摘要:本文主要介绍使用kettle 来建立一个Type 2的Slowly Changing Dimension 以及其中一些细节问题
1. Kettle 简介
Kettle 是一个强大的,元数据驱动的ETL工具被设计用来填补商业和IT之前的差距,将你公司的数据变成可增长的利润.
我们先来看看Kettle能做什么:
1. Data warehouse population with built-in support for slowly changing dimensions, junk dimensions and much, much more.
2. Export of database(s) to text-file(s) or other databases
3. Import of data into databases, ranging from text-files to excel sheets
4. Data migration between database applications
5. Exploration of data in existing databases. (tables, views, synonyms, )
6. Information enrichment by looking up data in various information stores (databases, text-files, excel sheets, )
7. Data cleaning by applying complex conditions in data transformations
8. Application integration
本系列文章主要介绍如下几点:
1. 数据仓库内建支持缓慢增长维SCD ,
2. 在数据转换中使用复杂条件判断来清理数据
3. 如何使用kettle 来处理增量更形
4. 将Kettle 集成到你的应用程序里
5. 使用kettle中应该注意的一些地方
2. Kettle 文档
最好的kettle教程就在你身边,我们下载的kettle-version. zip 文件里其实已经包括了非常多的示例和文档,在你的kettle文件夹下,docs 文件夹下包含了所有的文档,samples文件夹下包含了一些示例,后面的介绍中一部分示例都来自kettle自带的这个示例文件夹下。docs里面最主要的是Spoon-version-User-Guide. zip ,里面记录了kettle 的技术性文档,包括支持的操作系统,数据库平台,文本格式,图形化的界面,其中最重要的是所有的转换对象(Transformation Core Objects) 和Job对象(Job Core Objects) 的解释,包括截图和每一个参数的解释。
3. Kettle与Slowly Changing Dimension
我们使用kettle自带的samples文件下的示例,来看kettle如何支持SCD的。
打开samples / jobs / Slowly Changing Dimension 文件夹,发现里面有三个文件,
create - populate - update slowly changing dimension.kjb
DimensionLookup - update dimension table 2.ktr
DimensionLookup - update dimension table.ktr
其中后缀以 .kjb 结尾的是kettle 的job 文件导出的格式,而以ktr 结尾的是kettle 的transformation 导出的格式,打开其中的DimensionLookup - update dimension table.ktr , 出现如下所示 :
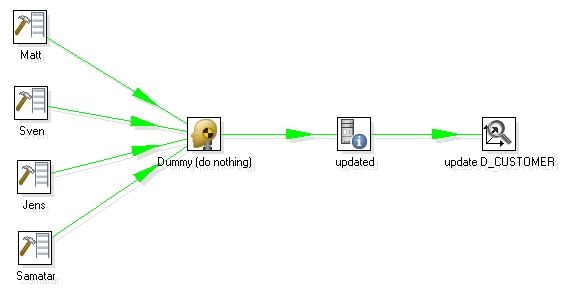
图1
1. 最左边的是产生测试数据,如果是实际环境的话应该是连接真实的数据库,产生的真实数据格式打开如下:
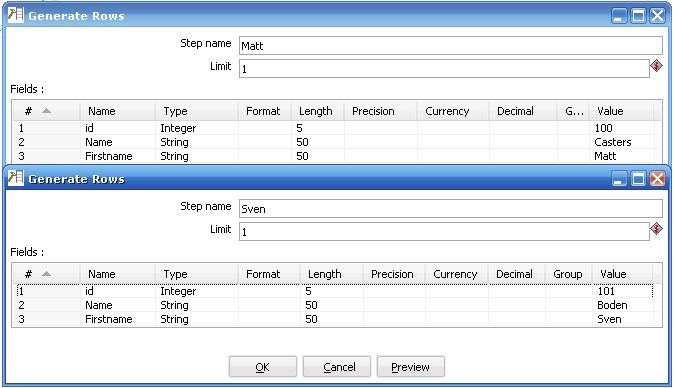
图2
2 第二个步骤Dummy 就是把前面的数据合并起来,Dummy 步骤本身不做任何事情,不过由于前面有四个输入指向它,所以它在第二步的作用等同于数据合并。
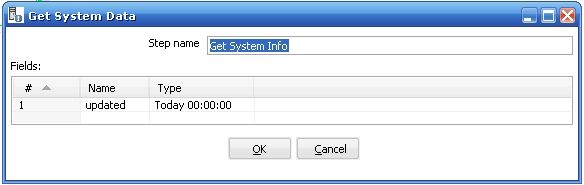
3 第三个步骤是取得系统参数(get system date) , 它取得当前系统时间的日期,并且格式是当天的 00:00:00 , 如图所示
4. 最后一步是真正的重点,执行Dimension Lookup / Update 步骤来更新和插入数据,以此来实现Type 1 ,2 ,3 的不同Slowly Changing Dimension
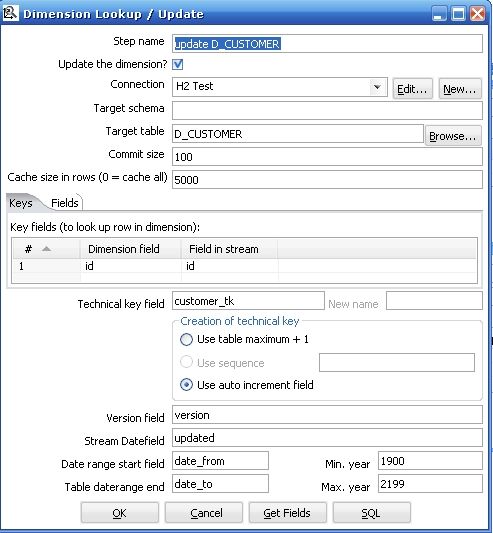
图4
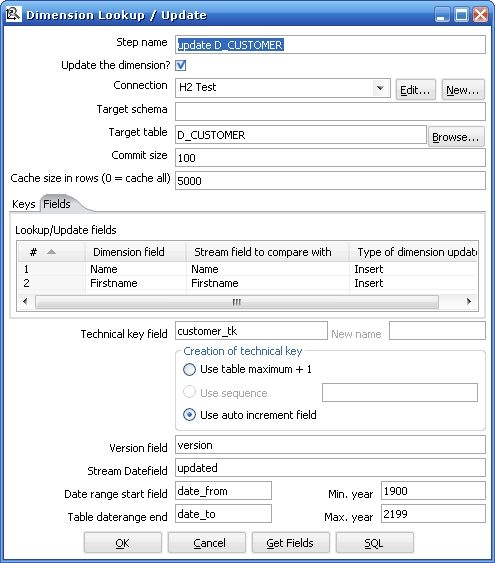
图5
在开始介绍Dimension Lookup / Update 之前,先看看在执行这个步骤之前的输入和输入:
输入:
|
字段名
|
数据类型
|
说明
|
|
id
|
int
|
前面步骤的输入
|
|
name
|
Varchar(50)
|
前面步骤的输入
|
|
firstname
|
Varchar(50)
|
前面步骤的输入
|
|
updated
|
time
|
从第三步来的时间参数
|
输出:
|
字段名
|
数据类型
|
说明
|
|
id
|
INT
|
来自输入
|
|
name
|
varchar(50)
|
来自输入
|
|
firstname
|
varchar(50)
|
来自输入
|
|
customer_tk
|
BIGINT
|
代理主键
|
|
version
|
INT
|
版本变更号
|
|
Date_from
|
datetime
|
有效期起始日期
|
|
Date_to
|
Datetime
|
有效期失效日期
|
注意: 上图中所使用的是mysql 5 数据库做测试,所以数据类型一栏都是mysql 的数据类型,如果你使用其他数据库,可能数据类型会有所不同,其中的datetime 的格式 yyyy/mon/day hh:mm:ss:sss
我们再来看看当我们第一次运行以后出现的数据输出:

图6
注意图6中所有的 version 值都是 1
Date_from 都是 1900/01/01 00:00:00.000
Date_to 都是 2199/12/31 23:59:59.000 这两列都是根据图4下面部分定义的
Id , name , firstname 都是测试数据,从前面步骤来的.
然后我们修改图1中generate row 的部分数据(一共两条),并且只有测试数据变了的情况下,我们再次运行转换,查看数据输出:

图7
注意到其中customer_tk 并没有什么变化,仍然在产生类似序列的输出
Version 的值中出现了 2 , 并且只有在我们改变的数据中
在出现了改变的行中的date_from 变成了2007/11/28/ 00:00:00.000
在出现了改变的行中原来数据的date_to 变成了 2007-11-28 00:00:00.000
Id 列没有变化,(变化了也没用,图5中的中间部分 Field 选项卡没有选id)
Name , firstname 有两个值变了(我们手工改变的)
Dimension Lookup / Update 参数解释
|
Step name
|
步骤的名称,在一个转换中必须是唯一的
|
|
Update the dimension?
|
当找到符合条件记录的时候更新这条记录,如果这个复选框没有选择,找到了符合条件记录的时候就是插入新纪录而不是更新
|
|
Connection
|
数据库连接的名字
|
|
Target schema
|
|
|
Target table
|
要更新的维表的名称
|
|
Commit size
|
批处理更新的记录数
|
|
Cache size in rows
|
这是把维表的数据放在缓存中用来提高数据查找速度从而减少数据库查询的次数
注意只有最近一次的记录会被放在缓存中,如果记录数超过缓存大小,最有最有关的最近的最高版本号记录会被放在缓存中
如果把cache size 设置成0 ,kettle会一直把记录放在缓存中直到JVM没有内存了,如果你这样设置要确保维的记录数不要太大
设置成 1 表示不使用缓存
|
|
Keys tab
|
设置在流中的主键和目标维表的业务主键,当两个键相等时认为这条记录匹配
|
|
Fields tab
|
设定要更新的字段,当主键记录匹配的时候,只有设定更新的字段不一样才认为是这条记录是不一样的,需要更新或者插入(注意图5的中间部分,Fields tab 右边设定的是Insert ,所以实现的是Type2 的SCD)
|
|
Technical key field
|
维的主键,也可以叫做代理主键(Surrogate Key)
|
|
Creation of technical key
|
指定技术主键的生成方式,对于你数据库连接不适合的方式会自动被去掉,一共有三种:
1 .Use table maximum + 1 : 使用当前表最大记录数加一的方式产生新主键,注意新的最大值会被缓存,所以不用每次需要产生新记录的时候就计算
2 . Use sequence : 使用一个数据库支持的序列来产生技术主键(比如Oracle ,你也可以看到图4中这一条是灰色的因为使用的是mysql 数据库)
3. Use auto increment field : 使用一个数据库支持的自动增长来产生技术主键(比如DB2)
|
|
Version field
|
使用这个字段来储存版本号
|
|
Stream Datafield
|
你可以指定维记录最后一次被更改的时间,它能指定你要更新的维的精度,如果不指定,就会默认是系统时间
|
|
Date range start field
|
维记录其实有效时间
|
|
Table daterange end
|
维记录失效时间
|
|
Get Fields button
|
指定所有你想要更新的字段,除了你指定的主键
|
|
SQL button
|
产生sql 来创建维表
|
官方文档中提到的注意事项:
1. Stream date field : 如果你不想每次都改变时间的范围,你需要添加一个额外的这个字段,比如你打算每天的午夜来进行ETL过程,可以考虑加一个Join 步骤”Yesterday 23:59:59” 作为输入的时间字段.
2. 这必须是一个Date 字段(不能是转换后的字符串,即使他们有相同的格式也不行),我们(Kettle 的开发小组)把功能实现隔离出来,如果你需要的话自己要先转换.
3. 对于Date range start and end fields : 你只能指定一个表示年的数据,而不是时间戳,如果你输入YYYY(比如2100) ,这将会被当成一个时间戳来用: YYYY-01-01 00:00:00.000 ,(注意图6中的格式)
另外需要注意的地方:
1. Technical key field : 其他一些ETL工具(比如OWB)也许叫做代理主键,只是名字上不同而已.
2. SQL Button : 当你在目标数据库中还没有建立维表的时候,你点击SQL Button ,Kettle 会弹出如下对话框帮你建立维表,你会发现它默认帮你在代理主键和业务主键上建立索引。
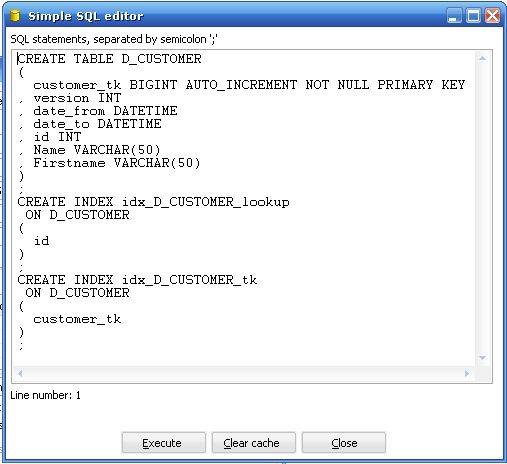
图8
3 Creation of technical key : 在这个选项的第二种实现方式上,Use sequence ,这个要视你数据库支持而定,mysql 就不支持,Oracle 支持sequence , 但是你要自己创建和管理这个sequence , 如果这个sequence 的值因某种外部因素改变了,你要自己确定sequence 产生的值处于何种状态,如果可以的话尽量不要用,尽量用第一种:table maximum + 1 ,这种方式永远不要担心数据库的不同和实现方式的不同,而且简单易懂。
4 Stream Datefield
4.1 这个选项是用来控制时间的精度的,有的时候我们可能只是一个月进行一次ETL,这个时候Datefield 显然没有必要到秒的精度,而且这个选项严重影响你后面如果使用缓慢增长维的sql 的复杂度,因为你需要先把时间的精度调到你需要的精度,比如你使用的数据是到秒的精度,但是你实际需要的只是天的精度,你在sql 里面有大量的时间都浪费在toString( stream date field) ,然后把这个字符串substring() ,执行效率会低一些.
4.2 不要轻易改这个精度,一旦你确定了精度问题,不要尝试改变它,尤其是当精度变细的时候,你可能会损失掉已经存在与数据库中的数据的精度,如果你只是从 “Today 00:00:00.000” 改成 “Today 23.59.59.000” 的情况,需要手动处理好已经存在的数据格式问题.
4.3 执行ETL的时间可能决定这个值,如果你一天可能存在5次执行ETL过程(包括自动执行或者手工执行)那么你显然不希望时间的精度是按天来计算的(比如Today 00.00.00这种格式)
4.4 精度的损失并不可怕:考虑一下你的应用场景,比如我们要做表,列出2006年11月份和2006年12月份的所有销售总和,结合上图中的customer 的例子,假设是按客户聚合的, 我们对于customer 的精度要求只要求到月,没有要求到天,如果我们执行ETL的过程是一个星期执行一次,可能一个客户在一个星期内改变了三次他的名字(虽然不是个好例子,完全是为了配合上面的图),而只有最后一次的改变被记录了下来,这完全跟你执行ETL的频度有关,但是考虑到用户需求,只要精度到月就够了,即使这种精度有数据损失也完全没关系,所以你如何指定你的Stream date field 的精度主要是看用户需求的精度。
4.5 如果以上四点你觉得只是一堆让你头疼的字符串,那你完全可以把stream date field 设置成空(默认的到时间戳的精度)
执行Type 2 SCD
1. “Update the dimension?” 选中
2. 在Field tabs 里面,对于每一个你想要保持全部记录的字段都要选择Insert 方式.
错误处理和依赖问题
如果你运行了这个转换,你会发现你的输出中有一条customer_tk为1,version为1的数据,你在图6和图7中没有看到这条数据是因为我不想一开始把这条数据跟SCD的实现混在一起,SCD的实现本身并不会告诉你要添加这条数据,这完全是跟数据建模有关系,为了理解这个问题,我们看一下如下情况该如何处理:
一个产品销售的记录是作为一个立方体的主要事实表,它包括一个客户维,现在因为某种原因客户维需要删除掉一部分数据,但是对映的产品销售记录却要保存起来,该如何处理外键约束的问题?
SCD实现本身并不会考虑这个问题,因为它跟维表没有什么关系,你要处理的是事实表里面那些引用了维表的记录,如果你没有这个空行(它唯一的一个值就是id ,而且是为了满足主键约束,version那个字段有没有值不重要),事实表中的记录就不好处理这种情况,因为你把它赋予任何一个值都是不合适的。这种方法是为了处理像数据依赖(外键的关系)和错误处理比较常见的方法。