2012年8月27日
#
项目中有时会用到自动补全查询,就像Google搜索框、淘宝商品搜索功能,输入汉字或字母,则以该汉字或字母开头的相关条目会显示出来供用户选择, autocomplete插件就是完成这样的功能。
autocomplete官网 : http://bassistance.de/jquery-plugins/jquery-plugin-autocomplete/ (可下载jQuery autocomplete插件)。
淘宝商品搜索功能 效果:

下面来使用 autocomplete插件来实现类似效果。
1. 创建 AjaxPage.aspx 页面,在其中定义 WebMethod 方法来返回 搜索页面需要的输入框所有提示条目。 后台代码如下:
1 using System.Collections.Generic;
2 using System.IO;
3 using System.Runtime.Serialization.Json;
4 using System.Web.Services;
5
6 public partial class AjaxPage : System.Web.UI.Page
7 {
8 [WebMethod]
9 public static string GetAllHints()
10 {
11 Dictionary<string, string> data = new Dictionary<string, string>();
12 data.Add("苹果4代iphone正品", "21782");
13 data.Add("苹果4代 手机套", "238061");
14 data.Add("苹果4", "838360");
15 data.Add("苹果皮", "242721");
16 data.Add("苹果笔记本", "63348");
17 data.Add("苹果4s", "24030");
18 data.Add("戴尔笔记本", "110105");
19 data.Add("戴尔手机", "18870");
20 data.Add("戴尔键盘", "30367");
21
22 DataContractJsonSerializer serializer = new DataContractJsonSerializer(data.GetType());
23
24 using (MemoryStream ms = new MemoryStream())
25 {
26 serializer.WriteObject(ms, data);
27 return System.Text.Encoding.UTF8.GetString(ms.ToArray());
28 }
29 }
30 }
注:该方法返回的数据格式为json字符串。
2. 创建搜索页面 Index.aspx, 前台代码如下:

1 <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Index.aspx.cs" Inherits="_Default" %>
2
3 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
4
5 <html xmlns="http://www.w3.org/1999/xhtml">
6 <head runat="server">
7 <title></title>
8 <link rel="Stylesheet" href="Styles/jquery.autocomplete.css" />
9 <script type="text/javascript" src="Scripts/jquery-1.4.1.js"></script>
10 <script type="text/javascript" src="Scripts/jquery.autocomplete.js"></script>
11 <script type="text/javascript">
12 var v = 1;
13 $(document).ready(function () {
14 $.ajax({
15 type: "POST",
16 contentType: "application/json",
17 url: "AjaxPage.aspx/GetAllHints",
18 data: "{}",
19 dataType: "json",
20 success: function (msg) {
21 var datas = eval('(' + msg.d + ')');
22 $("#txtIput").autocomplete(datas, {
23 formatItem: function (row, i, max) {
24 return "<table width='400px'><tr><td align='left'>" + row.Key + "</td><td align='right'><font style='color: #009933; font-family: 黑体; font-style: italic'>约" + row.Value + "个宝贝</font> </td></tr></table>";
25 },
26 formatMatch: function(row, i, max){
27 return row.Key;
28 }
29 });
30 }
31 });
32 });
33 </script>
34 </head>
35 <body>
36 <form id="form1" runat="server">
37 <div>
38 <center>
39 <asp:TextBox ID="txtIput" runat="server" Width="400px"></asp:TextBox>
40 </center>
41 </div>
42 </form>
43 </body>
44 </html>
实现效果如下:

3. autocomplete 参数说明
* minChars (Number)
在触发autoComplete前用户至少需要输入的字符数.Default: 1,如果设为0,在输入框内双击或者删除输入框内内容时显示列表
* width (Number)
指定下拉框的宽度. Default: input元素的宽度
* max (Number)
autoComplete下拉显示项目的个数.Default: 10
* delay (Number)
击键后激活autoComplete的延迟时间(单位毫秒).Default: 远程为400 本地10
* autoFill (Boolean)
要不要在用户选择时自动将用户当前鼠标所在的值填入到input框. Default: false
* mustMatch (Booolean)
如果设置为true,autoComplete只会允许匹配的结果出现在输入框,所有当用户输入的是非法字符时将会得不到下拉框.Default: false
* matchContains (Boolean)
决定比较时是否要在字符串内部查看匹配,如ba是否与foo bar中的ba匹配.使用缓存时比较重要.不要和autofill混用.Default: false
* selectFirst (Boolean)
如果设置成true,在用户键入tab或return键时autoComplete下拉列表的第一个值将被自动选择,尽管它没被手工选中(用键盘或鼠标).当然如果用户选中某个项目,那么就用用户选中的值. Default: true
* cacheLength (Number)
缓存的长度.即对从数据库中取到的结果集要缓存多少条记录.设成1为不缓存.Default: 10
* matchSubset (Boolean)
autoComplete可不可以使用对服务器查询的缓存,如果缓存对foo的查询结果,那么如果用户输入foo就不需要再进行检索了,直接使用缓存.通常是打开这个选项以减轻服务器的负担以提高性能.只会在缓存长度大于1时有效.Default: true
* matchCase (Boolean)
比较是否开启大小写敏感开关.使用缓存时比较重要.如果你理解上一个选项,这个也就不难理解,就好比foot要不要到FOO的缓存中去找.Default: false
* multiple (Boolean)
是否允许输入多个值即多次使用autoComplete以输入多个值. Default: false
* multipleSeparator (String)
如果是多选时,用来分开各个选择的字符. Default: ","
* scroll (Boolean)
当结果集大于默认高度时是否使用卷轴显示 Default: true
* scrollHeight (Number)
自动完成提示的卷轴高度用像素大小表示 Default: 180
* formatItem (Function)
为每个要显示的项目使用高级标签.即对结果中的每一行都会调用这个函数,返回值将用LI元素包含显示在下拉列表中. Autocompleter会提供三个参数(row, i, max): 返回的结果数组, 当前处理的行数(即第几个项目,是从1开始的自然数), 当前结果数组元素的个数即项目的个数. Default: none, 表示不指定自定义的处理函数,这样下拉列表中的每一行只包含一个值.
* formatResult (Function)
和formatItem类似,但可以将将要输入到input文本框内的值进行格式化.同样有三个参数,和formatItem一样.Default: none,表示要么是只有数据,要么是使用formatItem提供的值.
* formatMatch (Function)
对每一行数据使用此函数格式化需要查询的数据格式. 返回值是给内部搜索算法使用的. 参数值row
* extraParams (Object)
为后台(一般是服务端的脚本)提供更多的参数.和通常的作法一样是使用一个键值对对象.如果传过去的值是{ bar:4 },将会被autocompleter解析成my_autocomplete_backend.php?q=foo&bar=4 (假设当前用户输入了foo). Default: {}
* result (handler)
此事件会在用户选中某一项后触发,参数为:
event: 事件对象. event.type为result.
data: 选中的数据行.
formatted:formatResult函数返回的值
例如:
$("#singleBirdRemote").result(function(event, data, formatted) {
//如选择后给其他控件赋值,触发别的事件等等
});
过页头生成Token,进行请求验证,解决Ajax请求安全问题。目前为止我做的最多的防止ajax请求攻击的就是添加验证码、添加随机Token,限制同一请求在规定时间内的最大请求数。
下面重点说说添加随机Token限制:
token是为了防止表单重复提交,token 原理大致为:
1:显示表单的那个 action 中使用 createToken() 生成一个随机的 token值,并存放在服务端(session或者cache中),并且传递一份到页面中
2:表单页面使用一个隐藏表单域获取后端传过来的 token值,该表单页面提交时会将此 token 值一同提交到后端
3:在表单页面提交到的 actioin 中使用 validateToken() 将服务端与表单隐藏域中的 token 值进行对比,如果服务端存在 token值并且与表单提交过来的值相等,证明是第一次提交。
4:每次校验过后服务端的 token 值会立即被清除,所以当用户重复提交时,后面的提交校验都再也无法通过。从而实现了防止重复提交的功能,validateToken 是在 synchronized 块中执行的保障了多线程下的安全性。
token 会优先存入 me.setTokenCache(ITokenCache) 指定的 TokenCache 中,如果未指定则默认使用 session 来存放
但是这种机制是有问题的,比如我是用ajax提交表单,提交完成以后表单页面并不刷新,然后我修改了部分数据以后再次提交页面,那么token还是之前的那个token,后台会以为这个为重复提交不能通过校验,那么请求就不能完成,数据无法得到正确的处理。我认为合理的机制应该是这样的:
1:显示表单的那个 action 中使用 createToken() 生成一个随机的 token值,并且传递一份到页面中
2:表单页面使用一个隐藏表单域获取后端传过来的 token值,该表单页面提交时会将此 token 值一同提交到后端
3:将提交过来的token值放入session或者cache中,然后执行controller中的代码,代码全部执行完以后,再把存入session或cache中的token值删除掉;验证用户是否为重复提交只需要验证提交过来的token是否存在于session或cache中,有则为重复提交,无则为正常提交。
4:该逻辑应该可以写成一个Interceptor,在需要的地方加上,或者直接设为全局拦截器都是可以的,简单,快捷;
JDK1.6版添加了新的ScriptEngine类,允许用户直接执行js代码。
在Java中直接调用js代码
不能调用浏览器中定义的js函数,会抛出异常提示ReferenceError: “alert” is not defined。
| | package com.sinaapp.manjushri; import javax.script.ScriptEngine; import javax.script.ScriptEngineManager; import javax.script.ScriptException; /** * 直接调用js代码 */ public class ScriptEngineTest { public static void main(String[] args) { ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("javascript"); try{ engine.eval("var a=3; var b=4;print (a+b);"); // engine.eval("alert(\"js alert\");"); // 不能调用浏览器中定义的js函数 // 错误,会抛出alert引用不存在的异常 }catch(ScriptException e){ e.printStackTrace(); } } } |
输出结果:7
在Java中绑定js变量
在调用engine.get(key);时,如果key没有定义,则返回null
| | package com.sinaapp.manjushri; import javax.script.Bindings; import javax.script.ScriptContext; import javax.script.ScriptEngine; import javax.script.ScriptEngineManager; import javax.script.ScriptException; public class ScriptEngineTest2 { public static void main(String[] args) { ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("javascript"); engine.put("a", 4); engine.put("b", 3); Bindings bindings = engine.getBindings(ScriptContext.ENGINE_SCOPE); try { // 只能为Double,使用Float和Integer会抛出异常 Double result = (Double) engine.eval("a+b"); System.out.println("result = " + result); engine.eval("c=a+b"); Double c = (Double)engine.get("c"); System.out.println("c = " + c); } catch (ScriptException e) { e.printStackTrace(); } } } |
输出:
result = 7.0
c = 7.0
在Java中调用js文件中的function,传入调用参数,并获取返回值
js文件中的merge函数将两个参数a,b相加,并返回c。
| | // expression.js function merge(a, b) { c = a * b; return c; } |
在Java代码中读取js文件,并参数两个参数,然后回去返回值。
| | package com.sinaapp.manjushri; import java.io.FileReader; import javax.script.Invocable; import javax.script.ScriptEngine; import javax.script.ScriptEngineManager; /** * Java调用并执行js文件,传递参数,并活动返回值 * * @author manjushri */ public class ScriptEngineTest { public static void main(String[] args) throws Exception { ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("javascript"); String jsFileName = "expression.js"; // 读取js文件 FileReader reader = new FileReader(jsFileName); // 执行指定脚本 engine.eval(reader); if(engine instanceof Invocable) { Invocable invoke = (Invocable)engine; // 调用merge方法,并传入两个参数 // c = merge(2, 3); Double c = (Double)invoke.invokeFunction("merge", 2, 3); System.out.println("c = " + c); } reader.close(); } } |
输出结果:
c = 5.0
java调用脚本语言笔记(jython,jruby,groovy)
有两种方法
1.java se 6以后实现了jsr 223规范
java代码:
- ScriptEngineManager factory = new ScriptEngineManager();
- ScriptEngineManager scriptEngine = factory.getEngineByName("javascript");//或者"js"
- scriptEngine.eval(code);//执行一段脚本,code是js代码
很方便调用脚本
2.可以使用脚本语方本身提供的与java的集成手段
jython集成
使用jsr223:
前提下载jython的包,已实现jsr223
(建议在官网上下载,在安装目录下有jython.jar,http://repo2.maven.org/maven2/org/python/jython/2.5.0/ 这里也有,但是这个包里没有jsr223的实现,看包下存不存在org.python.jsr223)
- ScriptEngineManager factory = new ScriptEngineManager();
- ScriptEngineManager scriptEngine = factory.getEngineByName("python");//或者"jython"
- scriptEngine.eval(code);
使用PythonInterpreter,可以调用exec(String code)方法:
- PythonInterpreter interpreter = new PythonInterpreter();
- interpreter.exec(code);
访问数据库
使用jdbc:
- from oracle.jdbc.driver import OracleDriver
- from java.sql import DriverManager
-
- username = 'hr'
- password = '123456'
- url = 'jdbc:oracle:thin:@localhost:1521:XE'
- driver = OracleDriver()
- DriverManager.registerDriver(driver)
- conn = DriverManager.getConnection(url, username, password)
- stmt = conn.createStatement()
- sql = "select salary from EMPLOYEES t where t.salary<2300"
- rs = stmt.executeQuery(sql)
- while (rs.next()):
- print rs.getInt('salary')
- rs.close()
- stmt.close()
结果:
2200
2100
2200
使用zxJDBC :
- from com.ziclix.python.sql import zxJDBC
-
- url = 'jdbc:oracle:thin:@localhost:1521:XE'
- username = 'hr'
- password = '123456'
- driverName = 'oracle.jdbc.driver.OracleDriver'
- mysqlConn = zxJDBC.connect(url,username, password,driverName)
- cursor = mysqlConn.cursor()
- cursor.execute("select last_name from EMPLOYEES t where t.salary<2300");
- #print cursor.fetchone()
- list = cursor.fetchall()
- for record in list:
- print "name:"+record[0]
- #print cursor.description[0]
- #print cursor.description[1]
结果:
name:麦克
name:Olson
name:Philtanker
从数据库中查出的中文内容正常的。
而在代码里面的中文全部是乱码或抛异常,未解决。
与jruby集成
使用jsr223:Java代码
- ScriptEngineManager factory = new ScriptEngineManager();
- ScriptEngineManager scriptEngine = factory.getEngineByName("jruby");//或者"ruby"
- scriptEngine.eval(code);
访问数据库
Ruby代码
- require 'java'
-
- module JavaLang
- include_package "java.lang"
- end
-
- module JavaSql
- include_package 'java.sql'
- end
-
- begin
- username = 'hr'
- password = '123456'
- url = 'jdbc:oracle:thin:@localhost:1521:XE'
- driverName = 'oracle.jdbc.driver.OracleDriver'
- JavaLang::Class.forName(driverName).newInstance
- conn = JavaSql::DriverManager.getConnection(url, username, password)
- stmt = conn.createStatement
- sql = "select last_name from EMPLOYEES t where t.salary<2300"
- rs = stmt.executeQuery(sql)
- while (rs.next) do
- puts "名字:"+rs.getString("last_name")
- end
- rs.close
- stmt.close
- conn.close()
- rescue JavaLang::ClassNotFoundException
- puts "ClassNotFoundException"
- rescue JavaSql::SQLException
- puts "SQLException"
- end
结果:
名字:楹﹀厠
名字:Olson
名字:Philtanker
从数据库中查出的中文内容为乱码的。
而在代码里面的中文正常。
与groovy集成
使用jsr223:
Java代码
- ScriptEngineManager factory = new ScriptEngineManager();
- ScriptEngineManager scriptEngine = factory.getEngineByName("groovy");//或者"Groovy"
- scriptEngine.eval(code);
使用GroovyShell:
Java代码
- GroovyShell shell = new GroovyShell();
- Script script = shell.parse(code);
- Object result = script.run();
访问数据库
- import groovy.sql.Sql
-
- def username = 'hr'
- def password = '123456'
- def url = 'jdbc:oracle:thin:@localhost:1521:XE'
- def driverName = 'oracle.jdbc.driver.OracleDriver'
- def sql = Sql.newInstance(url, username, password, driverName)
-
- sql.eachRow("select last_name from EMPLOYEES t where t.salary<2300") {
- println "名字:${it.last_name}"
- }
结果:
名字:麦克
名字:Olson
名字:Philtanker
在使用groovy过程中碰到了一个异常
Exception in thread "main" java.lang.VerifyError: (class: groovy/runtime/metaclass/java/util/ArrayListMetaClass, method: super$2$invokeMethod signature: (Ljava/lang/Class;Ljava/lang/Object;Ljava/lang/String;[Ljava/lang/Object;ZZ)Ljava/lang/Object;) Illegal use of nonvirtual function call
这个异常解决花了很长时间
是因为在原来项目中存在json-lib-2.1.jar(有可能名称为json-lib-2.1-jdk15.jar),这个包是用来处理json的,与groovy1.7.5存在冲突,更新为json-lib-2.3.jar即可
(json-lib里有一些groovy运行时处理的内容)
这两天Java服务器上忽然遇到这样的异常:
avax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
问题的根本是:
缺少安全证书时出现的异常。
解决问题方法:
将你要访问的webservice/url....的安全认证证书导入到客户端即可。
以下是获取安全证书的一种方法,通过以下程序获取安全证书:
/*
* Copyright 2006 Sun Microsystems, Inc. All Rights Reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
*
* - Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
*
* - Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
*
* - Neither the name of Sun Microsystems nor the names of its
* contributors may be used to endorse or promote products derived
* from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS
* IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO,
* THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
* PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
* CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
* EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
* PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
* PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
* LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
* SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.security.KeyStore;
import java.security.MessageDigest;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLException;
import javax.net.ssl.SSLSocket;
import javax.net.ssl.SSLSocketFactory;
import javax.net.ssl.TrustManager;
import javax.net.ssl.TrustManagerFactory;
import javax.net.ssl.X509TrustManager;
public class InstallCert {
public static void main(String[] args)
throws Exception {
String host;
int port;
char[] passphrase;
if ((args.length == 1) || (args.length == 2)) {
String[] c = args[0].split(":");
host = c[0];
port = (c.length == 1) ? 443 : Integer.parseInt(c[1]);
String p = (args.length == 1) ? "changeit" : args[1];
passphrase = p.toCharArray();
}
else {
System.out
.println("Usage: java InstallCert <host>[:port] [passphrase]");
return;
}
File file =
new File("jssecacerts");
if (file.isFile() ==
false) {
char SEP = File.separatorChar;
File dir =
new File(System.getProperty("java.home") + SEP + "lib"
+ SEP + "security");
file =
new File(dir, "jssecacerts");
if (file.isFile() ==
false) {
file =
new File(dir, "cacerts");
}
}
System.out.println("Loading KeyStore " + file + "

");
InputStream in =
new FileInputStream(file);
KeyStore ks = KeyStore.getInstance(KeyStore.getDefaultType());
ks.load(in, passphrase);
in.close();
SSLContext context = SSLContext.getInstance("TLS");
TrustManagerFactory tmf = TrustManagerFactory
.getInstance(TrustManagerFactory.getDefaultAlgorithm());
tmf.init(ks);
X509TrustManager defaultTrustManager = (X509TrustManager) tmf
.getTrustManagers()[0];
SavingTrustManager tm =
new SavingTrustManager(defaultTrustManager);
context.init(
null,
new TrustManager[] { tm },
null);
SSLSocketFactory factory = context.getSocketFactory();
System.out
.println("Opening connection to " + host + ":" + port + "
");
SSLSocket socket = (SSLSocket) factory.createSocket(host, port);
socket.setSoTimeout(10000);
try {
System.out.println("Starting SSL handshake
");
socket.startHandshake();
socket.close();
System.out.println();
System.out.println("No errors, certificate is already trusted");
}
catch (SSLException e) {
System.out.println();
e.printStackTrace(System.out);
}
X509Certificate[] chain = tm.chain;
if (chain ==
null) {
System.out.println("Could not obtain server certificate chain");
return;
}
BufferedReader reader =
new BufferedReader(
new InputStreamReader(
System.in));
System.out.println();
System.out.println("Server sent " + chain.length + " certificate(s):");
System.out.println();
MessageDigest sha1 = MessageDigest.getInstance("SHA1");
MessageDigest md5 = MessageDigest.getInstance("MD5");
for (
int i = 0; i < chain.length; i++) {
X509Certificate cert = chain[i];
System.out.println(" " + (i + 1) + " Subject "
+ cert.getSubjectDN());
System.out.println(" Issuer " + cert.getIssuerDN());
sha1.update(cert.getEncoded());
System.out.println(" sha1 " + toHexString(sha1.digest()));
md5.update(cert.getEncoded());
System.out.println(" md5 " + toHexString(md5.digest()));
System.out.println();
}
System.out
.println("Enter certificate to add to trusted keystore or 'q' to quit: [1]");
String line = reader.readLine().trim();
int k;
try {
k = (line.length() == 0) ? 0 : Integer.parseInt(line) - 1;
}
catch (NumberFormatException e) {
System.out.println("KeyStore not changed");
return;
}
X509Certificate cert = chain[k];
String alias = host + "-" + (k + 1);
ks.setCertificateEntry(alias, cert);
OutputStream out =
new FileOutputStream("jssecacerts");
ks.store(out, passphrase);
out.close();
System.out.println();
System.out.println(cert);
System.out.println();
System.out
.println("Added certificate to keystore 'jssecacerts' using alias '"
+ alias + "'");
}
private static final char[] HEXDIGITS = "0123456789abcdef".toCharArray();
private static String toHexString(
byte[] bytes) {
StringBuilder sb =
new StringBuilder(bytes.length * 3);
for (
int b : bytes) {
b &= 0xff;
sb.append(HEXDIGITS[b >> 4]);
sb.append(HEXDIGITS[b & 15]);
sb.append(' ');
}
return sb.toString();
}
private static class SavingTrustManager
implements X509TrustManager {
private final X509TrustManager tm;
private X509Certificate[] chain;
SavingTrustManager(X509TrustManager tm) {
this.tm = tm;
}
public X509Certificate[] getAcceptedIssuers() {
throw new UnsupportedOperationException();
}
public void checkClientTrusted(X509Certificate[] chain, String authType)
throws CertificateException {
throw new UnsupportedOperationException();
}
public void checkServerTrusted(X509Certificate[] chain, String authType)
throws CertificateException {
this.chain = chain;
tm.checkServerTrusted(chain, authType);
}
}
}
编译InstallCert.java,然后执行:java InstallCert hostname,比如:
java InstallCert www.twitter.com
会看到如下信息:
java InstallCert www.twitter.com
Loading KeyStore /usr/java/jdk1.6.0_16/jre/lib/security/cacerts
Opening connection to www.twitter.com:443
Starting SSL handshake
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at com.sun.net.ssl.internal.ssl.Alerts.getSSLException(Alerts.java:150)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1476)
at com.sun.net.ssl.internal.ssl.Handshaker.fatalSE(Handshaker.java:174)
at com.sun.net.ssl.internal.ssl.Handshaker.fatalSE(Handshaker.java:168)
at com.sun.net.ssl.internal.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:846)
at com.sun.net.ssl.internal.ssl.ClientHandshaker.processMessage(ClientHandshaker.java:106)
at com.sun.net.ssl.internal.ssl.Handshaker.processLoop(Handshaker.java:495)
at com.sun.net.ssl.internal.ssl.Handshaker.process_record(Handshaker.java:433)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:815)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1025)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1038)
at InstallCert.main(InstallCert.java:63)
Caused by: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:221)
at sun.security.validator.PKIXValidator.engineValidate(PKIXValidator.java:145)
at sun.security.validator.Validator.validate(Validator.java:203)
at com.sun.net.ssl.internal.ssl.X509TrustManagerImpl.checkServerTrusted(X509TrustManagerImpl.java:172)
at InstallCert$SavingTrustManager.checkServerTrusted(InstallCert.java:158)
at com.sun.net.ssl.internal.ssl.JsseX509TrustManager.checkServerTrusted(SSLContextImpl.java:320)
at com.sun.net.ssl.internal.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:839)
7 more
Caused by: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.provider.certpath.SunCertPathBuilder.engineBuild(SunCertPathBuilder.java:236)
at java.security.cert.CertPathBuilder.build(CertPathBuilder.java:194)
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:216)
13 more
Server sent 2 certificate(s):
1 Subject CN=www.twitter.com, O=example.com, C=US
Issuer CN=Certificate Shack, O=example.com, C=US
sha1 2e 7f 76 9b 52 91 09 2e 5d 8f 6b 61 39 2d 5e 06 e4 d8 e9 c7
md5 dd d1 a8 03 d7 6c 4b 11 a7 3d 74 28 89 d0 67 54
2 Subject CN=Certificate Shack, O=example.com, C=US
Issuer CN=Certificate Shack, O=example.com, C=US
sha1 fb 58 a7 03 c4 4e 3b 0e e3 2c 40 2f 87 64 13 4d df e1 a1 a6
md5 72 a0 95 43 7e 41 88 18 ae 2f 6d 98 01 2c 89 68
Enter certificate to add to trusted keystore or 'q' to quit: [1]
输入1,回车,然后会在当前的目录下产生一个名为“ssecacerts”的证书。
将证书拷贝到$JAVA_HOME/jre/lib/security目录下,或者通过以下方式:
System.setProperty("javax.net.ssl.trustStore", "你的jssecacerts证书路径");
注意:因为是静态加载,所以要重新启动你的Web Server,证书才能生效。
试了以上的方法,后来发现还不行。最后突然心血来潮:我把Myeclipse关闭,直接启动Tomcat,然后运行,居然就可以了。具体原因没有找到。估计是
我的Myeclipse引用的JDK引用不对。后来就没有具体找原因了。
MySQL的SQL语句写法,除了那些基本的之外,还有一些也算比较常用的,这里记录下来,以便以后查找。
好记性不如烂笔头,这话说的太有道理了,一段时间不写它,还真容易忘记。大家不要纠结这些SQL语句包含的业务或是其它问题,本文只是一篇笔记而已。
将数据从T1表导入到T2表INSERT INTO T2 (C1,C2) SELECT C1,C2 FROM T1 [WHERE C1 = XX AND C2 = XX ORDER BY C1]
使用T2表的NAME来更新T1表的NAME
UPDATE T1 AS A, T2 AS B SET A.NAME = B.NAME WHERE A.TID = B.ID
两表的关联更新UPDATE T_ROLE_USER AS A,
(
SELECT
ID
FROM
T_USER
WHERE
DEPARTID IN (
SELECT
ID
FROM
T_DEPART
WHERE
LENGTH(ORG_CODE) = 9
)
) AS B
SET A.ROLEID = '123456'
WHERE
A.USERID = B.ID
自己和自己关联更新UPDATE T_DEPART AS A,
(
SELECT
ID,
SUBSTRING(ORG_CODE, 1, 6) ORG_CODE
FROM
T_DEPART
WHERE
LENGTH(ORG_CODE) = 8
AND PARENT_DEPART_ID IS NOT NULL
) AS B
SET A.PARENT_DEPART_ID = B.ID
WHERE
SUBSTRING(A.ORG_CODE, 1, 6) = B.ORG_CODE
两表关联删除,将删除两表中有关联ID并且T2表NAME为空的两表记录DELETE A,B FROM T1 AS A LEFT JOIN T2 AS B ON A.TID = B.ID WHERE B.NAME IS NULL
将统计结果插入到表INSERT INTO SE_STAT_ORG (
RECORD_DATE,
ORG_ID,
ORG_NAME,
SIGN_CONT_COUNT,
SIGN_ARRI_CONT_COUNT,
SIGN_CONT_MONEY,
SIGN_ARRI_CONT_MONEY,
TOTAL_ARRI_CONT_COUNT,
TOTAL_ARRI_MONEY,
PUBLISH_TOTAL_COUNT,
PROJECT_COUNT
) SELECT
*
FROM
(
SELECT
'2012-06-09' RECORD_DATE,
PARENT_ORG_ID,
PARENT_ORG_NAME,
SUM(SIGN_CONT_COUNT) SIGN_CONT_COUNT,
SUM(SIGN_ARRI_CONT_COUNT) SIGN_ARRI_CONT_COUNT,
SUM(SIGN_CONT_MONEY) SIGN_CONT_MONEY,
SUM(SIGN_ARRI_CONT_MONEY) SIGN_ARRI_CONT_MONEY,
SUM(TOTAL_ARRI_CONT_COUNT) TOTAL_ARRI_CONT_COUNT,
SUM(TOTAL_ARRI_MONEY) TOTAL_ARRI_MONEY,
SUM(PUBLISH_TOTAL_COUNT) PUBLISH_TOTAL_COUNT,
SUM(PROJECT_COUNT) PROJECT_COUNT,
FROM SE_STAT_USER
WHERE DATE_FORMAT(RECORD_DATE, '%Y-%m-%d') = '2012-06-09'
GROUP BY PARENT_ORG_ID
) M
三表关联更新UPDATE SE_STAT_USER A,
(
SELECT
USER_ID,
SUM(INVEST_ORG_COUNT + FINANCIAL_ORG_COUNT + INTERMEDIARY_ORG_COUNT + ENTERPRISE_COUNT) AS COMMON_COUNT
FROM SE_STAT_USER
WHERE DATE_FORMAT(RECORD_DATE, '%Y-%m-%d') = '2012-06-09'
GROUP BY USER_ID
) B,
(
SELECT
USER_ID,
SUM(ESTABLISH_COUNT + STOCK_COUNT + MERGER_COUNT + ACHIEVE_COUNT) AS PROJECT_COUNT
FROM SE_STAT_USER
WHERE DATE_FORMAT(RECORD_DATE, '%Y-%m-%d') = '2012-06-09'
GROUP BY USER_ID
) C
SET A.COMMON_COUNT = B.COMMON_COUNT, A.PROJECT_COUNT = C.PROJECT_COUNT
WHERE A.USER_ID = B.USER_ID
AND A.USER_ID = C.USER_ID
AND DATE_FORMAT(A.RECORD_DATE, '%Y-%m-%d') = '2012-06-09'
带条件的关联更新UPDATE SE_STAT_USER A,
(
SELECT
P.CHANNEL,
COUNT(P.CONT_ID) AS CONT_COUNT,
C.CUST_MGR_ID
FROM
(
SELECT
CHANNEL,
CONT_ID
FROM SK_PROJECT
WHERE PROJECT_STATUS = 6
AND DATE_FORMAT(AUDIT_TIME, '%Y-%m-%d') = '2012-06-11'
) p
INNER JOIN SE_CONTRACT C ON P.CONT_ID = C.CONT_ID
GROUP BY P.CHANNEL, C.CUST_MGR_ID
) B
SET
A.STOCK_COUNT = CASE WHEN B.CHANNEL = 2 THEN B.CONT_COUNT ELSE 0 END,
A.ESTABLISH_COUNT = CASE WHEN B.CHANNEL = 3 THEN B.CONT_COUNT ELSE 0 END,
A.ACHIEVE_COUNT = CASE WHEN B.CHANNEL = 4 THEN B.CONT_COUNT ELSE 0 END,
A.BRAND_COUNT = CASE WHEN B.CHANNEL = 5 THEN B.CONT_COUNT ELSE 0 END,
A.MERGER_COUNT = CASE WHEN B.CHANNEL = 6 THEN B.CONT_COUNT ELSE 0 END
WHERE
A.USER_ID = B.CUST_MGR_ID
AND DATE_FORMAT(A.RECORD_DATE, '%Y-%m-%d') = '2012-06-11'
加索引ALTER TABLE PROJECT ADD INDEX INDEX_USER_ID (USER_ID),
ADD INDEX INDEX_PROJECT_STATUS (PROJECT_STATUS);
删除列ALTER TABLE PROJECT DROP COLUMN PROJECT_STATUS,
DROP COLUMN EXPECT_RETURN,DROP COLUMN CURRENCY;
增加列ALTER TABLE PROJECT
ADD COLUMN DICT_ID INT DEFAULT NULL COMMENT 'xxx' AFTER PROJECT_SITE,
ADD COLUMN INTRODUCE TEXT DEFAULT NULL COMMENT 'xx' AFTER DICT_ID,
ADD COLUMN STAGE INT DEFAULT NULL COMMENT 'xx' AFTER ID,
ADD COLUMN ATTACH_URI VARCHAR(8) DEFAULT NULL COMMENT 'xxx' AFTER INTRODUCE;
修改列,一般用MODIFY修改数据类型,CHANGE修改列名ALTER TABLE PROJECT CHANGE DICT_ID DICT_ID1 INT NOT NULL,
MODIFY PROJECT_STATUS TINYINT NOT NULL COMMENT 'xxx';
做为一名程序员,如果你只顾得写代码,那是不行的,要抽出一下时间来丰富自己的知识,多看看书,在这里我将为程序员们推荐一些不错的书。能够给程序员们带来帮助。
大数据时代

《大数据时代》是国外大数据研究的先河之作,本书作者维克托•迈尔•舍恩伯格被誉为"大数据商业应用第一人",拥有在哈佛大学、牛津大学、耶鲁大学和新加坡国立大学等多个互联网研究重镇任教的经历,早在2010年就在《经济学人》上发布了长达14页对大数据应用的前瞻性研究。
维克托•迈尔•舍恩伯格在书中前瞻性地指出,大数据带来的信息风暴正在变革我们的生活、工作和思维,大数据开启了一次重大的时代转型,并用三个部分讲述了大数据时代的思维变革、商业变革和管理变革。
维克托最具洞见之处在于,他明确指出,大数据时代最大的转变就是,放弃对因果关系的渴求,而取而代之关注相关关系。也就是说只要知道"是什么",而不需要知道"为什么"。这就颠覆了千百年来人类的思维惯例,对人类的认知和与世界交流的方式提出了全新的挑战。
淘宝技术这十年

《淘宝技术这十年》内容简介:任何网站的发展都不是一蹴而就的。它在发展过程中会遇到各种各样的问题和业务带来的压力。正是这些问题和压力推动着技术的进步和发展,而技术的发展反过来又会促进业务的更大提升。如今淘宝网的流量排名已是全球前15名、国内前3名,其系统服务器也从一台发展到万台以上。
《淘宝技术这十年》从工程师的角度讲述淘宝这个超大规模互联网系统的成长历程,及其所有主动和被动的技术变革的前因后果。书中有幕后故事、产品经验、架构演进、技术启蒙,也有大牛成长、业内八卦、失败案例、励志故事。《淘宝技术这十年》文风流畅,有技术人员特有的幽默感;内容积极正面,有现场感,全部是作者亲身经历。
白帽子讲Web安全

《白帽子讲Web安全》内容简介:在互联网时代,数据安全与个人隐私受到了前所未有的挑战,各种新奇的攻击技术层出不穷。如何才能更好地保护我们的数据?《白帽子讲Web安全》将带你走进Web安全的世界,让你了解Web安全的方方面面。黑客不再变得神秘,攻击技术原来我也可以会,小网站主自己也能找到正确的安全道路。大公司是怎么做安全的,为什么要选择这样的方案呢?你能在《白帽子讲Web安全》中找到答案。详细的剖析,让你不仅能"知其然",更能"知其所以然"。
重构:改善既有代码的设计

《重构:改善既有代码的设计》清晰地揭示了重构的过程,解释了重构的原理和最佳实践方式,并给出了何时以及何地应该开始挖掘代码以求改善。书中给出了70多个可行的重构,每个重构都介绍了一种经过验证的代码变换手法的动机和技术。《重构:改善既有代码的设计》提出的重构准则将帮助你一次一小步地修改你的代码,从而减少了开发过程中的风险。
《重构:改善既有代码的设计》适合软件开发人员、项目管理人员等阅读,也可作为高等院校计算机及相关专业师生的参考读物。
代码整洁之道

软件质量,不但依赖于架构及项目管理,而且与代码质量紧密相关。这一点,无论是敏捷开发流派还是传统开发流派,都不得不承认。《代码整洁之道》提出一种观念:代码质量与其整洁度成正比。干净的代码,既在质量上较为可靠,也为后期维护、升级奠定了良好基础。
作为编程领域的佼佼者,《代码整洁之道》作者给出了一系列行之有效的整洁代码操作实践。这些实践在《代码整洁之道》中体现为一条条规则(或称"启示"),并辅以来自现实项目的正、反两面的范例。只要遵循这些规则,就能编写出干净的代码,从而有效提升代码质量。
《代码整洁之道》阅读对象为一切有志于改善代码质量的程序员及技术经理。书中介绍的规则均来自作者多年的实践经验,涵盖从命名到重构的多个编程方面,虽为一"家"之言,然诚有可资借鉴的价值。
设计模式之禅 (第2版)

本书是设计模式领域公认的3本经典著作之一,"极具趣味,容易理解,但讲解又极为严谨和透彻"是本书的写作风格和方法的最大特点。第1版2010年出版,畅销至今,广受好评,是该领域的里程碑著作。深刻解读6大设计原则和28种设计模式的准确定义、应用方法和最佳实践,全方位比较各种同类模式之间的异同,详细讲解将不同的模式组合使用的方法。第2版在第1版的基础上有两方面的改进,一方面结合读者的意见和建议对原有内容中的瑕疵进行了修正和完善,另一方面增加了4种新的设计模式,希望这一版能为广大程序员们奉上一场更加完美的设计模式盛宴!
程序员修炼之道

《程序员修炼之道》由一系列的独立的部分组成,涵盖的主题从个人责任、职业发展,直到用于使代码保持灵活、并且易于改编和复用的各种架构技术。利用许多富有娱乐性的奇闻轶事、有思想性的例子以及有趣的类比,全面阐释了软件开发的许多不同方面的最佳实践和重大陷阱。无论你是初学者,是有经验的程序员,还是软件项目经理,本书都适合你阅读。
平台战略:正在席卷全球的商业模式革命

《平台战略:正在席卷全球的商业模式革命》内容简介:平台商业模式的精髓,在于打造一个完善的、成长潜能强大的"生态圈"。它拥有独树一帜的精密规范和机制系统,能有效激励多方群体之间互动,达成平台企业的愿景。纵观全球许多重新定义产业架构的企业,我们往往就会发现它们成功的关键——建立起良好的"平台生态圈",连接两个以上群体,弯曲、打碎了既有的产业链。
平台生态圈里的一方群体,一旦因为需求增加而壮大,另一方群体的需求也会随之增长。如此一来,一个良性循环机制便建立了,通过此平台交流的各方也会促进对方无限增长。而通过平台模式达到战略目的,包括规模的壮大和生态圈的完善,乃至对抗竞争者,甚至是拆解产业现状、重塑市场格局。
互联网创业启示录

《互联网创业启示录》是一部互联网公司的创业指南,内容涉及网站创业的现状和机遇、创业公司价值、平台选择、工具和群组、资金的筹集、管理和盈利、社会化媒体环境、行动执行管理、开发人员方法论和工作效率、创始人的角色等方面,既有纲领和指导性理论,又有具体操作方法。书中大量对互联网创业成功人士的访谈介绍,以及创业公司的成功案例,更可以作为初次创业者的良好借鉴。
《互联网创业启示录》主要写给想自己创业的程序员,但同样适合非技术人员,适合网络创业者、大学生创业者、网络营销人员及一切有志创业者。做网络不一定要懂技术,互联网的成功是可以借鉴和延伸的!
程序员健康指南

本书是为程序员量身制作的健康指南,针对头痛、眼部疲劳、背部疼痛和手腕疼痛等常见的问题,简要介绍了其成因、测试方法,并列出了每天的行动计划,从运动、饮食等方面给出详细指导,帮助程序员在不改变工作方式的情况下轻松拥有健康。
本书适合程序员、长期伏案工作的其他人群以及所有关心健康的人士阅读。
结网@改变世界的互联网产品经理

本书以如何创建、发布、推广互联网产品为主线,介绍了互联网产品经理的工作内容以及应对每一部分工作所需的方法和工具。为用户创造价值是产品经理的第一要务,产品经理的工作是围绕用户及具体任务展开的,本书丰富的案例和透彻的分析道出了从发现用户到最终满足用户这一过程背后的玄机。
本书面向现在正在从事及未来将要从事互联网相关工作的创业者和产品经理,也可以作为互联网产品策划人员或相关专业学生的参考书。新版完善了各章节,增加了优雅降级等内容,读者也可从中更深地去感受一名产品经理的感悟。
程序员面试逻辑题解析

程序员面试逻辑题解析》共分为3个部分。第一部分从有趣且锻炼头脑的谜题入手,继而给出解题思路和详细答案,更有"热身问题"给大家提供充分的思考空间。第二部分综合了不同类型的谜题,如数独、调度问题及概率题等。神秘的第三部分带领大家不断历险,开动脑筋,解决大量密码及银行账户等方面的问题。几十道简洁的小谜题不仅充分锻炼了我们的思维方式,更为提高面试成功率奠定了基础。
《程序员面试逻辑题解析》不仅适合程序员阅读,更是谜题爱好者的饕餮盛宴。
程序员,你伤不起

本书是作者博客文章的精选集。是作者作为老牌程序员、现在的IT 创业者15 年软件开发生涯的心路历程和经验总结。涉及程序人生、开发经验、职业规划、创业心得。对任何的软件开发者和IT 从业人员都有借鉴价值。作者语言风趣幽默,读起来津津有味。字里行间充满了不屈不挠的码农正能量。
像程序员一样思考

编程的真正挑战不是学习一种语言的语法,而是学习创造性地解决问题,从而构建美妙的应用。《像程序员一样思考》分析了程序员解决问题的方法,并且教授你其他图书所忽略的一种能力,即如何像程序员一样思考。
全书分为8章。第1章通对几个经典的算法问题切入,概括了问题解决的基本技巧和步骤。第2章通过实际编写C++代码来解决几个简单的问题,从而让读者进一步体会到问题解决的思路和应用。第3到7章是书中的主体部分,分别探讨了用数组、指针和动态内存、类、递归和代码复用来解决问题的途径和实际应用。最后,第8章从培养程序员思维的角度,进行了总结和概括,告诉读者如何才能像程序员一样思考。
编写可读代码的艺术

细节决定成败,思路清晰、言简意赅的代码让程序员一目了然;而格式凌乱、拖沓冗长的代码让程序员一头雾水。除了可以正确运行以外,优秀的代码必须具备良好的可读性,编写的代码要使其他人能在最短的时间内理解才行。本书旨在强调代码对人的友好性和可读性。
本书关注编码的细节,总结了很多提高代码可读性的小技巧,看似都微不足道,但是对于整个软件系统的开发而言,它们与宏观的架构决策、设计思想、指导原则同样重要。编码不仅仅只是一种技术,也是一门艺术,编写可读性高的代码尤其如此。如果你要成为一位优秀的程序员,要想开发出高质量的软件系统,必须从细处着手,做到内外兼修,本书将为你提供有效的指导。
分析函数是什么?
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
分析函数和聚合函数的不同之处是什么?
普通的聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。
分析函数的形式
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,他们的使用形式如下:over(partition by xxx order by yyy rows between zzz)。
注:窗口子句在这里我只说rows方式的窗口,range方式和滑动窗口也不提
分析函数例子(在scott用户下模拟)
示例目的:显示各部门员工的工资,并附带显示该部分的最高工资。
--显示各部门员工的工资,并附带显示该部分的最高工资。
SELECT E.DEPTNO,
E.EMPNO,
E.ENAME,
E.SAL,
LAST_VALUE(E.SAL)
OVER(PARTITION BY E.DEPTNO
ORDER BY E.SAL ROWS
--unbounded preceding and unbouned following针对当前所有记录的前一条、后一条记录,也就是表中的所有记录
--unbounded:不受控制的,无限的
--preceding:在...之前
--following:在...之后
BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) MAX_SAL
FROM EMP E;
运行结果:

示例目的:按照deptno分组,然后计算每组值的总和
SELECT EMPNO,
ENAME,
DEPTNO,
SAL,
SUM(SAL) OVER(PARTITION BY DEPTNO ORDER BY ENAME) max_sal
FROM SCOTT.EMP;
运行结果:

示例目的:对各部门进行分组,并附带显示第一行至当前行的汇总
SELECT EMPNO,
ENAME,
DEPTNO,
SAL,
--注意ROWS BETWEEN unbounded preceding AND current row 是指第一行至当前行的汇总
SUM(SAL) OVER(PARTITION BY DEPTNO
ORDER BY ENAME
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) max_sal
FROM SCOTT.EMP;
运行结果:

示例目标:当前行至最后一行的汇总
SELECT EMPNO,
ENAME,
DEPTNO,
SAL,
--注意ROWS BETWEEN current row AND unbounded following 指当前行到最后一行的汇总
SUM(SAL) OVER(PARTITION BY DEPTNO
ORDER BY ENAME
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) max_sal
FROM SCOTT.EMP;
运行结果:

示例目标:当前行的上一行(rownum-1)到当前行的汇总
SELECT EMPNO,
ENAME,
DEPTNO,
SAL,
--注意ROWS BETWEEN 1 preceding AND current row 是指当前行的上一行(rownum-1)到当前行的汇总
SUM(SAL) OVER(PARTITION BY DEPTNO
ORDER BY ENAME ROWS
BETWEEN 1 PRECEDING AND CURRENT ROW) max_sal
FROM SCOTT.EMP;
运行结果:

示例目标: 当前行的上一行(rownum-1)到当前行的下辆行(rownum+2)的汇总
SELECT EMPNO,
ENAME,
DEPTNO,
SAL,
--注意ROWS BETWEEN 1 preceding AND 1 following 是指当前行的上一行(rownum-1)到当前行的下辆行(rownum+2)的汇总
SUM(SAL) OVER(PARTITION BY DEPTNO
ORDER BY ENAME
ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING) max_sal
FROM SCOTT.EMP;
运行结果:

摘要: 三、常见分析函数详解为了方便进行实践,特将演示表和数据罗列如下:一、创建表create table t( bill_month varchar2(12) , area_code number, net_type varchar(2), local_fare number ); 二、插入数据insert i...
阅读全文
这个系列我将整理一些日常我们经常使用到的ORACLE函数,鉴于篇幅太长,我大体会按下面分类来整理、汇总这些常用的ORACLE函数,如果有些常用函数没有被整理进来,也希望大家指点一二。
1: 聚合函数
2: 日期函数
3: 字符串函数
4: 格式化函数
5: 类型转换函数
6: 加密函数
7: 控制流函数
8: 数学函数
9: 系统信息函数10:分析函数------------------------------------------聚合函数---------------------------------------------
--1: AVG(DISTINCT|ALL)
ALL表示对所有的值求平均值,DISTINCT只对不同的值求平均值
SELECT AVG(SAL) FROM SCOTT.EMP;
SELECT AVG(DISTINCT SAL) FROM SCOTT.EMP;
--2: MAX(DISTINCT|ALL)
求最大值,ALL表示对所有的值求最大值,DISTINCT表示对不同的值求最大值,相同的只取一次
(加不加查询结果一致,不知DISTINCT有什么用途,不同于AVG等聚合函数)
SELECT MAX(DISTINCT SAL) FROM SCOTT.EMP;
SELECT MAX(SAL) FROM SCOTT.EMP
--3: MIN(DISTINCT|ALL)
求最小值,ALL表示对所有的值求最小值,DISTINCT表示对不同的值求最小值,相同的只取一次
SELECT MIN(SAL) FROM SCOTT.EMP;
SELECT MIN(DISTINCT SAL) FROM SCOTT.EMP;
--4: STDDEV(distinct|all)
求标准差,ALL表示对所有的值求标准差,DISTINCT表示只对不同的值求标准差
SELECT STDDEV(SAL) FROM SCOTT.EMP;
SELECT STDDEV(DISTINCT SAL) FROM SCOTT.EMP;
--5: VARIANCE(DISTINCT|ALL)
求协方差 ALL表示对所有的值求协方差,DISTINCT表示只对不同的值求协方差
SELECT VARIANCE(SAL) FROM SCOTT.EMP;
SELECT VARIANCE(DISTINCT SAL) FROM SCOTT.EMP;
--6: SUM(DISTINCT|ALL)
求和 ALL表示对所有值求和,DISTINCT表示只对不同值求和(相同值只取一次)
SELECT SUM(SAL) FROM SCOTT.EMP;
SELECT SUM(DISTINCT SAL) FROM SCOTT.EMP;
--7:COUNT(DISTINCT|ALL)
求记录、数据个数。 ALL对所有记录,数组做统计, DISTINCT只对不同值统计(相同值只取一次)
SELECT COUNT(SAL) FROM SCOTT.EMP;
SELECT COUNT(DISTINCT SAL) FROM SCOTT.EMP;
----8: MEDIAN
求中位数
SELECT MEDIAN(SAL) FROM SCOTT.EMP;
SELECT MEDIAN(DISTINCT SAL) FROM SCOTT.EMP; --错误:DISTINCT 选项在此函数中禁用。
----------------------------------------------------------------------------------------------
在使用PHP时,我们需要将自己写好的php文件上传到已申请的php空间。由于租用或申请的php空间是不允许用户进行配置的,那么对于php的一些功能是否开启,如curl, allow_url_fopen, gzip,就需要提前判断,而不是等写完代码后发现不能使用时,那样改动就大了。
方法/步骤
其实判断功能是否开启,很简单,我们只需要写一个php文件上传之php空间服务器中。v.php的源代码如图。
其含义很简单,就是传入一个函数的名字,服务器判断是否存在这个函数,如果存在则表示支持该函数对应的功能,输出“支持”,反之输出“不支持”。将文件上传至php空间中。
再通过访问空间,地址+v.php?f=+要测试的功能所包括的函数,比如curl功能可以是v.php?f=curl_init,allow_url_fopen功能可以用v.php?f=fopen来测试。
在技术方面无论我们怎么学习,总感觉需要提升自已不知道自己处于什么水平了。但如果有清晰的指示图供参考还是非常不错的,这样我们清楚的知道我们大概处于那个阶段和水平。

Java程序员
高级特性
反射、泛型、注释符、自动装箱和拆箱、枚举类、可变
参数、可变返回类型、增强循环、静态导入
核心编程
IO、多线程、实体类、
集合类、正则表达式、
XML和属性文件
图形编程
AWT(Java2D/JavaSound/JMF)、Swing、SWT、JFace
网路编程
Applet、Socket/TCP/UDP、NIO、RMI、CORBA
Java语法基础
类、抽象类、接口、最终类、静态类、匿名类、内部类、异常类、编码规范
Java开发环境
JDK、JVM、Eclipse、Linux
Java核心编程技术
Java,设计而又非常精巧的语言。学习Java,须从Java开发环境开始,到Java语法,再到Java的核心API。
1.Java开发入门:Java开发环境的安装与使用,包括JDK命令、EclipseIDE、Linux下Java程序的开发和部署等。
2.Java语法基础:基于JDK和Eclipse环境,进行Java核心功能开发,掌握Java面向对象的语法构成,包括类、抽象类、接口、最终类、静态类、匿名类、内部类、异常的编写。
3.Java核心API:基于JDK提供的类库,掌握三大核心功能:
A。Java核心编程:包括Java编程的两大核心功能——Java输入/输出流和多线程,以及常用的辅助类库——实体类、集合类、正则表达式、XML和属性文件。
B。Java图形编程:包括Sun的GUI库AWT(Java2D、JavaSound、JMF)和Swing,IBM和GUI库SWT和Jface;
C. Java网路编程:Applet组件编程,Socket编程,NIO非阻塞Socket编程、RMI和CORBA分布式开发。
4.Java高级特性:掌握JDK1.4、JDK5.0、JDK6.0中的Java高级特性,包括反射、泛型、注释,以及java高级特性——自动装箱和拆箱、枚举类、可变参数、可变返回类型、增强循环、静态导入等。
JavaEE初级软件工程师
JSF框架开发技术
配置文件(页面导航、后台Bean)、JSF组件库(JSF EL语言、HTML标签、事件处理、)、JSF核心库(格式转换、输入验证、国际化)
Javaweb核心开发技术
开发环境(Eclipse、Linux)
三大组件(JSP、JavaBean、Servlet)
扩展技术(EL、JSTL、Taglib)
网页开发技术
HTML、XML、CSS、JavaScript、AJAX
数据库设计技术
SQL、MySql、Oracle、SQLServer、JDBC
Web服务器(Tomcat/Jetty/Resin/JBossWeb)
JavaWeb核心技术:
JavaWeb项目开发的全过程可以分解为:
网页开发+数据库设计——>JavaWeb项目开发,其中,javaWeb由6项基本技术组成:JSP+JavaBean+Servlet+EL+JSTL+Taglib,而JSF正是将这6种技术进行有机结合的技术框架:
JavaEE中级软件工程师
四种经典架构SSH1、SSI1、SSH2、SSI2
Struts1表现层框架
入门配置、核心组件、标签库、国际化、数据检验、数据库开发、Sitemesh集成、集成Hibernate/iBATIS
Struts2表现层框架
入门配置、核心组件、标签库、国际化、数据校验、Sitemesh集成转换器、拦截器、集成Hibernate/iBATIS
Spring业务层框架
入门配置、IoC容器、MVC、标签库、国际化、数据校验、数据库开发
Hibernate持久层框架
MySQL、Oracle、SQLServer iBATIS持久层框架
MySQL、Oracle、SQLServer
Web服务器(Tomcat/Jetty/Resin/JBossWeb)
Java高级软件工程师
javaWeb开源技术与框架
工作流、
规则引擎
搜索引擎、
缓存引擎 、
任务调度、
身份认证
报表服务、
系统测试、
集群、
负载平衡、
故障转移
JavaWeb分布式开发技术
JTA(Java事物管理)
JAAS(Java验证和授权服务)
JNDI(Java命名和目录服务)
JavaMail(Java邮件服务)
JMS(java信息服务)
WebService(web服务)
JCA(java连接体系)
JMS(java管理体系)
应用服务器(JBossAS/WebLogic/WebSphere)
JavaEE系统架构师
面向云架构(COA)
COA、SaaS、网格计算、集群计算、分布式计算、云计算
面向资源架构(ROA)
ROA、RESI
面向web服务架构(SOA)
WebService、SOA、SCA、ESB、OSGI、EAI
Java设计模式
创建式模式:抽象工厂/建造者/工厂方法/原型/单例
构造型模式:适配器/桥接/组合/装饰/外观/享元/代理
行为型模式:责任链/命令/解释器/迭代子/中介者/备忘录/观察者/状态/策略/模板方法/访问者
Java与UML建模
对象图、用例图、组件图、部署图、序列图、交互图、活动图、正向工程与逆向工程
CTO首席技术官
发展战略
技术总监
团队提升
团队建设
项目管理
产品管理
企业级项目实战(带源码)地址:http://zz563143188.iteye.com/blog/1825168
收集五年的开发资料下载地址: http://pan.baidu.com/share/home?uk=4076915866&view=share
下面的更深入的有兴趣可以了解一下,我的目的不是要大家掌握下面的知识,只是希望扩展自己的思维,摘自牛人的技术博客。
/**************************************************牛人必看*****************************************************************/
系统后台框架:

前端工程师技能:

B2C电子商务基础系统架构解析
运营B2C日 久,越来越深刻的意识到IT系统对确保规范化业务流转,支撑消费者端的均一服务有着决定性的作用。于是,一直想好好整理下相关的系统架构,怎奈俗务缠身, 一直拖到今日,猛然发现下周娃很可能就要出生,拖无可拖,快马加笔,居然整出来了。本文的重点是理清系统的逻辑关系,详细的功能模块请参见结尾附上的系统 架构图。
首先,聊下对系统逻辑架构的看法;我个人始终坚持认为,系统的开发与演化,前台严格follow消费者的购买流程,后台则盯牢订单流转,牢牢抓住这两条主线,才能高屋建瓴的看清B2C的逻辑链和数据流,更深刻的规划功能模块,从而更有效支撑实际业务的流转。
前台系统包括:商品展示,内容展示,订单确认,支付系统,用户中心四大模块
一,商品展示
按照Ebay的内部分类,任何将商品以单个或批量的方式展示给消费者的功能均应归入此系统。因此,该系统至少包括:
A,站内搜索(搜索提示,搜索规则,搜索成功页,搜索不成功页,相似推荐)
B,导航(频道导航,其他导航如销售排行,广告位,推荐位,文字链,Also buy等)
C,商品分类(品牌分类,品类分类,属性分类如剪裁形式)
D, 登陆页(商品列表页,商品详细页,商品活动页)
这里的访问逻辑是:A /B/C分流消费者去往相对个性化的页面,由登陆页体现商家的核心诉求和价值传递,完成call-to-action的第一步。
二,内容展示
内容展示较为简单,对纯购物品牌而言包括:
A,公告区
B,帮助中心
C,论坛(如需商城与论坛发生交互,则需自行开发,否则可集成discuz做同步登陆即可)
大家都知道,就不多说了。
三,订单确认
订单确认,就是帮助消费者正确提交订单信息的环节,看似简单,实则非常复杂,需要对很多信息逻辑判断和处理,一般由2个部分组成:
A,购物车(购物车浮层,购物车页面,无注册购买)
无注册购买是需要慎用的功能,除非刻意追求用户的短平快下单,如团购/换购,一般不推荐使用,会造成系统异常复杂,开发量也很大。
B,订单提交(返回购物车,收货地址&地址薄,支付方式判断,配送方式,发票,订单标记,实付金额计算等等)
值得一提的是,几乎大多数的促销逻辑运算在这个环节完成,充分考虑各种促销方式之间的互斥与重叠是系统设计的核心,需要充分考虑各种情况,避免出现逻辑漏洞。
四,支付系统
与一般的想象不同,支付系统其实并不简单等于第三方支付工具接入:
A,外部支付系统(支付宝将接口,财付通接口,网银直联端口,信用ka分期端口)
B,内部支付系统(账户余额,积分,礼品卡,优惠券)
支付系统的逻辑设计不但需要考虑到各种极端情况的发生(如一张订单先用礼品卡,再用积分,最后网银支付),还要预留财务做账所需的相关字段,并充分考虑订单取消之后如何回滚各类内部账户。
五,用户中心
用户中心的实质是用户自助功能的dashboard,一般4个部分组成:
A,注册&登陆(快速注册,完整注册,注册有礼,推荐注册,密码找回,主站id登陆,open-id登陆如QQ,新浪微博等)
B,订单中心(历史订单状态,中间状态订单修改,物流追踪)
C,服务中心(各类自助服务如退款申请,退换货申请,建议与投诉等)
D, 信息管理(用户基本信息管理和账户信息管理)
用户中心的价值在于:尽可能引导用户自行获取所需的信息并提交所需的服务,在提升服务准确率,及时性的同时降低对人工成本。
后台系统包括:商品&促销,CRM,订单处理,WMS,采购管理,财务管理,报表管理,系统设置,WA系统9大模块
一, 商品&促销
商品&促销模块的核心在于确保消费者下单之前,前台内容所见即所得
A, 商品管理(品类管理,品牌管理,单品管理)
B, 促销管理(活动管理和自定义活动模板管理)
在上述模块中,最重要的是2个部分:单品管理中的批量产品生成的自动程序和活动管理中“共享与互斥”管理。前者用于大幅提升上新速度,后者避免促销活动失控。
二, CRM
CRM是对B2C核心资源—会员的管理,服务与再营销系统,包括如下部分:
A,会员管理(会员信息的增删改查和到其他系统的链接)
B,用户关怀(条件触发和人工触发相关EDM & 短信 & OB)
C,定向营销(会员分组和营销活动管理)
D, 客服管理(内容非常多,集成所有需前台与后台交互的功能,详情还是看图吧)
E, 呼叫中心(IVR,坐席管理,统计报表,参数传递与窗口嵌入)
值得注意的,EDM和短信通道市面上已经有成熟的外包服务商,一般都会外包;呼叫中心和在线客服自行开发成本太高,特别是呼叫中心系统,业务初期也都是外包的。
三, 订单处理
订单处理是在订单未正式进入仓储部门处理之前,对订单的前置性处理环节。
A,订单录入(电话订购,网上下单,外部团购订单,无金额订单录入如礼品单)
B,订单审核(自动审核和人工审核)
C,RMA处理(RMA申请单和RMA处理单)
RMA的逻辑也异常复杂,需要在效率和成本之间找平衡,确保在不拖垮仓储部门的正常出入库的前提下对消费者端快速有效close工单;对内部则需要控制成本,货损不能超过预算上限。
四, WMS(Warehouse Management system仓库管理系统)
WMS的流程很长,功能模块也很多,大致分为入库管理,库存管理,出库管理和票据管理4个模块四个模块,细细道来就是另外一篇文章了,各位可以参考 我这篇文章:庖丁解牛—B2C仓储内部运作解密(上,中,下)http://blog.sina.com.cn/wangxida0855
五, 采购管理
采购管理的核心是有效跟进采购合同/发票的状态,大货的采购入库/退库,财务结算和在仓库存查询和处理。
A,供应商管理(供应商信息管理,合同发票管理)
B,采购单管理(PO单管理,负PO单管理)
C,库存管理(库存查询,库存占用单,库存变动log)
六, 财务管理
B2C的财务管理,主要是对供应商,渠道和内部费用支出的成本控制。
A,供应商结算
B,渠道结算
C,配送结算
D, 内部结算
说实在的,哥对财务这块也不算很了解,大家将就看看,图片上有明细。
七, 报表管理
报表是B2C业务的宏观表现,理论上说,每个部门的KPI都应该从中找到。
A,搜索报表(站内搜索量查询)
B,销售报表(多个维度销量查询,优惠券使用情况,报表导出)
C,财务报表
D, 客服报表(客服日报和坐席报表)
前者反映与消费者发生的日常交互(包括正常与异常),后者考核客服的工作绩效
E, 仓储物流报表
这几块报表,是业务运作的核心,涉及到公司机密,就不能写的太细了,见谅。
八, 系统设置
这块大家都知道是干嘛的,也就不多说了,分成三块。
A,基础设置(和业务有关的一些字段值)
B,权限设置(不同账号的操作权限和操作记录)
C,其他设置
九, WA系统(Web Analytcis)
网站分析系 统,几乎全是外购,很少有能够自建的,即使自建,最多做几个简单的模块。用于实战的,要么是免费的GA(Google Analytics),要么是昂贵的Omniture。这块的知识,细细说来也是另外一篇文章了,有兴趣的同学可以看我这篇科普文章:揭秘—我所知道的网 站分析(上,下) http://blog.sina.com.cn/wangxida0855
最后,上全系统大图,再感慨一句,B2C系统,真是一个大工程啊。

fr http://blog.sina.com.cn/s/blog_59d6717c0100syh3.html
摘要: ajax+json+Struts2实现list传递(转载)一、首先需要下载JSON依赖的jar包。它主要是依赖如下: json-lib-2.2.2-jdk15 ezmorph-1.0.4 commons-logging-1.0.4&nbs...
阅读全文
摘要: Batis 简介:iBatis 是apache 的一个开源项目,一个O/R Mapping 解决方案,iBatis 最大的特点就是小巧,上手很快。如果不需要太多复杂的功能,iBatis 是能够满足你的要求又足够灵活的最简单的解决方案,现在的iBatis 已经改名为Mybatis 了。官网为:http://www.myb...
阅读全文
第一篇: JavaScript 跳转方法一:
| <script language="javascript">
window.location= "http://www.baidu.com";
</script>
|
方法二:
| <script language="javascript">
document.location = "http://www.baidu.com";
</script>
|
方法三: (带进度条)
| <html>
<head>
<meta http-equiv="Content-Language" content="zh-cn">
<meta HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=gb2312">
<title>跳转到baidu.com</title>
</head>
<body>
<form name=loading>
<P align=center><FONT face=Arial color=#0066ff size=2>loading...</FONT>
<INPUT style="PADDING-RIGHT: 0px; PADDING-LEFT: 0px; FONT-WEIGHT: bolder; PADDING-BOTTOM: 0px; COLOR: #0066ff; BORDER-TOP-style: none; PADDING-TOP: 0px; BORDER-RIGHT-style: none; BORDER-LEFT-style: none; BACKGROUND-COLOR: white; BORDER-BOTTOM-style: none"
size=46 name=chart>
<BR>
<INPUT style="BORDER-RIGHT: medium none; BORDER-TOP: medium none; BORDER-LEFT: medium none; COLOR: #0066ff; BORDER-BOTTOM: medium none;" size=47 name=percent>
<script language="javascript">
var bar=0
var line="||"
var amount="||"
count()
function count(){
bar=bar+2
amount =amount + line
document.loading.chart.value=amount
document.loading.percent.value=bar+"%"
if (bar<99){
setTimeout("count()",100);
}else{
window.location = "http://www.baidu.com/";
}
}
</script>
</P>
</form>
</body>
</html>
|
第二篇: 页面跳转
| <head>
<meta http-equiv="refresh" content="10; url=http://www.baidu.com">
</head>
|
第三篇: 动态页面跳转
方法一: PHP 跳转
| <?php
header("location: http://www.baidu.com");
?>
|
方法二: ASP 跳转
<%
response.redirect "http://www.baidu.com"
%>
FYI:
<%
Dim ID1
Dim ID2
dim str
ID1 = Request("forumID")
ID2 = Request("threadID")
str="/blog/threadview.asp?forumID="& ID1 &"&threadID=" & ID2
response.redirect str
%>
<%
response.redirect "http://www.baidu.com"
%>
FYI:
<%
Dim ID1
Dim ID2
dim str
ID1 = Request("forumID")
ID2 = Request("threadID")
str="/blog/threadview.asp?forumID="& ID1 &"&threadID=" & ID2
response.redirect str
%>
zencart如何设置smtp发邮件,zencart不能发email,发email失败怎么办?zen cart要使用gmail发送邮件,首先要把你的gmail账户开通pop/smtp, 然后再zencart后台设置邮件发送方式,邮箱帐号,密码。
具体操作方法如:
进入后台--商店设置--电子邮件,首先选择”电子邮件发送方式“为smtpauth。然后输入你的gamil邮箱地址。
最后设置
1)首先后台电子邮件 发送方式是:smtpauth
2)smtp帐号邮箱:xxx@gmail.com
3)smtp帐号密码:xxxxxxxx
4)smtp主机:smtp.gmail.com
5)smtp服务器端口:465或者587
注意:国内的邮箱最好使用163邮箱:服务器:smtp.163.com 端口:465/25,其他的邮箱不能发,具体原因暂时不清楚。
如果这样设置是正确的。但是有些主机还是会出现Email Error: SMTP Error: Could not connect to SMTP host.这样的情况 。
这个需要服务器支持。检查下后台-工具-服务器信息里是否有OpenSSL。因为google 传输是ssl://smtp.gmail.com协议。
所以需要服务器支持Openssl这个尤为重要。
补充重要情况:电子邮件必须从现有域名发送 设置成 no
zencart-email-smtp.png

如果还是发不了email,可参考下面的技术细节:
在服务器上 telnet smtp.gmail.com 465 确定能连接
yum -y install openssl 安装ssl,重启apache在试一试
开通gmail帐号的pop/smtp功能:

Zen Cart后台邮件发送不成功的解决办法,错误提示“电子邮件错误: The following From address failed: ”
几个需要注意的设置项:
1、服务器应启用SMTPAUTH电子邮件发送方式;
2、检查SMTP帐号、邮箱、密码、邮件服务器域名和端口是否设置正确。
3、发件人邮件地址要用你的SMTP邮箱帐号,并且电子邮件必须从现有域名发送设为Yes.
* 如果上述都没错,请多换其他SMTP账户/邮箱测试。推荐gmail
收费调试服务
我们希望您能自己搞定这些问题,但是如果你多方测试都无法找到发邮件不成功的解决办法,我们也提供收费调试服务。诊断调试要花费技术很多时间,调试一次需要的时间可能很长,估计2-5小时。每次调试收费200元。保证帮你调试到前台 联系我们 contact us 页面能发送邮件
一、导出数据库用mysqldump命令(注意mysql的安装路径,即此命令的路径):
1、导出数据和表结构:
mysqldump -u用户名 -p密码 数据库名 > 数据库名.sql
#/usr/local/mysql/bin/ mysqldump -uroot -p abc > abc.sql
敲回车后会提示输入密码
2、只导出表结构
mysqldump -u用户名 -p密码 -d 数据库名 > 数据库名.sql
#/usr/local/mysql/bin/ mysqldump -uroot -p -d abc > abc.sql
注:/usr/local/mysql/bin/ ---> mysql的data目录
二、导入数据库
1、首先建空数据库
mysql>create database abc;
2、导入数据库
方法一:
(1)选择数据库
mysql>use abc;
(2)设置数据库编码
mysql>set names utf8;
(3)导入数据(注意sql文件的路径)
mysql>source /home/abc/abc.sql;
方法二:
mysql -u用户名 -p密码 数据库名 < 数据库名.sql
#mysql -uabc_f -p abc < abc.sql
建议使用第二种方法导入。
注意:有命令行模式,有sql命令
摘要: 我们以一个学习的心态来对待这些PHP后门程序,很多PHP后门代码让我们看到程序员们是多么的用心良苦。强悍的PHP一句话后门这类后门让网站、服务器管理员很是头疼,经常要换着方法进行各种检测,而很多新出现的编写技术,用普通的检测方法是没法发现并处理的。今天我们细数一些有意思的PHP一句话木马。利用404页面隐藏PHP小马:01<!DOCTYPE HTML PUBLIC "-...
阅读全文
步骤:
1.创建一个Hello World模块
2.为这个模块配置路由
3.为这个模块创建执行控制器
创建Hello World模块
创建模块的结构目录:
app/core/local/Sjolzy/HelloWorld/Block
app/core/local/Sjolzy/HelloWorld/controllers
app/core/local/Sjolzy/HelloWorld/etc
app/core/local/Sjolzy/HelloWorld/Helper
app/core/local/Sjolzy/HelloWorld/Model
app/core/local/Sjolzy/HelloWorld/sql
创建config.xml的内容(app/core/local/Sjolzy/HelloWorld/etc/config.xml):
<config>
<modules>
<Sjolzy_HelloWorld>
<version>0.1.0</version>
</Sjolzy_HelloWorld>
</modules>
</config>
然后创建一个系统配置文件激活这个模块
Sjolzy_HelloWorld.xml(app/etc/modules/Sjolzy_HelloWorld.xml)
<config>
<modules>
<Sjolzy_HelloWorld>
<active>true</active>
<codePool>local</codePool>
</Sjolzy_HelloWorld>
</modules>
</config>
检查是否模块已经激活:先清空magento缓存(var/cache),在后台管理:System->Configuration->Advanced 展开Disable Modules Output,看是否Sjolzy_HelloWorld显示出来。
配置路由
路由是用来把一个URL请求转换成一个执行控制器的方法。
需要在magento的全局配置中显式的定义你的路由。
在config.xml(app/core/local/Sjolzy/HelloWorld/etc/config.xml)中:
<config>
...
<!-- /* fontend:指向网站的前台(也可以是admin|install) */ -->
<frontend>
<!-- /* routers:路由对象的定义或路由路径的定义 */ -->
<routers>
<!-- /* helloworld:指向网站的前台 */ -->
<helloworld>
<use>standard</use>
<args>
<!-- /* module:模块名字的小写版本 */ -->
<module>Sjolzy_HelloWorld</module>
<!-- /* fontName:路由过程中的一个参数,只跟路由相关(Front Controller则是用来实例化所有路由) */ -->
<frontName>helloworld</frontName>
</args>
</helloworld>
</routers>
</frontend>
</config>
为路由创建执行控制器
路由会把控制权交给控制器,我们已经定义了路由,现在来定义我们的执行控制器。
app/code/local/Sjolzy/HelloWorld/controllers/IndexAction.php(模块的控制器放在子目录controllers<小写>里,这是magento的规定)
<?php
class Sjolzy_HelloWorld_IndexController extends Mage_Core_Controller_Front_Action{
public function indexAction(){
echo 'Hello World!';
}
}
?>
还是情况缓存,请求URL:http://example.com/helloworld/index/index
注:http://example.com/frontName/执行控制器/执行方法
如果看到空白页面上写着'Hello World!',则你的模块创建成功!
老话重提,我们还是通过URL来进行分析http://<host>/<Magento虚拟目录>/<config.xm中的frontName>/<Controller文件名去掉Controller>/<Controller文件的方法名去掉Action>例如,我们现在想在paypal的模块中,增加一个查看帮助的页面。访问url为:http://youip/paypal/standard/help那么我们反向分析。根据之前的分析,我们找到控制文件\app\code\core\Mage\Paypal\controllers\StandardController.php在里面增加一个方法- public function helpAction()
- {
-
- $this->loadLayout();
- $this->_initLayoutMessages('paypal/session');
- $this->renderLayout();
- }
- <paypal_standard_help>
- <!-- Mage_Paypal -->
- <remove name="right"/>
- <remove name="left"/>
- <reference name="root">
- <action method="setTemplate">
- <template>/page/1column.phtml</template>
- </action>
- </reference>
- <reference name="content">
- <block type="paypal/standard_help" name="paypal_standard_help" template="paypal/standard/help.phtml"/>
- </reference>
- </paypal_standard_help>
- class Mage_Paypal_Block_Standard_Help extends Mage_Directory_Block_Data
- {
- public function getHelp(){
- return "this is paypal help file content!";
- }
- }
- <?php echo $this->getHelp(); ?>
近几年很流行 Ajax,而 Ajax 的本质就 是 XMLHttpRequest,是客户端 XMLHttpRequest 对象的使用。相对于 Ajax,服务端 XMLHTTP 就是在服务端使 用 XMLHttpRequest 对象了。虽然说,在服务端使用异步请求是比较不方便的,但是做为可以服务端发送 HTTP 请求的组件,学习一下也是 没有坏处的。[喝小酒的网摘]http://blog.const.net.cn/a/2589.htm
这里,我讲的是在 ASP 环境中使用服务端 XMLHttpRequest,并以 JScript 做为演示代码的语言,因此,你需要了解 ASP 以及 JScript。
服 务端 XMLHTTP,通常会用在获取远程主机的网页或者其他内容,新闻聚合系统一般就是使用服务端 XMLHTTP 对象来获取要聚合的 Feed 的 内容,然后使用 XMLDOM 对象来分析 Feed 的内容,取出新闻的标题、作者、内容等信息,再存在数据库中,然后将若干个数据源的新闻一起显示在 一起。抓虾就是这样一个新闻聚合器,但是它不是用 ASP 写的就是了 :)
在 ASP 中,我们可以用以下代码来创建一个 ServerXMLHTTP 对象,而这个对象,就是我们在服务端进行一切操作的基础。
程序代码:
// demo code from xujiwei
// @website: http://www.xujiwei.cn/
var xmlhttp = new ActiveXObject("MSXML2.ServerXMLHTTP.5.0");
首先来了解一下 ServerXMLHTTP 对象有哪些比较有用的方法:
1. abort 这个方法用于取消 XMLHTTP 的请求。如果 XMLHTTP 对象以异步方式发送请求,如果到达一定的时间请求仍然没有返回,就可以使用这个方法来取消请求。
2. getAllResponseHeaders 这个方法的返回值是一个字符串,相当于 HTTP 请求的头部去掉了请求方法、URI和协议版本信息。
3. getResponseHeader 这个方法用来获取指定头部信息,比较有用的就是可以用来获取返回数据的 Content-Type、Referer 等。
4. open 使用指定的请求方法、URI和同步方式以及认证信息等初始化一个请求。
5. send 发 送 HTTP 请求,等待接收响应数据,注意,如果是以同步方式发送请求,send方法调用后不会立即返回,而是等到请求完成后才会返回,而以异步方法请 求时,则会立即返回。另外,send方法带有一个可选参数body,表示要发送的数据,这在使用 POST 方法时比较有用。
6. setTimeout 设置 ServerXMLHTTP 对象的 4 个超时时间,分别是:域名解析、连接服务器、发送数据、接收响应。可以通过设置相应的超时时间来控制 ServerXMLHTTP 对象,以免 ServerXMLHTTP 不能及时返回而造成程序停止响应。
7. setRequestHeader 设 置请求的 Header,在客户端 XMLHttpRequest中,通常用来设置请求的数据类型,或者标识请求的方法等等,例如 jquery 会增加 头部标识 X-Request-With,表示请求是从 XMLHttpRequest 对象发出,以方便服务端做出相应的动作。
8. waitForResponse 在使用异步方式发送请求时,可以用这个方法来控制请求的进程。在服务端脚本中,不可以像客户端那样直接使用回调函数来控制异步请求,也没有相应的函数来使用程序休眠一定的时间,因此,为了等待请求返回,我们可以使用这个方法来等待一定时间。
另外,还有其他一些方法,如 getOption、setOption、setProxy 等,这些方法用得比较少,因此这里不再介绍,需要了解的朋友可以查阅 MSDN。
接下来,再看看 ServerXMLHTTP 对象的属性:
1. onreadystatechange XMLHTTP 对象状态改变时的回调函数,这个属性为异步操作奠定了一个基础,可以让程序在不用查询 XMLHTTP 对象状态的情况获知 XMLHTTP 操作是否已经完成。
2. readyState XMLHTTP 对象状态,有 5 个值,从 0 到 4,分别代表的意思是:
0 - 未初始化,刚使用 new ActiveXObject("MSXML.ServerXMLHTTP.5.0") 创建时对象所处的状态
1 - 载入中,这个时候,已经调用了 open 方法,但是还没有使用 send 方法发送数据
2 - 已经载入,已经调用了 send 方法发送数据,但是还没有可用的响应流
3 - 正在交互,正在接收数据,这个时候可以使用 responseBody 和 responseText 属性来获取已经得到的部分数据了
4 - 完成请求,全部数据已经接收完成
通常情况下,我们只需要判断一下状态 4 即可,这个时候数据已经全部载入,使用 responseBody 或 responseText 属性就能获取需要的数据。
3. status HTTP 响应状态码,正常情况应该为 200,如果请求的资源不存在,就会返回 404,还有其他状态码如服务器错误 500 等。
4. statusText HTTP 响应状态文本,用于描述响应状态码所代表的意思,诸如 200 OK 中的 OK,404 Not Found 中的 Not Found
5. responseBody 响应数据的字节数组,这在 VBScript 里是可以直接使用的,但是在 JScript 里就需要转换过了。
6. responseText 以文本方式获取响应数据
7. responseXML 将响应数据作为一个 XMLDOM 对象来返回,这在请求的数据是一个 XML 文档时特别有用
8. responseStream 响应流对象,这个属性不常用
在 ServerXMLHTTP中,异步请求不再是主要用途,往往是同步的请求用得更多,因为在服务端编程中,程序的执行是需要迅速结束并返回结果的,不像在 桌面程序中,有一个消息循环。这样就导致了在服务端编程中,同步编程用得更多。当然,这并不是说异步请求没有用处,在一定的情况下,异步请求会有很大的作 用。
1. 简单的使用ServerXMLHTTP请求并显示指定Url
首先来看一下很简单的例子,使用ServerXMLHTTP请求Google的首页并显示出来:
程序代码:
<%@LANGUAGE="JScript" CODEPAGE="65001"%>
<%
// code from xujiwei
// http://www.xujiwei.cn
var url = "http://www.google.cn";
var xmlhttp = new ActiveXObject("MSXML2.ServerXMLHTTP.5.0");
xmlhttp.open("GET", url, false);
xmlhttp.send("");
Response.BinaryWrite(xmlhttp.responseBody);
xmlhttp = null;
%>
在浏览器查看这个页面,你就可以看到Google的首页了:
图片附件
但是,我们可以看到,这里的Logo图片是没有显示的,因为这个logo在网页源代码里是以相对路径的方式来指定的:
<img src=/intl/zh-CN/images/logo_cn.gif width=286 height=110 border=0 alt="Google" title="Google">
但是,我们的测试服务器里并没有这个图片文件,因此浏览器就会显示此图片的替代文字“Google”。
这 里我使用了xmlhttp的responseBody属性,这是因为,在不知道所请求的网页是使用什么编码的情况下,可以让浏览器来处理这个问题,而不用 在服务器处理编码。如果要在服务器处理编码,你必需知道你所请求的URL所返回的内容是使用什么编码的,并且正确的将返回内容进行转码以使得客户端浏览器 能正常的显示。
例如,我们请求Baidu的首页,就会因为编码问题而导致页面完全错乱:
图片附件
所以,使用responseText或者responseBody,完全取决于我们的需要,并不是一成不变的,或者,在某些时候,我们要使用的并不是这两个中的一个,而是responseXML:)
2. 设置超时
在 使用ServerXMLHTTP发送同步请求时,整个ASP程序的执行是被阻塞了的,也就意味着在开始发送请求到请求完成响应这段时间里,我们是做不了任 何事情的。那么这里就有几个问题,如果所请求的域名解析很慢怎么办?如果程序运行的服务器与请求的服务器之间的网络环境比较差导致连接很慢怎么办?如果要 发送的数据量很大但是带宽不够怎么办?同样如果响应的数据量很大但是带宽不够怎么办?
服务器所在环境及网络条件我们是无法改善的,因为,面对这些问题,我们只能采取回避的策略,即如果碰到这些问题,我们就直接丢掉这个请求。这时,ServerXMLHTTP的超时机制就有很大的用处了。
在 前一篇中,我介绍了ServerXMLHTTP的常用方法,其中有一个setTimeouts方法,就是用来设置ServerXMLHTTP对象的四个超 时时间,分别是:域名解析超时时间(resolveTimeout)、连接超时时间(connectTimeout)、数据发送超时时间 (sendTimeout)、数据接收超时时间(receiveTimeout)。这四个超时时间所代表的意义可以从它们的字面来理解,它们分别对应了这 一节开头所提出一的四个问题。
在不使用setTimeouts方法进行设置的情况下,域名解析超时时间(resolveTimeout)是 无限的,即不会在域名解析时产生超时,连接超时时间(connectTimeout)的默认值为60秒,数据发送超时时间(sendTimeout)的默 认值为30秒,数据接收超时时间(receiveTimeout)的默认值也是30秒。
通常情况下,我们不需要默认值中所指定的那么长的超时时间,因为碰到了最坏的情况下,在一个页面显示时,访客将要面对2分钟左右的无响应时间,这时访客往往认为这个页面是无效的并且会离开这个页面。
所 以我们要做的就是给ServerXMLHTTP设置一个较短的超时时间,一般情况下,域名解析和连接远程服务器都可以在2秒内完成,发送数据时间视数据量 而定,如果只是使用GET请求,这个数据量是很小的,也可以在2秒内完成,而响应,则可以稍微长一点,定在10秒左右,超过10秒时可以认为远程服务器没 有响应。
需要注意的是,setTimeouts方法所使用的参数单位是以毫秒为单位的,也就是说,如果 要指定2秒的超时时间,所用的参数为2000。另外,setTimeouts的参数顺序也是固定的,按顺序为:域名解析超时时间 (resolveTimeout)、连接超时时间(connectTimeout)、数据发送超时时间(sendTimeout)、数据接收超时时间 (receiveTimeout)。
那么,可以使用下面的代码来完成超时设置:
程序代码:
<%@LANGUAGE="JScript" CODEPAGE="65001"%>
<%
// code from xujiwei
// http://www.xujiwei.cn
var url = "http://www.google.com";
var xmlhttp = new ActiveXObject("MSXML2.ServerXMLHTTP.5.0");
// 设置超时时间,注意参数顺序
xmlhttp.setTimeouts(2000, 2000, 2000, 10000);
xmlhttp.open("GET", url, false);
xmlhttp.send("");
Response.BinaryWrite(xmlhttp.responseBody);
xmlhttp = null;
%>
如 果在某个阶段超时了,程序会抛出异常,在JScript里可以使用try...catch来捕获,并根据ServerXMLHTTP对象的 readyState属性来获知是在哪个阶段产生了超时异常。注意,同步请求时,超时异常会发生在调用send方法所在的行,例如上例中的 xmlhttp.send("")。
程序代码:
<%@LANGUAGE="JScript" CODEPAGE="65001"%>
<%
// code from xujiwei
// http://www.xujiwei.cn
var url = "http://www.youtube.com/";
var xmlhttp = new ActiveXObject("MSXML2.ServerXMLHTTP.5.0");
// 设置超时时间,注意参数顺序
xmlhttp.setTimeouts(2000, 2000, 2000, 10000);
xmlhttp.open("GET", url, false);
try {
xmlhttp.send("");
}
catch(e) {
Response.Write("发生异常:" + e.message + "<br/>");
// 判断是否为超时错误
if(e.number == -2147012894) {
var step = "";
// 判断超时错误发生所在的阶段
switch(xmlhttp.readyState) {
case 1:
step = "解析域名或连接远程服务器"
break;
case 2:
step = "发送请求";
break;
case 3:
step = "接收数据";
break;
default:
step = "未知阶段";
}
Response.Write("在 " + step + " 时发生超时错误");
}
Response.End();
}
Response.BinaryWrite(xmlhttp.responseBody);
xmlhttp = null;
%>
3. 请求使用HTTP认证的页面
呃,虽然说目前使用HTTP基本认证的已经少之又少,但是,总该知道ServerXMLHTTP有这么一个功能,可以直接实现HTTP基本认证。
在ServerXMLHTTP对象的open中,我们通常用到的只是它的前3个参数,即method、uri、async,但事实上,它还有另外两个可选参数,即用于HTTP基本认证的username及password。
那么,如果某天,我们要使用ServerXMLHTTP访问某个使用HTTP基本认证的网站,并且我们已经有了认证所需要的用户名及密码,那么可以使用以下密码来访问需要认证的内容:
程序代码:
<%@LANGUAGE="JScript" CODEPAGE="65001"%>
<%
// code from xujiwei
// http://www.xujiwei.cn
// 访问www.google.cn并不需要HTTP认证,这里只是作为一个演示
var url = "http://www.google.cn";
var xmlhttp = new ActiveXObject("MSXML2.ServerXMLHTTP.5.0");
// 用户名和密码分别为username和password
xmlhttp.open("GET", url, false, "username", "password");
xmlhttp.send("");
Response.BinaryWrite(xmlhttp.responseBody);
xmlhttp = null;
%>
4. 使用responseXML属性
有时候,我们所需要的结果并不是文本的,而是一个XML文档,譬如目前最常用的RSS。这个时候,responseXML属性就是我们的不二选择了。
使用responseXML属性所得到的对象,就是一个DOMDocument对象,这个对象可以使用诸如selectNodes、selectSingleNode这样的方法来操作XML文档对象。
例如,我们可以利用ServerXMLHTTP抓取新浪新闻的RSS并显示出来:
程序代码:
<%@LANGUAGE="JScript" CODEPAGE="65001"%>
<%
// code from xujiwei
// http://www.xujiwei.cn
// 新浪新闻的RSS地址
var url = "http://rss.sina.com.cn/news/marquee/ddt.xml";
var xmlhttp = new ActiveXObject("MSXML2.ServerXMLHTTP.5.0");
xmlhttp.open("GET", url, false);
xmlhttp.send("");
var xml = xmlhttp.responseXML;
Response.Write("<h1>" + xml.selectSingleNode("/rss/channel/title").text + "</h1>");
var items = xml.selectNodes("/rss/channel/item");
for(var i = 0; i < items.length; i++) {
Response.Write("<h3>" + items[i].selectSingleNode("title").text + "</h3>");
Response.Write("<small>" + items[i].selectSingleNode("pubDate").text + "</small>");
Response.Write("<div>" + items[i].selectSingleNode("description").text + "</div><hr />");
}
items = null;
xmlhttp = null;
%>
这些如果弄明白了,写一个RSS新闻聚合器就不是难事了。当然XMLDOM操作就不在本系列的范围之类了。
服务端XMLHTTP(ServerXMLHTTP in ASP)进阶应用-User Agent伪装
这篇开始讲讲ServerXMLHTTP的进阶应用。说是进阶应用,但也就是讲一些在基本应用里没有讲到的属性或者方法之类:)
使用setRequestHeader伪装User-Agent
User-Agent一般是服务端程序用来判断客户端浏览器、操作系统等信息的标志,它的说明可以参考Wiki,譬如在我的电脑 IE7 的UA就是:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ;
SLCC1; .NET CLR 2.0.50727; .NET CLR 3.5.21022; .NET CLR 3.5.30729; .NET CLR 3.0.30618)
可以看到,这个UA提供了不少信息,IE版本、Windows版本、.NET版本都有。再看看 Firefox 的:
Mozilla/5.0 (Windows; U; Windows NT 6.0; zh-CN; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3 (.NET CLR 3.5.30729)
UA的格式不是本文的重点,因此,如果需要了解UA的具体格式,可以去Google上找找,另外,在http://www.user-agents.org/这里可以找到目前大多数浏览器、搜索引擎Spider等的UA。
在我们使用 ServerXMLHTTP 发送请求时,它所用的 User-Agent 是以下内容:
Mozilla/4.0 (compatible; Win32; WinHttp.WinHttpRequest.5)
但是,某些网站会限制这个UA的访问,比如Google,如果我们使用以下代码来请求Google的页面,它使用的是默认UA“Mozilla/4.0 (compatible; Win32; WinHttp.WinHttpRequest.5)”:
程序代码:
<%@LANGUAGE="JScript" CODEPAGE="65001"%>
<%
// code from xujiwei
// http://www.xujiwei.cn
var url = "http://news.google.cn/?output=rss";
var xmlhttp = new ActiveXObject("MSXML2.ServerXMLHTTP.5.0");
xmlhttp.open("GET", url, false);
//xmlhttp.setRequestHeader("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 6.0; zh-CN; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3 (.NET CLR 3.5.30729)");
xmlhttp.send("");
Response.BinaryWrite(xmlhttp.responseBody);
xmlhttp = null;
%>
你会发现,我们会收到一个 403 Forbidden 的错误:
图片附件
为 了使得Google的RSS输出程序能把我们的识别成正常的RSS阅读或者一般浏览器,就需要在请求发出前设置 Request Header。要设 置 Request Header,只需要简单的在调用 open 方法之后,send 方法之前使用 setRequestHeader 来设置就行 了,它的语法是 xmlhttp.setRequestHeader(key, value)。下面我们就让Google的RSS输出程序把我们的请求识 别为Firefox的请求:
程序代码:
<%@LANGUAGE="JScript" CODEPAGE="65001"%>
<%
// code from xujiwei
// http://www.xujiwei.cn
var url = "http://news.google.cn/?output=rss";
var xmlhttp = new ActiveXObject("MSXML2.ServerXMLHTTP.5.0");
xmlhttp.open("GET", url, false);
// 设置 User Agent 为 Firefox 的UA
xmlhttp.setRequestHeader("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 6.0; zh-CN; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3 (.NET CLR 3.5.30729)");
xmlhttp.send("");
Response.BinaryWrite(xmlhttp.responseBody);
xmlhttp = null;
%>
刷新浏览器,显示出了Firefox的RSS预览界面,获取Google资讯RSS成功!
图片附件
ok,我们能正确得到Google资讯的RSS了,再通过XMLDOM来操作返回的RSS文档,就可以采集Google资讯那海量的新闻了。
[喝小酒的网摘]http://blog.const.net.cn/a/2589.htm
相关文章
发生msxml3.dll,错误800c0005错误的原因和解决方法Function getHTTPPage(url)
dim http
set http=Server.createobject("Microsoft.XMLHTTP")
Http.open "GET",url,false
Http.send()
if Http.readystate<
定时运行ASP文件在一定的时候,要定时的运行某个ASP文件去执行一个任务,如一个工厂在早上9点钟要采集所有的电表的读数,当然这要通过IN SQL连接到各个电表中,我们现在就是用一个ASP文件把IN SQL中表的读数再集中到MS SQL中。
可能你看到的定时运行ASP文件的方法有多种,不过我现在要说的是一种简单的方法,利用计划任务就可简单的实现。
首先,你要
安装asppdf的几种方式asppdf其实只有一个文件,也就是asppdf.dll,安装的时候只需要复制到系统system32目录下,然后regsvr32就可以了,当然你 也可以去官方网站下载asppdf.exe,安装程序不会把asppdf.dll复制到system32,但他还是已经regsvr32了,并且有一些示 例代码,也自动新建了一个虚拟目录/asppdf。也就是说可以直接http://localhost/asppd
xmlhttp属性和方法下面是WinHttpRequest component,不过我想也应该适用于xmlhttp,
前文有讲到xmlhttp的属性与方法,但觉得不是很完整,所以就有了下面的补充,下面的这些数据是来自于Microsoft,估计这个是比较全的,但里面提到的一些方法,例如属性(property-get)Option,在xmlhttp中平时都没有用过,又比如function SetTimeouts
asp中使用xmlhttp下载图片代码asp中使用xmlhttp下载图片代码:
<%
function getHTTPimg(url)
dim http
set http=server.createobject("MSXML2.XMLHTTP")
Http.open "GET",url,false
Http
国外的开源技术也影响和推动了国内开源程序的发展,上文我介绍的《国外优秀开源PHP建站程序一览》中,很多国外开源程序并不太符合中国人的使用习惯,而国内有一些厂家或个人也做了一些不错的产品,不少程序是提供源代码下载的,虽然有些在许可协议上和开源许可证有些出入,但其在使用上还是挺符合中国人的使用习惯,今天我就介绍一些国内的PHP“开源”建站程序。
论坛:Discuz
Discuz非常流行,也是中国地区最多用户使用的论坛程序,论坛搭建非常简单易用,使用风格符合中国人的口味。另一个流行的论坛程序是PHPWind。
SNS:Ucenter Home
UCenter Home是采用PHP+MySQL构建的社会化网络软件(Social Network Software,简称SNS)。 通过 UCenter Home,建站者可以轻松构建一个以好友关系为核心的交流网络,用户可以使用迷你博客记录;方便快捷地发布日志、上传图片;与其好友们一起分享信息、讨论话题;了解好友最新动态。
E-Commerce:ECSHOP
ECSHOP是一款开源免费的网上商店系统,用户可以根据自己的商务特征对ECSHOP进行定制,增加自己商城的特色功能。另一个流行的网上商城系统是shopex。
点评:Modoer
Modoer一款PHP点评系统,可针对多种行业进行点评,可以自由调控点评项目,类型,采用Web 2.0的建站方式,网站会员能让快速上手。
Digg:PBDigg
PBDigg是基于PHP+MYSQL的开源Digg社区资讯系统,融合了社会性标签、主题评论、Rss订阅等多种WEB2.0元素,是一个高效、快速的网站解决方案。
Wiki:HDWiki
HDWiki是专为中文用户设计和开发的开源、高效的中文百科建站解决方案,免费、易用、功能强大,和UCenter可无缝整合。
RSS:IXNA
IXNA是国内开源PHP新闻聚合程序,支持RSS多核心切换,默认支持lastrss、simplepie、magpierss,支持RDF、RSS、ATOM,支持智能识别。
CMS:关于CMS的PHP产品很多,这里主要介绍下面三个。
SupeSite
SupeSite 是一套独立的内容管理系统(CMS),并且拥有对Discuz!论坛信息和UCenter Home个人空间信息聚合的功能,是一个不错的社区门户解决方案。
DedeCMS
DedeCMS是一个比较老的PHP CMS系统,很多早期的用户都是使用这个建立网站的。
KingCMS
KingCMS是一套简单易学,操作简单的开源内容管理系统(CMS),KingCMS分为PHP+MySQL和ASP+MSSQL/ACCESS两种语言版本的系统。
最后是一次快讯,Twitter又无法访问了,估计XJ那里完事后可能会恢复,现在的解决方法在这里。
大量的PHP开源(开放源代码/Open Source)应用改变了这个世界,改变了互联网,以下我们总结从数据库到购物、博客等众多类型的开源PHP软件,供网站开发者们参考。
博客:WordPress
WordPress是使用PHP开发的著名博客平台,免费开源,功能强大,不仅仅用于博客搭建,还可以广泛应用于各类网络信息发布平台。
论坛:phpBB
phpBB是一种广泛流行的开源论坛软件,具有易于使用的管理面板和友好的用户安装界面,可以轻松地在数分钟内建立起一个论坛,功能上具有很高的可配置性,能够完全定制出相当个性化的论坛。
CMS:Drupal
Drupal是一个开源的内容管理系统(CMS)平台,拥有强大并可自由配置的功能,能支持从个人博客到大型社区驱动的网站等各种不同应用的网站项目。
Wiki:MediaWiki
MediaWiki是PHP语言写成开源Wiki引擎,全世界最大的Wiki项目维基百科就是使用MediaWiki引擎。
Digg:Pligg
Pligg是一套灵活的类似Digg的Web2.0 CMS系统,系统使用PHP开发,模仿了国外流行的DIGG系统。
图像:Gallery
Gallery 是一个非常有名的免费开源图库相册软件,基于 PHP 和 MySQL, PostgreSQL 等数据库。功能非常强大,有丰富的扩展可以下载,安装很简单,有很多插件可用。
RSS:Gregarius
Gregarius是一个RSS聚合程序,免费开源,具备不错的用户体验,易于操作和管理。可以把其当成RSS阅读器使用。
电子商务:osCommerce
osCommerce是一套由自由软件开发社团开发并维护的在线商店的解决方案,免费开源,并可以应用到任何的商业环境中,可以在短时间内生成一个功能强大的电子商务网站。
广告:OpenX
OpenX(原名phpAdsNew)是一个用PHP开发的广告管理与跟踪系统,适合各类网站使用,能够管理每个广告主拥有的多种任何尺寸横幅广告,按天查看,详细和概要统计并通过电子邮件发送报表给广告主。
微博客:Laconica
Laconica是一个开源的微型博客系统,也是一个Twitter克隆,可以实现Microblog的常用功能,国外不少微博客系统都是通过这个开源系统架设的。
英文原文:Top Ten Open Source PHP Apps
1 JS方式调用PHP文件并取得php中的值
举一个简单的例子来说明:
如在页面a.html中用下面这句调用:
<script type="text/javascript" src="b.php?action=test"></script>
<script type="text/javascript" >
alert(jstext);
</script>
在b.php中有这样一段PHP代码:
<? $action=$_GET['action']; //echo "var jstext='$action'"; //输出一句JS语句,生成一个JS变量,并赋颠值为PHP变量 $action的值 //echo "var jstext='aa'"; echo "var jstext="."'$action'"; ?>
当执行a.html文件时,就会调用b.php文件,并将b.php文件的输出作为JS语句来执行,所以此处会弹出一个提示框,内容为JS变量jstext的值,也就是在PHP文件中赋给jstext的值.
小结:
在HTML里用JS 调用文件的方式调PHP文件,则PHP文件的输出将会被调用页作为JS的代码来用.
2 php调用js中的值
在z.php页面中有这样一段代码:
<script type="text/javascript" > var url="aaaa*"; </script> <? $key="<script type=text/javascript>document.write(url)</script>"; echo $key; ?>
3 php调用js中的方法(函数)
<script type="text/javascript"> function test() { var t1=3; t1 = t1+2; alert(t1); //return t1; } </script>
<?php echo "<script type='text/javascript'>test();</script>"; ?>
4 JS调用PHP变量
(1)
<?php
$userId=100;
?> <script>
var userId;
userId=document.getElementByIdx_x_x_x("userId").value;
alert (userId);
</script>
<input type="text" name="userId" id="userId" value="<?php echo $userId; ?>">
(2)
<?php
$url = '变化的网址'; //定义变量
?>
<script type="text/javascript">
//js调用php变量
var ds ="<?php echo $url?>" ; //赋值 alert(ds); //输出效果 </script>
5 -------------------------------
<script language="JavaScript"> <!--
var Y=<?php echo date('Y')?>,M=<?php echo date('n')?>,D=<?php echo date('j')?>;
-->
</script>
6 自己写的js和php互相调用
1.php内容:
<?php
//echo "<script LANGUAGE='javascript'>alert('$php变量');</script>"; //最简单的php调用js
//echo "<a href=#><img width=50 src='$fruit_pic_array[$i]' onMouseOver=’javascript:a();‘></a>";
//echo "<a href='3.php'>aaaa</a>"; //php中超链接
//echo "<script type='text/javascript' language='javascript'>phpmake('PHP建站学习笔记网');</script>"; //有时候需要在PHP执行过程中,需要调用JavaScript自定义函数(验证时出错)
echo "function ok(msg){alert(msg);}";
?>
<HTML>
<HEAD>
<TITLE> php调用js文件的好办法</TITLE>
</HEAD>
<BODY>
<!--js调用php中定义的js-->
<scrīpt language=''javascrīpt'' type=''text/javascrīpt'' src=''1.php''></scrīpt>
<scrīpt>
ok("aaaaaa!");
</scrīpt>
</script>
</BODY>
</HTML>
2.php内容:
<!--js调用php-->
<?php
$userId=100;
?>
<script>
var userId;
userId=document.getElementByIdx_x("userId").value;
alert (userId);
</script>
<input type="text" name="userId" id="userId" value="<?php echo $userId; ?>">
<!--js调用php-->
<?php
if($_GET["action"]=="ok")
{
echo "I'm OK!";
}
else
{
echo "I'm not OK!";
}
?>
<SCRIPT Language = "JavaScript">
function func()
{
if(confirm("Are you OK with this?"))
{
this.location = "ok.php?action=ok";
}
else
{
this.location = "ok.php?action=cancel";
}
}
</SCRIPT>
<html>
<head>
</head>
<body>
<a href="#" href="#" onClick="javascript:func();">Please Click</a>
</body>
</html>
<!--js调用php-->
<html>
<head>
<script>
function isMail(PostString)
{
re=/\w*/
if(re.test(PostString))
{
return true;
}
else
{
return false;
}
}
function test(){
if (isMail(<?php echo $email?>))
{document.write("<?php echo "N";?>");}
else
{document.write('<?php echo 'Y';?>');}
}
</script>
</head>
<body>
<?php
$email="aa";
?>
<input type=button value=click onclick= 'test() '>
</body>
</html>
<!--php中含有js代码-->
<?php
echo "
<script language=javascript>
function test(){
alert( 'hello ');
}
</script> ";
?>
<input type=button value=click onclick= 'test() '>
摘要: 下面的例子列出几种情形交互场景,列出JS和php交互的方法。总结下,以免日后再为cookie问题困扰。setcookie.php01<?php02 setcookie('php_cn_ck','php_中文_cookie');03 setcookie('php_en_ck','php_english_...
阅读全文
<?php
/**
* Socket版本
* 使用方法:
* $post_string = "app=socket&version=beta";
* request_by_socket('facebook.cn','/restServer.php',$post_string);
*/
function request_by_socket($remote_server,$remote_path,$post_string,$port = 80,$timeout = 30){
$socket = fsockopen($remote_server,$port,$errno,$errstr,$timeout);
if (!$socket) die("$errstr($errno)");
fwrite($socket,"POST $remote_path HTTP/1.0\r\n");
fwrite($socket,"User-Agent: Socket Example\r\n");
fwrite($socket,"HOST: $remote_server\r\n");
fwrite($socket,"Content-type: application/x-www-form-urlencoded\r\n");
fwrite($socket,"Content-length: ".strlen($post_string)+8."\r\n");
fwrite($socket,"Accept:*/*\r\n");
fwrite($socket,"\r\n");
fwrite($socket,"mypost=$post_string\r\n");
fwrite($socket,"\r\n");
$header = "";
while ($str = trim(fgets($socket,4096))) {
$header.=$str;
}
$data = "";
while (!feof($socket)) {
$data .= fgets($socket,4096);
}
return $data;
}
/**
* Curl版本
* 使用方法:
* $post_string = "app=request&version=beta";
* request_by_curl('http://facebook.cn/restServer.php',$post_string);
*/
function request_by_curl($remote_server,$post_string){
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL,$remote_server);
curl_setopt($ch,CURLOPT_POSTFIELDS,'mypost='.$post_string);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
curl_setopt($ch,CURLOPT_USERAGENT,"Jimmy's CURL Example beta");
$data = curl_exec($ch);
curl_close($ch);
return $data;
}
/**
* 其它版本
* 使用方法:
* $post_string = "app=request&version=beta";
* request_by_other('http://facebook.cn/restServer.php',$post_string);
*/
function request_by_other($remote_server,$post_string){
$context = array(
'http'=>array(
'method'=>'POST',
'header'=>'Content-type: application/x-www-form-urlencoded'."\r\n".
'User-Agent : Jimmy\'s POST Example beta'."\r\n".
'Content-length: '.strlen($post_string)+8,
'content'=>'mypost='.$post_string)
);
$stream_context = stream_context_create($context);
$data = file_get_contents($remote_server,FALSE,$stream_context);
return $data;
}
function curl_file_get_contents($durl) {
$ch = curl_init (); curl_setopt ( $ch, CURLOPT_URL, $durl ); curl_setopt ( $ch, CURLOPT_POST, 1 ); curl_setopt ( $ch, CURLOPT_TIMEOUT, 5 ); curl_setopt ( $ch, CURLOPT_USERAGENT, _USERAGENT_ ); curl_setopt ( $ch, CURLOPT_REFERER, _REFERER_ ); curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); $r = curl_exec ( $ch ); curl_close ( $ch ); return $r; }
php读取网络文件 curl, fsockopen ,file_get_contents 几个方法的效率对比
最近需要获取别人网站上的音乐数据。用了file_get_contents函数,但是总是会遇到获取失败的问题,尽管按照手册中的 例子设置了超时,可多数时候不会奏效:
$config['context'] = stream_context_create(array(‘http’ => array(‘method’ => “GET”, ’timeout’ => 5//这个超时时间不稳定,经常不奏效 ) ));这时候,看一下服务器的连接池,会发现一堆类似的错误,让我头疼万分:file_get_contents(http://***): failed to open stream…现在改用了curl库,写了一个函数替换:function curl_file_get_contents($durl){ $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $durl); curl_setopt($ch, CURLOPT_TIMEOUT, 5); curl_setopt($ch, CURLOPT_USERAGENT, _USERAGENT_); curl_setopt($ch, CURLOPT_REFERER,_REFERER_); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $r = curl_exec($ch); curl_close($ch); return $r;}如此,除了真正的网络问题外,没再出现任何问题。这是别人做过的关于curl和file_get_contents的测试:file_get_contents抓取google.com需用秒数:
2.31319094
2.303742172.215126043.305538892.30124092curl使用的时间:
0.68719101
0.646755930.643260.819831130.63956594差距很大?呵呵,从我使用的经验来说,这两个工具不只是速度有差异,稳定性也相差很大。建议对网络数据抓取稳定性要求比较高的朋友使用上面的 curl_file_get_contents函数,不但稳定速度快,还能假冒浏览器欺骗目标地址哦!
看到的其他文章收藏于此===============================
php fsockopen
方法1: 用file_get_contents 以get方式获取内容
<?php
$url='http://www.domain.com/';
$html = file_get_contents($url);
echo $html;
?>
方法2: 用fopen打开url, 以get方式获取内容
<?php
$fp = fopen($url, 'r');
stream_get_meta_data($fp);
while(!feof($fp)) {
$result .= fgets($fp, 1024);
}
echo "url body: $result";
fclose($fp);
?>
方法3:用file_get_contents函数,以post方式获取url
<?php
$data = array ('foo' => 'bar');
$data = http_build_query($data);
$opts = array (
'http' => array (
'method' => 'POST',
'header'=> "Content-type: application/x-www-form-urlencoded\r\n" .
"Content-Length: " . strlen($data) . "\r\n",
'content' => $data
)
);
$context = stream_context_create($opts);
$html = file_get_contents('http://localhost/e/admin/test.html', false, $context);
echo $html;
?>
方法4:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
<?php
function get_url ($url,$cookie=false)
{
$url = parse_url($url);
$query = $url[path]."?".$url[query];
echo "Query:".$query;
$fp = fsockopen( $url[host], $url[port]?$url[port]:80 , $errno, $errstr, 30);
if (!$fp) {
return false;
} else {
$request = "GET $query HTTP/1.1\r\n";
$request .= "Host: $url[host]\r\n";
$request .= "Connection: Close\r\n";
if($cookie) $request.="Cookie: $cookie\n";
$request.="\r\n";
fwrite($fp,$request);
while()) {
$result .= @fgets($fp, 1024);
}
fclose($fp);
return $result;
}
}
//获取url的html部分,去掉header
function GetUrlHTML($url,$cookie=false)
{
$rowdata = get_url($url,$cookie);
if($rowdata)
{
$body= stristr($rowdata,"\r\n\r\n");
$body=substr($body,4,strlen($body));
return $body;
}
return false;
}
?>
方法5:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
<?php
function HTTP_Post($URL,$data,$cookie, $referrer="")
{
// parsing the given URL
$URL_Info=parse_url($URL);
// Building referrer
if($referrer=="") // if not given use this script as referrer
$referrer="111";
// making string from $data
foreach($data as $key=>$value)
$values[]="$key=".urlencode($value);
$data_string=implode("&",$values);
// Find out which port is needed - if not given use standard (=80)
if(!isset($URL_Info["port"]))
$URL_Info["port"]=80;
// building POST-request:
$request.="POST ".$URL_Info["path"]." HTTP/1.1\n";
$request.="Host: ".$URL_Info["host"]."\n";
$request.="Referer: $referer\n";
$request.="Content-type: application/x-www-form-urlencoded\n";
$request.="Content-length: ".strlen($data_string)."\n";
$request.="Connection: close\n";
$request.="Cookie: $cookie\n";
$request.="\n";
$request.=$data_string."\n";
$fp = fsockopen($URL_Info["host"],$URL_Info["port"]);
fputs($fp, $request);
while(!feof($fp)) {
$result .= fgets($fp, 1024);
}
fclose($fp);
return $result;
}
?>
方法6:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
<?php
$ch = curl_init();
$timeout = 5;
curl_setopt ($ch, CURLOPT_URL, 'http://www.domain.com/');
curl_setopt ($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt ($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$file_contents = curl_exec($ch);
curl_close($ch);
echo $file_contents;
?>
php中 curl, fsockopen ,file_get_contents 三个函数 都可以实现采集模拟发言 。 三者有什么区别,或者讲究么
赵永斌:
有些时候用file_get_contents()调用外部文件,容易超时报错。换成curl后就可以.具体原因不清楚
curl 效率比file_get_contents()和fsockopen()高一些,原因是CURL会自动对DNS信息进行缓存(亮点啊 有我待亲测)
范佳鹏:
file_get_contents curl fsockopen
在当前所请求环境下选择性操作,没有一概而论:
具我们公司开发KBI应用来看:
刚开始采用:file_get_contents
后来采用:fsockopen
最后到至今采用:curl
(远程)我个人理解到的表述如下(不对请指出,不到位请补充)
file_get_contents 需要php.ini里开启allow_url_fopen,请求http时,使用的是http_fopen_wrapper,不会keeplive.curl是可以的。
file_get_contents()单个执行效率高,返回没有头的信息。
这个是读取一般文件的时候并没有什么问题,但是在读取远程问题的时候就会出现问题。
如果是要打一个持续连接,多次请求多个页面。那么file_get_contents和fopen就会出问题。
取得的内容也可能会不对。所以做一些类似采集工作的时候,肯定就有问题了。
sock较底层,配置麻烦,不易操作。 返回完整信息。
潘少宁-腾讯:
file_get_contents 虽然可以获得某URL的内容,但不能post get啊。
curl 则可以post和get啊。还可以获得head信息
而socket则更底层。可以设置基于UDP或是TCP协议去交互
file_get_contents 和 curl 能干的,socket都能干。
socket能干的,curl 就不一定能干了
file_get_contents 更多的时候 只是去拉取数据。效率比较高 也比较简单。
赵的情况这个我也遇到过,我通过CURL设置host 就OK了。 这和网络环境有关系
首先说下啥是socket:
php使用berkely的socket库来创建他的连接,socket是一个数据结果,你可以通过这个socket来开启服务器和客户端的会话。服务器端一直处于监听状态,当一个客户端连接服务器,他就打开服务器端正在监听的一个端口进行会话。这时服务器端接收客户端的连接请求,那么就进行一次循环。现在这个客户端就能够发送信息到服务器,服务器也可以发送信息给客户端。
产生一个socket你一共需要三个变量:
1、一个协议
2、一个socket类型
3、一个公共协议类型
以下是对这三个变量的详细解释,大概了解下吧
协议:产生一个socket有三个协议供选择:
1、AF_INET 这个是使用比较广泛的产生socket的协议,使用tcp或者udp协议传输,使用ipv4地址
2、AF_INET6 显而易见哈,同上,不同的是使用ipv6地址
3、AF_UNIX 使用在unix或者linux机器上,这个很少使用,仅在服务器端和客户端均为unix或者linux系统上使用。
socket类型:
1、SOCK_STREAM 这个协议是按照顺序的、可靠的、数据完整的基于字节流的连接。这是一个使用最多的socket类型,这个socket是使用TCP来进行传输。
2、SOCK_DGRAM 这个协议是无连接的、固定长度的传输调用。该协议是不可靠的,使用UDP来进行它的连接。
3、SOCK_SEQPACKET 这个协议是双线路的、可靠的连接,发送固定长度的数据包进行传输。必须把这个包完整的接受才能进行读取。
4、SOCK_RAW 这个socket类型提供单一的网络访问,这个socket类型使用ICMP公共协议。(ping、traceroute使用该协议)
5、SOCK_RDM 这个类型是很少使用的,在大部分的操作系统上没有实现,它是提供给数据链路层使用,不保证数据包的顺序
公共协议类型:
1、ICMP (Internet Control Message Protocol)互联网控制报文协议,主要用在网关和主机上,用来检测网络状况和报告错误信息
2、TCP (Transmission Control Protocol) 传输控制协议,他是使用最广泛的协议,他能够保证数据包到达接收者那里,如果中途出现错误,那么此协议从新发送数据包。
3、UDP (User Datagram Protocol)用户数据包协议,他是无连接的,不可靠的数据传输协议。
好啦,你现在知道了产生一个socke需要三个元素,那么在php中socket_create()就需要三个参数,一个协议,一个socket类型,一个公共协议。如果创建成功,socket_create()返回一个socket资源类型,如果不成功,嘿嘿,那你会收到一个false.
CURL
cURL 是利用URL语法规定来传输文件和数据的工具。他支持HTTP、FTP、TELNET。
为啥要使用cURL呢?
因为,如果我们有时候想灵活的获取网页上的内容,例如处理coockies、验证、表单提交、文件上传等等等等。那么你就需要用到cURL.据说php有着功能强大的cURL库(因为偶也说不清强大在哪里啦,
php使用cURL的选项基本步骤如下:
1、初始化
2、参数设置
3、页面内容获取或者操作
4、释放句柄
看看下面这个简单的例子吧。
<?php
//初始化curl
$ch = curl_init ();
/*
* 设置curl
* php手册对于curl_setopt的解释为:设置对于curl传输的操作
* curl_setopt有三个参数:资源(一般为你建立的curl句柄)、操作(你将对这个句柄作何操作)、参数(对于这个操作你给出的参数)
*/
//例如你想对百度进行某些操作
curl_setopt ( $ch, CURLOPT_URL, "http://www.baidu.com");
//现在看来你要向百度post数据
curl_setopt ( $ch, CURLOPT_POST, 1 );
/*给出了要post的数据:$post_string,post的数据可以是一个文件,
*那么你需要以@加上文件的全路径给出,或者你要post一些数据,
*那么你可以按照数组形式给出,或者按照字符串给出,
*如果你想按照字符串形式给出,请把字符串urlencode,嘿嘿
*/
curl_setopt ( $ch, CURLOPT_POSTFIELDS, $post_string );
/*
*把curl操作的结果以字符串形式 从curl_exec ()返回,而不是直接就输出了
*/
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, true );
//得到操作返回结果
$result = curl_exec ( $ch );
//关闭curl句柄
curl_close ( $ch );
?>
因为php的curl有很多操作,要都记住估计很困难,反正偶记不住啦,说些大家可能用的上的吧。大笑
获取服务器的一些信息
[php] view plaincopy
<?php
//初始化curl
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, "http://www.baidu.com");
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, true );
curl_exec($ch);
$info = curl_getinfo($ch);
var_dump($info);
?>
通过上面的例子,你将会获得如下信息:
“url” //资源网络地址
“content_type” //内容编码
“http_code” //HTTP状态码
“header_size” //header的大小
“request_size” //请求的大小
“filetime” //文件创建时间
“ssl_verify_result” //SSL验证结果
“redirect_count” //跳转技术
“total_time” //总耗时
“namelookup_time” //DNS查询耗时
“connect_time” //等待连接耗时
“pretransfer_time” //传输前准备耗时
“size_upload” //上传数据的大小
“size_download” //下载数据的大小
“speed_download” //下载速度
“speed_upload” //上传速度
“download_content_length”//下载内容的长度
“upload_content_length” //上传内容的长度
“starttransfer_time” //开始传输的时间
“redirect_time”//重定向耗时
利用curl你还可以做以下操作:
模拟页面的post操作
文件上传
HTTP 认证
FTP 上传
回调函数
以上关于curl的大前提是你的php在安装编译时加了 --with-curlwrappers ,你可以通过phpinfo()操作来查看你是不是在编译时加了这个扩展库。
如果加载了这个扩展,你将能看见类似:
如果你没有这个扩展,你需要改一下php.ini文件,去掉extension=php_curl.dll前面的分号。
好啦,现在我们知道socket和curl是咋回事了,socket是一种数据结构,他可以用来在服务器和客户端进行对话。而curl是利用url语法规定来传输文件和数据的规定,支持很多协议,例如FTP,HTTP、TELNET等。
抓取远程内容,之前一直都在用file_get_content函数,其实早就知道有curl这么一个好东西的存在,但是看了一眼后感觉使用颇有些复杂,没有file_get_content那么简单,再就是需求也不大,所以没有学习使用curl。
直到最近,要做一个网页小偷程序的时候才发现file_get_content已经完全不能满足需求了。我觉得,在读取远程内容的时候,file_get_content除了使用比curl便捷以外,其他都没有curl好。
php中curl和file_get_content的一些比较
主要区别:
学习才发现,curl支持很多协议,有FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE以及LDAP,也就是说,它能做到很多file_get_content做不到的事情。curl在php可以实现远程获取和采集内容;实现PHP网页版的FTP上传下载;实现模拟登陆;实现接口对接(API),数据传输;实现模拟Cookie;下载文件断点续传等等,功能十分强大。
了解curl一些基本的使用后,才发现其实并不难,只不过记住里面一些设置参数,难弄一点,但是我们记住几个常用的就可以了。
开启curl:
因为PHP默认是不支持curl功能的,因此如果要用curl的话,首先需要在php.ini中开启该功能,即去掉 ;extension= php_curl.dll 前面的分号,然后保存后重启apache/iis就好了。
基本语法:
$my_curl = curl_init(); //初始化一个curl对象
curl_setopt($my_curl, CURLOPT_URL, "http://www.jb51.net"); //设置你需要抓取的URL
curl_setopt($my_curl,CURLOPT_RETURNTRANSFER,1); //设置是将结果保存到字符串中还是输出到屏幕上,1表示将结果保存到字符串
$str = curl_exec($curl); //执行请求
echo $str; //输出抓取的结果
curl_close($curl); //关闭url请求
最近需要获取别人网站上的音乐数据。用了file_get_contents函数,但是总是会遇到获取失败的问题,尽管按照手册中的例子设置了超时,可多数时候不会奏效:
$config['context'] = stream_context_create(array('http' => array('method' => "GET",
'timeout' => 5//这个超时时间不稳定,经常不奏效
)
));
这时候,看一下服务器的连接池,会发现一堆类似的错误,让我头疼万分:
file_get_contents(http://***): failed to open stream…
现在改用了curl库,写了一个函数替换:
function curl_file_get_contents($durl){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $durl);
curl_setopt($ch, CURLOPT_TIMEOUT, 5);
curl_setopt($ch, CURLOPT_USERAGENT, _USERAGENT_);
curl_setopt($ch, CURLOPT_REFERER,_REFERER_);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$r = curl_exec($ch);
curl_close($ch);
return $r;
}
如此,除了真正的网络问题外,没再出现任何问题。
这是别人做过的关于curl和file_get_contents的测试:
file_get_contents抓取google.com需用秒数:
2.31319094
2.30374217
2.21512604
3.30553889
2.30124092
curl使用的时间:
0.68719101
0.64675593
0.64326
0.81983113
0.63956594
差距很大?呵呵,从我使用的经验来说,这两个工具不只是速度有差异,稳定性也相差很大。
建议对网络数据抓取稳定性要求比较高的朋友使用上面的 curl_file_get_contents函数,不但稳定速度快,还能假冒浏览器欺骗目标地址哦!
方法1: 用file_get_contents 以get方式获取内容
<?php
$url='http://www.domain.com/';
$html = file_get_contents($url);
echo $html;
?>
方法2: 用fopen打开url, 以get方式获取内容
<?php
$fp = fopen($url, 'r');
stream_get_meta_data($fp);
while(!feof($fp)) {
$result .= fgets($fp, 1024);
}
echo "url body: $result";
fclose($fp);
?>
方法3:用file_get_contents函数,以post方式获取url
<?php
$data = array ('foo' => 'bar');
$data = http_build_query($data);
$opts = array (
'http' => array (
'method' => 'POST',
'header'=> "Content-type: application/x-www-form-urlencodedrn" .
"Content-Length: " . strlen($data) . "rn",
'content' => $data
)
);
$context = stream_context_create($opts);
$html = file_get_contents('http://localhost/e/admin/test.html', false, $context);
echo $html;
?>
方法4:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
<?php
function get_url ($url,$cookie=false)
{
$url = parse_url($url);
$query = $url[path]."?".$url[query];
echo "Query:".$query;
$fp = fsockopen( $url[host], $url[port]?$url[port]:80 , $errno, $errstr, 30);
if (!$fp) {
return false;
} else {
$request = "GET $query HTTP/1.1rn";
$request .= "Host: $url[host]rn";
$request .= "Connection: Closern";
if($cookie) $request.="Cookie: $cookien";
$request.="rn";
fwrite($fp,$request);
while()) {
$result .= @fgets($fp, 1024);
}
fclose($fp);
return $result;
}
}
//获取url的html部分,去掉header
function GetUrlHTML($url,$cookie=false)
{
$rowdata = get_url($url,$cookie);
if($rowdata)
{
$body= stristr($rowdata,"rnrn");
$body=substr($body,4,strlen($body));
return $body;
}
return false;
}
?>
方法5:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
<?php
function HTTP_Post($URL,$data,$cookie, $referrer="")
{
// parsing the given URL
$URL_Info=parse_url($URL);
// Building referrer
if($referrer=="") // if not given use this script as referrer
$referrer="111″;
// making string from $data
foreach($data as $key=>$value)
$values[]="$key=".urlencode($value);
$data_string=implode("&",$values);
// Find out which port is needed – if not given use standard (=80)
if(!isset($URL_Info["port"]))
$URL_Info["port"]=80;
// building POST-request:
$request.="POST ".$URL_Info["path"]." HTTP/1.1n";
$request.="Host: ".$URL_Info["host"]."n";
$request.="Referer: $referern";
$request.="Content-type: application/x-www-form-urlencodedn";
$request.="Content-length: ".strlen($data_string)."n";
$request.="Connection: closen";
$request.="Cookie: $cookien";
$request.="n";
$request.=$data_string."n";
$fp = fsockopen($URL_Info["host"],$URL_Info["port"]);
fputs($fp, $request);
while(!feof($fp)) {
$result .= fgets($fp, 1024);
}
fclose($fp);
return $result;
}
?>
方法6:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
<?php
$ch = curl_init();
$timeout = 5;
curl_setopt ($ch, CURLOPT_URL, 'http://www.domain.com/');
curl_setopt ($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt ($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$file_contents = curl_exec($ch);
curl_close($ch);
echo $file_contents;
?>
php中 curl, fsockopen ,file_get_contents 三个函数 都可以实现采集模拟发言 。三者有什么区别,或者讲究么
赵永斌:
有些时候用file_get_contents()调用外部文件,容易超时报错。换成curl后就可以.具体原因不清楚
curl 效率比file_get_contents()和fsockopen()高一些,原因是CURL会自动对DNS信息进行缓存(亮点啊有我待亲测)
范佳鹏:
file_get_contents curl fsockopen
在当前所请求环境下选择性操作,没有一概而论:
具我们公司开发KBI应用来看:
刚开始采用:file_get_contents
后来采用:fsockopen
最后到至今采用:curl
(远程)我个人理解到的表述如下(不对请指出,不到位请补充)
file_get_contents 需要php.ini里开启allow_url_fopen,请求http时,使用的是http_fopen_wrapper,不会keeplive.curl是可以的。
file_get_contents()单个执行效率高,返回没有头的信息。
这个是读取一般文件的时候并没有什么问题,但是在读取远程问题的时候就会出现问题。
如果是要打一个持续连接,多次请求多个页面。那么file_get_contents和fopen就会出问题。
取得的内容也可能会不对。所以做一些类似采集工作的时候,肯定就有问题了。
sock较底层,配置麻烦,不易操作。 返回完整信息。
潘少宁-腾讯:
file_get_contents 虽然可以获得某URL的内容,但不能post get啊。
curl 则可以post和get啊。还可以获得head信息
而socket则更底层。可以设置基于UDP或是TCP协议去交互
file_get_contents 和 curl 能干的,socket都能干。
socket能干的,curl 就不一定能干了
file_get_contents 更多的时候 只是去拉取数据。效率比较高 也比较简单。
赵的情况这个我也遇到过,我通过CURL设置host 就OK了。 这和网络环境有关系
<?php
/**
* Socket版本
* 使用方法:
* $post_string = "app=socket&version=beta";
* request_by_socket('jb51.net','/restServer.php',$post_string);
*/
function request_by_socket($remote_server,$remote_path,$post_string,$port = 80,$timeout = 30){
$socket = fsockopen($remote_server,$port,$errno,$errstr,$timeout);
if (!$socket) die("$errstr($errno)");
fwrite($socket,"POST $remote_path HTTP/1.0");
fwrite($socket,"User-Agent: Socket Example");
fwrite($socket,"HOST: $remote_server");
fwrite($socket,"Content-type: application/x-www-form-urlencoded");
fwrite($socket,"Content-length: ".strlen($post_string)+8."");
fwrite($socket,"Accept:*/*");
fwrite($socket,"");
fwrite($socket,"mypost=$post_string");
fwrite($socket,"");
$header = "";
while ($str = trim(fgets($socket,4096))) {
$header.=$str;
}
$data = "";
while (!feof($socket)) {
$data .= fgets($socket,4096);
}
return $data;
}
/**
* Curl版本
* 使用方法:
* $post_string = "app=request&version=beta";
* request_by_curl('http://jb51.net/restServer.php',$post_string);
*/
function request_by_curl($remote_server,$post_string){
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL,$remote_server);
curl_setopt($ch,CURLOPT_POSTFIELDS,'mypost='.$post_string);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
curl_setopt($ch,CURLOPT_USERAGENT,"Jimmy's CURL Example beta");
$data = curl_exec($ch);
curl_close($ch);
return $data;
}
/**
* 其它版本
* 使用方法:
* $post_string = "app=request&version=beta";
* request_by_other('http://jb51.net/restServer.php',$post_string);
*/
function request_by_other($remote_server,$post_string){
$context = array(
'http'=>array(
'method'=>'POST',
'header'=>'Content-type: application/x-www-form-urlencoded'."".
'User-Agent : Jimmy's POST Example beta'."".
'Content-length: '.strlen($post_string)+8,
'content'=>'mypost='.$post_string)
);
$stream_context = stream_context_create($context);
$data = file_get_contents($remote_server,FALSE,$stream_context);
return $data;
}
?>
/**
* 发送post请求
* @param string $url 请求地址
* @param array $post_data post键值对数据
* @return string
*/
function send_post($url, $post_data) {
$postdata = http_build_query($post_data);
$options = array(
'http' =>; array(
'method' =>; 'POST',
'header' =>; 'Content-type:application/x-www-form-urlencoded',
'content' =>; $postdata,
'timeout' =>; 15 * 60 // 超时时间(单位:s)
)
);
$context = stream_context_create($options);
$result = file_get_contents($url, false, $context);
return $result;
}
使用如下:
post_data = array(
'username' => 'stclair2201',
'password' => 'handan'
);
send_post('http://blog.snsgou.com', $post_data);
实战经验:
当我利用上述代码给另一台服务器发送http请求时,发现,如果服务器处理请求时间过长,本地的PHP会中断请求,即所谓的超时中断,第一个怀疑的是PHP本身执行时间的超过限制,但想想也不应该,因为老早就按照这篇文章设置了“PHP执行时间限制”(【推荐】PHP上传文件大小限制大全 ),仔细琢磨,想想,应该是http请求本身的一个时间限制,于是乎,就想到了怎么给http请求时间限制搞大一点。。。。。。查看PHP手册,果真有个参数 “ timeout ”,默认不知道多大,当把它的值设大一点,问题得已解决
Socket版本:
/**
* Socket版本
* 使用方法:
* $post_string = "app=socket&version=beta";
* request_by_socket('blog.snsgou.com', '/restServer.php', $post_string);
*/
function request_by_socket($remote_server,$remote_path,$post_string,$port = 80,$timeout = 30) {
$socket = fsockopen($remote_server, $port, $errno, $errstr, $timeout);
if (!$socket) die("$errstr($errno)");
fwrite($socket, "POST $remote_path HTTP/1.0");
fwrite($socket, "User-Agent: Socket Example");
fwrite($socket, "HOST: $remote_server");
fwrite($socket, "Content-type: application/x-www-form-urlencoded");
fwrite($socket, "Content-length: " . (strlen($post_string) + 8) . "");
fwrite($socket, "Accept:*/*");
fwrite($socket, "");
fwrite($socket, "mypost=$post_string");
fwrite($socket, "");
$header = "";
while ($str = trim(fgets($socket, 4096))) {
$header .= $str;
}
$data = "";
while (!feof($socket)) {
$data .= fgets($socket, 4096);
}
return $data;
}
Curl版本:
/**
* Curl版本
* 使用方法:
* $post_string = "app=request&version=beta";
* request_by_curl('http://blog.snsgou.com/restServer.php', $post_string);
*/
function request_by_curl($remote_server, $post_string) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $remote_server);
curl_setopt($ch, CURLOPT_POSTFIELDS, 'mypost=' . $post_string);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_USERAGENT, "snsgou.com's CURL Example beta");
$data = curl_exec($ch);
curl_close($ch);
return $data;
}
Curl版本(2)
/**
* 发送HTTP请求
*
* @param string $url 请求地址
* @param string $method 请求方式 GET/POST
* @param string $refererUrl 请求来源地址
* @param array $data 发送数据
* @param string $contentType
* @param string $timeout
* @param string $proxy
* @return boolean
*/
function send_request($url, $data, $refererUrl = '', $method = 'GET', $contentType = 'application/json', $timeout = 30, $proxy = false) {
$ch = null;
if('POST' === strtoupper($method)) {
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_HEADER,0 );
curl_setopt($ch, CURLOPT_FRESH_CONNECT, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_FORBID_REUSE, 1);
curl_setopt($ch, CURLOPT_TIMEOUT, $timeout);
if ($refererUrl) {
curl_setopt($ch, CURLOPT_REFERER, $refererUrl);
}
if($contentType) {
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type:'.$contentType));
}
if(is_string($data)){
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
} else {
curl_setopt($ch, CURLOPT_POSTFIELDS, http_build_query($data));
}
} else if('GET' === strtoupper($method)) {
if(is_string($data)) {
$real_url = $url. (strpos($url, '?') === false ? '?' : ''). $data;
} else {
$real_url = $url. (strpos($url, '?') === false ? '?' : ''). http_build_query($data);
}
$ch = curl_init($real_url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type:'.$contentType));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_TIMEOUT, $timeout);
if ($refererUrl) {
curl_setopt($ch, CURLOPT_REFERER, $refererUrl);
}
} else {
$args = func_get_args();
return false;
}
if($proxy) {
curl_setopt($ch, CURLOPT_PROXY, $proxy);
}
$ret = curl_exec($ch);
$info = curl_getinfo($ch);
$contents = array(
'httpInfo' => array(
'send' => $data,
'url' => $url,
'ret' => $ret,
'http' => $info,
)
);
curl_close($ch);
return $ret;
}
调用 WCF接口 的一个例子:$json = restRequest($r_url,'POST', json_encode($data));
实际上magento模版默认就是接入了paypal的,用户只需要到magento的后台,对Paypal帐户进行设置即可。
如何在magento后台设置paypal呢? 这边我简单跟大家分享一下。
1、System -> Configuration -> Paypal
如果没看到Paypal,则在

2:
OFOL_DE.jpg)

3:

后台设定好了,保存,然后刷新缓存,就可以支付了。
注意可能会出现的问题:(测试的时候很容易出现的问题)
因为测试的时候大家一般随便写地址,所以测试的时候会出现错误:无法处理付款。由于商家提供的送货地址无效,而且商家要求您的订单必须送到该地址,因此,请与该商家进行联系。
解决方法:找到Paypal/Mode/Standard.php,里面有’address_override’ =1,这一行改成’address_override’=0,就可以了,大致在158行。
设置二、app/code/core/mage/paypal/model/api/standard.php 237行
$request['address_override'] = 1;将这个值设置为0 ,填写假的地址也可以跳转过去了!
摘要: 1 J2me开发网 http://www.j2medev.com/bbs/index.asp2 J2me社区 http://www.j2meforums.com/forum/3 csdn http://www.csdn.net/4 Vc知识库 http://www.vckbase.com/5 codeproject http://www.codep...
阅读全文
一、使用方法:
1、在页面<head>中引入ckeditor核心文件ckeditor.js
<script type="text/javas cript" src="ckeditor/ckeditor.js"></script>
2、在使用编辑器的地方插入HTML控件<textarea>
<textarea id="TextArea1" cols="20" rows="2" class="ckeditor"></textarea>
如果是ASP.NET环境,也可用服务器端控件<TextBox>
<asp:TextBox ID="tbContent" runat="server" TextMode="MultiLine" class="ckeditor"></asp:TextBox>
注意在控件中加上 class="ckeditor" 。
3、将相应的控件替换成编辑器代码
<script type="text/javas cript">
CKEDITOR.replace('TextArea1');
//如果是在ASP.NET环境下用的服务器端控件<TextBox>
CKEDITOR.replace('tbContent');
//如果<TextBox>控件在母版页中,要这样写
CKEDITOR.replace('<%=tbContent.ClientID.Replace("_","$") %>');
</script>
4、配置编辑器
ckeditor的配置都集中在 ckeditor/config.js 文件中,下面是一些常用的配置参数:
// 界面语言,默认为 'en'
config.language = 'zh-cn';
// 设置宽高
config.width = 400;
config.height = 400;
// 编辑器样式,有三种:'kama'(默认)、'office2003'、'v2'
config.skin = 'v2';
// 背景颜色
config.uiColor = '#FFF';
// 工具栏(基础'Basic'、全能'Full'、自定义)plugins/toolbar/plugin.js
config.toolbar = 'Basic';
config.toolbar = 'Full';
这将配合:
config.toolbar_Full = [
['Source','-','Save','NewPage','Preview','-','Templates'],
['Cut','Copy','Paste','PasteText','PasteFromWord','-','Print', 'SpellChecker', 'Scayt'],
['Undo','Redo','-','Find','Replace','-','SelectAll','RemoveFormat'],
['Form', 'Checkbox', 'Radio', 'TextField', 'Textarea', 'Select', 'Button', 'ImageButton', 'HiddenField'],
'/',
['Bold','Italic','Underline','Strike','-','Subscript','Superscript'],
['NumberedList','BulletedList','-','Outdent','Indent','Blockquote'],
['JustifyLeft','JustifyCenter','JustifyRight','JustifyBlock'],
['Link','Unlink','Anchor'],
['Image','Flash','Table','HorizontalRule','Smiley','SpecialChar','PageBreak'],
'/',
['Styles','Format','Font','FontSize'],
['TextColor','BGColor']
];
//工具栏是否可以被收缩
config.toolbarCanCollapse = true;
//工具栏的位置
config.toolbarLocation = 'top';//可选:bottom
//工具栏默认是否展开
config.toolbarStartupExpanded = true;
// 取消 “拖拽以改变尺寸”功能 plugins/resize/plugin.js
config.resize_enabled = false;
//改变大小的最大高度
config.resize_maxHeight = 3000;
//改变大小的最大宽度
config.resize_maxWidth = 3000;
//改变大小的最小高度
config.resize_minHeight = 250;
//改变大小的最小宽度
config.resize_minWidth = 750;
// 当提交包含有此编辑器的表单时,是否自动更新元素内的数据
config.autoUpdateElement = true;
// 设置是使用绝对目录还是相对目录,为空为相对目录
config.baseHref = ''
// 编辑器的z-index值
config.baseFloatZIndex = 10000;
//设置快捷键
config.keystrokes = [
[ CKEDITOR.ALT + 121 /*F10*/, 'toolbarFocus' ], //获取焦点
[ CKEDITOR.ALT + 122 /*F11*/, 'elementsPathFocus' ], //元素焦点
[ CKEDITOR.SHIFT + 121 /*F10*/, 'contextMenu' ], //文本菜单
[ CKEDITOR.CTRL + 90 /*Z*/, 'undo' ], //撤销
[ CKEDITOR.CTRL + 89 /*Y*/, 'redo' ], //重做
[ CKEDITOR.CTRL + CKEDITOR.SHIFT + 90 /*Z*/, 'redo' ], //
[ CKEDITOR.CTRL + 76 /*L*/, 'link' ], //链接
[ CKEDITOR.CTRL + 66 /*B*/, 'bold' ], //粗体
[ CKEDITOR.CTRL + 73 /*I*/, 'italic' ], //斜体
[ CKEDITOR.CTRL + 85 /*U*/, 'underline' ], //下划线
[ CKEDITOR.ALT + 109 /*-*/, 'toolbarCollapse' ]
]
//设置快捷键 可能与浏览器快捷键冲突 plugins/keystrokes/plugin.js.
config.blockedKeystrokes = [
CKEDITOR.CTRL + 66 /*B*/,
CKEDITOR.CTRL + 73 /*I*/,
CKEDITOR.CTRL + 85 /*U*/
]
//设置编辑内元素的背景色的取值 plugins/colorbutton/plugin.js.
config.colorButton_backStyle = {
element : 'span',
styles : { 'background-color' : '#(color)' }
}
//设置前景色的取值 plugins/colorbutton/plugin.js
config.colorButton_colors = '000,800000,8B4513,2F4F4F,008080,000080,4B0082,696969,B22222,A52A2A,DAA520,
006400,40E0D0,0000CD,800080,808080,F00,FF8C00,FFD700,008000,0FF,00F,EE82EE,
A9A9A9,FFA07A,FFA500,FFFF00,00FF00,AFEEEE,ADD8E6,DDA0DD,D3D3D3,FFF0F5,
FAEBD7,FFFFE0,F0FFF0,F0FFFF,F0F8FF,E6E6FA,FFF’
//是否在选择颜色时显示“其它颜色”选项 plugins/colorbutton/plugin.js
config.colorButton_enableMore = false
//区块的前景色默认值设置 plugins/colorbutton/plugin.js
config.colorButton_foreStyle = {
element : 'span',
styles : { 'color' : '#(color)' }
};
//所需要添加的CSS文件 在此添加 可使用相对路径和网站的绝对路径
config.contentsCss = './contents.css';
//文字方向
config.contentsLangDirection = 'rtl'; //从左到右
//CKeditor的配置文件 若不想配置 留空即可
CKEDITOR.replace( 'myfiled', { customConfig : './config.js' } );
//界面编辑框的背景色 plugins/dialog/plugin.js
config.dialog_backgroundCoverColor = '#fffefd'; //可设置参考
config.dialog_backgroundCoverColor = 'white' //默认
//背景的不透明度 数值应该在:0.0~1.0 之间 plugins/dialog/plugin.js
config.dialog_backgroundCoverOpacity = 0.5
//移动或者改变元素时 边框的吸附距离 单位:像素 plugins/dialog/plugin.js
config.dialog_magnetDistance = 20;
//是否拒绝本地拼写检查和提示 默认为拒绝 目前仅firefox和safari支持 plugins/wysiwygarea/plugin.js.
config.disableNativeSpellChecker = true
//进行表格编辑功能 如:添加行或列 目前仅firefox支持 plugins/wysiwygarea/plugin.js
config.disableNativeTableHandles = true; //默认为不开启
//是否开启 图片和表格 的改变大小的功能 config.disableObjectResizing = true;
config.disableObjectResizing = false //默认为开启
//设置HTML文档类型
config.docType = '<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd%22' ;
//是否对编辑区域进行渲染 plugins/editingblock/plugin.js
config.editingBlock = true;
//编辑器中回车产生的标签
config.enterMode = CKEDITOR.ENTER_P; //可选:CKEDITOR.ENTER_BR或CKEDITOR.ENTER_DIV
//是否使用HTML实体进行输出 plugins/entities/plugin.js
config.entities = true;
//定义更多的实体 plugins/entities/plugin.js
config.entities_additional = '#39'; //其中#代替了&
//是否转换一些难以显示的字符为相应的HTML字符 plugins/entities/plugin.js
config.entities_greek = true;
//是否转换一些拉丁字符为HTML plugins/entities/plugin.js
config.entities_latin = true;
//是否转换一些特殊字符为ASCII字符 如"This is Chinese: 汉语."转换为"This is Chinese: 汉语." plugins/entities/plugin.js
config.entities_processNumerical = false;
//添加新组件
config.extraPlugins = 'myplugin'; //非默认 仅示例
//使用搜索时的高亮色 plugins/find/plugin.js
config.find_highlight = {
element : 'span',
styles : { 'background-color' : '#ff0', 'color' : '#00f' }
};
//默认的字体名 plugins/font/plugin.js
config.font_defaultLabel = 'Arial';
//字体编辑时的字符集 可以添加常用的中文字符:宋体、楷体、黑体等 plugins/font/plugin.js
config.font_names = 'Arial;Times New Roman;Verdana';
//文字的默认式样 plugins/font/plugin.js
config.font_style = {
element : 'span',
styles : { 'font-family' : '#(family)' },
overrides : [ { element : 'font', attributes : { 'face' : null } } ]
};
//字体默认大小 plugins/font/plugin.js
config.fontSize_defaultLabel = '12px';
//字体编辑时可选的字体大小 plugins/font/plugin.js
config.fontSize_sizes ='8/8px;9/9px;10/10px;11/11px;12/12px;14/14px;16/16px;18/18px;20/20px;22/22px;24/24px;26/26px;28/28px;36/36px;48/48px;72/72px'
//设置字体大小时 使用的式样 plugins/font/plugin.js
config.fontSize_style = {
element : 'span',
styles : { 'font-size' : '#(size)' },
overrides : [ { element : 'font', attributes : { 'size' : null } } ]
};
//是否强制复制来的内容去除格式 plugins/pastetext/plugin.js
config.forcePasteAsPlainText =false //不去除
//是否强制用“&”来代替“&”plugins/htmldataprocessor/plugin.js
config.forceSimpleAmpersand = false;
//对address标签进行格式化 plugins/format/plugin.js
config.format_address = { element : 'address', attributes : { class : 'styledAddress' } };
//对DIV标签自动进行格式化 plugins/format/plugin.js
config.format_div = { element : 'div', attributes : { class : 'normalDiv' } };
//对H1标签自动进行格式化 plugins/format/plugin.js
config.format_h1 = { element : 'h1', attributes : { class : 'contentTitle1' } };
//对H2标签自动进行格式化 plugins/format/plugin.js
config.format_h2 = { element : 'h2', attributes : { class : 'contentTitle2' } };
//对H3标签自动进行格式化 plugins/format/plugin.js
config.format_h1 = { element : 'h3', attributes : { class : 'contentTitle3' } };
//对H4标签自动进行格式化 plugins/format/plugin.js
config.format_h1 = { element : 'h4', attributes : { class : 'contentTitle4' } };
//对H5标签自动进行格式化 plugins/format/plugin.js
config.format_h1 = { element : 'h5', attributes : { class : 'contentTitle5' } };
//对H6标签自动进行格式化 plugins/format/plugin.js
config.format_h1 = { element : 'h6', attributes : { class : 'contentTitle6' } };
//对P标签自动进行格式化 plugins/format/plugin.js
config.format_p = { element : 'p', attributes : { class : 'normalPara' } };
//对PRE标签自动进行格式化 plugins/format/plugin.js
config.format_pre = { element : 'pre', attributes : { class : 'co de' } };
//用分号分隔的标签名字 在工具栏上显示 plugins/format/plugin.js
config.format_tags = 'p;h1;h2;h3;h4;h5;h6;pre;address;div';
//是否使用完整的html编辑模式 如使用,其源码将包含:<html><body></body></html>等标签
config.fullPage = false;
//是否忽略段落中的空字符 若不忽略 则字符将以“”表示 plugins/wysiwygarea/plugin.js
config.ignoreEmptyParagraph = true;
//在清除图片属性框中的链接属性时 是否同时清除两边的<a>标签 plugins/image/plugin.js
config.image_removeLinkByEmptyURL = true;
//一组用逗号分隔的标签名称,显示在左下角的层次嵌套中 plugins/menu/plugin.js.
config.menu_groups ='clipboard,form,tablecell,tablecellproperties,tablerow,tablecolumn,table,anchor,link,image,flash,checkbox,radio,textfield,hiddenfield,imagebutton,button,select,textarea';
//显示子菜单时的延迟,单位:ms plugins/menu/plugin.js
config.menu_subMenuDelay = 400;
//当执行“新建”命令时,编辑器中的内容 plugins/newpage/plugin.js
config.newpage_html = '';
//当从word里复制文字进来时,是否进行文字的格式化去除 plugins/pastefromword/plugin.js
config.pasteFromWordIgnoreFontFace = true; //默认为忽略格式
//是否使用<h1><h2>等标签修饰或者代替从word文档中粘贴过来的内容 plugins/pastefromword/plugin.js
config.pasteFromWordKeepsStructure = false;
//从word中粘贴内容时是否移除格式 plugins/pastefromword/plugin.js
config.pasteFromWordRemoveStyle = false;
//对应后台语言的类型来对输出的HTML内容进行格式化,默认为空
config.protectedSource.push( /<\?[\s\S]*?\?>/g ); // PHP Co de
config.protectedSource.push( //g ); // ASP Co de
config.protectedSource.push( /(]+>[\s|\S]*?<\/asp:[^\>]+>)|(]+\/>)/gi ); // ASP.Net Co de
//当输入:shift+Enter时插入的标签
config.shiftEnterMode = CKEDITOR.ENTER_P; //可选:CKEDITOR.ENTER_BR或CKEDITOR.ENTER_DIV
//可选的表情替代字符 plugins/smiley/plugin.js.
config.smiley_descriptions = [
':)', ':(', ';)', ':D', ':/', ':P',
'', '', '', '', '', '',
'', ';(', '', '', '', '',
'', ':kiss', '' ];
//对应的表情图片 plugins/smiley/plugin.js
config.smiley_images = [
'regular_smile.gif','sad_smile.gif','wink_smile.gif','teeth_smile.gif','confused_smile.gif','tounge_smile.gif',
'embaressed_smile.gif','omg_smile.gif','whatchutalkingabout_smile.gif','angry_smile.gif','angel_smile.gif','shades_smile.gif',
'devil_smile.gif','cry_smile.gif','lightbulb.gif','thumbs_down.gif','thumbs_up.gif','heart.gif',
'broken_heart.gif','kiss.gif','envelope.gif'];
//表情的地址 plugins/smiley/plugin.js
config.smiley_path = 'plugins/smiley/images/';
//页面载入时,编辑框是否立即获得焦点 plugins/editingblock/plugin.js plugins/editingblock/plugin.js.
config.startupFocus = false;
//载入时,以何种方式编辑 源码和所见即所得 "source"和"wysiwyg" plugins/editingblock/plugin.js.
config.startupMode ='wysiwyg';
//载入时,是否显示框体的边框 plugins/showblocks/plugin.js
config.startupOutlineBlocks = false;
//是否载入样式文件 plugins/stylescombo/plugin.js.
config.stylesCombo_stylesSet = 'default';
//以下为可选
config.stylesCombo_stylesSet = 'mystyles';
config.stylesCombo_stylesSet = 'mystyles:/editorstyles/styles.js';
config.stylesCombo_stylesSet = 'mystyles:http://www.example.com/editorstyles/styles.js';
//起始的索引值
config.tabIndex = 0;
//当用户键入TAB时,编辑器走过的空格数,( ) 当值为0时,焦点将移出编辑框 plugins/tab/plugin.js
config.tabSpaces = 0;
//默认使用的模板 plugins/templates/plugin.js.
config.templates = 'default';
//用逗号分隔的模板文件plugins/templates/plugin.js.
config.templates_files = [ 'plugins/templates/templates/default.js' ]
//当使用模板时,“编辑内容将被替换”框是否选中 plugins/templates/plugin.js
config.templates_replaceContent = true;
//主题
config.theme = 'default';
//撤销的记录步数 plugins/undo/plugin.js
config.undoStackSize =20;
// 在 CKEditor 中集成 CKFinder,注意 ckfinder 的路径选择要正确。
//CKFinder.SetupCKEditor(null, '/ckfinder/');
二、 一些使用技巧
1、在页面中即时设置编辑器
<script type="text/javas cript">
//示例1:设置工具栏为基本工具栏,高度为70
CKEDITOR.replace('<%=tbLink.ClientID.Replace("_","$") %>',
{ toolbar:'Basic', height:70 });
//示例2:工具栏为自定义类型
CKEDITOR.replace( 'editor1',
{
toolbar :
[
//加粗 斜体, 下划线 穿过线 下标字 上标字
['Bold','Italic','Underline','Strike','Subscript','Superscript'],
//数字列表 实体列表 减小缩进 增大缩进
['NumberedList','BulletedList','-','Outdent','Indent'],
//左对齐 居中对齐 右对齐 两端对齐
['JustifyLeft','JustifyCenter','JustifyRight','JustifyBlock'],
//超链接 取消超链接 锚点
['Link','Unlink','Anchor'],
//图片 flash 表格 水平线 表情 特殊字符 分页符
['Image','Flash','Table','HorizontalRule','Smiley','SpecialChar','PageBreak'],
'/',
//样式 格式 字体 字体大小
['Styles','Format','Font','FontSize'],
//文本颜色 背景颜色
['TextColor','BGColor'],
//全屏 显示区块
['Maximize', 'ShowBlocks','-']
]
}
);
</script>
三、精简ckeditor
在部署到Web服务器上时,下列文件夹和文件都可以删除:
/_samples :示例文件夹;
/_source :未压缩源程序;
/lang文件夹下除 zh-cn.js、en.js 以外的文件(也可以根据需要保留其他语言文件);
根目录下的 changes.html(更新列表),install.html(安装指向),license.html(使用许可);
iframe去除边框
<iframe name="file_frame" src="UploadFile.jsp" frameborder=no border=0 marginwidth=0 marginheight=0 scrolling=no></iframe>
iframe元素的功能是在一个文档里内嵌一个文档,创建一个浮动的帧。iframe参数列表
name:内嵌帧名称
width:内嵌帧宽度(可用像素值或百分比)
height:内嵌帧高度(可用像素值或百分比)
frameborder:内嵌帧边框 是否显示边缘;填”1″表示”是”,填”0″表示”否”
marginwidth:帧内文本的左右页边距
marginheight:帧内文本的上下页边距
scrolling:是否出现滚动条(“auto”为自动,“yes”为显示,“no”为不显示)
src:内嵌入文件的地址
style:内嵌文档的样式(如设置文档背景等)
allowtransparency:是否允许透明
(1)session过期后登陆页面跳出iframe页面问题
登陆页面增加javascript:
function window.onload()
{
if(window.parent.length>0)
window.parent.location=location;
}
或者:
<script>
if (window != top)
top.location.href = location.href;
</script>
(2)自动跳出iframe的代码
<script type="text/javascript">
if (top.location !== self.location) {
top.location=self.location;
}
</script>
(3)在框架页内的退出操作:
<script type="text/javascript">
if (top.location !== self.location) {
top.location = "../index.jsp";//跳出框架,并回到首页
}
</script>

symfony
简单的模板功能symfony是一个开源的PHP Web框架。基于最佳Web开发实践,已经有多个网站完全采用此框架开发,symfony的目的是加速Web应用的创建与维护。它的特点如下:缓存管理 、自定义URLs、搭建了一些基础模块、多语言与I18N支持、采用对象模型与MVC分离、Ajax支持、适用于企业应用开发。
【项目主页】【CODE托管地址】【查看教程及示例】

CodeIgniter
CodeIgniter 是一个简单快速的PHP MVC 框架。它为组织提供了足够的自由支持,允许开发人员更迅速地工作。使用 CodeIgniter 时,您不必以某种方式命名数据库表,也不必根据表命名模型。这使 CodeIgniter 成为重构遗留 PHP 应用程序的理想选择,在此类遗留应用程序中,可能存在需要移植的所有奇怪的结构。
【项目主页】【CODE托管地址】【查看教程及示例】

Laravel
Laravel 是一个简单优雅的 PHP web 开发框架,将你从意大利面条式的代码中解放出来。通过简单的、表达式语法开发出很棒的 Web 应用。
【项目主页】【CODE托管地址】【查看教程及示例】

CakePHP
CakePHP是一个运用了诸如ActiveRecord、Association Data Mapping、Front Controller和MVC等著名设计模式的快速开发框架。该项目主要目标是提供一个可以让各种层次的PHP开发人员快速地开发出健壮的Web应用,而 又不失灵活性。
【项目主页】【CODE托管地址】【查看教程及示例】

Yii
Yii是一个高性能的PHP5的web应用程序开发框架。通过一个简单的命令行工具 yiic 可以快速创建一个web应用程序的代码框架,开发者可以在生成的代码框架基础上添加业务逻辑,以快速完成应用程序的开发。
【项目主页】【CODE托管地址】【查看教程及示例】

PHPUnit
PHPUnit是一个轻量级的PHP测试框架。它是在PHP5下面对JUnit3系列版本的完整移植。这个工具也可以被Xdebug扩展用来生成代码覆盖率报告 ,并且可以与phing集成来自动测试,最合它还可以和Selenium整合来完成大型的自动化集成测试。
【项目主页】【CODE托管地址】【查看教程及示例】

SlimFramework
这是一个简单的 PHP5 框架用来创建 RESTful 的 Web 应用。可以帮助你快速编写简单功能强大的 RESTful 风格的web应用程序 和APIs。Slim很简单,可以让新手和专业人士使用。
【项目主页】【CODE托管地址】【查看教程及示例】

PHP Silex
Symfony团队出品的php5.3微框架, 可大量复用Symfony2组件。Silex是Symfony 2的简化版本,比大多数PHP框架更适合开发简单应用。
【项目主页】【CODE托管地址】【查看教程及示例】

FuelPHP
FuelPHP 是一个简单、灵活的 PHP 5.3 的 Web 框架,其思路结合了来自主流框架的优点。
【项目主页】【代码托管地址】【查看教程及示例】

ThinkPHP
ThinkPHP是一个快速、简单、面向对象的轻量级PHP开发框架,遵循Apache2协议,为了敏捷Web应用开发和简化企业应用开发而诞生。
【项目主页】【CODE托管地址】【查看教程及示例】
目前 ZenCart 最新版本是 1.5.1,在 1.5 版本后,ZenCart 就多了一项密码保护功能,后台的密码只能使用 90 天,90 天后自动过期。
这是强制人家修改密码,我觉得这功能有点鸡肋,而且很添乱,会修改密码的会很神经质的经常修改,像我这样不修改密码的,都是可悲的什么时候过期都忘记了,最最郁闷的是,它的数据库中的 md5 密码还加后缀,不是随便复制个通用的密码就可以用,所以每次我只能看着后台那个简陋的登陆界面抓耳挠腮。
今天已经是第三次遇到这个问题了,于是我决定把方法记录下来。
方法还是复制通用的密码的 MD5 格式,官方提供的。进入 phpMyAdmin,在对应的数据库下运行下面的 SQL 语句:
DELETE FROM admin WHERE admin_name = 'Admin';
INSERT INTO admin (admin_name, admin_email, admin_pass, admin_profile)
VALUES ('Admin', 'admin@localhost', '351683ea4e19efe34874b501fdbf9792:9b', 1);
如果你后台登陆名不是 Admin,那就得改成你的登录名,邮箱当然也要改。这个通用密码直接复制是不行的,必须清空整个 admin 项后再写入才有效。哦,对了,这个通用密码是:admin。
修改后用密码 admin 登陆后会提示你修改密码,当然,修改后的密码仍然是90天有效。
那有没有办法去掉这个 1.5 版本后的 ZenCart 这个 90 天的密码设定呢?老外提供了个办法,不知道管用不管用。
方法一:找到 admin/login.php 文件内的 define('ADMIN_PASSWORD_EXPIRES_INTERVAL', strtotime('- 90 day'));,把里面的 90 改成大大的数字,比如 36500 ,嗯,100年应该够了。
方法二:找到 admin/includes/functions/admin_access.php 文件内的 zen_check_for_password_problems() 函数,在函数下的第一行插入 return FALSE;
方法三:也是在方法二的这个文件里,修改某个函数里的天数,像方法一那样改的无限大,不过都没经过测试,就不要发了,还是用数据库修改法吧。
后面的三种方法你如果想测试,最后搞个 DEMO 站测试,因为老外是这么提示的,好像很严重的样子,英文我看不懂,但或许你懂得:
*** Warning: This change will violate the PCI status of your cart. You should only do this on test carts on your own PC or on carts which do not require PCI certification. ***
网友安装的时候,最长遇到的就是PHP curl函数不支持。这里有几种解决方法。
windows下开启方法:
1、拷贝PHP目录中的libeay32.dll, ssleay32.dll, php5ts.dll, php_curl.dll文件到 system32 目录。
2、修改php.ini:配置好 extension_dir ,去掉 extension = php_curl.dll 前面的分号。
3、重起apache或者IIS。
测试是否安装成功:
<?php
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL,"http://www.google.cn");
curl_setopt($ch,CURLOPT_HEADER,1);
curl_exec($ch);
curl_close($ch);
?>
linux下开启方法:
方法一
安装cURL
# wget http://curl.haxx.se/download/curl-7.17.1.tar.gz
# tar -zxf curl-7.17.1.tar.gz
# ./configure --prefix=/usr/local/curl
# make; make install
安装php
只要打开开关 --with-curl=/usr/local/curl
就可以了。
这个扩展库还是非常棒,是fsockopen等等相关的有效的替代品。
方法二
进入安装 原php 的源码目录,
cd ext
cd curl
phpize
./configure --with-curl =DIR
make
就会在PHPDIR/ext/curl /moudles/下生成curl .so的文件。
复制curl .so文件到extensions的配置目录,修改php .ini就好了
<?
//获取当前的域名:
echo $_SERVER['SERVER_NAME'];
//获取来源网址,即点击来到本页的上页网址
echo $_SERVER["HTTP_REFERER"];
$_SERVER['REQUEST_URI'];//获取当前域名的后缀
$_SERVER['HTTP_HOST'];//获取当前域名
dirname(__FILE__);//获取当前文件的物理路径
dirname(__FILE__)."/../";//获取当前文件的上一级物理路径
?>
Shadow Security Scanner v 网络入侵机_V2.0 波尔远程控制V6.32 VIP破解版
superscan4.0扫描器 HttpsMimTools nohackasp木马生成器
拿站和思路 Oracle_专用注射器 远程控制软件ntshell v1.0(开源
挖掘鸡4.02 Willcome急速批量抓鸡全能 PcShare远程控制软件
多功能S扫描器 php168漏洞利用工具 中华经典网络军刀NC
小马上线及绑困和抓鸡 iebho攻击程序 终极Rootkit
超详细讲解鸽子上线 QQEAMIL攻击器 PHP木马修改增强版
金豹多顶下载者 framework-2.6-snapshot 提权工具集
EditPlus v2.31 Buil
最新过XP2网马
剑煞BetaV7.6.8
扫描端口V2.0
X-way扫描器
SpyNet Sniffer
网站猎手2.0
X-Scan-v3.3
流光5.0黑客基地专用破解版
NBSI网站漏洞检测工具
明小子旁注工具3.5
端口过滤扫描器
mysql_pwd_crack
Advanced IP Scanner v1.5
IPScanner
扫描软件THC-Amap v5.0
php注入辅助工具:phpsend
PackInter,sniffer工具含源代码
X-Scan-v3.2-cn
X-Scan-v3.2-beta版
超级扫描工具:nmap-3.81-win32
流光 5.0 时间限制破解
Domain3.2正式版(5.2修正)
sql扫描加自动攻击工具:Sqlpoke
THC-Amap v4.8
mysql字段扫描:numscan
第一款php漏洞扫描器:rpvs
Oscanner
端口扫描器红魂专用版
atk-3.1
金山毒霸可疑文件扫描工具 v2.01
GUI界面的WED和WIS综合工具
超强adsl破解器
俄罗斯专业扫描工具SSS6.67.58破解版
Attack Toolkit 3.0
Roman ADSL帐号扫描工具升级版
针对广东电信漏洞的扫描工具
IPv4和IPv6通用扫描工具:scan6
adsl帐号扫描工具+动画
MS Webserver 漏洞扫描器
网络主机扫描(HostScan)
T-PsKit
Retina Network Security Scanner
WildPackets ProCovert
Angry IP Scanner
wlan无线网络诊断/WildPackets AiroPe
APort
铁血扫描器
无处藏身(Seekyou)
nScan
SQL Injection测试工具
FloodScan
rpcscan信息扫描工具
优秀的ShadowScan
经典扫描程序Amap
Superscan
漏洞扫描Nessus
ipc批处理扫描工具
Angry IP Scanner 汉化版
强大的漏洞扫描NessusWX
WindowsNT/2000自动攻击探测机
网络黑客控制中心使用教程+工具
扫描工具SuperScan4
NMap最新版本:nmap-3.70-win32
Retina DCOM Scanner
SQLScan
很好的扫描工具 NetScanTools
ipc扫描工具scanipc
非常有名的扫描 工具X-way
流光 for win98/ME
最好的ipc$扫描essential nettools
不错的扫描工具easyscan
鼎鼎大名的扫描工具 流光
大范围网段快速ipc$猜解机ipscan
N.E.W.T.网络扫描器
端口扫描A Complete Subnet Scanner
自动攻击探测机
扫描工具:Vsan
IIS漏洞扫描Easyscan
高速端口扫描Bluesportscanner
扫描工具X-port
最好的扫描器:X-SAN 3.0 beta
扫描工具:STAT Scanner Pro
阿拉丁扫描器
小巧的黑客工具:NBTScan
非常优秀的扫描工具X-scan 2.3
扫描工具IPScanner
扫描工具Dsns
著名的且功能强大的WEB扫描工具Wnikto32
小巧的端口扫描NetBurn
扫描工具GFI LANguard Scanner
不错的扫描工具:Scan
中华经典网络军刀
优秀的扫描工具Nmap命令行版本
多线程扫描XPortScan
专业的扫描工具Shadow Security Scanner
ASP漏洞集
扫描工具Retina Network Security Scann
快速端口扫描Shadowscan
优秀的WEB扫描工具Nikto
扫描Shadow Security Scanner v6.6.41
SuperScan V4.0汉化版
极为优秀的Shadow Security Scanner
基于命令行下的RPC扫描器
多线程扫描SinScan
局域网扫描大师 V1.0
推荐:免费短信发送工具
IP端口扫描软件
最新漏洞扫描器MS05051Scan
推荐:图形界面的NMAP扫描器
dcomrpc漏洞X-Scan23插件
啊D网络工具包2.专用免杀版
极速漏洞扫描攻击器[升级版]
猎手-旁注工具
黑客基地专用极速漏洞扫描器
X-Scan v3.3
超强扫描器:NMAP 3.90
IP地址扫描器
地址分类搜索机
多线程后台扫描器
超强扫描器superscan4.0
nmap-3.81源代码(Linux平台)
nmap-3.81源代码(FreeBSD平台)
X-Scan-v3.3
mysql弱口令扫描工具:mysqlweak
DFind_v0.83扫描工具
MySql Weak Pass Scanner
Cain & Abel v2.68 for Win
阿D工具包2.01
HScan v1.20
动网大扫描
多线程网站后台扫描工具
MS06040漏洞扫描器
挖掘鸡v3.5
BluesPortScan超快的端口扫描工具
动网大扫描 1.0测试版
啊D网络工具包2.1免杀版
sql注入中文转换器
明小子Domain3.6
guastbook漏洞利用
德国的SQL注射工具
流光FluXay 5 闪亮发布!
注入攻击综合软件包
BBSXP论坛漏洞完全注射工具
MS06007漏洞扫描器
高速扫描:风雪端口扫描器
动易2005 sp2漏洞利用工具
webhacking-WEB渗透超级助手
简洁高速的扫描器:HScan
BBS论坛群发机 破解版
mssql注射辅助工具-getwebsehll
软件名称超级扫描器nmap-4.00
挖掘鸡 V2.2
啊D注入工具 V2.32 免杀版
SQL注射综合程序
扫描器IPtools2.5破解版
SSPort高速端口扫描器 V1.0
局域网查看工具V1.60
NCPH影子扫描器
目前最完美的注入工具
IP物理地址探测器
网站猎手
网络端口扫描工具
震荡波扫描工具:Sasser Scanner
MS04-011漏洞扫描器RetinaSasser
SQL跨库查询动画教程
命令行下NohackerScanner扫描器
IP扫描IPScanner 1.79中文破解版
嗅探监听:局域网密码查看工具1.46
经典工具:X-Scan-v3.1
监听工具:PromiScan v3.0
扫描工具:FtpList 1.13
经典漏洞扫描:X-Scan v3.0
扫描工具:Remoxec
数据扫描工具:Oracle Auditing Tools
Web漏洞扫描工具Trapserver
著名的漏洞扫描:SSS
扫描工具:RpcScan v1.1.1
经典的扫描工具:nmap 3.50
漏洞扫描:GFI LANguard Scanner
小巧的IPC扫描工具
CC6.0扫描程序
nmap 3.75 for win
rootkit扫描工具:Rkdscan
动画教程:JOEKOE留言本漏洞
NBWS网站后台路径猜测工具
web路径猜解工具:ScanWebPath
未公布的动力系统漏洞演示
SQL扫描工具:SQL ping
IIS权限探测:IIS Write Scanner V1.0
扫描软件SImpsons'CGI Scanner及使用教程
LANguard Network Security Scanner 5.0
加密工具:Morphine v1.3+GUI
DFind v0.8
L-ScanPort2.0
扫描工具:Scanner
X-Scan-v3.1-cn
Advanced IP Scanner V1.4 汉化版
飞狐-网络扫描工具试用版
Linux/UNIX扫描软件:XTHC-Amap v4.6
动画教程:动力破解任何收费漏洞
动画教程:'or''='漏洞最新演示
天意阿里巴巴企业商务网V3.7上传漏洞
代理猎手获取ADSL帐号冲Q币
扫描器:nessuswx-1.4.4-install
IP扫描软件:Angry IP Scanner
端口/漏洞/组件扫描工具:DFind v0.6
可获取Web Server类型的端口扫描器
135端口扫描器RpcScan v1.2.1
4899空口令探测器
经典工具:namp v3.50 命令行版
猜解后台路径工具
流光5.0黑客基地专用破解版
免验证版NBSI(附加扫描器)
U-scan(UNICODE漏洞扫描器)
自定义多线程后台扫描程序:ScanLogin
75款全球强劲工具大集合之一 Nessus
75款全球强劲工具大集合之二 NessusWX
Accessdiver 汉化版+使用教程
优秀的X-way
75款全球强劲工具大集合之十八SuperScan
75款全球强劲工具大集合之十六Nikto
75款全球强劲工具大集合之十一Libwhisker
75款全球强劲工具大集合之十二JOHN16
75款全球强劲工具大集合之十二John
75款全球强劲工具大集合之十三SSH
75款全球强劲工具大集合之十五Tripwire
最快的端口扫描工具
高速端口扫描PortScanner源代码
ScanMs Tool
PHP扫描器
注:我的运行环境是widnows xp professional + MySQL5.0
一, 创建用户:
命令:CREATE USER 'username'@'host' IDENTIFIED BY 'password';
说 明:username - 你将创建的用户名, host - 指定该用户在哪个主机上可以登陆,如果是本地用户可用localhost, 如果想让该用户可以从任意远程主机登陆,可以使用通配符%. password - 该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器.
例子: CREATE USER 'dog'@'localhost' IDENTIFIED BY '123456';
CREATE USER 'pig'@'192.168.1.101_' IDENDIFIED BY '123456';
CREATE USER 'pig'@'%' IDENTIFIED BY '123456';
CREATE USER 'pig'@'%' IDENTIFIED BY '';
CREATE USER 'pig'@'%';
二,授权:
命令:GRANT privileges ON databasename.tablename TO 'username'@'host'
说 明: privileges - 用户的操作权限,如SELECT , INSERT , UPDATE 等(详细列表见该文最后面).如果要授予所的权限则使用ALL.;databasename - 数据库名,tablename-表名,如果要授予该用户对所有数据库和表的相应操作权限则可用*表示, 如*.*.
例子: GRANT SELECT, INSERT ON test.user TO 'pig'@'%';
GRANT ALL ON *.* TO 'pig'@'%';
注意:用以上命令授权的用户不能给其它用户授权,如果想让该用户可以授权,用以下命令:
GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTION;
三.设置与更改用户密码
命令:SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword');如果是当前登陆用户用SET PASSWORD = PASSWORD("newpassword");
例子: SET PASSWORD FOR 'pig'@'%' = PASSWORD("123456");
四.撤销用户权限
命令: REVOKE privilege ON databasename.tablename FROM 'username'@'host';
说明: privilege, databasename, tablename - 同授权部分.
例子: REVOKE SELECT ON *.* FROM 'pig'@'%';
注 意: 假如你在给用户'pig'@'%'授权的时候是这样的(或类似的):GRANT SELECT ON test.user TO 'pig'@'%', 则在使用REVOKE SELECT ON *.* FROM 'pig'@'%';命令并不能撤销该用户对test数据库中user表的SELECT 操作.相反,如果授权使用的是GRANT SELECT ON *.* TO 'pig'@'%';则REVOKE SELECT ON test.user FROM 'pig'@'%';命令也不能撤销该用户对test数据库中user表的Select 权限.
具体信息可以用命令SHOW GRANTS FOR 'pig'@'%'; 查看.
五.删除用户
命令: DROP USER 'username'@'host';
附表:在MySQL中的操作权限
| ALTER | Allows use of ALTER TABLE. |
| ALTER ROUTINE | Alters or drops stored routines. |
| CREATE | Allows use of CREATE TABLE. |
| CREATE ROUTINE | Creates stored routines. |
| CREATE TEMPORARY TABLE | Allows use of CREATE TEMPORARY TABLE. |
| CREATE USER | Allows use of CREATE USER, DROP USER, RENAME USER, and REVOKE ALL PRIVILEGES. |
| CREATE VIEW | Allows use of CREATE VIEW. |
| DELETE | Allows use of DELETE. |
| DROP | Allows use of DROP TABLE. |
| EXECUTE | Allows the user to run stored routines. |
| FILE | Allows use of SELECT... INTO OUTFILE and LOAD DATA INFILE. |
| INDEX | Allows use of CREATE INDEX and DROP INDEX. |
| INSERT | Allows use of INSERT. |
| LOCK TABLES | Allows use of LOCK TABLES on tables for which the user also has SELECT privileges. |
| PROCESS | Allows use of SHOW FULL PROCESSLIST. |
| RELOAD | Allows use of FLUSH. |
| REPLICATION | Allows the user to ask where slave or master |
| CLIENT | servers are. |
| REPLICATION SLAVE | Needed for replication slaves. |
| SELECT | Allows use of SELECT. |
| SHOW DATABASES | Allows use of SHOW DATABASES. |
| SHOW VIEW | Allows use of SHOW CREATE VIEW. |
| SHUTDOWN | Allows use of mysqladmin shutdown. |
| SUPER | Allows use of CHANGE MASTER, KILL, PURGE MASTER LOGS, and SET GLOBAL SQL statements. Allows mysqladmin debug command. Allows one extra connection to be made if maximum connections are reached. |
| UPDATE | Allows use of UPDATE. |
| USAGE | Allows connection without any specific privileges. |
思维导图
点击图片,可查看大图。
介绍
情况:如果你的表结构设计不良或你的索引设计不佳,那么请你优化你的表结构设计和给予合适的索引,这样你的查询性能就能提高几个数量级。——数据越大,索引的价值越能体现出来。
我们要提高性能,需要考虑的因素:
今天要讲的是表列的设计,暂不谈索引设计。我会在下一章讲索引设计。
选择数据类型
选择正确的数据类型,对于提高性能至关重要。
下面给出几种原则,有利于帮助你选择何种类型。
1、更小通常更好。
使用最小的数据类型。——更少的磁盘空间,内存和CPU缓存。而且需要的CPU的周期也更少。
2、简单就好。
整数代价小于字符。——因为字符集和排序规则使字符比较更复杂。
1>mysql内建类型(如timestamp,date)优于使用字符串保存。
2>使用整数保存ip地址。
3、尽量避免NULL——如果计划对列进行索引,尽量避免把列设置为NULL
尽可能把字段定义为NOT NULL。——可以放置一个默认值,如‘',0,特殊字符串。
原因:
(1)MYSQL难以优化NULL列。NULL列会使索引,索引统计和值更加复杂。
(2)NULL列需要更多的存储空间,还需要在MYSQL内部进行特殊处理。
(3)NULL列加索引,每条记录都需要一个额外的字节,还导致MyISAM中固定大小的索引变成可变大小的索引。
决定列的数据类型,我们应该遵循下面两步。
第一步、大致决定数据类型。——判断是数字,字符串还是时间等。这通常很直观。
第二步、确定特定的类型。
很多数据类型能够保存同类型的数据,但是我们要发现,他们在存储的范围,精度和物理空间之间的差别(磁盘或内存空间)。如:datetime和timestamp能保存同样类型的数据:日期和时间。——timestamp使用datetime一半的空间;能保存时区;拥有特殊的自动更新能力。

品味数据类型
整数
1、存储类型——数据范围为-2^(n-1)到2^(n-1)-1,这里的n是所需存储空间的位数。
类型名称 占用位数 数据范围 TINYINT 8 -2^7 ~ 2^7-1 SMALLINT 16 -2^15~2^15-1 MEDIUMINT 24 -2^23~2^23-1 INT 32 -2^31~2^23-1 BIGINT 64 -2^63~2^63-1
2、unsigned属性表示不允许负数,并大致把正上限提高了一倍。如TINYINT UNSIGNED保存的范围为0到255而不是-127到128
3、MYSQL对整数类型定义宽度,比如int(1)和int(22)对于存储和计算是一样的。只规定了MYSQL的交互工具(如命令行客户端)用来显示字符的个数。

实数
实数有分数部分(小数部分)。
存储类型:FLOAT和DOUBLE,DECIMAL。
占用大小:FLOAT 4个字节,DOUBLE 8个字节。DECIMAL受到MYSQL版本影响,早期版本254个数字,5.0以上65个数字。
区别:1、FLOAT和DOUBLE支持标准浮点运算进行近似计算。
2、DECIMAL进行DECIMAL运算,CPU并不支持对它进行直接计算。浮点运算会快一点,因为计算直接在CPU上进行。
3、DECIMAL只是一个存储格式,在计算时会被转换为DOUBLE类型。
4、DECIMAL(18,9)使用9个字节,小数点前4个字节,小数点1个字节,小数点后4个字节。
5、DECIMAL只有对小数进行精确计算的时候才使用它,如保存金融数据。

字符串类型
1、varchar
(1)保存可变长字符串。
理解:比固定长度占用更少的存储空间,因为它只占用自己需要的空间。例外情况:使用ROW_FORMAT=FIXED创建的MyISAM表,它为每行使用固定长度的空间,可能会造成浪费。
(2)存储长度信息。如果定义的列小于或等于255,则使用1个字节存储长度值,假设使用latin1字符集,如varchar(10)将占用11个字节的存储空间。反过来,varchar(1000),则占用1002个字节的存储空间。
(3)节约空间,对性能有帮助。
(4)5.0版本以上,无论是取值还是保存,MySQL都会保留字符串末尾的空格。
只分配真正需要的空间
使用varchar(5)和varchar(200)保存'hello'占用空间是一样的。——这里应该指的是磁盘上的空间。
那么使用较短列有何优势?——巨大的优势
较大的列会使用更多的内存,因为MySQL通常会分配固定大小的内存块(如varchar(200)会用200个字符大小的内存空间)来保存值(然后对值进行trim操作,最后放入磁盘)或取值。——这对排序或使用基于内存的临时表尤其不好。
2、char
(1)固定长度。
(2)保存值时,去掉末尾的空格。
(3)char常用于很短字符串或长度近似相同的字符串的时候很有用。如存储用户密码的MD5哈希值,它的长度总是一样的。
char优于varchar的地方?
1>> 对于经常改变的值,char优于varchar,因为固定长度行不容易产生碎片。——当最长长度远大于平均长度,并且很少发生更新的时候,通常适合使用varchar。
2>>对于很短的列,char的效率也是高于varchar的。如对于单字节字符集(如latin1),char(1)只会占用1个字节,而varchar(2)会占用2个字节(有一个字节用来存储长度的信息)。
3、text
用于保存大量数据。
(1)InnoDB在它们较大的时候会使用“外部”存储区域来进行保存。——所以需要足够的外部存储空间来保存实际的值。
(2)排序方式不同于其他字符类型,不会按照完整长度进行排序,而只是按照max_sort_length规定的前若干个字节进行排序。
4、使用ENUM代替字符串类型
(1)ENUM列可以存储65 535个不同的字符串。
(2)以紧凑方式保存。根据列表中值的数量,把它们压缩到1到2个字节中。
(3)MySQL在内部把每个值都保存为整数,以表示值在列表中的位置。
(4)保留了一份“查找表”,来表示整数和字符串在表的.frm文件中的映射关系。
(5)ENUM字符列是固定的,添加、删除字符串须使用ALTER TABLE。
(6)使用案例:权限表中使用ENUM来保存Y值和N值。
使用方法:


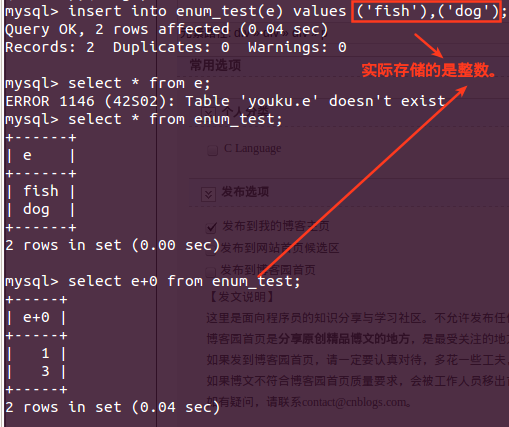
在对enum列使用order by的时候,是按数字排序的,而不是字符串排序。
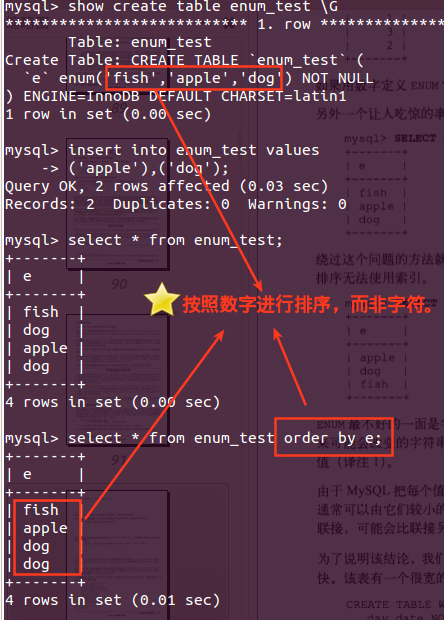
日期和时间类型
DATETIME:保存大范围的值。封装格式:YYYYMMDDHHMMSS。——与时区无关,使用8字节存储空间。
TIMESTAMP:保存自1970年1月1日午夜(格林尼治标准时间)以来的秒数。——使用4字节存储空间。
通常使用TIMESTAMP,它比DATETIME更节约空间。有时人们把Unix的时间戳保存为整数值,但是这通常没有任何好处。——这种格式处理起来不太方便,我们并不推荐它。
经验交谈
1、我们在为列选择数据类型的时候,不仅要考虑存储类型大小,还要考虑MySQL如何对它们进行计算和比较。例如:MySQL在内部把ENUM和SET类型保存为整数,但是在比较的时候把它们转换为字符串。
2、我们要在相关表中使用同样的类型,类型之间要精确匹配,包括诸如UNSIGNED这样的属性。
3、混合不同的数据类型会导致性能问题,即使没有性能问题,隐式的类型转换也能导致难以察觉的错误。
4、选择最小的数据类型要考虑将来留出的增长空间。如,中国的省份,我们知道不会有成千上万个,因此不必用INT。TINYINT就足够了,它比INT小3字节。
5、整数通常是最佳的数据类型,因为它速度快,并且能使用AUTO_INCREMENT。
6、要尽可能避免字符串做为列的数据类型,因为它们占用了很多空间并且通常必整数类型要慢。MyISAM默认情况下为字符串使用了压缩索引,这使查找更为缓慢。
where 1=1有什么用?在SQL语言中,写这么一句话就跟没写一样。
select * from table1 where 1=1与select * from table1完全没有区别,甚至还有其他许多写法,1<>2,'a'='a','a'<>'b',其目的就只有一个,where 的条件为永真,得到的结果就是未加约束条件的。
在SQL注入时会用到这个,例如select * from table1 where name='lala'给强行加上select * from table1 where name='lala' or 1=1这就又变成了无约束的查询了。
最近发现的妙用在于,在不定数量查询条件情况下,1=1可以很方便的规范语句。例如一个查询可能有name,age,height,weight约束,也可能没有,那该如何处理呢?
String sql=select * from table1 where 1=1
为什么要写多余的1=1?马上就知道了。
if(!name.equals("")){
sql=sql+"name='"+name+"'";
}
if(!age.equals("")){
sql=sql+"age'"+age+"'";
}
if(!height.equals("")){
sql=sql+"height='"+height+"'";
}
if(!weight.equals("")){
sql=sql+"weight='"+weight+"'";
}
如果不写1=1呢,那么在每一个不为空的查询条件面前,都必须判断有没有where字句,否则要在第一个出现的地方加where
where 1=1的写法是为了检化程序中对条件的检测
打个比方有三个参数a, b, c
@sql=select * from tb'
这三个参数都可能为空
这时你要构造语句的话,一个个检测再写语句就麻烦
比如
if @a is not null
@sql=@sql + " where a=' + @a
if @b is not null
这里你怎么写?要不要加where 或直接用 and ?,你这里还要对@a是否为空进行检测
用上 where 1=1 之后,就不存在这样的问题, 条件是 and 就直接and ,是or就直接接 or
拷贝表
create table_name as select * from Source_table where 1=1;
复制表结构
create table_name as select * from Source_table where 1 <> 1;
摘要: Groovy入门教程 kmyhy@126.com 2009-5-13 一、groovy是什么 简单地说,Groovy 是下一代的java语言,跟java一样,它也运行在 JVM 中。 作为跑在JVM中的另一种语言,groovy语法与 Java 语言的语法很相似。同时,Groovy 抛弃了java烦琐的文法。同样的语句,使用groovy能在最大限度上减少你的击键次数—R...
阅读全文
response.encodeRedirectURL作用
session对象能和客户建立意义对应的关系依赖于客户的浏览器是否支持cookie,如果客户的浏览器不支持的话,那么客户再不同网页之间的session对象可能时互不相同的,因为服务器无法将ID存放到客户端,就不能建立session对象和客户的一一对应关系。可以通过URL重写来实现session对象的唯一性。所谓URL重写就是当客户从一个页面重新连接到一个页面时,通过向这个新的URL添加参数,把session对象的id传过去,这样能够保证session对象是完全相同的。可以使用response对象调用encodeURL()或encodeRedirectURL()方法实现URL重写。
eg:
String str=response.encodeRedirectURL("hope.jsp");
连接目标写成:<%=str%>即可。
encodeURL()是本应用级别的,encodeRedirectURL()是跨应用的。
以下时网上搜索到的解析:
第一种解释:
作用:
Encodes the specified URL for use with redirect( ) by adding an necessary session ID.
Example
Response.redirect( Response( ).encodeRedirectURL( url ) )
第二种解释:
1.response.encodeRedirectURL(url)是一个进行URL重写的方法, 使用这个方法的作用是为了在原来的url后面追加上Jsessionid 。 目的是保证即使在客户端浏览器禁止了cookie的情况下,服务器端仍然能够对其进行事务跟踪.
2.response.sendRedirect(url) 是一个url重定向的方法, 服务器端的通过该方法,“告诉”客户端的浏览器去访问url所指向的资源
第三种解释:
对于要进行跳转时把url encode
如: response.sendRedirect(response.encodeRedirectURL("dfddf.jsp?na=上海"));
不encode时getParameter("na")是乱码
paypal集成到网站一般有两种:Website Payment Standard WPS 网站付款专业版和 Express Checkout快速结账;
但是有的用户也会问道 Website Payments Pro,这里就来给大家讲讲这三者的区别。
一、Website Payment Standard WPS(IPN)网站标准版,客户需要在网站注册才可以完成购买流程。不会在购物车显示paypal按钮。
二、Express Checkout快速结账专业版的与WPS主要区别是:check out为快速支付,在购物车页面直接显示paypal支付的按钮,可直接进入paypal页面付款,不注册成网店会员即可完成购买,但是也可以走正常的注册会员流程。
三、Website Payments Pro需要是美国的账号才可以用。且收取月服务费用。
另外美国账户在国内是无法享受客户服务和顾问服务的,一般的商家不建议使用
注意:这三个paypal只能集成其中的一个,如果同时出现多个,会导致冲突,收款出错。
一般的商家,如果有自己专业的技术团队,可选择Express Checkout,如果没有专门的技术维护,建议选择WPS.
众所周知,对于链接和图片,我们可以通过添加title属性以显示一些说明文字,一般情况下,这些文字都是显示成一行,那么有没有办法让它以多行的方式显示呢?解决的方法有两种:
1.将title属性分成几行来写,例如:
<a href=#" title="说明一
说明二
说明三">印象派</a>
2.第一行相对来说不够直观,我们还可以在需换行的地方添加
(将&改为半角,下同)或
来实现:
<a href=#" title="说明一
说明二
说明三">印象派</a>
<a href=#" title="说明一
说明二
说明三">印象派</a>
==================
response.write " title='标 题:" & rsArticleList("Title") & vbcrlf & "作 者:" & rsArticleList("Author") & vbcrlf & "转 贴 自:" & rsArticleList("CopyFrom") & vbcrlf & "更新时间:" & rsArticleList("UpdateTime") & vbcrlf
response.write "点 击 数:" & rsArticleList("Hits") & vbcrlf & "关 键 字:" & mid(rsArticleList("Key"),2,len(rsArticleList("Key"))-2) & vbcrlf & "推荐等级:"
直接换行就可以
=======================
<a href='http://www.updateweb.cn' target='_ablank' title='标 题:更新网络
作 者:Sundy
转 贴 自:本站原创
更新时间:2008-6-6 10:31:00
点 击 数:0
关 键 字:更新网络
推荐等级:无
分页方式:不分页
阅读等级:游客
阅读点数:0'>更新网络</a>
<div title="123"
456">text</div>
<p><a href=#" title="说明一
说明二
说明三">印象派</a>
<a href=#" title="说明一
说明二
说明三">印象派</a></p>
===========================
function decodeHTML(fString)
if not isnull(fString) then
fString = replace(fString, ">", ">")
fString = replace(fString, "<", "<")
fString = Replace(fString, " ", CHR(32))
fString = Replace(fString, " ", CHR(9))
fString = Replace(fString, """, CHR(34))
fString = Replace(fString, CHR(39),"'")
fString = Replace(fString, "</P><P> ",CHR(10) & CHR(10))
fString = Replace(fString, "<BR> ", CHR(10))
decodeHTML = fString
end if
end function
function encodeHtml()
替换成unicode字符就可以
摘要: 一:PHP本身的SOAP所有的webservice都包括服务端(server)和客户端(client)。要使用php本身的soap首先要把该拓展安装好并且启用。下面看具体的code首先这是服务端实现:PHP Code复制内容到剪贴板<?php class test { &nb...
阅读全文
function get_client_ip() {
if(getenv('HTTP_CLIENT_IP')){
$client_ip = getenv('HTTP_CLIENT_IP');
} elseif(getenv('HTTP_X_FORWARDED_FOR')) {
$client_ip = getenv('HTTP_X_FORWARDED_FOR');
} elseif(getenv('REMOTE_ADDR')) {
$client_ip = getenv('REMOTE_ADDR');
} else {
$client_ip = $_SERVER['REMOTE_ADDR'];
}
return $client_ip;
}
获取服务器端IP地址
function get_server_ip() {
if (isset($_SERVER)) {
if($_SERVER['SERVER_ADDR']) {
$server_ip = $_SERVER['SERVER_ADDR'];
} else {
$server_ip = $_SERVER['LOCAL_ADDR'];
}
} else {
$server_ip = getenv('SERVER_ADDR');
}
return $server_ip;
}
如何让自己在面试中脱颖而出,给招聘人员留下深刻的影响,想必很多求职者都想过这类问题?本文作者通过对国外大中小的面试调查,发现他们看重面试者以下技能:定量分析、Excel、创造性思维、沟通能力和谦逊的品格。

Becky Fisher是Beyond Business Summer Bootcamp公司的创始人,最近她总结了面试者在面试过程中招聘方最看重的技能。以下为译文:
不管你是大学生还是刚打算找工作,或是想在一个新的领域重新开始工作,你都该反问下自己:“我想找什么样的工作?”或者是“怎样才能获得一份更好的工作?”
通过对Google、Amazon、Facebook这样的巨头公司,和类似Castlight、Room77的中小型企业的面试调查,我们发现,他们招聘员工时,看重很多技能,出人意料的是,他们并不看重员工是否精明。而他们特别需要的技能都是可以通过后天学习取得的。一起来看下可以让你从众多招聘者中脱颖而出的5个技能吧。
1. 定量分析
定量分析是对社会现象的数量特性、数量关系与数量变化的分析。数据是许多组织的重要组成部分,所以你的组织、分析、解释和呈现数据能力是很重要的。不管是在做应用程序还是寻找不同的办法来吸引用户。特别说明下,招聘公司很重视组织数据和基于数据进行组织的能力。如果你有挖掘数据的能力,并有自己的见解,那么在竞争中将很有优势。(面试时,你可以带上曾经做过的关于数据分析的项目)。
技能获得方法:MOOCs是学习数据分析的重要资源。你可点击进入Exploratory Data Analysis、Udemy或者EdX,学习定量分析的方法。
2. Excel
管理数据分析中最主要工具是什么?Excel。Excel在工作中会经常遇到,而且公司不会花时间去教你怎样使用Excel。所以,如果你能精通Excel,在录取中也会占有一定的优势。
技能获得方法:可以上网搜索下Excel的使用方法教程,或者点击进入微软免费的Excel视频教程,进入学习。
3. 创造性思维
当今企业界发展步伐异常快,招聘企业对那些有创新能力和能超越现状的求职者很感兴趣。他们希望自己的员工能够有拓展性思维,不安于现状,从第一天上班时起就能有与其他员工分享自己的想法,最好可以提高公司当前的工作系统。但是,创造性思维有点不好学习。
技能获得方法:实际上,根本没有什么教程可以帮你提高创造性思维,但你可通过斯坦福大学的Design Thinking Class或者Creative Confidence进行学习。
4. 沟通能力
一般情况下,招聘公司都想找一些沟通能力比较强的员工。因为公司日后需要你可以有效的与客户进行电话、邮件及日常生活的交流,你的一言一行都将代表公司的形象。更重要的是,公司希望你能以简洁专业的语言来表达自己的某些看法。所以,在面试过程中,多向招聘人员展示下你的沟通能力。
技能获得方法:多与他人进行沟通,可以提高你的沟通能力,而且还要听取别人的反馈意见。
5. 谦逊的品格
有人看到谦逊会觉得奇怪,但是这个技能却是招聘人员看中的重要技能之一。当然,招聘公司需要有自信、有激情,也要乐于学习的员工。在面试时,如果被要求分享自己的想法或主意的时候,大胆的说出来。如果被指出错误,虚心的接受。多问面试人员一些问题,比如公司的一些情况和应聘岗位的一些工作。
技能获得方法:就像Nike说的,Just Do It。大方一点、谦逊,证明自己不仅工作灵活性强,还乐于接受别人的意见。最重要的是,还能把别人提的有利意见融入到工作中。
摘要: 【题目要求】模拟实现十字路口的交通灯管理系统逻辑,具体有以下需求1). 异步随机生成按照各个路线行驶的车辆举例说明如下:. 由南向北行驶的车辆 ----直行车辆. 由西向南行驶的车辆 ----右转车辆. 由东向南行驶的车辆 ----左转车辆…2). 信号灯颜色选择范围忽略黄灯,只考虑红灯和绿灯3). 左转车辆和右转车辆的要求. 左转车辆受到控制信号灯的控制. 但是右转车辆不受信号灯控制...
阅读全文
摘要: 这几天主要是狂看源程序,在弥补了一些以前知识空白的同时,也学会了不少新的知识(比如 NIO),或者称为新技术吧。线程池就是其中之一,一提到线程,我们会想到以前《操作系统》的生产者与消费者,信号量,同步控制等等。一提到池,我们会想到数据库连接池,但是线程池又如何呢?建议:在阅读本文前,先理一理同步的知识,特别是syncronized同步关键字的用法。关于我对同步的认识,要缘于大三年的一本书,书名好像...
阅读全文
摘要: 题目要求:银行业务调度系统模拟实现银行业务调度系统逻辑,具体需求如下:*银行内有6个业务窗口,1 - 4号窗口为普通窗口,5号窗口为快速窗口,6号窗口为VIP窗口。*有三种对应类型的客户:VIP客户,普通客户,快速客户(办理如交水电费、电话费之类业务的客户)。*异步随机生成各种类型的客户,生成各类型用户的概率比例为:VIP客户 :普通客户 :快速客户 = 1 :6 :3。*...
阅读全文
tomcat采用默认安装,要想tamcat直接绑定多个域名,这里我们需要修改配置文件:C:\Program Files\Apache Software Foundation\Tomcat 5.5\conf\server.xml
server.xml 的修改方式如下:
(一)多域名绑定
1.如果你要绑定网站,首先是要把tomcat的默认访问端口8080,修改成80
原始:
<Connector port="8080" maxHttpHeaderSize="8192" maxThreads="150" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" redirectPort="8443" acceptCount="100" connectionTimeout="20000" disableUploadTimeout="true" />
修改后:
<Connector port="80" maxHttpHeaderSize="8192" maxThreads="150" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" redirectPort="8443" acceptCount="100" connectionTimeout="20000" disableUploadTimeout="true" />
其实这里就是把port:8080,修改成port:80就可以了,其他的参数不变
2.接下来就是重点了哈哈...
原始:
<Engine name="Catalina" defaultHost="localhost">
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false" />
</Engine>
当然这里我把注释代码统统删除掉了,省的碍眼
修改后:
<Engine name="Catalina" defaultHost=www.abc.com>
<Host name="www.abc.com" appBase=="abcapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false"
<Host name=www.cba.com appBase=="D:\cba" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false" />
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false" />
</Engine>
这里解释一下上面的配置
Engine 的 dafaultHost :表示访问该tomcat默认进入的主机,注意一定不能是localhost,不然别人通过你的ip访问,就会默认进入tomcat的管理界面.
Host 的 name:表示该主机绑定的域名,如果绑定localhost则可以通过在浏览器中输入localhost访问该Host.
Host的 appBase:表示该主机绑定的文件存放路径,可以使用相对路径或绝对路径.
按照上面的配置:
1.如果我在浏览器中输入http://localhost 则访问 C:\Program Files\Apache Software Foundation\Tomcat 5.5\webapps\ROOT 下的网站
2.如果输入http://www.abc.com 则访问 C:\Program Files\Apache Software Foundation\Tomcat 5.5\abcapps\ROOT 下的网站
3.如果输入http://www.cba.com 则访问 D:\cba\ROOT 下的网站.
注意这里有一个ROOT目录需要创建,我们只要把网站放到相应的ROOT目录向下面,即可通过相应域名访问了.
这里面的参数还有很多,我也不是很清楚,不过这样做确实可以实现多域名绑定哈哈.而且网站页面修改了只要直接覆盖就可以了,tomcat可以自动更新类和页面,当然如果修改了web.xml或lib,则需要重启tomcat才可以.
(二)虚拟目录
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
<Context path="/cqq" docBase="f:\java\cqqapp" debug="0" reloadable="true" crossContext="true">
</Host>
其中,Host标记是用来配置虚拟主机的,就是可以多个域名指向一个tomcat,格式只要参考默认的就
可以了。
<context>是Host标记的子元素吧,表示一个虚拟目录,它主要有两个属性,path就相当于虚拟目录名字,
而 docbase则是具体的文件位置。在这里我的虚拟路径名称为cqq,实际上我的程序也就是html、jsp、
servlet都 放在了f:\java\cqqapp这个目录下了。
这样我就可以通过 http://127.0.0.1/cqq/ 访问我的这个虚拟目录了。
另外一种方法是:
配置两个站点
<Host name="www.xyz.com" debug="0" appBase="D:\Tomcat5.5\portal" unpackWARs="true" autoDeploy="true">
<Context path="" docBase="D:/Tomcat5.5/portal" debug="0" reloadable="true"/>
</Host>
<Host name="www.abc.com" appBase="D:\Tomcat5.5\hxw"
unpackWARs="true" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
<Context path="" docBase="D:\Tomcat5.5\abc" debug="0" reloadable="true"/>
</Host>
这样设置以后,输入域名可以分别到两个站点
但由于没有指定默认站点,所以直接输入IP的时候,无法访问。
于是增加 D:\Tomcat5.5\conf\Catalina\localhost\ROOT.xml
内容如
<Context path="/" docBase="${catalina.home}/portal" debug="5" reloadable="true" crossContext="true">
</Context>
这样可以实现输入域名分别到个站点,输入IP就默认到D:/Tomcat5.5/portal这个站点
可是,可是,问题出现了
这两个站点启动相当消耗内存,TOMCAT内存设置我已经设到1400M了(再高TOMCAT5无法启动),所以不能同时启动三个应用。
数据库
.
.
test.html
..
<html>
<head><title>php_ajax联动下拉菜单</title>
<meta http-equiv="content-type" content="text/html;charset=gb2312">
<script language="javascript" src="ajax.js"></script>
<script language="javascript">
function query(){
var pid = document.getElementByIdx("bigClassName").value;
if(pid!=""){
createRequest('query.php?pid='+pid);
}
}
</script>
</head>
<body>
<form action="<?=$PHP_SELF?>?" name="class" method="get" >
<select name="bigClassName" id="bigClassName" onchange="query()">
<option value="">--选择大类--</option>
<?php
$link=mysql_connect("localhost","root","root");
mysql_select_db("sortclass") or die("没有此数据库!");
$sql="select cid,cname from class where pid=0";
mysql_query("set names gb2312");
$res=mysql_query($sql,$link);
while($result=mysql_fetch_assoc($res)){
echo "<option value='".$result["cid"]."'>".$result["cname"]."</option>";
}
?>
</select>
<select name="smallClassName" id="smallClassName">
<option value="">--选择小类--</option>
</select>
<input type="submit" value="提交" />
</form>
</body>
</html>
.
ajax.js
.
var http_request =
false;
function createRequest(url) {
//初始化对象并发出XMLHttpRequest请求
http_request =
false;
if (window.XMLHttpRequest) {
//Mozilla等其他浏览器
http_request =
new XMLHttpRequest();
if (http_request.overrideMimeType) {
http_request.overrideMimeType("text/xml");
}
}
else if (window.ActiveXObject) {
//IE浏览器
try {
http_request =
new ActiveXObject("Msxml2.XMLHTTP");
}
catch (e) {
try {
http_request =
new ActiveXObject("Microsoft.XMLHTTP");
}
catch (e) {}
}
}
if (!http_request) {
alert("不能创建XMLHTTP实例!");
return false;
}
http_request.onreadystatechange = alertContents;
//指定响应方法
http_request.open("GET", url,
true);
//发出HTTP请求
http_request.send(
null);
}
function alertContents() {
//处理服务器返回的信息
if (http_request.readyState == 4) {
if (http_request.status == 200) {
var smallClassName=document.getElementByIdx("smallClassName");
var dataArray=[];
//alert(http_request.responseText);
myVariable=http_request.responseText;
//形如: 1,新闻中心;2,学习园地;
var stringArray = myVariable.split(";");
//以;分隔字符串
stringArray.pop();
//移除数组最后一个元素,stringArray[0]==1,新闻中心 stringArray[1]==2,学习园地
var len=stringArray.length;
for(var i=0;i<len;i++){
dataArray[i]= stringArray[i].split(",");
// 循环数据条数按,分割字符串
}
//alert(dataArray[1][0]);//返回 新闻中心
//初始化smallClassName的数据
smallClassName.length=0;
var alertOption=document.createElement_x("OPTION");
alertOption.value="";
alertOption.text="--选择小类--";
smallClassName.add(alertOption);
for(var j=0;j<len;j++){
//添加数据
var objOption=document.createElement_x("OPTION");
objOption.value = dataArray[j][0];
objOption.text = dataArray[j][1];
smallClassName.add(objOption);
}
}
else {
alert('您请求的页面发现错误');
}
}
}
..
query.php
..
<?php
error_reporting(E_ERROR|E_WARNING|E_PARSE);
$link=mysql_connect("localhost","root","root");
mysql_select_db("sortclass",$link) or die("no such database!");
//$GB2312string=iconv( 'UTF-8', 'gb2312//IGNORE' , $RequestAjaxString); //Ajax中先用encodeURIComponent对要提交的中文进行编码
mysql_query("set names gb2312");
$pid=$_GET[pid];
$res=mysql_query("select cid,cname from class where pid='$pid'",$link);
header('Content-type: text/html;charset=GB2312');
//指定发送数据的编码格式为GB2312
while($info=mysql_fetch_array($res)){
$str.=$info["cid"].",".$info["cname"];
$str.=";";
}
echo $str;
?>
1、什么是cookie?
0Cookie技术是一个非常有争议的技术,自经诞生它就成了广大网络用户和Web开发人员的一个争论焦点。有一些网络用户,甚至包括一些资深的Web专家也对它的产生和推广感到不满,这倒不是因为Cookie技术的功能太弱或别的技术性能上的原因,而仅仅是因为他们觉得Cookie的使用,对网络用户的隐私构成了危害。因为Cookie是由Web服务器保存在用户浏览器上的小文本文件,它包含有关用户的信息(如身份识别号码、密码、用户在Web站点上购物的方式或用户访问该站点的次数)。
那么Cookie技术究竟怎样呢?是否真的给网络用户带来了个人隐私的危害呢?还是让我们看了下面的内容,再做回答吧。
在WEB技术发展史上,Cookie技术的出现是一个重大的变革。最先是Netscape在它的Netscape Navigator 浏览器中引入了Cookie技术,从那时起,World Wide Web 协会就开始支持Cookie标准。以后又经过微软的大力推广(因为微软的IIS Web服务器所采用的ASP技术很大程度的使用了Cookie技术),即在微软的Internet Explorer浏览器中完全支持Cookie技术。到现在,绝大多数的浏览器都支持Cookie技术,或者至少兼容Cookie技术的使用。
按照Netscape官方文档中的定义,Cookie是在HTTP协议下,服务器或脚本可以维护客户工作站上信息的一种方式。Cookie是由Web服务器保存在用户浏览器上的小文件,它可以包含有关用户的信息(如身份识别号码、密码、用户在Web站点购物的方式或用户访问该站点的次数)。无论何时用户链接到服务器,Web站点都可以访问Cookie信息。
如果你使用的是windows系统,那么请打开C:\Documents and Settings\用户名\Cookies,你会发现该目录下有好多*.txt格式的小文件。那就是cookie文件。当然,在该目录下你也可能什么都发现不了,那时因为你新装了系统或者从未浏览过因特网,也或者你的浏览器禁用了cookie。否则该目录下总会有点东西的。
通俗地讲,浏览器用一个或多个限定的文件来支持Cookie。这些文件在使用Windows操作系统的机器上叫做Cookie文件,在Macintosh 机器上叫做magic Cookie 文件,这些文件被网站用来在上面存储Cookie数据。网站可以在这些Cookie文件中插入信息,这样对有些网络用户就有些副作用。有些用户认为这造成了对个人隐私的侵犯,更糟的是,有些人认为Cookie是对个人空间的侵占,而且会对用户的计算机带来安全性的危害。
目前有些Cookie是临时的,另一些则是持续的。临时的Cookie只在浏览器上保存一段规定的时间,一旦超过规定的时间该Cookie就会被系统清除。例如在PHP中Cookie被用来跟踪用户进程直到用户离开网站。持续的Cookie则保存在用户的Cookie文件中,下一次用户返回时,仍然可以对它进行调用。
在Cookie文件中保存Cookie,一些用户会过分地认为这将带来很大的问题。主要是有些用户担心Cookie会跟踪用户网上冲浪的习惯,譬如用户喜爱到那些类型的站点、爱从事些什么活动等。害怕这种个人信息一旦落入一些别有用心的家伙手中,那么个人也就可能成为一大堆广告垃圾的对象,甚至遭到意外的损害。不过,这种担心压根儿不会发生,因为网站以外的用户是无法跨过网站来获得Cookie信息的。所以想以这种目的来应用Cookie是不可能的。不过,由于一些用户错误的理解以及“以讹传讹”,一些浏览器开发商别无选择,只好作出相适的响应(例如Netscape Navigator4.0和Internet Explorer3.0都提供了屏蔽Cookie的选项)。个人认为,无风不起浪,如果网站程序员没有严谨思路的话,cookie确实也存在些许安全问题,不过这些瑕疵并不足以掩盖cookie的优秀品质,大多数人还是非常乐意使用它的。
对Cookie技术期待了这么久的结果是,迫使许多浏览器开发商在它们的浏览器中提供了对Cookie的灵活性控制功能。例如,目前的两大主流浏览器 Netscape Navigator 和 Internet Explorer是这样处理Cookie的:Netscape Navigator4.0不但可以接受Cookie进行警告,而且还可以屏蔽掉Cookie;InternetExplorer3.0也可以屏蔽 Cookie,但在Internet Explorer4.0中就只能进行接受警告而没有提供屏蔽选项,不过在Internet Explorer4.0之后的更新版本中又加入了屏蔽Cookie的功能选项。
此外,很多最新的技术甚至已经可以在不能屏蔽Cookie的浏览器上进行Cookie的屏蔽了。例如,可以通过将Cookie文件设置成不同的类型来限制 Cookie的使用。但是,非常不幸地是,要是你想完全屏蔽Cookie的话,肯定会因此拒绝许多的站点页面。因为当今已经有许多Web站点开发人员爱上了Cookie技术的强大功能,例如Session对象的使用就离不开Cookie的支持。
2、Cookie工作原理?
当客户访问某个基于PHP技术的网站时,在PHP中可以使用setcookie函数生成一个cookie,系统经处理把这个cookie发送到客户端并保存在C:\Documents and Settings\用户名\Cookies目录下。cookie是 HTTP标头的一部分, 因此setcookie函数必须在任何内容送到浏览器之前调用。这种限制与header()函数一样(如需了解head()函数,请自行查阅)。当客户再次访问该网站时,浏览器会自动把C:\Documents and Settings\用户名\Cookies目录下与该站点对应的cookie发送到服务器,服务器则把从客户端传来的cookie将自动地转化成一个 PHP变量。在PHP5中,客户端发来的cookie将被转换成全局变量。你可以通过$_COOKIE[‘xxx’]读取。
尽管今天仍有一些网络用户对于Cookie的争论乐此不倦,但是对于绝大多数的网络用户来说还是倾向于接受Cookie的。因此,我们尽可以放心地使用Cookie技术来开发我们的WEB页面。
3、Cookie常见函数
● SetCookie 函数创建了一个Cookie,并且把它附加在HTTP头的后面。必须注意的一点是:Cookie是HTTP协议头的一部分,用于浏览器和服务器之间传递信息,所以必须在任何属于HTML文件本身的内容输出之前调用SetCookie函数,调用该函数前即使有空格、空白行都不行。如果setCookie()认了第二,就没有哪个元素敢认第一。使用setcookie()函数的前提是客户浏览器支持cookie,如果客户将之禁用的话,setcookie()也就英雄无用武之地了。
int SetCookie(string name, string value, int expire, string path, string domain, int secure,bool httponly);
参数说明:
name;设置cookie变量的名称。
value;设置cookie的值。
expire;设置cookie过期时间。如果要把cookie保存为浏览器进程,即浏览器关闭后就失效。那么可以直接把expiretime设为0。 Eg:setcookie(“name”,”value”,0)。该参数不设置的话,关闭浏览器也能结束一个cookie。
path:表示web服务器上的目录,默认为被调用页面所在目录. 这里还有一点要说明的,比如你的站点有几个不同的目录(比如一个购物目录,一个论坛目录),那么如果只用不带路径的Cookie的话,在一个目录下的页面里设的Cookie在另一个目录的页面里是看不到的,也就是说,Cookie是面向路径的。实际上,即使没有指定路径,WEB服务器会自动传递当前的路径给浏览器的,指定路径会强制服务器使用设置的路径。解决这个问题的办法是在调用 SetCookie时加上路径和域名,域名的格式可以是“http://www.phpuser.com/”,也可是“.phpuser.com”。 SetCookie函数里表示value的部分,在传递时会自动被encode,也就是说,如果value的值是“test value”在传递时就变成了“test%20value”,跟URL的方法一样。当然,对于程序来说这是透明的,因为在PHP接收Cookie的值时会自动将其decode。
domain:cookie可以使用的域名,默认为被调用页面的域名。这个域名必须包含两个".",所以如果你指定你的顶级域名,你必须用 ".mydomain.com" 。设定域名后,必须采用该域名访问网站cookie才有效。如果你使用多个域名访问该页,那么这个地方可以为空或者访问这个cookie的域名都是一个域下面的。
secure:如果设为"1",表示cookie只能被用户的浏览器认为是安全的服务器所记住。
除了name之外所有的参数都是可选的。value,path,domain三个参数可以用空字符串""代换,表示没有设置;expire 和 secure两个参数是数值型的,可以用0表示。expire参数是一个标准的Unix时间标记,可以用time()或mktime()函数取得,以秒为单位。secure参数表示这个Cookie是否通过加密的HTTPS协议在网络上传输。
httponly:如果设为1,则表示cookie只能被http协议所使用,任何脚本语言,比如javascrīpt是不能获取PHP所创建的 cookie的,这就有效削弱了来自XSS的攻击。(注意了:这是PHP5才有的选项,咱也没有用过。看了官方手册尝试着翻译的,如有疑问,请参考官方手册。)
当前设置的Cookie不是立即生效的,而是要等到下一个页面或刷新后才能看到.这是由于在设置的这个页面里Cookie由服务器传递给客户浏览器,在下一个页面或刷新后浏览器才能把Cookie从客户的机器里取出传回服务器的原因。
小道消息
Cookie应用案例:
●创建一个cookie:
SetCookie()
●创建cookie数组:
其一:
SetCookie("CookieArray[]", "Value 1");
SetCookie("CookieArray[]", "Value 2");
其二:
SetCookie("CookieArray[0]", "Value 1");
SetCookie("CookieArray[1]", "Value 2");
● 接收和处理Cookie
PHP对Cookie的接收和处理的支持非常好,是完全自动的,跟GET,POST变量的原则一样,特别简单。
比如设置一个名为MyCookier的Cookie,PHP会自动从WEB服务器接收的HTTP头里把它分析出来,并形成一个可直接使用的全局变量,名为$_COOKIE[‘MyCookie’],这个变量的值就是Cookie的值。数组同样适用。
分别举例如下:(假设这些都在以前的页面里设置过了,并且仍然有效)
echo $_COOKIE[‘MyCookie’];
取出cookie数组的例子:
<?php
// 创建一个cookie数组
setcookie("cookie[three]", "cookiethree");
setcookie("cookie[two]", "cookietwo");
setcookie("cookie[one]", "cookieone");
// 页面刷新之后,用foreach提取cookie数组。
if (isset($_COOKIE['cookie'])) {
foreach ($_COOKIE['cookie'] as $name => $value) {
echo "$name : $value <br />\n";
}
}
?>
就这么简单。
● 删除Cookie
要删除一个已经存在的Cookie,有两个办法:
1、调用只带有name参数的SetCookie,那么名为这个name的Cookie将被从关系户机上删掉;
setcookie(“MyCookie”); //删除MyCookie。
2、设置Cookie的失效时间为time()或time()-1//time()减多少没有关系啦,只要是过期时间就行//,那么这个Cookie在这个页面的浏览完之后就被删除了(其实是失效了)。例如:
setcookie(“MyCookie”,”Value”,time()-1); //删除MyCookie。
要注意的是,当一个Cookie被删除时,它的值在当前页在仍然有效的。
如果要把cookie保存为浏览器进程,即浏览器关闭后就失效。那么可以直接把expiretime设为0。例如:setcookie(“name”,”value”,0)。该参数不设置的话,关闭浏览器也能结束一个cookie。
Cookie注意事项
1、SetCookie()之前不能有任何html输出,它认了第二,没有哪个元素敢认第一,就是空格,空白行都不行。
2、SetCookie()后,你在当前页调用echo $_COOKIE["name"]不会有输出。必须刷新或到下一个页面才可以看到Cookie值。原因很简单。SetCookie()执行之后,往客户端发送一个cookie,你不刷新或浏览下一个页面,客户端怎么把cookie给你送回去呀?浏览器创建了一个Cookie后,对于每一个针对该网站的请求,都会在Header中带着这个Cookie;不过,对于其他网站的请求Cookie是绝对不会跟着发送的。而且浏览器会这样一直发送,直到 Cookie过期为止。
3、使用Cookie的限制。一个浏览器能创建的Cookie数量最多为30个,并且每个不能超过4KB,每个WEB站点能设置的Cookie总数不能超过20个。 (这是书上看到的说法,应该是一个web站点能创建的Cookie不能超过30个吧,要不然,我机子里的cookie少说也上百了,请达人指教!)
4、Cookie是保存在客户端的,用户禁用了Cookie,你的Cookie自然也就没作用啦!现在的浏览器,每当咱发送一个Cookie给客户端,他就像看门狗一样给拦截住了,并询问用户是否允许Cookie进门。天,用户又不是专家,有几个人知道啥叫Cookie呀?搞不好都当病毒拒之门外了。
<?php
$im = imagecreatetruecolor(80,23);//创建画布
$bgcolor = imagecolorallocate($im,220,230,230);//调制背景色
$bordercolor = imagecolorallocate($im,0,0,255);//调制边框颜色
$tcolor = imagecolorallocate($im,255,0,0);
$green = imagecolorallocate($im,0,255,0);
imagefill($im,10,10,$bgcolor);//填充背景色
imagerectangle($im,1,1,79,22,$bordercolor);//绘制边框
for($i = 0;$i < 4; $i++){
$num_case = rand(0,2);//产生随机数0-2,根据数值的不同决定产生的是数字|小写|大写
switch($num_case){
case 0:$num = rand(48,57);break;//数字
case 1:$num = rand(65,90);break;//大写
default:$num = rand(97,122);//小写
}
$text[$i] = sprintf("%c",$num);//将随机产生的ASCII码转换为相应的字符
imagettftext($im,rand(10,20),rand(0,30),15*$i+5,20,$tcolor,"simkai.ttf",$text[$i]);//显示字符
}
for($i=0;$i<100;$i++){
imagesetpixel($im,rand(1,79),rand(1,22),$green);
}
session_start();
$_SESSION["ckcode"]=implode($text);
header("Content-type:image/png");//设置输出类型
imagepng($im);//输出图像
imagedestroy($im);
<html>
<head>
<script>
var flag = true;
function getNum(num){
if(!flag){
document.getElementById('res').value = '';
flag = true;
}
document.getElementById('res').value += num;
}
function getResult(){
var result = eval(document.getElementById('res').value);
document.getElementById('res').value = result;
flag = false;
}
</script>
</head>
<body>
<table border='1px' width='300px'>
<caption>计算器</caption>
<tr>
<td colspan='4'><input type='text' id='res' size=47></td>
</tr>
<tr>
<td><input type='button' value='1' style="width:75px" onclick="getNum(1)"></td>
<td><input type='button' value='2' style="width:75px" onclick="getNum(2)"></td>
<td><input type='button' value='3' style="width:75px" onclick="getNum(3)"></td>
<td><input type='button' value='+' style="width:75px" onclick="getNum('+')"></td>
</tr>
<tr>
<td><input type='button' value='4' style="width:75px" onclick="getNum(4)"></td>
<td><input type='button' value='5' style="width:75px" onclick="getNum(5)"></td>
<td><input type='button' value='6' style="width:75px" onclick="getNum(6)"></td>
<td><input type='button' value='-' style="width:75px" onclick="getNum('-')"></td>
</tr>
<tr>
<td><input type='button' value='7' style="width:75px" onclick="getNum(7)"></td>
<td><input type='button' value='8' style="width:75px" onclick="getNum(8)"></td>
<td><input type='button' value='9' style="width:75px" onclick="getNum(9)"></td>
<td><input type='button' value='*' style="width:75px" onclick="getNum('*')"></td>
</tr>
<tr>
<td><input type='button' value='0' style="width:75px" onclick="getNum(0)"></td>
<td><input type='button' value='.' style="width:75px" onclick="getNum('.')"></td>
<td><input type='button' value='=' style="width:75px" onclick="getResult()"></td>
<td><input type='button' value='/' style="width:75px" onclick="getNum('/')"></td>
</tr>
</table>
</body>
</html>
1、FORM标签enctype属性
表单中enctype="multipart/form-data"的意思,是设置表单的MIME编码。默认情况,
这个编码格式是application/x-www-form-urlencoded,不能用于文件上传;
只有使用了multipart/form-data,才能完整的传递文件数据
<form enctype="multipart/form-data" method="post" name="upform">
input标签 type 属性中的 "file"
<input name="upfile" type="file">
2、$_FILES 系统函数
$_FILES['myFile']['name'] 客户端文件的原名称。
$_FILES['myFile']['type'] 文件的 MIME 类型,例如"image/gif"。
$_FILES['myFile']['size'] 已上传文件的大小,单位为字节。
$_FILES['myFile']['tmp_name'] 储存的临时文件名,一般是系统默认。
$_FILES['myFile']['error'] 该文件上传相关的错误代码。
3、move_uploaded_file函数
上传后移动文件到目标位置的函数
move_uploaded_file(临时文件,目标位置和文件名);
4、is_uploaded_file 函数
判断上传MIME类型的文件函数
关于用PHPExcel从数据库表导出到Excel表在网上查了好多关于这方面的资料,今天终于把这个问题解决了。我个人感觉 PHPExcel还是很好用的,首先到官方网站http://phpexcel.codeplex.com/下载最近版本的PHPExcel,解压后会发现里面有class、
Documentation、Tests三个文件夹和三个txt的日志文件,主要用到的是Class文件,而Tests主要是一些demo示例下面来介绍一下PHPExcel的简单用法,这里是与数据库连接的:首先,要包含PHPExcel.phprequire_once 'Classes/PHPExcel.php'; //路径根据自己实际项目的路径进行设置
$objPHPExcel = new PHPExcel(); //创建PHPExcel实例
//下面是对mysql数据库的连接
$conn = mysql_connect("localhost","root","") or die("数据库连接失败!"); mysql_select_db("image",$conn); //连接数据库
mysql_query("set names 'GBK'"); //转换字符编码
$sql = mysql_query("select * from test"); //查询sql语句
/*--------------设置表头信息------------------*/$objPHPExcel->setActiveSheetIndex(0)->setCellValue('A1', 'ID编号')->setCellValue('B1', '月份')->setCellValue('C1', '产品一')->setCellValue('D1', '产品二')->setCellValue('E1', '产品三');/*--------------开始从数据库提取信息插入Excel表中------------------*/$i=2; //定义一个i变量,目的是在循环输出数据是控制行数
while($rs=mysql_fetch_array($sql)){$rm = iconv("GB2312","UTF-8",$rs[1]); //对字符进行编码将数据库里GB2312的中文字符转换成UTF-8格式
$objPHPExcel->setActiveSheetIndex(0)->setCellValue("A".$i, $rs[0])->setCellValue("B".$i, $rm)->setCellValue("C".$i, $rs[2])->setCellValue("D".$i, $rs[3])->setCellValue("E".$i, $rs[4]); $i++;}/*--------------下面是设置其他信息------------------*/$objPHPExcel->getActiveSheet()->setTitle('Example1'); //设置sheet的名称
$objPHPExcel->setActiveSheetIndex(0); //设置sheet的起始位置
$objWriter = PHPExcel_IOFactory::createWriter($objPHPExcel, 'Excel5'); //通过PHPExcel_IOFactory的写函数将上面数据写出来
$objWriter->save(str_replace('.php', '.xls', __FILE__)); //设置以什么格式保存,及保存位置
至此,一个完整的将mysql数据库里的信息用PHP导出Excel实例做完,可能在运行的时候会发生一些问题,如中文乱码,表头可能显示不出来,这是因为文件编码格式的原因,将文件编码设置成UTF-8就行了,在此我就不做太多解释了。二: PHPExcel从excel表导入到mysql数据库 error_reporting(E_ALL);
require './Common/Extend/Classes/PHPExcel.php';
require './Common/Extend/Classes/PHPExcel/Reader/Excel2007.php';
require './Common/Extend/Classes/PHPExcel/Reader/Excel5.php';
$info = $upload->getUploadFileInfo();
$filepath = "./Upimg/".$info[0][savename];
$PHPExcel = new PHPExcel();
$PHPReader = new PHPExcel_Reader_Excel2007();
$PHPExcel = $PHPReader->load($filepath);
$sheet = $PHPExcel->getActiveSheet();
$allCol=PHPExcel_Cell::columnIndexFromString($sheet->getHighestColumn());
$allRow=$sheet->getHighestRow();
$M=new Model;
for($j=2;$j<=$allRow;$j++){
$a = $PHPExcel->getActiveSheet()->getCell("A".$j)->getValue();//获取A列的值
$b = $PHPExcel->getActiveSheet()->getCell("B".$j)->getValue();//获取B列的值
$c = $PHPExcel->getActiveSheet()->getCell("C".$j)->getValue();//获取C列的值
$d = $PHPExcel->getActiveSheet()->getCell("D".$j)->getValue();//获取D列的值
$e = $PHPExcel->getActiveSheet()->getCell("E".$j)->getValue();//获取E列的值
$f = $PHPExcel->getActiveSheet()->getCell("F".$j)->getValue();//获取F列的值
$g = $PHPExcel->getActiveSheet()->getCell("G".$j)->getValue();//获取G列的值
$h = $PHPExcel->getActiveSheet()->getCell("H".$j)->getValue();//获取X列的值
$i = $PHPExcel->getActiveSheet()->getCell("I".$j)->getValue();//获取I列的值
$jj = $PHPExcel->getActiveSheet()->getCell("J".$j)->getValue();//获取J列的值
$k = $PHPExcel->getActiveSheet()->getCell("K".$j)->getValue();//获取K列的值
$l = $PHPExcel->getActiveSheet()->getCell("L".$j)->getValue();//获取L列的值
$m = $PHPExcel->getActiveSheet()->getCell("M".$j)->getValue();//获取M列的值
$n = $PHPExcel->getActiveSheet()->getCell("N".$j)->getValue();//获取N列的值
$p = $PHPExcel->getActiveSheet()->getCell("P".$j)->getValue();//获取P列的值
$qq = $PHPExcel->getActiveSheet()->getCell("Q".$j)->getValue();//获取Q列的值
$r = $PHPExcel->getActiveSheet()->getCell("R".$j)->getValue();//获取R列的值
$sql="insert into law_constant(true_name,email,sex,birthday,certificate_num,first_date,law_firm_name,law_firm_address,lawer_xueli,professional,school,work_year,occup_language,word_experience,hobbies) values('".$c."','".$p."','".$d."','".$jj."','".$b."','".$e."','".$f."','".$h."','".$i."','".$k."','".$l."','".$m."','".$n."','".$qq."','".$r."');";
$res=$M->query($sql);
}
if($res[0]==''){
$this->success("导入数据库成功!",'__APP__/Lawerinfo/index');
}else{
$this->error("导入数据库失败!","__APP__/Lawerinfo/index");
}
}
}
}
我的学历不高,不过就是一个路上比比皆是的专科生而已,再加上家中没
有恒产,所以很早就出脱离学生单纯的生活,到处在为三餐温饱打拼。
在这十几年的工作历程中,只有在从事业务行销工作时让我的年收入达到
了千万,不仅有了进口豪华轿车,还拥有了独栋透天别墅,而当时我也不
过才三十岁左右。
今天在版面上看到有人批评业务工作的种种不是,其实我有着深刻的亲身
经历,当各位业务急先锋在市场上真枪实弹搏斗时,低声下气根本就是一
种太肤浅的形容词,请问有人被狗追过吗?有人被人家用扫把扫出来过吗
?如果没有,那我认为应该还需要再加强磨练一番。
我认为干业务的绝对不需要跟人低声下气,除非你愿意跟人低声下气;业
务工作是一个正正当当的职业,名片上印有响当当的头衔,不偷不抢没什
么好丢脸的;没有业务的招揽,再好的产品也出不了工厂大门;业务人员
的心中只有一句座右铭:成王败寇;业务员的人生是由他自己所定义的,
要住什么样的房子、开什么样的车子、等等,自己可以掌握,连老板都无
法为你定夺;业务员的养成不需要专门的科系来培训,但是的确需要一点
天生的傻劲。
我认为任何人都应该学习业务行销的技巧,因为你必须不断地推销你的理
念让别人接受,哪怕你是文书工作人员、程序设计师、美工、总机小姐、
乃至于董事长,我们每天都在推销我们的想法给别人,就像我老婆接受了
我的求婚推销一样,其实一点都不难,也没什么了不起,我们每天都在作
,祇是没有察觉而已。
所以说,千万不要再说不喜欢从事推销、我讨厌干业务,那是骗人的,事
实上我们每天都在作,就像我现在打字的这一篇文章一样,我在将我的想
法推销给你,你的反应只有四种:Yes、No、Yes But、No But,如此而已,
不要太排斥,因为我从来都不认为全世界的人会百分之百相信我,连上帝
都也有人反对,不是吗?
一些社会应对进退技巧或人格特质的确是可以被后天塑造出来的,这一点
我持肯定态度,因为我是一个极为渴望安静的人,我不喜欢一天到晚出门
奔波,常常喜欢自己静静地窝在一个小天地里作我感兴趣的事情,但是我
却被我以前的公司训练成超级业务高手,打破公司所有的历史纪录,这是
如何做到的呢?说穿了不稀奇,已经有人说过了, 什么卡内基、火凤凰.
....等等的,它的确有效,至少在我以及我周遭的同事身上发挥了作
用,而且屡试不爽,因为我也用在我的部属身上,真的蛮有效的。
但是我还是不快乐,因为我已经失去了自我价值,而追寻自我价值这件事
对于我而言又是一件很重要的人生大事,但是我还是去做了,原因很简单
,因为我娶妻生子,每个月付不完的帐单逼得我必须去做一大堆我不喜欢
的事情,甚至连我老婆也是一样,没什么好抱怨的,因为这就是人生,一
个非常真实在你我身边发生的事情,我在这个版面上看到好多人说如果景
气好转的话,他就要跳槽到比较具规模的公司去上班,唉,我就来说明一
下企业主的想法吧。
现在的我早已是一位公司负责人,我经常要陪客户应酬,推销我的产品及
服务,每个月要张罗员工薪资,遇到员工身体有病痛或是心情不佳,我还
得小心伺候,免得他一时之间突然离职,日常作业会陷入停顿,这一阵子
实在是很不景气,客户的预算大幅缩水不说,连决行的时程都一再往后延
,造成业务及生产单位极大的困扰。
然后一下子是下大雨,一下子淹水,搞得我都不知道该怎么办,在我的立
场来说(我要特别强调这是我作为老板的立场),每放一天假我就损失多
少钱,每泡掉一台计算机我就损失多钱,钱、钱、钱、钱、钱、钱、钱,通
通都要钱,我常在想说万一不幸有一天我垮台了,有多少员工会替这家公
司或这个事业来着想?
当景气还不错的时候,我得用很多花招来吸引这些所谓的人才,其中股票
选择权是我最反感的一件事情,我常想为什么我用我多年来辛苦存下来的
钱创办一个事业,而这些员工却要轻易跟我分享我辛苦的成果?
当景气变差的时候,就像是现在,有多少员工会念在当初曾经一起奋斗的
情谊呢?不会,因为我永远叫老板,你永远叫员工,这是千古以来无法保
持和谐的关系。
用比较感性的角度来看,与员工们朝夕相处共同奋斗,所以日久生情算大
家一份股份,这倒也无可厚非,但是刚面试就急着问说这家公司福利政策
如何?薪资待遇如何?的这些人,通常我都会请他们自己创业比较好,因
为这些问题永远没有办法找到平衡点。
如果用比较理性的角度来看,既然这个现实社会都是要用钱才能生存得下
去,那么废话就不要说太多,直接了当说明工作内容为何,期限到了的时
候该产出多少产品或是业绩,那这个样子的情况之下薪资及福利为何,我
想如此还比较节省彼此双方的时间。情?那就别闹了!
这些话听起来很刺耳,几乎所有的求职者听完一定会破口大骂,但是我只
能说这个就是绝大多数企业主的想法,这些基本上都是根据一个简单不过
的逻辑:「我一样每个月要花这么多钱来聘请员工作事情,我为什么没有
权利去选择那些已经有技巧、有经验,甚至于是有客户在手上的新人呢?
如果有一天这位员工表现突出,那么我就酌予提拔或奖励,再过一阵子,
当这位员工表现大不如前,或是突然出现了薪资待遇更便宜的高手来加入
公司,那我实在没有理由还要留着这位坐领高薪及福利的前朝重臣,却拒
绝掉一位这么价廉物美的新人。这位前朝重臣的丰功伟业呢?别傻了,老
板会回你一句话:我当初不是已经给了你相对的报酬吗?」
最刚开始的时候,台商找去大陆上班的台籍干部差不多都有三倍于台湾行
情的薪资,到了今天差不多已经掉到1.2倍而已了。台湾工厂的女工大
约一个月可以领个1.5~2万元,大陆工厂相同的工作却只需要600
~1000元人民币,但是生产出来的产品品质却都差不多。请问如果你
是老板,你会作何决定?当贸易商持续给你压力要求你降价,不然就要把
订单转给你认识的同业时,你的心情会好才奇怪!
各位可以不相信我所说的话,但是务必去查证一下我所讲的,如果没去过
大陆,那么趁失业中的空档前进一下东莞或是广州(大约只要准备三万元
就很够用了)。随便去一家工厂门口,从早上七点一直到下午六点,你会
发现到门口都有人排队想争取应征的机会,甚至贿赂门口警卫,为的是希
望获得一份300元起薪的现场操作员工作。
300元人民币大约等于1300元台币,当我从香港搭机回台湾,在机
场买了一瓶香水给我老婆,结帐时我才发现我花掉了两个大陆工厂新人的
一个月薪资所得,结果害得我整个人在飞机上心情都好不起来。
其实我蛮赞成神奇狮子文中的一些说法,在上海找一个什么工具软件都很
厉害的美工,一个月最高也只要4000元人民币(这已经是很高很高了
),比照到台湾的行情,没有7~8万,你大概别想请得到人。
前一阵子我有一些朋友应聘到大陆内地,而且是到大陆人开设的公司上班
,要我帮他恶补一下大陆文化,我才惊然发现我也快要被淘汰了,因为我
根本无法跟计算机沟通:中文输入法的问题!
先前我都没感觉到,那是因为我都是到台商公司去交货,碰到的计算机青一
色都是繁体中文的操作系统,这难不倒我,而且大陆员工都已经学会了仓
颉或是其它的输入法。但是大陆人开设的公司就只有简体中文的操作系统
了,这个时候换做是你,怎么办?
我要讲的意思是说接下来的二三十年,我们这一代或是下一代到底要跟谁
竞争?跟多少人竞争?我已经很慎重地在思考这个问题,各位想过没有?
我去了大陆这样子走马看花的逛了一下子,就觉得快活不下去了,各位的
危机意识到底在哪里?
大陆员工其实是相当糟糕的,几乎完全没有主动积极进取的精神,我看了
这么多公司工厂,只让我看到一个人会自己动脑筋想解决方案,这个就是
我们目前台湾员工的优势所在,但是能维持多久呢?
侏罗纪公园中很清晰的一句话:生命自会寻找出路!只要我们脑袋里确实
有料,其实企业老板是不太看学历的,有朝一日他必会回馈相当的报酬给
你。但如果你让老板觉得不放心你的时候,就算是需要作出违法的行为,
他还是会毅然下决心请你走路的。呆伯特这本书其实害了好多年轻人,这
是我的真实感觉。
最后谈到经验。经验是一种非常宝贵的人类资产,我绝对不会录用一个刚
出校门的年轻人,因为我曾经吃足了苦头,大学或大专资管资工科班毕业
,竟然还要我花费十几万元送去接受半个月的专业讲习训练,结训回来后
叫他们集思广益改写一个javascript,竟然在搞了一个星期之后跟我说这是
不可能写得出来的东西,然后在二个月之后的发薪日,因为香港机场罢工
我赶不回来(公司大小章刚好带在身上),以致晚了两天发薪水,这些新
人竟然就联合起来指着我说这是一家骗人的公司,当时那种情况,你认为
我的感觉会好吗?
后来我请一位朋友的小孩,帮我看一下系统分析纪录, 不到三个小时程序
就已经寄到我的电子邮件信箱了。这两者之间的差别在哪里 ?在经验!
这位朋友的小孩平时就在帮人家写案子,收费非常便宜,因为他把这件事
情当成是在作作业,练习练习,以便为将来出社会时找工作之用;而这些
花了大把钞票的国立大学大专同学,心中老是以为自己是全世界的重心,
一看到公司只有四十几坪,人没几个,听也没听说过,于是就....!
所以我现在宁愿用极高的薪资,来聘请一位二专毕业,但是拥有相当丰富
经验的人来帮我作事情,那些连接个电话留个信息在别人桌上的基本技巧
都不懂的人,我是绝对敬而远之的。
人类只是一种智商比较高级一点的动物,如果你常看Discovery或是国家地
理频道的话,你就会发现老年的动物最可怜,因为又不能狩猎,又不能保
卫家园,群体行动时还经常拖泥带水,影响整个行程进度,这是我们所谓
的动物界。其实我们人类也好不到哪里去,顶多批着一张道德的皮在身上
,当我们走进浴室衣服一脱掉,哪有什么不一样,眼、耳、鼻、口、四肢
、生殖器官...,差不多的啦!但是又为什么会出现圣人、先贤、总统
呢?因为脑袋里的东西不一样。
我们一辈子活在世上,无非就是要想尽办法来创造出被人家利用的价值。
如果我每天只被老板利用一个小时,但是老板没有我这一个小时的帮忙,
他就会赚不到钱,而且又找不到什么替代方案的话,那么我这一个小时就
会相当值钱,比如说我担任这家公司的技术总顾问。
反之如果我的被利用价值相当低,随便一个人或一套硬设备就可以取代
掉我,那么就算是我花了十几个小时,累得跟狗一样,老板还是会随时请
我走路,因为我没有被利用的价值,比如说我客户的一些总机小姐。
常常有很久没联络的朋友或客户突然打电话给我,霹雳啪啦的问了一大堆
问题,我也几哩呱啦地回答他们,生意就上门了,因为我有一些特定的印
象停留在他们的脑海中,凡是他们遇到这一方面的问题时,通常都会先来
问我,他们知道像这种事情找我准没错,这就是我个人独具的被利用价值
。 你的被利用价值在哪里?有多少?能持续产生新的价值吗?跟得上时代脉
动吗?
我想这才是老板最想了解的,其它的,我认为都不是重点。
愿共勉之!祝大家都能找到理想的工作! 主管欣賞的人 在職場上,苦勞不會成功,其實企業最欣賞的人才,是具有高度common sense的人,換句話說,就是要work hard,work smart,work happy,特質的A級人才。 努力工作≠績效 是不是最努力工作的人就一定受到主管賞識呢?
有三個檢視標準或許可以提供 大家做為一個參考:
Work Hard, Work Smart, Work Happy
你是不是很努力工作,但不快樂呢?這時或許可以檢核自己一下,工作的方式是不是夠smart?
在這裡跟大家分享一個故事,或許可以引發大家一些思考與想法。
小芬與小美畢業於某國立大學企管系,同時進入一家中型企業,擔任企劃專員的工作。小芬做事努力認真、守分務實,常常自動留下來為公司加班,工作到很晚才下班。
小美呢?只見她每天嘻嘻哈哈,工作輕鬆又愉快,每天都會主動去找主管聊天,給人一種跟主管感情很好的印象。
1年後,小美獲得主管升遷,委以重任,小芬則只獲得象徵性的加薪鼓勵。這讓小芬非常不平,認為小美工作又沒自己認真,只會逢迎拍主管馬屁,憑什麼考績反而比她好?而且還受到公司的重用。自己為公司付出許多,夙夜匪懈地工作,
反而落得一場空,於是遞了辭呈。
少了一根筋
就在小芬工作的最後一天,總經理找小芬晤談。剛好中秋節快到了,公司正在考慮該買什麼中秋禮送給客戶。總經理說,「小芬,可不可以請妳到南門巿場跑一趟,看看有沒有賣大閘蟹?」
小芬心裡很疑惑,不知道主管為什麼要她跑這一趟,因為這並不是她負責的工作啊!但她還是乖乖地依照主管的要求,搭計程車到南門巿場。過了20分鐘,小芬回到辦公室,向總經理報告,「南門巿場有賣大閘蟹。」
總經理接著問她,「南門巿場的大閘蟹怎麼賣?算斤?還是算隻?」小芬一臉茫然,無法回答。於是又跑了一趟南門巿場,30分鐘後又回來報告,「南門巿場大閘蟹算隻賣,每隻350元。」
總經理聽了之後,當著小芬的面,把小美找了進來,並吩咐小美,「麻煩妳到南門巿場去一趟,看看有沒有賣大閘蟹?」
小美馬上問總經理,「請問大閘蟹是有什麼用途嗎?」
總經理回答她,「中秋節快到了,打算送客戶大閘蟹做為中秋賀禮。」
小美立即出門。過了1個多小時,小美回來了。
一進門,就見她眉飛色舞地拎著兩隻大閘蟹。向總經理報告,「南門巿場有兩家攤位賣大閘蟹。第一家的大閘蟹,每隻平均4兩重,每隻賣350元。第二家的大閘蟹,每隻平均6兩重,一隻550元。我建議,如果總經理自家食用可以買4兩重的,肚白、背綠、金毛,看起來很新鮮。如果總經理要送人,我建議買6兩重的,看起來比較有份量。我各買了一隻帶回來給總經理參考。」
做事Smart有方法
聽完小美的報告之後,總經理轉頭問小芬,「妳看出妳們之間有什麼不同了嗎?」小芬一副恍然大悟的神情,趕忙點頭表示她明白了!
總經理向小芬進一步說明,「一樣是去南門巿場看看有沒有賣大閘蟹,妳們蒐集回來的巿場情報與態度截然不同。小芬,妳很認真沒有錯,但是妳並沒有思考這項任務的需求是什麼?只是一個口令一個動作,得來來回回好幾趟才能把一件事情做好。而小美呢?不用我多交待,一次就把事情搞定,她不僅蒐集了完整的巿場情報,甚至也提出建議與分析,協助我做為判斷的參考。」
苦勞不會成功
小芬聽了不禁自慚形穢,她最感慚愧的是,為何她與小美是最好的同學,居然沒有學習小美的做事優點,暗地嫉妒她。同時她也很謝謝總經理為她上了一堂寶貴的一課,點醒她的負面思維。
在職場上,苦勞不會成功,其實企業最欣賞的人才,是具有高度common sense的人,換句話說,就是要有work hard, work smart, work happy特質的A級人才。這樣的人才能快速掌握主管的需求與期待,為公司開創更大的格局。
The race is not to the swift or the battle to the strong, nor does food come to wise or wealth to the brilliant or favor to the learned: but time and chance happen to them all.
快跑的未必能贏,力戰的未必得勝;
智慧的未必得糧食,明哲的未必得資財,靈巧的未必得喜悅;
所臨到眾人的,是因為「時間」與「機會」。
親愛的好友們!你們學到了嗎?
你我是不是只懂得做個『努力工作、認真、守分務實』的人呢?
对于SQL的Join,在学习起来可能是比较乱的。我们知道,SQL的Join语法有很多inner的,有outer的,有left的,有时候,对于Select出来的结果集是什么样子有点不是很清楚。Coding Horror上有一篇文章,通过文氏图 Venn diagrams 解释了SQL的Join。我觉得清楚易懂,转过来。
假设我们有两张表。Table A 是左边的表。Table B 是右边的表。其各有四条记录,其中有两条记录name是相同的,如下所示:让我们看看不同JOIN的不同
| A表 |
| id | name |
| 1 | Pirate |
| 2 | Monkey |
| 3 | Ninja |
| 4 | Spaghetti |
| B表 |
| id | name |
| 1 | Rutabaga |
| 2 | Pirate |
| 3 | Darth Vade |
| 4 | Ninja |
1.INNER JOIN
SELECT * FROM TableA INNER JOIN TableB ON TableA.name = TableB.name
| 结果集 |
| (TableA.) | (TableB.) |
| id | name | id | name |
| 1 | Pirate | 2 | Pirate |
| 3 | Ninja | 4 | Ninja |

Inner join 产生的结果集中,是A和B的交集。
2.FULL [OUTER] JOIN
(1)
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name
| 结果集 |
| (TableA.) | (TableB.) |
| id | name | id | name |
| 1 | Pirate | 2 | Pirate |
| 2 | Monkey | null | null |
| 3 | Ninja | 4 | Ninja |
| 4 | Spaghetti | null | null |
| null | null | 1 | Rutabaga |
| null | null | 3 | Darth Vade |

Full outer join 产生A和B的并集。但是需要注意的是,对于没有匹配的记录,则会以null做为值。
可以使用IFNULL判断。
(2)
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name
WHERE TableA.id IS null OR TableB.id IS null
| 结果集 |
| (TableA.) | (TableB.) |
| id | name | id | name |
| 2 | Monkey | null | null |
| 4 | Spaghetti | null | null |
| null | null | 1 | Rutabaga |
| null | null | 3 | Darth Vade |

产生A表和B表没有交集的数据集。
3.LEFT [OUTER] JOIN
(1)
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name
| 结果集 |
| (TableA.) | (TableB.) |
| id | name | id | name |
| 1 | Pirate | 2 | Pirate |
| 2 | Monkey | null | null |
| 3 | Ninja | 4 | Ninja |
| 4 | Spaghetti | null | null |

Left outer join 产生表A的完全集,而B表中匹配的则有值,没有匹配的则以null值取代。
(2)
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.nameWHERE TableB.id IS null
| 结果集 |
| (TableA.) | (TableB.) |
| id | name | id | name |
| 2 | Monkey | null | null |
| 4 | Spaghetti | null | null |

产生在A表中有而在B表中没有的集合。
4.RIGHT [OUTER] JOIN
RIGHT OUTER JOIN 是后面的表为基础,与LEFT OUTER JOIN用法类似。这里不介绍了。
5.UNION 与 UNION ALL
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。UNION 只选取记录,而UNION ALL会列出所有记录。
(1)SELECT name FROM TableA UNION SELECT name FROM TableB
| 新结果集 |
| name |
| Pirate |
| Monkey |
| Ninja |
| Spaghetti |
| Rutabaga |
| Darth Vade |
选取不同值
(2)SELECT name FROM TableA UNION ALL SELECT name FROM TableB
| 新结果集 |
| name |
| Pirate |
| Monkey |
| Ninja |
| Spaghetti |
| Rutabaga |
| Pirate |
| Darth Vade |
| Ninja |
全部列出来
(3)注意:
SELECT * FROM TableA UNION SELECT * FROM TableB
| 新结果集 |
| id | name |
| 1 | Pirate |
| 2 | Monkey |
| 3 | Ninja |
| 4 | Spaghetti |
| 1 | Rutabaga |
| 2 | Pirate |
| 3 | Darth Vade |
| 4 | Ninja |
由于 id 1 Pirate 与 id 2 Pirate 并不相同,不合并
还需要注册的是我们还有一个是“交差集” cross join, 这种Join没有办法用文式图表示,因为其就是把表A和表B的数据进行一个N*M的组合,即笛卡尔积。表达式如下:SELECT * FROM TableA CROSS JOIN TableB
这个笛卡尔乘积会产生 4 x 4 = 16 条记录,一般来说,我们很少用到这个语法。但是我们得小心,如果不是使用嵌套的select语句,一般系统都会产生笛卡尔乘积然再做过滤。这是对于性能来说是非常危险的,尤其是表很大的时候。
Object param = params.get(i);
if (param instanceof Integer) {
int value = ((Integer) param).intValue();
prepStatement.setInt(i + 1, value);
} else if (param instanceof String) {
String s = (String) param;
prepStatement.setString(i + 1, s);
} else if (param instanceof Double) {
double d = ((Double) param).doubleValue();
prepStatement.setDouble(i + 1, d);
} else if (param instanceof Float) {
float f = ((Float) param).floatValue();
prepStatement.setFloat(i + 1, f);
} else if (param instanceof Long) {
long l = ((Long) param).longValue();
prepStatement.setLong(i + 1, l);
} else if (param instanceof Boolean) {
boolean b = ((Boolean) param).booleanValue();
prepStatement.setBoolean(i + 1, b);
} else if (param instanceof Date) {
Date d = (Date) param;
prepStatement.setDate(i + 1, (Date) param);
}
函数:upper()
功能:将字符串中的小写字母转换为大写字母。
语法:Upper( string )
参数string:要将其中的小写字母转换为大写字母的字符串返回值String。函数执行成功时返回将小写字母转换为大写字母后的字符串,发生错误时返回空字符串("")。如果string参数的值为NULL,Upper()函数返回NULL。
更新table表的name列为大写:
UPDATE table SET name = upper(name);
在程序中实现大写查询:
select * from table where name=upper('admin');
在程序中实现大小写忽略查训:
select * from table where upper(name)=upper('admin');
1.Js函数可以传入不同的参数,如
function writeNString(strMsg){
document.write(strMsg + "<br>");
}
2.Js函数返回值,js函数可以将运行的结果返回,函数可以视为一个黑盒子,使用参数输入数据后产生所需的运行结果,如
function one2N(intnumber){
var intTotal = 0;
for(var i=0;i<=intnumber;i++){
intTotal +=i;}
return intTotal;
}
3.Js函数的传值和传址参数
传值:只是将变量的值传入函数,函数会另外配置内存保存参数值,所以并不会改变原变量的值。
传址:将变量实际保存的内存位置传入函数,所以如果在函数中变更参数的值,也会同时变动原参数的值。
数字、字符串和布尔----传值
对象、数组和函数----传址
字符串对象-------传址
4.Js函数的参数数组
Js的函数都拥有一个参数数组(Arguments Array)对象,叫做arguments对象。当调用函数传入参数时,函数即使没有指明参数名称,也一样可以使用参数数组的对象获取参数的个数和个别的参数值。
function sumInteger(){
var total = 0;
for(var i=0; i<sumInteger.arguments.length;i++){
total += sumInteger.arguments[i];
}
return total;
}
//调用函数
inntotal = sumInteger(100,45,567,234);
document.write("函数sumInteger(100,45,567,234):"+inttotal+"<br>");
5.JS函数的变量范围
JS函数有两种变量:
局部变量(local Variables)在函数内声明的变量,变量只能在函数内的程序行内使用,函数外的程序代码并无法访问此变量。
全局变量(Global Variables)在函数外声明的变量,整个JS程序的函数和程序代码都能访问此变量。
1. 实现函数类
JSTL对函数类没有任何要求,只要求方法类是公开的,方法必须是静态的、公用的方法。下面是这个函数实现的代码,把它编译后放到 WEB-INF\classes\demo 目录下。
package demo; /**
* 用于JSTL的函数类
* @author Winter Lau
*/
public class EmailFunction {
/**
* 转换EMAIL地址为链接的形式
* @param email
* @return
*/
public static String emailLink(String email){
StringBuffer sb = new StringBuffer();
sb.append("<a href=\"mailto:");
sb.append(email);
sb.append("\">");
sb.append(email);
sb.append("</a>");
return sb.toString();
} }
|
2. 描述文件
接下来我们必须通知JSTL怎么来使用这个函数,跟标签库一样,我们必须编写一个tld文件,姑且把文件名叫做email.tld,该文件存放在{webapp}/WEB-INF目录下,该文件中包含对该函数的说明,文件如下:
3. 测试页面
万事俱备,接下来就是这个测试页面了,页面的代码如下
打开浏览器运行该页面,显示的结果如下:
Click javayou@gmail.com to feedback.
判断一个人的编程水平,就看他用键盘多,还是鼠标多。用键盘一是为了输入代码(当然了,也包括注释),再有就是熟练使用快捷键。
所以在网上找了一下,自己也总结了些用得比较多的,和大家一起分享一下。
Ctrl+K 光标放在一个变量上(注意,是变量,如果你的光标放在了字符串上,如http://keleyi.com则没有任何作用的),按下Ctrl+K光标会定位到下一个相同的变量
Shift+Ctrl+K 跟Ctrl+K功能一样,方向相反
Ctrl+O 打开类似大纲视图的小窗口
Alt+ 左右方向键,跳到前一次/后一次的编辑位置 (经常会用到)
双击左括号(小括号,中括号,大括号),将选择括号内的所有内容
F3打开声明该引用的文件
F4打开类型层次结构
Ctrl+H打开搜索窗口
Shift+Ctrl+S保存全部
Shift+Ctrl+R打开资源
Ctrl+Q回到最后一次编辑的地方
Ctrl+Shift+G在workspace中搜索引用
Alt+上、下方向键,将选中的行向上或向下移动
Shift+Enter在当前行的下面添加一个空行,光标可以当前行的任意位置
Ctrl+L跳转到某行
Ctrl+M最大化当前的Edit或View,再按则反之
Ctrl+/注释当前行,再按则反之
Ctrl+T显示当前类的继承情况(可以查看类的目录树)
Ctrl+E显示当前Edit的下拉列表
Ctrl+/(小键盘) 折叠当前类中的所有代码
Ctrl+*(小键盘) 展开当前类中的所有代码
Alt+/代码助手,提示代码
Ctrl+J正向增量查找
Ctrl+Shift+J反向增量查找
Ctrl+Shift+F4关闭所有打开的edit
Ctrl+Shift+R查找文件
Ctrl+Shift+T查找类
Alt+Shift+R重名命
Alt+Shift+M抽取方法
Alt+Shift+Z取消重构
磨刀不误砍柴工啊,一定要用熟来。。。。
下载地址:http://archive.apache.org/dist/jakarta/taglibs/standard/binaries/
JSTL 标签库的配置:
按照上面的地址下载 jar 包。然后按照下面的步骤在 tomcat 服务器上进行配置。
首先,在 Tomcat 的工作目录,也就是安装目录下的 webapps/Root 目录下,新建一个 WEB-INF 文件夹,并在 WEB-INF 文件夹下新建一个 lib 文件夹,然后把下载下来的压缩包中 lib 文件夹中的 standard.jar 和 jstl.jar 复制到该 lib 文件夹中,接下来把压缩包中整个 tld 文件夹复制到 WEB-INF 文件夹下。在 WEB-INF 文件夹中的 web.xml 中修改(如果没有,新建一个):
<?xml version="1.0" encoding="utf-8"?>
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
version="2.5">
<display-name>Welcome to Tomcat</display-name>
<description>
Welcome to Tomcat
</description>
<taglib>
<taglib-uri>http://java.sun.com/jstl/fmt</taglib-uri>
<taglib-location>/WEB-INF/tld/fmt.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>http://java.sun.com/jstl/core</taglib-uri>
<taglib-location>/WEB-INF/tld/c.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>http://java.sun.com/jstl/sql</taglib-uri>
<taglib-location>/WEB-INF/tld/sql.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>http://java.sun.com/jstl/x</taglib-uri>
<taglib-location>/WEB-INF/tld/x.tld</taglib-location>
</taglib>
</web-app>
摘要: 前言=========================================================================JSTL标签库,是日常开发经常使用的,也是众多标签中性能最好的。把常用的内容,放在这里备份一份,随用随查。尽量做到不用查,就可以随手就可以写出来。这算是Java程序员的基本功吧,一定要扎实。 JSTL全名为JavaServer Pages ...
阅读全文
摘要: 1. 条件标签 JSTL<c:if test="${user.password == 'hello'}"> <c:choose> <c:when test="${user.age <...
阅读全文
引入STRUTS2标签库和JSTL标签库
Java代码
<%@ taglib prefix="s" uri="/struts-tags"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
1、if 标签
Java代码
<s:if test="#parameters['siteId']!=null">
</s:if>
因为JSTL没有else标签 所以比较好的方法是
Java代码
<c:if var="current" test="${page.pageNo == i}">
${i}
</c:if>
<c:if test="${not current}">
</c:if>
action里有boolean属性
Java代码
<s:if test="!emptySite"></s:if>
Java代码
<c:if test="${emptySite}"></c:if>
2、select 标签
Java代码
<s:select list="pageList" listKey="key" id="swpTplCata" listValue="value" name="pageId" />
pageList 对应action里的pageList属性 arrayList
listKey="key" listValue="value" 为固定写法
name="pageId" 为下拉框的默认值 pageId也是action里的属性 要提供get方法
3、radio 标签
Java代码
<s:if test="checkedRoleIds.size() == 0">
<s:radio name="checkedRoleIds" list="allRoleList" listKey="id" listValue="desc" />
</s:if>
<s:else>
<s:radio name="checkedRoleIds" list="allRoleList" listKey="id" listValue="desc" value="checkedRoleIds[0]" />
</s:else>
value="checkedRoleIds[0]" 默认选中的值
Java代码
private List<Long> checkedRoleIds; //用户角色
public List<Long> getCheckedRoleIds() {
return checkedRoleIds;
}
public void setCheckedRoleIds(List<Long> checkedRoleIds) {
this.checkedRoleIds = checkedRoleIds;
}
4、form 标签
Java代码
<s:form method="post" action="%{#request.contextPath}/account/user!save"
theme="simple" enctype="multipart/form-data" id="register_form"
name="form">
5、iterator 标签
Java代码
<s:iterator value="page.result">
</s:iterator>
6、jstl循环
Java代码
<c:forEach var="i" begin="1" end="${page.totalPages}" step="1">
${i}
</c:forEach>
7、jstl循环map
Java代码
<c:forEach items="${model}" var="model">
${model.key}
${model.value}
<br />
</c:forEach>
自定义标签
http://dingbuoyi.iteye.com/admin/blogs/818950
struts2标签与jstl标签的混合使用 1.在jstl中使用struts2
<c:forEach var="ee" items="${requestScope.serviceList}" >
jstl:<c:out value="${ee.id}"></c:out>
el:${ee.id}
struts2: <s:property value="Ettr.ee.id"/>
</c:forEach>
通过struts2标签取jstl标签的变量时,如果有设置scope,可以从scope中取值如果没有就需要用Ettr来取值
2.从jstl标签中获取值
<c:set var="ctime" value="${el.createtime}" scope="request"/>
<c:set var="ctime2" value="${el.createtime}" />
<s:property value="#request.ctime"/>
<s:property value="Ettr.ctime2"/>
3.在struts2标签中使用jstl
<s:iterator value="#request.serviceList" id="bs">
struts2:<s:property value="#bs.keyid"/>
el:${bs.keyid}
jstl:<c:out value="${bs.keyid}"></c:out>
</s:iterator>
4.从struts2标签中取值
<!-- 数字类型-->
<s:set name="pp" value="11"></s:set>
struts2:<s:property value="#pp"/>
el:${pp}
jstl:<c:out value="${pp}"></c:out>
<!-- 字符串类型-->
<s:set name="pp2" value="'abc'" scope="request"></s:set>
struts2:<s:property value="#request.pp2"/>
el:${pp2}
jstl:<c:out value="${pp2}"></c:out>
--选择和循环<c:choose>
<c:when test="${empty sessionScope.indexList}">
没有你搜索的歌曲..<br />
</c:when>
<c:otherwise>
<c:forEachitems="${sessionScope.indexList}" var="list"
varStatus="vs">
<a href="#"> ${list.tone_name}</a> -- ${list.singer}
<br />
</c:forEach>
</c:otherwise>
</c:choose>
<s:
if test="#session.indexList==null">
没有你搜索的歌曲..<br />
</s:
if>
<s:
else>
<s:iterator value="#session.indexList" var="list">
<a href="#"><s:property value="#list.tone_name" /></a>--
<s:property value="#list.singer" />
<br/>
</s:iterator>
</s:
else>
</div>
Struts2常用标签总结
一 介绍
1.Struts2的作用
Struts2标签库提供了主题、模板支持,极大地简化了视图页面的编写,而且,struts2的主题、模板都提供了很好的扩展性。实现了更好的代码复用。Struts2允许在页面中使用自定义组件,这完全能满足项目中页面显示复杂,多变的需求。
Struts2的标签库有一个巨大的改进之处,struts2标签库的标签不依赖于任何表现层技术,也就是说strtus2提供了大部分标签,可以在各种表现技术中使用。包括最常用的jsp页面,也可以说Velocity和FreeMarker等模板技术中的使用
2.Struts2分类
(1)UI标签:(User Interface, 用户界面)标签,主要用于生成HTML元素标签,UI标签又可分为表单标签非表单标签
(2)非UI标签,主要用于数据访问,逻辑控制等的标签。非UI标签可分为流程控制标签(包括用于实现分支、循环等流程控制的标签)和数据访问标签(主要包括用户输出ValueStack中的值,完成国际化等功能的)
(3)ajax标签
3.Struts2标签使用前的准备:
(1)在要使用标签的jsp页面引入标签库:
<%@ taglib uri="/struts-tags" prefix="s"%>
(2)在web.xml中声明要使用的标签 这样是struts2 2.3.1.2版本的引入方式
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter>
4.标签的使用
(1)property标签
用于输出指定的值:
<s:property value="%{@cn.csdn.hr.domain.User@Name}"/><br/>
<s:property value="@cn.csdn.hr.domain.User@Name"/><Br/><!-- 以上两种方法都可以 -->
<s:property value="%{@cn.csdn.hr.domain.User@study()}"/>
以上可以访问某一个包的类的属性的集中方式,study()是访问方法的方法,并输出。
以下用java代码代替的,访问某一个范围内的属性
<%
//采用pageContext对象往page范围内存入值来 验证#attr搜索顺序是从page开始的 ,搜索的顺序为:page,reques,session,application。
set存值的时候存到的是request中,在jsp页面中访问的时候不用加任何的标识符,即可直接访问,如果不同的作用域不一样了,
pageContext.setAttribute("name", "laoowang", PageContext.PAGE_SCOPE);
%>
<s:property value="#attr.name" />
假设在action中设置了不同作用域的类
不同的作用域的标签的访问:
<h3>获取的是requet中的对象值</h3>
第一种方式:<s:property value="#request.user1.realName"/>
<br/>
第二种方式:<s:property value="#request.user1['realName']"/>
<br/>
第三种方式:<s:property value="#user1.realName"/>
<br/>
第四种方式:<s:property value="#user1['realName']"/>
<br/>
第五种方式:${requestScope.user1.realName } || ${requestScope.user1['realName'] }
第六种:<s:property value="#attr.user1.realName"/>
attr对象按page==> request sessionapplictio找的
<h3>获取session中的值</h3>
第一种方式:<s:property value="#session.user1.realName"/>
<br/>
第二种方式:<s:property value="#session.user1['realName']"/>
第五种方式:${sessionScope.user1.realName } || ${sessionScope.user1['realName'] }
<h3>获取application中的对象的值</h3>
第一种方式:<s:property value="#application.user1.realName"/>
<br/>
第二种方式:<s:property value="#application.user1['realName']"/>
第五种方式:${applicationScope.user1.realName } || ${applicationScope.user1['realName'] }
(2)iterator标签的使用
第一种:list集合
<!-- 设置set集合 value-->
<!-- status 可选属性,该属性指定迭代时的IteratorStatus实例 -->
<!-- value="#attr.list" list存放到了request中 可以value="#request.list"
statu.odd返回当前被迭代元素的索引是否是奇数
-->
<s:set name="list" value="{'a','b','c','d'}"></s:set>
<s:iterator var="ent" value="#request.list" status="statu">
<s:if test="%{#statu.odd}">
<font color="red"><s:property value="#ent" />
</font>
</s:if>
<s:else>
<s:property value="#ent" />
</s:else>
</s:iterator>
第二种:map集合中的使用
<h3>Map集合</h3>
<!-- map集合的特点:
语法格式:# {key:value,key1:value1,key2:value2,.....}
以上的语法中就直接生成了一个Map类型的集合,该Map对象中的每个key-value对象之间用英文的冒号隔开
,多个元素之间用逗号分隔。
-->
</div>
<s:set var="map" value="#{'1':'laowang','2':'老王','3':'猩猩'}"></s:set>
遍历Map:
<br />
<s:iterator value="#map">
<s:property value="key" />:::<s:property value="value" />
<Br />
</s:iterator>\
第三种:集合的变量
<h3>遍历集合:::</h3>
<div>
<!-- 遍历出价格大于3000的 -->
<s:iterator var="user" value="#session['users']">
<s:if test="%{#user['price']>3000}">
<s:property value="#user['price']"/>
</s:if>
</s:iterator>
<hr color="blue"/><!-- $是取出价格 大于3000的最后一个值 -->
<s:iterator var="u" value="#session.users.{$(#this['price']>3000)}">
<s:property value="price"/>
</s:iterator>
</div>
注:users是User的对象,price是User中的一个属性
简述一下iterator的介绍:
iterator标签用于对集合进行迭代,这里的集合包含List、Set和数组。
<s:set name="list" value="{'zhangming','xiaoi','liming'}" />
<s:iterator value="#list" status="st">
<font color=<s:if test="#st.odd">red</s:if><s:else>blue</s:else>>
<s:property /></font><br>
</s:iterator>
value:可选属性,指定被迭代的集合,如果没有设置该属性,则使用ValueStack栈顶的集合。
id:可选属性,指定集合里元素的id。
status:可选属性,该属性指定迭代时的IteratorStatus实例。该实例包含如下几个方法:
int getCount(),返回当前迭代了几个元素。
int getIndex(),返回当前迭代元素的索引。
boolean isEven(),返回当前被迭代元素的索引是否是偶数
boolean isOdd(),返回当前被迭代元素的索引是否是奇数
boolean isFirst(),返回当前被迭代元素是否是第一个元素。
boolean isLast(),返回当前被迭代元素是否是最后一个元素。
(3)if else语句的使用
<s:set name="age" value="21" />
<s:if test="#age==23">
23
</s:if>
<s:elseif test="#age==21">
21
</s:elseif>
<s:else>
都不等
</s:else>
(4)URL标签
<!-- 声明一个URL地址 -->
<s:url action="test" namespace="/tag" var="add">
<s:param name="username">laowangang</s:param>
<s:param name="id">12</s:param>
</s:url>
<s:a href="%{add}">测试URL</s:a>
<s:a action="test" namespace="/tag"></s:a>
以上的两个<s:a>标签的作用是一样的。
(5)data标签
<%
pageContext.setAttribute("birth",new Date(200,03,10),PageContext.REQUEST_SCOPE);
%>
<s:date name="#request.birth" format="yyyy年MM月dd日"/>
<s:date name="#request.birth" nice="true"/>
这个标签是按照format的格式去输出的。
(6)表单
<h1>from表单</h1>
<s:form action="test" namespace="/tag">
<s:textfield label="用户名" name="uname" tooltip="你的名字" javascriptTooltip="false"></s:textfield>
<s:textarea name="rmake" cols="40" rows="20" tooltipDelay="300" tooltip="hi" label="备注" javascriptTooltip="true"></s:textarea>
<s:password label="密码" name="upass"></s:password>
<s:file name="file" label="上传文件"></s:file>
<s:hidden name="id" value="1"></s:hidden>
<!--
<select name="edu">
<option value="listKey">listValue</option>
-->
<s:select list="#{'1':'博士','2':'硕士'}" name="edu" label="学历" listKey="key" listValue="value"></s:select>
<s:select list="{'java','.net'}" value="java"></s:select><!-- value是选中的 -->
<!-- 必须有name -->
<s:checkbox label="爱好 " fieldValue="true" name="checkboxFiled1"></s:checkbox>
<!-- 多个checkbox -->
<s:checkboxlist list="{'java','css','html','struts2'}" label="喜欢的编程语言" name="box" value="{'css','struts2'}"></s:checkboxlist>
<!-- map集合前要加# -->
<s:checkboxlist list="#{1:'java',2:'css',3:'html',4:'struts2',5:'spring'}" label="喜欢的编程语言" name="boxs" value="{1,2}"></s:checkboxlist>
<!-- listKey
listValue
<input type="text" name="boxs" value="listKey">显示值listValue
-->
<!-- radio -->
<%
//从服务器传过来值
pageContext.setAttribute("sex","男",PageContext.REQUEST_SCOPE);
pageContext.setAttribute("sex1","男",PageContext.REQUEST_SCOPE);
%>
<s:radio list="{'男','女'}" name="sex" value="#request.sex"></s:radio>
<s:radio list="#{1:'男',2:'女'}" name="sex1" listKey="key" listValue="value" value="#request.sex1"></s:radio>
<!-- 防止表单提交的方式 -->
<s:token></s:token>
<s:submit value="提交"></s:submit>
</s:form>
[正则表达式]文本框输入内容控制
整数或者小数:^[0-9]+\.{0,1}[0-9]{0,2}$
只能输入数字:"^[0-9]*$"。
只能输入n位的数字:"^\d{n}$"。
只能输入至少n位的数字:"^\d{n,}$"。
只能输入m~n位的数字:。"^\d{m,n}$"
只能输入零和非零开头的数字:"^(0|[1-9][0-9]*)$"。
只能输入有两位小数的正实数:"^[0-9]+(.[0-9]{2})?$"。
只能输入有1~3位小数的正实数:"^[0-9]+(.[0-9]{1,3})?$"。
只能输入非零的正整数:"^\+?[1-9][0-9]*$"。
只能输入非零的负整数:"^\-[1-9][]0-9"*$。
只能输入长度为3的字符:"^.{3}$"。
只能输入由26个英文字母组成的字符串:"^[A-Za-z]+$"。
只能输入由26个大写英文字母组成的字符串:"^[A-Z]+$"。
只能输入由26个小写英文字母组成的字符串:"^[a-z]+$"。
只能输入由数字和26个英文字母组成的字符串:"^[A-Za-z0-9]+$"。
只能输入由数字、26个英文字母或者下划线组成的字符串:"^\w+$"。
验证用户密码:"^[a-zA-Z]\w{5,17}$"正确格式为:以字母开头,长度在6~18之间,只能包含字符、数字和下划线。
验证是否含有^%&',;=?$\"等字符:"[^%&',;=?$\x22]+"。
只能输入汉字:"^[\u4e00-\u9fa5]{0,}$"
验证Email地址:"^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$"。
验证InternetURL:"^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$"。
验证电话号码:"^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$"正确格式为:"XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX"。
验证身份证号(15位或18位数字):"^\d{15}|\d{18}$"。
验证一年的12个月:"^(0?[1-9]|1[0-2])$"正确格式为:"01"~"09"和"1"~"12"。
验证一个月的31天:"^((0?[1-9])|((1|2)[0-9])|30|31)$"正确格式为;"01"~"09"和"1"~"31"。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String.prototype.len=function(){return this.replace(/[^\x00-\xff]/g,"aa").length;}
匹配空行的正则表达式:\n[\s| ]*\r
匹配html标签的正则表达式:<(.*)>(.*)<\/(.*)>|<(.*)\/>
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
应用:javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现,如下:
String.prototype.trim = function()
{
return this.replace(/(^\s*)|(\s*$)/g, "");
}
利用正则表达式分解和转换IP地址:
下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:
function IP2V(ip)
{
re=/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匹配IP地址的正则表达式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error("Not a valid IP address!")
}
}
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
var ip="10.100.20.168"
ip=ip.split(".")
alert("IP值是:"+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
利用正则表达式限制网页表单里的文本框输入内容:
用正则表达式限制只能输入中文:onkeyup="value=value.replace(/[^\u4E00-\u9FA5]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\u4E00-\u9FA5]/g,''))"
用正则表达式限制只能输入全角字符: onkeyup="value=value.replace(/[^\uFF00-\uFFFF]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\uFF00-\uFFFF]/g,''))"
用正则表达式限制只能输入数字:onkeyup="value=value.replace(/[^\d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
用正则表达式限制只能输入数字和英文:onkeyup="value=value.replace(/[\W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
<input onkeyup="value=value.replace(/[^\u4E00-\u9FA5\w]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\u4E00-\u9FA5\w]/g,''))" value="允许下划线,数字字母和汉字">
<script language="javascript">
if (document.layers)//触发键盘事件
document.captureEvents(Event.KEYPRESS)
function xz(thsv,nob){
if(nob=="2"){
window.clipboardData.setData("text","")
alert("避免非法字符输入,请勿复制字符");
return false;
}
if (event.keyCode!=8 && event.keyCode!=16 && event.keyCode!=37 && event.keyCode!=38 && event.keyCode!=39 && event.keyCode!=40){
thsvv=thsv.value;//输入的值
thsvs=thsvv.substring(thsvv.length-1);//输入的最后一个字符
//thsvss=thsvv.substring(0,thsvv.length-1);//去掉最后一个错误字符
if (!thsvs.replace(/[^\u4E00-\u9FA5\w]/g,'') || event.keyCode==189){//正则除去符号和下划线 key
thsv.value='请勿输入非法符号 ['+thsvs+']';
alert('请勿输入非法符号 ['+thsvs+']');
thsv.value="";
return false;
}
}
}
</script>
<input onkeyup="xz(this,1)" onPaste="xz(this,2)" value="">允许数字字母和汉字
<script language="javascript">
<!--
function MaxLength(field,maxlimit){
var j = field.value.replace(/[^\x00-\xff]/g,"**").length;
//alert(j);
var tempString=field.value;
var tt="";
if(j > maxlimit){
for(var i=0;i<maxlimit;i++){
if(tt.replace(/[^\x00-\xff]/g,"**").length < maxlimit)
tt = tempString.substr(0,i+1);
else
break;
}
if(tt.replace(/[^\x00-\xff]/g,"**").length > maxlimit)
tt=tt.substr(0,tt.length-1);
field.value = tt;
}else{
;
}
}
</script>
单行文本框控制<br />
<INPUT type="text" id="Text1" name="Text1" onpropertychange="MaxLength(this, 5)"><br />
多行文本框控制:<br />
<TEXTAREA rows="14"
cols="39" id="Textarea1" name="Textarea1" onpropertychange="MaxLength(this, 15)"></TEXTAREA><br />
控制表单内容只能输入数字,中文....
<script>
function test()
{
if(document.a.b.value.length>50)
{
alert("不能超过50个字符!");
document.a.b.focus();
return false;
}
}
</script>
<form name=a onsubmit="return test()">
<textarea name="b" cols="40" wrap="VIRTUAL" rows="6"></textarea>
<input type="submit" name="Submit" value="check">
</form>
只能是汉字
<input onkeyup="value=value.replace(/[^\u4E00-\u9FA5]/g,'')">
只能是英文字符
<script language=javascript>
function onlyEng()
{
if(!(event.keyCode>=65&&event.keyCode<=90))
event.returnValue=false;
}
</script>
<input onkeydown="onlyEng();">
<input name="coname" type="text" size="50" maxlength="35" class="input2" onkeyup="value=value.replace(/[\W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))">
只能是数字
<script language=javascript>
function onlyNum()
{
if(!((event.keyCode>=48&&event.keyCode<=57)||(event.keyCode>=96&&event.keyCode<=105)))
//考虑小键盘上的数字键
event.returnValue=false;
}
</script>
<input onkeydown="onlyNum();">
只能是英文字符和数字
<input onkeyup="value=value.replace(/[\W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))">
验证为email格式
<SCRIPT LANGUAGE=Javascript RUNAT=Server>
function isEmail(strEmail) {
if (strEmail.search(/^\w+((-\w+)|(\.\w+))*\@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/) != -1)
return true;
else
alert("oh");
}
</SCRIPT>
<input type=text onblur=isEmail(this.value)>
屏蔽关键字(sex , fuck) - 已修改
<script language="JavaScript1.2">
function test() {
if((a.b.value.indexOf ("sex") == 0)||(a.b.value.indexOf ("fuck") == 0)){
alert("五讲四美三热爱");
a.b.focus();
return false;}
}
</script>
<form name=a onsubmit="return test()">
<input type=text name=b>
<input type="submit" name="Submit" value="check">
</form>
限制文本框里只能输入数字
<input onkeyup="if(event.keyCode !=37 && event.keyCode != 39) value=value.replace(/\D/g,'');"onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/\D/g,''))">
<PIXTEL_MMI_EBOOK_2005>2 </PIXTEL_MMI_EBOOK_2005>
JAVA正则表达式语法(转)
正则表达式语法
正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式示例
表达式 匹配
/^\s*$/
匹配空行。
/\d{2}-\d{5}/
验证由两位数字、一个连字符再加 5 位数字组成的 ID 号。
/<\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*>/
匹配 HTML 标记。
下表包含了元字符的完整列表以及它们在正则表达式上下文中的行为:
字符 说明
\
将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,“n”匹配字符“n”。“\n”匹配换行符。序列“\\”匹配“\”,“\(”匹配“(”。
^
匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与“\n”或“\r”之后的位置匹配。
$
匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与“\n”或“\r”之前的位置匹配。
*
零次或多次匹配前面的字符或子表达式。例如,zo* 匹配“z”和“zoo”。* 等效于 {0,}。
+
一次或多次匹配前面的字符或子表达式。例如,“zo+”与“zo”和“zoo”匹配,但与“z”不匹配。+ 等效于 {1,}。
?
零次或一次匹配前面的字符或子表达式。例如,“do(es)?”匹配“do”或“does”中的“do”。? 等效于 {0,1}。
{n}
n 是非负整数。正好匹配 n 次。例如,“o{2}”与“Bob”中的“o”不匹配,但与“food”中的两个“o”匹配。
{n,}
n 是非负整数。至少匹配 n 次。例如,“o{2,}”不匹配“Bob”中的“o”,而匹配“foooood”中的所有 o。“o{1,}”等效于“o+”。“o{0,}”等效于“o*”。
{n,m}
M 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,“o{1,3}”匹配“fooooood”中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。
?
当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是“非贪心的”。“非贪心的”模式匹配搜索到的、尽可能短的字符串,而默认的“贪心的”模式匹配搜索到的、尽可能长的字符串。例如,在字符串“oooo”中,“o+?”只匹配单个“o”,而“o+”匹配所有“o”。
.
匹配除“\n”之外的任何单个字符。若要匹配包括“\n”在内的任意字符,请使用诸如“[\s\S]”之类的模式。
(pattern)
匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果“匹配”集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用“\(”或者“\)”。
(?:pattern)
匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用“or”字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 'industry|industries' 更经济的表达式。
(?=pattern)
执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?=95|98|NT|2000)' 匹配“Windows 2000”中的“Windows”,但不匹配“Windows 3.1”中的“Windows”。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。
(?!pattern)
执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?!95|98|NT|2000)' 匹配“Windows 3.1”中的 “Windows”,但不匹配“Windows 2000”中的“Windows”。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。
x|y
匹配 x 或 y。例如,'z|food' 匹配“z”或“food”。'(z|f)ood' 匹配“zood”或“food”。
[xyz]
字符集。匹配包含的任一字符。例如,“[abc]”匹配“plain”中的“a”。
[^xyz]
反向字符集。匹配未包含的任何字符。例如,“[^abc]”匹配“plain”中的“p”。
[a-z]
字符范围。匹配指定范围内的任何字符。例如,“[a-z]”匹配“a”到“z”范围内的任何小写字母。
[^a-z]
反向范围字符。匹配不在指定的范围内的任何字符。例如,“[^a-z]”匹配任何不在“a”到“z”范围内的任何字符。
\b
匹配一个字边界,即字与空格间的位置。例如,“er\b”匹配“never”中的“er”,但不匹配“verb”中的“er”。
\B
非字边界匹配。“er\B”匹配“verb”中的“er”,但不匹配“never”中的“er”。
\cx
匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是“c”字符本身。
\d
数字字符匹配。等效于 [0-9]。
\D
非数字字符匹配。等效于 [^0-9]。
\f
换页符匹配。等效于 \x0c 和 \cL。
\n
换行符匹配。等效于 \x0a 和 \cJ。
\r
匹配一个回车符。等效于 \x0d 和 \cM。
\s
匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。
\S
匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。
\t
制表符匹配。与 \x09 和 \cI 等效。
\v
垂直制表符匹配。与 \x0b 和 \cK 等效。
\w
匹配任何字类字符,包括下划线。与“[A-Za-z0-9_]”等效。
\W
与任何非单词字符匹配。与“[^A-Za-z0-9_]”等效。
\xn
匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,“\x41”匹配“A”。“\x041”与“\x04”&“1”等效。允许在正则表达式中使用 ASCII 代码。
\num
匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,“(.)\1”匹配两个连续的相同字符。
\n
标识一个八进制转义码或反向引用。如果 \n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。
\nm
标识一个八进制转义码或反向引用。如果 \nm 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 \nm 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 \nm 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。
\nml
当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。
\un
匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (?)。
1、windows->Preferences……打开"首选项"对话框,左侧导航树,导航到general->Workspace,
右侧Text file encoding,选择Other,改变为UTF-8,以后新建立工程其属性对话框中的Text file encoding即为UTF-8.
2、 windows->Preferences……打开"首选项"对话框,左侧导航树,导航到general->Content Types,右侧Context Types树,点开Text中每一颗子项,并在中输入"UTF-8",点update! 其他java应用开发相关的文件如:properties、XML等已经由Eclipse缺省指定,分别为ISO8859-1,UTF-8,如开发中确需 改变编码格式则可以在此指定。
3、window——>preference——>MyEclipse——>Files and Editors,将每个子项的"Encoding"改为"ISO 10645/Unicode(UTF-8)",点Apply!
4、 选中工程---->右键--->properties---->Resource---->Text Fiel Encoding---->设置成UTF-8
4、经过上述三步,新建java文件即为UTF-8编码,Eclipse编译、运行、调试都没问题。
myeclipse中java文件头注释格式设置
windows->preferences->java->Code Templates->comments->Type->edit
Eclipse注释规范模版总结
新建类文件
/**
* @ClassName: ${file_name}
* @Description: ${todo}(用一句话描述该文件做什么)
*
* @author ${user}
* @version V1.0
* @Date ${date} ${time}
*/
方法
/**
* @Title: ${enclosing_method}
* @Description: ${todo}(这里用一句话描述这个方法的作用)
* @param: ${tags}
* @return: ${return_type}
* @throws
* @author ${user}
* @Date ${date} ${time}
*/
输入设置模板:
/**
* ${file_name} Create on ${date}
*
* Copyright (c) ${date} by taotaosoft
*
* @author <a href="xiuzhong.li@gmail.com">Jerryli</a>
* @version 1.0
*
*/
注意选择自动添加注释,养成一个规范的习惯是最好的。
选菜单
windows-->preference --> Java-->Code Style-->Code Templates --> code-->new Java files
选中点编辑
${filecomment}
${package_declaration}
/**
* @author 作者姓名 E-mail: email地址
* @version 创建时间:${date} ${time}
* 类说明
*/
${typecomment}
${type_declaration}
Eclipse注释规范模版总结
1、 具体操作
(1)在eclipse中,打开Window->Preference->Java->Code Style->Code Template
(2)然后展开Comments节点就是所有需设置注释的元素,参照2注释规范对应设置即可
2、 注释规范
(1)文件(Files)注释标签
/**
* FileName: ${file_name}
* @Description: ${todo}(用一句话描述该文件做什么)
* All rights Reserved, Designed By ZTE-ITS
* Copyright: Copyright(C) 2010-2011
* Company ZTE-ITS WuXi LTD.
* @author: 名字
* @version V1.0
* Createdate: ${date} ${time}
*
* Modification History:
* Date Author Version Discription
* -----------------------------------------------------------------------------------
* ${date} wu.zh 1.0 1.0
* Why & What is modified: <修改原因描述>
*/
(2)类型(Types)注释标签(类的注释):
/**
* @ClassName: ${type_name}
* @Description:${todo}(这里用一句话描述这个类的作用)
* @author: Android_Robot
* @date: ${date} ${time}
*
* ${tags}
*/
(3)字段(Fields)注释标签:
/**
* @Fields ${field} : ${todo}(用一句话描述这个变量表示什么)
*/
(4)构造函数标签:
/**
* @Title: ${enclosing_type}
* @Description: ${todo}(这里用一句话描述这个方法的作用)
* @param: ${tags}
* @throws
*/
(5)方法(Methods)标签:
/**
* @Title: ${enclosing_method}
* @Description: ${todo}(这里用一句话描述这个方法的作用)
* @param: ${tags}
* @return: ${return_type}
* @throws
*/
(6)覆盖方法(Overriding Methods)标签:
/**
* <p>Title: ${enclosing_method}</p>
* <p>Description: </p>
* ${tags}
* ${see_to_overridden}
*/
(7)代表方法(Delegate Methods)标签:
/**
* ${tags}
* ${see_to_target}
*/
(8)getter方法标签:
/**
* @Title: ${enclosing_method} <BR>
* @Description: please write your description <BR>
* @return: ${field_type} <BR>
*/
(9)setter方法标签:
/**
* @Title: ${enclosing_method} <BR>
* @Description: please write your description <BR>
* @return: ${field_type} <BR>
*/
说明:本文转载自http://hi.baidu.com/%BF%AA%D0%C4%BE%CD%BA%C3_999/blog/item/cbc81c4a9666d32608f7efd7.html
2008年06月05日 星期四 21:23
WebLogic如何设置session超时时间
1 web.xml
设置WEB应用程序描述符web.xml里的<session-timeout>元素。这个值以分钟为
单位,并覆盖weblogic.xml中的TimeoutSecs属性
<session-config>
<session-timeout>54</session-timeout>
</session-config>
此例表示Session将在54分钟后过期
当<session-timeout>设置为-2,表示将使用在weblogic.xml中设置的
TimeoutSecs这个属性值。
当<session-timeout>设置为-1,表示Session将永不过期,而忽略在
weblogic.xml中设置的TimeoutSecs属性值。
该属性值可以通过console控制台来设置
2 weblogic.xml
设置WebLogic特有部署描述符weblogic.xml的<session-descriptor>元素的
TimeoutSecs属性。这个值以秒为单位
<session-descriptor>
<session-param>
<param-name>TimeoutSecs</param-name>
<param-value>3600</param-value>
</session-param>
</session-descriptor>
默认值是3600秒
3,jsp中控制
session.setmaxinactiveinterval(7200);
session是默认对象,可以直接引用,单位秒s
4,servlet中控制
httpsession session = request.getsession();
session.setmaxinactiveinterval(7200);
单位秒s
在weblgoic的console中:xxDomain->Servers->xxServer->Protocols->HTTP 中有一个关于Post Timeout的配置,但这个参数一般使用默认值即可
一般是通过Services-->JDBC-->Connection Pools-->MyConnection(你所建立的连接池名)-->Configration-->Connections 里的Inactive Connection Timeout这个参数来设置的,默认的为0,表示连接时间无限长。你可以设一个时间值,连接超过这个时间值,它会把连接强制放回连接池
<Server AcceptBacklog="62" CompleteHTTPMessageTimeout="480"
CompleteMessageTimeout="480" IdleConnectionTimeout="600"
ListenAddress="" ListenPort="7001" Name="myserver"
NativeIOEnabled="true" ReliableDeliveryPolicy="RMDefaultPolicy"
ServerVersion="8.1.4.0">
是否IdleConnectionTimeout参数
看连接池中高级选项内的Inactive Connection Timeout和Connection Reserve Timeout时多少, 把这两项设大些试试
如果在两个文件中同时设置了超时时间,则会以web.xml中为准。
所以在weblogic环境中,最好将web.xml中关于超时的设置删掉,保持唯一性。
这也是一个客户发现了问题后,多次实验后发现的。
如果使用WEBLOGIC作为应用服务器,设置SESSION超时时间会选择在WEBLOGIC的控制台设定。实际上,WEBLOGIC是将超时设定保存在WEB-INF下的weblogic.xml中,格式如下:
<session-descriptor>
<session-param>
<param-name>TimeoutSecs</param-name>
<param-value>7200</param-value>
</session-param>
</session-descriptor>
param-value中的数值就是超时时间,单位为秒。在设置完这个参数后,会发现超时时间并一定起效。这是为什么呢?
原来在WEB-INF下还有一个配置文件web.xml,里面同样会有一段设置session,格式如下:
<session-config>
<session-timeout>30</session-timeout>
</session-config>
session-timeout中的值也是超时时间,单位为分钟。
如果在两个文件中同时设置了超时时间,则会以web.xml中为准。
所以在weblogic环境中,最好将web.xml中关于超时的设置删掉,保持唯一性。
这也是一个客户发现了问题后,多次实验后发现的。
今天上午联创科技的一个朋友问题一个他们的问题.出现大量的:
ueue: ‘billproxyqueue’ has been busy for “727″ seconds working on the request “Http Request: /bill/y
nQueryPublic.go”, which is more than the configured time (StuckThreadMaxTime) of “600″ seconds.>
一看明显是连接超时, 导致的错误.
- 程序问题,是不是程序中没有关闭连接
- 如果程序没问题,则是weblogic的
StuckThreadMaxTime设置过小而引起的,一般weblogic server 的StuckThreadMaxTime默认参数是600s,即10分钟,如果并发量过大,而导致等待处理过多,导致系统不停的增加线程,造成线程阻塞,你可以把该参数设置大点这个是稍微调大StuckThreadMaxTime的参数即可. - 看线程数设置,可适当增加线程数,这个在WLS控制台中可以调整
为什么会有cookie呢,大家都知道,http是无状态的协议,客户每次读取web页面时,服务器都打开新的会话,而且服务器也不会自动维护客户的上下文信息,那么要怎么才能实现网上商店中的购物车呢,session就是一种保存上下文信息的机制,它是针对每一个用户的,变量的值保存在服务器端,通过 SessionID来区分不同的客户,session是以cookie或URL重写为基础的,默认使用cookie来实现,系统会创造一个名为 JSESSIONID的输出cookie,我们叫做session cookie,以区别persistent cookies,也就是我们通常所说的cookie,注意session cookie是存储于浏览器内存中的,并不是写到硬盘上的,这也就是我们刚才看到的JSESSIONID,我们通常情是看不到JSESSIONID的,但是当我们把浏览器的cookie禁止后,web服务器会采用URL重写的方式传递Sessionid,我们就可以在地址栏看到 sessionid=KWJHUG6JJM65HS2K6之类的字符串。 明白了原理,我们就可以很容易的分辨出persistent cookies和session cookie的区别了,网上那些关于两者安全性的讨论也就一目了然了,session cookie针对某一次会话而言,会话结束session cookie也就随着消失了,而persistent cookie只是存在于客户端硬盘上的一段文本(通常是加密的),而且可能会遭到cookie欺骗以及针对cookie的跨站脚本攻击,自然不如 session cookie安全了。 通常session cookie是不能跨窗口使用的,当你新开了一个浏览器窗口进入相同页面时,系统会赋予你一个新的sessionid,这样我们信息共享的目的就达不到了,此时我们可以先把sessionid保存在persistent cookie中,然后在新窗口中读出来,就可以得到上一个窗口SessionID了,这样通过session cookie和persistent cookie的结合我们就实现了跨窗口的session tracking(会话跟踪)。 在一些web开发的书中,往往只是简单的把Session和cookie作为两种并列的http传送信息的方式,session cookies位于服务器端,persistent cookie位于客户端,可是session又是以cookie为基础的,明白的两者之间的联系和 区别,我们就不难选择合适的技术来开发web service了 cookie Session是由应用服务器维持的一个服务器端的存储空间,用户在连接服务器时,会由服务器生成一个唯一的SessionID,用该SessionID 为标识符来存取服务器端的Session存储空间。而SessionID这一数据则是保存到客户端,用Cookie保存的,用户提交页面时,会将这一 SessionID提交到服务器端,来存取Session数据。这一过程,是不用开发人员干预的。所以一旦客户端禁用Cookie,那么Session也会失效。 服务器也可以通过URL重写的方式来传递SessionID的值,因此不是完全依赖Cookie。如果客户端Cookie禁用,则服务器可以自动通过重写URL的方式来保存Session的值,并且这个过程对程序员透明。 可以试一下,即使不写Cookie,在使用request.getCookies();取出的Cookie数组的长度也是1,而这个Cookie的名字就是JSESSIONID,还有一个很长的二进制的字符串,是SessionID的值。 Cookie是客户端的存储空间,由浏览器来维持。
总结:1:cookie是通过头部header返回到浏览器中并保存在磁盘中,下次再次访问该服务器中。浏览器会自动把该cookie传输到服务器中。
2:Session与Cookie是一对的,Session使用的基础就是cookie。
3:cookie分为两种,如果设置cookie时没有设置有效时间,就表示该cookie是临时性的,只保存在浏览器的内存中,即seesion-cookie,只要关闭浏览器,该cookie即将消失。
如果cookie设置了有效时间,就表示该cookie是持久化的,即
persistent cookie。此外还可以为持久化cookie设置域名和路径。
4:当禁止cookie后,就返回通过url地址返回cookie Id。
5:如来是否自定义cookie值,服务器都会自动产生一个cookie值,名称为:
JSESSIONID,而值就是服务器中的sessionid值。创建cookie的步骤: 以java为例:
1: 创建cookie对象:
Cookie cookie = new Cookie("cookiename","cookievalue"); 2:设置有效期:
cookie.setMaxAge(3600); 3:设置路径:
cookie.setPath("/"); //设置路径,这个路径即该工程下都可以访问该cookie 如果不设置路径,那么只有设置该cookie路径及其子路径可以访问 4:设置域名:
cookie.setDomain(".zl.org") ; //域名要以“.”开头 5:在返回对象中添加cookie对象:
response.addCookie(cookie) ; 6:返回对象
response其他的操作。
以下为Java操作Cookie实例:
java对cookie的操作比较简单,主要介绍下建立cookie和读取cookie,以及如何设定cookie的生命周期和cookie的路径问题。
建立一个无生命周期的cookie,即随着浏览器的关闭即消失的cookie,代码如下
HttpServletRequest request
HttpServletResponse response
Cookie cookie = new Cookie("cookiename","cookievalue");
response.addCookie(cookie);
下面建立一个有生命周期的cookie,可以设置他的生命周期
cookie = new Cookie("cookiename","cookievalue");
cookie.setMaxAge(3600);
//设置路径,这个路径即该工程下都可以访问该cookie 如果不设置路径,那么只有设置该cookie路径及其子路径可以访问
cookie.setPath("/");
response.addCookie(cookie);
下面介绍如何读取cookie,读取cookie代码如下
Cookie[] cookies = request.getCookies();//这样便可以获取一个cookie数组
for(Cookie cookie : cookies){
cookie.getName();// get the cookie name
cookie.getValue(); // get the cookie value
}
上面就是基本的读写cookie的操作。我们在实际中最好进行一下封装,比如增加一个cookie,我们关注的是cookie的name,value,生命周期,所以进行封装一个函数,当然还要传入一个response对象,addCookie()代码如下
/**
* 设置cookie
* @param response
* @param name cookie名字
* @param value cookie值
* @param maxAge cookie生命周期 以秒为单位
*/
public static void addCookie(HttpServletResponse response,String name,String value,int maxAge){
Cookie cookie = new Cookie(name,value);
cookie.setPath("/");
if(maxAge>0) cookie.setMaxAge(maxAge);
response.addCookie(cookie);
}
读取cookie的时候,为了方便我们的操作,我们希望封装一个函数,只要我们提供cookie的name,我们便可以获取cookie的value,带着这个想法,很容易想到将cookie封装到Map里面,于是进行下面的封装.
/**
* 根据名字获取cookie
* @param request
* @param name cookie名字
* @return
*/
public static Cookie getCookieByName(HttpServletRequest request,String name){
Map<String,Cookie> cookieMap = ReadCookieMap(request);
if(cookieMap.containsKey(name)){
Cookie cookie = (Cookie)cookieMap.get(name);
return cookie;
}else{
return null;
}
}
/**
* 将cookie封装到Map里面
* @param request
* @return
*/
private static Map<String,Cookie> ReadCookieMap(HttpServletRequest request){
Map<String,Cookie> cookieMap = new HashMap<String,Cookie>();
Cookie[] cookies = request.getCookies();
if(null!=cookies){
for(Cookie cookie : cookies){
cookieMap.put(cookie.getName(), cookie);
}
}
return cookieMap;
}
1、Cookie的来历与作用
Cookie是WEB服务器通过浏览器保存在WWW用户端硬盘上的一个文本文件,这个文本文件中包含了文本信息。
文本信息的内容以“名/值”对(key/value)的形式进行存储。
可以让WEB开发者通过程序读写这个文本文件。
XP中保存Cookie的目录是“C:
//Documents and Settings\用户名\Cookies”
Cookie的作用
解决浏览器用户与Web服务器之间无状态通信。
2Cookie编程
//创建对象
Date date =
new Date() ;
Cookie c =
new Cookie("lastVisited",date.toString()) ;
//设定有效时间 以s为单位
c.setMaxAge(60) ;
//设置Cookie路径和域名
c.setPath("/") ;
c.setDomain(".zl.org") ;
//域名要以“.”开头
//发送Cookie文件
response.addCookie(c) ;
//读取Cookie
Cookie cookies[] = request.getCookies() ;
Cookie c1 =
null ;
if(cookies !=
null){
for(
int i=0;i<cookies.length;i++){
c1 = cookies[i] ;
out.println("cookie name : " + c1.getName() + " ") ;
out.println("cookie value :" + c1.getValue() + "<br>");
}
}
//修改Cookie
Cookie cookies[] = request.getCookies() ;
Cookie c =
null ;
for(
int i=0;i<cookies.length;i++){
c = cookies[i] ;
if(c.getName().equals("lastVisited")){
c.setValue("2010-04-3-28") ;
c.setMaxAge(60*60*12) ;
response.addCookie(c) ;
//修改后,要更新到浏览器中
}
}
//删除Cookie,(将Cookie的有效时间设为0)
Cookie cookies[] = request.getCookies() ;
Cookie c =
null ;
for(
int i=0;i<cookies.length;i++){
c = cookies[i] ;
if(c.getName().equals("lastVisited")){
c.setMaxAge(0);
response.addCookie(c) ;
}
}
4、使用Cookie的注意事项
·Cookie的大小和数量是有限制的。
·Cookie在个人硬盘上所保存的文本信息是以明文格式进行保存的,没有任何的加密措施。
·浏览器用户可以设定不使用Cookie。
5、实例:Servlet中的Cookie编程
cookieInput.html页面
SetCookie.java
GetCookie.java
cookieInput.html页面中的参数提交到SetCookie.java中,由SetCookie.java保存在浏览器的Cookie中,在SerCookie.java中链接到GetCookie.java从而读取刚刚保存的Cookie。
SetCookie.java :
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
String username = request.getParameter("username") ;
//保存Cookie
if(username !=""){
Cookie c1 = new Cookie("username",username) ;
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd") ;
Cookie c2 = new Cookie("lastVisited",sdf.format(new java.util.Date())) ;
c1.setMaxAge(60*60*60*12*30) ;
c2.setMaxAge(60*60*60*12*30) ;
response.addCookie(c1) ;
response.addCookie(c2) ;
out.println("Cookie保存成功!");
out.println("<br><br>") ;
out.println("<a href=GetCookie02>读取Cookie</a>") ;
}else{
response.sendRedirect("../cookieInput.html") ;
}
out.flush();
out.close();
}
GetCookie.java:
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
out.println("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">");
out.println("<HTML>");
out.println(" <HEAD><TITLE>A Servlet</TITLE></HEAD>");
out.println(" <BODY>");
//读取Cookie
Cookie cookies[] = request.getCookies() ;
Cookie c = null ;
if(cookies != null){
for(int i=0;i<cookies.length;i++){
c = cookies[i] ;
if(c.getName().equals("username")){
out.println("用户名: "+c.getValue());
out.println("<br>");
}
if(c.getName().equals("lastVisited")){
out.println("上次登录的时间: "+c.getValue());
}
}
}else{
out.println("No cookie !");
}
out.println(" </BODY>");
out.println("</HTML>");
out.flush();
out.close();
}
/**
* 功能:Java读取目录下txt文件的内容
* 步骤:先获得目录句柄,如果是文件直接读取文件,如果是目录,继续迭代处理
* @param directoryPath
*/
public static void readTxtDirectory(String directoryPath){
File dir = new File(directoryPath);
if(dir.isFile()) { //读取文件
readTxtFile(directoryPath);
} else if(dir.isDirectory()) { //读取目录
File[] files = dir.listFiles();
for(int i=0;i<files.length;i++){
System.out.println((files[i].isDirectory()?"目录 :":"文件 :")+files[i].getName());
if(files[i].isFile()) {
readTxtFile(files[i].getAbsolutePath());
} else {
readTxtDirectory(files[i].getAbsolutePath());
}
}
} else {
System.out.println("路径不存在!");
}
}
/**
* 功能:Java读取Txt文件的内容
* 步骤:1:先获得文件句柄
* 2:获得文件句柄当做是输入一个字节码流,需要对这个输入流进行读取
* 3:读取到输入流后,需要读取生成字节流
* 4:一行一行的输出。readline()。
* 备注:需要考虑的是异常情况
* @param filePath
*/
public static void readTxtFile(String filePath){
try {
String encoding="GBK";
File file = new File(filePath);
if(file.isFile() && file.exists()){ //判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file),encoding);//考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while((lineTxt = bufferedReader.readLine()) != null){
lineTxt = lineTxt.trim();
if(lineTxt.length() > 0) {
String regEx = "[' ']+"; // 一个或多个空格
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(lineTxt);
String[] txtArray = m.replaceAll(";").trim().split(";");
if(txtArray.length == 6 && txtArray[0].length() == 15) {
System.out.println(lineTxt);
}
}
}
read.close();
} else {
System.out.println("文件不存在!");
}
} catch (Exception e) {
System.out.println("读取文件内容出错");
e.printStackTrace();
}
}
HttpClient 4:
连接超时:
httpclient.getParams().setParameter(CoreConnectionPNames.CONNECTION_TIMEOUT,60000);
// 或者
HttpConnectionParams.setConnectionTimeout(params, 6000);
读取超时:
httpclient.getParams().setParameter(CoreConnectionPNames.SO_TIMEOUT,60000);
// 或者
HttpConnectionParams.setSoTimeout(params, 60000);
HttpClient 3:
连接超时:
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(60000);
读取超时:
httpClient.getHttpConnectionManager().getParams().setSoTimeout(60000);
设置get方法请求超时为 5 秒
GetMethod getMethod= new GetMethod(url);
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT,5000 );
设置连接超时和请求超时,这两个超时的意义不同,需要分别设置
问:当定义了方法A和方法B,当实例化类后,多线程如何保证调用方法A时方法B即使被调用也不会被执行?Java有保证这种机制的关键字吗?
答:用 synchronized  修饰方法 例如:
修饰方法 例如:
public class O
{
public synchronized void A(){}
public synchronized void B(){}
}
同一个类中的所有synchronized修饰的方法是不能同时调用的,也就是说同时只能调用其中一个方法,比如线程1调用A方法,在A方法执行完之前,线程2调用B方法,这个时候线程2就会阻塞,直到线程1调用完A方法后,线程2才开始执行B方法!
还有一个解决方法就是加一个同步对象锁
public class O
{
Object lock;
public void A()
{
synchronized(lock)
{
//这里写方法内容
}
}
public void B()
{
synchronized(lock)
{
//这里写方法内容
}
}
}
注意:同一个类中所有的同步的静态方法,它们在类范围类是同步的,也就是同一时间只能有一个线程可以访问所有同步静态方法中的一个。
不同类中的静态同步方法互不影响。前面所说,静态同步方法是类级别的,也就是以类为单位进行控制的。如果两个线程访问不同类中的同步方法,这两个线程是不需要等待的,即使是静态方法。
1. 复制表结构及其数据:
create table table_name_new as select * from table_name_old
2. 只复制表结构:
create table table_name_new as select * from table_name_old where 1=2;
或者:
create table table_name_new like table_name_old
3. 只复制表数据:
如果两个表结构一样:
insert into table_name_new select * from table_name_old
如果两个表结构不一样:
insert into table_name_new(column1,column2...) select column1,column2... from table_name_old
以下内容是经过自己整理资料、官方文档所得:
web.xml 配置:
<servlet> <servlet-name>dispatcher</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <description>加载/WEB-INF/spring-mvc/目录下的所有XML作为Spring MVC的配置文件</description> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/spring-mvc/*.xml</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>dispatcher</servlet-name> <url-pattern>*.htm</url-pattern> </servlet-mapping>
这样,所有的.htm的请求,都会被DispatcherServlet处理;
初始化 DispatcherServlet 时,该框架在 web 应用程序WEB-INF 目录中寻找一个名为[servlet-名称]-servlet.xml的文件,并在那里定义相关的Beans,重写在全局中定义的任何Beans,像上面的web.xml中的代码,对应的是dispatcher-servlet.xml;当然也可以使用<init-param>元素,手动指定配置文件的路径;
dispatcher-servlet.xml 配置:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:mvc="http://www.springframework.org/schema/mvc" xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.0.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd"> <!-- 使Spring支持自动检测组件,如注解的Controller --> <context:component-scan base-package="com.minx.crm.web.controller"/> <bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver" p:prefix="/WEB-INF/jsp/" p:suffix=".jsp" /> </beans>
第一个Controller:
package com.minx.crm.web.controller; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; @Controller public class IndexController { @RequestMapping("/index") public String index() { return "index"; } }@Controller注解标识一个控制器,@RequestMapping注解标记一个访问的路径(/index.htm),return "index"标记返回视图(index.jsp);
注:如果@RequestMapping注解在类级别上,则表示一相对路径,在方法级别上,则标记访问的路径;
从@RequestMapping注解标记的访问路径中获取参数:
Spring MVC 支持RESTful风格的URL参数,如:
@Controller public class IndexController { @RequestMapping("/index/{username}") public String index(@PathVariable("username") String username) { System.out.print(username); return "index"; } }在@RequestMapping中定义访问页面的URL模版,使用{}传入页面参数,使用@PathVariable 获取传入参数,即可通过地址:http://localhost:8080/crm/index/tanqimin.htm 访问;
根据不同的Web请求方法,映射到不同的处理方法:
使用登陆页面作示例,定义两个方法分辨对使用GET请求和使用POST请求访问login.htm时的响应。可以使用处理GET请求的方法显示视图,使用POST请求的方法处理业务逻辑;
@Controller public class LoginController { @RequestMapping(value = "/login", method = RequestMethod.GET) public String login() { return "login"; } @RequestMapping(value = "/login", method = RequestMethod.POST) public String login2(HttpServletRequest request) { String username = request.getParameter("username").trim(); System.out.println(username); return "login2"; } }在视图页面,通过地址栏访问login.htm,是通过GET请求访问页面,因此,返回登陆表单视图login.jsp;当在登陆表单中使用POST请求提交数据时,则访问login2方法,处理登陆业务逻辑;
防止重复提交数据,可以使用重定向视图:
return "redirect:/login2"
可以传入方法的参数类型:
@RequestMapping(value = "login", method = RequestMethod.POST) public String testParam(HttpServletRequest request, HttpServletResponse response, HttpSession session) { String username = request.getParameter("username"); System.out.println(username); return null; }
可以传入HttpServletRequest、HttpServletResponse、HttpSession,值得注意的是,如果第一次访问页面,HttpSession没被创建,可能会出错;
其中,String username = request.getParameter("username");可以转换为传入的参数:
@RequestMapping(value = "login", method = RequestMethod.POST) public String testParam(HttpServletRequest request, HttpServletResponse response, HttpSession session,@RequestParam("username") String username) { String username = request.getParameter("username"); System.out.println(username); return null; }
使用@RequestParam 注解获取GET请求或POST请求提交的参数;
获取Cookie的值:使用@CookieValue :
获取PrintWriter:
可以直接在Controller的方法中传入PrintWriter对象,就可以在方法中使用:
@RequestMapping(value = "login", method = RequestMethod.POST) public String testParam(PrintWriter out, @RequestParam("username") String username) { out.println(username); return null; }
获取表单中提交的值,并封装到POJO中,传入Controller的方法里:
POJO如下(User.java):
public class User{ private long id; private String username; private String password; …此处省略getter,setter... }
通过表单提交,直接可以把表单值封装到User对象中:
@RequestMapping(value = "login", method = RequestMethod.POST) public String testParam(PrintWriter out, User user) { out.println(user.getUsername()); return null; }
可以把对象,put 入获取的Map对象中,传到对应的视图:
@RequestMapping(value = "login", method = RequestMethod.POST) public String testParam(User user, Map model) { model.put("user",user); return "view"; }
在返回的view.jsp中,就可以根据key来获取user的值(通过EL表达式,${user }即可);
Controller中方法的返回值:
void:多数用于使用PrintWriter输出响应数据;
String 类型:返回该String对应的View Name;
任意类型对象:
返回ModelAndView:
自定义视图(JstlView,ExcelView):
拦截器(Inteceptors):
public class MyInteceptor implements HandlerInterceptor { public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object o) throws Exception { return false; } public void postHandle(HttpServletRequest request, HttpServletResponse response, Object o, ModelAndView mav) throws Exception { } public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object o, Exception excptn) throws Exception { } }
拦截器需要实现HandleInterceptor接口,并实现其三个方法:
preHandle:拦截器的前端,执行控制器之前所要处理的方法,通常用于权限控制、日志,其中,Object o表示下一个拦截器;
postHandle:控制器的方法已经执行完毕,转换成视图之前的处理;
afterCompletion:视图已处理完后执行的方法,通常用于释放资源;
在MVC的配置文件中,配置拦截器与需要拦截的URL:
<mvc:interceptors> <mvc:interceptor> <mvc:mapping path="/index.htm" /> <bean class="com.minx.crm.web.interceptor.MyInterceptor" /> </mvc:interceptor> </mvc:interceptors>
国际化:
在MVC配置文件中,配置国际化属性文件:
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource" p:basename="message"> </bean>
那么,Spring就会在项目中搜索相关的国际化属性文件,如:message.properties、message_zh_CN.properties
在VIEW中,引入Spring标签:<%@taglib uri="http://www.springframework.org/tags" prefix="spring" %>,使用<spring:message code="key" />调用,即可;
如果一种语言,有多个语言文件,可以更改MVC配置文件为:
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"> <property name="basenames"> <list> <value>message01</value> <value>message02</value> <value>message03</value> </list> </property> </bean>
sql server中如何连接表更新数据
假设a,b两表有外键关联,想要从b表中取出相应字段的值更新a表字段,可以有如下几种写法:
update a set a.name=b.name from a,b where a.id=b.id
update a inner join b on a.id=b.id set a.name=b.name where ...
update table1 set a.name = b.name from table1 a inner join table2 b on a.id =b
二:
表hotel中有id,hotel_city。
表hotel_room中有id,hotel_id,其中hotel_id与表hotel中的id对应。
表hotel_room_price中有room_id,price,price_year_month,其中room_id与hotel_room中的id对应。其余各项数据之间没有关联。
现在要求更新表hotel_room_price中的price字段,符合的条件是room_id对应的hotel_city是744,且price_year_month是'20114'。
SQL语句:
update hotel_room_price set price = 0 from hotel_room_price a,hotel_room b,hotel c where a.room_id = b.id and b.hotel_id = c.id and c.hotel_city = 744 and a.price_year_month = '20114'
重点看红色的部分。from后跟的是需要联立的三个表。用where a.room_id = b.id and b.hotel_id = c.id来将三个表当中需要对应的字段联立起来。and c.hotel_city = 744 and a.price_year_month = '20114'则是最后指定的两个条件。
运行无错误。
在调试zencart网店时,有时修改了某些文件,网店前台显示不完整了,或者出现了空白页面,可以通过以下方法打开错误提示:
版本 v1.3.9 的排错方法
错误记录在 /cache/ 目录下,前台的错误记录文件名为 "myDebug-xxxxxx.log" ,后台的错误记录文件名为 "myDebug-adm-xxxxxxx.log"
如果需要在浏览器中显示出错误信息(注意,客户也会看到错误信息),执行下面的操作:
如果是前台错误,打开文件 \includes\extra_configures\enable_error_logging.php
如果是后台错误,打开文件 \admin\includes\extra_configures\enable_error_logging.php
查找 @ini_set('display_errors', 0);
修改为 @ini_set('display_errors', 1);
版本 v1.3.8 的排错方法
前台界面排错适用
打开文件 \includes\application_top.php ,找到
if (defined('STRICT_ERROR_REPORTING') && STRICT_ERROR_REPORTING == true) {
在前面增加一行
define('STRICT_ERROR_REPORTING', true);
保存后重新刷新网页,就会有错误提示了。
把上面的语句修改为
define('STRICT_ERROR_REPORTING', false);
就能关闭错误提示了。
后台界面排错适用
打开文件 \admin\includes\application_top.php,找到
error_reporting(E_ALL & ~E_NOTICE);
修改为
@ini_set('display_errors', '1');
error_reporting(E_ALL);
找到错误后,再修改回去关闭错误提示
前两天在本地搭建一个网站,准备做下数据,安装好以后,发现登陆后台很慢,等了好久出现后台空白,开启错误提示也没用,根本就没错误,当时想,难道我这个站搭建的有问题。所以我又访问了以前搭建的站点,出现同样的错误。
难道是我本地环境出现问题了?或许是吧,所以一气之下就把本地环境重新搭建了一下,发现还是不行;难道是集成环境版本太低了,我又从官网下载一个新的,最后发现还是不行,不是这个问题。无语了……
然后我就再网上找啊找,最后根据一个的提示,我找到了一个解决办法,原来是线路的问题。前段时间我一直用的电信线路,最近换成了联通线路,就遇到这 样的问题,可能是最近联通线路有点问题。MD。折腾老子一下午才找到原因,为了避免和我一样的“程序猿”浪费时间,所以我就写下来,希望对你们有用。
解决办法:
把admin(网站后台目录)\includes\local\skip_version_check.ini文件里面的version_check=no修改成version_check=off 就可以了。
因为安装zen-cart的时候,默认会选择那个版本更新选项,当进入后台的时候,一直更新不了,所以会出现那个问题了。
自从上一篇
zen-cart采集规则和数据库发布模块下载以后。很多人问我为什么他的不能采集,原来发现他们用的几乎都是免费版的,不能直接导入数据库中,可以做成CVS格式的,但是遗憾的是不能下载图片,所以这次我就做个简单的教程,大致说一下。
quill.com 测试网站我用的是这个
第一种方式不能直接下载图片,但是可以通过迅雷下载。
第二种方式可以直接下载图片,但是批量中的那个图片字段有点乱,可以批量替换。
这两种方式下载图片的区别在于如图对比
第一种方式图1

第二种方式图2

今天答应两位朋友的要求,说说如何采集细节图!首先说说我是如何学会采集的吧,当时接触火车头采集器的时候,发现这方面的资料很少(针对 zencart的),什么采集规则,数据库发布模块,第一次用这玩意,有太多不明白的地方。我每天就不断查资料,不断测试,还好我是计算机专业的,学过一 些编程知识,将近花了一个星期才学会采集,当你看到你这篇文章时,希望你们也好好不断测试,不断分析问题,只有这样,以后遇到跟复杂的问题,才能会解决, 或许有些问题,只有少量的人遇到,只能靠自己了。好像很多人认为这个简单,也没有这方面的教程,可是对于我们这样的菜鸟来说,入门是必要的。也有一些收费 的,给别人采集一个站,做个批量表收多少钱等等。互联网提倡的就是资源共享,授人之鱼不如授人之渔。其实我对火车头采集器更多的功能没有深入了解,我只是 把我工作中学会的东西分享出来,再某些人看来,可能没有什么意义。我不会给别人采集一个网站收多少钱,说实话我现在还没那个能力,也没有太多的时间。废话 不多说了,开始今天的教程。
前面我的就不再介绍了,首先我找了一个有细节图的网站,例如www.jerseyscool.com。我们只看第二步:采集内容规则。我们添加一个标签名,就叫商品细节图,我的规则如下图(其实与商品图像差不多了)

然后要注意左下角的标签循环匹配,选择“添加为新记录”。看我采集的效果,只是我的网速慢,还没下载完 ,看到那个第几条记录没,就说明我们规则写对了,可以进行采集了。

最后一步要注意,搞zencart应该都知道,细节图是不写入数据库的,是根据图片名称匹配的,第三步设置如下图,不再在写入数据了,放到一个文件夹就行了。

最后需要说明的,我们做这一步是纯粹为了得到细节图。所以我要首先按照上一次的教程,采集完数据,然后再采集细节图。采集细节图我们可以一下子采集完,具体怎么采集明天到公司再补充(家里的网络实在太慢了,没法搞了)。这一次我就不把采集规则发上来了,其实很简单。
最近有人问我采集完了才做成批量表,其实很简单了,你在你的网站上安装一个批量表不就行了,可以把采集的数据放到另一个网站上,这一步我就操作了,不明白的可以给我留言或者加我q,最好是留言,我会认真回答你们的!
你们的鼓励是我最大的动力,我也是菜鸟,我们一起共同进步,最近一直在学习magento,下一步可能要针对magento进行采集了,呵呵,欢迎朋友们批评和指正!
首先安装zen-cart,我用的是zen-cart1.9中文版的,安装步骤我就不写了,这个很简单了。安装以后根据你要采集的网站建立对应的目录就OK了。例如我要测试采集的网站www.yankeesjerseystore.com这 是我随便找的网站,我首先建立大分类Shop By Players 然后建立相应的小分类Alex Rodriguez Jersey(多页面,等会解释这个)和Folder Alfonso Soriano Jersey(单页面)。我只是测试采集就先建一个大分类两个小分类。如下图
大分类
小分类
然后开始写采集规则了,每个网站的采集规则是不一样的,针对每个网站写不同的规则,不过zen-cart网站的规则差不多了,写多了就会发现很简单。
第一步写采集网址规则,首先添加采集地址(我添加的是http://www.yankeesjerseystore.com/new-york- yankees-jersey-alex-rodriguez-jersey-c-6_16.html?page=(*)&sort=20a)如 下图
然后为了采集自己想要的页面,就必须过滤一些网址了,就要写一些限制性的标志了,必须包含,不得包含,页面内选定区域采集网址从xx到xx等请看下图我是如何写的,这个不是唯一性的,每个人写的可能不一样。
这一步算是完成了。
第二步写采集内容规则,我把每个标签名对应规则放出来,如下图
商品名称
商品型号
商品价格
商品特价
商品图像,注意哪个文件保存格式,我选择了[原文件名],根据自己的需要也可以改
商品描述,注意用哪个html标签排除,我用了去首尾空白符
OK,规则写完了,可以找个内容页测试一下,如下图
看,已经测试成功了,注意图片一定要显示完整。
第三步发布内容设置,有几种发布方式,我选择方式三,导入到自定义数据库,如下图
然后点击数据库发布全局配置,选择编辑你要编辑数据库发布配置,如下图
点击编辑以后,出现下图
然后编辑数据库发布模块,如下图
看到你刚才写的标签名没,注意这个地方的标签与刚才写的标签名要对应着,,不然就会失败的,看到最后那个“2”没,就是刚才我们建立栏目时的分 类ID,每采集一个栏目的时候变换不同的ID,上面我已经写了,不需要改动了,最后我会把发布模块分享给朋友们。修改完以后,要点击那个“修改配置”这样 才能保存着。
第四步文件保存及部分高级设置,如下图,基本上不用改变。
最后一步,点击更新,然后就可以点击开始采集了,采集效果如下图
OK,采集成功了,可以发布到数据库了,然后我到网站后台看一下,是不是已经导入到数据库了,呵呵!如下图,成功了
后台效果
前台效果
最后要说明一点,采集单网址也是一样,注意选择如下图
好了,教程写完了,挺累的,写了两个小时,不知道你们看明白没,反正我是很明白(呵呵),根据不同的网站灵活运用就OK了,稍后我把采集规则放出来,供朋友下载,有不明白的地方可以给我留言或者加我qq
zen-cart.rar(点击下载哦)
PreparedStatement 使用like
在使用PreparedStatement进行模糊查询的时候废了一番周折,以前一直都没有注意这个问题。一般情况下我们进行精确查询,sql语句类似:select * from table where name =?,然后调用 PreparedStatement的setString等方法给?指定值。那么模糊查询的时候应该怎么写呢?我首先尝试了:select * from customer where name like ‘%?%’。
此时程序报错,因为?被包含在了单引号中,PreparedStatement并不视它为一个参数。后来上网查了相关的一些资料,发现可以这样写select * from table where name like ?;但是在指定参数的时候把?指定为”%”+name+”%”,name是指定的查询条件。这样就OK了。
一般情况下,我总是潜意识的认定了?就是取代所指定的参数,但是实际上我们可以对指定的参数进行了一定的包装之后再传给?,比如这里我们在参数的前后都加了一个%,然后再传给?
String expr = "select * from table where url like ?";
pstmt = con.prepareStatement(expr);
String a="a";
pstmt.setString(1, "%"+a+"%");//自动添加单引号 (包装后的参数)
pstmt.execute();
System.out.println(pstmt.toString());//打印sql
//会默认生成sql: select * from table where url like '%http%'
PHP $_GET
$_GET 变量是一个数组,内容是由 HTTP GET 方法发送的变量名称和值。
PHP $_POST
$_POST 变量用于收集来自 method="post" 的表单中的值。
$_POST 变量
$_POST 变量是一个数组,内容是由 HTTP POST 方法发送的变量名称和值。
$_POST 变量用于收集来自 method="post" 的表单中的值。从带有 POST 方法的表单发送的信息,对任何人都是不可见的(会显示在浏览器的地址栏),并且对发送信息的量也没有限制。
例子
<form action="welcome.php" method="post"> Enter your name: <input type="text" name="name" /> Enter your age: <input type="text" name="age" /> <input type="submit" /> </form>
当用户点击提交按钮,URL 不会含有任何表单数据,看上去类似这样:
http://www.w3school.com.cn/welcome.php
"welcome.php" 文件现在可以通过 $_POST 变量来获取表单数据了(请注意,表单域的名称会自动成为 $_POST 数组中的 ID 键):
Welcome <?php echo $_POST["name"]; ?>.<br /> You are <?php echo $_POST["age"]; ?> years old!
为什么使用 $_POST?
- 通过 HTTP POST 发送的变量不会显示在 URL 中。
- 变量没有长度限制。
不过,由于变量不显示在 URL 中,所有无法把页面加入书签。
$_REQUEST 变量
PHP 的 $_REQUEST 变量包含了 $_GET, $_POST 以及 $_COOKIE 的内容。
PHP 的 $_REQUEST 变量可用来取得通过 GET 和 POST 方法发送的表单数据的结果。
例子
Welcome <?php echo $_REQUEST["name"]; ?>.<br /> You are <?php echo $_REQUEST["age"]; ?> years old!
ATTENTION:慎用$_REQUEST
如果get的一个变令名称和post的一个变量名称相同,则POST的值会覆盖GET的变量值
以为REQYEST先获取了get的值,然后获取了post的值,post的值会覆盖get值
我们可以来看php.ini中的配置
; This directive describes the order in which PHP registers GET, POST, Cookie,
; Environment and Built-in variables (G, P, C, E & S respectively, often
; referred to as EGPCS or GPC). Registration is done from left to right, newer
; values override older values.
variables_order = "EGPCS"
这个EGPCS就是说明用$_REQUEST数组获取内容的优先级,其字母的含义分别代表为:E代表$_ENV,G代表$_GET,P代表$_POST,C代表$_COOKIE,S代表$_SESSION。后面出现的数据会覆盖前面写入的数据,其默认的数据写入方式就是EGPCS,所以POST包含的数据将覆盖GET中使用相同关键字的数据。
通过这个我们也可以看出PHP获取参数的步骤
环境变量=》GET=》POST=》COOKIE=>SESSION
PHP中有$_REQUEST与$_POST、$_GET用于接受表单数据。
一、$_REQUEST与$_POST、$_GET的区别和特点
$_REQUEST[]具用$_POST[] $_GET[]的功能,但是$_REQUEST[]比较慢。通过POST和GET方法提交的所有数据都可以通过$_REQUEST数组获得。
二、$_POST、$_GET的区别和特点
1. GET是从服务器上获取数据,POST是向服务器传送数据。
2. GET是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段一一对应,在URL中可以看到。POST是通过HTTP POST机制,将表单内各个字段与其内容放置在HTML HEADER内一起传送到ACTION属性所指的URL地址。用户看不到这个过程。
3. 对于GET方式提交表单数据,服务器端用$_GET[‘name’]获取变量的值,对于POST方式提交表单数据,服务器端用$_POST[‘name’]获取提交的数据,当然,两者都可以通过$_REQUEST[‘name’]获得表单数据。对于REQUEST方式提交表单数据,服务器端用$_REQUEST[‘name’]获取变量的值,但这种方式很少用。
4. GET传送的数据量较小,不能大于2KB。POST传送的数据量较大,一般被默认为不受限制。但理论上,一般认为不能超过100KB。
5. GET安全性非常低,POST安全性较高。
6. GET表单值可以通过_GET获取;但通过action的url设置的参数总是获取不到的,<form method="get" action="a.asp?b=b">跟<form method="get"action="a.asp">是一样的,也就是说,在这种情况下,GET方式会忽略action页面后边带的参数列表。POST表单值可以通过_POST获取;但通过action的url参数设置的参数则可以不能通过_POST获取到。action=test.php?id=1这种就是GET方式传值,可以用$_REQUEST和$_GET接受传值,但不能用POST方式获取到值,即使表单是POST方式提交。所在,在提交表单时,如果action中同时有参数,最好只能通过POST表单方式,对于表单内数据,直接通过POST获取,对于action中参数,童工GET获取。
在做数据查询时,建议用GET方式,而在做数据添加、修改或删除时,建议用POST方式。
request是先读取 get再读post 的, 同时存在, 即覆盖掉前面的变量。
经典实例:
<?php
echo "get\n";
print_r($_GET);
echo "post\n";
print_r($_POST);
echo "request\n";
print_r($_REQUEST);
?>
<form method=post action='?a=1&b=2'>
<input type=text name=a value='a'>
<input type=text name=b value='b'>
<input type=submit value=test>
</form>
输出结果:
get:
Array
(
[a] => 1
[b] => 2
)
post:
Array
(
[a] => a
[b] => b
)
request:
Array
(
[a] => a
[b] => b
)
其实,在php配置文件php.ini中有一个设置项:variables_order = "GPCS" ,GPCS分别是GET,POST,Cookie,Server的首字母缩写,variables_order = "GPCS"含义是php文件中变量的解析顺序是GET,POST,Cookie和Server。
代码 POS显示的内容原因/操作员应采取的措施
00 交易成功 承兑或交易成功
01 交易失败 请联系发卡行 查发卡行
02 交易失败 请联系发卡行向发卡行查询
03 商户未登记 联系银行卡服务中心处理
04 没收卡 请联系收单行 操作员没收卡
05 交易失败 请联系发卡行 发卡不予承兑,与发银行联系查询
06 交易失败 请联系发卡行发卡行故障
07 没收卡 请联系收单行 特殊条件下没收卡
09 交易失败 请重试 重做该交易
12 交易失败 请重试 发卡行不支持的交易
13 交易金额超限 请重试交易金额无效,采用小金额交易或与发卡行联系
14 无效卡号 请联系发卡行无效卡号,与银行卡服务中心或发卡行联系
15 此卡不能受理 请与银行卡服务中心联系处理
19 交易失败 请联系发卡行 刷卡读取数据有误,重新刷卡
20 交易失败 请联系发卡行 与银行卡服务中心或发卡行联系
21 交易失败 请联系发卡行 与银行卡服务中心或发卡行联系
22 操作有误 请重试 POS状态与中心不符,重新签到
23 交易失败 请联系发卡行 不可接受的交易费
25 交易失败 请联系发卡行发卡行未能找到有关记录,核对有关资料重做该交易或与发卡行联系
30 交易失败 请重试 检查卡磁条是否完好或反方向刷卡
31 此卡不能受理 此发卡方未与中心开通业务
33 过期卡 请联系发卡行 过期的卡或与发卡行联系
34 没收卡 请联系收单行 有作弊嫌疑的卡,操作员可以没收
35 没收卡 请联系收单行 有作弊嫌疑的卡,操作员可以没收
36 此卡有误 请换卡重试 有作弊嫌疑的卡,操作员可以没收
37 没收卡 请联系收单行 有作弊嫌疑的卡,操作员可以没收
38 密码错误次数超限 密码输错的次数超限
39 交易失败 请联系发卡行 可能刷卡操作有误
40 交易失败 请联系发卡行 发卡行不支持的交易类型
41 没收卡 请联系收单行 挂失的卡,与发卡行联系处理
42 交易失败 请联系发卡方 发卡行找不到此帐户
43 没收卡 请联系收单行 被窃卡, 操作员可以没收
44 交易失败 请联系发卡行 可能刷卡操作有误
51 余额不足 请查询 帐户内余额不足
52 交易失败 请联系发卡行 无此支票账户
53 交易失败 请联系发卡行 无此储蓄卡账户
54 过期卡 请联系发卡行 过期的卡
55 密码错 请重试 密码输错,可重新输入
56 交易失败 请联系发卡行 发卡行找不到此帐户,与发卡行联系
57 交易失败 请联系发卡行不允许持卡人进行的交易,与发卡行联系
58 终端无效 请联系收单行或银联重新签到再试或与银行卡服务中心联系
59 交易失败 请联系发卡行 与发卡行联系
60 交易失败 请联系发卡行 与发卡行联系
61 金额太大 超出去款金额限制
62 交易失败 请联系发卡行 受限制的卡
63 交易失败 请联系发卡行 违反安全保密规定
64 交易失败 请联系发卡行原始金额不正确,核对原始资料或与发卡行联系
65 超出取款次数限制 超出取款次数限制
66 交易失败 请联系收单行或银联 与发卡放联系处理
67 没收卡 没收卡
68 交易超时 请重试发卡行规定时间内没有应答,与银行卡服务中心或发卡行联系
75 密码错误次数超限允许的输入PIN次数超限 该卡要重置密码方能使用
77 请向网络中心签到 重做签到
79 POS终端重传脱机数据 POS终端上传的脱机数据对帐不平
90 交易失败 请稍后重试日期切换正在处理,与银行卡服务中心或发卡行联系
91 交易失败 请稍后重试 电话查询发卡方或银联,可重作
92 交易失败 请稍后重试银行通讯故障,电话查询发卡方或网络中心
93 交易失败 请联系发卡行 交易违法、不能完成。重新签到后再试
94 交易失败 请稍后重试重新签到后再交易或与银行卡服务中心联系
95 交易失败 请稍后重试发卡行调节控制错,与发卡行联系
96 交易失败 请稍后重试 与发卡行或银行卡服务中心联系
97 终端未登记 请联系收单行或银联与银行卡服务中心联系
98 交易超时 请重试银联收不到发卡行应答,与银行卡服务中心或发卡行联系
99 校验错 请重新签到 重新签到再作交易
A0 校验错 请重新签到 重新签到作交易
摘要: POS机的主要功能点: 1. 签到 2. 输入密码 3. 消费 4. 余额查询 5. 撤销 6. 系统设置 我公司建议: 1:为统一格式及今后扩展,近可能按照银联标准开发: 2:增加“批结算”功能; 3:建议把卡号信息写在磁条卡“2磁道”; 4:报文格式: TPDU(10字节) + 报文头(12字节)+ 消息类型(4字节)+ 位图(8字节)+位图保护...
阅读全文
-------------------------------------
MyEclipse 快捷键1(CTRL)
-------------------------------------
Ctrl+1 快速修复
Ctrl+D: 删除当前行
Ctrl+Q 定位到最后编辑的地方
Ctrl+L 定位在某行
Ctrl+O 快速显示 OutLine
Ctrl+T 快速显示当前类的继承结构
Ctrl+W 关闭当前Editer
Ctrl+K 快速定位到下一个
Ctrl+E 快速显示当前Editer的下拉列表
Ctrl+J 正向增量查找(按下Ctrl+J后,你所输入的每个字母编辑器都提供快速匹配定位到某个单词,如果没有,则在stutes line中显示没有找到了,)
Ctrl+Z 返回到修改前的状态
Ctrl+Y 与上面的操作相反
Ctrl+/ 注释当前行,再按则取消注释
Ctrl+D删除当前行。
Ctrl+Q跳到最后一次的编辑处
Ctrl+M切换窗口的大小
Ctrl+I格式化激活的元素Format Active Elements。
Ctrl+F6切换到下一个Editor
Ctrl+F7切换到下一个Perspective
Ctrl+F8切换到下一个View
------------------------------------------
MyEclipse 快捷键2(CTRL+SHIFT)
------------------------------------------
Ctrl+Shift+E 显示管理当前打开的所有的View的管理器(可以选择关闭,激活等操作)
Ctrl+Shift+/ 自动注释代码
Ctrl+Shift+\自动取消已经注释的代码
Ctrl+Shift+O 自动引导类包
Ctrl+Shift+J 反向增量查找(和上条相同,只不过是从后往前查)
Ctrl+Shift+F4 关闭所有打开的Editer
Ctrl+Shift+X 把当前选中的文本全部变为小写
Ctrl+Shift+Y 把当前选中的文本全部变为小写
Ctrl+Shift+F 格式化当前代码
Ctrl+Shift+M(先把光标放在需导入包的类名上) 作用是加Import语句
Ctrl+Shift+P 定位到对于的匹配符(譬如{}) (从前面定位后面时,光标要在匹配符里面,后面到前面,则反之)
Ctrl+Shift+F格式化文件Format Document。
Ctrl+Shift+O作用是缺少的Import语句被加入,多余的Import语句被删除。
Ctrl+Shift+S保存所有未保存的文件。
Ctrl+Shift+/ 在代码窗口中是这种/*~*/注释,在JSP文件窗口中是 <!--~-->。
Shift+Ctrl+Enter 在当前行插入空行(原理同上条)
-----------------------------------------
MyEclipse 快捷键3(ALT)
-----------------------------------------
Alt+/ 代码助手完成一些代码的插入 ,自动显示提示信息
Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)
Alt+↑ 当前行和上面一行交互位置(同上)
Alt+← 前一个编辑的页面
Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)
Alt+Enter 显示当前选择资源(工程,or 文件 or文件)的属性
MyEclipse 快捷键4(ALT+CTRL)
Alt+CTRL+↓ 复制当前行到下一行(复制增加)
Alt+CTRL+↑ 复制当前行到上一行(复制增加)
-------------------------------------------
MyEclipse 快捷键5(ALT+SHIFT)
-------------------------------------------
Alt+Shift+R 重命名
Alt+Shift+M 抽取方法
Alt+Shift+C 修改函数结构(比较实用,有N个函数调用了这个方法,修改一次搞定)
Alt+Shift+L 抽取本地变量
Alt+Shift+F 把Class中的local变量变为field变量
Alt+Shift+I 合并变量
Alt+Shift+V 移动函数和变量
Alt+Shift+Z 重构的后悔药(Undo) Shift+Enter 在当前行的下一行插入空行(这时鼠标可以在当前行的任一位置,不一定是最后)
Alt+Shift+O(或点击工具栏中的Toggle Mark Occurrences按钮) 当点击某个标记时可使本页面中其他地方的此标记黄色凸显,并且窗口的右边框会出现白色的方块,点击此方块会跳到此标记处。
下面的快捷键是重构里面常用的,本人就自己喜欢且常用的整理一下(注:一般重构的快捷键都是Alt+Shift开头的了)
--------------------------------------------
MyEclipse 快捷键(6)
--------------------------------------------
F2当鼠标放在一个标记处出现Tooltip时候按F2则把鼠标移开时Tooltip还会显示即Show Tooltip Description。
F3跳到声明或定义的地方。
F5单步调试进入函数内部。
F6单步调试不进入函数内部,如果装了金山词霸2006则要把“取词开关”的快捷键改成其他的。
F7由函数内部返回到调用处。
F8一直执行到下一个断点。
Java对象的持久化主要使用
ObjectInputStream与ObjectOutputStream类 来实现!
public class Student implements Serializable {
String name;
int id ;
int age;
String department;
public Student(String name, int id, int age, String department) {
this.age = age;
this.department = department;
this.id = id;
this.name = name;
}
public static void saveObjects(Student student, String fileName) {
FileOutputStream os = new FileOutputStream("fileName.dat");
ObjectOutputStream oos = new ObjectOutputStream(os);
oos.writeObject(student);
}
public static Student readObjects(String fileName) {
Student student;
Object obj;
try{
FileInputStream is = new FileInputStream("fileName.dat");
ObjectInputStream ois = new ObjectInputStream(is);
obj = ois.readObject();
}catch (Exception e) {
e.printStackTrace();
}
if(obj instanceof Student){
Student stu= (Student)obj;
return stu;
}
return null;
}
JAVA获取文件绝对路径:Thread.currentThread().getContextClassLoader().getResource("abc.properties");
配置文件:XXX.properties 常用操作
1:加载properties配置文件 /** * 根据key从Properties对象中得到相应的值
* @param key
* @return 对应的值
*/ public static String getValue(String key) {
if (p !=
null) {
return p.getProperty(key);
}
String property =
null;
InputStream in =
null;
try {
System.out.println("gleepay.properties is path : " + gleepayURL.getFile());
File file =
new File(gleepayURL.getFile());
in =
new FileInputStream(file);
p =
new Properties();
p.load(in);
property = p.getProperty(key);
}
catch (FileNotFoundException e) {
e.printStackTrace();
}
catch (IOException e) {
e.printStackTrace();
}
finally {
if (in !=
null) {
try {
in.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
}
return property;
}
2:写入propertis配置信息/**
* 写入properties信息
* @param parameterKey
* @param parameterValue
*
* @return
*/
public static void writeProperties_MACkey(String parameterKey, String parameterValue) {
String filePath = MACkeyURL.getFile();
Properties prop = new Properties();
try {
InputStream fis = new FileInputStream(filePath);
// 从输入流中读取属性列表(键和元素对)
prop.load(fis);
// 调用 Hashtable 的方法 put。使用 getProperty 方法提供并行性。
// 强制要求为属性的键和值使用字符串。返回值是 Hashtable 调用 put 的结果。
OutputStream fos = new FileOutputStream(filePath);
prop.setProperty(parameterKey, parameterValue);
// 以适合使用 load 方法加载到 Properties 表中的格式,
// 将此 Properties 表中的属性列表(键和元素对)写入输出流
prop.store(fos, "Update '" + parameterKey + "' value");
} catch (IOException e) {
System.err.println("Visit " + filePath + " for updating "
+ parameterKey + " value error");
e.printStackTrace();
}
}
3:根据key读取propertis文件value值
/**
* 根据key读取value
* @param filePath
* @param key
* @return 对应的值
*/
public static String readValueByKey(String filePath, String key) {
System.out.println("properties file is path : " + filePath);
Properties props = new Properties();
try {
InputStream in = new BufferedInputStream(new FileInputStream(filePath));
props.load(in);
String value = props.getProperty(key);
System.out.println(" --> " + key + "=" + value);
return value;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
4:读取properties配置文件所有信息
/**
* 读取properties的全部信息
* @param filePath
* @return
*/
@SuppressWarnings("unchecked")
public static void readPropertiesAll(String filePath) {
System.out.println("properties file is path : " + filePath);
Properties props = new Properties();
try {
InputStream in = new BufferedInputStream(new FileInputStream(filePath));
props.load(in);
Enumeration en = props.propertyNames();
while (en.hasMoreElements()) {
String key = (String) en.nextElement();
String Property = props.getProperty(key);
System.out.println(" --> " + key + "=" + Property);
}
} catch (Exception e) {
e.printStackTrace();
}
}
摘要: JAVA 对象拷贝 为什么需要有对象拷贝? 对象拷贝相对的自然是引用拷贝。java初学者经常会问,我这个方法要改变一个对象的属性,可以把参数传进去了,为什么没有改变了? ——基本数据类型传值,而对象传引用或引用的拷贝。 而有时候我们要获取到一个当前状态的对象复制品,他们是两个独立对象。不再是引用或者引用拷贝(实质都是指向对象本身)。就是说a是b的拷贝,b发生变化的时候,不要...
阅读全文
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.Enumeration;
import java.util.Properties;
public class TestMain {
//根据key读取value
public static String readValue(String filePath,String key) {
Properties props = new Properties();
try {
InputStream in = new BufferedInputStream (new FileInputStream(filePath));
props.load(in);
String value = props.getProperty (key);
System.out.println(key+value);
return value;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
//读取properties的全部信息
public static void readProperties(String filePath) {
Properties props = new Properties();
try {
InputStream in = new BufferedInputStream (new FileInputStream(filePath));
props.load(in);
Enumeration en = props.propertyNames();
while (en.hasMoreElements()) {
String key = (String) en.nextElement();
String Property = props.getProperty (key);
System.out.println(key+Property);
}
} catch (Exception e) {
e.printStackTrace();
}
}
//写入properties信息
public static void writeProperties(String filePath,String parameterName,String parameterValue) {
Properties prop = new Properties();
try {
InputStream fis = new FileInputStream(filePath);
//从输入流中读取属性列表(键和元素对)
prop.load(fis);
//调用 Hashtable 的方法 put。使用 getProperty 方法提供并行性。
//强制要求为属性的键和值使用字符串。返回值是 Hashtable 调用 put 的结果。
OutputStream fos = new FileOutputStream(filePath);
prop.setProperty(parameterName, parameterValue);
//以适合使用 load 方法加载到 Properties 表中的格式,
//将此 Properties 表中的属性列表(键和元素对)写入输出流
prop.store(fos, "Update '" + parameterName + "' value");
} catch (IOException e) {
System.err.println("Visit "+filePath+" for updating "+parameterName+" value error");
}
}
public static void main(String[] args) {
readValue("info.properties","url");
writeProperties("info.properties","age","21");
readProperties("info.properties" );
System.out.println("OK");
}
}
今天介绍的Scanner这个类是java 5新增加的类,不仅使用方便,功能更是强大。先来看一个简单的例子:
import java.util.*;
public class ScannerTest {
public static void main(String[] args){
Scanner scanner=new Scanner(System.in);
double a=scanner.nextDouble();
System.out.println(a);
}
} 运行
输入 一个任意数然后输出这个数
注意粗体字的地方,这一行就实现了从控制台输入数字的功能,如果要输入字符串
可以用
String a=scanner.next();//注意不是nextString()
Scanner还可以直接扫描文件。比如(有点长,耐心一点):
import java.util.*;
import java.io.*;
public class ScannerTest {
public static void main(String[] args) throws IOException{//这里涉及到文件io操作
double sum=0.0;
int count=0;
FileWriter fout=new FileWriter("text.txt");
fout.write("2 2.2 3 3.3 4 4.5 done");//往文件里写入这一字符串
fout.close();
FileReader fin=new FileReader("text.txt");
Scanner scanner=new Scanner(fin);//注意这里的参数是FileReader类型的fin
while(scanner.hasNext()){//如果有内容
if(scanner.hasNextDouble()){//如果是数字
sum=sum+scanner.nextDouble();
count++;
}else{
String str=scanner.next();
if(str.equals("done")){
break;
}else{
System.out.println("文件格式错误!");
return;