本文首先以一个简单的sed命令应用示例,说明如何使用sed命令进行文本处理,接着从sed命令的用法、工作原理、行地址模式以及sed命令支持的脚本命令详细介绍sed命令的用法。
一个完整的sed命令使用简单示例
现在有一个待处理文件test.txt,文件中包含一系列的位图数据1和0,它们位于<Figure Begin>和<Figure End>之间,需要将它们写入一个单独的文件,并使用.FG <insert figure here> .FE替换着部分内容。替换输入文件中的<para> 标识为.LP并删除其下的空行。最后,删除输入文件中的所有空行。
处理文件内容如下:cat test.txt
- <para>
-
-
- This is a test paragraph.
-
-
- <Figure Begin>
-
-
- 111111111111111101000000000000000000000000000000111111111111111111100000000
- 000000000000000000000000000000000001111111111111111111111111111111111111111
- 11111111111111111110000000000000000000
-
-
- <Figure End>
-
-
- <para>
-
-
- MOre lines of text to be found after the figure.
- These lines should print.
sed脚本命令内容及解释如下:cat sedscr
- /<para>/{
- N #读入下一行,因为下一行为空行,
- c\ #使用下面的内容替换模式空间中的内容,之所以使用N命令,也是想把<para>下面的空行删除
- .LP
- }
- /<Figure Begin>/,/<Figure End>/{ #匹配<Figure Begin>到<Figure End>行之间的内容
- w fig.test #将这部分中的当前模式空间中的内容写入文件fig.test中,因为sed命令式按行读取文件内容的
- /<Figure End>/i\ #在<Figure End>行前插入下面的内容
- .FG\
- <inset figure here>\
- .FE
- d #删除匹配的行,即删除模式空间中的内容,这样模式空间中的这部分内容不会被输出
- }
- /^$/d #删除所有空行
sed脚本执行命令:sed -f sedscr test.txt
sed脚本执行完成后输出内容如下:
- .LP
- This is a test paragraph.
- .FG
- <inset figure here>
- .FE
- .LP
- MOre lines of text to be found after the figure.
- These lines should print.
上面简单演示了一个使用sed命令的实际例子,初学时看不懂没有关系,只需知道大概是这么个流程,然后下面会详细的解释sed命令的用法。
sed命令用法
sed[选项] {脚本 | 脚本文件} [输入文件],其中[ ]表示可选,{}表示必须。
首先将3个经常出现的选项解释如下:
-n, --quiet, --silent 取消自动打印模式空间
-e 脚本, --expression=脚本 添加“脚本”到程序的运行列表
-f 脚本文件, --file=脚本文件 添加“脚本文件”到程序的运行列表
上面出现了sed命令的三个最基本最常见的参数选项,其意思如下表所示:
| -n选项 |
抑制sed命令的默认输出 |
| -e选项 |
后接单引号包含的命令脚本,仅应用单个命令于输入文件时适用 |
| -f 选项 |
指定一个文件包含多个脚本命令 |
这几个选项的使用模式大致如下:
sed -n -e 'cmd_script' input_file #注意,单引号扩住脚本命令
sed -f script_file input_file #将脚本命令写入一个单独的文件
其实,sed命令的选项并不是学习sed命令的主要内容,主要内容是对于sed命令脚本部分的学习。sed支持的脚本命令比较多,后面会详细介绍该部分内容,介绍sed支持的脚本命令之前,先介绍一下sed命令执行的原理。
sed工作原理
下面以sed -f script_file input_file为例,其工作原理如下图所示:
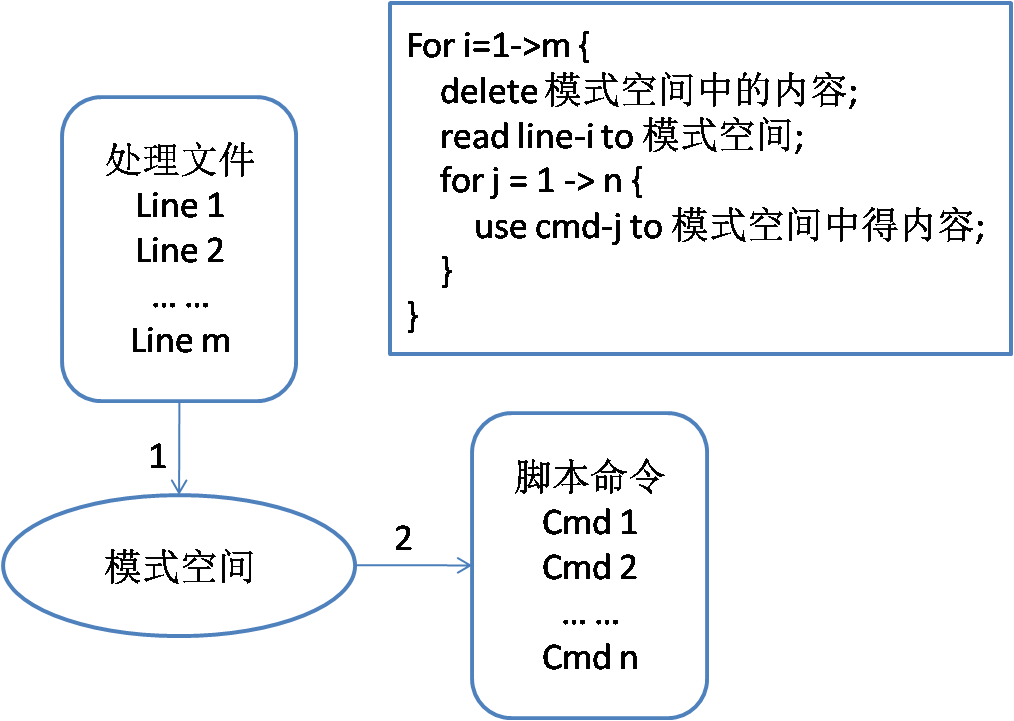
其中input_file表示处理文件,script_file表示脚本命令。
工作原理如下:
a) 首先将处理文件的第一行读入模式空间。
b) 接着对模式空间中的这一行内容执行脚本命令中设置的命令,从上至下依次执行脚本命令中设置的命令。
c) 脚本命令执行完成后,输出模式空间中的内容。
d) 清空模式空间中得内容,并读入处理文件中得第二行内容,并重复b) 和 c) 步骤的内容,直至处理完文件中的所有内容。
苦逼的码农可以查看图片右上角的伪代码,可能解释得更加清晰一点。
下面先对几个经常出现的名词进行解释:
模式空间
以上描述中出现了一个词叫模式空间,下面对其进行解释。由于sed命令的执行并不修改原始文件,也就是说输入文件是什么,执行完sed命令后,输入文件没有变化,这么说来,肯定不能在输入文件的基础上对其进行编辑,所以需要一块单独的空间,用于转存文件中得内容,然后进行处理并输出。模式空间就是这么一块转存输入文件内容的空间,并且sed命令一次读入输入文件中得一行内容到模式空间,使用sed命令支持的脚步执行处理完模式空间中得内容后,输出处理完的结果并删除模式空间中得内容,准备读入下一行输入文件中得内容。
多行模式空间
如上所述,模式空间每次读入输入文件中的一行进行处理,有时只读入一行内容到模式空间对输入文件的处理能力很有限,比如它很难处理一个在一行末尾处开始,并在下一行开始处结束的短语。而多行模式空间就是为了解决这个问题而提出的,他允许将模式空间中的内容从一行扩展到多行。具体内容在本文后面会有讲解。
保持空间
模式空间是容纳当前输入行的缓冲区,而保持空间是预留的一部分缓冲区,用于临时存储模式空间中的内容。模式空间中的内容可以复制到保持空间,保持空间中的内容也可以复制回模式空间。具体内容在本文后面会有讲解。
sed命令的行地址模式
为什么需要行地址模式呢?因为并不是输入文件中的每一行内容都需要被sed命令处理,sed命令当然只处理它感兴趣的部分,于是需要使用行地址模式对要处理的行进行控制。
行地址是由斜杠、行号或者行寻址符号扩住的正则表达式描述。sed命令可以指定 0 或者 1 或者 2 个地址,每个地址都是一个描述模式、行号或者行选址符号的正则表达式。
1. 如果没有制定地址,表示命令将应用于每一行。
2. 如果只有一个地址,表示命令将应用于与这个地址匹配的所有行。
3. 如果指定了由逗号分隔的两个地址,表示命令应用于匹配第一个地址的第一性和它后面的行,直到匹配第二个地址的行(包含此行)。
4. 如果地址后面跟有感叹号,表示命令将应用于不匹配该地址的所有行。
例:
a) [address]command
b) [line-address]command
c) address {
command1 #在command后面添加空格可能会产生意想不到的错误,建议每个command都单独一行
command2
command3
} #右大括号必须单独位于一行
sed命令支持的脚本命令
sed命令所支持的脚本命令很多,常见的脚本命令有s、d、p、n、i、a、c、y等。其中还包括与多行模式空间相关的N、D、P命令(均大写)。与保持空间相关的h、H、g、G、x命令。
1. s命令(替换)
语法:[address]s/pattern/replacement/flags
解释:替换命令应用于与address匹配的行(address的匹配见行地址模式一节),如果没有指定address,就应用于与pattern匹配的所有行。
flags标注可能是以下几种情况中得一种:
g: 对模式空间中所有出现匹配的情况均进行替换。没有指定g时表示仅对第1次出现匹配的情况进行替换。
n: 1-512之间的一个数字,表示对当前模式空间中第n次出现所匹配部分的内容进行替换,其余所匹配部分的内容不变。
p: 打印模式空间中的内容。
w file: 将模式空间中的内容写入file中。
换行符在计算机内部只是一个字符,所有正则表达式可以使用"\n"来匹配换行符。
replacement部分,下列字符具有特殊含义:
&: 用正则表达式匹配的内容进行替换。
\n: 匹配第n个子串,这个子串以前在pattern中使用"\("和"\)"指定。
\: 转义字符,如上所述的&字符,在replacement中出现是就需要使用转义字符。
例:
s/UNIX/\\s-&\\s0/g脚本将 on the UNIX OS 替换为 on the \s-UNIX\s0 OS,其中UNIX为正则表达式匹配的内容,替换replacement中的&字符。其中第一个"\"字符为转义字符。
s!/usr/mail!/usr2/mail!g #定界符并不一定必须是"/",也可以选择其他字符,如本例中使用"!"作为定界符。
有一个test.txt文件内容为first:second,现在想要将first和second替换位置。可以使用如下命令实现:
sed -e 's/\(.*\):\(.*\)/\2:\1/' test.txt #"\("、"\)"在pattern中指定了两个子串,"\1"、"\2"表示匹配第1个和第2个子串。
2. d命令(删除)
待续......