作者:江南白衣,原文出处: http://www.blogjava.net/calvin/archive/2007/01/31/96844.html ,转载请保留出处。
如果说Google的搜索引擎是免费的早餐,Gmail们是免费的午餐的话,
http://labs.google.com/papers/ 就是Google给开发人员们的一份免费的晚餐。
不过,咋看着一桌饭菜可能不知道从哪吃起,在自己不熟悉的领域啃英文也不是一件愉快的事情。
一、一份PPT与四份中文翻译
幸好,有一位面试google不第的老兄,自我爆发搞了一份Google Interal的PPT:
http://cbcg.net/talks/googleinternals/index.html,大家鼠标点点就能跟着他匆匆过一遍google的内部架构。
然后又有崮崮山路上走9遍(http://sharp838.mblogger.cn)与美人他爹(http://my.donews.com/eraera/),翻译了其中最重要的四份论文:
二、Google帝国的技术基石
Google帝国,便建立在大约45万台的Server上,其中大部分都是"cheap x86 boxes"。而这45万台Server,则建立于下面的key infrastructure:
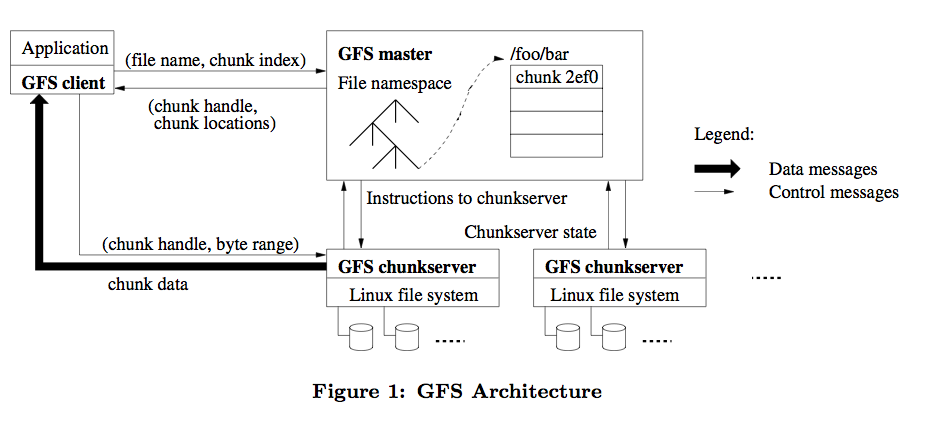
1.GFS(Google File System):
GFS是适用于大规模分布式数据处理应用的分布式文件系统,是Google一切的基础,它基于普通的硬件设备,实现了容错的设计与极高的性能。
李开复说:Google最厉害的技术是它的storage。我认为学计算机的学生都应该看看这篇文章(再次感谢翻译的兄弟)。
它以64M为一个Chunk(Block),每个Chunk至少存在于三台机器上,交互的简单过程见:
2.MapReduce
MapReduce是一个分布式处理海量数据集的编程模式,让程序自动分布到一个由普通机器组成的超大集群上并发执行。像Grep-style job,日志分析等都可以考虑采用它。
MapReduce的run-time系统会解决输入数据的分布细节,跨越机器集群的程序执行调度,处理机器的失效,并且管理机器之间的通讯请求。这样的模式允许程序员可以不需要有什么并发处理或者分布式系统的经验,就可以处理超大的分布式系统得资源。
我自己接触MapReduce是Lucene->Nutch->Hadoop的路线。
Hadoop是Lucene之父Doug Cutting的又一力作,是Java版本的分布式文件系统与Map/Reduce实现。
Hadoop的文档并不详细,再看一遍Google这篇中文版的论文,一切清晰很多(又一次感谢翻译的兄弟)。
孟岩也有一篇很清晰的博客:Map Reduce - the Free Lunch is not over?
3.BigTable
BigTable 是Google Style的数据库,使用结构化的文件来存储数据。
虽然不支持关系型数据查询,但却是建立GFS/MapReduce基础上的,分布式存储大规模结构化数据的方案。
BigTable是一个稀疏的,多维的,排序的Map,每个Cell由行关键字,列关键字和时间戳三维定位.Cell的内容是一个不解释的字符串。
比如下表存储每个网站的内容与被其他网站的反向连接的文本。
反向的URL com.cnn.www(www.cnn.com)是行的关键字;contents列存储网页内容,每个内容有一个时间戳;因为有两个反向连接,所以archor列族有两列:anchor:cnnsi.com和anchhor:my.look.ca,列族的概念,使得表可以横向扩展,archor的列数并不固定。
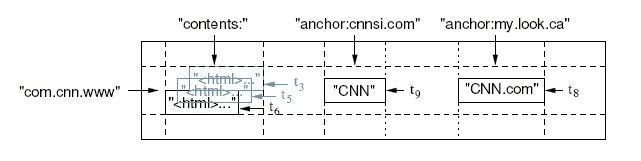
为了并发读写,热区,HA等考虑,BigTable当然不会存在逗号分割的文本文件中,,是存储在一种叫SSTable的数据库结构上,并有BMDiff和Zippy两种不同侧重点的压缩算法。
4.Sawzall
Sawzall是一种建立在MapReduce基础上的领域语言,可以被认为是分布式的awk。它的程序控制结构(if,while)与C语言无异,但它的领域语言语义使它完成相同功能的代码与MapReduce的C++代码相比简化了10倍不止。
1 proto "cvsstat.proto"
2 submits: table sum[hour: int] of count: int;
3 log: ChangelistLog = input;
4 hour: int = hourof(log.time)
5 emit submits[hour] <- 1;
天书吗?慢慢看吧。
我们这次是统计在每天24小时里CVS提交的次数。
首先它的变量定义类似Pascal (i:int=0; 即定义变量i,类型为int,初始值为0)
1:引入cvsstat.proto协议描述,作用见后。
2:定义int数组submits 存放统计结果,用hour作下标。
3.循环的将文件输入转换为ChangelistLog 类型,存储在log变量里,类型及转换方法在前面的cvsstat.proto描述。
4.取出changlog中的提交时间log.time的hour值。
5.emit聚合,在sumits结果数组里,为该hour的提交数加1,然后自动循环下一个输入。
居然读懂了,其中1、2步是准备与定义,3、4步是Map,第5步是Reduce。
三. 小结:
本文只是简单的介绍Google的技术概貌,大家知道以后除了可作谈资外没有任何作用,我们真正要学习的骨血,是论文里如何解决高并发,高可靠性等的设计思路和细节.....