关系型数据的分布式处理系统MyCAT
——概述和基本使用教程
日期:2014/12/24
文:阿蜜果
1、 MyCAT概述
1.1 背景
随着传统的数据库技术日趋成熟、计算机网络技术的飞速发展和应用范围的扩充,数据库应用已经普遍建立于计算机网络之上。这时集中式数据库系统表现出它的不足:
(1)集中式处理,势必造成性能瓶颈;
(2)应用程序集中在一台计算机上运行,一旦该计算机发生故障,则整个系统受到影响,可靠性不高;
(3)集中式处理引起系统的规模和配置都不够灵活,系统的可扩充性差。
在这种形势下,集中式数据库将向分布式数据库发展。
1.2 发展历程
MyCAT的诞生,要从其前身Amoeba和Cobar说起。
Amoeba(变形虫)项目,该开源框架于2008年开始发布一款 Amoeba for Mysql软件。这个软件致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当SQL路由功能,专注于分布式数据库代理层(Database Proxy)开发。座落与 Client、DB Server(s)之间,对客户端透明。具有负载均衡、高可用性、SQL过滤、读写分离、可路由相关的到目标数据库、可并发请求多台数据库合并结果。 通过Amoeba你能够完成多数据源的高可用、负载均衡、数据切片的功能,目前Amoeba已在很多企业的生产线上面使用。
阿里巴巴于2012年6月19日,正式对外开源的数据库中间件Cobar,前身是早已经开源的Amoeba,不过其作者陈思儒离职去盛大之后,阿里巴巴内部考虑到Amoeba的稳定性、性能和功能支持,以及其他因素,重新设立了一个项目组并且更换名称为Cobar。Cobar 是由 Alibaba 开源的 MySQL 分布式处理中间件,它可以在分布式的环境下看上去像传统数据库一样提供海量数据服务。
Cobar自诞生之日起, 就受到广大程序员的追捧,但是自2013年后,几乎没有后续更新。在此情况下,MyCAT应运而生,它基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能,以及众多成熟的使用案例使得MyCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,MyCAT能看到更远。目前MyCAT的最新发布版本为1.2版本。
1.3介绍
1.3.1 MyCat的下载方式
MyCAT的SVN地址为:http://code.taobao.org/svn/openclouddb/
目录结构如下图所示:

读者可在doc/1.2子目录,可查看该产品1.2版本的主要文档,如下图所示:

1.3.2 什么是MyCat?
简单的说,MyCAT就是:
- 一个新颖的数据库中间件产品;
- 一个彻底开源的、面向企业应用开发的“大数据库集群”;
- 支持事务、ACID、可以替代MySQL的加强版数据库;
- 一个可以视为“MySQL”集群的企业级数据库,用来替代昂贵的Oracle集群;
- 一个融合内存缓存技术、Nosql技术、HDFS大数据的新型SQL Server;
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品。
1.3.3 MyCat的目标
MyCAT的目标是:低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。
1.3.4 MyCat的关键特性
· 支持 SQL 92标准;
· 支持MySQL集群,可以作为Proxy使用;
· 支持JDBC连接ORACLE、DB2、SQL Server,将其模拟为MySQL Server使用;
· 支持galera for mysql集群,percona-cluster或者mariadb cluster,提供高可用性数据分片集群;
· 自动故障切换,高可用性;
· 支持读写分离,支持MySQL双主多从,以及一主多从的模式;
· 支持全局表,数据自动分片到多个节点,用于高效表关联查询;
· 支持独有的基于E-R 关系的分片策略,实现了高效的表关联查询;
· 多平台支持,部署和实施简单。
1.3.5 MyCat的优势
· 基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能,以及众多成熟的使用案例使得MyCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,能看到更远。
· 广泛吸取业界优秀的开源项目和创新思路,将其融入到MyCAT的基因中,使得MyCAT在很多方面都领先于目前其他一些同类的开源项目,甚至超越某些商业产品。
· MyCAT背后有一只强大的技术团队,其参与者都是5年以上资深软件工程师、架构师、DBA等,优秀的技术团队保证了MyCAT的产品质量。
· MyCAT并不依托于任何一个商业公司,因此不像某些开源项目,将一些重要的特性封闭在其商业产品中,使得开源项目成了一个摆设。
1.4 总体架构
MyCAT的架构如下图所示:
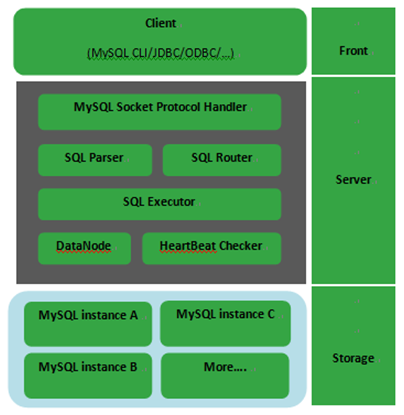
MyCAT使用MySQL的通讯协议模拟成一个MySQL服务器,并建立了完整的Schema(数据库)、Table (数据表)、User(用户)的逻辑模型,并将这套逻辑模型映射到后端的存储节点DataNode(MySQL Instance)上的真实物理库中,这样一来,所有能使用MySQL的客户端以及编程语言都能将MyCAT当成是MySQLServer来使用,不必开发新的客户端协议。
当MyCAT收到一个客户端发送的SQL请求时,会先对SQL进行语法分析和检查,分析的结果用于SQL路由,SQL路由策略支持传统的基于表格的分片字段方式进行分片,也支持独有的基于数据库E-R关系的分片策略,对于路由到多个数据节点(DataNode)的SQL,则会对收到的数据集进行“归并”然后输出到客户端。
SQL执行的过程,简单的说,就是把SQL通过网络协议发送给后端的真正的数据库上进行执行,对于MySQL Server来说,是通过MySQL网络协议发送报文,并解析返回的结果,若SQL不涉及到多个分片节点,则直接返回结果,写入客户端的SOCKET流中,这个过程是非阻塞模式(NIO)。
DataNode是MyCAT的逻辑数据节点,映射到后端的某一个物理数据库的一个Database,为了做到系统高可用,每个DataNode可以配置多个引用地址(DataSource),当主DataSource被检测为不可用时,系统会自动切换到下一个可用的DataSource上,这里的DataSource即可认为是Mysql的主从服务器的地址。
1.5 逻辑库
与任何一个传统的关系型数据库一样,MyCAT也提供了“数据库”的定义,并有用户授权的功能,下面是MyCAT逻辑库相关的一些概念:
- schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
- table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode,这是通过表格的分片规则定义来实现的,table可以定义其所属的“子表(childTable)”,子表的分片依赖于与“父表”的具体分片地址,简单的说,就是属于父表里某一条记录A的子表的所有记录都与A存储在同一个分片上。
- 分片规则:是一个字段与函数的捆绑定义,根据这个字段的取值来返回所在存储的分片(DataNode)的序号,每个表格可以定义一个分片规则,分片规则可以灵活扩展,默认提供了基于数字的分片规则,字符串的分片规则等。
- dataNode: MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上,一般来说,为了高可用性,每个DataNode都设置两个DataSource,一主一从,当主节点宕机,系统自动切换到从节点。
- dataHost:定义某个物理库的访问地址,用于捆绑到dataNode上。
MyCAT目前通过配置文件的方式来定义逻辑库和相关配置:
· MYCAT_HOME/conf/schema.xml中定义逻辑库,表、分片节点等内容;
· MYCAT_HOME/conf/rule.xml中定义分片规则;
· MYCAT_HOME/conf/server.xml中定义用户以及系统相关变量,如端口等。
下图给出了MyCAT 一个可能的逻辑库到物理库(MySQL的完整映射关系),可以看出其强大的分片能力以及灵活的Mysql集群整合能力。 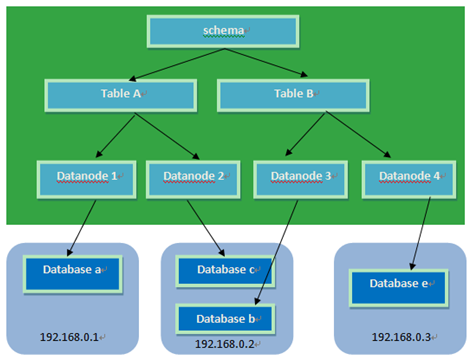
1.6 交流方式
MyCAT的QQ群还比较活跃,都已经900多人,有兴趣的朋友可以加入,群号:106088787。
2、 基本使用教程
2.1 下载和安装
MyCAT使用Java开发,因为用到了JDK 7的部分功能,所以在使用前请确保安装了JDK 7.0,并设置了正确的Java环境变量(可在命令行窗口输入:“java –version”获知是否安装成功,以及获取JDK的版本)。
笔者的Windows操作系统的下载是:
http://code.taobao.org/svn/openclouddb/downloads/old/MyCat-Sever-1.2/
目录下的“Mycat-server-1.2-GA-win.tar.gz ”文件,解压后的目录结构如下图所示:

安装完成后,需要添加MYCAT_HOME环境变量,值对应MyCAT安装的根目录。
目录说明见下表所示:
|
目录名称 |
说明 |
|
bin |
存放window版本和linux版本,除了提供封装成服务的版本之外,也提供nowrap的shell脚本命令,方便大家选择和修改。
Windows 下 运行:mycat.bat console 在控制台启动程序,也可以装载成服务,若此程序运行有问题,也可以运行startup_nowrap.bat,确保java命令可以在命令执行。
Warp方式的命令,可以安装成服务并启动或停止。
l mycat install (可选)
l mycat start
注意,wrap方式的程序,其JVM配置参数在conf/wrap.conf中,可以修改为合适的参数,参数调整参照http://wrapper.tanukisoftware.com/doc/english/properties.html。 |
|
conf |
存放配置文件:
l server.xml:是Mycat服务器参数调整和用户授权的配置文件。
l schema.xml:是逻辑库定义和表以及分片定义的配置文件。
l rule.xml:是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件,也在这个目录下,配置文件修改,需要重启MyCAT或者通过9066端口reload。
l wrapper.conf:JVM配置参数等设置。
l log4j.xml:日志存放在logs/mycat.log中,每天一个文件,日志的配置是在conf/log4j.xml中,根据自己的需要,可以调整输出级别为debug,debug级别下,会输出更多的信息,方便排查问题。 |
|
lib |
MyCAT自身的jar包或依赖的jar包的存放目录。 |
|
logs |
MyCAT日志的存放目录。日志存放在logs/mycat.log中,每天一个文件 |
2.2 启动和停止
启动前,一般需要修改JVM配置参数,打开conf/wrapper.conf文件,如下行的内容为2G和2048,可根据本机配置情况修改为512M或其它值。
 wrapper.java.additional.5=-XX:MaxDirectMemorySize=512M
wrapper.java.additional.5=-XX:MaxDirectMemorySize=512M
wrapper.java.additional.6=-Dcom.sun.management.jmxremote
wrapper.java.additional.7=-Dcom.sun.management.jmxremote.port=1984
wrapper.java.additional.8=-Dcom.sun.management.jmxremote.authenticate=false
wrapper.java.additional.9=-Dcom.sun.management.jmxremote.ssl=false
# Initial Java Heap Size (in MB)
#wrapper.java.initmemory=3
wrapper.java.initmemory=512
# Maximum Java Heap Size (in MB)
#wrapper.java.maxmemory=64
wrapper.java.maxmemory=512 在命令行窗口中进入MyCAT安装解压文件下的bin目录,输入如下命令可安装(可选)、启动和停止MyCAT,参考结果如下所示:
D:\software\Mycat-server-1.2-GA-win\bin>mycat install
wrapper | Mycat-server installed.
D:\software\Mycat-server-1.2-GA-win\bin>mycat start
wrapper | Starting the Mycat-server service
wrapper | Waiting to start
wrapper | Mycat-server started.
D:\software\Mycat-server-1.2-GA-win\bin>mycat stop
wrapper | Stopping the Mycat-server service
wrapper | Mycat-server stopped.
2.3 简单使用教程
2.3.1 安装MySQL以及客户端
安装MySQL服务器和MySQL客户端,笔者使用的MySQL服务器是免安装版本:mysql-noinstall-5.1.73-winx64,MySQL客户端是:Navicat for MySQL,免安装版本安装方法请参考:http://blog.csdn.net/q98842674/article/details/12094777,不再赘述。
2.3.2 创建数据库和表
创建weixin、yixin和sms三个数据库,并分别建立表结构。
2.3.3 垂直切分
2.3.3.1 垂直切分定义
数据的垂直切分,也可以称为纵向切分。将数据库想象成由很多个一大块一大块的“数据块”(表)组成,垂直地将这些“数据块”切开,然后把它们分散到多台数据库主机上面。这样的切分方法就是垂直(纵向)的数据切分。
一个架构设计较好的应用系统,其总体功能肯定是由很多个功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一个或多个表。而在架构设计中,各个功能模块相互之间的交互点越统一、越少,系统的耦合度就越低,系统各个模块的维护性及扩展性也就越好。这样的系统,实现数据的垂直切分也就越容易。
2.3.3.2 优缺点
垂直切分优点:
(1)数据库的拆分简单明了,拆分规则明确;
(2)应用程序模块清晰明确,整合容易;
(3)数据维护方便易行,容易定位。
垂直切分缺点:
(1)部分表关联无法在数据库级别完成,要在程序中完成;
(2)对于访问极其频繁且数据量超大的表仍然存在性能瓶颈,不一定能满足要求;
(3)事务处理相对复杂;
(4)切分达到一定程度之后,扩展性会受到限制;
(5)过度切分可能会带来系统过于复杂而难以维护。
2.3.3.3 垂直切分实现
在如下的实例中,需要将
编辑MYCAT_HOME/conf/schema.xml文件,修改dataHost和schema对应的连接信息,weixin、yixin和photo垂直切分后的配置如下所示:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="weixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="weixin" />
<schema name="yixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="yixin" />
<schema name="photo" checkSQLschema="false" sqlMaxLimit="100" dataNode="photo" />
<dataNode name="weixin" dataHost="testhost" database="weixin" />
<dataNode name="yixin" dataHost="testhost" database="yixin" />
<dataNode name="photo" dataHost="testhost" database="photo" />
<dataHost name="testhost" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="" />
<writeHost host="hostM2" url="10.18.96.133:3306" user="test" password="test" />
</dataHost>
</mycat:schema>
注意:writeHost/readHost中的location,user,password的值需要根据实际的MySQL的连接信息进行修改。
查看conf/server.xml文件,该文件是Mycat服务器参数调整和用户授权的配置文件,默认的MyCat的数据库连接的用户名/密码为test/test,文件内容参考如下:
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="sequnceHandlerType">0</property>
</system>
<user name="test">
<property name="password">test</property>
<property name="schemas">weixin,yixin,photo</property>
</user>
</mycat:server>
上述文件中的schemas属性需要配置对应的schema(在schema.xml)中进行配置。
重启MyCAT,使用MySQL客户端连接MyCAT,需要注意的是,默认数据端口为8066,管理端口为9066,在MySQL客户端连接MyCAT时,注意填写端口为8066,用户名/密码根据server.xml中的配置进行填写。
连接后可查看后端连接的三个数据库,如下图所示:
2.3.4 水平分库
2.3.4.1 水平切分定义
水平切分所指的是通过一系列的切分规则将数据水平分布到不同的DB或table中,在通过相应的DB路由 或者table路由规则找到需要查询的具体的DB或者table以进行Query操作,比如根据用户ID将用户表切分到多台数据库上。
将某个访问极其频繁的表再按照某个字段的某种规则来分散到多个表之中,每个表中包含一部分数据。
例如,所有数据都是和用户关联的,那么我们就可以根据用户来进行水平拆分,将不同用户的数据切分到不同的数据库中。
现在互联网非常火爆的web 2.0类型的网站,基本上大部分数据都能够通过会员用户信息关联上,可能很多核心表都非常适合通过会员ID来进行数据的水平切分。而像论坛社区讨论系统,就更容易切分了,非常容易按照论坛编号来进行数据的水平切分。切分之后基本上不会出现各个库之间的交互。
2.3.4.2 优缺点
水平切分的优点:
l 表关联基本能够在数据库端全部完成;
l 不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
l 应用程序端整体架构改动相对较少;
l 事务处理相对简单;
l 只要切分规则能够定义好,基本上较难遇到扩展性限制。
水平切分的缺点:
l 切分规则相对更为复杂,很难抽象出一个能够满足整个数据库的切分规则;
l 后期数据的维护难度有所增加,人为手工定位数据更困难;
应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
2.3.4.3 水平切分实现
在一般的应用系统中,用户表及其密切相关的关联表,可根据“用户表”(eg:t_user)中的“用户ID”(user_id)进行水平切分,并基于MyCAT的E-R关系分片策略将其密切相关的表(eg:t_user_class_rel)也分到对应的库中。
(1)创建表结构
在user0~user2创建同样的表结构,t_user和t_user_class_rel的建表语句参考如下:
DROP TABLE IF EXISTS `t_user_ext`;
CREATE TABLE `t_user_ext` (
`user_id` int(11) NOT NULL COMMENT '用户ID',
`receive_address` varchar(256) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '收货地址',
`create_time` datetime NOT NULL,
`province_code` varchar(10) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='用户信息表';
DROP TABLE IF EXISTS `t_user_class_rel`;
CREATE TABLE `t_user_class_rel` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`caller` varchar(16) CHARACTER SET utf8 NOT NULL COMMENT '调用方系统表示',
`province_code` varchar(10) CHARACTER SET utf8 DEFAULT NULL COMMENT '省份编码',
`user_id` int(11) NOT NULL COMMENT '用户ID',
`class_id` int(11) NOT NULL COMMENT '班级ID',
`role_type` int(11) DEFAULT NULL COMMENT '用户在该班的角色(1学生2家长3教师)',
`create_time` datetime NOT NULL COMMENT '创建时间',
`modify_time` datetime DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_rel_user_class_id` (`user_id`,`class_id`,`role_type`),
KEY `idx_rel_user_id` (`user_id`) USING BTREE,
KEY `idx_rel_class_id` (`class_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
(2)配置schema.xml文件
首先配置schema.xml文件,添加user0~user3数据库的dataNode设置,并添加t_user和t_user_class_rel表的schema设置,修改后的schema.xml文件内容如下所示:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="test_mycat" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="t_user" dataNode="user0,user1,user2,user3" rule="rule1">
<childTable name="t_user_class_rel" primaryKey="id" joinKey="user_id" parentKey="user_id" />
</table>
</schema>
<schema name="weixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="weixin" />
<schema name="yixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="yixin" />
<schema name="photo" checkSQLschema="false" sqlMaxLimit="100" dataNode="photo" />
<dataNode name="weixin" dataHost="testhost" database="weixin" />
<dataNode name="yixin" dataHost="testhost" database="yixin" />
<dataNode name="photo" dataHost="testhost" database="photo" />
<dataNode name="user0" dataHost="testhost" database="user0" />
<dataNode name="user1" dataHost="testhost" database="user1" />
<dataNode name="user2" dataHost="testhost" database="user2" />
<dataNode name="user3" dataHost="testhost" database="user3" />
<dataHost name="testhost" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="" />
<writeHost host="hostM2" url="10.18.96.133:3306" user="test" password="test" />
</dataHost>
</mycat:schema>
(3)配置rule.xml文件
在schema.xml的文件内容中可看到t_user表指定的分片规则是rule1,需要在conf/rule.xml文件中设置rule1的规则为根据user_id进行分片,并按照类“org.opencloudb.route.function.PartitionByLong”的规则进行分片,即将user_id模除1024后每256内分到一个数据库中,即模除后0~255到user0数据库库,256~511到user1数据库,512~767到user2数据库,768~1023到user3数据库。
该文件的参考内容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://org.opencloudb/">
<tableRule name="rule1">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">4</property>
<property name="partitionLength">256</property>
</function>
</mycat:rule>
(4)配置server.xml文件
在server.xml文件中的schemas属性中添加test_mycat的schema。修改后的文件如下所示:
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="sequnceHandlerType">0</property>
</system>
<user name="test">
<property name="password">test</property>
<property name="schemas">weixin,yixin,photo,test_mycat</property>
</user>
</mycat:server>
(5)水平切分测试
重启MyCAT,使用MySQL客户端连接后,连接后可在test_mycat数据库下看到t_user和t_user_class_rel表,如下图所示:
在MySQL客户端连接的MyCat的test_mycat数据库的t_user表运行如下插入语句,插入2000条数据:
INSERT INTO `t_user` VALUES ('1', '广州市越秀区广州大道中599号', '2014-07-17 10:53:15', 'GD');
INSERT INTO `t_user` VALUES ('2', '广州市越秀区广州大道中599号', '2014-07-17 10:53:17', 'GD');
INSERT INTO `t_user` VALUES ('3', '广州市越秀区广州大道中599号', '2014-07-17 10:53:17', 'GD');
INSERT INTO `t_user` VALUES ('4', '广州市越秀区广州大道中599号', '2014-07-17 10:53:17', 'GD');
INSERT INTO `t_user` VALUES ('5', '广州市越秀区广州大道中599号', '2014-07-17 10:53:17', 'GD');
……
INSERT INTO `t_user` VALUES (2000, '广州市越秀区广州大道中599号', '2014-07-17 10:54:37', 'GD');
而后在MyCAT的test_mycat数据库的t_user表运行select查看记录执行情况。进入localhost的user0~user3数据库,查看数据是否按照之前确定的rule1的规则写入不同的数据库。
读者可在test_mycat数据库的t_user表执行update和delete等语句,并去分库查看执行结果,可得知MyCAT对MySQL客户端基本透明,对程序也几乎透明,在select语句运行时,MyCAT会自行去各个分库按照规则获取合并结果。
接着测试按照ER关系策略分片的t_user_class_rel表是否按照user_id的分片策略,同样user_id的数据分布在同一个user库的t_user表和t_user_class_rel表。
在MyCAT的test_mycat数据库的t_user_class_rel表运行如下语句:
INSERT INTO `t_user_class_rel` VALUES ('257', 'eip', 'GD', '2', '35', '3', '2012-08-05 17:32:13', '2013-12-27 16:07:32');
INSERT INTO `t_user_class_rel` VALUES ('512', 'eip', 'GD', '1', '35', '3', '2012-08-05 17:32:13', '2013-12-27 16:07:32');
INSERT INTO `t_user_class_rel` VALUES ('1', 'eip', 'GD', '257', '35', '3', '2012-08-05 17:32:13', '2013-12-27 16:07:32');
INSERT INTO `t_user_class_rel` VALUES ('2', 'eip', 'GD', '513', '35', '3', '2012-08-05 17:32:13', '2013-12-27 16:07:32');
INSERT INTO `t_user_class_rel` VALUES ('3', 'eip', 'GD', '769', '35', '3', '2012-08-05 17:32:13', '2013-12-27 16:07:32');
而后在MyCAT的test_mycat数据库的t_user_class_rel表运行select查看记录执行情况。进入localhost的user0~user3数据库,查看数据是否按照之前确定的rule1的规则和ER分片策略写入不同的数据库。
2.3.5 读写分离
2.3.5.1 读写分离定义
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器,是对外提供增删改查业务的生产服务器;第二台数据库服务器,仅仅接收来自第一台服务器的备份数据。一般来说,为了配置方便,以及稳定性,这两台数据库服务器,都用的是相同的配置。
在实际运行中,第一台数据库服务器的压力,远远大于第二台数据库服务器。因此,很多人希望合理利用第二台数据库服务器的空闲资源。
从数据库的基本业务来看,数据库的操作无非就是增删改查这4个操作。但对于“增删改”这三个操作,如果是双机热备的环境中做,一台机器做了这三个操作的某一个之后,需要立即将这个操作,同步到另一台服务器上。出于这个原因,第二台备用的服务器,就只做了查询操作。进一步,为了降低第一台服务器的压力,干脆就把查询操作全部丢给第二台数据库服务器去做,第一台数据库服务器就只做增删改了。
2.3.5.2 优缺点
优点:合理利用从数据库服务器的空闲资源。
缺点:本来第二台数据库服务器,是用来做热备的,它就应该在一个压力非常小的环境下,保证运行的稳定性。而读写分离,却增加了它的压力,也就增加了不稳定性。因此,读写分离,实质上是一个在资金比较缺乏,但又需要保证数据安全的需求下,在双机热备方案上,做出的一种折中的扩展方案。
2.3.5.3 读写分离实现
MyCAT的读写分离机制如下:
- 事务内的SQL,全部走写节点,除非某个select语句以注释/*balance*/开头
- 自动提交的select语句会走读节点,并在所有可用读节点中间随机负载均衡
- 当某个主节点宕机,则其全部读节点都不再被使用,因为此时,同步失败,数据已经不是最新的,MyCAT会采用另外一个主节点所对应的全部读节点来实现select负载均衡。
- 当所有主节点都失败,则为了系统高可用性,自动提交的所有select语句仍将提交到全部存活的读节点上执行,此时系统的很多页面还是能出来数据,只是用户修改或提交会失败。
例如将本机作为写库,10.18.96.133作为读库,MyCAT的读写分离的配置如下:
<dataHost name="testhost" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="">
<readHost host="hostM2" url="10.18.96.133:3306" user="test" password="test" />
</writeHost>
</dataHost>
dataHost的balance属性设置为:
- 0,不开启读写分离机制
- 1,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。
- 2,所有的readHost与writeHost都参与select语句的负载均衡,也就是说,当系统的写操作压力不大的情况下,所有主机都可以承担负载均衡。
一个dataHost元素,表明进行了数据同步的一组数据库,DBA需要保证这一组数据库服务器是进行了数据同步复制的。writeHost相当于Master DB Server,而其下的readHost则是与从数据库同步的Slave DB Server。当dataHost配置了多个writeHost的时候,任何一个writeHost宕机,Mycat 都会自动检测出来,并尝试切换到下一个可用的writeHost。
在没有配置数据同步复制的情况下,重启后进行测试,可使用MySQL客户端直接连接读库,插入几条数据后,使用MySQL客户端连接MyCat,运行select语句验证是否在读库上执行。
2.3.6 全局表
2.3.6.1 全局表定义
一个真实的业务系统中,往往存在大量的类似字典表的表格,它们与业务表之间可能有关系,这种关系,可以理解为“标签”,而不应理解为通常的“主从关系”,这些表基本上很少变动,可以根据主键ID进行缓存,下面这张图说明了一个典型的“标签关系”图:
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,考虑到字典表具有以下几个特性:
- 变动不频繁;
- 数据量总体变化不大;
- 数据规模不大,很少有超过数十万条记录。
鉴于此,MyCAT定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
- 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
- 全局表的查询操作,只从一个节点获取
- 全局表可以跟任何一个表进行JOIN操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JOIN的难题。通过全局表+基于E-R关系的分片策略,MyCAT可以满足80%以上的企业应用开发。
2.3.6.2 全局表实现
(1)创建表结构
在各个库分别创建全局表(例如:t_area)的表结构,表结构保持一致,例如:
DROP TABLE IF EXISTS `t_area`;
CREATE TABLE `t_area` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`caller` varchar(16) CHARACTER SET utf8 DEFAULT NULL COMMENT '调用方系统表示',
`province_code` varchar(10) CHARACTER SET utf8 NOT NULL COMMENT '省份编码',
`area_code` varchar(10) CHARACTER SET utf8 NOT NULL COMMENT '区域编码',
`area_name` varchar(100) CHARACTER SET utf8 DEFAULT NULL COMMENT '区域名称',
`parent_area_code` varchar(10) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '父区域编码',
`create_time` datetime NOT NULL COMMENT '创建时间',
`modify_time` datetime DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3792 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
(2)配置schema.xml
全局表配置比较简单,不用写Rule规则,在schema.xml中修改test_schema,添加t_area的table子元素,参考如下配置即可:
<schema name="test_mycat" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="t_user" dataNode="user0,user1,user2,user3" rule="rule1">
<childTable name="t_user_class_rel" primaryKey="id" joinKey="user_id" parentKey="user_id" />
</table>
<table name="t_area" primaryKey="id" type="global" dataNode="weixin,yixin,photo,user0,user1,user2,user3" />
</schema>
(3)全局表测试
运行如下insert语句,往test_mycat的t_area表插入10条数据,如下所示:
INSERT INTO `t_area` VALUES ('100', 'test', 'ZX', '1', '全国', '0', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('101', 'test', 'BJ', '110000', '北京市', '1', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('102', 'test', 'BJ', '110100', '市辖区', '110000', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('103', 'test', 'BJ', '110101', '东城区', '110100', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('104', 'test', 'BJ', '110102', '西城区', '110100', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('105', 'test', 'BJ', '110103', '崇文区', '110100', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('106', 'test', 'BJ', '110104', '宣武区', '110100', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('107', 'test', 'BJ', '110105', '朝阳区', '110100', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('108', 'test', 'BJ', '110106', '丰台区', '110100', '2012-09-25 08:30:23', null);
INSERT INTO `t_area` VALUES ('109', 'test', 'BJ', '110107', '石景山区', '110100', '2012-09-25 08:30:23', null);
插入后去user0~user3数据库中查找,可看到这4个库中的t_area表都被插入10条数据。执行select语句能返回t_area表的对应记录,执行update和delete语句能对应对全局表相关的4个库中的记录进行更新和删除操作。
3、 参考文档
(1)《Amoeba使用指南》:http://docs.hexnova.com/amoeba/
(2)《MySQL-5.6.13免安装版配置方法》:
http://blog.csdn.net/q98842674/article/details/12094777
(3)《MyCat inAction中文版》
posted on 2014-12-24 16:12
阿蜜果 阅读(47761)
评论(3) 编辑 收藏 所属分类:
Java 、
database