InnoDB的锁
InnoDB的行锁:共享锁、排他锁、MDL锁
共享锁:又称读锁、S锁。一个事务获取一个数据行的共享锁,其他事务能获取该行对应的共享锁,但不能获得排他锁;即一个事务在读取一个数据行时,其他事务也可以读,但不能对数据进行增删改查。
应用:
1.自动提交模式下的select查询,不加任何锁,直接返回查询结果
2.通过select……lock in share mode在被读取的行记录或范围上加一个读锁,其他事务可以读,但是申请加写锁会被阻塞
排他锁:又称写锁、X锁。一个事务获取了一个数据行的写锁,其他事务就不能再获取该行的其他锁,写锁优先级最高。
应用:
1.一些DML操作会对行记录加写锁
2.select for update会对读取的行记录上加一个写锁,其他任何事务都不能对锁定的行加任何锁,否则会被阻塞
MDL锁:MySQL5.5引入,用于保证表中元数据的信息。在会话A中,表开启了查询事务后,会自动获得一个MDL锁,会话B就不能执行任何DDL语句的操作
行锁实现方式
InnoDB 行锁是通过给索引上的索引项加锁来实现的,这一点 MySQL 与 Oracle 不同,后者是
通过在数据块中对相应数据行加锁来实现的。InnoDB 这种行锁实现特点意味着:只有通过 索引条件检索数据,InnoDB
才使用行级锁,否则,InnoDB 将使用表锁! 在实际应用中,要特别注意 InnoDB 行锁的这一特性,不然的话,可能导致大量的锁冲突,
从而影响并发性能。
行锁的三种算法
InnoDB 存储引擎有三种行锁的算法,其分别是:
- Record Lock: 单个行记录上的锁
- Gap Lock: 间隙锁,锁定一个范围,但不包含记录本身
- Next-Key 锁: Gap Lock + Record Lock,锁定一个范围,并且会锁定记录本身
RC模式下只采用Record Lock,RR模式下采用了Next-Key
加锁场景分析
如果我们加锁的行上存在主键索引,那么就会在这个主键索引上添加一个 Record Lock。
如果我们加锁的行上存在辅助索引,那么我们就会在这行的辅助索引上添加 Next-Key Lock,并在这行之后的辅助索引上添加一个 Gap Lock
辅助索引上的 Next-Key Lock 和 Gap Lock 都是针对 Repeatable Read 隔离模式存在的,这两种锁都是为了防止幻读现象的发生。
这里有一个特殊情况,如果辅助索引是唯一索引的话,MySQL 会将 Next-Key Lock 降级为 Record Lock,只会锁定当前记录的辅助索引。
如果唯一索引由多个列组成的,而我们只锁定其中一个列的话,那么此时并不会进行锁降级,还会添加 Next-Key Lock 和 Gap Lock。
在 InnoDB 存储引擎中,对于 Insert 的操作,其会检查插入记录的下一条记录是否被锁定,若已经被锁定,则不允许查询。
意向锁
意向锁可以分为意向共享锁(Intention Shared Lock, IS)和意向排他锁(Intention eXclusive
Lock,
IX)。但它的锁定方式和共享锁和排他锁并不相同,意向锁上锁只是表示一种“意向”,并不会真的将对象锁住,让其他事物无法修改或访问。例如事物T1想要修改表test中的行r1,它会上两个锁:
- 在表
test上意向排他锁 - 在行
r1上排他锁
事物T1在test表上上了意向排他锁,并不代表其他事物无法访问test了,它上的锁只是表明一种意向,它将会在db中的test表中的某几行记录上上一个排他锁。
|
意向共享锁 |
意向排他锁 |
共享锁 |
排他锁 |
| 意向共享锁 |
兼容 |
兼容 |
兼容 |
不兼容 |
| 意向排他锁 |
兼容 |
兼容 |
不兼容 |
不兼容 |
| 共享锁 |
兼容 |
不兼容 |
兼容 |
不兼容 |
| 排他锁 |
不兼容 |
不兼容 |
不兼容 |
不兼容 |
一致性非锁定读
一致性非锁定读是指 InnoDB 存储引擎通过行多版本控制(multi
version)的方式来读取当前执行时间数据库中行的数据。具体来说就是如果一个事务读取的行正在被锁定,那么它就会去读取这行数据之前的快照数据,而不会等待这行数据上的锁释放。这个读取流程如图1所示:
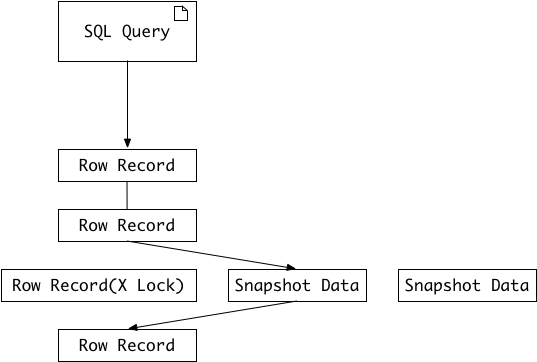
行的快照数据是通过undo段来实现的,而undo段用来回滚事务,所以快照数据本身没有额外的开销。此外,读取快照数据时不需要上锁的,因为没有事务会对快照数据进行更改。
MySQL 中并不是每种隔离级别都采用非一致性非锁定读的读取模式,而且就算是采用了一致性非锁定读,不同隔离级别的表现也不相同。在 READ
COMMITTED 和 REPEATABLE READ 这两种隔离级别下,InnoDB存储引擎都使用一致性非锁定读。但是对于快照数据,READ
COMMITTED 隔离模式中的事务读取的是当前行最新的快照数据,而 REPEATABLE READ
隔离模式中的事务读取的是事务开始时的行数据版本。
一致性锁定读
在 InnoDB 存储引擎中,select语句默认采取的是一致性非锁定读的情况,但是有时候我们也有需求需要对某一行记录进行锁定再来读取,这就是一致性锁定读。
InnoDB 对于select语句支持以下两种锁定读:
select ... for updateselect ... lock in share mode
select ... for update会对读取的记录加一个X锁,其他事务不能够再来为这些记录加锁。select ... lock in share mode会对读取的记录加一个S锁,其它事务能够再为这些记录加一个S锁,但不能加X锁。
对于一致性非锁定读,即使行记录上加了X锁,它也是能够读取的,因为它读取的是行记录的快照数据,并没有读取行记录本身。
select ... for update和select ... lock in share mode这两个语句必须在一个事务中,当事务提交了,锁也就释放了。因此在使用这两条语句之前必须先执行begin, start transaction,或者执行set autocommit = 0。
InnoDB 在不同隔离级别下的一致性读及锁的差异
consisten read //一致性读
share locks //共享锁
Exclusive locks //排他锁
|
|
读未提交 |
读已提交 |
可重复读 |
串行化 |
| SQL |
条件 |
|
|
|
|
| select |
相等 |
None locks |
Consisten read/None lock |
Consisten read/None lock |
Share locks |
|
范围 |
None locks |
Consisten read/None lock |
Consisten read/None lock |
Share Next-Key |
| update |
相等 |
Exclusive locks |
Exclusive locks |
Exclusive locks |
Exclusive locks |
|
范围 |
Exclusive next-key |
Exclusive next-key |
Exclusive next-key |
Exclusive next-key |
| Insert |
N/A |
Exclusive locks |
Exclusive locks |
Exclusive locks |
Exclusive locks |
| Replace |
无键冲突 |
Exclusive locks |
Exclusive locks |
Exclusive locks |
Exclusive locks |
|
键冲突 |
Exclusive next-key |
Exclusive next-key |
Exclusive next-key |
Exclusive next-key |
| delete |
相等 |
Exclusive locks |
Exclusive locks |
Exclusive locks |
Exclusive locks |
|
范围 |
Exclusive next-key |
Exclusive next-key |
Exclusive next-key |
Exclusive next-key |
| Select … from … Lock in share mode |
相等 |
Share locks |
Share locks |
Share locks |
Share locks |
|
范围 |
Share locks |
Share locks |
Exclusive next-key |
Exclusive next-key |
| Select * from … For update |
相等 |
Exclusive locks |
Exclusive locks |
Exclusive locks |
Exclusive locks |
|
范围 |
Exclusive locks |
Exclusive locks |
Exclusive next-key |
Exclusive next-key |
| Insert into … Select … |
innodb_locks_ unsafe_for_bi nlog=off |
Share Next-Key |
Share Next-Key |
Share Next-Key |
Share Next-Key |
| (指源表锁) |
innodb_locks_ unsafe_for_bi nlog=on |
None locks |
Consisten read/None lock |
Consisten read/None lock |
Share Next-Key |
| create table … Select … |
innodb_locks_ unsafe_for_bi nlog=off |
Share Next-Key |
Share Next-Key |
Share Next-Key |
Share Next-Key |
| (指源表锁) |
innodb_locks_ unsafe_for_bi nlog=on |
None locks |
Consisten read/None lock |
Consisten read/None lock |
Share Next-Key |
在了解 InnoDB 锁特性后,用户可以通过设计和 SQL 调整等措施减少锁冲突和死锁,包括:
- 尽量使用较低的隔离级别;
- 精心设计索引,并尽量使用索引访问数据,使加锁更精确,从而减少锁冲突的机会;
- 选择合理的事务大小, 小事务发生锁冲突的几率也更小;
- 给记录集显示加锁时,最好一次性请求足够级别的锁。比如要修改数据的话,最好直接申请排他锁,而不是先申请共享锁,修改时再请求排他锁,这样容易产生死锁;
- 不同的程序访问一组表时,应尽量约定以相同的顺序访问各表,对一个表而言,尽可能以固定的顺序存取表中的行。这样可以大大减少死锁的机会;
- 尽量用相等条件访问数据,这样可以避免间隙锁对并发插入的影响;
- 不要申请超过实际需要的锁级别;除非必须,查询时不要显示加锁;
- 对于一些特定的事务,可以使用表锁来提高处理速度或减少死锁的可能。
参考资料
1.https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-intention-locks mysql官网开发手册
2.《MySQL 技术内幕 – InnoDB 存储引擎》
3.《深入浅出MySQL》
4.https://www.modb.pro/db/33873