我们一般关注逻辑读的次数,当多个表联合查询时,这里会现时每一个表的IO信息,当某个表的逻辑读的次数很大时,你就要重点关注和分析这个表了,是不是查询时涉及到这个表中的记录条数过多,是不是没有合理使用到Index,是不是可以增加其它的过滤条件来减少相关的记录集合等等。下面是简单说明:
| 输出项 | 含义 |
| Table | 表的名称。 |
| Scan count | 执行的索引或表扫描数。 |
| logical reads | 从数据缓存读取的页数。 |
| physical reads | 从磁盘读取的页数。 |
| read-ahead reads | 为进行查询而放入缓存的页数。 |
| lob logical reads | 从数据缓存读取的 text、ntext、image 或大值类型 (varchar(max)、nvarchar(max)、varbinary(max)) 页的数目。 |
| lob physical reads | 从磁盘读取的 text、ntext、image 或大值类型页的数目。 |
| lob read-ahead reads | 为进行查询而放入缓存的 text、ntext、image 或大值类型页的数目。 |
磁盘IO相关信息先介绍到这里,另外一个参考数据是使用 set statistics time on 参考显示分析、编译和执行语句所需的毫秒数。具体的使用方法同set statistics io on 基本相同,只不过显示的是本次查询所使用的分析编译、执行等的时间信息。聪明的你一定一看就明白了。在此不再赘述。
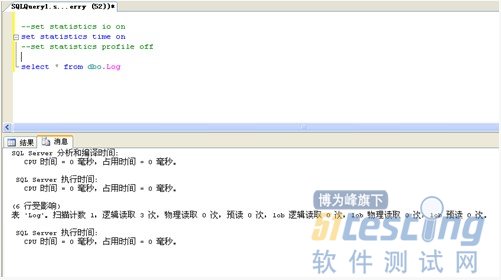
1、使用 set statistics profile on 参考显示当前语句执行的配置文件信息,执行步骤等信息,使用方法同上。
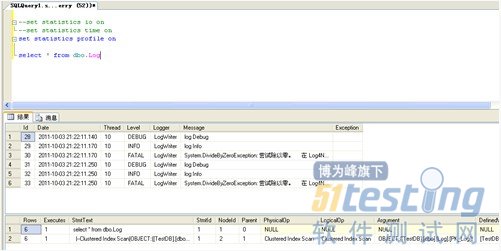
执行查询后,除了显示所执行的结果集合外,还另外显示本次sql语句执行的相关配置信息,采用记录树的形式显示,对应执行计划中的各个步骤,比如某个步骤使用的索引类型,评估行数,IO信息,时间信息等。这些信息都可以用来参考,以确定该段sql语句的问题在哪里。
参考当前语句的估计的执行计划或实际的执行计划,分析当前语句执行时SQL Server 查询优化器所选择的数据检索方法。
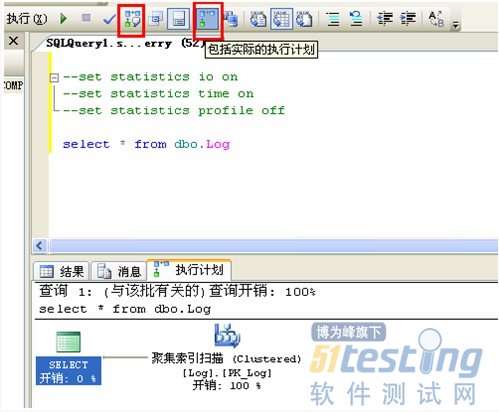
实际的执行计划显示了本次执行所使用的执行计划。该图应该从右向左看,由下向上看,如果是多个表连接查询的话,这里也会显示多个执行步骤,你可以检查每一个步骤相关的操作相关信息,如IO开销,CPU开销,估计的行数,有没有使用到Index,以及使用的何种Index等信息。行数过多则需要留意了。所使用的Indexl类型也是需要关注的信息之一。
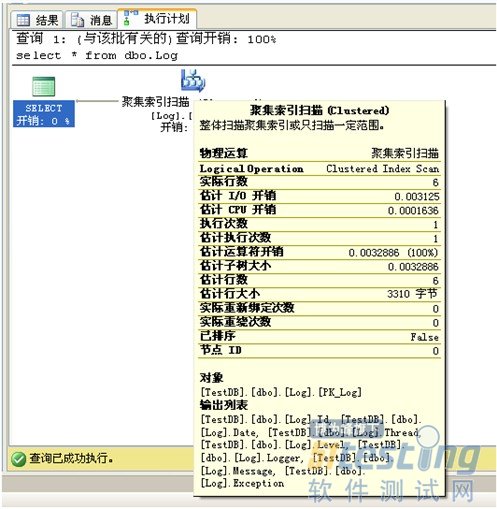
下面是执行计划中一些概念的简单说明:
| 工具提示项 | 说明 |
Physical Operation | 使用的物理运算符,例如 Hash Join 或 Nested Loops。以红色显示的物理运算符表示查询优化器已发出警告,例如丢失列统计信息或丢失联接谓词。这可能导致查询优化器选择比预期的效率低的查询计划。有关列统计信息的详细信息,请参阅使用统计信息提高查询性能。 当图形执行计划建议创建统计信息、更新统计信息或创建索引时,使用 SQL Server Management Studio 对象资源管理器中的快捷菜单可以立即创建或更新丢失的列统计信息和索引。有关详细信息,请参阅索引操作指南主题。 |
Logical Operation | 与物理运算符匹配的逻辑运算符,如 Inner Join 运算符。逻辑运算符列在物理运算符之后,两者均位于工具提示的顶部。 |
Estimated Row Size | 操作符生成的行的估计大小(字节)。 |
Estimated I/O Cost | 用于执行操作的所有 I/O 活动的估计开销。此值应尽可能低。 |
Estimated CPU Cost | 用于执行操作的所有 CPU 活动的估计开销。 |
Estimated Operator Cost | 用于执行此操作的查询优化器的开销。此操作的开销以占查询总开销的百分比的形式显示在括号中。由于查询引擎选择最高效的操作来执行查询或执行语句,因此此值应尽可能低。 |
Estimated Subtree Cost | 查询优化器执行此操作及同一子树内位于此操作之前的所有操作的总开销。 |
Estimated Number of Rows | 运算符生成的行数。 |
综合以上介绍的几种参考信息的方法,一般都可以确定问题sql的问题所在,然后对症下药,剩下的就是进行针对性的修改了,这里只是抛砖引玉,聪明的你一定会有方法解决的。