package com.test.yjw;
public class Sort {
//冒泡
/**
*
*/
public static void bubbleSort(int a[]) {
int len = a.length;
for (int i = 0; i < len - 1; i++) {
for (int j = 0; j < len - 1 - i; j++) {
if (a[j] > a[j + 1]) {
int temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
}
for(int t : a){
System.out.println(t);
}
}
//选择排序
public static void selectSort(int a[]) {
int temp = 0;
int len = a.length;
for (int i = 0; i < len - 1; i++) {
int min = a[i];
int index = i;
for (int j = i + 1; j < len; j++) {
if (min > a[j]) {
min = a[j];
index = j;
}
}
temp = a[i];
a[i] = a[index];
a[index] = temp;
}
for(int t : a){
System.out.println(t);
}
}
// 插入排序{9,5,1,3,7,8,6,2,0,4}
public static void insertSort(int a[]) {
int len = a.length;
for (int i = 1; i < len; i++) {
int temp = a[i];// 待插入的值
int index = i;// 待插入的位置
while (index > 0 && a[index - 1] > temp) {
a[index] = a[index - 1];// 待插入的位置重新赋更大的值
index--;// 位置往前移
}
a[index] = temp;
}
for(int t : a){
System.out.println(t);
}
}
//快速排序
public static void quickSort(int a[], int low, int height) {
if (low < height) {
int result = partition(a, low, height);
quickSort(a, low, result - 1);
quickSort(a, result + 1, height);
}
}
public static int partition(int a[], int low, int height) {
int key = a[low];
while (low < height) {
while (low < height && a[height] >= key)
height--;
a[low] = a[height];
while (low < height && a[low] <= key)
low++;
a[height] = a[low];
}
a[low] = key;
return low;
}
public static void swap(int a[], int i, int j) { // 通过临时变量,交换数据
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
} // 第一次交换分析
public static void quicksort(int a[], int low, int high) { // 假设传入low=0; high=a.length-1;
if (low < high) { // 条件判断
int pivot, p_pos, i; // 声明变量
p_pos = low; // p_pos指向low,即位索引为0位置 ;
pivot = a[p_pos]; // 将0位置上的数值赋给pivot;
for (i = low + 1; i <= high; i++) { // 循环次数, i=1;
if (a[i]>pivot) { // 1位置的数与0位置数作比较: a[1]>a[0]
p_pos++; // 2位与1位比较,3位与2位比较......
swap(a, p_pos, i); // 传参并调用swap
}
}
swap(a, low, p_pos); // 将p_pos设为high再次调用swap
quicksort(a, low, p_pos - 1); // 递归调用,排序左半区
quicksort(a, p_pos + 1, high); // 递归调用,排序右半区
}
}
public static void main(String[] args) {
int[] a =new int[]{9,5,1,3,7,8,6,2,0,4};
//Sort.bubbleSort(a);
//Sort.selectSort(a);
//Sort.insertSort(a);
Sort.quickSort(a, 0, a.length-1);
for(int t : a){
System.out.println(t);
}
}
}
在java语言 I/O库的设计中,使用了两个结构模式,即装饰模式和适配器模式。
在任何一种计算机语言中,输入/输出都是一个很重要的部分。与一般的计算机语言相比,java将输入/输出的功能和使用范畴做了很大的扩充。因此输入输出在java语言中占有极为重要的位置。
java语言采用流的机制来实现输入/输出。所谓流,就是数据的有序排列,流可以是从某个源(称为流源,或者 Source of Stream)出来,到某个目的(Sink of Stream)地去。根据流的方向可以将流分成输出流和输入流。程序通过输入流读取数据,想输出流写出数据。
例如:一个java程序可以使用FileInputStream类从一个磁盘文件读取数据,如下图:
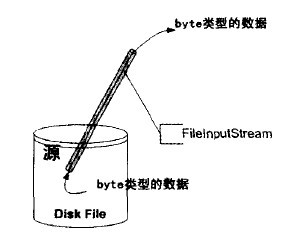
像FileInputStream这样的处理器叫流处理器。一个流处理器就像一个流的管道一样,从一个流源吸入某种类型的数据,并输出某种类型的数据。上面的示意图叫流的管道图。
类似地,也可以用FileOutputStream类向一个磁盘文件写数据,如下图:

在实际的应用当中,这样简单的机制并没有太大的用处。程序需要写出的往往是非常结构话的信息,因此这些Byte类型的数据实际上是一些数字、文字、源代码等。java的I/O库提供了一个称作链接(Chaining)的机制,可以将一个流处理器与另一个流处理器首尾相接,以其中之一的输出为输入,形成一个流管道的链接。
例如,DateInputStream流处理器可以把FileInputStream流对象的输出当做输入,将Byte类型的数据转换成java的原始数据类型和String数据类型,如下图:

类似地,向一个文件中写入Byte类型的数据也不是一个简单的过程。一个程序需要向一个文件里写入的数据往往是结构化的,而Byte类型则是原始的类型,因此,在写入的时候必须首先经过转换。DateOutputStream流处理器提供了接受原始数据类型和String数据类型的方法,而这个流处理器的输出数据则是Byte类型。换而言之,DateOutputStream可以将源数据转换成Byte类型的数据,在输出出来。
这样一来,就可以将DateOutputStream与FileOutputStream链接起来。这样做的结果就是,程序可以将原始数据类型和String数据类型的源数据写到这个链接好的双重管道里面,达到将结构话数据写到磁盘文件里的目的,如下图所示:

这是链接的威力。
流处理器所处理的流必定都有流源,如果将流类所处理的流源分类的话,那么基本可以分成两大类:
(1)数组、String、File等,这一种叫原始流源。
(2)同样类型的流用做链接流类的流源,就叫做链接流源。
java I/O库的设计原则
java语言的I/O库是对各种常见的流源、流汇以及处理过程的抽象化。客户端的java 程序不必知道最终的的流源、流汇是磁盘上的文件还是一个数组,或者是一个线程;也不比插手到诸如数据是否缓存、可否按照行号读取等处理的细节中去。
要理解java I/O 这个庞大而复杂的库,关键是掌握两个对称性和两个设计模式。
java I/O库的两个对称性
java I/O库具有两个对称性,它们分别是:
(1)输入-输出对称:比如InputStream 和OutputStream 各自占据Byte流的输入和输出的两个平行的等级结构的根部;而Reader和Writer各自占据Char流的输入和输出的两个平行的等级结构的根部。
(2)byte-char对称:InputStream和Reader的子类分别负责byte和插入流的输入;OutputStream和Writer的子类分别负责byte和Char流的输出,它们分别形成平行的等级结构。
java I/O库的两个设计模式
ava I/O库的总体设计是符合装饰模式和适配器模式的。如前所述,这个库中处理流的类叫流类。
装饰模式:在由InputStream、OutputStream、Reader和Writer代表的等级结构内部,有一些流处理器可以对另一些流处理器起到装饰作用,形成新的、具有改善了的功能的流处理器。
适配器模式:在由InputStream、OutputStream、Reader和Writer代表的等级结构内部,有一些流处理器是对其他类型的流处理器的适配。这就是适配器的应用。
装饰模式的应用
装饰模式在java中的最著名的应用莫过于java I/O标准库的设计了。
由于java I/O库需要很多性能的各种组合,如果这些性能都是用继承来实现,那么每一种组合都需要一个类,这样就会造成大量行重复的类出现。如果采用装饰模式,那么类的数目就会大大减少,性能的重复也可以减至最少。因此装饰模式是java I/O库基本模式。
装饰模式的引进,造成灵活性和复杂性的提高。因此在使用 java I/O 库时,必须理解java I/O库是由一些基本的原始流处理器和围绕它们的装饰流处理器所组成的。
InputStream类型中的装饰模式 InputStream有七个直接的具体子类,有四个属于FilterInputStream的具体子类,如下图所示:
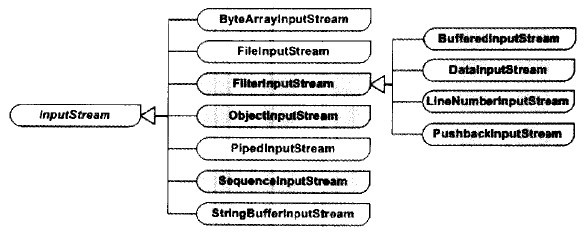
上图中所有的类都叫做流处理器,这个图叫做(InputStream类型)流处理器图。根据输入流的源的类型,可以将这些流分为两种,即原始流类和链接流处理器。
原始流处理器
原始流处理器接收一个Byte数组对象、String对象、FileDescriptor对象或者不同类型的流源对象(就是前面所说的原始流源),并生成一个InputStream类型的流对象。在InputStream类型的流处理器中,原始流处理器包括以下四种:
(1)ByteArrayInputStream:为多线程的通讯提供缓冲区操作工作,接受一个Byte数组作为流的源。
(2)FileInputStream:建立一个与文件有关的输入流。接受一个File对象作为流的源。
(3)PipedInputStream:可以和PipedOutputStream配合使用,用于读入一个数据管道的数据。接受一个PipedOutputStream作为源。
(4)StringBufferInputStream:将一个字符串缓冲区抓换为一个输入流。接受一个String对象作为流的源。
与原始流处理器相对应的是链接流处理器。
链接流处理器
所谓链接流处理器就是可以接受另一个(同种类的)流对象(就是链接流源)作为流源,并对之进行功能扩展的类。InputStream类型的链接流处理器包括以下几种,它们接受另一个InputStream对象作为流源。
(1)FilterInputStream称为过滤输入流,它将另一个输入流作为流源。这个类的子类包括以下几种:
BufferInputStream:用来从硬盘将数据读入到一个内存缓冲区中,并从此缓冲区提供数据。
DateInputStream:提供基于多字节的读取方法,可以读取原始数据类型的数据。
LineNumberInputStream:提供带有行计算功能的过滤输入流。
PushbackInputStream: 提供特殊的功能,可以将已读取的直接“推回”输入流中。
(2)ObjectInputStream 可以将使用ObjectInputStream串行化的原始数据类型和对象重新并行化。
(3)SequenceInputStream可以将两个已有的输入流连接起来,形成一个输入流,从而将多个输入流排列构成一个输入流序列。
必须注意的是,虽然PipedInuptStream接受一个流对象PipedOutputStream作为流的源,但是PipedOutputStream流对象的类型不是InputStream,因此PipedInputStream流处理器仍属于原始流处理器。
抽象结构图
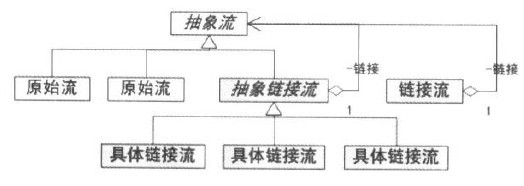
上面流处理器图与装饰模式的结构图有明显的相同之处。实际上InputStream类型的流处理器结构确实符合装饰模式,而这可以从它们在结构中所扮演的角色中分辩出来。
装饰模式的各个角色 在所有InputStream类型的链接流处理其中,使用频率最大的就是FilterInputStream类,以这个类为抽象装饰角色的装饰模式结构非常明显和典型。以这个类为核心说明装饰模式的各个角色是由哪些流处理器扮演:
抽象构件(Component)角色:由InputStream扮演。这是一个抽象类,为各种子类型处理器提供统一的接口。
具体构建(Concrete Component)角色:由ByteArrayInputStream、FileInputStream、PipedInputStream以及StringBufferInputStream等原始流处理器扮演。它们实现了抽象构建角色所规定的接口,可以被链接流处理器所装饰。
抽象装饰(Decorator)角色:由FilterInputStream扮演。它实现了InputStream所规定的接口。
具体装饰(Concrete Decorator)角色:由几个类扮演,分别是DateInputStream、BufferedInputStream 以及两个不常用到的类LineNumberInputStream和PushbackInputStream。
链接流其实就是装饰角色,原始流就是具体构建角色,如下图所示:

一方面,链接流对象接受一个(同类型的)原始流对象或者另一个(同类型的)链接流对象作为流源;另一方面,它们都对流源对象的内部工作方法做了相应的改变,这种改变是装饰模式所要达到的目的。比如:
(1)BufferedInputStream “装饰” 了InputStream的内部工作方式,使得流的读入操作使用缓冲机制。在使用了缓冲机制后,不会对每一次的流读入操作都产生一个物理的读盘动作,从而提高了程序的效率。在涉及到物理流的读入时,都应当使用这个装饰流类。
(2)LineNumberInputStream和PushbackInputStream也同样“装饰”了InputStream的内部工作方式,前者使得程序能够按照行号读入数据;后者能使程序在读入的过程中退后一个字符。后两个装饰类可能在实际的编程工作中很少用到,因为它们是为了支持用java语言做编译器而准备的。
(3)DateInputStream子类读入各种不同的原始数据类型以及String类型的数据,这一点可以从它提供的各种read()方法看出来:
readByte()、readUnsignedByte()、readShort()、readUnsignedShort()、readChar()、readInt()、readLong()、readFloat()、readDouble()、readUTF()。使用这个流处理器以及它的搭档DateOutputStream,可以将原始数据通过流从一个地方移到另一个地方。
OutputStream 类型中的装饰模式 outputStream是一个用于输出的抽象类,它的接口、子类的等级结构、子类的功能都和InputStream有很好的对称性。在OutputStream给出的接口里,将write换成read就得到了InputStream的接口,而其具体子类则在功能上面是平行的。
(1)针对byte数字流源的链接流类,以ByteArrayInputStream描述输入流,以ByteArrayOutputStream描述输出流。
(2)针对String流源的链接流类,以StringBufferInputStream描述输入流,以StringBufferOutputStream描述输出流。
(3)针对文件流源的链接流类,以FileInputStream描述输入流,以FileOutputStream描述输出流。
(4)针对数据管道流源的链接流类,以PipedInputStream描述输入流,以PipedOutputStream描述输出流。
(5)针对以多个流组成的序列,以SequenceInputStream描述输入流,以SequenceOutputStream描述输出流。
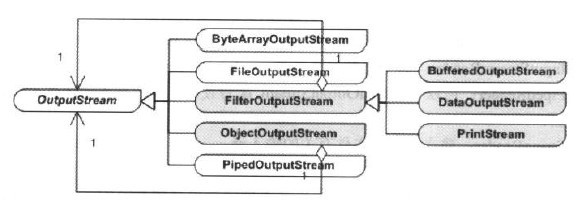
OutputStream类型有哪些子类
outputStream有5个直接的具体子类,加上三个属于FilterInputStream的具体子类,一共有8个具体子类,如下图:
 原始流处理器
原始流处理器
在OutputStream类型的流处理器中,原始流处理器包括以下三种:
ByteArrayOutputStream:为多线程的通信提供缓冲区操作功能。输出流的汇集是一个byte数组。
FileOutputStream:建立一个与文件有关的输出流。输出流的汇集是一个文件对象。
PipedOutputStream: 可以与PipedInputStream配合使用,用于向一个数据管道输出数据。
链接流处理器 OutputStream类型的链接流处理器包括以下几种:
(1)FilterOutputStream:称为过滤输出流,它将另一个输出流作为流汇。这个类的子类有如下几种:
BufferedOutputStream:用来向一个内存缓冲区中写数据,并将此缓冲区的数据输入到硬盘中。
DataOutputStream:提供基于多字节的写出方法,可以写出原始数据类型的数据。
PrintStream:用于产生格式化输出。System.out 静态对象就是一个
PrintStream。
(2)ObjectOutputStream 可以将原始数据类型和对象串行化。
装饰模式的各个角色
在所有的链接流处理器中,最常见的就是FilterOutputStream类。以这个类为核心的装饰模式结构非常明显和典型,如下图:
装饰模式所涉及的各个角色:
抽象构件(Component)角色:由OutputStream扮演,这是一个抽象类,为各种的子类型流处理器提供统一的接口。
具体构件(Concrete Component)角色:由ByteArrayOutputStream、FileOutputStream、PipedOutputStream等扮演,它们均实现了OutputStream所声明的接口。
抽象装饰(Decorator)角色:由FilterOutputStream扮演,它与OutputStream有相同的接口,而这正是装饰类的关键。
具体装饰(Concrete Decorator)角色:由几个类扮演,分别是BufferedOutputStream、DateOutputStream、以及PrintStream。
所谓链接流,就是装饰模式中的装饰角色,原始流就是具体构件角色。
与DateInputStream相对应的是DataOutputStream,后者负责将由原始数据类型和String对象组成的数据格式化,并输出到一个流中,使得任何机器上的任何DataInputStream类型的对象都可以读入这些数据。所有的方法都是以write开始。
如果需要对数据进行真正的格式化,以便输出到像控制台显示那样,那就需要使用PrintStream。
PrintStream可以对由原始数据类型和String对象组成的数据进行格式化,以形成可以阅读的格式;而DataOutputStream则不同,它将数据输出到一个流中,以便DataInputStream可以在任何机器而后操作系统中都可以重新将数据读入,并进行结构重建。
PrintStream对象最重要的两个方法是print() 和println(),这两个方法都是重载的,以便可以打印出所有使用类型的数据。这两个方法之间的区别是后者每行结束时多打印出一个换行符号。
BufferedOutputStream对一个输出流进行装饰,使得流的写出操作使用缓冲机制。在使用缓冲机制后,不会对每一次的流的写入操作都产生一个物理的写动作,从而提高的程序的效率。在涉及到物理流的地方,比如控制台I/O、文件I/O等,都应当使用这个装饰流处理器。
Reader类型中的装饰模式 在Reader类型的流处理器中,
原始流处理器包括以下四种:
(1)CharArrayReader:为多线程的通信提供缓冲区操作功能。
(2)InputStreamReader:这个类有一个子类--FileReader。
(3)PipedReader:可以与PipedOutputStream配合使用,用于读入一个数据管道的数据。
(4)StringReader:建立一个与文件有关的输入流。
链接流处理器包括以下:
(1)BufferedReader:用来从硬盘将数据读入到一个内存缓冲区,并从此缓冲区提供数据,这个类的子类为
LineNumberReader。
(2)FilterReader:成为过滤输入流,它将另一个输入流作为流的来源。这个类的子类有PushbackReader,提供基于多字节的读取方法,可以读取原始数据类型的数据,Reader类型的类图如下所示:
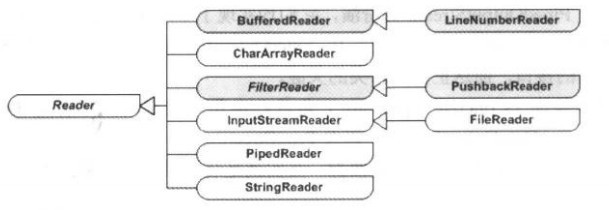
Reader类型中,装饰模式所涉及的各个角色:
(1)抽象构建(Component)角色:有Reader扮演。这是一个抽象类,为各种的子类型流处理器提供统一的接口。
(2)具体构建(Concrete Component)角色:由CharArrayReader、InputStreamReader、PiPedReader、StringReader等扮演,他们均实现了Reader所声明的接口。
(3)抽象装饰(Decorator)角色:由BufferedReader和FilterReader扮演。这两者有着与Reader相同的接口,它们分别给出两个装饰角色的等级结构,第一个给出LineNumberReader作为具体装饰角色,另一个给出PushbackReader 作为具体装饰角色。
(4)具体装饰(Concrete Decorator)角色:LineNumberReader作为BufferedReader的具体装饰角色,BufferedReader作为FilterReader的具体装饰角色。
如下图所示,标有聚合连线的就是抽象装饰角色:
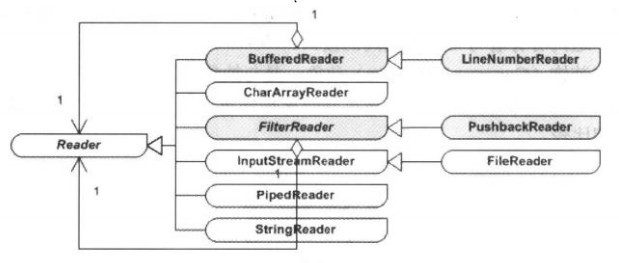 Writer类型中的装饰模式
Writer类型中的装饰模式 Writer类型是一个与Reader类型平行的等级结构,而且Writer类型的等级结构几乎与Reader的等级结构关于输入/输出是对称的。如图所示:

在Writer类型的流处理器中,原始流处理器包括以下四种:
(1)CharArrayWriter:为多线程的通信提供缓冲区的操作功能。
(2)OutputStreamWriter:建立一个与文件有关的输出流。含有一个具体子类FileWrite,为Write类型的输出流提供文件输出功能。
(3)PipedWriter:可以和PipedOutputStream配合使用,用于读如果一个数据管道的数据。
(4)StringWriter:想一个StringBuffer写出数据。
链接流处理器包括以下三种:
(1)BufferedWriter:为Writer类型的流处理器提供缓冲区功能。
(2)FilterWriter:称为过滤输入流,它将另一个输入流作为流的来源。这是一个没有子类的抽象类。
(3)PrintWriter:支持格式化的文字输出。
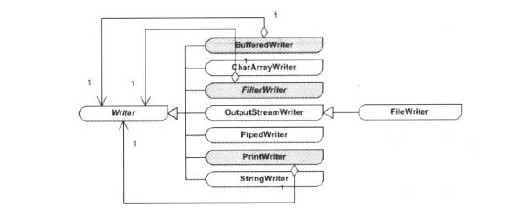
Writer类型中,装饰模式所涉及的各个角色:
(1)抽象构建(Component)角色:由Write扮演。这是一个抽象类,为为各种子类型的流处理器提供统一的接口。
(2)具体构建(Concrete Component):角色由
CharArrayWriter、OutputStreamWriter、
PipedWriter、StringWriter扮演,它们实现了Writer所声明的接口。 (3)抽象装饰(Decorator)角色:由
BufferedWriter、FilterWriter、PrintWriter扮演,它们有着与Write
相同的接口。
(4)具体装饰(Concrete Decorator)角色:与抽象装饰角色合并。
如下图所示,标出了从抽象装饰角色到抽象构件角色的聚合连线,更易于与装饰模式的结构图比较。
 适配器模式的应用
适配器模式的应用
适配器模式是java I/O库中第二个最重要的设计模式。
InputStream原始流处理器中的适配器模式 InputStream类型的原始流处理器是适配器模式的应用。
ByteArrayInputStream是一个适配器类
ByteArrayInputStream继承了InputStream的接口,而封装了一个byte数组。换而言之,它将一个byte数组的接口适配成了InputStream流处理器的接口。
java语言支持四种类型:java类、java接口、java数组和原始类型。前三章是引用类型,类和数组的实例都是对象,原始类型的值不少对象。java语言的数组是像所有其他对象一样的对象,而不管数组中所存放的元素的类型是什么。这样一来,ByteArrayInputStream就符合适配器模式的描述,而且是一个对象形式的适配器类。如下图所示:
 StringBufferInputStream是一个适配器类
StringBufferInputStream是一个适配器类
StringBufferInputStream继承了InputStream类型,同时持有一个对String类型的引用。这是将String对象适配成InputStream类型的对象形式的适配器模式,如下图:
 OutputStream原始流处理器中的适配器模式
OutputStream原始流处理器中的适配器模式
在OutputStream类型中,所有的原始流处理器都是适配器类。
ByteArrayOutputStream是一个适配器类
ByteArrayOutputStream继承了OutputStream类型,同事持有一个对byte数组的引用。它把一个byte数组的接口适配成OutputStream类型的接口,因此也是一个对象类型的适配器模式的应用。如下图:
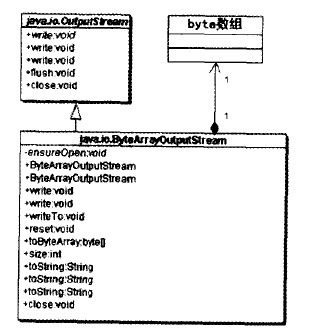
FileOutputStream是一个适配器类
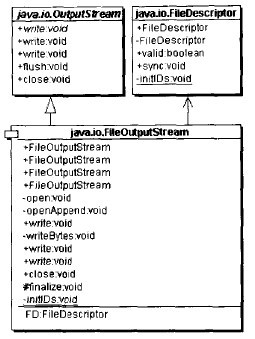
FileOutputStream继承OutputStream,同时持有一个对FileDescriptor对象的引用。这是一个将FileDescriptor适配成OutputStream接口的对象形式的适配器模式,如下图所示:
PipedOutputStream是一个适配器类
PipedOutputStream总是和PipedInputStream一起使用,它接收一个类型为PipedInputStream的输入类型,并将之转换成OutputStream类型的输出流,这是一个对象形式的适配器模式应用。如下图:

Reader原始流处理器中的适配器模式
Reader 类型的原始流处理器都是适配器模式的应用。
CharArrayReader是一个适配器类。
CharArrayReader将一个Char数组适配成Reader类型的输入流,因此它是一个对象形式的适配器应用,如下图所示:
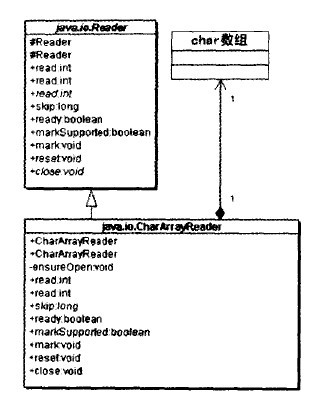
StringReader是一个适配器类
StringReader 继承了Reader类型,持有一个对String类型的引用。它将String的接口适配成Reader类型的接口,如下图所示:

Writer类型中的适配器模式
Writer类型中的原始流处理器就是适配器模式的具体应用。
CharArrayWriter是一个适配器类。
CharArrayWriter将一个Char数组适配成Writer 接口,如下图所示:
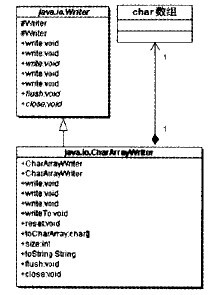
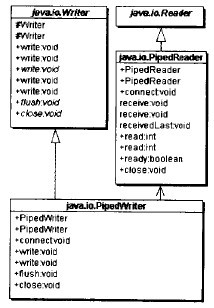
PipedWriter是一个适配器类
PipedWriter总是与PiPedReader一同使用,它将一个PipedReader对象的接口适配成一个Writer类型的接口,如下图所示:
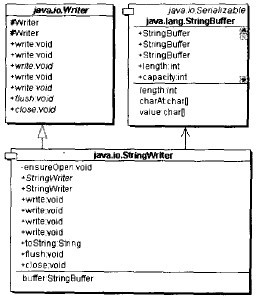
StringWriter是一个适配器类
StringWriter继承Writer类型,同时持有一个StringBuffer对象,它将StringBuffer对象的接口适配成为了
Writer类型的接口,是一个对象形式的适配器 模式的应用,如下图所示:
从byte流到char流的适配
在java语言的标准库 java I/O 里面,有一个InputStreamReader类叫做桥梁(bridge)类。InputStreamReader是从byte流到char流的一个桥梁,它读入byte数据并根据指定的编码将之翻译成char数据。
InputStreamReader虽然叫“桥梁”,但它不爽桥梁模式,是适配器模式的应用。
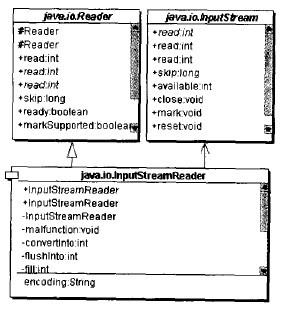
InputStreamReader
InputStreamReader是从byte输入流到char输入流的一个适配器。下图所示就是InputStreamReader 的结构图:
为了说明适配器类InputStreamReader是如何使用,请看下面例子。Echo类可以将控制台输入的任何字符串从新打印出来,源代码如下:
Echo.java
01 |
package com.think.cla; |
03 |
import java.io.BufferedReader; |
04 |
import java.io.IOException; |
05 |
import java.io.InputStreamReader; |
09 |
public static void main(String [] args)throws IOException{ |
11 |
InputStreamReader input = new InputStreamReader(System.in); |
12 |
System.out.println("Enter data and push enter:"); |
13 |
BufferedReader reader = new BufferedReader(input); |
14 |
line = reader.readLine(); |
15 |
System.out.println("Data entered :"+line); |
可以看出,这个类接受一个类型为inputStream的System.in对象,将之适配成Reader类型,然后再使用
BufferedReader类“装饰”它,将缓冲功能加上去。这样一来,就可以使用BufferedReader对象的readerLine()
方法读入整行的输入数据,数据类型是String。
在得到这个数据之后,程序又将它写出到System.out 中去,完成了全部的流操作,下图所示为其管道图:
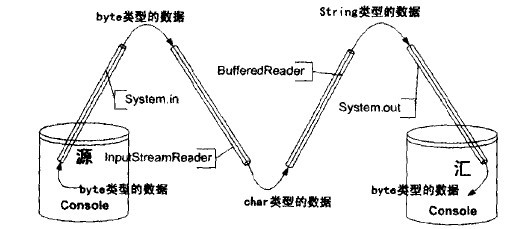
本系统使用了BufferedReader来为流的读入提供缓冲功能,这样做的直接效果是可以使用readLine()方法按行读入数据。但是由于Reader接口并不提供readLine()方法,所以这样一来,系统就必须声明一个BufferedReader类型的流处理器,而不是一个Reader类型的流处理器,这意味着装饰模式的退化。
在上面的管道连接过程中,InputStreamReader 起到了适配器的作用,它将一个byte类型的输入流适配成为一个char类型的输入流。在这之后,BufferedReader则起到了装饰模式的作用,将缓冲机制引入到流的读入中。因此这个例子涉及到了两个设计模式。
package com.scpii.ent.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import com.scpii.ent.mode.bean.DataSet;
public class ExcelOperClass {
private static String EXCEL_2003 = ".xls";
private static String EXCEL_2007 = ".xlsx";
public static void readExcelJXL() {
}
/**
* 通过POI方式读取Excel
*
* @param excelFile
*/
public static DataSet readExcelPOI(String filePath, Integer cons) throws Exception {
File excelFile = new File(filePath);
if (excelFile != null) {
String fileName = excelFile.getName();
fileName = fileName.toLowerCase();
if (fileName.toLowerCase().endsWith(EXCEL_2003)) {
DataSet dataSet = readExcelPOI2003(excelFile, cons);
return dataSet;
}
if (fileName.toLowerCase().endsWith(EXCEL_2007)) {
DataSet dataSet = readExcelPOI2007(excelFile, cons);
return dataSet;
}
}
return null;
}
/**
* 读取Excel2003的表单
*
* @param excelFile
* @return
* @throws Exception
*/
private static DataSet readExcelPOI2003(File excelFile, Integer rCons)
throws Exception {
List<String[]> datasList = new ArrayList<String[]>();
Set<String> colsSet = new HashSet<String>();
InputStream input = new FileInputStream(excelFile);
HSSFWorkbook workBook = new HSSFWorkbook(input);
// 获取Excel的sheet数量
Integer sheetNum = workBook.getNumberOfSheets();
// 循环Sheet表单
for (int i = 0; i < sheetNum; i++) {
HSSFSheet sheet = workBook.getSheetAt(i);
if (sheet == null) {
continue;
}
// 获取Sheet里面的Row数量
Integer rowNum = sheet.getLastRowNum() + 1;
for (int j = 0; j < rowNum; j++) {
if (j>rCons) {
System.out.println("===========");
HSSFRow row = sheet.getRow(j);
if (row == null) {
continue;
}
Integer cellNum = row.getLastCellNum() + 1;
String[] datas = new String[cellNum];
for (int k = 0; k < cellNum; k++) {
HSSFCell cell = row.getCell(k);
if (cell == null) {
continue;
}
if (cell != null) {
cell.setCellType(HSSFCell.CELL_TYPE_STRING);
String cellValue = "";
int cellValueType = cell.getCellType();
if (cellValueType == cell.CELL_TYPE_STRING) {
cellValue = cell.getStringCellValue();
}
if (cellValueType == cell.CELL_TYPE_NUMERIC) {
Double number = cell.getNumericCellValue();
System.out.println("字符串+++=========="+number.intValue());
cellValue = cell.getNumericCellValue() + "";
}
if (rCons==k) {
colsSet.add(cellValue);
}
System.out.println(cellValue);
datas[k] = cellValue;
}
}
datasList.add(datas);
}
}
}
DataSet dataSet = new DataSet(null, null, datasList, colsSet);
return dataSet;
}
/**
* 读取Excel2007的表单
*
* @param excelFile
* @return
* @throws Exception
*/
private static DataSet readExcelPOI2007(File excelFile, Integer rCons) throws Exception {
List<String[]> datasList = new ArrayList<String[]>();
Set<String> cosSet = new HashSet<String>();
InputStream input = new FileInputStream(excelFile);
XSSFWorkbook workBook = new XSSFWorkbook(input);
// 获取Sheet数量
Integer sheetNum = workBook.getNumberOfSheets();
for (int i = 0; i < sheetNum; i++) {
XSSFSheet sheet = workBook.getSheetAt(i);
if (sheet == null) {
continue;
}
// 获取行值
Integer rowNum = sheet.getLastRowNum() + 1;
for (int j = 0; j < rowNum; j++) {
if (j > rCons) {
System.out.println("=============");
XSSFRow row = sheet.getRow(j);
if (row == null) {
continue;
}
Integer cellNum = row.getLastCellNum() + 1;
String[] datas = new String[cellNum];
for (int k = 0; k < cellNum; k++) {
XSSFCell cell = row.getCell(k);
if (cell==null) {
continue;
}
if (cell != null) {
cell.setCellType(XSSFCell.CELL_TYPE_STRING);
String cellValue = "";
int cellValueType = cell.getCellType();
if (cellValueType == cell.CELL_TYPE_STRING) {
cellValue = cell.getStringCellValue();
}
if (cellValueType == cell.CELL_TYPE_NUMERIC) {
Double number = cell.getNumericCellValue();
System.out.println("字符串+++=========="+number.toString());
cellValue = cell.getNumericCellValue() + "";
}
System.out.println(cellValue);
if (rCons == k) {
cosSet.add(cellValue);
}
datas[k] = cellValue;
}
}
datasList.add(datas);
}
}
}
DataSet dataSet = new DataSet(null, null, datasList,cosSet);
return dataSet;
}
public static void main(String[] args) {
// try {
// DataSet dataSet = readExcelPOI("D:\\部门员工资料.xls", 0);
// System.out.println("================================");
// Set<String> datas = dataSet.getConStrctSet();
// String[] datastr = new String[datas.size()];
// datastr = datas.toArray(datastr);
// for (int i = 0; i < datastr.length; i++) {
// System.out.println(datastr[i]);
// }
// } catch (Exception e) {
// e.printStackTrace();
// }
System.out.println(52%4);
}
}
package com.scpii.ent.mode.bean;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
public class DataSet {
private String[] headers;
private String[] rowHeaders;
private List<String[]> datasList = new ArrayList<String[]>();
private Set<String> conStrctSet;
public DataSet(String[] headers, String[] rowHeaders,
List<String[]> datasList, Set<String> conStrctSet) {
this.headers = headers;
this.rowHeaders = rowHeaders;
this.datasList = datasList;
this.conStrctSet = conStrctSet;
}
public DataSet(String[] header, String[] rowsHeader,
List<String[]> datasList2) {
this.headers = header;
this.rowHeaders = rowsHeader;
this.datasList = datasList2;
}
public String[] getHeaders() {
return headers;
}
public void setHeaders(String[] headers) {
this.headers = headers;
}
public String[] getRowHeaders() {
return rowHeaders;
}
public void setRowHeaders(String[] rowHeaders) {
this.rowHeaders = rowHeaders;
}
public List<String[]> getDatasList() {
return datasList;
}
public void setDatasList(List<String[]> datasList) {
this.datasList = datasList;
}
public Set<String> getConStrctSet() {
return conStrctSet;
}
public void setConStrctSet(Set<String> conStrctSet) {
this.conStrctSet = conStrctSet;
}
}