理论知识终于告一段落啦。接下来要和大家分享的是S型曲线模型中的重要模型——Gompertz模型和Logistic模型在公司内部实际项目中的应用。下面的数据都是来自于公司内部实际项目,应用主要分4个场景:进入测试阶段前、测试阶段过程中、测试退出时、以及其它的应用。下面将依据场景,从测试阶段开始一直到结束,分阶段介绍S型曲线的应用。
● 进入测试阶段前的缺陷发现目标的预测
进入测试阶段前的缺陷预测过程可以说是一个静态的预估过程。简单来说,即根据经验、历史数据、预测开始时的缺陷数、release时的缺陷数和遗留缺陷数来预测整个测试阶段的缺陷趋势,这个过程通过三点法来完成。最后预测得出的缺陷模型是最初模型,可作为后期阶段的指导模型。
● 测试阶段每周缺陷发现进度跟踪与预测
● 测试退出评价时,对无偿维护阶段发现缺陷数的估计
● 其他
上面介绍的几种应用场景,都在实际项目中得到了印证。但要想确定推广模型的使用,首先需要的,就是数据的收集工作。只有数据收集的准确、完整,才有可能得到较为精确的成长曲线模型。
本篇主要介绍第一个场景,即进入测试阶段前缺陷发现目标的预测。下面选择了公司内过程稳定的软件产品线上的一个升级版本项目作为试点,选择最常用的S型曲线中的Gompertz和Logistic曲线,在测试阶段对缺陷发现趋势和遗漏进行了估计和跟踪。实验过程中使用的工具为公司内部针对软件缺陷预测开发的基于SRGM的成长曲线预测工具。
1)测试阶段准备期对缺陷发现趋势的估计
进入测试阶段前的缺陷预测过程基本是一个静态的预估过程,即根据软件规模与经验、历史数据、之前开发阶段发现的缺陷数等已有数据,版本发布的质量目标(如:单位规模缺陷漏出率)来估计测试阶段的缺陷发现趋势。可通过对进入测试、版本发布判定和版本发布后维护期的三组数据使用三点法来完成。这时估出的缺陷发现趋势只是初步结果,作为测试阶段根据实际数据不断改进的基础。
以试点项目为例,根据测试用例实施计划以及历史数据,估计出进入测试阶段后第一周应发现缺陷25件。根据前一个迭代周期的测试阶段缺陷发现率约为12件/KLOC,本次迭代估计代码规模约为85KLOC;估计出版本发布时(进入测试阶段起第14周)应发现缺陷数为1020件。对应版本维护阶段(进入测试阶段起第27周),根据组织级质量目标,得到遗漏缺陷约68件,合计应发现缺陷数为1088件,由这些数据得到release时的百分比(通过计算得出)。应用三点法,得到如下缺陷发现累积估计值,可作为测试负责人制订每周发现缺陷目标的重要参考。预测方法如图1所示。
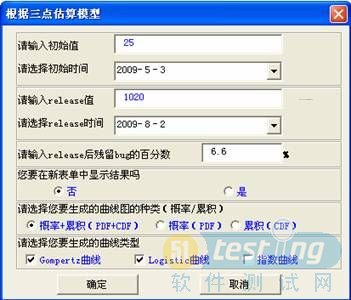
图1 测试准备阶段对缺陷发现趋势估计
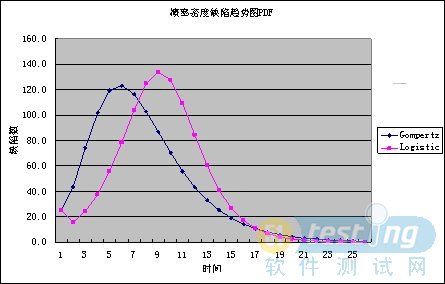
图2 趋势预测图PDF
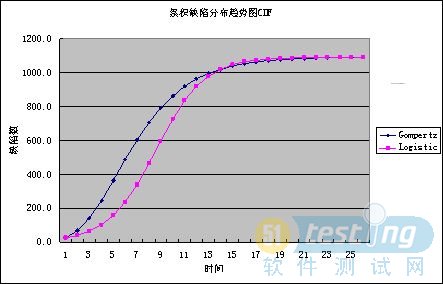
图3 趋势预测图CDF
估计结果如表1数据所示。(看了上面的图示,相信大家都已经知道百分比的计算方法啦。)
表1 应用三点法得到的缺陷发现累积估计值
所在周 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
原始估计 | 25 | | | | | | | | | | | | | 1020 |
Gompertz | 25 | 68 | 142 | 244 | 363 | 486 | 603 | 706 | 792 | 863 | 919 | 962 | 995 | 1020 |
Logistic | 25 | 40 | 65 | 102 | 157 | 236 | 340 | 464 | 598 | 726 | 835 | 919 | 979 | 1020 |
所在周 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 |
原始估计 | 1020 | | | | | | | | | | | | | 1088 |
Gompertz | 1020 | 1039 | 1053 | 1063 | 1071 | 1077 | 1081 | 1084 | 1086 | 1088 | 1089 | 1090 | 1091 | 1091 |
Logistic | 1020 | 1047 | 1064 | 1074 | 1081 | 1085 | 1088 | 1089 | 1090 | 1091 | 1091 | 1091 | 1091 | 1091 |
实际项目中,测试负责人根据历史数据,选择了Gompertz曲线拟合出的估计值作为每周发现缺陷目标。这样,就在进入测试阶段前,初步确定了测试阶段每周应当发现的缺陷目标。当然,这只是一个初始值。
2)测试阶段每周对缺陷发现趋势的进度跟踪
我们虽然已经利用缺陷预测工具得到了一个每周应当发现缺陷个数的初始值,然而,这个初始值不应当是固定不变的,每周实际发现的缺陷数也可能不会严格与预测值一致,可能更多,也可能更少。因此,进入测试阶段后,测试负责人跟踪每周发现的缺陷情况,进行预测值与实际值的对照。在数据量符合算法要求后,使用三和法或高斯-牛顿法(GNL法)模拟、更新缺陷发现趋势的渐近值K。若有必要,比如测试阶段准备期选择的模型估计值与实际数据发生严重偏差时,可能仅更新K值并不能拟合实际的情况,而是需要选择其它的成长曲线模型。
同样利用我们的缺陷预测工具。当具有一定的数据量后,即可使用三和法或GNL法重新模拟缺陷趋势,更新最早发现的缺陷情况。利用同样的例子,当数据量收集到14个,利用三和法进行预测,分别生成Gompertz曲线和Logistic曲线。下图4中,选择要预测的样本数据;下图5中,设置预测条件。
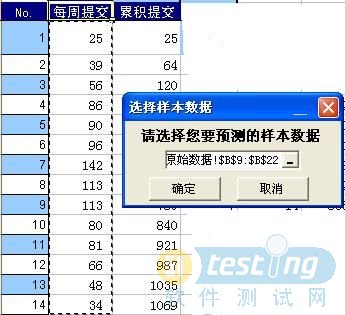
图4 选择样本数据

图5 缺陷预测参数选择
选择预测的数据为27个,得到14周之后的结果如表2。
表2 应用三和法得到的缺陷发现累积估计值
所在周 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
原始估计 | 25 | 64 | 120 | 206 | 296 | 392 | 534 | 647 | 760 | 840 | 921 | 987 | 1035 | 1069 |
Gompertz | 24 | 58 | 116 | 198 | 300 | 413 | 529 | 640 | 743 | 833 | 910 | 974 | 1027 | 1070 |
Logistic | 26 | 47 | 84 | 144 | 237 | 366 | 521 | 676 | 807 | 902 | 964 | 1020 | 1024 | 1036 |
所在周 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 |
原始估计 | 1069 | 1092 | 1114 | 1139 | 1142 | 1145 | 1158 | 1162 | 1164 | 1165 | 1165 | 1166 | 1166 | 1166 |
Gompertz | 1070 | 1104 | 1131 | 1153 | 1170 | 1183 | 1194 | 1202 | 1208 | 1213 | 1217 | 1220 | 1222 | 1224 |
Logistic | 1036 | 1043 | 1046 | 1049 | 1050 | 1050 | 1051 | 1051 | 1051 | 1051 | 1051 | 1051 | 1051 | 1051 |
从拟合程度可以看出,Gompertz曲线的拟合程度近似100%,而Logistic曲线的拟合程度低于Gompertz曲线,因此,选择Gompertz曲线作为拟合曲线。
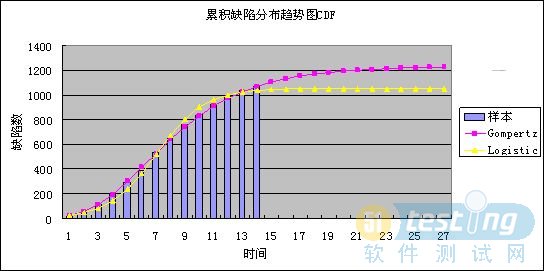
图6 缺陷趋势图CDF
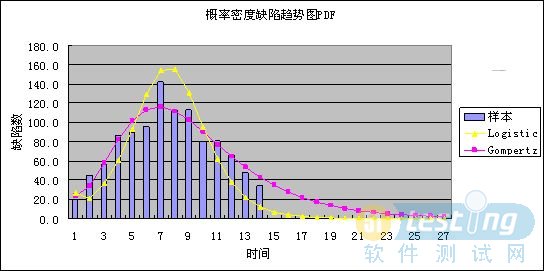
图7 缺陷趋势图PDF
选择Gompertz曲线得到的K值为1230,即整个系统应当共发现1230个bug。然而如同我们之前关于K值的描述,K值并不是始终都不变的,因此需要在测试阶段持续的进行预测,得到更为可靠的结果。
根据预实对照的结果,按照需要调整目前测试的状态。
-----------------------------------------------------------------------------------------------------------------------
作为一个项目经理或者测试经理,上面提到的内容对你来说应当很容易理解,但你要考虑的恐怕更多。比如,选定要release的时间,根据release时间的安排每周发现缺陷的任务;再比如,公共假期的时间考虑(可能没有几个人愿意在春节这样的假期里继续工作吧,不过release的时间可是不能修改的)。根据实际情况考虑的更多更全面,才能让你的预测更加贴近实际,预测的结果才能有效。
3)测试阶段结束前的退出标准的评价
准备退出测试阶段前,根据预测得到的应发现的缺陷总数、缺陷预测模型和实际发现的缺陷数据,可以模拟版本中仍然遗留的缺陷数,据此可以确定:
● 根据软件发布标准决定软件是否能够如期发布;
● 估计在后续软件维护阶段会发现缺陷的情况,以指导项目确保客户满意度的前提下,合理安排人员退出。
以试点项目为例,根据测试阶段14周的实际缺陷发现数据,使用三和法,对最常用的Gompertz和Logistic曲线模型,重新实施拟合,结果如表2和图8所示。
表2 应用三和法重新拟合的缺陷发现累积估计值
所在周 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
原始估计 | 25 | 64 | 120 | 206 | 296 | 392 | 534 | 647 | 760 | 840 | 921 | 987 | 1035 | 1069 |
Gompertz | 24 | 58 | 116 | 198 | 300 | 413 | 529 | 640 | 743 | 833 | 910 | 974 | 1027 | 1070 |
Logistic | 26 | 47 | 84 | 144 | 237 | 366 | 521 | 676 | 807 | 902 | 964 | 1020 | 1024 | 1036 |
所在周 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 |
原始估计 | 1069 | 1092 | 1114 | 1139 | 1142 | 1145 | 1158 | 1162 | 1164 | 1165 | 1165 | 1166 | 1166 | 1166 |
Gompertz | 1070 | 1104 | 1131 | 1153 | 1170 | 1183 | 1194 | 1202 | 1208 | 1213 | 1217 | 1220 | 1222 | 1224 |
Logistic | 1036 | 1043 | 1046 | 1049 | 1050 | 1050 | 1051 | 1051 | 1051 | 1051 | 1051 | 1051 | 1051 | 1051 |

图8 试点项目的缺陷预测情况
经过计算,Gompertz曲线的R2值高达99.93%,说明模型对实际数据的拟合程度很高,其渐近值对发布后缺陷趋势有较高参考价值。根据Gompertz曲线的预估趋势,发现若第14周结束测试阶段,则缺陷遗留率有可能高达14%,无法满足本项目的质量目标。因此增加了2周时间的回归测试,使版本发布后的缺陷遗留率最终控制在5%以内。而实际项目中,往往不希望额外的2周测试时间造成版本发布时间推后,这样可以在版本发布预定时间之前采取一些补救措施。首先,在版本发布之前,就根据模型预估的缺陷图计算出发布时的缺陷遗留率,若不能满足发布要求,则即时采取措施,比如,邀请客户提前参与回归测试;对测试人员进行培训;派遣测试人员到客户处进行业务学习,提高业务能力等等。
4)其他场景
除了测试阶段利用S型曲线对缺陷进行预测外,还可以对Gompertz和Logistic曲线模型使用三点法与三和法,来预测与跟踪测试阶段缺陷修改累积趋势(即每周应当修改多少缺陷,以此来控制缺陷修改的进度)和编码阶段代码规模增长趋势(即每周应当完成的代码工作量,以此来控制编码开发的资源投入与进度)。在软件开发不同的生命周期阶段中,可靠性增长模型还有更多的实际应用场景,支持对过程的量化管理。
至此,软件可靠性增长模型之S型曲线的介绍就暂时告一段落了。后续我们还将进行补充,利用实际项目中的数据对趋势预测模型不断进行完善。