
2012年7月4日
js通过ajax传给后台一个json数组字符串:
[{'prjcode':'4209222012A00','countyname':'大悟县','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'},{'prjcode':'4209222005A03','countyname':'大悟县','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'},{'prjcode':'4209222005B00','countyname':'大悟县','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'}]
String jsonstr = request.getParameter("jsonstr");
JSONArray json = JSONArray.fromObject(jsonstr);
Object[] obj=json.toArray();
for(int i=0;i<obj.length;i++){
JSONObject object = JSONObject.fromObject(obj[i]);
String prjcode=object.get("prjcode").toString();
String countyname=object.getString("countyname").toString();
String pro_1=object.getString("pro_1").toString();
String pro_2=object.getString("pro_2").toString();
String pro_3=object.getString("pro_3").toString();
String pro_4=object.getString("pro_4").toString();
String pro_5=object.getString("pro_5").toString();
String pro_6=object.getString("pro_6").toString();
String pro_7=object.getString("pro_7").toString();
String pro_8=object.getString("pro_8").toString();
String pro_9=object.getString("pro_9").toString();
String pro_10=object.getString("pro_10").toString();
String pro_11=object.getString("pro_11").toString();
String pro_12=object.getString("pro_12").toString();
String pro_13=object.getString("pro_13").toString();
String pro_14=object.getString("pro_14").toString();
String pro_15=object.getString("pro_15").toString();
}
posted @
2012-08-16 22:36 zhanghu198901 阅读(2482) |
评论 (0) |
编辑 收藏
CSS之所以会如此流行,是它具备以下的优点
1、符合W3C标准。保证网站不会因为将来网络应用的升级而被淘汰。
2、支持浏览器的向后兼容,也就是无论未来的浏览器大战,胜利的是IE、chrome或者是火狐,网站都能很好的兼容。
3、搜索引擎更加友好。相对与传统的table, 采用DIV+CSS技术的网页,更加容易被搜索引擎找到。
4、样式的调整更加方便。内容和样式的分离,使页面和样式的调整变得更加方便,可以一次性修改多个网页的样式,只修改样式不需要重新发布。
5、降低网页大小,对于一个大型网站来说,可以节省大量带宽,大大提高用户体验,这是非常重要的一点——用户至上。
posted @
2012-08-16 22:36 zhanghu198901 阅读(1115) |
评论 (0) |
编辑 收藏在网上会有很多关于struts2结合autocomplet插件的实例,但是不怎么完整,让人感觉不清楚,刚刚在公司做了一个关于这个的项目,页面也用到了这个插件,所以把详细的步骤和注意事项贴出来和大家分享,废话不多说,贴铁代码:本文代码下载地址:http://download.csdn.net/detail/harderxin/4504612
一、我的资源中有autcomplet的json实例和autocomplet的源代码,也是copy网上的,大家可以免费下载,下载地址:http://download.csdn.net/detail/harderxin/4504288
二、开始我们的案例旅程
1、编写页面index.jsp
<body>
自动提示:
<!-- autocomplete防止一些浏览器的自动提示完成功能 -->
<input type="text" name="content" id="content" autocomplete="off" onkeyup="value=value.replace(/[^\a-\z\A-\Z0-9\u4E00-\u9FA5]/g,'')"/>
<input type="button" id="button" name="button" value="提交" onclick="" />
<br />
<p>
</p>
</body>
显示效果如下: 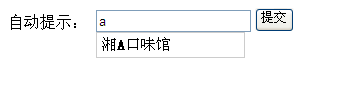
posted @
2012-08-16 22:34 zhanghu198901 阅读(1259) |
评论 (0) |
编辑 收藏PS:在所有例子中正则表达式匹配结果包含在源文本中的【和】之间,有的例子会使用java来实现,如果是java本身正则表达式的用法,会在相应的地方说明。所有java例子都在JDK1.6.0_13下测试通过。
一、对特殊字符进行转义
元字符是一些在正则表达式里有着特殊含义的字符。因为元字符在正则表达式里有着特殊的含义,所以这些字符就无法用来代表它们本身。在元字符前面加上一个反斜杠就可以对它进行转义,这样得到的转义序列将匹配那个字符本身而不是它特殊的元字符含义。如,如果想要匹配[和],就必须对它进行转义:\[和\]。
对元字符转义需要用到斜杠\字符,这就意味着\字符本向也是一个元字符,要匹配\字符本身,必须转义成\\。如匹配windows文件路径。
二、匹配空白字符
元字符大致可以分为两种:一种是用来匹配文本的(如.),另一种是正则表达式的语法所要求的(如[和])。
在进行正则表达式搜索的时候,我们经常会遇到需要对原始文本中里的非打印空白字符进行匹配的情况。比如说,我们可能需要把所有的制表符找出来,或者我们需要把换行符找出来,这类字符很难被直接输入到一个正则表达式里,这时我们可以使用如下列出的特殊元字符来输入它们:
\b 回退(并删除)一个字符(Backspace键)
\f 换页符
\n 换行符
\r 回车符
\t 制表符(Tab键)
\v 垂直制表符
来看一个例子,把文件中的空白行去掉:
文本:
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 26 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
正则表达式:\r\n\r\n
分析:\r\n匹配一个回车+换行组合,windows操作系统中把它作为文本行的结束标签。使用正则表达式\r\n\r\n进行的搜索将匹配两个连续的行尾标签,而这正好是空白行。
注意:Unix和Linux操作系统中只使用一个换行符来结束一个文本行,换句话说,在Unix或Linux系统中匹配空白行只使用\n\n即可,不需要加上\r。同时适用于windows和Unix/Linux的正则表达式应该包括一个可先的\r和一个必须匹配的\n,即\r?\n\r?\n,这将会在后面的文章中讲到。
Java代码如下:
public static void matchBlankLine() throws Exception{
BufferedReader br = new BufferedReader(new FileReader(new File("E:/九宫格.txt")));
StringBuilder sb = new StringBuilder();
char[] cbuf = new char[1024];
int len = 0;
while(br.ready() && (len = br.read(cbuf)) > 0){
br.read(cbuf);
sb.append(cbuf, 0, len);
}
String reg = "\r\n\r\n";
System.out.println("原内容:\n" + sb.toString());
System.out.println("处理后:-----------------------------");
System.out.println(sb.toString().replaceAll(reg, "\r\n"));
}
运行结果如下:原内容:
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 2 6 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
处理后:-----------------------------
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 2 6 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
三、匹配特定的字符类别
字符集合(匹配多个字符中的某一个)是最常见的匹配形式,而一些常用的字符集合可以用特殊元字符来代替。这些元字符匹配的是某一类别的字符(类元字符),类元字符并不是必不可少的,因为可以通过逐一列举有关字符或通过定义一个字符区间来匹配某一类字符,但是使用它们构造出来的正则表达式简明易懂,在实际应用中很常用。
1、匹配数字与非数字
\d 任何一个数字,等价于[0-9]或[0123456789]
\D 任何一个非数字,等价于[^0-9]或[^0123456789]
2、匹配字母和数字与非字母和数字
字母(A-Z不区分大小写)、数字、下划线是一种常用的字符集合,可用如下类元字符:
\w 任何一个字母(不区分大小写)、数字、下划线,等价于[0-9a-zA-Z_]
\W 任何一个非字母数字和下划线,等价于[^0-9a-zA-Z_]
3、匹配空白字符与非空白字符
\s 任何一下空白字符,等价于[\f\n\r\t\v]
\S 任何一下空白字符,等价于[^\f\n\r\t\v]
注意:退格元字符\b没有不在\s的范围之内。
4、匹配十六进制或八进制数值
十六进制:用前缀\x来给出,如:\x0A对应于ASCII字符10(换行符),其效果等价于\n。
八进制:用前缀\0来给出,数值本身可以是两位或三位数字,如:\011对应于ASCII字符9(制表符),其效果等价于\t。
四、使用POSIX字符类
POSIX字符类是很多正则表达式实现都支持的一种简写形式。Java也支持它,但JavaScript不支持。POSIX字符如下所示:
[:alnum:] 任何一个字母或数字,等价于[a-zA-Z0-9]
[:alpha:] 任何一个字母,等价于[a-zA-Z]
[:blank:] 空格或制表符,等价于[\t]
[:cntrl:] ASCII控制字符(ASCII 0到31,再加上ASCII 127)
[:digit:] 任何一个数字,等价于[0-9]
[:graph:] 任何一个可打印字符,但不包括空格
[:lower:] 任何一个小写字母,等价于[a-z]
[:print:] 任何一个可打印字符
[:punct:] 既不属于[:alnum:]和[:cntrl:]的任何一个字符
[:space:] 任何一个空白字符,包括空格,等价于[^\f\n\r\t\v]
[:upper:] 任何一个大写字母,等价于[A-Z]
[:xdigit:] 任何一个十六进制数字,等价于[a-fA-F0-9]
POSIX字符和之前见过的元字符不太一样,我们来看一个前面利用正则表达式来匹配网页中的颜色的例子:
文本:<span style="background-color:#3636FF;height:30px;width:60px;">测试</span>
正则表达式:#[[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]]
结果:<span style="background-color:【#3636FF】;height:30px;width:60px;">测试</span>
注意:这里使用的模式以[[开头、以]]结束,这是使用POSIX字符类所必须的,POSIX字符必须括在[:和:]之间,外层[和]字符用来定义一个集合,内层的[和]字符是POSIX字符类本身的组成部分。
在java中的POSIX字符表示有所不同,不是包括在[:和:]之间,而是以\p开头,包括在{和}之间,且大小写有区别,同时增加了\p{ASCII},如下所示:
\p{Alnum} 字母数字字符:[\p{Alpha}\p{Digit}]
\p{Alpha} 字母字符:[\p{Lower}\p{Upper}]
\p{ASCII} 所有 ASCII:[\x00-\x7F]
\p{Blank} 空格或制表符:[ \t]
\p{Cntrl} 控制字符:[\x00-\x1F\x7F]
\p{Digit} 十进制数字:[0-9]
\p{Graph} 可见字符:[\p{Alnum}\p{Punct}]
\p{Lower} 小写字母字符:[a-z]
\p{Print} 可打印字符:[\p{Graph}\x20]
\p{Punct} 标点符号:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
\p{Space} 空白字符:[ \t\n\x0B\f\r]
\p{Upper} 大写字母字符:[A-Z]
\p{XDigit} 十六进制数字:[0-9a-fA-F]
posted @
2012-08-12 23:00 zhanghu198901 阅读(2092) |
评论 (2) |
编辑 收藏PS:在所有例子中正则表达式匹配结果包含在源文本中的【和】之间,有的例子会使用java来实现,如果是java本身正则表达式的用法,会在相应的地方说明。所有java例子都在JDK1.6.0_13下测试通过。
一、有多少个匹配
前面几篇讲的都是匹配一个字符,但是一个字符或字符集合要匹配多次,应该怎么做呢?比如要匹配一个电子邮件地址,用之前说到的方法,可能有人会写出像\w@\w\.\w这样的正则表达式,但这个只能匹配到像a@b.c这样的地址,明显是不正确的,接下来就来看看如何匹配电子邮件地址。
首先要知道电子邮件地址的组成:以字母数字或下划线开头的一组字符,后面跟@符号,再后面是域名,即用户名@域名地址。不过这也跟具体的邮箱服务提供商有关,有的在用户名中也允许.字符。
1、匹配一个或多个字符
要想匹配同一个字符(或字符集合)的多次重复,只要简单地给这个字符(或字符集合)加上一个+字符作为后缀就可以了。+匹配一个或多个字符(至少一个)。如:a匹配a本身,a+将匹配一个或多个连续出现的a;[0-9]+匹配多个连续的数字。
注意:在给一个字符集合加上+后缀的时候,必须把+放在字符集合的外面,否则就不是重复匹配了。如[0-9+]这样就表示数字或+号了,虽然语法上正确,但不是我们想要的了。
文本:Hello, mhmyqn@qq.com or mhmyqn@126.com is my email.
正则表达式:\w+@(\w+\.)+\w+
结果:Hello, 【mhmyqn@qq.com】 or 【mhmyqn@126.com】 is my email.
分析:\w+可以匹配一个或多个字符,而子表达式(\w+\.)+可匹配像xxxx.edu.这样的字符串,而最后不会是.字符结尾,所以后面还会有一个\w+。像mhmyqn@xxxx.edu.cn这样的邮件地址也会匹配到。
2、匹配零个或多个字符
匹配零个或多个字符使用元符*,它的用法和+完全一样,只要把它放在一下字符或字符集合的后面,就可以匹配该字符(或字符集合)连续出现零次或多次。如正则表达式ab*c可以匹配ac、abc、abbbbbc等。
3、匹配零个或一个字符
匹配零个或一个字符使用元字符?。像上一篇说到的匹配一个空白行使用正则表达式\r\n\r\n,但在Unix和Linux中不需要\r,就可以使用元字符?,\r?\n\r?\n这样既可匹配windows中的空白行,也可匹配Unix和Linux中的空白行。下面来看一个匹配http或https协议的URL的例子:
文本:The URL is http://www.mikan.com, to connect securely use https://www.mikan.cominstead.
正则表达式:https?://(\w+\.)+\w+
结果:The URL is 【http://www.mikan.com】, to connect securely use 【https://www.mikan.com】 instead.
分析:这个模式以https?开头,表示?之前的一个字符可以有,也可以没有,所以它能匹配http或https,后面部分和前一个例子一样。
二、匹配的重复次数
正则表达式里的+、*和?解决了很多问题,但是:
1)+和*匹配的字符个数没有上限。我们无法为它们将匹配的字符个数设定一个最大值。
2)+、*和?至少匹配一个或零个字符。我们无法为它们将匹配的字符个数另行设定一个最小值。
3)如果只使用*和+,我们无法把它们将匹配的字符个数设定为一个精确的数字。
正则表达式里提供了一个用来设定重复次数的语法,重复次数要用{和}字符来给出,把数值写在它们中间。
1、为重复匹配次数设定一个精确值
如果想为重复匹配次数设定一个精确的值,把那个数字写在{和}之间即可。如{4}表示它前面的那个字符(或字符集合)必须在原始文本中连续重复出现4次才算是一个匹配,如果只出现了3次,也不算是一个匹配。
如前面几篇中说到的匹配页面中颜色的例子,就可以用重复次数来匹配:#[[:xdigit:]]{6}或#[0-9a-fA-F]{6},POSIX字符在java中是#\\p{XDigit}{6}。
2、为重复匹配次数设定一个区间
{}语法还可以用来为重复匹配次数设定一个区间,也就是为重复匹配次数设定一个最小值和最大值。这种区间必须以{n, m}这样的形式给出,其中n>=m>=0。如检查日期格式是否正确(不检查日期的有效性)的正则表达式(如日期2012-08-12或2012-8-12):\d{4}-\d{1,2}-\d{1,2}。
3、匹配至少重复多少次
{}语法的最后一种用法是给出一个最小的重复次数(但不必给出最大重复次数),如{3,}表示至少重复3次。注意:{3,}中一定要有逗号,而且逗号后不能有空格。否则会出错。
来看一个例子,使用正则表达式把所有金额大于$100的金额找出来:
文本:
$25.36
$125.36
$205.0
$2500.44
$44.30
正则表达式:$\d{3,}\.\d{2}
结果:
$25.36
【$125.36】
【$205.0】
【$2500.44】
$44.30
+、*、?可以表示成重复次数:
+等价于{1,}
*等价于{0,}
?等价于{0,1}
三、防止过度匹配
?只能匹配零个或一个字符,{n}和{n,m}也有匹配重复次数的上限,但是像*、+、{n,}都没有上限值,这样有时会导致过度匹配的现象。
来看匹配一个html标签的例子
文本:
Yesterday is <b>history</b>,tomorrow is a <B>mystery</B>, but today is a <b>gift</b>.
正则表达式:<[Bb]>.*</[Bb]>
结果:
Yesterday is 【<b>history</b>,tomorrow is a <B>mystery</B>, but today is a <b>gift</b>】.
分析:<[Bb]>匹配<b>标签(不区分大小写),</[Bb]>匹配</b>标签(不区分大小写)。但结果却不是预期的那样有三个,第一个</b>标签之后,一直到最后一个</b>之间的东西全部匹配出来了。
为什么会这样呢?因为*和+都是贪婪型的元字符,它们在匹配时的行为模式是多多益善,它们会尽可能从一段文本的开头一直匹配到这段文本的末尾,而不是从这段文本的开头匹配到碰到第一个匹配时为止。
当不需要这种贪婪行为时,可以使用这些元字符的懒惰型版本。懒惰意思是匹配尽可能少的字符,与贪婪型相反。懒惰型元字符只需要给贪婪型元字符加上一个?后缀即可。下面是贪婪型元字符的对应懒惰型版本:
* *?
+ +?
{n,} {n,}?
所以上面的例子中,正则表达式只需要改成<[Bb]>.*?</[Bb]>即可,结果如下:
<b>history</b>
<B>mystery</B>
<b>gift</b>
四、总结
正则表达式的真下威力体现在重复次数匹配方面。这里介绍了+、*、?几种元字符的用法,如果要精确的确定匹配次数,使用{}。元字符分贪婪型和懒惰型两种,在需要防止过度匹配的场合下,请使用懒惰型元字符来构造正则表达式
posted @
2012-08-12 23:00 zhanghu198901 阅读(13327) |
评论 (1) |
编辑 收藏 根据我近些年在IT行业的摸爬滚打,发现作为一个合格的开发经理需要做的第一件事情是:规范。
1、规范代码
每个公司都有自己的规范文档,但是很少有同学按照规范标准来写自己的代码。这样导致代码风格多元化、代码逻辑可爱化,更有甚者,会有人连自己的代码都看不懂。为什么?原因很简单,虽然写了规范文档,做了规范培训,但是没有强制的执行和跟踪。
我认为作为一个合格的开发经理,需要做如下三件事情。第一步,写代码规范文档,做培训。第二步,按照规范生成开发模版,规定手下的所有开发人员的开发工具中导入此模版。第三步,反复核查开发人员的代码(3-6个月),直到规范成为一种习惯。
2、规范文档
文档在中国IT公司几乎不受太大的重视。
在项目型的公司,要么就是没有文档,要么就是文档泛滥(要知道,有很多文档是做给QA看的,其实都是垃圾),我有时候就想,这样有意义吗?文档的目的是开发人员的辅助工具,尤其对于刚入职公司的新人而言,不会有几个“好心肠”的老员工去帮助新员工讲解项目架构和原理的,进来了就是靠自己摸索,那么文档对于新人就显得尤为重要了。所以,要么就建立一个好的培训机制,要么就写好文档,如果两者都做的很好为最佳。
在互联网公司,对于一些生命周期短暂的小项目不写文档我同意,毕竟需要时间成本。但是这样的项目代码规范一定严格,尽量精细到数据库字段的规范。因为这种类型的项目开发人员一般为1人,如果此人离开,后来人员交接时,能够更快的看懂对方的代码,以节省时间。此外,对于核心项目,一定需要一套完整的API文档,以供各项目组之间的互通,减少不必要的沟通。
总结:正是因为没有合理的规范,某个模块的开发人员离职,会消耗公司的巨大维护成本。如果能够做到以上两点规范,相信能够给公司带来更多的效能。
posted @
2012-08-12 22:58 zhanghu198901 阅读(1887) |
评论 (1) |
编辑 收藏 如果 mysql 是刚安装, 那么 root 的密码默认为空。 可以使用以下方法修改密码:
- mysqladmin -u root password PASSWORD
如果 root 有密码, 那么使用以下命令修改:
- mysqladmin -u root -p'oldpassword' password newpass
另外还可以通过登录 sql 控制台后修改:
- update user set password=PASSWORD("NEWPASSWORD") where User='root';
- flush privileges;
posted @
2012-07-21 22:16 zhanghu198901 阅读(849) |
评论 (0) |
编辑 收藏APNS 是什么?
APNS (Android Push Notification Service) 是一种在 android 上轻松实现 push notification 的功能的解决方案. 只需申请一个 API Key, 经过简单的步骤即可实现 push notification 的功能.
特点:
快速集成:提供一种比C2DM更加快捷的使用方式,避免各种限制.无需架设服务器:通过使用"云服务",减少额外服务器负担.可以同时推送消息到网站页面,android 手机耗电少,占用流量少.
http://zen-mobi.com/get_api_key.php获取apikey
如何在 Android 应用中使用 Notification ?
a) 在应用中添加 APNS 功能
- 下载 libaray: com_apns.jar
- 将com_apns.jar添加到工程
在工程上右键打开“属性”,选择 “Java Build Path”, 在 Libraries 中选择 “Add External JARs”, 选择下载的 com_apns.jar.
- 接收 push notification
使用BroadcastReceiver接收系统广播: public class MyBroadcastReceiver extends BroadcastReceiver { @Override public void onReceive(Context context, Intent intent) { if (intent.getAction().equals(APNService.ON_NOTIFICATION)) { String str = intent.getStringExtra("data"); //todo, 处理收到的消息 } } } - 启动 Push Notification Service
发送Intent 启动服务,将 chanel Id 以及 此设备的标识 (chanel中唯一表示此设备的字符串) 传递过去: Intent intent = new Intent(APNService.START); intent.putExtra("ch", chanel); intent.putExtra("devId", devId); startService(intent); Notes Chanel Id 在申请 API 后,登录开发者页面会看到. devId: chanel 内设备标识,要在chanel内保持唯一.- 配置 AndroidManifest.xml
... <application android:icon="@drawable/icon" ... <service android:name="com.apns.APNSService" android:label="APNS"> <intent-filter> <action android:name="com.apns.APNService.START" /> <action android:name="com.apns.APNService.STOP" /> <category android:name="android.intent.category.DEFAULT"/> </intent-filter> </service> <receiver android:name="MyBroadcastReceiver"> <intent-filter> <action android:name="com.apnsd.APNService.NOTIFICATION" /> </intent-filter> </receiver> </application> <uses-permission android:name="android.permission.INTERNET" /> <uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" /> ...
b) 发送 Notification 到设备
通过 rest 接口发送 Notification:
http://www.push-notification.org/handlers/apns_v1.php?ch=YourChannelId&devId=xxxxx&msg =hello world&random=0123&hash=HashCode
ch:Channel Id devId:接收设备 Id msg:消息 random:随机数 hash:md5(ch + devId + msg + random + apiKey)
posted @
2012-07-21 22:15 zhanghu198901 阅读(1742) |
评论 (1) |
编辑 收藏默认的浏览器都列出让用户选择的
Java代码
Uri u = Uri.parse(url);
Intent it = new Intent(Intent.ACTION_VIEW, url); TestActivity.this.startActivity(it);
Uri u = Uri.parse(url);
Intent it = new Intent(Intent.ACTION_VIEW, url); TestActivity.this.startActivity(it);
指定浏览器的
Java代码
Uri u = Uri.parse(url);
it.setData(u);
it.setAction( Intent.ACTION_VIEW);
it.setClassName("com.android.browser","com.android.browser.BrowserActivity");
TestActivity.this.startActivity(it);
posted @
2012-07-21 22:15 zhanghu198901 阅读(1660) |
评论 (1) |
编辑 收藏posted @
2012-07-18 21:35 zhanghu198901 阅读(1067) |
评论 (2) |
编辑 收藏var stack = new Array();
var scanned = false;
var temp = root;
while (temp) {
stack.push(temp);
if(!scanned&&temp.firstChild){
temp = temp.firstChild;
continue;
}
if(temp.nextSibling){
temp = temp.nextSibling;
scanned = false;
continue;
}
scanned = true;
temp = temp.parentNode;
}
posted @
2012-07-18 21:34 zhanghu198901 阅读(725) |
评论 (0) |
编辑 收藏spring 的三种注入方式
1. 接口注入( 不推荐 )
2. getter , setter 方式注入( 比较常用 )
3. 构造器注入( 死的应用 )
关于 getter 和 setter 方式的注入
· autowire="defualt"
· autowire=“byName”
· autowire="bytype"
详细解析注入方式
例如:有如下两个类需要注入
第一个类:
- package org.jia;
-
- public class Order {
- private String orderNum;
- @SuppressWarnings ( "unused" )
- private OrderItem orderitem;
-
- public OrderItem getOrderitem() {
- return orderitem;
- }
-
- public void setOrderitem(OrderItem orderitem) {
- this .orderitem = orderitem;
- }
-
- public String getOrderNum() {
- return orderNum;
- }
-
- public void setOrderNum(String orderNum) {
- this .orderNum = orderNum;
- }
- }
第二个类:
- package org.jia;
-
- public class OrderItem {
- private String orderdec;
-
- public String getOrderdec() {
- return orderdec;
- }
-
- public void setOrderdec(String orderdec) {
- this .orderdec = orderdec;
- }
- }
常用getter&&setter方式介绍
方式第一种注入:
- <? xml version = "1.0" encoding = "UTF-8" ?>
- <!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
-
- < beans >
- < bean id = "orderItem" class = "org.jia.OrderItem" >
- < property name = "orderdec" value = "item00001" > </ property >
- </ bean >
- < bean id = "order" class = "org.jia.Order" >
- <!-----注入变量 名字必须与类中的名字一样------->
- < property name = "orderNum" value = "order000007" > </ property >
- < !--注入对象 名字为orderitem,所属的类的应用id为orderItem-- >
- < property name = "orderitem" ref = "orderItem" > </ property >
-
- --> </ bean >
- </ beans >
方式第二种注入: byName
- <? xml version = "1.0" encoding = "UTF-8" ?>
- <!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
- < beans >
- <!--此时的id就必须与Order.java中所定义的OrderItem的对象名称一样了,不然就会找不到-->
- < bean id = "orderitem" class = "org.jia.OrderItem" >
- < property name = "orderdec" value = "item00001" > </ property >
- </ bean >
- < bean id = "order" class = "org.jia.Order" < span style = "color: #ff0000;" > autowire = "byName" </ span > >
- < property name = "orderNum" value = "order000007" > </ property >
- </ bean >
- </ beans >
方式第三种注入: byType
- <? xml version = "1.0" encoding = "UTF-8" ?>
- <!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
- < beans >
- <!--按照byType注入则就与id没有关系,可以随便定义id !!!但是不能出现多个此类的id-->
- < bean id = "orderitdfadafaem" class = "org.jia.OrderItem" >
- < property name = "orderdec" value = "item00001" > </ property >
- </ bean >
- < bean id = "order" class = "org.jia.Order" < span style = "color: #ff0000;" > autowire = "byType" </ span > >
- < property name = "orderNum" value = "order000007" > </ property >
- </ bean >
- </ beans >
autowire="constructor"
需要在 Order.java 中加入一个构造器
- public Order(OrderItem item )
- {
- orderitem = item;
- }
XML配置文件
- <? xml version = "1.0" encoding = "UTF-8" ?>
- <!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
- < beans >
- < bean id = "orderItem" class = "org.jia.OrderItem" >
- < property name = "orderdec" value = "item00001" > </ property >
- </ bean >
- < bean id = "order" class = "org.jia.Order" autowire = "constructor" >
- < property name = "orderNum" value = "order000007" > </ property >
- </ bean >
- </ beans >
三种注入方式比较
接口注入:
接口注入模式因为具备侵入性,它要求组件必须与特定的接口相关联,因此并不被看好,实际使用有限。
Setter 注入:对于习惯了传统 javabean 开发的程序员,通过 setter 方法设定依赖关系更加直观。
如果依赖关系较为复杂,那么构造子注入模式的构造函数也会相当庞大,而此时设值注入模式则更为简洁。
如果用到了第三方类库,可能要求我们的组件提供一个默认的构造函数,此时构造子注入模式也不适用。
构造器注入:在构造期间完成一个完整的、合法的对象。
所有依赖关系在构造函数中集中呈现。
依赖关系在构造时由容器一次性设定,组件被创建之后一直处于相对“不变”的稳定状态。
只有组件的创建者关心其内部依赖关系,对调用者而言,该依赖关系处于“黑盒”之中。
总结
Spring使用注入方式,为什么使用注入方式,这系列问题实际归结起来就是一句话,Spring的注入和
IoC (本人关于IoC的阐述)反转控制是一回事。
理论上:第三种注入方式(构造函数注入)在符合java使用原则上更加合理,第二种注入方式(setter注入)作为补充。
posted @
2012-07-18 21:33 zhanghu198901 阅读(1327) |
评论 (0) |
编辑 收藏统一目录下的资源结构图:

<html>
<head>
<link rel="stylesheet" href="gallery.css" type="text/css" media="screen" charset="utf-8"/>
<script type="text/javascript" src="script.js"></script>
</head>
<body>
<div id="container">
<div id="header">
<h1>StarTrackr!</h1>
</div>
<div id="content">
<h2>Around Town Last Night</h2>
<div id="ajaxInProgress"></div>
<div id="photos">
<fieldset id="photoDetails">
<legend>Photo Tagging</legend>
<form id="details">
<p id="status"></p>
<p>
<label for="name">Name:</label><br/>
<input type="text" class="textField" name="name" id="name" />
</p>
<p>
<label for="tags">Tags:</label><br/>
<input type="text" class="textField" name="tags" id="tags" />
</p>
<p>
<input type="hidden" name="id" id="id">
<input type="button" value="update" id="update" />
</p>
</form>
<div id="gallery"></div>
</fieldset>
</div>
</div>
</div>
</body>
</html>
posted @
2012-07-18 21:32 zhanghu198901 阅读(874) |
评论 (0) |
编辑 收藏只有在学会处理异常之后,我们才能说自己是一个合格的java程序员。只有在摆脱了以下六种异常处理的陋习之后,才能威慑一下刚毕业的小菜鸟。
现在就来测试一下大家对异常的掌握程度。不用担心,事实上,这些不合理的设计很容易看出来。那么,以下六种不合理的代码,大家能看出每一种的问题出在哪儿吗?
OutputStreamWriter out = ...
java.sql.Connection conn = ...
try { // ⑸
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery(
"select uid, name from user");
while (rs.next())
{
out.println("ID:" + rs.getString("uid") // ⑹
+ ",姓名:" + rs.getString("name"));
}
conn.close(); // ⑶
out.close();
}
catch(Exception ex) // ⑵
{
ex.printStackTrace(); //⑴,⑷
}
作为一个Java程序员,你至少应该能够找出两个问题。但是,如果你不能找出全部六个问题,请继续阅读本文。
本文讨论的不是Java异常处理的一般性原则,因为这些原则已经被大多数人熟知。我们要做的是分析各种可称为“反例”(anti-pattern)的违背优秀编码规范的常见坏习惯,帮助读者熟悉这些典型的反面例子,从而能够在实际工作中敏锐地察觉和避免这些问题。
反例之一:丢弃异常
代码:15行-18行。
这段代码捕获了异常却不作任何处理,可以算得上Java编程中的杀手。从问题出现的频繁程度和祸害程度来看,它也许可以和C/C++程序的一个恶名远播的问题相提并论??不检查缓冲区是否已满。如果你看到了这种丢弃(而不是抛出)异常的情况,可以百分之九十九地肯定代码存在问题(在极少数情况下,这段代码有存在的理由,但最好加上完整的注释,以免引起别人误解)。
这段代码的错误在于,异常(几乎)总是意味着某些事情不对劲了,或者说至少发生了某些不寻常的事情,我们不应该对程序发出的求救信号保持沉默和无动于衷。调用一下printStackTrace算不上“处理异常”。不错,调用printStackTrace对调试程序有帮助,但程序调试阶段结束之后,printStackTrace就不应再在异常处理模块中担负主要责任了。
丢弃异常的情形非常普遍。打开JDK的ThreadDeath类的文档,可以看到下面这段说明:“特别地,虽然出现ThreadDeath是一种‘正常的情形’,但ThreadDeath类是Error而不是Exception的子类,因为许多应用会捕获所有的Exception然后丢弃它不再理睬。”这段话的意思是,虽然ThreadDeath代表的是一种普通的问题,但鉴于许多应用会试图捕获所有异常然后不予以适当的处理,所以JDK把 ThreadDeath定义成了Error的子类,因为Error类代表的是一般的应用不应该去捕获的严重问题。可见,丢弃异常这一坏习惯是如此常见,它甚至已经影响到了Java本身的设计。
那么,应该怎样改正呢?主要有四个选择:
1、处理异常。针对该异常采取一些行动,例如修正问题、提醒某个人或进行其他一些处理,要根据具体的情形确定应该采取的动作。再次说明,调用printStackTrace算不上已经“处理好了异常”。
2、重新抛出异常。处理异常的代码在分析异常之后,认为自己不能处理它,重新抛出异常也不失为一种选择。
3、把该异常转换成另一种异常。大多数情况下,这是指把一个低级的异常转换成应用级的异常(其含义更容易被用户了解的异常)。
4、不要捕获异常。
结论一:既然捕获了异常,就要对它进行适当的处理。不要捕获异常之后又把它丢弃,不予理睬。
反例之二:不指定具体的异常
代码:15行。
许多时候人们会被这样一种“美妙的”想法吸引:用一个catch语句捕获所有的异常。最常见的情形就是使用catch(Exceptionex)语句。但实际上,在绝大多数情况下,这种做法不值得提倡。为什么呢?
要理解其原因,我们必须回顾一下catch语句的用途。catch语句表示我们预期会出现某种异常,而且希望能够处理该异常。异常类的作用就是告诉Java编译器我们想要处理的是哪一种异常。由于绝大多数异常都直接或间接从java.lang.Exception派生,catch(Exceptionex)就相当于说我们想要处理几乎所有的异常。
再来看看前面的代码例子。我们真正想要捕获的异常是什么呢?最明显的一个是SQLException,这是JDBC操作中常见的异常。另一个可能的异常是IOException,因为它要操作OutputStreamWriter.显然,在同一个catch块中处理这两种截然不同的异常是不合适的。如果用两个catch块分别捕获SQLException和IOException就要好多了。这就是说,catch语句应当尽量指定具体的异常类型,而不应该指定涵盖范围太广的Exception类。
另一方面,除了这两个特定的异常,还有其他许多异常也可能出现。例如,如果由于某种原因,executeQuery返回了null,该怎么办?答案是让它们继续抛出,即不必捕获也不必处理。实际上,我们不能也不应该去捕获可能出现的所有异常,程序的其他地方还有捕获异常的机会??直至最后由 JVM处理。
结论二:在catch语句中尽可能指定具体的异常类型,必要时使用多个catch.不要试图处理所有可能出现的异常。
反例之三:占用资源不释放
代码:3行-14行。
异常改变了程序正常的执行流程。这个道理虽然简单,却常常被人们忽视。如果程序用到了文件、Socket、JDBC连接之类的资源,即使遇到了异常,也要正确释放占用的资源。为此,Java提供了一个简化这类操作的关键词finally.
finally是样好东西:不管是否出现了异常,Finally保证在try/catch/finally块结束之前,执行清理任务的代码总是有机会执行。遗憾的是有些人却不习惯使用finally.
当然,编写finally块应当多加小心,特别是要注意在finally块之内抛出的异常??这是执行清理任务的最后机会,尽量不要再有难以处理的错误。
结论三:保证所有资源都被正确释放。充分运用finally关键词。
反例之四:不说明异常的详细信息
代码:3行-18行。
仔细观察这段代码:如果循环内部出现了异常,会发生什么事情?我们可以得到足够的信息判断循环内部出错的原因吗?不能。我们只能知道当前正在处理的类发生了某种错误,但却不能获得任何信息判断导致当前错误的原因。
printStackTrace的堆栈跟踪功能显示出程序运行到当前类的执行流程,但只提供了一些最基本的信息,未能说明实际导致错误的原因,同时也不易解读。
因此,在出现异常时,最好能够提供一些文字信息,例如当前正在执行的类、方法和其他状态信息,包括以一种更适合阅读的方式整理和组织printStackTrace提供的信息。
结论四:在异常处理模块中提供适量的错误原因信息,组织错误信息使其易于理解和阅读。
反例之五:过于庞大的try块
代码:3行-14行。
经常可以看到有人把大量的代码放入单个try块,实际上这不是好习惯。这种现象之所以常见,原因就在于有些人图省事,不愿花时间分析一大块代码中哪几行代码会抛出异常、异常的具体类型是什么。把大量的语句装入单个巨大的try块就象是出门旅游时把所有日常用品塞入一个大箱子,虽然东西是带上了,但要找出来可不容易。
一些新手常常把大量的代码放入单个try块,然后再在catch语句中声明Exception,而不是分离各个可能出现异常的段落并分别捕获其异常。这种做法为分析程序抛出异常的原因带来了困难,因为一大段代码中有太多的地方可能抛出Exception.
结论五:尽量减小try块的体积。
反例之六:输出数据不完整
代码:7行-11行。
不完整的数据是Java程序的隐形杀手。仔细观察这段代码,考虑一下如果循环的中间抛出了异常,会发生什么事情。循环的执行当然是要被打断的,其次,catch块会执行??就这些,再也没有其他动作了。已经输出的数据怎么办?使用这些数据的人或设备将收到一份不完整的(因而也是错误的)数据,却得不到任何有关这份数据是否完整的提示。对于有些系统来说,数据不完整可能比系统停止运行带来更大的损失。
较为理想的处置办法是向输出设备写一些信息,声明数据的不完整性;另一种可能有效的办法是,先缓冲要输出的数据,准备好全部数据之后再一次性输出。
结论六:全面考虑可能出现的异常以及这些异常对执行流程的影响。
改写后的代码
根据上面的讨论,下面给出改写后的代码。也许有人会说它稍微有点?嗦,但是它有了比较完备的异常处理机制。
OutputStreamWriter out = ...
java.sql.Connection conn = ...
try {
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery(
"select uid, name from user");
while (rs.next())
{
out.println("ID:" + rs.getString("uid") + ",姓名: " + rs.getString("name"));
}
}
catch(SQLException sqlex)
{
out.println("警告:数据不完整");
throw new ApplicationException("读取数据时出现SQL错误", sqlex);
}
catch(IOException ioex)
{
throw new ApplicationException("写入数据时出现IO错误", ioex);
}
finally
{
if (conn != null) {
try {
conn.close();
}
catch(SQLException sqlex2)
{
System.err(this.getClass().getName() + ".mymethod - 不能关闭数据库连接: " + sqlex2.toString());
}
}
if (out != null) {
try {
out.close();
}
catch(IOException ioex2)
{
System.err(this.getClass().getName() + ".mymethod - 不能关闭输出文件" + ioex2.toString());
}
}
}
本文的结论不是放之四海皆准的教条,有时常识和经验才是最好的老师。如果你对自己的做法没有百分之百的信心,务必加上详细、全面的注释。
另一方面,不要笑话这些错误,不妨问问你自己是否真地彻底摆脱了这些坏习惯。即使最有经验的程序员偶尔也会误入歧途,原因很简单,因为它们确确实实带来了“方便”。所有这些反例都可以看作Java编程世界的恶魔,它们美丽动人,无孔不入,时刻诱惑着你。也许有人会认为这些都属于鸡皮蒜毛的小事,不足挂齿,但请记住:勿以恶小而为之,勿以善小而不为。
posted @
2012-07-16 22:20 zhanghu198901 阅读(1770) |
评论 (1) |
编辑 收藏单表继承映射
每棵类继承树使用一个表。


映射文件Extends.hbm.xml。
<hibernate-mapping package="com.snail.hibernate">
<class name="Animal" table="t_animal" lazy="false">
<id name="id">
<generator class="native"/>
</id>
<discriminator column="type" type="string"/>
<property name="name"/>
<property name="sex"/>
<subclass name="Pig" discriminator-value="P">
<property name="weight"/>
</subclass>
<subclass name="Brid" discriminator-value="B">
<property name="height"/>
</subclass>
</class>
</hibernate-mapping>
因为类继承树肯定是对应多个类,要把多个类的信息存放在一张表中,必须有某种机制来区分哪些记录是属于哪个类的。这种机制就是,在表中添加一个字段,用这个字段的值来进行区分。用hibernate实现这种策略的时候,有如下步骤:
(一)父类用普通的<class>标签定义
(二)在父类中定义一个discriminator,即指定这个区分的字段的名称和类型
如:<discriminator column=”XXX” type=”string”/>
(三)子类使用<subclass>标签定义,在定义subclass的时候,需要注意如下几点:
1.Subclass标签的name属性是子类的全路径名;
2.在Subclass标签中,用discriminator-value属性来标明本子类的discriminator字段(用来区分不同类的字段)的值;
3.Subclass标签,既可以被class标签所包含(这种包含关系正是表明了类之间的继承关系),也可以与class标签平行。 当subclass标签的定义与class标签平行的时候,需要在subclass标签中,添加extends属性,里面的值是父类的全路径名称。
4.子类的其它属性,像普通类一样,定义在subclass标签的内部。
具体表继承映射
每个具体类一张表。(同上例)

映射文件Extends.hbm.xml。
<hibernate-mapping package="com.snail.hibernate">
<class name="Animal" table="t_animal" lazy="false" abstract="true">
<id name="id">
<generator class="assigned"/>
</id>
<property name="name"/>
<property name="sex"/>
<union-subclass name="Pig" table="t_pig">
<property name="weight"/>
</union-subclass>
<union-subclass name="Brid" table="t_brid">
<property name="height"/>
</union-subclass>
</class>
</hibernate-mapping>
这种策略是使用union-subclass标签来定义子类的。每个子类对应一张表,而且这个表的信息是完备的,即包含了所有从父类继承下来的属性映射的字段(这就是它跟joined-subclass的不同之处,joined-subclass定义的子类的表,只包含子类特有属性映射的字段)。实现这种策略的时候,有如下步骤:
(一)父类用普通<class>标签定义即可;
(二)子类用<union-subclass>标签定义,在定义union-subclass的时候,需要注意如下几点:
1.Union-subclass标签不再需要包含key标签(与joined-subclass不同)。
2.Union-subclass标签,既可以被class标签所包含(这种包含关系正是表明了类之间的继承关系),也可以与class标签平行。 当Union-subclass标签的定义与class标签平行的时候,需要在Union-subclass标签中,添加extends属性,里面的值是父类的全路径名称。
3.子类的其它属性,像普通类一样,定义在Union-subclass标签的内部。这个时候,虽然在union-subclass里面定义的只有子类的属性,但是因为它继承了父类,所以,不需要定义其它的属性,在映射到数据库表的时候,依然包含了父类的所有属性的映射字段。
注意:在保存对象的时候id不能重复(不能使用数据库的自增方式生成主键)
类表继承映射
每个类一张表。(同上例)

映射文件Extends.hbm.xml。
- <hibernate-mapping package="com.snail.hibernate">
- <class name="Animal" table="t_animal" lazy="false">
- <id name="id">
- <generator class="native"/>
- </id>
- <property name="name"/>
- <property name="sex"/>
- <joined-subclass name="Pig" table="t_pig">
- <key column="pid"/>
- <property name="weight"/>
- </joined-subclass>
- <joined-subclass name="Brid" table="t_brid">
- <key column="bid"/>
- <property name="height"/>
- </joined-subclass>
- </class>
- </hibernate-mapping>
这种策略是使用joined-subclass标签来定义子类的。父类、子类,每个类都对应一张数据库表。在父类对应的数据库表中,实际上会存储所有的记录,包括父类和子类的记录;在子类对应的数据库表中,这个表只定义了子类中所特有的属性映射的字段。子类与父类,通过相同的主键值来关联。实现这种策略的时候,有如下步骤:
(一)父类用普通的<class>标签定义即可,父类不再需要定义discriminator字段;
(二)子类用<joined-subclass>标签定义,在定义joined-subclass的时候,需要注意如下几点:
1.Joined-subclass标签的name属性是子类的全路径名
2.Joined-subclass标签需要包含一个key标签,这个标签指定了子类和父类之间是通过哪个字段来关联的。
如:<key column=”PARENT_KEY_ID”/>,这里的column,实际上就是父类的主键对应的映射字段名称。
3.Joined-subclass标签,既可以被class标签所包含(这种包含关系正是表明了类之间的继承关系),也可以与class标签平行。 当Joined-subclass标签的定义与class标签平行的时候,需要在Joined-subclass标签中,添加extends属性,里面的值是父类的全路径名称。
4.子类的其它属性,像普通类一样,定义在joined-subclass标签的内部。
posted @
2012-07-16 22:16 zhanghu198901 阅读(997) |
评论 (0) |
编辑 收藏 function MillisecondToDate(msd) {
var time = parseFloat(msd) /1000;
if (null!= time &&""!= time) {
if (time >60&& time <60*60) {
time = parseInt(time /60.0) +"分钟"+ parseInt((parseFloat(time /60.0) -
parseInt(time /60.0)) *60) +"秒";
}else if (time >=60*60&& time <60*60*24) {
time = parseInt(time /3600.0) +"小时"+ parseInt((parseFloat(time /3600.0) -
parseInt(time /3600.0)) *60) +"分钟"+
parseInt((parseFloat((parseFloat(time /3600.0) - parseInt(time /3600.0)) *60) -
parseInt((parseFloat(time /3600.0) - parseInt(time /3600.0)) *60)) *60) +"秒";
}else {
time = parseInt(time) +"秒";
}
}else{
time = "0 时 0 分0 秒";
}
return time;
}
posted @
2012-07-12 22:30 zhanghu198901 阅读(2746) |
评论 (1) |
编辑 收藏1、windows->Preferences...打开"首选项"对话框,左侧导航树,导航到general->Workspace,右侧Text file encoding,选择Other,改变为 utf-8(必须小写),以后新建立工程其属性对话框中的Text file encoding即为UTF-8。
2、windows->Preferences...打开"首选项"对话框,左侧导航树,导航到general->Content Types,右侧Content Types树,点开Text,选择 Java Source File,在下面的Default encoding输入框中输入UTF-8,点Update,则设置Java文件编码为UTF-8。然后设置jsp、js、css等类型的Default encoding,设置方式同Java Source File。
3.windows->Preferences...打开"首选项"对话框,左侧导航树,导航到MyEclipse->Files and Editors->JSP,把Encoding改为UTF-8
posted @
2012-07-12 22:30 zhanghu198901 阅读(6145) |
评论 (0) |
编辑 收藏1、java.lang包下的80%以上的类的功能的灵活运用。
2、java.util包下的80%以上的类的灵活运用,特别是集合类体系、正规表达式、时间、属性、和Timer.
3、java.io包下的60%以上的类的使用,理解IO体系的基于管道模型的设计思路以及常用IO类的特性和使用场合。
4、java.math包下的100%的内容。
5、java.net包下的60%以上的内容,对各个类的功能比较熟悉。
6、java.text包下的60%以上的内容,特别是各种格式化类。
7、熟练运用JDBC.
8、java.security包下40%以上的内容,如果对于安全没有接触的话根本就不可能掌握java.
9、AWT的基本内容,包括各种组件事件、监听器、布局管理器、常用组件、打印。
10、Swing的基本内容,和AWT的要求类似。
11、XML处理,熟悉SAX、DOM以及JDOM的优缺点并且能够使用其中的一种完成XML的解析及内容处理。
posted @
2012-07-12 22:30 zhanghu198901 阅读(1108) |
评论 (2) |
编辑 收藏posted @
2012-07-12 22:29 zhanghu198901 阅读(965) |
评论 (0) |
编辑 收藏 在JDK1.2以前的版本中,当一个对象不被任何变量引用,那么程序就无法再使用这个对象。也就是说,只有对象处于可触及状态,程序才能使用它。这 就像在日常生活中,从商店购买了某样物品后,如果有用,就一直保留它,否则就把它扔到垃圾箱,由清洁工人收走。一般说来,如果物品已经被扔到垃圾箱,想再 把它捡回来使用就不可能了。
但有时候情况并不这么简单,你可能会遇到类似鸡肋一样的物品,食之无味,弃之可惜。这种物品现在已经无用了,保留它会占空间,但是立刻扔掉它也不划算,因 为也许将来还会派用场。对于这样的可有可无的物品,一种折衷的处理办法是:如果家里空间足够,就先把它保留在家里,如果家里空间不够,即使把家里所有的垃 圾清除,还是无法容纳那些必不可少的生活用品,那么再扔掉这些可有可无的物品。从JDK1.2版本开始,把对象的引用分为四种级别,从而使程序能更加灵活的控制对象的生命周期。这四种级别由高到低依次为:强引用、软引用、弱引用和虚引用。
1.强引用
本章前文介绍的引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空 间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2.软引用(SoftReference)
如果一个对象只具有软引用,那就类似于可有可物的生活用品。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
3.弱引用(WeakReference)
如果一个对象只具有弱引用,那就类似于可有可物的生活用品。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
4.虚引用(PhantomReference)
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。虚引用主要用来跟踪对象被垃圾回收的活动。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列(ReferenceQueue)联合使用。当垃 圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是 否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。
posted @
2012-07-12 22:28 zhanghu198901 阅读(812) |
评论 (0) |
编辑 收藏1.float类型
float列类型默认长度查不到结果,必须指定精度,
比如 num float, insert into table (num) values (0.12); select * from table where num=0.12的话,empty set。
num float(9,7), insert into table (num) values (0.12); select * from table where num=0.12的话会查到这条记录。
mysql> create table tt
-> (
-> num float(9,3)
-> );
Query OK, 0 rows affected (0.03 sec)
mysql> insert into tt(num)values(1234567.8);
ERROR 1264 (22003): Out of range value for column 'num' at row 1
注:超出字段范围,无法插入
mysql> insert into tt(num)values(123456.8);
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt;
+------------+
| num |
+------------+
| 123456.797 |
+------------+
1 row in set (0.00 sec)
注:小数位数不够,自动补齐,但是存在一个问题就是如上的近似值。
mysql> insert into tt(num)values(123456.867);
Query OK, 1 row affected (0.04 sec)
mysql> select * from tt;
+------------+
| num |
+------------+
| 123456.797 |
| 123456.797 |
| 123456.867 |
+------------+
3 rows in set (0.00 sec)
mysql> select * from tt where num=123456.867;
+------------+
| num |
+------------+
| 123456.867 |
+------------+
1 row in set (0.00 sec)
mysql> insert into tt(num)values(2.8);
Query OK, 1 row affected (0.04 sec)
mysql> select * from tt;
+------------+
| num |
+------------+
| 123456.797 |
| 123456.797 |
| 123456.867 |
| 2.800 |
+------------+
4 rows in set (0.00 sec)
mysql> select * from tt where num=2.8;
+-------+
| num |
+-------+
| 2.800 |
+-------+
1 row in set (0.00 sec)
mysql> insert into tt(num)values(2.888888);
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt;
+------------+
| num |
+------------+
| 123456.797 |
| 123456.797 |
| 123456.867 |
| 2.800 |
| 2.889 |
+------------+
5 rows in set (0.00 sec)
注:小数位数超了,自动取近似值。
--------------------------------------------------------------------------------------
2.double类型
mysql> create table tt(
-> num double(9,3)
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into tt(num) values(234563.9);
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt;
+------------+
| num |
+------------+
| 234563.900 |
+------------+
1 row in set (0.00 sec)
mysql> insert into tt(num) values(2345623.2);
ERROR 1264 (22003): Out of range value for column 'num' at row 1
mysql> insert into tt(num) values(234563.2);
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt;
+------------+
| num |
+------------+
| 234563.900 |
| 234563.200 |
+------------+
2 rows in set (0.00 sec)
mysql> insert into tt(num) values(2.8);
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt;
+------------+
| num |
+------------+
| 234563.900 |
| 234563.200 |
| 2.800 |
+------------+
3 rows in set (0.00 sec)
FLOAT(M,D)或REAL(M,D)或DOUBLE PRECISION(M,D)。这里,“(M,D)”表示该值一共显示M位整数,其中D位位于小数点后面。
例如,定义为FLOAT(7,4)的一个列可以显示为-999.9999。MySQL保存值时进行四舍五入,因此如果在FLOAT(7,4)列内插入999.00009,近似结果是999.0001。
posted @
2012-07-09 23:15 zhanghu198901 阅读(8785) |
评论 (0) |
编辑 收藏所谓编程达人,就是工作时要用多个显示屏幕,甚至多台计算机的人
在他们眼里,一个显示器,再大都是小的,哪里有两个显示器用得爽,感觉好
但弱水三千只取一瓢饮,多的时候还是只看一个显示器,这时另一个显示器(下称辅助显示器)怎么办呢?
一般有两个选择:
一是不管他,亮着就亮着呗
二是把辅助显示器电源关了,要用的时候再开
当然,屏保就不成其为选择了,因为它需要时间,其次它会把所有屏幕全部屏保,最后是因为它是自动的,就象汽车,自动挡没有手动挡那么爽
利弊自己体会,以过来人的感觉说一下:
前者,倒是方便,只是时间长了,眼睛难受,一直有两个高亮度的屏幕在距离你头部几十CM的地方亮着,闪烁着,会不会导致头晕就看你体质而定了。
后者,有点麻烦,有时候找电源开关还得换下脑筋
不才区区在下,自己归于编程达人一类,自己发现这个需求,所以就编了个小软件
运行时有两种状态,一种是黑辅助屏,一种是在托盘显示图标,即世界还是正常的。
posted @
2012-07-09 23:15 zhanghu198901 阅读(794) |
评论 (0) |
编辑 收藏
摘要: 一些要说的话:如果你没有正则表达式的基础,请跟着教程“一步步来”。请不要大概地扫两眼就说看不懂——以这种态度我写成什么样你也看不懂。当我告诉你这是“30分钟入门教程”时,请不要试图在30秒内入门。事实是,我身边有个才接触电脑,对操作都不是很熟练的人通过自己学习这篇教程,最后都能在文章采集系统中使用正则表达式完成任务。而且,他写...
阅读全文
posted @
2012-07-09 23:14 zhanghu198901 阅读(782) |
评论 (0) |
编辑 收藏 学习web这块儿的知识已经有一段儿时间了,最基础也是最常用的便是HTML标签。今天便对HTML知识进行一个小节。
HTML,超文本标记语言,即Hypertext Markup Language,是用于描述网页文档的一种标记语言。HTML是一种规范,一种标准,它通过标记符号来标记要显示的网页中的各个部分。它功能强大,具有简易性,可扩展性,平台无关性三大特点,支持不同数据格式的文件镶入,这也是万维网盛行的原因。
一、总结图

二、标签解析


三、总结
HTML的知识非常重要,它是我们学习以后知识的基础。精确掌握这一部分知识,对我们无疑是非常必要的。
posted @
2012-07-09 23:14 zhanghu198901 阅读(1431) |
评论 (2) |
编辑 收藏Sql注入.
简介.
我们很容易从网上查找到sql注入的定义: 就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令,很容易遭到SQL注入式攻击.
用户可以提交一段数据库的查代码,根据程序返回结果,获得一些敏感的信息或是控制整个服务器.sql注入就发生了.
当然我们要魔高一尺,道高一丈.
防止sql注入:
 永远不要信任用户的输入,对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和双 - - (在数据库中认为是数据库语句的连接)进行转换等.
永远不要信任用户的输入,对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和双 - - (在数据库中认为是数据库语句的连接)进行转换等.
永远不要动态拼接sql,可以使用参数化的sql或者直接使用存储过程来进行数据查询存取.
永远不要使用管理员权限的数据库的连接,为每个应用使用单独的权限书库连接.
不要把机密的信息直接存放,加密.
应用的异常信息应该处仅少量的提示,最好使用自定义的错误信息对原始的错误进行封装.
采用软件和有效的网站平台来检测sql注入.
实例.(用参数化的sql进行插入来防止Sql注入)
向数据库的新闻类别表(category)通过字符串拼接的方法插入一条语句。
插入函数的代码.
- <span style="font-size:16px;">public bool Insert(string caName)
- {
-
- bool flag = false;
- string sql = "insert into category(name) values('" + caName + "')";
- flag = sqlhelper.ExecuteNonQuery(sql);
-
- return flag;
- }</span>
我们的界面:
我们在调试中可以看到传入数据库中的sql语句。

Ctrl+F5我们不调试直接执行,或是我们把此sql语句复制在查询分析器中执行。界面中我们可以看到。
在增加一行的基础同时我们id为3的记录消失了,被删除了。
让我们对插入数据库的插入代码修改,用参数传递来代替数据库字符串的拼接。
在SQLHelper加上个ExecuteQuery(string sql ,sqlParam[] paras)的重载.
- <span style="font-size: 14pt; "> </span><span style="font-size:16px;">
-
-
-
-
-
- public bool ExecuteNonquery(string sql, SqlParameter[] paras)
- {
- bool flag=false ;
- using (cmd = new SqlCommand(sql, GetConn()))
- {
-
- cmd.Parameters .Add (paras );
- if (cmd.ExecuteNonQuery()>0)
- {
- flag =true;
- }
- }
-
- return flag;
- }</span><span style="font-size: 14pt;">
- </span>
- <span style="font-size:16px;">
-
-
-
-
- public bool Insert(string caName)
- {
-
- bool flag = false;
- string sql = "insert into category(name) values(@caName)";
- SqlParameter[] paras = new SqlParameter[] { new SqlParameter("@caName", caName) };
- flag = sqlhelper.ExecuteNonQuery(sql);
-
- return flag;
- }</span><span style="font-size: 14pt;">
- </span>

posted @
2012-07-09 23:13 zhanghu198901 阅读(781) |
评论 (0) |
编辑 收藏DOM文档对象模型(Document Object Model,DOM)是一种用于HTML和XML文档的编程接口。它给文档提供了一种结构化的表示方法,可以改变文档的内容和呈现方式。
DOM 被分为不同的部分(核心、XML及HTML)和级别(DOM Level 1/2/3):
Core DOM
定义了一套标准的针对任何结构化文档的对象
XML DOM
定义了一套标准的针对 XML 文档的对象
HTML DOM
定义了一套标准的针对 HTML 文档的对象。
JavaScript是一种能让你的网页更加生动活泼的程式语言,也是目前网页中设计中最容易学又最方便的语言。
Dom和JavaScript的关系就像是C#语言和.Net的关系一样
通过 JavaScript,你可以操作DOM来重构整个 HTML 文档。您可以添加、移除、改变或重排页面上的项目。
posted @
2012-07-06 15:48 zhanghu198901 阅读(1034) |
评论 (0) |
编辑 收藏网上看到一篇博文,是一位原网易的产品总监辞职进行创业。他针对如果大公司抄袭自己的话如何来应对。
整篇文章通过分析大公司中的各种弊端,来确定创业型公司的优点和长处。通过这篇文章一些想要创业的同学会获得一些信心和动力。
不过我个人感觉,如果以前在大公司里遇到的问题的根源是自身的毛病话,即使换个环境也不会自动消失的。
很多人总是会抱怨环境不好,时机不好,境遇不好。而实际很多困境或难题是自己造成的。希望大家共勉。
原文如下:
腾讯抄你肿么办
2012-06-10 23:13:04| 分类: 行业 |字号 订阅
对不住腾讯的同行,我标题党了。
其实,这篇文章是打算写“大公司抄你肿么办?”很明显腾讯最典型嘛,以至于我还在网易的时候,Boss也问我,腾讯抄你怎么办?此时屡屡有一股邪火在胸口燃烧着,想大吼一声:腾讯抄我怎么办?老子跳槽去腾讯!
最后我还是选择了创业。
我在网易5年,一直带业务部门,从内容总监转职产品总监,算得上资深中层吧。网易做产品的环境,放在业内大约是中等偏上,它的好处别家未必有,弊端则是寰球同此凉热。年初跟VC谈天使融资的时候,对方大统领换了一个问法:如果网易抄你怎么办?我很吃惊地回答,如果留在网易就能把这个项目做出来,我还创什么业?难道你以为我创业是为了发财、专权,或者给自己戴上SB风格的CEO头衔?
那么大公司到底是真老虎还是纸老虎?我得从大公司业务运作的常识说起。
▎部门背景
大公司是一个笼统的概念,由若干个事业部>大部门>中小部门>项目组构成。其中战斗力过硬的项目组是少数,王牌军不足十分之一,而水货项目组的占比至少超过一半。
我们品头论足说XX公司的产品做得很好,其实是某几个项目组实力非凡。如果不与他们正面对抗,其他组做产品也就是60出头的平均分。难道你连产品70分都没有自信?没这自信你还做个屁啊。
所以在忌惮大公司之前,先摸摸底,和你竞争的大公司项目组归属在哪个部门下面,它又是什么背景。正如我以前对某大公司很是好奇,为什么一部分业务很烂,另一部分很赞?内部人士答:因为它们分属于两个不同的事业部,一队落魄边沿化,另一队则是常胜王牌军。
▎业务关联
有些时候,你发现某大公司和你进入了同一个竞争领域。别着急,先看看做这个项目的部门,主营业务是否和该项目在同一条中轴线上。
由于野心的驱动,部门主管常常会批准一些和主营业务关系不大的,想象空间又很大的项目,妄想别错过金矿。然而这只是投石问路,买张彩票,主要的资源仍然在主营业务线集中,更不可能忍受平缓的增长曲线(掘金心态嘛,哪怕掘到铜矿也会断然放弃)。外界看见“XX公司悍然进入XX领域”……屁嘞,只有做这个项目的团队甘苦自知,时间紧/期待高/投入少/管理制度别手,不挂基本上不可能。
紧接着上一条,对大公司对手的部门背景作详细调查,或许能解除你对那个庞然大物的恐惧心。如我以前在网易门户做摄影分享社区,第一年里,有8个月分到了1位工程师的工时;接下来一年总算有3位工程师了,其中2位又是实习生。我熬了整整3年,3年呐,才熬到基本够用的技术人员配置,那时市场机遇早已消失不见。
▎公共资源
大公司的公共资源往往包括如下部分:UED、QA、推广位,集中调度以提高利用率。有时候运营人员也是公共资源,有时候更惨一点,连程序员都是公共资源。虽然家底殷实,公共资源摊薄到每个项目上便很寒碜,所谓僧多粥少。项目经理可能把自己有招聘权的人给凑齐了,但他还得腆着脸找各个公共部门老大要资源,有时是恳求,有时是苦苦哀求。
跪下来舔鞋都提不上工单的时候,我以前还使过一茅招,搞点部门经费,请前端组的同事私底下帮忙切图……当作付费外包来对待。那时视觉稿已经堆了个把月,没法推进一步。类似的木桶效应多如牛毛,几乎每个大公司项目都会遇到,偏偏使不上力,被短板卡得上气不接下气。
即便抢到了(勉强够用的)公共资源,你还得面对分配资源的随机性问题。比如说小清新风格的产品,能分到擅长此风格的设计师吗?不能,谁空下来分派谁。擅长小清新的设计师当然也有,人家正在别的项目组,即便那个项目恶俗,设计师也很不开心,做到一半怎可能中途离场。所以我以前跟PM说:有人帮你做就快去烧香还愿,有推广位到手就感恩热泪盈眶,你还挑啥子挑喃?十几个部门几十个项目都闹着要最好的最合适的,你让UED情何以堪喃?
由于公共部门采用派单制,大部分人员缺乏项目归属感,荣誉感,他既无法全程参与,也很难真正融入项目组里边。座位经常隔了几百米,一周只能碰头两三面,甚至因为参与时间短暂,就连对产品的理解也比较浅,应付完这个应付那个,“应付了事”的心态极为常见。往往只有项目经理把产品当儿子看,别人都当成牵到自己家里来串门的邻居小孩儿。
更能理解的是,公共部门这个月做A项目的单,下个月做B的单,这个月A项目组请饭请求加班,下个月B请饭请求加班。项目上线你们倒是领功/打赏/休假,下一个项目组又声泪俱下说这单子特别重要,非得拉兄弟一把不可。这岂不是“无穷无尽的加班”“无穷无尽的拼这一仗”?你们少来诳老子……
曾见以前合作的设计师,私底下为自己做了款玩票的APP,比当初花两三个月为我们部门设计的APP,起码高出两个等级。当真刮目相看。
▎KPI
KPI是万恶的,没有KPI又是万万不能的。
所谓KPI,属于体制的一部分,也是大企业病的一部分。这个世界上不靠谱的人和项目占多数,衡量创业团队是否靠谱的标准很简单——剩者为王。这是一款生存游戏。
随着公司活下来并且膨胀起来,自然淘汰的筛选法很快失了效。创业意味着高风险和高收益,当创业团队成长为中型公司,大公司,则个人的风险降低(收入增加,薪资职位稳定),收益也降低(期权减少甚至没有),容易滋生更多轻浮的冒险,拿公司的钱去玩自己的票,修筑各种烂尾楼。如果不用KPI来制衡,十八般瞎折腾便掏空公司资源。人家旱涝保收底薪很高的,人家从折腾中赚到了经验值,就算引咎辞职,下一份工作还能拿到更高薪水的,而你老板呢,资产耗光只能去摆地摊了。
鉴定和约束各种瞎折腾的管理手段之一,我们称之为项目KPI,即阶段性的项目考核。在这个过程中证明自己靠谱,项目有戏,公司才会继续支持你。以我所见,虽有不少被KPI整死的好项目,但95%以上被涮掉的,确为次品,事后一齐流泪控诉KPI之恶贯满盈,觉得失败原因是“公司不给支持”。问题是怎么证明你和这个项目值得更多的支持?怎么证明你是有可能成功那5%,而不是注定失败的95%?
老板毕竟不是天网,他不可能什么都懂,尤其对新拓展的业务,一旦超出了高层的成功经验领域,只能靠KPI来判断项目前景。这同时意味着[要命的]公司对项目缺乏耐心和远见。若不能看到短期数据利好,则支持度快速下降,资源供给减少,方向盘立刻打到一条名为“黄泉”的路上。预见到灭顶之灾又会干扰项目经理的判断,往往使些目光短浅,饮鸩止渴的茅招出来,苟且保得眼前性命。
▎高层干预
刚才提到大公司对新业务缺乏耐心和远见,这根子还在公司高层身上。所谓高层,最低也是管辖几百人的方面大员,通常从VP起计。能做到大公司高层必有过人之能,不幸人过30岁后对新领域的学习能力直线下降,再加上行政事务缠身,无法专注于业务。故而对于市场拓展,大部分高层混合了视野狭窄与刚愎自用这两种特质,必然大量依赖KPI管理。
反过来看,如果高层瞄准了某个项目,下决心赌上一把呢,它就会得到更多的资源和宽容,初期KPI有可能压根不设,所有公共部门都围着你打转。高层力挺可以解决掉60%的大企业病,作为创业团队,遇到这样的对手是件挺可怕的事情,还好它们只是极少数,占比不足5%。而你会因为大晴天也有可能下雨沾湿鞋,就畏畏缩缩不敢出门吗?
何况高层的支持是一把双刃剑,他会给你喂足粮草,钉好蹄铁,同时也给你戴上嚼子,圈定方向甚至策略。那么高层指定的方向策略出错呢?恭喜,贵项目挂了。长官意志令如山,最怕长官是外行。
另一些情况下,大公司项目因为资源不足,资源错位而做砸,其实还是高层的决策影响。他认为给这些支持已经足够看清前景,若是败局,又何必豪赌下去。毕竟主营业务还赚钱嘛,还有得选择,反倒是“没得选择”转化为创业团队背水一战的韧性所在。
▎齐心协力
说句听上去挺刺耳的话,大公司里很难谈真正的齐心协力。按我的理解,齐心协力的基石不是个人素质,而是成员都适合这个项目,喜欢这个项目,自然努力团结。可你加入某一家大公司,往往受其光环/福利/资历的吸引,有个坑就猛往里跳,其后转岗不易。做什么项目亦受到部门限制,自主权有限得很。
换句话说,参与大公司项目组的,并不是最适合,最喜欢这个项目的人,而是项目经理目前能搞到的人(调动、招聘以及公共部门派单)。甚至项目经理本人也是奉命而为,或无奈抓阄。驱动工作的动力是职业道德,季度考核,奖金与功名,却非你对这款产品的爱。老实承认,我自己即是一例。哪怕在网易加班极多,直到辞职出来做有爱的产品,方才觉得过去皆是行尸走肉。
而我目前的创业团队只有6个人,来自5家大公司(上市或即将上市)。你说大家放弃了高薪福利,稳定工作,来上海做一款前途未卜的产品是为什么?当然不是服了我的三尸脑神丸……
于是我现在的项目速度比之前在网易快3倍,工作进展有规划,无管理,队员的主动性之强,内部合作的愉快与默契是过去从未经历过的。两个字:“开心”。换回大公司,那得打多少鸡血开多少动员大会啊,最后有人还在会上睡着了。
▎人多嘴杂
小团队凭什么跟大公司竞争呢?有人说是“专注”,有人说是“耐心”,有人说是“远见”。这些都对,我还要补充一点,小团队一定要比大公司犯更少的错。
这句话听上去挺莫名其妙的,大公司人才济济,小团队凭什么跟人家比正确率?回答很简单:人才济济,同时也人多嘴杂。给项目提意见的人越多,执行效率越低,这是铁一般的定律。尤其当建议者中包括各级领导的时候,决断就更加飘忽不定。你非得考虑上司的立场,部门的立场,微妙的公司政治环境,固然不乏真知灼见,合拢在一起便成噪音干扰。大量时间花费在报审/修改/开会/争吵/写文档/走流程上面,行动迟缓举棋难定,更增加误入歧途的概率。
相比之下,小团队的快速决策,快速行动,正好击中了大公司的软肋。一款新产品出来,大公司实权派发现它起码得2个月,看懂它2个月,立项组好队还得花2个月。再加上市场前景不明朗,在创新者大红大紫之前,大公司愿意投入(冒险)的资源是极少的,试水而已,复制抄袭多于革新改良,保守跟随多于锐意开拓。结果一两年过去了,创新者勇猛精进已成气候,大公司才回过神来,欲与之全力一搏。人家的前期积累已领跑市场,后来者未必追赶得上。
类似案例,多不胜数。创业者眼里唯一的好机会,大公司看来却只是1000个模糊不清的机会之一,拿捏不定。由此逆向思维的话,创业团队最好不要插入大公司的主营业务去虎口夺食。人家苦心经营多年,凭借对这块市场的理解力和戒备心,会更快发现你,重视你,然后高层吹响号角击溃你。但你去开辟新战场呢,大公司跟还是不跟,用多大力跟,往哪个方向走,它就很难统一内部意见。
▎基因转移
人都艳羡大公司“资源多”,所谓资源,一半是人才资源,一半是海量用户,即推广资源。然而不常被提及的是,大平台的团队基因/用户构成/用户习惯,与新项目是否吻合。或者笼统点说,大平台的资源优势是否能向新项目平滑过渡。
我一直是“基因论”的支持者,公司实权派的个人偏好,决定了团队构成与文化,进而决定了主场优势与劣势。正如APPLE在社交网络几战皆败,伟大如Google也被Facebook压得抬不起头来。只是受到野心蛊惑,即便八字不合,大公司也会悍然进入新领域(凭什么我不行),随后又惨然退出(原来我真不行)。
比团队基因更令人恼火的,是用户基因,即当前用户群的构成与使用习惯。做产品经常遇到“跨域”这个问题,借势推广也一样。新项目的产品诉求,用户构成,如果和母体在同一个域内,则资源优势平滑过渡,对竞争者是致命的杀伤力。但其实……平滑过渡又是一件特别不多见的事情。有时新项目整个的跨域,比如腾讯做拍拍,做朋友,导入损耗率惊人;有时大平台向垂直市场细分,无法精准过滤推广目标,导入用户良莠不齐得厉害,对于重视“气质、氛围”的垂直市场则是拔苗助长。
以我之前做网易摄影为例,不推吧,在大公司做产品跟创业有多大区别,生怕浪费了资源。推吧,不搭边的人路过都来踩一脚,各种低端用户、自拍用户、审美低下热情万丈的中老年用户蜂拥而入,氛围混乱,运营成本指数级上升,最终受困多过受益。反倒是独立摄影产品如图虫,用户气味相投而来,自然增长营造的社区气质远胜从大平台引流,气质恰恰又是社区的核心竞争力。
做产品,鲜有一夜暴富,尤其UGC,口碑带动增长才是最稳健的方法。道理固然大路货,KPI压力下却容易急于求成。母体供血一旦大量掺水,相当于修炼邪道武功,起步快而后力不济,很快会触碰到天花板。这时大平台所谓海量用户,反倒成为盛满鲜花的陷阱,涂抹蜜糖的慢性毒药。好似小时候四环素治病,长大后灿然一笑露出满口黄牙。
——————————我是总结分割线——————————
总之,在大公司里做产品的雷区多多。与内部环境作战所使的力气,往往占到血槽的2/3强,只留下不足1/3去对付市场。它抄你,不见得就打得过你。它是个大家伙,但也喜欢把两个脚拇指绑起来走路。在多数情况下,大公司的新项目只是全身挂满钻石镣铐的,虚弱的巨人,被活活抄死抄残多半说明你太逊色,而不是大家伙太凶恶。
不过,这个行业的主流论调并不这么看。
最近几个月,各式各样的人纷纷来问我,既然立志“不走寻常路”,大公司抄你怎么办?
对这个问题,我有各种具体的回答,但都不是真心话。只是面对某些人,比如投资人的时候,你跟他讲虚的,会被当成喷子,得表示我有明确的对策……其实对策易变,反倒是“产品哲学”这类虚的东西更加恒定。
我真心的态度可以用三次自问自答来概括。
1、我的产品质量能不能打败跟随者,至少是与跟随者各擅其长?
如果做不到,这不是我被抄的问题,是我技不如人,我认栽。竞争会刺激我提高产品质量,未必是一件坏事。
2、假定产品通过创新,打开一个新的细分市场,这个市场是否足够大,大到可以容纳下多个竞争者同时生存?
如此则对手亦是队友,我们一边互相作战,一边共同开垦荒地,联手培育市场。即便最后我只拿到第三、第四的份额,也不错啊,谁规定创新者就非得独吞整个市场不可——初夜权不等于占有权,市场又不是从一而终的贞洁牌坊。
3、除了用户口碑之外,产品是否有具象化的的价值沉淀?
比如黏性强的用户关系,比如用户留存的他看重的内容,比如有忠诚度的优质内容发布者,比如含金量与时效性较长的信息。这些沉淀即防御壁垒,从产品架构阶段就应该提前考虑,决定了防守反击的难度。
所以别人来不来抄这种事情,我从来都是不大关心的,偶尔想想,从不忧虑。周鸿祎有句话说得很好,少盯着对手,多研究用户。一天到晚担心“腾讯抄我怎么办”?担心有屁用啊,万一产品做得不好,腾讯抄都不屑于抄,那得白白浪费多少脑能量。我只管埋头做自己的产品,洪兴罩我去战斗~
换个角度看,哪怕比较倒霉,很快被大公司看得起并临幸了,对手在高层力挺下全力以赴地复制并改良,它的基因刚好又平滑过渡……那么,我挂了。但产品创新若是如我所愿地打开某个细分市场,改善某类用户体验,作为始作俑者,老子倾家荡产,虽败犹荣。“小小改变世界”比“赚到三千万退休”更值得追求。
正如我在微博里所说:阻挡你创新的是“无能”而不是“抄袭”,鼓舞你创新的是内心骄傲而不是永远独占鳌头。
——————————我是后记分割线——————————
4月张罗着创业以来,写IT文章的频度锐减。一方面是忙不过来,另外,创业相关的经验虽然多(招聘/产品设计/内部协作),却不适合大嗓门讲,毕竟八字还没一撇呢。有些话说得太早,难免被人等着看笑话。还是等产品落地生根之后再写比较稳当。
所以,亲们,祝福我接下来走得顺利吧,汇集正能量。创业历程中可写的东西,比我在网易时多太多了。萌叔有宝不轻弹,只是未到话痨时。
转载随意,但请带上我的微博地址……
http://weibo.com/cicada
posted @
2012-07-06 15:48 zhanghu198901 阅读(1004) |
评论 (0) |
编辑 收藏java.lang.ClassNotFoundException: javax.transaction.UserTransaction
解决办法:
到 http://java.sun.com/products/jta/ 下载
Java Transaction API classes 的zip包,解压然后用命令将jta-1_1-classes下都javax文件夹压缩成jar
命令:jar cf jta.jar javax
生成一个jta.jar文件,把这个文件添加到classpath
或者直接在Spring lib中查找,复制添加到classpath
posted @
2012-07-06 15:47 zhanghu198901 阅读(3710) |
评论 (0) |
编辑 收藏posted @
2012-07-05 14:09 zhanghu198901 阅读(860) |
评论 (0) |
编辑 收藏
摘要: 昨天下午参加了一个面试,因为自己本身的面试经验不足,所以面试效果也不是非常令自己满意。
至于这个面试中问到的问题,其实大多数还是一些关于项目开发过程中的一些问题是怎样解决的,也就是所说的项目经验;还有一些原理性的东西和基础性的东西(基础性的比较少)。
阅读全文
posted @
2012-07-04 20:25 zhanghu198901 阅读(1240) |
评论 (2) |
编辑 收藏
摘要: java.util.Date implements java.io.Serializable, Cloneable, Comparable
所有日期类型的父类,已知子类Date、 Time、TimestampDate , Date 表示特定的瞬间,精确到毫秒。
//默认是创建一个代表系统当前日期的Date对象 阅读全文
posted @
2012-07-04 19:38 zhanghu198901 阅读(1006) |
评论 (0) |
编辑 收藏