译者:原始文章有点性能测试工具软文的感觉,毕竟文章来源于某工具官方博客。高手请略过。
对于我这种新手,此文还是给我带来一些惊喜,从上到下地,从表象到根源地,定位他们遇到性能问题-响应时间过长-的根本原因,有具体的步骤,思考和判断依据,这就是一个比较不错性能测试分析实例。可以更清楚看到性能测试如何分析定位,可以学习其思路。故分享之。
原文连接:http://apmblog.compuware.com/2013/06/04/how-to-accurately-identify-impact-of-system-issues-on-end-user-response-time/
以下为正文
我们希望检测下我们社区网站的负载能力,所以我们开发团队进行了一个任务,验证生产环境的系统是否能在现有的硬件基础上处理10倍于目前的负载。为了将网站在高负载下可能的崩溃影响降到最低,我们决定在周日下午进行第一轮测试。在运行测试之前,我们给运维团队提了一个醒:他们可能在这次两小时的期间观察到明显的负载变化,从而可能影响到运行在同一环境下的其他应用程序。
在测试过程中,运维团队和开发团队一起监控实时性能数据,当达到一定的负载水平后,我们看到最终用户的响应时间和耗尽资源。在本次测试中非常有趣的是,开发团队和运维团队都看着相同的数据,但是却从不同的角度去审视这些结果。然而,他们都是依赖于最近才公布的Compuware的PureStack技术,这是——整合dynaTrace和PurePath——的第一个解决方案,显示出在高负载下生产环境的硬件是如何影响到关键业务应用程序的性能。
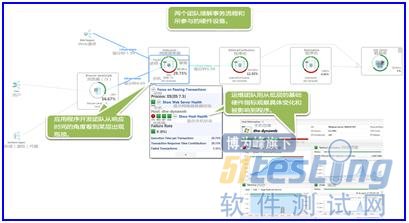
上下文为运维团队和开发团队的数据之间架起桥梁:这张图片显示"横向"事务以及"纵向"层面的热点区域(BridgingtheGapbetweenOpsandAppsDatabyaddingContext:OnepicturethatshowstheHotspotsof"Horizontal"Transactionaswellasthe"Vertical"Stack.)。
在我们的场景中表现不佳的根本原因-一个运行着Web和应用程序服务的主服务器的CPU被耗尽-从而导致达不到我们的负载目标。事实证明,这个问题是跟硬件设备和应用程序都有关系(ThisturnedouttobebothanITprovisioningandanapplicationproblem)。让我解释一下团队的步骤以及他们是如何得出他们的行动项列表,以便改善目前的系统性能,以便在第二轮测试中得到更好的结果。
第1步:监控和识别硬件健康状况
运维团队希望能够看着他们的服务器列表,而所有关键指标(CPU,内存,网络,磁盘等)都能很快地呈现出绿色状态(OperationsTeamslikehavingtheabilitytolookattheirlistofserversandquicklyseethatallcriticalindicators(CPU,Memory,Network,Disk,etc)aregreen)。但是,当我们的负载测试达到了顶峰时,他们看向服务器的状态时,显示出来却是,他们有2台机器正出现了异常:
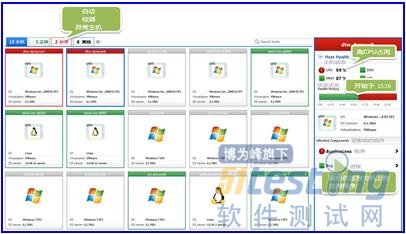
我们的社区网站核心服务器出现CPU相关的问题,并影响到另一运行在这台服务器上的应用程序。
步骤2:哪些运行中的应用程序被真正影响到了?
单击受影响的程序选项卡,它会显示受影响的机器上所有运行的应用程序,以及目前受影响的应用程序:

增加的负载不仅影响到社区网站,而且也影响到我们支持网站
这次负载测试已经让我们明白:如果我们希望未来的社区网站能够承担更高的负载,那我们可能需要移动支持网站到其他的机器,以避免不必要的影响。
当两个团队孤立检查,运维导向的监测是不会有这个的结论(Whenexaminedindependently,operations-orientedmonitoringwouldnotbethattelling.)。但是,当它被放到具体的上下文中,并涉及到关联的数据(最终用户响应时间,用户体验,...),这对开发团队来说是非常重要的,两个团队将获得更多的灵感和视角。这是一个良好的开端,但仍然还有很多需要了解的。
步骤3:哪些关键事务被真正影响到了?
点击社区应用程序的链接,它会显示实际受硬件状态影响的事务和页面,但仍然存在着两个关键的却又悬而未决的问题:
这些事务,是否是我们成功运行的关键?
这些事务和个人用户受性能问题影响后,有多严重的后果?
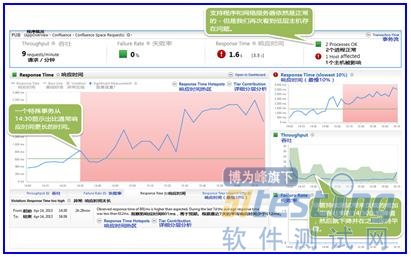
自动基线告诉我们,社区网站主要页面的响应时间受到明显的的性能影响。也包括我们的首页,这是我们最有价值的一个页面。
步骤4:可视化受硬件问题影响的事务流
事务流图表是一个令人满意的方式,能使得运维团队和开发团队达到一个基本的共识,并根据其完整的上下文查看关键的数据。它能显示涉及到的应用层,正在运行的物理机器和虚拟机器,以及哪里是热点区域。

运维团队和开发团队有相同的概要图表,告诉他们无论是在"横向"事务和"纵向"层面的热点区域。
我们知道,我们的网页内容非常"丰富"(图像,JavaScript和CSS),高达80%的事务时间花费在浏览器上。看到热点区域这样的表现,现在整体页面加载时间下降到50%,我们马上就知道更多的事务时间已经转移到新的热点区域:服务器端。好消息是,数据库是没有问题的(只用了1%的响应时间),整个性能热点区域似乎转到Web和应用程序服务器,它们都运行在同一台机器上-即那台存在CPU问题的机器。
第5步:精确定位存在问题的机器的健康问题
点击主机健康图表(HostHealthDashboard),它会显示了那个特定的服务器出了什么问题:
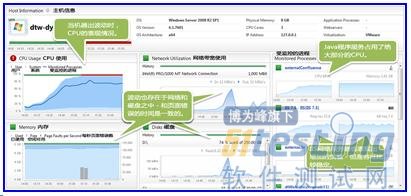
运维团队立即看到了CPU的消耗主要来自于一个Java应用服务器。网络,磁盘和页面错误在一些某些特定的时间也都存在不寻常的波动。
第6步:进程健康图表显示应用程序服务器上响应缓慢
我们可以看到,这台机器上的两个主要进程是IIS(Web服务器)和Tomcat(应用程序服务器)。再进一步看看,随着时间的推移,他们具体的表现情况:
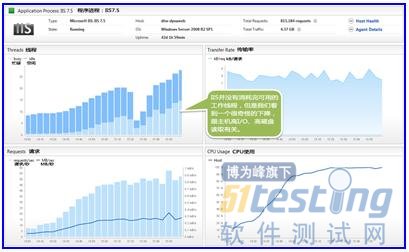
我们并不是没有足够的工作线程。传输速率是相当平缓。这就说明,Web服务器正在等待应用服务器的响应。

它表明应用程序服务器的CPU被耗尽。负载测试工具发送的持续请求在排队等待,因为服务器无法及时处理掉这些请求。实际上已处理的事务数量在下降。
第7步:精确定位CPU的大量消耗
现在我们开发团队非常有兴趣搞清楚到底是什么在消耗着CPU,以及是否我们可以在应用程序代码里面修复,或者是否只是我们需要更多的CPU:

热点区域显示应用程序的两层都消耗CPU比较多。让我们进一步深入。
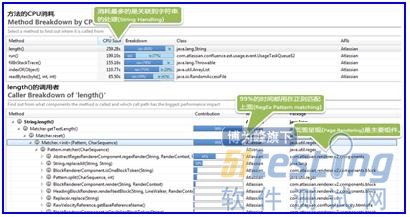
我们有些相当复杂的页面(包含大量Confluencemacros)导致大量的CPU占用。
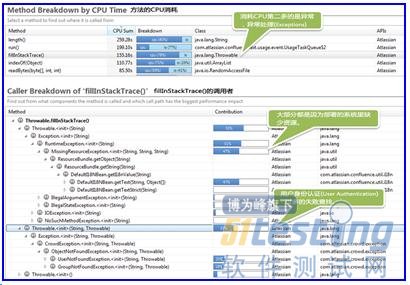
缺少资源和身份验证问题导致了这些异常。
运维和开发团队现在可以轻松地划分处理硬件和应用程序问题的优先级
所以如前所述,上下文是关键。但这些数据不是轻而易举就能获得的-上下文依赖于智能关联的能力,使所有相关的数据组成一个连贯的故事。当"横向"的事务数据(最终用户响应时间的分析)关联到"纵向"的硬件层面信息,这就很容易让两个团队达到一个共识,并规划影响最小的修复的优先级。
这次实验使我们能够确定以下几个行动项:
当应用程序对其他程序造成负面影响时,部署我们的关键应用程序到其他的机器上。
优化我们的页面生成方式,以便降低CPU使用率。
为虚拟机分配更多的CPU,以便能够处理更多的负载。
版权声明:本文出自 在劫录 的51Testing软件测试博客: http://www.51testing.com/?166582
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。