Posted on 2021-06-04 15:36
为自己代言 阅读(641)
评论(0) 编辑 收藏 所属分类:
spring cloud 微服务

整体架构
从日志生成到抓取、存储、分析、展现的多个系统间交互过程。
在复杂的分布式系统环境下,EagleEye是一个有广泛用途的调用分析和问题排查工具。与一般的调用信息埋点日志相比,EagleEye埋点的一个显著的不同点在于它的每条日志都有与每次请求关联的上下文ID,我们称为TraceId。通过TraceId,后期的日志处理时可以把一次前端请求在不同服务器记录的调用日志关联起来,重新组合成当时这个请求的调用链。因此,EagleEye不仅可以分析到应用之间的直接调用关系,还可以得到他们的间接调用关系、以及上下游的业务处理信息;对于调用链的底层系统,可以追溯到它的最上层请求来源以及中间经过的所有节点;对于调用链的上层入口,可以收集到它的整棵调用树,从而定位下游系统的处理瓶颈,当下游某个应用有异常发生时,能迅速定位到问题发生的位置。
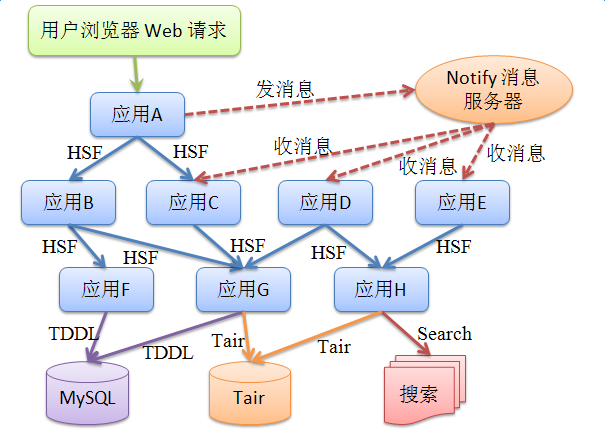
如上图所示,应用A是接受到来自用户浏览器的Web请求的前端服务器,它是一条调用链的开始端,在TBSession和EagleEyeFilter中都做了EagleEye上下文埋点。请求收到后它会先调用EagleEye StartTrace生成TraceId并放置在当前线程的ThreadLocal,日志埋点请求信息(如URL、SessionId、UserId等)。在请求处理完毕提交相应时,再调用EndTrace清理线程中的EagleEye信息。 在应用A调用应用B、C的HSF服务,或者发送Notify消息时,TraceId被包含在EagleEye上下文中,随网络请求到达应用B、C、D、E之中,并放置在线程ThreadLocal内,因此后续调用到的这些系统都会有EagleEye这次请求的上下文。这些系统再发起网络请求时,也类似的携带了上下文信息的。
为了区别同一个调用链下多个网络调用的顺序和嵌套层次,EagleEye还需要传输和记录RpcId。 RpcId用0.X1.X2.X3.....Xi来表示,Xi都是非负整数,根节点的RpcId固定从0开始,第一层网络调用的RpcId是0.X1,第二层的则为0.X1.X2,依次类推。*例如,从根节点发出的调用的RpcId是0.1、0.2、0.3,RpcId是0.1的节点发出的RpcId则为0.1.1、0.1.2、0.1.3。如下图所示
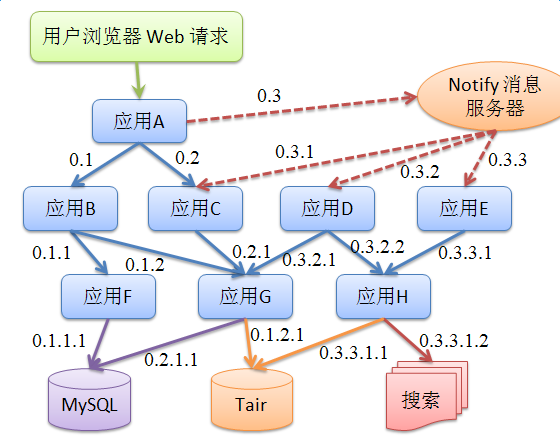
通过RpcId,可以准确的还原出调用链上每次调用的层次关系和兄弟调用之间的先后顺序。 例如上图应用 G 的两次调用0.2.1.1和0.1.2.1,可以看出对 DB 的访问0.2.1.1源于 C 到 G 的调用0.2.1,对 Tair 的访问0.1.2.1源于B 到 G 的调用0.1.2。 很多调用场景会比上面说的完全同步的调用更为复杂,比如会遇到异步、单向、广播、并发、批处理等等,这时候需要妥善处理好ThreadLocal上的调用上下文,避免调用上下文混乱和无法正确释放。另外,采用多级序号的RpcId设计方案会比单级序号递增更容易准确还原当时的调用情况。