通过 29-31 为期 3 天的 IBM WPS 培训。使我对 IBM WID 有了感观上的认识,并对炒的火热的一些概念( SOA 、 SCA 、 SDO )更进一步的认识。现就我理解对 WID 的培训进行总结,若哪里有问题,请各位指正。
SCA
刚上课, IBM 讲师就开始大谈 SCA ,现在就我理解谈下对 SCA 的认识。 Service Component Architecture 是 SCA 的缩写,可译为“组件(构件)服务体系架构”。 SCA 是基于组件开发,目的是为了可复用、可组装,将几个组件组装到一起就形成一个新的应用。其实在 SCA 的概念出现前,我们就已经使用基于组件方式开发了。所以 SCA 概念也可谓是新瓶装老酒。现在 SCA 已经逐渐规范,相关组织已经对其制定规范、标准。其中国内普元软件也参与制定,在国内 SCA 厂商算是首屈一指。
而在 WID 中, IBM 对 SCA 编程模型的概念包括:服务组件、服务模块、导入导出、共享库、 Standalone Reference 。现对其概念进行阐述。
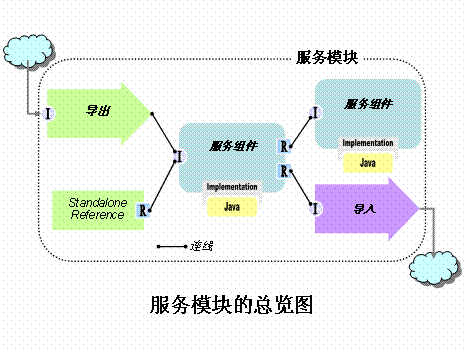
服务组件是 SCA 中的基本组成元素和基本构建单位,也是我们具体实现业务逻辑的地方。我们可以把它看成是构建我们应用的积木。我们可以非常容易地把传统的 POJO ,无状态会话 BEAN 等包装成 SCA 中的服务组件。 SCA 服务组件的主要接口规范是基于 WSDL ( Web Service Description Language )的,另外为了给 Java 编程人员提供一个比较直接的接口, SCA 的部分服务组件也提供了 Java 接口。因此,使用服务组件的客户端可以选择使用 WSDL 接口或 Java 接口。
服务模块(简称模块)由一个或多个具有内在业务联系的服务组件构成。把多少服务组件放在一个模块中,或者把哪些服务组件放在一起主要取决于业务需求和部署上灵活性的要求。
导入、导出是导入( Import ),它的作用是使得模块中的服务组件可以调用模块外部的服务。另一个是导出( Export ),它的作用是使得模块外部的应用可以调用模块中的服务组件。
当我们在构建了多个模块的时候,如果有一些资源可以在不同模块之间共享,那么我们可以选择创建一份可以在不同模块之间进行共享的资源,而不是在不同模块中重复创建。共享库就是存放这些共享资源的地方。
模块中的服务组件是不能直接被外部 Java 代码使用的,为了外部的 Java 代码,比如 JSP/Servlet 使用模块中的服务组件, WID 工具在模块中提供了一个特殊的端点,叫做 Standalone Reference 。这个端点只有引用( Reference ),而没有接口( Interface )。只要把这个端点的引用连接到需要调用的服务组件的接口,外部的 Java 代码通过这个引用的名称来调用相应的服务组件了。
在讲师讲完 SCA 概念及 WID 概述的时候,我曾私下问过,“ BEA WORKSPACE 360 与 WID 有什么区别?”。老师的回答是, WID 以 SCA 模型开发,而 WORKSPACE 360 的开发模型为 SOA ,因为 SCA 已经规范化,标准化,所以更规范一些,适合企业集成。而 SOA 的概念还是显得相对抽象的,没有正确的标准。
图一 SCA 编程模型
SDO
SDO 全称 Service Data Objects , SDO 应有服务引擎做支持,服务引擎主要的工作:整合多个 DB 、 LDAP 作为同一个数据源。通过数据源可以访问多个 DB 、 LDAP ,访问多个 DB 、 LDAP 对开发人员是透明的,开发人员只访问一个数据源,就相当于访问一个 DB ,而引擎内部使用 XML 存储,引擎应支持事务及安全管理。
SDO 是 IBM 提出的一个框架规范。 SDO 框架由三部分组成: DMS ( Data Mediator Services ), Data Graph 和 DataObject 。 DMS 负责生成 Data Graph , Data Graph 包含一系列关联的 Data Object 。客户和 DataGraph 打交道,而 DMS 如何生成 Data Graph 又如何从 Data Graph 更新后面的数据则无需关心。 Data Graph 是 Disconnected Mode 的数据处理方式,即对其进行的修改操作,将不会立刻体现,需要将修改过的 Data Graph 由 DMS 来更新到数据源。 Data Graph 是通过 log change summary 来实现的。
在 Spec 中说道, Data Graph 被序列化为 XML 也能从 XML 中被反序列化。这使得在 Services 和其 Caller 之间传递 DataGraph 非常直接。同时也提出了系统内部、系统之间数据交互的一致方式 —— 通过 XML 序列化过的 Data Graph 。
Data Object 可以被动态实现(程序里将看不见具体的 Data Object 类,比如 Employee 类,因此也无需定义 XML Schema ),也可以被静态生成(例如预先建模后使用工具生成,目前 IBM 基于 EMF 的 RI 可以使用 EMF 来生成)。
DMS 可以有许多实现方式,在 IBM 的 SDO Specification 中并没有任何关于 DMS 实现方式的规范。实际上, DMS 在 SDO Spec V2.0 里面已经改称 DAS ( Data Access Services ),我们发现这命名和 DAO ( Data Access Object )模式何其相似。不过这里是 Service 。那么可以想象在 SOA 中,我们可以提供这样的 DAS 来提供数据并作数据更新。难道与 DAO 类似这将会成为一种 SOA 模式?
更重要的是, DAS 可以在 J2EE 的各层都能被使用。你可以使用 JDBC 实现 DAS 用它做一个持久化服务层,你可以用 EJB 实现 DAS 并且暴露成 Web Service…… 你甚至可以使用 Hibernate 、 JDO 这样的持久化工具来实现 DAS 。
所以我们不可能混淆 SDO 框架和 Hibernate 、 JDO 等工具 —— 因为后者只是持久化工具存在于 EIS 之上;也无需怀疑 SDO 的价值 ——SDO 确实可以为整个 J2EE 应用尤其是 SOA 提供一个一致的数据处理方式。
BPEL
BPEL 全程为 Business Process Execution Language 提供了一种 XML 注释和语义,内部描述为 XML 。是一种处理流程的语言,会通过流程来编排 Web 服务。向合作伙伴暴露 web 服务接口。也就是因为这个,实现向 ESB 上发布服务接口。现在想想 BEA 的流程引擎应该也是基于 BPEL 开发的。
Human Task
Human Task (人工任务)组件类型实现在业务流程和任意服务编排中涉及到相关人员的 Human Task 。人工任务在 Human Task Manager 内运行,后者是 WebSphere Process Server 内的人工任务的一个特殊容器。
Business Rule
商业规则引擎,其实就是说有些业务相当复杂, if else 的业务判断很多。 IBM 的 Business Rule 可以做到业务人员使用业务语言配置开发人员要写的 if else 才能实现业务判断工作。这使我们的应用程序的核心行为和用户界面对象能保持完整和不改变的,即使业务逻辑的更改。
State Machine
State Machine (状态机)是一些服务组件,它们对象或交互在其使用期间响应事件时的状态顺序、响应顺序以及所采取操作的顺序。
状态机提供了其他对业务流程进行建模的方法。这使您能够选择基于状态和事件而非连续的业务流程模型来描述业务流程。利用状态机机制,可以方便的将改变流程的流向。
至于什么时候用 BPEL ?什么时候用 State Machine ? IBM 讲师给出解释,若流程为顺序的(包括流转),没有跳跃性质的,连续性的。应该选用 BPEL ,否则应选用 State Machine 。
CEI (Common Event Infrastructure) 本质上是一种用来封装应用程序中产生事件的通用机制。 State Machine 采用 CEI 机制。 CEI 是 WebSphere Process Server 的重要组成部分 , 并通过它为每一个 SCA 服务组件生成一组特定的事件。
ESB
Enterprise Service Bus 企业总线, ESB 是 SOA 体系架构中的信息流动与交换的基础。 ESB 的参与主体是服务,总线提供了服务间消息的识别,转换与路由的载体, ESB 是一种概念。 ESB 的主要作用: 1 、通过 ESB 统一服务接口。很多厂商需要共享服务接口,这时各厂商相互提供的接口就显得零落,考虑可以命名用 ESB 管理,所有服务接口需注册到 ESB ,各厂商调用服务接口时,需向 ESB 调用,由 ESB 转发。有点路由的意思。 2 、通过 ESB 进行协议的转换, ESB 应支持 EJB 、 RMI 、 COBRA 、 WEB SERVICE 等,应支持 HTTP 、 TELNET 、 FTP 、 SOCKET 协议。其中多种协议及接口可以相互转换,例如: A 厂商将 COBRA 接口注册到 ESB ,而 B 厂商可以通过 WEB SERVICE 方式访问。其中的转换工作由 ESB 完成。
以下是我在网络上找到的几句话、供参考。
SCA/SDO/BPEL 之所以会成为未来十年软件开发的主流,就是因为他们正彻底地解决新的十年中客户的关键问题,程朝辉表示。
可以说, SCA 与 SDO/BPEL 一道,将成为简化 SOA ( 面向服务架构 ) 的应用程序开发新模式,让 SOA 更容易落地的新技术与事实标准。
IBM WebSphere Integration Developer 与 Bea WorkSpace 360 的异同。
相同点:
1 .都是实现 SOA 体系架构。
2 .基本概念相同, SDO , ESB , PORTAL 。
不同点:
1. WID SCA 模型实现 SOA 体系架构。更规范、更利于企业集成。而 WorkSpace 在 SCA 标准方面相对差些。
2. WID 在流程中提供业务规则引擎。而 BEA 中的 ALBPM 没有。
3. 如果看 WID 的图就可以看出, WID 本身自己就是 SCA 的例子,更方便扩展。而且 WID 由 eclipse 开发,使合作伙伴开发扩展工具成为可能。
4. 相对来讲 BEA 的 ALBPM 开发流程相对简单,而 WID 相对复杂。
5. 据 IBM 讲师介绍, WID 提供的 Process API 可以做到事务控制,在组织结构集成方面,可以实现 IBM 提供的接口,可以做到组织结构的同步。相对 BEA 来说要简单, BEA ALBPM 的 FDI , PAPI 的事务问题未能解决。
6. WID 的 SCA ,相对来讲做业务(非流程)开发时相对简单,用鼠标拖来拖去,就可实现 component 的开发。接口的实现也可以有多种方式,比如 POJO , EJB , WEB SERVICE 。事务由 WID 控制。 WORKSPACE 没有使用过,对这方面不了解。
7.WID基于BPEL,而albpm基于bpm