An LDAP schema is nothing more than a convenient packaging unit for containing broadly similar objectClasses and attributes.
There may have been a time when a single schema was designed to hold
everything required for an LDAP implementation (like a relational
database schema) but that is no longer true. You will find useful
attributes and objectclases scattered all over the place - the power of
LDAP arguably comes from the ease of creating and using this apparent
anarchy.
The rule is: Every attribute or objectclass (including its superior
objectclass or attribute) used in an LDAP implementation must be
defined in a schema and that schema must be known to the LDAP server. In OpenLDAP the schemas are made known using the include statement in the slapd.conf configuration file).
The following diagram illustrates the use of schemas as packaging units:
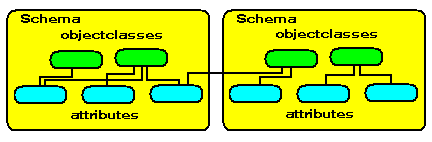

3.3 LDAP objectClasses
An objectClass is a collection of attributes (or an attribute container) and has the following characteristics:
-
An objectclass is defined within a Schema
-
An objectclass may be a part of an objectclass hierarchy in which case it inherits all the properties of its parents, for example, inetOrgPerson is the child of organizationalPerson which is the child of person which is the child of top (the ABSTRACT objectClass which terminates every objectClass hirearchy).
-
An objectclass has a globally unique name or identifier
-
An objectclass, as well as being an attribute container, is also an attribute and may be searched on
-
An objectclass defines its member attributes and whether these MUST (mandatory) be present or MAY (optional) be present in an entry.
-
One or more objectclass(es) must be present in an LDAP entry.
-
Each objectclass supported by a LDAP server forms part of a collection called objectclasses which can be discovered via the subschema.
Defining an objectClass
The formal objectclass definition is defined in RFC 2252 section 4.4 and looks like this:
ObjectClassDescription = "(" whsp
numericoid whsp ; ObjectClass identifier
[ "NAME" qdescrs ]
[ "DESC" qdstring ]
[ "OBSOLETE" whsp ]
[ "SUP" oids ] ; Superior ObjectClasses
[ ( "ABSTRACT" / "STRUCTURAL" / "AUXILIARY" ) whsp ]
; default structural
[ "MUST" oids ] ; AttributeTypes
[ "MAY" oids ] ; AttributeTypes
whsp ")"
Ooof! whsp means a space character and when they say it
should be there believe them. Rather than try and explain all these
entries lets start with some examples.
An objectClass is defined using ASN.1 notation - the following is a simple standard objectclass definition for country taken from the core.schema supplied with OpenLDAP distributions.
objectclass ( 2.5.6.2 NAME 'country' SUP top STRUCTURAL
MUST c
MAY ( searchGuide $ description ) )
Now lets deconstruct this definition:
objectclass is a keyword indicating this is an objectclass definition - see it's not so complicated!
2.5.6.2 NAME 'country' defines a globally unique name for this objectclass and is comprised of two parts: NAME 'country' just allows you to refer to this objectclass by some semi-understandable text - in this case the english word country. The globally unique part is defined by 2.5.6.2 which is called an OID (ObjectIdentifier).
The OID 2.5.6.2 was probably the third objectclass ever defined by
X.500 (2.5.6 is the joint itu-iso x.500 object classes, the last 2 is a
sequence number within that family of OIDs). It does not matter what
organization assigns this number but it must be UNIQUE. Obtaining an
enterprise OID that allows you to define your own attributes and objectclasses is a trivial and zero cost process via IANA. It is a VERY BAD THING™ to re-use existing OIDs.
SUP 'top' indicates that this objectclass has a PARENT (or
SUPerior) objectclass - it is part of a hierarchy. In this case the
parent is top which is a special class that terminates (is the
highest level) in all objectclasses. An objectclass may have one or
more objectclass(es) as Parents.
STRUCTURAL indicates that this objectclass contains data and can form an entry in a DIT. objectClasses may also be ABSTRACT which indicates a non-existent objectclass used for convenience. The most common ABSTRACT objectclass is top which just terminates an objectclass hierarchy. Finally an objectClass
may be AUXILIARY which indicates it may be used with any STRUCTURAL
objectclass to form an entry but cannot alone form an entry in a DIT.
DESC 'description' OK so we picked a lousy example which does
not have a DESC part - but it was short. DESC is an optional value that
provides a short text description of the use or contents of the
objectclass. It's meant for human beings to read and has no other use.
Here is what country could have looked like with a DESC statement included:
objectclass ( 2.5.6.2 NAME 'country' SUP top STRUCTURAL
DESC '2 character iso assigned country code'
MUST c
MAY ( searchGuide $ description ) )
MUST c MUST indicates that the attributes in the following list are mandatory in this case the attribute c
has to be present or the entry will fail to load. Single values are
written as shown, multiple attributes are enclosed in parentheses and
separated with a $ (dollar) sign, such as ( attr1 $ attr2 $ attrn). If
there are no mandatory attributes this section is not included.
MAY ( searchGuide $ description ) MAY indicates that the
attributes in the following list are optional. Multiple values are
written as shown, single attributes do not need the parentheses (see
above). If there are no optional attributes this section is not
included.
Some more objectClasses
This is how the top objectclass is defined:
objectclass ( 2.5.6.0 NAME 'top' ABSTRACT
MUST objectClass )
Illustrates the use of the ABSTRACT statement in an objectclass. Since top is always the top of a hierarchy - clearly it cannot have a SUP statement. The OID is also assigned by the X.500 standards group.
Many documents insist that the objectclass top is included in LDIF files - it is not always necessary.
This is how the dcObject objectclass is defined:
objectclass ( 1.3.6.1.4.1.1466.344 NAME 'dcObject'
DESC 'RFC2247: domain component object'
SUP top AUXILIARY MUST dc )
Illustrates the use of the AUXILLIARY statement. An AUXILLIARY
cannot on its own create an entry. The OID in this example shows the
use of a private enterprise OID (ObjectIdentifier). The following fragment shows a fairly typical base DN definition using dcObject:
dn: dc=example,dc=com
dc: example.com
objectclass: dcObject
objectclass: organization
o: Example, Inc.
It is the objectclass: organization that creates the entry. dcObject piggy-backs on this objectclass.
This is how the pilotOrganization objectclass is defined and
illustrates that there may be one or more SUPerior (Parent)
objectclasses in which the child inherits the properties of ALL its
parents (bit like humans really):
objectClasses: ( 0.9.2342.19200300.100.4.20 NAME 'pilotOrganization'
SUP ( organization $ organizationalUnit ) STRUCTURAL
MAY buildingName )
We have omitted explaining a couple of values (well one actually) -
OBSOLETE if it is present it means the objectclass should not be used
(duh).
LDAP Attributes
Attributes typically contain data and have the following characteristics:
-
Every attribute is included in one or more objectclass.
-
An objectclass is also an attribute and can be used in searches.
-
To use an attribute in an entry its objectclass must be included in the entry definition and its objectclass must be included in a schema which must be identified to the LDAP server.
-
An attribute's characteristics are defined using ASN.1 notation.
-
An attribute can appear once in any instance of its containing ObjectClass (SINGLE-VALUE) or can apear more than once in any instance of its containing ObjectClass (MULTI-VALUE). MULTI-VALUE is default.
-
An attribute definition may be part of a hierarchy in
which case it inherits all the properties of its parents, for example,
commonName (cn), givenName (gn), surname (sn) are all children of the name attribute.
-
An attribute definition includes its type, for instance
string, number etc., how it behaves in certain conditions, for example
are compares case sensitive or case-insensitive and other
characteristics (properties).
-
An attribute supported by a LDAP server forms part of a collection called attributetypes which can be interrogated via the subschema.
Defining an Attribute
The formal attribute definition is defined in RFC 2252 section 4.2 and looks like this:
AttributeTypeDescription = "(" whsp
numericoid whsp ; AttributeType identifier
[ "NAME" qdescrs ] ; name used in AttributeType
[ "DESC" qdstring ] ; description
[ "OBSOLETE" whsp ]
[ "SUP" woid ] ; derived from this other
; AttributeType
[ "EQUALITY" woid ; Matching Rule name
[ "ORDERING" woid ; Matching Rule name
[ "SUBSTR" woid ] ; Matching Rule name
[ "SYNTAX" whsp noidlen whsp ] ; Syntax OID
[ "SINGLE-VALUE" whsp ] ; default multi-valued
[ "COLLECTIVE" whsp ] ; default not collective
[ "NO-USER-MODIFICATION" whsp ]; default user modifiable
[ "USAGE" whsp AttributeUsage ]; default userApplications
whsp ")"
Ouch! whsp means a space character and must be present. Rather than explain each bit of gobbledegook lets again start with some examples.
An attribute is defined using ASN.1 notation - the following is a simple standard attribute definition for commonName (cn) taken from the core.schema supplied with OpenLDAP distributions.
attributetype ( 2.5.4.3 NAME ( 'cn' 'commonName' ) SUP name )
Now lets deconstruct this definition:
attributetype indicates this defines an attribute - wow.
2.5.4.3 NAME ('cn' 'commonName') defines a globally unique name for this attribute and is comprised of two parts: NAME ('cn' 'commonName' just allows you to refer to this attribute by some semi-understandable text - in this case either the english word commonName OR the shortform (or alias) cn
in principle there are no limits to the number of definitions or
aliases you can have as long as they are unique. In this multiple entry
form the names are enclosed in parentheses and space separated. Since cn appears first it is called the primary name which is very important when it comes to indexing entries.
The globally unique part is defined by 2.5.4.3 which is called an OID (ObjectIdentifier).
The OID 2.5.4.3 was possibly the fourth attribute ever defined by X.500
(2.5.4 is the joint itu-iso x.500 attribute types, the last 3 is a
sequence number within that family of OIDs). It does not matter what
organization assigns this number but it must be UNIQUE. Obtaining an
enterprise OID that allows you to define your own attributes and objectclasses is a trivial process via IANA. It is a VERY BAD THING™ to re-use existing OIDs.
SUP 'name' indicates that this attribute has a PARENT (or SUPerior) attribute - it is part of a hierarchy. In this case the parent is name
which we will now look at in detail since, if you recall, the child
always inherits the properties of the parent (or SUPerior) attribute
(and itself may have additional properties). The SUP entry can use
either a 'name' or an OID. The definition SUP 'top' and SUP 2.5.4.41
mean exactly the same - except to the poor reader!
This is the attribute definition of name which is a much more serious definition and the SUPerior (parent) attribute of cn above:
attributetype ( 2.5.4.41 NAME 'name'
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15{32768} )
Now for some more serious deconstruction:
attributetype indicates this defines an attribute - same as before.
2.5.4.41 NAME 'name' defines the globally unique name for this attribute and as before is comprised of two parts: NAME 'name' just allows reference to this attribute by some semi-understandable text and the OID 2.5.4.41
indicates it was defined by the X.500 standards group. The format used,
because there is only a single name value, does not need enclosing
parentheses as in the commonName example above.
EQUALITY caseIgnoreMatch indicates how this (and any child attributes) will behave when used in a search filter e.g. (cn=jimbob) (cn is a child of name) and no wildcards exist in the search. In this case it defines the match to be case-insensitive. caseIgnoreMatch is a matchingRule and is defined in the subschema.
SUBSTR caseIgnoreSubstringsMatch indicates how this (and any child attributes) will behave when used in a search filter which uses a substring e.g. (cn=jim*) (cn is a child of name) and contains one or more wildcards. In this case it defines that the match is case-insensitive. caseIgnoreSubstringMatch is again a matchingRule and is defined in the subschema.
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15{32768} is an OID which defines the data type and what rules (data validation) are applied to the data. The full list is in RFC 2252 section 4.3.2 and in this case the OID defines it to be a Directory String type which is defined in RFC 2252 section 6.10 to be in the UTF-8 form of the ISO 10646 character set. The value {32768} indicates the maximum length of the string and is optional. Some more on LDAP Data Types
Other Characteristics
SINGLE-VALUE Omission of this entry means that it is multi-valued i.e. it can appear more than once in an objectclass or an entry. If the attribute can only accept single values it must be explicitly defined as in the definition of dc below.
attributetype ( 0.9.2342.19200300.100.1.25
NAME ( 'dc' 'domainComponent' )
DESC 'RFC1274/2247: domain component'
EQUALITY caseIgnoreIA5Match
SUBSTR caseIgnoreIA5SubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.26
SINGLE-VALUE )
ORDERING 'matchingrule' is rarely defined and is used to
define the collation match - the lexicographic sorting order (allowing
searches of <= and >=).
attributetype ( 2.5.4.46 NAME 'dnQualifier'
EQUALITY caseIgnoreMatch
ORDERING caseIgnoreOrderingMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.44 )
3.5 Matching Rules
Matching rules are part of what is called the operational characteristics of the LDAP server.
matchingrules define the methods of comparison available in the LDAP server:
- matchingrules are typically built-in to the LDAP server and do not need to be defined explicitly.
- A matchingrule forms part of a collection called matchingrules which can be discovered via the subschema.
- A matchingrule is defined for each attribute using the EQUALITY, SUBSTR, ORDERING properties as required - only those properties required are defined. If the search cannot use a wildcard there will be no SUBSTR property defined.
3.5.1 Defining matchingRule
Most matchingrules are built-in and you almost never need to
define them but like everything in LDAP it has a defining syntax. The
following is an example of a matchingrule definition using caseIgnoreMatch:
matchingRule ( 2.5.13.2 NAME 'caseIgnoreMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
The deconstruction shows the following:
matchingrule indicates this is a matchingrule definition.
2.5.13.2 NAME 'caseIgnoreMatch' defines the globally unique name for this matching rule and as always is comprised of two parts: NAME 'caseIgnoreMatch' allows reference to this matchingrule using some semi-understandable text and the OID 2.5.13.2 indicates the matching rule was defined by the X.500 standards group. Rule description:
"The Case Ignore Match rule compares for equality a presented string
with an attibute value of type PrintableString, NumericString,
TeletexString, BMPString, UniversalString or DirectoryString without
regard for case (upper or lower) of the strings (e.g., "Dundee" and
"DUNDEE" match).
The rule returns TRUE if the strings are the same length and
corresponding characters are identical except possibly with regard to
case.
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 defines that this matchingrule operates on the type(s) defined - in this case a DirectoryString (a UTF-8 format string).
OpenLDAP built-in matchingRules
This list below can be found for OpenLDAP by interrogating the subschema using a command like:
ldapsearch -H ldap://ldap.example.com -x -s base -b "cn=subschema"
"(objectclass=*)" matchingrules
# matchingrules may be changed to
# attributetypes objectclasses etc., etc.
The above command should be on a single line - it is split for HTML
formatting reasons only. Replace ldap.example.com with the host name of
your LDAP server. If the server is running locally you can omit the -H
argument.
Alternatively use any good LDAP browser with a Root DN of "cn=subschema"
The above command will return this list (OpenLDAP 2.1.12 on FreeBSD):
# Subschema
dn: cn=Subschema
matchingRules: ( 2.5.13.0 NAME 'objectIdentifierMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.38 )
matchingRules: ( 2.5.13.1 NAME 'distinguishedNameMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.12 )
matchingRules: ( 2.5.13.2 NAME 'caseIgnoreMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
matchingRules: ( 2.5.13.3 NAME 'caseIgnoreOrderingMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
matchingRules: ( 2.5.13.4 NAME 'caseIgnoreSubstringsMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.58 )
matchingRules: ( 2.5.13.5 NAME 'caseExactMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
matchingRules: ( 2.5.13.6 NAME 'caseExactOrderingMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
matchingRules: ( 2.5.13.7 NAME 'caseExactSubstringsMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.58 )
matchingRules: ( 2.5.13.8 NAME 'numericStringMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.36 )
matchingRules: ( 2.5.13.10 NAME 'numericStringSubstringsMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.58 )
matchingRules: ( 2.5.13.13 NAME 'booleanMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.7 )
matchingRules: ( 2.5.13.14 NAME 'integerMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.27 )
matchingRules: ( 2.5.13.15 NAME 'integerOrderingMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.27 )
matchingRules: ( 2.5.13.16 NAME 'bitStringMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.6 )
matchingRules: ( 2.5.13.17 NAME 'octetStringMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.40 )
matchingRules: ( 2.5.13.18 NAME 'octetStringOrderingMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.40 )
matchingRules: ( 2.5.13.20 NAME 'telephoneNumberMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.50 )
matchingRules: ( 2.5.13.21 NAME 'telephoneNumberSubstringsMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.58 )
matchingRules: ( 2.5.13.23 NAME 'uniqueMemberMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.34 )
matchingRules: ( 2.5.13.27 NAME 'generalizedTimeMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.24 )
matchingRules: ( 2.5.13.28 NAME 'generalizedTimeOrderingMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.24 )
matchingRules: ( 2.5.13.29 NAME 'integerFirstComponentMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.27 )
matchingRules: ( 2.5.13.30 NAME 'objectIdentifierFirstComponentMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.38 )
matchingRules: ( 2.5.13.34 NAME 'certificateExactMatch'
SYNTAX 1.2.826.0.1.3344810.7.1 )
matchingRules: ( 1.3.6.1.4.1.1466.109.114.1 NAME 'caseExactIA5Match'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.26 )
matchingRules: ( 1.3.6.1.4.1.1466.109.114.2 NAME 'caseIgnoreIA5Match'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.26 )
matchingRules: ( 1.3.6.1.4.1.1466.109.114.3 NAME 'caseIgnoreIA5SubstringsMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.26 )
matchingRules: ( 1.3.6.1.4.1.4203.1.2.1 NAME 'caseExactIA5SubstringsMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.26 )
matchingRules: ( 1.2.840.113556.1.4.803 NAME 'integerBitAndMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.27 )
matchingRules: ( 1.2.840.113556.1.4.804 NAME 'integerBitOrMatch'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.27 )
You can find what the OIDs are and therefore the exact english description of the matchingRule using this wonderful site.
3.6 LDAP Operational Attributes and Objects
There are a bunch of attributes and objectclasses that are built
into the LDAP server and govern how it works or functions. These
attributes and object classes are typically called operational.
These operational thingies all live under the rootDSE and are not visible in normal operations.
The relationship between the DIT(s) and its entries and the RootDSE and its objects is shown below:
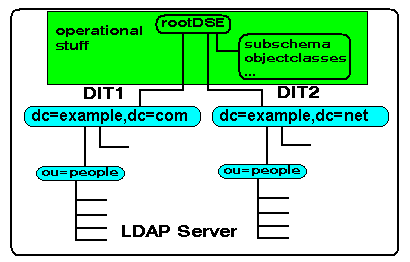
The rootDSE can be inspected using either a suitable LDAP browser (instructions for LDAPBrowser/Editor) with an empty Root DN or the following command:
ldapsearch -H ldap://ldap.mydomain.com -x -s base -b "" +
# note the + returns operational attributes
This should return something similar to that shown below (from
OpenLDAP 2.4.8) - the values in parentheses are added explanations and
are not returned by the server:
dn:
structuralObjectClass: OpenLDAProotDSE
configContext: cn=config
namingContexts: dc=example,dc=com
namingContexts: dc=example,dc=net
monitorContext: cn=Monitor
supportedControl: 1.3.6.1.4.1.4203.1.9.1.1 (Contentsync RFC 4530)
supportedControl: 2.16.840.1.113730.3.4.18 (ProxiedAuthv2 RFC 4370)
supportedControl: 2.16.840.1.113730.3.4.2 (ManageDSAIT RFC3377)
supportedControl: 1.3.6.1.4.1.4203.1.10.1 (SubEntries RFC3673)
supportedControl: 1.2.840.113556.1.4.319 (pagedResults RFC2696)
supportedControl: 1.2.826.0.1.3344810.2.3 (MatchedValues RFC3876)
supportedControl: 1.3.6.1.1.13.2 (Post Read RFC4527)
supportedControl: 1.3.6.1.1.13.1 (Pre-Read RFC4527))
supportedControl: 1.3.6.1.1.12 (Assertion RFC4528)
supportedExtension: 1.3.6.1.4.1.4203.1.11.1 (ModifyPassword RFC3088)
supportedExtension: 1.3.6.1.4.1.4203.1.11.3 (WhoAmI RFC4532)
supportedExtension: 1.3.6.1.1.8 (Cancel RFC3909)
supportedFeatures: 1.3.6.1.1.14 (Modify-Increment RFC4525)
supportedFeatures: 1.3.6.1.4.1.4203.1.5.1 (OperationalAttrs RFC3674)
supportedFeatures: 1.3.6.1.4.1.4203.1.5.2 (ObjectClassAttrs RFC4529)
supportedFeatures: 1.3.6.1.4.1.4203.1.5.3 (TrueFalse RFC4526)
supportedFeatures: 1.3.6.1.4.1.4203.1.5.4 (LanguageTag RFC3866)
supportedFeatures: 1.3.6.1.4.1.4203.1.5.5 (LanguageRange RFC3866)
supportedLDAPVersion: 3
supportedSASLMechanisms: NTLM
supportedSASLMechanisms: GSSAPI
supportedSASLMechanisms: DIGEST-MD5
supportedSASLMechanisms: CRAM-MD5
entryDN:
subschemaSubentry: cn=Subschema
An explanation of each supportedExtension can be found using this wonderful site. The above listing shows this LDAP server supports two DITs - shown as namingContexts - which were configured using this process.
It is possible to add extensions using the OpenLDAP slapd.conf rootDSE directive.
参见URL:
http://www.zytrax.com/books/ldap/ch3/