sqli://123.45.67.89:1533/testDB:INFORMIXSERVER=myserver;
user=testuser;password=testpassword";
Lib:jdbcdrv.zip<br><br>Class.forName( "com.sybase.jdbc.SybDriver" )
url="jdbc:sybase:Tds:127.0.0.1:2638/asademo";
SybConnection connection= (SybConnection)DriverManager.getConnection(url,"dba","sql");
13.SAP DB
Class.forName ("com.sap.dbtech.jdbc.DriverSapDB");
java.sql.Connection connection = java.sql.DriverManager.getConnection ( "jdbc:sapdb://" + host + "/" + database_name,user_name, password)
14.InterBase
String url = "jdbc:interbase://localhost/e:/testbed/database/employee.gdb";
Class.forName("interbase.interclient.Driver");
//Driver d = new interbase.interclient.Driver (); /* this will also work if you do not want the line above */
Connection conn = DriverManager.getConnection( url, "sysdba", "masterkey" );
15.HSqlDB
url: http://hsqldb.sourceforge.net/
driver: org.hsqldb.jdbcDriver
连接方式有4种,分别为:
con-str(内存): jdbc:hsqldb.
con-str(本地): jdbc:hsqldb:/path/to/the/db/dir
con-str(http): jdbc:hsqldb:http://dbsrv
con-str(hsql): jdbc:hsqldb:hsql://dbsrv
posted @
2007-09-14 09:07 xzc 阅读(318) |
评论 (1) |
编辑 收藏
begin
sys.dbms_job.submit(job => :jobno,
what => 'p_report_bb_install;',
next_date => to_date('05-09-2007', 'dd-mm-yyyy'),
interval => 'TRUNC(SYSDATE)+1');
commit;
end;
/
posted @
2007-09-04 17:42 xzc 阅读(244) |
评论 (2) |
编辑 收藏数据字典dict总是属于Oracle用户sys的。
1、用户:
select username from dba_users;
改口令
alter user spgroup identified by spgtest;
2、表空间:
select * from dba_data_files;
select * from dba_tablespaces;//表空间
select tablespace_name,sum(bytes), sum(blocks)
from dba_free_space group by tablespace_name;//空闲表空间
select * from dba_data_files
where tablespace_name='RBS';//表空间对应的数据文件
select * from dba_segments
where tablespace_name='INDEXS';
3、数据库对象:
select * from dba_objects;
CLUSTER、DATABASE LINK、FUNCTION、INDEX、LIBRARY、PACKAGE、PACKAGE BODY、
PROCEDURE、SEQUENCE、SYNONYM、TABLE、TRIGGER、TYPE、UNDEFINED、VIEW。
4、表:
select * from dba_tables;
analyze my_table compute statistics;->dba_tables后6列
select extent_id,bytes from dba_extents
where segment_name='CUSTOMERS' and segment_type='TABLE'
order by extent_id;//表使用的extent的信息。segment_type='ROLLBACK'查看回滚段的空间分配信息
列信息:
select distinct table_name
from user_tab_columns
where column_name='SO_TYPE_ID';
5、索引:
select * from dba_indexes;//索引,包括主键索引
select * from dba_ind_columns;//索引列
select i.index_name,i.uniqueness,c.column_name
from user_indexes i,user_ind_columns c
where i.index_name=c.index_name
and i.table_name ='ACC_NBR';//联接使用
6、序列:
select * from dba_sequences;
7、视图:
select * from dba_views;
select * from all_views;
text 可用于查询视图生成的脚本
8、聚簇:
select * from dba_clusters;
9、快照:
select * from dba_snapshots;
快照、分区应存在相应的表空间。
10、同义词:
select * from dba_synonyms
where table_owner='SPGROUP';
//if owner is PUBLIC,then the synonyms is a public synonym.
if owner is one of users,then the synonyms is a private synonym.
11、数据库链:
select * from dba_db_links;
在spbase下建数据库链
create database link dbl_spnew
connect to spnew identified by spnew using 'jhhx';
insert into acc_nbr@dbl_spnew
select * from acc_nbr where nxx_nbr='237' and line_nbr='8888';
12、触发器:
select * from dba_trigers;
存储过程,函数从dba_objects查找。
其文本:select text from user_source where name='BOOK_SP_EXAMPLE';
建立出错:select * from user_errors;
oracle总是将存储过程,函数等软件放在SYSTEM表空间。
13、约束:
(1)约束是和表关联的,可在create table或alter table table_name add/drop/modify来建立、修改、删除约束。
可以临时禁止约束,如:
alter table book_example
disable constraint book_example_1;
alter table book_example
enable constraint book_example_1;
(2)主键和外键被称为表约束,而not null和unique之类的约束被称为列约束。通常将主键和外键作为单独的命名约束放在字段列表下面,而列约束可放在列定义的同一行,这样更具有可读性。
(3)列约束可从表定义看出,即describe;表约束即主键和外键,可从dba_constraints和dba_cons_columns 查。
select * from user_constraints
where table_name='BOOK_EXAMPLE';
select owner,CONSTRAINT_NAME,TABLE_NAME
from user_constraints
where constraint_type='R'
order by table_name;
(4)定义约束可以无名(系统自动生成约束名)和自己定义约束名(特别是主键、外键)
如:create table book_example
(identifier number not null);
create table book_example
(identifier number constranit book_example_1 not null);
14、回滚段:
在所有的修改结果存入磁盘前,回滚段中保持恢复该事务所需的全部信息,必须以数据库发生的事务来相应确定其大小(DML语句才可回滚,create,drop,truncate等DDL不能回滚)。
回滚段数量=并发事务/4,但不能超过50;使每个回滚段大小足够处理一个完整的事务;
create rollback segment r05
tablespace rbs;
create rollback segment rbs_cvt
tablespace rbs
storage(initial 1M next 500k);
使回滚段在线
alter rollback segment r04 online;
用dba_extents,v$rollback_segs监测回滚段的大小和动态增长。
回滚段的区间信息
select * from dba_extents
where segment_type='ROLLBACK' and segment_name='RB1';
回滚段的段信息,其中bytes显示目前回滚段的字节数
select * from dba_segments
where segment_type='ROLLBACK' and segment_name='RB1';
为事物指定回归段
set transaction use rollback segment rbs_cvt
针对bytes可以使用回滚段回缩。
alter rollback segment rbs_cvt shrink;
select bytes,extents,max_extents from dba_segments
where segment_type='ROLLBACK' and segment_name='RBS_CVT';
回滚段的当前状态信息:
select * from dba_rollback_segs
where segment_name='RB1';
比多回滚段状态status,回滚段所属实例instance_num
查优化值optimal
select n.name,s.optsize
from v$rollname n,v$rollstat s
where n.usn=s.usn;
回滚段中的数据
set transaction use rollback segment rb1;/*回滚段名*/
select n.name,s.writes
from v$rollname n,v$rollstat s
where n.usn=s.usn;
当事务处理完毕,再次查询$rollstat,比较writes(回滚段条目字节数)差值,可确定事务的大小。
查询回滚段中的事务
column rr heading 'RB Segment' format a18
column us heading 'Username' format a15
column os heading 'Os User' format a10
column te heading 'Terminal' format a10
select r.name rr,nvl(s.username,'no transaction') us,s.osuser os,s.terminal te
from v$lock l,v$session s,v$rollname r
where l.sid=s.sid(+)
and trunc(l.id1/65536)=R.USN
and l.type='TX'
and l.lmode=6
order by r.name;
15、作业
查询作业信息
select job,broken,next_date,interval,what from user_jobs;
select job,broken,next_date,interval,what from dba_jobs;
查询正在运行的作业
select * from dba_jobs_running;
使用包exec dbms_job.submit(:v_num,'a;',sysdate,'sysdate + (10/(24*60*60))')加入作业。间隔10秒钟
exec dbms_job.submit(:v_num,'a;',sysdate,'sysdate + (11/(24*60))')加入作业。间隔11分钟使用包exec dbms_job.remove(21)删除21号作业。
posted @
2007-07-30 17:03 xzc 阅读(221) |
评论 (0) |
编辑 收藏
1. stream代表的是任何有能力产出数据的数据源,或是任何有能力接收数据的接收源。在Java的IO中,所有的stream(包括Input和Out stream)都包括两种类型:
1.1 以字节为导向的stream
以字节为导向的stream,表示以字节为单位从stream中读取或往stream中写入信息。以字节为导向的stream包括下面几种类型:
1) input stream:
1) ByteArrayInputStream:把内存中的一个缓冲区作为InputStream使用
2) StringBufferInputStream:把一个String对象作为InputStream
3) FileInputStream:把一个文件作为InputStream,实现对文件的读取操作
4) PipedInputStream:实现了pipe的概念,主要在线程中使用
5) SequenceInputStream:把多个InputStream合并为一个InputStream
2) Out stream
1) ByteArrayOutputStream:把信息存入内存中的一个缓冲区中
2) FileOutputStream:把信息存入文件中
3) PipedOutputStream:实现了pipe的概念,主要在线程中使用
4) SequenceOutputStream:把多个OutStream合并为一个OutStream
1.2 以Unicode字符为导向的stream
以Unicode字符为导向的stream,表示以Unicode字符为单位从stream中读取或往stream中写入信息。以Unicode字符为导向的stream包括下面几种类型:
1) Input Stream
1) CharArrayReader:与ByteArrayInputStream对应
2) StringReader:与StringBufferInputStream对应
3) FileReader:与FileInputStream对应
4) PipedReader:与PipedInputStream对应
2) Out Stream
1) CharArrayWrite:与ByteArrayOutputStream对应
2) StringWrite:无与之对应的以字节为导向的stream
3) FileWrite:与FileOutputStream对应
4) PipedWrite:与PipedOutputStream对应
以字符为导向的stream基本上对有与之相对应的以字节为导向的stream。两个对应类实现的功能相同,字是在操作时的导向不同。如CharArrayReader:和ByteArrayInputStream的作用都是把内存中的一个缓冲区作为InputStream使用,所不同的是前者每次从内存中读取一个字节的信息,而后者每次从内存中读取一个字符。
1.3 两种不现导向的stream之间的转换
InputStreamReader和OutputStreamReader:把一个以字节为导向的stream转换成一个以字符为导向的stream。
2. stream添加属性
2.1 “为stream添加属性”的作用
运用上面介绍的Java中操作IO的API,我们就可完成我们想完成的任何操作了。但通过FilterInputStream和FilterOutStream的子类,我们可以为stream添加属性。下面以一个例子来说明这种功能的作用。
如果我们要往一个文件中写入数据,我们可以这样操作:
FileOutStream fs = new FileOutStream(“test.txt”);
然后就可以通过产生的fs对象调用write()函数来往test.txt文件中写入数据了。但是,如果我们想实现“先把要写入文件的数据先缓存到内存中,再把缓存中的数据写入文件中”的功能时,上面的API就没有一个能满足我们的需求了。但是通过FilterInputStream和FilterOutStream的子类,为FileOutStream添加我们所需要的功能。
2.2 FilterInputStream的各种类型
2.2.1 用于封装以字节为导向的InputStream
1) DataInputStream:从stream中读取基本类型(int、char等)数据。
2) BufferedInputStream:使用缓冲区
3) LineNumberInputStream:会记录input stream内的行数,然后可以调用getLineNumber()和setLineNumber(int)
4) PushbackInputStream:很少用到,一般用于编译器开发
2.2.2 用于封装以字符为导向的InputStream
1) 没有与DataInputStream对应的类。除非在要使用readLine()时改用BufferedReader,否则使用DataInputStream
2) BufferedReader:与BufferedInputStream对应
3) LineNumberReader:与LineNumberInputStream对应
4) PushBackReader:与PushbackInputStream对应
2.3 FilterOutStream的各种类型
2.2.3 用于封装以字节为导向的OutputStream
1) DataIOutStream:往stream中输出基本类型(int、char等)数据。
2) BufferedOutStream:使用缓冲区
3) PrintStream:产生格式化输出
2.2.4 用于封装以字符为导向的OutputStream
1) BufferedWrite:与对应
2) PrintWrite:与对应
3. RandomAccessFile
1) 可通过RandomAccessFile对象完成对文件的读写操作
2) 在产生一个对象时,可指明要打开的文件的性质:r,只读;w,只写;rw可读写
3) 可以直接跳到文件中指定的位置
4. I/O应用的一个例子
import java.io.*;
public class TestIO{
public static void main(String[] args)
throws IOException{
//1.以行为单位从一个文件读取数据
BufferedReader in =
new BufferedReader(
new FileReader("F:\\nepalon\\TestIO.java"));
String s, s2 = new String();
while((s = in.readLine()) != null)
s2 += s + "\n";
in.close();
//1b. 接收键盘的输入
BufferedReader stdin =
new BufferedReader(
new InputStreamReader(System.in));
System.out.println("Enter a line:");
System.out.println(stdin.readLine());
//2. 从一个String对象中读取数据
StringReader in2 = new StringReader(s2);
int c;
while((c = in2.read()) != -1)
System.out.println((char)c);
in2.close();
//3. 从内存取出格式化输入
try{
DataInputStream in3 =
new DataInputStream(
new ByteArrayInputStream(s2.getBytes()));
while(true)
System.out.println((char)in3.readByte());
}
catch(EOFException e){
System.out.println("End of stream");
}
//4. 输出到文件
try{
BufferedReader in4 =
new BufferedReader(
new StringReader(s2));
PrintWriter out1 =
new PrintWriter(
new BufferedWriter(
new FileWriter("F:\\nepalon\\ TestIO.out")));
int lineCount = 1;
while((s = in4.readLine()) != null)
out1.println(lineCount++ + ":" + s);
out1.close();
in4.close();
}
catch(EOFException ex){
System.out.println("End of stream");
}
//5. 数据的存储和恢复
try{
DataOutputStream out2 =
new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream("F:\\nepalon\\ Data.txt")));
out2.writeDouble(3.1415926);
out2.writeChars("\nThas was pi:writeChars\n");
out2.writeBytes("Thas was pi:writeByte\n");
out2.close();
DataInputStream in5 =
new DataInputStream(
new BufferedInputStream(
new FileInputStream("F:\\nepalon\\ Data.txt")));
BufferedReader in5br =
new BufferedReader(
new InputStreamReader(in5));
System.out.println(in5.readDouble());
System.out.println(in5br.readLine());
System.out.println(in5br.readLine());
}
catch(EOFException e){
System.out.println("End of stream");
}
//6. 通过RandomAccessFile操作文件
RandomAccessFile rf =
new RandomAccessFile("F:\\nepalon\\ rtest.dat", "rw");
for(int i=0; i<10; i++)
rf.writeDouble(i*1.414);
rf.close();
rf = new RandomAccessFile("F:\\nepalon\\ rtest.dat", "r");
for(int i=0; i<10; i++)
System.out.println("Value " + i + ":" + rf.readDouble());
rf.close();
rf = new RandomAccessFile("F:\\nepalon\\ rtest.dat", "rw");
rf.seek(5*8);
rf.writeDouble(47.0001);
rf.close();
rf = new RandomAccessFile("F:\\nepalon\\ rtest.dat", "r");
for(int i=0; i<10; i++)
System.out.println("Value " + i + ":" + rf.readDouble());
rf.close();
}
}
关于代码的解释(以区为单位):
1区中,当读取文件时,先把文件内容读到缓存中,当调用in.readLine()时,再从缓存中以字符的方式读取数据(以下简称“缓存字节读取方式”)。
1b区中,由于想以缓存字节读取方式从标准IO(键盘)中读取数据,所以要先把标准IO(System.in)转换成字符导向的stream,再进行BufferedReader封装。
2区中,要以字符的形式从一个String对象中读取数据,所以要产生一个StringReader类型的stream。
4区中,对String对象s2读取数据时,先把对象中的数据存入缓存中,再从缓冲中进行读取;对TestIO.out文件进行操作时,先把格式化后的信息输出到缓存中,再把缓存中的信息输出到文件中。
5区中,对Data.txt文件进行输出时,是先把基本类型的数据输出屋缓存中,再把缓存中的数据输出到文件中;对文件进行读取操作时,先把文件中的数据读取到缓存中,再从缓存中以基本类型的形式进行读取。注意in5.readDouble()这一行。因为写入第一个writeDouble(),所以为了正确显示。也要以基本类型的形式进行读取。
6区是通过RandomAccessFile类对文件进行操作。
posted @
2007-06-20 21:49 xzc 阅读(245) |
评论 (0) |
编辑 收藏业务常用,供大家学习:
引用地址:http://www.easydone.cn/014/200604022353065155.htm
package org.easydone.file;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* <p>Title: File 常用操作(部分)</p>
* <p>Description: 业务用</p>
* <p>Copyright: Copyright (c) 2006
www.easydone.cn</p>
* <p>Company: 北京聚能易成科技有限公司</p>
* @authory dirboy
* @version 1.0
*/
public class FileOperate {
/**
* 创建目录
* @param folderPath:目录路径
* @return
* @throws IOException
*/
public static boolean createFolder(String folderPath) throws IOException {
boolean result = false;
File f = new File(folderPath);
result = f.mkdirs();
return result;
}
/**
* 删除目录下所有文件
* @param directory (File 对象)
*/
public void emptyDirectory(File directory) {
File[] entries = directory.listFiles();
for (int i = 0; i < entries.length; i++) {
entries[i].delete();
}
}
/**
* 创建文件
* @param filepath:文件所在目录路径,比如:c:/test/test.txt
* @return
*/
public static boolean makeFile(String filepath) throws IOException {
boolean result = false;
File file = new File(filepath);
result = file.createNewFile();
file = null;
return result;
}
/**
* 删除文件
* @param filepath:文件所在物理路径
* @return
*/
public static boolean isDel(String filepath) {
boolean result = false;
File file = new File(filepath);
result = file.delete();
file = null;
return result;
}
/**
* 文件重命名
* @param filepath:文件所在物理路径
* @param destname:新文件名
* @return
*/
public static boolean renamefile(String filepath,String destname) {
boolean result = false;
File f = new File(filepath);
String fileParent = f.getParent();
String filename = f.getName();
File rf = new File(fileParent+"//"+destname);
if(f.renameTo(rf)) {
result = true;
}
f = null;
rf = null;
return result;
}
/**
* 将文件内容写入数据库中
* @param filepath:文件所在物理路径
* @param content:写入内容
* @throws Exception
*/
public static void WriteFile(String filepath,String content) throws Exception {
FileWriter filewriter = new FileWriter(filepath,true);//写入多行
PrintWriter printwriter = new PrintWriter(filewriter);
printwriter.println(content);
printwriter.flush();
printwriter.close();
filewriter.close();
}
/**
* 日志备份
* @param filePath:日志备份路径
* @param baksize:日志备份大小参考值(字节大小)
* @throws IOException
*/
public static void logBak(String filePath,long baksize) throws IOException {
File f = new File(filePath);
long len = f.length();
SimpleDateFormat simpledateformat = new SimpleDateFormat("yyyyMMddHHmmss");
String s = simpledateformat.format(new Date());
String fileName = f.getName();
int dot = fileName.indexOf(".");
String bakName = s+fileName.substring(dot);
System.out.println(bakName);
if(len>=baksize) {
renamefile(filePath,bakName);
makeFile(filePath);
}
f = null;
}
}
posted @
2007-06-14 16:52 xzc 阅读(2056) |
评论 (0) |
编辑 收藏摘要:收集一些常用的正则表达式。
正则表达式用于字符串处理,表单验证等场合,实用高效,但用到时总是不太把握,以致往往要上网查一番。我将一些常用的表达式收藏在这里,作备忘之用。本贴随时会更新。
匹配中文字符的正则表达式:
匹配双字节字符(包括汉字在内):
应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String
.
prototype
.
len
=
function
(){
return
this
.
replace
([
^\
x00
-\
xff
]
/
g,"aa").length; }
匹配空行的正则表达式:
匹配HTML标记的正则表达式:
/
<(.*)>.*<
\/
\1>|<(.*)
\/
>
/
匹配首尾空格的正则表达式:
应用:j avascript中没有像v bscript那样的trim函数,我们就可以利用这个表达式来实现,如下:
String
.
prototype
.
trim
=
function
()
{
return
this
.
replace
(
/
(^\s*)|(\s*$)
/g
,
""
)
;
}
利用正则表达式分解和转换IP地址
下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:
function
IP2V
(
ip
)
{
re
=
/
(\d+)\.(\d+)\.(\d+)\.(\d+)
/g
//匹配IP地址的正则表达式
if
(
re
.
test
(
ip
))
{
return
RegExp
.$
1
*
Math
.
pow
(
255
,
3
)
)+
RegExp
.$
2
*
Math
.
pow
(
255
,
2
)
)+
RegExp
.$
3
*
255
+
RegExp
.$
4
*
1
}
else
{
throw
new
Error
(
"
Not a valid IP address!
"
)
}
}
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
var
ip
=
"
10.100.20.168
"
ip
=
ip
.
split
(
"
.
"
)
alert
(
"
IP值是:
"
+
(
ip
[
0
]
*
255
*
255
*
255
+
ip
[
1
]
*
255
*
255
+
ip
[
2
]
*
255
+
ip
[
3
]
*
1
))
匹配Email地址的正则表达式:
\
w
+
([
-+.
]
\
w
+
)
*@\
w
+
([
-.
]
\
w
+
)
*\.\
w
+
([
-.
]
\
w
+
)
*
匹配网址URL的正则表达式:
http
:
//([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
利用正则表达式去除字串中重复的字符的算法程序:[*注:此程序不正确]
var
s
=
"
abacabefgeeii
"
var
s1
=
s
.
replace
(
/
(.).*\1
/g
,
"
$1
"
)
var
re
=
new
RegExp
(
"
[
"
+
s1
+
"
]
"
,
"
g
"
)
var
s2
=
s
.
replace
(
re
,
""
)
alert
(
s1
+
s2
)
//结果为:abcefgi
*注
===============================
如果var s = “abacabefggeeii”
结果就不对了,结果为:abeicfgg
正则表达式的能力有限
===============================
我原来在CSDN上发贴寻求一个表达式来实现去除重复字符的方法,最终没有找到,这是我能想到的最简单的实现方法。思路是使用后向引用取出包括重复的字符,再以重复的字符建立第二个表达式,取到不重复的字符,两者串连。这个方法对于字符顺序有要求的字符串可能不适用。
得用正则表达式从URL地址中提取文件名的javascript程序,如下结果为page1
s
=
"
http://blog.penner.cn/page1.htm
"
s
=
s
.
replace
(
/
(.*
\/
){ 0, }([^\.]+).*
/i
g
,
"
$2
"
)
alert
(
s
)
利用正则表达式限制网页表单里的文本框输入内容:
用正则表达式限制只能输入中文:
onkeyup
=
"
value=value.replace(/[^\u4E00-\u9FA5]/g,'')
"
onbeforepaste
=
"
clipboardData.setData('text',clipboardData.getData('text').replace(/[^\u4E00-\u9FA5]/g,''))
"
用正则表达式限制只能输入全角字符:
onkeyup
=
"
value=value.replace(/[^\uFF00-\uFFFF]/g,'')
"
onbeforepaste
=
"
clipboardData.setData('text',clipboardData.getData('text').replace(/[^\uFF00-\uFFFF]/g,''))
"
用正则表达式限制只能输入数字:
onkeyup
=
"
value=value.replace(/[^\d]/g,'')
"
onbeforepaste
=
"
clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))
"
用正则表达式限制只能输入数字和英文:
onkeyup
=
"
value=value.replace(/[\W]/g,'')
"
onbeforepaste
=
"
clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))
"
匹配非负整数(正整数 + 0)
匹配正整数
^
[
0
-
9
]
*
[
1
-
9
][
0
-
9
]
*$
匹配非正整数(负整数 + 0)
^
((
-\
d
+
)
|
(
0
+
))
$
匹配负整数
^-
[
0
-
9
]
*
[
1
-
9
][
0
-
9
]
*$
匹配整数
匹配非负浮点数(正浮点数 + 0)
匹配正浮点数
^
(([
0
-
9
]
+\.
[
0
-
9
]
*
[
1
-
9
][
0
-
9
]
*
)
|
([
0
-
9
]
*
[
1
-
9
][
0
-
9
]
*\.
[
0
-
9
]
+
)
|
([
0
-
9
]
*
[
1
-
9
][
0
-
9
]
*
))
$
匹配非正浮点数(负浮点数 + 0)
^
((
-\
d
+
(
\.\
d
+
)
?
)
|
(
0
+
(
\
.0
+
)
?
))
$
匹配负浮点数
^
(
-
(([
0
-
9
]
+\.
[
0
-
9
]
*
[
1
-
9
][
0
-
9
]
*
)
|
([
0
-
9
]
*
[
1
-
9
][
0
-
9
]
*\.
[
0
-
9
]
+
)
|
([
0
-
9
]
*
[
1
-
9
][
0
-
9
]
*
)))
$
匹配浮点数
^
(
-?\
d
+
)(
\.\
d
+
)
?$
匹配由26个英文字母组成的字符串
匹配由26个英文字母的大写组成的字符串
匹配由26个英文字母的小写组成的字符串
匹配由数字和26个英文字母组成的字符串
匹配由数字、26个英文字母或者下划线组成的字符串
匹配email地址
^
[
\
w
-
]
+
(
\.
[
\
w
-
]
+
)
*@
[
\
w
-
]
+
(
\.
[
\
w
-
]
+
)
+$
匹配url
^
[
a
-
zA
-
z
]
+:
//匹配(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$
匹配html tag
<\
s
*
(
\
S
+
)(
\
s
[
^>
]
*
)
?>
(
.*?
)
<\
s
*\
/
\1\s*>
Visual Basic & C# Regular Expression
1.确认有效电子邮件格式
下面的示例使用静态 Regex.IsMatch 方法验证一个字符串是否为有效电子邮件格式。如果字符串包含一个有效的电子邮件地址,则 IsValidEmail 方法返回 true,否则返回 false,但不采取其他任何操作。您可以使用 IsValidEmail,在应用程序将地址存储在数据库中或显示在 ASP.NET 页中之前,筛选出包含无效字符的电子邮件地址。
[Visual Basic]
Function IsValidEmail(strIn As String) As Boolean
' Return true if strIn is in valid e-mail format.
Return Regex.IsMatch(strIn, ("^([\w-\.]+)@((\[[0-9]{ 1,3 }\.[0-9]{ 1,3 }\.[0-9]{ 1,3 }\.)|(([\w-]+\.)+))([a-zA-Z]{ 2,4 }|[0-9]{ 1,3 })(\]?)$")
End Function
[C#]
bool IsValidEmail(string strIn)
{
// Return true if strIn is in valid e-mail format.
return Regex.IsMatch(strIn, @"^([\w-\.]+)@((\[[0-9]{ 1,3 }\.[0-9]{ 1,3 }\.[0-9]{ 1,3 }\.)|(([\w-]+\.)+))([a-zA-Z]{ 2,4 }|[0-9]{ 1,3 })(\]?)$");
}
2.清理输入字符串
下面的代码示例使用静态 Regex.Replace 方法从字符串中抽出无效字符。您可以使用这里定义的 CleanInput 方法,清除掉在接受用户输入的窗体的文本字段中输入的可能有害的字符。CleanInput 在清除掉除 @、-(连字符)和 .(句点)以外的所有非字母数字字符后返回一个字符串。
[Visual Basic]
Function CleanInput(strIn As String) As String
' Replace invalid characters with empty strings.
Return Regex.Replace(strIn, "[^\w\.@-]", "")
End Function
[C#]
String CleanInput(string strIn)
{
// Replace invalid characters with empty strings.
return Regex.Replace(strIn, @"[^\w\.@-]", "");
}
3.更改日期格式
以下代码示例使用 Regex.Replace 方法来用 dd-mm-yy 的日期形式代替 mm/dd/yy 的日期形式。
[Visual Basic]
Function MDYToDMY(input As String) As String
Return Regex.Replace(input, _
"\b(?<month>\d{ 1,2 })/(?<day>\d{ 1,2 })/(?<year>\d{ 2,4 })\b", _
"${ day }-${ month }-${ year }")
End Function
[C#]
String MDYToDMY(String input)
{
return Regex.Replace(input,"\\b(?<month>\\d{ 1,2 })/(?<day>\\d{ 1,2 })/(?<year>\\d{ 2,4 })\\b","${ day }-${ month }-${ year }");
}
Regex 替换模式
本示例说明如何在 Regex.Replace 的替换模式中使用命名的反向引用。其中,替换表达式 ${ day } 插入由 (?…) 组捕获的子字符串。
有几种静态函数使您可以在使用正则表达式操作时无需创建显式正则表达式对象,而 Regex.Replace 函数正是其中之一。如果您不想保留编译的正则表达式,这将给您带来方便
4.提取 URL 信息
以下代码示例使用 Match.Result 来从 URL 提取协议和端口号。例如,“http://www.penner.cn:8080……将返回“http:8080”。
[Visual Basic]
Function Extension(url As String) As String
Dim r As New Regex("^(?<proto>\w+)://[^/]+?(?<port>:\d+)?/", _
RegexOptions.Compiled)
Return r.Match(url).Result("${ proto }${ port }")
End Function
[C#]
String Extension(String url)
{
Regex r = new Regex(@"^(?<proto>\w+)://[^/]+?(?<port>:\d+)?/",
RegexOptions.Compiled);
return r.Match(url).Result("${ proto }${ port }");
}
只有字母和数字,不小于6位,且数字字母都包含的密码的正则表达式
在C#中,可以用这个来表示:
一个将需要将路径字符串拆分为根目录和子目录两部分的算法程序,考虑路径格式有:C:\aa\bb\cc ,\\aa\bb\cc , ftp://aa.bb/cc 上述路径将分别被拆分为:C:\和aa\bb\cc ,\\aa 和 \bb\cc , ftp:// 和 aa.bb/cc 用javascript实现如下:
var
strRoot
,
strSub
var
regPathParse
=
/
^([^\\^
\/
]+[\\
\/
]+|\\\\[^\\]+)(.*)$
/
if
(
regPathParse
.
test
(
strFolder
))
{
strRoot
=
RegExp
.$
1
strSub
=
RegExp
.$
2
}
Tags: JavaScript»正则表达式»This entry was posted on 星期二, 三月 22nd, 2005 at 11:12:25 and is filed under Tech, JavaScript. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.
posted @
2007-03-16 17:08 xzc 阅读(442) |
评论 (0) |
编辑 收藏Selenium备忘手册
最近的项目准备用Selenium作一部分的Regression Test。在SpringSide里参考了一下,又下了个Selenium IDE玩玩,觉得还蛮容易上手,基本上不需要手动写测试代码。
但实操起来时面对各种复杂的页面情况遇到不少麻烦。感觉Selenium 的offical documentation写的比较high level, 最后找了个though works的ppt,算得上比较全面易懂。匆匆翻译了一下,供后来者参考。
一、 格式
1. Test Case 格式
| |
Title |
|
| 命令(Command) |
目标(Target) |
值(Value) |
| 命令(Command) |
目标(Target) |
( ) |
| 判断(Assertion) |
期望值(Expected) |
实际值(Actual) |
2. Test Suites 格式
| Title |
| TestCase1.html |
| TestCase2.html |
| TestCase3.html |
二、 Commands (命令)
-
Action
对当前状态进行操作
失败时,停止测试
-
Assertion
校验是否有产生正确的值
-
Element Locators
指定HTML中的某元素
-
Patterns
用于模式匹配
1. Element Locators (元素定位器)
-
id=id
id locator 指定HTML中的唯一id的元素
-
name=name
name locator指定 HTML中相同name的元素中的第一个元素
-
identifier=id
identifier locator 首先查找HTML是否存在该id的元素, 若不存在,查找第一个该name的元素
-
dom=javascriptExpression
dom locator用JavaScript表达式来定位HTML中的元素,注意必须要以”document”开头
例如:
dom=document.forms[‘myForm’].myDropdown
dom=document.images[56]
-
xpath=xpathExpression
xpath locator用 XPath 表达式来定位HTML中的元素,必须注意要以”//”开头
例如:
xpath=//img[@alt=’The image alt text’]
xpath=//table[@id=’table1’]//tr[4]/td[2]
-
link=textPattern
link locator 用link来选择HTML中的连接或锚元素
例如:
link=The link text
- 在没有locator前序的情况下 Without a locator prefix, Selenium uses:
如果以”document.”开头,则默认是使用 dom locator,如果是以“//”开头,则默认使用xpath locator,其余情况均认作identifier locator
2. String Matching Patterns (字符串匹配模式)
-
glob:patthern
glob模式,用通配符”*”代表任意长度字符,“?”代表一个字符
-
regexp:regexp
正则表达式模式,用JavaScript正则表达式的形式匹配字符串
-
exact:string
精确匹配模式,精确匹配整个字符串,不能用通配符
- 在没有指定字符串匹配前序的时候,selenium 默认使用golb 匹配模式
3. Select Option Specifiers (Select选项指定器)
-
label=labelPattern
通过匹配选项中的文本指定选项
例如:label=regexp:^[Oo]ther
-
value=valuePattern
通过匹配选项中的值指定选项
例如:value=other
-
id=id
通过匹配选项的id指定选项
例如: id=option1
-
index=index
通过匹配选项的序号指定选项,序号从0开始
例如:index=2
- 在没有选项选择前序的情况下,默认是匹配选项的文本
三、 Actions
描述了用户所会作出的操作。
Action 有两种形式: action和actionAndWait, action会立即执行,而actionAndWait会假设需要较长时间才能得到该action的相响,而作出等待,open则是会自动处理等待时间。
-
click
click(elementLocator)
- 点击连接,按钮,复选和单选框
- 如果点击后需要等待响应,则用”clickAndWait”
- 如果是需要经过JavaScript的alert或confirm对话框后才能继续操作,则需要调用verify或assert来告诉Selenium你期望对对话框进行什么操作。
| click | aCheckbox | |
| clickAndWait | submitButton | |
| clickAndWait | anyLink | |
-
open
open(url)
- 在浏览器中打开URL,可以接受相对和绝对路径两种形式
- 注意:该URL必须在与浏览器相同的安全限定范围之内
-
type
type(inputLocator, value)
- 模拟人手的输入过程,往指定的input中输入值
- 也适合给复选和单选框赋值
- 在这个例子中,则只是给钩选了的复选框赋值,注意,而不是改写其文本
| type | nameField | John Smith |
| typeAndWait | textBoxThatSubmitsOnChange | newValue |
-
select
select(dropDownLocator, optionSpecifier)
- 根据optionSpecifier选项选择器来选择一个下拉菜单选项
- 如果有多于一个选择器的时候,如在用通配符模式,如”f*b*”,或者超过一个选项有相同的文本或值,则会选择第一个匹配到的值
| select | dropDown | Australian Dollars |
| select | dropDown | index=0 |
| selectAndWait | currencySelector | value=AUD |
| selectAndWait | currencySelector | label=Auslian D*rs |
- goBack,close
goBack()
模拟点击浏览器的后退按钮
close()
模拟点击浏览器关闭按钮
-
selectWindow
select(windowId)
- 选择一个弹出窗口
- 当选中那个窗口的时候,所有的命令将会转移到那窗口中执行
| selectWindow | myPopupWindow | |
| selectWindow | null | |
-
pause
pause(millisenconds)
- 根据指定时间暂停Selenium脚本执行
- 常用在调试脚本或等待服务器段响应时
-
fireEvent
fireEvent(elementLocatore,evenName)
模拟页面元素事件被激活的处理动作
| fireEvent | textField | focus |
| fireEvent | dropDown | blur |
-
waitForCondition
waitForCondition(JavaScriptSnippet,time)
- 在限定时间内,等待一段JavaScript代码返回true值,超时则停止等待
| waitForCondition | var value=selenium.getText("foo"); value.match(/bar/); | 3000 |
-
waitForValue
waitForValue(inputLocator, value)
- 等待某input(如hidden input)被赋予某值,
- 会轮流检测该值,所以要注意如果该值长时间一直不赋予该input该值的话,可能会导致阻塞
| waitForValue | finishIndication | isfinished |
| | | |
-
store,stroreValue
store(valueToStore, variablename)
保存一个值到变量里。
该值可以由自其他变量组合而成或通过JavaScript表达式赋值给变量
| store | Mr John Smith | fullname |
| store | ${title} ${firstname} ${suname} | fullname |
| store | javascript{Math.round(Math.PI*100)/100} | PI |
| storeValue | inputLocator | variableName |
把指定的input中的值保存到变量中
| storeValue | userName | userID |
| type | userName | ${userID} |
-
storeText, storeAttribute
storeText(elementLocator, variablename)
把指定元素的文本值赋予给变量
| storeText | currentDate | expectedStartDate |
| verifyValue | startDate | ${expectedStartDate} |
storeAttribute(elementLocator@attributeName,variableName)
把指定元素的属性的值赋予给变量
| storeAttribute | input1@class | classOfInput1 |
| verifyAttribute | input2@class | ${classOfInput1} |
-
chooseCancel.., answer..
chooseCancelOnNextConfirmation()
- 当下次JavaScript弹出confirm对话框的时候,让selenium选择Cancel
- 如果没有该命令时,遇到confirm对话框Selenium默认返回true,如手动选择OK按钮一样
| chooseCancelOnNextConfirmation | | |
- 如果已经运行过该命令,当下一次又有confirm对话框出现时,也会同样地再次选择Cancel
answerOnNextPrompt(answerString)
- 在下次JavaScript弹出prompt提示框时,赋予其anweerString的值,并选择确定
| answerOnNextPrompt | Kangaroo | |
四、 Assertions
允许用户去检查当前状态。两种模式: Assert 和 Verify, 当Assert失败,则退出测试;当Verify失败,测试会继续运行。
-
assertLocation, assertTitle
assertLocation(relativeLocation)
判断当前是在正确的页面
| verifyLocation | /mypage | |
| assertLocation | /mypage | |
-
assertTitle(titlePattern)
检查当前页面的title是否正确
| verifyTitle | My Page | |
| assertTitle | My Page | |
-
assertValue
assertValue(inputLocator, valuePattern)
- 检查input的值
- 对于 checkbox或radio,如果已选择,则值为”on”,反之为”off”
| verifyValue | nameField | John Smith |
| assertValue | document.forms[2].nameField | John Smith |
-
assertSelected, assertSelectedOptions
assertSelected(selectLocator, optionSpecifier)
检查select的下拉菜单中选中的选型是否和optionSpecifer(Select选择选项器)的选项相同
| verifySelected | dropdown2 | John Smith |
| verifySelected | dorpdown2 | value=js*123 |
| assertSelected | document.forms[2].dropDown | label=J*Smith |
| assertSelected | document.forms[2].dropDown | index=0 |
-
assertSelectOptions(selectLocator, optionLabelList)
- 检查下拉菜单中的选项的文本是否和optionLabelList相同
- optionLabelList是以逗号分割的一个字符串
| verifySelectOptions | dropdown2 | John Smith,Dave Bird |
| assertSelectOptions | document.forms[2].dropdown | Smith,J,Bird,D |
-
assertText
assertText(elementLocator,textPattern)
- 检查指定元素的文本
- 只对有包含文本的元素生效
- 对于Mozilla类型的浏览器,用textContent取元素的文本,对于IE类型的浏览器,用innerText取元素文本
| verifyText | statusMessage | Successful |
| assertText | //div[@id='foo']//h1 | Successful |
-
assertTextPresent, assertAttribute
assertTextPresent(text)
检查在当前给用户显示的页面上是否有出现指定的文本
| verifyTextPresent | You are now logged in | |
| assertTextPresent | You are now logged in | |
-
assertAttribute(
elementLocator@attributeName
, ValuePattern)
检查当前指定元素的属性的值
| verifyAttribute | txt1@class | bigAndBlod |
| assertAttribute | document.images[0]@alt | alt-text |
| verifyAttribute | //img[@id='foo']/alt | alt-text |
-
assertTextPresent, etc.
assertTextPresent(text)
assertTextNotPresent(text)
assertElementPresent(elementLocator)
| verifyElementPresent | submitButton | |
| assertElementPresent | //img[@alt='foo'] | |
assertElementNotPresent(elementLocator)
-
assertTable
assertTable(cellAddress, valuePattern)
- 检查table里的某个cell中的值
- cellAddress的语法是tableName.row.column, 注意行列序号都是从0开始
| verifyTable | myTable.1.6 | Submitted |
| assertTable | results0.2 | 13 |
-
assertVisible, nonVisible
assertVisible(elementLocator)
- 检查指定的元素是否可视的
- 隐藏一个元素可以用设置css的‘visibility’属性为’hidden’,也可以设置‘display’属性为‘none’
| verfyVisible | postcode | |
| assertVisible | postcode | |
-
assertNotVisible(elementLocator)
| verfyNotVisible | postcode | |
| assertNotVisible | postcode | |
-
Editable, non-editable
assertEditable(inputLocator)
检查指定的input是否可以编辑
| verifyEditable | shape | |
| assertEditable | colour | |
-
assertNotEditable(inputLocator)
检查指定的input是否不可以编辑
-
assertAlert
assertAlert(messagePattern)
- 检查JavaScript是否有产生带指定message的alert对话框
- alert产生的顺序必须与检查的顺序一致
- 检查alert时会产生与手动点击’OK’按钮一样的效果。如果一个alert产生了,而你却没有去检查它,selenium会在下个action中报错。
- 注意:Selenium 不支持 JavaScript 在onload()事件时 调用alert();在这种情况下,Selenium需要你自己手动来点击OK.
-
assertConfirmation
assertConfirmation(messagePattern)
- 检查JavaScript是否有产生带指定message的confirmation对话框和alert情况一样,confirmation对话框也必须在它们产生的时候进行检查
- 默认情况下,Selenium会让confirm() 返回true, 相当于手动点击Ok按钮的效果。你能够通过chooseCancelOnNextConfirmation命令让confirm()返回false.同样地,如果一个cofirmation对话框出现了,但你却没有检查的话,Selenium将会在下个action中报错
- 注意:在Selenium的环境下,confirmation对话框框将不会再出现弹出显式对话框
- 注意:Selenium不支持在onload()事件时调用confirmation对话框,在这种情况下,会出现显示confirmatioin对话框,并需要你自己手动点击。
-
assertPrompt
assertPrompt(messagePattern)
- 检查JavaScript是否有产生带指定message的Prompt对话框
- 你检查的prompt的顺序Prompt对话框产生的顺序必须相同
- 必须在verifyPrompt之前调用answerOnNextPrompt命令
- 如果prompt对话框出现了但你却没有检查,则Selenium会在下个action中报错
| answerOnNextPrompt | Joe | |
| click | id=delegate | |
| verifyPrompt | Delegate to who? | |
五、 Parameters and Variables
参数和变量的声明范围由简单的赋值到JavaScript表达式赋值。
Store,storeValue 和storeText 为下次访问保存值。
在Selenium内部是用一个叫storeVars的map来保存变量名。
-
Variable Substitution 变量替换
提供了一个简单的方法去访问变量,语法 ${xxx}
| store | Mr | title |
| storeValue | nameField | surname |
| store | ${title} ${suname} | fullname |
| type | textElement | Full name is: ${fullname} |
-
JavaScript Evaluation JavaScript赋值
你能用JavaScript来构建任何你所需要的值。
这个参数是以javascript开头,语法是 javascript{‘with a trailing’}。
可以通过JavaScript表达式给某元素赋值。
| store | javascript{'merchant'+(new Date()).getTime()} | merchantId |
| type | textElement | javascript{storedVars['merchantId'].toUpperCase()} |
-
Generating Unique values 产生唯一值.
问题:你需要唯一的用户名
解决办法: 基于时间来产生用户名,如’fred’+(new Date().getTime())
posted @
2007-02-12 10:49 xzc 阅读(2042) |
评论 (1) |
编辑 收藏
作者:Radic 来源:sun
摘要:
本文是来自Sun官方站点的一篇关于如何编写安全的Java代码的指南,开发者在编写一般代码时,可以参照本文的指南
本文是来自Sun官方站点的一篇关于如何编写安全的Java代码的指南,开发者在编写一般代码时,可以参照本文的指南:
• 静态字段
• 缩小作用域
• 公共方法和字段
• 保护包
• equals方法
• 如果可能使对象不可改变
• 不要返回指向包含敏感数据的内部数组的引用
• 不要直接存储用户提供的数组
• 序列化
• 原生函数
• 清除敏感信息静态字段• 避免使用非final的公共静态变量
应尽可能地避免使用非final公共静态变量,因为无法判断代码有无权限改变这些变量值。
• 一般地,应谨慎使用易变的静态状态,因为这可能导致设想中相互独立的子系统之间发生不可预知的交互。
缩小作用域作为一个惯例,尽可能缩小方法和字段的作用域。检查包访问权限的成员能否改成私有的,保护类型的成员可否改成包访问权限的或者私有的,等等。
公共方法/字段避免使用公共变量,而是使用访问器方法访问这些变量。用这种方式,如果需要,可能增加集中安全控制。
对于任何公共方法,如果它们能够访问或修改任何敏感内部状态,务必使它们包含安全控制。
参考如下代码段,该代码段中不可信任代码可能设置TimeZone的值:
private static TimeZone defaultZone = null;
public static synchronized void setDefault(TimeZone zone)
{
defaultZone = zone;
}
保护包有时需要在全局防止包被不可信任代码访问,本节描述了一些防护技术:
• 防止包注入:如果不可信任代码想要访问类的包保护成员,可以尝试在被攻击的包内定义自己的新类用以获取这些成员的访问权。防止这类攻击的方式有两种:
1. 通过向java.security.properties文件中加入如下文字防止包内被注入恶意类。
...
package.definition=Package#1 [,Package#2,...,Package#n]
...
这会导致当试图在包内定义新类时类装载器的defineClass方法会抛出异常,除非赋予代码一下权限:
...
RuntimePermission("defineClassInPackage."+package)
...
2. 另一种方式是通过将包内的类加入到封装的Jar文件里。
(参看http://java.sun.com/j2se/sdk/1.2/docs/guide/extensions/spec.html)
通过使用这种技巧,代码无法获得扩展包的权限,因此也无须修改java.security.properties文件。
• 防止包访问:通过限制包访问并仅赋予特定代码访问权限防止不可信任代码对包成员的访问。通过向java.security.properties文件中加入如下文字可以达到这一目的:
...
package.access=Package#1 [,Package#2,...,Package#n]
...
这会导致当试图在包内定义新类时类装载器的defineClass方法会抛出异常,除非赋予代码一下权限:
...
RuntimePermission("defineClassInPackage."+package)
...
如果可能使对象不可改变如果可能,使对象不可改变。如果不可能,使得它们可以被克隆并返回一个副本。如果返回的对象是数组、向量或哈希表等,牢记这些对象不能被改变,调用者修改这些对象的内容可能导致安全漏洞。此外,因为不用上锁,不可改变性能够提高并发性。参考Clear sensitive information了解该惯例的例外情况。
不要返回指向包含敏感数据的内部数组的引用该惯例仅仅是不可变惯例的变型,在这儿提出是因为常常在这里犯错。即使数组中包含不可变的对象(如字符串),也要返回一个副本这样调用者不能修改数组中的字符串。不要传回一个数组,而是数组的拷贝。
不要直接在用户提供的数组里存储该惯例仅仅是不可变惯例的另一个变型。使用对象数组的构造器和方法,比如说PubicKey数组,应当在将数组存储到内部之前克隆数组,而不是直接将数组引用赋给同样类型的内部变量。缺少这个警惕,用户对外部数组做得任何变动(在使用讨论中的构造器创建对象后)可能意外地更改对象的内部状态,即使该对象可能是无法改变的
序列化当对对象序列化时,直到它被反序列化,它不在Java运行时环境的控制之下,因此也不在Java平台提供的安全控制范围内。
在实现Serializable时务必将以下事宜牢记在心:
• transient
在包含系统资源的直接句柄和相对地址空间信息的字段前使用transient关键字。 如果资源,如文件句柄,不被声明为transient,该对象在序列化状态下可能会被修改,从而使得被反序列化后获取对资源的不当访问。
• 特定类的序列化/反序列化方法
为了确保反序列化对象不包含违反一些不变量集合的状态,类应该定义自己的反序列化方法并使用ObjectInputValidation接口验证这些变量。
如果一个类定义了自己的序列化方法,它就不能向任何DataInput/DataOuput方法传递内部数组。所有的DataInput/DataOuput方法都能被重写。注意默认序列化不会向DataInput/DataOuput字节数组方法暴露私有字节数组字段。
如果Serializable类直接向DataOutput(write(byte [] b))方法传递了一个私有数组,那么黑客可以创建ObjectOutputStream的子类并覆盖write(byte [] b)方法,这样他可以访问并修改私有数组。下面示例说明了这个问题。
你的类:
public class YourClass implements Serializable {
private byte [] internalArray;
....
private synchronized void writeObject(ObjectOutputStream stream) {
...
stream.write(internalArray);
...
}
}黑客代码
public class HackerObjectOutputStream extends ObjectOutputStream{
public void write (byte [] b) {
Modify b
}
}
...
YourClass yc = new YourClass();
...
HackerObjectOutputStream hoos = new HackerObjectOutputStream();
hoos.writeObject(yc);• 字节流加密
保护虚拟机外的字节流的另一方式是对序列化包产生的流进行加密。字节流加密防止解码或读取被序列化的对象的私有状态。如果决定加密,应该管理好密钥,密钥的存放地点以及将密钥交付给反序列化程序的方式等。
• 需要提防的其他事宜
如果不可信任代码无法创建对象,务必确保不可信任代码也不能反序列化对象。切记对对象反序列化是创建对象的另一途径。
比如说,如果一个applet创建了一个frame,在该frame上创建了警告标签。如果该frame被另一应用程序序列化并被一个applet反序列化,务必使该frame出现时带有同一个警告标签。
原生方法应从以下几个方面检查原生方法:
• 它们返回什么
• 它们需要什么参数
• 它们是否绕过了安全检查
• 它们是否是公共的,私有的等
• 它们是否包含能绕过包边界的方法调用,从而绕过包保护
清除敏感信息当保存敏感信息时,如机密,尽量保存在如数组这样的可变数据类型中,而不是保存在字符串这样的不可变对象中,这样使得敏感信息可以尽早显式地被清除。不要指望Java平台的自动垃圾回收来做这种清除,因为回收器可能不会清除这段内存,或者很久后才会回收。尽早清除信息使得来自虚拟机外部的堆检查攻击变得困难。
摘自:
http://www.matrix.org.cn/resource/article/2006-12-15/Java+Code+Security_199f1a70-8bf4-11db-ab77-2bbe780ebfbf.htmlposted @
2006-12-29 20:47 xzc 阅读(237) |
评论 (0) |
编辑 收藏
1、Create Sequence
你首先要有CREATE SEQUENCE或者CREATE ANY SEQUENCE权限,
CREATE SEQUENCE emp_sequence
INCREMENT BY 1 -- 每次加几个
START WITH 1 -- 从1开始计数
NOMAXVALUE -- 不设置最大值
NOCYCLE -- 一直累加,不循环
CACHE 10;
一旦定义了emp_sequence,你就可以用CURRVAL,NEXTVAL
CURRVAL=返回 sequence的当前值
NEXTVAL=增加sequence的值,然后返回 sequence 值
比如:
emp_sequence.CURRVAL
emp_sequence.NEXTVAL
可以使用sequence的地方:
- 不包含子查询、snapshot、VIEW的 SELECT 语句
- INSERT语句的子查询中
- NSERT语句的VALUES中
- UPDATE 的 SET中
可以看如下例子:
INSERT INTO emp VALUES
(empseq.nextval, 'LEWIS', 'CLERK',7902, SYSDATE, 1200, NULL, 20);
SELECT empseq.currval FROM DUAL;
但是要注意的是:
- 第一次NEXTVAL返回的是初始值;随后的NEXTVAL会自动增加你定义的INCREMENT BY值,然后返回增加后的值。CURRVAL 总是返回当前SEQUENCE的值,但是在第一次NEXTVAL初始化之后才能使用CURRVAL,否则会出错。一次NEXTVAL会增加一次SEQUENCE的值,所以如果你在同一个语句里面使用多个NEXTVAL,其值就是不一样的。明白?
- 如果指定CACHE值,ORACLE就可以预先在内存里面放置一些sequence,这样存取的快些。cache里面的取完后,oracle自动再取一组到cache。 使用cache或许会跳号, 比如数据库突然不正常down掉(shutdown abort),cache中的sequence就会丢失. 所以可以在create sequence的时候用nocache防止这种情况。
2、Alter Sequence
你或者是该sequence的owner,或者有ALTER ANY SEQUENCE 权限才能改动sequence. 可以alter除start至以外的所有sequence参数.如果想要改变start值,必须 drop sequence 再 re-create .
Alter sequence 的例子
ALTER SEQUENCE emp_sequence
INCREMENT BY 10
MAXVALUE 10000
CYCLE -- 到10000后从头开始
NOCACHE ;
影响Sequence的初始化参数:
SEQUENCE_CACHE_ENTRIES =设置能同时被cache的sequence数目。
可以很简单的Drop Sequence
DROP SEQUENCE order_seq;
-------------------------------------
drop sequence SEQ_GROUP_ID
-- Create sequence
create sequence SEQ_GROUP_ID
minvalue 1
maxvalue 9999999999
start with 1
increment by 1
cache 20;
select seq_group_id.nextval from dual
-------------------------------------
posted @
2006-12-28 11:01 xzc 阅读(280) |
评论 (0) |
编辑 收藏 第一个理财概念:
区分“投资”与“消费”
区分“投资”行为与“消费”行为。一般人消费前,没有这种概念,学经济学的人消费前会考虑,这个消费是属于“投资”行为或是“消费”行为。
先请看一个明显的例子:
10年前甲和乙是本科的同学,在社会工作5年后,不约而同积蓄了30万元人民币。5年前,他们都花掉了这30万元。
甲去通州购买了一套房。
乙去买了一辆“奥迪”。
5年后的今天:
甲的房子,市值60万元。
乙的二手车,市值只有5万元。
两人目前的资产,明显有了很大差异,但他们的收入都一样,而且同样学历、基本具备同样的社会经验,为何大家财富不一样?
甲花钱买房是“投资”行为——钱其实没有花出去,只是转移在了房子里,以后还是都归自己。
乙花钱买车是“消费”行为——钱是花出去的,给了别人,二手车用过10年后,几乎一分不值。车跟房子不一样,房子10年后,说不定已翻了好几番。
再看第二个例子:
有一天,我的秘书向我提出一个问题:陈老师,我觉得客户甲有点怪。她说:客户甲去买一张演唱会的票,300元他嫌贵,犹豫很久,始终没买,但客户甲其实并不缺钱。但有一次,有一个著名企业总裁出版了一套“教导管理”光盘,6张光盘卖到天价1500元,客户甲却毫不犹豫将它买下来。为何¥300演唱票,客户甲嫌贵,却去买¥1500的几张光盘呢?
解答如下:客户甲是将学的经济学的知识应用到日常生活里,客户甲每花费钱的时候,会先想这花钱是‘投资’行为或是‘消费’行为?
买光盘,这1500元是“投资”行为,它其实没有花出去,它增长了客户甲的知识,让客户甲更有智慧,在未来的日子,客户甲用新学的智慧,会赚回1500元的好几倍,钱始终还在客户甲的口袋。
但购买演唱会的票,是“消费”行为,是给了别人,再也拿不回来了。
在生活中,还有更多的日常例子:
(1) 客户甲会花3万人民币去买一幅油画,但不会花3万去买二手车。
(2) 客户甲会花1万去买人寿保险,但不会花1万去欧洲度假。
(3) 客户甲会很舍得花钱买书,但不舍得花钱去看电影。
以上哪些是“投资”行为,那些是“消费”行为,每个人都会有自己的判断。下面是更多的例子,如果属于“投资”行为,那么,多贵都不必讨价还价,因为钱最终还是归自己。
第二个理财概念:
“哈佛”教条
大家每个月都会将工资一部分储蓄起来,有些人储蓄10%工资,有些20%,有些30%。大部分人是一个月后,把没有花出去的钱储蓄起来,而且每个月储蓄多少基本没谱。
在著名的美国第一学府哈佛大学,第一堂的经济学课,只教两个概念。
第一个概念:花钱要区分“投资”行为或“消费”行为。
第二个概念:每月先储蓄30%的工资,剩下来才进行消费。
哈佛教导出来的人,以后都很富有,并非主要因为他们是名校出身、收入丰厚,而是他们每月的行为,跟一般的普通老百姓,只有一点不一样:
哈佛教条:储蓄30%的工资是硬指标,剩下才消费。每月储蓄的钱是每月最重要的目标,只会超额完成,剩下的钱就越来越多。
一般人:先花钱,能剩多少便储蓄多少,储蓄剩下的钱并不多。
第三个理财概念:
“理财三句话”
理财走不出三句话,如果每句话都能吃透,并且完全执行,那么,打工一族都可以变得非常富有。
很多朋友都知道客户甲的出身——难民,一无所有。到加拿大学经济学也是拿着奖学金,家里七兄弟姐妹,没有钱送客户甲们上大学,上大学后,从来没问家里拿过钱。毕业后打工,但客户甲坚持“理财三句话”原则,用经济学学到的学问,用到日常生活里,一步步走下去。现在20年后,客户甲有4套房,每月收租便有1万多的收入,也算是半个富有的人。
其实每个人都做得到,在这公开这秘密。以前这些重要的理财概念,课程里面都有教。
再举一些实例给大家看:巴菲特在他的书本里说他6岁开始储蓄,每月30块。到13岁时,当他有了3千块,他买了一只股票。年年坚持储蓄,年年坚持投资,十年如一日,他坚持了80年。现在85岁,是美国首富,比“微软”主席比尔·盖茨还有钱。
学员有时候会问,如何能每年回报率达到10%以上。答:其实现在要银行里面,它们提供很多理财产品:基金,外币,QDII。 这些银行产品略有一点风险,但风险假如你能有效的管理它,10%的回报率其实也不难。当然,假如没有受过专业培训,你自己是瞎摸,你会亏掉很多钱。但你有两个途径:
(1) 花点钱去学。
(2)你自己没时间,那么可以去找专业的理财师。
找专业理财师,要分辨他们的专业资格,你可以参考几个条件:
(1) 已经考取了的理财规划师认证:中国注册理财规划师(CFP),全名是Certified Financial Planner。2005年已经在北京举行公开考试,现在很多银行的从业人员都在考。合格率偏低,暂时银行里面有资格的人也不多。
(2) 有10年以上的理财经验。但其它有兴趣想多认识理财学问的,可以参加公开课程,费用只是几百元一节。参加学习的费用,是“投资”行为,并没有“花出去”,以后还是归你自己,学过以后,就不会“小钱精明,大钱糊涂”了。
一般人错误的理财观念:
挣得多,所以富有
很多人认为,甲收入每月1.5万元,乙收入每月8000元,甲便应该比乙富有,这观念在社会上很普遍。但这是错的观念,错得很离谱。错在哪里?
富有的定义,并不是你每月工资挣得多,而是你每月“剩下多少”——剩下的才是财富。请看例子:
美国人每月工资高中国二、三倍,照一般的观念看,一般的美国人应比中国人富有。但实际情况却不是这样。一般美国人都有几张信用卡,他们喜欢消费,每月不单只是“月光一族”,更普遍是欠下信用卡不少的债。在美国,理财规划师的理财讲座,一般时间花在讲“如何减少你的债务”。
一般美国人,银行的储蓄都不够美金几千元。在中国,没有这种情况,中国人善于储蓄,一般人在银行都有存款,超过十几万元的,人数还不少。
所以,不要以为老美每月挣钱多就富有。其实,一般老美的白领比中国人的白领穷得多。当然,在北京见到的很多外派到北京工作的老美,是美国的精英,不是一般的美国白领,有钱人占多数。
中国的中层白领,比美国的白领富有。请记住:富有不是比较每月工资,而是比较“剩下储蓄在银行里的存款”,以这个定义来讲,中国人中层白领在银行的存款,远比美国中层白领高。
还有一个例子:
一般人以为台湾人工资平均高出内地一倍,他们自然比我们富有,这也是一个错误的观念。
去过台湾的朋友都知道,台湾地铁单程平均是12元,北京是3元;台湾午饭平均要50元,北京平均15元;在台湾租一套房6500元,北京在通州租一套房1500元。假如台湾人每月挣15000元,减去房租6500元,交通费1000元,吃饭300元,交税1500元,一点点娱乐2000元,“每月剩下1000元”。
北京的初级工程师,每月工资8000元,减去交税1000元,减去房租1500元,交通费300元,吃饭1000元,娱乐1000元,“每月剩下3200元”。
请问:是台湾人每月工资15000元,每月只剩下1000元的人富有,还是北京工程师,每月工资只有8000元,但每月剩下3200元的人富有呢?
中国经过20多年的改革,已经造就了富有的一批人,请看《财富》杂志一年前的“富有”的人的调查报告,他们调查手头上持有“现金100万美元存款的人”,在亚洲区有多少人拥有这种财富。
答案是:香港4万人,台湾8万人,日本12万,中国30万。中国每年增长率远远超出其他亚洲国家。所以人们不会觉得奇怪,外资银行到北京开业,老是在推广“理财服务”,因为中国这个地方,正是比较欠缺这一块的知识。
posted @
2006-12-16 13:09 xzc 阅读(345) |
评论 (0) |
编辑 收藏作为一名专栏作家,我的目标并不是报导新闻、或是向读者提供一份不断更新的专家投资建议。相反我认为,有些金融投资指南是放之四海皆准的,因此我会反复加以琢磨。
其中有些投资建议是我经常挂在嘴边的,而另一些是最近突然闪现在我的脑海里。想更好地管理你的资金吗?我在这里向您提供九条最重要的理财法则。
1)勇于说“不”
为了成功地进行储蓄和投资,没什么比自律更重要了。
这意味着看准一些股票、债券和货币市场基金后进行投资,然后坚持持有这一投资组合,无论动荡的市场是多么令人烦恼不安,也无论你是多么想购买最新的热门股。
更重要的是,你不能轻易自满,因此可进行适量的定期储蓄。
2)别患上享乐适应症
花钱并不能给你带来快乐。然而许多人都这么做,于是他们一生都要面对高额的信用卡帐单,以及失望的情绪。
知道这个心理循环吗?你看中了某件商品,然后认定非要得到它不可,于是付帐。然而几周或几个月之后,你就把这件事忘得一干二净,又开始新的物质追求了。
学者们把这种现象称为“快乐水车”或“享乐适应症”(hedonic treadmill)。从中可以吸取的教训是什么呢?如果你想得到快乐,别到购物中心去寻找,那里是找不到的。
3)我们就是市场
尽管大家都在谈论跑赢大市,但事实上我们的前进道路上存在着一个不可逾越的障碍。
不可能所有的人都跑赢大市,因为我们本身就是市场的组成部份。如果有人跑赢大市,那么必然有人被市场打败。
实际上,如果再算上投资成本,能跑赢大市的投资者就寥寥无几了,而大多数投资者都落后于市场平均水平。
4)谁分了你的钱
还有一点你得记住,不管你是否乐意,你还有两位投资伙伴:华尔街和收税员。你们三个人共同分配你的投资收益。
想自己多留一点,给华尔街和收税员少点?最好的办法是降低投资成本,同时最大限度地利用避税的退休金帐户。
5)请专家帮忙
十年前,我认为大多数投资者有能力自己进行投资。如今,我可不这么想了。
看上去大多数投资者是没有时间、兴趣和精力亲自进行成功的投资的。
不过遗憾的是,即使你聘请了经纪人或是理财规划师,你的感觉也好不了多少。许多顾问收费昂贵,但他们自己也只有少得可怜的正规理财教育,因此你在挑选顾问的时候得特别小心。
6)别落在后面
当专家们讨论投资多样化的时候,他们会指出,购买各种投资产品能降低投资风险,因为其中一些投资会带来收益,而另一些会出现亏损。
但问题在于:每当我们面临重大金融危机的时候,投资多样化──特别在全球股票市场上进行多样化的投资──常常被证明是起不了什么作用的,因为所有的股票都在暴跌。
不过我觉得这种想法忽略了关键要点。即使美国股票和海外股票一同涨跌,它们的年投资回报还是存在着惊人的差距。那些仅仅投资于一个市场的投资者们可能会面临较长的低迷时期。
此外,投资多样化也不仅仅是为了减少投资组合的短期波动。你还想限制金融灾难给你带来的损失,无论是因为政局动荡而导致金融市场出现混乱,还是金融市场本身出现崩溃,例如上世纪九十年代的日本市场。
7)家庭很重要
孩子是你的继承人。他们将继承你的资产,也极有可能接受你的理财观念。
你的家庭是你最大的资产,同时也是最大的负债。如果你的孩子或父母陷入了财务困境,你将伸出援手。同样,在你碰到困难时,他们也会伸出援手。
记住这些很重要。可以与你的父母谈谈他们的财务状况,也可以教导孩子们如何理财。
想想你自己是如何管理财产的吧,特别是想想当出现问题时,它们会给家庭带来什么影响。
8)进行长期投资
如果你年纪轻轻就离开人世,这对你的配偶和孩子来说是沉重的打击。但是请别忽略了其他风险:如果你活得远比预计的长呢?
许多退休人士非常担心英年早逝,因此他们急着申请社会保障金,而拒绝购买终生年金。如果你确信自己和配偶生命短暂的话,采取这样的策略是正确的,至少你活着的时候手头充裕。
然而,如果你早早地领取了社会保障金,而且也不购买年金,但实际却活得很长呢?那你就得一分一厘地算着花钱了。
9)最后一根稻草
在金融市场开盘的交易日里,我通常每隔几小时就会查看与通货膨胀挂钩的国债的收益率。
在我看来,与通货膨胀挂钩的国债可作为其他所有投资的基准。如果我购买了十年期通货膨胀挂钩国债,我在今后十年内获得的投资收益将比通货膨胀率高2.3个百分点。
除非我确信其他投资的表现优于这一基准,否则我将继续持有十年期通货膨胀挂钩国债。在我看来,这项投资是我的最后一根救命稻草。
posted @
2006-12-14 13:07 xzc 阅读(217) |
评论 (0) |
编辑 收藏
Ajax(Asynchronous JavaScript and XML)说到底就是一种浏览器异步读取服务器上XML内容的技术。现在的技术凡是跟XML扯上关系,再加上个概念做幌子,就像金装了一样,拽得不行。门外 的人看得很是热闹,门里的人摇摇头不外如是。XML呢,跨平台的新潮语言?其实XML=TXT。XML只是符合很多规范的文本。它本身什么都不是,只是保 存字符的文件。而浏览器异步读取的只是服务器上的文本内容,所以在Ajax开发时完全不必拘泥于XML。[版权所有,www.jialing.net]
XML 的作用是格式化数据内容。如果我们不用XML还有什么更好的方法吗?这个答案是JSON。介绍JSON之前我先介绍一下JavaScript这门脚本语 言。脚本语言自身有动态执行的天赋。即我们可以把想要执行的语句放在字符串里,通过eval()这个动态执行函数来执行。字符串里的内容会像我们写的脚本 一样被执行。
示例1:
<HTML>
<HEAD>
<TITLE>eval example 1</TITLE>
</HEAD>
<BODY>
<script>
str = "alert('hello')";
eval(str);
</script>
</BODY>
</HTML>
打开页面会弹出hello窗口。
我们可以在字符串中放任何脚本语句,包括声明语句:
<HTML>
<HEAD>
<TITLE>eval example 2</TITLE>
</HEAD>
<BODY>
<script>
define = "{name:'Michael',email:'17bity@gmail.com'}";
eval("data = "+define);
alert("name:"+data.name);
alert("email:"+data.email);
</script>
</BODY>
</HTML>
如果我们在后台异步传来的文本是JavaScript的声明语句,那么不是一条eval方法就能解析了?对于解析复杂的XML,这样的效率是多么大的提高啊!
现在就来告诉你什么是JSON:JavaScript Object Notation。我更愿意把它翻译为JavaScript对象声明。比如要从后台载入一些通讯录的信息,如果写成XML,如下:
<contact>
<friend>
<name>Michael</name>
<email>17bity@gmail.com</email>
<homepage>http://www.jialing.net</homepage>
</friend>
<friend>
<name>John</name>
<email>john@gmail.com</email>
<homepage>http://www.john.com</homepage>
</friend>
<friend>
<name>Peggy</name>
<email>peggy@gmail.com</email>
<homepage>http://www.peggy.com</homepage>
</friend>
</contact>
而写成JSON呢:
[
{
name:"Michael",
email:"17bity@gmail.com",
homepage:"http://www.jialing.net"
},
{
name:"John",
email:"john@gmail.com",
homepage:"http://www.jobn.com"
},
{
name:"Peggy",
email:"peggy@gmail.com",
homepage:"http://www.peggy.com"
}
]
简 单的不只是表达上,最重要的是可以丢弃让人晕头转向的DOM解析了。因为只要符合JavaScript的声明规范,JavaScrip会自动帮你解析好 的。Ajax中使用JSON的基本方法是前台载入后台声明JavaScript对象的字符串,用eval方法来将它转为实际的对象,最后通过 DHTML更新页面信息。
JSON的基本格式如下,图片来自json.org:
对象是属性、值对的集合。一个对象的开始于"{",结束于"}"。每一个属性名和值间用":"提示,属性间用","分隔。

数组是有顺序的值的集合。一个数组开始于"[",结束于"]",值之间用","分隔。

值可以是引号里的字符串、数字、true、false、null,也可以是对象或数组。这些结构都能嵌套。

字符串的定义和C或Java基本一致。

数字的定义也和C或Java基本一致。

可读性
JSON和XML的可读性可谓不相上下,一边是建议的语法,一边是规范的标签形式,很难分出胜负。
可扩展性
XML天生有很好的扩展性,JSON当然也有,没有什么是XML能扩展,JSON不能的。
编码难度
XML有丰富的编码工具,比如Dom4j、JDom等,JSON也有json.org提供的工具,但是JSON的编码明显比XML容易许多,即使不借助工具也能写出JSON的代码,可是要写好XML就不太容易了。
解码难度
XML的解析得考虑子节点父节点,让人头昏眼花,而JSON的解析难度几乎为0。这一点XML输的真是没话说。
流行度
XML已经被业界广泛的使用,而JSON才刚刚开始,但是在Ajax这个特定的领域,未来的发展一定是XML让位于JSON。到时Ajax应该变成Ajaj(Asynchronous JavaScript and JSON)了。
[版权所有,www.jialing.net]
附:
JSON.org : http://www.json.org/
JSON in JavaScript : http://www.json.org/js.html
JSON: The Fat-Free Alternative to XML : http://www.json.org/xml.html
JSON and the Dynamic Script Tag: Easy, XML-less Web Services for JavaScript: http://www.xml.com/pub/a/2005/12/21/json-dynamic-script-tag.html
Using JSON (JavaScript Object Notation) with Yahoo! Web Services: http://developer.yahoo.com/common/json.html
posted @
2006-12-13 12:32 xzc 阅读(146) |
评论 (0) |
编辑 收藏
上海的一个普通报贩在日常经营中发现,很多人对高档杂志有大量的阅读需求,但往往因为动辄几十元的零售价格望而却步。于是,他自创了一套崭新的经营模式,发展会员制将杂志租给客户,每个客户每月交30元会费和20元押金,就可以不断租杂志回家看。
很快发展了几百名会员,测算下来他一个月能挣到8000元,收入水平远远超过了同行。
这个在市井街头上演的真实故事近日通过上海某投资管理公司老总的个人博客在网上广泛流传,成为大家津津乐道的话题。看完这个故事,很多人或许都会想,同样都是卖书报杂志的,为什么差别会那么大呢?
这个小贩的故事,给我们提出了一个命题,在给定的外部环境、产业空间、成本产出比的条件下,如何获得超过同行业平均水平的回报?在这个案例中,报贩的选择是改变商业模式,将原有的终端书报发行模式从“零售”改变为“出租”,从而将获利机制中的“销售利润”转换成“出租利润”。由于每个报摊本来每月就有冗余产品的沉淀,出租成本几乎为零,而市场吸引力又远大于销售,因此具备了成功的基础。此外,由于每个客户还要交20元押金,这样上百人的押金又成为报贩手中的一笔可流动资金,相当于无息贷款。用这笔钱可以继续投入运营,比如根据客户需求引进品种更多的书报商品,扩大自己的产品竞争力。
很多人或许会想,这样模式设计并不难,为什么只有这个报贩做成了呢?除了人家脚踏实地敢于实践之外,可能还有细节方面不为人知的控制能力。网文虽未对此作更多描述,但我们可以设想,比如他可能会向客户推荐介绍近期的热点事件、精彩新闻,提供信息增值服务,他还可能会用短信提醒一些平时太忙的客户他要的杂志到了,提供“阅读小秘书”之类的服务。类似的这些增值服务,都可以提高“出租”模式的核心竞争力,让客户得到更多回报,从而保证了新商业模式的运行。
从为微软MBA上课的出租车司机,到月入8000的报贩,他们都在做一件很多人都在做的普通事情上,走出了自己的新路,也获得了超过他人的回报。比起深奥的教科书,这样的民间智慧或许是大多数平凡的创业者更需要学习的。
最近,单位附近一家饭店生意火爆,原因之一是推出了一项别人没有的简单优惠。这家饭店规定,等候20分钟以上的顾客可以全单打八折,等候10分钟的可以打九折,而在晚上6点半以前离开饭店的客人也可以打八折。如此一来,餐桌的翻台率大大提高,愿意等的人数量也大大增加,小小的折扣杠杆为这家店撬动了更大的市场。
来自草根的管理智慧到处都是,只需要我们睁大眼睛。
posted @
2006-11-27 08:59 xzc 阅读(256) |
评论 (0) |
编辑 收藏
native2ascii -encoding utf-8 project.properties.GBK project.properties
utf-8编码格式的文件转换成原来的格式
native2ascii -reverse -encoding utf-8 project.properties project.properties.GBK
posted @
2006-11-21 14:54 xzc 阅读(513) |
评论 (1) |
编辑 收藏posted @
2006-11-19 13:50 xzc 阅读(355) |
评论 (0) |
编辑 收藏
2、世界会向那些有目标和远见的人让路(冯两努——香港著名推销商)
3、造物之前,必先造人。
4、与其临渊羡鱼,不如退而结网。
5、若不给自己设限,则人生中就没有限制你发挥的藩篱。
6、赚钱之道很多,但是找不到赚钱的种子,便成不了事业家。
7、蚁穴虽小,溃之千里。
8、最有效的资本是我们的信誉,它24小时不停为我们工作。
9、绊脚石乃是进身之阶。
10、销售世界上第一号的产品——不是汽车,而是自己。在你成功地把自己推销给别人之前,你必须百分之百的把自己推销给自己。
11、即使爬到最高的山上,一次也只能脚踏实地地迈一步。
12、积极思考造成积极人生,消极思考造成消极人生。
13、人之所以有一张嘴,而有两只耳朵,原因是听的要比说的多一倍。
14、别想一下造出大海,必须先由小河川开始。
15、有事者,事竟成;破釜沉舟,百二秦关终归楚;苦心人,天不负;卧薪尝胆,三千越甲可吞吴。
16、你的脸是为了呈现上帝赐给人类最贵重的礼物——微笑,一定要成为你工作最大的资产。
17、以诚感人者,人亦诚而应。
18、世上并没有用来鼓励工作努力的赏赐,所有的赏赐都只是被用来奖励工作成果的。
19、即使是不成熟的尝试,也胜于胎死腹中的策略。
20、积极的人在每一次忧患中都看到一个机会,而消极的人则在每个机会都看到某种忧患。
21、出门走好路,出口说好话,出手做好事。
22、旁观者的姓名永远爬不到比赛的计分板上。
23、上帝助自助者。
24、怠惰是贫穷的制造厂。
25、莫找借口失败,只找理由成功。(不为失败找理由,要为成功找方法)
26、如果我们想要更多的玫瑰花,就必须种植更多的玫瑰树。
27、伟人之所以伟大,是因为他与别人共处逆境时,别人失去了信心,他却下决心实现自己的目标。
28、世上没有绝望的处境,只有对处境绝望的人。
29、回避现实的人,未来将更不理想。
30、先知三日,富贵十年。
31、当你感到悲哀痛苦时,最好是去学些什么东西。学习会使你永远立于不败之地。
32、伟人所达到并保持着的高处,并不是一飞就到的,而是他们在同伴们都睡着的时候,一步步艰辛地向上攀爬的。
33、世界上那些最容易的事情中,拖延时间最不费力。
34、坚韧是成功的一大要素,只要在门上敲得够久、够大声,终会把人唤醒的。
35、夫妇一条心,泥土变黄金。
36、人之所以能,是相信能。
37、没有口水与汗水,就没有成功的泪水。
38、一个有信念者所开发出的力量,大于99个只有兴趣者。
39、忍耐力较诸脑力,尤胜一筹。
40、环境不会改变,解决之道在于改变自己。
41、两粒种子,一片森林。
42、每一发奋努力的背后,必有加倍的赏赐。
43、如果你希望成功,以恒心为良友,以经验为参谋,以小心为兄弟,以希望为哨兵。
44、大多数人想要改造这个世界,但却罕有人想改造自己。
45、未曾失败的人恐怕也未曾成功过。
46、人生伟业的建立 ,不在能知,乃在能行。
47、挫折其实就是迈向成功所应缴的学费。
48、任何的限制,都是从自己的内心开始的。
49、忘掉失败,不过要牢记失败中的教训。
50、不是境况造就人,而是人造就境况。
51、含泪播种的人一定能含笑收获。
52、靠山山会倒,靠水水会流,靠自己永远不倒。
53、欲望以提升热忱,毅力以磨平高山。
54、只要路是对的,就不怕路远。
55、一滴蜂蜜比一加仑胆汁能够捕到更多的苍蝇。
56、真心的对别人产生点兴趣,是推销员最重要的品格。
57、自古成功在尝试。
58、一个能从别人的观念来看事情,能了解别人心灵活动的人,永远不必为自己的前途担心。
59、当一个人先从自己的内心开始奋斗,他就是个有价值的人。
60、生命对某些人来说是美丽的,这些人的一生都为某个目标而奋斗。
61、推销产品要针对顾客的心,不要针对顾客的头。
62、没有人富有得可以不要别人的帮助,也没有人穷得不能在某方面给他人帮助。
63、凡真心尝试助人者,没有不帮到自己的。
64、积极者相信只有推动自己才能推动世界,只要推动自己就能推动世界。
65、每一日你所付出的代价都比前一日高,因为你的生命又消短了一天,所以每一日你都要更积极。 今天太宝贵,不应该为酸苦的忧虑和辛涩的悔恨所销蚀,抬起下巴,抓住今天,它不再回来。
66、一个人最大的破产是绝望,最大的资产是希望。
67、行动是成功的阶梯,行动越多,登得越高。
68、环境永远不会十全十美,消极的人受环境控制,积极的人却控制环境。
69、事实上,成功仅代表了你工作的1%,成功是99%失败的结果。
70、不要等待机会,而要创造机会。
71、成功的法则极为简单,但简单并不代表容易。
72、如果寒暄只是打个招呼就了事的话,那与猴子的呼叫声有什么不同呢?事实上,正确的寒暄必须在短短一句话中明显地表露出你他的关怀。
73、昨晚多几分钟的准备,今天少几小时的麻烦。
74、拿望远镜看别人,拿放大镜看自己。
75、使用双手的是劳工,使用双手和头脑的舵手,使用双手、头脑与心灵的是艺术家,只有合作双手、头脑、心灵再加上双脚的才是推销员。
76、做对的事情比把事情做对重要。
77、“人”的结构就是相互支撑,“众”人的事业需要每个人的参与。
78、竞争颇似打网球,与球艺胜过你的对手比赛,可以提高你的水平。(戏从对手来。)
79、只有不断找寻机会的人才会及时把握机会。
80、你可以选择这样的“三心二意”:信心、恒心、决心;创意、乐意。
81、无论才能、知识多么卓著,如果缺乏热情,则无异纸上画饼充饥,无补于事。
82、如同磁铁吸引四周的铁粉,热情也能吸引周围的人,改变周围的情况。
83、网络事业创造了富裕,又延续了平等。
84、好的想法是十分钱一打,真正无价的是能够实现这些想法的人。
85、人格的完善是本,财富的确立是末。
86、高峰只对攀登它而不是仰望它的人来说才有真正意义。
87、贫穷是不需要计划的,致富才需要一个周密的计划——并去实践它。
88、智者一切求自己,愚者一切求他人。
89、没有一种不通过蔑视、忍受和奋斗就可以征服的命运。
90、苦想没盼头,苦干有奔头。
91、当一个小小的心念变成成为行为时,便能成了习惯;从而形成性格,而性格就决定你一生的成败。
92、穷不一定思变,应该是思富思变。
93、自己打败自己的远远多于比别人打败的。
94、如果我们做与不做都会有人笑,如果做不好与做得好还会有人笑,那么我们索性就做得更好,来给人笑吧!
95、这个世界并不是掌握在那些嘲笑者的手中,而恰恰掌握在能够经受得住嘲笑与批评忍不断往前走的人手中。
96、成功需要成本,时间也是一种成本,对时间的珍惜就是对成本的节约。
97、行动是治愈恐惧的良药,而犹豫、拖延将不断滋养恐惧。
98、投资知识是明智的,投资网络中的知识就更加明智。
99、没有天生的信心,只有不断培养的信心。
100、顾客后还有顾客,服务的开始才是销售的开始。
101、忍别人所不能忍的痛,吃别人所别人所不能吃的苦,是为了收获得不到的收获。
102、销售是从被别人拒绝开始的。
103、好咖啡要和朋友一起品尝,好机会也要和朋友一起分享。
104、生命之灯因热情而点燃,生命之舟因拼搏而前行。
105、拥有梦想只是一种智力,实现梦想才是一种能力。
106、只有一条路不能选择——那就是放弃的路;只有一条路不能拒绝——那就是成长的路。
107、人的才华就如海绵的水,没有外力的挤压,它是绝对流不出来的。流出来后,海绵才能吸收新的源泉。
108、每天早上醒来,你荷包里的最大资产是24个小时——你生命宇宙中尚未制造的材料。
109、如果要挖井,就要挖到水出为止。
110、成功决不喜欢会见懒汉,而是唤醒懒汉。
111、未遭拒绝的成功决不会长久。
112、外在压力增加时,就应增强内在的动力。
113、股票有涨有落,然而打着信心标志的股票将使你永涨无落。
114、只要我们能梦想的,我们就能实现。
115、凡事要三思,但比三思更重要的是三思而行。
116、做的技艺来自做的过程。
117、成功的信念在人脑中的作用就如闹钟,会在你需要时将你唤醒。
118、伟大的事业不是靠力气、速度和身体的敏捷完成的,而是靠性格、意志和知识的力量完成的。
119、只有千锤百炼,才能成为好钢。
120、肉体是精神居住的花园,意志则是这个花园的园丁。意志既能使肉体“贫瘠”下去,又能用勤劳使它“肥沃”起来。
121、对于最有能力的领航人风浪总是格外的汹涌。
122、知识给人重量,成就给人光彩,大多数人只是看到了光彩,而不去称量重量。
123、最重要的就是不要去看远方模糊的,而要做手边清楚的事。
124、为明天做准备的最好方法就是集中你所有智慧,所有的热忱,把今天的工作做得尽善尽美,这就是你能应付未来的唯一方法。
125、人性最可怜的就是:我们总是梦想着天边的一座奇妙的玫瑰园,而不去欣赏今天就开在我们窗口的玫瑰。
126、征服畏惧、建立自信的最快最确实的方法,就是去做你害怕的事,直到你获得成功的经验。
127、世上最重要的事,不在于我们在何处,而在于我们朝着什么方向走。
128、行动不一定带来快乐,而无行动则决无快乐。
129、如果我们都去做自己能力做得到的事,我们真会叫自己大吃一惊。
130、失去金钱的人损失甚少,失去健康的人损失极多,失去勇气的人损失一切。
131、这世上的一切都借希望而完成,农夫不会剥下一粒玉米,如果他不曾希望它长成种粒;单身汉不会娶妻,如果他不曾希望有孩子;商人也不会去工作,如果他不曾希望因此而有收益。
132、相信就是强大,怀疑只会抑制能力,而信仰就是力量。
133、那些尝试去做某事却失败的人,比那些什么也不尝试做却成功的人不知要好上多少。
134、恐惧自己受苦的人,已经因为自己的恐惧在受苦。
135、在真实的生命里,每桩伟业都由信心开始,并由信心跨出第一步。
136、要冒一险!整个生命就是一场冒险,走得最远的人常是愿意去做、愿意去冒险的人。
137、“稳妥”之船从未能从岸边走远。
138、目标的坚定是性格中最必要的力量源泉之一,也是成功的利器之一。没有它,天才也会在矛盾无定的迷径中徒劳无功。
139、在世界的历史中,每一伟大而高贵的时刻都是某种热忱的胜利。
140、没有热忱,世间便无进步。
141、没有什么事情有象热忱这般具有传染性,它能感动顽石,它是真诚的精髓。
142、一个人几乎可以在任何他怀有无限热忱的事情上成功。
143、强烈的信仰会赢取坚强的人,然后又使他们更坚强。
144、失败是什么?没有什么,只是更走近成功一步;成功是什么?就是走过了所有通向失败的路,只剩下一条路,那就是成功的路。
145、如果不想做点事情,就甭想到达这个世界上的任何地方。
146、没有哪种教育能及得上逆境。
147、一个人除非自己有信心,否则带给别人信心。
148、障碍与失败,是通往成功最稳靠的踏脚石,肯研究、利用它们,便能从失败中培养出成功。
149、让我们将事前的忧虑,换为事前的思考和计划吧!
150、人生舞台的大幕随时都可能拉开,关键是你愿意表演,还是选择躲避。
151、能把在面前行走的机会抓住的人,十有八九都会成功。
152、金钱损失了还能挽回,一旦失去信誉就很难挽回。
153、在你不害怕的时间去斗牛,这不算什么;在你害怕时不去斗牛,也没有什么了不起;只有在你害怕时还去斗牛才是真正了不起。
154、再长的路,一步步也能走完,再短的路,不迈开双脚也无法到达。
155、有志者自有千计万计,无志者只感千难万难。
156、不大可能的事也许今天实现,根本不可能的事也许明天会实现。
157、我成功因为我志在成功!
158、再冷的石头,坐上三年也会暖。
159、任何业绩的质变都来自于量变的积累。
160、平凡的脚步也可以走完伟大的行程。
161、嘲讽是一种力量,消极的力量。赞扬也是一种力量,但却是积极的力量。
162、诚心诚意,“诚”字的另一半就是成功。
163、领导的速度决定团队的效率。
164、成功呈概率分布,关键是你能不能坚持到成功开始呈现的那一刻。
165、成功与不成功之间有时距离很短——只要后者再向前几步。
166、空想会想出很多绝妙的主意,但却办不成任何事情。
167、自己打败自己是最可悲的失败,自己战胜自己是最可贵的胜利。
168、你可以这样理解 impossible(不可能)——I’m possible (我是可能的)。
169、为别人鼓掌的人也是在给自己的生命加油。
170、用行动祈祷比用言语更能够使上帝了解。
171、成功的人是跟别人学习经验,失败的人只跟自己学习经验。
172、很多事先天注定,那是“命”;但你可以可以决定怎么面对,那是“运”!
173、不要问别人为你做了什么,而要问你为别人做了什么。
174、成功不是将来才有的,而是从决定去做的那一刻起,持续累积而成。
175、你一天的爱心可能带来别人一生的感谢。
176、山不辞土,故能成其高;海不辞水,故能成其深!
posted @
2006-11-17 15:26 xzc 阅读(261) |
评论 (0) |
编辑 收藏Parsing XML
或许你想要做的第一件事情就是解析一个某种类型的XML文档,用dom4j很容易做到。请看下面的示范代码:
import java.net.URL;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
public class Foo {
public Document parse(URL url) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(url);
return document;
}
}
使用迭代器(Iterators)
我们可以通过多种方法来操作XML文档,这些方法返回java里标准的迭代器(Iterators)。例如:
public void bar(Document document) throws DocumentException {
Element root = document.getRootElement();
//迭代根元素下面的所有子元素
for ( Iterator i = root.elementIterator(); i.hasNext(); ) {
Element element = (Element) i.next();
//处理代码
}
//迭代根元素下面名称为"foo"的子元素
for ( Iterator i = root.elementIterator( "foo" ); i.hasNext(); ) {
Element foo = (Element) i.next();
//处理代码
}
// 迭代根元素的属性attributes)元素
for ( Iterator i = root.attributeIterator(); i.hasNext(); ) {
Attribute attribute = (Attribute) i.next();
// do something
}
}
强大的XPath导航
在dom4j中XPath可以表示出在XML树状结构中的Document或者任意的节点(Node)(例如:Attribute,Element 或者 ProcessingInstruction等)。它可以使在文档中复杂的操作仅通过一行代码就可以完成。例如:
public void bar(Document document) {
List list = document.selectNodes( "//foo/bar" );
Node node = document.selectSingleNode( "//foo/bar/author" );
String name = node.valueOf( "@name" );
}
如果你想得到一个XHTML文档中的所有超文本链接(hypertext links)你可以使用下面的代码:
public void findLinks(Document document) throws DocumentException {
List list = document.selectNodes( "//a/@href" );
for (Iterator iter = list.iterator(); iter.hasNext(); ) {
Attribute attribute = (Attribute) iter.next();
String url = attribute.getValue();
}
}
如果你需要关于XPath语言的任何帮助,我们强烈推荐这个站点Zvon tutorial他会通过一个一个的例子引导你学习。
快速遍历(Fast Looping)
如果你不得不遍历一个非常大的XML文档,然后才去执行,我们建议你使用快速遍历方法(fast looping method),它可以避免为每一个循环的节点创建一个迭代器对象,如下所示:
public void treeWalk(Document document) {
treeWalk( document.getRootElement() );
}
public void treeWalk(Element element) {
for ( int i = 0, size = element.nodeCount(); i < size; i++ ) {
Node node = element.node(i);
if ( node instanceof Element ) {
treeWalk( (Element) node );
}
else {
// do something....
}
}
}
生成一个新的XML文档对象
在dom4j中你可能常常希望用程序生成一个XML文档对象,下面的程序为你进行了示范:
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
public class Foo {
public Document createDocument() {
Document document = DocumentHelper.createDocument();
Element root = document.addElement( "root" );
Element author1 = root.addElement( "author" )
.addAttribute( "name", "James" )
.addAttribute( "location", "UK" )
.addText( "James Strachan" );
Element author2 = root.addElement( "author" )
.addAttribute( "name", "Bob" )
.addAttribute( "location", "US" )
.addText( "Bob McWhirter" );
return document;
}
}
将一个文档对象写入文件中
将一个文档对象写入Writer对象的一个简单快速的途径是通过write()方法。
FileWriter out = new FileWriter( "foo.xml" );
document.write( out );
如果你想改变输出文件的排版格式,比如你想要一个漂亮的格式或者是一个紧凑的格式,或者你想用Writer 对象或者OutputStream 对象来操作,那么你可以使用XMLWriter 类。
import org.dom4j.Document;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Foo {
public void write(Document document) throws IOException {
// 写入文件
XMLWriter writer = new XMLWriter(
new FileWriter( "output.xml" )
);
writer.write( document );
writer.close();
// 以一种优雅的格式写入System.out对象
OutputFormat format = OutputFormat.createPrettyPrint();
writer = new XMLWriter( System.out, format );
writer.write( document );
// 以一种紧凑的格式写入System.out对象
format = OutputFormat.createCompactFormat();
writer = new XMLWriter( System.out, format );
writer.write( document );
}
}
转化为字符串,或者从字符串转化
如果你有一个文档(Document)对象或者任何一个节点(Node)对象的引用(reference),象属性(Attribute)或者元素(Element),你可以通过asXML()方法把它转化为一个默认的XML字符串:
Document document = ...;
String text = document.asXML();
如果你有一些XML内容的字符串表示,你可以通过DocumentHelper.parseText()方法将它重新转化为文档(Document)对象:
String text = "James";
Document document = DocumentHelper.parseText(text);
通过XSLT样式化文档(Document)
使用Sun公司提供的JAXP API将XSLT 应用到文档(Document)上是很简单的。它允许你使用任何的XSLT引擎(例如:Xalan或SAXON等)来开发。下面是一个使用JAXP创建一个转化器(transformer),然后将它应用到文档(Document)上的例子:
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import org.dom4j.Document;
import org.dom4j.io.DocumentResult;
import org.dom4j.io.DocumentSource;
public class Foo {
public Document styleDocument(
Document document,
String stylesheet
) throws Exception {
// 使用 JAXP 加载转化器
TransformerFactory factory = TransformerFactory.newInstance();
Transformer transformer = factory.newTransformer(
new StreamSource( stylesheet )
);
// 现在来样式化一个文档(Document)
DocumentSource source = new DocumentSource( document );
DocumentResult result = new DocumentResult();
transformer.transform( source, result );
// 返回经过样式化的文档(Document)
Document transformedDoc = result.getDocument();
return transformedDoc;
}
}
原文地址
dom4j下载地址
初次尝试翻译,如果有翻译不妥的地方,希望大家指出来,我们共同进步!
谢谢!!
[:)]
posted @
2006-11-17 15:14 xzc 阅读(431) |
评论 (0) |
编辑 收藏1. 介绍
1)DOM(JAXP Crimson解析器)
DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。DOM以及广义的基于树的处理具有几个优点。首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。它还可以在任何时候在树中上下导航,而不是像SAX那样是一次性的处理。DOM使用起来也要简单得多。
2)SAX
SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。一般来说,SAX还比它的替代者DOM快许多。
选择DOM还是选择SAX? 对于需要自己编写代码来处理XML文档的开发人员来说, 选择DOM还是SAX解析模型是一个非常重要的设计决策。 DOM采用建立树形结构的方式访问XML文档,而SAX采用的事件模型。
DOM解析器把XML文档转化为一个包含其内容的树,并可以对树进行遍历。用DOM解析模型的优点是编程容易,开发人员只需要调用建树的指令,然后利用navigation APIs访问所需的树节点来完成任务。可以很容易的添加和修改树中的元素。然而由于使用DOM解析器的时候需要处理整个XML文档,所以对性能和内存的要求比较高,尤其是遇到很大的XML文件的时候。由于它的遍历能力,DOM解析器常用于XML文档需要频繁的改变的服务中。
SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。SAX对内存的要求通常会比较低,因为它让开发人员自己来决定所要处理的tag。特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展能力得到了更好的体现。但用SAX解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据。
3)JDOM http://www.jdom.org
JDOM的目的是成为Java特定文档模型,它简化与XML的交互并且比使用DOM实现更快。由于是第一个Java特定模型,JDOM一直得到大力推广和促进。正在考虑通过“Java规范请求JSR-102”将它最终用作“Java标准扩展”。从2000年初就已经开始了JDOM开发。
JDOM与DOM主要有两方面不同。首先,JDOM仅使用具体类而不使用接口。这在某些方面简化了API,但是也限制了灵活性。第二,API大量使用了Collections类,简化了那些已经熟悉这些类的Java开发者的使用。
JDOM文档声明其目的是“使用20%(或更少)的精力解决80%(或更多)Java/XML问题”(根据学习曲线假定为20%)。JDOM对于大多数Java/XML应用程序来说当然是有用的,并且大多数开发者发现API比DOM容易理解得多。JDOM还包括对程序行为的相当广泛检查以防止用户做任何在XML中无意义的事。然而,它仍需要您充分理解XML以便做一些超出基本的工作(或者甚至理解某些情况下的错误)。这也许是比学习DOM或JDOM接口都更有意义的工作。
JDOM自身不包含解析器。它通常使用SAX2解析器来解析和验证输入XML文档(尽管它还可以将以前构造的DOM表示作为输入)。它包含一些转换器以将JDOM表示输出成SAX2事件流、DOM模型或XML文本文档。JDOM是在Apache许可证变体下发布的开放源码。
4)DOM4J http://dom4j.sourceforge.net
虽然DOM4J代表了完全独立的开发结果,但最初,它是JDOM的一种智能分支。它合并了许多超出基本XML文档表示的功能,包括集成的XPath支持、XML Schema支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项,它通过DOM4J API和标准DOM接口具有并行访问功能。从2000下半年开始,它就一直处于开发之中。
为支持所有这些功能,DOM4J使用接口和抽象基本类方法。DOM4J大量使用了API中的Collections类,但是在许多情况下,它还提供一些替代方法以允许更好的性能或更直接的编码方法。直接好处是,虽然DOM4J付出了更复杂的API的代价,但是它提供了比JDOM大得多的灵活性。
在添加灵活性、XPath集成和对大文档处理的目标时,DOM4J的目标与JDOM是一样的:针对Java开发者的易用性和直观操作。它还致力于成为比JDOM更完整的解决方案,实现在本质上处理所有Java/XML问题的目标。在完成该目标时,它比JDOM更少强调防止不正确的应用程序行为。
DOM4J是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的Java软件都在使用DOM4J来读写XML,特别值得一提的是连Sun的JAXM也在用DOM4J。
2.. 比较
1)DOM4J性能最好,连Sun的JAXM也在用DOM4J。目前许多开源项目中大量采用DOM4J,例如大名鼎鼎的Hibernate也用DOM4J来读取XML配置文件。如果不考虑可移植性,那就采用DOM4J.
2)JDOM和DOM在性能测试时表现不佳,在测试10M文档时内存溢出。在小文档情况下还值得考虑使用DOM和JDOM。虽然JDOM的开发者已经说明他们期望在正式发行版前专注性能问题,但是从性能观点来看,它确实没有值得推荐之处。另外,DOM仍是一个非常好的选择。DOM实现广泛应用于多种编程语言。它还是许多其它与XML相关的标准的基础,因为它正式获得W3C推荐(与基于非标准的Java模型相对),所以在某些类型的项目中可能也需要它(如在JavaScript中使用DOM)。
3)SAX表现较好,这要依赖于它特定的解析方式-事件驱动。一个SAX检测即将到来的XML流,但并没有载入到内存(当然当XML流被读入时,会有部分文档暂时隐藏在内存中)。
3. 四种xml操作方式的基本使用方法
xml文件:
<?xml version="1.0" encoding="GB2312"?>
<RESULT>
<VALUE>
<NO>A1234</NO>
<ADDR>四川省XX县XX镇XX路X段XX号</ADDR>
</VALUE>
<VALUE>
<NO>B1234</NO>
<ADDR>四川省XX市XX乡XX村XX组</ADDR>
</VALUE>
</RESULT>
1)DOM
import java.io.*;
import java.util.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class MyXMLReader{
public static void main(String arge[]){
long lasting =System.currentTimeMillis();
try{
File f=new File("data_10k.xml");
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document doc = builder.parse(f);
NodeList nl = doc.getElementsByTagName("VALUE");
for (int i=0;i<nl.getLength();i++){
System.out.print("车牌号码:" + doc.getElementsByTagName("NO").item(i).getFirstChild().getNodeValue());
System.out.println("车主地址:" + doc.getElementsByTagName("ADDR").item(i).getFirstChild().getNodeValue());
}
}catch(Exception e){
e.printStackTrace();
}
2)SAX
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class MyXMLReader extends DefaultHandler {
java.util.Stack tags = new java.util.Stack();
public MyXMLReader() {
super();
}
public static void main(String args[]) {
long lasting = System.currentTimeMillis();
try {
SAXParserFactory sf = SAXParserFactory.newInstance();
SAXParser sp = sf.newSAXParser();
MyXMLReader reader = new MyXMLReader();
sp.parse(new InputSource("data_10k.xml"), reader);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("运行时间:" + (System.currentTimeMillis() - lasting) + "毫秒");}
public void characters(char ch[], int start, int length) throws SAXException {
String tag = (String) tags.peek();
if (tag.equals("NO")) {
System.out.print("车牌号码:" + new String(ch, start, length));
}
if (tag.equals("ADDR")) {
System.out.println("地址:" + new String(ch, start, length));
}
}
public void startElement(String uri,String localName,String qName,Attributes attrs) {
tags.push(qName);}
}
3) JDOM
import java.io.*;
import java.util.*;
import org.jdom.*;
import org.jdom.input.*;
public class MyXMLReader {
public static void main(String arge[]) {
long lasting = System.currentTimeMillis();
try {
SAXBuilder builder = new SAXBuilder();
Document doc = builder.build(new File("data_10k.xml"));
Element foo = doc.getRootElement();
List allChildren = foo.getChildren();
for(int i=0;i<allChildren.size();i++) {
System.out.print("车牌号码:" + ((Element)allChildren.get(i)).getChild("NO").getText());
System.out.println("车主地址:" + ((Element)allChildren.get(i)).getChild("ADDR").getText());
}
} catch (Exception e) {
e.printStackTrace();
}
}
4)DOM4J
import java.io.*;
import java.util.*;
import org.dom4j.*;
import org.dom4j.io.*;
public class MyXMLReader {
public static void main(String arge[]) {
long lasting = System.currentTimeMillis();
try {
File f = new File("data_10k.xml");
SAXReader reader = new SAXReader();
Document doc = reader.read(f);
Element root = doc.getRootElement();
Element foo;
for (Iterator i = root.elementIterator("VALUE"); i.hasNext();) {
foo = (Element) i.next();
System.out.print("车牌号码:" + foo.elementText("NO"));
System.out.println("车主地址:" + foo.elementText("ADDR"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
转自:http://blog.dl.net.cn/xd/3/archives/2005/15.html
posted @
2006-11-17 15:01 xzc 阅读(345) |
评论 (0) |
编辑 收藏『本文地址:
http://v2.djasp.net/Static/ie/1147.stm 』
1.文档对象模型(DOM)
DOM是HTML和XML文档的编程基础,它定义了处理执行文档的途径。
编程者可以使用DOM增加文档、定位文档结构、填加修改删除文档元素。W3C的重要目标是把利用DOM提供一个使用于多个平台的编程接口。W3C DOM被设计成适合多个平台,可使用任意编程语言实现的方法。
2.节点接口
XML parser用来装载XML文档到缓存中,文档装载时,可以使用DOM进行检索和处理。DOM采用树形结构表示 XML文档,文档元素是树的最高阶层,该元素有一个或多个孩子节点用来表示树的分枝。
节点接口程序通常用来读和写XML节点树中的个别元素,文档元素的孩子节点属性可以用来构造个别元素节点。XML parser用来证明Web中的DOM支持遍历节点树的所有函数,并可通过它们访问节点和及其属性、插入删除节点、转换节点树到XML中。
所有Microsoft XML parser函数得到W3C XML DOM的正式推荐,除了load和loadXML函数(正式的DOM不包括标准函数loading XML文档)。有13个节点类型被Microsoft XML parser支持,下面列出常用节点:
节点类型 例子Document type <!DOCTYPE food SYSTEM "food.dtd">
Processing instruction <?xml version="1.0"?>
Element <drink type="beer">Carlsberg</drink>
Attribute type="beer"
Text Carlsberg
3.使用XML parser
为了更加熟练的处理XML文档,必须使用XML parser。Microsoft XML parser是IIS5.0所带的一个COM组件,一旦安装了IIS5.0,parser可以利用HTML文档和ASP文件中的脚本。
Microsoft XMLDOM parser支持以下编程模式:
----支持 JavaScript, VBScript, Perl, VB, Java, C++ 等等
----支持 W3C XML 1.0 和 XML DOM
----支持 DTD 和 validation
如果使用IE5.0中的JavaScript,可以使用下面的XML文档对象:
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
如果使用VBScript,可以使用下面的XML文档对象:
set xmlDoc = CreateObject("Microsoft.XMLDOM")
如果使用ASP,可以使用下面的XML文档对象:
set xmlDoc = Server.CreateObject("Microsoft.XMLDOM")
4.装载一个XML文件到parser中下面的代码装载存在的XML文档进入XML parser:
<script language="JavaScript">
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note.xml")
// ....... processing the document goes here
</script>
第一行脚本增加了一个Microsoft XML parser实例,第三行装载名为”note.xml”的XML文档进入parser中。第二行保证文档装载完成以后parser进行下一步工作。
5. parseError对象
打开XMl文档时,XML Parser产生错误代码,并存在parseError对象中,包括错误代码、错误文本和错误行号,等信息。
6.文件错误
下面的例子将试图装载一个不存在的文件,然后产生相应的错误代码:
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("ksdjf.xml")
document.write("<br>Error Code: ")
document.write(xmlDoc.parseError.errorCode)
document.write("<br>Error Reason: ")
document.write(xmlDoc.parseError.reason)
document.write("<br>Error Line: ")
document.write(xmlDoc.parseError.line)
7.XML错误
下面使用不正确的格式装载XMl文档,
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note_error.xml")
document.write("<br>Error Code: ")
document.write(xmlDoc.parseError.errorCode)
document.write("<br>Error Reason: ")
document.write(xmlDoc.parseError.reason)
document.write("<br>Error Line: ")
document.write(xmlDoc.parseError.line)
8. parseError属性
属性描述:
errorCode 返回长整型错误代码
reason 返回字符串型错误原因
line 返回长整型错误行号
linePos 返回长整型错误行号位置
srcText 返回字符串型产生错误原因
url 返回url装载文档指针
filePos 返回长整型错误文件位置
9.遍历节点树
一种通用的析取XML文档的方法是遍历节点树和它的元素值。
您查看的内容转载自 ★点击设计★ www.djasp.Net
点击设计是一个专业的网页编程资讯站点,欢迎访问!
盗用它人网站上的内容可耻,您查看的站点未经点击设计许可,大量盗用点击设计网站上的内容,,请关闭该网站然后访问点击设计官方网址:http://www.djasp.net/
下面是使用VBScript写的遍历节点树的程序代码:
set xmlDoc=CreateObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note.xml")
for each x in xmlDoc.documentElement.childNodes
document.write(x.nodename)
document.write(": ")
document.write(x.text)
next10.为XML文件提供HTML格式
XML的一个优点是把HTML文档和它的数据分离开。通过使用浏览器中的XML parser,HTML页面可以被构造成静态文档,通过JavaScript提供动态数据。下面的例子使用JavaScript读取XML文档,写XML数据成HTML元素:
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note.xml")
nodes = xmlDoc.documentElement.childNodes
to.innerText = nodes.item(0).text
from .innerText = nodes.item(1).text
header.innerText = nodes.item(2).text
body.innerText = nodes.item(3).text
11.通过名称访问XML元素
下面的例子使用JavaScript读取XML文档,写XML数据成HTML元素:
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note.xml")
document.write(xmlDoc.getElementsByTagName("from").item(0).text)
12.装载纯XML文本进入parser
下面的代码装载文本字符串进入XML parser :
<script language="JavaScript">
var text="<note>"
text=text+"<to>Tove</to><from>Jani</from>"
text=text+"<heading>Reminder</heading>"
text=text+"<body>Don't forget me this weekend!</body>"
text=text+"</note>"
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.loadXML(text)
// ....... processing the document goes here
</script>
13.装载XML进入Parser
<html>
<body>
<script language="javascript">
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note.xml")
document.write("The first XML element in the file contains: ")
document.write(xmlDoc.documentElement.childNodes.item(0).text)
</script>
</body>
</html>
遍历XML节点树:
<html>
<body>
<script language="VBScript">
txt="<h1>Traversing the node tree</h1>"
document.write(txt)
set xmlDoc=CreateObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note.xml")
for each x in xmlDoc.documentElement.childNodes
document.write("<b>" & x.nodename & "</b>")
document.write(": ")
document.write(x.text)
document.write("<br>")
next
</script>
</body>
</html>
装载XML 进入 HTML
<html>
<head>
<script language="JavaScript"
for="window" event="onload">
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note.xml")
nodes = xmlDoc.documentElement.childNodes
to.innerText = nodes.item(0).text
from.innerText = nodes.item(1).text
header.innerText = nodes.item(2).text
body.innerText = nodes.item(3).text
</script>
<title>HTML using XML data</title>
</head>
<body bgcolor="yellow">
<h1>Refsnes Data Internal Note</h1>
<b>To: </b><span id="to"></span>
<br>
<b>From: </b><span id="from"></span>
<hr>
<b><span id="header"></span></b>
<hr>
<span id="body"></span>
</body>
</html>posted @
2006-11-16 12:28 xzc 阅读(1019) |
评论 (0) |
编辑 收藏『本文地址:
http://v3.djasp.net/Static/vb/1949.stm 』
我的xml文件Login.xml如下.
<?xml version="1.0" encoding="utf-8" ?>
<Login>
<Character>
<C Text="热血" Value="0"></C>
<C Text="弱气" Value="1"></C>
<C Text="激情" Value="2"></C>
<C Text="冷静" Value="3"></C>
<C Text="冷酷" Value="4"></C>
</Character>
<Weapon>
<W Text="光束剑" Value="0"></W>
<W Text="光束配刀" Value="1"></W>
</Weapon>
<EconomyProperty>
<P Text="平均型" Value="0"></P>
<P Text="重视攻击" Value="1"></P>
<P Text="重视敏捷" Value="2"></P>
<P Text="重视防御" Value="3"></P>
<P Text="重视命中" Value="4"></P>
</EconomyProperty>
</Login>
现在我需要对这个xml文件的内容进行操作.
首先,我们需要加载这个xml文件,js中加载xml文件,是通过XMLDOM来进行的.
// 加载xml文档
loadXML = function(xmlFile)
{
var xmlDoc;
if(window.ActiveXObject)
{
xmlDoc = new ActiveXObject(’Microsoft.XMLDOM’);
xmlDoc.async = false;
xmlDoc.load(xmlFile);
}
else if (document.implementation&&document.implementation.createDocument)
{
xmlDoc = document.implementation.createDocument(’’, ’’, null);
xmlDoc.load(xmlFile);
}
else
{
return null;
}
return xmlDoc;
}
xml文件对象出来了, 接下去我就要对这个文档进行操作了.
比如说,我们现在需要得到节点Login/Weapon/W的第一个节点的属性,那么我们可以如下进行.
本文由 点击设计 http://www.djasp.Net 收集整理。谢绝无聊之人转载!
// 首先对xml对象进行判断
checkXMLDocObj = function(xmlFile)
{
var xmlDoc = loadXML(xmlFile);
if(xmlDoc==null)
{
alert(’您的浏览器不支持xml文件读取,于是本页面禁止您的操作,推荐使用IE5.0以上可以解决此问题!’);
window.location.href=’/Index.aspx’;
}
return xmlDoc;
}
★点击设计★ http://www.djasp.Net 全力打造WEB技术站点,欢迎大家访问!
// 然后开始获取需要的Login/Weapon/W的第一个节点的属性值
var xmlDoc = checkXMLDocObj(’/EBS/XML/Login.xml’);
var v = xmlDoc.getElementsByTagName(’Login/Weapon/W’)[0].childNodes.getAttribute(’Text’)
而我在我的程序中的写法是这样子的,当然我在程序中的写法是已经应用到实际中的了.一并给出来,以供查看
本文由 ★点击设计★ http://www.djasp.Net 收集整理。谢绝无聊之人转载!
initializeSelect = function(oid, xPath)
{
var xmlDoc = checkXMLDocObj(’/EBS/XML/Login.xml’);
var n;
var l;
var e = $(oid);
if(e!=null)
{
n = xmlDoc.getElementsByTagName(xPath)[0].childNodes;
l = n.length;
for(var i=0; i<l; i++)
{
var option = document.createElement(’option’);
option.value = n[i].getAttribute(’Value’);
option.innerHTML = n[i].getAttribute(’Text’);
e.appendChild(option);
}
}
}
上面的访问代码中,我们是通过xmlDoc.getElementsByTagName(xPath)来进行的.
还可以通过xmlDoc.documentElement.childNodes(1)..childNodes(0).getAttribute(’Text’)进行访问.
一些常用方法:
xmlDoc.documentElement.childNodes(0).nodeName,可以得到这个节点的名称.
xmlDoc.documentElement.childNodes(0).nodeValue,可以得到这个节点的值. 这个值是来自于这样子的xml格式:<a>b</b>, 于是可以得到b这个值.
xmlDoc.documentElement.childNodes(0).hasChild,可以判断是否有子节点
盗版它人网站的内容可耻,您查看的内容来源于★点击设计★www.djasp.Net
根据我的经验,最好是使用getElementsByTagName(xPath)的方法对节点进行访问,因为这样子可以直接通过xPath来定位节点,这样子会有更好的性能.
posted @
2006-11-16 12:25 xzc 阅读(316) |
评论 (0) |
编辑 收藏To read and update - create and manipulate - an XML document, you will need an XML parser.
Microsoft's XML Parser
Microsoft's XML parser is a COM component that comes with Internet Explorer 5 and higher. Once you have installed Internet Explorer, the parser is available to scripts.
Microsoft's XML parser supports all the necessary functions to traverse the node tree, access the nodes and their attribute values, insert and delete nodes, and convert the node tree back to XML.
The following table lists the most commonly used node types supported by Microsoft's XML parser:
| Node Type | Example |
|---|
| Processing instruction | <?xml version="1.0"?> |
| Element | <drink type="beer">Carlsberg</drink> |
| Attribute | type="beer" |
| Text | Carlsberg |
MSXML Parser 2.5 is the XML parser that is shipped with Windows 2000 and IE 5.5.
MSXML Parser 3.0 is the XML parser that is shipped with IE 6.0 and Windows XP.
The MSXML 3.0 parser features:
- JavaScript, VBScript, Perl, VB, Java, C++, etc. support
- Complete XML support
- Full DOM and Namespace support
- DTD and validation
- Complete XSLT and XPath support
- SAX2 support
- Server-safe HTTP
To create an instance of Microsoft's XML parser with JavaScript, use the following code:
var xmlDoc=new ActiveXObject("Microsoft.XMLDOM") |
To create an instance of Microsoft's XML parser with VBScript, use the following code:
set xmlDoc=CreateObject("Microsoft.XMLDOM") |
To create an instance of Microsoft's XML parser in an ASP page (using VBScript), use the following code:
set xmlDoc=Server.CreateObject("Microsoft.XMLDOM") |
The following code loads an existing XML document ("note.xml") into Microsoft's XML parser:
<script type="text/javascript">
var xmlDoc=new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.load("note.xml")
...
...
...
</script> |
The first line of the script above creates an instance of the Microsoft XML parser. The third line tells the parser to load an XML document called "note.xml". The second line turns off asynchronized loading, to make sure that the parser will not continue execution of the script before the document is fully loaded.
XML Parser in Mozilla Browsers
Plain XML documents are displayed in a tree-like structure in Mozilla (just like IE).
Mozilla also supports parsing of XML data using JavaScript. The parsed data can be displayed as HTML.
To create an instance of the XML parser with JavaScript in Mozilla browsers, use the following code:
var xmlDoc=document.implementation.createDocument("ns","root",null) |
The first parameter, ns, defines the namespace used for the XML document. The second parameter, root, is the XML root element in the XML file. The third parameter, null, is always null because it is not implemented yet.
The following code loads an existing XML document ("note.xml") into Mozillas' XML parser:
<script type="text/javascript">
var xmlDoc=document.implementation.createDocument("","",null);
xmlDoc.load("note.xml");
...
...
...
</script> |
The first line of the script above creates an instance of the XML parser. The second line tells the parser to load an XML document called "note.xml".
Loading an XML File - A Cross browser Example
The following example is a cross browser example that loads an existing XML document ("note.xml") into the XML parser:
<html>
<head>
<script type="text/javascript">
var xmlDoc
function loadXML()
{
//load xml file
// code for IE
if (window.ActiveXObject)
{
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async=false;
xmlDoc.load("note.xml");
getmessage()
}
// code for Mozilla, etc.
else if (document.implementation &&
document.implementation.createDocument)
{
xmlDoc= document.implementation.createDocument("","",null);
xmlDoc.load("note.xml");
xmlDoc.onload=getmessage
}
else
{
alert('Your browser cannot handle this script');
}
}function getmessage()
{
document.getElementById("to").innerHTML=
xmlDoc.getElementsByTagName("to")[0].firstChild.nodeValue
document.getElementById("from").innerHTML=
xmlDoc.getElementsByTagName("from")[0].firstChild.nodeValue
document.getElementById("message").innerHTML=
xmlDoc.getElementsByTagName("body")[0].firstChild.nodeValue
}
</script>
</head><body onload="loadXML()" bgcolor="yellow">
<h1>W3Schools Internal Note</h1>
<p><b>To:</b> <span id="to"></span><br />
<b>From:</b> <span id="from"></span>
<hr />
<b>Message:</b> <span id="message"></span>
</p>
</body>
</html> |
Try it yourself
Loading XML Text Into the Parser
Internet Explorer supports two ways of loading XML into a document object: the load() method and the loadXML() method. The load() method loads an XML file and the loadXML() method loads a text string that contains XML code.
The following code loads a text string into Microsoft's XML parser:
<script type="text/javascript"> var txt="<note>"
txt=txt+"<to>Tove</to><from>Jani</from>"
txt=txt+"<heading>Reminder</heading>"
txt=txt+"<body>Don't forget me this weekend!</body>"
txt=txt+"</note>" var xmlDoc=new ActiveXObject("Microsoft.XMLDOM")
xmlDoc.async="false"
xmlDoc.loadXML(txt)
...
...
...</script> |
If you have Internet Explorer, you can try it yourself.
posted @
2006-11-16 12:20 xzc 阅读(2229) |
评论 (1) |
编辑 收藏 多年来,我惊叹于有如此大量能够使 Microsoft Word 崩溃的坏文件。少数字节错位,会使整个应用程序毁于一旦。在旧式的、无内存保护的操作系统中,整个计算机通常就这样宕掉了。Word 为什么不能意识到它接收到了坏的数据,并发出一条错误信息呢?为什么它会仅仅因为少数字节被损坏就破坏自己的栈、堆呢?当然,Word 并不是惟一一个面对畸形文件时表现得如此糟糕的程序。
本文介绍了一种试图避免这种灾难的技术。在模糊测试中,用随机坏数据(也称做 fuzz)攻击一个程序,然后等着观察哪里遭到了破坏。模糊测试的技巧在于,它是不符合逻辑的:自动模糊测试不去猜测哪个数据会导致破坏(就像人工测试员那样),而是将尽可能多的杂乱数据投入程序中。由这个测试验证过的失败模式通常对程序员来说是个彻底的震憾,因为任何按逻辑思考的人都不会想到这种失败。
模糊测试是一项简单的技术,但它却能揭示出程序中的重要 bug。它能够验证出现实世界中的错误模式并在您的软件发货前对潜在的应当被堵塞的攻击渠道进行提示。
模糊测试如何运行
模糊测试的实现是一个非常简单的过程:
- 准备一份插入程序中的正确的文件。
- 用随机数据替换该文件的某些部分。
- 用程序打开文件。
- 观察破坏了什么。
可以用任意多种方式改变该随机数据。例如,可以将整个文件打乱,而不是仅替换其中的一部分,也可以将该文件限制为 ASCII 文本或非零字节。不管用什么方式进行分割,关键是将大量随机数据放入应用程序并观察出故障的是什么。
 | 测试基于 C 的应用程序
当字符串包含额外的零时,许多用 C 编写的程序都会出问题 —— 这类问题太过频繁以至于额外的零能够彻底隐藏代码中其他的问题。一旦验证出程序存在零字节问题,就可以移除它们,从而让其他的问题浮现出来。 |
|
可以手动进行初始化测试,但要想达到最佳的效果则确实需要采用自动化模糊测试。在这种情况下,当面临破坏输入时首先需要为应用程序定义适当的错误行为。(如果当输入数据被破坏时,您发现程序正常运行,且未定义发生的事件,那么这就是第一个 bug。)随后将随机数据传递到程序中直到找到了一个文件,该文件不会触发适当的错误对话框、消息、异常,等等。存储并记录该文件,这样就能在稍后重现该问题。如此重复。
尽管模糊测试通常需要一些手动编码,但还有一些工具能提供帮助。例如,清单 1 显示了一个简单的 Java™ 类,该类随机更改文件的特定长度。我常愿意在开始的几个字节后面启动模糊测试,因为程序似乎更可能注意到早期的错误而不是后面的错误。(您的目的是想找到程序未检测到的错误,而不是寻找已经检测到的。)
清单 1. 用随机数据替换文件部分的类
import java.io.*;
import java.security.SecureRandom;
import java.util.Random;
public class Fuzzer {
private Random random = new SecureRandom();
private int count = 1;
public File fuzz(File in, int start, int length) throws IOException
{
byte[] data = new byte[(int) in.length()];
DataInputStream din = new DataInputStream(new FileInputStream(in));
din.readFully(data);
fuzz(data, start, length);
String name = "fuzz_" + count + "_" + in.getName();
File fout = new File(name);
FileOutputStream out = new FileOutputStream(fout);
out.write(data);
out.close();
din.close();
count++;
return fout;
}
// Modifies byte array in place
public void fuzz(byte[] in, int start, int length) {
byte[] fuzz = new byte[length];
random.nextBytes(fuzz);
System.arraycopy(fuzz, 0, in, start, fuzz.length);
}
} |
| 关于代码
我可以用很多种方式优化 清单 1 中的代码。例如,有着 java.nio 的内存映射文件是一个相当不错的选择。我也能够改进这个错误处理及可配置性。因为不想让这些细节混淆这里所要说明的观点,所以我将代码保持了原样。 |
|
模糊测试文件很简单。将其传至应用程序通常不那么困难。如 AppleScript 或 Perl 脚本语言通常是编写模糊测试的最佳选择。对于 GUI 程序,最困难的部分是辨认出应用程序是否检测出正确的故障模式。有时,最简单的方法是让一个人坐在程序前将每一个测试通过或失败的结果都标记下来。一定要将所有生成的随机测试用例单独地命名并保存下来,这样就能够重现这个过程中检测到的任何故障。
防护性编码
可靠的编码遵循了这样的基本原则:绝不会让程序中插入未经过一致性及合理性验证的外部数据。
如果从文件中读入一个数字并期望其为正数,那么,在使用其进行进一步处理前对其先验证一下。如果期望字符串只包含 ASCII 字母,请确定它确实是这样。如果认为文件包含一个四字节的整数倍的数据,请验证一下。一定不要假设任何外部提供的数据中的字符都会如您所料。
最常见的错误是做出这样的假设:因为程序将该数据写出,该程序就能不用验证再一次将该数据读回去。这是很危险的!因为该数据很可能已经被另一个程序在磁盘上复写过了。它也可能已经被一个故障磁盘或坏的网络传输所破坏了或已经被另一个带 bug 的程序更改过了。它甚至可能已经被故意更改过以破坏程序的安全性。所以不要假设任何事,要进行验证。
当然,错误处理及验证十分令人生厌,也很不方便,并被全世界程序员们所轻视。计算机的诞生已进入了六十个年头,我们仍旧没有检查基本的东西,如成功打开一个文件及内存分配是否成功。让程序员们在阅读一个文件时测试每一个字节和每一个不变量似乎是无望的 —— 但不这样做就会使程序易被模糊攻击。幸运的是,可以寻求帮助。恰当使用现代工具和技术能够显著减轻加固应用程序的痛苦,特别是如下三种技术更为突出:
- 校验和
- 基于语法的格式,如 XML
- 验证过的代码如 Java
用校验和进行的模糊试验
能够保护程序抵御模糊攻击的最简单的方法是将一个检验和添加到数据中。例如,可以将文件中所有的字节都累加起来,然后取其除以 256 的余数。将得到的值存储到文件尾部的一个额外字节中。然后,在输入数据前,先验证检验和是否匹配。这项简单模式将未被发现的意外故障的风险降低到约 1/256 。
健壮的校验和算法如 MD5 和 SHA 并不仅仅取其除以 256 的余数,它完成的要多得多。在 Java 语言中,java.security.DigestInputStream 和 java.security.DigestOutputStream 类为将一个校验和附属到数据中提供了便捷的方式。使用这些校验和算法中的一种可以将程序遭受意外破坏的机率降低到少于十亿分之一(尽管故意攻击仍有可能)。
XML 存储及验证
将数据以 XML 形式存储是一种避免数据损坏的好方法。XML 最初即着力于 Web 页面、书籍、诗歌、文章及相似文档,它几乎在每个领域都获取了巨大的成功,从金融数据到矢量图形到序列化对象等等。
| 不切实际的限定
如果真想要破坏一个 XML 解析器,有几种方法可以试试。例如,大多数 XML 解析器服从于特定的最大尺寸。如果一个元素名长度超过 22 亿字符(Java String 的最大尺寸),SAX 解析器将会失败。尽管如此,在实践中这些极限值如此之高,以至于在达到之前内存就已经耗尽。 |
|
使 XML 格式抵制模糊攻击的关键特征是一个对输入不做任何 假设的解析器。这就是真正想在一个健壮的文件格式中所获得的。设计 XML 解析器是为了让任何输入(格式良好的或无格式的,有效的或无效的)都以定义好的形式处理。XML 解析器能够处理任何 字节流。如果数据首先通过了 XML 解析器,则仅需要准备好接受解析器所能提供的东西。例如,不需要检查数据是否包含空字符,因为 XML 解析器绝不会传送一个空值。如果 XML 解析器在其输入中看到一个空字符,它就会发出异常并停止处理。当然还需要处理这个异常,但编写一个 catch 块来处理检测到的错误比起编写代码来检测所有可能的错误来说要简单得多。
为使程序更加安全,可以用 DTD 和/或模式来验证文档。这不仅检查了 XML 是否格式良好,而且至少与所预期更加接近。验证并不会告知关于文档所需了解的一切,但它却使编写大量简单检查变得很简单。用 XML,很明显能够将所接受的文档严格地限定为能够处理的格式。
尽管如此,还有多段代码不能用 DTD 或模式进行验证。例如,不能测试发票上商品的价格是否和数据库中库存商品的价格一致。当从客户接收到一份包含价格的订单文档时,不论其是 XML 格式或是其他格式,在提交前通常都会检查一下,以确保客户并未修改价格。可以用定制代码实现这些最后的检查。
基于语法的格式
使 XML 能够对模糊攻击具有如此的抵御能力的是其使用巴科斯-诺尔范式(Backus-Naur Form,BNF)语法仔细且标准地定义的格式。许多解析器都是使用如 JavaCC 或 Bison 等解析器-生成器工具直接从此语法中构建的。这种工具的实质是阅读一个任意的输入流并确定其是否符合此语法。
如果 XML 并不适合于您的文件格式,您仍可以从基于解析器的解决方案的健壮性中获益。您必须为文件格式自行编写语法,随后开发自己的解析器来阅读它。相比使用唾手可得的 XML 解析器,开发自己的解析器需要更多的工作。然而它是一个更为健壮的解决方案,而不是不根据语法正式地进行验证就将数据简单地装载到内存中。
Java 代码验证
由模糊测试导致的许多故障都是内存分配错误及缓冲器溢出的结果。用一种安全的垃圾收集语言(在如 Java 或 managed C# 等虚拟机上执行的)来编写应用程序避免了许多潜在问题。即使用 C 或 C++ 来编写代码,还是需要使用一个可靠的垃圾收集库。在 2006 年,台式机程序员或服务器程序员不应该还需要管理内存。
Java 运行时对其自身的代码起到了额外保护层的作用。在将一个 .class 文件装载到虚拟机之前,该文件要由一个字节符验证器或一个可选的 SecurityManager 进行验证。Java 并不假设创建 .class 文件的编译器没有 bug 且运转正常。设计 Java 语言之初就是为了允许在一个安全沙箱中运行不信任的、潜在恶意的代码。它甚至不信任其自身编译过的代码。毕竟,也许有人已经用十六进制编辑器手工修改了字节符,试图触发缓冲器溢出。我们大家都应该对我们的程序也有对输入这样的偏执。
以敌人的角度思考
之前介绍的每项技术都在阻止意外破坏方面造诣颇深。将它们综合起来恰当地实现,会将未被发现的非蓄意破坏发生的可能性几乎减少到零。(当然,并不会减少到零,但其发生的可能性就如同一束偏离轨道的宇宙射线将您 CPU 运算 1+1 的结果变为 3 的可能性一样微乎其微。)但不是所有的数据损坏都是非蓄意的。如果有人故意引入坏数据来破坏程序的安全性又该如何呢?以一个攻击者的角度进行思考是防护代码的下一个步骤。
转回到一个攻击者的角度进行思考,假设要攻击的应用程序是用 Java 编程语言编写的、使用非本地代码且将所有额外数据都以 XML(在接受前经过彻底验证)形式存储,还能成功攻击吗?是的,能。但用随机改变文件字节的低级方法显然不行。需要一种更为复杂的方法来说明程序自身的错误检测机制及路径。
当测试一个抵御模糊攻击的应用程序时,不可能做纯黑盒测试,但通过一些明显的修改,基本的想法还是可以应用的。例如,考虑校验和,如果文件格式包含一个校验和,在将文件传至应用程序前仅仅修改此校验和就可以使其同随机数据相匹配。
对于 XML,试着模糊单独的元素内容和属性值,而不是从文档中挑选一部分随机的字节进行替换。一定要用合法的 XML 字符替换数据,而不要用随机字节,因为即使一百字节的随机数据也一定是畸形的。也可以改变元素名称和属性名称,只要细心地确保得到的文档格式仍是正确的就可以了。如果该 XML 文档是由一个限制非常严格的模式进行检查的,还需要计算出该模式没有 检查什么,以决定在哪里进行有效的模糊。
一个结合了对剩余数据进行代码级验证的真正严格的模式也许不会留下可操纵的空间。这就是作为一个开发人员所需要追求的。应用程序应能够处理所发送的任何有意义的字节流,而不会因权利上( de jure ) 无效而拒绝。
结束语
模糊测试能够说明 bug 在程序中的出现。并不证明不存在这样的 bug。而且,通过模糊测试会极大地提高您对应用程序的健壮性及抵御意外输入的安全性的自信心。如果您用 24 小时对程序进行模糊测试而其依然无事,那么随后同种类型的攻击就不大可能再危及到它。(并不是不可能,提醒您,只是可能性很小。)如果模糊测试揭示出程序中的 bug,就应该进行修正,而不是当 bug 随机出现时再对付它们。模糊测试通过明智地使用校验和、XML、垃圾收集和/或基于语法的文件格式,更有效地从根本上加固了文件格式。
模糊测试是一项用于验证程序中真实错误的重要工具,也是所有意识到安全性问题且着力于程序健壮性的程序员们的工具箱中所必备的工具。
关于作者
|

| | Elliotte Rusty Harold 来自新奥尔良, 现在他还定期回老家喝一碗美味的秋葵汤。不过目前,他和妻子 Beth 定居在纽约临近布鲁克林的 Prospect Heights,同住的还有他的猫咪 Charm(取自夸克)和 Marjorie(取自他岳母的名字)。他是 Polytechnic 大学计算机科学的副教授,他在该校讲授 Java 和面向对象编程。他的 Web 站点 Cafe au Lait 已经成为 Internet 上最流行的独立 Java 站点之一,它的姊妹站点 Cafe con Leche 已经成为最流行的 XML 站点之一。他的书包括 Effective XML、 Processing XML with Java、 Java Network Programming 和 The XML 1.1 Bible。他目前在从事处理 XML 的 XOM API、Jaxen XPath 引擎和 Jester 测试覆盖率工具的开发工作。 |
posted @
2006-11-08 12:49 xzc 阅读(363) |
评论 (0) |
编辑 收藏
Xdoclet是一个代码自动生成的工具
XDoclet任务就是Ant的自定义任务,除此以外,没有其他运行XDoclet任务的方法。
XDoclet它有两个重要的组件:
进行特殊标记的 Java 源文件。
预先定义的模板。[引用]
Merge File用来处理无法在Source Code中加xdoclet tag的情况。
Ø XDoclet中的核心任务:
<ejbdoclet>:面向EJB领域,生成EJB、工具类和布署描述符。
<webdoclet>:面向Web开发,生成serlvet、自定义标签库和web框架文件。
<hibernatedoclet>:Hibernate持续,配置文件、Mbeans
<jdodoclet>:JDO,元数据,vender configuration
<jmxdoclet>:JMX,MBean接口,mlets,配置文件。
<doclet>:使用用户自定义模板来生成代码。
<documentdoclet>:生成项目文件(例如todo列报表)
Ø webdoclet sub task
XDoclet并没有和Ant一起发布,所以如果你想要使用XDoclet的话,就需要单独的下载和
安装。在使用任何一个XDoclet的任务之前,你首先需要在使用Ant的<taskdef>任务来声
明它。
<deploymentdescriptor>:产生标准的web引用配置文件web.xml,destdir属性设定
web.xml文件的存放位置。
XDoclet通过合并点(merge points)支持定制,合并点是在模板文件定义里允许运行时插入定制代码的地方,使用mergedir属性设置。
<target name="webdoclet" depends="compile-web"
unless="webdoclet.unnecessary"
description="Generate web and Struts descriptors">
<taskdef name="webdoclet" classname="xdoclet.modules.web.WebDocletTask">
<classpath>
<path refid="xdoclet.classpath"/>
<path refid="web.compile.classpath"/>
</classpath>
</taskdef>
<!—mergedir完成模板文件合并的功能-->
<webdoclet destdir="${webapp.target}/WEB-INF"
force="${xdoclet.force}"
mergedir="metadata/web"
excludedtags="@version,@author"
verbose="true">
<!—找出目录src/web 和${build.dir}/web/gen文件中的webdoclet注
释,生成web.xml,struts-config.xml等配置信息文件-->
<fileset dir="src/web"/>
<fileset dir="${build.dir}/web/gen"/>
<!—生成的web.xml文件放在build/appName/WEB-INF/-->
<deploymentdescriptor validateXML="true"
servletspec="2.3" sessiontimeout="10"
destdir="${webapp.target}/WEB-INF" distributable="false"
displayname="${ant.project.name}">
<configParam name="httpPort" value="${http.port}"/>
<configParam name="httpsPort" value="${https.port}"/>
<configParam name="daoType" value="${dao.type}"/>
<configParam name="security" value="${security.mode}"/>
</deploymentdescriptor>
<jsptaglib validateXML="true"
description="Custom tag library for this application"
shortName="${webapp.name}" filename="${webapp.name}.tld"/>
<strutsconfigxml validateXML="true" version="1.2"/>
<strutsvalidationxml/>
</webdoclet>
</target>
图表 1引用一张网友发表的非常直观的使用说明图
Ø XDoclet 中的合并点
在 XDoclet 的文档中,您会非常频繁地看到术语 合并点(merge point)和 合并文件(merge file)。合并文件是文本文件,您可以把它合并到 XDoclet 生成代码的指定位置——“合并点”上(由模板指定)。可以用合并文件来包含静态文本(例如代码片断和 XML 片断),这些文本可能很难或者不能用 XDoclet 的能力生成。例如,在示例代码的 metadata/web 目录下,您会找到这些文件。在代码生成期间,可以用到这些文件合并配置文件的一部分[引用]。
ØXDoclet中的模板
XDoclet使用代码模板来生成代码。模板(template)是你想生成文件的原型。模板里使
用一些XML标签来指导模板引擎如何根据输入类以及它们的元数据来调整代码的生成。
模板有点像JSP文件。它们都包含文件和XML标签,生成输出文件时XML标签会被解析,
然后生成文本并显示在XML标签所处的位置上。除了以XDt为命名空间打头的XML标签
会被XDoclet引擎解析以外,其余的XML标签XDoclet会忽略不管。
Ø AppFuse中生成Action类的XDoclet模板
public final class <XDtClass:className/>Action extends BaseAction {
public ActionForward cancel(ActionMapping mapping, ActionForm form,HttpServletRequest request,
HttpServletResponse response)
throws Exception {
return search(mapping, form, request, response);
}
public ActionForward delete(ActionMapping mapping, ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
if (log.isDebugEnabled()) {
log.debug("Entering 'delete' method");
}
ActionMessages messages = new ActionMessages();
<XDtClass:className/>Form <XDtForm:classNameLower/>Form = (<XDtClass:className/>Form) form;
// Exceptions are caught by ActionExceptionHandler
Manager mgr = (Manager) getBean("manager");
mgr.removeObject(<XDtClass:className/>.class, new Long(<XDtForm:classNameLower/>Form.getId()));
messages.add(ActionMessages.GLOBAL_MESSAGE,
new ActionMessage("<XDtForm:classNameLower/>.deleted"));
// save messages in session, so they'll survive the redirect
saveMessages(request.getSession(), messages);
return search(mapping, form, request, response);
}
… …
}
Ø AppFuse中自动生成的对应Action类
public final class PersonAction extends BaseAction {
public ActionForward cancel(ActionMapping mapping, ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
return search(mapping, form, request, response);
}
public ActionForward delete(ActionMapping mapping, ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
if (log.isDebugEnabled()) {
log.debug("Entering 'delete' method");
}
ActionMessages messages = new ActionMessages();
PersonForm personForm = (PersonForm) form;
// Exceptions are caught by ActionExceptionHandler
Manager mgr = (Manager) getBean("manager");
mgr.removeObject(Person.class, new Long(personForm.getId()));
messages.add(ActionMessages.GLOBAL_MESSAGE,
new ActionMessage("person.deleted"));
// save messages in session, so they'll survive the redirect
saveMessages(request.getSession(), messages);
return search(mapping, form, request, response);
}
… …
}
posted @
2006-11-05 09:00 xzc 阅读(442) |
评论 (0) |
编辑 收藏
XDoclet起步
XDoclet是一个代码生成工具,它可以把你从Java开发过程中繁重的重复劳动中解脱出来。XDoclet可以让你的应用系统开发的更加快速,而你只要付比原先更少的努力。你可以把你手头上的冗长而又必需的代码交给它帮你完成,你可以逃脱“deployment descriptor地狱”,你还可以使你的应用系统更加易于管理。而你所要做的,只不过是在你的注释里,多加一些类javadoc属性。然后,你会惊讶于XDoclet为了做到的一切。
讨论XDoclet,有一点比较容易产生混淆,那就是XDoclet不但是一系统的代码生成应用程序,而且它本身还是一个代码生成框架。虽然每个应用系统的细节千变万化(比如EJB代码生成和Struts代码生成是不一样的,而JMX代码生成又是另一番景象),但这些代码生成的核心概念和用法却是类似的。
在这一章里,我们将会看到渗透到所有XDoclet代码生成程序当中的XDoclet框架基础概念。但在之前,我们先从一个例子入手。
2.1 XDoclet in action
每一个程序员都会认识到,他们的程序永远也不会完成。总会有另一些的功能需要添加,另一些的BUG需要修正,或者需要不断的进行重构。所以,在代码里添加注释,提醒自己(或者其他的程序员)有哪些任务需要完成已成为一个共识。
如何来跟踪这些任务是否完成了呢?理想情况下,你会收集整理出来一个TODO任务列表。在这方面,XDoclet提供了一个强大的TODO生成器,来帮助你完成这个任务。这是一个把XDoclet引入项目的好机会。
2.1.1 一个公共的任务
假设你正在开发一个使用了勺子的类。
public class Matrix {
// TODO – 需要处理当没有勺子的情况
public void reload() {
// ...
Spoon spoon = getSpoon();
// ...
}
}
理想情况下,你在下一次阅读这段代码的时候,你会处理这个“空勺子”(null spoon)的问题。但如果你过了很久才回来看这段代码,你还会记得在这个类里还有一些工作要做吗?当然,你可以在你的源码里全局搜索TODO,甚至你的集成开发环境有一个内建的TODO列表支持。但如果你想把任务所在的类和方法也标注出来的话,XDoclet可以是另一种选择。XDoclet可以为你的项目生成一个TODO报表。
2.1.2 添加XDoclet标签
为了把你的TODO项目转换成另一种更加正式的格式,你需要对代码进行一些细微的改动。如下所示:
public class Matrix {
/** @todo 需要处理当没有勺子的情况 */
public void reload() {
// ...
}
}
这里加入了一个XDoclet需要的类javadoc标签。XDoclet会使用这些标签标记的信息,以及在这种情况下标签所处的类和方法,来生成TODO报表。
2.1.3 与Ant集成
要生成TODO报表,你需要确保在你的机器上正确安装了XDoclet。
在Ant任务里,最少要包含一个目标(例如init目标)定义<documentdoclet>任务,这是一个Ant自定义任务,例如:
<taskdef name=”documentdoclet”
classname=”xdoclet.modules.doc.DocumentDocletTask”
classname=”xdoclet.lib.path” />
这个<documentdoclet>任务是XDoclet核心代码生成应用程序中的一个。
现在,你可以在Ant构建文件中加入一个todo目标调用这个任务来生成TODO报表,如:
<target name=”todo” depends=”init”>
<documentdoclet destdir=”todo”>
<fileset dir=”${dir.src}”>
<include name=”**/*.java” />
</fileset>
<info/>
</documentdoclet>
</target>
<info>子任务会遍历你的源文件,查找todo标签,并在todo子目录下生成HTML格式的TODO报表。
2.1.4 创建一个更加职业化的TODO报表
XDoclet生成的TODO报表可以有一个更加职业化的外表。报表会列出一个概览,显示在哪个包哪个类里有todo项(以及todo项的个数)。Todo项可以跟在方法、类和域上,从报表上可以清楚的区别它们。类级别的todo项会标注class,方法级别的todo项会在方法签名上标注M。构造函数和域相关的todo项也会进行相似的标注。
这个任务看起来很简单,但考虑到你所需要做的只是在注释上添加一些格式化的@todo标签,相对于那种只有人才可以理解的无格式的松散的注释,这种标签是机器可读的,也更容易编程处理。生成的输出也更容易阅读并且更加的商业化。
2.2 任务和子任务
生成todo报表,只是XDoclet可以完成的事情当中的冰山一角。当初,XDoclet因为可以自动生成EJB繁杂的接口和布署描述文件而声名鹊起。然而,现在的XDoclet已经发展成了一个全功能的、面向属性的代码生成框架。J2EE代码生成只是XDoclet的一个应用方面,它可以完成的任务已经远远超越了J2EE和项目文档的生成。
2.2.1 XDoclet 任务
到现在为止,我们一直在讨论使用XDoclet生成代码,但事实上,更确切的说法应该是,我们使用XDoclet的一个特定的任务来生成代码,比如<ejbdoclet>。每一个XDoclet任务关注于一个特定的领域,并提供这个领域的丰富的代码生成工具。
[定义:任务(Tasks)是XDoclet里可用的代码生成应用程序的高层概念。]
在XDoclet里,目前已有如下所示的七个核心任务。
<ejbdoclet>:面向EJB领域,生成EJB、工具类和布署描述符。
<webdoclet>:面向Web开发,生成serlvet、自定义标签库和web框架文件。
<hibernatedoclet>:Hibernate持续,配置文件、Mbeans
<jdodoclet>:JDO,元数据,vender configuration
<jmxdoclet>:JMX,MBean接口,mlets,配置文件。
<doclet>:使用用户自定义模板来生成代码。
<documentdoclet>:生成项目文件(例如todo列报表)
这其中,<ejbdoclet>最常用,并且很多项目也仅仅使用XDoclet来进行EJB代码生成。<webdoclet>是其次一个常用的代码生成任务。当然,在一个项目中同时使用几个XDoclet任务是可能的(并且也是推荐的),但在这些任务之间是完全独立的,它们彼此之间并不能进行直接的交流。
2.2.2 XDoclet子任务
XDoclet的任务是领域相关的,而在某个特定领域的XDoclet任务,又由许许多多紧密耦合在一起的子任务组成的,这些子任务每个都仅仅执行一个非常特定和简单的代码生成任务。
[定义:子任务(subtasks)是由任务提供的单目标的代码生成过程]
任务提供子任务执行时的上下文,并且把这些相关的子任务组织管理了起来。任务会依赖这些子任务来生成代码。在一个任务当中调用多个子任务来协同完成各种各样比较大型的代码生成任务是非常常见的。比如,在开发EJB时,你可能想要为每一个bean生成一个home接口,一个remote接口以及ejb-jar.xml布署描述符文件。这就是在<ejbdoclet>任务的上下文环境中的三个独立的代码生成子任务。
子任务可以随意的组合排列,以满足项目代码生成的需要。某个XDoclet任务包含的子任务经常会共享功能和在源文件中使用相同的XDoclet标签。这意味着当你开始一个任务的时候,你可以很容易的集成进一个相关的子任务,而不需要很大的改动。
子任务交互
让我们以<ejbdoclet>任务为例,看一下相关的子任务之间是如何进行关联的。假设你正在开发一个CMP(容器管理持久化)实体Bean。你想要使用一些<ejbdoclet>的子任务:
•<deploymentdescriptor>:生成ejb-jar.xml布署描述符文件。
•<localhomeinterface>:生成local home接口。
•<localinterface>:生成local接口。
在执行如上子任务的时候,你需要标记出你的实体Bean的CMP域。当你发布你的bean的时候,你还需要在开发商相关的布署描述符中提供某个特定的关系数据库中的特定表和列与你的CMP实体Bean的映射关系。XDoclet可以让你在原先已存在的CMP XDoclet属性基础上再加上一些关系映射属性,然后,你就可以在任务中加入一个开发商相关的子任务(例如<jboss>或者<weblogic>)来生成布署描述符文件。XDoclet提供了几乎所有的应用服务器的支持,你只需要一些初始化的小改动,就可以进行这些应用服务器相关的代码生成了。
但那只是冰山一角。你还可以使用<entitycmp>子任务为为你的bean生成一个实体bean接口的实现子类。如果你使用<valueobject>子任务来为了你的bean生成值对象,<entityemp>子任务还会为你的值对象生成方法的实现代码。
觉得不可思议了吧。可惜XDoclet没有提供<cupofcoffee>子任务,要不然我们可以喝杯咖啡,休息一下啦。
这里不是想向你介绍<ejbdoclet>所有的子任务或者<ejbdoclet>可以完成的所有代码生成功能,而仅仅是想向你展示一下任务的子任务之间是如何工作在一起的。一旦你开始并熟悉了一个XDoclet 子任务,熟悉另一个子任务会变得非常简单- 那种每个子任务都是孤立的相比,使用这种可以相互协作的子任务,开发成本会显著的降低,效果也更加的立竿见影。
2.3 使用Ant执行任务
XDoclet“嫁”给了Ant。XDoclet任务就是Ant的自定义任务,除此以外,没有其他运行XDoclet任务的方法。所幸的是,Ant已经成为了Java构建工具事实上的标准,所以这不算什么限制。事实上,反过来,XDoclet与Ant的这种“亲密”关系使得XDoclet可以参与到任何Ant构建过程当中去。
2.3.1 声明任务
XDoclet并没有和Ant一起发布,所以如果你想要使用XDoclet的话,就需要单独的下载和安装。在使用任何一个XDoclet的任务之前,你首先需要在使用Ant的<taskdef>任务来声明它。例如:
<taskdef name=”ejbdoclet”
classname=”xdoclet.modules.ejb.EjbDocletTask”
classpathref=”xdoclet.lib.path”/>
如果你熟悉Ant的话,你就会知道这段代码是告诉Ant加载<ejbdoclet>的任务定义。当然,你也可以以你喜欢的任何方式来命名这个自定义任务,但最好还是遵守标准的命名规律以免发生混淆。classname和classpathref属性告诉Ant到哪里去找实现这个自定义任务的XDoclet类。如果你想使用其他的XDoclet任务,就必须要类似这样首先声明这个任务。
一般共通的做法是,把所有需要使用的XDoclet任务都放在Ant的一个目标里声明,这样在其他的目标里如果需要使用这些任务,只要depends这个任务就可以了。你可能已经在Ant的构建文件里包含了init目标,这就是放置XDoclet任务声明的好地方(当然如果你没有,你也可以建一个)。下面的例子就是在一个init目标里加入了<ejbdoclet>和<webdoclet>的声明:
<target name=”init”>
<taskdef name=”documentdoclet”
classname=”xdoclet.modules.doc.DocumentDocletTask”
classpathref=”xdoclet.lib.path” />
<taskdef name=”ejbdoclet”
classname=”xdoclet.modules.ejb.EjbDocletTask”
classpathref=”xdoclet.lib.path” />
<taskdef name=”webdoclet”
classname=”xdoclet.modules.web.WebDocletTask”
classpathref=”xdoclet.lib.path” />
</target>
现在,任务声明好了,XDoclet“整装待发”。
2.3.2 使用任务
你可以在任何目标里使用声明好的任务。在任务的上下文环境里,可以调动相关的子任务。让我们看一个例子,这个例子调用了<ejbdoclet>任务。不要担心看不懂语法的细节,现在你只需要关心一些基础概念就可以了。
<target name=”generateEjb” depends=”init”>
<ejbdoclet destdir=”${gen.src.dir}”>
<fileset dir=”${src.dir}”>
<include name=”**/*Bean.java”/>
</fileset>
<deploymentdescriptor destdir=”${ejb.deployment.dir}”/>
<homeinterface/>
<remoteinterface/>
<localinterface/>
<localhomeinterface/>
</ejbdoclet>
</target>
把任务想像成一个子程序运行时需要的一个配置环境(记住,子任务才是真正进行代码生成工作的)。当调用一个子任务时,子任务从任务继承上下文环境,当然,你也可以根据需要随意的覆盖这些值。在上面的例子里,因为<deploymentdescriptor>子任务生成的布署描述符文件和其他生成各种接口的子任务生成的Java源文件需要放在不同的位置,所以覆盖了destdir的属性值。布署描述符文件需要放在一个在打包EJB JAR文件的时候可以容易包含进来的地方,而生成的Java代码则需要放置在一个可以调用Java编译器进行编译的地方。需要这些子任务之间是紧密关联的,但只要你需要,你可以有足够的自主权控制任务的生成环境。
<fileset>属性同样被应用到所有的子任务。这是一个Ant的复杂类型(相对于文本和数值的简单类型),所以以子元素的方式在任务中声明。不要把它和子任务混为一谈。当然,如果你想在某个子任务中另外指定一个不同的输入文件集,你也可以在这个子任务中放置一个<fileset>子元素来覆盖它。
子任务的可配置选项远远不止这些。我们会在下一章继续介绍所有的任务和子任务,以及常用的配置选项。
2.4 用属性标注你的代码
可重用的代码生成系统需要输入来生成感兴趣的输出。一个解析器生成器也需要一个语言描述来解析生成解析器。一个商务对象代码生成器需要领域模型来知道要生成哪些商务对象。XDoclet则需要Java源文件做为输出来生成相关的类或者布署/配置文件。
然而,源文件可能并没有提供代码生成所需要的所有信息。考虑一个基于servlet的应用,当你想生成web.xml文件的时候,servlet源文件仅可以提供类名和适当的servlet接口方法。其他的信息比如URI pattern映射、servlet需要的初始化参数等信息并没有涵盖。显而易见,如果class并没有提供这些信息给你,你就需要自己手动在web.xml文件时填写这些信息。
XDoclet当然也不会知道这些信息。幸运的是,解决方法很简单。如果所需信息在源文件时没有提供,那就提供它,做法就是在源文件里加入一些XDoclet属性。XDoclet解析源文件,提取这些属性,并把它们传递给模板,模板使用这些信息生成代码。
2.4.1 剖析属性
XDoclet属性其实就是javadoc的扩展。它们在外表上和使用上都有javadoc属性一样,可以放置在javadoc文档注释里。文档注释以/**开始,*/结尾。下面是一个简单的例子:
/**
* 这是一段javadoc注释。
* 注释可以被分解成多行,每一行都以星号 开始。
开始。
*/
在注释里的所有文本都被视为javadoc注释,并且都能够被XDoclet访问到。注释块一般都与Java源文件中的某个实体有关,并紧跟在这个实体的前面。没有紧跟实体的注释块将不会被处理。类(或者接口)可以有注释块,方法和域也可以有自己的注释块,比如:
/**
* 类注释块
*/
public class SomeClass {
/** 域注释块 */
private int id;
/**
* 构造函数注释块
*/
public SomeClass() {
// ...
}
/**
* 方法注释块
*/
public int getId() {
return id;
}
}
注释块分成两部分:描述部分和标签部分。当遇到第一个javadoc标签时,标签部分开始。Javadoc标签也分成两部分:标签名和标签描述。标签描述是可选的,并且可以多行。例如:
/**
* 这是描述部分
* @tag1 标签部分从这里开始
* @tag2
* @tag3 前面一个标签没有标签描述。
* 这个标签有多行标签描述。
*/
XDoclet使用参数化标签扩展了javadoc标签。在XDoclet里,你可以在javadoc标签的标签描述部分加入name=”value”参数。这个微小的改动大大增强了javadoc标签的表达能力,使得javadoc标签可以用来描述复杂的元数据。下面的代码显示了使用XDoclet属性描述实体Bean方法:
/**
* @ejb.interface-method
* @ejb.relation
* name=”blog-entries”
* role-name=”blog-has-entries”
* @ejb.value-object
* compose=”com.xdocletbook.blog.value.EntryValue”
* compose-name=”Entry”
* members=”com.xdocletbook.blog.interfaces.EntryLocal”
* members-name=”Entries”
* relation=”external”
* type=”java.util.Set”
*/
public abstract Set getEntries();
参数化标签允许组合逻辑上相关联的属性。你可以加入描述这个类的元信息,使得这个类的信息足够生成代码。另外,程序员借由阅读这样的元信息,可以很快的理解这个类是如何使用的。(如果这个例子上的元信息你看不懂,不要担心,在第4章里,我们会学到EJB相关的标签以及它们的涵意。)
另外,请注意上面的例子中,所有的标签名都以ejb开头。XDoclet使用namespace.tagname的方式给标签提供了一个命名空间。这样做除了可以跟javadoc区别开来以外,还可以把任务相关的标签组织起来,以免任务之间的标签产生混淆。
2.5 代码生成模式
XDoclet是一种基于模板的代码生成引擎。从高层视图上来看,输出文件其实就是由解析执行各式各样的模板生成出来的。如果你理解了模板以及它所执行的上下文环境,就可以确切的认识到,XDoclet可以生成什么,不可以生成什么。如果你正在评估XDoclet平台,理解这些概念是非常重要的。要不然,你可能会错过XDoclet的许多强大的功能,也可能会被XDoclet的一些限制感到迷惑。
XDoclet运行在在Ant构建文件环境中,它提供了Ant自定义任务和子任务来与XDoclet引擎交互。任务是子任务的容器,子任务负责执行代码生成。子任务调用模板。模板提供了你将生成代码的饼干模子。XDoclet解析输入的源文件,提取出源文件中的XDoclet属性元数据,再把这些数据提供给模板,驱动模板执行。除此之外,模板还可以提供合并点(merge points),允许用户插入一些模板片断(合并文件merge files)来根据需要定制代码生成。
2.5.1 模板基础
XDoclet使用代码模板来生成代码。模板(template)是你想生成文件的原型。模板里使用一些XML标签来指导模板引擎如何根据输入类以及它们的元数据来调整代码的生成。
[定义:模板(template)是生成代码或描述文件的抽象模视图。当模板被解析的时候,指定的细节信息会被填入。]
模板一般情况下会有一个执行环境。模板可能应用在一个类环境(转换生成transform generation),也有可能应用在一个全局环境(聚集生成aggregate generation)。转换生成和聚集生成是XDoclet的两种类型的任务模式,理解它们之间的区别对于理解XDoclet是非常重要的。
当你使用XDoclet生成布置描述符文件时,你使用的是聚集生成。布置描述符文件并不仅仅只与一个类相关,相反,它需要从多个类里聚集信息到一个输入文件。在这种生成模式里,解析一次模板只会生成一个输出文件,不管有多少个输入文件。
在转换生成模式里,模板遇到每一个源文件就会解析一次,根据该文件类的上下文环境生成输出。这种生成模式会为每一个输入文件生成一个输出文件。
转换生成模式的一个很好的例子是生成EJB的local和remote接口。显然,接口是和Bean类一一相关的。从每一个类里提取信息(类以及它的方法、域、接口以及XDoclet属性等信息)转换出接口。除此以外,不需要其他的信息。
从实现里提取出接口似乎有点反向。如果你手写程序的话,一般来说会先定义一个接口,然后再写一个类来关现它。但XDoclet做不到,XDoclet不可能帮你实现一个已有接口,因为它不可能帮你生成你的业务逻辑。当然,如果业务逻辑可以从接口本身得到(比如JavaBean的get/set访问器)或者使用XDoclet属性声明好,那么生成业务逻辑代码来实现一个接口也不是不可能。但一般情况下,这样做不太现实。相比而言,提供一个实现,并描述接口与这个实现之间的关联就容易多了。
聚集生成和转换生成主要区别在它们的环境信息上。即使一个代码生成任务中生成一个Java文件,一般也不常用聚集生成,因为生成一个Java类还需要一些重要信息如类所处的包以及你想生成的类名,在这种环境下是无法提供的。如果一定要使用聚集生成的话,那就需要在另一个单独的地方提供好配置信息了。
2.5.2 模板标签
在还没见到模板长啥样子之前,我们已经比较深入的认识它了。那模板文件究竟长啥样子呢?它有点像JSP文件。它们都包含文件和XML标签,生成输出文件时XML标签会被解析,然后生成文本并显示在XML标签所处的位置上。除了以XDt为命名空间打头的XML标签会被XDoclet引擎解析以外,其余的XML标签XDoclet会忽略不管。下面的代码片断显示了XDoclet模板的“经典造型”:
public class
<XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/></XDtClass:classOf>
Extends Observabe {
static <XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/></XDtClass:classOf>
_instance = null;
public static <XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/></XDtClassOf>
getInstance() {
if (_instance == null) {
_instance =
new <XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/>
</XDtClass:classOf>();
}
return _instance;
}
}
研究一下这个模板,你会发现,它生成的是一个类定义。这个类里定义了一个静态变量instance,并且使用一个静态方法来控制这个静态文件的访问。借助Java语法,你可以很容易的推断出那些XDoclet模板标签的目录是生成类名,虽然对于这个标签如何工作你还并不是很了解。
即使你从没打算过要自己写模板,但理解模板是如何被解析运行的还是很有必要的。迟早你会调用到一个运行失败的XDoclet任务,没有产生你所期望的输出,那么最快捷的找出原因的方法就是直接检查模板文件,看看是哪里出了问题。
让我们看一下生成静态域定义的片断:
static <XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/></XDtClass:classOf>
_instance = null;
在XDoclet的眼里,这段模板代码很简单,那就是:
static <tag/> _instance = null;
XDoclet解析执行标签,如果有输出的话,把输入置回到文本里去。有些标签会执行一些运算,把输出放回到一个流里。这样的标签称之为内容标签(content tags),因为它们产生内容。
另一种类型的标签称之为BODY标签。BODY标签在开始和结束标签之间存在文本。而BODY标签强大就强大在这些文本自己也可以是一断可以由外围标签解析的模板片断。比如在上面的例子里,XDtClass:classOf标签,它们的内容就是模板片断:
<XDtEjbFacade:remoteFacadeClass/>
classOf标签解析这段模板,提取出全限制的内容,然后剃除前面的包面,只输出类名。BODY标签并不总是会解析它的内容,在做这件事之前,它们会事先检查一些外部判断条件(比如检查检查你正在生成的是一个接口还是一个类)。这里标标签称之为条件标签(conditional tags)。还有一些BODY标签提供类似迭代的功能,它的内容会被解析多次。比如一个标签针对类里的每一个方法解析一次内容。
XDoclet标签提供了许多高层次的代码生成功能,但是有时候,它们可能显得不够灵活,或者表达能力满足不了你的需要。这时候,相对于另外开发一套通用功能的模板引擎相比,你可以选择扩展XDoclet模板引擎。你可以使用更具表述能力、功能更加强大的Java平台开发你自己的一套标签。
2.6 使用合并定制
代码生成系统之所以使用的不多,主要原因就在于它们往往只能生成一些死板的、不够灵活的代码。大多数代码生成系统不允许你改动它们生成的代码;如果,如果这个系统不够灵活,你所能做到的最好的扩展就是应用继承扩展生成的代码,或者使用一些共通的设计模式(比如Proxy和Adaptor)来满足你的需要。无论如此,这都不是产生你想生成的代码的好办法。代码生成器最好能做到所生成即所得WYGIWYG(what you generate is what you get),来取代你需要花费大量的时间来粉饰生成出来的并不满足要求的代码。所以,对于代码生成器来说,支持灵活的定制,是生成能够完全满足要求的代码的前提条件。
XDoclet通过合并点(merge points)支持定制——合并点是在模板文件定义里允许运行时插入定制代码的地方。有时候,合并点甚至可以影响到全局代码的生成,不但允许你添加一些定制内容,还可以从根本上改变将要生成出来的东西。
[定义:合并点(Merge points)是模板预先定义的允许你在代码生成的运行时加入定制内容的扩展点]
让我们研究一段从XDoclet源代码里摘取出来的模板代码。在为实体Bean生成主键的模板末尾,定义了这样一个合并点:
<XDtMerge:merge file=”entitypk-custom.xdt”></XDtMerge:merge>
如果你在你的merge目录下创建了一个名为entitypk-custom.xdt文件,那么这个模板文件的内容将会在这个合并点被包含进来。你的定制可以执行高层模板可以执行的所有强大功能,可以进行所有模板可以进行的运算(包括定义自定义标签,定义它们自己的合并点)。
上面的这种合并点,为所有的类环境使用了同一个文件。当然,也可以为每一个类环境使用不同的合并文件。如果你不想定制全部的类文件,或者你不想为了某些改动而重写模板的时候,这会很有用。不管动机是什么,逐类的合并点很容易识别出来:他们会在名字里包含一个XDoclet的逐类标记{0}。这里有一个生成ejb-jar.xml文件里的安全角色引用的例子:
<XDtMerge:merge file=”ejb-sec-rolerefs-{0}.xml”>
<XDtClass:forAllClassTags tagName=”ejb:security-role-ref”>
<security-role-ref>
<role-name>
<XDtClass:classTagValue
tagName=”ejb:security-roleref”
paramName=”role-name”/>
</role-name>
<role-link>
<XDtClass:classTagValue
tagName=”ejb:security-roleref”
paramName=”role-link”/>
</role-link>
</security-role-ref>
</XDtClass:forAllClassTags>
</XDtMerge:merge>
这段模板会遍历工程里的所有Bean。对于每一个Bean,XDoclet先从Bean的文件名里提取出Bean名,然后替换{0},再根据替换后的文件名去寻找合并文件。例如,如果你有一个名为BlogFacadeBean的Bean,XDoclet会尝试寻找一个名为ejb-src-rolerefs-BlogFacade.xml的合并文件。
如果找不到这个合并文件,则这个<merge>标签的内容模板会被解析。这意味着合并点不仅可以提供定制内容,还可以在一个模板文件里定义一个替换点,当定制内容不存在的时候使用替换点里的内容。不是所有的XDoclet任务都提供了有替换内容的合并点,一般来说,它们更倾向于只提供一个简单的合并点,仅仅当合并文件存在的时候解析并导入合并文件的内容。这取决于任务的开发者觉得哪种合并点更符合他的要求。
还有一点没有介绍到的是XDoclet如何定位合并文件,每一个XDoclet任务或者子任务都会提供一个mergeDir属性,这个属性用于设置你存放合并文件的目录。
posted @
2006-11-05 08:34 xzc 阅读(364) |
评论 (0) |
编辑 收藏posted @
2006-11-05 08:33 xzc 阅读(261) |
评论 (0) |
编辑 收藏XDoclet是生成配置文件的强有力的工具,在使用Spring框架时,手动编写Spring配置文件极其繁琐,而且容易遗漏,利用XDoclet即可轻松生成配置文件。
XDoclet支持的Spring方法注入包括:ref,list,name和value。遗憾的是,在某个项目中,我需要注入一个包含Bean引用的List:
public void setHandlers(List handlers) {
...
}
然后,XDoclet并不支持元素为引用类型的List,倘若使用下列注释:
/**
* @spring.property list="articleHandler,imageHandler"
*/
public void setHandlers(List handlers) {
...
}
生成的配置文件如下:
<property name="handlers">
<list>
<value>articleHandler</value>
<value>imageHandler</value>
</list>
</property>
毫无疑问,在Spring启动时,一个ClassCastException将被抛出,因为无法将String类型转化为我们自定义的Handler引用类型。
幸运的是,XDoclet良好的可扩展性使我们能够轻松扩展需要的配置,甚至不需要我们利用XDoclet提供的API编写代码。XDoclet提供一种XML结构的模版语言来生成配置文件,对于Spring配置文件,对应的XML配置文件在xdoclet-spring-module-1.2.3.jar/xdoclet/modules/spring/resources/spring_xml.xdt中。
解开jar包,修改spring_xml.xdt,增加如下XML片断(红色部分):
<XDtMethod:forAllMethods superclasses="true">
<XDtMethod:ifHasMethodTag tagName="spring.property">
<property name="<XDtMethod:propertyName/>">
<XDtMethod:ifHasMethodTag tagName="spring.property" paramName="value">
<value><XDtMethod:methodTagValue tagName="spring.property" paramName="value"/></value>
</XDtMethod:ifHasMethodTag>
<XDtMethod:ifHasMethodTag tagName="spring.property" paramName="ref">
<ref bean="<XDtMethod:methodTagValue tagName="spring.property" paramName="ref"/>"/>
</XDtMethod:ifHasMethodTag>
<XDtMethod:ifHasMethodTag tagName="spring.property" paramName="list">
<list>
<XDtMethod:forAllMethodTagTokens tagName="spring.property" paramName="list">
<value><XDtMethod:currentToken/></value>
</XDtMethod:forAllMethodTagTokens>
</list>
</XDtMethod:ifHasMethodTag>
<XDtMethod:ifHasMethodTag tagName="spring.property" paramName="list.ref">
<list>
<XDtMethod:forAllMethodTagTokens tagName="spring.property" paramName="list.ref">
<ref bean="<XDtMethod:currentToken/>"/>
</XDtMethod:forAllMethodTagTokens>
</list>
</XDtMethod:ifHasMethodTag>
</property>
</XDtMethod:ifHasMethodTag>
</XDtMethod:forAllMethods>
注意红色部分的代码,我们仿照list,增加一个list.ref来实现引用类型的List。
现在,修改注释如下:
/**
* @spring.property list.ref="articleHandler,imageHandler"
*/
public void setHandlers(List handlers) {
...
}
备份好原有的xdoclet-spring-module-1.2.3.jar,然后将修改后的目录打包:
jar cvf xdoclet-spring-module-1.2.3.jar .
替换原来的xdoclet-spring-module-1.2.3.jar,运行XDoclet,顺利生成预期配置:<property name="handlers">
<list>
<ref bean="articleHandler"/>
<ref bean="imageHandler"/>
</list>
</property>
类似的,我们还可以增加XDoclet对Map注入的支持。
posted @
2006-11-05 08:32 xzc 阅读(599) |
评论 (0) |
编辑 收藏本文的目的是让你用最短的时间了解xdoclet技术,本人并未对其作深入的研究,若理解有误请指正。
XDoclet是一个开源项目,可以从这里得到他:http://xdoclet.sourceforge.net/xdoclet/ 。
XDoclet可以通过你在java源代码中的一些特殊的注释信息,自动为你生成配置文件、源代码等等,例如web、ejb的部署描述文件、为你生成struts的struts-config.xml配置文件、javascript校验等。
正如《XDoclet in Action》部分章节中文版 一文中所说的“当初,XDoclet因为可以自动生成EJB繁杂的接口和布署描述文件而声名鹊起。然而,现在的XDoclet已经发展成了一个全功能的、面向属性的代码生成框架。J2EE代码生成只是XDoclet的一个应用方面,它可以完成的任务已经远远超越了J2EE和项目文档的生成。”
目前的版本可以为web、ejb、struts、webwork、hibnaate、jdo、jmx等等生成描述文件、源码等,XDoclet提供了ant的任务target支持,完全通过ant来完成任务。
展开XDoclet的发布包,samples目录下有直接可以运行的ant脚本文件。这里以web应用target为例,说明XDoclet能为我们作些什么。
下面是samples中一个struts的action代码:
import javax.servlet.http.HttpServletResponse;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
/**
* Simple class to test Jakarta Struts generation (Jakarta Struts 1.2 beta 2 only).
*
* @struts.action
* path="/struts/foo"
*
* @struts.action-forward
* name="success"
* path="/struts/getAll.do"
* redirect="false"
*/
public final class StrutsAction extends Action
{
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
{
return mapping.findForward("success");
}
}
注意红色的注释部分,注意执行完ant脚本后,将为你生成struts-config.xml中相关的配置项,以下是脚本执行后生成的struts-config.xml文件中的配置:
<action-mappings>
<action
path="/struts/foo"
type="test.web.StrutsAction"
unknown="false"
validate="true"
>
<forward
name="success"
path="/struts/getAll.do"
redirect="false"
/>
</action>
至此一点我们便可以了解XDoclet是如何工作的了,想想struts中的vaild配置文件、struts-config配置文件等需要我们大量的手工工作,如果再写代码的时候把相关的元数据信息写在注释里,XDoclet将为我们自动完成这些工作,当然像 @struts.action ?#162;@struts.action-forward 等这些特定的注释标签需要去查XDoclet的相关文档了,像前面说的一样,Xdoclet对目前流行的多种框架、技术都提供了相关的支持。相信在一些情况下,Xdoclet会大大提高我们的工作效率的,了解更多信息请参考Xdoclet网站http://xdoclet.sourceforge.net/xdoclet/ 。
posted @
2006-11-05 08:31 xzc 阅读(333) |
评论 (0) |
编辑 收藏
|
发现多功能的模板驱动的代码生成器

|

|
|
|
级别: 初级
Sing Li
, 作者, Wrox Press
2004 年 11 月 05 日
开放源代码的 XDoclet 代码生成引擎,是许多领先的 Java 框架不可缺少的组成部分,常常被用作面向属性的编程和持续集成的引擎。但是 XDoclet 还有一些不太惹人注目的地方:对初级开发人员来说,它太难掌握、太难精通。在这篇文章中,流行作者 Sing Li 以 XDoclet 为对象,揭示了其内部简单却优雅的设计,使您能够理解这项技术,并将它应用在实践当中。
XDoclet 能够很容易成为您的 Java 编程工具箱中的一个更加通用的跨技术代码生成工具。不幸的是,开发人员经常忽视 XDoclet 的一般用途,只有将它捆绑在大型开发框架或者 IDE 中,作为其中的一个隐藏元素时,才会用到它。人们常常认为很难将 XDoclet 应用在定制解决方案上。这篇文章的目的就是要消除这个迷惑,把 XDoclet 从常见的复杂陷阱中解脱出来,并向您展示了如何能够利用这个代码生成引擎。
我会用一个实际的例子演示 XDoclet 的用途,该例子将接收一个 POJO(plain old Java object),并用 XDoclet 生成完整 Web 应用程序的全部文件,这些文件是把数据输入关系数据库所必需的。该示例使用了 XDoclet 的 自定义模板代码生成功能,以及它对 Hibernate 对象关系映射工具、Struct Web 应用程序框架和应用程序服务器的内部支持。(请参阅 参考资料)。
智能代码生成器
XDoclet 的核心功能是根据以下组合来生成代码的(或者生成其他配置/数据文件):
- 进行特殊标记的 Java 源文件。
- 预先定义的模板。
与其他基于模板的代码生成技术(例如 Velocity;请参阅 参考资料)相比,XDoclet 具有以下独特优势:
- XDoclet 与 Apache Ant(请参阅 参考资料)紧密集成,从而提供了高度自动化的操作。
- 把控制代码生成和模板处理的 XDoclet 标签作为内联注释嵌入到 Java 源代码文件中。这消除了同步多个相关文件和控制文件的需要。
- XDoclet 的内置 Java 解析器使用它对 Java 代码结构的深入理解,为输入的 Java 代码建立内部 结构模型。该结构模型又经常被叫作 元数据(metadata),因为它包含与关联代码有关的数据。
- XDoclet 的模板生成逻辑拥有对输入 Java 代码的内部结构模型的完全访问权。
接下来,我将进一步研究 XDoclet 是如何工作的,以帮助您理解这些特性。
XDoclet 操作
图 1 显示了 XDoclet 要求的输入和生成的输出。
图 1. XDoclet 黑盒子

您可以看到,包含嵌入式 XDoclet 标签的 Java 源代码是系统的输入。在 Apache Ant 的驱动下,XDoclet 处理输入的代码,生成的输出文本文件可以是 Java 源代码、HTML 页面、XML 文件等。为了处理输入,XDoclet 需要使用模板(保存在 .xdt 文件中)和标签处理器(用 Java 编码)。XDoclet 把模板和标签处理器打包成“模块”,不同的“模块”处理不同的问题域。
XDoclet 生成的结构模型
XDoclet 对包含嵌入式 XDoclet 标签的输入 Java 源代码进行解析,并为代码建立非常详细的结构模型。结构模型中的每个元素都代表源代码中的一个 Java 结构。图 2 显示的结构模型,揭示了 XDoclet 跟踪的代码构造和关系。
图 2. XDoclet 的解析的 Java 源代码的内部结构模型

图 2 中的结构模型跟踪类、接口、方法之类的代码构造(模型元素)。该模型还跟踪元素之间的关系,例如继承和接口实现。以内联注释的形式嵌入在源代码中的 XDoclet 标签被解析为模型元素的属性,并被跟踪。
|
|
通用的 Javadoc 引擎
能够理解 Java 代码结构模型的智能代码生成引擎不是什么新概念。实际上,它是 JDK 自带的 Javadoc 工具的运作方式。通过解析带有特殊 Javadoc 标签的 Java 源文件,Javadoc 工具可以为所有 Java 程序的内置结构元素(包括类、接口、字段和方法)生成 HTML 文档。Javadoc 还具有特殊 Java 语言概念方面的知识,例如继承、抽象类、存储类和修饰符。
XDoclet 的诞生,来自这样一个观察:适用于任意代码生成的 Javadoc 的通用版本,在许多编程场合下会极为有用。但是,实际的 Javadoc 源代码不是为通用的代码生成设计的,而只是为了生成 HTML 文档。由于无法重用现有代码,XDoclet 开发小组从头开始重写了引擎,并显著优化了它的性能。
|
|
深入 XDoclet
图 3 显示了 XDoclet 的内部结构,揭示了使其运行的功能块。
图 3. XDoclet 内部的功能块

|
如图 3 所示,Apache Ant 在运行的时候控制着 XDoclet 的配置和操作。XDoclet 解析输入的 Java 源代码,并在内存中生成结构模型。模板引擎通过处理一组模板和标签处理器,生成输出文件。模板和标签处理器可以是内置的,也可以是定制的。在代码生成期间,模板和标签处理器拥有对结构模型的完全访问。
XDoclet 虚假的复杂性
XDoclet 实质上就是一个通用的 Javadoc 引擎(请参阅侧栏, 通用的 Javadoc 引擎)。那么,是什么让它看起来这么复杂呢?答案在于:XDoclet 几乎从未被单独讨论过,而总是藏在其他许多复杂的技术中。图 4 显示了了围绕在 XDoclet 周围的复杂性迷雾(请参阅侧栏 为什么 XDoclet 看起来比实际的要复杂得多)。
| 为什么 XDoclet 看起来比实际的要复杂得多
Apache Ant 自动进行 Java 软件的生成过程。构建管理过程通常是生产项目中更复杂过程中的一部分。构建管理的术语和概念被集成到 Apache Ant 中,而且是理解其操作的先决条件。成熟的 Ant 脚本可能会非常复杂。Ant 的每个新版本,都会引入一些新的特性集,从而进一步增加了复杂性。这形成了 XDoclet 表面的复杂性,因为 XDoclet 需要 Ant 才能执行。 XDoclet 处理的问题领域是复杂性的另一个来源。在发布 XDoclet 的时候,XDoclet 已经可以为 EJB 组件集成、J2EE Web 容器集成、Hibernate 持久性层、Struts 框架、Java 管理扩展(JMX)等生成代码。这些问题领域中的每一个领域都有一大套该领域专用的行话和概念。从这些复杂的问题领域出来的问题,经常主导着 XDoclet 的讨论,这也提高了 XDoclet 表面的复杂性。可能是“只见森林,不见树木”。 |
|
图 4. XDoclet 的复杂耦合

在图 4 中,您可以看到 XDoclet 与以下内容是紧密相关的:
- Apache Ant,它控制着 XDoclet 的操作。XDoclet 是作为一组 Ant 任务存在的,没有 Ant 则不能执行。
- 与生成文件关联的具体问题领域的一些细节。
XDoclet 本身却是惊人地简单,正如下面示例中的工作代码所示的那样。
使用 XDoclet
现在,您可以通过研究我向您提供的数据入口应用程序示例,来观察 XDoclet 的实际工作。(要下载这个示例中使用的 Java 代码、XDoclet 模板和 Ant 脚本,请单击本文顶部或底部的 Code图标,或者请参阅 下载部分。)我们将从检查清单 1 所示的 Java 代码开始,这部分代码表示了一个客户的地址。该地址被编码成 JavaBean 组件,其中的 XDoclet 标签是以黑体字形式显示的:
清单 1. 用 XDoclet 标签标记的 AddressBean.java 源文件
package com.ibm.dw.beans;import java.io.Serializable;/** * @dw.genStrutsAction action="/addAddress.do"* @hibernate.class table="ADDRESS"*/public class AddressBean implements Serializable {private String streetNumber = "";private String street = "";private String city = "";private String country = "";private String postalCode = "";private long id = 0;public AddressBean() {}/** * @dw.genStruts formlabel="Street Number"* @hibernate.property length="10"*/public String getStreetNumber() { return streetNumber;}public void setStreetNumber(String inpStreetNumber) { streetNumber = inpStreetNumber;}/** * @dw.genStruts formlabel="Street"* @hibernate.property length="40"*/public String getStreet() { return street;}public void setStreet(String inpStreet) { street = inpStreet;} ...... more Address bean properties ....../** * @hibernate.id generator-class="native"*/public long getId( ){ return id;}public void setId(long inId) { id = inId;}}
|
在清单 1 中,需要注意的是,要把 XDoclet 标签嵌入到注释中,紧放在相关代码元素(例如字段、方法、接口或类)的前面。在解析源代码时,XDoclet 会为每个标签建立一个属性,并将该属性附加到结构模型的代码元素上。现在,请注意 @dw.genStruts 标签,因为这是在本例中将用到的第一个模板。
生成另外一个 Java 类
对于本例,您需要生成新的 Java 类的代码 —— 一个 Struts 表单 bean。Struts 会用这个 bean 保存并传输用户输入。bean 必须以 bean 属性的形式包含所有数据字段,而且它必须是 org.apache.struts.action.ActionForm 的子类。
为了生成表单 bean 的代码,您要根据清单 2 所示的伪代码生成 XDoclet 模板。括号中的黑体字代表控制流逻辑和您要进行替换的文本。请注意模板是如何从已解析的 Java 源代码文件的结构模型中提取信息的:
清单 2. 建立 AddressBeanForm.java Struts 表单 bean 代码的伪代码模板
package {package name of source class};import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import org.apache.struts.action.ActionForm;import org.apache.struts.action.ActionMapping;import org.apache.struts.upload.FormFile;/** * Form Bean class for {name of source class};. * * @struts.form name=" {name of source class}Form" */public class {name of source class}Form extends ActionForm { {loop through all the methods in the source class} {if the method is a JavaBean "getter" method} {if the method has been marked with the @dw.genStruts tag } private {return type of method}{name of the JavaBean property}; public {return type of method}{name of the getter method for this property}(){ return {name of JavaBean property}; } public void {name of the setter method for this property}( {return type of method} value) { {name of the JavaBean property} = value; } {end of if @dw.genStruts} {end of if JavaBean getter}{end of loop}
|
| 用 XDoclet 建立 XDoclet 标签
请注意在 清单 2 的模板中生成的 XDoclet @struts.form 标签。您可以用 XDoclet 在 Java 源代码中生成 XDoclet 标签,XDoclet 会在后面的操作中再次处理这些标签。在示例后面建立 structs-config.xml 的时候,XDoclet 会使用 @struts.form 标签。 |
|
在清单 2 的循环中的代码生成了一个字段声明和一个访问器方法,还为输入源代码中每个用 @dw.genStruts 标记的访问器方法生成了一个设置器方法。
清单 2 使用了易于理解的伪代码来表示模板替换标签。实际的 XDoclet 模板标签则相当繁琐。清单 3 显示了 genformbean.xdt 模板(所有的 XDoclet 模板都保存在 .xdt 文件中)。我已经用黑体字强调了 XDoclet 模板标签,以方便在伪代码中对其进行引用。
清单 3. 建立 Structs 表单 bean Java 代码的实际 XDoclet 模板代码
package <XDtPackage:packageName/>;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import org.apache.struts.action.ActionForm;import org.apache.struts.action.ActionMapping;import org.apache.struts.upload.FormFile;/** * Form Bean class for <XDtClass:className/>. * * @struts.form name=" <XDtClass:className/>Form" */public class <XDtClass:className/>Form extends ActionForm { <XDtMethod:forAllMethods> <XDtMethod:ifIsGetter> <XDtMethod:ifHasMethodTag tagName="dw.genStruts"> private <XDtMethod:methodType/> <XDtMethod:propertyName/>; public <XDtMethod:methodType/> <XDtMethod:getterMethod/>(){ return <XDtMethod:propertyName/>; } public void <XDtMethod:setterMethod/>( <XDtMethod:methodType/> value) { <XDtMethod:propertyName/> = value; } </XDtMethod:ifHasMethodTag> </XDtMethod:ifIsGetter></XDtMethod:forAllMethods>
|
| 熟悉 Ant 脚本编写
Ant 脚本 build.xml(我已经随本文的示例代码提供了这个文件,请参阅 下载部分找到代码的链接)定义了示例应用程序使用的全部必要 Ant 目标。如果您想修改脚本,就需要熟悉 Ant。请参阅 参考资料 了解 Ant 的更多信息。 |
|
您可以参考 XDoclet 的“模板语言”文档,查找 XDoclet 所有可用标签的列表(请参阅 参考资料)。
要运行用于 AddressBean.java 源文件的模板,请使用以下 Ant 命令行:
ant -Dbase.class.java=Address genstruts
|
这个命令可以执行定制 Ant 目标(请参阅侧栏 熟悉 Ant 脚本编写)来处理 genbeanform.xdt 模板。XDoclet 提供的 Ant 任务叫作 xdoclet.DocletTask ,它被用来运行模板文件。如果您对 Ant 的细节感兴趣,请参阅示例代码中的 build.xml 文件,以了解更多信息。
在 XDoclet 处理模板的时候,它在名为 generated的子目录下生成一个 AddressBeanForm.java 文件。清单 4 显示了该文件,它包含模板处理期间替换的所有文本:
清单 4. XDoclet 生成的包含 Struts 表单 bean 的 Java 源代码
package com.ibm.dw.beans;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import org.apache.struts.action.ActionForm;import org.apache.struts.action.ActionMapping;import org.apache.struts.upload.FormFile;/** * Form Bean class for AddressBean. * * @struts.form name=" AddressBeanForm" */public class AddressBeanForm extends ActionForm { private java.lang.String streetNumber; public java.lang.String getStreetNumber(){ return streetNumber; } public void setStreetNumber( java.lang.String value) { streetNumber = value; } private java.lang.Stringstreet; public java.lang.String getStreet(){ return street; } public void setStreet( java.lang.String value) { street = value; } ...... more bean properties .....}
|
为数据表单输入生成 JSP 页面
您可以用相同的 AddressBean.java 源文件,但是用 genformjsp.xdt 模板生成数据入口表单 JSP 页面。清单 5 显示了 genformjsp.xdt:
清单 5. 使用 Struts 标签库生成 JSP 页面来显示 HTML 表单的 XDoclet 模板
<%@ page language="java" %><%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html" %><html:html><head></head><body bgcolor="white"><html:errors/><html:form action=" <XDtClass:classTagValue tagName='dw.genStrutsAction' paramName='action' /> >"<table border="0" width="100%"> <XDtMethod:forAllMethods> <XDtMethod:ifIsGetter> <XDtMethod:ifHasMethodTag tagName="dw.genStruts" > <tr> <th align="right"> <XDtMethod:methodTagValue tagName="dw.genStruts" paramName="formlabel"/> </th> <td align="left"> <html:text property=" <XDtMethod:propertyName/>" size=" <XDtMethod:ifHasMethodTag tagName="hibernate.property" > <XDtMethod:methodTagValue tagName="hibernate.property" paramName="length"/> </XDtMethod:ifHasMethodTag>"/> </td> </tr> </XDtMethod:ifHasMethodTag> </XDtMethod:ifIsGetter></XDtMethod:forAllMethods> <tr> <td align="right"> <html:submit> Submit </html:submit> </td> <td align="left"> <html:reset> Reset </html:reset> </td> </tr></table></html:form></body></html:html>
|
请注意,代码中用 <XDt:methodTagValue> 取得原始 AddressBean.java 代码中在 XDoclet 标签中指定的属性值。
当您执行 genstruts Ant 目标的时候,也会处理清单 5 显示的 genformjsp.xdt 模板。您可以在 generated 子目录中找到生成的 AddressBeanForm.jsp 文件,检查文件内容,可以看到要对模板进行的替换。
| 试验示例,但是首先...
要试验本文示例中的模板化代码生成,您需要安装并测试好 Ant 和 XDoclet。本文中的代码全都基于 Ant 1.5.4 和 XDoclet 1.2.1。要生成所有的工件,并试验生成的 Web 应用程序,还需要安装 Hibernate,Struts,以及应用程序服务器,还需要能够访问关系数据库。示例基于 Hibernate 2.1.4,Struts 1.1,以及 Servlet 2.3。请参阅 参考资料 了解有关这些技术的更多信息。请一定要阅读我随源代码一起提供的 README 文件。 |
|
生成其他工件
您可以用 XDoclet 生成任意基于文本的输出。我向您展示的例子使用 XDoclet 生成了 Java 代码、JSP 页面、XML 文件、配置文件以及其他更多输出。它从一个简单的用 XDoclet 进行标记的 Java 源文件 AddressBean.java,建立了一个完整的数据入口 Web 应用程序。为了做到这一点,它执行了 XDoclet 的内置模板(位于 JAR 文件中,称为模块),从而生成:
- Struts 配置和支持文件。
- Hibernate 配置和支持文件。
- Web 应用程序的部署描述符(web.xml)。
表 1 显示了为示例应用程序生成的所有文件(通常称为 工件(artifact)):
表 1. XDoclet 为 AddressBean.java 生成的工件
| 生成的工件 | 说明 | 位置 |
| AddressBeanForm.java | Java 源文件,包含表单 bean 类,在 Struts 的表单处理中使用 | generated目录 |
| AddressBeanForm.jsp | JSP 表单,用 Struts 标签库接受用户地址输入 | jsp目录 |
| AddressBeanAction.java | Struts 动作类,接受输入值,用 Hibernate 把值保存到关系数据库 | generated目录 |
| AddressBean.hbm.xml | Hibernate 映射文件,在 AddressBean Java 对象和数据库的关系型 ADDRESS 表之间进行映射 | web/classes目录 |
| dwschema.sql | RDBMS 表的架构,用来对 AddressBean 对象的实例进行持久化 | sql目录 |
| hibernate.cfg.xml | Hibernate 运行时的配置文件 | web/classes目录 |
| web.xml | 生成的 Web 应用程序的部署描述符 | web目录 |
| struts-config.xml | Struts 框架的配置文件 | web目录 |
在这篇文章中,您详细了解了表 1 中所列的两个工件中的第一个工件的生成,深入了解了生成它们的模板。工件 AdddressBeanAction.java 则用类似的方法,利用叫作 genaction.xdt 的模板生成。XDoclet 具有内置模板和标签处理器,可以生成表 1 中的其他工件。
表 2 列出了每个生成的工件对应的 Ant 目标和 Ant 任务。您可以执行表格中的每个 Ant 目标,生成对应的工件。所有这些生成的工件,再加上原始和 AddressBean.java,共同构成了示例 Web 应用程序。您还会发现叫作 all 的默认 Ant 目标,它会为您做任何事,包括为应用程序建立 WAR(可以部署的 Web 归档)。在进行处理之前,一定要阅读代码发布包中的 README.txt 文件。
| XDoclet 中的合并点
在 XDoclet 的文档中,您会非常频繁地看到术语 合并点(merge point)和 合并文件(merge file)。合并文件是文本文件,您可以把它合并到 XDoclet 生成代码的指定位置——“合并点”上(由模板指定)。可以用合并文件来包含静态文本(例如代码片断和 XML 片断),这些文本可能很难或者不能用 XDoclet 的能力生成。例如,在示例代码的 merge/web 目录下,您会找到 struts-action.xml 文件。在代码生成期间,可以用该文件合并到 Struts 的动作映射中,构成生成的 struts-config.xml 文件的一部分。 |
|
表 2. 对应于生成工件的 Ant 目录和 Ant 任务
| Ant 目标 | Ant 任务 | 工件 |
genstruts | xdoclet.DocletTask | AddressBeanForm.java |
genstruts | xdoclet.DocletTask | AddressBeanForm.jsp |
genstruts | xdoclet.DocletTask | AddressBeanAction.java |
generateHIB | xdoclet.modules.hibernate.HibernateDocletTask | AddressBean.hbm.xml |
generateHIB | xdoclet.modules.hibernate.HibernateDocletTask | hibernate.cfg.xml |
createDDL | xdoclet.modules.hibernate.HibernateDocletTask | dwschema.sql |
generateDD | xdoclet.modules.web.WebDocletTask | web.xml |
generateDD | xdoclet.modules.web.WebDocletTask | struts-config.xml |
结束语
XDoclet 是一个有用的、智能的代码生成器,您可以用它自动进行许多日常的 Java 开发任务。不要被它表面的复杂所吓退。随着逐渐精通 XDoclet(以及与之相关的 Apache Ant),您会节约您宝贵的时间,并在未来的开发工作中,得到数倍的回报。
下载
| 名字 | 大小 | 下载方法 |
|---|
| j-xdoclet-code.zip | | FTP |
参考资料

|
|
关于作者
posted @
2006-11-05 08:30 xzc 阅读(448) |
评论 (0) |
编辑 收藏
XDoclet 操作
图 1 显示了 XDoclet 要求的输入和生成的输出。
图 1. XDoclet 黑盒子

您可以看到,包含嵌入式 XDoclet 标签的 Java 源代码是系统的输入。在 Apache Ant 的驱动下,XDoclet 处理输入的代码,生成的输出文本文件可以是 Java 源代码、HTML 页面、XML 文件等。为了处理输入,XDoclet 需要使用模板(保存在 .xdt 文件中)和标签处理器(用 Java 编码)。XDoclet 把模板和标签处理器打包成“模块”,不同的“模块”处理不同的问题域。
XDoclet 生成的结构模型
XDoclet 对包含嵌入式 XDoclet 标签的输入 Java 源代码进行解析,并为代码建立非常详细的结构模型。结构模型中的每个元素都代表源代码中的一个 Java 结构。图 2 显示的结构模型,揭示了 XDoclet 跟踪的代码构造和关系。
图 2. XDoclet 的解析的 Java 源代码的内部结构模型

图 2 中的结构模型跟踪类、接口、方法之类的代码构造(模型元素)。该模型还跟踪元素之间的关系,例如继承和接口实现。以内联注释的形式嵌入在源代码中的 XDoclet 标签被解析为模型元素的属性,并被跟踪
深入 XDoclet
图 3 显示了 XDoclet 的内部结构,揭示了使其运行的功能块。
图 3. XDoclet 内部的功能块

如图 3 所示,Apache Ant 在运行的时候控制着 XDoclet 的配置和操作。XDoclet 解析输入的 Java 源代码,并在内存中生成结构模型。模板引擎通过处理一组模板和标签处理器,生成输出文件。模板和标签处理器可以是内置的,也可以是定制的。在代码生成期间,模板和标签处理器拥有对结构模型的完全访问。
XDoclet 虚假的复杂性
XDoclet 实质上就是一个通用的 Javadoc 引擎(请参阅侧栏,通用的 Javadoc 引擎)。那么,是什么让它看起来这么复杂呢?答案在于:XDoclet 几乎从未被单独讨论过,而总是藏在其他许多复杂的技术中。图 4 显示了了围绕在 XDoclet 周围的复杂性迷雾(请参阅侧栏为什么 XDoclet 看起来比实际的要复杂得多)。
|
为什么 XDoclet 看起来比实际的要复杂得多
Apache Ant 自动进行 Java 软件的生成过程。构建管理过程通常是生产项目中更复杂过程中的一部分。构建管理的术语和概念被集成到 Apache Ant 中,而且是理解其操作的先决条件。成熟的 Ant 脚本可能会非常复杂。Ant 的每个新版本,都会引入一些新的特性集,从而进一步增加了复杂性。这形成了 XDoclet 表面的复杂性,因为 XDoclet 需要 Ant 才能执行。
XDoclet 处理的问题领域是复杂性的另一个来源。在发布 XDoclet 的时候,XDoclet 已经可以为 EJB 组件集成、J2EE Web 容器集成、Hibernate 持久性层、Struts 框架、Java 管理扩展(JMX)等生成代码。这些问题领域中的每一个领域都有一大套该领域专用的行话和概念。从这些复杂的问题领域出来的问题,经常主导着 XDoclet 的讨论,这也提高了 XDoclet 表面的复杂性。可能是“只见森林,不见树木”。
|
图 4. XDoclet 的复杂耦合

在图 4 中,您可以看到 XDoclet 与以下内容是紧密相关的:
- Apache Ant,它控制着 XDoclet 的操作。XDoclet 是作为一组 Ant 任务存在的,没有 Ant 则不能执行。
- 与生成文件关联的具体问题领域的一些细节。
posted @
2006-11-05 08:29 xzc 阅读(520) |
评论 (0) |
编辑 收藏
XDoclet是一个代码生成工具,它可以把你从Java开发过程中繁重的重复劳动中解脱出来。XDoclet可以让你的应用系统开发的更加快速,而你只要付比原先更少的努力。你可以把你手头上的冗长而又必需的代码交给它帮你完成,你可以逃脱“deployment descriptor地狱”,你还可以使你的应用系统更加易于管理。而你所要做的,只不过是在你的注释里,多加一些类javadoc属性。然后,你会惊讶于XDoclet为了做到的一切。
讨论XDoclet,有一点比较容易产生混淆,那就是XDoclet不但是一系统的代码生成应用程序,而且它本身还是一个代码生成框架。虽然每个应用系统的细节千变万化(比如EJB代码生成和Struts代码生成是不一样的,而JMX代码生成又是另一番景象),但这些代码生成的核心概念和用法却是类似的。
在这一章里,我们将会看到渗透到所有XDoclet代码生成程序当中的XDoclet框架基础概念。但在之前,我们先从一个例子入手。
2.1 XDoclet in action
每一个程序员都会认识到,他们的程序永远也不会完成。总会有另一些的功能需要添加,另一些的BUG需要修正,或者需要不断的进行重构。所以,在代码里添加注释,提醒自己(或者其他的程序员)有哪些任务需要完成已成为一个共识。
如何来跟踪这些任务是否完成了呢?理想情况下,你会收集整理出来一个TODO任务列表。在这方面,XDoclet提供了一个强大的TODO生成器,来帮助你完成这个任务。这是一个把XDoclet引入项目的好机会。
2.1.1 一个公共的任务
假设你正在开发一个使用了勺子的类。
public class Matrix {
// TODO ? 需要处理当没有勺子的情况
public void reload() {
// ...
Spoon spoon = getSpoon();
// ...
}
}
理想情况下,你在下一次阅读这段代码的时候,你会处理这个“空勺子”(null spoon)的问题。但如果你过了很久才回来看这段代码,你还会记得在这个类里还有一些工作要做吗?当然,你可以在你的源码里全局搜索TODO,甚至你的集成开发环境有一个内建的TODO列表支持。但如果你想把任务所在的类和方法也标注出来的话,XDoclet可以是另一种选择。XDoclet可以为你的项目生成一个TODO报表。
2.1.2 添加XDoclet标签
为了把你的TODO项目转换成另一种更加正式的格式,你需要对代码进行一些细微的改动。如下所示:
public class Matrix {
/** @todo 需要处理当没有勺子的情况 */
public void reload() {
// ...
}
}
这里加入了一个XDoclet需要的类javadoc标签。XDoclet会使用这些标签标记的信息,以及在这种情况下标签所处的类和方法,来生成TODO报表。
2.1.3 与Ant集成
要生成TODO报表,你需要确保在你的机器上正确安装了XDoclet。
在Ant任务里,最少要包含一个目标(例如init目标)定义<documentdoclet>任务,这是一个Ant自定义任务,例如:
<taskdef name=”documentdoclet”
classname=”xdoclet.modules.doc.DocumentDocletTask”
classname=”xdoclet.lib.path” />
这个<documentdoclet>任务是XDoclet核心代码生成应用程序中的一个。
现在,你可以在Ant构建文件中加入一个todo目标调用这个任务来生成TODO报表,如:
<target name=”todo” depends=”init”>
<documentdoclet destdir=”todo”>
<fileset dir=”${dir.src}”>
<include name=”**/*.java” />
</fileset>
<info/>
</documentdoclet>
</target>
<info>子任务会遍历你的源文件,查找todo标签,并在todo子目录下生成HTML格式的TODO报表。
2.1.4 创建一个更加职业化的TODO报表
XDoclet生成的TODO报表可以有一个更加职业化的外表。报表会列出一个概览,显示在哪个包哪个类里有todo项(以及todo项的个数)。Todo项可以跟在方法、类和域上,从报表上可以清楚的区别它们。类级别的todo项会标注class,方法级别的todo项会在方法签名上标注M。构造函数和域相关的todo项也会进行相似的标注。
这个任务看起来很简单,但考虑到你所需要做的只是在注释上添加一些格式化的@todo标签,相对于那种只有人才可以理解的无格式的松散的注释,这种标签是机器可读的,也更容易编程处理。生成的输出也更容易阅读并且更加的商业化。
2.2 任务和子任务
生成todo报表,只是XDoclet可以完成的事情当中的冰山一角。当初,XDoclet因为可以自动生成EJB繁杂的接口和布署描述文件而声名鹊起。然而,现在的XDoclet已经发展成了一个全功能的、面向属性的代码生成框架。J2EE代码生成只是XDoclet的一个应用方面,它可以完成的任务已经远远超越了J2EE和项目文档的生成。
2.2.1 XDoclet 任务
到现在为止,我们一直在讨论使用XDoclet生成代码,但事实上,更确切的说法应该是,我们使用XDoclet的一个特定的任务来生成代码,比如<ejbdoclet>。每一个XDoclet任务关注于一个特定的领域,并提供这个领域的丰富的代码生成工具。
[定义:任务(Tasks)是XDoclet里可用的代码生成应用程序的高层概念。]
在XDoclet里,目前已有如下所示的七个核心任务。
<ejbdoclet>:面向EJB领域,生成EJB、工具类和布署描述符。
<webdoclet>:面向Web开发,生成serlvet、自定义标签库和web框架文件。
<hibernatedoclet>:Hibernate持续,配置文件、Mbeans
<jdodoclet>:JDO,元数据,vender configuration
<jmxdoclet>:JMX,MBean接口,mlets,配置文件。
<doclet>:使用用户自定义模板来生成代码。
<documentdoclet>:生成项目文件(例如todo列报表)
这其中,<ejbdoclet>最常用,并且很多项目也仅仅使用XDoclet来进行EJB代码生成。<webdoclet>是其次一个常用的代码生成任务。当然,在一个项目中同时使用几个XDoclet任务是可能的(并且也是推荐的),但在这些任务之间是完全独立的,它们彼此之间并不能进行直接的交流。
2.2.2 XDoclet子任务
XDoclet的任务是领域相关的,而在某个特定领域的XDoclet任务,又由许许多多紧密耦合在一起的子任务组成的,这些子任务每个都仅仅执行一个非常特定和简单的代码生成任务。
[定义:子任务(subtasks)是由任务提供的单目标的代码生成过程]
任务提供子任务执行时的上下文,并且把这些相关的子任务组织管理了起来。任务会依赖这些子任务来生成代码。在一个任务当中调用多个子任务来协同完成各种各样比较大型的代码生成任务是非常常见的。比如,在开发EJB时,你可能想要为每一个bean生成一个home接口,一个remote接口以及ejb-jar.xml布署描述符文件。这就是在<ejbdoclet>任务的上下文环境中的三个独立的代码生成子任务。
子任务可以随意的组合排列,以满足项目代码生成的需要。某个XDoclet任务包含的子任务经常会共享功能和在源文件中使用相同的XDoclet标签。这意味着当你开始一个任务的时候,你可以很容易的集成进一个相关的子任务,而不需要很大的改动。
子任务交互
让我们以<ejbdoclet>任务为例,看一下相关的子任务之间是如何进行关联的。假设你正在开发一个CMP(容器管理持久化)实体Bean。你想要使用一些<ejbdoclet>的子任务:
•<deploymentdescriptor>:生成ejb-jar.xml布署描述符文件。
•<localhomeinterface>:生成local home接口。
•<localinterface>:生成local接口。
在执行如上子任务的时候,你需要标记出你的实体Bean的CMP域。当你发布你的bean的时候,你还需要在开发商相关的布署描述符中提供某个特定的关系数据库中的特定表和列与你的CMP实体Bean的映射关系。XDoclet可以让你在原先已存在的CMP XDoclet属性基础上再加上一些关系映射属性,然后,你就可以在任务中加入一个开发商相关的子任务(例如<jboss>或者<weblogic>)来生成布署描述符文件。XDoclet提供了几乎所有的应用服务器的支持,你只需要一些初始化的小改动,就可以进行这些应用服务器相关的代码生成了。
但那只是冰山一角。你还可以使用<entitycmp>子任务为为你的bean生成一个实体bean接口的实现子类。如果你使用<valueobject>子任务来为了你的bean生成值对象,<entityemp>子任务还会为你的值对象生成方法的实现代码。
觉得不可思议了吧。可惜XDoclet没有提供<cupofcoffee>子任务,要不然我们可以喝杯咖啡,休息一下啦。
这里不是想向你介绍<ejbdoclet>所有的子任务或者<ejbdoclet>可以完成的所有代码生成功能,而仅仅是想向你展示一下任务的子任务之间是如何工作在一起的。一旦你开始并熟悉了一个XDoclet 子任务,熟悉另一个子任务会变得非常简单- 那种每个子任务都是孤立的相比,使用这种可以相互协作的子任务,开发成本会显著的降低,效果也更加的立竿见影。
2.3 使用Ant执行任务
XDoclet“嫁”给了Ant。XDoclet任务就是Ant的自定义任务,除此以外,没有其他运行XDoclet任务的方法。所幸的是,Ant已经成为了Java构建工具事实上的标准,所以这不算什么限制。事实上,反过来,XDoclet与Ant的这种“亲密”关系使得XDoclet可以参与到任何Ant构建过程当中去。
2.3.1 声明任务
XDoclet并没有和Ant一起发布,所以如果你想要使用XDoclet的话,就需要单独的下载和安装。在使用任何一个XDoclet的任务之前,你首先需要在使用Ant的<taskdef>任务来声明它。例如:
<taskdef name=”ejbdoclet”
classname=”xdoclet.modules.ejb.EjbDocletTask”
classpathref=”xdoclet.lib.path”/>
如果你熟悉Ant的话,你就会知道这段代码是告诉Ant加载<ejbdoclet>的任务定义。当然,你也可以以你喜欢的任何方式来命名这个自定义任务,但最好还是遵守标准的命名规律以免发生混淆。classname和classpathref属性告诉Ant到哪里去找实现这个自定义任务的XDoclet类。如果你想使用其他的XDoclet任务,就必须要类似这样首先声明这个任务。
一般共通的做法是,把所有需要使用的XDoclet任务都放在Ant的一个目标里声明,这样在其他的目标里如果需要使用这些任务,只要depends这个任务就可以了。你可能已经在Ant的构建文件里包含了init目标,这就是放置XDoclet任务声明的好地方(当然如果你没有,你也可以建一个)。下面的例子就是在一个init目标里加入了<ejbdoclet>和<webdoclet>的声明:
<target name=”init”>
<taskdef name=”documentdoclet”
classname=”xdoclet.modules.doc.DocumentDocletTask”
classpathref=”xdoclet.lib.path” />
<taskdef name=”ejbdoclet”
classname=”xdoclet.modules.ejb.EjbDocletTask”
classpathref=”xdoclet.lib.path” />
<taskdef name=”webdoclet”
classname=”xdoclet.modules.web.WebDocletTask”
classpathref=”xdoclet.lib.path” />
</target>
现在,任务声明好了,XDoclet“整装待发”。
2.3.2 使用任务
你可以在任何目标里使用声明好的任务。在任务的上下文环境里,可以调动相关的子任务。让我们看一个例子,这个例子调用了<ejbdoclet>任务。不要担心看不懂语法的细节,现在你只需要关心一些基础概念就可以了。
<target name=”generateEjb” depends=”init”>
<ejbdoclet destdir=”${gen.src.dir}”>
<fileset dir=”${src.dir}”>
<include name=”**/*Bean.java”/>
</fileset>
<deploymentdescriptor destdir=”${ejb.deployment.dir}”/>
<homeinterface/>
<remoteinterface/>
<localinterface/>
<localhomeinterface/>
</ejbdoclet>
</target>
把任务想像成一个子程序运行时需要的一个配置环境(记住,子任务才是真正进行代码生成工作的)。当调用一个子任务时,子任务从任务继承上下文环境,当然,你也可以根据需要随意的覆盖这些值。在上面的例子里,因为<deploymentdescriptor>子任务生成的布署描述符文件和其他生成各种接口的子任务生成的Java源文件需要放在不同的位置,所以覆盖了destdir的属性值。布署描述符文件需要放在一个在打包EJB JAR文件的时候可以容易包含进来的地方,而生成的Java代码则需要放置在一个可以调用Java编译器进行编译的地方。需要这些子任务之间是紧密关联的,但只要你需要,你可以有足够的自主权控制任务的生成环境。
<fileset>属性同样被应用到所有的子任务。这是一个Ant的复杂类型(相对于文本和数值的简单类型),所以以子元素的方式在任务中声明。不要把它和子任务混为一谈。当然,如果你想在某个子任务中另外指定一个不同的输入文件集,你也可以在这个子任务中放置一个<fileset>子元素来覆盖它。
子任务的可配置选项远远不止这些。我们会在下一章继续介绍所有的任务和子任务,以及常用的配置选项。
2.4 用属性标注你的代码
可重用的代码生成系统需要输入来生成感兴趣的输出。一个解析器生成器也需要一个语言描述来解析生成解析器。一个商务对象代码生成器需要领域模型来知道要生成哪些商务对象。XDoclet则需要Java源文件做为输出来生成相关的类或者布署/配置文件。
然而,源文件可能并没有提供代码生成所需要的所有信息。考虑一个基于servlet的应用,当你想生成web.xml文件的时候,servlet源文件仅可以提供类名和适当的servlet接口方法。其他的信息比如URI pattern映射、servlet需要的初始化参数等信息并没有涵盖。显而易见,如果class并没有提供这些信息给你,你就需要自己手动在web.xml文件时填写这些信息。
XDoclet当然也不会知道这些信息。幸运的是,解决方法很简单。如果所需信息在源文件时没有提供,那就提供它,做法就是在源文件里加入一些XDoclet属性。XDoclet解析源文件,提取这些属性,并把它们传递给模板,模板使用这些信息生成代码。
2.4.1 剖析属性
XDoclet属性其实就是javadoc的扩展。它们在外表上和使用上都有javadoc属性一样,可以放置在javadoc文档注释里。文档注释以/**开始,*/结尾。下面是一个简单的例子:
/**
* 这是一段javadoc注释。
* 注释可以被分解成多行,每一行都以星号开始。
*/
在注释里的所有文本都被视为javadoc注释,并且都能够被XDoclet访问到。注释块一般都与Java源文件中的某个实体有关,并紧跟在这个实体的前面。没有紧跟实体的注释块将不会被处理。类(或者接口)可以有注释块,方法和域也可以有自己的注释块,比如:
/**
* 类注释块
*/
public class SomeClass {
/** 域注释块 */
private int id;
/**
* 构造函数注释块
*/
public SomeClass() {
// ...
}
/**
* 方法注释块
*/
public int getId() {
return id;
}
}
注释块分成两部分:描述部分和标签部分。当遇到第一个javadoc标签时,标签部分开始。Javadoc标签也分成两部分:标签名和标签描述。标签描述是可选的,并且可以多行。例如:
/**
* 这是描述部分
* @tag1 标签部分从这里开始
* @tag2
* @tag3 前面一个标签没有标签描述。
* 这个标签有多行标签描述。
*/
XDoclet使用参数化标签扩展了javadoc标签。在XDoclet里,你可以在javadoc标签的标签描述部分加入name=”value”参数。这个微小的改动大大增强了javadoc标签的表达能力,使得javadoc标签可以用来描述复杂的元数据。下面的代码显示了使用XDoclet属性描述实体Bean方法:
/**
* @ejb.interface-method
* @ejb.relation
* name=”blog-entries”
* role-name=”blog-has-entries”
* @ejb.value-object
* compose=”com.xdocletbook.blog.value.EntryValue”
* compose-name=”Entry”
* members=”com.xdocletbook.blog.interfaces.EntryLocal”
* members-name=”Entries”
* relation=”external”
* type=”java.util.Set”
*/
public abstract Set getEntries();
参数化标签允许组合逻辑上相关联的属性。你可以加入描述这个类的元信息,使得这个类的信息足够生成代码。另外,程序员借由阅读这样的元信息,可以很快的理解这个类是如何使用的。(如果这个例子上的元信息你看不懂,不要担心,在第4章里,我们会学到EJB相关的标签以及它们的涵意。)
另外,请注意上面的例子中,所有的标签名都以ejb开头。XDoclet使用namespace.tagname的方式给标签提供了一个命名空间。这样做除了可以跟javadoc区别开来以外,还可以把任务相关的标签组织起来,以免任务之间的标签产生混淆。
2.5 代码生成模式
XDoclet是一种基于模板的代码生成引擎。从高层视图上来看,输出文件其实就是由解析执行各式各样的模板生成出来的。如果你理解了模板以及它所执行的上下文环境,就可以确切的认识到,XDoclet可以生成什么,不可以生成什么。如果你正在评估XDoclet平台,理解这些概念是非常重要的。要不然,你可能会错过XDoclet的许多强大的功能,也可能会被XDoclet的一些限制感到迷惑。
XDoclet运行在在Ant构建文件环境中,它提供了Ant自定义任务和子任务来与XDoclet引擎交互。任务是子任务的容器,子任务负责执行代码生成。子任务调用模板。模板提供了你将生成代码的饼干模子。XDoclet解析输入的源文件,提取出源文件中的XDoclet属性元数据,再把这些数据提供给模板,驱动模板执行。除此之外,模板还可以提供合并点(merge points),允许用户插入一些模板片断(合并文件merge files)来根据需要定制代码生成。
2.5.1 模板基础
XDoclet使用代码模板来生成代码。模板(template)是你想生成文件的原型。模板里使用一些XML标签来指导模板引擎如何根据输入类以及它们的元数据来调整代码的生成。
[定义:模板(template)是生成代码或描述文件的抽象模视图。当模板被解析的时候,指定的细节信息会被填入。]
模板一般情况下会有一个执行环境。模板可能应用在一个类环境(转换生成transform generation),也有可能应用在一个全局环境(聚集生成aggregate generation)。转换生成和聚集生成是XDoclet的两种类型的任务模式,理解它们之间的区别对于理解XDoclet是非常重要的。
当你使用XDoclet生成布置描述符文件时,你使用的是聚集生成。布置描述符文件并不仅仅只与一个类相关,相反,它需要从多个类里聚集信息到一个输入文件。在这种生成模式里,解析一次模板只会生成一个输出文件,不管有多少个输入文件。
在转换生成模式里,模板遇到每一个源文件就会解析一次,根据该文件类的上下文环境生成输出。这种生成模式会为每一个输入文件生成一个输出文件。
转换生成模式的一个很好的例子是生成EJB的local和remote接口。显然,接口是和Bean类一一相关的。从每一个类里提取信息(类以及它的方法、域、接口以及XDoclet属性等信息)转换出接口。除此以外,不需要其他的信息。
从实现里提取出接口似乎有点反向。如果你手写程序的话,一般来说会先定义一个接口,然后再写一个类来关现它。但XDoclet做不到,XDoclet不可能帮你实现一个已有接口,因为它不可能帮你生成你的业务逻辑。当然,如果业务逻辑可以从接口本身得到(比如JavaBean的get/set访问器)或者使用XDoclet属性声明好,那么生成业务逻辑代码来实现一个接口也不是不可能。但一般情况下,这样做不太现实。相比而言,提供一个实现,并描述接口与这个实现之间的关联就容易多了。
聚集生成和转换生成主要区别在它们的环境信息上。即使一个代码生成任务中生成一个Java文件,一般也不常用聚集生成,因为生成一个Java类还需要一些重要信息如类所处的包以及你想生成的类名,在这种环境下是无法提供的。如果一定要使用聚集生成的话,那就需要在另一个单独的地方提供好配置信息了。
2.5.2 模板标签
在还没见到模板长啥样子之前,我们已经比较深入的认识它了。那模板文件究竟长啥样子呢?它有点像JSP文件。它们都包含文件和XML标签,生成输出文件时XML标签会被解析,然后生成文本并显示在XML标签所处的位置上。除了以XDt为命名空间打头的XML标签会被XDoclet引擎解析以外,其余的XML标签XDoclet会忽略不管。下面的代码片断显示了XDoclet模板的“经典造型”:
public class
<XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/></XDtClass:classOf>
Extends Observabe {
static <XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/></XDtClass:classOf>
_instance = null;
public static <XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/></XDtClassOf>
getInstance() {
if (_instance == null) {
_instance =
new <XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/>
</XDtClass:classOf>();
}
return _instance;
}
}
研究一下这个模板,你会发现,它生成的是一个类定义。这个类里定义了一个静态变量instance,并且使用一个静态方法来控制这个静态文件的访问。借助Java语法,你可以很容易的推断出那些XDoclet模板标签的目录是生成类名,虽然对于这个标签如何工作你还并不是很了解。
即使你从没打算过要自己写模板,但理解模板是如何被解析运行的还是很有必要的。迟早你会调用到一个运行失败的XDoclet任务,没有产生你所期望的输出,那么最快捷的找出原因的方法就是直接检查模板文件,看看是哪里出了问题。
让我们看一下生成静态域定义的片断:
static <XDtClass:classOf><XDtEjbFacade:remoteFacadeClass/></XDtClass:classOf>
_instance = null;
在XDoclet的眼里,这段模板代码很简单,那就是:
static <tag/> _instance = null;
XDoclet解析执行标签,如果有输出的话,把输入置回到文本里去。有些标签会执行一些运算,把输出放回到一个流里。这样的标签称之为内容标签(content tags),因为它们产生内容。
另一种类型的标签称之为BODY标签。BODY标签在开始和结束标签之间存在文本。而BODY标签强大就强大在这些文本自己也可以是一断可以由外围标签解析的模板片断。比如在上面的例子里,XDtClass:classOf标签,它们的内容就是模板片断:
<XDtEjbFacade:remoteFacadeClass/>
classOf标签解析这段模板,提取出全限制的内容,然后剃除前面的包面,只输出类名。BODY标签并不总是会解析它的内容,在做这件事之前,它们会事先检查一些外部判断条件(比如检查检查你正在生成的是一个接口还是一个类)。这里标标签称之为条件标签(conditional tags)。还有一些BODY标签提供类似迭代的功能,它的内容会被解析多次。比如一个标签针对类里的每一个方法解析一次内容。
XDoclet标签提供了许多高层次的代码生成功能,但是有时候,它们可能显得不够灵活,或者表达能力满足不了你的需要。这时候,相对于另外开发一套通用功能的模板引擎相比,你可以选择扩展XDoclet模板引擎。你可以使用更具表述能力、功能更加强大的Java平台开发你自己的一套标签。
2.6 使用合并定制
代码生成系统之所以使用的不多,主要原因就在于它们往往只能生成一些死板的、不够灵活的代码。大多数代码生成系统不允许你改动它们生成的代码;如果,如果这个系统不够灵活,你所能做到的最好的扩展就是应用继承扩展生成的代码,或者使用一些共通的设计模式(比如Proxy和Adaptor)来满足你的需要。无论如此,这都不是产生你想生成的代码的好办法。代码生成器最好能做到所生成即所得WYGIWYG(what you generate is what you get),来取代你需要花费大量的时间来粉饰生成出来的并不满足要求的代码。所以,对于代码生成器来说,支持灵活的定制,是生成能够完全满足要求的代码的前提条件。
XDoclet通过合并点(merge points)支持定制??合并点是在模板文件定义里允许运行时插入定制代码的地方。有时候,合并点甚至可以影响到全局代码的生成,不但允许你添加一些定制内容,还可以从根本上改变将要生成出来的东西。
[定义:合并点(Merge points)是模板预先定义的允许你在代码生成的运行时加入定制内容的扩展点]
让我们研究一段从XDoclet源代码里摘取出来的模板代码。在为实体Bean生成主键的模板末尾,定义了这样一个合并点:
<XDtMerge:merge file=”entitypk-custom.xdt”></XDtMerge:merge>
如果你在你的merge目录下创建了一个名为entitypk-custom.xdt文件,那么这个模板文件的内容将会在这个合并点被包含进来。你的定制可以执行高层模板可以执行的所有强大功能,可以进行所有模板可以进行的运算(包括定义自定义标签,定义它们自己的合并点)。
上面的这种合并点,为所有的类环境使用了同一个文件。当然,也可以为每一个类环境使用不同的合并文件。如果你不想定制全部的类文件,或者你不想为了某些改动而重写模板的时候,这会很有用。不管动机是什么,逐类的合并点很容易识别出来:他们会在名字里包含一个XDoclet的逐类标记{0}。这里有一个生成ejb-jar.xml文件里的安全角色引用的例子:
<XDtMerge:merge file=”ejb-sec-rolerefs-{0}.xml”>
<XDtClass:forAllClassTags tagName=”ejb:security-role-ref”>
<security-role-ref>
<role-name>
<XDtClass:classTagValue
tagName=”ejb:security-roleref”
paramName=”role-name”/>
</role-name>
<role-link>
<XDtClass:classTagValue
tagName=”ejb:security-roleref”
paramName=”role-link”/>
</role-link>
</security-role-ref>
</XDtClass:forAllClassTags>
</XDtMerge:merge>
这段模板会遍历工程里的所有Bean。对于每一个Bean,XDoclet先从Bean的文件名里提取出Bean名,然后替换{0},再根据替换后的文件名去寻找合并文件。例如,如果你有一个名为BlogFacadeBean的Bean,XDoclet会尝试寻找一个名为ejb-src-rolerefs-BlogFacade.xml的合并文件。
如果找不到这个合并文件,则这个<merge>标签的内容模板会被解析。这意味着合并点不仅可以提供定制内容,还可以在一个模板文件里定义一个替换点,当定制内容不存在的时候使用替换点里的内容。不是所有的XDoclet任务都提供了有替换内容的合并点,一般来说,它们更倾向于只提供一个简单的合并点,仅仅当合并文件存在的时候解析并导入合并文件的内容。这取决于任务的开发者觉得哪种合并点更符合他的要求。
还有一点没有介绍到的是XDoclet如何定位合并文件,每一个XDoclet任务或者子任务都会提供一个mergeDir属性,这个属性用于设置你存放合并文件的目录。
posted @
2006-11-05 08:26 xzc 阅读(369) |
评论 (0) |
编辑 收藏一、读大学,究竟读什么?
大学生和非大学生最主要的区别绝对不在于是否掌握了一门专业技能……一个经过独立思考而坚持错误观点的人比一个不假思索而接受正确观点的人更值得肯定……草木可以在校园年复一年地生长,而我们却注定要很快被另外一群人替代……尽管每次网到鱼的不过是一个网眼,但要想捕到鱼,就必须要编织一张网……
二、人生规划:三岔路口的抉择
不走弯路就是捷径……仕途,商界,学术。在这人生的三岔路口,你将何去何从……与其跟一百个人去竞争五个职位,不如跟一个人去竞争一个职位……学术精神天然的应当与尘嚣和喧哗保持足够的距离……商场不忌讳任何神话。你也完全可能成为下一个传奇……
三、专业无冷热,学校无高低
没有哪个用人单位会认为你代表了你的学校或者你的专业……既然是概率,就存在不止一种可能性……如果是选择学术,冷门专业比热门专业更容易获得成就……跨专业几乎早已成为一种流行一种时尚……大学之间的实力之争到了考研考场和人才市场原来是那样的微不足道……
四、不可一业不专,不可只专一业
千招会,不如一招熟……十个百分之十并不是百分之百,而是零……在这个现实的社会,真正实现个人价值才是最体面最有面子最有尊严的事情……要想知道需要学什么,最好的方式就是留意招聘信息……很多专业因为不具备专长的有效性,所以成为了屠龙之术……为什么不将“买一送一”的促销思维运用到求职应聘的过程中来呢……
五、不逃课的学生不是好学生
什么课都不逃,跟什么课都逃掉没什么两样……读大学,关键是学会思考问题的方法……逃课没有错,但是不要逃错课……英语角绝对不是学英语的地方……为了英语丢了专业,那就舍本逐末了……招聘单位是用人才的地方,而不是培养人才的地方……既要逃课,又要让老师给高分……
六、勤工俭学的辩证法
对于贫困生来说,首先要做的不是挣钱,而是省钱……大部分女生将电脑当成了影碟机,大部分男生将电脑当成了游戏机……在这个处女膜都可以随意伪造的年代,还有什么值得轻易相信……态度决定一切……当学习下降到次要的地位,大学生就只能说是兼职的学生了……
七、做事不如做人,人脉决定成败
学问好不如做事好,做事好不如做人好……会说话,就能减少奋斗三十年……一个人有多少钱并不是指他拥有多少钱的所有权,而是指他拥有多少钱的使用权……一个人赚的钱,12.5%是靠自身的知识,87.5%则来自人脉关系……三十岁以前靠专业赚钱,三十岁以后拿人脉赚钱……你和世界上的任何一个人之间只隔着四个人……
八、互联网:倚天剑与达摩克利斯之剑
花两个小时就写出一篇天衣无缝的优秀毕业论文……在互联网领域创业的技术门槛并不高,关键的是市场眼光和营销能力……轻舞飞扬已经红颜薄命了,而痞子蔡却继续跟别的女孩发生着一次又一次的亲密接触……很多大学生的网友遍布祖国大江南北,可他们却从未主动向周围的人说一声:你好,我们可以聊聊吗…
九、恋爱:花开堪折方须折
爱情是不期而至的,可以期待,但不可以制造……越是寂寞,越要警惕爱情……既然单身是可耻的,那西门庆是不是应该被评为宋朝十大杰出青年……花开堪折方须折,莫让鲜花败残枝……一个有一万块钱的人为你花掉一百元,你只占了他的百分之一;而一个只有十块钱的人为你花掉十块,你就成了他的全部……
十、性:上帝死了,众神在堕落
爱要说,爱要做……我只有在肉体一下一下的撞击中才感到快乐。经过之后,将是更大的寂寞更大的空虚……为何要让别人的虚荣成为对自己的伤害……当她机械地躺在床上张开双腿,她的父母正在憧憬着女儿的未来……一朝春尽红颜老,花落人亡两不知……
十一、考研:痛苦的安乐死
没有比浪费青春更失败的事情了……研究生扩招的速度是30%,也就意味着硕士学历贬值的速度是30%……同样是付出三年的努力,你可以让E1的值增加1,也可以让E2的值增加2甚至增加3……读完硕士或博士并不等于工作能力更强……面对13.54万的成本,你还会毫不犹豫地投资读研究生吗……努力就会有结果,但不一定是好结果……
十二、留学:“海龟”变“海带”
月薪2500元的工作,居然引得三个“海归”硕士争相竞聘……对于某些专业而言,去美国留学和去埃塞俄比亚留学没什么两样……既然全世界的公司都想到中国的市场上来瓜分蛋糕,为什么中国人还要一门心思到国外去留学然后给外国人打工……
十三、非统招:养卑照样处优
她在中国信息产业界创下了几项纪录。她被称为中国的“打工皇后”。而她不过是一名自考大专生……要想把曾经输掉的东西赢回来,就必须把自己比别人少付出的努力补上来……非统招生不但要有一定的实力,而且必须掌握一定的技巧,做到扬长避短出奇制胜……路在脚下。好走,走好……
十四、毕业:十面埋伏的陷阱
母校不把自己当母亲,你又何必把自己当儿女……听辅导班不过是花钱买踏实……人才市场就是一个地雷阵……通过多种方式求职固然没有错,但是千万不要饥不择食……只要用人单位一说要你交钱,你掉头就走便是了……这年头立字尚且不足以为据,更何况一个口头约定……
十五、求职:做人不要太厚道
求职简历必须突出自己的核心竞争力……求职的时候大可不必像严守一那样“有一说一”……一个人说假话并不难,难的是把假话说到底,并且不露一丝破绽……在填写自己的特长时,一定要尽可能详细……一份求职简历只要用一张A4纸做个表格就足够了……面试其实是有规律的,每次面试的时候只要背标准答案就行了……
十六、骑一头能找千里马的驴
美国铁路两条铁轨之间的标准距离是4英尺8.5英寸,为什么呢?因为两匹马臀部之间的宽度是4英尺8.5英寸……垃圾是放错位置的人才……世界上最大的悲剧莫过于有太多的年轻人从来没有发现自己真正想做什么……中小型企业或许能够让你得到更充分的锻炼……从基层做起并不意味着可以从基层的每一个职位做起……要“钱途”,更要前途……
十七、写字楼政治:白领必修课
大公司是做人,小公司是做事……职员能否得到提升,很大程度不在于是否努力,而在于老板对你的赏识程度……公司的事情和秘密永远比你想象的还要复杂和深奥……在适当的时候装糊涂不但是必要的,而且是睿智的……就把你的同事当成一群你可以叫得出名字的陌生人好了……
十八、创业 -做富翁
瘦死的骆驼比马大……撑死胆大的,饿死胆小的……不再是“大鱼吃小鱼”,而是“快鱼吃慢鱼”……对于趋势的把握是一个创业者最重要的能力……高科技行业留给毕业生的空间已经很小……欲速则不达。在创业以前通过给别人打工而积累经验是非常必要的……市场永远比产品更重要……钱不够花,怎么办?第一,看菜吃饭;第二,借鸡生蛋……
posted @
2006-11-04 11:30 xzc 阅读(315) |
评论 (0) |
编辑 收藏 永远是10%的人赚钱,90%的人赔钱,这是市场的铁律,不论是股市,还是开公司、办企业,都不会改变。
如果人人都赚钱,那么谁赔钱,钱从何处来?
天下人不可能都是富人,也不可能都是穷人!
但富人永远是少数,穷人永远是多数!
这是上帝定的,谁也没办法。
但赚钱总是有办法,就是你去做10%的人,不要去做大多数人。
做少数富人,你需要换思想,转变观念,拥有富人的思维,就是和大多数人不一样的思维。
有人说得好:“换个方向,你就是第一。”因为大多数人都是一个方向,千军万马都一样的思维,一样的行为,是群盲,就象羊群一样。
你要做羊,还是做狼?
数英雄,论成败,天下财富在谁手?10%的人拥有90%的财富,90%的人拥有10%的财富。你要想富,你就得研究富的办法,研究富翁的思想和行为,象富人那样做,立下雄心壮志,做出不凡的业绩,很快你就是富翁!
“富人思来年,穷人思眼前”,这就是赚钱第一定律!
赚钱第二定律:金钱遍地都是,赚钱很容易!
问苍茫大地,谁主财富!为什么他能赚钱,你不能赚钱。追根求源,想赚钱——首先你要对钱有兴趣,对钱有一个正确的认识,不然钱不会找你。钱不是罪恶,她是价值的化身,是业绩的体现,是智慧的回报。
物以类聚,钱以人分。你必须对钱有浓厚的兴趣,感觉赚钱很有意思,很好玩,你喜欢钱,钱才能喜欢你。这决不是拜金主义,而是金钱运行的内在规律,不信你看那些富翁都喜欢钱,都能把钱玩得非常了得,看看比尔盖茨,看看沃伦巴菲特,看看乔治索罗斯。
金钱遍地都是,赚钱很容易。你必须确立这样的观念。如果你觉得赚钱很难,那么赚钱真的很难。那些大富翁没有一个认为赚钱难的,反倒认为花钱太难。你要牢记,赚钱真的很容易,随便动动脑筋就能来钱。这可不是教你吹牛,这是赚大钱,当富翁的思想基础,你不得不信!
股市赚钱难吗?不难,其实股市赚钱就6个字:“低点买,高难卖”。你只要用好这6个字,保你日进斗金,富得流油。华尔街经营之神巴菲特,就是善用这6字真言的世界级大师。说句实话,用活6字真言,你可以不用看K线图,不用盯着大盘,边玩边赚钱,这叫休闲贸易!
眼见他高楼起,气得你心口疼。你仇富吗,千万别。仇富说明你还不富,说明你还有穷人思维,赚钱第一定律怎么讲的,赶快重温。
如今经济全球化车轮势不可挡,市场经济大潮波澜壮阔,中国将飞速发展,风景这边独好,我们是遇到了“千年未遇之变局”,真是生逢良时,你不赚钱,干啥?赚钱玩呗!
正确认识钱,树立正确的金钱观念,这是赚钱的第二定律!
赚钱第三定律:最简单的方法最赚钱!
天下赚钱方法千千万,但最简单的方法最赚钱。
虽说条条大路通罗马,但万法归一,简单的才是最好的。
复杂的方法只能赚小钱,简单的方法才能赚大钱,而且方法越简单越赚大钱。
比如,比尔盖茨只做软件,就做到了世界首富;沃伦巴菲特专做股票,很快做到了亿万富翁;
乔治索罗斯一心搞对冲基金,结果做到金融大鳄;英国女作家罗琳,40多岁才开始写作,而且专写哈里波特,竟然写成了亿万富婆。
具体讲,每个行业都有赚大钱的方法:在商品零售业,沃尔玛始终坚持“天天平价”的理念,想方设法靠最低价取胜,结果做成了世界最大;在股市,沃伦巴菲特一直坚持“如果一只股票我不想持有10年,那我根本就不碰它一下”的原则炒股;在日本战败后,美国品质大师戴明博士应邀到日本给松下、索尼、本田等许多家企业讲课,他只讲了最简单的方法——“每天进步1%”,结果日本这些企业家真照着做了,并取得了神效,可以说日本战后经济的崛起有戴明博士的功劳。你说明他们的方法简单不简单?
炒股赚钱也有简单的方法。现在大多数人炒股都是“不要把所有的鸡蛋放在一个篮子里”,实行“多样化”,但沃伦巴菲特告诉你“不要多样化,要把所有的鸡蛋放在一个篮子里,然后密切关注它。”炒股其实真的就这么简单。
我的炒股原则是“一年操作一两次,低点买、高点卖”,集中资金买3支以内的股票,有时每年只买一支股票天津磁卡(600800),结果每年都赚得钵满盆盈。我从不看K线图,也不盯大盘,只是偶尔看一眼行情,简单判断一下,就万事大吉了。
世界没有免费的午餐,也没有天上掉下来的馅饼。你要研究赚钱,总结自己的简单赚钱方法,然后坚持它,不要轻易改变。现在大多数人没有主心骨,炒股太善变了,今天炒长线,明天炒短线,今天听个消息就买,明天听个消息就卖,结果六心不定,输得干干净净。这个教训要切记!
简单的方法赚大钱,复杂的方法赚小钱,这是赚钱的第三定律。
赚钱第四定律:赚大钱一定要有目标!
年年岁岁花相似,赚钱方法各不同。
但有一点是相同的,就是你要赚钱一定要有目标。
成功的道路是由目标铺成的。没有目标的人是在为有目标的人完成目标的。
有大目标的人赚大钱,有小目标的人赚小钱,没有目标的人永远为衣食发愁。你是哪类人?
没有目标,欲说还休,欲说还休,却道赚钱真忧愁!
要赚钱,你必须有赚钱的野心。野心是什么?野心就是目标,就是理想,就是梦想,就是企图,就是行动的动力!
试看天下财富英雄,都是野心家,比如洛克菲勒、比尔盖茨、孙正义等等。没有财富野心,就没有财富。
有野心不是坏事,有野心才有动力、有办法、有行动。
赚钱的野心要越大越好,这不是教你干坏事,干坏事的野心要越小越好。
从现在开始,你要立即“做梦”,当一个野心家,设定赚钱的大目标:终生目标,10年目标,5年目标,3年目标,以及年度目标。然后制定具体计划,开始果敢的行动。
万事开头难,有目标就不难,创富是从制定目标开始的。天下没有不赚钱的行业,没有不赚钱的方法,只有不赚钱的人。
“人穷烧香,志短算命。”要赚钱,你一定要有目标,一定要有野心,这是赚钱的第四定律。
赚钱第五定律:一定要用脑子赚钱!
天下熙熙皆为名来,天下攘攘皆为利往。在财富时代,你一定要用脑子赚钱。
你见过谁用四肢赚大钱的?一些运动员赚钱不菲,但迈克尔乔丹说:“我不是用四肢打球,而是用脑子打球。”用四肢不用脑子只能是别人的工具,是别人大脑的奴隶,是赚不了大钱的!
用四肢只能赚小钱,用脑子才能赚大钱。
人的想像力太伟大了,爱因斯坦说过:“想象力比知识更重要”,美国通用电器公司前总裁杰克韦尔奇说过:“有想法就是英雄”。人类如果没有想像力就如同猿猴和黑猩猩。
赚钱始于想法,富翁的钱都是“想”出来的!
想当初,比尔盖茨怎么就会做软件,怎么就会搞视窗,因为他想到了,正如他自己说的“我眼光好”。亚洲首富孙正义在美国读书时没钱就发明翻译机,一下卖了一百万美元,后来开办软件银行,他的头脑和眼光也了不得。好孩子集团老板宋郑还是靠卖发明专利起家的,第一项发明卖了4万元,第二项发明别人出价8万元要买,但他不卖,自己投入生产,结果成了世界童车大王。
现在有的人确实靠嘴巴赚了钱,但他说话之前首先必须想好说什么。也有些人企图靠耳朵赚钱,自己不动脑,到处打听消息,特别在股市里,今天听个内幕消息就买,明天听个小道消息就卖,跟风头,随大流,最后被套赔钱,现在大多数股民都这样,不知道自己的脑子是干什么的!
世界上所有富翁都是最会用脑子赚钱的,你就是把他变成穷光蛋,他很快又是富翁,因为他会用脑。洛克菲勒曾放言:“如果把我所有财产都抢走,并将我扔到沙漠上,只要有一支驼队经过,我很快就会富起来。”让我们再来看看脑白金和黄金搭档,史玉柱的东山再起启示我们,只要把脑子用活,失败了还会成功,再赚钱是不成问题的。
我郑重地告诉大家:你要赚钱你就想吧,想好了就行动,保准你有好收成。
莎仕比亚在《哈姆雷特》中讲过:“你就是把我关在胡桃盒子里,我也是无限想像空间的君主。”展开你想像的翅膀吧,赚钱的第五定律是,你一定要用脑子赚钱!
赚钱第六定律:要赚大钱一定要敢于行动!
天下财富遍地流,看你敢求不敢求。金钱多么诱人啊,但要赚大钱一定要敢于行动!
世界没有免费的午餐,也没有天上掉下来的馅饼。
不行动你不可能赚钱,不敢行动你赚不了大钱。敢想还要敢干,不敢冒险只能小打小闹,赚个小钱。
我行我富!试看天下财富英雄都是有胆有识有行动力的,想当年比尔盖茨放弃哈佛大学学业,白手起家创办微软,是何等的胆识和行动力。美国最年轻的亿万富翁迈克戴尔,在大学读书时就组装电脑卖,感到不过瘾便开办电脑公司,是何等另人钦佩。
甲骨文公司老板埃里森不仅放哈佛学业,赚取260亿美金,还回哈佛演讲,鼓动学生退学,被警察拖下讲坛。还有网易丁磊、健力宝张海、实德徐明等等,他们之所以有今天的业绩,就在于他们当初敢于冒险,敢于行动。
你敢富吗?绝大多数人不敢!其实大多数人都没想富,别说敢富。
现在人们谈论财富越来越多,但许多人说得多,做得少。
要知道:“说是做的仆人,做是说的主人”。我们许多经济学家谈财富头头是道,但他们谁富了?中国的股评家评起股来夸夸其谈,但他们谁炒股赚大钱了?如果他们能赚大钱,就不会当股评家了!所以你要炒股,千万不要相信股评家!
德国行动主义哲学家费希特说过:“行动,行动,这是我们最终目的。”要想富,快行动,不要怕,先迈出一小步,然后再迈出一大步。记住:“利润和风险是成正比的”。
赚钱第七定律:想赚大钱一定要学习赚钱!
天下聪明人很多,但为什么绝大多数聪明人都不富?在财智时代,要赚大钱一定要学习赚钱!
你学过赚钱吗?绝大多数人没有,所以绝大多数人还不会赚钱。我们在小学没学过赚钱,在中学没学过赚钱,在大学还是没学过赚钱,就连金融、财经类的大学也学不到真正赚钱的知识,看来我们的教育确实有了大问题!
聪明的穷人们啊,你们的智商很高,但你们的财商太低,你们穷得太可怜了!不过高尔基说过:“自学是没有围墙的大学”,你们可以自学赚钱知识。
人非生而知之,谁天生就会赚钱?财商和智商不同,智商有天生的成份,而财商100%需要后天学习提高。孙正义、李嘉诚、史玉柱等所有大富翁,都不是一生下来就会赚钱,但他们都有两个共同特点:一是有强烈的赚钱企图心,二是有很强的学习力,正是由于他们善于学习赚钱,所以他们超越常人,登上财富巅峰。
聪明不等于智慧,聪明赚不到钱,智慧能赚大钱。真正白手起家的富豪,学历不一定高,但一定很有智慧,他们是最善于学习赚钱的一族,他们都有学习赚钱的不凡历程,他们通过学习摸到了赚钱的规律,掌握了赚钱门道,执掌了赚钱的牛耳,成为财富英雄!
英雄起于草莽,英雄不问出处。真正的赚钱者,都是阅读者。你想当富翁吗?你想跨入财富英雄行列吗?那你就赶快学习赚钱:读赚钱书报、听赚钱讲座、向财富精英学习、向身边高人请教等等。比如,炒股你要学习沃伦巴菲特,尤其学他简单的投资理念。创业你要学习孙正义,他在两年之内读了4000本书(不知道是怎么读的)。还有李嘉诚,他为了创业专门到别的公司打工偷艺。向成功者学,像成功者那样干,增长你的智慧,提高你的财商,总结赚钱的秘笈,很快你就会富。
赚钱的第七定律是,要赚大钱一定要学习赚钱!
赚钱的第八定律:赚大钱一定要选择!
风水轮流转,今天到你家。如今金钱遍地都是,赚钱方法多如牛毛,但要赚大钱一定要选择。
选择就是命运,选择就是财富。不选择你就会迷失,财富就会与你擦肩而过。
你是命运的主宰,你是财富的上帝。在二十多年前,美国一个17岁少年,一头乱发,一身脏衣,戴着一付高度近视眼镜,但他竟选择了编写软件,创办软件公司,正是由于这一选择,才有今天的微软和今天的比尔盖茨!
亚洲首富孙正义19岁开始创业,一年之内制定了40个创业计划,但他只选择其中一个最好的计划——开办软件银行,由此登上了财富的天梯!
在市场多样化加速、越来越细分的时代,只有选择才能成功。沃尔玛只选择做商品零售,可口可乐只卖饮料,肯德基、麦当劳只卖汉堡,日本的松下、索尼、三洋只做电器。
选择的目的就是专一和专注。我国许多知名大企业现在开始走多元化的路子,包括海尔在内,其实多元化之路危机四伏,很有可能要失败,四通、飞龙、轻骑的失败就是例证。史玉柱做保健品很成功,刚一多元化就失败,现在他吸取教训,做保健品重新获得成功。
你要创业,你选择什么?根据多年对世界财富精英的分析,富豪们大多涉猎股票和地产。事实上美国和欧洲60%以上的人投资股票。
炒股也需要选择,例如选择什么投资理念和原则,选择长线还是短线,选择什么股票,是组合投资还是专一投资。
现在许多人热衷炒短线,在股市频繁进出,频繁换股,一年到头忙忙碌碌,很象操盘高手,结果不仅赚不到钱,还深套其中,既辛苦又心酸。
炒股一定要专一,就象对老婆一样。中外股市大赢家很少是短线高手,大多是长线老牛,沃伦巴菲特是其中最著名的。他告诉我们:“如果一只股票我不想持有10年,我就根本不碰它一下”;“不要多样化,要把所有鸡蛋放到一个篮子里,然后密切关注它。”我国一些庄家多年来专做几只股票,有的甚至2、3年内只炒一只股票,结果赢利甚丰。
你要炒股千万别花心,精心选择好股去爱她,她会为你下金蛋!
赚钱的第八定律是,赚大钱一定要选择!
posted @
2006-11-04 11:29 xzc 阅读(419) |
评论 (0) |
编辑 收藏有狗死于沙漠。好事者经过分析发现,狗的死因与找不到可供便溺的树或者墙有关。人类似乎有些时候做出这种被一泡尿憋死的事情来,所以关于情商管理方面的研究大行其道颇具规模。甚至有人认为,IQ高的人经过努力成了医生、科学家和技术专家,而EQ高的人经过努力成了医生、科学家和技术专家们的管理者。电影里那个大智若愚的家伙一脸严肃地喊:IP、IC、IQ统统给我密码,我想也许世界上真的存在打开一个人智力之门的钥匙,同时也一定有破解人类情商之迷的超级密码。
1、世事洞明皆学问,人情练达即文章
经常读的人知道这是红楼梦里面的一副对联。这应该是对做人处世之道概括得最好的一句话了,世事洞明说的是智商能力,人情练达说的则是情商能力,需二者兼修决不可偏废。
2、我们每个人都守着一扇只能自内开启的改变之门
一个人需要有对于变化的因应能力,而最积极的因应态度则是预知变化并主动寻求改变,倘倘若等到变化来敲你的门时恐怕为时已晚。同时也因为任何改变自内开启,其决心愈坚则其效果愈明显。
3、生气就是拿别人的过错来惩罚自己
情绪失控已经成了我们最危险的职业病,据说我们正在变得越来越容易发脾气,而幸福指数越来越低。聪明的人不一定都念过佛,但往往比我们更能够展现宽容和豁达。不会生气的人一定是笨蛋,不去生气的人才聪明。
4、成功的人不在于摸到了一副好牌,而在于打好一副坏牌
不管是作为自我安慰还是自我激励,这句话都应该能够帮得上忙。英雄不问出处,我们虽然不能决定自己出身在什么样的家庭,但我们可以决定一生中可以达到的高度;我们之所以会有成就感,那是因为我们完成挑战了一个需要跳一跳才够得着的目标。
5、如果要等到所有的灯都变成绿灯才行动,那永远别想有开始
同样是砍一颗树,有人说我哪有时间磨刀呢忙着砍树呢,而另一种人则光磨刀不砍树。这第二种人要么是磨刀主义者,要么完美主义者。有一个开着车子的女人停在路口,眼看红灯变成黄灯又变成绿灯却依然一动不动,无奈的交警走过来问:怎么啦,没有你喜欢的颜色吗?
6、将80%的时间关注在20%的事情的,因为这20%的事情会给你带来80%的效果
合理的运用二八法则可以规划好你的时间,因而可以让生活看起来更有质量,让你的努力更容易接近理想和目标。所以我们至少要学会在所有的目标中找到那些将要影响我们一生的关键的少数,然后有效地进行时间和资源的倾斜和投资。
7、把船泊在港口时是安全的,但那并不是造船的目的
人生的价值又如一尾船的价值。过于担心未来不可知的风险,那么失去的将不只是风景,而是价值实现的机会和可能。期待远航不如现在就启航,如果要飞得高,就该把地平线忘掉,歌里面都已经有了很好的解释。
8、未来成功的典范,不在于你赢过多少人,而在于你帮助过多少人,服务过多少地方
人脉无疑是重要的情商能力之一。上帝给了我们手和脚,我们可以用脚跑过别人甚至伴倒别人,但也可以用手来援助别人。一心想要赢过别人的我们,不如从现在开始换一种赢法,在开放和合作中实现双赢甚至多赢。
9、没有追赶不会奔跑,没有竞争不会进步
草食动物不用为了食物而奔跑,却要为了避免成为别人的食物而跑;动物世界里为了生存而进行的竞争远比人类进行的商业竞争残酷多了,正如那只被猎狗追赶的狐狸对另一只狐狸所说的,我不一定跑得过猎狗,但一定要跑过你。
posted @
2006-11-04 11:29 xzc 阅读(239) |
评论 (0) |
编辑 收藏作者:薛谷雨
作者简介
薛谷雨,NORDSAN(北京)信息科技开发有限公司高级JAVA研发工程师,正致力于企业级异构数据交换的服务器产品的研发,在J2EE和WEB SERVICE方面有较为丰富的开发经验,您可以通过rainight@126.com与他联系。
前言
代码生成器(code generator,CG),顾名思义就是生成代码的工具。有了它,你就可以从一组简单的设定或者数据库设计中获得几百、几千行代码。如果不采用这项技术的话,开发者就不得不花上几个小时或者几天的时间来手工编写这些代码。另一方面,优秀的开发工具为了提供其独特的功能或者屏蔽一些容易出错的细节,也往往采用代码生成技术为使用者提供一个程序的模板框架,其目的也是为了提高编程的效率。以上观点仅是对代码生成器的一般理解,换句话说,这似乎是一个可有可无的东西,没有它,不过是多费一些人工而已。然而,本文要介绍的这套名为ASM的JAVA工具类的功能非同小可,它可以生成JAVA字节码,也就是class文件。你可以在应用程序中根据情况动态生成各式各样的class,然后就调用,达到一种近乎上帝造物般的神奇。心动不如行动,如果你也想在自己的开发中引入这一超前的编程技术,请看此文。
小巧而神奇的ASM
ASM是一套JAVA字节码生成架构。它可以动态生成二进制格式的stub类或其他代理类,或者在类被JAVA虚拟机装入内存之前,动态修改类。ASM 提供了与 BCEL( http://jakarta.apache.org/bcel )和SERP( http://serp.sourceforge.net/ )相似的功能,只有22K的大小,比起350K的BCEL和150K的SERP来说,是相当小巧的,并且它有更高的执行效率,是BCEL的7倍,SERP的11倍以上。ASM一贯的设计思想就是将其应用于动态生成领域,因此小巧和快捷一直是这个产品的设计和实现的指导思想。
此产品由法国电信公司的研发工程师Eric Bruneton负责。从2002年7月ASM的第一个版本发布至今,此产品已经升级了五次,日臻完美。到目前为止,ASM最新的版本是1.3.5,你可以去 http://asm.objectweb.org/ 下载。
ASM的最终目标是创建一个生成工具,可以被用来执行对任何类的处理操作(不像一些工具,比如Javassit,它只支持预先定义的类操作,然而在许多场合这一功能是有局限性的)。
JAVA的CLASS文件格式
要想驾驭ASM,先要了解一下JAVA的CLASS文件格式。JAVA的CLASS文件通常是树型结构。根节点包含以下元素:
- ConstantPool:符号表;
- FieldInfo:类中的成员变量信息;
- MethodInfo:类中的方法描述;
- Attribute:可选的附加节点。
FieldInfo节点包含成员变量的名称,诸如public,private,static等的标志。ConstantValue属性用来存储静态的不变的成员变量的值。Deprecated和Synthetic被用来标记一个成员变量是不被推荐的或由编译器生成的。
MethodInfo节点包含方法的名称,参数的类型和和它的返回值,方法是公有的,私有的或静态的等标志。MethodInfo包含可选的附加属性,其中最重要的是Code属性,它包含非抽象的方法的代码。Exceptions属性包含方法将抛出的Exception的名称。Deprecated和Synthetic属性的信息同上面的FieldInfo的定义一样。
根节点的可选属性有SourceFile,InnerClasses和Deprecated。SourceFile用来存储被编译成字节码的源代码文件的原始名称;InnerClasses存储内部类的信息。由于这些属性的存在,java 的类格式是可以扩展的,也就是说可以在一个class中附加一些非标准的属性, java虚拟机会忽略这些不可识别的属性,正常的加载这个class。
ConstantPool是一个由数字或字符串常量的索引组成的队列,或由此类的树的其他节点引用的,由其他对象创建的被引用常量的索引组成的队列。这个表的目标是为了减少冗余。例如,FieldInfo节点不包含节点的名称,只包含它在这一表中的索引。同样的,GETFIELD和PUTFIELD不直接包含成员变量的名称,只包含名称的索引。
精通ASM
Asm架构整体都围绕着两个接口,即ClassVisitor 和 CodeVisitor,它们能访问每个类的方法,成员变量,包含在每个方法中的字节码指令。ClassReader用来读取class文件;ClassWriter类用来写生成的Class文件。
为了修改已经存在的class,你必须使用分析class文件的ClassReader,类的修正器和写class文件的ClassWriter。类的修正器就是一个ClassVisitor,它可以委派一部分工作到其他的ClassVisitor,但是为了实现预期的修改步骤,它将改变一些参数的值,或者调用一些其他方法。为了比较容易的实现这种类的修正器,ASM提供了一个ClassAdapter和CodeAdapter,这两个适配器类分别实现了ClassVistor和CodeVistor接口。
HelloWorld,体验造类的神奇
下面是一个应用ASM动态生成字节码的类,并调用其中方法的完整的HelloWorld 程序,程序的功能是动态生成一个Example.class类,并实例化一个Example对象,调用对象的main函数,在屏幕上打印出"Hello world!"
import org.objectweb.asm.*;
import java.lang.reflect.*;
import java.io.FileOutputStream;
public class Helloworld extends ClassLoader implements Constants {
public static void main (final String args[]) throws Exception {
/*
* 此程序将生成一个class,对应的java源代码是:
*
* public class Example {
* public static void main (String[] args) {
* System.out.println("Hello world!");
* }
* }
*
*/
// 创建一个ClassWriter
ClassWriter cw = new ClassWriter(false);
cw.visit(ACC_PUBLIC, "Example", "java/lang/Object", null, null);
// 创建一个 MethodWriter
CodeVisitor mw = cw.visitMethod(ACC_PUBLIC, "", "()V", null);
// 推入 'this' 变量
mw.visitVarInsn(ALOAD, 0);
// 创建父类的构造函数
mw.visitMethodInsn(INVOKESPECIAL, "java/lang/Object", "", "()V");
mw.visitInsn(RETURN);
// 这段代码使用最多一个栈元素和一个本地变量
mw.visitMaxs(1, 1);
// 为main方法创建一个MethodWriter
mw = cw.visitMethod(
ACC_PUBLIC + ACC_STATIC, "main", "([Ljava/lang/String;)V", null);
// 使用System类的out成员类
mw.visitFieldInsn(
GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
// pushes the "Hello World!" String constant
mw.visitLdcInsn("Hello world!");
// 调用System.out的'println' 函数
mw.visitMethodInsn(
INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V");
mw.visitInsn(RETURN);
// 这段代码使用最多两个栈元素和两个本地变量
mw.visitMaxs(2, 2);
// 生成字节码形式的类
byte[] code = cw.toByteArray();
FileOutputStream fos = new FileOutputStream("Example.class");
//写文件
fos.write(code);
//关闭输出流
fos.close();
//实例化刚刚生成的类
Helloworld loader = new Helloworld();
Class exampleClass = loader.defineClass("Example", code, 0, code.length);
// 使用动态生成的类打印 'Helloworld'
Method main = exampleClass.getMethods()[0];
main.invoke(null, new Object[] {null});
}
}
|
posted @
2006-11-04 11:05 xzc 阅读(440) |
评论 (0) |
编辑 收藏posted @
2006-11-02 09:41 xzc 阅读(307) |
评论 (0) |
编辑 收藏
1 关键名词
Project:任何您想build的事物,Maven都可以认为它们是工程。这些工程被定义为工程对象模型(POM,Poject Object Model)。一个工程可以依赖其它的工程;一个工程也可以由多个子工程构成。
POM:POM(pom.xml)是Maven的核心文件,它是指示Maven如何工作的元数据文件,类似于Ant中的build.xml文件。POM文件位于每个工程的根目录中。
GroupId:groupId是一个工程的在全局中唯一的标识符,一般地,它就是工程名。groupId有利于使用一个完全的包名,将一个工程从其它有类似名称的工程里区别出来。
Artifact:artifact是工程将要产生或需要使用的文件,它可以是jar文件,源文件,二进制文件,war文件,甚至是pom文件。每个artifact都由groupId和artifactId组合的标识符唯一识别。需要被使用(依赖)的artifact都要放在仓库(见Repository)中,否则Maven无法找到(识别)它们。
Dependency:为了能够build或运行,一个典型的Java工程会依赖其它的包。在Maven中,这些被依赖的包就被称为dependency。dependency一般是其它工程的artifact。
Plug-in:Maven是由插件组织的,它的每一个功能都是由插件提供的。插件提供goal(类似于Ant中的target),并根据在POM中找到的元数据去完成工作。主要的Maven插件要是由Java写成的,但它也支持用Beanshell或Ant脚本写成的插件。
Repository:仓库用于存放artifact,它可以是本地仓库,也可以是远程仓库。Maven有一个默认的远程仓库--central,可以从http://www.ibiblio.org/maven2/下载其中的artifact。在Windows平台上,本地仓库的默认地址是User_Home\.m2\repository。
Snapshot:工程中可以(也应该)有一个特殊版本,它的版本号包括SNAPSHOT字样。该版本可以告诉Maven,该工程正处于开发阶段,会经常更新(但还未发布)。当其它工程使用此类型版本的artifact时,Maven会在仓库中寻找该artifact的最新版本,并自动下载、使用该最新版。
2 Maven Build Life Cycle
软件项目一般都有相似的开发过程:准备,编译,测试,打包和部署,Maven将上述过程称为Build Life Cycle。在Maven中,这些生命周期由一系列的短语组成,每个短语对应着一个(或多个)操作;或对应着一个(或多个)goal(类似于Ant中的target)。
如编译源文件的命令mvn compile中的compile是一个生命周期短语。同时该命令也可以等价于mvn compiler:compile,其中的compiler是一个插件,它提供了compile(此compile与mvn compile中的compile意义不同)goal;compiler还可提供另一个goal--testCompile,该goal用于编译junit测试类。
在执行某一个生命周期时,Maven会首先执行该生命周期之前的其它周期。如要执行compile,那么将首先执行validate,generate-source,process-source和generate-resources,最后再执行compile本身。关于Maven中默认的生命周期短语,请见参考资源[6]中的附录B.3。
3 标准目录布局
Maven为工程中的源文件,资源文件,配置文件,生成的输出和文档都制定了一个标准的目录结构。Maven鼓励使用标准目录布局,这样就不需要进行额外的配置,而且有助于各个不同工程之间的联接。当然,Maven也允许定制个性的目录布局,这就需要进行更多的配置。关于Maven的标准目录布局,请见参考资源[6]中的附录B.1。
4 Maven的优点
[1]build逻辑可以被重用。在Ant中可能需要多次重复地写相同的语句,但由于POM的继承性,可以复用其它的POM文件中的语句。这样既可以写出清晰的build语句,又可以构造出层次关系良好的build工程。
[2]不必关注build工作的实现细节。我们只需要使用一些build生命周期短语就可以达到我们的目标,而不必管Maven是如何做到这些的。如,只需要告诉Maven要安装(install),那么它自然就会验证,编译,打包,及安装。
[3]Maven会递归加载工程依赖的artifact所依赖的其它artifact,而不用显示的将这些artifact全部写到dependency中。
[4]如果完全使用Maven的标准目录布局,那么可以极大地减少配置细节。
5 实例
5.1 构想
由于只是阐述Maven的基本使用方法,所以本文将要设计的实例,只是一个简单的Maven demo。该实例包含两个工程:普通应用程序工程(app)和Web应用工程(webapp)。app工程提供一个简单的Java类;webapp工程只包含一个Servlet,并将使用app中的Java类。
该Demo的目标是能够正确地将webapp制成war包,以供部署时使用。要能够正确制作war,自然首先就必须要能够正确的编译源代码,且要将App模块制成jar包。本文创建的工程所在的目录是D:\maven\demo。
5.2 App工程
可以使用Maven的archetype插件来创建新工程,命令如下:
D:\maven\demo>mvn archetype:create -DgroupId=ce.demo.mvn -DartifactId=app
该工程的groupId是ce.demo.mvn,那么该工程的源文件将放在Java包ce.demo.mvn中。artifactId是app,那么该工程根目录的名称将为app。
当第一次执行该命令时,Maven会从central仓库中下载一些文件。这些文件包含插件archetype,以及它所依赖的其它包。该命令执行完毕后,在目录D:\maven\demo下会出现如下目录布局:
app
|-- pom.xml
`-- src
|-- main
| `-- java
| `-- ce
| `-- demo
| `-- mvn
| `-- App.java
`-- test
`-- java
`-- ce
`-- demo
`-- mvn
`-- AppTest.java
因本文暂时不涉及JUnit测试,故请将目录app\src\test目录删除(不删除也没关系 ^_^)。然后再修改App.java文件,其完全内容如下:
 package ce.demo.mvn;
package ce.demo.mvn;

 public class App
public class App  {
{

 public String getStr(String str) {
public String getStr(String str) {
 return str;
return str;
 }
}
 }
}
5.3 WebApp工程
我们仍然如创建app工程一样使用archetype插件来创建webapp工程,命令如下:
D:\maven\demo>mvn archetype:create -DgroupId=ce.demo.mvn -DartifactId=webapp -DarchetypeArtifactId=maven-archetype-webapp
第一次运行此命令时,也会从central仓库中下载一些与Web应用相关的artifact(如javax.servlet)。此命令与创建app的命令的不同之处是,多设置了一个属性archetypeArtifacttId,该属性的值为maven-archetype-webapp。即告诉Maven,将要创建的工程是一个Web应用工程。创建app工程时没有使用该属性值,是由于archetype默认创建的是应用程序工程。同样的,执行完该命令之后,会出现如下标准目录布局:
webapp
|-- pom.xml
`-- src
`-- main
`-- webapp
|-- index.jsp
|-- WEB-INF
`-- web.xml
根据5.1节的构想,webapp工程将只包含一个Servlet,所以我们不需要index.jsp文件,请将其删除。此时大家可以发现,目前的目录布局中并没有放Servlet,即Java源文件的地方。根据参考资源[6]中的附录B.1,以及app工程中Java源文件的布局,可以知道Servlet(它仍然是一个Java类文件)仍然是放在webapp\src\main\java目录中,请新建该目录。此处的Servlet是一个简单HelloServlet,其完整代码如下:
package hello;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import ce.demo.mvn.App; // 引用app工程中的App类
public class HelloServlet extends HttpServlet {
private static final long serialVersionUID = -3696470690560528247L;
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
App app = new App();
String str = app.getStr("CE Maven Demo");
PrintWriter out = response.getWriter();
out.print("<html><body>");
out.print("<h1>" + str);
out.print("</body></html>");
}
} 5.4 POM文件
大家可以发现,在前面新建工程时,我们并没有提到各个工程中的pom.xml文件。现在将要讨论这个问题。我们先看看app工程中的POM文件,其完整内容如下:
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>ce.demo.mvn</groupId>
<artifactId>app</artifactId>
<packaging>jar</packaging>
<version>1.0</version>
<name>CE Maven Demo -- App</name>
</project> 大家可以发现此我帖出来的内容与实际由archetype插件生成的POM文件的内容有些不同,但基本上是一致的。只是为了使文件中的语句更清晰,此处删除了一些冗余的内容,并修改了该工程的version和name的值,以与此例子的背景来符合。在目前情况下modelVersion值将被固定为4.0.0,这也是Maven2唯一能够识别的model版本。groupId,artifactId的值与创建工程时使用的命令中的相关属性值是一致的。packaging的值由工程的类型决定,如应用程序工程的packaging值为jar,Web应用工程的packaging值为war。上述情况也可以从webapp的POM文件中看出,下面将看看这个pom的完整内容。
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>ce.demo.mvn</groupId>
<artifactId>webapp</artifactId>
<packaging>war</packaging>
<version>1.0</version>
<name>CE Maven Demo -- WebApp</name>
<dependencies>
<dependency>
<groupId>ce.demo.mvn</groupId>
<artifactId>app</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.4</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project> 比较app与webapp中的POM,除前面已经提过的packaging的差别外,我们还可以发现webapp中的POM多了dependencies项。由于webapp需要用到app工程中的类(见HelloServlet源代码),它还需要javax.servlet包(因为该包并不默认存在于jsdk中)。故,我们必须要将它们声明到依赖关系中。
5.5 执行
上述两个工程创建完毕后,就需要执行一些命令来看看会有什么结果出现。我们首先进入app目录,并执行命令mvn compile,然后会在该目录下发现新生成的目录target\classes,即编译后的class文件(包括它的包目录)就放在了这里。再执行命令mvn package,在目录target中就会生成app-1.0.jar文件。该文件的全名由如下形式确定:artifactId-version.packaging。根据第2章的叙述可以知道,执行命令mvn package时,将首先将产生执行命令mvn compile之后的结果,故如果要打包,那么只需要执行mvn package即可。
在app工程中执行完之后,就需要进入webapp工程了。进入webapp目录,此次将只执行mvn package命令(隐示地执行了compile过程)。此次命令的执行并不成功,会出现如下问题:
D:\maven\demo\webapp>mvn package
……
Downloading: http://repo1.maven.org/maven2/ce/demo/mvn/app/1.0/app-1.0.pom
[INFO] ------------------------------------------------------------------------
[ERROR] BUILD ERROR
[INFO] ------------------------------------------------------------------------
[INFO] Error building POM (may not be this project's POM).
Project ID: ce.demo.mvn:app
Reason: Error getting POM for 'ce.demo.mvn:app' from the repository: Error transferring file
ce.demo.mvn:app:pom:1.0
from the specified remote repositories:
central (http://repo1.maven.org/maven2)
……
由粗体内容可知,Maven正试图从central仓库下载app工程的artifact,但central仓库肯定不会有这个artifact,其结果只能是执行失败!由第1章artifact名词的解释可知,被依赖的artifact必须存在于仓库(远程或本地)中,但目前webapp所依赖的app必不存在于仓库中,所以执行只能失败。
解决这个问题有两种方法:[1]将app-1.0.jar安装到仓库中,使它成为一个artifact;[2]构建一个更高层次的工程,使app和webapp成为这个工程的子工程,然后从这个更高层次工程中执行命令。
第一种方法比较简单(见http://www.blogjava.net/jiangshachina/admin/EditPosts.aspx中的第一个主题),此处将详细讨论第2种方法(见5.6节)。
5.6 更高层次工程
我们可以将app和webapp的上一级目录demo作为这两个工程的 一个 更高层次工程,即使用app和webapp成为这个工程的子工程。为了使demo目录成为一个demo工程,只需要在这个目录下添加一个pom.xml文件,该文件内容如下:
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>ce.demo</groupId>
<artifactId>mvn-demo</artifactId>
<packaging>pom</packaging>
<version>1.0</version>
<name>CE Maven Demo</name>
<modules>
<module>app</module>
<module>webapp</module>
</modules>
</project> 与app和webapp中的POM相比,demo的POM使用了modules项,modules用于声明本工程的子工程,module中的值对应于子工程的artifact名。而且该POM的packaging类型必须为pom。
有了demo工程后,我们只需要在demo目录下执行相关命令就可以了。通过如下命令即可验证:
[1]mvn clean – 消除工程(包括所有子工程)中产生的所有输出。这本文的实例中,实际上是删除target目录。由于之前的操作只有app工程产生了target目录,而webapp并没有,所以将只会删除app工程中的target目录。
[2]mvn package – 将工程制作成相应的包,app工程是作成jar包(app-1.0.jar),webapp工程是作成war包(webapp-1.0.war)。打开webapp-1.0.war包,可以发现app-1.0.jar被放到了WEB-INF的lib目录中。
6 小结
通过以上的叙述与实例,应该可以对Maven有一个粗略的认识了。使用Maven关键是要弄清楚如何写pom.xml文件,就如同使用Ant要会写build.xml文件一样。在POM中可以直接写入Ant的task脚本,也可以调用Ant的build.xml文件(推荐),所以Maven也可以完成Ant的绝大多数工作(但不必安装Ant)。注意:使用Maven就不要再过多的使用Ant脚本。
利用好Maven的继承特性及子工程的关系,可以很好地简化POM文件,并能够构建层次结构良好的工程,有利于工程的维护。
7 参考资源
[1]Maven官方网站. http://maven.apache.org
[2]Maven POM文件参考结构. http://maven.apache.org/ref/current/maven-model/maven.html
[3]Super POM. http://maven.apache.org/guides/introduction/introduction-to-the-pom.html
[4]Maven主要插件的列表. http://maven.apache.org/plugins
[5]Maven基本使用指南. http://maven.apache.org/guides/index.html
[6]Better Build with Maven. http://www.mergere.com/m2book_download.jsp -- 强烈推荐
[7]介绍Maven2. http://www.javaworld.com/javaworld/jw-12-2005 /jw-1205-maven_p.html
[8]揭秘Maven2 POM. http://www.javaworld.com/javaworld/jw-05-2006/jw-0529-maven.html
[9]Maven让事情变得简单. http://www-128.ibm.com/developerworks/cn/java/j-maven
[10]Maven文档集. http://docs.codehaus.org/display/MAVENUSER/Home
[11]有效利用Maven2的站点生成功能. http://www.matrix.org.cn/resource/article/44/44491_Maven2.html
文中例子程序下载:http://www.blogjava.net/files/jiangshachina/maven.rar
posted @
2006-10-29 16:29 xzc 阅读(1245) |
评论 (0) |
编辑 收藏 1、应答上司交代的工作:我立即去办。
冷静、迅速地做出这样的回应,会让上司直观地感觉你是一个工作讲效率、处理问题果断,并且服从领导的好下属。如果你犹豫不决,只会让上司不快,会给上司留下优柔寡断的印象,下次重要的机会可能就轮不到你了。
2、传递坏消息时:我们似乎碰到一些情况……
一笔业务出现麻烦,或市场出现危机,如果你立刻冲到上司的办公室报告这个坏消息,就算不关你的事,也会让上司怀疑你对待危机的能力,弄不好还会惹得上司的责骂,成为出气筒。
正确的方式是你可以从容不迫地说:我们似乎碰到一些情况……千万不要乱了阵脚,要让上司觉得事情并没有到不可收拾的地步,并且感到你会与他并肩作战,解决问题。
3、体现团队精神:XX的主意真不错!
小马的创意或设计得到了上司的欣赏,虽然你心里为自己不成功的设计而难过,甚至有些妒忌,你还是要在上司的听力范围内夸夸小马:小马的主意真不错。在明争暗斗的职场,善于欣赏别人,会让上司认为你本性善良,并富有团队精神,从而给你更多的信任。
4、如果你不知道某件事:让我再认真地想一想,2点前答复您好吗?
上司问了你某个与业务有关的问题,你不知道如何作答,千万不要说“不知道”。而“让我再认真地想一想,2点前答复您好吗?”不仅暂时让你解围,也让上司认为你不轻率行事,而是个三思而后行的人。当然,要记得按时给出答复。
5、请同事帮忙:这个策划没有你真不行啊!
有个策划,你一个人搞不定,得找个比较内行的人帮忙,怎么开口呢?你可以诚恳地说:这个策划没有你真不行啊!同事为了不负自己内行的形象,通常是不会拒绝的。当然,事后要记得感谢人家。
6、拒绝黄段子:这种话好像不适合在办公室讲哦! 男人有时总喜欢说些黄段子,并且不大注意场合。如果有男同事对你开“黄腔”,让你无法忍受,这句话可以让他们识趣地闭嘴。
7、减轻工作量:我知道这件事很重要,我们不妨先排一排手头的工作,按重要性排出先后顺序。
首先,强调你了解这项工作的重要性,然后请求上司指示,将这项工作与其它工作一起排出先后顺序,不露痕迹地让上司知道你的工作量其实很大,如果不是非你不可,有些事就可交给其他人或延期处理。
8、承认过失:是我一时疏忽,不过幸好……
犯错误在所难免,所以勇于承认自己的过失很重要,推卸责任只会使你错上加错。不过,承认过失也有诀窍,就是不要让所有的错误都自己扛,这句话可以转移别人的注意力,淡化你的过失。
9、打破冷场的话题:我很想知道您对这件事的看法……
当你与上司相处时,有时不得不找点话题,以打破冷场。不过,这正是你赢得上司青睐的好机会,最恰当的话题就是谈一些与公司有关、上司很关心又熟悉的话题。当上司滔滔不绝地发表看法时,也会对你这样一个谦虚的听众欣赏有加。
10、面对批评:谢谢你告诉我,我会仔细考虑你的建议的。
面对批评或责难,不管自己有没有不当之处,都不要将不满写在脸上,但要让对方知道,你已接受到他的信息,不卑不亢让你看起来又自信又稳重,更值得敬重。
posted @
2006-10-24 15:39 xzc 阅读(287) |
评论 (0) |
编辑 收藏 1.长相不令人讨厌,如果长得不好,就让自己有才气;如果才气也没有,那就总是微笑。
2.气质是关键。如果时尚学不好,宁愿纯朴。
3.与人握手时,可多握一会儿。真诚是宝。
4.不必什么都用“我”做主语。
5.不要向朋友借钱。
6.不要“逼”客人看你的家庭相册。
7.与人打“的”时,请抢先坐在司机旁。
8.坚持在背后说别人好话,别担心这好话传不到当事人耳朵里。
9.有人在你面前说某人坏话时,你只微笑。
10.自己开小车,不要特地停下来和一个骑自行车的同事打招呼。人家会以为你在炫耀。
11.同事生病时,去探望他。很自然地坐在他病床上,回家再认真洗手。
12.不要把过去的事全让人知道。
13.尊敬不喜欢你的人。
14.对事不对人;或对事无情,对人要有情;或做人第一,做事其次。
15.自我批评总能让人相信,自我表扬则不然。
16.没有什么东西比围观者们更能提高你的保龄球的成绩了。所以,平常不要吝惜你的喝彩声。
17.不要把别人的好,视为理所当然。要知道感恩。
18.榕树上的“八哥”在讲,只讲不听,结果乱成一团。学会聆听。
19.尊重传达室里的师傅及搞卫生的阿姨。
20.说话的时候记得常用“我们”开头。
21.为每一位上台唱歌的人鼓掌。
22.有时要明知故问:你的钻戒很贵吧!有时,即使想问也不能问,比如:你多大了?
23.话多必失,人多的场合少说话。
24.把未出口的“不”改成:“这需要时间”、“我尽力”、“我不确定”、“当我决定后,会给你打电话”……
25.不要期望所有人都喜欢你,那是不可能的,让大多数人喜欢就是成功的表现。
26.当然,自己要喜欢自己。
27.如果你在表演或者是讲演的时候,如果只要有一个人在听也要用心的继续下去,即使没有人喝采也要演,因为这是你成功的道路,是你成功的摇篮,你不要看的人成功,而是要你成功。
28.如果你看到一个贴子还值得一看的话,那么你一定要回复,因为你的回复会给人继续前进的勇气,会给人很大的激励。同时也会让人感激你。
posted @
2006-10-24 15:36 xzc 阅读(250) |
评论 (0) |
编辑 收藏本文介绍怎样把jBPM组件添加到Web应用程序中。所需要用到的资源,可以在jbpm-starters-kit-3.1.2中找到。
一、首先安装jBPM数据库。jBPM是一个停止状态的组件,需要数据库表持久化保存:1)业务程序定义和业务程序实例及相关的工作流数据。保障工作流引擎的执行。2)异步系统使用数据库表来模拟消息系统的功能。需要把消息到数据库表中,由消息系统的命令执行器异步查询和执行。不像专业的消息系统那样是远程的。它仅仅使用数据库模拟消息系统。
1,打开MySQL的命令执行工具Query Browser。
2,当前选定应用程序的数据库,如wcms。
3,导入脚本文件:mysql.drop.create.sql
4,执行该脚本。会在当前数据库中增加jBPM的数据库表。
二、导入jBPM所需的.jar文件
1,jbpmlib目录中包含了jBPM所需的全部jar包。包括MySQL的jdbc包。
2,把它整个复制到应用程序的lib目录下。
3,应用程序的构建器路径的“库”中,把这些jar都加进来。
这些classpath下的jar包,都会被该Web应用程序的类载入器载入。
三、创建config.files和processes目录,并加入classpath的源代码路径
(一)config.files目录的功能
这个目录存放jBPM的各类配置文件。放在这里(就是classpath顶层)的配置文件会取代jBPM的jar包中各处的配置文件。
这里,由于需要使用mysql,而不是内置的hsql内存数据库。所以我们提供了一个修改过的配置文件:hibernate.cfg.xml。这里提供了Hibernate3的配置。
hibernate.cfg.xml配置文件的部分内容
<hibernate-configuration>
<session-factory>
<!-- jdbc connection properties
原来的HSQL配置被注释掉,使用MySQL数据库的配置
<property name="hibernate.dialect">org.hibernate.dialect.HSQLDialect</property>
<property name="hibernate.connection.driver_class">org.hsqldb.jdbcDriver</property>
<property name="hibernate.connection.url">jdbc:hsqldb:mem:.;sql.enforce_strict_size=true</property>
<property name="hibernate.connection.username">sa</property>
<property name="hibernate.connection.password"></property>
-->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLInnoDBDialect</property>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/wcms</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
(二)processes目录的功能
这个目录存放process流程定义。如:manageNews\内有3个文件。
在jBPM应用程序导入.par或.xml文件时,使用相对路径(如:withubCMS/processdefinition.xml)来定位业务程序定义资源文件。
怎样把它们放到classpath下,需要根据不同的环境进行不同的处理。
一、一般Java程序
1,创建config.files和processes目录。
2,配置构建器路径,将这2个目录设为到classpath的源代码路径。
这样,运行时,会把它们中的内容复制到classpath目录下。
二、Eclipse下的Web程序
我们使用Eclipse自带的功能发布Web程序。
1,创建config.files和processes目录。
2,配置构建器路径,将这2个目录设为到classpath的源代码路径。
3,配置classpath,也就是“缺省输出文件夹”,为:
内容管理(应用程序根路径名)/webapps/WEB-INF/classes
4,这样,在Eclipse编译时(默认是保存即编译),把这2个文件夹中的内容复制到classpath下。
5,然后,使用Eclipse自带的功能,发布该Web应用程序。
Eclipse会把/webapps/文件夹下的所有内容复制到Web服务器下,并且把webapps改名为该Web应用程序的Eclipse项目名字。
这样,我们的配置,对于classpath来说也是正确的!Web应用程序可以顺利地运行。
三、Ant发布的Web程序
可以和上面一样。把这些classpath的源文件,编译,然后把内部的内容复制到classpath下。
Web项目运行时的classpath是classes和lib。当然也需要把jar包都复制到lib下。
最后,在内容管理\webapps\WEB-INF\jbpm\下放置那2个目录。并把它们设为classpath的源路径。
目标classpath路径是内容管理\webapps\WEB-INF\classes。
四、测试jBPM和数据库
建立test源文件夹。提供一个junit测试类:org.jbpm.test.db.HelloWorldDbTest。
这个类使用字符串定义了一个简单的业务程序,然后在数据库上完整的执行它。
执行该单元测试。在应用程序的数据库中的2个表:
SELECT * FROM jbpm_processdefinition j;
SELECT * FROM jbpm_processinstance j;
应该有数据。
至此,jBPM组件就成功地加入到Web应用程序中了!
附录:HelloWorldDbTest.java源代码
package org.jbpm.test.db;
import java.util.List;
import junit.framework.TestCase;
import org.jbpm.JbpmConfiguration;
import org.jbpm.JbpmContext;
import org.jbpm.db.GraphSession;
import org.jbpm.graph.def.ProcessDefinition;
import org.jbpm.graph.exe.ProcessInstance;
import org.jbpm.graph.exe.Token;
public class HelloWorldDbTest extends TestCase {
static JbpmConfiguration jbpmConfiguration = null;
static {
// An example configuration file such as this can be found in
// 'src/config.files'. Typically the configuration information is in the
// resource file 'jbpm.cfg.xml', but here we pass in the configuration
// information as an XML string.
// First we create a JbpmConfiguration statically. One JbpmConfiguration
// can be used for all threads in the system, that is why we can safely
// make it static.
/**
*单例对象。
*JbpmConfiguration能够被系统中所有线程所使用。
*jbpm.cfg.xml这个命名方式和Hibernate配置文件的命名方式一致。
*
*/
jbpmConfiguration = JbpmConfiguration.parseXmlString(
"<jbpm-configuration>" +
// A jbpm-context mechanism separates the jbpm core
// engine from the services that jbpm uses from
// the environment.
/*jbpm-context机制在环境中把jbpm核心引擎和jbpm使用的服务分开。
* 持久化服务是jbpm核心引擎使用的一个服务。
*
* */
" <jbpm-context>" +
" <service name='persistence' " +
" factory='org.jbpm.persistence.db.DbPersistenceServiceFactory' />" +
" </jbpm-context>" +
// Also all the resource files that are used by jbpm are
// referenced from the jbpm.cfg.xml
/*
*string,配置了所有jbpm使用的资源文件的路径。
* */
" <string name='resource.hibernate.cfg.xml' " +
" value='hibernate.cfg.xml' />" +
" <string name='resource.business.calendar' " +
" value='org/jbpm/calendar/jbpm.business.calendar.properties' />" +
" <string name='resource.default.modules' " +
" value='org/jbpm/graph/def/jbpm.default.modules.properties' />" +
" <string name='resource.converter' " +
" value='org/jbpm/db/hibernate/jbpm.converter.properties' />" +
" <string name='resource.action.types' " +
" value='org/jbpm/graph/action/action.types.xml' />" +
" <string name='resource.node.types' " +
" value='org/jbpm/graph/node/node.types.xml' />" +
" <string name='resource.varmapping' " +
" value='org/jbpm/context/exe/jbpm.varmapping.xml' />" +
"</jbpm-configuration>"
);
}
public void setUp() {
//创建数据库表
//jbpmConfiguration.createSchema();
}
public void tearDown() {
//删除数据库表
//jbpmConfiguration.dropSchema();
}
public void testSimplePersistence() {
// Between the 3 method calls below, all data is passed via the
// database. Here, in this unit test, these 3 methods are executed
// right after each other because we want to test a complete process
// scenario情节. But in reality, these methods represent different
// requests to a server.
// Since we start with a clean, empty in-memory database, we have to
// deploy the process first. In reality, this is done once by the
// process developer.
/**
* 这个方法把业务处理定义通过Hibernate保存到数据库中。
*/
deployProcessDefinition();
// Suppose we want to start a process instance (=process execution)
// when a user submits a form in a web application...
/*假设当一个用户提交一个表单时,我们要开始一个业务处理的实例/执行。
* 这可以在Action中执行处理。
*/
processInstanceIsCreatedWhenUserSubmitsWebappForm();
// Then, later, upon the arrival of an asynchronous message the
// execution must continue.
/*
* 然后,直到异步消息来到,才继续执行业务处理实例的余下的工作流程。
* */
theProcessInstanceContinuesWhenAnAsyncMessageIsReceived();
}
public void deployProcessDefinition() {
// This test shows a process definition and one execution
// of the process definition. The process definition has
// 3 nodes: an unnamed start-state, a state 's' and an
// end-state named 'end'.
/*
* 这个方法把业务处理定义通过Hibernate保存到数据库中。
*
* */
ProcessDefinition processDefinition = ProcessDefinition.parseXmlString(
"<process-definition name='hello world'>" +
" <start-state name='start'>" +
" <transition to='s' />" +
" </start-state>" +
" <state name='s'>" +
" <transition to='end' />" +
" </state>" +
" <end-state name='end' />" +
"</process-definition>"
);
// Lookup the pojo persistence context-builder that is configured above
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
// Deploy the process definition in the database
jbpmContext.deployProcessDefinition(processDefinition);
} finally {
// Tear down the pojo persistence context.
// This includes flush the SQL for inserting the process definition
// to the database.
/*
* 关闭jbpm上下文。删除pojo持久化上下文。
* 这包括刷新SQL来真正的把业务处理定义插入到数据库中。
* */
jbpmContext.close();
}
}
public void processInstanceIsCreatedWhenUserSubmitsWebappForm() {
// The code in this method could be inside a struts-action
// or a JSF managed bean.
// Lookup the pojo persistence context-builder that is configured above
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
/*
* 图表会话,是图表定义/业务处理定义 相关的数据库层面的会话。应该也是一个Hibernate会话。
* 可以从JBpm上下文这个数据库----业务处理定义、实例等 得到 业务处理定义会话。
*
* */
GraphSession graphSession = jbpmContext.getGraphSession();
//从数据库中根据业务处理定义的名字得到一个业务处理定义。
ProcessDefinition processDefinition =
graphSession.findLatestProcessDefinition("hello world");
// With the processDefinition that we retrieved from the database, we
// can create an execution of the process definition just like in the
// hello world example (which was without persistence).
/*
* 创建业务处理定义的一个实例。
*
* */
ProcessInstance processInstance =
new ProcessInstance(processDefinition);
Token token = processInstance.getRootToken();
assertEquals("start", token.getNode().getName());
// Let's start the process execution
token.signal();
// Now the process is in the state 's'.
assertEquals("s", token.getNode().getName());
// Now the processInstance is saved in the database. So the
// current state of the execution of the process is stored in the
// database.
/*
* 执行一步工作流程后,使用jbpmContext保存这个业务处理实例进数据库。
* 所以现在就把业务处理实例的执行状态也保存进了数据库。
* 因为,业务处理定义的实例 这个类也是一个Model类,用于管理一个业务处理定义的执行的所有信息,
* 是一个多例模式的Model。
*
* */
jbpmContext.save(processInstance);
// The method below will get the process instance back out
// of the database and resume execution by providing another
// external signal.
} finally {
// Tear down the pojo persistence context.
jbpmContext.close();
}
}
public void theProcessInstanceContinuesWhenAnAsyncMessageIsReceived() {
// The code in this method could be the content of a message driven bean.
//这个方法可能在消息驱动Bean这个远程业务代理类中。
// Lookup the pojo persistence context-builder that is configured above
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
GraphSession graphSession = jbpmContext.getGraphSession();
// First, we need to get the process instance back out of the database.
// There are several options to know what process instance we are dealing
// with here. The easiest in this simple test case is just to look for
// the full list of process instances. That should give us only one
// result. So let's look up the process definition.
ProcessDefinition processDefinition =
graphSession.findLatestProcessDefinition("hello world");
// Now, we search for all process instances of this process definition.
/*
* 根据业务处理定义的id得到数据库中所有的业务处理实例。这表明,数据库中应该存在2张表
* 它们是 一对多 的关系。
*
* */
List processInstances =
graphSession.findProcessInstances(processDefinition.getId());
// Because we know that in the context of this unit test, there is
// only one execution. In real life, the processInstanceId can be
// extracted from the content of the message that arrived or from
// the user making a choice.
ProcessInstance processInstance =
(ProcessInstance) processInstances.get(0);
// Now we can continue the execution. Note that the processInstance
// delegates signals to the main path of execution (=the root token).
processInstance.signal();
// After this signal, we know the process execution should have
// arrived in the end-state.
assertTrue(processInstance.hasEnded());
// Now we can update the state of the execution in the database
jbpmContext.save(processInstance);
} finally {
// Tear down the pojo persistence context.
jbpmContext.close();
}
}
}
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=1346877
posted @
2006-10-24 14:18 xzc 阅读(997) |
评论 (0) |
编辑 收藏
把属性的设置都放一个
XML
文件中
props.xml
文件
<
property
name
="build.dir"
value
="build"
/>
然后在
build.xml
文件中加入如下
<!
DOCTYPE
project
[
<!ENTITY properties SYSTEM "file:props.xml">
]>
二,将多个目录的源文件编译到一个地方
<
javac
destdir
="build/classes">
<
src
path
="src1"/>
<
src
path
="src2"/>
</
javac
>
三,保存构建时的信息
<
project
default
="init">
<
target
name
="init"></
target
>
<
property
environment
="env"
/>
<
property
name
="env.COMPUTERNAME"
value
="${env.HOSTNAME}"
/>
<
propertyfile
comment
="Build Information"
file
="./buildinfo.properties">
<
entry
key
="build.host"
value
="${env.COMPUTERNAME}"
/>
<
entry
key
="build.user.name"
value
="${user.name}"
/>
<
entry
key
="build.os.name"
value
="${os.name}"
/>
</
propertyfile
>
</
project
>
四,去除属性文件的注释
属性文件:
#
这里是注释,会给过滤掉
build.dir =build
build
文件:
<
copy
file
="props.properties"
todir
="sample">
<
filterchain
>
<
striplinecomments
>
<
comment
value
="#"
/>
</
striplinecomments
>
</
filterchain
>
</
copy
>
五,两个花俏的功能
1.
声音提示
<
project
name
="Sound"
default
="all">
<
property
file
="build.properties"
/>
<
target
name
="init">
<
sound
>
<
success
source
="${sound.dir}/success.wav"
duration
="500"
/>
<
fail
source
="${sound.dir}/fail.wav"
loops
="2"
/>
</
sound
>
</
target
>
<
target
name
="fail"
depends
="init">
<
fail
/>
</
target
>
<
target
name
="success"
depends
="init"
/>
<
target
name
="all"
depends
="success"
/>
</
project
>
2.
进度条提示
<
project
name
="splash"
default
="init">
<
target
name
="init">
<
splash
imageurl
="http://java.chinaitlab.com/UploadFiles_8734/200610/20061021103415601.gif"
showduration
="5000"
/>
<
sleep
seconds
="1"
/>
<
sleep
seconds
="1"
/>
<
sleep
seconds
="1"
/>
<
sleep
seconds
="1"
/>
<
sleep
seconds
="1"
/>
<
sleep
seconds
="1"
/>
</
target
>
</
project
>
posted @
2006-10-23 13:40 xzc 阅读(336) |
评论 (0) |
编辑 收藏
摘要:
本文根据BJUG maillist讨论整理,取自Buffalo网站,在此对Michael的贡献表示感谢!文中引用的评论仅表示个人观点,供大家作为技术参考。先敬佩Michael一个,能做到这样,Michael付出了很多。下文简单比较一下Buffalo和DWR,两者的思路基本类似,有很多共性的东西。总的看来,Buffalo能满足基本的需要,但DWR已经在整体系统结构上有了更多优势...
Buffalo VS DWR
作者:cleverpig
声明:文中引用的评论仅表示个人观点,供大家作为技术参考。
开篇言:
本文根据
BJUG maillist讨论整理,取自
Buffalo网站,在此对Michael的贡献表示感谢!文中引用的评论仅表示个人观点,供大家作为技术参考。先敬佩Michael一个,能做到这样,Michael付出了很多。下文简单比较一下Buffalo和DWR,两者的思路基本类似,有很多共性的东西。总的看来,Buffalo能满足基本的需要,但DWR已经在整体系统结构上有了更多优势。框架的生命周期是有限的,如果不能与时俱进,将迟早面临被淘汰的局面。
版权声明:任何获得Matrix授权的网站,转载时请务必保留以下作者信息和链接作者:cleverpig;
cleverpig原文:
http://www.matrix.org.cn/resource/article/2006-10-18/Buffalo+DWR_4ebd1e01-5e90-11db-a5c2-7f23a8944cb0.html关键字:buffalo,dwr,ajax,比较
一、两个Ajax框架: Buffalo
Buffalo是一个为java web项目而设计的轻量级AJAX框架。它是开源的(Apache License 2.0),其功能强大且易用。主要解决在j2ee ajax开发中的常见问题。它承诺为开发者和最终用户都能受益。最重要的Buffalo的作者Michael Chen是位中国开发者,他就生活在北京。
 DWR
DWR是一个Java开源库,帮助你实现Ajax网站。它可以让你在浏览器中的Javascript代码调用Web服务器上的Java,就像在Java代码就在浏览器中一样。DWR会根据你的Java类动态的生成Javascript代码。这些代码的魔力是让你感觉整个Ajax调用都是在浏览器上发生的,但事实上是服务器执行了这些代码,DWR负责数据的传递和转换。
二、共性: 支持Spring集成:均支持。
使用一个Servlet来接收所有的AJAX请求: Buffalo使用ApplicationServlet<————>DWR使用DWRServlet。
使用XMLHttpRequest + JavaScript 传输数据: Buffalo使用buffalo.js<————>DWR使用dwr.js & util.js。
在Java和Javascript之间转换数据: Buffalo使用marshallingContext<————>DWR使用Converter。
协议: Buffalo在1.2.x之前采用burlap, Buffalo解析大数据量可能会比较慢,然而可以适用于多种服务器端和客户端,并且burlap协议的完整性和支持的数据类型更加丰富。2.0开始采用自定义的基于xml的协议(来自burlap,做了更适合web的修改),并自行编写了解析器,性能更高。
DWR使用自定义的简单文本协议。
三、Buffalo特性: 1. 基于prototype:如果你的AJAX应用也是基于prototype,那么可以减少重复加载prototype的带宽,并且获得相当一致的编程概念。
2. Bind:提供了对结果数据的处理,直接将数据绑定到页面对象并展示,这是一个动人的特性。(DWR在Util.js中也提供了一些方法来简化数据的展示,但不如 Buffalo做的更多。) 在2.0中,Bind能力更加强大,能够将值直接绑定到表单元素、表格、DIV/Span、甚至整个表单上。关键是这种绑定是无侵入并且与buffalo 整体结构完全整合,对外表现只有一个简单的buffalo.bindReply或者Buffalo.Bind.bind即可。http://buffalo.sourceforge.net/binding.html有一些描述。
3. 序列化:Buffalo支持任意对象,任意深度,任意数据结构的java到javascript以及javascript到java的双向序列化。并且支持引用。这里有完整的协议说明。由于文档和演示不充分,很多人以为buffalo不支持任意对象了 ~
4. 生命周期对象访问:1.2.4之前需要继承一个BuffaloService,
从1.2.4开始就不需要继承了,引入了线程安全的BuffaloContext对象,只需要通过BuffaloContext.getContext()即可获得一个线程安全的引用,并且对Request的各种属性进行操作。更方便的是:
Map BuffaloContext.getContext.getSession()
Map BuffaloContext.getContext.getApplication()
Map BuffaloContext.getContext.getCookie()
即可获得session/application/cookie的Map,操作这些Map即可获得对这些生命周期的各种变量进行查询和更新。这个特性参考了webwork中ActionContext的设计。
5. 对Collection/Array的模糊处理:buffalo中提供了对Collection/Array对象的模糊识别能力。例如:服务器端有一个方法需要List参数,客户端传递过去一个javascript数组就可以了,不需要费心的组装对象。buffalo通过这些很细小的地方来提高程序员生产力。
6. 客户端组装对象:据报告DWR只支持简单数据类型作为参数在客户端传入。buffalo支持在客户端组装对象,甚至可以直接将整个表单序列化为一个对象作为参数传给远程客户端。DWR协议天生不足,这方面,我猜想它完全没有能力。
7. 对重载方法的处理能力:由于java与javascript之间类型的不匹配,DWR的代码生成无法对重载方法进行处理。例如,sum(double,double), sum(int, int) DWR很可能不知道你要调用哪一个。从2.0开始buffalo支持了对重载的处理。
四、DWR特性: 1. 支持Batch:可以将多个Service函数调用放在一个XMLHttpRequest请求中完成。
Michael Chen评论:我一直认为这不是一个好的实践。在客户端发起多个请求并获得响应除了获得编程的复杂外,还增加了服务器端设计service的自由度。这种方式感觉上更鼓励为远程调用设计细粒度的服务、将组装逻辑放在客户端。这种设计风格我不太喜欢,因此batch也一直没有考虑实现,虽然实现不太麻烦。
2. Converter:可以转换任意类型的Java对象到JavaScript,并允许直接使用。例如:Customer类包含一个address变量,当AjaxCall返回Customer对象的时候,可以直接在Javascript中使用customer.address来获得Address的信息。
3. HttpServlet:支持在被调用的Service方法中获得HttpServletRequest和HttpServletResponse对象,这样可以访问当前Session中的数据。
4. 允许Expose部分函数和属性。(Buffalo无限制,可以访问Service中的任意函数。)
Michael Chen评论: 这个我也考虑过...DWR的代码生成机制使得它不得不通过这种方式减小些流量。Buffalo如果想实现这个特性也不是不行,只是我觉得,既然 Service辛辛苦苦实现了,还需要通过这种方式来让别人不能用么?况且buffalo没有代码生成,无论你暴露多少方法流量都是一样的。考虑到实际情况,buffalo没有实现这个特性。
5. DWR2.0中提出了Reverse Ajax:提供在Java代码中来处理页面上元素的功能。
Michael Chen评论: 这个东东...也还是代码生成的trick...然而我的态度是javascript与java同样重要的,因此不会让代码生成类的东西破坏javascript的整体性。
五、相关资源:
在过去的两年间,baffalo的开发者拥有值得兴奋的积极反馈:buffalo非常适于在java web项目的ajax开发。为了帮助更多的用户更好地使用buffalo,他们期待你的帮助:发布文档、bug报告和bug修正等。
baffalo Maillist:
buffalo-users@lists.sourceforge.net baffalo 论坛:
http://groups.google.com/group/amowa
cleverpig写的Buffalo的最佳实践
posted @
2006-10-19 15:31 xzc 阅读(414) |
评论 (0) |
编辑 收藏posted @
2006-10-19 15:12 xzc 阅读(328) |
评论 (0) |
编辑 收藏
|
注释简化了数据验证
|
|
级别: 中级
Ted Bergeron
(ted@triview.com), 合作创始人, Triview, Inc.
2006 年 10 月 10 日
尽管在 Web 应用程序中尽可能多的层次中构建数据验证非常重要,但是这样做却非常耗时,以至于很多开发人员都会干脆忽略这个步骤 —— 这可能会导致今后大量问题的产生。但是随着最新版本的 Java 平台中引入了注释,验证变得简单得多了。在本文中,Ted Bergeron 将向您介绍如何使用 Hibernate Annotations 的 Validator 组件在 Web 应用程序中轻松构建并维护验证逻辑。
有时会有一种工具,它可以真正满足开发人员和架构师的需求。开发人员在第一次下载这种工具当天就可以在自己的应用程序中开始使用这种工具。理论上来说,这种工具在开发人员花费大量时间来掌握其用法之前就可以从中获益。架构师也很喜欢这种工具,因为它可以将开发人员导向更高理论层次的实现。Hibernate Annotations 的 Validator 组件就是一种这样的工具。
|
|
开始之前需要了解的内容
在阅读本文之前,应该对 Java 平台版本 5(尤其是注释)、JSP 2.0(因为本文中创建了一些标签文件,并在 TLD 中定义了一些函数,它们都是 JSP 2.0 的新特性)和 Hibernate 及 Spring 框架有一个基本的了解。请注意即使不使用 Hibernate 来实现持久性,也可以在自己的应用程序中使用 Hibernate Validator。
|
|
Java SE 5 为 Java 语言提供了很多需要的增强功能,不过其他增强功能可能都不如 注释 这样潜力巨大。使用 注释,我们就终于具有了一个标准、一级的元数据框架为 Java 类使用。Hibernate 用户手工编写 *.hbm.xml 文件已经很多年了(或者使用 XDoclet 来自动实现这个任务)。如果手工创建了 XML 文件,那就必须对每个所需要的持久属性都更新这两个文件(类定义和 XML 映射文档)。使用 HibernateDoclet 可以简化这个过程(请参看清单 1 给出的例子),但是这需要我们确认自己的 HibernateDoclet 版本支持要使用的 Hibernate 的版本。doclet 信息在运行时也是不可用的,因为它被编写到了 Javadoc 风格的注释中了。Hibernate Annotations,如图 2 所示,通过提供一个标准、简明的映射类的方法和所添加的运行时可用性来对这些方式进行改进。
清单 1. 使用 HibernateDoclet 的 Hibernate 映射代码
/**
* @hibernate.property column="NAME" length="60" not-null="true"
*/
public String getName() {
return this.name;
}
/**
* @hibernate.many-to-one column="AGENT_ID" not-null="true" cascade="none"
* outer-join="false" lazy="true"
*/
public Agent getAgent() {
return agent;
}
/**
* @hibernate.set lazy="true" inverse="true" cascade="all" table="DEPARTMENT"
* @hibernate.collection-one-to-many class="com.triview.model.Department"
* @hibernate.collection-key column="DEPARTMENT_ID" not-null="true"
*/
public List<Department> getDepartment() {
return department;
}
|
清单 2. 使用 Hibernate Annotations 的 Hibernate 映射代码
@NotNull
@Column(name = "name")
@Length(min = 1, max = NAME_LENGTH) // NAME_LENGTH is a constant declared elsewhere
public String getName() {
return name;
}
@NotNull
@ManyToOne(cascade = {CascadeType.MERGE }, fetch = FetchType.LAZY)
@JoinColumn(name = "agent_id")
public Agent getAgent() {
return agent;
}
@OneToMany(mappedBy = "customer", fetch = FetchType.LAZY)
public List<Department> getDepartment() {
return department;
}
|
如果使用 HibernateDoclet,那么直到生成 XML 文件或运行时才能捕获错误。使用 注释,在编译时就可以检测出很多错误;或者如果在编辑时使用了很好的 IDE,那么在编辑时就可以检测出部分错误。在从头创建应用程序时,可以利用 hbm2ddl 工具为自己的数据库从 hbm.xml 文件中生成 DDL。一些重要的信息 —— 比如name 属性的最大长度必须是 60 个字符,或者 DDL 应该添加非空约束 —— 都被从 HibernateDoclet 项添加到 DDL 中。当使用注释时,我们可以以类似的方式自动生成 DDL。
尽管这两种代码映射方式都可以使用,不过注释的优势更为明显。使用注释,可以用一些常量来指定长度或其他值。编译循环的速度更快,并且不需要生成 XML 文件。其中最大的优势是可以访问一些有用信息,例如运行时的非空注释或长度。除了清单 2 给出的注释之外,还可以指定一些验证的约束。所包含的部分约束如下:
-
@Max(value = 100)
-
@Min(value = 0)
-
@Past
-
@Future
-
@Email
在适当条件下,这些注释会引起由 DDL 生成检查约束。(显然,@Future 并不是一个适当的条件。)还可以根据需要创建定制约束注释。
验证和应用程序层
编写验证代码是一个烦人且耗时的过程。通常,很多开发人员都会放弃在特定的层进行有效性验证,从而可以节省一些时间;但是所节省的时间是否能够弥补在这个地方因忽略部分功能所引起的缺陷却非常值得探讨。如果在所有应用程序层中创建并维护验证所需要的时间可以极大地减少,那么争论的焦点就会转向是否要在多个层次中进行有效性验证。假设有一个应用程序,它让用户使用一个用户名、密码和信用卡号来创建一个帐号。在这个应用程序中所希望进行验证的组件如下:
-
视图: 通过 JavaScript 进行验证可以避免与服务器反复进行交互,这样可以提供更好的用户体验。用户可以禁用 JavaScript,因此这个层次的验证最好要有,但是却并不可靠。对所需要的域进行简单的验证是必须的。
-
控制器: 验证必须在服务器端的逻辑中进行处理。这个层次中的代码可以以适合某个特定用途的方式处理验证。例如,在添加新用户时,控制器可以在进行处理之前检查指定的用户名是否已经存在。
-
服务: 相对复杂的业务逻辑验证通常都最适合放到服务层中。例如,一旦有一个信用卡对象看起来有效,就应该使用信用卡处理服务对这个信用卡的信息进行确认。
-
DAO: 在数据到达这个层次时,应该已经是有效的了。尽管如此,执行一次快速检查从而确保所需要的域都非空并且值也都在特定的范围或遵循特定的格式(例如 e-mail 地址域就应该包含一个有效的 e-mail 地址)也是非常有益的。在此处捕获错误总比产生可以避免的
SQLException 错误要好。
-
DBMS: 这是通常可以忽略验证的地方。即使当前正在构建的应用程序是数据库的惟一客户机,将来还可能会添加其他客户机。如果应用程序有一些 bug(大部分应用程序都可能会有 bug),那么无效的数据也可能会被发送给数据库。在这种情况中,如果走运,就可以找到无效的数据,并且需要分析这些数据是否可以清除,以及如何清除。
-
模型: 这是进行验证的一个理想地方,它不需要访问外部服务,也不需要了解持久性数据。例如,某业务逻辑可能会要求用户至少提供一个联系信息,这可以是一个电话号码也可以是一个 e-mail 地址;可以使用模型层的验证来确保用户的确提供了这种信息。
进行验证的一种典型方法是对简单的验证使用 Commons Validator,并在控制器中编写其他一些验证逻辑。Commons Validator 可以生成 JavaScript 来对视图中的验证进行处理。但是 Commons Validator 也有自己的缺陷:它只能处理简单的验证问题,并且将验证的信息都保存到了 XML 文件中。Commons Validator 被设计用来与 Struts 一起使用,而且没有提供一种简单的方法在应用程序层间重用验证的声明。
在规划有效性验证策略时,选择在错误发生时简单地处理这些错误是远远不够的。一种良好的设计同时还要通过生成一个友好的用户界面来防止出现错误。采用预先进行的方法进行验证可以极大地增强用户对于应用程序的理解。不幸的是,Commons Validator 并没有对此提供支持。假设希望 HTML 文件设置文本域的 maxlength 属性来与验证匹配,或者在文本域之后放上一个百分号(%)来表示要输入百分比的值。通常,这些信息都被硬编写到 HTML 文档中了。如果决定修改 name 属性来支持 75 个字符,而不是 60 个字符,那么需要改动多少地方呢?在很多应用程序中,通常都需要:
- 更新 DDL 来增大数据库列的长度(通过 HibernateDoclet、 hbm.xml 或 Hibernate Annotations)。
- 更新 Commons Validator XML 文件将最大值增加到 75。
- 更新所有与这个域有关的 HTML 表单,以修改
maxlength 属性。
更好的方法是使用 Hibernate Validator。验证的定义都被通过注释 添加到了模型层中,同时还有对所包含的验证处理的支持。如果选择充分利用所有的 Hibernate,这个 Validator 就可以在 DAO 和 DBMS 层也提供验证。在下面给出的样例代码中,将使用 reflection 和 JSP 2.0 标签文件多执行一个步骤,从而充分利用注释 为视图层动态生成代码。这可以清除在视图中使用的硬编写的业务逻辑。
在清单 3 中,dateOfBirth 被注释为 NotNull 和过去的日期。 Hibernate 的 DDL 生成代码对这个列添加了一个非空约束,以及一个要求日期必须是之前日期的检查约束。e-mail 地址也是非空的,必须匹配 e-mail 地址的格式。这会生成一个非空约束,但是不会生成匹配这种格式的检查约束。
清单 3. 通过 Hibernate Annotations 进行映射的简单联系方式
/**
* A Simplified object that stores contact information.
*
* @author Ted Bergeron
* @version $Id: Contact.java,v 1.1 2006/04/24 03:39:34 ted Exp $
*/
@MappedSuperclass
@Embeddable
public class Contact implements Serializable {
public static final int MAX_FIRST_NAME = 30;
public static final int MAX_MIDDLE_NAME = 1;
public static final int MAX_LAST_NAME = 30;
private String fname;
private String mi;
private String lname;
private Date dateOfBirth;
private String emailAddress;
private Address address;
public Contact() {
this.address = new Address();
}
@Valid
@Embedded
public Address getAddress() {
return address;
}
public void setAddress(Address a) {
if (a == null) {
address = new Address();
} else {
address = a;
}
}
@NotNull
@Length(min = 1, max = MAX_FIRST_NAME)
@Column(name = "fname")
public String getFirstname() {
return fname;
}
public void setFirstname(String fname) {
this.fname = fname;
}
@Length(min = 1, max = MAX_MIDDLE_NAME)
@Column(name = "mi")
public String getMi() {
return mi;
}
public void setMi(String mi) {
this.mi = mi;
}
@NotNull
@Length(min = 1, max = MAX_LAST_NAME)
@Column(name = "lname")
public String getLastname() {
return lname;
}
public void setLastname(String lname) {
this.lname = lname;
}
@NotNull
@Past
@Column(name = "dob")
public Date getDateOfBirth() {
return dateOfBirth;
}
public void setDateOfBirth(Date dateOfBirth) {
this.dateOfBirth = dateOfBirth;
}
@NotNull
@Email
@Column(name = "email")
public String getEmailAddress() {
return emailAddress;
}
public void setEmailAddress(String emailAddress) {
this.emailAddress = emailAddress;
}
|
|
|
样例应用程序
在 下载 一节,您可以下载一个样例应用程序,它展示了本文中采用的设计思想和代码。由于这是一个可以工作的应用程序,因此代码比本文中讨论的的内容更为复杂。例如,清单 9 就节选于标签文件 text.tag;这个样例应用程序具有标签文件使用的所有代码,以及其他三个类似的标签文件使用的代码(用于选择、隐藏和检查框的 HTML 元素)。由于这是一个可以工作的应用程序,它包含了一个在这种类型的应用程序中都可以找到的架构。还有一个 Ant 构建文件、Spring 和 Hibernate XML 封装代码,以及 log4j 配置。虽然这些都不是本文介绍的重点,但是您会发现仔细研究一下这个样例应用程序的源代码是非常有用的。 |
|
如果需要,Hibernate DAO 实现也可以使用 Validation Annotations。所需做的是在 hibernate.cfg.xml 文件中指定基于 Hibernate 事件的验证规则。(更多信息请参考 Hibernate Validator 的文档;可以在 参考资料 一节中找到相关的链接)。如果真地希望抄近路,您可以只捕获服务或控制器中的 InvalidStateException 异常,并循环遍历 InvalidValue 数组。
对控制器添加验证
要执行验证,需要创建一个 Hibernate 的 ClassValidator 实例。这个类进行实例化的代价可能会很高,因此最好只对希望进行验证的每个类来进行实例化。一种方法是创建一个实用工具类,对每个模型对象存储一个 ClassValidator 实例,如清单 4 所示:
清单 4. 处理验证的实用工具类
/**
* Handles validations based on the Hibernate Annotations Validator framework.
* @author Ted Bergeron
* @version $Id: AnnotationValidator.java,v 1.5 2006/01/20 17:34:09 ted Exp $
*/
public class AnnotationValidator {
private static Log log = LogFactory.getLog(AnnotationValidator.class);
// It is considered a good practice to execute these lines once and
// cache the validator instances.
public static final ClassValidator<Customer> CUSTOMER_VALIDATOR =
new ClassValidator<Customer>(Customer.class);
public static final ClassValidator<CreditCard> CREDIT_CARD_VALIDATOR =
new ClassValidator<CreditCard>(CreditCard.class);
private static ClassValidator<? extends BaseObject> getValidator(Class<?
extends BaseObject> clazz) {
if (Customer.class.equals(clazz)) {
return CUSTOMER_VALIDATOR;
} else if (CreditCard.class.equals(clazz)) {
return CREDIT_CARD_VALIDATOR;
} else {
throw new IllegalArgumentException("Unsupported class was passed.");
}
}
public static InvalidValue[] getInvalidValues(BaseObject modelObject) {
String nullProperty = null;
return getInvalidValues(modelObject, nullProperty);
}
public static InvalidValue[] getInvalidValues(BaseObject modelObject,
String property) {
Class<? extends BaseObject>clazz = modelObject.getClass();
ClassValidator validator = getValidator(clazz);
InvalidValue[] validationMessages;
if (property == null) {
validationMessages = validator.getInvalidValues(modelObject);
} else {
// only get invalid values for specified property.
// For example, "city" applies to getCity() method.
validationMessages = validator.getInvalidValues(modelObject, property);
}
return validationMessages;
}
}
|
在清单 4 中,创建了两个 ClassValidator,一个用于 Customer,另外一个用于 CreditCard。这两个希望进行验证的类可以调用 getInvalidValues(BaseObject modelObject),会返回 InvalidValue[]。这则会返回一个包含模型对象实例错误的数组。另外,这个方法也可以通过提供一个特定的属性名来调用,这样做会只返回与该域有关的错误。
在使用 Spring MVC 和 Hibernate Validator 时,为信用卡创建一个验证过程变得非常简单,如清单 5 所示:
清单 5. Spring MVC 控制器使用的 CreditCardValidator
/**
* Performs validation of a CreditCard in Spring MVC.
*
* @author Ted Bergeron
* @version $Id: CreditCardValidator.java,v 1.2 2006/02/10 21:53:50 ted Exp $
*/
public class CreditCardValidator implements Validator {
private CreditCardService creditCardService;
public void setCreditCardService(CreditCardService service) {
this.creditCardService = service;
}
public boolean supports(Class clazz) {
return CreditCard.class.isAssignableFrom(clazz);
}
public void validate(Object object, Errors errors) {
CreditCard creditCard = (CreditCard) object;
InvalidValue[] invalids = AnnotationValidator.getInvalidValues(creditCard);
// Perform "expensive" validation only if no simple errors found above.
if (invalids == null || invalids.length == 0) {
boolean validCard = creditCardService.validateCreditCard(creditCard);
if (!validCard) {
errors.reject("error.creditcard.invalid");
}
} else {
for (InvalidValue invalidValue : invalids) {
errors.rejectValue(invalidValue.getPropertyPath(),
null, invalidValue.getMessage());
}
}
}
}
|
validate() 方法只需要将 creditCard 实例传递给这个验证过程,从而返回 InvalidValue 数组。如果发现了一个或多个这种简单错误,那么就可以将 Hibernate 的 InvalidValue 数组转换成 Spring 的 Errors 对象。如果用户已经创建了这个信用卡并且没有出现任何简单错误,就可以将更加彻底的验证委托给服务层进行。这一层可以与商业服务提供者一起对信用卡进行验证。
现在我们已经看到这个简单的模型层注释是如何平衡到控制器、DAO 和 DBMS 层的验证的。在 HibernateDoclet 和 Commons Validator 中发现的验证逻辑的重合现在都已经统一到模型中了。尽管这是一个非常受欢迎的改进,但是视图层传统上来说一直是最需要进行详细验证的地方。
为视图添加验证
在下面的例子中,使用了 Spring MVC 和 JSP 2.0 标签文件。JSP 2.0 允许在 TLD 文件中对定制函数进行注册,并在一个标签文件中进行调用。标签文件类似于 taglibs,但是它们是使用 JSP 代码编写的,而不是使用 Java 代码编写的。采用这种方法,使用 Java 语言写好的代码就可以封装成函数,而使用 JSP 写好的代码则可以放入标签文件中。在这种情况中,对注释的处理需要使用映像,这会由几个函数来执行。绑定 Spring 或呈现 XHTML 的代码也是标签文件的一部分。
清单 6 中节选的 TLD 代码定义 text.tag 文件可以使用,并定义了一个名为 required 的函数。
清单 6. 创建表单 TLD
<?xml version="1.0" encoding="ISO-8859-1" ?>
<taglib xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-jsptaglibrary_2_0.xsd"
version="2.0">
<tlib-version>1.0</tlib-version>
<short-name>form</short-name>
<uri>formtags</uri>
<tag-file>
<name>text</name>
<path>/WEB-INF/tags/form/text.tag</path>
</tag-file>
<function>
<description>determine if field is required from Annotations</description>
<name>required</name>
<function-class>com.triview.web.Utilities</function-class>
<function-signature>Boolean required(java.lang.Object,java.lang.String)
</function-signature>
</function>
</taglib>
|
清单 7 节选自 Utilities 类,其中包含了标签文件使用的所有函数。在前文中我们曾经说过,最适合使用 Java 代码编写的代码都被放到了几个 TLD 可以映射的函数中,这样标签文件就可以使用它们了;这些函数都是在 Utilities 类中进行编码的。因此,我们需要三样东西:定义这些类的 TLD 文件、Utilities 中的函数,以及标签文件本身,后者要使用这些函数。(第四样应该是使用这个标签文件的 JSP 页面。)
在清单 7 中,给出了在 TLD 中引用的函数和另外一个表示给定属性是否是 Date 的方法。在这个类中要涉及到比较多的代码,但是本文限于篇幅,不会给出所有的代码;不过需要注意 findGetterMethod() 除了将表达式语言(Expression Language,EL)方法表示(customer.contact)转换成 Java 表示(customer.getContact())之外,还执行了基本的映像操作。
清单 7. Utilities 节选
public static Boolean required(Object object, String propertyPath) {
Method getMethod = findGetterMethod(object, propertyPath);
if (getMethod == null) {
return null;
} else {
return getMethod.isAnnotationPresent(NotNull.class);
}
}
public static Boolean isDate(Object object, String propertyPath) {
return java.util.Date.class.equals(getReturnType(object, propertyPath));
}
public static Class getReturnType(Object object, String propertyPath) {
Method getMethod = findGetterMethod(object, propertyPath);
if (getMethod == null) {
return null;
} else {
return getMethod.getReturnType();
}
}
|
此处可以清楚地看到在运行时使用 Validation annotations 是多么容易。可以简单地引用对象的 getter 方法,并检查这个方法是否有相关的给定的注释 。
清单 8 中给出的 JSP 例子进行了简化,这样就可以着重查看相关的部分了。此处,这里有一个表单,它有一个选择框和两个输入域。所有这些域都是通过在 form.tld 文件中声明的标签文件进行呈现的。标签文件被设计成使用智能缺省值,这样就可以根据需要允许简单编码的 JSP 可以有定义更多信息的选项。关键的属性是 propertyPath,它使用 EL 符号将这个域映射为模型层属性,就像是使用 Spring MVC 的 bind 标签一样。
清单 8. 一个包含表单的简单 JSP 页面
<%@ taglib tagdir="/WEB-INF/tags/form" prefix="form" %>
<form method="post" action="<c:url value="/signup/customer.edit"/>">
<form:select propertyPath="creditCard.type" collection="${creditCardTypeCollection}"
required="true" labelKey="prompt.creditcard.type"/>
<form:text propertyPath="creditCard.number" labelKey="prompt.creditcard.number">
<img src="<c:url value="/images/icons/help.png"/>" alt="Help"
onclick="new Effect.SlideDown('creditCardHelp')"/>
</form:text>
<form:text propertyPath="creditCard.expirationDate"/>
</form>
|
text.tag 文件的完整源代码太大了,不好放在这儿,因此清单 9 给出了其中关键的部分:
清单 9. 标签文件 text.tag 节选
<%@ attribute name="propertyPath" required="true" %>
<%@ attribute name="size" required="false" type="java.lang.Integer" %>
<%@ attribute name="maxlength" required="false" type="java.lang.Integer" %>
<%@ attribute name="required" required="false" type="java.lang.Boolean" %>
<%@ taglib uri="http://www.springframework.org/tags" prefix="spring" %>
<%@ taglib uri="formtags" prefix="form" %>
<c:set var="objectPath" value="${form:getObjectPath(propertyPath)}"/>
<spring:bind path="${objectPath}">
<c:set var="object" value="${status.value}"/>
<c:if test="${object == null}">
<%-- Bind ignores the command object prefix, so simple properties of the command object
return null above. --%>
<c:set var="object" value="${commandObject}"/>
<%-- We depend on the controller adding this to request. --%>
</c:if>
</spring:bind>
<%-- If user did not specify whether this field is required,
query the object for this info. --%>
<c:if test="${required == null}">
<c:set var="required" value="${form:required(object,propertyPath)}"/>
</c:if>
<c:choose>
<c:when test="${required == null || required == false}">
<c:set var="labelClass" value="optional"/>
</c:when>
<c:otherwise>
<c:set var="labelClass" value="required"/>
</c:otherwise>
</c:choose>
<c:if test="${maxlength == null}">
<c:set var="maxlength" value="${form:maxLength(object,propertyPath)}"/>
</c:if>
<c:set var="isDate" value="${form:isDate(object,propertyPath)}"/>
<c:set var="cssClass" value="input_text"/>
<c:if test="${isDate}">
<c:set var="cssClass" value="input_date"/>
</c:if>
<div class="field">
<spring:bind path="${propertyPath}">
<label for="${status.expression}" class="${labelClass}"><fmt:message
key="prompt.${propertyPath}"/></label>
<input type="text" name="${status.expression}" value="${status.value}"
id="${status.expression}"<c:if test="${size != null}"> size="${size}"</c:if>
<c:if test="${maxlength != null}"> maxlength="${maxlength}"</c:if>
class="${cssClass}"/>
<c:if test="${isDate}">
<img id="${status.expression}_button"
src="<c:url value="/images/icons/calendar.png"/>" alt="calendar"
style="cursor: pointer;"/>
<script type="text/javascript">
Calendar.setup(
{
inputField : "${status.expression}", // ID of the input field
ifFormat : "%m/%d/%Y", // the date format
button : "${status.expression}_button" // ID of the button
}
);
</script>
</c:if>
<span class="icons"><jsp:doBody/></span>
<c:if test="${status.errorMessage != null && status.errorMessage != ''}">
<p class="fieldError"><img id="${status.expression}_error"
src="<c:url value="/images/icons/error.png"/>"
alt="error"/>${status.errorMessage}</p>
</c:if>
</spring:bind>
</div>
|
我们马上就可以看出 propertyPath 是惟一需要的属性。size、 maxlength 和 required 都可以忽略。objectPath var 被设置为在 propertyPath 中引用的属性的父对象。因此,如果 propertyPath 是 customer.contact.fax.number, 那么 objectPath 就应该被设置为 customer.contact.fax。我们现在就使用 Spring 的 bind 标签绑定到了包含属性的对象上。这会将对象变量设置成对包含属性的实例的引用。接下来,检查这个标签的用户是否已经指定他/她们是否希望属性是必须的。允许表单开发人员覆盖从注释中返回的值是非常重要的,因为有时他/她们希望让控制器为所需要的域设置缺省值,而用户可能并不希望为这个域提供值。如果表单开发人员没有为 required 指定值,那么就可以调用这个表单 TLD 的 required 函数。这个函数调用了在 TLD 文件中映射的方法。这个方法简单地检查 @NotNull 注释;如果它发现某个属性具有这个注释,就将 labelClass 变量设置为必须的。可以类似地确定正确的 maxlength 以及这个域是否是一个 Date。
接下来使用 Spring 来绑定到 propertyPath 上,而不是像前面一样只绑定到包含这个属性的对象上。这允许在生成 label 和 input HTML 标签时使用 status.expression 和 status.value。 input 标签也可以使用一个大小 maxlength 以及适当的类来生成。如果前面已经确定属性是一个 Date,现在就可以添加 JavaScript 日历了。(可以在 参考资料 一节找到一个很好的日历组件的链接)。注意根据需要链接属性、输入 ID 和图像 ID 的标签是多么简单。)这个 JavaScript 日历需要一个图像 ID 来匹配输入域,其后缀是 _button。
最后,可以将 <jsp:doBody/> 封装到一个 span 标签中,这样允许表单开发人员在页面中添加其他图标,例如用来寻求帮助的图标。(清单 8 给出了一个为信用卡号域添加的帮助图标。)最后的部分是检查 Spring 是否为这个属性报告和显示了一个错误,并和一个错误图标一起显示。
使用 CSS,就可以对必须的域进行一下装饰 —— 例如,让它们以红色显示、在文本边上显示一个星号,或者使用一个背景图像来装饰它。在清单 10 中,将必须的域的标签设置成黑色,而且后面显示一个红色的星号(在 Firefox 以及其他标准兼容的浏览器中),如果是在 IE 中则还会在左边加上一个小旗子的背景图像:
清单 10. 对必须域进行装饰的 CSS 代码
label.required {
color: black;
background-image: url( /images/icons/flag_red.png );
background-position: left;
background-repeat: no-repeat;
}
label.required:after {
content: '*';
}
label.optional {
color: black;
}
|
日期输入域自动会在右边放上一个 JavaScript 日历图标。对所有的文本域设置正确的 maxlength 属性可以防止用户输入太多文本所引起的错误。可以扩展 text 标签来为输入域类设置其他的数据类型。可以修改 text 标签使用 HTML,而不是 XHTML(如果希望这样)。可以不太费力地获得具有正确语义的 HTML 表单,而且不需学习基于组件的框架知识,就可以利用基于组件的 Web 框架的优点。
尽管标签文件生成的 HTML 文件可以帮助防止一些错误的产生,但是在视图层并没有任何代码来真正进行错误检查。由于可以使用类属性,现在就可以添加一些简单的 JavaScript 来实现这种功能了,如清单 11 所示。这里的 JavaScript 也可以是通用的,在任一表单中都可以重用。
清单 11. 简单的 JavaScript 验证程序
<script type="text/javascript">
function checkRequired(form) {
var requiredLabels = document.getElementsByClassName("required", form);
for (i = 0; i < requiredLabels.length; i++) {
var labelText = requiredLabels[i].firstChild.nodeValue; // Get the label's text
var labelFor = requiredLabels[i].getAttribute("for"); // Grab the for attribute
var inputTag = document.getElementById(labelFor); // Get the input tag
if (inputTag.value == null || inputTag.value == "") {
alert("Please make sure all required fields have been entered.");
return false; // Abort Submit
}
}
return true;
}
</script>
|
这个 JavaScript 是通过为表单声明添加 onsubmit="return checkRequired(this);" 被调用的。这个脚本简单地获取具有所需要的类的表单中的所有元素。由于我们的习惯是在标签标记中使用这个类,因此代码会通过 for 属性来查找与这个标签连接在一起的输入域。如果任何输入域为空,就会生成一条简单的警告消息,表单提交就会取消。可以简单地对这个脚本进行扩充,使其扫描多个类,并相应地进行验证。
对于基于 JavaScript 的综合的验证集合来说,最好是使用开源实现,而不是自行开发。在清单 8 中您可能已经注意到下面的代码:
onclick="new Effect.SlideDown('creditCardHelp')"
|
这个函数是 Script.aculo.us 库的一部分,这个库提供了很多高级的效果。如果正在使用 Script.aculo.us,就需要对所构建的内容使用 Prototype 库。 JavaScript 验证库的一个例子是由 Andrew Tetlaw 在 Prototype 基础上构建的。(请参看 参考资料 一节中的链接。)他的框架依赖于被添加到输入域的类:
<input class="required validate-number" id="field1" name="field1" />
|
可以简单地修改 text.tag 的逻辑在 input 标签中插入几个类。将 class="required" 添加到输入标签和 label 标签中不会影响 CSS 规则,但会破坏清单 10 中给出的简单 JavaScript 验证程序。如果要混合使用框架中的代码和简单的 JavaScript 代码,最好使用不同的类名,或在使用类名搜索元素时确保类名有效并检查标签类型。
最后的考虑
本文已经介绍了模型层的注释如何充分用来在视图、控制器、DAO 和 DBMS 层中创建验证。必须手工创建服务层的验证,例如信用卡验证。其他模型层的验证,例如强制属性 C 是必须的,而属性 A 和 B 都处于指定的状态,这也是一个手工任务。然而,使用 Hibernate Annotations 的 Validator 组件,就可以轻松地声明并应用大多数验证。
展望
不论是简单例子还是所引用框架的 JavaScript 验证都可以对简单的条件进行检查,例如域必须要填写,或者客户机端代码中的数据类型必须要匹配预期的类型。需要用到服务器端逻辑的验证可以使用 Ajax 添加到 JavaScript 验证程序中。您可以使用一个用户注册界面来让用户可以选择用户名。文本标签可以进行增强来检查 @Column(unique = true) 注释。在找到这个注释时,标签可以添加一个用来触发 Ajax 调用的类。
现在您不需要在应用程序层间维护重复的验证逻辑了,这样就可以节省出大量的开发时间。想像一下您最终可以为应用程序所能添加的增强功能!
下载
| 描述 |
名字 |
大小 |
下载方法 |
| 示例应用程序 |
j-hibval-source.zip |
8MB |
HTTP
|
参考资料
学习
获得产品和技术
讨论
关于作者
|
|
|

|
|
Ted Bergeron 是 Triview 的合作创始人之一,Triview 是一家企业软件咨询公司,位于加利福尼亚的圣地亚哥。Ted 从事基于 Web 的应用程序的设计已经有十 多年的时间了。他所做过的一些知名的项目包括为 Sybase、Orbitz、Disney 和 Qualcomm 所设计的项目。Ted 还曾用三 年的时间作为一名技术讲师来教授有关 Web 开发、Java 开发和数据库逻辑设计的课程。您可以在 Triview 的 Web 站点 上了解有关 Triview 公司的更多内容,或者也可以拨打该公司的免费电话 (866)TRIVIEW。
|
posted @
2006-10-16 14:19 xzc 阅读(726) |
评论 (0) |
编辑 收藏posted @
2006-10-16 13:46 xzc 阅读(3129) |
评论 (0) |
编辑 收藏
1.基本配置:
知之为知之,不知google之。关于FCKeditor的基本配置在网上自有高人指点,这里我也不多耽误大家时间。主要是谈下自己当初配置的问题:
a.基本路径:
注意FCKeditor的基本路径应该是/(你的web应用名称)/(放置FCKeditor文件的文件夹名)/
我的目录结构为:

因此,我的基本路径设置为:/fck/FCKeditor/
b.文件浏览以及上传路径设置:
我个人的参考如下:
FCKConfig.LinkBrowser = true ;
FCKConfig.LinkBrowserURL = FCKConfig.BasePath + 'filemanager/browser/default/browser.html?Connector=connectors/jsp/connector' ;
FCKConfig.LinkBrowserWindowWidth = FCKConfig.ScreenWidth * 0.7 ; // 70%
FCKConfig.LinkBrowserWindowHeight = FCKConfig.ScreenHeight * 0.7 ; // 70%
FCKConfig.ImageBrowser = true ;
FCKConfig.ImageBrowserURL = FCKConfig.BasePath + 'filemanager/browser/default/browser.html?Type=Image&Connector=connectors/jsp/connector';
FCKConfig.ImageBrowserWindowWidth = FCKConfig.ScreenWidth * 0.7 ; // 70% ;
FCKConfig.ImageBrowserWindowHeight = FCKConfig.ScreenHeight * 0.7 ; // 70% ;
FCKConfig.FlashBrowser = true ;
FCKConfig.FlashBrowserURL = FCKConfig.BasePath + 'filemanager/browser/default/browser.html?Type=Flash&Connector=connectors/jsp/connector' ;
FCKConfig.FlashBrowserWindowWidth = FCKConfig.ScreenWidth * 0.7 ; //70% ;
FCKConfig.FlashBrowserWindowHeight = FCKConfig.ScreenHeight * 0.7 ; //70% ;
FCKConfig.LinkUpload = true ;
FCKConfig.LinkUploadURL = FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=File' ;
FCKConfig.LinkUploadAllowedExtensions = "" ; // empty for all
FCKConfig.LinkUploadDeniedExtensions = ".(php|php3|php5|phtml|asp|aspx|ascx|jsp|cfm|cfc|pl|bat|exe|dll|reg|cgi)$" ; // empty for no one
FCKConfig.ImageUpload = true ;
FCKConfig.ImageUploadURL =FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=Image' ;
FCKConfig.ImageUploadAllowedExtensions = ".(jpg|gif|jpeg|png)$" ; // empty for all
FCKConfig.ImageUploadDeniedExtensions = "" ; // empty for no one
FCKConfig.FlashUpload = true ;
FCKConfig.FlashUploadURL = FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=Flash' ;
FCKConfig.FlashUploadAllowedExtensions = ".(swf|fla)$" ; // empty for all
FCKConfig.FlashUploadDeniedExtensions = "" ; // empty for no one
2.与JSF整合。
FCKeditor与JSF整合的最大问题,在于需要从JSF环境中相应Bean读取值赋予给FCKeditor,同时从FCKeditor里面读取结果赋予给相应的数据持有Bean。由于这一过程在传统的JSF标签中是通过值绑定有框架自动完成,因此这里需要我们手动来实现这一过程。
以下要展示的demo由两部分组成:
form.jsp显示编辑内容,点击其submit按钮跳转至test.jsp,test.jsp调用FCKeditor对form.jsp中显示的已有内容进行显示和编辑。编辑完后点击submit,页面将重新跳转到form.jsp,显示修改后的内容。
其实,这就是一个很基本的编辑功能,在论坛和blog中都可以看到它的身影。
而ContextBean用于持有待编辑的内容,它的scope是session范围。ContextServlet用于读取FCKeditor修改后的内容,并赋予ContextBean中。
首先来看form.jsp
<body>
<f:view>
<h:form>
<pre>
<h:outputText value="#{td.name}" escape="false"></h:outputText>
</pre>
<br/>
<h:commandButton value="submit" action="#{td.submit}"></h:commandButton>
</h:form>
</f:view>
</body>
这个页面很简单,其中td对应的就是ContextBean,ContextBean.name用于保存编辑内容
package com.dyerac;
public class ContextBean {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String submit() {
return "edit";
}
}
下面来看test.jsp
用过FCKeditor的都知道,FCKeditor可以通过三种方式来调用:
script, jsp 标签以及java代码。
这里,为了方便从ContextBean中读取name属性内容作为其初始值,我使用了第三种方法
其中FCKeditor fck=new FCKeditor(request,"EditorDefault");初始化FCKeditor,第二个参数即为该FCKeditor实例的id,当提交后FCKeditor内的内容将以该参数为变量名保存在request中。
比如,这里我选择了EditorDefault,所以日后读取FCKeditor内容时,可以通过以下语句:
request.getParameter("EditorDefault")
<body>
<form action="/fck/servlet/ContextServlet" method="post" target="_blank">
<%FCKeditor fck=new FCKeditor(request,"EditorDefault");
FacesContext fcg=FacesContext.getCurrentInstance();
ContextBean td=(ContextBean)fcg.getApplication().getVariableResolver().resolveVariable(fcg,"td");
fck.setBasePath("/fck/FCKeditor/");
fck.setValue(td.getName());
fck.setHeight(new Integer(600).toString());
out.print(fck.create());
%>
<input type="submit" value="Submit">
</body> 修改后的结果以post方式提交给/fck/servlet/ContextServlet,该url对应的即为ContextServlet。
ContextServlet负责读取FCKeditor里的内容,并赋予给session中的ContextBean。doPost()方法用于实现该功能
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
FacesContext fcg = getFacesContext(request,response);
ContextBean td = (ContextBean) fcg.getApplication()
.getVariableResolver().resolveVariable(fcg, "td");
String name=new String(request.getParameter("EditorDefault").getBytes("ISO-8859-1"),"UTF-8");
td.setName(name);
RequestDispatcher rd=getServletContext().getRequestDispatcher("/form.faces");
rd.forward(request, response);
} 需要注意两个问题,
其一:FCKeditor内的中文信息读取是可能出现乱码,需要额外的处理:
String name=new String(request.getParameter("EditorDefault").getBytes("ISO-8859-1"),"UTF-8");
其二:由于servlet处于FacesContext范围外,因此不能通过FacesContext.getCurrentInstance()来得到当前FacesContext,因此ContextServlet定义了自己的方法用于获取FacesContext:
// You need an inner class to be able to call FacesContext.setCurrentInstance
// since it's a protected method
private abstract static class InnerFacesContext extends FacesContext
{
protected static void setFacesContextAsCurrentInstance(FacesContext facesContext) {
FacesContext.setCurrentInstance(facesContext);
}
}
private FacesContext getFacesContext(ServletRequest request, ServletResponse response) {
// Try to get it first
FacesContext facesContext = FacesContext.getCurrentInstance();
if (facesContext != null) return facesContext;
FacesContextFactory contextFactory = (FacesContextFactory)FactoryFinder.getFactory(FactoryFinder.FACES_CONTEXT_FACTORY);
LifecycleFactory lifecycleFactory = (LifecycleFactory)FactoryFinder.getFactory(FactoryFinder.LIFECYCLE_FACTORY);
Lifecycle lifecycle = lifecycleFactory.getLifecycle(LifecycleFactory.DEFAULT_LIFECYCLE);
// Either set a private member servletContext = filterConfig.getServletContext();
// in you filter init() method or set it here like this:
// ServletContext servletContext = ((HttpServletRequest)request).getSession().getServletContext();
// Note that the above line would fail if you are using any other protocol than http
ServletContext servletContext = ((HttpServletRequest)request).getSession().getServletContext();
// Doesn't set this instance as the current instance of FacesContext.getCurrentInstance
facesContext = contextFactory.getFacesContext(servletContext, request, response, lifecycle);
// Set using our inner class
InnerFacesContext.setFacesContextAsCurrentInstance(facesContext);
// set a new viewRoot, otherwise context.getViewRoot returns null
//UIViewRoot view = facesContext.getApplication().getViewHandler().createView(facesContext, "yourOwnID");
//facesContext.setViewRoot(view);
return facesContext;
} ContextServlet处理完了FCKeditor内容后,将跳转到form.jsp。
这样一个简单的编辑功能就完成了。
3.遗留问题:
我在上传文件时还是会出现中文乱码的问题,按照其他人说的那样把网页的charset=utf-8改成gb2312一样会有问题,还请各位高手赐教^_^
另外,关于整个demo的源代码如果大家需要,可以留言给我,我用邮箱发给您。不足之处,还请各位多多指点
posted @
2006-10-14 17:13 xzc 阅读(413) |
评论 (0) |
编辑 收藏
关键字:
|
开发环境:
Tomcat5.5 Eclipse3.2
FCKeditor 版本 FCKeditor_2.3.1 FCKeditor.Java 2.3
下载地址: http://www.fckeditor.net/download/default.html
开始:
新建工程,名称为 fekeditor
解压 FCKeditor_2.3.1 包中的 edit 文件夹到项目中的 WebContent 目录
解压 FCKeditor_2.3.1 包中的 fckconfig.js、fckeditor.js、fckstyles.xml、fcktemplates.xml 文件夹到项目中的 WebContent 目录
解压 FCKeditor-2.3.zip 包中的 \web\WEB-INF\lib 下的两个 jar 文件到项目的 WebContent\WEB-INF\lib 目录
解压 FCKeditor-2.3.zip 包中的 \src 下的 FCKeditor.tld 文件到项目的 WebContent\WEB-INF 目录
删除 WebContent\edit 目录下的 _source 文件夹
修改 web.xml 文件,加入以下内容
代码
<
servlet
>
<
servlet
-
name
>
Connector
</
servlet-name>
<servlet-class>
com.fredck.FCKeditor.connector.ConnectorServlet
<
/
servlet
-
class
>
<
init
-
param
>
<
param
-
name
>
baseDir
</
param-name>
<!-- 此为文件浏览路径 -->
<param-value>
/
UserFiles
/</
param-value>
<
/
init
-
param
>
<
init
-
param
>
<
param
-
name
>
debug
</
param-name>
<param-value>true<
/
param
-
value
>
</
init-param>
<load-on-startup>1<
/
load
-
on
-
startup
>
</
servlet> <servlet>
<servlet-name>SimpleUploader<
/
servlet
-
name
>
<
servlet
-
class
>
com
.
fredck
.
FCKeditor
.
uploader
.
SimpleUploaderServlet
</
servlet-class>
<init-param>
<param-name>baseDir<
/
param
-
name
>
<!-- 此为文件上传路径,需要在WebContent 目录下新建 UserFiles 文件夹 -->
<!-- 根据文件的类型还需要新建相关的文件夹 Image、Flash-->
<param-value>/UserFiles/</param-value>
</init-param>
<init-param>
<param-name>debug</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<!-- 此参数为是否开启上传功能 -->
<param-name>enabled</param-name>
<param-value>false</param-value>
</init-param>
<init-param>
<param-name>AllowedExtensionsFile</param-name>
<param-value></param-value>
</init-param>
<init-param> <!-- 此参数为文件过滤,以下的文件类型都不可以上传 -->
<param-name>DeniedExtensionsFile</param-name>
<param-value>
php|php3|php5|phtml|asp|aspx|ascx|jsp|cfm|cfc|pl|bat|exe|dll|reg|cgi
</param-value>
</init-param>
<init-param>
<param-name>AllowedExtensionsImage</param-name>
<param-value>jpg|gif|jpeg|png|bmp</param-value>
</init-param>
<init-param>
<param-name>DeniedExtensionsImage</param-name>
<param-value></param-value>
</init-param>
<init-param>
<param-name>AllowedExtensionsFlash</param-name>
<param-value>swf|fla</param-value>
</init-param>
<init-param>
<param-name>DeniedExtensionsFlash</param-name>
<param-value></param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet><servlet-mapping>
<servlet-name>Connector</servlet-name>
<url-pattern>
/editor/filemanager/browser/default/connectors/jsp/connector
</url-pattern>
</servlet-mapping><servlet-mapping>
<servlet-name>SimpleUploader</servlet-name>
<url-pattern>
/editor/filemanager/upload/simpleuploader
</url-pattern>
</servlet-mapping>
新建一个提交页 jsp1.jsp 文件和一个接收页 jsp2.jsp 文件
jsp1.jsp 代码如下: 代码 <%@ page contentType = "text/html;charset=UTF-8" language = "java" %>
<%@tagliburi="/WEB-INF/FCKeditor.tld"prefix="fck"%><html>
<head>
<title>Test</title>
</head><body>
<FORMaction="jsp2.jsp">
<fck:editorid="testfck"basePath="/fekeditor/"
height="100%"
skinPath="/fekeditor/editor/skins/default/"
toolbarSet="Default"
imageBrowserURL="/fekeditor/editor/filemanager/browser/default/browser.html?Type=Image&Connector=connectors/jsp/connector"
linkBrowserURL="/fekeditor/editor/filemanager/browser/default/browser.html?Connector=connectors/jsp/connector"
flashBrowserURL="/fekeditor/editor/filemanager/browser/default/browser.html?Type=Flash&Connector=connectors/jsp/connector"
imageUploadURL="/fekeditor/editor/filemanager/upload/simpleuploader?Type=Image"
linkUploadURL="/fekeditor/editor/filemanager/upload/simpleuploader?Type=File"
flashUploadURL="/fekeditor/editor/filemanager/upload/simpleuploader?Type=Flash">
</fck:editor>
<input type="submit" />
</FORM>
</body>
</html>jsp2.jsp 代码如下:<html>
<head>
<title>TEST</title>
</head> <body>
<%=request.getParameter( "testfck" )%>
</body>
</html>
在 WebContent 目录下新建 UserFiles 文件夹,在此文件夹下新建 File,Image,Flash 三个文件夹。
ok现在运行一下看看吧!
|
posted @
2006-10-14 17:08 xzc 阅读(490) |
评论 (0) |
编辑 收藏
试用了一下FCKeditor,根据网上的文章小结一下:
1.下载
FCKeditor.java 2.3 (FCKeditot for java)
FCKeditor 2.2 (FCKeditor基本文件)
2.建立项目:tomcat/webapps/TestFCKeditor.
3.将FCKeditor2.2解压缩,将整个目录FCKeditor复制到项目的根目录下,
目录结构为:tomcat/webapps/TestFCKeditor/FCKeditor
然后将FCKeditor-2.3.zip(java)压缩包中\web\WEB-INF\lib\目录下的两个jar文件拷到项目的\WEB-INF\lib\目录下。把其中的src目录下的FCKeditor.tld文件copy到TestFCKedit/FCKeitor/WEB-INF/下
4.将FCKeditor-2.3.zip压缩包中\web\WEB-INF\目录下的web.xml文件合并到项目的\WEB-INF\目录下的web.xml文件中。
|
5. 修改合并后的web.xml文件,将名为SimpleUploader的Servlet的enabled参数值改为true,
以允许上传功能,Connector Servlet的baseDir参数值用于设置上传文件存放的位置。
添加标签定义:
<taglib>
<taglib-uri>/TestFCKeditor</taglib-uri>
<taglib-location>/WEB-INF/FCKeditor.tld</taglib-location>
</taglib>
运行图:

6. 上面文件中两个servlet的映射分别为:/editor/filemanager/browser/default/connectors/jsp/connector
和/editor/filemanager/upload/simpleuploader,需要在两个映射前面加上/FCKeditor,
即改为/FCKeditor/editor/filemanager/browser/default/connectors/jsp/connector和
/FCKeditor/editor/filemanager/upload/simpleuploader。
7.进入skin文件夹,如果你想使用fckeditor默认的这种奶黄色,
那就把除了default文件夹外的另两个文件夹直接删除.
8.删除/FCKeditor/目录下除fckconfig.js, fckeditor.js, fckstyles.xml, fcktemplates.xml四个文件以外的所有文件
删除目录/editor/_source,
删除/editor/filemanager/browser/default/connectors/下的所有文件
删除/editor/filemanager/upload/下的所有文件
删除/editor/lang/下的除了fcklanguagemanager.js, en.js, zh.js, zh-cn.js四个文件的所有文件
9.打开/FCKeditor/fckconfig.js
修改 FCKConfig.DefaultLanguage = 'zh-cn' ;
把FCKConfig.LinkBrowserURL等的值替换成以下内容:
FCKConfig.LinkBrowserURL
= FCKConfig.BasePath + "filemanager/browser/default/browser.html?Connector=connectors/jsp/connector" ;
FCKConfig.ImageBrowserURL
= FCKConfig.BasePath + "filemanager/browser/default/browser.html?Type=Image&Connector=connectors/jsp/connector" ;
FCKConfig.FlashBrowserURL
= FCKConfig.BasePath + "filemanager/browser/default/browser.html?Type=Flash&Connector=connectors/jsp/connector" ;
FCKConfig.LinkUploadURL = FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=File' ;
FCKConfig.FlashUploadURL = FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=Flash' ;
FCKConfig.ImageUploadURL = FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=Image' ;
10.其它
fckconfig.js总配置文件,可用记录本打开,修改后将文件存为utf-8 编码格式。找到:
FCKConfig.TabSpaces = 0 ; 改为FCKConfig.TabSpaces = 1 ; 即在编辑器域内可以使用Tab键。
如果你的编辑器还用在网站前台的话,比如说用于留言本或是日记回复时,那就不得不考虑安全了,
在前台千万不要使用Default的toolbar,要么自定义一下功能,要么就用系统已经定义好的Basic,
也就是基本的toolbar,找到:
FCKConfig.ToolbarSets["Basic"] = [
['Bold','Italic','-','OrderedList','UnorderedList','-',/*'Link',*/'Unlink','-','Style','FontSize','TextColor','BGColor','-',
'Smiley','SpecialChar','Replace','Preview'] ] ;
这是改过的Basic,把图像功能去掉,把添加链接功能去掉,因为图像和链接和flash和图像按钮添加功能都能让前台
页直接访问和上传文件, fckeditor还支持编辑域内的鼠标右键功能。
FCKConfig.ContextMenu = ['Generic',/*'Link',*/'Anchor',/*'Image',*/'Flash','Select','Textarea','Checkbox','Radio','TextField','HiddenField',
/*'ImageButton',*/'Button','BulletedList','NumberedList','TableCell','Table','Form'] ;
这也是改过的把鼠标右键的“链接、图像,FLASH,图像按钮”功能都去掉。
找到: FCKConfig.FontNames = 'Arial;Comic Sans MS;Courier New;Tahoma;Times New Roman;Verdana' ;
加上几种我们常用的字体
FCKConfig.FontNames
= '宋体;黑体;隶书;楷体_GB2312;Arial;Comic Sans MS;Courier New;Tahoma;Times New Roman;Verdana' ;
7.添加文件 /TestFCKeditor/test.jsp:
<%@ page language="java" import="com.fredck.FCKeditor.*" %>
<%@ taglib uri="/TestFCKeditor" prefix="FCK" %>
<script type="text/javascript" src="/TestFCKeditor/FCKeditor/fckeditor.js"></script>
<%--
三种方法调用FCKeditor
1.FCKeditor自定义标签 (必须加头文件 <%@ taglib uri="/TestFCKeditor" prefix="FCK" %> )
2.script脚本语言调用 (必须引用 脚本文件 <script type="text/javascript" src="/TestFCKeditor/FCKeditor/fckeditor.js"></script> )
3.FCKeditor API 调用 (必须加头文件 <%@ page language="java" import="com.fredck.FCKeditor.*" %> )
--%>
<%--
<form action="show.jsp" method="post" target="_blank">
<FCK:editor id="content" basePath="/TestFCKeditor/FCKeditor/"
width="700"
height="500"
skinPath="/TestFCKeditor/FCKeditor/editor/skins/silver/"
toolbarSet = "Default"
>
input
</FCK:editor>
<input type="submit" value="Submit">
</form>
--%>
<form action="show.jsp" method="post" target="_blank">
<table border="0" width="700"><tr><td>
<textarea id="content" name="content" style="WIDTH: 100%; HEIGHT: 400px">input</textarea>
<script type="text/javascript">
var oFCKeditor = new FCKeditor('content') ;
oFCKeditor.BasePath = "/TestFCKeditor/FCKeditor/" ;
oFCKeditor.Height = 400;
oFCKeditor.ToolbarSet = "Default" ;
oFCKeditor.ReplaceTextarea();
</script>
<input type="submit" value="Submit">
</td></tr></table>
</form>
<%--
<form action="show.jsp" method="post" target="_blank">
<%
FCKeditor oFCKeditor ;
oFCKeditor = new FCKeditor( request, "content" ) ;
oFCKeditor.setBasePath( "/TestFCKeditor/FCKeditor/" ) ;
oFCKeditor.setValue( "input" );
out.println( oFCKeditor.create() ) ;
%>
<br>
<input type="submit" value="Submit">
</form>
--%>
添加文件/TestFCKeditor/show.jsp:
<%
String content = request.getParameter("content");
out.print(content);
%>
8.浏览http://localhost:8080/TestFCKeditor/test.jsp
ok!
posted @
2006-10-11 17:19 xzc 阅读(213) |
评论 (0) |
编辑 收藏最近写书,写到JNDI,到处查资料,发现所有的中文资料都对JNDI解释一通,配置代码也是copy的,调了半天也没调通,最后到SUN的网站参考了一下他的JNDI tutorial,终于基本上彻底明白了
和多数java服务一样,SUN对JNDI也只提供接口,使用JNDI只需要用到JNDI接口而不必关心具体实现:
private static Object jndiLookup() throws Exception {
InitialContext ctx = new InitialContext();
return ctx.lookup("java:comp/env/systemStartTime");
}
上述代码在J2EE服务器环境下工作得很好,但是在main()中就会报一个NoInitialContextException,许多文章会说你创建InitialContext的时候还要传一个Hashtable或者Properties,像这样:
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, "weblogic.jndi.WLInitialContextFactory");
env.put(Context.PROVIDER_URL,"t3://localhost:7001");
InitialContext ctx = new InitialContext(env);
这个在WebLogic环境下是对的,但是换到JBoss呢?再用JBoss的例子?
其实之所以有NoInitialContextException是因为无法从System.properties中获得必要的JNDI参数,在服务器环境下,服务器启动时就把这些参数放到System.properties中了,于是直接new InitialContext()就搞定了,不要搞env那么麻烦,搞了env你的代码还无法移植,弄不好管理员设置服务器用的不是标准端口还照样抛异常。
但是在单机环境下,可没有JNDI服务在运行,那就手动启动一个JNDI服务。我在JDK 5的rt.jar中一共找到了4种SUN自带的JNDI实现:
LDAP,CORBA,RMI,DNS。
这4种JNDI要正常运行还需要底层的相应服务。一般我们没有LDAP或CORBA服务器,也就无法启动这两种JNDI服务,DNS用于查域名的,以后再研究,唯一可以在main()中启动的就是基于RMI的JNDI服务。
现在我们就在main()中启动基于RMI的JNDI服务并且绑一个Date对象到JNDI上:
LocateRegistry.createRegistry(1099);
System.setProperty(Context.INITIAL_CONTEXT_FACTORY, "com.sun.jndi.rmi.registry.RegistryContextFactory");
System.setProperty(Context.PROVIDER_URL, "rmi://localhost:1099");
InitialContext ctx = new InitialContext();
class RemoteDate extends Date implements Remote {};
ctx.bind("java:comp/env/systemStartTime", new RemoteDate());
ctx.close();
注意,我直接把JNDI的相关参数放入了System.properties中,这样,后面的代码如果要查JNDI,直接new InitialContext()就可以了,否则,你又得写Hashtable env = ...
在RMI中绑JNDI的限制是,绑定的对象必须是Remote类型,所以就自己扩展一个。
其实JNDI还有两个Context.SECURITY_PRINCIPAL和Context.SECURITY_CREDENTIAL,如果访问JNDI需要用户名和口令,这两个也要提供,不过一般用不上。
在后面的代码中查询就简单了:
InitialContext ctx = new InitialContext();
Date startTime = (Date) ctx.lookup("java:comp/env/systemStartTime");
在SUN的JNDI tutorial中的例子用的com.sun.jndi.fscontext.RefFSContextFactory类,但是我死活在JDK 5中没有找到这个类,也就是NoClassDefFoundError,他也不说用的哪个扩展包,我也懒得找了。
posted @
2006-10-11 14:55 xzc 阅读(1861) |
评论 (0) |
编辑 收藏
摘要:
本文阐述了怎么使用DBMS存储过程。我阐述了使用存储过程的基本的和高级特性,比如返回ResultSet。本文假设你对DBMS和JDBC已经非常熟悉,也假设你能够毫无障碍地阅读其它语言写成的代码(即不是Java的语言),但是,并不要求你有任何存储过程的编程经历。
本文阐述了怎么使用DBMS存储过程。我阐述了使用存储过程的基本的和高级特性,比如返回ResultSet。本文假设你对DBMS和JDBC已经非常熟悉,也假设你能够毫无障碍地阅读其它语言写成的代码(即不是Java的语言),但是,并不要求你有任何存储过程的编程经历。
存储过程是指保存在数据库并在数据库端执行的程序。你可以使用特殊的语法在Java类中调用存储过程。在调用时,存储过程的名称及指定的参数通过JDBC连接发送给DBMS,执行存储过程并通过连接(如果有)返回结果。
使用存储过程拥有和使用基于EJB或CORBA这样的应用服务器一样的好处。区别是存储过程可以从很多流行的DBMS中免费使用,而应用服务器大都非常昂贵。这并不只是许可证费用的问题。使用应用服务器所需要花费的管理、编写代码的费用,以及客户程序所增加的复杂性,都可以通过DBMS中的存储过程所整个地替代。
你可以使用Java,Python,Perl或C编写存储过程,但是通常使用你的DBMS所指定的特定语言。Oracle使用PL/SQL,PostgreSQL使用pl/pgsql,DB2使用Procedural SQL。这些语言都非常相似。在它们之间移植存储过程并不比在Sun的EJB规范不同实现版本之间移植Session Bean困难。并且,存储过程是为嵌入SQL所设计,这使得它们比Java或C等语言更加友好地方式表达数据库的机制。
因为存储过程运行在DBMS自身,这可以帮助减少应用程序中的等待时间。不是在Java代码中执行4个或5个SQL语句,而只需要在服务器端执行1个存储过程。网络上的数据往返次数的减少可以戏剧性地优化性能。
使用存储过程简单的老的JDBC通过CallableStatement类支持存储过程的调用。该类实际上是PreparedStatement的一个子类。假设我们有一个poets数据库。数据库中有一个设置诗人逝世年龄的存储过程。下面是对老酒鬼Dylan Thomas(old soak Dylan Thomas,不指定是否有关典故、文化,请批评指正。译注)进行调用的详细代码:
try{
int age = 39;
String poetName = "dylan thomas";
CallableStatement proc = connection.prepareCall("{ call set_death_age(?, ?) }");
proc.setString(1, poetName);
proc.setInt(2, age);
cs.execute();
}catch (SQLException e){ // ....} 传给prepareCall方法的字串是存储过程调用的书写规范。它指定了存储过程的名称,?代表了你需要指定的参数。
和JDBC集成是存储过程的一个很大的便利:为了从应用中调用存储过程,不需要存根(stub)类或者配置文件,除了你的DBMS的JDBC驱动程序外什么也不需要。
当这段代码执行时,数据库的存储过程就被调用。我们没有去获取结果,因为该存储过程并不返回结果。执行成功或失败将通过例外得知。失败可能意味着调用存储过程时的失败(比如提供的一个参数的类型不正确),或者一个应用程序的失败(比如抛出一个例外指示在poets数据库中并不存在“Dylan Thomas”)
结合SQL操作与存储过程映射Java对象到SQL表中的行相当简单,但是通常需要执行几个SQL语句;可能是一个SELECT查找ID,然后一个INSERT插入指定ID的数据。在高度规格化(符合更高的范式,译注)的数据库模式中,可能需要多个表的更新,因此需要更多的语句。Java代码会很快地膨胀,每一个语句的网络开销也迅速增加。
将这些SQL语句转移到一个存储过程中将大大简化代码,仅涉及一次网络调用。所有关联的SQL操作都可以在数据库内部发生。并且,存储过程语言,例如PL/SQL,允许使用SQL语法,这比Java代码更加自然。下面是我们早期的存储过程,使用Oracle的PL/SQL语言编写:
create procedure set_death_age(poet VARCHAR2, poet_age NUMBER)
poet_id NUMBER;
begin SELECT id INTO poet_id FROM poets WHERE name = poet;
INSERT INTO deaths (mort_id, age) VALUES (poet_id, poet_age);
end set_death_age;
很独特?不。我打赌你一定期待看到一个poets表上的UPDATE。这也暗示了使用存储过程实现是多么容易的一件事情。set_death_age几乎可以肯定是一个很烂的实现。我们应该在poets表中添加一列来存储逝世年龄。Java代码中并不关心数据库模式是怎么实现的,因为它仅调用存储过程。我们以后可以改变数据库模式以提高性能,但是我们不必修改我们代码。
下面是调用上面存储过程的Java代码:
public static void setDeathAge(Poet dyingBard, int age) throws SQLException{
Connection con = null;
CallableStatement proc = null;
try {
con = connectionPool.getConnection();
proc = con.prepareCall("{ call set_death_age(?, ?) }");
proc.setString(1, dyingBard.getName());
proc.setInt(2, age);
proc.execute();
}
finally {
try { proc.close(); }
catch (SQLException e) {}
con.close();
}
} 为了确保可维护性,建议使用像这儿这样的static方法。这也使得调用存储过程的代码集中在一个简单的模版代码中。如果你用到许多存储过程,就会发现仅需要拷贝、粘贴就可以创建新的方法。因为代码的模版化,甚至也可以通过脚本自动生产调用存储过程的代码。
Functions存储过程可以有返回值,所以CallableStatement类有类似getResultSet这样的方法来获取返回值。当存储过程返回一个值时,你必须使用registerOutParameter方法告诉JDBC驱动器该值的SQL类型是什么。你也必须调整存储过程调用来指示该过程返回一个值。
下面接着上面的例子。这次我们查询Dylan Thomas逝世时的年龄。这次的存储过程使用PostgreSQL的pl/pgsql:
create function snuffed_it_when (VARCHAR) returns integer ''declare
poet_id NUMBER;
poet_age NUMBER;
begin
--first get the id associated with the poet.
SELECT id INTO poet_id FROM poets WHERE name = $1;
--get and return the age.
SELECT age INTO poet_age FROM deaths WHERE mort_id = poet_id;
return age;
end;'' language ''pl/pgsql'';
另外,注意pl/pgsql参数名通过Unix和DOS脚本的$n语法引用。同时,也注意嵌入的注释,这是和Java代码相比的另一个优越性。在Java中写这样的注释当然是可以的,但是看起来很凌乱,并且和SQL语句脱节,必须嵌入到Java String中。
下面是调用这个存储过程的Java代码:
connection.setAutoCommit(false);
CallableStatement proc = connection.prepareCall("{ ? = call snuffed_it_when(?) }");
proc.registerOutParameter(1, Types.INTEGER);
proc.setString(2, poetName);
cs.execute();
int age = proc.getInt(2);
如果指定了错误的返回值类型会怎样?那么,当调用存储过程时将抛出一个RuntimeException,正如你在ResultSet操作中使用了一个错误的类型所碰到的一样。
复杂的返回值关于存储过程的知识,很多人好像就熟悉我们所讨论的这些。如果这是存储过程的全部功能,那么存储过程就不是其它远程执行机制的替换方案了。存储过程的功能比这强大得多。
当你执行一个SQL查询时,DBMS创建一个叫做cursor(游标)的数据库对象,用于在返回结果中迭代每一行。ResultSet是当前时间点的游标的一个表示。这就是为什么没有缓存或者特定数据库的支持,你只能在ResultSet中向前移动。
某些DBMS允许从存储过程中返回游标的一个引用。JDBC并不支持这个功能,但是Oracle、PostgreSQL和DB2的JDBC驱动器都支持在ResultSet上打开到游标的指针(pointer)。
设想列出所有没有活到退休年龄的诗人,下面是完成这个功能的存储过程,返回一个打开的游标,同样也使用PostgreSQL的pl/pgsql语言:
create procedure list_early_deaths () return refcursor as ''declare
toesup refcursor;
begin
open toesup for SELECT poets.name, deaths.age FROM poets, deaths -- all entries in deaths are for poets. -- but the table might become generic.
WHERE poets.id = deaths.mort_id AND deaths.age < 60;
return toesup;
end;'' language ''plpgsql'';
下面是调用该存储过程的Java方法,将结果输出到PrintWriter:
PrintWriter:
static void sendEarlyDeaths(PrintWriter out){
Connection con = null;
CallableStatement toesUp = null;
try {
con = ConnectionPool.getConnection();
// PostgreSQL needs a transaction to do this... con.
setAutoCommit(false); // Setup the call.
CallableStatement toesUp = connection.prepareCall("{ ? = call list_early_deaths () }");
toesUp.registerOutParameter(1, Types.OTHER);
toesUp.execute();
ResultSet rs = (ResultSet) toesUp.getObject(1);
while (rs.next()) {
String name = rs.getString(1);
int age = rs.getInt(2);
out.println(name + " was " + age + " years old.");
}
rs.close();
}
catch (SQLException e) { // We should protect these calls. toesUp.close(); con.close();
}
}
因为JDBC并不直接支持从存储过程中返回游标,我们使用Types.OTHER来指示存储过程的返回类型,然后调用getObject()方法并对返回值进行强制类型转换。
这个调用存储过程的Java方法是mapping的一个好例子。Mapping是对一个集上的操作进行抽象的方法。不是在这个过程上返回一个集,我们可以把操作传送进去执行。本例中,操作就是把ResultSet打印到一个输出流。这是一个值得举例的很常用的例子,下面是调用同一个存储过程的另外一个方法实现:
public class ProcessPoetDeaths{
public abstract void sendDeath(String name, int age);
}
static void mapEarlyDeaths(ProcessPoetDeaths mapper){
Connection con = null;
CallableStatement toesUp = null;
try {
con = ConnectionPool.getConnection();
con.setAutoCommit(false);
CallableStatement toesUp = connection.prepareCall("{ ? = call list_early_deaths () }");
toesUp.registerOutParameter(1, Types.OTHER);
toesUp.execute();
ResultSet rs = (ResultSet) toesUp.getObject(1);
while (rs.next()) {
String name = rs.getString(1);
int age = rs.getInt(2);
mapper.sendDeath(name, age);
}
rs.close();
} catch (SQLException e) { // We should protect these calls. toesUp.close();
con.close();
}
} 这允许在ResultSet数据上执行任意的处理,而不需要改变或者复制获取ResultSet的方法:
static void sendEarlyDeaths(final PrintWriter out){
ProcessPoetDeaths myMapper = new ProcessPoetDeaths() {
public void sendDeath(String name, int age) {
out.println(name + " was " + age + " years old.");
}
};
mapEarlyDeaths(myMapper);
} 这个方法使用ProcessPoetDeaths的一个匿名实例调用mapEarlyDeaths。该实例拥有sendDeath方法的一个实现,和我们上面的例子一样的方式把结果写入到输出流。当然,这个技巧并不是存储过程特有的,但是和存储过程中返回的ResultSet结合使用,是一个非常强大的工具。
结论存储过程可以帮助你在代码中分离逻辑,这基本上总是有益的。这个分离的好处有:
• 快速创建应用,使用和应用一起改变和改善的数据库模式。
• 数据库模式可以在以后改变而不影响Java对象,当我们完成应用后,可以重新设计更好的模式。
• 存储过程通过更好的SQL嵌入使得复杂的SQL更容易理解。
• 编写存储过程比在Java中编写嵌入的SQL拥有更好的工具--大部分编辑器都提供语法高亮!
• 存储过程可以在任何SQL命令行中测试,这使得调试更加容易。
并不是所有的数据库都支持存储过程,但是存在许多很棒的实现,包括免费/开源的和非免费的,所以移植并不是一个问题。Oracle、PostgreSQL和DB2都有类似的存储过程语言,并且有在线的社区很好地支持。
存储过程工具很多,有像TOAD或TORA这样的编辑器、调试器和IDE,提供了编写、维护PL/SQL或pl/pgsql的强大的环境。
存储过程确实增加了你的代码的开销,但是它们和大多数的应用服务器相比,开销小得多。
posted @
2006-10-11 14:22 xzc 阅读(216) |
评论 (0) |
编辑 收藏
近日学习了一下AJAX,照做了几个例子,感觉比较新奇。
第一个就是自动完成的功能即Autocomplete,具体的例子可以在这里看:http://www.b2c-battery.co.uk
在Search框内输入一个产品型号,就可以看见效果了。
这里用到了一个开源的代码:AutoAssist ,有兴趣的可以看一下。
以下为代码片断:
index.htm
<script type="text/javascript" src="javascripts/prototype.js"></script>
<script type="text/javascript" src="javascripts/autoassist.js"></script>
<link rel="stylesheet" type="text/css" href="styles/autoassist.css"/>
<div>
<input type="text" name="keyword" id="keyword"/>
<script type="text/javascript">
Event.observe(window, "load", function() {
var aa = new AutoAssist("keyword", function() {
return "forCSV.php?q=" + this.txtBox.value;
});
});
</script>
</div>
不知道为什么不能用keywords做文本框的名字,我试了很久,后来还是用keyword,搞得还要修改原代码。
forCSV.php
<?php
$keyword = $_GET['q'];
$count = 0;
$handle = fopen("products.csv", "r");
while (($data = fgetcsv($handle, 1000)) !== FALSE) {
if (preg_match("/$keyword/i", $data[0])) {
if ($count++ > 10) { break; }
?>
<div onSelect="this.txtBox.value='<?php echo $data[0]; ?>';">
<?php echo $data[0]; ?>
</div>
<?php
}
}
fclose($handle);
if ($count == 0) {
?>
: (, nothing found.
<?php
}
?>
原来的例子中的CSV文件是根据\t来分隔的,我们也可以用空格或其它的来分隔,这取决于你的数据结构。
当然你也可以不读文件,改从数据库里读资料,就不再废话了。
效果图如下:

Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=635858
posted @
2006-10-08 14:12 xzc 阅读(388) |
评论 (1) |
编辑 收藏
Spring支持从数据动态生成PDF或Excel文件
下面这个简单实现的例子实现了spring输出PDF和Excel文件,为了使用Excel电子表格,你需要在你的classpath中加入poi-2.5.1.jar库文件,而对PDF文件,则需要iText.jar文件。它们都包含在Spring的主发布包中。
下面是测试项目代码:
1、控制器配置代码
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="beanNameViewResolver"
class="org.springframework.web.servlet.view.BeanNameViewResolver" />
<bean id="viewController" class="com.zhupan.spring.ViewController" />
<bean id="urlMapping"
class="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping">
<property name="mappings">
<props>
<prop key="/view*.shtml">viewController</prop>
</props>
</property>
</bean>
</beans>
3、用于Excel视图的视图子类化
为了在生成输出文档的过程中实现定制的行为,我们将继承合适的抽象类。对于Excel,这包括提供一个 org.springframework.web.servlet.view.document.AbstractExcelView的子类,并实现 buildExcelDocument方法。
package com.zhupan.view;
import java.util.Date;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFCellStyle;
import org.apache.poi.hssf.usermodel.HSSFDataFormat;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.springframework.web.servlet.view.document.AbstractExcelView;
public class ViewExcel extends AbstractExcelView {
public void buildExcelDocument(
Map model, HSSFWorkbook workbook,
HttpServletRequest request, HttpServletResponse response)
throws Exception {
HSSFSheet sheet = workbook.createSheet("list");
sheet.setDefaultColumnWidth((short) 12);
HSSFCell cell = getCell(sheet, 0, 0);
setText(cell, "Spring Excel test");
HSSFCellStyle dateStyle = workbook.createCellStyle();
dateStyle.setDataFormat(HSSFDataFormat.getBuiltinFormat("m/d/yy"));
cell = getCell(sheet, 1, 0);
cell.setCellValue(new Date());
cell.setCellStyle(dateStyle);
getCell(sheet, 2, 0).setCellValue(458);
HSSFRow sheetRow = sheet.createRow(3);
for (short i = 0; i < 10; i++) {
sheetRow.createCell(i).setCellValue(i * 10);
}
}
}
4、用于PDF视图的视图子类化
需要象下面一样继承org.springframework.web.servlet.view.document.AbstractPdfView,并实现buildPdfDocument()方法。
package com.zhupan.view;
import java.util.List;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.view.document.AbstractPdfView;
import com.lowagie.text.Document;
import com.lowagie.text.Paragraph;
import com.lowagie.text.pdf.PdfWriter;
public class ViewPDF extends AbstractPdfView {
public void buildPdfDocument(Map model, Document document,
PdfWriter writer, HttpServletRequest request,
HttpServletResponse response) throws Exception {
List list = (List) model.get("list");
for (int i = 0; i < list.size(); i++)
document.add(new Paragraph((String) list.get(i)));
}
}
5、其他文件
1)控制器ViewController
package com.zhupan.spring;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.mvc.multiaction.MultiActionController;
import com.zhupan.view.ViewExcel;
import com.zhupan.view.ViewPDF;
public class ViewController extends MultiActionController{
public ModelAndView viewPDF(HttpServletRequest request, HttpServletResponse response) throws Exception {
List list = new ArrayList();
Map model=new HashMap();
list.add("test1");
list.add("test2");
model.put("list",list);
ViewPDF viewPDF=new ViewPDF();
return new ModelAndView(viewPDF,model);
}
public ModelAndView viewExcel(HttpServletRequest request, HttpServletResponse response) throws Exception {
List list = new ArrayList();
Map model=new HashMap();
list.add("test1");
list.add("test2");
model.put("list",list);
ViewExcel viewExcel=new ViewExcel();
return new ModelAndView(viewExcel,model);
}
} 2)web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>springPDFTest</display-name>
<servlet>
<servlet-name>springPDFTest</servlet-name>
<servlet-class>
org.springframework.web.servlet.DispatcherServlet
</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>springPDFTest</servlet-name>
<url-pattern>*.shtml</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
</web-app>
3)index.jsp
<%@ page contentType="text/html; charset=gb2312"%>
<a href="viewPDF.shtml">PDF视图打开 </a>
<br>
<a href="viewExcel.shtml">Excel视图打开</a>
posted @
2006-10-06 15:07 xzc 阅读(805) |
评论 (0) |
编辑 收藏
一、 安装Tomcat5.0.28
二、 安装MS JDBC Driver
假设安装路径是F:\green\Microsoft SQL Server 2000 JDBC,那么在F:\green\Microsoft SQL Server 2000 JDBC\lib下面有三个文件msbase.jar、sqlserver.jar、msutil.jar,并将此三个文件复制到%TOMMCAT_HOME%\common\lib目录下
三、 注册JNDI数据源
修改%TOMCAT_HOME%\conf\Catalina\localhost\目录下您的应用程序对应的配置文件
如:我的一个应用WebDemo.xml文件如下:
<?xml version='1.0' encoding='utf-8'?>
<Context workDir="work\Catalina\localhost\WebDemo" path="/WebDemo" docBase="D:\jakarta-tomcat-5.0.28\webapps\WebDemo">
<Resource type="javax.sql.DataSource" auth="Container" name="jdbc/northwind"/>
<ResourceParams name="jdbc/northwind">
<parameter>
<name>maxWait</name>
<value>5000</value>
</parameter>
<parameter>
<name>maxActive</name>
<value>4</value>
</parameter>
<parameter>
<name>password</name>
<value>jckjdkmcj</value>
</parameter>
<parameter>
<name>url</name>
<value>jdbc:microsoft:sqlserver://10.0.0.168:1433;databaseName=northwind</value>
</parameter>
<parameter>
<name>driverClassName</name>
<value>com.microsoft.jdbc.sqlserver.SQLServerDriver</value>
</parameter>
<parameter>
<name>maxIdle</name>
<value>2</value>
</parameter>
<parameter>
<name>username</name>
<value>sa</value>
</parameter>
</ResourceParams>
<Resource type="javax.sql.DataSource" name="jdbc/zydb"/>
<ResourceParams name="jdbc/zydb">
<parameter>
<name>url</name>
<value>jdbc:oracle:thin:@10.0.0.168:1521:ZYDB</value>
</parameter>
<parameter>
<name>password</name>
<value>jckjdkmcj</value>
</parameter>
<parameter>
<name>maxActive</name>
<value>4</value>
</parameter>
<parameter>
<name>maxWait</name>
<value>5000</value>
</parameter>
<parameter>
<name>driverClassName</name>
<value>oracle.jdbc.driver.OracleDriver</value>
</parameter>
<parameter>
<name>username</name>
<value>zhangyi</value>
</parameter>
<parameter>
<name>maxIdle</name>
<value>2</value>
</parameter>
</ResourceParams>
</Context>
四、 如果你在Eclipse或JBuilder中开发的话,你需要在你的Web应用程序的WEB-INF\Web.xml文件中注册数据源,文件添加如下内容:
<resource-ref>
<res-ref-name>jdbc/northwind</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
一定注意:同时检查一下你部署到Tomcat中对应的
彩色的加粗文字是添加上的,用来注册数据源的JNDI,在这我注册了两个数据源,一个是oracle的,一个是MSSQL Server 2000的。
在做任何配置时最好不要修改Tomcat服务器的任何文件,如servel.xml或web.xml文件,而所有的操作和配置都可以在你自己的应用配置文件中来完成,这样即使培植错误也不至于服务器的崩溃。
按以上步骤就可以完成数据源的配置,你可以写一些程序来测试。
用JSP来测试,Index.jsp文件程序如下:
<%@ page language="java" import="java.util.*" %>
<%@ page import="javax.sql.*" %>
<%@ page import="java.sql.*" %>
<%@ page import="javax.naming.*" %>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
out.println(basePath);
%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<base href="<%=basePath%>">
<title>My JSP 'index.jsp' starting page</title>
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="This is my page">
<!--
<link rel="stylesheet" type="text/css" href="styles.css">
-->
</head>
<body>
This is my JSP page. <br>
<%
Context ctx=null;
Connection cnn=null;
java.sql.Statement stmt=null;
ResultSet rs=null;
try
{
ctx=new InitialContext();
if(ctx==null)
throw new Exception("initialize the Context failed");
DataSource ds=(DataSource)ctx.lookup("java:comp/env/jdbc/northwind");
out.println(ds);
if(ds==null)
throw new Exception("datasource is null");
try{
cnn=ds.getConnection();
out.println("<br> connection:"+cnn);
}catch(Exception e){
e.printStackTrace();
}
}
finally
{
if(rs!=null)
rs.close();
if(stmt!=null)
stmt.close();
if(cnn!=null)
cnn.close();
if(ctx!=null)
ctx.close();
}
%>
</body>
</html>
在你的浏览器中运行http://10.0.0.168:8888/WebDemo/web/即可以看到结果:如下:

你看到连接成功的标志,就意味这你的数据源配置成功!!!
记住:要想配置成功,就要认真检查需要配置的每一个细节。
posted @
2006-10-06 14:55 xzc 阅读(278) |
评论 (0) |
编辑 收藏 JNDI(The Java Naming and Directory Interface,Java命名和目录接口)是一组在Java应用中访问命名和目录服务的API.命名服务将名称和对象联系起来,使得我们可以用名称访问对象。目录服务是一种命名服务,在这种服务里,对象不但有名称,还有属性。
命名或目录服务使你可以集中存储共有信息,这一点在网络应用中是重要的,因为这使得这样的应用更协调、更容易管理。例如,可以将打印机设置存储在目录服务中,以便被与打印机有关的应用使用。
本文用代码示例的方式给出了一个快速教程,使你可以开始使用JNDI.它:
l 提供了JNDI概述 l 描述了JNDI的特点 l 体验了一下用JNDI开发应用 l 表明了如何利用JNDI访问LDAP服务器,例如,Sun ONE 目录服务器 l 表明了如何利用JNDI访问J2EE服务 l 提供了示例代码,你可以将其改编为自己的应用
JNDI概述
我们大家每天都不知不觉地使用了命名服务。例如,当你在web浏览器输入URL,http://java.sun.com时,DNS(Domain Name System,域名系统)将这个符号URL名转换成通讯标识(IP地址)。命名系统中的对象可以是DNS记录中的名称、应用服务器中的EJB组件(Enterprise JavaBeans Component)、LDAP(Lightweight Directory Access Protocol)中的用户Profile.
目录服务是命名服务的自然扩展。两者之间的关键差别是目录服务中对象可以有属性(例如,用户有email地址),而命名服务中对象没有属性。因此,在目录服务中,你可以根据属性搜索对象。JNDI允许你访问文件系统中的文件,定位远程RMI注册的对象,访问象LDAP这样的目录服务,定位网络上的EJB组件。
对于象LDAP 客户端、应用launcher、类浏览器、网络管理实用程序,甚至地址薄这样的应用来说,JNDI是一个很好的选择。
JNDI架构
JNDI架构提供了一组标准的独立于命名系统的API,这些API构建在与命名系统有关的驱动之上。这一层有助于将应用与实际数据源分离,因此不管应用访问的是LDAP、RMI、DNS、还是其他的目录服务。换句话说,JNDI独立于目录服务的具体实现,只要你有目录的服务提供接口(或驱动),你就可以使用目录。如图1所示。 图1:JNDI架构
关于JNDI要注意的重要一点是,它提供了应用编程接口(application programming interface,API)和服务提供者接口(service provider interface,SPI)。这一点的真正含义是,要让你的应用与命名服务或目录服务交互,必须有这个服务的JNDI服务提供者,这正是JNDI SPI发挥作用的地方。服务提供者基本上是一组类,这些类为各种具体的命名和目录服务实现了JNDI接口?很象JDBC驱动为各种具体的数据库系统实现了JDBC接口一样。作为一个应用开发者,你不必操心JNDI SPI.你只需要确认你要使用的每一个命名或目录服务都有服务提供者。
J2SE和JNDI
Java 2 SDK 1.3及以上的版本包含了JNDI.对于JDK 1.1和1.2也有一个标准的扩展。Java 2 SDK 1.4.x的最新版本包括了几个增强和下面的命名/目录服务提供者:
l LDAP(Lightweight Directory Access Protocol)服务提供者 l CORBA COS(Common Object Request Broker Architecture Common Object Services)命名服务提供者 l RMI(Java Remote Method Invocation)注册服务提供者 l DNS(Domain Name System)服务提供者
更多的服务提供者
可以在如下网址找到可以下载的服务提供者列表:
http://java.sun.com/products/jndi/serviceproviders.html 特别有意思的或许是如下网址提供的Windows 注册表JNDI服务提供者:http://cogentlogic.com/cocoon/CogentLogicCorporation/JNDI.xml 这个服务提供者使你可以访问Windows XP/2000/NT/Me/9x的windows注册表。
也可以在如下网址下载JNDI/LDAP Booster Pack:http://java.sun.com/products/jndi/ 这个Booster Pack包含了对流行的LDAP控制的支持和扩展。它代替了与LDAP 1.2.1服务提供者捆绑在一起的booster pack.关于控制和扩展的更多信息可以在如下网站看到: http://java.sun.com/products/jndi/tutorial/ldap/ext/index.html 另一个有趣的服务提供者是Sun的支持DSML v2.0(Directory Service Markup Language,目录服务标记语言)的服务提供者。DSML的目的是在目录服务和XML之间架起一座桥梁。
JNDI API
JNDI API由5个包组成:
l Javax.naming:包含了访问命名服务的类和接口。例如,它定义了Context接口,这是命名服务执行查询的入口。 l Javax.naming.directory:对命名包的扩充,提供了访问目录服务的类和接口。例如,它为属性增加了新的类,提供了表示目录上下文的DirContext接口,定义了检查和更新目录对象的属性的方法。 l Javax.naming.event:提供了对访问命名和目录服务时的时间通知的支持。例如,定义了NamingEvent类,这个类用来表示命名/目录服务产生的事件,定义了侦听NamingEvents的NamingListener接口。 l Javax.naming.ldap:这个包提供了对LDAP 版本3扩充的操作和控制的支持,通用包javax.naming.directory没有包含这些操作和控制。 l Javax.naming.spi:这个包提供了一个方法,通过javax.naming和有关包动态增加对访问命名和目录服务的支持。这个包是为有兴趣创建服务提供者的开发者提供的。
JNDI 上下文
正如在前面提到的,命名服务将名称和对象联系起来。这种联系称之为绑定(binding)。一组这样的绑定称之为上下文(context),上下文提供了解析(即返回对象的查找操作)。其他操作包括:名称的绑定和取消绑定,列出绑定的名称。注意到一个上下文对象的名称可以绑定到有同样的命名约定的另一个上下文对象。这称之为子上下文。例如,如果UNIX中目录/home是一个上下文,那么相对于这个目录的子目录就是子上下文?例如,/home/guests中guests就是home的子上下文。在JNDI中,上下文用接口javax.naming.Context表示,这个接口是与命名服务交互的关键接口。在Context(或稍后讨论的
DirContext)接口中的每一个命名方法都有两种重载形式:
l Lookup(String name):接受串名 l Lookup(javax.naming.Name):接受结构名,例如,CompositeName(跨越了多个命名系统的名称)或CompondName(单个命名系统中的名称);它们都实现了Name接口。Compound name的一个例子是:cn=mydir,cn=Q Mahmoud,ou=People,composite name的一个例子是:cn=mydir,cn=Q Mahmoud,ou=People/myfiles/max.txt(这里,myfiles/max.txt是表示第二部分的文件名) Javax.naming.InitialContext是实现了Context接口的类。用这个类作为命名服务的入口。为了创建InitialContext对象,构造器以java.util.Hashtable或者是其子类(例如,Properties)的形式设置一组属性。下面给出了一个例子:
Hashtable env = new Hashtable(); // select a service provider factory env.put(Context.INITIAL_CONTEXT_FACTORY, "com.sun.jndi.fscontext.RefFSContext"); // create the initial context Context contxt = new InitialContext(env);
INITIAL_CONTEXT_FACTORY指定了JNDI服务提供者中工厂类(factory class)的名称。Factory负责为其服务创建适当的InitialContext对象。在上面的代码片断中,为文件系统服务提供者指定了工厂类。表1给出了所支持的服务提供者的工厂类。要注意的是文件系统服务提供者的工厂类需要从Sun公司单独下载,J2SE 1.4.x没有包含这些类。
表1:上下文INITIAL_CONTEXT_FACTORY的值 Name Service Provider Factory File System com.sun.jndi.fscontext.RefFSContextFactory LDAP com.sun.jndi.ldap.LdapCtxFactory RMI com.sun.jndi.rmi.registry.RegistryContextFactory CORBA com.sun.jndi.cosnaming.CNCtxFactory DNS com.sun.jndi.dns.DnsContextFactory
为了用名称从命名服务或目录中取得或解析对象,使用Context的lookup方法:Object obj=contxt.lookup(name)。Lookup方法返回一个对象,这个对象表示的是你想要找的上下文的儿子。
转载:转载请保留本信息,本文来自http://www.matrix.org.cn/resource/article/1/1038.html感谢译者的辛勤工作,请大家参加Matrix的翻译计划:http://www.matrix.org.cn/translation/Wiki.jsp?page=Main
posted @
2006-10-02 18:08 xzc 阅读(288) |
评论 (0) |
编辑 收藏
{关键字}
测试驱动开发/Test Driven Development/TDD
测试用例/TestCase/TC
设计/Design
重构/Refactoring
{TDD的目标}
Clean Code That Works
这句话的含义是,事实上我们只做两件事情:让代码奏效(Work)和让代码洁净(Clean),前者是把事情做对,后者是把事情做好。想想看,其实我们平时所做的所有工作,除去无用的工作和错误的工作以外,真正正确的工作,并且是真正有意义的工作,其实也就只有两大类:增加功能和提升设计,而TDD 正是在这个原则上产生的。如果您的工作并非我们想象的这样,(这意味着您还存在第三类正确有意义的工作,或者您所要做的根本和我们在说的是两回事),那么这告诉我们您并不需要TDD,或者不适用TDD。而如果我们偶然猜对(这对于我来说是偶然,而对于Kent Beck和Martin Fowler这样的大师来说则是辛勤工作的成果),那么恭喜您,TDD有可能成为您显著提升工作效率的一件法宝。请不要将信将疑,若即若离,因为任何一项新的技术——只要是从根本上改变人的行为方式的技术——就必然使得相信它的人越来越相信,不信的人越来越不信。这就好比学游泳,唯一能学会游泳的途径就是亲自下去游,除此之外别无他法。这也好比成功学,即使把卡耐基或希尔博士的书倒背如流也不能拥有积极的心态,可当你以积极的心态去成就了一番事业之后,你就再也离不开它了。相信我,TDD也是这样!想试用TDD的人们,请遵循下面的步骤:
| 编写TestCase |
--> |
实现TestCase |
--> |
重构 |
| (确定范围和目标) |
|
(增加功能) |
|
(提升设计) |
[友情提示:敏捷建模中的一个相当重要的实践被称为:Prove it With Code,这种想法和TDD不谋而合。]
{TDD的优点}
『充满吸引力的优点』
- 完工时完工。表明我可以很清楚的看到自己的这段工作已经结束了,而传统的方式很难知道什么时候编码工作结束了。
- 全面正确的认识代码和利用代码,而传统的方式没有这个机会。
- 为利用你成果的人提供Sample,无论它是要利用你的源代码,还是直接重用你提供的组件。
- 开发小组间降低了交流成本,提高了相互信赖程度。
- 避免了过渡设计。
- 系统可以与详尽的测试集一起发布,从而对程序的将来版本的修改和扩展提供方便。
- TDD给了我们自信,让我们今天的问题今天解决,明天的问题明天解决,今天不能解决明天的问题,因为明天的问题还没有出现(没有TestCase),除非有TestCase否则我决不写任何代码;明天也不必担心今天的问题,只要我亮了绿灯。
『不显而易见的优点』
- 逃避了设计角色。对于一个敏捷的开发小组,每个人都在做设计。
- 大部分时间代码处在高质量状态,100%的时间里成果是可见的。
- 由于可以保证编写测试和编写代码的是相同的程序员,降低了理解代码所花费的成本。
- 为减少文档和代码之间存在的细微的差别和由这种差别所引入的Bug作出杰出贡献。
- 在预先设计和紧急设计之间建立一种平衡点,为你区分哪些设计该事先做、哪些设计该迭代时做提供了一个可靠的判断依据。
『有争议的优点』
- 事实上提高了开发效率。每一个正在使用TDD并相信TDD的人都会相信这一点,但观望者则不同,不相信TDD的人甚至坚决反对这一点,这很正常,世界总是这样。
- 发现比传统测试方式更多的Bug。
- 使IDE的调试功能失去意义,或者应该说,避免了令人头痛的调试和节约了调试的时间。
- 总是处在要么编程要么重构的状态下,不会使人抓狂。(两顶帽子)
- 单元测试非常有趣。
{TDD的步骤}
| 编写TestCase |
--> |
实现TestCase |
--> |
重构 |
| (不可运行) |
|
(可运行) |
|
(重构) |
| 步骤 |
制品 |
| (1)快速新增一个测试用例 |
新的TestCase |
| (2)编译所有代码,刚刚写的那个测试很可能编译不通过 |
原始的TODO List |
| (3)做尽可能少的改动,让编译通过 |
Interface |
| (4)运行所有的测试,发现最新的测试不能编译通过 |
-(Red Bar) |
| (5)做尽可能少的改动,让测试通过 |
Implementation |
| (6)运行所有的测试,保证每个都能通过 |
-(Green Bar) |
| (7)重构代码,以消除重复设计 |
Clean Code That Works |
{FAQ}
[什么时候重构?]
如果您在软件公司工作,就意味着您成天都会和想通过重构改善代码质量的想法打交道,不仅您如此,您的大部分同事也都如此。可是,究竟什么时候该重构,什么情况下应该重构呢?我相信您和您的同事可能有很多不同的看法,最常见的答案是“该重构时重构”,“写不下去的时候重构”,和“下一次迭代开始之前重构”,或者干脆就是“最近没时间,就不重构了,下次有时间的时候重构吧”。正如您已经预见到我想说的——这些想法都是对重构的误解。重构不是一种构建软件的工具,不是一种设计软件的模式,也不是一个软件开发过程中的环节,正确理解重构的人应该把重构看成一种书写代码的方式,或习惯,重构时时刻刻有可能发生。在TDD中,除去编写测试用例和实现测试用例之外的所有工作都是重构,所以,没有重构任何设计都不能实现。至于什么时候重构嘛,还要分开看,有三句话是我的经验:实现测试用例时重构代码,完成某个特性时重构设计,产品的重构完成后还要记得重构一下测试用例哦。
[什么时候设计?]
这个问题比前面一个要难回答的多,实话实说,本人在依照TDD开发软件的时候也常常被这个问题困扰,总是觉得有些问题应该在写测试用例之前定下来,而有些问题应该在新增一个一个测试用例的过程中自然出现,水到渠成。所以,我的建议是,设计的时机应该由开发者自己把握,不要受到TDD方式的限制,但是,不需要事先确定的事一定不能事先确定,免得捆住了自己的手脚。
[什么时候增加新的TestCase?]
没事做的时候。通常我们认为,如果你要增加一个新的功能,那么先写一个不能通过的 TestCase;如果你发现了一个bug,那么先写一个不能通过的TestCase;如果你现在什么都没有,从0开始,请先写一个不能通过的 TestCase。所有的工作都是从一个TestCase开始。此外,还要注意的是,一些大师要求我们每次只允许有一个TestCase亮红灯,在这个 TestCase没有Green之前不可以写别的TestCase,这种要求可以适当考虑,但即使有多个TestCase亮红灯也不要紧,并未违反TDD 的主要精神。
[TestCase该怎么写?]
测试用例的编写实际上就是两个过程:使用尚不存在的代码和定义这些代码的执行结果。所以一个 TestCase也就应该包括两个部分——场景和断言。第一次写TestCase的人会有很大的不适应的感觉,因为你之前所写的所有东西都是在解决问题,现在要你提出问题确实不大习惯,不过不用担心,你正在做正确的事情,而这个世界上最难的事情也不在于如何解决问题,而在于ask the right question!
[TDD能帮助我消除Bug吗?]
答:不能!千万不要把“测试”和“除虫”混为一谈!“除虫”是指程序员通过自己的努力来减少bug的数量(消除bug这样的字眼我们还是不要讲为好^_^),而“测试”是指程序员书写产品以外的一段代码来确保产品能有效工作。虽然TDD所编写的测试用例在一定程度上为寻找bug提供了依据,但事实上,按照TDD的方式进行的软件开发是不可能通过TDD再找到bug的(想想我们前面说的“完工时完工”),你想啊,当我们的代码完成的时候,所有的测试用例都亮了绿灯,这时隐藏在代码中的bug一个都不会露出马脚来。
但是,如果要问“测试”和“除虫”之间有什么联系,我相信还是有很多话可以讲的,比如TDD事实上减少了bug的数量,把查找bug战役的关注点从全线战场提升到代码战场以上。还有,bug的最可怕之处不在于隐藏之深,而在于满天遍野。如果你发现了一个用户很不容易才能发现的bug,那么不一定对工作做出了什么杰出贡献,但是如果你发现一段代码中,bug的密度或离散程度过高,那么恭喜你,你应该抛弃并重写这段代码了。TDD避免了这种情况,所以将寻找bug的工作降低到了一个新的低度。
[我该为一个Feature编写TestCase还是为一个类编写TestCase?]
初学者常问的问题。虽然我们从TDD 的说明书上看到应该为一个特性编写相应的TestCase,但为什么著名的TDD大师所写的TestCase都是和类/方法一一对应的呢?为了解释这个问题,我和我的同事们都做了很多试验,最后我们得到了一个结论,虽然我不知道是否正确,但是如果您没有答案,可以姑且相信我们。
我们的研究结果表明,通常在一个特性的开发开始时,我们针对特性编写测试用例,如果您发现这个特性无法用TestCase表达,那么请将这个特性细分,直至您可以为手上的特性写出TestCase为止。从这里开始是最安全的,它不会导致任何设计上重大的失误。但是,随着您不断的重构代码,不断的重构 TestCase,不断的依据TDD的思想做下去,最后当产品伴随测试用例集一起发布的时候,您就会不经意的发现经过重构以后的测试用例很可能是和产品中的类/方法一一对应的。
[什么时候应该将全部测试都运行一遍?]
Good Question!大师们要求我们每次重构之后都要完整的运行一遍测试用例。这个要求可以理解,因为重构很可能会改变整个代码的结构或设计,从而导致不可预见的后果,但是如果我正在开发的是一个ERP怎么办?运行一遍完整的测试用例可能将花费数个小时,况且现在很多重构都是由工具做到的,这个要求的可行性和前提条件都有所动摇。所以我认为原则上你可以挑几个你觉得可能受到本次重构影响的TestCase去run,但是如果运行整个测试包只要花费数秒的时间,那么不介意你按大师的要求去做。
[什么时候改进一个TestCase?]
增加的测试用例或重构以后的代码导致了原来的TestCase的失去了效果,变得无意义,甚至可能导致错误的结果,这时是改进TestCase的最好时机。但是有时你会发现,这样做仅仅导致了原来的TestCase在设计上是臃肿的,或者是冗余的,这都不要紧,只要它没有失效,你仍然不用去改进它。记住,TestCase不是你的产品,它不要好看,也不要怎么太科学,甚至没有性能要求,它只要能完成它的使命就可以了——这也证明了我们后面所说的“用Ctrl-C/Ctrl-V编写测试用例”的可行性。
但是,美国人的想法其实跟我们还是不太一样,拿托尼巴赞的MindMap来说吧,其实画MindMap只是为了表现自己的思路,或记忆某些重要的事情,但托尼却建议大家把MindMap画成一件艺术品,甚至还有很多艺术家把自己画的抽象派MindMap拿出来帮助托尼做宣传。同样,大师们也要求我们把TestCase写的跟代码一样质量精良,可我想说的是,现在国内有几个公司能把产品的代码写的精良??还是一步一步慢慢来吧。
[为什么原来通过的测试用例现在不能通过了?]
这是一个警报,Red Alert!它可能表达了两层意思——都不是什么好意思——1)你刚刚进行的重构可能失败了,或存在一些错误未被发现,至少重构的结果和原来的代码不等价了。2)你刚刚增加的TestCase所表达的意思跟前面已经有的TestCase相冲突,也就是说,新增的功能违背了已有的设计,这种情况大部分可能是之前的设计错了。但无论哪错了,无论是那层意思,想找到这个问题的根源都比TDD的正常工作要难。
[我怎么知道那里该有一个方法还是该有一个类?]
这个问题也是常常出现在我的脑海中,无论你是第一次接触TDD或者已经成为 TDD专家,这个问题都会缠绕着你不放。不过问题的答案可以参考前面的“什么时候设计”一节,答案不是唯一的。其实多数时候你不必考虑未来,今天只做今天的事,只要有重构工具,从方法到类和从类到方法都很容易。
[我要写一个TestCase,可是不知道从哪里开始?]
从最重要的事开始,what matters most?从脚下开始,从手头上的工作开始,从眼前的事开始。从一个没有UI的核心特性开始,从算法开始,或者从最有可能耽误时间的模块开始,从一个最严重的bug开始。这是TDD主义者和鼠目寸光者的一个共同点,不同点是前者早已成竹在胸。
[为什么我的测试总是看起来有点愚蠢?]
哦?是吗?来,握个手,我的也是!不必担心这一点,事实上,大师们给的例子也相当愚蠢,比如一个极端的例子是要写一个两个int变量相加的方法,大师先断言2+3=5,再断言5+5=10,难道这些代码不是很愚蠢吗?其实这只是一个极端的例子,当你初次接触TDD时,写这样的代码没什么不好,以后当你熟练时就会发现这样写没必要了,要记住,谦虚是通往TDD的必经之路!从经典开发方法转向TDD就像从面向过程转向面向对象一样困难,你可能什么都懂,但你写出来的类没有一个纯OO的!我的同事还告诉我真正的太极拳,其速度是很快的,不比任何一个快拳要慢,但是初学者(通常是指学习太极拳的前10年)太不容易把每个姿势都做对,所以只能慢慢来。
[什么场合不适用TDD?]
问的好,确实有很多场合不适合使用TDD。比如对软件质量要求极高的军事或科研产品——神州六号,人命关天的软件——医疗设备,等等,再比如设计很重要必须提前做好的软件,这些都不适合TDD,但是不适合TDD不代表不能写TestCase,只是作用不同,地位不同罢了。
{Best Practise}
[微笑面对编译错误]
学生时代最害怕的就是编译错误,编译错误可能会被老师视为上课不认真听课的证据,或者同学间相互嘲笑的砝码。甚至离开学校很多年的老程序员依然害怕它就像害怕迟到一样,潜意识里似乎编译错误极有可能和工资挂钩(或者和智商挂钩,反正都不是什么好事)。其实,只要提交到版本管理的代码没有编译错误就可以了,不要担心自己手上的代码的编译错误,通常,编译错误都集中在下面三个方面:
(1)你的代码存在低级错误
(2)由于某些Interface的实现尚不存在,所以被测试代码无法编译
(3)由于某些代码尚不存在,所以测试代码无法编译
请注意第二点与第三点完全不同,前者表明设计已存在,而实现不存在导致的编译错误;后者则指仅有TestCase而其它什么都没有的情况,设计和实现都不存在,没有Interface也没有Implementation。
另外,编译器还有一个优点,那就是以最敏捷的身手告诉你,你的代码中有那些错误。当然如果你拥有Eclipse这样可以及时提示编译错误的IDE,就不需要这样的功能了。
[重视你的计划清单]
在非TDD的情况下,尤其是传统的瀑布模型的情况下,程序员不会不知道该做什么,事实上,总是有设计或者别的什么制品在引导程序员开发。但是在TDD的情况下,这种优势没有了,所以一个计划清单对你来说十分重要,因为你必须自己发现该做什么。不同性格的人对于这一点会有不同的反应,我相信平时做事没什么计划要依靠别人安排的人(所谓将才)可能略有不适应,不过不要紧,Tasks和Calendar(又称效率手册)早已成为现代上班族的必备工具了;而平时工作生活就很有计划性的人,比如我:),就会更喜欢这种自己可以掌控Plan的方式了。
[废黜每日代码质量检查]
如果我没有记错的话,PSP对于个人代码检查的要求是蛮严格的,而同样是在针对个人的问题上, TDD却建议你废黜每日代码质量检查,别起疑心,因为你总是在做TestCase要求你做的事情,并且总是有办法(自动的)检查代码有没有做到这些事情 ——红灯停绿灯行,所以每日代码检查的时间可能被节省,对于一个严格的PSP实践者来说,这个成本还是很可观的!
此外,对于每日代码质量检查的另一个好处,就是帮助你认识自己的代码,全面的从宏观、微观、各个角度审视自己的成果,现在,当你依照TDD做事时,这个优点也不需要了,还记得前面说的TDD的第二个优点吗,因为你已经全面的使用了一遍你的代码,这完全可以达到目的。
但是,问题往往也并不那么简单,现在有没有人能告诉我,我如何全面审视我所写的测试用例呢?别忘了,它们也是以代码的形式存在的哦。呵呵,但愿这个问题没有把你吓到,因为我相信到目前为止,它还不是瓶颈问题,况且在编写产品代码的时候你还是会自主的发现很多测试代码上的没考虑到的地方,可以就此修改一下。道理就是如此,世界上没有任何方法能代替你思考的过程,所以也没有任何方法能阻止你犯错误,TDD仅能让你更容易发现这些错误而已。
[如果无法完成一个大的测试,就从最小的开始]
如果我无法开始怎么办,教科书上有个很好的例子:我要写一个电影列表的类,我不知道如何下手,如何写测试用例,不要紧,首先想象静态的结果,如果我的电影列表刚刚建立呢,那么它应该是空的,OK,就写这个断言吧,断言一个刚刚初始化的电影列表是空的。这不是愚蠢,这是细节,奥运会五项全能的金牌得主玛丽莲·金是这样说的:“成功人士的共同点在于……如果目标不够清晰,他们会首先做通往成功道路上的每一个细小步骤……”。
[尝试编写自己的xUnit]
Kent Beck建议大家每当接触一个新的语言或开发平台的时候,就自己写这个语言或平台的xUnit,其实几乎所有常用的语言和平台都已经有了自己的 xUnit,而且都是大同小异,但是为什么大师给出了这样的建议呢。其实Kent Beck的意思是说通过这样的方式你可以很快的了解这个语言或平台的特性,而且xUnit确实很简单,只要知道原理很快就能写出来。这对于那些喜欢自己写底层代码的人,或者喜欢控制力的人而言是个好消息。
[善于使用Ctrl-C/Ctrl-V来编写TestCase]
不必担心TestCase会有代码冗余的问题,让它冗余好了。
[永远都是功能First,改进可以稍后进行]
上面这个标题还可以改成另外一句话:避免过渡设计!
[淘汰陈旧的用例]
舍不得孩子套不着狼。不要可惜陈旧的用例,因为它们可能从概念上已经是错误的了,或仅仅会得出错误的结果,或者在某次重构之后失去了意义。当然也不一定非要删除它们,从TestSuite中除去(JUnit)或加上Ignored(NUnit)标签也是一个好办法。
[用TestCase做试验]
如果你在开始某个特性或产品的开发之前对某个领域不太熟悉或一无所知,或者对自己在该领域里的能力一无所知,那么你一定会选择做试验,在有单元测试作工具的情况下,建议你用TestCase做试验,这看起来就像你在写一个验证功能是否实现的 TestCase一样,而事实上也一样,只不过你所验证的不是代码本身,而是这些代码所依赖的环境。
[TestCase之间应该尽量独立]
保证单独运行一个TestCase是有意义的。
[不仅测试必须要通过的代码,还要测试必须不能通过的代码]
这是一个小技巧,也是不同于设计思路的东西。像越界的值或者乱码,或者类型不符的变量,这些输入都可能会导致某个异常的抛出,或者导致一个标示“illegal parameters”的返回值,这两种情况你都应该测试。当然我们无法枚举所有错误的输入或外部环境,这就像我们无法枚举所有正确的输入和外部环境一样,只要TestCase能说明问题就可以了。
[编写代码的第一步,是在TestCase中用Ctrl-C]
这是一个高级技巧,呃,是的,我是这个意思,我不是说这个技巧难以掌握,而是说这个技巧当且仅当你已经是一个TDD高手时,你才能体会到它的魅力。多次使用TDD的人都有这样的体会,既然我的TestCase已经写的很好了,很能说明问题,为什么我的代码不能从TestCase拷贝一些东西来呢。当然,这要求你的TestCase已经具有很好的表达能力,比如断言f (5)=125的方式显然没有断言f(5)=5^(5-2)表达更多的内容。
[测试用例包应该尽量设计成可以自动运行的]
如果产品是需要交付源代码的,那我们应该允许用户对代码进行修改或扩充后在自己的环境下run整个测试用例包。既然通常情况下的产品是可以自动运行的,那为什么同样作为交付用户的制品,测试用例包就不是自动运行的呢?即使产品不需要交付源代码,测试用例包也应该设计成可以自动运行的,这为测试部门或下一版本的开发人员提供了极大的便利。
[只亮一盏红灯]
大师的建议,前面已经提到了,仅仅是建议。
[用TestCase描述你发现的bug]
如果你在另一个部门的同事使用了你的代码,并且,他发现了一个bug,你猜他会怎么做?他会立即走到你的工位边上,大声斥责说:“你有bug!”吗?如果他胆敢这样对你,对不起,你一定要冷静下来,不要当面回骂他,相反你可以微微一笑,然后心平气和的对他说:“哦,是吗?那么好吧,给我一个TestCase证明一下。”现在局势已经倒向你这一边了,如果他还没有准备好回答你这致命的一击,我猜他会感到非常羞愧,并在内心责怪自己太莽撞。事实上,如果他的TestCase没有过多的要求你的代码(而是按你们事前的契约),并且亮了红灯,那么就可以确定是你的bug,反之,对方则无理了。用TestCase描述bug的另一个好处是,不会因为以后的修改而再次暴露这个bug,它已经成为你发布每一个版本之前所必须检查的内容了。
{关于单元测试}
单元测试的目标是
Keep the bar green to keep the code clean
这句话的含义是,事实上我们只做两件事情:让代码奏效(Keep the bar green)和让代码洁净(Keep the code clean),前者是把事情做对,后者是把事情做好,两者既是TDD中的两顶帽子,又是xUnit架构中的因果关系。
单元测试作为软件测试的一个类别,并非是xUnit架构创造的,而是很早就有了。但是xUnit架构使得单元测试变得直接、简单、高效和规范,这也是单元测试最近几年飞速发展成为衡量一个开发工具和环境的主要指标之一的原因。正如Martin Fowler所说:“软件工程有史以来从没有如此众多的人大大收益于如此简单的代码!”而且多数语言和平台的xUnit架构都是大同小异,有的仅是语言不同,其中最有代表性的是JUnit和NUnit,后者是前者的创新和扩展。一个单元测试框架xUnit应该:1)使每个TestCase独立运行;2)使每个TestCase可以独立检测和报告错误;3)易于在每次运行之前选择TestCase。下面是我枚举出的xUnit框架的概念,这些概念构成了当前业界单元测试理论和工具的核心:
[测试方法/TestMethod]
测试的最小单位,直接表示为代码。
[测试用例/TestCase]
由多个测试方法组成,是一个完整的对象,是很多TestRunner执行的最小单位。
[测试容器/TestSuite]
由多个测试用例构成,意在把相同含义的测试用例手动安排在一起,TestSuite可以呈树状结构因而便于管理。在实现时,TestSuite形式上往往也是一个TestCase或TestFixture。
[断言/Assertion]
断言一般有三类,分别是比较断言(如assertEquals),条件断言(如isTrue),和断言工具(如fail)。
[测试设备/TestFixture]
为每个测试用例安排一个SetUp方法和一个TearDown方法,前者用于在执行该测试用例或该用例中的每个测试方法前调用以初始化某些内容,后者在执行该测试用例或该用例中的每个方法之后调用,通常用来消除测试对系统所做的修改。
[期望异常/Expected Exception]
期望该测试方法抛出某种指定的异常,作为一个“断言”内容,同时也防止因为合情合理的异常而意外的终止了测试过程。
[种类/Category]
为测试用例分类,实际使用时一般有TestSuite就不再使用Category,有Category就不再使用TestSuite。
[忽略/Ignored]
设定该测试用例或测试方法被忽略,也就是不执行的意思。有些被抛弃的TestCase不愿删除,可以定为Ignored。
[测试执行器/TestRunner]
执行测试的工具,表示以何种方式执行测试,别误会,这可不是在代码中规定的,完全是与测试内容无关的行为。比如文本方式,AWT方式,swing方式,或者Eclipse的一个视图等等。
{实例:Fibonacci数列}
下面的Sample展示TDDer是如何编写一个旨在产生Fibonacci数列的方法。
(1)首先写一个TC,断言fib(1) = 1;fib(2) = 1;这表示该数列的第一个元素和第二个元素都是1。
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
}
(2)上面这段代码不能编译通过,Great!——是的,我是说Great!当然,如果你正在用的是Eclipse那你不需要编译,Eclipse 会告诉你不存在fib方法,单击mark会问你要不要新建一个fib方法,Oh,当然!为了让上面那个TC能通过,我们这样写:
public
int
fib(
int
n ) {
return
1
;
}
(3)现在那个TC亮了绿灯,wow!应该庆祝一下了。接下来要增加TC的难度了,测第三个元素。
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
assertEquals(
2
, fib(
3
));
}
不过这样写还不太好看,不如这样写:
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
assertEquals(fib(
1
)
+
fib(
2
), fib(
3
));
}
(4)新增加的断言导致了红灯,为了扭转这一局势我们这样修改fib方法,其中部分代码是从上面的代码中Ctrl-C/Ctrl-V来的:
public
int
fib(
int
n ) {
if
( n
==
3
)
return
fib(
1
)
+
fib(
2
);
return
1
;
}
(5)天哪,这真是个贱人写的代码!是啊,不是吗?因为TC就是产品的蓝本,产品只要恰好满足TC就ok。所以事情发展到这个地步不是fib方法的错,而是TC的错,于是TC还要进一步要求:
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
assertEquals(fib(
1
)
+
fib(
2
), fib(
3
));
assertEquals(fib(
2
)
+
fib(
3
), fib(
4
));
}
(6)上有政策下有对策。
public
int
fib(
int
n ) {
if
( n
==
3
)
return
fib(
1
)
+
fib(
2
);
if
( n
==
4
)
return
fib(
2
)
+
fib(
3
);
return
1
;
}
(7)好了,不玩了。现在已经不是贱不贱的问题了,现在的问题是代码出现了冗余,所以我们要做的是——重构:
public
int
fib(
int
n ) {
if
( n
==
1
||
n
==
2
)
return
1
;
else
return
fib( n
-
1
)
+
fib( n
-
2
);
}
(8)好,现在你已经fib方法已经写完了吗?错了,一个危险的错误,你忘了错误的输入了。我们令0表示Fibonacci中没有这一项。
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
assertEquals(fib(
1
)
+
fib(
2
), fib(
3
));
assertEquals(fib(
2
)
+
fib(
3
), fib(
4
));
assertEquals(
0
, fib(
0
));
assertEquals(
0
, fib(
-
1
));
}
then change the method fib to make the bar grean:
public
int
fib(
int
n ) {
if
( n
<=
0
)
return
0
;
if
( n
==
1
||
n
==
2
)
return
1
;
else
return
fib( n
-
1
)
+
fib( n
-
2
);
}
(9)下班前最后一件事情,把TC也重构一下:
public
void
testFab() {
int
cases[][]
=
{
{
0
,
0
}, {
-
1
,
0
},
//
the wrong parameters
{
1
,
1
}, {
2
,
1
}};
//
the first 2 elements
for
(
int
i
=
0
; i
<
cases.length; i
++
)
assertEquals( cases[i][
1
], fib(cases[i][
0
]) );
//
the rest elements
for
(
int
i
=
3
; i
<
20
; i
++
)
assertEquals(fib(i
-
1
)
+
fib(i
-
2
), fib(i));
}
(10)打完收工。
{关于本文的写作}
在本文的写作过程中,作者也用到了TDD的思维,事实上作者先构思要写一篇什么样的文章,然后写出这篇文章应该满足的几个要求,包括功能的要求(要写些什么)和性能的要求(可读性如何)和质量的要求(文字的要求),这些要求起初是一个也达不到的(因为正文还一个字没有),在这种情况下作者的文章无法编译通过,为了达到这些要求,作者不停的写啊写啊,终于在花尽了两个月的心血之后完成了当初既定的所有要求(make the bar green),随后作者整理了一下文章的结构(重构),在满意的提交给了Blog系统之后,作者穿上了一件绿色的汗衫,趴在地上,学了两声青蛙叫。。。。。。。^_^
{后记:Martin Fowler在中国}
从本文正式完成到发表的几个小时里,我偶然读到了Martin Fowler先生北京访谈录,其间提到了很多对测试驱动开发的看法,摘抄在此:
Martin Fowler:当然(值得花一半的时间来写单元测试)!因为单元测试能够使你更快的完成工作。无数次的实践已经证明这一点。你的时间越是紧张,就越要写单元测试,它看上去慢,但实际上能够帮助你更快、更舒服地达到目的。
Martin Fowler:什么叫重要?什么叫不重要?这是需要逐渐认识的,不是想当然的。我为绝大多数的模块写单元测试,是有点烦人,但是当你意识到这工作的价值时,你会欣然的。
Martin Fowler:对全世界的程序员我都是那么几条建议:……第二,学习测试驱动开发,这种新的方法会改变你对于软件开发的看法。……
——《程序员》,2005年7月刊
{鸣谢}
fhawk
Dennis Chen
般若菩提
Kent Beck
Martin Fowler
c2.com
(转载本文需注明出处:Brian Sun @ 爬树的泡泡[http://www.blogjava.net/briansun])
posted @
2006-09-29 11:43 xzc 阅读(412) |
评论 (0) |
编辑 收藏
源代码如下
/************************************************
MD5 算法的Java Bean
Last Modified:10,Mar,2001
*************************************************/
import java.lang.reflect.*;
/*************************************************
md5 类实现了RSA Data Security, Inc.在提交给IETF
的RFC1321中的MD5 message-digest 算法。
*************************************************/
public class MD5 {
/* 下面这些S11-S44实际上是一个4*4的矩阵,在原始的C实现中是用#define 实现的,
这里把它们实现成为static final是表示了只读,切能在同一个进程空间内的多个
Instance间共享*/
static final int S11 = 7;
static final int S12 = 12;
static final int S13 = 17;
static final int S14 = 22;
static final int S21 = 5;
static final int S22 = 9;
static final int S23 = 14;
static final int S24 = 20;
static final int S31 = 4;
static final int S32 = 11;
static final int S33 = 16;
static final int S34 = 23;
static final int S41 = 6;
static final int S42 = 10;
static final int S43 = 15;
static final int S44 = 21;
static final byte[] PADDING = { -128, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
/* 下面的三个成员是MD5计算过程中用到的3个核心数据,在原始的C实现中
被定义到MD5_CTX结构中
*/
private long[] state = new long[4]; // state (ABCD)
private long[] count = new long[2]; // number of bits, modulo 2^64 (lsb first)
private byte[] buffer = new byte[64]; // input buffer
/* digestHexStr是MD5的唯一一个公共成员,是最新一次计算结果的
16进制ASCII表示.
*/
public String digestHexStr;
/* digest,是最新一次计算结果的2进制内部表示,表示128bit的MD5值.
*/
private byte[] digest = new byte[16];
/*
getMD5ofStr是类MD5最主要的公共方法,入口参数是你想要进行MD5变换的字符串
返回的是变换完的结果,这个结果是从公共成员digestHexStr取得的.
*/
public String getMD5ofStr(String inbuf) {
md5Init();
md5update(inbuf.getBytes(), inbuf.length());
md5Final();
digestHexStr = "";
for (int i = 0; i < 16; i++) {
digestHexStr += byteHEX(digest[i]);
}
return digestHexStr;
}
// 这是MD5这个类的标准构造函数,JavaBean要求有一个public的并且没有参数的构造函数
public MD5() {
md5Init();
return;
}
/* md5Init是一个初始化函数,初始化核心变量,装入标准的幻数 */
private void md5Init() {
count[0] = 0L;
count[1] = 0L;
///* Load magic initialization constants.
state[0] = 0x67452301L;
state[1] = 0xefcdab89L;
state[2] = 0x98badcfeL;
state[3] = 0x10325476L;
return;
}
/* F, G, H ,I 是4个基本的MD5函数,在原始的MD5的C实现中,由于它们是
简单的位运算,可能出于效率的考虑把它们实现成了宏,在java中,我们把它们
实现成了private方法,名字保持了原来C中的。 */
private long F(long x, long y, long z) {
return (x & y) | ((~x) & z);
}
private long G(long x, long y, long z) {
return (x & z) | (y & (~z));
}
private long H(long x, long y, long z) {
return x ^ y ^ z;
}
private long I(long x, long y, long z) {
return y ^ (x | (~z));
}
/*
FF,GG,HH和II将调用F,G,H,I进行近一步变换
FF, GG, HH, and II transformations for rounds 1, 2, 3, and 4.
Rotation is separate from addition to prevent recomputation.
*/
private long FF(long a, long b, long c, long d, long x, long s,
long ac) {
a += F (b, c, d) + x + ac;
a = ((int) a << s) | ((int) a >>> (32 - s));
a += b;
return a;
}
private long GG(long a, long b, long c, long d, long x, long s,
long ac) {
a += G (b, c, d) + x + ac;
a = ((int) a << s) | ((int) a >>> (32 - s));
a += b;
return a;
}
private long HH(long a, long b, long c, long d, long x, long s,
long ac) {
a += H (b, c, d) + x + ac;
a = ((int) a << s) | ((int) a >>> (32 - s));
a += b;
return a;
}
private long II(long a, long b, long c, long d, long x, long s,
long ac) {
a += I (b, c, d) + x + ac;
a = ((int) a << s) | ((int) a >>> (32 - s));
a += b;
return a;
}
/*
md5update是MD5的主计算过程,inbuf是要变换的字节串,inputlen是长度,这个
函数由getMD5ofStr调用,调用之前需要调用md5init,因此把它设计成private的
*/
private void md5update(byte[] inbuf, int inputLen) {
int i, index, partLen;
byte[] block = new byte[64];
index = (int)(count[0] >>> 3) & 0x3F;
// /* update number of bits */
if ((count[0] += (inputLen << 3)) < (inputLen << 3))
count[1]++;
count[1] += (inputLen >>> 29);
partLen = 64 - index;
// Transform as many times as possible.
if (inputLen >= partLen) {
md5Memcpy(buffer, inbuf, index, 0, partLen);
md5Transform(buffer);
for (i = partLen; i + 63 < inputLen; i += 64) {
md5Memcpy(block, inbuf, 0, i, 64);
md5Transform (block);
}
index = 0;
} else
i = 0;
///* Buffer remaining input */
md5Memcpy(buffer, inbuf, index, i, inputLen - i);
}
/*
md5Final整理和填写输出结果
*/
private void md5Final () {
byte[] bits = new byte[8];
int index, padLen;
///* Save number of bits */
Encode (bits, count, 8);
///* Pad out to 56 mod 64.
index = (int)(count[0] >>> 3) & 0x3f;
padLen = (index < 56) ? (56 - index) : (120 - index);
md5update (PADDING, padLen);
///* Append length (before padding) */
md5update(bits, 8);
///* Store state in digest */
Encode (digest, state, 16);
}
/* md5Memcpy是一个内部使用的byte数组的块拷贝函数,从input的inpos开始把len长度的
字节拷贝到output的outpos位置开始
*/
private void md5Memcpy (byte[] output, byte[] input,
int outpos, int inpos, int len)
{
int i;
for (i = 0; i < len; i++)
output[outpos + i] = input[inpos + i];
}
/*
md5Transform是MD5核心变换程序,有md5update调用,block是分块的原始字节
*/
private void md5Transform (byte block[]) {
long a = state[0], b = state[1], c = state[2], d = state[3];
long[] x = new long[16];
Decode (x, block, 64);
/* Round 1 */
a = FF (a, b, c, d, x[0], S11, 0xd76aa478L); /* 1 */
d = FF (d, a, b, c, x[1], S12, 0xe8c7b756L); /* 2 */
c = FF (c, d, a, b, x[2], S13, 0x242070dbL); /* 3 */
b = FF (b, c, d, a, x[3], S14, 0xc1bdceeeL); /* 4 */
a = FF (a, b, c, d, x[4], S11, 0xf57c0fafL); /* 5 */
d = FF (d, a, b, c, x[5], S12, 0x4787c62aL); /* 6 */
c = FF (c, d, a, b, x[6], S13, 0xa8304613L); /* 7 */
b = FF (b, c, d, a, x[7], S14, 0xfd469501L); /* 8 */
a = FF (a, b, c, d, x[8], S11, 0x698098d8L); /* 9 */
d = FF (d, a, b, c, x[9], S12, 0x8b44f7afL); /* 10 */
c = FF (c, d, a, b, x[10], S13, 0xffff5bb1L); /* 11 */
b = FF (b, c, d, a, x[11], S14, 0x895cd7beL); /* 12 */
a = FF (a, b, c, d, x[12], S11, 0x6b901122L); /* 13 */
d = FF (d, a, b, c, x[13], S12, 0xfd987193L); /* 14 */
c = FF (c, d, a, b, x[14], S13, 0xa679438eL); /* 15 */
b = FF (b, c, d, a, x[15], S14, 0x49b40821L); /* 16 */
/* Round 2 */
a = GG (a, b, c, d, x[1], S21, 0xf61e2562L); /* 17 */
d = GG (d, a, b, c, x[6], S22, 0xc040b340L); /* 18 */
c = GG (c, d, a, b, x[11], S23, 0x265e5a51L); /* 19 */
b = GG (b, c, d, a, x[0], S24, 0xe9b6c7aaL); /* 20 */
a = GG (a, b, c, d, x[5], S21, 0xd62f105dL); /* 21 */
d = GG (d, a, b, c, x[10], S22, 0x2441453L); /* 22 */
c = GG (c, d, a, b, x[15], S23, 0xd8a1e681L); /* 23 */
b = GG (b, c, d, a, x[4], S24, 0xe7d3fbc8L); /* 24 */
a = GG (a, b, c, d, x[9], S21, 0x21e1cde6L); /* 25 */
d = GG (d, a, b, c, x[14], S22, 0xc33707d6L); /* 26 */
c = GG (c, d, a, b, x[3], S23, 0xf4d50d87L); /* 27 */
b = GG (b, c, d, a, x[8], S24, 0x455a14edL); /* 28 */
a = GG (a, b, c, d, x[13], S21, 0xa9e3e905L); /* 29 */
d = GG (d, a, b, c, x[2], S22, 0xfcefa3f8L); /* 30 */
c = GG (c, d, a, b, x[7], S23, 0x676f02d9L); /* 31 */
b = GG (b, c, d, a, x[12], S24, 0x8d2a4c8aL); /* 32 */
/* Round 3 */
a = HH (a, b, c, d, x[5], S31, 0xfffa3942L); /* 33 */
d = HH (d, a, b, c, x[8], S32, 0x8771f681L); /* 34 */
c = HH (c, d, a, b, x[11], S33, 0x6d9d6122L); /* 35 */
b = HH (b, c, d, a, x[14], S34, 0xfde5380cL); /* 36 */
a = HH (a, b, c, d, x[1], S31, 0xa4beea44L); /* 37 */
d = HH (d, a, b, c, x[4], S32, 0x4bdecfa9L); /* 38 */
c = HH (c, d, a, b, x[7], S33, 0xf6bb4b60L); /* 39 */
b = HH (b, c, d, a, x[10], S34, 0xbebfbc70L); /* 40 */
a = HH (a, b, c, d, x[13], S31, 0x289b7ec6L); /* 41 */
d = HH (d, a, b, c, x[0], S32, 0xeaa127faL); /* 42 */
c = HH (c, d, a, b, x[3], S33, 0xd4ef3085L); /* 43 */
b = HH (b, c, d, a, x[6], S34, 0x4881d05L); /* 44 */
a = HH (a, b, c, d, x[9], S31, 0xd9d4d039L); /* 45 */
d = HH (d, a, b, c, x[12], S32, 0xe6db99e5L); /* 46 */
c = HH (c, d, a, b, x[15], S33, 0x1fa27cf8L); /* 47 */
b = HH (b, c, d, a, x[2], S34, 0xc4ac5665L); /* 48 */
/* Round 4 */
a = II (a, b, c, d, x[0], S41, 0xf4292244L); /* 49 */
d = II (d, a, b, c, x[7], S42, 0x432aff97L); /* 50 */
c = II (c, d, a, b, x[14], S43, 0xab9423a7L); /* 51 */
b = II (b, c, d, a, x[5], S44, 0xfc93a039L); /* 52 */
a = II (a, b, c, d, x[12], S41, 0x655b59c3L); /* 53 */
d = II (d, a, b, c, x[3], S42, 0x8f0ccc92L); /* 54 */
c = II (c, d, a, b, x[10], S43, 0xffeff47dL); /* 55 */
b = II (b, c, d, a, x[1], S44, 0x85845dd1L); /* 56 */
a = II (a, b, c, d, x[8], S41, 0x6fa87e4fL); /* 57 */
d = II (d, a, b, c, x[15], S42, 0xfe2ce6e0L); /* 58 */
c = II (c, d, a, b, x[6], S43, 0xa3014314L); /* 59 */
b = II (b, c, d, a, x[13], S44, 0x4e0811a1L); /* 60 */
a = II (a, b, c, d, x[4], S41, 0xf7537e82L); /* 61 */
d = II (d, a, b, c, x[11], S42, 0xbd3af235L); /* 62 */
c = II (c, d, a, b, x[2], S43, 0x2ad7d2bbL); /* 63 */
b = II (b, c, d, a, x[9], S44, 0xeb86d391L); /* 64 */
state[0] += a;
state[1] += b;
state[2] += c;
state[3] += d;
}
/*Encode把long数组按顺序拆成byte数组,因为java的long类型是64bit的,
只拆低32bit,以适应原始C实现的用途
*/
private void Encode (byte[] output, long[] input, int len) {
int i, j;
for (i = 0, j = 0; j < len; i++, j += 4) {
output[j] = (byte)(input[i] & 0xffL);
output[j + 1] = (byte)((input[i] >>> 8) & 0xffL);
output[j + 2] = (byte)((input[i] >>> 16) & 0xffL);
output[j + 3] = (byte)((input[i] >>> 24) & 0xffL);
}
}
/*Decode把byte数组按顺序合成成long数组,因为java的long类型是64bit的,
只合成低32bit,高32bit清零,以适应原始C实现的用途
*/
private void Decode (long[] output, byte[] input, int len) {
int i, j;
for (i = 0, j = 0; j < len; i++, j += 4)
output[i] = b2iu(input[j]) |
(b2iu(input[j + 1]) << 8) |
(b2iu(input[j + 2]) << 16) |
(b2iu(input[j + 3]) << 24);
return;
}
/*
b2iu是我写的一个把byte按照不考虑正负号的原则的"升位"程序,因为java没有unsigned运算
*/
public static long b2iu(byte b) {
return b < 0 ? b & 0x7F + 128 : b;
}
/*byteHEX(),用来把一个byte类型的数转换成十六进制的ASCII表示,
因为java中的byte的toString无法实现这一点,我们又没有C语言中的
sprintf(outbuf,"%02X",ib)
*/
public static String byteHEX(byte ib) {
char[] Digit = { 0,1,2,3,4,5,6,7,8,9,
A,B,C,D,E,F };
char [] ob = new char[2];
ob[0] = Digit[(ib >>> 4) & 0X0F];
ob[1] = Digit[ib & 0X0F];
String s = new String(ob);
return s;
}
}
posted on 2006-09-28 14:09
圣域飞侠
阅读(435)
评论(1)
编辑
收藏
收藏至365Key

FeedBack:
2006-09-29 08:41 |
/**
* Alipay.com Inc. Copyright (c) 2004-2005 All Rights Reserved.
*
* <p>
* Created on 2005-7-9
* </p>
*/
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
/**
* MD5加密算法
*/
public class Md5Encrypt {
/**
* 对字符串进行MD5加密
*
* @param text 明文
*
* @return 密文
*/
public static String md5(String text) {
MessageDigest msgDigest = null;
try {
msgDigest = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException("System doesn't support MD5 algorithm.");
}
msgDigest.update(text.getBytes());
byte[] bytes = msgDigest.digest();
byte tb;
char low;
char high;
char tmpChar;
String md5Str = new String();
for (int i = 0; i < bytes.length; i++) {
tb = bytes[i];
tmpChar = (char) ((tb >>> 4) & 0x000f);
if (tmpChar >= 10) {
high = (char) (('a' + tmpChar) - 10);
} else {
high = (char) ('0' + tmpChar);
}
md5Str += high;
tmpChar = (char) (tb & 0x000f);
if (tmpChar >= 10) {
low = (char) (('a' + tmpChar) - 10);
} else {
low = (char) ('0' + tmpChar);
}
md5Str += low;
}
return md5Str;
}
}
posted @
2006-09-29 11:35 xzc 阅读(196) |
评论 (0) |
编辑 收藏这几天花了点时间弄了个 db4o 连接池,比较简单,连接池原型是论坛上面的一篇文章。很简单,欢迎拍砖。
从 servlet 开始,在这里初始化连接池:
package
com;
import
java.io.File;
import
java.util.Enumeration;
import
javax.servlet.ServletConfig;
import
javax.servlet.ServletException;
import
javax.servlet.http.HttpServlet;
public
class
ConnectionPollServlet
extends
HttpServlet {
private
static
final
String XML_FILE_PROPERTY
=
"
xmlFile
"
;
/**
* servlet init
*/
public
void
init(ServletConfig servletConfig)
throws
ServletException{
super
.init(servletConfig);
String appDir
=
servletConfig.getServletContext().getRealPath(
"
/
"
);
Enumeration names
=
servletConfig.getInitParameterNames();
while
(names.hasMoreElements()){
String name
=
(String) names.nextElement();
String value
=
servletConfig.getInitParameter(name);
if
(name.equals(XML_FILE_PROPERTY)) {
File file
=
new
File(value);
if
(file.isAbsolute()) {
XMLReader.configure(value);
}
else
{
XMLReader.configure(appDir
+
File.separator
+
value);
}
}
}
}
/**
* servlet destroy
*/
public
void
destroy() {
super
.destroy();
ConnectionPoll.destroy();
}
}
然后是 XML 解析类:
package com;
import java.io.File;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class XMLReader {
/**
* parse XML file
* @param xmlFileName
*/
public static void configure(String xmlFileName) {
try {
File file = new File(xmlFileName);
SAXReader reader = new SAXReader();
Document doc = reader.read(file);
Element root = doc.getRootElement();
String fileName = file.getParent()+"\\"
+root.elementText("fileName");
String sport = root.elementText("port");
String sminConn = root.elementText("minConn");
String sidelTime = root.elementText("idelTime");
int port = Integer.parseInt(sport);
int minConn = Integer.parseInt(sminConn);
int idelTime = Integer.parseInt(sidelTime);
ConnectionPoll.init(fileName,port,minConn,idelTime);
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
连接池类:
package com;
import java.util.concurrent.ConcurrentLinkedQueue;
import com.db4o.Db4o;
import com.db4o.ObjectContainer;
import com.db4o.ObjectServer;
public class ConnectionPoll {
private static int idelTime;
private static ConcurrentLinkedQueue<ObjectContainer> connectionQueue;
private ConnectionPoll(){
}
/**
* init pool
*/
protected static void init(String fileName,int port,int minConn,int it) {
idelTime=it;
ObjectServer objectServer = Db4o.openServer(fileName,port);
connectionQueue = new ConcurrentLinkedQueue<ObjectContainer>();
for (int i = 0; i<minConn; i++) {
connectionQueue.offer(objectServer.openClient());
}
}
/**
* get connection
* @return ObjectContainer
* @throws ConnectionTimeoutException
* @throws InterruptedException
*/
public static synchronized ObjectContainer getConnection() throws ConnectionTimeoutException{
long expiration = System.currentTimeMillis() + idelTime;
while (connectionQueue.isEmpty())
{
if (expiration < System.currentTimeMillis())
{
throw new ConnectionTimeoutException("connection timeout!");
}
}
ObjectContainer objectContainer = connectionQueue.poll();
return objectContainer;
}
/**
* release connection
* @return ObjectContainer
* @throws InterruptedException
*/
public static synchronized void releaseConnection(ObjectContainer objectContainer) {
connectionQueue.offer(objectContainer);
}
/**
* destroy connection
*
*/
protected static void destroy() {
while (connectionQueue.iterator().hasNext()){
ObjectContainer objectContainer = connectionQueue.poll();
objectContainer.close();
}
}
}
超时异常类:
package com;
public class ConnectionTimeoutException extends Exception{
public ConnectionTimeoutException()
{
}
public ConnectionTimeoutException(String s)
{
super(s);
}
}
XML 配置文件,从上到下依次是,数据库文件名、端口、初始连接数、等待时间:
<?xml version="1.0" encoding="utf-8"?>
<config>
<fileName>auto.yap</fileName>
<port>1010</port>
<minConn>10</minConn>
<idelTime>1000</idelTime>
</config>
web.xml 用于初始化的时候加载:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<servlet>
<servlet-name>ConnectionPoll</servlet-name>
<servlet-class>com.ConnectionPollServlet</servlet-class>
<init-param>
<param-name>xmlFile</param-name>
<param-value>WEB-INF/poolConfig.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
</web-app>
数据库文件和参数配置文件都放在 WEB-INF 文件夹下。这个连接池还未实现 maxConn(最大连接数)和对多数据库文件的支持以及日志等。
posted @
2006-09-28 17:19 xzc 阅读(262) |
评论 (0) |
编辑 收藏
人生有三重境界,这三重境界可以用一段充满禅机的语言来说明,这段语言便是:
看山是山,看水是水;
看山不是山,看水不是水;
看山还是山。看水还是水。
“看山是山,看水是水”就是说一个人的人生之初纯洁无瑕,初识世界,一切都是新鲜的,眼睛看见什么就是什么,人家告诉他这是山,他就认识了山;告诉他这是水,他就认识了水。这就是人生的第一重境界。
“看山不是山,看水不是水”,随着年龄渐长,经历的世事渐多,就发现这个世界的问题了。这个世界问题越来越多,越来越复杂,经常是黑白颠倒,是非混淆,无理走遍天下,有理寸步难行,好人无好报,恶人活千年。进人这个阶段,人是激愤的,不平的,忧虑的,疑问的,警惕的,复杂的。人不愿意再轻易地相信什么。
人到了这个时候看山也感慨,看水也叹息,借古讽今,指桑骂槐。山自然不再是单纯的山,水自然不再是单纯的水。一切的一切都是人的主观意志的载体,所谓“好风凭借力,送我上青云”。一个人倘若停留在人生的这一阶段,那就苦了这条性命了。人就会这山望了那山高,不停地攀登,争强好胜,与人比较,怎么做人,如何处世,绞尽脑汁,机关算尽,永无休止和满足的一天。因为这个世界原本就是一个圆的,人外还有人,天外还有天,循环往复,绿水长流。而人的生命是短暂的有限的,哪里能够去与永恒和无限计较呢?
许多人到了人生的第二重境界就到了人生的终点。追求一生.劳碌一生,心高气傲一生,最后发现自己并没有达到自己的理想,于是抱恨终生。但是有些人通过自己的修炼,终于把自己提升到了第三重人生境界。茅塞顿开,回归自然。人这个时候便会专心致志做自己应该做的事情,不与旁人有任何计较。任你红尘滚滚,我自清风朗月。面对芜杂世俗之事,一笑了之,了了有何不了,这个时候的人看山又是山,看水又是水了。
正是:人本是人,不必刻意去做人;世本是世,无须精心去处世;便也就是真正的做人与处世了。
posted @
2006-09-20 17:40 xzc 阅读(284) |
评论 (0) |
编辑 收藏package com.hoten.util;
import java.util.*;
import java.io.*;
/**
* <p>Title: Time </p>
* <p>Description: </p>
* 此类主要用来取得本地系统的系统时间并用下面5种格式显示
* 1. YYMMDDHH 8位
* 2. YYMMDDHHmm 10位
* 3. YYMMDDHHmmss 12位
* 4. YYYYMMDDHHmmss 14位
* 5. YYMMDDHHmmssxxx 15位 (最后的xxx 是毫秒)
* <p>Copyright: Copyright (c) 2003</p>
* <p>Company: c-platform</p>
* @author WuJiaQian
* @version 1.0
*/
public class CTime {
public static final int YYMMDDhhmmssxxx = 15;
public static final int YYYYMMDDhhmmss = 14;
public static final int YYMMDDhhmmss = 12;
public static final int YYMMDDhhmm = 10;
public static final int YYMMDDhh = 8;
/**
* 取得本地系统的时间,时间格式由参数决定
* @param format 时间格式由常量决定
* @return String 具有format格式的字符串
*/
public static String getTime(int format) {
StringBuffer cTime = new StringBuffer(15);
Calendar time = Calendar.getInstance();
int miltime = time.get(Calendar.MILLISECOND);
int second = time.get(Calendar.SECOND);
int minute = time.get(Calendar.MINUTE);
int hour = time.get(Calendar.HOUR_OF_DAY);
int day = time.get(Calendar.DAY_OF_MONTH);
int month = time.get(Calendar.MONTH) + 1;
int year = time.get(Calendar.YEAR);
time = null;
if (format != 14) {
if (year >= 2000) year = year - 2000;
else year = year - 1900;
}
if (format >= 2) {
if (format == 14) cTime.append(year);
else cTime.append(getFormatTime(year, 2));
}
if (format >= 4)
cTime.append(getFormatTime(month, 2));
if (format >= 6)
cTime.append(getFormatTime(day, 2));
if (format >= 8)
cTime.append(getFormatTime(hour, 2));
if (format >= 10)
cTime.append(getFormatTime(minute, 2));
if (format >= 12)
cTime.append(getFormatTime(second, 2));
if (format >= 15)
cTime.append(getFormatTime(miltime, 3));
return cTime.toString().trim();
}
/**
* 产生任意位的字符串
* @param time int 要转换格式的时间
* @param format int 转换的格式
* @return String 转换的时间
*/
public synchronized static String getYearAdd(int format, int iyear) {
StringBuffer cTime = new StringBuffer(10);
Calendar time = Calendar.getInstance();
time.add(Calendar.YEAR, iyear);
int miltime = time.get(Calendar.MILLISECOND);
int second = time.get(Calendar.SECOND);
int minute = time.get(Calendar.MINUTE);
int hour = time.get(Calendar.HOUR_OF_DAY);
int day = time.get(Calendar.DAY_OF_MONTH);
int month = time.get(Calendar.MONTH) + 1;
int year = time.get(Calendar.YEAR);
if (format != 14) {
if (year >= 2000) year = year - 2000;
else year = year - 1900;
}
if (format >= 2) {
if (format == 14) cTime.append(year);
else cTime.append(getFormatTime(year, 2));
}
if (format >= 4)
cTime.append(getFormatTime(month, 2));
if (format >= 6)
cTime.append(getFormatTime(day, 2));
if (format >= 8)
cTime.append(getFormatTime(hour, 2));
if (format >= 10)
cTime.append(getFormatTime(minute, 2));
if (format >= 12)
cTime.append(getFormatTime(second, 2));
if (format >= 15)
cTime.append(getFormatTime(miltime, 3));
return cTime.toString();
}
/**
* 产生任意位的字符串
* @param time int 要转换格式的时间
* @param format int 转换的格式
* @return String 转换的时间
*/
private static String getFormatTime(int time, int format) {
StringBuffer numm = new StringBuffer(format);
int length = String.valueOf(time).length();
if (format < length)return null;
for (int i = 0; i < format - length; i++) {
numm.append("0");
}
numm.append(time);
return numm.toString().trim();
}
/**
* 本函数主要作用是返回当前年份
* @param len int 要转换年的位数
* @return String 处理后的年
*/
public static String getYear(int len) {
Calendar time = Calendar.getInstance();
int year = time.get(Calendar.YEAR);
String djyear = Integer.toString(year);
if (len == 2) {
djyear = djyear.substring(2);
}
return djyear;
}
/*
#本函数作用是返回当前月份(2位)
*/
public static String getMonth() {
Calendar time = Calendar.getInstance();
int month = time.get(Calendar.MONTH) + 1;
String djmonth = "";
if (month < 10) {
djmonth = "0" + Integer.toString(month);
}
else {
djmonth = Integer.toString(month);
}
return djmonth;
}
/*
#本函数作用是返回上个月份(2位)
*/
public static String getPreMonth() {
Calendar time = Calendar.getInstance();
int month = time.get(Calendar.MONTH);
if (month == 0) month = 12;
String djmonth = "";
if (month < 10) {
djmonth = "0" + Integer.toString(month);
}
else {
djmonth = Integer.toString(month);
}
return djmonth;
}
/*
#本函数主要作用是返回当前天数
*/
public static String getDay() {
Calendar time = Calendar.getInstance();
int day = time.get(Calendar.DAY_OF_MONTH);
String djday = "";
if (day < 10) {
djday = "0" + Integer.toString(day);
}
else {
djday = Integer.toString(day);
}
return djday;
}
/*
本函数作用是返回当前小时
*/
public static String getHour() {
Calendar time = Calendar.getInstance();
int hour = time.get(Calendar.HOUR_OF_DAY);
String djhour = "";
if (hour < 10) {
djhour = "0" + Integer.toString(hour);
}
else {
djhour = Integer.toString(hour);
}
return djhour;
}
/*
#本函数作用是返回当前分钟
*/
public static String getMin() {
Calendar time = Calendar.getInstance();
int min = time.get(Calendar.MINUTE);
String djmin = "";
if (min < 10) {
djmin = "0" + Integer.toString(min);
}
else {
djmin = Integer.toString(min);
}
return djmin;
}
/*
#本函数的主要功能是格式化时间,以便于页面显示
#time 时间 可为6位、8位、12位、15位
#return 返回格式化后的时间
#6位 YY年MM月DD日
#8位 YYYY年MM月DD日
#12位 YY年MM月DD日 HH:II:SS
#15位 YY年MM月DD日 HH:II:SS:CCC
*/
public static String formattime(String time) {
int length = 0;
length = time.length();
String renstr = "";
switch (length) {
case 6:
renstr = time.substring(0, 2) + "年" + time.substring(2, 4) +
"月" + time.substring(4) + "日";
break;
case 8:
renstr = time.substring(0, 4) + "年" + time.substring(4, 6) +
"月" + time.substring(6, 8) + "日";
break;
case 12:
renstr = time.substring(0, 2) + "年" + time.substring(2, 4) +
"月" + time.substring(4, 6) + "日 " + time.substring(6, 8) +
"时" + time.substring(8, 10) + "分" +
time.substring(10, 12) + "秒";
break;
case 14:
renstr = time.substring(0, 4) + "-" + time.substring(4, 6) +
"-" + time.substring(6, 8) + " " + time.substring(8, 10) +
":" + time.substring(10, 12) + ":" +
time.substring(12, 14) + "";
break;
case 15:
renstr = time.substring(0, 2) + "年" + time.substring(2, 4) +
"月" + time.substring(4, 6) + "日 " + time.substring(6, 8) +
":" + time.substring(8, 10) + ":" +
time.substring(10, 12) + ":" + time.substring(12);
break;
default:
renstr = time.substring(0, 2) + "年" + time.substring(2, 4) +
"月" + time.substring(4) + "日";
break;
}
return renstr;
}
}
posted @
2006-09-19 19:32 xzc 阅读(281) |
评论 (0) |
编辑 收藏 许多语言,包括Perl、PHP、Python、JavaScript和JScript,都支持用正则表达式处理文本,一些文本编辑器用正则表达式实现高级“搜索-替换”功能。那么Java又怎样呢?
本文写作时,一个包含了用正则表达式进行文本处理的Java规范需求(Specification Request)已经得到认可,你可以期待在JDK的下一版本中看到它。
然而,如果现在就需要使用正则表达式,又该怎么办呢?你可以从Apache.org下载源代码开放的Jakarta-ORO库。本文接下来的内容先简要地介绍正则表达式的入门知识,然后以Jakarta-ORO API为例介绍如何使用正则表达式。
一、正则表达式基础知识
我们先从简单的开始。假设你要搜索一个包含字符“cat”的字符串,搜索用的正则表达式就是“cat”。如果搜索对大小写不敏感,单词“ctalog”、“Catherine”、“sophisticated”都可以匹配。也就是说:

1.1 句点符号
假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以“t”字母开头,以“n”字母结束。另外,假设有一本英文字典,你可以用正则表达式搜索它的全部内容。要构造出这个正则表达式,你可以使用一个通配符——句点符号“。”。这样,完整的表达式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,还匹配“t#n”、“tpn”甚至“t n”,还有其他许多无意义的组合。这是因为句点符号匹配所有字符,包括空格、Tab字符甚至换行符:

1.2 方括号符号
为了解决句点符号匹配范围过于广泛这一问题,你可以在方括号(“[]”)里面指定看来有意义的字符。此时,只有方括号里面指定的字符才参与匹配。也就是说,正则表达式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因为在方括号之内你只能匹配单个字符:

1.3 “或”符号
如果除了上面匹配的所有单词之外,你还想要匹配“toon”,那么,你可以使用“|”操作符。“|”操作符的基本意义就是“或”运算。要匹配“toon”,使用“t(a|e|i|o|oo)n”正则表达式。这里不能使用方扩号,因为方括号只允许匹配单个字符;这里必须使用圆括号“()”。圆括号还可以用来分组,具体请参见后面介绍。

1.4 表示匹配次数的符号
表一显示了表示匹配次数的符号,这些符号用来确定紧靠该符号左边的符号出现的次数:

假设我们要在文本文件中搜索美国的社会安全号码。这个号码的格式是999-99-9999.用来匹配它的正则表达式如图一所示。在正则表达式中,连字符(“-”)有着特殊的意义,它表示一个范围,比如从0到9.因此,匹配社会安全号码中的连字符号时,它的前面要加上一个转义字符“\”。

图一:匹配所有123-12-1234形式的社会安全号码
假设进行搜索的时候,你希望连字符号可以出现,也可以不出现——即,999-99-9999和999999999都属于正确的格式。这时,你可以在连字符号后面加上“?”数量限定符号,如图二所示:

图二:匹配所有123-12-1234和123121234形式的社会安全号码
下面我们再来看另外一个例子。美国汽车牌照的一种格式是四个数字加上二个字母。它的正则表达式前面是数字部分“[0-9]{4}”,再加上字母部分“[A-Z]{2}”。图三显示了完整的正则表达式。

图三:匹配典型的美国汽车牌照号码,如8836KV
1.5 “否”符号
“^”符号称为“否”符号。如果用在方括号内,“^”表示不想要匹配的字符。例如,图四的正则表达式匹配所有单词,但以“X”字母开头的单词除外。

图四:匹配所有单词,但“X”开头的除外
1.6 圆括号和空白符号
假设要从格式为“June 26, 1951”的生日日期中提取出月份部分,用来匹配该日期的正则表达式可以如图五所示:

图五:匹配所有Moth DD,YYYY格式的日期
新出现的“\s”符号是空白符号,匹配所有的空白字符,包括Tab字符。如果字符串正确匹配,接下来如何提取出月份部分呢?只需在月份周围加上一个圆括号创建一个组,然后用ORO API(本文后面详细讨论)提取出它的值。修改后的正则表达式如图六所示:

图六:匹配所有Month DD,YYYY格式的日期,定义月份值为第一个组
1.7 其它符号
为简便起见,你可以使用一些为常见正则表达式创建的快捷符号。如表二所示:
表二:常用符号

例如,在前面社会安全号码的例子中,所有出现“[0-9]”的地方我们都可以使用“\d”。修改后的正则表达式如图七所示:

图七:匹配所有123-12-1234格式的社会安全号码二、Jakarta-ORO库
二、Jakarta-ORO库
有许多源代码开放的正则表达式库可供Java程序员使用,而且它们中的许多支持Perl 5兼容的正则表达式语法。我在这里选用的是Jakarta-ORO正则表达式库,它是最全面的正则表达式API之一,而且它与Perl 5正则表达式完全兼容。另外,它也是优化得最好的API之一。
Jakarta-ORO库以前叫做OROMatcher,Daniel Savarese大方地把它赠送给了Jakarta Project.你可以按照本文最后参考资源的说明下载它。
我首先将简要介绍使用Jakarta-ORO库时你必须创建和访问的对象,然后介绍如何使用Jakarta-ORO API.
▲ PatternCompiler对象
首先,创建一个Perl5Compiler类的实例,并把它赋值给PatternCompiler接口对象。Perl5Compiler是PatternCompiler接口的一个实现,允许你把正则表达式编译成用来匹配的Pattern对象。

Pattern对象
要把正则表达式编译成Pattern对象,调用compiler对象的compile()方法,并在调用参数中指定正则表达式。例如,你可以按照下面这种方式编译正则表达式“t[aeio]n”:

默认情况下,编译器创建一个大小写敏感的模式(pattern)。因此,上面代码编译得到的模式只匹配“tin”、“tan”、 “ten”和“ton”,但不匹配“Tin”和“taN”。要创建一个大小写不敏感的模式,你应该在调用编译器的时候指定一个额外的参数:

创建好Pattern对象之后,你就可以通过PatternMatcher类用该Pattern对象进行模式匹配。
▲ PatternMatcher对象
PatternMatcher对象根据Pattern对象和字符串进行匹配检查。你要实例化一个Perl5Matcher类并把结果赋值给PatternMatcher接口。Perl5Matcher类是PatternMatcher接口的一个实现,它根据Perl 5正则表达式语法进行模式匹配:

用PatternMatcher对象,你可以用多个方法进行匹配操作,这些方法的第一个参数都是需要根据正则表达式进行匹配的字符串:
“· boolean matches(String input, Pattern pattern):当输入字符串和正则表达式要精确匹配时使用。换句话说,正则表达式必须完整地描述输入字符串。
· boolean matchesPrefix(String input, Pattern pattern):当正则表达式匹配输入字符串起始部分时使用。
· boolean contains(String input, Pattern pattern):当正则表达式要匹配输入字符串的一部分时使用(即,它必须是一个子串)。
另外,在上面三个方法调用中,你还可以用PatternMatcherInput对象作为参数替代String对象;这时,你可以从字符串中最后一次匹配的位置开始继续进行匹配。当字符串可能有多个子串匹配给定的正则表达式时,用PatternMatcherInput对象作为参数就很有用了。用PatternMatcherInput对象作为参数替代String时,上述三个方法的语法如下:。 boolean matches(PatternMatcherInput input, Pattern pattern)。 boolean matchesPrefix(PatternMatcherInput input, Pattern pattern)。 boolean contains(PatternMatcherInput input, Pattern pattern)
三、应用实例
下面我们来看看Jakarta-ORO库的一些应用实例。
3.1 日志文件处理
任务:分析一个Web服务器日志文件,确定每一个用户花在网站上的时间。在典型的BEA WebLogic日志文件中,日志记录的格式如下:

分析这个日志记录,可以发现,要从这个日志文件提取的内容有两项:IP地址和页面访问时间。你可以用分组符号(圆括号)从日志记录提取出IP地址和时间标记。
首先我们来看看IP地址。IP地址有4个字节构成,每一个字节的值在0到255之间,各个字节通过一个句点分隔。因此,IP地址中的每一个字节有至少一个、最多三个数字。图八显示了为IP地址编写的正则表达式:

图八:匹配IP地址
IP地址中的句点字符必须进行转义处理(前面加上“\”),因为IP地址中的句点具有它本来的含义,而不是采用正则表达式语法中的特殊含义。句点在正则表达式中的特殊含义本文前面已经介绍。
日志记录的时间部分由一对方括号包围。你可以按照如下思路提取出方括号里面的所有内容:首先搜索起始方括号字符(“[”),提取出所有不超过结束方括号字符(“]”)的内容,向前寻找直至找到结束方括号字符。图九显示了这部分的正则表达式。

图九:匹配至少一个字符,直至找到“]”
现在,把上述两个正则表达式加上分组符号(圆括号)后合并成单个表达式,这样就可以从日志记录提取出IP地址和时间。注意,为了匹配“- -”(但不提取它),正则表达式中间加入了“\s-\s-\s”。完整的正则表达式如图十所示。

图十:匹配IP地址和时间标记
现在正则表达式已经编写完毕,接下来可以编写使用正则表达式库的Java代码了。
为使用Jakarta-ORO库,首先创建正则表达式字符串和待分析的日志记录字符串:

这里使用的正则表达式与图十的正则表达式差不多完全相同,但有一点例外:在Java中,你必须对每一个向前的斜杠(“\”)进行转义处理。图十不是Java的表示形式,所以我们要在每个“\”前面加上一个“\”以免出现编译错误。遗憾的是,转义处理过程很容易出现错误,所以应该小心谨慎。你可以首先输入未经转义处理的正则表达式,然后从左到右依次把每一个“\”替换成“\\”。如果要复检,你可以试着把它输出到屏幕上。
初始化字符串之后,实例化PatternCompiler对象,用PatternCompiler编译正则表达式创建一个Pattern对象:

现在,创建PatternMatcher对象,调用PatternMatcher接口的contain()方法检查匹配情况:

接下来,利用PatternMatcher接口返回的MatchResult对象,输出匹配的组。由于logEntry字符串包含匹配的内容,你可以看到类如下面的输出:

3.2 HTML处理实例一
下面一个任务是分析HTML页面内FONT标记的所有属性。HTML页面内典型的FONT标记如下所示:

程序将按照如下形式,输出每一个FONT标记的属性:

在这种情况下,我建议你使用两个正则表达式。第一个如图十一所示,它从字体标记提取出“"face="Arial, Serif" size="+2" color="red"”。

图十一:匹配FONT标记的所有属性
第二个正则表达式如图十二所示,它把各个属性分割成名字-值对。

图十二:匹配单个属性,并把它分割成名字-值对
分割结果为:

现在我们来看看完成这个任务的Java代码。首先创建两个正则表达式字符串,用Perl5Compiler把它们编译成Pattern对象。编译正则表达式的时候,指定Perl5Compiler.CASE_INSENSITIVE_MASK选项,使得匹配操作不区分大小写。
接下来,创建一个执行匹配操作的Perl5Matcher对象。

假设有一个String类型的变量html,它代表了HTML文件中的一行内容。如果html字符串包含FONT标记,匹配器将返回true.此时,你可以用匹配器对象返回的MatchResult对象获得第一个组,它包含了FONT的所有属性:

接下来创建一个PatternMatcherInput对象。这个对象允许你从最后一次匹配的位置开始继续进行匹配操作,因此,它很适合于提取FONT标记内属性的名字-值对。创建PatternMatcherInput对象,以参数形式传入待匹配的字符串。然后,用匹配器实例提取出每一个FONT的属性。这通过指定PatternMatcherInput对象(而不是字符串对象)为参数,反复地调用PatternMatcher对象的contains()方法完成。PatternMatcherInput对象之中的每一次迭代将把它内部的指针向前移动,下一次检测将从前一次匹配位置的后面开始。
本例的输出结果如下:

3.3 HTML处理实例二
下面我们来看看另一个处理HTML的例子。这一次,我们假定Web服务器从widgets.acme.com移到了newserver.acme.com.现在你要修改一些页面中的链接:

执行这个搜索的正则表达式如图十三所示:

图十三:匹配修改前的链接
如果能够匹配这个正则表达式,你可以用下面的内容替换图十三的链接:

注意#字符的后面加上了$1.Perl正则表达式语法用$1、$2等表示已经匹配且提取出来的组。图十三的表达式把所有作为一个组匹配和提取出来的内容附加到链接的后面。
现在,返回Java.就象前面我们所做的那样,你必须创建测试字符串,创建把正则表达式编译到Pattern对象所必需的对象,以及创建一个PatternMatcher对象:

接下来,用com.oroinc.text.regex包Util类的substitute()静态方法进行替换,输出结果字符串:

Util.substitute()方法的语法如下:

这个调用的前两个参数是以前创建的PatternMatcher和Pattern对象。第三个参数是一个Substiution对象,它决定了替换操作如何进行。本例使用的是Perl5Substitution对象,它能够进行Perl5风格的替换。第四个参数是想要进行替换操作的字符串,最后一个参数允许指定是否替换模式的所有匹配子串(Util.SUBSTITUTE_ALL),或只替换指定的次数。
「结束语」
在这篇文章中,我为你介绍了正则表达式的强大功能。只要正确运用,正则表达式能够在字符串提取和文本修改中起到很大的作用。另外,我还介绍了如何在Java程序中通过Jakarta-ORO库利用正则表达式。至于最终采用老式的字符串处理方式(使用StringTokenizer,charAt,和substring),还是采用正则表达式,这就有待你自己决定了。
posted @
2006-09-19 19:31 xzc 阅读(17845) |
评论 (5) |
编辑 收藏权限往往是一个极其复杂的问题,但也可简单表述为这样的逻辑表达式:判断“Who对What(Which)进行How的操作”的逻辑表达式是否为真。针对不同的应用,需要根据项目的实际情况和具体架构,在维护性、灵活性、完整性等N多个方案之间比较权衡,选择符合的方案。
目标:
直观,因为系统最终会由最终用户来维护,权限分配的直观和容易理解,显得比较重要,系统不辞劳苦的实现了组的继承,除了功能的必须,更主要的就是因为它足够直观。
简单,包括概念数量上的简单和意义上的简单还有功能上的简单。想用一个权限系统解决所有的权限问题是不现实的。设计中将常常变化的“定制”特点比较强的部分判断为业务逻辑,而将常常相同的“通用”特点比较强的部分判断为权限逻辑就是基于这样的思路。
扩展,采用可继承在扩展上的困难。的Group概念在支持权限以组方式定义的同时有效避免了重定义时
现状:
对于在企业环境中的访问控制方法,一般有三种:
1.自主型访问控制方法。目前在我国的大多数的信息系统中的访问控制模块中基本是借助于自主型访问控制方法中的访问控制列表(ACLs)。
2.强制型访问控制方法。用于多层次安全级别的军事应用。
3.基于角色的访问控制方法(RBAC)。是目前公认的解决大型企业的统一资源访问控制的有效方法。其显著的两大特征是:1.减小授权管理的复杂性,降低管理开销。2.灵活地支持企业的安全策略,并对企业的变化有很大的伸缩性。
名词:
粗粒度:表示类别级,即仅考虑对象的类别(the type of object),不考虑对象的某个特
定实例。比如,用户管理中,创建、删除,对所有的用户都一视同仁,并不区分操作的具体对象实例。
细粒度:表示实例级,即需要考虑具体对象的实例(the instance of object),当然,细
粒度是在考虑粗粒度的对象类别之后才再考虑特定实例。比如,合同管理中,列表、删除,需要区分该合同实例是否为当前用户所创建。
原则:
权限逻辑配合业务逻辑。即权限系统以为业务逻辑提供服务为目标。相当多细粒度的权限问题因其极其独特而不具通用意义,它们也能被理解为是“业务逻辑”的一部分。比如,要求:“合同资源只能被它的创建者删除,与创建者同组的用户可以修改,所有的用户能够浏览”。这既可以认为是一个细粒度的权限问题,也可以认为是一个业务逻辑问题。在这里它是业务逻辑问题,在整个权限系统的架构设计之中不予过多考虑。当然,权限系统的架构也必须要能支持这样的控制判断。或者说,系统提供足够多但不是完全的控制能力。即,设计原则归结为:“系统只提供粗粒度的权限,细粒度的权限被认为是业务逻辑的职责”。
需要再次强调的是,这里表述的权限系统仅是一个“不完全”的权限系统,即,它不提供所有关于权限的问题的解决方法。它提供一个基础,并解决那些具有“共性”的(或者说粗粒度的)部分。在这个基础之上,根据“业务逻辑”的独特权限需求,编码实现剩余部分(或者说细粒度的)部分,才算完整。回到权限的问题公式,通用的设计仅解决了Who+What+How 的问题,其他的权限问题留给业务逻辑解决。
概念:
Who:权限的拥用者或主体(Principal、User、Group、Role、Actor等等)
What:权限针对的对象或资源(Resource、Class)。
How:具体的权限(Privilege, 正向授权与负向授权)。
Role:是角色,拥有一定数量的权限。
Operator:操作。表明对What的How 操作。
说明:
User:与 Role 相关,用户仅仅是纯粹的用户,权限是被分离出去了的。User是不能与 Privilege 直接相关的,User 要拥有对某种资源的权限,必须通过Role去关联。解决 Who 的问题。
Resource:就是系统的资源,比如部门新闻,文档等各种可以被提供给用户访问的对象。资源可以反向包含自身,即树状结构,每一个资源节点可以与若干指定权限类别相关可定义是否将其权限应用于子节点。
Privilege:是Resource Related的权限。就是指,这个权限是绑定在特定的资源实例上的。比如说部门新闻的发布权限,叫做"部门新闻发布权限"。这就表明,该Privilege是一个发布权限,而且是针对部门新闻这种资源的一种发布权限。Privilege是由Creator在做开发时就确定的。权限,包括系统定义权限和用户自定义权限用户自定义权限之间可以指定排斥和包含关系(如:读取,修改,管理三个权限,管理 权限 包含 前两种权限)。Privilege 如"删除" 是一个抽象的名词,当它不与任何具体的 Object 或 Resource 绑定在一起时是没有任何意义的。拿新闻发布来说,发布是一种权限,但是只说发布它是毫无意义的。因为不知道发布可以操作的对象是什么。只有当发布与新闻结合在一起时,才会产生真正的 Privilege。这就是 Privilege Instance。权限系统根据需求的不同可以延伸生很多不同的版本。
Role:是粗粒度和细粒度(业务逻辑)的接口,一个基于粗粒度控制的权限框架软件,对外的接口应该是Role,具体业务实现可以直接继承或拓展丰富Role的内容,Role不是如同User或Group的具体实体,它是接口概念,抽象的通称。
Group:用户组,权限分配的单位与载体。权限不考虑分配给特定的用户。组可以包括组(以实现权限的继承)。组可以包含用户,组内用户继承组的权限。Group要实现继承。即在创建时必须要指定该Group的Parent是什么Group。在粗粒度控制上,可以认为,只要某用户直接或者间接的属于某个Group那么它就具备这个Group的所有操作许可。细粒度控制上,在业务逻辑的判断中,User仅应关注其直接属于的Group,用来判断是否“同组” 。Group是可继承的,对于一个分级的权限实现,某个Group通过“继承”就已经直接获得了其父Group所拥有的所有“权限集合”,对这个Group而言,需要与权限建立直接关联的,仅是它比起其父Group需要“扩展”的那部分权限。子组继承父组的所有权限,规则来得更简单,同时意味着管理更容易。为了更进一步实现权限的继承,最直接的就是在Group上引入“父子关系”。
User与Group是多对多的关系。即一个User可以属于多个Group之中,一个Group可以包括多个User。子Group与父Group是多对一的关系。Operator某种意义上类似于Resource + Privilege概念,但这里的Resource仅包括Resource Type不表示Resource Instance。Group 可以直接映射组织结构,Role 可以直接映射组织结构中的业务角色,比较直观,而且也足够灵活。Role对系统的贡献实质上就是提供了一个比较粗颗粒的分配单位。
Group与Operator是多对多的关系。各概念的关系图示如下:
解释:
Operator的定义包括了Resource Type和Method概念。即,What和How的概念。之所以将What和How绑定在一起作为一个Operator概念而不是分开建模再建立关联,这是因为很多的How对于某What才有意义。比如,发布操作对新闻对象才有意义,对用户对象则没有意义。
How本身的意义也有所不同,具体来说,对于每一个What可以定义N种操作。比如,对于合同这类对象,可以定义创建操作、提交操作、检查冲突操作等。可以认为,How概念对应于每一个商业方法。其中,与具体用户身份相关的操作既可以定义在操作的业务逻辑之中,也可以定义在操作级别。比如,创建者的浏览视图与普通用户的浏览视图要求内容不同。既可以在外部定义两个操作方法,也可以在一个操作方法的内部根据具体逻辑进行处理。具体应用哪一种方式应依据实际情况进行处理。
这样的架构,应能在易于理解和管理的情况下,满足绝大部分粗粒度权限控制的功能需要。但是除了粗粒度权限,系统中必然还会包括无数对具体Instance的细粒度权限。这些问题,被留给业务逻辑来解决,这样的考虑基于以下两点:
一方面,细粒度的权限判断必须要在资源上建模权限分配的支持信息才可能得以实现。比如,如果要求创建者和普通用户看到不同的信息内容,那么,资源本身应该有其创建者的信息。另一方面,细粒度的权限常常具有相当大的业务逻辑相关性。对不同的业务逻辑,常常意味着完全不同的权限判定原则和策略。相比之下,粗粒度的权限更具通用性,将其实现为一个架构,更有重用价值;而将细粒度的权限判断实现为一个架构级别的东西就显得繁琐,而且不是那么的有必要,用定制的代码来实现就更简洁,更灵活。
所以细粒度控制应该在底层解决,Resource在实例化的时候,必需指定Owner和GroupPrivilege在对Resource进行操作时也必然会确定约束类型:究竟是OwnerOK还是GroupOK还是AllOK。Group应和Role严格分离User和Group是多对多的关系,Group只用于对用户分类,不包含任何Role的意义;Role只授予User,而不是Group。如果用户需要还没有的多种Privilege的组合,必须新增Role。Privilege必须能够访问Resource,同时带User参数,这样权限控制就完备了。
思想:
权限系统的核心由以下三部分构成:1.创造权限,2.分配权限,3.使用权限,然后,系统各部分的主要参与者对照如下:1.创造权限 - Creator创造,2.分配权限 - Administrator 分配,3.使用权限 - User:
1. Creator 创造 Privilege, Creator 在设计和实现系统时会划分,一个子系统或称为模块,应该有哪些权限。这里完成的是 Privilege 与 Resource 的对象声明,并没有真正将 Privilege 与具体Resource 实例联系在一起,形成Operator。
2. Administrator 指定 Privilege 与 Resource Instance 的关联。在这一步, 权限真正与资源实例联系到了一起, 产生了Operator(Privilege Instance)。Administrator利用Operator这个基本元素,来创造他理想中的权限模型。如,创建角色,创建用户组,给用户组分配用户,将用户组与角色关联等等...这些操作都是由 Administrator 来完成的。
3. User 使用 Administrator 分配给的权限去使用各个子系统。Administrator 是用户,在他的心目中有一个比较适合他管理和维护的权限模型。于是,程序员只要回答一个问题,就是什么权限可以访问什么资源,也就是前面说的 Operator。程序员提供 Operator 就意味着给系统穿上了盔甲。Administrator 就可以按照他的意愿来建立他所希望的权限框架可以自行增加,删除,管理Resource和Privilege之间关系。可以自行设定用户User和角色Role的对应关系。(如果将 Creator看作是 Basic 的发明者, Administrator 就是 Basic 的使用者,他可以做一些脚本式的编程) Operator是这个系统中最关键的部分,它是一个纽带,一个系在Programmer,Administrator,User之间的纽带。
用一个功能模块来举例子。
一.建立角色功能并做分配:
1.如果现在要做一个员工管理的模块(即Resources),这个模块有三个功能,分别是:增加,修改,删除。给这三个功能各自分配一个ID,这个ID叫做功能代号:
Emp_addEmp,Emp_deleteEmp,Emp_updateEmp。
2.建立一个角色(Role),把上面的功能代码加到这个角色拥有的权限中,并保存到数据库中。角色包括系统管理员,测试人员等。
3.建立一个员工的账号,并把一种或几种角色赋给这个员工。比如说这个员工既可以是公司管理人员,也可以是测试人员等。这样他登录到系统中将会只看到他拥有权限的那些模块。
二.把身份信息加到Session中。
登录时,先到数据库中查找是否存在这个员工,如果存在,再根据员工的sn查找员工的权限信息,把员工所有的权限信息都入到一个Hashmap中,比如就把上面的Emp_addEmp等放到这个Hashmap中。然后把Hashmap保存在一个UserInfoBean中。最后把这个UserInfoBean放到Session中,这样在整个程序的运行过程中,系统随时都可以取得这个用户的身份信息。
三.根据用户的权限做出不同的显示。
可以对比当前员工的权限和给这个菜单分配的“功能ID”判断当前用户是否有打开这个菜单的权限。例如:如果保存员工权限的Hashmap中没有这三个ID的任何一个,那这个菜单就不会显示,如果员工的Hashmap中有任何一个ID,那这个菜单都会显示。
对于一个新闻系统(Resouce),假设它有这样的功能(Privilege):查看,发布,删除,修改;假设对于删除,有"新闻系统管理者只能删除一月前发布的,而超级管理员可删除所有的这样的限制,这属于业务逻辑(Business logic),而不属于用户权限范围。也就是说权限负责有没有删除的Permission,至于能删除哪些内容应该根据UserRole or UserGroup来决定(当然给UserRole or UserGroup分配权限时就应该包含上面两条业务逻辑)。
一个用户可以拥有多种角色,但同一时刻用户只能用一种角色进入系统。角色的划分方法可以根据实际情况划分,按部门或机构进行划分的,至于角色拥有多少权限,这就看系统管理员赋给他多少的权限了。用户—角色—权限的关键是角色。用户登录时是以用户和角色两种属性进行登录的(因为一个用户可以拥有多种角色,但同一时刻只能扮演一种角色),根据角色得到用户的权限,登录后进行初始化。这其中的技巧是同一时刻某一用户只能用一种角色进行登录。
针对不同的“角色”动态的建立不同的组,每个项目建立一个单独的Group,对于新的项目,建立新的 Group 即可。在权限判断部分,应在商业方法上予以控制。比如:不同用户的“操作能力”是不同的(粗粒度的控制应能满足要求),不同用户的“可视区域”是不同的(体现在对被操作的对象的权限数据,是否允许当前用户访问,这需要对业务数据建模的时候考虑权限控制需要)。
扩展性:
有了用户/权限管理的基本框架,Who(User/Group)的概念是不会经常需要扩展的。变化的可能是系统中引入新的 What (新的Resource类型)或者新的How(新的操作方式)。那在三个基本概念中,仅在Permission上进行扩展是不够的。这样的设计中Permission实质上解决了How 的问题,即表示了“怎样”的操作。那么这个“怎样”是在哪一个层次上的定义呢?将Permission定义在“商业方法”级别比较合适。比如,发布、购买、取消。每一个商业方法可以意味着用户进行的一个“动作”。定义在商业逻辑的层次上,一方面保证了数据访问代码的“纯洁性”,另一方面在功能上也是“足够”的。也就是说,对更低层次,能自由的访问数据,对更高层次,也能比较精细的控制权限。
确定了Permission定义的合适层次,更进一步,能够发现Permission实际上还隐含了What的概念。也就是说,对于What的How操作才会是一个完整的Operator。比如,“发布”操作,隐含了“信息”的“发布”概念,而对于“商品”而言发布操作是没有意义的。同样的,“购买”操作,隐含了“商品”的“购买”概念。这里的绑定还体现在大量通用的同名的操作上,比如,需要区分“商品的删除”与“信息的删除”这两个同名为“删除”的不同操作。
提供权限系统的扩展能力是在Operator (Resource + Permission)的概念上进行扩展。Proxy 模式是一个非常合适的实现方式。实现大致如下:在业务逻辑层(EJB Session Facade [Stateful SessionBean]中),取得该商业方法的Methodname,再根据Classname和 Methodname 检索Operator 数据,然后依据这个Operator信息和Stateful中保存的User信息判断当前用户是否具备该方法的操作权限。
应用在 EJB 模式下,可以定义一个很明确的 Business层次,而一个Business 可能意味着不同的视图,当多个视图都对应于一个业务逻辑的时候,比如,Swing Client以及 Jsp Client 访问的是同一个 EJB 实现的 Business。在 Business 层上应用权限较能提供集中的控制能力。实际上,如果权限系统提供了查询能力,那么会发现,在视图层次已经可以不去理解权限,它只需要根据查询结果控制界面就可以了。
灵活性:
Group和Role,只是一种辅助实现的手段,不是必需的。如果系统的Role很多,逐个授权违背了“简单,方便”的目的,那就引入Group,将权限相同的Role组成一个Group进行集中授权。Role也一样,是某一类Operator的集合,是为了简化针对多个Operator的操作。
Role把具体的用户和组从权限中解放出来。一个用户可以承担不同的角色,从而实现授权的灵活性。当然,Group也可以实现类似的功能。但实际业务中,Group划分多以行政组织结构或业务功能划分;如果为了权限管理强行将一个用户加入不同的组,会导致管理的复杂性。
Domain的应用。为了授权更灵活,可以将Where或者Scope抽象出来,称之为Domain,真正的授权是在Domain的范围内进行,具体的Resource将分属于不同的Domain。比如:一个新闻机构有国内与国外两大分支,两大分支内又都有不同的资源(体育类、生活类、时事政治类)。假如所有国内新闻的权限规则都是一样的,所有国外新闻的权限规则也相同。则可以建立两个域,分别授权,然后只要将各类新闻与不同的域关联,受域上的权限控制,从而使之简化。
权限系统还应该考虑将功能性的授权与资源性的授权分开。很多系统都只有对系统中的数据(资源)的维护有权限控制,但没有对系统功能的权限控制。
权限系统最好是可以分层管理而不是集中管理。大多客户希望不同的部门能且仅能管理其部门内部的事务,而不是什么都需要一个集中的Administrator或Administrators组来管理。虽然你可以将不同部门的人都加入Administrators组,但他们的权限过大,可以管理整个系统资源而不是该部门资源。
正向授权与负向授权:正向授权在开始时假定主体没有任何权限,然后根据需要授予权限,适合于权限要求严格的系统。负向授权在开始时假定主体有所有权限,然后将某些特殊权限收回。
权限计算策略:系统中User,Group,Role都可以授权,权限可以有正负向之分,在计算用户的净权限时定义一套策略。
系统中应该有一个集中管理权限的AccessService,负责权限的维护(业务管理员、安全管理模块)与使用(最终用户、各功能模块),该AccessService在实现时要同时考虑一般权限与特殊权限。虽然在具体实现上可以有很多,比如用Proxy模式,但应该使这些Proxy依赖于AccessService。各模块功能中调用AccessService来检查是否有相应的权限。所以说,权限管理不是安全管理模块自己一个人的事情,而是与系统各功能模块都有关系。每个功能模块的开发人员都应该熟悉安全管理模块,当然,也要从业务上熟悉本模块的安全规则。
技术实现:
1.表单式认证,这是常用的,但用户到达一个不被授权访问的资源时,Web容器就发
出一个html页面,要求输入用户名和密码。
2.一个基于Servlet Sign in/Sign out来集中处理所有的Request,缺点是必须由应用程序自己来处理。
3.用Filter防止用户访问一些未被授权的资源,Filter会截取所有Request/Response,
然后放置一个验证通过的标识在用户的Session中,然后Filter每次依靠这个标识来决定是否放行Response。
这个模式分为:
Gatekeeper :采取Filter或统一Servlet的方式。
Authenticator: 在Web中使用JAAS自己来实现。
用户资格存储LDAP或数据库:
1. Gatekeeper拦截检查每个到达受保护的资源。首先检查这个用户是否有已经创建
好的Login Session,如果没有,Gatekeeper 检查是否有一个全局的和Authenticator相关的session?
2. 如果没有全局的session,这个用户被导向到Authenticator的Sign-on 页面,
要求提供用户名和密码。
3. Authenticator接受用户名和密码,通过用户的资格系统验证用户。
4. 如果验证成功,Authenticator将创建一个全局Login session,并且导向Gatekeeper
来为这个用户在他的web应用中创建一个Login Session。
5. Authenticator和Gatekeepers联合分享Cookie,或者使用Tokens在Query字符里。
————————————————————————————————————
权限表及相关内容大体可以用六个表来描述,如下:
1 角色(即用户组)表:包括三个字段,ID,角色名,对该角色的描述;
2 用户表:包括三个或以上字段,ID,用户名,对该用户的描述,其它(如地址、电话等信息);
3 角色-用户对应表:该表记录用户与角色之间的对应关系,一个用户可以隶属于多个角色,一个角色组也可拥有多个用户。包括三个字段,ID,角色ID,用户ID;
4 权限列表:该表记录所有要加以控制的权限,如录入、修改、删除、执行等,也包括三个字段,ID,名称,描述;
5 权限-角色对应表:该表记录权限与角色之间的对应关系,一个角色可以拥有多个权限,一个权限也可以隶属多个角色。包括三个字段,ID, 角色ID,权限ID;
posted @
2006-09-18 20:48 xzc 阅读(399) |
评论 (0) |
编辑 收藏
---------------------- 单维数组------------------------
DECLARE
TYPE emp_ssn_array IS TABLE OF NUMBER
INDEX BY BINARY_INTEGER;
best_employees emp_ssn_array;
worst_employees emp_ssn_array;
BEGIN
best_employees(1) := '123456';
best_employees(2) := '888888';
worst_employees(1) := '222222';
worst_employees(2) := '666666';
FOR i IN 1..best_employees.count LOOP
DBMS_OUTPUT.PUT_LINE('i='|| i || ', best_employees= ' ||best_employees(i)
|| ', worst_employees= ' ||worst_employees(i));
END LOOP;
END;
---------------------- 多维数组------------------------
DECLARE
TYPE emp_type IS RECORD
( emp_id employee_table.emp_id%TYPE,
emp_name employee_table.emp_name%TYPE,
emp_gender employee_table.emp_gender%TYPE );
TYPE emp_type_array IS TABLE OF
emp_type INDEX BY BINARY_INTEGER;
emp_rec_array emp_type_array;
emp_rec emp_type;
BEGIN
emp_rec.emp_id := 300000000;
emp_rec.emp_name := 'Barbara';
emp_rec.emp_gender := 'Female';
emp_rec_array(1) := emp_rec;
emp_rec.emp_id := 300000008;
emp_rec.emp_name := 'Rick';
emp_rec.emp_gender := 'Male';
emp_rec_array(2) := emp_rec;
FOR i IN 1..emp_rec_array.count LOOP
DBMS_OUTPUT.PUT_LINE('i='||i
||', emp_id ='||emp_rec_array(i).emp_id
||', emp_name ='||emp_rec_array(i).emp_name
||', emp_gender = '||emp_rec_array(i).emp_gender);
END LOOP;
END;
-------------- Result --------------
i=1, emp_id =300000000, emp_name =Barbara, emp_gender = Female
i=2, emp_id =300000008, emp_name =Rick, emp_gender = Male
注:在PL/SQL 中是没有数组(Array) 概念的. 但是如果程序员想用Array 的话, 就得变通一下, 用TYPE 和Table of Record 来代替多维数组, 一样挺好用的。
emp_type 就好象一个table 中的一条record 一样, 里面有id, name,gender等。emp_type_array 象个table, 里面含有一条条这样的record (emp_type),就象多维数组一样。
posted @
2006-09-18 20:41 xzc 阅读(249) |
评论 (0) |
编辑 收藏package com.xgll.util;
/**
* <p>Title: </p>
* <p>Description: 主要提供文件和目录操作的一些常用的方法。</p>
* <p>Copyright: Copyright (c) 2006</p>
* <p>Company: C-Platform</p>
* @author wujiaqian
* @version 1.0
*/
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.util.StringTokenizer;
public class TestUtil {
public TestUtil() {
}
/**
* 新建目录
* @param folderPath 目录
* @return 返回目录创建后的路径
*/
public String createFolder(String folderPath) {
String txt = folderPath;
try {
java.io.File myFilePath = new java.io.File(txt);
txt = folderPath;
if (!myFilePath.exists()) {
myFilePath.mkdir();
}
}
catch (Exception e) {
}
return txt;
}
/**
* 多级目录创建
* @param folderPath 准备要在本级目录下创建新目录的目录路径 例如 c:myf
* @param paths 无限级目录参数,各级目录以单数线区分 例如 a|b|c
* @return 返回创建文件后的路径 例如 c:myfa�c
*/
public String createFolders(String folderPath, String paths){
String txts = folderPath;
try{
String txt;
txts = folderPath;
StringTokenizer st = new StringTokenizer(paths,"|");
for(int i=0; st.hasMoreTokens(); i++){
txt = st.nextToken().trim();
if(txts.lastIndexOf("/")!=-1){
txts = createFolder(txts+txt);
}else{
txts = createFolder(txts+txt+"/");
}
}
}catch(Exception e){
}
return txts;
}
/**
* 新建文件
* @param filePathAndName 文本文件完整绝对路径及文件名
* @param fileContent 文本文件内容
* @return
*/
public void createFile(String filePathAndName, String fileContent) {
try {
String filePath = filePathAndName;
filePath = filePath.toString();
File myFilePath = new File(filePath);
if (!myFilePath.exists()) {
myFilePath.createNewFile();
}
FileWriter resultFile = new FileWriter(myFilePath);
PrintWriter myFile = new PrintWriter(resultFile);
String strContent = fileContent;
myFile.println(strContent);
myFile.close();
resultFile.close();
}
catch (Exception e) {
}
}
/**
* 有编码方式的文件创建
* @param filePathAndName 文本文件完整绝对路径及文件名
* @param fileContent 文本文件内容
* @param encoding 编码方式 例如 GBK 或者 UTF-8
* @return
*/
public void createFile(String filePathAndName, String fileContent, String encoding) {
try {
String filePath = filePathAndName;
filePath = filePath.toString();
File myFilePath = new File(filePath);
if (!myFilePath.exists()) {
myFilePath.createNewFile();
}
PrintWriter myFile = new PrintWriter(myFilePath,encoding);
String strContent = fileContent;
myFile.println(strContent);
myFile.close();
}
catch (Exception e) {
}
}
/**
* 删除文件
* @param filePathAndName 文本文件完整绝对路径及文件名
* @return Boolean 成功删除返回true遭遇异常返回false
*/
public boolean delFile(String filePathAndName) {
boolean flag = false;
try {
String filePath = filePathAndName;
File myDelFile = new File(filePath);
if(myDelFile.exists()){
myDelFile.delete();
flag = true;
}else{
flag = false;
}
}
catch (Exception e) {
}
return flag;
}
/**
* 删除文件夹
* @param folderPath 文件夹完整绝对路径
* @return
*/
public void delFolder(String folderPath) {
try {
delAllFile(folderPath); //删除完里面所有内容
String filePath = folderPath;
filePath = filePath.toString();
java.io.File myFilePath = new java.io.File(filePath);
myFilePath.delete(); //删除空文件夹
}
catch (Exception e) {
}
}
/**
* 删除指定文件夹下所有文件
* @param path 文件夹完整绝对路径
* @return
* @return
*/
public boolean delAllFile(String path) {
boolean flag = false;
File file = new File(path);
if (!file.exists()) {
return flag;
}
if (!file.isDirectory()) {
return flag;
}
String[] tempList = file.list();
File temp = null;
for (int i = 0; i < tempList.length; i++) {
if (path.endsWith(File.separator)) {
temp = new File(path + tempList[i]);
}else{
temp = new File(path + File.separator + tempList[i]);
}
if (temp.isFile()) {
temp.delete();
}
if (temp.isDirectory()) {
delAllFile(path+"/"+ tempList[i]);//先删除文件夹里面的文件
delFolder(path+"/"+ tempList[i]);//再删除空文件夹
flag = true;
}
}
return flag;
}
/**
* 复制单个文件
* @param oldPathFile 准备复制的文件源
* @param newPathFile 拷贝到新绝对路径带文件名
* @return
*/
public void copyFile(String oldPathFile, String newPathFile) {
try {
int bytesum = 0;
int byteread = 0;
File oldfile = new File(oldPathFile);
if (oldfile.exists()) { //文件存在时
InputStream inStream = new FileInputStream(oldPathFile); //读入原文件
FileOutputStream fs = new FileOutputStream(newPathFile);
byte[] buffer = new byte[1444];
while((byteread = inStream.read(buffer)) != -1){
bytesum += byteread; //字节数 文件大小
System.out.println(bytesum);
fs.write(buffer, 0, byteread);
}
inStream.close();
}
}catch (Exception e) {
}
}
/**
* 复制整个文件夹的内容
* @param oldPath 准备拷贝的目录
* @param newPath 指定绝对路径的新目录
* @return
*/
public void copyFolder(String oldPath, String newPath) {
try {
new File(newPath).mkdirs(); //如果文件夹不存在 则建立新文件夹
File a=new File(oldPath);
String[] file=a.list();
File temp=null;
for (int i = 0; i < file.length; i++) {
if(oldPath.endsWith(File.separator)){
temp=new File(oldPath+file[i]);
}else{
temp=new File(oldPath+File.separator+file[i]);
}
if(temp.isFile()){
FileInputStream input = new FileInputStream(temp);
FileOutputStream output = new FileOutputStream(newPath + "/" +
(temp.getName()).toString());
byte[] b = new byte[1024 * 5];
int len;
while ((len = input.read(b)) != -1) {
output.write(b, 0, len);
}
output.flush();
output.close();
input.close();
}
if(temp.isDirectory()){//如果是子文件夹
copyFolder(oldPath+"/"+file[i],newPath+"/"+file[i]);
}
}
}catch (Exception e) {
}
}
/**
* 移动文件
* @param oldPath
* @param newPath
* @return
*/
public void moveFile(String oldPath, String newPath) {
copyFile(oldPath, newPath);
delFile(oldPath);
}
/**
* 移动目录
* @param oldPath
* @param newPath
* @return
*/
public void moveFolder(String oldPath, String newPath) {
copyFolder(oldPath, newPath);
delFolder(oldPath);
}
/**
* 读取文本文件内容
* @param filePathAndName 带有完整绝对路径的文件名
* @param encoding 文本文件打开的编码方式
* @return 返回文本文件的内容
*/
public String readTxt(String filePathAndName,String encoding) throws IOException{
encoding = encoding.trim();
StringBuffer str = new StringBuffer("");
String st = "";
try{
FileInputStream fs = new FileInputStream(filePathAndName);
InputStreamReader isr;
if(encoding.equals("")){
isr = new InputStreamReader(fs);
}else{
isr = new InputStreamReader(fs,encoding);
}
BufferedReader br = new BufferedReader(isr);
try{
String data = "";
while((data = br.readLine())!=null){
str.append(data+" ");
}
}catch(Exception e){
str.append(e.toString());
}
st = str.toString();
}catch(IOException es){
st = "";
}
return st;
}
}
posted @
2006-09-14 16:21 xzc 阅读(158) |
评论 (0) |
编辑 收藏主要就我所了解的J2EE开发的框架或开源项目做个介绍,可以根据需求选用适当的开源组件进行开发.主要还是以Spring为核心,也总结了一些以前web开发常用的开源工具和开源类库
1持久层:
1)Hibernate
这个不用介绍了,用的很频繁,用的比较多的是映射,包括继承映射和父子表映射
对于DAO在这里介绍个在它基础上开发的包bba96,目前最新版本是bba96 2.0它对Hibernate进行了封装, 查询功能包括执行hsql或者sql查询/更新的方法,如果你要多层次逻辑的条件查询可以自己组装QueryObject.可以参考它做HibernateDAO.也可以直接利用它
2) iBATIS
另一个ORM工具,没有Hibernate那么集成,自由度比较大,所以使用时普遍性能上比Hibernate要快一些.
2:SpringMVC
原理说明和快速入门:
配置文件为:
Spring的配置文件默认为WEB-INF/xxxx-servelet.xm其中xxx为web.xml中org.springframework.web.servlet.DispatcherServlet的servlet-name。
Action分发:
Spring将按照配置文件定义的URL,Mapping到具体Controller类,再根据URL里的action= xxx或其他参数,利用反射调用Controller里对应的Action方法。
输入数据绑定:
Spring提供Binder 通过名字的一一对应反射绑定Pojo,也可以直接从request.getParameter()取数据。
输入数据验证
Sping 提供了Validator接口当然还可以使用开源的Commons-Validaor支持最好
Interceptor(拦截器)
Spring的拦截器提供接口需要自己编写,在这点不如WebWork做的好.全面
(这里提一下WebWork和Struts的区别最主要的区别在于WebWork在建立一个Action时是新New一个对象而Struts是SingleMoule所有的都继承它的一个Action,所以根据项目需要合适的选择.)
3:View层
1) 标签库:JSP2.0/JSTL
由于Webwork或Spring的标签确实很有限,一般view层用JSTL标签,而且据说JSTL设计很好速度是所有标签中最快的使用起来也很简单
2) 富客户端:DOJO Widgets, YUI(YahooUI),FCKEditor, Coolest日历控件
Dojo主要提供Tree, Tab等富客户端控件,可以用其进行辅助客户端开发
YahooUI和DOJO一样它有自己的一套javascript调试控制台,主要支持ajax开发也有很多Tree,Table,Menu等富客户端控件
FCKEditor 最流行的文本编辑器
Coolest日历控件 目前很多日历控件可用,集成在项目中也比较简单,这个只是其中的一个,界面不错的说..
3) JavaScript:Prototype.js
Prototype.js作为javascript的成功的开源框架,封装了很多好用的功能,通过它很容易编写AJAX应用,现在AJAX技术逐渐成熟,框架资源比较丰富,比如YUI,DWR等等,也是因为JavaScript没有合适的调试工具,所以没有必要从零开始编写AJAX应用,个人认为多用一些成熟的Ajax框架实现无刷新更新页面是不错的选择.
4)表格控件:Display Tag ,Extreme Table
这两个的功能差不多,都是View层表格的生成,界面也比较相向,可以导出Excel,Pdf,对Spring支持很容易.
相比较而言比较推荐ExtremeTable,它的设计很好功能上比DisplayTag多一些,支持Ajax,封装了一些拦截器,而且最方面的是在主页wiki中有详细的中文使用文档.
5):OSCache
OSCache是OpenSymphony组织提供的一个J2EE架构中Web应用层的缓存技术实现组件,Cache是一种用于提高系统响应速度、改善系统运行性能的技术。尤其是在Web应用中,通过缓存页面的输出结果,可以很显著的改善系统的稳定性和运行性能。
它主要用在处理短时间或一定时间内一些数据或页面不会发生变化,或将一些不变的统计报表,缓冲在内存,可以充分的减轻服务器的压力,防治负载平衡,快速重启服务器(通过硬盘缓存).
6)SiteMesh
sitemesh应用Decorator模式主要用于提高页面的可维护性和复用性,其原理是用Filter截取request和response,把页面组件head,content,banner结合为一个完整的视图。通常我们都是用include标签在每个jsp页面中来不断的包含各种header, stylesheet, scripts and footer,现在,在sitemesh的帮助下,我们删掉他们轻松达到复合视图模式.
Sitemesh也是 OpenSymphony的一个项目现在最近的版本是2.2,目前OpenSymphony自从04年就没有更新的版本了..感觉它还是比较有创新的一种页面组装方式, OpenSymphony开源组织的代码一般写的比较漂亮,可以改其源代码对自己的项目进行适配.
测试发现Sitemesh还存在一些问题,比如中文问题,它的默认编码是iso-8859-1在使用时候需要做一些改动.
7)CSS,XHTML
这个不用说了,遵循W3C标准的web页面开发.
8)分页标签: pager-taglib组件
Pager-taglib 是一套分页标签库,可以灵活地实现多种不同风格的分页导航页面,并且可以很好的与服务器分页逻辑分离.使用起来也比较简单.
9)Form: Jodd Form taglib
Jodd Form taglib使用比较简单,只要把<form>的头尾以<jodd:form bean= "mybean">包住
就会自动绑定mybean, 自动绑定mybean的所有同名属性到普通html标记input, selectbox, checkbox,radiobox.....在这些input框里不用再写任何代码…
10)Ajax:DWR
J2EE应用最常用的ajax框架
11)报表 图表
Eclipse BIRT功能比较强大,也很庞大..好几十M,一般没有特别需求或别的图表设计软件可以解决的不用它
JasperReports+ iReport是一个基于Java的开源报表工具,它可以在Java环境下像其它IDE报表工具一样来制作报表。JasperReports支持PDF、HTML、XLS、CSV和XML文件输出格式。JasperReports是当前Java开发者最常用的报表工具。
JFreeChart主要是用来制作各种各样的图表,这些图表包括:饼图、柱状图(普通柱状图以及堆栈柱状图)、线图、区域图、分布图、混合图、甘特图以及一些仪表盘等等。
琴棋报表,国产的..重点推荐,适合中国的情况,开放源代码,使用完全免费。纯JAVA开发,适用多种系统平台。特别适合B/S结构的系统。官方网站有其优点介绍,看来用它还是不错的选择,最重要的是支持国产呵呵
4:权限控制: Acegi
Acegi是Spring Framework 下最成熟的安全系统,它提供了强大灵活的企业级安全服务,如完善的认证和授权机制,Http资源访问控制,Method 调用访问控制等等,支持CAS
(耶鲁大学的单点登陆技术,这个单点登陆方案比较出名.我也进行过配置使用,可以根据项目需要,如果用户分布在不同的地方不同的系统通用一套登陆口令可以用它进行解决,一般注册机登陆机就是这样解决的)
Acegi只是于Spring结合最好的安全框架,功能比较强大,当然还有一些其他的安全框架,这里列举一些比较流行的是我从网上找到的,使用方法看其官方文档把…
JAAS, Seraph, jSai - Servlet Security, Gabriel, JOSSO, Kasai, jPAM, OpenSAML都是些安全控制的框架..真够多的呵呵
5:全文检索
1) Lucene
Lucene是一套全文索引接口,可以通过它将数据进行倒排文件处理加入索引文件,它的索引速度和查询速度是相当快的,查询百万级数据毫秒级出结果,现在最火的Apache开源项目,版本更新速度很快现在已经到了2.0,每个版本更新的都比较大,目前用的最多的版本应该是1.4.3,但它有个不太方面的地方单个索引文件有2G文件限制,现在2.0版本没有这个限制,我研究的比较多,它的扩展性比较好,可以很方面的扩充其分词接口和查询接口.
基于它的开发的系统很多,比如最常用的Eclipse的搜索功能,还有一些开源的软件比如Compass,Nutch,Lius,还有我最近做的InSearch(企业级FTP文件网页搜索)
6:公共Util类
主要是Jakarta-Commons类库,其中最常用得是以下几个类库
1) Jakarta-Commons-Language
最常用得类是StringUtils类,提供了使用的字符串处理的常用方法效率比较高
2) Jakarta-Commons-Beantuils
主要用Beantuils能够获得反射函数封装及对嵌套属性,map,array型属性的读取。
3) Jakarta-Commons-Collections
里面有很多Utils方法
7 日志管理
Log4J
任务是日志记录,分为Info,Warn,error几个层次可以更好的调试程序
8 开源的J2EE框架
1) Appfuse
Appfuse是Matt Raible 开发的一个指导性的入门级J2EE框架, 它对如何集成流行的Spring、Hibernate、iBatis、Struts、Xdcolet、JUnit等基础框架给出了示范. 在持久层,AppFuse采用了Hibernate O/R映射工具;在容器方面,它采用了Spring,用户可以自由选择Struts、Spring/MVC,Webwork,JSF这几个Web框架。
2) SpringSide
.SpringSide较完整的演示了企业应用的各个方面,是一个电子商务网站的应用 SpringSide也大量参考了Appfuse中的优秀经验。最重要的是它是国内的一个开源项目,可以了解到国内现在的一些实际技术动态和方向很有指导意义…
9:模版 Template
主要有Veloctiy和Freemarker
模板用Servlet提供的数据动态地生成 HTML。编译器速度快,输出接近静态HTML 页面的速度。
10:工作流
我所知道比较出名的主要有JBpm Shark Osworkflow,由于对它没有过多的研究所以还不是很清楚之间有什么区别.
项目管理软件
dotProject:是一个基于LAMP的开源项目管理软件。最出名的项目管理软件
JIRA: 项目计划,任务安排,错误管理
Bugzilla:提交和管理bug,和eclipse集成,可以通过安装MyEclipse配置一下即可使用
BugFree借鉴微软公司软件研发理念、免费开放源代码、基于Web的精简版Bug管理
CVS:这个就不介绍了都在用.
SVN: SubVersion已逐渐超越CVS,更适应于JavaEE的项目。Apache用了它很久后,Sourceforge刚刚推出SVN的支持。
测试用例:主要JUnit单元测试,编写TestCase,Spring也对Junit做了很好的支持
后记:
以Spring为主的应用开发可选用的组件中间件真是眼花缭乱,所以针对不同的项目需求可以利用不同的开源产品解决,比如用Spring+Hibernate/ iBATIS或Spring+WebWork+Hibernate/ iBATIS或Spring+Struts+Hibernate/ iBATIS,合理的框架设计和代码复用设计对项目开发效率和程序性能有很大的提高,也有利于后期的维护.
posted @
2006-09-11 13:41 xzc 阅读(432) |
评论 (0) |
编辑 收藏
约定:POI项目2.0版现在已经接近正式发行阶段,开发进度迅速,不断有新的功能集成到原有的系统,同时也有对原有系统的修改。
为了保证本文的及时性,本文将按照最近的1.9开发版说明。虽然编译最近的发行版源代码也能正常运行,但现在的代码和2.0的发行版会有一些出入。
一、Excel基础
Microsoft Excel 97文件格式也被称为BIFF8,最近版本的Excel只对该格式作了少量的改动。增加对新格式的支持除了增加项目的复杂性之外,唯一的效果也许只是不得不使每个用户升级代码,没有什么实际的好处。
因此,在下文说明中,凡是提到Excel 97格式的地方其实都是指Excel从97到XP的格式。
二、HSSF概况
POI项目实现的Excel 97文件格式称为HSSF??也许你已经猜到,HSSF是Horrible SpreadSheet Format的缩写,也即“讨厌的电子表格格式”(微软使某些原本简单的事情过分复杂,同时又过分简单地处理了某些原本需要灵活性的事情,让人不胜佩服!)
也许HSSF的名字有点滑稽,就本质而言它是一个非常严肃、正规的API。通过HSSF,你可以用纯Java代码来读取、写入、修改Excel文件。
前面一篇文章提到了POIFS,那么HSSF和POIFS又有什么关系呢?就象其他POI的API一样,HSSF建立在POIFS的基础上,因此在HSSF内的有些代码和前文的某些代码很相似。不过,当我们编写基于HSSF API的代码时,一般不需要了解POIFS API的细节。
HSSF为读取操作提供了两类API:usermodel和eventusermodel,即“用户模型”和“事件-用户模型”。前者很好理解,后者比较抽象,但操作效率要高得多。usermodel主要有org.apache.poi.hssf.usermodel和org.apache.poi.hssf.eventusermodel包实现(在HSSF的早期版本中,org.apache.poi.hssf.eventusermodel属于eventmodel包)。
usermodel包把Excel文件映射成我们熟悉的结构,诸如Workbook、Sheet、Row、Cell等,它把整个结构以一组对象的形式保存在内存之中。eventusermodel要求用户熟悉文件格式的底层结构,它的操作风格类似于XML的SAX API和AWT的事件模型(这就是eventusermodel名称的起源),要掌握窍门才能用好。
另外,eventusermodel的API只提供读取文件的功能,也就是说不能用这个API来修改文件。
三、通过usermodel读取文件
用HSSF的usermodel读取文件很简单。首先创建一个InputStream,然后创建一个HSSFWorkbook:
InputStream myxls = new FileInputStream("workbook.xls"));
HSSFWorkbook wb = new HSSFWorkbook(myxls);
有了HSSFWorkbook实例,接下来就可以提取工作表、工作表的行和列,例如:
HSSFSheet sheet = wb.getSheetAt(0); // 第一个工作表
HSSFRow row = sheet.getRow(2); // 第三行
HSSFCell cell = row.getCell((short)3); // 第四个单元格
上面这段代码提取出第一个工作表第三行第四单元格。利用单元格对象可以获得它的值,提取单元格的值时请注意它的类型:
if (cell.getCellType() == HSSFCell.CELL_TYPE_STRING) {
("单元格是字符串,值是: " + cell.getStringCellValue());
} else if (cell.getCellType() == HSSFCell.CELL_TYPE_NUMERIC) {
("单元格是数字,值是: " + cell.getCellValue());
} else () {
("单元格的值不是字符串或数值。");
}
如果搞错了数据类型,程序将遇到异常。特别地,用HSSF处理日期数据要小心。Excel内部以数值的形式保存日期数据,区别日期数据的唯一办法是通过单元格的格式(如果你曾经在Excel中设置过日期格式,应该明白这是什么意思)。
因此,对于包含日期数据的单元格,cell.getCellType()将返回HSSFCell.CELL_TYPE_NUMERIC,不过利用工具函数HSSFDateUtil.isCellDateFormatted(cell)可以判断出单元格的值是否为日期。isCellDateFormatted函数通过比较单元格的日期和Excel的内置日期格式得出结论??可以想象,按照这种判断方法,很多时候isCellDateFormatted函数会返回否定的结论,存在一定的误判可能。
本文附录包含了一个在Servlet环境中利用HSSF创建和返回Excel工作簿的实例。
四、通过usermodel写入文件
写入XLS文件比读取XLS文件还要简单。创建一个HSSFWorkbook实例,然后在适当的时候创建一个把文件写入磁盘的OutputStream,但延迟到处理结束时创建OutputStream也可以:
HSSFWorkbook wb = new HSSFWorkbook();
FileOutputStream fileOut
= new FileOutputStream("workbook.xls");
wb.write(fileOut);
fileOut.close();
创建工作表及其内容必须从相应的父对象出发,例如:
HSSFSheet sheet = wb.createSheet();
HSSFRow row = sheet.createRow((short)0);
HSSFCell cell = row.createCell((short)0);
cell.setCellValue(1);
row.createCell((short)1).setCellValue(1.2);
row.createCell((short)2).setCellValue("一个字符串");
row.createCell((short)3).setCellValue(true);
如果要设置单元格的样式,首先要创建一个样式对象,然后把它指定给一个单元格??或者把它指定给多个具有相同样式的单元格,例如,如果Excel表格中有一个摘要行,摘要行的数据必须是粗体、斜体,你可以创建一个summaryRowStyle样式对象,然后把这个样式指定给所有摘要行上的单元格。
注意,CellFormat和CellStyle对象是工作簿对象的成员,单元格对象只是引用它们。
...
HSSFCellStyle style = workbook.createCellStyle();
style.setDataFormat
(HSSFDataFormat.getBuiltinFormat("($#,##0_);[Red]($#,##0)"));
style.setFillBackgroundColor(HSSFColor.AQUA.index);
style.setFillPattern(HSSFCellStyle.BIG_SPOTS);
...
someCell.setCellStyle(style);
someOtherCell.setCellStyle(style);
版本较新的HSSF允许使用数量有限的Excel公式。这一功能目前还是“Beta级质量”,正式使用之前务必仔细测试。指定公式的方式类如:someCell.setCellFormula(SUM(A1:A2:);。
当前,公式中已经可以调用所有内建的函数或操作符,但逻辑操作符和函数(例如IF函数)除外,这部分功能目前还在开发之中。
五、通过eventusermodel读取文件
通过eventusermodel读取文件要比使用usermodel复杂得多,但效率也要高不少,因为它要求应用程序一边读取数据,一边处理数据。
eventusermodel实际上模拟了DOM环境下SAX处理XML文档的办法,应用程序首先要注册期望处理的数据,eventusermodel将在遇到匹配的数据结构时回调应用程序注册的方法。使用eventusermodel最大的困难在于你必须熟悉Excel工作簿的内部结构。
在HSSF中,低层次的二进制结构称为记录(Record)。记录有不同的类型,每一种类型由org.apache.poi.hssf.record包中的一个Java类描述。例如,BOFRecord记录表示Workbook或Sheet区域的开始,RowRecord表示有一个行存在并保存其样式信息。
所有具有CellValueRecordInterface接口的记录表示Excel的单元格,包括NumericRecord、LabelSSTRecord和FormulaRecord(还有其他一些,其中部分已被弃置不用,部分用于优化处理,但一般而言,HSSF可以转换它们)。
下面是一个注册事件处理句柄的例子:
private EventRecordFactory factory = new EventRecordFactory();
factory.registerListener(new ERFListener() {
public boolean processRecord(Record rec) {
(got BOF Record);
return true;
}
}, new short[] {BOFRecord.sid});
factory.processRecords(someInputStream);
六、HSSF电子表格结构
如前所述,HSSF建立在POIFS的基础上。具体地说,Excel 97+文件是OLE 2复合文档( OLE 2 Compound Document),底层的OLE 2复合文档保存了一个总是命名为Workbook(Excel 95除外,HSSF不支持Excel 95)的流。
然而,宏和图片并不保存在Workbook流,它们有自己独立的流,有时甚至会放到OLE 2 CDF文件之内的另一个目录。理想情况下,宏也应该被保留,不过目前POI项目中还没有合适的API来处理宏。
每一个流之内是一组记录,一个记录其实就是一个字节数组,可分为记录头、记录体两部分。记录头指明了记录的类型(也即ID)以及后继数据的长度,记录体被分割成多个字段(Field),字段包含数值数据(包括对其他记录的引用)、字符数据或标记。
Excel工作簿的顶级结构:
Bla.xls {
OLE2CDF headers
"Workbook" stream {
Workbook {
Static String Table Record..
Sheet names… and pointers
}
Sheet {
ROW
ROW
…
NUMBER RECORD (cell)
LABELSST Record (cell)
…
}
Sheet
}
}
… images, macros, etc.
Document Summary
Summary
七、通过HPSF读取文档属性
在Microsoft Word、Excel、PowerPoint等软件中,用户可以通过“文件”→“属性”菜单给文档添加附加信息,包括文档的标题、主题、摘要、类别、关键词等,同时应用软件本身还会加入最后访问的用户、最后访问和修改/打印的日期时间等信息。
文档的属性和正文是分开保存的。如前所述,OLE 2 CDF文件内部就象是一个容器,里面包含许多类似目录和文件的结构,而POIFS就是用来访问其中的文件的工具。这些文件也称为流,文档的属性就保存在POIFS文件系统中专用的流里面。
以一个Word文档为例:虽然在资源管理器中你只看到一个叫做MyFile.doc的文档,其实在这个文档的内部,又包含了一个WordDocument、一个SummaryInformation和一个DocumentSummaryInformation文档;通常还会有其他的文档,这里暂且不管。
你能够猜出这些文档(流)分别包含什么内容吗?不错,WordDocument包含了你在Word里面编辑的文本,文档的属性保存在SummaryInformation和DocumentSummaryInformation流里面。也许将所有属性保存在单个文档里面看起来太简单了,所以Microsoft决心要使用两个流,为了使事情更复杂一点,这两个流的名字前面还加上了八进制的\005字符??这是一个不可打印的字符,因此前面就把它省略了。
Microsoft定义的标准属性有一个好处,它们并不在乎主文档到底是什么类型??不管是Word文档、Excel工作簿还是PowerPoint幻灯。只要你知道如何读取Excel文档的属性,就知道了如何读取其他文档的属性。
读取文档属性其实并不复杂,因为Java程序可以利用POI项目的HPSF包。HPSF是 Horrible Property Set Format的缩写,译成中文就是“讨厌的属性集格式”。HPSF包是POI项目实现的读取属性工具,目前还不支持属性写入。
对于读取Microsoft定义的标准属性,通过HPSF提供的API可以很方便地办到;但如果要读取任意属性集就要用到更一般化的API,可以想象它要比读取标准属性的API复杂不少。本文只介绍读取标准属性的简单API,因为对大多数应用程序来说这已经完全足够了。
下面就是一个读取OLE 2 CDF文档的标题(title)属性的Java程序:
import java.io.*;
import org.apache.poi.hpsf.*;
import org.apache.poi.poifs.eventfilesystem.*;
/**
* 读取OLE 2文档标题的示例程序,
* 在命令行参数中指定文档的文件名字。
*/
public class ReadTitle
{
public static void main(String[] args) throws IOException
{
final String filename = args[0];
POIFSReader r = new POIFSReader();
r.registerListener(new MyPOIFSReaderListener(),
"\005SummaryInformation");
r.read(new FileInputStream(filename));
}
static class MyPOIFSReaderListener
implements POIFSReaderListener
{
public void processPOIFSReaderEvent(POIFSReaderEvent event)
{
SummaryInformation si = null;
try
{
si = (SummaryInformation)
PropertySetFactory.create(event.getStream());
}
catch (Exception ex)
{
throw new RuntimeException
("属性集流\"" + event.getPath() +
event.getName() + "\": " + ex);
}
final String title = si.getTitle();
if (title != null)
System.out.println("标题: \"" + title + "\"");
else
System.out.println("该文档没有标题.");
}
}
}
main()方法利用POIFS的事件系统从命令行指定的OLE 2文档读取名为\005SummaryInformation的流,当POIFSReader 遇到这个流时,它把控制传递给MyPOIFSReaderListener的processPOIFSReaderEvent()方法。
processPOIFSReaderEvent()到底有什么用呢?它通过参数获得一个输入流,该输入流包含了文档标题等属性。为了访问文档的属性,我们从输入流创建一个PropertySet实例,如下所示:
si = (SummaryInformation) PropertySetFactory.create(event.getStream());
这个语句其实包含三个步骤的操作:
◆ event.getStream()从POIFSReader传入的POIFSReaderEvent获得输入流。
◆ 以刚才获得的输入流为参数,调用PropertySetFactory的静态方法create()。正如其名字所暗示的,PropertySetFactory是一个工厂类,它有一台“机器”能够把一个输入流转换成一个PropertySet实例,这台机器就是create()方法。
◆ 把create()方法返回的PropertySet定型(cast)成为SummaryInformation。PropertySet提供了按照一般办法读取属性集的各种机制,SummaryInformation是PropertySet的子类,即SummaryInformation类在PropertySet类的基础上增加了操作Microsoft标准属性的便捷方法。
在这个处理过程中,可能引起错误的因素很多,因此我们把这部分内容放入了一个try块,不过这个示例程序只按照最简单的方式处理了异常,在实际应用中,最好能够对可能出现的不同异常类型分别处理。
除了一般的I/O异常之外,还有可能遇到HPSF特有的异常,例如,如果输入流不包含属性集或属性集非法,就会抛出NoPropertySetStreamException异常。
有一种错误不太常见,但也不是绝无可能\005SummaryInformation包含一个合法的属性集,但不是摘要信息属性集。如果出现这种情况,则定型成SummaryInformation操作会失败,引发ClassCastException异常。
获得SummaryInformation实例之后,剩下的事情就很简单了,只要调用getTitle()方法,然后输出结果。
除了getTitle()之外,SummaryInformation还包含其他一些便捷方法,例如getApplicationName()、getAuthor()、getCharCount()、和getCreateDateTime()等。HPSF的JavaDoc文档详细说明了所有这些方法。
八、文档摘要信息
遗憾的是,并非所有的属性都保存在摘要信息属性集之中。许多(但不是全部)OLE 2文件还有另一个属性集,称为“文档摘要信息”,对应的流是\005DocumentSummaryInformation。这个属性集保存的属性包括文档的类别、PowerPoint幻灯的多媒体剪辑数量,等等。
要访问文档摘要信息属性集,程序的处理过程也和上例相似,只是注册的目标应该改成\005DocumentSummaryInformation有时,你可能想要同时注册到摘要信息和文档摘要信息这两个流。其余的处理方式和前面的例子差不多,你应该把包含文档摘要信息的流传递给PropertySetFactory.create(),但这次工厂方法将返回一个DocumentSummaryInformation对象(而不是前面例子中的SummaryInformation对象)。
如果同时注册到了两个流,注意检查返回值的具体类型,或者使用Java的instanceof操作符,或者使用专用的isSummaryInformation()和isDocumentSummaryInformation()方法。记住,create()方法返回的总是一个PropertySet对象,因此你总是可以对create()返回对象调用isSummaryInformation()和isDocumentSummaryInformation()方法,PropertySet类之所以要提供这两个方法,是因为属性集可能是自定义的。
如果你想要处理自定义的属性集,或者要从标准的属性集读取用户定义的属性,必须使用一个更一般化的API,前面已经提到,这个API要复杂得多,本文不再讨论,请参见HPSF的HOW-TO文档和POI的文档。
结束语:本文探讨了HSSF的应用以及如何输出到Excel文件,另外还涉及了HPSF以及如何读取属性集文档摘要信息。POI是一个功能非常强大的项目,许多主题本文尚未涉及,例如如何用HSSF Serializer将XML文档转换成Excel格式等,这一切仍有待您去研究了。
九、附录
实例:利用Servlet创建和返回一个工作簿。
package org.apache.poi.hssf.usermodel.examples;
import java.io.*;
import java.net.*;
import javax.servlet.*;
import javax.servlet.http.*;
import org.apache.poi.hssf.usermodel.*;
public class HSSFCreate extends HttpServlet {
public void init(ServletConfig config)
throws ServletException {
super.init(config);
}
public void destroy() {
}
/** 处理HTTP GET 和POST请求
* @param request:请求
* @param response:应答
*/
protected void processRequest(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("application/vnd.ms-excel");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("new sheet");
// 创建一个新的行,添加几个单元格。
// 行号从0开始计算
HSSFRow row = sheet.createRow((short)0);
// 创建一个单元格,设置单元格的值
HSSFCell cell = row.createCell((short)0);
cell.setCellValue(1);
row.createCell((short)1).setCellValue(1.2);
row.createCell((short)2).setCellValue("一个字符串值");
row.createCell((short)3).setCellValue(true);
// 写入输出结果
OutputStream out = response.getOutputStream();
wb.write(out);
out.close();
}
/** 处理HTTP GET请求
* @param request:请求
* @param response:应答
*/
protected void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
/** 处理HTTP POST请求
* @param request:请求
* @param response:应答
*/
protected void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
/** 返回关于Servlet的简单说明
*/
public String getServletInfo() {
return "示例:在Servlet中用HSSF创建Excel工作簿";
}
}
posted @
2006-09-09 11:45 xzc 阅读(415) |
评论 (0) |
编辑 收藏
本篇文章就举例示范如何利用Java 创建和读取Excel文档,并设置单元格的字体和格式。
为了保证示例程序的运行,必须安装Java 2 sdk1.4.0 和Jakarta POI,Jakarta POI的Web站点是: http://jakarta.apache.org/poi/
创建Excel 文档
示例1将演示如何利用Jakarta POI API 创建Excel 文档。
示例1程序如下:
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFCell;
import java.io.FileOutputStream;
public class CreateXL {
/** Excel 文件要存放的位置,假定在D盘JTest目录下*/
public static String outputFile="D:/JTest/ gongye.xls";
public static void main(String argv[]){
try{
// 创建新的Excel 工作簿
HSSFWorkbook workbook = new HSSFWorkbook();
// 在Excel工作簿中建一工作表,其名为缺省值
// 如要新建一名为"效益指标"的工作表,其语句为:
// HSSFSheet sheet = workbook.createSheet("效益指标");
HSSFSheet sheet = workbook.createSheet();
// 在索引0的位置创建行(最顶端的行)
HSSFRow row = sheet.createRow((short)0);
//在索引0的位置创建单元格(左上端)
HSSFCell cell = row.createCell((short) 0);
// 定义单元格为字符串类型
cell.setCellType(HSSFCell.CELL_TYPE_STRING);
// 在单元格中输入一些内容
cell.setCellValue("增加值");
// 新建一输出文件流
FileOutputStream fOut = new FileOutputStream(outputFile);
// 把相应的Excel 工作簿存盘
workbook.write(fOut);
fOut.flush();
// 操作结束,关闭文件
fOut.close();
System.out.println("文件生成...");
}catch(Exception e) {
System.out.println("已运行 xlCreate() : " + e );
}
}
}
读取Excel文档中的数据
示例2将演示如何读取Excel文档中的数据。假定在D盘JTest目录下有一个文件名为gongye.xls的Excel文件。
示例2程序如下:
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFCell;
import java.io.FileInputStream;
public class ReadXL {
/** Excel文件的存放位置。注意是正斜线*/
public static String fileToBeRead="D:/JTest/ gongye.xls";
public static void main(String argv[]){
try{
// 创建对Excel工作簿文件的引用
HSSFWorkbook workbook = new HSSFWorkbook(new FileInputStream(fileToBeRead));
// 创建对工作表的引用。
// 本例是按名引用(让我们假定那张表有着缺省名"Sheet1")
HSSFSheet sheet = workbook.getSheet("Sheet1");
// 也可用getSheetAt(int index)按索引引用,
// 在Excel文档中,第一张工作表的缺省索引是0,
// 其语句为:HSSFSheet sheet = workbook.getSheetAt(0);
// 读取左上端单元
HSSFRow row = sheet.getRow(0);
HSSFCell cell = row.getCell((short)0);
// 输出单元内容,cell.getStringCellValue()就是取所在单元的值
System.out.println("左上端单元是: " + cell.getStringCellValue());
}catch(Exception e) {
System.out.println("已运行xlRead() : " + e );
}
}
}
设置单元格格式
在这里,我们将只介绍一些和格式设置有关的语句,我们假定workbook就是对一个工作簿的引用。在Java中,第一步要做的就是创建和设置字体和单元格的格式,然后再应用这些格式:
1、创建字体,设置其为红色、粗体:
HSSFFont font = workbook.createFont();
font.setColor(HSSFFont.COLOR_RED);
font.setBoldweight(HSSFFont.BOLDWEIGHT_BOLD);
2、创建格式
HSSFCellStyle cellStyle= workbook.createCellStyle();
cellStyle.setFont(font);
3、应用格式
HSSFCell cell = row.createCell((short) 0);
cell.setCellStyle(cellStyle);
cell.setCellType(HSSFCell.CELL_TYPE_STRING);
cell.setCellValue("标题 ");
posted @
2006-09-09 11:44 xzc 阅读(255) |
评论 (0) |
编辑 收藏
结构化查询语言(Structured Query Language,简称SQL)是用来访问关系型数据库一种通用语言,它属于第四代语言(4GL),其执行特点是非过程化,即不用指明执行的具体方法和途径,而是简单的调用相应语句来直接取得结果即可。显然,这种不关注任何实现细节的语言对于开发者来说有着极大的便利。 然而,对于有些复杂的业务流程又要求相应的程序来描述,那么4GL就有些无能为力了。PL/SQL的出现正是为了解决这一问题,PL/SQL是一种过程化语言,属于第三代语言,它与C,C++,Java等语言一样关注于处理细节,因此可以用来实现比较复杂的业务逻辑。
本教程分两部分,第一部分主要对PL/SQL的编程基础进行讨论,第二部分结合一个案例来讲解PL/SQL编程。希望读者阅读本文后能够对PL/SQL编程有一个总体上的认识,为今后深入PL/SQL编程打下一个基础。
二、PL/SQL编程基础
掌握一门编程语言首要是要了解其基本的语法结构,即程序结构、数据类型、控制结构以及相应的内嵌函数(或编程接口)。
1、PL/SQL程序结构
PL/SQL程序都是以块(block)为基本单位。如下所示为一段完整的PL/SQL块:
/*声明部分,以declare开头*/
declare
v_id integer;
v_name varchar(20);
cursor c_emp is select * from employee where emp_id=3;
/*执行部分,以begin开头*/
begin
open c_emp; --打开游标
loop
fetch c_emp into v_id,v_name; --从游标取数据
exit when c_emp%notfound ;
end loop ;
close c_emp; --关闭游标
dbms_output.PUT_LINE(v_name);
/*异常处理部分,以exception开始*/
exception
when no_data_found then
dbms_output.PUT_LINE('没有数据');
end ; |
从上面的PL/SQL程序段看出,整个PL/SQL块分三部分:声明部分(用declare开头)、执行部分(以begin开头)和异常处理部分(以exception开头)。其中执行部分是必须的,其他两个部分可选。无论PL/SQL程序段的代码量有多大,其基本结构就是由这三部分组成。
2、变量声明与赋值
PL/SQL主要用于数据库编程,所以其所有数据类型跟oracle数据库里的字段类型是一一对应的,大体分为数字型、布尔型、字符型和日期型。为方便理解后面的例程,这里简单介绍两种常用数据类型:number、varchar2。
number
用来存储整数和浮点数。范围为1E-130 ~10E125,其使用语法为:
| number[(precision, scale)] |
其中(precision, scale)是可选的,precision表示所有数字的个数,scale表示小数点右边数字的个数。
varchar2
用来存储变长的字符串,其使用语法为:
其中size为可选,表示该字符串所能存储的最大长度。
在PL/SQL中声明变量与其他语言不太一样,它采用从右往左的方式声明,比如声明一个number类型的变量v_id,那其形式应为:
如果给上面的v_id变量赋值,不能用”=”应该用”:=”,即形式为:
3、控制结构
PL/SQL程序段中有三种程序结构:条件结构、循环结构和顺序结构。
条件结构
与其它语言完全类似,语法结构如下:
if condition then
statement1
else
statement2
end if ; |
循环结构
这一结构与其他语言不太一样,在PL/SQL程序中有三种循环结构:
a. loop … end loop;
b. while condition loop … end loop;
c. for variable in low_bound . . upper_bound loop … end loop; |
其中的“…”代表循环体。
顺序结构
实际就是goto的运用,不过从程序控制的角度来看,尽量少用goto可以使得程序结构更加的清晰。
4、SQL基本命令
PL/SQL使用的数据库操作语言还是基于SQL的,所以熟悉SQL是进行PL/SQL编程的基础。表1-1为SQL语言的分类。
表1-1 SQL语言分类
| 类别 | SQL语句 |
| 数据定义语言(DDL) | Create ,Drop,Grant,Revoke, … |
| 数据操纵语言(DML) | Update,Insert,Delete, … |
| 数据控制语言(DCL) | Commit,Rollback,Savapoint, … |
| 其他 | Alter System,Connect,Allocate, … |
可以参阅其他关于SQL语言的资料来了解具体的语法结构,这里就不多赘述了。
三、过程与函数
PL/SQL中的过程和函数与其他语言的过程和函数的概念一样,都是为了执行一定的任务而组合在一起的语句。过程无返回值,函数有返回值。其语法结构为:
过程:Create or replace procedure procname(参数列表) as PL/SQL语句块
函数:Create or replace function funcname(参数列表) return 返回值 as PL/SQL语句块
这里为了更为方面的说明过程的运用,下面给出一个示例:
问题:假设有一张表t1,有f1和f2两个字段,f1为number类型,f2为varchar2类型,然后往t1里写两条记录,内容自定。
Create or replace procedure test_procedure as
V_f11 number :=1; /*声明变量并赋初值*/
V_f12 number :=2;
V_f21 varchar2(20) :=’first’;
V_f22 varchar2(20) :=’second’;
Begin
Insert into t1 values (V_f11, V_f21);
Insert into t1 values (V_f12, V_f22);
End test_procedure; /*test_procedure可以省略*/ |
至此,test_procedure存储过程已经完成,然后经过编译后就可以在其他PL/SQL块或者过程中调用了。由于函数与过程具有很大的相似性,所以这里就不再重复了。
四、游标
这里特别提出游标的概念,是因为它在PL/SQL的编程中非常的重要。其定义为:用游标来指代一个DML SQL操作返回的结果集。即当一个对数据库的查询操作返回一组结果集时,用游标来标注这组结果集,以后通过对游标的操作来获取结果集中的数据信息。定义游标的语法结构如下:
| cursor cursor_name is SQL语句; |
在本文第一段代码中有一句话如下:
| cursor c_emp is select * from employee where emp_id=3; |
其含义嵌ㄒ逡桓鲇伪阠_emp,其代表着employee表中所有emp_id字段为3的结果集。当需要操作该结果集时,必须完成三步:打开游标、使用fetch语句将游标里的数据取出、关闭游标。请参照本文第一段代码的注释理解游标操作的三步骤。
五、其他概念
PL/SQL中包的概念很重要,主要是对一组功能相近的过程和函数进行封装,类似于面向对象中的名字空间的概念。
触发器是一种特殊的存储过程,其调用者比较特殊,是当发生特定的事件才被调用,主要用于多表之间的消息通知。
六、调试环境
PL/SQL的调试环境目前比较多,除了Oracle自带有调试环境Sql*plus以外,本人推荐TOAD这个工具,该工具用户界面友好,可以提高程序的编制效率。
本文主要讲解PL/SQL的基础部分,熟悉这部分内容后可以进行存储过程的编写和应用,对于提高数据库服务器端的执行效率很有帮助。
原载:http://www.yesky.com/SoftChannel/72342371928965120/20040913/1853193.shtml
posted @
2006-09-05 21:14 xzc 阅读(412) |
评论 (1) |
编辑 收藏
摘要:
JavaMail API是读取、撰写、发送电子信息的可选包。我们可用它来建立如Eudora、Foxmail、MS Outlook Express一般的邮件用户代理程序(Mail User Agent,简称MUA)。让我们看看JavaMail API是如何提供信息访问功能的吧!JavaMail API被设计用于以不依赖协议的方式去发送和接收电子信息,文中着重:如何以不依赖于协议的方式发送接收电子信息,这也是本文所要描述的.
作者:cleverpig(作者的Blog:
http://blog.matrix.org.cn/page/cleverpig)
原文:
http://www.matrix.org.cn/resource/article/44/44101_JavaMail.html关键字:java,mail,pop,smtp
一、JavaMail API简介JavaMail API是读取、撰写、发送电子信息的可选包。我们可用它来建立如Eudora、Foxmail、MS Outlook Express一般的邮件用户代理程序(Mail User Agent,简称MUA)。而不是像sendmail或者其它的邮件传输代理(Mail Transfer Agent,简称MTA)程序那样可以传送、递送、转发邮件。从另外一个角度来看,我们这些电子邮件用户日常用MUA程序来读写邮件,而MUA依赖着MTA处理邮件的递送。
在清楚了到MUA与MTA之间的关系后,让我们看看JavaMail API是如何提供信息访问功能的吧!JavaMail API被设计用于以不依赖协议的方式去发送和接收电子信息,这个API被分为两大部分:
基本功能:如何以不依赖于协议的方式发送接收电子信息,这也是本文所要描述的,不过在下文中,大家将看到这只是一厢情愿而已。
第二个部分则是依赖特定协议的,比如SMTP、POP、IMAP、NNTP协议。在这部分的JavaMail API是为了和服务器通讯,并不在本文的内容中。
二、相关协议一览在我们步入JavaMail API之前,先看一下API所涉及的协议。以下便是大家日常所知、所乐于使用的4大信息传输协议:
SMTP
POP
IMAP
MIME
当然,上面的4个协议,并不是全部,还有NNTP和其它一些协议可用于传输信息,但是由于不常用到,所以本文便不提及了。理解这4个基本的协议有助于我们更好的使用JavaMail API。然而JavaMail API是被设计为与协议无关的,目前我们并不能克服这些协议的束缚。确切的说,如果我们使用的功能并不被我们选择的协议支持,那么JavaMail API并不可能如魔术师一样神奇的赋予我们这种能力。
1.SMTP简单邮件传输协议定义了递送邮件的机制。在下文中,我们将使用基于Java-Mail的程序与公司或者ISP的SMTP服务器进行通讯。这个SMTP服务器将邮件转发到接收者的SMTP服务器,直至最后被接收者通过POP或者IMAP协议获取。这并不需要SMTP服务器使用支持授权的邮件转发,但是却的确要注意SMTP服务器的正确设置(SMTP服务器的设置与JavaMail API无关)。
2.POPPOP是一种邮局协议,目前为第3个版本,即众所周知的POP3。POP定义了一种用户如何获得邮件的机制。它规定了每个用户使用一个单独的邮箱。大多数人在使用POP时所熟悉的功能并非都被支持,例如查看邮箱中的新邮件数量。而这个功能是微软的Outlook内建的,那么就说明微软Outlook之类的邮件客户端软件是通过查询最近收到的邮件来计算新邮件的数量来实现前面所说的功能。因此在我们使用JavaMail API时需要注意,当需要获得如前面所讲的新邮件数量之类的信息时,我们不得不自己进行计算。
3.IMAPIMAP使用在接收信息的高级协议,目前版本为第4版,所以也被称为IMAP4。需要注意的是在使用IMAP时,邮件服务器必须支持该协议。从这个方面讲,我们并不能完全使用IMAP来替代POP,不能期待IMAP在任何地方都被支持。假如邮件服务器支持IMAP,那么我们的邮件程序将能够具有以下被IMAP所支持的特性:每个用户在服务器上可具有多个目录,这些目录能在多个用户之间共享。
其与POP相比高级之处显而易见,但是在尝试采取IMAP时,我们认识到它并不是十分完美的:由于IMAP需要从其它服务器上接收新信息,将这些信息递送给用户,维护每个用户的多个目录,这都为邮件服务器带来了高负载。并且IMAP与POP的一个不同之处是POP用户在接收邮件时将从邮件服务器上下载邮件,而IMAP允许用户直接访问邮件目录,所以在邮件服务器进行备份作业时,由于每个长期使用此邮件系统的用户所用的邮件目录会占有很大的空间,这将直接导致邮件服务器上磁盘空间暴涨。
4.MIMEMIME并不是用于传送邮件的协议,它作为多用途邮件的扩展定义了邮件内容的格式:信息格式、附件格式等等。一些RFC标准都涉及了MIME:RFC 822, RFC 2045, RFC 2046, RFC 2047,有兴趣的Matrixer可以阅读一下。而作为JavaMail API的开发者,我们并不需关心这些格式定义,但是这些格式被用在了程序中。
5.NNTP和其它的第三方协议正因为JavaMail API在设计时考虑到与第三方协议实现提供商之间的分离,故我们可以很容易的添加一些第三方协议。SUN维护着一个第三方协议实现提供商的列表:
http://java.sun.com/products/javamail/Third_Party.html,通过此列表我们可以找到所需要的而又不被SUN提供支持的第三方协议:比如NNTP这个新闻组协议和S/MIME这个安全的MIME协议。
三、安装1.安装JavaMail为了使用JavaMail API,需要从
http://java.sun.com/products/javamail/downloads/index.html下载文件名格式为javamail-[version].zip的文件(这个文件中包括了JavaMail实现),并将其中的mail.jar文件添加到CLASSPATH中。这个实现提供了对SMTP、IMAP4、POP3的支持。
注意:在安装JavaMail实现之后,我们将在demo目录中发现许多有趣的简单实例程序。
在安装了JavaMail之后,我们还需要安装JavaBeans Activation Framework,因为这个框架是JavaMail API所需要的。如果我们使用J2EE的话,那么我们并无需单独下载JavaMail,因为它存在于J2EE.jar中,只需将J2EE.jar加入到CLASSPATH即可。
2.安装JavaBeans Activation Framework从
http://java.sun.com/products/javabeans/glasgow/jaf.html下载JavaBeans Activation Framework,并将其添加到CLASSPATH中。此框架增加了对任何数据块的分类、以及对它们的处理的特性。这些特性是JavaMail API需要的。虽然听起来这些特性非常模糊,但是它对于我们的JavaMail API来说只是提供了基本的MIME类型支持。
到此为止,我们应当把mail.jar和activation.jar都添加到了CLASSPATH中。
当然如果从方便的角度讲,直接把这两个Jar文件复制到JRE目录的lib/ext目录中也可以。
四、初次认识JavaMail API1.了解我们的JavaMail环境A.纵览JavaMail核心类结构打开JavaMail.jar文件,我们将发现在javax.mail的包下面存在着一些核心类:Session、Message、Address、Authenticator、Transport、Store、Folder。而且在javax.mail.internet包中还有一些常用的子类。
B.SessionSession类定义了基本的邮件会话。就像Http会话那样,我们进行收发邮件的工作都是基于这个会话的。Session对象利用了java.util.Properties对象获得了邮件服务器、用户名、密码信息和整个应用程序都要使用到的共享信息。
Session类的构造方法是私有的,所以我们可以使用Session类提供的getDefaultInstance()这个静态工厂方法获得一个默认的Session对象:
Properties props = new Properties();
// fill props with any information
Session session = Session.getDefaultInstance(props, null);
或者使用getInstance()这个静态工厂方法获得自定义的Session:
Properties props = new Properties();
// fill props with any information
Session session = Session.getInstance(props, null);
从上面的两个例子中不难发现,getDefaultInstance()和getInstance()方法的第二个参数都是null,这是因为在上面的例子中并没有使用到邮件授权,下文中将对授权进行详细介绍。
从很多的实例看,在对mail server进行访问的过程中使用共享的Session是足够的,即使是工作在多个用户邮箱的模式下也不例外。
C.Message当我们建立了Session对象后,便可以被发送的构造信息体了。在这里SUN提供了Message类型来帮助开发者完成这项工作。由于Message是一个抽象类,大多数情况下,我们使用javax.mail.internet.MimeMessage这个子类,该类是使用MIME类型、MIME信息头的邮箱信息。信息头只能使用US-ASCII字符,而非ASCII字符将通过编码转换为ASCII的方式使用。
为了建立一个MimeMessage对象,我们必须将Session对象作为MimeMessage构造方法的参数传入:
MimeMessage message = new MimeMessage(session);
注意:对于MimeMessage类来讲存在着多种构造方法,比如使用输入流作为参数的构造方法。
在建立了MimeMessage对象后,我们需要设置它的各个part,对于MimeMessage类来说,这些part就是MimePart接口。最基本的设置信息内容的方法就是通过表示信息内容和米么类型的参数调用setContent()方法:
message.setContent("Hello", "text/plain");
然而,如果我们所使用的MimeMessage中信息内容是文本的话,我们便可以直接使用setText()方法来方便的设置文本内容。
message.setText("Hello");
前面所讲的两种方法,对于文本信息,后者更为合适。而对于其它的一些信息类型,比如HTML信息,则要使用前者。
别忘记了,使用setSubject()方法对邮件设置邮件主题:
message.setSubject("First");
D.Address到这里,我们已经建立了Session和Message,下面将介绍如何使用邮件地址类:Address。像Message一样,Address类也是一个抽象类,所以我们将使用javax.mail.internet.InternetAddress这个子类。
通过传入代表邮件地址的字符串,我们可以建立一个邮件地址类:
Address address = new InternetAddress("president@whitehouse.gov");
如果要在邮件地址后面增加名字的话,可以通过传递两个参数:代表邮件地址和名字的字符串来建立一个具有邮件地址和名字的邮件地址类:
Address address = new InternetAddress("president@whitehouse.gov", "George Bush");
本文在这里所讲的邮件地址类是为了设置邮件信息的发信人和收信人而准备的,在建立了邮件地址类后,我们通过message的setFrom()和setReplyTo()两种方法设置邮件的发信人:
message.setFrom(address);
message.setReplyTo(address);
若在邮件中存在多个发信人地址,我们可用addForm()方法增加发信人:
Address address[] = ...;
message.addFrom(address);
为了设置收信人,我们使用addRecipient()方法增加收信人,此方法需要使用Message.RecipientType的常量来区分收信人的类型:
message.addRecipient(type, address)
下面是Message.RecipientType的三个常量:
Message.RecipientType.TO
Message.RecipientType.CC
Message.RecipientType.BCC
因此,如果我们要发送邮件给总统,并发用一个副本给第一夫人的话,下面的方法将被用到:
Address toAddress = new InternetAddress("vice.president@whitehouse.gov");
Address ccAddress = new InternetAddress("first.lady@whitehouse.gov");
message.addRecipient(Message.RecipientType.TO, toAddress);
message.addRecipient(Message.RecipientType.CC, ccAddress);
JavaMail API并没有提供检查邮件地址有效性的机制。当然我们可以自己完成这个功能:验证邮件地址的字符是否按照RFC822规定的格式书写或者通过DNS服务器上的MX记录验证等。
E.Authenticator像java.net类那样,JavaMail API通过使用授权者类(Authenticator)以用户名、密码的方式访问那些受到保护的资源,在这里“资源”就是指邮件服务器。在javax.mail包中可以找到这个JavaMail的授权者类(Authenticator)。
在使用Authenticator这个抽象类时,我们必须采用继承该抽象类的方式,并且该继承类必须具有返回PasswordAuthentication对象(用于存储认证时要用到的用户名、密码)getPasswordAuthentication()方法。并且要在Session中进行注册,使Session能够了解在认证时该使用哪个类。
下面代码片断中的MyAuthenticator就是一个Authenticator的子类。
Properties props = new Properties();
// fill props with any information
Authenticator auth = new MyAuthenticator();
Session session = Session.getDefaultInstance(props, auth);
F.Transport在发送信息时,Transport类将被用到。这个类实现了发送信息的协议(通称为SMTP),此类是一个抽象类,我们可以使用这个类的静态方法send()来发送消息:
Transport.send(message);
当然,方法是多样的。我们也可由Session获得相应协议对应的Transport实例。并通过传递用户名、密码、邮件服务器主机名等参数建立与邮件服务器的连接,并使用sendMessage()方法将信息发送,最后关闭连接:
message.saveChanges(); // implicit with send()
Transport transport = session.getTransport("smtp");
transport.connect(host, username, password);
transport.sendMessage(message, message.getAllRecipients());
transport.close();
评论:上面的方法是一个很好的方法,尤其是在我们在同一个邮件服务器上发送多个邮件时。因为这时我们将在连接邮件服务器后连续发送邮件,然后再关闭掉连接。send()这个基本的方法是在每次调用时进行与邮件服务器的连接的,对于在同一个邮件服务器上发送多个邮件来讲可谓低效的方式。
注意:如果需要在发送邮件过程中监控mail命令的话,可以在发送前设置debug标志:
session.setDebug(true)。
G.Store和Folder接收邮件和发送邮件很类似都要用到Session。但是在获得Session后,我们需要从Session中获取特定类型的Store,然后连接到Store,这里的Store代表了存储邮件的邮件服务器。在连接Store的过程中,极有可能需要用到用户名、密码或者Authenticator。
// Store store = session.getStore("imap");
Store store = session.getStore("pop3");
store.connect(host, username, password);
在连接到Store后,一个Folder对象即目录对象将通过Store的getFolder()方法被返回,我们可从这个Folder中读取邮件信息:
Folder folder = store.getFolder("INBOX");
folder.open(Folder.READ_ONLY);
Message message[] = folder.getMessages();
上面的例子首先从Store中获得INBOX这个Folder(对于POP3协议只有一个名为INBOX的Folder有效),然后以只读(Folder.READ_ONLY)的方式打开Folder,最后调用Folder的getMessages()方法得到目录中所有Message的数组。
注意:对于POP3协议只有一个名为INBOX的Folder有效,而对于IMAP协议,我们可以访问多个Folder(想想前面讲的IMAP协议)。而且SUN在设计Folder的getMessages()方法时采取了很智能的方式:首先接收新邮件列表,然后再需要的时候(比如读取邮件内容)才从邮件服务器读取邮件内容。
在读取邮件时,我们可以用Message类的getContent()方法接收邮件或是writeTo()方法将邮件保存,getContent()方法只接收邮件内容(不包含邮件头),而writeTo()方法将包括邮件头。
System.out.println(((MimeMessage)message).getContent());
在读取邮件内容后,别忘记了关闭Folder和Store。
folder.close(aBoolean);
store.close();
传递给Folder.close()方法的boolean 类型参数表示是否在删除操作邮件后更新Folder。
H.继续向前进!在讲解了以上的七个Java Mail核心类定义和理解了简单的代码片断后,下文将详细讲解怎样使用这些类实现JavaMail API所要完成的高级功能。
五、使用JavaMail API在明确了JavaMail API的核心部分如何工作后,本人将带领大家学习一些使用Java Mail API任务案例。
1.发送邮件在获得了Session后,建立并填入邮件信息,然后发送它到邮件服务器。这便是使用Java Mail API发送邮件的过程,在发送邮件之前,我们需要设置SMTP服务器:通过设置Properties的mail.smtp.host属性。
String host = ...;
String from = ...;
String to = ...;
// Get system properties
Properties props = System.getProperties();
// Setup mail server
props.put("mail.smtp.host", host);
// Get session
Session session = Session.getDefaultInstance(props, null);
// Define message
MimeMessage message = new MimeMessage(session);
message.setFrom(new InternetAddress(from));
message.addRecipient(Message.RecipientType.TO,
new InternetAddress(to));
message.setSubject("Hello JavaMail");
message.setText("Welcome to JavaMail");
// Send message
Transport.send(message);
由于建立邮件信息和发送邮件的过程中可能会抛出异常,所以我们需要将上面的代码放入到try-catch结构块中。
2.接收邮件为了在读取邮件,我们获得了session,并且连接到了邮箱的相应store,打开相应的Folder,然后得到我们想要的邮件,当然别忘记了在结束时关闭连接。
String host = ...;
String username = ...;
String password = ...;
// Create empty properties
Properties props = new Properties();
// Get session
Session session = Session.getDefaultInstance(props, null);
// Get the store
Store store = session.getStore("pop3");
store.connect(host, username, password);
// Get folder
Folder folder = store.getFolder("INBOX");
folder.open(Folder.READ_ONLY);
// Get directory
Message message[] = folder.getMessages();
for (int i=0, n=message.length; i<n; i++) {
System.out.println(i + ": " + message[i].getFrom()[0]
+ "\t" + message[i].getSubject());
}
// Close connection
folder.close(false);
store.close();
上面的代码所作的是从邮箱中读取每个邮件,并且显示邮件的发信人地址和主题。从技术角度讲,这里存在着一个异常的可能:当发信人地址为空时,getFrom()[0]将抛出异常。
下面的代码片断有效的说明了如何读取邮件内容,在显示每个邮件发信人和主题后,将出现用户提示从而得到用户是否读取该邮件的确认,如果输入YES的话,我们可用Message.writeTo(java.io.OutputStream os)方法将邮件内容输出到控制台上,关于Message.writeTo()的具体用法请看JavaMail API。
BufferedReader reader = new BufferedReader (
new InputStreamReader(System.in));
// Get directory
Message message[] = folder.getMessages();
for (int i=0, n=message.length; i<n; i++) {
System.out.println(i + ": " + message[i].getFrom()[0]
+ "\t" + message[i].getSubject());
System.out.println("Do you want to read message? " +
"[YES to read/QUIT to end]");
String line = reader.readLine();
if ("YES".equals(line)) {
message[i].writeTo(System.out);
} else if ("QUIT".equals(line)) {
break;
}
}
3.删除邮件和标志设置与message相关的Flags是删除邮件的常用方法。这些Flags表示了一些系统定义和用户定义的不同状态。在Flags类的内部类Flag中预定义了一些标志:
Flags.Flag.ANSWERED
Flags.Flag.DELETED
Flags.Flag.DRAFT
Flags.Flag.FLAGGED
Flags.Flag.RECENT
Flags.Flag.SEEN
Flags.Flag.USER
但需要在使用时注意的:标志存在并非意味着这个标志被所有的邮件服务器所支持。例如,对于删除邮件的操作,POP协议不支持上面的任何一个。所以要确定哪些标志是被支持的——通过访问一个已经打开的Folder对象的getPermanetFlags()方法,它将返回当前被支持的Flags类对象。
删除邮件时,我们可以设置邮件的DELETED标志:
message.setFlag(Flags.Flag.DELETED, true);
但是首先要采用READ_WRITE的方式打开Folder:
folder.open(Folder.READ_WRITE);
在对邮件进行删除操作后关闭Folder时,需要传递一个true作为对删除邮件的擦除确认。
folder.close(true);
Folder类中另一种用于删除邮件的方法expunge()也同样可删除邮件,但是它并不为sun提供的POP3实现支持,而其它第三方提供的POP3实现支持或者并不支持这种方法。
另外,介绍一种检查某个标志是否被设置的方法:Message.isSet(Flags.Flag flag)方法,其中参数为被检查的标志。
4.邮件认证我们在前面已经学会了如何使用Authenticator类来代替直接使用用户名和密码这两字符串作为Session.getDefaultInstance()或者Session.getInstance()方法的参数。在前面的小试牛刀后,现在我们将了解到全面认识一下邮件认证。
我们在此取代了直接使用邮件服务器主机名、用户名、密码这三个字符串作为连接到POP3 Store的方式,使用存储了邮件服务器主机名信息的属性文件,并在获得Session时传入自定义的Authenticator实例:
// Setup properties
Properties props = System.getProperties();
props.put("mail.pop3.host", host);
// Setup authentication, get session
Authenticator auth = new PopupAuthenticator();
Session session = Session.getDefaultInstance(props, auth);
// Get the store
Store store = session.getStore("pop3");
store.connect();
PopupAuthenticator类继承了抽象类Authenticator,并且通过重载Authenticator类的getPasswordAuthentication()方法返回PasswordAuthentication类对象。而getPasswordAuthentication()方法的参数param是以逗号分割的用户名、密码组成的字符串。
import javax.mail.*;
import java.util.*;
public class PopupAuthenticator extends Authenticator {
public PasswordAuthentication getPasswordAuthentication(String param) {
String username, password;
StringTokenizer st = new StringTokenizer(param, ",");
username = st.nextToken();
password = st.nextToken();
return new PasswordAuthentication(username, password);
}
}
5.回复邮件回复邮件的方法很简单:使用Message类的reply()方法,通过配置回复邮件的收件人地址和主题(如果没有提供主题的话,系统将默认将“Re:”作为邮件的主体),这里不需要设置任何的邮件内容,只要复制发信人或者reply-to到新的收件人。而reply()方法中的boolean参数表示是否将邮件回复给发送者(参数值为false),或是恢复给所有人(参数值为true)。
补充一下,reply-to地址需要在发信时使用setReplyTo()方法设置。
MimeMessage reply = (MimeMessage)message.reply(false);
reply.setFrom(new InternetAddress("president@whitehouse.gov"));
reply.setText("Thanks");
Transport.send(reply);
6.转发邮件转发邮件的过程不如前面的回复邮件那样简单,它将建立一个转发邮件,这并非一个方法就能做到。
每个邮件是由多个部分组成,每个部分称为一个邮件体部分,是一个BodyPart类对象,对于MIME类型邮件来讲就是MimeBodyPart类对象。这些邮件体包含在成为Multipart的容器中对于MIME类型邮件来讲就是MimeMultiPart类对象。在转发邮件时,我们建立一个文字邮件体部分和一个被转发的文字邮件体部分,然后将这两个邮件体放到一个Multipart中。说明一下,复制一个邮件内容到另一个邮件的方法是仅复制它的DataHandler(数据处理者)即可。这是由JavaBeans Activation Framework定义的一个类,它提供了对邮件内容的操作命令的访问、管理了邮件内容操作,是不同的数据源和数据格式之间的一致性接口。
// Create the message to forward
Message forward = new MimeMessage(session);
// Fill in header
forward.setSubject("Fwd: " + message.getSubject());
forward.setFrom(new InternetAddress(from));
forward.addRecipient(Message.RecipientType.TO,
new InternetAddress(to));
// Create your new message part
BodyPart messageBodyPart = new MimeBodyPart();
messageBodyPart.setText(
"Here you go with the original message:\n\n");
// Create a multi-part to combine the parts
Multipart multipart = new MimeMultipart();
multipart.addBodyPart(messageBodyPart);
// Create and fill part for the forwarded content
messageBodyPart = new MimeBodyPart();
messageBodyPart.setDataHandler(message.getDataHandler());
// Add part to multi part
multipart.addBodyPart(messageBodyPart);
// Associate multi-part with message
forward.setContent(multipart);
// Send message
Transport.send(forward);
7.使用附件附件作为与邮件相关的资源经常以文本、表格、图片等格式出现,如流行的邮件客户端一样,我们可以用JavaMail API从邮件中获取附件或是发送带有附件的邮件。
A.发送带有附件的邮件发送带有附件的邮件的过程有些类似转发邮件,我们需要建立一个完整邮件的各个邮件体部分,在第一个部分(即我们的邮件内容文字)后,增加一个具有DataHandler的附件而不是在转发邮件时那样复制第一个部分的DataHandler。
如果我们将文件作为附件发送,那么要建立FileDataSource类型的对象作为附件数据源;如果从URL读取数据作为附件发送,那么将要建立URLDataSource类型的对象作为附件数据源。
然后将这个数据源(FileDataSource或是URLDataSource)对象作为DataHandler类构造方法的参数传入,从而建立一个DataHandler对象作为数据源的DataHandler。
接着将这个DataHandler设置为邮件体部分的DataHandler。这样就完成了邮件体与附件之间的关联工作,下面的工作就是BodyPart的setFileName()方法设置附件名为原文件名。
最后将两个邮件体放入到Multipart中,设置邮件内容为这个容器Multipart,发送邮件。
// Define message
Message message = new MimeMessage(session);
message.setFrom(new InternetAddress(from));
message.addRecipient(Message.RecipientType.TO,
new InternetAddress(to));
message.setSubject("Hello JavaMail Attachment");
// Create the message part
BodyPart messageBodyPart = new MimeBodyPart();
// Fill the message
messageBodyPart.setText("Pardon Ideas");
Multipart multipart = new MimeMultipart();
multipart.addBodyPart(messageBodyPart);
// Part two is attachment
messageBodyPart = new MimeBodyPart();
DataSource source = new FileDataSource(filename);
messageBodyPart.setDataHandler(new DataHandler(source));
messageBodyPart.setFileName(filename);
multipart.addBodyPart(messageBodyPart);
// Put parts in message
message.setContent(multipart);
// Send the message
Transport.send(message);
如果我们使用servlet实现发送带有附件的邮件,则必须上传附件给servlet,这时需要注意提交页面form中对编码类型的设置应为multipart/form-data。
<FORM ENCTYPE="multipart/form-data"
method=post action="/myservlet">
<INPUT TYPE="file" NAME="thefile">
<INPUT TYPE="submit" VALUE="Upload">
</FORM>
B.读取邮件中的附件读取邮件中的附件的过程要比发送它的过程复杂一点。因为带有附件的邮件是多部分组成的,我们必须处理每一个部分获得邮件的内容和附件。
但是如何辨别邮件信息内容和附件呢?Sun在Part类(BodyPart类实现的接口类)中提供了getDisposition()方法让开发者获得邮件体部分的部署类型,当该部分是附件时,其返回之将是Part.ATTACHMENT。但附件也可以没有部署类型的方式存在或者部署类型为Part.INLINE,无论部署类型为Part.ATTACHMENT还是Part.INLINE,我们都能把该邮件体部分导出保存。
Multipart mp = (Multipart)message.getContent();
for (int i=0, n=multipart.getCount(); i<n; i++) {
Part part = multipart.getBodyPart(i));
String disposition = part.getDisposition();
if ((disposition != null) &&
((disposition.equals(Part.ATTACHMENT) ||
(disposition.equals(Part.INLINE))) {
saveFile(part.getFileName(), part.getInputStream());
}
}
下列代码中使用了saveFile方法是自定义的方法,它根据附件的文件名建立一个文件,如果本地磁盘上存在名为附件的文件,那么将在文件名后增加数字表示区别。然后从邮件体中读取数据写入到本地文件中(代码省略)。
// from saveFile()
File file = new File(filename);
for (int i=0; file.exists(); i++) {
file = new File(filename+i);
}
以上是邮件体部分被正确设置的简单例子,如果邮件体部分的部署类型为null,那么我们通过获得邮件体部分的MIME类型来判断其类型作相应的处理,代码结构框架如下:
if (disposition == null) {
// Check if plain
MimeBodyPart mbp = (MimeBodyPart)part;
if (mbp.isMimeType("text/plain")) {
// Handle plain
} else {
// Special non-attachment cases here of
// image/gif, text/html, ...
}
...
}
8.处理HTML邮件前面的例子中发送的邮件都是以文本为内容的(除了附件),下面将介绍如何接收和发送基于HTML的邮件。
A.发送HTML邮件假如我们需要发送一个HTML文件作为邮件内容,并使邮件客户端在读取邮件时获取相关的图片或者文字的话,只要设置邮件内容为html代码,并设置内容类型为text/html即可:
String htmlText = "<H1>Hello</H1>" +
"<img src=\"http://www.jguru.com/images/logo.gif\">";
message.setContent(htmlText, "text/html"));
请注意:这里的图片并不是在邮件中内嵌的,而是在URL中定义的。邮件接收者只有在线时才能看到。
在接收邮件时,如果我们使用JavaMail API接收邮件的话是无法实现以HTML方式显示邮件内容的。因为JavaMail API邮件内容视为二进制流。所以要显示HTML内容的邮件,我们必须使用JEditorPane或者第三方HTML展现组件。
以下代码显示了如何使用JEditorPane显示邮件内容:
if (message.getContentType().equals("text/html")) {
String content = (String)message.getContent();
JFrame frame = new JFrame();
JEditorPane text = new JEditorPane("text/html", content);
text.setEditable(false);
JScrollPane pane = new JScrollPane(text);
frame.getContentPane().add(pane);
frame.setSize(300, 300);
frame.setDefaultCloseOperation(JFrame.DISPOSE_ON_CLOSE);
frame.show();
}
B.在邮件中包含图片如果我们在邮件中使用HTML作为内容,那么最好将HTML中使用的图片作为邮件的一部分,这样无论是否在线都会正确的显示HTML中的图片。处理方法就是将HTML中用到的图片作为邮件附件并使用特殊的cid URL作为图片的引用,这个cid就是对图片附件的Content-ID头的引用。
处理内嵌图片就像向邮件中添加附件一样,不同之处在于我们必须通过设置图片附件所在的邮件体部分的header中Content-ID为一个随机字符串,并在HTML中img的src标记中设置为该字符串。这样就完成了图片附件与HTML的关联。
String file = ...;
// Create the message
Message message = new MimeMessage(session);
// Fill its headers
message.setSubject("Embedded Image");
message.setFrom(new InternetAddress(from));
message.addRecipient(Message.RecipientType.TO,
new InternetAddress(to));
// Create your new message part
BodyPart messageBodyPart = new MimeBodyPart();
String htmlText = "<H1>Hello</H1>" +
"<img src=\"cid:memememe\">";
messageBodyPart.setContent(htmlText, "text/html");
// Create a related multi-part to combine the parts
MimeMultipart multipart = new MimeMultipart("related");
multipart.addBodyPart(messageBodyPart);
// Create part for the image
messageBodyPart = new MimeBodyPart();
// Fetch the image and associate to part
DataSource fds = new FileDataSource(file);
messageBodyPart.setDataHandler(new DataHandler(fds));
messageBodyPart.setHeader("Content-ID","<memememe>");
// Add part to multi-part
multipart.addBodyPart(messageBodyPart);
// Associate multi-part with message
message.setContent(multipart);
9.在邮件中搜索短语JavaMail API提供了过滤器机制,它被用来建立搜索短语。这个短语由javax.mail.search包中的SearchTerm抽象类来定义,在定义后我们便可以使用Folder的Search()方法在Folder中查找邮件:
SearchTerm st = ...;
Message[] msgs = folder.search(st);
下面有22个不同的类(继承了SearchTerm类)供我们使用:
AND terms (class AndTerm)
OR terms (class OrTerm)
NOT terms (class NotTerm)
SENT DATE terms (class SentDateTerm)
CONTENT terms (class BodyTerm)
HEADER terms (FromTerm / FromStringTerm, RecipientTerm / RecipientStringTerm, SubjectTerm, etc.)
使用这些类定义的断语集合,我们可以构造一个逻辑表达式,并在Folder中进行搜索。下面是一个实例:在Folder中搜索邮件主题含有“ADV”字符串或者发信人地址为friend@public.com的邮件。
SearchTerm st =
new OrTerm(
new SubjectTerm("ADV:"),
new FromStringTerm("friend@public.com"));
Message[] msgs = folder.search(st);
六、参考资源JavaMail API HomeSun’s JavaMail API基础JavaBeans Activation Framework Homejavamail-interest mailing listSun's JavaMail FAQjGuru's JavaMail FAQThird Party Products List七、代码下载http://java.sun.com/developer/onlineTraining/JavaMail/exercises.html
posted @
2006-09-04 17:12 xzc 阅读(211) |
评论 (0) |
编辑 收藏
摘要:
本文描述了apache commons中的commons loggings部分,Commons Logging和Log4J用来提供日志支持。
介绍
命令行参数解析、应用程序配置和日志记录,作为一个应用程序的骨架,随处可见。因此,Apache软件组织开发出了一套通用的类库,用来帮助软件开发人员完成这些“骨架”的建立。其中:
•Commons CLI用于命令行解析
•Commons Configuration用于读取properties格式或者XML格式的配置信息
•Commons Logging和Log4J用来提供日志支持。
这些通用的类库都在http://jakarta.apache.org/commons/index.html网址上提供下载
Apache组织开发了一套用于支持Logging的Log4J,Java 1.4版本也引入了一套内置的Logging框架,如果开发者想在这两套Logging系统之间自由的切换,该怎么办呢?答案就是,使用Commons Logging。Commons Logging定义了一套抽象的Logging接口,用户可以通过配置,使这些接口指向任何一个已存在的Logging系统。
•使用抽象Logging接口问题:
你在编写一个可以重复使用的库,需要写入Log信息,但你不想使你的Logging功能绑定在Apache Log4J或者JDK 1.4 Logging框架上。
解决方案:
public static void main(String[] args) {//自己替换[]
System.setProperty("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.Jdk14Logger");
Log log = LogFactory.getLog("com.discursive.jccook.SomeApp");
if (log.isTraceEnabled()) {
log.trace("This is a trace message");
}
if (log.isDebugEnabled()) {
log.debug("This is a debug message");
}
log.info("This is an informational message");
log.warn("This is a warning");
log.error("This is an error");
log.fatal("This is fatal");
}
LogFactory.getLog方法会根据底层环境返回一个适当的Log实现。如果用户想指定一个具体的Logging系统实现,可以设置org.apache.commons.logging.Log系统属性。例如:
System.setProperty("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.Log4JLogger");
这样就会使用Log4J作为Logging系统。
org.apache.commons.logging.Log可以设定为:
•org.apache.commons.logging.impl.Log4JLogger 使用Log4J
•org.apache.commons.logging.impl.Jdk14Logger 使用JDK 1.4 Logging框架
•org.apache.commons.logging.impl.SimpleLog 使用Commons Logging内置的简单Log实现
其他:
总结一下,Commons Logging会按照下列顺序来指定具体的Log实现。
•如果定义了org.apache.commons.logging.Log系统参数,实用指定的Logging实现。
•如果在CLASSPATH里发现了Log4J,使用Log4J。
•如果使用的是JDK1.4,使用JDK1.4内置的Logging框架。
•如果都没有找到,则使用Commons Logging内置的简单Log实现。
Jakarta Commons Logging学习笔记 转载
1、Commons-Loggin简介
Jakarta Commons Logging (JCL)提供的是一个日志(Log)接口(interface),同时兼顾轻量级和不依赖于具体的日志实现工具。 它提供给中间件/日志工具开发者一个简单的日志操作抽象,允许程序开发人员使用不同的具体日志实现工具。用户被假定已熟悉某种日志实现工具的更高级别的细节。JCL提供的接口,对其它一些日志工具,包括Log4J, Avalon LogKit, and JDK 1.4等,进行了简单的包装,此接口更接近于Log4J和LogKit的实现.
2、快速入门
JCL有两个基本的抽象类:Log(基本记录器)和LogFactory(负责创建Log实例)。当commons-logging.jar被加入到CLASSPATH之后,它会心可能合理地猜测你喜欢的日志工具,然后进行自我设置,用户根本不需要做任何设置。默认的LogFactory是按照下列的步骤去发现并决定那个日志工具将被使用的(按照顺序,寻找过程会在找到第一个工具时中止):
寻找当前factory中名叫org.apache.commons.logging.Log配置属性的值
寻找系统中属性中名叫org.apache.commons.logging.Log的值
如果应用程序的classpath中有log4j,则使用相关的包装(wrapper)类(Log4JLogger)
如果应用程序运行在jdk1.4的系统中,使用相关的包装类(Jdk14Logger)
使用简易日志包装类(SimpleLog)
3、开发使用logging
//在程序文件头部import相关的类
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
......
//在类中获取一个实例
public class MYCLASS
{
private static Log log = LogFactory.getLog(MyCLASS.class);
...
}
日志信息被送往记录器,如上例中的log。这个发送过程,是通过调用Log接口中定义的方法完成的,不同方法跟不同的级别联系在一起,日志信息通过哪个级别的方法发送,就标明了日志信息的级别。org.apache.commons.logging.Log接口中定义的方法,按严重性由高到低的顺序有:
log.fatal(Object message);
log.fatal(Object message, Throwable t);
log.error(Object message);
log.error(Object message, Throwable t);
log.warn(Object message);
log.warn(Object message, Throwable t);
log.info(Object message);
log.info(Object message, Throwable t);
log.debug(Object message);
log.debug(Object message, Throwable t);
log.trace(Object message);
log.trace(Object message, Throwable t);
除此以外,还提供下列方法以便代码保护.
log.isFatalEnabled();
log.isErrorEnabled();
log.isWarnEnabled();
log.isInfoEnabled();
log.isDebugEnabled();
log.isTraceEnabled();
信息级别
确保日志信息在内容上和反应问题的严重程度上的恰当,是非常重要的。
fatal非常严重的错误,导致系统中止。期望这类信息能立即显示在状态控制台上。
error其它运行期错误或不是预期的条件。期望这类信息能立即显示在状态控制台上。
warn使用了不赞成使用的API、非常拙劣使用API, '几乎就是'错误, 其它运行时不合需要和不合预期的状态但还没必要称为 "错误"。期望这类信息能立即显示在状态控制台上。
info运行时产生的有意义的事件。期望这类信息能立即显示在状态控制台上。
debug系统流程中的细节信息。期望这类信息仅被写入log文件中。
trace更加细节的信息。期望这类信息仅被写入log文件中。
通常情况下,记录器的级别不应低于info.也就是说,通常情况下debug的信息不应被写入log文件中。
工作机理
生命周期
JCL LogFactory必须实现建立/断开到日志工具的连接,实例化/初始化/解构一个日志工具.
异常处理
JCL Log 接口没有指定任何异常处理,对接口的实现必须捕获并处理异常。
多线程
JCL Log 和 LogFactory 的实现,必须确保任何日志工具对并行的要求.
记录器的设置
JCL采用的记录器的不同其设置内容也不同。Log4J是默认首选记录器,对其设置可通过系统属性(system properties)或一个属性文件进行设置,下面是其设置参数。
<table border="1"><tr><td>参数</td><td>值域</td><td>默认值</td><td>说明</td></tr><tr><td>log4j.configuration</td><td></td><td>log4j.properties</td><td>指定配置文件的名字</td></tr><tr><td>log4j.rootCategory</td><td>priority [, appender]*</td><td></td><td>设定根记录器的级别</td></tr><tr><td>log4j.logger<.logger.name></td><td>DEBUG, INFO, WARN, ERROR, or FATAL</td><td>设定logger.name这个记录器的级别</td></tr><tr><td>log4j.appender<.appender>.Threshold</td><td>priority</td><td>指定记录设备appender(console, files, sockets, and others)的最低级别。</td></tr></table><br />
posted @
2006-09-04 00:48 xzc 阅读(915) |
评论 (0) |
编辑 收藏 一、定义配置文件
其实您也可以完全不使用配置文件,而是在代码中配置Log4j环境。但是,使用配置文件将使您的应用程序更加灵活。Log4j支持两种配置文件格式,一种是XML格式的文件,一种是Java特性文件(键=值)。下面我们介绍使用Java特性文件做为配置文件的方法:
1.配置根Logger,其语法为:
log4j.rootLogger = [ level ] , appenderName, appenderName, …
其中,level 是日志记录的优先级,分为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL或者您定义的级别。Log4j建议只使用四个级别,优先级从高到低分别是ERROR、WARN、INFO、DEBUG。通过在这里定义的级别,您可以控制到应用程序中相应级别的日志信息的开关。比如在这里定义了INFO级别,则应用程序中所有DEBUG级别的日志信息将不被打印出来。 appenderName就是指定日志信息输出到哪个地方。您可以同时指定多个输出目的地。
2.配置日志信息输出目的地Appender,其语法为:
log4j.appender.appenderName = fully.qualified.name.of.appender.class
log4j.appender.appenderName.option1 = value1
…
log4j.appender.appenderName.option = valueN
其中,Log4j提供的appender有以下几种:
org.apache.log4j.ConsoleAppender(控制台),
org.apache.log4j.FileAppender(文件),
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件),
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
3.配置日志信息的格式(布局),其语法为:
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
log4j.appender.appenderName.layout.option1 = value1
…
log4j.appender.appenderName.layout.option = valueN
其中,Log4j提供的layout有以下几种:
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
Log4J采用类似C语言中的printf函数的打印格式格式化日志信息,打印参数如下:
%m 输出代码中指定的消息
%n 输出一个回车换行符,Windows平台为“\r\n”,Unix平台为“\n”
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
%r 输出自应用启动到输出该log信息耗费的毫秒数
%c 输出所属的类目,通常就是所在类的全名
%t 输出产生该日志事件的线程名
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,
比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。
举例:Testlog4.main(TestLog4.java:10)
%F 类目名
%L 代码中的行数
二、在代码中使用Log4j
1.得到记录器
使用Log4j,第一步就是获取日志记录器,这个记录器将负责控制日志信息。其语法为:
public static Logger getLogger( String name)
通过指定的名字获得记录器,如果必要的话,则为这个名字创建一个新的记录器。Name一般取本类的名字,比如:
static Logger logger = Logger.getLogger ( ServerWithLog4j.class.getName () )
2.读取配置文件
当获得了日志记录器之后,第二步将配置Log4j环境,其语法为:
BasicConfigurator.configure (): 自动快速地使用缺省Log4j环境。
PropertyConfigurator.configure ( String configFilename) :读取使用Java的特性文件编写的配置文件。
DOMConfigurator.configure ( String filename ) :读取XML形式的配置文件。
3.插入记录信息(格式化日志信息)
当上两个必要步骤执行完毕,您就可以轻松地使用不同优先级别的日志记录语句插入到您想记录日志的任何地方,其语法如下:
Logger.debug ( Object message ) ;
Logger.info ( Object message ) ;
Logger.warn ( Object message ) ;
Logger.error ( Object message ) ;
介绍
命令行参数解析、应用程序配置和日志记录,作为一个应用程序的骨架,随处可见。因此,Apache软件组织开发出了一套通用的类库,用来帮助软件开发人员完成这些“骨架”的建立。其中:
•Commons CLI用于命令行解析
•Commons Configuration用于读取properties格式或者XML格式的配置信息
•Commons Logging和Log4J用来提供日志支持。
这些通用的类库都在http://jakarta.apache.org/commons/index.html网址上提供下载
Log4J是一个高度可配置的Logging框架,提供了结构化,多种目标和格式支持。
•配置Log4J
问题:
Log4J支持Properties和XML两种格式的配置文件。
解决方案:
定义log4j.properties配置文件
# 所有Log信息输出到标准输出(System.out)和在下面指定的一个文件
# WARN是默认的logging级别
log4j.rootCategory = WARN, STDOUT, FILE
# 应用程序的logging级别是DEBUG
log4j.logger.com.discursive = DEBUG
# 配置标准输出Appender
log4j.appender.STDOUT = org.apache.log4j.ConsoleAppender
log4j.appender.STDOUT.layout = org.apache.log4j.PatternLayout
log4j.appender.STDOUT.layout.ConversionPattern = %5p (%F:%L) %m%n
# 配置输出文件Appender
log4j.appender.FILE = org.apache.log4j.RollingFileAppender
log4j.appender.FILE.File = output.log
log4j.appender.FILE.MaxFileSize = 2000KB
log4j.appender.FILE.MaxBackupIndex = 5
log4j.appender.FILE.layout = org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern = %d %-5p %c - %m%n
PropertyConfigurator.configure(getClass()
.getResource("/resources/log4j.properties"));
Logger logger = Logger.getLogger("com.discursive.SomeApp");
logger.info("This is a info message");
logger.error("This is a error message");
使用BasicConfigurator类来加载log4j.properties配置。使用Logger.getLogger获得一个logger实例。
配置文件中的rootCategory指定将log输出到控制台和output.log文件。文件Appender使用了RollingFileAppender,当文件大小达到最大文件大小(MaxFileSize)2000KB时,RollingFileAppender会备份原log文件,并再创建一个新的log文件。
配置文件指定默认的logging级别是DEBUG(log4j.logger.com.discursive = DEBUG)。所以,所有级别低于DEBUG的log信息都不会被输出。Log4J按重要度定义了五个log级别,分别是:DEBUG, INFO, WARN, ERROR, 和FATAL。
其他:
Log4J还可以使用XML格式的配置文件,使用DOMConfigurator读取。
Log4J使用Appender和Layout来定制log输出。Appender指定输出到何处,Layout指定如何输出(输出的格式)。
Log4J内置的Appender有:
•SMTPAppender
•RollingFileAppender
•SocketAppender
•SyslogAppender
•NTEventLogAppender
Log4J支持的Layout有
•XMLLayout
•PatternLayout
•HTMLLayout
•DateLayout.
附1
# 所有Log信息输出到标准输出(System.out)和在下面指定的一个文件
# WARN是默认的logging级别
log4j.rootCategory = INFO, STDOUT
#log4j.rootCategory = INFO, STDOUT, FILE
# 配置标准输出Appender
log4j.appender.STDOUT = org.apache.log4j.ConsoleAppender
log4j.appender.STDOUT.layout = org.apache.log4j.PatternLayout
log4j.appender.STDOUT.layout.ConversionPattern = %d{ABSOLUTE} %-5p [%c:%L] %m%n
# 配置输出文件Appender
log4j.appender.FILE = org.apache.log4j.RollingFileAppender
log4j.appender.FILE.File = output.log
log4j.appender.FILE.MaxFileSize = 2000KB
log4j.appender.FILE.MaxBackupIndex = 5
log4j.appender.FILE.layout = org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern = %d %-5p [%c:%L] %m%n
# 应用程序的logging级别是DEBUG
log4j.logger.com.xzc = DEBUG
附2
### direct log messages to stdout ###
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - <%m>%n
### direct messages to file hibernate.log ###
#log4j.appender.file=org.apache.log4j.FileAppender
#log4j.appender.file.File=hibernate.log
#log4j.appender.file.layout=org.apache.log4j.PatternLayout
#log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### set log levels - for more verbose logging change 'info' to 'debug' ###
log4j.rootLogger=warn, stdout
log4j.logger.net.sf.hibernate=warn
### log just the SQL
#log4j.logger.net.sf.hibernate.SQL=debug
### log JDBC bind parameters ###
log4j.logger.net.sf.hibernate.type=info
### log schema export/update ###
log4j.logger.net.sf.hibernate.tool.hbm2ddl=debug
### log cache activity ###
#log4j.logger.net.sf.hibernate.cache=debug
### enable the following line if you want to track down connection ###
### leakages when using DriverManagerConnectionProvider ###
#log4j.logger.net.sf.hibernate.connection.DriverManagerConnectionProvider=trace
附3
log4j.rootLogger=debug, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
# Pattern to output the caller's file name and line number.
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=example.log
log4j.appender.R.MaxFileSize=100KB
# Keep one backup file
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
附4
# Log4j由三个重要的组件构成:日志信息的优先级,日志信息的输出目的地,日志信息的输出格式
# 1.配置根Logger,其语法为:
# log4j.rootLogger = [ level ] , appenderName, appenderName, …
# 2.配置日志信息输出目的地Appender,其语法为:
# log4j.appender.appenderName = fully.qualified.name.of.appender.class
# log4j.appender.appenderName.option1 = value1
# …
# log4j.appender.appenderName.option = valueN
# Log4j提供的appender有以下几种:
# org.apache.log4j.ConsoleAppender(控制台),
# org.apache.log4j.FileAppender(文件),
# org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),
# org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件),
# org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
# 3.配置日志信息的格式(布局),其语法为:
# log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
# log4j.appender.appenderName.layout.option1 = value1
# …
# log4j.appender.appenderName.layout.option = valueN
# Log4j提供的layout有以下几种:
# org.apache.log4j.HTMLLayout(以HTML表格形式布局),
# org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
# org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
# org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
# Log4J采用类似C语言中的printf函数的打印格式格式化日志信息,打印参数如下:
# %m 输出代码中指定的消息
# %n 输出一个回车换行符,Windows平台为“\r\n”,Unix平台为“\n”
# %p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
# %r 输出自应用启动到输出该log信息耗费的毫秒数
# %c 输出所属的类目,通常就是所在类的全名
# %t 输出产生该日志事件的线程名
# %d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,
# 比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
# %l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。
# 举例:Testlog4.main(TestLog4.java:10)
# %F 类目名
# %L 代码中的行数
# 所有Log信息输出到标准输出(System.out)和在下面指定的一个文件
# 日志信息的优先级从从高到低有ERROR、WARN、INFO、DEBUG
# WARN是默认的logging级别
log4j.rootCategory = INFO, STDOUT
#log4j.rootCategory = INFO, STDOUT, FILE
#log4j.rootCategory = INFO, STD
# 配置标准输出Appender
log4j.appender.STDOUT = org.apache.log4j.ConsoleAppender
log4j.appender.STDOUT.layout = org.apache.log4j.PatternLayout
#log4j.appender.STDOUT.layout.ConversionPattern = %d{ABSOLUTE} %-5p [%c:%t:%L] %m%n
log4j.appender.STDOUT.layout.ConversionPattern = %d{ABSOLUTE} %-5p [ %l ] %m%n
# 配置输出文件Appender
log4j.appender.FILE = org.apache.log4j.RollingFileAppender
log4j.appender.FILE.File = output.log
log4j.appender.FILE.MaxFileSize = 2000KB
log4j.appender.FILE.MaxBackupIndex = 5
log4j.appender.FILE.layout = org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern = %d %-5p [%c:%L] %m%n
# 配置默认输出layout
log4j.appender.STD = org.apache.log4j.ConsoleAppender
log4j.appender.STD.layout = org.apache.log4j.TTCCLayout
# 应用程序的logging级别是DEBUG
log4j.logger.com.xzc = DEBUG
posted @
2006-09-04 00:42 xzc 阅读(8292) |
评论 (4) |
编辑 收藏
Java提供了两类主要的异常:runtime exception和checked exception。所有的checked exception是从java.lang.Exception类衍生出来的,而runtime exception则是从java.lang.RuntimeException或java.lang.Error类衍生出来的。
它们的不同之处表现在两方面:机制上和逻辑上。
一、机制上
它们在机制上的不同表现在两点:1.如何定义方法;2. 如何处理抛出的异常。请看下面CheckedException的定义:
public class CheckedException extends Exception
{
public CheckedException() {}
public CheckedException( String message )
{
super( message );
}
} |
以及一个使用exception的例子:
public class ExceptionalClass
{
public void method1()
throws CheckedException
{
// ... throw new CheckedException( "...出错了" );
}
public void method2( String arg )
{
if( arg == null )
{
throw new NullPointerException( "method2的参数arg是null!" );
}
}
public void method3() throws CheckedException
{
method1();
}
}
|
你可能已经注意到了,两个方法method1()和method2()都会抛出exception,可是只有method1()做了声明。另外,method3()本身并不会抛出exception,可是它却声明会抛出CheckedException。在向你解释之前,让我们先来看看这个类的main()方法:
public static void main( String[] args )
{
ExceptionalClass example = new ExceptionalClass();
try
{
example.method1();
example.method3();
}
catch( CheckedException ex ) { } example.method2( null );
} |
在main()方法中,如果要调用method1(),你必须把这个调用放在try/catch程序块当中,因为它会抛出Checked exception。
相比之下,当你调用method2()时,则不需要把它放在try/catch程序块当中,因为它会抛出的exception不是checked exception,而是runtime exception。会抛出runtime exception的方法在定义时不必声明它会抛出exception。
现在,让我们再来看看method3()。它调用了method1()却没有把这个调用放在try/catch程序块当中。它是通过声明它会抛出method1()会抛出的exception来避免这样做的。它没有捕获这个exception,而是把它传递下去。实际上main()方法也可以这样做,通过声明它会抛出Checked exception来避免使用try/catch程序块(当然我们反对这种做法)。
小结一下:
* Runtime exceptions:
在定义方法时不需要声明会抛出runtime exception;
在调用这个方法时不需要捕获这个runtime exception;
runtime exception是从java.lang.RuntimeException或java.lang.Error类衍生出来的。
* Checked exceptions:
定义方法时必须声明所有可能会抛出的checked exception;
在调用这个方法时,必须捕获它的checked exception,不然就得把它的exception传递下去;
checked exception是从java.lang.Exception类衍生出来的。
二、逻辑上
从逻辑的角度来说,checked exceptions和runtime exception是有不同的使用目的的。checked exception用来指示一种调用方能够直接处理的异常情况。而runtime exception则用来指示一种调用方本身无法处理或恢复的程序错误。
checked exception迫使你捕获它并处理这种异常情况。以java.net.URL类的构建器(constructor)为例,它的每一个构建器都会抛出MalformedURLException。MalformedURLException就是一种checked exception。设想一下,你有一个简单的程序,用来提示用户输入一个URL,然后通过这个URL去下载一个网页。如果用户输入的URL有错误,构建器就会抛出一个exception。既然这个exception是checked exception,你的程序就可以捕获它并正确处理:比如说提示用户重新输入。
再看下面这个例子:
public void method()
{
int [] numbers = { 1, 2, 3 };
int sum = numbers[0] + numbers[3];
} |
在运行方法method()时会遇到ArrayIndexOutOfBoundsException(因为数组numbers的成员是从0到2)。对于这个异常,调用方无法处理/纠正。这个方法method()和上面的method2()一样,都是runtime exception的情形。上面我已经提到,runtime exception用来指示一种调用方本身无法处理/恢复的程序错误。而程序错误通常是无法在运行过程中处理的,必须改正程序代码。
总而言之,在程序的运行过程中一个checked exception被抛出的时候,只有能够适当处理这个异常的调用方才应该用try/catch来捕获它。而对于runtime exception,则不应当在程序中捕获它。如果你要捕获它的话,你就会冒这样一个风险:程序代码的错误(bug)被掩盖在运行当中无法被察觉。因为在程序测试过程中,系统打印出来的调用堆栈路径(StackTrace)往往使你更快找到并修改代码中的错误。有些程序员建议捕获runtime exception并纪录在log中,我反对这样做。这样做的坏处是你必须通过浏览log来找出问题,而用来测试程序的测试系统(比如Unit Test)却无法直接捕获问题并报告出来。
在程序中捕获runtime exception还会带来更多的问题:要捕获哪些runtime exception?什么时候捕获?runtime exception是不需要声明的,你怎样知道有没有runtime exception要捕获?你想看到在程序中每一次调用方法时,都使用try/catch程序块吗?
--------------附加程序-------------------------
public class Junk {
// public static void main(String args[]) {
// try {
// a();
// } catch(HighLevelException e) {
// e.printStackTrace();
// }
// }
public static void main(String args[]) {
try {
a();
} catch(Exception e) {
e.printStackTrace();
System.out.println("-------------------------");
System.out.println(e.getMessage());
}
}
static void a() throws HighLevelException {
try {
b();
} catch(MidLevelException e) {
throw new HighLevelException(e);
}
}
static void b() throws MidLevelException {
c();
}
static void c() throws MidLevelException {
try {
d();
} catch(LowLevelException e) {
throw new MidLevelException(e);
}
}
static void d() throws LowLevelException {
e();
}
static void e() throws LowLevelException {
throw new LowLevelException("e throw exception!");
}
}
class HighLevelException extends Exception {
HighLevelException(Throwable cause) { super(cause); }
HighLevelException(String message,Throwable cause) {
super(message,cause);
}
}
class MidLevelException extends Exception {
MidLevelException(Throwable cause) { super(cause); }
MidLevelException(String message,Throwable cause) {
super(message,cause);
}
}
class LowLevelException extends Exception {
public LowLevelException(){
}
public LowLevelException(String message){
super(message);
}
}
posted @
2006-08-24 21:08 xzc 阅读(227) |
评论 (0) |
编辑 收藏posted @
2006-08-24 10:37 xzc 阅读(8521) |
评论 (6) |
编辑 收藏文档对象模型(Document Object Model,DOM)是用于操纵 XML 和 HTML 数据的最常用工具之一,然而它的潜力却很少被充分挖掘出来。通过利用 DOM 的优势,并使它更加易用,您将获得一款应用于 XML 应用程序(包括动态 Web 应用程序)的强大工具。
本期文章介绍了一位客串的专栏作家,同时也是我的朋友和同事 Dethe Elza。Dethe 在利用 XML 进行 Web 应用程序开发方面经验丰富,在此,我要感谢他对我在介绍使用 DOM 和 ECMAScript 进行 XML 编程这一方面的帮助。请密切关注本专栏,以了解 Dethe 的更多专栏文章。 —— David Mertz
DOM 是处理 XML 和 HTML 的标准 API 之一。由于它占用内存大、速度慢,并且冗长,所以经常受到人们的指责。尽管如此,对于很多应用程序来说,它仍然是最佳选择,而且比 XML 的另一个主要 API —— SAX 无疑要简单得多。DOM 正逐渐出现在一些工具中,比如 Web 浏览器、SVG 浏览器、OpenOffice,等等。
DOM 很好,因为它是一种标准,并且被广泛地实现,同时也内置到其他标准中。作为标准,它对数据的处理与编程语言无关(这可能是优点,也可能是缺点,但至少使我们处理数据的方式变得一致)。DOM 现在不仅内置于 Web 浏览器,而且也成为许多基于 XML 的规范的一部分。既然它已经成为您的工具的一部分,并且或许您偶尔还会使用它,我想现在应该充分利用它给我们带来的功能了。
在使用 DOM 一段时间后,您会看到形成了一些模式 —— 您想要反复做的事情。快捷方式可以帮助您处理冗长的 DOM,并创建自解释的、优雅的代码。这里收集了一些我经常使用的技巧和诀窍,还有一些 JavaScript 示例。
insertAfter 和 prependChild
第一个诀窍就是“没有诀窍”。DOM 有两种方法将孩子节点添加到容器节点(常常是一个 Element,也可能是一个 Document 或 DocumentFragment):appendChild(node) 和 insertBefore(node, referenceNode)。看起来似乎缺少了什么。假如我想在一个参考节点后面插入或者由前新增(prepend)一个子节点(使新节点位于列表中的第一位),我该怎么做呢?很多年以来,我的解决方法是编写下列函数:
清单 1. 插入和由前新增的错误方法
function insertAfter(parent, node, referenceNode) {
if(referenceNode.nextSibling) {
parent.insertBefore(node, referenceNode.nextSibling);
} else {
parent.appendChild(node);
}
}
function prependChild(parent, node) {
if (parent.firstChild) {
parent.insertBefore(node, parent.firstChild);
} else {
parent.appendChild(node);
}
}
|
实际上,像清单 1 一样,insertBefore() 函数已经被定义为,在参考节点为空时返回到 appendChild()。因此,您可以不使用上面的方法,而使用 清单 2 中的方法,或者跳过它们仅使用内置函数:
清单 2. 插入和由前新增的正确方法
function insertAfter(parent, node, referenceNode) {
parent.insertBefore(node, referenceNode.nextSibling);
}
function prependChild(parent, node) {
parent.insertBefore(node, parent.firstChild);
}
|
如果您刚刚接触 DOM 编程,有必要指出的是,虽然您可以使多个指针指向一个节点,但该节点只能存在于 DOM 树中的一个位置。因此,如果您想将它插入到树中,没必要先将它从树中移除,因为它会自动被移除。当重新将节点排序时,这种机制很方便,仅需将节点插入到新位置即可。
根据这种机制,若想交换两个相邻节点(称为 node1 和 node2)的位置,可以使用下列方案之一:
node1.parentNode.insertBefore(node2, node1);
node1.parentNode.insertBefore(node2, node1);
|
或
node1.parentNode.insertBefore(node1.nextSibling, node1);
node1.parentNode.insertBefore(node1.nextSibling, node1);
|
还可以使用 DOM 做什么?
Web 页面中大量应用了 DOM。若访问 bookmarklets 站点(参阅 参考资料),您会发现很多有创意的简短脚本,它们可以重新编排页面,提取链接,隐藏图片或 Flash 广告,等等。
但是,因为 Internet Explorer 没有定义 Node 接口常量(可以用于识别节点类型),所以您必须确保在遗漏接口常量时,首先为 Web 在 DOM 脚本中定义接口常量。
清单 3. 确保节点被定义
if (!window['Node']) {
window.Node = new Object();
Node.ELEMENT_NODE = 1;
Node.ATTRIBUTE_NODE = 2;
Node.TEXT_NODE = 3;
Node.CDATA_SECTION_NODE = 4;
Node.ENTITY_REFERENCE_NODE = 5;
Node.ENTITY_NODE = 6;
Node.PROCESSING_INSTRUCTION_NODE = 7;
Node.COMMENT_NODE = 8;
Node.DOCUMENT_NODE = 9;
Node.DOCUMENT_TYPE_NODE = 10;
Node.DOCUMENT_FRAGMENT_NODE = 11;
Node.NOTATION_NODE = 12;
}
|
清单 4
展示如何提取包含在节点中的所有文本节点:
清单 4. 内部文本
function innerText(node) {
// is this a text or CDATA node?
if (node.nodeType == 3 || node.nodeType == 4) {
return node.data;
}
var i;
var returnValue = [];
for (i = 0; i < node.childNodes.length; i++) {
returnValue.push(innerText(node.childNodes[i]));
}
return returnValue.join('');
}
|
快捷方式
人们常常抱怨 DOM 太过冗长,并且简单的功能也需要编写大量代码。例如,如果您想创建一个包含文本并响应点击按钮的 <div> 元素,代码可能类似于:
清单 5. 创建 <div> 的“漫长之路”
function handle_button() {
var parent = document.getElementById('myContainer');
var div = document.createElement('div');
div.className = 'myDivCSSClass';
div.id = 'myDivId';
div.style.position = 'absolute';
div.style.left = '300px';
div.style.top = '200px';
var text = "This is the first text of the rest of this code";
var textNode = document.createTextNode(text);
div.appendChild(textNode);
parent.appendChild(div);
}
|
若频繁按照这种方式创建节点,键入所有这些代码会使您很快疲惫不堪。必须有更好的解决方案 —— 确实有这样的解决方案!下面这个实用工具可以帮助您创建元素、设置元素属性和风格,并添加文本子节点。除了 name 参数,其他参数都是可选的。
清单 6. 函数 elem() 快捷方式
function elem(name, attrs, style, text) {
var e = document.createElement(name);
if (attrs) {
for (key in attrs) {
if (key == 'class') {
e.className = attrs[key];
} else if (key == 'id') {
e.id = attrs[key];
} else {
e.setAttribute(key, attrs[key]);
}
}
}
if (style) {
for (key in style) {
e.style[key] = style[key];
}
}
if (text) {
e.appendChild(document.createTextNode(text));
}
return e;
}
|
使用该快捷方式,您能够以更加简洁的方法创建 清单 5 中的 <div> 元素。注意,attrs 和 style 参数是使用 JavaScript 文本对象而给出的。
清单 7. 创建 <div> 的简便方法
function handle_button() {
var parent = document.getElementById('myContainer');
parent.appendChild(elem('div',
{class: 'myDivCSSClass', id: 'myDivId'}
{position: 'absolute', left: '300px', top: '200px'},
'This is the first text of the rest of this code'));
}
|
在您想要快速创建大量复杂的 DHTML 对象时,这种实用工具可以节省您大量的时间。模式在这里就是指,如果您有一种需要频繁创建的特定的 DOM 结构,则使用实用工具来创建它们。这不但减少了您编写的代码量,而且也减少了重复的剪切、粘贴代码(错误的罪魁祸首),并且在阅读代码时思路更加清晰。
接下来是什么?
DOM 通常很难告诉您,按照文档的顺序,下一个节点是什么。下面有一些实用工具,可以帮助您在节点间前后移动:
清单 8. nextNode 和 prevNode
// return next node in document order
function nextNode(node) {
if (!node) return null;
if (node.firstChild){
return node.firstChild;
} else {
return nextWide(node);
}
}
// helper function for nextNode()
function nextWide(node) {
if (!node) return null;
if (node.nextSibling) {
return node.nextSibling;
} else {
return nextWide(node.parentNode);
}
}
// return previous node in document order
function prevNode(node) {
if (!node) return null;
if (node.previousSibling) {
return previousDeep(node.previousSibling);
}
return node.parentNode;
}
// helper function for prevNode()
function previousDeep(node) {
if (!node) return null;
while (node.childNodes.length) {
node = node.lastChild;
}
return node;
}
|
轻松使用 DOM
有时候,您可能想要遍历 DOM,在每个节点调用函数或从每个节点返回一个值。实际上,由于这些想法非常具有普遍性,所以 DOM Level 2 已经包含了一个称为 DOM Traversal and Range 的扩展(为迭代 DOM 所有节点定义了对象和 API),它用来为 DOM 中的所有节点应用函数和在 DOM 中选择一个范围。因为这些函数没有在 Internet Explorer 中定义(至少目前是这样),所以您可以使用 nextNode() 来做一些类似的事情。
在这里,我们的想法是创建一些简单、普通的工具,然后以不同的方式组装它们来达到预期的效果。如果您很熟悉函数式编程,这看起来会很亲切。Beyond JS 库(参阅 参考资料)将此理念发扬光大。
清单 9. 函数式 DOM 实用工具
// return an Array of all nodes, starting at startNode and
// continuing through the rest of the DOM tree
function listNodes(startNode) {
var list = new Array();
var node = startNode;
while(node) {
list.push(node);
node = nextNode(node);
}
return list;
}
// The same as listNodes(), but works backwards from startNode.
// Note that this is not the same as running listNodes() and
// reversing the list.
function listNodesReversed(startNode) {
var list = new Array();
var node = startNode;
while(node) {
list.push(node);
node = prevNode(node);
}
return list;
}
// apply func to each node in nodeList, return new list of results
function map(list, func) {
var result_list = new Array();
for (var i = 0; i < list.length; i++) {
result_list.push(func(list[i]));
}
return result_list;
}
// apply test to each node, return a new list of nodes for which
// test(node) returns true
function filter(list, test) {
var result_list = new Array();
for (var i = 0; i < list.length; i++) {
if (test(list[i])) result_list.push(list[i]);
}
return result_list;
}
|
清单 9 包含了 4 个基本工具。listNodes() 和 listNodesReversed() 函数可以扩展到一个可选的长度,这与 Array 的 slice() 方法效果类似,我把这个作为留给您的练习。另一个需要注意的是,map() 和 filter() 函数是完全通用的,用于处理任何 列表(不只是节点列表)。现在,我向您展示它们的几种组合方式。
清单 10. 使用函数式实用工具
// A list of all the element names in document order
function isElement(node) {
return node.nodeType == Node.ELEMENT_NODE;
}
function nodeName(node) {
return node.nodeName;
}
var elementNames = map(filter(listNodes(document),isElement), nodeName);
// All the text from the document (ignores CDATA)
function isText(node) {
return node.nodeType == Node.TEXT_NODE;
}
function nodeValue(node) {
return node.nodeValue;
}
var allText = map(filter(listNodes(document), isText), nodeValue);
|
您可以使用这些实用工具来提取 ID、修改样式、找到某种节点并移除,等等。一旦 DOM Traversal and Range API 被广泛实现,您无需首先构建列表,就可以用它们修改 DOM 树。它们不但功能强大,并且工作方式也与我在上面所强调的方式类似。
DOM 的危险地带
注意,核心 DOM API 并不能使您将 XML 数据解析到 DOM,或者将 DOM 序列化为 XML。这些功能都定义在 DOM Level 3 的扩展部分“Load and Save”,但它们还没有被完全实现,因此现在不要考虑这些。每个平台(浏览器或其他专业 DOM 应用程序)有自己在 DOM 和 XML 间转换的方法,但跨平台转换不在本文讨论范围之内。
DOM 并不是十分安全的工具 —— 特别是使用 DOM API 创建不能作为 XML 序列化的树时。绝对不要在同一个程序中混合使用 DOM1 非名称空间 API 和 DOM2 名称空间感知的 API(例如,createElement 和 createElementNS)。如果您使用名称空间,请尽量在根元素位置声明所有名称空间,并且不要覆盖名称空间前缀,否则情况会非常混乱。一般来说,只要按照惯例,就不会触发使您陷入麻烦的临界情况。
如果您一直使用 Internet Explorer 的 innerText 和 innerHTML 进行解析,那么您可以试试使用 elem() 函数。通过构建类似的一些实用工具,您会得到更多便利,并且继承了跨平台代码的优越性。将这两种方法混合使用是非常糟糕的。
某些 Unicode 字符并没有包含在 XML 中。DOM 的实现使您可以添加它们,但后果是无法序列化。这些字符包括大多数的控制字符和 Unicode 代理对(surrogate pair)中的单个字符。只有您试图在文档中包含二进制数据时才会遇到这种情况,但这是另一种转向(gotcha)情况。
结束语
我已经介绍了 DOM 能做的很多事情,但是 DOM(和 JavaScript)可以做的事情远不止这些。仔细研究、揣摩这些例子,看看是如何使用它们来解决可能需要客户端脚本、模板或专用 API 的问题。
DOM 有自己的局限性和缺点,但同时也拥有众多优点:它内置于很多应用程序中;无论使用 Java 技术、Python 或 JavaScript,它都以相同方式工作;它非常便于使用 SAX;使用上述的模板,它使用起来既简洁又强大。越来越多的应用程序开始支持 DOM,这包括基于 Mozilla 的应用程序、OpenOffice 和 Blast Radius 的 XMetaL。越来越多的规范需要 DOM,并对它加以扩展(例如,SVG),因此 DOM 时时刻刻就在您的身边。使用这种被广泛部署的工具,绝对是您的明智之举。
参考资料
posted @
2006-08-22 15:21 xzc 阅读(315) |
评论 (0) |
编辑 收藏
(1)<script defer>
function SetPrintSettings() {
// -- advanced features
factory.printing.SetMarginMeasure(2) // measure margins in inches
factory.SetPageRange(false, 1, 3) // need pages from 1 to 3
factory.printing.printer = "HP DeskJet 870C"
factory.printing.copies = 2
factory.printing.collate = true
factory.printing.paperSize = "A4"
factory.printing.paperSource = "Manual feed"
// -- basic features
factory.printing.header = "This is MeadCo"
factory.printing.footer = "Advanced Printing by scriptX"
factory.printing.portrait = false
factory.printing.leftMargin = 1.0
factory.printing.topMargin = 1.0
factory.printing.rightMargin = 1.0
factory.printing.bottomMargin = 1.0
}
</script>
(2)
<script language="javascript">
function printsetup(){
// 打印页面设置
wb.execwb(8,1);
}
function printpreview(){
// 打印页面预览
wb.execwb(7,1);
}
function printit()
{
if (confirm(''确定打印吗?'')) {
wb.execwb(6,6)
}
}
</script>
</head>
<body>
<OBJECT classid="CLSID:8856F961-340A-11D0-A96B-00C04FD705A2"
height=0 id=wb name=wb width=0></OBJECT>
<input type=button name=button_print value="打印"
onclick="javascript:printit()">
<input type=button name=button_setup value="打印页面设置"
onclick="javascript:printsetup();">
<input type=button name=button_show value="打印预览"
onclick="javascript:printpreview();">
<input type=button name=button_fh value="关闭"
onclick="javascript:window.close();">
------------------------------------------------
关于这个组件还有其他的用法,列举如下:
WebBrowser.ExecWB(1,1) 打开
Web.ExecWB(2,1) 关闭现在所有的IE窗口,并打开一个新窗口
Web.ExecWB(4,1) 保存网页
Web.ExecWB(6,1) 打印
Web.ExecWB(7,1) 打印预览
Web.ExecWB(8,1) 打印页面设置
Web.ExecWB(10,1) 查看页面属性
Web.ExecWB(15,1) 好像是撤销,有待确认
Web.ExecWB(17,1) 全选
Web.ExecWB(22,1) 刷新
Web.ExecWB(45,1) 关闭窗体无提示
2、分页打印
<HTML>
<HEAD>
<STYLE>
P {page-break-after: always}
</STYLE>
</HEAD>
<BODY>
<%while not rs.eof%>
<P><%=rs(0)%></P>
<%rs.movenext%>
<%wend%>
</BODY>
</HTML>
3、ASP页面打印时如何去掉页面底部的路径和顶端的页码编号
(1)ie的文件-〉页面设置-〉讲里面的页眉和页脚里面的东西都去掉,打印就不出来了。
(2)<HTML>
<HEAD>
<TITLE> New Document </TITLE>
<META NAME="Generator" CONTENT="EditPlus">
<META NAME="Author" CONTENT="YC">
<script language="VBscript">
dim hkey_root,hkey_path,hkey_key
hkey_root="HKEY_CURRENT_USER"
hkey_path="\Software\Microsoft\Internet Explorer\PageSetup"
''//设置网页打印的页眉页脚为空
function pagesetup_null()
on error resume next
Set RegWsh = CreateObject("Wscript.Shell")
hkey_key="\header"
RegWsh.RegWrite hkey_root+hkey_path+hkey_key,""
hkey_key="\footer"
RegWsh.RegWrite hkey_root+hkey_path+hkey_key,""
end function
''//设置网页打印的页眉页脚为默认值
function pagesetup_default()
on error resume next
Set RegWsh = CreateObject("Wscript.Shell")
hkey_key="\header"
RegWsh.RegWrite hkey_root+hkey_path+hkey_key,"&w&b页码,&p/&P"
hkey_key="\footer"
RegWsh.RegWrite hkey_root+hkey_path+hkey_key,"&u&b&d"
end function
</script>
</HEAD>
<BODY>
<br/>
<br/>
<br/>
<br/>
<br/>
<br/><p align=center>
<input type="button" value="清空页码" onclick=pagesetup_null()> <input type="button" value="恢复页吗" onclick=pagesetup_default()><br/>
</p>
</BODY>
</HTML>
4、浮动帧打印
<script LANGUAGE=javascript>
function button1_onclick() {
var odoc=window.iframe1.document;
var r=odoc.body.createTextRange();
var stxt=r.htmlText;
alert(stxt)
var pwin=window.open("","print");
pwin.document.write(stxt);
pwin.print();
}
</script>
4、用FileSystem组件实现WEB应用中的本地特定打印
<script Language=VBscript>
function print_onclick //打印函数
dim label
label=document.printinfo.label.value //获得HTML页面的数据
set objfs=CreateObject("scripting.FileSystemObject") //创建FileSystem组件对象的实例
set objprinter=objfs.CreateTextFile ("LPT1:",true) //建立与打印机的连接
objprinter.Writeline("__________________________________") //输出打印的内容
objprinter.Writeline("| |")
objprinter.Writeline("| 您打印的数据是:"&label& " |”)
objprinter.Writeline("| |")
objprinter.Writeline("|_________________________________|")
objprinter.close //断开与打印机的连接
set objprinter=nothing
set objfs=nothing // 关闭FileSystem组件对象
end function
</script>
服务器端脚本:
<%………
set conn=server.CreateObject ("adodb.connection")
conn.Open "DSN=name;UID=XXXX;PWD=XXXX;"
set rs=server.CreateObject("adodb.recordset")
rs.Open(“select ……”),conn,1,1
……….%> //与数据库进行交互
HTML页面编码:
<HTML>
………
<FORM ID=printinfo NAME="printinfo" >
<INPUT type="button" value="打印>>" id=print name=print > //调用打印函数
<INPUT type=hidden id=text1 name=label value=<%=………%>> //保存服务器端传来的数据
………
</HTML>
posted @
2006-08-22 15:07 xzc 阅读(747) |
评论 (4) |
编辑 收藏posted @
2006-08-19 10:23 xzc 阅读(410) |
评论 (0) |
编辑 收藏
首先需要配置好eclipse。我这里主要说明weblogic的配置。

注意JDK选择JDK5.0的版本。
顺便将weblogic8的配置也贴上来,供大家比较参考

注意weblogic8的JDK版本必须是JDK1.4。
接下来就开始我们的开发了。





下面就是SessionBean的代码
30
1 package com.ejb;
2
3 import java.rmi.RemoteException;
4
5 import javax.ejb.EJBException;
6 import javax.ejb.SessionBean;
7 import javax.ejb.SessionContext;
8
9 /**
10 * XDoclet-based session bean. The class must be declared
11 * public according to the EJB specification.
12 *
13 * To generate the EJB related files to this EJB:
14 * - Add Standard EJB module to XDoclet project properties
15 * - Customize XDoclet configuration for your appserver
16 * - Run XDoclet
17 *
18 * Below are the xdoclet-related tags needed for this EJB.
19 *
20 * @ejb.bean name="HelloWorld"
21 * display-name="Name for HelloWorld"
22 * description="Description for HelloWorld"
23 * jndi-name="ejb/HelloWorld"
24 * type="Stateless"
25 * view-type="remote"
26 */
27 public class HelloWorld implements SessionBean {
28
29 /** The session context */
30 private SessionContext context;
31
32 public HelloWorld() {
33 super();
34 // TODO 自动生成构造函数存根
35 }
36
37 /**
38 * Set the associated session context. The container calls this method
39 * after the instance creation.
40 *
41 * The enterprise bean instance should store the reference to the context
42 * object in an instance variable.
43 *
44 * This method is called with no transaction context.
45 *
46 * @throws EJBException Thrown if method fails due to system-level error.
47 */
48 public void setSessionContext(SessionContext newContext)
49 throws EJBException {
50 context = newContext;
51 }
52
53 public void ejbRemove() throws EJBException, RemoteException {
54 // TODO 自动生成方法存根
55
56 }
57
58 public void ejbActivate() throws EJBException, RemoteException {
59 // TODO 自动生成方法存根
60
61 }
62
63 public void ejbPassivate() throws EJBException, RemoteException {
64 // TODO 自动生成方法存根
65
66 }
67
68 /**
69 * An example business method
70 *
71 * @ejb.interface-method view-type = "remote"
72 *
73 * @throws EJBException Thrown if method fails due to system-level error.
74 */
75 public String hello() throws EJBException {
76 // rename and start putting your business logic here
77 return new String("HelloEJBWorld!");
78 }
79
80 }
81
其实就是修改了其中的一个方法:
1 /**
2 * An example business method
3 *
4 * @ejb.interface-method view-type = "remote"
5 *
6 * @throws EJBException Thrown if method fails due to system-level error.
7 */
8 public String hello() throws EJBException {
9 // rename and start putting your business logic here
10 return new String("HelloEJBWorld!");
11 }
注意:代码中的解释文字不要删除,因为XDoclet需要。
配置属性

添加weblogic.jar。我的路径是:bea\weblogic90\server\lib\weblogic.jar










就下来写EJBTest类:
1 package com;
2
3 import java.rmi.RemoteException;
4 import java.util.Properties;
5
6 import javax.ejb.CreateException;
7 import javax.naming.Context;
8 import javax.naming.InitialContext;
9 import javax.naming.NamingException;
10
11 import com.interfaces.HelloWorld;
12 import com.interfaces.HelloWorldHome;
13
14 public class EJBTest {
15
16 /**
17 * @param args
18 */
19 public static void main(String[] args) {
20 // TODO 自动生成方法存根
21 Properties properties=new Properties();
22 properties.setProperty(Context.INITIAL_CONTEXT_FACTORY,"weblogic.jndi.WLInitialContextFactory");
23 properties.setProperty(Context.PROVIDER_URL,"t3://localhost:7001");
24
25 Context context;
26 try {
27 context = new InitialContext(properties);
28 HelloWorldHome hwh=(HelloWorldHome)context.lookup("ejb/HelloWorld");
29 HelloWorld hw=hwh.create();
30 String s=hw.hello();
31 System.out.println(s);
32 } catch (NamingException e) {
33 // TODO 自动生成 catch 块
34 e.printStackTrace();
35 } catch (RemoteException e) {
36 // TODO 自动生成 catch 块
37 e.printStackTrace();
38 } catch (CreateException e) {
39 // TODO 自动生成 catch 块
40 e.printStackTrace();
41 }
42
43 }
44
45
46 }
47
最后就是看结果了,先启动weblogic,然后运行EJBTest程序。

posted @
2006-08-14 10:13 xzc 阅读(406) |
评论 (0) |
编辑 收藏
数学函数:
1.绝对值
S:select abs(-1) value
O:select abs(-1) value from dual
2.取整(大)
S:select ceiling(-1.001) value
O:select ceil(-1.001) value from dual
3.取整(小)
S:select floor(-1.001) value
O:select floor(-1.001) value from dual
4.取整(截取)
S:select cast(-1.002 as int) value
O:select trunc(-1.002) value from dual
5.四舍五入
S:select round(1.23456,4) value 1.23460
O:select round(1.23456,4) value from dual 1.2346
6.e为底的幂
S:select Exp(1) value 2.7182818284590451
O:select Exp(1) value from dual 2.71828182
7.取e为底的对数
S:select log(2.7182818284590451) value 1
O:select ln(2.7182818284590451) value from dual; 1
8.取10为底对数
S:select log10(10) value 1
O:select log(10,10) value from dual; 1
9.取平方
S:select SQUARE(4) value 16
O:select power(4,2) value from dual 16
10.取平方根
S:select SQRT(4) value 2
O:select SQRT(4) value from dual 2
11.求任意数为底的幂
S:select power(3,4) value 81
O:select power(3,4) value from dual 81
12.取随机数
S:select rand() value
O:select sys.dbms_random.value(0,1) value from dual;
13.取符号
S:select sign(-8) value -1
O:select sign(-8) value from dual -1
14.圆周率
S:SELECT PI() value 3.1415926535897931
O:不知道
15.sin,cos,tan 参数都以弧度为单位
例如:select sin(PI()/2) value 得到1(SQLServer)
16.Asin,Acos,Atan,Atan2 返回弧度
17.弧度角度互换(SQLServer,Oracle不知道)
DEGREES:弧度-〉角度
RADIANS:角度-〉弧度
数值间比较:
18. 求集合最大值
S:select max(value) value from
(select 1 value
union
select -2 value
union
select 4 value
union
select 3 value)a
O:select greatest(1,-2,4,3) value from dual
19. 求集合最小值
S:select min(value) value from
(select 1 value
union
select -2 value
union
select 4 value
union
select 3 value)a
O:select least(1,-2,4,3) value from dual
20.如何处理null值(F2中的null以10代替)
S:select F1,IsNull(F2,10) value from Tbl
O:select F1,nvl(F2,10) value from Tbl
21.求字符序号
S:select ascii('a') value
O:select ascii('a') value from dual
22.从序号求字符
S:select char(97) value
O:select chr(97) value from dual
23.连接
S:select '11'+'22'+'33' value
O:select CONCAT('11','22') 33 value from dual
23.子串位置 --返回3
S:select CHARINDEX('s','sdsq',2) value
O:select INSTR('sdsq','s',2) value from dual
23.模糊子串的位置 --返回2,参数去掉中间%则返回7
S:select patindex('%d%q%','sdsfasdqe') value
O:oracle没发现,但是instr可以通过第四个参数控制出现次数
select INSTR('sdsfasdqe','sd',1,2) value from dual 返回6
24.求子串
S:select substring('abcd',2,2) value
O:select substr('abcd',2,2) value from dual
25.子串代替 返回aijklmnef
S:SELECT STUFF('abcdef', 2, 3, 'ijklmn') value
O:SELECT Replace('abcdef', 'bcd', 'ijklmn') value from dual
26.子串全部替换
S:没发现
O:select Translate('fasdbfasegas','fa','我' ) value from dual
27.长度
S:len,datalength
O:length
28.大小写转换 lower,upper
29.单词首字母大写
S:没发现
O:select INITCAP('abcd dsaf df') value from dual
30.左补空格(LPAD的第一个参数为空格则同space函数)
S:select space(10)+'abcd' value
O:select LPAD('abcd',14) value from dual
31.右补空格(RPAD的第一个参数为空格则同space函数)
S:select 'abcd'+space(10) value
O:select RPAD('abcd',14) value from dual
32.删除空格
S:ltrim,rtrim
O:ltrim,rtrim,trim
33. 重复字符串
S:select REPLICATE('abcd',2) value
O:没发现
34.发音相似性比较(这两个单词返回值一样,发音相同)
S:SELECT SOUNDEX ('Smith'), SOUNDEX ('Smythe')
O:SELECT SOUNDEX ('Smith'), SOUNDEX ('Smythe') from dual
SQLServer中用SELECT DIFFERENCE('Smithers', 'Smythers') 比较soundex的差
返回0-4,4为同音,1最高
日期函数:
35.系统时间
S:select getdate() value
O:select sysdate value from dual
36.前后几日
直接与整数相加减
37.求日期
S:select convert(char(10),getdate(),20) value
O:select trunc(sysdate) value from dual
select to_char(sysdate,'yyyy-mm-dd') value from dual
38.求时间
S:select convert(char(8),getdate(),108) value
O:select to_char(sysdate,'hh24:mm:ss') value from dual
39.取日期时间的其他部分
S:DATEPART 和 DATENAME 函数 (第一个参数决定)
O:to_char函数 第二个参数决定
参数---------------------------------下表需要补充
year yy, yyyy
quarter qq, q (季度)
month mm, m (m O无效)
dayofyear dy, y (O表星期)
day dd, d (d O无效)
week wk, ww (wk O无效)
weekday dw (O不清楚)
Hour hh,hh12,hh24 (hh12,hh24 S无效)
minute mi, n (n O无效)
second ss, s (s O无效)
millisecond ms (O无效)
----------------------------------------------
40.当月最后一天
S:不知道
O:select LAST_DAY(sysdate) value from dual
41.本星期的某一天(比如星期日)
S:不知道
O:SELECT Next_day(sysdate,7) vaule FROM DUAL;
42.字符串转时间
S:可以直接转或者select cast('2004-09-08'as datetime) value
O:SELECT To_date('2004-01-05 22:09:38','yyyy-mm-dd hh24-mi-ss') vaule FROM DUAL;
43.求两日期某一部分的差(比如秒)
S:select datediff(ss,getdate(),getdate()+12.3) value
O:直接用两个日期相减(比如d1-d2=12.3)
SELECT (d1-d2)*24*60*60 vaule FROM DUAL;
44.根据差值求新的日期(比如分钟)
S:select dateadd(mi,8,getdate()) value
O:SELECT sysdate+8/60/24 vaule FROM DUAL;
45.求不同时区时间
S:不知道
O:SELECT New_time(sysdate,'ydt','gmt' ) vaule FROM DUAL;
-----时区参数,北京在东8区应该是Ydt-------
AST ADT 大西洋标准时间
BST BDT 白令海标准时间
CST CDT 中部标准时间
EST EDT 东部标准时间
GMT 格林尼治标准时间
HST HDT 阿拉斯加?夏威夷标准时间
MST MDT 山区标准时间
NST 纽芬兰标准时间
PST PDT 太平洋标准时间
YST YDT YUKON标准时间
posted @
2006-08-11 09:55 xzc 阅读(453) |
评论 (2) |
编辑 收藏select * from a, b where a.id = b.id;
对于外连接,Oracle中可以使用“(+)”来表示,9i可以使用LEFT/RIGHT/FULL OUTER JOIN,下面将配合实例一一介绍。
1. LEFT OUTER JOIN:左外关联
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON (e.department_id = d.department_id);
等价于
SELECT e.last_name, e.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id=d.department_id(+);
结果为:所有员工及对应部门的记录,包括没有对应部门编号department_id的员工记录。
2. RIGHT OUTER JOIN:右外关联
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id);
等价于
SELECT e.last_name, e.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id(+)=d.department_id;
结果为:所有员工及对应部门的记录,包括没有任何员工的部门记录。
3. FULL OUTER JOIN:全外关联
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
FULL OUTER JOIN departments d
ON (e.department_id = d.department_id);
结果为:所有员工及对应部门的记录,包括没有对应部门编号department_id的员工记录和没有任何员工的部门记录。
你的SID应该是你的数据库所在的SID呀,你可以用sqlplus登陆到服务器
$sqlplus / as sysdba
SQL> select * from v$instance;
看一下你的机器正在跑的SID的名字是什么
posted @
2006-08-11 09:53 xzc 阅读(157) |
评论 (0) |
编辑 收藏
Day:
dd number 12
dy abbreviated fri
day spelled out friday
ddspth spelled out, ordinal twelfth
Month:
mm number 03
mon abbreviated mar
month spelled out march
Year:
yy two digits 98
yyyy four digits 1998
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1.
日期和字符转换函数用法(to_date,to_char)
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.
求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4.
两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not
in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9.
select months_between(to_date('01-31-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),
to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.
获得小时数
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
获取年月日与此类似
13.
年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),
12 ) MONTHS,
newer_date,
older_date
from ( select hiredate older_date,
add_months(hiredate,rownum)+rownum newer_date
from emp )
)
14.
处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.
找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' || :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.
yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.
5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.
一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
mod(mod(date2-date1, 365), 30)作为日.
23.next_day函数
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
posted @
2006-08-10 16:34 xzc 阅读(2673) |
评论 (8) |
编辑 收藏
1 定义头和根元素
部署描述符文件就像所有XML文件一样,必须以一个XML头开始。这个头声明可以使用的XML版本并给出文件的字符编码。
DOCYTPE声明必须立即出现在此头之后。这个声明告诉服务器适用的servlet规范的版本(如2.2或2.3)并指定管理此文件其余部分内容的语法的DTD(Document Type Definition,文档类型定义)。
所有部署描述符文件的顶层(根)元素为web-app。请注意,XML元素不像HTML,他们是大小写敏感的。因此,web-App和WEB-APP都是不合法的,web-app必须用小写。
2 部署描述符文件内的元素次序
XML 元素不仅是大小写敏感的,而且它们还对出现在其他元素中的次序敏感。例如,XML头必须是文件中的第一项,DOCTYPE声明必须是第二项,而web- app元素必须是第三项。在web-app元素内,元素的次序也很重要。服务器不一定强制要求这种次序,但它们允许(实际上有些服务器就是这样做的)完全拒绝执行含有次序不正确的元素的Web应用。这表示使用非标准元素次序的web.xml文件是不可移植的。
下面的列表给出了所有可直接出现在web-app元素内的合法元素所必需的次序。例如,此列表说明servlet元素必须出现在所有servlet-mapping元素之前。请注意,所有这些元素都是可选的。因此,可以省略掉某一元素,但不能把它放于不正确的位置。
l icon icon元素指出IDE和GUI工具用来表示Web应用的一个和两个图像文件的位置。
l display-name display-name元素提供GUI工具可能会用来标记这个特定的Web应用的一个名称。
l description description元素给出与此有关的说明性文本。
l context-param context-param元素声明应用范围内的初始化参数。
l filter 过滤器元素将一个名字与一个实现javax.servlet.Filter接口的类相关联。
l filter-mapping 一旦命名了一个过滤器,就要利用filter-mapping元素把它与一个或多个servlet或JSP页面相关联。
l listener servlet API的版本2.3增加了对事件监听程序的支持,事件监听程序在建立、修改和删除会话或servlet环境时得到通知。Listener元素指出事件监听程序类。
l servlet 在向servlet或JSP页面制定初始化参数或定制URL时,必须首先命名servlet或JSP页面。Servlet元素就是用来完成此项任务的。
l servlet-mapping 服务器一般为servlet提供一个缺省的URL:
http://host/webAppPrefix/servlet/ServletName
。但是,常常会更改这个URL,以便servlet可以访问初始化参数或更容易地处理相对URL。在更改缺省URL时,使用servlet-mapping元素。
l session-config 如果某个会话在一定时间内未被访问,服务器可以抛弃它以节省内存。可通过使用HttpSession的setMaxInactiveInterval方法明确设置单个会话对象的超时值,或者可利用session-config元素制定缺省超时值。
l mime-mapping 如果Web应用具有想到特殊的文件,希望能保证给他们分配特定的MIME类型,则mime-mapping元素提供这种保证。
l welcom-file-list welcome-file-list元素指示服务器在收到引用一个目录名而不是文件名的URL时,使用哪个文件。
l error-page error-page元素使得在返回特定HTTP状态代码时,或者特定类型的异常被抛出时,能够制定将要显示的页面。
l taglib taglib元素对标记库描述符文件(Tag Libraryu Descriptor file)指定别名。此功能使你能够更改TLD文件的位置,而不用编辑使用这些文件的JSP页面。
l resource-env-ref resource-env-ref元素声明与资源相关的一个管理对象。
l resource-ref resource-ref元素声明一个资源工厂使用的外部资源。
l security-constraint security-constraint元素制定应该保护的URL。它与login-config元素联合使用
l login-config 用login-config元素来指定服务器应该怎样给试图访问受保护页面的用户授权。它与sercurity-constraint元素联合使用。
l security-role security-role元素给出安全角色的一个列表,这些角色将出现在servlet元素内的security-role-ref元素的role-name子元素中。分别地声明角色可使高级IDE处理安全信息更为容易。
l env-entry env-entry元素声明Web应用的环境项。
l ejb-ref ejb-ref元素声明一个EJB的主目录的引用。
l ejb-local-ref ejb-local-ref元素声明一个EJB的本地主目录的应用。
3 分配名称和定制的UL
在web.xml中完成的一个最常见的任务是对servlet或JSP页面给出名称和定制的URL。用servlet元素分配名称,使用servlet-mapping元素将定制的URL与刚分配的名称相关联。
3.1 分配名称
为了提供初始化参数,对servlet或JSP页面定义一个定制URL或分配一个安全角色,必须首先给servlet或JSP页面一个名称。可通过 servlet元素分配一个名称。最常见的格式包括servlet-name和servlet-class子元素(在web-app元素内),如下所示:
<servlet>
<servlet-name>Test</servlet-name>
<servlet-class>moreservlets.TestServlet</servlet-class>
</servlet>
这表示位于WEB-INF/classes/moreservlets/TestServlet的servlet已经得到了注册名Test。给 servlet一个名称具有两个主要的含义。首先,初始化参数、定制的URL模式以及其他定制通过此注册名而不是类名引用此servlet。其次,可在 URL而不是类名中使用此名称。因此,利用刚才给出的定义,URL
http://host/webAppPrefix/servlet/Test
可用于
http://host/webAppPrefix/servlet/moreservlets.TestServlet
的场所。
请记住:XML元素不仅是大小写敏感的,而且定义它们的次序也很重要。例如,web-app元素内所有servlet元素必须位于所有servlet- mapping元素(下一小节介绍)之前,而且还要位于5.6节和5.11节讨论的与过滤器或文档相关的元素(如果有的话)之前。类似地,servlet 的servlet-name子元素也必须出现在servlet-class之前。5.2节"部署描述符文件内的元素次序"将详细介绍这种必需的次序。
例如,程序清单5-1给出了一个名为TestServlet的简单servlet,它驻留在moreservlets程序包中。因为此servlet是扎根在一个名为deployDemo的目录中的Web应用的组成部分,所以TestServlet.class放在deployDemo/WEB- INF/classes/moreservlets中。程序清单5-2给出将放置在deployDemo/WEB-INF/内的web.xml文件的一部分。此web.xml文件使用servlet-name和servlet-class元素将名称Test与TestServlet.class相关联。图 5-1和图5-2分别显示利用缺省URL和注册名调用TestServlet时的结果。
程序清单5-1 TestServlet.java
package moreservlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** Simple servlet used to illustrate servlet naming
* and custom URLs.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
*
http://www.moreservlets.com/.
* © 2002 Marty Hall; may be freely used or adapted.
*/
public class TestServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
String uri = request.getRequestURI();
out.println(ServletUtilities.headWithTitle("Test Servlet") +
"<BODY BGCOLOR=\"#FDF5E6\">\n" +
"<H2>URI: " + uri + "</H2>\n" +
"</BODY></HTML>");
}
}
程序清单5-2 web.xml(说明servlet名称的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"
http://java.sun.com/dtd/web-app_2_3.dtd
">
<web-app>
<!-- … -->
<servlet>
<servlet-name>Test</servlet-name>
<servlet-class>moreservlets.TestServlet</servlet-class>
</servlet>
<!-- … -->
</web-app>
3.2 定义定制的URL
大多数服务器具有一个缺省的serlvet URL:
http://host/webAppPrefix/servlet/packageName.ServletName
。虽然在开发中使用这个URL很方便,但是我们常常会希望另一个URL用于部署。例如,可能会需要一个出现在Web应用顶层的URL(如,http: //host/webAppPrefix/Anyname),并且在此URL中没有servlet项。位于顶层的URL简化了相对URL的使用。此外,对许多开发人员来说,顶层URL看上去比更长更麻烦的缺省URL更简短。
事实上,有时需要使用定制的URL。比如,你可能想关闭缺省URL映射,以便更好地强制实施安全限制或防止用户意外地访问无初始化参数的servlet。如果你禁止了缺省的URL,那么你怎样访问servlet呢?这时只有使用定制的URL了。
为了分配一个定制的URL,可使用servlet-mapping元素及其servlet-name和url-pattern子元素。Servlet- name元素提供了一个任意名称,可利用此名称引用相应的servlet;url-pattern描述了相对于Web应用的根目录的URL。url- pattern元素的值必须以斜杠(/)起始。
下面给出一个简单的web.xml摘录,它允许使用URL
http://host/webAppPrefix/UrlTest
而不是
http://host/webAppPrefix/servlet/Test
或
http: //host/webAppPrefix/servlet/moreservlets.TestServlet。请注意,仍然需要XML头、 DOCTYPE声明以及web-app封闭元素。此外,可回忆一下,XML元素出现地次序不是随意的。特别是,需要把所有servlet元素放在所有 servlet-mapping元素之前。
<servlet>
<servlet-name>Test</servlet-name>
<servlet-class>moreservlets.TestServlet</servlet-class>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name>Test</servlet-name>
<url-pattern>/UrlTest</url-pattern>
</servlet-mapping>
URL模式还可以包含通配符。例如,下面的小程序指示服务器发送所有以Web应用的URL前缀开始,以..asp结束的请求到名为BashMS的servlet。
<servlet>
<servlet-name>BashMS</servlet-name>
<servlet-class>msUtils.ASPTranslator</servlet-class>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name>BashMS</servlet-name>
<url-pattern>/*.asp</url-pattern>
</servlet-mapping>
3.3 命名JSP页面
因为JSP页面要转换成sevlet,自然希望就像命名servlet一样命名JSP页面。毕竟,JSP页面可能会从初始化参数、安全设置或定制的URL中受益,正如普通的serlvet那样。虽然JSP页面的后台实际上是servlet这句话是正确的,但存在一个关键的猜疑:即,你不知道JSP页面的实际类名(因为系统自己挑选这个名字)。因此,为了命名JSP页面,可将jsp-file元素替换为servlet-calss元素,如下所示:
<servlet>
<servlet-name>Test</servlet-name>
<jsp-file>/TestPage.jsp</jsp-file>
</servlet>
命名JSP页面的原因与命名servlet的原因完全相同:即为了提供一个与定制设置(如,初始化参数和安全设置)一起使用的名称,并且,以便能更改激活 JSP页面的URL(比方说,以便多个URL通过相同页面得以处理,或者从URL中去掉.jsp扩展名)。但是,在设置初始化参数时,应该注意,JSP页面是利用jspInit方法,而不是init方法读取初始化参数的。
例如,程序清单5-3给出一个名为TestPage.jsp的简单JSP页面,它的工作只是打印出用来激活它的URL的本地部分。TestPage.jsp放置在deployDemo应用的顶层。程序清单5-4给出了用来分配一个注册名PageName,然后将此注册名与
http://host/webAppPrefix/UrlTest2/anything
形式的URL相关联的web.xml文件(即,deployDemo/WEB-INF/web.xml)的一部分。
程序清单5-3 TestPage.jsp
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE>
JSP Test Page
</TITLE>
</HEAD>
<BODY BGCOLOR="#FDF5E6">
<H2>URI: <%= request.getRequestURI() %></H2>
</BODY>
</HTML>
程序清单5-4 web.xml(说明JSP页命名的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"
http://java.sun.com/dtd/web-app_2_3.dtd
">
<web-app>
<!-- ... -->
<servlet>
<servlet-name>PageName</servlet-name>
<jsp-file>/TestPage.jsp</jsp-file>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name> PageName </servlet-name>
<url-pattern>/UrlTest2/*</url-pattern>
</servlet-mapping>
<!-- ... -->
</web-app>
4 禁止激活器servlet
对servlet或JSP页面建立定制URL的一个原因是,这样做可以注册从 init(servlet)或jspInit(JSP页面)方法中读取得初始化参数。但是,初始化参数只在是利用定制URL模式或注册名访问 servlet或JSP页面时可以使用,用缺省URL
http://host/webAppPrefix/servlet/ServletName
访问时不能使用。因此,你可能会希望关闭缺省URL,这样就不会有人意外地调用初始化servlet了。这个过程有时称为禁止激活器servlet,因为多数服务器具有一个用缺省的servlet URL注册的标准servlet,并激活缺省的URL应用的实际servlet。
有两种禁止此缺省URL的主要方法:
l 在每个Web应用中重新映射/servlet/模式。
l 全局关闭激活器servlet。
重要的是应该注意到,虽然重新映射每个Web应用中的/servlet/模式比彻底禁止激活servlet所做的工作更多,但重新映射可以用一种完全可移植的方式来完成。相反,全局禁止激活器servlet完全是针对具体机器的,事实上有的服务器(如ServletExec)没有这样的选择。下面的讨论对每个Web应用重新映射/servlet/ URL模式的策略。后面提供在Tomcat中全局禁止激活器servlet的详细内容。
4.1 重新映射/servlet/URL模式
在一个特定的Web应用中禁止以
http://host/webAppPrefix/servlet/
开始的URL的处理非常简单。所需做的事情就是建立一个错误消息servlet,并使用前一节讨论的url-pattern元素将所有匹配请求转向该 servlet。只要简单地使用:
<url-pattern>/servlet/*</url-pattern>
作为servlet-mapping元素中的模式即可。
例如,程序清单5-5给出了将SorryServlet servlet(程序清单5-6)与所有以
http://host/webAppPrefix/servlet/
开头的URL相关联的部署描述符文件的一部分。
程序清单5-5 web.xml(说明JSP页命名的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"
http://java.sun.com/dtd/web-app_2_3.dtd
">
<web-app>
<!-- ... -->
<servlet>
<servlet-name>Sorry</servlet-name>
<servlet-class>moreservlets.SorryServlet</servlet-class>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name> Sorry </servlet-name>
<url-pattern>/servlet/*</url-pattern>
</servlet-mapping>
<!-- ... -->
</web-app>
程序清单5-6 SorryServlet.java
package moreservlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** Simple servlet used to give error messages to
* users who try to access default servlet URLs
* (i.e.,
http://host/webAppPrefix/servlet/ServletName
)
* in Web applications that have disabled this
* behavior.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
*
http://www.moreservlets.com/.
* © 2002 Marty Hall; may be freely used or adapted.
*/
public class SorryServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
String title = "Invoker Servlet Disabled.";
out.println(ServletUtilities.headWithTitle(title) +
"<BODY BGCOLOR=\"#FDF5E6\">\n" +
"<H2>" + title + "</H2>\n" +
"Sorry, access to servlets by means of\n" +
"URLs that begin with\n" +
"
http://host/webAppPrefix/servlet/
\n" +
"has been disabled.\n" +
"</BODY></HTML>");
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
4.2 全局禁止激活器:Tomcat
Tomcat 4中用来关闭缺省URL的方法与Tomcat 3中所用的很不相同。下面介绍这两种方法:
1.禁止激活器: Tomcat 4
Tomcat 4用与前面相同的方法关闭激活器servlet,即利用web.xml中的url-mapping元素进行关闭。不同之处在于Tomcat使用了放在 install_dir/conf中的一个服务器专用的全局web.xml文件,而前面使用的是存放在每个Web应用的WEB-INF目录中的标准 web.xml文件。
因此,为了在Tomcat 4中关闭激活器servlet,只需在install_dir/conf/web.xml中简单地注释出/servlet/* URL映射项即可,如下所示:
<!--
<servlet-mapping>
<servlet-name>invoker</servlet-name>
<url-pattern>/servlet/*</url-pattern>
</servlet-mapping>
-->
再次提醒,应该注意这个项是位于存放在install_dir/conf的Tomcat专用的web.xml文件中的,此文件不是存放在每个Web应用的WEB-INF目录中的标准web.xml。
2.禁止激活器:Tomcat3
在Apache Tomcat的版本3中,通过在install_dir/conf/server.xml中注释出InvokerInterceptor项全局禁止缺省 servlet URL。例如,下面是禁止使用缺省servlet URL的server.xml文件的一部分。
<!--
<RequsetInterceptor
className="org.apache.tomcat.request.InvokerInterceptor"
debug="0" prefix="/servlet/" />
-->
5 初始化和预装载servlet与JSP页面
这里讨论控制servlet和JSP页面的启动行为的方法。特别是,说明了怎样分配初始化参数以及怎样更改服务器生存期中装载servlet和JSP页面的时刻。
5.1 分配servlet初始化参数
利用init-param元素向servlet提供初始化参数,init-param元素具有param-name和param-value子元素。例如,在下面的例子中,如果initServlet servlet是利用它的注册名(InitTest)访问的,它将能够从其方法中调用getServletConfig(). getInitParameter("param1")获得"Value 1",调用getServletConfig().getInitParameter("param2")获得"2"。
<servlet>
<servlet-name>InitTest</servlet-name>
<servlet-class>moreservlets.InitServlet</servlet-class>
<init-param>
<param-name>param1</param-name>
<param-value>value1</param-value>
</init-param>
<init-param>
<param-name>param2</param-name>
<param-value>2</param-value>
</init-param>
</servlet>
在涉及初始化参数时,有几点需要注意:
l 返回值。GetInitParameter的返回值总是一个String。因此,在前一个例子中,可对param2使用Integer.parseInt获得一个int。
l JSP中的初始化。JSP页面使用jspInit而不是init。JSP页面还需要使用jsp-file元素代替servlet-class。
l 缺省URL。初始化参数只在通过它们的注册名或与它们注册名相关的定制URL模式访问Servlet时可以使用。因此,在这个例子中,param1和 param2初始化参数将能够在使用URL
http://host/webAppPrefix/servlet/InitTest
时可用,但在使用URL
http://host/webAppPrefix/servlet/myPackage.InitServlet
时不能使用。
例如,程序清单5-7给出一个名为InitServlet的简单servlet,它使用init方法设置firstName和emailAddress字段。程序清单5-8给出分配名称InitTest给servlet的web.xml文件。
程序清单5-7 InitServlet.java
package moreservlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** Simple servlet used to illustrate servlet
* initialization parameters.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
*
http://www.moreservlets.com/.
* © 2002 Marty Hall; may be freely used or adapted.
*/
public class InitServlet extends HttpServlet {
private String firstName, emailAddress;
public void init() {
ServletConfig config = getServletConfig();
firstName = config.getInitParameter("firstName");
emailAddress = config.getInitParameter("emailAddress");
}
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
String uri = request.getRequestURI();
out.println(ServletUtilities.headWithTitle("Init Servlet") +
"<BODY BGCOLOR=\"#FDF5E6\">\n" +
"<H2>Init Parameters:</H2>\n" +
"<UL>\n" +
"<LI>First name: " + firstName + "\n" +
"<LI>Email address: " + emailAddress + "\n" +
"</UL>\n" +
"</BODY></HTML>");
}
}
程序清单5-8 web.xml(说明初始化参数的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"
http://java.sun.com/dtd/web-app_2_3.dtd
">
<web-app>
<!-- ... -->
<servlet>
<servlet-name>InitTest</servlet-name>
<servlet-class>moreservlets.InitServlet</servlet-class>
<init-param>
<param-name>firstName</param-name>
<param-value>Larry</param-value>
</init-param>
<init-param>
<param-name>emailAddress</param-name>
<param-value>
Ellison@Microsoft.com
</param-value>
</init-param>
</servlet>
<!-- ... -->
</web-app>
5.2 分配JSP初始化参数
给JSP页面提供初始化参数在三个方面不同于给servlet提供初始化参数。
1)使用jsp-file而不是servlet-class。因此,WEB-INF/web.xml文件的servlet元素如下所示:
<servlet>
<servlet-name>PageName</servlet-name>
<jsp-file>/RealPage.jsp</jsp-file>
<init-param>
<param-name>...</param-name>
<param-value>...</param-value>
</init-param>
...
</servlet>
2) 几乎总是分配一个明确的URL模式。对servlet,一般相应地使用以
http://host/webAppPrefix/servlet/
开始的缺省URL。只需记住,使用注册名而不是原名称即可。这对于JSP页面在技术上也是合法的。例如,在上面给出的例子中,可用URL
http://host/webAppPrefix/servlet/PageName
访问RealPage.jsp的对初始化参数具有访问权的版本。但在用于JSP页面时,许多用户似乎不喜欢应用常规的servlet的URL。此外,如果 JSP页面位于服务器为其提供了目录清单的目录中(如,一个既没有index.html也没有index.jsp文件的目录),则用户可能会连接到此 JSP页面,单击它,从而意外地激活未初始化的页面。因此,好的办法是使用url-pattern(5.3节)将JSP页面的原URL与注册的 servlet名相关联。这样,客户机可使用JSP页面的普通名称,但仍然激活定制的版本。例如,给定来自项目1的servlet定义,可使用下面的 servlet-mapping定义:
<servlet-mapping>
<servlet-name>PageName</servlet-name>
<url-pattern>/RealPage.jsp</url-pattern>
</servlet-mapping>
3)JSP页使用jspInit而不是init。自动从JSP页面建立的servlet或许已经使用了inti方法。因此,使用JSP声明提供一个init方法是不合法的,必须制定jspInit方法。
为了说明初始化JSP页面的过程,程序清单5-9给出了一个名为InitPage.jsp的JSP页面,它包含一个jspInit方法且放置于 deployDemo Web应用层次结构的顶层。一般,
http://host/deployDemo/InitPage.jsp
形式的URL将激活此页面的不具有初始化参数访问权的版本,从而将对firstName和emailAddress变量显示null。但是, web.xml文件(程序清单5-10)分配了一个注册名,然后将该注册名与URL模式/InitPage.jsp相关联。
程序清单5-9 InitPage.jsp
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD><TITLE>JSP Init Test</TITLE></HEAD>
<BODY BGCOLOR="#FDF5E6">
<H2>Init Parameters:</H2>
<UL>
<LI>First name: <%= firstName %>
<LI>Email address: <%= emailAddress %>
</UL>
</BODY></HTML>
<%!
private String firstName, emailAddress;
public void jspInit() {
ServletConfig config = getServletConfig();
firstName = config.getInitParameter("firstName");
emailAddress = config.getInitParameter("emailAddress");
}
%>
程序清单5-10 web.xml(说明JSP页面的init参数的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"
http://java.sun.com/dtd/web-app_2_3.dtd
">
<web-app>
<!-- ... -->
<servlet>
<servlet-name>InitPage</servlet-name>
<jsp-file>/InitPage.jsp</jsp-file>
<init-param>
<param-name>firstName</param-name>
<param-value>Bill</param-value>
</init-param>
<init-param>
<param-name>emailAddress</param-name>
<param-value>
gates@oracle.com
</param-value>
</init-param>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name> InitPage</servlet-name>
<url-pattern>/InitPage.jsp</url-pattern>
</servlet-mapping>
<!-- ... -->
</web-app>
5.3 提供应用范围内的初始化参数
一般,对单个地servlet或JSP页面分配初始化参数。指定的servlet或JSP页面利用ServletConfig的getInitParameter方法读取这些参数。但是,在某些情形下,希望提供可由任意servlet或JSP页面借助ServletContext的getInitParameter方法读取的系统范围内的初始化参数。
可利用context-param元素声明这些系统范围内的初始化值。context-param元素应该包含param-name、param-value以及可选的description子元素,如下所示:
<context-param>
<param-name>support-email</param-name>
<param-value>
blackhole@mycompany.com
</param-value>
</context-param>
可回忆一下,为了保证可移植性,web.xml内的元素必须以正确的次序声明。但这里应该注意,context-param元素必须出现任意与文档有关的元素(icon、display-name或description)之后及filter、filter-mapping、listener或 servlet元素之前。
5.4 在服务器启动时装载servlet
假如servlet或JSP页面有一个要花很长时间执行的init (servlet)或jspInit(JSP)方法。例如,假如init或jspInit方法从某个数据库或ResourceBundle查找产量。这种情况下,在第一个客户机请求时装载servlet的缺省行为将对第一个客户机产生较长时间的延迟。因此,可利用servlet的load-on- startup元素规定服务器在第一次启动时装载servlet。下面是一个例子。
<servlet>
<servlet-name> … </servlet-name>
<servlet-class> … </servlet-class> <!-- Or jsp-file -->
<load-on-startup/>
</servlet>
可以为此元素体提供一个整数而不是使用一个空的load-on-startup。想法是服务器应该在装载较大数目的servlet或JSP页面之前装载较少数目的servlet或JSP页面。例如,下面的servlet项(放置在Web应用的WEB-INF目录下的web.xml文件中的web-app元素内)将指示服务器首先装载和初始化SearchServlet,然后装载和初始化由位于Web应用的result目录中的index.jsp文件产生的 servlet。
<servlet>
<servlet-name>Search</servlet-name>
<servlet-class>myPackage.SearchServlet</servlet-class> <!-- Or jsp-file -->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet>
<servlet-name>Results</servlet-name>
<servlet-class>/results/index.jsp</servlet-class> <!-- Or jsp-file -->
<load-on-startup>2</load-on-startup>
</servlet>
6 声明过滤器
servlet版本2.3引入了过滤器的概念。虽然所有支持servlet API版本2.3的服务器都支持过滤器,但为了使用与过滤器有关的元素,必须在web.xml中使用版本2.3的DTD。
过滤器可截取和修改进入一个servlet或JSP页面的请求或从一个servlet或JSP页面发出的相应。在执行一个servlet或JSP页面之前,必须执行第一个相关的过滤器的doFilter方法。在该过滤器对其FilterChain对象调用doFilter时,执行链中的下一个过滤器。如果没有其他过滤器,servlet或JSP页面被执行。过滤器具有对到来的ServletRequest对象的全部访问权,因此,它们可以查看客户机名、查找到来的cookie等。为了访问servlet或JSP页面的输出,过滤器可将响应对象包裹在一个替身对象(stand-in object)中,比方说把输出累加到一个缓冲区。在调用FilterChain对象的doFilter方法之后,过滤器可检查缓冲区,如有必要,就对它进行修改,然后传送到客户机。
例如,程序清单5-11帝国难以了一个简单的过滤器,只要访问相关的servlet或JSP页面,它就截取请求并在标准输出上打印一个报告(开发过程中在桌面系统上运行时,大多数服务器都可以使用这个过滤器)。
程序清单5-11 ReportFilter.java
package moreservlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import java.util.*;
/** Simple filter that prints a report on the standard output
* whenever the associated servlet or JSP page is accessed.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
*
http://www.moreservlets.com/.
* © 2002 Marty Hall; may be freely used or adapted.
*/
public class ReportFilter implements Filter {
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws ServletException, IOException {
HttpServletRequest req = (HttpServletRequest)request;
System.out.println(req.getRemoteHost() +
" tried to access " +
req.getRequestURL() +
" on " + new Date() + ".");
chain.doFilter(request,response);
}
public void init(FilterConfig config)
throws ServletException {
}
public void destroy() {}
}
一旦建立了一个过滤器,可以在web.xml中利用filter元素以及filter-name(任意名称)、file-class(完全限定的类名)和(可选的)init-params子元素声明它。请注意,元素在web.xml的web-app元素中出现的次序不是任意的;允许服务器(但不是必需的)强制所需的次序,并且实际中有些服务器也是这样做的。但这里要注意,所有filter元素必须出现在任意filter-mapping元素之前, filter-mapping元素又必须出现在所有servlet或servlet-mapping元素之前。
例如,给定上述的ReportFilter类,可在web.xml中作出下面的filter声明。它把名称Reporter与实际的类ReportFilter(位于moreservlets程序包中)相关联。
<filter>
<filter-name>Reporter</filter-name>
<filter-class>moresevlets.ReportFilter</filter-class>
</filter>
一旦命名了一个过滤器,可利用filter-mapping元素把它与一个或多个servlet或JSP页面相关联。关于此项工作有两种选择。
首先,可使用filter-name和servlet-name子元素把此过滤器与一个特定的servlet名(此servlet名必须稍后在相同的 web.xml文件中使用servlet元素声明)关联。例如,下面的程序片断指示系统只要利用一个定制的URL访问名为SomeServletName 的servlet或JSP页面,就运行名为Reporter的过滤器。
<filter-mapping>
<filter-name>Reporter</filter-name>
<servlet-name>SomeServletName</servlet-name>
</filter-mapping>
其次,可利用filter-name和url-pattern子元素将过滤器与一组servlet、JSP页面或静态内容相关联。例如,相面的程序片段指示系统只要访问Web应用中的任意URL,就运行名为Reporter的过滤器。
<filter-mapping>
<filter-name>Reporter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
例如,程序清单5-12给出了将ReportFilter过滤器与名为PageName的servlet相关联的web.xml文件的一部分。名字 PageName依次又与一个名为TestPage.jsp的JSP页面以及以模式http: //host/webAppPrefix/UrlTest2/ 开头的URL相关联。TestPage.jsp的源代码已经JSP页面命名的谈论在前面的3节"分配名称和定制的URL"中给出。事实上,程序清单5- 12中的servlet和servlet-name项从该节原封不动地拿过来的。给定这些web.xml项,可看到下面的标准输出形式的调试报告(换行是为了容易阅读)。
audit.irs.gov tried to access
http://mycompany.com/deployDemo/UrlTest2/business/tax-plan.html
on Tue Dec 25 13:12:29 EDT 2001.
程序清单5-12 Web.xml(说明filter用法的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"
http://java.sun.com/dtd/web-app_2_3.dtd
">
<web-app>
<filter>
<filter-name>Reporter</filter-name>
<filter-class>moresevlets.ReportFilter</filter-class>
</filter>
<!-- ... -->
<filter-mapping>
<filter-name>Reporter</filter-name>
<servlet-name>PageName</servlet-name>
</filter-mapping>
<!-- ... -->
<servlet>
<servlet-name>PageName</servlet-name>
<jsp-file>/RealPage.jsp</jsp-file>
</servlet>
<!-- ... -->
<servlet-mapping>
<servlet-name> PageName </servlet-name>
<url-pattern>/UrlTest2/*</url-pattern>
</servlet-mapping>
<!-- ... -->
</web-app>
7 指定欢迎页
假如用户提供了一个像http: //host/webAppPrefix/directoryName/ 这样的包含一个目录名但没有包含文件名的URL,会发生什么事情呢?用户能得到一个目录表?一个错误?还是标准文件的内容?如果得到标准文件内容,是 index.html、index.jsp、default.html、default.htm或别的什么东西呢?
Welcome-file-list 元素及其辅助的welcome-file元素解决了这个模糊的问题。例如,下面的web.xml项指出,如果一个URL给出一个目录名但未给出文件名,服务器应该首先试用index.jsp,然后再试用index.html。如果两者都没有找到,则结果有赖于所用的服务器(如一个目录列表)。
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
<welcome-file>index.html</welcome-file>
</welcome-file-list>
虽然许多服务器缺省遵循这种行为,但不一定必须这样。因此,明确地使用welcom-file-list保证可移植性是一种良好的习惯。
8 指定处理错误的页面
现在我了解到,你在开发servlet和JSP页面时从不会犯错误,而且你的所有页面是那样的清晰,一般的程序员都不会被它们的搞糊涂。但是,是人总会犯错误的,用户可能会提供不合规定的参数,使用不正确的URL或者不能提供必需的表单字段值。除此之外,其它开发人员可能不那么细心,他们应该有些工具来克服自己的不足。
error-page元素就是用来克服这些问题的。它有两个可能的子元素,分别是:error-code和exception- type。第一个子元素error-code指出在给定的HTTP错误代码出现时使用的URL。第二个子元素excpetion-type指出在出现某个给定的Java异常但未捕捉到时使用的URL。error-code和exception-type都利用location元素指出相应的URL。此 URL必须以/开始。location所指出的位置处的页面可通过查找HttpServletRequest对象的两个专门的属性来访问关于错误的信息,这两个属性分别是:javax.servlet.error.status_code和javax.servlet.error.message。
可回忆一下,在web.xml内以正确的次序声明web-app的子元素很重要。这里只要记住,error-page出现在web.xml文件的末尾附近,servlet、servlet-name和welcome-file-list之后即可。
8.1 error-code元素
为了更好地了解error-code元素的值,可考虑一下如果不正确地输入文件名,大多数站点会作出什么反映。这样做一般会出现一个404错误信息,它表示不能找到该文件,但几乎没提供更多有用的信息。另一方面,可以试一下在
www.microsoft.com
、
www.ibm.com
处或者特别是在
www.bea.com
处输出未知的文件名。这是会得出有用的消息,这些消息提供可选择的位置,以便查找感兴趣的页面。提供这样有用的错误页面对于Web应用来说是很有价值得。事实上rm-error-page子元素)。由form-login-page给出的HTML表单必须具有一个j_security_check的 ACTION属性、一个名为j_username的用户名文本字段以及一个名为j_password的口令字段。
例如,程序清单5-19指示服务器使用基于表单的验证。Web应用的顶层目录中的一个名为login.jsp的页面将收集用户名和口令,并且失败的登陆将由相同目录中名为login-error.jsp的页面报告。
程序清单5-19 web.xml(说明login-config的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"
http://java.sun.com/dtd/web-app_2_3.dtd
">
<web-app>
<!-- ... -->
<security-constraint> ... </security-constraint>
<login-config>
<auth-method> FORM </auth-method>
<form-login-config>
<form-login-page>/login.jsp</form-login-page>
<form-error-page>/login-error.jsp</form-error-page>
</form-login-config>
</login-config>
<!-- ... -->
</web-app>
9.2 限制对Web资源的访问
现在,可以指示服务器使用何种验证方法了。"了不起,"你说道,"除非我能指定一个来收到保护的 URL,否则没有多大用处。"没错。指出这些URL并说明他们应该得到何种保护正是security-constriaint元素的用途。此元素在 web.xml中应该出现在login-config的紧前面。它包含是个可能的子元素,分别是:web-resource-collection、 auth-constraint、user-data-constraint和display-name。下面各小节对它们进行介绍。
l web-resource-collection
此元素确定应该保护的资源。所有security-constraint元素都必须包含至少一个web-resource-collection项。此元素由一个给出任意标识名称的web-resource-name元素、一个确定应该保护的URL的url-pattern元素、一个指出此保护所适用的 HTTP命令(GET、POST等,缺省为所有方法)的http-method元素和一个提供资料的可选description元素组成。例如,下面的 Web-resource-collection项(在security-constratint元素内)指出Web应用的proprietary目录中所有文档应该受到保护。
<security-constraint>
<web-resource-coolection>
<web-resource-name>Proprietary</web-resource-name>
<url-pattern>/propritary/*</url-pattern>
</web-resource-coolection>
<!-- ... -->
</security-constraint>
重要的是应该注意到,url-pattern仅适用于直接访问这些资源的客户机。特别是,它不适合于通过MVC体系结构利用 RequestDispatcher来访问的页面,或者不适合于利用类似jsp:forward的手段来访问的页面。这种不匀称如果利用得当的话很有好处。例如,servlet可利用MVC体系结构查找数据,把它放到bean中,发送请求到从bean中提取数据的JSP页面并显示它。我们希望保证决不直接访问受保护的JSP页面,而只是通过建立该页面将使用的bean的servlet来访问它。url-pattern和auth-contraint元素可通过声明不允许任何用户直接访问JSP页面来提供这种保证。但是,这种不匀称的行为可能让开发人员放松警惕,使他们偶然对应受保护的资源提供不受限制的访问。
l auth-constraint
尽管web-resource-collention元素质出了哪些URL应该受到保护,但是auth-constraint元素却指出哪些用户应该具有受保护资源的访问权。此元素应该包含一个或多个标识具有访问权限的用户类别role- name元素,以及包含(可选)一个描述角色的description元素。例如,下面web.xml中的security-constraint元素部门规定只有指定为Administrator或Big Kahuna(或两者)的用户具有指定资源的访问权。
<security-constraint>
<web-resource-coolection> ... </web-resource-coolection>
<auth-constraint>
<role-name>administrator</role-name>
<role-name>kahuna</role-name>
</auth-constraint>
</security-constraint>
重要的是认识到,到此为止,这个过程的可移植部分结束了。服务器怎样确定哪些用户处于任何角色以及它怎样存放用户的口令,完全有赖于具体的系统。
例如,Tomcat使用install_dir/conf/tomcat-users.xml将用户名与角色名和口令相关联,正如下面例子中所示,它指出用户joe(口令bigshot)和jane(口令enaj)属于administrator和kahuna角色。
<tomcat-users>
<user name="joe" password="bigshot" roles="administrator,kahuna" />
<user name="jane" password="enaj" roles="kahuna" />
</tomcat-users>
l user-data-constraint
这个可选的元素指出在访问相关资源时使用任何传输层保护。它必须包含一个transport-guarantee子元素(合法值为NONE、 INTEGRAL或CONFIDENTIAL),并且可选地包含一个description元素。transport-guarantee为NONE值将对所用的通讯协议不加限制。INTEGRAL值表示数据必须以一种防止截取它的人阅读它的方式传送。虽然原理上(并且在未来的HTTP版本中),在 INTEGRAL和CONFIDENTIAL之间可能会有差别,但在当前实践中,他们都只是简单地要求用SSL。例如,下面指示服务器只允许对相关资源做 HTTPS连接:
<security-constraint>
<!-- ... -->
<user-data-constraint>
<transport-guarantee>CONFIDENTIAL</transport-guarantee>
</user-data-constraint>
</security-constraint>
l display-name
security-constraint的这个很少使用的子元素给予可能由GUI工具使用的安全约束项一个名称。
9.3 分配角色名
迄今为止,讨论已经集中到完全由容器(服务器)处理的安全问题之上了。但servlet以及JSP页面也能够处理它们自己的安全问题。
例如,容器可能允许用户从bigwig或bigcheese角色访问一个显示主管人员额外紧贴的页面,但只允许bigwig用户修改此页面的参数。完成这种更细致的控制的一种常见方法是调用HttpServletRequset的isUserInRole方法,并据此修改访问。
Servlet的 security-role-ref子元素提供出现在服务器专用口令文件中的安全角色名的一个别名。例如,假如编写了一个调用 request.isUserInRole("boss")的servlet,但后来该servlet被用在了一个其口令文件调用角色manager而不是boss的服务器中。下面的程序段使该servlet能够使用这两个名称中的任何一个。
<servlet>
<!-- ... -->
<security-role-ref>
<role-name>boss</role-name> <!-- New alias -->
<role-link>manager</role-link> <!-- Real name -->
</security-role-ref>
</servlet>
也可以在web-app内利用security-role元素提供将出现在role-name元素中的所有安全角色的一个全局列表。分别地生命角色使高级IDE容易处理安全信息。
10 控制会话超时
如果某个会话在一定的时间内未被访问,服务器可把它扔掉以节约内存。可利用HttpSession的setMaxInactiveInterval方法直接设置个别会话对象的超时值。如果不采用这种方法,则缺省的超时值由具体的服务器决定。但可利用session-config和session- timeout元素来给出一个适用于所有服务器的明确的超时值。超时值的单位为分钟,因此,下面的例子设置缺省会话超时值为三个小时(180分钟)。
<session-config>
<session-timeout>180</session-timeout>
</session-config>
11 Web应用的文档化
越来越多的开发环境开始提供servlet和JSP的直接支持。例子有Borland Jbuilder Enterprise Edition、Macromedia UltraDev、Allaire JRun Studio(写此文时,已被Macromedia收购)以及IBM VisuaAge for Java等。
大量的web.xml元素不仅是为服务器设计的,而且还是为可视开发环境设计的。它们包括icon、display-name和discription等。
可回忆一下,在web.xml内以适当地次序声明web-app子元素很重要。不过,这里只要记住icon、display-name和description是web.xml的web-app元素内的前三个合法元素即可。
l icon
icon元素指出GUI工具可用来代表Web应用的一个和两个图像文件。可利用small-icon元素指定一幅16 x 16的GIF或JPEG图像,用large-icon元素指定一幅32 x 32的图像。下面举一个例子:
<icon>
<small-icon>/images/small-book.gif</small-icon>
<large-icon>/images/tome.jpg</large-icon>
</icon>
l display-name
display-name元素提供GUI工具可能会用来标记此Web应用的一个名称。下面是个例子。
<display-name>Rare Books</display-name>
l description
description元素提供解释性文本,如下所示:
<description>
This Web application represents the store developed for
rare-books.com, an online bookstore specializing in rare
and limited-edition books.
</description>
12 关联文件与MIME类型
服务器一般都具有一种让Web站点管理员将文件扩展名与媒体相关联的方法。例如,将会自动给予名为mom.jpg的文件一个image/jpeg的MIME 类型。但是,假如你的Web应用具有几个不寻常的文件,你希望保证它们在发送到客户机时分配为某种MIME类型。mime-mapping元素(具有 extension和mime-type子元素)可提供这种保证。例如,下面的代码指示服务器将application/x-fubar的MIME类型分配给所有以.foo结尾的文件。
<mime-mapping>
<extension>foo</extension>
<mime-type>application/x-fubar</mime-type>
</mime-mapping>
或许,你的Web应用希望重载(override)标准的映射。例如,下面的代码将告诉服务器在发送到客户机时指定.ps文件作为纯文本(text/plain)而不是作为PostScript(application/postscript)。
<mime-mapping>
<extension>ps</extension>
<mime-type>application/postscript</mime-type>
</mime-mapping>
13 定位TLD
JSP taglib元素具有一个必要的uri属性,它给出一个TLD(Tag Library Descriptor)文件相对于Web应用的根的位置。TLD文件的实际名称在发布新的标签库版本时可能会改变,但我们希望避免更改所有现有JSP页面。此外,可能还希望使用保持taglib元素的简练性的一个简短的uri。这就是部署描述符文件的taglib元素派用场的所在了。Taglib包含两个子元素:taglib-uri和taglib-location。taglib-uri元素应该与用于JSP taglib元素的uri属性的东西相匹配。Taglib-location元素给出TLD文件的实际位置。例如,假如你将文件chart-tags- 1.3beta.tld放在WebApp/WEB-INF/tlds中。现在,假如web.xml在web-app元素内包含下列内容。
<taglib>
<taglib-uri>/charts.tld</taglib-uri>
<taglib-location>
/WEB-INF/tlds/chart-tags-1.3beta.tld
</taglib-location>
</taglib>
给出这个说明后,JSP页面可通过下面的简化形式使用标签库。
<%@ taglib uri="/charts.tld" prefix="somePrefix" %>
14 指定应用事件监听程序
应用事件监听器程序是建立或修改servlet环境或会话对象时通知的类。它们是servlet规范的版本2.3中的新内容。这里只简单地说明用来向Web应用注册一个监听程序的web.xml的用法。
注册一个监听程序涉及在web.xml的web-app元素内放置一个listener元素。在listener元素内,listener-class元素列出监听程序的完整的限定类名,如下所示:
<listener>
<listener-class>package.ListenerClass</listener-class>
</listener>
虽然listener元素的结构很简单,但请不要忘记,必须正确地给出web-app元素内的子元素的次序。listener元素位于所有的servlet 元素之前以及所有filter-mapping元素之后。此外,因为应用生存期监听程序是serlvet规范的2.3版本中的新内容,所以必须使用 web.xml DTD的2.3版本,而不是2.2版本。
例如,程序清单5-20给出一个名为ContextReporter的简单的监听程序,只要Web应用的Servlet-Context建立(如装载Web应用)或消除(如服务器关闭)时,它就在标准输出上显示一条消息。程序清单5-21给出此监听程序注册所需要的web.xml文件的一部分。
程序清单5-20 ContextReporterjava
package moreservlets;
import javax.servlet.*;
import java.util.*;
/** Simple listener that prints a report on the standard output
* when the ServletContext is created or destroyed.
* <P>
* Taken from More Servlets and JavaServer Pages
* from Prentice Hall and Sun Microsystems Press,
*
http://www.moreservlets.com/.
* © 2002 Marty Hall; may be freely used or adapted.
*/
public class ContextReporter implements ServletContextListener {
public void contextInitialized(ServletContextEvent event) {
System.out.println("Context created on " +
new Date() + ".");
}
public void contextDestroyed(ServletContextEvent event) {
System.out.println("Context destroyed on " +
new Date() + ".");
}
}
程序清单5-21 web.xml(声明一个监听程序的摘录)
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"
http://java.sun.com/dtd/web-app_2_3.dtd
">
<web-app>
<!-- ... -->
<filter-mapping> … </filter-mapping>
<listener>
<listener-class>package.ListenerClass</listener-class>
</listener>
<servlet> ... </servlet>
<!-- ... -->
</web-app>
15 J2EE元素
本节描述用作J2EE环境组成部分的Web应用的web.xml元素。这里将提供一个简明的介绍,详细内容可以参阅
http://java.sun.com/j2ee/j2ee-1_3-fr-spec.pdf
的Java 2 Plantform Enterprise Edition版本1.3规范的第5章。
l distributable
distributable 元素指出,Web应用是以这样的方式编程的:即,支持集群的服务器可安全地在多个服务器上分布Web应用。例如,一个可分布的应用必须只使用 Serializable对象作为其HttpSession对象的属性,而且必须避免用实例变量(字段)来实现持续性。distributable元素直接出现在discription元素之后,并且不包含子元素或数据,它只是一个如下的标志。
<distributable />
l resource-env-ref
resource -env-ref元素声明一个与某个资源有关的管理对象。此元素由一个可选的description元素、一个resource-env-ref- name元素(一个相对于java:comp/env环境的JNDI名)以及一个resource-env-type元素(指定资源类型的完全限定的类),如下所示:
<resource-env-ref>
<resource-env-ref-name>
jms/StockQueue
</resource-env-ref-name>
<resource-env-ref-type>
javax.jms.Queue
</resource-env-ref-type>
</resource-env-ref>
l env-entry
env -entry元素声明Web应用的环境项。它由一个可选的description元素、一个env-entry-name元素(一个相对于java: comp/env环境JNDI名)、一个env-entry-value元素(项值)以及一个env-entry-type元素(java.lang程序包中一个类型的完全限定类名,java.lang.Boolean、java.lang.String等)组成。下面是一个例子:
<env-entry>
<env-entry-name>minAmout</env-entry-name>
<env-entry-value>100.00</env-entry-value>
<env-entry-type>minAmout</env-entry-type>
</env-entry>
l ejb-ref
ejb -ref元素声明对一个EJB的主目录的应用。它由一个可选的description元素、一个ejb-ref-name元素(相对于java: comp/env的EJB应用)、一个ejb-ref-type元素(bean的类型,Entity或Session)、一个home元素(bean的主目录接口的完全限定名)、一个remote元素(bean的远程接口的完全限定名)以及一个可选的ejb-link元素(当前bean链接的另一个 bean的名称)组成。
l ejb-local-ref
ejb-local-ref元素声明一个EJB的本地主目录的引用。除了用local-home代替home外,此元素具有与ejb-ref元素相同的属性并以相同的方式使用。
posted @
2006-08-10 15:12 xzc 阅读(1401) |
评论 (0) |
编辑 收藏
在分析web.xml文档之前我想先说一下web.xml中根元素<web-app>各子元素的顺序问题,因为在web.xml中元素定义的先后顺序是不能颠倒的(除非在web.xml文件中使用XML Schema,本文不做讨论),否则Tomcat服务器可能抛出SAXParseException。
顺序如下:
<web-app>
<display-name>
<description>
<distributable>
<context-param>
<filter>
<filter-mapping>
<listener>
<servlet>
<servlet-mapping>
<session-config>
<mime-mapping>
<welcome-file-list>
<error-page>
<taglib>
<resource-env-ref>
<resource-ref>
<security-constraint>
<login-config>
<security-role>
<env-entry>
<ejb-ref>
<ejb-local-ref>
web.xml中的开头几行是固定的,它定义了该文件的字符编码,XML版本以及引用的DTD文件。
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
在web.xml中顶层元素为<web-app>,其他所有的子元素都必须定义在<web-app>内
<display-name>元素定义这个web应用的名字,Java Web 服务器的Web管理工具将用这个名字来标志Web应用。
<description>元素用来声明Web应用的描述信息
<context-param>元素用来配置外部引用的,在servlet中如果要获得该元素中配置的值,String param-value = getServletContext().getInitParameter("param-name")
<filter>
<filter-name>SampleFilter</filter-name>
<filter-class>com.lpdev.SampleFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>SampleFilter</filter-name>
<url-pattern>*.jsp</url-pattern>
</filter-mapping>
以上是配置了一个servlet过滤器,对于servlet容器收到的客户请求以及发出的响应结果,servlet都能检查和修改其中的信息,以上代码指名当客户请求访问Web应用中的所有JSP文件时,将触发SampleFilter过滤器工作,具体的过滤事务在由<filter-class>中指定的类来完成
<servlet>
<servlet-name>IncludeServlet</servlet-name>
<servlet-class>com.lpdev.IncludeServlet</servlet-class>
<init-param>
<param-name>copyright</param-name>
<param-value>/foot.jspf</param-value>
<load-on-startup>1</load-on-startup>
</init-param>
</servlet>
配置Servlet,<servlet-name>是servlet的名字,<servlet-class>是实现这个Servlet的类,<init-param>定义Servlet的初始化参数(参数名和参数值),一个Servlet可以有多个<init-param>,在Servlet类中通过getInitParameter(String name)方法访问初始化参数
<servlet-mapping>
<servlet-name>IncludeServlet</servlet-name>
<url-pattern>/IncludeServlet</url-pattern>
</servlet-mapping>
配置Servlet映射,<servlet-mapping>元素用来设定客户访问某个Servlet的URL,这里只需给出对于整个web应用的相对的URL路径,<url-pattern>中的“/”表示开始于Web应用的根目录例如,如果你在你本地机器上使用Tomcat4.1.x,并且创建了名为“myapp”的应用程序,<url-pattern>/IncludeServlet</url-pattern>该Servlet的完整web地址就是http://localhost:8080/myapp/IncludeServlet
<session-config>元素用来设定HttpSession的生命周期,该元素只有一个<session-timeout>属性,时间单位是“秒”。
<welcome-file-list>当用户访问web时,如果仅仅给出web应用的Root URL,没有指定具体文件名,容器调用该配置,该元素可以包含多个<welcome-file>属性。
<taglib>元素用来设置web引用的tag library,例示定义了一个“/mytaglib”标签库,它对应的tld文件为:/WEB_INF/mytaglib.tld
<taglib>
<taglib-url>/mytaglib</taglib-url>
<taglib-locationg>/WEB-INF/mytaglib.tld</taglib-location>
</taglib>
<resource-ref>如果web应用由Servlet容器管理的某个JNDI Resource,必须在web.xml中声明对这个JNDI Resource的引用。
<resource-ref>
<description>DB Connection</description> //说明
<res-ref-name>jdbc/sampleDB</res-ref-name> //引用资源的JNDI名字
<res-type>javax.sql.DataSource</res-type> //引用资源的类名字
<res-auth>Container</res-auth> //管理引用资源的Manager
</resource-ref>
<security-constraint>用来为Web应用定义安全约束
<security-constraint>
<web-resource-collection>//声明受保护的web资源
<web-resource-name>ResourceServlet</web-resource-name>//标识受保护web资源
<url-pattern>/ResourceServlet</url-pattern>//指定受保护的URL路径
<http-method>GET</http-method>//指定受保护的方法
<http-method>POST</http-method>
</web-resource-collection>
<auth-constraint>//可以访问受保护资源的角色
<description>this applies only to admin secrity role</description>
<role-name>admin</role-name>
</auth-constraint>
<user-data-constraint>
<transport-guarantee>NONE</transport-guarantee>
</user-data-constraint>
</security-constraint>
<login-config>元素指定当Web客户访问受保护资源时,系统弹出的登陆对话框的类型。例示配置了基于表单验证的登陆界面
<login-config>
<auth-method>FORM</auth-method>//BASIC(基本验证法),DIGEST(摘要验证),FORM(表单验证)
<real-name>设定安全域的名称</realname>
<form-login-config>
<form-login-page>/login.jsp</form-login-page>
<form-error-page>/error.jsp</form-error-page>
</form-login-config>
<security-role>指明这个Web应用引用的所有角色名字
<security-role>
<description>描述</description>
<role-name>admin</role-name>
</security-role>
posted @
2006-08-10 15:10 xzc 阅读(2398) |
评论 (0) |
编辑 收藏
 <!--
<!--
var doc = new ActiveXObject("Msxml2.DOMDocument"); //ie5.5+,CreateObject("Microsoft.XMLDOM")
//加载文档
//doc.load("b.xml");
//创建文件头
var p = doc.createProcessingInstruction("xml","version='1.0' encoding='gb2312'");
//添加文件头
doc.appendChild(p);
//用于直接加载时获得根接点
//var root = doc.documentElement;
//两种方式创建根接点
// var root = doc.createElement("students");
var root = doc.createNode(1,"students","");
//创建子接点
var n = doc.createNode(1,"ttyp","");
//指定子接点文本
//n.text = " this is a test";
//创建孙接点
var o = doc.createElement("sex");
o.text = "男"; //指定其文本
//创建属性
var r = doc.createAttribute("id");
r.value="test";
//添加属性
n.setAttributeNode(r);
//创建第二个属性
var r1 = doc.createAttribute("class");
r1.value="tt";
//添加属性
n.setAttributeNode(r1);
//删除第二个属性
n.removeAttribute("class");
//添加孙接点
n.appendChild(o);
//添加文本接点
n.appendChild(doc.createTextNode("this is a text node."));
//添加注释
n.appendChild(doc.createComment("this is a comment\n"));
//添加子接点
root.appendChild(n);
//复制接点
var m = n.cloneNode(true);
root.appendChild(m);
//删除接点
root.removeChild(root.childNodes(0));
//创建数据段
var c = doc.createCDATASection("this is a cdata");
c.text = "hi,cdata";
//添加数据段
root.appendChild(c);
//添加根接点
doc.appendChild(root);
//查找接点
var a = doc.getElementsByTagName("ttyp");
//var a = doc.selectNodes("//ttyp");
//显示改接点的属性
for(var i= 0;i<a.length;i++)


 {
{
 alert(a[i].xml);
alert(a[i].xml);
for(var j=0;j<a[i].attributes.length;j++)

 {
{
alert(a[i].attributes[j].name);
 }
}
 }
}
//修改节点,利用XPATH定位节点
var b = doc.selectSingleNode("//ttyp/sex");
b.text = "女";
//alert(doc.xml);
//XML保存(需要在服务端,客户端用FSO)
//doc.save();
//查看根接点XML
if(n)
{
alert(n.ownerDocument.xml);
}
//-->
</script>
7.4、文档对象模型(DOM)
文档对象模型(DOM)是表示文档(比如HTML和XML)和访问、操作构成文档的各种元素的应用程序接口(API)。一般的,支持Javascript的所有浏览器都支持DOM。本文所涉及的DOM,是指W3C定义的标准的文档对象模型,它以树形结构表示HTML和XML文档,定义了遍历这个树和检查、修改树的节点的方法和属性。
7.4.1、DOM眼中的HTML文档:树
在DOM眼中,HTML跟XML一样是一种树形结构的文档,<html>是根(root)节点,<head>、<title>、<body>是<html>的子(children)节点,互相之间是兄弟(sibling)节点;<body>下面才是子节点<table>、<span>、<p>等等。如下图:

这个是不是跟XML的结构有点相似呢。不同的是,HTML文档的树形主要包含表示元素、标记的节点和表示文本串的节点。
7.4.2、HTML文档的节点
DOM下,HTML文档各个节点被视为各种类型的Node对象。每个Node对象都有自己的属性和方法,利用这些属性和方法可以遍历整个文档树。由于HTML文档的复杂性,DOM定义了nodeType来表示节点的类型。这里列出Node常用的几种节点类型:
| 接口 | nodeType常量 | nodeType值 | 备注 |
| Element | Node.ELEMENT_NODE | 1 | 元素节点 |
| Text | Node.TEXT_NODE | 3 | 文本节点 |
| Document | Node.DOCUMENT_NODE | 9 | document |
| Comment | Node.COMMENT_NODE | 8 | 注释的文本 |
| DocumentFragment | Node.DOCUMENT_FRAGMENT_NODE | 11 | document片断 |
| Attr | Node.ATTRIBUTE_NODE | 2 | 节点属性 |
DOM树的根节点是个Document对象,该对象的documentElement属性引用表示文档根元素的Element对象(对于HTML文档,这个就是<html>标记)。Javascript操作HTML文档的时候,document即指向整个文档,<body>、<table>等节点类型即为Element。Comment类型的节点则是指文档的注释。具体节点类型的含义,请参考《Javascript权威指南》,在此不赘述。
Document定义的方法大多数是生产型方法,主要用于创建可以插入文档中的各种类型的节点。常用的Document方法有:
| 方法 | 描述 |
| createAttribute() | 用指定的名字创建新的Attr节点。 |
| createComment() | 用指定的字符串创建新的Comment节点。 |
| createElement() | 用指定的标记名创建新的Element节点。 |
| createTextNode() | 用指定的文本创建新的TextNode节点。 |
| getElementById() | 返回文档中具有指定id属性的Element节点。 |
| getElementsByTagName() | 返回文档中具有指定标记名的所有Element节点。 |
对于Element节点,可以通过调用getAttribute()、setAttribute()、removeAttribute()方法来查询、设置或者删除一个Element节点的性质,比如<table>标记的border属性。下面列出Element常用的属性:
| 属性 | 描述 |
| tagName | 元素的标记名称,比如<p>元素为P。HTML文档返回的tabName均为大写。 |
Element常用的方法:
| 方法 | 描述 |
| getAttribute() | 以字符串形式返回指定属性的值。 |
| getAttributeNode() | 以Attr节点的形式返回指定属性的值。 |
| getElementsByTabName() | 返回一个Node数组,包含具有指定标记名的所有Element节点的子孙节点,其顺序为在文档中出现的顺序。 |
| hasAttribute() | 如果该元素具有指定名字的属性,则返回true。 |
| removeAttribute() | 从元素中删除指定的属性。 |
| removeAttributeNode() | 从元素的属性列表中删除指定的Attr节点。 |
| setAttribute() | 把指定的属性设置为指定的字符串值,如果该属性不存在则添加一个新属性。 |
| setAttributeNode() | 把指定的Attr节点添加到该元素的属性列表中。 |
Attr对象代表文档元素的属性,有name、value等属性,可以通过Node接口的attributes属性或者调用Element接口的getAttributeNode()方法来获取。不过,在大多数情况下,使用Element元素属性的最简单方法是getAttribute()和setAttribute()两个方法,而不是Attr对象。
7.4.3、使用DOM操作HTML文档
Node对象定义了一系列属性和方法,来方便遍历整个文档。用parentNode属性和childNodes[]数组可以在文档树中上下移动;通过遍历childNodes[]数组或者使用firstChild和nextSibling属性进行循环操作,也可以使用lastChild和previousSibling进行逆向循环操作,也可以枚举指定节点的子节点。而调用appendChild()、insertBefore()、removeChild()、replaceChild()方法可以改变一个节点的子节点从而改变文档树。
需要指出的是,childNodes[]的值实际上是一个NodeList对象。因此,可以通过遍历childNodes[]数组的每个元素,来枚举一个给定节点的所有子节点;通过递归,可以枚举树中的所有节点。下表列出了Node对象的一些常用属性和方法:
Node对象常用属性:
| 属性 | 描述 |
| attributes | 如果该节点是一个Element,则以NamedNodeMap形式返回该元素的属性。 |
| childNodes | 以Node[]的形式存放当前节点的子节点。如果没有子节点,则返回空数组。 |
| firstChild | 以Node的形式返回当前节点的第一个子节点。如果没有子节点,则为null。 |
| lastChild | 以Node的形式返回当前节点的最后一个子节点。如果没有子节点,则为null。 |
| nextSibling | 以Node的形式返回当前节点的兄弟下一个节点。如果没有这样的节点,则返回null。 |
| nodeName | 节点的名字,Element节点则代表Element的标记名称。 |
| nodeType | 代表节点的类型。 |
| parentNode | 以Node的形式返回当前节点的父节点。如果没有父节点,则为null。 |
| previousSibling | 以Node的形式返回紧挨当前节点、位于它之前的兄弟节点。如果没有这样的节点,则返回null。 |
Node对象常用方法:
| 方法 | 描述 |
| appendChild() | 通过把一个节点增加到当前节点的childNodes[]组,给文档树增加节点。 |
| cloneNode() | 复制当前节点,或者复制当前节点以及它的所有子孙节点。 |
| hasChildNodes() | 如果当前节点拥有子节点,则将返回true。 |
| insertBefore() | 给文档树插入一个节点,位置在当前节点的指定子节点之前。如果该节点已经存在,则删除之再插入到它的位置。 |
| removeChild() | 从文档树中删除并返回指定的子节点。 |
| replaceChild() | 从文档树中删除并返回指定的子节点,用另一个节点替换它。 |
接下来,让我们使用上述的DOM应用编程接口,来试着操作HTML文档。
posted @
2006-06-22 12:28 xzc 阅读(972) |
评论 (0) |
编辑 收藏
posted @
2006-06-22 12:23 xzc 阅读(260) |
评论 (0) |
编辑 收藏