原文链接:http://www.cnblogs.com/juandx/p/4962089.html
python中对文件、文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块。
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split()
eg os.path.split(‘/home/swaroop/byte/code/poem.txt’)
结果:(‘/home/swaroop/byte/code’, ‘poem.txt’)
分离扩展名:os.path.splitext()
获取路径名:os.path.dirname()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取和设置环境变量:os.getenv() 与os.putenv()
给出当前平台使用的行终止符:os.linesep Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’
指示你正在使用的平台:os.name 对于Windows,它是’nt’,而对于Linux/Unix用户,它是’posix’
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
终止当前进程:os.exit()
获取文件大小:os.path.getsize(filename)
文件操作:
os.mknod(“test.txt”) 创建空文件
fp = open(“test.txt”,w) 直接打开一个文件,如果文件不存在则创建文件
关于open 模式:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
fp.read([size]) #size为读取的长度,以byte为单位
fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
fp.flush() #把缓冲区的内容写入硬盘
fp.fileno() #返回一个长整型的”文件标签“
fp.isatty() #文件是否是一个终端设备文件(unix系统中的)
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
目录操作:
os.mkdir(“file”) 创建目录
复制文件:
shutil.copyfile(“oldfile”,”newfile”) oldfile和newfile都只能是文件
shutil.copy(“oldfile”,”newfile”) oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
复制文件夹:
shutil.copytree(“olddir”,”newdir”) olddir和newdir都只能是目录,且newdir必须不存在
重命名文件(目录)
os.rename(“oldname”,”newname”) 文件或目录都是使用这条命令
移动文件(目录)
shutil.move(“oldpos”,”newpos”)
删除文件
os.remove(“file”)
删除目录
os.rmdir(“dir”)只能删除空目录
shutil.rmtree(“dir”) 空目录、有内容的目录都可以删
转换目录
os.chdir(“path”) 换路径
Python读写文件
1.open
使用open打开文件后一定要记得调用文件对象的close()方法。比如可以用try/finally语句来确保最后能关闭文件。
file_object = open(‘thefile.txt’)
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法。
2.读文件
读文本文件
input = open('data', 'r')
#第二个参数默认为r
input = open('data')
1
2
3
读二进制文件
input = open('data', 'rb')
1
读取所有内容
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
1
2
3
4
5
读固定字节
file_object = open('abinfile', 'rb')
try:
while True:
chunk = file_object.read(100)
if not chunk:
break
do_something_with(chunk)
finally:
file_object.close( )
1
2
3
4
5
6
7
8
9
读每行
list_of_all_the_lines = file_object.readlines( )
1
如果文件是文本文件,还可以直接遍历文件对象获取每行:
for line in file_object:
process line
1
2
3.写文件
写文本文件
output = open('data', 'w')
1
写二进制文件
output = open('data', 'wb')
1
追加写文件
output = open('data', 'w+')
1
写数据
file_object = open('thefile.txt', 'w')
file_object.write(all_the_text)
file_object.close( )
1
2
3
写入多行
file_object.writelines(list_of_text_strings)
1
注意,调用writelines写入多行在性能上会比使用write一次性写入要高。
在处理日志文件的时候,常常会遇到这样的情况:日志文件巨大,不可能一次性把整个文件读入到内存中进行处理,例如需要在一台物理内存为 2GB 的机器上处理一个 2GB 的日志文件,我们可能希望每次只处理其中 200MB 的内容。
在 Python 中,内置的 File 对象直接提供了一个 readlines(sizehint) 函数来完成这样的事情。以下面的代码为例:
file = open('test.log', 'r')sizehint = 209715200 # 200Mposition = 0lines = file.readlines(sizehint)while not file.tell() - position < 0: position = file.tell() lines = file.readlines(sizehint)
1
每次调用 readlines(sizehint) 函数,会返回大约 200MB 的数据,而且所返回的必然都是完整的行数据,大多数情况下,返回的数据的字节数会稍微比 sizehint 指定的值大一点(除最后一次调用 readlines(sizehint) 函数的时候)。通常情况下,Python 会自动将用户指定的 sizehint 的值调整成内部缓存大小的整数倍。
file在python是一个特殊的类型,它用于在python程序中对外部的文件进行操作。在python中一切都是对象,file也不例外,file有file的方法和属性。下面先来看如何创建一个file对象:
file(name[, mode[, buffering]])
1
file()函数用于创建一个file对象,它有一个别名叫open(),可能更形象一些,它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。name是文件的名字。
mode是打开的模式,可选的值为r w a U,分别代表读(默认) 写 添加支持各种换行符的模式。用w或a模式打开文件的话,如果文件不存在,那么就自动创建。此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清空,因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。由于历史的原因,换行符在不同的系统中有不同模式,比如在 unix中是一个\n,而在windows中是‘\r\n’,用U模式打开文件,就是支持所有的换行模式,也就说‘\r’ ‘\n’ ‘\r\n’都可表示换行,会有一个tuple用来存贮这个文件中用到过的换行符。不过,虽说换行有多种模式,读到python中统一用\n代替。在模式字符的后面,还可以加上+ b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
buffering如果为0表示不进行缓冲;如果为1表示进行“行缓冲“;如果是一个大于1的数表示缓冲区的大小,应该是以字节为单位的。
file对象有自己的属性和方法。先来看看file的属性。
closed #标记文件是否已经关闭,由close()改写
encoding #文件编码
mode #打开模式
name #文件名
newlines #文件中用到的换行模式,是一个tuple
softspace #boolean型,一般为0,据说用于print
1
2
3
4
5
6
file的读写方法:
F.read([size]) #size为读取的长度,以byte为单位
F.readline([size])
#读一行,如果定义了size,有可能返回的只是一行的一部分
F.readlines([size])
#把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
F.write(str)
#把str写到文件中,write()并不会在str后加上一个换行符
F.writelines(seq)
#把seq的内容全部写到文件中。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
file的其他方法:
F.close()
#关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。如果一个文件在关闭后还对其进行操作会产生ValueError
F.flush()
#把缓冲区的内容写入硬盘
F.fileno()
#返回一个长整型的”文件标签“
F.isatty()
#文件是否是一个终端设备文件(unix系统中的)
F.tell()
#返回文件操作标记的当前位置,以文件的开头为原点
F.next()
#返回下一行,并将文件操作标记位移到下一行。把一个file用于for ... in file这样的语句时,就是调用next()函数来实现遍历的。
F.seek(offset[,whence])
#将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
F.truncate([size])
#把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
http://www.cnblogs.com/allenblogs/archive/2010/09/13/1824842.html
http://www.cnblogs.com/rollenholt/archive/2012/04/23/2466179.html
首先 dfs.replication这个参数是个client参数,即node level参数。需要在每台datanode上设置。
其实默认为3个副本已经够用了,设置太多也没什么用。
一个文件,上传到hdfs上时指定的是几个副本就是几个。以后你修改了副本数,对已经上传了的文件也不会起作用。可以再上传文件的同时指定创建的副本数
Hadoop dfs -D dfs.replication=1 -put 70M logs/2
可以通过命令来更改已经上传的文件的副本数:
hadoop fs -setrep -R 3 /
查看当前hdfs的副本数
hadoop fsck -locations
FSCK started by hadoop from /172.18.6.112 for path / at Thu Oct 27 13:24:25 CST 2011
....................Status: HEALTHY
Total size: 4834251860 B
Total dirs: 21
Total files: 20
Total blocks (validated): 82 (avg. block size 58954290 B)
Minimally replicated blocks: 82 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Thu Oct 27 13:24:25 CST 2011 in 10 milliseconds
The filesystem under path '/' is HEALTHY
某个文件的副本数,可以通过ls中的文件描述符看到
hadoop dfs -ls
-rw-r--r-- 3 hadoop supergroup 153748148 2011-10-27 16:11 /user/hadoop/logs/201108/impression_witspixel2011080100.thin.log.gz
如果你只有3个datanode,但是你却指定副本数为4,是不会生效的,因为每个datanode上只能存放一个副本。
参考:http://blog.csdn.net/lskyne/article/details/8898666
转自:https://www.cnblogs.com/shabbylee/p/6792555.html
由于历史原因,Python有两个大的版本分支,Python2和Python3,又由于一些库只支持某个版本分支,所以需要在电脑上同时安装Python2和Python3,因此如何让两个版本的Python兼容,如何让脚本在对应的Python版本上运行,这个是值得总结的。
对于Ubuntu 16.04 LTS版本来说,Python2(2.7.12)和Python3(3.5.2)默认同时安装,默认的python版本是2.7.12。
当然你也可以用python2来调用。
如果想调用python3,就用python3.
对于Windows,就有点复杂了。因为不论python2还是python3,python可执行文件都叫python.exe,在cmd下输入python得到的版本号取决于环境变量里哪个版本的python路径更靠前,毕竟windows是按照顺序查找的。比如环境变量里的顺序是这样的:
那么cmd下的python版本就是2.7.12。
反之,则是python3的版本号。
这就带来一个问题了,如果你想用python2运行一个脚本,一会你又想用python3运行另一个脚本,你怎么做?来回改环境变量显然很麻烦。
网上很多办法比较简单粗暴,把两个python.exe改名啊,一个改成python2.exe,一个改成python3.exe。这样做固然可以,但修改可执行文件的方式,毕竟不是很好的方法。
我仔细查找了一些python技术文档,发现另外一个我觉得比较好的解决办法。
借用py的一个参数来调用不同版本的Python。py -2调用python2,py -3调用的是python3.
当python脚本需要python2运行时,只需在脚本前加上,然后运行py xxx.py即可。
#! python2
当python脚本需要python3运行时,只需在脚本前加上,,然后运行py xxx.py即可。
#! python3
就这么简单。
同时,这也完美解决了在pip在python2和python3共存的环境下报错,提示Fatal error in launcher: Unable to create process using '"'的问题。
当需要python2的pip时,只需
py -2 -m pip install xxx
当需要python3的pip时,只需
py -3 -m pip install xxx
python2和python3的pip package就这样可以完美分开了。
Sentry权限控制通过Beeline(Hiveserver2 SQL 命令行接口)输入Grant 和 Revoke语句来配置。语法跟现在的一些主流的关系数据库很相似。需要注意的是:当sentry服务启用后,我们必须使用beeline接口来执行hive查询,Hive Cli并不支持sentry。
CREATE ROLE Statement
CREATE ROLE语句创建一个可以被赋权的角色。权限可以赋给角色,然后再分配给各个用户。一个用户被分配到角色后可以执行该角色的权限。
只有拥有管理员的角色可以create/drop角色。默认情况下,hive、impala和hue用户拥有管理员角色。
CREATE ROLE [role_name];
DROP ROLE Statement
DROP ROLE语句可以用来从数据库中移除一个角色。一旦移除,之前分配给所有用户的该角色将会取消。之前已经执行的语句不会受到影响。但是,因为hive在执行每条查询语句之前会检查用户的权限,处于登录活跃状态的用户会话会受到影响。
DROP ROLE [role_name];
GRANT ROLE Statement
GRANT ROLE语句可以用来给组授予角色。只有sentry的管理员用户才能执行该操作。
GRANT ROLE role_name [, role_name]
TO GROUP (groupName) [,GROUP (groupName)]
REVOKE ROLE Statement
REVOKE ROLE语句可以用来从组移除角色。只有sentry的管理员用户才能执行该操作。
REVOKE ROLE role_name [, role_name]
FROM GROUP (groupName) [,GROUP (groupName)]
GRANT (PRIVILEGE) Statement
授予一个对象的权限给一个角色,该用户必须为sentry的管理员用户。
GRANT
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
TO ROLE (roleName) [,ROLE (roleName)]
REVOKE (PRIVILEGE) Statement
因为只有认证的管理员用户可以创建角色,从而只有管理员用户可以取消一个组的权限。
REVOKE
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
FROM ROLE (roleName) [,ROLE (roleName)]
GRANT (PRIVILEGE) ... WITH GRANT OPTION
在cdh5.2中,你可以委托给其他角色来授予和解除权限。比如,一个角色被授予了WITH GRANT OPTION的权限可以GRANT/REVOKE同样的权限给其他角色。因此,如果一个角色有一个库的所有权限并且设置了 WITH GRANT OPTION,该角色分配的用户可以对该数据库和其中的表执行GRANT/REVOKE语句。
GRANT
(PRIVILEGE)
ON (OBJECT) (object_name)
TO ROLE (roleName)
WITH GRANT OPTION
只有一个带GRANT选项的特殊权限的角色或者它的父级权限可以从其他角色解除这种权限。一旦下面的语句执行,所有跟其相关的grant权限将会被解除。
REVOKE
(RIVILEGE)
ON (BJECT) (bject_name)
FROM ROLE (roleName)
Hive目前不支持解除之前赋予一个角色 WITH GRANT OPTION 的权限。要想移除WITH GRANT OPTION、解除权限,可以重新去除 WITH GRANT OPTION这个标记来再次附权。
SET ROLE Statement
SET ROLE语句可以给当前会话选择一个角色使之生效。一个用户只能启用分配给他的角色。任何不存在的角色和当前用户不能使用的角色是不能生效的。如果没有使用任何角色,用户将会使用任何一个属于他的角色的权限。
选择一个角色使用:
To enable a specific role:
使用所有的角色:
To enable a specific role:
关闭所有角色
SET ROLE NONE;
SHOW Statement
显示当前用户拥有库、表、列相关权限的数据库:
SHOW DATABASES;
显示当前用户拥有表、列相关权限的表;
SHOW TABLES;
显示当前用户拥有SELECT权限的列:
SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name];
显示当前系统中所有的角色(只有管理员用户可以执行):
SHOW ROLES;
显示当前影响当前会话的角色:
SHOW CURRENT ROLES;
显示指定组的被分配到的所有角色(只有管理员用户和指定组内的用户可以执行)
SHOW ROLE GRANT GROUP (groupName);
SHOW语句可以用来显示一个角色被授予的权限或者显示角色的一个特定对象的所有权限。
显示指定角色的所有被赋予的权限。(只有管理员用户和指定角色分配到的用户可以执行)。下面的语句也会显示任何列级的权限。
SHOW GRANT ROLE (roleName);
显示指定对象的一个角色的所有被赋予的权限(只有管理员用户和指定角色分配到的用户可以执行)。下面的语句也会显示任何列级的权限。
SHOW GRANT ROLE (roleName) on (OBJECT) (objectName);
----------------------------我也是有底线的-----------------------------
摘要: Python 里面的编码和解码也就是 unicode 和 str 这两种形式的相互转化。编码是 unicode -> str,相反的,解码就是 str -> unicode。剩下的问题就是确定何时需要进行编码或者解码了.关于文件开头的"编码指示",也就是 # -*- codin...
摘要: 我们每次执行hive的hql时,shell里都会提示一段话:[python] view plaincopy... Number of reduce tasks not specified. Estimated from input data size: 50...
摘要: spark 累加历史主要用到了窗口函数,而进行全部统计,则需要用到rollup函数
1 应用场景:
1、我们需要统计用户的总使用时长(累加历史)
2、前台展现页面需要对多个维度进行查询,如:产品、地区等等
3、需要展现的表格头如: 产品、2015-04、2015-05、2015-06
2 原始数据:
product_code |event_date |dur...
摘要: Spark1.4发布,支持了窗口分析函数(window functions)。在离线平台中,90%以上的离线分析任务都是使用Hive实现,其中必然会使用很多窗口分析函数,如果SparkSQL支持窗口分析函数,
那么对于后面Hive向SparkSQL中的迁移的工作量会大大降低,使用方式如下:
1、初始化数据
创建表
[sql] view plain cop...
如果用传统SCP远程拷贝,速度是比较慢的。现在采用lz4压缩传输。LZ4是一个非常快的无损压缩算法,压缩速度在单核300MB/S,可扩展支持多核CPU。它还具有一个非常快速的解码器,速度单核可达到和超越1GB/S。通常能够达到多核系统上的RAM速度限制。
你PV 全命为Pipe Viewer,利用它我们可以查看到命令执行的进度。
下面介绍下lz4和pv的安装,下载软件:
下载pv-1.1.4.tar.gz wget http://sourceforge.jp/projects/sfnet_pipeviewer/downloads/pipeviewer/1.1.4/pv-1.1.4.tar.bz2/
下lz4的包难一些,可能要FQ:https://dl.dropboxusercontent.com/u/59565338/LZ4/lz4-r108.tar.gz
安装灰常简单:
pv安装:
[root ~]$ tar jxvf pv-1.1.4.tar.bz2
[root ~]$ cd pv-1.1.4
[root pv-1.1.4]$ ./configure && make && make install
lz4安装:
[root ~]$ tar zxvf lz4-r108.tar.gz
[root ~]$ cd lz4-r108
[root lz4-r108]$ make && make install
用法:(-c 后指定要传输的文件,ssh -p 是指定端口,后面的ip是目标主机的ip, -xC指定传到目标主机下的那个目录下,别的不用修改):
tar -c mysql-slave-3307 |pv|lz4 -B4|ssh -p10022 -c arcfour128 -o"MACs umac-64@openssh.com" 192.168.100.234 "lz4 -d |tar -xC /data"
下面是我线上传一个从库的效果:
看到了吧,25.7G 只需要接近3分钟,这样远比scp速度快上了好几倍,直接scp拷贝离散文件,很消耗IO,而使用LZ4快速压缩,对性能影响不大,传输速度快
PS:下次补充同机房不同网段的传输效果及跨机房的传输效果^0^
作者:陆炫志
出处:xuanzhi的博客 http://www.cnblogs.com/xuanzhi201111
您的支持是对博主最大的鼓励,感谢您的认真阅读。本文版权归作者所有,欢迎转载,但请保留该声明。
王 腾腾 和 邵 兵
2015 年 11 月 26 日发布
WeiboGoogle+用电子邮件发送本页面
Comments 1
引子
随着云时代的来临,大数据(Big data)也获得了越来越多的关注。著云台的分析师团队认为,大数据(Big data)通常用来形容一个公司创造的大量非结构化和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像 MapReduce 一样的框架来向数十、数百或甚至数千的电脑分配工作。
“大数据”在互联网行业指的是这样一种现象:互联网公司在日常运营中生成、累积的用户网络行为数据。这些数据的规模是如此庞大,以至于不能用 G 或 T 来衡量。所以如何高效的处理分析大数据的问题摆在了面前。对于大数据的处理优化方式有很多种,本文中主要介绍在使用 Hadoop 平台中对数据进行压缩处理来提高数据处理效率。
压缩简介
Hadoop 作为一个较通用的海量数据处理平台,每次运算都会需要处理大量数据,我们会在 Hadoop 系统中对数据进行压缩处理来优化磁盘使用率,提高数据在磁盘和网络中的传输速度,从而提高系统处理数据的效率。在使用压缩方式方面,主要考虑压缩速度和压缩文件的可分割性。综合所述,使用压缩的优点如下:
1. 节省数据占用的磁盘空间;
2. 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度。
压缩格式
Hadoop 对于压缩格式的是自动识别。如果我们压缩的文件有相应压缩格式的扩展名(比如 lzo,gz,bzip2 等)。Hadoop 会根据压缩格式的扩展名自动选择相对应的解码器来解压数据,此过程完全是 Hadoop 自动处理,我们只需要确保输入的压缩文件有扩展名。
Hadoop 对每个压缩格式的支持, 详细见下表:
表 1. 压缩格式
压缩格式 工具 算法 扩展名 多文件 可分割性
DEFLATE 无 DEFLATE .deflate 不 不
GZIP gzip DEFLATE .gzp 不 不
ZIP zip DEFLATE .zip 是 是,在文件范围内
BZIP2 bzip2 BZIP2 .bz2 不 是
LZO lzop LZO .lzo 不 是
如果压缩的文件没有扩展名,则需要在执行 MapReduce 任务的时候指定输入格式。
1
2
3
4
5
hadoop jar /usr/home/hadoop/hadoop-0.20.2/contrib/streaming/
hadoop-streaming-0.20.2-CD H3B4.jar -file /usr/home/hadoop/hello/mapper.py -mapper /
usr/home/hadoop/hello/mapper.py -file /usr/home/hadoop/hello/
reducer.py -reducer /usr/home/hadoop/hello/reducer.py -input lzotest -output result4 -
jobconf mapred.reduce.tasks=1*-inputformatorg.apache.hadoop.mapred.LzoTextInputFormat*
性能对比
Hadoop 下各种压缩算法的压缩比,压缩时间,解压时间见下表:
表 2. 性能对比
压缩算法 原始文件大小 压缩文件大小 压缩速度 解压速度
gzip 8.3GB 1.8GB 17.5MB/s 58MB/s
bzip2 8.3GB 1.1GB 2.4MB/s 9.5MB/s
LZO-bset 8.3GB 2GB 4MB/s 60.6MB/s
LZO 8.3GB 2.9GB 49.3MB/s 74.6MB/s
因此我们可以得出:
1) Bzip2 压缩效果明显是最好的,但是 bzip2 压缩速度慢,可分割。
2) Gzip 压缩效果不如 Bzip2,但是压缩解压速度快,不支持分割。
3) LZO 压缩效果不如 Bzip2 和 Gzip,但是压缩解压速度最快!并且支持分割!
这里提一下,文件的可分割性在 Hadoop 中是很非常重要的,它会影响到在执行作业时 Map 启动的个数,从而会影响到作业的执行效率!
所有的压缩算法都显示出一种时间空间的权衡,更快的压缩和解压速度通常会耗费更多的空间。在选择使用哪种压缩格式时,我们应该根据自身的业务需求来选择。
下图是在本地压缩与通过流将压缩结果上传到 BI 的时间对比。
图 1. 时间对比
图 1. 时间对比
使用方式
MapReduce 可以在三个阶段中使用压缩。
1. 输入压缩文件。如果输入的文件是压缩过的,那么在被 MapReduce 读取时,它们会被自动解压。
2.MapReduce 作业中,对 Map 输出的中间结果集压缩。实现方式如下:
1)可以在 core-site.xml 文件中配置,代码如下
图 2. core-site.xml 代码示例
图 2. core-site.xml 代码示例
2)使用 Java 代码指定
1
2
conf.setCompressMapOut(true);
conf.setMapOutputCompressorClass(GzipCode.class);
最后一行代码指定 Map 输出结果的编码器。
3.MapReduce 作业中,对 Reduce 输出的最终结果集压。实现方式如下:
1)可以在 core-site.xml 文件中配置,代码如下
图 3. core-site.xml 代码示例
图 3. core-site.xml 代码示例
2)使用 Java 代码指定
1
2
conf.setBoolean(“mapred.output.compress”,true);
conf.setClass(“mapred.output.compression.codec”,GzipCode.class,CompressionCodec.class);
最后一行同样指定 Reduce 输出结果的编码器。
压缩框架
我们前面已经提到过关于压缩的使用方式,其中第一种就是将压缩文件直接作为入口参数交给 MapReduce 处理,MapReduce 会自动根据压缩文件的扩展名来自动选择合适解压器处理数据。那么到底是怎么实现的呢?如下图所示:
图 4. 压缩实现情形
图 4. 压缩实现情形
我们在配置 Job 作业的时候,会设置数据输入的格式化方式,使用 conf.setInputFormat() 方法,这里的入口参数是 TextInputFormat.class。
TextInputFormat.class 继承于 InputFormat.class,主要用于对数据进行两方面的预处理。一是对输入数据进行切分,生成一组 split,一个 split 会分发给一个 mapper 进行处理;二是针对每个 split,再创建一个 RecordReader 读取 split 内的数据,并按照
的形式组织成一条 record 传给 map 函数进行处理。此类在对数据进行切分之前,会首先初始化压缩解压工程类 CompressionCodeFactory.class,通过工厂获取实例化的编码解码器 CompressionCodec 后对数据处理操作。
下面我们来详细的看一下从压缩工厂获取编码解码器的过程。
压缩解压工厂类 CompressionCodecFactory
压缩解压工厂类 CompressionCodeFactory.class 主要功能就是负责根据不同的文件扩展名来自动获取相对应的压缩解压器 CompressionCodec.class,是整个压缩框架的核心控制器。我们来看下 CompressionCodeFactory.class 中的几个重要方法:
1. 初始化方法
图 5. 代码示例
图 5. 代码示例
① getCodeClasses(conf) 负责获取关于编码解码器 CompressionCodec.class 的配置信息。下面将会详细讲解。
② 默认添加两种编码解码器。当 getCodeClass(conf) 方法没有读取到相关的编码解码器 CompressionCodec.class 的配置信息时,系统会默认添加两种编码解码器 CompressionCodec.class,分别是 GzipCode.class 和 DefaultCode.class。
③ addCode(code) 此方法用于将编码解码器 CompressionCodec.class 添加到系统缓存中。下面将会详细讲解。
2. getCodeClasses(conf)
图 6. 代码示例
图 6. 代码示例
① 这里我们可以看,系统读取关于编码解码器 CompressionCodec.class 的配置信息在 core-site.xml 中 io.compression.codes 下。我们看下这段配置文件,如下图所示:
图 7. 代码示例
图 7. 代码示例
Value 标签中是每个编码解码 CompressionCodec.class 的完整路径,中间用逗号分隔。我们只需要将自己需要使用到的编码解码配置到此属性中,系统就会自动加载到缓存中。
除了上述的这种方式以外,Hadoop 为我们提供了另一种加载方式:代码加载。同样最终将信息配置在 io.compression.codes 属性中,代码如下:
1
2
conf.set("io.compression.codecs","org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,com.hadoop.compression.lzo.LzopCodec");)
3. addCode(code) 方法添加编码解码器
图 8. 代码示例
图 8. 代码示例
addCodec(codec) 方法入口参数是个编码解码器 CompressionCodec.class,这里我们会首先接触到它的一个方法。
① codec.getDefaultExtension() 方法看方法名的字面意思我们就可以知道,此方法用于获取此编码解码所对应文件的扩展名,比如,文件名是 xxxx.gz2,那么这个方法的返回值就是“.bz2”,我们来看下 org.apache.hadoop.io.compress.BZip2Codec 此方法的实现代码:
图 9. 代码示例
图 9. 代码示例
② Codecs 是一个 SortedMap 的示例。这里有个很有意思的地方,它将 Key 值,也就是通过 codec.getDefaultExtension() 方法获取到的文件扩展名进行了翻转,举个例子,比如文件名扩展名“.bz2”,将文件名翻转之后就变成了“2zb.”。
系统加载完所有的编码解码器后,我们可以得到这样一个有序映射表,如下:
图 10. 代码示例
图 10. 代码示例
现在编码解码器都有了,我们怎么得到对应的编码解码器呢?看下面这个方法。
4. getCodec() 方法
此方法用于获取文件所对应的的编码解码器 CompressionCodec.class。
图 11. 代码示例
图 11. 代码示例
getCodec(Path) 方法的输入参数是 Path 对象,保存着文件路径。
① 将文件名翻转。如 xxxx.bz2 翻转成 2zb.xxxx。
② 获取 codecs 集合中最接近 2zb.xxxx 的值。此方法有返回值同样是个 SortMap 对象。
在这里对返回的 SortMap 对象进行第二次筛选。
编码解码器 CompressionCodec
刚刚在介绍压缩解压工程类 CompressionCodeFactory.class 的时候,我们多次提到了压缩解压器 CompressionCodecclass,并且我们在上文中还提到了它其中的一个用于获取文件扩展名的方法 getDefaultExtension()。
压缩解压工程类 CompressionCodeFactory.class 使用的是抽象工厂的设计模式。它是一个接口,制定了一系列方法,用于创建特定压缩解压算法。下面我们来看下比较重要的几个方法:
1. createOutputStream() 方法对数据流进行压缩。
图 12. 代码示例
图 12. 代码示例
此方法提供了方法重载。
① 基于流的压缩处理;
② 基于压缩机 Compress.class 的压缩处理
2. createInputStream() 方法对数据流进行解压。
图 13. 代码示例
图 13. 代码示例
这里的解压方法同样提供了方法重载。
① 基于流的解压处理;
② 基于解压机 Decompressor.class 的解压处理;
关于压缩/解压流与压缩/解压机会在下面的文章中我们会详细讲解。此处暂作了解。
3. getCompressorType() 返回需要的编码器的类型。
getDefaultExtension() 获取对应文件扩展名的方法。前文已提到过,不再敖述。
压缩机 Compressor 和解压机 Decompressor
前面在编码解码器部分的 createInputStream() 和 createInputStream() 方法中我们提到过 Compressor.class 和 Decompressor.class 对象。在 Hadoop 的实现中,数据编码器和解码器被抽象成了两个接口:
1. org.apache.hadoop.io.compress.Compressor;
2. org.apache.hadoop.io.compress.Decompressor;
它们规定了一系列的方法,所以在 Hadoop 内部的编码/解码算法实现都需要实现对应的接口。在实际的数据压缩与解压缩过程,Hadoop 为用户提供了统一的 I/O 流处理模式。
我们看一下压缩机 Compressor.class,代码如下:
图 14. 代码示例
图 14. 代码示例
① setInput() 方法接收数据到内部缓冲区,可以多次调用;
② needsInput() 方法用于检查缓冲区是否已满。如果是 false 则说明当前的缓冲区已满;
③ getBytesRead() 输入未压缩字节的总数;
④ getBytesWritten() 输出压缩字节的总数;
⑤ finish() 方法结束数据输入的过程;
⑥ finished() 方法用于检查是否已经读取完所有的等待压缩的数据。如果返回 false,表明压缩器中还有未读取的压缩数据,可以继续通过 compress() 方法读取;
⑦ compress() 方法获取压缩后的数据,释放缓冲区空间;
⑧ reset() 方法用于重置压缩器,以处理新的输入数据集合;
⑨ end() 方法用于关闭解压缩器并放弃所有未处理的输入;
⑩ reinit() 方法更进一步允许使用 Hadoop 的配置系统,重置并重新配置压缩器;
为了提高压缩效率,并不是每次用户调用 setInput() 方法,压缩机就会立即工作,所以,为了通知压缩机所有数据已经写入,必须使用 finish() 方法。finish() 调用结束后,压缩机缓冲区中保持的已经压缩的数据,可以继续通过 compress() 方法获得。至于要判断压缩机中是否还有未读取的压缩数据,则需要利用 finished() 方法来判断。
压缩流 CompressionOutputStream 和解压缩流 CompressionInputStream
前文编码解码器部分提到过 createInputStream() 方法返回 CompressionOutputStream 对象,createInputStream() 方法返回 CompressionInputStream 对象。这两个类分别继承自 java.io.OutputStream 和 java.io.InputStream。从而我们不难理解,这两个对象的作用了吧。
我们来看下 CompressionInputStream.class 的代码:
图 15. 代码示例
图 15. 代码示例
可以看到 CompressionOutputStream 实现了 OutputStream 的 close() 方法和 flush() 方法,但用于输出数据的 write() 方法以及用于结束压缩过程并将输入写到底层流的 finish() 方法和重置压缩状态的 resetState() 方法还是抽象方法,需要 CompressionOutputStream 的子类实现。
Hadoop 压缩框架中为我们提供了一个实现了 CompressionOutputStream 类通用的子类 CompressorStream.class。
图 16. 代码示例
图 16. 代码示例
CompressorStream.class 提供了三个不同的构造函数,CompressorStream 需要的底层输出流 out 和压缩时使用的压缩器,都作为参数传入构造函数。另一个参数是 CompressorStream 工作时使用的缓冲区 buffer 的大小,构造时会利用这个参数分配该缓冲区。第一个可以手动设置缓冲区大小,第二个默认 512,第三个没有缓冲区且不可使用压缩器。
图 17. 代码示例
图 17. 代码示例
在 write()、compress()、finish() 以及 resetState() 方法中,我们发现了压缩机 Compressor 的身影,前面文章我们已经介绍过压缩机的的实现过程,通过调用 setInput() 方法将待压缩数据填充到内部缓冲区,然后调用 needsInput() 方法检查缓冲区是否已满,如果缓冲区已满,将调用 compress() 方法对数据进行压缩。流程如下图所示:
图 18. 调用流程图
图 18. 调用流程图
结束语
本文深入到 Hadoop 平台压缩框架内部,对其核心代码以及各压缩格式的效率进行对比分析,以帮助读者在使用 Hadoop 平台时,可以通过对数据进行压缩处理来提高数据处理效率。当再次面临海量数据处理时, Hadoop 平台的压缩机制可以让我们事半功倍。
相关主题
Hadoop 在线 API
《Hadoop 技术内幕深入解析 HADOOP COMMON 和 HDFS 架构设计与实现原理》
developerWorks 开源技术主题:查找丰富的操作信息、工具和项目更新,帮助您掌握开源技术并将其用于 IBM 产品。
posted @
2017-09-14 17:35 xzc 阅读(557) |
评论 (0) |
编辑 收藏Linux系统查看当前主机CPU、内存、机器型号及主板信息:
查看CPU信息(型号)
# cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看内存信息
# cat /proc/meminfo
查看主板型号:
# dmidecode |grep -A16 "System Information$"
查看机器型号
# dmidecode | grep "Product Name"
查看当前操作系统内核信息
# uname -a
查看当前操作系统发行版信息
# cat /etc/issue | grep Linux
posted @
2017-09-10 16:37 xzc 阅读(246) |
评论 (0) |
编辑 收藏posted @
2017-09-07 11:37 xzc 阅读(277) |
评论 (0) |
编辑 收藏posted @
2017-08-30 21:05 xzc 阅读(306) |
评论 (0) |
编辑 收藏1. 日期输出格式化
所有日期、时间的api都在datetime模块内。
1. datetime => string
now = datetime.datetime.now()
now.strftime('%Y-%m-%d %H:%M:%S')
#输出2012-03-05 16:26:23.870105
strftime是datetime类的实例方法。
2. string => datetime
t_str = '2012-03-05 16:26:23'
d = datetime.datetime.strptime(t_str, '%Y-%m-%d %H:%M:%S')
strptime是datetime类的静态方法。
2. 日期比较操作
在datetime模块中有timedelta类,这个类的对象用于表示一个时间间隔,比如两个日期或者时间的差别。
构造方法:
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
所有的参数都有默认值0,这些参数可以是int或float,正的或负的。
可以通过timedelta.days、tiemdelta.seconds等获取相应的时间值。
timedelta类的实例,支持加、减、乘、除等操作,所得的结果也是timedelta类的实例。比如:
year = timedelta(days=365)
ten_years = year *10
nine_years = ten_years - year
同时,date、time和datetime类也支持与timedelta的加、减运算。
datetime1 = datetime2 +/- timedelta
timedelta = datetime1 - datetime2
这样,可以很方便的实现一些功能。
1. 两个日期相差多少天。
d1 = datetime.datetime.strptime('2012-03-05 17:41:20', '%Y-%m-%d %H:%M:%S')
d2 = datetime.datetime.strptime('2012-03-02 17:41:20', '%Y-%m-%d %H:%M:%S')
delta = d1 - d2
print delta.days
输出:3
2. 今天的n天后的日期。
now = datetime.datetime.now()
delta = datetime.timedelta(days=3)
n_days = now + delta
print n_days.strftime('%Y-%m-%d %H:%M:%S')
输出:2012-03-08 17:44:50
#coding=utf-8
import datetime
now=datetime.datetime.now()
print now
#将日期转化为字符串 datetime => string
print now.strftime('%Y-%m-%d %H:%M:%S')
t_str = '2012-03-05 16:26:23'
#将字符串转换为日期 string => datetime
d=datetime.datetime.strptime(t_str,'%Y-%m-%d %H:%M:%S')
print d
#在datetime模块中有timedelta类,这个类的对象用于表示一个时间间隔,比如两个日#期或者时间的差别。
#计算两个日期的间隔
d1 = datetime.datetime.strptime('2012-03-05 17:41:20', '%Y-%m-%d %H:%M:%S')
d2 = datetime.datetime.strptime('2012-03-02 17:41:20', '%Y-%m-%d %H:%M:%S')
delta = d1 - d2
print delta.days
print delta
#今天的n天后的日期。
now=datetime.datetime.now()
delta=datetime.timedelta(days=3)
n_days=now+delta
print n_days.strftime('%Y-%m-%d %H:%M:%S')
posted @
2017-08-14 23:09 xzc 阅读(1368) |
评论 (0) |
编辑 收藏Shell中并没有真正意义的多线程,要实现多线程可以启动多个后端进程,最大程度利用cpu性能。
直接看代码示例吧。
(1) 顺序执行的代码
1 #!/bin/bash 2 date 3 for i in `seq 1 5` 4 do 5 { 6 echo "sleep 5" 7 sleep 5 8 } 9 done 10 date 输出:
Sat Nov 19 09:21:51 CST 2016 sleep 5 sleep 5 sleep 5 sleep 5 sleep 5 Sat Nov 19 09:22:16 CST 2016
(2) 并行代码
使用'&'+wait 实现“多进程”实现
1 #!/bin/bash 2 date 3 for i in `seq 1 5` 4 do 5 { 6 echo "sleep 5" 7 sleep 5 8 } & 9 done 10 wait ##等待所有子后台进程结束 11 date输出:
Sat Nov 19 09:25:07 CST 2016 sleep 5 sleep 5 sleep 5 sleep 5 sleep 5 Sat Nov 19 09:25:12 CST 2016
(3) 对于大量处理任务如何实现启动后台进程的数量可控?
简单的方法可以使用2层for/while循环实现,每次wait内层循环的多个后台程序执行完成。
但是这种方式的问题是,如果内层循环有“慢节点”可能导致整个任务的执行执行时间长。
更高级的实现可以看(4)
(4) 使用命名管道(fifo)实现每次启动后台进程数量可控。
1 #!/bin/bash 2 3 function my_cmd(){ 4 t=$RANDOM 5 t=$[t%15] 6 sleep $t 7 echo "sleep $t s" 8 } 9 10 tmp_fifofile="/tmp/$$.fifo" 11 mkfifo $tmp_fifofile # 新建一个fifo类型的文件 12 exec 6<>$tmp_fifofile # 将fd6指向fifo类型 13 rm $tmp_fifofile #删也可以 14 15 thread_num=5 # 最大可同时执行线程数量 16 job_num=100 # 任务总数 17 18 #根据线程总数量设置令牌个数 19 for ((i=0;i<${thread_num};i++));do 20 echo 21 done >&6 22 23 for ((i=0;i<${job_num};i++));do # 任务数量 24 # 一个read -u6命令执行一次,就从fd6中减去一个回车符,然后向下执行, 25 # fd6中没有回车符的时候,就停在这了,从而实现了线程数量控制 26 read -u6 27 28 #可以把具体的需要执行的命令封装成一个函数 29 { 30 my_cmd 31 } & 32 33 echo >&6 # 当进程结束以后,再向fd6中加上一个回车符,即补上了read -u6减去的那个 34 done 35 36 wait 37 exec 6>&- # 关闭fd6 38 echo "over"
参考:http://lawrence-zxc.github.io/2012/06/16/shell-thread/
posted @
2017-08-02 17:01 xzc 阅读(354) |
评论 (0) |
编辑 收藏 之前在论坛看到一个关于HDFS权限的问题,当时无法回答该问题。无法回答并不意味着对HDFS权限一无所知,而是不能准确完整的阐述HDFS权限,因此决定系统地学习HDFS文件权限。HDFS的文件和目录权限模型共享了POSIX(Portable Operating System Interface,可移植操作系统接口)模型的很多部分,比如每个文件和目录与一个拥有者和组相关联,文件或者目录对于拥有者、组内的其它用户和组外的其它用户有不同的权限等。与POSIX模型不同的是,HDFS中的文件没有可执行文件的概念,因而也没有setuid和setgid,虽然目录依然保留着可执行目录的概念(x),但对于目录也没有setuid和setgid。粘贴位(sticky bit)可以用在目录上,用于阻止除超级用户,目录或文件的拥有者外的任何删除或移动目录中的文件,文件上的粘贴位不起作用。
当创建文件或目录时,拥有者为运行客户端进程的用户,组为父目录所属的组。每个访问HDFS的客户端进程有一个由用户姓名和组列表两部分组的成标识,无论何时HDFS必须对由客户端进程访问的文件或目录进行权限检查,规则如下:
- 如果进程的用户名匹配文件或目录的拥有者,那么测试拥有者权限
- 否则如果文件或目录所属的组匹配组列表中任何组,那么测试组权限
- 否则测试其它权限
如果权限检查失败,则客户端操作失败。
从hadoop-0.22开始,hadoop支持两种不同的操作模式以确定用户,分别为simple和kerberos具体使用哪个方式由参数hadoop.security.authentication设置,该参数位于core-site.xml文件中,默认值为simple。在simple模式下,客户端进程的身份由主机的操作系统确定,比如在类Unix系统中,用户名为命令whoami的输出。在kerberos模式下,客户端进程的身份由Kerberos凭证确定,比如在一个Kerberized环境中,用户可能使用kinit工具得到了一个Kerberos ticket-granting-ticket(TGT)且使用klist确定当前的principal。当映射一个Kerberosprincipal到HDFS的用户名时,除了最主要的部分外其余部分都被丢弃,比如一个principal为todd/foobar@CORP.COMPANY.COM,将映射为HDFS上的todd。无论哪种操作模式,对于HDFS来说用户标识机制都是外部的,HDFS本身没有创建用户标,建立组或者处理用户凭证的规定。
上面讨论了确定用户的两种模式,即simple和kerberos,下面学习如何确定用户组。用户组是通过由参数hadoop.security.group.mapping设置的组映射服务确定的,默认实现是org.apache.hadoop.security.JniBasedUnixGroupsMappingWithFallback,该实现首先确定Java本地接口(JNI)是否可用,如果JNI可用,该实现将使用hadoop中的API为用户解析用户组列表。如果JNI不可用,那么使用ShellBasedUnixGroupsMapping,该实现将使用Linux/Unix中的bash –cgroups命令为用户解析用户组列表。其它实现还有LdapGroupsMapping,通过直接连接LDAP服务器来解析用户组列表。对HDFS来说,用户到组的映射是在NameNode上执行的,因而NameNode的主机系统配置决定了用户的组映射。HDFS将文件或目录的用户和组存储为字符串,并且不像Linux/Unix那样可以将用户和组转换为数字。
每个针对文件或者目录的操作都将全路径名称传递到NameNode,然后对该路径的每次操作都将应用权限检查。客户端隐含地关联用户身份到NameNode的连接,减少改变现存客户端API的需要。总是存在这么一种情景,当在一个文件上的操作成功后,当重复该操作时可能失败,因为该文件或者路径中的某些目录已经不再存在。例如,当客户端第一次开始读取一个文件时,它向NameNode发出的第一个请求来发现该文件第一个块的位置,第二个寻找其他块的请求可能失败。另一方面,对于已经知道文件块的客户端来说,删除文件不会取消访问。通过添加权限,客户端对文件的访问在请求之间可能撤回,对于已经知道文件块的客户端来说,改变权限不会取消客户端的访问。
HDFS中超级用户与通常熟悉的Linux或Unix中的root用户不同,HDFS的超级用户是与NameNode进程有相同标示的用户,更简单易懂些,启动NameNode的用户就为超级用户。对于谁是超级用户没有固定的定义,当NameNode启动后,该进程的标示决定了谁是超级用户。HDFS的超级用户不必是NameNode主机的超级用户,也需用所有的集群使用相同的超级用户,出于实验目的在个人工作站上运行HDFS的人自然而然的称为超级用户而不需要任何配置。另外参数dfs.permissions.superusergroup设置了超级用户,该组中的所有用户也为超级用户。超级用户在HDFS中可以执行任何操作而针对超级用户的权限检查永远不会失败。
HDFS也提供了对POSIX ACL(访问控制列表)支持来为特定的用户或者用户组提供更加细粒度的文件权限。ACL是不同于用户和组的自然组织层次的有用的权限控制方式,ACL可以为特定的用户和组设置不同的权限,而不仅仅是文件的拥有者和文件所属的组。默认情况下,HDFS禁用ACL,因此NameNode禁止ACL的创建,为了启用ACL,需要在hdfs-site.xml中将参数dfs.namenode.acls.enabled设置为true。
访问控制列表由一组ACL项组成,每个ACL项命名了特定的用户或组,并为其授予或拒绝读,写和执行的权限,例如:
user::rw- user:bruce:rwx #effective:r-- group::r-x #effective:r-- group:sales:rwx #effective:r-- mask::r-- other::r--
每个ACL项由类型,可选的名称和权限字符串组成,它们之间使用冒号(:)。在上面的例子中文件的拥有者具有读写权限,文件所属的组具有读和执行的权限,其他用户具有读权限,这些设置与将文件设置为654等价(6表示拥有者的读写权限,5表示组的读和执行权限,4表示其他用户的读权限)。除此之外,还有两个扩展的ACL项,分别为用户bruce和组sales,并都授予了读写和执行的权限。mask项是一个特殊的项,用于过滤授予所有命名用户,命名组及未命名组的权限,即过滤除文件拥有者和其他用户(other)之外的任何ACL项。在该例子中,mask值有读权限,则bruce用户、sales组和文件所属的组只具有读权限。每个ACL必须有mask项,如果用户在设置ACL时没有使用mask项,一个mask项被自动加入到ACL中,该mask项是通过计算所有被mask过滤项的权限与(&运算)得出的。对拥有ACL的文件执行chmod实际改变的是mask项的权限,因为mask项扮演的是过滤器的角色,这将有效地约束所有扩展项的权限,而不是仅改变组的权限而可能漏掉其它扩展项的权限。
访问控制列表和默认访问控制列表存在着不同,前者定义了在执行权限检查实施的规则,后者定义了新文件或者子目录创建时自动接收的ACL项,例如:
user::rwx group::r-x other::r-x default:user::rwx default:user:bruce:rwx #effective:r-x default:group::r-x default:group:sales:rwx #effective:r-x default:mask::r-x default:other::r-x
只有目录可能拥有默认访问控制列表,当创建新文件或者子目录时,自动拷贝父辈的默认访问控制列表到自己的访问控制列表中,新的子目录也拷贝父辈默认的访问控制列表到自己的默认访问控制列表中。这样,当创建子目录时默认ACL将沿着文件系统树被任意深层次地拷贝。在新的子ACL中,准确的权限由模式参数过滤。默认的umask为022,通常新目录权限为755,新文件权限为644。模式参数为未命名用户(文件的拥有者),mask及其他用户过滤拷贝的权限值。在上面的例子中,创建权限为755的子目录时,模式对最终结果没有影响,但是如果创建权限为644的文件时,模式过滤器导致新文件的ACL中文件拥有者的权限为读写,mask的权限为读以及其他用户权限为读。mask的权限意味着用户bruce和组sales只有读权限。拷贝ACL发生在文件或子目录的创建时,后面如果修改父辈的默认ACL将不再影响已存在子类的ACL。
默认ACL必须包含所有最小要求的ACL项,包括文件拥有者项,文件所属的组项和其它用户项。如果用户没有在默认ACL中配置上述三项中的任何一个,那么该项将通过从访问ACL拷贝对应的权限来自动插入,或者如果没有访问ACL则自动插入权限位。默认ACL也必须拥有mask,如果mask没有被指定,通过计算所有被mask过滤项的权限与(&运算)自动插入mask。当一个文件拥有ACL时,权限检查的算法变为:
- 如果用户名匹配文件的拥有者,则测试拥有者权限
- 否则,如果用户名匹配命名用户项中的用户名,则测试由mask权限过滤后的该项的权限
- 否则,如果文件所属的组匹配组列表中的任何组,并且如果这些被mask过滤的权限具有访问权限,那么使用这么权限
- 否则,如果存在命名组项匹配组列表中的成员,并且如果这些被mask过滤的权限具有访问权限,那么使用这么权限
- 否则,如果文件所属的组或者任何命名组项匹配组列表中的成员,但不具备访问权限,那么访问被拒绝
- 否则测试文件的其他用户权限
最佳实践时基于传统的权限位设置大部分权限要求,然后定义少量带有特殊规则的ACL增加权限位。相比较只是用权限位的文件,使用ACL的文件会在NameNode中产生额外的内存消耗。
上面学习了HDFS中的文件权限和访问控制列表,最后学习一下如何针对权限和ACL进行配置,下表列出了其中的重要参数:
| 参数名 | 位置 | 用途 |
| dfs.permissions.enabled | hdfs-site.xml | 默认值为true,即启用权限检查。如果为 false,则禁用权限检查。 |
| hadoop.http.staticuser.user | core-site.xml | 默认值为dr.who,查看web UI的用户 |
| dfs.permissions.superusergroup | hdfs-site.xml | 超级用户的组名称,默认为supergroup |
| <fs.permissions.umask-mode | core-site.xml | 创建文件和目录时使用的umask,默认值为八进制022,每位数字对应了拥有者,组和其他用户。该值既可以使用八进制数字,如022,也可以使用符号,如u=rwx,g=r-x,o=r-x(对应022) |
| dfs.cluster.administrators | hdfs-site.xml | 被指定为ACL的集群管理员 |
| dfs.namenode.acls.enabled | hdfs-site.xml | 默认值为false,禁用ACL,设置为true则启用ACL。当ACL被禁用时,NameNode拒绝设置或者获取ACL的请求 |
posted @
2017-07-28 10:55 xzc 阅读(981) |
评论 (0) |
编辑 收藏1. crontab 命令:用于在某个时间,系统自动执行你所希望的程序文件或命令。
2. crontab 的参数
-e (edit user's crontab)
-l (list user's crontab)
-r (delete user's crontab)
-i (prompt before deleting user's crontab)
3.下面进行一个例子:在8月6号18时每隔3分钟执行以下命令:who >> /apple/test_crontab.log
步骤一:先创建一个文件cronfile:内容为如下:
*/3 18 6 8 * who >> /apple/test_crontab_log
步骤二:将文件cronfile 加入到cron守护进行(命令为:crontab cronfile)
4. 检查是否加入到守护进程cron中,用命令:crontab -l
如何出来的内容中包含你刚刚的内容,则加入成功。每隔3分钟查看下test_crontab.log文件,看看是否有内容。
5. 对crontab内容格式的解释:f1 f2 f3 f4 f5 program
f1 是表示分钟(0-59),f2 表示小时(0-23),f3 表示一个月份中的第几日(1-(31、30、29、28)),f4 表示月份(1-12),f5 表示一个星期中的第几天(0-6(0表示周日))。program 表示要执行的程式(可以理解为文件或命令)
f1:为*时候表示每隔1分钟,如果为*/n 表示每隔n分钟,如果为3,4 表示第3,4分钟,如果为2-6表示第2分钟到第6分钟。
f2:为*时候表示每隔1小说。如果为*/n 表示每隔n小时,如果为3,4 表示第3,4小时,如果为2-6表示第2小时到第6小时
f3: 为*时候表示每天。n 表示第n天
f4: 为*时候表示每月。n 表示第n个月
f5: 为*时候表示每周。0表示周日,6表示周六,1-4表示周一到周六
6. 具体例子:(来自crontab百度百科)
a. 每月每天每小时的第 0 分钟执行一次 /bin/ls : 0 * * * * /bin/ls
b. 在 12 月内, 每天的早上 6 点到 12 点中,每隔 20 分钟执行一次 /usr/bin/backup :
*/20 6-12 * 12 * /usr/bin/backup
c. 周一到周五每天下午 5:00 寄一封信给 alex_mail_name :
0 17 * * 1-5 mail -s "hi" alex_mail_name < /tmp/maildata
d. 每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha"
20 0-23/2 * * * echo "haha"
e. 晚上11点到早上8点之间每两个小时和早上8点 显示日期 0 23-7/2,8 * * * date
posted @
2017-07-27 18:59 xzc 阅读(307) |
评论 (0) |
编辑 收藏最近一段时间,在处理Shell 脚本时候,遇到时间的处理问题。 时间的加减,以及时间差的计算。
1。 时间加减
这里处理方法,是将基础的时间转变为时间戳,然后,需要增加或者改变时间,变成 秒。
如:1990-01-01 01:01:01 加上 1小时 20分
处理方法:
a.将基础时间转为时间戳
time1=$(date +%s -d '1990-01-01 01:01:01')
echo $time1
631126861 【时间戳】
b.将增加时间变成秒
[root@localhost ~]# time2=$((1*60*60+20*60))
[root@localhost ~]# echo $time2
4800
c.两个时间相加,计算出结果时间
time1=$(($time1+$time2))
time1=$(date +%Y-%m-%d\ %H:%M:%S -d "1970-01-01 UTC $time1 seconds");
echo $time1
1990-01-01 02:21:01
2。时间差计算方法
如:2010-01-01 与 2009-01-01 11:11:11 时间差
原理:同样转成时间戳,然后计算天,时,分,秒
time1=$(($(date +%s -d '2010-01-01') - $(date +%s -d '2009-01-01 11:11:11')));
echo time1
将time1 / 60 秒,就变成分了。
补充说明:
shell 单括号运算符号:
a=$(date);
等同于:a=`date`;
双括号运算符:
a=$((1+2));
echo $a;
等同于:
a=`expr 1 + 2`
posted @
2017-07-06 16:33 xzc 阅读(3336) |
评论 (1) |
编辑 收藏可参照:http://www.voidcn.com/blog/Vindra/article/p-4917667.html
一、get请求
curl "http://www.baidu.com" 如果这里的URL指向的是一个文件或者一幅图都可以直接下载到本地
curl -i "http://www.baidu.com" 显示全部信息
curl -l "http://www.baidu.com" 只显示头部信息
curl -v "http://www.baidu.com" 显示get请求全过程解析
wget "http://www.baidu.com"也可以
二、post请求
curl -d "param1=value1¶m2=value2" "http://www.baidu.com"
三、json格式的post请求
curl -l -H "Content-type: application/json" -X POST -d '{"phone":"13521389587","password":"test"}' http://domain/apis/users.json
例如:
curl -l -H "Content-type: application/json" -X POST -d '{"ver": "1.0","soa":{"req":"123"},"iface":"me.ele.lpdinfra.prediction.service.PredictionService","method":"restaurant_make_order_time","args":{"arg2":"\"stable\"","arg1":"{\"code\":[\"WIND\"],\"temperature\":11.11}","arg0":"{\"tracking_id\":\"100000000331770936\",\"eleme_order_id\":\"100000000331770936\",\"platform_id\":\"4\",\"restaurant_id\":\"482571\",\"dish_num\":1,\"dish_info\":[{\"entity_id\":142547763,\"quantity\":1,\"category_id\":1,\"dish_name\":\"[0xe7][0x89][0xb9][0xe4][0xbb][0xb7][0xe8][0x85][0x8a][0xe5][0x91][0xb3][0xe5][0x8f][0x89][0xe7][0x83][0xa7][0xe5][0x8f][0x8c][0xe6][0x8b][0xbc][0xe7][0x85][0xb2][0xe4][0xbb][0x94][0xe9][0xa5][0xad]\",\"price\":31.0}],\"merchant_location\":{\"longitude\":\"121.47831425\",\"latitude\":\"31.27576153\"},\"customer_location\":{\"longitude\":\"121.47831425\",\"latitude\":\"31.27576153\"},\"created_at\":1477896550,\"confirmed_at\":1477896550,\"dishes_total_price\":0.0,\"food_boxes_total_price\":2.0,\"delivery_total_price\":2.0,\"pay_amount\":35.0,\"city_id\":\"1\"}"}}' http://vpcb-lpdinfra-stream-1.vm.elenet.me:8989/rpc
ps:json串内层参数需要格式化
posted @
2017-05-18 11:28 xzc 阅读(1646) |
评论 (1) |
编辑 收藏
1)统计80端口连接数
netstat -nat|grep -i "80"|wc -l
2)统计httpd协议连接数
ps -ef|grep httpd|wc -l
3)、统计已连接上的,状态为“established
netstat -na|grep ESTABLISHED|wc -l
4)、查出哪个IP地址连接最多,将其封了.
netstat -na|grep ESTABLISHED|awk {print $5}|awk -F: {print $1}|sort|uniq -c|sort -r +0n
netstat -na|grep SYN|awk {print $5}|awk -F: {print $1}|sort|uniq -c|sort -r +0n
---------------------------------------------------------------------------------------------
1、查看apache当前并发访问数:
netstat -an | grep ESTABLISHED | wc -l
对比httpd.conf中MaxClients的数字差距多少。
2、查看有多少个进程数:
ps aux|grep httpd|wc -l
3、可以使用如下参数查看数据
server-status?auto
#ps -ef|grep httpd|wc -l
1388
统计httpd进程数,连个请求会启动一个进程,使用于Apache服务器。
表示Apache能够处理1388个并发请求,这个值Apache可根据负载情况自动调整。
#netstat -nat|grep -i "80"|wc -l
4341
netstat -an会打印系统当前网络链接状态,而grep -i "80"是用来提取与80端口有关的连接的,wc -l进行连接数统计。
最终返回的数字就是当前所有80端口的请求总数。
#netstat -na|grep ESTABLISHED|wc -l
376
netstat -an会打印系统当前网络链接状态,而grep ESTABLISHED 提取出已建立连接的信息。 然后wc -l统计。
最终返回的数字就是当前所有80端口的已建立连接的总数。
netstat -nat||grep ESTABLISHED|wc - 可查看所有建立连接的详细记录
查看Apache的并发请求数及其TCP连接状态:
Linux命令:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果示例:
LAST_ACK 5
SYN_RECV 30
ESTABLISHED 1597
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057
其中的
SYN_RECV表示正在等待处理的请求数;
ESTABLISHED表示正常数据传输状态;
TIME_WAIT表示处理完毕,等待超时结束的请求数。
---------------------------------------------------------------------------------------------
查看httpd进程数(即prefork模式下Apache能够处理的并发请求数):
Linux命令:
ps -ef | grep httpd | wc -l
查看Apache的并发请求数及其TCP连接状态:
Linux命令:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果示例:
LAST_ACK 5
SYN_RECV 30
ESTABLISHED 1597
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057
说明:
SYN_RECV表示正在等待处理的请求数;
ESTABLISHED表示正常数据传输状态;
TIME_WAIT表示处理完毕,等待超时结束的请求数。
posted @
2017-05-17 23:12 xzc 阅读(1470) |
评论 (2) |
编辑 收藏一、回收站简介:
在HDFS里,删除文件时,不会真正的删除,其实是放入回收站/trash,回收站里的文件可以快速恢复。
可以设置一个时间阀值,当回收站里文件的存放时间超过这个阀值或是回收站被清空时,文件才会被彻底删除,并且释放占用的数据块。
二、实例:
Hadoop的回收站trash功能默认是关闭的,所以需要在core-site.xml中手动开启。
1、修改core-site.xml,增加:
<property> <name>fs.trash.interval</name> <value>1440</value> <description>Number of minutes between trash checkpoints. If zero, the trash feature is disabled. </description> </property>
默认是0,单位是分钟,这里设置为1天。
删除数据rm后,会将数据move到当前文件夹下的.Trash目录。
2、测试
1)、新建目录input
hadoop/bin/hadoop fs -mkdir input
2)、上传文件
root@master:/data/soft# hadoop/bin/hadoop fs -copyFromLocal /data/soft/file0* input
3)、删除目录input
[root@master data]# hadoop fs -rmr input Moved to trash: hdfs://master:9000/user/root/input
4)、查看当前目录
[root@master data]# hadoop fs -ls Found 2 items drwxr-xr-x - root supergroup 0 2011-02-12 22:17 /user/root/.Trash
发现input删除了,多了一个目录.Trash
5)、恢复刚刚删除的目录
[root@master data]# hadoop fs -mv /user/root/.Trash/Current/user/root/input /user/root/input
6)、查看恢复的数据
[root@master data]# hadoop fs -ls input Found 2 items -rw-r--r-- 3 root supergroup 22 2011-02-12 17:40 /user/root/input/file01 -rw-r--r-- 3 root supergroup 28 2011-02-12 17:40 /user/root/input/file02
7)、删除.Trash目录(清理垃圾)
[root@master data]# hadoop fs -rmr .Trash Deleted hdfs://master:9000/user/root/.Trash
posted @
2017-05-12 11:20 xzc 阅读(214) |
评论 (0) |
编辑 收藏posted @
2017-05-10 10:49 xzc 阅读(318) |
评论 (0) |
编辑 收藏
一、为什么需要消息系统
1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 3.扩展性: 因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。 4.灵活性 & 峰值处理能力: 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 5.可恢复性: 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 6.顺序保证: 在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性) 7.缓冲: 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。 8.异步通信: 很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
二、kafka 架构
2.1 拓扑结构
如下图:
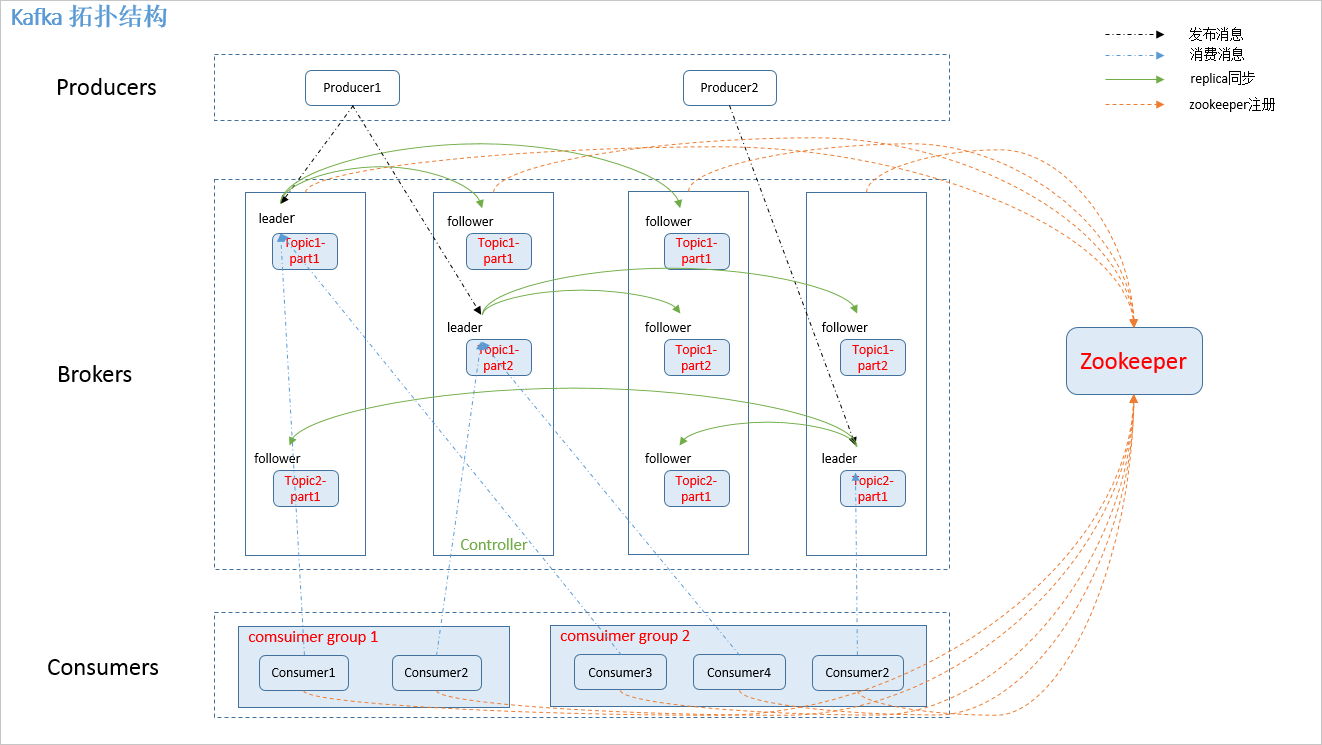
图.1
2.2 相关概念
如图.1中,kafka 相关名词解释如下:
1.producer: 消息生产者,发布消息到 kafka 集群的终端或服务。 2.broker: kafka 集群中包含的服务器。 3.topic: 每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。 4.partition: partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。 5.consumer: 从 kafka 集群中消费消息的终端或服务。 6.Consumer group: high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。 7.replica: partition 的副本,保障 partition 的高可用。 8.leader: replica 中的一个角色, producer 和 consumer 只跟 leader 交互。 9.follower: replica 中的一个角色,从 leader 中复制数据。 10.controller: kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。 12.zookeeper: kafka 通过 zookeeper 来存储集群的 meta 信息。
2.3 zookeeper 节点
kafka 在 zookeeper 中的存储结构如下图所示:

图.2
三、producer 发布消息
3.1 写入方式
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。
3.2 消息路由
producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。其路由机制为:
1. 指定了 patition,则直接使用; 2. 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition 3. patition 和 key 都未指定,使用轮询选出一个 patition。
附上 java 客户端分区源码,一目了然:

//创建消息实例 public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) { if (topic == null) throw new IllegalArgumentException("Topic cannot be null"); if (timestamp != null && timestamp < 0) throw new IllegalArgumentException("Invalid timestamp " + timestamp); this.topic = topic; this.partition = partition; this.key = key; this.value = value; this.timestamp = timestamp; } //计算 patition,如果指定了 patition 则直接使用,否则使用 key 计算 private int partition(ProducerRecord<K, V> record, byte[] serializedKey , byte[] serializedValue, Cluster cluster) { Integer partition = record.partition(); if (partition != null) { List<PartitionInfo> partitions = cluster.partitionsForTopic(record.topic()); int lastPartition = partitions.size() - 1; if (partition < 0 || partition > lastPartition) { throw new IllegalArgumentException(String.format("Invalid partition given with record: %d is not in the range [0...%d].", partition, lastPartition)); } return partition; } return this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); } // 使用 key 选取 patition public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (keyBytes == null) { int nextValue = counter.getAndIncrement(); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) { int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { return DefaultPartitioner.toPositive(nextValue) % numPartitions; } } else { //对 keyBytes 进行 hash 选出一个 patition return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } }3.3 写入流程
producer 写入消息序列图如下所示:

图.3
流程说明:
1. producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader 2. producer 将消息发送给该 leader 3. leader 将消息写入本地 log 4. followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK 5. leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
3.4 producer delivery guarantee
一般情况下存在三种情况:
1. At most once 消息可能会丢,但绝不会重复传输 2. At least one 消息绝不会丢,但可能会重复传输 3. Exactly once 每条消息肯定会被传输一次且仅传输一次
当 producer 向 broker 发送消息时,一旦这条消息被 commit,由于 replication 的存在,它就不会丢。但是如果 producer 发送数据给 broker 后,遇到网络问题而造成通信中断,那 Producer 就无法判断该条消息是否已经 commit。虽然 Kafka 无法确定网络故障期间发生了什么,但是 producer 可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了 Exactly once,但目前还并未实现。所以目前默认情况下一条消息从 producer 到 broker 是确保了 At least once,可通过设置 producer 异步发送实现At most once。
四、broker 保存消息
4.1 存储方式
物理上把 topic 分成一个或多个 patition(对应 server.properties 中的 num.partitions=3 配置),每个 patition 物理上对应一个文件夹(该文件夹存储该 patition 的所有消息和索引文件),如下:
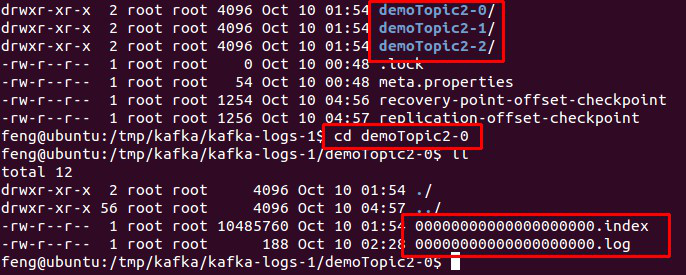
图.4
4.2 存储策略
无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据:
1. 基于时间:log.retention.hours=168 2. 基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
4.3 topic 创建与删除
4.3.1 创建 topic
创建 topic 的序列图如下所示:
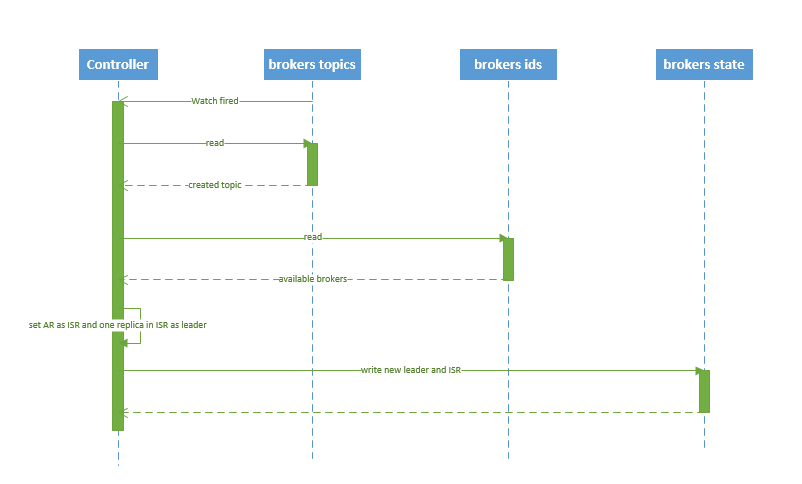
图.5
流程说明:
1. controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。 2. controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition: 2.1 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR 2.2 将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state 3. controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。
4.3.2 删除 topic
删除 topic 的序列图如下所示:
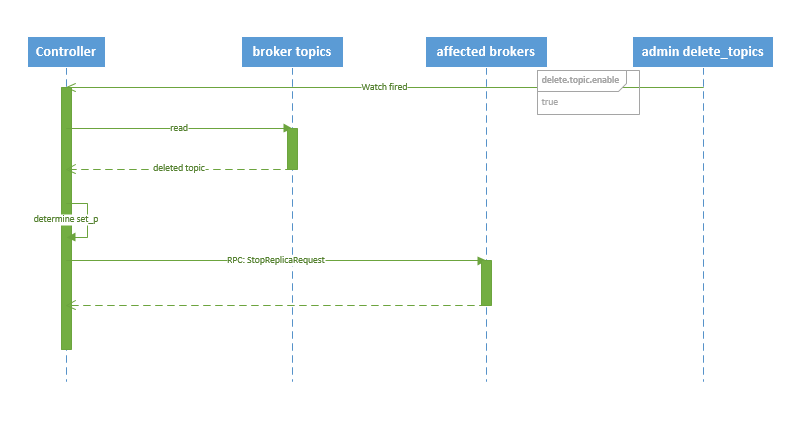
图.6
流程说明:
1. controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。 2. 若 delete.topic.enable=false,结束;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest。
五、kafka HA
5.1 replication
如图.1所示,同一个 partition 可能会有多个 replica(对应 server.properties 配置中的 default.replication.factor=N)。没有 replica 的情况下,一旦 broker 宕机,其上所有 patition 的数据都不可被消费,同时 producer 也不能再将数据存于其上的 patition。引入replication 之后,同一个 partition 可能会有多个 replica,而这时需要在这些 replica 之间选出一个 leader,producer 和 consumer 只与这个 leader 交互,其它 replica 作为 follower 从 leader 中复制数据。
Kafka 分配 Replica 的算法如下:
1. 将所有 broker(假设共 n 个 broker)和待分配的 partition 排序 2. 将第 i 个 partition 分配到第(i mod n)个 broker 上 3. 将第 i 个 partition 的第 j 个 replica 分配到第((i + j) mode n)个 broker上
5.2 leader failover
当 partition 对应的 leader 宕机时,需要从 follower 中选举出新 leader。在选举新leader时,一个基本的原则是,新的 leader 必须拥有旧 leader commit 过的所有消息。
kafka 在 zookeeper 中(/brokers/.../state)动态维护了一个 ISR(in-sync replicas),由3.3节的写入流程可知 ISR 里面的所有 replica 都跟上了 leader,只有 ISR 里面的成员才能选为 leader。对于 f+1 个 replica,一个 partition 可以在容忍 f 个 replica 失效的情况下保证消息不丢失。
当所有 replica 都不工作时,有两种可行的方案:
1. 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长。 2. 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短。
kafka 0.8.* 使用第二种方式。
kafka 通过 Controller 来选举 leader,流程请参考5.3节。
5.3 broker failover
kafka broker failover 序列图如下所示:
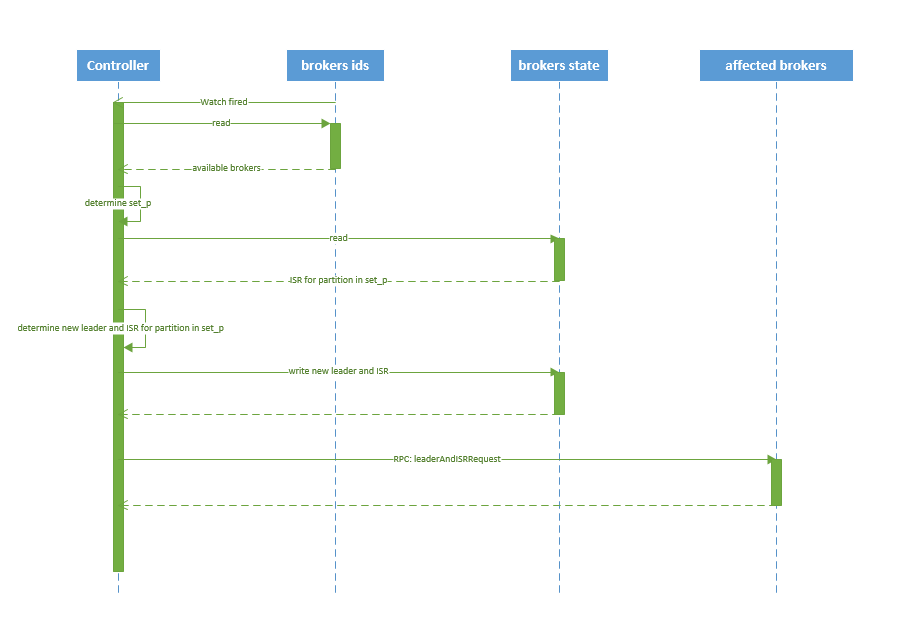
图.7
流程说明:
1. controller 在 zookeeper 的 /brokers/ids/[brokerId] 节点注册 Watcher,当 broker 宕机时 zookeeper 会 fire watch 2. controller 从 /brokers/ids 节点读取可用broker 3. controller决定set_p,该集合包含宕机 broker 上的所有 partition 4. 对 set_p 中的每一个 partition 4.1 从/brokers/topics/[topic]/partitions/[partition]/state 节点读取 ISR 4.2 决定新 leader(如4.3节所描述) 4.3 将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点 5. 通过 RPC 向相关 broker 发送 leaderAndISRRequest 命令
5.4 controller failover
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher,当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
当新的 controller 当选时,会触发 KafkaController.onControllerFailover 方法,在该方法中完成如下操作:
1. 读取并增加 Controller Epoch。 2. 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注册 watcher。 3. 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注册 watcher。 4. 通过 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注册 watcher。 5. 若 delete.topic.enable=true(默认值是 false),则 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注册 watcher。 6. 通过 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注册Watch。 7. 初始化 ControllerContext 对象,设置当前所有 topic,“活”着的 broker 列表,所有 partition 的 leader 及 ISR等。 8. 启动 replicaStateMachine 和 partitionStateMachine。 9. 将 brokerState 状态设置为 RunningAsController。 10. 将每个 partition 的 Leadership 信息发送给所有“活”着的 broker。 11. 若 auto.leader.rebalance.enable=true(默认值是true),则启动 partition-rebalance 线程。 12. 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,则删除相应的Topic。
6. consumer 消费消息
6.1 consumer API
kafka 提供了两套 consumer API:
1. The high-level Consumer API 2. The SimpleConsumer API
其中 high-level consumer API 提供了一个从 kafka 消费数据的高层抽象,而 SimpleConsumer API 则需要开发人员更多地关注细节。
6.1.1 The high-level consumer API
high-level consumer API 提供了 consumer group 的语义,一个消息只能被 group 内的一个 consumer 所消费,且 consumer 消费消息时不关注 offset,最后一个 offset 由 zookeeper 保存。
使用 high-level consumer API 可以是多线程的应用,应当注意:
1. 如果消费线程大于 patition 数量,则有些线程将收不到消息 2. 如果 patition 数量大于线程数,则有些线程多收到多个 patition 的消息 3. 如果一个线程消费多个 patition,则无法保证你收到的消息的顺序,而一个 patition 内的消息是有序的
6.1.2 The SimpleConsumer API
如果你想要对 patition 有更多的控制权,那就应该使用 SimpleConsumer API,比如:
1. 多次读取一个消息 2. 只消费一个 patition 中的部分消息 3. 使用事务来保证一个消息仅被消费一次
但是使用此 API 时,partition、offset、broker、leader 等对你不再透明,需要自己去管理。你需要做大量的额外工作:
1. 必须在应用程序中跟踪 offset,从而确定下一条应该消费哪条消息 2. 应用程序需要通过程序获知每个 Partition 的 leader 是谁 3. 需要处理 leader 的变更
使用 SimpleConsumer API 的一般流程如下:
1. 查找到一个“活着”的 broker,并且找出每个 partition 的 leader 2. 找出每个 partition 的 follower 3. 定义好请求,该请求应该能描述应用程序需要哪些数据 4. fetch 数据 5. 识别 leader 的变化,并对之作出必要的响应
以下针对 high-level Consumer API 进行说明。
6.2 consumer group
如 2.2 节所说, kafka 的分配单位是 patition。每个 consumer 都属于一个 group,一个 partition 只能被同一个 group 内的一个 consumer 所消费(也就保障了一个消息只能被 group 内的一个 consuemr 所消费),但是多个 group 可以同时消费这个 partition。
kafka 的设计目标之一就是同时实现离线处理和实时处理,根据这一特性,可以使用 spark/Storm 这些实时处理系统对消息在线处理,同时使用 Hadoop 批处理系统进行离线处理,还可以将数据备份到另一个数据中心,只需要保证这三者属于不同的 consumer group。如下图所示:

图.8
6.3 消费方式
consumer 采用 pull 模式从 broker 中读取数据。
push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
对于 Kafka 而言,pull 模式更合适,它可简化 broker 的设计,consumer 可自主控制消费消息的速率,同时 consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
6.4 consumer delivery guarantee
如果将 consumer 设置为 autocommit,consumer 一旦读到数据立即自动 commit。如果只讨论这一读取消息的过程,那 Kafka 确保了 Exactly once。
但实际使用中应用程序并非在 consumer 读取完数据就结束了,而是要进行进一步处理,而数据处理与 commit 的顺序在很大程度上决定了consumer delivery guarantee:
1.读完消息先 commit 再处理消息。 这种模式下,如果 consumer 在 commit 后还没来得及处理消息就 crash 了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于 At most once 2.读完消息先处理再 commit。 这种模式下,如果在处理完消息之后 commit 之前 consumer crash 了,下次重新开始工作时还会处理刚刚未 commit 的消息,实际上该消息已经被处理过了。这就对应于 At least once。 3.如果一定要做到 Exactly once,就需要协调 offset 和实际操作的输出。 精典的做法是引入两阶段提交。如果能让 offset 和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,consumer 拿到数据后可能把数据放到 HDFS,如果把最新的 offset 和数据本身一起写到 HDFS,那就可以保证数据的输出和 offset 的更新要么都完成,要么都不完成,间接实现 Exactly once。(目前就 high-level API而言,offset 是存于Zookeeper 中的,无法存于HDFS,而SimpleConsuemr API的 offset 是由自己去维护的,可以将之存于 HDFS 中)
总之,Kafka 默认保证 At least once,并且允许通过设置 producer 异步提交来实现 At most once(见文章《kafka consumer防止数据丢失》)。而 Exactly once 要求与外部存储系统协作,幸运的是 kafka 提供的 offset 可以非常直接非常容易得使用这种方式。
更多关于 kafka 传输语义的信息请参考《Message Delivery Semantics》。
6.5 consumer rebalance
当有 consumer 加入或退出、以及 partition 的改变(如 broker 加入或退出)时会触发 rebalance。consumer rebalance算法如下:
1. 将目标 topic 下的所有 partirtion 排序,存于PT 2. 对某 consumer group 下所有 consumer 排序,存于 CG,第 i 个consumer 记为 Ci 3. N=size(PT)/size(CG),向上取整 4. 解除 Ci 对原来分配的 partition 的消费权(i从0开始) 5. 将第i*N到(i+1)*N-1个 partition 分配给 Ci
在 0.8.*版本,每个 consumer 都只负责调整自己所消费的 partition,为了保证整个consumer group 的一致性,当一个 consumer 触发了 rebalance 时,该 consumer group 内的其它所有其它 consumer 也应该同时触发 rebalance。这会导致以下几个问题:
1.Herd effect 任何 broker 或者 consumer 的增减都会触发所有的 consumer 的 rebalance 2.Split Brain 每个 consumer 分别单独通过 zookeeper 判断哪些 broker 和 consumer 宕机了,那么不同 consumer 在同一时刻从 zookeeper 看到的 view 就可能不一样,这是由 zookeeper 的特性决定的,这就会造成不正确的 reblance 尝试。 3. 调整结果不可控 所有的 consumer 都并不知道其它 consumer 的 rebalance 是否成功,这可能会导致 kafka 工作在一个不正确的状态。
基于以上问题,kafka 设计者考虑在0.9.*版本开始使用中心 coordinator 来控制 consumer rebalance,然后又从简便性和验证要求两方面考虑,计划在 consumer 客户端实现分配方案。(见文章《Kafka Detailed Consumer Coordinator Design》和《Kafka Client-side Assignment Proposal》),此处不再赘述。
七、注意事项
7.1 producer 无法发送消息的问题
最开始在本机搭建了kafka伪集群,本地 producer 客户端成功发布消息至 broker。随后在服务器上搭建了 kafka 集群,在本机连接该集群,producer 却无法发布消息到 broker(奇怪也没有抛错)。最开始怀疑是 iptables 没开放,于是开放端口,结果还不行(又开始是代码问题、版本问题等等,倒腾了很久)。最后没办法,一项一项查看 server.properties 配置,发现以下两个配置:
# The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = security_protocol://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
以上说的就是 advertised.listeners 是 broker 给 producer 和 consumer 连接使用的,如果没有设置,就使用 listeners,而如果 host_name 没有设置的话,就使用 java.net.InetAddress.getCanonicalHostName() 方法返回的主机名。
修改方法:
1. listeners=PLAINTEXT://121.10.26.XXX:9092 2. advertised.listeners=PLAINTEXT://121.10.26.XXX:9092
修改后重启服务,正常工作。关于更多 kafka 配置说明,见文章《Kafka学习整理三(borker(0.9.0及0.10.0)配置)》。
八、参考文章
1. 《Kafka剖析(一):Kafka背景及架构介绍》
2. 《Kafka设计解析(二):Kafka High Availability (上)》
3. 《Kafka设计解析(二):Kafka High Availability (下)》
4. 《Kafka设计解析(四):Kafka Consumer解析》
5. 《Kafka设计解析(五):Kafka Benchmark》
6. 《Kafka学习整理三(borker(0.9.0及0.10.0)配置)》
7. 《Using the High Level Consumer》
8. 《Using SimpleConsumer》
9. 《Consumer Client Re-Design》
10. 《Message Delivery Semantics》
11. 《Kafka Detailed Consumer Coordinator Design》
12. 《Kafka Client-side Assignment Proposal》
13. 《Kafka和DistributedLog技术对比》
14. 《kafka安装和启动》
15. 《kafka consumer防止数据丢失》
本文版权归作者和博客园共有,欢迎转载,未经同意须保留此段声明,且在文章页面明显位置给出原文连接。欢迎指正与交流。
posted @
2017-04-28 10:37 xzc 阅读(313) |
评论 (0) |
编辑 收藏1. Kerberos简介
1.1. 功能
一个安全认证协议
用tickets验证
避免本地保存密码和在互联网上传输密码
包含一个可信任的第三方
使用对称加密
客户端与服务器(非KDC)之间能够相互验证
Kerberos只提供一种功能——在网络上安全的完成用户的身份验证。它并不提供授权功能或者审计功能。
1.2. 概念
首次请求,三次通信方
- the Authentication Server
- the Ticket Granting Server
- the Service or host machine that you’re wanting access to.

图 1‑1 角色
其他知识点
- 每次通信,消息包含两部分,一部分可解码,一部分不可解码
- 服务端不会直接有KDC通信
- KDC保存所有机器的账户名和密码
- KDC本身具有一个密码
2. 3次通信

我们这里已获取服务器中的一张表(数据)的服务以为,为一个http服务。
2.1. 你和验证服务
如果想要获取http服务,你首先要向KDC表名你自己的身份。这个过程可以在你的程序启动时进行。Kerberos可以通过kinit获取。介绍自己通过未加密的信息发送至KDC获取Ticket Granting Ticket (TGT)。
(1)信息包含
Authentication Server收到你的请求后,会去数据库中验证,你是否存在。注意,仅仅是验证是否存在,不会验证对错。
如果存在,Authentication Server会产生一个随机的Session key(可以是一个64位的字符串)。这个key用于你和Ticket Granting Server (TGS)之间通信。
(2)回送信息
Authentication Server同样会发送两部分信息给你,一部分信息为TGT,通过KDC自己的密码进行加密,包含:
- 你的name/ID
- TGS的name/ID
- 时间戳
- 你的IP地址
- TGT的生命周期
- TGS session key
另外一部分通过你的密码进行加密,包含的信息有
- TGS的name/ID
- 时间戳
- 生命周期
- TGS session key

图 2‑1 第一次通信
如果你的密码是正确的,你就能解密第二部分信息,获取到TGS session key。如果,密码不正确,无法解密,则认证失败。第一部分信息TGT,你是无法解密的,但需要展示缓存起来。
2.2. 你和TGS
如果第一部分你已经成功,你已经拥有无法解密的TGT和一个TGS Session Key。
(1) 请求信息
a) 通过TGS Session Key加密的认证器部分:
b) 明文传输部分:
- 请求的Http服务名(就是请求信息)
- HTTP Service的Ticket生命周期
c) TGT部分
Ticket Granting Server收到信息后,首先检查数据库中是否包含有你请求的Http服务名。如果无,直接返回错误信息。
如果存在,则通过KDC的密码解密TGT,这个时候。我们就能获取到TGS Session key。然后,通过TGS Session key去解密你传输的第一部分认证器,获取到你的用户名和时间戳。
TGS再进行验证:
- 对比TGT中的用户名与认证器中的用户名
- 比较时间戳(网上有说认证器中的时间错和TGT中的时间错,个人觉得应该是认证器中的时间戳和系统的时间戳),不能超过一定范围
- 检查是否过期
- 检查IP地址是否一致
- 检查认证器是否已在TGS缓存中(避免应答攻击)
- 可以在这部分添加权限认证服务
TGS随机产生一个Http Service Session Key, 同时准备Http Service Ticket(ST)。
(2) 回答信息
a) 通过Http服务的密码进行加密的信息(ST):
- 你的name/ID
- Http服务name/ID
- 你的IP地址
- 时间戳
- ST的生命周期
- Http Service Session Key
b) 通过TGS Session Key加密的信息
- Http服务name/ID
- 时间戳
- ST的生命周期
- Http Service Session Key
你收到信息后,通过TGS Session Key解密,获取到了Http Service Session Key,但是你无法解密ST。

图 2‑2 第二次通信
2.3. 你和Http服务
在前面两步成功后,以后每次获取Http服务,在Ticket没有过期,或者无更新的情况下,都可直接进行这一步。省略前面两个步骤。
(1) 请求信息
a) 通过Http Service Session Key,加密部分
b) ST
Http服务端通过自己的密码解压ST(KDC是用Http服务的密码加密的),这样就能够获取到Http Service Session Key,解密第一部分。
服务端解密好ST后,进行检查
- 对比ST中的用户名(KDC给的)与认证器中的用户名
- 比较时间戳(网上有说认证器中的时间错和TGT中的时间错,个人觉得应该是认证器中的时间戳和系统的时间戳),不能超过一定范围
- 检查是否过期
- 检查IP地址是否一致
- 检查认证器是否已在HTTP服务端的缓存中(避免应答攻击)
(2) 应答信息
a) 通过Http Service Session Key加密的信息

图 2‑3 第三次通信
你在通过缓存的Http Service Session Key解密这部分信息,然后验证是否是你想要的服务器发送给你的信息。完成你的服务器的验证。
至此,整个过程全部完成。
posted @
2017-04-25 15:56 xzc 阅读(255) |
评论 (2) |
编辑 收藏posted @
2017-04-14 11:25 xzc 阅读(546) |
评论 (2) |
编辑 收藏问题导读
1.CM的安装目录在什么位置?
2.hadoop配置文件在什么位置?
3.Cloudera manager运行所需要的信息存在什么位置?4.CM结构和功能是什么? 1. 相关目录
1. 相关目录- /var/log/cloudera-scm-installer : 安装日志目录。
- /var/log/* : 相关日志文件(相关服务的及CM的)。
- /usr/share/cmf/ : 程序安装目录。
- /usr/lib64/cmf/ : Agent程序代码。
- /var/lib/cloudera-scm-server-db/data : 内嵌数据库目录。
- /usr/bin/postgres : 内嵌数据库程序。
- /etc/cloudera-scm-agent/ : agent的配置目录。
- /etc/cloudera-scm-server/ : server的配置目录。
- /opt/cloudera/parcels/ : Hadoop相关服务安装目录。
- /opt/cloudera/parcel-repo/ : 下载的服务软件包数据,数据格式为parcels。
- /opt/cloudera/parcel-cache/ : 下载的服务软件包缓存数据。
- /etc/hadoop/* : 客户端配置文件目录。
2. 配置Hadoop配置文件
配置文件放置于/var/run/cloudera-scm-agent/process/目录下。如:/var/run/cloudera-scm-agent/process/193-hdfs-NAMENODE/core-site.xml。这些配置文件是通过Cloudera Manager启动相应服务(如HDFS)时生成的,内容从数据库中获得(即通过界面配置的参数)。
在CM界面上更改配置是不会立即反映到配置文件中,这些信息会存储于数据库中,等下次重启服务时才会生成配置文件。且每次启动时都会产生新的配置文件。
CM Server主要数据库为scm基中放置配置的数据表为configs。里面包含了服务的配置信息,每一次配置的更改会把当前页面的所有配置内容添加到数据库中,以此保存配置修改历史。
scm数据库被配置成只能从localhost访问,如果需要从外部连接此数据库,修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
查看配置内容
- 直接查询scm数据库的configs数据表的内容。
- 访问REST API: http://hostname:7180/api/v4/cm/deployment,返回JSON格式部署配置信息。
3. 数据库Cloudera manager主要的数据库为scm,存储Cloudera manager运行所需要的信息:配置,主机,用户等。
4. CM结构CM分为Server与Agent两部分及数据库(自带更改过的嵌入Postgresql)。它主要做三件事件:
- 管理监控集群主机。
- 统一管理配置。
- 管理维护Hadoop平台系统。
实现采用C/S结构,Agent为客户端负责执行服务端发来的命令,执行方式一般为使用python调用相应的服务shell脚本。Server端为Java REST服务,提供REST API,Web管理端通过REST API调用Server端功能,Web界面使用富客户端技术(Knockout)。
- Server端主体使用Java实现。
- Agent端主体使用Python, 服务的启动通过调用相应的shell脚本进行启动,如果启动失败会重复4次调用启动脚本。
- Agent与Server保持心跳,使用Thrift RPC框架。
5. 升级在CM中可以通过界面向导升级相关服务。升级过程为三步:
- 下载服务软件包。
- 把所下载的服务软件包分发到集群中受管的机器上。
- 安装服务软件包,使用软链接的方式把服务程序目录链接到新安装的软件包目录上。
6. 卸载sudo /usr/share/cmf/uninstall-scm-express.sh, 然后删除/var/lib/cloudera-scm-server-db/目录,不然下次安装可能不成功。
7. 开启postgresql远程访问CM内嵌数据库被配置成只能从localhost访问,如果需要从外部查看数据,数据修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
posted @
2017-04-13 14:36 xzc 阅读(316) |
评论 (0) |
编辑 收藏- 新版本的 hbck 可以修复各种错误,修复选项是:
- (1)-fix,向下兼容用,被-fixAssignments替代
- (2)-fixAssignments,用于修复region assignments错误
- (3)-fixMeta,用于修复meta表的问题,前提是HDFS上面的region info信息有并且正确。
- (4)-fixHdfsHoles,修复region holes(空洞,某个区间没有region)问题
- (5)-fixHdfsOrphans,修复Orphan region(hdfs上面没有.regioninfo的region)
- (6)-fixHdfsOverlaps,修复region overlaps(区间重叠)问题
- (7)-fixVersionFile,修复缺失hbase.version文件的问题
- (8)-maxMerge <n> (n默认是5),当region有重叠是,需要合并region,一次合并的region数最大不超过这个值。
- (9)-sidelineBigOverlaps ,当修复region overlaps问题时,允许跟其他region重叠次数最多的一些region不参与(修复后,可以把没有参与的数据通过bulk load加载到相应的region)
- (10)-maxOverlapsToSideline <n> (n默认是2),当修复region overlaps问题时,一组里最多允许多少个region不参与
- 由于选项较多,所以有两个简写的选项
- (11) -repair,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps
- (12)-repairHoles,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans
-
-
-
- 新版本的 hbck
- (1)缺失hbase.version文件
- 加上选项 -fixVersionFile 解决
- (2)如果一个region即不在META表中,又不在hdfs上面,但是在regionserver的online region集合中
- 加上选项 -fixAssignments 解决
- (3)如果一个region在META表中,并且在regionserver的online region集合中,但是在hdfs上面没有
- 加上选项 -fixAssignments -fixMeta 解决,( -fixAssignments告诉regionserver close region),( -fixMeta删除META表中region的记录)
- (4)如果一个region在META表中没有记录,没有被regionserver服务,但是在hdfs上面有
- 加上选项 -fixMeta -fixAssignments 解决,( -fixAssignments 用于assign region),( -fixMeta用于在META表中添加region的记录)
- (5)如果一个region在META表中没有记录,在hdfs上面有,被regionserver服务了
- 加上选项 -fixMeta 解决,在META表中添加这个region的记录,先undeploy region,后assign
- (6)如果一个region在META表中有记录,但是在hdfs上面没有,并且没有被regionserver服务
- 加上选项 -fixMeta 解决,删除META表中的记录
- (7)如果一个region在META表中有记录,在hdfs上面也有,table不是disabled的,但是这个region没有被服务
- 加上选项 -fixAssignments 解决,assign这个region
- (8)如果一个region在META表中有记录,在hdfs上面也有,table是disabled的,但是这个region被某个regionserver服务了
- 加上选项 -fixAssignments 解决,undeploy这个region
- (9)如果一个region在META表中有记录,在hdfs上面也有,table不是disabled的,但是这个region被多个regionserver服务了
- 加上选项 -fixAssignments 解决,通知所有regionserver close region,然后assign region
- (10)如果一个region在META表中,在hdfs上面也有,也应该被服务,但是META表中记录的regionserver和实际所在的regionserver不相符
- 加上选项 -fixAssignments 解决
-
- (11)region holes
- 需要加上 -fixHdfsHoles ,创建一个新的空region,填补空洞,但是不assign 这个 region,也不在META表中添加这个region的相关信息
- (12)region在hdfs上面没有.regioninfo文件
- -fixHdfsOrphans 解决
- (13)region overlaps
- 需要加上 -fixHdfsOverlaps
-
-
- 说明:
- (1)修复region holes时,-fixHdfsHoles 选项只是创建了一个新的空region,填补上了这个区间,还需要加上-fixAssignments -fixMeta 来解决问题,( -fixAssignments 用于assign region),( -fixMeta用于在META表中添加region的记录),所以有了组合拳 -repairHoles 修复region holes,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans
- (2) -fixAssignments,用于修复region没有assign、不应该assign、assign了多次的问题
- (3)-fixMeta,如果hdfs上面没有,那么从META表中删除相应的记录,如果hdfs上面有,在META表中添加上相应的记录信息
- (4)-repair 打开所有的修复选项,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps
-
- 新版本的hbck从(1)hdfs目录(2)META(3)RegionServer这三处获得region的Table和Region的相关信息,根据这些信息判断并repair
新版本的 hbck 可以修复各种错误,修复选项是: (1)-fix,向下兼容用,被-fixAssignments替代 (2)-fixAssignments,用于修复region assignments错误 (3)-fixMeta,用于修复meta表的问题,前提是HDFS上面的region info信息有并且正确。 (4)-fixHdfsHoles,修复region holes(空洞,某个区间没有region)问题 (5)-fixHdfsOrphans,修复Orphan region(hdfs上面没有.regioninfo的region) (6)-fixHdfsOverlaps,修复region overlaps(区间重叠)问题 (7)-fixVersionFile,修复缺失hbase.version文件的问题 (8)-maxMerge <n> (n默认是5),当region有重叠是,需要合并region,一次合并的region数最大不超过这个值。 (9)-sidelineBigOverlaps ,当修复region overlaps问题时,允许跟其他region重叠次数最多的一些region不参与(修复后,可以把没有参与的数据通过bulk load加载到相应的region) (10)-maxOverlapsToSideline <n> (n默认是2),当修复region overlaps问题时,一组里最多允许多少个region不参与 由于选项较多,所以有两个简写的选项 (11) -repair,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps (12)-repairHoles,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans 新版本的 hbck (1)缺失hbase.version文件 加上选项 -fixVersionFile 解决 (2)如果一个region即不在META表中,又不在hdfs上面,但是在regionserver的online region集合中 加上选项 -fixAssignments 解决 (3)如果一个region在META表中,并且在regionserver的online region集合中,但是在hdfs上面没有 加上选项 -fixAssignments -fixMeta 解决,( -fixAssignments告诉regionserver close region),( -fixMeta删除META表中region的记录) (4)如果一个region在META表中没有记录,没有被regionserver服务,但是在hdfs上面有 加上选项 -fixMeta -fixAssignments 解决,( -fixAssignments 用于assign region),( -fixMeta用于在META表中添加region的记录) (5)如果一个region在META表中没有记录,在hdfs上面有,被regionserver服务了 加上选项 -fixMeta 解决,在META表中添加这个region的记录,先undeploy region,后assign (6)如果一个region在META表中有记录,但是在hdfs上面没有,并且没有被regionserver服务 加上选项 -fixMeta 解决,删除META表中的记录 (7)如果一个region在META表中有记录,在hdfs上面也有,table不是disabled的,但是这个region没有被服务 加上选项 -fixAssignments 解决,assign这个region (8)如果一个region在META表中有记录,在hdfs上面也有,table是disabled的,但是这个region被某个regionserver服务了 加上选项 -fixAssignments 解决,undeploy这个region (9)如果一个region在META表中有记录,在hdfs上面也有,table不是disabled的,但是这个region被多个regionserver服务了 加上选项 -fixAssignments 解决,通知所有regionserver close region,然后assign region (10)如果一个region在META表中,在hdfs上面也有,也应该被服务,但是META表中记录的regionserver和实际所在的regionserver不相符 加上选项 -fixAssignments 解决 (11)region holes 需要加上 -fixHdfsHoles ,创建一个新的空region,填补空洞,但是不assign 这个 region,也不在META表中添加这个region的相关信息 (12)region在hdfs上面没有.regioninfo文件 -fixHdfsOrphans 解决 (13)region overlaps 需要加上 -fixHdfsOverlaps 说明: (1)修复region holes时,-fixHdfsHoles 选项只是创建了一个新的空region,填补上了这个区间,还需要加上-fixAssignments -fixMeta 来解决问题,( -fixAssignments 用于assign region),( -fixMeta用于在META表中添加region的记录),所以有了组合拳 -repairHoles 修复region holes,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans (2) -fixAssignments,用于修复region没有assign、不应该assign、assign了多次的问题 (3)-fixMeta,如果hdfs上面没有,那么从META表中删除相应的记录,如果hdfs上面有,在META表中添加上相应的记录信息 (4)-repair 打开所有的修复选项,相当于-fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps 新版本的hbck从(1)hdfs目录(2)META(3)RegionServer这三处获得region的Table和Region的相关信息,根据这些信息判断并repair
示例:
- 查看hbasemeta情况
- hbase hbck
- 1.重新修复hbase meta表(根据hdfs上的regioninfo文件,生成meta表)
- hbase hbck -fixMeta
- 2.重新将hbase meta表分给regionserver(根据meta表,将meta表上的region分给regionservere)
- hbase hbck -fixAssignments
查看hbasemeta情况 hbase hbck 1.重新修复hbase meta表(根据hdfs上的regioninfo文件,生成meta表) hbase hbck -fixMeta 2.重新将hbase meta表分给regionserver(根据meta表,将meta表上的region分给regionservere) hbase hbck -fixAssignments
- 当出现漏洞
- hbase hbck -fixHdfsHoles (新建一个region文件夹)
- hbase hbck -fixMeta (根据regioninfo生成meta表)
- hbase hbck -fixAssignments (分配region到regionserver上)
当出现漏洞 hbase hbck -fixHdfsHoles (新建一个region文件夹) hbase hbck -fixMeta (根据regioninfo生成meta表) hbase hbck -fixAssignments (分配region到regionserver上)
- 一、故障原因
- IP为10.191.135.3的服务器在2013年8月1日出现服务器重新启动的情况,导致此台服务器上的所有服务均停止。从而造成NTP服务停止。当NTP服务停止后,导致HBase集群中大部分机器时钟和主机时间不一致,造成regionserver服务中止。并在重新启动后,出现region的hole。需要对数据进行重新修复,以正常提供插入数据的服务。
-
- 二、恢复方式
- 1、集群50个regionserver,宕掉服务41个,namenode所在机器10.191.135.3不明重启(原因查找中)导致本机上的namenode、zookeeper、时间同步服务器服务挂掉。
- 2、重启hbase服务时,没能成功stop剩余的9个regionserver服务,进行了人为kill进程,
- 3、在hdfs上移走了hlog(避免启动时split log花费过多时间影响服务),然后重启hbase。发现10.191.135.30机器上的时间与时间同步服务器10.191.135.3不同步。手工同步后重启成功。hbase可以正常提供查询服务。
- 4、运行mapreduce put数据。抛出异常,数据无法正常插入;
- 5、执行/opt/hbase/bin/hbase hbck -fixAssignments,尝试重新分配region。结果显示hbase有空洞,即region之间数据不连续了;
- 6、通过上述操作可以定位是在regionserver服务宕掉的后重启的过程中丢了数据。需要进行空洞修复。然而hbase hbck命令总是只显示三条空洞。
- 7、通过编写的regionTest.jar工具进行进一步检测出空洞所在的regionname然后停掉hbase,进而进行region合并修复空洞;
- 8、合并的merge 操作需要先去.META.表里读取该region的信息,由于.META.表也在regionserver宕机过程中受到损坏,所以部分region的.META.信息没有,merge操作时就抛出空指针异常。因此只能将hdfs这些region进行移除,然后通过regionTest.jar 检测新的空洞所在的regionname,进行合并操作修复空洞;
- 9、关于region重叠,即regionname存在.META.表内,但是在hdfs上被错误的移出,并进行了region合并。这种情况下需要通过regionTest.jar检测重叠的regionname然后手动去.META.表删除,.META.表修改之后需要flush;
- 10、最后再次执行 hbase hbck 命令,hbase 所有表status ok。
-
- 三、相关命令及页面报错信息
- 1.手工同步时间命令
service ntpd stop
ntpdate -d 192.168.1.20
service ntpd start
-
-
- 2.org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException: Failed 2 actions: WrongRegionException: 2 times, servers with issues: datanode10:60020,
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.processBatchCallback(HConnectionManager.java:1641)
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.processBatch(HConnectionManager.java:1409)
at org.apache.hadoop.hbase.client.HTable.flushCommits(HTable.java:949)
at org.apache.hadoop.hbase.client.HTable.doPut(HTable.java:826)
at org.apache.hadoop.hbase.client.HTable.put(HTable.java:801)
at org.apache.hadoop.hbase.mapreduce.TableOutputFormat$TableRecordWriter.write(TableOutputFormat.java:123)
at org.apache.hadoop.hbase.mapreduce.TableOutputFormat$TableRecordWriter.write(TableOutputFormat.java:84)
at org.apache.hadoop.mapred.MapTask$NewDirectOutputCollector.write(MapTask.java:533)
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:88)
at o
-
- 3.13/08/01 18:30:02 DEBUG util.HBaseFsck: There are 22093 region info entries
ERROR: There is a hole in the region chain between +8615923208069cmnet201303072132166264580 and +861592321. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
ERROR: There is a hole in the region chain between +8618375993383cmwap20130512235639430 and +8618375998629cmnet201305040821436779670. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
ERROR: There is a hole in the region chain between +8618725888080cmnet201212271719506311400 and +8618725889786cmnet201302131646431671140. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
ERROR: Found inconsistency in table cqgprs
Summary:
-ROOT- is okay.
Number of regions: 1
Deployed on: datanode14,60020,1375330955915
.META. is okay.
Number of regions: 1
Deployed on: datanode21,60020,1375330955825
cqgprs is okay.
Number of regions: 22057
Deployed on: datanode1,60020,1375330955761 datanode10,60020,1375330955748 datanode11,60020,1375330955736 datanode12,60020,1375330955993 datanode13,60020,1375330955951 datanode14,60020,1375330955915 datanode15,60020,1375330955882 datanode16,60020,1375330955892 datanode17,60020,1375330955864 datanode18,60020,1375330955703 datanode19,60020,1375330955910 datanode2,60020,1375330955751 datanode20,60020,1375330955849 datanode21,60020,1375330955825 datanode22,60020,1375334479752 datanode23,60020,1375330955835 datanode24,60020,1375330955932 datanode25,60020,1375330955856 datanode26,60020,1375330955807 datanode27,60020,1375330955882 datanode28,60020,1375330955785 datanode29,60020,1375330955799 datanode3,60020,1375330955778 datanode30,60020,1375330955748 datanode31,60020,1375330955877 datanode32,60020,1375330955763 datanode33,60020,1375330955755 datanode34,60020,1375330955713 datanode35,60020,1375330955768 datanode36,60020,1375330955896 datanode37,60020,1375330955884 datanode38,60020,1375330955918 datanode39,60020,1375330955881 datanode4,60020,1375330955826 datanode40,60020,1375330955770 datanode41,60020,1375330955824 datanode42,60020,1375449245386 datanode43,60020,1375330955880 datanode44,60020,1375330955902 datanode45,60020,1375330955881 datanode46,60020,1375330955841 datanode47,60020,1375330955790 datanode48,60020,1375330955848 datanode49,60020,1375330955849 datanode5,60020,1375330955880 datanode50,60020,1375330955802 datanode6,60020,1375330955753 datanode7,60020,1375330955890 datanode8,60020,1375330955967 datanode9,60020,1375330955948
test1 is okay.
Number of regions: 1
Deployed on: datanode43,60020,1375330955880
test2 is okay.
Number of regions: 1
Deployed on: datanode21,60020,1375330955825
35 inconsistencies detected.
Status: INCONSISTENT
-
- 4.hadoop jar regionTest.jar com.region.RegionReaderMain /hbase/cqgprs 检测cqgprs表里的空洞所在的regionname。
-
- 5.==================================
first endKey = +8615808059207cmnet201307102326567966800
second startKey = +8615808058578cmnet201212251545557984830
first regionNmae = cqgprs,+8615808058578cmnet201212251545557984830,1375241186209.0f8266ad7ac45be1fa7233e8ea7aeef9.
second regionNmae = cqgprs,+8615808058578cmnet201212251545557984830,1362778571889.3552d3db8166f421047525d6be39c22e.
==================================
first endKey = +8615808060140cmnet201303051801355846850
second startKey = +8615808059207cmnet201307102326567966800
first regionNmae = cqgprs,+8615808058578cmnet201212251545557984830,1362778571889.3552d3db8166f421047525d6be39c22e.
second regionNmae = cqgprs,+8615808059207cmnet201307102326567966800,1375241186209.09d489d3df513bc79bab09cec36d2bb4.
==================================
-
- 6.Usage: bin/hbase org.apache.hadoop.hbase.util.Merge [-Dfs.default.name=hdfs://nn:port] <table-name> <region-1> <region-2>
./hbase org.apache.hadoop.hbase.util.Merge -Dfs.defaultFS=hdfs://bdpha cqgprs cqgprs,+8615213741567cmnet201305251243290802280,1369877465524.3c13b460fae388b1b1a70650b66c5039. cqgprs,+8615213745577cmnet201302141725552206710,1369534940433.5de80f59071555029ac42287033a4863. &
-
- 7.13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618225125357cmnet201212290358070667800
ERROR: (regions cqgprs,+8618225123516cmnet201304131404096748520,1375363774655.b3cf5cc752f4427a4e699270dff9839e. and cqgprs,+8618225125357cmnet201212290358070667800,1364421610707.7f7038bfbe2c0df0998a529686a3e1aa.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618225127504cmnet201302182135452100210
13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618285642723cmnet201302031921019768070
ERROR: (regions cqgprs,+8618285277826cmnet201306170027424674330,1375363962312.9d1e93b22cec90fd75361fa65b1d20d2. and cqgprs,+8618285642723cmnet201302031921019768070,1360873307626.f631cd8c6acc5e711e651d13536abe94.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618286275556cmnet201212270713444340110
13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618323968833cmnet201306010239025175240
ERROR: (regions cqgprs,+8618323967956cmnet201306091923411365860,1375364143678.665dba6a14ebc9971422b39e079b00ae. and cqgprs,+8618323968833cmnet201306010239025175240,1372821719159.6d2fecc1b3f9049bbca83d84231eb365.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618323992353cmnet201306012336364819810
ERROR: There is a hole in the region chain between +8618375993383cmwap20130512235639430 and +8618375998629cmnet201305040821436779670. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618723686187cmnet201301191433522129820
ERROR: (regions cqgprs,+8618723683087cmnet201301300708363045080,1375364411992.4ee5787217c1da4895d95b3b92b8e3a2. and cqgprs,+8618723686187cmnet201301191433522129820,1362003066106.70b48899cc753a0036f11bb27d2194f9.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618723689138cmnet201301051742388948390
13/08/01 22:24:02 WARN util.HBaseFsck: Naming new problem group: +8618723711808cmnet201301031139206225900
ERROR: (regions cqgprs,+8618723710003cmnet201301250809235976320,1375364586329.40eed10648c9a43e3d5ce64e9d63fe00. and cqgprs,+8618723711808cmnet201301031139206225900,1361216401798.ebc442e02f5e784bce373538e06dd232.) There is an overlap in the region chain.
13/08/01 22:24:02 WARN util.HBaseFsck: reached end of problem group: +8618723714626cmnet201302122009459491970
ERROR: There is a hole in the region chain between +8618725888080cmnet201212271719506311400 and +8618725889786cmnet201302131646431671140. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
-
- 8. delete '.META.','regionname','info:serverstartcode'
- delete '.META.','regionname','info:regionserver'
- delete '.META.','regionname','info:regioninfo'
-
- 9. flush '.META.'
major_compact '.META.'
posted @
2017-04-11 16:01 xzc 阅读(449) |
评论 (0) |
编辑 收藏自从开源中国的maven仓库挂了之后就一直在用国外的仓库,慢得想要砸电脑的心都有了。如果你和我一样受够了国外maven仓库的龟速下载?快试试阿里云提供的maven仓库,从此不在浪费生命……
仓库地址:http://maven.aliyun.com/nexus/#view-repositories;public~browsestorage
仓库配置
在maven的settings.xml文件里的mirrors节点,添加如下子节点:
<mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>
或者直接在profiles->profile->repositories节点,添加如下子节点:
<repository> <id>nexus-aliyun</id> <name>Nexus aliyun</name> <layout>default</layout> <url>http://maven.aliyun.com/nexus/content/groups/public</url> <snapshots> <enabled>false</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository>
settings文件的路径
settings.xml的默认路径就:个人目录/.m2/settings.xml
如:
windowns: C:\Users\你的用户名\.m2\settings.xml
linux: /home/你的用户名/.m2/settings.xml
posted @
2017-04-11 10:08 xzc 阅读(258) |
评论 (0) |
编辑 收藏所谓BOM,全称是Byte Order Mark,它是一个Unicode字符,通常出现在文本的开头,用来标识字节序(Big/Little Endian),除此以外还可以标识编码(UTF-8/16/32),如果出现在文本中间,则解释为zero width no-break space。 注:Unicode相关知识的详细介绍请参考UTF-8, UTF-16, UTF-32 & BOM。
对于UTF-8/16/32而言,它们名字中的8/16/32指的是编码单位是多少位的,也就是说,它们的编码单位分别是8/16/32位,换算成字节就
是1/2/4字节,如果是多字节,就要牵扯到字节序,UTF-8以单字节为编码单位,所以不存在字节序。
UTF-8主要的优点是可以兼容ASCII,但如果使用BOM的话,这个好处就荡然无存了,除此以外,BOM的存在还可能引发一些问题,比如下面错误便都
有可能是BOM导致的:
- Shell: No such file or directory
- PHP: Warning: Cannot modify header information – headers already sent
在详细讨论UTF-8编码中BOM的检测与删除问题前,不妨先通过一个例子热热身:
shell> curl -s http://phone.10086.cn/ | head -1 | sed -n l
\357\273\277<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional\
//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\r$
如上所示,前三个字节分别是357、273、277,这就是八进制的BOM。
shell> curl -s http://phone.10086.cn/ | head -1 | hexdump -C
00000000 ef bb bf 3c 21 44 4f 43 54 59 50 45 20 68 74 6d |...<!DOCTYPE htm|
00000010 6c 20 50 55 42 4c 49 43 20 22 2d 2f 2f 57 33 43 |l PUBLIC "-//W3C|
00000020 2f 2f 44 54 44 20 58 48 54 4d 4c 20 31 2e 30 20 |//DTD XHTML 1.0 |
00000030 54 72 61 6e 73 69 74 69 6f 6e 61 6c 2f 2f 45 4e |Transitional//EN|
00000040 22 20 22 68 74 74 70 3a 2f 2f 77 77 77 2e 77 33 |" "http://www.w3|
00000050 2e 6f 72 67 2f 54 52 2f 78 68 74 6d 6c 31 2f 44 |.org/TR/xhtml1/D|
00000060 54 44 2f 78 68 74 6d 6c 31 2d 74 72 61 6e 73 69 |TD/xhtml1-transi|
00000070 74 69 6f 6e 61 6c 2e 64 74 64 22 3e 0d 0a |tional.dtd">..|
如上所示,前三个字节分别是EF、BB、BF,这就是十六进制的BOM。 注:用到了第三方网站的页面,不能保证例子始终可用。
实际做项目开发时,可能会面对成百上千个文本文件,如果有几个文件混入了BOM,那么很难察觉,如果没有带BOM的UTF-8文本文件,可以用vi杜撰几
个,相关命令如下:
设置UTF-8编码:
:set fileencoding=utf-8
添加BOM:
:set bomb
删除BOM:
:set nobomb
查询BOM:
:set bomb?
如何检测UTF-8编码中的BOM呢?
shell> grep -r -I -l $'^\xEF\xBB\xBF' /path
如何删除UTF-8编码中的BOM呢?
shell> grep -r -I -l $'^\xEF\xBB\xBF' /path | xargs sed -i 's/^\xEF\xBB\xBF//;q'
推荐:如果你使用SVN的话,可以在pre-commit钩子里加上相关代码用以杜绝BOM。
#!/bin/bash
REPOS="$1"
TXN="$2"
SVNLOOK=/usr/bin/svnlook
for FILE in $($SVNLOOK changed -t "$TXN" "$REPOS" | awk '/^[AU]/ {print $NF}'); do
if $SVNLOOK cat -t "$TXN" "$REPOS" "$FILE" | grep -q $'^\xEF\xBB\xBF'; then
echo "Byte Order Mark be found in $FILE" 1>&2
exit 1
fi
done
本文用到了很多shell命令,篇幅所限,恕不详述,如果有不明白的就请自己搜索吧。
posted @
2016-09-18 09:38 xzc 阅读(949) |
评论 (0) |
编辑 收藏当我们需要把二进制转成c语言中使用的16进制字符数组时,命令xxd是很有用的。
xxd 帮助信息如下:关键选项标黑。
[root@localhost ]# xxd --help
Usage:
xxd [options] [infile [outfile]]
or
xxd -r [-s [-]offset] [-c cols] [-ps] [infile [outfile]]
Options:
-a toggle autoskip: A single '*' replaces nul-lines. Default off.
-b binary digit dump (incompatible with -p,-i,-r). Default hex.
-c cols format <cols> octets per line. Default 16 (-i: 12, -ps: 30).
-E show characters in EBCDIC. Default ASCII.
-g number of octets per group in normal output. Default 2. 每个goup的字节数,默认为2,可设置。
-h print this summary.
-i output in C include file style. :输出为c包含文件的风格,数组方式存在。
-l len stop after <len> octets. :转换到len个字节后停止转换。
-ps output in postscript plain hexdump style.
-r reverse operation: convert (or patch) hexdump into binary.
-r -s off revert with <off> added to file positions found in hexdump.
-s [+][-]seek start at <seek> bytes abs. (or +: rel.) infile offset.
-u use upper case hex letters. : 字节大写方式
-v show version: "xxd V1.10 27oct98 by Juergen Weigert".
比如运行:
> xxd -g 1 -i -u -l 10000000 nm.ts > xxd_test.txt
生成的文本显示:
unsigned char __0513_1634_ch32_666_10_ts[] = {
0X47, 0X02, 0X03, 0X13, 0XF8, 0X5A, 0XC5, 0X40, 0X26, 0XE4, 0XD0, 0XDE,
0XAD, 0XB8, 0X76, 0X89, 0X85, 0X23, 0X06, 0X04, 0X6E, 0X05, 0X8B, 0X09,
0XC0, 0X5C, 0X96, 0X4F, 0X18, 0X51, 0X41, 0XC8, 0X40, 0X9F, 0X06, 0X93,
0X38, 0XC1, 0XBB, 0X1A, 0XBC, 0XAC, 0X47, 0XFF, 0X5E, 0X54, 0XEB, 0XA7,
0X14, 0X36, 0X85, 0X8A, 0X90, 0X14, 0X17, 0XA2, 0X9D, 0XC0, 0X84, 0X56,
0XCB, 0X97, 0X78, 0XC8, 0X57, 0X15, 0X3E, 0X61, 0X6F, 0XFE, 0XC9, 0X39,
0XEF, 0XD3, 0XB6, 0X6A, 0XD2, 0XE4, 0XFB, 0X4C, 0X05, 0XF6, 0X03, 0XED,
0X50, 0XB3, 0XE7, 0X46, 0X57, 0X24, 0X71, 0X16, 0X38, 0X45, 0X53, 0X19,
0X56, 0X25, 0X3C, 0X8D, 0X4C, 0XA9, 0X28, 0X9A, 0XB2, 0X99, 0X76, 0X52,
0X28, 0XE9, 0XD6, 0XD6, 0X11, 0X94, 0X89, 0X19, 0X4D, 0XEA, 0X68, 0X76,
0X53, 0XC6, 0XAA, 0X3A, 0XD4, 0XA1, 0X25, 0XA5, 0X03, 0XB0, 0X73, 0XA0,
0XAE, 0X11, 0XC9, 0XBD, 0X37, 0X17, 0X11, 0X5F, 0X30, 0X34, 0X34, 0X0B
.....
};
unsigned int nm.ts_len = 10000000;
另外,在vim中也可以把文件转换为16进制来显示:
:%!xxd
返回正常显示:
:%!xxd -r
linux下查看二进制文件
以十六进制格式输出:
od [选项] 文件
od -d 文件 十进制输出
-o 文件 八进制输出
-x 文件 十六进制输出
xxd 文件 输出十六进制
在vi命令状态下:
:%!xxd :%!od 将当前文本转化为16进制格式
:%!xxd -c 12 每行显示12个字节
:%!xxd -r 将当前文本转化回文本格式
posted @
2016-09-18 09:38 xzc 阅读(2530) |
评论 (0) |
编辑 收藏一、IFS 介绍
Shell 脚本中有个变量叫 IFS(Internal Field Seprator) ,内部域分隔符。完整定义是The shell uses the value stored in IFS, which is the space, tab, and newline characters by default, to delimit words for the read and set commands, when parsing output from command substitution, and when performing variable substitution.
Shell 的环境变量分为 set, env 两种,其中 set 变量可以通过 export 工具导入到 env 变量中。其中,set 是显示设置shell变量,仅在本 shell 中有效;env 是显示设置用户环境变量 ,仅在当前会话中有效。换句话说,set 变量里包含了 env 变量,但 set 变量不一定都是 env 变量。这两种变量不同之处在于变量的作用域不同。显然,env 变量的作用域要大些,它可以在 subshell 中使用。
而 IFS 是一种 set 变量,当 shell 处理"命令替换"和"参数替换"时,shell 根据 IFS 的值,默认是 space, tab, newline 来拆解读入的变量,然后对特殊字符进行处理,最后重新组合赋值给该变量。
二、IFS 简单实例
1、查看变量 IFS 的值。
- $ echo $IFS
-
- $ echo "$IFS" | od -b
- 0000000 040 011 012 012
- 0000004
$ echo $IFS $ echo "$IFS" | od -b 0000000 040 011 012 012 0000004
直接输出IFS是看不到的,把它转化为二进制就可以看到了,"040"是空格,"011"是Tab,"012"是换行符"\n" 。最后一个 012 是因为 echo 默认是会换行的。
2、$* 和 $@ 的细微差别
从下面的例子中可以看出,如果是用冒号引起来,表示这个变量不用IFS替换!!所以可以看到这个变量的"原始值"。反之,如果不加引号,输出时会根据IFS的值来分割后合并输出! $* 是按照IFS中的第一个值来确定的!下面这两个例子还有细微的差别!
- $ IFS=:;
- $ set x y z
- $ echo $*
- x y z
- $ echo "$*"
- x:y:z
- $ echo $@
- x y z
- $ echo "$@"
- x y z
$ IFS=:; $ set x y z $ echo $* x y z $ echo "$*" x:y:z $ echo $@ x y z $ echo "$@" x y z
上例 set 变量其实是3个参数,而下面这个例子实质是2个参数,即 set "x y z" 和 set x y z 是完全不同的。
- $ set "x" "y z"
- $ echo $*
- x y z
- $ echo "$*"
- x:y z
- $ echo $@
- x y z
- $ echo "$@"
- x y z
- $ echo $* |od -b
- 0000000 170 040 171 040 172 012
- 0000006
- $ echo "$*" |od -b
- 0000000 170 072 171 040 172 012
- 0000006
$ set "x" "y z" $ echo $* x y z $ echo "$*" x:y z $ echo $@ x y z $ echo "$@" x y z $ echo $* |od -b 0000000 170 040 171 040 172 012 0000006 $ echo "$*" |od -b 0000000 170 072 171 040 172 012 0000006
小结:$* 会根据 IFS 的不同来组合值,而 $@ 则会将值用" "来组合值!
3、for 循环中的奇怪现象
- $ for x in $var ;do echo $x |od -b ;done
- 0000000 012
- 0000001
- 0000000 040 141 012
- 0000003
- 0000000 142 012
- 0000002
- 0000000 012
- 0000001
- 0000000 143 012
- 0000002
$ for x in $var ;do echo $x |od -b ;done 0000000 012 0000001 0000000 040 141 012 0000003 0000000 142 012 0000002 0000000 012 0000001 0000000 143 012 0000002
先暂且不解释 for 循环的内容!看下面这个输出!IFS 的值同上! var=": a:b::c:",
- $ echo $var |od -b
- 0000000 040 040 141 040 142 040 040 143 012
- 0000011
- $ echo "$var" |od -b
- 0000000 072 040 141 072 142 072 072 143 072 012
- 0000012
$ echo $var |od -b 0000000 040 040 141 040 142 040 040 143 012 0000011 $ echo "$var" |od -b 0000000 072 040 141 072 142 072 072 143 072 012 0000012
"$var"的值应该没做替换,所以还是 ": a:b::c:" (注 "072" 表示冒号),但是$var 则发生了变化!注意输出的最后一个冒号没有了,也没有替换为空格!Why?
使用 $var 时是经历了这样一个过程!首先,按照这样的规则 [变量][IFS][变量][IFS]……根据原始 var 值中所有的分割符(此处是":")划分出变量,如果IFS的值是有多个字符组成,如IFS=":;",那么此处的[IFS]指的是IFS中的任意一个字符($* 是按第一个字符来分隔!),如 ":" 或者 ";" ,后面不再对[IFS]做类似说明!(注:[IFS]会有多个值,多亏 #blackold 的提醒);然后,得到类似这样的 list, "" " a" "b" "" "c" 。如果此时 echo $var,则需要在这些变量之间用空格隔开,也就是"" [space] " a" [space] "b" [space] "" [space] "c" ,忽略掉空值,最终输出是 [space][space]a[space]b[space][space]c !
如果最后一个字符不是分隔符,如 var="a:b",那么最后一个分隔符后的变量就是最后一个变量!
这个地方要注意下!!如果IFS就是空格,那么类似于" [space][space]a[space]b[space][space]c "会合并重复的部分,且去头空格,去尾空格,那么最终输出会变成类似 a[space]b[space]c ,所以,如果IFS是默认值,那么处理的结果就很好算出来,直接合并、忽略多余空格即可!
另外,$* 和 $@ 在函数中的处理过程是这样的(只考虑"原始值"!)!"$@",就是像上面处理后赋值,但是 "$*" 却不一样!它的值是用分隔符(如":")而不是空格隔开!具体例子见最后一个例子!
好了,现在来解释 for 循环的内容。for 循环遍历上面这个列表就可以了,所以 for 循环的第一个输出是空!("012"是echo输出的换行符 )。。。。后面的依次类推!不信可以试试下面这个例子,结果是一样的!
- $ for x in "" " a" "b" "" "c" ;do echo $x |od -b ;done
- 0000000 012
- 0000001
- 0000000 040 141 012
- 0000003
- 0000000 012
- 0000001
- 0000000 142 012
- 0000002
- 0000000 012
- 0000001
- 0000000 143 012
- 0000002
$ for x in "" " a" "b" "" "c" ;do echo $x |od -b ;done 0000000 012 0000001 0000000 040 141 012 0000003 0000000 012 0000001 0000000 142 012 0000002 0000000 012 0000001 0000000 143 012 0000002
三、IFS的其他实例
Example 1:
- $ IFS=:
- $ var=ab::cd
- $ echo $var
- ab cd
- $ echo "$var"
- ab::cd
$ IFS=: $ var=ab::cd $ echo $var ab cd $ echo "$var" ab::cd
解释下:x 的值是 "ab::cd",当进行到 echo $x 时,因为$符,所以会进行变量替换。Shell 根据 IFS 的值将 x 分解为 ab "" cd,然后echo,插入空隔,ab[space]""[space]cd,忽略"",输出 ab cd 。
Example 2 :
- $ read a
- xy z
- $ echo $a
- xy z
$ read a xy z $ echo $a xy z
解释:这是 http://bbs.chinaunix.net/thread-207178-1-1.html 上的一个例子。此时IFS是默认值,本希望把所有的输入(包括空格)都放入变量a中,但是输出的a却把前面的空格给忽略了!!原因是:默认的 IFS 会按 space tab newline 来分割。这里需要注意的一点是,read 命令的实现过程,即在读入时已经替换了。解决办法是在开头加上一句 IFS=";" ,这里必须加上双引号,因为分号有特殊含义。
Example 3 :
- $ tmp=" xy z"
- $ a=$tmp
- $ echo $a
- $ echo "$a"
$ tmp=" xy z" $ a=$tmp $ echo $a $ echo "$a"
解释:什么时候会根据 IFS 来"处理"呢?我觉得是,对于不加引号的变量,使用时都会参考IFS,但是要注意其原始值!
Example 4 :
- #!/bin/bash
- IFS_old=$IFS #将原IFS值保存,以便用完后恢复
- IFS=$’\n’ #更改IFS值为$’\n’ ,注意,以回车做为分隔符,IFS必须为:$’\n’
- for i in $((cat pwd.txt)) #pwd.txt 来自这个命令:cat /etc/passwd >pwd.txt
- do
- echo $i
- done
- IFS=$IFS_old #恢复原IFS值
#!/bin/bash IFS_old=$IFS #将原IFS值保存,以便用完后恢复 IFS=$’\n’ #更改IFS值为$’\n’ ,注意,以回车做为分隔符,IFS必须为:$’\n’ for i in $((cat pwd.txt)) #pwd.txt 来自这个命令:cat /etc/passwd >pwd.txt do echo $i done IFS=$IFS_old #恢复原IFS值
另外一个例子,把IP地址逆转输出:
Example 5 :
- #!/bin/bash
-
- IP=220.112.253.111
- IFS="."
- TMPIP=$(echo $IP)
- IFS=" " # space
- echo $TMPIP
- for x in $TMPIP ;do
- Xip="${x}.$Xip"
- done
- echo ${Xip%.}
#!/bin/bash IP=220.112.253.111 IFS="." TMPIP=$(echo $IP) IFS=" " # space echo $TMPIP for x in $TMPIP ;do Xip="${x}.$Xip" done echo ${Xip%.}Complex_Example 1: http://bbs.chinaunix.net/forum.php?mod=viewthread&tid=3660898&page=1#pid21798049
- function output_args_ifs(){
- echo "=$*"
- echo "="$*
- for m in $* ;do
- echo "[$m]"
- done
- }
-
- IFS=':'
- var='::a:b::c:::'
- output_args_ifs $var
function output_args_ifs(){ echo "=$*" echo "="$* for m in $* ;do echo "[$m]" done } IFS=':' var='::a:b::c:::' output_args_ifs $var
输出为:
- =::a:b::c:: # 少了最后一个冒号!看前面就知道为什么了
- = a b c
- []
- []
- [a]
- [b]
- []
- [c]
- []
=::a:b::c:: # 少了最后一个冒号!看前面就知道为什么了 = a b c [] [] [a] [b] [] [c] []
由于 "output_args_ifs $var" 中 $var 没有加引号,所以根据IFS替换!根据IFS划分出变量: "" "" "a" "b" "" "c" "" ""(可以通过输出 $# 来测试参数的个数!),重组的结果为
"$@" 的值是 "" [space] "" [space] "a" [space] "b" [space] "" [space] "c" [space] "" [space] "",可以通过,echo==>" a b c "
"$*" 的值是 "" [IFS] "" [IFS] "a" [IFS] "b" [IFS] "" [IFS] "c" [IFS] "" [IFS] "",忽略"",echo=>"::a:b::c::"
注意, $* 和 $@ 的值都是 "" "" "a" "b" "" "c" "" "" 。可以说是一个列表……因为他们本来就是由 $1 $2 $3……组成的。
所以,《Linux程序设计》里推荐使用 $@,而不是$*
总结:IFS 其实还是很麻烦的,稍有不慎就会产生很奇怪的结果,因此使用的时候要注意!我也走了不少弯路,只希望能给后来者一些帮助。本文若有问题,欢迎指正!!谢谢!
如有转载,请注明blog.csdn.net/whuslei
参考:
http://blog.chinaunix.net/space.php?uid=20543672&do=blog&id=94358
http://smilejay.com/2011/12/bash_ifs/#comment-51
posted @
2016-04-01 15:00 xzc 阅读(277) |
评论 (1) |
编辑 收藏MYSQL 获取当前日期及日期格式
获取系统日期: NOW()
格式化日期: DATE_FORMAT(date, format)
注: date:时间字段
format:日期格式
返回系统日期,输出 2009-12-25 14:38:59
select now();
输出 09-12-25
select date_format(now(),'%y-%m-%d');
根据format字符串格式化date值:
%S, %s 两位数字形式的秒( 00,01, ..., 59)
%I, %i 两位数字形式的分( 00,01, ..., 59)
%H 两位数字形式的小时,24 小时(00,01, ..., 23)
%h 两位数字形式的小时,12 小时(01,02, ..., 12)
%k 数字形式的小时,24 小时(0,1, ..., 23)
%l 数字形式的小时,12 小时(1, 2, ..., 12)
%T 24 小时的时间形式(hh:mm:ss)
%r 12 小时的时间形式(hh:mm:ss AM 或hh:mm:ss PM)
%p AM或PM
%W 一周中每一天的名称(Sunday, Monday, ..., Saturday)
%a 一周中每一天名称的缩写(Sun, Mon, ..., Sat)
%d 两位数字表示月中的天数(00, 01,..., 31)
%e 数字形式表示月中的天数(1, 2, ..., 31)
%D 英文后缀表示月中的天数(1st, 2nd, 3rd,...)
%w 以数字形式表示周中的天数( 0 = Sunday, 1=Monday, ..., 6=Saturday)
%j 以三位数字表示年中的天数( 001, 002, ..., 366)
%U 周(0, 1, 52),其中Sunday 为周中的第一天
%u 周(0, 1, 52),其中Monday 为周中的第一天
%M 月名(January, February, ..., December)
%b 缩写的月名( January, February,...., December)
%m 两位数字表示的月份(01, 02, ..., 12)
%c 数字表示的月份(1, 2, ...., 12)
%Y 四位数字表示的年份
%y 两位数字表示的年份
%% 直接值“%”
curdate()
MySQL 获得当前日期时间 函数
1.1 获得当前日期+时间(date + time)函数:now()
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2008-08-08 22:20:46 |
+---------------------+
除了 now() 函数能获得当前的日期时间外,MySQL 中还有下面的函数:
current_timestamp()
,current_timestamp
,localtime()
,localtime
,localtimestamp -- (v4.0.6)
,localtimestamp() -- (v4.0.6)
这些日期时间函数,都等同于 now()。鉴于 now() 函数简短易记,建议总是使用 now() 来替代上面列出的函数。
1.2 获得当前日期+时间(date + time)函数:sysdate()
sysdate() 日期时间函数跟 now() 类似,不同之处在于:now() 在执行开始时值就得到了, sysdate() 在函数执行时动态得到值。看下面的例子就明白了:
mysql> select now(), sleep(3), now();
+---------------------+----------+---------------------+
| now() | sleep(3) | now() |
+---------------------+----------+---------------------+
| 2008-08-08 22:28:21 | 0 | 2008-08-08 22:28:21 |
+---------------------+----------+---------------------+mysql> select sysdate(), sleep(3), sysdate();
+---------------------+----------+---------------------+
| sysdate() | sleep(3) | sysdate() |
+---------------------+----------+---------------------+
| 2008-08-08 22:28:41 | 0 | 2008-08-08 22:28:44 |
+---------------------+----------+---------------------+
可以看到,虽然中途 sleep 3 秒,但 now() 函数两次的时间值是相同的; sysdate() 函数两次得到的时间值相差 3秒。MySQL Manual 中是这样描述 sysdate() 的:Return the time at which the functionexecutes。
sysdate() 日期时间函数,一般情况下很少用到。
2. 获得当前日期(date)函数:curdate()
mysql> select curdate();
+------------+
| curdate() |
+------------+
| 2008-08-08 |
+------------+
其中,下面的两个日期函数等同于 curdate():
current_date()
,current_date
3. 获得当前时间(time)函数:curtime()
mysql> select curtime();
+-----------+
| curtime() |
+-----------+
| 22:41:30 |
+-----------+
其中,下面的两个时间函数等同于 curtime():
current_time()
,current_time
4. 获得当前 UTC 日期时间函数:utc_date(), utc_time(), utc_timestamp()
mysql> select utc_timestamp(), utc_date(), utc_time(), now()
+---------------------+------------+------------+---------------------+
| utc_timestamp() | utc_date() | utc_time() | now() |
+---------------------+------------+------------+---------------------+
| 2008-08-08 14:47:11 | 2008-08-08 | 14:47:11 | 2008-08-08 22:47:11 |
+---------------------+------------+------------+---------------------+
因为我国位于东八时区,所以本地时间 = UTC 时间 + 8 小时。UTC 时间在业务涉及多个国家和地区的时候,非常有用。
二、MySQL 日期时间 Extract(选取) 函数。
1. 选取日期时间的各个部分:日期、时间、年、季度、月、日、小时、分钟、秒、微秒
set @dt = '2008-09-10 07:15:30.123456';
select date(@dt); -- 2008-09-10
select time(@dt); -- 07:15:30.123456
select year(@dt); -- 2008
select quarter(@dt); -- 3
select month(@dt); -- 9
select week(@dt); -- 36
select day(@dt); -- 10
select hour(@dt); -- 7
select minute(@dt); -- 15
select second(@dt); -- 30
select microsecond(@dt); -- 123456
2. MySQL Extract() 函数,可以上面实现类似的功能:
set @dt = '2008-09-10 07:15:30.123456';
select extract(year from @dt); -- 2008
select extract(quarter from @dt); -- 3
select extract(month from @dt); -- 9
select extract(week from @dt); -- 36
select extract(day from @dt); -- 10
select extract(hour from @dt); -- 7
select extract(minute from @dt); -- 15
select extract(second from @dt); -- 30
select extract(microsecond from @dt); -- 123456select extract(year_month from @dt); -- 200809
select extract(day_hour from @dt); -- 1007
select extract(day_minute from @dt); -- 100715
select extract(day_second from @dt); -- 10071530
select extract(day_microsecond from @dt); -- 10071530123456
select extract(hour_minute from @dt); -- 715
select extract(hour_second from @dt); -- 71530
select extract(hour_microsecond from @dt); -- 71530123456
select extract(minute_second from @dt); -- 1530
select extract(minute_microsecond from @dt); -- 1530123456
select extract(second_microsecond from @dt); -- 30123456
MySQLExtract() 函数除了没有date(),time() 的功能外,其他功能一应具全。并且还具有选取‘day_microsecond’等功能。注意这里不是只选取 day 和 microsecond,而是从日期的 day 部分一直选取到 microsecond 部分。够强悍的吧!
MySQL Extract() 函数唯一不好的地方在于:你需要多敲几次键盘。
3. MySQL dayof… 函数:dayofweek(), dayofmonth(), dayofyear()
分别返回日期参数,在一周、一月、一年中的位置。
set @dt = '2008-08-08';
select dayofweek(@dt); -- 6
select dayofmonth(@dt); -- 8
select dayofyear(@dt); -- 221
日期 ‘2008-08-08′ 是一周中的第 6 天(1 = Sunday, 2 = Monday, …, 7 = Saturday);一月中的第 8 天;一年中的第 221 天。
4. MySQL week… 函数:week(), weekofyear(), dayofweek(), weekday(), yearweek()
set @dt = '2008-08-08';
select week(@dt); -- 31
select week(@dt,3); -- 32
select weekofyear(@dt); -- 32
select dayofweek(@dt); -- 6
select weekday(@dt); -- 4
select yearweek(@dt); -- 200831
MySQL week() 函数,可以有两个参数,具体可看手册。 weekofyear() 和 week() 一样,都是计算“某天”是位于一年中的第几周。 weekofyear(@dt) 等价于 week(@dt,3)。
MySQLweekday() 函数和 dayofweek() 类似,都是返回“某天”在一周中的位置。不同点在于参考的标准, weekday:(0 =Monday, 1 = Tuesday, …, 6 = Sunday); dayofweek:(1 = Sunday, 2 = Monday,…, 7 = Saturday)
MySQL yearweek() 函数,返回 year(2008) + week 位置(31)。
5. MySQL 返回星期和月份名称函数:dayname(), monthname()
set @dt = '2008-08-08';
select dayname(@dt); -- Friday
select monthname(@dt); -- August
思考,如何返回中文的名称呢?
6. MySQL last_day() 函数:返回月份中的最后一天。
select last_day('2008-02-01'); -- 2008-02-29
select last_day('2008-08-08'); -- 2008-08-31
MySQL last_day() 函数非常有用,比如我想得到当前月份中有多少天,可以这样来计算:
mysql> select now(), day(last_day(now())) as days;
+---------------------+------+
| now() | days |
+---------------------+------+
| 2008-08-09 11:45:45 | 31 |
+---------------------+------+ 三、MySQL 日期时间计算函数
1. MySQL 为日期增加一个时间间隔:date_add()
set @dt = now();
select date_add(@dt, interval 1 day); -- add 1 day
select date_add(@dt, interval 1 hour); -- add 1 hour
select date_add(@dt, interval 1 minute); -- ...
select date_add(@dt, interval 1 second);
select date_add(@dt, interval 1 microsecond);
select date_add(@dt, interval 1 week);
select date_add(@dt, interval 1 month);
select date_add(@dt, interval 1 quarter);
select date_add(@dt, interval 1 year);select date_add(@dt, interval -1 day); -- sub 1 day
MySQL adddate(), addtime()函数,可以用 date_add() 来替代。下面是 date_add() 实现 addtime() 功能示例:
mysql> set @dt = '2008-08-09 12:12:33';
mysql>
mysql> select date_add(@dt, interval '01:15:30' hour_second);
+------------------------------------------------+
| date_add(@dt, interval '01:15:30' hour_second) |
+------------------------------------------------+
| 2008-08-09 13:28:03 |
+------------------------------------------------+mysql> select date_add(@dt, interval '1 01:15:30' day_second);
+-------------------------------------------------+
| date_add(@dt, interval '1 01:15:30' day_second) |
+-------------------------------------------------+
| 2008-08-10 13:28:03 |
+-------------------------------------------------+
date_add() 函数,分别为 @dt 增加了“1小时 15分 30秒” 和 “1天 1小时 15分 30秒”。建议:总是使用 date_add() 日期时间函数来替代 adddate(), addtime()。
2. MySQL 为日期减去一个时间间隔:date_sub()
mysql> select date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second);
+----------------------------------------------------------------+
| date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second) |
+----------------------------------------------------------------+
| 1997-12-30 22:58:59 |
+----------------------------------------------------------------+
MySQL date_sub() 日期时间函数 和 date_add() 用法一致,不再赘述。另外,MySQL 中还有两个函数 subdate(), subtime(),建议,用 date_sub() 来替代。
3. MySQL 另类日期函数:period_add(P,N), period_diff(P1,P2)
函数参数“P” 的格式为“YYYYMM” 或者 “YYMM”,第二个参数“N” 表示增加或减去 N month(月)。
MySQL period_add(P,N):日期加/减去N月。
mysql> select period_add(200808,2), period_add(20080808,-2)
+----------------------+-------------------------+
| period_add(200808,2) | period_add(20080808,-2) |
+----------------------+-------------------------+
| 200810 | 20080806 |
+----------------------+-------------------------+
MySQL period_diff(P1,P2):日期 P1-P2,返回 N 个月。
mysql> select period_diff(200808, 200801);
+-----------------------------+
| period_diff(200808, 200801) |
+-----------------------------+
| 7 |
+-----------------------------+
在 MySQL 中,这两个日期函数,一般情况下很少用到。
4. MySQL 日期、时间相减函数:datediff(date1,date2), timediff(time1,time2)
MySQL datediff(date1,date2):两个日期相减 date1 - date2,返回天数。
select datediff('2008-08-08', '2008-08-01'); -- 7
select datediff('2008-08-01', '2008-08-08'); -- -7
MySQL timediff(time1,time2):两个日期相减 time1 - time2,返回 time 差值。
select timediff('2008-08-08 08:08:08', '2008-08-08 00:00:00'); -- 08:08:08
select timediff('08:08:08', '00:00:00'); -- 08:08:08
注意:timediff(time1,time2) 函数的两个参数类型必须相同。
四、MySQL 日期转换函数、时间转换函数
1. MySQL (时间、秒)转换函数:time_to_sec(time), sec_to_time(seconds)
select time_to_sec('01:00:05'); -- 3605
select sec_to_time(3605); -- '01:00:05'
2. MySQL (日期、天数)转换函数:to_days(date), from_days(days)
select to_days('0000-00-00'); -- 0
select to_days('2008-08-08'); -- 733627select from_days(0); -- '0000-00-00'
select from_days(733627); -- '2008-08-08'
3. MySQL Str to Date (字符串转换为日期)函数:str_to_date(str, format)
select str_to_date('08/09/2008', '%m/%d/%Y'); -- 2008-08-09
select str_to_date('08/09/08' , '%m/%d/%y'); -- 2008-08-09
select str_to_date('08.09.2008', '%m.%d.%Y'); -- 2008-08-09
select str_to_date('08:09:30', '%h:%i:%s'); -- 08:09:30
select str_to_date('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30
可以看到,str_to_date(str,format) 转换函数,可以把一些杂乱无章的字符串转换为日期格式。另外,它也可以转换为时间。“format” 可以参看 MySQL 手册。
4. MySQL Date/Time to Str(日期/时间转换为字符串)函数:date_format(date,format), time_format(time,format)
mysql> select date_format('2008-08-08 22:23:00', '%W %M %Y');
+------------------------------------------------+
| date_format('2008-08-08 22:23:00', '%W %M %Y') |
+------------------------------------------------+
| Friday August 2008 |
+------------------------------------------------+mysql> select date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s');
+----------------------------------------------------+
| date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s') |
+----------------------------------------------------+
| 20080808222301 |
+----------------------------------------------------+mysql> select time_format('22:23:01', '%H.%i.%s');
+-------------------------------------+
| time_format('22:23:01', '%H.%i.%s') |
+-------------------------------------+
| 22.23.01 |
+-------------------------------------+
MySQL 日期、时间转换函数:date_format(date,format), time_format(time,format) 能够把一个日期/时间转换成各种各样的字符串格式。它是 str_to_date(str,format) 函数的 一个逆转换。
5. MySQL 获得国家地区时间格式函数:get_format()
MySQL get_format() 语法:
get_format(date|time|datetime, 'eur'|'usa'|'jis'|'iso'|'internal'
MySQL get_format() 用法的全部示例:
select get_format(date,'usa') ; -- '%m.%d.%Y'
select get_format(date,'jis') ; -- '%Y-%m-%d'
select get_format(date,'iso') ; -- '%Y-%m-%d'
select get_format(date,'eur') ; -- '%d.%m.%Y'
select get_format(date,'internal') ; -- '%Y%m%d'
select get_format(datetime,'usa') ; -- '%Y-%m-%d %H.%i.%s'
select get_format(datetime,'jis') ; -- '%Y-%m-%d %H:%i:%s'
select get_format(datetime,'iso') ; -- '%Y-%m-%d %H:%i:%s'
select get_format(datetime,'eur') ; -- '%Y-%m-%d %H.%i.%s'
select get_format(datetime,'internal') ; -- '%Y%m%d%H%i%s'
select get_format(time,'usa') ; -- '%h:%i:%s %p'
select get_format(time,'jis') ; -- '%H:%i:%s'
select get_format(time,'iso') ; -- '%H:%i:%s'
select get_format(time,'eur') ; -- '%H.%i.%s'
select get_format(time,'internal') ; -- '%H%i%s'
MySQL get_format() 函数在实际中用到机会的比较少。
6. MySQL 拼凑日期、时间函数:makdedate(year,dayofyear), maketime(hour,minute,second)
select makedate(2001,31); -- '2001-01-31'
select makedate(2001,32); -- '2001-02-01'select maketime(12,15,30); -- '12:15:30' 五、MySQL 时间戳(Timestamp)函数
1. MySQL 获得当前时间戳函数:current_timestamp, current_timestamp()
mysql> select current_timestamp, current_timestamp();
+---------------------+---------------------+
| current_timestamp | current_timestamp() |
+---------------------+---------------------+
| 2008-08-09 23:22:24 | 2008-08-09 23:22:24 |
+---------------------+---------------------+
2. MySQL (Unix 时间戳、日期)转换函数:
unix_timestamp(),
unix_timestamp(date),
from_unixtime(unix_timestamp),
from_unixtime(unix_timestamp,format)
下面是示例:
select unix_timestamp(); -- 1218290027
select unix_timestamp('2008-08-08'); -- 1218124800
select unix_timestamp('2008-08-08 12:30:00'); -- 1218169800select from_unixtime(1218290027); -- '2008-08-09 21:53:47'
select from_unixtime(1218124800); -- '2008-08-08 00:00:00'
selectfrom_unixtime(1218169800); -- '2008-08-08 12:30:00'selectfrom_unixtime(1218169800, '%Y %D %M %h:%i:%s %x'); -- '2008 8th August12:30:00 2008'
3. MySQL 时间戳(timestamp)转换、增、减函数:
timestamp(date) -- date to timestamp
timestamp(dt,time) -- dt + time
timestampadd(unit,interval,datetime_expr) --
timestampdiff(unit,datetime_expr1,datetime_expr2) --
请看示例部分:
select timestamp('2008-08-08'); -- 2008-08-08 00:00:00
select timestamp('2008-08-08 08:00:00', '01:01:01'); -- 2008-08-08 09:01:01
selecttimestamp('2008-08-08 08:00:00', '10 01:01:01'); -- 2008-08-1809:01:01select timestampadd(day, 1, '2008-08-08 08:00:00'); --2008-08-09 08:00:00
select date_add('2008-08-08 08:00:00', interval 1 day); -- 2008-08-09 08:00:00
MySQL timestampadd() 函数类似于 date_add()。
select timestampdiff(year,'2002-05-01','2001-01-01'); -- -1
select timestampdiff(day ,'2002-05-01','2001-01-01'); -- -485
select timestampdiff(hour,'2008-08-08 12:00:00','2008-08-08 00:00:00'); -- -12
select datediff('2008-08-08 12:00:00', '2008-08-01 00:00:00'); -- 7
MySQL timestampdiff() 函数就比 datediff() 功能强多了,datediff() 只能计算两个日期(date)之间相差的天数。
六、MySQL 时区(timezone)转换函数convert_tz(dt,from_tz,to_tz)selectconvert_tz('2008-08-08 12:00:00', '+08:00', '+00:00'); -- 2008-08-0804:00:00
时区转换也可以通过 date_add, date_sub, timestampadd 来实现。
select date_add('2008-08-08 12:00:00', interval -8 hour); -- 2008-08-08 04:00:00
select date_sub('2008-08-08 12:00:00', interval 8 hour); -- 2008-08-08 04:00:00
select timestampadd(hour, -8, '2008-08-08 12:00:00'); -- 2008-08-08 04:00:00
posted @
2016-03-30 10:33 xzc 阅读(338) |
评论 (2) |
编辑 收藏在项目中遇到一个奇怪的bug,是由一行简单代码引起的。
代码作用:比较两个UNIX文本文件,找出并打印文本2比文本1新增加的内容。
代码调用了diff命令,例如:
# temp1.txt文件内容
$> cat temp1.txt
20110224
20110225
20110228
20110301
20110302
# temp2.txt文件内容
$> cat temp2.txt
20110228
20110301
20110302
20110303
20110304
# diff命令输出结果
$> diff temp1.txt temp2.txt
1,2d0
< 20110224
< 20110225
5a4,5
> 20110303
> 20110304
# 只输出temp2.txt文件独有的内容
$> diff temp1.txt temp2.txt | grep "> " | sed 's/> //g'
20110303
20110304
说明:输出结果去掉了两个文件的共同内容,只输出了temp2.txt的新增部分,和预想的结果一样。
但是,随着temp1.txt文件内容的增加,diff命令出现了不同预期的结果:
$> cat temp1.txt
20101216
20101217
20101220
20101221
20101223
20101224
20101227
20101228
20101229
20101230
20101231
20110103
20110104
20110105
20110106
20110107
20110110
20110111
20110112
20110113
20110114
20110117
20110118
20110119
20110120
20110121
20110124
20110125
20110126
20110127
20110128
20110131
20110201
20110202
20110203
20110204
20110207
20110208
20110209
20110210
20110211
20110214
20110215
20110216
20110217
20110218
20110221
20110222
20110223
20110224
20110225
20110228
20110301
20110302
20110303
$> cat temp2.txt
20110228
20110301
20110302
20110303
20110304
20110307
20110308
20110309
20110310
20110311
20110314
$> diff temp1.txt temp2.txt
1,55c1,11
< 20101216
< 20101217
< 20101220
< 20101221
< 20101223
< 20101224
< 20101227
< 20101228
< 20101229
< 20101230
< 20101231
< 20110103
< 20110104
< 20110105
< 20110106
< 20110107
< 20110110
< 20110111
< 20110112
< 20110113
< 20110114
< 20110117
< 20110118
< 20110119
< 20110120
< 20110121
< 20110124
< 20110125
< 20110126
< 20110127
< 20110128
< 20110131
< 20110201
< 20110202
< 20110203
< 20110204
< 20110207
< 20110208
< 20110209
< 20110210
< 20110211
< 20110214
< 20110215
< 20110216
< 20110217
< 20110218
< 20110221
< 20110222
< 20110223
< 20110224
< 20110225
< 20110228
< 20110301
< 20110302
< 20110303
---
> 20110228
> 20110301
> 20110302
> 20110303
> 20110304
> 20110307
> 20110308
> 20110309
> 20110310
> 20110311
> 20110314
$> diff temp1.txt temp2.txt | grep "> " | sed 's/> //g'
20110228
20110301
20110302
20110303
20110304
20110307
20110308
20110309
20110310
20110311
20110314
可以看到,diff命令不但输出了temp2.txt文件的新增部分(20110304-20110314),也同时输出了两个文件的共同内容(20110228-20110303),从而导致了与预期不一致的结果。
查看diff命令的man手册发现,diff的作用是比较两个文件的内容,并输出两个文件之间的差异,产生一个能够将两个文件互相转换的列表,但这个列表并不能100%保证是最小集。
于是,以上例子中,可以看到diff给出了temp1.txt和temp2.txt文件的比较差异结果,但其中包含了两个文件的共同部分,因此与预期不一样。
解决方法:
用comm命令代替diff,例如:
$> comm -13 temp1.txt temp2.txt
20110304
20110307
20110308
20110309
20110310
20110311
20110314
comm命令用来比较两个文件,具体用法:
comm [-123] file1 file2
-1 过滤file1独有的内容
-2 过滤file2独有的内容
-3 过滤file1和file2重复的内容
备注:
diff的输出格式,主要有以下几种:
n1 a n3,n4
n1,n2 d n3
n1,n2 c n3,n4
例如"1,2d0" "5a4,5" "1,55c1,11"等。
其中n1和n2指第一个文件的行数,n3和n4指第二个文件的行数。"a"代表add增加,"d"代表delete删除,"c"代表change整块变动。
有了diff的输出结果,可以使用patch命令将一个文件恢复成另一个,例如:
$> cat temp1.txt
20110224
20110225
20110228
20110301
20110302
$> cat temp2.txt
20110228
20110301
20110302
20110303
20110304
$> diff temp1.txt temp2.txt > temp.diff
$> cat temp.diff
1,2d0
< 20110224
< 20110225
5a4,5
> 20110303
> 20110304
# 使用temp.diff和temp1.txt恢复temp2文件
$> patch -i temp.diff -o temp2_restore.txt temp1.txt
Looks like a normal diff.
done
# 完成后temp2_restore和原temp2文件内容一致
$> cat temp2_restore.txt
20110228
20110301
20110302
20110303
20110304
posted @
2016-03-24 12:09 xzc 阅读(1072) |
评论 (1) |
编辑 收藏 status=`ftp -v -n $ip<<END_SCRIPT
user $name $code
binary
cd $remote_dir
lcd $local_dir
prompt
mget *.txt
#mdelete *.txt
close
bye
END_SCRIPT`
echo $status|grep "226 Transfer complete"
if [ $? -eq 0 ]
then
echo "Connect Succeed!!!"
exit 0
else
echo $status|grep "530 Login incorrect"
if [ $? -eq 0 ]
then
echo "FTP Connect Error!!!"
exit 1
else
echo "No data transferred!!!"
exit 0
posted @
2016-03-24 12:08 xzc 阅读(1181) |
评论 (0) |
编辑 收藏获得当前日期+时间(date + time)函数:now()
mysql> select now(); +---------------------+ | now() | +---------------------+ | 2008-08-08 22:20:46 | +---------------------+
获得当前日期+时间(date + time)函数:sysdate()
sysdate() 日期时间函数跟 now() 类似,不同之处在于:now() 在执行开始时值就得到了, sysdate() 在函数执行时动态得到值。看下面的例子就明白了:
mysql> select now(), sleep(3), now(); +---------------------+----------+---------------------+ | now() | sleep(3) | now() | +---------------------+----------+---------------------+ | 2008-08-08 22:28:21 | 0 | 2008-08-08 22:28:21 | +---------------------+----------+---------------------+
sysdate() 日期时间函数,一般情况下很少用到。
MySQL 获得当前时间戳函数:current_timestamp, current_timestamp()
mysql> select current_timestamp, current_timestamp(); +---------------------+---------------------+ | current_timestamp | current_timestamp() | +---------------------+---------------------+ | 2008-08-09 23:22:24 | 2008-08-09 23:22:24 | +---------------------+---------------------+
MySQL 日期转换函数、时间转换函数
MySQL Date/Time to Str(日期/时间转换为字符串)函数:date_format(date,format), time_format(time,format)
mysql> select date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s'); +----------------------------------------------------+ | date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s') | +----------------------------------------------------+ | 20080808222301 | +----------------------------------------------------+MySQL 日期、时间转换函数:date_format(date,format), time_format(time,format) 能够把一个日期/时间转换成各种各样的字符串格式。它是 str_to_date(str,format) 函数的 一个逆转换。
MySQL Str to Date (字符串转换为日期)函数:str_to_date(str, format)
select str_to_date('08/09/2008', '%m/%d/%Y'); -- 2008-08-09 select str_to_date('08/09/08' , '%m/%d/%y'); -- 2008-08-09 select str_to_date('08.09.2008', '%m.%d.%Y'); -- 2008-08-09 select str_to_date('08:09:30', '%h:%i:%s'); -- 08:09:30 select str_to_date('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30可以看到,str_to_date(str,format) 转换函数,可以把一些杂乱无章的字符串转换为日期格式。另外,它也可以转换为时间。“format” 可以参看 MySQL 手册。
MySQL (日期、天数)转换函数:to_days(date), from_days(days)
select to_days('0000-00-00'); -- 0 select to_days('2008-08-08'); -- 733627
MySQL (时间、秒)转换函数:time_to_sec(time), sec_to_time(seconds)
select time_to_sec('01:00:05'); -- 3605 select sec_to_time(3605); -- '01:00:05'
MySQL 拼凑日期、时间函数:makdedate(year,dayofyear), maketime(hour,minute,second)
select makedate(2001,31); -- '2001-01-31' select makedate(2001,32); -- '2001-02-01' select maketime(12,15,30); -- '12:15:30'
MySQL (Unix 时间戳、日期)转换函数
unix_timestamp(), unix_timestamp(date), from_unixtime(unix_timestamp), from_unixtime(unix_timestamp,format)
下面是示例:
select unix_timestamp(); -- 1218290027 select unix_timestamp('2008-08-08'); -- 1218124800 select unix_timestamp('2008-08-08 12:30:00'); -- 1218169800 select from_unixtime(1218290027); -- '2008-08-09 21:53:47' select from_unixtime(1218124800); -- '2008-08-08 00:00:00' select from_unixtime(1218169800); -- '2008-08-08 12:30:00' select from_unixtime(1218169800, '%Y %D %M %h:%i:%s %x'); -- '2008 8th August 12:30:00 2008'
MySQL 日期时间计算函数
MySQL 为日期增加一个时间间隔:date_add()
set @dt = now(); select date_add(@dt, interval 1 day); -- add 1 day select date_add(@dt, interval 1 hour); -- add 1 hour select date_add(@dt, interval 1 minute); -- ... select date_add(@dt, interval 1 second); select date_add(@dt, interval 1 microsecond); select date_add(@dt, interval 1 week); select date_add(@dt, interval 1 month); select date_add(@dt, interval 1 quarter); select date_add(@dt, interval 1 year); select date_add(@dt, interval -1 day); -- sub 1 day
MySQL adddate(), addtime()函数,可以用 date_add() 来替代。下面是 date_add() 实现 addtime() 功能示例:
mysql> set @dt = '2008-08-09 12:12:33'; mysql> mysql> select date_add(@dt, interval '01:15:30' hour_second); +------------------------------------------------+ | date_add(@dt, interval '01:15:30' hour_second) | +------------------------------------------------+ | 2008-08-09 13:28:03 | +------------------------------------------------+ mysql> select date_add(@dt, interval '1 01:15:30' day_second); +-------------------------------------------------+ | date_add(@dt, interval '1 01:15:30' day_second) | +-------------------------------------------------+ | 2008-08-10 13:28:03 | +-------------------------------------------------+
MySQL 为日期减去一个时间间隔:date_sub()
mysql> select date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second); +----------------------------------------------------------------+ | date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second) | +----------------------------------------------------------------+ | 1997-12-30 22:58:59 | +----------------------------------------------------------------+MySQL date_sub() 日期时间函数 和 date_add() 用法一致,不再赘述。
MySQL 日期、时间相减函数:datediff(date1,date2), timediff(time1,time2)
MySQL datediff(date1,date2):两个日期相减 date1 - date2,返回天数。 select datediff('2008-08-08', '2008-08-01'); -- 7 select datediff('2008-08-01', '2008-08-08'); -- -7MySQL timediff(time1,time2):两个日期相减 time1 - time2,返回 time 差值。
select timediff('2008-08-08 08:08:08', '2008-08-08 00:00:00'); -- 08:08:08 select timediff('08:08:08', '00:00:00'); -- 08:08:08注意:timediff(time1,time2) 函数的两个参数类型必须相同。
MySQL 时间戳(timestamp)转换、增、减函数:
timestamp(date) -- date to timestamp timestamp(dt,time) -- dt + time timestampadd(unit,interval,datetime_expr) -- timestampdiff(unit,datetime_expr1,datetime_expr2) --
请看示例部分:
select timestamp('2008-08-08'); -- 2008-08-08 00:00:00 select timestamp('2008-08-08 08:00:00', '01:01:01'); -- 2008-08-08 09:01:01 select timestamp('2008-08-08 08:00:00', '10 01:01:01'); -- 2008-08-18 09:01:01 select timestampadd(day, 1, '2008-08-08 08:00:00'); -- 2008-08-09 08:00:00 select date_add('2008-08-08 08:00:00', interval 1 day); -- 2008-08-09 08:00:00 MySQL timestampadd() 函数类似于 date_add()。 select timestampdiff(year,'2002-05-01','2001-01-01'); -- -1 select timestampdiff(day ,'2002-05-01','2001-01-01'); -- -485 select timestampdiff(hour,'2008-08-08 12:00:00','2008-08-08 00:00:00'); -- -12 select datediff('2008-08-08 12:00:00', '2008-08-01 00:00:00'); -- 7MySQL timestampdiff() 函数就比 datediff() 功能强多了,datediff() 只能计算两个日期(date)之间相差的天数。
MySQL 时区(timezone)转换函数
convert_tz(dt,from_tz,to_tz) select convert_tz('2008-08-08 12:00:00', '+08:00', '+00:00'); -- 2008-08-08 04:00:00时区转换也可以通过 date_add, date_sub, timestampadd 来实现。
select date_add('2008-08-08 12:00:00', interval -8 hour); -- 2008-08-08 04:00:00 select date_sub('2008-08-08 12:00:00', interval 8 hour); -- 2008-08-08 04:00:00 select timestampadd(hour, -8, '2008-08-08 12:00:00'); -- 2008-08-08 04:00:00
更多参考 http://www.cnblogs.com/she27/archive/2009/01/16/1377089.html
posted @
2016-02-22 14:46 xzc 阅读(365) |
评论 (1) |
编辑 收藏[转载]http://www.blogjava.net/hongqiang/archive/2012/07/12/382939.html
假如你要在linux下删除大量文件,比如100万、1000万,像/var/spool/clientmqueue/的mail邮件,
像/usr/local/nginx/proxy_temp的nginx缓存等,那么rm -rf *可能就不好使了。
rsync提供了一些跟删除相关的参数
rsync --help | grep delete
--del an alias for --delete-during
--delete delete files that don't exist on the sending side
--delete-before receiver deletes before transfer (default)
--delete-during receiver deletes during transfer, not before
--delete-after receiver deletes after transfer, not before
--delete-excluded also delete excluded files on the receiving side
--ignore-errors delete even if there are I/O errors
--max-delete=NUM don't delete more than NUM files
其中--delete-before 接收者在传输之前进行删除操作
可以用来清空目录或文件,如下:
1、先建立一个空目录
mkdir /data/blank
2、用rsync删除目标目录
rsync --delete-before -d /data/blank/ /var/spool/clientmqueue/
这样目标目录很快就被清空了
又假如你有一些特别大的文件要删除,比如nohup.out这样的实时更新的文件,动辄都是几十个G上百G的,也可
以用rsync来清空大文件,而且效率比较高
1、创建空文件
touch /data/blank.txt
2、用rsync清空文件
rsync -a --delete-before --progress --stats /root/blank.txt /root/nohup.out
building file list ...
1 file to consider
blank.txt
0 100% 0.00kB/s 0:00:00 (xfer#1, to-check=0/1)
Number of files: 1
Number of files transferred: 1
Total file size: 0 bytes
Total transferred file size: 0 bytes
Literal data: 0 bytes
Matched data: 0 bytes
File list size: 27
File list generation time: 0.006 seconds
File list transfer time: 0.000 seconds
Total bytes sent: 73
Total bytes received: 31
sent 73 bytes received 31 bytes 208.00 bytes/sec
total size is 0 speedup is 0.00
tips:
当SRC和DEST文件性质不一致时将会报错
当SRC和DEST性质都为文件【f】时,意思是清空文件内容而不是删除文件
当SRC和DEST性质都为目录【d】时,意思是删除该目录下的所有文件,使其变为空目录
最重要的是,它的处理速度相当快,处理几个G的文件也就是秒级的事
最核心的内容是:rsync实际上用的就是替换原理
另外一种方式:利用xagr与ls结合
ls | xargs -n 20 rm -fr
ls当然是输出所有的文件名(用空格分割)
xargs就是将ls的输出,每20个为一组(以空格为分隔符),作为rm -rf的参数
也就是说将所有文件名20个为一组,由rm -rf删除,这样就不会超过命令行的长度了
posted @
2016-02-14 11:05 xzc 阅读(360) |
评论 (1) |
编辑 收藏Cloudera Manager分析
目录
1. 相关目录
2. 配置
3. 数据库
4. CM结构
5. 升级
6. 卸载
7. 开启postgresql远程访问
/var/log/cloudera-scm-installer : 安装日志目录。/var/log/* : 相关日志文件(相关服务的及CM的)。/usr/share/cmf/ : 程序安装目录。/usr/lib64/cmf/ : Agent程序代码。/var/lib/cloudera-scm-server-db/data : 内嵌数据库目录。/usr/bin/postgres : 内嵌数据库程序。/etc/cloudera-scm-agent/ : agent的配置目录。/etc/cloudera-scm-server/ : server的配置目录。/opt/cloudera/parcels/ : Hadoop相关服务安装目录。/opt/cloudera/parcel-repo/ : 下载的服务软件包数据,数据格式为parcels。/opt/cloudera/parcel-cache/ : 下载的服务软件包缓存数据。/etc/hadoop/* : 客户端配置文件目录。
Hadoop配置文件
配置文件放置于/var/run/cloudera-scm-agent/process/目录下。如:/var/run/cloudera-scm-agent/process/193-hdfs-NAMENODE/core-site.xml。这些配置文件是通过Cloudera Manager启动相应服务(如HDFS)时生成的,内容从数据库中获得(即通过界面配置的参数)。
在CM界面上更改配置是不会立即反映到配置文件中,这些信息会存储于数据库中,等下次重启服务时才会生成配置文件。且每次启动时都会产生新的配置文件。
CM Server主要数据库为scm基中放置配置的数据表为configs。里面包含了服务的配置信息,每一次配置的更改会把当前页面的所有配置内容添加到数据库中,以此保存配置修改历史。
scm数据库被配置成只能从localhost访问,如果需要从外部连接此数据库,修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
查看配置内容
- 直接查询scm数据库的configs数据表的内容。
- 访问REST API:
http://hostname:7180/api/v4/cm/deployment,返回JSON格式部署配置信息。
配置生成方式
CM为每个服务进程生成独立的配置目录(文件)。所有配置统一在服务端查询数据库生成(因为scm数据库只能在localhost下访问)生成配置文件,再由agent通过网络下载包含配置文件的zip包到本地解压到指定的目录。
配置修改
CM对于需要修改的配置预先定义,对于没有预先定义的配置,则通过在高级配置项中使用xml配置片段的方式进行配置。而对于/etc/hadoop/下的配置文件是客户端的配置,可以在CM通过部署客户端生成客户端配置。
Cloudera manager主要的数据库为scm,存储Cloudera manager运行所需要的信息:配置,主机,用户等。
CM分为Server与Agent两部分及数据库(自带更改过的嵌入Postgresql)。它主要做三件事件:
- 管理监控集群主机。
- 统一管理配置。
- 管理维护Hadoop平台系统。
实现采用C/S结构,Agent为客户端负责执行服务端发来的命令,执行方式一般为使用python调用相应的服务shell脚本。Server端为Java REST服务,提供REST API,Web管理端通过REST API调用Server端功能,Web界面使用富客户端技术(Knockout)。
- Server端主体使用Java实现。
- Agent端主体使用Python, 服务的启动通过调用相应的shell脚本进行启动,如果启动失败会重复4次调用启动脚本。
- Agent与Server保持心跳,使用Thrift RPC框架。
在CM中可以通过界面向导升级相关服务。升级过程为三步:
- 下载服务软件包。
- 把所下载的服务软件包分发到集群中受管的机器上。
- 安装服务软件包,使用软链接的方式把服务程序目录链接到新安装的软件包目录上。
sudo /usr/share/cmf/uninstall-scm-express.sh, 然后删除/var/lib/cloudera-scm-server-db/目录,不然下次安装可能不成功。
CM内嵌数据库被配置成只能从localhost访问,如果需要从外部查看数据,数据修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
posted @
2015-12-25 17:28 xzc 阅读(435) |
评论 (0) |
编辑 收藏除了在一个目录结构下查找文件这种基本的操作,你还可以用find命令实现一些实用的操作,使你的命令行之旅更加简易。
本文将介绍15种无论是于新手还是老鸟都非常有用的Linux find命令。
首先,在你的home目录下面创建下面的空文件,来测试下面的find命令示例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # vim create_sample_files.sh
touch MybashProgram.sh
touch mycprogram.c
touch MyCProgram.c
touch Program.c
mkdir backup
cd backup
touch MybashProgram.sh
touch mycprogram.c
touch MyCProgram.c
touch Program.c
# chmod +x create_sample_files.sh
# ./create_sample_files.sh
# ls -R
.:
backup MybashProgram.sh MyCProgram.c
create_sample_files.sh mycprogram.c Program.c
./backup:
MybashProgram.sh mycprogram.c MyCProgram.c Program.c
|
1. 用文件名查找文件
这是find命令的一个基本用法。下面的例子展示了用MyCProgram.c作为查找名在当前目录及其子目录中查找文件的方法。
1 2 3 | # find -name "MyCProgram.c"
./backup/MyCProgram.c
./MyCProgram.c
|
2.用文件名查找文件,忽略大小写
这是find命令的一个基本用法。下面的例子展示了用MyCProgram.c作为查找名在当前目录及其子目录中查找文件的方法,忽略了大小写。
1 2 3 4 5 | # find -iname "MyCProgram.c"
./mycprogram.c
./backup/mycprogram.c
./backup/MyCProgram.c
./MyCProgram.c
|
3. 使用mindepth和maxdepth限定搜索指定目录的深度
在root目录及其子目录下查找passwd文件。
1 2 3 4 5 | # find / -name passwd
./usr/share/doc/nss_ldap-253/pam.d/passwd
./usr/bin/passwd
./etc/pam.d/passwd
./etc/passwd
|
在root目录及其1层深的子目录中查找passwd. (例如root — level 1, and one sub-directory — level 2)
1 2 | # find -maxdepth 2 -name passwd
./etc/passwd
|
在root目录下及其最大两层深度的子目录中查找passwd文件. (例如 root — level 1, and two sub-directories — level 2 and 3 )
1 2 3 4 | # find / -maxdepth 3 -name passwd
./usr/bin/passwd
./etc/pam.d/passwd
./etc/passwd
|
在第二层子目录和第四层子目录之间查找passwd文件。
1 2 3 | # find -mindepth 3 -maxdepth 5 -name passwd
./usr/bin/passwd
./etc/pam.d/passwd
|
4. 在find命令查找到的文件上执行命令
下面的例子展示了find命令来计算所有不区分大小写的文件名为“MyCProgram.c”的文件的MD5验证和。{}将会被当前文件名取代。
1 2 3 4 5 | find -iname "MyCProgram.c" -exec md5sum {} \;
d41d8cd98f00b204e9800998ecf8427e ./mycprogram.c
d41d8cd98f00b204e9800998ecf8427e ./backup/mycprogram.c
d41d8cd98f00b204e9800998ecf8427e ./backup/MyCProgram.c
d41d8cd98f00b204e9800998ecf8427e ./MyCProgram.c
|
5. 相反匹配
显示所有的名字不是MyCProgram.c的文件或者目录。由于maxdepth是1,所以只会显示当前目录下的文件和目录。
1 2 3 4 5 6 | find -maxdepth 1 -not -iname "MyCProgram.c"
.
./MybashProgram.sh
./create_sample_files.sh
./backup
./Program.c
|
6. 使用inode编号查找文件
任何一个文件都有一个独一无二的inode编号,借此我们可以区分文件。创建两个名字相似的文件,例如一个有空格结尾,一个没有。
1 2 3 4 5 6 | touch "test-file-name"
# touch "test-file-name "
[Note: There is a space at the end]
# ls -1 test*
test-file-name
test-file-name
|
从ls的输出不能区分哪个文件有空格结尾。使用选项-i,可以看到文件的inode编号,借此可以区分这两个文件。
1 2 3 | ls -i1 test*
16187429 test-file-name
16187430 test-file-name
|
你可以如下面所示在find命令中指定inode编号。在此,find命令用inode编号重命名了一个文件。
1 2 3 4 5 | find -inum 16187430 -exec mv {} new-test-file-name \;
# ls -i1 *test*
16187430 new-test-file-name
16187429 test-file-name
|
你可以在你想对那些像上面一样的糟糕命名的文件做某些操作时使用这一技术。例如,名为file?.txt的文件名字中有一个特殊字符。若你想执行“rm file?.txt”,下面所示的所有三个文件都会被删除。所以,采用下面的步骤来删除”file?.txt”文件。
1 2 | ls
file1.txt file2.txt file?.txt
|
找到每一个文件的inode编号。
1 2 3 4 | ls -i1
804178 file1.txt
804179 file2.txt
804180 file?.txt
|
如下所示:?使用inode编号来删除那些具有特殊符号的文件名。
1 2 3 4 | find -inum 804180 -exec rm {} \;
# ls
file1.txt file2.txt
[Note: The file with name "file?.txt" is now removed]
|
7. 根据文件权限查找文件
下面的操作时合理的:
- 找到具有指定权限的文件
- 忽略其他权限位,检查是否和指定权限匹配
- 根据给定的八进制/符号表达的权限搜索
此例中,假设目录包含以下文件。注意这些文件的权限不同。
1 2 3 4 5 6 7 8 | ls -l
total 0
-rwxrwxrwx 1 root root 0 2009-02-19 20:31 all_for_all
-rw-r--r-- 1 root root 0 2009-02-19 20:30 everybody_read
---------- 1 root root 0 2009-02-19 20:31 no_for_all
-rw------- 1 root root 0 2009-02-19 20:29 ordinary_file
-rw-r----- 1 root root 0 2009-02-19 20:27 others_can_also_read
----r----- 1 root root 0 2009-02-19 20:27 others_can_only_read
|
找到具有组读权限的文件。使用下面的命令来找到当前目录下对同组用户具有读权限的文件,忽略该文件的其他权限。
1 2 3 4 5 | find . -perm -g=r -type f -exec ls -l {} \;
-rw-r--r-- 1 root root 0 2009-02-19 20:30 ./everybody_read
-rwxrwxrwx 1 root root 0 2009-02-19 20:31 ./all_for_all
----r----- 1 root root 0 2009-02-19 20:27 ./others_can_only_read
-rw-r----- 1 root root 0 2009-02-19 20:27 ./others_can_also_read
|
找到对组用户具有只读权限的文件。
1 2 | find . -perm g=r -type f -exec ls -l {} \;
----r----- 1 root root 0 2009-02-19 20:27 ./others_can_only_read
|
找到对组用户具有只读权限的文件(使用八进制权限形式)。
1 2 | find . -perm 040 -type f -exec ls -l {} \;
----r----- 1 root root 0 2009-02-19 20:27 ./others_can_only_read
|
8. 找到home目录及子目录下所有的空文件(0字节文件)
下面命令的输出文件绝大多数都是锁定文件盒其他程序创建的place hoders
只列出你home目录里的空文件。
1 | find . -maxdepth 1 -empty
|
只列出当年目录下的非隐藏空文件。
1 | find . -maxdepth 1 -empty -not -name ".*"
|
9. 查找5个最大的文件
下面的命令列出当前目录及子目录下的5个最大的文件。这会需要一点时间,取决于命令需要处理的文件数量。
1 | find . -type f -exec ls -s {} \; | sort -n -r | head -5
|
10. 查找5个最小的文件
方法同查找5个最大的文件类似,区别只是sort的顺序是降序。
1 | find . -type f -exec ls -s {} \; | sort -n | head -5
|
上面的命令中,很可能你看到的只是空文件(0字节文件)。如此,你可以使用下面的命令列出最小的文件,而不是0字节文件。
1 | find . -not -empty -type f -exec ls -s {} \; | sort -n | head -5
|
11. 使用-type查找指定文件类型的文件
只查找socket文件
查找所有的目录
查找所有的一般文件
查找所有的隐藏文件
1 | find . -type f -name ".*"
|
查找所有的隐藏目录
12. 通过和其他文件比较修改时间查找文件
显示在指定文件之后做出修改的文件。下面的find命令将显示所有的在ordinary_file之后创建修改的文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | ls -lrt
total 0
-rw-r----- 1 root root 0 2009-02-19 20:27 others_can_also_read
----r----- 1 root root 0 2009-02-19 20:27 others_can_only_read
-rw------- 1 root root 0 2009-02-19 20:29 ordinary_file
-rw-r--r-- 1 root root 0 2009-02-19 20:30 everybody_read
-rwxrwxrwx 1 root root 0 2009-02-19 20:31 all_for_all
---------- 1 root root 0 2009-02-19 20:31 no_for_all
# find -newer ordinary_file
.
./everybody_read
./all_for_all
./no_for_all
|
13. 通过文件大小查找文件
使用-size选项可以通过文件大小查找文件。
查找比指定文件大的文件
查找比指定文件小的文件
查找符合给定大小的文件
注意: – 指比给定尺寸小,+ 指比给定尺寸大。没有符号代表和给定尺寸完全一样大。
14. 给常用find操作取别名
若你发现有些东西很有用,你可以给他取别名。并且在任何你希望的地方执行。
常用的删除a.out文件。
1 2 | alias rmao="find . -iname a.out -exec rm {} \;"
# rmao
|
删除c程序产生的core文件。
1 2 | alias rmc="find . -iname core -exec rm {} \;"
# rmc
|
15. 用find命令删除大型打包文件
下面的命令删除大于100M的*.zip文件。
1 | find / -type f -name *.zip -size +100M -exec rm -i {} \;"
|
用别名rm100m删除所有大雨100M的*.tar文件。使用同样的思想可以创建rm1g,rm2g,rm5g的一类别名来删除所有大于1G,2G,5G的文件。
1 2 3 4 5 6 7 8 9 | alias rm100m="find / -type f -name *.tar -size +100M -exec rm -i {} \;"
# alias rm1g="find / -type f -name *.tar -size +1G -exec rm -i {} \;"
# alias rm2g="find / -type f -name *.tar -size +2G -exec rm -i {} \;"
# alias rm5g="find / -type f -name *.tar -size +5G -exec rm -i {} \;"
# rm100m
# rm1g
# rm2g
# rm5g
|
Find命令示例(第二部分)
若你喜欢这篇关于find命令的Mommy文章,别忘了看看第二部分的关于find命令的Daddy文章。《爹地,我找到了!15个极好的Linux find命令示例》
posted @
2015-12-23 10:34 xzc 阅读(411) |
评论 (3) |
编辑 收藏posted @
2015-12-21 15:54 xzc 阅读(2576) |
评论 (1) |
编辑 收藏一:需要包含的包
import java.security.*;
import java.io.*;
import java.util.*;
import java.security.*;
import java.security.cert.*;
import sun.security.x509.*
import java.security.cert.Certificate;
import java.security.cert.CertificateFactory;
二:从文件中读取证书
用keytool将.keystore中的证书写入文件中,然后从该文件中读取证书信息
CertificateFactory cf=CertificateFactory.getInstance("X.509");
FileInputStream in=new FileInputStream("out.csr");
Certificate c=cf.generateCertificate(in);
String s=c.toString();
三:从密钥库中直接读取证书
String pass="123456";
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,pass.toCharArray());
java.security.cert.Certificate c=ks.getCertificate(alias);//alias为条目的别名
四:JAVA程序中显示证书指定信息
System.out.println("输出证书信息:\n"+c.toString());
System.out.println("版本号:"+t.getVersion());
System.out.println("序列号:"+t.getSerialNumber().toString(16));
System.out.println("主体名:"+t.getSubjectDN());
System.out.println("签发者:"+t.getIssuerDN());
System.out.println("有效期:"+t.getNotBefore());
System.out.println("签名算法:"+t.getSigAlgName());
byte [] sig=t.getSignature();//签名值
PublicKey pk=t.getPublicKey();
byte [] pkenc=pk.getEncoded();
System.out.println("公钥");
for(int i=0;i<pkenc.length;i++)System.out.print(pkenc[i]+",");
五:JAVA程序列出密钥库所有条目
String pass="123456";
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,pass.toCharArray());
Enumeration e=ks.aliases();
while(e.hasMoreElements())
java.security.cert.Certificate c=ks.getCertificate((String)e.nextElement());
六:JAVA程序修改密钥库口令
String oldpass="123456";
String newpass="654321";
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,oldpass.toCharArray());
in.close();
FileOutputStream output=new FileOutputStream(".keystore");
ks.store(output,newpass.toCharArray());
output.close();
七:JAVA程序修改密钥库条目的口令及添加条目
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,storepass.toCharArray());
Certificate [] cchain=ks.getCertificate(alias);获取别名对应条目的证书链
PrivateKey pk=(PrivateKey)ks.getKey(alias,oldkeypass.toCharArray());获取别名对应条目的私钥
ks.setKeyEntry(alias,pk,newkeypass.toCharArray(),cchain);向密钥库中添加条目
第一个参数指定所添加条目的别名,假如使用已存在别名将覆盖已存在条目,使用新别名将增加一个新条目,第二个参数为条目的私钥,第三个为设置的新口令,第四个为该私钥的公钥的证书链
FileOutputStream output=new FileOutputStream("another");
ks.store(output,storepass.toCharArray())将keystore对象内容写入新文件
八:JAVA程序检验别名和删除条目
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,storepass.toCharArray());
ks.containsAlias("sage");检验条目是否在密钥库中,存在返回true
ks.deleteEntry("sage");删除别名对应的条目
FileOutputStream output=new FileOutputStream(".keystore");
ks.store(output,storepass.toCharArray())将keystore对象内容写入文件,条目删除成功
九:JAVA程序签发数字证书
(1)从密钥库中读取CA的证书
FileInputStream in=new FileInputStream(".keystore");
KeyStore ks=KeyStore.getInstance("JKS");
ks.load(in,storepass.toCharArray());
java.security.cert.Certificate c1=ks.getCertificate("caroot");
(2)从密钥库中读取CA的私钥
PrivateKey caprk=(PrivateKey)ks.getKey(alias,cakeypass.toCharArray());
(3)从CA的证书中提取签发者的信息
byte[] encod1=c1.getEncoded();提取CA证书的编码
X509CertImpl cimp1=new X509CertImpl(encod1); 用该编码创建X509CertImpl类型对象
X509CertInfo cinfo1=(X509CertInfo)cimp1.get(X509CertImpl.NAME+"."+X509CertImpl.INFO); 获取X509CertInfo对象
X500Name issuer=(X500Name)cinfo1.get(X509CertInfo.SUBJECT+"."+CertificateIssuerName.DN_NAME); 获取X509Name类型的签发者信息
(4)获取待签发的证书
CertificateFactory cf=CertificateFactory.getInstance("X.509");
FileInputStream in2=new FileInputStream("user.csr");
java.security.cert.Certificate c2=cf.generateCertificate(in);
(5)从待签发的证书中提取证书信息
byte [] encod2=c2.getEncoded();
X509CertImpl cimp2=new X509CertImpl(encod2); 用该编码创建X509CertImpl类型对象
X509CertInfo cinfo2=(X509CertInfo)cimp2.get(X509CertImpl.NAME+"."+X509CertImpl.INFO); 获取X509CertInfo对象
(6)设置新证书有效期
Date begindate=new Date(); 获取当前时间
Date enddate=new Date(begindate.getTime()+3000*24*60*60*1000L); 有效期为3000天
CertificateValidity cv=new CertificateValidity(begindate,enddate); 创建对象
cinfo2.set(X509CertInfo.VALIDITY,cv); 设置有效期
(7)设置新证书序列号
int sn=(int)(begindate.getTime()/1000);以当前时间为序列号
CertificateSerialNumber csn=new CertificateSerialNumber(sn);
cinfo2.set(X509CertInfo.SERIAL_NUMBER,csn);
(8)设置新证书签发者
cinfo2.set(X509CertInfo.ISSUER+"."+CertificateIssuerName.DN_NAME,issuer);应用第三步的结果
(9)设置新证书签名算法信息
AlgorithmId algorithm=new AlgorithmId(AlgorithmId.md5WithRSAEncryption_oid);
cinfo2.set(CertificateAlgorithmId.NAME+"."+CertificateAlgorithmId.ALGORITHM,algorithm);
(10)创建证书并使用CA的私钥对其签名
X509CertImpl newcert=new X509CertImpl(cinfo2);
newcert.sign(caprk,"MD5WithRSA"); 使用CA私钥对其签名
(11)将新证书写入密钥库
ks.setCertificateEntry("lf_signed",newcert);
FileOutputStream out=new FileOutputStream("newstore");
ks.store(out,"newpass".toCharArray()); 这里是写入了新的密钥库,也可以使用第七条来增加条目
十:数字证书的检验
(1)验证证书的有效期
(a)获取X509Certificate类型对象
CertificateFactory cf=CertificateFactory.getInstance("X.509");
FileInputStream in1=new FileInputStream("aa.crt");
java.security.cert.Certificate c1=cf.generateCertificate(in1);
X509Certificate t=(X509Certificate)c1;
in2.close();
(b)获取日期
Date TimeNow=new Date();
(c)检验有效性
try{
t.checkValidity(TimeNow);
System.out.println("OK");
}catch(CertificateExpiredException e){ //过期
System.out.println("Expired");
System.out.println(e.getMessage());
}catch((CertificateNotYetValidException e){ //尚未生效
System.out.println("Too early");
System.out.println(e.getMessage());}
(2)验证证书签名的有效性
(a)获取CA证书
CertificateFactory cf=CertificateFactory.getInstance("X.509");
FileInputStream in2=new FileInputStream("caroot.crt");
java.security.cert.Certificate cac=cf.generateCertificate(in2);
in2.close();
(c)获取CA的公钥
PublicKey pbk=cac.getPublicKey();
(b)获取待检验的证书(上步已经获取了,就是C1)
(c)检验证书
boolean pass=false;
try{
c1.verify(pbk);
pass=true;
}catch(Exception e){
pass=false;
System.out.println(e);
}
posted @
2015-12-11 11:40 xzc 阅读(401) |
评论 (0) |
编辑 收藏原文地址:http://www.itwis.com/html/os/linux/20100202/7360.html
linux中用shell获取昨天、明天或多天前的日期:
在Linux中对man date -d 参数说的比较模糊,以下举例进一步说明:
# -d, --date=STRING display time described by STRING, not `now’
- [root@Gman root]# date -d next-day +%Y%m%d #明天日期
- 20091024
- [root@Gman root]# date -d last-day +%Y%m%d #昨天日期
- 20091022
- [root@Gman root]# date -d yesterday +%Y%m%d #昨天日期
- 20091022
- [root@Gman root]# date -d tomorrow +%Y%m%d # 明天日期
- 20091024
- [root@Gman root]# date -d last-month +%Y%m #上个月日期
- 200909
- [root@Gman root]# date -d next-month +%Y%m #下个月日期
- 200911
- [root@Gman root]# date -d next-year +%Y #明年日期
- 2010
DATE=$(date +%Y%m%d --date '2 days ago') #获取昨天或多天前的日期
名称 : date
使用权限 : 所有使用者
使用方式 : date [-u] [-d datestr] [-s datestr] [--utc] [--universal] [--date=datestr] [--set=datestr] [--help] [--version] [+FORMAT] [MMDDhhmm[[CC]YY][.ss]]
说明 : date 能用来显示或设定系统的日期和时间,在显示方面,使用者能设定欲显示的格式,格式设定为一个加号后接数个标记,其中可用的标记列表如下 :
- 时间方面 :
- % : 印出
- % %n : 下一行
- %t : 跳格
- %H : 小时(00..23)
- %I : 小时(01..12)
- %k : 小时(0..23)
- %l : 小时(1..12)
- %M : 分钟(00..59)
- %p : 显示本地 AM 或 PM
- %r : 直接显示时间 (12 小时制,格式为 hh:mm:ss [AP]M)
- %s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数 %S : 秒(00..61)
- %T : 直接显示时间 (24 小时制)
- %X : 相当于 %H:%M:%S
- %Z : 显示时区
- 日期方面 :
- %a : 星期几 (Sun..Sat)
- %A : 星期几 (Sunday..Saturday)
- %b : 月份 (Jan..Dec)
- %B : 月份 (January..December)
- %c : 直接显示日期和时间
- %d : 日 (01..31)
- %D : 直接显示日期 (mm/dd/yy)
- %h : 同 %b
- %j : 一年中的第几天 (001..366)
- %m : 月份 (01..12)
- %U : 一年中的第几周 (00..53) (以 Sunday 为一周的第一天的情形)
- %w : 一周中的第几天 (0..6)
- %W : 一年中的第几周 (00..53) (以 Monday 为一周的第一天的情形)
- %x : 直接显示日期 (mm/dd/yy)
- %y : 年份的最后两位数字 (00.99)
- %Y : 完整年份 (0000..9999)
若是不以加号作为开头,则表示要设定时间,而时间格式为 MMDDhhmm[[CC]YY][.ss],
其中 MM 为月份,
DD 为日,
hh 为小时,
mm 为分钟,
CC 为年份前两位数字,
YY 为年份后两位数字,
ss 为秒数
把计 :
-d datestr : 显示 datestr 中所设定的时间 (非系统时间)
--help : 显示辅助讯息
-s datestr : 将系统时间设为 datestr 中所设定的时间
-u : 显示目前的格林威治时间
--version : 显示版本编号
例子 :
显示时间后跳行,再显示目前日期 : date +%T%n%D
显示月份和日数 : date +%B %d
显示日期和设定时间(12:34:56) : date --date 12:34:56
设置系统当前时间(12:34:56):date --s 12:34:56
注意 : 当你不希望出现无意义的 0 时(比如说 1999/03/07),则能在标记中插入 - 符号,比如说 date +%-H:%-M:%-S 会把时分秒中无意义的 0 给去掉,像是原本的 08:09:04 会变为 8:9:4。另外,只有取得权限者(比如说 root)才能设定系统时间。 当你以 root 身分更改了系统时间之后,请记得以 clock -w 来将系统时间写入 CMOS 中,这样下次重新开机时系统时间才会持续抱持最新的正确值。
ntp时间同步
linux系统下默认安装了ntp服务,手动进行ntp同步如下
ntpdate ntp1.nl.net
当然,也能指定其他的ntp服务器
-------------------------------------------------------------------
扩展功能
date 工具可以完成更多的工作,不仅仅只是打印出当前的系统日期。您可以使用它来得到给定的日期究竟是星期几,并得到相对于当前日期的相对日期。了解某一天是星期几
GNU 对 date 命令的另一个扩展是 -d 选项,当您的桌上没有日历表时(UNIX 用户不需要日历表),该选项非常有用。使用这个功能强大的选项,通过将日期作为引号括起来的参数提供,您可以快速地查明一个特定的日期究竟是星期几:
$ date -d "nov 22"
Wed Nov 22 00:00:00 EST 2006
$
在本示例中,您可以看到今年的 11 月 22 日是星期三。
所以,假设在 11 月 22 日召开一个重大的会议,您可以立即了解到这一天是星期三,而这一天您将赶到驻地办公室。
获得相对日期
d 选项还可以告诉您,相对于 当前日期若干天的究竟是哪一天,从现在开始的若干天或若干星期以后,或者以前(过去)。通过将这个相对偏移使用引号括起来,作为 -d 选项的参数,就可以完成这项任务。
例如,您需要了解两星期以后的日期。如果您处于 Shell 提示符处,那么可以迅速地得到答案:
$ date -d ’2 weeks’
- 关于使用该命令,还有其他一些重要的方法。使用 next/last指令,您可以得到以后的星期几是哪一天:
- $ date -d 'next monday' (下周一的日期)
- $ date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
- $ date -d last-day +%Y%m%d(昨天的日期) 或者:date -d yesterday +%Y%m%d
- $ date -d last-month +%Y%m(上个月是几月)
- $ date -d next-month +%Y%m(下个月是几月)
- 使用 ago 指令,您可以得到过去的日期:
- $ date -d '30 days ago' (30天前的日期)
- 您可以使用负数以得到相反的日期:
- $ date -d 'dec 14 -2 weeks' (相对:dec 14这个日期的两周前的日期)
- $ date -d '-100 days' (100天以前的日期)
- $ date -d '50 days'(50天后的日期)
这个技巧非常有用,它可以根据将来的日期为自己设置提醒,可能是在脚本或 Shell 启动文件中,如下所示:
DAY=`date -d '2 weeks' +"%b %d"`
if test "`echo $DAY`" = "Aug 16"; then echo 'Product launch is now two weeks away!'; fi
posted @
2015-12-08 09:33 xzc 阅读(954) |
评论 (0) |
编辑 收藏LINUX - awk命令之NF和$NF区别
LINUX - awk命令之NF和$NF区别
NF和$NF 区别问答:
1.awk中$NF是什么意思?
#pwd
/usr/local/etc
~# echo $PWD | awk -F/ '{print $NF}'
etc
NF代表:浏览记录的域的个数
$NF代表 :最后一个Field(列)
2.awk下面的变量NF和$NF有什么区别?
{print NF} 也有{print $NF}
前者是输出了域个数,后者是输出最后一个字段的内容
如:~# echo $PWD | awk -F/ '{print $NF}'
posted @
2015-12-07 10:23 xzc 阅读(1508) |
评论 (0) |
编辑 收藏bash shell 脚本执行的方法有多种,本文作一个总结,供大家学习参考。
假设我们编写好的shell脚本的文件名为hello.sh,文件位置在/data/shell目录中并已有执行权限。
方法一:切换到shell脚本所在的目录(此时,称为工作目录)执行shell脚本:
cd /data/shell
./hello.sh
./的意思是说在当前的工作目录下执行hello.sh。如果不加上./,bash可能会响应找到不到hello.sh的错误信息。因为目前的工作目录(/data/shell)可能不在执行程序默认的搜索路径之列,也就是说,不在环境变量PASH的内容之中。查看PATH的内容可用 echo $PASH 命令。现在的/data/shell就不在环境变量PASH中的,所以必须加上./才可执行。
方法二:以绝对路径的方式去执行bash shell脚本:
/data/shell/hello.sh
方法三:直接使用bash 或sh 来执行bash shell脚本:
cd /data/shell
bash hello.sh
或
cd /data/shell
sh hello.sh
注意,若是以方法三的方式来执行,那么,可以不必事先设定shell的执行权限,甚至都不用写shell文件中的第一行(指定bash路径)。因为方法三是将hello.sh作为参数传给sh(bash)命令来执行的。这时不是hello.sh自己来执行,而是被人家调用执行,所以不要执行权限。那么不用指定bash路径自然也好理解了啊,呵呵……。
方法四:在当前的shell环境中执行bash shell脚本:
cd /data/shell
. hello.sh
或
cd /data/shell
source hello.sh
前三种方法执行shell脚本时都是在当前shell(称为父shell)开启一个子shell环境,此shell脚本就在这个子shell环境中执行。shell脚本执行完后子shell环境随即关闭,然后又回到父shell中。而方法四则是在当前shell中执行的。
假设shell脚本文件为hello.sh
放在/root目录下。
下面介绍几种在终端执行shell脚本的方法:
复制代码代码如下:
[root@localhost home]# cd /root/
[root@localhost ~]#vim hello.sh
#! /bin/bash
cd /tmp
echo "hello guys!"
echo "welcome to my Blog:linuxboy.org!"
1.切换到shell脚本所在的目录,执行:
复制代码代码如下:
[root@localhost ~]# ./hello.sh
-bash: ./ hello.sh: 权限不够
2.以绝对路径的方式执行:
复制代码代码如下:
[root@localhost ~]# /root/Desktop/hello.sh
-bash: /root/Desktop/ hello.sh: 权限不够
3.直接用bash或sh执行:
复制代码代码如下:
[root@localhost ~]# bash hello.sh
hello guys!
welcome to my Blog:linuxboy.org!
[root@localhost ~]# pwd
/root
[root@localhost ~]# sh hello.sh
hello guys!
welcome to my Blog:linuxboy.org!
[root@localhost ~]# pwd
/root
注意:用以上三种方法执行shell脚本,现行的shell会开启一个子shell环境,去执行shell脚本,前两种必须要有执行权限才能够执行。也可以让shell脚本在现行的shell中执行:
4.现行的shell中执行
复制代码代码如下:
[root@localhost ~]# . hello.sh
hello guys!
welcome to my Blog:linuxboy.org!
[root@localhost tmp]# pwd
/tmp
[root@localhost ~]# source hello.sh
hello guys!
welcome to my Blog:linuxboy.org!
[root@localhost tmp]# pwd
/tmp
对于第4种不会创建子进程,而是在父进程中直接执行。
上面的差异是因为子进程不能改变父进程的执行环境,所以CD(内建命令,只有内建命令才可以改变shell 的执行环境)没有成功,但是第4种没有子进程,所以CD成功。
posted @
2015-12-02 10:33 xzc 阅读(388) |
评论 (0) |
编辑 收藏posted @
2015-11-26 23:35 xzc 阅读(289) |
评论 (0) |
编辑 收藏posted @
2015-11-26 23:20 xzc 阅读(379) |
评论 (0) |
编辑 收藏Python语法简单,而且通过缩进的方式来表现层次结构,代码非常简明易懂,对初学者来说,比较容易上手。
Perl的模式匹配非常强大,同时匹配的符号有很多种,难以阅读和维护。
在文本处理方面,python通过加载re模块来实现模式匹配的查找和替换。而Perl内置就有模式匹配功能。
note:内置命令和外部命令的区别。
通过代码来直接做比较。
python版:
#!/usr/bin/python
import re
import fileinput
exists_re = re.compile(r'^(.*?) INFO.*Such a record already exists', re.I)
location_re = re.compile(r'^AwbLocation (.*?) insert into', re.I)
for line in fileinput.input():
fn = fileinput.filename()
currline = line.rstrip()
mprev = exists_re.search(currline)
if(mprev):
xlogtime = mprev.group(1)
mcurr = location_re.search(currline)
if(mcurr):
print fn, xlogtime, mcurr.group(1)
Perl版:
#!/usr/bin/perl
while (<>) {
chomp;
if (m/^(.*?) INFO.*Such a record already exists/i) {
$xlogtime = $1;
}
if (m/^AwbLocation (.*?) insert into/i) {
print "$ARGV $xlogtime $1\n";
}
}
time process_file.py *log > summarypy.log
real 0m8.185s
user 0m8.018s
sys 0m0.092s
time process_file.pl *log > summaypl.log
real 0m1.481s
user 0m1.294s
sys 0m0.124s
在文本处理方面,Perl 比Python快8倍左右。
所以在处理大文件如大日志方面,用perl更好,因为更快。
如果对速度要求不是很严格的话,用python更好,因为python简洁易懂,容易维护和阅读。
为什么在文本处理时,Perl比Python快很多呢?
这是因为Perl的模式匹配是其内置功能,而Python需要加载re模块,使用内置命令比外部命令要快很多。
内置命令和外部命令的区别
Linux命令有内置命令和外部命令之分,功能基本相同,但是调用有些细微差别。
内置命令实际上是shell程序的一部分,其中包含的是一些简单的linux系统命令,这些命令在shell程序识别并在shell程序内部完成运行,通常在linux系统加载运行时shell就被加载并驻留在系统内存中。内部命令是设在bash源代码里面的,其执行速度比外部命令快,因为解析内部命令shell不需要创建子进程,比如exit,cd,pwd,echo,history等。
外部命令是linux系统中的实用应用程序,因为实用程序的功能通常比较强大,其包含的程序量也很大,在系统加载的时候并不随系统一起被加载到内存中,而是在需要的时候才将其调入内存。通常外部命令的实体并不包含在shell中,但是其命令执行过程是由shell程序控制的。shell程序管理外部命令执行的路径查找,加载存放,并控制命令的执行。外部命令是在bash之外额外安装的,通常放在/bin, /usr/bin, /sbin, /usr/sbin,....等。
用type命令可以分辨内部命令与外部命令。

posted @
2015-11-26 23:15 xzc 阅读(1576) |
评论 (0) |
编辑 收藏转自:
http://blog.csdn.net/caihaijiang/article/details/5903154Eclipse下Debug时,弹出错误提示:“Unable to install breakpoint due to missing line number attributes. Modify compiler options to generate line number attributes”,无法进行调试。
遇到这个错误时找到的解答方案汇总:
1、修改Eclipse的java编译器使用jdk,而不是jre;
2、使用Ant编译时,未打开debug开关,在写javac 任务时,设置debug="true",否则不能调试。THe settings for the eclipse compiler don't affect the ant build and even if you launch the ant build from withineclipse. ant controls it's own compiler settings.you can tell ant to generate debugging info like this 'javac ... debug="true".../>;(我遇到的问题,是采用这个办法解决的)
3、编译器的设置问题,window->preferences->java->Compiler在compiler起始页,classfile Generation区域中确认已经勾选了All line number attributes to generated class files。如果已经勾选,从新来一下再Apply一下。或者从项目层次进行设定,项目属性->java compiler同样在起始页,确定已经勾选。
Eclipse编译时出现Outof Memory问题,解决办法如下:
window->preferences->java->Installed JREs,选择安装的jre(如jdk1.5.0),单击右边按钮“Edit”,弹出“Edit JRE”的对话框,在Default VM Argument的输入框中输入:-Xmx512m,然后按确定,即可。(-Xms是设定最小内存,-Xmx是设定最大内存)
posted @
2015-11-26 15:56 xzc 阅读(761) |
评论 (0) |
编辑 收藏一:前言
防火墙,其实说白了讲,就是用于实现Linux下访问控制的功能的,它分为硬件的或者软件的防火墙两种。无论是在哪个网络中,防火墙工作的地方一定是在网络的边缘。而我们的任务就是需要去定义到底防火墙如何工作,这就是防火墙的策略,规则,以达到让它对出入网络的IP、数据进行检测。
目前市面上比较常见的有3、4层的防火墙,叫网络层的防火墙,还有7层的防火墙,其实是代理层的网关。
对于TCP/IP的七层模型来讲,我们知道第三层是网络层,三层的防火墙会在这层对源地址和目标地址进行检测。但是对于七层的防火墙,不管你源端口或者目标端口,源地址或者目标地址是什么,都将对你所有的东西进行检查。所以,对于设计原理来讲,七层防火墙更加安全,但是这却带来了效率更低。所以市面上通常的防火墙方案,都是两者结合的。而又由于我们都需要从防火墙所控制的这个口来访问,所以防火墙的工作效率就成了用户能够访问数据多少的一个最重要的控制,配置的不好甚至有可能成为流量的瓶颈。
二:iptables 的历史以及工作原理
1.iptables的发展:
iptables的前身叫ipfirewall (内核1.x时代),这是一个作者从freeBSD上移植过来的,能够工作在内核当中的,对数据包进行检测的一款简易访问控制工具。但是ipfirewall工作功能极其有限(它需要将所有的规则都放进内核当中,这样规则才能够运行起来,而放进内核,这个做法一般是极其困难的)。当内核发展到2.x系列的时候,软件更名为ipchains,它可以定义多条规则,将他们串起来,共同发挥作用,而现在,它叫做iptables,可以将规则组成一个列表,实现绝对详细的访问控制功能。
他们都是工作在用户空间中,定义规则的工具,本身并不算是防火墙。它们定义的规则,可以让在内核空间当中的netfilter来读取,并且实现让防火墙工作。而放入内核的地方必须要是特定的位置,必须是tcp/ip的协议栈经过的地方。而这个tcp/ip协议栈必须经过的地方,可以实现读取规则的地方就叫做 netfilter.(网络过滤器)
作者一共在内核空间中选择了5个位置,
1.内核空间中:从一个网络接口进来,到另一个网络接口去的
2.数据包从内核流入用户空间的
3.数据包从用户空间流出的
4.进入/离开本机的外网接口
5.进入/离开本机的内网接口
2.iptables的工作机制
从上面的发展我们知道了作者选择了5个位置,来作为控制的地方,但是你有没有发现,其实前三个位置已经基本上能将路径彻底封锁了,但是为什么已经在进出的口设置了关卡之后还要在内部卡呢? 由于数据包尚未进行路由决策,还不知道数据要走向哪里,所以在进出口是没办法实现数据过滤的。所以要在内核空间里设置转发的关卡,进入用户空间的关卡,从用户空间出去的关卡。那么,既然他们没什么用,那我们为什么还要放置他们呢?因为我们在做NAT和DNAT的时候,目标地址转换必须在路由之前转换。所以我们必须在外网而后内网的接口处进行设置关卡。
这五个位置也被称为五个钩子函数(hook functions),也叫五个规则链。
1.PREROUTING (路由前)
2.INPUT (数据包流入口)
3.FORWARD (转发管卡)
4.OUTPUT(数据包出口)
5.POSTROUTING(路由后)
这是NetFilter规定的五个规则链,任何一个数据包,只要经过本机,必将经过这五个链中的其中一个链。
3.防火墙的策略
防火墙策略一般分为两种,一种叫“通”策略,一种叫“堵”策略,通策略,默认门是关着的,必须要定义谁能进。堵策略则是,大门是洞开的,但是你必须有身份认证,否则不能进。所以我们要定义,让进来的进来,让出去的出去,所以通,是要全通,而堵,则是要选择。当我们定义的策略的时候,要分别定义多条功能,其中:定义数据包中允许或者不允许的策略,filter过滤的功能,而定义地址转换的功能的则是nat选项。为了让这些功能交替工作,我们制定出了“表”这个定义,来定义、区分各种不同的工作功能和处理方式。
我们现在用的比较多个功能有3个:
1.filter 定义允许或者不允许的
2.nat 定义地址转换的
3.mangle功能:修改报文原数据
我们修改报文原数据就是来修改TTL的。能够实现将数据包的元数据拆开,在里面做标记/修改内容的。而防火墙标记,其实就是靠mangle来实现的。
小扩展:
对于filter来讲一般只能做在3个链上:INPUT ,FORWARD ,OUTPUT
对于nat来讲一般也只能做在3个链上:PREROUTING ,OUTPUT ,POSTROUTING
而mangle则是5个链都可以做:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
iptables/netfilter(这款软件)是工作在用户空间的,它可以让规则进行生效的,本身不是一种服务,而且规则是立即生效的。而我们iptables现在被做成了一个服务,可以进行启动,停止的。启动,则将规则直接生效,停止,则将规则撤销。
iptables还支持自己定义链。但是自己定义的链,必须是跟某种特定的链关联起来的。在一个关卡设定,指定当有数据的时候专门去找某个特定的链来处理,当那个链处理完之后,再返回。接着在特定的链中继续检查。
注意:规则的次序非常关键,谁的规则越严格,应该放的越靠前,而检查规则的时候,是按照从上往下的方式进行检查的。
三.规则的写法:
iptables定义规则的方式比较复杂:
格式:iptables [-t table] COMMAND chain CRETIRIA -j ACTION
-t table :3个filter nat mangle
COMMAND:定义如何对规则进行管理
chain:指定你接下来的规则到底是在哪个链上操作的,当定义策略的时候,是可以省略的
CRETIRIA:指定匹配标准
-j ACTION :指定如何进行处理
比如:不允许172.16.0.0/24的进行访问。
iptables -t filter -A INPUT -s 172.16.0.0/16 -p udp --dport 53 -j DROP
当然你如果想拒绝的更彻底:
iptables -t filter -R INPUT 1 -s 172.16.0.0/16 -p udp --dport 53 -j REJECT
iptables -L -n -v #查看定义规则的详细信息
四:详解COMMAND:
1.链管理命令(这都是立即生效的)
-P :设置默认策略的(设定默认门是关着的还是开着的)
默认策略一般只有两种
iptables -P INPUT (DROP|ACCEPT) 默认是关的/默认是开的
比如:
iptables -P INPUT DROP 这就把默认规则给拒绝了。并且没有定义哪个动作,所以关于外界连接的所有规则包括Xshell连接之类的,远程连接都被拒绝了。
-F: FLASH,清空规则链的(注意每个链的管理权限)
iptables -t nat -F PREROUTING
iptables -t nat -F 清空nat表的所有链
-N:NEW 支持用户新建一个链
iptables -N inbound_tcp_web 表示附在tcp表上用于检查web的。
-X: 用于删除用户自定义的空链
使用方法跟-N相同,但是在删除之前必须要将里面的链给清空昂了
-E:用来Rename chain主要是用来给用户自定义的链重命名
-E oldname newname
-Z:清空链,及链中默认规则的计数器的(有两个计数器,被匹配到多少个数据包,多少个字节)
iptables -Z :清空
2.规则管理命令
-A:追加,在当前链的最后新增一个规则
-I num : 插入,把当前规则插入为第几条。
-I 3 :插入为第三条
-R num:Replays替换/修改第几条规则
格式:iptables -R 3 …………
-D num:删除,明确指定删除第几条规则
3.查看管理命令 “-L”
附加子命令
-n:以数字的方式显示ip,它会将ip直接显示出来,如果不加-n,则会将ip反向解析成主机名。
-v:显示详细信息
-vv
-vvv :越多越详细
-x:在计数器上显示精确值,不做单位换算
--line-numbers : 显示规则的行号
-t nat:显示所有的关卡的信息
五:详解匹配标准
1.通用匹配:源地址目标地址的匹配
-s:指定作为源地址匹配,这里不能指定主机名称,必须是IP
IP | IP/MASK | 0.0.0.0/0.0.0.0
而且地址可以取反,加一个“!”表示除了哪个IP之外
-d:表示匹配目标地址
-p:用于匹配协议的(这里的协议通常有3种,TCP/UDP/ICMP)
-i eth0:从这块网卡流入的数据
流入一般用在INPUT和PREROUTING上
-o eth0:从这块网卡流出的数据
流出一般在OUTPUT和POSTROUTING上
2.扩展匹配
2.1隐含扩展:对协议的扩展
-p tcp :TCP协议的扩展。一般有三种扩展
--dport XX-XX:指定目标端口,不能指定多个非连续端口,只能指定单个端口,比如
--dport 21 或者 --dport 21-23 (此时表示21,22,23)
--sport:指定源端口
--tcp-fiags:TCP的标志位(SYN,ACK,FIN,PSH,RST,URG)
对于它,一般要跟两个参数:
1.检查的标志位
2.必须为1的标志位
--tcpflags syn,ack,fin,rst syn = --syn
表示检查这4个位,这4个位中syn必须为1,其他的必须为0。所以这个意思就是用于检测三次握手的第一次包的。对于这种专门匹配第一包的SYN为1的包,还有一种简写方式,叫做--syn
-p udp:UDP协议的扩展
--dport
--sport
-p icmp:icmp数据报文的扩展
--icmp-type:
echo-request(请求回显),一般用8 来表示
所以 --icmp-type 8 匹配请求回显数据包
echo-reply (响应的数据包)一般用0来表示
2.2显式扩展(-m)
扩展各种模块
-m multiport:表示启用多端口扩展
之后我们就可以启用比如 --dports 21,23,80
六:详解-j ACTION
常用的ACTION:
DROP:悄悄丢弃
一般我们多用DROP来隐藏我们的身份,以及隐藏我们的链表
REJECT:明示拒绝
ACCEPT:接受
custom_chain:转向一个自定义的链
DNAT
SNAT
MASQUERADE:源地址伪装
REDIRECT:重定向:主要用于实现端口重定向
MARK:打防火墙标记的
RETURN:返回
在自定义链执行完毕后使用返回,来返回原规则链。
练习题1:
只要是来自于172.16.0.0/16网段的都允许访问我本机的172.16.100.1的SSHD服务
分析:首先肯定是在允许表中定义的。因为不需要做NAT地址转换之类的,然后查看我们SSHD服务,在22号端口上,处理机制是接受,对于这个表,需要有一来一回两个规则,如果我们允许也好,拒绝也好,对于访问本机服务,我们最好是定义在INPUT链上,而OUTPUT再予以定义就好。(会话的初始端先定义),所以加规则就是:
定义进来的: iptables -t filter -A INPUT -s 172.16.0.0/16 -d 172.16.100.1 -p tcp --dport 22 -j ACCEPT
定义出去的: iptables -t filter -A OUTPUT -s 172.16.100.1 -d 172.16.0.0/16 -p tcp --dport 22 -j ACCEPT
将默认策略改成DROP:
iptables -P INPUT DROP
iptables -P OUTPUT DROP
iptables -P FORWARD DROP
七:状态检测:
是一种显式扩展,用于检测会话之间的连接关系的,有了检测我们可以实现会话间功能的扩展
什么是状态检测?对于整个TCP协议来讲,它是一个有连接的协议,三次握手中,第一次握手,我们就叫NEW连接,而从第二次握手以后的,ack都为1,这是正常的数据传输,和tcp的第二次第三次握手,叫做已建立的连接(ESTABLISHED),还有一种状态,比较诡异的,比如:SYN=1 ACK=1 RST=1,对于这种我们无法识别的,我们都称之为INVALID无法识别的。还有第四种,FTP这种古老的拥有的特征,每个端口都是独立的,21号和20号端口都是一去一回,他们之间是有关系的,这种关系我们称之为RELATED。
所以我们的状态一共有四种:
NEW
ESTABLISHED
RELATED
INVALID
所以我们对于刚才的练习题,可以增加状态检测。比如进来的只允许状态为NEW和ESTABLISHED的进来,出去只允许ESTABLISHED的状态出去,这就可以将比较常见的反弹式木马有很好的控制机制。
对于练习题的扩展:
进来的拒绝出去的允许,进来的只允许ESTABLISHED进来,出去只允许ESTABLISHED出去。默认规则都使用拒绝
iptables -L -n --line-number :查看之前的规则位于第几行
改写INPUT
iptables -R INPUT 2 -s 172.16.0.0/16 -d 172.16.100.1 -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -R OUTPUT 1 -m state --state ESTABLISHED -j ACCEPT
此时如果想再放行一个80端口如何放行呢?
iptables -A INPUT -d 172.16.100.1 -p tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -R INPUT 1 -d 172.16.100.1 -p udp --dport 53 -j ACCEPT
练习题2:
假如我们允许自己ping别人,但是别人ping自己ping不通如何实现呢?
分析:对于ping这个协议,进来的为8(ping),出去的为0(响应).我们为了达到目的,需要8出去,允许0进来
在出去的端口上:iptables -A OUTPUT -p icmp --icmp-type 8 -j ACCEPT
在进来的端口上:iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT
小扩展:对于127.0.0.1比较特殊,我们需要明确定义它
iptables -A INPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT
iptables -A OUTPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT
八:SNAT和DNAT的实现
由于我们现在IP地址十分紧俏,已经分配完了,这就导致我们必须要进行地址转换,来节约我们仅剩的一点IP资源。那么通过iptables如何实现NAT的地址转换呢?
1.SNAT基于原地址的转换
基于原地址的转换一般用在我们的许多内网用户通过一个外网的口上网的时候,这时我们将我们内网的地址转换为一个外网的IP,我们就可以实现连接其他外网IP的功能。
所以我们在iptables中就要定义到底如何转换:
定义的样式:
比如我们现在要将所有192.168.10.0网段的IP在经过的时候全都转换成172.16.100.1这个假设出来的外网地址:
iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -j SNAT --to-source 172.16.100.1
这样,只要是来自本地网络的试图通过网卡访问网络的,都会被统统转换成172.16.100.1这个IP.
那么,如果172.16.100.1不是固定的怎么办?
我们都知道当我们使用联通或者电信上网的时候,一般它都会在每次你开机的时候随机生成一个外网的IP,意思就是外网地址是动态变换的。这时我们就要将外网地址换成 MASQUERADE(动态伪装):它可以实现自动寻找到外网地址,而自动将其改为正确的外网地址。所以,我们就需要这样设置:
iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -j MASQUERADE
这里要注意:地址伪装并不适用于所有的地方。
2.DNAT目标地址转换
对于目标地址转换,数据流向是从外向内的,外面的是客户端,里面的是服务器端通过目标地址转换,我们可以让外面的ip通过我们对外的外网ip来访问我们服务器不同的服务器,而我们的服务却放在内网服务器的不同的服务器上。
如何做目标地址转换呢?:
iptables -t nat -A PREROUTING -d 192.168.10.18 -p tcp --dport 80 -j DNAT --todestination 172.16.100.2
目标地址转换要做在到达网卡之前进行转换,所以要做在PREROUTING这个位置上
九:控制规则的存放以及开启
注意:你所定义的所有内容,当你重启的时候都会失效,要想我们能够生效,需要使用一个命令将它保存起来
1.service iptables save 命令
它会保存在/etc/sysconfig/iptables这个文件中
2.iptables-save 命令
iptables-save > /etc/sysconfig/iptables
3.iptables-restore 命令
开机的时候,它会自动加载/etc/sysconfig/iptabels
如果开机不能加载或者没有加载,而你想让一个自己写的配置文件(假设为iptables.2)手动生效的话:
iptables-restore < /etc/sysconfig/iptables.2
则完成了将iptables中定义的规则手动生效
十:总结
Iptables是一个非常重要的工具,它是每一个防火墙上几乎必备的设置,也是我们在做大型网络的时候,为了很多原因而必须要设置的。学好Iptables,可以让我们对整个网络的结构有一个比较深刻的了解,同时,我们还能够将内核空间中数据的走向以及linux的安全给掌握的非常透彻。我们在学习的时候,尽量能结合着各种各样的项目,实验来完成,这样对你加深iptables的配置,以及各种技巧有非常大的帮助。
附加iptables比较好的文章:
posted @
2015-11-24 17:17 xzc 阅读(238) |
评论 (0) |
编辑 收藏如果你的IPTABLES基础知识还不了解,建议先去看看.
开始配置
我们来配置一个filter表的防火墙.
(1)查看本机关于IPTABLES的设置情况
[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain RH-Firewall-1-INPUT (0 references)
target prot opt source destination
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmp type 255
ACCEPT esp -- 0.0.0.0/0 0.0.0.0/0
ACCEPT ah -- 0.0.0.0/0 0.0.0.0/0
ACCEPT udp -- 0.0.0.0/0 224.0.0.251 udp dpt:5353
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:631
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:80
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:25
REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited
可以看出我在安装linux时,选择了有防火墙,并且开放了22,80,25端口.
如果你在安装linux时没有选择启动防火墙,是这样的
[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
什么规则都没有.
(2)清除原有规则.
不管你在安装linux时是否启动了防火墙,如果你想配置属于自己的防火墙,那就清除现在filter的所有规则.
[root@tp ~]# iptables -F 清除预设表filter中的所有规则链的规则
[root@tp ~]# iptables -X 清除预设表filter中使用者自定链中的规则
我们在来看一下
[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
什么都没有了吧,和我们在安装linux时没有启动防火墙是一样的.(提前说一句,这些配置就像用命令配置IP一样,重起就会失去作用),怎么保存.
[root@tp ~]# /etc/rc.d/init.d/iptables save
这样就可以写到/etc/sysconfig/iptables文件里了.写入后记得把防火墙重起一下,才能起作用.
[root@tp ~]# service iptables restart
现在IPTABLES配置表里什么配置都没有了,那我们开始我们的配置吧
(3)设定预设规则
[root@tp ~]# iptables -p INPUT DROP
[root@tp ~]# iptables -p OUTPUT ACCEPT
[root@tp ~]# iptables -p FORWARD DROP
上面的意思是,当超出了IPTABLES里filter表里的两个链规则(INPUT,FORWARD)时,不在这两个规则里的数据包怎么处理呢,那就是DROP(放弃).应该说这样配置是很安全的.我们要控制流入数据包
而对于OUTPUT链,也就是流出的包我们不用做太多限制,而是采取ACCEPT,也就是说,不在着个规则里的包怎么办呢,那就是通过.
可以看出INPUT,FORWARD两个链采用的是允许什么包通过,而OUTPUT链采用的是不允许什么包通过.
这样设置还是挺合理的,当然你也可以三个链都DROP,但这样做我认为是没有必要的,而且要写的规则就会增加.但如果你只想要有限的几个规则是,如只做WEB服务器.还是推荐三个链都是DROP.
注:如果你是远程SSH登陆的话,当你输入第一个命令回车的时候就应该掉了.因为你没有设置任何规则.
怎么办,去本机操作呗!
(4)添加规则.
首先添加INPUT链,INPUT链的默认规则是DROP,所以我们就写需要ACCETP(通过)的链
为了能采用远程SSH登陆,我们要开启22端口.
[root@tp ~]# iptables -A INPUT -p tcp --dport 22 -j ACCEPT
[root@tp ~]# iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT (注:这个规则,如果你把OUTPUT 设置成DROP的就要写上这一部,好多人都是望了写这一部规则导致,始终无法SSH.在远程一下,是不是好了.
其他的端口也一样,如果开启了web服务器,OUTPUT设置成DROP的话,同样也要添加一条链:
[root@tp ~]# iptables -A OUTPUT -p tcp --sport 80 -j ACCEPT ,其他同理.)
如果做了WEB服务器,开启80端口.
[root@tp ~]# iptables -A INPUT -p tcp --dport 80 -j ACCEPT
如果做了邮件服务器,开启25,110端口.
[root@tp ~]# iptables -A INPUT -p tcp --dport 110 -j ACCEPT
[root@tp ~]# iptables -A INPUT -p tcp --dport 25 -j ACCEPT
如果做了FTP服务器,开启21端口
[root@tp ~]# iptables -A INPUT -p tcp --dport 21 -j ACCEPT
[root@tp ~]# iptables -A INPUT -p tcp --dport 20 -j ACCEPT
如果做了DNS服务器,开启53端口
[root@tp ~]# iptables -A INPUT -p tcp --dport 53 -j ACCEPT
如果你还做了其他的服务器,需要开启哪个端口,照写就行了.
上面主要写的都是INPUT链,凡是不在上面的规则里的,都DROP
允许icmp包通过,也就是允许ping,
[root@tp ~]# iptables -A OUTPUT -p icmp -j ACCEPT (OUTPUT设置成DROP的话)
[root@tp ~]# iptables -A INPUT -p icmp -j ACCEPT (INPUT设置成DROP的话)
允许loopback!(不然会导致DNS无法正常关闭等问题)
IPTABLES -A INPUT -i lo -p all -j ACCEPT (如果是INPUT DROP)
IPTABLES -A OUTPUT -o lo -p all -j ACCEPT(如果是OUTPUT DROP)
下面写OUTPUT链,OUTPUT链默认规则是ACCEPT,所以我们就写需要DROP(放弃)的链.
减少不安全的端口连接
[root@tp ~]# iptables -A OUTPUT -p tcp --sport 31337 -j DROP
[root@tp ~]# iptables -A OUTPUT -p tcp --dport 31337 -j DROP
有些些特洛伊木马会扫描端口31337到31340(即黑客语言中的 elite 端口)上的服务。既然合法服务都不使用这些非标准端口来通信,阻塞这些端口能够有效地减少你的网络上可能被感染的机器和它们的远程主服务器进行独立通信的机会
还有其他端口也一样,像:31335、27444、27665、20034 NetBus、9704、137-139(smb),2049(NFS)端口也应被禁止,我在这写的也不全,有兴趣的朋友应该去查一下相关资料.
当然出入更安全的考虑你也可以包OUTPUT链设置成DROP,那你添加的规则就多一些,就像上边添加
允许SSH登陆一样.照着写就行了.
下面写一下更加细致的规则,就是限制到某台机器
如:我们只允许192.168.0.3的机器进行SSH连接
[root@tp ~]# iptables -A INPUT -s 192.168.0.3 -p tcp --dport 22 -j ACCEPT
如果要允许,或限制一段IP地址可用 192.168.0.0/24 表示192.168.0.1-255端的所有IP.
24表示子网掩码数.但要记得把 /etc/sysconfig/iptables 里的这一行删了.
-A INPUT -p tcp -m tcp --dport 22 -j ACCEPT 因为它表示所有地址都可以登陆.
或采用命令方式:
[root@tp ~]# iptables -D INPUT -p tcp --dport 22 -j ACCEPT
然后保存,我再说一边,反是采用命令的方式,只在当时生效,如果想要重起后也起作用,那就要保存.写入到/etc/sysconfig/iptables文件里.
[root@tp ~]# /etc/rc.d/init.d/iptables save
这样写 !192.168.0.3 表示除了192.168.0.3的ip地址
其他的规则连接也一样这么设置.
在下面就是FORWARD链,FORWARD链的默认规则是DROP,所以我们就写需要ACCETP(通过)的链,对正在转发链的监控.
开启转发功能,(在做NAT时,FORWARD默认规则是DROP时,必须做)
[root@tp ~]# iptables -A FORWARD -i eth0 -o eth1 -m state --state RELATED,ESTABLISHED -j ACCEPT
[root@tp ~]# iptables -A FORWARD -i eth1 -o eh0 -j ACCEPT
丢弃坏的TCP包
[root@tp ~]#iptables -A FORWARD -p TCP ! --syn -m state --state NEW -j DROP
处理IP碎片数量,防止攻击,允许每秒100个
[root@tp ~]#iptables -A FORWARD -f -m limit --limit 100/s --limit-burst 100 -j ACCEPT
设置ICMP包过滤,允许每秒1个包,限制触发条件是10个包.
[root@tp ~]#iptables -A FORWARD -p icmp -m limit --limit 1/s --limit-burst 10 -j ACCEPT
我在前面只所以允许ICMP包通过,就是因为我在这里有限制.
二,配置一个NAT表放火墙
1,查看本机关于NAT的设置情况
[root@tp rc.d]# iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
SNAT all -- 192.168.0.0/24 anywhere to:211.101.46.235
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
我的NAT已经配置好了的(只是提供最简单的代理上网功能,还没有添加防火墙规则).关于怎么配置NAT,参考我的另一篇文章
当然你如果还没有配置NAT的话,你也不用清除规则,因为NAT在默认情况下是什么都没有的
如果你想清除,命令是
[root@tp ~]# iptables -F -t nat
[root@tp ~]# iptables -X -t nat
[root@tp ~]# iptables -Z -t nat
2,添加规则
添加基本的NAT地址转换,(关于如何配置NAT可以看我的另一篇文章),
添加规则,我们只添加DROP链.因为默认链全是ACCEPT.
防止外网用内网IP欺骗
[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 10.0.0.0/8 -j DROP
[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 172.16.0.0/12 -j DROP
[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 192.168.0.0/16 -j DROP
如果我们想,比如阻止MSN,QQ,BT等的话,需要找到它们所用的端口或者IP,(个人认为没有太大必要)
例:
禁止与211.101.46.253的所有连接
[root@tp ~]# iptables -t nat -A PREROUTING -d 211.101.46.253 -j DROP禁用FTP(21)端口
[root@tp ~]# iptables -t nat -A PREROUTING -p tcp --dport 21 -j DROP
这样写范围太大了,我们可以更精确的定义.
[root@tp ~]# iptables -t nat -A PREROUTING -p tcp --dport 21 -d 211.101.46.253 -j DROP
这样只禁用211.101.46.253地址的FTP连接,其他连接还可以.如web(80端口)连接.
按照我写的,你只要找到QQ,MSN等其他软件的IP地址,和端口,以及基于什么协议,只要照着写就行了.
最后:
drop非法连接
[root@tp ~]# iptables -A INPUT -m state --state INVALID -j DROP
[root@tp ~]# iptables -A OUTPUT -m state --state INVALID -j DROP
[root@tp ~]# iptables-A FORWARD -m state --state INVALID -j DROP
允许所有已经建立的和相关的连接
[root@tp ~]# iptables-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
[root@tp ~]# iptables-A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
[root@tp ~]# /etc/rc.d/init.d/iptables save
这样就可以写到/etc/sysconfig/iptables文件里了.写入后记得把防火墙重起一下,才能起作用.
[root@tp ~]# service iptables restart
别忘了保存,不行就写一部保存一次.你可以一边保存,一边做实验,看看是否达到你的要求,上面的所有规则我都试过,没有问题.
写这篇文章,用了我将近1个月的时间.查找资料,自己做实验,希望对大家有所帮助.如有不全及不完善的地方还请提出.
因为本篇文章以配置为主.关于IPTABLES的基础知识及指令命令说明等我会尽快传上,当然你可以去网上搜索一下,还是很多的.
posted @
2015-11-24 16:15 xzc 阅读(210) |
评论 (0) |
编辑 收藏posted @
2015-11-19 18:08 xzc 阅读(1394) |
评论 (0) |
编辑 收藏 echo "Cfoo'barxml" | sed "s/'/::/g" | sed 's/::/\\:/g' | sed "s/:/'/g" 替换单引号为 \'
------------------------
sed 替换单引号'
echo "mmm'sss" > test
cat test
把test内容中单引号替换成双引号
sed 's/'"'"/'"''/g' test ==> sed 's/' " ' " / ' " ' '/g' test
解析下:
's/' => 要进行替换操作,后紧跟匹配字符
"'" => 用双引号包裹着单引号
/ =>分割符
'"' => 用单引号包裹着双引号
'/g' =>分隔符,全局替换
当然还可以使用下面这两种方法替换:
sed s#\'#\"#g test 最外层使用#分隔,里面使用转义单引号,转义双引号
sed "s/'/\"/g" test 最外层使用双引号,里面使用单引号,转义双引号
echo "mmm'sss" | sed 's/'"'"/'"''/g'
echo "mmm'sss" | sed s#\'#\"#g
echo "mmm'sss" | sed "s/'/\"/g"
awk '{print "sed '\''s/"$1"\\t/"$2"\\t/g'\'' ref_Zv9_top_level.bed.chrom"}' ref_Zv9_top_level.gff3_transID
sed 's/rna10004\t/XR_223343.1\t/g' ref_Zv9_top_level.bed.chrom
sed 's/rna10000\t/XR_223342.1\t/g' ref_Zv9_top_level.bed.chrom
sed 's/\]/\"/g' 替换]为“
sed 's/\[/\"/g' 替换[为“
posted @
2015-10-29 19:52 xzc 阅读(1831) |
评论 (1) |
编辑 收藏shell中${}的妙用
1. 截断功能
${file#*/}: 拿掉第一条/及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##*/}: 拿掉最后一条/及其左边的字符串:my.file.txt
${file#*.}: 拿掉第一个.及其左边的字符串:file.txt
${file##*.}: 拿掉最后一个.及其左边的字符串:txt
${file%/*}: 拿掉最后条/及其右边的字符串:/dir1/dir2/dir3
${file%%/*}: 拿掉第一条/及其右边的字符串:(空值)
${file%.*}: 拿掉最后一个.及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}: 拿掉第一个.及其右边的字符串:/dir1/dir2/dir3/my
记忆的方法为:
[list]#是去掉左边, ##最后一个
%是去掉右边, %%第一个
2. 字符串提取
单一符号是最小匹配﹔两个符号是最大匹配。
${file:0:5}:提取最左边的 5 个字节:/dir1
${file:5:5}:提取第 5 个字节右边的连续 5 个字节:/dir2
3. 字符串替换
${file/dir/path}:将第一个 dir 提换为 path:/path1/dir2/dir3/my.file.txt
${file//dir/path}:将全部 dir 提换为 path:/path1/path2/path3/my.file.txt
4. 针对不同的变量状态赋值(没设定、空值、非空值):
${file-my.file.txt}: 若$file没有设定,则使用my.file.txt作返回值。(空值及非空值时不作处理)
${file:-my.file.txt}:若$file没有设定或为空值,则使用my.file.txt作返回值。(非空值时不作处理)
${file+my.file.txt}: 若$file设为空值或非空值,均使用my.file.txt作返回值。(没设定时不作处理)
${file:+my.file.txt}:若$file为非空值,则使用my.file.txt作返回值。(没设定及空值时不作处理)
${file=my.file.txt}: 若$file没设定,则使用my.file.txt作返回值,同时将$file 赋值为 my.file.txt。(空值及非空值时不作处理)
${file:=my.file.txt}:若$file没设定或为空值,则使用my.file.txt作返回值,同时将 $file 赋值为 my.file.txt。(非空值时不作处理)
${file?my.file.txt}: 若$file没设定,则将my.file.txt输出至 STDERR。(空值及非空值时不作处理)
${file:?my.file.txt}:若$file没设定或为空值,则将my.file.txt输出至STDERR。(非空值时不作处理)
注意:
":+"的情况是不包含空值的.
":-", ":="等只要有号就是包含空值(null).
5. 变量的长度
${#file}
6. 数组运算
A=(a b c def)
${A[@]} 或 ${A[*]} 可得到 a b c def (全部组数)
${A[0]} 可得到 a (第一个组数),${A[1]} 则为第二个组数...
${#A[@]} 或 ${#A[*]} 可得到 4 (全部组数数量)
${#A[0]} 可得到 1 (即第一个组数(a)的长度),${#A[3]} 可得到 3 (第四个组数(def)的长度)
posted @
2015-10-29 16:18 xzc 阅读(154) |
评论 (0) |
编辑 收藏在linux操作系统中,find命令非常强大,在文件与目录的查找方面可谓无所不至其极,如果能结合xargs命令使得,更是强大无比。
以下来看看find命令忽略目录查找的用法吧。
例1,根据文件属性查找:
find . -type f -name "*config*" ! -path "./tmp/*" ! -path "./scripts/*" ! -path "./node_modules/*"
Explanation:
find . - Start find from current working directory (recursively by default)
-type f - Specify to find that you only want files in the results
-name "*_peaks.bed" - Look for files with the name ending in _peaks.bed
! -path "./tmp/*" - Exclude all results whose path starts with ./tmp/
! -path "./scripts/*" - Also exclude all results whose path starts with ./scripts/
例2,根据文件内容查找:
grep -n -r --exclude-dir='node_modules' --exclude-dir='logs' --exclude="nohup.out" 192 *
使用find命令在linux系统中查找文件时,有时需要忽略某些目录,可以使用 -prune 参数来进行过滤。
不过必须注意:要忽略的路径参数要紧跟着搜索的路径之后,否则该参数无法起作用。
例如:指定搜索/home/zth目录下的所有文件,但是会忽略/home/zth/astetc的路径:
find /home/zth -path "/home/zth/astetc" -prune -o -type f -print
按照文件名来搜索则为:
find /home/zth -path "/home/zth/astetc" -prune -o -type f -name "cdr_*.conf" -print
要忽略两个以上的路径如何处理?
find /home/zth /( -path "/home/zth/astetc" -o -path "/home/zth/etc" /) -prune -o -type f -print
find /home/zth /( -path "/home/zth/astetc" -o -path "/home/zth/etc" /) -prune -o -type f -name "cdr_*.conf" -print
注意:/( 和/) 前后都有空格。
查找某个文件包含内容,以下语句可以解决目录带空格的问题:
find ./ -name "mysql*" -print0 |xargs -0 grep "SELECT lead_id FROM vicidial_list where vendor_lead_code"
如果目录不带空格,可以这样:
find ./ -name "mysql*" |xargs grep "SELECT lead_id FROM vicidial_list where vendor_lead_code"
通过以上的例子,大家应该可以掌握find命令查找文件时,忽略相关目录的方法了。
posted @
2015-10-28 11:33 xzc 阅读(1380) |
评论 (1) |
编辑 收藏X509 文件扩展名
首先我们要理解文件的扩展名代表什么。DER、PEM、CRT和CER这些扩展名经常令人困惑。很多人错误地认为这些扩展名可以互相代替。尽管的确有时候有些扩展名是可以互换的,但是最好你能确定证书是如何编码的,进而正确地标识它们。正确地标识证书有助于证书的管理。
编码 (也用于扩展名)
- .DER = 扩展名DER用于二进制DER编码的证书。这些证书也可以用CER或者CRT作为扩展名。比较合适的说法是“我有一个DER编码的证书”,而不是“我有一个DER证书”。
- .PEM = 扩展名PEM用于ASCII(Base64)编码的各种X.509 v3 证书。文件开始由一行"—– BEGIN …“开始。
常用的扩展名
- .CRT = 扩展名CRT用于证书。证书可以是DER编码,也可以是PEM编码。扩展名CER和CRT几乎是同义词。这种情况在各种unix/linux系统中很常见。
- CER = CRT证书的微软型式。可以用微软的工具把CRT文件转换为CER文件(CRT和CER必须是相同编码的,DER或者PEM)。扩展名为CER的文件可以被IE识别并作为命令调用微软的cryptoAPI(具体点就是rudll32.exe cryptext.dll, CyrptExtOpenCER),进而弹出一个对话框来导入并/或查看证书内容。
- .KEY = 扩展名KEY用于PCSK#8的公钥和私钥。这些公钥和私钥可以是DER编码或者PEM编码。
CRT文件和CER文件只有在使用相同编码的时候才可以安全地相互替代。
posted @
2015-10-01 10:12 xzc 阅读(451) |
评论 (0) |
编辑 收藏原文地址: http://www.thegeekstuff.com/2012/04/curl-examples/
下载单个文件,默认将输出打印到标准输出中(STDOUT)中
curl http://www.centos.org
通过-o/-O选项保存下载的文件到指定的文件中:
-o:将文件保存为命令行中指定的文件名的文件中
-O:使用URL中默认的文件名保存文件到本地
1 # 将文件下载到本地并命名为mygettext.html
2 curl -o mygettext.html http://www.gnu.org/software/gettext/manual/gettext.html
3
4 # 将文件保存到本地并命名为gettext.html
5 curl -O http://www.gnu.org/software/gettext/manual/gettext.html
同样可以使用转向字符">"对输出进行转向输出
同时获取多个文件
若同时从同一站点下载多个文件时,curl会尝试重用链接(connection)。
通过-L选项进行重定向
默认情况下CURL不会发送HTTP Location headers(重定向).当一个被请求页面移动到另一个站点时,会发送一个HTTP Loaction header作为请求,然后将请求重定向到新的地址上。
例如:访问google.com时,会自动将地址重定向到google.com.hk上。
1 curl http://www.google.com
2 <HTML>
3 <HEAD>
4 <meta http-equiv="content-type" content="text/html;charset=utf-8">
5 <TITLE>302 Moved</TITLE>
6 </HEAD>
7 <BODY>
8 <H1>302 Moved</H1>
9 The document has moved
10 <A HREF="http://www.google.com.hk/url?sa=p&hl=zh-CN&pref=hkredirect&pval=yes&q=http://www.google.com.hk/&ust=1379402837567135amp;usg=AFQjCNF3o7umf3jyJpNDPuF7KTibavE4aA">here</A>.
11 </BODY>
12 </HTML>
上述输出说明所请求的档案被转移到了http://www.google.com.hk。
这是可以通过使用-L选项进行强制重定向
1 # 让curl使用地址重定向,此时会查询google.com.hk站点
2 curl -L http://www.google.com
断点续传
通过使用-C选项可对大文件使用断点续传功能,如:
1 # 当文件在下载完成之前结束该进程
2 $ curl -O http://www.gnu.org/software/gettext/manual/gettext.html
3 ############## 20.1%
4
5 # 通过添加-C选项继续对该文件进行下载,已经下载过的文件不会被重新下载
6 curl -C - -O http://www.gnu.org/software/gettext/manual/gettext.html
7 ############### 21.1%
对CURL使用网络限速
通过--limit-rate选项对CURL的最大网络使用进行限制
1 # 下载速度最大不会超过1000B/second
2
3 curl --limit-rate 1000B -O http://www.gnu.org/software/gettext/manual/gettext.html
下载指定时间内修改过的文件
当下载一个文件时,可对该文件的最后修改日期进行判断,如果该文件在指定日期内修改过,就进行下载,否则不下载。
该功能可通过使用-z选项来实现:
1 # 若yy.html文件在2011/12/21之后有过更新才会进行下载
2 curl -z 21-Dec-11 http://www.example.com/yy.html
CURL授权
在访问需要授权的页面时,可通过-u选项提供用户名和密码进行授权
1 curl -u username:password URL
2
3 # 通常的做法是在命令行只输入用户名,之后会提示输入密码,这样可以保证在查看历史记录时不会将密码泄露
4 curl -u username URL
从FTP服务器下载文件
CURL同样支持FTP下载,若在url中指定的是某个文件路径而非具体的某个要下载的文件名,CURL则会列出该目录下的所有文件名而并非下载该目录下的所有文件
1 # 列出public_html下的所有文件夹和文件
2 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/
3
4 # 下载xss.php文件
5 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/xss.php
上传文件到FTP服务器
通过 -T 选项可将指定的本地文件上传到FTP服务器上
# 将myfile.txt文件上传到服务器
curl -u ftpuser:ftppass -T myfile.txt ftp://ftp.testserver.com
# 同时上传多个文件
curl -u ftpuser:ftppass -T "{file1,file2}" ftp://ftp.testserver.com
# 从标准输入获取内容保存到服务器指定的文件中
curl -u ftpuser:ftppass -T - ftp://ftp.testserver.com/myfile_1.txt获取更多信息
通过使用 -v 和 -trace获取更多的链接信息
通过字典查询单词
1 # 查询bash单词的含义
2 curl dict://dict.org/d:bash
3
4 # 列出所有可用词典
5 curl dict://dict.org/show:db
6
7 # 在foldoc词典中查询bash单词的含义
8 curl dict://dict.org/d:bash:foldoc
为CURL设置代理
-x 选项可以为CURL添加代理功能
1 # 指定代理主机和端口
2 curl -x proxysever.test.com:3128 http://google.co.in
其他网站整理
保存与使用网站cookie信息
1 # 将网站的cookies信息保存到sugarcookies文件中
2 curl -D sugarcookies http://localhost/sugarcrm/index.php
3
4 # 使用上次保存的cookie信息
5 curl -b sugarcookies http://localhost/sugarcrm/index.php
传递请求数据
默认curl使用GET方式请求数据,这种方式下直接通过URL传递数据
可以通过 --data/-d 方式指定使用POST方式传递数据
1 # GET
2 curl -u username https://api.github.com/user?access_token=XXXXXXXXXX
3
4 # POST
5 curl -u username --data "param1=value1¶m2=value" https://api.github.com
6
7 # 也可以指定一个文件,将该文件中的内容当作数据传递给服务器端
8 curl --data @filename https://github.api.com/authorizations
注:默认情况下,通过POST方式传递过去的数据中若有特殊字符,首先需要将特殊字符转义在传递给服务器端,如value值中包含有空格,则需要先将空格转换成%20,如:
1 curl -d "value%201" http://hostname.com
在新版本的CURL中,提供了新的选项 --data-urlencode,通过该选项提供的参数会自动转义特殊字符。
1 curl --data-urlencode "value 1" http://hostname.com
除了使用GET和POST协议外,还可以通过 -X 选项指定其它协议,如:
1 curl -I -X DELETE https://api.github.cim
上传文件
1 curl --form "fileupload=@filename.txt" http://hostname/resource
http://curl.haxx.se/docs/httpscripting.html
posted @
2015-09-23 16:55 xzc 阅读(319) |
评论 (2) |
编辑 收藏方法一: 使用全局变量
- g_result=""
-
- function testFunc()
- {
- g_result='local value'
- }
-
- testFunc
- echo $g_result
方法二: 把shell函数作为子程序调用,将其结果写到子程序的标准输出- function testFunc()
- {
- local_result='local value'
- echo $local_result
- }
-
- result=$(testFunc)
- echo $result
看到一篇关于函数返回值的好文章,分享一下: http://www.linuxjournal.com/content/return-values-bash-functions
posted @
2015-09-21 10:20 xzc 阅读(4440) |
评论 (2) |
编辑 收藏posted @
2015-09-15 20:07 xzc 阅读(246) |
评论 (0) |
编辑 收藏posted @
2015-09-15 14:52 xzc 阅读(2000) |
评论 (1) |
编辑 收藏posted @
2015-09-10 11:24 xzc 阅读(550) |
评论 (1) |
编辑 收藏posted @
2015-09-09 15:11 xzc 阅读(509) |
评论 (0) |
编辑 收藏posted @
2015-09-09 11:54 xzc 阅读(356) |
评论 (0) |
编辑 收藏posted @
2015-09-09 11:54 xzc 阅读(344) |
评论 (0) |
编辑 收藏posted @
2015-09-09 11:21 xzc 阅读(500) |
评论 (0) |
编辑 收藏自从Hadoop集群搭建以来,我们一直使用的是Gzip进行压缩
当时,我对gzip压缩过的文件和原始的log文件分别跑MapReduce测试,最终执行速度基本差不多
而且Hadoop原生支持Gzip解压,所以,当时就直接采用了Gzip压缩的方式
关于Lzo压缩,twitter有一篇文章,介绍的比较详细,见这里:
Lzo压缩相比Gzip压缩,有如下特点:
- 压缩解压的速度很快
- Lzo压缩是基于Block分块的,这样,一个大的文件(在Hadoop上可能会占用多个Block块),就可以由多个MapReduce并行来进行处理
虽然Lzo的压缩比没有Gzip高,不过由于其前2个特性,在Hadoop上使用Lzo还是能整体提升集群的性能的
我测试了12个log文件,总大小为8.4G,以下是Gzip和Lzo压缩的结果:
- Gzip压缩,耗时480s,Gunzip解压,耗时180s,压缩后大小为2.5G
- Lzo压缩,耗时160s,Lzop解压,耗时110s,压缩后大小为4G
以下为在Hadoop集群上使用Lzo的步骤:
1. 在集群的所有节点上安装Lzo库,可从这里下载
cd /opt/ysz/src/lzo-2.04
./configure –enable-shared
make
make install
#编辑/etc/ld.so.conf,加入/usr/local/lib/后,执行/sbin/ldconfig
或者cp /usr/local/lib/liblzo2.* /usr/lib64/
#如果没有这一步,最终会导致以下错误:
lzo.LzoCompressor: java.lang.UnsatisfiedLinkError: Cannot load liblzo2.so.2 (liblzo2.so.2: cannot open shared object file: No such file or directory)!
2. 编译安装Hadoop Lzo本地库以及Jar包,从这里下载
export CFLAGS=-m64
export CXXFLAGS=-m64
ant compile-native tar
#将本地库以及Jar包拷贝到hadoop对应的目录下,并分发到各节点上
cp lib/native/Linux-amd64-64/* /opt/sohuhadoop/hadoop/lib/native/Linux-amd64-64/
cp hadoop-lzo-0.4.10.jar /opt/sohuhadoop/hadoop/lib/
3. 设置Hadoop,启用Lzo压缩
vi core-site.xml
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
vi mapred-site.xml
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
4. 安装lzop,从这里下载
下面就是使用lzop压缩log文件,并上传到Hadoop上,执行MapReduce操作,测试的Hadoop是由3个节点组成集群
lzop -v 2011041309.log
hadoop fs -put *.lzo /user/pvlog
#给Lzo文件建立Index
hadoop jar /opt/sohuhadoop/hadoop/lib/hadoop-lzo-0.4.10.jar com.hadoop.compression.lzo.LzoIndexer /user/pvlog/
写一个简单的MapReduce来测试,需要指定InputForamt为Lzo格式,否则对单个Lzo文件仍不能进行Map的并行处理
job.setInputFormatClass(com.hadoop.mapreduce.LzoTextInputFormat.class);
可以通过下面的代码来设置Reduce的数目:
job.setNumReduceTasks(8);
最终,12个文件被切分成了36个Map任务来并行处理,执行时间为52s,如下图:

我们配置Hadoop默认的Block大小是128M,如果我们想切分成更多的Map任务,可以通过设置其最大的SplitSize来完成:
FileInputFormat.setMaxInputSplitSize(job, 64 *1024 * 1024);
最终,12个文件被切分成了72个Map来处理,但处理时间反而长了,为59s,如下图:

而对于Gzip压缩的文件,即使我们设置了setMaxInputSplitSize,最终的Map数仍然是输入文件的数目12,执行时间为78s,如下图:
.jpg)
从以上的简单测试可以看出,使用Lzo压缩,性能确实比Gzip压缩要好不少
posted @
2015-09-09 11:19 xzc 阅读(419) |
评论 (0) |
编辑 收藏posted @
2015-08-06 17:36 xzc 阅读(706) |
评论 (0) |
编辑 收藏最近在看《Hadoop:The Definitive Guide》,对其分布式文件系统HDFS的Streaming data access不能理解。基于流的数据读写,太抽象了,什么叫基于流,什么是流?Hadoop是Java语言写的,所以想理解好Hadoop的Streaming Data Access,还得从Java流机制入手。流机制也是JAVA及C++中的一个重要的机制,通过流使我们能够自由地操作包括文件,内存,IO设备等等中的数据。
首先,流是什么?
流是个抽象的概念,是对输入输出设备的抽象,Java程序中,对于数据的输入/输出操作都是以“流”的方式进行。设备可以是文件,网络,内存等。

流具有方向性,至于是输入流还是输出流则是一个相对的概念,一般以程序为参考,如果数据的流向是程序至设备,我们成为输出流,反之我们称为输入流。
可以将流想象成一个“水流管道”,水流就在这管道中形成了,自然就出现了方向的概念。

当程序需要从某个数据源读入数据的时候,就会开启一个输入流,数据源可以是文件、内存或网络等等。相反地,需要写出数据到某个数据源目的地的时候,也会开启一个输出流,这个数据源目的地也可以是文件、内存或网络等等。
流有哪些分类?
可以从不同的角度对流进行分类:
1. 处理的数据单位不同,可分为:字符流,字节流
2.数据流方向不同,可分为:输入流,输出流
3.功能不同,可分为:节点流,处理流
1. 和 2. 都比较好理解,对于根据功能分类的,可以这么理解:
节点流:节点流从一个特定的数据源读写数据。即节点流是直接操作文件,网络等的流,例如FileInputStream和FileOutputStream,他们直接从文件中读取或往文件中写入字节流。

处理流:“连接”在已存在的流(节点流或处理流)之上通过对数据的处理为程序提供更为强大的读写功能。过滤流是使用一个已经存在的输入流或输出流连接创建的,过滤流就是对节点流进行一系列的包装。例如BufferedInputStream和BufferedOutputStream,使用已经存在的节点流来构造,提供带缓冲的读写,提高了读写的效率,以及DataInputStream和DataOutputStream,使用已经存在的节点流来构造,提供了读写Java中的基本数据类型的功能。他们都属于过滤流。

举个简单的例子:
public static void main(String[] args) throws IOException {
// 节点流FileOutputStream直接以A.txt作为数据源操作
FileOutputStream fileOutputStream = new FileOutputStream("A.txt");
// 过滤流BufferedOutputStream进一步装饰节点流,提供缓冲写
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(
fileOutputStream);
// 过滤流DataOutputStream进一步装饰过滤流,使其提供基本数据类型的写
DataOutputStream out = new DataOutputStream(bufferedOutputStream);
out.writeInt(3);
out.writeBoolean(true);
out.flush();
out.close();
// 此处输入节点流,过滤流正好跟上边输出对应,读者可举一反三
DataInputStream in = new DataInputStream(new BufferedInputStream(
new FileInputStream("A.txt")));
System.out.println(in.readInt());
System.out.println(in.readBoolean());
in.close();
}流结构介绍:
Java所有的流类位于java.io包中,都分别继承字以下四种抽象流类型。
| | 字节流 | 字符流 |
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
1.继承自InputStream/OutputStream的流都是用于向程序中输入/输出数据,且数据的单位都是字节(byte=8bit),如图,深色的为节点流,浅色的为处理流。


2.继承自Reader/Writer的流都是用于向程序中输入/输出数据,且数据的单位都是字符(2byte=16bit),如图,深色的为节点流,浅色的为处理流。


常见流类介绍:
节点流类型常见的有:
对文件操作的字符流有FileReader/FileWriter,字节流有FileInputStream/FileOutputStream。
处理流类型常见的有:
缓冲流:缓冲流要“套接”在相应的节点流之上,对读写的数据提供了缓冲的功能,提高了读写效率,同事增加了一些新的方法。
字节缓冲流有BufferedInputStream/BufferedOutputStream,字符缓冲流有BufferedReader/BufferedWriter,字符缓冲流分别提供了读取和写入一行的方法ReadLine和NewLine方法。
对于输出地缓冲流,写出的数据,会先写入到内存中,再使用flush方法将内存中的数据刷到硬盘。所以,在使用字符缓冲流的时候,一定要先flush,然后再close,避免数据丢失。
转换流:用于字节数据到字符数据之间的转换。
仅有字符流InputStreamReader/OutputStreamWriter。其中,InputStreamReader需要与InputStream“套接”,OutputStreamWriter需要与OutputStream“套接”。
数据流:提供了读写Java中的基本数据类型的功能。
DataInputStream和DataOutputStream分别继承自InputStream和OutputStream,需要“套接”在InputStream和OutputStream类型的节点流之上。
对象流:用于直接将对象写入写出。
流类有ObjectInputStream和ObjectOutputStream,本身这两个方法没什么,但是其要写出的对象有要求,该对象必须实现Serializable接口,来声明其是可以序列化的。否则,不能用对象流读写。
还有一个关键字比较重要,transient,由于修饰实现了Serializable接口的类内的属性,被该修饰符修饰的属性,在以对象流的方式输出的时候,该字段会被忽略。
posted @
2015-07-16 11:36 xzc 阅读(380) |
评论 (0) |
编辑 收藏Hive:
利用squirrel-sql 连接hive
add driver -> name&example url(jdbc:hive2://xxx:10000)->extra class path ->Add
{hive/lib/hive-common-*.jar
hive/lib/hive-contrib-*.jar
hive/lib/hive-jdbc-*.jar
hive/lib/libthrift-*.jar
hive/lib/hive-service-*.jar
hive/lib/httpclient-*.jar
hive/lib/httpcore-*.jar
hadoop/share/hadoop/common/hadoop-common--*.jar
hadoop/share/hadoop/common/lib/common-configuration-*.jar
hadoop/share/hadoop/common/lib/log4j-*.jar
hadoop/share/hadoop/common/lib/slf4j-api-*.jar
hadoop/share/hadoop/common/lib/slf4j-log4j-*.jar}
->List Drivers(wait ..then class name will auto set org.apache.hive.jdbc/HiveDriver)->OK->Add aliases ->chose the hive driver->done
Hive数据迁移
1.导出表
EXPORT TABLE <table_name> TO 'path/to/hdfs';
2.复制数据到另一个hdfs
hadoop distcp hdfs://:8020/path/to/hdfs hdfs:///path/to/hdfs
3.导入表
IMPORT TABLE <table_name> FROM 'path/to/another/hdfs';
Hive 输出查询结果到文件
输出到本地文件:
insert overwrite local directory './test-04'
row format delimited
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
select * from src;
输出到hdfs:
输出到hdfs好像不支持 row format,只能另辟蹊径了
INSERT OVERWRITE DIRECTORY '/outputable.txt'
select concat(col1, ',', col2, ',', col3) from myoutputtable;
当然默认的分隔符是\001
若要直接对文件进行操作课直接用stdin的形式
eg. hadoop fs -cat ../000000_0 |python doSomeThing.py
#!/usr/bin/env python
import sys
for line in sys.stdin:
(a,b,c)=line.strip().split('\001')
Hive 语法:
hive好像不支持select dicstinct col1 as col1 from table group by col1
需要用grouping sets
select col1 as col1 from table group by col1 grouping sets((col1))
Beeline:
文档:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
利用jdbc连接hive:
hive2='JAVA_HOME=/opt/java7 HADOOP_HOME=/opt/hadoop /opt/hive/bin/beeline -u jdbc:hive2://n1.hd2.host.dxy:10000 -n hadoop -p fake -d org.apache.hive.jdbc.HiveDriver --color=true --silent=false --fastConnect=false --verbose=true'
beeline利用jdbc连接hive若需要执行多条命令使用
hive2 -e "xxx" -e "yyy" -e...
posted @
2015-06-13 16:48 xzc 阅读(3437) |
评论 (0) |
编辑 收藏posted @
2015-04-28 11:48 xzc 阅读(255) |
评论 (0) |
编辑 收藏
show tables like '*name*';
2.查看表结构信息
desc formatted table_name;
desc table_name;
3.查看分区信息
show partitions table_name;
4.根据分区查询数据
select table_coulm from table_name where partition_name = '2014-02-25';
5.查看hdfs文件信息
dfs -ls /user/hive/warehouse/table02;
6.从文件加载数据进表(OVERWRITE覆盖,追加不需要OVERWRITE关键字)
LOAD DATA LOCAL INPATH 'dim_csl_rule_config.txt' OVERWRITE into table dim.dim_csl_rule_config;
--从查询语句给table插入数据
INSERT OVERWRITE TABLE test_h02_click_log PARTITION(dt) select *
from stage.s_h02_click_log where dt='2014-01-22' limit 100;
7.导出数据到文件
insert overwrite directory '/tmp/csl_rule_cfg' select a.* from dim.dim_csl_rule_config a;
hive -e "select day_id,pv,uv,ip_count,click_next_count,second_bounce_rate,return_visit,pg_type from tmp.tmp_h02_click_log_baitiao_ag_sum where day_id in ('2014-03-06','2014-03-07','2014-03-08','2014-03-09','2014-03-10');"> /home/jrjt/testan/baitiao.dat;
8.自定义udf函数
1.继承UDF类
2.重写evaluate方法
3.把项目打成jar包
4.hive中执行命令add jar /home/jrjt/dwetl/PUB/UDF/udf/GetProperty.jar;
5.创建函数create temporary function get_pro as 'jd.Get_Property'//jd.jd.Get_Property为类路径;
9.查询显示列名 及 行转列显示
set hive.cli.print.header=true; // 打印列名
set hive.cli.print.row.to.vertical=true; // 开启行转列功能, 前提必须开启打印列名功能
set hive.cli.print.row.to.vertical.num=1; // 设置每行显示的列数
10.查看表文件大小,下载文件到某个目录,显示多少行到某个文件
dfs -du hdfs://BJYZH3-HD-JRJT-4137.jd.com:54310/user/jrjt/warehouse/stage.db/s_h02_click_log;
dfs -get /user/jrjt/warehouse/ods.db/o_h02_click_log_i_new/dt=2014-01-21/000212_0 /home/jrjt/testan/;
head -n 1000 文件名 > 文件名
11.杀死某个任务 不在hive shell中执行
hadoop job -kill job_201403041453_58315
12.hive-wui路径
http://172.17.41.38/jobtracker.jsp
13.删除分区
alter table tmp_h02_click_log_baitiao drop partition(dt='2014-03-01');
alter table d_h02_click_log_basic_d_fact drop partition(dt='2014-01-17');
14.hive命令行操作
执行一个查询,在终端上显示mapreduce的进度,执行完毕后,最后把查询结果输出到终端上,接着hive进程退出,不会进入交互模式。
hive -e 'select table_cloum from table'
-S,终端上的输出不会有mapreduce的进度,执行完毕,只会把查询结果输出到终端上。这个静音模式很实用,,通过第三方程序调用,第三方程序通过hive的标准输出获取结果集。
hive -S -e 'select table_cloum from table'
执行sql文件
hive -f hive_sql.sql
15.hive上操作hadoop文件基本命令
查看文件大小
dfs -du /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-15;
删除文件
dfs -rm /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-15;
16.插入数据sql、导出数据sql
1.insert 语法格式为:
基本的插入语法:
INSERT OVERWRITE TABLE tablename [PARTITON(partcol1=val1,partclo2=val2)]select_statement FROM from_statement
insert overwrite table test_insert select * from test_table;
对多个表进行插入操作:
FROM fromstatte
INSERT OVERWRITE TABLE tablename1 [PARTITON(partcol1=val1,partclo2=val2)]select_statement1
INSERT OVERWRITE TABLE tablename2 [PARTITON(partcol1=val1,partclo2=val2)]select_statement2
from test_table
insert overwrite table test_insert1
select key
insert overwrite table test_insert2
select value;
insert的时候,from子句即可以放在select 子句后面,也可以放在 insert子句前面。
hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。
2.通过查询将数据保存到filesystem
INSERT OVERWRITE [LOCAL] DIRECTORY directory SELECT.... FROM .....
导入数据到本地目录:
insert overwrite local directory '/home/zhangxin/hive' select * from test_insert1;
产生的文件会覆盖指定目录中的其他文件,即将目录中已经存在的文件进行删除。
导出数据到HDFS中:
insert overwrite directory '/user/zhangxin/export_test' select value from test_table;
同一个查询结果可以同时插入到多个表或者多个目录中:
from test_insert1
insert overwrite local directory '/home/zhangxin/hive' select *
insert overwrite directory '/user/zhangxin/export_test' select value;
17.mapjoin的使用 应用场景:1.关联操作中有一张表非常小 2.不等值的链接操作
select /*+ mapjoin(A)*/ f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802)
18.perl启动任务
perl /home/jrjt/dwetl/APP/APP/A_H02_CLICK_LOG_CREDIT_USER/bin/a_h02_click_log_credit_user.pl
APP_A_H02_CLICK_LOG_CREDIT_USER_20140215.dir >& /home/jrjt/dwetl/LOG/APP/20140306/a_h02_click_log_credit_user.pl.4.log
19.查看perl进程
ps -ef|grep perl
20.hive命令移动表数据到另外一张表目录下并添加分区
dfs -cp /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-18 /user/jrjt/warehouse/ods.db/o_h02_click_log/;
dfs -cp /user/jrjt/warehouse/tmp.db/tmp_h02_click_log_baitiao/* /user/jrjt/warehouse/dw.db/d_h02_click_log_baitiao_basic_d_fact/;--复制所有分区数据
alter table d_h02_click_log_baitiao_basic_d_fact add partition(dt='2014-03-11') location '/user/jrjt/warehouse/dw.db/d_h02_click_log_baitiao_basic_d_fact/dt=2014-03-11';
21.导出白条数据
hive -e "select day_id,pv,uv,ip_count,click_next_count,second_bounce_rate,return_visit,pg_type from tmp.tmp_h02_click_log_baitiao_ag_sum where day_id like '2014-03%';"> /home/jrjt/testan/baitiao.xlsx;
22.hive修改表名
ALTER TABLE o_h02_click_log_i RENAME TO o_h02_click_log_i_bk;
23.hive复制表结构
CREATE TABLE d_h02_click_log_baitiao_ag_sum LIKE tmp.tmp_h02_click_log_baitiao_ag_sum;
24.hive官网网址
https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-InstallationandConfiguration
http://www.360doc.com/content/12/0111/11/7362_178698714.shtml
25.hive添加字段
alter table tmp_h02_click_log_baitiao_ag_sum add columns(current_session_timelenth_count bigint comment '页面停留总时长');
ALTER TABLE tmp_h02_click_log_baitiao CHANGE current_session_timelenth current_session_timelenth bigint comment '当前会话停留时间';
26.hive开启简单模式不启用mr
set hive.fetch.task.conversion=more;
27.以json格式输出执行语句会读取的input table和input partition信息
Explain dependency query
posted @
2015-02-13 15:20 xzc 阅读(362) |
评论 (0) |
编辑 收藏转自:http://www.aboutyun.com/forum.php?mod=viewthread&tid=8590&highlight=hive
问题导读:
1.如何查看hive表结构?
2.如何查看表结构信息?
3.如何查看分区信息?
4.哪个命令可以模糊搜索表
1.hive模糊搜索表
show tables like '*name*';
2.查看表结构信息
desc formatted table_name;
desc table_name;
3.查看分区信息
show partitions table_name;
4.根据分区查询数据
select table_coulm from table_name where partition_name = '2014-02-25';
5.查看hdfs文件信息
dfs -ls /user/hive/warehouse/table02;
6.从文件加载数据进表(OVERWRITE覆盖,追加不需要OVERWRITE关键字)
LOAD DATA LOCAL INPATH 'dim_csl_rule_config.txt' OVERWRITE into table dim.dim_csl_rule_config;
--从查询语句给table插入数据
INSERT OVERWRITE TABLE test_h02_click_log PARTITION(dt) select *
from stage.s_h02_click_log where dt='2014-01-22' limit 100;
7.导出数据到文件
insert overwrite directory '/tmp/csl_rule_cfg' select a.* from dim.dim_csl_rule_config a;
hive -e "select day_id,pv,uv,ip_count,click_next_count,second_bounce_rate,return_visit,pg_type from tmp.tmp_h02_click_log_baitiao_ag_sum where day_id in ('2014-03-06','2014-03-07','2014-03-08','2014-03-09','2014-03-10');"> /home/jrjt/testan/baitiao.dat;
8.自定义udf函数
1.继承UDF类
2.重写evaluate方法
3.把项目打成jar包
4.hive中执行命令add jar /home/jrjt/dwetl/PUB/UDF/udf/GetProperty.jar;
5.创建函数create temporary function get_pro as 'jd.Get_Property'//jd.jd.Get_Property为类路径;
9.查询显示列名 及 行转列显示
set hive.cli.print.header=true; // 打印列名
set hive.cli.print.row.to.vertical=true; // 开启行转列功能, 前提必须开启打印列名功能
set hive.cli.print.row.to.vertical.num=1; // 设置每行显示的列数
10.查看表文件大小,下载文件到某个目录,显示多少行到某个文件
dfs -du hdfs://BJYZH3-HD-JRJT-4137.jd.com:54310/user/jrjt/warehouse/stage.db/s_h02_click_log;
dfs -get /user/jrjt/warehouse/ods.db/o_h02_click_log_i_new/dt=2014-01-21/000212_0 /home/jrjt/testan/;
head -n 1000 文件名 > 文件名
11.杀死某个任务 不在hive shell中执行
hadoop job -kill job_201403041453_58315
12.hive-wui路径
http://172.17.41.38/jobtracker.jsp
13.删除分区
alter table tmp_h02_click_log_baitiao drop partition(dt='2014-03-01');
alter table d_h02_click_log_basic_d_fact drop partition(dt='2014-01-17');
14.hive命令行操作
执行一个查询,在终端上显示mapreduce的进度,执行完毕后,最后把查询结果输出到终端上,接着hive进程退出,不会进入交互模式。
hive -e 'select table_cloum from table'
-S,终端上的输出不会有mapreduce的进度,执行完毕,只会把查询结果输出到终端上。这个静音模式很实用,,通过第三方程序调用,第三方程序通过hive的标准输出获取结果集。
hive -S -e 'select table_cloum from table'
执行sql文件
hive -f hive_sql.sql
15.hive上操作hadoop文件基本命令
查看文件大小
dfs -du /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-15;
删除文件
dfs -rm /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-15;
16.插入数据sql、导出数据sql
1.insert 语法格式为:
基本的插入语法:
INSERT OVERWRITE TABLE tablename [PARTITON(partcol1=val1,partclo2=val2)]select_statement FROM from_statement
insert overwrite table test_insert select * from test_table;
对多个表进行插入操作:
FROM fromstatte
INSERT OVERWRITE TABLE tablename1 [PARTITON(partcol1=val1,partclo2=val2)]select_statement1
INSERT OVERWRITE TABLE tablename2 [PARTITON(partcol1=val1,partclo2=val2)]select_statement2
from test_table
insert overwrite table test_insert1
select key
insert overwrite table test_insert2
select value;
insert的时候,from子句即可以放在select 子句后面,也可以放在 insert子句前面。
hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。
2.通过查询将数据保存到filesystem
INSERT OVERWRITE [LOCAL] DIRECTORY directory SELECT.... FROM .....
导入数据到本地目录:
insert overwrite local directory '/home/zhangxin/hive' select * from test_insert1;
产生的文件会覆盖指定目录中的其他文件,即将目录中已经存在的文件进行删除。
导出数据到HDFS中:
insert overwrite directory '/user/zhangxin/export_test' select value from test_table;
同一个查询结果可以同时插入到多个表或者多个目录中:
from test_insert1
insert overwrite local directory '/home/zhangxin/hive' select *
insert overwrite directory '/user/zhangxin/export_test' select value;
17.mapjoin的使用 应用场景:1.关联操作中有一张表非常小 2.不等值的链接操作
select /*+ mapjoin(A)*/ f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802)
18.perl启动任务
perl /home/jrjt/dwetl/APP/APP/A_H02_CLICK_LOG_CREDIT_USER/bin/a_h02_click_log_credit_user.pl
APP_A_H02_CLICK_LOG_CREDIT_USER_20140215.dir >& /home/jrjt/dwetl/LOG/APP/20140306/a_h02_click_log_credit_user.pl.4.log
19.查看perl进程
ps -ef|grep perl
20.hive命令移动表数据到另外一张表目录下并添加分区
dfs -cp /user/jrjt/warehouse/tmp.db/tmp_h02_click_log/dt=2014-02-18 /user/jrjt/warehouse/ods.db/o_h02_click_log/;
dfs -cp /user/jrjt/warehouse/tmp.db/tmp_h02_click_log_baitiao/* /user/jrjt/warehouse/dw.db/d_h02_click_log_baitiao_basic_d_fact/;--复制所有分区数据
alter table d_h02_click_log_baitiao_basic_d_fact add partition(dt='2014-03-11') location '/user/jrjt/warehouse/dw.db/d_h02_click_log_baitiao_basic_d_fact/dt=2014-03-11';
21.导出白条数据
hive -e "select day_id,pv,uv,ip_count,click_next_count,second_bounce_rate,return_visit,pg_type from tmp.tmp_h02_click_log_baitiao_ag_sum where day_id like '2014-03%';"> /home/jrjt/testan/baitiao.xlsx;
22.hive修改表名
ALTER TABLE o_h02_click_log_i RENAME TO o_h02_click_log_i_bk;
23.hive复制表结构
CREATE TABLE d_h02_click_log_baitiao_ag_sum LIKE tmp.tmp_h02_click_log_baitiao_ag_sum;
24.hive官网网址
https://cwiki.apache.org/conflue ... ionandConfiguration
http://www.360doc.com/content/12/0111/11/7362_178698714.shtml
25.hive添加字段
alter table tmp_h02_click_log_baitiao_ag_sum add columns(current_session_timelenth_count bigint comment '页面停留总时长');
ALTER TABLE tmp_h02_click_log_baitiao CHANGE current_session_timelenth current_session_timelenth bigint comment '当前会话停留时间';
26.hive开启简单模式不启用mr
set hive.fetch.task.conversion=more;
27.以json格式输出执行语句会读取的input table和input partition信息
Explain dependency query
posted @
2015-02-13 15:19 xzc 阅读(3915) |
评论 (0) |
编辑 收藏posted @
2015-02-09 10:52 xzc 阅读(660) |
评论 (0) |
编辑 收藏 JAVA 命令参数详解:
1、-D<name>=<value> set a system property 设置系统属性。
java命令引入jar时可以-cp参数,但时-cp不能用通配符(多个jar时什么烦要一个个写,不能*.jar),面通常的jar都在同一目录,且多于1个。前些日子找到(发现)-Djava.ext.dirs太好。
如:
java -Djava.ext.dirs=lib MyClass
可以在运行前配置一些属性,比如路径什么的。
java -Dconfig="d:/config/config.xml" Abc
这样在Abc中就可以通过System.getProperty("config");获得这个值了。
在虚拟机的系统属性中设置属性名/值对,运行在此虚拟机之上的应用程序可用
当虚拟机报告类找不到或类冲突时可用此参数来诊断来查看虚拟机从装入类的情况。
另外,javac -d <目录> 指定存放生成的类文件的位置
Standard System Properties
| Key | Meaning |
"file.separator" | Character that separates components of a file path. This is "/" on UNIX and "\" on Windows. |
"java.class.path" | Path used to find directories and JAR archives containing class files. Elements of the class path are separated by a platform-specific character specified in the path.separator property. |
"java.home" | Installation directory for Java Runtime Environment (JRE) |
"java.vendor" | JRE vendor name |
"java.vendor.url" | JRE vender URL |
"java.version" | JRE version number |
"line.separator" | Sequence used by operating system to separate lines in text files |
"os.arch" | Operating system architecture |
"os.name" | Operating system name |
"os.version" | Operating system version |
"path.separator" | Path separator character used in java.class.path |
"user.dir" | User working directory |
"user.home" | User home directory |
"user.name" | User account name |
所谓的 system porperty,system 指的是 JRE (runtime)system,不是指 OS。
System.setProperty("net.jxta.tls.principal", "client");
System.setProperty("net.jxta.tls.password", "password");
System.setProperty("JXTA_HOME",System.getProperty("JXTA_HOME","client"));
可以利用系统属性来加载多个驱动
posted @
2015-01-21 10:09 xzc 阅读(870) |
评论 (0) |
编辑 收藏在linux系统下进程遇到查看文件的权限、修改文件的权限以及修改文件的所有者等操作,主要涉及到chmod、chgrp、chown三个命令。本文简单讲述下这三个命令的使用。
- chgrp 修改文件所属组
- chown 修改文件所有者
- chmod 修改文件属性
一、chgrp 使用说明
用法:chgrp [-cfhRv][--help][--version][所属群组][文件或目录...]
或者:chgrp [-cfhRv][--help][--reference=参考文件或目录][--version][文件或目录...]
参数[-R] 用于整个目录下递归
参数[-h] 有且只有改变符号连接的用户组
参数[-c]与[-v]类似,但是v表示无论如何也要显示结果,c表示只有更改组之后才显示结果
实例:chgrp [-R] test test.txt
表示把test.txt文件的群组修改成test
二、chown 使用说明
用法:chown [选项]... 所有者[:[组]] 文件...
或:chown [选项]... :组 文件...
或:chown [选项]... --reference=参考文件 文件...
chown [-cfhvR] [--help] [--version] user[:group] file...
<参数>[-cfvR] 类似上面的chgrp的用法
范例
chown test:users test.txt
将档案 test.txt 的拥有者设为 users 群的使用者 test
chown -R test:users *
将目前目录下的所有档案与子目录的拥有者皆设为 users 群体的使用者 test
chgrp和chown 的都是转移文件属主 但是chown只能在同一个用户组里面转换而chgrp可以转移到不同的用户组
三、chmod 使用说明
用法:chmod [选项]... 模式[,模式]... 文件...
或:chmod [选项]... 八进制模式 文件...
或:chmod [选项]... --reference=参考文件 文件...
<模式>由三部份组成:一个或以上的 ugoa 字母,一个或以上的 +-= 符号,
和一个或以上的 rwxXstugo 字母。
<参数>[-cfvR] 类似上面的chgrp的用法
具体比如 chmod [-R] u/g/o/a +/-/= rwx 檔案或目錄
【u/g/o/a】说明
- u:user表示该档案的拥有者
- g:group表示与该档案的拥有者属于同一个群体(group)者
- o:other表示其他以外的人
- a:all表示这三者皆是
【+-=】说明
【rwx】说明
- r:read表示可读取
- w:write表示可写入
- x:excute表示可执行
- X 表示只有当该档案是个子目录或者该档案已经被设定过为可执行
当然rwx这些权限也可以用数字来代替
r:4 w:2 x:1 -:0
比如执行:chmod u=rwx,g=rx,o=r filename
就等同于: chmod u=7,g=5,o=4 filename
范例:
chmod o-r test.txt
表示给其他人撤销test.txt这个文件的读权限
chmod -R a+r *
将目前目录下的所有档案与子目录皆设为任何人可读取
chmod ug+w,o-w test1.txt test2.txt
将档案 test1.txt 与 test2.txt 设为该档案拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入
chmod ug=rwx,o=x file 效果等同于 chmod 771 file
chmod a=rwx file 效果等同于 chmod 777 file
posted @
2015-01-20 11:33 xzc 阅读(246) |
评论 (0) |
编辑 收藏posted @
2015-01-15 19:57 xzc 阅读(389) |
评论 (3) |
编辑 收藏本文总结了Linux添加或者删除用户和用户组时常用的一些命令和参数。
1、建用户:
adduser phpq //新建phpq用户
passwd phpq //给phpq用户设置密码
2、建工作组
groupadd test //新建test工作组
3、新建用户同时增加工作组
useradd -g test phpq //新建phpq用户并增加到test工作组
注::-g 所属组 -d 家目录 -s 所用的SHELL
4、给已有的用户增加工作组
usermod -G groupname username
或者:gpasswd -a user group
5、临时关闭:在/etc/shadow文件中属于该用户的行的第二个字段(密码)前面加上*就可以了。想恢复该用户,去掉*即可。
或者使用如下命令关闭用户账号:
passwd peter –l
重新释放:
passwd peter –u
6、永久性删除用户账号
userdel peter
groupdel peter
usermod –G peter peter (强制删除该用户的主目录和主目录下的所有文件和子目录)
7、从组中删除用户
编辑/etc/group 找到GROUP1那一行,删除 A
或者用命令
gpasswd -d A GROUP
8、显示用户信息
id user
cat /etc/passwd
更详细的用户和用户组的解说请参考
Linux 用户和用户组详细解说
本文主要讲述在Linux 系统中用户(user)和用户组(group)管理相应的概念;用户(user)和用户组(group)相关命令的列举;其中也对单用户多任务,多用户多任务也做以解说。
本篇文章来源于 PHP资讯 原文链接:http://www.phpq.net/linux/linux-add-delete-user-group.html
Linux 用户(user)和用户组(group)管理概述
、理解Linux的单用户多任务,多用户多任务概念;
Linux 是一个多用户、多任务的操作系统;我们应该了解单用户多任务和多用户多任务的概念;
1、Linux 的单用户多任务;
单用户多任务;比如我们以beinan 登录系统,进入系统后,我要打开gedit 来写文档,但在写文档的过程中,我感觉少点音乐,所以又打开xmms 来点音乐;当然听点音乐还不行,MSN 还得打开,想知道几个弟兄现在正在做什么,这样一样,我在用beinan 用户登录时,执行了gedit 、xmms以及msn等,当然还有输入法fcitx ;这样说来就有点简单了,一个beinan用户,为了完成工作,执行了几个任务;当然beinan这个用户,其它的人还能以远程登录过来,也能做其它的工作。
2、Linux 的多用户、多任务;
有时可能是很多用户同时用同一个系统,但并不所有的用户都一定都要做同一件事,所以这就有多用户多任务之说;
举个例子,比如LinuxSir.Org 服务器,上面有FTP 用户、系统管理员、web 用户、常规普通用户等,在同一时刻,可能有的弟兄正在访问论坛;有的可能在上传软件包管理子站,比如luma 或Yuking 兄在管理他们的主页系统和FTP ;在与此同时,可能还会有系统管理员在维护系统;浏览主页的用的是nobody 用户,大家都用同一个,而上传软件包用的是FTP用户;管理员的对系统的维护或查看,可能用的是普通帐号或超级权限root帐号;不同用户所具有的权限也不同,要完成不同的任务得需要不同的用户,也可以说不同的用户,可能完成的工作也不一样;
值得注意的是:多用户多任务并不是大家同时挤到一接在一台机器的的键盘和显示器前来操作机器,多用户可能通过远程登录来进行,比如对服务器的远程控制,只要有用户权限任何人都是可以上去操作或访问的;
3、用户的角色区分;
用户在系统中是分角色的,在Linux 系统中,由于角色不同,权限和所完成的任务也不同;值得注意的是用户的角色是通过UID和识别的,特别是UID;在系统管理中,系统管理员一定要坚守UID 唯一的特性;
root 用户:系统唯一,是真实的,可以登录系统,可以操作系统任何文件和命令,拥有最高权限;
虚拟用户:这类用户也被称之为伪用户或假用户,与真实用户区分开来,这类用户不具有登录系统的能力,但却是系统运行不可缺少的用户,比如bin、daemon、adm、ftp、mail等;这类用户都系统自身拥有的,而非后来添加的,当然我们也可以添加虚拟用户;
普通真实用户:这类用户能登录系统,但只能操作自己家目录的内容;权限有限;这类用户都是系统管理员自行添加的;
4、多用户操作系统的安全;
多用户系统从事实来说对系统管理更为方便。从安全角度来说,多用户管理的系统更为安全,比如beinan用户下的某个文件不想让其它用户看到,只是设置一下文件的权限,只有beinan一个用户可读可写可编辑就行了,这样一来只有beinan一个用户可以对其私有文件进行操作,Linux 在多用户下表现最佳,Linux能很好的保护每个用户的安全,但我们也得学会Linux 才是,再安全的系统,如果没有安全意识的管理员或管理技术,这样的系统也不是安全的。
从服务器角度来说,多用户的下的系统安全性也是最为重要的,我们常用的Windows 操作系统,它在系纺权限管理的能力只能说是一般般,根本没有没有办法和Linux或Unix 类系统相比;
二、用户(user)和用户组(group)概念;
1、用户(user)的概念;
通过前面对Linux 多用户的理解,我们明白Linux 是真正意义上的多用户操作系统,所以我们能在Linux系统中建若干用户(user)。比如我们的同事想用我的计算机,但我不想让他用我的用户名登录,因为我的用户名下有不想让别人看到的资料和信息(也就是隐私内容)这时我就可以给他建一个新的用户名,让他用我所开的用户名去折腾,这从计算机安全角度来说是符合操作规则的;
当然用户(user)的概念理解还不仅仅于此,在Linux系统中还有一些用户是用来完成特定任务的,比如nobody和ftp 等,我们访问LinuxSir.Org 的网页程序,就是nobody用户;我们匿名访问ftp 时,会用到用户ftp或nobody ;如果您想了解Linux系统的一些帐号,请查看 /etc/passwd ;
2、用户组(group)的概念;
用户组(group)就是具有相同特征的用户(user)的集合体;比如有时我们要让多个用户具有相同的权限,比如查看、修改某一文件或执行某个命令,这时我们需要用户组,我们把用户都定义到同一用户组,我们通过修改文件或目录的权限,让用户组具有一定的操作权限,这样用户组下的用户对该文件或目录都具有相同的权限,这是我们通过定义组和修改文件的权限来实现的;
举例:我们为了让一些用户有权限查看某一文档,比如是一个时间表,而编写时间表的人要具有读写执行的权限,我们想让一些用户知道这个时间表的内容,而不让他们修改,所以我们可以把这些用户都划到一个组,然后来修改这个文件的权限,让用户组可读,这样用户组下面的每个用户都是可读的;
用户和用户组的对应关系是:一对一、多对一、一对多或多对多;
一对一:某个用户可以是某个组的唯一成员;
多对一:多个用户可以是某个唯一的组的成员,不归属其它用户组;比如beinan和linuxsir两个用户只归属于beinan用户组;
一对多:某个用户可以是多个用户组的成员;比如beinan可以是root组成员,也可以是linuxsir用户组成员,还可以是adm用户组成员;
多对多:多个用户对应多个用户组,并且几个用户可以是归属相同的组;其实多对多的关系是前面三条的扩展;理解了上面的三条,这条也能理解;
三、用户(user)和用户组(group)相关的配置文件、命令或目录;
1、与用户(user)和用户组(group)相关的配置文件;
1)与用户(user)相关的配置文件;
/etc/passwd 注:用户(user)的配置文件;
/etc/shadow 注:用户(user)影子口令文件;
2)与用户组(group)相关的配置文件;
/etc/group 注:用户组(group)配置文件;
/etc/gshadow 注:用户组(group)的影子文件;
2、管理用户(user)和用户组(group)的相关工具或命令;
1)管理用户(user)的工具或命令;
useradd 注:添加用户
adduser 注:添加用户
passwd 注:为用户设置密码
usermod 注:修改用户命令,可以通过usermod 来修改登录名、用户的家目录等等;
pwcov 注:同步用户从/etc/passwd 到/etc/shadow
pwck 注:pwck是校验用户配置文件/etc/passwd 和/etc/shadow 文件内容是否合法或完整;
pwunconv 注:是pwcov 的立逆向操作,是从/etc/shadow和 /etc/passwd 创建/etc/passwd ,然后会删除 /etc/shadow 文件;
finger 注:查看用户信息工具
id 注:查看用户的UID、GID及所归属的用户组
chfn 注:更改用户信息工具
su 注:用户切换工具
sudo 注:sudo 是通过另一个用户来执行命令(execute a command as another user),su 是用来切换用户,然后通过切换到的用户来完成相应的任务,但sudo 能后面直接执行命令,比如sudo 不需要root 密码就可以执行root 赋与的执行只有root才能执行相应的命令;但得通过visudo 来编辑/etc/sudoers来实现;
visudo 注:visodo 是编辑 /etc/sudoers 的命令;也可以不用这个命令,直接用vi 来编辑 /etc/sudoers 的效果是一样的;
sudoedit 注:和sudo 功能差不多;
2)管理用户组(group)的工具或命令;
groupadd 注:添加用户组;
groupdel 注:删除用户组;
groupmod 注:修改用户组信息
groups 注:显示用户所属的用户组
grpck
grpconv 注:通过/etc/group和/etc/gshadow 的文件内容来同步或创建/etc/gshadow ,如果/etc/gshadow 不存在则创建;
grpunconv 注:通过/etc/group 和/etc/gshadow 文件内容来同步或创建/etc/group ,然后删除gshadow文件;
3、/etc/skel 目录;
/etc/skel目录一般是存放用户启动文件的目录,这个目录是由root权限控制,当我们添加用户时,这个目录下的文件自动复制到新添加的用户的家目录下;/etc/skel 目录下的文件都是隐藏文件,也就是类似.file格式的;我们可通过修改、添加、删除/etc/skel目录下的文件,来为用户提供一个统一、标准的、默认的用户环境;
[root@localhost beinan]# ls -la /etc/skel/
总用量 92
drwxr-xr-x 3 root root 4096 8月 11 23:32 .
drwxr-xr-x 115 root root 12288 10月 14 13:44 ..
-rw-r--r-- 1 root root 24 5月 11 00:15 .bash_logout
-rw-r--r-- 1 root root 191 5月 11 00:15 .bash_profile
-rw-r--r-- 1 root root 124 5月 11 00:15 .bashrc
-rw-r--r-- 1 root root 5619 2005-03-08 .canna
-rw-r--r-- 1 root root 438 5月 18 15:23 .emacs
-rw-r--r-- 1 root root 120 5月 23 05:18 .gtkrc
drwxr-xr-x 3 root root 4096 8月 11 23:16 .kde
-rw-r--r-- 1 root root 658 2005-01-17 .zshrc
/etc/skel 目录下的文件,一般是我们用useradd 和adduser 命令添加用户(user)时,系统自动复制到新添加用户(user)的家目录下;如果我们通过修改 /etc/passwd 来添加用户时,我们可以自己创建用户的家目录,然后把/etc/skel 下的文件复制到用户的家目录下,然后要用chown 来改变新用户家目录的属主;
4、/etc/login.defs 配置文件;
/etc/login.defs 文件是当创建用户时的一些规划,比如创建用户时,是否需要家目录,UID和GID的范围;用户的期限等等,这个文件是可以通过root来定义的;
比如Fedora 的 /etc/logins.defs 文件内容;
# *REQUIRED*
# Directory where mailboxes reside, _or_ name of file, relative to the
# home directory. If you _do_ define both, MAIL_DIR takes precedence.
# QMAIL_DIR is for Qmail
#
#QMAIL_DIR Maildir
MAIL_DIR /var/spool/mail 注:创建用户时,要在目录/var/spool/mail中创建一个用户mail文件;
#MAIL_FILE .mail
# Password aging controls:
#
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_MIN_LEN Minimum acceptable password length.
# PASS_WARN_AGE Number of days warning given before a password expires.
#
PASS_MAX_DAYS 99999 注:用户的密码不过期最多的天数;
PASS_MIN_DAYS 0 注:密码修改之间最小的天数;
PASS_MIN_LEN 5 注:密码最小长度;
PASS_WARN_AGE 7 注:
#
# Min/max values for automatic uid selection in useradd
#
UID_MIN 500 注:最小UID为500 ,也就是说添加用户时,UID 是从500开始的;
UID_MAX 60000 注:最大UID为60000;
#
# Min/max values for automatic gid selection in groupadd
#
GID_MIN 500 注:GID 是从500开始;
GID_MAX 60000
#
# If defined, this command is run when removing a user.
# It should remove any at/cron/print jobs etc. owned by
# the user to be removed (passed as the first argument).
#
#USERDEL_CMD /usr/sbin/userdel_local
#
# If useradd should create home directories for users by default
# On RH systems, we do. This option is ORed with the -m flag on
# useradd command line.
#
CREATE_HOME yes 注:是否创用户家目录,要求创建;
5、/etc/default/useradd 文件;
通过useradd 添加用户时的规则文件;
# useradd defaults file
GROUP=100
HOME=/home 注:把用户的家目录建在/home中;
INACTIVE=-1 注:是否启用帐号过期停权,-1表示不启用;
EXPIRE= 注:帐号终止日期,不设置表示不启用;
SHELL=/bin/bash 注:所用SHELL的类型;
SKEL=/etc/skel 注: 默认添加用户的目录默认文件存放位置;也就是说,当我们用adduser添加用户时,用户家目录下的文件,都是从这个目录中复制过去的;
后记:
关于用户(user)和用户组(group)管理内容大约就是这么多;只要把上面所说的内容了解和掌握,用户(user)和用户组(group)管理就差不多了;由于用户(user)和用户组(group)是和文件及目录权限联系在一起的,所以文件及目录权限的操作也会独立成文来给大家介绍;
摘自 http://fedora.linuxsir.org/main/?q=node/91
posted @
2015-01-09 18:18 xzc 阅读(344) |
评论 (0) |
编辑 收藏posted @
2015-01-06 17:01 xzc 阅读(433) |
评论 (0) |
编辑 收藏posted @
2014-12-29 16:53 xzc 阅读(411) |
评论 (1) |
编辑 收藏posted @
2014-12-08 21:13 xzc 阅读(497) |
评论 (1) |
编辑 收藏hbase(main):001:0> scan '-ROOT-'
ROW COLUMN+CELL
.META.,,1 column=info:regioninfo, timestamp=1340249081981, value={NAME => '.META.,,
1', STARTKEY => '', ENDKEY => '', ENCODED => 1028785192,}
.META.,,1 column=info:server, timestamp=1341304672637, value=Hadoop46:60020
.META.,,1 column=info:serverstartcode, timestamp=1341304672637, value=1341301228326
.META.,,1 column=info:v, timestamp=1340249081981, value=\x00\x00
1 row(s) in 1.3230 seconds
hbase(main):002:0> import java.util.Date
=> Java::JavaUtil::Date
hbase(main):003:0> Date.new(1341304672637).toString()
=> "Tue Jul 03 16:37:52 CST 2012"
hbase(main):004:0> Date.new(1341301228326).toString()
=> "Tue Jul 03 15:40:28 CST 2012"
在shell中,如果有可读日期,能否转成long类型呢?
hbase(main):005:0> import java.text.SimpleDateFormat
=> Java::JavaText::SimpleDateFormat
hbase(main):006:0> import java.text.ParsePosition
=> Java::JavaText::ParsePosition
hbase(main):015:0> SimpleDateFormat.new("yy/MM/dd").parse("12/07/03",ParsePosition.new(0)).getTime()
=> 1341244800000
参考
http://abloz.com/hbase/book.html
posted @
2014-12-01 09:39 xzc 阅读(5126) |
评论 (1) |
编辑 收藏posted @
2014-09-27 12:53 xzc 阅读(2155) |
评论 (0) |
编辑 收藏HBase 为用户提供了一个非常方便的使用方式, 我们称之为“HBase Shell”。
HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建、删除及修改表, 还可以向表中添加数据、列出表中的相关信息等。
备注:写错 HBase Shell 命令时用键盘上的“Delete”进行删除,“Backspace”不起作用。
在启动 HBase 之后,用户可以通过下面的命令进入 HBase Shell 之中,命令如下所示:
hadoop@ubuntu:~$ hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.94.3, r1408904, Wed Nov 14 19:55:11 UTC 2012
hbase(main):001:0>
具体的 HBase Shell 命令如下表 1.1-1 所示:

下面我们将以“一个学生成绩表”的例子来详细介绍常用的 HBase 命令及其使用方法。

这里 grad 对于表来说是一个列,course 对于表来说是一个列族,这个列族由三个列组成 china、math 和 english,当然我们可以根据我们的需要在 course 中建立更多的列族,如computer,physics 等相应的列添加入 course 列族。(备注:列族下面的列也是可以没有名字的。)
1). create 命令
创建一个具有两个列族“grad”和“course”的表“scores”。其中表名、行和列都要用单引号括起来,并以逗号隔开。
hbase(main):012:0> create 'scores', 'name', 'grad', 'course'
2). list 命令
查看当前 HBase 中具有哪些表。
hbase(main):012:0> list
3). describe 命令
查看表“scores”的构造。
hbase(main):012:0> describe 'scores'
4). put 命令
使用 put 命令向表中插入数据,参数分别为表名、行名、列名和值,其中列名前需要列族最为前缀,时间戳由系统自动生成。
格式: put 表名,行名,列名([列族:列名]),值
例子:
a. 加入一行数据,行名称为“xiapi”,列族“grad”的列名为”(空字符串)”,值位 1。
hbase(main):012:0> put 'scores', 'xiapi', 'grad:', '1'
hbase(main):012:0> put 'scores', 'xiapi', 'grad:', '2' --修改操作(update)
b. 给“xiapi”这一行的数据的列族“course”添加一列“<china,97>”。
hbase(main):012:0> put 'scores', 'xiapi', 'course:china', '97'
hbase(main):012:0> put 'scores', 'xiapi', 'course:math', '128'
hbase(main):012:0> put 'scores', 'xiapi', 'course:english', '85'
5). get 命令
a.查看表“scores”中的行“xiapi”的相关数据。
hbase(main):012:0> get 'scores', 'xiapi'
b.查看表“scores”中行“xiapi”列“course :math”的值。
hbase(main):012:0> get 'scores', 'xiapi', 'course :math'
或者
hbase(main):012:0> get 'scores', 'xiapi', {COLUMN=>'course:math'}
hbase(main):012:0> get 'scores', 'xiapi', {COLUMNS=>'course:math'}
备注:COLUMN 和 COLUMNS 是不同的,scan 操作中的 COLUMNS 指定的是表的列族, get操作中的 COLUMN 指定的是特定的列,COLUMNS 的值实质上为“列族:列修饰符”。COLUMN 和 COLUMNS 必须为大写。
6). scan 命令
a. 查看表“scores”中的所有数据。
hbase(main):012:0> scan 'scores'
注意:
scan 命令可以指定 startrow,stoprow 来 scan 多个 row。
例如:
scan 'user_test',{COLUMNS =>'info:username',LIMIT =>10, STARTROW => 'test', STOPROW=>'test2'}
b.查看表“scores”中列族“course”的所有数据。
hbase(main):012:0> scan 'scores', {COLUMN => 'grad'}
hbase(main):012:0> scan 'scores', {COLUMN=>'course:math'}
hbase(main):012:0> scan 'scores', {COLUMNS => 'course'}
hbase(main):012:0> scan 'scores', {COLUMNS => 'course'}
7). count 命令
hbase(main):068:0> count 'scores'
8). exists 命令
hbase(main):071:0> exists 'scores'
9). incr 命令(赋值)
10). delete 命令
删除表“scores”中行为“xiaoxue”, 列族“course”中的“math”。
hbase(main):012:0> delete 'scores', 'xiapi', 'course:math'
11). truncate 命令
hbase(main):012:0> truncate 'scores'
12). disbale、drop 命令
通过“disable”和“drop”命令删除“scores”表。
hbase(main):012:0> disable 'scores' --enable 'scores'
hbase(main):012:0> drop 'scores'
13). status命令
hbase(main):072:0> status
14). version命令
hbase(main):073:0> version
另外,在 shell 中,常量不需要用引号引起来,但二进制的值需要双引号引起来,而其他值则用单引号引起来。HBase Shell 的常量可以通过在 shell 中输入“Object.constants”。
posted @
2014-09-27 11:53 xzc 阅读(975) |
评论 (0) |
编辑 收藏 最近在hadoop实际使用中有以下几个小细节分享: i=m5M��]Ef
1 中文问题
从url中解析出中文,但hadoop中打印出来仍是乱码?我们曾经以为hadoop是不支持中文的,后来经过查看源代码,发现hadoop仅仅是不支持以gbk格式输出中文而己。
这是TextOutputFormat.class中的代码,hadoop默认的输出都是继承自FileOutputFormat来的,FileOutputFormat的两个子类一个是基于二进制流的输出,一个就是基于文本的输出TextOutputFormat。
public class TextOutputFormat<K, V> extends FileOutputFormat<K, V> {
protected static class LineRecordWriter<K, V> &E��{CQ#k
implements RecordWriter<K, V> {
private static final String utf8 = “UTF-8″;//这里被写死成了utf-8 2� kP0/�/
private static final byte[] newline; �k�TC'�`xv
static { ��:�h��tz]
try { �0 _!�')+
newline = “/n”.getBytes(utf8); R�y$zF~[ �
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException(”can’t find ” + utf8 + ” encoding”);
}
}
… k��-:wM`C�
public LineRecordWriter(DataOutputStream out, String keyValueSeparator) {
this.out = out;
try {
this.keyValueSeparator = keyValueSeparator.getBytes(utf8);
} catch (UnsupportedEncodingException uee) { �@r.�w�+E=
throw new IllegalArgumentException(”can’t find ” + utf8 + ” encoding”);
}
} ab�}��Kt($
…
private void writeObject(Object o) throws IOException {
if (o instanceof Text) {
Text to = (Text) o;
out.write(to.getBytes(), 0, to.getLength());//这里也需要修改 q&�D�M*!Jq
} else { �5 O't�-'�
out.write(o.toString().getBytes(utf8));
}
}
… qxQuXF�>:#
} |3bCq(ZR/P
可以看出hadoop默认的输出写死为utf-8,因此如果decode中文正确,那么将Linux客户端的character设为utf-8是可以看到中文的。因为hadoop用utf-8的格式输出了中文。
因为大多数数据库是用gbk来定义字段的,如果想让hadoop用gbk格式输出中文以兼容数据库怎么办? _.{I1*6�Y2
我们可以定义一个新的类: .c5�)�`�
public class GbkOutputFormat<K, V> extends FileOutputFormat<K, V> { sTS �N��u+
protected static class LineRecordWriter<K, V>
implements RecordWriter<K, V> {
//写成gbk即可 F"�ua`ercI
private static final String gbk = “gbk”;
private static final byte[] newline;
static {
try {
newline = “/n”.getBytes(gbk);
} catch (UnsupportedEncodingException uee) { @}�<b���42
throw new IllegalArgumentException(”can’t find ” + gbk + ” encoding”);
}
}
… S�jL&/�),�
public LineRecordWriter(DataOutputStream out, String keyValueSeparator) { P?o|N<4��6
this.out = out; X�-<�l�+WP
try { 0,]m.�)w�s
this.keyValueSeparator = keyValueSeparator.getBytes(gbk); J�s'j��}w�
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException(”can’t find ” + gbk + ” encoding”);
}
} �J|aU}Z�8m
… �/��(&UDG$
private void writeObject(Object o) throws IOException {
if (o instanceof Text) {
// Text to = (Text) o;
// out.write(to.getBytes(), 0, to.getLength()); �+A-z>T(��
// } else { @h,3"2W{Ev
out.write(o.toString().getBytes(gbk));
}
} ��is�U4D�
… �e�L_Il.�:
}
然后在mapreduce代码中加入conf1.setOutputFormat(GbkOutputFormat.class)
即可以gbk格式输出中文。
2 关于计算过程中的压缩和效率的对比问题 h�f//2V�l
之前曾经介绍过对输入文件采用压缩可以提高部分计算效率。现在作更进一步的说明。
为什么压缩会提高计算速度?这是因为mapreduce计算会将数据文件分散拷贝到所有datanode上,压缩可以减少数据浪费在带宽上的时间,当这些时间大于压缩/解压缩本身的时间时,计算速度就会提高了。
hadoop的压缩除了将输入文件进行压缩外,hadoop本身还可以在计算过程中将map输出以及将reduce输出进行压缩。这种计算当中的压缩又有什么样的效果呢?
测试环境:35台节点的hadoop cluster,单机2 CPU,8 core,8G内存,redhat 2.6.9, 其中namenode和second namenode各一台,namenode和second namenode不作datanode
输入文件大小为2.5G不压缩,records约为3600万条。mapreduce程序分为两个job: ��;R]~9Aan
job1:map将record按user字段作key拆分,reduce中作外连接。这样最后reduce输出为87亿records,大小540G
job2:map读入这87亿条数据并输出,reduce进行简单统计,最后的records为2.5亿条,大小16G
计算耗时54min
仅对第二个阶段的map作压缩(第一个阶段的map输出并不大,没有压缩的必要),测试结果:计算耗时39min
可见时间上节约了15min,注意以下参数的不同。 U&W/���Nj
不压缩时:
Local bytes read=1923047905109 :3[;9xC�Hj
Local bytes written=1685607947227 "j8`�)XXa(
压缩时: /U>|^$4 #5
Local bytes read=770579526349 ��|RL/�2j|
Local bytes written=245469534966
本地读写的的数量大大降低了
至于对reduce输出的压缩,很遗憾经过测试基本没有提高速度的效果。可能是因为第一个job的输出大多数是在本地机上进行map,不经过网络传输的原因。
附:对map输出进行压缩,只需要添加 jobConf.setMapOutputCompressorClass(DefaultCodec.class)
3 关于reduce的数量设置问题
reduce数量究竟多少是适合的。目前测试认为reduce数量约等于cluster中datanode的总cores的一半比较合适,比如 cluster中有32台datanode,每台8 core,那么reduce设置为128速度最快。因为每台机器8 core,4个作map,4个作reduce计算,正好合适。 �u�/�(�>a�
附小测试:对同一个程序 j�&[u�$P*K
reduce num=32,reduce time = 6 min
reduce num=128, reduce time = 2 min
reduce num=320, reduce time = 5min
4某次正常运行mapreduce实例时,抛出错误
java.io.IOException: All datanodes xxx.xxx.xxx.xxx:xxx are bad. Aborting…
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream.processDatanodeError(DFSClient.java:2158)
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream.access$1400(DFSClient.java:1735)
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream$DataStreamer.run(DFSClient.java:1889)
java.io.IOException: Could not get block locations. Aborting…
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream.processDatanodeError(DFSClient.java:2143)
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream.access$1400(DFSClient.java:1735)
at org.apache.hadoop.dfs.DFSClient$DFSOutputStream$DataStreamer.run(DFSClient.java:1889)
经查明,问题原因是linux机器打开了过多的文件导致。用命令ulimit -n可以发现linux默认的文件打开数目为1024,修改/ect/security/limit.conf,增加hadoop soft 65535
再重新运行程序(最好所有的datanode都修改),问题解决
P.S:据说hadoop dfs不能管理总数超过100M个文件,有待查证
5 运行一段时间后hadoop不能stop-all.sh的问题,显示报错
no tasktracker to stop ,no datanode to stop
问题的原因是hadoop在stop的时候依据的是datanode上的mapred和dfs进程号。而默认的进程号保存在/tmp下,linux 默认会每隔一段时间(一般是一个月或者7天左右)去删除这个目录下的文件。因此删掉hadoop-hadoop-jobtracker.pid和 hadoop-hadoop-namenode.pid两个文件后,namenode自然就找不到datanode上的这两个进程了。
在配置文件中的export HADOOP_PID_DIR可以解决这个问题
posted @
2013-10-17 17:14 xzc 阅读(4717) |
评论 (0) |
编辑 收藏 linux中用shell获取昨天、明天或多天前的日期:
在Linux中对man date -d 参数说的比较模糊,以下举例进一步说明:
# -d, --date=STRING display time described by STRING, not `now’
[root@Gman root]# date -d next-day +%Y%m%d #明天日期
20091024
[root@Gman root]# date -d last-day +%Y%m%d #昨天日期
20091022
[root@Gman root]# date -d yesterday +%Y%m%d #昨天日期
20091022
[root@Gman root]# date -d tomorrow +%Y%m%d # 明天日期
20091024
[root@Gman root]# date -d last-month +%Y%m #上个月日期
200909
[root@Gman root]# date -d next-month +%Y%m #下个月日期
200911
[root@Gman root]# date -d next-year +%Y #明年日期
2010
DATE=$(date +%Y%m%d --date ’2 days ago’) #获取昨天或多天前的日期
名称 : date
使用权限 : 所有使用者
使用方式 : date [-u] [-d datestr] [-s datestr] [--utc] [--universal] [--date=datestr] [--set=datestr] [--help] [--version] [+FORMAT] [MMDDhhmm[[CC]YY][.ss]]
说明 : date 能用来显示或设定系统的日期和时间,在显示方面,使用者能设定欲显示的格式,格式设定为一个加号后接数个标记,其中可用的标记列表如下 :
时间方面 :
% : 印出
% %n : 下一行
%t : 跳格
%H : 小时(00..23)
%I : 小时(01..12)
%k : 小时(0..23)
%l : 小时(1..12)
%M : 分钟(00..59)
%p : 显示本地 AM 或 PM
%r : 直接显示时间 (12 小时制,格式为 hh:mm:ss [AP]M)
%s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数 %S : 秒(00..61)
%T : 直接显示时间 (24 小时制)
%X : 相当于 %H:%M:%S
%Z : 显示时区
日期方面 :
%a : 星期几 (Sun..Sat)
%A : 星期几 (Sunday..Saturday)
%b : 月份 (Jan..Dec)
%B : 月份 (January..December)
%c : 直接显示日期和时间
%d : 日 (01..31)
%D : 直接显示日期 (mm/dd/yy)
%h : 同 %b
%j : 一年中的第几天 (001..366)
%m : 月份 (01..12)
%U : 一年中的第几周 (00..53) (以 Sunday 为一周的第一天的情形)
%w : 一周中的第几天 (0..6)
%W : 一年中的第几周 (00..53) (以 Monday 为一周的第一天的情形)
%x : 直接显示日期 (mm/dd/yy)
%y : 年份的最后两位数字 (00.99)
%Y : 完整年份 (0000..9999)
若是不以加号作为开头,则表示要设定时间,而时间格式为 MMDDhhmm[[CC]YY][.ss],
其中 MM 为月份,
DD 为日,
hh 为小时,
mm 为分钟,
CC 为年份前两位数字,
YY 为年份后两位数字,
ss 为秒数
把计 :
-d datestr : 显示 datestr 中所设定的时间 (非系统时间)
--help : 显示辅助讯息
-s datestr : 将系统时间设为 datestr 中所设定的时间
-u : 显示目前的格林威治时间
--version : 显示版本编号
例子 :
显示时间后跳行,再显示目前日期 : date +%T%n%D
显示月份和日数 : date +%B %d
显示日期和设定时间(12:34:56) : date --date 12:34:56
设置系统当前时间(12:34:56):date --s 12:34:56
注意 : 当你不希望出现无意义的 0 时(比如说 1999/03/07),则能在标记中插入 - 符号,比如说 date +%-H:%-M:%-S 会把时分秒中无意义的 0 给去掉,像是原本的 08:09:04 会变为 8:9:4。另外,只有取得权限者(比如说 root)才能设定系统时间。 当你以 root 身分更改了系统时间之后,请记得以 clock -w 来将系统时间写入 CMOS 中,这样下次重新开机时系统时间才会持续抱持最新的正确值。
ntp时间同步
linux系统下默认安装了ntp服务,手动进行ntp同步如下
ntpdate ntp1.nl.net
当然,也能指定其他的ntp服务器
-------------------------------------------------------------------
扩展功能
date 工具可以完成更多的工作,不仅仅只是打印出当前的系统日期。您可以使用它来得到给定的日期究竟是星期几,并得到相对于当前日期的相对日期。了解某一天是星期几
GNU 对 date 命令的另一个扩展是 -d 选项,当您的桌上没有日历表时(UNIX 用户不需要日历表),该选项非常有用。使用这个功能强大的选项,通过将日期作为引号括起来的参数提供,您可以快速地查明一个特定的日期究竟是星期几:
$ date -d "nov 22"
Wed Nov 22 00:00:00 EST 2006
$
在本示例中,您可以看到今年的 11 月 22 日是星期三。
所以,假设在 11 月 22 日召开一个重大的会议,您可以立即了解到这一天是星期三,而这一天您将赶到驻地办公室。
获得相对日期
d 选项还可以告诉您,相对于 当前日期若干天的究竟是哪一天,从现在开始的若干天或若干星期以后,或者以前(过去)。通过将这个相对偏移使用引号括起来,作为 -d 选项的参数,就可以完成这项任务。
例如,您需要了解两星期以后的日期。如果您处于 Shell 提示符处,那么可以迅速地得到答案:
$ date -d ’2 weeks’
关于使用该命令,还有其他一些重要的方法。使用 next/last指令,您可以得到以后的星期几是哪一天:
$ date -d ’next monday’ (下周一的日期)
$ date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
$ date -d last-day +%Y%m%d(昨天的日期) 或者:date -d yesterday +%Y%m%d
$ date -d last-month +%Y%m(上个月是几月)
$ date -d next-month +%Y%m(下个月是几月)
使用 ago 指令,您可以得到过去的日期:
$ date -d ’30 days ago’ (30天前的日期)
您可以使用负数以得到相反的日期:
$ date -d ’dec 14 -2 weeks’ (相对:dec 14这个日期的两周前的日期)
$ date -d ’-100 days’ (100天以前的日期)
$ date -d ’50 days’(50天后的日期)
这个技巧非常有用,它可以根据将来的日期为自己设置提醒,可能是在脚本或 Shell 启动文件中,如下所示:
DAY=`date -d ’2 weeks’ +"%b %d"`
if test "`echo $DAY`" = "Aug 16"; then echo ’Product launch is now two weeks away!’; fi
posted @
2013-02-07 12:28 xzc 阅读(5014) |
评论 (0) |
编辑 收藏Sybase 函数
Sybase字符串函数
长度和语法分析
datalength(char_expr)
在char_expr中返回字符的长度值,忽略尾空
substring(expression,start,length)
返回部分字符串
right(char_expr,int_expr)
返回char_expr右边的int_expr字符
基本字符串运算
upper(char_expr)
把char_expr转换成大写形式
lower(char_expr)
把char_expr转换成小写形式
space(int_expr)
生成有int_expr个空格的字符串
replicate(char_expr,int_expr)
重复char_expr,int_expr次
stuff(expr1,start,length,expr2)
用expr2代替epxr1中start起始长为length的字符串
reverse(char_expr)
反写char_expr中的文本
ltrim(char_expr)
删除头空
rtrim(char_expr)
删除尾空
格式转换
ascii(char_expr)
返回char_expr中第一个字符的ASCII值
char(int_expr)
把ASCII码转换为字符
str(float_expr[,length[,decimal]])
进行数值型到字符型转换
soundex(char_expr)
返回char_expr的soundex值
difference(char_expr1,char_expr2)
返回表达式soundex值之差
串内搜索
charindex(char_expr,expression)
返回指定char_expr的开始位置,否则为0
patindex("%pattern%",expression)
返回指定样式的开始位置,否则为0
datalength用于确定可变字符串的长度
soundex用于确定字符串是否发音相似
difference返回0-4之间的值,0表示最不相似,4表示最相似
通配符
% 匹配任何数量的字符或无字符
_ 匹配任何单个字符(空间占位符)
[] 规定有效范围,或某个"OR"条件
[ABG] A,B,G
[A-C] A,B,C
[A-CE-G] A,B,C,E,F,G
[^ABG] 除了A,B,G
[^A-C] 除了A,B,C
escape子句
用某个转义字符可在搜索字符串时将通配符作为文字来包含。
ANSI-89 SQL标准定义了escape子句指定某个转义字符
缺省情况下,[]来转义某个通配符,例:
select * from test_tab
where description like "%20[%]%"
语法:
like char_expression escape escape_character
例
select * from test_tab
where description like "%20#%%" escape "#"
+ 可用于串接字符
select au_laname+","+au_fname from authors
数学函数
abs(numeric_expr)
返回指定值的绝对值
ceiling(numeric_expr)
返回大于或等于指定值的最小整数
exp(float_expr)
给出指定值的指数值
floor(numeric_expr)
返回小于或等于指定值的最大整数
pi()
返回常数3.1415926
power(numeric_expr,power)
返回numeric_expr的值给power的幂
rand([int_expr])
返回0-1之间的随机浮点数,可指定基值
round(numeric_expr,int_expr)
把数值表达式圆整到int_expr指定的精度
sign(int_expr)
返回正+1,零0或负-1
sqrt(float_expr)
返回指定值的平方根
SQL SERVER支持所有标准的三角函数和其他有用的函数
日期函数
getdate()
返回当前的系统日期和时间
datename(datepart,date_expr)
以字符串形式返回date_expr指定部分的值,转换成合适的名字
datepart(datepart,date_expr)
作为整数返回date_expr值的指定部分
datediff(datepart,date_expr1,date_expr2)
返回date_expr2-date_expr1,通过指定的datepart度量
dateadd(datepart,number,date_expr)
返回日期,通过在date_expr上增加指定number的日期部件而产生的
datepart
日期部件 缩写 值范围
年 yy 1753-9999
季度 qq 1-4
月 mm 1-12
每年中的天 dy 1-366
天 dd 1-31
星期 wk 1-54
星期天 dw 1-7(1=sunday)
小时 hh 0-23
分钟 mi 0-59
秒 ss 0-59
毫秒 ms 0-999
例:
select invoice_no,
datediff(dd,date_shipped,getdate())
from invoices
where balance_due>0
转换函数convert
此函数把值从一种类型改变成另一种类型
convert(datetype [(length)],expression)
select "Advance="+convert(char(12),advance)
from titles
日期转换
convert(datetype[(length)],expression,format)
format指定将日期转换为什么格式,有以下值:
没有世纪 有世纪 转换字符串中日期格式
0 or 100 mon dd yyy hh:miAM(or PM)
1 101 mm/dd/yy
2 102 yy.mm.dd
3 103 dd/mm/yy
4 104 dd.mm.yy
5 105 dd-mm-yy
6 106 dd mon yy
7 107 mon dd,yy
8 108 hh:mm:ss
9 or 109 mon dd,yyyy hh:mi:ss:mmmAM(or PM)
10 110 mm-dd-yy
11 111 yy/mm/dd
12 112 yymmdd
系统函数
函数 定义
访问和安全性信息
host_id() 客户进程的当前主机进程ID号
host_name() 客户进程的当前主计算机名
suser_id(["login_name"]) 用户的SQL Server ID号
suser_name([server_user_id]) 用户的SQL Server登录名
user_id(["name_in_db"]) 用户在数据库中的ID号
user_name([user_id]) 用户在数据库中的名字
user 用户在数据库中的名字
show_role() 用户的当前活动角色
数据库和对象信息
db_id(["db_name"]) 数据库ID号
db_name([db_id]) 数据库名
object_id("objname") 数据库对象ID号
object_name(obj_id]) 数据库对象号
col_name(obj_id,col_id) 对象的栏名
col_length("objname","colname") 栏的长度
index_col("objname",index_id,key#) 已索引的栏名
valid_name(char_expr) 若char_expr不是有效标识符,则返回0
数据函数
datalength(expression) 按字节返回expression的长度
tsequal(timestamp1,timestamp2) 比较时戳值,若时戳值不匹配,则返回出错消息
isnull()
isnull函数用指定的值代替查询栏或合计中的空值
例:
select avg(isnull(total_order,$0))
from invoices
posted @
2012-08-21 10:49 xzc 阅读(5170) |
评论 (1) |
编辑 收藏日期函数
getdate()
得到当前时间,可以设置得到各种时间格式.
datepart(日期部分,日期)
取指定时间的某一个部分,年月天时分秒.
datediff(日期部分,日期1,日期2)
计算指定的日期1和日期2的时间差多少.
dateadd(日期部分,数值表达式,日期)
计算指定时间,再加上表达式指定的时间长度.
--取时间的某一个部分
select datepart(yy,getdate()) --year
select datepart(mm,getdate()) --month
select datepart(dd,getdate()) --day
select datepart(hh,getdate()) --hour
select datepart(mi,getdate()) --min
select datepart(ss,getdate()) --sec
--取星期几
set datefirst 1
select datepart(weekday,getdate()) --weekday
--字符串时间
select getdate() -- '03/11/12'
select convert(char,getdate(),101) -- '09/27/2003'
select convert(char,getdate(),102) -- '2003.11.12'
select convert(char,getdate(),103) -- '27/09/2003'
select convert(char,getdate(),104) -- '27.09.2003'
select convert(char,getdate(),105) -- '27-09-2003'
select convert(char,getdate(),106) -- '27 Sep 2003'
select convert(char,getdate(),107) --'Sep 27, 2003'
select convert(char,getdate(),108) --'11:16:06'
select convert(char,getdate(),109) --'Sep 27 2003 11:16:28:746AM'
select convert(char,getdate(),110) --'09-27-2003'
select convert(char,getdate(),111) --'2003/09/27'
select convert(char,getdate(),112) --'20030927'
select rtrim(convert(char,getdate(),102))+' '+(convert(char,getdate(),108)) -- '2003.11.12 11:03:41'
--整数时间
select convert(int,convert(char(10),getdate(),112)) -- 20031112
select datepart(hh,getdate())*10000 + datepart(mi,getdate())*100 + datepart(ss,getdate()) -- 110646
--时间格式 "YYYY.MM.DD HH:MI:SS" 转换为 "YYYYMMDDHHMISS"
declare @a datetime,@tmp varchar(20),@tmp1 varchar(20)
select @a=convert(datetime,'2004.08.03 12:12:12')
select @tmp=convert(char(10),@a,112)
select @tmp
select @tmp1=convert(char(10),datepart(hh,@a)*10000 + datepart(mi,@a)*100 + datepart(ss,@a))
select @tmp1
select @tmp=@tmp+@tmp1
select @tmp
--当月最后一天
declare
@tmpstr varchar(10)
@mm int,
@premm int,
@curmmlastday varchar(10)
begin
select @mm=datepart(month,getdate())--当月
select @premm=datepart(month,dateadd(month,-1,getdate())) --上个月
if (@mm>=1 and @mm<=8)
select @tmpstr=convert(char(4),datepart(year,getdate()))+'.0'+convert(char(1),datepart(month,dateadd(month,1,getdate())))+'.'+'01'
else if (@mm>=9 and @mm<=11)
select @tmpstr=convert(char(4),datepart(year,getdate()))+'.'+convert(char(2),datepart(month,dateadd(month,1,getdate())))+'.'+'01'
else
select @tmpstr=convert(char(4),datepart(year,dateadd(year,1,getdate())))+'.0'+convert(char(1),datepart(month,dateadd(month,1,getdate())))+'.'+'01'
select @curmmlastday=convert(char(10),dateadd(day,-1,@tmpstr),102) --当月最后一天
end
源文档 <http://hi.baidu.com/hwaspf/blog/item/a0ef87be66326e0d18d81f17.html>
posted @
2012-08-21 10:49 xzc 阅读(5056) |
评论 (0) |
编辑 收藏posted @
2012-07-24 13:45 xzc 阅读(4624) |
评论 (0) |
编辑 收藏
心得和大家分享,希望对大家会有帮助。
1、字母大小写比对不敏感,也就是在值比对判断时大小写字母都一样;
2、等值,或<>判断,系统默认对等式两边比对值去右边空格再进行比较;
3、GROUP BY 可以根据SELECT字段或表达式的别名来 汇总,在编写时也尽量避免SELECT 语句的别
名与FROM表中的字段有重复,不然会出现莫名其妙的错误;
4、FROM后的子查询 要定义别名才可使用;
5、存储过程要返回IQ系统错误信息 SQLCODE || ERRORMSG(*) :(两者都为EXCEPTION后第一条SQL
语句才有效果);
6、IQ中若采用 FULL JOIN 连接则不能使用 WHERE 条件,否则FULL JOIN将失效,要筛选条件则用
子查询先过滤记录后再FULL JOIN;
7、建表时,字段默认为非空;
8、UPDATE语句,如果与目标表关联的表有多条,则不会报错,而是随机取一条更新(第一条);
9、RANK() OVER(PARTITION BY .. ORDER BY ..) 分组分析函数,相同的ORDER BY值,返回顺序值
一样,且PARTITION BY 只支持一个字段或一个字段组(需多个字段分组的则要用 || 拼为一个字
段(待确认,该问题以前碰过一次,再次验证却不存在这问题))
10、返回可读的 全局唯一字符:UUIDTOSTR(NEWID())
11、存储过程隐式游标语法:
FOR A AS B CURSOR FOR SELECT ... FROM ...
DO
.... 过程语句
END FOR;
需要注意的时,这边的A 和 B 在 过程语句中都不能引用,所以为避免过程语句其他字段名与FOR
SELECT 语句的字段名称重复,FOR SELECT 语句的字段最好都定义别名区分
12、根据SELECT 语句建立[临时]表的方法(ORACLE的CREATE TABLE)为 SELECT ..[*] INTO [#]
table_name FROM ..; 其中如果在table_name加前缀#,则为会话级临时表,否则为实体表;
13、因Sybase为列存储模式,在执行上INSERT语句会比UPDATE语句慢,尤其表数据越多INSERT效率
就越慢;所以在ETL时建议多用UPDATE而不是INSERT
14、虽说Sybase为列存储模式,每个字段上都有默认索引,但对于经常的两表的关联键还是要建立
索引否则会经常报QUERY_TEMP_SPACE_LIMIT不足的错误;
15、存储过程中也可以显示的执行DDL语句,这点与Oracle不同;
16、空字符串''在Sybase中也是个字符而不是null值,这点要注意;
17、调整SESSION的临时空间SET TEMPORARY OPTION QUERY_TEMP_SPACE_LIMIT = '150000'; 15000
为大小,如写0则没限制大小
==================================常用函数===========================================
字符串函数
1)ISNULL(EXP1,EXP2,EXP3,...) :返回第一个非空值,用法与COALESCE(exp1,exp2[,exp3...])相
同
3)TRIM(exp) :去除两边空格
4)DATEFORMAT(date_exp,date_format) :日期型转字符型;
5)STRING(exp):转为字符型;
6)SUBSTRING(exp,int-exp1,[int-exp2]):截取exp从int-exp1开始,截取int-exp2个字符;
7)REPLACE(o-exp,search-exp,replace-exp):从o-exp搜索search-exp,替换为replace-exp;
8)SPACE(int_exp):返回int个空格;
8)UPPER(exp):转为大写字母,等价于UCASE(exp);
8)LOWER(exp):转为小写字母,
8)CHARINDEX(exp1,exp2):返回exp2字符串中exp1的位置!定位,exp1 查找的字符,exp2 被查找
的字符串;
8)DATALENGTH(CHAR_EXPR):在char_expr中返回字符的长度值,忽略尾空;
8)RIGHT(char_expr,int_expr):返回char_expr右边的int_expr个字符;
8)LEFT(char_expr,int_expr):返回char_expr左边的int_expr个字符;
8)REPLICATE(char_expr,int_expr):重复char_expr,int_expr次;
8)STUFF(expr1,start,length,expr2):用expr2代替epxr1中start起始长为length的字符串;
8)REVERSE(char_expr):反写char_expr中的文本;
8)LTRIM(char_expr):删除头空;
8)RTRIM(char_expr):删除尾空;
8)STR(float_expr[,length[,decimal]]):进行数值型到字符型转换;
8)PATINDEX("%pattern%",expression):返回指定样式的开始位置,否则为0;
8)NULLIF(exp1,exp1):比较两个表达式,如果相等则返回null值,否则返回exp1
8)NUMBER(*):返回序号,相当于ORACLE的rowid,但有区别;
其他函数
8)RANK() OVER(PARTITION BY .. ORDER BY ..) 分组分析函数,相同的ORDER BY值,返回顺序值
一样,且PARTITION BY 只支持一个字段或一个字段组(需多个字段分组的则要用 || 拼为一个字
段(待确认))
8)返回可读的 全局ID UUIDTOSTR(NEWID())
8)COL_LENGTH(tab_name,col_name):返回定义的列长度;兼容性:IQ&ASE
8)LENGTH(exp):返回exp的长度;兼容性:IQ
转换函数
8)CONVERT(datetype,exp[,format-style]):字符转日期型 或DATE(exp);兼容性:IQ&ASE
format-style值 输出:
112 yyyymmdd
120 yyyy-mm-dd hh:nn:ss
SELECT CONVERT(date,'20101231',112),CONVERT(varchar(10),getdate(),120) ;
--结果
2010-12-31 2011-04-07
8)CAST(exp AS data-type):返回转换为提供的数据类型的表达式的值; 兼容性:IQ
日期函数
8)DAY(date_exp):返回日期天值,DAYS(date_exp,int):返回日期date_exp加int后的日期;MONTH
与MONTHS、YEAR与YEARS同理;
8)DATE(exp):将表达式转换为日期,并删除任何小时、分钟或秒;兼容性:IQ
8)DATEPART(date-part,date-exp): 返回日期分量的对应值(整数);
8)GETDATE():返回系统时间;
8)DATENAME(datepart,date_expr):以字符串形式返回date_expr指定部分的值,转换成合适的名字
;
8)DATEDIFF(datepart,date_expr1,date_expr2):返回date_expr2-date_expr1,通过指定的
datepart度量;
8)DATEADD(date-part,num-exp,date-exp):返回按指定date-part分量加num-exp值后生成的
date-exp值;兼容性:IQ&ASE
date-part日期分量代表值:
缩写 值
YY 0001-9999
QQ 1-4
MM 1-12
WK 1-54
DD 1-31
DY 1--366
DW 1-7(周日-周六)
HH 0-23
MI 0-59
SS 0-59
MS 0-999
数值函数
8)CEIL(num-exp):返回大于或等于指定表达式的最小整数;兼容性:IQ&ASE;
8)FLOOR(numeric_expr):返回小于或等于指定值的最大整数;
8)ABS(num-exp):返回数值表达式的绝对值;兼容性:IQ&ASE;
8)TRUNCNUM(1231.1251,2):截取数值;不四舍五入;
8)ROUND(numeric_expr,int_expr):把数值表达式圆整到int_expr指定的精度;
8)RAND([int_expr]):返回0-1之间的随机浮点数,可指定基值;
8)SIGN(int_expr):返回正+1,零0或负-1;
8)SQRT(float_expr):返回指定值的平方根;
8)PI():返回常数3.1415926;
8)POWER(numeric_expr,power):返回numeric_expr的值给power的幂;
8)EXP(float_expr):给出指定值的指数值;
==================================常用DDL语句
===========================================
Sybase中DDL语句不能修改字段的数据类型,只能修改空与非空:
1.删除列:
ALTER TABLE table_name DELETE column_name;
2.增加列:
ALTER TABLE table_name ADD (column_name DATA_TYPE [NOT] NULL);
3.修改列的空与非空:
ALTER TABLE table_name MODIFY column_name [NOT] NULL;
4.修改列名:
ALTER TABLE table_name RENAME old_column_name TO new_column_name;
5.快速建立临时表:
SELECT * INTO [#]table_name FROM .....;
6、修改表名:
ALTER TABLE old_table_name RENAME new_table_name
7.增加主键约束:
ALTER TABLE tb_name ADD CONSTRAINT pk_name PRIMARY KEY(col_name,..)
8.删除主键约束:
ALTER TABLE tb_name DROP CONSTRAINT pk_name;
9.建立自增长字段,与Oracle的SEQUENCE类似:
CREATE TABLE TMP_001 (RES_ID INTEGER IDENTITY NOT NULL);
10.添加表注释:
COMMENT ON TABLE table_name IS '....';
11.创建索引:
CREATE INDEX index_name ON table_name(column_name);
posted @
2012-06-18 10:57 xzc 阅读(5664) |
评论 (0) |
编辑 收藏posted @
2012-03-20 09:09 xzc 阅读(4687) |
评论 (0) |
编辑 收藏posted @
2012-03-10 15:44 xzc 阅读(8219) |
评论 (0) |
编辑 收藏将ociuldr.exe复制到H:\oracle\product\10.2.0\db_1\BIN下, 或者path中的某个文件夹中
用法:
C:\Documents and Settings\tgm>ociuldr
Usage: ociuldr user=... query=... field=... record=... file=...
(@) Copyright Lou Fangxin 2004/2005, all rights reserved.
Notes:
-si = enable logon as SYSDBA
user = username/password@tnsname
sql = SQL file name,one sql per file, do not include ";"
query = select statement
field = seperator string between fields
record= seperator string between records
file = output file name(default: uldrdata.txt)
read = set DB_FILE_MULTIBLOCK_READ_COUNT at session level
sort = set SORT_AREA_SIZE & SORT_AREA_RETAINED_SIZE at session level (UNIT:MB)
hash = set HASH_AREA_SIZE at session level (UNIT:MB)
serial= set _serial_direct_read to TRUE at session level
trace = set event 10046 to given level at session level
table = table name in the sqlldr control file
mode = sqlldr option, INSERT or APPEND or REPLACE or TRUNCATE
log = log file name, prefix with + to append mode
long = maximum long field size
array = array fetch size
head = 第一行是否为字段名(head=on), 默认为off
for field and record, you can use '0x' to specify hex character code,
\r=0x0d \n=0x0a |=0x7c ,=0x2c \t=0x09
一、导出数据
d:\>ociuldr user=test/test@acf query="select * from test" file=test.txt table=test
二、查看导出内容
1,a
2,b
3,c
4,d
5,e
6,f
三、查看自动生成的控制文件
--
-- Generated by OCIULDR
--
OPTIONS(BINDSIZE=8388608,READSIZE=8388608,ERRORS=-1,ROWS=50000)
LOAD DATA
INFILE 'test.txt' "STR X'0a'"
INTO TABLE test
FIELDS TERMINATED BY X'2c' TRAILING NULLCOLS
(
ID CHAR(40),
NAME CHAR(10)
)
四、可以尝试使用这个控制文件将数据加载到数据库中
d:\>sqlldr test/test@acf control=test_sqlldr.ctl
这样数据就加载到数据库中。对于大数据库表的导出ociuldr工具还支持按照不同的批量导出数据,这通过一个参数batch来实现,默认一个batch是50万条记录,如果不指定batch为2就表示100万条记录换一个文件,默认这个选项值是0,就是指不生成多个文件。
在指定batch选项后,需要指定file选项来定义生成的文件名,文件名中间需要包含“%d”字样,在生成文件时,“%d”会打印成序号,请看以下一个测试:
D:\>ociuldr user=test/test@acf query="select * from test" batch=1 file=test_%d.txt table=test
刚才测试了一下,果然是强悍, 用spool按要求导出10万条记录要好几分钟, 用ociuldr导出来用了一秒,或许一秒都不到, NB!
posted @
2012-03-03 15:39 xzc 阅读(6005) |
评论 (1) |
编辑 收藏在ajax应用流行时,有时我们可能为了降低服务器的负担,把动态内容生成静态html页面或者是xml文件,供客户端访问!但是在我们的网站或系统中往住页面中某些部分是在后台没有进行修改时,其内容不会发生变化的。但是页面中也往往有部分内容是动态的更新的,比如一个新闻页面,新闻内容往往生成了之后就是静态的,但是新闻的最新评论往往是变化的,在这个时候有几种解决方案:
1、重新生成该静态页面,优点是用户访问时页面上的肉容可以实现全静态,不与服务器程序及数据库后端打交道!缺点是每次用户对页面任何部分更新都必须重新生成。
2、js调用请求动态内容,优点是静态页面只生成一次,动态部分才动态加载,却点是服务器端要用输出一段js代码并用js代码输出网页内容,也不利于搜索引擎收录。
3、ajax调用动态内容,和js基本相似,只是与服务器交互的方式不同!并且页面显示不会受到因动态调用速度慢而影响整个页面的加载速度!至于ajax不利于搜索收录,当然在《ajax in acation》等相关书籍中也介绍有变向的解决方案!
4、在服务器端ssl动态内容,用服务器端优化及缓存解决是时下最流行的方法!
对于第二种和第三种方法都是我最青睐的静态解决方法,适合以内容为主的中小型网站。那么在有时候可能会有js读取url参数的需求,事实证明的确也有很多时候有这种需求,特别是在胖客户端的情况下!以前也写过这样的代码,其实原理很简单就是利用javascript接口提供location对像得到url地址,然后通过分析url以取得参数,以下是我收录的一些优秀的url参数读取代码:
一、字符串分割分析法。
这里是一个获取URL+?带QUESTRING参数的JAVASCRIPT客户端解决方案,相当于asp的request.querystring,PHP的$_GET
函数:
<script>
function GetRequest()
{
var url = location.search; //获取url中"?"符后的字串
var theRequest = new Object();
if(url.indexOf("?") != -1)
{
var str = url.substr(1);
strs = str.split("&");
for(var i = 0; i < strs.length; i ++)
{
theRequest[strs[i].split("=")[0]]=unescape(strs[i].split("=")[1]);
}
}
return theRequest;
}
</script>
然后我们通过调用此函数获取对应参数值:
<script>
var Request=new Object();
Request=GetRequest();
var 参数1,参数2,参数3,参数N;
参数1=Request['参数1'];
参数2=Request['参数2'];
参数3=Request['参数3'];
参数N=Request['参数N'];
</script>
以此获取url串中所带的同名参数
二、正则分析法。
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
alert(GetQueryString("参数名1"));
alert(GetQueryString("参数名2"));
alert(GetQueryString("参数名3"));
posted @
2011-12-12 17:15 xzc 阅读(5066) |
评论 (0) |
编辑 收藏
转自:http://blog.csdn.net/wh62592855/article/details/4988336
例如说吧,对DEPTNO 10中的每个员工,确定聘用他们的日期及聘用下一个员工(可能是其他部门的员工)的日期之间相差的天数。
SQL> select ename,hiredate,deptno from emp order by hiredate;
ENAME HIREDATE DEPTNO
---------- --------------- ----------
SMITH 17-DEC-80 20
ALLEN 20-FEB-81 30
WARD 22-FEB-81 30
JONES 02-APR-81 20
BLAKE 01-MAY-81 30
CLARK 09-JUN-81 10
TURNER 08-SEP-81 30
MARTIN 28-SEP-81 30
KING 17-NOV-81 10
JAMES 03-DEC-81 30
FORD 03-DEC-81 20
ENAME HIREDATE DEPTNO
---------- --------------- ----------
MILLER 23-JAN-82 10
SCOTT 19-APR-87 20
ADAMS 23-MAY-87 20
14 rows selected.
SQL> select ename,hiredate,next_hd,
2 next_hd-hiredate diff
3 from
4 (
5 select deptno,ename,hiredate,
6 lead(hiredate) over(order by hiredate) next_hd
7 from emp
8 )
9 where deptno=10;
ENAME HIREDATE NEXT_HD DIFF
---------- --------------- --------------- ----------
CLARK 09-JUN-81 08-SEP-81 91
KING 17-NOV-81 03-DEC-81 16
MILLER 23-JAN-82 19-APR-87 1912
这里的LEAD OVER非常有用,它能够访问“未来的”行(“未来的”行相对于当前行,由ORDER BY子句决定)。这种无需添加联接就能够访问当前行附近行的功能,提高了代码的可读性和有效性。在采用窗口函数时,一定要记住,它在WHERE子句之后求值,因此在该解决方案中,需要使用内联视图。如果把对DEPTNO的筛选移到内联视图,则结果会发生改变(仅考虑了DETPNO 10中的HIREDATE)。
所以下面的结果是错误的:
SQL> select ename,hiredate,next_hd,
2 next_hd-hiredate diff
3 from
4 (
5 select deptno,ename,hiredate,
6 lead(hiredate) over(order by hiredate) next_hd
7 from emp
8 where deptno=10
9 );
ENAME HIREDATE NEXT_HD DIFF
---------- --------------- --------------- ----------
CLARK 09-JUN-81 17-NOV-81 161
KING 17-NOV-81 23-JAN-82 67
MILLER 23-JAN-82
对于ORACLE的LEAD和LAG函数还需要特别注意,它们的结果中可能会有重复。在上面的例子中表EMP内不包含重复的HIREDATE,所以“看起来”似乎没有什么问题。下面我们向表中插入4个重复值来看看
SQL> insert into emp(empno,ename,deptno,hiredate)
2 values(1,'a',10,to_date('17-NOV-1981'));
1 row created.
SQL> insert into emp(empno,ename,deptno,hiredate)
2 values(2,'b',10,to_date('17-NOV-1981'));
1 row created.
SQL> insert into emp(empno,ename,deptno,hiredate)
2 values(3,'c',10,to_date('17-NOV-1981'));
1 row created.
SQL> insert into emp(empno,ename,deptno,hiredate)
2 values(4,'d',10,to_date('17-NOV-1981'));
1 row created.
SQL> select ename,hiredate
2 from emp
3 where deptno=10
4 order by 2;
ENAME HIREDATE
---------- ---------------
CLARK 09-JUN-81
b 17-NOV-81
c 17-NOV-81
a 17-NOV-81
d 17-NOV-81
KING 17-NOV-81
MILLER 23-JAN-82
7 rows selected.
现在还是用以前那个查询语句来试试
SQL> select ename,hiredate,next_hd,
2 next_hd-hiredate diff
3 from
4 (
5 select deptno,ename,hiredate,
6 lead(hiredate) over(order by hiredate) next_hd
7 from emp
8 )
9 where deptno=10;
ENAME HIREDATE NEXT_HD DIFF
---------- --------------- --------------- ----------
CLARK 09-JUN-81 08-SEP-81 91
d 17-NOV-81 17-NOV-81 0
c 17-NOV-81 17-NOV-81 0
a 17-NOV-81 17-NOV-81 0
b 17-NOV-81 17-NOV-81 0
KING 17-NOV-81 03-DEC-81 16
MILLER 23-JAN-82 19-APR-87 1912
7 rows selected.
可以看到其中有4个员工的DIFF列值都是0,这是错误的,同一天聘用的所有员工都应该跟下一个聘用其他员工的HIREDATE进行计算。
幸运的是ORACLE针对这类情况提供了一个非常简单的措施:当调用LEAD函数时,可以给LEAD传递一个参数,以便准确的指定“未来的”行(是下一行?10行之后?等等)。
select ename,hiredate,next_hd,
next_hd-hiredate diff
from
(
select deptno,ename,hiredate,
lead(hiredate,cnt-rn+1) over(order by hiredate) next_hd
from
(
select deptno,ename,hiredate,
count(*) over(partition by hiredate) cnt,
row_number() over(partition by hiredate order by empno) rn
from emp
where deptno=10
)
)
posted @
2011-12-09 10:40 xzc 阅读(4198) |
评论 (1) |
编辑 收藏Java 定义的位运算(bitwise operators )直接对整数类型的位进行操作,这些整数类型包括long,int,short,char,and byte 。表4-2 列出了位运算:
表4.2 位运算符及其结果
运算符 结果
~ 按位非(NOT)(一元运算)
& 按位与(AND)
| 按位或(OR)
^ 按位异或(XOR)
>> 右移
>>> 右移,左边空出的位以0填充
运算符 结果
<< 左移
&= 按位与赋值
|= 按位或赋值
^= 按位异或赋值
>>= 右移赋值
>>>= 右移赋值,左边空出的位以0填充
<<= 左移赋值
续表
既然位运算符在整数范围内对位操作,因此理解这样的操作会对一个值产生什么效果是重要的。具体地说,知道Java 是如何存储整数值并且如何表示负数的是有用的。因此,在继续讨论之前,让我们简短概述一下这两个话题。
所有的整数类型以二进制数字位的变化及其宽度来表示。例如,byte 型值42的二进制代码是00101010 ,其中每个位置在此代表2的次方,在最右边的位以20开始。向左下一个位置将是21,或2,依次向左是22,或4,然后是8,16,32等等,依此类推。因此42在其位置1,3,5的值为1(从右边以0开始数);这样42是21+23+25的和,也即是2+8+32 。
所有的整数类型(除了char 类型之外)都是有符号的整数。这意味着他们既能表示正数,又能表示负数。Java 使用大家知道的2的补码(two’s complement )这种编码来表示负数,也就是通过将与其对应的正数的二进制代码取反(即将1变成0,将0变成1),然后对其结果加1。例如,-42就是通过将42的二进制代码的各个位取反,即对00101010 取反得到11010101 ,然后再加1,得到11010110 ,即-42 。要对一个负数解码,首先对其所有的位取反,然后加1。例如-42,或11010110 取反后为00101001 ,或41,然后加1,这样就得到了42。
如果考虑到零的交叉(zero crossing )问题,你就容易理解Java (以及其他绝大多数语言)这样用2的补码的原因。假定byte 类型的值零用00000000 代表。它的补码是仅仅将它的每一位取反,即生成11111111 ,它代表负零。但问题是负零在整数数学中是无效的。为了解决负零的问题,在使用2的补码代表负数的值时,对其值加1。即负零11111111 加1后为100000000 。但这样使1位太靠左而不适合返回到byte 类型的值,因此人们规定,-0和0的表示方法一样,-1的解码为11111111 。尽管我们在这个例子使用了byte 类型的值,但同样的基本的原则也适用于所有Java 的整数类型。
因为Java 使用2的补码来存储负数,并且因为Java 中的所有整数都是有符号的,这样应用位运算符可以容易地达到意想不到的结果。例如,不管你如何打算,Java 用高位来代表负数。为避免这个讨厌的意外,请记住不管高位的顺序如何,它决定一个整数的符号。
4.2.1 位逻辑运算符
位逻辑运算符有“与”(AND)、“或”(OR)、“异或(XOR )”、“非(NOT)”,分别用“&”、“|”、“^”、“~”表示,4-3 表显示了每个位逻辑运算的结果。在继续讨论之前,请记住位运算符应用于每个运算数内的每个单独的位。
表4-3 位逻辑运算符的结果
A 0 1 0 1 B 0 0 1 1 A | B 0 1 1 1 A & B 0 0 0 1 A ^ B 0 1 1 0 ~A 1 0 1 0
按位非(NOT)
按位非也叫做补,一元运算符NOT“~”是对其运算数的每一位取反。例如,数字42,它的二进制代码为:
00101010
经过按位非运算成为
11010101
按位与(AND)
按位与运算符“&”,如果两个运算数都是1,则结果为1。其他情况下,结果均为零。看下面的例子:
00101010 42 &00001111 15
00001010 10
按位或(OR)
按位或运算符“|”,任何一个运算数为1,则结果为1。如下面的例子所示:
00101010 42 | 00001111 15
00101111 47
按位异或(XOR)
按位异或运算符“^”,只有在两个比较的位不同时其结果是 1。否则,结果是零。下面的例子显示了“^”运算符的效果。这个例子也表明了XOR 运算符的一个有用的属性。注意第二个运算数有数字1的位,42对应二进制代码的对应位是如何被转换的。第二个运算数有数字0的位,第一个运算数对应位的数字不变。当对某些类型进行位运算时,你将会看到这个属性的用处。
00101010 42 ^ 00001111 15
00100101 37
位逻辑运算符的应用
下面的例子说明了位逻辑运算符:
// Demonstrate the bitwise logical operators.
class BitLogic {
public static void main(String args[]) {
String binary[] = {"0000", "0001", "0010", "0011", "0100", "0101", "0110", "0111", "1000", "1001", "1010", "1011", "1100", "1101", "1110", "1111"
};
int a = 3; // 0 + 2 + 1 or 0011 in binary
int b = 6; // 4 + 2 + 0 or 0110 in binary
int c = a | b;
int d = a & b;
int e = a ^ b;
int f = (~a & b) | (a & ~b);
int g = ~a & 0x0f;
System.out.println(" a = " + binary[a]);
System.out.println(" b = " + binary[b]);
System.out.println(" a|b = " + binary[c]);
System.out.println(" a&b = " + binary[d]);
System.out.println(" a^b = " + binary[e]);
System.out.println("~a&b|a&~b = " + binary[f]);
System.out.println(" ~a = " + binary[g]);
}
}
在本例中,变量a与b对应位的组合代表了二进制数所有的 4 种组合模式:0-0,0-1,1-0 ,和1-1 。“|”运算符和“&”运算符分别对变量a与b各个对应位的运算得到了变量c和变量d的值。对变量e和f的赋值说明了“^”运算符的功能。字符串数组binary 代表了0到15 对应的二进制的值。在本例中,数组各元素的排列顺序显示了变量对应值的二进制代码。数组之所以这样构造是因为变量的值n对应的二进制代码可以被正确的存储在数组对应元素binary[n] 中。例如变量a的值为3,则它的二进制代码对应地存储在数组元素binary[3] 中。~a的值与数字0x0f (对应二进制为0000 1111 )进行按位与运算的目的是减小~a的值,保证变量g的结果小于16。因此该程序的运行结果可以用数组binary 对应的元素来表示。该程序的输出如下:
a = 0011 b = 0110 a|b = 0111 a&b = 0010 a^b = 0101 ~a&b|a&~b = 0101 ~a = 1100
4.2.2 左移运算符
左移运算符<<使指定值的所有位都左移规定的次数。它的通用格式如下所示:
value << num
这里,num 指定要移位值value 移动的位数。也就是,左移运算符<<使指定值的所有位都左移num位。每左移一个位,高阶位都被移出(并且丢弃),并用0填充右边。这意味着当左移的运算数是int 类型时,每移动1位它的第31位就要被移出并且丢弃;当左移的运算数是long 类型时,每移动1位它的第63位就要被移出并且丢弃。
在对byte 和short类型的值进行移位运算时,你必须小心。因为你知道Java 在对表达式求值时,将自动把这些类型扩大为 int 型,而且,表达式的值也是int 型。对byte 和short类型的值进行移位运算的结果是int 型,而且如果左移不超过31位,原来对应各位的值也不会丢弃。但是,如果你对一个负的byte 或者short类型的值进行移位运算,它被扩大为int 型后,它的符号也被扩展。这样,整数值结果的高位就会被1填充。因此,为了得到正确的结果,你就要舍弃得到结果的高位。这样做的最简单办法是将结果转换为byte 型。下面的程序说明了这一点:
// Left shifting a byte value.
class ByteShift {
public static void main(String args[]) {
byte a = 64, b;
int i;
i = a << 2;
b = (byte) (a << 2);
System.out.println("Original value of a: " + a);
System.out.println("i and b: " + i + " " + b);
}
}
该程序产生的输出下所示:
Original value of a: 64
i and b: 256 0
因变量a在赋值表达式中,故被扩大为int 型,64(0100 0000 )被左移两次生成值256 (10000 0000 )被赋给变量i。然而,经过左移后,变量b中惟一的1被移出,低位全部成了0,因此b的值也变成了0。
既然每次左移都可以使原来的操作数翻倍,程序员们经常使用这个办法来进行快速的2 的乘法。但是你要小心,如果你将1移进高阶位(31或63位),那么该值将变为负值。下面的程序说明了这一点:
// Left shifting as a quick way to multiply by 2.
class MultByTwo {
public static void main(String args[]) {
int i;
int num = 0xFFFFFFE;
for(i=0; i<4; i++) {
num = num << 1;
System.out.println(num);
}
}
这里,num 指定要移位值value 移动的位数。也就是,左移运算符<<使指定值的所有位都左移num位。每左移一个位,高阶位都被移出(并且丢弃),并用0填充右边。这意味着当左移的运算数是int 类型时,每移动1位它的第31位就要被移出并且丢弃;当左移的运算数是long 类型时,每移动1位它的第63位就要被移出并且丢弃。
在对byte 和short类型的值进行移位运算时,你必须小心。因为你知道Java 在对表达式求值时,将自动把这些类型扩大为 int 型,而且,表达式的值也是int 型。对byte 和short类型的值进行移位运算的结果是int 型,而且如果左移不超过31位,原来对应各位的值也不会丢弃。但是,如果你对一个负的byte 或者short类型的值进行移位运算,它被扩大为int 型后,它的符号也被扩展。这样,整数值结果的高位就会被1填充。因此,为了得到正确的结果,你就要舍弃得到结果的高位。这样做的最简单办法是将结果转换为byte 型。下面的程序说明了这一点:
// Left shifting a byte value.
class ByteShift {
public static void main(String args[]) {
byte a = 64, b;
int i;
i = a << 2;
b = (byte) (a << 2);
System.out.println("Original value of a: " + a);
System.out.println("i and b: " + i + " " + b);
}
}
该程序产生的输出下所示:
Original value of a: 64
i and b: 256 0
因变量a在赋值表达式中,故被扩大为int 型,64(0100 0000 )被左移两次生成值256 (10000 0000 )被赋给变量i。然而,经过左移后,变量b中惟一的1被移出,低位全部成了0,因此b的值也变成了0。
既然每次左移都可以使原来的操作数翻倍,程序员们经常使用这个办法来进行快速的2 的乘法。但是你要小心,如果你将1移进高阶位(31或63位),那么该值将变为负值。下面的程序说明了这一点:
// Left shifting as a quick way to multiply by 2.
class MultByTwo {
public static void main(String args[]) {
int i;
int num = 0xFFFFFFE;
for(i=0; i<4; i++) {
num = num << 1;
System.out.println(num);
}
}
}
该程序的输出如下所示:
536870908
1073741816
2147483632
-32
初值经过仔细选择,以便在左移 4 位后,它会产生-32。正如你看到的,当1被移进31 位时,数字被解释为负值。
4.2.3 右移运算符
右移运算符>>使指定值的所有位都右移规定的次数。它的通用格式如下所示:
value >> num
这里,num 指定要移位值value 移动的位数。也就是,右移运算符>>使指定值的所有位都右移num位。下面的程序片段将值32右移2次,将结果8赋给变量a:
int a = 32;
a = a >> 2; // a now contains 8
当值中的某些位被“移出”时,这些位的值将丢弃。例如,下面的程序片段将35右移2 次,它的2个低位被移出丢弃,也将结果8赋给变量a:
int a = 35;
a = a >> 2; // a still contains 8
用二进制表示该过程可以更清楚地看到程序的运行过程:
00100011 35
>> 2
00001000 8
将值每右移一次,就相当于将该值除以2并且舍弃了余数。你可以利用这个特点将一个整数进行快速的2的除法。当然,你一定要确保你不会将该数原有的任何一位移出。
右移时,被移走的最高位(最左边的位)由原来最高位的数字补充。例如,如果要移走的值为负数,每一次右移都在左边补1,如果要移走的值为正数,每一次右移都在左边补0,这叫做符号位扩展(保留符号位)(sign extension ),在进行右移操作时用来保持负数的符号。例如,–8 >> 1 是–4,用二进制表示如下:
11111000 –8 >>1 11111100 –4
一个要注意的有趣问题是,由于符号位扩展(保留符号位)每次都会在高位补1,因此-1右移的结果总是–1。有时你不希望在右移时保留符号。例如,下面的例子将一个byte 型的值转换为用十六
进制表示。注意右移后的值与0x0f进行按位与运算,这样可以舍弃任何的符号位扩展,以便得到的值可以作为定义数组的下标,从而得到对应数组元素代表的十六进制字符。
// Masking sign extension.
class HexByte {
static public void main(String args[]) {
char hex[] = {
’0’, ’1’, ’2’, ’3’, ’4’, ’5’, ’6’, ’7’,
’8’, ’9’, ’a’, ’b’, ’c’, ’d’, ’e’, ’f’’
};
byte b = (byte) 0xf1;
System.out.println("b = 0x" + hex[(b >> 4) & 0x0f] + hex[b & 0x0f]);}}
该程序的输出如下:
b = 0xf1
4.2.4 无符号右移
正如上面刚刚看到的,每一次右移,>>运算符总是自动地用它的先前最高位的内容补它的最高位。这样做保留了原值的符号。但有时这并不是我们想要的。例如,如果你进行移位操作的运算数不是数字值,你就不希望进行符号位扩展(保留符号位)。当你处理像素值或图形时,这种情况是相当普遍的。在这种情况下,不管运算数的初值是什么,你希望移位后总是在高位(最左边)补0。这就是人们所说的无符号移动(unsigned shift )。这时你可以使用Java 的无符号右移运算符>>> ,它总是在左边补0。
下面的程序段说明了无符号右移运算符>>> 。在本例中,变量a被赋值为-1,用二进制表示就是32位全是1。这个值然后被无符号右移24位,当然它忽略了符号位扩展,在它的左边总是补0。这样得到的值255被赋给变量a。
int a = -1; a = a >>> 24;
下面用二进制形式进一步说明该操作:
11111111 11111111 11111111 11111111 int型-1的二进制代码>>> 24 无符号右移24位00000000 00000000 00000000 11111111 int型255的二进制代码
由于无符号右移运算符>>> 只是对32位和64位的值有意义,所以它并不像你想象的那样有用。因为你要记住,在表达式中过小的值总是被自动扩大为int 型。这意味着符号位扩展和移动总是发生在32位而不是8位或16位。这样,对第7位以0开始的byte 型的值进行无符号移动是不可能的,因为在实际移动运算时,是对扩大后的32位值进行操作。下面的例子说明了这一点:
// Unsigned shifting a byte value.
class ByteUShift {
static public void main(String args[]) {
进制表示。注意右移后的值与0x0f进行按位与运算,这样可以舍弃任何的符号位扩展,以便得到的值可以作为定义数组的下标,从而得到对应数组元素代表的十六进制字符。
// Masking sign extension.
class HexByte {
static public void main(String args[]) {
char hex[] = {
’0’, ’1’, ’2’, ’3’, ’4’, ’5’, ’6’, ’7’,
’8’, ’9’, ’a’, ’b’, ’c’, ’d’, ’e’, ’f’’
};
byte b = (byte) 0xf1;
System.out.println("b = 0x" + hex[(b >> 4) & 0x0f] + hex[b & 0x0f]);}}
该程序的输出如下:
b = 0xf1
4.2.4 无符号右移
正如上面刚刚看到的,每一次右移,>>运算符总是自动地用它的先前最高位的内容补它的最高位。这样做保留了原值的符号。但有时这并不是我们想要的。例如,如果你进行移位操作的运算数不是数字值,你就不希望进行符号位扩展(保留符号位)。当你处理像素值或图形时,这种情况是相当普遍的。在这种情况下,不管运算数的初值是什么,你希望移位后总是在高位(最左边)补0。这就是人们所说的无符号移动(unsigned shift )。这时你可以使用Java 的无符号右移运算符>>> ,它总是在左边补0。
下面的程序段说明了无符号右移运算符>>> 。在本例中,变量a被赋值为-1,用二进制表示就是32位全是1。这个值然后被无符号右移24位,当然它忽略了符号位扩展,在它的左边总是补0。这样得到的值255被赋给变量a。
int a = -1; a = a >>> 24;
下面用二进制形式进一步说明该操作:
11111111 11111111 11111111 11111111 int型-1的二进制代码>>> 24 无符号右移24位00000000 00000000 00000000 11111111 int型255的二进制代码
由于无符号右移运算符>>> 只是对32位和64位的值有意义,所以它并不像你想象的那样有用。因为你要记住,在表达式中过小的值总是被自动扩大为int 型。这意味着符号位扩展和移动总是发生在32位而不是8位或16位。这样,对第7位以0开始的byte 型的值进行无符号移动是不可能的,因为在实际移动运算时,是对扩大后的32位值进行操作。下面的例子说明了这一点:
// Unsigned shifting a byte value.
class ByteUShift {
static public void main(String args[]) {
int b = 2;
int c = 3;
a |= 4;
b >>= 1;
c <<= 1;
a ^= c;
System.out.println("a = " + a);
System.out.println("b = " + b);
System.out.println("c = " + c);
}
}
该程序的输出如下所示:
a = 3
b = 1
c = 6
posted @
2011-11-04 11:56 xzc 阅读(269) |
评论 (1) |
编辑 收藏- import java.net.*;
- String key=URLEncoder.encode("中文key","GBK");
- String value=URLEncoder.encode("中文value","GBK");
- Cookie cook=new Cookie(key,value);
- String key=cook.getName(),value=cook.getValue();
- key=URLDecoder.decode(key,"GBK");
- value=URLDecoder.decode(value,"GBK");
String value = java.net.URLEncoder.encode("中文","utf-8");
Cookie cookie = new Cookie("chinese_code",value);
cookie.setMaxAge(60*60*24*6);
response.addCookie(cookie);
encode() 只有一个参数的已经过时了,现在可以设置编码格式, 取cookie值的时候 也不用解码了。
posted @
2011-10-03 11:29 xzc 阅读(6369) |
评论 (3) |
编辑 收藏
<servlet>
<servlet-name>dwr-invoker</servlet-name>
<servlet-class>org.directwebremoting.servlet.DwrServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>true</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>dwr-invoker</servlet-name>
<url-pattern>/dwr/*</url-pattern>
</servlet-mapping>
我们注意到它里面包含了这段配置:<load-on-startup>1</load-on-startup>,那么这个配置有什么作用呢?
贴一段英文原汁原味的解释如下:
Servlet specification:
The load-on-startup element indicates that this servlet should be loaded (instantiated and have its init() called) on the startup of the web application. The optional contents of these element must be an integer indicating the order in which the servlet should be loaded. If the value is a negative integer, or the element is not present, the container is free to load the servlet whenever it chooses. If the value is a positive integer or 0, the container must load and initialize the servlet as the application is deployed. The container must guarantee that servlets marked with lower integers are loaded before servlets marked with higher integers. The container may choose the order of loading of servlets with the same load-on-start-up value.
翻译过来的意思大致如下:
1)load-on-startup元素标记容器是否在启动的时候就加载这个servlet(实例化并调用其init()方法)。
2)它的值必须是一个整数,表示servlet应该被载入的顺序
2)当值为0或者大于0时,表示容器在应用启动时就加载并初始化这个servlet;
3)当值小于0或者没有指定时,则表示容器在该servlet被选择时才会去加载。
4)正数的值越小,该servlet的优先级越高,应用启动时就越先加载。
5)当值相同时,容器就会自己选择顺序来加载。
所以,<load-on-startup>x</load-on-startup>,中x的取值1,2,3,4,5代表的是优先级,而非启动延迟时间。
如下题目:
2.web.xml中不包括哪些定义(多选)
a.默认起始页
b.servlet启动延迟时间定义
c.error处理页面
d.jsp文件改动后重新载入时间
答案:b,d
通常大多数Servlet是在用户第一次请求的时候由应用服务器创建并初始化,但<load-on-startup>n</load-on-startup> 可以用来改变这种状况,根据自己需要改变加载的优先级!
posted @
2011-09-29 15:22 xzc 阅读(149941) |
评论 (22) |
编辑 收藏Keytool是一个Java数据证书的管理工具 ,Keytool将密钥(key)和证书(certificates)存在一个称为keystore的文件中在keystore里,包含两种数据:
密钥实体(Key entity)——密钥(secret key)又或者是私钥和配对公钥(采用非对称加密)
可信任的证书实体(trusted certificate entries)——只包含公钥
ailas(别名)每个keystore都关联这一个独一无二的alias,这个alias通常不区分大小写
JDK中keytool常用命令:
-genkey 在用户主目录中创建一个默认文件".keystore",还会产生一个mykey的别名,mykey中包含用户的公钥、私钥和证书
(在没有指定生成位置的情况下,keystore会存在用户系统默认目录,如:对于window xp系统,会生成在系统的C:\Documents and Settings\UserName\文件名为“.keystore”)
-alias 产生别名
-keystore 指定密钥库的名称(产生的各类信息将不在.keystore文件中)
-keyalg 指定密钥的算法 (如 RSA DSA(如果不指定默认采用DSA))
-validity 指定创建的证书有效期多少天
-keysize 指定密钥长度
-storepass 指定密钥库的密码(获取keystore信息所需的密码)
-keypass 指定别名条目的密码(私钥的密码)
-dname 指定证书拥有者信息 例如: "CN=名字与姓氏,OU=组织单位名称,O=组织名称,L=城市或区域名称,ST=州或省份名称,C=单位的两字母国家代码"
-list 显示密钥库中的证书信息 keytool -list -v -keystore 指定keystore -storepass 密码
-v 显示密钥库中的证书详细信息
-export 将别名指定的证书导出到文件 keytool -export -alias 需要导出的别名 -keystore 指定keystore -file 指定导出的证书位置及证书名称 -storepass 密码
-file 参数指定导出到文件的文件名
-delete 删除密钥库中某条目 keytool -delete -alias 指定需删除的别 -keystore 指定keystore -storepass 密码
-printcert 查看导出的证书信息 keytool -printcert -file yushan.crt
-keypasswd 修改密钥库中指定条目口令 keytool -keypasswd -alias 需修改的别名 -keypass 旧密码 -new 新密码 -storepass keystore密码 -keystore sage
-storepasswd 修改keystore口令 keytool -storepasswd -keystore e:\yushan.keystore(需修改口令的keystore) -storepass 123456(原始密码) -new yushan(新密码)
-import 将已签名数字证书导入密钥库 keytool -import -alias 指定导入条目的别名 -keystore 指定keystore -file 需导入的证书
下面是各选项的缺省值。
-alias "mykey"
-keyalg "DSA"
-keysize 1024
-validity 90
-keystore 用户宿主目录中名为 .keystore 的文件
-file 读时为标准输入,写时为标准输出
1、keystore的生成:
分阶段生成:
keytool -genkey -alias yushan(别名) -keypass yushan(别名密码) -keyalg RSA(算法) -keysize 1024(密钥长度) -validity 365(有效期,天单位) -keystore
e:\yushan.keystore(指定生成证书的位置和证书名称) -storepass 123456(获取keystore信息的密码);回车输入相关信息即可;
一次性生成:
keytool -genkey -alias yushan -keypass yushan -keyalg RSA -keysize 1024 -validity 365 -keystore e:\yushan.keystore -storepass 123456 -dname "CN=(名字与
姓氏), OU=(组织单位名称), O=(组织名称), L=(城市或区域名称), ST=(州或省份名称), C=(单位的两字母国家代码)";(中英文即可)
2、keystore信息的查看:
keytool -list -v -keystore e:\keytool\yushan.keystore -storepass 123456
显示内容:
---------------------------------------------------------------------
Keystore 类型: JKS
Keystore 提供者: SUN
您的 keystore 包含 1 输入
别名名称: yushan
创建日期: 2009-7-29
项类型: PrivateKeyEntry
认证链长度: 1
认证 [1]:
所有者:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
签发人:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
序列号:4a6f29ed
有效期: Wed Jul 29 00:40:13 CST 2009 至Thu Jul 29 00:40:13 CST 2010
证书指纹:
MD5:A3:D7:D9:74:C3:50:7D:10:C9:C2:47:B0:33:90:45:C3
SHA1:2B:FC:9E:3A:DF:C6:C4:FB:87:B8:A0:C6:99:43:E9:4C:4A:E1:18:E8
签名算法名称:SHA1withRSA
版本: 3
--------------------------------------------------------------------
缺省情况下,-list 命令打印证书的 MD5 指纹。而如果指定了 -v 选项,将以可读格式打印证书,如果指定了 -rfc 选项,将以可打印的编码格式输出证书。
keytool -list -rfc -keystore e:\yushan.keystore -storepass 123456
显示:
-------------------------------------------------------------------------------------------------------
Keystore 类型: JKS
Keystore 提供者: SUN
您的 keystore 包含 1 输入
别名名称: yushan
创建日期: 2009-7-29
项类型: PrivateKeyEntry
认证链长度: 1
认证 [1]:
-----BEGIN CERTIFICATE-----
MIICSzCCAbSgAwIBAgIESm8p7TANBgkqhkiG9w0BAQUFADBqMQ8wDQYDVQQGDAbkuK3lm70xDzAN
BgNVBAgMBua5luWNlzEPMA0GA1UEBwwG5rmY5r2tMREwDwYDVQQKDAh4eOWNj+S8mjERMA8GA1UE
CwwIeHjlhazlj7gxDzANBgNVBAMTBnl1c2hhbjAeFw0wOTA3MjgxNjQwMTNaFw0xMDA3MjgxNjQw
MTNaMGoxDzANBgNVBAYMBuS4reWbvTEPMA0GA1UECAwG5rmW5Y2XMQ8wDQYDVQQHDAbmuZjmva0x
ETAPBgNVBAoMCHh45Y2P5LyaMREwDwYDVQQLDAh4eOWFrOWPuDEPMA0GA1UEAxMGeXVzaGFuMIGf
MA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCJoru1RQczRzTnBWxefVNspQBykS220rS8Y/oX3mZa
hjL4wLfOURzUuxxuVQR2jx7QI+XKME+DHQj9r6aAcLBCi/T1jwF8mVYxtpRuTzE/6KEZdhowEe70
liWLVE+hytLBHZ03Zhwcd6q5HUMu27du3MPQvqiwzTY7MrwIvQQ8iQIDAQABMA0GCSqGSIb3DQEB
BQUAA4GBAGoQQ1/FnTfkpQh+Ni6h3fZdn3sR8ZzDMbOAIYVLAhBb85XDJ8QZTarHbZMJcIdHxAl1
i08ct3E8U87V9t8GZFWVC4BFg/+zeFEv76SFpVE56iX7P1jpsu78z0m69hHlds77VJTdyfMSvtXv
sYHP3fxfzx9WyhipBwd8VPK/NgEP
-----END CERTIFICATE-----
-------------------------------------------------------------------------------------------------------
3、证书的导出:
keytool -export -alias yushan -keystore e:\yushan.keystore -file e:\yushan.crt(指定导出的证书位置及证书名称) -storepass 123456
4、查看导出的证书信息
keytool -printcert -file yushan.crt
显示:(在windows下可以双击yushan.crt查看)
-----------------------------------------------------------------------
所有者:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
签发人:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
序列号:4a6f29ed
有效期: Wed Jul 29 00:40:13 CST 2009 至Thu Jul 29 00:40:13 CST 2010
证书指纹:
MD5:A3:D7:D9:74:C3:50:7D:10:C9:C2:47:B0:33:90:45:C3
SHA1:2B:FC:9E:3A:DF:C6:C4:FB:87:B8:A0:C6:99:43:E9:4C:4A:E1:18:E8
签名算法名称:SHA1withRSA
版本: 3
-----------------------------------------------------------------------
5、证书的导入:
准备一个导入的证书:
keytool -genkey -alias shuany -keypass shuany -keyalg RSA -keysize 1024 -validity 365 -keystore e:\shuany.keystore -storepass 123456 -dname "CN=shuany,
OU=xx, O=xx, L=xx, ST=xx, C=xx";
keytool -export -alias shuany -keystore e:\shuany.keystore -file e:\shuany.crt -storepass 123456
现在将shuany.crt 加入到yushan.keystore中:
keytool -import -alias shuany(指定导入证书的别名,如果不指定默认为mykey,别名唯一,否则导入出错) -file e:\shuany.crt -keystore e:\yushan.keystore -storepass
123456
keytool -list -v -keystore e:\keytool\yushan.keystore -storepass 123456
显示:
------------------------------------------------------------------------------
Keystore 类型: JKS
Keystore 提供者: SUN
您的 keystore 包含 2 输入
别名名称: yushan
创建日期: 2009-7-29
项类型: PrivateKeyEntry
认证链长度: 1
认证 [1]:
所有者:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
签发人:CN=yushan, OU=xx公司, O=xx协会, L=湘潭, ST=湖南, C=中国
序列号:4a6f29ed
有效期: Wed Jul 29 00:40:13 CST 2009 至Thu Jul 29 00:40:13 CST 2010
证书指纹:
MD5:A3:D7:D9:74:C3:50:7D:10:C9:C2:47:B0:33:90:45:C3
SHA1:2B:FC:9E:3A:DF:C6:C4:FB:87:B8:A0:C6:99:43:E9:4C:4A:E1:18:E8
签名算法名称:SHA1withRSA
版本: 3
*******************************************
*******************************************
别名名称: shuany
创建日期: 2009-7-29
输入类型: trustedCertEntry
所有者:CN=shuany, OU=xx, O=xx, L=xx, ST=xx, C=xx
签发人:CN=shuany, OU=xx, O=xx, L=xx, ST=xx, C=xx
序列号:4a6f2cd9
有效期: Wed Jul 29 00:52:41 CST 2009 至Thu Jul 29 00:52:41 CST 2010
证书指纹:
MD5:15:03:57:9B:14:BD:C5:50:21:15:47:1E:29:87:A4:E6
SHA1:C1:4F:8B:CD:5E:C2:94:77:B7:42:29:35:5C:BB:BB:2E:9E:F0:89:F5
签名算法名称:SHA1withRSA
版本: 3
*******************************************
*******************************************
------------------------------------------------------------------------------
6、证书条目的删除:
keytool -delete -alias shuany(指定需删除的别名) -keystore yushan.keystore -storepass 123456
7、证书条目口令的修改:
keytool -keypasswd -alias yushan(需要修改密码的别名) -keypass yushan(原始密码) -new 123456(别名的新密码) -keystore e:\yushan.keystore -storepass 123456
8、keystore口令的修改:
keytool -storepasswd -keystore e:\yushan.keystore(需修改口令的keystore) -storepass 123456(原始密码) -new yushan(新密码)
9、修改keystore中别名为yushan的信息
keytool -selfcert -alias yushan -keypass yushan -keystore e:\yushan.keystore -storepass 123456 -dname "cn=yushan,ou=yushan,o=yushan,c=us
posted @
2011-09-15 08:30 xzc 阅读(420) |
评论 (0) |
编辑 收藏转自:
http://www.iteye.com/topic/255397
1.那即将离我远去的
用buffalo作为我的ajax类库也有些历史了,几乎是和Spring同时开始接触的.
按照官方的方式,Buffalo与Spring的集成是很简单:
在Spring中配置一个BuffaloServiceConfigure bean,把spring托管的服务在其中声明即可,Buffalo可以通过ServletContext得到Spring的WebApplicationContext,进而得到所需的服务:
- <bean name="buffaloConfigBean"
- class="net.buffalo.service.BuffaloServiceConfigurer">
- <property name="services">
- <map>
- <entry key="springSimpleService">
- <ref bean="systemService" />
- </entry>
- <entry key="springSimpleService2">
- <ref bean="systemService2" />
- </entry>
- </map>
- </property>
- </bean>
<bean name="buffaloConfigBean"
class="net.buffalo.service.BuffaloServiceConfigurer">
<property name="services">
<map>
<entry key="springSimpleService">
<ref bean="systemService" />
</entry>
<entry key="springSimpleService2">
<ref bean="systemService2" />
</entry>
</map>
</property>
</bean>
似乎很简单,但,有没有觉得似乎很傻?只是把Spring里已经配置好的bean再引用一次而已,
一旦面临协作开发,和所有的全局配置文件一样,BuffaloServiceConfigure bean下面就会囊括几十上百个service ref,一大堆人围着这个配置文件转,CVS冲突就成了家常便饭了,苦恼不已.当然,按我们这么多年的开发经验是不会出现这种低级错误的,早早的在项目设计阶段就会按模块划分出多个配置文件,一人独用,无需和别人共享配置,轻松面对冲突问题,带来的局面就是每个包里都塞着一个buffalo.xml,一个项目里配置文件到处有,不断得copy/paste,层层套套,那可不是硕果累累的满足感.
当然,Spring本身在2.5之前也因XML配置繁琐而让人诟病,Guice才能异军突起,那时Spring比Buffalo的配置更多,所以Buffalo的问题也就不是问题了.但有一天,我终于要正式升级到Spring2.5.
世界清静了!使用annotation,看到怎么多配置文件消失,看到简洁的Bean/MVC配置,呵呵,还真是令人心情愉悦的.
诶,等等,怎么还有大堆XML?哦?原来是Buffalo...
Buffalo像个刺头,傻愣愣地杵在XML里.
2.于是我开始把Buffalo也Annotation化.
话说Spring的扩展能力还是ganggang的,一天时间,就有成果了.
先写个注解:
- package cn.tohot.common.annotation;
-
- import java.lang.annotation.ElementType;
- import java.lang.annotation.Retention;
- import java.lang.annotation.RetentionPolicy;
- import java.lang.annotation.Target;
-
-
-
-
-
-
- @Retention(RetentionPolicy.RUNTIME)
- @Target(ElementType.TYPE)
- public @interface Buffalo {
-
-
-
- String value();
- }
package cn.tohot.common.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* buffalo扩展接口,用于表明该类是一个buffalo服务.
* @author tedeyang
*
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Buffalo {
/**
* @return 远程调用时的服务名.
*/
String value();
}
接着再写Spring的扩展
-
-
-
- package cn.tohot.common.annotation;
-
- import java.util.HashMap;
-
- import net.buffalo.service.BuffaloServiceConfigurer;
-
- import org.apache.log4j.Logger;
- import org.springframework.beans.BeansException;
- import org.springframework.beans.factory.DisposableBean;
- import org.springframework.beans.factory.FactoryBean;
- import org.springframework.beans.factory.InitializingBean;
- import org.springframework.beans.factory.config.BeanPostProcessor;
-
-
-
-
-
-
- @SuppressWarnings("unchecked")
- public class BuffaloAnnotationServiceFactoryBean implements FactoryBean, InitializingBean, DisposableBean, BeanPostProcessor {
- private static final Logger log = Logger.getLogger(BuffaloAnnotationServiceFactoryBean.class);
-
- private BuffaloServiceConfigurer buffaloConfigurer = null;
-
- public BuffaloAnnotationServiceFactoryBean() {
- buffaloConfigurer = new BuffaloServiceConfigurer();
- buffaloConfigurer.setServices(new HashMap());
- }
-
- private void addBuffaloBean(String buffaloServiceName,Object bean) {
- buffaloConfigurer.getServices().put(buffaloServiceName, bean);
- log.info("Add a buffalo service :"+buffaloServiceName);
- }
-
- public Object getObject() throws Exception {
- return this.buffaloConfigurer;
- }
-
- public Class getObjectType() {
- return BuffaloServiceConfigurer.class;
- }
-
- public boolean isSingleton() {
- return true;
- }
-
- public void afterPropertiesSet() throws Exception {
- }
-
- public void destroy() throws Exception {
- if (buffaloConfigurer != null)
- buffaloConfigurer.setServices(null);
- buffaloConfigurer = null;
- }
-
- public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
- return bean;
- }
-
- public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
- log.debug("find a bean:"+beanName);
- if (bean.getClass().isAnnotationPresent(Buffalo.class)) {
- Buffalo buffalo = bean.getClass().getAnnotation(Buffalo.class);
- addBuffaloBean(buffalo.value(), bean);
- }
- return bean;
- }
-
- }
/**
*
*/
package cn.tohot.common.annotation;
import java.util.HashMap;
import net.buffalo.service.BuffaloServiceConfigurer;
import org.apache.log4j.Logger;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.FactoryBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.config.BeanPostProcessor;
/**
* 该类作为FactoryBean可以无缝替换buffalo 2.0自带的配置类,并使用annotation进行配置.
* @author tedeyang
*
*/
@SuppressWarnings("unchecked")
public class BuffaloAnnotationServiceFactoryBean implements FactoryBean, InitializingBean, DisposableBean, BeanPostProcessor {
private static final Logger log = Logger.getLogger(BuffaloAnnotationServiceFactoryBean.class);
private BuffaloServiceConfigurer buffaloConfigurer = null;
public BuffaloAnnotationServiceFactoryBean() {
buffaloConfigurer = new BuffaloServiceConfigurer();
buffaloConfigurer.setServices(new HashMap());
}
private void addBuffaloBean(String buffaloServiceName,Object bean) {
buffaloConfigurer.getServices().put(buffaloServiceName, bean);
log.info("Add a buffalo service :"+buffaloServiceName);
}
public Object getObject() throws Exception {
return this.buffaloConfigurer;
}
public Class getObjectType() {
return BuffaloServiceConfigurer.class;
}
public boolean isSingleton() {
return true;
}
public void afterPropertiesSet() throws Exception {
}
public void destroy() throws Exception {
if (buffaloConfigurer != null)
buffaloConfigurer.setServices(null);
buffaloConfigurer = null;
}
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
log.debug("find a bean:"+beanName);
if (bean.getClass().isAnnotationPresent(Buffalo.class)) {
Buffalo buffalo = bean.getClass().getAnnotation(Buffalo.class);
addBuffaloBean(buffalo.value(), bean);
}
return bean;
}
}
主要思路是用FactoryBean替换原BuffaloServiceConfigurer,并挂上BeanPostProcessor的钩子,检测一下annotation,发现buffalo服务就添加到原BuffaloServiceConfigurer中去.
3.今天我这样配置Buffalo:
- <?xml version="1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
- xmlns:tx="http://www.springframework.org/schema/tx" xmlns:context="http://www.springframework.org/schema/context"
- xsi:schemaLocation="http:
- http:
- http:
- http:
-
- <!-- Spring Annotation配置, 自动搜索组件 -->
- <context:component-scan base-package="cn.tohot.demo"/>
- <bean id="buffalo" class="cn.tohot.common.annotation.BuffaloAnnotationServiceFactoryBean" />
- </beans>
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<!-- Spring Annotation配置, 自动搜索组件 -->
<context:component-scan base-package="cn.tohot.demo"/>
<bean id="buffalo" class="cn.tohot.common.annotation.BuffaloAnnotationServiceFactoryBean" />
</beans>
服务端的Buffalo bean 类:
- package cn.tohot.demo;
-
- import org.springframework.stereotype.Service;
-
- import cn.tohot.common.annotation.Buffalo;
-
- @Service
- @Buffalo("testbean")
- public class BuffaloBeanTestService {
- public String run() {
- System.out.println("run");
- return "run";
- }
- }
package cn.tohot.demo;
import org.springframework.stereotype.Service;
import cn.tohot.common.annotation.Buffalo;
@Service //声明Spring bean,
@Buffalo("testbean") //声明一个名为"testbean"的Buffalo service
public class BuffaloBeanTestService {
public String run() {
System.out.println("run");
return "run";
}
}
很简洁,不是吗?
posted @
2011-08-26 09:21 xzc 阅读(232) |
评论 (0) |
编辑 收藏转自:
http://www.iteye.com/topic/11738前几天解释了Spring的抽象事务机制。这次讲讲Spring中的DataSource 事务。
DataSource事务相关的类比较多,我们一步步来拨开其中的密团。
1 如何获得连接
看DataSourceUtils代码
- protected static Connection doGetConnection(DataSource dataSource, boolean allowSynchronization);
- throws SQLException {
-
- ConnectionHolder conHolder = (ConnectionHolder); TransactionSynchronizationManager.getResource(dataSource);;
- if (conHolder != null); {
- conHolder.requested();;
- return conHolder.getConnection();;
- }
-
-
- Connection con = dataSource.getConnection();;
- if (allowSynchronization && TransactionSynchronizationManager.isSynchronizationActive();); {
- conHolder = new ConnectionHolder(con);;
- TransactionSynchronizationManager.bindResource(dataSource, conHolder);;
- TransactionSynchronizationManager.registerSynchronization(new ConnectionSynchronization(conHolder, dataSource););;
- conHolder.requested();;
- }
-
- return con;
- }
protected static Connection doGetConnection(DataSource dataSource, boolean allowSynchronization);
throws SQLException {
ConnectionHolder conHolder = (ConnectionHolder); TransactionSynchronizationManager.getResource(dataSource);;
if (conHolder != null); {
conHolder.requested();;
return conHolder.getConnection();;
}
Connection con = dataSource.getConnection();;
if (allowSynchronization && TransactionSynchronizationManager.isSynchronizationActive();); {
conHolder = new ConnectionHolder(con);;
TransactionSynchronizationManager.bindResource(dataSource, conHolder);;
TransactionSynchronizationManager.registerSynchronization(new ConnectionSynchronization(conHolder, dataSource););;
conHolder.requested();;
}
return con;
}原来连接是从TransactionSynchronizationManager中获取,如果TransactionSynchronizationManager中已经有了,那么拿过来然后调用conHolder.requested()。否则从原始的DataSource这创建一个连接,放到一个ConnectionHolder,然后再调用TransactionSynchronizationManager.bindResource绑定。
好,我们又遇到两个新的类TransactionSynchronizationManager和ConnectionHolder和。继续跟踪
2 TransactionSynchronizationManager
看其中的一些代码
- private static ThreadLocal resources = new ThreadLocal();;
- public static Object getResource(Object key); {
- Map map = (Map); resources.get();;
- if (map == null); {
- return null;
- }
- Object value = map.get(key);;
- return value;
- }
- public static void bindResource(Object key, Object value); throws IllegalStateException {
- Map map = (Map); resources.get();;
- if (map == null); {
- map = new HashMap();;
- resources.set(map);;
- }
- map.put(key, value);;
- }
private static ThreadLocal resources = new ThreadLocal();;
public static Object getResource(Object key); {
Map map = (Map); resources.get();;
if (map == null); {
return null;
}
Object value = map.get(key);;
return value;
}
public static void bindResource(Object key, Object value); throws IllegalStateException {
Map map = (Map); resources.get();;
if (map == null); {
map = new HashMap();;
resources.set(map);;
}
map.put(key, value);;
}原来TransactionSynchronizationManager内部建立了一个ThreadLocal的resources,这个resources又是和一个map联系在一起的,这个map在某个线程第一次调用bindResource时生成。
联系前面的DataSourceUtils代码,我们可以总结出来。
某个线程使用DataSourceUtils,当第一次要求创建连接将在TransactionSynchronizationManager中创建出一个ThreadLocal的map。然后以DataSource作为键,ConnectionHolder为值放到map中。等这个线程下一次再请求的这个DataSource的时候,就从这个map中获取对应的ConnectionHolder。用map是为了解决同一个线程上多个DataSource。
然后我们来看看ConnectionHolder又是什么?
3 对连接进行引用计数
看ConnectionHolder代码,这个类很简单,看不出个所以然,只好再去看父类代码ResourceHolderSupport,我们感兴趣的是这两个方法
- public void requested(); {
- this.referenceCount++;
- }
-
- public void released(); {
- this.referenceCount--;
- }
public void requested(); {
this.referenceCount++;
}
public void released(); {
this.referenceCount--;
}看得出这是一个引用计数的技巧。原来Spring中对Connection是竟量使用已创建的对象,而不是每次都创建一个新对象。这就是DataSourceUtils中
- if (conHolder != null); {
- conHolder.requested();;
- return conHolder.getConnection();;
- }
if (conHolder != null); {
conHolder.requested();;
return conHolder.getConnection();;
}的原因
4 释放连接
完成事物后DataSourceTransactionManager有这样的代码
- protected void doCleanupAfterCompletion(Object transaction); {
- DataSourceTransactionObject txObject = (DataSourceTransactionObject); transaction;
-
-
- TransactionSynchronizationManager.unbindResource(this.dataSource);;
- txObject.getConnectionHolder();.clear();;
-
-
- }
protected void doCleanupAfterCompletion(Object transaction); {
DataSourceTransactionObject txObject = (DataSourceTransactionObject); transaction;
// Remove the connection holder from the thread.
TransactionSynchronizationManager.unbindResource(this.dataSource);;
txObject.getConnectionHolder();.clear();;
//... DataSourceUtils.closeConnectionIfNecessary(con, this.dataSource);;
}DataSourceUtils
- protected static void doCloseConnectionIfNecessary(Connection con, DataSource dataSource); throws SQLException {
- if (con == null); {
- return;
- }
-
- ConnectionHolder conHolder = (ConnectionHolder); TransactionSynchronizationManager.getResource(dataSource);;
- if (conHolder != null && con == conHolder.getConnection();); {
-
- conHolder.released();;
- return;
- }
-
-
-
- if (!(dataSource instanceof SmartDataSource); || ((SmartDataSource); dataSource);.shouldClose(con);); {
- logger.debug("Closing JDBC connection");;
- con.close();;
- }
- }
protected static void doCloseConnectionIfNecessary(Connection con, DataSource dataSource); throws SQLException {
if (con == null); {
return;
}
ConnectionHolder conHolder = (ConnectionHolder); TransactionSynchronizationManager.getResource(dataSource);;
if (conHolder != null && con == conHolder.getConnection();); {
// It's the transactional Connection: Don't close it.
conHolder.released();;
return;
}
// Leave the Connection open only if the DataSource is our
// special data source, and it wants the Connection left open.
if (!(dataSource instanceof SmartDataSource); || ((SmartDataSource); dataSource);.shouldClose(con);); {
logger.debug("Closing JDBC connection");;
con.close();;
}
}恍然大悟。如果事物完成,那么就
TransactionSynchronizationManager.unbindResource(this.dataSource);将当前的ConnectionHolder
从TransactionSynchronizationManager上脱离,然后doCloseConnectionIfNecessary。最后会把连接关闭掉。
5 两个辅助类JdbcTemplate和TransactionAwareDataSourceProxy
JdbcTemplate中的execute方法的第一句和最后一句
- public Object execute(PreparedStatementCreator psc, PreparedStatementCallback action);
- throws DataAccessException {
-
- Connection con = DataSourceUtils.getConnection(getDataSource(););;
-
- DataSourceUtils.closeConnectionIfNecessary(con, getDataSource(););;
- }
- }
public Object execute(PreparedStatementCreator psc, PreparedStatementCallback action);
throws DataAccessException {
Connection con = DataSourceUtils.getConnection(getDataSource(););;
//其他代码
DataSourceUtils.closeConnectionIfNecessary(con, getDataSource(););;
}
}作用不言自明了吧
从TransactionAwareDataSourceProxy中获取的连接是这个样子的
- public Connection getConnection(); throws SQLException {
- Connection con = DataSourceUtils.doGetConnection(getTargetDataSource();, true);;
- return getTransactionAwareConnectionProxy(con, getTargetDataSource(););;
- }
public Connection getConnection(); throws SQLException {
Connection con = DataSourceUtils.doGetConnection(getTargetDataSource();, true);;
return getTransactionAwareConnectionProxy(con, getTargetDataSource(););;
}万变不离其宗,不过我们还是看看getTransactionAwareConnectionProxy
- protected Connection getTransactionAwareConnectionProxy(Connection target, DataSource dataSource); {
- return (Connection); Proxy.newProxyInstance(
- ConnectionProxy.class.getClassLoader();,
- new Class[] {ConnectionProxy.class},
- new TransactionAwareInvocationHandler(target, dataSource););;
- }
protected Connection getTransactionAwareConnectionProxy(Connection target, DataSource dataSource); {
return (Connection); Proxy.newProxyInstance(
ConnectionProxy.class.getClassLoader();,
new Class[] {ConnectionProxy.class},
new TransactionAwareInvocationHandler(target, dataSource););;
}原来返回的是jdk的动态代理。继续看TransactionAwareInvocationHandler
- public Object invoke(Object proxy, Method method, Object[] args); throws Throwable {
-
- if (this.dataSource != null); {
- DataSourceUtils.doCloseConnectionIfNecessary(this.target, this.dataSource);;
- }
- return null;
- }
-
- }
public Object invoke(Object proxy, Method method, Object[] args); throws Throwable {
//... if (method.getName();.equals(CONNECTION_CLOSE_METHOD_NAME);); {
if (this.dataSource != null); {
DataSourceUtils.doCloseConnectionIfNecessary(this.target, this.dataSource);;
}
return null;
}
}TransactionAwareDataSourceProxy会先从DataSourceUtils获取连接。然后将这个连接用jdk的动态代理包一下返回。外部代码如果调用的这个冒牌的Connection,就会先调用TransactionAwareInvocationHandler的invoke,在这个invoke 中,完成原来调用DataSourceUtils的功能。
总结上面的流程
Spring 对DataSource进行事务管理的关键在于ConnectionHolder和TransactionSynchronizationManager。
0.先从TransactionSynchronizationManager中尝试获取连接
1.如果前一步失败则在每个线程上,对每个DataSouce只创建一个Connection
2.这个Connection用ConnectionHolder包装起来,由TransactionSynchronizationManager管理
3.再次请求同一个连接的时候,从TransactionSynchronizationManager返回已经创建的ConnectionHolder,然后调用ConnectionHolder的request将引用计数+1
4.释放连接时要调用ConnectionHolder的released,将引用计数-1
5.当事物完成后,将ConnectionHolder从TransactionSynchronizationManager中解除。当谁都不用,这个连接被close
以上所有都是可以调用DataSourceUtils化简代码,而JdbcTemplate又是调用DataSourceUtils的。所以在Spring文档中要求尽量首先使用JdbcTemplate,其次是用DataSourceUtils来获取和释放连接。至于TransactionAwareDataSourceProxy,那是下策的下策。不过可以将Spring事务管理和遗留代码无缝集成。
所以如某位朋友说要使用Spring的事务管理,但是又不想用JdbcTemplate,那么可以考虑TransactionAwareDataSourceProxy。这个类是原来DataSource的代理。
其次,想使用Spring事物,又不想对Spring进行依赖是不可能的。与其试图自己模拟DataSourceUtils,不如直接使用现成的。
posted @
2011-08-09 14:59 xzc 阅读(4007) |
评论 (1) |
编辑 收藏
在HP-UX文件系统中,系统默认的是小文件系统(即不支持大于2GB的文件),如果用户希望当前的文件系统能支持大于2GB的文件时,我们可以这样做:
1、新建文件系统时:
mkfs -F vxfs -o largefiles /dev/vg02/rlvol1
或者
newfs -F vxfs -o largefiles /dev/vg02/rlvol1
2、文件系统内有数据文件时:
fsadm -F vxfs -o largefiles /inffile
当然,你也可以将大文件系统转换为小文件系统,不过要注意的是这个大文件系统中不能有大于2GB的文件,否则无法转换成功。示例如下:
fsadm -F vxfs -o nolargefiles /inffile
posted @
2011-08-08 16:57 xzc 阅读(770) |
评论 (2) |
编辑 收藏SELECT ename
FROM scott.emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
--得到结果为:
KING
JONES
SCOTT
ADAMS
FORD
SMITH
BLAKE
ALLEN
WARD
MARTIN
TURNER
JAMES
而:
SELECT SYS_CONNECT_BY_PATH(ename, '>') "Path"
FROM scott.emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
--得到结果为:
>KING
>KING>JONES
>KING>JONES>SCOTT
>KING>JONES>SCOTT>ADAMS
>KING>JONES>FORD
>KING>JONES>FORD>SMITH
>KING>BLAKE
>KING>BLAKE>ALLEN
>KING>BLAKE>WARD
>KING>BLAKE>MARTIN
>KING>BLAKE>TURNER
>KING>BLAKE>JAMES
>KING>CLARK
>KING>CLARK>MILLER
SELECT ename
FROM scott.emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
--得到结果为:
KING
JONES
SCOTT
ADAMS
FORD
SMITH
BLAKE
ALLEN
WARD
MARTIN
TURNER
JAMES
而:
SELECT SYS_CONNECT_BY_PATH(ename, '>') "Path"
FROM scott.emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
--得到结果为:
>KING
>KING>JONES
>KING>JONES>SCOTT
>KING>JONES>SCOTT>ADAMS
>KING>JONES>FORD
>KING>JONES>FORD>SMITH
>KING>BLAKE
>KING>BLAKE>ALLEN
>KING>BLAKE>WARD
>KING>BLAKE>MARTIN
>KING>BLAKE>TURNER
>KING>BLAKE>JAMES
>KING>CLARK
>KING>CLARK>MILLER
其实SYS_CONNECT_BY_PATH这个函数是oracle9i才新提出来的!
它一定要和connect by子句合用!
第一个参数是形成树形式的字段,第二个参数是父级和其子级分隔显示用的分隔符!
START WITH 代表你要开始遍历的的节点!
CONNECT BY PRIOR 是标示父子关系的对应!
如下例子:
view plaincopy to clipboardprint?
select max(
substr(
sys_connect_by_path(column_name,',')
,2)
)
from (select column_name,rownum rn from user_tab_columns where table_name ='AA_TEST')
start with rn=1 connect by rn=rownum ;
select max(
substr(
sys_connect_by_path(column_name,',')
,2)
)
from (select column_name,rownum rn from user_tab_columns where table_name ='AA_TEST')
start with rn=1 connect by rn=rownum ;
是将列用,进行分割成为一行,然后将首个,去掉,只取取最大的那个数据。
---------------------------------------------
下面是别人的例子:
1、带层次关系
view plaincopy to clipboardprint?
SQL> create table dept(deptno number,deptname varchar2(20),mgrno number);
Table created.
SQL> insert into dept values(1,'总公司',null);
1 row created.
SQL> insert into dept values(2,'浙江分公司',1);
1 row created.
SQL> insert into dept values(3,'杭州分公司',2);
1 row created.
SQL> commit;
Commit complete.
SQL> select max(substr(sys_connect_by_path(deptname,','),2)) from dept connect by prior deptno=mgrno;
MAX(SUBSTR(SYS_CONNECT_BY_PATH(DEPTNAME,','),2))
--------------------------------------------------------------------------------
总公司,浙江分公司,杭州分公司
SQL> create table dept(deptno number,deptname varchar2(20),mgrno number);
Table created.
SQL> insert into dept values(1,'总公司',null);
1 row created.
SQL> insert into dept values(2,'浙江分公司',1);
1 row created.
SQL> insert into dept values(3,'杭州分公司',2);
1 row created.
SQL> commit;
Commit complete.
SQL> select max(substr(sys_connect_by_path(deptname,','),2)) from dept connect by prior deptno=mgrno;
MAX(SUBSTR(SYS_CONNECT_BY_PATH(DEPTNAME,','),2))
--------------------------------------------------------------------------------
总公司,浙江分公司,杭州分公司
2、行列转换
如把一个表的所有列连成一行,用逗号分隔:
view plaincopy to clipboardprint?
SQL> select max(substr(sys_connect_by_path(column_name,','),2))
from (select column_name,rownum rn from user_tab_columns where table_name ='DEPT')
start with rn=1 connect by rn=rownum ;
MAX(SUBSTR(SYS_CONNECT_BY_PATH(COLUMN_NAME,','),2))
--------------------------------------------------------------------------------
DEPTNO,DEPTNAME,MGRNO
posted @
2011-08-05 11:03 xzc 阅读(1404) |
评论 (3) |
编辑 收藏posted @
2011-07-18 18:51 xzc 阅读(622) |
评论 (0) |
编辑 收藏转自:
http://blog.csdn.net/tianlesoftware/article/details/4680230
在Oracle中建库,通常有两种方法。一是使用Oracle的建库工
且DBCA,这是一个图形界面工且,使用起来方便且很容易理解,因为它的界面友好、美观,而且提示也比较齐全。在Windows系统中,这个工具可以在Oracle程序组中打开(”开始”—“程序”—“ Oracle OraDb10g_home1”—“ Configuration and Migration Tools”—“ Database ConfigurationAssistant”),也可以在命令行(”开始”—“运行”—“cmd”)工具中直接输入dbca来打开。另一种方法就是手工建库,这也就是下面所要讲的内容。 手工建库比起使用DBCA建库来说,是比较麻烦的,但是如果我们学好了手工建库的话,就可以使我们更好地理解Oracle数据库的体系结构。手工建库须要经过几个步骤,每一个步骤都非常关键。它包括:
1、 创建必要的相关目录
2、 创建初始化参数文件
3、 设置环境变量Oracle_sid
4、 创建实例
5、 创建口令文件
6、 启动数据库到nomount(实例)状态
7、 执行建库脚本
8、 执行catalog脚步本创建数据字典
9、 执行catproc创建package包
10、 执行pupbld
11、 由初始化参数文件创建spfile文件
12、 执行scott脚本创建scott模式
做完了以上的步骤之后就可以使用“SQL>alterdatabase open;”打开数据库正常的使用了。下面,我将具体地把以上的几个步骤用实验展开来讲。 实验系统平台:Windows Server 2000 数据库系统版本:Oracle Database 10G Oracle的安装路径:D盘 .创建的数据库名称:book 1、打开命令行工具,创建必要有相关目录
C:/>mkdir D:/oracle/product/10.1.0/admin/book
C:/>mkdir D:/oracle/product/10.1.0/admin/book/bdump
C:/>mkdir D:/oracle/product/10.1.0/admin/book/udump
C:/>mkdir D:/oracle/product/10.1.0/admin/book/cdump
C:/>mkdir D:/oracle/product/10.1.0/admin/book/pfile
C:/>mkdir D:/oracle/product/10.1.0/admin/book/create
C:/>mkdir D:/oracle/product/10.1.0/oradata/book
上面创建目录的过程也可以在Windows的图形界面中去创建。其中
D:/oracle/product/10.1.0/admin/book目录下的几个子目录主要用于存放数据库运行过程中的跟踪信息。最重要的两上子目录是bdump和udump目录,bdump目录存放的是数据库动行过程中的各个后台进程的跟踪信息,当中alert文件是警告文件,其文件名称为alert_book.log,当数据库出现问题时,首先就可以去查看此文件以找出原因,手工创建过程中出现的各种问题往往也可以通过查看这个文件找到原因。Udump目录存放特定会话相关的跟踪信息D:/oracle/product/10.1.0/oradata/book目录存放各种数据库文件,包括控制文件、数据文件、重做日志文件。
2、创建初始化参数文件
数据库系统启动时须要用初始化参数文件的设置分配内存、启动必要的后台进程的。因此,初始化参数文件创建的是否正确、参数设置是否正确关系着整个建库的“命运”。 创建初始化参数文件可以通过拷贝现在的初始化参数文件并将其做适当的修改即可,从而不必要用
手工去一句一句地写出来,因为初始化参数文件的结构体系基本上都是一样的。在我们安装Oracle的时候,系统已经为我们安装了一个名为orcl的数据库,于是我们可以从它那里得到一份初始化参数文件。打开D:/oracle/product/10.1.0/admin/orcl/pfile,找到init.ora文件,把它拷贝到D:/oracle/product/10.1.0/bd_1/databse下,并将其改名为initbook.ora。接着用记事本的方式打开initbook.ora,修改以下的内容: db_domain=""
db_name=book
control_files=("D:/oracle/product/10.1.0/oradata/book/control01.ctl",
"D:/oracle/product/10.1.0/oradata/book/control02.ctl",
"D:/oracle/product/10.1.0/oradata/book/control03.ctl") undo_management=AUTO
undo_tablespace=UNDOTBS1
――注意此处的“UNDOTBS1”要和建库脚步本中对应
background_dump_dest=D:/oracle/product/10.1.0/admin/book/bdump
core_dump_dest=D:/oracle/product/10.1.0/admin/book/cdump
user_dump_dest=D:/oracle/product/10.1.0/admin/book/udump
3、打开命令行,设置环境变量oracle_sid
C:/>set oracle_sid=book 设置环境变量的目地是在默认的情况下,指定命令行中所操作的数据库实例是book。
4、创建实例(即后台控制服务)
C:/>oradim –new –sid book oradim是创建实例的工具程序名称,-new表明执行新建实例,-delete表明执行删掉实例,-sid指定害例的名称。 5、创建口令文件
C:/>orapwd file=D:/oracle/product/10.1.0/db_1/database/pwdbook.ora password=bookstore entries=2
orapwd是创建口令文件的工肯程序各称,file参数指定口令文件所在的目录和文件名称,password参数指定sys用户的口令,entries参数指定数据库拥用DBA权限的用户的个数,当然还有一个force参数,相信您不指即明,这里就不再细述。 请注意,这里的命令要一行输入,中间不得换行,否则会出现不必要的错误。 口令文件是专门存放sys用户的口令,因为sys用户要负责建库、启动数据库、关闭数据库等特殊任务,把以sys用户的中令单独存放于口令文件中,这样数据库末打开时也能进行口令验证。
6、启动数据
库到nomount(实例)状态 C:/>sqlplus /nolog SQL*Plus:Release 10.1.0.2.0 - Production on 星期三 6月 29
23:09:35 2005 Copyright 1982,2004,Oracle. All rights reserved. SQL>connect sys/bookstore as sysdba
---这里是用sys连接数据库 已连接到空闲例程
SQL>startup nomount ORACLE 例程已经启动。
Total System Global Area 319888364
bytes Fixed Size 453612bytes
Variable Size 209715200bytes
DatabaseBuffers 109051904bytes
Redo Buffers 667648bytes
SQL>
7、执行建库脚本
执行建库脚本,首先要有建库的脚本。(去哪找建库脚本呢?我又没有!)不用着急,请接着往下看。 得到一个符合自己要求的建库脚本有两种方法,一种方法是在自己的电脑上用DBCA来建,接照它的提示一步步地去做,在做到第十二步的时候,请选择“生成建库脚本”,然后就大功告成,你就可以到相应的目录上去找到那个脚本并适当地修它便可便用。另一种方法就是自己手工去写一份建库脚本,这也是这里要见意使用的方法,用记事本编辑如下的内容,并将其保存为文件名任取而后缀名为(*.sql)的SQL脚本,这里保存到E盘根本录下且文件名称为book.sql。
Create database book datafile 'D:/oracle/product/10.1.0/oradata/book/system01.dbf' size 300M reuse
autoextend on next 10240Kmaxsize unlimited extent management local sysaux datafile
'D:/oracle/product/10.1.0/oradata/book/sysaux01.dbf' size 120M reuse autoextend on next 10240K
maxsize unlimited default temporary tablespace temp tempfile
'D:/oracle/product/10.1.0/oradata/book/temp01.dbf' size 20M reuse autoextend on next 640Kmaxsize unlimited undo tablespace "UNDOTBS1"
--请注意这里的undo表空间要和参数文件对应 datafile
'D:/oracle/product/10.1.0/oradata/book/undotbs01.dbf' size 200M reuse autoextend on next 5120K
maxsize unlimited logfile
group 1 ('D:/oracle/product/10.1.0/oradata/book/redo01.log') size 10240K,
group 2 ('D:/oracle/product/10.1.0/oradata/book/redo02.log') size 10240K, group 3('D:/oracle/product/10.1.0/oradata/book/redo03.log') size 10240K 接着就执行刚建的建库脚本:
SQL>start E:/book.sql
8、执行catalog脚步本创建数据字典
SQL>start D:/oracle/product/10.1.0/db_1/rdbms/admin/catalog.sql
9、执行catproc创建package包 SQL>start
D:/oracle/product/10.1.0/db_1/rdbms/admin/catproc.sql
10、执行pupbld
在执行pupbld之前要把当前用户(sys)转换成system,即以system账户连接数据库。因为此数据库是刚建的,所以system的口令是系统默认的口令,即manager。你可以在数据库建好以后再来重新设置此账户的口令。
SQL>connectsystem/manager
SQL>start D:/oracle/product/10.1.0/db_1/sqlplus/admin/pupbld.sql
11、由初始化参
数文件创建spfile文件 SQL>create spfile from pfile;
12、执行scott脚本创建scott模式 SQL>start
D:/oracle/product/10.1.0/db_1/rdbms/admin/scott.sql
13、把数据库打开到正常状态 SQL>alterdatabase open;
14、以scott连接到数据库(口令为tiger),测试新建数据库是否可以正常运行 至此,整个数据库就已经建好了。接着你就可以在此数据库上建立自己的账户和表空间啦以及数据库对象,这里就不再作更
多地叙述。
附:本意是想在linux上创建个oracle实例的,用这个文档捣鼓了半天,都快结束了才发现这个方法只能在window上使用。晕死了。自己机子上装的oracle 11i的,看了下与oracle 10g还是有点区别的:
没仔细研究,就发现amin下目录不一样:
Oracle 10G下有bdump ,udump ,cdump,pfile,create
Oracle 11i 只有 adump,dpdump,pfile 三个。有空在研究吧。
还是想在linux下手动创建个。
unix和linux下没有oradim命令,因为没用,oradim主要就是用来控制服务的,unix/linux上oracle 实例不需要建立服务,所以就没有。
posted @
2011-07-18 18:50 xzc 阅读(681) |
评论 (0) |
编辑 收藏WINDOWS是很脆弱的系统,可能装完没几天就会崩溃,如果你在WINDOWS下装有oracle,那怎么来恢复这个数据库呢?
一种方法是重装数据库后用IMP来导入原来的数据,但使用这种方法的前提是你有以前数据的备份,并且这种方法还有许多不足的地方,如备份过旧,可能会丢失许多数据、导入数据太长等。
一般情况下我们可以采用重用原来的数据库的方法来恢复。在讲步骤前先说说这种方法的原理。
数据库与实例对应,当数据库服务启动后,我们可以用SQLPLUS "/AS SYSDBA"方法连接到一个空闲的例程,当执行startup启动数据库时,首先会在%ORACLE_HOME%/database下找当前SID对应的参数文件(PFILE或者SPFILE)和密码文件,然后启动例程;接着根据参数文件记录的信息找到控制文件,读取控制文件的信息,这就是mount数据库了;最终根据控制文件的信息打开数据库。这个过程相当于对数据库着了一次冷备份的恢复。
下面的具体步骤:(我们假设原库的所有相关文件都存在)
1、安装数据库软件
只需安装同版本的数据库软件即可,不需要创建数据库。最好安装在和原来数据库同样的%ORACLE_HOME%下,省得还要修改参数文件路径等。(直接覆盖原来的oracle即可)
再次强调,只安装软件,不创建数据库,否则将数据库软件安装在同样的目录下旧的部分数据文件会被覆盖,这样数据库也不能被恢复了。
2、新建一个实例
在cmd窗口执行
oradim -new -sid oracle9i
注意,这个SID名称最好与你以前的SID一样,否则在启动的数据需要指明pfile,并且需要重建密码文件,比较麻烦。(当然,如果你就不想用原来的SID也可以,把参数文件、密码文件的名称都改成与新SID对应的名称)。
3、启动数据库
做完以上两步,就可以启动数据库了。
用net start 检查oracle服务是否已经启动,如果oracle服务没有启动,则在cmd下运行如下命令:
net start oracleserviceoracle9i
然后设定必要的环境变量,在cmd窗口运行
set ORACLE_SID=oracle9i
接着连接数据库
sqlplus "/as sysdba"
startup
如果正常的话,数据库应该就能起来了
4、启动监听
lsnrctl start
5、后续工作
经过以上几步后,基本上就可以使用oracle了,但是使用起来有点不方便,如每次在cmd中启动数据库都需要先SET ORACLE_SID、在本机连接数据库也都需要加上@TNSNAME等。我们可以修改注册表,添加ORACLE_SID的信息,避免这些麻烦。
在注册表的HKEY_LOCAL_MACHINESOFTWAREORACLE下新建字符串值,名称为ORACLE_SID,值为oracle9i。
也可以将以下内容保持成一个后缀名为reg的文件(文件名随便起),然后双击,即可将信息导入到注册表中。
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESOFTWAREORACLE]
"ORACLE_SID"="oracle9i"
注意,以上步骤都是在%ORACLE_HOME%、%ORACLE_SID%都与原库一样的情况下讨论的,虽然%ORACLE_HOME%和%ORACLE_SID%可以与原库不一样,但为了减少麻烦和出错的几率,建议不要改变则两个值。
posted @
2011-07-17 13:45 xzc 阅读(570) |
评论 (1) |
编辑 收藏
研究发现:属性(变量)可分为三类(对象属性、全局变量和局部变量)
对象属性:声明时以“this.”开头,只能被“类的实例”即对象所调用,不能被“类内部(对外不对内)”调用;全局变量:声明时直接以变量名开头,可以任意调用(对内对外);局部变量:只能被
“类内部(对内不对外)”调用。
JS函数的声明与访问原理
<script type="text/javascript">
//类
var testClass = function(){
//对象属性(对外不对内,类调用)
this.age ="25";
//全局变量(对内对外)
name="jack";
//局部变量(对内不对外)
var address = "beijing";
//全局函数(对内对外)
add = function(a,b){
//可访问:全局变量和局部变量
multiply(a,b);
return a+b;
}
//实例函数(由类的对象调用)
this.minus = function(a,b){
//可以访问:对象属性、全局变量和局部变量
return a-b;
}
//局部函数(内部直接调用)
var multiply = function(a,b){
//只能访问:全局变量和局部变量
return a*b;
}
}
//类函数(由类名直接调用)
testClass.talk= function(){
//只能访问:全局变量和全局函数
this.what = function(){
alert("What can we talk about?");
about();
}
var about = function(){
alert("about name:"+name);
alert("about add(1,1):"+add(1,1));
}
}
//原型函数(由类的对象调用)
testClass.prototype.walk = function(){
//只能访问:全局变量和全局函数
this.where = function(){
alert("Where can we go?");
go();
}
var go = function(){
alert("go name:"+name);
alert("go add(1,1):"+add(1,1));
}
}
</script>
下面看看如何调用:
<script type="text/javascript">
//获取一个cbs类的实例
var cbs= new testClass();
//调用类的对象属性age
alert("age:"+cbs.age);
//获取类函数talk的实例
var talk = new testClass.talk();
//调用类函数的实例函数
talk.what();
//获取原型函数walk的实例
var walk = new cbs.walk();
//调用原型函数的实例函数
walk.where();
</script>
posted @
2011-07-09 11:34 xzc 阅读(1007) |
评论 (2) |
编辑 收藏常用命令
Maven2 的运行命令为 : mvn ,
常用命令为 :
mvn archetype:create :创建 Maven 项目
mvn compile :编译源代码
mvn test-compile :编译测试代码
mvn test : 运行应用程序中的单元测试
mvn site : 生成项目相关信息的网站
mvn clean :清除目标目录中的生成结果
mvn package : 依据项目生成 jar 文件
mvn install :在本地 Repository 中安装 jar
mvn eclipse:eclipse :生成 Eclipse 项目文件
生成项目
建一个 JAVA 项目 : mvn archetype:create -DgroupId=com.demo -DartifactId=App
建一个 web 项目 : mvn archetype:create -DgroupId=com.demo -DartifactId=web-app -DarchetypeArtifactId=maven-archetype-webapp
简单解释一下:
archetype 是一个内建插件,他的create任务将建立项目骨架
archetypeArtifactId 项目骨架的类型
DartifactId 项目名称
可用项目骨架有:
* maven-archetype-archetype
* maven-archetype-j2ee-simple
* maven-archetype-mojo
* maven-archetype-portlet
* maven-archetype-profiles (currently under development)
* maven-archetype-quickstart
* maven-archetype-simple (currently under development)
* maven-archetype-site
* maven-archetype-site-simple, and
* maven-archetype-webapp
附maven2 生成项目标准目录布局
src/main/java Application/Library sources
src/main/resources Application/Library resources
src/main/filters Resource filter files
src/main/assembly Assembly descriptors
src/main/config Configuration files
src/main/webapp Web application sources
src/test/java Test sources
src/test/resources Test resources
src/test/filters Test resource filter files
src/site Site
LICENSE.txt Project's license
README.txt Project's readme
posted @
2011-07-08 11:20 xzc 阅读(3895) |
评论 (0) |
编辑 收藏
如果你想定义一个maven工程模板,有一种很快的方法:
1.定义你开发环境的目录结构,写一个pom.xml.
2.使用命令,mvn archetype:create-from-project 创建一个工程模板。
3.在target目录下执行mvn install.执行完之后你就可以使用你的模板了。
4.执行命令,mvn archetype:generate -DarchetypeCatalog=local就可以开始使用你定义的模板创建工程。
例子:
1.创建目录结构如下:
Demo
--src
--main
--resources
--test
--webapp
pom.xml
pom.xml内容:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>gDemo</groupId>
<artifactId>demo</artifactId>
<packaging>jar</packaging>
<version>1.0</version>
<name>Maven Quick Start Archetype</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
2.在Demo目录下执行命令,mvn archetype:create-from-project
3.在创建的target\generated-sources\archetype目录下执行,mvn install.
到此你的工程模板创建完成。在以后开发中就可以使用它。
4.执行mvn archetype:generate -DarchetypeCatalog=local会看到模板选项,选择刚才创建的模板,然后进行下面的设置。
到此恭喜你,成功使用。
posted @
2011-07-08 10:13 xzc 阅读(1566) |
评论 (0) |
编辑 收藏总体解释:
DML(data manipulation language):
它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言
DDL(data definition language):
DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
DCL(Data Control Language):
是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权力执行DCL
详细解释:
一、DDL is Data Definition Language statements. Some examples:数据定义语言,用于定义和管理 SQL 数据库中的所有对象的语言
1.CREATE - to create objects in the database 创建
2.ALTER - alters the structure of the database 修改
3.DROP - delete objects from the database 删除
4.TRUNCATE - remove all records from a table, including all spaces allocated for the records are removed
TRUNCATE TABLE [Table Name]。
下面是对Truncate语句在MSSQLServer2000中用法和原理的说明:
Truncate table 表名 速度快,而且效率高,因为:
TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。
DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 DROP TABLE 语句。
对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
TRUNCATE TABLE 不能用于参与了索引视图的表。
5.COMMENT - add comments to the data dictionary 注释
6.GRANT - gives user's access privileges to database 授权
7.REVOKE - withdraw access privileges given with the GRANT command 收回已经授予的权限
二、DML is Data Manipulation Language statements. Some examples:数据操作语言,SQL中处理数据等操作统称为数据操纵语言
1.SELECT - retrieve data from the a database 查询
2.INSERT - insert data into a table 添加
3.UPDATE - updates existing data within a table 更新
4.DELETE - deletes all records from a table, the space for the records remain 删除
5.CALL - call a PL/SQL or Java subprogram
6.EXPLAIN PLAN - explain access path to data
Oracle RDBMS执行每一条SQL语句,都必须经过Oracle优化器的评估。所以,了解优化器是如何选择(搜索)路径以及索引是如何被使用的,对优化SQL语句有很大的帮助。Explain可以用来迅速方便地查出对于给定SQL语句中的查询数据是如何得到的即搜索路径(我们通常称为Access Path)。从而使我们选择最优的查询方式达到最大的优化效果。
7.LOCK TABLE - control concurrency 锁,用于控制并发
三、DCL is Data Control Language statements. Some examples:数据控制语言,用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等
1.COMMIT - save work done 提交
2.SAVEPOINT - identify a point in a transaction to which you can later roll back 保存点
3.ROLLBACK - restore database to original since the last COMMIT 回滚
4.SET TRANSACTION - Change transaction options like what rollback segment to use 设置当前事务的特性,它对后面的事务没有影响.
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/level_level/archive/2009/06/08/4248685.aspx
posted @
2011-06-27 10:53 xzc 阅读(503) |
评论 (0) |
编辑 收藏
1,REGEXP_LIKE :与LIKE的功能相似
2,REGEXP_INSTR :与INSTR的功能相似
3,REGEXP_SUBSTR :与SUBSTR的功能相似
4,REGEXP_REPLACE :与REPLACE的功能相似
它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法相同,
但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
POSIX 正则表达式由标准的元字符(metacharacters)所构成:
'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹
配 '\n' 或 '\r'。
'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的
字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少
出现m次。
\num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
各种操作符的运算优先级
\转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
|
*/
--创建表
create table fzq
(
id varchar(4),
value varchar(10)
);
--数据插入
insert into fzq values
('1','1234560');
insert into fzq values
('2','1234560');
insert into fzq values
('3','1b3b560');
insert into fzq values
('4','abc');
insert into fzq values
('5','abcde');
insert into fzq values
('6','ADREasx');
insert into fzq values
('7','123 45');
insert into fzq values
('8','adc de');
insert into fzq values
('9','adc,.de');
insert into fzq values
('10','1B');
insert into fzq values
('10','abcbvbnb');
insert into fzq values
('11','11114560');
insert into fzq values
('11','11124560');
--regexp_like
--查询value中以1开头60结束的记录并且长度是7位
select * from fzq where value like '1____60';
select * from fzq where regexp_like(value,'1....60');
--查询value中以1开头60结束的记录并且长度是7位并且全部是数字的记录。
--使用like就不是很好实现了。
select * from fzq where regexp_like(value,'1[0-9]{4}60');
-- 也可以这样实现,使用字符集。
select * from fzq where regexp_like(value,'1[[:digit:]]{4}60');
-- 查询value中不是纯数字的记录
select * from fzq where not regexp_like(value,'^[[:digit:]]+$');
-- 查询value中不包含任何数字的记录。
select * from fzq where regexp_like(value,'^[^[:digit:]]+$');
--查询以12或者1b开头的记录.不区分大小写。
select * from fzq where regexp_like(value,'^1[2b]','i');
--查询以12或者1b开头的记录.区分大小写。
select * from fzq where regexp_like(value,'^1[2B]');
-- 查询数据中包含空白的记录。
select * from fzq where regexp_like(value,'[[:space:]]');
--查询所有包含小写字母或者数字的记录。
select * from fzq where regexp_like(value,'^([a-z]+|[0-9]+)$');
--查询任何包含标点符号的记录。
select * from fzq where regexp_like(value,'[[:punct:]]');
/*
理解它的语法就可以了。其它的函数用法类似。
作者:tshfang
来源: 泥胚文章写作http://www.nipei.com原文地址:http://www.nipei.com/article/9865
posted @
2011-06-21 15:39 xzc 阅读(1495) |
评论 (0) |
编辑 收藏
早起的国内互联网都使用GBK编码,久之,所有项目都以GBK来编码了。对于J2EE项目,为了减少编码的干扰通常都是设置一个编码的Filter,强制将Request/Response编码改为GBK。例如一个Spring的常见配置如下:
<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>GBK</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
毫无疑问,这在GBK编码的页面访问、提交数据时是没有乱码问题的。但是遇到Ajax就不一样了。Ajax强制将中文内容进行UTF-8编码,这样导致进入后端后使用GBK进行解码时发生乱码。网上的所谓的终极解决方案都是扯淡或者过于复杂,例如下面的文章:
这样的文章很多,显然:
- 使用VB进行UTF-8转换成GBK提交是完全不可行(多浏览器、多平台完全不可用)
- 使用复杂的js函数进行一次、多次编码,后端进行一次、多次解码也是不靠谱的,成本太高,无法重复使用
如果提交数据的时候能够告诉后端传输的编码信息是否就可以避免这种问题?比如Ajax请求告诉后端是UTF-8,其它请求告诉后端是GBK,这样后端分别根据指定的编码进行解码是不是就解决问题了。
有两个问题:
- 如何通过Ajax告诉后端的编码?Header过于复杂,Cookie成本太高,使用参数最方便。
- 后端何时进行解码?每一个请求进行解码,过于繁琐;获取参数时解码,此时已经乱码;在Filter里面动态设置编码是最完善的方案。
- 如何从参数中获取编码?如果是POST的body显然无法获取,因此在获取之前所有参数就已经按照某种编码解码过了,无法还原。所以通过URL传递编码最有效。支持GET/POST,同时成本很低。
解决了上述问题,来看具体实现方案。 列一段Java代码:
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.util.ClassUtils;
import org.springframework.web.filter.OncePerRequestFilter;
/** 自定义编码过滤器
* @author imxylz (imxylz#gmail.com)
* @sine 2011-6-9
*/
public class MutilCharacterEncodingFilter extends OncePerRequestFilter {
static final Pattern inputPattern = Pattern.compile(".*_input_encode=([\\w-]+).*");
static final Pattern outputPattern = Pattern.compile(".*_output_encode=([\\w-]+).*");
// Determine whether the Servlet 2.4 HttpServletResponse.setCharacterEncoding(String)
// method is available, for use in the "doFilterInternal" implementation.
private final static boolean responseSetCharacterEncodingAvailable = ClassUtils.hasMethod(HttpServletResponse.class,
"setCharacterEncoding", new Class[] { String.class });
private String encoding;
private boolean forceEncoding = false;
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
String url = request.getQueryString();
Matcher m = null;
if (url != null && (m = inputPattern.matcher(url)).matches()) {//输入编码
String inputEncoding = m.group(1);
request.setCharacterEncoding(inputEncoding);
m = outputPattern.matcher(url);
if (m.matches()) {//输出编码
response.setCharacterEncoding(m.group(1));
} else {
if (this.forceEncoding && responseSetCharacterEncodingAvailable) {
response.setCharacterEncoding(this.encoding);
}
}
} else {
if (this.encoding != null && (this.forceEncoding || request.getCharacterEncoding() == null)) {
request.setCharacterEncoding(this.encoding);
if (this.forceEncoding && responseSetCharacterEncodingAvailable) {
response.setCharacterEncoding(this.encoding);
}
}
}
filterChain.doFilter(request, response);
}
public void setEncoding(String encoding) {
this.encoding = encoding;
}
public void setForceEncoding(boolean forceEncoding) {
this.forceEncoding = forceEncoding;
}
}
解释下:
- 如果URL的QueryString中包含_input_encode就使用此编码进行设置Request编码,以后参数按照此编码进行解析,例如如果是Ajax就传入UTF-8,如果是普通的GBK请求则无视此参数。
- 如果无视此参数,则按照web.xml中配置的编码规则进行反编码,如果是GBK就按照GBK规则解析。
- 对于输出编码同样使用上述规则。需要输出编码依赖输入编码,也就是说如果有一个_output_encode的输出编码,则同时需要有一个_input_encode编码来指定输入编码。当然你可以改造成不依赖输入编码。
- 完全兼容Spring的org.springframework.web.filter.CharacterEncodingFilter编码规则,只需要替换类即可。
- 没有继承org.springframework.web.filter.CharacterEncodingFilter类的原因是,org.springframework.web.filter.CharacterEncodingFilter里面的encoding参数和forceEncoding参数是private,子类无法使用。在有_input_encode而无_output_encode的时候想依然保持Spring的Response解析规则的话无法做到,所以将里面的代码拷贝过来使用。(为了展示方便,注释都删掉了)
- 正则表达式可以改进成只需要匹配一次,从而可以提高一点点效率。
- 所有后端请求将无视编码的存在,前端Ajax的GET/POST请求也将无视编码的存在,只是在URL地址中加上一个_input_encode=UTF-8的参数。仅此而已。
- 如果想输出的编码也是UTF-8,比如手机端请求、跨站请求等,则需要URL地址参数_input_encode=UTF-8&_output_encode=UTF-8。
- 对于POST请求,编码参数不能写在body里面,否则无法解析。
- 显然,这种终极解决方案,在任何编码中都可以解决,GBK/UTF-8/ISO8859-1等编码任何组合都可以实现。
- 唯一局限性是,此解决方案限制在J2EE项目中,其它平台不知是否有类似Filter这样的组件能够设置编码的概念。
posted @
2011-06-21 11:54 xzc 阅读(2107) |
评论 (1) |
编辑 收藏
下载地址:http://sourceforge.net/project/showfiles.php?group_id=178867
1.buffalo-2.0.jar
在buffalo-2.0-bin里,把它加到Web应用程序里的lib
2.buffalo.js和prototype.js
我把这两个文件放到Web应用程序的scripts/目录下,buffalo.js在buffalo-2.0-bin里,prototype.js在buffalo-demo.war里找
4.web.xml内容
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<servlet>
<servlet-name>bfapp</servlet-name>
<servlet-class>net.buffalo.web.servlet.ApplicationServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>bfapp</servlet-name>
<url-pattern>/bfapp/*</url-pattern>
</servlet-mapping>
</web-app>
5.index.jsp文件
<%@ page language="java" pageEncoding="UTF-8"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>第一个 buffalo 示例程序</title>
<script language="JavaScript" src="scripts/prototype.js"></script>
<script language="JavaScript" src="scripts/buffalo.js"></script>
<script type="text/javascript">
var endPoint="<%=request.getContextPath()%>/bfapp";
var buffalo = new Buffalo(endPoint);
function hello(me) {
buffalo.remoteCall("demoService.getHello", [me.value], function(reply) {
alert(reply.getResult());
})
}
</script>
</head>
<body>
输入你的名字:<input type="text" name="myname">
<input type="button" value="Buffao远程调用" onclick="hello($('myname'));"><br>
</body>
</html>
说明:remoteCall是远程调用方法,demoService是buffalo-service.properties文件的键,getHello是被调用java类方法名,me.value是传给getHello方法的参数,reply.getResult()是getHello返回的值。
6.DemoService.java文件
package demo.buffalo;
/**
*
* @文件名 demo.buffalo.DemoService.java
* @作者 chenlb
* @创建时间 2007-7-14 下午12:42:17
*/
public class DemoService {
public String getHello(String name) {
return "Hello , "+name +" 这是第一个buffalo示例程序";
}
}
7.buffalo-service.properties文件放到WEB-INF/classes/目录下
demoService=demo.buffalo.DemoService
说明:框架是通过此文件来查找远程调用的类的。
8.现在可以运行了。
示例下载
注意:Eclipse项目,文件编码是UTF-8
官方地址:
Buffalo中文论坛:http://groups.google.com/group/amowa
http://buffalo.sourceforge.net/tutorial.html
http://confluence.redsaga.com/pages/viewpage.action?pageId=1643
JavaScript API :http://confluence.redsaga.com/display/BUFFALO/JavaScript+API
http://www.amowa.net/buffalo/zh/index.html
posted @
2011-06-16 16:44 xzc 阅读(386) |
评论 (0) |
编辑 收藏转自:http://dingyu.me/blog/posts/view/flowchart-howtos
一个哥们在MSN上告诉我,他们公司的交互设计师只产出流程图,并问我用什么标准评价流程图的好坏。他的说法把我彻底震了-这分工也太细了吧!也不知道该说他们那里这样是好还是不好。
不过仔细想来,我倒的确没有仔细考虑过流程图的好坏,正好借此机会自我总结一下。
1、各司其职的形状
在我的流程图中,适用于不同目的和功能的形状都有各自确定的规范。到目前为止,我一共定义了以下一些形状:
(1)开始和结束

作为整张流程图的头和尾,必须标清楚到底具体指哪个页面,以免日后出现歧义。
(2)网页

如你所见,网页的形状是一个带有漂亮的淡蓝色过渡效果的长方形,它的边框为深蓝色,中间写明了这个网页的用途,括号中的数字代表这个形状所对应的demo文件的名称(比如这里是2.html),我有时会把流程图输出为网页的形式,并把每个网页形状和它所对应的demo文件链接起来,这样查看起来非常方便。对OmniGraffle来说这是小菜一碟,如果你被迫用Visio,嗯……
另外,所有从形状出来的线条,都具有和此形状边框一样的颜色。这样的做法不仅看起来漂亮,在复杂的流程图中还能轻易地标明各形状的关系。我没有见过类似的做法,所以这是由我首创也说不定,呵。
(3)后台判断

很常见的一个形状。我在用法上有一点和其他人的不同在于,我几乎总是让‘是’的分支往下流动,让‘否’的分支向右流动。因为流程图一般都是从上向下、从左到右绘制的,遵循上述规则一方面可以让绘制者不用为选择方向操心,另一方面也方便了读者阅读。
(4)表单错误页

既然有表单,当然会有错误信息。其实这个信息很重要,用户出错时惶恐不安,就靠着错误提示来解决问题了。你不在流程图里说什么时候显示错误页、不在demo里提供错误页,有些程序员会直接在网页上写个“错误,请检查”,所以UI设计师一定要对这个东西重视起来。
但一般来说也没必要把每种错误都在流程图中表示出来,因为含有两个文本框的表单就有三种出错情况了,多了就更不用说了。所以我都是把错误页变为表单的附属页,比如表单页的编号为2,那么此表单错误页的编号就从2.1开始排下去,每种错误放到一个附属页中,这样程序员在拿到demo时也能搞清楚什么意思。
结合网页和表单的形状,一个表单验证的流程图就是这样的:

(5)后台动作

并非所有后台动作都绘入流程图中(否则流程图就会变成庞然大物了),只有需要特别强调的后台动作(和用户体验直接相关的)才使用此形状。
(6)多重分支

多重分支指的是几种并列的情况,每种情况都有发生的可能,发生哪种取决于分支起始处的判断结果。
(7)对话框

有时候一些操作可以利用对话框来完成, 这些对话框由js生成,显示在父界面之上。
(8)注释

这个形状(比如页面)详细的内容,或者需要解释的业务逻辑,甚至用户此处的情况等,我都会放到注释中,这样既降低沟通成本,又可作为备忘。
(9)跳转点

在一个复杂的流程图中,往往出现跳转到另外一个远处结点的情况,此时如果直接用线连过去,未免使得流程图显得凌乱,用一个跳转点就解决问题了。在点内标明跳转到的形状的编号,画起来容易,看起来也清楚。
此外,也可以利用跳转点来分割篇幅巨大的流程图,Yahoo!就这么用。
(10)子流程

分割篇幅巨大的流程图,更好的办法是用子流程。
要注意的是,如果你在流程图中使用了子流程这一形状,一定记得同时附上子流程图,以消除影响项目质量的不确定性因素。另外,在子流程图中也可以标明其所属关系。
(11)流程块


可以用流程块将整张流程图分隔为几个部分,并为每个部分单独命名(比如“流程块1”等)。这样做的目的在于从视觉上使复杂的流程图变得更为清晰,在沟通时也方便。
2、图例和流程图信息

在团队合作中,图例是必须的,否则没人知道你画出来的东西到底是什么。即使流程图只给自己看,也最好养成标注图例的好习惯。其实这道理有点类似程序中的注释。
流程图信息也是必备的。其内容至少应包括作者、时间、流程图名称和版本(如下图)。这一方面可以让读者(其他同事)在有问题时能够方便地找到作者你,也起到了meta的作用。
3、绘制流程图的工具
Mac下首选OmniGraffle,Windows下除了Visio,似乎没有更好的选择(虽然Visio已经很难用了)。
4、评价流程图的好坏
我觉得一个好的流程图至少应做到以下几点:
- 密切地迎合了用户的心理状态、如实的反映了用户的操作习惯。流程图是要指导UI设计的,是UI设计的参照物,如果流程图本身无法正确描绘出用户的情况的话,UI十有八九会出问题;
- 覆盖了各种可能的情况和细节。这非常重要。任何在先期不确定的因素,都会在项目中成为随时引爆的地雷,都会直接降低最终上线的UI质量。此种情况真是屡见不鲜。但同时这条又很难做到,因为它不仅要求设计师熟悉用户,也要设计师充分知晓产品的商业逻辑,还要了解系统的运作机制,落下以上任何一个方面,都会在流程图中留下死角。这个问题我不知道有没有更好的解决方案,不过与PD和系分反复沟通是个行之有效的方法;
- 考虑到系统的设计和承受能力。系统的运作机制和承受能力必须在绘制流程图过程中考虑进去,以免出现流程图被开发人员枪毙的情况。我的习惯是,在绘制流程图时和系统分析师频繁沟通和交流,确保每一个环节都是可行的;
- 确保别人看得懂你的流程图。别人现在看不懂,你自己以后也一样看不懂。为了降低沟通成本,把流程图画清楚吧。
5、其它
(1)想办法把流程图绘制得漂亮些。谁不喜欢漂亮的东西呢?
这是我做过的一些流程图,当然文字全部模糊掉了(放图之前犹豫了好长时间-这样做不知是否有损我的职业道德。我特意请教了Fenng,他觉得没事。如果谁觉得有问题请直言不讳地告诉我)。


(2)如果你在公司里不是一锤定音式的人物的话,你就需要对你的文档进行版本管理。流程图也不例外,什么时间发布的什么版本,都要清楚地标出来,“ 最新”是个用不得的词。
我就说这么多了,抛砖引玉而已,蓉儿等人看你们的了!
噢对了,问个事儿:大家有没有觉得我每次写的文章都太长了?
posted @
2011-05-27 17:07 xzc 阅读(690) |
评论 (1) |
编辑 收藏从ftp定时下载按日期生成的文件
1、下载脚本get.bat如下
f:
cd f:/beifen (脚本所在目录)
set cicdate=%date:~0,4%%date:~5,2%%date:~8,2%
(echo open ftp地址
echo 用户名
echo 密码
echo prompt
echo get %cicdate%.txt
echo bye) > ftp_beifen.src
ftp -s:ftp_beifen.src
echo %date%导出数据库备份结束,时间:%time% >> getftp_beifen.log
2、在xp上定时自动运行批处理文件
AT命令是Windows XP中内置的命令,它也可以媲美Windows中的“计划任务”,而且在计划的安排、任务的管理、工作事务的处理方面,
AT命令具有更强大更神通的功能。AT命令可在指定时间和日期、在指定计算机上运行命令和程序。
查看所有安排的计划 at
取消已经安排的计划 at 5 /Delete
在dos下运行一下命令,系统就会在每天的16:46分自动运行批处理文件get.bat
net stop schedule
net start schedule
at 16:46 /every:Monday,Tuesday,Wednesday,Thursday,Friday,Saturday,Sunday F:\beifen\get.bat
posted @
2011-05-21 12:11 xzc 阅读(4717) |
评论 (1) |
编辑 收藏转自:http://blog.csdn.net/tianlesoftware/archive/2009/12/01/4915223.aspx
一、什么是Oracle字符集
Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。
影响Oracle数据库字符集最重要的参数是NLS_LANG参数。
它的格式如下: NLS_LANG = language_territory.charset
它有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中:
Language: 指定服务器消息的语言, 影响提示信息是中文还是英文
Territory: 指定服务器的日期和数字格式,
Charset: 指定字符集。
如:AMERICAN _ AMERICA. ZHS16GBK
从NLS_LANG的组成我们可以看出,真正影响数据库字符集的其实是第三部分。
所以两个数据库之间的字符集只要第三部分一样就可以相互导入导出数据,前面影响的只是提示信息是中文还是英文。
二.字符集的相关知识:
2.1 字符集
实质就是按照一定的字符编码方案,对一组特定的符号,分别赋予不同数值编码的集合。Oracle数据库最早支持的编码方案是US7ASCII。
Oracle的字符集命名遵循以下命名规则:
<Language><bit size><encoding>
即: <语言><比特位数><编码>
比如: ZHS16GBK表示采用GBK编码格式、16位(两个字节)简体中文字符集
2.2 字符编码方案
2.2.1 单字节编码
(1)单字节7位字符集,可以定义128个字符,最常用的字符集为US7ASCII
(2)单字节8位字符集,可以定义256个字符,适合于欧洲大部分国家
例如:WE8ISO8859P1(西欧、8位、ISO标准8859P1编码)
2.2.2 多字节编码
(1)变长多字节编码
某些字符用一个字节表示,其它字符用两个或多个字符表示,变长多字节编码常用于对亚洲语言的支持, 例如日语、汉语、印地语等
例如:AL32UTF8(其中AL代表ALL,指适用于所有语言)、zhs16cgb231280
(2)定长多字节编码
每一个字符都使用固定长度字节的编码方案,目前oracle唯一支持的定长多字节编码是AF16UTF16,也是仅用于国家字符集
2.2.3 unicode编码
Unicode是一个涵盖了目前全世界使用的所有已知字符的单一编码方案,也就是说Unicode为每一个字符提供唯一的编码。UTF-16是unicode的16位编码方式,是一种定长多字节编码,用2个字节表示一个unicode字符,AF16UTF16是UTF-16编码字符集。
UTF-8是unicode的8位编码方式,是一种变长多字节编码,这种编码可以用1、2、3个字节表示一个unicode字符,AL32UTF8,UTF8、UTFE是UTF-8编码字符集
2.3 字符集超级
当一种字符集(字符集A)的编码数值包含所有另一种字符集(字符集B)的编码数值,并且两种字符集相同编码数值代表相同的字符时,则字符集A是字符集B的超级,或称字符集B是字符集A的子集。
Oracle8i和oracle9i官方文档资料中备有子集-超级对照表(subset-superset pairs),例如:WE8ISO8859P1是WE8MSWIN1252的子集。由于US7ASCII是最早的Oracle数据库编码格式,因此有许多字符集是US7ASCII的超集,例如WE8ISO8859P1、ZHS16CGB231280、ZHS16GBK都是US7ASCII的超集。
2.4 数据库字符集(oracle服务器端字符集)
数据库字符集在创建数据库时指定,在创建后通常不能更改。在创建数据库时,可以指定字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。
2.4.1字符集
(1)用来存储CHAR, VARCHAR2, CLOB, LONG等类型数据
(2)用来标示诸如表名、列名以及PL/SQL变量等
(3)用来存储SQL和PL/SQL程序单元等
2.4.2国家字符集:
(1)用以存储NCHAR, NVARCHAR2, NCLOB等类型数据
(2)国家字符集实质上是为oracle选择的附加字符集,主要作用是为了增强oracle的字符处理能力,因为NCHAR数据类型可以提供对亚洲使用定长多字节编码的支持,而数据库字符集则不能。国家字符集在oracle9i中进行了重新定义,只能在unicode编码中的AF16UTF16和UTF8中选择,默认值是AF16UTF16
2.4.3查询字符集参数
可以查询以下数据字典或视图查看字符集设置情况
nls_database_parameters、props$、v$nls_parameters
查询结果中NLS_CHARACTERSET表示字符集,NLS_NCHAR_CHARACTERSET表示国家字符集
2.4.4修改数据库字符集
按照上文所说,数据库字符集在创建后原则上不能更改。不过有2种方法可行。
1. 如果需要修改字符集,通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换。
2. 通过ALTER DATABASE CHARACTER SET语句修改字符集,但创建数据库后修改字符集是有限制的,只有新的字符集是当前字符集的超集时才能修改数据库字符集,例如UTF8是US7ASCII的超集,修改数据库字符集可使用ALTER DATABASE CHARACTER SET UTF8。
2.5 客户端字符集(NLS_LANG参数)
2.5.1客户端字符集含义
客户端字符集定义了客户端字符数据的编码方式,任何发自或发往客户端的字符数据均使用客户端定义的字符集编码,客户端可以看作是能与数据库直接连接的各种应用,例如sqlplus,exp/imp等。客户端字符集是通过设置NLS_LANG参数来设定的。
2.5.2 NLS_LANG参数格式
NLS_LANG=<language>_<territory>.<client character set>
Language: 显示oracle消息,校验,日期命名
Territory:指定默认日期、数字、货币等格式
Client character set:指定客户端将使用的字符集
例如:NLS_LANG=AMERICAN_AMERICA.US7ASCII
AMERICAN是语言,AMERICA是地区,US7ASCII是客户端字符集
2.5.3客户端字符集设置方法
1)UNIX环境
$NLS_LANG=“simplified chinese”_china.zhs16gbk
$export NLS_LANG
编辑oracle用户的profile文件
2)Windows环境
编辑注册表
Regedit.exe ---》 HKEY_LOCAL_MACHINE ---》SOFTWARE ---》 ORACLE-HOME
2.5.4 NLS参数查询
Oracle提供若干NLS参数定制数据库和用户机以适应本地格式,例如有NLS_LANGUAGE,NLS_DATE_FORMAT,NLS_CALENDER等,可以通过查询以下数据字典或v$视图查看。
NLS_DATABASE_PARAMETERS:显示数据库当前NLS参数取值,包括数据库字符集取值
NLS_SESSION_PARAMETERS: 显示由NLS_LANG 设置的参数,或经过alter session 改变后的参数值(不包括由NLS_LANG 设置的客户端字符集)
NLS_INSTANCE_PARAMETE: 显示由参数文件init<SID>.ora 定义的参数
V$NLS_PARAMETERS:显示数据库当前NLS参数取值
2.5.5修改NLS参数
使用下列方法可以修改NLS参数
(1)修改实例启动时使用的初始化参数文件
(2)修改环境变量NLS_LANG
(3)使用ALTER SESSION语句,在oracle会话中修改
(4)使用某些SQL函数
NLS作用优先级别:Sql function > alter session > 环境变量或注册表 > 参数文件 > 数据库默认参数
三.EXP/IMP 与 字符集
3.1 EXP/IMP
Export 和 Import 是一对读写Oracle数据的工具。Export 将 Oracle 数据库中的数据输出到操作系统文件中, Import 把这些文件中的数据读到Oracle 数据库中,由于使用exp/imp进行数据迁移时,数据从源数据库到目标数据库的过程中有四个环节涉及到字符集,如果这四个环节的字符集不一致,将会发生字符集转换。
EXP
____________ _________________ _____________
|imp导入文件|<-|环境变量NLS_LANG|<-|数据库字符集|
------------ ----------------- -------------
IMP
____________ _________________ _____________
|imp导入文件|->|环境变量NLS_LANG|->|数据库字符集|
------------ ----------------- -------------
四个字符集是
(1)源数据库字符集
(2)Export过程中用户会话字符集(通过NLS_LANG设定)
(3)Import过程中用户会话字符集(通过NLS_LANG设定)
(4)目标数据库字符集
3.2导出的转换过程
在Export过程中,如果源数据库字符集与Export用户会话字符集不一致,会发生字符集转换,并在导出文件的头部几个字节中存储Export用户会话字符集的ID号。在这个转换过程中可能发生数据的丢失。
例:如果源数据库使用ZHS16GBK,而Export用户会话字符集使用US7ASCII,由于ZHS16GBK是16位字符集,而US7ASCII是7位字符集,这个转换过程中,中文字符在US7ASCII中不能够找到对等的字符,所以所有中文字符都会丢失而变成“?? ”形式,这样转换后生成的Dmp文件已经发生了数据丢失。
因此如果想正确导出源数据库数据,则Export过程中用户会话字符集应等于源数据库字符集或是源数据库字符集的超集
3.3导入的转换过程
(1)确定导出数据库字符集环境
通过读取导出文件头,可以获得导出文件的字符集设置
(2)确定导入session的字符集,即导入Session使用的NLS_LANG环境变量
(3)IMP读取导出文件
读取导出文件字符集ID,和导入进程的NLS_LANG进行比较
(4)如果导出文件字符集和导入Session字符集相同,那么在这一步骤内就不需要转换, 如果不同,就需要把数据转换为导入Session使用的字符集。可以看出,导入数据到数据库过程中发生两次字符集转换
第一次:导入文件字符集与导入Session使用的字符集之间的转换,如果这个转换过程不能正确完成,Import向目标数据库的导入过程也就不能完成。
第二次:导入Session字符集与数据库字符集之间的转换。
四. 查看数据库字符集
涉及三方面的字符集,
1. oracel server端的字符集;
2. oracle client端的字符集;
3. dmp文件的字符集。
在做数据导入的时候,需要这三个字符集都一致才能正确导入。
4.1 查询oracle server端的字符集
有很多种方法可以查出oracle server端的字符集,比较直观的查询方法是以下这种:
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
SQL>select userenv(‘language’) from dual;
AMERICAN _ AMERICA. ZHS16GBK
4.2 如何查询dmp文件的字符集
用oracle的exp工具导出的dmp文件也包含了字符集信息,dmp文件的第2和第3个字节记录了dmp文件的字符集。如果dmp文件不大,比如只有几M或几十M,可以用UltraEdit打开(16进制方式),看第2第3个字节的内容,如0354,然后用以下SQL查出它对应的字符集:
SQL> select nls_charset_name(to_number('0354','xxxx')) from dual;
ZHS16GBK
如果dmp文件很大,比如有2G以上(这也是最常见的情况),用文本编辑器打开很慢或者完全打不开,可以用以下命令(在unix主机上):
cat exp.dmp |od -x|head -1|awk '{print $2 $3}'|cut -c 3-6
然后用上述SQL也可以得到它对应的字符集。
4.3 查询oracle client端的字符集
在windows平台下,就是注册表里面相应OracleHome的NLS_LANG。还可以在dos窗口里面自己设置,
比如: set nls_lang=AMERICAN_AMERICA.ZHS16GBK
这样就只影响这个窗口里面的环境变量。
在unix平台下,就是环境变量NLS_LANG。
$echo $NLS_LANG
AMERICAN_AMERICA.ZHS16GBK
如果检查的结果发现server端与client端字符集不一致,请统一修改为同server端相同的字符集。
补充:
(1).数据库服务器字符集
select * from nls_database_parameters
来源于props$,是表示数据库的字符集。
(2).客户端字符集环境
select * from nls_instance_parameters
其来源于v$parameter,表示客户端的字符集的设置,可能是参数文件,环境变量或者是注册表
(3).会话字符集环境
select * from nls_session_parameters
来源于v$nls_parameters,表示会话自己的设置,可能是会话的环境变量或者是alter session完成,如果会话没有特殊的设置,将与nls_instance_parameters一致。
(4).客户端的字符集要求与服务器一致,才能正确显示数据库的非Ascii字符。
如果多个设置存在的时候,NLS作用优先级别:Sql function > alter session > 环境变量或注册表 > 参数文件 > 数据库默认参数
字符集要求一致,但是语言设置却可以不同,语言设置建议用英文。如字符集是zhs16gbk,则nls_lang可以是American_America.zhs16gbk。
五. 修改oracle的字符集
按照上文所说,数据库字符集在创建后原则上不能更改。因此,在设计和安装之初考虑使用哪一种字符集十分重要。对数据库server而言,错误的修改字符集将会导致很多不可测的后果,可能会严重影响数据库的正常运行,所以在修改之前一定要确认两种字符集是否存在子集和超集的关系。一般来说,除非万不得已,我们不建议修改oracle数据库server端的字符集。特别说明,我们最常用的两种字符集ZHS16GBK和ZHS16CGB231280之间不存在子集和超集关系,因此理论上讲这两种字符集之间的相互转换不受支持。
不过修改字符集有2种方法可行。
1. 通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换。
2. 通过ALTER DATABASE CHARACTER SET语句修改字符集,但创建数据库后修改字符集是有限制的,只有新的字符集是当前字符集的超集时才能修改数据库字符集,例如UTF8是US7ASCII的超集,修改数据库字符集可使用ALTER DATABASE CHARACTER SET UTF8。
5.1 修改server端字符集(不建议使用)
1. 关闭数据库
SQL>SHUTDOWN IMMEDIATE
2. 启动到Mount
SQL>STARTUP MOUNT;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;
SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
SQL>ALTER DATABASE CHARACTER SET ZHS16GBK;
SQL>ALTER DATABASE national CHARACTER SET ZHS16GBK;
SQL>SHUTDOWN IMMEDIATE;
SQL>STARTUP
注意:如果没有大对象,在使用过程中进行语言转换没有什么影响,(切记设定的字符集必须是ORACLE支持,不然不能start) 按上面的做法就可以。
若出现‘ORA-12717: Cannot ALTER DATABASE NATIONAL CHARACTER SET when NCLOB data exists’ 这样的提示信息,
要解决这个问题有两种方法
1. 利用INTERNAL_USE 关键字修改区域设置,
2. 利用re-create,但是re-create有点复杂,所以请用internal_use
SQL>SHUTDOWN IMMEDIATE;
SQL>STARTUP MOUNT EXCLUSIVE;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;
SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
SQL>ALTER DATABASE NATIONAL CHARACTER SET INTERNAL_USE UTF8;
SQL>SHUTDOWN immediate;
SQL>startup;
如果按上面的做法做,National charset的区域设置就没有问题
5.2 修改dmp文件字符集
上文说过,dmp文件的第2第3字节记录了字符集信息,因此直接修改dmp文件的第2第3字节的内容就可以‘骗’过oracle的检查。这样做理论上也仅是从子集到超集可以修改,但很多情况下在没有子集和超集关系的情况下也可以修改,我们常用的一些字符集,如US7ASCII,WE8ISO8859P1,ZHS16CGB231280,ZHS16GBK基本都可以改。因为改的只是dmp文件,所以影响不大。
具体的修改方法比较多,最简单的就是直接用UltraEdit修改dmp文件的第2和第3个字节。
比如想将dmp文件的字符集改为ZHS16GBK,可以用以下SQL查出该种字符集对应的16进制代码: SQL> select to_char(nls_charset_id('ZHS16GBK'), 'xxxx') from dual;
0354
然后将dmp文件的2、3字节修改为0354即可。
如果dmp文件很大,用ue无法打开,就需要用程序的方法了。
5.3客户端字符集设置方法
1)UNIX环境
$NLS_LANG=“simplified chinese”_china.zhs16gbk
$export NLS_LANG
编辑oracle用户的profile文件
2)Windows环境
编辑注册表
Regedit.exe ---》 HKEY_LOCAL_MACHINE ---》SOFTWARE ---》 ORACLE-HOME
或者在窗口设置:
set nls_lang=AMERICAN_AMERICA.ZHS16GBK
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/tianlesoftware/archive/2009/12/01/4915223.aspx
posted @
2011-04-15 10:58 xzc 阅读(909) |
评论 (0) |
编辑 收藏
从10g开始,oracle开始提供Shrink的命令,假如我们的表空间中支持自动段空间管理 (ASSM),就可以使用这个特性缩小段,即降低HWM。这里需要强调一点,10g的这个新特性,仅对ASSM表空间有效,否则会报 ORA-10635: Invalid segment or tablespace type。
有关ASSM的详细信息,请参考我的Blog:Oracle 自动段空间管理
http://blog.csdn.net/tianlesoftware/archive/2009/12/07/4958989.aspx
如果经常在表上执行DML操作,会造成数据库块中数据分布稀疏,浪费大量空间。同时也会影响全表扫描的性能,因为全表扫描需要访问更多的数据块。从oracle10g开始,表可以通过shrink来重组数据使数据分布更紧密,同时降低HWM释放空闲数据块。
segment shrink分为两个阶段:
1、数据重组(compact):通过一系列insert、delete操作,将数据尽量排列在段的前面。在这个过程中需要在表上加RX锁,即只在需要移动的行上加锁。由于涉及到rowid的改变,需要enable row movement.同时要disable基于rowid的trigger.这一过程对业务影响比较小。
2、HWM调整:第二阶段是调整HWM位置,释放空闲数据块。此过程需要在表上加X锁,会造成表上的所有DML语句阻塞。在业务特别繁忙的系统上可能造成比较大的影响。
shrink space语句两个阶段都执行。
shrink space compact只执行第一个阶段。
如果系统业务比较繁忙,可以先执行shrink space compact重组数据,然后在业务不忙的时候再执行shrink space降低HWM释放空闲数据块。
shrink必须开启行迁移功能。
alter table table_name enable row movement ;
注意:alter table XXX enable row movement语句会造成引用表XXX的对象(如存储过程、包、视图等)变为无效。执行完成后,最好执行一下utlrp.sql来编译无效的对象。
语法:
alter table <table_name> shrink space [ <null> | compact | cascade ];
alter table <table_name> shrink space compcat;
收缩表,相当于把块中数据打结实了,但会保持 high water mark;
alter table <tablespace_name> shrink space;
收缩表,降低 high water mark;
alter table <tablespace_name> shrink space cascade;
收缩表,降低 high water mark,并且相关索引也要收缩一下下。
alter index idxname shrink space;
回缩索引
1:普通表
Sql脚本,改脚本会生成相应的语句
select'alter table '||table_name||' enable row movement;'||chr(10)||'alter table '||table_name||' shrink space;'||chr(10)from user_tables;
select'alter index '||index_name||' shrink space;'||chr(10)from user_indexes;
2:分区表的处理
进行shrink space时 发生ORA-10631错误.shrink space有一些限制.
在表上建有函数索引(包括全文索引)会失败。
Sql脚本,改脚本会生成相应的语句
select 'alter table '||table_name||' enable row movement;'||chr(10)||'alter table '||table_name||' shrink space;'||chr(10) from user_tables where ;
select 'alter index '||index_name||' shrink space;'||chr(10) from user_indexes where uniqueness='NONUNIQUE' ;
select 'alter table '||segment_name||' modify subpartition '||partition_name||' shrink space;'||chr(10) from user_segments where segment_type='TABLE SUBPARTITION' ';
详细测试:
我们用系统视图all_objects来在上个测试的tablespace ASSM上创建测试表my_objects
/* Formatted on 2009-12-7 20:42:45 (QP5 v5.115.810.9015) */
CREATE TABLESPACE ASSM DATAFILE 'd:\ASSM01.dbf' SIZE 100M EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO;
/* Formatted on 2009-12-7 20:39:26 (QP5 v5.115.810.9015) */
SELECT TABLESPACE_NAME,
BLOCK_SIZE,
EXTENT_MANAGEMENT,
ALLOCATION_TYPE,
SEGMENT_SPACE_MANAGEMENT
FROM dba_tablespaces
WHERE TABLESPACE_NAME = 'ASSM';
TABLESPACE_NAME BLOCK_SIZE EXTENT_MAN ALLOCATIO SEGMEN
--------------------- ---------- ---------- --------- ------
ASSM 8192 LOCAL SYSTEM AUTO
1 row selected.
/* Formatted on 2009-12-7 20:44:15 (QP5 v5.115.810.9015) */
CREATE TABLE my_objects
TABLESPACE assm
AS
SELECT * FROM all_objects;
然后我们随机地从table MY_OBJECTS中删除一部分数据:
SQL> SELECT COUNT ( * ) FROM my_objects;
COUNT(*)
----------
49477
SQL> delete from my_objects where object_name like '%C%';
SQL> delete from my_objects where object_name like '%U%';
SQL> delete from my_objects where object_name like '%A%';
现在我们使用show_space()来看看my_objects的数据存储状况:
注: show_space() 存储过程代码参看一下连接的附件
http://blog.csdn.net/tianlesoftware/archive/2009/12/07/4958989.aspx
SQL>exec show_space('my_objects','auto','T','Y');
Total Blocks............................768
Total Bytes.............................6291456
Unused Blocks...........................68
Unused Bytes............................557056
Last Used Ext FileId....................8
Last Used Ext BlockId...................649
Last Used Block.........................60
*************************************************
The segment is analyzed
0% -- 25% free space blocks.............41
0% -- 25% free space bytes..............335872
25% -- 50% free space blocks............209
25% -- 50% free space bytes.............1712128
50% -- 75% free space blocks............190
50% -- 75% free space bytes.............1556480
75% -- 100% free space blocks...........229
75% -- 100% free space bytes............1875968
Unused Blocks...........................0
Unused Bytes............................0
Total Blocks............................11
Total bytes.............................90112
PL/SQL 过程已成功完成。
这里,table my_objects的HWM下有767个block,其中,free space为25-50%的block有209个,free space为50-75%的block有190个,free space为75-100%的block有229个. Total blocks 11个。
这种情况下,我们需要对这个table的现有数据行进行重组。
要使用assm上的shink,首先我们需要使该表支持行移动,可以用这样的命令来完成:
alter table my_objects enable row movement;
现在,就可以来降低my_objects的HWM,回收空间了,使用命令:
alter table bookings shrink space;
我们具体的看一下实验的结果:
SQL> alter table my_objects enable row movement;
表已更改。
SQL> alter table my_objects shrink space;
表已更改。
SQL>exec show_space('my_objects','auto','T','Y');
Total Blocks............................272
Total Bytes.............................2228224
Unused Blocks...........................0
Unused Bytes............................0
Last Used Ext FileId....................8
Last Used Ext BlockId...................265
Last Used Block.........................16
*************************************************
The segment is analyzed
0% -- 25% free space blocks.............0
0% -- 25% free space bytes..............0
25% -- 50% free space blocks............0
25% -- 50% free space bytes.............0
50% -- 75% free space blocks............1
50% -- 75% free space bytes.............8192
75% -- 100% free space blocks...........0
75% -- 100% free space bytes............0
Unused Blocks...........................0
Unused Bytes............................0
Total Blocks............................257
Total bytes.............................2105344
在执行玩shrink命令后,我们可以看到,table my_objects的HWM现在降到了271的位置,而且HWM下的block的空间使用状况,Total blocks 的block有257个,free space 为25-50% Block只有0个。
Shrink 的实现机制:
我们接下来讨论一下shrink的实现机制,我们同样使用讨论move机制的那个实验来观察。
/* Formatted on 2009-12-7 20:58:40 (QP5 v5.115.810.9015) */
CREATE TABLE TEST_HWM (id INT, name CHAR (2000))
TABLESPACE ASSM;
INSERT INTO TEST_HWM VALUES (1, 'aa');
INSERT INTO TEST_HWM VALUES (2, 'bb');
INSERT INTO TEST_HWM VALUES (2, 'cc');
INSERT INTO TEST_HWM VALUES (3, 'dd');
INSERT INTO TEST_HWM VALUES (4, 'ds');
INSERT INTO TEST_HWM VALUES (5, 'dss');
INSERT INTO TEST_HWM VALUES (6, 'dss');
INSERT INTO TEST_HWM VALUES (7, 'ess');
INSERT INTO TEST_HWM VALUES (8, 'es');
INSERT INTO TEST_HWM VALUES (9, 'es');
INSERT INTO TEST_HWM VALUES (10, 'es');
我们来看看这个table的rowid和block的ID和信息:
/* Formatted on 2009-12-7 21:00:02 (QP5 v5.115.810.9015) */
SQL>SELECT ROWID, id, name FROM TEST_HWM;ROWID ID NAME
ROWID ID NAME
------------------------------------- ---------- --------
AAANMEAAIAAAAEcAAA 3 dd
AAANMEAAIAAAAEcAAB 4 ds
AAANMEAAIAAAAEcAAC 5 dss
AAANMEAAIAAAAEdAAA 6 dss
AAANMEAAIAAAAEdAAB 7 ess
AAANMEAAIAAAAEdAAC 8 es
AAANMEAAIAAAAEeAAA 9 es
AAANMEAAIAAAAEeAAB 10 es
AAANMEAAIAAAAEgAAA 1 aa
AAANMEAAIAAAAEgAAB 2 bb
AAANMEAAIAAAAEgAAC 2 cc
/* Formatted on 2009-12-7 21:00:49 (QP5 v5.115.810.9015) */
SQL>SELECT EXTENT_ID,
FILE_ID,
RELATIVE_FNO,
BLOCK_ID,
BLOCKS
FROM dba_extents
WHERE segment_name = 'TEST_HWM';
EXTENT_ID FILE_ID RELATIVE_FNO BLOCK_ID BLOCKS
---------- ---------- ------------ ---------- ----------
0 8 8 281 8
1 row selected.
然后从table test_hwm中删除一些数据:
delete from TEST_HWM where id = 2;
delete from TEST_HWM where id = 4;
delete from TEST_HWM where id = 3;
delete from TEST_HWM where id = 7;
delete from TEST_HWM where id = 8;
观察table test_hwm的rowid和blockid的信息:
SQL> select rowid , id,name from TEST_HWM;
ROWID ID NAME
------------------------------------------ ---------- ---------
AAANMEAAIAAAAEcAAC 5 dss
AAANMEAAIAAAAEdAAA 6 dss
AAANMEAAIAAAAEeAAA 9 es
AAANMEAAIAAAAEeAAB 10 es
AAANMEAAIAAAAEgAAA 1 aa
/* Formatted on 2009-12-7 21:00:49 (QP5 v5.115.810.9015) */
SQL>SELECT EXTENT_ID,
FILE_ID,
RELATIVE_FNO,
BLOCK_ID,
BLOCKS
FROM dba_extents
WHERE segment_name = 'TEST_HWM';
EXTENT_ID FILE_ID RELATIVE_FNO BLOCK_ID BLOCKS
---------- ---------- ------------ ---------- ----------
0 8 8 281 8
1 row selected.
从以上的信息,我们可以看到,在table test_hwm中,剩下的数据是分布在AAAAEc,AAAAEd,AAAAEf,AAAAEg这样四个连续的block中。
SQL> exec show_space('TEST_HWM','auto','T','Y');
Total Blocks............................8
Total Bytes.............................65536
Unused Blocks...........................0
Unused Bytes............................0
Last Used Ext FileId....................8
Last Used Ext BlockId...................281
Last Used Block.........................8
*************************************************
The segment is analyzed
0% -- 25% free space blocks.............0
0% -- 25% free space bytes..............0
25% -- 50% free space blocks............1
25% -- 50% free space bytes.............8192
50% -- 75% free space blocks............3
50% -- 75% free space bytes.............24576
75% -- 100% free space blocks...........1
75% -- 100% free space bytes............8192
Unused Blocks...........................0
Unused Bytes............................0
Total Blocks............................0
Total bytes.............................0
我们可以看到目前这四个block的空间使用状况,AAAAEc,AAAAEd,AAAAEf,AAAAEg上各有一行数据,我们猜测free space为50-75%的3个block是这三个block,那么free space为25-50%的1个block就是AAAAEg了,剩下free space为 75-100% 的3个block,是HWM下已格式化的尚未使用的block。(在extent不大于于16个block时,是以一个extent为单位来移动的)
然后,我们对table my_objects执行shtink的操作:
SQL> alter table test_hwm enable row movement;
Table altered
SQL> alter table test_hwm shrink space;
Table altered
SQL> select rowid ,id,name from TEST_HWM;
ROWID ID NAME
------------------ ---------- ------------
AAANMEAAIAAAAEcAAA 10 es
AAANMEAAIAAAAEcAAC 5 dss
AAANMEAAIAAAAEcAAD 1 aa
AAANMEAAIAAAAEcAAE 9 es
AAANMEAAIAAAAEdAAA 6 dss
/* Formatted on 2009-12-7 21:00:49 (QP5 v5.115.810.9015) */
SQL>SELECT EXTENT_ID,
FILE_ID,
RELATIVE_FNO,
BLOCK_ID,
BLOCKS
FROM dba_extents
WHERE segment_name = 'TEST_HWM';
EXTENT_ID FILE_ID RELATIVE_FNO BLOCK_ID BLOCKS
---------- ---------- ------------ ---------- ----------
0 8 8 281 8
1 row selected.
当执行了shrink操作后,有意思的现象出现了。我们来看看oracle是如何移动行数据的,这里的情况和move已经不太一样了。我们知道,在move操作的时候,所有行的rowid都发生了变化,table所位于的block的区域也发生了变化,但是所有行物理存储的顺序都没有发生变化,所以我们得到的结论是,oracle以block为单位,进行了block间的数据copy。那么shrink后,我们发现,部分行数据的rowid发生了变化,同时,部分行数据的物理存储的顺序也发生了变化,而table所位于的block的区域却没有变化,这就说明,shrink只移动了table其中一部分的行数据,来完成释放空间,而且,这个过程是在table当前所使用的block中完成的。
那么Oracle具体移动行数据的过程是怎样的呢?我们根据这样的实验结果,可以来猜测一下:
Oracle是以行为单位来移动数据的。Oracle从当前table存储的最后一行数据开始移动,从当前table最先使用的block开始搜索空间,所以,shrink之前,rownum=10的那行数据(10,es),被移动到block AAAAEc上,写到(1,aa)这行数据的后面,所以(10,es)的rownum和rowid同时发生改变。然后是(9,es)这行数据,重复上述过程。这是oracle从后向前移动行数据的大致遵循的规则,那么具体移动行数据的的算法是比较复杂的,包括向ASSM的table中insert数据使用block的顺序的算法也是比较复杂的,大家有兴趣的可以自己来研究,在这里我们不多做讨论。
在shrink table的同时shrink这个table上的index:
alter table my_objects shrink space cascade;
同样地,这个操作只有当table上的index也是ASSM时,才能使用。
Move 和 Shrink 产生日志的对比
我们对比了同样数据量和分布状况的两张table,在move和shrink下生成的redo size(table上没有index的情况下):
/* Formatted on 2009-12-7 21:20:43 (QP5 v5.115.810.9015) */
SQL>SELECT tablespace_name, SEGMENT_SPACE_MANAGEMENT
FROM dba_tablespaces
WHERE tablespace_name IN ('ASSM', 'HWM');
TABLESPACE_NAME SEGMENT_SPACE_MANAGEMENT
------------------------------ ------------------------
ASSM AUTO
HWM MANUAL
SQL> create table my_objects tablespace ASSM as select * from all_objects where rownum<20000;
Table created
SQL> create table my_objects1 tablespace HWM as select * from all_objects where rownum<20000;
Table created
SQL> select bytes/1024/1024 from user_segments where segment_name = 'MY_OBJECTS';
BYTES/1024/1024
---------------
2.1875
SQL> delete from my_objects where object_name like '%C%';
7278 rows deleted
SQL> delete from my_objects1 where object_name like '%C%';
7278 rows deleted
SQL> delete from my_objects where object_name like '%U%';
2732 rows deleted
SQL> delete from my_objects1 where object_name like '%U%';
2732 rows deleted
SQL> commit;
Commit complete
SQL> alter table my_objects enable row movement;
Table altered
/* Formatted on 2009-12-7 21:21:48 (QP5 v5.115.810.9015) */
SQL>SELECT VALUE
FROM v$mystat, v$statname
WHERE v$mystat.statistic# = v$statname.statistic#
AND v$statname.name = 'redo size';
VALUE
----------
27808792
SQL> alter table my_objects shrink space;
Table altered
SQL>SELECT VALUE
FROM v$mystat, v$statname
WHERE v$mystat.statistic# = v$statname.statistic#
AND v$statname.name = 'redo size';
VALUE
----------
32579712
SQL> alter table my_objects1 move;
Table altered
SQL>SELECT VALUE
FROM v$mystat, v$statname
WHERE v$mystat.statistic# = v$statname.statistic#
AND v$statname.name = 'redo size';
VALUE
----------
32676784
对于table my_objects,进行shrink,产生了32579712 – 27808792=4770920,约4.5M的redo ;对table my_objects1进行move,产生了32676784-32579712= 97072,约95K的redo size。
结论:与move比较起来,shrink的日志写要大得多。
Shrink的几点问题:
1. shrink后index是否需要rebuild:
因为shrink的操作也会改变行数据的rowid,那么,如果table上有index时,shrink table后index会不会变为UNUSABLE呢?
我们来看这样的实验,同样构建my_objects的测试表:
create table my_objects tablespace ASSM as select * from all_objects where rownum<20000;
create index i_my_objects on my_objects (object_id);
delete from my_objects where object_name like '%C%';
delete from my_objects where object_name like '%U%';
现在我们来shrink table my_objects:
SQL> alter table my_objects enable row movement;
Table altered
SQL> alter table my_objects shrink space;
Table altered
SQL> select index_name,status from user_indexes where index_name='I_MY_OBJECTS';
INDEX_NAME STATUS
------------------------------ --------
I_MY_OBJECTS VALID
我们发现,table my_objects上的index的状态为VALID,估计shrink在移动行数据时,也一起维护了index上相应行的数据rowid的信息。我们认为,这是对于move操作后需要rebuild index的改进。但是如果一个table上的index数量较多,我们知道,维护index的成本是比较高的,shrink过程中用来维护index的成本也会比较高。
2. shrink时对table的lock
在对table进行shrink时,会对table进行怎样的锁定呢?当我们对table MY_OBJECTS进行shrink操作时,查询v$locked_objects视图可以发现,table MY_OBJECTS上加了row-X (SX) 的lock:
SQL>select OBJECT_ID, SESSION_ID,ORACLE_USERNAME,LOCKED_MODE from v$locked_objects;
OBJECT_ID SESSION_ID ORACLE_USERNAME LOCKED_MODE
---------- ---------- ------------------ -----------
55422 153 DLINGER 3
SQL> select object_id from user_objects where object_name = 'MY_OBJECTS';
OBJECT_ID
----------
55422
那么,当table在进行shrink时,我们对table是可以进行DML操作的。
3. shrink对空间的要求
我们在前面讨论了shrink的数据的移动机制,既然oracle是从后向前移动行数据,那么,shrink的操作就不会像move一样,shrink不需要使用额外的空闲空间。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/tianlesoftware/archive/2009/11/04/4764254.aspx
posted @
2011-04-15 10:57 xzc 阅读(9352) |
评论 (0) |
编辑 收藏转自:http://blog.csdn.net/rein07/archive/2010/11/25/6033937.aspx
1.SQL>shutdown abort 如果数据库是打开状态,强行关闭
2.SQL>sqlplus / as sysdba
3.SQL>startup
ORACLE 例程已经启动。
Total System Global Area 293601280 bytes
Fixed Size 1248624 bytes
Variable Size 121635472 bytes
Database Buffers 167772160 bytes
Redo Buffers 2945024 bytes
数据库装载完毕。
ORA-01122: 数据库文件 1 验证失败
ORA-01110: 数据文件 1:
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\SYSTEM01.DBF'
ORA-01207: 文件比控制文件更新 - 旧的控制文件
4.SQL>alter database backup controlfile to trace as 'f:\aa';
数据库已更改。
5.SQL>shutdown immediate 如果数据库是打开状态,则关闭
ORA-01109: 数据库未打开
已经卸载数据库
6.SQL>startup nomount;
ORACLE 例程已经启动。
Total System Global Area 105979576 bytes
Fixed Size 454328 bytes
Variable Size 79691776 bytes
Database Buffers 25165824 bytes
Redo Buffers 667648 bytes
7.Editplus之类的编辑器打开在第四步生成的f:\aa文件;
其实在这个文件中的已经告诉你咋样恢复你的数据库了,找到STARTUP NOMOUNT字样,然后下面可以看到类似语句,这个文件有好几个类似的生成控制文件语句,主要针对不懂的环境执行不同的语句,象我的数据库没有做任何备份,也不是在归档模式,就执行这句
CREATE CONTROLFILE REUSE DATABASE "ORCLDW" NORESETLOGS NOARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\REDO01.LOG' SIZE 50M,
GROUP 2 'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\REDO02.LOG' SIZE 50M,
GROUP 3 'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\REDO03.LOG' SIZE 50M
DATAFILE
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\SYSTEM01.DBF',
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\UNDOTBS01.DBF',
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\SYSAUX01.DBF',
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\USERS01.DBF',
'F:\ORACLE\PRODUCT\10.2.0\DB_1\ORADATA\ORCLDW\EXAMPLE01.DBF'
CHARACTER SET ZHS16GBK
;
执行上面这段语句,这个语句重建控制文件,然后你可以看着f:\aa文件完成下面的恢复工作了,
8.SQL>RECOVER DATABASE (恢复指定表空间、数据文件或整个数据库)
9.SQL>ALTER DATABASE OPEN 打开数据库
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/rein07/archive/2010/11/25/6033937.aspx
posted @
2011-04-15 10:56 xzc 阅读(6991) |
评论 (0) |
编辑 收藏引用
trailblizer 的 Oracle:Rank,Dense_Rank,Row_Number比较
Oracle:Rank,Dense_Rank,Row_Number比较
一个员工信息表
Create Table EmployeeInfo (CODE Number(3) Not Null,EmployeeName varchar2(15),DepartmentID Number(3),Salary NUMBER(7,2),
Constraint PK_EmployeeInfo Primary Key (CODE));
Select * From EMPLOYEEINFO

现执行SQL语句:
Select EMPLOYEENAME,SALARY,
RANK() OVER (Order By SALARY Desc) "RANK",
DENSE_RANK() OVER (Order By SALARY Desc ) "DENSE_RANK",
ROW_NUMBER() OVER(Order By SALARY Desc) "ROW_NUMBER"
From EMPLOYEEINFO
结果如下:

Rank,Dense_rank,Row_number函数为每条记录产生一个从1开始至N的自然数,N的值可能小于等于记录的总数。这3个函数的唯一区别在于当碰到相同数据时的排名策略。
①ROW_NUMBER:
Row_number函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
②DENSE_RANK:
Dense_rank函数返回一个唯一的值,除非当碰到相同数据时,此时所有相同数据的排名都是一样的。
③RANK:
Rank函数返回一个唯一的值,除非遇到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
同时也可以分组排序,也就是在Over从句内加入Partition by groupField:
Select DEPARTMENTID,EMPLOYEENAME,SALARY,
RANK() OVER ( Partition By DEPARTMENTID Order By SALARY Desc) "RANK",
DENSE_RANK() OVER ( Partition By DEPARTMENTID Order By SALARY Desc ) "DENSE_RANK",
ROW_NUMBER() OVER( Partition By DEPARTMENTID Order By SALARY Desc) "ROW_NUMBER"
From EMPLOYEEINFO
结果如下:

现在如果插入一条工资为空的记录,那么执行上述语句,结果如下:

会发现空值的竟然排在了第一位,这显然不是想要的结果。解决的办法是在Over从句Order By后加上 NULLS Last即:
Select EMPLOYEENAME,SALARY,
RANK() OVER (Order By SALARY Desc Nulls Last) "RANK",
DENSE_RANK() OVER (Order By SALARY Desc Nulls Last) "DENSE_RANK",
ROW_NUMBER() OVER(Order By SALARY Desc Nulls Last ) "ROW_NUMBER"
From EMPLOYEEINFO
结果如下:

posted @
2011-04-03 21:46 xzc 阅读(645) |
评论 (0) |
编辑 收藏Oracle Sql Loader中文字符导入乱码的解决方案
服务器端字符集NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK
控制文件ctl:
LOAD DATA
CHARACTERSET ZHS16GBK
INFILE 'c:\testfile.txt'
id name desc
FIELDS TERMINATED BY ","
(id,name ,desc )
导入成功
其中c:\testfile.txt文件中有中文,在将此文件导入到oracle数据库中时,需要设置字符集CHARACTERSET ZHS16GBK
(1)查看服务器端字符集
通过客户端或服务器端的sql*plus登录ORACLE的一个合法用户,执行下列SQL语句:
SQL > select * from V$NLS_PARAMETERS
------------------------
(2)控制文件ctl:
LOAD DATA
CHARACTERSET ZHS16GBK
INFILE '/inffile/vac/subs-vac.csv'
TRUNCATE
INTO TABLE INF_VAC_SUBS_PRODUCT
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
(
USER_NUMBER,
PRODUCT_ID,
EFFECTIVE_DATE DATE "YYYY/MM/DD HH24:MI:SS",
EXPIRATION_DATE DATE "YYYY/MM/DD HH24:MI:SS"
)
posted @
2011-03-08 17:20 xzc 阅读(9068) |
评论 (2) |
编辑 收藏
要测试sql loader 以及快速产生大量测试数据
生成大量测试数据思路。
一,用plsql developer 生成csv 文件
二,用>>输出重定向,追加到一个cvs 文件里。
三,再用sql loader 快速载入。
在plsql developer 执行
- SELECT object_id,object_name FROM dba_objects;
SELECT object_id,object_name FROM dba_objects;
右键plsql developer 导出csv 格式 1.csv。在linux 上执行下面的脚本
- #!/bin/bash
-
- for((i=1;i<200;i=i+1))
- do
- cat 1.csv >> 2.csv;
- echo $i;
- done
#!/bin/bash
for((i=1;i<200;i=i+1))
do
cat 1.csv >> 2.csv;
echo $i;
done
这样 50000 * 200 差不到就有一千万的数据了。我测试的 11047500 392M
可以用:
wc -l 2.csv
查看csv 里有多少条数据。现在测试数据有了。我们来试一下sql loader 的载入效果吧。
创建sqlloader 控制文件如下,保存为1.ctl
- load data
- infile '2.csv'
- into table my_objects
- fields terminated by ','optionally enclosed by '"'
- (object_id,
- object_name
- );
load data
infile '2.csv'
into table my_objects
fields terminated by ','optionally enclosed by '"'
(object_id,
object_name
);
控制文件简要说明:
-- INFILE 'n.csv' 导入多个文件
-- INFILE * 要导入的内容就在control文件里 下面的BEGINDATA后面就是导入的内容
--BADFILE '1.bad' 指定坏文件地址
--apend into table my_objects 追加
-- INSERT 装载空表 如果原先的表有数据 sqlloader会停止 默认值
-- REPLACE 原先的表有数据 原先的数据会全部删除
-- TRUNCATE 指定的内容和replace的相同 会用truncate语句删除现存数据
--可以指定位置加载
--(object_id position(1:3) char,object_name position(5:7) char)
--分别指定分隔符
--(object_id char terminated by ",", object_name char terminated by ",")
--执行sqlldr userid=scott/a123 control=1.ctl log=1.out direct=true
--30秒可以载入200万的测试数据 79MB
--sqlldr userid=/ control=result1.ctl direct=true parallel=true
--sqlldr userid=/ control=result2.ctl direct=true parallel=true
--sqlldr userid=/ control=result2.ctl direct=true parallel=true
--当加载大量数据时(大约超过10GB),最好抑制日志的产生:
--SQLALTER TABLE RESULTXT nologging;
--这样不产生REDO LOG,可以提高效率。然后在CONTROL文件中load data上面加一行:unrecoverable
--此选项必须要与DIRECT共同应用。
--在并发操作时,ORACLE声称可以达到每小时处理100GB数据的能力!其实,估计能到1-10G就算不错了,开始可用结构
--相同的文件,但只有少量数据,成功后开始加载大量数据,这样可以避免时间的浪费
下面就是执行了
- sqlldr userid=scott/a123 control=1.ctl log=1.out direct=true
sqlldr userid=scott/a123 control=1.ctl log=1.out direct=true
结果:30秒可以载入200万的测试数据 79MB
226秒载入1100万的测试数据 392Mb
我的环境是在虚拟机,测得的结果
MemTotal: 949948 kB
model name : Intel(R) Pentium(R) D CPU 2.80GHz
stepping : 8
cpu MHz : 2799.560
cache size : 1024 KB
还是挺快的:)
posted @
2011-03-08 16:47 xzc 阅读(4002) |
评论 (0) |
编辑 收藏一、构造字符串
直接构造
STR_ZERO=hello
STR_FIRST="i am a string"
STR_SECOND='success'
重复多次
#repeat the first parm($1) by $2 times
strRepeat()
{
local x=$2
if [ "$x" == "" ]; then
x=0
fi
local STR_TEMP=""
while [ $x -ge 1 ];
do
STR_TEMP=`printf "%s%s" "$STR_TEMP" "$1"`
x=`expr $x - 1`
done
echo $STR_TEMP
}
举例:
STR_REPEAT=`strRepeat "$USER_NAME" 3`
echo "repeat = $STR_REPEAT"
二、赋值与拷贝
直接赋值
与构造字符串一样
USER_NAME=terry
从变量赋值
ALIASE_NAME=$USER_NAME
三、联接
直接联接两个字符串
STR_TEMP=`printf "%s%s" "$STR_ZERO" "$USER_NAME"`
使用printf可以进行更复杂的联接
四、求长
获取字符串变量的长度:${#string}
求字符数(char)
COUNT_CHAR=`echo "$STR_FIRST" | wc -m`
echo $COUNT_CHAR
求字节数(byte)
COUNT_BYTE=`echo "$STR_FIRST" | wc -c`
echo $COUNT_BYTE
求字数(word)
COUNT_WORD=`echo "$STR_FIRST" | wc -w`
echo $COUNT_WORD
五、比较
相等比较 str1 = str2
不等比较 str1 != str2
举例:
if [ "$USER_NAME" = "terry" ]; then
echo "I am terry"
fi
小于比较
#return 0 if the two string is equal, return 1 if $1 < $2, else 2strCompare() { local x=0 if [ "$1" != "$2" ]; then x=2 localTEMP=`printf "%s\n%s" "$1" "$2"` local TEMP2=`(echo "$1"; echo "$2") |sort` if [ "$TEMP" = "$TEMP2" ]; then x=1 fi fi echo $x }
六、测试
判空 -z str
判非空 -n str
是否为数字
# return 0 if the string is num, otherwise 1
strIsNum()
{
local RET=1
if [ -n "$1" ]; then
local STR_TEMP=`echo "$1" | sed 's/[0-9]//g'`
if [ -z "$STR_TEMP" ]; then
RET=0
fi
fi
echo $RET
}
举例:
if [ -n "$USER_NAME" ]; then
echo "my name is NOT empty"
fi
echo `strIsNum "9980"`
七、分割
以符号+为准,将字符分割为左右两部分
使用sed
举例:
命令 date --rfc-3339 seconds 的输出为
2007-04-14 15:09:47+08:00
取其+左边的部分
date --rfc-3339 seconds | sed 's/+[0-9][0-9]:[0-9][0-9]//g'
输出为
2007-04-14 15:09:47
取+右边的部分
date --rfc-3339 seconds | sed 's/.*+//g'
输出为
08:00
以空格为分割符的字符串分割
使用awk
举例:
STR_FRUIT="Banana 0.89 100"
取第3字段
echo $STR_FRUIT | awk '{ print $3; }'
八、子字符串
字符串1是否为字符串2的子字符串
# return 0 is $1 is substring of $2, otherwise 1
strIsSubstring()
{
local x=1
case "$2" in
*$1*) x=0;;
esac
echo $x
}
Shell字符串截取
一、Linux shell 截取字符变量的前8位,有方法如下:
1.expr substr “$a” 1 8
2.echo $a|awk ‘{print substr(,1,8)}’
3.echo $a|cut -c1-8
4.echo $
5.expr $a : ‘\(.\\).*’
6.echo $a|dd bs=1 count=8 2>/dev/null
二、按指定的字符串截取
1、第一种方法:
- ${varible##*string} 从左向右截取最后一个string后的字符串
- ${varible#*string}从左向右截取第一个string后的字符串
- ${varible%%string*}从右向左截取最后一个string后的字符串
- ${varible%string*}从右向左截取第一个string后的字符串
“*”只是一个通配符可以不要
例子:
$ MYVAR=foodforthought.jpg
$ echo ${MYVAR##*fo}
rthought.jpg
$ echo ${MYVAR#*fo}
odforthought.jpg
2、第二种方法:${varible:n1:n2}:截取变量varible从n1开始的n2个字符,组成一个子字符串。可以根据特定字符偏移和长度,使用另一种形式的变量扩展,来选择特定子字符串。试着在 bash 中输入以下行:
$ EXCLAIM=cowabunga
$ echo ${EXCLAIM:0:3}
cow
$ echo ${EXCLAIM:3:7}
abunga
这种形式的字符串截断非常简便,只需用冒号分开来指定起始字符和子字符串长度。
三、按照指定要求分割:
比如获取后缀名
ls -al | cut -d “.” -f2
shell (bash) 比较运算符
| 运算符 |
描述 |
示例 |
| 文件比较运算符 |
| -efilename |
如果filename存在,则为真 |
[ -e /var/log/syslog ] |
| -dfilename |
如果filename为目录,则为真 |
[ -d /tmp/mydir ] |
| -ffilename |
如果filename为常规文件,则为真 |
[ -f /usr/bin/grep ] |
| -Lfilename |
如果filename为符号链接,则为真 |
[ -L /usr/bin/grep ] |
| -rfilename |
如果filename可读,则为真 |
[ -r /var/log/syslog ] |
| -wfilename |
如果filename可写,则为真 |
[ -w /var/mytmp.txt ] |
| -xfilename |
如果filename可执行,则为真 |
[ -L /usr/bin/grep ] |
| filename1-ntfilename2 |
如果filename1比filename2新,则为真 |
[ /tmp/install/etc/services -nt /etc/services ] |
| filename1-otfilename2 |
如果filename1比filename2旧,则为真 |
[ /boot/bzImage -ot arch/i386/boot/bzImage ] |
| 字符串比较运算符[size=-1](请注意引号的使用,这是防止空格扰乱代码的好方法) |
| -zstring |
如果string长度为零,则为真 |
[ -z "$myvar" ] |
| -nstring |
如果string长度非零,则为真 |
[ -n "$myvar" ] |
| string1=string2 |
如果string1与string2相同,则为真 |
[ "$myvar" = "one two three" ] |
| string1!=string2 |
如果string1与string2不同,则为真 |
[ "$myvar" != "one two three" ] |
| 算术比较运算符 |
| num1-eqnum2 |
等于 |
[ 3 -eq $mynum ] |
| num1-nenum2 |
不等于 |
[ 3 -ne $mynum ] |
| num1-ltnum2 |
小于 |
[ 3 -lt $mynum ] |
| num1-lenum2 |
小于或等于 |
[ 3 -le $mynum ] |
| num1-gtnum2 |
大于 |
[ 3 -gt $mynum ] |
| num1-genum2 |
大于或等于 |
[ 3 -ge $mynum ] |
posted @
2011-03-04 18:13 xzc 阅读(9090) |
评论 (2) |
编辑 收藏#!/sbin/sh
######################################
## 名称: infuser_load.sh
## 描述: 通用接口文件 导入数据库
## 参数: owner table_name
## 作者: xxx
## 日期: 2011-03-04
######################################
##owner
owner=$1
##table_name
table_name=$2
##batchId
batchId=$3
##day_id
day_id=$4
##日期[YYYYMMDD]
DAYID=`date +'%Y%m%d'`
##月份[YYYYMM]
MONTHID=`date +'%Y%m'`
##shell文件目录
sh_dir=/inffile/shell/
cd ${sh_dir}
##load文件###########################
##file_name
file_name=`sqlplus -s infuser/xxx@DATACK <<EOF
set heading off feedback off pagesize 0 verify off echo off
select replace(replace(to_char(file_name), '@DAYID@', '${DAYID}'), '@MONTHID@', '${MONTHID}')
from datackdb.inf_file_def
where owner = '${owner}'
and table_name = '${table_name}'
and state = '00A'
and rownum <= 1;
exit
EOF`
#echo "${file_name}"
##ctl_file
ctl_file=`sqlplus -s infuser/xxx@DATACK <<EOF
set heading off feedback off pagesize 0 verify off echo off
select replace(replace(to_char(ctl_file), '@DAYID@', '${DAYID}'), '@MONTHID@', '${MONTHID}')
from datackdb.inf_file_def
where owner = '${owner}'
and table_name = '${table_name}'
and state = '00A'
and rownum <= 1;
exit
EOF`
#echo "${ctl_file}"
infile=""
for fname in $file_name
do
if [ -r ${fname} ]
then
infile=$infile"INFILE '${fname}'\n"
fi
done
#是否包含@INFILE@字符串的判断
if echo "$ctl_file"|grep -q "@INFILE@"
then
#分隔符前字符串
echo "${ctl_file%%@INFILE@*}" >${table_name}.ctl
#文件名
echo "${infile}" >>${table_name}.ctl
#分隔符后字符串
echo "${ctl_file##*@INFILE@}" >>${table_name}.ctl
else
echo "${ctl_file}" >${table_name}.ctl
fi
#导入数据
sqlldr infuser/infuser@DATACK control=${table_name}.ctl direct=y errors=1000
#删除控制文件
#rm ${table_name}.ctl
#rm ${table_name}.log
##写消息
sqlplus infuser/infuser@DATACK <<EOF
insert into datackdb.inf_data_msg (OWNER, TABLE_NAME, FWF_NO, LAN_ID, DAY_ID, STATE, STATE_DATE, COMMENTS)
values ('${owner}', '${table_name}', '${batchId}', -1, '${day_id}', '00A', sysdate, '');
exit
EOF
date +'%Y-%m-%d %T' >>param.txt
echo "$0 $*" >>param.txt
echo "$0 $* -- 成功"
posted @
2011-03-04 15:23 xzc 阅读(552) |
评论 (0) |
编辑 收藏#! /bin/bash
var1="hello"
var2="he"
#方法1
if [ ${var1:0:2} = $var2 ]
then
echo "1:include"
fi
#方法2
echo "$var1" |grep -q "$var2"
if [ $? -eq 0 ]
then
echo "2:include"
fi
#方法3
echo "$var1" |grep -q "$var2" && echo "include" ||echo "not"
#方法4
[[ "${var1/$var2/}" != "$var2" ]] && echo "include" || echo "not"
其他方法:
expr或awk的index函数
${var#...}
${var%...}
${var/.../...}
posted @
2011-03-04 15:16 xzc 阅读(26433) |
评论 (1) |
编辑 收藏shell判断文件,目录是否存在或者具有权限
www.firnow.com 时间 : 2009-03-04 作者:匿名 编辑:sky 点击: 1632 [ 评论 ]
-
-
shell判断文件,目录是否存在或者具有权限
#!/bin/sh
myPath="/var/log/httpd/"
myFile="/var /log/httpd/access.log"
#这里的-x 参数判断$myPath是否存在并且是否具有可执行权限
if [ ! -x "$myPath"]; then
mkdir "$myPath"
fi
#这里的-d 参数判断$myPath是否存在
if [ ! -d "$myPath"]; then
mkdir "$myPath"
fi
#这里的-f参数判断$myFile是否存在
if [ ! -f "$myFile" ]; then
touch "$myFile"
fi
#其他参数还有-n,-n是判断一个变量是否是否有值
if [ ! -n "$myVar" ]; then
echo "$myVar is empty"
exit 0
fi
#两个变量判断是否相等
if [ "$var1" = "$var2" ]; then
echo '$var1 eq $var2'
else
echo '$var1 not eq $var2'
fi
posted @
2011-03-04 15:14 xzc 阅读(1375) |
评论 (1) |
编辑 收藏shell字符串的截取的问题:
一、Linux shell 截取字符变量的前8位,有方法如下:
1.expr substr “$a” 1 8
2.echo $a|awk ‘{print substr(,1,8)}’
3.echo $a|cut -c1-8
4.echo $
5.expr $a : ‘\(.\\).*’
6.echo $a|dd bs=1 count=8 2>/dev/null
二、按指定的字符串截取
1、第一种方法:
${varible##*string} 从左向右截取最后一个string后的字符串
${varible#*string}从左向右截取第一个string后的字符串
${varible%%string*}从右向左截取最后一个string后的字符串
${varible%string*}从右向左截取第一个string后的字符串
“*”只是一个通配符可以不要
例子:
$ MYVAR=foodforthought.jpg
$ echo ${MYVAR##*fo}
rthought.jpg
$ echo ${MYVAR#*fo}
odforthought.jpg
2、第二种方法:${varible:n1:n2}:截取变量varible从n1到n2之间的字符串。
可以根据特定字符偏移和长度,使用另一种形式的变量扩展,来选择特定子字符串。试着在 bash 中输入以下行:
$ EXCLAIM=cowabunga
$ echo ${EXCLAIM:0:3}
cow
$ echo ${EXCLAIM:3:7}
abunga
这种形式的字符串截断非常简便,只需用冒号分开来指定起始字符和子字符串长度。
三、按照指定要求分割:
比如获取后缀名
ls -al | cut -d “.” -f2
应用心得:
$MYVAR="12|dadg"
echo ${MYVAR##*|} #打印分隔符后的字符串
dafa
echo ${MYVAR%%|*} #打印分隔符前的字符串
12
posted @
2011-03-04 15:09 xzc 阅读(3604) |
评论 (1) |
编辑 收藏