多数人知道
SQL注入,也知道SQL参数化查询可以防止SQL注入,可为什么能防止注入却并不是很多人都知道的。
首先:我们要了解SQL收到一个指令后所做的事情:
在这里,简单的表示为: 收到指令 -> 编译SQL生成执行计划 ->选择执行计划 ->执行执行计划。
具体可能有点不一样,但大致的步骤如上所示。
接着我们来分析为什么拼接SQL 字符串会导致SQL注入的风险呢?
首先创建一张表Users:
CREATE TABLE [dbo].[Users]( [Id] [uniqueidentifier] NOT NULL, [UserId] [int] NOT NULL, [UserName] [varchar](50) NULL, [Password] [varchar](50) NOT NULL, CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] 3F3ECD42B7A24B139ECA0A7D584CA195 |
插入一些数据:
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),1,'name1','pwd1');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),2,'name2','pwd2');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),3,'name3','pwd3');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),4,'name4','pwd4');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),5,'name5','pwd5');
假设我们有个用户登录的页面,代码如下:
验证用户登录的sql 如下:
select COUNT(*) from Users where Password = 'a' and UserName = 'b'
这段代码返回Password 和UserName都匹配的用户数量,如果大于1的话,那么就代表用户存在。
本文不讨论SQL 中的密码策略,也不讨论代码规范,主要是讲为什么能够防止SQL注入,请一些同学不要纠结与某些代码,或者和SQL注入无关的主题。
可以看到执行结果:
这个是SQL profile 跟踪的SQL 语句。
注入的代码如下:
select COUNT(*) from Users where Password = 'a' and UserName = 'b' or 1=1—'
这里有人将UserName设置为了 “b' or 1=1 –”.
实际执行的SQL就变成了如下:
可以很明显的看到SQL注入成功了。很多人都知道参数化查询可以避免上面出现的注入问题,比如下面的代码:
class Program { private static string connectionString = "Data Source=.;Initial Catalog=Test;Integrated Security=True"; static void Main(string[] args) { Login("b", "a"); Login("b' or 1=1--", "a"); } private static void Login(string userName, string password) { using (SqlConnection conn = new SqlConnection(connectionString)) { conn.Open(); SqlCommand comm = new SqlCommand(); comm.Connection = conn; //为每一条数据添加一个参数 comm.CommandText = "select COUNT(*) from Users where Password = @Password and UserName = @UserName"; comm.Parameters.AddRange( new SqlParameter[] { new SqlParameter("@Password", SqlDbType.VarChar) {Value = password}, new SqlParameter("@UserName", SqlDbType.VarChar) {Value = userName}, }); comm.ExecuteNonQuery(); } } } |
实际执行的SQL 如下所示:
exec sp_executesql N'select COUNT(*) from Users where Password = @Password and UserName = @UserName',N'@Password varchar(1),@UserName varchar(1)',@Password='a',@UserName='b'
exec sp_executesql N'select COUNT(*) from Users where Password = @Password and UserName = @UserName',N'@Password varchar(1),@UserName varchar(11)',@Password='a',@UserName='b'' or 1=1—'
可以看到参数化查询主要做了这些事情:
1:参数过滤,可以看到 @UserName='b'' or 1=1—'
2:执行计划重用
因为执行计划被重用,所以可以防止SQL注入。
首先分析SQL注入的本质,
用户写了一段SQL 用来表示查找密码是a的,用户名是b的所有用户的数量。
通过注入SQL,这段SQL现在表示的含义是查找(密码是a的,并且用户名是b的) 或者1=1 的所有用户的数量。
可以看到SQL的语意发生了改变,为什么发生了改变呢?,因为没有重用以前的执行计划,因为对注入后的SQL语句重新进行了编译,因为重新执行了语法解析。所以要保证SQL语义不变,即我想要表达SQL就是我想表达的意思,不是别的注入后的意思,就应该重用执行计划。
如果不能够重用执行计划,那么就有SQL注入的风险,因为SQL的语意有可能会变化,所表达的查询就可能变化。
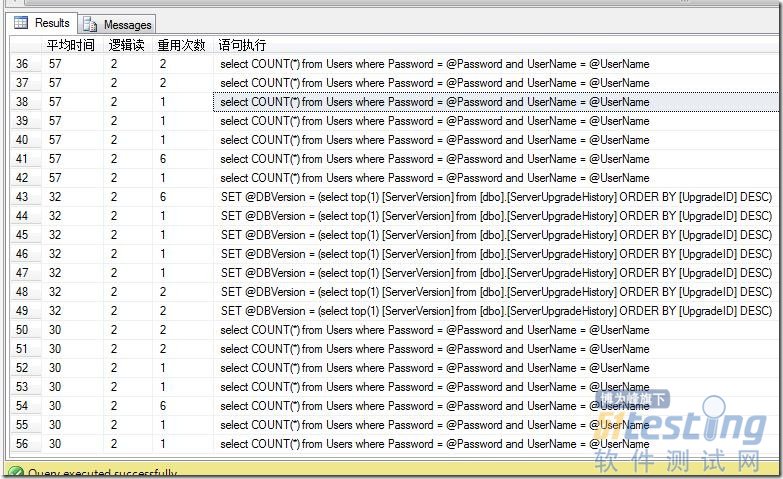
在SQL Server 中查询执行计划可以使用下面的脚本:
DBCC FreeProccache select total_elapsed_time / execution_count 平均时间,total_logical_reads/execution_count 逻辑读, usecounts 重用次数,SUBSTRING(d.text, (statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(text) ELSE statement_end_offset END - statement_start_offset)/2) + 1) 语句执行 from sys.dm_exec_cached_plans a cross apply sys.dm_exec_query_plan(a.plan_handle) c ,sys.dm_exec_query_stats b cross apply sys.dm_exec_sql_text(b.sql_handle) d --where a.plan_handle=b.plan_handle and total_logical_reads/execution_count>4000 ORDER BY total_elapsed_time / execution_count DESC; 18EFAED775BF4DB9A36C57B39EC6913D |
在这篇文章中有这么一段:
这里作者有一句话:”不过这种写法和直接拼SQL执行没啥实质性的区别”
任何拼接SQL的方式都有SQL注入的风险,所以如果没有实质性的区别的话,那么使用exec 动态执行SQL是不能防止SQL注入的。
比如下面的代码:
private static void TestMethod() { using (SqlConnection conn = new SqlConnection(connectionString)) { conn.Open(); SqlCommand comm = new SqlCommand(); comm.Connection = conn; //使用exec动态执行SQL //实际执行的查询计划为(@UserID varchar(max))select * from Users(nolock) where UserID in (1,2,3,4) //不是预期的(@UserID varchar(max))exec('select * from Users(nolock) where UserID in ('+@UserID+')') comm.CommandText = "exec('select * from Users(nolock) where UserID in ('+@UserID+')')"; comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4" }); //comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4); delete from Users;--" }); comm.ExecuteNonQuery(); } } |
执行的SQL 如下:
exec sp_executesql N'exec(''select * from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID varchar(max) ',@UserID='1,2,3,4'
可以看到SQL语句并没有参数化查询。
如果你将UserID设置为”1,2,3,4); delete from Users;—-”,那么执行的SQL就是下面这样:
exec sp_executesql N'exec(''select * from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID varchar(max) ',@UserID='1,2,3,4); delete from Users;--'
不要以为加了个@UserID 就代表能够防止SQL注入,实际执行的SQL 如下:
任何动态的执行SQL 都有注入的风险,因为动态意味着不重用执行计划,而如果不重用执行计划的话,那么就基本上无法保证你写的SQL所表示的意思就是你要表达的意思。
这就好像小时候的填空题,查找密码是(____) 并且用户名是(____)的用户。
不管你填的是什么值,我所表达的就是这个意思。
最后再总结一句:因为参数化查询可以重用执行计划,并且如果重用执行计划的话,SQL所要表达的语义就不会变化,所以就可以防止SQL注入,如果不能重用执行计划,就有可能出现SQL注入,存储过程也是一样的道理,因为可以重用执行计划。