1、引言
在《IM消息ID技术专题》系列文章的前几篇中,我们已经深切体会到消息ID在分布式IM聊天系统中的重要性以及技术实现难度,各种消息ID生成算法及实现虽然各有优势,但受制于具体的应用场景,也并不能一招吃遍天下,所以真正在IM系统中该如何落地消息ID算法和实现逻辑,还是要因地致宜,根据自已系统的设计逻辑和产品定义取其精华,综合应用之。
本文将基于网易严选的订单ID使用现状,分享我们是如何结合业内常用的分布式ID解决方案,从而在此基础之上进行ID特性丰富,并不断提升系统可用性和稳定性保障。同时,也对ID生成算法的落地实践过程中遇到坑进行了深入剖析。
本篇中的订单ID虽然不同于IM系统中的消息ID,但其技术实践仍然相通,希望能给你的IM系统消息ID技术选型也来更多的启发。
(本文已同步发布于:http://www.52im.net/thread-4069-1-1.html)
2、关于作者
西狂:服务端研发工程师, 早期参与严选采购、严选财务、严选合伙人以及报警平台等系统后端建设,目前主要致力于严选交易域技术演进以及业务研发工作。
3、系列文章
本文是系列文章中的第7篇,本系列总目录如下:
4、为什么需要分布式ID?
4.1 业务背景
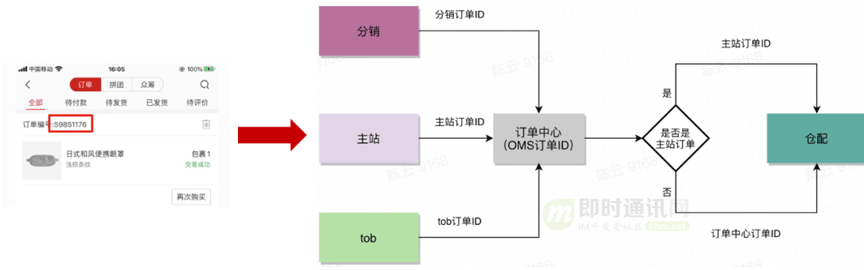
如上图所示,对于网易严选的主站、分销和tob都会生成各自的订单ID,在同步订单数据到订单中心的时候,订单中心会生成一个订单中心内部的一个订单号,只是推送给到下游仓配时使用的订单ID略有不同。
4.2 带来的问题
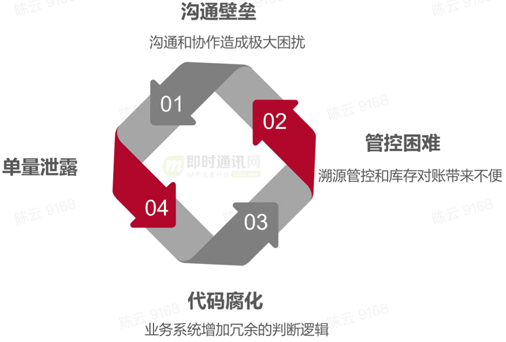
因为订单ID使用的混乱,导致了一系列问题的产生,例如: 沟通壁垒 、管控困难以及代码腐化等等。
4.3 技术目标

我们希望通过分布式ID来帮助生成订单ID,在业务规则上必须全局唯一、安全性高,在性能上要高可用、低延迟。
5、我们的分布式ID架构原理
5.1 技术选型
下表是业内常见的分布式ID解决方案:
综合考虑是否支持水平扩展以及能够显示指定ID长度,最终选择的是Leaf的Segment模式(详见《深度解密美团的分布式ID生成算法》)。
5.2 架构简介
Leaf采用了预分发的方式来生成ID(如下图所示),在DB之上搭载若干个Server,每个Server在启动的时候,都会去DB中拿固定长度的ID列表,存放于内存中,因为ID是基于内存分发的,所以可以做到很高效。
在数据持久化方面,每次去DB拿固定长度的ID列表,只是把最大的ID持久化。
整体架构实现比较简单,主要是为了尽快解决业务层DB压力的问题,但是在生产环境中也暴露出一些问题。
比如:
- 1)TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tp999数据会出现偶尔的尖刺;
- 2)当更新DB号段的时候,如果DB宕机或者发生主从切换,会导致一段时间的服务不可用。
5.3 可用性优化
为了解决上面提到这个两个问题,引入双Buffer机制和异步更新策略,当一个Buffer消耗到某个临界点时,就会异步的触发任务,把下一个号段加载到内存中。
保证无论何时DB出现问题,都能有一个Buffer的号段可以正常对外提供服务,只要DB在一个Buffer的下发的周期内恢复,就不会影响整个Leaf的可用性。
5.4 步长动态调整
号段长度在固定不变的前提下,流量的突增和锐减都会使得正常流量下维持原有号段正常工作的时间缩短和提升。
可以尝试使用以下关系表达式来描述:
Q * T = L
(Q:服务qps L:号段长度 T:号段更新周期)
但是Leaf的本质是希望T固定,如果Q和L可以正相关,T就可以趋于一个定值。
所以在Leaf每次更新号段的时候,会根据上一次号段更新的周期T和号段长度step,来决定下一次号段长度nextStep。
如下所示:
T < 15min,nextStep = step * 2
15min < T < 30min,nextStep = step
T > 30min,nextStep = step / 2
(初始指定step <= nextStep <= 最大值(自定义:100W))
6、我们做了什么改进?
6.1 特性丰富
通过结合严选的实际业务场景,进行了特性化支持,例如支持批量ID获取、大促提前扩容以及提前跳段处理。
6.2 可用性保障
1)针对DB:
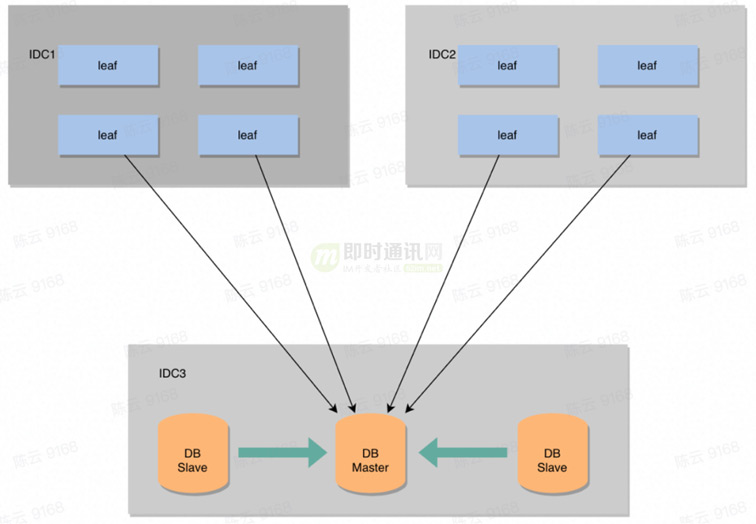
DB(MySql)采用主从模式(读写分离、降低主库压力),一主两从的配置方式,Master和Slave之间采用的是半同步复制(数据一致性要求,后期可考虑使用MySql Group Replication)。同时还添加了双1配置,保证不丢数据。
2)引入SDK:
通过引入SDK可以降低各个业务方的接入成本、降低Leaf服务端压力以及在Leaf服务不可用时,客户端起到短暂降级的效果。
SDK的实现原理和Leaf类似,在项目启动之初会加载业务关心参数配置信息,在应用构建本地缓存,同样采用了双Buffer存储模式。
6.3 稳定性保障
1)运维方面:
主要分为3个方面:
- 1)日志监控:可以帮助发现预期之外的异常情况;
- 2)流量监控:流有助于号段长度的评估范围,预防号段被快速消费的极端场景;
- 3)线上巡检:可以时刻对服务进行存活校验。
2)SLA高可用方面:
除了运维之外还做了SLA的接入,通常用SLA来衡量系统的稳定性,除此之外我们还按照接口维度设定了SLO目标规则,目前的指标项比较单一只有请求延迟和错误率这两项。
7、我们遇到的坑
7.1 问题发现
如下图所示,我们发现每次服务启动上线接口的rt(响应时间)都要比平时高的多,但是过了一段时间之后却又恢复成正常水平。
7.2 问题探究
在分析之前,我们可以先简单的回顾下java虚拟机是如何运行Java字节码的。
虚拟机视角下Java字节码如何被虚拟机运行:
Java虚拟机将class文件加载到虚拟机中,然后将字节码翻译成机器码给底层硬件执行,而这里的翻译有两种形式,解释执行和编译执行。前者的优势在于无需等待编译,后者的优势在于实际运行速度更快。HotSpot默认采用混合模式,它会先解释执行字节码,然后将其中反复执行的热点代码,以方法为单位进行即时编译,JVM是依据方法的调用次数以及循环回边的执行次数来触发JIT编译的。
在Java7之前我们可以根据程序的特性选择对应的即时编译器。Java7开始引入分层编译机制(-XX:+TieredCompilation):综合了C1的启动性能优势和C2的峰值性能优势。
分层编译将JVM的执行状态分为了5个层次:
- L0:解释执行(也会profiling);
- L1:执行不带profiling的C1代码;
- L2:执行仅带方法调用次数和循环回边执行次数profiling的C1代码;
- L3:执行带所有profiling的C1代码;
- L4:执行C2代码。
对于C1编译的三个层次,按执行效率从高至低:L1 > L2 > L3, 这是因为profiling越多,额外的性能开销越大。通常情况下,C2代码的执行效率比C1代码高出30%以上。(这里需要注意的是Java8默认开启了分层编译)
这张图列出了常见的分层编译的编译路径:
- 1)通常情况下,热点方法会被第三层的C1编译器编译,再被C2编译器编译(0-> 3-> 4);
- 2)如果方法的字节数目比较少并且第三层的profilling没有可收集的数据,jvm会判定该方法对于C1和C2的执行效率相同,在经过3层的C1编译过后,直接回到1层的C1(0-> 3-> 1);
- 3)在C1忙碌的情况下,JVM在解释执行过程中对程序进行profiling,而后直接由4层的C2编译(0-> 4);
- 4)在C2忙碌的情况下,方法会被2层的C1编译,然后再被3层的C1编译,以减少方法在3层的执行时间(0-> 2-> 3-> 4)。
上图是项目启动时的分层编译日志以及整个过程接口响应RT。
从图中可以看到先是执行了C1编译,再执行C2编译(日志文件中的3和4分别打标L3和L4),满足 0->3->4 编译顺序。
发现从C1编译到C2编译耗时过程比较长,这符合我们一开始提出的疑问,为什么项目启动需要经过一段时间接口RT才能趋于稳定。
7.3 解决方案
为了能在项目启动之初,快速达到接口RT峰值,因此只要尽最大程度缩短解释执行这个中间过程即可。
相应的解决方案:
- 方案 1:关闭分层编译,降低编译阈值;
- 方案 2:Mock接口数据, 快速触发JIT编译以及C2编译;
- 方案 3:Java9 AOT提前编译。
针对方案3:Java9中支持新特性AOT提前编译,相比较于JIT即时编译而言,AOT在运行前就已经编译好了,避免 JIT 编译器的运行时性能消耗,同时避免解释程序的早期性能开销,可以极大提高java代码性能。
8、落地使用概况
Leaf已经在线上环境投入使用,各个业务方(包括主站、渠道、tob)也相应接入进行统一整改,自此严选订单ID生成得到统一收拢。
在整个严选的落地情况,按照业务维度,目前累计接入3个业务,分别是订单ID、订单快照ID、订单商品快照ID,都经受住了双十一和双十二考验。
9、参考资料
[1] 微信的海量IM聊天消息序列号生成实践(算法原理篇)
[2] 解密融云IM产品的聊天消息ID生成策略
[3] 深度解密美团的分布式ID生成算法
[4] 深度解密滴滴的高性能ID生成器(Tinyid)
(本文已同步发布于:http://www.52im.net/thread-4069-1-1.html)