原文链接:http://www.cnblogs.com/juandx/p/4962089.html
python中对文件、文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块。
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split()
eg os.path.split(‘/home/swaroop/byte/code/poem.txt’)
结果:(‘/home/swaroop/byte/code’, ‘poem.txt’)
分离扩展名:os.path.splitext()
获取路径名:os.path.dirname()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取和设置环境变量:os.getenv() 与os.putenv()
给出当前平台使用的行终止符:os.linesep Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’
指示你正在使用的平台:os.name 对于Windows,它是’nt’,而对于Linux/Unix用户,它是’posix’
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
终止当前进程:os.exit()
获取文件大小:os.path.getsize(filename)
文件操作:
os.mknod(“test.txt”) 创建空文件
fp = open(“test.txt”,w) 直接打开一个文件,如果文件不存在则创建文件
关于open 模式:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
fp.read([size]) #size为读取的长度,以byte为单位
fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
fp.flush() #把缓冲区的内容写入硬盘
fp.fileno() #返回一个长整型的”文件标签“
fp.isatty() #文件是否是一个终端设备文件(unix系统中的)
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
目录操作:
os.mkdir(“file”) 创建目录
复制文件:
shutil.copyfile(“oldfile”,”newfile”) oldfile和newfile都只能是文件
shutil.copy(“oldfile”,”newfile”) oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
复制文件夹:
shutil.copytree(“olddir”,”newdir”) olddir和newdir都只能是目录,且newdir必须不存在
重命名文件(目录)
os.rename(“oldname”,”newname”) 文件或目录都是使用这条命令
移动文件(目录)
shutil.move(“oldpos”,”newpos”)
删除文件
os.remove(“file”)
删除目录
os.rmdir(“dir”)只能删除空目录
shutil.rmtree(“dir”) 空目录、有内容的目录都可以删
转换目录
os.chdir(“path”) 换路径
Python读写文件
1.open
使用open打开文件后一定要记得调用文件对象的close()方法。比如可以用try/finally语句来确保最后能关闭文件。
file_object = open(‘thefile.txt’)
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法。
2.读文件
读文本文件
input = open('data', 'r')
#第二个参数默认为r
input = open('data')
1
2
3
读二进制文件
input = open('data', 'rb')
1
读取所有内容
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
1
2
3
4
5
读固定字节
file_object = open('abinfile', 'rb')
try:
while True:
chunk = file_object.read(100)
if not chunk:
break
do_something_with(chunk)
finally:
file_object.close( )
1
2
3
4
5
6
7
8
9
读每行
list_of_all_the_lines = file_object.readlines( )
1
如果文件是文本文件,还可以直接遍历文件对象获取每行:
for line in file_object:
process line
1
2
3.写文件
写文本文件
output = open('data', 'w')
1
写二进制文件
output = open('data', 'wb')
1
追加写文件
output = open('data', 'w+')
1
写数据
file_object = open('thefile.txt', 'w')
file_object.write(all_the_text)
file_object.close( )
1
2
3
写入多行
file_object.writelines(list_of_text_strings)
1
注意,调用writelines写入多行在性能上会比使用write一次性写入要高。
在处理日志文件的时候,常常会遇到这样的情况:日志文件巨大,不可能一次性把整个文件读入到内存中进行处理,例如需要在一台物理内存为 2GB 的机器上处理一个 2GB 的日志文件,我们可能希望每次只处理其中 200MB 的内容。
在 Python 中,内置的 File 对象直接提供了一个 readlines(sizehint) 函数来完成这样的事情。以下面的代码为例:
file = open('test.log', 'r')sizehint = 209715200 # 200Mposition = 0lines = file.readlines(sizehint)while not file.tell() - position < 0: position = file.tell() lines = file.readlines(sizehint)
1
每次调用 readlines(sizehint) 函数,会返回大约 200MB 的数据,而且所返回的必然都是完整的行数据,大多数情况下,返回的数据的字节数会稍微比 sizehint 指定的值大一点(除最后一次调用 readlines(sizehint) 函数的时候)。通常情况下,Python 会自动将用户指定的 sizehint 的值调整成内部缓存大小的整数倍。
file在python是一个特殊的类型,它用于在python程序中对外部的文件进行操作。在python中一切都是对象,file也不例外,file有file的方法和属性。下面先来看如何创建一个file对象:
file(name[, mode[, buffering]])
1
file()函数用于创建一个file对象,它有一个别名叫open(),可能更形象一些,它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。name是文件的名字。
mode是打开的模式,可选的值为r w a U,分别代表读(默认) 写 添加支持各种换行符的模式。用w或a模式打开文件的话,如果文件不存在,那么就自动创建。此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清空,因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。由于历史的原因,换行符在不同的系统中有不同模式,比如在 unix中是一个\n,而在windows中是‘\r\n’,用U模式打开文件,就是支持所有的换行模式,也就说‘\r’ ‘\n’ ‘\r\n’都可表示换行,会有一个tuple用来存贮这个文件中用到过的换行符。不过,虽说换行有多种模式,读到python中统一用\n代替。在模式字符的后面,还可以加上+ b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
buffering如果为0表示不进行缓冲;如果为1表示进行“行缓冲“;如果是一个大于1的数表示缓冲区的大小,应该是以字节为单位的。
file对象有自己的属性和方法。先来看看file的属性。
closed #标记文件是否已经关闭,由close()改写
encoding #文件编码
mode #打开模式
name #文件名
newlines #文件中用到的换行模式,是一个tuple
softspace #boolean型,一般为0,据说用于print
1
2
3
4
5
6
file的读写方法:
F.read([size]) #size为读取的长度,以byte为单位
F.readline([size])
#读一行,如果定义了size,有可能返回的只是一行的一部分
F.readlines([size])
#把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
F.write(str)
#把str写到文件中,write()并不会在str后加上一个换行符
F.writelines(seq)
#把seq的内容全部写到文件中。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
file的其他方法:
F.close()
#关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。如果一个文件在关闭后还对其进行操作会产生ValueError
F.flush()
#把缓冲区的内容写入硬盘
F.fileno()
#返回一个长整型的”文件标签“
F.isatty()
#文件是否是一个终端设备文件(unix系统中的)
F.tell()
#返回文件操作标记的当前位置,以文件的开头为原点
F.next()
#返回下一行,并将文件操作标记位移到下一行。把一个file用于for ... in file这样的语句时,就是调用next()函数来实现遍历的。
F.seek(offset[,whence])
#将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
F.truncate([size])
#把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
http://www.cnblogs.com/allenblogs/archive/2010/09/13/1824842.html
http://www.cnblogs.com/rollenholt/archive/2012/04/23/2466179.html
首先 dfs.replication这个参数是个client参数,即node level参数。需要在每台datanode上设置。
其实默认为3个副本已经够用了,设置太多也没什么用。
一个文件,上传到hdfs上时指定的是几个副本就是几个。以后你修改了副本数,对已经上传了的文件也不会起作用。可以再上传文件的同时指定创建的副本数
Hadoop dfs -D dfs.replication=1 -put 70M logs/2
可以通过命令来更改已经上传的文件的副本数:
hadoop fs -setrep -R 3 /
查看当前hdfs的副本数
hadoop fsck -locations
FSCK started by hadoop from /172.18.6.112 for path / at Thu Oct 27 13:24:25 CST 2011
....................Status: HEALTHY
Total size: 4834251860 B
Total dirs: 21
Total files: 20
Total blocks (validated): 82 (avg. block size 58954290 B)
Minimally replicated blocks: 82 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Thu Oct 27 13:24:25 CST 2011 in 10 milliseconds
The filesystem under path '/' is HEALTHY
某个文件的副本数,可以通过ls中的文件描述符看到
hadoop dfs -ls
-rw-r--r-- 3 hadoop supergroup 153748148 2011-10-27 16:11 /user/hadoop/logs/201108/impression_witspixel2011080100.thin.log.gz
如果你只有3个datanode,但是你却指定副本数为4,是不会生效的,因为每个datanode上只能存放一个副本。
参考:http://blog.csdn.net/lskyne/article/details/8898666
转自:https://www.cnblogs.com/shabbylee/p/6792555.html
由于历史原因,Python有两个大的版本分支,Python2和Python3,又由于一些库只支持某个版本分支,所以需要在电脑上同时安装Python2和Python3,因此如何让两个版本的Python兼容,如何让脚本在对应的Python版本上运行,这个是值得总结的。
对于Ubuntu 16.04 LTS版本来说,Python2(2.7.12)和Python3(3.5.2)默认同时安装,默认的python版本是2.7.12。
当然你也可以用python2来调用。
如果想调用python3,就用python3.
对于Windows,就有点复杂了。因为不论python2还是python3,python可执行文件都叫python.exe,在cmd下输入python得到的版本号取决于环境变量里哪个版本的python路径更靠前,毕竟windows是按照顺序查找的。比如环境变量里的顺序是这样的:
那么cmd下的python版本就是2.7.12。
反之,则是python3的版本号。
这就带来一个问题了,如果你想用python2运行一个脚本,一会你又想用python3运行另一个脚本,你怎么做?来回改环境变量显然很麻烦。
网上很多办法比较简单粗暴,把两个python.exe改名啊,一个改成python2.exe,一个改成python3.exe。这样做固然可以,但修改可执行文件的方式,毕竟不是很好的方法。
我仔细查找了一些python技术文档,发现另外一个我觉得比较好的解决办法。
借用py的一个参数来调用不同版本的Python。py -2调用python2,py -3调用的是python3.
当python脚本需要python2运行时,只需在脚本前加上,然后运行py xxx.py即可。
#! python2
当python脚本需要python3运行时,只需在脚本前加上,,然后运行py xxx.py即可。
#! python3
就这么简单。
同时,这也完美解决了在pip在python2和python3共存的环境下报错,提示Fatal error in launcher: Unable to create process using '"'的问题。
当需要python2的pip时,只需
py -2 -m pip install xxx
当需要python3的pip时,只需
py -3 -m pip install xxx
python2和python3的pip package就这样可以完美分开了。
Sentry权限控制通过Beeline(Hiveserver2 SQL 命令行接口)输入Grant 和 Revoke语句来配置。语法跟现在的一些主流的关系数据库很相似。需要注意的是:当sentry服务启用后,我们必须使用beeline接口来执行hive查询,Hive Cli并不支持sentry。
CREATE ROLE Statement
CREATE ROLE语句创建一个可以被赋权的角色。权限可以赋给角色,然后再分配给各个用户。一个用户被分配到角色后可以执行该角色的权限。
只有拥有管理员的角色可以create/drop角色。默认情况下,hive、impala和hue用户拥有管理员角色。
CREATE ROLE [role_name];
DROP ROLE Statement
DROP ROLE语句可以用来从数据库中移除一个角色。一旦移除,之前分配给所有用户的该角色将会取消。之前已经执行的语句不会受到影响。但是,因为hive在执行每条查询语句之前会检查用户的权限,处于登录活跃状态的用户会话会受到影响。
DROP ROLE [role_name];
GRANT ROLE Statement
GRANT ROLE语句可以用来给组授予角色。只有sentry的管理员用户才能执行该操作。
GRANT ROLE role_name [, role_name]
TO GROUP (groupName) [,GROUP (groupName)]
REVOKE ROLE Statement
REVOKE ROLE语句可以用来从组移除角色。只有sentry的管理员用户才能执行该操作。
REVOKE ROLE role_name [, role_name]
FROM GROUP (groupName) [,GROUP (groupName)]
GRANT (PRIVILEGE) Statement
授予一个对象的权限给一个角色,该用户必须为sentry的管理员用户。
GRANT
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
TO ROLE (roleName) [,ROLE (roleName)]
REVOKE (PRIVILEGE) Statement
因为只有认证的管理员用户可以创建角色,从而只有管理员用户可以取消一个组的权限。
REVOKE
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
FROM ROLE (roleName) [,ROLE (roleName)]
GRANT (PRIVILEGE) ... WITH GRANT OPTION
在cdh5.2中,你可以委托给其他角色来授予和解除权限。比如,一个角色被授予了WITH GRANT OPTION的权限可以GRANT/REVOKE同样的权限给其他角色。因此,如果一个角色有一个库的所有权限并且设置了 WITH GRANT OPTION,该角色分配的用户可以对该数据库和其中的表执行GRANT/REVOKE语句。
GRANT
(PRIVILEGE)
ON (OBJECT) (object_name)
TO ROLE (roleName)
WITH GRANT OPTION
只有一个带GRANT选项的特殊权限的角色或者它的父级权限可以从其他角色解除这种权限。一旦下面的语句执行,所有跟其相关的grant权限将会被解除。
REVOKE
(RIVILEGE)
ON (BJECT) (bject_name)
FROM ROLE (roleName)
Hive目前不支持解除之前赋予一个角色 WITH GRANT OPTION 的权限。要想移除WITH GRANT OPTION、解除权限,可以重新去除 WITH GRANT OPTION这个标记来再次附权。
SET ROLE Statement
SET ROLE语句可以给当前会话选择一个角色使之生效。一个用户只能启用分配给他的角色。任何不存在的角色和当前用户不能使用的角色是不能生效的。如果没有使用任何角色,用户将会使用任何一个属于他的角色的权限。
选择一个角色使用:
To enable a specific role:
使用所有的角色:
To enable a specific role:
关闭所有角色
SET ROLE NONE;
SHOW Statement
显示当前用户拥有库、表、列相关权限的数据库:
SHOW DATABASES;
显示当前用户拥有表、列相关权限的表;
SHOW TABLES;
显示当前用户拥有SELECT权限的列:
SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name];
显示当前系统中所有的角色(只有管理员用户可以执行):
SHOW ROLES;
显示当前影响当前会话的角色:
SHOW CURRENT ROLES;
显示指定组的被分配到的所有角色(只有管理员用户和指定组内的用户可以执行)
SHOW ROLE GRANT GROUP (groupName);
SHOW语句可以用来显示一个角色被授予的权限或者显示角色的一个特定对象的所有权限。
显示指定角色的所有被赋予的权限。(只有管理员用户和指定角色分配到的用户可以执行)。下面的语句也会显示任何列级的权限。
SHOW GRANT ROLE (roleName);
显示指定对象的一个角色的所有被赋予的权限(只有管理员用户和指定角色分配到的用户可以执行)。下面的语句也会显示任何列级的权限。
SHOW GRANT ROLE (roleName) on (OBJECT) (objectName);
----------------------------我也是有底线的-----------------------------
摘要: Python 里面的编码和解码也就是 unicode 和 str 这两种形式的相互转化。编码是 unicode -> str,相反的,解码就是 str -> unicode。剩下的问题就是确定何时需要进行编码或者解码了.关于文件开头的"编码指示",也就是 # -*- codin...
一、前言
早上醒来打开微信,同事反馈kafka集群从昨天凌晨开始写入频繁失败,赶紧打开电脑查看了kafka集群的机器监控,日志信息,发现其中一个节点的集群负载从昨天凌晨突然掉下来了,和同事反馈的时间点大概一致,于是乎就登录服务器开始干活。
二、排错
1、查看机器监控,看是否能大概定位是哪个节点有异常
技术分享
2、根据机器监控大概定位到其中一个异常节点,登录服务器查看kafka日志,发现有报错日志,并且日志就停留在这个这个时间点:
[2017-06-01 16:59:59,851] ERROR Processor got uncaught exception. (kafka.network.Processor)
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306)
at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:174)
at sun.nio.ch.IOUtil.read(IOUtil.java:195)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:379)
at org.apache.kafka.common.network.PlaintextTransportLayer.read(PlaintextTransportLayer.java:108)
at org.apache.kafka.common.network.NetworkReceive.readFromReadableChannel(NetworkReceive.java:97)
at org.apache.kafka.common.network.NetworkReceive.readFrom(NetworkReceive.java:71)
at org.apache.kafka.common.network.KafkaChannel.receive(KafkaChannel.java:160)
at org.apache.kafka.common.network.KafkaChannel.read(KafkaChannel.java:141)
at org.apache.kafka.common.network.Selector.poll(Selector.java:286)
at kafka.network.Processor.run(SocketServer.scala:413)3、查看kafka进程和监听端口情况,发现都正常,尼玛假死了
ps -ef |grep kafka ## 查看kafka的进程
netstat -ntlp |grep 9092 ##9092kafka的监听端口4、既然已经假死了,只能重启了
ps -ef |grep kafka |grep -v grep |awk ‘{print $2}‘ | xargs kill -9
/usr/local/kafka/bin;nohup ./kafka-server-start.sh ../config/server.properties &5、重启后在观察该节点的kafka日志,在一顿index重建之后,上面的报错信息在疯狂的刷,最后谷歌一番,解决了该问题
三、解决方案:
在
/usr/local/kafka/binkafka-run-class.sh去掉
-XX:+DisableExplicitGC添加
-XX:MaxDirectMemorySize=512m在一次重启kafka,问题解决。
摘要: 我们每次执行hive的hql时,shell里都会提示一段话:[python] view plaincopy... Number of reduce tasks not specified. Estimated from input data size: 50...
摘要: spark 累加历史主要用到了窗口函数,而进行全部统计,则需要用到rollup函数
1 应用场景:
1、我们需要统计用户的总使用时长(累加历史)
2、前台展现页面需要对多个维度进行查询,如:产品、地区等等
3、需要展现的表格头如: 产品、2015-04、2015-05、2015-06
2 原始数据:
product_code |event_date |dur...
摘要: Spark1.4发布,支持了窗口分析函数(window functions)。在离线平台中,90%以上的离线分析任务都是使用Hive实现,其中必然会使用很多窗口分析函数,如果SparkSQL支持窗口分析函数,
那么对于后面Hive向SparkSQL中的迁移的工作量会大大降低,使用方式如下:
1、初始化数据
创建表
[sql] view plain cop...
1.in 不支持子查询 eg. select * from src where key in(select key from test);
支持查询个数 eg. select * from src where key in(1,2,3,4,5);
in 40000个 耗时25.766秒
in 80000个 耗时78.827秒
2.union all/union
不支持顶层的union all eg. select key from src UNION ALL select key from test;
支持select * from (select key from src union all select key from test)aa;
不支持 union
支持select distinct key from (select key from src union all select key from test)aa;
3.intersect 不支持
4.minus 不支持
5.except 不支持
6.inner join/join/left outer join/right outer join/full outer join/left semi join 都支持
left outer join/right outer join/full outer join 中间必须有outer
join是最简单的关联操作,两边关联只取交集;
left outer join是以左表驱动,右表不存在的key均赋值为null;
right outer join是以右表驱动,左表不存在的key均赋值为null;
full outer join全表关联,将两表完整的进行笛卡尔积操作,左右表均可赋值为null;
left semi join最主要的使用场景就是解决exist in;
Hive不支持where子句中的子查询,SQL常用的exist in子句在Hive中是不支持的
不支持子查询 eg. select * from src aa where aa.key in(select bb.key from test bb);
可用以下两种方式替换:
select * from src aa left outer join test bb on aa.key=bb.key where bb.key <> null;
select * from src aa left semi join test bb on aa.key=bb.key;
大多数情况下 JOIN ON 和 left semi on 是对等的
A,B两表连接,如果B表存在重复数据
当使用JOIN ON的时候,A,B表会关联出两条记录,应为ON上的条件符合;
而是用LEFT SEMI JOIN 当A表中的记录,在B表上产生符合条件之后就返回,不会再继续查找B表记录了,
所以如果B表有重复,也不会产生重复的多条记录。
left outer join 支持子查询 eg. select aa.* from src aa left outer join (select * from test111)bb on aa.key=bb.a;
7. hive四中数据导入方式
1)从本地文件系统中导入数据到Hive表
create table wyp(id int,name string) ROW FORMAT delimited fields terminated by '\t' STORED AS TEXTFILE;
load data local inpath 'wyp.txt' into table wyp;
2)从HDFS上导入数据到Hive表
[wyp@master /home/q/hadoop-2.2.0]$ bin/hadoop fs -cat /home/wyp/add.txt
hive> load data inpath '/home/wyp/add.txt' into table wyp;
3)从别的表中查询出相应的数据并导入到Hive表中
hive> create table test(
> id int, name string
> ,tel string)
> partitioned by
> (age int)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE;
注:test表里面用age作为了分区字段,分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。
比如wyp表有dt和city两个分区,则对应dt=20131218city=BJ对应表的目录为/user/hive/warehouse/dt=20131218/city=BJ,
所有属于这个分区的数据都存放在这个目录中。
hive> insert into table test
> partition (age='25')
> select id, name, tel
> from wyp;
也可以在select语句里面通过使用分区值来动态指明分区:
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> insert into table test
> partition (age)
> select id, name,
> tel, age
> from wyp;
Hive也支持insert overwrite方式来插入数据
hive> insert overwrite table test
> PARTITION (age)
> select id, name, tel, age
> from wyp;
Hive还支持多表插入
hive> from wyp
> insert into table test
> partition(age)
> select id, name, tel, age
> insert into table test3
> select id, name
> where age>25;
4)在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中
hive> create table test4
> as
> select id, name, tel
> from wyp;
8.查看建表语句
hive> show create table test3;
9.表重命名
hive> ALTER TABLE events RENAME TO 3koobecaf;
10.表增加列
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT);
11.添加一列并增加列字段注释
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
12.删除表
hive> DROP TABLE pokes;
13.top n
hive> select * from test order by key limit 10;
14.创建数据库
Create Database baseball;
14.alter table tablename change oldColumn newColumn column_type 修改列的名称和类型
alter table yangsy CHANGE product_no phone_no string
15.导入.sql文件中的sql
spark-sql --driver-class-path /home/hadoop/hive/lib/mysql-connector-java-5.1.30-bin.jar -f testsql.sql
insert into table CI_CUSER_20141117154351522 select mainResult.PRODUCT_NO,dw_coclbl_m02_3848.L1_01_02_01,dw_coclbl_d01_3845.L2_01_01_04 from (select PRODUCT_NO from CI_CUSER_20141114203632267) mainResult left join DW_COCLBL_M02_201407 dw_coclbl_m02_3848 on mainResult.PRODUCT_NO = dw_coclbl_m02_3848.PRODUCT_NO left join DW_COCLBL_D01_20140515 dw_coclbl_d01_3845 on dw_coclbl_m02_3848.PRODUCT_NO = dw_coclbl_d01_3845.PRODUCT_NO
insert into CI_CUSER_20141117142123638 ( PRODUCT_NO,ATTR_COL_0000,ATTR_COL_0001) select mainResult.PRODUCT_NO,dw_coclbl_m02_3848.L1_01_02_01,dw_coclbl_m02_3848.L1_01_03_01 from (select PRODUCT_NO from CI_CUSER_20141114203632267) mainResult left join DW_COCLBL_M02_201407 dw_coclbl_m02_3848 on mainResult.PRODUCT_NO = dw_coclbl_m02_3848.PRODUCT_NO
CREATE TABLE ci_cuser_yymmddhhmisstttttt_tmp(product_no string) row format serde 'com.bizo.hive.serde.csv.CSVSerde' ;
LOAD DATA LOCAL INPATH '/home/ocdc/coc/yuli/test123.csv' OVERWRITE INTO TABLE test_yuli2;
创建支持CSV格式的testfile文件
CREATE TABLE test_yuli7 row format serde 'com.bizo.hive.serde.csv.CSVSerde' as select * from CI_CUSER_20150310162729786;
不依赖CSVSerde的jar包创建逗号分隔的表
"create table " +listName+ " ROW FORMAT DELIMITED FIELDS TERMINATED BY ','" +
" as select * from " + listName1;
create table aaaa ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE as select * from
ThriftServer 开启FAIR模式
SparkSQL Thrift Server 开启FAIR调度方式:
1. 修改$SPARK_HOME/conf/spark-defaults.conf,新增
2. spark.scheduler.mode FAIR
3. spark.scheduler.allocation.file /Users/tianyi/github/community/apache-spark/conf/fair-scheduler.xml
4. 修改$SPARK_HOME/conf/fair-scheduler.xml(或新增该文件), 编辑如下格式内容
5. <?xml version="1.0"?>
6. <allocations>
7. <pool name="production">
8. <schedulingMode>FAIR</schedulingMode>
9. <!-- weight表示两个队列在minShare相同的情况下,可以使用资源的比例 -->
10. <weight>1</weight>
11. <!-- minShare表示优先保证的资源数 -->
12. <minShare>2</minShare>
13. </pool>
14. <pool name="test">
15. <schedulingMode>FIFO</schedulingMode>
16. <weight>2</weight>
17. <minShare>3</minShare>
18. </pool>
19. </allocations>
20. 重启Thrift Server
21. 执行SQL前,执行
22. set spark.sql.thriftserver.scheduler.pool=指定的队列名
等操作完了 create table yangsy555 like CI_CUSER_YYMMDDHHMISSTTTTTT 然后insert into yangsy555 select * from yangsy555
创建一个自增序列表,使用row_number() over()为表增加序列号 以供分页查询
create table yagnsytest2 as SELECT ROW_NUMBER() OVER() as id,* from yangsytest;

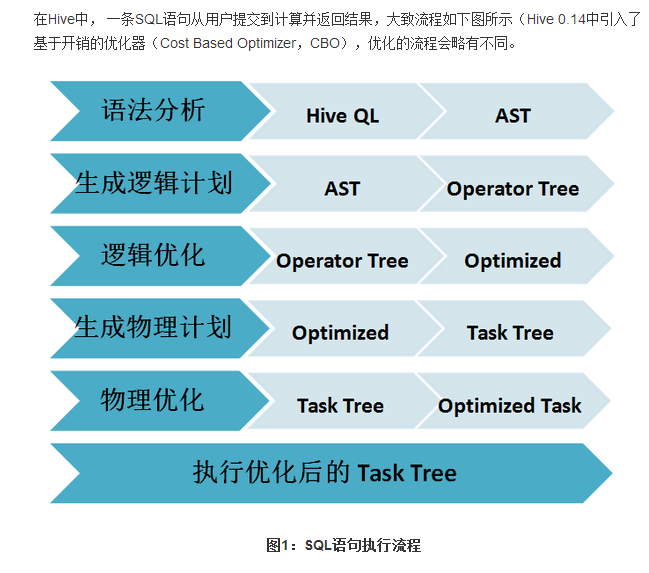
Sparksql的解析与Hiveql的解析的执行流程: